Изобретение касается накопления информации и относится к системам поиска изображений, содержащим носитель записи и воспроизводящее устройство.
Известна система с носителем записи и воспроизводящим устройством, позволяющая закодированные изображения записывать на компактных дисках. Представления записанных кодированных изображений могут воспроизводиться посредством проигрывателя CD-1. Для специальных операций обработки изображения, например воспроизведения увеличенных представлений выбранной части изображения, записанные кодированные изображения приходится воспроизводить лишь частично. Поскольку общее время воспроизведения закодированного изображения может быть большим для закодированных изображений высокого разрешения, желательно, чтобы закодированные строки изображения могли отыскиваться по выбору.
Задача изобретения предоставить средства, позволяющие быстро отыскивать те части дорожки записи, в которых находятся выбранные строки кодированного изображения.
Для этого вместе с кодированными строками изображения на носителе записи записаны синхронизирующие сигналы строки и номера строк, причем каждый номер строки задает номер последовательности соответствующей кодированной строки изображения в закодированном изображении, и каждая синхронизация строк указывает начало соответствующей кодированной строки изображения. На носителе записи также записаны адреса нескольких закодированных строк кодированного изображения, адреса которых указывают, где соответствующие строки изображения были записаны на дорожке. Устройство содержит средства для выбора строки кодированного изображения внутри выбранного кодированного изображения, средства для считывания записанных адресов строк выбранного изображения, средства для выбора на основе адресов, считанных таким образом, адреса части дорожки, находящейся перед частью дорожки, где начинается запись выбранной строки закодированного изображения, средства для вызывания движения считывающей головки к части дорожки, указанной выбранным адресом, и средства для последующего обнаружения начала выбранной строки закодированного изображения на основе считанных номеров строк и строчной синхронизации.
Посредством добавления строчной синхронизации и номера строки к каждой кодированной строке изображения в файле изображения, а также посредством записи адресов некоторого количества кодированных строк можно быстро найти адрес части дорожки, расположенной на малом расстоянии перед началом записи желаемой строки кодированного изображения. Предлагаемое устройство особенно выгодно, если было выбрано кодирование переменной длины для изображения, причем длина дорожки, требуемая для записи строки закодированного изображения, изменяется от строки к строке изображения. Действительно, в этом случае положение на дорожке, где начинается запись определенной строки кодированного изображения, уже не может быть однозначно определено из начального положения записи первой строки кодированного изображения.
Кроме того, добавление строчной синхронизации и номера строки дает то преимущество, что в случае неправильного считывания распространение ошибки может быть ограничено максимум длиной одной строки кодированного изображения, так как в начале каждой строки изображения известен номер строки, известно и начало кодированной строки, так что декодирование и воспроизведение неправильно считанной строки может быть просто восстановлено.
В предлагаемом устройстве длины порций дорожки, расположенных между положениями, указанными записанными адресами строк кодированного изображения, практически соответствуют точности поиска.
Если при смещении считывающей головки эта головка попала на порцию с адресом, указывающим строку кодированного изображения, предшествующую выбранной строке кодированного изображения, весьма вероятно, что после перемещения считывающей головки головка достигнет положения, находящегося перед местом, где начинается запись желаемой строки кодированного изображения. Таким образом избегают того, что после перемещения считывающей головки потребуется еще одно перемещение считывающей головки в противоположном направлении. Время ожидания от момента, когда закончилось перемещение головки, до момента, когда будет достигнута выбранная строка кодированного изображения, ограничено, позволяя таким образом получить короткое суммарное время доступа. Кроме того, количество пространства дорожки для записи адресов номера строк изображения минимально.
Дорожка может быть выполнена спиральной дорожкой, средства для движения считывающей головки приспособлены для движения считывающей головки в направлении поперек дорожки, длина порций дорожки, расположенных между положениями, указанными записанными адресами строк кодированного изображения, может соответствовать половине длины витка спиральной дорожки.
Это исполнение оптимально использует тот факт, что точность поиска в случае, когда используется считывающая головка, которая движется радиально над спиральной дорожкой, равна плюс-минус половине длины витка спиральной дорожки.
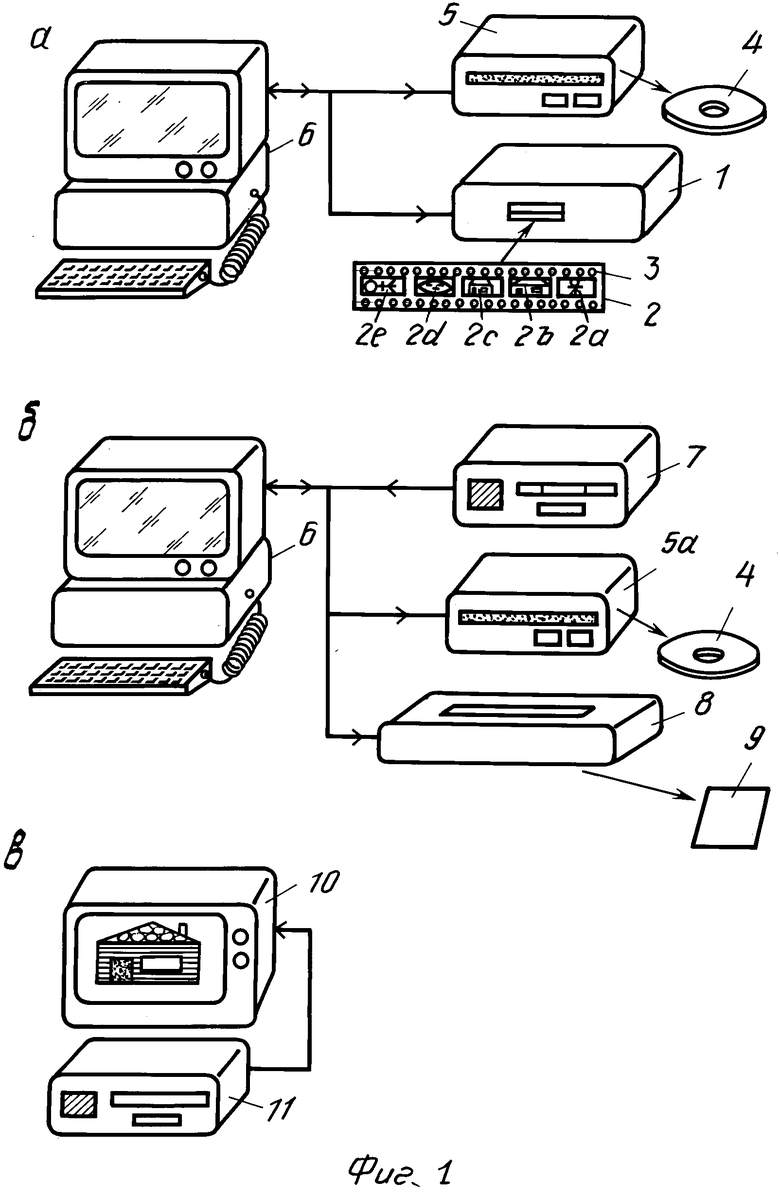
На фиг. 1а-в представлена система хранения изображений, система поиска и воспроизведения изображений и упрощенная система поиска и воспроизведения изображений соответственно; на фиг. 2 формат для записи информации изображений на носителе записи; на фиг. 3 кодирование информации изображения; на фиг. 4 остаточное кодирование для использования при кодировании информации изображения; на фиг. 5 расположение информации цветности изображения для серии кодированных изображений увеличивающегося разрешения; на фиг. 6 формат субфайла, содержащего остаточно закодированное изображение; на фиг. 7 носитель записи, на котором записанные закодированные строки изображения расположены подходящим образом; на фиг. 8 изображение, составленное из строк изображения; на фиг. 9 несколько различных функций обработки изображения; на фиг. 10 исполнение системы поиска и воспроизведения изображений, способное воспроизводить информацию изображения соответственно предпочтительными установки воспроизведения; на фиг. 11 формат для записи предпочтительных установок воспроизведения на носителе записи; на фиг. 12 формат для хранения предпочтительных установок воспроизведения в памяти без потери информации; на фиг. 13 мозаичное изображение, составленное из 16 изображений с малым разрешением; на фиг. 14 более подробное изображение упрощенного исполнения системы поиска и воспроизведения изображений; на фиг. 15 исполнение, в котором группы данных управления могут быть расположены в пакетах; на фиг. 16 а и б схема извлечения данных для использования в системе поиска и воспроизведения изображений на фиг. 14; на фиг. 17 более подробное изображение исполнения системы хранения изображений; на фиг. 18 блок записи для использования в системе хранения изображений; на фиг. 19 диаграммы формата CD ROМ XA; на фиг. 20 организация носителя записи, если информация изображения была записана в формате Си Ди-Ай (СД-1); на фиг. 21, 23 и 24 подходящие конфигурации строк изображения абсолютно закодированных изображений для нескольких различных разрешений, если записанная информация была разделена на блоки в соответствии с форматом Си Ди-Ай; на фиг. 22 изображение, составленное из строк изображения, для иллюстрации конфигурации, показанной на фиг. 21; на фиг. 25 пример блока обработки изображения; на фиг. 26 и 27а-г функции обработки изображений, подлежащие исполнению в блоке обработки изображений; на фиг. 28 пример выполнения считывающего устройства; на фиг. 29 и 31 блок-схемы примеров упрощенного блока обработки изображений; на фиг. 30 а-г работа упрощенного блока обработки изображений, показанного на фиг. 29 и 31.
На фиг.1а показана система хранения изображений, в которой может использоваться предлагаемое устройство. Система содержит блок 1 сканирования изображения с носителя 2, 3 изображений, например с ленты, несущей фотонегативы или слайды. Закодированная информация изображения записывается на носитель 4 записи посредством блока 5 записи при управлении от блока 6 управления. Перед записью блок 6 управления может при желании производить обработку изображения, например повысить контрастность, исправить или отредактировать изображение, имеющее вид закодированной информации изображения. Блок 5 записи может содержать, например, оптическое, магнитное или магнитооптическое записывающее устройство. Ввиду высокой емкости хранимой информации оптических и магнитооптических носителей записи предпочтительно использовать оптическое или магнитооптическое устройство записи. Блок 6 управления может содержать компьютерную систему, например персональный компьютер или рабочее место с соответствующей аппаратурой и программным обеспечением.
На фиг.1б показана система поиска и воспроизведения изображений для отыскивания и воспроизведения закодированных изобpажений, хранимых на носителе 4 записи, посредством системы хранения изображений. Система поиска и воспроизведения изображений содержит считывающий блок 7 для нахождения и считывания выбранных закодированных изображений при управлении от блока 6 управления. Воспроизведение считанных таким образом кодированных изображений может производиться на блоке дисплея. Такой дисплей для изображений может содержать экран, который, например, является частью блока управления или электронным принтером 8 изображений для получения бумажной копии 9 воспроизводимого кодированного изображения. Система поиска и воспроизведения изображения может содержать добавочное устройство 5а записи, посредством которого закодированная информация изображения проходит обработку в блоке 6 управления с целью повышения контраста, исправления или редактирования.
На фиг. 1в показана упрощенная система поиска и воспроизведения изображения, которая содержит дисплей 10 и блок 11 поиска и считывания, содержащий блок 7 считывания.
Вследствие их сравнительно высокой стоимости система хранения изображений, показанная на фиг.1а, и система поиска и воспроизведения изображений, показанная на фиг. 1б, особенно подходят для центрального использования, например, в фотолабораториях.
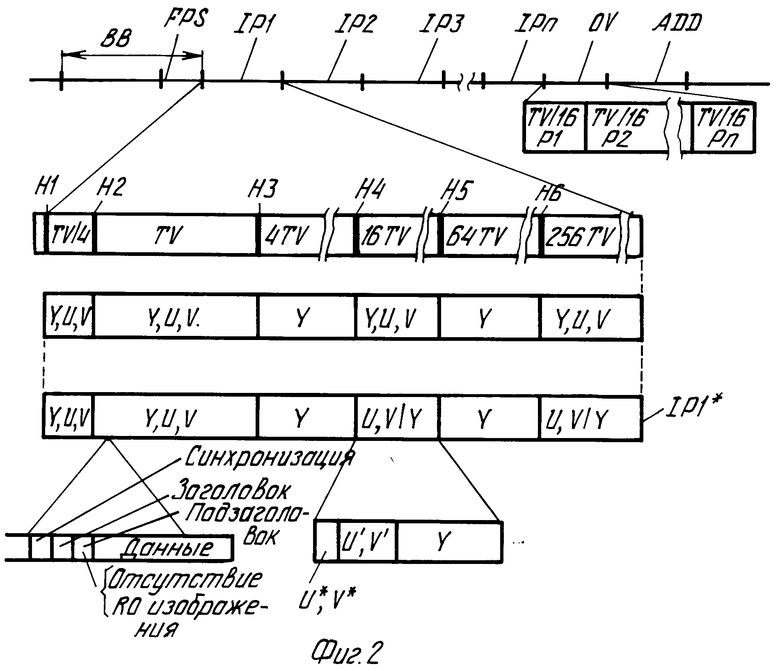
Для записи закодированной информации изображения предпочитают записывать информацию на носителе записи в заранее определенном формате и порядке; На фиг.2 показан подходящий формат и порядок, в котором файлы, содержащие закодированную информацию изображения, названы IР1, IР2, IРn. Далее файлы IР1-IРn будут называться файлами изображения. Кроме того, записаны несколько файлов управления ВВ. Эти файлы содержат информацию, которая используется для управления считыванием закодированной информации изображений, для целей обработки, при необходимости считываемой информации изображения и с целью воспроизведения закодированной информации изображения. Следует заметить, что часть данных управления может быть включена в файлы изображения. Предпочтительно эта часть данных управления является частью, специально предназначенной для управления считыванием, воспроизведением и обработкой закодированной информации изображения, содержащейся в соответствующем файле изображения. Преимуществом здесь является то, что требуемые данные управления имеются в распоряжении тогда, когда они нужны, т.е. тогда, когда считывается файл изображения.
