Область техники, к которой относится изобретение
Настоящее изобретение относится к области облачных вычислений и, более конкретно, к способам обработки запросов и распределения нагрузки между ресурсами обработки данных в среде облачных вычислений.
Уровень техники
Облачные вычисления предназначены для предоставления компьютерных услуг, таких как серверы, хранилища, базы данных, сети, программное обеспечение и так далее. Вместо того чтобы иметь собственную компьютерную инфраструктуру или центры обработки данных, предприятия и отдельные пользователи могут использовать облачные вычисления для доступа ко всему, начиная от приложений и заканчивая достаточным пространством для хранения.
Одним из применений сервисов облачных вычислений является мобильная среда для предоставления услуг пользователям мобильных телефонов (мобильные облачные вычисления, MCC). Поскольку все сложные вычисления могут быть вычислены в облаке, мобильным устройствам не нужно иметь надежные характеристики, такие как быстрый процессор, большой объем памяти и так далее. Основной задачей планировщика в среде мобильных облачных вычислений является распределение задач между ресурсами для сокращения времени выполнения.
Этот подход предполагает, что существует набор пользовательских задач, каждая из которых имеет множество компонентов. Каждая задача может быть выполнена с использованием того или иного доступного ресурса. Каждый облачный ресурс имеет свой уровень производительности (например, процессор, память, скорость сети), и каждая подзадача может быть выполнена только на одном ресурсе одновременно. В планировщик, подключенный к M ресурсам, вводится набор из N задач, и результатом работы алгоритма является расписание (например в виде диаграммы Ганта), содержащее распределение задач по доступным ресурсам. Задача алгоритма состоит в том, чтобы распределить каждый участок работы по соответствующим ресурсам и организовать график выполнения задач на ресурсах таким образом, чтобы минимизировать общие затраты на выполнение.
В уровне техники существует множество алгоритмов и механизмов оптимизации и управления ресурсами, обеспечивающих оптимальное распределение нагрузки в системе облачных вычислений с учетом вычислительных мощностей (например, RU 2543962 C2), однако по-прежнему существует потребность в их развитии.
Сущность изобретения
Согласно настоящему изобретению, предложен способ обработки запросов в среде облачных вычислений, выполняемый в устройстве планирования и содержащий этапы, на которых:
принимают набор запросов от мобильных устройств и устройств, обладающих малой вычислительной мощностью, причем каждый запрос содержит задачу обработки данных и параметры задачи;
создают исходный набор решений, причем решением в наборе решений является одномерный массив чисел, размер которого равен общему числу допустимых соответствий между всеми задачами и ресурсами в среде облачных вычислений согласно параметрам задач и параметрам ресурсов;
для каждого решения формируют расписание выполнения задач согласно упомянутым соответствиям между задачами и ресурсами в порядке возрастания или убывания значений элементов массива;
определяют пригодность каждого решения, причем пригодность равна сумме значений времени обработки и энергопотребления с учетом предварительно заданных весовых коэффициентов времени и энергии, причем значения времени обработки и энергопотребления вычисляют на основе расписания выполнения задач;
выбирают целевое решение в наборе решений на основе значений времени обработки и энергопотребления;
далее итеративно выполняют следующие этапы до достижения предварительно заданного числа итераций:
- преобразуют решения в наборе решений методом оптимизации;
- выбирают лучшее решение в текущем наборе на основе значений времени обработки и энергопотребления решений в текущем наборе;
- задают лучшее решение в текущем наборе в качестве целевого решения, если его пригодность лучше пригодности ранее заданного целевого решения; и
определяют расписание, соответствующее целевому решению, в качестве целевого расписания для выполнения задач.
В одном из вариантов осуществления создание исходного набора решений содержит этапы, на которых:
выявляют для каждой задачи, какой из набора ресурсов способен ее выполнять, согласно параметрам задачи и параметрам ресурса;
каждое выявленное соответствие между задачей и ресурсом рассматривают в качестве возможного исполнения и присваивают ему уникальный идентификатор среди всех задач;
формируют одномерный массив чисел, причем каждому возможному исполнению среди всех задач соответствует один элемент массива, и каждый элемент массива имеет случайное значение в предварительно заданном промежутке;
повторяют этап формирования массива предварительно заданное количество раз и рассматривают каждый массив в качестве возможного решения, формируя тем самым исходный набор решений.
В одном из вариантов осуществления формирование расписания содержит этапы, на которых итеративно в порядке возрастания или убывания значений элементов массива определяют для текущего элемента массива номер задачи и номер ресурса согласно уникальному идентификатору, соответствующему этому элементу массива, и если эта задача еще не присутствует в расписании, формируют запись в расписании, содержащую номер задачи и номер ресурса.
В одном из вариантов осуществления энергопотребление равно сумме энергий для выполнения каждой задачи в расписании и энергий, потребляемых ресурсами в режиме бездействия, причем энергия для одной задачи равна сумме энергии, потребляемой соответствующим ресурсом при передаче и приеме данных этой задачи, и энергии, потребляемой ресурсом при обработке данных этой задачи, и
время обработки равно сумме времен для каждой задачи в расписании, причем время для одной задачи равно сумме времени, необходимого для передачи и приема данных этой задачи на соответствующий ресурс и от него, времени, необходимого для выполнения этой задачи данным ресурсом, и времени ожидания этой задачи в очереди данного ресурса.
В одном из вариантов осуществления целевое решение в наборе решений выбирают посредством формирования упорядоченного списка из всех решений в соответствии с взвешенным роевым расстоянием и взвешенным рангом решений по времени и по энергии, причем роевое расстояние представляет собой расстояние от данного решения до остальных решений в наборе, причем ранг решения по времени или по энергии равен числу событий сравнения, при которых данное решение превосходит сравниваемое с ним другое решение, соответственно, по времени обработки или по энергопотреблению.
В одном из вариантов осуществления выбор целевого решения в наборе решений содержит этапы, на которых:
определяют ранг каждого решения по времени и ранг каждого решения по энергии путем сравнения всех решений между собой;
определяют взвешенный ранг каждого решения путем сложения рангов данного решения по времени и по энергии с учетом предварительно заданных весовых коэффициентов времени и энергии;
формируют упорядоченный список по времени из всех решений в соответствии с возрастанием времени обработки;
определяют роевое расстояние для каждого решения в списке по времени, причем роевое расстояние представляет собой расстояние от данного решения до остальных решений в списке и определяется путем деления разности значений между последующим и предшествующим решениями в списке на разность значений между последним и первым решениями в списке;
формируют упорядоченный список по энергии из всех решений в соответствии с возрастанием энергопотребления;
определяют роевое расстояние для каждого решения в списке по энергии;
определяют взвешенное роевое расстояние каждого решения путем сложения роевого расстояния данного решения по времени и по энергии с учетом предварительно заданных весовых коэффициентов времени и энергии;
формируют упорядоченный список из всех решений в соответствии с взвешенным роевым расстоянием, причем решения, имеющие одинаковое взвешенное роевое расстояние, дополнительно упорядочивают между собой в соответствии с взвешенным рангом; и
первое решение в сформированном списке задают в качестве целевого решения.
В одном из вариантов осуществления цикл итераций дополнительно содержит этапы, на которых:
определяют значение сходства каждого решения в текущем наборе с тем же решением в предыдущей итерации, причем в качестве меры сходства используют косинусное сходство;
формируют проверочный массив из решений текущего набора, значение сходства которых превышает предварительно заданный порог сходства;
для каждого решения из проверочного массива создают дополнительные решения с помощью генетического алгоритма, определяют лучшее из них по пригодности, и если пригодность лучшего из дополнительных решений лучше пригодности самого решения из проверочного массива, заменяют решение в текущем наборе, соответствующее данному решению из проверочного массива, на упомянутое лучшее из дополнительных решений.
В одном из вариантов осуществления дополнительные решения содержат дополнительное решение на основе мутации и дополнительное решение на основе кроссинговера;
создание дополнительного решения на основе мутации содержит этапы, на которых случайным образом выбирают элемент массива, соответствующего данному решению, и присваивают ему новое случайное значение;
создание дополнительного решения на основе кроссинговера содержит этапы, на которых: из набора наилучших решений выбирают родительское решение; случайным образом выбирают номер элемента; заменяют элементы массива, соответствующего текущему решению, от начального или конечного элемента до элемента с выбранным номером, на соответствующие элементы массива, соответствующего родительскому решению; и обновляют набор наилучших решений.
В одном из вариантов осуществления набор наилучших решений первоначально является копией исходного набора решений, а обновление набора наилучших решений содержит этапы, на которых добавляют созданные дополнительные решения в набор наилучших решений и удаляют из него соответствующее количество решений, имеющих наихудшую пригодность.
