Перекрестные ссылки на родственные заявки
В соответствии с применимым патентным законодательством и/или правилами Парижской конвенции, настоящая заявка оформлена для того, чтобы своевременно заявить о праве на приоритет и преимущества международной заявки на выдачу патента No. PCT/CN2019/077429, поданной 8 марта 2019 г. Для всех целей согласно законодательству, полное описание указанной выше заявки включено посредством ссылки в качестве части описания настоящей заявки.
Область техники, к которой относится изобретение
Настоящий патентный документ относится к способам, устройствам и системам для кодирования видео.
Уровень техники
Сегодня много усилий прилагается для совершенствования характеристик и производительности современных технологий видео кодеков с целью достижения более высоких коэффициентов сжатия данных или разработки алгоритмов кодирования и декодирования видео, обладающих меньшей сложностью или допускающих параллельную реализацию. Эксперты из промышленности недавно предложили несколько новых инструментов кодирования видео, и в настоящее время проводится тестирование для определения их эффективности.
Раскрытие сущности изобретения
Предложены устройства, системы и способы, относящиеся к кодированию цифрового видео и, в частности, к передаче в виде сигнализации сообщения об этапе квантования и взаимодействию внутриконтурного переформирования на блочной основе с другими инструментами при кодировании видео. Это может быть применено к существующим стандартам кодирования видео, таким как стандарт высокоэффективного видеокодирования (HEVC), или к стандартам (например, универсальное видео кодирование ((Versatile Video Coding)), разработка которых еще не завершена. Это может быть также применимо к будущим стандартам кодирования видео или к будущим видеокодекам.
Согласно одному репрезентативному аспекту предлагаемая технология может быть использована для предоставления способа обработки видео. Этот способ содержит этапы, на которых: определяют, для преобразования между множеством видеоединиц видеообласти видео и кодированным представлением указанного множества видеоединиц, информацию о модели переформирования, обычно совместно используемой указанным множеством видеоединиц; и выполняют преобразование между кодированным представлением видео и самим видео, причем указанная информация о модели переформирования предоставляет информацию для построения видеоотсчетов в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видеоединицы цветностной составляющей.
Согласно другому репрезентативному аспекту предлагаемая технология может быть использована для предоставления способа обработки видео. Этот способ содержит этапы, на которых определяют, для преобразования между кодированным представлением видео, содержащего одну или более видеообластей, и самим видеороликом, значение переменной в информации о модели переформирования в зависимости от битовой глубины видео, и выполняют преобразование на основе определения, при этом информация о переформировании применима для внутриконтурного переформирования (in-loop reshaping (ILR)) некоторых из указанной одной или более видеообластей, и информация о модели переформирования предоставляет информацию о реконструкции видеоединицы видеообласти на основе представления в первой области и во второй области и/или о масштабировании остатка цветностной составляющей от видеоединицы цветностной составляющей.
Согласно другому репрезентативному аспекту, предлагаемая технология может быть использована для предоставления способа обработки видео. Этот способ содержит этап, на котором выполняют преобразование между кодированным представлением видео, содержащего одну или более видеообластей, и самим видео, причем кодированное представление содержит информацию о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из указанной одной или более видеообластей, при этом информация о модели переформирования предоставляет информацию для реконструкции видеоединицы видеообласти на основе представления видеоединицы в первой области и во второй области и/или о масштабировании остатка цветностной составляющей от видеоединицы цветностной составляющей, и информация о модели переформирования была инициализирована на основе правила инициализации.
Согласно другому репрезентативному аспекту, предлагаемая технология может быть использована для предоставления способа обработки видео. Этот способ содержит этапы, на которых определяют, для преобразования между кодированным представлением видео, содержащего одну или более видеообластей, и самим видео, следует ли активизировать или отменить активизацию внутриконтурного переформирования (ILR); и выполняют преобразование на основе указанного определения, при этом кодированное представление содержит информацию о модели переформирования, применимой для переформирования ILR некоторых из указанной одной или более видеообластей, и информация о модели переформирования предоставляет информацию для реконструкции видеообласти на основе первой области и второй области и/или масштабирования остатка цветностной составляющей от видеоединицы цветностной составляющей, при этом на этапе определения определяют отменить активизацию переформирования ILR в случае, когда информация о модели переформирования не инициализирована.
Согласно другому репрезентативному аспекту, предлагаемая технология может быть использована для предоставления способа обработки видео. Способ содержит этап, на котором выполняют преобразование между кодированным представлением видео, содержащим одну или боле видеообластей, и самим видео, причем кодированное представление содержит информацию о модели переформирования, применимой к внутриконтурному переформированию (ILR) для некоторых из указанной одной или более видеообластей, при этом информация о модели переформирования предоставляет информацию для реконструкции видеоединицы видеообласти на основе первой области и второй области и/или масштабирования остатка цветностной составляющей от видеоединицы цветностной составляющей, причем информация о модели переформирования включена в кодированное представление, только если видеообласть кодирована с использованием конкретного типа кодирования.
Согласно другому репрезентативному аспекту, предлагаемая технология может быть использована для предоставления способа обработки видео. Этот способ содержит этапы, на которых определяют для преобразования между первой видеообластью видео и кодированным представлением первой видеообласти, может ли информация о переформировании из второй видео области быть использована для преобразования на основе правила; и выполняют преобразование в соответствии с определением.
Согласно другому репрезентативному аспекту, предлагаемая технология может быть использована для предоставления способа обработки видео. Этот способ содержит этап, на котором выполняют преобразование между видеообластью видеоролика и кодированным представлением видеообласти, так что текущая видеообласть кодирована с использованием кодирования с внутрикадровым прогнозированием, при этом кодированное представление соответствует правилу форматирования, которое определяет информацию о модели переформирования в кодированном представлении условно на основе значения флага в кодированном представлении на уровне видеообласти.
Согласно другому репрезентативному аспекту, предлагаемая технология может быть использована для предоставления способа обработки видео. Этот способ содержит этап, на котором выполняют преобразование между кодированным представлением видео, содержащего одну или более видеообластей, и самим видео, причем кодированное представление содержит информацию о модели переформирования, применимую для внутриконтурного переформирования (ILR) некоторых из указанной одной или более видеообластей, причем информация о модели переформирования предоставляет информацию для реконструкции видеоединицы видеообласти на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видеоединицы цветностной составляющей, при этом информация о модели переформирования содержит набор параметров, куда входит синтаксический элемент, определяющий разность между допустимым максимальным индексом бина и максимальным индексом бина, подлежащим использованию при реконструкции, и указанный параметр находится в некоем диапазоне.
Согласно другому репрезентативному аспекту, предлагаемая технология может быть использована для предоставления способа обработки видео. Способ содержит этап, на котором выполняют преобразование между кодированным представлением видео, содержащим одну или более видеообластей, и самим видео, причем кодированное представление содержит информацию о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из указанной одной или более видеообластей, при этом информация о модели переформирования предоставляет информацию для реконструкции видеоединицы видеообласти на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видеоединицы цветностной составляющей, причем указанная информация о модели переформирования содержит набор параметров, куда входит максимальный индекс бина, подлежащий использованию при реконструкции, и максимальный индекс бина выводится как первое значение, равное сумме минимального индекса бина, подлежащего использованию при реконструкции, и синтаксического элемента, который представляет собой целое число без знака и который передается в виде сигнализации после минимального индекса бина.
Согласно другому репрезентативному аспекту, предлагаемая технология может быть использована для предоставления способа обработки видео. Этот способ содержит этап, на котором выполняют преобразование между кодированным представлением видео, содержащего одну или более видеообластей, и самим видео, причем кодированное представление содержит информацию о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из указанной одной или более видеообластей, при этом информация о модели переформирования предоставляет информацию для реконструкции видеоединицы видеообласти на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видеоединицы цветностной составляющей, причем информация о модели переформирования содержит набор параметров, куда входит первый синтаксический элемент, определяющий число битов, используемых для представления второго синтаксического элемента, специфицирующего абсолютное значение кодового слова приращения, из соответствующего бина, причем первый синтаксический элемент имеет значение меньше порогового значения.
Согласно другому репрезентативному аспекту, предлагаемая технология может быть использована для предоставления способа обработки видео. Этот способ содержит этап, на котором выполняют преобразование между кодированным представлением видео, содержащего одну или более видеообластей, и самим видео, причем кодированное представление содержит информацию о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из указанной одной или более видеообластей, причем указанная информация о модели переформирования предоставляет информацию для реконструкции видеоединицы видеообласти на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видеоединицы цветностной составляющей, при этом информация о модели переформирования содержит набор параметров, куда входит i-ый параметр, который представляет крутизну i-ого бина, используемого при переформировании ILR, и имеет значение на основе (i-1)-го параметра, причем i является положительным целым числом.
Согласно другому репрезентативному аспекту, предлагаемая технология может быть использована для предоставления способа обработки видео. Этот способ содержит этап, на котором выполняют преобразование между кодированным представлением видео, содержащего одну или более видеообластей, и самим видео, причем кодированное представление содержит информацию о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из указанной одной или более видеообластей, при этом информация о модели переформирования предоставляет информацию для реконструкции видеоединицы видеообласти на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видеоединицы цветностной составляющей, причем информация о модели переформирования, используемой при переформировании ILR, содержит набор параметров, куда входит параметр reshape_model_bin_delta_sign_CW [ i ], каковой не передается в виде сигнализации, и параметр RspDeltaCW[ i ] = reshape_model_bin_delta_abs_CW [ i ], который всегда является положительным числом.
Согласно другому репрезентативному аспекту, предлагаемая технология может быть использована для предоставления способа обработки видео. Этот способ содержит этап, на котором выполняют преобразование между кодированным представлением видео, содержащего одну или более видеообластей, и самим видео, причем кодированное представление содержит информацию о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из указанной одной или более видеообластей, при этом информация о модели переформирования предоставляет информацию для реконструкции видеоединицы видеообласти на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видеоединицы цветностной составляющей, причем информация о модели переформирования содержит набор параметров, куда входит параметр invAvgLuma, для использования значений яркостной составляющей для масштабирования в зависимости от цветового формата видеообласти.
Согласно другому репрезентативному аспекту, предлагаемая технология может быть использована для предоставления способа обработки видео. Этот способ содержит этап, на котором выполняют преобразование между текущим видеоблоком видео и кодированным представлением видео, причем процедура преобразования содержит процедуру обратного отображения изображения для преобразования реконструированных отсчетов яркостной составляющей изображения в модифицированные реконструированные отсчетов яркостной составляющей изображения, при этом процедура обратного отображения изображения содержит процедуру усечения, при которой верхняя граница и нижняя граница устанавливаются по отдельности друг от друга.
Согласно другому репрезентативному аспекту, предлагаемая технология может быть использована для предоставления способа обработки видео. Способ содержит этап, на котором выполняют преобразование между кодированным представлением видео, содержащего одну или более видеообластей, и самим видео, причем кодированное представление содержит информацию о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из указанной одной или более видео областей, причем информация о модели переформирования предоставляет информацию для реконструкции видеоединицы видеообласти на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видеоединицы цветностной составляющей, при этом информации о модели переформирования содержит набор параметров, куда входит величина поворота, ограниченная функцией Pivot[ i ]<=T.
Согласно другому репрезентативному аспекту, предлагаемая технология может быть использована для предоставления способа обработки видео. Этот способ содержит этап, на котором выполняют преобразование между представлением видео, содержащего одну или более видеообластей, и самим видео, причем кодированное представление содержит информацию, применимую для внутриконтурного переформирования (ILR), и предоставляет параметры для реконструкции видеоединицы видеообласти на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видеоединицы цветностной составляющей, при этом параметр квантования (quantization parameter (QP)) цветностной составляющей имеет сдвиг, значение которого выводится для каждого блока или единицы преобразования.
Согласно другому репрезентативному аспекту, предлагаемая технология может быть использована для предоставления способа обработки видео. Этот способ содержит этап, на котором выполняют преобразование между представлением видео, содержащего одну или более видеообластей, и самим видео, причем кодированное представление содержит информацию, применимую для внутриконтурного переформирования (ILR), и предоставляет параметры для реконструкции видеоединицы видеообласти на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видеоединицы цветностной составляющей, при этом параметр квантования (QP) яркостной составляющей имеет сдвиг, значение которого выводится для каждого блока или единицы преобразования.
Один или более описанных выше способов могут быть применены, как в вариантах реализации на стороне кодирующего устройства, так и в вариантах реализации на стороне декодирующего устройства.
Кроме того, в соответствии с одним из репрезентативных аспектов предложено устройство в видеосистеме, содержащее процессор и энергонезависимое запоминающее устройство с записанными в нем командами. Команды при исполнении процессором вызывают выполнение процессором любого одного или более из раскрытых способов.
Кроме того, предложен компьютерный программный продукт, хранящийся на энергонезависимых читаемых компьютером носителях информации, причем компьютерный программный продукт содержит программный код для выполнения любого одного или более из раскрытых способов.
Приведенные выше и другие аспекты и признаки предлагаемой технологии рассмотрены более подробно на прилагаемых чертежах, в описании и в формуле изобретения.
Краткое описание чертежей
Фиг. 1 показывает пример построения списка объединяемых кандидатов.
Фиг. 2 показывает пример позиций пространственных кандидатов.
Фиг. 3. показывает пример пар кандидатов, подвергаемых контролю избыточности, из совокупности пространственных объединяемых кандидатов
Фиг. 4A и 4B показывают примеры положения второй единицы прогнозирования (prediction unit (PU)) на основе размера и формы текущего блока.
Фиг. 5 показывает пример масштабирования векторов движения для временных объединяемых кандидатов.
Фиг. 6 показывает пример позиций кандидатов для временных объединяемых кандидатов.
Фиг. 7 показывает пример комбинированного двунаправлено интерполированного (прогнозируемого) объединяемого кандидата.
Фиг. 8 показывает пример построения кандидата с прогнозированием вектора движения.
Фиг. 9 показывает пример масштабирования векторов движения для пространственных объединяемых кандидатов.
Фиг. 10 показывает пример прогнозирования движения с использованием алгоритма прогнозирования альтернативного временного вектора движения (alternative temporal motion vector prediction (ATMVP)).
Фиг. 11 показывает пример прогнозирования пространственно-временного вектора движения.
Фиг. 12 показывает пример соседних отсчетов для определения параметров компенсации освещенности.
Фиг. 13A и 13B показывают иллюстрации в соединении с 4-параметрической аффинной моделью и 6-параметрической аффинной моделью, соответственно.
Фиг. 14 показывает пример аффинного поля вектора движения на один суб-блок.
Фиг. 15A и 15B показывают примеры 4-параметрической и 6-параметрической аффинных моделей, соответственно.
Фиг. 16 показывает пример прогнозирования вектора движения для аффинного режима межкадрового прогнозирования для изначально аффинных кандидатов.
Фиг. 17 показывает пример прогнозирования вектора движения для аффинного режима межкадрового прогнозирования для сконструированных аффинных кандидатов.
Фиг. 18A и 18B показывает иллюстрацию в соединении с аффинным режимом объединения.
Фиг. 19 показывает пример положений кандидатов для режима объединения аффинных объектов.
Фиг. 20 показывает пример процедуры поиска выражения окончательного вектора движения (ultimate motion vector expression (UMVE)).
Фиг. 21 показывает пример точки поиска выражения UMVE.
Фиг. 22 показывает пример уточнения вектора движения на стороне декодирующего устройства (decoder side motion vector refinement (DMVR)).
Фиг. 23 показывает пример логической схемы процедуры декодирования с применением этапа переформирования.
Фиг. 24 показывает пример отсчетов в двустороннем фильтре.
Фиг. 25 показывает примеры отсчетов в окнах, используемых при вычислениях весовых коэффициентов.
Фиг. 26 показывает пример схемы сканирования.
Фиг. 27A и 27B показывают блок-схемы примеров аппаратной платформы для реализации способа обработки визуальной информации, описываемого в настоящем документе.
Фиг. 28A – 28E показывают логические схемы примеров способов обработки видео на основе некоторых вариантов реализации предлагаемой технологии.
Осуществление изобретения
1. Кодирование видео в стандарте кодирования HEVC/H.265
Стандарты кодирования видео развивались главным образом через разработку хорошо известных стандартов ITU-T и ISO/IEC. Союз ITU-T выпустил стандарты H.261 и H.263, организация ISO/IEC выпустила стандарты MPEG-1 и MPEG-4 Visual, а также эти две организации совместно выпустили стандарты H.262/MPEG-2 Video и H.264/MPEG-4 Advanced Video Coding (AVC) (усовершенствованное видео кодирование) и H.265/HEVC. Со времени стандарта H.262, стандарты кодирования видео основаны на гибридной структуре кодирования видео, использующей временное прогнозирование плюс трансформационное кодирование. Для исследований в области технологий кодирования видео будущего, которые будут разработаны после технологии кодирования HEVC, группа экспертов по кодированию видео (VCEG) и группа экспертов по кинематографии (MPEG) в 2015 г. совместно основали Объединенную группу исследований в области видео (Joint Video Exploration Team (JVET)). С тех пор группа JVET разработала множество способов и ввела их в эталонное программное обеспечение, называемое Совместной исследовательской моделью (Joint Exploration Model (JEM)). В апреле 2018 г. группа VCEG (Q6/16) и отдел ISO/IEC JTC1 SC29/WG11 (MPEG) создали объединенную группу экспертов в области видео (Joint Video Expert Team (JVET)) для работ над стандартом VVC, имея целью добиться снижения требуемой скорости передачи битов данных на 50% по сравнению с кодированием HEVC. Самая последняя версия проекта стандарта VVC, т.е. Универсального видео кодирования (Проект 2) (Versatile Video Coding (Draft 2)), может быть найдена по адресу: http://phenix.it-sudparis.eu/jvet/doc_end_user/documents/11_Ljubljana/wg11/JVET-K1001-v7.zip.
Самая последняя эталонная версия программного обеспечения для стандарта кодирования VVC, называемая VTM, может быть найдена по адресу: https://vcgit.hhi.fraunhofer.de/jvet/VVCSoftware_VTM/tags/VTM-2.1
2.1. Межкадровое прогнозирование в стандарте кодирования HEVC/H.265
Каждая единица межкадрового прогнозирования PU (prediction unit (единица прогнозирования)) имеет параметры движения для одного или двух списков опорных изображений. Совокупность параметров движения содержит вектор движения и индекс опорного изображения. Сообщение об использовании одного или двух списков опорных изображений может быть также передано в виде сигнализации с применением параметра inter_pred_idc. Векторы движения могут быть в явной форме закодированы в виде приращений относительно предикторов.
Когда единица CU кодирована в режиме пропуска, с этой единицей CU ассоциирована одна единица PU, и при этом нет ни значительных коэффициентов остатка, ни кодированного приращения вектора движения или индекса опорного изображения. Режим объединения специфицирован таким образом, что параметры движения для текущей единицы PU получают из соседних единиц PU, включая пространственные и временные кандидаты. Режим объединения может быть применен к любой единице PU межкадрового прогнозирования, не только в режиме пропуска. Альтернативой для режима объединения является передача параметров движения в явном виде, где векторы движения (более точно, разности векторов движения (motion vector difference (MVD)) относительно предиктора вектора движения), соответствующий индекс опорного изображения для каждого списка опорных изображений и показатель использования списка опорных изображений передают в виде сигнализации в явной форме для каждой единицы PU. Этот тип режима называется в этом документе усовершенствованным прогнозированием вектора движения (advanced motion vector prediction (AMVP)).
Когда сигнализация указывает, что следует использовать один из двух списков опорных изображений, единицу PU создают из одного блока отсчетов. Это называется «однонаправленным прогнозированием» (‘uni-prediction’). Однонаправленное прогнозирование доступно для срезов обоих видов – P-среза (P-slice) или среза со ссылкой на предыдущий срез (предсказанного среза) и B-среза (B-slice) или среза со ссылками на предыдущий и последующий срезы (или двунаправлено интерполированного среза).
Когда сигнализация указывает, что следует использовать оба списка опорных изображений, единицу PU создают из двух блоков отсчетов. Это называется «двунаправленной интерполяцией (прогнозированием)» (‘bi-prediction’). Двунаправленная интерполяция доступна только для B-срезов.
Следующий текст предлагает подробности режимов межкадрового прогнозирования, специфицированных в стандарте кодирования HEVC. Описание будет начато с режима объединения.
2.1.1. Список опорных изображений
В стандарте кодирования HEVC, термин «межкадровое прогнозирование» используется для обозначения прогнозирования, выводимого из элементов данных (например, значений отсчетов или векторов движения) опорных изображений, отличных от декодируемого в текущий момент изображения (текущего изображения). Аналогично стандарту кодирования H.264/AVC, изображение можно прогнозировать из нескольких опорных изображений. Опорные изображения, используемые для межкадрового прогнозирования, организованы в одном или нескольких списках опорных изображений. Индекс опоры идентифицирует, какие из опорных изображений в списке следует использовать для создания прогнозируемого сигнала.
Один список опорных изображений, Список 0, используется для P-среза, и два списка опорных изображений, Список 0 и Список 1, используются для B-срезов. Следует отметить, что опорные изображения из Списка 0/1 могут быть из прошлых и будущих изображений с точки зрения захвата/представления на дисплее этих изображений.
2.1.2. Режим объединения
2.1.2.1. Определение кандидатов для режима объединения
Когда единицу PU прогнозируют с использованием режима объединения, индекс, указывающий на входную позицию в список объединяемых кандидатов, выделяют путем синтаксического анализа из потока битов данных и используют для извлечения информации о движении. Процедура построения указанного списка специфицирована в стандарте кодирования HEVC и может быть суммирована в соответствии со следующей последовательностью этапов:
• Этап 1: Определение первоначального списка кандидатов
• Этап 1.1: Определение пространственных кандидатов
• Этап 1.2: Контроль избыточности для пространственных кандидатов
• Этап 1.3: Определение временных кандидатов
• Этап 2: Вставка дополнительных кандидатов
• Этап 2.1: Создание двунаправлено интерполированных кандидатов
• Этап 2.2: Вставка кандидатов с нулевым движением
Эти этапы схематично показаны на фиг. 1. Для получения пространственных объединяемых кандидатов, выбирают максимум четверых объединяемых кандидатов из совокупности кандидатов, расположенных в пяти различных позициях. Для получения временных объединяемых кандидатов выбирают максимум одного объединяемого кандидата из двух кандидатов. Поскольку в декодирующем устройстве предполагается постоянное число кандидатов для каждой единицы PU, если число кандидатов, полученное после этапа 1, не достигает максимального числа объединяемых кандидатов (MaxNumMergeCand), передаваемого в форме сигнализации в заголовке среза, генерируют дополнительных кандидатов. Поскольку число кандидатов является постоянным, индекс наилучшего объединяемого кандидата кодируют с использованием усеченной унарной бинаризации (truncated unary binarization (TU)). Если размер единицы CU равен 8, все единицы PU из текущей единицы CU совместно используют один список объединяемых кандидатов, который идентичен списку объединяемых кандидатов для единицы прогнозирования размером 2N×2N.
В последующем, операции, ассоциированные с приведенными выше этапами, описаны подробно.
2.1.2.2. Определение пространственных кандидатов
При получении пространственных объединяемых кандидатов выбирают максимум четырех объединяемых кандидатов из совокупности кандидатов, расположенных в позициях, показанных на фиг. 2. Кандидатов выбирают в следующем порядке A1, B1, B0, A0 и B2. Позицию B2 учитывают только тогда, когда какая-либо из единиц PU, которые должны быть в позициях A1, B1, B0, A0, недоступна (например, потому, что эта единица принадлежит другому срезу или другой плитке) или кодирована с применением внутрикадрового прогнозирования. После добавления кандидата в позиции A1 добавление остальных кандидатов должно происходить с контролем избыточности, что обеспечивает исключение кандидатов с одинаковой информацией о движении из списка, так что эффективность кодирования улучшается. Для уменьшения вычислительной сложности не все возможные пары кандидатов рассматривают в процессе упомянутого контроля избыточности. Напротив, учитывают только пары, связанные стрелкой на фиг. 3, и какого-либо кандидата добавляют в список только в том случае, если соответствующий кандидат, использованный для контроля избыточности, не имеет такую же самую информацию о движении. Другим источником дублированной информации о движении является “вторая единица PU”, ассоциированная с разбиениями, отличными от 2Nx2N. В качестве примера, фиг. 4A и 4B показывают вторую единицу PU для случаев N×2N и 2N×N, соответственно. Когда текущую единицу PU разбивают как N×2N, кандидат в позиции A1 не учитывается при построении списка. На деле, добавление этого кандидата приведет к тому, что две единицы прогнозирования будут иметь одинаковую информацию о движении, что является избыточным с точки зрения требования иметь только одну единицу PU в единице кодирования. Аналогично, позицию B1 не учитывают, когда текущую единицу PU разбивают как 2N×N.
2.1.2.3. Определение временных кандидатов
На этом этапе в список добавляют только одного кандидата. В частности, при получении этого временного объединяемого кандидата, формируют масштабированный вектор движения на основе расположенной в этом же месте единицы PU, принадлежащей изображению, имеющему наименьшую разницу порядковых номеров картинки (Picture Order Count (POC)) относительно текущего изображения в рассматриваемом списке опорных изображений. О списке опорных изображений, который должен быть использован для получения расположенной в том же месте единицы PU, сигнализируют в явной форме в заголовке среза, а фиг. 5 показывает пример получения масштабированного вектора движения для временного объединяемого кандидата (как показывает штриховая линия), который масштабируют из вектора движения для расположенной в том же месте единицы PU с использованием расстояний по порядковым номерам (POC-расстояний), tb и td, где расстояние tb определяют как разницу номеров POC между опорным изображением для текущего изображения и самим текущим изображением и расстояние td определяют как разницу номеров POC между опорным изображением для расположенного в том же месте изображения и самим расположенным в том же месте изображением. Индекс опорного изображения для временного объединяемого кандидата устанавливают равным нулю. Практическая реализация процедуры масштабирования описана в спецификации стандарта кодирования HEVC. Для B-среза получают два вектора движения, один для списка 0 опорных изображений и другой для списка 1 опорных изображений, и комбинируют эти векторы для получения двунаправлено интерполированного объединяемого кандидата.
В расположенной в том же месте единице PU (Y), принадлежащей опорному кадру, позицию для временного кандидата выбирают между кандидатами C0 и C1, как показано на фиг. 6. Если единица PU в позиции C0 недоступна, кодирована с применением внутрикадрового прогнозирования или находится вне текущей строки единиц дерева кодирования (current coding tree unit (CTU)) (единица CTU также называется наибольшей единицей кодирования (LCU, largest coding unit)), используют позицию C1. В противном случае, для получения временного объединяемого кандидата используют позицию C0.
2.1.2.4. Вставка дополнительных кандидатов
Помимо пространственно-временных объединяемых кандидатов имеются еще два дополнительных типа объединяемых кандидатов: комбинированный двунаправлено интерполированный объединяемый кандидат и нулевой объединяемый кандидат. Комбинированных двунаправлено интерполированных объединяемых кандидатов генерируют с использованием пространственных и временных объединяемых кандидатов. Комбинированный двунаправлено интерполированный объединяемый кандидат используется только для B-среза. Таких комбинированных двунаправлено интерполированных кандидатов генерируют путем комбинирования параметров движения из первого списка опорных изображений для первоначального кандидата с параметрами движения из второго списка опорных изображений для другого кандидата. Если эти две группы параметров формируют разные гипотезы движения, они создадут нового двунаправлено интерполированного кандидата. В качестве примера, на фиг. 7 показан случай, где двух кандидатов из исходного списка (слева), имеющих параметры mvL0 и refIdxL0 или mvL1 и refIdxL1, используют для создания комбинированного двунаправлено интерполированного объединяемого кандидата, добавляемого в конечный список (справа). Имеются многочисленные правила относительно построения таких комбинаций, учитываемые при генерации таких дополнительных объединяемых кандидатов.
Кандидатов с нулевым движением вставляют для заполнения оставшихся входных позиций в списке объединяемых кандидатов и тем самым достижения максимальной емкости MaxNumMergeCand списка. Эти кандидаты имеют нулевое пространственное смещение, а индекс опорного изображения начинается с нуля и увеличивается каждый раз, когда в список добавляют нового кандидата с нулевым движением. Число опорных кадров, используемых этими кандидатами, равно одному и двум для однонаправленного прогнозирования и двунаправленного прогнозирования, соответственно. В некоторых вариантах, для этих кандидатов контроль избыточности не осуществляется.
2.1.3. Усовершенствованное прогнозирование вектора движения (AMVP)
Прогнозирование AMVP использует пространственно-временную корреляцию вектора движения с соседними единицами PU, что используется для передачи параметров движения в явной форме. При построении списка векторов-кандидатов движения сначала проверяют доступность временных соседних единиц PU в позициях слева сверху, исключают избыточных кандидатов и добавляют нулевой вектор, чтобы сделать список кандидатов постоянной длины. Тогда кодирующее устройство может выбрать наилучшего предиктора из списка кандидатов и передать соответствующий индекс, указывающий выбранного кандидата. Аналогично передаче индекса объединения посредством сигнализации, индекс наилучшего вектора движения кодируют с использованием усеченной унарной бинаризации. Максимальное значение, подлежащее кодированию, в этом случае равно 2 (например, см. фиг. 8). В последующих разделах приведены подробности процедуры получения кандидата при прогнозировании вектора движения.
2.1.3.1. Получение кандидатов при прогнозировании AMVP
Фиг. 8 суммирует процедуру получения кандидата при прогнозировании вектора движения.
При прогнозировании векторов движения рассматривают два типа векторов-кандидатов движения: пространственный вектор-кандидат движения и временной вектор-кандидат движения. Для формирования пространственного вектора-кандидата движения в конечном итоге получают два вектора-кандидата движения на основе векторов движения для каждой из единиц PU, расположенных в пяти разных позициях, как было ранее показано на фиг. 2.
Для формирования временного вектора-кандидата движения выбирают одного вектора-кандидата движения из двух кандидатов, получаемых на основе двух разных расположенных в одном месте позиций. После создания первого списка пространственно-временных кандидатов из этого списка исключают дублированные векторы-кандидаты движения. Если число потенциальных кандидатов больше двух, векторы-кандидаты движения, для которых индекс опорного изображения в ассоциированном списке опорных изображений больше 1, исключают из этого списка. Если это число пространственно-временных векторов движения кандидатов меньше двух, в список добавляют дополнительный нулевой вектор-кандидат движения.
2.1.3.2. Пространственные векторы-кандидаты движения
Для получения пространственных векторов-кандидатов движения, учитывают максимум двух потенциальных кандидатов из совокупности пяти потенциальных кандидатов, получаемых из единиц PU, расположенных в позициях, как это ранее показано на фиг. 2, эти позиции являются такими же, как при объединении движения. Порядок формирования для левой стороны от текущей единицы PU задан как кандидат A0, кандидат A1 и масштабированный кандидат A0, масштабированный кандидат A1. Порядок формирования для верхней стороны от текущей единицы PU задан как кандидат B0, кандидат B1, кандидат B2, масштабированный кандидат B0, масштабированный кандидат B1, масштабированный кандидат B2. Для каждой стороны, поэтому, имеются четыре случая, которые могут быть использованы в качестве вектора-кандидата движения, где в двух случаях не требуется использовать пространственное масштабирование, и в двух случаях пространственное масштабирование применяется. Эти четыре разных случая суммированы следующим образом.
• Нет пространственного масштабирования
- (1) Одинаковый список опорных изображений и одинаковый индекс опорного изображения (одинаковый порядок POC)
- (2) Разные списки опорных изображений, но одинаковое опорное изображение (одинаковый порядок POC)
• Пространственное масштабирование
- (3) Одинаковый список опорных изображений, но разные опорные изображения (разный порядок POC)
- (4) Разные списки опорных изображений и разные опорные изображения (разный порядок POC)
Случаи без пространственного масштабирования проверяют первыми, после чего проверяют случаи, позволяющие пространственное масштабирование. Пространственное масштабирование рассматривается, когда порядок POC различается между опорным изображением для соседней единицы PU и опорным изображением для текущей единицы PU независимо от списка опорных изображений. Если все единицы PU кандидатов слева недоступны или кодированы с применением внутрикадрового прогнозирования, допускается масштабирование вектора движения для единицы сверху, чтобы способствовать параллельному определению векторов-кандидатов MV слева и сверху. В противном случае для вектора движения единицы сверху пространственное масштабирование не допускается.
Как показано в примере, приведенном на фиг. 9, для случая пространственного масштабирования, вектор движения для соседней единицы PU масштабируют способом, аналогичным временному масштабированию. Основное различие состоит в том, что в качестве входных данных используют список опорных изображений и индекс текущей единицы PU; фактическая процедура масштабирования является такой же, как в случае временного масштабирования.
2.1.3.3. Временные векторы-кандидаты движения
Помимо получения индекса опорного изображения, все процедуры для формирования временных объединяемых кандидатов являются такими же, как и для формирования пространственных векторов-кандидатов движения (как показано в примере на фиг. 6). Индекс опорного изображения сообщают посредством сигнализации декодирующему устройству.
2.2. Способы прогнозирования векторов движения на основе суб-единиц CU в модели JEM
В модели JEM с использованием деревьев квадратов плюс двоичные деревья (quadtrees plus binary trees (QTBT)), каждая единица CU может иметь самое большее один набор параметров движения на каждое направление прогнозирования. В некоторых вариантах, рассматриваются два способа прогнозирования векторов движения на уровне суб-единиц CU в кодирующем устройстве путем разделения большой единицы CU на суб-единицы CU и формирования информации движения для всех суб-единиц CU из большой единицы CU. Способ прогнозирования альтернативного временного вектора движения (ATMVP) позволяет каждой единице CU осуществлять выборку нескольких наборов информации движения из нескольких блоков меньше текущей единицы CU в расположенном в том же месте опорном изображении. При использовании способа прогнозирования пространственно-временного вектора движения (spatial-temporal motion vector prediction (STMVP)) векторы движения суб-единиц CU формируют рекурсивным способом с применением предиктора временного вектора движения и пространственного соседнего вектора движения.
С целью сохранения более точного поля движения для прогнозирования движения суб-единицы CU сжатие движения для опорных кадров может быть в текущий момент не активизировано.
2.2.1. Прогнозирование альтернативного временного вектора движения
На фиг. 10 показан пример прогнозирования альтернативного временного вектора движения (ATMVP). Согласно способу прогнозирования альтернативного временного вектора движения (ATMVP), способ прогнозирования временного вектора движения (temporal motion vector prediction (TMVP)) модифицируют путем выборки нескольких наборов информации о движении (включая векторы движения и опорные индексы) из блоков меньше текущей единицы CU. Суб-единицы CU представляют собой квадратные блоки размером N×N (по умолчанию N устанавливают равным 4).
Способ прогнозирования ATMVP осуществляет прогнозирование векторов движения суб-единиц CU в пределах единицы CU в два этапа. На первом этапе идентифицируют соответствующий блок в опорном изображении с так называемым временным вектором. Опорное изображение также называется изображением источника движения. На втором этапе разбивают единицу CU на суб-единицы CU и получают векторы движения, равно как опорные индексы каждой суб-единицы CU, из блока, соответствующего каждой суб-единице CU.
На первом этапе, опорное изображение и соответствующий блок определяют посредством информации о движения пространственно соседних блоков для текущей единицы CU. Чтобы избежать повторяющихся процедур сканирования соседних блоков, используют первого объединяемого кандидата из списка объединяемых кандидатов для текущей единицы CU. Первый доступный вектор движения, равно как и ассоциированный опорный индекс устанавливают в качестве временного вектора и индекса для изображения источника движения. Таким способом, при использовании прогнозирования ATMVP, соответствующий блок может быть более точно идентифицирован, по сравнению со способом прогнозирования TMVP, где соответствующий блок (иногда называемый расположенным в том же месте блоком) всегда находится в нижней правой или в центральной позиции относительно текущей единицы CU.
На втором этапе, соответствующий блок суб-единицы CU идентифицируют посредством временного вектора в изображении источника движения путем добавления временного вектора к координате текущей единице CU. Для каждой суб-единицы CU, информацию о движении ее соответствующего блока (наименьшую сетку движения, покрывающую центральный отсчет) используют для получения информации о движении для рассматриваемой суб-единицы CU. После идентификации информации о движении соответствующего блока размером N×N ее преобразуют в векторы движения и опорные индексы текущей суб-единицы CU, таким же образом как способ прогнозирования TMVP в стандарте кодирования HEVC, где применяются масштабирование движения и другие процедуры. Например, декодирующее устройство проверяет, удовлетворяется ли условие малой задержки, (т.е. порядковые номера POC для всех опорных изображений для текущего изображения меньше порядкового номера POC для текущего изображения) и возможно использует вектор MVx движения (например, вектор движения, соответствующий списку опорных изображений X) для прогнозирования вектора MVy движения (при X равном 0 или 1 и Y равным 1−X) для каждой суб-единицы CU.
2.2.2. Прогнозирования пространственно-временного вектора движения (STMVP)
Согласно этому способу векторы движения суб-единиц CU формируют рекурсивным способом, следуя порядку сканирования растра. Фиг. 11 иллюстрирует эту концепцию. Рассмотрим единицу CU размером 8×8, содержащую четыре суб-единицы CU размером 4×4, а именно A, B, C и D. Соседние блоки размером 4×4 в текущем кадре маркированы как a, b, c и d.
Процедура определения движения для суб-единицы CU A начинается с идентификации ее двух соседей в пространстве. Первый сосед представляет собой блок размером N×N, расположенный выше суб-единицы CU A (блок c). Если этот блок c недоступен или кодирован с применением внутрикадрового прогнозирования, проверяют другие блоки размером N×N, находящиеся выше суб-единицы CU A, (слева направо, начиная с блока c). Второй сосед представляет собой блок слева от суб-единицы CU A (блок b). Если блок b недоступен или кодирован с применением внутрикадрового прогнозирования, проверяют другие блоки, находящиеся слева от суб-единицы CU A (сверху вниз, начиная с блока b). Информацию о движении, получаемую от соседних блоков для каждого списка, масштабируют к первому опорному кадру для конкретного рассматриваемого списка. Далее, формируют предиктор временного вектора движения (TMVP) для суб-блока A с применением такой же процедуры формирования предиктора TMVP, как это специфицировано в стандарте кодирования HEVC. Информацию о блоке, расположенном в одном месте с блоком D, выбирают и масштабируют соответственно. В конечном итоге, после вызова и масштабирования информации о движения все доступные векторы движения (до 3 векторов) усредняют по отдельности для каждого опорного списка. Усредненный вектор движения назначают в качестве вектора движения для текущей суб-единицы CU.
2.2.3. Сигнализация о режиме прогнозирования движения для суб-единицы CU
Режимы суб-единицы CU активизированы в качестве дополнительных объединяемых кандидатов, так что для сигнализации об этих режимах не требуется никакой дополнительный синтаксический элемент. В список объединяемых кандидатов для каждой единицы CU добавляют двух дополнительных объединяемых кандидатов для представления режима прогнозирования ATMVP и режима прогнозирования STMVP. Если набор параметров последовательности указывает, что активизированы режим прогнозирования ATMVP и режим прогнозирования STMVP, могут быть использованы вплоть до семи объединяемых кандидатов. Логика кодирования дополнительных объединяемых кандидатов является такой же, как для объединяемых кандидатов в основной модели HM, что означает, для каждой единицы CU в P-срезе или в B-срезе, что могут потребоваться две дополнительные проверки избыточности (RD) для двух дополнительных объединяемых кандидатов.
В модели JEM, все бины с индексом объединения кодированы с применением контекстно-зависимого двоичного арифметического кодирования (CABAC (Context-based Adaptive Binary Arithmetic Coding)). В то же время, при кодировании HEVC, только первый бин подвергают контекстно-зависимому кодированию, а остальные бины кодируют независимо от контекста.
2.3. Локальная компенсация освещенности в модели JEM
Локальная компенсация освещенности (Local Illumination Compensation (LIC)) основана на линейной модели изменений освещенности, использующей масштабный коэффициент a и сдвиг b. Причем эту компенсацию активизируют и отменяют активизацию адаптивно для каждой единицы кодирования (CU), кодированной с применением межкадрового прогнозирования.
Когда компенсация LIC применяется для единицы CU, применяют метод наименьших квадратов для получения параметров a и b с использованием соседних отсчетов относительно текущей единицы CU и соответствующих им опорных отсчетов. Более конкретно, как иллюстрирует фиг. 12, используются субдискретизированные (субдискретизация в соотношении 2:1) соседние отсчеты относительно единицы CU и соответствующие отсчеты (идентифицированные информацией о движении текущей единицы CU или суб-единицы CU) из опорного изображения.
2.3.1. Получение прогнозируемых блоков
Параметры компенсации IC получают и применяют для каждого направления прогнозирования по отдельности. Для каждого направления прогнозирования генерируют первый прогнозируемый блок с использованием декодированной информации о движении, а затем получают временной прогнозируемый блок путем применения модели компенсации LIC. После этого, указанные два временных прогнозируемых блока используют для получения конечного прогнозируемого блока.
Когда единицу CU кодируют с применением режима объединения, копируют флаг компенсации LIC из соседних блоков способом, аналогичным кодированию информации о движении в режиме объединения; в противном случае флаг компенсации LIC передают в виде сигнализации для единицы CU, чтобы указать, применяется компенсация LIC или нет.
Когда для некоторого изображения активизирована компенсация LIC, необходимо осуществить дополнительную проверку избыточности (RD) на уровне единиц CU, чтобы определить, применяется ли компенсация LIC для какой-либо единицы CU. Если для какой-то единицы CU активизирована компенсация LIC, используют сумму абсолютных разностей с исключением среднего (mean-removed sum of absolute difference (MR-SAD)) и трансформированную по преобразованию Адамара сумму абсолютных разностей с исключением среднего (mean-removed sum of absolute Hadamard-transformed difference (MR-SATD)) вместо суммы абсолютных разностей (SAD) и трансформированной по преобразованию Адамара суммы абсолютных разностей (SATD), для поиска целочисленного движения элементов изображения и поиска дробного движения элементов изображения, соответственно.
Для уменьшения сложности кодирования, в модели JEM применяется следующая схема кодирования.
• Компенсацию LIC не активизируют для всего изображения, когда нет заметных изменений освещенности между текущим изображением и соответствующими ему опорными изображениями. Для идентификации этой ситуации, в кодирующем устройстве вычисляют гистограммы для текущего изображения и для каждого опорного изображения, соответствующего этому текущему изображения. Если разница гистограмм между текущим изображением и каждым из опорных изображений для этого текущего изображения меньше конкретной порогового значения, компенсацию LIC для текущего изображения не активизируют; в противном случае активизируют эту компенсацию LIC для текущего изображения.
2.4. Способы межкадрового прогнозирования при кодировании VVC
Имеется ряд новых инструментов кодирования для усовершенствования межкадрового прогнозирования, таких как адаптивное разрешение разницы векторов движения (Adaptive motion vector difference resolution (AMVR)) для передачи сигнализации о разнице MVD, аффинный режим прогнозирования, треугольный режим прогнозирования (Triangular prediction mode (TPM)), режим прогнозирования ATMVP, обобщенное двунаправленное прогнозирование (Generalized Bi-Prediction (GBI)), двунаправленный оптический поток (Bi-directional Optical flow (BIO)).
2.4.1. Структура блоков кодирования в стандарте кодирования VVC
В стандарте кодирования VVC, принята структура Дерево квадратов/Двоичное дерево/Множественное дерево (QuadTree/BinaryTree/MulitpleTree (QT/BT/TT)) для разбиения изображения на квадратные или прямоугольные блоки.
Помимо структуры QT/BT/TT, в стандарте кодирования VVC также принято раздельное дерево (известное как двойное дерево кодирования) для I-кадров (кадров с внутрикадровым прогнозированием). В случае раздельного дерева, сигнализацию о структуре блоков кодирования передают по отдельности для яркостной и цветностной составляющих.
2.4.2 Адаптивное разрешение разницы векторов движения
В стандарте кодирования HEVC, разности векторов движения (motion vector difference (MVD)) (между вектором движения и прогнозируемым вектором движения для единицы PU) сообщают в виде сигнализации в единицах четвертей яркостных отсчетов, когда флаг use_integer_mv_flag равен 0 в заголовке среза. В стандарт кодирования VVC, введено локально адаптивное разрешение векторов движения (AMVR). В стандарте кодирования VVC, разность MVD может быть кодирована в единицах четвертей яркостных отсчетов, целых яркостных отсчетов или четверок яркостных отсчетов (т.е. ¼-pel, 1-pel, 4-pel, здесь pel = элемент изображения (picture element)). Разрешением разностей MVD управляют на уровне единиц кодирования (CU), а флаги разрешения разностей MVD условно передают в виде сигнализации для каждой единицы CU, имеющей по меньшей мере одну ненулевую составляющую разности MVD.
Для единицы CU, имеющей по меньшей мере одну ненулевую составляющую разности MVD, передают в виде сигнализации первый флаг для указания, используется ли точность в одну четверть единицы измерения яркостного отсчета для вектора MV в этой единице CU. Когда первый флаг (равный 1) указывает, что точность в четверть единицы измерения яркостного отсчета не используется для вектора MV, передают в виде сигнализации другой флаг для указания, что используется точность в одну целую единицу измерения яркостного отчета или в четыре единицы измерения яркостных отсчета для вектора MV.
Когда первый флаг разрешения разности MVD для единицы CU равен нулю, или не кодирован для единицы CU (это означает, что все разности MVD для этой единицы CU являются нулевыми), для этой единицы CU используется точность в четверть единицы измерения яркостного отсчета для вектора MV. Когда единица CU использует точность в одну единицу измерения яркостного отсчета для вектора MV или в четыре единицы измерения яркостных отсчетов для вектора MV, прогнозы MVP в списке кандидатов прогнозирования AMVP для этой единицы CU округляют до соответствующей точности.
2.4.3 Аффинное прогнозирование с компенсацией движения
В стандарте кодирования HEVC, для прогнозирования с компенсацией движения (motion compensation prediction (MCP)) применяется только модель поступательного движения. Однако в реальном мире возможны движения многих типов, например, приближение/удаление, вращение, перспективные движения и/или другие нерегулярные движения. В стандарте кодирования VVC, применяется упрощенное аффинное прогнозирование с компенсацией движения с 4-параметрической аффинной моделью и 6-параметрической аффинной моделью. Как показано на фиг. 13A и 13B, поле аффинного движения блока описывается двумя векторами движения контрольной точки (control point motion vectors (CPMV)) для 4-параметрической аффинной модели, и тремя векторами CPMV для 6-параметрической аффинной модели, соответственно.
Поле вектора движения (motion vector field (MVF)) для блока описывается следующим уравнением в соответствии с 4-параметрической аффинной моделью (где 4 параметра модели определены как переменные a, b, e и f) в уравнении (1) и 6-параметрической аффинной моделью (где 6 параметров модели определены как переменные a, b, c, d, e и f) в уравнении (2), соответственно:


