Область ТЕХНИКИ
[1] Настоящее раскрытие относится к методу кодирования изображения и, в частности, к способу и устройству для кодирования изображения на основе преобразования в системе кодирования изображения.
Связанная область техники
[2] В настоящее время потребность в изображениях/видео высокого разрешения и высокого качества, таких как изображения/видео сверхвысокой четкости (UHD) 4K или 8K или выше, возросла в различных областях. Так как данные изображения/видео имеют высокое разрешение и высокое качество, передаваемое количество информации или количество битов увеличивается по сравнению с данными обычного изображения. Поэтому, когда данные изображения передаются с использованием носителей, таких как обычная проводная/беспроводная широкополосная линия, или данные изображения/видео сохраняются с использованием существующего носителя информации, затраты на их передачу и затраты на хранение увеличиваются.
[3] К тому же в настоящее время возрастают интерес и потребность в иммерсивных медиа, таких как контент или голограмма виртуальной реальности (VR) и искусственной реальности (AR) или тому подобное, возрастает трансляция изображения/видео, имеющих признаки изображения, отличные от признаков реальных изображений, таких как игровое изображение.
[4] Соответственно, существует необходимость в высокоэффективном методе сжатия изображения/видео для эффективного сжатия, передачи или хранения и воспроизведения информации изображений/видео высокого разрешения и высокого качества, имеющих различные признаки, как описано выше.
Краткое описание сущности изобретения
[5] Технический аспект настоящего раскрытия заключается в обеспечении способа и устройства для повышения эффективности кодирования изображения.
[6] Другой технический аспект настоящего раскрытия заключается в обеспечении способа и устройства для повышения эффективности квантования.
[7] Еще один технический аспект настоящего раскрытия заключается в обеспечении способа и устройства для повышения эффективности квантования компонента цветности в дереве одиночного типа.
[8] В соответствии с вариантом осуществления настоящего раскрытия, обеспечен способ декодирования изображения, выполняемый устройством декодирования. Способ может включать в себя: прием остаточной информации посредством битового потока; выведение коэффициентов преобразования для текущего блока путем выполнения деквантования на основе остаточной информации; и выведение модифицированных коэффициентов преобразования путем применения LFNST к коэффициентам преобразования, причем деквантование может выполняться на основе предопределенного списка масштабирования, и то, следует ли применять список масштабирования, может выводиться на основе того, применяется ли LFNST, и типа дерева текущего блока.
[9] Когда типом дерева текущего блока является одиночное дерево и текущий блок является компонентом яркости, список масштабирования может не применяться, а когда типом дерева текущего блока является одиночное дерево и текущий блок является компонентом цветности, список масштабирования может применяться.
[10] Дополнительно может приниматься информация флага, указывающая, доступен ли список масштабирования, когда выполняется LFNST.
[11] Когда информация флага указывает, что список масштабирования не доступен, и индекс LFNST больше чем 0, список масштабирования не может применяться к компоненту яркости.
[12] Когда информация флага указывает, что список масштабирования не доступен, и индекс LFNST больше, чем 0, если типом дерева текущего блока является дуальное дерево цветности, список масштабирования может не применяться к компоненту цветности.
[13] Когда информация флага указывает, что список масштабирования не доступен, и индекс LFNST больше чем 0, если типом дерева текущего блока является дуальное дерево яркости, список масштабирования может не применяться к компоненту яркости.
[14] Текущий блок может включать в себя блок преобразования.
[15] В соответствии с другим вариантом осуществления настоящего раскрытия, обеспечен способ кодирования изображения, выполняемый устройством кодирования. Способ может включать в себя: выведение выборок (дискретных отсчетов) предсказания для текущего блока; выведение остаточных выборок для текущего блока на основе выборок предсказания; выведение коэффициентов преобразования для текущего блока на основе первичного преобразования остаточных выборок; выведение модифицированных коэффициентов преобразования из коэффициентов преобразования путем применения LFNST; и квантование коэффициентов преобразования или модифицированных коэффициентов преобразования, причем квантование может выполняться на основе предопределенного списка масштабирования, и то, следует ли применять список масштабирования, может выводиться на основе того, применяется ли LFNST, и типа дерева текущего блока.
[16] В соответствии с еще одним вариантом осуществления настоящего раскрытия, может быть обеспечен цифровой носитель информации, который хранит данные изображения, включающие в себя закодированную информацию изображения и битовый поток, сгенерированный в соответствии со способом кодирования изображения, выполняемым устройством кодирования.
[17] В соответствии с еще одним вариантом осуществления настоящего раскрытия, может быть обеспечен цифровой носитель информации, который хранит данные изображения, включающие в себя закодированную информацию изображения и битовый поток, чтобы побуждать устройство декодирования выполнять способ декодирования изображения.
[18] В соответствии с настоящим раскрытием, становится возможным повысить общую эффективность сжатия изображения/видео.
[19] В соответствии с настоящим раскрытием, становится возможным повысить эффективность квантования.
[20] В соответствии с настоящим раскрытием, становится возможным повысить эффективность квантования компонента цветности в дереве одиночного типа.
[21] Результаты, которые могут быть получены с помощью конкретных примеров настоящего раскрытия, не ограничены результатами, перечисленными выше. Например, могут достигаться различные технические результаты, которые специалист в данной области техники сможет понять или получить на основе настоящего раскрытия. Соответственно, конкретные результаты настоящего раскрытия не ограничены теми, которые явно описаны в настоящем раскрытии, и могут включать в себя различные результаты, которые можно понять или получить с помощью технических признаков настоящего раскрытия.
Краткое описание чертежей
[22] Фиг. 1 схематично иллюстрирует пример системы кодирования видео/изображения, в которой применимо настоящее раскрытие.
[23] Фиг. 2 является диаграммой, схематично иллюстрирующей конфигурацию устройства кодирования видео/изображения, в котором применимо настоящее раскрытие.
[24] Фиг. 3 является диаграммой, схематично иллюстрирующей конфигурацию устройства декодирования видео/изображения, в котором применимо настоящее раскрытие.
[25] Фиг. 4 иллюстрирует структуру системы стриминга контента, в которой применяется настоящее раскрытие.
[26] Фиг. 5 схематично иллюстрирует технологию множественного преобразования в соответствии с вариантом осуществления настоящего раскрытия.
[27] Фиг. 6 схематично показывает интра-направленные режимы 65 направлений предсказания.
[28] Фиг. 7 является диаграммой для пояснения RST в соответствии с вариантом осуществления настоящего раскрытия.
[29] Фиг. 8 является диаграммой, иллюстрирующей последовательность компоновки выходных данных прямого первичного преобразования в одномерный вектор в соответствии с примером.
[30] Фиг. 9 является диаграммой, иллюстрирующей последовательность компоновки выходных данных прямого вторичного преобразования в двумерный блок в соответствии с примером.
[31] Фиг. 10 является диаграммой, иллюстрирующей широкоугольные режимы интра-предсказания в соответствии с вариантом осуществления настоящего документа.
[32] Фиг. 11 является диаграммой, иллюстрирующей форму блока, к которой применяется LFNST.
[33] Фиг. 12 является диаграммой, иллюстрирующей компоновку выходных данных прямого LFNST в соответствии с примером.
[34] Фиг. 13 иллюстрирует обнуление в блоке, к которому применяется 4×4 LFNST в соответствии с примером.
[35] Фиг. 14 иллюстрирует обнуление в блоке, к которому применяется 8×8 LFNST в соответствии с примером.
[36] Фиг. 15 является блок-схемой последовательности операций, иллюстрирующей работу устройства декодирования видео в соответствии с вариантом осуществления настоящего раскрытия.
[37] Фиг. 16 является блок-схемой последовательности операций, иллюстрирующей работу устройства кодирования видео в соответствии с вариантом осуществления настоящего раскрытия.
Описание примерных вариантов осуществления
[38] Хотя настоящий документ допускает различные модификации и включает различные варианты осуществления, его конкретные варианты осуществления, показанные на чертежах в качестве примера, будут далее описаны детально. Однако это не подразумевает ограничения настоящего раскрытия конкретными вариантами осуществления, описанными здесь. Терминология, используемая здесь, предназначена только для описания конкретных вариантов осуществления, но не предназначена для ограничения технической идеи настоящего раскрытия. Формы единственного числа могут включать в себя формы множественного числа, если только контекст явно не указывает иное. Термины, такие как "включать в себя" и "иметь", предназначены указывать, что признаки, числа, этапы, операции, элементы, компоненты или их комбинации, используемые в следующем описании, существуют, и, таким образом, не должны пониматься так, что возможность существования или добавления одного или более других признаков, чисел, этапов, операций, элементов, компонентов или их комбинация заранее исключается.
[39] Между тем, каждый компонент на чертежах, описанный в настоящем документе, иллюстрируется независимо для удобства описания касательно различных характеристических функций, однако это не означает, что каждый компонент реализуется как отдельные аппаратные средства или программное обеспечение. Например, два или более из этих компонентов могут комбинироваться для образования одного компонента, и любой одиночный компонент может делиться на множество компонентов. Варианты осуществления, в которых компоненты комбинируются и/или разделяются, будут включены в объем патентных прав настоящего раскрытия, если они не отклоняются от сущности настоящего раскрытия.
[40] Далее, предпочтительные варианты осуществления настоящего раскрытия будут пояснены более подробно со ссылкой на прилагаемые чертежи. К тому же одинаковые ссылочные позиции используются для одинаковых компонентов на чертежах, и повторные описания одинаковых компонентов будут опущены.
[41] Настоящий документ относится к кодированию видео/изображения. Например, способ/пример, раскрытый в настоящем документе, может относиться к стандарту VVC (многоцелевого кодирования видео) (ITU-T Rec. H.266), стандарту кодирования видео/изображения следующего поколения после VVC или к другим стандартам, относящимся к кодированию видео (например, стандарт HEVC (высокоэффективного кодирования видео) (ITU-T Rec. H.265), стандарт EVC (существенного кодирования видео), стандарт AVS2 и т.д.).
[42] В настоящем документе, могут быть обеспечены различные варианты осуществления, относящиеся к кодированию видео/изображения, и, если только не специфицировано иначе, варианты осуществления могут также комбинироваться друг с другом и выполняться.
[43] В настоящем документе, видео может относиться к набору из серии изображений по времени. Картинка обычно означает единицу, представляющую изображение в конкретной временной зоне, и вырезка (слайс) / мозаичный элемент (клетка) представляет собой единицу, составляющую часть картинки. Вырезка/мозаичный элемент может включать в себя одну или более единиц дерева кодирования (CTU). Одна картинка может состоять из одной или более вырезок/мозаичных элементов. Одна картинка может состоять из одной или более групп мозаичных элементов. Одна группа мозаичных элементов может включать в себя один или более мозаичных элементов.
[44] Пиксел или пел может означать наименьшую единицу, составляющую одну картинку (кадр) (или изображение). Также, ‘выборка’ может использоваться как термин, соответствующий пикселу. Выборка может, в общем, представлять пиксел или значение пиксела и может представлять только пиксел/значение пиксела компонента яркости или только пиксел/значение пиксела компонента цветности. Альтернативно, выборка может относиться к значению пиксела в пространственной области, или когда это значение пиксела преобразуется в частотную область, она может относиться к коэффициенту преобразования в частотной области.
[45] Единица может представлять базовую единицу обработки изображения. Единица может включать в себя по меньшей мере одно из конкретной области и информации, относящейся к области. Одна единица может включать в себя один блок яркости и два блока цветности (например, cb, cr). Единица и такой термин как блок, область или тому подобное, могут использоваться взаимозаменяемо соответственно обстоятельствам. В общем случае, блок M×N может включать в себя набор (или массив) выборок (или массивов выборок) или коэффициентов преобразования, состоящих из M столбцов и N строк.
[46] В этом документе, символы "/" или "," должны интерпретироваться как указывающие "и/или". Например, выражение "A/B" может означать "A и/или B". Дополнительно, "A, B" может означать "A и/или B". Кроме того, "А/В/С" может означать "по меньшей мере одно из А, В и/или С". Также, "А/В/С" может означать "по меньшей мере одно из А, В и/или С".
[47] Кроме того, в настоящем документе, термин "или" должен интерпретироваться как указывающий "и/или". Например, выражение "A или B" может включать 1) только A, 2) только B и/или 3) как A, так и B. Другими словами, термин "или" в настоящем документе должен интерпретироваться как указывающий "дополнительно или альтернативно".
[48] В настоящем раскрытии, "по меньшей мере одно из A и B" может означать "только A", "только B" или "как A, так и B". Также, в настоящем раскрытии, выражение "по меньшей мере одно из A или B" или "по меньшей мере одно из A и/или B" может интерпретироваться как "по меньшей мере одно из A и B".
[49] Кроме того, в настоящем раскрытии, по меньшей мере одно из A, B и C" может означать "только A", "только B", "только C" или "любая комбинация A, B и C". Также, "по меньшей мере одно из A, B или C" или "по меньшей мере одно из A, B и/или C" может означать "по меньшей мере одно из A, B и C".
[50] Кроме того, круглые скобки, используемые в настоящем раскрытии, могут означать "например". Конкретно, когда указано "предсказание (интра-предсказание)", это может означать, что "интра-предсказание" предлагается как пример "предсказания". Другими словами, "предсказание" в настоящем раскрытии не ограничено "интра-предсказанием", и "интра-предсказание" может предлагаться в качестве примера "предсказания". Также, когда указано "предсказание (т.е. интра-предсказание)", это также означает, что "интра-предсказание" предлагается как пример "предсказания".
[51] Технические признаки, отдельно описанные на одном чертеже в настоящем раскрытии, могут быть реализованы по отдельности или могут быть реализованы одновременно.
[52] Фиг. 1 схематично иллюстрирует пример системы кодирования видео/изображения, в которой применимо настоящее раскрытие.
[53] Со ссылкой на фиг. 1, система кодирования видео/изображения может включать в себя первое устройство (устройство-источник) и второе устройство (устройство приема). Устройство-источник может доставлять закодированную информацию или данные видео/изображения в форме файла или потоковой передачи (стриминга) на устройство приема через цифровой носитель хранения или сеть.
[54] Устройство-источник может включать в себя источник видео, устройство кодирования и передатчик. Устройство приема может включать в себя приемник, устройство декодирования и устройство рендеринга (визуализации). Устройство кодирования может называться устройством кодирования видео/изображения, и устройство декодирования может называться устройством декодирования видео/изображения. Передатчик может быть включен в устройство кодирования. Приемник может быть включен в устройство декодирования. Устройство визуализации может включать в себя дисплей, и дисплей может быть сконфигурирован как отдельное устройство или внешний компонент.
[55] Источник видео может получать видео/изображение через процесс захвата, синтеза или генерации видео/изображения. Источник видео может включать в себя устройство захвата видео/изображения и/или устройство генерации видео/изображения. Устройство захвата видео/изображения может включать в себя, например, одну или более камер, архивы видео/изображений, включающие в себя ранее захваченные видео/изображения, и тому подобное. Устройство генерации видео/изображения может включать в себя, например, компьютер, планшет и смартфон и может (электронным способом) генерировать видео/изображения. Например, виртуальное видео/изображение может генерироваться через компьютер или тому подобное. В этом случае, процесс захвата видео/изображения может быть заменен на процесс генерации связанных данных.
[56] Устройство кодирования может кодировать введенное видео/изображение. Устройство кодирования может выполнять последовательность процедур, таких как предсказание, преобразование и квантование для эффективности сжатия и кодирования. Закодированные данные (закодированная информация видео/изображения) могут выводиться в форме битового потока.
[57] Передатчик может передавать закодированную информацию или данные видео/изображения, выведенные в форме битового потока, на приемник устройства приема через цифровой носитель хранения или сеть в форме файла или потоковой передачи. Цифровой носитель хранения может включать в себя различные носители хранения, такие как USB, SD, CD, DVD, Blu-ray, HDD, SSD и тому подобное. Передатчик может включать в себя элемент для генерации медиа-файла посредством предопределенного формата файла и может включать в себя элемент для передачи через сеть вещания/связи. Приемник может принимать/извлекать битовый поток и передавать принятый/извлеченный битовый поток на устройство декодирования.
[58] Устройство декодирования может декодировать видео/изображение путем выполнения последовательности процедур, таких как деквантование, обратное преобразование и предсказание, соответствующих операции устройства кодирования.
[59] Устройство визуализации может визуализировать декодированное видео/изображение. Визуализированное видео/ изображение может отображаться посредством дисплея.
[60] Фиг. 2 является диаграммой, схематично иллюстрирующей конфигурацию устройства кодирования видео/изображения, в котором могут применяться варианты осуществления настоящего раскрытия. Далее, то, что упоминается как устройство кодирования видео, может включать в себя устройство кодирования изображения.
[61] Со ссылкой на фиг. 2, устройство 200 кодирования включает в себя модуль 210 разбиения изображения, предсказатель 220, процессор 230 остатка, энтропийный кодер 240, сумматор 250, фильтр 260 и память 270. Предсказатель 220 может включать в себя интер-предсказатель 221 и интра-предсказатель 222. Процессор 230 остатка может включать в себя преобразователь 232, квантователь 233, деквантователь 234 и обратный преобразователь 235. Процессор 230 остатка может дополнительно включать в себя вычитатель 231. Сумматор 250 может называться реконструктором или генератором восстановленного блока. Модуль 210 разбиения изображения, предсказатель 220, процессор 230 остатка, энтропийный кодер 240, сумматор 250 и фильтр 260, которые были описаны выше, могут быть образованы одним или более аппаратными компонентами (например, чипсетами или процессорами кодера) в соответствии с вариантом осуществления. К тому же, память 270 может включать в себя буфер декодированной картинки (DPB) или может быть образована цифровым носителем хранения. Аппаратный компонент может дополнительно включать в себя память 270 как внутренний/внешний компонент.
[62] Модуль 210 разбиения изображения может разбивать входное изображение (или картинку или кадр), введенное в устройство 200 кодирования, на одну или более единиц обработки. Например, единица обработки может называться единицей кодирования (CU). В этом случае, начиная с единицы дерева кодирования (CTU) или наибольшей единицы кодирования (LCU), единица кодирования может рекурсивно разбиваться в соответствии со структурой квадродерева/двоичного дерева/троичного дерева (QTBTTT). Например, одна единица кодирования может разбиваться на множество единиц кодирования большей глубины на основе структуры квадродерева, структуры двоичного дерева и/или структуры троичного дерева. В этом случае, например, структура квадродерева может применяться первой, и структура двоичного дерева и/или структура троичного дерева может применяться позже. Альтернативно, структура двоичного дерева может применяться первой. Процедура кодирования в соответствии с настоящим раскрытием может выполняться на основе конечной единицы кодирования, которая больше не разбивается. В этом случае, наибольшая единица кодирования может использоваться непосредственно как конечная единица кодирования на основе эффективности кодирования в соответствии с характеристикой изображения. Альтернативно, единица кодирования может рекурсивно разбиваться на единицы кодирования большей глубины, по мере необходимости, так что единица кодирования оптимального размера может использоваться как конечная единица кодирования. Здесь, процедура кодирования может включать в себя такие процедуры как предсказание, преобразование и восстановление, которые будут описаны далее. В качестве другого примера, единица обработки может дополнительно включать в себя единицу предсказания (PU) или единицу преобразования (TU). В этом случае, единица предсказания и единица преобразования могут разделяться или разбиваться из вышеописанной конечной единицы кодирования. Единица предсказания может представлять собой единицу предсказания выборки, и единица преобразования может представлять собой единицу для выведения коэффициента преобразования и/или единицу для выведения остаточного сигнала из коэффициента преобразования.
[63] Единица может использоваться взаимозаменяемо с такими терминами, как блок, область или тому подобное, в соответствии с обстоятельствами. В общем случае, блок M×N может представлять набор выборок или коэффициентов преобразования, состоящих из M столбцов и N строк. Выборка может, в общем, представлять пиксел или значение пиксела, может представлять только пиксел/значение пиксела компонента яркости или представлять только пиксел/значение пиксела компонента цветности. Выборка может использоваться как термин, соответствующий пикселу или пелу одной картинки (или изображения).
[64] Вычитатель 231 вычитает сигнал предсказания (предсказанный блок, массив выборок предсказания), выведенный из предсказателя 220, из входного сигнала изображения (исходного блока, исходного массива выборок), чтобы сгенерировать остаточный сигнал (остаточный блок, остаточный массив выборок), и сгенерированный остаточный сигнал передается на преобразователь 232. Предсказатель 220 может выполнять предсказание на целевом блоке обработки (далее называемом текущим блоком) и может генерировать предсказанный блок, включающий в себя выборки предсказания для текущего блока. Предсказатель 220 может определять, применяется ли интра-предсказание или интер-предсказание на текущем блоке или на основе CU. Как обсуждается далее в описании каждого режима предсказания, предсказатель может генерировать различную информацию, относящуюся к предсказанию, такую как информация режима предсказания, и передавать сгенерированную информацию на энтропийный кодер 240. Информация о предсказании может кодироваться в энтропийном кодере 240 и выводиться в форме битового потока.
[65] Интра-предсказатель 222 может предсказывать текущий блок путем обращения к выборкам в текущей картинке. Указанные выборки могут быть расположены по соседству или с разнесением от текущего блока в соответствии с режимом предсказания. В интра-предсказании режимы предсказания могут включать в себя множество ненаправленных режимов и множество направленных режимов. Ненаправленные режимы могут включать в себя, например, режим DC и планарный режим. Направленный режим может включать в себя, например, 33 направленных режима предсказания или 65 направленных режимов предсказания в соответствии со степенью детализации направления предсказания. Однако это только пример, и больше или меньше направленных режимов предсказания могут использоваться в зависимости от настройки. Интра-предсказатель 222 может определять режим предсказания, применяемый к текущему блоку, путем использования режима предсказания, применяемого к соседнему блоку.
[66] Интер-предсказатель 221 может выводить предсказанный блок для текущего блока на основе опорного блока (опорного массива выборок), специфицированного вектором движения на опорной картинке. В это время, чтобы уменьшить количество информации движения, передаваемой в режиме интер-предсказания, информация движения может предсказываться на базе блока, подблока или выборки на основе корреляции информации движения между соседним блоком и текущим блоком. Информация движения может включать в себя вектор движения и индекс опорной картинки. Информация движения может дополнительно включать в себя информацию направления интер-предсказания (L0-предсказания, L1-предсказания, Bi-предсказания и т.д.). В случае интер-предсказания, соседний блок может включать в себя пространственный соседний блок, существующий в текущей картинке, и временной соседний блок, существующий в опорной картинке. Опорная картинка, включающая в себя опорный блок, и опорная картинка, включающая в себя временной соседний блок, могут быть одинаковыми или разными. Временной соседний блок может называться совместно расположенным (совмещенным) опорным блоком, co-located CU (colCU) и т.п., и опорная картинка, включающая в себя временной соседний блок, может называться совмещенной картинкой (colPic). Например, интер-предсказатель 221 может конфигурировать список потенциально подходящих вариантов (кандидатов) информации движения на основе соседних блоков и генерировать информацию, указывающую, какой кандидат используется, чтобы вывести вектор движения и/или индекс опорной картинки текущего блока. Интер-предсказание может выполняться на основе различных режимов предсказания. Например, в случае режима пропуска и режима объединения, интер-предсказатель 221 может использовать информацию движения соседнего блока как информацию движения текущего блока. В режиме пропуска, в отличие от режима объединения, остаточный сигнал может не передаваться. В случае режима предсказания вектора движения (MVP), вектор движения соседнего блока может использоваться как предиктор вектора движения, и вектор движения текущего блока может указываться путем сигнализации разности векторов движения.
[67] Предсказатель 220 может генерировать сигнал предсказания на основе различных способов предсказания, описанных ниже. Например, предсказатель может применять интра-предсказание или интер-предсказание для предсказания на одном блоке, а также может одновременно применять интра-предсказание и интер-предсказание. Это может называться комбинированным интер- и интра-предсказанием (CIIP). К тому же, предсказатель может быть основан на режиме предсказания внутри-блочного копирования (IBC) или режиме палитры для выполнения предсказания на блоке. Режим предсказания IBC или режим палитры могут использоваться для кодирования контента изображения/видео игры или тому подобного, например, кодирования экранного контента (SCC). Хотя IBC в основном выполняет предсказание в текущем блоке, оно может выполняться аналогично интер-предсказанию тем, что оно выводит опорный блок в текущем блоке. То есть IBC может использовать по меньшей мере один из методов интер-предсказания, описанных в настоящем раскрытии.
[68] Сигнал предсказания, сгенерированный интер-предсказателем 221 и/или интра-предсказателем 222, может использоваться, чтобы генерировать восстановленный сигнал или чтобы генерировать остаточный сигнал. Преобразователь 232 может генерировать коэффициенты преобразования путем применения метода преобразования к остаточному сигналу. Например, метод преобразования может включать в себя по меньшей мере одно из дискретного косинусного преобразования (DCT), дискретного синусного преобразования (DST), преобразования Карунена-Лоэва (KLT), преобразования на основе графа (GBT) или условно-нелинейного преобразования (CNT). Здесь, GBT означает преобразование, полученное из графа, когда информация отношения между пикселами представлена графом. CNT относится к преобразованию, полученному на основе сигнала предсказания, сгенерированного с использованием всех ранее восстановленных пикселов. К тому же процесс преобразования может применяться к квадратным блокам пикселов, имеющим одинаковый размер, или может применяться к блокам, имеющим переменный размер, а не квадратным.
[69] Квантователь 233 может квантовать коэффициенты преобразования и передавать их на энтропийный кодер 240, и энтропийный кодер 240 может кодировать квантованный сигнал (информацию о квантованных коэффициентах преобразования) и выводить закодированный сигнал в битовом потоке. Информация о квантованных коэффициентах преобразования может называться остаточной информацией. Квантователь 233 может переупорядочивать квантованные коэффициенты преобразования типа блока в форму одномерного вектора на основе порядка сканирования коэффициентов и генерировать информацию о квантованных коэффициентах преобразования на основе квантованных коэффициентов преобразования в форме одномерного вектора. Энтропийный кодер 240 может выполнять различные способы кодирования, такие как, например, экспоненциальное кодирование Голомба, контекстно-адаптивное кодирование с переменной длиной (CAVLC), контекстно-адаптивное двоичное арифметическое кодирование (CABAC) и тому подобное. Энтропийный кодер 240 может кодировать информацию, необходимую для восстановления видео/изображения, отличную от квантованных коэффициентов преобразования (например, значения синтаксических элементов и т.д.), вместе или отдельно. Закодированная информация (например, закодированная информация видео/изображения) может передаваться или сохраняться в единицах уровня сетевой абстракции (NAL) в форме битового потока. Информация видео/изображения может дополнительно включать в себя информацию о различных наборах параметров, таких как набор параметров адаптации (APS), набор параметров картинки (PPS), набор параметров последовательности (SPS), набор параметров видео (VPS) и тому подобное. К тому же информация видео/изображения может дополнительно включать в себя общую информацию ограничения. В настоящем раскрытии, информация и/или синтаксические элементы, передаваемые/сигнализируемые от устройства кодирования на устройство декодирования, могут быть включены в информацию видео/изображения. Информация видео/изображения может кодироваться посредством вышеописанной процедуры кодирования и включаться в битовый поток. Битовый поток может передаваться по сети или может сохраняться в цифровом носителе хранения. Здесь, сеть может включать в себя сеть вещания, сеть связи и/или тому подобное, и цифровой носитель хранения может включать в себя различные носители хранения, такие как USB, SD, CD, DVD, Blu-ray, HDD, SSD и тому подобное. Передатчик (не показан), передающий сигнал, выведенный из энтропийного кодера 240, и/или модуль хранения (не показан), хранящий сигнал, могут быть сконфигурированы как внутренний/внешний элемент устройства 200 кодирования, или передатчик может быть включен в энтропийный кодер 240.
[70] Квантованные коэффициенты преобразования, выведенные из квантователя 233, могут использоваться, чтобы генерировать сигнал предсказания. Например, остаточный сигнал (остаточный блок или остаточные выборки) может восстанавливаться путем применения деквантования и обратного преобразования к квантованным коэффициентам преобразования деквантователем 234 и обратным преобразователем 235. Сумматор 250 суммирует восстановленный остаточный сигнал с сигналом предсказания, выведенным из интер-предсказателя 221 или интра-предсказателя 222, так что может генерироваться восстановленный сигнал (восстановленная картинка, восстановленный блок, восстановленный массив выборок). Если отсутствует остаток для целевого блока обработки, как в случае, где применяется режим пропуска, предсказанный блок может использоваться как восстановленный блок. Сумматор 250 может называться реконструктором или генератором восстановленного блока. Сгенерированный восстановленный сигнал может использоваться для интра-предсказания следующего целевого блока обработки в текущей картинке и, как описано ниже, может использоваться для интер-предсказания следующей картинки посредством фильтрации.
[71] Между тем отображение яркости с масштабированием цветности (LMCS) может применяться в процессе кодирования и/или восстановления картинки.
[72] Фильтр 260 может улучшать субъективное/объективное качество видео путем применения фильтрации к восстановленному сигналу. Например, фильтр 260 может генерировать модифицированную восстановленную картинку путем применения различных способов фильтрации к восстановленной картинке и может сохранять модифицированную восстановленную картинку в памяти 270, конкретно, в DPB памяти 270. Различные способы фильтрации могут включать в себя, например, фильтрацию с устранением блочности, адаптивное смещение выборки, адаптивный контурный фильтр, двунаправленный фильтр и тому подобное. Фильтр 260 может генерировать различную информацию, относящуюся к фильтрации, и передавать сгенерированную информацию на энтропийный кодер 240, как описано далее в описании каждого способа фильтрации. Информация о фильтрации может кодироваться энтропийным кодером 240 и выводиться в форме битового потока.
[73] Модифицированная восстановленная картинка, которая была передана в память 270, может использоваться как опорная картинка в интер-предсказателе 221. Посредством этого устройство кодирования может предотвратить несогласованность предсказания в устройстве 200 кодирования и устройстве декодирования, когда применяется интер-предсказание, и может также улучшить эффективность кодирования.
[74] DPB памяти 270 может хранить модифицированную восстановленную картинку для использования ее в качестве опорной картинки в интер-предсказателе 221. Память 270 может сохранить информацию движения блока в текущей картинке, из которого была выведена (или закодирована) информация движения, и/или информацию движения блоков в уже восстановленной картинке. Сохраненная информация движения может передаваться на интер-предсказатель 221 для использования в качестве информации движения соседнего блока или информации движения временного соседнего блока. Память 270 может хранить восстановленные выборки восстановленных блоков в текущей картинке и может передавать их на интра-предсказатель 222.
[75] Фиг. 3 является диаграммой, схематично иллюстрирующей конфигурацию устройства декодирования видео/изображения, в котором может применяться настоящее раскрытие.
[76] Со ссылкой на фиг. 3, устройство 300 декодирования может включать в себя энтропийный декодер 310, процессор 320 остатка, предсказатель 330, сумматор 340, фильтр 350 и память 360. Предсказатель 330 может включать в себя интер-предсказатель 331 и интра-предсказатель 332. Процессор 220 остатка может включать в себя деквантователь 321 и обратный преобразователь 321. Энтропийный декодер 310, процессор 320 остатка, предсказатель 330, сумматор 340 и фильтр 350, которые были описаны выше, могут быть сконфигурированы одним или более аппаратными компонентами (например, чипсетами или процессорами декодера) в соответствии с вариантом осуществления. К тому же память 360 может включать в себя буфер декодированной картинки (DPB) или может быть сконфигурирована цифровым носителем информации. Аппаратный компонент может дополнительно включать в себя память 360 как внутренний/внешний компонент.
