ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
[1] Настоящая заявка испрашивает преимущество приоритета патентной заявки США № 17/231695 «КОНТЕКСТНОЕ МОДЕЛИРОВАНИЕ КОДИРОВАНИЯ ЗАНЯТОСТИ ДЛЯ КОДИРОВАНИЯ ОБЛАКА ТОЧЕК», поданной 15 апреля 2021 г., испрашивающей приоритет на основе предварительных заявок США № 63/034113, «ОБНОВЛЕНИЯ ДЛЯ КОНТЕКСТНОГО МОДЕЛИРОВАНИЯ КОДИРОВАНИЯ ЗАНЯТОСТИ ДЛЯ КОДИРОВАНИЯ ОБЛАКА ТОЧЕК», поданной 3 июня 2020 г., и 63/066099, «ОБНОВЛЕНИЯ ДЛЯ КОНТЕКСТНОГО МОДЕЛИРОВАНИЯ НА УРОВНЕ РОДИТЕЛЬСКОГО УЗЛА КОДИРОВАНИЯ ЗАНЯТОСТИ ДЛЯ КОДИРОВАНИЯ ОБЛАКА ТОЧЕК», поданной 14 августа 2020 г., которые полностью включены в данный документ посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[2] Данное изобретение в целом относится к области обработки данных и в частности к облакам точек.
[3] Облако точек широко используется в последние годы. Например, оно используется в автономных транспортных средствах для обнаружения и локализации объектов; оно также используется в географических информационных системах (GIS) для составления карт и используется в культурном наследии для визуализации и архивирования объектов и коллекций культурного наследия и т.д. Облака точек содержат набор многомерных точек, обычно трехмерных (3D), каждая из которых включает в себя информацию о трехмерном положении и дополнительные атрибуты, такие как цвет, отражательная способность и т.д. Они могут быть захвачены с использованием нескольких камер и датчиков глубины или лидара в различных настройках и могут состоять из от тысяч до миллиардов точек для реалистичного представления исходных сцен. Требуются технологии сжатия для уменьшения объема данных, необходимых для представления облака точек, для более быстрой передачи или уменьшения памяти. В ISO/IEC MPEG (JTC 1/SC 29/WG 11) была создана специальная группа (MPEG-PCC) для стандартизации технологий сжатия для статических или динамических облаков точек.
РАСКРЫТИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
[4] Варианты осуществления относятся к способу, системе и машиночитаемому носителю для декодирования данных облака точек. Согласно одному аспекту предложен способ декодирования данных облака точек. Способ может включать в себя получение данных, соответствующих облаку точек. Количество контекстов, связанных с полученными данными, уменьшают на основе данных занятости, соответствующих одному или более родительским узлам и одному или более дочерним узлам в полученных данных. Данные, соответствующие облаку точек, декодируют на основе уменьшенного количества контекстов.
[5] Согласно другому аспекту предложена компьютерная система для декодирования данных облака точек. Компьютерная система может включать в себя один или более процессоров, одно или более машиночитаемых запоминающих устройств, одно или более машиночитаемых физических устройств хранения и программные инструкции, хранящиеся на по меньшей мере одном из одного или более устройств хранения, для выполнения по меньшей мере одним из одного или более процессоров через, по меньшей мере, одно из одного или более запоминающих устройств, причем компьютерная система способна выполнять способ. Способ может включать в себя получение данных, соответствующих облаку точек. Количество контекстов, связанных с полученными данными, уменьшают на основе данных занятости, соответствующих одному или более родительским узлам и одному или более дочерним узлам в полученных данных. Данные, соответствующие облаку точек, декодируют на основе уменьшенного количества контекстов.
[6] Согласно еще одному аспекту предложен машиночитаемый носитель для декодирования данных облака точек. Машиночитаемый носитель может включать в себя одно или более машиночитаемых устройств хранения и программные инструкции, хранящихся на по меньшей мере одном из одного или более физических устройств хранения, причем программные инструкции могут выполняться процессором. Программные инструкции могут выполняться процессором для выполнения способа, который, соответственно, может включать в себя получение данных, соответствующих облаку точек. Количество контекстов, связанных с полученными данными, уменьшают на основе данных занятости, соответствующих одному или более родительским узлам и одному или более дочерним узлам в полученных данных. Данные, соответствующие облаку точек, декодируют на основе уменьшенного количества контекстов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[7] Эти и другие задачи, признаки и преимущества станут очевидными из нижеследующего подробного описания иллюстративных вариантов осуществления, которое следует читать вместе с прилагаемыми чертежами. Различные элементы чертежей приведены не в масштабе, поскольку изображения приведены для ясности и облегчения понимания специалистом в данной области техники вместе с подробным описанием. На чертежах:
фиг.1 иллюстрирует сетевую компьютерную среду согласно по меньшей мере одному варианту осуществления;
фиг.2А - схема структуры октодерева для данных облака точек согласно по меньшей мере одному варианту осуществления;
фиг.2В - схема разделения октодерева для данных облака точек согласно по меньшей мере одному варианту осуществления;
фиг.2С - структурная схема соседей узла родительского уровня для данных облака точек согласно по меньшей мере одному варианту осуществления;
фиг.2D - структурная схема контекстов уровня родительского узла для данных облака точек согласно по меньшей мере одному варианту осуществления;
фиг.2E - структурная схема соседей родительского уровня текущего кодированного узла для данных облака точек согласно по меньшей мере одному варианту осуществления;
фиг.2F - структурная схема контекстов уровня родительского узла для данных облака точек согласно по меньшей мере одному варианту осуществления;
фиг.2G - структурная схема соседей родительского уровня текущего кодированного узла для данных облака точек согласно по меньшей мере одному варианту осуществления;
фиг.2Н - структурная схема соседей уровня дочернего узла для данных облака точек согласно по меньшей мере одному варианту осуществления;
фиг.3A - элемент синтаксиса для сигнализации уменьшения контекстов данных облака точек согласно по меньшей мере одному варианту осуществления;
фиг.3B - хеш-таблица для кодированной информации геометрии облака точек согласно по меньшей мере одному варианту осуществления;
фиг.4 - функциональная блок-схема, иллюстрирующая этапы, выполняемые программой, декодирующей данные облака точек, согласно по меньшей мере одному варианту осуществления;
фиг.5 - структурная схема внутренних и внешних компонентов компьютеров и серверов, изображенных на фиг.1, согласно по меньшей мере одному варианту осуществления;
фиг.6 - структурная схема иллюстративной среды облачных вычислений, включающей в себя компьютерную систему, изображенную на фиг.1 согласно по меньшей мере одному варианту осуществления; и
фиг.7 - структурная схема функциональных слоев иллюстративной среды облачных вычислений на фиг.6 согласно по меньшей мере одному варианту осуществления.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[8] В данном документе раскрыты подробные варианты осуществления заявленных структур и способов; однако понятно, что раскрытые варианты осуществления являются просто иллюстративными для заявленных структур и способов, которые могут быть реализованы в различных формах. Эти структуры и способы могут быть, однако, реализованы в многочисленных различных формах, и они не должны рассматриваться как ограниченные примерными вариантами осуществления, приведенными в данном документе. Скорее, эти примерные варианты осуществления приведены с тем, чтобы это раскрытие было исчерпывающим и полным, и полностью передавало объем для специалистов в данной области техники. В описании могут быть опущены детали хорошо известных признаков и технологий, чтобы избежать ненужного затруднения понимания представленных вариантов осуществления.
[9] Варианты осуществления в целом относятся к области обработки данных и, в частности, к облакам точек. Нижеследующие описанные примерные варианты осуществления относятся к системе, способу и компьютерной программе, среди прочего, для уменьшения количества контекстов, связанных с данными облака точек. Следовательно, некоторые варианты осуществления могут улучшить область вычисления за счет обеспечения улучшенных сжатия и распаковки облака точек посредством рассмотрения соответствующего поднабора соседних узлов из всех соседних узлов текущего узла в данных облака точек.
[10] Как описано выше, облако точек широко используется в последние годы. Например, оно используется в автономных транспортных средствах для обнаружения и локализации объектов; оно также используется в географических информационных системах (GIS) для составления карт и используется в культурном наследии для визуализации и архивирования объектов и коллекций культурного наследия и т.д. Облака точек содержат набор многомерных точек, обычно трехмерных (3D), каждая из которых включает в себя информацию о трехмерном положении и дополнительные атрибуты, такие как цвет, отражательная способность и т.д. Они могут быть захвачены с использованием нескольких камер и датчиков глубины или лидара в различных настройках и могут состоять из от тысяч до миллиардов точек для реалистичного представления исходных сцен. Технологии сжатия требуются для уменьшения объема данных, необходимых для представления облака точек, для более быстрой передачи или уменьшения памяти. В ISO/IEC MPEG (JTC 1/SC 29/WG 11) была создана специальная группа (MPEG-PCC) для стандартизации технологий сжатия для статических или динамических облаков точек.
[11] Однако, контекстное моделирование кодирования занятости на уровне родительского узла ограничивается доступом к вплоть до 6 соседним кодированным узлам. Это может привести к относительно небольшому количеству контекстов. Соответственно, рассмотрение только 6 ближайших соседей может в значительной степени ограничить диапазон рецептивного поля и, таким образом, ограничить вызванный прирост производительности. Кроме того, контекстное моделирование кодирования занятости может привести к большому количеству контекстов. Однако в отношении аппаратной реализации очень большое количество контекстов не является предпочтительным, поскольку они потребляют большой объем памяти. Следовательно, может быть предпочтительно улучшить производительность контекста уровня родительского узла с сохранением небольшого количества контекстов за счет уменьшения количества представленных контекстов.
[12] Аспекты описываются в данном документе со ссылкой на изображения блок-схем и/или структурные схемы способов, устройства (систем) и машиночитаемых носителей согласно различным вариантам осуществления. Следует понимать, что каждый блок изображений блок-схем и/или структурных схем, и комбинации блоков в изображениях блок-схем и/или структурных схемах могут быть реализованы с помощью машиночитаемых программных инструкций.
