Область техники
Настоящее изобретение относится в целом к способам маршрутизации для пересылки пакетов по месту назначения в сети Интернет и, в частности, касается устройства и способа для выполнения высокоскоростного поиска IP (протокол Интернет) маршрута и управления таблицей маршрутизации (или пересылки).
Уровень техники
В связи с увеличением количества пользователей сети Интернет, расширением перечня поддерживаемых услуг и областей обслуживания, таких как прикладные системы VoIP (протокол передачи речи через сеть Интернет) и системы, ориентированные на обработку потоков, наблюдается экспоненциальный рост трафика в Интернете. Возможным решением этой проблемы может стать пересылка пакетов на следующий транзитный интерфейс путем нахождения пути к месту назначения практически без задержек с использованием появившихся высокоскоростных маршрутизаторов со скоростями порядка гигабит/с или терабит/с. Для того чтобы найти путь к месту назначения пакетов, пересылаемых через физические входные интерфейсы маршрутизатора, требуется поддерживать таблицу маршрутизации (или пересылки) в компактном виде и минимизировать время поиска.
Что касается известного маршрутизатора, то до появления недавно введенных в эксплуатацию высокоскоростных маршрутизаторов, когда время, требуемое для обработки пакетов и нахождения их адресатов, меньше времени, необходимого для трактов передачи, маршрутизатор как ретрансляционный узел, соединяющий подсети или другие сети, хорошо выполнял свои функции. В последнее время рост пропускной способности оптического сетевого интерфейса, такого как РОS ОС-192 (10 Гбит/с) или IP посредством DWDM (мультиплексирование по длине волны высокой плотности), привел к тому, что маршрутизатор, требующий определенного времени обработки, оказался самым узким местом в высокоскоростной сети Интернет. Описание маршрутизаторов можно найти в работах: Keshav, S. and Sharma, R., Issues and Trends in Router Design, IEEE Communications Magazine, pages 144-151, May, 1998; Kumar, V. and Lakshman, T. and Stiliadis, D., Beyond Best Effort: Router Architectures for the Differentiated Services of Tomorrow's Internet, IEEE Communications Magazine, pages 152-164, May, 1998; Chan, H., Alnuweiri, H. and Leung, V., A Framework for Optimizing the Cost and Performance of Next Generation IP Routers, IEEE Journal of Selected Areas in Communications, Vol. 17, No. 6, pages 1013-1029, June 1999; Partridge, C. et al., A 50-Gb/s IP Router, IEEE/ACM Trans. on Networking, vol. 6, no. 3, pages 237-248,1998; and Metz, C., IP Routers: New Tool for Gigabit Networking, IEEE Internet Computing, pages 14-18, Nov.-Dec., 1998.
В начале 1990 рабочая группа IETF (Проблемная группа проектирования средств Интернет) ввела новую схему IP адресации под названием CIDR (бесклассовая междоменная маршрутизация) для эффективного использования IP адресов в IPv4 (IP, версия 4) (См. RFC 1518, An Architecture for IP Address Allocation with CIDR, Sept., 1993; and RFC 1517, Applicability Statement for the Implementation of Classless Inter-Domain Routing (CIDR), Sept., 1993).
В этом случае для захвата префикса в пакетах, имеющих префиксы разной длины, и нахождения IP адреса, соответствующего самому длинному префиксу, широко используется алгоритм LPM (совпадение по самому длинному префиксу) на основе так называемой "trie-структуры", или структуры данных Patricia (Рациональный алгоритм для поиска информации, закодированной алфавитно-цифровыми символами) (См. Doeringer, W., Karjoth, G. and Nassehi, M., Routing on Longest-Matching Prefixes, IEEE/ACM Trans. on Networking, vol. 4, no. 1, pages 86-97, Feb., 1996).
Алгоритм LPM подробно описывается ниже со ссылками на таблицу 1. Таблица 1 является простым примером маршрутных записей, содержащихся в таблице маршрутизации (или пересылки). Звездочка указывает на возможность заполнения позиции любой цифрой: "0" или "1", хотя в случае использования протокола IPv4 длина самого префикса не может превышать 32.
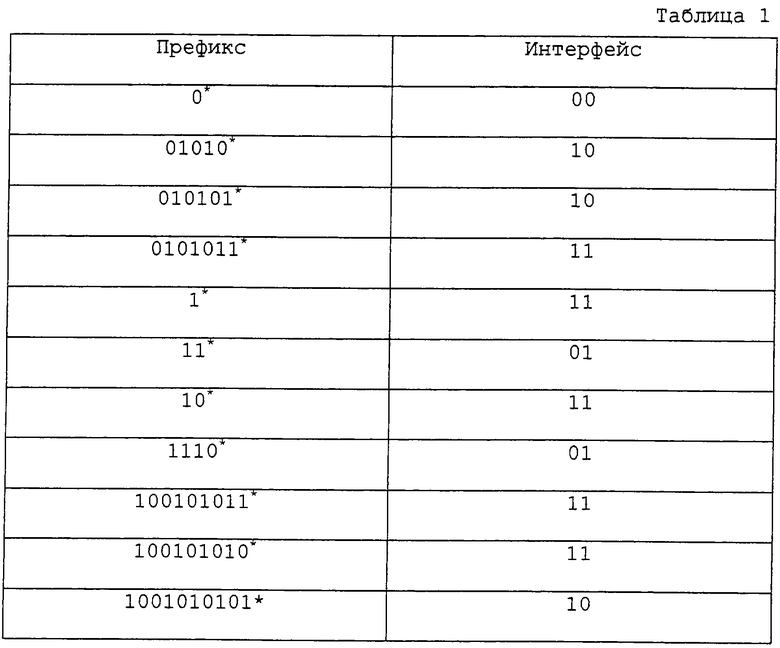
Маршрутная запись или маршрут представляется IP адресом: :={<networkprefix>,<xost number>}. Когда IP адрес назначения представляет собой '10010101000...0', первый бит IP адреса назначения сравнивается с сетевыми префиксами (просто префиксами), содержащимися в таблице маршрутизации. В результате такие префиксы, как '0*', '01010*', '010101*' и '0101011*' отбрасываются, поскольку у них первый бит начинается с '0'. Когда данный адрес назначения сравнивается с остальными префиксами, префиксы '11*', '1110*' и '1001010101*' исключаются, поскольку они не совпадают с адресом назначения, начиная со второго или десятого бита. Из подходящих префиксов (например, '1*', '10*' и '100101010*') в качестве самого длинного (или самого конкретного) префикса выбирается '100101010*', и IP пакет с IP адресом назначения пересылается на соседний маршрутизатор через интерфейс '10'.
Кроме того, в кэш-памяти того или иного процессора (процессора маршрутизации или процессора пересылки) хранится недавно анонсированный алгоритм поиска маршрутов для сокращения времени доступа к памяти. Хотя алгоритм поиска маршрутов на основе таблицы маршрутизации гарантирует эффективный поиск, он не может изменить таблицу маршрутизации (или пересылки). Следовательно, использование алгоритма поиска маршрутов может вызвать задержку, связанную с необходимостью отражения изменений в таблице маршрутизации.
Вдобавок таблица маршрутизации в процессоре маршрутизации копируется через карту DMA (прямой доступ к памяти), карту IPC (межпроцессорная связь) или коммутационную структуру, а затем подается в таблицу пересылки в процессоре пересылки. В этот момент необходимо построить новую таблицу пересылки, а не только добавить или удалить измененные маршруты. Это может привести к дополнительной временной задержке, а также к тому, что внутренняя память маршрутизатора или системная шина станет узким местом из-за увеличения пропускной способности памяти при запросе на доступ к памяти со стороны маршрутизатора.
Кроме того, в ряде алгоритмов начальную таблицу маршрутизации (или пересылки) необходимо строить с использованием информации о достижимости связей, представляющей текущее состояние связей маршрутизатора. Следовательно, для того чтобы последовательно вводить в таблицу маршрутизации информацию о достижимости связей, заранее необходим дополнительный процесс сортировки каждого маршрута в соответствии с длиной префикса (См. Degermark, М., Brodnik, A., Carlsson, S. and Pink, S., Small Forwarding Tables for Fast Routing Lookups, In Proceedings of ACM SIGCOMM '97, pages 3-14, Cannes, France, 1997; Srinivasan, V. and Varghese, G., Faster IP Lookups using Controlled Prefix Expansion, In Proceedings of ACM Sigmetries '98 Conf., pages 1-11, 1998; Lampson, В., Srinivasan, V. and Varghese, G., IP Lookups using Multi-way and Multicolumn Search, In IEEE Infocom, pages 1248-1256, 1998; Tzeng, H. and Pryzygienda, Т., On Fast Address-Lookup Algorithms, IEEE Journal on Selected Areas in Communications, Vol. 17, No. 6, pages 1067-1082, June, 1999; Waldvogel, M., Varghese, G., Turner, J. and Plattner, В., Scalable High Speed IP Routing Lookups, In Proceedings of ACM SIGCOMM '97, Cannes, France, pages 25-37, 1997; and Waldvogel, M., Varghese, G., Turner, J. and Plattner, В., Scalable Best Matching Prefix Lookups, In Proceedings of PODC '98, Puerto Vallarta, page, 1998).
Использование в таблице маршрутизации обычных структур данных, таких как базисное дерево или trie-структура Patricia, не только приводит к увеличению количества обращений к памяти, необходимых для нахождения пути для пакета, но также требует значительного времени обновления для отражения изменений в маршрутах, возникших в результате установки или удаления маршрутов из соседних маршрутизаторов соответствующего маршрутизатора. В работе Degermark, M., Brodnik, A., Carlsson, S. and Pink, S. в "Small Forwarding Tables for Fast Routing Lookups", in Proceedings of ACM SIGCOMM'97, pages 3-14, Cannes, France, 1997 предложена компактная таблица пересылки, которая может храниться в кэш-памяти процессора пересылки, но в ней трудно отражать изменения в маршрутах. Способ управляемого расширения префикса, предложенный в работе Srinivasan, V. and Varghese, G., Faster IP Lookups using Controlled Prefix Expansion, in Proceedings of ACM Sigmetrics 98 Conf., pages 1-11, 1998 (см. патент США №6011795, выданный George Varghese и Srinivasan на "Способ и устройство быстрого иерархического поиска адреса с использованием управляемого расширения префикса”), и алгоритм быстрого поиска адреса, предложенный Tzeng, Н. и Pryzygienda, Т., "On Fast Address-Lookup Algoritms, IEEE Journal on Selected Areas in Communications, Vol. 17, No.6, pages 1067-1082, June 1999, также основаны на использовании trie-структуры с переменной разрешающей способностью, но при применении этого алгоритма возникают проблемы при добавлении и удалении маршрутов, поскольку структуры данных основаны на trie-структуре (см. патент США №6061712 на “Способ поиска с использованием IP таблицы маршрутизации” IP и патент США №6067574 на “Высокоскоростную маршрутизацию с использованием процедуры сжатия дерева” на имя Hong-Yi Tzeng). Алгоритм связного поиска (Waldvogel, M., Varghese, G., Turner, J. and Plattner, В., Scalable High Speed IP Routing Lookups, In Proceedings of ACM SIGCOMM '97, Cannes, France, pages 25-37, 1997; and Waldvogel, M., Varghese, G., Turner, J. and Plattner, В., Scalable Best Matching Prefix Lookups, In Proceedings of PODC '98, Puerto Vallarta, page, 1998), основанный на отображении trie-структуры в двоичное дерево с помощью хэш-таблиц и полной префиксной trie-структуры на основе trie-структуры с переменной разрешающей способностью (Tzeng, H. and Pryzygienda, Т., On Fast Address-Lookup Algorithms, IEEE Journal on Selected Areas in Communications, Vol. 17, No. 6, pages 1067-1082, June, 1999), оказывается неэффективным из-за необходимости обновления записей измененных маршрутов, поскольку эти структуры данных основаны на trie-структуре (см. патент США №6018524, выданный Jonathan Turner, George Varghese и Marcel Waldvogel "Scalable High Speed IP Routing Lookups".