[77] Когда битовый поток, включающий в себя информацию видео/изображения, вводится, устройство 300 декодирования может восстанавливать изображение в соответствии с процессом, посредством которого информация видео/изображения была обработана в устройстве кодирования согласно фиг. 2. Например, устройство 300 декодирования может выводить единицы/блоки на основе информации, относящейся к разбиению блока, полученной из битового потока. Устройство 300 декодирования может выполнять декодирование с использованием единицы обработки, применяемой в устройстве кодирования. Поэтому единица обработки декодирования может представлять собой, например, единицу кодирования, которая может разбиваться в соответствии со структурой квадродерева, структурой двоичного дерева и/или структурой троичного дерева из единицы дерева кодирования или наибольшей единицы кодирования. Одна или более единиц преобразования могут выводиться из единицы кодирования. И восстановленный сигнал изображения, декодированный и выведенный посредством устройства 300 декодирования, может воспроизводиться посредством устройства воспроизведения.
[78] Устройство 300 декодирования может принимать сигнал, выведенный из устройства кодирования согласно фиг. 2 в форме битового потока, и принятый сигнал может декодироваться посредством энтропийного декодера 310. Например, энтропийный декодер 310 может выполнять синтаксический анализ битового потока, чтобы вывести информацию (например, информацию видео/изображения), необходимую для восстановления изображения (или восстановления картинки). Информация видео/изображения может дополнительно включать в себя информацию о различных наборах параметров, таких как набор параметров адаптации (APS), набор параметров картинки (PPS), набор параметров последовательности (SPS), набор параметров видео (VPS) и тому подобное. К тому же информация видео/изображения может дополнительно включать в себя общую информацию ограничения. Устройство декодирования может дополнительно декодировать картинку на основе информации о наборе параметров и/или общей информации ограничения. Сигнализированная/принятая информация и/или синтаксические элементы, описанные далее в настоящем раскрытии, могут быть декодированы посредством процедуры декодирования и получены из битового потока. Например, энтропийный декодер 310 может декодировать информацию в битовом потоке на основе способа кодирования, такого как экспоненциальное кодирование Голомба, CAVLC или CABAC, и может выводить значение синтаксического элемента, требуемое для восстановления изображения, и квантованные значения коэффициентов преобразования для остатка. Более конкретно, способ энтропийного декодирования CABAC может принимать двоичный элемент (бин), соответствующий каждому синтаксическому элементу в битовом потоке, определять контекстную модель с использованием информации целевого синтаксического элемента декодирования и информации декодирования соседнего и целевого блоков декодирования или информации символа/бина, декодированного на предыдущей стадии, предсказывать вероятность генерации бина в соответствии с определенной контекстной моделью и выполнять арифметическое декодирование бина, чтобы генерировать символ, соответствующий значению каждого синтаксического элемента. Здесь способ энтропийного декодирования CABAC может обновлять контекстную модель с использованием информации декодированного символа/бина для контекстной модели следующего символа/бина после определения контекстной модели. Информация о предсказании среди информации, декодированной энтропийным декодером 310, может предоставляться на предсказатель (интер-предсказатель 332 и интра-предсказатель 331), и остаточные значения, то есть, квантованные коэффициенты преобразования, на которых энтропийное декодирование было выполнено в энтропийном декодере 310, и ассоциированная информация параметров могут вводиться в процессор 320 остатка. Процессор 320 остатка может выводить остаточный сигнал (остаточный блок, остаточные выборки, остаточный массив выборок). К тому же информация о фильтрации среди информации, декодированной энтропийным декодером 310, может предоставляться на фильтр 350. Между тем приемник (не показан), который принимает сигнал, выведенный из устройства кодирования, может быть дополнительно сконфигурирован как внутренний/внешний элемент устройства 300 декодирования, или приемник может быть компонентом энтропийного декодера 310. Между тем, устройство декодирования в соответствии с настоящим раскрытием может называться устройством декодирования видео/изображения/картинки, и устройство декодирования может классифицироваться на декодер информации (декодер информации видео/изображения/картинки) и декодер выборки (декодер выборки видео/изображения/картинки). Декодер информации может включать в себя энтропийный декодер 310, и декодер выборки может включать в себя по меньшей мере одно из деквантователя 321, обратного преобразователя 322, сумматора 340, фильтра 350, памяти 360, интер-предсказателя 332 и интра-предсказателя 331.
[79] Деквантователь 321 может выводить коэффициенты преобразования путем деквантования квантованных коэффициентов преобразования. Деквантователь 321 может переупорядочивать квантованные коэффициенты преобразования в форме двумерного блока. В этом случае, переупорядочивание может выполняться на основе порядка сканирования коэффициентов, выполняемого в устройстве кодирования. Деквантователь 321 может выполнять деквантование на квантованных коэффициентах преобразования с использованием параметра квантования (например, информации размера шага квантования) и получать коэффициенты преобразования.
[80] Деквантователь 322 получает остаточный сигнал (остаточный блок, остаточный массив выборок) путем обратного преобразования коэффициентов преобразования.
[81] Предсказатель может выполнять предсказание на текущем блоке и генерировать предсказанный блок, включающий в себя выборки предсказания для текущего блока. Предсказатель может определять, применяется ли интра-предсказание или интер-предсказание к текущему блоку, на основе информации о предсказании, выведенной из энтропийного декодера 310, и может определять, в частности, режим интра/интер-предсказания.
[82] Предсказатель может генерировать сигнал предсказания на основе различных способов предсказания. Например, предсказатель может применять интра-предсказание или интер-предсказание на одном блоке, а также может одновременно применять интра-предсказание и интер-предсказание. Это может называться комбинированным интер- и интра-предсказанием (CIIP). К тому же предсказатель может выполнять внутри-блочное копирование (IBC) для предсказания на блоке. Режим внутри-блочного копирования может использоваться для кодирования контента изображения/видео игры или тому подобного, например, кодирования экранного контента (SCC). Хотя IBC в основном выполняет предсказание в текущем блоке, оно может выполняться аналогично интер-предсказанию тем, что оно выводит опорный блок в текущем блоке. То есть IBC может использовать по меньшей мере один из методов интер-предсказания, описанных в настоящем раскрытии.
[83] Интра-предсказатель 331 может предсказывать текущий блок путем обращения к выборкам в текущей картинке. Указанные выборки могут быть расположены по соседству или с разнесением от текущего блока в соответствии с режимом предсказания. В интра-предсказании, режимы предсказания могут включать в себя множество ненаправленных режимов и множество направленных режимов. Интра-предсказатель 331 может определять режим предсказания, применяемый к текущему блоку, с использованием режима предсказания, применяемого к соседнему блоку.
[84] Интер-предсказатель 332 может выводить предсказанный блок для текущего блока на основе опорного блока (опорного массива выборок), специфицированного вектором движения на опорной картинке. В это время, чтобы уменьшить количество информации движения, передаваемой в режиме интер-предсказания, информация движения может предсказываться на базе блока, подблока или выборки на основе корреляции информации движения между соседним блоком и текущим блоком. Информация движения может включать в себя вектор движения и индекс опорной картинки. Информация движения может дополнительно включать в себя информацию направления интер-предсказания (L0-предсказания, L1-предсказания, Bi-предсказания и т.д.). В случае интер-предсказания, соседний блок может включать в себя пространственный соседний блок, существующий в текущей картинке, и временной соседний блок, существующий в опорной картинке. Например, интер-предсказатель 332 может конфигурировать список кандидатов информации движения на основе соседних блоков и выводить вектор движения и/или индекс опорной картинки текущего блока на основе принятой информации выбора кандидата. Интер-предсказание может выполняться на основе различных режимов предсказания, и информация о предсказании может включать в себя информацию, указывающую режим интер-предсказания для текущего блока.
[85] Сумматор 340 может генерировать восстановленный сигнал (восстановленную картинку, восстановленный блок, восстановленный массив выборок) путем суммирования полученного остаточного сигнала с сигналом предсказания (предсказанным блоком, предсказанным массивом выборок), выведенным из предсказателя 330. Если отсутствует остаток для целевого блока обработки, как в случае, когда применяется режим пропуска, предсказанный блок может использоваться как восстановленный блок.
[86] Сумматор 340 может называться реконструктором или генератором восстановленного блока. Сгенерированный восстановленный сигнал может использоваться для интра-предсказания следующего целевого блока обработки в текущем блоке и, как описано ниже, может выводиться посредством фильтрации или использоваться для интер-предсказания следующей картинки.
[87] Между тем в процессе декодирования картинки может применяться отображение яркости с масштабированием цветности (LMCS).
[88] Фильтр 350 может улучшать субъективное/объективное качество изображения путем применения фильтрации к восстановленному сигналу. Например, фильтр 350 может генерировать модифицированную восстановленную картинку путем применения различных способов фильтрации к восстановленной картинке и может передавать модифицированную восстановленную картинку в память 260, конкретно, в DPB памяти 360. Различные способы фильтрации могут включать в себя, например, фильтрацию с устранением блочности, адаптивное смещение выборки, адаптивный контурный фильтр, двунаправленный фильтр и тому подобное.
[89] (Модифицированная) восстановленная картинка, которая была сохранена в DPB памяти 360, может использоваться как опорная картинка в интер-предсказателе 332. Память 360 может хранить информацию движения блока в текущей картинке, из которого выводится (или декодируется) информация движения, и/или информацию движения блоков в уже восстановленной картинке. Сохраненная информация движения может передаваться на интер-предсказатель 332 для использования в качестве информации движения соседнего блока или информации движения временного соседнего блока. Память 360 может хранить восстановленные выборки восстановленных блоков в текущей картинке и передавать их на интра-предсказатель 331.
[90] В настоящем описании примеры, описанные для предсказателя 330, деквантователя 321, обратного преобразователя 322 и фильтра 350 устройства 300 декодирования, могут аналогично или соответственно применяться к предсказателю 220, деквантователю 234, обратному преобразователю 235 и фильтру 260 устройства 200 кодирования, соответственно.
[91] Как описано выше, предсказание выполняется, чтобы повысить эффективность сжатия при выполнении кодирования видео. Посредством этого может генерироваться предсказанный блок, включающий в себя выборки предсказания для текущего блока, то есть, целевой блок кодирования. Здесь предсказанный блок включает в себя выборки предсказания в пространственной области (или области пикселов). Предсказанный блок может выводиться одинаково в устройстве кодирования и устройстве декодирования, и устройство кодирования может повысить эффективность кодирования изображения путем сигнализации на устройство декодирования не исходного значения выборки самого исходного блока, а информации об остатке (остаточной информации) между исходным блоком и предсказанным блоком. Устройство декодирования может вывести остаточный блок, включающий в себя остаточные выборки, на основе остаточной информации, генерировать восстановленный блок, включающий в себя восстановленные выборки, путем суммирования остаточного блока и предсказанного блока и генерировать восстановленную картинку, включающую в себя восстановленные блоки.
[92] Остаточная информация может генерироваться посредством процедур преобразования и квантования. Например, устройство кодирования может выводить остаточный блок между исходным блоком и предсказанным блоком, выводить коэффициенты преобразования путем выполнения процедуры преобразования на остаточных выборках (остаточном массиве выборок), включенных в остаточный блок, и выводить квантованные коэффициенты преобразования путем выполнения процедуры квантования на коэффициентах преобразования, так что оно может сигнализировать ассоциированную остаточную информацию на устройство декодирования (посредством битового потока). Здесь остаточная информация может включать в себя информацию значения, информацию местоположения, метод преобразования, ядро преобразования, параметр квантования или тому подобное квантованных коэффициентов преобразования. Устройство декодирования может выполнять процедуру деквантования/обратного преобразования и выводить остаточные выборки (или остаточный блок выборок) на основе остаточной информации. Устройство декодирования может генерировать восстановленный блок на основе предсказанного блока и остаточного блока. Устройство кодирования может выводить остаточный блок путем деквантования/обратного преобразования квантованных коэффициентов преобразования для ссылки для интер-предсказания следующей картинки и может генерировать восстановленную картинку на этой основе.
[93] Фиг. 4 показывает структуру системы стриминга контента, в которой применимо настоящее раскрытие.
[94] Система стриминга контента, в которой применяется настоящее раскрытие, может в широком смысле включать в себя сервер кодирования, стриминговый сервер, веб-сервер, медиа-хранилище, пользовательское оборудование и устройство мультимедийного ввода.
[95] Сервер кодирования функционирует для сжатия цифровых данных контента, введенного из устройств мультимедийного ввода, таких как смартфон, камера, камера-регистратор (записывающая видеокамера) и т.д., в цифровые данные, чтобы сгенерировать битовый поток и передать его на стриминговый сервер. В качестве другого примера, когда устройство мультимедийного ввода, такое как смартфон, камера, записывающая видеокамера и т.д., непосредственно генерирует битовый поток, сервер кодирования может опускаться. Битовый поток может генерироваться способом кодирования или способом генерации битового потока, в котором применяется настоящее раскрытие, и стриминговый сервер может временно хранить битовый поток в процессе передачи или приема битового потока.
[96] Стриминговый сервер передает мультимедийные данные на пользовательское оборудование на основе запроса пользователя через веб-сервер, который функционирует как инструмент, который информирует пользователя об услуге. Когда пользователь запрашивает желаемую услугу, веб-сервер переносит запрос на стриминговый сервер, и стриминговый сервер передает мультимедийные данные пользователю. В этом отношении, система стриминга контента может включать в себя отдельный сервер управления, и в этом случае, сервер управления функционирует, чтобы управлять командами/ответами между соответствующими оборудованиями в системе стриминга контента.
[97] Стриминговый сервер может принимать контент из медиа-хранилища и/или сервера кодирования. Например, когда контент принимается от сервера кодирования, контент может приниматься в реальном времени. В этом случае, чтобы обеспечить плавную стриминговую услугу, стриминговый сервер может хранить битовый поток в течение предопределенного периода времени.
[98] Например, пользовательское оборудование может включать в себя мобильный телефон, смартфон, ноутбук, терминал цифрового вещания, персональный цифровой помощник (PDA), портативный мультимедийный плеер (PMP), навигатор, тонкий PC, планшетный PC, ультрабук, носимое устройство (например, терминал типа часов (умные часы), терминал типа очков (умные очки), наголовный дисплей (HMD)), цифровой телевизор, настольный компьютер, цифровой указатель и тому подобное. Каждый из серверов в системе стриминга контента может работать как распределенный сервер, и в этом случае, данные, принимаемые каждым сервером, могут обрабатываться распределенным образом.
[99] Фиг. 5 схематично иллюстрирует технологию множественного преобразования в соответствии с вариантом осуществления настоящего раскрытия.
[100] Со ссылкой на фиг. 5, преобразователь может соответствовать преобразователю в устройстве кодирования согласно фиг. 2, и обратный преобразователь может соответствовать обратному преобразователю в устройстве кодирования согласно фиг. 2 или обратному преобразователю в устройстве декодирования согласно фиг. 3.
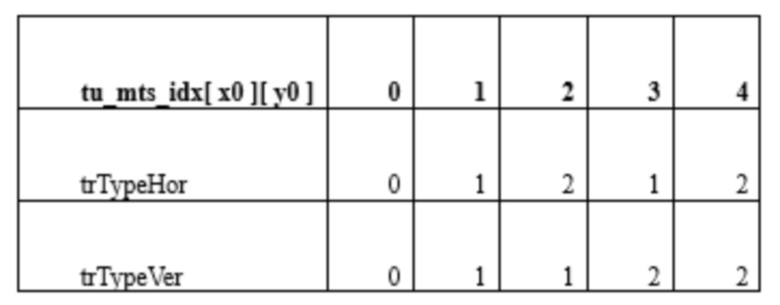
[101] Преобразователь может выводить коэффициенты (первичного) преобразования путем выполнения первичного преобразования на основе остаточных выборок (массива остаточных выборок) в остаточном блоке (S510). Это первичное преобразование может упоминаться как основное (базовое) преобразование. Здесь, первичное преобразование может быть основано на выборе множественного преобразования (MTS), и когда множественное преобразование применяется как первичное преобразование, оно может упоминаться как множественное основное преобразование.
[102] Множественное основное преобразование может представлять способ преобразования, дополнительно использующий дискретное косинусное преобразование (DCT) типа 2 и дискретное синусное преобразование (DST) типа 7, DCT типа 8 и/или DST типа 1. То есть, множественное основное преобразование может представлять способ преобразования для преобразования остаточного сигнала (или остаточного блока) пространственной области в коэффициенты преобразования (или коэффициенты первичного преобразования) частотной области на основе множества ядер преобразования, выбранных из DCT типа 2, DST типа 7, DCT типа 8 и DST типа 1. Здесь, коэффициенты первичного преобразования могут называться коэффициентами временного преобразования с точки зрения преобразователя.
[103] Иными словами, когда применяется обычный способ преобразования, коэффициенты преобразования могут генерироваться путем применения преобразования из пространственной области в частотную область для остаточного сигнала (или остаточного блока) на основе DCT типа 2. В отличие от этого, когда применяется множественное основное преобразование, коэффициенты преобразования (или коэффициенты первичного преобразования) могут генерироваться путем применения преобразования из пространственной области в частотную область для остаточного сигнала (или остаточного блока) на основе DCT типа 2, DST типа 7, DCT типа 8 и/или DST типа 1. Здесь, DCT типа 2, DST типа 7, DCT типа 8 и DST типа 1 могут упоминаться как типы преобразования, ядра преобразования или базы преобразования. Эти типы преобразования DCT/DST могут определяться на основе базисных функций.
[104] Когда выполняется множественное основное преобразование, ядро вертикального преобразования и ядро горизонтального преобразования для целевого блока могут быть выбраны из ядер преобразования, вертикальное преобразование может выполняться на целевом блоке на основе ядра вертикального преобразования, и горизонтальное преобразование может выполняться на целевом блоке на основе ядра горизонтального преобразования. Здесь, горизонтальное преобразование может указывать преобразование на горизонтальных компонентах целевого блока, и вертикальное преобразование может указывать преобразование на вертикальных компонентах целевого блока. Ядро вертикального преобразования/ядро горизонтального преобразования может адаптивно определяться на основе режима предсказания и/или индекса преобразования для целевого блока (CU или подблока), включающего в себя остаточный блок.
[105] Кроме того, в соответствии с примером, если первичное преобразование выполняется путем применения MTS, отношение отображения для ядер преобразования может быть установлено путем установки специальных базисных функций в предопределенные значения и комбинирования базисных функций для применения в вертикальном преобразовании или горизонтальном преобразовании. Например, когда ядро горизонтального преобразования выражено как trTypeHor и ядро преобразования вертикального направления выражено как trTypeVer, значение 0 для trTypeHor или trTypeVer может быть установлено в DCT2, значение 1 для trTypeHor или trTypeVer может быть установлено в DST7, и значение 2 для trTypeHor или trTypeVer может быть установлено в DCT8.
[106] В этом случае, информация индекса MTS может кодироваться и сигнализироваться на устройство декодирования, чтобы указывать любой один из множества наборов ядер преобразования. Например, индекс MTS 0 может указывать, что значения как trTypeHor, так и trTypeVer равны 0, индекс MTS 1 может указывать, что значения как trTypeHor, так и trTypeVer равны 1, индекс MTS 2 может указывать, что значение trTypeHor равно 2 и значение trTypeVer равно 1, индекс MTS 3 может указывать, что значение trTypeHor равно 1 и значение trTypeVer равно 2, и индекс MTS 4 может указывать, что значения как trTypeHor, так и trTypeVer равны 2.
[107] В одном примере, наборы ядер преобразования в соответствии с информацией индекса MTS показаны в следующей таблице.
[108] [Таблица 1]
[109] Преобразователь может выводить модифицированные коэффициенты (вторичного) преобразования путем выполнения вторичного преобразования на основе коэффициентов (первичного) преобразования (S520). Первичное преобразование является преобразованием из пространственной области в частотную область, и вторичное преобразование относится к преобразованию в более сжатое выражение с использованием корреляции, существующей между коэффициентами (первичного) преобразования. Вторичное преобразование может включать в себя неразделимое преобразование. В этом случае вторичное преобразование может называться неразделимым вторичным преобразованием (NSST) или зависимым от режима неразделимым вторичным преобразованием (MDNSST). Неразделимое вторичное преобразование может представлять преобразование, которое генерирует модифицированные коэффициенты преобразования (или коэффициенты вторичного преобразования) для остаточного сигнала путем вторичного преобразования, на основе матрицы неразделимого преобразования, коэффициентов (первичного) преобразования, выведенных посредством первичного преобразования. При этом вертикальное преобразование и горизонтальное преобразование не могут применяться отдельно (или горизонтальное и вертикальное преобразования не могут применяться независимо) к коэффициентам (первичного) преобразования, но преобразования могут применяться одновременно на основе матрицы неразделимого преобразования. Иными словами, неразделимое вторичное преобразование может представлять способ преобразования, которое отдельно не применяется в вертикальном направлении и горизонтальном направлении для коэффициентов (первичного) преобразования, и, например, двумерные сигналы (коэффициенты преобразования) переупорядочиваются в одномерный сигнал посредством некоторого определенного направления (например, направления "сначала по строке" или направления "сначала по столбцу"), и затем модифицированные коэффициенты преобразования (или коэффициенты вторичного преобразования) генерируются на основе матрицы неразделимого преобразования. Например, в соответствии с порядком сначала по строке, блоки M×N располагаются в линию в порядке первой строки, второй строки, … и N-й строки. В соответствии с порядком сначала по столбцу, блоки M×N располагаются в линию в порядке первого столбца, второго столбца, … и N-го столбца. Неразделимое вторичное преобразование может применяться к верхней-левой области блока, сконфигурированного с коэффициентами (первичного) преобразования (далее может упоминаться как блок коэффициентов преобразования). Например, если ширина (W) и высота (H) блока коэффициентов преобразования равны или больше чем 8, то неразделимое вторичное преобразование 8×8 может применяться к верхней-левой области 8×8 блока коэффициентов преобразования. Кроме того, если ширина (W) и высота (H) блока коэффициентов преобразования равны или больше чем 4, и ширина (W) или высота (H) блока коэффициентов преобразования меньше чем 8, то неразделимое вторичное преобразование 4×4 может применяться к верхней-левой области min(8,W) × min(8,H) блока коэффициентов преобразования. Однако вариант осуществления не ограничен этим, и например, даже если только условие, что ширина (W) или высота (H) блока коэффициентов преобразования равна или больше чем 4, удовлетворяется, то неразделимое вторичное преобразование 4×4 может применяться к верхней-левой области min(8,W) × min(8,H) блока коэффициентов преобразования.
[110] Конкретно, например, если используется входной блок 4×4, то неразделимое вторичное преобразование может выполняться следующим образом.
[111] Входной блок X 4×4 может быть представлен следующим образом.
[112] [Уравнение 1]
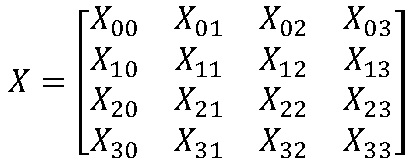
[113] Если X представлен в форме вектора, то вектор 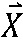 может быть представлен, как указано ниже.
может быть представлен, как указано ниже.
[114] [Уравнение 2]
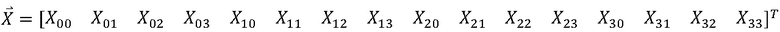
[115] В Уравнении 2, вектор является одномерным вектором, полученным переупорядочением двумерного блока X в Уравнении 1 в соответствии с порядком сначала по строке.
[116] В этом случае, вторичное неразделимое преобразование может вычисляться, как указано ниже.
[117] [Уравнение 3]
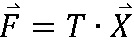
[118] В этом уравнении, 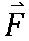 представляет вектор коэффициентов преобразования, и T представляет матрицу 16×16 (неразделимого) преобразования.
представляет вектор коэффициентов преобразования, и T представляет матрицу 16×16 (неразделимого) преобразования.
[119] Посредством приведенного выше Уравнения 3, можно вывести вектор 16×1 коэффициентов преобразования , и может быть переупорядочен в блок 4×4 с помощью порядка сканирования (горизонтальное, вертикальное, диагональное и т.п.). Однако вышеописанное вычисление является примером, и может использоваться преобразование гиперкуба Гивенса (HyGT) или тому подобное для вычисления неразделимого вторичного преобразования, чтобы уменьшить вычислительную сложность неразделимого вторичного преобразования.
[120] Между тем, в неразделимом вторичном преобразовании ядро преобразования (база преобразования, тип преобразования) может выбираться как зависимое от режима. В этом случае режим может включать в себя режим интра-предсказания и/или режим интер-предсказания.
[121] Как описано выше, неразделимое вторичное преобразование может выполняться на основе преобразования 8×8 или преобразования 4×4, определенного на основе ширины (W) и высоты (H) блока коэффициентов преобразования. Преобразование 8×8 относится к преобразованию, которое применимо к области 8×8, включенной в блок коэффициентов преобразования, когда как W, так и H равны или больше чем 8, и область 8×8 может быть верхней-левой областью 8×8 в блоке коэффициентов преобразования. Аналогично, преобразование 4×4 относится к преобразованию, которое применимо к области 4×4, включенной в блок коэффициентов преобразования, когда как W, так и H равны или больше, чем 4, и область 4×4 может быть верхней-левой областью 4×4 в блоке коэффициентов преобразования. Например, матрица 8×8 ядра преобразования может быть матрицей 64×64/16×64, и матрица 4×4 ядра преобразования может быть матрицей 16×16/8×16.
[122] Здесь, чтобы выбрать зависимое от режима ядро преобразования, два неразделимых ядра вторичного преобразования на каждый набор преобразований для неразделимого вторичного преобразования могут быть сконфигурированы как для преобразования 8×8, так и преобразования 4×4, и может иметься четыре набора преобразований. То есть четыре набора преобразований могут быть сконфигурированы для преобразования 8×8, и четыре набора преобразований могут быть сконфигурированы для преобразования 4×4. В этом случае, каждый из четырех наборов преобразований для преобразования 8×8 может включать в себя два ядра преобразования 8×8, и каждый из четырех наборов преобразований для преобразования 4×4 может включать в себя два ядра преобразования 4×4.
[123] Однако, поскольку размер преобразования, то есть размер области, к которой применяется преобразование, может иметь, например, размер иной, чем 8×8 или 4×4, число наборов может составлять n, и число ядер преобразования в каждом наборе может составлять k.
[124] Набор преобразований может упоминаться как набор NSST или набор LFNST. Конкретный набор среди наборов преобразований может быть выбран, например, на основе режима интра-предсказания текущего блока (CU или подблока). Низкочастотное неразделимое преобразование (LFNST) может быть примером сокращенного неразделимого преобразования, которое будет описано далее, и представляет неразделимое преобразование для низкочастотного компонента.
[125] Для ссылки, например, режим интра-предсказания может включать в себя два ненаправленных (или неугловых) режима интра-предсказания и 65 направленных (или угловых) режимов интра-предсказания. Ненаправленные режимы интра-предсказания могут включать в себя планарный режим интра-предсказания № 0 и DC режим интра-предсказания № 1, и направленные режимы интра-предсказания могут включать в себя 65 режимов интра-предсказания от № 2 до 66. Однако это является примером, и этот документ может применяться, даже если число режимов интра-предсказания отличается. Между тем, в некоторых случаях, режим интра-предсказания № 67 может быть дополнительно использован, и режим интра-предсказания № 67 может представлять режим линейной модели (LM).
[126] Фиг. 6 показывает в качестве примера интра-направленные режимы 65 направлений предсказания.
[127] Со ссылкой на фиг. 6, на основе режима интра-предсказания 34, имеющего диагональное влево-вверх направление предсказания, режимы интра-предсказания могут быть разделены на режимы интра-предсказания, имеющие горизонтальную направленность, и режимы интра-предсказания, имеющие вертикальную направленность. На фиг. 6, H и V обозначают горизонтальную направленность и вертикальную направленность, соответственно, и числа от -32 до 32 указывают смещения в единицах 1/32 по дискретной позиции сетки. Эти числа могут представлять смещение для значения индекса режима. Режимы интра-предсказания от 2 до 33 имеют горизонтальную направленность, и режимы интра-предсказания от 34 до 66 имеют вертикальную направленность. Строго говоря, режим 34 интра-предсказания может рассматриваться как ни горизонтальный, ни вертикальный, но может классифицироваться как принадлежащий горизонтальной направленности при определении набора преобразований вторичного преобразования. Это объясняется тем, что входные данные транспонируются, чтобы использоваться для режима вертикального направления симметрично на основе режима 34 интра-предсказания, и способ выравнивания входных данных для горизонтального режима используется для режима 34 интра-предсказания. Транспонирование входных данных означает, что строки и столбцы двумерного блока M×N данных переключаются на N×M данные. Режим 18 интра-предсказания и режим 50 интра-предсказания могут представлять горизонтальный режим интра-предсказания и вертикальный режим интра-предсказания, соответственно, и режим 2 интра-предсказания может упоминаться как диагональный вправо-вверх режим интра-предсказания, так как режим 2 интра-предсказания имеет левый опорный пиксел и выполняет предсказание в направлении вправо-вверх. Аналогичным образом, режим 34 интра-предсказания может упоминаться как диагональный вправо-вниз режим интра-предсказания, и режим 66 интра-предсказания может упоминаться как диагональный влево-вниз режим интра-предсказания.
[128] В соответствии с примером, четыре набора преобразований в соответствии с режимом интра-предсказания могут отображаться, например, как показано в следующей таблице.
[129] [Таблица 2]
[130] Как показано в Таблице 2, любой один из четырех наборов преобразований, то есть, lfnstTrSetIdx, может быть отображен на любой из четырех индексов, то есть, от 0 до 3, в соответствии с режимом интра-предсказания.
[131] Когда определено, что конкретный набор используется для неразделимого преобразования, одно из k ядер преобразования в конкретном наборе может быть выбрано с помощью индекса неразделимого вторичного преобразования. Устройство кодирования может выводить индекс неразделимого вторичного преобразования, указывающий конкретное ядро преобразования, на основе проверки по критерию "скорость-искажение" (RD) и может сигнализировать индекс неразделимого вторичного преобразования на устройство декодирования. Устройство декодирования может выбрать одно из k ядер преобразования в конкретном наборе на основе индекса неразделимого вторичного преобразования. Например, значение 0 индекса lfnst может относиться к первому ядру неразделимого вторичного преобразования, значение 1 индекса lfnst может относиться ко второму ядру неразделимого вторичного преобразования, и значение 2 индекса lfnst может относиться к третьему ядру неразделимого вторичного преобразования. Альтернативно, значение 0 индекса lfnst может указывать, что первое неразделимое вторичное преобразование не применяется к целевому блоку, и значения от 1 до 3 индекса lfnst могут указывать три ядра преобразования.
[132] Преобразователь может выполнять неразделимое вторичное преобразование на основе выбранного ядра преобразования и может получать модифицированные коэффициенты (вторичного) преобразования. Как описано выше, модифицированные коэффициенты преобразования могут быть выведены как коэффициенты преобразования, квантованные с помощью квантователя, и могут кодироваться и сигнализироваться на устройство декодирования и передаваться на деквантователь/обратный преобразователь в устройстве кодирования.
[133] Между тем как описано выше, если вторичное преобразование опущено, коэффициенты (первичного) преобразования, которые являются выходом первичного (разделимого) преобразования, могут быть выведены как коэффициенты преобразования, квантованные с помощью квантователя, как описано выше, и могут кодироваться и сигнализироваться на устройство декодирования и передаваться на деквантователь/обратный преобразователь в устройстве кодирования.
[134] Обратный преобразователь может выполнять ряд процедур в обратном порядке по отношению к тому, как они выполнялись в вышеописанном преобразователе. Обратный преобразователь может принимать (деквантованные) коэффициенты преобразования и выводить коэффициенты (первичного) преобразования путем выполнения вторичного (обратного) преобразования (S550) и может получать остаточный блок (остаточные выборки) путем выполнения первичного (обратного) преобразования на коэффициентах (первичного) преобразования (S560). В этой связи, коэффициенты первичного преобразования могут называться модифицированными коэффициентами преобразования с точки зрения обратного преобразователя. Как описано выше, устройство кодирования и устройство декодирования могут генерировать восстановленный блок на основе остаточного блока и предсказанного блока и могут генерировать восстановленную картинку на основе восстановленного блока.
