Перекрестная ссылка на родственную заявку
[1] Настоящая заявка испрашивает приоритет предварительной заявки на патент США № 63/003 123, поданной 31 марта 2020 г., и заявки на патент США № 17/081392, поданной 27 октября 2020 г., содержание которых полностью включено в настоящий документ.
Область техники, к которой относится изобретение
[2] Раскрытый объект изобретения относится к кодированию и декодированию видео, а более конкретно, к сигнализации разделения субизображений в кодированном видеопотоке.
Уровень техники
[1] Известно кодирование и декодирование видео с использованием межкадрового предсказания с компенсацией движения. Несжатое цифровое видео может состоять из серии изображений, причем каждое изображение имеет пространственный размер, например, 1920 x 1080 отсчетов яркости и связанных отсчетов цветности. Серия изображений может иметь фиксированную или переменную частоту изображений (неофициально также известную как частота кадров), например, 60 изображений в секунду или 60 Гц. Несжатое видео имеет значительные требования к битрейту. Например, для видео 1080p60 4:2:0 с частотой 8 бит на отсчет (разрешение 1920x1080 отсчетов яркости при частоте кадров 60 Гц) требуется полоса пропускания, близкая к 1,5 Гбит/с. Час такого видео требует более 600 гигабайт (ГБ) дискового пространства.
[2] Одной из целей кодирования и декодирования видео может быть уменьшение избыточности входного видеосигнала посредством сжатия. Сжатие может помочь снизить вышеупомянутые требования к полосе пропускания или пространству для хранения, в некоторых случаях на два порядка или более. Могут использоваться как сжатие без потерь, так и сжатие с потерями, а также их комбинация. Сжатие без потерь относится к методам, при которых из сжатого исходного сигнала может быть восстановлена точная копия исходного сигнала. При использовании сжатия с потерями восстановленный сигнал может не быть идентичным исходному сигналу, но искажение между исходным и восстановленным сигналами достаточно мало, чтобы сделать восстановленный сигнал пригодным для предполагаемого приложения. В случае видео широко применяется сжатие с потерями. Допустимая степень искажения зависит от приложения; например, для пользователей определенных потребительских приложений потоковой передачи допустимы более высокие искажения, чем для пользователей приложений вещательного телевидения. Достижимая степень сжатия может отражать следующее: более высокое разрешаемое/допустимое искажение может привести к более высокой степени сжатия.
[3] Видеокодер и видеодекодер могут использовать методы из нескольких широких категорий, включая, например, компенсацию движения, преобразование, квантование и энтропийное кодирование, некоторые из которых будут представлены ниже.
[4] Исторически видеокодеры и видеодекодеры имели тенденцию работать с заданным размером изображения, который в большинстве случаев был определен и оставался постоянным для кодированной видеопоследовательности (CVS), группы изображений (GOP) или аналогичного временного кадра с множеством изображений. Например, в MPEG-2 известно, что конструкция системы изменяет горизонтальное разрешение (и, следовательно, размер изображения) в зависимости от таких факторов, как активность сцены, но только для I-изображений, следовательно, обычно для GOP. Передискретизация опорных изображений для использования различных разрешений в CVS известна, например, из Рекомендаций МСЭ-Т H.263, Приложение P. Однако здесь размер изображения не изменяется, только опорные изображения подвергаются передискретизации, в результате чего потенциально могут использоваться только части холста изображения (в случае понижающей дискретизации) или захватываться только части сцены (в случае повышающей дискретизации). Кроме того, Приложение Q H.263 разрешает передискретизацию отдельного макроблока с коэффициентом два (в каждом измерении), в сторону повышения или понижения. Опять же, размер изображения остается прежним. Размер макроблока фиксирован в H.263, и поэтому его не нужно сигнализировать.
[5] Изменение размера изображения в предсказанных изображениях стало более распространенным явлением в современном кодировании видео. Например, VP9 позволяет выполнять передискретизацию опорного изображения и изменять разрешение для всего изображения. Аналогичным образом, некоторые предложения, сделанные в отношении VVC (включая, например, Hendry, et. al, «On adaptive resolution change (ARC) for VVC», документ Объединенной команды видеоэкспертов (JVT) JVET-M0135-v1, 9-19 января 2019 г., полностью включенный в настоящий документ) позволяют выполнять передискретизацию целых опорных изображений с другим - более высоким или более низким - разрешением. В этом документе предлагается кодировать различные кандидаты разрешения в наборе параметров последовательности и ссылаться на них с помощью элементов синтаксиса для каждого изображения в наборе параметров изображения.
Раскрытие сущности изобретения
[6] В варианте осуществления предусмотрен способ декодирования кодированного битового потока видео с использованием по меньшей мере одного процессора, включающий в себя: на основании числа по меньшей мере одного субизображения текущего изображения больше одного, получение флага, указывающего, явно ли сигнализирована информация разделения субизображений; на основании флага, указывающего, что информация разделения субизображений сигнализирована явно, получение информации разделения субизображений; и декодирование текущего изображения на основании информации разделения субизображений
[7] В варианте осуществления предусмотрено устройство для декодирования кодированного битового потока видео, содержащее по меньшей мере один элемент памяти, конфигурированный для хранения программного кода; и по меньшей мере один процессор, конфигурированный для чтения программного кода и работы в соответствии с инструкциями программного кода, при этом программный код включает в себя: первый код получения, конфигурированный так, чтобы предписывать по меньшей мере одному процессору, на основании числа по меньшей мере одного субизображения текущего изображения больше одного, получать флаг, указывающий, явно ли сигнализирована информация разделения субизображений; второй код получения, конфигурированный так, чтобы предписывать по меньшей мере одному процессору, на основании флага, указывающего, что информация разделения субизображений сигнализирована явно, получать информацию разделения субизображений; и код декодирования, конфигурированный так, чтобы предписывать по меньшей мере одному процессору декодировать текущее изображение на основании информации разделения субизображений.
[8] В варианте осуществления предоставляется невременный машиночитаемый носитель, хранящий инструкции, причем инструкции включают в себя одну или более инструкций, которые при выполнении одним или более процессорами устройства для декодирования кодированного битового потока видео предписывают одному или более процессорам: на основании числа по меньшей мере одного субизображения текущего изображения больше одного, получать флаг, указывающий, явно ли сигнализирована информация разделения субизображений; на основании флага, указывающего, что информация разделения субизображений сигнализирована явно, получать информацию разделения субизображений; и декодировать текущее изображение на основании информации разделения субизображений.
Краткое описание чертежей
[9] Дополнительные признаки, сущность и различные преимущества раскрытого объекта изобретения будут более понятны из следующего подробного описания и прилагаемых чертежей, на которых изображено следующее:
[10] На фиг. 1 показана схематическая иллюстрация упрощенной блок-схемы системы связи в соответствии с вариантом осуществления.
[11] На фиг. 2 показана схематическая иллюстрация упрощенной блок-схемы системы связи в соответствии с вариантом осуществления.
[12] На фиг. 3 показана схематическая иллюстрация упрощенной блок-схемы декодера в соответствии с вариантом осуществления.
[13] На фиг. 4 показана схематическая иллюстрация упрощенной блок-схемы кодера в соответствии с вариантом осуществления.
[14] На фиг. 5A-5E показаны схематические иллюстрации вариантов сигнализации параметров ARC в соответствии с вариантом осуществления, в соответствии с вариантом осуществления.
[15] На фиг. 6A-6B показаны схематические иллюстрации примеров синтаксических таблиц в соответствии с вариантом осуществления.
[16] На фиг.7 показан пример структуры предсказания для масштабируемости с изменением адаптивного разрешения в соответствии с вариантом осуществления.
[17] На фиг.8 показан пример таблицы синтаксиса в соответствии с вариантом осуществления.
[18] На фиг. 9 показана схематическая иллюстрация упрощенной блок-схемы синтаксического анализа и декодирования цикла POC на единицу доступа и значение счетчика единиц доступа в соответствии с вариантом осуществления.
[19] На фиг. 10 показана схематическая иллюстрация структуры битового потока видео, содержащей многослойные субизображения, в соответствии с вариантом осуществления.
[20] На фиг. 11 показана схематическая иллюстрация отображения выбранного субизображения с улучшенным разрешением в соответствии с вариантом осуществления.
[21] На фиг. 12 показана блок-схема процесса декодирования и отображения битового видеопотока, содержащего многослойные субизображения, в соответствии с вариантом осуществления.
[22] На фиг. 13 показана схематическая иллюстрация отображения видео 360° с улучшенным слоем субизображения в соответствии с вариантом осуществления.
[23] На фиг.14 показан пример информации компоновки субизображения и его соответствующего слоя и структуры предсказания изображения в соответствии с вариантом осуществления.
[24] На фиг. 15 показан пример информации компоновки субизображения и их соответствующего слоя и структуры предсказания изображения с модальностью пространственной масштабируемости локальной области в соответствии с вариантом осуществления.
[25] На фиг. 16A-16B показаны примеры таблиц синтаксиса для информации компоновки субизображения в соответствии с вариантами осуществления.
[26] На фиг. 17 показан пример таблицы синтаксиса сообщения SEI для информации компоновки субизображения в соответствии с вариантом осуществления.
[27] На фиг. 18 показан пример таблицы синтаксиса для указания выходных слоев и информации профиля/ступени/уровня для каждого набора выходных слоев согласно варианту осуществления.
[28] На фиг. 19 показан пример таблицы синтаксиса, чтобы указать режим выходного слоя для каждого набора выходных слоев согласно варианту осуществления.
[29] На фиг. 20 показан пример таблицы синтаксиса для указания текущего субизображения каждого слоя для каждого набора выходных слоев в соответствии с вариантом осуществления.
[30] На фиг.21 показан пример таблицы синтаксиса для указания идентификатора субизображения в соответствии с вариантом осуществления.
[31] Фиг.22 - пример таблицы синтаксиса для указания информации разделения субизображений в соответствии с вариантом осуществления.
[32] На фиг. 23 показана блок-схема примерного процесса декодирования кодированного битового потока видео в соответствии с вариантом осуществления.
[33] На фиг. 24 показана схематическая иллюстрация компьютерной системы в соответствии с одним вариантом осуществления.
Осуществление изобретения
[34] На фиг.1 проиллюстрирована упрощенная блок-схема системы (100) связи согласно варианту осуществления настоящего раскрытия. Система (100) может включать в себя по меньшей мере два терминала (110-120), соединенных между собой через сеть (150). Для однонаправленной передачи данных первый терминал (110) может кодировать видеоданные в локальном местоположении для передачи другому терминалу (120) через сеть (150). Второй терминал (120) может принимать кодированные видеоданные другого терминала из сети (150), декодировать кодированные данные и отображать восстановленные видеоданные. Однонаправленная передача данных может быть обычным явлением в приложениях обслуживания мультимедиа и т. п.
[35] На фиг.1 показана вторая пара терминалов (130, 140), обеспечивающая поддержку двунаправленной передачи кодированного видео, которая может происходить, например, во время видеоконференц-связи. Для двунаправленной передачи данных каждый терминал (130, 140) может кодировать видеоданные, захваченные в локальном местоположении, для передачи другому терминалу через сеть (150). Каждый терминал (130, 140) также может принимать кодированные видеоданные, переданные другим терминалом, может декодировать кодированные данные и может отображать восстановленные видеоданные на локальном устройстве отображения.
[36] На фиг.1 терминалы (110-140) могут быть изображены как серверы, персональные компьютеры и смартфоны, но принципы настоящего раскрытия не могут быть ограничены этим. Варианты осуществления настоящего изобретения находят применение в портативных компьютерах, планшетных компьютерах, медиаплеерах и/или специализированном оборудовании для видеоконференц-связи. Сеть (150) представляет собой любое количество сетей, которые передают кодированные видеоданные между терминалами (110-140), включая, например, сети проводной и/или беспроводной связи. Сеть (150) связи может обмениваться данными в каналах с коммутацией каналов и/или с коммутацией пакетов. Репрезентативные сети включают в себя телекоммуникационные сети, локальные сети, глобальные сети и/или Интернет. Для целей настоящего обсуждения архитектура и топология сети (150) могут быть несущественными для работы настоящего раскрытия, если это не объясняется в данном документе ниже.
[37] На фиг.2 проиллюстрировано, в качестве примера применения для раскрытого объекта изобретения, размещение видеокодера и видеодекодера в потоковой среде. Раскрытый объект изобретения может быть в равной степени применим к другим приложениям с поддержкой видео, включая, например, видеоконференц-связь, цифровое телевидение, хранение сжатого видео на цифровых носителях, включая CD, DVD, карту памяти и т.п., и так далее.
[38] Система потоковой передачи может включать в себя подсистему (213) захвата, которая может включать в себя источник (201) видео, например цифровую камеру, создающую, например, поток (202) отсчетов несжатого видео. Данный поток (202) отсчетов, изображенный жирной линией, чтобы подчеркнуть большой объем данных по сравнению с кодированными битовыми потоками видео, может быть обработан кодером (203), подключенным к камере (201). Кодер (203) может включать в себя аппаратное обеспечение, программное обеспечение или их комбинацию для включения или реализации аспектов раскрытого объекта изобретения, как более подробно описано ниже. Кодированный битовый поток (204) видео, изображенный тонкой линией, чтобы подчеркнуть меньший объем данных по сравнению с потоком отсчетов, может храниться на сервере (205) потоковой передачи для будущего использования. Один или более клиентов (206, 208) потоковой передачи могут получить доступ к серверу (205) потоковой передачи для извлечения копий (207, 209) кодированного битового потока (204) видео. Клиент (206) может включать в себя видеодекодер (210), который декодирует входящую копию кодированного битового видеопотока (207) и создает исходящий поток (211) отсчетов видео, который может отображаться на дисплее (212) или другом устройстве визуализации (не изображено). В некоторых системах потоковой передачи битовые потоки (204, 207, 209) видео могут кодироваться в соответствии с определенными стандартами кодирования/сжатия видео. Примеры этих стандартов включают Рекомендацию ITU-T H.265. В стадии разработки находится стандарт кодирования видео, неофициально известный как универсальное кодирование видео или VVC. Раскрытый объект изобретения может использоваться в контексте VVC.
[39] Фиг.3 может быть функциональной блок-схемой видеодекодера (210) согласно варианту осуществления настоящего раскрытия.
[40] Приемник (310) может принимать одну или более кодированных видеопоследовательностей, которые должны быть декодированы декодером (210); в том же или другом варианте осуществления - по одной кодированной видеопоследовательности за раз, где декодирование каждой кодированной видеопоследовательности не зависит от других кодированных видеопоследовательностей. Кодированная видеопоследовательность может быть принята из канала (312), который может быть аппаратным/программным соединением с устройством хранения, в котором хранятся кодированные видеоданные. Приемник (310) может принимать кодированные видеоданные с другими данными, например, кодированными аудиоданными и/или потоками вспомогательных данных, которые могут быть отправлены их соответствующим использующим объектам (не изображены). Приемник (310) может отделять кодированную видеопоследовательность от других данных. Для борьбы с дрожанием в сети между приемником (310) и энтропийным декодером/парсером (320) (далее «парсер») может быть подключена буферная память (315). Когда приемник (310) принимает данные от устройства хранения/пересылки с достаточной полосой пропускания и управляемостью или из изосинхронной сети, буферная память (315) может не понадобиться или может быть небольшой. Для использования в пакетных сетях наилучшего качества, таких как Интернет, может потребоваться буфер (315), который может быть сравнительно большим и может быть предпочтительно адаптивного размера.
[41] Видеодекодер (210) может включать в себя синтаксический анализатор (320) для восстановления символов (321) из энтропийной кодированной видеопоследовательности. Категории этих символов включают в себя информацию, используемую для управления работой декодера (210), и потенциально информацию для управления устройством визуализации, таким как дисплей (212), который не является неотъемлемой частью декодера, но может быть подключен к нему, как это было показано на фиг.3. Управляющая информация для устройства (устройств) визуализации может быть в форме дополнительной информации улучшения (сообщения SEI) или фрагментов набора параметров информации о пригодности видео (VUI) (не изображены). Синтаксический анализатор (320) может выполнять синтаксический анализ и/или энтропийно декодировать принятую кодированную видеопоследовательность. Кодирование кодированной видеопоследовательности может осуществляться в соответствии с технологией или стандартом кодирования видео и может следовать принципам, хорошо известным специалистам в уровне техники, включая кодирование переменной длины, кодирование Хаффмана, арифметическое кодирование с контекстной чувствительностью или без нее и так далее. Синтаксический анализатор (320) может извлекать из кодированной видеопоследовательности набор параметров подгруппы по меньшей мере для одной из подгрупп пикселей в видеодекодере на основании по меньшей мере одного параметра, соответствующего группе. Субгруппы могут включать в себя группы изображений (GOP), изображения, тайлы, слайсы, бруски, макроблоки, единицы дерева кодирования (CTU), единицы кодирования (CU), блоки, единицы преобразования (TU), единицы предсказания (PU) и так далее. Тайл может указывать прямоугольную область CU/CTU в конкретном столбце и ряде тайлов в изображении. Брусок может указывать на прямоугольную область рядов CU/CTU в пределах конкретного тайла. Слайс может указывать на один или более брусков изображения, которые содержатся в единице NAL. Субизображение может указывать на прямоугольную область одного или более слайсов в изображении. Энтропийный декодер/парсер также может извлекать из кодированной видеопоследовательности информацию, такую как коэффициенты преобразования, значения параметров квантователя, векторы движения и так далее.
[42] Парсер (320) может выполнять операцию энтропийного декодирования и/или синтаксического анализа видеопоследовательности, принятой из буфера (315), чтобы создавать символы (321).
[43] Восстановление символов (321) может включать в себя множество различных модулей в зависимости от типа кодированного видеоизображения или его частей (таких как: внешнее и внутреннее изображение, внешний и внутренний блок) и других факторов. Какие модули задействованы и как, можно контролировать с помощью управляющей информации субгруппы, синтаксический анализ которой был выполнен из кодированной видеопоследовательности с помощью синтаксического анализатора (320). Поток такой управляющей информации субгруппы между синтаксическим анализатором (320) и множеством модулей ниже не показан для ясности.
[44] Помимо уже упомянутых функциональных блоков, декодер 210 может быть концептуально подразделен на ряд функциональных модулей, как описано ниже. В практическом осуществлении, работающем в условиях коммерческих ограничений, многие из этих модулей тесно взаимодействуют друг с другом и могут быть, по меньшей мере частично, интегрированы друг в друга. Однако для целей описания раскрытого объекта изобретения уместно концептуальное подразделение на функциональные модули, приведенные ниже.
[45] Первым модулем является модуль (351) масштабирования и/или обратного преобразования. Модуль (351) масштабирования и/или обратного преобразования принимает квантованный коэффициент преобразования, а также управляющую информацию, включая то, какое преобразование использовать, размер блока, коэффициент квантования, матрицы масштабирования квантования и так далее, в виде символа(ов) (321) от синтаксического анализатора (320). Он может выводить блоки, содержащие значения отсчетов, которые могут быть введены в агрегатор (355).
[46] В некоторых случаях выходные отсчеты модуля (351) масштабирования и/или обратного преобразования могут относиться к блоку с интракодированием; то есть к блоку, который не использует информацию предсказания из ранее восстановленных изображений, но может использовать информацию предсказания из ранее восстановленных частей текущего изображения. Такая информация предсказания может быть предоставлена модулем (352) внутрикадрового предсказания. В некоторых случаях модуль (352) внутрикадрового предсказания генерирует блок того же размера и формы, что и восстанавливаемый блок, используя окружающую уже восстановленную информацию, извлеченную из текущего (частично восстановленного) изображения (358). Агрегатор (355), в некоторых случаях, добавляет для каждого отсчета информацию предсказания, сгенерированную модулем (352) интрапредсказания, к информации выходных отсчетов, предоставляемой модулем (351) масштабирования и/или обратного преобразования.