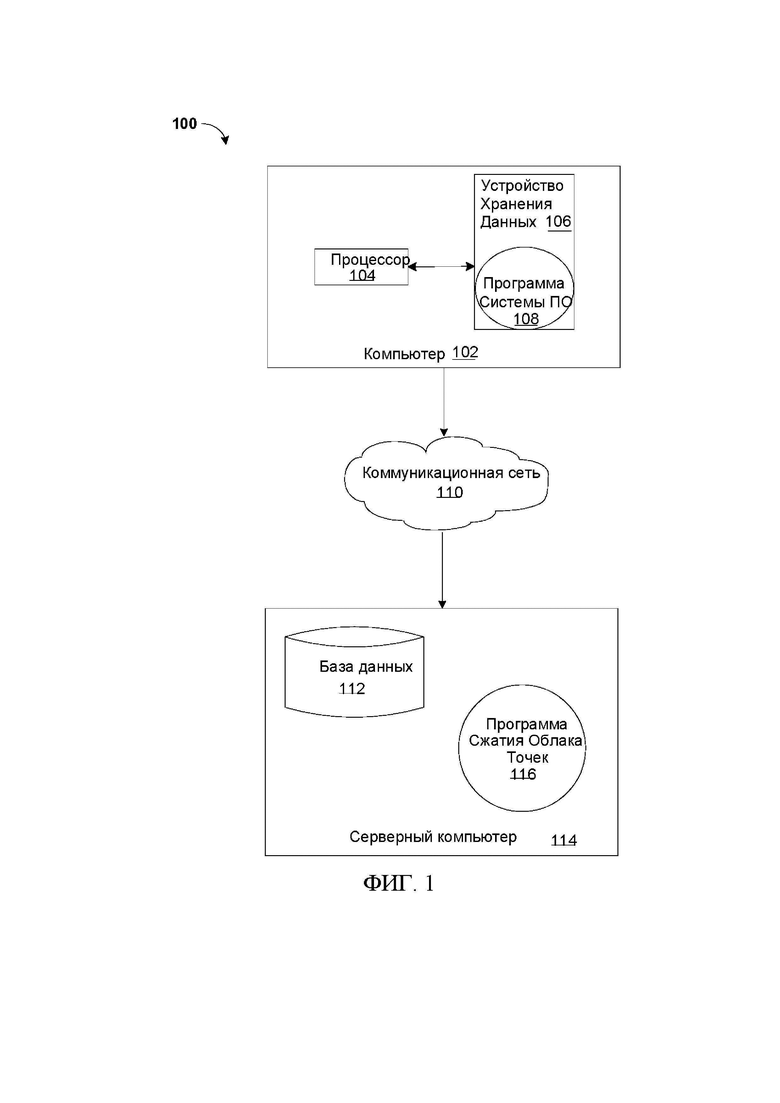
[13] Нижеследующие описанные примерные варианты осуществления относятся к системе, способу и компьютерной программе, сжимающей и распаковывающей данные облака точек на основе уменьшения расширенного набора контекстов, связанных с данными облака точек. Со ссылкой на фиг.1 представлена функциональная структурная схема сетевой компьютерной среды, иллюстрирующая систему 100 сжатия облака точек (ниже «система») для сжатия и распаковки данных облака точек. Следует понимать, что фиг.1 относится только к иллюстрации одной реализации и не подразумевает каких-либо ограничений в отношении сред, в которых могут быть реализованы различные варианты осуществления. Для показанных сред могут быть сделаны многочисленные модификации на основе требований к конструкции и реализации.
[14] Система 100 может включать в себя компьютер 102 и серверный компьютер 114. Компьютер 102 может коммуницировать с серверным компьютером 114 через коммуникационную сеть 110 (ниже «сеть»). Компьютер 102 может включать в себя процессор 104 и программу 108 системы программного обеспечения, которая хранится на устройстве 106 хранения данных и может взаимодействовать с пользователем и коммуницировать с серверным компьютером 114. Как описывается ниже со ссылкой на фиг.5, компьютер 102 может включать в себя внутренние компоненты 800A и внешние компоненты 900A соответственно, а серверный компьютер 114 может включать в себя внутренние компоненты 800B и внешние компоненты 900B соответственно. Компьютер 102 может представлять собой, например, мобильное устройство, телефон, персональный цифровой помощник, нетбук, портативный компьютер, планшетный компьютер, настольный компьютер или вычислительные устройства любого типа, способные запускать программу, получать доступ к сети и доступ к базе данных.
[15] Серверный компьютер 114 также может работать в модели услуг облачных вычислений, такой как программное обеспечение как услуга (SaaS), платформа как услуга (PaaS) или инфраструктура как услуга (laaS), как описывается ниже со ссылкой на фиг. 6 и 7. Серверный компьютер 114 также может быть расположен в модели развертывания облачных вычислений, такой как частное облако, коллективное облако, общедоступное облако или гибридное облако.
[16] Серверный компьютер 114, который может использоваться для сжатия и распаковки облака точек, может запускать Программу 116 Сжатия Облака Точек (ниже «программа»), которая может взаимодействовать с базой 112 данных. Способ Программы Сжатия Облака Точек объясняется более подробно ниже в отношении фиг.4. В одном варианте осуществления компьютер 102 может работать как устройство ввода, включая пользовательский интерфейс, тогда как программа 116 может работать в основном на серверном компьютере 114. В альтернативном варианте осуществления программа 116 может работать в основном на одном или более компьютерах 102, тогда как серверный компьютер 114 может использоваться для обработки и хранения данных, используемых программой 116. Следует отметить, что программа 116 может быть отдельной программой или может быть интегрирована в более крупную программу сжатия и распаковки облака точек.
[17] Следует, однако, отметить, что обработка для программы 116 в некоторых случаях может быть распределена между компьютерами 102 и серверными компьютерами 114 в любом соотношении. В другом варианте осуществления программа 116 может работать более чем на одном компьютере, сервере или некоторой комбинации компьютеров и серверных компьютеров, например, на множестве компьютеров 102, коммуницирующих по сети 110 с одним серверным компьютером 114. В другом варианте осуществления, например, программа 116 может работать на множестве серверных компьютеров 114, коммуницирующих по сети 110 с множеством клиентских компьютеров. Как альтернатива, программа может работать на сетевом сервере, коммуницирующем по сети с сервером и множеством клиентских компьютеров.
[18] Сеть 110 может включать в себя проводные соединения, беспроводные соединения, оптоволоконные соединения или некоторую их комбинацию. В целом, сеть 110 может представлять собой любую комбинацию соединений и протоколов, которые могут поддерживать коммуникации между компьютером 102 и серверным компьютером 114. Сеть 110 может включать в себя сети различных типов, такие как, например, локальная сеть (LAN), глобальная сеть (WAN), такая как Интернет, телекоммуникационная сеть, такая как коммутируемая телефонная сеть общего пользования (PSTN), беспроводная сеть, коммутируемая сеть общего пользования, спутниковая сеть, сотовая сеть (например, сеть пятого поколения (5G), сеть стандарта долгосрочного развития (LTE), сеть третьего поколения (3G), сеть множественного доступа с кодовым разделением каналов (CDMA) и т.д.), наземная сеть мобильной связи общего пользования (PLMN), городская сеть (MAN), частная сеть, децентрализованная сеть, интрасеть, волоконно-оптическая сеть и т.п., и/или комбинацию сетей этих или других типов.
[19] Количество и расположение устройств и сетей, показанных на фиг.1, приведены в качестве примера. На практике могут иметься дополнительные устройства и/или сети, меньшее количество устройств и/или сетей, другие устройства и/или сети, или устройства и/или сети, расположенные иначе, чем показанные на фиг.1. Кроме того, два или более устройств, показанных на фиг.1, могут быть реализованы внутри одного устройства или одно устройство, показанное на фиг.1, может быть реализовано как несколько распределенных устройств. Дополнительно или как альтернатива, набор устройств (например, одно или более устройств) системы 100 может выполнять одну или более функций, описанных как выполняемые другим набором устройств системы 100.
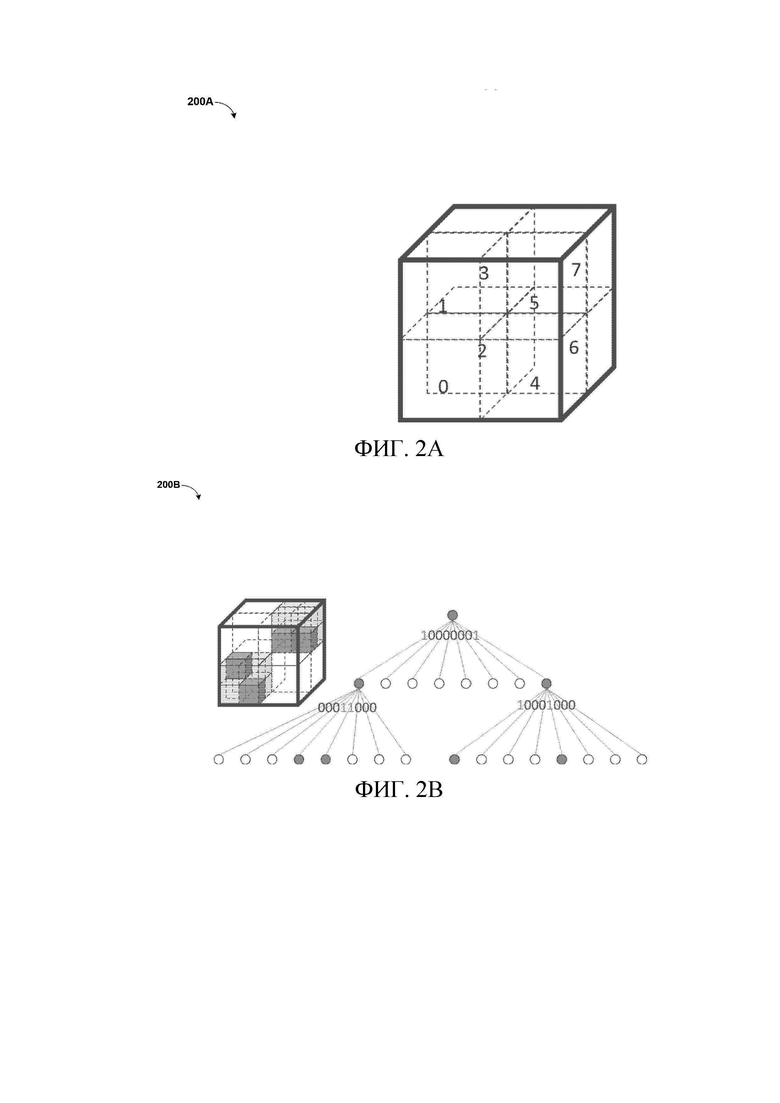
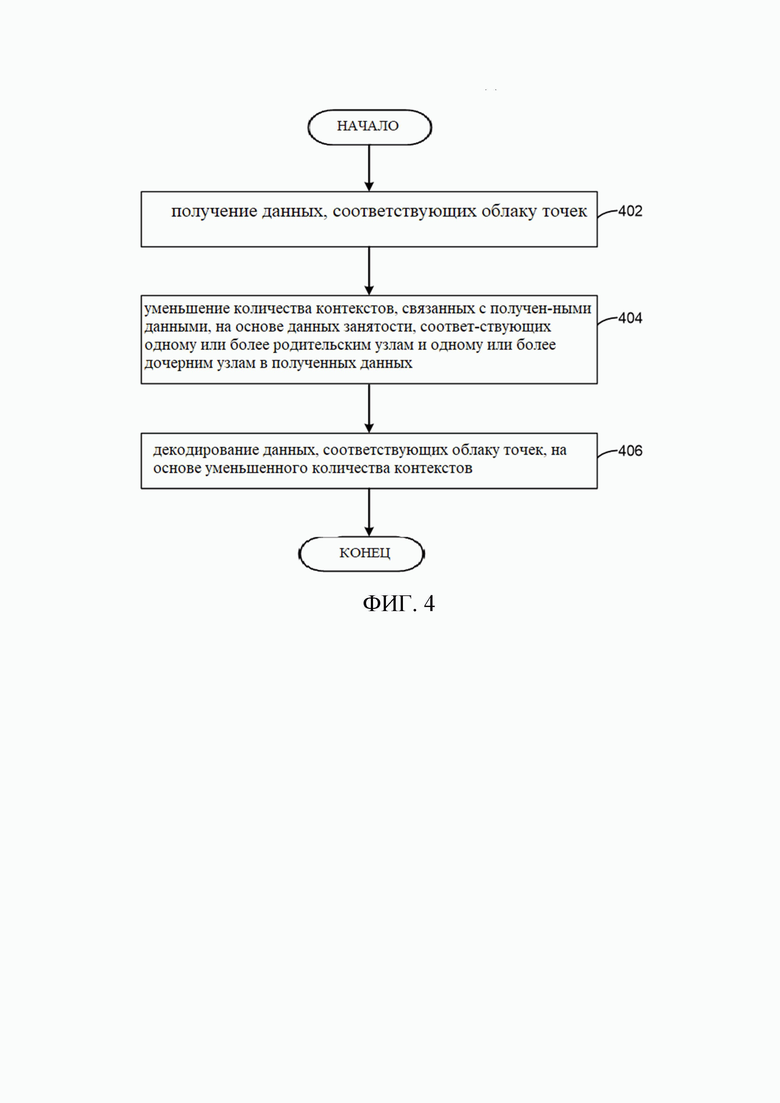
[20] Со ссылкой фиг.2A изображена схема структуры 200A октодерева. В TMC13, если используется кодек с геометрией октодерева, кодирование геометрии происходит следующим образом. Сначала кубический ограничивающий блок B, выровненный по оси, определяется двумя точками (0,0,0) и 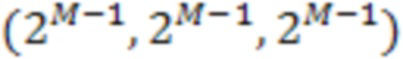 , где
, где 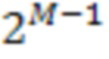 определяет размер B, а
определяет размер B, а 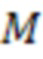 задается в битовом потоке. Структура 200A октодерева строится затем путем рекурсивного деления B. На каждом этапе куб разделяется на 8 субкубов. Затем генерируется 8-битовый код, а именно код занятости, путем связывания 1-битового значения с каждым субкубом, чтобы указать, содержит ли он точки (т.е. полный и имеет значение 1) или нет (т.е. пустой и имеет значение 0). Дальше разделяются только полные субкубы с размером больше 1 (т.е. не вокселы).