[135] Устройство декодирования может, кроме того, включать в себя определитель применения вторичного обратного преобразования (или элемент для определения, следует ли применять вторичное обратное преобразование) и определитель вторичного обратного преобразования (или элемент для определения вторичного обратного преобразования). Определитель применения вторичного обратного преобразования может определять, следует ли применять вторичное обратное преобразование. Например, вторичное обратное преобразование может представлять собой NSST, RST или LFNST, и определитель применения вторичного обратного преобразования может определять, следует ли применять вторичное обратное преобразование, на основе флага вторичного преобразования, полученного путем синтаксического анализа битового потока. В другом примере, определитель применения вторичного обратного преобразования может определять, следует ли применять вторичное обратное преобразование, на основе коэффициента преобразования остаточного блока.
[136] Определитель вторичного обратного преобразования может определять вторичное обратное преобразование. В этом случае, определитель вторичного обратного преобразования может определять вторичное обратное преобразование, применяемое к текущему блоку, на основе набора преобразований LFNST (NSST или RST), специфицированного в соответствии с режимом интра-предсказания. В варианте осуществления, способ определения вторичного преобразования может определяться в зависимости от способа определения первичного преобразования. Различные комбинации первичных преобразований и вторичных преобразований могут определяться в соответствии с режимом интра-предсказания. Кроме того, в примере, определитель вторичного обратного преобразования может определять область, к которой применяется вторичное обратное преобразование, на основе размера текущего блока.
[137] Между тем как описано выше, если вторичное (обратное) преобразование опущено, могут приниматься (деквантованные) коэффициенты преобразования, может выполняться первичное (разделимое) обратное преобразование, и может быть получен остаточный блок (остаточные выборки). Как описано выше, устройство кодирования и устройство декодирования могут генерировать восстановленный блок на основе остаточного блока и предсказанного блока и могут генерировать восстановленную картинку на основе восстановленного блока.
[138] Между тем в настоящем раскрытии сокращенное вторичное преобразование (RST), в котором размер матрицы (ядра) преобразования уменьшен, может применяться в концепции NSST, чтобы уменьшить объем вычислений и памяти, требуемый для неразделимого вторичного преобразование.
[139] Между тем ядро преобразования, матрица преобразования и коэффициент, образующий матрицу ядра преобразования, то есть коэффициент ядра или коэффициент матрицы, описанные в настоящем раскрытии, могут быть выражены в 8 битах. Это может быть условием для реализации в устройстве декодирования и устройстве кодирования и может уменьшить объем памяти, требуемой для хранения ядра преобразования, при снижении производительности, которое может рационально допускаться, по сравнению с существующими случаями 9 битов или 10 битов. Дополнительно, выражение матрицы ядра в 8 битах может позволить использовать небольшой умножитель и может быть более подходящим для инструкций архитектуры одного потока инструкций и множества потоков данных (SIMD), используемых для оптимальной реализации программного обеспечения.
[140] В настоящей спецификации, термин "RST" может означать преобразование, которое выполняется на остаточных выборках для целевого блока на основе матрицы преобразования, размер которой уменьшен в соответствии с коэффициентом уменьшения. В случае выполнения сокращенного преобразования, объем вычислений, требуемых для преобразования, может быть уменьшен, вследствие сокращения в размере матрицы преобразования. То есть, RST может использоваться для решения проблемы вычислительной сложности, проявляющейся при неразделимом преобразовании или преобразовании блока большого размера.
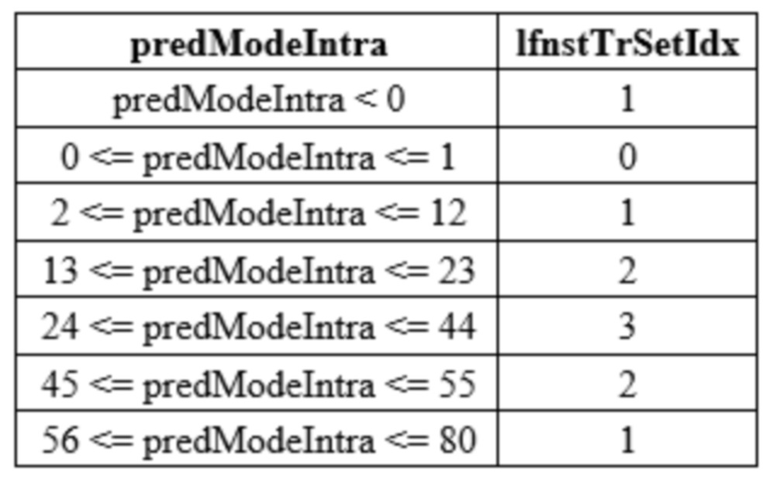
[141] RST может определяться различными терминами, такими как сокращенное преобразование, сокращенное вторичное преобразование, преобразование сокращения, упрощенное преобразование, простое преобразование и тому подобное, и наименование RST не ограничивается перечисленными примерами. Альтернативно, поскольку RST в основном выполняется в низкочастотной области, включающей ненулевой коэффициент в блоке преобразования, оно может упоминаться как низкочастотное неразделимое преобразование (LFNST). Индекс преобразования может упоминаться как индекс LFNST.
[142] Между тем, когда вторичное обратное преобразование выполняется на основе RST, обратный преобразователь 235 устройства 200 кодирования и обратный преобразователь 322 устройства 300 декодирования могут включать в себя обратный сокращенный вторичный преобразователь, который выводит модифицированные коэффициенты преобразования на основе обратного RST коэффициентов преобразования, и обратный первичный преобразователь, который выводит остаточные выборки для целевого блока на основе обратного первичного преобразования модифицированных коэффициентов преобразования. Обратное первичное преобразование относится к обратному преобразованию первичного преобразования, применяемого к остатку. В настоящем раскрытии, выведение коэффициента преобразования на основе преобразования может относиться к выведению коэффициента преобразования путем применения преобразования.
[143] Фиг. 7 является диаграммой, иллюстрирующей RST в соответствии с вариантом осуществления настоящего раскрытия.
[144] В настоящем раскрытии, "целевой блок" может относиться к текущему блоку, подлежащему кодированию, остаточному блоку или блоку преобразования.
[145] В RST в соответствии с примером, N-мерный вектор может быть отображен на R-мерный вектор, расположенный в другом пространстве, так что может определяться матрица сокращенного преобразования, где R меньше, чем N. N может означать квадрат длины стороны блока, к которому применяется преобразование, или общее число коэффициентов преобразования, соответствующих блоку, к которому применяется преобразование, и сокращенный фактор может означать значение R/N. Сокращенный показатель может упоминаться как сокращенный коэффициент, коэффициент сокращения, упрощенный коэффициент, простой коэффициент или определяться различными другими терминами. Между тем R может упоминаться как сокращенный коэффициент, но в зависимости от обстоятельств, сокращенный коэффициент может означать R. Кроме того, в зависимости от обстоятельств, сокращенный коэффициент может означать значение N/R.
[146] В примере, сокращенный показатель или сокращенный коэффициент может сигнализироваться посредством битового потока, но пример не ограничен этим. Например, предопределенное значение для сокращенного показателя или сокращенного коэффициента может быть сохранено в каждом из устройства 200 кодирования и устройства 300 декодирования, и в этом случае, сокращенный показатель или сокращенный коэффициент может не сигнализироваться отдельно.
[147] Размер матрицы сокращенного преобразования в соответствии с примером может быть R×N меньше, чем N×N, размер матрицы обычного преобразования, и может быть определен как в Уравнении 4 ниже.
[148] [Уравнение 4]

[149] Матрица T в блоке сокращенного преобразования, показанном на фиг. 7(a) может означать матрицу TR×N Уравнения 4. Как показано на фиг. 7(a), когда матрица TR×N сокращенного преобразования умножается на остаточные выборки для целевого блока, могут быть выведены коэффициенты преобразования для целевого блока.
[150] В примере, если размер блока, к которому применяется преобразование, составляет 8×8 и R=16 (т.е. R/N=16/64=1/4), то RST в соответствии с фиг. 7(a) может быть выражено как матричная операция, как показано в Уравнение 5 ниже. В этом случае, память и вычисление умножения могут быть сокращены до примерно 1/4 посредством сокращенного коэффициента.
[151] В настоящем раскрытии матричная операция может пониматься как операция умножения вектор-столбца на матрицу, расположенную слева от вектор-столбца, чтобы получить вектор-столбец.
[152] [Уравнение 5]
[153] В Уравнении 5, r1 до r64 могут представлять остаточные выборки для целевого блока и могут быть конкретно коэффициентами преобразования, сгенерированными путем применения первичного преобразования. В результате вычисления Уравнения 5 могут быть выведены коэффициенты преобразования ci для целевого блока, и процесс выведения ci может быть таким, как в Уравнении 6.
[154] [Уравнение 6]

[155] В результате вычисления Уравнения 6, могут быть выведены коэффициенты преобразования c1 до cR для целевого блока. То есть, когда R=16, могут быть выведены коэффициенты преобразования c1 до c16 для целевого блока. Если, вместо RST применяется регулярное преобразование и матрица преобразования размером 64×64 (N×N) умножается на остаточные выборки размером 64×1 (N×1), то только 16 (R) коэффициентов преобразования выводятся для целевого блока, поскольку применялось RST, хотя 64 (N) коэффициентов преобразования выведены для целевого блока. Поскольку общее число коэффициентов преобразования для целевого блока сокращается от N до R, объем данных, передаваемых устройством 200 кодирования на устройство 300 декодирования, уменьшается, так что эффективность передачи между устройством 200 кодирования и устройством 300 декодирования может быть повышена.
[156] При рассмотрении с точки зрения размера матрицы преобразования, размер матрицы регулярного преобразования составляет 64×64 (N×N), но размер матрицы сокращенного преобразования уменьшается до 16×64 (R×N), поэтому использование памяти в случае выполнения RST может быть сокращено в отношении R/N по сравнению со случаем выполнения регулярного преобразования. Кроме того, по сравнению с числом вычислений умножения N×N в случае использования матрицы регулярного преобразования, использование матрицы сокращенного преобразования может уменьшить число вычислений умножения в отношении R/N (R×N).
[157] В примере, преобразователь 232 устройства 200 кодирования может выводить коэффициенты преобразования для целевого блока путем выполнения первичного преобразования и основанного на RST вторичного преобразования на остаточных выборках для целевого блока. Эти коэффициенты преобразования могут передаваться на обратный преобразователь устройства 300 декодирования, и обратный преобразователь 322 устройства 300 декодирования может выводить модифицированные коэффициенты преобразования на основе обратного сокращенного вторичного преобразования (RST) для коэффициентов преобразования и может выводить остаточные выборки для целевого блока на основе обратного первичного преобразования для модифицированных коэффициентов преобразования.
[158] Размер матрицы TN×R обратного RST в соответствии с примером на N×R меньше, чем размер N×N матрицы регулярного обратного преобразования, и находится в отношении транспозиции с матрицей TR×N сокращенного преобразования, показанной в уравнении 4.
[159] Матрица Tt в блоке сокращенного обратного преобразования, показанном на фиг. 7(b), может означать матрицу TR×NТ обратного RST (надстрочный индекс T означает транспозицию). Когда матрица TR×NТ обратного RST умножается на коэффициенты преобразования для целевого блока, как показано на фиг. 7(b), могут быть выведены модифицированные коэффициенты преобразования для целевого блока или остаточные выборки для текущего блока. Матрица TR×NТ обратного RST может быть выражена как (TR×NТ)N×R.
[160] Более конкретно, когда обратное RST применяется как вторичное обратное преобразование, модифицированные коэффициенты преобразования для целевого блока могут быть выведены, когда матрица TR×NТ обратного RST умножается на коэффициенты преобразования для целевого блока. Между тем, обратное RST может применяться как обратное первичное преобразование, и в этом случае могут быть выведены остаточные выборки для целевого блока, когда матрица TR×NТ обратного RST умножается на коэффициенты преобразования для целевого блока.
[161] В примере, если размер блока, к которому применяется обратное преобразование, составляет 8×8 и R=16 (т.е. R/N=16/64= 1/4), то RST в соответствии с фиг. 7(b) может быть выражено как матричная операция, как показано в Уравнение 7 ниже.
[162] [Уравнение 7]

[163] В Уравнении 7, c1-c16 могут представлять коэффициенты преобразования для целевого блока. В результате вычисления Уравнения 7 могут быть выведены ri, представляющие модифицированные коэффициенты преобразования для целевого блока или остаточные выборки для целевого блока, и процесс выведения ri может быть таким, как в Уравнении 8.
[164] [Уравнение 8]

[165] В результате вычисления Уравнения 8 могут быть выведены r1 до rN, представляющие модифицированные коэффициенты преобразования для целевого блока или остаточные выборки для целевого блока. При рассмотрении с точки зрения размера матрицы обратного преобразования, размер матрицы регулярного обратного преобразования составляет 64×64 (N×N), но размер матрицы сокращенного обратного преобразования уменьшается до 64×16 (R×N), так что использование памяти в случае выполнения обратного RST может быть уменьшено в отношении R/N по сравнению со случаем выполнения регулярного обратного преобразования. Дополнительно, по сравнению с числом вычислений умножения N×N в случае использования матрицы регулярного обратного преобразования, использование матрицы сокращенного обратного преобразования может уменьшить число вычислений умножения в отношении R/N (N×R).
[166] Конфигурация набора преобразований, показанная в Таблице 2, может применяться к 8×8 RST. То есть 8×8 RST может применяться в соответствии с набором преобразований в Таблице 2. Поскольку один набор преобразований включает в себя два или три преобразования (ядра) в соответствии с режимом интра-предсказания, он может быть сконфигурирован для выбора одного из до четырех преобразований, включая случай, когда вторичное преобразование не применяется. В преобразовании, где вторичное преобразование не применяется, это может учитываться, чтобы применять единичную матрицу. Предполагая, что индексы 0, 1, 2 и 3 соответственно назначены четырем преобразованиям (например, индекс 0 может быть выделен для случая, когда применяется единичная матрица, то есть, случая, когда вторичное преобразование не применяется), индекс преобразование или индекс lfnst в качестве синтаксического элемента может сигнализироваться для каждого блока коэффициентов преобразования, тем самым указывая применяемое преобразование. То есть, для верхнего-левого блока 8×8, с помощью индекса преобразования, можно указать 8×8 RST в конфигурации RST или указать 8×8 lfnst, когда применяется LFNST. 8×8 lfnst и 8×8 RST относятся к преобразованиям, применимым к области 8×8, включенной в блок коэффициентов преобразования, когда W и H целевого блока, подлежащего преобразованию, равны или больше чем 8, и область 8×8 может быть верхней-левой областью 8×8 в блоке коэффициентов преобразования. Аналогично, 4×4 lfnst и 4×4 RST относятся к преобразованиям, применимым к области 4×4, включенной в блок коэффициентов преобразования, когда W и H целевого блока равны или больше чем 4, и область 4×4 может быть верхней-левой областью 4×4 в блоке коэффициентов преобразования.
[167] В соответствии с вариантом осуществления настоящего раскрытия, для преобразования в процессе кодирования, только 48 частей данных могут быть выбраны, и матрица максимум 16×48 ядра преобразования может применяться к ним, вместо применения матрицы 16×64 ядра преобразования к 64 частям данных, образующих область 8×8. Здесь, "максимум" означает, что m имеет максимальное значение 16 в матрице m×48 ядра преобразования для генерации m коэффициентов. То есть, когда RST выполняется путем применения матрицы m×48 ядра преобразования (m≤16) к области 8×8, вводятся 48 частей данных, и генерируются m коэффициентов. Когда m равно 16, вводятся 48 частей данных, и генерируются 16 коэффициентов. То есть, предполагая, что 48 частей данных формируют вектор 48×1, матрица 16×48 и вектор 48×1 последовательно умножаются, тем самым генерируя вектор 16×1. Здесь, 48 частей данных, формирующих область 8×8, могут надлежащим образом располагаться, формируя при этом вектор 48×1. Например, вектор 48×1 может быть сформирован на основе 48 частей данных, образующих область, исключая нижнюю-правую область 4×4 среди областей 8×8. Здесь, когда матричная операция выполняется путем применения матрицы максимум 16×48 ядра преобразования, генерируются 16 модифицированных коэффициентов преобразования, и 16 модифицированных коэффициентов преобразования могут быть упорядочены в верхней-левой области 4×4 в соответствии с порядком сканирования, и верхняя-правая область 4×4 и нижняя-левая область 4×4 могут быть заполнены нулями.
[168] Для обратного преобразования в процессе декодирования, может использоваться транспонированная матрица вышеописанной матрицы ядра преобразования. То есть, когда обратное RST или LFNST выполняется в процессе обратного преобразования устройством декодирования, входные данные коэффициентов, к которым применяется обратное RST, конфигурируются в одномерный вектор в соответствии с предопределенным порядком расположения, и вектор модифицированных коэффициентов, полученный умножением одномерного вектора и соответствующей матрицы обратного RST слева от одномерного вектора, может быть упорядочен в двумерный блок в соответствии с предопределенным порядком расположения.
[169] В итоге в процессе преобразования, когда RST или LFNST применяется к области 8×8, матричная операция применяется к 48 коэффициентам преобразования в верхней-левой, верхней-правой и нижней-левой областях области 8×8, исключая нижнюю-правую область среди коэффициентов преобразования в области 8×8 и матрицы 16×48 ядра преобразования. Для матричной операции, 48 коэффициентов преобразования вводятся в одномерном массиве. Когда выполняется матричная операция, выводятся 16 модифицированных коэффициентов преобразования, и модифицированные коэффициенты преобразования могут быть упорядочены в верхней-левой области в области 8×8.
[170] Напротив, в процессе обратного преобразования, когда обратное RST или LFNST применяется к области 8×8, 16 коэффициентов преобразования, соответствующих верхней-левой области в области 8×8 среди коэффициентов преобразования в области 8×8, могут вводиться в одномерном массиве в соответствии с порядком сканирования и могут подвергаться матричной операции с матрицей 48×16 ядра преобразования. То есть матричная операция может быть выражена как (матрица 48×16)*(вектор 16×1 коэффициентов преобразования)=(вектор 48×1 модифицированных коэффициентов преобразования). Здесь вектор n×1 может интерпретироваться, чтобы иметь то же самое значение, что и матрица n×1, и может, таким образом, выражаться как вектор-столбец n×1. Кроме того, * означает матричное умножение. Когда выполняется матричная операция, могут быть выведены 48 модифицированных коэффициентов преобразования, и 48 модифицированных коэффициентов преобразования могут быть упорядочены в верхней-левой, верхней-правой и нижней-левой областях в области 8×8, исключая нижнюю-правую область.
[171] Когда вторичное обратное преобразование основано на RST, обратный преобразователь 235 устройства 200 кодирования и обратный преобразователь 322 устройства 300 декодирования могут включать в себя обратный сокращенный вторичный преобразователь для выведения модифицированных коэффициентов преобразования на основе обратного RST на коэффициентах преобразования и обратный первичный преобразователь для выведения остаточных выборок для целевого блока на основе обратного первичного преобразования на модифицированных коэффициентах преобразования. Обратное первичное преобразование относится к обратному преобразованию первичного преобразования, применяемого к остатку. В настоящем раскрытии, выведение коэффициента преобразования на основе преобразования может относиться к выведению коэффициента преобразования путем применения преобразования.
[172] Вышеописанное неразделенное преобразование, LFNST, будет описано детально следующим образом. LFNST может включать в себя прямое преобразование устройством кодирования и обратное преобразование устройством декодирования.
[173] Устройство кодирования принимает результат (или часть результата), выведенный после применения первичного (основного) преобразования в качестве входа, и применяет прямое вторичное преобразование (вторичное преобразование).
[174] [Уравнение 9]
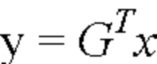
[175] В Уравнении 9, x и y являются входами и выходами вторичного преобразования, соответственно, и G является матрицей, представляющей вторичное преобразование, и базисные векторы преобразования образованы вектор-столбцами. В случае обратного LFNST, когда размерность матрицы преобразования G выражается как [число строк × число столбцов], в случае прямого LFNST, транспозиция матрицы G становится размерностью GT.
[176] Для обратного LFNST, размерностями матрицы G являются [48×16], [48×8], [16×16], [16×8], и матрица [48×8] и матрица [16×8] являются частичными матрицами, полученными дискретизацией 8 базисных векторов преобразования слева матрицы [48×16] и матрицы [16×16], соответственно.
[177] С другой стороны, для прямого LFNST, размерностями матрицы GT являются [16×48], [8×48], [16×16], [8×16], и матрица [8×48] и матрица [8×16] являются частичными матрицами, полученными дискретизацией 8 базисных векторов преобразования сверху матрицы [16×48] и матрицы [16×16], соответственно.
[178] Поэтому, в случае прямого LFNST, вектор [48×1] или вектор [16×1] возможен как вход x, и вектор [16×1] или вектор [8×1] возможен как выход y. В кодировании и декодировании видео, выход прямого первичного преобразования является двумерными (2D) данными, поэтому для формирования вектора [48×1] или вектора [16×1] в качестве входа x, одномерный вектор должен формироваться путем надлежащего упорядочивания 2D данных, которые являются выходом прямого преобразования.
[179] Фиг. 8 является диаграммой, иллюстрирующей последовательность компоновки выходных данных прямого первичного преобразования в одномерный вектор в соответствии с примером. Левые диаграммы (a) и (b) на фиг. 8 показывают последовательность для формирования вектора [48×1], и правые диаграммы (a) и (b) на фиг. 8 показывают последовательность для формирования вектора [16×1]. В случае LFNST, одномерный вектор x может быть получен путем последовательной компоновки 2D данных в том же порядке, что и в (a) и (b) на фиг. 8.
[180] Направление компоновки выходных данных прямого первичного преобразования может определяться в соответствии с режимом интра-предсказания текущего блока. Например, когда режим интра-предсказания текущего блока находится в горизонтальном направлении относительно диагонального направления, выходные данные прямого первичного преобразования могут быть скомпонованы в порядке согласно фиг. 8(a), и когда режим интра-предсказания текущего блока находится в вертикальном направлении относительно диагонального направления, выходные данные прямого первичного преобразования могут быть скомпонованы в порядке согласно фиг. 8(b).
[181] В соответствии с примером, может применяться порядок компоновки, отличающийся от порядков компоновки на фиг. 8(a) и (b), и чтобы получить тот же результат (вектор y), что и получаемый при применении порядков компоновки на фиг. 8(a) и (b), вектор-столбцы матрицы G могут быть переупорядочены в соответствии с порядком компоновки. То есть можно переупорядочить вектор-столбцы G так, что каждый элемент, составляющий вектор x, всегда умножается на тот же самый базисный вектор преобразования.
[182] Поскольку выход y, полученный с помощью Уравнения 9, является одномерным вектором, когда требуются двумерные данные в качестве входных данных в процессе использования результата прямого вторичного преобразования в качестве входа, например, в процессе выполнения квантования или кодирования остатка, выходной вектор y в Уравнении 9 должен быть надлежащим образом снова скомпонован как 2D данные.
[183] Фиг. 9 является диаграммой, иллюстрирующей последовательность компоновки выходных данных прямого вторичного преобразования в двумерный вектор в соответствии с примером.
[184] В случае LFNST выходные значения могут быть скомпонованы в 2D блок в соответствии с предопределенным порядком сканирования. Фиг. 9(a) показывает, что когда выходом y является вектор [16×1], выходные значения скомпонованы в 16 положениях 2D блока в соответствии с порядком диагонального сканирования. Фиг. 9(b) показывает, что когда выходом y является вектор [8×1], выходные значения скомпонованы в 8 положениях 2D блока в соответствии с порядком диагонального сканирования, и остальные 8 положений заполнены нулями. X на фиг. 9(b) указывает, что это положение заполнено нулем.
[185] В соответствии с другим примером, поскольку порядок, в котором обрабатывается выходной вектор y при выполнении квантования или кодирования остатка, может быть предварительно установлен, выходной вектор y может не компоноваться в 2D блок, как показано на фиг. 9. Однако в случае кодирования остатка кодирование данных может выполняться в единицах 2D блока (например, 4×4), таких как CG (группа коэффициентов), и в этом случае, данные компонуются в соответствии с конкретным порядком, как в порядке диагонального сканирования на фиг. 9.
[186] Между тем устройство декодирования может конфигурировать одномерный входной вектор y путем компоновки двумерных данных, выводимых с помощью процесса деквантования или тому подобного, в соответствии с предварительно установленным порядком сканирования для обратного преобразования. Входной вектор y может выводиться как выходной вектор x посредством следующего уравнения.
[187] [Уравнение 10]
x=Gy
[188] В случае обратного LFNST выходной вектор x может выводиться путем умножения входного вектора y, который представляет собой вектор [16×1] или вектор [8×1], на матрицу G. Для обратного LFNST, выходной вектор x может представлять собой либо вектор [48×1], либо вектор [16×1].
[189] Выходной вектор x компонуется в двумерный блок в соответствии с порядком, показанным на фиг. 8, и компонуется как двумерные данные, и эти двумерные данные становятся входными данными (или частью входных данных) обратного первичного преобразования.
[190] Соответственно, обратное вторичное преобразование представляет собой в целом процесс, противоположный процессу прямого вторичного преобразования, и в случае обратного преобразования, в отличие от прямого направления, сначала применяется обратное вторичное преобразование, а затем применяется обратное первичное преобразование.
[191] В обратном LFNST, одна из 8 матриц [48×16] и 8 матриц [16×16] может быть выбрана как матрица G преобразования. Следует ли применять матрицу [48×16] или матрицу [16×16], зависит от размера и формы блока.
[192] Кроме того, 8 матриц могут быть выведены из четырех наборов преобразований, как показано в Таблице 2 выше, и каждый набор преобразований может состоять из двух матриц. То, какой набор преобразований использовать среди 4 наборов преобразований, определяется в соответствии с режимом интра-предсказания, и более конкретно, набор преобразований определяется на основе значения режима интра-предсказания, расширенного с учетом широкоугольного интра-предсказания (WAIP). То, какую матрицу выбрать из двух матриц, составляющих выбранный набор преобразований, выводится с помощью сигнализации индекса. Более конкретно, 0, 1 и 2 возможны в качестве передаваемого значения индекса, 0 может указывать, что LFNST не применяется, и 1 и 2 могут указывать любую одну из двух матриц преобразования, составляющих набор преобразований, выбранный на основе значения режима интра-предсказания.
[193] Фиг. 10 является диаграммой, иллюстрирующей широкоугольные режимы интра-предсказания в соответствии с вариантом осуществления настоящего документа.
[194] Обычное значение режима интра-предсказания может иметь значения от 0 до 66 и от 81 до 83, а значение режима интра-предсказания, расширенное вследствие WAIP, может иметь значение от -14 до 83, как показано. Значения от 81 до 83 указывают режим CCLM (линейная модель перекрестного компонента), и значения от -14 до -1 и значения от 67 до 80 указывают режим интра-предсказания, расширенный вследствие применения WAIP.
[195] Когда ширина текущего блока предсказания больше, чем высота, верхние опорные пикселы обычно ближе к положениям внутри предсказываемого блока. Поэтому, было бы более точным предсказывать в нижнем-левом направлении, чем в верхнем-правом направлении. Напротив, когда высота блока больше, чем ширина, левые опорные пикселы обычно ближе к положениям внутри предсказываемого блока. Поэтому, может быть более точным предсказывать в верхнем-правом направлении, чем в нижнем-левом направлении. Поэтому, может быть предпочтительным применить повторное отображение, т.е. модификацию индекса режима, на индекс режима широкоугольного интра-предсказания.
[196] Когда применяется широкоугольное интра-предсказание, информация о существующем интра-предсказании может сигнализироваться, и после того как данная информация будет получена посредством синтаксического анализа, эта информация может повторно отображаться на индекс режима широкоугольного интра-предсказания. Поэтому, общее число режимов интра-предсказания для конкретного блока (например, неквадратного блока конкретного размера) может не изменяться, и общее число режимов интра-предсказания равно 67, и кодирование режима интра-предсказания для конкретного блока может не изменяться.
[197] Таблица 3 ниже показывает процесс выведения модифицированного интра-режима путем повторного отображения режима интра-предсказания на режим широкоугольного интра-предсказания.
[198] [Таблица 3]
- переменная predModeIntra, специфицирующая режим интра-предсказания,
- переменная nTbW, специфицирующая ширину блока преобразования,
- переменная nTbH, специфицирующая высоту блока преобразования,
- переменная cIdx, специфицирующая цветовой компонент текущего блока.
Выходом этого процесса является модифицированный режим интра-предсказания predModeIntra.
Переменные nW и nH выводятся следующим образом:
- Если IntraSubPartitionsSplitType равно ISP_NO_SPLIT или cIdx не равно 0, то применимо следующее:
nW=nTbW (8-97)
nH=nTbH (8-98)
- Иначе (IntraSubPartitionsSplitType не равно ISP_NO_SPLIT, и cIdx равно 0), применимо следующее:
nW=nCbW (8-99)
nH=nCbH (8-100)
Переменная whRatio устанавливается равной Abs(Log2(nW/nH)).
Для неквадратных блоков (nW не равно nH), режим интра-предсказания predModeIntra модифицируется следующим образом:
- Если все из следующих условий справедливы, то predModeIntra устанавливается равным (predModeIntra+65),
-- nW больше, чем nH
-- predModeIntra больше или равно 2
-- predModeIntra меньше, чем (whRatio > 1)?(8+2* whRatio) : 8
- Иначе, если все из следующих условий справедливы, то predModeIntra устанавливается равным (predModeIntra - 67),
-- nH больше, чем nW
-- predModeIntra меньше или равно 66
-- predModeIntra больше, чем (whRatio > 1)?(60-2* whRatio): 60
[199] В Таблице 3 значение расширенного режима интра-предсказания окончательно сохраняется в переменной predModeIntra, и ISP_NO_SPLIT указывает, что блок CU не делится на подразбиения посредством метода интра-подразбиений (ISP), принятого в настоящее время в стандарте VVC, и значения 0, 1 и 2 переменной cIdx указывают случай компонентов яркости, Cb и Cr, соответственно. Функция Log2, показанная в Таблице 3, возвращает значение log с основанием 2, и функция Abs возвращает абсолютное значение.
[200] Переменная predModeIntra, указывающая режим интра-предсказания, и высота и ширина блока преобразования и т.д. используются как входные значения процесса отображения режима широкоугольного интра-предсказания, и выходным значением является модифицированный режим интра-предсказания predModeIntra. Высота и ширина блока преобразования или блока кодирования могут быть высотой и шириной текущего блока для повторного отображения режима интра-предсказания. При этом, переменная whRatio, отражающая отношение ширины к высоте, может быть установлена в Abs(Log2(nW/nH)).
[201] Для неквадратного блока режим интра-предсказания может быть разделен на два случая и модифицирован.
[202] Во-первых, если все условия от (1) до (3) удовлетворены, (1) ширина текущего блока больше, чем высота, (2) режим интра-предсказания перед модифицированием равен или больше чем 2, (3) режим интра-предсказания меньше, чем значение, выведенное из (8+2*whRatio), когда переменная whRatio больше чем 1, и меньше чем 8, когда переменная whRatio меньше или равна 1 [predModeIntra меньше, чем (whRatio>1)?(8+2*whRatio):8], режим интра-предсказания установлен в значение 65 больше, чем режим интра-предсказания [predModeIntra установлено равным (predModeIntra+65)].
