УРОВЕНЬ ТЕХНИКИ
В настоящее время корпоративная сеть организации является магистралью связи, которая надежно соединяет различные офисы и подразделения корпорации. Эта сеть обычно представляет собой глобальную сеть (WAN), которая соединяет (1) пользователей в филиальных офисах и региональных кампусах, (2) корпоративные дата-центры, в которых размещаются бизнес-приложения, интрасети и соответствующие им данные, и (3) глобальный Интернет через корпоративные файрволы и DMZ (демилитаризованную зону). Сети организации включают в себя специализированное оборудование, такое как коммутаторы, маршрутизаторы и мидлбокс-устройства, соединенные дорогостоящими арендованными линиями, такими как Frame Relay и MPLS (многопротокольная коммутация по меткам).
За последние несколько лет произошла смена парадигмы в том, как корпорации обслуживают и потребляют сервисы связи. Во-первых, революция мобильности позволила пользователям получать доступ к сервисам из любого места в любое время с помощью мобильных устройств, в основном смартфонов. Такие пользователи получают доступ к сервисам для бизнеса через общедоступный Интернет и сотовые сети. В то же время сторонние вендоры SaaS (программного обеспечения как сервиса) (например, Salesforce, Workday, Zendesk) заменили традиционные локальные приложения, а другие приложения, размещенные в частных дата-центрах, были перемещены в общедоступные облака. Несмотря на то, что этот трафик по-прежнему передается внутри сети организации, значительная его часть исходит и заканчивается за пределами периметра корпоративной сети и должна пересекать как общедоступный Интернет (один или два раза), так и корпоративную сеть. Недавние исследования показали, что 40% корпоративных сетей сообщают, что процент транзитного трафика (т.е. Интернет-трафика, наблюдаемого в корпоративной сети) превышает 80%. Это означает, что большая часть корпоративного трафика проходит как по дорогим выделенным линиям, так и по потребительскому Интернету.
В качестве сервиса, ориентированного на потребителя. Интернет сам по себе является плохой средой для бизнес-трафика. Ему не хватает надежности, гарантий QoS (качества сервисов) и безопасности, ожидаемых от критически важных бизнес-приложений. Кроме того, постоянно растущие потребности потребителей трафика, правила сетевой нейтральности и технологии обхода Интернета, созданные крупными игроками (например, Netflix, Google, общедоступными облаками), снизили денежную отдачу на единицу трафика. Эти тенденции уменьшили стимулы провайдеров сервисов к быстрому удовлетворению запросов потребителей и предложению соответствующих сервисов для бизнеса.
В условиях роста общедоступных облаков корпорации переносят большую часть своей вычислительной инфраструктуры в дата-центры общедоступных облаков. Провайдеры общедоступных облаков были в авангарде инвестиций в вычислительную и сетевую инфраструктуру. Эти облачные сервисы создали множество дата-центров по всему миру, при этом в 2016 году Azure, AWS, IBM и Google расширились соответственно до 38, 16, 25 и 14 регионов мира. Каждый провайдер общедоступного облака связал свои собственные дата-центры с помощью дорогостоящих высокоскоростных сетей, которые используют темное волокно и подводные кабели, развертываемые подводными лодками.
В настоящее время, несмотря на эти изменения, политика корпоративных сетей зачастую вынуждают весь корпоративный трафик проходить через свои безопасные шлюзы WAN. По мере того, как пользователи становятся мобильными, а приложения переносятся в SaaS и общедоступные облака, корпоративные WAN становятся дорогостоящими обходными путями, замедляющими все корпоративные коммуникации. Большая часть корпоративного трафика WAN поступает из Интернета или направляется в Интернет. Альтернативные безопасные решения, которые отправляют этот трафик через Интернет, не подходят из-за своей плохой и ненадежной работы.
КРАТКОЕ СОДЕРЖАНИЕ
Некоторые варианты осуществления создают для организации виртуальную сеть поверх нескольких дата-центров общедоступных облаков одного или более провайдеров общедоступных облаков в одном или более регионах (например, в нескольких городах, штатах, странах и т.д.). Пример организации, для которой может быть создана такая виртуальная сеть, включает в себя коммерческую организацию (например, корпорацию), некоммерческую организацию (например, больницу, исследовательскую организацию и т.д.) и образовательную организацию (например, университет, колледж и т.д.) или любой другой тип организации. Примеры провайдеров общедоступных облаков включают в себя Amazon Web Services (AWS), Google Cloud Platform (GCP), Microsoft Azure и т.д.
В некоторых вариантах осуществления высокоскоростные надежные частные сети соединяют два или более дата-центров общедоступных облаков (общедоступные облака) друг с другом. Некоторые варианты осуществления определяют виртуальную сеть как оверлейную сеть, которая охватывает несколько общедоступных облаков для соединения одной или нескольких частных сетей (например, сетей внутри филиалов, подразделений, отделов организации или связанных с ними дата-центров), мобильных пользователей, машин провайдеров SaaS (программного обеспечения как сервиса), машин и/или сервисов в общедоступном(ых) облаке(ах) и других web-приложений друг с другом.
В некоторых вариантах осуществления виртуальная сеть может быть сконфигурирована для оптимизации маршрутизации сообщений с данными организации к их пунктам назначения для достижения наилучшей сквозной производительности, надежности и безопасности при стремлении минимизировать маршрутизацию этого трафика через Интернет. Кроме того, в некоторых вариантах осуществления виртуальная сеть может быть сконфигурирована для оптимизации обработки уровня 4 потоков сообщений с данными, проходящих через сеть. Например, в некоторых вариантах осуществления виртуальная сеть оптимизирует сквозную скорость ТСР-соединений (TCP - протокол управления транспортом) за счет разделения механизмов управления скоростью по пути соединения.
Некоторые варианты осуществления создают виртуальную сеть в результате конфигурирования нескольких компонентов, которые развернуты в нескольких общедоступных облаках. В некоторых вариантах осуществления эти компоненты включают в себя программные агенты измерений, программные элементы пересылки (например, программные маршрутизаторы, коммутаторы, шлюзы и т.д.), прокси-серверы соединений уровня 4 и машины мидлбокс-обслуживания (например, устройства, VM, контейнеры и т.д.). В некоторых вариантах осуществления один или более из этих компонентов используют стандартизированные или общедоступные решения, такие как Open vSwitch, OpenVPN, strong Swan и Ryu.
Некоторые варианты осуществления используют логически централизованный кластер контроллеров (например, набор из одного или более серверов контроллеров), который конфигурирует компоненты общедоступных облаков для реализации виртуальной сети поверх нескольких общедоступных облаков. В некоторых вариантах осуществления контроллеры в этом кластере находятся в разных местоположениях (например, в разных дата-центрах общедоступных облаков), чтобы улучшить избыточность и высокую доступность. В некоторых вариантах осуществления кластер контроллеров увеличивает или уменьшает число компонентов общедоступных облаков, которые используются для создания виртуальной сети, или вычислительных или сетевых ресурсов, выделенных этим компонентам.
Некоторые варианты осуществления создают разные виртуальные сети для разных организаций поверх одного и того же набора общедоступных облаков одних и тех же провайдеров общедоступных облаков и/или поверх разных наборов общедоступных облаков одного и того же или разных провайдеров общедоступных облаков. В некоторых вариантах осуществления провайдер виртуальных сетей предоставляет программное обеспечение и сервисы, которые позволяют разным арендаторам определять разные виртуальные сети поверх одних и тех же или разных общедоступных облаков. В некоторых вариантах осуществления один и тот же кластер контроллеров или разные кластеры контроллеров могут быть использованы для конфигурирования компонентов общедоступных облаков для реализации разных виртуальных сетей поверх одних и тех же или разных наборов общедоступных облаков для нескольких разных организаций.
Чтобы развернуть виртуальную сеть для арендатора поверх одного или более общедоступных облаков кластер контроллеров (1) идентифицирует возможные входные и выходные маршрутизаторы для входа в виртуальную сеть и выхода из нее для арендатора на основе местоположений филиальных офисов арендатора, дата-центров, мобильных пользователей и провайдеров SaaS и (2) идентифицирует маршруты, которые проходят от идентифицированных входных маршрутизаторов к идентифицированным выходным маршрутизаторам через другие промежуточные маршрутизаторы общедоступных облаков, реализующие виртуальную сеть. После идентификации этих маршрутов кластер контроллеров направляет эти маршруты в таблицы пересылки виртуальных сетевых маршрутизаторов в общедоступном(ых) облаке(ах). В вариантах осуществления, которые используют виртуальные сетевые маршрутизаторы на основе OVS, контроллер распределяет маршруты с помощью OpenFlow.