задается в битовом потоке. Структура 200A октодерева строится затем путем рекурсивного деления B. На каждом этапе куб разделяется на 8 субкубов. Затем генерируется 8-битовый код, а именно код занятости, путем связывания 1-битового значения с каждым субкубом, чтобы указать, содержит ли он точки (т.е. полный и имеет значение 1) или нет (т.е. пустой и имеет значение 0). Дальше разделяются только полные субкубы с размером больше 1 (т.е. не вокселы).
[21] Со ссылкой фиг.2В изображена схема разделения 200В октодерева. Разделение 200B октодерева может включать в себя двухуровневое разделение 202 октодерева и соответствующий код 204 занятости, где темные кубы и узлы указывают, что они заняты точками. Код 204 занятости каждого узла затем сжимается арифметическим кодером. Код 204 занятости может быть обозначен как S, представляющее собой 8-битовое целое число, а каждый бит в S указывает статус занятости каждого дочернего узла. В TMC13 существуют два способа кодирования для кода 204 занятости, т.е. способы побитового кодирования и побайтного кодирования, и побитовое кодирование разрешено по умолчанию. В любом случае выполняется арифметическое кодирование с контекстным моделированием для кодирования кода 204 занятости, в котором статус контекста инициализируется в начале всего процесса кодирования и обновляется во время процесса кодирования.
[22] Для побитового кодирования восемь бинов в S кодируются в определенном порядке, где каждый бин кодируется посредством обращения к статусу занятости соседних узлов и дочерних узлов соседних узлов, где соседние узлы находятся на одном и том же уровне текущего узла. Для побайтного кодирования S кодируется посредством обращения к адаптивной поисковой таблице (A-LUT), отслеживающей N (например, 32) наиболее частых кодов занятости, и кэшу, отслеживающему последние различные наблюдаемые M (например, 16) кодов занятости.
[23] Кодируется двоичный флаг, указывающий, находится ли S в A-LUT или нет. Если S находится в A-LUT, индекс в A-LUT кодируется путем использования двоичного арифметического кодера. Если S не находится в A-LUT, то кодируется двоичный флаг, указывающий, находится ли S в кэше или нет. Если S находится в кэше, то двоичное представление его индекса кодируется с использованием двоичного арифметического кодера. В противном случае, если S не находится в кэше, то двоичное представление S кодируется путем использования двоичного арифметического кодера. Процесс декодирования начинается с синтаксического анализа размеров ограничивающего блока B из битового потока. Такая же структура октодерева затем строится путем разделения B в соответствии с декодированными кодами занятости.
[24] Код занятости текущего узла обычно имеет 8 бит, где каждый бит представляет, занят его дочерний узел i или нет. При кодировании кода занятости текущего узла вся информация из соседних кодированных узлов может быть использована для контекстного моделирования. Информация контекста может быть дополнительно группирована на основании уровня разделения и расстояния до текущего узла. Без потери общности, индекс контекста дочернего узла i в текущем узле может быть получен следующим образом,
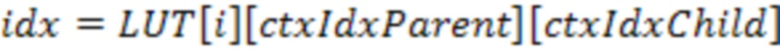 ,
,
где LUT - таблица поиска индексов контекста. 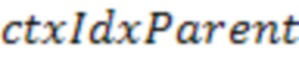 и
и 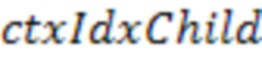 обозначают индексы LUT, представляющие информацию о соседях на уровне родительского узла и на уровне дочернего узла.
обозначают индексы LUT, представляющие информацию о соседях на уровне родительского узла и на уровне дочернего узла.
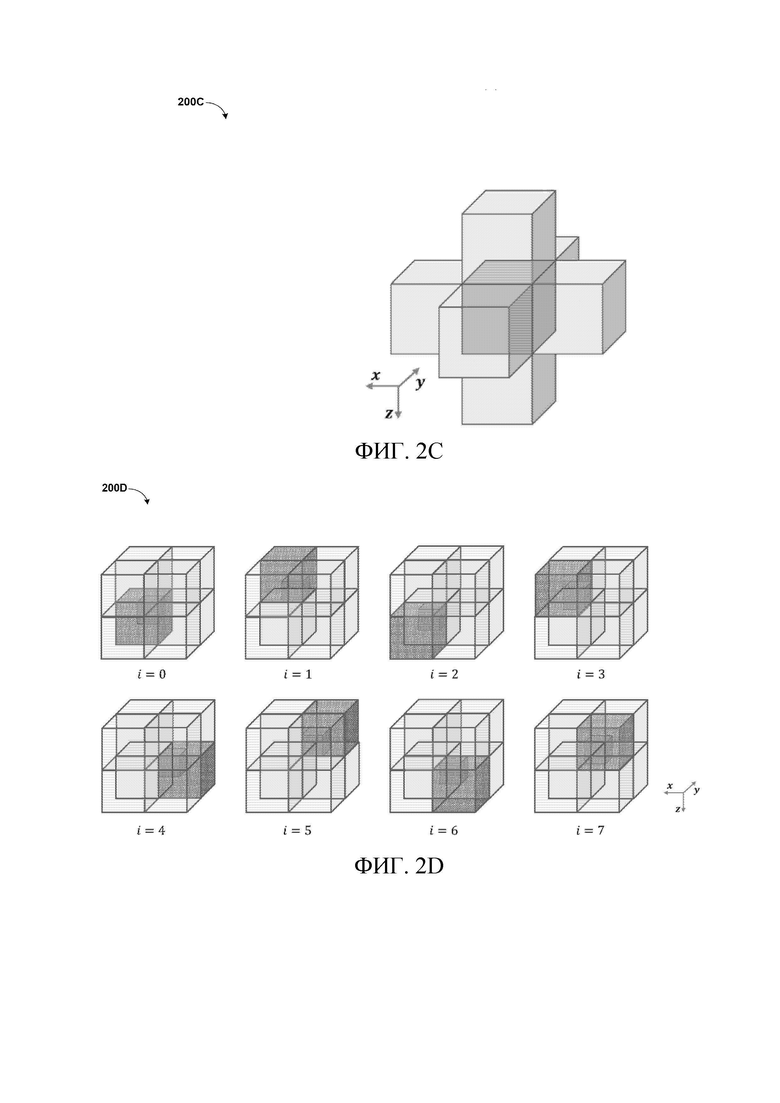
[25] Со ссылкой на фиг.2C изображена структурная схема 200C соседей узла родительского уровня. Согласно одному или более вариантам осуществления предположим, что октодерево пересекается по порядку в ширину. Шесть соседних узлов текущего узла могут быть использованы как установка контекстов уровня родительского узла. Блок в центре может быть текущим узлом, а остальные шесть блоков могут быть ближайшими соседями, где их расстояние до текущего узла составляет 1 единицу блока. Пусть 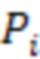 обозначает статус занятости соседа i, т.е.
обозначает статус занятости соседа i, т.е. 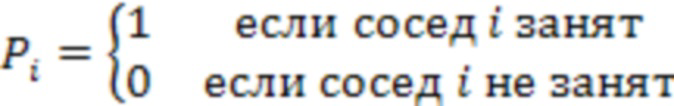 , где i =0,1,…,5. Тогда индекс контекста уровня родительского узла может быть получен следующим образом
, где i =0,1,…,5. Тогда индекс контекста уровня родительского узла может быть получен следующим образом
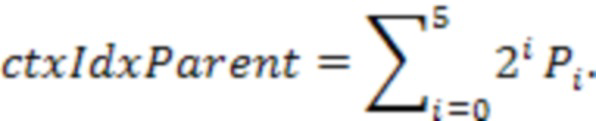
Следовательно, если все соседи заняты, максимальное значение составляет 63, что указывает на то, что количество контекстов на уровне родительского узла в этом случае составляет 64.
[26] Со ссылкой на фиг.2D изображена структурная схема 200D контекстов уровня родительского узла. Согласно одному или более вариантам осуществления октодерево пересекается по порядку в ширину. Все узлы в занятости родительского уровня могут быть кодированы, и они могут быть использованы как контексты на текущем уровне. Способ доступа к контексту на уровне родительского узла может отличаться для каждого дочернего узла с индексом i. Например, 8 субфигур могут изображать способ доступа к контексту уровня родительского узла для дочернего узла i (i=0,1,…,7) текущего кодированного узла. На каждой субфигуре текущий кодированный узел выделен темно-серым цветом, а меньший субблок в текущем узле является дочерним узлом i (i =0,1,…,7); каждый дочерний узел имеет различное положение относительно текущего узла. Способ доступа к контексту уровня родительского узла отличается для каждого дочернего узла в зависимости от его относительного положения по отношению к текущему узлу.
