Изобретение относится к способу преобразования последовательности m-битовых информационных слов в модулированный сигнал, где m - целое число, при котором n-битовое кодовое слово выдается для каждого полученного информационного слова, где n - целое число, превышающее m, и выданные кодовые слова преобразуются в модулированный сигнал, и в котором последовательность информационных слов преобразуется в последовательность кодовых слов в соответствии с правилами преобразования таким образом, что соответствующий модулированный сигнал удовлетворяет заранее определенному критерию, и в котором кодовые слова распределяются, по меньшей мере, на группу первого типа и, по меньшей мере, группу второго типа, при этом выдача каждого из кодовых слов, принадлежащих группе первого типа, устанавливает первый тип состояния кодирования, определяемого связанной группой, выдача каждого из кодовых слов, принадлежащих группе второго типа, устанавливает второй тип состояния кодирования, определяемого связанной группой и информационным словом, связанным с выдаваемым кодовым словом, и, когда одно из кодовых слов присваивается полученному информационному слову, это кодовое слово выбирается из множества кодовых слов, которое зависит от состояния кодирования, установленного при выдаче предшествующего кодового слова, причем множества кодовых слов, принадлежащих состояниям кодирования второго типа, не содержат никаких кодовых слов совместно, а группа второго типа содержит, по меньшей мере, одно кодовое слово, связанное с множеством информационных слов, среди которых соответствующее информационное слово распознается обнаружением соответствующего множества, элементом которого является следующее кодовое слово.
Изобретение также относится к способу для изготовления носителя записи, на который записывается сигнал в соответствии с вышеупомянутым способом.
Изобретение, кроме того, относится к устройству кодирования для выполнения этого способа, как заявлено в формуле изобретения, устройство содержит преобразователь m бит в n бит для преобразования m-битовых информационных слов в n-битовые кодовые слова и средство для преобразования n-битовых кодовых слов в модулированный сигнал.
Изобретение также относится к записывающему устройству, в котором используется устройство кодирования этого типа.
Изобретение также относится к сигналу.
И, кроме того, изобретение относится к носителю записи, на котором записывается этот сигнал.
Подобные способы, подобные устройства, подобный носитель записи и подобный сигнал известны из публикации заявки WO 95/22802 (соответствующей заявке на европейский патент EP-A-94200387. 2, PHN 14746). Этот документ относится к способу преобразования последовательности m-битовых информационных слов в модулированный сигнал, называемому M-способом. Для каждого информационного слова последовательности выдается n-битовое кодовое слово. Выданные кодовые слова преобразуются в модулированный сигнал. Кодовые слова распределяются на, по меньшей мере, одну группу первого типа и, по меньшей мере, одну группу второго типа. Для выдачи каждого из кодовых слов, принадлежащих к группе первого типа, соответствующая группа устанавливает состояние кодирования первого типа. Когда выдается кодовое слово, принадлежащее к группе второго типа, устанавливается состояние кодирования второго типа. Кодовое слово присваивается к полученному информационному слову, выбранному из множества кодовых слов, которое зависит от установленного состояния кодирования. Множества кодовых слов, принадлежащих состояниям кодирования второго типа, разъединены (не пересекаются). Выбранное одно из возможных состояний кодирование второго типа определяется информационным словом, связанным с выданным кодовым словом. Это позволяет связывать несколько информационных слов с одним и тем же кодовым словом при различном установленном состоянии кодирования. В этом способе кодирования число уникальных комбинаций бит, которое может быть использовано кодовыми словами в последовательности, увеличивается, таким образом повышая эффективность кодирования. Модулированный сигнал, полученный таким образом, может быть обратно преобразован в информационные слова путем преобразования модулированного сигнала сначала в последовательность кодовых слов и затем присвоения информационного слова каждому из кодовых слов последовательности в зависимости от преобразуемого кодового слова, а также в зависимости от логических значений битов строки бит, которые расположены в заранее определенных позициях относительно кодового слова, причем упомянутые логические значения указывают на заранее установленное состояние кодирования. Кроме того, в вышеупомянутой публикации раскрыты устройство записи и устройство считывания.
Низкочастотные составляющие модулированного сигнала могут создавать помехи другим сигналам в системе, например, сервосигналам в системе записи. Хотя вышеописанный способ преобразования приводит к получению модулированного сигнала с ограниченным низкочастотным спектром, однако по-прежнему имеется необходимость в дальнейшем уменьшении низкочастотных составляющих.
Поэтому задачей настоящего изобретения является создание средства преобразования, обеспечивающего уменьшение низкочастотных составляющих спектра модулированного сигнала.
В соответствии с первым аспектом изобретения, указанный технический результат достигается способом, определенным во вступительном абзаце и отличающимся тем, что после установления первого типа состояния кодирования, кодовое слово выбирается из множества, принадлежащего к установленному состоянию кодирования, или из множества, принадлежащего к другому состоянию кодирования первого типа, без нарушения заранее определенного критерия в зависимости от низкочастотного спектра модулированного сигнала.
В соответствии с другими аспектами изобретения, указанный результат достигается с помощью сигнала, носителя записи, устройства кодирования, записывающего устройства и способа изготовления носителя записи, как заявлено в формуле изобретения в пунктах со 2-го по 12-й. Мероприятия, предусматриваемые в соответствии с изобретением, обеспечивают то преимущество, что низкочастотные составляющие спектра модулированного сигнала могут быть уменьшены при сохранении той же эффективности кодирования информации.