Отдельно от файлов изображения IР и связанных с ними файлов управления ВВ желательно в ряде случаев записывать файлы с добавочной информацией, например, к закодированной информации изображения и воспроизводить одновременно с воспроизведением соответствующей информации изображения. Файлы с добавочной информации обозначены ADD и могут быть записаны, например, после закодированной информации изображения.
Для каждого хранимого изображения файлы изображения содержат несколько субфайлов, каждый из которых определяет представление одной и той же сканированной картинки, но разрешение этих представлений различное. На фиг.2 различные субфайлы для файла изображения 1Р1 названы TV/4, TV, 4 TV, 16 TV, 64 TV, 256 TV. Субфайл TV определяет представление сканированного изображения с разрешением, соответствующим стандартному разрешению телевизионного изображения по системе НТСЦ или ПАЛ. Такое изображение может содержать 512 строк по 768 пикселей (элементов изображения) каждая. Субфайл 4 TV, 16 TV, 64 TV и 256 TV определяют представления изображений, горизонтальное и вертикальное разрешение которых линейно увеличено в 2, 4, 8 и 16 раз соответственно. Предпочтительно субфайлы расположены таким образом, что разрешения представлений, определяемых последовательными кодированными изображениями, увеличиваются (линейно) ступенями в 2 раза. При воспроизведении, когда последовательно расположенных субфайлы считываются друг за другом, становится просто сначала воспроизвести изображение с малой разрешающей способностью, а затем заменять изображение полностью или частично тем же изображением, каждый раз увеличивая разрешение. Это дает то преимущество, что время ожидания до появления изображения на экране уменьшается. Действительно, вследствие ограниченного количества информации, которое для этого нужно, время считывания закодированного изображения представления с низким разрешением является коротким по сравнению с временем считывания закодированных изображений, имеющих большее разрешение.
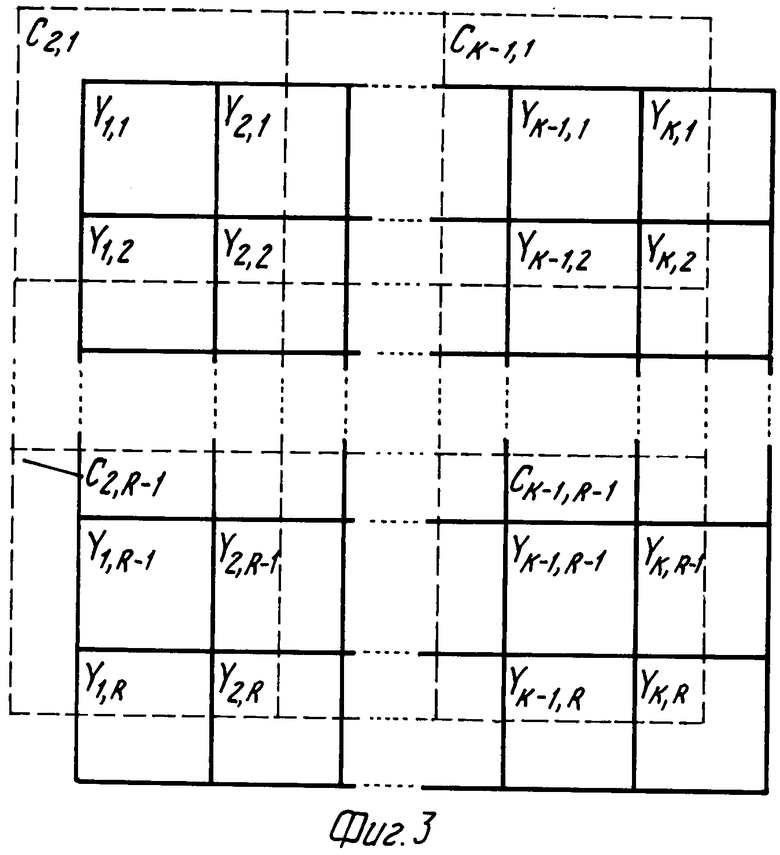
На фиг. 3 показана структура изображения из цветных пикселей и яркостных пикселей. Яркостные пикселя обозначены Y21,YК-1, р-1. Пиксели цвета имеют обозначение С1, 1; Ск,р. Следует отметить, что на фиг.3, как это обычно бывает, размеры пикселей цветности в горизонтальном и вертикальном направлениях вдвое больше, чем размеры пикселей яркости. Это значит, что разрешение информации цвета в горизонтальном и вертикальном направлениях вдвое ниже, чем разрешение информации яркости.
Подходящим кодированием для изображения является такое, когда цифровой код или цифровые коды приписаны каждому пикселю яркости и каждому пикселю цветности, причем коды определяют абсолютную величину составляющей яркости Y и абсолютные величины цветоразностных составляющих U и V соответственно. Такое кодирование далее будет называться абсолютным кодированием изображения. Предпочтительно представления нескольких изображений с низким разрешением записывать в виде абсолютно закодированных изображений. Это позволяет просто восстановить информацию изображений, что особенно выгодно для упрощенного поиска изображения и воспроизведения в системе, потому что это позволяет снизить стоимость такой системы, предназначенной для широкого потребителя, за счет использования простых систем декодирования.
Использование файла изображения с несколькими абсолютно кодированными изображениями с различным разрешением упрощает воспроизведение составных изображений, где представление малого изображения с низким разрешением изображается внутри представления изображения более высокого разрешения. Воспроизведение такого представления составного изображения называется "картинка в картинке" (РIР). Кроме того, запись нескольких абсолютно кодированных изображений, представляющих одно и то же изображение с различным разрешением, упрощает воспроизведение увеличенных представлений деталей закодированного изображения. Такая функция называется функцией ТЕДЕ (или ЗУМ). Наличие абсолютно закодированных изображений с различным разрешением предполагает, что для некоторых ТЕДЕ функций или РIР функций нужная информация изображения прямо доступна и не должна получаться за счет дополнительных операций обработки изображения с помощью сложных схем.
При записи принято записывать закодированные пиксели рядами (или строками) или иногда столбцами. Запись в строки предпочтительна, потому что в обычно используемых дисплеях информация изображения должна быть в форме строк.
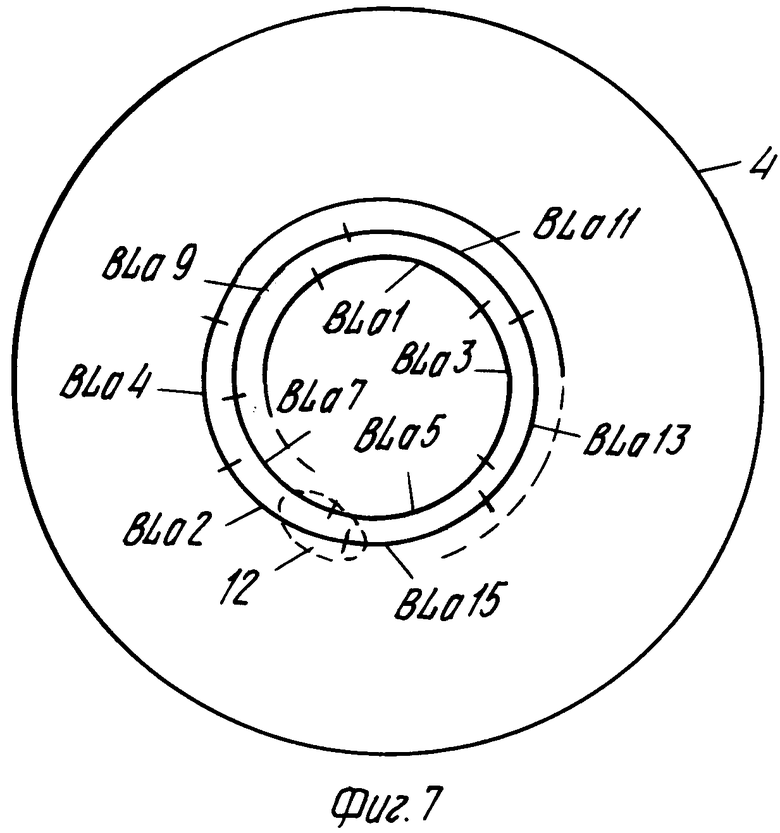
На фиг.7 показан дисковый носитель 4 записи, на котором записано изображение, состоящее из последовательных строк изображения l1.ln, которые записывают на спиральную дорожку в виде серии абсолютно закодированных строк изображения Bl a 1, BL a 3, BL a 5, BL a 7, BL a 9, BL a 11, BL a 13, BL a 2, BL a 4. Абсолютно закодированные строки изображения BL a 1 и BL a 13 представляют строки изображения l1 и l13 соответственно. Абсолютно закодированные строки изображения записаны таким образом, что информация последовательных строк изображения не размещена слитно ни в радиальном, ни в касательном направлении. Позиционный номер 12 относится к нечитаемой части диска, также называемой дефектом диска. Указанный дефект простирается более, чем на один оборот спиральной дорожки. Поскольку кодированные строки изображения, определяющие соседние строки изображения, не примыкают друг к другу ни в продольном (касательном), ни в радиальном направлении, это предотвращает попадание дефекта диска на соседние строки изображения.
Для высоких разрешений хранение абсолютно закодированной информации изображения имеет недостаток в том, что количество подлежащей записи информации очень велико. Для таких изображений высокого разрешения очень подходит остаточное кодирование. В таком остаточном кодировании определяют разности величины сигнала пикселей изображения высокого разрешения и величины сигнала, соответствующей части изображения с меньшим разрешением, и затем кодируют их.
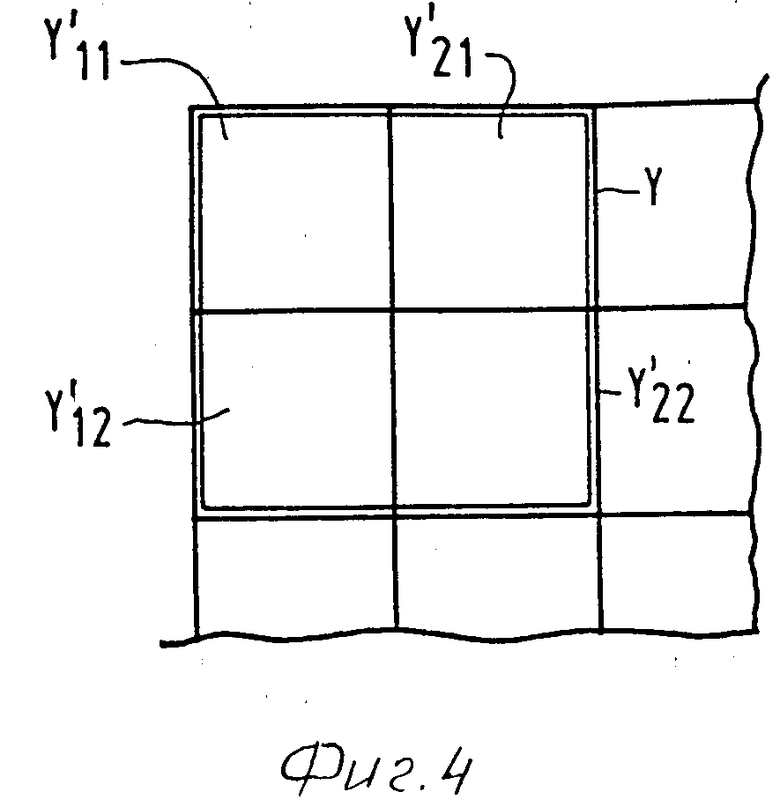
Чтобы показать этот метод кодирования, на фиг. 4 показан пиксель яркости Y изображения низкого разрешения и четыре пикселя яркости Y11, Y21, Y12, Y22 соответствующего изображения большего разрешения, в случае, когда горизонтальное и вертикальное разрешение увеличено вдвое. Вместо абсолютного значения яркости для пикселей Y11.Y22 остаточное кодирование берет разности (далее называемые остаточными величинами) между величинами яркостей пикселей Y11.Y22 и пикселя яркости Y. Таким образом остаточные величины всего изображения могут быть определены как для яркостей, так и для цветностной информации. Поскольку количество остаточных величин, равных или близких к нулю, велико по сравнению с количеством больших остаточных величин, можно получить значительное сокращение объема информации применением добавочного кодирования, при котором остаточные величины нелинейно квантизируют и затем подвергают, например, кодированию по Хаффмену.
Остаточно закодированное изображение может использоваться в качестве основы для нового остаточного кодирования для изображения с еще более высоким разрешением. Таким образом, записаны одно абсолютно закодированное изображение низкого разрешения и серия остаточно закодированных изображений увеличивающегося разрешения в сокращенной форме. Можно записать множество закодированных изображений, представляющих то же изображение с увеличивающимся разрешением. В файле изображения IР1 (фиг.2) изображения в субфайлах TV/4 и TV закодированы абсолютно, а изображения в субфайлах 4 TV, 16 TV, 64 TV, 256 TV закодированы остаточно с нелинейной квантизацией и кодированием по Хаффману. Такое закодированное изображение далее будет называться остаточно закодированным изображением.