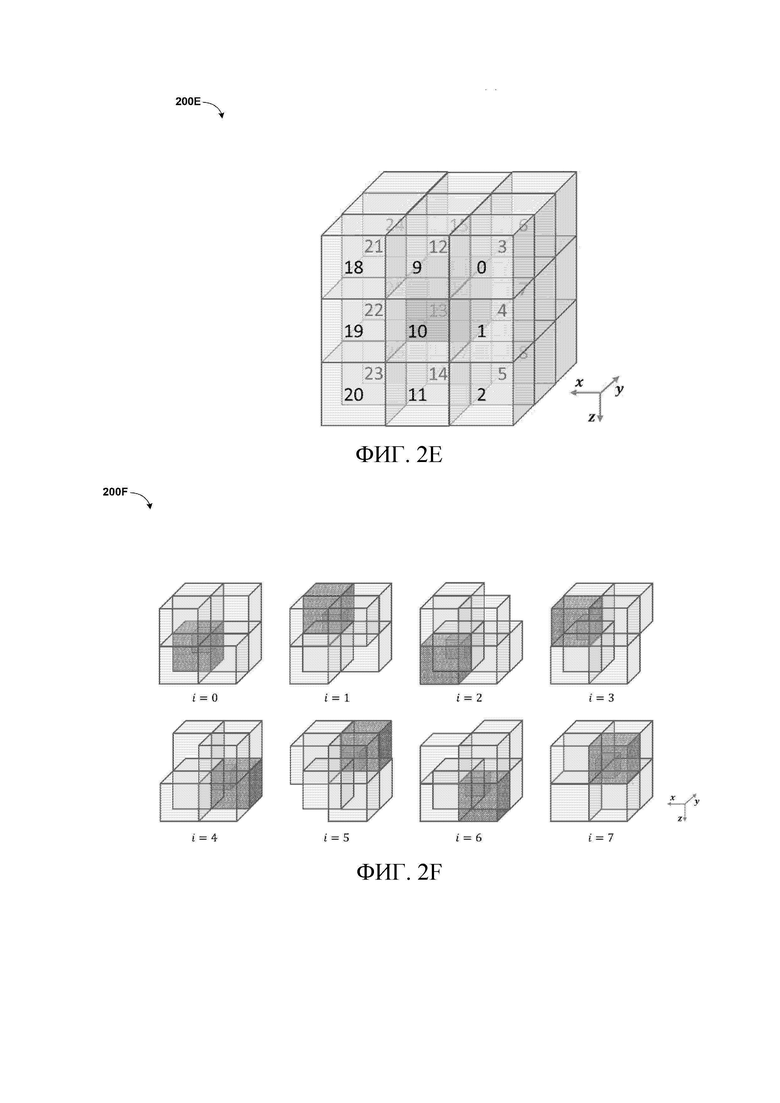
[27] Со ссылкой на фиг.2E изображена структурная схема 200E соседей родительского уровня текущего кодированного узла. В одном или более вариантах осуществления при кодировании дочернего узла i (i=0,1,…,7) 7 смежных узлов дочернего узла i на родительском уровне используются как контексты. 7 смежных узлов дочернего узла i включают в себя 3 узла, имеющих общую грань с дочерним узлом, и 3 узла, имеющих общее ребро, и 1 узел, имеющий общую вершину. Поскольку разные дочерние узлы относятся к разным наборам родительских узлов, при кодировании текущего узла используются всего 26 соседних узлов родительского уровня. По сравнению с использованием только 6 соседних узлов родительского уровня, использование 26 соседних узлов родительского уровня позволяет получить гораздо больше информации.
[28] Соответственно, индекс контекста дочернего узла i в текущем узле может быть получен как:
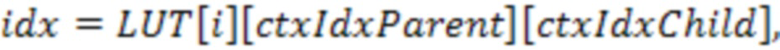
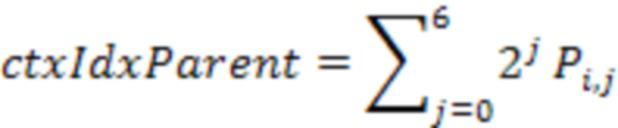
где 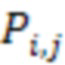 обозначает занятость смежного узла j на родительском уровне дочернего узла i. равна 1, если смежный узел j на родительском уровне дочернего узла i занят, и равен 0 в противном случае, где i=0,1,…,7 и j=0,1,…,6.
обозначает занятость смежного узла j на родительском уровне дочернего узла i. равна 1, если смежный узел j на родительском уровне дочернего узла i занят, и равен 0 в противном случае, где i=0,1,…,7 и j=0,1,…,6.
[29] Для уменьшения количества контекстов на уровне родительского узла, в другом варианте осуществления индекс контекста уровня родительского узла может быть получен с помощью,
 ,
,
в этом случае максимальное количество уменьшается до 6, что означает, что количество контекстов на уровне родительского узла уменьшается до 7 от 64.
[30] Для дополнительного уменьшения количества контекстов на уровне родительского узла, в другом варианте осуществления контекст уровня родительского узла отключен за счет установки
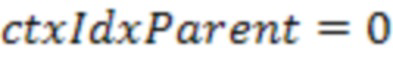 .
.
В этом случае информация о соседях на уровне родительского узла вообще не используется.
[31] Со ссылкой на фиг.2F изображена структурная схема 200F контекстов уровня родительского узла. Согласно одному или более вариантам осуществления количество соседей родительского уровня может быть изменено. Например, каждый дочерний узел может использовать только 6 ближайших соседей родительского уровня. 8 субфигур изображают способ доступа к контексту уровня родительского узла для дочернего узла i (i=0,1,…,7) текущего кодированного узла. На каждой субфигуре текущий кодированный узел выделен темно-серым цветом, а меньший субблок в текущем узле является дочерним узлом i (i=0,1,…,7); каждый дочерний узел имеет различное положение относительно текущего узла. Способ доступа к контексту уровня родительского узла отличается для каждого дочернего узла в зависимости от его относительного положения по отношению к текущему узлу. При кодировании дочернего узла i (i=0,1,…,7) только 6 смежных узлов дочернего узла i на родительском уровне используются как контексты. 6 смежных узлов дочернего узла i могут включать в себя 3 узла, имеющих общую грань с дочерним узлом, и 3 узла, имеющих общее ребро. По сравнению с фиг.2D, узел, имеющий общую вершину с дочерним узлом, в этом случае не может использоваться.
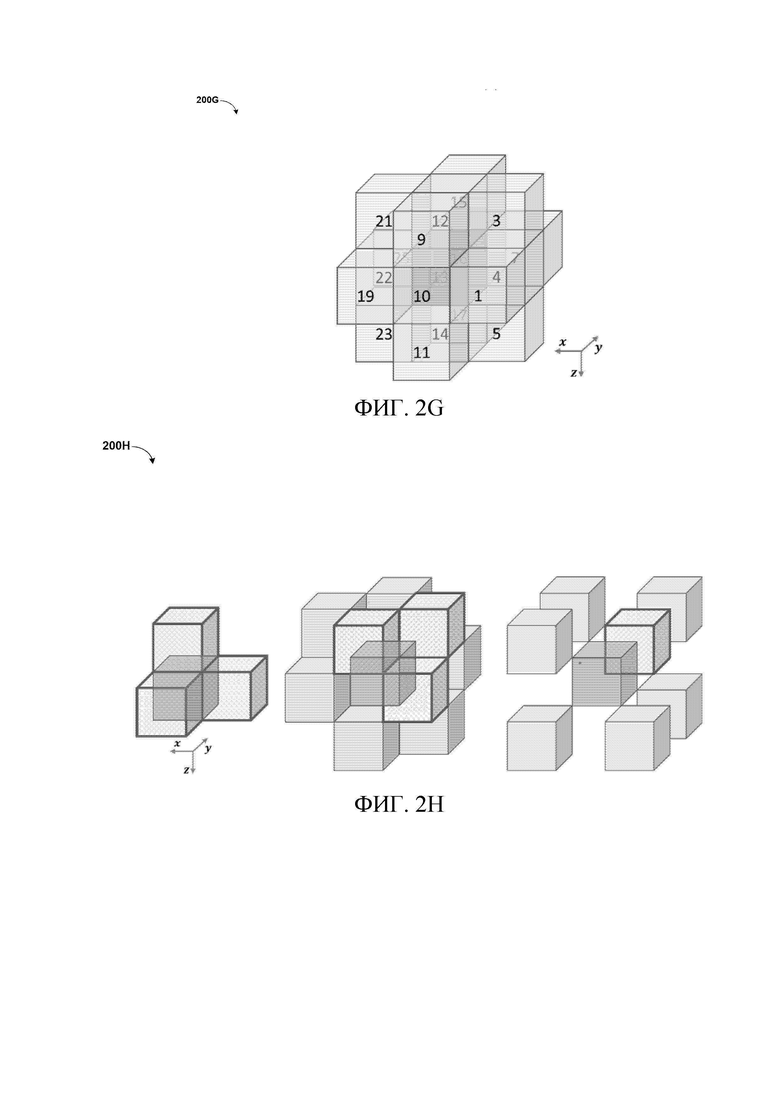
[32] Со ссылкой на фиг.2G изображена структурная схема, изображающая 200G, изображающий соседей родительского уровня текущего кодированного узла, на основе контекстов уровня родительского узла на фиг.2F. В одном или более вариантах осуществления узел, имеющий общую вершину с дочерним узлом, может не использоваться. Соответственно, всего может использоваться до 18 соседних узлов родительского уровня, с уменьшением от 26 на фиг. 2D и 2E. Следовательно, индекс контекста дочернего узла i в текущем узле может быть получен как:
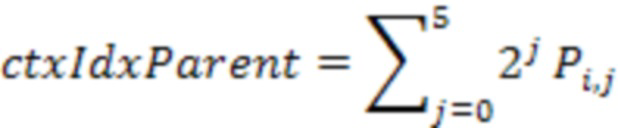
где обозначает занятость смежного узла j на родительском уровне дочернего узла i. равна 1, если смежный узел j на родительском уровне дочернего узла i занят, и равен 0 в противном случае, где i=0,1,…,7 и j=0,1,…,5. Следует принять во внимание, что количество соседей родительского уровня может быть дополнительно уменьшено за счет использования только поднабора соседей.
[33] Для дополнительного уменьшения количества контекстов можно упростить получение . В одном варианте осуществления каждый дочерний узел относится к 6 соседям родительского уровня, как показано на фиг.6, и индекс контекста родительского уровня может быть получен как:
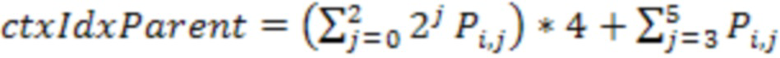 ),
),
где (j=0,1,2) обозначает статус занятости трех узлов родительского уровня, имеющих общую грань с дочерним узлом i, а (j=3,4,5) обозначает статус занятости трех узлов родительского уровня, имеющих общее ребро с дочерним узлом i. В этом случае соседи, имеющие общую грань, имеют более высокую важность, и индекс контекста вычисляется путем учета всех их возможных комбинаций, тогда как соседи, имеющие общее ребро, имеют меньшую важность, и индекс контекста вычисляется путем простого подсчета, сколько из них заняты. Таким образом, максимальное значение уменьшается от 26 - 1 до 25 - 1, поэтому общее количество контекстов уменьшается вдвое. Следует отметить, что для получения контекста родительского уровня могут быть применены другие сходные способы упрощения.