[47] В других случаях выходные отсчеты модуля (351) масштабирования и/или обратного преобразования могут относиться к блоку с интеркодированием и потенциально с компенсацией движения. В таком случае модуль (353) предсказания с компенсацией движения может обращаться к памяти (357) опорных изображений, чтобы извлекать отсчеты, используемые для предсказания. После компенсации движения выбранных отсчетов в соответствии с символами (321), относящимися к блоку, эти отсчеты могут быть добавлены агрегатором (355) к выходу модуля масштабирования и/или обратного преобразования (в данном случае называемые остаточными отсчетами или остаточным сигналом), чтобы генерировать информацию о выходных отсчетах. Адреса в памяти опорных изображений, откуда модуль предсказания с компенсацией движения выбирает отсчеты предсказания, могут управляться векторами движения, доступными модулю предсказания с компенсацией движения в форме символов (321), которые могут иметь, например, компоненты X, Y и опорного изображения. Компенсация движения также может включать в себя интерполяцию значений отсчетов, извлеченных из памяти опорных изображений, когда используются точные векторы движения суботсчетов, механизмы предсказания вектора движения и так далее.
[48] Выходные отсчеты агрегатора (355) могут подвергаться различным методам петлевой фильтрации в модуле (356) петлевого фильтра. Технологии сжатия видео могут включать в себя технологии внутрипетлевой фильтрации, которые управляются параметрами, включенными в битовый поток кодированного видео и предоставляются модулю (356) петлевой фильтрации как символы (321) из синтаксического анализатора (320), но также могут реагировать на метаинформацию, полученную во время декодирования предыдущих (в порядке декодирования) частей кодированного изображения или кодированной видеопоследовательности, а также реагировать на ранее восстановленные и отфильтрованные посредством петлевой фильтрации значения отсчетов.
[49] Выходной сигнал модуля (356) петлевого фильтра может быть потоком отсчетов, который может быть выведен на устройство (212) визуализации, а также сохранен в памяти опорных изображений для использования в будущем межкадровом предсказании.
[50] Определенные кодированные изображения после полного восстановления могут использоваться в качестве опорных изображений для будущего предсказания. После того, как кодированное изображение полностью восстановлено и кодированное изображение было идентифицировано как опорное изображение (например, синтаксическим анализатором (320)), текущее опорное изображение (358) может стать частью буфера (357) опорных изображений, и свежая память текущих изображений может быть перераспределена перед началом восстановления следующего кодированного изображения.
[51] Видеодекодер 210 может выполнять операции декодирования согласно заранее определенной технологии сжатия видео, которая может быть задокументирована в стандарте, таком как ITU-T Rec. H.265. Кодированная видеопоследовательность может соответствовать синтаксису, заданному используемой технологией или стандартом сжатия видео, в том смысле, что она соответствует синтаксису технологии или стандарта сжатия видео, как указано в документе или стандарте технологии сжатия видео и, в частности, в их документе профилей. Также для соответствия может быть необходимым, чтобы сложность кодированной видеопоследовательности находилась в пределах границ, определенных уровнем технологии или стандарта сжатия видео. В некоторых случаях уровни ограничивают максимальный размер изображения, максимальную частоту кадров, максимальную частоту дискретизации восстановления (измеряемую, например, в мегаотсчетах в секунду), максимальный размер опорного изображения и так далее. Пределы, установленные уровнями, в некоторых случаях могут быть дополнительно ограничены с помощью спецификаций гипотетического эталонного декодера (HRD) и метаданных для управления буфером HRD, сигнализируемых в кодированной видеопоследовательности.
[52] В варианте осуществления приемник (310) может принимать дополнительные (избыточные) данные с кодированным видео. Дополнительные данные могут быть включены как часть кодированной видеопоследовательности(ей). Дополнительные данные могут использоваться видеодекодером (210) для правильного декодирования данных и/или для более точного восстановления исходных видеоданных. Дополнительные данные могут быть в форме, например, временных, пространственных слоев или слоев улучшения отношения сигнал/шум (SNR), избыточных слайсов, избыточных изображений, кодов прямого исправления ошибок и так далее.
[53] Фиг.4 может быть функциональной блок-схемой видеокодера (203) согласно варианту осуществления настоящего раскрытия.
[54] Кодер (203) может принимать отсчеты видео от источника (201) видео (который не является частью кодера), который может захватывать видеоизображение(я) для кодирования кодером (203).
[55] Источник (201) видео может предоставлять исходную видеопоследовательность для кодирования кодером (203) в форме цифрового потока отсчетов видео, который может иметь любую подходящую битовую глубину (например: 8 бит, 10 бит, 12 бит, ...), любое цветовое пространство (например, BT.601 Y CrCB, RGB, …) и любую подходящую структуру отсчетов (например, Y CrCb 4:2:0, Y CrCb 4:4:4). В системе обслуживания мультимедиа источник (201) видео может быть запоминающим устройством, хранящим предварительно подготовленное видео. В системе видеоконференц-связи источник (203) видео может быть камерой, которая захватывает информацию о локальном изображении в виде видеопоследовательности. Видеоданные могут быть предоставлены как множество отдельных изображений, которые при последовательном просмотре передают движение. Сами изображения могут быть организованы как пространственный массив пикселей, в котором каждый пиксель может содержать один или более отсчетов в зависимости от используемой структуры отсчетов, цветового пространства и т. д. Специалист в данной области техники может легко понять взаимосвязь между пикселями и отсчетами. Описание ниже ориентировано на отсчеты.
[56] Согласно варианту осуществления кодер (203) может кодировать и сжимать изображения исходной видеопоследовательности в кодированную видеопоследовательность (443) в реальном времени или с любыми другими временными ограничениями, как того требует приложение. Обеспечение соответствующей скорости кодирования - одна из функций контроллера (450). Контроллер управляет другими функциональными модулями, как описано ниже, и функционально связан с этими модулями. Связь не изображена для ясности. Параметры, устанавливаемые контроллером, могут включать в себя параметры, относящиеся к управлению скоростью (пропуск изображения, квантователь, значение лямбда методов оптимизации скорость-искажение, …), размеру изображения, макету группы изображений (GOP), максимальному диапазону поиска вектора движения и так далее. Специалист в данной области техники может легко определить другие функции контроллера (450), поскольку они могут относиться к видеокодеру (203), оптимизированному для определенной конструкции системы.
[57] Некоторые видеокодеры работают в том, что специалист в данной области легко распознает как «петля кодирования». В качестве упрощенного описания петля кодирования может состоять из кодирующей части кодера (430) (далее «кодер источника») (ответственной за создание символов на основании входного изображения, которое должно быть кодировано, и опорного изображения(й)), и (локального) декодера (433), встроенного в кодер (203), который восстанавливает символы для создания данных отсчетов, которые (удаленный) декодер также может создать (поскольку любое сжатие между символами и кодированным битовым видеопотоком не имеет потерь в технологиях сжатия видео, рассматриваемых в раскрытом объекте). Этот восстановленный поток отсчетов вводится в память (434) опорных изображений. Поскольку декодирование потока символов приводит к результатам с точностью до бита, независимо от местоположения декодера (локально или удаленно), содержимое буфера опорных изображений также является точным до бита между локальным кодером и удаленным кодером. Другими словами, часть предсказания кодера «видит» в качестве отсчетов опорного изображения точно такие же значения отсчетов, которые декодер «видел» бы при использовании предсказания во время декодирования. Этот фундаментальный принцип синхронности опорного изображения (и результирующего дрейфа, если синхронность не может поддерживаться, например, из-за ошибок канала) хорошо известен специалисту в данной области техники.
[58] Работа «локального» декодера (433) может быть такой же, как у «удаленного» декодера (210), который уже был подробно описан выше со ссылкой на фиг.3. Кратко ссылаясь также на фиг.4, однако, поскольку символы доступны, и кодирование и/или декодирование символов в кодированную видеопоследовательность энтропийным кодером (445) и синтаксическим анализатором (320) может осуществляться без потерь, части энтропийного декодирования декодера (210), включая канал (312), приемник (310), буфер (315) и синтаксический анализатор (320), не могут быть полностью реализованы в локальном декодере (433).
[59] На этом этапе можно сделать наблюдение, что любая технология декодирования, кроме синтаксического анализа и/или энтропийного декодирования, которая присутствует в декодере, также обязательно должна присутствовать в, по существу, идентичной функциональной форме в соответствующем кодере. По этой причине раскрытый объект изобретения фокусируется на работе декодера. Описание технологий кодирования может быть сокращено, поскольку они являются инверсией полностью описанных технологий декодирования. Только в некоторых областях требуется более подробное описание, которое приводится ниже.
[60] В качестве части своей работы кодер (430) источника может выполнять кодирование с предсказанием с компенсацией движения, которое кодирует входной кадр с предсказанием со ссылкой на один или более ранее кодированных кадров из видеопоследовательности, которые были обозначены как «опорные кадры». Таким образом, механизм (432) кодирования кодирует различия между блоками пикселей входного кадра и блоками пикселей опорного кадра(ов), которые могут быть выбраны в качестве эталона(ов) предсказания для входного кадра.
[61] Локальный видеодекодер (433) может декодировать кодированные видеоданные кадров, которые могут быть обозначены как опорные кадры, на основании символов, созданных кодером (430) источника. Операции механизма (432) кодирования могут быть предпочтительно процессами с потерями. Когда кодированные видеоданные могут быть декодированы в видеодекодере (не показан на фиг.4), восстановленная видеопоследовательность обычно может быть копией исходной видеопоследовательности с некоторыми ошибками. Локальный видеодекодер (433) копирует процессы декодирования, которые могут выполняться видеодекодером на опорных кадрах, и может вызывать сохранение восстановленных опорных кадров в кэше (434) опорных изображений. Таким образом, кодер (203) может локально хранить копии восстановленных опорных кадров, которые имеют общее содержимое, в качестве восстановленных опорных кадров, которые будут получены видеодекодером на дальнем конце (при отсутствии ошибок передачи).
[62] Предиктор (435) может выполнять поиски с предсказанием для механизма (432) кодирования. То есть, для нового изображения, которое должно быть кодировано, предиктор (435) может искать в памяти (434) опорных изображений данные отсчетов (в качестве кандидатов блоков опорных пикселей) или определенные метаданные, такие как векторы движения опорных изображений, формы блоков и так далее, которые могут служить подходящим эталоном предсказания для новых изображений. Предиктор (435) может работать на основании блока отсчетов "блок-за-пикселем", чтобы найти соответствующие эталоны предсказания. В некоторых случаях, как определено результатами поиска, полученными предиктором (435), входное изображение может иметь эталоны предсказания, взятые из множества опорных изображений, сохраненных в памяти (434) опорных изображений.
[63] Контроллер (450) может управлять операциями кодирования видеокодера (430), включая, например, установку параметров и параметров подгруппы, используемых для кодирования видеоданных.
[64] Выходные сигналы всех вышеупомянутых функциональных модулей могут подвергаться энтропийному кодированию в энтропийном кодере (445). Энтропийный кодер переводит символы, сгенерированные различными функциональными модулями, в кодированную видеопоследовательность путем сжатия без потерь символов согласно технологиям, известным специалистам в данной области техники, как, например, кодирование Хаффмана, кодирование переменной длины, арифметическое кодирование и так далее.
[65] Передатчик (440) может буферизовать кодированную видеопоследовательность(и), созданную энтропийным кодером (445), чтобы подготовить ее к передаче через канал (460) связи, который может быть аппаратным/программным соединением с запоминающим устройством, которое будет хранить кодированные видеоданные. Передатчик (440) может обеспечивать слияние кодированных видеоданных из видеокодера (430) с другими данными, подлежащими передаче, например, кодированными аудиоданными и/или потоками вспомогательных данных (источники не показаны).
[66] Контроллер (450) может управлять работой кодера (203). Во время кодирования контроллер (450) может назначить каждому кодированному изображению определенный тип кодированного изображения, что может повлиять на методы кодирования, которые могут быть применены к соответствующему изображению. Например, изображения часто могут быть отнесены к одному из следующих типов кадров:
[67] Интра-изображение (I-изображение) может быть таким, которое можно кодировать и декодировать без использования какого-либо другого кадра в последовательности в качестве источника предсказания. Некоторые видеокодеки допускают различные типы интра-изображений, включая, например, изображения с независимым обновлением декодера. Специалисту в области техники известны эти варианты I-изображений и их соответствующие применения и особенности.
[68] Изображение с предсказанием (P-изображение) может быть таким, которое может быть кодировано и декодировано с использованием интрапредсказания или интерпредсказания с использованием не более одного вектора движения и опорного индекса для предсказания значений отсчетов каждого блока.
[69] Изображение с двунаправленным предсказанием (B-изображение) может быть таким, которое может быть кодировано и декодировано с использованием интрапредсказания или интерпредсказания с использованием не более двух векторов движения и опорных индексов для предсказания значений отсчетов каждого блока. Аналогично, изображения с множественным предсказанием могут использовать более двух опорных изображений и связанных метаданных для восстановления одного блока.
[70] Исходные изображения обычно могут быть пространственно разделены на множество блоков отсчетов (например, блоки из 4x4, 8x8, 4x8 или 16x16 отсчетов каждый) и кодированы на поблочной основе. Блоки могут кодироваться с предсказанием со ссылкой на другие (уже кодированные) блоки, как определено назначением кодирования, применяемым к соответствующим изображениям блоков. Например, блоки I-изображений могут кодироваться без предсказания или они могут кодироваться с предсказанием со ссылкой на уже кодированные блоки одного и того же изображения (пространственное предсказание или интрапредсказание). Пиксельные блоки P-изображений могут кодироваться без предсказания, посредством пространственного предсказания или посредством временного предсказания со ссылкой на одно ранее кодированное опорное изображение. Блоки B-изображений могут кодироваться без предсказания, посредством пространственного предсказания или посредством временного предсказания со ссылкой на одно или два ранее кодированных опорных изображения.
[71] Видеокодер (203) может выполнять операции кодирования в соответствии с заранее определенной технологией или стандартом кодирования видео, такой как Рекомендация МСЭ-Т H.265. В своей работе видеокодер (203) может выполнять различные операции сжатия, включая операции кодирования с предсказанием, которые используют временную и пространственную избыточность во входной видеопоследовательности. Кодированные видеоданные, следовательно, могут соответствовать синтаксису, заданному используемой технологией или стандартом кодирования видео.
[72] В варианте осуществления передатчик (440) может передавать дополнительные данные с кодированным видео. Видеокодер (430) может включать в себя такие данные как часть кодированной видеопоследовательности. Дополнительные данные могут содержать временные/пространственные слои/слои улучшения SNR, другие формы избыточных данных, такие как избыточные изображения и слайсы, сообщения дополнительной информации улучшения (SEI), фрагменты набора параметров информации о пригодности видео (VUI) и так далее.
[73] В последнее время некоторое внимание привлекла агрегация сжатой области или извлечение множества семантически независимых частей изображения в одно видеоизображение. В частности, в контексте, например, кодирования 360 или определенных приложений наблюдения, несколько семантически независимых исходных изображений (например, поверхность шести кубов проектируемой кубом сцены 360 или входы отдельных камер в случае многокамерного наблюдения setup) могут потребоваться отдельные настройки адаптивного разрешения, чтобы справиться с различной активностью каждой сцены в данный момент времени. Другими словами, кодеры в данный момент времени могут выбирать использование разных коэффициентов передискретизации для разных семантически независимых изображений, составляющих всю 360-градусную сцену или сцену наблюдения. При объединении в одно изображение, в свою очередь, возникает необходимость в выполнении передискредизации опорного изображения и доступности сигнализирования кодирования с адаптивным разрешением для частей кодированного изображения.
[74] Ниже представлены несколько терминов, на которые приводится ссылка в оставшейся части этого описания.
[75] Субизображение может относиться к, в некоторых случаях, прямоугольной компоновке отсчетов, блоков, макроблоков, единиц кодирования или подобных объектов, которые семантически сгруппированы и которые могут быть независимо кодированы с измененным разрешением. Одно или более субизображений могут образовывать изображение. Одно или более кодированных субизображений могут образовывать кодированное изображение. Одно или более субизображений могут быть собраны в изображение, и одно или более субизображений могут быть извлечены из изображения. В определенных средах одно или более кодированных субизображений могут быть собраны в сжатой области без перекодирования до уровня отсчетов в кодированное изображение, и в тех же или других случаях одно или более кодированных субизображений могут быть извлечены из кодированного изображения в сжатой области.
[76] Адаптивное изменение разрешения (ARC) может относится к механизмам, которые позволяют изменять разрешение изображения или субизображения в кодированной видеопоследовательности, например, посредством передискретизации опорного изображения. В дальнейшем параметры ARC относятся к управляющей информации, необходимой для выполнения адаптивного изменения разрешения, которая может включать в себя, например, параметры фильтра, коэффициенты масштабирования, разрешения выходных и/или опорных изображений, различные флаги управления и так далее.
[77] В вариантах осуществления кодирование и декодирование могут выполняться для одного семантически независимого кодированного видеоизображения. Перед описанием последствий кодирования/декодирования множества субизображений с независимыми параметрами ARC и их подразумеваемой дополнительной сложности должны быть описаны варианты сигнализации параметров ARC.
[78] На фиг. 5A-5E показаны несколько вариантов осуществления сигнализирования параметров ARC. Как отмечено для каждого из вариантов осуществления, они могут иметь определенные преимущества и определенные недостатки с точки зрения эффективности кодирования, сложности и архитектуры. Стандарт или технология кодирования видео могут выбрать один или более из этих вариантов осуществления или вариантов, известных из уровня техники, для передачи параметров ARC. Варианты осуществления могут не быть взаимоисключающими и, возможно, могут быть взаимозаменяемыми в зависимости от потребностей приложения, используемых стандартов или выбора кодера.
[79] Классы параметров ARC могут включать в себя:
[80] - коэффициенты повышающей и/или понижающей дискретизации, отдельные или объединенные в измерениях X и Y,
[81] - коэффициенты повышающей и/или понижающей дискретизации с добавлением временного измерения, указывающие на увеличение/уменьшение размера с постоянной скоростью для заданного количества изображений,
[82] - любой из двух вышеупомянутых вариантов может включать в себя кодирование одного или более предположительно коротких элементов синтаксиса, которые могут указывать на таблицу, содержащую коэффициент(ы),
[83] Разрешение в измерении X или Y в единицах отсчетов, блоках, макроблоках, единицах кодирования (CU) или любой другой подходящей степени детализации входного изображения, выходного изображения, опорного изображения, кодированного изображения, в сочетании или по отдельности. Если существует более одного разрешения (например, одно для входного изображения, одно для опорного изображения), то в некоторых случаях один набор значений может быть выведен из другого набора значений. Это может быть передано, например, путем использования флагов. Более подробный пример см. ниже.
[84] - координаты «деформации», подобные тем, которые используются в Приложении P H.263, опять же с подходящей степенью детализации, как описано выше. Приложение P H.263 определяет один эффективный способ кодирования таких координат деформации, но, возможно, также разрабатываются другие, потенциально более эффективные способы. Например, реверсивное кодирование Хаффмана с переменной длиной координат деформации согласно Приложению P может быть заменено двоичным кодированием подходящей длины, где длина двоичного кодового слова может быть, например, получена из максимального размера изображения, возможно, умноженного на определенный коэффициент и смещенного на определенное значение, чтобы учесть «деформацию» за пределами границ максимального размера изображения.