В одном из вариантов осуществления в качестве родительского решения выбирают решение, значение косинусного сходства которого с текущим решением является наименьшим из набора наилучших решений.
Технический результат
Настоящее изобретение позволяет повысить эффективность способов обработки запросов и распределения нагрузки между ресурсами обработки данных в среде облачных вычислений. При этом обеспечивается повышение скорости получения результата, повышение точности распределения, уменьшение среднего времени выполнения задач и энергопотребления, уменьшение доли невыполненных задач.
Следует понимать, что не каждый из вариантов осуществления может обеспечивать одновременно все указанные преимущества по сравнению со всеми известными решениями из уровня техники. Соответственно, некоторые варианты осуществления могут обладать лишь некоторыми из указанных преимуществ или иными преимуществами относительно некоторых известных решений.
Эти и другие преимущества настоящего изобретения станут понятны при прочтении нижеследующего подробного описания со ссылкой на сопроводительные чертежи.
Краткое описание чертежей
Фиг. 1 – архитектура системы облачных вычислений.
Фиг. 2 – способ предварительной оценки запроса на обработку данных.
Фиг. 3 – выявление соответствий между задачами и ресурсами.
Фиг. 4 – присвоение идентификаторов выявленным соответствиям между задачами и ресурсами.
Фиг. 5 – формирование массива.
Фиг. 6 – сортировка массива.
Фиг. 7 – формирование расписания.
Фиг. 8 – мутация.
Фиг. 9 – кроссинговер.
Фиг. 10 – первый пример предложенного способа.
Фиг. 11 – второй пример предложенного способа.
Фиг. 12 – третий пример предложенного способа.
Следует понимать, что фигуры могут быть представлены схематично и не в масштабе и предназначены, главным образом, для улучшения понимания настоящего изобретения.
Подробное описание
Общее описание системы
Далее настоящее изобретение будет описано более подробно. Следует отметить, что данное описание не является ограничивающим и предназначено лишь для того, чтобы предоставить общее понимание предложенных принципов изобретения.
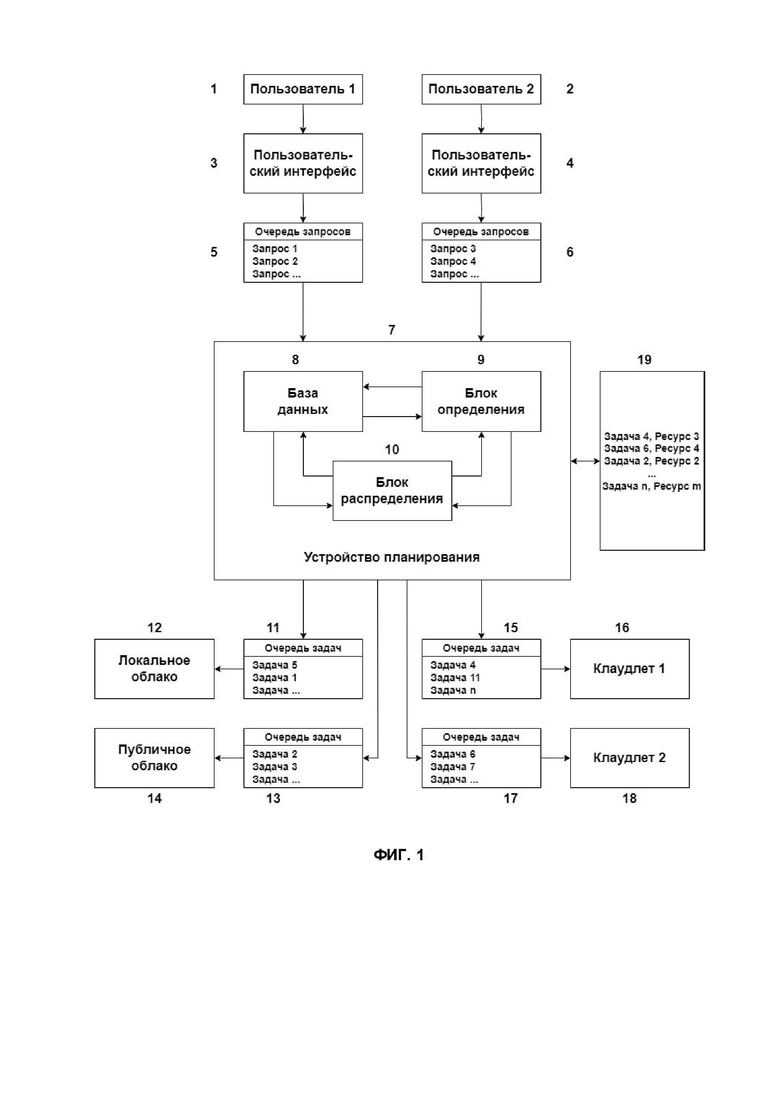
В системе облачных вычислений, изображенной на Фиг. 1, пользователь 1 мобильного устройства или иного устройства, обладающего малой вычислительной мощностью, совершает множество действий через пользовательский интерфейс 3, требующих обработки данных. Устройство пользователя представляет собой любое устройство с процессором и памятью, которое нуждается в разгрузке от сложных вычислений и способно выдавать запросы и отправлять их по проводной или беспроводной сети передачи данных в систему облачных вычислений. Под мобильным устройством подразумевается любое подвижное, передвижное, носимое, переносное, карманное, портативное устройство, которое перемещается пользователем (например, смартфон, планшет, ноутбук, умные часы, умные очки и т.д.), в связи с пользователем (автомагнитола, бортовой компьютер, видеорегистратор, радар-детектор, навигатор, камера заднего вида, блок пользовательского интерфейса самоката, велосипеда, мопеда и т.д.) или самостоятельно (например, дрон, ровер, робот-доставщик, автономное транспортное средство). Следует понимать, что не только мобильные, но и стационарные устройства (например, пользовательские компьютеры, IoT-устройства и даже маломощные серверы) могут нуждаться в дополнительных вычислительных ресурсах. В общем случае со стороны устройства пользователь может отсутствовать, а устройство может формировать запросы обработки данных без участия пользователя.
Устройство пользователя 1 формирует очередь 5 запросов и отправляет запросы на устройство 7 планирования. Аналогичным образом, устройство 7 планирования получает запросы от устройства пользователя 3, совершающего действия через пользовательский интерфейс 4, из очереди 6 запросов, и от множества других пользователей. Каждый запрос содержит параметры задачи - например, объем данных (или инструкций), время запроса, расстояние от устройства до сервера во времени и в пространстве, срок выполнения задачи и т.д.
Устройство 7 планирования реализовано на базе компьютера, содержащего процессор, память и сетевой модуль, находится в среде облачных вычислений и подключено ко множеству ресурсов обработки данных, таких как локальное облако 12, публичное облако 14, клаудлеты 16, 18 и т.д. Целью устройства 7 планирования является перекладывание задач пользователя с пользовательского устройства на облачные вычислительные ресурсы таким образом, чтобы минимизировать общие затраты на выполнение этих задач.
Устройство 7 планирования содержит базу 8 данных, в которой сохраняются всех поступающие запросы. Кроме того, в базе 8 данных хранятся и регулярно обновляются сведения о вычислительных ресурсах, к которым подключено устройство 7 планирования, такие как доступность ресурса, скорость обмена данными с ресурсом, параметры задач, доступные для выполнения этим ресурсом, вычислительная мощность ресурса, объем памяти ресурса и т.д.
Устройство 7 планирования также содержит блок 9 определения, который определяет расписание 19 выполнения задач для задач, которые еще не поступили в обработку, среди доступных ресурсов с учетом параметров задач и параметров ресурсов.
Устройство 7 планирования также содержит блок 10 распределения, который распределяет задачи по ресурсам обработки данных, подключенным к устройству 7 планирования по сети передачи данных, согласно расписанию 19 выполнения задач. Например, блок 10 распределения распределяет задачу 4, которая значится первой в расписании 19, ресурсу 3, которым в данном случае выступает клаудлет 16. Аналогичным образом, блок 10 распределения распределяет задачу 6, которая значится следующей в расписании 19, ресурсу 4, которым в данном случае выступает клаудлет 18. Разобрав таким образом расписание 19, блок 10 распределения формирует очереди 11, 13, 15, 17 задач для каждого ресурса.
По мере выполнения задач ресурсами блок 10 распределения передает им данные следующих задач из соответствующей очереди и удаляет задачи, которые поступили в обработку, из базы 8 данных. Результаты обработанных задач отправляются соответствующим пользователям.