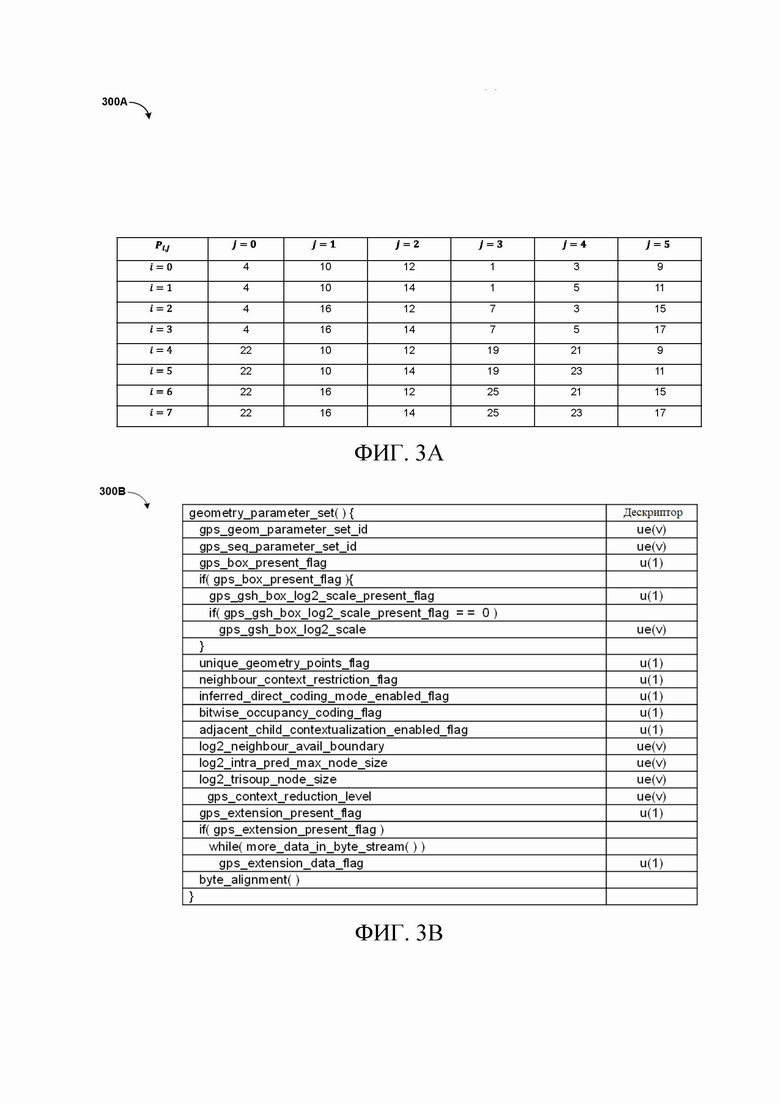
[34] Со ссылкой на фиг.2H изображена структурная схема 200H соседей уровня дочернего узла. Согласно одному или более вариантам осуществления соседи уровня дочернего узла могут быть определены многими способами. Например, узлы соседей уровня дочернего узла, которые уже кодированы, могут быть классифицированы на основании их расстояния до центрального узла. Без потери общности, предполагая, что размер каждого ребра дочерних узлов равен 1, расстояние l2 до центра составляет 1, 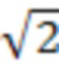 и
и 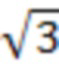 слева направо соответственно.
слева направо соответственно.
[35] Пусть 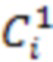 ,
, 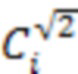 и
и 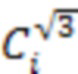 обозначают статус занятости соседа i на уровне дочернего узла с расстоянием l2, равным 1, и , соответственно, т.е.
обозначают статус занятости соседа i на уровне дочернего узла с расстоянием l2, равным 1, и , соответственно, т.е. 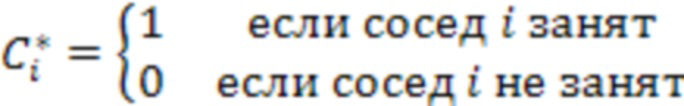 . Следует отметить, что максимальное количество кодированных соседних узлов дочернего уровня с расстоянием 1, и может составлять 3, 9 и 7, соответственно.
. Следует отметить, что максимальное количество кодированных соседних узлов дочернего уровня с расстоянием 1, и может составлять 3, 9 и 7, соответственно.
[36] Соответственно, индекс контекста уровня дочернего узла может быть получен как:
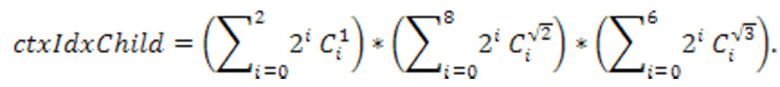
Следовательно, максимальное количество контекстов на уровне дочернего узла равно 219, что слишком много для приложений. Для уменьшения количества контекстов в одном или более вариантах осуществления могут быть учтены частичные соседи на уровне дочернего узла. Это может уменьшить максимальное количество контекстов на уровне дочернего узла до 27=128.
[37] В другом варианте осуществления максимальное количество контекстов может быть дополнительно упрощено как:
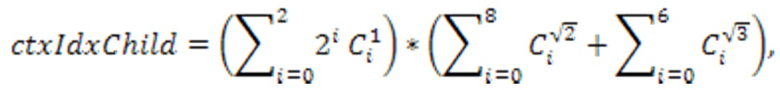
где максимальное количество контекстов на уровне дочернего узла уменьшено до 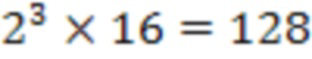 .
.
[38] Для дополнительного уменьшения количества контекстов можно использовать только три ближайших узла с расстоянием l2, равным 1, и индекс контекста вычисляется как:
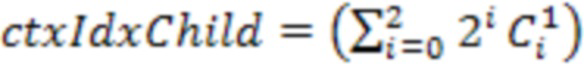 ,
,
где максимальное количество контекстов на уровне дочернего узла уменьшено до 23=8.
[39] Для дополнительного уменьшения количества контекстов может быть разорвана взаимосвязь между контекстом родительского уровня и индексом i дочернего узла. Для достижения этого можно определить некоторые правила. В одном варианте осуществления каждый дочерний узел относится к 6 соседям родительского уровня. Индекс контекста дочернего узла i в текущем узле может быть получен как:
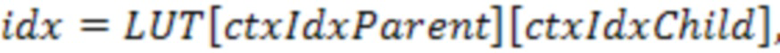
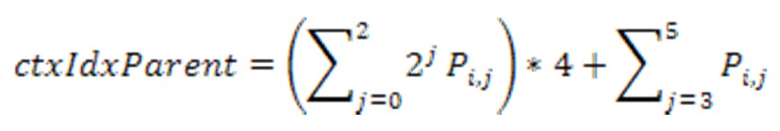
где (j=0,1,2) обозначает статус занятости трех узлов родительского уровня, имеющих общую грань с дочерним узлом i, а (j=3,4,5) обозначает статус занятости трех узлов родительского уровня, имеющих общее ребро с дочерним узлом i. Следует отметить, что конечный индекс контекста не зависит от дочернего индекса i. Для достижения этого может быть определено преобразование для каждого дочернего узла относительно упорядоченного расположения соседних узлов родительского уровня, т.е. . Преобразование описывается со ссылкой на фиг.3B. Разрыв отражает симметричную геометрию между каждым дочерним узлом и его 6 соседними узлами родительского уровня. Следует принять во внимание, что могут быть использованы другие способы разрыва за счет определения сходных таблиц преобразования в других вариантах осуществления.
[40] Согласно одному или более вариантам осуществления может не существовать различения между различными дочерними узлами при вычислении контекста для уменьшения количества контекстов. В частности индекс контекста дочернего узла i в текущем узле может быть получен как:
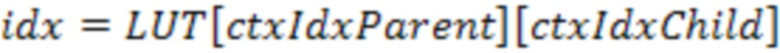 ,
,
где i больше не является измерением в LUT. Другими словами, все дочерние узлы считаются одинаковыми.
[41] Со ссылкой на фиг.3A изображен элемент 300A синтаксиса. Для достижения адаптивности к различным типам контента и сценариям, для разных случаев могут быть задействованы разные стратегии уменьшения контекста. Соответственно, синтаксис высокого уровня может быть сигнализирован либо в наборе параметров последовательности, либо в наборе параметров геометрии, либо в заголовке данных слайсов, либо где-нибудь еще для указания уровня уменьшения контекстов. На основании значения заданного уровня уменьшения контекстов кодер и декодер затем могут решить, как использовать информацию контекстов из соседних кодированных узлов. Уровень уменьшения контекстов может соответствовать схеме комбинации способов уменьшения контекстов.
[42] В одном или более вариантах осуществления элемент 300A синтаксиса может быть сигнализирован в наборе параметров геометрии, указывая уровень уменьшения контекстов, как показано в таблице ниже. Если уровень уменьшения контекстов равен 0, что означает отсутствие уменьшения контекстов, то применяется обычная установка контекстов. Если уровень уменьшения контекстов составляет 1, применяется низкоуровневое уменьшение. Если уровень уменьшения контекстов составляет 2, применяется среднеуровневое уменьшение. Если уровень уменьшения контекстов составляет 3, применяется высокоуровневое уменьшение. При большем количестве уровней уменьшения контекстов используется меньшее количество контекстов. В этом случае могут быть выбраны различные конфигурации контекста на основании контентов и сценариев. Таким образом, gps_context_reduction_level может задавать уровень уменьшения контекстов в наборе параметров геометрии.
[43] Со ссылкой на фиг.3B изображена хеш-таблица 300B. В одном или более вариантах осуществления кодированная информация занятости геометрии должна быть сохранена в кэш-памяти, поскольку более поздним кодированным узлам требуется использовать эту информацию как контекст. Хеш-таблица 300B может использоваться для кэширования информации занятости. Для каждой глубины d разделения октодерева поддерживается хеш-таблица 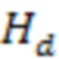 , где ключом является код Мортона узла октодерева на глубине d, т.е.
, где ключом является код Мортона узла октодерева на глубине d, т.е. 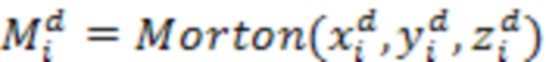 , где
, где 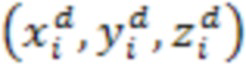 - трехмерные координаты узла октодерева. Используя код Мортона
- трехмерные координаты узла октодерева. Используя код Мортона 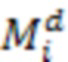 как ключ, можно получить доступ к его значению занятости в хеш-таблице . Значение занятости узла i октодерева на глубине d может быть получено как:
как ключ, можно получить доступ к его значению занятости в хеш-таблице . Значение занятости узла i октодерева на глубине d может быть получено как:
 .
.
При кодировании/декодировании значения занятости текущего узла информация занятости соседних узлов получается из хеш-таблицы . После кодирования/декодирования значение занятости текущего узла, кодированное значение занятости затем сохраняется в .
[44] Со ссылкой на фиг.4 изображена функциональная блок-схема, иллюстрирующая этапы способа 400, выполняемого программой, сжимающей и распаковывающей данные облака точек.
[45] На 402 способ может включать в себя получение данных, соответствующих облаку точек.
[46] На 404 способ 400 может включать в себя уменьшение количества контекстов, связанных с полученными данными, на основе данных занятости, соответствующих одному или более родительским узлам и одному или более дочерним узлам в полученных данных.