[85] Параметры фильтра с повышающей и/или понижающей дискретизацией. В вариантах осуществления может быть только один фильтр для повышающей и/или понижающей дискретизации. Однако в вариантах осуществления может быть желательным обеспечить большую гибкость в конструкции фильтра, и для этого может потребоваться сигнализирование параметров фильтра. Такие параметры могут быть выбраны с помощью индекса в списке возможных конструкций фильтров, фильтр может быть полностью определен (например, с помощью списка коэффициентов фильтра с использованием подходящих методов энтропийного кодирования), фильтр может быть неявно выбран с помощью соответствующих соотношений повышающей и/или понижающей дискретизации, которые, в свою очередь, передаются в соответствии с любым из механизмов, упомянутых выше, и так далее.
[86] Ниже описание предполагает кодирование конечного набора коэффициентов повышающей и/или понижающей дискретизации (тот же коэффициент, который должен использоваться в измерениях X и Y), указанных с помощью кодового слова. Это кодовое слово может быть закодировано с переменной длиной, например, с использованием экспоненциального кода Голомба, общего для определенных элементов синтаксиса в спецификациях кодирования видео, таких как H.264 и H.265. Одно подходящее сопоставление значений для коэффициентов повышающей и/или понижающей дискретизации может, например, соответствовать Таблице 1:
[89] Многие аналогичные сопоставления могут быть разработаны в соответствии с потребностями приложения и возможностями механизмов повышения и понижения дискретизации, доступных в технологии или стандарте сжатия видео. Таблица может быть расширена до большего количества значений. Значения также могут быть представлены механизмами энтропийного кодирования, отличными от Экспоненциальных кодов Голомба, например, с использованием двоичного кодирования. Это может иметь определенные преимущества, когда коэффициенты передискретизации представляли интерес за пределами самих механизмов обработки видео (прежде всего кодера и декодера), например, посредством MANE. Следует отметить, что для ситуаций, когда изменение разрешения не требуется, может быть выбран Экспоненциальный код Голомба, который является коротким; в таблице выше только один бит. Это может иметь преимущество в эффективности кодирования по сравнению с использованием двоичных кодов для наиболее распространенного случая.
[90] Количество записей в таблице, а также их семантика могут быть полностью или частично настраиваемыми. Например, основная структура таблицы может быть передана в «высоком» наборе параметров, таком как последовательность или набор параметров декодера. В вариантах осуществления, одна или более таких таблиц могут быть определены в технологии или стандарте кодирования видео и могут быть выбраны, например, с помощью декодера или набора параметров последовательности.
[91] Ниже приведено описание того, как коэффициент повышающей и/или понижающей дискретизации (информация ARC), закодированный, как описано выше, может быть включен в технологию кодирования видео или стандартный синтаксис. Подобные соображения могут применяться к одному или более кодовым словам, управляющим фильтрами повышающей/понижающей дискретизации. Смотри ниже обсуждение, когда для фильтра или других структур данных требуются сравнительно большие объемы данных.
[92] Как показано на фиг.5А, приложение P H.263 включает информацию (502) ARC в форме четырех координат деформации в заголовок (501) изображения, в частности, в расширение заголовка PLUSPTYPE (503) H.263. Это может быть разумным выбором структуры, когда а) имеется доступный заголовок изображения и б) ожидаются частые изменения информации ARC. Однако служебные данные при использовании сигнализации в стиле H.263 могут быть довольно высокими, и коэффициенты масштабирования могут не относиться к границам изображения, поскольку заголовок изображения может иметь временный характер.
[93] Как показано на фиг.5В, JVCET-M135-v1 включает эталонную информацию ARC (505) (индекс), расположенную в наборе (504) параметров изображения, индексирует таблицу (506), включая целевые разрешения, которая, в свою очередь, находится внутри набора (507) параметров последовательности. Размещение возможного разрешения в таблице (506) в наборе (507) параметров последовательности может, в соответствии со словесными заявлениями, сделанными авторами, быть оправдано использованием SPS в качестве точки согласования совместимости во время обмена возможностями. Разрешение может изменяться в пределах, установленных значениями в таблице (506) от изображения к изображению, путем обращения к соответствующему набору (504) параметров изображения.
[94] Ссылаясь на фиг. 5C-5E, следующие варианты осуществления могут существовать для передачи информации ARC в битовом потоке видео. Каждая из этих опций имеет определенные преимущества по сравнению с вариантами осуществления, описанными выше. Варианты осуществления могут одновременно присутствовать в одной и той же технологии или стандарте видеокодирования.
[95] В вариантах осуществления, например, в варианте осуществления с фиг. 5C, информация (509) ARC , такая как коэффициент передискретизации (масштабирования), может присутствовать в заголовке слайса, заголовке GOP, заголовке тайла или заголовке группы тайлов. Фиг. 5C иллюстрирует вариант осуществления, в котором используется заголовок (508) группы тайлов. Этого может быть достаточно в случае информации ARC небольшого размера, такой как одиночное кодовое слово переменной длины ue(v) или кодовое слово фиксированной длины из нескольких битов, например, как показано выше. Наличие информации ARC непосредственно в заголовке группы тайлов имеет дополнительное преимущество, поскольку информация ARC может быть применима к субизображению, представленному, например, этой группой тайлов, а не ко всему изображению. См. также ниже. Кроме того, даже если технология или стандарт сжатия видео предусматривает только изменение адаптивного разрешения всего изображения (в отличие, например, от изменений адаптивного разрешения на основании группы тайлов), размещение информации ARC в заголовке группы тайлов вместо помещения ее в заголовок изображения в стиле H.263 имеет определенные преимущества с точки зрения устойчивости к ошибкам.
[96] В вариантах осуществления, например, в варианте осуществления с фиг. 5D, информация (512) ARC сама по себе может присутствовать в соответствующем наборе параметров, таком как, например, набор параметров изображения, набор параметров заголовка, набор параметров мозаичного элемента, набор параметров адаптации и так далее. Фиг. 5D иллюстрирует вариант осуществления, в котором используется набор (511) параметров адаптации. Объем этого набора параметров предпочтительно может быть не больше, чем изображение, например группа тайлов. Использование информации ARC неявно осуществляется путем активации соответствующего набора параметров. Например, когда технология или стандарт кодирования видео рассматривают только ARC на основании изображения, тогда подходящим вариантом может быть набор параметров изображения или эквивалент.
[97] В вариантах осуществления, например, в варианте осуществления с фиг. 5E, опорная информация (513) ARC может присутствовать в заголовке (514) группы тайлов или аналогичной структуре данных. Данная эталонная информация (513) может относиться к субнабору информации (515) ARC, доступному в наборе (516) параметров с объемом, выходящим за рамки одного изображения, например, наборе параметров последовательности или наборе параметров декодера.
[98] Как показано на фиг.6А, заголовок группы тайлов (601) в качестве примерной синтаксической структуры заголовка, применимого к (возможно, прямоугольной) части изображения, может условно содержать, кодированный с помощью экспоненциального кода Голомба элемент синтаксиса переменной длины dec_pic_size_idx (602) (выделен жирным шрифтом). Наличие этого элемента синтаксиса в заголовке группы тайлов может быть ограничено использованием адаптивного разрешения (603) - здесь значение флага не выделено жирным шрифтом, что означает, что флаг присутствует в битовом потоке в той точке, где он встречается на синтаксической диаграмме. Тот факт, используется ли адаптивное разрешение для этого изображения или его частей, можно быть сигнализировано в любой синтаксической структуре высокого уровня внутри или вне битового потока. В показанном примере это сигнализируется в наборе параметров последовательности, как показано ниже.
[99] На фиг.6В показана также выборка набора (610) параметров последовательности. Первый показанный элемент синтаксиса - это adaptive_pic_resolution_change_flag (611). При значении истина (true), этот флаг может указывать на использование адаптивного разрешения, которое, в свою очередь, может требовать определенной управляющей информации. В примере такая управляющая информация присутствует условно на основании значения флага на основании оператора if() в наборе (612) параметров и заголовке (601) группы тайлов.
[100] Когда используется адаптивное разрешение, в этом примере кодировано выходное разрешение в единицах отсчетов (613). Номер позиции 613 относится как к output_pic_width_in_luma_samples, так и к output_pic_height_in_luma_samples, которые вместе могут определять разрешение выходного изображения. В другом месте технологии или стандарта кодирования видео могут быть определены определенные ограничения для любого значения. Например, определение уровня может ограничивать количество общих выходных отсчетов, которые могут быть произведением значений этих двух элементов синтаксиса. Также, определенные технологии или стандарты кодирования видео, или внешние технологии или стандарты, такие как, например, системные стандарты, могут ограничивать диапазон нумерации (например, одно или оба измерения должны делиться на степень 2) или соотношение ширины и высоты (например, ширина и высота должны быть в таком соотношении, как 4:3 или 16:9). Такие ограничения могут быть введены для облегчения аппаратных реализаций или по другим причинам, и они хорошо известны в данной области техники.
[101] В некоторых приложениях может быть целесообразно, чтобы кодер инструктировал декодер использовать определенный размер опорного изображения вместо того, чтобы неявно предполагать, что этот размер является размером выходного изображения. В этом примере элемент синтаксиса reference_pic_size_present_flag (614) передает условное присутствие размеров (615) опорного изображения (опять же, номер позиции относится как к ширине, так и к высоте).
[102] Наконец, показана таблица возможной ширины и высоты изображения декодирования. Такая таблица может быть выражена, например, указанием таблицы (num_dec_pic_size_in_luma_samples_minus1) (616). «Minus1» может относиться к интерпретации значения этого элемента синтаксиса. Например, если кодированное значение равно нулю, присутствует одна запись в таблице. Если значение равно пяти, присутствуют шесть записей таблицы. Затем для каждой «строки» в таблице в синтаксис (617) включаются ширина и высота декодированного изображения.
[103] Представленные записи (617) таблицы могут быть проиндексированы с использованием элемента синтаксиса dec_pic_size_idx (602) в заголовке группы тайлов, тем самым разрешая различные декодированные размеры - в сущности, коэффициенты масштабирования - для каждой группы тайлов.
[104] Некоторые технологии или стандарты кодирования видео, например VP9, поддерживают пространственную масштабируемость путем реализации определенных форм передискретизации опорного изображения (сигнализируемую совершенно иначе, чем в раскрытом объекте изобретения) в сочетании с временной масштабируемостью, чтобы обеспечить пространственную масштабируемость. В частности, некоторые опорные изображения могут подвергаться повышающей дискретизации с использованием технологий в стиле ARC до более высокого разрешения для формирования базы слоя пространственного улучшения. Эти изображения с повышенной дискретизацией можно улучшить, используя нормальные механизмы предсказания с высоким разрешением, чтобы добавить деталей.
[105] Обсуждаемые здесь варианты осуществления могут использоваться в такой среде. В некоторых случаях, в том же или другом варианте осуществления, значение в заголовке единицы NAL, например поле временного идентификатора, может использоваться для указания не только временного, но и пространственного слоя. Это может иметь определенные преимущества для определенных конфигураций систем; например, существующая архитектура Selected Forwarding Units (SFU), созданная и оптимизированная для выбранных временных слоев, пересылаемых на основании значения временного идентификатора заголовка единицы NAL, может использоваться без модификации для масштабируемых сред. Для того чтобы сделать это возможным, может существовать требование для сопоставления между размером кодированного изображения и временным слоем, указываемым полем временного идентификатора в заголовке единицы NAL.
[106] В некоторых технологиях кодирования видео единица доступа (AU) может относиться к кодированному изображению(ям), слайсу(ам), тайлу(ам), блоку(ам) NAL и так далее, которые были захвачены и скомпонованы в соответствующие изображение, слайс, тайл и/или битовый поток единицы NAL в данный момент времени. Таким моментом во времени может быть, например, время компоновки.
[107] В HEVC и некоторых других технологиях кодирования видео значение счетчика порядка изображений (POC) может использоваться для указания выбранного опорного изображения среди множества опорных изображений, хранящихся в буфере декодированных изображений (DPB). Когда единица доступа (AU) содержит одно или более изображений, слайсов или тайлов, каждое изображение, слайс или тайл, принадлежащие одной и той же AU, могут нести одно и то же значение POC, из которого можно сделать вывод, что они были созданы из содержимого то же времени компоновки. Другими словами, в сценарии, где два изображения/слайса/тайла несут одно и то же заданное значение POC, это может указывать на то, что два изображений/слайсов/ тайлов принадлежат одной и той же AU и имеют одинаковое время компоновки. И наоборот, два изображения/среза/мозаичных элемента, имеющие разные значения POC, могут указывать, что эти изображения/срезы/мозаичных элемента принадлежат разным AU и имеют разное время композиции.
[108] В вариантах осуществления эта жесткая взаимосвязь может быть ослаблена, поскольку блок доступа может содержать изображения, срезы или мозаичные элементы с разными значениями POC. Допуская различные значения POC в AU, становится возможным использовать значение POC для идентификации потенциально независимо декодируемых изображений/слайсов/тайлов с идентичным временем представления. Это, в свою очередь, может обеспечить поддержку множества масштабируемых слоев без изменения сигнализации выбора опорного изображения (например, сигнализации набора опорных изображений или сигнализации списка опорных изображений), как более подробно описано ниже.
[109] Однако все еще желательно иметь возможность идентифицировать AU, которой принадлежит изображение/слайс/тайл, по отношению к другому изображению/слайсу/тайлу, имеющему другие значения POC, только на основании значения POC. Этого можно добиться, как описано ниже.
[110] В вариантах осуществления счетчик единиц доступа (AUC) может сигнализироваться в синтаксической структуре высокого уровня, такой как заголовок единицы NAL, заголовок слайса, заголовок группы тайлов, сообщение SEI, набор параметров или ограничитель AU. Значение AUC может использоваться, чтобы идентифицировать, какие единицы NAL, изображения, слайсы или тайлы принадлежат данной AU. Значение AUC может соответствовать отдельному моменту времени компоновки. Значение AUC может быть кратным значению POC. Путем деления значения POC на целочисленное значение можно вычислить значение AUC. В некоторых случаях операции деления могут накладывать определенную нагрузку на реализации декодеров. В таких случаях небольшие ограничения в пространстве нумерации значений AUC могут позволить заменить операцию деления операциями сдвига. Например, значение AUC может быть равно значению старшего значащего бита (MSB) диапазона значений POC.
[111] В вариантах осуществления значение цикла POC для каждой AU (poc_cycle_au) может сигнализироваться в синтаксической структуре высокого уровня, такой как заголовок единицы NAL, заголовок слайса, заголовок группы тайлов, сообщение SEI, набор параметров или ограничитель AU. Величина poc_cycle_au может указывать, сколько различных и последовательных значений POC может быть связано с одной и той же AU. Например, если значение poc_cycle_au равно 4, изображения, слайсы или тайлы со значением POC, равным 0-3 включительно, могут быть связаны с AU со значением AUC, равным 0, а изображения, слайсы или тайлы со значением POC, равным 4-7 включительно, могут быть связаны с AU со значением AUC, равным 1. Следовательно, значение AUC может быть выведено путем деления значения POC на значение poc_cycle_au.
[112] В вариантах осуществления значение poc_cyle_au может быть получено из информации, расположенной, например, в наборе параметров видео (VPS), которая идентифицирует количество пространственных слоев или слоев SNR в кодированной видеопоследовательности. Пример такой возможной взаимосвязи кратко описывается ниже. Хотя получение, как описано выше, может сэкономить несколько битов в VPS и, следовательно, может повысить эффективность кодирования, в некоторых вариантах осуществления poc_cycle_au может быть явно кодирован в соответствующей синтаксической структуре высокого уровня иерархически ниже набора параметров видео, чтобы иметь возможность минимизировать poc_cycle_au для данной небольшой части битового потока, такого как изображение. Эта оптимизация может сэкономить больше битов, чем может быть сохранено посредством процесса получения, описанного выше, потому что значения POC и/или значения элементов синтаксиса, косвенно относящиеся к POC могут быть кодированы в синтаксических структурах низкого уровня.
[113] В вариантах осуществления на фиг.8 показан пример таблиц синтаксиса для сигнализации элемента синтаксиса vps_poc_cycle_au в VPS (или SPS), который указывает poc_cycle_au, используемый для всех изображений/слайсов в кодированной видеопоследовательности, и элемента синтаксиса slice_poc_cycle_au, который указывает poc_cycle_au текущего слайса в заголовке слайса. Если значение POC увеличивается равномерно для каждого AU, vps_contant_poc_cycle_per_au в VPS может быть установлено равным 1, и vps_poc_cycle_au может сигнализироваться в VPS. В этом случае slice_poc_cycle_au может сигнализируется неявно, и значение AUC для каждой AU может вычисляться путем деления значения POC на vps_poc_cycle_au. Если значение POC не увеличивается равномерно на AU, vps_contant_poc_cycle_per_au в VPS может устанавливаться равным 0. В этом случае vps _access_unit_cnt может не сигнализироваться, в то время как slice_access_unit_cnt может сигнализироваться в заголовке слайса для каждого слайса или изображения. Каждый слайс или изображение может иметь различное значение slice_access_unit_cnt. Значение AUC для каждой AU может вычисляться путем деления значения POC на slice_poc_cycle_au.
[114] На фиг. 9 показана блок-схема, иллюстрирующая пример вышеописанного процесса. Например, в операции S910 может быть проанализирован VPS (или SPS), а в операции S920 может быть определено, является ли цикл POC на AU постоянным в пределах кодированной видеопоследовательности. Если цикл POC на AU является постоянным (ДА в операции S920), то значение счетчика единиц доступа для конкретной единицы доступа может быть вычислено из poc_cycle_au, который сигнализируется для кодированной видеопоследовательности, и значения POC конкретной единицы доступа в операции S930. Если цикл POC на AU не является постоянным (НЕТ в операции S920), то значение счетчика единиц доступа для конкретной единицы доступа может быть вычислено из poc_cycle_au, который сигнализируется на уровне изображения, и значения POC конкретной единицы доступа в операции S940. В операции S950 новый VPS (или SPS) может быть проанализирован.
[115] В вариантах осуществления, даже если значение POC изображения, слайса или тайла может быть другим, изображение, слайс или тайл, соответствующие AU с одинаковым значением AUC, могут быть связаны с одним и тем же моментом времени декодирования или вывода. Следовательно, без какой-либо зависимости от интерпарсинга и/или декодирования между изображениями, слайсами или тайлами в одной и той же AU, все или субнабор изображений, слайсов или тайлов, связанных с одной и той же AU, могут быть декодированы параллельно и могут быть выведены в один и тот же момент времени.
[116] В вариантах осуществления, даже если значение POC изображения, слайса или тайла может быть другим, изображение, слайс или тайл, соответствующие AU с одинаковым значением AUC, могут быть связаны с одним и тем же моментом времени компоновки/отображения. Когда время компоновки содержится в формате контейнера, даже если изображения соответствуют разным AU, если изображения имеют одинаковое время компоновки, изображения могут отображаться в один и тот же момент времени.
[117] В вариантах осуществления каждое изображение, слайс или тайл может иметь один и тот же временной идентификатор (temporal_id) в одной и той же AU. Все или субнабор изображений, слайсов или тайлов, соответствующих моменту времени, могут быть связаны с одним и тем же временным субслоем. В вариантах осуществления каждое изображение, слайс или тайл может иметь одинаковый или другой идентификатор пространственного слоя (layer_id) в одной и той же AU. Все или субнабор изображений, слайсов или тайлов, соответствующих моменту времени, могут быть связаны с тем же или другим пространственным слоем.