Приведенное выше краткое содержание предназначено для использования в качестве краткого введения в некоторые варианты осуществления изобретения. Оно не является введением или обзором всего объекта изобретения, раскрытого в этом документе. Подробное описание, которое следует ниже, и чертежи, которые упоминаются в подробном описании, будут дополнительно описывать варианты осуществления, описанные в кратком содержании, а также другие варианты осуществления. Таким образом, чтобы понять все варианты осуществления, описанные в этом документе, требуется полный обзор краткого содержания, подробного описания, чертежей и формулы изобретения. Кроме того, заявленные объекты не должны ограничиваться иллюстративными деталями в кратком описании, подробном описании и на чертежах.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Новые признаки изобретения изложены в прилагаемой формуле изобретения. Однако в целях пояснения описание нескольких вариантов осуществления изобретения представлено с иллюстрациями на следующих фигурах.
Фиг. 1А представляет виртуальную сеть, которая определена для корпорации поверх нескольких дата-центров общедоступных облаков двух провайдеров общедоступных облаков.
Фиг. 1В иллюстрирует пример двух виртуальных сетей для двух корпоративных арендаторов, которые развернуты поверх общедоступных облаков.
Фиг. 1С в качестве альтернативы иллюстрирует пример двух виртуальных сетей, при этом одна сеть развернута поверх одной пары общедоступных облаков, а другая виртуальная сеть развернута поверх другой пары общедоступных облаков.
Фиг. 2 иллюстрирует пример управляемого узла пересылки и кластера контроллеров в некоторых вариантах осуществления изобретения.
Фиг. 3 иллюстрирует пример графа измерений, который уровень обработки результатов измерений контроллера создает в некоторых вариантах осуществления.
Фиг. 4А иллюстрирует пример графа маршрутизации, который уровень идентификации пути контроллера создает в некоторых вариантах осуществления из графа измерений.
Фиг. 4В иллюстрирует пример добавления известных IP-адресов для двух провайдеров SaaS к двум узлам в графе маршрутизации, которые находятся в дата-центрах, ближайших к дата-центрам этих провайдеров SaaS.
Фиг. 4С иллюстрирует граф маршрутизации, который сгенерирован в результате добавления двух узлов для представления двух провайдеров SaaS.
Фиг. 4D иллюстрирует граф маршрутизации с дополнительными узлами, добавленными для представления филиальных офисов и дата-центров с известными IP-адресами, которые соединяются с каждым из двух общедоступных облаков.
Фиг. 5 иллюстрирует процесс, который уровень идентификации пути контроллера использует, чтобы генерировать граф маршрутизации из графа измерений, полученного из уровня измерений контроллера.
Фиг. 6 иллюстрирует формат сообщения с IPsec-данными в соответствии с некоторыми вариантами осуществления.
Фиг. 7 иллюстрирует пример двух инкапсулирующих заголовков в соответствии с некоторыми вариантами осуществления, а фиг. 8 представляет пример, который иллюстрирует, как эти два заголовка используются в некоторых вариантах осуществления.
Фиг. 9-11 иллюстрируют процессы обработки сообщений, которые выполняются соответственно входным, промежуточным и выходным MFN, когда они принимают сообщение, которое отправляется между двумя вычислительными устройствами в двух разных филиальных офисах.
Фиг. 12 иллюстрирует пример, который не включает в себя промежуточный MFN между входным и выходным MFN.
Фиг. 13 иллюстрирует процесс обработки сообщений, который выполняется CFE входного MFN, когда он принимает сообщение, которое отправлено с корпоративного вычислительного устройства в филиальном офисе на другое устройство в другом филиальном офисе или в дата-центре провайдера SaaS.
Фиг. 14 иллюстрирует операцию NAT, выполняемую на выходном маршрутизаторе.
Фиг. 15 иллюстрирует процесс обработки сообщений, который выполняется входным маршрутизатором, который принимает сообщение, которое отправлено с машины провайдера SaaS на машину арендатора.
Фиг. 16 иллюстрирует такие механизмы ТМ, которые размещены в каждом шлюзе виртуальной сети, который находится на пути выхода виртуальной сети в Интернет.
Фиг. 17 иллюстрирует метод двойного NAT, который используется в некоторых вариантах осуществления вместо метода одиночного NAT с иллюстрацией на фиг. 16.
Фиг. 18 представляет пример, который иллюстрирует преобразование порта источника входным механизмом NAT.
Фиг. 19 иллюстрирует обработку ответного сообщения, которое SaaS-машина отправляет в ответ на обработку сообщения с данными на фиг. 18.
Фиг. 20 представляет пример, который показывает М виртуальных корпоративных WAN для М арендаторов провайдера виртуальных сетей, который имеет сетевую инфраструктуру и кластер(ы) контроллеров в N общедоступных облаках одного или нескольких провайдеров общедоступных облаков.
Фиг. 21 концептуально иллюстрирует процесс, выполняемый кластером контроллеров провайдера виртуальных сетей для развертывания и управления виртуальной WAN для конкретного арендатора.
Фиг. 22 концептуально иллюстрирует компьютерную систему, в которой реализованы некоторые варианты осуществления изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
В приводимом ниже подробном описании настоящего изобретения изложены и описаны многочисленные детали, примеры и варианты осуществления настоящего изобретения. Однако для специалиста в данной области техники будет ясно и очевидно, что настоящее изобретение не ограничивается изложенными вариантами осуществления и что настоящее изобретение может быть реализовано на практике без некоторых обсуждаемых конкретных деталей и примеров.
Некоторые варианты осуществления создают для организации виртуальную сеть поверх нескольких дата-центров общедоступных облаков одного или нескольких провайдеров общедоступных облаков в одном или нескольких регионах (например, в нескольких городах, штатах, странах и т.д.). Пример организации, для которой может быть создана такая виртуальная сеть, включает в себя коммерческую организацию (например, корпорацию), некоммерческую организацию (например, больницу, исследовательскую организацию и т.д.) и образовательную организацию (например, университет, колледж и т.д.) или любой другой тип организации. Примеры провайдеров общедоступных облаков включают в себя Amazon Web Services (AWS), Google Cloud Platform (GCP), Microsoft Azure и т.д.
Некоторые варианты осуществления определяют виртуальную сеть как оверлейную сеть, которая охватывает несколько дата-центров общедоступных облаков (несколько общедоступных облаков) для соединения одной или нескольких частных сетей (например, сетей в филиалах, подразделениях, отделах организации или связанных с ними дата-центров), мобильных пользователей, машин провайдеров SaaS (программного обеспечение как сервиса), машин и/или сервисов в общедоступном(ых) облаке(ах) и других web-приложений друг с другом. В некоторых вариантах осуществления высокоскоростные, надежные частные сети соединяют два или более дата-центров общедоступных облаков друг с другом.
В некоторых вариантах осуществления виртуальная сеть может быть сконфигурирована так, чтобы оптимизировать маршрутизацию сообщений с данными организации к их пунктам назначения для наилучшей сквозной производительности, надежности и безопасности при стремлении минимизировать маршрутизацию этого трафика через Интернет. Кроме того, в некоторых вариантах осуществления виртуальная сеть может быть сконфигурирована для оптимизации обработки уровня 4 потоков сообщений с данными, проходящих через сеть. Например, в некоторых вариантах осуществления виртуальная сеть оптимизирует сквозную скорость TCP (протокол управления транспортом) - соединений за счет разделения механизмов управления скоростью по пути соединения.
Некоторые варианты осуществления создают виртуальную сеть в результате конфигурирования нескольких компонентов, которые развернуты в нескольких общедоступных облаках. В некоторых вариантах осуществления эти компоненты включают в себя программные агенты измерений, программные элементы пересылки (например, программные маршрутизаторы, коммутаторы, шлюзы и т.д.), прокси-серверы соединений уровня 4 и машины мидлбокс-обслуживания (например, устройства, VM, контейнеры и т.д.).