здесь, (mvh0, mvh0) обозначает вектор движения контрольной точки (CP) в верхнем левом углу, и (mvh1, mvh1) обозначает вектор движения контрольной точки в верхнем правом углу и (mvh2, mvh2) обозначает вектор движения контрольной точки в нижнем левом углу, все три этих вектора движения называются векторами движения контрольной точки (CPMV), (x, y) представляет координаты репрезентативной точки относительно верхнего левого отсчета в текущем блоке и (mvh(x,y), mvv(x,y)) обозначает вектор движения, полученный для отсчета, расположенного в точке (x, y). Векторы движения точек CP можно передать в виде сигнализации (как в аффинном режиме прогнозирования AMVP) или получить в реальном времени (как в аффинном режиме объединения). Параметры w и h представляют ширину и высоту текущего блока. На практике разбиение осуществляется посредством операции сдвига вправо и округления. В документе VTM, репрезентативная точка определена как центральная позиция суб-блока, например, когда координаты левого верхнего угла суб-блока относительно верхнего левого отсчета в текущем блоке обозначены (xs, ys), координаты репрезентативной точки определены как (xs+2, ys+2). Для каждого суб-блока (например, размером 4×4 в документе VTM), репрезентативную точку используют для определения вектора движения для всего суб-блока в целом.
С целью дальнейшего упрощения прогнозирования с компенсацией движения применяется прогнозирование с аффинным преобразованием. Для получения вектора движения для каждого суб-блока размером M×N (оба числа M и N установлены равными 4 в сегодняшней версии кодирования VVC) можно вычислить вектор движения центрального отсчета соответствующего суб-блока, как показано на фиг. 14, согласно Уравнениям (1) и (2) и округлить его в соответствии с дробной точностью 1/16 вектора движения. Затем могут быть применены интерполяционные фильтры для компенсации движения с точностью 1/16-элемента изображения с целью генерации прогноза для каждого суб-блока с полученным вектором движения. Аффинный режим вводит интерполяционные фильтры для 1/16-элемента изображения.
После прогнозирования MCP, высокоточный вектор движения для каждого суб-блока округляют и сохраняют с той же точностью, как и обычный вектор движения.
2.4.3.1. Передача сигнализации об аффинном прогнозировании
Аналогично модели поступательного движения здесь также имеются два режима передачи сигнализации дополнительной информации вследствие аффинного прогнозирования. Это режимы AFFINE_INTER и AFFINE_Merge.
2.4.3.2. Режим AF_INTER
Для единиц CU, у которых и ширина, и высота больше 8, может быть применен режим AF_INTER. Сигнализацию флага аффинности на уровне единиц CU передают в потоке битов данных для индикации, используется ли режим AF_INTER.
В этом режиме, для каждого списка опорных изображений (Список 0 или Список 1), конструируют список кандидатов аффинного прогнозирования AMVP с тремя типами аффинных предикторов движения в следующем порядке, где каждый кандидат содержит оценку векторов CPMV для текущего блока. В виде сигнализации передают разности между наилучшими векторами CPMV, найденными на стороне кодирующего устройства, (такими как mv0 mv1 mv2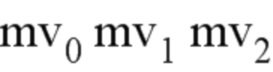 на фиг. 17) и оценками этих векторов CPMV. В дополнение к этому, получают индекс кандидата аффинного прогнозирования AMVP, от которого определяют оценки векторов CPMV, и далее передают в виде сигнализации.
на фиг. 17) и оценками этих векторов CPMV. В дополнение к этому, получают индекс кандидата аффинного прогнозирования AMVP, от которого определяют оценки векторов CPMV, и далее передают в виде сигнализации.
1) Первоначальные аффинные предикторы движения
Порядок проверки аналогичен случаю пространственного прогнозирования MVP при построении списка прогнозирования AMVP в стандарте кодирования HEVC. Во-первых, получают левый первоначальный аффинный предиктор движения от первого блока в группе {A1, A0}, кодированной в аффинном режиме и имеющей то же самое опорное изображение, как и текущий блок. Во-вторых, указанный выше первоначальный аффинный предиктор движения получают из первого блока в группе {B1, B0, B2}, кодированной в аффинном режиме и имеющей то же самое опорное изображение, как и текущий блок. На фиг. 16 показаны пять блоков A1, A0, B1, B0, B2.
Когда найден соседний блок для кодирования в аффинном режиме, векторы CPMV для единицы кодирования, покрывающей этот соседний блок, используются для получения предикторов векторов CPMV для текущего блока. Например, если блок A1 кодирован в неаффинном режиме и блок A0 кодирован в 4-параметрическом аффинном режиме, из блока A0 будет получен левый первоначальный аффинный предиктор вектора MV. В таком случае, векторы CPMV для единицы CU, покрывающей блок A0, обозначенные как MV0N для верхнего левого вектора CPMV и MV1N
для верхнего левого вектора CPMV и MV1N для верхнего правого вектора CPMV на фиг. 18B, используются для получения оценок векторов CPMV для текущего блока, обозначенных как MV0C, MV1C, MV2C для верхней левой (с координатами (x0, y0)), верхней правой (с координатами (x1, y1)) и нижней правой позиций (с координатами (x2, y2)) текущего блока.
для верхнего правого вектора CPMV на фиг. 18B, используются для получения оценок векторов CPMV для текущего блока, обозначенных как MV0C, MV1C, MV2C для верхней левой (с координатами (x0, y0)), верхней правой (с координатами (x1, y1)) и нижней правой позиций (с координатами (x2, y2)) текущего блока.
2) Сконструированные аффинные предикторы движения
Сконструированный активный предиктор движения состоит из векторов движения контрольных точек (CPMV), полученных из соседних блоков, кодированных с применением межкадрового прогнозирования, как показано на фиг. 17, так что эти блоки имеют одно и то же опорное изображение. Если текущая аффинная модель движения является 4-параметрической аффинной моделью, число векторов CPMV равно 2, в противном случае, если текущая аффинная модель движения является 6-параметрической аффинной моделью, число векторов CPMV равно 3. Верхний левый вектор CPMV  получают посредством вектора MV в первом блоке из группы {A, B, C}, кодированном с применением межкадрового прогнозирования и имеющем то же самое опорное изображение, как текущий блок. Верхний правый вектор CPMV
получают посредством вектора MV в первом блоке из группы {A, B, C}, кодированном с применением межкадрового прогнозирования и имеющем то же самое опорное изображение, как текущий блок. Верхний правый вектор CPMV  получают посредством вектора MV в первом блоке из группы {D, E}, кодированном с применением межкадрового прогнозирования и имеющем то же самое опорное изображение, как текущий блок. Нижний левый вектор CPMV
получают посредством вектора MV в первом блоке из группы {D, E}, кодированном с применением межкадрового прогнозирования и имеющем то же самое опорное изображение, как текущий блок. Нижний левый вектор CPMV  получают посредством вектора MV в первом блоке из группы {F, G}, кодированном с применением межкадрового прогнозирования и имеющем то же самое опорное изображение, как текущий блок.
получают посредством вектора MV в первом блоке из группы {F, G}, кодированном с применением межкадрового прогнозирования и имеющем то же самое опорное изображение, как текущий блок.
- Если текущая аффинная модель движения является 4-параметрической аффинной моделью, тогда сконструированный аффинный предиктор движения вставляют в список кандидатов, только если найдены оба вектора и , иными словами, векторы и используются в качестве оценок векторов CPMV для верхней левой (с координатами (x0, y0)), и верхней правой (с координатами (x1, y1)) позиций текущего блока.
- Если текущая аффинная модель движения является 6-параметрической аффинной моделью, тогда сконструированный аффинный предиктор движения вставляют в список кандидатов, только если найдены все три вектора , 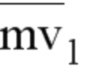 и , иными словами, векторы , и используются в качестве оценок векторов CPMV для верхней левой (с координатами (x0, y0)), верхней правой (с координатами (x1, y1)) и нижней правой (с координатами (x2, y2)) позиций текущего блока.
и , иными словами, векторы , и используются в качестве оценок векторов CPMV для верхней левой (с координатами (x0, y0)), верхней правой (с координатами (x1, y1)) и нижней правой (с координатами (x2, y2)) позиций текущего блока.
При вставке сконструированного аффинного предиктора движения в список кандидатов никакая процедура усечения не применяется.
3) Обычные предикторы движения AMVP
Последующее применяется до тех пор, пока число аффинных предикторов движения не достигнет максимума.
1) Формирование аффинного предиктора движения путем установления всех векторов CPMV равными вектору , если имеется.
2) Формирование аффинного предиктора движения путем установления всех векторов CPMV равными вектору , если имеется.
3) Формирование аффинного предиктора движения путем установления всех векторов CPMV равными вектору , если имеется.
4) Формирование аффинного предиктора движения путем установления всех векторов CPMV равными прогнозу HEVC TMVP, если имеется.
5) Формирование аффинного предиктора движения путем установления всех векторов CPMV равными нулевому вектору MV.
Отметим, что вектор 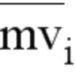 уже сформирован при построении аффинного предиктора движения.
уже сформирован при построении аффинного предиктора движения.
В режиме AF_INTER, если используется аффинный режим с 4/6 параметрами, требуются 2/3 контрольные точки, и поэтому необходимо кодировать 2/3 разности MVD для этих контрольных точек, как показано на фиг. 15A. В документе JVET-K0337 предлагается формировать вектор MV следующим образом, т.е. разности mvd1 и mvd2 прогнозируют на основе разности mvd0.

