Составление, а также поддержание в рабочем состоянии и готовность информаций, в частности информаций, относящихся к системным последовательностям операций и их визуализации и протоколированию, приобретают повышенное значение прежде всего в области промышленности. В рамках так называемых систем управления, которыми определяются все относящиеся к продукту последовательности операций и структуры на предприятии или организационной единице, является необходимым иметь возможность выполнять возможно простым образом изменения в существующих последовательностях операций, в их последовательности, в их структурировании, а также в трудах по регламентациях управления и тематических описаниях и делать доступными измененные или заново составленные материалы в качестве сборника документов для всех сотрудников.
Вообще при этом как преимущество следует рассматривать, если при составлении нового сборника документов можно иметь доступ к существующим документам или их частям. Например, документы, которые описывают общие действующие предписания, которые определяют стандартизованные или соответственно обусловленные операционной системой порядки действий или содержат уже составленные подобные представления, могут или соответственно должны содержаться также в новом сборнике документов.
Чтобы удовлетворить этим требованиям и, в частности, сделать измененные или заново изготовленные сборники документов по возможности быстро доступными для заинтересованных кругов лиц, было предложено основанное на технике обработки данных составление информаций и запоминание, а также передача данных через частную, например внутреннюю, для предприятия сеть данных.
Задачей настоящего изобретения является указание способа, с помощью которого можно составить структурированный сборник документов из существующих документов и предоставить его в распоряжение для возможно большого круга лиц при небольшой нагрузке сети данных и малой потребности в памяти.
Эта задача решается согласно изобретения признаками пункта 1 формулы изобретения.
Существенное преимущество способа, соответствующего изобретению, следует видеть между прочим в физическом разделении оригинальных данных, составленных автором, от считываемых данных, поставленных в распоряжение пользователю через систему сети данных. Это означает, в частности, что оригинальные данные не могут быть переписаны пользователем. Способ, соответствующий изобретению, позволяет кроме того иметь оптимальное управление прав доступа между автором и пользователем.
Дальнейшее преимущество способа, соответствующего изобретению, проявляется в том, что за счет развязки оригинальных данных и считываемых данных устройство генерации формата действует как звено связи, которое допускает в качестве базы различные платформы аппаратных средств и обеспечивает в значительной степени независимость от индивидуальных характеристик аппаратных средств.
Предпочтительные формы дальнейшего развития изобретения указаны в зависимых пунктах формулы изобретения.
Пример выполнения изобретения поясняется в последующем более подробно с помощью чертежей.
При этом на фигурах показано:
фиг. 1 - схематическое представление системы сети данных с серверным устройством данных;
фиг. 2 - символическое представление файлов, запомненных в авторской системе и в серверном устройстве;