Изобретение будет далее объяснено со ссылками на чертежи с фиг. 1 по фиг. 9, на которых представлено следующее:
фиг. 1 - последовательность информационных слов, соответствующая последовательность кодовых слов и модулированный сигнал;
фиг. 2 - упрощенное представление носителя записи;
фиг. 3 - увеличенный фрагмент носителя записи по фиг. 2;
фиг. 4 - схематичное представление записывающего устройства;
фиг. 5 - схематичное представление устройства декодирования и воспроизведения;
фиг. 6 - схематичное представление устройства кодирования;
фиг. 7 и фиг. 8 - таблицы, в которых устанавливается зависимость между информационными словами и кодовыми словами;
фиг. 9 - частотный спектр модулированного сигнала.
На фиг. 1 показаны три последовательных m-битовых информационных слова, в данном случае это 8-битовые информационные слова 1. Информация о способах кодирования может быть найдена в книге К.А. Шумахера, озаглавленной "Методы кодирования для цифровых кодирующих устройств" (ISBN 0-13-140047-9). В этой книге описывается так называемая система EFM-модуляции, которая используется для записи информации на компакт-диски. EFM-модулированный сигнал получается преобразованием последовательности 8-битовых информационных слов в последовательность 14-битовых кодовых слов, причем три бита слияния вводятся в кодовые слова. Кодовые слова выбираются так, что минимальное число нулевых битов, расположенных между единичными битами, равно d(2), а максимальное число равно k (10). Это ограничение также называют dk-ограничением. Последовательность кодовых слов преобразуется посредством операции суммирования по модулю 2 в соответствующий сигнал, образованный элементами бит, имеющих высокое или низкое значение сигнала, где бит "1" представляется в модулированном сигнале переходом с высокого на низкое значение сигнала или наоборот. Бит "0" представляется отсутствием изменения значения сигнала при переходе между двумя элементами бит. Биты слияния выбираются так, что даже в областях перехода между двумя кодовыми словами удовлетворяется dk-ограничение, и в соответствующем сигнале текущее значение цифровой суммы остается существенно постоянным. Текущее значение цифровой суммы в конкретный момент определяется разностью между числом элементов бит, имеющих высокое значение сигнала, и числом элементов бит, имеющих низкое значение сигнала, вычисленной для части модулированного сигнала перед рассматриваемым моментом времени. Существенно постоянное текущее значение цифровой суммы означает, что частотный спектр сигнала не содержит частотных составляющих в области низких частот. Такой сигнал также определяется как сигнал без постоянной составляющей. Отсутствие низкочастотных составляющих в сигнале весьма полезно, когда сигнал считывается с носителя записи, на котором сигнал записан на дорожке, поскольку тогда возможно непрерывное управление движением головки над дорожкой, не подверженное воздействию записанным сигналом. При записи информации имеется постоянная необходимость в повышении информационной плотности носителя записи. На фиг. 1 три информационных слова 1 имеют соответствующие значения слова "21", "121" и "34". Эта последовательность из 3-х информационных слов 1 преобразуется в три последовательных n-битовых кодовых слова, в данном случае 16-битовые кодовые слова 4. Кодовые слова 4 образуют битовую строку битов, имеющих логическое значение "0", и битов, имеющих логическое значение "1". Преобразование информационных слов таково, что в битовой строке минимальное число битов, имеющих логическое значение "0", расположенных между двумя битами, имеющими логическое значение "1", равно d, а максимальное - равно k, где d= 2, k = 10. Такая битовая строка определяется как RLL-строка (RLL = группа ограниченной длины) с dk-ограничением. Отдельные биты кодовых слов далее будут обозначаться x1,...,x16, где x1 обозначает первый бит (слева) кодового слова, а x16 обозначает последний бит кодового слова.
Битовая строка, образованная кодовыми словами 4, преобразуется в модулированный сигнал 7 посредством операции суммирования по модулю 2. Этот модулированный сигнал содержит три информационных части 8 сигнала, представляющие кодовые слова 4. Информационные части сигнала содержат элементы 11 бит, которые могут иметь высокое значение сигнала H или низкое значение сигнала L. Число элементов бит в информационной части сигнала равно числу битов соответствующего кодового слова. Каждому биту кодового слова, имеющему логическое значение "1", в модулированном сигнале 7 соответствует переход от элемента, имеющего высокое значение сигнала, к элементу, имеющему низкое значение сигнала, или наоборот. Каждому биту кодового слова, имеющему логическое значение "0", соответствует в модулированном сигнале 7 отсутствие изменения значения сигнала при переходе между элементами.
Кроме того, требуется, чтобы частотный спектр модулированного сигнала 7 включал существенно не низкочастотные составляющие. Другими словами, модулированный сигнал 7 должен быть без постоянной составляющей.
В последующем подробно будет описан вариант осуществления способа, соответствующего изобретению, посредством которого может быть получен модулированный сигнал.
Прежде всего существует требование, предъявляемое к кодовым словам, заключающееся в том, что для кодового слова должно быть удовлетворено dk-ограничение. Множество всех возможных кодовых слов, удовлетворяющих dk-ограничению, разделяется, по меньшей мере, на группу первого типа и, по меньшей мере, на группу второго типа. Когда кодовое слово выдается из одной из групп первого типа, устанавливается состояние кодирования, которое исключительно зависит от группы первого типа, к которой принадлежит выданное кодовое слово. Когда выдается одно из кодовых слов группы первого типа, устанавливается состояние кодирования, которое зависит как от группы первого типа, так и от информационного слова, представленного выданным кодовым словом. В описанном здесь варианте осуществления можно выделить две группы первого типа, то есть первую группу G11, которая содержит кодовые слова, оканчивающиеся a битами, имеющими логическое значение "0", где a - целое число, равное 0 или 1, и вторую группу G12 кодовых слов, оканчивающихся b битами, имеющими логическое значение "0", где b - целое число, которое меньше или равно 9 и больше или равно 6.