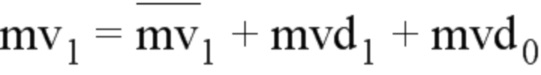

Здесь параметры , mvdi и mv1 представляют собой прогнозируемый вектор движения, разницу векторов движения и вектор движения верхнего левого пикселя (i = 0), верхнего правого пикселя (i = 1) или левого нижнего пикселя (i = 2) соответственно, как показано на фиг. 15B. Пожалуйста, отметьте, что добавление двух векторов движения (например, mvA(xA, yA) и mvB(xB, yB)) эквивалентно суммированию двух компонентов по отдельности, иными словами, формула newMV = mvA + mvB и два компонента вектора newMV установлены равными (xA + xB) и (yA + yB), соответственно.
2.4.3.3. Режим AF_Merge
Когда единицу CU применяют в режиме AF_Merge, она получает первый блок, кодированный в аффинном режиме от действительных соседних реконструированных блоков. При этом блок-кандидат выбирают в следующем порядке – от левого и далее верхний, сверху справа, слева снизу и к верхнему левому, как показано на фиг. 18A (обозначены по порядку как A, B, C, D, E). Например, если соседний слева снизу блок кодируют в аффинном режиме, как обозначено символом A0 на фиг. 18B, осуществляют выборку векторов mv0N, mv1N и mv2N движения контрольных точек (CP) в верхнем левом углу, верхнем правом углу и левом нижнем углу соседней единицы CU/PU, которая содержит блок A. И далее вектор движения mv0C, mv1C и mv2C (который используется только для 6-параметрической аффинной модели) для верхнего левого угла/верхнего правого/нижнего левого угла для текущей единицы CU/PU вычисляют на основе указанных векторов mv0N, mv1N и mv2N. Следует отметить, что в документе VTM-2.0, суб-блок (например, блок размером 4×4 в документе VTM), расположенный в верхнем левом углу, сохраняет вектор mv0, суб-блок, расположенный в верхнем правом углу, сохраняет вектор mv1, если текущий блок кодирован в аффинном режиме. Если текущий блок кодирован в соответствии с 6-параметрической аффинной моделью, тогда суб-блок, расположенный в нижнем левом углу, сохраняет вектор mv2; в противном случае (при 4-параметрической аффинной модели), левый нижний блок (LB) сохраняет вектор mv2’. Другие суб-блоки сохраняют векторы MV, используемые для компенсации MC.
После вычисления вектора CPMV для текущей единицы CU определяют векторы mv0C, mv1C и mv2C в соответствии с упрощенной аффинной моделью движения по Уравнениям (1) и (2), и генерируют поле MVF для текущей единицы CU. Для идентификации, кодирована ли текущая единица CU в режиме AF_Merge, может быть в виде сигнализации передан в потоке битов данных флаг аффинности, если по меньшей мере один соседний блок кодирован в аффинном режиме.
В документах JVET-L0142 и JVET-L0632 список аффинных объединяемых кандидатов конструируют в соответствии со следующими этапами:
1) Вставка первоначальных аффинных кандидатов
Термин «первоначальный аффинный кандидат» означает, что кандидат получен из аффинной модели движения соседнего с ним действительного блока, кодированного в аффинном режиме. Из аффинной модели движения соседних блоков получают максимум двух первоначальных аффинных кандидатов и вставляют их в список кандидатов. Для левого предиктора сканирование производится в порядке {A0, A1}; для верхнего предиктора сканирование производится в порядке {B0, B1, B2}.
2) Вставка сконструированных аффинных кандидатов
Если число кандидатов в списке аффинных объединяемых кандидатов меньше параметра MaxNumAffineCand (например, 5), в список кандидатов вставляют сконструированных аффинных кандидатов. Термин «сконструированный аффинный кандидат» означает, что кандидат сконструирован путем комбинирования информации о движении соседей в каждой контрольной точке.
а) Информацию о движении для контрольных точек определяют сначала на основе специфицированных соседей в пространстве и соседей во времени, показанных на фиг. 19. Символ CPk (k=1, 2, 3, 4) обозначает k-ую контрольную точку. Позиции A0, A1, A2, B0, B1, B2 и B3 являются пространственными позициями для прогнозирования точек CPk (k=1, 2, 3); символ T обозначает позицию во времени для прогнозирования точки CP4.
Точки CP1, CP2, CP3 и CP4 имеют координаты (0, 0), (W, 0), (H, 0) и (W, H), соответственно, где W и H представляют ширину и высоту текущего блока.
Информацию о движении для каждой контрольной точки получают в соответствии со следующим порядком приоритетности:
- Для точки CP1, приоритетность проверки имеет вид B2->B3->A2. Блок B2 используется, если он доступен. В противном случае, если блок B2 недоступен, используется блок B3. Если оба блока B2 и B3 недоступны, используется блок A2. Если все три кандидата недоступны, информация о движении для точки CP1 получена быть не может.
- Для точки CP2, приоритетность проверки имеет вид B1->B0.
- Для точки CP3, приоритетность проверки имеет вид A1->A0.
- Для точки CP4, используется параметр T.
b) Во-вторых, для конструирования аффинного объединяемого кандидата используется комбинация контрольных точек.
I. Для конструирования 6-параметрического аффинного кандидата необходима информация о движении для трех контрольных точек. Эти три контрольные точки можно выбрать из одной из следующих четырех комбинаций ({CP1, CP2, CP4}, {CP1, CP2, CP3}, {CP2, CP3, CP4}, {CP1, CP3, CP4}). Комбинации {CP1, CP2, CP3}, {CP2, CP3, CP4}, {CP1, CP3, CP4} будут преобразованы в 6-параметрическую модель движения, представленную верхней левой, верхней правой и нижней левой контрольными точками.
II. Для построения 4-параметрического аффинного кандидата необходима информация о движении двух контрольных точек. Эти две контрольные точки можно выбрать из одной из следующих двух комбинаций ({CP1, CP2}, {CP1, CP3}). Эти две комбинации будут преобразованы в 4-параметрическую модель движения, представленную верхней левой и верхней правой контрольными точками.
III. Комбинации сконструированных аффинных кандидатов вставляют в список кандидатов в следующем порядке:
{CP1, CP2, CP3}, {CP1, CP2, CP4}, {CP1, CP3, CP4}, {CP2, CP3, CP4}, {CP1, CP2}, {CP1, CP3}
i. Для каждой комбинации проверяют опорные индексы в списке X для каждой точки CP, если они все одинаковы, тогда такая комбинация имеет действительные векторы CPMV для списка X. Если комбинация не имеет действительных векторов CPMV для обоих списков – списка 0 и списка 1, тогда эту комбинацию маркируют как недействительную. В противном случае комбинация является действительной, и соответствующие векторы CPMV вносят в список объединения суб-блоков.
3) Заполнение нулевыми векторами движения
Если число кандидатов в списке аффинных объединяемых кандидатов меньше 5, в список кандидатов вставляют нулевые векторы движения до тех пор, пока список не станет полным.
Более конкретно, для списка объединяемых кандидатов суб-блоков, 4-параметрический объединяемый кандидат имеет векторы MV, установленные на (0, 0), а направление прогнозирования установлено в одну сторону от списка 0 (для P-среза) и в обе стороны (для B-среза).
2.4.4. Объединение с разностями векторов движения (Merge with motion vector difference (MMVD))
В документе JVET-L0054, представлено предельное выражение вектора движения (ultimate motion vector expression) (UMVE, также известное как MMVD). Параметр UMVE используется вместе с режимом пропуска или режимом объединения с предлагаемым способом выражения вектора движения.
Параметр UMVE повторно использует объединяемого кандидата, как такого же, как те, что входят в обычный список объединяемых кандидатов в стандарте кодирования VVC. Из совокупности объединяемых кандидатов может быть выбран базовый кандидат и далее расширен посредством предлагаемого способа выражения вектора движения.
Параметр UMVE предлагает новый способ представления разности векторов движения (MVD), согласно которому для представления такой разности MVD используются начальная точка, значение движения и направление движения.
Этот предлагаемый способ использует список объединяемых кандидатов, как он есть. Но для расширения UMVE рассматриваются только кандидаты, имеющие тип слияния по умолчанию (MRG_TYPE_DEFAULT_N).
Индекс базового кандидата определяет начальную точку. Этот индекс базового кандидата обозначает наилучшего кандидата из совокупности кандидатов, входящих в список, следующим образом.
Таблица 1. Индекс (IDX) базового кандидата
Если число базовых кандидатов равно 1, сигнализацию об этом индексе (IDX) базового кандидата не передают.
Индекс расстояния представляет собой информацию о значении движения. Индекс расстояния обозначает предварительно заданное расстояние от информации о начальной точке. Это предварительно заданное расстояние определено следующим образом:
Таблица 2. Индекс (IDX) расстояния
Индекс направления представляет направление разности MVD относительно начальной точки. Индекс направления может представлять четыре направления, как показано ниже.
Таблица 3. Индекс (IDX) направления
В некоторых вариантах, флаг расширения UMVE передают виде сигнализации сразу после передачи флага пропуска или флага объединения. Если флаг пропуска или объединения является истинным, выполняют синтаксический анализ флага UMVE. Если флаг UMVE равен 1, выполняют синтаксический анализ синтаксиса расширения UMVE. Но если этот флаг не равен 1, выполняют синтаксический анализ флага аффинности (AFFINE). Если флаг AFFINE равен 1, это означает аффинный (AFFINE) режим. Но если этот флаг не равен 1, выполняют синтаксический анализ индекса пропуска/объединения для режима пропуска/объединения в документе VTM.
Дополнительный буфер строк из-за появления кандидатов UMVE не требуется, поскольку кандидат пропуска/объединяемый кандидат из программного обеспечения непосредственно используется в качестве базового кандидата. Используя входной индекс UMVE, определяют дополнение вектора MV непосредственно перед компенсацией движения. Нет необходимости держать буфер длинной строки для этого.
В текущем состоянии общего текста либо первый, либо второй объединяемый кандидат из списка объединяемых кандидатов может быть выбран в качестве базового кандидата.
Параметр UMVE также известен как параметр «Объединение» (Merge) с разностями векторов MV Differences (MMVD).
2.4.5. Уточнение вектора движения на стороне декодирующего устройства (Decoder-side Motion Vector Refinement (DMVR))
При двунаправленном прогнозировании, для прогнозирования области одного блока, комбинируют два прогнозируемых блока, сформированных с использованием вектора движения (MV) из списка0 и вектора MV из списка1, соответственно, для образования одного прогнозируемого сигнала. Согласно способу уточнения вектора движения на стороне декодирующего устройства (DMVR) дополнительно уточняют два вектора движения, используемые при двунаправленном прогнозировании.
В модели JEM векторы движения уточняют посредством процедуры согласования двусторонних шаблонов. Такое согласование двусторонних шаблонов применяют в декодирующем устройстве для осуществления поиска на основе искажений между двусторонним шаблоном и реконструированными отсчетами в опорных изображениях с целью получения уточненного вектора MV без передачи дополнительной информации о движении. Пример изображен на фиг. 22. Двусторонний шаблон генерируют в виде взвешенной (т.е. усредненной) комбинации двух прогнозируемых блоков от первоначальных вектора MV0 из списка0 и вектора MV1 из списка1, соответственно, как показано на фиг. 22. Операция согласования шаблонов содержит вычисление стоимостных оценок между генерируемым шаблоном и областью отсчетов (вокруг первоначального прогнозируемого блока) в опорном изображении. Для каждого из двух опорных изображений вектор MV, который дает минимальную стоимость шаблонов, рассматривают в качестве обновленного вектора MV из соответствующего списка для замены исходного вектора. В модели JEM, осуществляют поиск среди девяти векторов MV кандидатов для каждого списка. Эта совокупность девяти векторов MV кандидатов содержит исходный вектор MV и 8 окружающих векторов MV со сдвигом на один яркостной отсчет от исходного вектора MV в каком-либо – в горизонтальном направлении или вертикальном направлении, или в обоих направлениях. Наконец, два новых вектора MV, т.е. векторы MV0′ и MV1′, как показано на фиг. 22, используются для генерации результатов двунаправленного прогнозирования. В качестве меры стоимости используется сумма абсолютных разностей (sum of absolute differences (SAD)). Пожалуйста, заметьте, что при вычислении стоимости прогнозируемого блока, генерируемого одним из окружающих векторов MV, для получения прогнозируемого блока фактически используется округленный (до целых элементов изображения (пикселей)) вектор MV вместо фактического вектора MV.
Для дальнейшего упрощения процедуры уточнения DMVR, документ JVET-M0147 предлагает ряд изменений в структуру модели JEM. Более конкретно, принятая процедура уточнения DMVR в документе VTM-4.0 (должен выйти в свет вскоре) имеет следующие основные признаки:
• Раннее завершение с (0,0) позиции в сумме SAD между списком0 и списком1
• Размер блока для процедуры уточнения DMVR W*H>=64 && H>=8
• Разбиение единицы CU на несколько суб-блоков размером 16x16 для процедуры уточнения DMVR при размере единицы CU > 16*16
• Размер опорного блока (W+7)*(H+7) (для яркостной составляющей)
• Поиск по 25 точкам на основе суммы SAD по целым пикселям (т.е. диапазон уточняющего поиска (+-) 2, один этап)
• Процедура уточнения DMVR на основе билинейной интерполяции
• Зеркальное отображение разности MVD между списком0 и списком1, чтобы позволить двустороннее согласование
• Уточнение на уровне долей пикселя на основе “уравнения параметрической погрешности поверхности”
• Компенсация MC яркостной/цветностной составляющей с заполнением опорного блока (если нужно)
• Уточненные векторы MV используются только для компенсации MC и прогнозирования TMVP
2.4.6. Комбинированное внутрикадровое и межкадровое прогнозирование
В документе JVET-L0100, предлагается прогнозирование с использованием нескольких гипотез, где комбинирование внутрикадрового и межкадрового прогнозирования является одним из способов генерации нескольких гипотез.
Когда прогнозирование с использованием нескольких гипотез применяется для усовершенствования режима внутрикадрового прогнозирования, прогнозирование с использованием нескольких гипотез комбинирует одно внутрикадровое прогнозирование и одно индексированное объединяемое прогнозирование. В объединяемой единице CU, передают один флаг в виде сигнализации для режима объединения, чтобы выбрать режим внутрикадрового прогнозирования из списка кандидатов для внутрикадрового прогнозирования, когда этот флаг является истинным. Для яркостной составляющей список кандидатов для внутрикадрового прогнозирования формируют из четырех режимов внутрикадрового прогнозирования, включая DC-режим, планарный режим, горизонтальный режим и вертикальный режим, а размер списка кандидатов для внутрикадрового прогнозирования может быть равен 3 или 4 в зависимости от формы блока. Когда ширина единицы CU больше удвоенной высоты этой единицы CU, горизонтальный режим исключают из списка для внутрикадрового прогнозирования, а когда высота единицы CU больше удвоенной ширины этой единицы CU, вертикальный режим исключают из этого списка режимов для внутрикадрового прогнозирования. Один режим внутрикадрового прогнозирования, выбранный по индексу режима внутрикадрового прогнозирования, и один объединяемый индексированный режим прогнозирования, выбранный по индексу объединения, комбинируют с использованием взвешенного усреднения. Для цветностной составляющей DM-режим всегда применяется без дополнительной сигнализации. Весовые коэффициенты для комбинирования прогнозов описываются следующим образом. Когда выбран DC-режим или планарный режим, либо ширина или высота блока CB меньше 4, применяются одинаковые весовые коэффициенты. Для блоков CB с шириной и высотой не меньше 4, когда выбран горизонтальный/вертикальный режим, один блок CB сначала разбивают вертикально/горизонтально на четыре области равной площади. Каждый набор весовых коэффициентов, обозначенный как (w_intrai, w_interi), где i составляет от 1 до 4 и (w_intra1, w_inter1) = (6, 2), (w_intra2, w_inter2) = (5, 3), (w_intra3, w_inter3) = (3, 5) и (w_intra4, w_inter4) = (2, 6), будет применен к соответствующей области. Коэффициенты (w_intra1, w_inter1) предназначены для области, ближайшей к опорным отсчетам, и коэффициенты (w_intra4, w_inter4) предназначены для области, наиболее удаленной от опорных отсчетов. Тогда комбинированное прогнозирование может быть вычислено путем суммирования двух взвешенных результатов прогнозирования и сдвига на 3 бита вправо. Более того, режим внутрикадрового прогнозирования для гипотез предикторов внутрикадрового прогнозирования может быть сохранен в качестве опоры для следующих соседних единиц CU.
2.5 Внутриконтурное переформирование (ILR) в документе JVET-M0427
Внутриконтурное переформирование (ILR) также известно под названием «Отображение яркостной составляющей с масштабированием цветностной составляющей» (Luma Mapping with Chroma Scaling (LMCS)).
Базовая идея внутриконтурного переформирования (ILR) состоит в преобразовании исходного (в первой области) сигнала (прогнозируемого/реконструированного сигнала) во вторую область (переформированную область).
Внутриконтурное устройство для переформирования яркостной составляющей реализовано в виде пары преобразовательных таблиц (look-up table (LUT)), но только об одной из этих двух таблиц LUT необходимо сообщить посредством сигнализации, тогда как другая таблица может быть вычислена на основе сообщенной таблицы LUT. Каждая таблица LUT является одномерной, 10-битовой, таблицей отображения с 1024 входными позициями (1D-LUT). Одна таблица LUT является таблицей LUT для прямого преобразования (прямая таблица LUT), FwdLUT, которая преобразует значения Yi входного яркостного кода в измененные значения Yr: Yr = FwdLUT[Yi]. Другая таблица LUT является таблицей LUT для обратного преобразования (обратная таблица LUT), InvLUT, которая преобразует измененные кодовые значения Yr в значения Ŷi : Ŷi = InvLUT[Yr]
: Ŷi = InvLUT[Yr] . (Ŷi представляет реконструированные значения Yi).
. (Ŷi представляет реконструированные значения Yi).
2.5.1 Кусочно-линейная модель (PWL)
Концептуально, кусочно-линейная (PWL) модель реализуется следующим образом:
Пусть x1, x2 являются двумя входными опорными точками, а y1, y2 являются соответствующими выходными опорными точками для одного отрезка. Выходное значение y для какого-либо входного значения x между значениями x1 и x2 может быть интерполировано посредством следующего уравнения:
y = ((y2-y1)/(x2-x1)) * (x-x1) + y1
В варианте реализации с фиксированной точкой это уравнение может быть переписано как:
y = ((m * x + 2FP_PREC-1) >> FP_PREC) + c
где m обозначает скаляр, c обозначает сдвиг и FP_PREC представляет собой константу для специфицирования точности.
Отметим, что в программном обеспечении CE-12 модель PWL используется для предварительного вычисления имеющих по 1024 входных позиций каждая таблиц прямого FwdLUT и обратного InvLUT отображения; но модель PWL также позволяет создать реализации для вычисления идентичных отображаемых значений в реальном времени без предварительного вычисления таблиц LUT; s.
2.5.2. Тест CE12-2
2.5.2.1. Переформирование яркостной составляющей
Тест 2 для внутриконтурного переформирования яркостной составляющей (т.е. CE12-2 в предложении) создает конвейер меньшей сложности, который также исключает задержку декодирования для поблочного внутрикадрового прогнозирования при реконструкции среза при межкадровом прогнозировании. Внутрикадровое прогнозирование осуществляется в переформированной области для обоих типов срезов – с внутрикадровым и с межкадровым прогнозированием.
Внутрикадровое прогнозирование всегда осуществляется в переформированной области независимо от типа среза. В такой конфигурации процесс внутрикадрового прогнозирования может начинаться сразу же после завершения реконструкции предыдущей единицы TU. Такая конфигурация может также предложить унифицированную процедуру для внутрикадрового прогнозирования вместо процедуры, зависимой от конкретного среза. На фиг. 23 показана блок-схема процедуры CE12-2 декодирования на основе режима.
Система CE12-2 также тестирует 16-элементные кусочно-линейные (PWL) модели для масштабирования остатков яркостной и цветностной составляющих вместо 32-элементных PWL моделей в системе CE12-1.
Реконструкция среза при внутрикадровом прогнозировании с применением устройства внутриконтурного переформирования яркостной составляющей в системе CE12-2 (заштрихованные светло-зеленым блоки обозначают сигнал в переформированной области: остаток яркостной составляющей; яркостную составляющую при внутрикадровом прогнозировании; и реконструированную яркостную составляющую при внутрикадровом прогнозировании)
2.5.2.2. Зависящее от яркостной составляющей масштабирование остатка цветностной составляющей
Зависящее от яркостной составляющей масштабирование остатка цветностной составляющей является мультипликативным процессом, реализуемым целочисленной операцией с фиксированной запятой. Масштабирование остатка цветностной составляющей компенсирует взаимодействие яркостного сигнала с цветностным сигналом. Масштабирование остатка цветностной составляющей применяется на уровне единиц TU. Более конкретно, применяется следующее:
- Для внутрикадрового прогнозирования, усредняют реконструированную яркостную составляющую.
- Для межкадрового прогнозирования, усредняют прогнозируемую яркостную составляющую.
Усреднение используется для идентификации индекса в модели PWL. Этот индекс идентифицирует масштабный коэффициент cScaleInv. Остаток цветностной составляющей умножают на этот коэффициент.
Отметим, что масштабный коэффициент для цветностной составляющей вычисляют на основе отображенных в прямом направлении значений яркостной составляющей, а не на основе реконструированных значений яркостной составляющей.
2.5.2.3. Передача сигнализации дополнительной информации о переформировании ILR
Эти параметры передают (в настоящий момент) в заголовке группы плиток (аналогично фильтрации ALF). Эти сообщения занимают 40 – 100 бит.
Следующие таблицы основаны на версии 9 документа JVET-L1001. Добавляемый синтаксис выделен ниже жирным курсивом с подчеркиванием.
В 7.3.2.1 Синтаксис параметров последовательности RBSP может быть установлен следующим образом:




В 7.3.3.1 синтаксис общего заголовка группы плиток может быть модифицирован путем вставки текста, обозначенного жирным курсивом с подчеркиванием, следующим образом:


Новая модель устройства переформирования группы плиток в синтаксической таблице может быть добавлена следующим образом:

В общую семантику набора параметров последовательности RBSP может быть добавлена следующая семантика:
Флаг sps_reshaper_enabled_flag, равный 1, специфицирует, что устройство переформирования используется в кодированной последовательности видео (coded video sequence (CVS)). Флаг sps_reshaper_enabled_flag, равный 0, специфицирует, что устройство переформирования не используется в последовательности CVS.
В синтаксис заголовка группы плиток может быть добавлена следующая семантика:
Флаг tile_group_reshaper_model_present_flag, равный 1, специфицирует, что параметр tile_group_reshaper_model() присутствует в заголовке группы плиток. Флаг tile_group_reshaper_model_present_flag, равный 0, специфицирует, что параметр tile_group_reshaper_model() не присутствует в заголовке группы плиток. Когда флаг tile_group_reshaper_model_present_flag не присутствует, его считают равным 0.
Флаг tile_group_reshaper_enabled_flag, равный 1, специфицирует, что устройство переформирования активизировано для текущей группы плиток. Флаг tile_group_reshaper_enabled_flag, равный 0, специфицирует, что устройство переформирования не активизировано для текущей группы плиток. Когда флаг tile_group_reshaper_enable_flag не присутствует, его считают равным 0.
Флаг tile_group_reshaper_chroma_residual_scale_flag, равный 1, специфицирует, что масштабирование остатка цветностной составляющей активизировано для текущей группы плиток. Флаг tile_group_reshaper_chroma_residual_scale_flag, равный 0, специфицирует, что масштабирование остатка цветностной составляющей не активизировано для текущей группы плиток. Когда флаг tile_group_reshaper_chroma_residual_scale_flag не присутствует, его считают равным 0.
Синтаксис tile_group_reshaper_model( ) может быть добавлен следующим образом:
Индекс reshape_model_min_bin_idx специфицирует индекс минимального бина (или отрезка) для использования в процессе конструирования устройства для переформирования. Значение этого индекса reshape_model_min_bin_idx должно быть в диапазоне от 0 до параметра MaxBinIdx, включительно. Значение параметра MaxBinIdx должно быть равна 15.
Индекс reshape_model_delta_max_bin_idx специфицирует индекс максимального допустимого бина (или отрезка) MaxBinIdx минус максимальный индекс Значение индекса reshape_model_max_bin_idx устанавливают равным MaxBinIdx – reshape_model_delta_max_bin_idx.
Параметр reshaper_model_bin_delta_abs_cw_prec_minus1 плюс 1 специфицирует число битов, используемое для представления синтаксиса reshape_model_bin_delta_abs_CW[ i ].
Параметр reshape_model_bin_delta_abs_CW[ i ] специфицирует абсолютное значение кодового слова приращения (дельта) для i-ого бина.
Параметр reshaper_model_bin_delta_sign_CW_flag[ i ] специфицирует знак параметра reshape_model_bin_delta_abs_CW[ i ] следующим образом:
- Если флаг reshape_model_bin_delta_sign_CW_flag[ i ] равен 0, соответствующая переменная RspDeltaCW[ i ] имеет положительное значение.
- В противном случае ( reshape_model_bin_delta_sign_CW_flag[ i ] не равно 0 ), соответствующая переменная RspDeltaCW[ i ] имеет отрицательное значение.
Когда флаг reshape_model_bin_delta_sign_CW_flag[ i ] не присутствуют, его считают равным 0.
Переменная RspDeltaCW[ i ] = (1 2*reshape_model_bin_delta_sign_CW [ i ]) * reshape_model_bin_delta_abs_CW [ i ];
Переменную RspCW[ i ] определяют посредством следующих этапов:
Переменную OrgCW устанавливают равной (1 << BitDepthY ) / ( MaxBinIdx + 1).
– Если reshaper_model_min_bin_idx < = i <= reshaper_model_max_bin_idx
RspCW[ i ] = OrgCW + RspDeltaCW[ i ].
– В противном случае, RspCW[ i ] = 0.
Значение RspCW [ i ] должно быть в диапазоне от 32 до 2 * OrgCW – 1, если значение BitDepthY равно 10.
Переменные InputPivot[ i ] с i в диапазоне от 0 до MaxBinIdx + 1, включительно, формируют следующим образом
InputPivot[ i ] = i * OrgCW
Переменную ReshapePivot[ i ] для i в диапазоне от 0 до MaxBinIdx + 1, включительно, переменную ScaleCoef[ i ] и переменную InvScaleCoeff[ i ] при i в диапазоне от 0 до MaxBinIdx , включительно, определяют следующим образом:
shiftY = 14
ReshapePivot[ 0 ] = 0;
for( i = 0; i <= MaxBinIdx ; i++) {
ReshapePivot[ i + 1 ] = ReshapePivot[ i ] + RspCW[ i ]
ScaleCoef[ i ] = ( RspCW[ i ] * (1 << shiftY) + (1 << (Log2(OrgCW) - 1))) >> (Log2(OrgCW))
если ( RspCW[ i ] == 0 )
InvScaleCoeff[ i ] = 0
иначе
InvScaleCoeff[ i ] = OrgCW * (1 << shiftY) / RspCW[ i ]
}
Переменная ChromaScaleCoef[ i ] при i в диапазоне от 0 до MaxBinIdx, включительно, может быть определена следующим образом:
ChromaResidualScaleLut[64] = {16384, 16384, 16384, 16384, 16384, 16384, 16384, 8192, 8192, 8192, 8192, 5461, 5461, 5461, 5461, 4096, 4096, 4096, 4096, 3277, 3277, 3277, 3277, 2731, 2731, 2731, 2731, 2341, 2341, 2341, 2048, 2048, 2048, 1820, 1820, 1820, 1638, 1638, 1638, 1638, 1489, 1489, 1489, 1489, 1365, 1365, 1365, 1365, 1260, 1260, 1260, 1260, 1170, 1170, 1170, 1170, 1092, 1092, 1092, 1092, 1024, 1024, 1024, 1024};
shiftC = 11
– если ( RspCW[ i ] == 0 )
ChromaScaleCoef [ i ] = (1 << shiftC)
– в противном случае (RspCW[ i ] != 0),
ChromaScaleCoef[ i ] = ChromaResidualScaleLut[RspCW[ i ] >> 1]
Следующий текст может быть добавлен в соединении с процедурой взвешенного прогнозирования отсчетов для комбинированного режима объединения и внутрикадрового прогнозирования. Дополнение отмечено курсивом с подчеркиванием.
8.4.6.6 Процедура взвешенного прогнозирования отсчетов для комбинированного режима объединения и внутрикадрового прогнозирования
Входными данными для этой процедуры являются:
- ширина текущего блока кодирования, cbWidth,
- высота текущего блока кодирования, cbHeight,
- два массива predSamplesInter и predSamplesIntra размером (cbWidth)x(cbHeight) каждый,
- указатель predModeIntra режима внутрикадрового прогнозирования,
- переменная cIdx, специфицирующая индекс цветовой составляющей.
Выходными данными этой процедуры является массив predSamplesComb прогнозируемых значений отсчетов размером (cbWidth)x(cbHeight).
Переменную bitDepth определяют следующим образом:
- Если переменная cIdx равна 0, параметр bitDepth устанавливают равным BitDepthY.
- В противном случае, параметр bitDepth устанавливают равным BitDepthC.
Прогнозируемые отсчеты predSamplesComb[ x ][ y ] при x = 0..cbWidth − 1 и y = 0..cbHeight − 1 определяют следующим образом:
- Весовой коэффициент w определяют следующим образом:
- Если параметр predModeIntra равен INTRA_ANGULAR50, коэффициент w специфицирован в Табл. 4 при nPos равно y и nSize равно cbHeight.
- В противном случае, если параметр predModeIntra равен INTRA_ANGULAR18, коэффициент w специфицирован в таблицах 810 при nPos равно x и nSize равно cbWidth.
- В противном случае, коэффициент w устанавливают равным 4.


- Прогнозируемые отсчеты predSamplesComb[ x ][ y ] определяют следующим образом:
predSamplesComb[ x ][ y ] = ( w * predSamplesIntra[ x ][ y ] + (8-740)
( 8 − w ) * predSamplesInter[ x ][ y ] ) >> 3 )
Таблица 4. Спецификация весового коэффициента w в функции позиции position nP и размера nS
( nS / 2 )
( 3 *nS / 4 )
Следующий текст, выполненный жирным курсивом с подчеркиванием, может быть добавлен к описанию процедуры реконструкции изображения:
8.5.5 Процедуры реконструкции изображения
Входными данными для этой процедуры являются:
– позиция ( xCurr, yCurr ), специфицирующая верхний левый отсчет текущего блока относительно верхнего левого отсчета текущего компонента изображения,
– переменные nCurrSw и nCurrSh, специфицирующие ширину и высоту, соответственно, текущего блока,
– переменная cIdx, специфицирующая цветовую составляющую текущего блока,
– массив predSamples размером (nCurrSw)x(nCurrSh), специфицирующий прогнозируемые отсчеты текущего блока,
– массив resSamples размером (nCurrSw)x(nCurrSh), специфицирующий отсчеты текущего блока.
В зависимости от значения cIdx цветовой составляющей делают следующие назначения:
– Если переменная cIdx равна 0, массив recSamples соответствует массиву SL реконструированных отсчетов изображения, и функция clipCidx1 соответствует Clip1Y.
– Иначе, если переменная cIdx равна 1, массив recSamples соответствует массиву SCb реконструированных отсчетов цветностной составляющей, а функция clipCidx1 соответствует Clip1C.
– Иначе (cIdx равно 2), массив recSamples соответствует массиву SCr реконструированных отсчетов цветностной составляющей, а функция clipCidx1 соответствует Clip1C.

В противном случае, этот блок размером (nCurrSw)x(nCurrSh) массива recSamples реконструированных отсчетов, расположенный в позиции ( xCurr, yCurr ), определяют следующим образом:

8.5.5.1 Процедура реконструкции изображения с использованием отображения
Эта статья специфицирует процедуру реконструкции изображения с использованием отображения. Процедура реконструкции изображения с использованием отображения для значений отсчетов яркостной составляющей специфицирована в статье 8.5.5.1.1. Процедура реконструкции изображения с использованием отображения для значений отсчетов цветностной составляющей специфицирована в статье 8.5.5.1.2.
8.5.5.1.1 Процедура реконструкции изображения с использованием отображения для значений отсчетов яркостной составляющей
Входными данными для этой процедуры являются:
– массив predSamples размером (nCurrSw)x(nCurrSh), специфицирующий прогнозируемые отсчеты яркостной составляющей для текущего блока,
– массив resSamples размером (nCurrSw)x(nCurrSh), специфицирующий отсчеты остатка яркостной составляющей для текущего блока.
Выходными данными этой процедуры являются:
– массив predMapSamples размером (nCurrSw)x(nCurrSh) отображенных прогнозируемых отсчетов яркостной составляющей,
– массив recSamples размером (nCurrSw)x(nCurrSh) реконструированных отсчетов яркостной составляющей.
Массив predMapSamples определяют следующим образом:
– Если ( CuPredMode[ xCurr ][ yCurr ] = = MODE_INTRA ) || ( CuPredMode[ xCurr ][ yCurr ] = = MODE_CPR) || ( CuPredMode[ xCurr ][ yCurr ] = = MODE_INTER && mh_intra_flag[ xCurr ][ yCurr ] )
predMapSamples[ xCurr + i ][ yCurr + j ] = predSamples[ i ][ j ] 
при i = 0..nCurrSw − 1, j = 0..nCurrSh – 1
– В противном случае ( ( CuPredMode[ xCurr ][ yCurr ] = = MODE_INTER && !mh_intra_flag[ xCurr ][ yCurr ] )), применимо следующее:
shiftY = 14
idxY = predSamples[ i ][ j ] >> Log2( OrgCW )
predMapSamples[ xCurr + i ][ yCurr + j ] = ReshapePivot[ idxY ]
+ ( ScaleCoeff[ idxY ] *(predSamples[ i ][ j ] - InputPivot[ idxY ] )
+ ( 1 << ( shiftY – 1 ) ) ) >> shiftY
при i = 0..nCurrSw − 1, j = 0..nCurrSh – 1
Массив recSamples определяют следующим образом:
recSamples[ xCurr + i ][ yCurr + j ] = Clip1Y ( predMapSamples[ xCurr + i ][ yCurr + j ]+ resSamples[ i ][ j ] ] )
при i = 0..nCurrSw − 1, j = 0..nCurrSh – 1
8.5.5.1.2 Процедура реконструкции изображения с использованием отображения для значений отсчетов цветностной составляющей
Входными данными для этой процедуры являются:
- массив predMapSamples размером (nCurrSwx2)x(nCurrShx2), специфицирующий отображенные отсчеты яркостной составляющей для текущего блока,
- массив predSamples размером (nCurrSw)x(nCurrSh), специфицирующий прогнозируемые отсчеты цветностной составляющей для текущего блока,
- массив resSamples размером (nCurrSw)x(nCurrSh), специфицирующий отсчеты остатка цветностной составляющей для текущего блока.
Выходными данными этой процедуры является массив recSamples реконструированных отсчетов цветностной составляющей.
Массив recSamples определяют следующим образом:
– Если ( !tile_group_reshaper_chroma_residual_scale_flag || ( (nCurrSw)x(nCurrSh) <= 4) )
recSamples[ xCurr + i ][ yCurr + j ] = Clip1C ( predSamples[ i ][ j ] + resSamples[ i ][ j ] )
при i = 0..nCurrSw − 1, j = 0..nCurrSh – 1
– В противном случае (tile_group_reshaper_chroma_residual_scale_flag && ( (nCurrSw)x(nCurrSh) > 4)), применимо следующее:
Переменную varScale определяют следующим образом:
1. invAvgLuma = Clip1Y( ( ΣiΣj predMapSamples[ (xCurr << 1 ) + i ][ (yCurr << 1) + j ]
+ nCurrSw * nCurrSh *2) / ( nCurrSw * nCurrSh *4 ) )
2. Переменную idxYInv определяют с привлечением идентификации индекса кусочной функции, как это специфицировано в статье 8.5.6.2, когда значение входного отсчета равно invAvgLuma.
3. varScale = ChromaScaleCoef[ idxYInv ]
Массив отсчетов recSamples определяют следующим образом:
– Если tu_cbf_cIdx [ xCurr ][ yCurr ] равно 1, применимо следующее:
shiftC = 11
recSamples[ xCurr + i ][ yCurr + j ] = ClipCidx1 ( predSamples[ i ][ j ] + Sign( resSamples[ i ][ j ] )
* ( ( Abs( resSamples[ i ][ j ] ) * varScale + ( 1 << ( shiftC – 1 ) ) ) >> shiftC ) )
при i = 0..nCurrSw − 1, j = 0..nCurrSh – 1
– В противном случае (tu_cbf_cIdx[ xCurr ][ yCurr ] равно 0)
recSamples[ xCurr + i ][ yCurr + j ] = ClipCidx1(predSamples[ i ][ j ] )
при i = 0..nCurrSw − 1, j = 0..nCurrSh – 1
8.5.6 Процедура обратного отображения изображения
Эту статью привлекают, когда значение флага tile_group_reshaper_enabled_flag равно 1. Входными данными является массив SL реконструированных отсчетов изображения яркостной составляющей, а выходными данными является массив S′L модифицированных реконструированных отсчетов изображения яркостной составляющей после процедуры обратного отображения.
Процедура обратного отображения значений отсчетов яркостной составляющей специфицирована в 8.4.6.1.
8.5.6.1 Процедура обратного отображения изображения значений отсчетов яркостной составляющей
Входными данными для этой процедуры является позиция ( xP, yP ), яркостной составляющей, специфицирующая положение отсчета яркостной составляющей относительно верхнего левого отсчета яркостной составляющей текущего изображения.
Выходными данными этой процедуры является значение invLumaSample пикселя яркостной составляющей, полученное в результате обратного отображения.
Это значение invLumaSample получают в результате применения следующих упорядоченных этапов:
1. Переменные idxYInv определяют путем привлечения индекса кусочной функции, как это специфицировано в статье 8.5.6.2 при входном значении SL[ xP ][ yP ] отсчета яркостной составляющей.
2. Значение отсчета reshapeLumaSample определяют следующим образом:
shiftY = 14
invLumaSample = InputPivot[ idxYInv ] + ( InvScaleCoeff[ idxYInv ] *( SL[ xP ][ yP ] ReshapePivot[ idxYInv ] )
+ ( 1 << ( shiftY – 1 ) ) ) >> shiftY 
3. clipRange = ((reshape_model_min_bin_idx > 0) && (reshape_model_max_bin_idx < MaxBinIdx));
– Если параметр clipRange равен 1, применяется следующее:
minVal = 16 << (BitDepthY – 8)
maxVal = 235<< (BitDepthY – 8)
invLumaSample = Clip3(minVal, maxVal, invLumaSample)
– иначе (параметр clipRange равен 0),
invLumaSample = ClipCidx1(invLumaSample),
8.5.6.2 Идентификация индекса кусочной функции для яркостных составляющих
Входными данными для этой процедуры является значение S отсчета яркостной составляющей.
Выходными данными этой процедуры является индекс idxS, идентифицирующий отрезок, которому принадлежит отсчет S. переменную idxS определяют следующим образом:
для idxS = 0, idxFound = 0; idxS <= MaxBinIdx; idxS++ ) {
если( (S < ReshapePivot[ idxS + 1 ] ) {
idxFound = 1
break
}
}
Отметим, что альтернативный способ нахождения индентификации idxS является следующим:
если (S < ReshapePivot[ reshape_model_min_bin_idx ])
idxS = 0
иначе если (S >= ReshapePivot[ reshape_model_max_bin_idx ])
idxS = MaxBinIdx
иначе
idxS = findIdx ( S, 0, MaxBinIdx + 1, ReshapePivot[ ] )
функция idx = findIdx (val, low, high, pivot[ ]) {
если ( high – low <= 1 )
idx = low
иначе {
mid = ( low + high) >> 1
если (val < pivot [mid] )
high = mid
иначе
low = mid
idx = findIdx (val, low, high, pivot[])
}
}
2.5.2.4. Использование переформирования ILR
На стороне кодирующего устройства каждое изображение (или группу плиток) сначала преобразуют в переформированную область. И всю процедуру кодирования осуществляют в переформированной области. Для внутрикадрового прогнозирования соседний блок находится в переформированной области; для межкадрового прогнозирования опорные блоки (генерируемые из исходной области из буфера декодированного изображения) сначала преобразуют в переформированную область. Затем генерируют остаток и кодируют его в потоке битов данных.
После завершения кодирования/декодирования полного изображения (или группы плиток) отсчеты в переформированной области преобразуют в исходную область и затем применяют деблокирующий фильтр и другие фильтры.
Прямое переформирование прогнозируемого сигнала не активизировано для следующих случаев:
- Текущий блок кодирован с применением внутрикадрового прогнозирования
- Текущий блок кодирован с применением ссылки на текущее изображение в качестве опоры (CPR (current picture referencing) также называется внутрикадровым копированием блоков, IBC)
- Текущий блок кодирован с применением комбинированного режима с внутрикадровым и межкадровым прогнозированием (combined inter-intra mode (CIIP)), а процедура прямого переформирования не активизирована для блоков с внутрикадровым прогнозированием
2.6. Единицы данных виртуального конвейера (Virtual Pipelining Data Units (VPDU))
Единицы данных виртуального конвейера (VPDU) определены как не накладывающиеся одна на другую единицы MxM-luma(L)/NxN-chroma(C) данных в изображении. В аппаратных декодирующих устройствах последовательные единицы VPDU обрабатывают в нескольких ступенях конвейера одновременно; разные ступени обрабатывают различные единицы VPDU одновременно. Размер единицы VPDU грубо пропорционален размеру буфера в большинстве ступеней конвейера, так что можно сказать, что очень важно сохранять небольшой размер единиц VPDU. В аппаратных декодирующих устройствах для стандарта кодирования HEVC размеры единицы VPDU устанавливают равными максимальному размеру блока преобразования (transform block (TB)). Увеличение максимального размера блока TB от 32x32-L/16x16-C (как в стандарте кодирования HEVC) до 64x64-L/32x32-C (как в сегодняшнем стандарте кодирования VVC) может принести выигрыш при кодировании, результатом чего является ожидаемое 4-кратное увеличение размера единицы VPDU (64x64-L/32x32-C) по сравнению со стандартом кодирования HEVC. Однако, в дополнение к разбиению единицы кодирования (CU) в соответствии с деревом квадратов (quadtree (QT)), в стандарте кодирования VVC приняты также троичное дерево единиц (ternary tree (TT)) и двоичное дерево (binary tree (BT)) для достижения дополнительного выигрыша при кодировании, а разбиение в соответствии с деревьями TT и BT может быть применено к единицам дерева кодирования (CTU) размером 128x128-L/64x64-C рекурсивно, что ведет к 16-кратному увеличению размера единицы VPDU (128x128-L/64x64-C) по сравнению со стандартом кодирования HEVC.
В современной конфигурации кодирования VVC, размер единицы VPDU определен как 64x64-L/32x32-C.
2.7. Набор параметров адаптации (APS)
В стандарте кодирования VVC, набор параметров адаптации (Adaptation Parameter Set (APS)) принят для передачи параметров фильтрации ALF. Заголовок группы плиток содержит параметр aps_id, который условно присутствует, когда фильтрация ALF активизирована. Набор APS содержит параметр aps_id и параметры фильтрации ALF. Для набора APS назначено новое значение типа NUT (тип единицы NAL (NAL unit type), как в стандартах кодирования AVC и HEVC) (из документа JVET-M0132). Для общих тестовых условий в документе VTM-4.0 (должен быть выпущен), предлагается просто использовать aps_id = 0 и передавать набор APS с каждым изображением. На сегодня, идентификатор APS ID будет иметь диапазон значений 0..31 и наборы APS могут совместно использоваться несколькими изображениями (и могут различаться в разных группах в одном изображении). Значения идентификатора ID должны быть, если они присутствуют, закодированы в коде фиксированной длины. Значения идентификатора ID не могут быть повторно использованы с другим контентом в одном и том же изображении.
2.8. Фильтры после реконструкции
2.8.1 Рассеивающий фильтр (Diffusion filter (DF))
В документе JVET-L0157, предложен рассеивающий фильтр, где сигнал внутрикадрового/межкадрового прогнозирования из единицы CU может быть дополнительно модифицирован рассеивающими фильтрами.
2.8.1.1. Однородный рассеивающий фильтр
Однородный рассеивающий фильтр (Uniform Diffusion Filter) реализуется посредством свертки прогнозируемого сигнала с фиксированной маской, задаваемой как hI или как hIV, что определено ниже.
или как hIV, что определено ниже.
В качестве входа для фильтрованного сигнала помимо самого прогнозируемого сигнала используют одну линию реконструированных отсчетов слева и сверху от рассматриваемого блока, где использования этих реконструированных отсчетов можно избежать для блоков с межкадровым прогнозированием.
Пусть pred обозначает прогнозируемый сигнал для некоего рассматриваемого блока, получаемый посредством внутрикадрового прогнозирования или прогнозирования с компенсацией движения. Для обработки граничных точек для фильтров, прогнозируемый сигнал необходимо расширить до прогнозируемого сигнала predex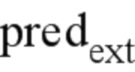 . Этот расширенный прогнозируемый сигнал может быть сформирован двумя способами: Либо, в качестве промежуточного этапа, добавляют одну линию реконструированных отсчетов слева и сверху от блока к прогнозируемому сигналу и затем зеркально отражают результирующий сигнал во всех направлениях. Либо только сам прогнозируемый сигнал зеркально отражают во всех направлениях. Последнее расширение используется для блоков с межкадровым прогнозированием. В этом случае, только сам прогнозируемый сигнал содержит входные данные для расширенного прогнозируемого сигнала predex.
. Этот расширенный прогнозируемый сигнал может быть сформирован двумя способами: Либо, в качестве промежуточного этапа, добавляют одну линию реконструированных отсчетов слева и сверху от блока к прогнозируемому сигналу и затем зеркально отражают результирующий сигнал во всех направлениях. Либо только сам прогнозируемый сигнал зеркально отражают во всех направлениях. Последнее расширение используется для блоков с межкадровым прогнозированием. В этом случае, только сам прогнозируемый сигнал содержит входные данные для расширенного прогнозируемого сигнала predex.
Если должен быть использован фильтр hI, предлагается заменить прогнозируемый сигнал pred сигналом
hI pred
pred
hI pred
используя упомянутое выше граничное расширение. Здесь фильтрующая маска hI имеет вид

Если следует использовать фильтр hIV , предлагается заменить прогнозируемый сигнал pred
, предлагается заменить прогнозируемый сигнал pred
pred сигналом.
hIV pred
Здесь фильтр hIV задан как
hIV = hI hI hI hI
2.8.1.2. Направленный рассеивающий фильтр
Вместо использования адаптивных к сигналу рассеивающих фильтров используются направленные, а именно – горизонтальный фильтр hhor и вертикальный фильтр hver, которые по-прежнему имеют фиксированную маску. Более точно, однородную рассеивающую фильтрацию, соответствующую маске hI из предыдущего раздела, просто ограничивают применением только вдоль вертикального или вдоль горизонтального направления. Вертикальный фильтр реализуют с применением фиксированной фильтрующей маски
и вертикальный фильтр hver, которые по-прежнему имеют фиксированную маску. Более точно, однородную рассеивающую фильтрацию, соответствующую маске hI из предыдущего раздела, просто ограничивают применением только вдоль вертикального или вдоль горизонтального направления. Вертикальный фильтр реализуют с применением фиксированной фильтрующей маски

к прогнозируемому сигналу и горизонтальный фильтр реализуют с использованием транспонированной маски hhor = htver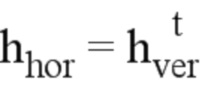

2.8.2. Двусторонний фильтр (Bilateral Filter (BF))
Двусторонний фильтр предложен в документе JVET-L0406, и всегда применяется к блокам яркостной составляющей с ненулевыми коэффициентами преобразованиями и параметром квантования среза больше 17. Поэтому нет необходимости сигнализировать о двустороннем фильтре. Двусторонний фильтр, если он применяется, воздействует на декодированные отсчеты сразу после обратной трансформации. В дополнение к этому, параметры фильтра, т.е. весовые коэффициенты в явном виде выводят из кодированной информации.
Процедура фильтрации определена как:
 … (1)
… (1)
Здесь, P0,0 обозначает интенсивность текущего отсчета, и P'0,0
обозначает интенсивность текущего отсчета, и P'0,0 обозначает модифицированную интенсивность текущего отсчета, Pk,0 и Wk обозначают интенсивность и весовой параметр для k-го соседнего отсчета, соответственно. Пример одного текущего отсчета и соседних с ним четырех отсчетов (т.е. K=4) показан фиг. 24.
обозначает модифицированную интенсивность текущего отсчета, Pk,0 и Wk обозначают интенсивность и весовой параметр для k-го соседнего отсчета, соответственно. Пример одного текущего отсчета и соседних с ним четырех отсчетов (т.е. K=4) показан фиг. 24.
Более конкретно, весовой коэффициент Wk(x) , ассоциированный с k-ым соседним отсчетом, определен следующим образом:
, ассоциированный с k-ым соседним отсчетом, определен следующим образом:
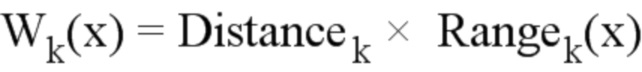 … (2)
… (2)
где
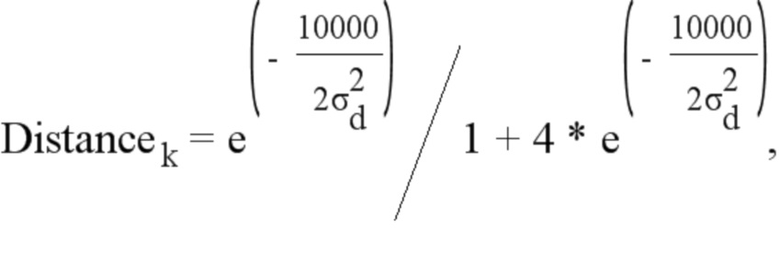 … (3)
… (3)