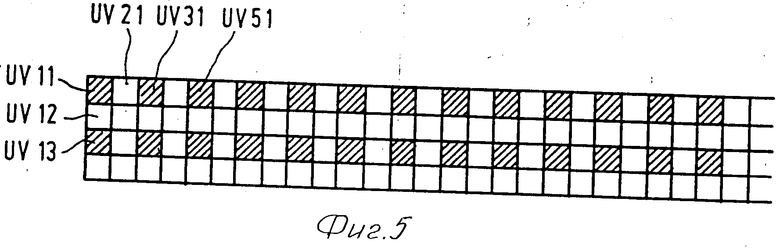
Информация цветности также кодируется остаточно подобно информации яркости. Однако горизонтальное и вертикальное разрешение последовательных остаточно закодированных изображений увеличивается в четыре раза, а не в два раза, как это делается с информацией яркости. Это значит, что файл изображения, содержащий только остаточно закодированную информацию яркости и без информации цветности (4 TV и 64 TV) чередуется с файлом изображения, содержащим как остаточно закодированную информацию яркости, так и остаточно закодированную информацию цветности (16 TV и 256 TV см. фиг.2). Выбрасывая информацию цветности в субфайлах 4 TV и 64 TV, уменьшают требуемую емкость хранения и время доступа к кодированной информации изображения в файле изображения. Однако отсутствие информации цветности в субфайлах 4 TV и 64 TV не обязательно влияет отрицательно на качество изображения при воспроизведении. Это происходит потому, что при воспроизведении кодированного изображения, для которого нет записи информации цветности, используют информацию цветности следующего по разрешению субфайла или предыдущего по разрешению субфайла. Чтобы уменьшить итоговое время доступа к требуемой информации изображения предпочтительно записывать информацию цветности U, V в субфайлах 16 TV и 256 TV слитно с яркостной информацией Y в субфайлах 4 TV и 64 TV, как показано для файла IР* на фиг.2. Еще более короткое время доступа к требуемой цветной информации высокого разрешения получают, если информация цвета в субфайлах 16 TV и 256 TV разделена на порции U*, V* и U', V', причем порция U*, V* определяет информацию цвета, имеющую горизонтальное и вертикальное разрешение, вдвое меньшее, чем разрешение, представленное порциями U*, V* и U', V' вместе. Можно, например, закодированную информацию цвета одного из четырех имеющихся в наличии пикселей сначала записать в U*, V*, а затем записать кодированную информацию цвета других пикселей изображения, как показано на фиг. 5. Там пиксели цвета, принадлежащие к U*, V* (UV11, UV31, UV51,), представлены в виде заштрихованных блоков, а пиксели цвета, принадлежащие к U', V' (UV21, UV41,UV12, UV22, UV2), представлены незаштрихованными блоками. Информация U*, V* в 16 TV и 256 TV определяет информацию цвета с горизонтальной и вертикальной четкостью, равной половине разрешения информации яркости, определяемой субфайлами 4 TV и 64 TV соответственно. Таким образом, информация цветности в субфайле 4 TV и 64 TV соответственно вместе с информацией цвета U*, V* в субфайлах 16 TV и 256 TV соответственно опять определяют представление, горизонтальное и вертикальное разрешение которого в цветной информации равно половине разрешения информации яркости. Это значит, что отношение между разрешением информации цвета и яркости представления определенного комбинацией информации яркости субфайла 4 TV и 64 TV и информации цвета U*V* субфайла 16 TV и 256 TV соответственно равно отношению между разрешением информации цвета и яркости представлений, определяемых субфайлами TV/4, TV, 16 TV и 256 TV в итоге, так что могут быть воспроизведены представления всех хранимых закодированных изображений с тем же отношением разрешений между информацией цвета и яркости.
Однако нужно заметить, что при воспроизведении представления закодированного изображения, записанного посредством субфайла 4 TV, также возможно использовать информацию цвета субфайла TV или полную информацию цвета субфайла 16 TV.
Обычно кодированные пиксели записывают строка за строкой.
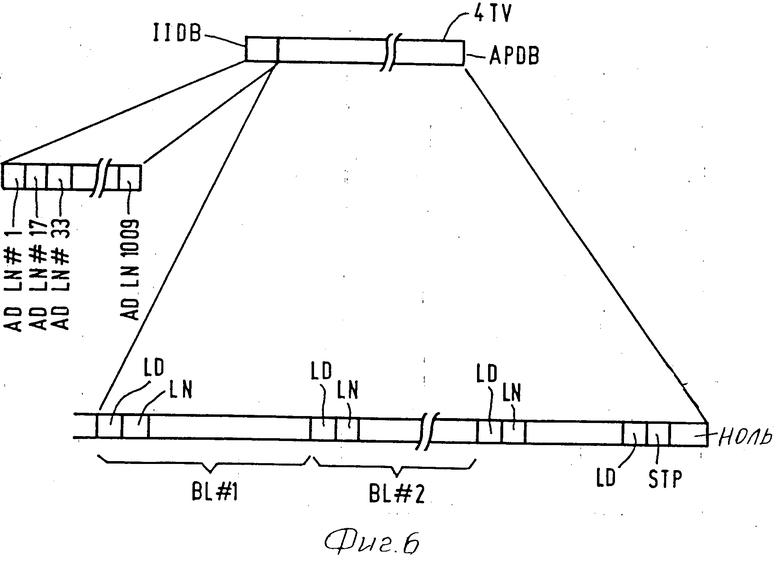
Когда используется остаточное кодирование, описанное выше, с использованием нелинейной квантизации и кодирования Хаффмана, остаточные величины представлены посредством кодов переменной длины. Это значит, что место, требуемое для записи остаточно закодированного изображения, не определено началом записи первой кодированной строки изображения. Это усложняет селективное считывание с кодированных строк изображения, например, только тех строк изображения, которые необходимы для осуществления функции ТЕЛЕ. Эта проблема может быть облегчена записью номера строки LN (см.фиг.6) в начале каждой кодированной строки изображения В и кода синхронизации строки LD. Код синхронизации строк может быть, например, уникальной комбинацией битов, которая не встречается в последовательности кодов Хаффмана, являющихся информацией остаточно закодированных элементов изображения. Нужно заметить, что добавление кодов строчной синхронизации LD и номеров строк LN дает добавочное преимущество, способствуя синхронизации считывания, и значительно уменьшает распространение ошибок после неправильно считанного остаточного кода.
Очень быстрое отыскание выбранных строк изображения может быть достигнуто за счет того, что адреса, под которыми начинаются записи кодированных строк изображения, записаны на носителе записи в отдельном файле управления, предпочтительно в начале каждого субфайла. На фиг.6 эти адреса показаны, в качестве примера, как AD LN 1,AD LN 1009 в файле управления IIDB в начале субфайла 4 TV. Информация строки изображения в форме последовательности остаточно закодированных строк изображения вставлена в секцию APDB субфайла 4 TV. Секция APDB представляет фактическую информацию изображения в субфайле 4 TV.
Вообще, при поиске начальных точек строк изображения на носителе записи в процессе грубого поиска считывающий элемент передвигают относительно носителя записи в положение на малом расстоянии перед начальной точкой, где начинается запись закодированной строки изображения. Затем проводится точный процесс поиска, в котором при сканировании носителя записи со скоростью, соответствующей нормальной скорости считывания, ожидают начала выбранной кодированной записи строки, после чего начинают считывание выбранной кодированной строки изображения. Точность, с которой считывающий элемент может позиционироваться относительно носителя записи в процессе грубого поиска, ограничена и в системах оптического хранения данных она в общем случае гораздо больше расстояний между положениями, в которых начинаются записи последовательных кодированных строк изображения на носителе записи. Поэтому предпочитают хранить только стартовые адреса ограниченного количества кодированных строк изображения, начальные точки которых разнесены друг от друга на расстояние, практически равное точности, с которой считывающий элемент может быть установлен в процессе грубого поиска. Это позволяет найти информацию выбранных кодированных строк изображения в запомненной кодированной картинке и быстро считать ее без расходования слишком большого места для хранения адресных данных. В случае дискового носителя записи средняя точность поиска в процессе грубого поиска, при котором считывающий элемент движется над диском в радиальном направлении, по определению равна половине длины одного оборота диска, что обозначает, что расстояния между положениями, указанными адресами, практически соответствует половине длины одного оборота диска при использовании дискового носителя записи.
Запомненные кодированные изображения в общем случае определяют несколько изображений ландшафтного формата (т.е. для правильного воспроизведения изображения должно индуцироваться в ориентации, когда ширина изображения превышает его высоту) и несколько изображений портретного формата (т.е. для правильного воспроизведения ориентация должна быть такой, что высота изображения больше его ширины).
На фиг. 1 для примера показан носитель изображений с несколькими изображениями в ландшафтном формате (2а, b, c и d) и одно изображение в портретном формате (2е). На носителе записи все кодированные изображения записаны, как если бы они представляли изображения в ландшафтном формате, для того, чтобы позволить одинаковое сканирование изображений без необходимости различать, какого типа сканируемое изображение на самом деле: ландшафтного или портретного и при сканировании и/или обработке изображения изменить в зависимости от результата детектирования. Это значит, что при воспроизведении представлений изображений портретного формата оно будет воспроизведено в неправильном повернутом положении. Это можно предотвратить, если предусмотреть возможность назначения кода поворота при записи, который обозначает, нужно ли повернуть изображение при воспроизведении на угол 90, 180 или 270о. Этот код поворота может присутствовать в каждом файле изображения IР1,IPn. Также возможно записывать коды поворота в файле управления ВВ или хранить эти коды поворота в не теряющей информацию памяти, находящейся в блоке считывания или соединенной с ним.
При воспроизведении тогда можно на основе кода поворота определить, нужно ли поворачивать воспроизводимое изображение, и если нужно, то произвести поворот на нужный угол до воспроизведения. Недостаток размещения кода поворота в файлах изображения IР заключается в том, что эти коды поворота приходится определять уже в процессе считывания изображений. На практике это обозначает, что необходимость поворота приходится определить и вводить оператору, потому что известные вспомогательные устройства не всегда в состоянии обнаружить, имеет ли сканируемое изображение ландшафтный или портретный формат и находится ли сканируемое изображение в сканирующем устройстве в правильно ориентированном положении, что нежелательно потому, что при этом оператору всегда нужно находиться на рабочем месте при записи, что затрудняет реализацию полностью автоматизированной системы хранения изображений.
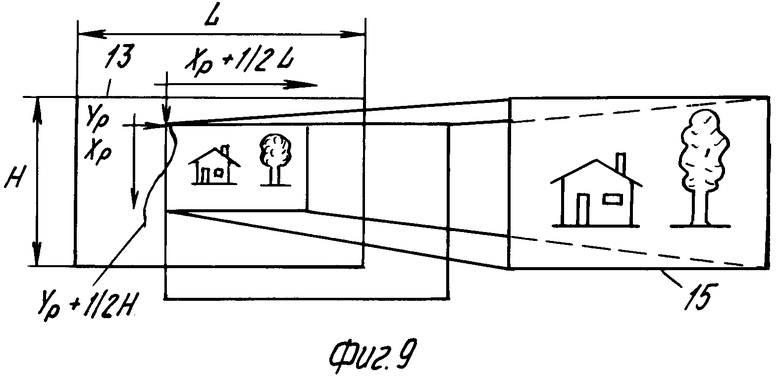
Если коды поворота уже имеются при записи кодированной информации изображения, выгодно записывать эти коды на носителе записи. В случае организации файлов по фиг.2 удобным местом для записи кода поворота является субфайл FRS в файле управления ВВ. Для удобства потребителя желательно указывать кроме необходимости поворота также необходимость небольшого сдвига при воспроизведении (влево, вправо, вверх или вниз). Это особенно желательно, если площадь экрана дисплея меньше размеров изображений, так как при этом важная деталь изображения может оказаться за краем экрана. Желаемый сдвиг может быть задан назначением кода сдвига в каждом закодированном изображении. На фиг.9 подходящие коды сдвига для изображения 13 определены координатами ХР и YР вершины 14 изображения для воспроизведения со сдвигом. Посредством кода сдвига и кода увеличения можно задать коэффициент увеличения, при котором должна воспроизводиться важная деталь изображения. Позиционный номер 15 обозначает увеличенное представление части изображения 13, определенное сдвигом ХР, YР и коэффициентом увеличения, равным 2. Добавочно к этим данным также возможно в субфайле FRS файла ВВ управления поместить другие данные воспроизведения, например параметры изменения цвета или яркости при воспроизведении изображения на дисплее. Кроме того, выгодно хранить в субфайле FRS файла управления ВВ желаемую последовательность воспроизведения изображений.
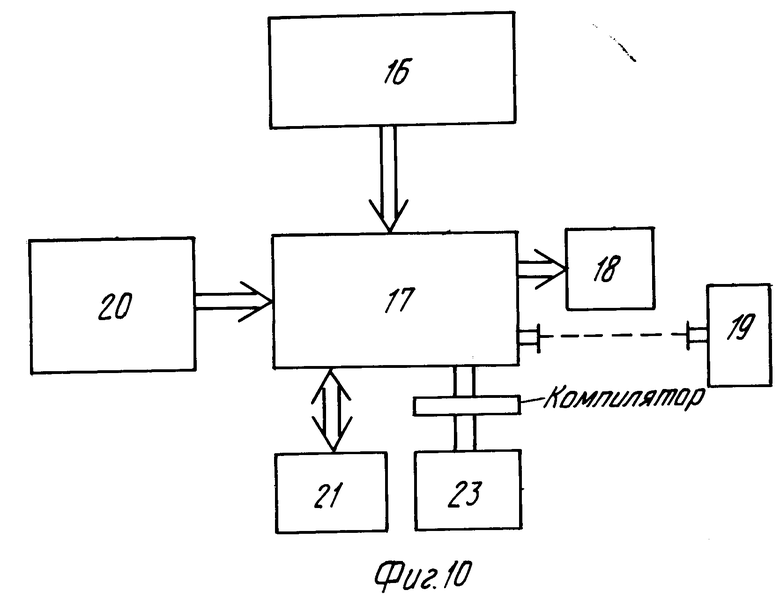
Упомянутая информация о последовательности воспроизведения, повороте, сдвига, увеличении яркости и цвете и других операций обработки изображения прежде его воспроизведения далее будут называться предпочтительными установками воспроизведения. В файле FRS выгодно записать больше одного набора предпочтительных установок. Это позволяет использовать различные последовательности воспроизведения и операции обработки для выборки различными лицами, например членами одной семьи, потребителей. Это также позволяет отдельному пользователю выбрать набор предпочтительных установок воспроизведения. Следует заметить, что при использовании носителя записи однократного типа наборы предпочтительных установок могут быть записаны на нем, только если они имеются в наличии при записи. Это требует вмешательства человека в процессе записи. При считывании носителя записи выбирают набор предпочтительных установок и представление кодированных изображений может производиться соответственно им. На фиг.10 показана блок-схема исполнения системы поиска и воспроизведения изображений, посредством которого закодированные изображения могут быть воспроизведены соответственно выбранному набору предпочтительных установок. Для выдачи считываемой информации блок 16 считывания соединен с блоком 17 управления и обработки сигнала. Из полученной с блока 16 информации блок 17 выбирает файл FRS, содержащий набор или наборы предпочтительных установок, и запоминает их в памяти 18 управления. Посредством блока 19 ввода данных, например устройства дистанционного управления, пользователь может выбрать набор из памяти управления и затем включить блок 17 в режим цикла считывания, в котором закодированная информация изображения считывается в последовательности, заданной выбранным набором предпочтительных установок при управлении от блока 17. После того, как кодированная информация изображения была считана, эта информация обрабатывается соответственно выбранному набору предпочтительных установок и выдается на блок 20 дисплея.