Через заданные интервалы времени блок 9 определения повторно определяет расписание 19 выполнения задач с учетом того, что часть задач за это время уже были выполнены или хотя бы поступили в обработку, а от пользователей могли быть получены новые запросы с новыми задачами. Кроме того, за это время могли измениться условия в среде облачных вычислений: например, некоторые могли добавиться новые ресурсы, какие-то ресурсы могли стать недоступны, с какими-то ресурсами могла измениться скорость передачи данных, у каких-то ресурсов могла измениться вычислительная мощность или память и т.д. Соответственно, на основе нового расписания 19 блок 10 распределения повторно формирует очереди задач для подключенных ресурсов обработки данных и выполняет обмен данными с ресурсами.
В одном из вариантов осуществления сами данные задач, подлежащие обработке, передаются от пользовательских устройств на устройство 7 планирования и сохраняются в нем, а затем передаются в ресурсы обработки данных, назначенные на выполнение этих задач. Соответственно, у пользовательских устройств нет необходимости подключения к отдельным вычислительным ресурсам. Тем не менее, при этом возрастает нагрузка на устройство 7 планирования и на сеть передачи данных, поскольку данные задачи фактически передаются по сети дважды. В другом варианте осуществления данные задач, подлежащие обработке, передаются от пользовательских устройств непосредственно на ресурсы обработки данных, назначенные на выполнение этих задач. Это может быть выгодно, если скорость установки соединения и обмена данными пользовательских устройств с ресурсами обработки данных является достаточно высокой – такой случай применим, например, при использовании клаудлетов. Соответственно, и результаты выполнения задач могут передаваться от ресурса к пользователю либо через устройство планирования, либо напрямую.
Передача данных может выполняться как беспроводным, так и проводным образом.
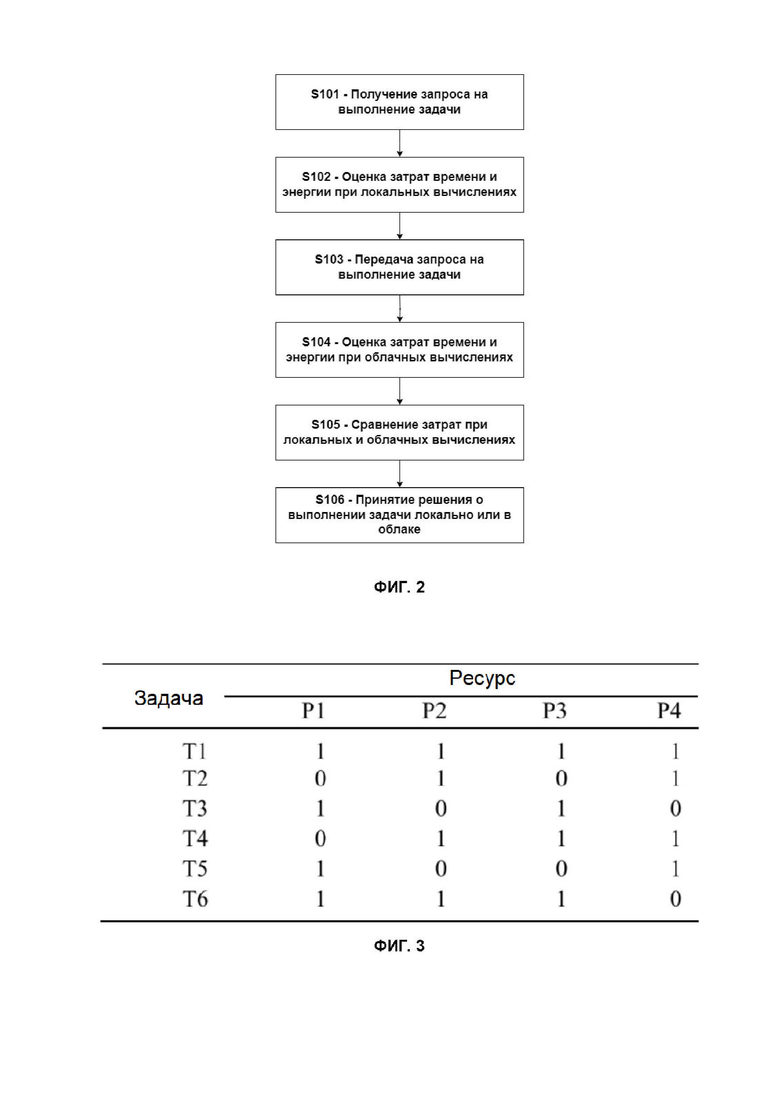
В одном из вариантов осуществления система облачных вычислений выполняет все задачи от пользователей. Тем не менее, возможны ситуации, когда затраты на выполнение задачи в системе могут оказаться выше, чем затраты в самом устройстве пользователя, поэтому в другом варианте осуществления может выполняться предварительная оценка запроса. Так, согласно способу предварительной оценки запроса на обработку данных, изображенному на Фиг. 2, на этапе S101 устройство пользователя регистрирует запрос на выполнение задачи от пользователя. На этапе S102 устройство пользователя оценивает затраты времени и энергии на выполнение задачи локально, в самом устройстве пользователя. На этапе S103 запрос на выполнение задачи передается также на устройство планирования, в котором на этапе S104 выполняется оценка затрат времени и энергии на выполнение задачи ресурсами системы облачных вычислений – например, блоком 9 определения в рамках формирования расписания выполнения задач. На этапе S105 в устройстве планирования или в устройстве пользователя (в зависимости от того, какая из сторон отправляет другой стороне свою оценку затрат) выполняется сравнение затрат при локальных и облачных вычислениях, и на этапе S106 принимается решение о выполнении задачи локально или в облаке. Если принято решение о выполнении задачи локально, данная задача удаляется из базы данных и из расписания выполнения задач и не подлежит выполнению ресурсами облачных вычислений.
Далее будут более подробно раскрыты особенности работы устройства планирования.
Инициализация
В настоящем изобретении предлагается для целей формирования расписания и распределения нагрузки между ресурсами в среде облачных вычислений использовать методы оптимизации на основе роя. Согласно таким методам, сначала необходимо выполнить инициализацию роя, а затем итеративно корректировать местоположение частиц в рое в поисках оптимального положения, при котором наилучшим образом достигаются заданные критерии. В данном случае критериями оптимизации являются время выполнения задачи и энергопотребление при выполнении задачи обработки данных, а частицами роя являются возможные варианты распределения задач обработки данных между ресурсами (или иными словами, решения задачи оптимизации). Соответственно, инициализация представляет собой создание исходного набора решений (частиц в рое).
Для этого сначала выявляют для каждой задачи, какой из набора ресурсов способен ее выполнять, согласно параметрам задачи и параметрам ресурса. Например, как показано на Фиг. 3, имеется набор ресурсов P1-P4, и они должны обработать набор задач T1-T6. В соответствии с уникальными параметрами задач и возможностями ресурсов, некоторые задачи могут выполняться не всеми ресурсами – например, только ресурсы P2 и P4 могут обрабатывать задачу T2.
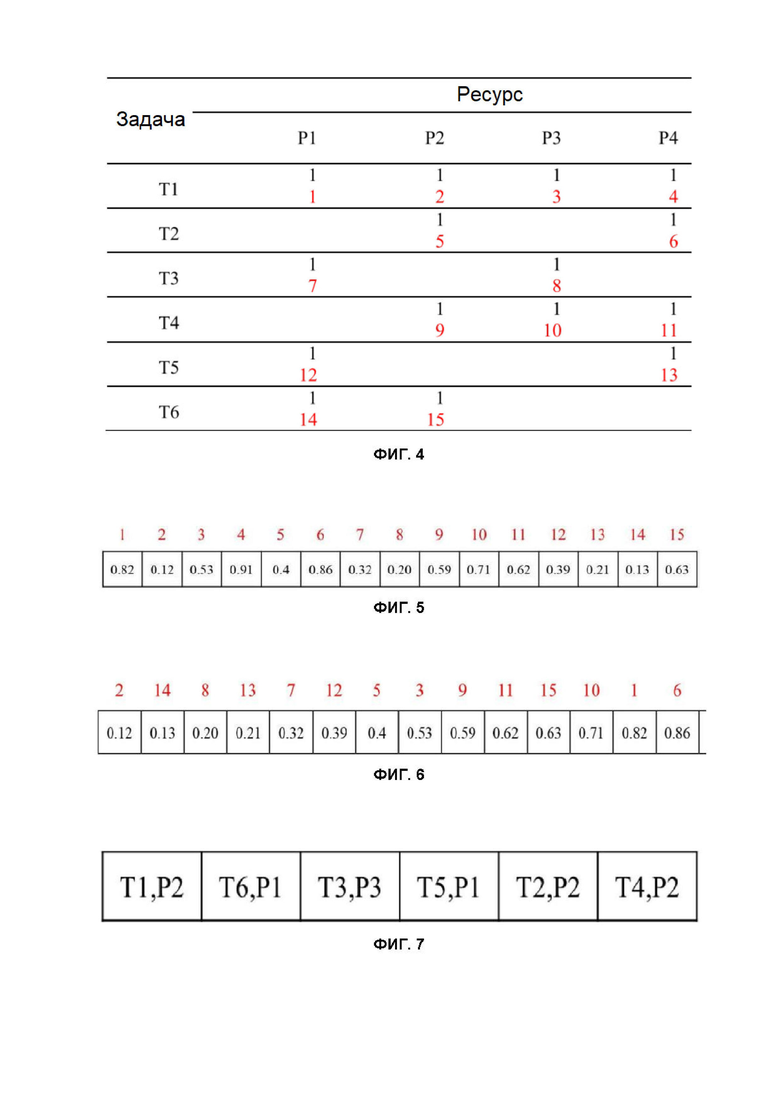
Каждое выявленное соответствие между задачей и ресурсом рассматривают в качестве возможного исполнения и присваивают ему уникальный идентификатор (номер) среди всех задач. Например, как показано на Фиг. 4, номер 12 означает, что процессор P1 способен обработать задачу T5.