и параметр σd зависит от режима кодирования и размера блока кодирования. Описываемая процедура фильтрации применяется к блокам, кодированным с применением внутрикадрового прогнозирования, и к блокам, кодированным с применением межкадрового прогнозирования, когда единицу TU далее разбивают, чтобы позволить параллельную обработку.
зависит от режима кодирования и размера блока кодирования. Описываемая процедура фильтрации применяется к блокам, кодированным с применением внутрикадрового прогнозирования, и к блокам, кодированным с применением межкадрового прогнозирования, когда единицу TU далее разбивают, чтобы позволить параллельную обработку.
Для лучшего захвата статистических свойств сигнала видео и улучшения функционирования фильтра весовую функцию, полученную из Уравнения (2), корректируют с использованием параметра σd, приведенного в таблице 5 в зависимости от режима кодирования и параметров разбиения блоков (минимальный размер).
Таблица 5. Значения параметра σd для разных размеров блоков и режимов кодирования
Для дальнейшего улучшения характеристик кодирования, для блоков, кодированных с применением межкадрового прогнозирования, когда единица TU не разделена, разность интенсивностей между текущим отсчетом и одним из соседних с ним отсчетов заменяют репрезентативной разностью интенсивностей между двумя окнами, покрывающими текущий отсчет и указанный соседний отсчет. Поэтому уравнение для процесса фильтрации оказывается пересмотрено и приведено к виду:
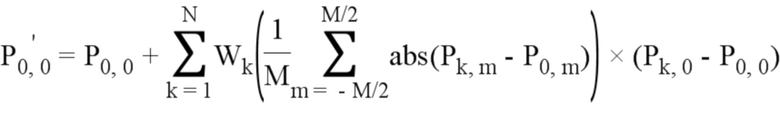 … (4)
… (4)
Здесь, Pk,m и P0,m
и P0,m представляют значение m-го отсчета в окнах, центрированных в точках Pk,0 и P0,0, соответственно. В этом предложении размер окна устанавливают равным 3×3. Пример двух окон, покрывающих отсчеты P2,0 и P0,0 показан на фиг. 25.
представляют значение m-го отсчета в окнах, центрированных в точках Pk,0 и P0,0, соответственно. В этом предложении размер окна устанавливают равным 3×3. Пример двух окон, покрывающих отсчеты P2,0 и P0,0 показан на фиг. 25.
2.8.3. Фильтр в области преобразования Адамара (Hadamard transform domain filter (HF))
В документе JVET-K0068, предложен внутриконтурный фильтр в области одномерного (1D) преобразования Адамара, применяемый на уровне единиц CU после реконструкции и реализованный без применения умножения. Предлагаемый фильтр применяется ко всем блокам единиц CU, удовлетворяющим заданному условию, а параметры фильтра получают из кодированной информации.
Предлагаемая фильтрация всегда применяется к реконструированным блокам яркостной составляющей с ненулевыми коэффициентами преобразования, исключая блоки размером 4x4 и случай, когда параметр квантования среза больше 17. Параметры фильтра выводят в явном виде из кодированной информации. Предлагаемый фильтр, если применяется, обрабатывает декодированные отсчеты сразу после обратного преобразования.
Для каждого пикселя из реконструированного блока обработка содержит следующие этапы:
• Сканирование 4 соседних пикселей вокруг обрабатываемого пикселя, включая текущий пиксель, согласно схеме сканирования
• 4-точечное преобразование Адамара прочитанных пикселей
•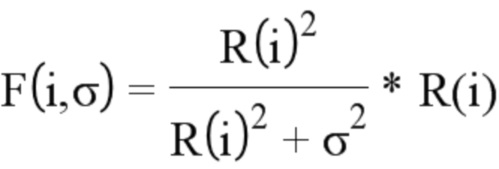 Спектральная фильтрация на основе следующей формулы:
Спектральная фильтрация на основе следующей формулы:
Здесь, (i) обозначает индекс спектральной составляющей в спектре Адамара, R(i) обозначает спектральную составляющую реконструированного пикселя, соответствующую индексу, σ обозначает параметр фильтрации, полученный из параметра квантования (quantization parameter (QP)) кодека с использованием следующего уравнения:

Пример схемы сканирования показан на фиг. 26.
Для пикселей, лежащих на границе единицы CU, схему сканирования корректируют, обеспечивая, чтобы все требуемые пиксели находились внутри текущей единицы CU.
3. Недостатки существующих вариантов реализации
В существующих вариантах реализации переформирования ILR могут иметь место следующие недостатки:
1. Есть возможность, что информация о модели переформирования никогда не была передана в виде сигнализации в последовательности, но флаг tile_group_reshaper_enable_flag устанавливают равным 1 в текущем срезе (или группе плиток).
2. Сохраненная модель переформирования может приходить из среза (или группы плиток), который не может быть использован в качестве опоры.
3. Одно изображение может быть разбито на несколько срезов (или групп плиток), и каждый срез (или группа плиток) может сигнализировать информацию о модели переформирования.
4. Некоторые значения и диапазоны (такие как диапазон RspCW [i]) определены только тогда, когда битовая глубина равна 10.
5. Параметр reshape_model_delta_max_bin_idx не является хорошо ограниченным.
6. Параметр reshaper_model_bin_delta_abs_cw_prec_minus1 не является хорошо ограниченным.
7. Параметр ReshapePivot[ i ] может быть больше 1<<BitDepth -1.
8. Фиксированные параметры усечения (т.е. минимальное значение равно 0 и максимальное значение равно (1 << BD) -1 ) используются без учета использования переформирования ILR. Здесь, BD обозначает битовую глубину.
9. Операция переформирования для цветностных составляющих учитывает только цветовой формат 4:2:0.
10. В отличие от яркостной составляющей, где каждое значение яркостной составляющей может быть переформировано отлично от других, только один фактор выбирают и используют для цветностных составляющих. Такое масштабирование может быть объединено с этапом квантования/деквантования для уменьшения дополнительной сложности.
11. Усечение в рамках процедуры обратного отображения изображения может учитывать верхнюю границу и нижнюю границу по отдельности.
12. Параметр ReshapePivot[ i ] для i, который не находится в диапазоне reshaper_model_min_bin_idx < = i <= reshaper_model_max_bin_idx не устанавливается правильно.
4. Примеры вариантов и способов
Варианты, подробно описываемые ниже, следует рассматривать в качестве примеров для пояснения общих концепций. Эти варианты не следует интерпретировать узко. Более того, эти варианты можно комбинировать каким-либо способом.
1. Предлагается инициализировать модель переформирования прежде декодирования последовательности.
a. В качестве альтернативы, модель переформирования инициализируют прежде декодирования I-среза (или изображения или группы плиток).
b. В качестве альтернативы, модель переформирования инициализируют прежде декодирования среза (или изображения или группы плиток) для мгновенного обновления декодирования (instantaneous decoding refresh (IDR)).
c. В качестве альтернативы, модель переформирования инициализируют прежде декодирования среза (или изображения или группы плиток) для чистого произвольного доступа (clean random access (CRA)).
d. В качестве альтернативы, модель переформирования инициализируют прежде декодирования среза (или изображения или группы плиток) с точкой произвольного доступа при внутрикадровом прогнозировании (intra random access point (I-RAP)). Совокупность срезов (или изображений или групп плиток) I-RAP-типа может содержать срезы (или изображения или группы плиток) IDR-типа и/или срезы (или изображения или группы плиток) CRA-типа и/или срезы (или изображения или группы плиток) с доступом к прерванным линиям (broken link access (BLA)).
e. В одном из примеров инициализации модели переформирования, параметр OrgCW устанавливают равным (1 << BitDepthY ) / ( MaxBinIdx + 1). ReshapePivot[ i ] = InputPivot [ i ] = i * OrgCW для i = 0, 1,…, MaxBinIdx;
f. В одном из примеров инициализации модели переформирования, ScaleCoef[ i ] = InvScaleCoeff[ i ]= 1 << shiftY для i = 0, 1,…, MaxBinIdx;
g. В одном из примеров инициализации модели переформирования, параметр OrgCW устанавливают равным (1 << BitDepthY ) / ( MaxBinIdx + 1). RspCW[ i ] = OrgCW для i = 0, 1,…, MaxBinIdx.
h. В качестве альтернативы, информация по умолчанию о модели переформирования может быть передана в виде сигнализации на уровне последовательности (как в наборе SPS), или на уровне изображения (как в наборе PPS) и модель переформирования инициализируют в качестве модели по умолчанию.
i. В качестве альтернативы, когда модель переформирования не инициализирована, ограничивают, что переформирование ILR не должно быть активизировано.
2. Предлагается, что информация о модели переформирования (такая как информация в параметре tile_group_reshaper_model( )) может быть передана в виде сигнализации только в I-срезе (или изображении, или группе плиток).
a. В качестве альтернативы, информация о модели переформирования (такая как информация в параметре tile_group_reshaper_model( )) может быть передана в виде сигнализации только в IDR-срезе (или изображении, или группе плиток).
b. В качестве альтернативы, информация о модели переформирования (такая как информация в параметре tile_group_reshaper_model( )) может быть передана в виде сигнализации только в CRA-срезе (или изображении, или группе плиток).
c. В качестве альтернативы, информация о модели переформирования (такая как информация в параметре tile_group_reshaper_model( )) может быть передана в виде сигнализации только в I-RAP-срезе (или изображении, или группе плиток). Совокупность срезов I-RAP-типа (или изображений или групп плиток) может содержать срезы (или изображения или группы плиток) IDR-типа и/или срезы (или изображения или группы плиток) CRA-типа и/или срезы (или изображения или группы плиток) с доступом к прерванным линиям (BLA).
d. В качестве альтернативы, информация о модели переформирования (такая как информация в параметре tile_group_reshaper_model( )) может быть передана в виде сигнализации на уровне последовательности (как в наборе SPS), или на уровне изображения (как в наборе PPS), или в наборе APS.
3. Предлагается не допустить использования информации о переформировании из одного изображения/среза/группы плиток для определенных типов изображений (таких как IRAP-изображения).
a. В одном из примеров, информация о модели переформирования, сообщаемая в виде сигнализации в первом срезе (или изображении, или группе плиток), не может быть использована вторым срезом (или изображением, или группой плиток), если I-срез (или изображение, или группу плиток) передают после первого среза (или изображения или группы плиток), но прежде второго среза (или изображения или группы плиток), или второй срез (или изображение, или группа плиток) сам является I-срезом (или изображением, или группой плиток).
b. В качестве альтернативы, информация о модели переформирования, сообщаемая в виде сигнализации в первом срезе (или изображении, или группе плиток), не может быть использована вторым срезом (или изображением, или группой плиток), если IDR-срез (или изображение, или группу плиток) передают после первого среза (или изображения или группы плиток), но прежде второго среза (или изображения или группы плиток), либо второй срез (или изображение, или группа плиток) сам является IDR-срезом (или изображением, или группой плиток).
c. В качестве альтернативы, информация о модели переформирования, сообщаемая в виде сигнализации в первом срезе (или изображении, или группе плиток), не может быть использована вторым срезом (или изображением, или группой плиток), если CRA-срез (или изображение, или группу плиток) передают после первого среза (или изображения или группы плиток), но прежде второго среза (или изображения или группы плиток), либо второй срез (или изображение, или группа плиток) сам является CRA-срезом (или изображением, или группой плиток).
d. В качестве альтернативы, информация о модели переформирования, сообщаемая в виде сигнализации в первом срезе (или изображении, или группе плиток), не может быть использована вторым срезом (или изображением, или группой плиток), если I-RAP-срез (или изображение, или группу плиток) передают после первого среза (или изображения или группы плиток), но прежде второго среза (или изображения или группы плиток), либо второй срез (или изображение, или группа плиток) сам является I-RAP-срезом (или изображением, или группой плиток). Совокупность срезов I-RAP-типа (или изображений или групп плиток) может содержать срезы (или изображения или группы плиток) IDR-типа и/или срезы (или изображения или группы плиток) CRA-типа и/или срезы (или изображения или группы плиток) с доступом к прерванным линиям (BLA).
4. В одном из примеров, флаг передают в виде сигнализации в I-срезе (или изображении или группе плиток). Если флаг равен X, информацию о модели переформирования передают в виде сигнализации в этом срезе (или изображении или группе плиток), В противном случае, the модель переформирования инициализируют прежде декодирования этого среза (или изображения, или группы плиток). Например, X = 0 или 1.
a. В качестве альтернативы, флаг передают в виде сигнализации в IDR-срезе (или изображении, или группе плиток). Если флаг равен X, информацию о модели переформирования сообщают в виде сигнализации в этом срезе (или изображении, или группе плиток), В противном случае, модель переформирования инициализируют прежде декодирования этого среза (или изображения, или группы плиток). Например, X = 0 или 1.
b. В качестве альтернативы, флаг передают в виде сигнализации в CRA-срезе (или изображении, или группе плиток). Если флаг равен X, информацию о модели переформирования сообщают в виде сигнализации в этом срезе (или изображении, или группе плиток), В противном случае, модель переформирования инициализируют прежде декодирования этого среза (или изображения, или группы плиток). Например, X = 0 или 1.
c. В качестве альтернативы, флаг передают в виде сигнализации в I-RAP-срезе (или изображении, или группе плиток). Если флаг равен X, информацию о модели переформирования сообщают в виде сигнализации в этом срезе (или изображении, или группе плиток), В противном случае, модель переформирования инициализируют прежде декодирования этого среза (или изображения, или группы плиток). Например, X = 0 или 1. Совокупность срезов I-RAP-типа (или изображений или групп плиток) может содержать срезы (или изображения или группы плиток) IDR-типа и/или срезы (или изображения или группы плиток) CRA-типа и/или срезы (или изображения или группы плиток) с доступом к прерванным линиям (BLA).
5. В одном из примеров, если одно изображение разбивают на несколько срезов (или групп плиток), каждый срез (или группа плиток) должен совместно с другими использовать одну и ту же информацию о модели переформирования.
a. В одном из примеров, если одно изображение разбивают на несколько срезов (или групп плиток), только первый срез (или группа плиток) должен сообщать в виде сигнализации информацию о модели переформирования.
6. Переменные, используемые при переформировании, следует инициализировать, манипулировать и ограничивать в зависимости от битовой глубины.
a. В одном из примеров, MaxBinIdx = f(BitDepth), где f – некоторая функция. Например, MaxBinIdx=4*2(BitDepth-8)-1
b. В одном из примеров, параметр RspCW [ i ] должен быть в диапазоне от g(BitDepth) до 2 * OrgCW - 1. Например, параметр RspCW [ i ] должен быть в диапазоне от 8*2(BitDepth-8) до 2 * OrgCW - 1.
7. В одном из примеров, ScaleCoef[ i ] = InvScaleCoeff[ i ]= 1 << shiftY, если RspCW[ i ] равно 0, для i = 0, 1,…, MaxBinIdx.
8. Предлагается, что параметр reshape_model_delta_max_bin_idx должен быть в диапазоне от 0 до MaxBinIdx-reshape_model_min_bin_idx, включительно.
a. В качестве альтернативы, параметр reshape_model_delta_max_bin_idx должен быть в диапазоне от 0 до MaxBinIdx, включительно.
b. В одном из примеров, параметр reshape_model_delta_max_bin_idx усечен для преобразования в диапазон от 0 до MaxBinIdx-reshape_model_min_bin_idx, включительно.
c. В одном из примеров, параметр reshape_model_delta_max_bin_idx усечен для преобразования в диапазон от 0 до MaxBinIdx, включительно.
d. В одном из примеров, параметр reshaper_model_min_bin_idx должен быть не больше параметра reshaper_model_max_bin_idx.
e. В одном из примеров, параметр reshaper_model_max_bin_idx усечен для преобразования в диапазон от reshaper_model_min_bin_idx до MaxBinIdx, включительно.
f. В одном из примеров, параметр reshaper_model_min_bin_idx усечен для преобразования в диапазон от 0 до reshaper_model_max_bin_idx, включительно.
g. Одно или несколько из приведенных выше ограничений могут потребоваться для соответствующего потока битов данных.
9. Предлагается устанавливать параметр reshape_model_max_bin_idx равным reshape_model_min_bin_idx +reshape_model_delta_maxmin_bin_idx, где параметр reshape_model_delta_maxmin_bin_idx, являющийся целым числом без знака, представляет собой синтаксический элемент, сообщаемый в виде сигнализации после параметра reshape_model_min_bin_idx.
b. В одном из примеров, параметр reshape_model_delta_maxmin_bin_idx должен быть в диапазоне от 0 до MaxBinIdx- reshape_model_min_bin_idx, включительно.
c. В одном из примеров, параметр reshape_model_delta_maxmin_bin_idx должен быть в диапазоне от 1 до MaxBinIdx- reshape_model_min_bin_idx, включительно.
d. В одном из примеров, параметр reshape_model_delta_maxmin_bin_idx должен быть усечен для преобразования в диапазон от 0 до MaxBinIdx- reshape_model_min_bin_idx, включительно.
e. В одном из примеров, параметр reshape_model_delta_maxmin_bin_idx должен быть усечен для преобразования в диапазон от 1 до MaxBinIdx- reshape_model_min_bin_idx, включительно.
f. Одно или несколько из приведенных выше ограничений могут потребоваться для соответствующего потока битов данных.
10. Предлагается, что параметр reshaper_model_bin_delta_abs_cw_prec_minus1 должен быть меньше порогового значения T.
a. В одном из примеров, значение T может быть фиксированным числом, таким как 6 или 7.
b. В одном из примеров, значение T может зависеть от битовой глубины.
c. Приведенные выше ограничения могут потребоваться для соответствующего потока битов данных.
11. Предлагается, что параметр RspCW[ i ] может быть предсказан посредством параметра RspCW[ i -1], т.е. RspCW[ i ] = RspCW[ i -1] + RspDeltaCW[ i ].
a. В одном из примеров, параметр RspCW[ i ] может быть предсказан посредством параметра RspCW[ i -1], когда reshaper_model_min_bin_idx < = i <= reshaper_model_max_bin_idx.
b. В одном из примеров, параметр RspCW[ i ] прогнозируют посредством параметра OrgCW, т.е. RspCW[ i ] = OrgCW + RspDeltaCW[ i ], когда i равно 0.
c. В одном из примеров, параметр RspCW[ i ] прогнозируют посредством параметра OrgCW, т.е. RspCW[ i ] = OrgCW + RspDeltaCW[ i ], когда i равно reshaper_model_min_bin_idx.
12. Предлагается никогда не передавать сигнализацию о параметре reshape_model_bin_delta_sign_CW [ i ], и параметр RspDeltaCW[ i ] = reshape_model_bin_delta_abs_CW [ i ] всегда является положительным целым числом.
a. В одном из примеров, RspCW[ i ] = MinV + RspDeltaCW[ i ].
i. В одном из примеров, MinV = 32;
ii. В одном из примеров, MinV = g(BitDepth). Например, MinV = 8*2(BitDepth-8).
13. Вычисление параметра invAvgLuma может зависеть от цветового формата.
a. В одном из примеров, invAvgLuma = Clip1Y( ( ΣiΣj predMapSamples[ (xCurr << scaleX ) + i ][ (yCurr << scaleY) + j ]
+ ((nCurrSw<<scaleX) * (nCurrSh<<scaleY) >>1)) / ( (nCurrSw<<scaleX) * (nCurrSh<<scaleY) ) )
i. scaleX=scaleY=1 для формата 4:2:0;
ii. scaleX=scaleY=0 для формата 4:4:4;
iii. scaleX = 1и scaleY = 0 для формата 4:2:2.
14. Предлагается, что при усечении в процедуре обратного отображения изображения верхняя граница и нижняя граница могут рассматриваться по отдельности.
a. В одном из примеров, invLumaSample = Clip3(minVal, maxVal, invLumaSample), minVal, maxVal вычисляют в соответствии с различными условиями.
i. Например, minVal = T1 << (BitDepth – 8), если reshape_model_min_bin_idx > 0; В противном случае, minVal=0; e.g. T1 = 16.
ii. Например, maxVal = T2 << (BitDepth – 8), если reshape_model_max_bin_idx < MaxBinIdx; В противном случае, maxVal =(1<< BitDepth)-1; e.g. T2 = 235. В другом примере, T2 = 40.
15. Предлагается, что параметр ReshapePivot[ i ] должен быть ограничен как ReshapePivot[ i ]<=T. Например, T = (1<< BitDepth)-1.
a. Например, ReshapePivot[ i + 1 ] = min(ReshapePivot[ i ] + RspCW[ i ], T).
16. Вместо переформирования каждого значения остатка в области пикселей для цветностных составляющих, сдвиг параметра QP для цветностной составляющей (обозначен как dChromaQp) может быть выведен в неявном виде для каждого блока или единицы TU, и может быть добавлен к параметру QP для цветностной составляющей. При таком подходе переформирование цветностных составляющих объединено в процедуре квантования/деквантования.
a. В одном из примеров, параметр dChromaQp может быть определен на основе репрезентативного значения яркостной составляющей, обозначенной как repLumaVal.
b. В одном из примеров, значение repLumaVal может быть определено с использованием части или всех прогнозируемых значений яркостной составляющей для блока или для единицы TU.
c. В одном из примеров, значение repLumaVal может быть определено с использованием части или всех реконструированных значений яркостной составляющей для блока или для единицы TU.
d. В одном из примеров, значение repLumaVal может быть определена как результат усреднения части или всех прогнозируемых или реконструированных значений яркостной составляющей для блока или для единицы TU.
e. Предположим, что ReshapePivot[ idx ] <= repLumaVal < ReshapePivot[ idx + 1 ], тогда параметр InvScaleCoeff[ idx ] может быть использован для определения параметра dChromaQp.
i. В одном из примеров, параметр dQp может быть выбран как argmin abs(2^(x/6 + shiftY) – InvScaleCoeff[ idx ]), x = -N…, M. Например, N = M = 63.
ii. В одном из примеров, параметр dQp может быть выбран как argmin abs(1 – (2^(x/6 + shiftY) / InvScaleCoeff[ idx ])), x = -N…, M. Например, N = M = 63.
iii. В одном из примеров, для разных значений InvScaleCoeff[ idx ] параметр dChromaQp может быть предварительно вычислен и сохранен в преобразовательной таблице.
17. Вместо переформирования каждого значения остатка в области пикселей для яркостных составляющих, сдвиг параметра QP для яркостной составляющей (обозначен как dQp) может быть выведен в неявном виде для каждого блока или единицы TU, и может быть добавлен к параметру QP для яркостной составляющей. При таком подходе переформирование яркостной составляющей объединено в процедуре квантования/деквантования.
a. В одном из примеров, параметр dQp может быть определен на основе репрезентативного значения яркостной составляющей, обозначенного как repLumaVal.
b. В одном из примеров, значение repLumaVal может быть определено с использованием части или всех прогнозируемых значений яркостной составляющей для блока или для единицы TU.
c. В одном из примеров, значение repLumaVal может быть определено как результат усреднения части или всех прогнозируемых значений яркостной составляющей для блока или для единицы TU.
d. Предположим, что idx = repLumaVal / OrgCW, тогда параметр InvScaleCoeff[ idx ] может быть испольнован для определения параметра dQp.
i. В одном из примеров, параметр dQp может быть выбран как argmin abs(2^(x/6 + shiftY) – InvScaleCoeff[ idx ]), x = -N…, M. Например, N = M = 63.
ii. В одном из примеров, параметр dQp может быть выбран как argmin abs(1 – (2^(x/6 + shiftY) / InvScaleCoeff[ idx ])), x = -N…, M. Например, N = M = 63.
iii. В одном из примеров, для разных значений InvScaleCoeff[ idx ], параметр dQp может быть предварительно вычислен и сохранен в преобразовательной таблице.
В этом случае, параметр dChromaQp может быть установлен равным параметру dQp.
5. Примеры реализации предлагаемой технологии
На фиг. 27A представлена блок-схема устройства 2700 для обработки видео. Устройство 2700 может быть использовано для реализации одного или нескольких описываемых здесь способов. Это устройство 2700 может представлять собой смартфон, планшетный компьютер, обычный компьютер, приемник Интернет вещей (Internet of Things (IoT)) и т.д. Устройство 2700 может содержать один или несколько процессоров 2702, одно или несколько запоминающих устройств 2704 и аппаратуру 2706 для обработки видео. Процессор (ы) 2702 может быть конфигурирован для реализации одного или нескольких способов, описываемых в настоящем документе. Запоминающее устройство (устройства) 2704 может быть использовано для сохранения данных и кода, применяемых для реализации способов и технологий, описываемых здесь. Аппаратура 2706 для обработки видео может быть использована для реализации, в аппаратной схеме, некоторых технологий, описываемых в настоящем документе, может частично или полностью быть частью процессоров 2702 (например, представлять собой графическое процессорное ядро GPU или другую схему обработки сигнала).
На фиг. 27B представлен другой пример блок-схемы системы обработки видео, в которой может быть реализована предлагаемая технология. На фиг. 27B представлена блок-схема, показывающая пример системы 4100 обработки видео, где могут быть реализованы разнообразные способы, описываемые здесь. Различные варианты реализации могут содержать некоторые или все компоненты системы 4100. Система 4100 может иметь вход 4102 для приема контента видео. Этот контент видео может быть принят в исходном или в несжатом формате, например, 8 или 10-битовые многокомпонентные значения пикселей, либо может быть в сжатом или кодированном формате. Вход 4102 может представлять сетевой интерфейс, интерфейс шины периферийных устройств или интерфейс запоминающего устройства. К примерам сетевых интерфейсов относятся проводные интерфейсы, такие как Этернет, пассивная оптическая сеть (passive optical network (PON)) и т.д., и беспроводные интерфейсы, такие Wi-Fi или сотовые интерфейсы.
Система 4100 может содержать кодирующий компонент 4104, которые может осуществлять разнообразные способы кодирования, описываемые в настоящем документе. Кодирующий компонент 4104 может уменьшить среднюю частоту передачи битов данных видео, поступающего от входа 4102 к выходу кодирующего компонента 4104 для получения кодированного представления видео. Поэтому такие способы кодирования иногда называют способами сжатия (компрессии) видео или способами транскодирования видео. Выходной сигнал кодирующего компонента 4104 может быть либо сохранен, либо передан по присоединенной линии связи, как это представлено компонентом 4106. Это сохраненное или переданное в потоке битов данных (или кодированное) представление видео, принятого на вход 4102, может быть использовано компонентом 4108 для генерации значений пикселей или представляемого на дисплее видео, которое передают интерфейсу 4110 дисплея. Процесс генерации наблюдаемого пользователем видео из представления в форме потока битов данных иногда называется расширением (или декомпрессией) видео. Кроме того, хотя определенные операции обработки видео называются операциями или инструментами «кодирования», должно быть понятно, что инструменты или операции кодирования используются в кодирующем устройстве, а соответствующие инструменты или операции декодирования, обращающие результаты кодирования будут производиться в декодирующем устройстве.
К примерам интерфейса шины периферийных устройств или интерфейса дисплея относятся универсальная последовательная шина (universal serial bus (USB)) или мультимедийный интерфейс высокой четкости (high definition multimedia interface (HDMI)) или Displayport, и т.д. К примерам интерфейса запоминающих устройств относятся интерфейс усовершенствованного последовательного соединения (SATA (serial advanced technology attachment)), интерфейс периферийных устройств (PCI), интерфейс IDE и другие подобные интерфейсы. Способы, описываемые в настоящем документе, могут быть реализованы в разнообразных электронных устройствах, таких как мобильные телефоны, портативные компьютеры, смартфоны или другие устройства, способные осуществлять цифровую обработку данных и/или представлять видео на дисплее.
В настоящем документе термин «обработка видео» может обозначать кодирование видео, декодирование видео, сжатие видео или расширение (декомпрессию) видео. Например, алгоритмы сжатия видео могут быть применены в процессе преобразования от пиксельного представления видео в соответствующее представление в форме потока битов данных или наоборот. Представление текущего видео блока в форме потока битов данных может, например, соответствовать битам, которые либо расположены в одном месте, либо распределены в разных местах в потоке битов данных, как это определено в синтаксисе. Например, макроблок может быть кодирован в терминах трансформированных и кодированных остаточных значений ошибок, а также использования битов в заголовках и в других полях в потоке битов данных.
Следует понимать, что рассмотренные здесь способы и технологии дадут преимущества для вариантов кодирующего устройства для видео и/или декодирующего устройства для видео, встроенных в устройства для обработки видео, такие как смартфоны, портативные компьютеры, настольные компьютеры и другие подобные устройства, позволяя пользователю использовать технологии, описываемые в настоящем документе.
На фиг. 28A представлена логическая схема примера способа 2810 обработки видео. Этот способ 2810 содержит, на этапе 2812, определение, для преобразования между несколькими видео единицами из видео области видеоролика и кодированным представлением этих нескольких видео единиц, информации о модели переформирования, которая совместно используется этими несколькими видео единицами. Способ 2810 далее содержит, на этапе 2814, осуществление преобразования между кодированным представлением видеоролика и самим этим видеороликом.
На фиг. 28B представлена логическая схема примера способа 2820 обработки видео. Этот способ 2820 содержит, на этапе 2822, определение, для преобразования между кодированным представлением видеоролика, содержащего одну или несколько видео областей, и самим этим видео роликом, значения некой переменной в информации о модели переформирования в функции битовой глубины видеоролика. Способ 2820 далее содержит, на этапе 2824, осуществление преобразования на основе результата определения.
На фиг. 28C представлена логическая схема примера способа 2830 обработки видео. Этот способ 2830 содержит, на этапе 2832, определение, для преобразования между кодированным представлением видеоролика, содержащего одну или несколько видео областей, и самим этим видео роликом, следует ли активизировать или отменить активизацию внутриконтурного переформирования (ILR). Способ 2830 далее содержит, на этапе 2834, осуществление преобразования на основе результата определения. В некоторых вариантах реализации, процедура определения решает, что следует отменить активизацию переформировании ILR в случае, когда информация о модели переформирования не инициализирована.
На фиг. 28D представлена логическая схема примера способа 2840 обработки видео. Этот способ 2840 содержит, на этапе 2842, определение, для преобразования между первой видео областью видеоролика и кодированным представлением этой первой видео области, может ли информация о переформировании из второй видео области быть использована для преобразования на основе некоторого правила. Способ 2840 далее содержит, на этапе 2844, осуществление преобразования на основе результата определения.
На фиг. 28E представлена логическая схема примера способа 2850 обработки видео. Этот способ 2850 содержит, на этапе 2852, осуществление преобразования между кодированным представлением видеоролика, содержащего одну или несколько видео областей, и самим этим видеороликом. В некоторых вариантах реализации, кодированное представление содержит информацию о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из совокупности указанных одной или нескольких видео областей. В некоторых вариантах реализации, информация о модели переформирования предоставляет информацию для реконструкции видео единицы видео области на основе представления видео единицы в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видео единицы цветностной составляющей. В некоторых вариантах реализации, информация о модели переформирования была инициализирована на основе правила инициализации. В некоторых вариантах реализации, информацию о модели переформирования включают в кодированное представление только в том случае, если рассматриваемую видео область кодируют с использованием конкретного типа кодирования. В некоторых вариантах реализации, осуществляют преобразование между текущей видео областью видеоролика и кодированным представлением этой текущей видео области, так что эту текущую видео область кодируют с использованием некого конкретного типа кодирования, где это кодированное представление соответствует правилу форматированию, условно специфицирующему информацию о модели переформирования в кодированном представлении на основе значения флага в кодированном представлении на уровне видео области.
В некоторых вариантах реализации, информация о модели переформирования предоставляет информацию для реконструкции видео единицы видео области на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видео единицы цветностной составляющей. В некоторых вариантах реализации, информация о модели переформирования содержит набор параметров, имеющий синтаксический элемент, специфицирующий разность между допустимым максимальным индексом бина и максимальным индексом бина, который должен быть использован при реконструкции, и где параметр находится в некотором диапазоне. В некоторых вариантах реализации, информация о модели переформирования содержит набор параметров, имеющий максимальный индекс бина, который должен быть использован при реконструкции, и где этот максимальный индекс бина определяют в качестве первого значения, равного сумме минимального индекса бина, который должен быть использован при реконструкции, и синтаксического элемента, представляющего собой целое число без знака и передаваемого в виде сигнализации после минимального индекса бина.
В некоторых вариантах реализации, информация о модели переформирования содержит набор параметров, куда входит первый синтаксический элемент, определяющий число битов, используемых для представления второго синтаксического элемента, специфицирующего абсолютное значение кодового слова приращения от соответствующего бина, и первый синтаксический элемент имеет значение меньше порогового значения. В некоторых вариантах реализации, информация о модели переформирования содержит набор параметров, куда входит i-ый параметр, который представляет крутизну i-ого бина, используемой при переформировании ILR, и имеет значение на основе (i-1)-го параметра, i является положительным целым числом. В некоторых вариантах реализации, информация о модели переформирования, используемая для переформирования ILR, содержит набор параметров, куда входит параметр reshape_model_bin_delta_sign_CW [ i ], не передаваемый в виде сигнализации, и параметр RspDeltaCW[ i ] = reshape_model_bin_delta_abs_CW [ i ] всегда является положительным числом. В некоторых вариантах реализации, информация о модели переформирования содержит набор параметров, куда входит параметр, invAvgLuma, для использования значений яркостной составляющей для масштабирования в зависимости от цветового формата рассматриваемой видео области. В некоторых вариантах реализации, процедура преобразования содержит процедуру обратного отображения изображения с целью трансформации реконструированных отсчетов яркостной составляющей изображения в модифицированные реконструированные отсчеты яркостной составляющей изображения, и процедура обратного отображения изображения содержит усечение, для которого верхнюю границу и нижнюю границу устанавливают отдельно одну от другой. В некоторых вариантах реализации, информация о модели переформирования содержит набор параметров, куда входит значение поворота, ограниченная так, что Pivot[ i ]<=T. В некоторых вариантах реализации, параметр (QP) квантования цветностной составляющей имеет сдвиг, значение которого определяют для каждого блока или единицы преобразования. В некоторых вариантах реализации, параметр (QP) квантования яркостной составляющей имеет сдвиг, значение которого определяют для каждого блока или единицы преобразования.
Различные способы и варианты могут быть описаны с использованием следующего постатейного формата.
Первая группа статей описывает определенные признаки и аспекты рассматриваемых способов, перечисленных в предыдущем разделе.
1. Способ обработки визуальных медиа данных, содержащий: осуществление преобразования между текущим видео блоком и представлением этого текущего видео блока в форме потока битов данных, где, в процессе преобразования, используют этап внутриконтурного переформирования для трансформации представления текущего видео блока из первой области во вторую область согласно дополнительной информации, ассоциированной с этапом внутриконтурного переформирования, где этот этап внутриконтурного переформирования основан частично на информации о модели переформирования, и где, в процессе преобразования, информацию о модели переформирования используют на одном или нескольких из следующих этапов: этапе инициализации, этапе передачи сигнализации или этапе декодирования.
2. Способ согласно статье 1, отличающийся тем, что этап декодирования относится к I-срезу, изображению или группе плиток.
3. Способ согласно статье 1, отличающийся тем, что этап декодирования относится к срезу с мгновенным обновлением декодирования (IDR), изображению или группе плиток.
4. Способ согласно статье 1, отличающийся тем, что этап декодирования относится к срезу для чистого произвольного доступа (CRA), изображению или группе плиток.
5. Способ согласно статье 1, отличающийся тем, что этап декодирования относится к срезу с точкой произвольного доступа при внутрикадровом прогнозировании (I-RAP), изображению или группе плиток.
6. Способ согласно статье 1, отличающийся тем, что I-RAP срез, изображение или группа плиток может содержать одно или более из: IDR-срез, изображение или группа плиток, CRA-срез, изображение или группа плиток, или срез с доступом к прерванным линиям (BLA), изображение или группа плиток.
7. Способ согласно какой-либо одной или нескольким из статей 1 – 6, отличающийся тем, что этап инициализации происходит прежде этапа декодирования.
8. Способ согласно какой-либо одной или нескольким из статей 1 – 7, отличающийся тем, что этап инициализации содержит установление значения OrgCW как (1 << BitDepthY ) / ( MaxBinIdx + 1). ReshapePivot[ i ] = InputPivot [ i ] = i * OrgCW, для i = 0, 1,…, MaxBinIdx, где OrgCW, BitDepthY, MaxBinIdx и ReshapePivot представляют собой значения, ассоциированные с информацией о модели переформирования.
9. Способ согласно какой-либо одной или нескольким из статей 1 – 7, отличающийся тем, что этап инициализации содержит установление значения как ScaleCoef[ i ] = InvScaleCoeff[ i ]= 1 << shiftY, для i = 0, 1,…, MaxBinIdx, где ScaleCoef, InvScaleCoeff и shiftY являются значениями, ассоциированными с информацией о модели переформирования.
10. Способ согласно какой-либо одной или нескольким из статей 1 – 7, отличающийся тем, что этап инициализации содержит установление значения OrgCW как (1 << BitDepthY ) / ( MaxBinIdx + 1). RspCW[ i ] = OrgCW для i = 0, 1,…, MaxBinIdx, a. OrgCW устанавливают равной (1 << BitDepthY ) / ( MaxBinIdx + 1). RspCW[ i ] = OrgCW, для i = 0, 1,…, MaxBinIdx, где OrgCW, BitDepthY, MaxBinIdx и RspCW являются значениями, ассоциированными с информацией о модели переформирования.
11. Способ согласно статье 1, отличающийся тем, что этап инициализации содержит установление информации о модели переформирования на значения по умолчанию, и отличающийся тем, что этап сигнализации содержит передачу в виде сигнализации указанных значений по умолчанию, входящих в набор параметров последовательности (SPS) или в набор параметров изображения (PPS).
12. Способ согласно статье 1, дополнительно содержащий: после определения, что информация о модели переформирования не инициализирована во время этапа инициализации, отмену активизации этапа внутриконтурного переформирования.
13. Способ согласно статье 1, отличающийся тем, что, в ходе этапа сигнализации, информацию о модели переформирования передают в виде сигнализации в каком-либо из: I-срезе, изображении или группе плиток, IDR-срезе, изображении или группе плиток, срезе с точкой произвольного доступа при внутрикадровом прогнозировании (I-RAP), изображении или группе плиток.
14. Способ согласно статье 1, отличающийся тем, что I-RAP-срез, изображение или группа плиток может содержать одно или несколько из: IDR-срез, изображение или группа плиток, CRA-срез, изображение или группа плиток, или срез с доступом к прерванным линиям (BLA), изображение или группа плиток.
15. Способ согласно статье 1, отличающийся тем, что этап сигнализации содержит передачу в виде сигнализации информации о модели переформирования, входящей в набор параметров последовательности (SPS) или в набор параметров изображения (PPS).
16. Способ обработки визуальных медиа данных, содержащий: осуществление преобразования между текущим видео блоком и представлением этого текущего видео блока в форме потока битов данных, где, во время преобразования, этап внутриконтурного переформирования используют для трансформации представления текущего видео блока из первой области во вторую область в соответствии с дополнительной информацией, ассоциированной с этапом внутриконтурного переформирования, где этот этап внутриконтурного переформирования основан частично на информации о модели переформирования, и где, во время преобразования, информацию о модели переформирования используют на одном или нескольких этапах: этап инициализации, этап сигнализации или этап декодирования и отменяют активизацию использования информации о модели переформирования во втором изображении, когда эту информацию о модели переформирования передают в виде сигнализации в первом изображении.
17. Способ согласно статье 16, дополнительно содержащий: если промежуточное изображение передают после первого изображения, но прежде второго изображения, отменяют активизацию использования информации о модели переформирования во втором изображении, когда эту информацию о модели переформирования передают в виде сигнализации в первом изображении.
18. Способ согласно статье 17, отличающийся тем, что второе изображение представляет собой I-изображение, IDR-изображение, CRA-изображение или I-RAP-изображение.
19. Способ согласно какой-либо одной или нескольким из статей 17 – 18, отличающийся тем, что промежуточное изображение представляет собой I-изображение, IDR-изображение, CRA-изображение или I-RAP-изображение.
20. Способ согласно какой-либо одной или нескольким из статей 16 – 19, отличающийся тем, что изображение содержит плитку или группу.
21. Способ обработки визуальных медиа данных, содержащий: осуществление преобразования между текущим видео блоком и представлением этого текущего видео блока в форме потока битов данных, где, во время преобразования, этап внутриконтурного переформирования используют для трансформации представления текущего видео блока из первой области во вторую область в соответствии с дополнительной информацией, ассоциированной с этапом внутриконтурного переформирования, где этап внутриконтурного переформирования основан частично на информации о модели переформирования, и где, во время преобразования, информацию о модели переформирования используют на одном или нескольких из: этапа инициализации, этапа сигнализации или этапа декодирования, и в ходе этапа сигнализации, передают в виде сигнализации флаг в изображении, так что на основе этого флага в изображении передают информацию о модели переформирования, в противном случае информацию о модели переформирования инициализируют на этапе инициализации прежде декодирования изображения на этапе декодирования.
22. Способ согласно статье 21, отличающийся тем, что изображение представляет собой I-изображение, IDR-изображение, CRA-изображения или I-RAP-изображения.
23. Способ согласно какой-либо одной или нескольким из статей 21-22, отличающийся тем, что рассматриваемое изображение содержит плитку или группу.
24. Способ согласно статье 21, отличающийся тем, что указанный флаг имеет значение 0 или 1.
25. Способ обработки визуальных медиа данных, содержащий: осуществление преобразования между текущим видео блоком и представлением этого текущего видео блока в форме потока битов данных, где, во время преобразования, этап внутриконтурного переформирования используют для трансформации представления текущего видео блока из первой области во вторую область в соответствии с дополнительной информацией, ассоциированной с этапом внутриконтурного переформирования, где этот этап внутриконтурного переформирования основан частично на информации о модели переформирования, и где, во время преобразования, информацию о модели переформирования используют на одном из нескольких из этапов: этапе инициализации, этапе сигнализации или этапе декодирования, и после разбиения изображения на множество единиц, информация о модели переформирования, ассоциированной с каждой из этих нескольких единиц, является одинаковой.
26. Способ обработки визуальных медиа данных, содержащий: осуществление преобразования между текущим видео блоком и представлением этого текущего видео блока в форме потока битов данных, где, во время преобразования, этап внутриконтурного переформирования используют для трансформации представления текущего видео блока из первой области во вторую область в соответствии с дополнительной информацией, ассоциированной с этапом внутриконтурного переформирования, где этап внутриконтурного переформирования основан частично на информации о модели переформирования, и где, во время преобразования, эту информацию о модели переформирования используют на одном или нескольких этапах: этапе инициализации, этапе сигнализации или этапе декодирования, и после разбиения изображения на множество единиц, информацию о модели переформирования передают в виде сигнализации только в первой из этого множества единиц.
27. Способ согласно какой-либо одной или нескольким из статей 25-26, отличающийся тем, что указанная единица соответствует срезу или группе плиток.
28. Способ обработки визуальных медиа данных, содержащий: осуществление преобразования между текущим видео блоком и представлением этого текущего видео блока в форме потока битов данных, где, во время преобразования, этап внутриконтурного переформирования используют для трансформации текущего видео блока из первой области во вторую область в соответствии с дополнительной информацией, ассоциированной с этапом внутриконтурного переформирования, где этот этап внутриконтурного переформирования основан частично на информации о модели переформирования, и где, во время преобразования, указанную информацию о модели переформирования используют на одном или нескольких этапах: этапе инициализации, этапе сигнализации или этапе декодирования, и где информацией о модели переформирования манипулируют на основе битовой глубины.
29. Способ согласно статье 28, отличающийся тем, что информация о модели переформирования содержит переменную MaxBinIdx, относящуюся к битовой глубине.
30. Способ согласно статье 28, отличающийся тем, что информация о модели переформирования содержит переменную RspCW, относящуюся к битовой глубине.
30. Способ согласно статье 29, отличающийся тем, что информация о модели переформирования содержит переменную reshape_model_delta_max_bin_idx, значение которой находится в диапазоне от 0 до переменной MaxBinIdx.
31. Способ согласно статье 29, отличающийся тем, что информация о модели переформирования содержит переменную reshape_model_delta_max_bin_idx, значение которой усечено до диапазона от 0 и до значения, соответствующего MaxBinIdx - reshape_model_min_bin_idx, где reshape_model_min_bin_idx является другой переменной в информации о модели переформирования.
32. Способ согласно статье 29, отличающийся тем, что информация о модели переформирования содержит переменную reshape_model_delta_max_bin_idx, значение которой усечено до диапазона от 0 и до переменной MaxBinIdx.
33. Способ согласно статье 29, отличающийся тем, что информация о модели переформирования содержит переменную reshaper_model_min_bin_idx и переменную reshaper_model_delta_max_bin_idx, где переменная reshaper_model_min_bin_idx меньше переменной reshaper_model_min_bin_idx .
34. Способ согласно статье 29, отличающийся тем, что информация о модели переформирования содержит переменную reshaper_model_min_bin_idx и переменную reshaper_model_delta_max_bin_idx, где значение переменной reshaper_model_max_bin_idx усечена в диапазон, изменяющийся от значения переменной reshaper_model_min_bin_idx до значения переменной MaxBinIdx.
35. Способ согласно статье 29, отличающийся тем, что информация о модели переформирования содержит переменную reshaper_model_min_bin_idx и переменную reshaper_model_delta_max_bin_idx, где значение переменной reshaper_model_min_bin_idx усечено до диапазона от 0 и до значения reshaper_model_max_bin_idx.