фиг. 3 - релевантные поля данных при составлении авторского файла;
фиг. 4 - выполненное устройством генерации формата составление регистра к файлу, в частности для определения навигационных управляющих адресов.
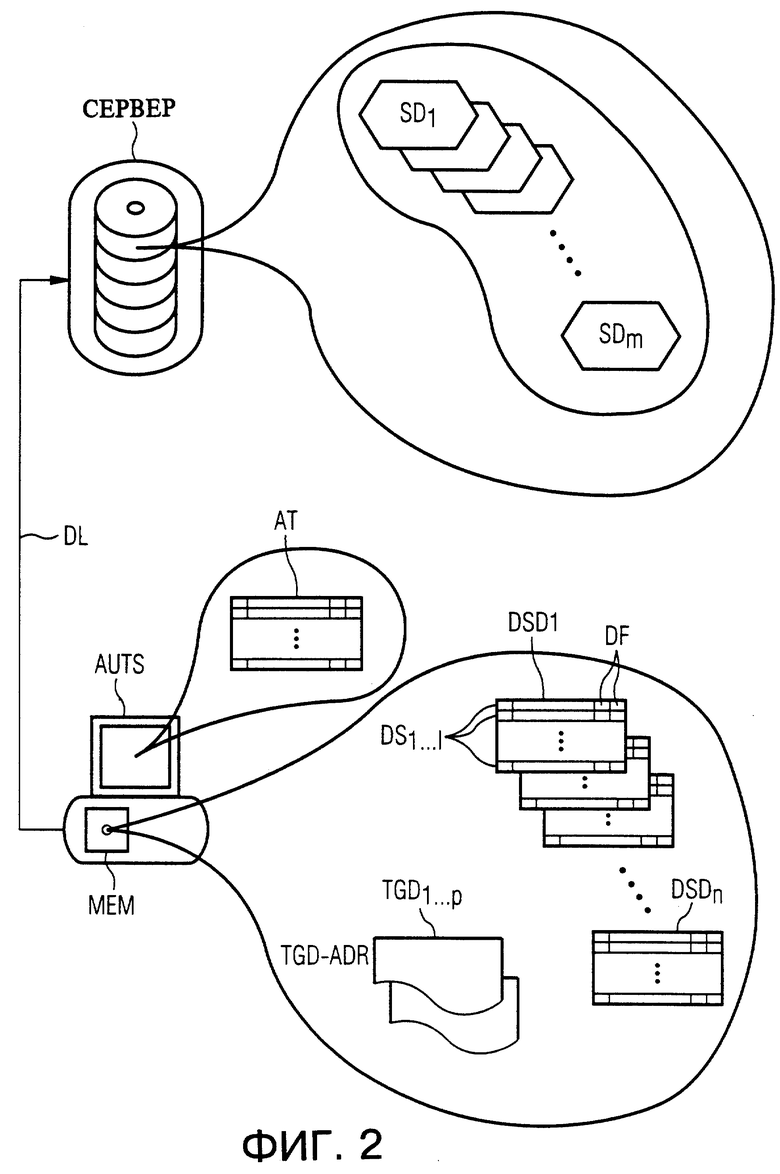
На фиг.1 в сильно упрощенном виде символически представлена система сети данных ИНТЕРНЕТ. Множество пользовательских систем обработки данных DV1,..., DVn непосредственно или при промежуточном включении дальнейших систем сети данных являются соединяемыми с серверным устройством данных СЕРВЕР; точно также авторская система обработки данных AUTS через линию передачи данных DL является связанной с серверным устройством данных СЕРВЕР. В качестве системы сети данных служит всемирно распространенная система Интернет/Интранет.
В серверном устройстве данных СЕРВЕР запомнено множество документов, которые соответственно разделены на так называемые страницы. Запомненный в серверном устройстве данных СЕРВЕР документ является адресуемым всеми соединенными с серверным устройством данных СЕРВЕР через систему сети данных ИНТЕРНЕТ, то есть подключенными к ней пользовательскими системами обработки данных DV1,...,DVn.
Для визуализации информации документов на пользовательских системах обработки данных DV1, ...,DVn в них требуются устройства страничного доступа, так называемые броузеры, которые выполняют интерпретацию содержащихся на страницах операторов управления и выдают полезное содержание на устройство индикации пользовательской системы обработки данных в соответствии с операторами управления. Страницы составлены на языке страничной разметки, например известном Web-языке HTML (HTML= HyperText Markup Language = гипертекстовый язык описания документов), дополнительные возможности форматирования которого в основном указывают, какой ранг имеет частичная информация внутри соответствующей страницы. Язык страничной разметки позволяет далее с помощью так называемых тегов, отложенных на странице, указывать отсылки (то есть адреса) к другим страницам документа.
В авторской системе обработки данных AUTS, которая так же как и отдельные пользовательские системы обработки данных DV1,...,DVn выполнена в виде персонального компьютера, - в качестве существенных для настоящего изобретения компонентов - находятся запоминающее устройство МЕМ и устройство генерирования формата HTML-GEN, реализованное программно-техническими средствами.
Для авторской системы обработки данных AUTS в серверном устройстве данных СЕРВЕР предусмотрена так называемая базовая страница, которая служит в качестве цели для документов, происходящих от авторской системы обработки данных AUTS, и используется пользовательскими системами обработки данных DV1, ...,DVn в качестве входного адреса для доступа к документам, составленным авторской системой обработки данных AUTS.
Согласно стандарту базовая страница ссылается на оглавление, в котором указаны отдельные документы или соответственно их оглавления. На каждой из пользовательских систем обработки данных DV1,...,DVn можно с помощью обычного броузера переключаться дальше через оглавление от одной страницы на следующую или другую страницу, что впрочем требует относительно больших времен ожидания и за счет чего значительно нагружается система сети.