Возникает проблема, особенно если носитель записи не может быть переписан на нем ничего изменить нельзя. Проблема может быть сглажена, если в системе поиска и воспроизведения (фиг.10) предусмотрена не теряющая информации память 21, в которую вместе с кодом идентификации носителя записи записывают новый набор предпочтительных установок или информацию о желательных изменениях предпочтительных установок воспроизведения относительно записанных на носителе записи для данного носителя с определенным кодом идентификации.
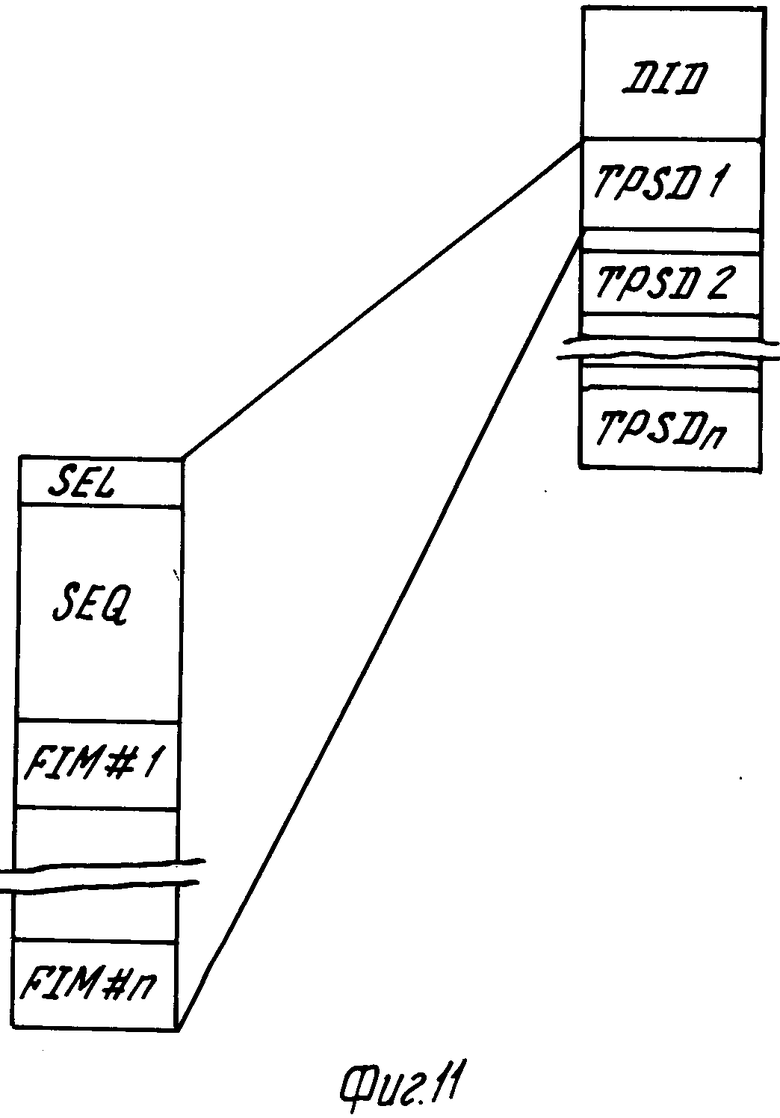
На фиг.11 в качестве примера показан подходящий формат предпочтительных установок воспроизведения, записанный в файле FRS, на носителе записи. Формат содержит секцию DID, в которой хранится уникальный код идентификации носителя записи. Такой код может содержать большой произвольный номер, генерируемый посредством генератора произвольных чисел и записанный на носителе записи. Код может содержать время в годах, месяцах, днях, часах, минутах, секундах и частях секунд. Альтеpнативно, код идентификации может содержать комбинацию кода времени и произвольного числа. После секции DID следуют секции FRS1, FRS2,FRSn, в которых хранятся различные наборы предпочтительных установок воспроизведения. Каждая из секций предпочтительных установок FRS1, FRSn cодержит часть SEL, в которой записан номер идентификации для каждого из различных наборов предпочтительных установок для выбора различными пользователями, и часть, указывающую последовательность SEQ, в которой подлежат воспроизведению хранимые изображения. После этой части идут кодированные секции FIM FIM n, хранящие для изображений 1.n предпочтительные операции обработки, подлежащие выполнению перед воспроизведением соответствующего изображения.
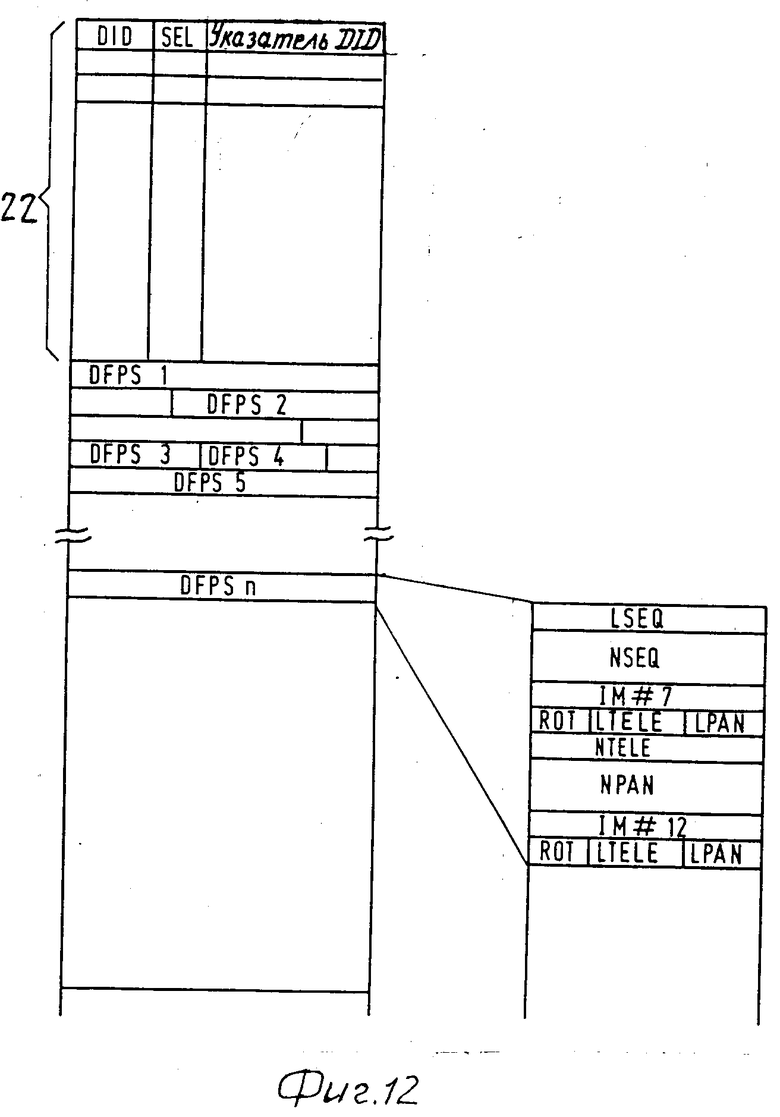
На фиг. 12 показан для примера подходящий формат, в котором может храниться информация о желаемых приспособлениях набора предпочтительных установок в нетеряющей информацию памяти 21. Формат содержит секцию 22, указывающую комбинации идентификаций носителя записи и номеров наборов, для которых в памяти имеется информация о предпочтительных установках при воспроизведении. Каждой из этих комбинаций назначена стрелка, которая записана в секции DID-POINT и указывает адрес секций DFPS1.DFPSn в памяти 21.
Каждая секция DFPS содержит часть LSEQ с кодом, указывающим размер (например, количество байтов), требуемый для указания новой последовательности. Если часть LSEQ указывает длину, не равную нулю, после LSEQ пойдет часть NSEQ с данными, указывающими новую последовательность воспроизведения. ROT указывает секцию с кодом поворота. Секции LTELE и LPAN указывают имеющуюся длину для хранения новых данных, относящихся к увеличению изображения (в секции NTELE) и сдвига изображения (в секции NPAN). Таким образом возможно, например, определить три различные длины, обозначающие три различные точности, LTELE и LPAN идут перед частями NTELE и NPAN. Если информация об увеличении и сдвиге изображения не изменяется, это показывается длиной, равной нулю в LTELE и LPAN; Хранением лишь предпочтительных операций обработки для изображений с модифицированной предпочтительной обработкой значительно снижают необходимый для хранения информации о новых предпочтительных установках объем памяти. Кроме уменьшения требуемого объема памяти указанной записью разностей можно получить добавочное уменьшение памяти за счет указания длины, требуемой для хранения измененных данных. При считывании носителя записи из предпочтительных установок, записанных на носителе записи, получают приспособленный набор предпочтительных установок и различия запомненные в памяти 21. Этот приспособленный набор хранится в памяти 18.
Вместо, или дополнительно к не теряющей информацию памяти 21, может применяться сменная память 23, например, в форме магнитной карточки, стираемой постоянной памяти типа EPROM, EEPROМ или NVRAM для хранения предпочтительных установок в системе поиска и воспроизведения, показанной на фиг. 10.
Это дает то преимущество, что пользователь может воспроизводить информацию изображений на носителе записи соответственно с одними и теми же предпочтительными установками на различных системах поиска и воспроизведения изображений, с которыми может быть соединена сменная память 23.
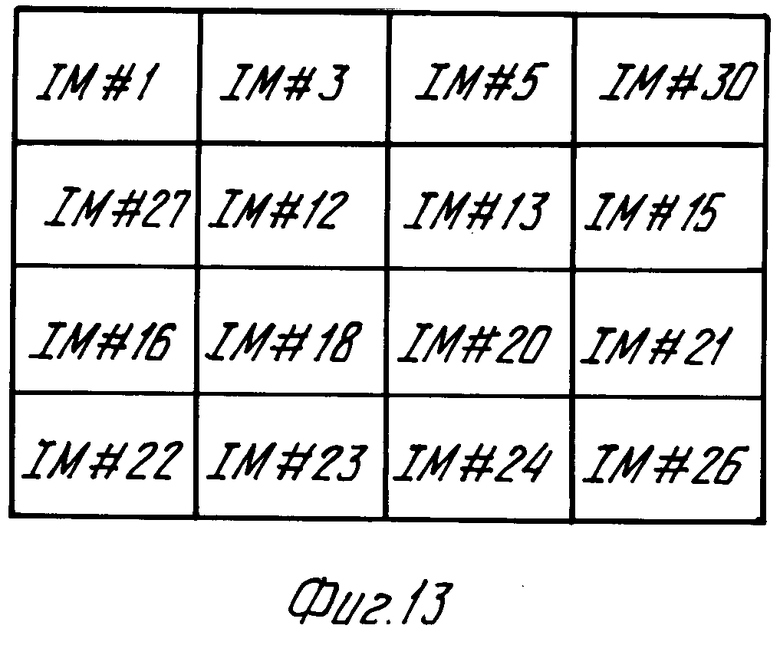
Файл OV (фиг.2) для всех файлов изображения IР1,IPW содержит субфайл TV 116, содержащий абсолютно закодированное изображение малой четкости. Записанный файл OV дает то преимущество, что возможен обзор кодированной информации изображений на носителе записи с минимальным временем доступа. Это возможно, например, посредством последовательного воспроизведения кодированных изображений в субфайле TV/16 в виде картинок, которые полностью или частично заполняют экран дисплея, предпочтительно в последовательности, определяемой выбранным набором предпочтительных установок. Однако также возможно составить изображение в виде так называемого мозаичного изображения из субфайлов, в котором большое количество кодированных изображений малой четкости, содержащихся в субфайлах TV/16, воспроизводятся в виде матрицы, предпочтительно в порядке, диктуемом выбранным набором предпочтительных установок. На фиг. 13 показано мозаичное изображение, составленное из представлений (IМ1, IМ3,IМ 26) шестнадцати изображений из субфайлов низкого разрешения.