Некоторые варианты осуществления используют логически централизованный кластер контроллеров (например, набор из одного или более серверов контроллеров), который конфигурирует компоненты общедоступных облаков для реализации виртуальной сети поверх нескольких общедоступных облаков. В некоторых вариантах осуществления контроллеры в этом кластере находятся в разных местоположениях (например, в разных дата-центрах общедоступных облаков), чтобы улучшить избыточность и высокую доступность. Когда разные контроллеры в кластере контроллеров расположены в разных дата-центрах общедоступных облаков, в некоторых вариантах осуществления контроллеры совместно используют свое состояние (например, данные конфигурации, которые они генерируют для идентификации арендаторов, маршрутов через виртуальные сети и т.д.). В некоторых вариантах осуществления кластер контроллеров увеличивает или уменьшает число компонентов общедоступных облаков, которые используются для создания виртуальной сети, или вычислительных или сетевых ресурсов, выделяемых этим компонентам.
Некоторые варианты осуществления создают разные виртуальные сети для разных организаций поверх одного и того же набора общедоступных облаков одних и тех же провайдеров общедоступных облаков и/или поверх разных наборов общедоступных облаков одного и того же или разных провайдеров общедоступных облаков. В некоторых вариантах осуществления провайдер виртуальных сетей обеспечивает программное обеспечение и сервисы, которые позволяют разным арендаторам определять разные виртуальные сети поверх одного и того же или разных общедоступных облаков. В некоторых вариантах осуществления один и тот же кластер контроллеров или разные кластеры контроллеров могут быть использованы для конфигурирования компонентов общедоступных облаков для реализации разных виртуальных сетей поверх одного и того же или разных наборов общедоступных облаков для нескольких разных организаций.
Несколько примеров корпоративных виртуальных сетей представлены на обсуждение ниже. Однако рядовой специалист поймет, что некоторые варианты осуществления определяют виртуальные сети для других типов организаций, таких как другие бизнес-организации, некоммерческие организации, образовательные учреждения и т.д. Кроме того, как используется в данном документе, сообщения с данными относятся к набору битов в определенном формате, отправляемому по сети. Специалист в данной области техники поймет, что термин «сообщение с данными» используется в данном документе для ссылки на разные форматированные наборы битов, которые отправляются по сети. Форматирование этих битов может быть определено стандартизированными протоколами или нестандартизированными протоколами. Примеры сообщений с данными, следующих стандартизованным протоколам, включают в себя кадры Ethernet, IP-пакеты, TCP-сегменты, UDP-дейтаграммы и т.д. Также, как используется в данном документе, ссылки на уровни L2, L3, L4 и L7 (или уровень 2, уровень 3, уровень 4 и уровень 7) являются ссылками соответственно на второй уровень канала связи данных, третий сетевой уровень, четвертый транспортный уровень и седьмой прикладной уровень OSI (уровень взаимодействия открытых систем).
Фиг. 1А представляет виртуальную сеть 100, которая определена для корпорации поверх нескольких дата-центров 105 и 110 общедоступных облаков провайдеров А и В общедоступных облаков. Как показано, виртуальная сеть 100 представляет собой защищенную оверлейную сеть, которая создана в результате развертывания разных узлов 150 управляемой пересылки в разных общедоступных облаках и соединения узлов управляемой пересылки (MFN) друг с другом через оверлейные туннели 152. В некоторых вариантах осуществления MFN представляет собой концептуальную группировку нескольких различных компонентов в дата-центре общедоступного облака, которые вместе с другими MFN (с другими группами компонентов) в других дата-центрах общедоступных облаков создают одну или более оверлейных виртуальных сетей для одной или более организаций.
Как дополнительно описано ниже, в некоторых вариантах осуществления группа компонентов, которые образуют MFN, включает в себя (1) один или более шлюзов VPN для создания VPN-соединений с вычислительными узлами организации (например, офисами, частными дата-центрами, удаленными пользователями и т.д.), которые являются местоположениями внешних машин за пределами дата-центров общедоступных облаков, (2) один или более элементов пересылки для пересылки инкапсулированных сообщений с данными между собой, чтобы определить оверлейную виртуальную сеть поверх общей сетевой архитектуры общедоступных облаков, (3) одну или более машин обслуживания для выполнения операций мидлбокс-обслуживания, а также оптимизации L4-L7 и (4) один или более агентов измерений для получения измерений, касающихся качества сетевых соединений между дата-центрами общедоступных облаков, чтобы идентифицировать требуемые пути через дата-центры общедоступных облаков. В некоторых вариантах осуществления разные MFN могут иметь разную компоновку и разное число таких компонентов, и один MFN может иметь разное число таких компонентов по причинам избыточности и масштабируемости.
Кроме того, в некоторых вариантах осуществления каждая группа компонентов MFN исполняется на разных компьютерах в дата-центре общедоступного облака MFN. В некоторых вариантах осуществления несколько или все компоненты MFN могут исполняться на одном компьютере дата-центра общедоступного облака. В некоторых вариантах осуществления компоненты MFN исполняются на хост-компьютерах, которые также исполняют другие машины других арендаторов. Эти другие машины могут быть другими машинами других MFN других арендаторов или они могут быть не связанными между собой машинами других арендаторов (например, вычислительными VM или контейнерами).
В некоторых вариантах осуществления виртуальная сеть 100 развертывается провайдером виртуальных сетей (VNP), который развертывает разные виртуальные сети поверх одних и тех же или разных дата-центров общедоступных облаков для разных организаций (например, поверх разных корпоративных потребителей/арендаторов провайдера виртуальных сетей). В некоторых вариантах осуществления провайдер виртуальных сетей является организацией, которая развертывает MFN и предоставляет кластер контроллеров для конфигурирования и управления этими MFN.
Виртуальная сеть 100 соединяет корпоративные конечные точки вычислений (такие как дата-центры, филиальные офисы и мобильные пользователи) друг с другом и с внешними сервисами (например, с общедоступными web-сервисами или SaaS-сервисами, такими как Office365 или Salesforce), которые находятся в общедоступном облаке или в частном дата-центре, доступном через Интернет. Эта виртуальная сеть эффективно использует разные местоположения разных общедоступных облаков для соединения разных корпоративных конечных точек вычислений (например, разных частных сетей и/или разных мобильных пользователей корпорации) с общедоступными облаками поблизости от них. Ниже корпоративные конечные точки вычислений также называются корпоративными вычислительными узлами.
В некоторых вариантах осуществления виртуальная сеть 100 также эффективно использует высокоскоростные сети, которые соединяют эти общедоступные облака друг с другом, для пересылки сообщений с данными через общедоступные облака к их пунктам назначения или для максимально возможного приближения к их пунктам назначения при сокращении их прохождения через Интернет. Когда корпоративные конечные точки вычислений находятся за пределами дата-центров общедоступных облаков, которые охватывает виртуальная сеть, эти конечные точки называются местоположениями внешних машин. Это касается корпоративных филиальных офисов, частных дата-центров и устройств удаленных пользователей.
В примере с иллюстрацией на фиг. 1А, виртуальная сеть 100 охватывает шесть дата-центров 105а-105f провайдера А общедоступного облака и четыре дата-центра 110a-110d провайдера В общедоступного облака. При охвате этих общедоступных облаков эта виртуальная сеть соединяет несколько филиальных офисов, корпоративных дата-центров, провайдеров SaaS и мобильных пользователей корпоративного арендатора, которые находятся в разных географических регионах. В частности, виртуальная сеть 100 соединяет два филиальных офиса 130а и 130b в двух разных городах (например, Сан-Франциско, Калифорния и Пуна, Индия), корпоративный дата-центр 134 в другом городе (например, Сиэтл, Вашингтон), два дата-центра 136а и 136b провайдера SaaS в двух других городах (Редмонд, Вашингтон и Париж, Франция) и мобильных пользователей 140 в разных точках мира. Таким образом, эту виртуальную сеть можно рассматривать как виртуальную корпоративную WAN.