Более подробную информацию об Интернет/Интранет, Web-языке HTML, о броузере и тому подобных, известных в связи с системой сети данных Интернет устройствах, можно получить из специальной литературы, например, Russ Jones, Adrian Nye, "HTML und das World Wide Web", O'Reilly & Associates, Бонн, 1995.
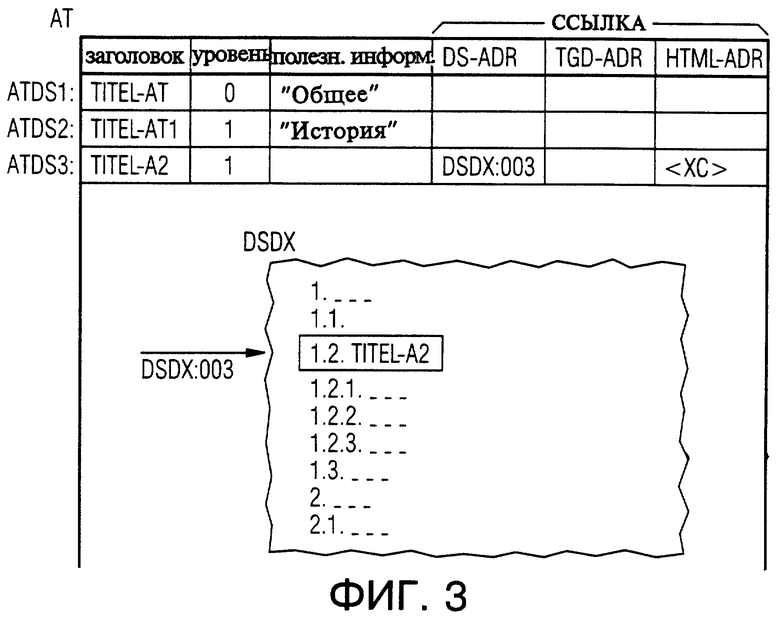
На фиг. 2 символически представлены серверное устройство данных СЕРВЕР с его запоминающей средой и авторская система обработки данных AUTS с ее запоминающим устройством MЕМ. Кроме того наглядно представлены страничные файлы SD1, . ..,SDm, которые запомнены в формате HTML в запоминающей среде серверного устройства данных СЕРВЕР. Также символически представлены структурированные по записям данных файлы DSD1,...,DSDn, которые запомнены в запоминающем устройстве МЕМ. Каждый из структурированных по записям данных файлов состоит из множества записей данных DS1,...,DS1, которые со своей стороны подразделены на поля данных DF. Структурированные по записям данных файлы DSD1,...,DSDn могут пониматься так же как банки данных или модули банков данных. К этим структурированным по записям данных файлам в запоминающем устройстве МЕМ запомнены также свободные от структур записей данных файлы TGD1,. . .,TGDp, которые не являются структурированными по записям данных или имеют структуру записи данных, которая отличается от выбранной структуры структурированных по записям данных файлов DSD1,...,DSDn. В частности, в свободных от структур записей данных файлах TGD1,...,TGDp могут содержаться чисто словесные и/или графические документы.
Далее на фигуре символически представлен структурированный по записям данных авторский файл AT, структура которого совпадает со структурой структурированных по записям данных файлов DSD1,...,DSDn. Авторский файл AT составляется на авторской системе обработки данных AUTS и само собой разумеется запоминается, в частности промежуточно запоминается также в запоминающем устройстве МЕМ.
К каждой записи данных DS1,...,DS1 структурированных по записям данных файлов DSD1,...,DSDn в запоминающей среде серверного устройства данных СЕРВЕР существует соответствующая приданная в соответствие страница, которые в последующем называются страничными файлами SD1,...,SDm. В авторской системе обработки данных AUTS можно иметь доступ для записи и считывания к каждой записи данных DS1, . ..,DS1 с помощью индивидуального адреса записи данных DS-ADR, который идентифицирует файл записи данных и соответствующую запись данных в нем. Страничные файлы SD1,...,SDm имеют индивидуальный HTML-адрес HTML-ADR, под которым они являются адресуемыми, то есть могут быть найдены в системе сети данных или соответственно в серверном устройстве данных СЕРВЕР.