[118] На фиг.7 показан пример структуры видеопоследовательности с комбинацией значений temporal_id, layer_id, POC и AUC с адаптивным изменением разрешения. В этом примере изображение, слайс или тайл в первой AU с AUC = 0 может иметь temporal_id = 0 и layer_id = 0 или 1, в то время как изображение, слайс или тайл во второй AU с AUC = 1 может иметь temporal_id = 1 и layer_id = 0 или 1 соответственно. Значение POC увеличивается на 1 для каждого изображения независимо от значений temporal_id и layer_id. В этом примере значение poc_cycle_au может быть равно 2. В вариантах осуществления значение poc_cycle_au может быть установлено равным количеству слоев (пространственной масштабируемости). Следовательно, в этом примере значение POC увеличивается на 2, а значение AUC увеличивается на 1.
[119] В вышеупомянутых вариантах осуществления все или субнабор структуры межкадрового или межслойного предсказания и индикация опорного изображения могут поддерживаться с использованием сигнализации существующего набора опорных изображений (RPS) в HEVC или сигнализации списка опорных изображений (RPL). В RPS или RPL выбранное опорное изображение может указываться посредством сигнализации значения POC или значения дельты POC между текущим изображением и выбранным опорным изображением. В вариантах осуществления RPS и RPL могут использоваться для указания структуры предсказания интер-изображения или интер-слоя без изменения сигнализации, но со следующими ограничениями. Если значение temporal_id опорного изображения больше, чем значение temporal_id текущего изображения, текущее изображение может не использовать опорное изображение для компенсации движения или других предсказаний. Если значение layer_id опорного изображения больше, чем значение layer_id текущего изображения, текущее изображение может не использовать опорное изображение для компенсации движения или других предсказаний.
[120] В вариантах осуществления масштабирование вектора движения на основании разности POC для временного предсказания вектора движения может быть отключено для множества изображений в единице доступа. Следовательно, хотя каждое изображение может иметь различное значение POC в единице доступа, вектор движения не масштабируется и используется для временного предсказания вектора движения в единице доступа. Это связано с тем, что опорное изображение с другим POC в одной и той же AU считается опорным изображением, имеющим тот же момент времени. Следовательно, в варианте осуществления функция масштабирования вектора движения может возвращать 1, когда опорное изображение принадлежит AU, связанной с текущим изображением.
[121] В вариантах осуществления масштабирование вектора движения на основании разности POC для временного предсказания вектора движения может быть опционально отключено для множества изображений, когда пространственное разрешение опорного изображения отличается от пространственного разрешения текущего изображения. Когда масштабирование вектора движения разрешено, вектор движения масштабируется на основании как разности POC, так и отношения пространственного разрешения между текущим изображением и опорным изображением.
[122] В вариантах осуществления вектор движения может масштабироваться на основании разности AUC вместо разности POC для временного предсказания вектора движения, особенно когда poc_cycle_au имеет неоднородное значение (когда vps_contant_poc_cycle_per_au == 0). В противном случае (например, когда vps_contant_poc_cycle_per_au == 1) масштабирование вектора движения на основании разности AUC может быть идентично масштабированию вектора движения на основании разности POC.
[123] В вариантах осуществления, когда вектор движения масштабируется на основании разности AUC, опорный вектор движения в том же AU (с тем же значением AUC) с текущим изображением не масштабируется на основании разности AUC и используется для предсказания вектора движения без масштабирования или с масштабированием на основании отношения пространственного разрешения между текущим изображением и опорным изображением.
[124] В вариантах осуществления значение AUC может использоваться для идентификации границы AU и используется для операции гипотетического эталонного декодера (HRD), для которой требуется синхронизация ввода и вывода с детализацией AU. В вариантах осуществления декодированное изображение с самым высоким слоем в AU может выводиться для отображения. Значение AUC и значение layer_id могут использоваться для идентификации выходного изображения.
[125] В вариантах осуществления изображение может включать в себя одно или более субизображения. Каждое субизображения может охватывать локальную область или всю область изображения. Область, поддерживаемая субизображением, может перекрываться или не перекрываться с областью, поддерживаемой другим субизображением. Область, покрытая одним или более субизображениями, может покрывать или не покрывать всю область изображения. Если изображение включает субизображения, область, поддерживаемая субизображением, может быть идентична области, поддерживаемой изображением.
[126] В вариантах осуществления субизображение может быть закодировано способом кодирования, аналогичным способу кодирования, используемому для кодированного изображения. Субизображение может быть независимо закодировано или может быть закодировано в зависимости от другого субизображения или кодированного изображения. Субизображение может иметь или не иметь какую-либо зависимость синтаксического анализа от другого субизображения или кодированного изображения.
[127] В варианте осуществления кодированное субизображение может содержаться в одном или более слоев. Кодированное субизображение в слое может иметь другое пространственное разрешение. Исходное субизображение может подвергаться пространственной передискретизации (например, повышающей или понижающей дискретизации), кодироваться с различными параметрами пространственного разрешения и содержаться в битовом потоке, соответствующем слою.
[128] В вариантах осуществления субизображение с (W, H), где W обозначает ширину субизображения, а H обозначает высоту субизображения, соответственно, может кодироваться и содержаться в кодированном битовом потоке, соответствующем слою 0, в то время как субизображение с повышающей (или понижающей) дискретизацией из субизображения с исходным пространственным разрешением, с (W*Sw,k, H* Sh,k), может быть кодировано и содержаться в кодированном битовом потоке, соответствующем слою k, где Sw,k, Sh,k указывают коэффициенты передискретизации по горизонтали и вертикали. Если значения Sw,k, Sh,k больше 1, передискретизация может быть повышающей дискретизацией. В то время как, если значения Sw,k, Sh,k меньше 1, передискретизация может быть понижающей дискретизацией.
[129] В вариантах осуществления кодированное субизображение в слое может иметь визуальное качество, отличное от качества кодированного субизображения в другом слое в том же субизображении или другом субизображении. Например, субизображение i в слое n может кодироваться параметром квантования Qi, n, тогда как субизображение j в слое m может кодироваться параметром квантования Qj, m.
[130] В вариантах осуществления кодированное субизображение в слое может быть декодировано независимо, без какой-либо зависимости от синтаксического анализа или декодирования, из кодированного субизображения в другом слое той же локальной области. Слой субизображения, который можно независимо декодировать без ссылки на другой слой субизображения той же локальной области, может быть независимым слоем субизображения. Кодированное субизображение в независимом слое субизображения может иметь или не иметь зависимость декодирования или синтаксического анализа от ранее кодированного субизображения в том же слое субизображения, но кодированное субизображение может не иметь никакой зависимости от кодированного изображения в другом слое субизображения.
[131] В вариантах осуществления кодированное субизображение в слое может быть декодировано зависимо, с определенной зависимостью синтаксического анализа или декодирования от кодированного субизображения в другом слое той же локальной области. Слой субизображения, который можно зависимо декодировать со ссылкой на другой слой субизображения той же локальной области, может быть зависимым слоем субизображения. Кодированное субизображение в зависимом субизображении может ссылаться на кодированное субизображение, принадлежащее тому же субизображению, ранее кодированное субизображение в том же слое субизображения или на оба опорных субизображения.
[132]В вариантах осуществления, кодированное субизображение может содержать один или более независимых слоев субизображений и один или более зависимых слоев субизображений. Однако по меньшей мере одно независимое субизображение может присутствовать для кодированного субизображения. Значение идентификатора уровня (layer_id), которое может присутствовать в заголовке единицы NAL или другой синтаксической структуре высокого уровня, независимого уровня субизображения может быть равно 0. Слой субизображения с layer_id, равным 0, может быть базовым слоем субизображения.
[133] В вариантах осуществления, изображение может включать в себя одно или более субизображений переднего плана и одно субизображение заднего плана. Область, поддерживаемая субизображением заднего плана, может быть равна области изображения. Область, поддерживаемая субизображением переднего плана, может перекрываться с областью, поддерживаемой субизображением заднего плана. Субзображение заднего плана может быть базовым слоем субизображения, тогда как субизображение переднего плана может быть не-базовым (улучшающим) слоем субизображения. Один или более неосновных слоев субизображения могут ссылаться на один и тот же базовый слой для декодирования. Каждый не-базовый слой субизображения с layer_id, равным a, может ссылаться на не-базовый слой субизображения с layer_id, равным b, где a больше b.
[134] В вариантах осуществления, изображение может включать в себя одно или более субизображений переднего плана с одним субизображением заднего плана или без него. Каждое субизображение может иметь свой собственный базовый слой субизображения и один или более не-базовых (улучшающих) слоев. На каждый базовый слой субизображения может ссылаться один или более не-базовых слоев субизображения. Каждый не-базовый слой субизображения с layer_id, равным a, может ссылаться на не-базовый слой субизображения с layer_id, равным b, где a больше b.
[135] В вариантах осуществления, изображение может включать в себя одно или более субизображений переднего плана с одним субизображением заднего плана или без него. На каждое кодированное субизображение в (базовом или не-базовом) слое субизображения может ссылаться одно или более субизображений не-базового слоя, принадлежащих одному и тому же субизображению, и одно или более субизображений не-базового слоя, которые не принадлежат одному и тому же субизображению.
[136] В вариантах осуществления, изображение может включать в себя одно или более субизображений переднего плана с одним субизображением заднего плана или без него. Субизображение в слое a может быть дополнительно разделено на множество субизображений в одном и том же слое. Одно или более кодированных субизображений в слое b могут ссылаться на разделенные субизображения в слое a.
[137] В вариантах осуществления, кодированная видеопоследовательность (CVS) может быть группой кодированных изображений. CVS может включать одну или более последовательность кодированных субизображений (CSPS), где CSPS может быть группой кодированных субизображений, покрывающих одну и ту же локальную область изображения. CSPS может иметь то же или другое временное разрешение, что и кодированная видеопоследовательность.
[138] В вариантах осуществления, CSPS может быть закодирована и содержаться на одном или более слоях. CSPS может включать в себя один или более слоев CSPS. Декодирование одного или более слоев CSPS, соответствующих CSPS, может восстанавливать последовательность субизображений, соответствующих одной и той же локальной области.
[139] В вариантах осуществления количество слоев CSPS, соответствующих CSPS, может быть идентичным или отличаться от количества слоев CSPS, соответствующих другой CSPS.
[140] В вариантах осуществления слой CSPS может иметь временное разрешение (например, частоту кадров), отличное от другого уровня CSPS. Исходная (несжатая) последовательность субизображений может подвергаться временной передискретизации (например, повышающей или понижающей дискретизации), кодироваться с различными параметрами временного разрешения и содержаться в битовом потоке, соответствующем слою.
[141] В вариантах осуществления последовательность субизображений с частотой кадров F может быть кодирована и содержаться в кодированном битовом потоке, соответствующем слою 0, в то время как последовательность субизображений с временной повышающей (или понижающей) дискретизацией из исходной последовательности субизображений с F* St,k может быть кодирована и содержаться в кодированном битовом потоке, соответствующем слою k, где St,k указывает коэффициент временной дискретизации для слоя k. Если значение St,k больше 1, процесс временной передискретизации может быть преобразованием с повышением частоты кадров. Тогда как, если значение St , k меньше 1, процесс временной передискретизации может быть преобразованием с понижением частоты кадров.
[142] В вариантах осуществления, когда на субизображения с уровнем a CSPS a ссылается субизображение с уровнем b CSPS для компенсации движения или любого межуровневого предсказания, если пространственное разрешение уровня a CSPS отличается исходя из пространственного разрешения уровня b CSPS, декодированные пиксели на уровне a CSPS повторно сэмплируются и используются в качестве опорных. Для процесса передискретизации может использоваться фильтрация с повышающей или понижающей дискретизацией.
[143] На фиг.10 показан примерный видеопоток, включающий в себя CSPS видео заднего плана с layer_id, равным 0, и множество слоев CSPS переднего плана. Хотя кодированное субизображение может включать один или более слоев CSPS, область заднего плана, которая не принадлежит какому-либо слою CSPS переднего плана, может включать базовый слой. Базовый слой может содержать область заднего плана и области переднего плана, в то время как слой CSPS улучшения может содержать область переднего плана. Слой CSPS улучшения может иметь лучшее визуальное качество, чем базовый слой, в той же области. Слой CSPS улучшения может ссылаться на восстановленные пиксели и векторы движения базового слоя, соответствующие одной и той же области.
[144] В вариантах осуществления битовый поток видео, соответствующий базовому слою, содержится в дорожке, в то время как слои CSPS, соответствующие каждому субизображению, содержатся в отдельной дорожке в видеофайле.
[145] В вариантах осуществления битовый поток видео, соответствующий базовому слою, содержится в дорожке, в то время как слои CSPS с тем же layer_id содержатся в отдельной дорожке. В этом примере дорожка, соответствующая уровню k , включает в себя только слои CSPS, соответствующие слою k.
[146] В вариантах осуществления каждый уровень CSPS каждого субизображения хранится в отдельной дорожке. Каждая дорожка может иметь или не иметь зависимости синтаксического анализа или декодирования от одной или более других дорожек.
[147] В вариантах осуществления каждая дорожка может содержать битовые потоки, соответствующие от слоям от i до j слоев CSPS всех или субнабора субизображений, где 0<i=<j=<k, и k является слоем наибольшего уровня CSPS.
[148] В вариантах осуществления изображение содержит один или более тип связанных мультимедийных данных, включая карту глубины, альфа-карту, данные трехмерной геометрии, карту занятости и т. д. Такие связанные синхронизированные мультимедийные данные могут быть разделены на один или множество субпотоков данных, каждый из которых соответствует одному субизображению.
[149] На фиг. 11 показан пример видеоконференции, основанной на способе создания многослойных субизображений. В видеопотоке содержатся один битовый поток видео базового слоя, соответствующий изображению заднего плана, и один или более битовых потоков видео уровня улучшения, соответствующих субизображениям переднего плана. Каждый битовый поток видео уровня улучшения может соответствовать слою CSPS. На дисплее по умолчанию отображается изображение, соответствующее базовому слою. Он содержит изображение одного или более пользователей в изображении (PIP). Когда конкретный пользователь выбирается управлением клиента, слой CSPS улучшения, соответствующий выбранному пользователю, может декодироваться и отображаться с улучшенным качеством или пространственным разрешением.
[150] На фиг. 12 показана блок-схема, иллюстрирующая пример описанного выше процесса. Например, в операции S1210 может быть декодирован битовый поток видео с множеством уровней. В операции S1220 могут быть идентифицированы задний план и одно или более субизображений переднего плана. В операции S1230 может быть определено, выбрана ли конкретная область субизображения, например одно из субизображений переднего плана. Если выбрана конкретная область субизображения (ДА в операции S1240), улучшенное субизображение может быть декодировано и отображено. Если конкретная область субизображения не выбрана (НЕТ в операции S1240), область заднего плана может быть декодирована и отображена.
[151] В вариантах осуществления промежуточный блок сети (например, маршрутизатор) может выбирать подмножество слоев для отправки пользователю в зависимости от своей полосы пропускания. Организация изображения/субизображения может использоваться для адаптации полосы пропускания. Например, если у пользователя нет полосы пропускания, маршрутизатор разделяет слои или выбирает некоторые субизображения из-за их важности или на основании используемых настроек, и это может делаться динамически для адаптации к полосе пропускания.
[152] НА фиг. 13 показан вариант осуществления, относящийся к варианту использования 360-градусного видео. Когда сферическое 360-градусное изображение, например изображение 1310, проецируется на плоское изображение, изображение проекции 360 может быть разделено на множество субизображений в качестве базового слоя. Например, несколько субизображений могут включать в себя обратное стандартное изображение, верхнее стандартное изображение, правое стандартное изображение, левое стандартное изображение, прямое стандартное изображение и нижнее стандартное изображение. Слой улучшения конкретного субизображения, например прямого субизображения, может быть кодирован и передан клиенту. Декодер может декодировать как базовый слой, включающий в себя все субизображения, так и слой улучшения выбранного субизображения. Когда текущее окно просмотра идентично выбранному субизображению, отображаемое изображение может иметь более высокое качество с декодированным субизображением со слоем улучшения. В противном случае декодированное изображение с базовым слоем может отображаться с более низким качеством.
[153] В вариантах осуществления любая информация компоновки для отображения может присутствовать в файле в качестве дополнительной информации (например, сообщения SEI или метаданные). Одно или более декодированных субизображений могут быть перемещены и отображены в зависимости от сигнализированной информации компоновки. Информация компоновки может быть сигнализирована сервером потоковой передачи или вещательной компанией, или может быть восстановлена сетевым объектом или облачным сервером, или может быть определена индивидуальной настройкой пользователя.
[154] В вариантах осуществления, когда входное изображение делится на одну или более (прямоугольных) субобластей, каждая субобласть может кодироваться как независимый слой. Каждый независимый слой, соответствующий локальной области, может иметь уникальное значение layer_id. Для каждого независимого слоя может сигнализироваться информация о размере и местоположении субизображения. Например, размер изображения (ширина, высота), информация о смещении левого верхнего угла (x_offset, y_offset). На фиг.14 показан пример макета разделенных субизображений, информации о размере и положении его субизображений и его соответствующей структуры предсказания изображения. Информация компоновки, включая размер(ы) субизображения и положение(я) субизображения, может сигнализироваться в синтаксической структуре высокого уровня, такой как набор(ы) параметров, заголовок группы слайсов или тайлов или сообщение SEI.
[155] В вариантах осуществления каждое субизображение, соответствующее независимому слою, может иметь свое уникальное значение POC в пределах AU. Когда опорное изображение среди изображений, хранящихся в DPB, указывается с использованием элемента(ов) синтаксиса в структуре RPS или RPL, может использоваться значение(я) POC каждого субизображения, соответствующего слою.
[156] В вариантах осуществления, чтобы указать структуру (межслойного) предсказания, layer_id может не использоваться, и может использоваться значение POC (дельта).
[157] В вариантах осуществления субизображение со значением POC, равным N, соответствующее слою (или локальной области), может использоваться или не использоваться в качестве опорного изображения субизображения со значением POC, равным N+K, соответствующего тому же слою (или той же локальной области) для предсказания с компенсацией движения. В большинстве случаев значение числа K может быть равно максимальному количеству (независимых) слоев, которое может быть идентично количеству субобластей.
[158] В вариантах осуществления, на фиг. 15 показан расширенный случай с фиг. 14. Когда входное изображение разделено на множество (например, четыре) субобластей, каждая локальная область может быть кодирована с одним или более слоями. В этом случае количество независимых слоев может быть равно количеству субобластей, и один или более слоев могут соответствовать субобласти. Таким образом, каждая субобласть может быть кодирована одним или более независимых слоев и нулем или более зависимых слоев.
[159] В вариантах осуществления с фиг.15, входное изображение может быть разделено на четыре субобласти. Например, правая верхняя субобласть может быть кодирована как два слоя, которые являются слоем 1 и слоем 4, в то время как правая нижняя субобласть может быть кодирована как два слоя, которые являются слоем 3 и слоем 5. В этом случае слой 4 может ссылаться на слой 1 для предсказания с компенсацией движения, тогда как слой 5 может ссылаться на слой 3 для компенсации движения.
[160] В вариантах осуществления внутриконтурная фильтрация (например, деблокирующая фильтрация, адаптивная внутриконтурная фильтрация, изменение формы, двусторонняя фильтрация или любая фильтрация на основании глубокого обучения) через границу слоя может быть (опционально) отключена.
[161] В вариантах осуществления предсказание с компенсацией движения или внутриблочное копирование через границу слоя может быть (опционально) отключено.
[162] В вариантах осуществления граничное заполнение для предсказания с компенсацией движения или внутриконтурная фильтрация на границе субизображения может обрабатываться опционально. Флаг, указывающий, обрабатывается ли граничное заполнение или нет, может сигнализироваться в синтаксической структуре высокого уровня, такой как набор(ы) параметров (VPS, SPS, PPS или APS), заголовок группы слайсов или тайлов или сообщение SEI.