Состояние кодирования, определяемое первой группой G11 первого типа, будет далее называться S1. Состояние кодирования, определяемое второй группой G12 первого типа, будет далее называться S4. Для описанного здесь варианта осуществления известна только одна группа второго типа. Эта группа содержит кодовые слова, оканчивающиеся на c бит, имеющих логическое значение "0", где c - целое число, которое больше или равно 2 и меньше или равно 5. Эта группа далее называется группой G2. В описанном здесь примере два состояния кодирования, то есть S2 и S3, могут быть установлены комбинацией кодового слова и связанного информационного слова.
Когда информационные слова преобразуются в кодовые слова, кодовое слово, принадлежащее множеству кодовых слов, зависящих от состояния кодирования, присваивается преобразуемому информационному слову. Множества кодовых слов, принадлежащих состояниям кодирования S1, S2, S3 и S4, будут далее называться V1, V2, V3 и V4 соответственно. Кодовые слова в множестве выбираются так, что каждая битовая строка, которая может быть образована кодовым словом из группы, которая установила состояние кодирования, и произвольным кодовым словом из множества, установленного этим состоянием кодирования, удовлетворяет dk-ограничению. В случае, когда состояние кодирования S4 устанавливается выдачей предыдущего выданного кодового слова и состояние кодирования, таким образом, означает, что предыдущее кодовое слово оканчивается битовой строкой, имеющей значение логического "0", которое больше или равно 6 и меньше или равно 9, то множество кодовых слов V4, которое устанавливается состоянием кодирования S4, может содержать только кодовые слова, начинающиеся максимум с 1 бита, имеющего логическое значение "0". В этом отношении кодовые слова, начинающиеся с большего числа битов, имеющих логическое значение "0", будут иметь переходные области между предыдущим выданным кодовым словом и кодовым словом, которое должно быть выдано, причем в этих областях число последовательных битов, имеющих логическое значение "0", не будет всегда меньше или равно 10 и, таким образом, не будет удовлетворять dk-ограничению. По аналогичным причинам множество V1 содержит только кодовые слова, начинающиеся с числа битов, имеющих логическое значение "0", которое больше или равно 2 и меньше или равно 9.
Множество V2 и V3 кодовых слов, принадлежащих состояниям кодирования S2 и S3, содержат только кодовые слова, начинающиеся с числа битов, имеющих логическое значение "0", которое больше или равно 0 и меньше или равно 5. Кодовые слова, удовлетворяющие этому условию, распределяются на два множества V2 и V3 так, что множества V2 и У3 не содержат вообще никаких общих кодовых слов. Множества V2 и V3 будут упоминаться в дальнейшем, как разъединенные (непересекающиеся) множества. Распределение кодовых слов по множествам V2 и V3 предпочтительно таково, что на основании логических значений ограниченного числа p битов можно определить, к какому множеству принадлежит кодовое слово. В описанном выше примере для этой цели используется комбинация битов x1...x13. Кодовые слова из множества V2 распознаются по комбинации битов x1. . .x13 = 0.0. Кодовые слова из множества V3 распознаются по комбинации битов x1. . . x13, которая не равна 0.0. Распознавание проводится между кодовыми словами, устанавливающими состояние кодирования S1 (группа G11) после выдачи, кодовыми словами, устанавливающими состояние кодирования S2 или S3 (группа G2) после выдачи и кодовыми словами, устанавливающими состояние кодирования S4 (группа G12) после выдачи. Множество VI содержит 138 кодовых слов из группы G11, 96 кодовых слов из группы G2 и 22 кодовых слова из группы G12. Очевидно, что число различных кодовых слов в множестве V1 меньше, чем число различных 8-битовых информационных слов.
Поскольку за кодовыми словами из группы G2 всегда следует кодовое слово из множества V2 или кодовое слово из множества V3 и, кроме того, на основании кодового слова, следующего за кодовым словом из группы G2, может быть установлено, к какому множеству принадлежит это слово, кодовое слово из группы G2, за которым следует кодовое слово из множества V2, можно отличить от того же кодового слова из группы G2, но за которым следует кодовое слово из множества V3. Другими словами, когда кодовые слова присваиваются информационному слову, каждое кодовое слово из группы G2 может быть использовано дважды. Каждое кодовое слово из группы G2 вместе со случайным кодовым словом из множества V2 образует уникальную комбинацию битов, которая неотделима от комбинации битов, образованной тем же кодовым словом и случайным кодовым словом из того же множества V3. Это означает, что для множества V1 могут быть использованы 138 уникальных комбинаций битов (кодовых слов) из группы G11, 22 уникальные комбинации битов (кодовых слов) из группы G12 и 2•96 уникальных комбинаций битов (кодовых слов из группы G2, объединенных с последующими кодовыми словами) из группы G2. Это доводит полное число пригодных для использования уникальных комбинаций битов до 352. Число уникальных комбинаций битов, образованных с кодовыми словами из множеств V2, V3 и V4, равно 352, 351 и 415 соответственно.