[47] На 406 способ 400 может включать в себя декодирование данных, соответствующих облаку точек, на основе уменьшенного количества контекстов.
[48] Следует понимать, что фиг.4 относится только к иллюстрации одной реализации и не подразумевает каких-либо ограничений в отношении того, как могут быть реализованы различные варианты осуществления. Для показанных сред могут быть сделаны многочисленные модификации на основе требований к конструкции и реализации.
[49] Фиг.5 является структурной схемой 500 внутренних и внешних компонентов компьютеров, изображенных на фиг.1, согласно иллюстративному варианту осуществления. Следует понимать, что фиг.5 относится только к иллюстрации одной реализации и не подразумевает каких-либо ограничений в отношении сред, в которых могут быть реализованы различные варианты осуществления. Для показанных сред могут быть сделаны многочисленные модификации на основе требований к конструкции и реализации.
[50] Компьютер 102 (фиг.1) и серверный компьютер 114 (фиг.1) могут включать в себя соответствующие наборы внутренних компонентов 800A, B и внешних компонентов 900A, B, показанных на фиг.5. Каждый из наборов внутренних компонентов 800 включает в себя один или более процессоров 820, одно или более машиночитаемых RAM 822 и одно или более машиночитаемых ROM 824 на одной или более шинах 826, одну или более операционных систем 828 и одно или более машиночитаемых физических устройств 830 хранения.
[51] Процессор 820 реализован в аппаратном обеспечении, встроенном программном обеспечении или комбинации аппаратного обеспечения и программного обеспечения. Процессор 820 представляет собой центральный процессор (CPU), графический процессор (GPU), ускоренный процессор (APU), микропроцессор, микроконтроллер, процессор цифровой обработки сигналов (DSP), программируемую пользователем вентильную матрицу (FPGA), специализированную интегральную схему (ASIC) или компонент обработки другого типа. В некоторых реализациях процессор 820 включает в себя один или более процессоров, которые могут быть программированы для выполнения функции. Шина 826 включает в себя компонент, обеспечивающий коммуникацию между внутренними компонентами 800A, B.
[52] Одна или более операционных систем 828, программа 108 системы программного обеспечения (фиг.1) и Программа 116 Сжатия Облака Точек (фиг.1) на серверном компьютере 114 (фиг.1) хранятся на одном или более из соответствующих машиночитаемых физических устройств 830 хранения для выполнения одним или более соответствующими процессорами 820 с использованием одного или более соответствующих RAM 822 (обычно включающих в себя кэш-память). В варианте осуществления, показанном на фиг.5, каждое из машиночитаемых физических устройств 830 хранения представляет собой устройство хранения на магнитных дисках внутреннего жесткого диска. Как альтернатива, каждое из машиночитаемых физических устройств 830 хранения представляет собой полупроводниковое устройство хранения, такое как ROM 824, EPROM, флэш-память, оптический диск, магнитооптический диск, твердотельный диск, компакт-диск (CD), цифровой универсальный диск (DVD), дискета, картридж, магнитная лента и/или невременное машиночитаемое физическое устройство хранения другого типа, которое может хранить компьютерную программу и цифровую информацию.
[53] Каждый набор внутренних компонентов 800A, B также включает в себя привод или интерфейс 832 чтения/записи для чтения из и записи на одно или более переносных машиночитаемых физических устройств 936 хранения, таких как CD-ROM, DVD, карта памяти, магнитная лента, магнитный диск, оптический диск или полупроводниковое устройство хранения. Программа системы программного обеспечения, такая как программа 108 системы программного обеспечения (фиг.1) и Программа 116 Сжатия Облака Точек (фиг.1), может храниться на одном или более соответствующих переносных машиночитаемых физических устройствах 936 хранения, считываемых с использованием соответствующего привода или интерфейса 832 чтения/записи и загружаемых на соответствующий жесткий диск 830.
[54] Каждый набор внутренних компонентов 800A, B также включает в себя сетевые адаптеры или интерфейсы 836, такие как адаптерные платы TCP/IP; платы беспроводного интерфейса Wi-Fi; платы беспроводного интерфейса 3G, 4G или 5G, или другие проводные или беспроводные коммуникационные каналы. Программа 108 системы программного обеспечения (фиг.1) и Программа 116 Сжатия Облака Точек (фиг.1) на серверном компьютере 114 (фиг.1) могут быть загружены в компьютер 102 (фиг.1) и серверный компьютер 114 из внешнего компьютера через сеть (например, Интернет, локальная сеть или другая глобальная сеть) и соответствующие сетевые адаптеры или интерфейсы 836. Из сетевых адаптеров или интерфейсов 836, программа 108 системы программного обеспечения и Программа 116 Сжатия Облака Точек на серверном компьютере 114 загружается в соответствующий жесткий диск 830. Сеть может содержать медные провода, оптические волокна, беспроводную передачу, маршрутизаторы, брандмауэры, коммутаторы, шлюзовые компьютеры и/или пограничные серверы.
[55] Каждый из наборов внешних компонентов 900A, B может включать в себя компьютерный экранный монитор 920, клавиатуру 930 и компьютерную мышь 934. Внешние компоненты 900A, B также могут включать в себя сенсорные экраны, виртуальные клавиатуры, сенсорные панели, указывающие устройства и другие устройства с человеческим интерфейсом. Каждый из наборов внутренних компонентов 800A, B также включает в себя драйверы 840 устройств для взаимодействия с компьютерным экранным монитором 920, клавиатурой 930 и компьютерной мышью 934. Драйверы 840 устройств, привод или интерфейс 832 чтения/записи и сетевой адаптер или интерфейс 836 содержат аппаратное обеспечение и программное обеспечение (хранящееся в устройстве 830 хранения и/или ROM 824).
[56] Понятно заранее, что, хотя это изобретение включает в себя подробное описание облачных вычислений, реализация упомянутых в данном документе идей не ограничивается средой облачных вычислений. Напротив, некоторые варианты осуществления могут быть реализованы в сочетании с вычислительной средой любого другого типа, известной в настоящее время или которая будет разработана позже.
[57] Облачные вычисления являются моделью предоставления услуг для обеспечения удобного сетевого доступа по запросу к общему пулу конфигурируемых вычислительных ресурсов (например, сети, пропускная способность сети, серверы, обработка, запоминающее устройство, хранилище, приложения, виртуальные машины и услуги), которые могут быть быстро предоставлены и отозваны с минимальными усилиями по управлению или взаимодействию с поставщиком услуги. Эта облачная модель может включать в себя по меньшей мере пять характеристик, по меньшей мере три модели услуг и по меньшей мере четыре модели развертывания.
[58] Характеристики включают в себя следующее:
Самообслуживание по запросу: пользователь облака может в одностороннем порядке предоставлять вычислительные возможности, такие как время сервера и сетевое хранилище, по необходимости автоматически, без необходимости взаимодействия человека с поставщиком услуг.
Широкий сетевой доступ: возможности могут быть доступны по сети и доступны через стандартные механизмы, способствующие использованию посредством гетерогенных платформ маломощных или полнофункциональных клиентов (например, мобильные телефоны, ноутбуки и PDA).
Объединение ресурсов: вычислительные ресурсы поставщика объединяются для обслуживания нескольких пользователей с использованием многопользовательской модели, при этом различные физические и виртуальные ресурсы динамически назначаются и переназначаются в соответствии с потребностями. Существует чувство независимости от местоположения в том смысле, что пользователь в целом не обладает контролем или знаниями о точном местоположении предоставляемых ресурсов, но он может задавать местоположение на более высоком уровне абстракции (например, страна, государство или центр обработки данных).
Быстрая адаптивность: возможности могут быть предоставлены быстро и адаптивно, в некоторых случаях автоматически, для быстрого горизонтального масштабирования с увеличением производительности и быстро отозваны для быстрого горизонтального масштабирования с уменьшением производительности. Для пользователя доступные для предоставления возможности часто кажутся неограниченными и могут быть приобретены в любом количестве в любое время.
Измеряемая услуга: облачные системы автоматически контролируют и оптимизируют использование ресурсов за счет эффективного использования возможности измерения на некотором уровне абстракции, соответствующем типу услуги (например, хранение, обработка, пропускная способность и активные учетные записи пользователей). Использование ресурсов можно отслеживать, контролировать и указывать в отчетах, что обеспечивает прозрачность как для поставщика, так и для пользователя используемой услуги.
[59] Модели услуг включают в себя следующие:
Программное Обеспечение как Услуга (SaaS): возможность, предоставляемая пользователю, заключается в использовании приложений поставщика, работающих в облачной инфраструктуре. Приложения доступны с различных клиентских устройств через интерфейс маломощного клиента, такой как веб-браузер (например, веб-служба электронной почты). Пользователь не управляет или не контролирует базовую облачную инфраструктуру, включая сеть, серверы, операционные системы, хранилище или даже возможности отдельных приложений, с возможным исключением задаваемых пользователем ограниченных параметров конфигурации приложения.
Платформа как Услуга (PaaS): эта возможность, предоставляемая пользователю, заключается в развертывании в облачной инфраструктуре приложений, созданных или приобретенных пользователем, созданных с использованием языков программирования и инструментов, поддерживаемых поставщиком. Пользователь не управляет или не контролирует базовую облачную инфраструктуру, включая сети, серверы, операционные системы или хранилище, но обладает контролем над развернутыми приложениями и, возможно, конфигурациями среды размещения приложений.
Инфраструктура как Услуга (laaS): эта возможность, предоставляемая пользователю, заключается в предоставлении обработки, хранения, сетей и других основных вычислительных ресурсов, в которых пользователь может развертывать и запускать произвольное программное обеспечение, которое может включать в себя операционные системы и приложения. Пользователь не управляет или не контролирует базовую облачную инфраструктуру, но обладает контролем над операционными системами, хранилищем, развернутыми приложениями и, возможно, ограниченным контролем над отдельными сетевыми компонентами (например, хостовый брандмауэр).
[60] Существуют следующие модели развертывания:
Частное облако: облачная инфраструктура используется исключительно для организации. Оно может управляться организацией или третьей стороной и может существовать как в локальной среде, так вне локальной среды.
Коллективное облако: облачная инфраструктура распределяется между несколькими организациями и поддерживает специальное сообщество, разделяющее общие интересы (например, миссия, требования безопасности, политика и соображения соответствия). Оно может управляться организациями или третьей стороной и может существовать как в локальной среде, так вне локальной среды.
Общедоступное облако: инфраструктура облака предоставляется широкому кругу лиц или крупной отраслевой группе и принадлежит организации, продающей облачные услуги.
Гибридное облако: инфраструктура облака представляет собой образование из двух или более облаков (частное, коллективное или общедоступное), остающихся уникальными объектами, но связанных вместе стандартизированной или проприетарной технологией, обеспечивающей переносимость данных и приложений (например, выход в облако для баланса нагрузки между облаками).
[61] Среда облачных вычислений ориентирована на сервисы с акцентом на бесструктурность, слабое связывание, модульность и семантическую интероперабельность. В основе облачных вычислений лежит инфраструктура, содержащая сеть взаимосвязанных узлов.