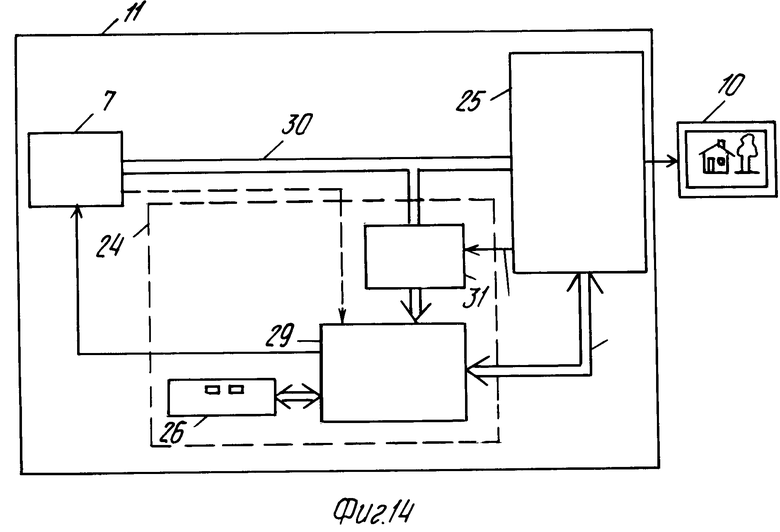
На фиг. 14 показан пример выполнения системы поиска и считывания изображений (фиг.1в) более подробно. В данной системе блок 11 поиска и считывания содержит блок 7 считывания, блок 24 управления и блок 25 обработки изображения. Блок 24 выбирает специфичную информацию, содержащуюся в файлах управления ВВ и IIDB из считанной информации. Блок 25 из считанной информации выбирает информацию изображения и преобразует эту информацию изображения в форму, подходящую для блока 10 дисплея. Блок 7 и блок 25 обработки информации управляются блоком 24 на основе данных, введенных пользователем, например, через блок 26 ввода данных и на основе данных управления в файлах управления ВВ и IIDB.
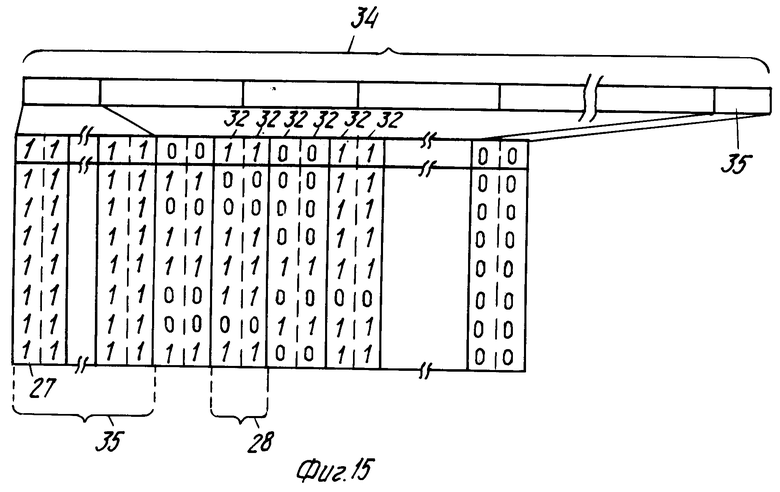
Ввиду большого количества информации для каждого записанного изображения предпочтительно считывать файлы, содержащие информацию изображения, с высокой скоростью, чтобы уменьшить время считывания изображения. Однако это значит, что данные в файле управления также считываются с высокой скоростью. Функции управления требуют лишь невысокой скорости обработки данных, позволяющей использовать для этого дешевый и простой микрокомпьютер с малой скоростью обработки. Однако в общем случае такой дешевый микрокомпьютер не способен обрабатывать информацию управления, подаваемую с высокой скоростью считывания файлов управления ВВ и IIDB, так как скорость, с которой данные управления подаются (которая практически равна скорости информации изображения) слишком высока для обработки дешевым микропроцессором, работающим с малой скоростью. Эта проблема может быть сглажена за счет того, что каждая группа битов, содержащая данные управления, записывается n раз (n целое число, большее или равное 2) последовательно на носителе записи. Пакеты с идентичными группами выдаются при считывании информации управления. На фиг. 15 показан способ выдачи информации управления из файлов ВВ и IIDB блоком 7 считывания, когда n равно 2, а количество битов в группе равно 8.
На фиг. 15 группы имеют позиционный номер 27, а пакеты позиционный номер 28. Количество битов в группе равно 8, а количество групп в пакете 2.
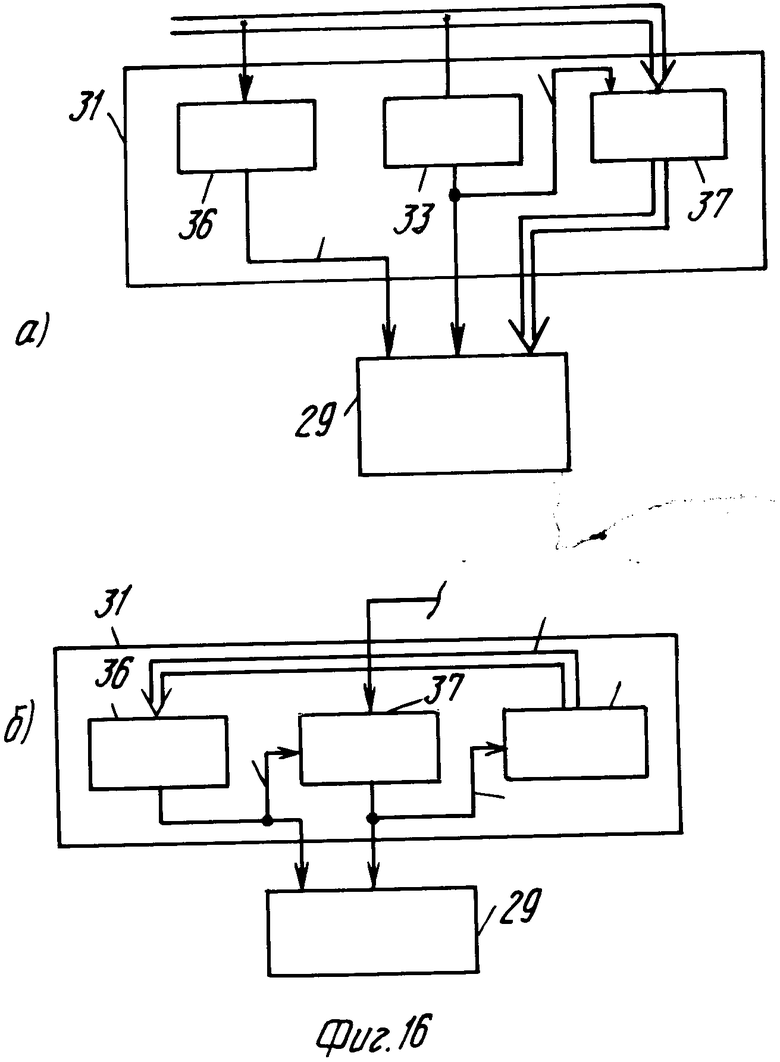
Посредством повторения идентичных групп достигают того, что скорость подачи данных управления с блока считывания уменьшается без использования добавочных функций. Соответствующим выбором величины n, таким образом, можно снизить скорость выдачи данных управления и медленно работающей микрокомпьютерной системе блока 25 управления до такой степени, что они могут обрабатываться медленно действующим микрокомпьютером 29. Между сигнальной шиной 30 и микрокомпьютерной системой 29 может быть установлена схема 31 извлечения данных. Чтобы выдавать каждый из пакетов 28 данных управления на микрокомпьютер 29 в виде одной группы битов со скоростью, равной скорости повторения групп битов, деленной на n.
Такая схема 31 извлечения данных может, например, содержать регистр (фиг.16а), который загружается с частотой синхронизации, равной частоте повторения групп битов, деленной на n. Этот сигнал синхронизации может быть просто получен использованием одного бита в каждой группе 27 битов в качестве бита 32 сихронизации. Биту синхронизации последовательных групп битов может быть назначена логическая величина, которая меняется с частотой, связанной с частотой повторения пакетов 28 групп 27 битов. Частота чередования может быть равна половине частоты повторения пакетов 28 и (как показано на фиг. 5) или в целое число раз больше. Это имеет то преимущество, что последовательность синхронизации получается прямо из битов синхронизации.
Схема 31 извлечения данных содержит схему 33 извлечения синхронизации, которая подает чередующийся сигнал синхронизации, соответствующий чередующимся логическим величинам битов синхронизации, на вход управления загрузкой регистра. Схема 33 также переносит сигнал синхронизации на микрокомпьютерную систему 29. Предпочтительно группы битов в файле управления размещены в так называемых кадрах, которые обозначены позиционным номером 34 на фиг.15. В этом случае желательно, чтобы можно было просто определять начало каждого кадра. Очень простое обнаружение может быть достигнуто вставлением в начале кадров нескольких групп 35 синхронизации кадров с битами 32 синхронизации, которые составляют определенный узор логических величин, которые явно отличаются от возможного узора логических величин битов 32 синхронизации, которые могут встретиться в других пакетах.
Каждый кадр имеет часть 35, содержащую избыточную информацию, с целью обнаружения, правильно ли был считан кадр микрокомпьютерной системы 29. Неправильный ввод может быть следствием, например, прерывания программы, на время которого прерывается считывание данных управления, чтобы выполнить другую программу управления. Такая программа управления может быть, например, вызвана в результате ввода данных в блок 26. Поскольку неправильный ввод данных из файлов управления ВВ и IIDB обычно вызывается прерыванием программы, то требуется, чтобы исправление ошибок на основе части 35 кадра производилось бы самим микрокомпьютером 29. Схема 31 содержит детектор 35 синхронизации кадров, который обнаруживает начало каждого кадра на основе битов 32 синхронизации в группах 35 битов синхронизации кадров. После обнаружения начала кадра детектор 36 выдает сигнал синхронизации на микрокомпьютер 29, который вводит данные управления, имеющиеся на регистре.
В описанном выше процессе считывания данных управления из файлов управления ВВ и IIDB сигнал синхронизации для регистра получают из битов 32 синхронизации. Однако, также возможно получать сигнал синхронизации изображения, который обычно вырабатывается в блоке 25. Сигнал синхронизации информации изображения имеет жесткую связь с частотой повторения групп при считывании файлов изображения и, следовательно, с частотой повторения групп в файлах управления ВВ и IIDB. Поэтому сигнал синхронизации для загрузки регистра может быть получен простым делением частоты сигнала синхронизации изображения в соответствующей схеме.
На фиг. 16б показан пример схемы 31 извлечения данных, которая использует делитель 37 частоты. Делитель получает сигнал синхронизации изображения, который подается с блока 25. Сигнал синхронизации для загрузки регистра должен быть привязан к началу кадров 34. Это может быть реализовано простым использованием обнуляемого счетчика в качестве делителя 37 частоты. Счетчик обнуляется каждый раз сигналом обнуления при обнаружении начала кадров. Сигнал обнуления может быть сигналом, выдаваемым детектором 36 при каждом обнаружении групп 35 битов синхронизации кадров.
Если информация в файлах управления расположена блоками, например так, как обычно делают в устройствах памяти типа CD-ROM и CD-ROM XA (который будет описан ниже), сигнал обнуления для счетчика может быть получен на основе секций блочной синхронизации (SYNC), расположенных в начале каждого блока (BLCK). Однако это требует, чтобы начало каждого кадра 34 всегда находилось в фиксированном положении относительно секции блочной синхронизации. Это может быть достигнуто просто селектированием начала каждого кадра 34 и в начале блока. При обнаружении начала каждого кадра микрокомпьютер вызывает программу ввода для управления вводом имеющихся данных управления. Однако в этот момент микрокомпьютер может быть занят выполнением другой задачи управления. Такая задача должна быть прервана, прежде чем будет вызвана программа ввода. Это прерывание активной задачи управления и последующий вызов программы ввода требует некоторого времени. Расположив несколько групп битов без данных управления в начале каждого кадра 34, с высокой вероятностью обеспечивают, что при считывании первого пакета 28 полезных данных правления в каждом кадре 34 микрокомпьютер 29 будет готов ввести данные управления при управлении программой ввода. Из этого следует, что группы 35 битов синхронизации в начале каждого кадра могут служить двум целям: давать синхронизацию и создавать время ожидания до поступления первых полезных данных управления.
В случае, если группы битов используются только для реализации времени ожидания, логические величины битов в этих группах могут быть произвольными.
Если группы битов также используются для целей синхронизации, то важно, чтобы группы имели бы логический узор, который не встречается в других группах.
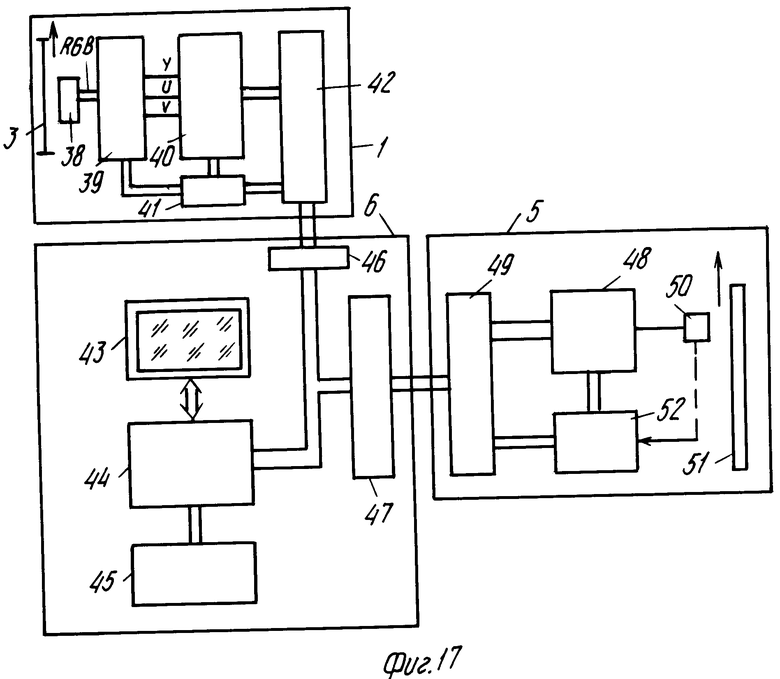
На фиг. 17 показана система хранения изображений более подробно. Блок 1 сканирования содержит сканирующий элемент 38 носителя 3 для преобразования информации в обычные сигналы информации, например сигналы RGB изображения. Сигналы изображения с выхода сканирующего элемента определяют самое высокое возможное разрешение в количестве пикселей на изображение. Сигналы информации, выдаваемые сканирующим элементом 38, преобразуются в сигнал яркости Y и два цветоразностных сигнала U и V посредством обычной матричной схемы 39. Схема 40 кодирования преобразует сигнал Y, U и V обычным образом в абсолютно закодированные сигналы (для изображений с низким разрешением) и остаточно кодированные сигналы изображения (для более высоких разрешений) соответственно ранее описанной логике кодирования. Сканирующий элемент, матричная схема и схема кодирования управляются с помощью обычной схемы 41 управления на основе команд управления, подаваемых с блока 6 управления через интерфейс 42. Абсолютно и остаточно закодированные данные изображения, создаваемые схемой кодирования, выдаются на блок 6 через интерфейс 42. Блок 6 может содержать компьютерную систему из блока 43 дисплея, блока 44 компьютера и памяти и блока 45 ввода, например клавиатуры, для ввода данных пользователем. Блок дисплея и блок ввода соединены с блоком компьютера и памяти и далее соединен с блоком сканирования изображения и блоком записи через схему интерфейса 46 и 47 соответственно. Блок 5 записи содержит форматирующий и кодирующий блок 48, преобразующий подлежащую записи информацию (которая получается с блока управления через интерфейс 49) в коды, которые подходят для записи и которые расположены в формате, подходящем для записи. Данные подаются на записывающую головку 50, которая записывает соответствующий информационный узор на носителе 51 записи. Процесс записи управляется схемой 52 управления на основе команд, получаемых с блока 6 управления и, если применимо, адресной информацией, показывающей положение записывающей головки 50 относительно носителя.