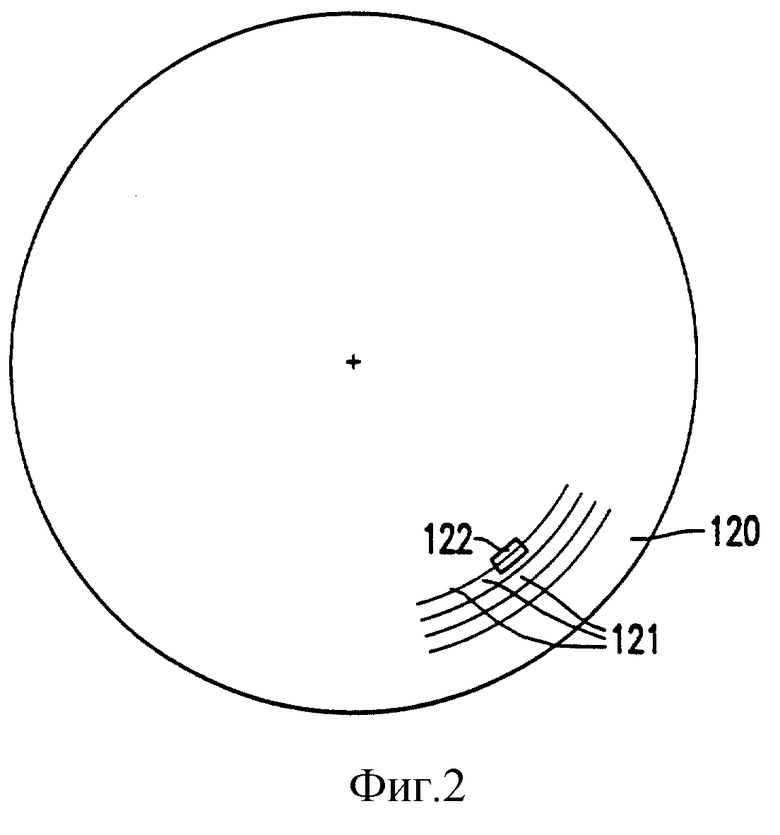
На фиг. 2 показан в качестве примера носитель записи 120, соответствующий изобретению. Показанный носитель записи является одним из носителей оптически детектируемого типа. Носитель записи может также быть другого типа, например, с магнитным считыванием. Носитель записи содержит информационные комбинации, упорядоченные на дорожках 121.
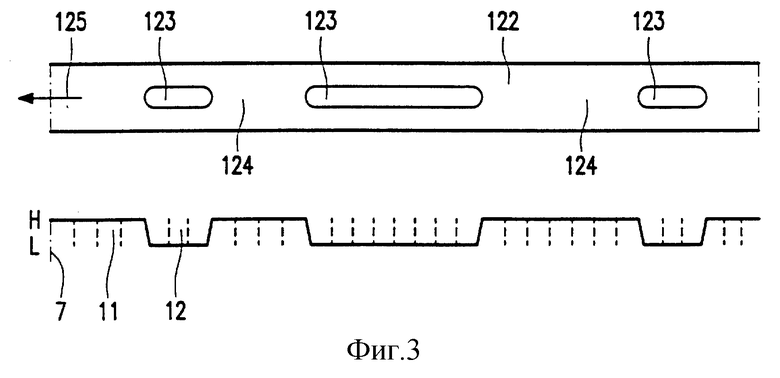
На фиг. 3 представлен увеличенный фрагмент 122 одной из дорожек 121. Информационная комбинация на фрагменте дорожки 121, показанная на фиг. 3, содержит первые участки 123, например, в виде оптически детектируемых меток и вторые участки 124, например, промежуточные области, расположенные между метками. Первые и вторые участки чередуются в направлении дорожки 125. Первые участки 123 представляют первые детектируемые характеристики, а вторые участки 124 представляют вторые характеристики, различимые относительно первых детектируемых характеристик. Первые участки 123 представляют элементы бит 12 модулируемого двоичного сигнала 7, имеющие один уровень сигнала, например, низкий уровень сигнала L. Вторые секции 124 представляют элементы бит 11, имеющие другой уровень сигнала, например, высокий уровень сигнала H. Носитель записи 12 может быть получен путем генерирования сначала модулированного сигнала, а затем нанесение на носитель записи информационной комбинации. Если носитель записи является носителем оптически детектируемого типа, тогда носитель записи может быть получен известным методом фотооригинала и копии, с использованием модулированного сигнала.
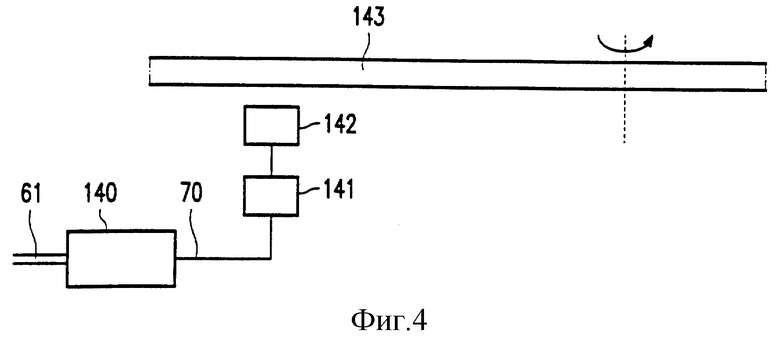
На фиг. 4 показано записывающее устройство для записи информации, в котором используется устройство кодирования в соответствии с изобретением, например, устройство кодирования 140, показанное на фиг. 6. В записывающем устройстве сигнальная линия для подачи модулированного сигнала соединена со схемой управления 141 для записывающей головки 142, вдоль которой движется носитель записи 143 записываемого типа. Записывающая головка 142 является головкой обычного типа, способная вводить метки, создающие детектируемые изменения на носителе записи 143. Схема управления 141 также может быть обычного типа, обеспечивающая генерирование управляющего сигнала для записывающей головки в ответ на модулированный сигнал, подаваемый на схему управления 141, так что записывающая головка 142 вводит комбинацию меток, которая соответствует модулируемому сигналу.