[163] В вариантах осуществления информация компоновки суб-области (суб-областей) (или субизображения, субизображений) может сигнализироваться в VPS или SPS. Фиг. 16A показывает пример элементов синтаксиса в VPS, а фиг. 16B показывает пример элементов синтаксиса в SPS. В этом примере vps_sub_picture_dividing_flag сигнализируется в VPS. Флаг может указывать, разделено ли входное(ые) изображение(я) на множество субобластей или нет. Когда значение vps _sub_picture_dividing_flag равно 0, входное изображение(я) в кодированной видеопоследовательности(ях), соответствующей текущей VPS, не может быть разделено на несколько субобластей. В этом случае размер входного изображения может быть равен размеру кодированного изображения (pic_width_in_luma_samples, pic_height_in_luma_samples), который сигнализируется в SPS. Когда значение vps _sub_picture_dividing_flag равно 1, входное изображение(я) может быть разделено на множество субобластей. В этом случае элементы синтаксиса vps_full_pic_width_in_luma_samples и vps_full_pic_height_in_luma_samples сигнализируются в VPS. Значения vps_full_pic_width_in_luma_samples и vps_full_pic_height_in_luma_samples могут быть равны ширине и высоте входного изображения(й) соответственно.
[164] В вариантах осуществления значения vps_full_pic_width_in_luma_samples и vps_full_pic_height_in_luma_samples не могут использоваться для декодирования, но могут использоваться для компоновки и отображения.
[165] В вариантах осуществления, когда значение vps_sub_picture_dividing_flag равно 1, элементы синтаксиса pic_offset_x и pic_offset_y могут сигнализироваться в SPS, что соответствует (а) конкретному слою (слоям). В этом случае размер кодированного изображения (pic_width_in_luma_samples, pic_height_in_luma_samples), сигнализируемый в SPS, может быть равен ширине и высоте субобласти, соответствующей конкретному слою. Также, положение (pic_offset_x, pic_offset_y) левого верхнего угла субобласти может сигнализироваться в SPS.
[166] В вариантах осуществления информация о положении (pic_offset_x, pic_offset_y) левого верхнего угла субобласти не может использоваться для декодирования, но может использоваться для компоновки и отображения.
[167] В вариантах осуществления информация компоновки (размер и положение) всех или суб-набора суб-областей входного изображения(й), информация о зависимости между слоем (слоями) может сигнализироваться в наборе параметров или сообщении SEI. На фиг.17 показан пример элементов синтаксиса для указания информации о макете субобластей, зависимости между слоями и отношения между субобластью и одним или более слоев. В этом примере элемент синтаксиса num_sub_region указывает количество (прямоугольных) субобластей в текущей кодированной видеопоследовательности; элемент синтаксиса num_layers указывает количество слоев в текущей кодированной видеопоследовательности. Значение num_layers может быть равно или больше значения num_sub_region. Когда любая субобласть кодируется как один слой, значение num_layers может быть равно значению num_sub_region. Когда одна или более субобластей кодируются как множество слоев, значение num_layers может быть больше, чем значение num_sub_region. Элемент синтаксиса direct_dependency_flag [i] [j] указывает зависимость от j-го уровня к i-му уровню; num_layers_for_region [i] указывает количество слоев, связанных с i-й субобластью; sub_region_layer_id [i] [j] указывает layer_id j-го слоя, связанного с i-й субобластью. Значения sub_region_offset_x [i] и sub_region_offset_y [i] указывают, соответственно, горизонтальное и вертикальное положение левого верхнего угла i-й субобласти. Значения sub_region_width [i] и sub_region_height [i] указывают, соответственно, ширину и высоту i-й субобласти.
[168] В вариантах осуществления один или более элементов синтаксиса, которые задают набор выходных слоев для указания одного или более слоев, которые должны выводиться с информацией уровня яруса профиля или без нее, могут сигнализироваться в синтаксической структуре высокого уровня, например VPS, DPS, SPS, PPS APS или сообщение SEI. Обращаясь к фиг.18, элемент синтаксиса num_output_layer_sets, указывающий количество наборов выходных слоев (OLS) в кодированной видеопоследовательности, относящейся к VPS, может сигнализироваться в VPS. Для каждого набора выходных слоев output_layer_flag может сигнализироваться столько, сколько имеется выходных слоев.
[169] В вариантах осуществления output_layer_flag [i], равное 1, задает, что выводится i-й слой; vps_output_layer_flag [i], равное 0, задает, что i-й слой не выводится.
[170] В вариантах осуществления один или более элементов синтаксиса, которые задают информацию уровня яруса профиля для каждого набора выходных слоев, могут передаваться в синтаксической структуре высокого уровня, например VPS, DPS, SPS, PPS, APS или сообщении SEI. По-прежнему обращаясь к фиг.18, элемент синтаксиса num_profile_tile_level, указывающий количество информации уровня яруса профиля на OLS в кодированной видеопоследовательности, относящейся к VPS, может сигнализироваться в VPS. Для каждого набора выходных слоев набор элементов синтаксиса для информации уровня яруса профиля или индекс, указывающий конкретную информацию уровня яруса профиля среди записей в информации уровня яруса профиля, может сигнализироваться столько, сколько имеется выходных слоев.
[171] В вариантах осуществления profile_tier_level_idx [i] [j] задает индекс в списке синтаксических структур profile_tier_level () в VPS синтаксической структуры profile_tier_level (), которая применяется к j-му слою i-го OLS.
[172] В вариантах осуществления, как показано на фиг.20, элементы синтаксиса num_profile_tile_level и/или num_output_layer_sets могут сигнализироваться, когда количество максимальных слоев больше 1 (vps_max_layers_minus1> 0).
[173] В вариантах осуществления, как показано на фиг.20, элемент синтаксиса vps_output_layers_mode [i], указывающий режим сигнализации выходного слоя для i-го набора выходных слоев, может присутствовать в VPS.
[174] В вариантах осуществления vps_output_layers_mode [i], равное 0, указывает, что только самый верхний слой выводится с i-м набором выходных слоев; vps_output_layer_mode [i], равное 1, указывает, что все слои выводятся с i-м набором выходных слоев; vps_output_layer_mode [i], равное 2, указывает, что выводимые слои - это слои с vps_output_layer_flag [i] [j], равным 1, с i-м набором выходных слоев. Могут быть зарезервированы другие значения.
[175] В вариантах осуществления output_layer_flag [i] [j] может сигнализироваться или не сигнализироваться в зависимости от значения vps_output_layers_mode [i] для i-го набора выходных слоев.
[176] В вариантах осуществления, со ссылкой на фиг. 19, флаг vps_ptl_signal_flag [i] может присутствовать для i-го набора выходных слоев. В зависимости от значения vps_ptl_signal_flag [i] информация уровня яруса профиля для i-го набора выходных слоев может сигнализироваться или не сигнализироваться.
[177] В вариантах осуществления, как показано на фиг.20, число субизображений, max_subpics_minus1, в текущем CVS может сигнализироваться в синтаксической структуре высокого уровня, например, в VPS, DPS, SPS, PPS, APS или сообщении SEI.
[178] В вариантах осуществления, как показано на фиг.21, идентификатор субизображения, sub_pic_id [i], для i-го субизображения может сигнализироваться, когда число субизображений больше 1 (max_subpics_minus1> 0).
[179] В вариантах осуществленияодин или более синтаксических элементов, указывающих идентификатор субкартинки, принадлежащий каждому уровню каждого набора выходных уровней, могут сигнализироваться в VPS. Обращаясь к фиг.20, sub_pic_id_layer [i] [j] [k], который указывает k-е субизображение, присутствующее в j-м слое i-го набора выходных слоев. С помощью этой информации декодер может определить, какое субизображение может быть декодировано и выведено для каждого слоя конкретного набора выходных слоев.
[180] В варианте осуществления заголовок изображения (PH) представляет собой синтаксическую структуру, содержащую элементы синтаксиса, которые применяются ко всем слайсам кодированного изображения. Единица изображения (PU) - это набор единиц NAL, которые связаны друг с другом согласно заданному правилу классификации, являются последовательными в порядке декодирования и содержат ровно одно кодированное изображение. PU может содержать заголовок изображения (PH) и один или более единиц NAL VCL, составляющих кодированное изображение.
[181] В варианте осуществления SPS (RBSP) может быть доступен процессу декодирования до того, как на него будет сделана ссылка, он будет включен по меньшей мере в одну AU с TemporalId, равным 0, или предоставлен через внешние средства.
[182] В варианте осуществления SPS (RBSP) может быть доступен процессу декодирования до того, как на него будет сделана ссылка, он будет включен по крайней мере в одну AU с TemporalId, равным 0, в CVS, который содержит один или более PPS, относящихся к SPS, или предоставлен через внешние средства.
[183] В варианте осуществления SPS (RBSP) может быть доступен процессу декодирования до того, как на него будет сделана ссылка одним или более PPS, он будет включен по меньшей мере в одну PU с nuh_layer_id, равным наименьшему значению nuh_layer_id единиц NAL PPS, которые относятся к единице NAL SPS в CVS, который содержит один или более PPS, относящихся к SPS, или предоставлен через внешние средства.
[184] В варианте осуществления SPS (RBSP) может быть доступен процессу декодирования до того, как на него будет сделана ссылка одним или более PPS, он будет включен по меньшей мере в одну PU с TemporalId, равным 0, и nuh_layer_id, равным наименьшему значению nuh_layer_id единиц NAL PPS, которые относятся к единице NAL SPS или предоставлены через внешние средства.
[185] В варианте осуществления SPS (RBSP) может быть доступен процессу декодирования до того, как на него будет сделана ссылка одним или более PPS, он будет включен по меньшей мере в одну PU с TemporalId, равным 0 и nuh_layer_id, равным наименьшему значению nuh_layer_id единиц NAL PPS, которые относятся к единице NAL SPS в CVS, который содержит один или более PPS, относящихся к SPS, или предоставлен через внешние средства.
[186] В том же или другом варианте осуществления pps_seq_parameter_set_id может указывать значение sps_seq_parameter_set_id для SPS, на который делается ссылка. Значение pps_seq_parameter_set_id может быть одинаковым во всех PPS, на которые ссылаются кодированные изображения в CLVS.
[187] В том же или другом варианте осуществления все единицы NAL SPS с конкретным значением sps_seq_parameter_set_id в CVS могут иметь одинаковое содержимое.
[188] В том же или другом варианте осуществления, независимо от значений nuh_layer_id, единицы NAL SPS могут совместно использовать одно и то же пространство значений sps_seq_parameter_set_id.
[189] В том же или другом варианте осуществления значение nuh_layer_id единицы NAL SPS может быть равно наименьшему значению nuh_layer_id единиц NAL PPS, которые относятся к единице NAL SPS.
[190] В варианте осуществления, когда на PPS с nuh_layer_id, равным m, делается ссылка одной или более PPS с nuh_layer_id, равным n, слой с nuh_layer_id, равным m, может быть таким же, как слой с nuh_layer_id, равным n, или (прямым или косвенным) опорным слоем слоя с nuh_layer_id, равным m.
[191] В варианте осуществления PPS (RBSP) может быть доступен процессу декодирования до того, как на него будет сделана ссылка, он будет включен по меньшей мере в одну AU с TemporalId, равным TemporalId единицы NAL PPS, или предоставлен через внешние средства.
[192] В варианте осуществления PPS (RBSP) может быть доступен процессу декодирования до того, как на него будет сделана ссылка, он будет включен по меньшей мере в одну AU с TemporalId, равным TemporalId единицы NAL PPS в CVS, который содержит один или более PH (или единиц NAL кодированного слайса), относящихся к PPS, или предоставлен через внешние средства.
[193] В варианте осуществления PPS (RBSP) может быть доступен процессу декодирования до того, как на него будет сделана ссылка одним или более PH (или единиц NAL кодированного слайса), он будет включен по меньшей мере в одну PU с nuh_layer_id, равным наименьшему значению nuh_layer_id единиц NAL кодированного слайса, которые относятся к единице NAL PPS в CVS, который содержит один или более PH (или единиц NAL кодированных слайсов), относящихся к PPS, или предоставлен через внешние средства.
[194] В варианте осуществления PPS (RBSP) может быть доступен процессу декодирования до того, как на него будет сделана ссылка одним или более PH (или единиц NAL кодированного слайса), включенный по меньшей мере в одну PU с TemporalId, равным TemporalId единицы NAL PPS и nuh_layer_id, равным наименьшему значению nuh_layer_id единиц NAL кодированного слайса, которые относятся к единице NAL PPS в CVS, который содержит один или более PH (или единиц NAL кодированных слайсов), относящихся к PPS, или предоставлен через внешние средства.
[195] В том же или другом варианте осуществления ph_pic_parameter_set_id в PH может указывать значение pps_pic_parameter_set_id для используемого PPS, на который делается ссылка. Значение pps_seq_parameter_set_id может быть одинаковым во всех PPS, на которые ссылаются кодированные изображения в CLVS.
[196] В том же или другом варианте осуществления все единицы NAL PPS с конкретным значением pps_pic_parameter_set_id в PU могут иметь одно и то же содержимое.
[197] В том же или другом варианте осуществления, независимо от значений nuh_layer_id, единицы NAL PPS могут совместно использовать одно и то же пространство значений pps_pic_parameter_set_id.
[198] В том же или другом варианте осуществления значение nuh_layer_id единицы NAL PPS может быть равно наименьшему значению nuh_layer_id единиц NAL кодированного слайса, которые ссылаются на единицу NAL PPS.
[199] В варианте осуществления, когда на PPS с nuh_layer_id, равным m, делается ссылка одной или более единицами NAL кодированного слайса с nuh_layer_id, равным n, слой с nuh_layer_id, равным m, может быть таким же, как слой с nuh_layer_id, равным n, или (прямым или косвенным) опорным слоем слоя с nuh_layer_id, равным m.
[200] В варианте осуществления PPS (RBSP) может быть доступен процессу декодирования до того, как на него будет сделана ссылка, он будет включен по меньшей мере в одну AU с TemporalId, равным TemporalId единицы NAL PPS, или предоставлен через внешние средства.
[201] В варианте осуществления PPS (RBSP) может быть доступен процессу декодирования до того, как на него будет сделана ссылка, он будет включен по меньшей мере в одну AU с TemporalId, равным TemporalId единицы NAL PPS в CVS, который содержит один или более PH (или единиц NAL кодированного слайса), относящихся к PPS, или предоставлен через внешние средства.
[202] В варианте осуществления PPS (RBSP) может быть доступен процессу декодирования до того, как на него будет сделана ссылка одним или более PH (или единиц NAL кодированного слайса), он будет включен по меньшей мере в одну PU с nuh_layer_id, равным наименьшему значению nuh_layer_id единиц NAL кодированного слайса, которые относятся к единице NAL PPS в CVS, который содержит один или более PH (или единиц NAL кодированных слайсов), относящихся к PPS, или предоставлен через внешние средства.
[203] В варианте осуществления PPS (RBSP) может быть доступен процессу декодирования до того, как на него будет сделана ссылка одним или более PH (или единиц NAL кодированного слайса), включенный по меньшей мере в одну PU с TemporalId, равным TemporalId единицы NAL PPS и nuh_layer_id, равным наименьшему значению nuh_layer_id единиц NAL кодированного слайса, которые относятся к единице NAL PPS в CVS, который содержит один или более PH (или единиц NAL кодированных слайсов), относящихся к PPS, или предоставлен через внешние средства.
[204] В том же или другом варианте осуществления ph_pic_parameter_set_id в PH может указывать значение pps_pic_parameter_set_id для используемого PPS, на который делается ссылка. Значение pps_seq_parameter_set_id может быть одинаковым во всех PPS, на которые ссылаются кодированные изображения в CLVS.
[205] В том же или другом варианте осуществления все единицы NAL PPS с конкретным значением pps_pic_parameter_set_id в PU могут иметь одно и то же содержимое.
[206] В том же или другом варианте осуществления, независимо от значений nuh_layer_id, единицы NAL PPS могут совместно использовать одно и то же пространство значений pps_pic_parameter_set_id.
[207] В том же или другом варианте осуществления значение nuh_layer_id единицы NAL PPS может быть равно наименьшему значению nuh_layer_id единиц NAL кодированного слайса, которые ссылаются на единицу NAL PPS.
[208] В варианте осуществления, когда на PPS с nuh_layer_id, равным m, делается ссылка одной или более единицами NAL кодированного слайса с nuh_layer_id, равным n, слой с nuh_layer_id, равным m, может быть таким же, как слой с nuh_layer_id, равным n, или (прямым или косвенным) опорным слоем слоя с nuh_layer_id, равным m.
[209] В варианте осуществления, как показано на фиг.21, pps_subpic_id [i] в наборе параметров изображения может указывать ID субизображения i-го субизображения. Длина элемента синтаксиса pps_subpic_id [i] составляет pps_subpic_id_len_minus1 + 1 бит.
[210] Переменная SubpicIdVal [i] для каждого значения i в диапазоне от 0 до sps_num_subpics_minus1 включительно может быть получена следующим образом:
for( i = 0; i <= sps_num_subpics_minus1; i++) if( subpic_id_mapping_explicitly_signalled_flag) SubpicIdVal[i] = subpic_id_mapping_in_pps_flag ? pps_subpic_id[i] : sps_subpic_id[i]else SubpicIdVal[i] = i
[211] В том же или другом варианте осуществления для любых двух разных значений i и j в диапазоне от 0 до sps_num_subpics_minus1 включительно SubpicIdVal [i] может не быть равным SubpicIdVal [j].
[212] В том же или другом варианте осуществления, когда текущее изображение не является первым изображением CLVS, для каждого значения i в диапазоне от 0 до sps_num_subpics_minus1 включительно, если значение SubpicIdVal[i] не равно значению SubpicIdVal[i] предыдущего изображения в порядке декодирования в том же слое, nal_unit_type для всех кодированных единиц NAL слайса субизображения в текущем изображении с индексом субизображения i может быть равно конкретному значению в диапазоне от IDR_W_RADL до CRA_NUT, включительно.
[213] В том же или другом варианте осуществления, когда текущее изображение не является первым изображением CLVS, для каждого значения i в диапазоне от 0 до sps_num_subpics_minus1 включительно, если значение SubpicIdVal[i] не равно значению SubpicIdVal[i] предыдущего изображения в порядке декодирования в том же слое, sps_independent_subpics_flag может быть равно 1.
[214] В том же или другом варианте осуществления, когда текущее изображение не является первым изображением CLVS, для каждого значения i в диапазоне от 0 до sps_num_subpics_minus1 включительно, если значение SubpicIdVal[i] не равно значению SubpicIdVal[i] предыдущего изображения в порядке декодирования в том же слое, subpic_treated_as_pic_flag[i] and loop_filter_across_subpic_enabled_flag[i] могут быть равны 1.
[215] В том же или другом варианте осуществления, когда текущее изображение не является первым изображением CLVS, для каждого значения i в диапазоне от 0 до sps_num_subpics_minus1 включительно, если значение SubpicIdVal[i] не равно значению SubpicIdVal[i] предыдущего изображения в порядке декодирования в том же слое, sps_independent_subpics_flag может быть равно 1, или subpic_treated_as_pic_flag[i] и loop_filter_across_subpic_enabled_flag[i] могут быть равны 1.
[216] В том же или другом варианте осуществления, когда субизображение кодируется независимо без какой-либо ссылки на другое субизображение, значение идентификатора субизображения области может быть изменено в кодированной видеопоследовательности.