Далее формируют одномерный массив чисел, причем каждому возможному исполнению среди всех задач соответствует один элемент массива, и каждый элемент массива имеет случайное значение в предварительно заданном промежутке. Например, как показано на Фиг. 5, элементы массива имеют значения от 0 до 1, и элемент массива, соответствующий упоминавшемуся выше возможному исполнению номер 12, имеет значение 0,39.
Как будет пояснено в следующем разделе, сформированный массив рассматривают в качестве возможного решения задачи оптимизации.
Этап формирования массива повторяют предварительно заданное количество раз, формируя тем самым исходный набор решений.
Формирование расписания
Затем для каждого решения формируют расписание выполнения задач. Для этого выполняют цикл, в ходе которого в порядке возрастания или убывания значений элементов массива определяют для текущего элемента массива номер задачи и номер ресурса согласно уникальному идентификатору, соответствующему этому элементу массива, и если эта задача еще не присутствует в расписании, формируют запись в расписании, содержащую номер задачи и номер ресурса.
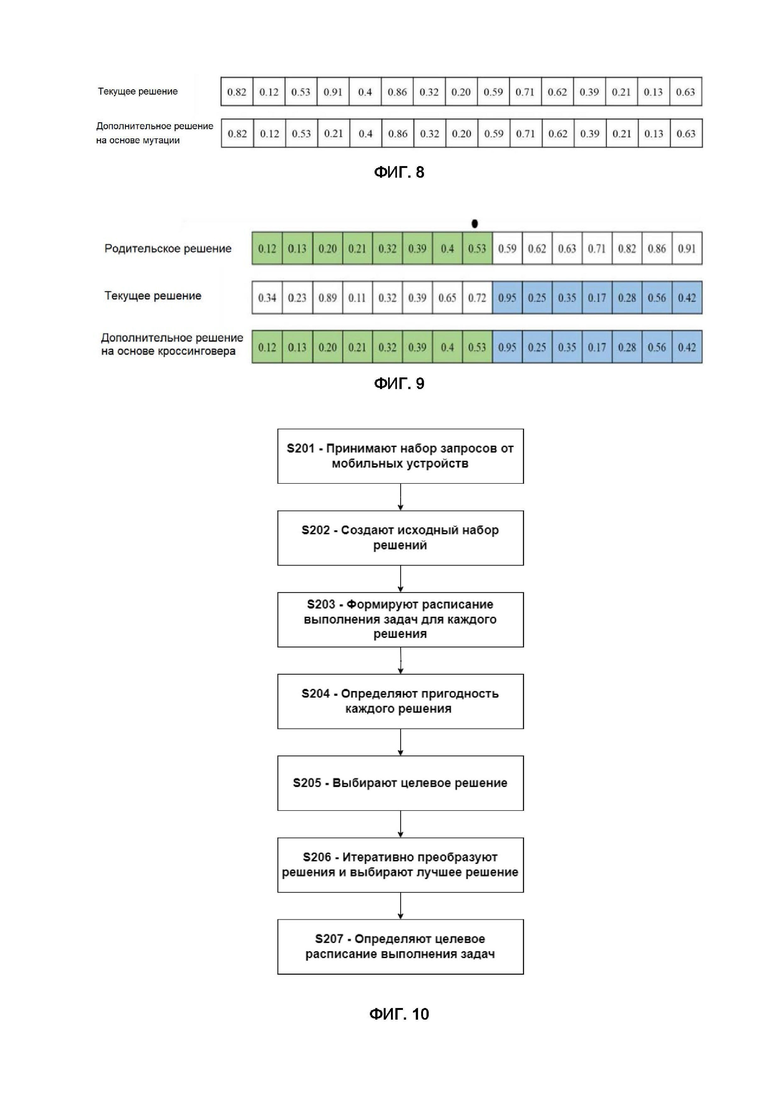
Например, как показано на Фиг. 6, массив может быть отсортирован по возрастанию. Первым элементом в отсортированном массиве является элемент, которому соответствует номер 2. Обратившись вновь к Фиг. 4, мы можем видеть, что согласно уникальному идентификатору 2 задача T1 должна быть обработана ресурсом P2. Соответственно, первой записью в расписании будет T1, P2, как можно видеть в примере расписания на Фиг. 7. Второй элемент в отсортированном массиве соответствует уникальному идентификатору 14, то есть задаче 6. Расписание еще не содержит задачу номер 6, поэтому следующая запись в расписании будет T6, P1. Для третьего элемента создается запись T3, P3. Далее аналогичным образом последовательно проверяются последующие элементы массива и формируются записи в расписании, так чтобы каждая задача встречалась в расписании только один раз. Например, пятый элемент в отсортированном массиве соответствует уникальному идентификатору 7, но поскольку соответствующая этому идентификатору задача 3 уже имеется в расписании, ее пропускают и переходят к следующему элементу массива. Если для всех задач уже имеются записи в расписании, цикл прекращают.
Функция пригодности
Чтобы оценить затраты на выполнение задач, определяют пригодность каждого решения на основе значений времени обработки и энергопотребления, вычисленных на основе расписания выполнения задач.
В частности, энергопотребление вычисляют как сумму энергий для выполнения каждой задачи в расписании и энергий, потребляемых ресурсами в режиме бездействия. Энергия для выполнения одной задачи равна сумме энергии, потребляемой соответствующим ресурсом при передаче и приеме данных этой задачи, и энергии, потребляемой ресурсом при обработке данных этой задачи.
Время обработки вычисляют как сумму времен для каждой задачи в расписании. Время для одной задачи равно сумме времени, необходимого для передачи и приема данных этой задачи на соответствующий ресурс и от него, времени, необходимого для выполнения этой задачи данным ресурсом, и времени ожидания этой задачи в очереди данного ресурса.
Все эти вычисления производятся на основе расписания, параметров задач и параметров ресурсов. Например, энергия, потребляемая ресурсом при передаче и приеме данных задачи, вычисляется исходя из объема данных задачи и удельной энергии, потребляемой ресурсом при передаче и приеме единицы объема данных. Время, необходимое для выполнения задачи, вычисляется исходя из объема данных задачи и вычислительной мощности ресурса, измеряемой в объеме данных/инструкций за единицу времени, которые обрабатывает этот ресурс. Время ожидания задачи в очереди ресурса – это время, которое данный ресурс потратит на обработку всех предыдущих задач в его очереди задач.
Поскольку применяется два критерия, и они могут иметь разную важность для поставщиков услуг, в настоящем изобретении предлагается в качестве функции пригодности использовать взвешенную сумму значений времени обработки и энергопотребления с учетом предварительно заданных весовых коэффициентов времени и энергии. Тем самым, обеспечивается повышение скорости сравнения решений между собой и выбора наилучшего решения с учетом особенностей сети и требований конкретного применения при обеспечении приемлемой точности.
Выбор целевого решения
После того, как сформирован набор решений, необходимо из них выбрать целевое решение, которое наилучшим образом будет отвечать заданным критериям оптимизации.
В одном из вариантов осуществления выбор целевого решения может заключаться в простом сравнении решений между собой по их пригодности. Такой подход является относительно быстрым, и хотя обеспечивает приемлемую точность, ее не всегда бывает достаточно в некоторых применениях.
В целях повышения точности сравнения решений в настоящем изобретении предлагается также другой вариант осуществления, в котором сортировка решений выполняется по многоступенчатой процедуре, которая является более объективной и обеспечивает повышенную точность оценки и выбора наилучшего решения.