Блок 44 загружается подходящим программным материалом для расположения остаточно закодированной информации изображения с блока сканирования обычным образом в соответствии с упомянутыми выше правилами форматирования, позволяющими создать файлы изображения IP и OV. Кроме того, блок 44 был загружен программой для вставления в файл управления, обычным образом и в соответствии с указанными выше правилами форматирования, предпочтительных установок воспроизведения от оператора вместе с другими автоматически генерируемыми данными управления, такими, например, как список адресов, под которыми были записаны различные файлы на носителе 51.
Блок 44 может далее иметь программу обработки сигнала изобретения, позволяющую обрабатывать информацию со сканирующего устройства, с целью исправления ошибок, например ошибок фокусировки и устранения зернистости, или с целью коррекции цвета или яркости изображения.
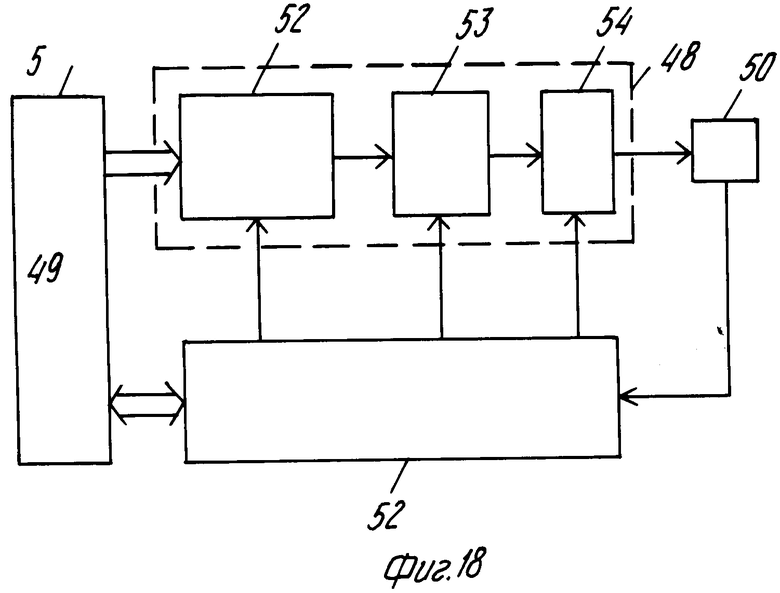
Файлы, составленные посредством блока 44, подаются на блок 5 записи в желаемой последовательности их записи. Устройство записи файлов на таком носителе записи содержит схему 52 форматирования, которая собирает подлежащую записи информацию, поданную через интерфейс 49 в соответствии со схемой форматирования.
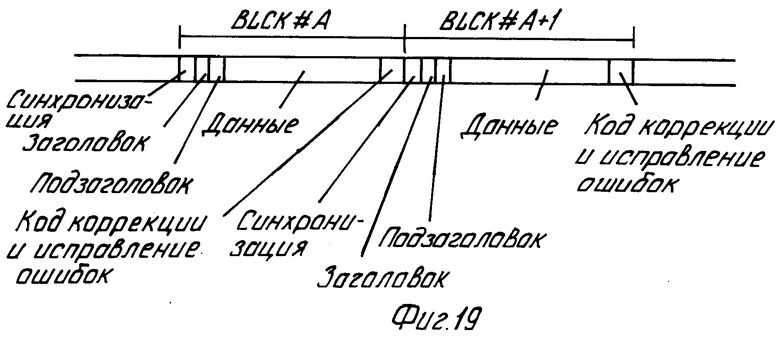
Соответственно этому формату, показанному на фиг.19, данные расположены в блоках BLCK с длиной, соответствующей длине субкодового кадра в сигнале Си Ди. Каждый блок BLCK содержит секцию синхронизации блока SYNC, головочную секцию HEAD, содержащую адрес в форме абсолютного кода времени, соответствующем абсолютному коду времени в субкодовой части, записанной с блоком. Блок BLCK далее содержит субголовную секцию SUBHEAD, содержащую среди прочего номер файла и номер канала. Добавочно, каждый блок BLCK содержит секцию DATA, содержащую подлежащую записи информацию. Каждый блок BLCK может также содержать секцию EDC8ECC, в которой находится избыточная информация для целей обнаружения и исправления ошибок. Блок 5 записи, показанный на фиг.18, содержит схему 53 кодирования для создания "тасовки" или чересстрочной структуры и для добавления кодов четности для обнаружения ошибок и исправления их. Схема 53 выполняет указанные выше операции над форматированной информацией, выдаваемой форматирующей схемой 52. После выполнения этих операций информация подается на модулятор EFМ 54, в котором информации придается форма, которая лучше подходит для записи на носителе записи. Кроме того, модулятор 54 добавляет субкодовую информацию, которая среди прочего содержит код абсолютного времени в качестве адресной информации, в так называемом субкодовом канале Q.
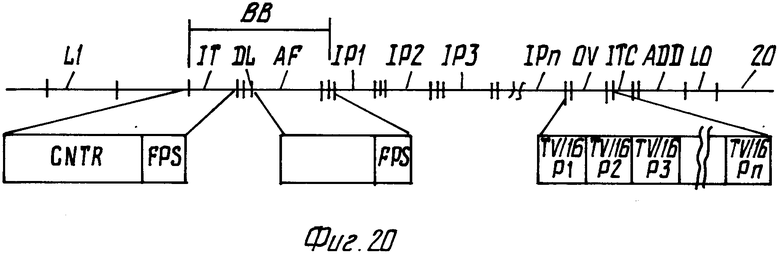
На фиг. 20 показана организация носителя записи в случае, когда информация записана в дорожке соответственно формату Си Ди.
Перед записанной информацией находится вводная секция LI (также называемая вводной дорожкой), как обычно в записи сигналов Си Ди, и заканчивается обычной выводной секцией LO (также называемой выводной дорожкой).
Если информация записывается в формате Си Ди, предпочтительно в файл управления ВВ включать секцию, записанную в стандарте Си Ди-Ай: эти секции являются "ярлыком диска и указателем", кратко обозначаемым DL, и так называемыми программами применения, обозначенными AF. Это позволяет записанную информацию изображения воспроизводить с помощью стандартной системы Си Ди-Ай. Предпочтительно также включают субфайл FPS с набором предпочтительных установок в секции программ применения. Добавочно к секциям DL и АТ файл управления ВВ содержит субфайл IT, содержащий секцию CNTL с данными управления и секцию FPS с наборами предпочтительных установок в уже описанном формате (фиг. 15). Предпочтительно секция IT записывается в заранее заданной площади носителя записи в секции заранее заданной длины. Если секция IT недостаточно велика для размещения всех данных управления, часть данных управления может быть записана в секции ITC после файла OV. В этом случае надо включить в секцию IT стрелку, указывающую начальный адрес ITC.
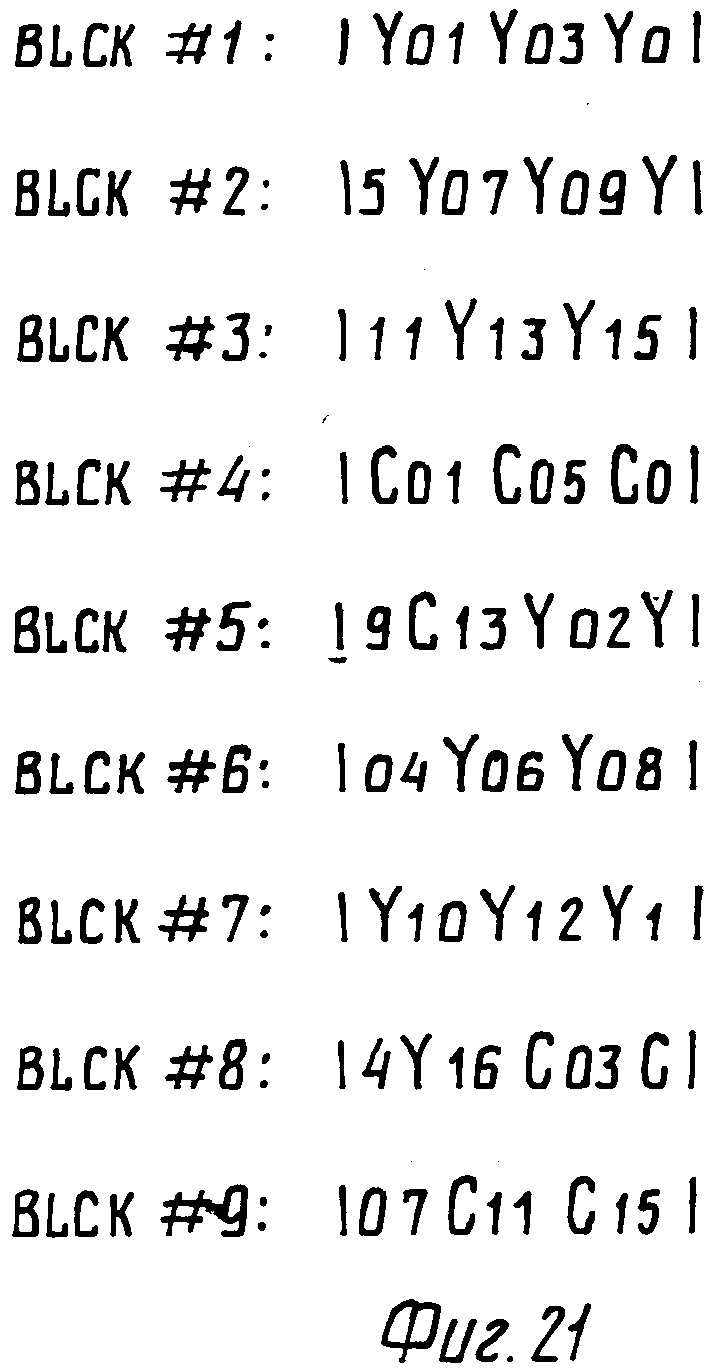
Для случая, когда информация была записана в формате Си Ди, на фиг.21 показано для абсолютно закодированного субфайла Т такое расположение строк изображения Y01, Y02,Y16 с абсолютно закодированной информацией яркости и строки изображения С01, С03,С15 с абсолютно закодированной информацией цвета, что последовательные строки не соседствуют друг с другом в направлении дорожки (касательное направление) и поперек дорожки (радиальное направление).
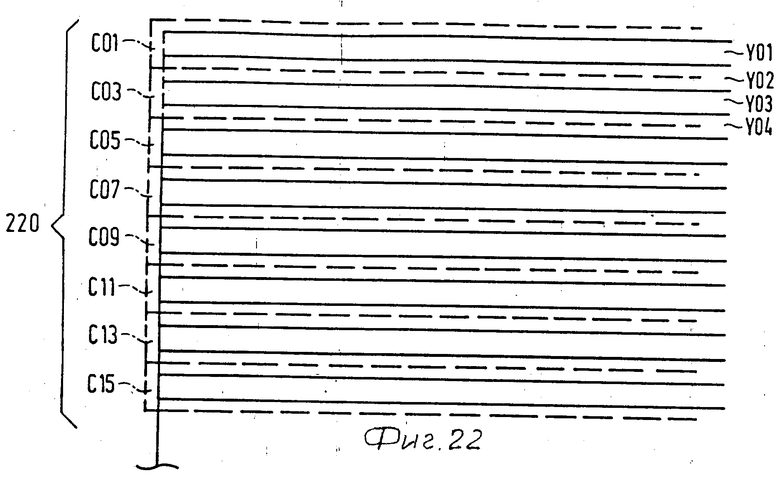
На фиг.22 показано положение строк изображения для воспроизведения. Как показано на фиг.21 и 22, несколько строк яркости Y01, Y03,Y15) с нечетными номерами с кодированной информацией яркости записано в секции, содержащей блоки BLCK1,2,3, затем несколько имеющих четные номера цветных строк изображения (С01, С05,С13) с кодированной цветной деформацией записано в секции, содержащей блоки CLCK4 и5, затем яркостные строки с четными номерами (Y02, Y16) с закодированной яркостной информацией в секции, содержащей блоки BLCK 5,8, и наконец, закодированные четные цветные строки изображения (С03, С07, С15) с кодированной цветной информацией записаны в секции, содержащей блоки BLCK 8 и9. Кодированные строки изображения в блоках BLCK1.BLCK9 определяют слитную часть представления и изображения, показанную на фиг.22. Группа секций, определяющая слитную часть представления, далее будет называться группой секций. По способу, подобному описанному выше, группы секций определяют другие слитные части представления в субфайле TV. Кодированные строки изображения с информацией изображения для субфайлов TV/4 и TV/16 могут быть расположены подобным образом, как показано на фиг.23 и 24.