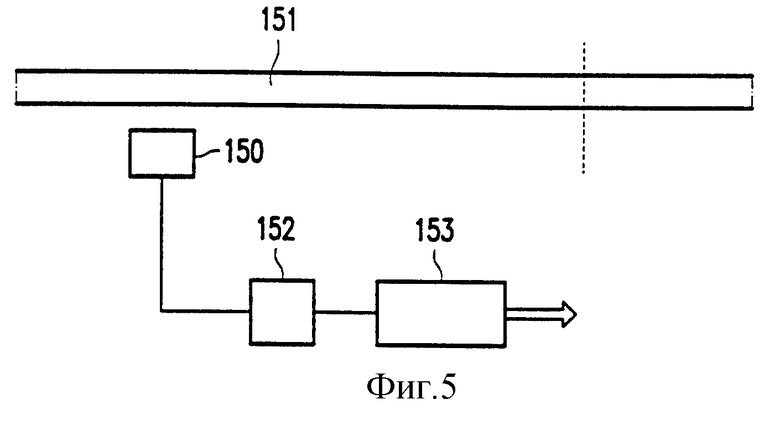
На фиг. 5 показано считывающее устройство, в котором используется устройство декодирования в соответствии с изобретением, например, устройство декодирования 153, как описано ниже. Считывающее устройство содержит считывающую головку обычного типа для считывания носителя записи в соответствии с изобретением, причем носитель записи содержит комбинацию информационных данных, которая соответствует модулированному сигналу. Считывающая головка 150 затем вырабатывает аналоговый считывающий сигнал, модулированный в соответствии с информационной комбинацией, считываемой считывающей головкой 150. Схема детектирования 152 преобразует этот считанный сигнал обычным образом в двоичный сигнал, который подается на схему декодирования 153.
Устройство декодирования 153 содержит матрицу логических схем, которая реализует инверсию функции кодирования. Используя таблицы кодирования, как описано на фиг. 7, слова могут быть однозначно декодированы посредством обнаружения 15-ти битового кодового слова, двойного кортежа x1•x3, образованного первым и третьим битом указанного кодового слова, и числа нулей, которыми оканчивается предыдущее кодовое слово. Инверсная функция может быть выражена следующим образом:
Bt = H-1(Xt-1, Xt, Xt+1...x1, Xt+1...x3).
Отметим, что достаточно контролировать 9 хвостовых битов предыдущего кодового слова Xt-1. Из вышеописанного видно, что нахождение ошибки ограничивается не больше, чем одним битом. Матрица логических схем, которая преобразует (9+15+2) канальных битов в 8 битов пользователя, может быть легко уменьшена за счет использования ряда свойств кода. 2-х битовый просмотр вперед является по существу одним битом (указывающим состояние 2 или 3), а 9-ти битовый просмотр назад может быть уменьшен до 2-х битов (указывающий состояние 1, 2, 3 или 4). Таким образом требуется просмотр (2+15+1) битов в 8 битах.
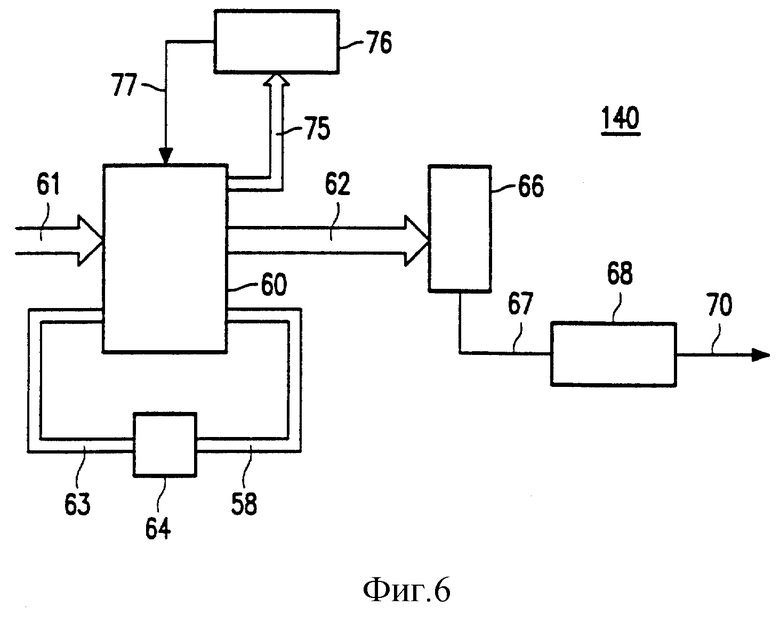
На фиг. 6 показан вариант осуществления устройства кодирования 140 в соответствии с изобретением, с помощью которого может быть реализован описанный выше способ. Устройство кодирования приспособлено для преобразования m-битовых информационных слов 1 в n-битовые кодовые слова 4, а число различных состояний кодирования может быть указано s битами. Устройство кодирования содержит преобразователь 60 для преобразования (m + s + 1) двоичных входных сигналов в (n + s + t) двоичных выходных сигналов. Из входов преобразователя m входов соединены с шиной 61 для приема m-битовых информационных слов. Из выходов преобразователя n выходов соединены с шиной 62 для выдачи n-битовых кодовых слов. Кроме того, s входов соединены с S-битовой шиной 63 для приема слова состояния, обозначающего текущее состояние кодирования. Слово состояния выдается буферной памятью 64, например, в виде s триггера. Буферная память 64 имеет s входов, соединенных с шиной 58 для приема слова состояния, запоминаемого в буферной памяти. Для выдачи слов состояния, запоминаемых в буферной памяти, используются s выходов преобразователя 60, которые соединены с шиной 58.