[217] В вариантах осуществления изображение может быть разделено на одно или более субизображений. Каждое субизображение может быть дополнительно разделено на один или более слайсов. Существует потребность в эффективном способе сигнализирования для сигнализирования информации разделения субизображений.
[218] Отсчеты могут обрабатываться в единицах CTB. Размер массива для каждого CTB яркости по ширине и высоте равен CtbSizeY в единицах отсчетов. Ширина и высота массива для каждого CTB цветности равны CtbWidthC и CtbHeightC, соответственно, в единицах отсчетов. Каждому CTB назначается разделение, сигнализируемое для идентификации размеров блоков для интра- или интер-предсказания и для кодирования с преобразованием. Разделение представляет собой это рекурсивное разделение квадрадерева. Корень квадродерева связан с CTB. Квадрадерево разделяется до тех пор, пока не будет достигнут лист, который называется листом дерева квадрантов. Когда ширина компонента не является целым числом от размера CTB, CTB на правой границе компонента являются неполными. Когда высота компонента не является целым числом, кратным размеру CTB, CTB на нижней границе компонента являются неполными.
[219] Информация о ширине и высоте каждого субизображения может передаваться в SPS в единицах CtbSizeY. На фиг. 22, например, subpic_width_minus1 [i] плюс 1 указывает ширину i-го субизображения в единицах CtbSizeY. Длина элемента синтаксиса составляет Ceil( Log2( ( pic_width_max_in_luma_samples + CtbSizeY - 1) >> CtbLog2SizeY)) бит. Если отсутствует, значение subpic_width_minus1 [i] выводится равным ((pic_width_max_in_luma_samples + CtbSizeY- 1) >> CtbLog2SizeY) - subpic_ctu_top_left_x [i] - 1. При этом subpic_height_minus1 [i] плюс 1 указывает высоту i-го субизображения в единицах CtbSizeY. Длина элемента синтаксиса составляет Ceil( Log2( ( pic_height_max_in_luma_samples + CtbSizeY - 1) >> CtbLog2SizeY)) бит. Если отсутствует, значение subpic_height_minus1 [i] выводится равным ((pic_height_max_in_luma_samples + CtbSizeY- 1) >> CtbLog2SizeY) - subpic_ctu_top_left_y [i] - 1.
[220] Ширина каждого субизображения может быть больше или равна CtbSizeY, когда ширина изображения больше или равна CtbSizeY. Высота каждого субизображения может быть больше или равна CtbSizeY, когда высота изображения больше или равна CtbSizeY.
[221] Если ширина изображения не больше, чем CtbSizeY, а высота изображения не больше, чем CtbSizeY, изображение не может быть разделено более чем на одно субизображение. В этом случае число субизображений может быть равно 1.
[222] Когда pic_width_max_in_luma_samples не больше CtbSizeY и pic_height_max_in_luma_samples не больше CtbSizeY, значение subpic_info_present_flag может быть равно 0. Когда subpic_info_present_flag равен 0, явное сигнализирование для информации разделения субизображений отсутствует, и число субизображений в изображении равно 1.
[223] В том же или другом варианте осуществления sps_subpic_id_len_minus1 плюс 1 указывает количество битов, используемых для представления синтаксического элемента sps_subpic_id [i], синтаксических элементов pps_subpic_id [i], если они есть, и синтаксического элемента slice_subpic_id, если они есть. Значение sps_subpic_id_len_minus1 может находиться в диапазоне от 0 до 15 включительно. Значение 1 << (sps_subpic_id_len_minus1) может быть больше или равно sps_num_subpics_minus1 + 1.
[224] В том же или другом варианте осуществления, когда число субизображений равно 1, subpic_info_present_flag может быть равен 0, и информация разделения субизображений может не сигнализироваться в явном виде, поскольку информация о ширине и высоте субизображения равна информации о ширине и высоте изображения, и в этом случае верхнее левое положение субизображения равно левому верхнему положению изображения.
[225] Например, subpic_ctu_top_left_x [i] указывает горизонтальное положение верхнего левого CTU в i-м субизображении в единицах CtbSizeY. Длина элемента синтаксиса составляет Ceil( Log2( ( pic_width_max_in_luma_samples + CtbSizeY - 1) >> CtbLog2SizeY)) бит. Если отсутствует, значение subpic_ctu_top_left_x [i] выводится равным 0. При этом subpic_ctu_top_left_y [i] указывает вертикальное положение верхнего левого CTU в i-м субизображении в единицах CtbSizeY. Длина элемента синтаксиса составляет Ceil( Log2( ( pic_height_max_in_luma_samples + CtbSizeY - 1) >> CtbLog2SizeY)) бит. Если отсутствует, значение subpic_ctu_top_left_y [i] выводится равным 0. subpic_width_minus1 [i] плюс 1 указывает ширину i-го субизображения в единицах CtbSizeY. Длина элемента синтаксиса составляет Ceil( Log2( ( pic_width_max_in_luma_samples + CtbSizeY - 1) >> CtbLog2SizeY)) бит. Если отсутствует, значение subpic_width_minus1 [i] выводится равным ((pic_width_max_in_luma_samples + CtbSizeY- 1) >> CtbLog2SizeY) - subpic_ctu_top_left_x [i] - 1. При этом subpic_height_minus1 [i] плюс 1 указывает высоту i-го субизображения в единицах CtbSizeY. Длина элемента синтаксиса составляет Ceil( Log2( ( pic_height_max_in_luma_samples + CtbSizeY - 1) >> CtbLog2SizeY)) бит. Если отсутствует, значение subpic_height_minus1 [i] выводится равным ((pic_height_max_in_luma_samples + CtbSizeY- 1) >> CtbLog2SizeY) - subpic_ctu_top_left_y [i] - 1.
[226] В том же или другом варианте осуществления, когда число субизображений больше 1, subpic_info_present_flag может быть равным 1, и информация разделения субизображений может быть явно сигнализирована в наборе параметров, как показано на фиг. 22.
[227] Например, как показано на фиг.22, sps_num_subpics_minus2 плюс 2 указывает число субизображений в каждом изображении в CLVS. Значение sps_num_subpics_minus2 может быть в диапазоне от 0 до Ceil(pic_width_max_in_luma_samples ÷ CtbSizeY) * Ceil(pic_height_max_in_luma_samples ÷ CtbSizeY) - 2 включительно. При отсутствии, значение sps_num_subpics_minus2 выводится равным 0.
[228] В том же варианте осуществления списки SubpicWidthInTiles [i] и SubpicHeightInTiles [i] для i в диапазоне от 0 до sps_num_subpics_minus1 включительно, указывающие ширину и высоту i-го субизображения в столбцах и рядах тайла, соответственно, и список subpicHeightLessThanOneTileFlag [i] для i в диапазоне от 0 до sps_num_subpics_minus1 включительно, указывающий, меньше ли высота i-го субизображения, чем один ряд тайла, могут быть получены следующим образом:
for( i = 0; i <= sps_num_subpics_minus2 + 1; i++) {leftX = subpic_ctu_top_left_x[i] rightX = leftX + subpic_width_minus1[i] SubpicWidthInTiles[i] = ctbToTileColIdx[rightX] + 1 - ctbToTileColIdx[leftX]topY = subpic_ctu_top_left_y[i] bottomY = topY + subpic_height_minus1[i]SubpicHeightInTiles[i] = ctbToTileRowIdx[bottomY] + 1 - ctbToTileRowIdx[topY] if( SubpicHeightInTiles[i] = = 1 && subpic_height_minus1[i] + 1 <RowHeight[ctbToTileRowIdx[topY]]) subpicHeightLessThanOneTileFlag[i] = 1 else subpicHeightLessThanOneTileFlag[i] = 0}
[229] Когда rect_slice_flag равен 1, список NumCtusInSlice [i] для i в диапазоне от 0 до num_slices_in_pic_minus1 включительно, указывающий количество CTU в i-м слайсе, список SliceTopLeftTileIdx [i] для i в диапазоне от 0 до num_slices_in_pic_minus1, включительно, указывающий индекс тайла, содержащего первую CTU в слайсе, и матрицу CtbAddrInSlice [i] [j] для i в диапазоне от 0 до num_slices_in_pic_minus1 включительно и j в диапазоне от 0 до NumCtusInSlice [i] - 1 включительно, указывающий адрес сканирования растра изображения j-го CTB в i-м срезе, и переменную NumSlicesInTile [i], определяющую количество срезов в тайле, содержащем i-й срез, можно получить следующим образом:
if( single_slice_per_subpic_flag) {for( i = 0; i <= sps_num_subpics_minus2 + 1; i++) {NumCtusInSlice[i] = 0 if( subpicHeightLessThanOneTileFlag[i]) /* Слайс состоит из определенного количества рядов CTU в тайле. */ AddCtbsToSlice( i, subpic_ctu_top_left_x[i], subpic_ctu_top_left_x[i] + subpic_width_minus1[i] + 1, subpic_ctu_top_left_y[i], subpic_ctu_top_left_y[i] + subpic_height_minus1[i] + 1) else {/* Слайс состоит из определенного количества полных тайлов, покрывающих прямоугольную область. */ tileX = CtbToTileColBd[subpic_ctu_top_left_x[i]] tileY = CtbToTileRowBd[subpic_ctu_top_left_y[i]] for( j = 0; j < SubpicHeightInTiles[i]; j++) for( k = 0; k < SubpicWidthInTiles[i]; k++) AddCtbsToSlice( i, tileColBd[tileX + k], tileColBd[tileX + k + 1], tileRowBd[tileY + j], tileRowBd[tileY + j + 1])}}} else {tileIdx = 0 for( i = 0; i <= num_slices_in_pic_minus1; i++) NumCtusInSlice[i] = 0 for( i = 0; i <= num_slices_in_pic_minus1; i++) {SliceTopLeftTileIdx[i] = tileIdx tileX = tileIdx % NumTileColumns tileY = tileIdx / NumTileColumns if( i < num_slices_in_pic_minus1) {sliceWidthInTiles[i] = slice_width_in_tiles_minus1[i] + 1 sliceHeightInTiles[i] = slice_height_in_tiles_minus1[i] + 1} else {sliceWidthInTiles[i] = NumTileColumns - tileX sliceHeightInTiles[i] = NumTileRows - tileY NumSlicesInTile[i] = 1} if( slicWidthInTiles[i] = = 1 && sliceHeightInTiles[i] = = 1) {if( num_exp_slices_in_tile[i] = = 0) {NumSlicesInTile[i] = 1 sliceHeightInCtus[i] = RowHeight[SliceTopLeftTileIdx[i] / NumTileColumns]} else {remainingHeightInCtbsY = RowHeight[SliceTopLeftTileIdx[i] / NumTileColumns] for( j = 0; j < num_exp_slices_in_tile[i] - 1; j++) {sliceHeightInCtus[i + j] = exp_slice_height_in_ctus_minus1[i][j] + 1 remainingHeightInCtbsY -= sliceHeightInCtus[i + j]} uniformSliceHeight = exp_slice_height_in_ctus_minus1[i][j] + 1 while( remainingHeightInCtbsY >= uniformSliceHeight) {sliceHeightInCtus[i + j] = uniformSliceHeight remainingHeightInCtbsY -= uniformSliceHeight j++} if( remainingHeightInCtbsY > 0) {sliceHeightInCtus[i + j] = remainingHeightInCtbsY j++} NumSlicesInTile[i] = j} ctbY = tileRowBd[tileY] for( j = 0; j < NumSlicesInTile[i]; j++) {AddCtbsToSlice( i + j, tileColBd[tileX], tileColBd[tileX + 1], ctbY, ctbY + sliceHeightInCtus[i + j]) ctbY += sliceHeightInCtus[i + j]} i += NumSlicesInTile[i] - 1} else for( j = 0; j < sliceHeightInTiles[i]; j++) for( k = 0; k < sliceWidthInTiles[i]; k++) AddCtbsToSlice( i, tileColBd[tileX + k], tileColBd[tileX + k + 1], tileRowBd[tileY + j], tileRowBd[tileY + j + 1]) if( i < num_slices_in_pic_minus1) {if( tile_idx_delta_present_flag) tileIdx += tile_idx_delta[i] else {tileIdx += sliceWidthInTiles[i] if( tileIdx % NumTileColumns = = 0) tileIdx += ( sliceHeightInTiles[i] - 1) * NumTileColumns}}}}
[230] На фиг. 23 показана примерная блок-схема процесса 2300 декодирования кодированного битового потока видео. В некоторых реализациях один или более блоков процессов с фиг.23 могут выполняться декодером 210. В некоторых реализациях один или более блоков процессов с фиг. 23 могут выполняться другим устройством или группой устройств, отдельной от декодера 210 или включающего в себя его, например кодером 203.
[231] Как показано на фиг. 23, процесс 2300 может включать в себя, на основании числа по меньшей мере одного субизображения текущего изображения, превышающего один, получение флага, указывающего, явно ли сигнализирована информация разделения субизображений (блок 2310). В вариантах осуществления первый флаг может соответствовать subpic_info_present_flag.
[232] Как дополнительно показано на фиг. 23, процесс 2300 может включать, на основании флага, указывающего, что информация разделения субизображений сигнализирована явно, получение информации разделения субизображений (блок 2320).
[233] Как дополнительно показано на фиг. 23, процесс 2300 может включать в себя декодирование текущего изображения на основании информации разделения субизображений (этап 2330).
[234] В вариантах осуществления, флаг и информация разделения субизображения могут сигнализироваться в наборе параметров последовательности (SPS).
[235] В вариантах осуществления число по меньшей мере одного субизображения может сигнализироваться в SPS.
[236] В вариантах осуществления на основании размера изображения текущего изображения, меньшего, чем размер единицы дерева кодирования компонента яркости текущего изображения, число по меньшей мере одного субизображения равно одному. Размер единицы дерева кодирования компонента яркости текущего изображения может соответствовать CtbSizeY.
[237] В вариантах осуществления на основании числа по меньшей мере одного субизображения, равного единице, флаг может указывать, что информация разделения субизображений не сигнализируется явно.
[238] В вариантах осуществления информация разделения субизображений может указывать размер субизображения из по меньшей мере одного субизображения.
[239] В вариантах осуществления размер субизображения может включать в себя высоту субизображения и ширину субизображения.
[240] В вариантах осуществления размер субизображения может быть указан в информации разделения субизображений в единицах размера единицы дерева кодирования компонента яркости текущего изображения. Размер единицы дерева кодирования компонента яркости текущего изображения может соответствовать CtbSizeY.
[241]В вариантах осуществления размер другого субизображения может быть определен на основании размера субизображения, указанного посредством информации разделения субизображений.
[242] Хотя фиг. 23 показывает примерные блоки процесса 2300, в некоторых реализациях процесс 2300 может включать в себя дополнительные блоки, меньшее количество блоков, отличные блоки или блоки, расположенные иначе, чем те, которые изображены на фиг. 23 Дополнительно или альтернативно два или более блока процесса 2300 могут выполняться параллельно.
[243] Кроме того, предложенные способы могут быть реализованы схемами обработки (например, одним или более процессорами или одной или более интегральными схемами). В одном примере один или более процессоров выполняют программу, которая хранится на невременном машиночитаемом носителе, для осуществления одного или более из предложенных способов.
[244] Методы, описанные выше, могут быть реализованы в виде компьютерного программного обеспечения с использованием машиночитаемых инструкций и физически сохранены на одном или более машиночитаемых носителях. Например, на фиг.24 показана компьютерная система 2400, подходящая для реализации определенных вариантов осуществления раскрытого объекта изобретения.
[245] Компьютерное программное обеспечение может быть кодировано с использованием любого подходящего машинного кода или компьютерного языка, который может быть объектом сборки, компиляции, связывания или подобных механизмов для создания кода, содержащего инструкции, которые могут выполняться напрямую или посредством интерпретации, выполнения микрокода и и т. п., центральными процессорами компьютера (CPU), графическими процессорами (GPU) и т. п.
[246] Инструкции могут исполняться на компьютерах различных типов или их компонентах, включая, например, персональные компьютеры, планшетные компьютеры, серверы, смартфоны, игровые устройства, устройства Интернета вещей и т. п.
[247] Компоненты, показанные на фиг.24 для компьютерной системы 2400, являются примерными по своей природе и не предназначены для предложения каких-либо ограничений в отношении объема использования или функциональных возможностей компьютерного программного обеспечения, реализующего варианты осуществления настоящего изобретения. Конфигурация компонентов также не должна интерпретироваться как имеющая какую-либо зависимость или требование, относящееся к любому одному или комбинации компонентов, проиллюстрированных в примерном варианте осуществления компьютерной системы 2400.
[248] Компьютерная система 2400 может включать в себя определенные устройства ввода с человеко-машинным интерфейсом. Такое устройство ввода с человеко-машинным интерфейсом может реагировать на ввод одним или более пользователями-людьми посредством, например, тактильного ввода (например, нажатия клавиш, смахивания, движения управляющей перчатки), звукового ввода (например, голоса, хлопков в ладоши), визуального ввода (например: жестов), обонятельного ввода (не изображен). Устройства с человеко-машинным интерфейсом также могут использоваться для захвата определенных носителей, не обязательно напрямую связанных с сознательным вводом человеком, таких как звук (например, речь, музыка, окружающий звук), изображения (например, сканированные изображения, фотографические изображения, полученные из камеры для неподвижных изображений), видео (например, двухмерное видео, трехмерное видео, включая стереоскопическое видео).
[249] Устройства ввода с человеческо-машинным интерфейсом могут включать в себя одно или более из (только одно из каждого изображенного): клавиатура 2401, мышь 2402, трекпад 2403, сенсорный экран 2410 и связанный графический адаптер 2450, управляющая перчатка, джойстик 2405, микрофон 2406, сканер 2407, камера 2408.
[250] Компьютерная система 2400 также может включать в себя определенные устройства вывода с человеко-машинным интерфейсом. Такие устройства вывода с человеко-машинным интерфейсом могут стимулировать чувства одного или более пользователей-людей посредством, например, тактильного вывода, звука, света и запаха/вкуса. Такие устройства вывода с человеко-машинным интерфейсом могут включать в себя тактильные устройства вывода (например, тактильную обратную связь от сенсорного экрана (2410), управляющей перчатки (2404) или джойстика (2405), но также могут иметься устройства тактильной обратной связи, которые не служат в качестве устройств ввода), устройства вывода звука (например: динамики (2409), наушники (не изображены)), устройства вывода изображения (например, экраны (2410), включая ЭЛТ-экраны, ЖК-экраны, плазменные экраны, OLED-экраны, каждое из которых имеет или не имеет возможности ввода с сенсорного экрана, каждое с возможностью тактильной обратной связи или без нее - некоторые из которых могут быть способны выводить двухмерный визуальный вывод или более, чем трехмерный вывод с помощью таких средств, как стереографический вывод; очки виртуальной реальности (не изображены), голографические дисплеи и дымовые баки (не изображены)) и принтеры (не изображены).
[251] Компьютерная система (2400) также может включать в себя доступные для человека устройства хранения и связанные с ними носители, такие как оптические носители, включая CD/DVD ROM/RW (2420) с CD/DVD или подобными носителями (2421), флэш-накопитель (2422), съемный жесткий диск или твердотельный накопитель (2423), ранее разработанные магнитные носители, такие как лента и дискета (не изображены), специализированные устройства на основании ROM/ASIC/PLD, такие как защитные ключи (не изображены) и т. п.
[242] Специалисты в данной области также должны понимать, что термин «машиночитаемый носитель», используемый в связи с раскрытым в настоящем документе объектом изобретения, не охватывает среды передачи, несущие волны или другие временные сигналы.