[203] Если в отличие от вышеизложенного, то есть, следующие условия от (1) до (3) удовлетворены: (1) высота текущего блока больше, чем ширина, (2) режим интра-предсказания перед модифицированием меньше или равен 66, (3) режим интра-предсказания больше, чем значение, выведенное из (60−2*whRatio), когда переменная whRatio больше чем 1, и больше чем 60, когда переменная whRatio меньше или равна 1 [predModeIntra больше, чем (whRatio>1) ? (60−2*whRatio):60], режим интра-предсказания установлен в значение 67 меньше, чем режим интра-предсказания [predModeIntra установлено равным (predModeIntra−67)].
[204] Таблица 2 выше показывает, как набор преобразований выбирается на основе значения режима интра-предсказания, расширенного посредством WAIP в LFNST. Как показано на фиг. 10, режимы от 14 до 33 и режимы от 35 до 80 симметричны относительно направления предсказания вокруг режима 34. Например, режим 14 и режим 54 симметричны относительно направления, соответствующего режиму 34. Поэтому, тот же самый набор преобразований применяется к режимам, расположенным во взаимно симметричных направлениях, и эта симметрия также отражается в Таблице 2.
[205] Между тем, предполагается, что входные данные прямого LFNST для режима 54 симметричны с входными данными прямого LFNST для режима 14. Например, для режима 14 и режима 54, двумерные данные переупорядочиваются в одномерные данные в соответствии с порядком компоновки, показанным на фиг. 8(a) и фиг. 8(b), соответственно. Кроме того, можно видеть, что шаблоны в порядке, показанном на фиг. 8(a) и фиг. 8(b), симметричны относительно направления (диагонального направления), указанного режимом 34.
[206] Между тем, как описано выше, то, какая матрица преобразования из матрицы [48×16] и матрицы [16 ×16] применяется к LFNST, определяется размером и формой целевого блока преобразования.
[207] Фиг. 11 является диаграммой, иллюстрирующей форму блока, к которой применяется LFNST. Фиг. 11(a) показывает блоки 4×4, (b) показывает блоки 4×8 и 8×4, (c) показывает блоки 4×N или блоки N×4, в которых N равно 16 или более, (d) показывает блоки 8×8, (e) показывает блоки M×N, где M≥8, N≥8 и N>8 или M>8.
[208] На фиг. 11 блоки с жирными границами указывают области, к которым применяется LFNST. Для блоков согласно фиг. 11(a) и (b), LFNST применяется к верхней-левой области 4×4, и для блока согласно фиг. 11(c), LFNST применяется индивидуально к двум верхним-левым областям 4×4, которые расположены смежно. На фиг. 11(a), (b) и (c), поскольку LFNST применяется в единицах областей 4×4, это LFNST будет далее упоминаться как "4×4 LFNST". В качестве соответствующей матрицы преобразования, матрица [16×16] или матрица [16×8] может применяться на основе размерности матрицы G в уравнениях 9 и 10.
[209] Более конкретно, матрица [16×8] применяется к блоку 4×4 (TU 4×4 или CU 4×4) согласно фиг. 11(a), и матрица [16×16] применяется к блокам на фиг. 11(b) и (c). Это предназначено для регулирования вычислительной сложности для наихудшего случая до 8 умножений на выборку.
[210] В отношении фиг. 11(d) и (e), LFNST применяется к верхней-левой области 8×8, и это LFNST далее упоминается как "8×8 LFNST". В качестве соответствующей матрицы преобразования, может применяться матрица [48×16] или матрица [48×8]. В случае прямого LFNST, поскольку вектор [48×1] (вектор x в Уравнении 9) вводится в качестве входных данных, значения всех выборок верхней-левой области 8×8 не используются в качестве входных значений прямого LFNST. То есть, как можно видеть в левой компоновке на фиг. 8(a) или левой компоновке на фиг. 8(b), вектор [48×1] может быть сформирован на основе выборок, принадлежащих остальным 3 блокам 4×4, оставляя нижний правый блок 4×4, как он есть.
[211] Матрица [48×8] может применяться к блоку 8×8 (TU 8×8 или CU 8×8) на фиг. 11(d), и матрица [48×16] может применяться к блоку 8×8 на фиг. 11(e). Это также предназначено для регулирования вычислительной сложности для наихудшего случая до 8 умножений на выборку.
[212] В зависимости от формы блока, когда применяется соответствующее прямое LFNST (4×4 LFNST или 8×8 LFNST), генерируется 8 или 16 выходных данных (вектор y в Уравнении 9, вектор [8×1] или [16×1]). В прямом LFNST, число выходных данных равно или меньше, чем число входных данных, вследствие характеристик матрицы GT.
[213] Фиг. 12 является диаграммой, иллюстрирующей компоновку выходных данных прямого LFNST в соответствии с примером, и показывает блок, в котором выходные данные прямого LFNST скомпонованы в соответствии с формой блока.
[214] Затененная область верхнего-левого блока, показанного на фиг. 12, соответствует области, где расположены выходные данные прямого LFNST, положения, маркированные 0, указывают выборки, заполненные значениями 0, и остальная область представляет области, не измененные прямым LFNST. В области, не измененной посредством LFNST, выходные данные прямого первичного преобразования остаются неизменными.
[215] Как описано выше, поскольку размерность примененной матрицы преобразования варьируется в соответствии с формой блока, число выходных данных также варьируется. Как показано на фиг. 12, выходные данные прямого LFNST могут не полностью заполнять верхний-левый блок 4×4. В случае фиг. 12(a) и (d), матрица [16×8] и матрица [48×8] применяются к блоку, указанному жирной линией, или частичной области внутри блока, соответственно, и вектор [8×1] генерируется в качестве выхода прямого LFNST. То есть в соответствии с порядком сканирования, показанным на фиг. 9(b), только 8 выходных данных может быть заполнено, как показано на фиг. 12(a) и (d), и 0 может быть заполнен в остальных 8 положениях. В случае применяемого блока LFNST согласно фиг. 11(d), как показано на фиг. 12(d), два блока 4×4 сверху-справа и снизу-слева от верхнего-левого блока 4×4 также заполнены значениями 0.
[216] Как описано выше, в основном, путем сигнализации индекса LFNST, задается то, следует ли применять LFNST, и матрица преобразования, подлежащая применению. Как показано на фиг. 12, когда применяется LFNST, поскольку число выходных данных прямого LFNST может быть равно или меньше, чем число входных данных, возникает область, заполненная нулевыми значениями, следующим образом.
[217] 1) Как показано на фиг. 12(a), выборки из 8-го и последующих положений в порядке сканирования в верхнем-левом блоке 4×4, то есть выборки от 9-ой до 16-ой.
[218] 2) Как показано на фиг. 12(d) и (e), когда применяется матрица [16×48] или матрица [8×48], два блока 4×4, смежные с верхним-левым блоком 4×4, или второй и третий блоки 4×4 в порядке сканирования.
[219] Поэтому, если ненулевые данные существуют при проверке областей 1) и 2), то ясно, что LFNST не применяется, так что сигнализация соответствующего индекса LFNST может опускаться.
[220] В соответствии с примером, например, в случае LFNST, принятого в стандарте VVC, поскольку сигнализация индекса LFNST выполняется после кодирования остатка, устройство кодирования может знать, имеются ли ненулевые данные (значимые коэффициенты) для всех положений в блоке TU или CU посредством кодирования остатка. Соответственно, устройство кодирования может определять, следует ли выполнять сигнализацию по индексу LFNST, на основе существования ненулевых данных, и устройство декодирования может определять, анализируется ли индекс LFNST. Когда ненулевые данные не существуют в области, указанной выше в 1) и 2), выполняется сигнализация индекса LFNST.
[221] Между тем для принятого LFNST, могут применяться следующие способы упрощения.
[222] (i) В соответствии с примером, число выходных данных для прямого LFNST может быть ограничено максимум до 16.
[223] В случае фиг. 11(с), 4×4 LFNST может применяться к двум областям 4×4, смежным сверху-слева, соответственно, и в этом случае может генерироваться максимум 32 LFNST выходных данных. Когда число выходных данных для прямого LFNST ограничено до максимум 16, в случае блоков 4×N/N×4 (N≥16) (TU или CU), 4×4 LFNST применяется только к одной области 4×4 сверху-слева, LFNST может применяться только однократно ко всем блокам на фиг. 11. За счет этого, реализация кодирования изображения может быть упрощена.
[224] (ii) В соответствии с примером, обнуление может дополнительно применяться к области, к которой не применяется LFNST. В этом документе, обнуление может означать заполнение значений всех позиций, принадлежащих конкретной области, значением 0. То есть, обнуление может применяться к области, которая не изменяется вследствие LFNST и сохраняет результат прямого первичного преобразования. Как описано выше, поскольку LFNST разделяется на 4×4 LFNST и 8×8 LFNST, обнуление может разделяться на два типа ((ii)-(A) и (ii)-(B)) следующим образом.
[225] (ii)-(A) Когда применяется 4×4 LFNST, область, к которой не применяется 4×4 LFNST, может быть обнулена. Фиг. 13 является диаграммой, иллюстрирующей обнуление в блоке, к которому применяется 4×4 LFNST, в соответствии с примером.
[226] Как показано на фиг. 13, в отношении блока, к которому применяется 4×4 LFNST, то есть, для всех блоков на фиг. 12(a), (b) и (c), вся область, к которой не применяется LFNST, может быть заполнена нулями.
[227] С другой стороны, фиг. 13(d) показывает, что когда максимальное значение числа выходных данных прямого LFNST ограничено до 16, обнуление выполняется на остальных блоках, к которым не применяется 4×4 LFNST, в соответствии с примером.
[228] (ii)-(B) Когда применяется 8×8 LFNST, область, к которой не применяется 8×8 LFNST, может быть обнулена. Фиг. 14 является диаграммой, иллюстрирующей обнуление в блоке, к которому применяется 8×8 LFNST, в соответствии с примером.
[229] Как показано на фиг. 14, в отношении блока, к которому применяется 8×8 LFNST, то есть для всех блоков на фиг. 12(d) и (e), вся область, к которой не применяется LFNST, может быть заполнена нулями.
[230] (iii) Вследствие обнуления, представленного в (ii) выше, область, заполненная нулями, может не быть той же самой, когда применяется LFNST. Соответственно, возможно проверить, существуют ли ненулевые данные, в соответствии с обнулением, предложенным в (ii), по более широкой области, чем в случае LFNST согласно фиг. 12.
[231] Например, когда применяется (ii)-(B), после проверки, существуют ли ненулевые данные, где область заполнена нулевыми значениями на фиг. 12(d) и (e) в дополнение к области, заполненной 0 дополнительно на фиг. 14, сигнализация для индекса LFNST может выполняться, только если ненулевые данные не существуют.
[232] Разумеется, даже если обнуление, предложенное в (ii), применяется, возможно проверить, существуют ли ненулевые данные, таким же образом, как существующая сигнализация индекса LFNST. То есть, после проверки, существуют ли ненулевые данные в блоке, заполненном нулями на фиг. 12, может применяться сигнализация индекса LFNST. В этом случае, только устройство кодирования выполняет обнуление, а устройство декодирования не предполагает обнуления, то есть, проверяя только, существуют ли ненулевые данные только в области, явно маркированной как 0 на фиг. 12, может выполнять синтаксический анализ индекса LFNST.
[233] Могут быть получены различные варианты осуществления, в которых применяются комбинации способов упрощения ((i), (ii)-(A), (ii)-(B), (iii)) для LFNST. Разумеется, комбинации вышеописанных способов упрощения не ограничены следующими вариантами осуществления, и любая комбинация может применяться к LFNST.
[234] Вариант осуществления
[235] - Ограничить число выходных данных для прямого LFNST до максимум 16 → (i)
[236] - Когда применяется 4×4 LFNST, все области, к которым не применяется 4×4 LFNST, обнуляются → (ii)-(A)
[237] - Когда применяется 8×8 LFNST, все области, к которым не применяется 8×8 LFNST, обнуляются → (ii)-(B)
[238] - После проверки, существуют ли ненулевые данные, также существующие области, заполненные нулевыми значениями, и области, заполненные нулями вследствие дополнительных обнулений ((ii)-(A), (ii)-(B)), индекс LFNST сигнализируется, только когда ненулевые данные не существуют → (iii)
[239] В случае варианта осуществления, когда применяется LFNST, область, в которой могут существовать ненулевые выходные данные, ограничена внутренностью верхней-левой области 4×4. Более детально, в случае фиг. 13(a) и фиг. 14(a), 8-ая позиция в порядке сканирования является последней позицией, где могут существовать ненулевые данные. В случае фиг. 13(b) и (c) и фиг. 14(b), 16-ая позиция в порядке сканирования (т.е. позиция нижнего-правого края верхнего-левого блока 4×4) является последней позицией, где могут существовать данные иные, чем 0.
[240] Поэтому, когда применяется LFNST, после проверки, существуют ли ненулевые данные в позиции, где процесс кодирования остатка не разрешен (в позиции за пределами последней позиции), может быть определено, сигнализируется ли индекс LFNST.
[241] В случае способа обнуления, предложенного в (ii), поскольку число данных, генерируемых окончательно, когда применяются как первичное преобразование, так и LFNST, объем вычислений, требуемых для выполнения всего процесса преобразования, может быть уменьшен. То есть, когда применяется LFNST, поскольку обнуление применяется к выходным данным прямого первичного преобразования, существующим в области, к которой не применяется LFNST, нет необходимости генерировать данные для области, которая становится обнуленной при выполнении прямого первичного преобразования. Соответственно, возможно уменьшить объем вычислений, требуемых для генерации соответствующих данных. Дополнительные эффекты способа обнуления, предложенного в (ii), можно резюмировать следующим образом.
[242] Во-первых, как описано выше, объем вычислений, требуемых для выполнения всего процесса преобразования, уменьшается.
[243] В частности, когда применяется (ii)-(B), объем вычислений для наихудшего случая уменьшается, так что процесс преобразования может облегчаться. Иными словами, обычно требуется большой объем вычислений для выполнения крупноразмерного первичного преобразования. Путем применения (ii)-(B), число данных, выводимых как результат выполнения прямого LFNST, может уменьшаться до 16 или менее. Кроме того, так как размер всего блока (TU или CU) увеличивается, эффект уменьшения величины операции преобразования дополнительно увеличивается.
[244] Во-вторых, объем вычислений, требуемых для всего процесса преобразования, может быть уменьшен, тем самым уменьшая энергопотребление, требуемое для выполнения преобразования.
[245] В-третьих, запаздывание, связанное с процессом преобразования, уменьшается.
[246] Вторичное преобразование, такое как LFNST, добавляет объем вычислений к существующему первичному преобразованию, таким образом, увеличивая общее время задержки, вовлеченное в выполнение преобразования. В частности, в случае интра-предсказания, поскольку восстановленные данные соседних блоков используются в процессе предсказания, во время кодирования, увеличения запаздывания вследствие вторичного преобразования приводит к увеличению в запаздывании до восстановления. Это может привести к увеличению общего запаздывания кодирования интра-предсказания.
[247] Однако, если применяется обнуление, предложенное в (ii), время задержки выполнения первичного преобразования может значительно уменьшиться, когда применяется LFNST, время задержки для всего преобразования сохраняется или уменьшается, так что устройство кодирования может быть реализовано более просто.
[248] Между тем в обычном интра-предсказании, целевой блок кодирования рассматривается как одна единица кодирования, и кодирование выполняется без ее разбиения. Однако кодирование ISP (интра-подразбиения) относится к выполнению кодирования интра-предсказания с целевым блоком кодирования, разделяемым в горизонтальном направлении или вертикальном направлении. В этом случае, восстановленный блок может генерироваться путем выполнения кодирования/декодирования в единицах разделенных блоков, и восстановленный блок может использоваться как опорный блок следующего разделенного блока. В соответствии с примером, в ISP-кодировании, один блок кодирования может разбиваться на два или четыре подблока и кодироваться, и в ISP, интра-предсказание выполняется на одном подблоке со ссылкой на восстановленное значение пиксела подблока, расположенного смежно слева или сверху от него. Далее, термин "кодирование" может использоваться как понятие, включающее в себя как кодирование, выполняемое устройством кодирования, так и декодирование, выполняемое устройством декодирования.
[249] ISP разбивает блок, предсказываемый как интра яркости, на два или четыре подразбиения в вертикальном направлении или горизонтальном направлении в соответствии с размером блока. Например, минимальный размер блока, к которому может применяться ISP, равен 4×8 или 8×4. Если размер блока больше, чем 4×8 или 8×4, блок разбивается на четыре подразбиения.
[250] Когда применяется ISP, подблоки последовательно кодируются в соответствии с типом разбиения, например по горизонтали или вертикали, слева направо или сверху вниз, и кодирование для следующего подблока может выполняться после выполнения процесса восстановления через обратное преобразование и интра-предсказание для одного подблока. Для самого левого или самого верхнего подблока, как в обычном способе интра-предсказания, ссылаются на восстановленный пиксел блока кодирования, который был уже кодирован. Дополнительно, если предыдущий подблок не является смежным с каждой стороной внутреннего подблока, который следует за ним, чтобы вывести опорные пикселы, смежные с соответствующей стороной, как в обычном способе интра-предсказания, ссылаются на восстановленный пиксел уже кодированного смежного блока кодирования.
[251] В способе ISP-кодирования все подблоки могут кодироваться с тем же самым режимом интра-предсказания, и флаг, указывающий, следует ли или нет использовать ISP-кодирование, и флаг, указывающий, в каком направлении (горизонтальном или вертикальном) должно выполняться разбиение, может сигнализироваться. В это время, число подблоков может корректироваться до 2 или 4 в зависимости от формы блока, и когда размер (ширина × высоту) одного подблока меньше, чем 16, разбиение не может разрешаться для соответствующих подблоков, и само применение ISP-кодирования может быть ограничено.
[252] Между тем в случае режима предсказания ISP, одна единица кодирования разбивается на два или четыре блока разбиения, то есть подблока, и предсказывается, и тот же самый режим интра-предсказания применяется к разделенным таким образом двум или четырем блокам разбиения.
[253] Как описано выше, как горизонтальное направление (если M×N единица кодирования, имеющая горизонтальную длину и вертикальную длину M и N, соответственно, делится в горизонтальном направлении, она делится на блоки M×(N/2) при делении на два и на блоки M×(N/4) при делении на четыре), так и вертикальное направление (если M×N единица кодирования делится в вертикальном направлении, она делится на блоки (M/2)×N при делении на два и делится на блоки (M/4)×N при делении на четыре) возможны в качестве направлений разбиения. При разбиении в горизонтальном направлении блоки разбиения кодируются в порядке сверху вниз, а при разбиении в вертикальном направлении блоки разбиения кодируются в порядке слева направо. Текущий кодируемый блок разбиения может предсказываться со ссылкой на значения восстановленных пикселов верхнего (левого) блока разбиения в случае разбиения в горизонтальном (вертикальном) направлении.
[254] Преобразование может применяться к остаточному сигналу, генерируемому способом предсказания ISP в единицах блоков разбиения. Технология MTS (выбор множественного преобразования), основанная на комбинации DST-7/DCT-8, а также существующего DCT-2, может применяться к первичному преобразованию (основному преобразованию или первичному преобразованию) на основе прямого направления, и LFNST (низкочастотное неразделимое преобразование) может применяться к коэффициенту преобразования, генерируемому в соответствии с первичным преобразованием, чтобы генерировать окончательно модифицированный коэффициент преобразования.
[255] То есть LFNST может также применяться к блокам разбиения, разделенным путем применения режима преобразования ISP, и тот же самый режим интра-предсказания применяется к разделенным блокам разбиения, как описано выше. Соответственно, при выборе набора LFNST, выведенного на основе режима интра-предсказания, выведенный набор LFNST может применяться ко всем блокам разбиения. То есть, один и тот же режим интра-предсказания применяется ко всем блокам разбиения, и при этом тот же самый набор LFNST может применяться ко всем блокам разбиения.
[256] Между тем в соответствии с примером, LFNST может применяться только к блокам преобразования, имеющим горизонтальную и вертикальную длину 4 или более. Поэтому, когда горизонтальная или вертикальная длина блока разбиения, разделенного в соответствии со способом предсказания ISP, меньше, чем 4, LFNST не применяется, и индекс LFNST не сигнализируется. Соответственно, когда LFNST применяется к каждому блоку разбиения, соответствующий блок разбиения может рассматриваться как один блок преобразования. Разумеется, когда способ предсказания ISP не применяется, LFNST может применяться к блоку кодирования.
[257] Применение LFNST к каждому блоку разбиения детально описывается следующим образом.
[258] В соответствии с примером, после применения прямого LFNST к индивидуальному блоку разбиения и после того как останется только 16 коэффициентов (8 или 16) в верхней-левой области 4×4 в соответствии с порядком сканирования коэффициентов преобразования, может применяться обнуление заполнения всех оставшихся положений и областей значением 0.
[259] Альтернативно, в соответствии с примером, когда длина одной стороны блока разбиения равна 4, LFNST применяется только к верхней-левой области 4×4, и когда длина всех сторон блока разбиения, то есть ширина и высота, равны 8 или более, LFNST может применяться к оставшимся 48 коэффициентам за исключением нижней-правой области 4×4 в верхней-левой области 8×8.
[260] Альтернативно, в соответствии с примером, чтобы отрегулировать вычислительную сложность наихудшего случая до 8 умножений на выборку, когда каждый блок разбиения равен 4×4 или 8×8, только 8 коэффициентов преобразования могут быть выведены после применения прямого LFNST. То есть, если блок разбиения равен 4×4, матрица 8×16 может применяться как матрица преобразования, и если блок разбиения равен 8×8, матрица 8×48 может применяться как матрица преобразования.
[261] Между тем, в современном стандарте VVC, сигнализация индекса LFNST выполняется в единицах кодирования. Соответственно, когда используется режим предсказания ISP и LFNST применяется ко всем блокам разбиения, одинаковое значение индекса LFNST может применяться к соответствующим блокам разбиения. То есть, когда значение индекса LFNST однократно передается на уровне единицы кодирования, соответствующий индекс LFNST может применяться ко всем блокам разбиения в единице кодирования. Как описано выше, значение индекса LFNST может иметь значения 0, 1 и 2; 0 указывает случай, в котором LFNST не применяется, 1 и 2 указывают две матрицы преобразования, присутствующие в одном наборе LFNST, когда LFNST применяется.
[262] Как описано выше, набор LFNST определяется режимом интра-предсказания, и поскольку все блоки разбиения в единице кодирования предсказываются в том же самом режиме интра-предсказания в случае режима предсказания ISP, блоки разбиения могут ссылаться на один и тот же набор LFNST.
[263] В качестве другого примера, сигнализация индекса LFNST все еще выполняется в единицах кодирования, но в случае режима предсказания ISP, без определения того, следует ли или нет применять LFNST равномерно ко всем блокам разбиения, то, следует ли применять значение индекса LFNST, сигнализируемое на уровне единицы кодирования, к каждому блоку разбиения или не применять LFNST, может определяться посредством отдельного условия. Здесь, отдельное условие может сигнализироваться в форме флага для каждого блока разбиения посредством битового потока, и когда значение флага равно 1, может применяться значение индекса LFNST, сигнализируемое на уровне единицы кодирования, а когда значение флага равно 0, LFNST может не применяться.
[264] Далее, будет описан способ поддержания вычислительной сложности для наихудшего случая, когда LFNST применяется к режиму ISP.
[265] В случае режима ISP, чтобы поддерживать число умножений на выборку (или на коэффициент, или на позицию) на определенном уровне или менее, когда применяется LFNST, применение LFNST может быть ограничено. В зависимости от размера блока разбиения, число умножений на выборку (или на коэффициент, или на позицию) может поддерживаться на 8 или менее путем применения LFNST следующим образом.
[266] 1. Когда как горизонтальная длина, так и вертикальная длина блока разбиения равны или больше чем 4, может применяться тот же самый способ, что и способ корректировки вычислительной сложности для наихудшего случая для LFNST в современном стандарте VVC.
[267] То есть, когда блок разбиения является блоком 4×4, вместо матрицы 16×16, в прямом направлении, может применяться матрица 8×16, полученная дискретизацией верхних 8 строк из матрицы 16×16, а в обратном направлении может применяться матрица 16×8, полученная дискретизацией левых 8 столбцов из матрицы 16×16. Дополнительно, когда блок разбиения представляет собой блок 8×8, в прямом направлении, вместо матрицы 16×48, может применяться матрица 8×48, полученная дискретизацией верхних 8 строк из матрицы 16×48, а в обратном направлении, вместо матрицы 48×16, может применяться матрица 48×8, полученная дискретизацией левых 8 столбцов из матрицы 48×16.
[268] В случае блока 4×N или N×4 (N>4), когда выполняется прямое преобразование, 16 коэффициентов, генерируемых после применения матрицы 16×16 только к верхнему-левому блоку 4×4, упорядочиваются в верхней-левой области 4×4, а другие области могут заполняться нулевыми значениями. Дополнительно, при выполнении обратного преобразования, 16 коэффициентов, расположенных в верхнем-левом блоке 4×4, могут упорядочиваться в порядке сканирования, чтобы конфигурировать входной вектор, и затем 16 выходных данных могут генерироваться путем умножения на матрицу 16×16. Сгенерированные выходные данные могут быть упорядочены в верхней-левой области 4×4, а остальные области за исключением верхней-левой области 4×4 могут быть заполнены нулями.
[269] В случае блока 8×N или N×8 (N>8), когда выполняется прямое преобразование, 16 коэффициентов, генерируемых после применения матрицы 16×48 только к области ROI в верхнем-левом блоке 8×8 (остальные области, исключающие нижний-правый блок 4×4 из верхнего-левого блока 8×8), могут упорядочиваться в верхней-левой области 4×4, а другие области могут быть заполнены нулевыми значениями. Дополнительно, при выполнении обратного преобразования, 16 коэффициентов, расположенных в верхнем-левом блоке 4×4, могут упорядочиваться в порядке сканирования, чтобы конфигурировать входной вектор, и затем 48 выходных данных могут генерироваться путем умножения на матрицу 48×16. Сгенерированные выходные данные могут заполнять область ROI, а другие области могут быть заполнены нулевыми значениями.
[270] В качестве другого примера, чтобы поддерживать число умножений на выборку (или на коэффициент или на положение) на некотором значении или менее, число умножений на выборку (или на коэффициент или на положение), основанное на размере единицы кодирования ISP, а не размере блока разбиения ISP, может поддерживаться на 8 или менее. Если имеется только один блок среди блоков разбиения ISP, который удовлетворяет условию, при котором применяется LFNST, вычисление сложности для наихудшего случая LFNST может применяться на основе соответствующего размера единицы кодирования, а не размера блока разбиения. Например, когда блок кодирования яркости для определенной единицы кодирования разбивается на 4 блока разбиения размером 4×4 и кодируется посредством ISP, и когда ненулевой коэффициент преобразования существует для двух блоков разбиения среди них, другие два блока разбиения могут быть соответственно установлены, чтобы генерировать 16 коэффициентов преобразования вместо 8 (на основе кодера).
[271] Далее будет описан способ сигнализации индекса LFNST в случае режима ISP.
[272] Как описано выше, индекс LFNST может иметь значения 0, 1 и 2, где 0 указывает, что LFNST не применяется, и 1 и 2 соответственно указывают любую одну из двух матриц ядра LFNST, включенных в выбранный набор LFNST. LFNST применяется на основе матрицы ядра LFNST, выбранной посредством индекса LFNST. Способ передачи индекса LFNST в текущем стандарте VVC будет описан следующим образом.
[273] 1. Индекс LFNST может передаваться однократно для каждой единицы кодирования (CU), и в случае дуального дерева индивидуальные индексы LFNST могут сигнализироваться для блока яркости и блока цветности, соответственно.
[274] 2. Когда индекс LFNST не сигнализируется, значение индекса LFNST подразумевается равным значению по умолчанию 0. Случай, когда значение индекса LFNST подразумевается равным 0, является следующим.
[275] A. В случае режима, в котором не применяется преобразование (например, пропуск преобразования, BDPCM, кодирование без потерь и т.д.)
[276] B. Когда первичным преобразованием является не DCT-2 (DST7 или DCT8), то есть, когда преобразованием в горизонтальном направлении или преобразованием в вертикальном направлении является не DCT-2
[277] C. Когда горизонтальная длина или вертикальная длина для блока яркости единицы кодирования превышает размер преобразуемого максимального преобразования яркости, например, когда размер преобразуемого максимального преобразования яркости равен 64, и когда размер для блока яркости блока кодирования равен 128×16, LFNST не может применяться.
[278] В случае дуального дерева определяется, превышается ли или нет размер максимального преобразования яркости для каждой из единицы кодирования для компонента яркости и единицы кодирования для компонента цветности. То есть для блока яркости проверяется, превышается ли размер максимального преобразуемого преобразования яркости, и для блока цветности проверяется, превышаются ли горизонтальная/вертикальная длина соответствующего блока яркости для цветового формата и размер преобразуемого максимального преобразования яркости. Например, когда цветовым форматом является 4:2:0, горизонтальная/вертикальная длина соответствующего блока яркости равна двукратной длине соответствующего блока цветности, и размер преобразования соответствующего блока яркости равен двукратному размеру соответствующего блока цветности. В качестве другого примера, когда цветовым форматом является 4:4:4, горизонтальная/вертикальная длина и размер преобразования соответствующего блока яркости являются теми же самыми, что и размеры соответствующего блока цветности.
[279] Преобразование длиной 64 или преобразование длиной 32 могут означать преобразование, применимое к ширине или высоте, имеющей длину 64 или 32, соответственно, и "размер преобразования" может означать 64 или 32 в качестве соответствующей длины.
[280] В случае одиночного дерева, после проверки того, превышает ли или нет горизонтальная длина или вертикальная длина блока яркости максимальный размер преобразуемого блока преобразования яркости, если он превышает, то сигнализация индекса LFNST может быть опущена.
[281] D. Индекс LFNST может передаваться, только когда горизонтальная длина и вертикальная длина единицы кодирования равны или больше чем 4.
[282] В случае дуального дерева, индекс LFNST может сигнализироваться, только когда как горизонтальная, так и вертикальная длины для соответствующего компонента (т.е. компонента яркости или цветности) равны или больше чем 4.
[283] В случае одиночного дерева, индекс LFNST может сигнализироваться, когда как горизонтальная, так и вертикальная длины для компонента яркости равны или больше чем 4.
[284] E. Если положение последнего ненулевого коэффициента не является DC-положением (верхним-левым положением блока) и если положение последнего ненулевого коэффициента не является DC-положением, в случае блока яркости дерева дуального типа, то индекс LFNST передается. В случае блока цветности дерева дуального типа, если любое одно из положения последнего ненулевого коэффициента для Cb и положения последнего ненулевого коэффициента для Cr не является DC-положением, соответствующий индекс LNFST передается.
[285] В случае дерева одиночного типа, если положение последнего ненулевого коэффициента любого одного из компонента яркости, компонента Cb и компонента Cr не является DC-положением, индекс LFNST передается.
[286] Здесь, если значение флага кодируемого блока (CBF), указывающее, существует ли или нет коэффициент преобразования для одного блока преобразования, равно 0, положение последнего ненулевого коэффициента для соответствующего блока преобразования не проверяется, чтобы определить, сигнализируется ли или нет LFNST. То есть, когда значение соответствующего CBF равно 0, поскольку преобразование не применяется к соответствующему блоку, положение последнего ненулевого коэффициента может не учитываться при проверке условия для сигнализации индекса LFNST.