36. Способ согласно статье 29, отличающийся тем, что информация о модели переформирования содержит переменную reshaper_model_bin_delta_abs_cw_prec_minus1, которая меньше порогового значения.
37. Способ согласно статье 36, отличающийся тем, что указанное пороговое значение представляет собой фиксированное число.
38. Способ согласно статье 36, отличающийся тем, что указанное пороговое значение основано на значении битовой глубины.
39. Способ согласно статье 28, отличающийся тем, что информация о модели переформирования содержит переменную invAvgLuma, вычисляемую как invAvgLuma = Clip1Y( ( ∑i∑j predMapSamples[ (xCurr << scaleX ) + i ][ (yCurr << scaleY) + j ]
+ ((nCurrSw<<scaleX) * (nCurrSh<<scaleY) >>1)) / ( (nCurrSw<<scaleX) * (nCurrSh<<scaleY) ) ).
40. Способ согласно статье 28, отличающийся тем, что scaleX=scaleY=1 для формата 4:2:0.
41 Способ согласно статье 28, отличающийся тем, что scaleX=scaleY=1 для формата 4:4:4.
42. Способ согласно статье 28, отличающийся тем, что scaleX = 1 и scaleY = 0 для формата 4:2:2.
43. Способ согласно статье 28, отличающийся тем, что информация о модели переформирования содержит переменную invLumaSample, вычисляемую как invLumaSample = Clip3(minVal, maxVal, invLumaSample).
44. Способ согласно статье 43, отличающийся тем, что minVal = T1 << (BitDepth – 8) if reshape_model_min_bin_idx > 0, в противном случае, minVal=0.
45. Способ согласно статье 43, отличающийся тем, что maxVal = T2 << (BitDepth – 8) if reshape_model_max_bin_idx < MaxBinIdx, в противном случае, maxVal =(1<< BitDepth)-1.
46. Способ согласно статье 44, отличающийся тем, что T1=16.
47. Способ согласно статье 45, отличающийся тем, что T2 принимает значение 235 или 40.
48. Способ согласно статье 28, отличающийся тем, что информация о модели переформирования содержит значение ReshapePivot, ограниченное так, что ReshapePivot[ i ]<=T.
49. Способ согласно статье 48, отличающийся тем, что значение T может быть вычислено как T = (1<< BitDepth)-1, где BitDepth соответствует битовой глубине.
50. Способ согласно какой-либо одной или нескольким из статей 1 – 49, отличающийся тем, что обработка видео реализована на стороне кодирующего устройства.
51. Способ согласно какой-либо одной или нескольким из статей 1 – 49, отличающийся тем, что обработка видео реализована на стороне декодирующего устройства.
52. Устройство в видео системе, содержащее процессор и энергонезависимое запоминающее устройство с записанными в нем командами, где при выполнении процессором этих команд процессор осуществляет способ согласно какой-либо одной или нескольким из статей 1 – 49.
53. Компьютерный программный продукт, сохраняемый на энергонезависимых читаемых компьютерах носителях информации, этот компьютерный программный продукт содержит программный код для осуществления способа согласно какой-либо одной или нескольким из статей 1 – 49.
Вторая группа статей описывает определенные признаки и аспекты рассматриваемой технологии, перечисленные в предыдущем разделе, включая, например, Пример 1 – 7.
1. Способ обработки видео содержащий: определение, для преобразования между несколькими видео единицами видео области видеоролика и кодированным представлением этих нескольких видео единиц, информации о модели переформирования, совместно используемой этими несколькими видео единицами; и осуществление преобразования между кодированным представлением видеоролика и самим этим видеороликом, где указанная информация о модели переформирования предоставляет информацию для построения видео отсчетов в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видео единицы цветностной составляющей.
2. Способ согласно статье 1, отличающийся тем, что указанные несколько видео единиц соответствуют нескольким срезам или нескольким группам плиток.
3. Способ согласно статье 2, отличающийся тем, что указанные несколько видео единиц ассоциированы с одним и тем же изображением.
4. Способ согласно статье 1, отличающийся тем, что информация о модели переформирования присутствует в кодированном представлении нескольких видео единиц только однажды.
5. Способ обработки видео содержащий: определение, для преобразования между кодированным представлением видеоролика, содержащим одну или несколько видео областей, и самим этим видеороликом, значения переменной в информации о модели переформирования как функции битовой глубины видеоролика, и осуществление преобразования на основе результатов определения, где указанная информация о переформировании применима для внутриконтурного переформирования (ILR) некоторых из совокупности указанных одной или нескольких видео областей, и где эта информация о переформировании предоставляет информацию для реконструкции видео единицы видео области на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видео единицы цветностной составляющей.
6. Способ согласно статье 5, отличающийся тем, что указанная переменная содержит переменную MaxBinIdx, относящуюся к значению битовой глубины.
7. Способ согласно статье 5, отличающийся тем, что указанная переменная содержит переменную RspCW, относящуюся к значению битовой глубины.
8. Способ согласно статье 7, отличающийся тем, что переменная RspCW используется для определения переменной ReshapePivot, используемой для определения реконструкции видео единицы видео области
9. Способ согласно статье 5, отличающийся тем, что указанная переменная содержит InvScaleCoef[ i ], удовлетворяющую InvScaleCoeff[ i ]= 1 << shiftY, если переменная RspCW[ i ] равна 0 для i, находящемся в диапазоне от 0 to MaxBinIdx, отличающийся тем, что параметр shiftY является целым числом, представляющим точность.
10. Способ согласно статье 9, отличающийся тем, что параметр shiftY равен 11 или 14.
11. Способ обработки видео содержащий: осуществление преобразования между кодированным представлением видеоролика, содержащего одну или несколько видео областей, и самим этим видеороликом, где это кодированное представление содержит информацию о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из совокупности указанных одной или нескольких видео областей, где указанная информация о модели переформирования предоставляет информацию для реконструкции видео единицы видео области на основе представления этой видео единицы в первой области и второй области и/или масштабирования остатка цветностной составляющей от видео единицы цветностной составляющей, и где указанная информация о модели переформирования была инициализирована на основе правила инициализации.
12. Способ согласно статье 11, отличающийся тем, что инициализация информации о модели переформирования происходит прежде декодирования последовательности видео.
13. Способ согласно статье 11, отличающийся тем, что инициализация информации о модели переформирования происходит прежде декодирования по меньшей мере одного из объектов i) видео области, кодированной с использованием внутрикадрового (I) типа кодирования, ii) видео области, кодированной с использованием типа кодирования с мгновенным обновлением декодирования (IDR), iii) видео области, кодированной с использованием типа кодирования с чистым произвольным доступом (CRA), или iv) видео области, кодированной с использованием типа кодирования с точкой произвольного доступа при внутрикадровом прогнозировании (I-RAP).
14. Способ согласно статье 13, отличающийся тем, что видео область, кодированная с использованием типа кодирования с точкой произвольного доступа при внутрикадровом прогнозировании (I-RAP), содержит по меньшей мере одно из i) видео область, кодированную с использованием типа кодирования с мгновенным обновлением декодирования (IDR), ii) видео область, кодированную с использованием типа кодирования с чистым произвольным доступом (CRA), и/или iii) видео область, кодированную с использованием типа кодирования с доступом к прерванным линиям (BLA).
15. Способ согласно статье 11, отличающийся тем, что процедура инициализации информации о модели переформирования содержит установление значение OrgCW как (1 << BitDepthY ) / ( MaxBinIdx + 1). ReshapePivot[ i ] = InputPivot [ i ] = i * OrgCW, для i = 0, 1,…, MaxBinIdx, где OrgCW, BitDepthY, MaxBinIdx и ReshapePivot представляют собой значения, ассоциированные с информацией о модели переформирования.
16. Способ согласно статье 11, отличающийся тем, что процедура инициализации информации о модели переформирования содержит установление значения как ScaleCoef[ i ] = InvScaleCoeff[ i ]= 1 << shiftY, for i = 0, 1,…, MaxBinIdx, где ScaleCoef, InvScaleCoeff и shiftY представляют собой значения, ассоциированные с информацией о модели переформирования.
17. Способ согласно статье 11, отличающийся тем, что процедура инициализации информации о модели переформирования содержит установление значения OrgCW как (1 << BitDepthY ) / ( MaxBinIdx + 1). RspCW[ i ] = OrgCW for i = 0, 1,…, MaxBinIdx, a значение OrgCW устанавливают равным (1 << BitDepthY ) / ( MaxBinIdx + 1). RspCW[ i ] = OrgCW, для i = 0, 1,…, MaxBinIdx, где OrgCW, BitDepthY, MaxBinIdx и RspCW представляют собой значения, ассоциированные с информацией о модели переформирования.
18. Способ согласно статье 11, отличающийся тем, что процедура инициализации информации о модели переформирования содержит установление информации о модели переформирования на значения по умолчанию, и отличающийся тем, что эти значения по умолчанию включены в набор параметров последовательности (SPS) или в набор параметров изображения (PPS).
19. Способ обработки видео содержащий: определение, для преобразования между кодированным представлением видеоролика, содержащего одну или несколько видео областей, и самим этим видеороликом, следует ли активизировать или отменить активизацию внутриконтурного переформирования (ILR); и осуществление преобразования на основе результата определения, и где указанное кодированное представление содержит информацию о модели переформирования, применимой для переформирования ILR некоторых из совокупности одной или нескольких видео областей, и где информация о модели переформирования предоставляет информацию для реконструкции видео области на основе первой области и второй области и/или масштабирования остатка цветностной составляющей от видео единицы цветностной составляющей, и где процедура определения принимает решение отменить активизацию переформирования ILR, если информация о модели переформирования не инициализирована.
20. Способ обработки видео содержащий: осуществление преобразования между кодированным представлением видеоролика, содержащего одну или несколько видео областей, и самим этим видеороликом, где это кодированное представление содержит информацию о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из совокупности указанных одной или нескольких видео областей, где информация о модели переформирования предоставляет информацию для реконструкции видео единицы видео области на основе первой области и второй области и/или масштабирования остатка цветностной составляющей от видео единицы цветностной составляющей, где указанную информацию о модели переформирования включают в указанное кодированное представление, только если видео область кодируют с использованием конкретного типа кодирования.
21. Способ согласно статье 20, отличающийся тем, что указанная видео область представляет собой срез или изображение или группу и отличающийся тем, что указанный конкретный тип кодирования представляет собой внутрикадровый (I) тип кодирования.
22. Способ согласно статье 20, отличающийся тем, что видео область представляет собой срез или изображение или группу плиток, и отличающийся тем, что указанный конкретный тип кодирования представляет собой тип кодирования с мгновенным обновлением декодирования (IDR).
23. Способ согласно статье 20, отличающийся тем, что видео область представляет собой срез или изображение или группу плиток, и отличающийся тем, что указанный конкретный тип кодирования представляет собой тип кодирования с чистым произвольным доступом (CRA).
24. Способ согласно статье 20, отличающийся тем, что видео область представляет собой срез или изображение или группу плиток, и отличающийся тем, что указанный конкретный тип кодирования представляет собой тип кодирования с точкой произвольного доступа при внутрикадровом прогнозировании (I-RAP).
25. Способ согласно статье 24, отличающийся тем, что промежуточная видео область, кодируемая с использованием типа кодирования с точкой произвольного доступа при внутрикадровом прогнозировании (I-RAP), содержит по меньшей мере одно из i) видео область, кодированную с использованием типа кодирования с мгновенным обновлением декодирования (IDR), ii) видео область, кодированную с использованием типа кодирования с чистым произвольным доступом (CRA), и/или iii) видео область, кодированную с использованием типа кодирования с доступом к прерванным линиям (BLA).
26. Способ согласно статье 20, отличающийся тем, что информация о модели переформирования включена на уровне последовательности, уровне изображения или в набор параметров адаптации (APS).
27. Способ обработки видео содержащий: определение, для преобразования между первой видео областью видеоролика и кодированным представлением этой первой видео области, может ли информация о переформировании из второй видео области быть использована для преобразования, на основе некоторого правила; и осуществление преобразования в соответствии с результатами определения.
28. Способ согласно статье 27, отличающийся тем, что информацию о переформировании используют для реконструкции видео единицы видео области на основе первой области и второй области и/или масштабирования остатка цветностной составляющей от видео единицы цветностной составляющей.
29. Способ согласно статье 27, отличающийся тем, что указанное правило не допускает использования информации о модели переформирования первой видео областью, если кодированное представление содержит промежуточную область, кодированную с использованием конкретного типа кодирования между указанными первой видео областью и второй видео областью.
30. Способ согласно статье 29, отличающийся тем, что указанную промежуточную область кодируют с использованием внутрикадрового (I) типа кодирования.
31. Способ согласно какой-либо из статей 29 – 30, отличающийся тем, что указанную промежуточную область кодируют с использованием типа кодирования с мгновенным обновлением декодирования (IDR).
32. Способ согласно какой-либо из статей 29 – 31, отличающийся тем, что указанную промежуточную область кодируют с использованием типа кодирования с чистым произвольным доступом (CRA).
33. Способ согласно какой-либо из статей 29 – 32, отличающийся тем, что указанную промежуточную область кодируют с использованием типа кодирования с точкой произвольного доступа при внутрикадровом прогнозировании (I-RAP).
34. Способ согласно статье 33, отличающийся тем, что указанная промежуточная область, кодируемая с использованием типа кодирования с точкой произвольного доступа при внутрикадровом прогнозировании (I-RAP), содержит по меньшей мере одно из i) видео область, кодированную с использованием типа кодирования с мгновенным обновлением декодирования (IDR), ii) видео область, кодированную с использованием типа кодирования с чистым произвольным доступом (CRA), и/или iii) видео область, кодированную с использованием типа кодирования с доступом к прерванным линиям (BLA).
35. Способ согласно какой-либо из статей 27 – 34, отличающийся тем, что указанные первая видео область, вторая видео область и/или промежуточная видео область, соответствуют срезам.
36. Способ согласно какой-либо из статей 27 – 35, отличающийся тем, что указанные первая видео область, вторая видео область и/или промежуточная видео область, соответствуют изображениям.
37. Способ согласно какой-либо из статей 27 – 36, отличающийся тем, указанные первая видео область, вторая видео область и/или промежуточная видео область, соответствуют группам плиток.
38. Способ обработки видео содержащий: осуществление преобразования между текущей видео областью видеоролика и кодированным представлением этой текущей видео области, так что текущую видео область кодируют с использованием некого конкретного типа кодирования, где указанное кодированное представление соответствует правилу форматирования, условно специфицирующему информацию о модели переформирования в кодированном представлении на основе значения флага в указанном кодированном представлении на уровне видео области.
39. Способ согласно статье 38, отличающийся тем, что информация о модели переформирования предоставляет информацию для реконструкции видео единицы видео области на основе первой области и второй области и/или масштабирования остатка цветностной составляющей от видео единицы цветностной составляющей.
40. Способ согласно статье 38, отличающийся тем, что, если флаг имеет первое значение, информацию о модели переформирования передают в виде сигнализации в видео области, а в противном случае эту информацию о модели переформирования инициализируют прежде декодирования видео области.
41. Способ согласно статье 38, отличающийся тем, что первое значение равно 0 или 1.
42. Способ согласно статье 38, отличающийся тем, что указанная видео область представляет собой срез, изображение или группу плиток, а указанный конкретный тип кодирования представляет собой внутрикадровый (I) тип кодирования.
43. Способ согласно статье 38, отличающийся тем, что указанная видео область представляет собой срез, изображение или группу плиток, а указанный конкретный тип кодирования представляет собой тип кодирования с мгновенным обновлением декодирования (IDR).
44. Способ согласно статье 38, отличающийся тем, что указанная видео область представляет собой срез, изображение или группу плиток, а указанный конкретный тип кодирования представляет собой тип кодирования с чистым произвольным доступом (CRA).
45. Способ согласно статье 38, отличающийся тем, что указанная видео область представляет собой срез, изображение или группу плиток, а указанный конкретный тип кодирования представляет собой тип кодирования с точкой произвольного доступа при внутрикадровом прогнозировании (I-RAP).
46. Способ согласно статье 45, отличающийся тем, что указанная видео область, кодируемая с использованием типа кодирования с точкой произвольного доступа при внутрикадровом прогнозировании (I-RAP), содержит по меньшей мере одно из i) видео область, кодированную с использованием типа кодирования с мгновенным обновлением декодирования (IDR), ii) видео область, кодированную с использованием типа кодирования с чистым произвольным доступом (CRA), и/или iii) видео область, кодированную с использованием типа кодирования с доступом к прерванным линиям (BLA).
47. Способ согласно какой-либо из статей 1 – 46, отличающийся тем, что процедура преобразования содержит генерацию видеоролика из кодированного представления.
48. Устройство в видео системе, содержащее процессор и энергонезависимое запоминающее устройство с записанными в нем командами, где при выполнении процессором этих команд процессор осуществляет способ согласно какой-либо одной или нескольким из статей 1 – 47.
49. Компьютерный программный продукт, сохраняемый на энергонезависимых читаемых компьютерах носителях информации, этот компьютерный программный продукт содержит программный код для осуществления способа согласно какой-либо одной или нескольким из статей 1 – 47.
Третья группа статей описывает определенные признаки и аспекты рассматриваемой технологии, перечисленные в предыдущем разделе, включая, например, Примеры 8 и 9.
1. Способ обработки видео содержащий: осуществление преобразования между кодированным представлением видеоролика, содержащего одну или несколько видео областей, и самим эти видеороликом, где это кодированное представление содержит информацию о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из совокупности указанных одной или нескольких видео областей, где указанная информация о модели переформирования предоставляет информацию для реконструкции видео единицы видео области на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видео единицы цветностной составляющей, и где эта информация о модели переформирования содержит набор параметров, куда входит синтаксический элемент, специфицирующий разность между допустимым максимальным индексом бина и максимальным индексом бина, который должен быть использован при реконструкции, и где параметр находится в некотором диапазоне.
2. Способ согласно статье 1, отличающийся тем, что указанный синтаксический элемент находится в диапазоне от 0 до разности между допустимым максимальным индексом бина и минимальным индексом бина, который должен быть использован при реконструкции.
3. Способ согласно статье 1, отличающийся тем, что указанный синтаксический элемент находится в диапазоне от 0 до допустимого максимального индекса бина.
4. Способ согласно какой-либо из статей 1 – 3, отличающийся тем, что допустимый максимальный индекс бина равен 15.
5. Способ согласно статье 1 или 4, отличающийся тем, что указанный синтаксический элемент был усечен для преобразования в указанный диапазон.
6. Способ согласно статье 1, отличающийся тем, что минимальный индекс бина не больше максимального индекса бина.
7. Способ согласно статье 1, отличающийся тем, что максимальный индекс бина был усечен для преобразования в диапазон от минимального индекса бина до допустимого максимального индекса бина.
8. Способ согласно статье 1, отличающийся тем, что минимальный индекс бина был усечен для преобразования в диапазон от 0 до максимального индекса бина.
9. Способ обработки видео содержащий: осуществление преобразования между кодированным представлением видеоролика, содержащего одну или несколько видео областей, и самим этим видеороликом, где указанное кодированное представление содержит информации о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из совокупности указанных одной или нескольких видео областей, где указанная информация о модели переформирования предоставляет информацию для реконструкции видео единицы видео области на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видео единицы цветностной составляющей, где информация о модели переформирования содержит набор параметров, куда входит максимальный индекс бина, который должен быть использован при реконструкции, и где максимальный индекс бина определяют как первое значение, равное сумме минимального индекса бина, который должен быть использован при реконструкции, и синтаксического элемента, представляющего собой целое число без знака и передаваемого в виде сигнализации после минимального индекса бина.
10. Способ согласно статье 9, отличающийся тем, что указанный синтаксический элемент специфицирует разность между максимальным индексом бина и допустимым максимальным индексом бина.
11. Способ согласно статье 10, отличающийся тем, что указанный синтаксический элемент находится в диапазоне от 0 до второго значения, которое равно разности между допустимым максимальным индексом бина и минимальным индексом бина.
12. Способ согласно статье 10, отличающийся тем, что указанный синтаксический элемент находится в диапазоне от 1 до второго значения, которое равно разности между минимальным индексом бина и допустимым максимальным индексом бина.
13. Способ согласно статье 11 или 12, отличающийся тем, что указанный синтаксический элемент был усечен для преобразования в указанный диапазон.
14. Способ согласно статье 9, отличающийся тем, что синтаксические элементы из набора параметров находятся в пределах требуемого диапазона в потоке битов данных соответствия.
15. Способ согласно какой-либо из статей 1 – 14, отличающийся тем, что процедура преобразования содержит генерацию видеоролика из его кодированного представления.
16. Устройство в видео системе, содержащее процессор и энергонезависимое запоминающее устройство с записанными в нем командами, где при выполнении процессором этих команд процессор осуществляет способ согласно какой-либо одной из статей 1 – 15.
17. Компьютерный программный продукт, сохраняемый на читаемых компьютером энергонезависимых носителях, этот компьютерный программный продукт содержит программный код для осуществления способа согласно какой-либо одной из статей 1 – 15.
Четвертая группа статей описывает определенные признаки и аспекты рассматриваемой технологии, перечисленные в предыдущем разделе, включая, например, Примеры 10 – 17.
1. Способ обработки видео содержащий: осуществление преобразования между кодированным представлением видеоролика, содержащего одну или несколько видео областей, и самим этим видеороликом, где это кодированное представление содержит информацию о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из совокупности указанных одной или нескольких видео областей, где эта информация о модели переформирования предоставляет информацию для реконструкции видео единицы видео области на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видео блока цветностной составляющей, и где указанная информация о модели переформирования содержит набор параметров, куда входит первый синтаксический элемент, определяющий число битов, используемое для представления второго синтаксического элемента, специфицирующего абсолютное значение кодового слова приращения от соответствующего бина, и где первый синтаксический элемент имеет значение меньше порогового значения.
2. Способ согласно статье 1, отличающийся тем, что первый синтаксический элемент специфицирует разность между числом битов, используемых для представления второго синтаксического элемента, и 1.
3. Способ согласно статье 1, отличающийся тем, что указанное пороговое значение имеет фиксированное значение.
4. Способ согласно статье 1, отличающийся тем, что пороговое значение имеет переменную, значение которой зависит от битовой глубины.
5. Способ согласно статье 4, отличающийся тем, что пороговое значение равно BitDepth – 1, где BitDepth представляет битовую глубину.
6. Способ согласно статье 1, отличающийся тем, что первый синтаксический элемент находится в потоке битов данных соответствия.
7. Способ обработки видео содержащий: осуществление преобразования между кодированным представлением видеоролика, содержащего одну или несколько видео областей, и самим этим видеороликом, где это кодированное представление содержит информацию о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из совокупности указанных одной или нескольких видео областей, где эта информация о модели переформирования предоставляет информацию для реконструкции видео единицы видео области на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видео единицы цветностной составляющей, и где указанная информация о модели переформирования содержит набор параметров, куда входит i-ый параметр, который представляет крутизну i-ого бина, используемой при переформировании ILR, и имеет значение на основе (i-1)-го параметра, i является положительным целым числом.
8. Способ согласно статье 7, отличающийся тем, что i-ый параметр прогнозируют от (i-1)-го параметра для случая reshaper_model_min_bin_idx < = i <= reshaper_model_max_bin_idx. Параметр reshaper_model_min_bin_idx и параметр reshaper_model_max_bin_index обозначают минимальный индекс бина и максимальный индекс бина, используемые для реконструкции.
9. Способ согласно статье 7, отличающийся тем, что i-ый параметр прогнозируют от параметра OrgCW для i равного 0.
10. Способ согласно статье 7, отличающийся тем, что i-ый параметр прогнозируют от другого параметра для i равного значению параметра reshaper_model_min_bin_idx, указывающего минимальный индекс бина, используемый при конструировании.
11. Способ обработки видео содержащий: осуществление преобразования между кодированным представлением видеоролика, содержащего одну или несколько видео областей, и самим эти видеороликом, где это кодированное представление содержит информацию о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из совокупности указанных одной или нескольких видео областей, где эта информация о модели переформирования предоставляет информацию для реконструкции видео единицы видео области на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видео единицы цветностной составляющей, и указанная информация о модели переформирования, используемая для переформирования ILR, содержит набор параметров, куда входит параметр reshape_model_bin_delta_sign_CW [ i ], не передаваемый в виде сигнализации, и параметр RspDeltaCW[ i ] = reshape_model_bin_delta_abs_CW [ i ] всегда является положительным числом.
12. Способ согласно статье 11, отличающийся тем, что переменную, CW[ i ], вычисляют как сумму параметров MinV и RspDeltaCW[ i ].
13. Способ согласно статье 12, отличающийся тем, что параметр MinV равен 32 или g(BitDepth), параметр BitDepth соответствует значению битовой глубины.
14. Способ обработки видео содержащий: осуществление преобразования между кодированным представлением видеоролика, содержащего одну или несколько видео областей, и самим этим видеороликом, где это кодированное представление содержит информацию о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из совокупности указанных одной или нескольких видео областей, где эта информация о модели переформирования предоставляет информацию для реконструкции видео единицы видео области на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей видео единицы цветностной составляющей, и где эта информация о модели переформирования содержит набор параметров, куда входит параметр, invAvgLuma, с целью использования значений яркостной составляющей для масштабирования в зависимости от цветового формата видео области.
15. Способ согласно статье 14, отличающийся тем, что параметр invAvgLuma вычисляют как invAvgLuma = Clip1Y( ( ΣiΣj predMapSamples[ (xCurr << scaleX ) + i ][ (yCurr << scaleY) + j ] + (cnt >>1)) / cnt, где массив predMapSamples представляет реконструированные отсчеты яркостной составляющей, ( xCurrY, yCurrY ) представляет координаты верхнего левого отсчета цветностной составляющей из текущего блока преобразования цветностной составляющей относительно верхнего левого отсчета цветностной составляющей из текущего изображения, (i, j) представляет позицию, относительно верхнего левого отсчета цветностной составляющей из текущего блока преобразования цветностной составляющей, для отсчета яркостной составляющей, участвующего при определении параметра invAvgLuma, и параметр cnt представляет число отсчетов яркостной составляющей, участвующих при определении параметра invAvgLuma.
16. Способ согласно статье 15, отличающийся тем, что scaleX=scaleY=1 для формата 4:2:0.
17. Способ согласно статье 15, отличающийся тем, что scaleX=scaleY=0 для формата 4:4:4.
18. Способ согласно статье 15, отличающийся тем, что scaleX = 1 и scaleY = 0 для формата 4:2:2.
19. Способ обработки видео содержащий: осуществление преобразования между текущим видео блоком видеоролика и кодированным представлением этого видеоролика, где процедура преобразования содержит процедуру обратного отображения изображения с целью преобразования реконструированных отсчетов яркостной составляющей изображения в модифицированные реконструированные отсчеты яркостной составляющей изображения, где процедура обратного отображения изображения содержит процедуру усечения, в которой верхнюю границу и нижнюю границу устанавливают независимо одну от другой.
20. Способ согласно статье 19, отличающийся тем, что совокупность модифицированных реконструированных отсчетов яркостной составляющей изображения содержит значение invLumaSample, вычисляемое как invLumaSample = Clip3(minVal, maxVal, invLumaSample), minVal, maxVal.
21. Способ согласно статье 20, отличающийся тем, что minVal = T1 << (BitDepth – 8) в случае, когда минимальный индекс бина, которая должна быть использована при конструировании, больше 0. и в противном случае minVal=0.
22. Способ согласно статье 20, отличающийся тем, что maxVal = T2 << (BitDepth – 8) в случае, когда максимальный индекс бина, которая должна быть использована при конструировании, меньше допустимого максимального индекса бина, и в противном случае maxVal = (1<< BitDepth)-1, параметр BitDepth соответствует значению битовой глубины.
23. Способ обработки видео содержащий: осуществление преобразования между кодированным представлением видеоролика, содержащего одну или несколько видео областей, и самим этим видеороликом, где это кодированное представление содержит информацию о модели переформирования, применимой для внутриконтурного переформирования (ILR) некоторых из совокупности указанных одной или нескольких видео областей, где эта информация о модели переформирования предоставляет информацию для реконструкции видео единицы видео области на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видео единицы цветностной составляющей, и где указанная информация о модели переформирования содержит набор параметров, куда входит значение поворота, ограниченная так, что Pivot[ i ]<=T.
24. Способ согласно статье 23, отличающийся тем, что значение T вычисляют как T = (1<< BitDepth)-1, где параметр BitDepth соответствует значению битовой глубины.
25. Способ обработки видео содержащий: осуществление преобразования между представлением видеоролика, содержащего одну или несколько видео областей, и самим этим видеороликом, где это кодированное представление содержит информацию, применимую для внутриконтурного переформирования (ILR), и предоставляет параметры для реконструкции видео единицы видео области на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видео единицы цветностной составляющей, и где параметр квантования (QP) цветностной составляющей имеет сдвиг, значение которого определяют для каждого блока или единицы преобразования.
26. Способ согласно статье 25, отличающийся тем, что этот сдвиг определяют на основе репрезентативного значения яркостной составляющей (repLumaVal).
27. Способ согласно статье 26, отличающийся тем, что указанное репрезентативное значение яркостной составляющей определяют с использованием части или всех прогнозируемых значений яркостной составляющей для блока или единицы преобразования.
28. Способ согласно статье 26, отличающийся тем, что репрезентативное значение яркостной составляющей определяют с использованием части или всех реконструированных значений яркостной составляющей для блока или единицы преобразования.
29. Способ согласно статье 26, отличающийся тем, что репрезентативное значение яркостной составляющей определяют как результат усреднения части или всех прогнозируемых значений яркостной составляющей или реконструированных значений яркостной составляющей для блока или единицы преобразования.
30. Способ согласно статье 26, отличающийся тем, что параметры ReshapePivot[ idx ] <= repLumaVal < ReshapePivot[ idx + 1 ], и InvScaleCoeff[ idx ] используют для определения сдвига.
31. Способ согласно статье 30, отличающийся тем, что значение сдвига параметра QP яркостной составляющей выбирают как argmin abs (2^(x/6 + shiftY) – InvScaleCoeff[ idx ]), x = -N…, M, и здесь N и M являются целыми числами.
32. Способ согласно статье 30, отличающийся тем, что значение сдвига параметра QP яркостной составляющей выбирают как argmin abs (1 – (2^(x/6 + shiftY) / InvScaleCoeff[ idx ])), x = -N…, M, и здесь N и M являются целыми числами.
33. Способ согласно статье 30, отличающийся тем, что, для различных значений параметра InvScaleCoeff[ idx ], значение сдвига вычисляют предварительно и сохраняют в преобразовательной таблице.
34. Способ обработки видео содержащий: осуществление преобразования между представлением видеоролика, содержащего одну или несколько видео областей, и самим этим видеороликом, где это кодированное представление содержит информацию, применимую для внутриконтурного переформирования (ILR), и предоставляет параметры для реконструкции видео единицы видео области на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видео единицы цветностной составляющей, и где параметр квантования (QP) яркостной составляющей имеет сдвиг, значение которого определяют для каждого блока или единицы преобразования.
35. Способ согласно статье 34, отличающийся тем, что значение сдвига определяют на основе репрезентативного значения яркостной составляющей (repLumaVal).
36. Способ согласно статье 35, отличающийся тем, что репрезентативное значение яркостной составляющей определяют с использованием части или всех прогнозируемых значений яркостной составляющей для блока или единицы преобразования.
37. Способ согласно статье 35, отличающийся тем, что репрезентативное значение яркостной составляющей определяют как результат усреднения части или всех прогнозируемых значений яркостной составляющей для блока или единицы преобразования.
38. Способ согласно статье 35, отличающийся тем, что idx = repLumaVal / OrgCW, и параметр InvScaleCoeff[ idx ] используют для определения сдвига.
39. Способ согласно статье 38, отличающийся тем, что значение сдвига выбирают как argmin abs (2^(x/6 + shiftY) – InvScaleCoeff[ idx ]), x = -N…, M, здесь N и M являются целыми числами.
40. Способ согласно статье 38, отличающийся тем, что значение у сдвига выбирают как argmin abs (1 – (2^(x/6 + shiftY) / InvScaleCoeff[ idx ])), x = -N…, M, здесь N и M являются целыми числами.
41. Способ согласно статье 38, отличающийся тем, что, различных значений параметра InvScaleCoeff[ idx ], значение сдвига вычисляют предварительно и сохраняют в преобразовательной таблице.
42. Способ согласно какой-либо из статей 1–41, отличающийся тем, что процедура преобразования содержит генерацию видео из кодированного представления.
43. Устройство в видео системе, содержащее процессор и энергонезависимое запоминающее устройство с записанными в нем командами, где при выполнении процессором этих команд процессор осуществляет способ согласно какой-либо одной из статей 1 – 42.
44. Компьютерный программный продукт, сохраняемый на энергонезависимых читаемых компьютерах носителях информации, этот компьютерный программный продукт содержит программный код для осуществления способа согласно какой-либо одной или нескольким из статей 1 – 42.
Предлагаемые и другие решения, примеры, варианты, модули и функциональные операции, описываемые в этом документе, могут быть реализованы в цифровой электронной схеме или в компьютерном загружаемом программном обеспечении, встроенном программном обеспечении или аппаратуре, включая структуры, рассматриваемые в настоящем документе, и их структурные эквиваленты, либо в комбинации одного или нескольких перечисленных компонентов. Рассмотренные и другие варианты могут быть реализованы в одном или нескольких компьютерных программных продуктах, т.е. в одном или нескольких модулях компьютерных программных команд, закодированных на читаемом компьютером носителе информации для выполнения посредством устройства обработки данных или для управления работой этого устройства обработки данных. Этот читаемый компьютером носитель может представлять собой машиночитаемое устройство для хранения информации, машиночитаемую подложку для хранения информации, запоминающее устройство, композицию объектов, генерирующую машиночитаемый распространяющийся сигнал или комбинацию одного или нескольких перечисленных объектов. Термин «устройство обработки данных» охватывает все устройства, аппаратуру и машины для обработки данных, включая, например, программируемый процессор, компьютер, либо нескольких процессоров или компьютеров. Такое устройство может содержать, в дополнение к аппаратуре, код, создающий среду для выполнения рассматриваемой компьютерной программы, например, код, составляющий встроенное программное обеспечение процессора, стек протоколов, систему управления базой данных, операционную систему или комбинацию одного или нескольких перечисленных объектов. Распространяющийся сигнал представляет собой искусственно генерируемый сигнал, например, генерируемый машиной электрический, оптический или электромагнитный сигнал, генерируемый для кодирования информации с целью передачи подходящему приемному устройству.
Компьютерная программа (также известная как программа, программное обеспечение, программное приложение, сценарий (скрипт) или код) может быть написана на каком-либо языке программирования, включая компилируемые или интерпретируемые языки, и может быть развернута в любой форме, включая автономную программу или в виде модуля, компонента, подпрограммы или другой единицы, подходящей для использования в компьютерной среде. Компьютерная программа необязательно соответствует файлу в файловой системе. Программа может быть сохранена в части файла, который содержит также другие программы или данные (например, один или несколько сценариев сохраняются в документе на языке разметки), в одном файле, специально предназначенном только для рассматриваемой программы, или в нескольких координированных файлах (например, в файлах, сохраняющих один или несколько модулей, подпрограмм или фрагментов кода). Компьютерная программа может быть развернута для выполнения на одном компьютере или на нескольких компьютерах, расположенных в одном пункте или распределенных по нескольким пунктам и соединенных посредством сети связи.
Процедуры и логические схемы, описываемые в настоящем документе, могут быть осуществлены одним или несколькими программируемыми процессорами, выполняющими одну или несколько компьютерных программ для реализации функций путем оперирования над входными данными и генерации выходных данных. Эти процедуры и логические схемы могут также быть осуществлены посредством, и аппаратура может также быть реализована в виде, логической схемы специального назначения, например, программируемой пользователем вентильной матрицы (FPGA (field programmable gate array)) или специализированной интегральной схемы (ASIC (application specific integrated circuit)).
К процессорам, подходящим для выполнения компьютерной программы, относятся, например, микропроцессоры общего и специального назначения и какие-либо один или несколько процессоров цифрового компьютера какого-либо типа. В общем случае, процессор будет принимать команды и данные из постоянного запоминающего устройства и/или из запоминающего устройства с произвольной выборкой. Основными элементами компьютера являются процессор для выполнения команд и одно или несколько запоминающих устройств для сохранения команд и данных. В общем случае, компьютер должен также содержать или быть оперативно связанным для приема данных и/или для передачи данных, одно или несколько запоминающих устройств большой емкости для хранения данных, например, магнитные устройства, магнитооптические диски или оптические диски. Однако компьютеру необязательно иметь такие устройства. К читаемым компьютером носителям для сохранения команд компьютерных программ и данных относятся все формы энергонезависимых запоминающих устройств и носителей информации, включая, например, полупроводниковые запоминающие устройства, например, стираемое, программируемое постоянное запоминающее устройство (СППЗУ (EPROM)), электрически стираемое программируемое запоминающее устройство (ЭСППЗУ (EEPROM)) и устройства флэш-памяти; магнитные диски, например, встроенные жесткие диски или съемные диски; магнитооптические диски; и диски CD ROM и DVD-ROM. Процессор и запоминающее устройство могут быть дополнены или встроены в логическую схему специального назначения.
Хотя настоящий патентный документ содержит много конкретных деталей, их не следует толковать в качестве ограничений объема какого-либо предмета изобретения или того, что может быть заявлено в Формуле изобретения, а всего лишь как описание признаков, которые могут быть специфичны для конкретных вариантов конкретных способов. Некоторые признаки, описываемые в настоящем патентном документе в контексте раздельных вариантов, могут также быть реализованы в сочетании в одном варианте. Напротив, различные признаки, описываемые в контексте одного варианта, могут также быть реализованы в нескольких вариантах по отдельности или в какой-либо подходящей субкомбинации. Более того, хотя признаки могут быть описаны выше как действующие в некоторых комбинациях и даже первоначально заявлены таковыми, один или несколько признаков из заявленной комбинации могут, в некоторых случаях, быть исключены из такой комбинации, и заявленная комбинация может быть превращена в субкомбинацию или в вариацию субкомбинации.
Аналогично, хотя операции показаны на чертежах в конкретном порядке, это не следует понимать как требование, чтобы такие операции всегда осуществлялись именно в показанном конкретном порядке, или в последовательном порядке, или чтобы все показанные операции были выполнены, для достижения желаемого результата. Более того, разделение разнообразных компонентов системы в описываемых в настоящем патентном документе вариантах не следует понимать как требование такого разделения во всех вариантах.
Здесь описано только небольшое число реализаций и примеров, но и другие варианты реализации, усовершенствования и вариации могут быть сделаны на основе того, что описано и иллюстрируется в настоящем патентном документе.