Для этого сначала определяют ранг каждого решения по времени и ранг каждого решения по энергии путем сравнения всех решений между собой. Ранг решения по времени или по энергии равен числу событий сравнения, при которых данное решение превосходит сравниваемое с ним другое решение, соответственно, по времени обработки или по энергопотреблению. Например, если в наборе из 10 решений одно решение оказалось по времени лучше остальных 5 раз, то его ранг равен 5.
Затем определяют взвешенный ранг каждого решения путем сложения рангов данного решения по времени и по энергии с учетом предварительно заданных весовых коэффициентов времени и энергии.
После этого формируют два списка: упорядоченный список по времени из всех решений в соответствии с возрастанием времени обработки и упорядоченный список по энергии из всех решений в соответствии с возрастанием энергопотребления. Следует отметить, что если два решения в списке по времени имеют одинаковое значение времени обработки, то выше ставится решение, имеющее меньшее значение энергопотребления. Соответственно, если два решения в списке по энергии имеют одинаковое значение энергопотребления, то выше ставится решение, имеющее меньшее значение времени обработки.
В каждом из эти двух списков определяют роевое расстояние для каждого решения. Роевое расстояние представляет собой расстояние от данного решения до остальных решений в списке и определяется путем деления разности значений между последующим и предшествующим решениями в списке на разность значений между последним и первым решениями в списке. Например, для третьего решения в списке по времени, состоящем из 10 решений, роевое расстояние по времени вычисляется как разность значений времени обработки между вторым и четвертым решениями, поделенная на разность значений времени обработки между десятым и первым решениями. Аналогично, для второго решения в списке по энергии, состоящем из 10 решений, роевое расстояние по энергии вычисляется как разность значений энергопотребления между первым и третьим решениями, поделенная на разность значений энергопотребления между десятым и первым решениями. Для крайних решений в числителе используется удвоенная разность значений между данным и соседним решениями.
Далее определяют взвешенное роевое расстояние каждого решения путем сложения роевого расстояния данного решения по времени и по энергии с учетом предварительно заданных весовых коэффициентов времени и энергии.
Затем формируют упорядоченный список из всех решений в соответствии с взвешенным роевым расстоянием. Если решения имеют одинаковое взвешенное роевое расстояние, выше ставится решение, имеющее больший взвешенный ранг.
Таким образом, формируется список, в котором первое решение задают в качестве целевого решения, при этом обеспечивается повышенная точность оценки и выбора наилучшего решения.
Коррекция набора решений
Как указывалось выше, после инициализации исходного набора решений необходимо произвести предварительно заданное количество итераций в поисках наилучшего решения.
В частности, итеративно выполняют следующие этапы до достижения предварительно заданного числа итераций:
- преобразуют решения в наборе решений методом оптимизации (например, методом оптимизации на основе роя частиц или методом ястребов Харриса);
- выбирают лучшее решение в текущем наборе на основе значений времени обработки и энергопотребления решений в текущем наборе (например, согласно варианту осуществления, в котором выполняется простое сравнение решений по их взвешенной функций пригодности или же согласно другому варианту осуществления, в котором выполняется упорядочивание решений в текущем наборе в соответствии с их взвешенным роевым расстоянием и взвешенным рангом); и
- задают лучшее решение в текущем наборе в качестве целевого решения, если его пригодность лучше пригодности ранее заданного целевого решения.
Соответственно, после выполнения предварительно заданного количества итераций имеется итоговое целевое решение, которое превосходит все проверявшиеся решения, то есть является оптимальным как с точки зрения времени обработки задачи, так и с точки зрения энергопотребления с учетом особенностей сети и требований конкретного применения.
Как указывалось выше, для целей настоящего изобретения применимы различные методы коррекции/преобразования решений – например, методы оптимизации на основе роя частиц. Вместе с тем, по мнению авторов наилучшие результаты в сочетании с другими особенностями настоящего изобретения могут достигаться при использовании метода ястребов Харриса. Данный метод является известным для специалистов в области облачных вычислений и не будет раскрываться здесь подробно, однако лишь для упрощенного понимания можно отметить, что он заключается в подборе местоположений популяции ястребов (значений массивов в наборе решений) таким образом, чтобы выследить и поймать кролика (произвести поиск наилучшего решения). Для этого на каждой итерации оценивается энергия кролика и его вероятность побега и на их основе выбирается стратегия коррекции местоположения: разведка, мягкая осада, жесткая осада, мягкая осада с прогрессивными быстрыми погружениями, жесткая осада с прогрессивными быстрыми погружениями.
Выход из локального оптимума
В процессе коррекции решений иногда может возникать проблема, связанная с тем, что решения застревают в локальном оптимуме и не могут из него выбраться при использовании типовых методов оптимизации. Из-за этого может не быть найдено истинно оптимальное решение, что снижает точность поиска, а также повышает время обработки задач и энергопотребление системы.
В настоящем изобретении предлагается подход, в котором выполняется регулярная проверка, не попало ли решение в локальный максимум, и производится попытка выхода из него.
Для этого сначала определяют значение сходства каждого решения в текущем наборе с тем же решением в предыдущей итерации. Соответственно, необходимо хранить решения из предыдущей итерации. В качестве меры сходства используют косинусное сходство.
Из решений текущего набора, значение сходства которых превышает предварительно заданный порог сходства, формируют проверочный массив. Например, порогом сходства является значение косинусного сходства 0,985, и тогда все решения текущего набора, которые имеют большее значение косинусного сходства, попадают в проверочный массив.
Для каждого решения из проверочного массива создают дополнительные решения с помощью генетического алгоритма, определяют лучшее из них по пригодности, и если пригодность лучшего из дополнительных решений лучше пригодности самого решения из проверочного массива, заменяют решение в текущем наборе, соответствующее данному решению из проверочного массива, на упомянутое лучшее из дополнительных решений.
Таким образом, обеспечивается возможность выхода решения из локального максимума, если в процессе генетических преобразований обнаруживается, что существуют решения с лучшей пригодностью.
Более подробно, в качестве дополнительных решений, создаваемых с помощью генетического алгоритма, могут применяться дополнительное решение на основе мутации и дополнительное решение на основе кроссинговера.
Создание дополнительного решения на основе мутации содержит этапы, на которых случайным образом выбирают элемент массива, соответствующего данному решению, и присваивают ему новое случайное значение. Например, как показано на Фиг. 8, случайным образом выбирается четвертый элемент массива, и вместо значения 0,91 ему присваивается значение 0,21.
Создание дополнительного решения на основе кроссинговера содержит этапы, на которых: из набора наилучших решений выбирают родительское решение, случайным образом выбирают номер элемента, заменяют элементы массива, соответствующего текущему решению, от начального или конечного элемента до элемента с выбранным номером, на соответствующие элементы массива, соответствующего родительскому решению, и обновляют набор наилучших решений.
Что касается набора наилучших решений, первоначально он является копией исходного набора решений, а впоследствии, по мере появления новых решений, он обновляется. Обновление набора наилучших решений содержит этапы, на которых добавляют созданные дополнительные решения в набор наилучших решений и удаляют из него соответствующее количество решений, имеющих наихудшую пригодность. Например, если оба дополнительных решения по своей пригодности превосходят решения, имеющиеся в наборе наилучших решений, из него удаляют два имевшихся там решения с наихудшей пригодностью. В настоящем изобретении набор наилучших решений специально не обновляется напрямую из набора решений, формируемого в цикле коррекции/преобразования решений, чтобы как можно дольше сохранить преемственность с исходным набором решений и иметь возможность радикальным образом менять направление поиска, если траектория решения застряла в локальном максимуме.
Предложенный подход обеспечивает повышение точности нахождения целевого решения, а значит, и повышение точности распределения, уменьшение среднего времени выполнения задач и энергопотребления.
В одном варианте осуществления родительское решение для кроссинговера выбирают из набора наилучших решений случайным образом. Этот подход является простым и быстрым.
В другом варианте осуществления в качестве родительского решения выбирают решение, значение сходства которого с текущим решением является наименьшим из набора наилучших решений. Это обеспечивает наибольшую вероятность выхода из локального максимума, то есть дополнительно повышает точность нахождения целевого решения. В качестве меры сходства тоже может использоваться косинусное сходство.