Шина 62 соединена с параллельными входами параллельно-последовательного преобразователя 66, который преобразует кодовые слова 4, принятые посредством шины 62, в последовательную битовую строку, подаваемую через сигнальный провод 67 в схему модулятора 68, которая преобразует битовую строку в модулированный сигнал 7, выдаваемый через сигнальный провод 70. Схема модулятора 68 может быть схемой обычного типа, например, так называемым интегратором по модулю 2.
Дополнительно к кодовым словам и словам состояния конвертор подает на шину 75 для каждой принятой комбинации информационных слов и слова состояния информацию, которая
- обозначает, присвоено ли для связанного слова состояния кодовое слово или пара кодовых слов связанному информационному слову;
- обозначает для каждого из этих присвоенных кодовых слов изменение dDSV значения цифровой суммы, вызванное кодовым словом, когда это изменение было бы для высокого значения сигнала в начале информационной части сигнала, соответствующей этому кодовому слову;
- указывает, является ли число битов "1" в кодовом слове нечетным или четным.
Для передачи информации в схему выбора 76 шина 75 соединена с входами схемы выбора 76. Схема выбора вычисляет текущие DSV для фрагмента модулированного сигнала. Этот фрагмент может начинаться в произвольной точке в прошедшем или в синхронизирующем слове. В другом варианте осуществления DSV может также быть вычислено для будущего фрагмента, но в этом случае требуется память для хранения возможных последовательностей кодовых слов.
На основании этой информации схема выбора 76 выдает сигнал выбора, который указывает, должно ли кодовое слово, поданное на шину 62 с представленным информационным словом, увеличивать или уменьшать значение DSV. Этот сигнал выбора подается в преобразователь 60 через сигнальный провод 77. Соответственно информационное слово должно быть преобразовано в соответствии с зависимостями, установленными в таблицах фиг. 8a, или в соответствии с зависимостями, установленными в таблицах фиг. 8b. Далее в соответствии с изобретением преобразователь устанавливает, возможен ли выбор из различных состояний кодирования первого типа. Для таблиц 8 это может быть применимо для информационных слов 87-255 и состояний 1 или 4. Для текущего кодового слова из других множеств первого типа преобразователь 60 проверяет, выполняется ли dk-ограничение. Если dk-ограничение не нарушается, слово из другого множества является выбранным. В этом случае выбор множества для использования основывается на сигнале выбора.
Преобразователь 60 может содержать постоянную память, в которой хранятся таблицы кодовых слов, показанные на фиг.8a или 8b, с адресами, определенными комбинацией слова состояния и информационного слова, поданных на входы преобразователя. В ответ на сигнал детектирования выбираются адреса ячеек памяти с кодовыми словами, соответствующими таблице, показанной на фиг. 8a, или адреса ячеек памяти с кодовыми словами, соответствующими таблице, показанной на фиг. 8b. Аналогичная постоянная память может быть использована для таблицы кодирования по фиг. 7, причем эта память должна также содержать ячейки для битов безразличного состояния, как указано с помощью x.
В варианте осуществления, показанном на фиг. 6, слова состояния хранятся в памяти 60. Как вариант, слова состояния можно получить с помощью вентильной схемы из кодовых слов, поданных в шину 62.
На фиг. 7 представлена таблица кодирования в соответствии с изобретением. Параметрами этого примера являются d=2, k=14, отношение =8/15, низкочастотные составляющие подавлены, распространение ошибки ограничивается не более чем одним байтом. Кроме того, пример имеет уникальную 20-ти битовую синхро-комбинацию и использует только 4 таблицы для кодирования и декодирования.
Кодировщиком для этого варианта осуществления является устройство с 8-ми битовым входом и 15-ти битовым выходом и внутренним состоянием, которое является функцией (дискретного) времени. Принцип работы может быть представлен традиционным конечным автоматом, хорошо известным в области теории вычислений и автоматизации. Кодировщик может быть смоделирован четырьмя состояниями. Состояния соединяются краями (концами), которые в свою очередь обозначены метками, называемыми кодовыми словами.