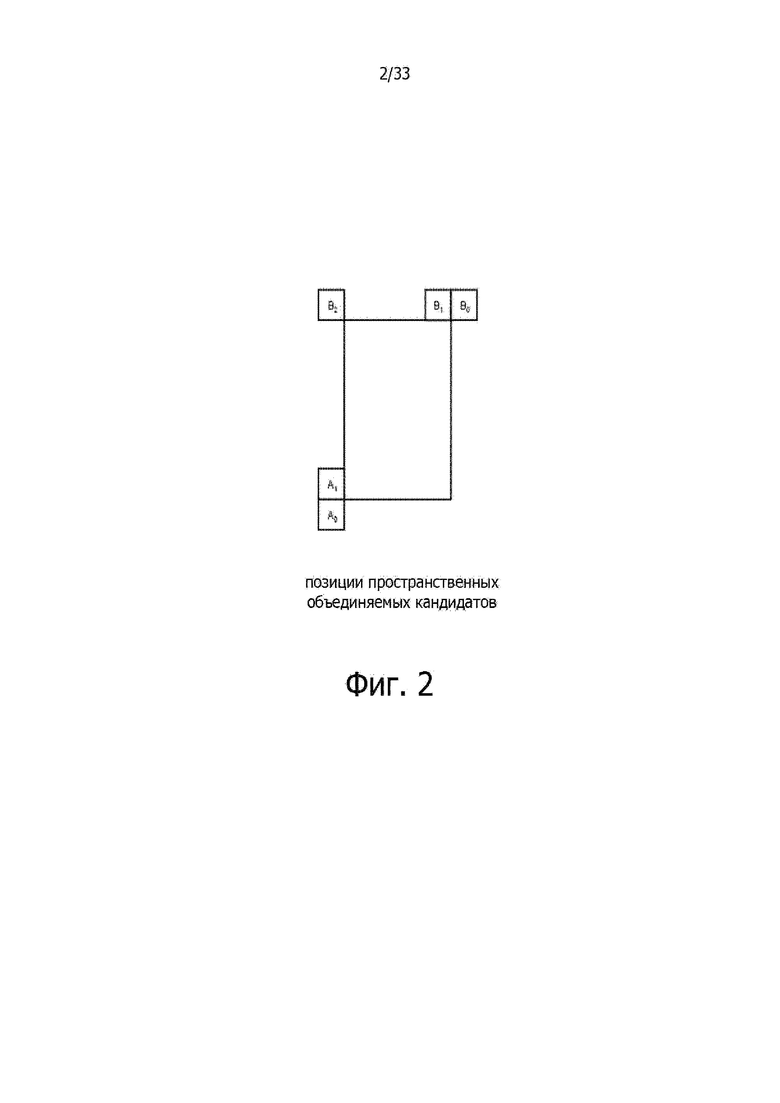















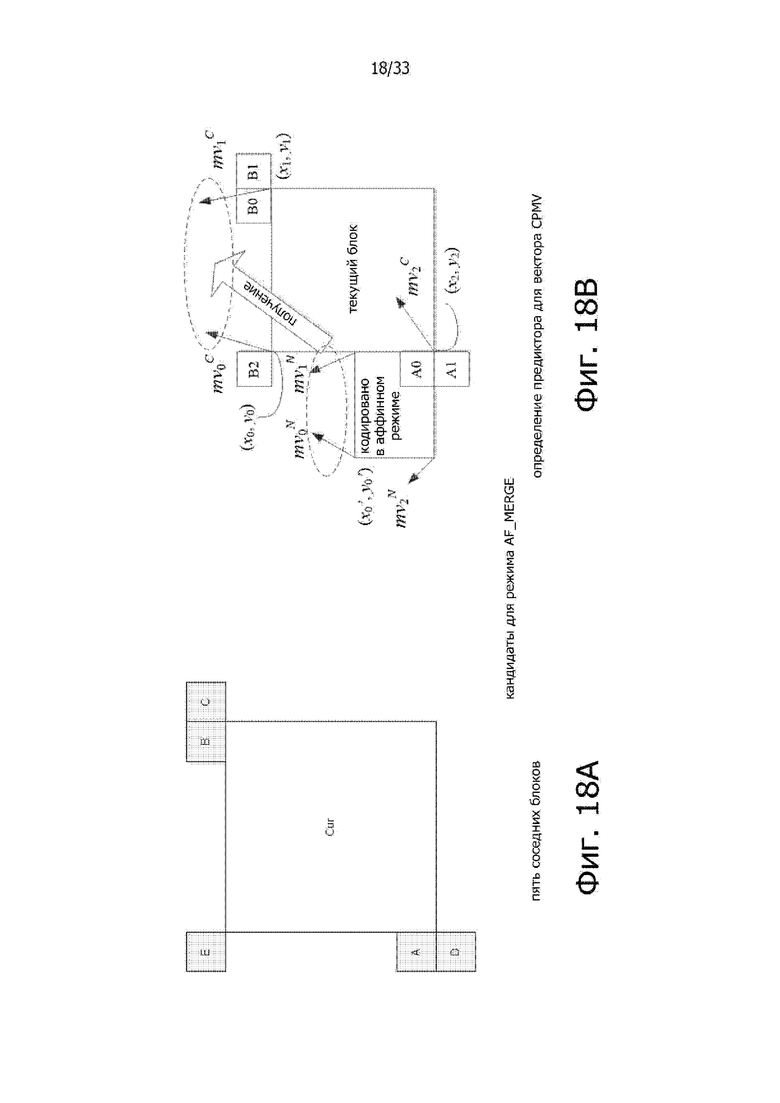



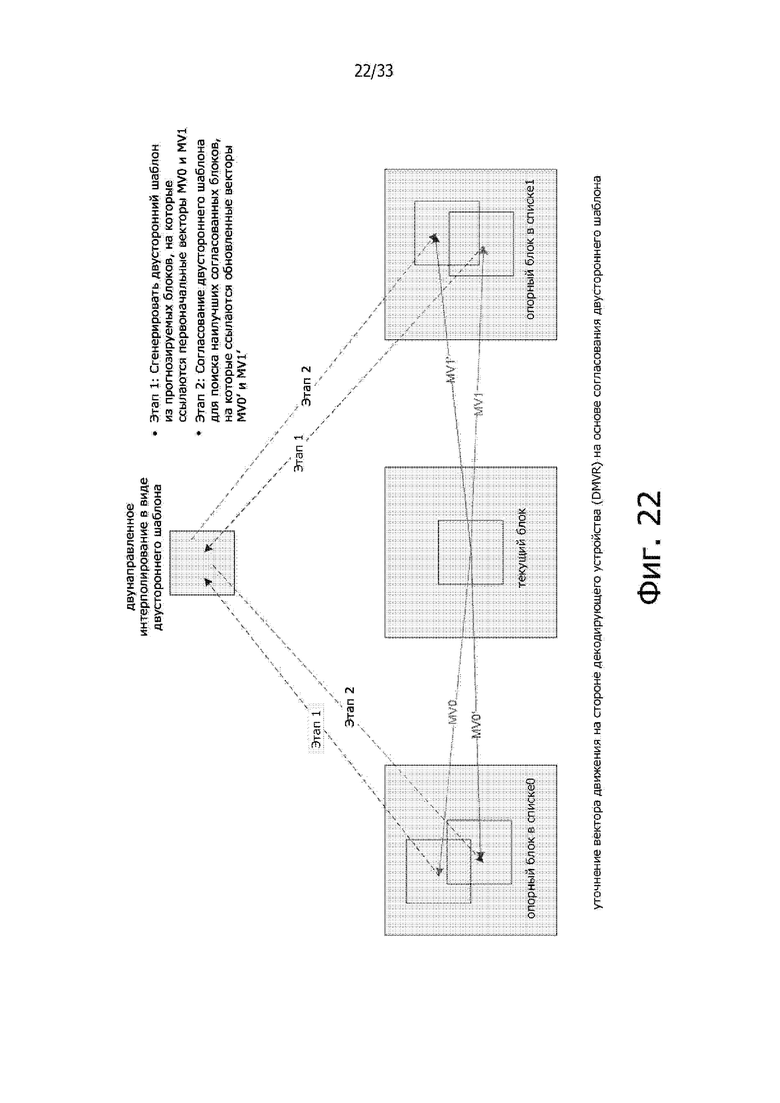






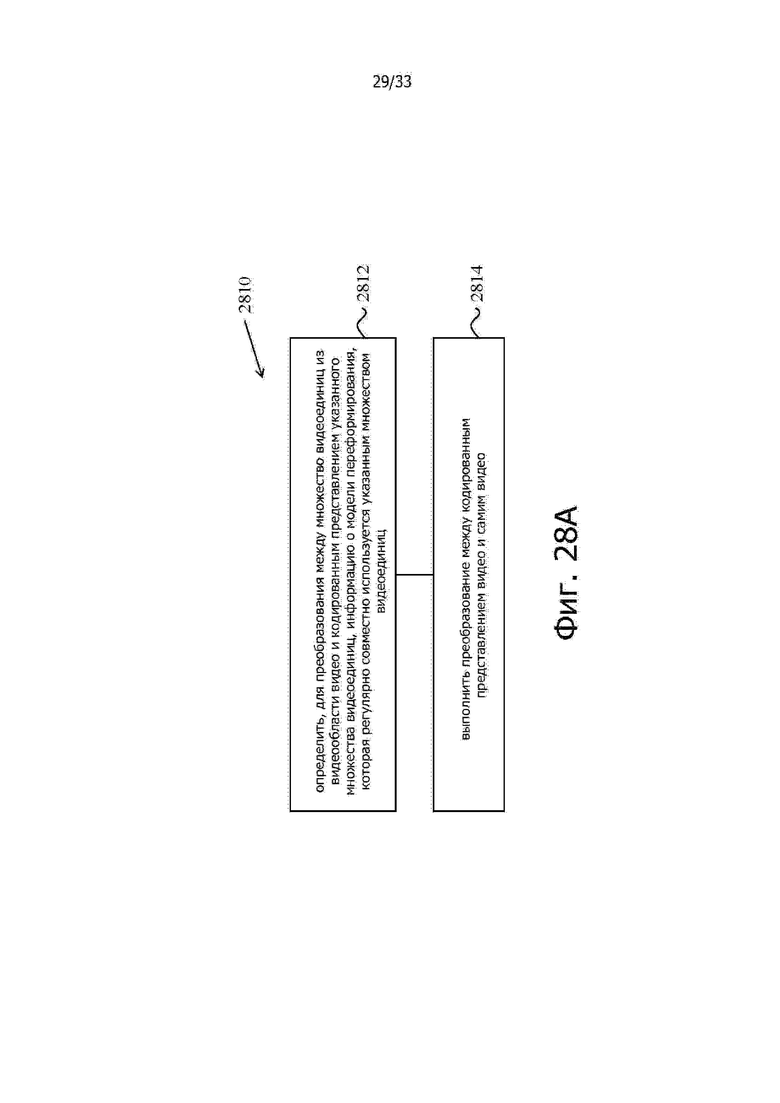
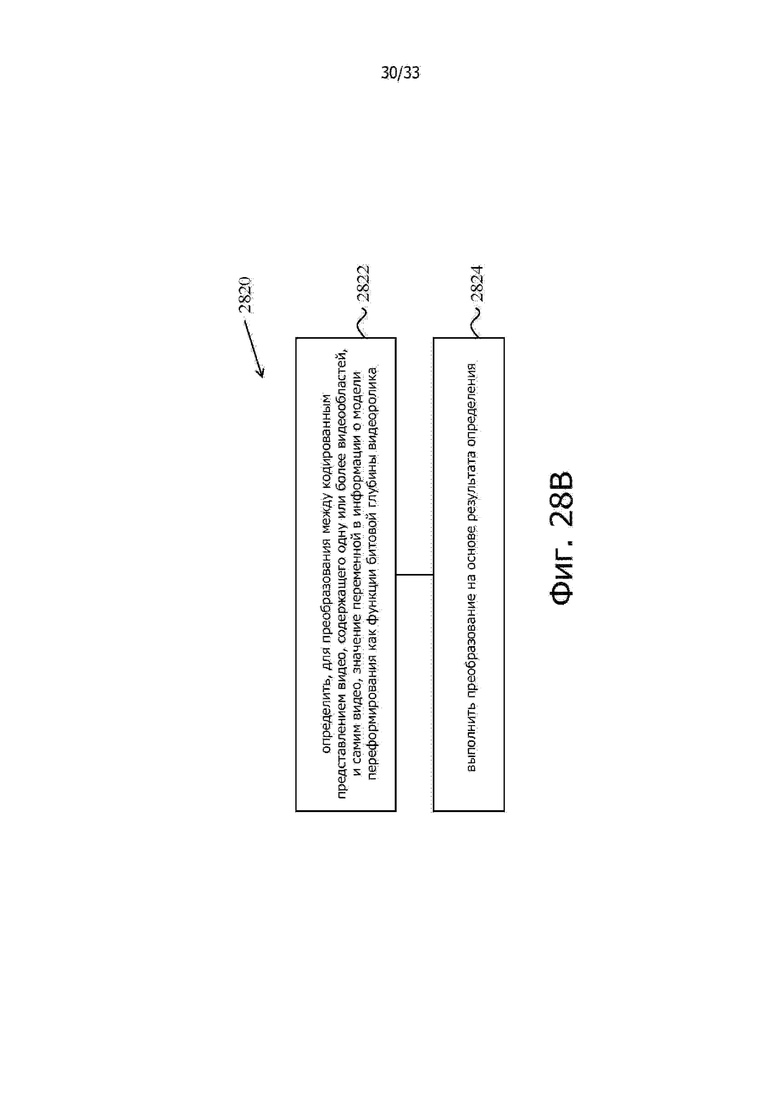



Изобретение относится к способам, устройствам и системам для кодирования видео. Техническим результатом является повышение эффективности кодирования видео. Результат достигается тем, что выполняют преобразование между кодированным представлением видео, содержащим одну или более видеообластей, и самим видео, причем кодированное представление содержит информацию о модели переформирования, применимую для внутриконтурного переформирования (ILR) некоторых из указанной одной или более видеообластей, при этом информация о модели переформирования предоставляет информацию для реконструкции видеоединицы видеообласти на основе представления в первой области и во второй области и/или масштабирования остатка цветностной составляющей от видеоединицы цветностной составляющей, и информация о модели переформирования содержит набор параметров, содержащий синтаксический элемент, определяющий разность между допустимым максимальным индексом бина и максимальным индексом бина, подлежащим использованию при реконструкции, и указанный параметр находится в некотором диапазоне. 4 н. и 15 з.п. ф-лы, 33 ил., 5 табл.
1. Способ обработки данных видео, содержащий этапы, на которых:
определяют, в процессе преобразования между текущей видеоединицей видеообласти видео и потоком битов данных видео, что для текущей видеоединицы используется инструмент кодирования;
выполняют преобразование с использованием указанного инструмента кодирования при преобразовании, причем текущая видеоединица конструируется на основе по меньшей мере одной из:
1) процедуры прямого отображения для яркостной составляющей текущей видеоединицы, в которой прогнозируемые отсчеты яркостной составляющей преобразуются из исходной области в переформированную область;
2) процедуры обратного отображения, представляющей собой операцию, обратную процедуре прямого отображения, в которой реконструированные отсчеты яркостной составляющей текущей видеоединицы из переформированной области преобразуются в исходную область; или
3) процедуры масштабирования, в которой отсчеты остатка цветностной составляющей текущей видеоединицы масштабируются перед использованием для реконструкции цветностной составляющей,
при этом информация о модели указанного инструмента кодирования для текущей видеоединицы включена в указанный поток битов данных, и
в ответ, что видеообласть содержит одну или более видеоединиц, включая текущую видеоединицу, каждая из указанной одной или более видеоединиц совместно использует одну и ту же информацию о модели инструмента кодирования для текущей видеоединицы.
2. Способ по п. 1, в котором указанные одна или более видеоединиц соответствуют одному или более срезам, одной или более группам плиток, одной или более единицам дерева кодирования или одной или более единицам кодирования.
3. Способ по п. 1, в котором указанная видеообласть представляет собой изображение.
4. Способ по п. 1, в котором модель инструмента кодирования представляет собой кусочно-линейную модель, используемую для отображения прогнозируемых отсчетов яркостной составляющей текущей видеоединицы в конкретные значения в ходе процедуры прямого отображения.
5. Способ по п. 4, в котором значение по меньшей мере одной переменной из кусочно-линейной модели зависит от битовой глубины видео.
6. Способ по п. 4, в котором диапазон значения кодового слова для i-го отрезка кусочно-линейной модели зависит от битовой глубины видео, и кодовое слово для указанного i-го отрезка ассоциировано с указанными конкретными значениями.
7. Способ по п. 1, в котором информация о модели инструмента кодирования для текущей видеоединицы содержит первый синтаксический элемент и второй синтаксический элемент, причем первый синтаксический элемент определяет разность между максимальным допустимым индексом бина и максимальным индексом бина, подлежащим использованию в процедуре прямого отображения, а второй синтаксический элемент определяет максимальный индекс бина, подлежащий использованию в процедуре прямого отображения.
8. Способ по п. 7, в котором значение первого синтаксического элемента находится в диапазоне от 0 до максимального допустимого индекса бина.
9. Способ по п. 7, в котором значение второго синтаксического элемента меньше или равно максимальному индексу бина, подлежащему использованию в процедуре прямого отображения.
10. Способ по п. 7, в котором значение второго синтаксического элемента находится в диапазоне от 0 до максимального индекса бина, подлежащего использованию в процедуре прямого отображения.
11. Способ по п. 7, в котором максимальный допустимый индекс бина равен 15.
12. Способ по п. 1, в котором к преобразованным реконструированным отсчетам в исходной области, генерируемым в ходе процедуры обратного отображения, применяется процедура фильтрации.
13. Способ по п. 6, в котором значение кодового слова для i-го отрезка определяется на основе информации о модели инструмента кодирования для текущей видеоединицы.
14. Способ по п. 1, в котором в набор параметров последовательности входит флаг использования указанного инструмента кодирования.
15. Способ по п. 1, в котором на этапе преобразования кодируют текущий видеоблок в поток битов данных.
16. Способ по п. 1, в котором на этапе преобразования декодируют текущий видеоблок из потока битов данных.
17. Устройство обработки данных видео, содержащее процессор и энергонезависимое запоминающее устройство с записанными в нем командами, причем команды при исполнении процессором вызывают выполнение процессором:
определения, в процессе преобразования между текущей видеоединицей видеообласти видео и потоком битов данных видео, что для текущей видеоединицы используется инструмент кодирования;
выполнения преобразования с использованием указанного инструмента кодирования при преобразовании, причем текущая видеоединица конструируется на основе по меньшей мере одной из:
1) процедуры прямого отображения для яркостной составляющей текущей видеоединицы, в которой прогнозируемые отсчеты яркостной составляющей преобразуются из исходной области в переформированную область;
2) процедуры обратного отображения, представляющей собой операцию, обратную процедуре прямого отображения, в которой реконструированные отсчеты яркостной составляющей текущей видеоединицы из переформированной области преобразуются в исходную область; или
3) процедуры масштабирования, в которой отсчеты остатка цветностной составляющей текущей видеоединицы масштабируются перед использованием для реконструкции цветностной составляющей,
при этом информация о модели указанного инструмента кодирования для текущей видеоединицы включена в указанный поток битов данных, и
в ответ на то, что видеообласть содержит одну или более видеоединиц, включая текущую видеоединицу, каждая из указанной одной или более видеоединиц совместно использует одну и ту же информацию о модели инструмента кодирования для текущей видеоединицы.
18. Энергонезависимый читаемый компьютером носитель для хранения информации, хранящий команды, которые вызывают выполнение процессором:
определения, в процессе преобразования между текущей видеоединицей видеообласти видео и потоком битов данных видео, что для текущей видеоединицы используется инструмент кодирования;
выполнения преобразования с использованием указанного инструмента кодирования при преобразовании, причем текущая видеоединица конструируется на основе по меньшей мере одной из:
1) процедуры прямого отображения для яркостной составляющей текущей видеоединицы, в которой прогнозируемые отсчеты яркостной составляющей преобразуются из исходной области в переформированную область;
2) процедуры обратного отображения, представляющей собой операцию, обратную процедуре прямого отображения, в которой реконструированные отсчеты яркостной составляющей текущей видеоединицы из переформированной области преобразуются в исходную область; или
3) процедуры масштабирования, в которой отсчеты остатка цветностной составляющей текущей видеоединицы масштабируются перед использованием для реконструкции цветностной составляющей,
при этом информация о модели указанного инструмента кодирования для текущей видеоединицы включена в указанный поток битов данных, и
в ответ на то, что видеообласть содержит одну или более видеоединиц, включая текущую видеоединицу, каждая из указанной одной или более видеоединиц совместно использует одну и ту же информацию о модели инструмента кодирования для текущей видео единицы.
19. Способ сохранения потока битов данных видео, содержащий этапы, на которых:
определяют, что для текущей видеоединицы используется инструмент кодирования;
генерируют поток битов данных с использованием инструмента кодирования, причем текущая видеоединица конструируются на основе по меньшей мере одной из:
1) процедуры прямого отображения для яркостной составляющей текущей видеоединицы, в которой прогнозируемые отсчеты яркостной составляющей преобразуются из исходной области в переформированную область;
2) процедуры обратного отображения, представляющей собой операцию, обратную процедуре прямого отображения, в которой реконструированные отсчеты яркостной составляющей текущей видеоединицы из переформированной области преобразуются в исходную область; или
3) процедуры масштабирования, в которой отсчеты остатка цветностной составляющей текущей видеоединицы масштабируются перед использованием для реконструкции цветностной составляющей; и
сохраняют поток битов данных видео на энергонезависимом читаемом компьютером носителе записи информации;
при этом информация о модели указанного инструмента кодирования для текущей видеоединицы включена в указанный поток битов данных, и
в ответ на то, что видеообласть содержит одну или более видеоединиц, включая текущую видеоединицу, каждая из указанной одной или более видеоединиц совместно использует одну и ту же информацию о модели инструмента кодирования для текущей видеоединицы.
| WO 2019006300 A1, 2019.01.03 | |||
| WO 2017165494 A2, 2017.09.28 | |||
| WO 2017138352 A1, 2017.08.17 | |||
| WO 2016164235 A1, 2016.10.13 | |||
| WO 2017144881 A1, 2017.08.31 | |||
| WO 2017158236 A2, 2017.09.21 | |||
| US 2015016512 A1, 2015.01.15 | |||
| US 2015373349 A1, 2015.12.24 | |||
| US 2011243232 A1, 2011.10.06 | |||
| RU 2015147886 A, 2017.05.15. |