Кроме того, были предложены другие варианты trie-структуры. Например, предложена схема со сдвоенной trie-структурой (Kijkanjanarat, Т. and Chao, H., Fast IP Lookups Using a Two-trie Data Structure, In Proceedings of Globecom '99, 1999), где для сокращения времени поиска связаны две trie-структуры, а также и trie-структура LC (Nillson, S. and Karlsoson, G., IP-Addresses Lookup Using LC-Tries, IEEE Journal on Selected Areas in Communications, Vol.17, No.16, pages 1083-1092, 1999) для уменьшения длины уровня в trie-структуре, и trie-структура DP (Doeringer, W., Karjoth, G. and Nassehi, M., Routing on Longest-Matching Prefixes, IEEE/ACM Trans. on Networking, vol.4, no.1, pages 86-97, Feb., 1996). Однако и в них возникают проблемы при отражении измененных маршрутов в таблице маршрутизации (или пересылки).
Кроме того, хотя вышеупомянутые схемы способствуют сокращению времени поиска, остается проблема, касающаяся обновления маршрутов. Также были предложены схемы для уменьшения времени поиска на основе аппаратных средств. В работе Gupta, P., Lin, S. and McKeown, N., Routing Lookups in Hardware at Memory Access Speeds, In Proceedings of IEEE INFOCOM '98 Conf., pages 1240-1247, 1998 предложено решение на основе использования многомерной памяти. При этом возможно сокращение времени поиска по сравнению с вариантами на основе программных средств, но это предполагает использование значительного объема памяти и дополнительных расходов при переходе на версию IPv6. В работе McAuley, A. and Francis, P., Fast Routing Table Lookup Using CAMs, In Proceedings of IEEE INFOCOM '93, Vol.3, pages 1382-1391, 1993, предложена схема с использованием САМ (ассоциативная память), но из-за высокой стоимости САМ этот вариант в настоящее время не рассматривается. В работе Huang, N. и Zhao, S., в A Novel IP-Routing Lookup Scheme and Hardware Architecture for Multigigabit Switching Routers, IEEE Journal on Selected Areas in Communications, Vol. 17, No. 6, pages 1093-1104, June, 1999 предложен алгоритм косвенного поиска с обращением к конвейерной памяти для уменьшения числа обращений к памяти, хотя этот вариант хуже, чем переход на версию IPv6.
Сущность изобретения
Таким образом, задачей настоящего изобретения является создание способа для выполнения высокоскоростных поисков IP маршрутов и управления таблицами маршрутизации/пересылки, способного минимизировать время доступа к памяти с использованием рандомизированного алгоритма, в результате чего гарантируется экономически эффективное использование памяти.
Также задачей настоящего изобретения является создание способа для высокоскоростных поисков IP маршрутов и управления таблицами маршрутизации/пересылки, который позволит легко изменять маршруты и управлять операциями добавления и удаления маршрутов.
Кроме того, задачей настоящего изобретения является создание способа для выполнения высокоскоростных поисков IP маршрутов и управления таблицами маршрутизации/пересылки, который позволит эффективно строить таблицу маршрутизации и/или таблицу пересылки без сортировки подходящих маршрутов в соответствии с длиной префикса маршрутов, вводимых в процессе построения таблиц.