Такое расположение предотвращает неправильное считывание двух или более соседних (слитных) строк изображения за счет дефекта носителя записи. Восстановление представлений изображений, в которых неправильно считанные строки изображения находятся рядом друг с другом, очень трудно реализовать. В отличие от этого восстановление неправильно считанной строки изображения, находящейся между двумя правильно считанными строками и представления, становится простым посредством замены неправильно считанных строк пикселями, взятыми из соседних строк изображения.
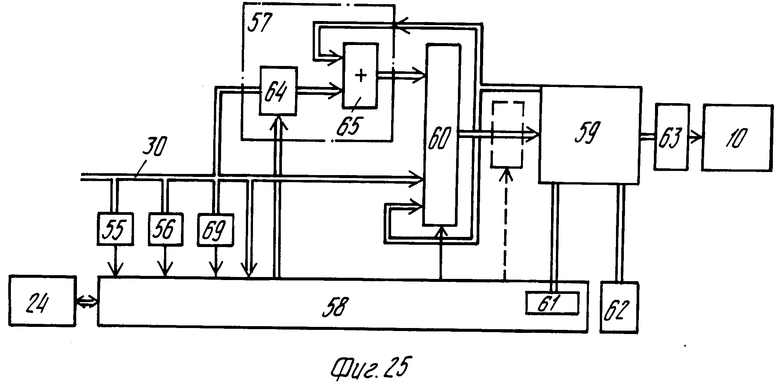
На фиг.25 показан блок обработки изображения более подробно. Он содержит первую схему детектора 55 для обнаружения кодов синхронизации LD и номеров строк изображения LN, показывающих начало каждой остаточно закодированной строки изображения. Вторая схема 56 детектора служит для обнаружения начала каждого субфайла в каждом файле изображения с остаточно закодированным изображением для индикации начала секции IIDB, содержащей адреса некоторого количества кодированных строк изображения. Следует заметить, что схемы детекторов нужны только для обработки остаточно закодированных изображений, а не для обработки абсолютно закодированных изображений. Для указанного обнаружения входы первой и второй детекторных схем соединены с сигнальной шиной 30. Схема 57 декодирования для остаточно закодированной информации изображения и схема 58 управления также соединены с сигнальной шиной 30. Эта шина и выходы схемы 57 соединены на входы данных памяти 59 изображения через мультиплексную схему 60, чтобы хранить считанную и декодированную информацию изображения. Выходы данных памяти 59 соединены с входами схемы 57 декодирования и с входами мультиплексной схемы 60. Схема 58 содержит генератор 61 адреса для адресования ячеек памяти изображения. Блок обработки изображения содержит второй генератор 62 адреса для адресования ячеек памяти, чтобы выдать содержимое памяти изображения на преобразователь 63 сигнала. Схема 57 декодирования может содержать, например, декодирующее устройство 64 для кодов Хаффмана с управлением от блока 58 управления и сумматор 65. Другой вход сумматора 65 соединен с выходами данных памяти 59. Результат операции суммирования подается на схему 60 мультиплекса. Схема 58 управления может содержать, например, программируемый блок управления и компьютера.
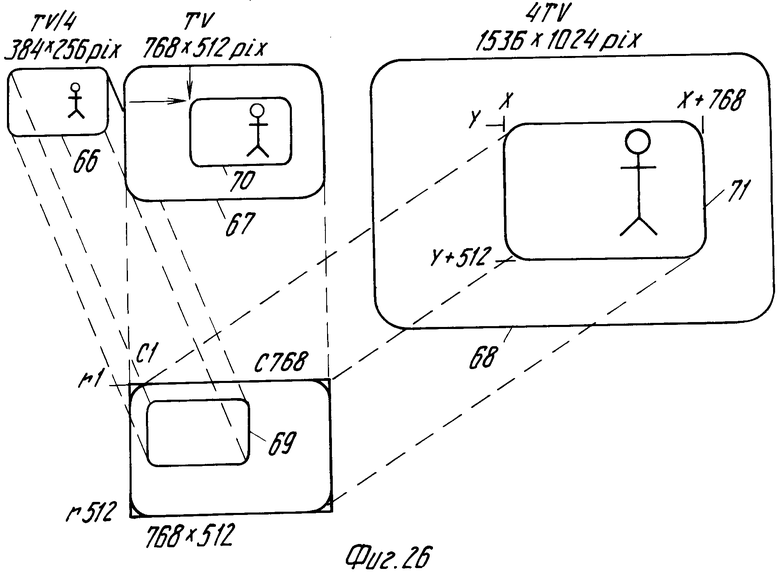
На фиг.26 позиционные номера 66-68 обозначают представления одного и того же изображения, но с различными разрешениями. Представление 66 содержит 256 строк изображения по 384 пикселей (элементов изображения) каждая. Представление 67 содержит 512 строк по 768 пикселей каждая, а представление 68 содержит 1024 строки изображения по 1536 пикселей каждая. Закодированные изображения в представлениях 66-68 содержатся в последовательных субфайлах TV/4, TV и 4 TV файла изображения IР. Емкость памяти 59 изображения, показанной на фиг.26, составляет 512 рядов, каждый по 768 ячеек (также называемых элементами памяти). Если представление должно представлять все закодированное изображение, то выбирают тот субфайл из файла изображения IР, количество пикселей в котором соответствует емкости памяти изображения, которое в данном случае является субфайлом, определяющим представление 67. Выбор может быть сделан на основе данных установок, таких как номера изображений и порядок разрешения (это индикация разрешения субфайла), которые хранятся в начале каждого субфайла, например в головной части НEAD и субголовной части SUBHEAD блоков BLCK. Для каждого субфайла эти данные вводятся схемой 58 управления в ответ на сигнал, выдаваемый детектором 69 синхронизации блока при обнаружении начала каждого блока BLCK.
В случае, когда нужно воспроизвести представление абсолютно закодированного изображения, при обнаружении начала подлежащего выбора субфайла, схема управления устанавливает схему 60 мультиплекса в состояние, в котором шина 30 сигнала соединена с входами данных памяти 59 изображения. Кроме того, генератор адреса ста вится в положение, в котором ячейки памяти адресуются синхронно с приемом информации последовательных пикселей таким образом, что информация для строк изображения 11.1512 запоминается в соответствующих рядах r1.r512 памяти. Последовательность считывания определяет- ся последовательностью, в которой генератор 62 адреса генерирует последовательные адреса. При нормальном воспроизведении эта последовательность такова, что память считывается по рядам, начиная с ряда r1 и столбца с1 в ряду. Это возможно как в соответствии с принципом чересстрочной развертки, так и последовательной развертки. В случае считывания по принципу чересстрочной развертки сначала считываются все нечетные ряды памяти 59 изображения. В случае считывания по принципу последовательной развертки, все ряды считываются последовательно.
Очень привлекательной альтернативой способа хранения информации изображения является такой, когда память изображения сначала заполняется информацией изображения с файла изображения, определяющего изображение с меньшим разрешением, а затем содержание памяти переписывается тем же изображением с более высоким разрешением. В вышеприведенном примере это возможно за счет того, что во время считывания каждого кодированного пикселя из субфайла TV/4 каждая группа из 2х2 элементов памяти каждый раз заполняется величиной сигнала, определяемой этим закодированным пикселем. Этот способ известен как "пространственная реплика". Лучшее качество изображения будет получено при заполнении лишь одного элемента из матрицы элементов 2х2 величиной сигнала, определяемой считанным пикселем, и при получении величин для остальных элементов матрицы 2х2 из соседних пикселей посредством известных методов интерполяции. Этот способ известен как способ "пространственной интерполяции". После обнаружения следующего субфайла (в данном случае субфайла TV) содержимое памяти изображения каждый раз переписывается содержимым следующего субфайла по указанному методу. Количество информации в субфайле TV/4 равно четверти информации в субфайле TV. Это дает значительную экономию времени, после которого первое временное изображение появится на экране дисплея. После считывания файла изображения TV/4 это изображение низкого разрешения переписывается представлением того же изображения с требуемым разрешением. Поскольку файлы изображения с повышающимся разрешением следуют на записи друг за другом, не тратится время на поиск субфайла TV после считывания субфайла TV/4.
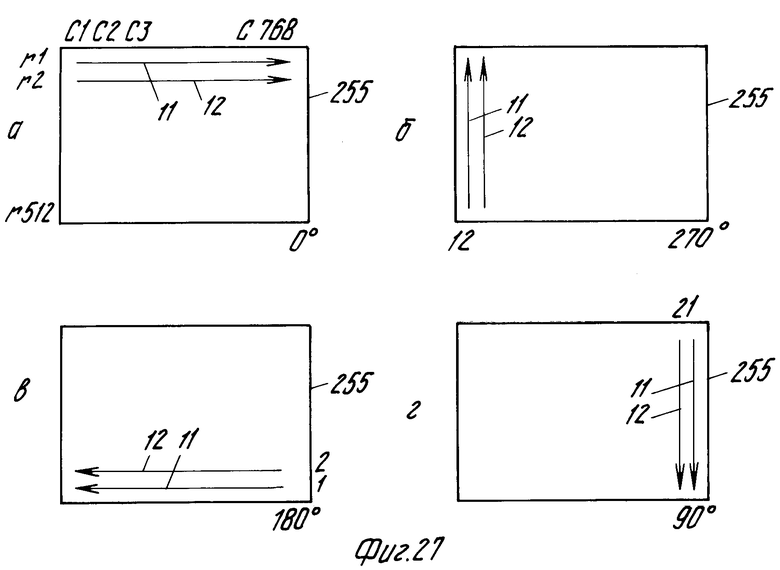
В случае, если изображение нужно повернуть, генератор 61 адреса переводится в состояние, в котором последовательность адресации элементов памяти изменена соответственно желаемому углу поворота. На фиг.27б-г показано каким образом информация изображения хранится в памяти для поворота на угол 270, 180 и 90о соответственно. Для ясности показаны только положения информации первых двух строк изображения.
В случае представления малого изображения, которое нужно воспроизвести в пределах другого изображения полной величины, или того же самого изображения (функция РIР), это может быть достигнуто просто заполнением соответствующей части памяти 59 изображения изображением низкого разрешения субфайла TV/4 без увеличения. Когда память изображения заполнена, генератор 61 адреса ставится в состояние, в котором адресуются элементы памяти, в которых нужно хранить малое изображение. Для иллюстрации этого эти элементы памяти представлены в виде рамки 69 на фиг.26. Во время описанной выше обработки изображения присутствие изображения малой четкости в субфайле TV/4 опять дает то преимущество, что информация изображения, нужная для выполнения этой функции, прямо имеется в файле изображения IР, так что не требуется дополнительной обработки.
Если нужно воспроизвести увеличенное представление части абсолютно закодированного изображения, выбирают информацию части изображения, например части, соответствующей рамке 70. Информация каждого пикселя выбранной части загружается в каждый элемент памяти группы из 2х2 элементов, так что получают увеличенное на весь формат изображение низкого разрешения на дисплее. Вместо повторения каждого дикселя 2х2 раз память может быть заполнена по принципу пространственной интерполяции.
Чтобы увеличить остаточно закодированное изображение, выполняют сперва указанный выше этап. Затем выбирают часть, представленную рамкой 71 в субфайле 4 TV. Часть в рамке 71 соответствует части в рамке 70 в представлении 67. Схема 53 управления устанавливает схему 60 мультиплекса в состояние, в котором выход схемы 57 остаточного декодирования соединен с входами данных памяти 59. Генератор 61 адреса ставится в состояние, в котором он адресует памяти 59 изображения синхронно с принимаемыми кодированными пикселями в последовательности, в которой остаточно кодированная информация изображения становится доступной с субфайла 4 TV. Информация изображения в адресуемых элементах памяти подается на схему 57 декодирования и посредством сумматора 65 добавляется к остаточной величине, после чего полученная таким образом информация загружается в адресуемый элемент памяти 59. Часть информации изображения, записанной на носителе записи, соответствующая рамке 71, предпочтительно считывается на основе информации в файле управления IIDB. Информация в секции IIDB вводится схемой 58 управления в ответ на сигнал с детектора 55. Затем выбирают адрес этой кодированной строки изображения из информации, которая находится близко перед первой кодированной строкой изображения, соответствующей строке изображения в рамке 71. После этого схема управления выдает команду на блок 24 управления, который начинает процесс поиска для обнаружения части с нужной строкой изображения. Когда эта часть найдена, начинается считывание информации изображения и согласование содержания памяти 59 изображения начинается как только будет достигнута часть первой кодированной строки изображения, которая соответствует части изображения в рамке 71. Обнаружение этой кодированной строки изображения осуществляется на основе номеров строк, которые вместе с кодами синхронизации LD были вставлены в начале каждой кодированной строки изображения. Схема управления вводит эти номера строк LN в ответ на сигнал с схемы детектора 56. Хранение адресной информации в начале субфайла 4 TV позволяет обеспечить быстрый доступ к желаемой информации. Обнаружение считывания желаемых остаточно закодированных строк изображения упрощается наличием кодов синхронизации строк и номеров строк в субфайле 4 TV.