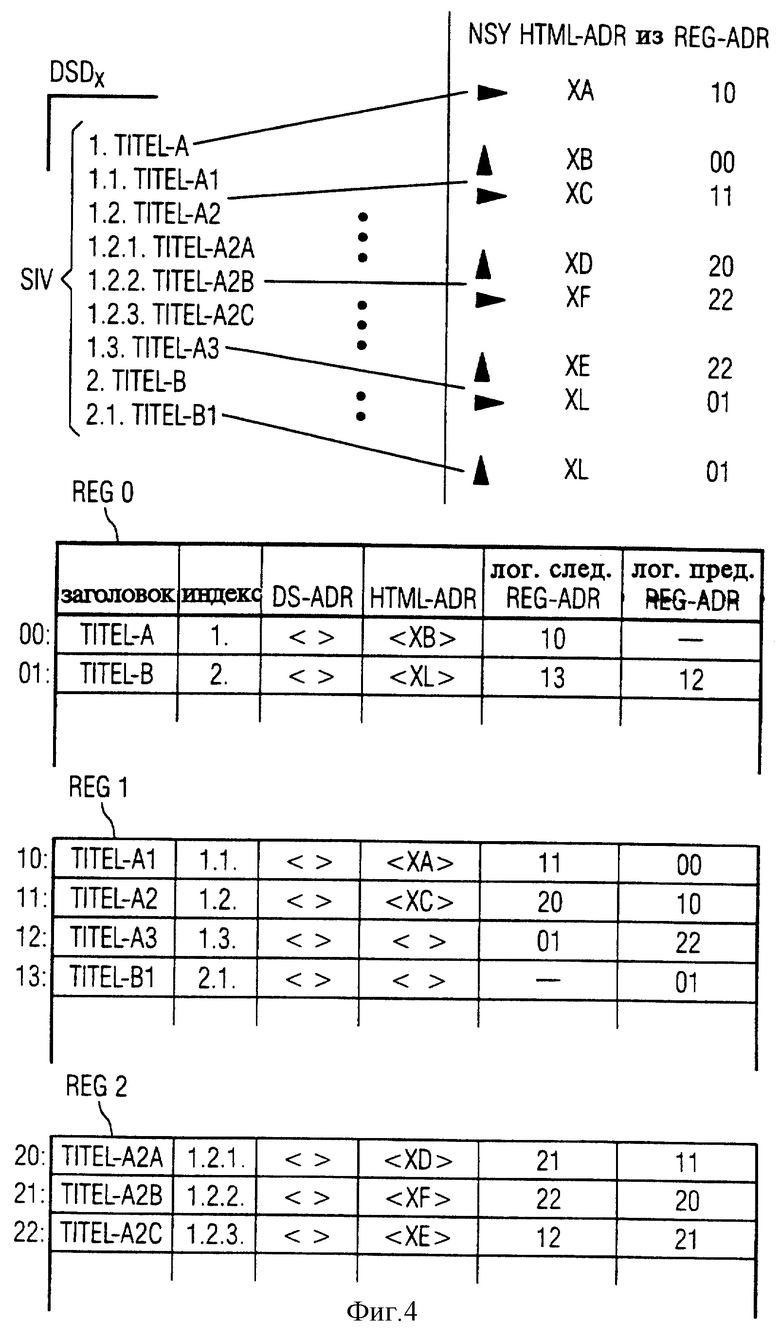
На фиг. 3 проиллюстрировано составление авторского файла AT на авторской системе обработки данных AUTS с помощью записей данных и полей данных авторского файла AT. В частности, каждый из структурированных по записям данных файлов DSD1,...,DSDn может рассматриваться как авторский файл AT.
При разработке сборника документов, который должен составляться в авторском файле AT, для каждой главы сборника документов, то есть для каждого заголовка и подзаголовка нужно предусматривать и соответственно резервировать новую запись данных. Записи данных DS подразделены на множество полей данных DF, из которых при составлении некоторые являются видимыми, например, поле данных Заголовок и поле данных Полезная информация, однако большинство являются невидимыми для составителя.
В настоящем примере выполнения при составлении документа в первой записи данных - с адресом записи данных ATDS1, который пользователь, впрочем, не видит - заголовок первой главы вводится составителем вручную. Кроме того, внутри той же записи данных составителем через клавиатуру вводится относящаяся к этому заголовку полезная информация в форме текстовой или графической информации Общее.