Согласно первому аспекту настоящего изобретения предлагается способ для поиска IP адреса, имеющего в качестве ключа диапазон длин префикса, с использованием списка пропусков, содержащего узел заголовка, который имеет ключ с заранее установленным максимальным значением, и множество узлов (подузлов), каждый из которых имеет ключ фиксированного (или переменного) диапазона, заранее установленный в убывающем порядке, и сохраняет маршрутные записи, соответствующие длинам префикса, в хэш-таблицах, связанных с соответствующими длинами префикса.
Согласно второму аспекту настоящего изобретения способ для создания таблицы IP маршрутизации с использованием списка пропусков включает: создание узла заголовка, имеющего максимальный уровень, для управления каждым узлом в списке пропусков; вставку множества узлов, имеющих выделенный диапазон префикса, в список пропусков; и создание хэш-таблицы для сохранения маршрутных записей, заданных в каждом узле, соответствующем диапазону префикса.
Согласно третьему аспекту настоящего изобретения предлагается способ для обновления таблицы маршрутизации, использующей список пропусков, где маршрутные записи запоминаются в виде хэш-таблицы в соответствии с длиной префикса, установленной в каждом узле, сформированном в соответствии с диапазоном длин префикса IP адреса. Способ включает: нахождение узла, в котором установлен диапазон префикса, соответствующий длине префикса обновляемого маршрута; поиск в хэш-таблице, имеющей ту же длину префикса, что и обновляемый маршрут в найденном узле; и обновление соответствующего маршрута в хэш-таблице, когда найдена хэш-таблица.
Согласно четвертому аспекту настоящего изобретения предлагается способ поиска маршрута по таблице маршрутизации с использованием списка пропусков, где маршрутные записи запоминаются в виде хэш-таблицы в соответствии с заранее установленными длинами префикса в каждом узле, сформированном в соответствии с распределением диапазона префикса IP адреса. Способ включает в себя: нахождение соседнего узла, начиная с первого узла списка пропусков; сравнение адреса назначения с соответствующими хэш-таблицами в соответствующем узле; и принятие совпадающего префикса в качестве самого длинного префикса, когда хэш-таблица содержит адрес назначения.
Краткое описание чертежей
Настоящее изобретение и присущие ему преимущества поясняются в последующем подробном описании, иллюстрируемом чертежами, на которых одинаковые ссылочные позиции указывают одинаковые или подобные компоненты и на которых представлено следующее:
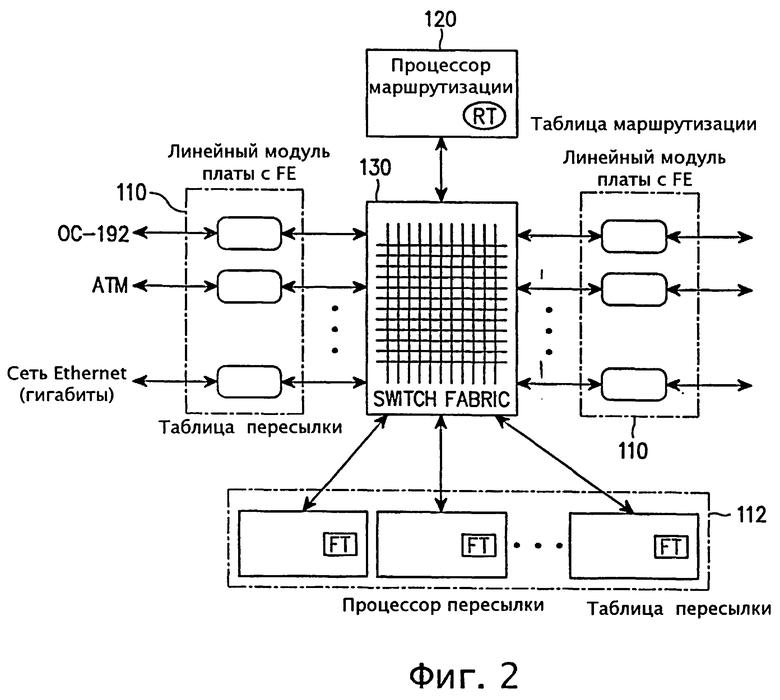
фиг.1 - схема, иллюстрирующая распределенную архитектуру маршрутизатора, для которой применимо настоящее изобретение;
фиг.2 - схема, иллюстрирующая параллельную архитектуру маршрутизатора, для которой применимо настоящее изобретение;
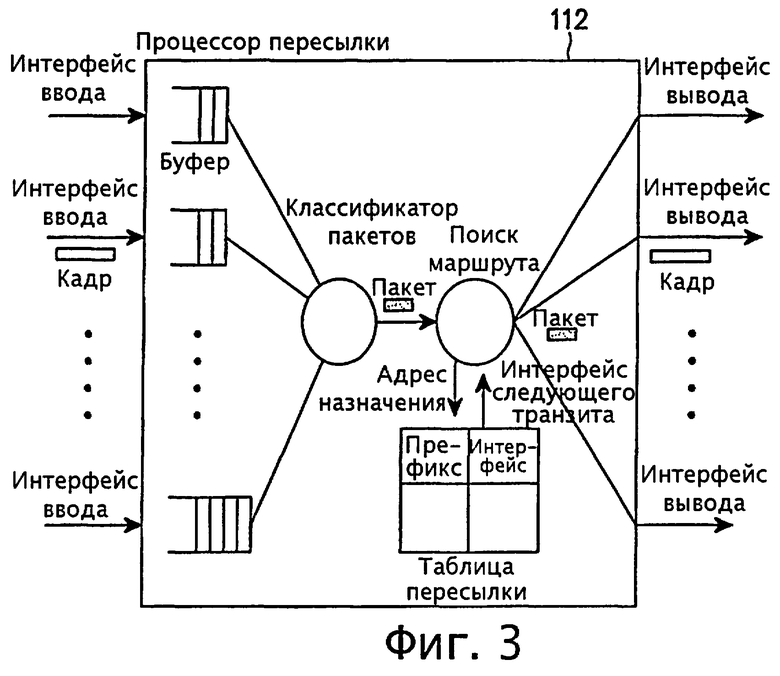
фиг.3 - схема, иллюстрирующая структуру механизма пересылки, для которой применимо настоящее изобретение;
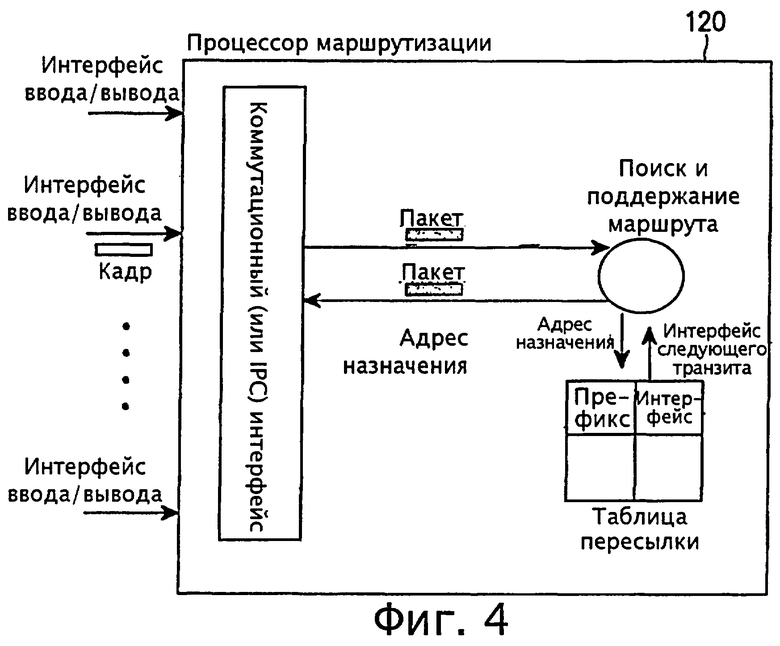
фиг.4 - схема, иллюстрирующая структуру процессора маршрутизации;
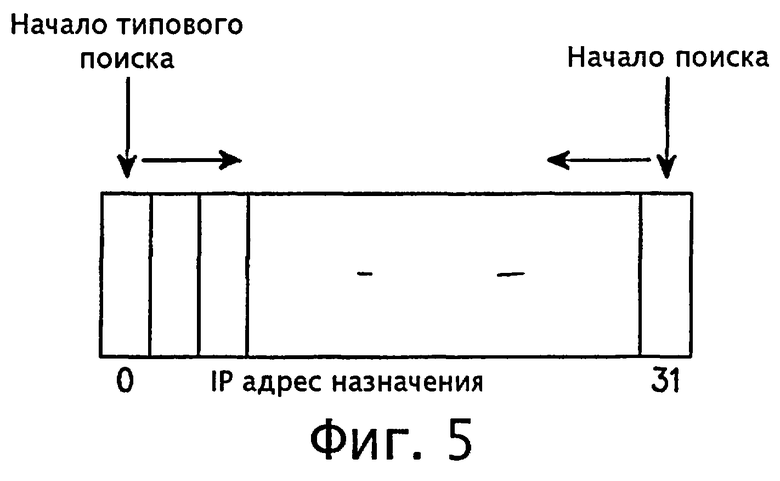
фиг.5 - диаграмма, поясняющая алгоритм совпадения по самому длинному префиксу (LPM) согласно варианту осуществления настоящего изобретения;
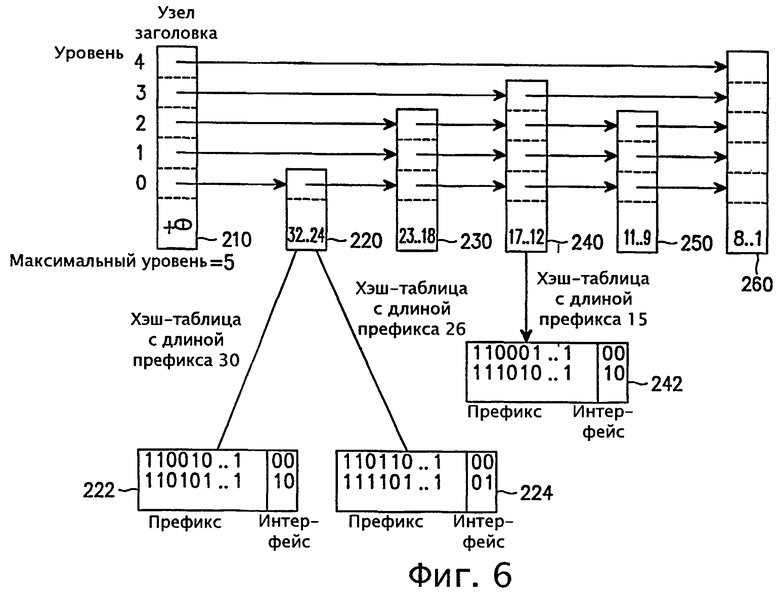