[287] Например, 1) в случае дерева дуального типа и компонента яркости, если значение соответствующего CBF равно 0, индекс LFNST не сигнализируется, 2) в случае дерева дуального типа и компонента цветности, если значение CBF для Cb равно 0 и значение CBF для Cr равно 1, то проверяется только положение последнего ненулевого коэффициента для Cr, и передается соответствующий индекс LFNST, 3) в случае дерева одиночного типа, положение последнего ненулевого коэффициента проверяется только для компонентов, имеющих значение CBF, равное 1 для каждого из яркости, Cb и Cr.
[288] F. Когда подтверждается, что коэффициент преобразования существует в положении ином, чем положение, где коэффициент преобразования LFNST может существовать, сигнализация индекса LFNST может опускаться. В случае блока преобразования 4×4 и блока преобразования 8×8, коэффициенты преобразования LFNST могут существовать в восьми положениях от DC-положения в соответствии с порядком сканирования коэффициентов преобразования в стандарте VVC, и остальные положения заполняются нулями. Дополнительно, когда блок преобразования 4×4 и блок преобразования 8×8 отсутствуют, коэффициенты преобразования LFNST могут существовать в шестнадцати положениях от DC-положения в соответствии с порядком сканирования коэффициентов преобразования в стандарте VVC, и остальные положения заполняются нулями.
[289] Соответственно, если ненулевые коэффициенты преобразования существуют в области, которая должна заполняться нулевым значением после продвижения кодирования остатка, сигнализация индекса LFNST может быть опущена.
[290] Между тем режим ISP может также применяться только к блоку яркости или может применяться как к блоку яркости, так и к блоку цветности. Как описано выше, когда применяется ISP-предсказание, соответствующая единица кодирования может разделяться на два или четыре блока разбиения и предсказываться, и преобразование может применяться к каждому из блоков разбиения. Поэтому также при определении условия для сигнализации индекса LFNST в единицах кодирования, необходимо учитывать тот факт, что LFNST может применяться к соответствующим блокам разбиения. Кроме того, когда режим предсказания ISP применяется только к конкретному компоненту (например, блоку яркости), индекс LFNST может сигнализироваться с учетом того факта, что только этот компонент разделен на блоки разбиения. Способы сигнализации индекса LFNST в режиме ISP могут быть резюмированы следующим образом.
[291] 1. Индекс LFNST может передаваться один раз для каждой единицы кодирования (CU), и в случае дуального дерева индивидуальные индексы LFNST могут сигнализироваться для блока яркости и блока цветности, соответственно.
[292] 2. Когда индекс LFNST не сигнализируется, значение индекса LFNST считается значением по умолчанию, равным 0. Случай, когда значение индекса LFNST считается равным 0, является следующим.
[293] A. В случае режима, в котором не применяется никакое преобразование (например, пропуск преобразования, BDPCM, кодирование без потерь и т.д.)
[294] B. Когда горизонтальная длина или вертикальная длина для блока яркости единицы кодирования превышает размер преобразуемого максимального преобразования яркости, например, когда размер преобразуемого максимального преобразования яркости равен 64 и когда размер для блока яркости блока кодирования равен 128×16, LFNST не может применяться.
[295] Следует или нет сигнализировать индекс LFNST, может определяться на основе размера блока разбиения вместо единицы кодирования. То есть, если горизонтальная или вертикальная длина блока разбиения для соответствующего блока яркости превышает размер преобразуемого максимального преобразования яркости, сигнализация индекса LFNST может быть опущена, и значение индекса LFNST может считаться равным 0.
[296] В случае дуального дерева, определяется, превышается ли или нет размер максимального преобразования яркости для каждой единицы кодирования или блока разбиения для компонента яркости и единицы кодирования или блока разбиения для компонента цветности. То есть, если горизонтальная или вертикальная длины единицы кодирования или блока разбиения для компонента яркости сравниваются с размером максимального преобразования яркости, соответственно, и по меньшей мере один из них больше, чем размер максимального преобразования яркости, LFNST не применяется, и в случае единицы кодирования или блока разбиения для цветности, горизонтальная/вертикальная длина соответствующего блока яркости для цветового формата и размер максимального преобразуемого преобразования яркости сравниваются. Например, когда цветовым форматом является 4:2:0, горизонтальная/вертикальная длина соответствующего блока яркости равна удвоенной длине соответствующего блока цветности, и размер преобразования соответствующего блока яркости равен удвоенному размеру для соответствующего блока цветности. В качестве другого примера, когда цветовым форматом является 4:4:4, горизонтальная/вертикальная длина и размер соответствующего блока яркости являются такими же, для соответствующего блока цветности.
[297] В случае одиночного дерева, после проверки того, превышает ли или нет горизонтальная длина или вертикальная длина блока яркости (единицы кодирования или блока разбиения) размер блока максимального преобразуемого преобразования яркости, если она превышает, то сигнализация индекса LFNST может быть опущена.
[298] C. Если применяется LFNST, включенное в текущий стандарт VVC, индекс LFNST может передаваться, только когда как горизонтальная длина, так и вертикальная длина блока разбиения равны или больше, чем 4.
[299] Если LFNST для блока 2×M (1×M) или M×2 (M×1) применяется в дополнение к LFNST, включенному в текущий стандарт VVC, индекс LFNST может передаваться, только если размер блока разбиения равен или больше, чем блок 2×M (1×M) или M×2 (M×1). Здесь, выражение "блок P×Q равен или больше, чем блок R×S" означает, что P≥R и Q≥S.
[300] В итоге, индекс LFNST может передаваться, только если блок разбиения равен или больше, чем минимальный размер, к которому применимо LFNST. В случае дуального дерева, индекс LFNST может сигнализироваться, только если блок разбиения для компонента яркости или цветности равен или больше, чем минимальный размер, к которому применимо LFNST. В случае одиночного дерева, индекс LFNST может сигнализироваться, только когда блок разбиения для компонента яркости равен или больше, чем минимальный размер, к которому применимо LFNST.
[301] В этом документе выражение "блок M×N больше или равен блоку K×L" означает, что M больше или равно K, и N больше или равно L. Выражение "блок M×N больше, чем блок K×L" означает, что M больше или равно K и N больше или равно L, и что M больше, чем K, или N больше, чем L. Выражение "блок M×N меньше или равен блоку K×L" означает, что M меньше или равно K, и N меньше или равно L, в то время как выражение "блок M×N меньше, чем блок K×L" означает, что M меньше или равно K, и N меньше или равно L, и что M меньше, чем K, или N меньше, чем L.
[302] D. Если положение последнего ненулевого коэффициента не является DC-положением (верхним-левым положением блока) и если положение последнего ненулевого коэффициента не является DC-положением в любом одном из всех блоков разбиения. В случае блока яркости дерева дуального типа, передается индекс LFNST. В случае дерева дуального типа и блока цветности, если по меньшей мере одно из положения последнего ненулевого коэффициента всех блоков разбиения для Cb (если режим ISP не применяется к компоненту цветности, число блоков разбиения рассматривается как равное одному) и положения последнего ненулевого коэффициента из всех блоков разбиения для Cr (если режим ISP не применяется к компоненту цветности, число блоков разбиения рассматривается как равное одному) не является DC-положением, соответствующий индекс LNFST может передаваться.
[303] В случае дерева одиночного типа, если положение последнего ненулевого коэффициента любого одного из всех блоков разбиения для компонента яркости, компонента Cb и компонента Cr не является DC-положением, соответствующий индекс LFNST должен передаваться.
[304] Здесь, если значение флага кодированного блока (CBF), указывающего, существует ли коэффициент преобразования для каждого блока разбиения, равен 0, положение последнего ненулевого коэффициента для соответствующего блока разбиения не проверяется, чтобы определить, сигнализируется ли или нет индекс LFNST. То есть, когда соответствующее значение CBF равно 0, поскольку преобразование не применяется к соответствующему блоку, положение последнего ненулевого коэффициента для соответствующего блока разбиения не учитывается при проверке условия для сигнализации индекса LFNST.
[305] Например, 1) в случае дерева дуального типа и компонента яркости, если соответствующее значение CBF для каждого блока разбиения равно 0, блок разбиения исключается при определении, сигнализировать ли или нет индекс LFNST, 2) в случае дерева дуального типа и компонента цветности, если значение CBF для Cb равно 0 и значение CBF для Cr равно 1 для каждого блока разбиения, только положение последнего ненулевого коэффициента для Cr проверяется, чтобы определить, сигнализировать ли или нет индекс LFNST, 3) в случае дерева одиночного типа, возможно определить, сигнализировать ли или нет индекс LFNST, путем проверки положения последнего ненулевого коэффициента только для блоков, имеющих значение CBF, равное 1 для всех блоков разбиения компонента яркости, компонента Cb и компонента Cr.
[306] В случае режима ISP, информация изображения может также конфигурироваться так, что положение последнего ненулевого коэффициента не проверяется, и вариант осуществления этого является следующим.
[307] i. В случае режима ISP сигнализация индекса LFNST может быть разрешена без проверки положения последнего ненулевого коэффициента как для блока яркости, так и для блока цветности. То есть, даже если положение последнего ненулевого коэффициента для всех блоков разбиения является DC-положением или соответствующее значение CBF равно 0, сигнализация индекса LFNST может быть разрешена.
[308] ii. В случае режима ISP проверка положения последнего ненулевого коэффициента только для блока яркости может быть опущена, а в случае блока цветности проверка положения последнего ненулевого коэффициента может выполняться вышеописанным способом. Например, в случае дерева дуального типа и блока яркости, сигнализация индекса LFNST разрешается без проверки положения последнего ненулевого коэффициента, а в случае дерева дуального типа и блока цветности, сигнализируется ли или нет соответствующий индекс LFNST, может определяться путем проверки того, существует ли или нет DC-положение для положения последнего ненулевого коэффициента вышеописанным способом.
[309] iii. В случае режима ISP и дерева одиночного типа может применяться способ i или ii. То есть в случае режима ISP и когда способ i применяется к дереву одиночного типа, можно опустить проверку положения последнего ненулевого коэффициента как для блока яркости, так и для блока цветности, и разрешить сигнализацию индекса LFNST. Альтернативно, путем применения способа ii, для блоков разбиения для компонента яркости, проверка положения последнего ненулевого коэффициента опускается, а для блоков разбиения для компонента цветности (если ISP не применяется для компонента цветности, число блоков разбиения может рассматриваться как 1), положение последнего ненулевого коэффициента проверяется вышеописанным способом, тем самым определяя, следует ли или нет сигнализировать индекс LFNST.
[310] E. Когда подтверждается, что коэффициент преобразования существует в положении ином, чем положение, где коэффициент преобразования LFNST может существовать даже для одного блока разбиения среди всех блоков разбиения, сигнализация индекса LFNST может быть опущена.
[311] Например, в случае блока разбиения 4×4 и блока разбиения 8×8, коэффициенты преобразования LFNST могут существовать в восьми положениях от DC-положения в соответствии с порядком сканирования коэффициентов преобразования в стандарте VVC, а остальные положения заполнены нулями. Дополнительно, если он равен или больше, чем блок разбиения 4×4, и не является ни блоком разбиения 4×4, ни блоком разбиения 8×8, коэффициенты преобразования LFNST могут существовать в 16 положениях от DC-положения в соответствии с порядком сканирования коэффициентов преобразования в стандарте VVC, а все остальные положения заполнены нулями.
[312] Соответственно, если ненулевые коэффициенты преобразования существуют в области, которая должна быть заполнена нулевым значением после прохождения кодирования остатка, сигнализация индекса LFNST может быть опущена.
[313] Между тем, в случае режима ISP, условие длины независимо рассматривается для горизонтального направления и вертикального направления, и DST-7 применяется вместо DCT-2 без сигнализации индекса MTS. Определяется, является ли горизонтальная или вертикальная длина большей или равной 4 и меньшей или равной 16, и ядро первичного преобразования определяется в соответствии с результатом определения. Соответственно, в случае режима ISP, когда может применяться LFNST, возможна следующая конфигурация комбинации преобразований.
[314] 1. Когда индекс LFNST равен 0 (включая случай, в котором индекс LFNST считается равным 0), можно следовать условию решения о первичном преобразовании во время ISP, включенному в текущий стандарт VVC. Иными словами, может проверяться, удовлетворяется ли или нет условие длины (равна или больше чем 4, или равна или меньше, чем 16) независимо для горизонтального и вертикального направлений, соответственно, и если оно удовлетворяется, DST-7 может применяться вместо DCT-2 для первичного преобразования, а если не удовлетворяется, то может применяться DCT-2.
[315] 2. Для случая, когда индекс LFNST больше, чем 0, следующие две конфигурации могут быть возможными в качестве первичного преобразования.
[316] A. DCT-2 может применяться как к вертикальному, так и к горизонтальному направлениям.
[317] B. Можно следовать условию решения о первичном преобразовании во время ISP, включенному в текущий стандарт VVC. Иными словами, может проверяться, удовлетворяется ли или нет условие длины (равна или больше чем 4, либо равна или меньше чем 16) независимо для горизонтального и вертикального направлений, соответственно, и если оно удовлетворяется, DST-7 может применяться вместо DCT-2, а если оно не удовлетворяется, может применяться DCT-2.
[318] В режиме ISP, информация изображения может конфигурироваться так, что индекс LFNST передается для каждого блока разбиения, а не для каждой единицы кодирования. В этом случае, в вышеописанном способе сигнализации индекса LFNST, может считаться, что только один блок разбиения существует в единице, в которой передается индекс LFNST, и может определяться, сигнализировать ли или нет индекс LFNST.
[319] Далее, описывается вариант осуществления для применения LFNST только к компоненту яркости в одиночном дереве.
[320] Таблица синтаксиса единицы кодирования для сигнализации индекса LFNST и индекса MTS в соответствии с примером показана ниже.
[321] [Таблица 4]
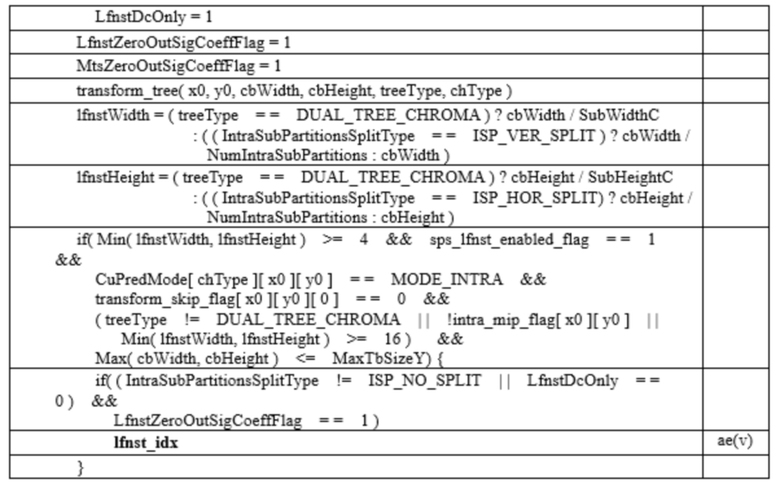
[322] Значения основных переменных в таблице выше являются следующими.
[323] 1. cbWidth, cbHeight: Ширина и высота текущего блока кодирования
[324] 2. log2TbWidth, log2TbHeight: Значения логарифма по основанию 2 ширины и высоты текущего блока преобразования. Размер текущего блока преобразования может уменьшаться до верхней-левой области, в которой может существовать ненулевой коэффициент, путем применения обнуления.
[325] 3. sps_lfnst_enabled_flag: Флаг, указывающий, включено ли LFNST. Значение флага, равное 0, указывает, что LFNST не включено, и значение флага, равное 1, указывает, что LFNST включено. Флаг определен в наборе параметров последовательности (SPS).
[326] 4. CuPredMode[chType][x0][y0]: Режим предсказания, соответствующий переменной chType и положению (x0, y0). chType может иметь значения 0 и 1, где 0 представляет компонент яркости, и 1 представляет компонент цветности. Положение (x0, y0) указывает положение на картинке, и MODE_INTRA (интра-предсказание) и MODE_INTER (интер-предсказание) возможны со значением CuPredMode[chType][x0][y0].
[327] 5. IntraSubPartitionsSplitType: Указывает, какое ISP применяется к текущей единице кодирования, и ISP_NO_SPLIT указывает, что единица кодирования не разделена на блоки разбиения.
[328] 6. intra_mip_flag[x0][y0]: Положение (x0, y0) описывается, как выше в 4. intra_mip_flag представляет собой флаг, указывающий, применяется ли режим интра-предсказания на матричной основе (MIP). Значение флага, равное 0, указывает, что MIP не применимо, и значение флага, равное 1, указывает, что MIP применяется.
[329] 7. cIdx: Значение 0 указывает яркость, и значения 1 и 2 указывают компоненты цветности Cb и Cr, соответственно.
[330] 8. treeType: Указывает одиночное дерево, дуальное дерево или тому подобное. (SINGLE_TREE: Одиночное дерево, DUAL_TREE_LUMA: Дуальное дерево для компонента яркости, DUAL_TREE_CHROMA: Дуальное дерево для компонента цветности).
[331] 9. lfnst_idx[x0][y0]: Синтаксический элемент индекса LFNST, подлежащий синтаксическому анализу. Если не получается посредством синтаксического анализа, то элемент считается имеющим значение 0. То есть значение по умолчанию установлено в 0, что указывает, что LFNST не применяется.
[332] Описание предшествующих синтаксических элементов может применяться к синтаксическим элементам, показанным в следующих таблицах.
[333] В Таблице 4, transform_skip_flag[x0][y0][0]==0 является условием для определения того, сигнализируется ли индекс lfnst по отношению к компоненту яркости в соответствии с тем, пропускается ли преобразование.
[334] Соответственно, в соответствии с примером, предложена следующая таблица синтаксиса единицы кодирования, чтобы устранить зависимость между сигнализацией флага пропуска преобразования для компонента яркости и сигнализацией индекса LFNST для компонента цветности.
[335] [Таблица 5]

[336] В варианте осуществления, показанном в Таблице 5, сигнализация индекса LFNST для компонента яркости зависит только от флага пропуска преобразования для компонента яркости для режима разбиения как дерева дуального типа, так и дерева одиночного типа. В режиме дуального дерева индекс LFNST для компонента цветности может сигнализироваться в зависимости только от флага пропуска преобразования для компонента цветности. В режиме разбиения одиночного дерева LFNST не применяется к компоненту цветности, чтобы снизить задержку для наихудшего случая.
[337] Переменная LfnstTransformNotSkipFlag, показанная в Таблице 5, устанавливается в соответствии с типом дерева текущего блока и значением флага пропуска преобразования для цветового компонента, и только когда значение переменной равно 1, индекс LFNST может сигнализироваться.
[338] Когда типом дерева является не дуальное дерево цветности (treeType != DUAL_TREE_CHROMA), то есть, когда типом дерева является одиночное дерево или дуальное дерево яркости, если значение флага пропуска преобразования для компонента яркости равно 0, переменная LfnstTransformNotSkipFlag может быть установлена в 1 (treeType!=DUAL_TREE_CHROMA?transform_skip_flag [x0][y0][0]==0:(transform_skip_flag[x0][y0][1]==0||transform_
skip_flag[x0][y0][2]==0)), а когда типом дерева является дуальное дерево цветности, если значение флага пропуска преобразования (transform_skip_flag[x0][y0][1]) для компонента цветности Cr равно 0 или значение флага пропуска преобразования (transform_skip_flag[x0][y0][1]) для компонента цветности Cr равно 0, переменная LfnstTransformNotSkipFlag может быть установлена в 1 (treeType!=DUAL_TREE_CHROMA?transform_skip_flag [x0][y0][0]==0:(transform_skip_flag[x0][y0][1]==0|| transform_skip_flag[x0][y0][2]==0)).
[339] В настоящем раскрытии оператор "x?y:z" указывает, что x есть y, если x есть TRUE (истинно), и x есть z в противном случае (если x есть TRUE, то принимает значение y; в противном случае принимает значение z).
[340] Текст спецификации для процесса преобразования с учетом Таблицы 5 является следующим.
[341] [Таблица 6]
8.7.4.1 Общие сведения
Входами этого процесса являются:
- местоположение яркости (xTbY, yTbY), задающее верхнюю-левую выборку текущего блока преобразования яркости относительно верхней-левой выборки яркости текущей картинки,
- переменная nTbW, задающая ширину текущего блока преобразования,
- переменная nTbH, задающая высоту текущего блока преобразования
- переменная cIdx, задающая цветовой компонент текущего блока,
- массив (nTbW)×(nTbH) d[x][y] масштабированных коэффициентов преобразования с x=0…nTbW-1, y=0…nTbH-1.
Выходом этого процесса является массив (nTbW)×(nTbH) res[x][y] остаточных выборок с x=0…nTbW-1, y=0…nTbH-1.
Переменная applyLfnstFlag выводится следующим образом:
- Если treeType равно SINGLE_TREE и lfnst_idx не равно 0 и transform_skip_flag[xTbY][yTbY][cIdx] равно 0 и cIdx равно 0, и как nTbW, так и nTbH больше или равны 4, applyLfnstFlag устанавливается в 1.
- В противном случае, если treeType не равно SINGLE_TREE и lfnst_idx не равно 0 и transform_skip_flag[xTbY][yTbY][cIdx] равно 0 и cIdx равно 0, и как nTbW, так и nTbH больше или равны 4, applyLfnstFlag устанавливается в 1.
- в противном случае, applyLfnstFlag устанавливается в 0.
Когда applyLfnstFlag равен 1, применяется следующее:
- Переменные predModeIntra, nLfnstOutSize, log2LfnstSize, nLfnstSize и nonZeroSize выводятся следующим образом:
predModeIntra=(cIdx==0) ? IntraPredModeY[xTbY][yTbY] : IntraPredModeC[xTbY][yTbY] (1149)
nLfnstOutSize=(nTbW >= 8 && nTbH >= 8) ? 48:16 (1150)
log2LfnstSize=(nTbW >= 8 && nTbH >= 8) ? 3:2 (1151)
nLfnstSize=1 << log2LfnstSize (1152)
nonZeroSize=(nTbW == 4 && nTbH == 4) || (nTbW == 8 && nTbH ==8) ? 8:16 (1153)
[342] Переменная LfnstZeroOutSigCoeffFlag в Таблице 4 равна 0, если имеется значимый коэффициент в положении обнуления, когда применяется LFNST, и равна 1 в противном случае. Переменная LfnstZeroOutSigCoeffFlag может быть установлена в соответствии с множеством условий, показанных ниже в Таблице 11.
[343] Переменная LfnstZeroOutSigCoeffFlag указывает, существует ли значимый коэффициент во второй области иной, чем верхняя-левая первая область текущего блока. Значение переменной первоначально установлено в 1 и может быть изменено на 0, когда значимый коэффициент существует во второй области. Индекс LFNST может быть получен посредством синтаксического анализа, только когда первоначально установленное значение переменной LfnstZeroOutSigCoeffFlag сохраняется. Когда определяется и выводится, равно ли 1 значение переменной LfnstZeroOutSigCoeffFlag, LFNST может применяться к компоненту яркости или всем компонентам цветности текущего блока, и, таким образом, индекс цвета текущего блока не определяется.
[344] В соответствии с примером, переменная LfnstDcOnly в Таблице 4 равна 1, когда все последние значимые коэффициенты для блоков преобразования, для которых соответствующий флаг кодированного блока (CBF, который равен 1, когда имеется по меньшей мере один значимый коэффициент в соответствующем блоке, и равен 0 в противном случае) равен 1, находятся в DC-положениях (верхние левые положения), и равна 0 в противном случае. Конкретно, положение последнего значимого коэффициента проверяется по отношению к одному блоку преобразования яркости в дуальном дереве яркости, и положение последнего значимого коэффициента проверяется по отношению как к блоку преобразования для Cb, так и к блоку преобразования для Cr в дуальном дереве цветности. В одиночном дереве, положение последнего значимого коэффициента может проверяться по отношению к блокам преобразования для яркости, Cb и Cr.
[345] Таблица синтаксиса единицы кодирования, сигнализирующей индекс LFNST, в соответствии с другим примером является следующей.
[346] [Таблица 7]

[347] В Таблице 7 переменная transform_skip_flag[x0][y0][cIdx] указывает, применяется ли пропуск преобразования к блоку кодирования для компонента, указанного посредством cIdx. cIdx может иметь значение 0, 1 и 2, где 0 указывает компонент яркости, и 1 и 2 указывают компонент Cb и компонент Cr, соответственно. Значение transform_skip_flag[x0][y0][cIdx], равное 1, указывает, что пропуск преобразования применяется, и 0 указывает, что пропуск преобразования не применяется.
[348] В Таблице 7 переменная LfnstNotSkipFlag может быть установлена в 1, только когда пропуск преобразования не применяется ко всем компонентам (всем блокам кодирования), образующим текущую единицу кодирования, и может быть установлена в 0 в других случаях, и индекс LFNST (lfnst_idx в Таблице 7) может сигнализироваться, только когда LfnstNotSkipFlag равен 1.
[349] Когда текущая единица кодирования кодируется в структуре одиночного дерева (когда treeType представляет собой SINGLE_TREE в Таблице 7), все из компонентов включают в себя Y, Cb и Cr, когда текущая единица кодирования кодируется в отдельной структуре дерева для яркости (когда treeType представляет собой DUAL_TREE_LUMA в Таблице 7), все из компонентов включают в себя только Y, и когда текущая единица кодирования кодируется в отдельной структуре дерева для цветности (когда treeType представляет собой DUAL_TREE_CHROMA в Таблице 7), все из компонентов включают в себя Cb и Cr.
[350] Иными словами, когда даже один из компонентов, состоящий из текущей единицы кодирования, кодируется путем пропуска преобразования, индекс LFNST не сигнализируется, и значение индекса LFNST считается равным 0. То есть LFNST не применяется.
[351] В структуре, ограничивающей, чтобы LFNST не применялось, когда даже один из компонентов (Y, Cb и Cr) кодируется путем пропуска преобразования, как в Таблице 7, когда множество компонентов (Y, Cb и Cr) последовательно кодируется в одиночном дереве, и определяется компонент, подвергаемый пропуску преобразования (например, когда пропуск преобразования определяется для Cb и Cr) во время синтаксического анализа, соответствующие коэффициенты преобразования могут быть сконфигурированы, чтобы не буферизоваться дополнительно по отношению соответствующим компонентам, кодируемым путем пропуска преобразования, пока значение индекса LFNST не будет синтаксически проанализировано.
[352] Например, когда найден какой-либо один компонент, чтобы кодироваться путем пропуска преобразования, можно быть уверенным, что LFNST не применяется, и, таким образом, обратное квантование, обратное преобразование и тому подобное может выполняться непосредственно после этого.
[353] Вместо Таблицы 7, таблица синтаксиса может быть кратко описана, как в Таблице 8.
[354] [Таблица 8]

[355] При определении, следует ли сигнализировать индекс LFNST, путем проверки только на предмет того, применяется ли пропуск преобразования к компоненту яркости в одиночном дереве, таблица синтаксиса для единицы кодирования может быть сконфигурирована следующим образом.
[356] [Таблица 9]

[357] В Таблице 9, LfnstNotSkipFlag определяется так же, как в Таблице 7 или Таблице 8, в отдельном дереве (то есть в отдельном дереве яркости LfnstNotSkipFlag устанавливается в 1, когда пропуск преобразования не применяется к компоненту яркости, и устанавливается в 0 в противном случае, и в отдельном дереве цветности, LfnstNotSkipFlag устанавливается в 1, когда пропуск преобразования не применяется ни к компоненту Cb, ни к компоненту Cr, и устанавливается в 0 в противном случае). В одиночном дереве, LfnstNotSkipFlag устанавливается в 1, когда пропуск преобразования не применяется только к компоненту яркости, и устанавливается в 0 в противном случае. Вместо Таблицы 8, может применяться таблица синтаксиса, показанная в Таблице 9.
[358] [Таблица 10]

[359] Ниже описан вариант осуществления для определения условия сигнализации индекса LFNST при применении LFNST только к компоненту яркости в одиночном дереве.
[360] В таблицах синтаксиса единицы кодирования согласно Таблице 4 и Таблице 5, Таблице 7, Таблице 8, Таблице 9 и Таблице 10, переменная LfnstDcOnly и переменная LfnstZeroOutSigCoeffFlag используются как условия для сигнализации индекса LFNST. В основном, как переменная LfnstDcOnly, так и переменная LfnstZeroOutSigCoeffFlag инициализируются в 1, как показано в Таблице 7, и значения двух переменных могут обновляться в 0 в таблице синтаксиса для кодирования остатка, как показано в Таблице 11. Для ссылки, когда компонент (которым может быть Y, Cb или Cr) кодируется с пропуском преобразования, импортируется другая таблица синтаксиса (transform_ts_coding) вместо импортирования кодирования остатка в Таблице 11, и, таким образом, переменная LfnstDcOnly и переменная LfnstZeroOutSigCoeffFlag не обновляются, когда индекс LFNST для компонента синтаксически анализируется.
[361] [Таблица 11]
[362]

[363] В Таблице 11 lastSubBlock указывает положение подблока (группы коэффициентов (CG)), в котором последний значимый (ненулевой) коэффициент позиционирован в порядке сканирования. 0 указывает подблок, включающий в себя DC-компонент, и значение больше, чем 0 указывает подблок, не включающий в себя DC-компонент.
[364] lastScanPos указывает положение последнего значимого коэффициента в одном подблоке в порядке сканирования. Когда один подблок включает в себя 16 положений, возможны значения от 0 до 15.
[365] LastSignificantCoeffX и LastSignificantCoeffY указывают x-координату и y-координату последнего значимого коэффициента, позиционированного в блоке преобразования. X-координаты начинаются от 0 и увеличиваются слева направо, и y-координаты начинаются от 0 и увеличиваются сверху вниз. Значения двух переменных, равные 0, означают, что последний значимый коэффициент позиционирован в DC.
[366] В основном, Таблица 11 применяется к варианту осуществления согласно Таблице 5, чтобы определить значения переменной LfnstDcOnly и переменной LfnstZeroOutSigCoeffFlag. Когда применяется Таблица 11 и блок кодирования кодируется в одиночном дереве, кодирование остатка, представленное в Таблице 11, может импортироваться для всех компонентов. Например, когда все из компонентов Y, Cb и Cr не кодируются с пропуском преобразования, кодирование остатка может выполняться по каждому компоненту.
[367] Поэтому, когда применяется Таблица 11, и текущий блок кодирования кодируется посредством одиночного дерева, если последний ненулевой коэффициент даже одного компонента позиционирован в положении ином, чем DC-положение (верхнее-левое положение блока преобразования), значение переменной LfnstDcOnly может быть обновлено в 0, и когда положение последнего ненулевого коэффициента даже одного компонента позиционировано в области, где коэффициент преобразования в случае, где применяется LFNST, не может быть позиционирован (то есть позиционирован в области иной, чем положения с первого по восьмое в соответствии с порядком сканирования коэффициентов прямого преобразования в блоке преобразования 4×4 или блоке преобразования 8×8, или позиционирован в области иной, чем верхняя-левая область 4×4 в блоке преобразования, к которому применимо LFNST в современном стандарте VVC), значение переменной LfnstZeroOutSigCoeffFlag может быть обновлено в 0. Как показано в таблице синтаксиса единицы кодирования Таблицы 5, Таблицы 7, Таблицы 8, Таблицы 9 и Таблицы 10, индекс LFNST может сигнализироваться, только когда значение переменной LfnstZeroOutSigCoeffFlag равно 1, и в режиме ином, чем режим ISP, индекс LFNST может сигнализироваться, только когда значение переменной LfnstDcOnly равно 0.
[368] Однако, когда LFNST применяется только к компоненту яркости в одиночном дереве, может быть не разрешено обновлять переменную LfnstDcOnly и переменную LfnstZeroOutSigCoeffFlag, когда кодирование остатка выполняется на компонентах, к которым не применяется LFNST (компонентах цветности Cb или Cr). Это объясняется тем, что нелогично, когда компоновка или распределение коэффициентов преобразования для компонента, к которому не применяется LFNST, определяет, сигнализируется ли LFNST, то есть применяется ли LFNST.