В некоторых вариантах осуществления филиальные офисы 130а и 130b имеют свои собственные частные сети (например, локальные сети), которые соединяют компьютеры в местоположениях филиалов и частных дата-центрах филиалов, которые находятся за пределами общедоступных облаков. Точно так же в некоторых вариантах осуществления корпоративный дата-центр 134 имеет свою собственную частную сеть и находится за пределами любого дата-центра общедоступного облака. Однако в других вариантах осуществления корпоративный дата-центр 134 или дата-центр филиала 130а или 130b может находиться в общедоступном облаке, но виртуальная сеть не охватывает это общедоступное облако, так как корпоративный дата-центр или дата-центр филиала соединен с границей виртуальной сети 100.
Как указано выше, виртуальная сеть 100 создана в результате соединения различных развернутых управляемых узлов 150 пересылки в разных общедоступных облаках через оверлейные туннели 152. Каждый управляемый узел 150 пересылки включает в себя несколько конфигурируемых компонентов. Как дополнительно указано выше и дополнительно указано ниже, в некоторых вариантах осуществления компоненты MFN включают себя программные агенты измерений, программные элементы пересылки (например, программные маршрутизаторы, коммутаторы, шлюзы и т.д.), прокси-серверы уровня 4 (например, прокси-серверы TCP) и машины мидлбокс-обслуживания (например. VM, контейнеры и т.д.). В некоторых вариантах осуществления один или несколько из этих компонентов используют стандартизированные или общедоступные решения, такие как Open vSwitch. Open VPN, strongSwan и т.д.
В некоторых вариантах осуществления каждый MFN (то есть группа компонентов, которые концептуально формируют MFN) может быть совместно использована разными арендаторами провайдера виртуальных сетей, который развертывает и конфигурирует MFN в дата-центрах общедоступного облака. В комбинации или альтернативно в некоторых вариантах осуществления провайдер виртуальных сетей может развернуть уникальный набор MFN в одном или нескольких дата-центрах общедоступного облака для конкретного арендатора. Например, по соображениям безопасности или качества обслуживания конкретный арендатор может не захотеть делиться ресурсами MFN с другим арендатором. Для такого арендатора провайдер виртуальных сетей может развернуть свой собственный набор MFN в нескольких дата-центрах общедоступного облака.
В некоторых вариантах осуществления логически централизованный кластер 160 контроллеров (например, набор из одного или более серверов контроллеров) работает внутри или за пределами одного или более общедоступных облаков 105 и 110 и конфигурирует компоненты управляемых узлов 150 пересылки в общедоступных облаках для реализации виртуальной сети поверх общедоступных облаков 105 и 110. В некоторых вариантах осуществления контроллеры в этом кластере находятся в разных местоположениях (например, в разных дата-центрах общедоступных облаков), чтобы улучшить избыточность и высокую доступность. В некоторых вариантах осуществления кластер контроллеров увеличивает или уменьшает число компонентов общедоступных облаков, которые используются для создания виртуальной сети, или вычислительных или сетевых ресурсов, выделяемых этим компонентам.
В некоторых вариантах осуществления кластер 160 контроллеров или другой кластер контроллеров провайдера виртуальных сетей создает другую виртуальную сеть для другого корпоративного арендатора поверх одних и тех же общедоступных облаков 105 и 110 и/или поверх разных общедоступных облаков разных провайдеров общедоступных облаков. В дополнение к кластеру(ам) контроллеров в других вариантах осуществления провайдер виртуальных сетей развертывает элементы пересылки и машины обслуживания в общедоступных облаках, которые позволяют разным арендаторам развертывать разные виртуальные сети поверх одного и того же или разных общедоступных облаков. Фиг. 1В иллюстрирует пример двух виртуальных сетей 100 и 180 для двух корпоративных арендаторов, которые развернуты поверх общедоступных облаков 105 и 110. Фиг 1С в качестве альтернативы иллюстрирует пример двух виртуальных сетей 100 и 182. при этом одна сеть 100 развернута поверх общедоступных облаков 105 и 110 а другая виртуальная сеть 182 развернута поверх другой пары общедоступных облаков 110 и 115.
Через сконфигурированные компоненты узлов MFN виртуальная сеть 100 на фиг. 1А позволяет различным частным сетям и/или разным мобильным пользователям корпоративного арендатора соединяться с разными общедоступными облаками, которые находятся в оптимальных местоположениях (например, при измерении в терминах физического расстояния, в терминах скорости соединения, потерь, задержки и/или стоимости, и/или в терминах надежности сетевых соединений и т.д.) в отношении этих частных сетей и/или мобильных пользователей. В некоторых вариантах осуществления эти компоненты также позволяют виртуальной сети 100 использовать высокоскоростные сети, которые соединяют между собой общедоступные облака, для пересылки сообщений с данными через общедоступные облака в их пункты назначения при сокращении их прохождения через Интернет.
В некоторых вариантах осуществления компоненты MFN также сконфигурированы для запуска новых процессов на сетевом, транспортном и прикладном уровнях, чтобы оптимизировать сквозную производительность, надежность и безопасность. В некоторых вариантах осуществления один или более из этих процессов реализуют проприетарные высокопроизводительные сетевые протоколы, свободные от консервативности существующих сетевых протоколов. По существу в некоторых вариантах осуществления виртуальная сеть 100 не ограничена автономными системами Интернета, протоколами маршрутизации или даже механизмами сквозного транспорта.
Например, в некоторых вариантах осуществления компоненты узлов MFN 150 (1) создают оптимизированную многопутевую и адаптивную централизованную маршрутизацию, (2) предоставляют надежные гарантии QoS (качества обслуживания), (3) оптимизируют скорости сквозного TCP за счет разделения и/или завершения промежуточного TCP, и (4) перемещают масштабируемые мидлбокс-сервисы уровня приложений (например, файрволы, системы обнаружения вторжений (IDS), систему предотвращения вторжений (IPS), оптимизацию WAN и т.д.) в вычислительную часть облака в рамках глобальной виртуализации сетевых функций (NFV). Таким образом, виртуальная сеть может быть оптимизирована для удовлетворения индивидуальных и меняющихся требований корпорации без привязки к существующему сетевому протоколу. Кроме того, в некоторых вариантах осуществления виртуальная сеть может быть сконфигурирована как инфраструктура с оплатой по мере использования, которую можно динамически и гибко масштабировать вверх и вниз как по производительности, так и по географическому охвату в соответствии с постоянными изменениями требований.
Для реализации виртуальной сети 100 по меньшей мере один управляемый узел 150 пересылки в каждом дата-центре 105а-105f и 110а-110d общедоступных облаков, охватываемых виртуальной сетью, должен быть сконфигурирован набором контроллеров. Фиг. 2 иллюстрирует пример управляемого узла 150 пересылки и кластера 160 контроллеров в некоторых вариантах осуществления изобретения. В некоторых вариантах осуществления каждый управляемый узел 150 пересылки представляет собой машину (например, VM или контейнер), которая исполняется на хост-компьютере в дата-центре общедоступного облака. В других вариантах осуществления каждый управляемый узел 150 пересылки реализован множеством машин (например, множеством VM или контейнеров), которые исполняются на одном и том же хост-компьютере в одном дата-центре общедоступного облака. В еще одних других вариантах осуществления два или более компонентов одного MFN могут быть реализованы двумя или более машинами, исполняющимися на двух или более хост-компьютерах в одном или более дата-центрах общедоступных облаков.
Как показано, управляемый узел 150 пересылки включает в себя агент 205 измерений, механизмы 210 и 215 мидлбокс-обслуживания файрвола и NAT, один или более механизмов 220 оптимизации, краевые шлюзы 225 и 230 и облачный элемент 235 пересылки (например, облачный маршрутизатор). В некоторых вариантах осуществления каждый из этих компонентов 205235 может быть реализован как кластер из двух или более компонентов.
В некоторых вариантах осуществления кластер 160 контроллеров может динамически увеличивать или уменьшать каждый кластер компонентов (1) для добавления или удаления машин (например, VM или контейнеров) для реализации функциональности каждого компонента и/или (2) для добавления или удаления вычислительных и/или сетевых ресурсов для ранее развернутых машин, которые реализуют компоненты этого кластера. При этом каждый развернутый MFN 150 в дата-центре общедоступного облака может рассматриваться как кластер узлов MFN, или он может рассматриваться как узел, который включает в себя множество различных кластеров компонентов, которые выполняют разные операции MFN.