Словом в этом воплощении является 15-ти битовая последовательность, которая удовлетворяет предписанным dk-ограничениям. Каждое из четырех состояний отличается типом слов, которые входят в данное состояние следующим образом:
- слова, входящие в состояние 1, оканчивающиеся на "единицу";
- слова, входящие в состояние 2 и 3, оканчивающиеся на (2,..., 8) хвостовых "нулей";
- слова, входящие в состояние 4, оканчивающиеся на (1,9,...,11) хвостовых "нулей";
слова, выходящие из состояний, выбираются таким образом, что конкатенация (сцепление) слов, входящих в состояние, и слова, выходящие из состояния, удовлетворяют dk-ограничению. Например, слова, выходящие из состояния 1, начинающиеся текущей длиной по меньшей мере из двух нулей. Слова, выходящие из состояния 2 и 4, подчиняются вышеуказанным ограничениям текущей длины, но они также подчиняются другим ограничениям. Слова, выходящие из состояния 3, выбраны таким образом, что, как первый старший бит x1, так и третий бит x3, равны нулю. Аналогичным образом слова, выходящие из состояния 2, отличаются тем, что двойной кортеж x1x3 не равен 00. Очевидно, что множества слов, выходящих из состояний 2 или 3, не имеют общих слов, то есть два множества не пересекаются.
График кодировщика определяется в терминах трех множеств: входов, выходов и состояний и двумя логическими функциями: выходной функцией H() и функцией следующего состояния G(). Конкретное кодовое слово, обозначенное Xt, переданное кодировщиком в момент t, является функцией информационного слова Bt, которое входит в кодировщик, но зависит, кроме того, от определенного состояния St кодировщика. Аналогично следующее состояние в момент t + 1 является функцией от Bt и St. Выходная функция H() и функция следующего состояния G() могут быть записаны как:
Xt=H(Bt,St)
St+1=G(Bt,St)
Обе функции описываются четырьмя перечнями с 256 элементами, как показано на фиг. 7. Первая колонка показывает информационные слова 0-255. Вторая колонка дает кодовые слова для состояния 1 и третья колонка дает следующее состояние кодирования (указанное 1, 2, 3 или 4). Последующие колонки указывают соответствующие состояния S2, S3 и S4. Состояния кодирования S1 и S4 являются состояниями первого типа, как описано в документации EFM+. Состояния кодирования S2 и S3 являются состояниями второго типа. Слова записываются в нотации NRZI. В первых 16-ти рядах на фиг. 7 даны некоторые биты, как "x" (означающие безразличное состояние). Это указывает, что для этой позиции бит может быть использован 0 или 1. Таким образом, для каждого информационного слова имеются два парных слова, которые отличаются только в одной позиции. Эта степень свободы должна быть использована для минимизации низкочастотных составляющих модулированного сигнала, также указанного, как управление постоянной составляющей.
В таблице кодирования фиг. 7 информационные слова 132 до 255 в состоянии S4 указаны попарно с соответствующими словами в S1. Как описано, при управлении постоянной составляющей слово из S1 может быть выбрано вместо слова S4, при состоянии кодирования S4. Для простоты декодирования парные слова в S1 не должны быть частью множества S4. Если общие слова используются в V1 и V4, они должны быть присвоены одному и тому же информационному слову. Это имеет преимущество в том, что кодовое слово может быть однозначно декодировано без знания установленного состояния.
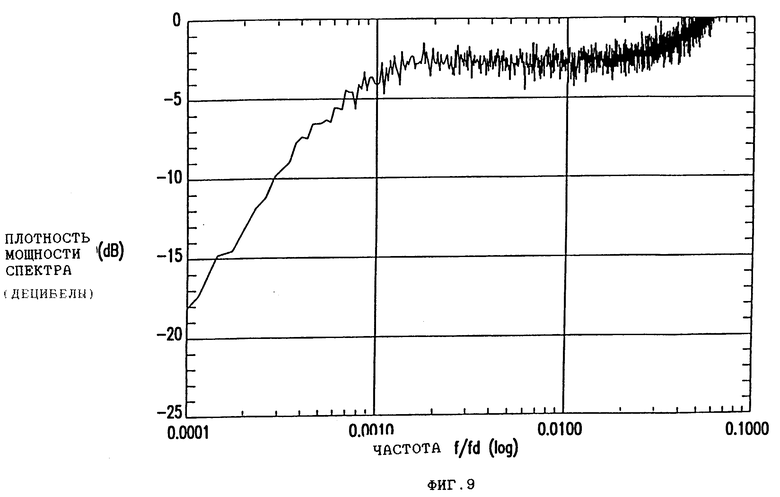
Управление постоянной составляющей возможно двумя различными путями. Во-первых, если таблица показывает безразличное состояние в выходной таблице, мы можем использовать эту степень свободы для оптимизации текущей цифровой суммы. Во-вторых, если текущее состояние S=4 и если ограничения текущей длины вместе с предыдущим кодовым словом Xt-1 допускает это (то есть, если соединение Xt-1 и H(Bt, 1) не нарушает dk-ограничения). В варианте, показанном на фиг. 7, выполняется дополнительное свойство за счет ограничения G(Bt, 1)= G(Bt, 4). Это приводит в результате к одинаковым кодовым словам, генерируемым последовательно в текущее кодовое слово. Преимуществом этого является то, что в системе, где решение о том, какое кодовое слово выбрать для DCC, откладывается, потоки возможных последовательностей отличаются только в одной позиции (при текущем кодовом слове). Это упрощает вычисление и требования к памяти для DCC блока. Выбирается альтернативный поток, который минимизирует текущую цифровую сумму кодированной последовательности. Спектральная плотность мощности для данного варианта показана на фиг. 9.
Синхронизирующая комбинация регулярным образом добавляется к модулированному сигналу. Определением уникальной и надежной комбинации является 20-ти битовая последовательность x0010 00000 00000 00001. Непосредственно перед началом синхронизирующей комбинации кодировщик находится в определенном состоянии, например, S. Фактическое значение старшего бита синхронизирующей комбинации, обозначенного x, управляется посредством s следующим образом. Если s=2, x устанавливается на 1, иначе x=0. После передачи синхронизирующей комбинации кодировщик предварительно устанавливается в состояние 1.