[369] Таблица 12 ограничивает переменную LfnstDcOnly и переменную LfnstZeroOutSigCoeffFlag так, чтобы обновляться только для компонента яркости в одиночном дереве. В случае ином, чем одиночное дерево, переменная LfnstDcOnly и переменная LfnstZeroOutSigCoeffFlag могут обновляться для всех компонентов, как в Таблице 11.
[370] [Таблица 12]
[371]

[372] На основе деталей Таблицы 5 некоторые детали могут быть заменены вариантами осуществления от Таблицы 7 до Таблицы 10, или могут применяться детали Таблицы 11 или Таблицы 12. Следующие возможные комбинации могут быть сконфигурированы на основе Таблицы 7 до Таблицы 10, Таблицы 11 или Таблицы 12.
[373] 1. Таблица 7 (или Таблица 8) + Таблица 11
[374] 2. Таблица 7 (или Таблица 8) + Таблица 12
[375] 3. Таблица 9 (или Таблица 10) + Таблица 11
[376] 4. Таблица 9 (или Таблица 10) + Таблица 12
[377] Далее, описывается способ для применения списка масштабирования к компонентам цветности, когда LFNST применяется только к компоненту яркости в одиночном дереве.
[378] В настоящее время, в VVC WD определен синтаксический элемент, называемый scaling_matrix_for_lfnst_disabled_flag. Когда scaling_matrix_for_lfnst_disabled_flag равен 1, список масштабирования не применяется, когда применяется LFNST, а когда scaling_matrix_for_lfnst_disabled_flag равен 0, список масштабирования может применяться, когда применяется LFNST.
[379] Здесь, список масштабирования является матрицей для специфицирования удельного веса (взвешенного значения) для каждого положения коэффициента преобразования в блоке преобразования и позволяет осуществлять деквантование или квантование путем умножения на вес для каждого коэффициента преобразования, таким образом, позволяя применять дифференциальное деквантование или квантование в соответствии с важностью коэффициента преобразования.
[380] В одиночном дереве, LFNST может применяться только к компоненту яркости, как в варианте осуществления по Таблице 5, и когда значение scaling_matrix_for_lfnst_disabled_flag равно 1 и LFNST применяется, когда блок кодирования кодируется в одиночном дереве, список масштабирования не применяется к компоненту яркости. Здесь, список масштабирования может применяться к компоненту цветности, к которому не применяется LFNST.
[381] Таблица 13 показывает пример процесса деквантования (процесса масштабирования), чтобы реализовать вышеописанный случай.
[382] Таблица 13
Входами в этот процесс являются:
- местоположение яркости (xTbY, yTbY), специфицирующее верхнюю-левую выборку текущего блока преобразования яркости относительно верхней-левой выборки яркости текущей картинки,
- переменная nTbW, задающая ширину блока преобразования,
- переменная nTbH, задающая высоту блока преобразования,
- переменная predMode, задающая режим предсказания единицы кодирования,
- переменная cIdx, задающая цветовой компонент текущего блока.
- переменная treeType, задающая, используется ли одиночное дерево (SINGLE_TREE) или дуальное дерево для разбиения узла дерева кодирования, и, когда используется дуальное дерево, и то, обрабатываются ли в текущее время компоненты яркости (DUAL_TREE_LUMA) или цветности (DUAL_TREE_CHROMA).
Выходом этого процесса является массив (nTbW)x(nTbH) d масштабированных коэффициентов преобразования с элементами d[x][y].
Параметр квантования qP выводится следующим образом:
- Если cIdx равно 0, то применяется следующее:
qP=Qp′Y
- В противном случае, если TuCResMode[xTbY][yTbY] равно 2, применяется следующее:
qP=Qp′CbCr
- В противном случае, если cIdx равно 1, применяется следующее:
qP=Qp′Cb
- В противном случае (cIdx равно 2), применяется следующее:
qP=Qp′Cr
Параметр квантования qP модифицируется, и переменные rectNonTsFlag и bdShift выводятся следующим образом:
- Если transform_skip_flag[xTbY][yTbY][cIdx] равен 0, применяется следующее :
qP=qP − (cu_act_enabled_flag[xTbY][yTbY] ? 5 : 0)
rectNonTsFlag=( ( (Log2( nTbW) + Log2(nTbH) ) & 1)== 1) ? 1 : 0 (1134)
bdShift=BitDepth+rectNonTsFlag + (1135) ( (Log2(nTbW) + Log2(nTbH) ) / 2) − 5+pic_dep_quant_enabled_flag
- В противном случае (transform_skip_flag[xTbY][yTbY][cIdx] равно 1), применяется следующее :
qP=Max(QpPrimeTsMin, qP) − (cu_act_enabled_flag[xTbY][yTbY] ? 5 : 0) (1136)
rectNonTsFlag=0
bdShift=10
[383]
bdOffset=(1 << bdShift) >> 1
Список levelScale[ ][ ] задается как levelScale[j][k]={{40, 45, 51, 57, 64, 72}, {57, 64, 72, 80, 90, 102}} with j=0..1, k=0..5.
Массив (nTbW)x(nTbH) dz установлен равным массиву (nTbW)x(nTbH) TransCoeffLevel[xTbY][yTbY][cIdx].
Для выведения масштабированных коэффициентов преобразования d[x][y] при x=0..nTbW − 1, y=0..nTbH − 1, применяется следующее:
- Промежуточный масштабирующий коэффициент m[x][y] выводится следующим образом:
- Если одно или более из следующих условий истинно, m[x][y] устанавливается равным 16:
-- sps_scaling_list_enabled_flag равен 0.
-- pic_scaling_list_present_flag равен 0.
-- transform_skip_flag[xTbY][yTbY][cIdx] равен 1.
-- scaling_matrix_for_lfnst_disabled_flag равен 1 и lfnst_idx[xTbY][yTbY] не равен 0 и одно из следующих условий истинно.
--- treeType равен SINGLE_TREE и cIdx равен 0.
--- treeType равен DUAL_TREE_LUMA или DUAL_TREE_CHROMA.
- В противном случае, применяется следующее :
-- Переменная id выводится на основе predMode, cIdx, nTbW и nTbH, как определено в Таблице 36 и переменная log2MatrixSize выводится следующим образом:
log2MatrixSize=(id < 2) ? 1 : (id < 8) ? 2 : 3
-- Масштабирующий коэффициент m[x][y] выводится следующим образом:
m[x][y]=ScalingMatrixRec[id][i][j]
при i=(x << log2MatrixSize) >> Log2(nTbW), j=(y << log2MatrixSize) >> Log2( nTbH )
-- Если id больше, чем 13, и x и y равны 0, m[0][0] дополнительно модифицируется следующим образом:
m[0][0]=ScalingMatrixDCRec[id−14]
……
[384] В Таблице 13, treeType указывает тип дерева единицы кодирования, которой принадлежит обрабатываемый в текущее время блок преобразования, и SINGLE_TREE, DUAL_TREE_LUMA и DUAL_TREE_CHROMA указывают одиночное дерево, отдельное дерево для яркости и отдельное дерево для цветности (дуальное дерево цветности), соответственно.
[385] В этом варианте осуществления, поскольку LFNST может применяться только к компоненту яркости в одиночном дереве, когда значение scaling_matrix_for_lfnst_disabled_flag равно 1 и применяется LFNST (значение lfnst_idx[xTbY][yTbY] больше, чем 0), список масштабирования не применяется к компоненту яркости (когда значение cIdx равно 0).
[386] Однако для компонента цветности (когда значение cIdx больше чем 0), то, следует ли применять список масштабирования, может быть определено посредством дополнительной проверки другого условия (например, проверки transform_skip_flag[xTbY][yTbY][cIdx]).
[387] В отдельном дереве, как в случае компонента яркости в одиночном дереве, когда значение scaling_matrix_for_lfnst_disabled_flag равно 1 и применяется LFNST (значение lfnst_idx[xTbY][yTbY] больше чем 0), список масштабирования не применяется к компонентам яркости и цветности.
[388] Далее, в отдельном дереве, как в случае компонента цветности в одиночном дереве, то, следует ли применять список масштабирования, может быть определено посредством дополнительной проверки другого условия (например, проверки transform_skip_flag[xTbY][yTbY][cIdx]).
[389] Поэтому, когда значение scaling_matrix_for_lfnst_disabled_flag равно 1 и LFNST может применяться только к компоненту яркости в одиночном дереве, список масштабирования может не применяться к компоненту яркости и может применяться к компоненту цветности.
[390] В соответствии с примером, может применяться комбинация Таблицы 13 и вышеописанных вариантов осуществления (комбинация замещения некоторых деталей с вариантами осуществления Таблицы 7 до Таблицы 10 или применения деталей Таблицы 11 или Таблица 12 на основе деталей Таблицы 5).
[391] В этом случае, как в тексте спецификации "Процесс преобразования для масштабированных коэффициентов преобразования" в Таблице 6, LFNST может быть сконфигурировано, чтобы применяться только к компоненту яркости в одиночном дереве.
[392] Следующие чертежи обеспечены, чтобы описывать конкретные примеры настоящего раскрытия. Поскольку конкретные термины для устройств или конкретные термины для сигналов/сообщений/полей, проиллюстрированных на чертежах, обеспечены для иллюстрации, технические признаки настоящего раскрытия не ограничены конкретными терминами, используемыми на следующих чертежах.
[393] Фиг. 15 представляет собой блок-схему последовательности операций, иллюстрирующую работу устройства декодирования в соответствии с вариантом осуществления настоящего раскрытия.
[394] Каждый процесс, раскрытый на фиг. 15, основан на некоторых из деталей, описанных со ссылкой на фиг. 5 - фиг. 14. Поэтому описание конкретных деталей, перекрывающееся с описанием со ссылкой на фиг. 3 и фиг. 5 до фиг. 14, будет опущено или будет представлено схематично.
[395] Устройство 300 декодирования в соответствии с вариантом осуществления может принимать информацию флага, указывающую, доступен ли список масштабирования, когда выполняется LFNST, индекс LFNST для текущего блока и остаточную информацию из битового потока (S1510).
[396] Конкретно, устройство 300 декодирования может декодировать информацию о квантованных коэффициентах преобразования для текущего блока из битового потока и может выводить квантованные коэффициенты преобразования для целевого блока на основе информации о квантованных коэффициентах преобразования для текущего блока. Информация о квантованных коэффициентах преобразования для целевого блока может быть включена в набор параметров последовательности (SPS) или заголовок вырезки и может включать в себя по меньшей мере одно из информации о том, применяется ли RST, информации о сокращенном показателе, информации о минимальном размере преобразования для применения RST, информации о максимальном размере преобразования для применения RST, размере обратного RST и информации об индексе преобразования, указывающем любую одну из матриц ядра преобразования, включенных в набор преобразований.
[397] Устройство декодирования может также принимать информацию о режиме интра-предсказания для текущего блока и информацию о том, применяется ли ISP к текущему блоку. Устройство декодирования может принимать и получать посредством синтаксического анализа информацию флага, указывающую, следует ли применять кодирование ISP или режим ISP, тем самым определяя, разделен ли текущий блок на предопределенное число блоков преобразования подразбиения. Здесь, текущий блок может быть блоком кодирования. Кроме того, устройство декодирования может выводить размер и число разделенных блоков подразбиения посредством информации флага, указывающей направление, в котором разделяется текущий блок.
[398] Индекс LFNST является значением для задания матрицы LFNST, когда LFNST применяется как обратное вторичное неразделимое преобразование, и может иметь значение в диапазоне от 0 до 2. Например, значение индекса LFNST 0 может указывать, что LFNST не применяется к текущему блоку, значение 1 индекса LFNST может указывать первую матрицу LFNST, и значение 2 индекса LFNST может указывать вторую матрицу LFNST.
[399] Информация о ISP и индексе LFNST может приниматься на уровне единицы кодирования.
[400] Информация флага, указывающая, доступен ли список масштабирования, когда выполняется LFNST, которая принимается устройством декодирования, может быть представлена посредством scaling_matrix_for_lfnst_disabled_flag или sps_scaling_matrix_for_lfnst_disabled_flag и может сигнализироваться в наборе параметров последовательности. Значение 1 этого флага указывает, что список масштабирования не применяется, когда применяется LFNST, и значение 0 флага указывает, что список масштабирования применим, когда применяется LFNST. Список масштабирования является матрицей для задания удельного веса (взвешенного значения) для каждого положения коэффициента преобразования в блоке преобразования позволяет осуществлять деквантование или квантование путем умножения на вес для каждого коэффициента преобразования, тем самым позволяя применять дифференциальное деквантование или квантование в соответствии с важностью коэффициента преобразования.
[401] Устройство 300 декодирования может выводить, применяется ли список масштабирования к текущему блоку, на основе применения LFNST и типа дерева текущего блока, чтобы деквантовать коэффициенты преобразования для текущего блока, и может выводить коэффициенты преобразования для текущего блока из остаточной информации на основе результата выведения (S1520).
[402] То, применяется ли список масштабирования, может определяться на основе информации флага и значения индекса LFNST.
[403] Когда типом дерева текущего блока является одиночное дерево, цветовые компоненты текущего блока могут включать в себя компонент яркости, первый компонент цветности, указывающий цветность Cb, и второй компонент цветности, указывающий цветность Cr, а когда типом дерева текущего блока является дуальное дерево яркости, текущий блок может включать в себя компонент яркости. Когда типом дерева текущего блока является дуальное дерево цветности, цветовые компоненты текущего блока могут включать в себя первый компонент цветности и второй компонент цветности.
[404] Здесь текущий блок может быть блоком преобразования, который является единицей преобразования, и когда типом дерева текущего блока является одиночное дерево, текущий блок может включать в себя блок преобразования для компонента яркости, блок преобразования для первого компонента цветности и блок преобразования для второго компонента цветности. Когда типом дерева текущего блока является дуальное дерево яркости, текущий блок может включать в себя блок преобразования для компонента яркости, и когда типом дерева текущего блока является дуальное дерево цветности, текущий блок может включать в себя блок преобразования для первого компонента цветности и блок преобразования для второго компонента цветности.
[405] В соответствии с примером, когда типом текущего блока является одиночное дерево, LFNST может применяться только к компоненту яркости, и когда текущий блок кодируется в одиночном дереве, значение scaling_matrix_for_lfnst_disabled_flag равно 1 и применяется LFNST, список масштабирования не применяется к компоненту яркости. Однако список масштабирования может применяться к компоненту цветности, к которому LFNST не применяется.
[406] В итоге в случае, когда информация флага о списке масштабирования указывает, что список масштабирования недоступен и индекс LFNST больше чем 0 (то есть LFNST применяется), когда типом дерева текущего блока является одиночное дерево и текущий блок является компонентом яркости, список масштабирования может не применяться, а когда типом дерева текущего блока является одиночное дерево и текущий блок является компонентом цветности, список масштабирования может применяться.
[407] В соответствии с примером, в случае, когда информация флага о списке масштабирования указывает, что список масштабирования недоступен и индекс LFNST больше чем 0, когда типом дерева текущего блока является дуальное дерево цветности, LFNST применимо к текущему блоку, и, таким образом, список масштабирования не применяется к компоненту цветности.
[408] В соответствии с примером, в случае, когда информация флага о списке масштабирования указывает, что список масштабирования недоступен и индекс LFNST больше чем 0, когда типом дерева текущего блока является дуальное дерево яркости, LFNST применимо к текущему блоку, и, таким образом, список масштабирования не применяется к компоненту яркости.
[409] Выведенные коэффициенты преобразования могут быть упорядочены в единицах блока 4×4 в соответствии с обратным диагональным порядком сканирования, и коэффициенты преобразования в блоке 4×4 могут быть также упорядочены в соответствии с обратным диагональным порядком сканирования. То есть, деквантованные коэффициенты преобразования могут быть упорядочены в соответствии с обратным порядком сканирования, применяемым в кодеке видео, как в VVC или HEVC.
[410] Устройство декодирования может выводить модифицированные коэффициенты преобразования из коэффициентов преобразования на основе индекса LFNST и матрицы LFNST для LFNST, то есть, путем применения LFNST (S1530).
[411] LFNST представляет собой неразделимое преобразование, в котором преобразование применяется к коэффициентам без разделения коэффициентов в конкретном направлении, в отличие от первичного преобразования вертикально или горизонтально разделяемых коэффициентов, подлежащих преобразованию, и их преобразования. Это неразделимое преобразование может быть низкочастотным неразделимым преобразованием применения прямого преобразования только в низкочастотном диапазоне, а не всей области блока.
[412] Устройство декодирования может выводить различные переменные, чтобы применять LFNST, и может определять, следует ли применять LFNST, на основе типа дерева и размера текущего блока.
[413] Устройство декодирования может выводить первую переменную (переменную LfnstDcOnly), указывающую, существует ли значимый коэффициент в положении ином, чем DC-компонент, в текущем блоке, и вторую переменную (переменную LfnstZeroOutSigCoeffFlag), указывающую, существует ли коэффициент преобразования во второй области иной, чем верхняя-левая первая область текущего блока.
[414] Первая переменная и вторая переменная первоначально установлены в 1, причем первая переменная может быть обновлена в 0, когда значимый коэффициент существует в положении ином, чем DC-компонент в текущем блоке, и вторая переменная может быть обновлена в 0, когда коэффициент преобразования существует во второй области.
[415] Когда первая переменная обновляется на 0, а вторая переменная сохраняет значение 1, LFNST может применяться к текущему блоку.
[416] Для компонента яркости, к которому применим режим интра-подразбиения (ISP), индекс LFNST может быть получен посредством синтаксического анализа без выведения переменной LfnstDcOnly.
[417] Конкретно, в случае, когда применяется режим ISP и флаг пропуска преобразования, то есть, transform_skip_flag[x0][y0][0], для компонента яркости равен 0, когда типом дерева текущего блока является одиночное дерево или дуальное дерево для яркости, индекс LFNST может сигнализироваться независимо от значения переменной LfnstDcOnly.
[418] Однако, для компонента цветности, к которому не применяется режим ISP, значение переменной LfnstDcOnly может быть установлено в 0 в соответствии со значением флага пропуска преобразования для компонента цветности Cb, transform_skip_flag[x0][y0][1], и значением флага пропуска преобразования для компонента цветности Cr, transform_skip_flag[x0][y0][2]. То есть, когда значение cIdx в transform_skip_flag[x0][y0][cIdx] равно 1, значение переменной LfnstDcOnly может быть установлено в 0, только когда значение transform_skip_flag[x0][y0][1] равно 0, а когда значение cIdx равно 2, значение переменной LfnstDcOnly может быть установлено в 0, только когда значение transform_skip_flag[x0][y0][2] равно 0. Когда значение переменной LfnstDcOnly равно 0, устройство декодирования может выполнять синтаксический анализ в отношении индекса LFNST, и в противном случае, индекс LFNST может считаться равным 0 без сигнализации.
[419] Вторая переменная может представлять собой переменную LfnstZeroOutSigCoeffFlag, которая может указывать, что выполняется обнуление, когда применяется LFNST. Вторая переменная может быть первоначально установлена в 1 и может быть изменена на 0, когда значимый коэффициент существует во второй области.
[420] Переменная LfnstZeroOutSigCoeffFlag может выводиться как 0, когда индекс подблока, в котором существует последний ненулевой коэффициент, больше чем 0, и как ширина, так и высота блока преобразования равны или больше чем 4, или когда положение последнего ненулевого коэффициента в подблоке, в котором существует последний ненулевой коэффициент, больше, чем 7, и размер блока преобразования равен 4×4 или 8×8. Подблок относится к блоку 4×4, используемому как единица кодирования в кодировании остатка, и может упоминаться как группа коэффициентов (CG). Индекс подблока 0 относится к верхнему-левому подблоку 4×4.
[421] То есть, когда ненулевой коэффициент выводится в области иной, чем верхняя-левая область, в которой может существовать коэффициент преобразования LFNST в блоке преобразования, или ненулевой коэффициент существует в положении ином, чем восьмая позиция в порядке сканирования для блока 4×4 или блока 8×8, переменная LfnstZeroOutSigCoeffFlag устанавливается в 0.
[422] Устройство декодирования может определять набор LFNST, включающий матицы LFNST, на основе режима интра-предсказания, выведенного из информации о режиме интра-предсказания, и может выбрать любую одну из матриц LFNST на основе набора LFNST и индекса LFNST.
[423] Здесь, тот же самый набор LFNST и тот же самый индекс LFNST может применяться к блокам преобразования подразбиения, на которые разделен текущий блок. То есть, поскольку тот же самый режим интра-предсказания применяется к блокам преобразования подразбиения, набор LFNST, определенный на основе режима интра-предсказания, может также равным образом применяться ко всем блокам преобразования подразбиения. Дополнительно, поскольку индекс LFNST сигнализируется на уровне единицы кодирования, та же самая матрица LFNST может применяться к блокам преобразования подразбиения, на которые разделен текущий блок.
[424] Как описано выше, набор преобразования может быть определен в соответствии с режимом интра-предсказания для блока преобразования, подлежащего преобразованию, и обратное LFNST может выполняться на основе матрицы ядра преобразования, то есть, любой одной из матриц LFNST, включенных в набор преобразования, указанный индексом LFNST. Матрица, применяемая к обратному LFNST, может называться матрицей обратного LFNST или матрицей LFNST, и определяется любым термином, если матрица представляет собой транспонирование матрицы, используемой для прямого LFNST.
[425] В примере, матрица обратного LFNST может быть неквадратной матрицей, в которой число столбцов меньше, чем число строк.
[426] Устройство декодирования может выводить остаточные выборки для текущего блока на основе первичного обратного преобразования для модифицированных коэффициентов преобразования (S1540).
[427] Здесь, в качестве первичного обратного преобразования может использоваться общее разделимое преобразование или вышеописанное MTS.
[428] Затем, устройство 300 декодирования может генерировать восстановленные выборки на основе остаточных выборок для текущего блока и выборок предсказания для текущего блока (S1550).
[429] Следующие чертежи обеспечены для описания конкретных примеров настоящего раскрытия. Поскольку конкретные термины для устройств или конкретные термины для сигналов/сообщений/полей, иллюстрируемых на чертежах, обеспечены для иллюстрации, технические признаки настоящего раскрытия не ограничены конкретными терминами, используемыми на последующих чертежах.
[430] Фиг. 16 представляет собой блок-схему последовательности операций, иллюстрирующую работу устройства кодирования видео в соответствии с вариантом осуществления настоящего раскрытия.
[431] Каждый процесс, раскрытый на фиг. 16, основан на некоторых из деталей, описанных со ссылкой на фиг. 4 - фиг. 14. Поэтому, описание конкретных деталей, перекрывающееся с описанием со ссылками на фиг. 2 и фиг. 4 - фиг. 14, будет опущено или представлено схематично.
[432] Устройство кодирования 200 в соответствии с вариантом осуществления может выводить выборки предсказания для текущего блока на основе режима интра-предсказания, применяемого к текущему блоку (S1610).
[433] Когда ISP применяется к текущему блоку, устройство кодирования может выполнять предсказание по каждому блоку преобразования подразбиения.
[434] Устройство кодирования может определять, следует ли применять кодирование ISP или режим ISP к текущему блоку, то есть, блоку кодирования, и может определять направление, в котором разбивается текущий блок, и может выводить размер и число разделенных подблоков в соответствии с результатом определения.
[435] Тот же самый режим интра-предсказания может применяться к блокам преобразования подразбиения, на которые разделен текущий блок, и устройство кодирования может выводить выборку предсказания для каждого блока преобразования подразбиения. То есть устройство кодирования последовательно выполняет интра-предсказание, например, по горизонтали или по вертикали, или слева направо или сверху вниз, в соответствии с формой разбиения блоков преобразования подразбиения. Для самого левого или самого верхнего подблока, на восстановленный пиксел уже кодированного блока кодирования ссылаются как в обычном способе интра-предсказания. Кроме того, для каждой стороны последующего внутреннего блока преобразования подразбиения, которая не является смежной с предыдущим блоком преобразования подразбиения, чтобы вывести опорные пикселы, смежные со стороной, на восстановленный пиксел уже кодированного смежного блока кодирования ссылаются, как в обычном способе интра-предсказания.
[436] Устройство 200 кодирования может выводить остаточные выборки для текущего блока на основе выборок предсказания (S1620).
[437] Устройство 200 кодирования может выводить коэффициенты преобразования для текущего блока путем применения по меньшей мере одного из LFNST или MTS к остаточным выборкам и может упорядочить коэффициенты преобразования в соответствии с предопределенным порядком сканирования.
[438] Устройство кодирования может выводить коэффициенты преобразования для текущего блока на основе процесса преобразования, такого как первичное преобразование и/или вторичное преобразование, на остаточных выборках, может применять LFNST, когда текущий блок является одиночным деревом и компонентом яркости, и не может применять LFNST, когда текущий блок является одиночным деревом и компонентом цветности.
[439] Устройство кодирования может выводить коэффициенты преобразования для текущего блока на основе первичного преобразования на остаточных выборках (S1630), и первичное преобразование может выполняться посредством множества ядер преобразования как в MTS, и в этом случае ядро преобразования может выбираться на основе режима интра-предсказания.
[440] Устройство 200 кодирования может определять, следует ли выполнять вторичное преобразование или неразделимое преобразование, конкретно LFNST, в отношении коэффициентов преобразования для текущего блока и может выводить модифицированные коэффициенты преобразования путем применения LFNST к коэффициентам преобразования (S1640).
[441] LFNST представляет собой неразделимое преобразование, в котором преобразование применяется к коэффициентам без разделения коэффициентов в конкретном направлении, в отличие от первичного преобразования вертикально или горизонтально разделяемых коэффициентов, подлежащих преобразованию, и их преобразования. Это неразделимое преобразование может быть низкочастотным неразделимым преобразованием применения преобразования только к низкочастотной области, а не ко всему целевому блоку, подлежащему преобразованию.
[442] Устройство кодирования может выводить различные переменные для применения LFNST и может определять, следует ли применять LFNST, на основе типа дерева и размера текущего блока.
[443] Устройство кодирования может выводить первую переменную (переменную LfnstDcOnly), указывающую, существует ли значимый коэффициент в позиции ином, чем позиция DC-компонента в текущем блоке, и вторую переменную (переменную LfnstZeroOutSigCoeffFlag), указывающую, существует ли коэффициент преобразования во второй области иной, чем верхняя-левая первая область текущего блока.
[444] Первая переменная и вторая переменная первоначально устанавливаются в 1, причем первая переменная может быть обновлена на 0, когда значимый коэффициент существует в позиции иной, чем позиция DC-компонента в текущем блоке, и вторая переменная может быть обновлена на 0, когда коэффициент преобразования существует во второй области.
[445] Когда первая переменная обновляется на 0 и вторая переменная сохраняет значение 1, LFNST может применяться к текущему блоку.
[446] Для компонента яркости, к которому применим режим интра-подразбиения (ISP), LFNST может применяться без выведения переменной LfnstDcOnly.
[447] Конкретно, в случае, когда применяется режим ISP, и флаг пропуска преобразования, то есть transform_skip_flag[x0][y0][0], для компонента яркости равен 0, когда типом дерева текущего блока является одиночное дерево или дуальное дерево для яркости, LFNST может применяться независимо от значения переменной LfnstDcOnly.
[448] Однако для компонента цветности, к которому не применяется режим ISP, значение переменной LfnstDcOnly может быть установлено в 0 в соответствии со значением флага пропуска преобразования для компонента цветности Cb, transform_skip_flag[x0][y0][1], и значением флага пропуска преобразования для компонента цветности Cr, transform_skip_flag[x0][y0][2]. То есть, когда значение cIdx в transform_skip_flag[x0][y0][cIdx] равно 1, значение переменной LfnstDcOnly может быть установлено в 0, только когда значение transform_skip_flag[x0][y0][1] равно 0, а когда значение cIdx равно 2, значение переменной LfnstDcOnly может быть установлено в 0, только когда значение transform_skip_flag[x0][y0][2] равно 0. Когда значение переменной LfnstDcOnly равно 0, устройство кодирования может применять LFNST, а в противном случае, устройство кодирования не может применять LFNST.
[449] Вторая переменная может быть переменной LfnstZeroOutSigCoeffFlag, которая может указывать, что выполняется обнуление, когда применяется LFNST. Вторая переменная может быть первоначально установлена в 1 и может быть изменена на 0, когда значимый коэффициент существует во второй области.
[450] Переменная LfnstZeroOutSigCoeffFlag может выводиться как 0, когда индекс подблока, в котором существует последний ненулевой коэффициент, больше чем 0, и как ширина, так и высота блока преобразования равны или больше чем 4, или когда позиция последнего ненулевого коэффициента в подблоке, в котором существует последний ненулевой коэффициент, больше чем 7, и размер блока преобразования равен 4×4 или 8×8. Подблок относится к блоку 4×4, используемому как единица кодирования в кодировании остатка, и может упоминаться как группа коэффициентов (CG). Индекс подблока 0 относится к верхнему-левому подблоку 4×4.
[451] То есть, когда ненулевой коэффициент выводится в области иной, чем верхняя-левая область, в которой может существовать коэффициент преобразования LFNST в блоке преобразования, или существует ненулевой коэффициент в позиции иной, чем восьмая позиция в порядке сканирования для блока 4×4 или блока 8×8, переменная LfnstZeroOutSigCoeffFlag устанавливается в 0.
[452] Устройство кодирования может определять набор LFNST, включающий матрицы LFNST, на основе режима интра-предсказания, выведенного из информации о режиме интра-предсказания, и может выбирать любую одну из множества матриц LFNST.
[453] Здесь тот же самый набор LFNST и тот же самый индекс LFNST может применяться к блокам преобразования подразбиения, на которые разбивается текущий блок. То есть, поскольку тот же самый режим интра-предсказания применяется к блокам преобразования подразбиения, набор LFNST, определяемый на основе режима интра-предсказания, может также равным образом применяться ко всем блокам преобразования подразбиения. Кроме того, поскольку индекс LFNST сигнализируется на уровне единицы кодирования, та же самая матрица LFNST может применяться к блокам преобразования подразбиения, на которые разбивается текущий блок.
[454] Как описано выше, набор преобразования может быть определен в соответствии с режимом интра-предсказания для блока преобразования, подлежащего преобразованию, и LFNST может выполняться на основе матрицы ядра преобразования, то есть любой одной из матриц LFNST, включенных в набор преобразования LFNST. Матрица, применяемая для LFNST, может называться матрицей LFNST или определяется любым термином, если матрица является транспонированием матрицы, используемой для обратного LFNST.
[455] В примере матрица LFNST может быть неквадратной матрицей, в которой число строк меньше, чем число столбцов.
[456] Устройство кодирования может выводить, применяется ли список масштабирования к текущему блоку, на основе того, выполняется ли LFNST в процессе преобразования, и типа дерева текущего блока, и может выполнять квантование на основе коэффициентов преобразования или модифицированных коэффициентов преобразования и списка масштабирования (S1650).
[457] Список масштабирования представляет собой матрицу для задания удельного веса (взвешенного значения) для каждой позиции коэффициента преобразования в блоке преобразования и позволяет осуществлять деквантование или квантование путем умножения на вес для каждого коэффициента преобразования, тем самым позволяя применять дифференциальное деквантование или квантование в соответствии с важностью коэффициента преобразования.
[458] В соответствии с примером, когда типом дерева текущего блока является одиночное дерево и текущий блок является компонентом яркости, устройство кодирования может не применять список масштабирования, а когда типом дерева текущего блока является одиночное дерево и текущий блок является компонентом цветности, устройство кодирования может применять список масштабирования.