Также заголовок следующей подглавы, а также соответствующая полезная информация История вводится составителем через клавиатуру. Занятая за счет этого запись данных DS имеет адрес записи данных ATDS2.
Заголовок второй подглавы составитель берет из оглавления структурированного по записям данных файла DSDx, которое он получает в окне на экране авторской системы обработки данных AUTS путем селектирования структурированного по записям данных файла DSDx. За счет соответствующей маркировки желаемой главы, как это показано на фигуре, путем заключения в рамку главы 1,2 и после последующего подтверждения маркированный заголовок вводится, то есть копируется в новую запись данных адреса ATDS3. Кроме того, для составителя не видимо запоминается адрес записи данных DS-ADR маркированной главы и HTML-адрес HTML-ADR страницы данных SD, которая придана в соответствие записи данных с адресом DSDх : 003.
За счет выше поясненного ввода заголовка из одного из структурированных по записям данных файлов DSD1,...DSDn в заново составляемый или обрабатываемый документ не явно вводятся также подзаголовки к выбранной главе.
Впрочем вместо явно заданной полезной информации можно откладывать также отсылочный адрес к текстовому или графическому файлу, например одному из свободных от структур записи данных файлов TGD1,...,TGDp. Кроме того, поясненным образом также уже имеющиеся главы внутри авторского файла AT могут быть введены на другом месте авторского файла AT. Далее можно также вводить (прямой) адрес свободного от структур записи данных файла TGD, причем, однако, ссылка в нем не предусмотрена.
После того, как составителем за счет ручного ввода и за счет ссылки на уже существующую главу желаемый документ был подготовлен по меньшей мере в предварительном объеме, к устройству генерации формата HTML-GEN подводят авторский файл AT. Им, начиная с первой записи данных, то есть при адресе записи данных ATDS1 авторского файла AT составляется структурированное оглавление (сравни фиг. 4 вверху) и преобразуются в HTML-формат те записи данных, которые еще в нем не находятся (в следующем примере первые две записи данных авторского файла AT). Кроме того, копия созданных HTML-страничных файлов через линию передачи данных DL передают на серверное устройство данных СЕРВЕР для запоминания там. Составленный авторский файл AT запоминают в качестве нового структурированного по записям данных файла DSDn+1 в запоминающем устройстве MEM авторской системы обработки данных.
На фиг. 4 наглядно поясняется составление оглавления, как оно было подготовлено устройством генерации формата HTML-GEN при предпринятом в прошлом составлении структурированного по записям данных файла, например DSDx.
Для пользователя является видимым составленное устройством генерации формата HTML-GEN оглавление с индексом и указанием заголовка (на фигуре слева сверху), причем индекс является многоразрядным, чтобы можно было выразить желаемую глубину структурирования разделения документа. В это видимое оглавление за счет ссылки, как это пояснено в связи с фиг. 3 относительно главы 1,2, интегрированы, то есть введены также все подглавы главы.
Для составителя является невидимым построение регистровых записей данных REGO, . . . ,REG2, которые, в частности, протоколируют логическую последовательность относящихся к документу страничных файлов SD1,...,SDm. Это предусмотрено, в частности, для того, чтобы при индикации соответствующего страничного файла SDy на пользовательской системе обработки данных DVx также навигационные символы NSY являлись представимыми и активируемыми наблюдателем на пользовательской системе обработки данных, чтобы позволить дальнейшее переключение (перелистывание) к логически следующей или соответственно предыдущей странице внутри структуры документа. Навигационные символы NSY должны, в частности, позволять наблюдателю на пользовательской системе обработки данных вызывать следующий в логической последовательности или предыдущий страничный файл, без необходимости активирования функции броузера, которая, как уже вначале упоминалось, через оглавление имеет доступ на страницу.
В качестве навигационных символов NSY индицируются стрелка вправо, за счет чего символизируется переключение к логически следующей странице и стрелка вверх, которой символизируется обратное переключение к предыдущей странице. Навигационным символам NSY соответствующей страницы приданы в соответствие HTML-адрес логически следующей в документе страницы или соответственно HTML-адрес логически предыдущей страницы.