[62] На фиг.6 изображена иллюстративная среда 600 облачных вычислений. Как показано, среда 600 облачных вычислений содержит один или более узлов 10 облачных вычислений, с которыми могут коммуницировать локальные вычислительные устройства, используемые пользователями облака, такие как, например, персональный цифровой помощник (PDA) или сотовый телефон 54A, настольный компьютер 54B, портативный компьютер 54C, и/или автомобильная компьютерная система 54N. Узлы 10 облачных вычислений могут коммуницировать друг с другом. Они могут быть группированы (не показано) физически или виртуально в одной или более сетях, таких как частные, коллективные, общедоступные или гибридные облака, как описано выше, или их комбинация. Это позволяет среде 600 облачных вычислений предлагать инфраструктуру, платформы и/или программное обеспечение как услуги, для которых пользователю облачных вычислений не нужно поддерживать ресурсы на локальном вычислительном устройстве. Понятно, что типы вычислительных устройств 54A-N, показанных на фиг.6, предназначены только для иллюстрации, и что узлы 10 облачных вычислений и среда 600 облачных вычислений могут коммуницировать с компьютеризированным устройством любого типа по сети и/или сетевому адресуемому соединению любого типа (например, с использованием веб-браузера).
[63] Со ссылкой на фиг.7 изображен набор уровней 700 функциональной абстракции, предоставляемых средой 600 облачных вычислений (фиг.6). Следует заранее понимать, как предполагается, что показанные на фиг.7 компоненты, уровни и функции являются лишь иллюстративными, и варианты осуществления не ограничиваются ими. Как показано, предусмотрены следующие уровни и соответствующие функции:
[64] Уровень 60 аппаратного обеспечения и программного обеспечения включает в себя компоненты аппаратного обеспечения и программного обеспечения. Примеры аппаратных компонентов включают в себя: мэйнфреймы 61; серверы 62 на основе архитектуры RISC (компьютер с сокращенным набором команд); серверы 63; блейд-серверы 64; устройства 65 хранения; и сети и сетевые компоненты 66. В некоторых вариантах осуществления компоненты программного обеспечения включают в себя программное обеспечение 67 сервера сетевых приложений и программное обеспечение 68 базы данных.
[65] Уровень 70 виртуализации обеспечивает уровень абстракции, из которого могут быть представлены следующие примеры виртуальных объектов: виртуальные серверы 71; виртуальное хранилище 72; виртуальные сети 73, включая виртуальные частные сети; виртуальные приложения и операционные системы 74; и виртуальные клиенты 75.
[66] В одном примере уровень 80 управления может предоставлять описанные ниже функции. Предоставление 81 ресурсов обеспечивает динамическую поставку вычислительных ресурсов и других ресурсов, используемых для выполнения задач в среде облачных вычислений. Измерение и Определение 82 стоимости обеспечивает отслеживание затрат по мере использования ресурсов в среде облачных вычислений, и формирование счетов или выставление счетов за потребление этих ресурсов. В одном примере эти ресурсы могут содержать лицензии на прикладное программное обеспечение. Безопасность обеспечивает верификацию идентичности для пользователей облака и задач, а также защиту для данных и других ресурсов. Пользовательский портал 83 обеспечивает доступ к среде облачных вычислений для пользователей и системных администраторов. Управление 84 уровнем обслуживания предоставляет распределение ресурсов облачных вычислений и управление так, чтобы обеспечить соблюдение требуемых уровней обслуживания. Планирование и выполнение 85 Соглашения об Уровне Услуг (SLA) предусматривает предварительную организацию и закупку ресурсов облачных вычислений, для которых ожидается будущее требование в соответствии с SLA.
[67] Уровень 90 рабочих нагрузок предоставляет примеры функциональности, для которой может использоваться среда облачных вычислений. Примеры рабочих нагрузок и функций, которые могут быть представлены на этом уровне, включают в себя: составление карт и навигацию 91; разработка программного обеспечения и управление 92 жизненным циклом; предоставление 93 обучения в виртуальной аудитории; аналитическая обработка 94 данных; обработка 95 транзакций; и Сжатие 96 Облака Точек. Сжатие 96 Облака Точек может уменьшить расширенный набор соседних узлов для текущего узла для сжатия и распаковки данных облака точек.
[68] Некоторые варианты осуществления могут относиться к системе, способу и/или машиночитаемому носителю на любом возможном уровне технических деталей интеграции. Машиночитаемый носитель может включать в себя машиночитаемый невременной носитель данных (или носители), содержащий машиночитаемые программные инструкции на нем, предписывать процессору выполнять операции.
[69] Машиночитаемый носитель может представлять собой физическое устройство, которое может сохранять и хранить инструкции для использования устройством выполнения инструкций. Машиночитаемый носитель данных может представлять собой, например, но без ограничения этим, электронное запоминающее устройство, магнитное запоминающее устройство, оптическое запоминающее устройство, электромагнитное запоминающее устройство, полупроводниковое запоминающее устройство или любую подходящую комбинацию вышеуказанного. Неисчерпывающий список более конкретных примеров машиночитаемого носителя данных включает в себя следующее: переносная компьютерная дискета, жесткий диск, оперативное запоминающее устройство (RAM), постоянное запоминающее устройство (ROM), стираемое программируемое постоянное запоминающее устройство (EPROM или флэш-память), статическое запоминающее устройство с произвольной выборкой (SRAM), переносное постоянное запоминающее устройство на компакт-дисках (CD-ROM), универсальный цифровой диск (DVD), карта памяти, дискета, механически кодированное устройство, такое как перфокарты или выпуклые структуры в канавке с записанными на них инструкциями, и любая подходящая комбинация вышеуказанного. Машиночитаемый носитель данных, используемый в данном документе, не следует рассматривать как представляющий собой собственно временные сигналы, такие как радиоволны или другие свободно распространяющиеся электромагнитные волны, электромагнитные волны, распространяющиеся через волновод или другую передающую среду (например, световые импульсы, проходящие через волоконно-оптический кабель) или электрические сигналы, передаваемые по проводам.
[70] Машиночитаемые программные инструкции, описанные в данном документе, могут быть загружены на соответствующие вычислительные/обрабатывающие устройства с машиночитаемого носителя данных или на внешний компьютер, или внешнее устройство хранение через сеть, например Интернет, локальную сеть, глобальную сеть и/или беспроводную сеть. Сеть может содержать медные кабели передачи, оптические волокна передачи, беспроводную передачу, маршрутизаторы, брандмауэры, коммутаторы, шлюзовые компьютеры и/или пограничные серверы. Плата сетевого адаптера или сетевой интерфейс в каждом вычислительном/обрабатывающем устройстве получает машиночитаемые программные инструкции из сети и пересылает машиночитаемые программные инструкции для хранения на машиночитаемом носителе данных в соответствующем вычислительном/обрабатывающем устройстве.
[71] Машиночитаемый программный код/инструкции для выполнения операций могут представлять собой инструкции ассемблера, инструкции архитектуры набора команд (ISA), машинные инструкции, машинно-зависимые инструкции, микрокод, инструкции встроенного программного обеспечения, данные настройки состояния, данные конфигурации для интегральной схемы или исходный код, или объектный код, написанный на любой комбинации одного или более языков программирования, включая объектно-ориентированный язык программирования, такой как Smalltalk, C++ и т.п., и процедурные языки программирования, такие как язык программирования «С» или сходные языки программирования. Машиночитаемые программные инструкции могут выполняться полностью на компьютере пользователя, частично на компьютере пользователя, как изолированный пакет программного обеспечения, частично на компьютере пользователя и частично на удаленном компьютере или полностью на удаленном компьютере или сервере. В последнем сценарии удаленный компьютер может быть соединен с компьютером пользователя через сеть любого типа, включая локальную сеть (LAN) или глобальную сеть (WAN), или соединение может быть выполнено с внешним компьютером (например, через Интернет с использованием поставщика Интернет-сервиса). В некоторых вариантах осуществления электронные схемы, включая, например, программируемые логические схемы, программируемые пользователем вентильные матрицы (FPGA) или программируемые логические матрицы (PLA), могут выполнять машиночитаемые программные инструкции за счет использования информации состояния машиночитаемых программных инструкций для настойки электронной схемы для выполнения аспектов или операции.
[72] Эти машиночитаемые программные инструкции могут быть переданы процессору компьютера общего назначения, компьютера специального назначения или другого программируемого устройства обработки данных для создания машины, так что инструкции, выполняемые процессором компьютера или другого программируемого устройства обработки данных, создают средства для реализации функций/действий, указанных в блок-схеме и/или блоке или блоках структурной схемы. Эти машиночитаемые программные инструкции также могут храниться на машиночитаемом носителе данных, который может управлять компьютером, программируемым устройством обработки данных и/или другими устройствами для функционирования определенным образом, так что машиночитаемый носитель данных, содержащий инструкции, хранящиеся на нем, содержит готовое изделие, включая инструкции, реализующие аспекты функции/действия, указанных в блок-схеме и/или блоке или блоках структурной схемы.
[73] Машиночитаемые программные инструкции также могут быть загружены в компьютер, другое программируемое устройство обработки данных или другое устройство, чтобы вызывать выполнение ряда операционных этапов на компьютере, другом программируемом устройстве или другом устройстве для создания реализуемого компьютером процесса, так что инструкции, выполняемые на компьютере, другом программируемом устройстве или другом устройстве, реализуют функции/действия, указанные в блок-схеме и/или блоке или блоках структурной схемы.
[74] Блок-схема и структурные схемы на чертежах иллюстрируют архитектуру, функциональность и работу возможных реализаций систем, способов и машиночитаемых носителей согласно различным вариантам осуществления. В этом отношении каждый блок в блок-схеме или структурных схемах может представлять модуль, сегмент или часть инструкций, содержащую одну или более выполняемых инструкций для реализации заданной логической функции (функций). Способ, компьютерная система и машиночитаемый носитель могут включать в себя дополнительные блоки, меньшее количество блоков, различные блоки или блоки, расположенные иначе, чем изображенные на чертежах. В некоторых альтернативных реализациях, функции, указанные в блоках, могут появляться не в порядке, указанном на чертежах. Например, два блока, показанные последовательно, могут фактически выполняться одновременно или по существу одновременно, или блоки могут иногда выполняться в обратном порядке, в зависимости от задействованной функциональности. Также следует отметить, что каждый блок структурных схем и/или изображения блок-схем, а также комбинации блоков в структурных схемах и/или изображении блок-схем могут быть реализованы с помощью ориентированных на аппаратное обеспечение систем специального назначения, выполняющих заданные функции или действия, или выполняющих комбинации аппаратных и компьютерных инструкций специального назначения.
[75] Понятно, что системы и/или способы, описанные в данном документе, могут быть реализованы в различных формах аппаратного обеспечения, встроенного программного обеспечения или комбинации аппаратного обеспечения и программного обеспечения. Фактический специализированный аппаратный или программный код управления, используемый для реализации этих систем и/или способов, не ограничивает реализации. Таким образом, работа и поведение систем и/или способов были описаны в данном документе без ссылки на конкретный программный код - при этом понятно, что программное обеспечение и аппаратное обеспечение могут быть разработаны для реализации систем и/или способов на основе описания в данном документе.