[459] Когда типом дерева текущего блока является одиночное дерево, цветовые компоненты текущего блока могут включать в себя компонент яркости, первый компонент цветности, указывающий цветность Cb, и второй компонент цветности, указывающий цветность Cr, и когда типом дерева текущего блока является дуальное дерево яркости, текущий блок может включать в себя компонент яркости. Когда типом дерева текущего блока является дуальное дерево цветности, цветовые компоненты текущего блока могут включать в себя первый компонент цветности и второй компонент цветности.
[460] Здесь текущий блок может быть блоком преобразования, который представляет собой единицу преобразования, и когда типом дерева текущего блока является одиночное дерево, текущий блок может включать в себя блок преобразования для компонента яркости, блок преобразования для первого компонента цветности, и блок преобразования для второго компонента цветности. Когда типом дерева текущего блока является дуальное дерево яркости, текущий блок может включать в себя блок преобразования для компонента яркости, и когда типом дерева текущего блока является дуальное дерево цветности, текущий блок может включать в себя блок преобразования для первого компонента цветности и блок преобразования для второго компонента цветности.
[461] В соответствии с примером, когда текущий блок является одиночным деревом, устройство кодирования может применять LFNST только к компоненту яркости, и когда применяется LFNST, устройство кодирования не применяет список масштабирования к компоненту яркости. Однако устройство кодирования может применять список масштабирования к компоненту цветности, к которому не применяется LFNST.
[462] В итоге в случае, когда индекс LFNST больше чем 0 (то есть применяется LFNST), когда типом дерева текущего блока является одиночное дерево и текущий блок является компонентом яркости, устройство кодирования может не применять список масштабирования, а когда типом дерева текущего блока является одиночное дерево и текущий блок является компонентом цветности, устройство кодирования может применять список масштабирования.
[463] В соответствии с примером, в случае, когда индекс LFNST больше чем 0, когда типом дерева текущего блока является дуальное дерево цветности, LFNST применимо к текущему блоку, и, таким образом, устройство кодирования не применяет список масштабирования.
[464] В соответствии с примером, в случае, когда индекс LFNST больше чем 0, когда типом дерева текущего блока является дуальное дерево яркости, LFNST применимо к текущему блоку, и, таким образом, устройство кодирования не применяет список масштабирования.
[465] Устройство кодирования может квантовать коэффициенты преобразования на основе определения того, применяется ли список масштабирования к текущему блоку.
[466] То есть устройство кодирования может квантовать коэффициенты преобразования для блока преобразования, к которому не применяется LFNST, используя список масштабирования, и может квантовать коэффициенты преобразования для блока преобразования, к которому применяется LFNST, без использования списка масштабирования.
[467] Устройство кодирования может кодировать и выводить остаточную информацию и информацию флага, указывающую, доступен ли список масштабирования, когда выполняется LFNST (S1660).
[468] Информация флага, указывающая, доступен ли список масштабирования, когда выполняется LFNST, может быть представлена посредством scaling_matrix_for_lfnst_disabled_flag или sps_scaling_matrix_for_lfnst_disabled_flag и может сигнализироваться в наборе параметров последовательности. Значение этого флага, равное 1, указывает, что список масштабирования не применяется, когда применяется LFNST, и значение флага, равное 0, указывает, что список масштабирования применим, когда применяется LFNST.
[469] Когда индекс LFNST больше чем 0, и текущий блок является одиночным деревом, LFNST применимо к компоненту яркости, и, таким образом, устройство кодирования может кодировать значение флага в 1.
[470] Однако, когда индекс LFNST больше чем 0 и текущий блок является одиночным деревом, LFNST не применяется к компоненту цветности, и, таким образом, устройство кодирования может конструировать информацию изображения так, что список масштабирования может применяться.
[471] Когда индекс LFNST больше чем 0, и типом дерева текущего блока является дуальное дерево цветности, LFNST применимо к текущему блоку, и, таким образом, устройство кодирования может кодировать значение флага в 1, так что список масштабирования не применяется к компоненту цветности.
[472] В соответствии с примером, когда индекс LFNST больше чем 0, и типом дерева текущего блока является дуальное дерево яркости, LFNST применимо к текущему блоку, и, таким образом, устройство кодирования может кодировать значение флага в 1, так что список масштабирования не применяется к компоненту яркости.
[473] Устройство кодирования может выводить квантованные коэффициенты преобразования путем квантования модифицированных коэффициентов преобразования для текущего блока и может кодировать индекс LFNST.
[474] Устройство кодирования может генерировать остаточную информацию, включая информацию о квантованных коэффициентах преобразования. Остаточная информация может включать в себя вышеописанные информацию/синтаксический элемент, относящиеся к преобразованию. Устройство кодирования может кодировать информацию изображения/видео, включая остаточную информацию, и может выводить информацию изображения/видео в форме битового потока.
[475] Конкретно, устройство 200 кодирования может генерировать информацию о квантованных коэффициентах преобразования и может кодировать информацию о квантованных коэффициентах преобразования.
[476] Синтаксический элемент индекса LFNST в соответствии с настоящим вариантом осуществления может указывать любое одно из того, применяется ли (обратное) LFNST и любая одна из матриц LFNST, включенных в набор LFNST, и когда набор LFNST включает в себя две матрицы ядра преобразования, синтаксический элемент индекса LFNST может иметь три значения.
[477] В соответствии с примером, когда структурой дерева разбиения текущего блока является дуальное дерево, индекс LFNST может кодироваться для каждого из блока яркости и блока цветности.
[478] В соответствии с вариантом осуществления, значения синтаксического элемента индекса преобразования могут включать в себя 0, указывающее, что (обратное) LFNST не применяется к текущему блоку, 1, указывающее первую матрицу LFNST среди матриц LFNST, и 2, указывающее вторую матрицу LFNST среди матриц LFNST.
[479] В настоящем раскрытии, по меньшей мере одно из квантования/деквантования и/или преобразования/обратного преобразования может быть опущено. Когда квантование/деквантование опущено, квантованный коэффициент преобразования может упоминаться как коэффициент преобразования. Когда преобразование/обратное преобразование опущено, коэффициент преобразования может упоминаться как коэффициент или остаточный коэффициент или все еще может упоминаться как коэффициент преобразования в целях непротиворечивости выражения.
[480] Кроме того, в настоящем раскрытии квантованный коэффициент преобразования и коэффициент преобразования могут упоминаться как коэффициент преобразования и масштабированный коэффициент преобразования, соответственно. В этом случае, остаточная информация может включать в себя информацию о коэффициенте(ах) преобразования, и информация о коэффициенте(ах) преобразования может сигнализироваться посредством синтаксиса кодирования остатка. Коэффициенты преобразования могут быть выведены на основе остаточной информации (или информации о коэффициенте(ах) преобразования), и масштабированные коэффициенты преобразования могут быть выведены посредством обратного преобразования (масштабирования) коэффициентов преобразования. Остаточные выборки могут быть выведены на основе обратного преобразования (преобразования) масштабированных коэффициентов преобразования. Эти детали также могут быть применены/выражены в других частях настоящего раскрытия.
[481] В вышеописанных вариантах осуществления, способы поясняются на основе блок-схем последовательностей операций, с помощью последовательности этапов или блоков, но настоящее раскрытие не ограничено этим порядком этапов или блоков, и определенный этап может выполняться в порядке ином, чем описано выше, или одновременно с другим этапом. Дополнительно, специалисту в данной области техники должно быть понятно, что этапы, показанные в блок-схеме последовательности операций выше, не являются исключительными, что другой этап может быть включен или что один или несколько этапов в блок-схеме последовательности операций могут быть удалены без влияния на объем настоящего раскрытия.
[482] Вышеописанные способы в соответствии с настоящим раскрытием могут быть реализованы в форме программного обеспечения, и устройство кодирования и/или устройство декодирования в соответствии с настоящим раскрытием могут быть включены в устройство для обработки изображения, такое как телевизор, компьютер, смартфон, телевизионная приставка, устройство отображения и т.д.
[483] Когда варианты осуществления настоящего раскрытия реализованы в программном обеспечении, вышеописанные способы могут быть реализованы как модули (процессы, функции и т.д.) для выполнения вышеописанных функций. Модули могут храниться в памяти и могут исполняться процессором. Память может быть внутренней или внешней по отношению к процессору и может быть соединена с процессором различными хорошо известными средствами. Процессор может включать в себя специализированную интегральную схему (ASIC), другие чипсеты, логическую схему и/или устройство обработки данных. Память может включать в себя постоянную память (ROM), память с произвольным доступом (RAM), флэш-память, карту памяти, носитель хранения и/или другое устройство хранения. То есть, варианты осуществления, описанные в настоящем раскрытии, могут реализовываться и выполняться на процессоре, микропроцессоре, контроллере или чипе. Например, функциональные блоки, показанные на каждом чертеже, могут реализовываться и выполняться на компьютере, процессоре, микропроцессоре, контроллере или чипе.