Для быстрого определения логически следующего или соответственно логически предыдущего страничного адреса соответствующей страницы устройством генерации формата HTML-GEN составляются регистровые записи данных REGO,..., REG2. Первая регистровая запись данных REGO содержит две записи, в которых запомнены заголовок иерархически высшего уровня (уровень 0), то есть главный заголовок соответствующего документа. Регистровая запись данных REG1 аналогично содержит заголовок глав, находящихся на следующем более низком иерархическом уровне (уровень 1), а регистровая запись данных REG2 содержит заголовок иерархического уровня 2.
Регистровые записи данных REGO,...,REG2 имеют наряду с полем данных для заголовка дальнейшие поля данных, например, для присвоенного заголовку индекса, для адреса записи данных DS-ADR относящейся к заголовку записи данных DS в авторской системе обработки данных AUTS и для HTML-адреса, под которым является адресуемым страничный файл SDy, относящийся к соответствующему заголовку.
В следующем первом поле данных - насколько это имеет смысл - указан адрес той регистровой записи, в которой запомнен логически следующий заголовок. В следующем втором поле данных - насколько это имеет смысл - указан адрес той регистровой записи, в которой запомнен логически предыдущий заголовок. Указанные адреса служат таким образом в качестве отсылки на записи данных регистровых записей данных REGO,...,REG2.
Исходя из указанного в качестве примера иерархического построения, представленного в верхней левой части фиг. 4 оглавления SIV и тем самым документа, первая глава имеет заголовок TITEL-A. Страничный файл SDy, приданный в соответствие этой логически первой записи данных структурированного по записям данных файла DSx, является равным образом также логически первым страничным файлом документа и является адресуемым под HTML-адресом ХВ. Следующий в логической последовательности заголовок относится к главе 1.1. и запомнен вследствие более низкого иерархического уровня в регистровой записи данных RG1 (под адресом 10). Относящийся к этому заголовку (TITEL-A1) страничный файл SD является достижимым под HTML-адресом ХА.
Следующая в логической последовательности глава в документе несет заголовок TITEL-A2 и имеет индекс 1.2. Заголовок также вследствие одинакового иерархического уровня, как и предыдущий, запомнен в регистровой записи данных REG1 (под адресом 11). Примыкающий в логической последовательности заголовок TITEL-A2A отложен в регистровой записи данных REG2 под адресом 20 (для иерархического уровня 2). Относящийся к этому заголовку (TITEL-A2A) страничный файл SD является адресуемым под HTML-адресом XD. Заголовок, следующий в логической последовательности, опять-таки может быть найден в той же регистровой записи данных REG2 под адресом 21 (TITEL-A2B). Предыдущий в логической последовательности заголовок (относительно заголовка TITEL-A2A) может быть найден в регистровой записи данных REG1 под адресом 11. Если регистровые записи данных REG0,...,REG2 построены показанным образом, тогда очень быстро и просто могут быть определены навигационные символы NSY с соответствующими HTML-адресами для логически следующего или соответственно предыдущего страничного файла и даны соответствующему страничному файлу SD. Итак, HTML-адреса логически следующих или соответственно предыдущих страничных файлов заносят на соответствующую страницу и затем передают в качестве ее составной части к серверному устройству данных СЕРВЕР.
В настоящем примере на странице с HTML-адресом ХВ отложен только навигационный символ NSY для дальнейшего переключения к логически следующему страничному файлу, HTML-адресом которого является ХА. Навигационный символ к предыдущей странице отсутствует, поскольку глава представляет собой начало документа. В страничном файле SD с HTML-адресом ХА под навигационным символом NSY к последующей странице запоминают HTML-адрес ХС и к предыдущей странице HTML-адрес ХВ. Для избежания передачи страничных файлов, которые уже запомнены в серверном устройстве данных СЕРВЕР, HTML-адреса которых, однако, были изменены для адресования логически следующего или, соответственно, предыдущего страничного файла SD, регистровые записи данных REG0,..., REG2 могут быть запомнены в серверном устройстве данных СЕРВЕР, причем HTML-адреса логически следующего и предыдущего страничного файла относительно соответствующего страничного файла определяют через отсылку из регистровых записей данных REG0,...,REG2.