Кроме того, в некоторых вариантах осуществления кластер контроллеров развертывает разные наборы узлов MFN в дата-центрах общедоступных облаков для разных арендаторов, для которых кластер контроллеров определяет виртуальные сети поверх дата-центров общедоступных облаков. При таком методе виртуальные сети любых двух арендаторов не имеют никакого общего MFN. Однако в вариантах осуществления, описываемых ниже, каждый MFN может быть использован для реализации разных виртуальных сетей для разных арендаторов. Специалист в данной области техники поймет, что в других вариантах осуществления кластер 160 контроллеров может реализовать виртуальную сеть каждого арендатора из первого набора арендаторов со своим собственным выделенным набором развернутых MFN при реализации виртуальной сети каждого арендатора из второго набора арендаторов с общим набором развернутых MFN.
В некоторых вариантах осуществления шлюз 225 филиала и шлюз 230 удаленного устройства создают безопасные VPN-соединения соответственно с одним или несколькими филиальными офисами 130 и удаленными устройствами (например, мобильными устройствами 140), которые соединяются с MFN 150, как показано на фиг. 2. Одним примером таких VPN-соединений являются IPsec-соединения, которые будут описаны ниже. Однако специалист в данной области техники поймет, что в других вариантах осуществления такие шлюзы 225 и/или 230 создают различные типы VPN-соединений.
В некоторых вариантах осуществления MFN 150 включает в себя один или более мидлбокс-механизмов, которые выполняют одну или более операций мидлбокс-обслуживания, такие как операции файрвола, операции NAT, операции IPS, операции IDS, операции балансировки нагрузки, операции оптимизации WAN и т.д. За счет включения этих операций мидлбоксов (например, операций файрвола, операций оптимизации WAN и т.д.) в MFN, которые развернуты в общедоступном облаке, виртуальная сеть 100 реализует в общедоступном облаке многие из функций, которые традиционно выполняются корпоративной инфраструктурой WAN в дата-центре(ах) и/или филиальном(ых) офисе(ах).
Таким образом, для многих мидлбокс-сервисов корпоративные вычислительные узлы (например, удаленные устройства, филиальные офисы и дата-центры) больше не должны иметь доступ к корпоративной инфраструктуре WAN корпорации в частном дата-центре или филиальном офисе, так как многие из этих сервисов теперь развернуты в общедоступных облаках. Такой метод ускоряет доступ корпоративных вычислительных узлов (например, удаленных устройств, филиальных офисов и дата-центров) к этим сервисам и позволяет избежать дорогостоящих узких мест перегруженных сетей в частных дата-центрах, которые в противном случае были бы предназначены для предоставления таких сервисов.
Такой метод эффективно распределяет функциональность шлюза WAN между разными MFN в дата-центрах общедоступных облаков. Например, в некоторых вариантах осуществления в виртуальной сети 100 большая часть или все традиционные функции безопасности корпоративного шлюза WAN (например, операции файрвола, операции обнаружения вторжений, операции предотвращения вторжений и т.д.) перемещены в MFN общедоступных облаков (например, во входные MFN, на которых данные от конечных точек вычислений поступают в виртуальную сеть). Это эффективно позволяет виртуальной сети 100 иметь распределенный шлюз WAN, который реализован на многих различных MFN, которые реализуют виртуальную сеть 100.
В примере с иллюстрацией на фиг. 2 показано, что MFN 150 включает в себя механизм 210 файрвола, механизм 215 NAT и один или более механизмов оптимизации L4-L7. Специалист в данной области техники поймет, что в других вариантах осуществления MFN 150 включает в себя другие мидлбокс-механизмы для выполнения других мидлбокс-операций. В некоторых вариантах осуществления механизм 210 файрвола обеспечивает принудительное применение правил файрвола в отношении (1) потоков сообщений с данными на их входных путях в виртуальную сеть (например, потоков сообщений с данными, которые шлюзы 225 и 230 получают и обрабатывают из филиальных офисов 130 и мобильных устройств 140) и (2) потоков сообщений с данными на их выходных путях из виртуальной сети (например, потоков сообщений с данными, которые отправляются в дата-центры провайдера SaaS через механизм 215 NAT и Интернет 202).
В некоторых вариантах осуществления механизм 210 файрвола MFN 150 также обеспечивает принудительное применение правил файрвола, когда механизм файрвола принадлежит MFN, который является промежуточным переходом между входным MFN, на котором поток сообщений с данными входит в виртуальную сеть, и выходным MFN, на котором поток сообщений с данными выходит из виртуальной сети. В других вариантах осуществления механизм 210 файрвола обеспечивает принудительное применение правил файрвола только тогда, когда он является частью входного MFN и/или выходного MFN потока сообщений с данными.
В некоторых вариантах осуществления механизм 215 NAT выполняет преобразование сетевых адресов для изменения сетевых адресов источников потоков сообщений с данными на их путях выхода из виртуальной сети на сторонние устройства (например, на машины провайдера SaaS) через Интернет 202. Такие преобразования сетевых адресов гарантируют, что сторонние машины (например, SaaS-машины) могут быть надлежащим образом сконфигурированы для обработки потоков сообщений с данными, которые без преобразования адресов могут определять частные сетевые адреса арендаторов и/или провайдеров общедоступных облаков. Это особенно проблематично, так как адреса частных сетей разных арендаторов и/или провайдеров облаков могут перекрываться. Преобразование адресов также гарантирует, что ответные сообщения от сторонних устройств (например, от SaaS-машин) могут быть надлежащим образом получены виртуальной сетью (например, механизмом NAT MFN, из которого сообщение вышло из виртуальной сети).
В некоторых вариантах осуществления механизмы 215 NAT MFN выполняют операции двойного NAT над каждым потоком сообщений с данными, который покидает виртуальную сеть, чтобы достичь сторонней машины, или который входит в виртуальную сеть от сторонней машины. Как дополнительно описано ниже, одна операция NAT в двух операциях NAT выполняется над таким потоком сообщений с данными на его входном MFN, когда он входит в виртуальную сеть, а другая операция NAT выполняется над потоком сообщений с данными на его выходном MFN, когда он выходит из виртуальной сети.
Такой метод двойного NAT позволяет сопоставить большее число частных сетей арендаторов с сетями провайдеров общедоступных облаков. Такой метод также снижает нагрузку для распределения в MFN данных, касающихся изменений в частных сетях арендаторов. Некоторые варианты осуществления перед операциями входного или выходного NAT выполняют операция сопоставления арендатора, которая использует идентификатор арендатора для первого сопоставления сетевого адреса источника арендатора с другим сетевым адресом источника, который затем сопоставляется с еще одним другим сетевым адресом источника с помощью операции NAT. Выполнение операции двойного NAT снижает нагрузку распределения данных для распределения данных, касающихся изменений в частных сетях арендаторов.
Механизм 220 оптимизации исполняет новые процессы, которые оптимизируют пересылку сообщений с данными в их пункты назначения для наилучшей сквозной производительности и надежности. Некоторые из этих процессов реализуют проприетарные высокопроизводительные сетевые протоколы, свободные от консервативности существующих сетевых протоколов. Например, в некоторых вариантах осуществления механизм 220 оптимизации оптимизирует скорости сквозного TCP за счет разделения и/или завершения промежуточного TCP.
Облачный элемент 235 пересылки представляет собой механизм MFN, который отвечает за пересылку потока сообщений с данными к облачному элементу пересылки (CFE) MFN следующего перехода, когда поток сообщений с данными должен пройти к другому общедоступному облаку, чтобы достичь своего пункта назначения, или к выходному маршрутизатору в том же общедоступном облаке, когда поток сообщений с данными может достичь своего пункта назначения через то же общедоступное облако. В некоторых вариантах осуществления CFE 235 MFN 150 представляет собой программный маршрутизатор.
Для пересылки сообщений с данными CFE инкапсулирует сообщения с заголовками туннелей. Разные варианты осуществления используют различные методы для инкапсуляции сообщений с данными с заголовками туннелей. Некоторые варианты осуществления, описываемые ниже, используют один заголовок туннеля для идентификации сетевых входных/выходных адресов для входа и выхода из виртуальной сети и используют другой заголовок туннеля для идентификации MFN следующего перехода, когда сообщение с данными должно пройти один или более промежуточных MFN для достижения выходного MFN.