фиг.6 - диаграмма, иллюстрирующая структуру списка пропусков согласно варианту осуществления настоящего изобретения;
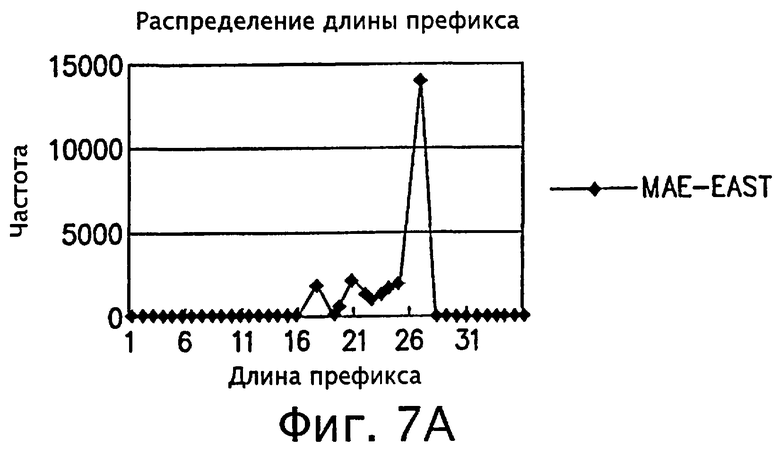
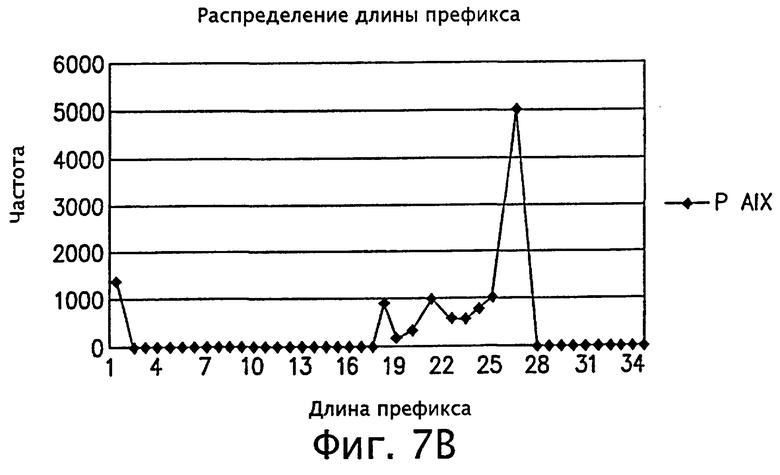
фигуры 7А и 7В - трафики, иллюстрирующие измеренные значения распределений длины префикса в сети Интернет;
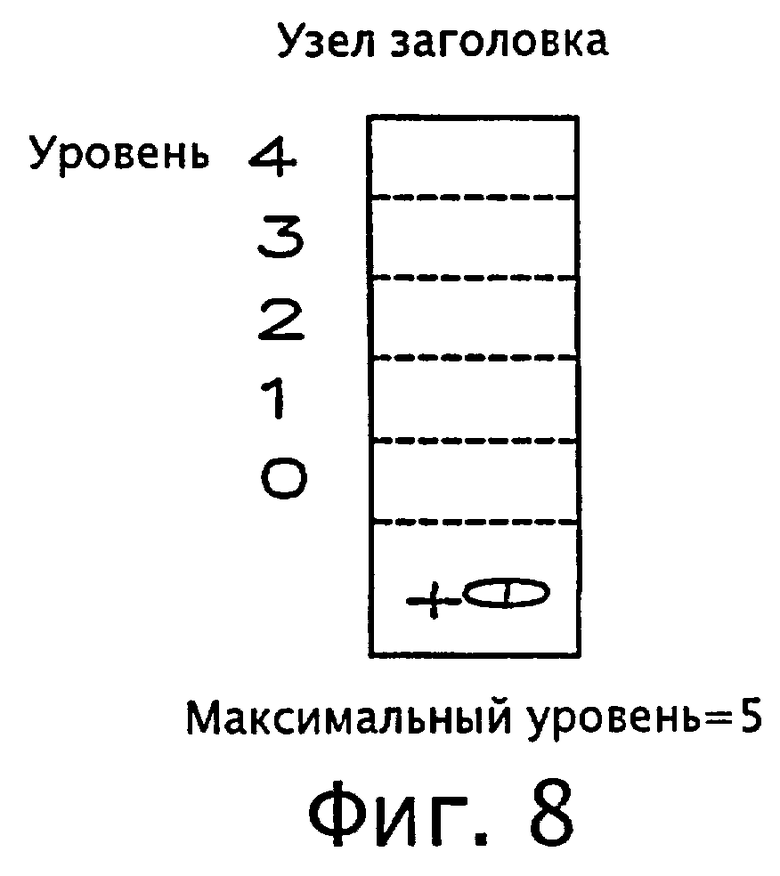
фиг.8 - диаграмма, иллюстрирующая структуру узла заголовка согласно варианту осуществления настоящего изобретения;
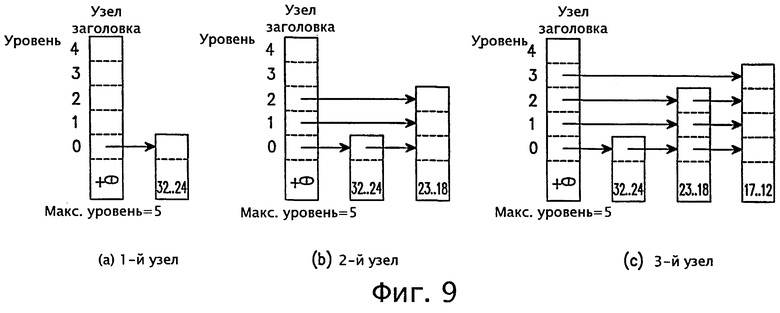
фиг.9 - диаграмма, объясняющая операцию построения списка пропусков согласно варианту осуществления настоящего изобретения;
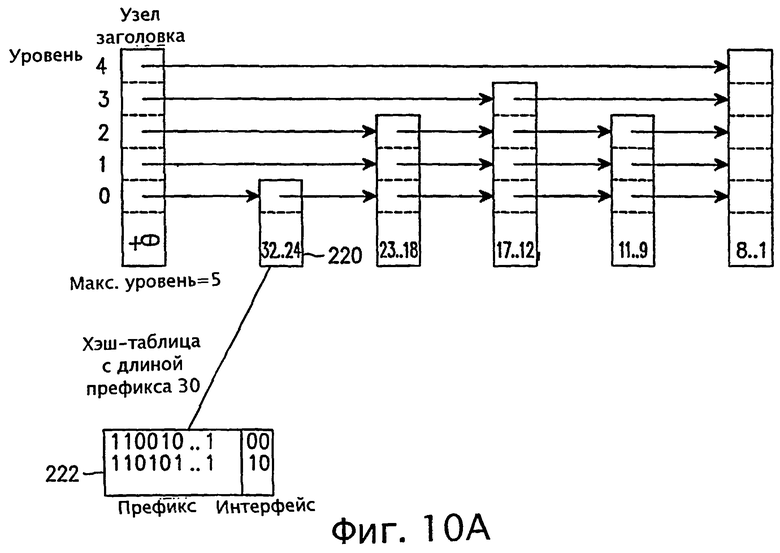
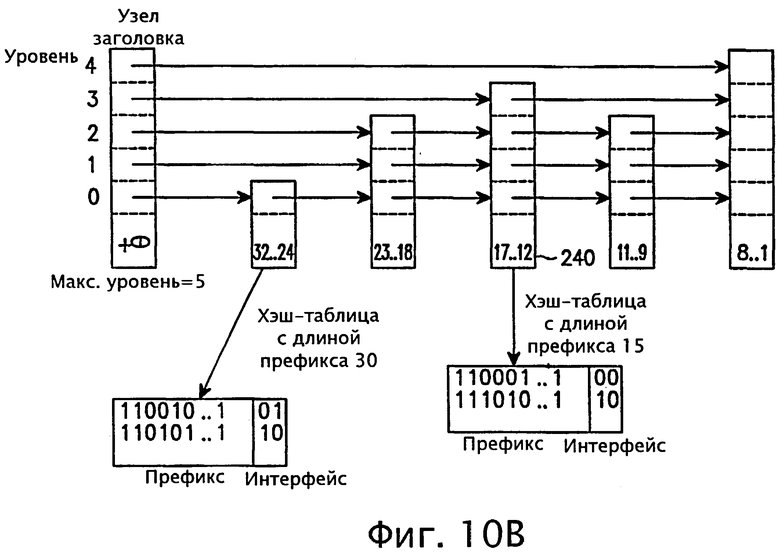
фигуры 10А и 10В - диаграммы, раскрывающие операцию построения таблицы маршрутизации в зависимости от значений длины префикса согласно варианту осуществления настоящего изобретения;
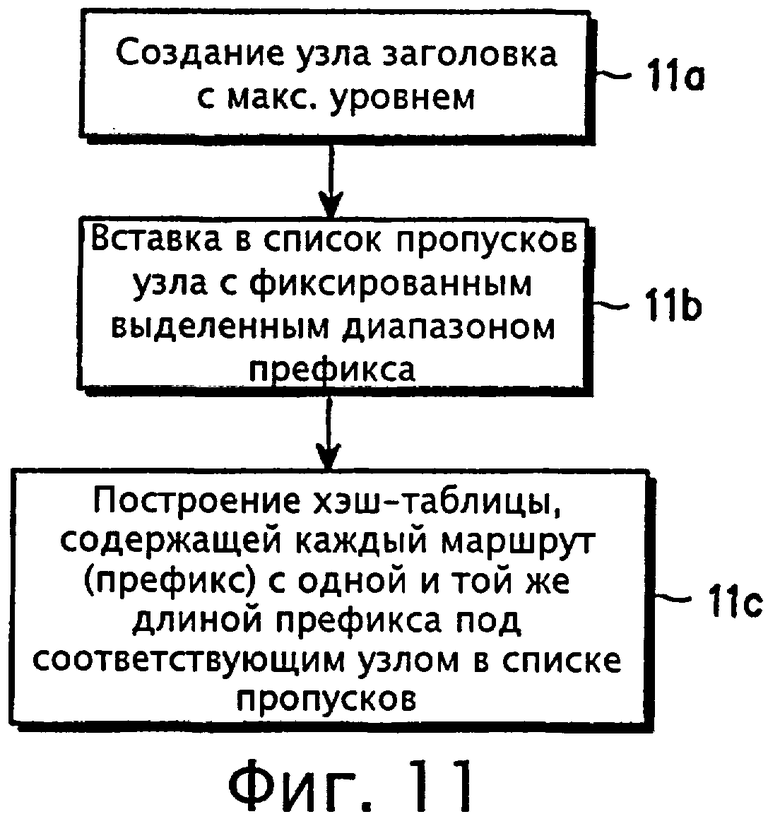
фиг.11 - блок-схема, иллюстрирующая процедуру создания таблицы маршрутизации согласно варианту осуществления настоящего изобретения;
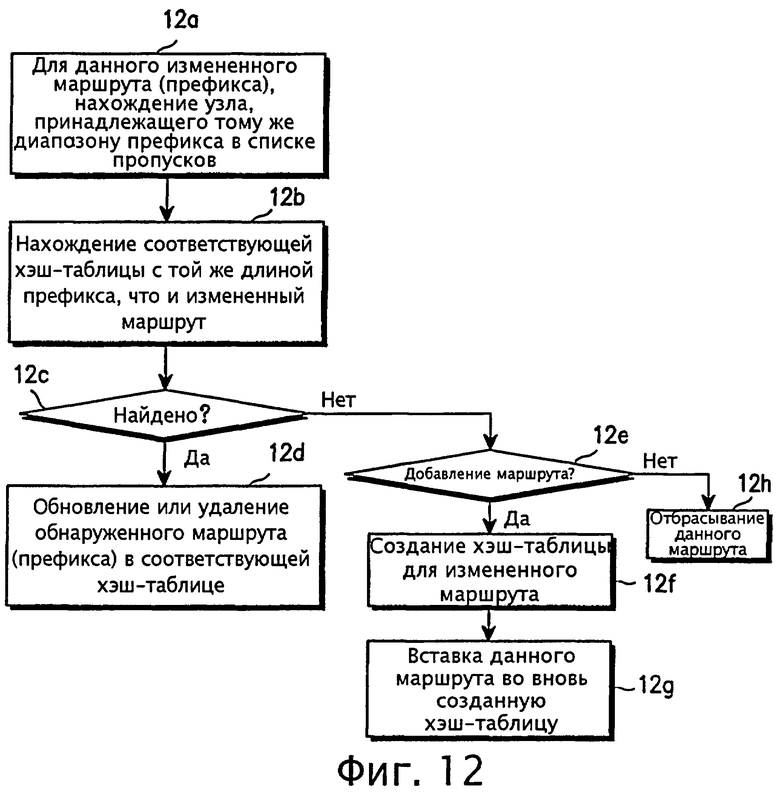
фиг.12 - блок-схема, иллюстрирующая процедуру обновления таблицы маршрутизации согласно варианту осуществления настоящего изобретения;
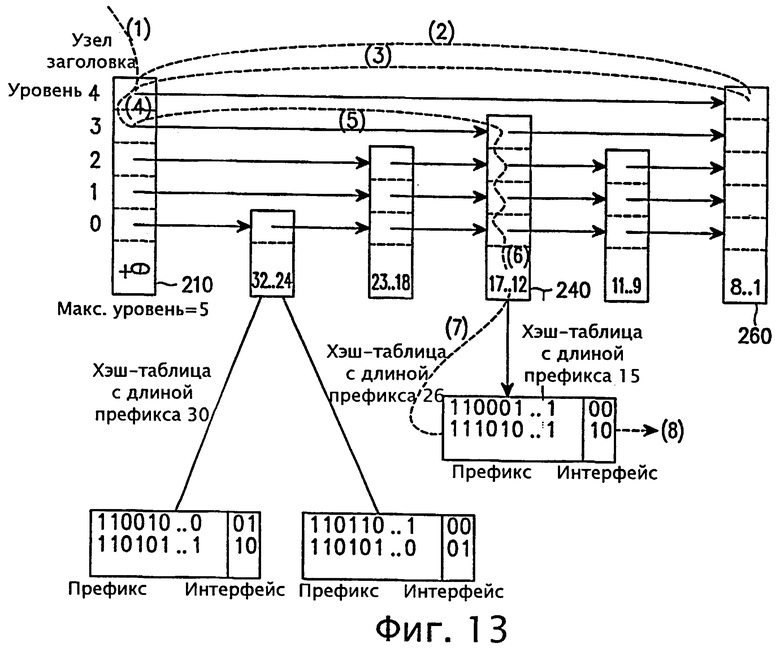
фигуры 13 и 14 - диаграммы, иллюстрирующие структуры списка пропусков для объяснения операций поиска и обновления маршрутов согласно варианту осуществления настоящего изобретения;
фиг.15 - блок-схема, иллюстрирующая процесс поиска маршрута согласно варианту осуществления настоящего изобретения; и
фиг.16 - диаграмма, иллюстрирующая структуру списка пропусков для объяснения полного процесса поиска согласно варианту осуществления настоящего изобретения.
Подробное описание предпочтительного варианта осуществления изобретения
Ниже со ссылками на чертежи описан предпочтительный вариант осуществления настоящего изобретения. В последующем описании известные функции и конструкции подробно не описываются, чтобы не затемнять сущность изобретения ненужными деталями.
Сначала описывается маршрутизатор и способ маршрутизации, к которому применимо настоящее изобретение. В работе Chan и др. (A Framework for Optimizing the Cost and Performance of Next-Generation IP Routers, IEEE Journal of Selected Areas, in Communications, Vol. 17, No.6, pages 1013-1029, June, 1999) классифицируют два главных варианта архитектуры высокоскоростного маршрутизатора: распределенная архитектура и параллельная архитектура, причем основное различие между ними определяется местоположением процессора пересылки. Тенденция развития структуры высокоскоростного магистрального маршрутизатора скорее направлена к распределенной, а не к известной централизованной архитектуре.
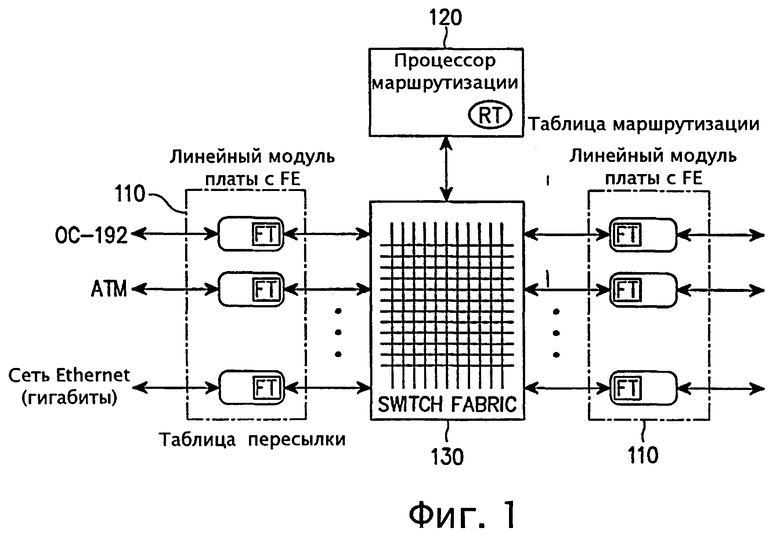
На фиг.1 показан маршрутизатор с распределенной архитектурой, к которой применимо настоящее изобретение. Согласно фиг.1 маршрутизатор включает в себя: линейный модуль платы 110, снабженный процессором пересылки FE, через который выполняется ввод и вывод пакетов; процессор маршрутизации 120 для построения начальной таблицы маршрутизации RT и управления таблицей маршрутизации и коммутационная структура 130, используемая при коммутации пакетов на определенный порт в маршрутизаторе.