[253] Компьютерная система (2400) также может включать в себя интерфейс к одной или более коммуникационным сетям (955). Сети могут быть, например, беспроводными, проводными, оптическими. Кроме того, сети могут быть локальными, глобальными, городскими, автомобильными и промышленными, работающими в реальном времени, устойчивыми к задержкам и т. д. Примеры сетей включают в себя локальные сети, такие как Ethernet, беспроводные локальные вычислительные сети (LAN), сотовые сети, включая глобальные системы мобильной связи (GSM), третьего поколения (3G), четвертого поколения (4G), пятого поколения (5G), сети стандарта "Долгосрочное развитие" (LTE) и т.п., проводные телевизионные или беспроводные глобальные цифровые сети, включая кабельное телевидение, спутниковое телевидение и наземное широковещательное телевидение, автомобильные и промышленные, включая CAN-шину, и так далее. Некоторым сетям обычно требуются внешние сетевые интерфейсные адаптеры (954), которые подключены к определенным портам данных общего назначения или периферийным шинам (949) (например, к портам универсальной последовательной шины (USB) компьютерной системы 2400); другие обычно интегрированы в ядро компьютерной системы 2400 путем присоединения к системной шине, как описано ниже (например, интерфейс Ethernet в компьютерную систему ПК или интерфейс сотовой сети в компьютерную систему смартфона). Например, сеть 2455 может быть подключена к периферийной шине 2449 с использованием сетевого интерфейса 2454. Используя любую из этих сетей, компьютерная система 2400 может связываться с другими объектами. Такая связь может быть однонаправленной, только для приема (например, широковещательное телевидение), однонаправленной только для отправки (например, CAN-шина на определенные устройства с CAN-шиной) или двунаправленной, например, для других компьютерных систем, использующих локальную или глобальную цифровую сеть. В каждой из этих сетей и сетевых интерфейсов (954) могут использоваться определенные протоколы и стеки протоколов, как описано выше.
[254] Вышеупомянутые устройства человеко-машинного интерфейса, доступные человеку устройства хранения и сетевые интерфейсы могут быть присоединены к ядру 2440 компьютерной системы 2400.
[255] Ядро (2440) может включать в себя один или более центральных процессоров (CPU) (2441), графических процессоров (GPU) (2442), специализированных программируемых процессоров в виде программируемых вентильных областей (FPGA) (2443), аппаратного обеспечения (2444) и т. д. Эти устройства, наряду с постоянным запоминающим устройством (ROM) 2445, оперативным запоминающим устройством (RAM) 2446, внутренним ЗУ большой емкости, таким как внутренние жесткие диски, недоступные пользователю, твердотельные накопители (SSD) и т. п. 2447, могут быть подключены через системную шину 2448. В некоторых компьютерных системах системная шина 2448 может быть доступна в виде одного или более физических разъемов для обеспечения возможности расширения за счет дополнительных ЦП, ГП и т. п. Периферийные устройства могут быть подключены либо непосредственно к системной шине 2448 ядра, либо через периферийную шину 2449. Архитектура периферийной шины включает соединение периферийных компонентов (PCI), USB и т.п.
[256] CPU 2441, GPU 2442, FGPA 2443 и ускорители 2444 могут выполнять определенные инструкции, которые в комбинации могут составлять вышеупомянутый компьютерный код. Этот компьютерный код может храниться в ROM 2445 или RAM 2446. Переходные данные также могут храниться в RAM 2446, тогда как постоянные данные могут храниться, например, во внутреннем ЗУ большой емкости 2447. Быстрое хранение и извлечение на любое из запоминающих устройств могут быть доступны посредством использования кэш-памяти, которая может быть тесно связана с одним или более CPU 2441, GPU 2442, ЗУ 2447 большой емкости, ROM 2445, RAM 2446 и т. п.
[257] Машиночитаемый носитель может содержать компьютерный код для выполнения различных операций, реализуемых компьютером. Носители и компьютерный код могут быть специально спроектированными и сконструированными для целей настоящего изобретения, или они могут быть хорошо известными и доступными для специалистов в области компьютерного программного обеспечения.
[258] В качестве примера, но не ограничения, компьютерная система, имеющая архитектуру (2400) и, в частности, ядро (2440), может обеспечивать функциональность за счет процессора(ов) (включая ЦП, ГП, ППВМ, ускорители и т. п.), исполняющего программное обеспечение, воплощенное на одном или более материальных машиночитаемых носителях. Такие машиночитаемые носители могут быть носителями, связанными с доступным для пользователя ЗУ большой емкости, как описано выше, а также определенными запоминающими устройствами ядра 2440, которые имеют невременную природу, такими как внутреннее ЗУ 2447 большой емкости или ROM 2445. Программное обеспечение, реализующее различные варианты осуществления настоящего изобретения, может храниться в таких устройствах и выполняться ядром 2440. Машиночитаемый носитель может включать в себя одно или более запоминающих устройств или микросхем в соответствии с конкретными потребностями. Программное обеспечение может побуждать ядро (2440) и, в частности, процессоры в нем (включая ЦП, ГП, ППВМ и т. п.) выполнять определенные процессы или определенные части конкретных процессов, описанных в данном документе, включая определение структур данных, хранящихся в RAM (2446) и изменение таких структур данных в соответствии с процессами, определенными программным обеспечением. В дополнение или в качестве альтернативы, компьютерная система может обеспечивать функциональность в результате логики, встроенной в аппаратную схему или иным образом воплощенной в схеме (например, ускоритель 2444), которая может работать вместо или вместе с программным обеспечением для выполнения определенных процессов или отдельных частей конкретных процессов, описанных в данном документе. Ссылка на программное обеспечение может включать в себя логику и наоборот, где это применимо. Ссылка на машиночитаемый носитель может включать в себя схему (например, интегральную схему (IC)), хранящую программное обеспечение для выполнения, схему, воплощающую логику для выполнения, или и то, и другое, где это применимо. Настоящее изобретение включает в себя любую подходящую комбинацию аппаратного и программного обеспечения.