[484] Кроме того, устройство декодирования и устройство кодирования, к которым применяется настоящее раскрытие, могут быть включены в приемопередатчик мультимедийного вещания, мобильный терминал связи, устройство домашнего кинотеатра, устройство цифрового кинотеатра, камеру наблюдения, устройство для разговора по видео, устройство связи в реальном времени, такой как видеосвязь, мобильное устройство стриминга, носитель хранения, камеру-регистратор, устройство обеспечения услуги видео по требованию (VoD), устройство доставки видео непосредственно от провайдера контента (OTT), устройство обеспечения услуги Интернет-стриминга, устройство трехмерного (3D) видео, устройство видео-телеконференции и медицинское видеоустройство, и могут использоваться для обработки сигнала видео и сигнала данных. Например, видеоустройство OTT может включать в себя игровую консоль, Blu-ray плеер, телевизор с Интернет-доступом, систему домашнего кинотеатра, смартфон, планшетный PC, цифровой рекордер видео (DVR) и тому подобное.
[485] Кроме того, способ обработки, к которому применяется настоящее раскрытие, может выполняться в форме программы, исполняемой компьютером, и может храниться в считываемом компьютером носителе записи. Мультимедийные данные, имеющие структуру данных в соответствии с настоящим раскрытием, могут также храниться в считываемых компьютером носителях записи. Считываемый компьютером носитель записи включает в себя все типы устройств хранения и распределенных устройств хранения, в которых хранятся считываемые компьютером данные. Считываемые компьютером носители записи могут включать в себя, например, Blu-ray диск (BD), универсальную последовательную шину (USB), ROM, PROM, EPROM, EEPROM, RAM, CD-ROM, магнитную ленту, флоппи-диск и устройство оптического хранения данных. Дополнительно, считываемый компьютером носитель записи включает в себя носители, реализуемые в форме несущей волны (например, передача через Интернет). Кроме того, битовый поток, сгенерированный способом кодирования, может храниться в считываемом компьютером носителе записи или может передаваться по сетям проводной или беспроводной связи. Дополнительно, варианты осуществления настоящего раскрытия могут быть реализованы как компьютерный программный продукт посредством программных кодов, и программные коды могут исполняться на компьютере посредством вариантов осуществления настоящего раскрытия. Программные коды могут храниться на считываемом компьютером носителе.
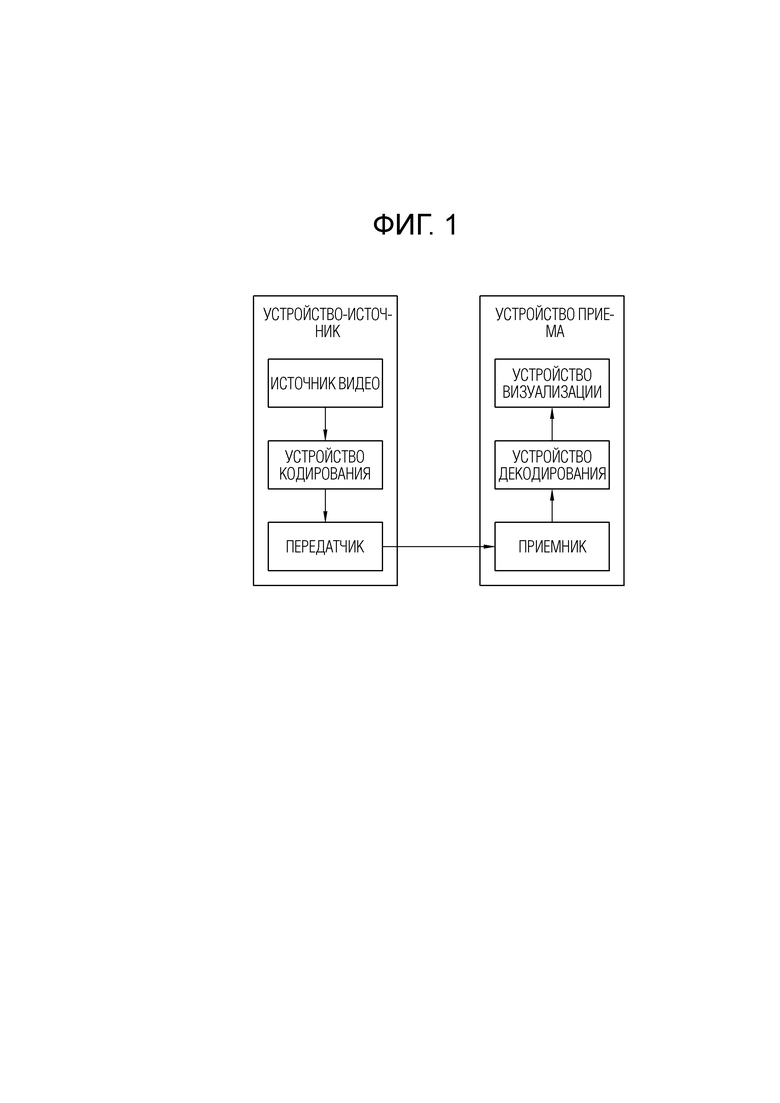
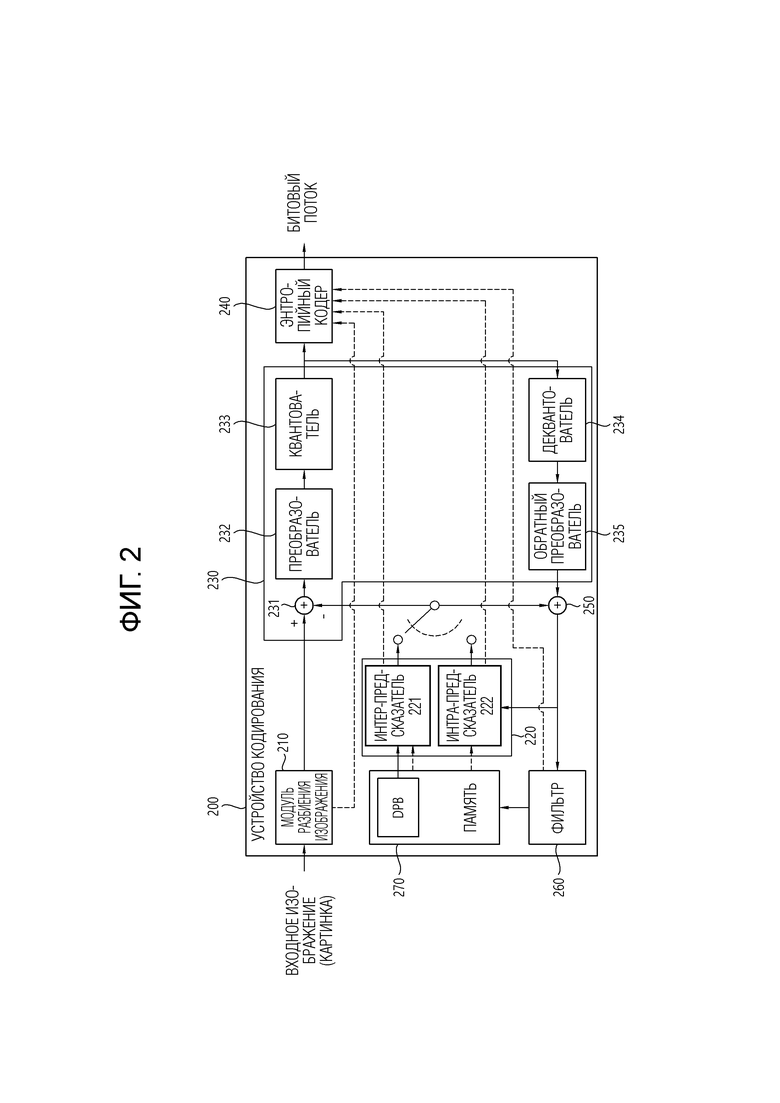
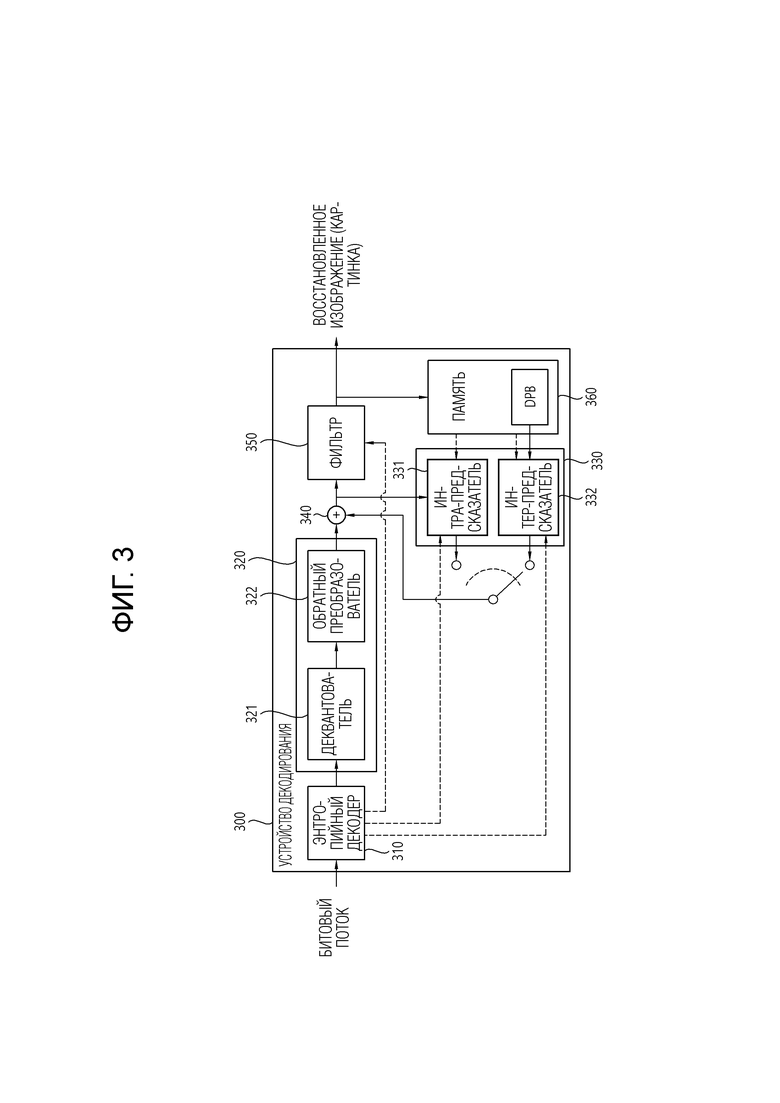
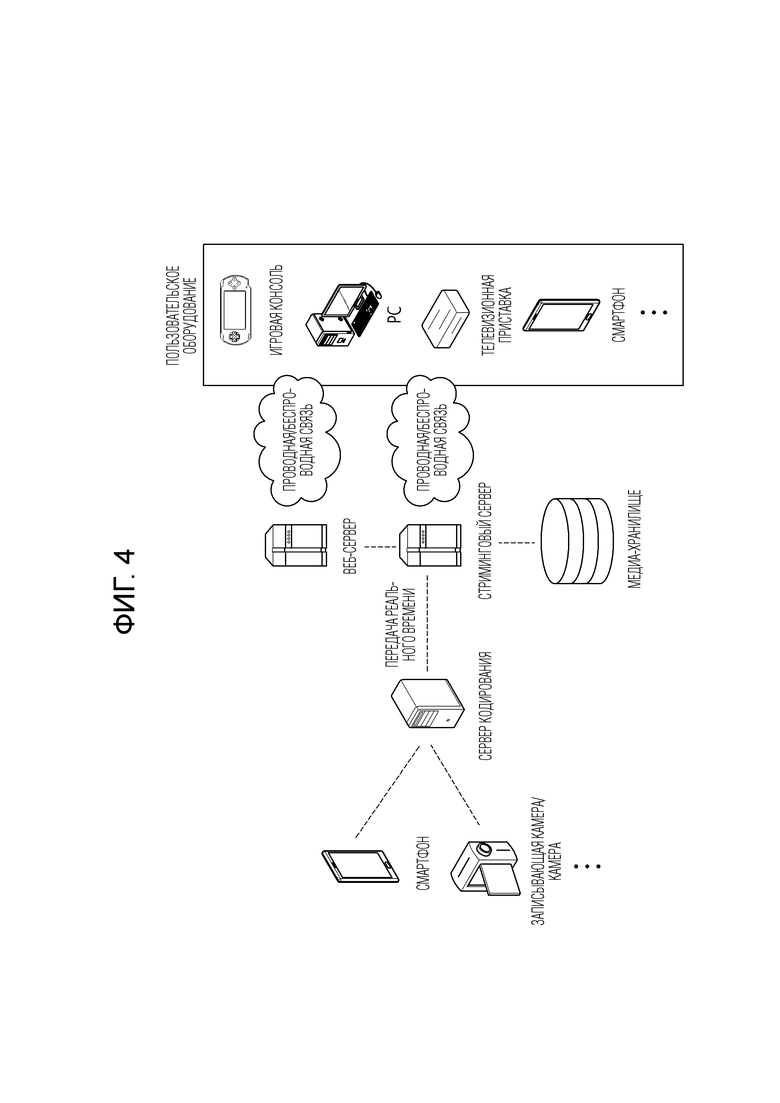
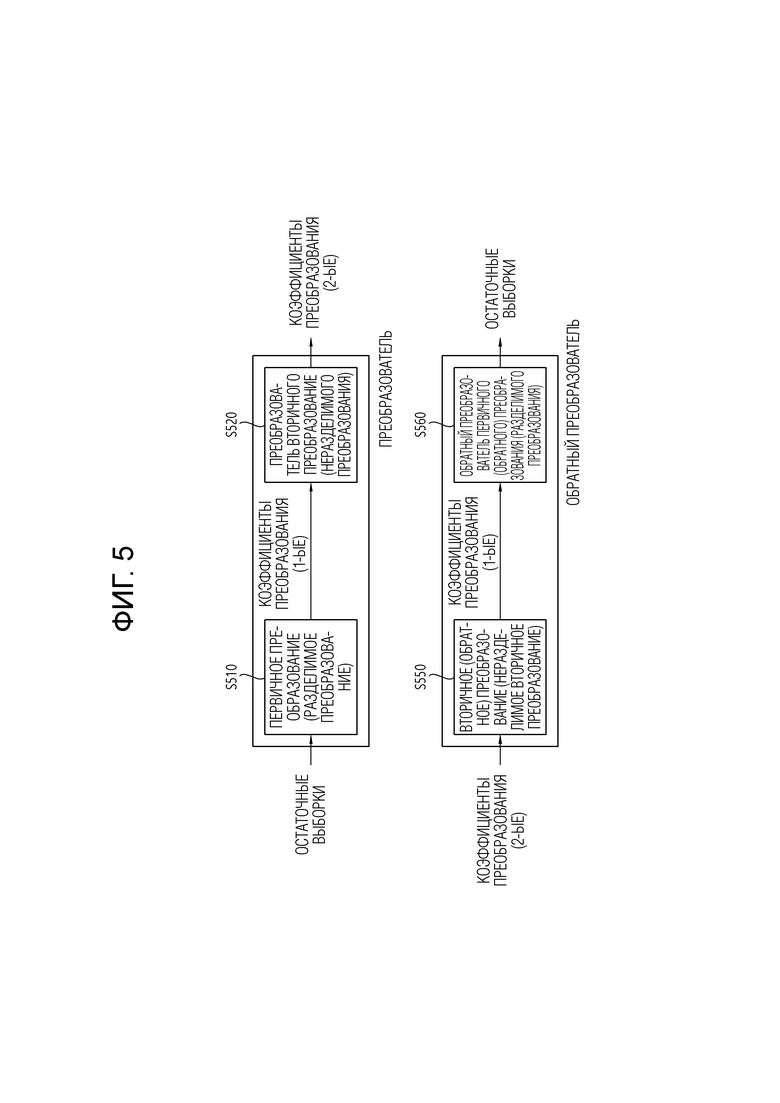
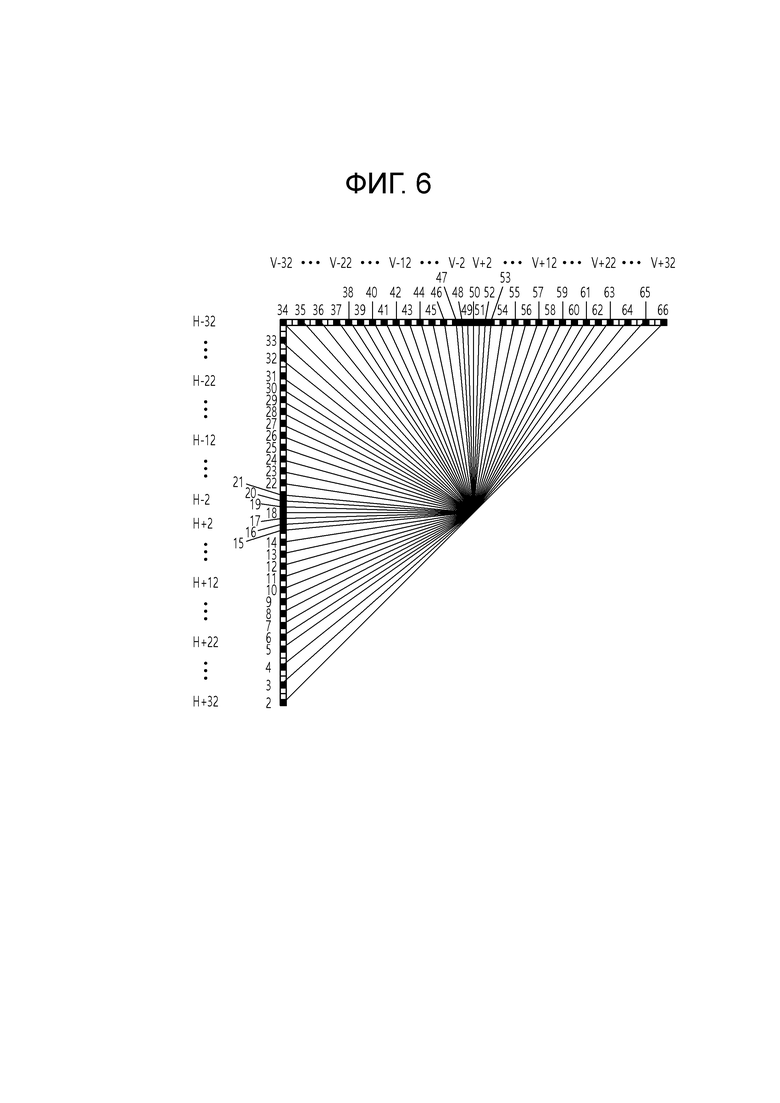
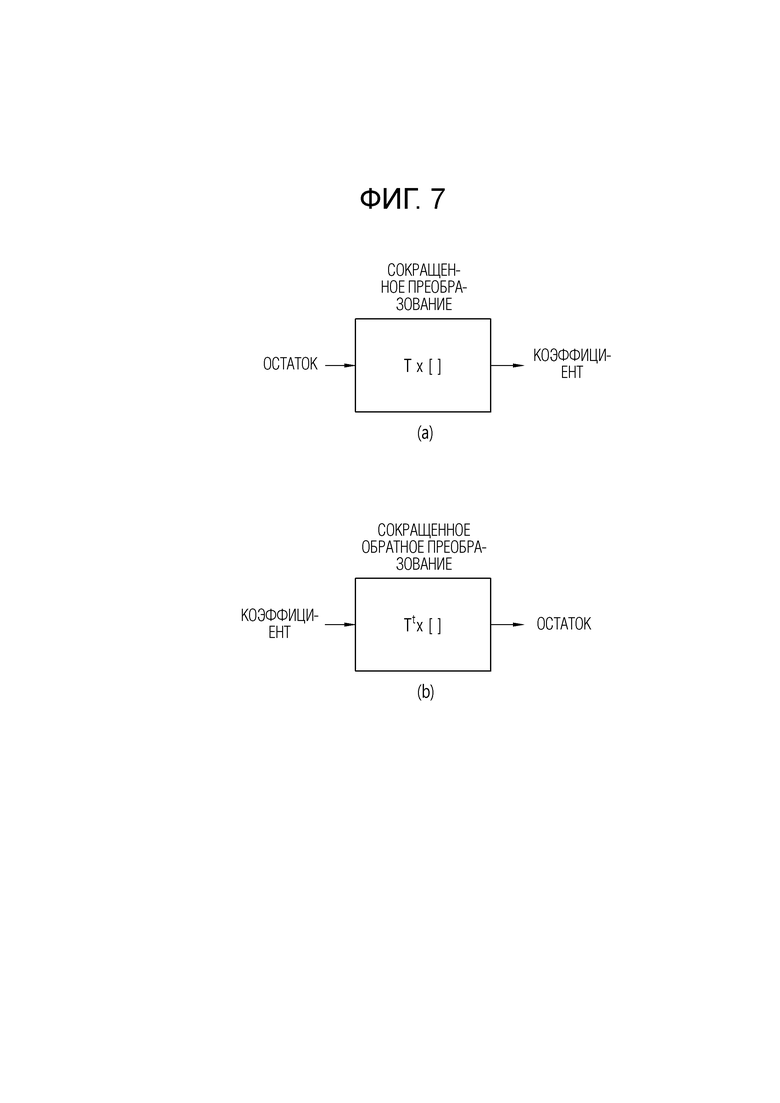
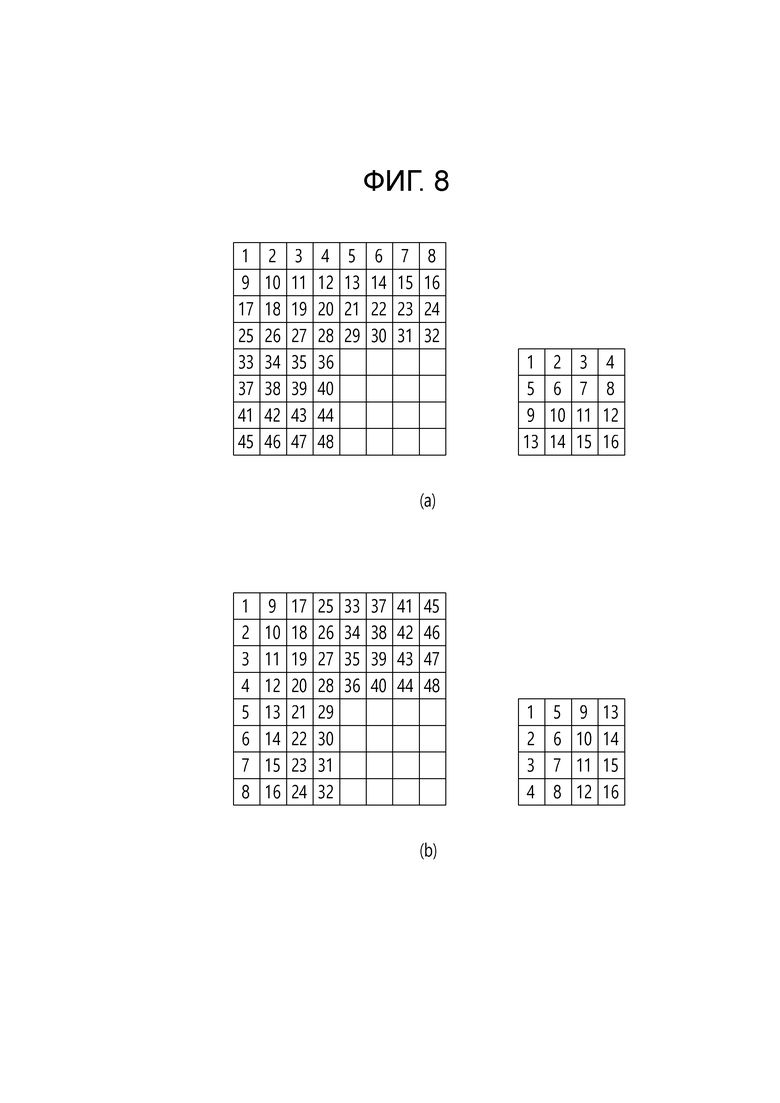
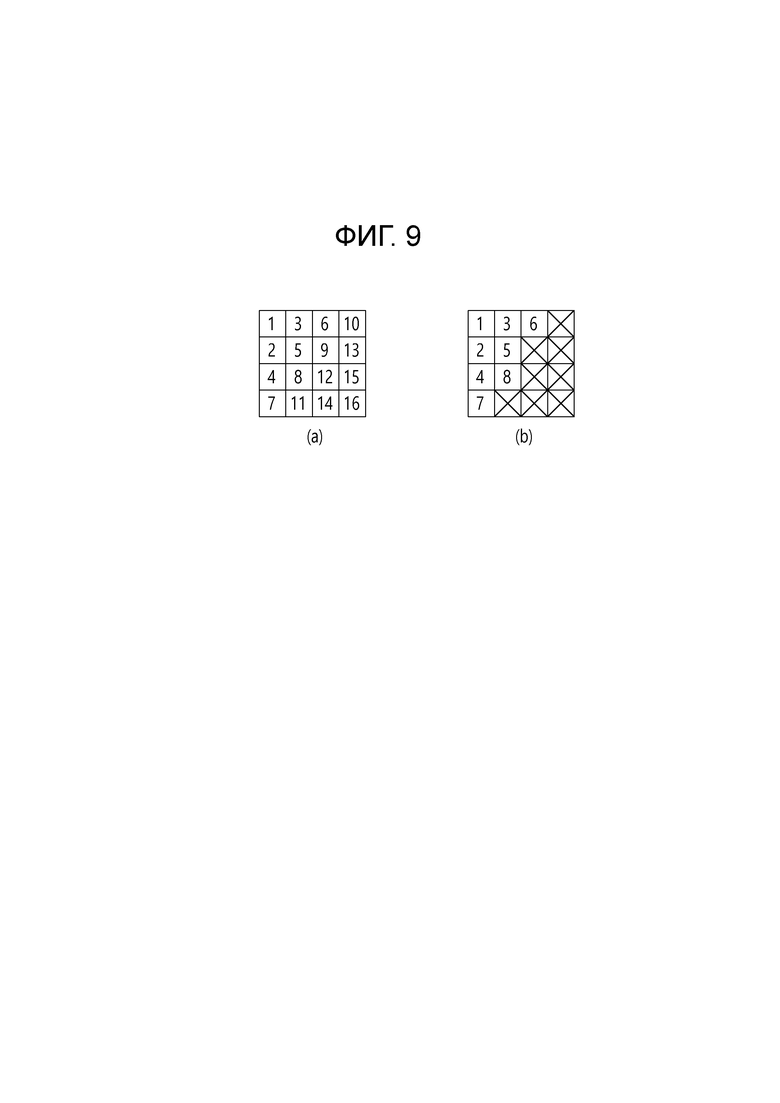
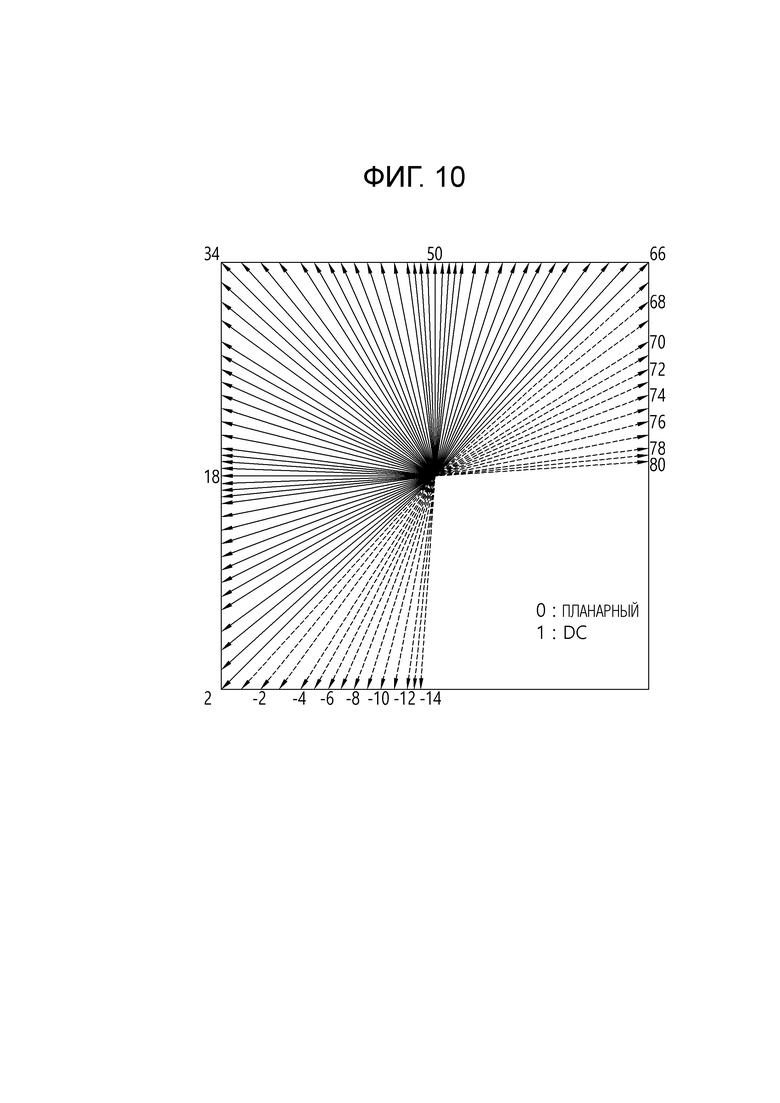
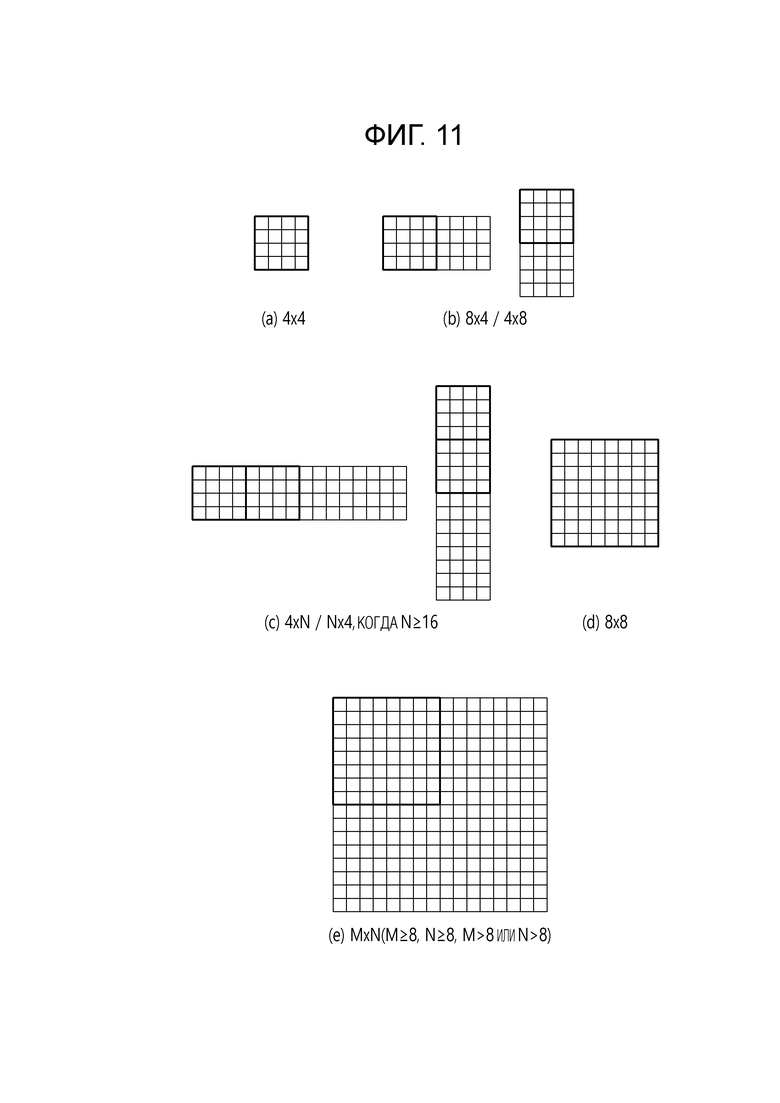
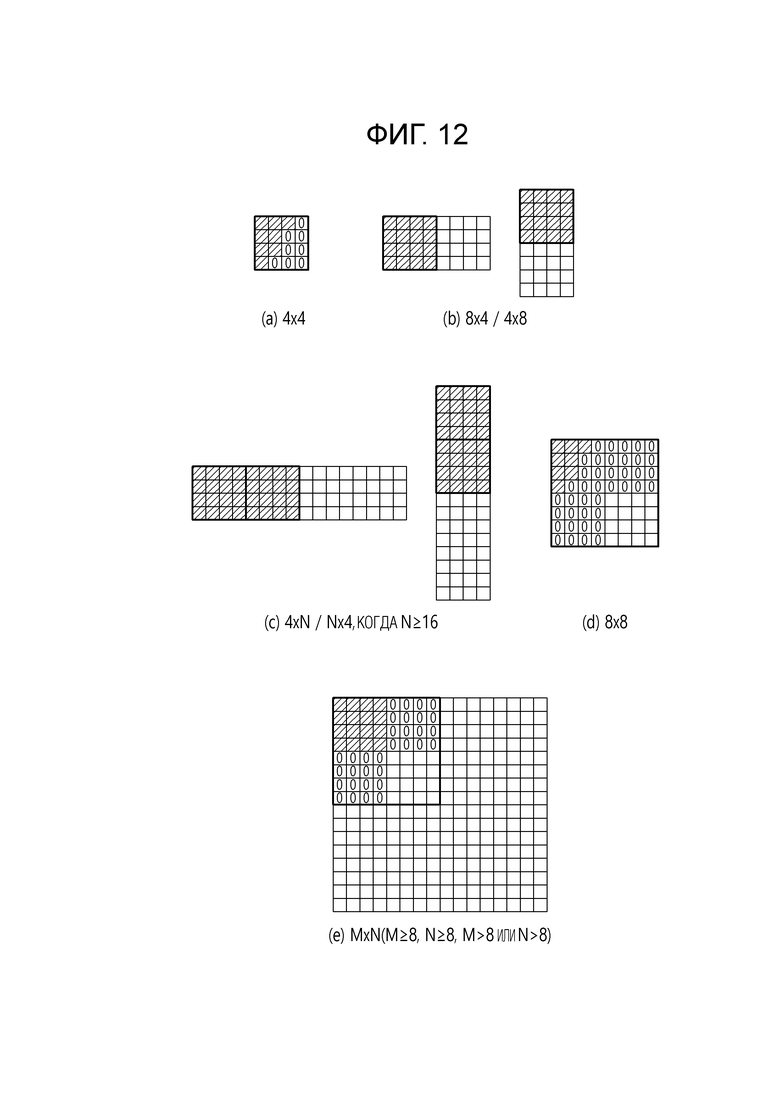
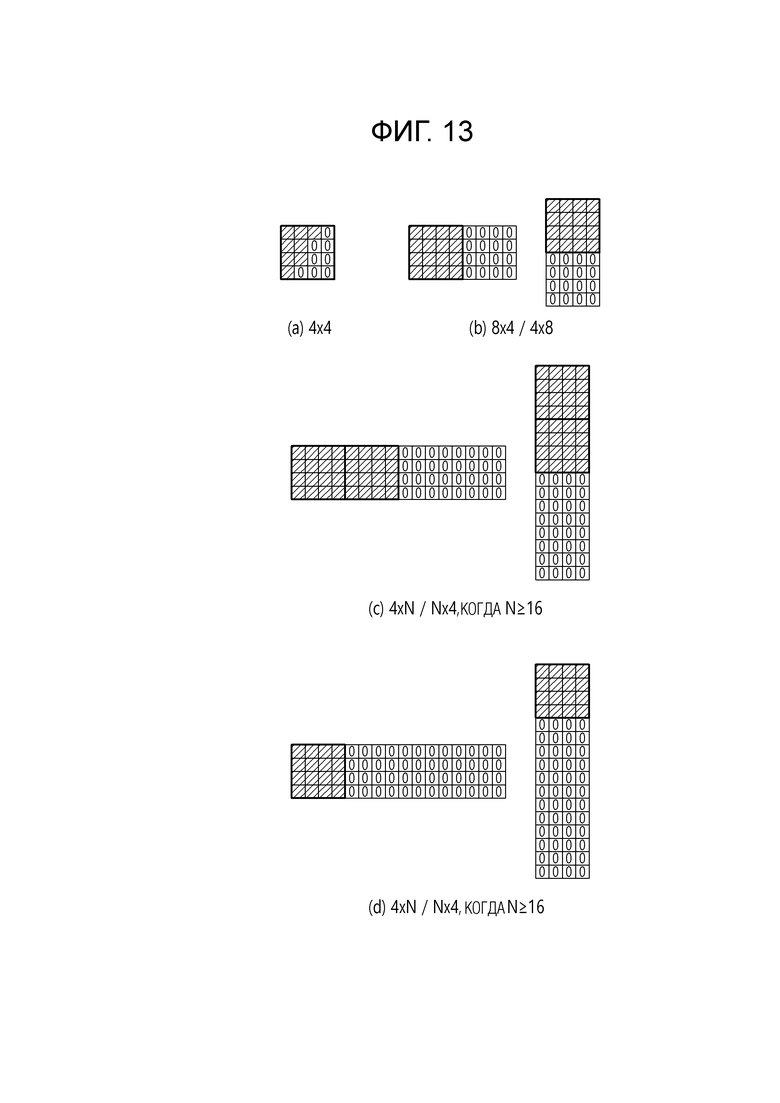
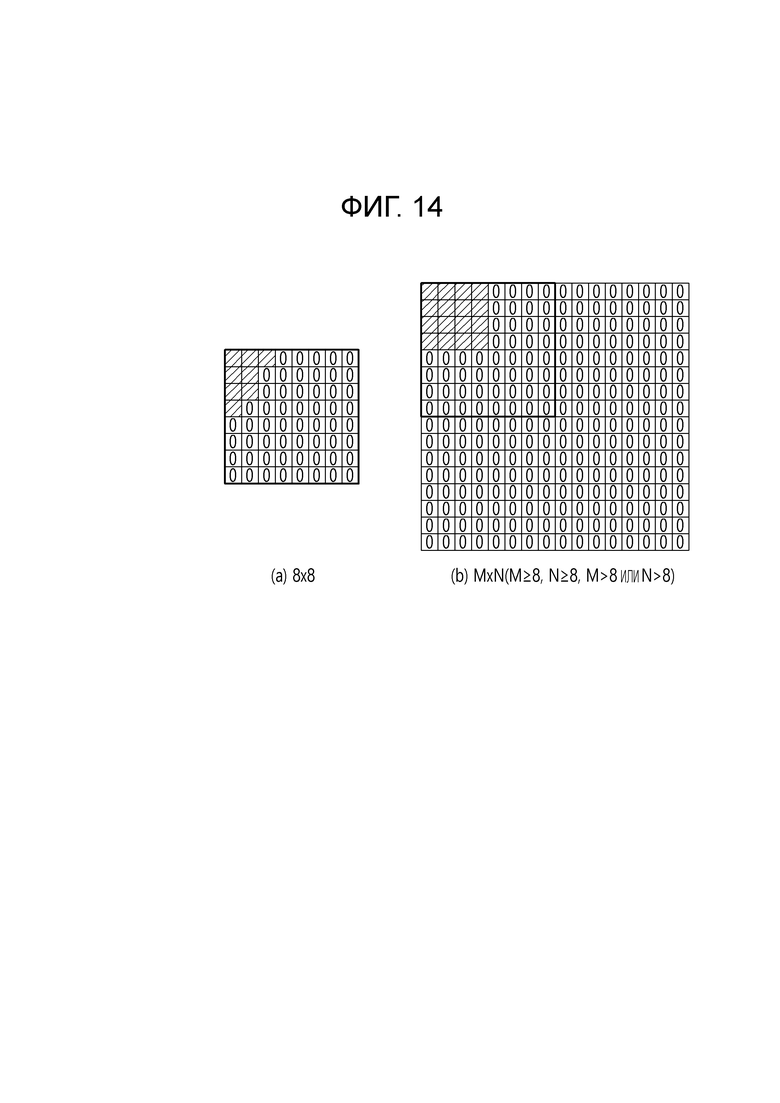
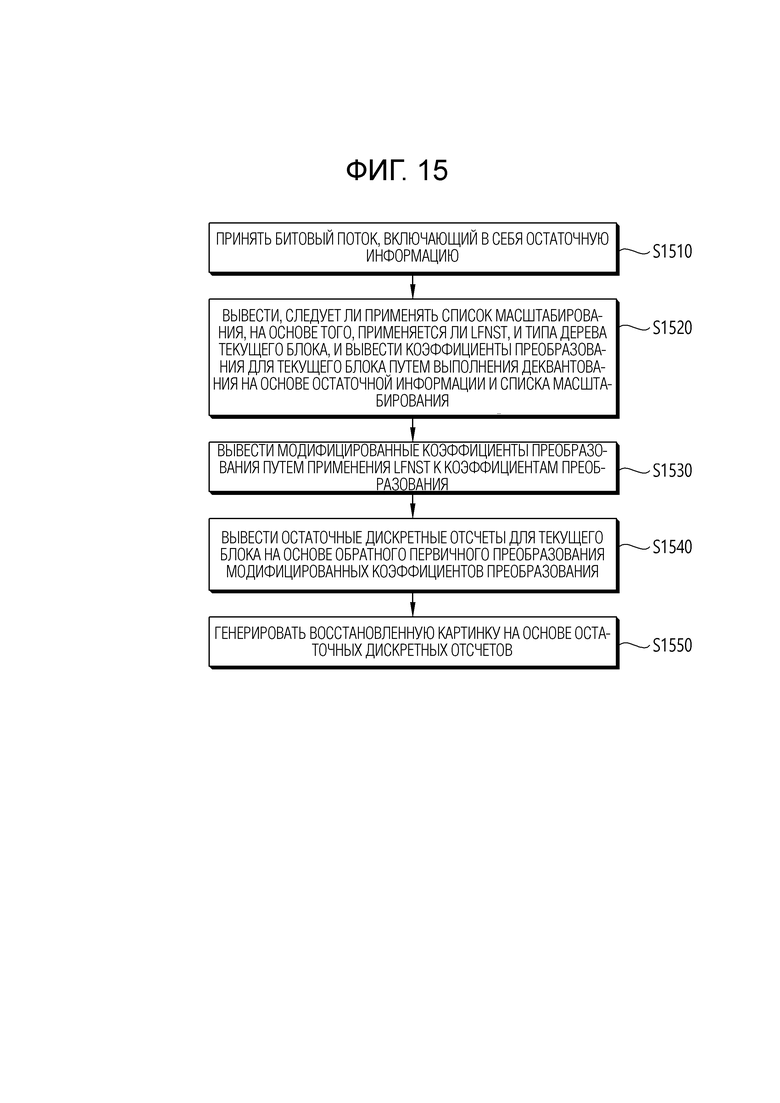
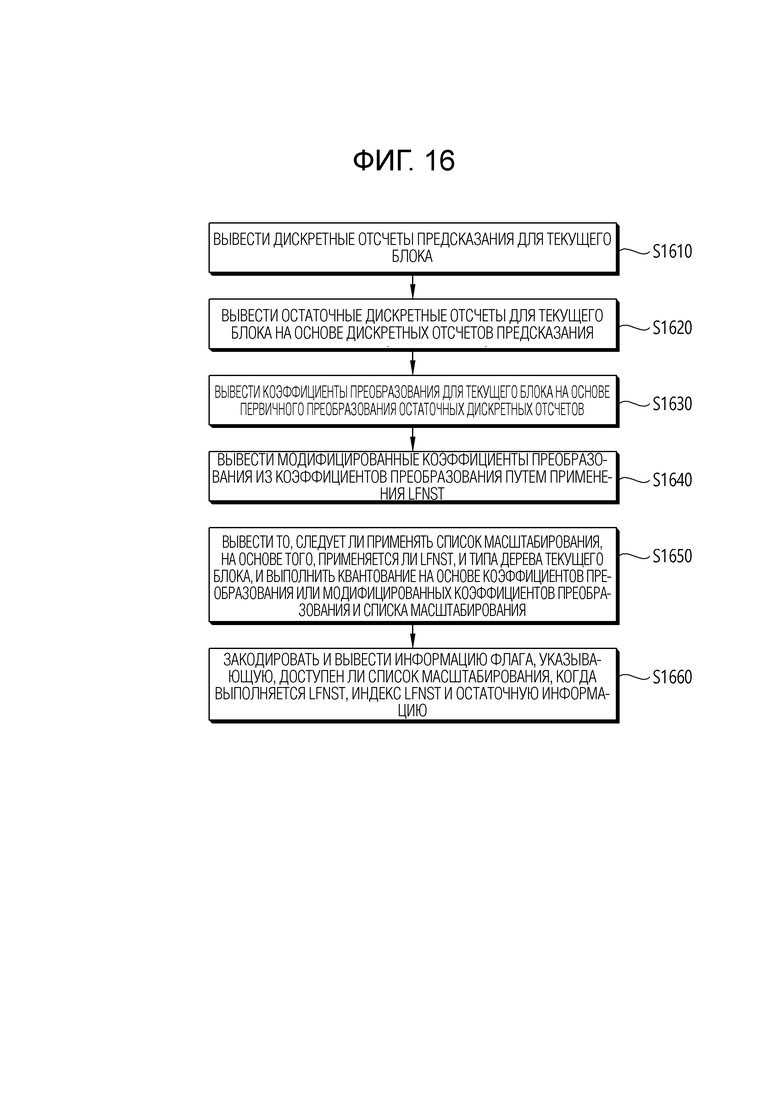
Изобретение относится к средствам для кодирования и декодирования изображений. Технический результат заключается в повышении эффективности кодирования. Выводят дискретные отсчеты предсказания для текущего блока. Выводят остаточные дискретные отсчеты для текущего блока на основе дискретных отсчетов предсказания. Выводят коэффициенты преобразования для текущего блока на основе первичного преобразования остаточных дискретных отсчетов. Выводят модифицированные коэффициенты преобразования из коэффициентов преобразования путем применения LFNST. Квантуют коэффициенты преобразования или модифицированные коэффициенты преобразования, на основе заранее определенного списка масштабирования. Определяют, следует ли применять список масштабирования, на основе того, применяется ли LFNST, и типа дерева текущего блока. Типом дерева текущего блока является один из трех типов дерева, включающих в себя одиночное дерево, дуальное дерево яркости, дуальное дерево цветности. Список масштабирования применяется к текущему блоку, когда типом дерева текущего блока является одиночное дерево и текущим блоком является компонент цветности. Список масштабирования не применяется к текущему блоку, когда типом дерева текущего блока является дуальное дерево цветности. 3 н. и 10 з.п. ф-лы, 13 табл., 16 ил.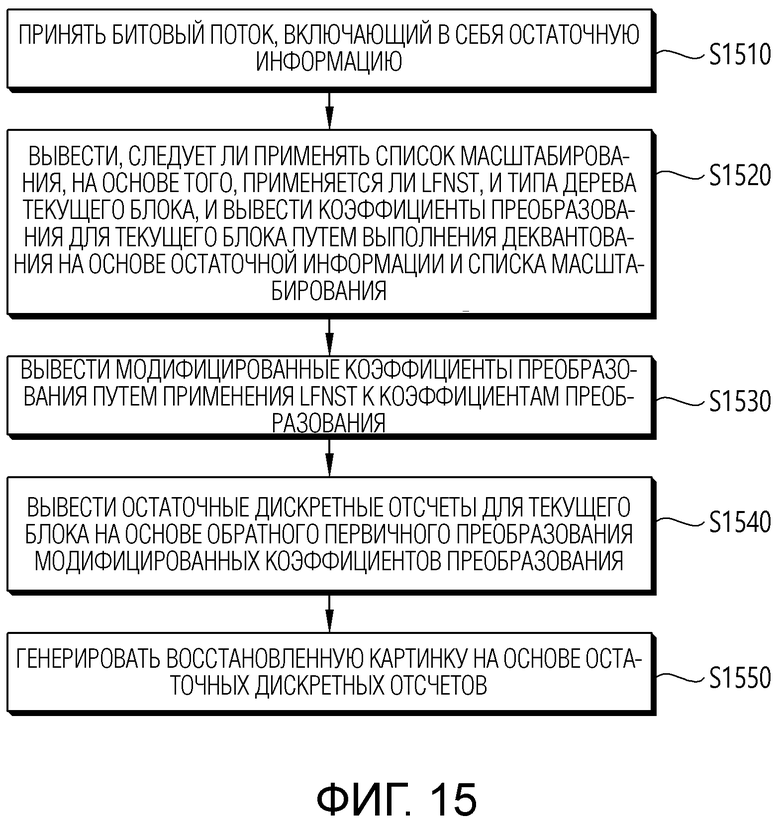
1. Способ декодирования изображения, выполняемый устройством декодирования, причем способ содержит:
прием остаточной информации из битового потока;
выведение коэффициентов преобразования для текущего блока путем выполнения деквантования на основе остаточной информации; и
выведение модифицированных коэффициентов преобразования путем применения LFNST к коэффициентам преобразования,
причем деквантование выполняется на основе заранее определенного списка масштабирования,
причем то, следует ли применять список масштабирования, определяют на основе того, применяется ли LFNST, и типа дерева текущего блока,
при этом типом дерева текущего блока является один из трех заранее заданных типов дерева,
причем заранее заданные типы дерева включают в себя одиночное дерево, дуальное дерево яркости, дуальное дерево цветности,
при этом в качестве реакции на случай, когда типом дерева текущего блока является одиночное дерево и текущим блоком является компонент цветности, определяют, что список масштабирования применяется к текущему блоку, и
при этом в качестве реакции на случай, когда типом дерева текущего блока является дуальное дерево цветности, определяют, что список масштабирования не применяется к текущему блоку.
2. Способ декодирования изображения по п.1, в котором в качестве реакции на случай, когда типом дерева текущего блока является одиночное дерево и текущий блок является компонентом яркости, определяют, что список масштабирования не применяется.
3. Способ декодирования изображения по п.2, в котором дополнительно принимается информация флага, указывающая, доступен ли список масштабирования, когда LFNST выполняется.
4. Способ декодирования изображения по п.3, в котором в качестве реакции на случай, когда информация флага указывает, что список масштабирования не доступен, и LFNST имеет индекс больше чем 0, определяют, что список масштабирования не применяется к компоненту яркости.
5. Способ декодирования изображения по п.3, в котором в качестве реакции на случай, когда информация флага указывает, что список масштабирования не доступен, и LFNST имеет индекс больше чем 0, если типом дерева текущего блока является дуальное дерево яркости, определяют, что список масштабирования не применяется к компоненту яркости.
6. Способ декодирования изображения по п.1, в котором текущий блок содержит блок преобразования.
7. Способ кодирования изображения, выполняемый устройством кодирования изображения, причем способ содержит:
выведение дискретных отсчетов предсказания для текущего блока;
выведение остаточных дискретных отсчетов для текущего блока на основе дискретных отсчетов предсказания;
выведение коэффициентов преобразования для текущего блока на основе первичного преобразования остаточных дискретных отсчетов;
выведение модифицированных коэффициентов преобразования из коэффициентов преобразования путем применения LFNST; и
квантование коэффициентов преобразования или модифицированных коэффициентов преобразования,
причем квантование выполняется на основе заранее определенного списка масштабирования, и
причем то, следует ли применять список масштабирования, определяют на основе того, применяется ли LFNST, и типа дерева текущего блока,
при этом типом дерева текущего блока является один из трех заранее заданных типов дерева,
причем заранее заданные типы дерева включают в себя одиночное дерево, дуальное дерево яркости, дуальное дерево цветности,
при этом в качестве реакции на случай, когда типом дерева текущего блока является одиночное дерево и текущим блоком является компонент цветности, определяют, что список масштабирования применяется к текущему блоку, и
при этом в качестве реакции на случай, когда типом дерева текущего блока является дуальное дерево цветности, определяют, что список масштабирования не применяется к текущему блоку.
8. Способ кодирования изображения по п.7, в котором в качестве реакции на случай, когда типом дерева текущего блока является одиночное дерево и текущий блок является компонентом яркости, определяют, что список масштабирования не применяется.
9. Способ кодирования изображения по п.8, в котором LFNST не выполняется на компоненте цветности текущего блока.
10. Способ кодирования изображения по п.7, в котором в качестве реакции на случай, когда типом дерева текущего блока является дуальное дерево яркости и LFNST выполняется на текущем блоке, определяют, что список масштабирования не применяется к компоненту яркости.
11. Способ кодирования изображения по п.7, дополнительно содержащий кодирование и выведение информации флага, указывающей, доступен ли список масштабирования, когда LFNST выполняется.
12. Способ кодирования изображения по п.7, в котором текущий блок содержит блок преобразования.
13. Способ передачи данных для информации изображения, содержащий этапы, на которых:
выводят дискретные отсчеты предсказания для текущего блока;
выводят остаточные дискретные отсчеты для текущего блока на основе дискретных отсчетов предсказания;
выводят коэффициенты преобразования для текущего блока на основе первичного преобразования остаточных дискретных отсчетов;
выводят модифицированные коэффициенты преобразования из коэффициентов преобразования путем применения LFNST;
выполняют квантование коэффициентов преобразования или модифицированных коэффициентов преобразования;
кодируют остаточную информацию, относящуюся к квантованным коэффициентам преобразования, чтобы генерировать битовый поток; и
передают данные, содержащие битовый поток,
причем квантование выполняется на основе заранее определенного списка масштабирования,
причем то, следует ли применять список масштабирования, определяют на основе того, применяется ли LFNST, и типа дерева текущего блока,
при этом типом дерева текущего блока является один из трех заранее заданных типов дерева,
причем заранее заданные типы дерева включают в себя одиночное дерево, дуальное дерево яркости, дуальное дерево цветности,
при этом в качестве реакции на случай, когда типом дерева текущего блока является одиночное дерево и текущим блоком является компонент цветности, определяют, что список масштабирования применяется к текущему блоку, и
при этом в качестве реакции на случай, когда типом дерева текущего блока является дуальное дерево цветности, определяют, что список масштабирования не применяется к текущему блоку.
| Benjamin Bross et al | |||
| Способ восстановления хромовой кислоты, в частности для получения хромовых квасцов | 1921 |
|
SU7A1 |
| T | |||
| Hashimoto et al | |||
| "Fix on LFNST condition", JVET- Q0133 17th meeting: Brussels, опубл | |||
| Прибор с двумя призмами | 1917 |
|
SU27A1 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| СПОСОБ ДЕКОДИРОВАНИЯ ВИДЕОСИГНАЛА | 2012 |
|
RU2648607C1 |