Процессор маршрутизации 120 содержит таблицу маршрутизации RT, обновляемую путем отражения в ней последних измененных маршрутов. Таблица маршрутизации RT формируется на основе таких протоколов маршрутизации, как RIP (протокол маршрутной информации), OSPF (первоочередное открытие кратчайших маршрутов) или BGP-4 (пограничный межсетевой протокол 4), но список протоколов не ограничивается здесь указанными. Из таблицы маршрутизации в процессоре маршрутизации 120 копируется компактная таблица, называемая таблицей пересылки FT, которая предназначена для эффективного поиска. Таблица пересылки FT предназначается для эффективного поиска, что достигается за счет снижения эффективности добавлений и удалений маршрутов.
Если пакет, поступающий из линейного модуля платы 110, не может найти путь к месту своего назначения из таблицы пересылки FT, то соответствующий пакет должен пройти через коммутационную структуру 130 в процессор маршрутизации 120 для решения проблемы несогласованного маршрута. После нахождения места назначения пакет снова должен быть направлен в коммутационную структуру 130 для пересылки в выходной линейный модуль платы 110. В противном случае, если процессор маршрутизации 120 не может найти путь к месту назначения даже с помощью таблицы маршрутизации RT, то тогда такой пакет в процессоре маршрутизации 120 отбрасывается.
В работе Asthana, A., Delph, С., Jagadish, H. и Krzyzanowski, P., Towards a Gigabit IP Router, J. High Speed Network, vol. 1, no. 4, pages 281-288, 1992 и Partridge и др. (А 50-Gb/s IP Router, IEEE/ACM Trans. on Networking, vol. 6, no. 3, pages 237-248, 1998) раскрывается маршрутизатор с параллельной архитектурой. На фиг.2 показан маршрутизатор с параллельной архитектурой, к которому применимо настоящее изобретение. В маршрутизаторе с параллельной архитектурой, показанной на фиг.2, каждый процессор пересылки 112 с таблицей пересылки FT отделен от линейного модуля платы 110. В указанной параллельной архитектуре для поиска маршрутов и параллельной пакетной обработки в каждом механизме пересылки используется модель "клиент-сервер".
Таблица маршрутизации в процессоре маршрутизации 120 должна быть разработана таким образом, чтобы она была способна оперативно отражать изменения в маршрутах и легко их поддерживать. Кроме того, добавляемый или удаляемый маршрут должен отражаться в таблице пересылки FT в процессор пересылки 112 настолько быстро, насколько это возможно, и при минимальных затратах. Когда маршрут не отражен, входящий пакет пересылается в процессор маршрутизации 120 через коммутационную структуру 130, что приводит к увеличению задержки передачи из-за прохождения по дополнительному маршруту, необходимому при обработке соответствующего пакета.
Хотя изобретение описано со ссылками на распределенный маршрутизатор и параллельный маршрутизатор, специалистам в данной области техники очевидно, что изобретение можно использовать в маршрутизаторе, имеющем архитектуру других типов.
На фиг.3 показана структура процессора пересылки 112 в маршрутизаторе с распределенной или параллельной архитектурой. На фиг.4 показана структура процессора маршрутизации 120.
Согласно фиг.3 процессор пересылки 112 включает n входных интерфейсов, m выходных интерфейсов, n буферов для буферизации пакетов, вводимых через входные интерфейсы, классификатор пакетов для классификации пакетов, запоминаемых в буфере в соответствии с классами или типами, и контроллер поиска маршрутов для передачи пакетов, классифицированных с помощью таблицы пересылки и классификатора пакетов, на соответствующие выходные интерфейсы путем обращения к таблице пересылки.
Согласно фиг.4, процессор маршрутизации 120 включает в себя n входных/выходных интерфейсов для приема и выдачи пакетов от/на коммутационную структуру 130, показанную на фиг. 1 и 2, коммутационный интерфейс для буферизации пакетов, вводимых и выводимых через входные/выходные интерфейсы, и обеспечения взаимодействия между коммутационной структурой 130 и контроллером для поиска маршрутов и обслуживания на следующей ступени, причем контроллер для поиска маршрутов и обслуживания обеспечивает пересылку пакетов, подаваемых из таблицы маршрутизации и коммутационного интерфейса, на соответствующий входной/выходной интерфейс через коммутационный интерфейс путем обращения к таблице маршрутизации.
Согласно стандарту RFC таблица маршрутизации (или пересылки) не ограничивается ни структурами, такими как матрица, дерево и trie-структура, которые в основном и используют для поиска, ни алгоритмами, применяемыми для их обработки. Однако для совпадения по самому длинному префиксу требуется минимальное количество обращений к памяти, а измененные маршруты должны легко обновляться в таблице маршрутизации (или пересылки).
С этой целью в данном варианте настоящего изобретения используется рандомизированный алгоритм. Рандомизированный алгоритм - это алгоритм, реализующий случайный выбор в ходе своего выполнения. Алгоритм ориентирован на установление вероятности состояния каждого входа. То есть обработка конкретных входных данных основана не на определенной гипотезе, а на вероятности Р (например, на основе подбрасывания монеты). Преимущества использования рандомизированного алгоритма заключаются в его простоте и эффективности.
Использование алгоритма согласно настоящему изобретению, основанного на рандомизированном алгоритме, гарантирует минимальное количество обращений к памяти и простое управление таблицей маршрутизации. Для управления маршрутными записями реконструируется только информация об изменении маршрута в отличие от известного способа, согласно которому реконструируется вся таблица. Кроме того, в отличие от алгоритма поиска маршрута на основе общего дерева или двоичной trie-структуры, алгоритм согласно настоящему изобретению ищет самый длинный префикс с хвоста IP адреса назначения, как показано на фиг.5.
Кроме того, в настоящем изобретении используется список пропусков для таблицы маршрутизации (См. Pugh, W, Skip Lists: A Probabilistic Alternatives to Balanced Trees, CACM 33(6), pages 6689-676, 1990).
Список пропусков рассматривается как связный список с n отсортированными узлами и обычно используется в структуре данных типа сбалансированного дерева, к примеру скошенного дерева (См. Sleator, D. и Tarjan, R., Self-Adjusting Binary Search Trees, JACM, Vol. 32, No. 3, July, 1985). Такой подход проще и эффективнее, чем использование сбалансированного дерева, с точки зрения операций ввода и удаления. В настоящем изобретении предлагается вариант списка пропусков для сопоставления по самому длинному префиксу, как показано на фиг.6.
На фиг.6 показан вариант списка пропусков согласно варианту осуществления настоящего изобретения. Согласно фиг.6 каждый узел имеет один указатель или множество указателей, а крайний левый узел называется узлом заголовка 210, поскольку все операции согласно данному варианту списка пропусков, такие как поиск, вставки, удаления и обновления, должны начинаться с узла заголовка 210.
Узел заголовка 210 в качестве значения ключа содержит +∞ и указатель (указатели) для указания на следующий узел (узлы). Ключи в узлах 220, 230, 240, 250 и 260 отсортированы в убывающем порядке. Ключ в каждом узле означает "диапазон длины префикса" или "кластеризацию значения длины префикса", причем этот ключ вносится в убывающем порядке. В данном варианте изобретения поиск начинается от "листьев" к "корню" (или "родителю"), то есть в обратной последовательности значений ключа, что в корне отличается от способа на основе известных trie-структур или структур типа дерева.
Ключ второго узла 220 имеет диапазон длин префикса 32-24, и любой маршрут, имеющий длину префикса, принадлежащую этому диапазону длин префикса, запоминается в хэш-таблице, соответствующей его длине префикса. На фиг.6 показана хэш-таблица 222 с длиной префикса 30 бит и хэш-таблица 224 с длиной префикса 26 бит как пример хэш-таблиц маршрута, принадлежащего диапазону второго узла 220. Кроме того, на фиг.6 показана хэш-таблица 242 с длиной префикса 15 бит в качестве примера хэш-таблицы маршрута, принадлежащего диапазону четвертого узла 240 с диапазоном длин префикса 17-12.
Хотя на фиг.6 показан пример, где диапазоны длин префикса различных узлов привязаны к разным значениям длины, то есть пример диапазона префиксов с фиксированным разделением, в диапазоне длин префикса можно также выделить группу узлов с переменной длиной, то есть получить диапазон префиксов с непостоянным (переменным) разделением. В работе Srinivasan, V. и Varghese, G., "Faster IP Lookups using Controlled Prefix Expansion, In Proceedings of ACM sigmetrics '98 Conf., стр. 1-11, 1998, обсуждается способ динамического программирования для разделения диапазона префикса с целью оптимизации хранения данных. В алгоритме согласно настоящему изобретению группу длин префикса можно выделить, используя аналогичный способ. Однако в варианте осуществления настоящего изобретения, показанном на фиг.6, предпочтительно иметь фиксированный диапазон длин префикса, что позволяет избежать дополнительного использования вычислительных ресурсов из-за динамического программирования.
В случае использования IPv4, если диапазон длин префикса является фиксированным и равен 8, то тогда общее количество вводимых узлов может составить 5(1+[32/8] (где 32 - максимальное количество битов в адресе IPv4)). Как видно из эмпирических результатов, полученных от IPMA (Система измерений и анализа работы сети Интернет) (http://nic.merit.edu/ipma), распределение действительной базовой длины префикса носит асимметричный характер, то есть предполагает существование локальных особенностей в распределении базовой длины префикса. Следовательно, в настоящем изобретении можно использовать меньшее количество узлов. Например, из фиг.7А и 7В видно, что к длинам префикса от 17 до 27 обращаются чаще всего. Соответственно, можно установить один узел со значением ключа диапазона длин префикса, включающего соответствующую длину префикса, и установить множество узлов, соответствующих другому диапазону длин префикса.
Согласно фиг.6, переменная 'MaxLevel' узла заголовка 210 представляет значение максимального уровня среди всех узлов, принадлежащих списку пропусков, то есть общее количество указателей в узле заголовка, указывающих на другие узлы, при этом каждый узел поддерживает значение ключа 'x→key' (или key(x)) и указатель (указатели) 'x→forward [L]' (или next (xL)) для обозначения указателя от узла х для указания на соседний узел на уровне L узла х.