[76] Никакие элемент, действие или инструкция, используемые в данном документе, не должны рассматриваться как критичные или существенные, если явно не описаны как таковые. Также подразумевается, что единственное число, используемое в данном документе, включает в себя один или более элементов и может использоваться взаимозаменяемо с «одним или более». Кроме того, подразумевается, что используемое в данном документе выражение «набор» включает в себя один или более элементов (например, связанных элементов, несвязанных элементов, комбинации связанных и несвязанных элементов и т.д.), и может использоваться взаимозаменяемо с «один или более». Если подразумевается только один элемент, используется выражение «один» или сходное выражение. Также подразумевается, что используемые в данном документе выражения «имеет», «иметь», «имеющий» и т.п. являются неограничивающими выражениями. Кроме того, подразумевается, что выражение «на основе» обозначает «основанный, по меньшей мере частично, на», если явно не указано иное.
[77] Описания различных аспектов и вариантов осуществления были представлены для целей иллюстрации, однако подразумевается, что они не являются исчерпывающими или ограниченными раскрытыми вариантами осуществления. Несмотря на то, что комбинации признаков изложены в формуле изобретения и/или раскрыты в описании, подразумевается, что эти комбинации не ограничивают раскрытие возможных реализаций. Фактически, многие из этих признаков могут быть объединены способами, специально не указанными в формуле изобретения и/или раскрытыми в описании. Хотя каждый зависимый пункт формулы изобретения, приведенный ниже, может зависеть непосредственно только от одного пункта формулы изобретения, раскрытие возможных реализаций включает в себя каждый зависимый пункт в комбинации с каждым другим пунктом в пунктах формулы изобретения. Специалистам в данной области техники могут быть очевидны многочисленные модификации и изменения без выхода за рамки описанных вариантов осуществления. Используемая в данном документе терминология была выбрана для лучшего объяснения принципов вариантов осуществления, практического применения или технического усовершенствования в отношении технологий, доступных на рынке, или чтобы позволить другим специалистам в данной области техники понять раскрытые здесь варианты осуществления.
Изобретение относится к области кодирования и декодирования данных. Техническим результатом является повышение эффективности кодирования и декодирования данных облака точек за счет уменьшения количества контекстов, связанных с данными облака точек. Технический результат достигается тем, что количество контекстов, связанных с принятыми данными, уменьшают на основе данных о занятости, соответствующих одному или нескольким родительским узлам и одному или нескольким дочерним узлам в полученных данных. Данные, соответствующие облаку точек, декодируют на основе уменьшенного количества контекстов. При этом для родительских узлов, имеющих общую грань с дочерними узлами, индекс контекста родительского уровня вычисляют путем учета всех возможных комбинаций, а для родительских узлов, имеющих общее ребро с дочерними узлами, индекс контекста родительского уровня вычисляют путем простого подсчета, сколько родительских узлов занято. 4 н. и 12 з.п. ф-лы, 15 ил.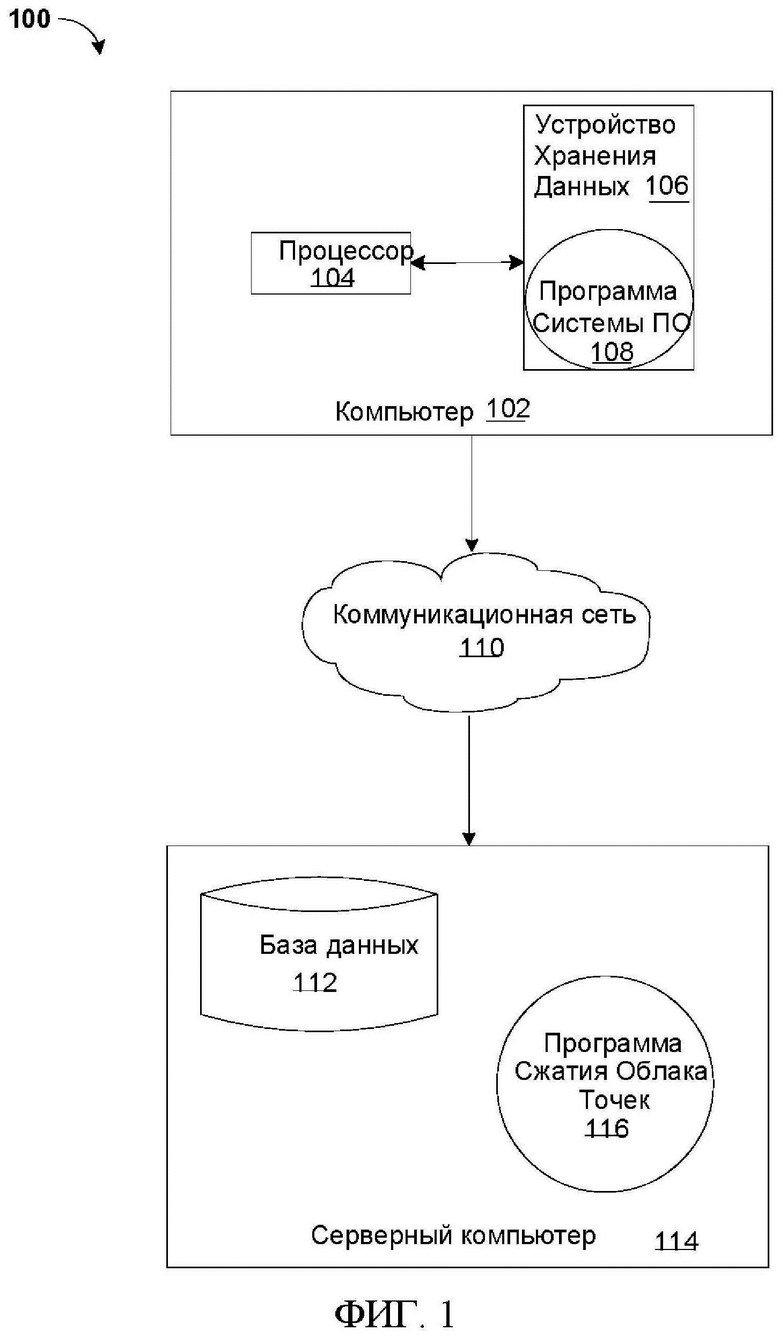
1. Способ декодирования данных облака точек, выполняемый процессором, содержащий:
получение данных, соответствующих облаку точек;
уменьшение количества контекстов, связанных с полученными данными, на основе данных занятости, соответствующих одному или более родительским узлам и одному или более дочерним узлам в полученных данных;
декодирование данных, соответствующих облаку точек, на основе уменьшенного количества контекстов,
причем для родительских узлов, имеющих общую грань с дочерними узлами, индекс контекста родительского уровня вычисляют путем учета всех возможных комбинаций, а для родительских узлов, имеющих общее ребро с дочерними узлами, индекс контекста родительского уровня вычисляют путем простого подсчета, сколько родительских узлов занято.
2. Способ по п.1, дополнительно содержащий кэширование информации занятости на основе хеш-таблицы.
3. Способ по п.1, дополнительно содержащий сигнализацию уровня уменьшения контекстов в наборе параметров последовательности, наборе параметров геометрии или заголовке данных слайсов.
4. Способ по п.1, причем количество контекстов уменьшают на основе одного или более дочерних узлов, имеющих наименьшее расстояние от текущего узла.
5. Способ по п.1, причем количество контекстов уменьшают на основе рассмотрения только поднабора дочерних узлов из одного или более дочерних узлов.
6. Способ по п.1, причем количество контекстов уменьшают на основе неразличения между одним или более дочерними узлами.
7. Способ по п.1, причем количество контекстов уменьшают на основе исключения данных занятости, связанных с одним или более родительскими узлами.
8. Компьютерная система для декодирования данных облака точек, причем компьютерная система содержит:
один или более машиночитаемых невременных носителей данных, конфигурированных для хранения компьютерного программного кода; и
один или более компьютерных процессоров, конфигурированных для доступа к указанному компьютерному программному коду и работы в соответствии с инструкциями указанного компьютерного программного кода, при этом указанный компьютерный программный код включает в себя:
код получения, конфигурированный предписывать одному или более компьютерным процессорам получать данные, соответствующие облаку точек;
код уменьшения, конфигурированный предписывать одному или более компьютерным процессорам уменьшать количество контекстов, связанных с полученными данными, на основе данных занятости, соответствующих одному или более родительским узлам и одному или более дочерним узлам в полученных данных;
код декодирования, конфигурированный предписывать одному или более компьютерным процессорам декодировать данные, соответствующие облаку точек, на основе уменьшенного количества контекстов,
причем для родительских узлов, имеющих общую грань с дочерними узлами, индекс контекста родительского уровня вычисляют путем учета всех возможных комбинаций, а для родительских узлов, имеющих общее ребро с дочерними узлами, индекс контекста родительского уровня вычисляют путем простого подсчета, сколько родительских узлов занято.
9. Компьютерная система по п.8, дополнительно содержащая код кэширования, конфигурированный предписывать одному или более компьютерным процессорам кэшировать информацию занятости на основе хеш-таблицы.
10. Компьютерная система по п.8, дополнительно содержащая код сигнализации, конфигурированный предписывать одному или более компьютерным процессорам сигнализировать уровень уменьшения контекстов в наборе параметров последовательности, наборе параметров геометрии или заголовке данных слайсов.
11. Компьютерная система по п.8, причем количество контекстов уменьшено на основе одного или более дочерних узлов, имеющих наименьшее расстояние от текущего узла.
12. Компьютерная система по п.8, причем количество контекстов уменьшено на основе рассмотрения только поднабора дочерних узлов из одного или более дочерних узлов.
13. Компьютерная система по п.8, причем количество контекстов уменьшено на основе неразличения между одним или более дочерними узлами.
14. Компьютерная система по п.8, причем количество контекстов уменьшено на основе исключения данных занятости, связанных с одним или более родительскими узлами.
15. Способ кодирования данных облака точек, выполняемый процессором, содержащий:
определение данных, соответствующих облаку точек;
уменьшение количества контекстов, связанных с данными, на основе данных занятости, соответствующих одному или более родительским узлам и одному или более дочерним узлам в данных;
кодирование данных, соответствующих облаку точек, на основе уменьшенного количества контекстов,
причем для родительских узлов, имеющих общую грань с дочерними узлами, индекс контекста родительского уровня вычисляют путем учета всех возможных комбинаций, а для родительских узлов, имеющих общее ребро с дочерними узлами, индекс контекста родительского уровня вычисляют путем простого подсчета, сколько родительских узлов занято.
16. Невременной машиночитаемый носитель, имеющий хранящуюся на нем компьютерную программу для декодирования/кодирования данных облака точек, причем компьютерная программа конфигурирована предписывать одному или более компьютерным процессорам осуществлять способ по любому из пп.1-7 и 15.
| WO 2019195920 A1, 17.10.2019 | |||
| US 20190080483 A1, 14.03.2019 | |||
| US 20150029186 A1, 29.01.2015 | |||
| US 20130177069 A1, 11.07.2013 | |||
| RU 2018115810 A, 30.10.2019 | |||
| УСТРОЙСТВО КОДИРОВАНИЯ И СПОСОБ КОДИРОВАНИЯ, УСТРОЙСТВО ДЕКОДИРОВАНИЯ И СПОСОБ ДЕКОДИРОВАНИЯ | 2016 |
|
RU2721678C2 |