В частности, в некоторых вариантах осуществления CFE отправляет сообщение с данными с двумя заголовками туннелей: (1) с внутренним заголовком, который идентифицирует входной CFE и выходной CFE для входа и выхода из виртуальной сети, и (2) с внешним заголовком, который идентифицирует CFE следующего перехода. В некоторых вариантах осуществления внутренний заголовок туннеля также включает в себя идентификатор арендатора (TID), чтобы позволить множеству разных арендаторов провайдера виртуальных сетей использовать общий набор CFE MFN провайдера виртуальных сетей. Другие варианты осуществления определяют заголовки туннеля по-разному, чтобы определить оверлейную виртуальную сеть.
Чтобы развернуть виртуальную сеть для арендатора поверх одного или более общедоступных облаков, кластер контроллеров (1) идентифицирует возможные входные и выходные маршрутизаторы для входа и выхода из виртуальной сети для арендатора на основе местоположений корпоративных вычислительных узлов арендатора (например, филиальных офисов, дата-центров, мобильных пользователей и провайдеров SaaS) и (2) идентифицирует маршруты, которые проходят от идентифицированных входных маршрутизаторов к идентифицированным выходным маршрутизаторам через другие промежуточные маршрутизаторы общедоступных облаков, которые реализуют виртуальную сеть. После идентификации этих маршрутов кластер контроллеров передает эти маршруты в таблицы пересылки CFE 235 MFN в общедоступном(ых) облаке(ах). В вариантах осуществления, которые используют виртуальные сетевые маршрутизаторы на основе OVS, контроллер распределяет маршруты с помощью OpenFlow.
В некоторых вариантах осуществления кластер 160 контроллеров также может конфигурировать компоненты 205-235 каждого MFN 150, который реализует виртуальную сеть, чтобы оптимизировать несколько уровней сетевой обработки для достижения наилучшей сквозной производительности, надежности и безопасности. Например, в некоторых вариантах осуществления эти компоненты сконфигурированы (1) для оптимизации маршрутизации трафика уровня 3 (например, кратчайшего пути, дублирования пакетов), (2) для оптимизации управления перегрузкой TCP уровня 4 (например, сегментации, управления скоростью), (3) для реализации функций безопасности (например, шифрования, глубокой проверки пакетов, файрвола) и (4) для реализации функций сжатия на уровне приложений (например, дедублирования, кэширования). Внутри виртуальной сети корпоративный трафик защищается, проверяется и регистрируется.
В некоторых вариантах осуществления один агент измерений развернут для каждого MFN в дата-центре общедоступного облака. В других вариантах осуществления множество MFN в дата-центре общедоступного облака или в группе дата-центров (например, в группе соседних связанных дата-центров, таких как дата-центры в одной зоне доступности) совместно используют один агент измерений. Чтобы оптимизировать обработку уровней 3 и 4, агент 205 измерений, связанный с каждым управляемым узлом 150 пересылки, с повторением генерирует значения измерений, которые количественно оценивают качество сетевого соединения между своим узлом и каждым из нескольких других «соседних» узлов.
Разные варианты осуществления определяют соседние узлы по-разному. Для конкретного MFN в одном дата-центре общедоступного облака конкретного провайдера общедоступного облака в некоторых вариантах осуществления соседний узел включает в себя (1) любой другой MFN, который работает в любом дата-центре общедоступного облака конкретного провайдера общедоступного облака, и (2) любой другой MFN, который работает в дата-центре другого провайдера общедоступного облака, который находится в том же «регионе», что и конкретный MFN.
Разные варианты осуществления определяют один и тот же регион по-разному. Например, некоторые варианты осуществления определяют регион с точки зрения расстояния, которое задает форму границы вокруг конкретного управляемого узла пересылки. Другие варианты осуществления определяют регионы с точки зрения городов, штатов или региональных областей, таких как северная Калифорния, южная Калифорния и т.д. Предполагается, что этот метод состоит в том, что разные дата-центры одного и того же провайдера общедоступного облака соединены с помощью чрезвычайно высокоскоростных сетевых соединений, а сетевые соединения между дата-центрами разных провайдеров общедоступных облаков могут быть быстрыми, когда дата-центры находятся в том же регионе, но, по-видимому, не такими быстрыми, когда дата-центры находятся в разных регионах. Когда дата-центры находятся в разных регионах, соединение между дата-центрами разных провайдеров общедоступных облаков может осуществляться через общедоступный Интернет с пересечением больших расстояний.
В разных вариантах осуществления агент 205 измерений генерирует значения измерений по-разному. В некоторых вариантах осуществления агент измерений периодически (например, раз в секунду, каждые N секунд, каждую минуту, каждые М минут и т.д.) отправляет сообщения проверки связи (например, UDP-эхо-сообщения) каждому из агентов измерений своих соседних управляемых узлов пересылки. С учетом небольшого размера сообщений проверки связи они не требуют больших расходов на соединение с сетью. Например, для 100 узлов, каждый из которых отправляет эхо-запрос на каждый другой узел каждые 10 секунд, для каждого узла генерируется около 10 кбит/с входного и выходного трафика измерений, и с учетом текущих цен на общедоступные облака это приводит к расходам на потребление сети в несколько долларов (например, 5 долларов США) за узел в год.
На основе скорости получаемых ответных сообщений агент 205 измерений вычисляет и обновляет значения показателей измерений, таких как производительность сетевого соединения, задержка, потери и надежность соединения. За счет повторного выполнения этих операций агент 205 измерений определяет и обновляет матрицу результатов измерений, которая выражает качество сетевых соединений со своими соседними узлами. Когда агент 205 взаимодействует с агентами измерений своих соседних узлов, его матрица измерений количественно оценивает только качество соединений с его локальной кликой узлов.
Агенты измерений разных управляемых узлов пересылки отправляют свои матрицы измерений к кластеру 160 контроллеров, который затем агрегирует все данные разных кликовых соединений для получения агрегированного вида сетки соединений между разными парами управляемых узлов пересылки. Когда кластер 160 контроллеров собирает различные измерения для канала связи между двумя парами узлов пересылки (например, измерения, выполненные одним узлом в разное время), кластер контроллеров создает смешанное значение из разных измерений (например, создает среднее или средневзвешенное значение измерений). В некоторых вариантах осуществления агрегированный вид сетки является полным видом сетки всех сетевых соединений между каждой парой управляемых узлов пересылки, а в других вариантах осуществления является более полным видом, чем тот, который создается агентами измерений отдельных управляемых узлов пересылки.
Как показано на Фиг. 2, кластер 160 контроллеров включает в себя кластер из одного или нескольких механизмов 280 обработки измерений, одного или нескольких механизмов 282 идентификации пути и одного или нескольких интерфейсов 284 управления. Чтобы не затруднять понимания описания ненужными деталями, каждый из этих кластеров будет именоваться ниже в терминах отдельных уровней механизма или интерфейса, то есть в терминах уровня 280 обработки измерений, уровня 282 идентификации пути и уровня 284 интерфейса управления.
Уровень 280 обработки измерений принимает матрицы измерений от агентов 205 измерений управляемых узлов пересылки и обрабатывает эти матрицы измерений для создания агрегированной матрицы сетки, которая выражает качество соединений между различными парами управляемых узлов пересылки. Уровень 280 обработки измерений доставляет агрегированную матрицу сетки на уровень 282 идентификации пути. На основе агрегированной матрицы сетки уровень 282 идентификации пути идентифицирует различные требуемые пути маршрутизации через виртуальную сеть для соединения различных конечных точек корпоративных данных (например, различные филиальные офисы, корпоративные дата-центры, дата-центры провайдеров SaaS и/или удаленные устройства). Затем этот уровень 282 доставляет эти пути маршрутизации в таблицы маршрутов, которые распределяются по облачным элементам 235 пересылки управляемых узлов 150 пересылки.