Для других таблиц кодирования, составленных при аналогичных ограничениях, также будет возможно использовать парные слова из S4, при состоянии кодирования S1. Однако с таблицей фиг. 7 никакие слова не могут быть использованы, так как будут нарушаться d,k-ограничения. Другая кодовая таблица с другим числом состояний кодирования первого типа, или другим присваиванием кодовых слов, или другими длинами слов m и n может быть составлена, в которой степень свободы выбора произвольно одного из состояний кодирования первого типа присваиванием парных слов может быть использована для улучшения низкочастотных характеристик модулированного сигнала.
На фиг. 8 показана таблица кодирования с отношением 8/16. Таким образом, m= 8, а n=16, dk-ограничениями являются d=2, k=10. Колонки организованы как на фиг. 7, но символ x используется для указания двойного слова, но вместо этого даются основная и подстановочная таблица. Фиг. 8a показывает основную таблицу кодирования, а фиг. 8b показывает отдельную подстановочную таблицу для информационных слов 0-87. Кодовые слова подстановочной таблицы могут быть выбраны для управления постоянной составляющей, как описано в документации EFM+ известного уровня техники. В этом варианте в состоянии 1 или 4, в соответствии с изобретением, кодовое слово может быть выбрано из другого состояния первого типа, состояния 4 или 1 соответственно. Кроме того может быть добавлена синхронизирующая комбинация. Синхронизирующие комбинации имеют уникальную комбинацию для простоты их распознавания, например, нарушение ограничения k включением последовательности из k+1 нулей. После синхронизирующей комбинации состояние возвращается к заранее определенному значению, например, состоянию 1.
На фиг. 9 показаны результаты компьютерного моделирования кода по фиг. 7. Спектральная плотность мощности вычислена относительно частоты, которая приведена как отношение в зависимости от частоты битов. Хорошая низкочастотная характеристика для кода с отношением 8/15 показана кривой.


































Предлагаемые способ, устройство преобразования последовательности m-битовых информационных слов в модулированный сигнал обеспечивают уменьшение низкочастотных составляющих спектра модулированного сигнала при сохранении той же эффективности кодирования информации. Способ преобразования последовательности m-битовых информационных слов в модулированный сигнал, где m - целое число, подразумевает, что n-битовое кодовое слово выдается для каждого полученного информационного слова, где n - целое число, превышающее m, и выданные кодовые слова преобразуются в модулированный сигнал, и что последовательность информационных слов преобразуется в последовательность кодовых слов в соответствии с правилами преобразования таким образом, что соответствующий модулированный сигнал удовлетворяет заранее определенному критерию, что кодовые слова распределяются на группу первого типа, при этом выдача каждого из кодовых слов, принадлежащих группе первого типа, устанавливает первый тип состояния кодирования, определяемого связанной группой, выдача каждого из кодовых слов, принадлежащих группе второго типа, устанавливает второй тип состояния кодирования, определяемого связанной группой и информационным словом, связанным с кодовым словом. Технический результат - уменьшение низкочастотной составляющей спектра достигается, например, за счет того, что после установления первого типа состояния кодирования, кодовое слово выбирается из множества, принадлежащего к установленному состоянию кодирования, или из множества, принадлежащего к другому состоянию кодирования первого типа, без нарушения заранее определенного критерия в зависимости от низкочастотного спектра модулированного сигнала. Способ может быть применен для кодов типа 8/15, 8/16 и других с использованием механизмов состояний кодирования. Заявлены также носитель записи, сигнал, устройство кодирования и декодирования, устройство для записи информации, способ изготовления носителя записи, 6 с. и 6 з.п.ф-лы, 9 ил.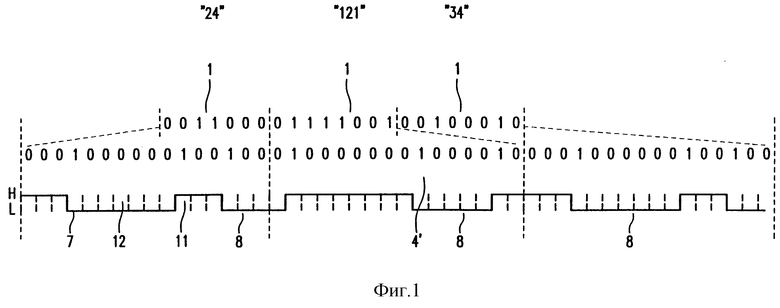
| Прибор для очистки паром от сажи дымогарных трубок в паровозных котлах | 1913 |
|
SU95A1 |
| УСТРОЙСТВО ДЛЯ ИЗМЕРЕНИЯ ПАРАМЕТРОВ КАНАЛОВ | 0 |
|
SU347934A1 |
| РЕШАЮЩЕЕ УСТРОЙСТВО | 0 |
|
SU392506A1 |
| Гидравлический распределитель управления | 1974 |
|
SU604927A1 |
| ЦЕНТРОБЕЖНАЯ ЗАПРАВОЧНАЯ МАШИНА | 0 |
|
SU351055A1 |
| Противоселевое устройство | 1976 |
|
SU586228A1 |