Примеры осуществления
Предложенное устройство планирования в процессе испытаний было реализовано на базе рабочей станции с ОС Windows 64, содержащей процессор Intel Core i5-3337U с частотой 1.8 ГГц и 6 ГБ оперативной памяти. Для эффективного сравнения предложенного изобретения с пятью известными методами оптимизации и распределения задач использована собственная реализация облачного симулятора в среде Visual Studio с использованием языка программирования C#, учитывающая всю предложенную архитектуру системы облачных вычислений. Размер сети выбран 300х300 точек. Для сравнения использовалось 14 наборов тестовых данных, имеющих разные параметры, выбранные случайным образом из заданных интервалов: число пользователей (15…70), число ресурсов обработки данных (10…30), число итераций (300…1000). Каждый ресурс в наборе тестовых данных имеет параметры, выбранные случайным образом из заданных интервалов: тип ресурса (локальное облако, публичное облако, клаудлет), вычислительная мощность ресурса (30…100 инструкций/сек), пропускная способность сети и т.д. Каждый пользователь в наборе тестовых данных имеет параметры, выбранные случайным образом из заданных интервалов: число запросов от данного пользователя (1…10), объем данных в запросе (2500…3000 инструкций) и т.д. Предельная дальность, на которой пользователь может подключиться к ресурсу, задана равной 90 точкам. Предельное расстояние, на которое может перемещаться пользователь, задано равным 5 точкам.
При тестировании оценивались такие критерии, как среднее время выполнения задач, среднее энергопотребление при выполнении задач, время работы самого предложенного способа распределения задач, доля пропущенных задач, процент ошибок нахождения наилучшего решения.
Результаты тестирования показали, что в большинстве тестов предложенное изобретение превосходит известные из уровня техники методы.
Пример 1
В первом примере со ссылкой на Фиг. 10 раскрывается способ обработки запросов в среде облачных вычислений, выполняемый в устройстве планирования и содержащий этапы, на которых:
принимают (S201) набор запросов от мобильных устройств и устройств, обладающих малой вычислительной мощностью, причем каждый запрос содержит задачу обработки данных и параметры задачи;
создают (S202) исходный набор решений, причем решением в наборе решений является одномерный массив чисел, размер которого равен общему числу допустимых соответствий между всеми задачами и ресурсами в среде облачных вычислений согласно параметрам задач и параметрам ресурсов;
для каждого решения формируют (S203) расписание выполнения задач согласно упомянутым соответствиям между задачами и ресурсами в порядке возрастания или убывания значений элементов массива;
определяют (S204) пригодность каждого решения, причем пригодность равна сумме значений времени обработки и энергопотребления с учетом предварительно заданных весовых коэффициентов времени и энергии, причем значения времени обработки и энергопотребления вычисляют на основе расписания выполнения задач;
выбирают (S205) целевое решение в наборе решений на основе значений времени обработки и энергопотребления;
далее итеративно выполняют (S206) следующие этапы до достижения предварительно заданного числа итераций:
- преобразуют решения в наборе решений методом оптимизации;
- выбирают лучшее решение в текущем наборе на основе значений времени обработки и энергопотребления решений в текущем наборе;
- задают лучшее решение в текущем наборе в качестве целевого решения, если его пригодность лучше пригодности ранее заданного целевого решения; и
определяют (S207) расписание, соответствующее целевому решению, в качестве целевого расписания для выполнения задач.
Пример 2
Во втором примере со ссылкой на Фиг. 11 раскрывается способ распределения нагрузки по вычислительным сетям, выполняемый в устройстве планирования и содержащий этапы, на которых:
принимают (S301) набор запросов от устройств, подключенных к устройству планирования по сети передачи данных, причем каждый запрос содержит задачу обработки данных и параметры задачи;
создают (S302) исходный набор решений, причем решением в наборе решений является одномерный массив чисел, размер которого равен общему числу допустимых соответствий между всеми задачами и ресурсами вычислительных сетей согласно параметрам задач и параметрам ресурсов;
для каждого решения формируют (S303) расписание выполнения задач согласно упомянутым соответствиям между задачами и ресурсами в порядке возрастания или убывания значений элементов массива;
определяют (S304) пригодность каждого решения на основе значений времени обработки и энергопотребления, вычисленных на основе расписания выполнения задач;
выбирают (S305) целевое решение в наборе решений на основе значений времени обработки и энергопотребления;
далее итеративно выполняют следующие этапы до достижения предварительно заданного числа итераций:
- преобразуют (S306) решения в наборе решений путем выполнения итерации по методу ястребов Харриса;
- определяют (S307) значение сходства каждого решения в текущем наборе с тем же решением в предыдущей итерации, причем в качестве меры сходства используют косинусное сходство;
- формируют (S308) проверочный массив из решений текущего набора, значение сходства которых превышает предварительно заданный порог сходства;
- для каждого решения из проверочного массива создают (S309) дополнительные решения с помощью генетического алгоритма, определяют лучшее из них по пригодности, и если (S310) пригодность лучшего из дополнительных решений лучше пригодности самого решения из проверочного массива, заменяют решение в текущем наборе, соответствующее данному решению из проверочного массива, на упомянутое лучшее из дополнительных решений;
- выбирают (S311) лучшее решение в текущем наборе на основе значений времени обработки и энергопотребления решений в текущем наборе;
- задают лучшее решение в текущем наборе в качестве целевого решения, если его пригодность лучше пригодности ранее заданного целевого решения; и
распределяют (S312) задачи по ресурсам вычислительных сетей, подключенных к устройству планирования по сети передачи данных, согласно расписанию выполнения задач из итогового целевого решения.
Пример 3
В третьем примере со ссылкой на Фиг. 12 раскрывается способ управления ресурсами обработки данных, выполняемый в устройстве планирования и содержащий этапы, на которых:
для имеющегося набора задач обработки данных создают (S401) исходный набор решений, причем решением в наборе решений является одномерный массив чисел, размер которого равен общему числу допустимых соответствий между всеми задачами и ресурсами обработки данных в среде облачных вычислений согласно параметрам задач и параметрам ресурсов;
для каждого решения формируют (S402) расписание выполнения задач согласно упомянутым соответствиям между задачами и ресурсами в порядке возрастания или убывания значений элементов массива;
определяют (S403) пригодность каждого решения на основе значений времени обработки и энергопотребления, вычисленных на основе расписания выполнения задач;
выбирают (S404) целевое решение в наборе решений посредством формирования упорядоченного списка из всех решений в соответствии с взвешенным роевым расстоянием и взвешенным рангом решений по времени и по энергии, причем роевое расстояние представляет собой расстояние от данного решения до остальных решений в наборе, причем ранг решения по времени или по энергии равен числу событий сравнения, при которых данное решение превосходит сравниваемое с ним другое решение, соответственно, по времени обработки или по энергопотреблению;
далее итеративно выполняют (S405) следующие этапы до достижения предварительно заданного числа итераций:
- преобразуют решения в наборе решений путем выполнения итерации по методу ястребов Харриса;
- выбирают лучшее решение в текущем наборе в соответствии с взвешенным роевым расстоянием и взвешенным рангом решений в текущем наборе;
- задают лучшее решение в текущем наборе в качестве целевого решения, если его пригодность лучше пригодности ранее заданного целевого решения; и
выдают (S406) задачи и передают данные задач ресурсам обработки данных согласно расписанию выполнения задач из целевого решения.
Дополнительные особенности реализации
По меньшей мере один из этапов в способе, блоков в устройстве или ресурсов обработки данных в системе облачных вычислений может использовать модель искусственного интеллекта (AI) для выполнения соответствующих операций. Функция, связанная с AI, может выполняться через энергонезависимую память, энергозависимую память и процессор.
Процессор может включать в себя один или несколько процессоров. В то же время, один или несколько процессоров могут быть процессором общего назначения, например, центральным процессором (CPU), прикладным процессором (AP) или т.п., блоком обработки только графики, таким как графический процессор (GPU), визуальный процессор (VPU) и/или специализированный процессор AI, такой как нейронный процессор (NPU).
Различные иллюстративные блоки и модули, описанные в связи с раскрытием сущности в данном документе, могут реализовываться или выполняться с помощью процессора общего назначения, процессора цифровых сигналов (DSP), специализированной интегральной схемы (ASIC), программируемой пользователем вентильной матрицы (FPGA) или другого программируемого логического устройства (PLD), дискретного логического элемента или транзисторной логики, дискретных аппаратных компонентов либо любой комбинации вышеозначенного, предназначенной для того, чтобы выполнять описанные в данном документе функции. Процессор общего назначения может представлять собой микропроцессор, но в альтернативном варианте, процессор может представлять собой любой традиционный процессор, контроллер, микроконтроллер или конечный автомат. Процессор также может реализовываться как комбинация вычислительных устройств (к примеру, комбинация DSP и микропроцессора, несколько микропроцессоров, один или более микропроцессоров вместе с DSP-ядром либо любая другая подобная конфигурация).