В некоторых вариантах осуществления идентифицированный путь маршрутизации для каждой пары конечных точек сообщений с данными является путем маршрутизации, который считается оптимальным на основании набора критериев оптимизации, например, это самый быстрый путь маршрутизации, самый короткий путь маршрутизации или путь который меньше всего использует Интернет. В других вариантах осуществления механизм идентификации пути может идентифицировать и доставлять (в таблицу маршрутизации) несколько разных путей маршрутизации между одними и теми же двумя конечными точками. В этих вариантах осуществления облачные элементы 235 пересылки в составе управляемых узлов 150 пересылки затем выбирают один из путей на основе QoS-критериев или других критериев времени выполнения, принудительное применение которых они обеспечивают. В некоторых вариантах осуществления каждый CFE 235 получает не весь путь маршрутизации от CFE до выходной точки виртуальной сети, а следующий переход для пути.
В некоторых вариантах осуществления уровень 282 идентификации пути использует значения измерений в агрегированной матрице сетки в качестве входных данных для алгоритмов маршрутизации, которые он исполняет для построения глобального графа маршрутизации. Этот глобальный граф маршрутизации представляет собой агрегированную и оптимизированную версию графа измерений, который уровень 280 обработки создает в некоторых вариантах осуществления. Фиг. 3 иллюстрирует пример графа 300 измерений, который уровень 280 обработки результатов измерений контроллера создает в некоторых вариантах осуществления. Этот граф показывает сетевые соединения между различными управляемыми узлами 150 пересылки в общедоступных облаках 310 и 320 AWS и GCP (т.е. в дата-центрах AWS и GCP). Фиг. 4А иллюстрирует пример графа 400 маршрутизации, который уровень 282 идентификации пути контроллера создает в некоторых вариантах осуществления из графа 300 измерений.
Фиг. 5 иллюстрирует процесс 500, который уровень идентификации путей контроллеров использует, чтобы генерировать граф маршрутизации из графа измерений, полученного из уровня измерений контроллера. Уровень 282 идентификации путей выполняет этот процесс 500 с повторением, когда он с повторением принимает обновленные графы измерений из уровня измерений контроллера (например, выполняет процесс 500 каждый раз, когда он получает новый граф измерений, или каждый N-раз, когда он получает новый граф измерений). В других вариантах осуществления уровень 282 идентификации путей периодически выполняет этот процесс (например, каждые 12 часов или 24 часа).
Как показано, уровень идентификации пути сначала определяет (на этапе 505) граф маршрутизации как идентичный графу измерений (то есть, чтобы иметь одни и те же каналы связи между одними и теми же парами управляемых узлов пересылки). На этапе 510 процесс удаляет плохие каналы связи из графа 300 измерений. Примеры плохих каналов связи - это каналы связи с чрезмерной потерей сообщений или низкой надежностью (например, каналы связи с потерей сообщений более 2% за последние 15 минут или с потерей сообщений более 10% за последние 2 минуты). На фиг. 4А показано, что каналы 302, 304 и 306 связи на графе 300 измерений исключены из графа 400 маршрутизации. Эта фигура иллюстрирует исключение этих каналов связи в результате обозначения этих каналов связи пунктирными линиями.
Затем на этапе 515 процесс 500 вычисляет оценку веса (оценку стоимости) канала как взвешенную комбинацию нескольких вычисленных и зависящих от провайдера значений. В некоторых вариантах осуществления оценка веса представляет собой взвешенную комбинацию (1) вычисленного значения задержки канала связи, (2) вычисленного значения потерь в канале связи, (3) стоимости сетевого соединения провайдера с каналом связи и (4) затрат провайдера на вычисления в канале связи. В некоторых вариантах осуществления затраты провайдера на вычисления учитываются, когда управляемые узлы пересылки, соединенные каналом связи, являются машинами (например, виртуальными машинами или контейнерами), которые исполняются на хост-компьютерах в дата-центре(ах) общедоступного(ых) облака(ов).
На этапе 520 процесс добавляет к графу маршрутизации известные IP-адреса источника и назначения (например, известные IP-адреса провайдеров SaaS, используемых корпоративной организацией) для потоков сообщений с данными в виртуальной сети. В некоторых вариантах осуществления процесс добавляет каждый известный IP-адрес возможной конечной точки потока сообщений к узлу (например, к узлу, представляющему MFN) в графе маршрутизации, который является ближайшим к этой конечной точке. При этом в некоторых вариантах осуществления процесс предполагает, что каждая такая конечная точка соединена с виртуальной сетью через канал связи с нулевой стоимостью задержки и нулевой стоимостью потерь. Фиг. 4В иллюстрирует пример добавления известных IP-адресов для двух провайдеров SaaS к двум узлам 402 и 404 (представляющим два MFN) в графе маршрутизации, которые находятся в дата-центрах, ближайших к дата-центрам этих провайдеров SaaS. В этом примере один узел находится в общедоступном облаке AWS, а другой узел - в общедоступном облаке GCP.
В качестве альтернативы или в комбинации в некоторых вариантах осуществления процесс 500 добавляет известные IP-адреса источника и назначения к графу маршрутизации за счет добавления узлов к этому графу для представления конечных точек источника и назначения, назначения IP-адресов этим узлам и присвоения значений веса каналам связи, которые соединяют эти добавленные узлы с другими узлами в графе маршрутизации (например, с узлами в графе маршрутизации, которые представляют MFN в общедоступных облаках). Когда конечные точки источника и назначения для потоков добавляются как узлы, механизм 282 идентификации пути может учитывать стоимость (например, стоимость расстояния, стоимость задержки и/или финансовые затраты и т.д.) достижения этих узлов, когда он идентифицирует различные маршруты через виртуальную сеть между разными конечными точками источника и назначения.
Фиг. 4С иллюстрирует граф 410 маршрутизации, который генерируется в результате добавления двух узлов 412 и 414 к графу 400 узлов на фиг. 4А, чтобы представлять двух провайдеров SaaS. В этом примере известные IP-адреса назначаются узлам 412 и 414, и эти узлы соединяются с узлами 402 и 404 (представляющими два MFN) через каналы 416 и 418 связи, которым присвоены веса W1 и W2. Этот метод является альтернативным методом для добавления известных IP-адресов двух провайдеров SaaS по отношению к методу с иллюстрацией на фиг. 4В.
Фиг. 4D иллюстрирует более подробный граф 415 маршрутизации. В этом более подробном графе маршрутизации добавлены дополнительные узлы 422 и 424 для представления внешних корпоративных вычислительных узлов (например, филиальных офисов и дата-центров) с известными IP-адресами, которые соединяются с каждым из общедоступны облаков 310 и 320 AWS и GCP. Каждый из этих узлов 422/424 соединен по меньшей мере одним каналом 426 связи со связанным значением Wi веса по меньшей мере с одним из узлов графа маршрутизации, который представляет MFN. Некоторые из этих узлов (например, некоторые из филиальных офисов) соединены с помощью множества каналов связи с одним и тем же MFN или с разными MFN.
Затем на этапе 525 процесс 500 вычисляет пути с наименьшей стоимостью (например, кратчайшие пути и т.д.) между каждым MFN и каждым другим MFN. который может служить в качестве выходного местоположения виртуальной сети для потока сообщений с данными корпоративной организации. В некоторых вариантах осуществления выходные MFN включают в себя MFN, соединенные с внешними корпоративными вычислительными узлами (например, с филиальными офисами, корпоративными дата-центрами и дата-центрами провайдеров SaaS), а также MFN, которые являются местоположениями-кандидатами для соединений мобильных устройств и выходных Интернет-соединений. В некоторых вариантах осуществления это вычисление использует традиционный процесс идентификации с наименьшими затратами (например, кратчайшего пути), который идентифицирует кратчайшие пути между разными парами MFN.
Для каждой пары MFN-кандидатов, когда существует множество таких путей между парами MFN, процесс идентификации с наименьшей стоимостью использует вычисленные оценки веса (то есть оценки, вычисленные на этапе 510), чтобы идентифицировать путь с наименьшей оценкой. Ниже приводится описание некоторых способов вычисления путей с наименьшей стоимостью. Как указано выше, в некоторых вариантах осуществления уровень 282 идентификации пути идентифицирует множество путей между двумя парами MFN. Это должно позволить облачным элементам 235 пересылки использовать разные пути при разных обстоятельствах. Таким образом, в этих вариантах осуществления процесс 500 может идентифицировать множество путей между двумя парами MFN.