Каждый ключ в узле, кроме узла заголовка 210, имеет диапазон или набор длин префикса. На фиг.6 узел 220 имеет маршрутные записи, лежащие в диапазоне от 32 до 24, причем каждое значение длины префикса имеет свою собственную хэш-таблицу для запоминания маршрутных записей, совпадающих с соответствующей длиной префикса. Если имеются маршрутные записи, соответствующие каждому значению длины префикса в диапазоне от 32 до 24 включительно, то тогда соответствующий узел будет иметь девять (9) указателей, указывающих на девять (9) разных хэш-таблиц. В каждой хэш-таблице хранятся только те маршрутные записи, которые точно соответствуют длине префикса. По этой причине этот вариант списка пропусков называют списком пропусков с k-нарным хэшированным узлом (узлами).
Алгоритм на основе списка пропусков согласно настоящему изобретению поясняется в последующем описании способа создания узла заголовка и построения вариантного списка пропусков.
На фиг.8 представлена диаграмма, поясняющая способ создания узла заголовка согласно варианту осуществления настоящего изобретения. Согласно фиг.8 узел заголовка имеет значение ключа +∞, a MaxLevel=5, (1+[32/8]), где MaxLevel=1+[W/n], W - длина IP адреса в битах, например, для IPv4 - 32, а для IPv6 - 128; a n - диапазон префикса. Поскольку узел заголовка должен покрыть все узлы исключительно в пределах списка пропусков, в случае использования версии IPv4 значение MaxLevel=33 подходит для структур данных, содержащих до 232 маршрутов, если вероятность р равна 1/2, а диапазон префикса равен 1. Узел заголовка имеет прямые указатели MaxLevel, проиндексированные от 0 до MaxLevel-1. В данном варианте настоящего изобретения из-за использования кластеризации диапазона префикса потребуется MaxLevel=5 в предположении, что фиксированный диапазон префикса равен 8.
После создания узла заголовка строится вариант списка пропусков, как показано на фиг.9, где раскрывается операция построения списка пропусков согласно варианту осуществления настоящего изобретения. Если указатель верхнего уровня в узле заголовка нулевой, то есть если нет соседних узлов, или, другими словами, подузлов, соединенных с указателями узла заголовка, то уровень уменьшают на 1, пока указатель не укажет на соседний узел. Как показано на фиг.9, создается первый узел (а) со значением диапазона префикса 32-24, где указатель уровня 0 в узле заголовка указывает на первый узел. После этого последовательно создаются второй узел (b) с диапазоном префикса 23-18 и третий узел (с) с диапазоном префикса 17-12. В ходе этого процесса создается множество узлов, покрывающих каждый диапазон длины префикса.
Уровень каждого созданного узла устанавливается случайным образом с использованием рандомизированного алгоритма, показанного ниже в Программе 3 согласно настоящему изобретению. Сначала формируется значение случайного действительного числа в интервале (0,1). Если сформированное значение действительного случайного числа меньше заранее установленного эталонного значения вероятности (здесь эталонное значение вероятности устанавливается равным р=1/2 для создания идеального списка пропусков), и уровень соответствующего создаваемого узла также меньше, чем MaxLevel, то тогда уровень соответствующего узла увеличивают. В противном случае создается узел, имеющий значение уровня 0.
После построения узлов с диапазонами префикса в списке пропусков необходимо построить таблицу маршрутизации, содержащую маршрутные записи. Далее со ссылками на фиг.10А описывается способ построения таблицы маршрутизации в случае, когда маршрутизатор имеет маршруты с длиной префикса 30.
Согласно фиг.10А, если маршрутизатор имеет маршруты с длиной префикса 30, то ведется поиск в первом узле 220 с диапазоном длин префикса 32-24, а затем добавляемые маршрутные записи вводятся в виде хэш-таблицы. Узел в списке пропусков может иметь разные хэш-таблицы в зависимости от диапазона длин префикса. Согласно этой процедуре, добавляются маршруты с длиной префикса 15, как показано на фиг.10В, где хэш-таблица с длиной префикса 15 создается под узлом 240 с диапазоном префикса 17-12.
Последовательность выполнения процедур создания таблицы маршрутизации согласно варианту осуществления настоящего изобретения представлена на фиг.11. На шаге 11а создается узел заголовка с MaxLevel для покрытия всех узлов в списке пропусков. Затем на шаге 11b в список вставляются узлы с фиксирование разделенным диапазоном префикса. Хотя для простоты в изобретении предполагается использование фиксированного разделения диапазона префикса, можно также допустить использование адаптивного разделения, отражающего действительное распределение длины префикса. После этого на шаге 11с для каждой данной маршрутной записи создается хэш-таблица под узлом с соответствующим диапазоном префикса. Новая схема согласно настоящему изобретению обеспечивает поиск, начиная с маршрутов, имеющих максимальную длину префикса, в отличие от поиска, начинающегося с самых коротких маршрутов, как это имеет место в известных trie-структурах и древовидных структурах.
Маршрутизатор часто получает изменения маршрутов от подсоединенного к нему маршрутизатора (маршрутизаторов). Эти изменения должны найти свое отражение в текущей таблице маршрутизации (или пересылки). Последовательность шагов обновления по новой схеме представлена на фиг.12. Для данного измененного маршрута (префикса), отражаемого в таблице маршрутизации, на шаге 12а узел, соответствующий данной длине префикса, должен быть отброшен. Далее на шаге 12b выполняется поиск в хэш-таблице, соответствующей длине префикса, равной длине префикса измененного маршрута. Если на шаге 12с соответствующая хэш-таблица найдена, то выполняется переход к шагу 12d, где отброшенный маршрут в соответствующей хэш-таблице обновляется или удаляется. Если на шаге 12с выясняется, что искомая хэш-таблица не существует, то тогда следующим выполняется шаг 12е. Если маршрут должен быть добавлен, то тогда выполняется переход к шагу 12f, где создается хэш-таблица, имеющая длину префикса, равную длине префикса измененного маршрута. Затем на шаге 12d измененный маршрут вводится во вновь созданную хэш-таблицу. В противном случае измененный маршрут на шаге 12h отбрасывается.
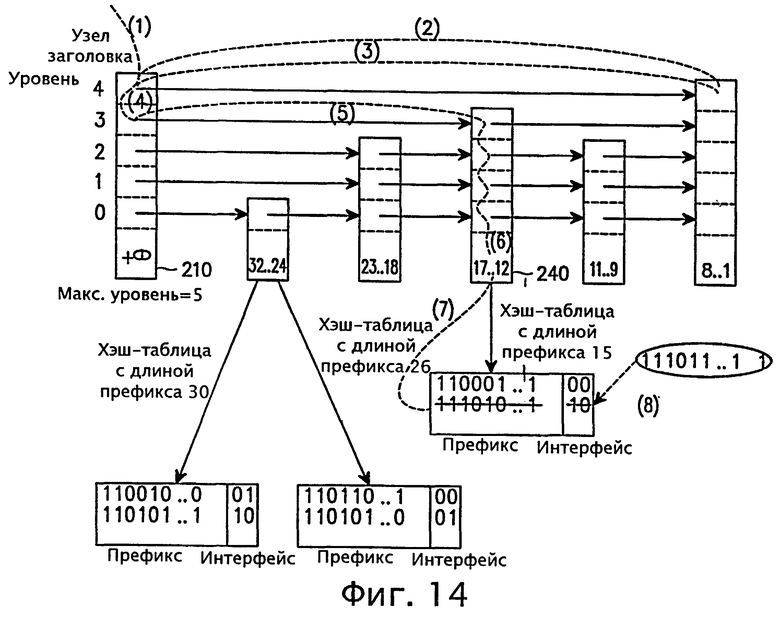
На фиг.13 и 14 представлены диаграммы, раскрывающие процедуры поиска и обновления маршрутов согласно варианту осуществления настоящего изобретения.
Со ссылками на фиг.13 ниже описана процедура поиска маршрута с длиной префикса 15. Необходимо найти узел с той же длиной префикса (15). Поиск начинается с верхнего уровня (то есть уровня 4) узла заголовка 210 (последовательность (1) на фиг.13). Указатель уровня 4 указывает на следующий узел, имеющий уровень 4, то есть узел 260 с диапазоном (ключом) длины префикса 8-1 (последовательность (2) на фиг.13). После этого выполняется сравнение длины префикса маршрута с ключом узла 200. Значение ключа не совпадает, и поиск возвращается на тот же уровень (то есть уровень 4) узла заголовка 210 (последовательность (3) на фиг.13). Уровень узла заголовка 210 уменьшается на единицу (последовательность (4) на фиг.13), и указатель следующего уровня (уровень 3) указывает на следующий узел, имеющий уровень 3, то есть узел 240 с ключом 17-12 (последовательность (5) на фиг.13). Когда в узле 240 обнаруживается совпадающее значение ключа (последовательность (6) на фиг.13), выполняется поиск в хэш-таблице, соответствующей длине префикса измененного маршрута (последовательность (7) на фиг.13). Если хэш-таблица существует, то выполняется следующий переход (последовательность (8) на фиг.13). Если хэш-таблица не существует, то для добавления нового маршрута она должна быть создана.
На фиг.14 показаны несколько последовательностей, где маршрут, имеющий префикс '111010...1' с интерфейсом следующего транзита '10' должен быть удален из хэш-таблицы, либо заменен на '111011...1' со следующим транзитом '1'. Процедура поиска соответствующего префикса (111010...1) выполняется таким же образом, как показано на фиг.13.