Изобретение относится к вычислительной технике. Его использование в сетевых приложениях позволяет получить технический результат в виде предоставления структурированного сборника документов для возможно большего круга лиц при небольшой загрузке сети и малой потребности в памяти. Способ реализуется в серверном устройстве данных системы сети данных (Интернет/Интранет), через которую страничные файлы являются адресуемыми множеством пользовательских систем обработки данных. Технический результат достигается благодаря тому, что на авторской системе обработки данных, соединяемой через линию передачи данных с серверным устройством данных, составляют структурированный по записям данных авторский файл, подводят его к устройству генерации формата авторской системы обработки данных, которое из записей данных авторского файла, а также из обозначенных ссылочными информациями (заголовками) записей данных, структурированных по записям данных файлов, создает соответствующий страничный файл на языке страничной разметки (HTML), после чего полученные таким образом и снабженные специфичными для языка страничной разметки связующими управляющими адресами (ссылками HTML) страничные файлы в виде компоновки передают через линию передачи данных (DL) в серверное устройство данных. 9 з.п.ф-лы, 4 ил.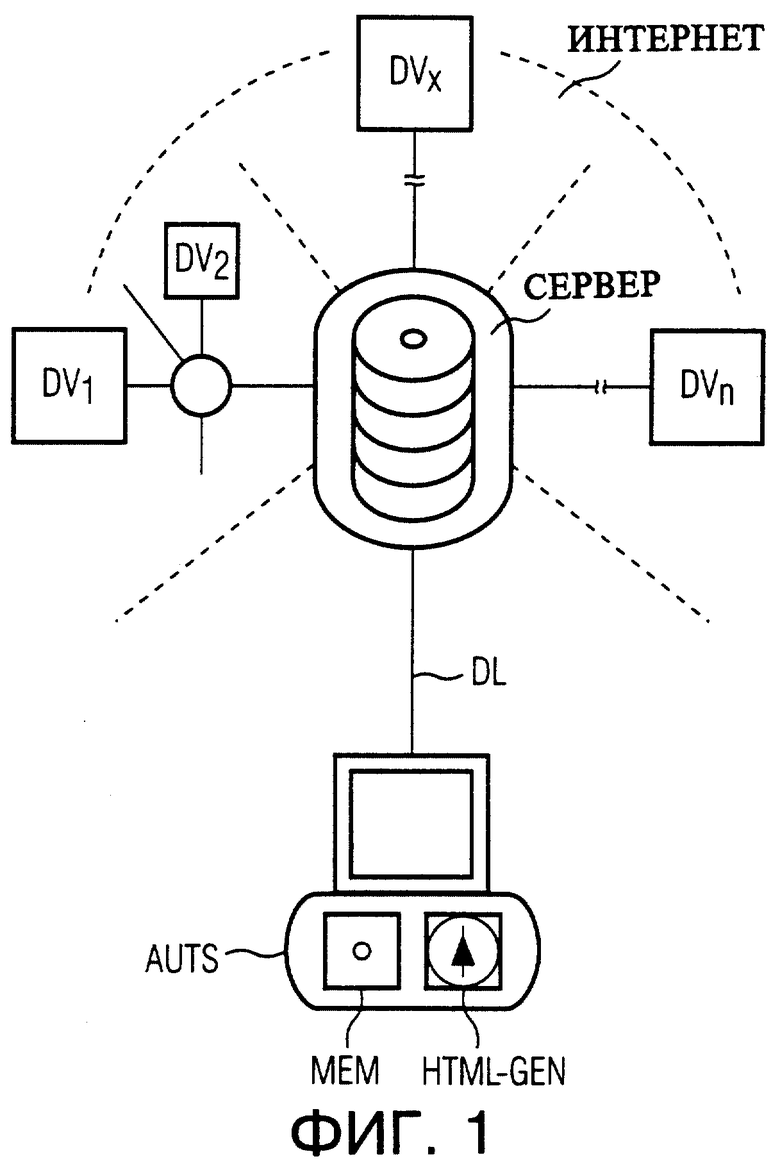
| RU 94028792 A1, 20.05.1996 | |||
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| US 5418949 А, 23.05.1995 | |||
| Приспособление в пере для письма с целью увеличения на нем запаса чернил и уменьшения скорости их высыхания | 1917 |
|
SU96A1 |