[259] Хотя это описание раскрывает несколько примерных вариантов осуществления, существуют изменения, перестановки и различные заменяющие эквиваленты, которые попадают в объем изобретения. Таким образом, будет принято во внимание, что специалисты в данной области техники смогут разработать многочисленные системы и способы, которые, хотя явно не показаны или не описаны здесь, воплощают принципы изобретения и, таким образом, находятся в рамках его сущности и объема.
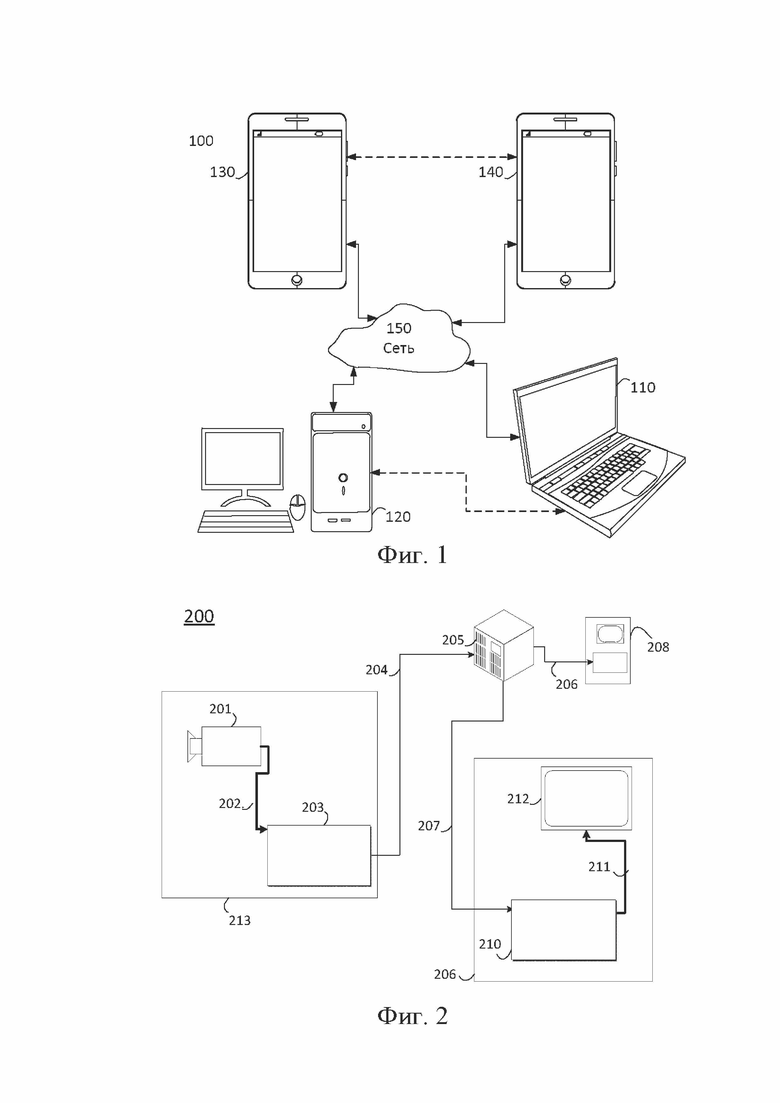
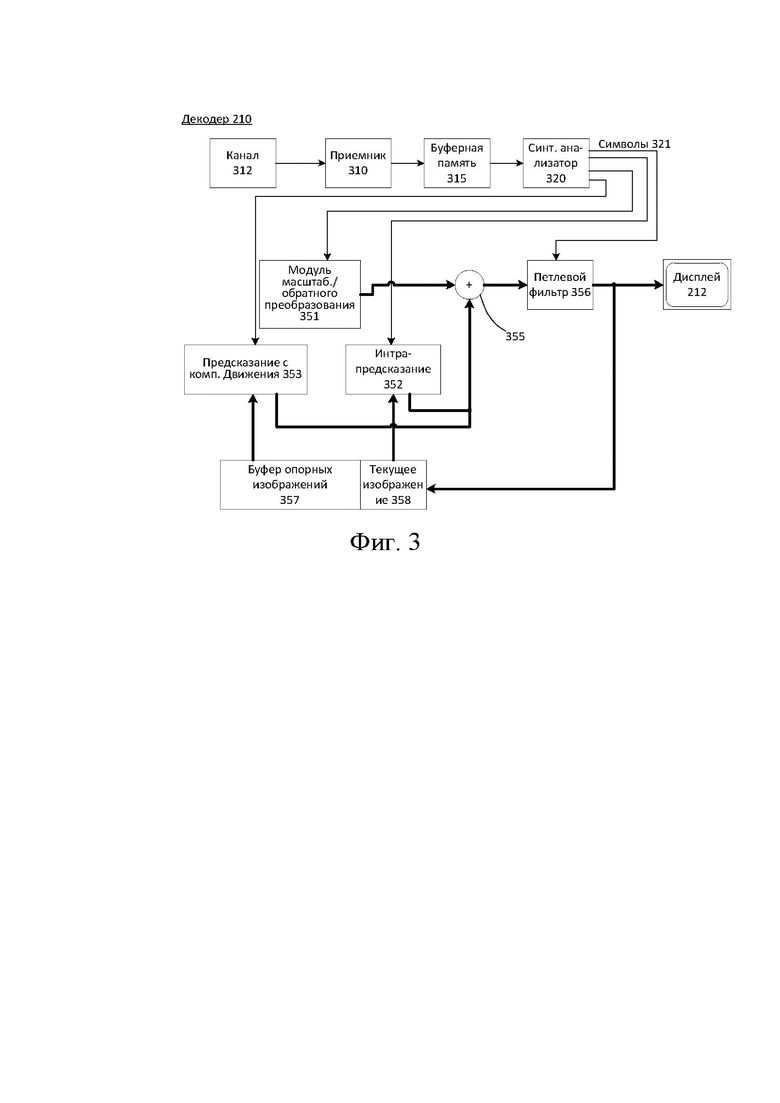
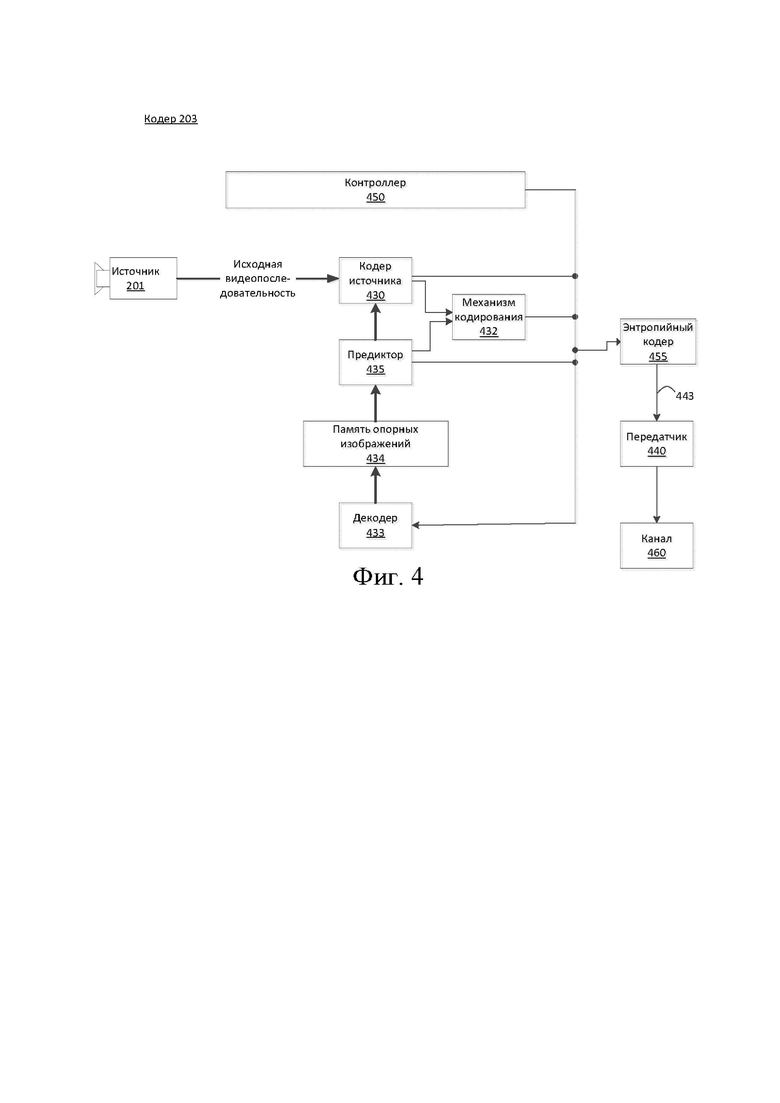
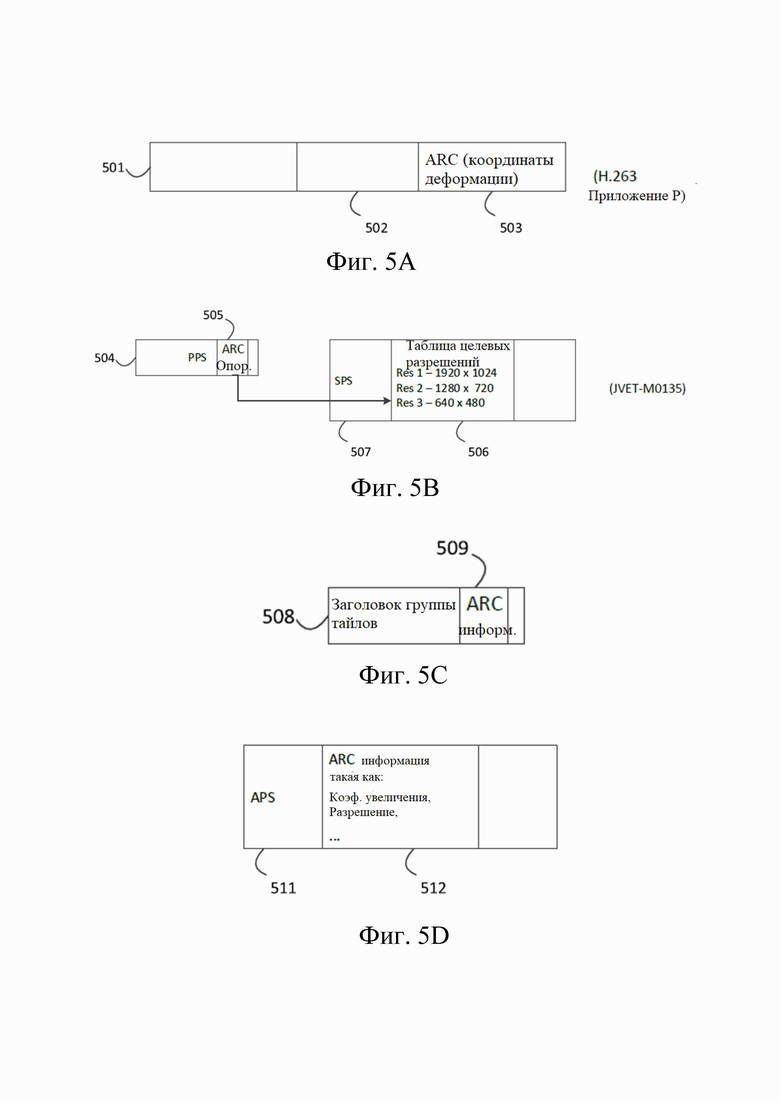
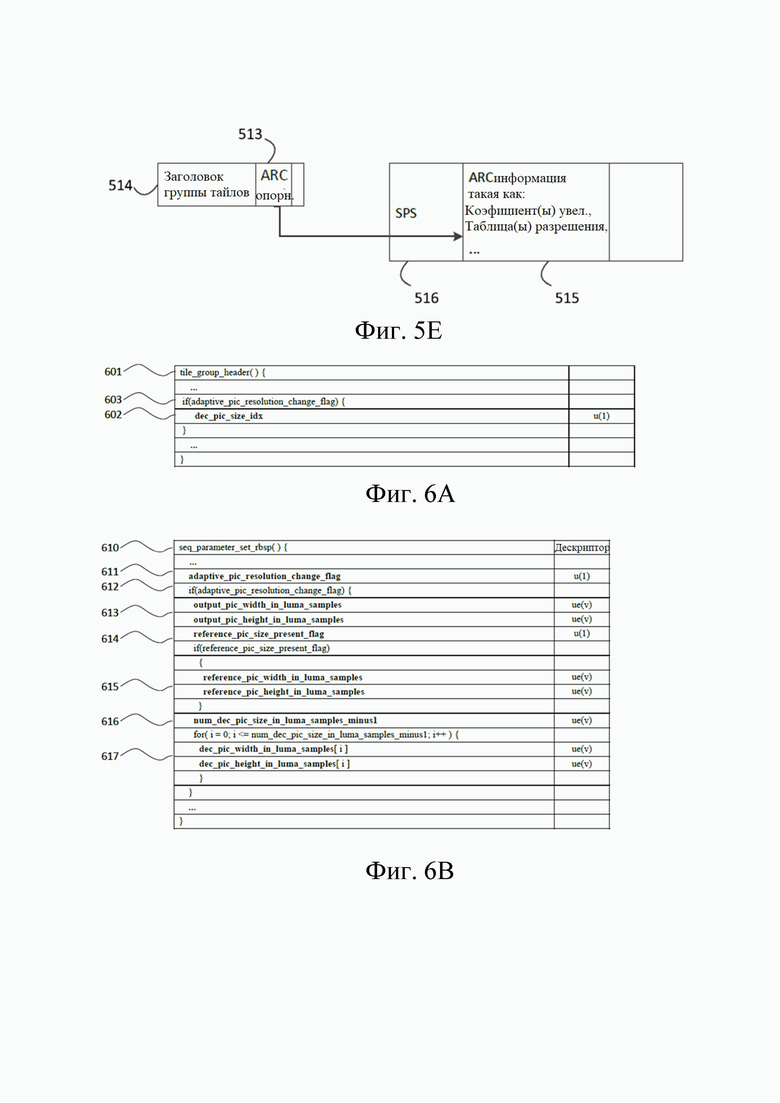
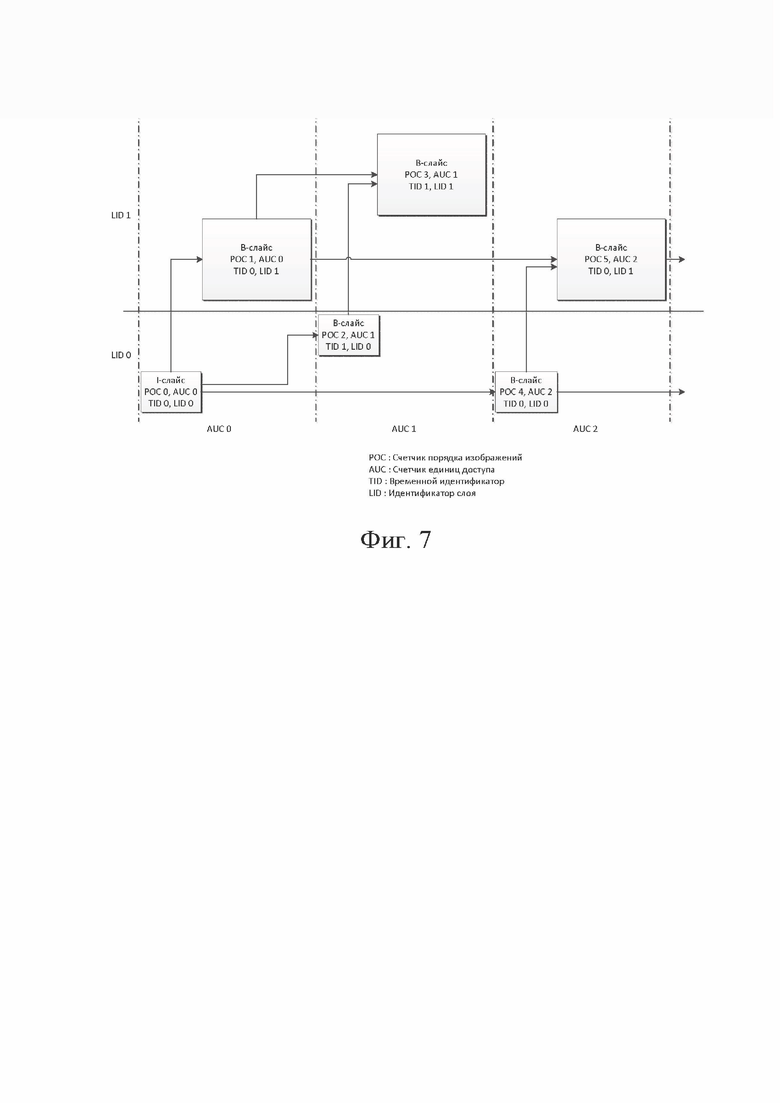

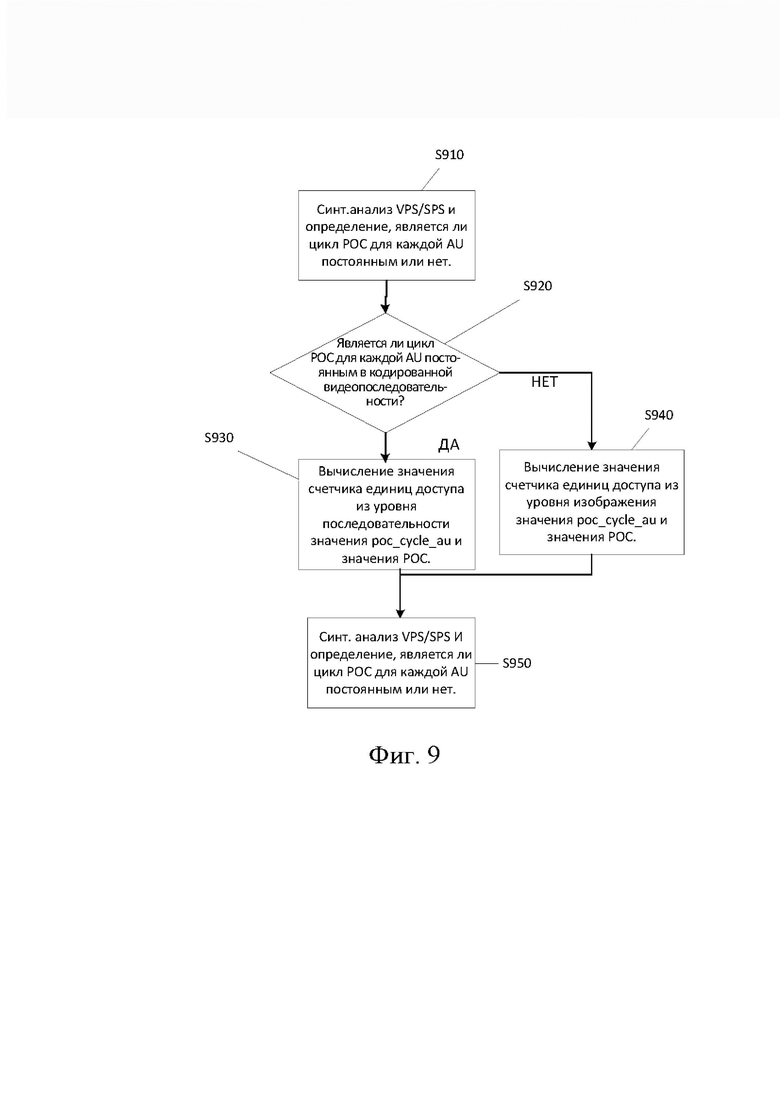
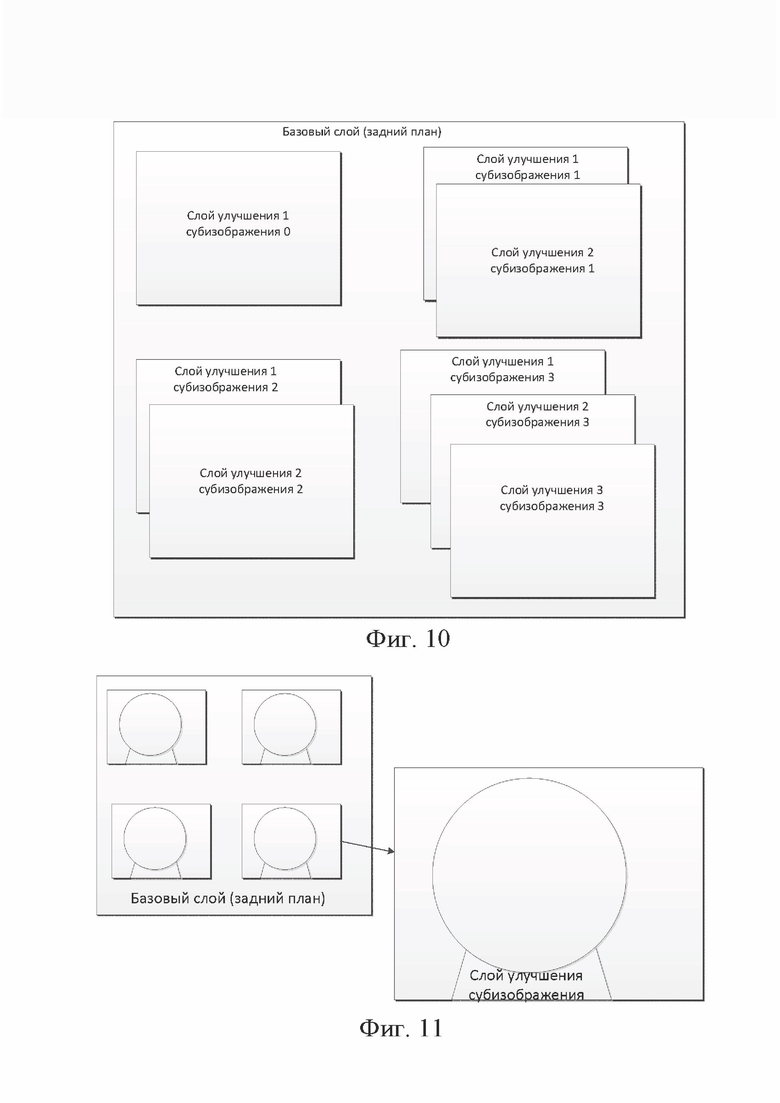
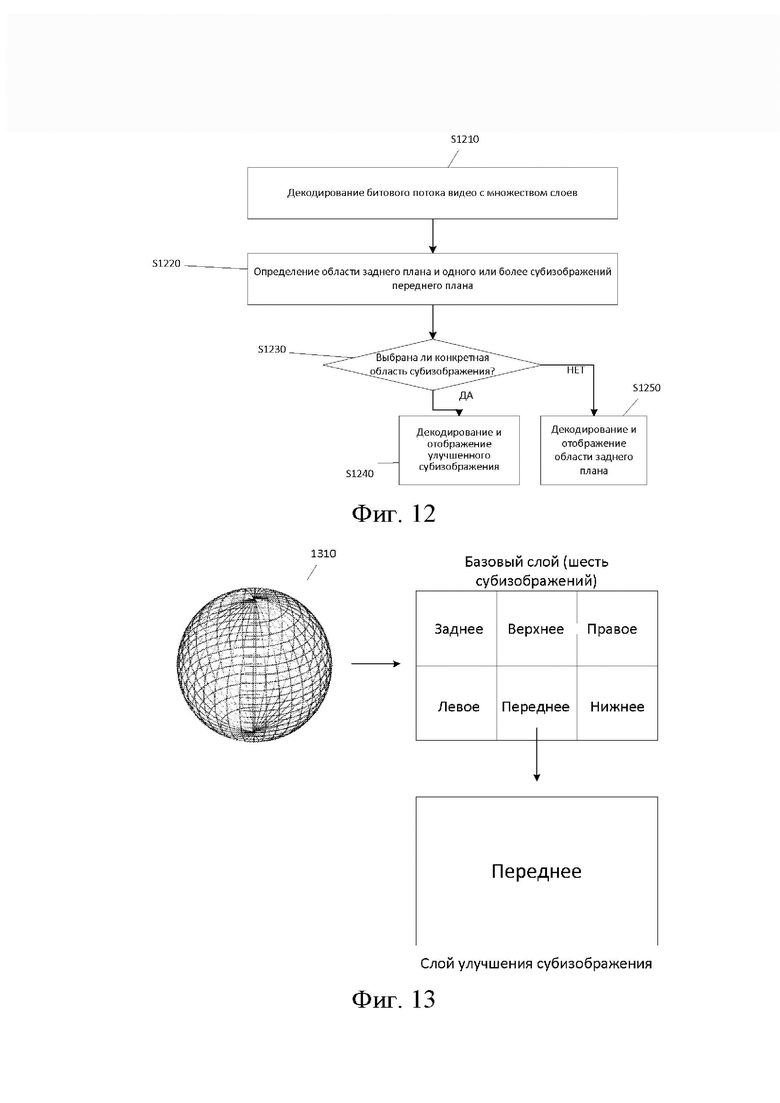

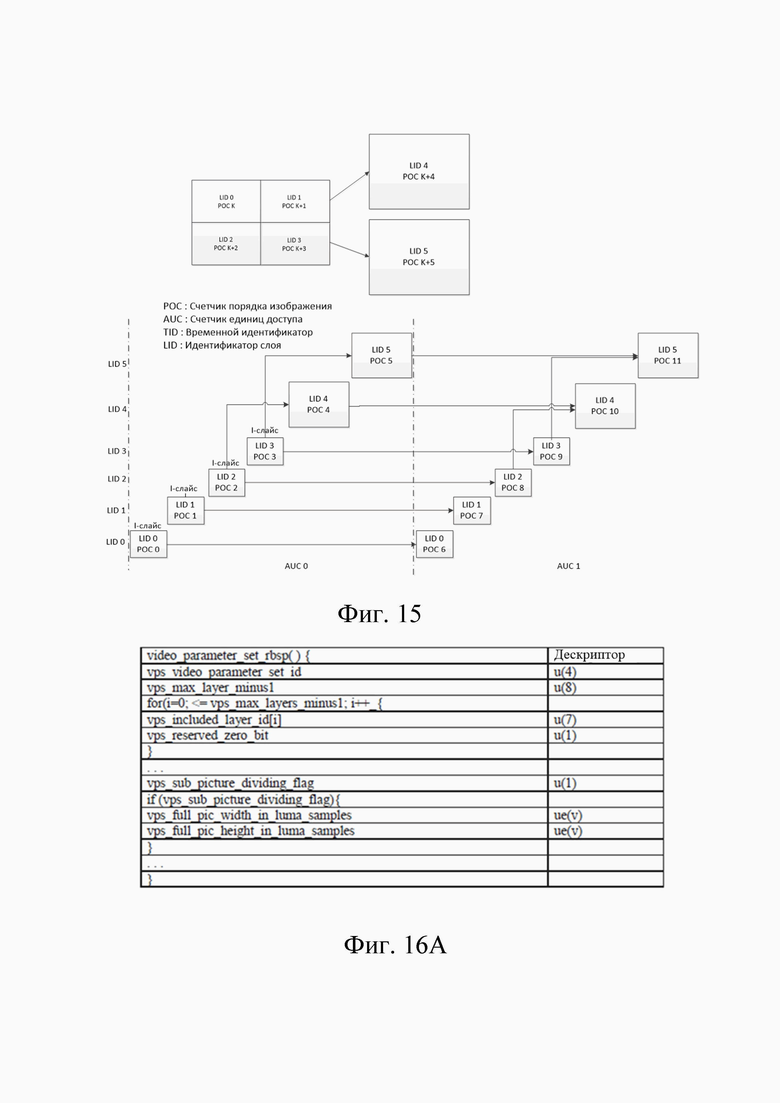





Изобретение относится к области кодирования и декодирования видео, а более конкретно к сигнализации разделения субизображений в кодированном видеопотоке. Техническим результатом изобретения является повышение эффективности кодирования. Предложены способ, устройство и энергонезависимый машиночитаемый носитель для декодирования кодированного битового потока видеоданных с использованием по меньшей мере одного процессора, причем способ включает в себя: на основании числа по меньшей мере одного субизображения текущего изображения больше одного, получение флага, указывающего, явно ли сигнализирована информация разделения субизображений; на основании флага, указывающего, что информация разделения субизображений сигнализирована явно, получение информации разделения субизображений и декодирование текущего изображения на основании информации разделения субизображений. 3 н. и 11 з.п. ф-лы, 30 ил., 1 табл.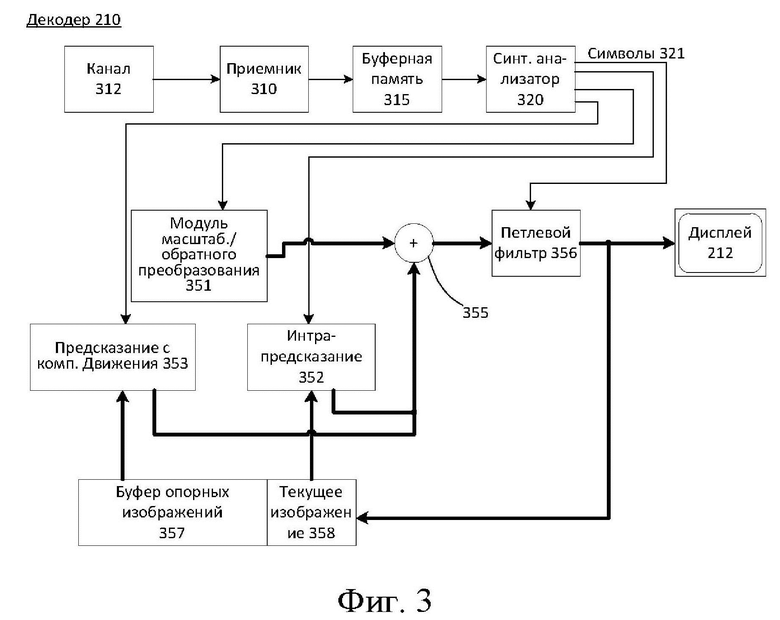
1. Способ декодирования кодированного битового потока видео, включающий: получение первого флага, указывающего число субизображений текущего изображения; на основании числа субизображений текущего изображения, превышающего один, получение второго флага, указывающего являются ли субизображения текущего изображения независимо кодированными; на основании второго флага, указывающего, что субизображения текущего изображения не являются независимо кодированными, получение третьего флага, указывающего обработано ли каждое из субизображений как изображение; и декодирование текущего изображения на основании первого флага, второго флага и третьего флага.
2. Способ по п.1, в котором первый флаг, второй флаг и третий флаг сигнализируются в наборе параметров последовательности (SPS).
3. Способ по п.2, в котором число субизображений сигнализируется в SPS.
4. Способ по п.1, в котором на основании размера изображения текущего изображения, меньшего, чем размер единицы дерева кодирования компонента яркости текущего изображения, число субизображений равно одному.
5. Способ по п.4, в котором на основании числа субизображений, равного единице, информация разделения субизображений не сигнализируется.
6. Способ по п.1, в котором информация разделения субизображений указывает размер субизображения из субизображений.
7. Способ по п.6, в котором размер субизображения включает в себя высоту субизображения и ширину субизображения.
8. Способ по п.6, в котором размер субизображения указан в информации разделения субизображений в единицах размера единицы дерева кодирования компонента яркости текущего изображения.
9. Способ по п.6, в котором размер другого субизображения определен на основании размера субизображения, указанного посредством информации разделения субизображений.
10. Способ по п.1, в котором первый флаг содержит sps_num_subpics_minus1, второй флаг содержит sps_independent_subpics_flag и третий флаг содержит sps_subpic_treated_as_pic_flag.
11. Способ по п.10, в котором, когда текущее изображение не является первым изображением CLVS, для каждого значения i в диапазоне от 0 до sps_num_subpics_minus1 включительно, если значение SubpicIdVal[i] не равно значению SubpicIdVal[i] предыдущего изображения в порядке декодирования в том же слое, subpic_treated_as_pic_flag[i] и loop_filter_across_subpic_enabled_flag[i] равны 1.
12. Способ по п.10, в котором, когда текущее изображение не является первым изображением CLVS, для каждого значения i в диапазоне от 0 до sps_num_subpics_minus1 включительно, если значение SubpicIdVal[i] не равно значению SubpicIdVal[i] предыдущего изображения в порядке декодирования в том же слое, sps_independent_subpics_flag равен 1 или subpic_treated_as_pic_flag[i] и loop_filter_across_subpic_enabled_flag[ i ] равны 1.
13. Устройство для декодирования кодированного битового потока видео, при этом устройство содержит: по меньшей мере один элемент памяти, конфигурированный для хранения программного кода; и по меньшей мере один процессор, конфигурированный для считывания программного кода и работы в соответствии с инструкциями программного кода для осуществления способа по любому из пп.1-12.
14. Невременный машиночитаемый носитель, хранящий инструкции, содержащие: одну или более инструкций, которые при исполнении одним или более процессорами устройства для декодирования кодированного битового потока видео предписывают одному или более процессорам осуществлять способ по любому из пп.1-12.
| BENJAMIN BROSS et al | |||
| Versatile Video Coding (Draft),Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, JVET-Q2001-vE; date 2020.03.12, 17th Meeting: Brussels, 7-17 January 2020 | |||
| US 2019373245 A1 - 2019.12.05 | |||
| SHIH-TA HSIANG et al | |||
| Разборный с внутренней печью кипятильник | 1922 |
|
SU9A1 |