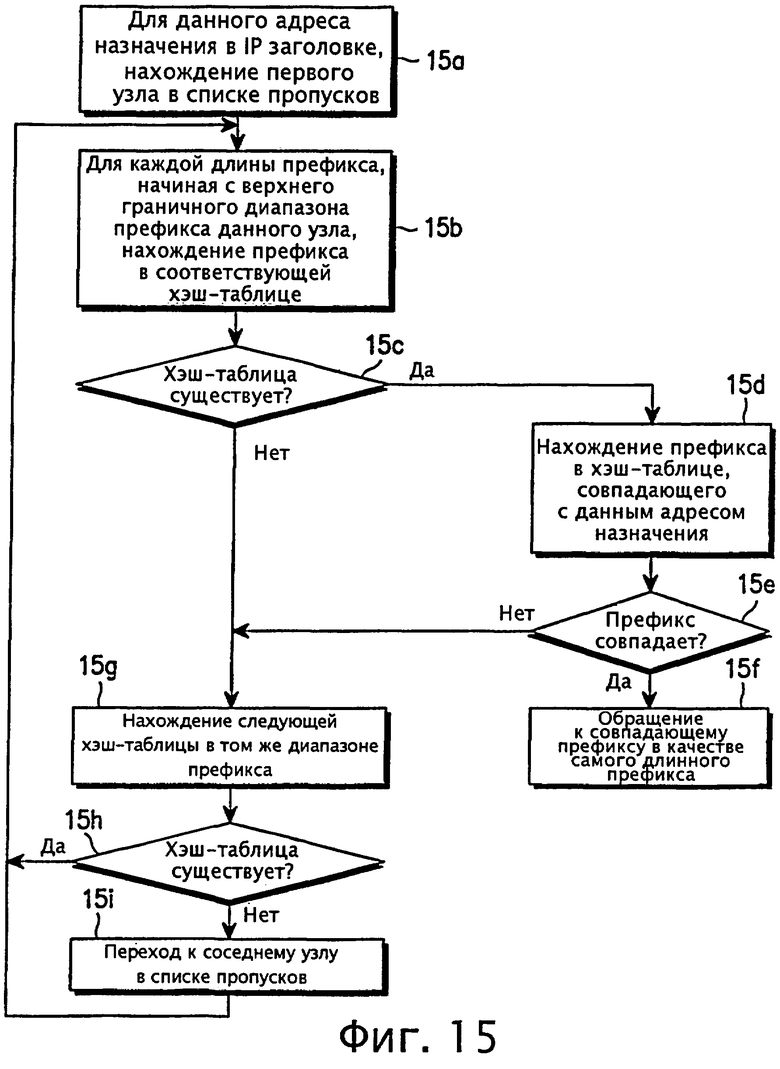
Со ссылками на фиг.15 и 16 ниже описана процедура поиска маршрута для отыскания маршрута по конкретному IP адресу назначения на основе таблицы маршрутизации.
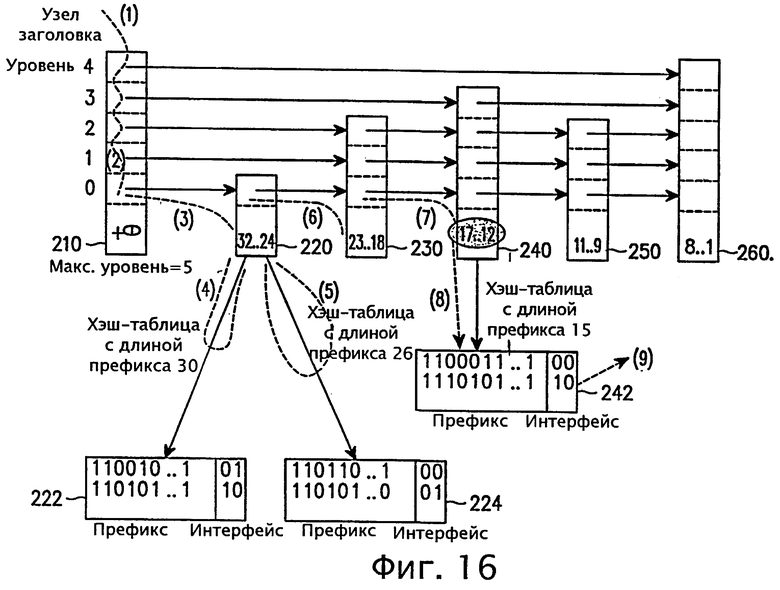
На фиг.15 и 16 показана процедура поиска маршрута, определенная как схема совпадения по самому длинному префиксу, согласно варианту осуществления настоящего изобретения. Поиск на основе схемы совпадения по самому длинному префиксу означает, что маршрутная запись должна сравниваться по самому длинному префиксу, например с длиной префикса 32 в версии IPv4. На фиг.16 представлена диаграмма, объясняющая всю схему поиска согласно варианту осуществления настоящего изобретения, где адрес назначения имеет длину префикса 15 '1110101...1'.
На шаге 15а (фиг.15) для данного адреса назначения, заключенного в IP заголовке, просматривают первый узел в списке пропусков, начиная тем самым просмотр маршрута, заданного адресом назначения (последовательность (1) на фиг.16) с уровня 4 узла заголовка 210, а уровень в узле заголовка 210 снижают на единицу до уровня 0 (последовательность (2) на фиг.16), причем уровень 0 имеет указатель, указывающий на первый узел 220 (последовательность (3) на фиг.16).
Затем на шаге 15b выполняют поиск по хэш-таблицам первого узла 220, начиная с верхнего значения ключа диапазона длин префикса, например 32 (текущая длина префикса). Если кэш-таблицы не существует, процедура переходит к шагу 15g. В противном случае, когда хэш-таблица на шаге 15с существует, выполняется переход к шагу 15d. На шаге 15d выполняют поиск среди префиксов в найденной хэш-таблице префикса, соответствующего адресу назначения. Если оказывается, что найденный префикс совпадает с адресом назначения (шаг 15е), то совпавший префикс возвращается как самый длинный префикс на шаге 15f. В то же время, если на шаге 15е префикс не совпал, то процедура продолжается на шаге 15g.
На шаге 15g обнаруживают следующую хэш-таблицу в том же диапазоне префикса. Если следующая хэш-таблица на шаге 15h существует, то процедура возвращается к шагу 15b для повторения вышеописанного процесса. Если на шаге 15h следующей хэш-таблицы не существует, то выполняется переход к шагу 15i, где осуществляют переход к соседнему узлу в списке пропусков, а затем процедура возвращается к шагу 15b для повторения вышеописанного процесса в соседнем узле. Как было описано выше, в отличие от известной схемы поиска, начинающегося с корневого узла, новая схема основана на поиске, начинающемся от самого длинного диапазона префикса с его хэш-таблицей.
Согласно фиг.16, сначала выполняется поиск в списке пропусков узла, как было описано ранее, причем поиск маршрута, заданного адресом назначения, начинается с узла заголовка (последовательность (1) на фиг.16). Уровень в узле заголовка 210 уменьшается до уровня 0 (последовательность (2) на фиг.16), где указатель указывает на узел, имеющий самый длинный диапазон префикса, а затем переходят к первому узлу 220, указанному указателем узла заголовка 210 (последовательность (3) на фиг.16). Затем выполняют поиск в первом узле 220 для нахождения хэш-таблицы, содержащей префиксы длиной 32. Если соответствующая таблица найдена, то тогда адрес назначения сравнивают с префиксами в хэш-таблице с целью обнаружения совпадения. Если в первом узле 220 хэш-таблица, содержащая префиксы длиной 32, не найдена, то, поскольку каждый узел в списке пропусков поддерживает матрицу указателей, которая указывает на каждую хэш-таблицу в диапазоне префикса узлов, то при отсутствии хэш-таблицы, содержащей префиксы длиной 32, соответствующий указатель окажется нулевым.
В примере на фиг.16 первый узел 220 имеет только две хэш-таблицы 222 и 224, соответствующие длине префикса 30 и длине префикса 26 соответственно. Поэтому, когда выполняется поиск в первом узле 220 для нахождения хэш-таблицы, проверяется каждый указатель в диапазоне префикса, причем указатели с нулевым значением пропускаются. Хэш-таблицы, соответствующие указателям с ненулевым значением, сравнивают с исходным адресом назначения для обнаружения совпадения.
Таким образом, первый указатель с ненулевым значением будет указывать на хэш-таблицу 222, и адрес назначения сравнивают с префиксами в хэш-таблице 222 (последовательность (4) на фиг.16). Если адрес назначения в хэш-таблице 222 не найден, то тогда с адресом назначения сравнивают следующую хэш-таблицу с ненулевым указателем, то есть хэш-таблицу 224 с длиной префикса 26 (последовательность (5) на фиг.16). Если адрес назначения все еще не найден и больше нет хэш-таблиц в первом узле 220, то тогда поиск для узла 220 оказывается безуспешным.
Если поиск для узла 220 безуспешен, то отыскивается указатель, указывающий на следующий узел в списке пропусков, имеющий следующий самый длинный диапазон префикса. В данном примере имеется указатель, показывающий, что следующим узлом в списке пропусков со вторым по длине диапазоном префикса является узел 230 (последовательность (6) на фиг.16). Соответственно, проверяют узел 230, чтобы выяснить, есть ли у него какие-либо хэш-таблицы, а поскольку их нет, выполняется поиск указателя в узле 230, указывающего на следующий узел в списке пропусков.
В данном случае выполняется переход к соседнему узлу 240 в списке пропусков (последовательность (7) на фиг.16), и обнаруживается указатель, указывающий на хэш-таблицу 242, в соответствии с шагами, показанными на фиг.15. Адрес назначения сравнивают с префиксами в хэш-таблице 242, имеющими длину 15 (последовательность (8) на фиг.16). При совпадении операция поиска маршрута успешно завершается (последовательность (9) на фиг.16). Если адрес назначения не найден даже в последней хэш-таблице последнего узла 260, то поиск заканчивается безуспешно, и пакет с соответствующим адресом отсылается по маршруту вместе с записью маршрута по умолчанию.
Структуры списка пропусков представлены в Программах 1, 2 и 3; процедуры отражения изменений в маршрутных записях в списке пропусков показаны в Программах 4, 5, 6 и 7; а основная часть нового алгоритма поиска маршрута показана в Программе 8.