Некоторые блоки или модули по отдельности или вместе могут представлять собой, например, компьютер, и включать в себя процессор, который сконфигурирован для вызова и выполнения компьютерных программ из памяти для выполнения этапов способа или функций блоков или модулей в соответствии с вариантами осуществления настоящего изобретения. Согласно вариантам осуществления, устройство может дополнительно включать в себя память. Процессор может вызывать и выполнять компьютерные программы из памяти для выполнения способа. Память может быть отдельным устройством, независимым от процессора, или может быть интегрирована в процессор. Память может хранить код, инструкции, команды и/или данные для исполнения на наборе из одного или более процессоров описанного устройства. Коды, инструкции, команды могут предписывать процессору выполнять этапы способа или функции устройства.
Функции, описанные в данном документе, могут реализовываться в аппаратном обеспечении, программном обеспечении, выполняемом посредством одного или более процессоров, микропрограммном обеспечении или в любой комбинации вышеозначенного, если это применимо. Аппаратные и программные средства, реализующие функции, также могут физически находиться в различных позициях, в том числе согласно такому распределению, что части функций реализуются в различных физических местоположениях, то есть может выполняться распределенная обработка или распределенные вычисления.
В случае если объем данных велик, может производиться многопоточная обработка данных, которая в простом представлении может выражаться в том, что все множество подлежащих обработке данных разделяется на набор подмножеств, и каждое ядро процессора выполняет обработку в отношении назначенного для него подмножества данных.
Вышеупомянутая память может быть энергозависимой или энергонезависимой памятью или может включать в себя как энергозависимую, так и энергонезависимую память. Специалисту в области техники должно быть также понятно, что, когда речь идет о памяти и о хранении данных, программ, кодов, инструкций, команд и т.п., подразумевается наличие машиночитаемого (или компьютерно-читаемого, процессорно-читаемого) запоминающего носителя. Машиночитаемый запоминающий носитель может представлять собой любой доступный носитель, который может использоваться для того, чтобы переносить или сохранять требуемое средство программного кода в форме инструкций или структур данных, и к которому можно осуществлять доступ посредством компьютера, процессора или иного устройства обработки общего назначения или специального назначения.
В качестве примера, а не ограничения, машиночитаемые носители могут содержать постоянное запоминающее устройство (ROM), программируемое постоянное запоминающее устройство (PROM), стираемое программируемое постоянное запоминающее устройство (EPROM), электронно-стираемое программируемое постоянное запоминающее устройство (EEPROM), флэш-память, оперативную память (RAM), статическую память с произвольным доступом (SRAM), динамическую память с произвольным доступом (DRAM), синхронную динамическую память с произвольным доступом (SDRAM), синхронную динамическую память с произвольной выборкой с двойной скоростью передачи данных (DDR SDRAM), синхронную динамическую память с произвольной выборкой с повышенной скоростью (ESDRAM), DRAM с синхронной линией связи (SLDRAM) и оперативную память с шиной прямого доступа (DR RAM) и т.п.
Информация и сигналы, описанные в данном документе, могут представляться с помощью любой из множества различных технологий. Например, данные, инструкции, команды, информация, сигналы, биты, символы и элементарные сигналы, которые могут приводиться в качестве примера в вышеприведенном описании, могут представляться посредством напряжений, токов, электромагнитных волн, магнитных полей или частиц, оптических полей или частиц либо любой комбинации вышеозначенного.
Следует понимать, что хотя в настоящем документе для описания различных элементов, компонентов, областей, слоев и/или секций могут использоваться такие термины, как "первый", "второй", "третий" и т.п., эти элементы, компоненты, области, слои и/или секции не должны ограничиваться этими терминами. Эти термины используются только для того, чтобы отличить один элемент, компонент, область, слой или секцию от другого элемента, компонента, области, слоя или секции. Так, первый элемент, компонент, область, слой или секция может быть назван вторым элементом, компонентом, областью, слоем или секцией без выхода за рамки объема настоящего изобретения. В настоящем описании термин "и/или" включает любые и все комбинации из одной или более из соответствующих перечисленных позиций. Элементы, упомянутые в единственном числе, не исключают множественности элементов, если отдельно не указано иное.
Функциональность элемента, указанного в описании или формуле изобретения как единый элемент, может быть реализована на практике посредством нескольких компонентов устройства, и наоборот, функциональность элементов, указанных в описании или формуле изобретения как несколько отдельных элементов, может быть реализована на практике посредством единого компонента.
В одном варианте осуществления элементы/блоки/модули предложенного устройства находятся в общем корпусе, могут быть размещены на одной раме/конструкции/печатной плате/кристалле и связаны друг с другом конструктивно посредством монтажных (сборочных) операций и функционально посредством линий связи. Упомянутые линии или каналы связи, если не указано иное, являются типовыми, известными специалистам линиями связи, материальная реализация которых не требует творческих усилий. Линией связи может быть провод, набор проводов, шина, дорожка, беспроводная линия связи (индуктивная, радиочастотная, инфракрасная, ультразвуковая и т.д.). Протоколы связи по линиям связи известны специалистам и не раскрываются отдельно.
Под функциональной связью элементов следует понимать связь, обеспечивающую корректное взаимодействие этих элементов друг с другом и реализацию той или иной функциональности элементов. Частными примерами функциональной связи может быть связь с возможностью обмена информацией, связь с возможностью передачи электрического тока, связь с возможностью передачи механического движения, связь с возможностью передачи света, звука, электромагнитных или механических колебаний и т.д. Конкретный вид функциональной связи определяется характером взаимодействия упомянутых элементов, и, если не указано иное, обеспечивается широко известными средствами, используя широко известные в технике принципы.
Несмотря на то, что примерные варианты осуществления были подробно описаны, следует понимать, что такие варианты осуществления являются лишь иллюстративными и не предназначены ограничивать настоящее изобретение, и что данное изобретение не должно ограничиваться конкретными описанными компоновками и конструкциями, поскольку специалисту в данной области техники на основе информации, изложенной в описании, и знаний уровня техники могут быть очевидны различные другие модификации и варианты осуществления изобретения, не выходящие за пределы сущности и объема данного изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ РАСПРЕДЕЛЕНИЯ НАГРУЗКИ ПО ВЫЧИСЛИТЕЛЬНЫМ СЕТЯМ | 2024 |
|
RU2834384C1 |
| СПОСОБ И СИСТЕМА ПЕРЕМЕЩЕНИЯ ДАННЫХ В ОБЛАЧНОЙ СРЕДЕ | 2023 |
|
RU2822554C1 |
| СПОСОБ И СИСТЕМА УПРАВЛЕНИЯ ОБЪЕКТАМИ И ПРОЦЕССАМИ В ВЫЧИСЛИТЕЛЬНОЙ СРЕДЕ | 2023 |
|
RU2820753C1 |
| Аппаратно-вычислительный комплекс виртуализации и управления ресурсами в среде облачных вычислений | 2017 |
|
RU2665246C1 |
| МЕЖ-ОБЛАЧНОЕ УПРАВЛЕНИЕ И УСТРАНЕНИЕ НЕПОЛАДОК | 2012 |
|
RU2604519C2 |
| Система управления энергопотреблением | 2022 |
|
RU2821067C2 |
| СИСТЕМА И СПОСОБ УЛУЧШЕНИЯ КАЧЕСТВА ОБСЛУЖИВАНИЯ ПЛАНИРОВЩИКОМ В СЕТИ | 2022 |
|
RU2802372C1 |
| СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ ОБЕСПЕЧЕНИЕМ, ОСНОВАННЫМ НА ЯЧЕИСТОЙ СЕТИ BLUETOOTH С НИЗКИМ ЭНЕРГОПОТРЕБЛЕНИЕМ (BLE), И ЭЛЕКТРОННОЕ УСТРОЙСТВО | 2023 |
|
RU2831298C2 |
| СПОСОБ ДИНАМИЧЕСКОГО КОНТРОЛЯ КОНФЛИКТНЫХ СИТУАЦИЙ В СЛОЖНЫХ ТЕХНИЧЕСКИХ СИСТЕМАХ СО СРЕДОЙ ОБЛАЧНЫХ ВЫЧИСЛЕНИЙ | 2017 |
|
RU2665224C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОНТРОЛЯ ПОТРЕБЛЕНИЯ ЭНЕРГИИ ВО ВРЕМЯ СОВМЕСТНОГО ИСПОЛЬЗОВАНИЯ РЕСУРСОВ | 2010 |
|
RU2483486C2 |

Изобретение относится к способу обработки запросов и распределения нагрузки между ресурсами обработки данных в среде облачных вычислений. Техническим результатом является повышение эффективности обработки запросов и распределения нагрузки между ресурсами обработки данных в среде облачных вычислений. Способ обработки запросов в среде облачных вычислений, выполняемый в устройстве планирования, содержит этапы, на которых: принимают набор запросов от мобильных устройств и устройств, обладающих малой вычислительной мощностью, причем каждый запрос содержит задачу обработки данных и параметры задачи; создают исходный набор решений; для каждого решения формируют расписание выполнения задач; определяют пригодность каждого решения на основе расписания выполнения задач; выбирают целевое решение в наборе решений на основе значений времени обработки и энергопотребления; далее итеративно преобразуют решения в наборе решений методом оптимизации, выбирают лучшее решение в текущем наборе и задают его в качестве целевого решения, если его пригодность лучше пригодности ранее заданного целевого решения; и определяют расписание, соответствующее целевому решению, в качестве целевого расписания для выполнения задач. 9 з.п. ф-лы, 12 ил.