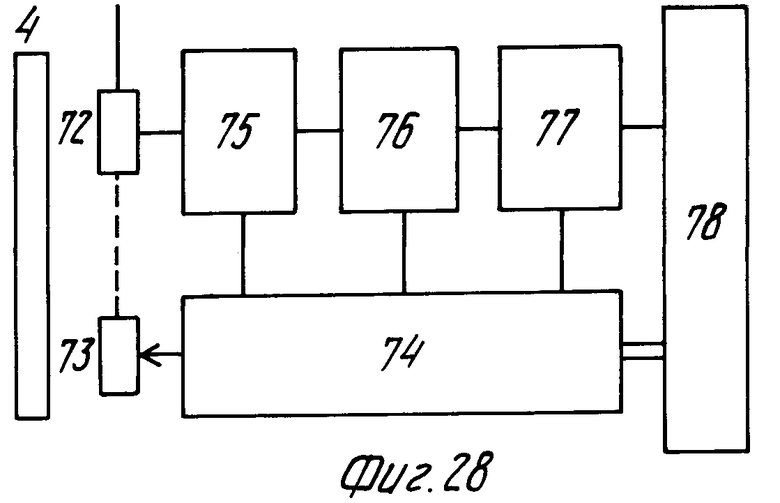
На фиг.28 показан пример выполнения блока считывания. Блок 7 считывания содержит обычную считывающую головку 72, которая считывает узоры информации на носителе 4 записи. Блок считывания содержит обычный блок 73 позиционирования. Движение головки 72 управляется блоком 74. Сигналы декодируются схемой 75 декодирования EFM и затем подаются на декодирующую схему CIRC 76, которая восстанавливает первоначальную структуру информации, которая была "перетасована" перед записью, обнаруживает и, если возможно, исправляет неправильно считанные коды. После обнаружения неисправимых ошибок блок 76 выдает сигнал флажка новой ошибки. Информация, которая была восстановлена и исправлена, подается на схему 77 деформатирования, которая удаляет добавочную информацию, добавленную схемой форматирования 52 перед записью. Информация, выдаваемая схемой 77, подается через схему 78 интерфейса. Схема деформатирования может содержать схему исправления ошибок, которые не могут быть исправлены схемой декодирования CIRC. Это осуществляется посредством избыточной информации ЕДС8 ЕСС, добавленной схемой форматирования. Неправильно считанные коды в абсолютно закодированном изображении могут быть просто замаскированы посредством замены неправильно считанных кодированных дикселей и/или полностью считанной строки изображения информацией изображения, взятой из одного или более соседних кодированных дикселей или соседних строк изображения. Такое исправление может быть осуществлено просто блоком обработки изображения (фиг. 25) посредством программирования схемы 58 управления так, чтобы она чувствовала сигналы флажка ошибки, выдаваемые декодирующей схемой 76 для управления генератором 61 адреса так, что считывается информация соседнего дикселя. Одновременно схема 60 мультиплекса устанавливается в состояние, в котором выходы данных памяти изображения соединены с входом данных. Затем адресный генератор возвращают в предыдущее состояние и вместо неправильно считанного кодированного дикселя в данной ячейке памяти закладывается информация, считанная с памяти изображения.
В случае остаточно закодированного изображения величина в элементе памяти изображения не согласуется при обнаружении неправильно считанного значения, а оставляется прежней. Это может быть достигнуто, например, путем выдачи со схемы управления сигнала, который предотвращает запись в память изображения в момент выдачи неправильного остаточного значения.
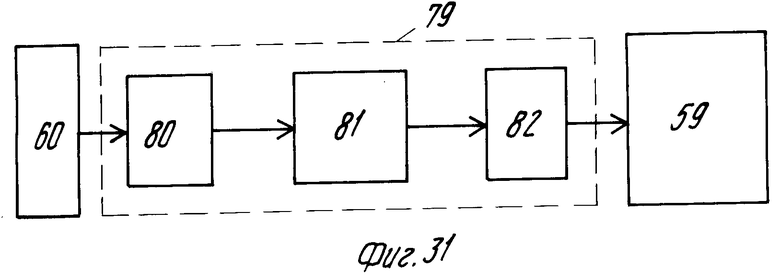
Емкость памяти может быть уменьшена посредством установки между мультиплексором 60 и памятью изображения простого преобразователя 79 частоты выборок обычного типа, что снижает количество дикселей в строке с 786 до 512.
На фиг. 31 показан пример преобразователя 79 частоты выборок. Данный пример содержит последовательное включение воспроизводящей и интерполирующей схемы 80 и фильтра 81 нижних частот, а также формирующей выборки и уменьшающей их количество схемы 82.
Использование преобразователя 79 частоты выборок позволяет использовать память изображения емкостью 512х512 ячеек. Поскольку для практических целей количество рядов и столбцов памяти предпочтительно является степенью 2, это дает память особенно подходящих размеров. Кроме того, в результате уменьшения количества ячеек памяти до 512 в ряду снижается требуемая скорость считывания, так что менее строгие требования предъявляются к скорости считывания из памяти.
Обычно используемые трубки-преобразователи изображения имеют максимальное разрешение, приблизительно равное 5 МГц, что соответствует примерно 500 дикселям в строке, поэтому уменьшение количества ячеек памяти в ряду не имеет видимого влияния на качество изображения при воспроизведении.
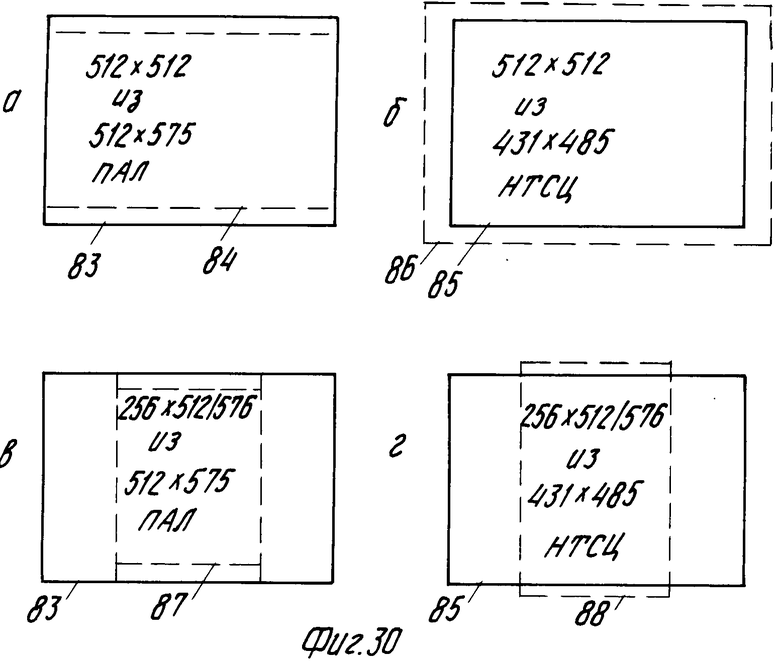
Использование преобразователя частоты выборок также выгодно при воспроизведении на экране дисплея изображений портретного формата, что поясняется на фиг.30а-г.
На фиг.30а позиционный номер 83 относится к размерам изображения соответственно телевизионному стандарту ПАЛ. Такое изображение содержит 575 используемых строк изображения. При воспроизведении информации в памяти изображения 512х512 ячеек используются 512 из этих 575 полезных строк изображения. Это значит, что представление 84 кодированного изображения в памяти изображения полностью входит в размеры изображения рамки 843 по стандарту ПАЛ, при этом лишь малая часть площади экрана остается неиспользованной.
На фиг.30б позиционный номер 85 обозначает кадр в соответствии с телевизионным стандартом НТСЦ. Этот кадр по стандарту содержит 431 полезную строку. Это значит, что лишь ограниченная часть представления 86 кодированного изображения, имеющегося в памяти 59 изображения, выходит за размеры изображения по стандарту НТСЦ.
На фиг.30а и б показаны воспроизведения в ландшафтном формате кодированных изображений. Однако, если требуются представления кодированных изображений в портретном формате, возникает проблема в том, что высота изображения соответствует 768 дикселям, количество полезных строк 575 по стандарту ПАЛ и 485 строк по стандарту НТСЦ. При памяти изображения из 512 рядов без использования преобразователя 79 частоты выборок кодированная строка изображения не помещается в один столбец памяти. Однако при использовании преобразователя 79 достигают того, что кодированные строки изображения из 768 дикселей преобразуются в кодированные строки изображения, состоящие из 512 кодированных дикселей, так что кодированная строка изображения поместится в одном столбце памяти. Это значит, что при воспроизведении изображения, хранимого в памяти 59, его высота в основном будет соответствовать высоте кадров изображения по телевизионным стандартам ПАЛ и НТСЦ.
Чтобы отношение между высокой и шириной представления закодированного изображения, хранимого в памяти 59, соответствовало первоначальному отношению, информация изображения должна заполнить только 256 из 512 столбцов памяти изображения. Это можно, например, осуществить запоминанием только четных или нечетных закодированных строк изображения в памяти 59. Однако могут использоваться и другие способы с применением техники интерполяции.
Способ уменьшения количества столбцов в памяти изображения с использованием интерполяции дает удовлетворительное качество изображения. Оно лучше, чем при использовании лишь части кодированных строк изображения для подачи их в столбцы памяти изображения.
Недостаток интерполяции заключается в том, что она сравнительно сложна и расходует время, так что она меньше подходит для упрощенной системы поиска и воспроизведения изображений. Способ, который дает изображения удовлетворительного качества простым образом, будет описан для случая, когда память имеет структуру 512х512 ячеек. Этот метод использует субфайл TV/4 с 384х256 закодированными дикселями вместо субфайла Т с 768х512 кодированными дикселями для загрузки в память изображения.
Использование преобразователя частоты выборок, посредством которого количество пикселей на считанную строку изображения может быть увеличено или уменьшено, позволяет количество пикселей на строку субфайла TV4 увеличить с 384 по 512. 256 имеющихся в наличии строк, каждая по 512 пикселей, заполняются информацией изображения. Считывание этой информации дает неискаженное представление портретного формата, высота которого практически совпадает с высотой экрана по системе ПАЛ или НТСЦ и качество которого значительно лучше, чем качество представления портретного формата, полученного на основе кодированного изображения 768х512 пикселей, ширина которого согласована посредством использования лишь половины (256) из имеющего количества 512 строк кодированного изображения.
На фиг. 30в показано представление в портретном формате 87 запомненного кодированного изображения (с 256х512 кодированными пикселями), полученное таким образом внутри рамки 83, определяемой телевизионным стандартом ПАЛ.
Все изображения находится в рамке, определяемой стандартом ПАЛ.
На фиг. 30г показано представление в портретном формате запомненного таким образом кодированного изображения 87. Представление в основном ложится в рамку 85 стандарта НТСЦ.
Использование преобразователя частоты выборок позволяет использовать память изображения с разным количеством рядов и столбцов, соответствующую основному количеству используемых строк изображения по стандарту ПАЛ или НТСЦ.
Это значит, что в случае использования портретного формата, а также ландшафтного формата представления кодированных изображений дают высоту представлений, практически соответствующую количеству полезных строк изображения, так что экран дисплея будет правильно заполнен для изображений обоих типов.

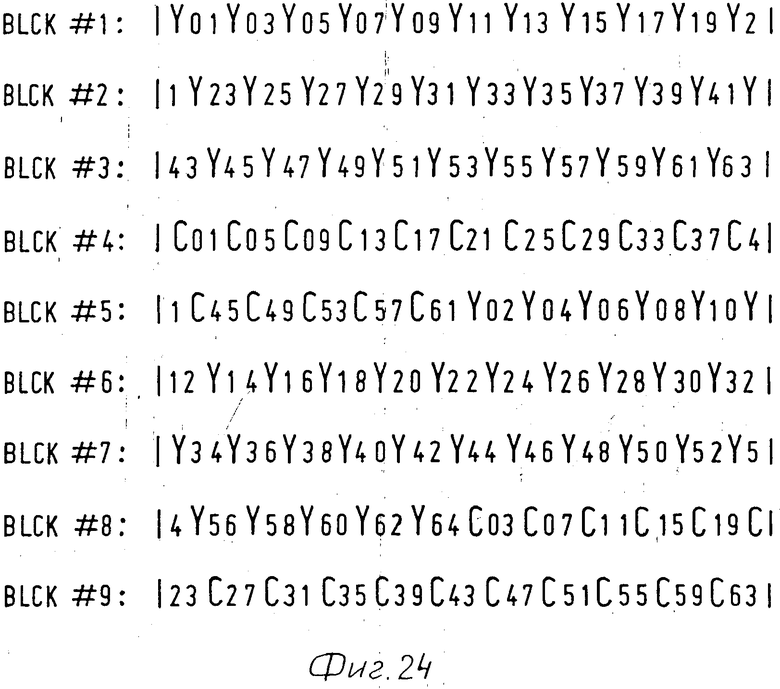
Использование: накопление информации в системах отыскания изображения, содержащих носитель записи и считывающее устройство. Сущность изобретения: кодированное изображение, составленное из последовательных закодированных строк изображения, записано на непрерывной дорожке записи носителя записи. Считывающее устройство содержит средства, которые сканируют дорожку посредством считывающей головки для считывания кодированных строк изображения, записанных в дорожке, и средства для движения считывающей головки к участку дорожки, имеющему выбранный адрес, с определенной точностью поиска. Вместе с закодированными строками изображения в дорожке записаны номер строки и строчная синхронизация. Номер строки указывает номер последовательности соответствующей строки кодированного изображения. Строчная синхронизация указывает начало соответствующей строки изображения. Кроме того, в участке дорожки записаны адреса для некоторого количества закодированных строк кодированного изображения, чтобы указать положения, где на дорожке были записаны соответствующие строки изображения. Устройство содержит средства для поиска кодированной строки изображения на основе адресов, считанных с участка дорожки записи. 2 с. и 1 з. п. ф-лы, 31 ил.
| Патент США N 4567534, кл | |||
| Очаг для массовой варки пищи, выпечки хлеба и кипячения воды | 1921 |
|
SU4A1 |
| Пневматический водоподъемный аппарат-двигатель | 1917 |
|
SU1986A1 |