Программа 1: Операция построения
var рх: bitstring init b'0'; (*префикс*)
interface: integer init 0; (*интерфейс следующего транзита *)
W: integer init 32; (* # адресных битов, IPv4 *]
k: integer init 8; (* фиксированный диапазон префикса, например, 8 или переменный диапазон префикса от 0 до W"*)
hrange: integer init W; (* верхняя граница диапазона префикса *)
Irange: integer-init W-k+1; (* нижняя граница диапазона префикса *)
MaxLevel: integer init [lg(W/k)]; (* в предположении, что р=1/2 (где р - вероятность, определяющая возможность создания узла с более высокими уровнями) *)
Buildup(list) (* построение списка пропусков *)
begin
L :=[W/k] (* L - целое число, равное предельному значению W/k и ближайшее к количеству создаваемых узлов *);
while L≥0 do
Insert_Node [list, hrange, Irange);
L :=L-1
hrange :=-Irange-1; - -
Irange :==Irange-k+1;
end while
end
Программа 2: Вставка узла в список пропусков
Insert-Node (list, hrange, Irange) (* вставка узла *)
begin
update [0..MaxLevel];
x :=list≥→header
for i :=list→level downto 0 do
while [hrange, Irange]∈x→forward [i]→key do
x :=x→forward [i]
end•while
update [i] :=x;
end for
x :=x→forward [0];
if[hrange, Irange}ex→key then
x→value:=[hrange, Irange];
else
v :=RandomLevel()
if v>list→level then
for i :==list→level+1 to v do
update[i] :=list→header;
end for
list→level :=v,
end if
x:=MakeNode (y, [hrange, Irange});
for i :=0 to level do
x→forward[i] :=update[i]→forward[i];
update [i]→forward [i] :=x;
end for
end if
end
Программа 3: Уровень рандомизации
RandomLevel() (* рандомизация уровня узла *)
begin
v:=0;
r :=Random (); (* r∈[0, 1) *)
while r<р and v<MaxLevel do
v.=v+l; - -
end while
return v;
end
Программа 4: Операция поиска
Search (list, px) (* поиск узла с префиксом рх в списке пропусков *)
begin
х :=list→header;
for i :=list→-level downto 0 do
while px∈х→forward[i]→key do
x : = x→forward[i];
end while
end for
x := x→forward [0];
if x→key=px then
for j: :=hrange downto Irange-1 do
if hash-get (j, px);
return hash-get (j, px);
end if
end for
return error
end if
end
Программа 5: Операция вставки
Insert(list, prefix, interface) (* вставка маршрутной записи *)
begin
if hash-insert (list, prefix, interface] then
else
return error;
end if
end
Программа 6: Операция удаления
Delete[list, prefix, interface) (* удаление
маршрутной записи *)
begin
if search (list, prefix) then - -
hash-delete (prefix, interface);
else
return error;
end if
end
Программа 7: Обновление маршрутной записи
Update(list, prefix, interface) (* обновление маршрутной
записи *)
begin
if search (list, prefix) then
hash-update (prefix, interface);
else
return error;
end if
end
Программа 8: Операция поиска
Lookup(list, destaddr) (* поиск маршрута с помощью самого длинного префикса *)
begin
х :=list→header;
х: =х→forward[0];
for i :=[W/k] downto 0 do
for j :=hrange downto lrange-1 do
if compare(destaddr, hash-get (j, destaddr)) then
return hash-get (j, destaddr);
end if
end for
x : = x→forward[i];
end for
return error;
end
Ниже со ссылками на чертежи оценивается эффективность способа маршрутизации согласно настоящему изобретению. На фиг.7А и 7В изображены графики, представляющие распределение измеренных значений длины префикса в сети Интернет. Данные, представленные графиками на фиг.7А и 7В, собраны в MAE-EAST NAP (точка доступа к сети) в рамках проекта IPMA (Измерения и анализ рабочих характеристик сети Интернет).
Статистические данные, собранные в проекте IPMA, широко используются как исходные данные для сравнительного анализа результатов поиска, выполняемого разработчиками алгоритмов поиска маршрутов. В настоящее время маршрутизатор в MAE-EAST NAP содержат максимальное количество маршрутных записей и используются главным образом в качестве модели магистрального маршрутизатора. PAIX NAP содержит минимальное количество маршрутных записей, собранных в текущем проекте IPMA, и используется главным образом в качестве модели маршрутизатора предприятия.
На фиг.7А и 7В изображены локальные диаграммы, показывающие, что наиболее часто повторяются значения длины префикса, лежащие в диапазоне 16-28. Таким образом, данные наблюдений показывают, что количество узлов, которые должны находиться в модифицированном списке пропусков, предложенном в изобретении, может быть значительно уменьшено. Другим интересным моментом в IPMA (http://nic.merit.edu/ipma) является то, что количество маршрутных префиксов, добавленных или изъятых в соответствии с протоколом BGP (Пограничный межсетевой протокол) за один день, достигает 1899851 (как для 1 ноября 1997). Это значит, что требуется 25 обновлений префиксов в секунду, и быстрое отражение каждого измененного маршрутного префикса в таблице маршрутизации (или пересылки) становится важным фактором, влияющим на время поиска.
Со ссылками на таблицу 2 ниже приведено сравнение нового алгоритма с известными алгоритмами. В общем случае при оценке того или иного алгоритма для наихудшего случая сравнивается время, необходимое для обработки соответствующего алгоритма, либо требуемый объем памяти, с использованием записи "большое О" (определяющей время выполнения алгоритма). В таблице 2 дана оценка сложности нового алгоритма согласно настоящему изобретению, где имеется N маршрутных записей, для выражения каждого адреса требуется W адресных бит, a k является константой, зависящей от алгоритма.
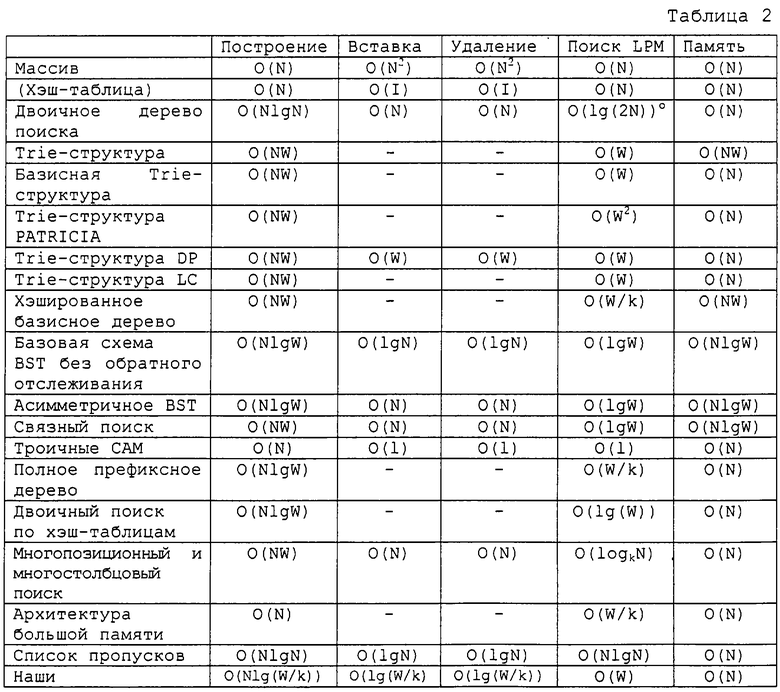
В таблице 2, чтобы избежать путаницы с другими логарифмами с основанием 10, "lg" обозначает логарифм с основанием 2.
В случае версии IPv4 W соответствует 32, а для IPv6 соответствует 128. В MAE-EAST и PAIX NAP количество N маршрутных записей составляет примерно 50000 и 6000 соответственно. В данном случае k в списке пропусков с k-нарными хэшированными узлами составляет 4, если диапазон префикса равен 8. В случае IPv6 он составит 16.
Новый алгоритм лучше, чем известный алгоритм, основанный на дереве поиска и trie-структуры (trie-структура Patricia или trie-структура LC) применительно к операциям построения таблицы маршрутизации, вставки и удаления. Кроме того, новый алгоритм согласно настоящему изобретению превосходит алгоритм двоичного поиска на основе хэш-таблиц (Waldvogel, М., Varghese, G., Turner, J. и Planner, В., Scalable High Speed IP Routing Lookups, In Proceedings of ACM SIGCOMM '97, Cannes, France, pages 25-37, 1997) и алгоритм на основе полной префиксной trie-структуры (Tzeng, H. и Pryzygienda, Т., On Fast Address-Lookup Algorithms, IEEE Journal on Selected Areas in Communications, Vol. 17, No. 6, pages 1067-1082, June, 1999) с точки зрения времени построения и операции вставки или удаления. Из таблицы 2 видно, что результаты оценки сложности показывают превосходство нового алгоритма над алгоритмом на основе чистого списка пропусков.
Как было описано выше, алгоритм согласно настоящему изобретению создает узлы в соответствии с диапазоном префикса IP адреса, используя список пропусков и хеш-таблицу, что составляет рандомизированный алгоритм. Кроме того, настоящее изобретение обеспечивает способ маршрутизации, использующий список пропусков, в котором маршрутные записи запоминаются в виде хэш-таблицы в соответствии с длиной префикса, установленной в каждом узле, в результате чего минимизируется время поиска маршрута и обеспечивается эффективное управление соответствующей таблицей. Таким путем можно выполнять высокоскоростной поиск маршрута. Данный алгоритм также можно применить для версии IPv6, которая будет использоваться в маршрутизаторе следующего поколения.
Из результатов оценки сложности следует, что новый алгоритм превосходит другие известные алгоритмы в любом аспекте, особенно с точки зрения операций построения таблицы маршрутизации (или пересылки), а также вставки и удаления. Кроме того, с учетом существующей тенденции развития современных архитектур, таких как распределенная архитектура маршрутизатора или параллельная архитектура маршрутизатора, где таблица пересылки в процессоре пересылки отделена от таблицы маршрутизации в процессоре маршрутизации, путем передачи на маршрутизатор вместе с соответствующими путями только обновленных маршрутов вместо всех маршрутных записей можно разгрузить память или разрешить конфликтные ситуации в системных шинах. Уменьшение времени поиска и поддержание согласованной информации о маршрутах по всем связанным таблицам маршрутизации может способствовать улучшению других показателей, таких как качество обслуживания (QoS), групповое вещание, протокол IPSec и др.
Хотя изобретение было продемонстрировано и описано со ссылками на конкретный предпочтительный вариант его осуществления, специалистам в данной области техники очевидно, что в него могут быть внесены различные изменения по форме и в деталях в рамках сущности и объема изобретения, определенного в прилагаемой формуле изобретения.
Изобретение относится к способам маршрутизации для пересылки пакетов по месту назначения в сети Интернет и может быть использовано, в частности, при выполнении высокоскоростного поиска IP (протокол Интернет) маршрута и при управлении таблицей маршрутизации или пересылки. Его использование позволяет получить технический результат в виде снижения времени доступа к памяти и ее эффективного использования, упрощения изменения маршрутов и управления операциями добавления и удаления маршрутов, эффективного построения таблицы маршрутизации и/или таблицы пересылки без сортировки подходящих маршрутов в соответствии с длиной префикса маршрутов, вводимых в процессе построения таблиц. Технический результат достигается за счет того что способ формирования таблиц маршрутизации/пересылки для поиска адреса протокола Интернет (IP-адреса) с использованием списка пропусков включает этапы разделения диапазона длин префикса IP-адреса заранее установленным способом, создания узла заголовка, имеющего максимальный уровень, на основе ряда кластеров, выделенных в диапазоне длин префикса, причем узел заголовка указывает каждый узел в списке пропусков, и создания подузлов с помощью ряда выделенных кластеров, причем каждый из подузлов имеет в качестве ключа выделенный диапазон длин префикса. 7 н. и 29 з.п. ф-лы, 2 табл., 18 ил.
| RU 95108549 A1, 10.02.1997 | |||
| СПОСОБ ПЕРЕДАЧИ СООБЩЕНИЙ ЭЛЕКТРОННОЙ ПОЧТЫ В ЛОКАЛЬНОЙ СЕТИ И УСТРОЙСТВО ДЛЯ ОСУЩЕСТВЛЕНИЯ СПОСОБА | 1996 |
|
RU2144270C1 |
| WO 00/24159 А2, 27.04.2000 | |||
| US 6065064 А, 16.05.2000 | |||
| JP 2000151691 А, 30.05.2000. | |||