1. Способ обработки запросов в среде облачных вычислений, выполняемый в устройстве планирования и содержащий этапы, на которых:
принимают набор запросов от мобильных устройств и устройств, обладающих малой вычислительной мощностью, причем каждый запрос содержит задачу обработки данных и параметры задачи;
создают исходный набор решений, причем решением в наборе решений является одномерный массив чисел, размер которого равен общему числу допустимых соответствий между всеми задачами и ресурсами в среде облачных вычислений согласно параметрам задач и параметрам ресурсов;
для каждого решения формируют расписание выполнения задач согласно упомянутым соответствиям между задачами и ресурсами в порядке возрастания или убывания значений элементов массива;
определяют пригодность каждого решения, причем пригодность равна сумме значений времени обработки и энергопотребления с учетом предварительно заданных весовых коэффициентов времени и энергии, причем значения времени обработки и энергопотребления вычисляют на основе расписания выполнения задач;
выбирают целевое решение в наборе решений на основе значений времени обработки и энергопотребления;
далее итеративно выполняют следующие этапы до достижения предварительно заданного числа итераций:
- преобразуют решения в наборе решений методом оптимизации;
- выбирают лучшее решение в текущем наборе на основе значений времени обработки и энергопотребления решений в текущем наборе;
- задают лучшее решение в текущем наборе в качестве целевого решения, если его пригодность лучше пригодности ранее заданного целевого решения; и
определяют расписание, соответствующее целевому решению, в качестве целевого расписания для выполнения задач.
2. Способ по п. 1, в котором создание исходного набора решений содержит этапы, на которых:
выявляют для каждой задачи, какой из набора ресурсов способен ее выполнять согласно параметрам задачи и параметрам ресурса;
каждое выявленное соответствие между задачей и ресурсом рассматривают в качестве возможного исполнения и присваивают ему уникальный идентификатор среди всех задач;
формируют одномерный массив чисел, причем каждому возможному исполнению среди всех задач соответствует один элемент массива, и каждый элемент массива имеет случайное значение в предварительно заданном промежутке;
повторяют этап формирования массива предварительно заданное количество раз и рассматривают каждый массив в качестве возможного решения, формируя тем самым исходный набор решений.
3. Способ по п. 1, в котором формирование расписания содержит этапы, на которых итеративно в порядке возрастания или убывания значений элементов массива определяют для текущего элемента массива номер задачи и номер ресурса согласно уникальному идентификатору, соответствующему этому элементу массива, и если эта задача еще не присутствует в расписании, формируют запись в расписании, содержащую номер задачи и номер ресурса.
4. Способ по п. 1, в котором энергопотребление равно сумме энергий для выполнения каждой задачи в расписании и энергий, потребляемых ресурсами в режиме бездействия, причем энергия для одной задачи равна сумме энергии, потребляемой соответствующим ресурсом при передаче и приеме данных этой задачи, и энергии, потребляемой ресурсом при обработке данных этой задачи, и
время обработки равно сумме времен для каждой задачи в расписании, причем время для одной задачи равно сумме времени, необходимого для передачи и приема данных этой задачи на соответствующий ресурс и от него, времени, необходимого для выполнения этой задачи данным ресурсом, и времени ожидания этой задачи в очереди данного ресурса.
5. Способ по п. 1, в котором целевое решение в наборе решений выбирают посредством формирования упорядоченного списка из всех решений в соответствии с взвешенным роевым расстоянием и взвешенным рангом решений по времени и по энергии, причем роевое расстояние представляет собой расстояние от данного решения до остальных решений в наборе, причем ранг решения по времени или по энергии равен числу событий сравнения, при которых данное решение превосходит сравниваемое с ним другое решение, соответственно, по времени обработки или по энергопотреблению.
6. Способ по п. 5, в котором выбор целевого решения в наборе решений содержит этапы, на которых:
определяют ранг каждого решения по времени и ранг каждого решения по энергии путем сравнения всех решений между собой;
определяют взвешенный ранг каждого решения путем сложения рангов данного решения по времени и по энергии с учетом предварительно заданных весовых коэффициентов времени и энергии;
формируют упорядоченный список по времени из всех решений в соответствии с возрастанием времени обработки;
определяют роевое расстояние для каждого решения в списке по времени, причем роевое расстояние представляет собой расстояние от данного решения до остальных решений в списке и определяется путем деления разности значений между последующим и предшествующим решениями в списке на разность значений между последним и первым решениями в списке;
формируют упорядоченный список по энергии из всех решений в соответствии с возрастанием энергопотребления;
определяют роевое расстояние для каждого решения в списке по энергии;
определяют взвешенное роевое расстояние каждого решения путем сложения роевого расстояния данного решения по времени и по энергии с учетом предварительно заданных весовых коэффициентов времени и энергии;
формируют упорядоченный список из всех решений в соответствии с взвешенным роевым расстоянием, причем решения, имеющие одинаковое взвешенное роевое расстояние, дополнительно упорядочивают между собой в соответствии с взвешенным рангом; и
первое решение в сформированном списке задают в качестве целевого решения.
7. Способ по п. 1, в котором цикл итераций дополнительно содержит этапы, на которых:
определяют значение сходства каждого решения в текущем наборе с тем же решением в предыдущей итерации, причем в качестве меры сходства используют косинусное сходство;
формируют проверочный массив из решений текущего набора, значение сходства которых превышает предварительно заданный порог сходства;
для каждого решения из проверочного массива создают дополнительные решения с помощью генетического алгоритма, определяют лучшее из них по пригодности, и если пригодность лучшего из дополнительных решений лучше пригодности самого решения из проверочного массива, заменяют решение в текущем наборе, соответствующее данному решению из проверочного массива, на упомянутое лучшее из дополнительных решений.
8. Способ по п. 7, в котором дополнительные решения содержат дополнительное решение на основе мутации и дополнительное решение на основе кроссинговера;
создание дополнительного решения на основе мутации содержит этапы, на которых случайным образом выбирают элемент массива, соответствующего данному решению, и присваивают ему новое случайное значение;
создание дополнительного решения на основе кроссинговера содержит этапы, на которых: из набора наилучших решений выбирают родительское решение; случайным образом выбирают номер элемента; заменяют элементы массива, соответствующего текущему решению, от начального или конечного элемента до элемента с выбранным номером, на соответствующие элементы массива, соответствующего родительскому решению; и обновляют набор наилучших решений.
9. Способ по п. 8, в котором набор наилучших решений первоначально является копией исходного набора решений, а обновление набора наилучших решений содержит этапы, на которых добавляют созданные дополнительные решения в набор наилучших решений и удаляют из него соответствующее количество решений, имеющих наихудшую пригодность.
10. Способ по п. 8, в котором в качестве родительского решения выбирают решение, значение косинусного сходства которого с текущим решением является наименьшим из набора наилучших решений.
| АППАРАТНО-ВЫЧИЛИСТЕЛЬНЫЙ КОМПЛЕКС ВИРТУАЛИЗАЦИИ И УПРАВЛЕНИЯ РЕСУРСАМИ В СРЕДЕ ОБЛАЧНЫХ ВЫЧИСЛЕНИЙ | 2013 |
|
RU2543962C2 |
| СПОСОБ И СИСТЕМА ИНТЕЛЛЕКТУАЛЬНОГО УПРАВЛЕНИЯ РАСПРЕДЕЛЕНИЕМ РЕСУРСОВ В ОБЛАЧНЫХ ВЫЧИСЛИТЕЛЬНЫХ СРЕДАХ | 2015 |
|
RU2609076C2 |
| СПОСОБ И СИСТЕМА ОБРАБОТКИ ЗАДАЧ В ОБЛАЧНОМ СЕРВИСЕ | 2016 |
|
RU2632125C1 |
| US 11586626 B1, 21.02.2023 | |||
| US 20240143316 A1, 02.05.2024 | |||
| US 20160140176 A1, 19.05.2016. | |||