На этапе 530 процесс удаляет из графа маршрутизации каналы связи между парами MFN, которые не используются ни одним из путей с наименьшей стоимостью, идентифицированных на этапе 525. Затем на этапе 535 процесс генерирует таблицы маршрутизации для облачных элементов пересылки 235 из графа маршрутизации. На этапе 535 процесс распределяет эти таблицы маршрутизации по облачным элементам 235 пересылки управляемых узлов пересылки. После этапа 535 процесс завершается.
В некоторых вариантах осуществления виртуальная сеть имеет два типа внешних соединений, а именно: (1) внешние безопасные соединения с вычислительными узлами (например, филиальными офисами, дата-центрами, мобильными пользователями и т.д.) организации и (2) внешние соединения со сторонними компьютерами (например, серверами провайдера SaaS) через Интернет. Некоторые варианты осуществления оптимизируют виртуальную сеть за счет нахождения оптимальных местоположений входа и выхода виртуальной сети для каждого пути данных, который заканчивается на узлах источника и назначения за пределами виртуальной сети. Например, чтобы соединить филиальный офис с сервером провайдера SaaS (например, с сервером salesforce.com) некоторые варианты осуществления соединяют филиальный офис с оптимальным краевым MFN (например, MFN. который имеет самое быстрое сетевое соединение с филиальным офисом или ближайшим к филиальному офису) и идентифицируют оптимальный краевой MFN для оптимально расположенного сервера провайдера SaaS (например, провайдера SaaS, ближайшего к краевому MFN для филиального офиса или имеющего самый быстрый путь к краевому MFN для филиального офиса через краевой MFN, соединенный с сервером провайдера SaaS).
В некоторых вариантах осуществления, чтобы связать каждый вычислительный узел (например, филиальный офис, мобильного пользователя и т.д.) организации с ближайшим MFN через VPN-соединение, провайдер виртуальных сетей развертывает один или более авторитетных серверов доменных имен (DNS) в общедоступных облаках для соединения с вычислительными узлами. В некоторых вариантах осуществления каждый раз, когда корпоративному вычислительному узлу в некоторых вариантах осуществления необходимо создать VPN-соединение (т.е. инициализировать или повторно инициализировать VPN-соединение) с MFN провайдера виртуальных сетей, вычислительный узел сначала разрешает адрес, связанный со своей виртуальной сетью (например, virtualnetworkX.net) с помощью этого авторитетного DNS-сервера, чтобы получить от этого сервера идентификационные данные MFN, который этот сервер идентифицирует как MFN, ближайший к корпоративному вычислительному узлу. В некоторых вариантах осуществления, чтобы идентифицировать этот MFN, авторитетный DNS-сервер предоставляет идентификатор MFN (например, IP-адрес MFN). Затем корпоративный вычислительный узел создает VPN-соединение с этим управляемым узлом пересылки.
В других вариантах осуществления корпоративный вычислительный узел не выполняет сначала DNS-разрешения (т.е. не сначала разрешает сетевой адрес для конкретного домена) каждый раз, когда ему необходимо создать соединение VPN с MFN VNP. Например, в некоторых вариантах осуществления корпоративный вычислительный узел продолжает использование MFN с DNS-разрешением в течение определенного времени (например, в течение дня, недели и т.д.) перед выполнением другого DNS-разрешения, чтобы определить, является ли этот MFN по-прежнему оптимальным MFN, с которым он должен соединиться.
Когда IP-адрес источника в DNS-запросе является IP-адресом источника локального DNS-сервера корпоративного вычислительного узла, а не самого узла, в некоторых вариантах осуществления авторитетный DNS-сервер идентифицирует MFN, ближайший к локальному DNS-серверу, а не MFN, ближайший к корпоративному вычислительному узлу. Для решения этой проблемы в некоторых вариантах осуществления DNS-запрос идентифицирует корпоративный вычислительный узел с точки зрения доменного имени, которое включает в себя одну или более частей (меток), которые объединены и разделены точками, где одна из этих частей идентифицирует корпорацию, а другая часть идентифицирует вычислительный узел корпорации.
В некоторых вариантах осуществления это доменное имя определяет иерархию доменов и поддоменов в порядке убывания от правой метки до левой метки в имени домена. Самая правая первая метка идентифицирует конкретный домен, вторая метка слева от первой метки идентифицирует корпоративную организацию, а третья метка слева от второй метки идентифицирует местоположение внешней машины организации в тех случаях, когда организация имеет более, чем одно местоположение внешних машин. Например, в некоторых вариантах осуществления DNS-запрос идентифицирует корпоративный вычислительный узел как myNode компании myCompany и запрашивает разрешение адреса myNode.myCompany.virtualnetwork.net. Затем DNS-сервер использует идентификатор myNode, чтобы лучше выбрать входной MFN, с которым корпоративный вычислительный узел должен создать VPN-соединение. В разных вариантах осуществления идентификатор myNode выражается по-разному. Например, он может быть адресован как IP-адрес, описание широты/долготы местоположения, GPS-местоположение (с помощью глобальной системы позиционирования), почтовый адрес и т.д.
Даже когда IP-адрес правильно отражает местоположение, может существовать несколько потенциальных входных маршрутизаторов, например, принадлежащих разным дата-центрам в одном и том же облаке или разным облакам в одном и том же регионе. В таком случае в некоторых вариантах осуществления авторитетный сервер виртуальной сети отправляет обратно список IP-адресов потенциальных CFE (например, С5, С8, С12) MFN. Затем в некоторых вариантах осуществления корпоративный вычислительный узел проверяет различные CFE в списке, чтобы произвести измерения (например, измерения расстояния или скорости), и выбирает ближайший из них в результате сравнения измерений среди набора CFE-кандидатов.
Кроме того, корпоративный вычислительный узел может базировать этот выбор на идентификации MFN, в настоящее время используемых другими вычислительными узлами корпоративной организации. Например, в некоторых вариантах осуществления корпоративный вычислительный узел добавляет затраты на соединение с каждым MFN, так что, если многие из корпоративных филиалов уже соединены с данным облаком, новые вычислительные узлы будут иметь стимул для соединения с тем же облаком и тем самым минимизировать межоблачные затраты с точки зрения обработки, задержки и долларов.
Другие варианты осуществления используют другие методы DNS-разрешения. Например, каждый раз, когда корпоративному вычислительному узлу (например, филиальному офису, дата-центру, мобильному пользователю и т.д.) необходимо выполнить DNS-разрешение, корпоративный вычислительный узел (например, мобильное устройство или локальный DNS-преобразователь в филиальном офисе или дата-центре) обменивается данными с провайдером DNS-сервиса, который служит авторитетным DNS-преобразователем для ряда организаций. В некоторых вариантах осуществления этот провайдер DNS-сервиса имеет машины DNS-разрешения, расположенные в одном или более частных дата-центрах, а в других вариантах осуществления он является частью одного или более дата-центров общедоступных облаков.
Чтобы идентифицировать, какой из N управляемых узлов пересылки, которые соединяются напрямую с Интернетом, следует использовать для доступа к серверу провайдера SaaS, в некоторых вариантах осуществления виртуальная сеть (например, входной MFN или кластер контроллеров, который конфигурирует MFN) идентифицирует набор из одного или более краевых MFN-кандидатов из N управляемых узлов пересылки. Как дополнительно описано ниже, в некоторых вариантах осуществления каждый краевой MFN-кандидат является краевым MFN, который считается оптимальным на основе набора критериев, таких как расстояние до сервера провайдера SaaS, скорость сетевого соединения, стоимость, задержка и/или потери, затраты на сетевые вычисления и т.д.).
Чтобы помочь в идентификации оптимальных краевых точек, в некоторых вариантах осуществления кластер контроллеров поддерживает для организации список наиболее популярных провайдеров SaaS и потребительских web-пунктов назначения и их подсетей IP-адресов. Для каждого такого пункта назначения кластер контроллеров назначает один или более оптимальных MFN (также с оценкой по физическому расстоянию, скорости сетевого соединения, стоимости, потерям и/или задержке, затратам на вычисления и т.д.) в качестве выходных узлов-кандидатов. Для каждого выходного MFN-кандидата кластер контроллеров затем вычисляет лучший маршрут от каждого возможного входного MNF к MFN-кандидату и настраивает результирующую таблицу следующих переходов в MFN соответственно так, чтобы Интернет-провайдер SaaS или wed-пункт назначения был связан с корректным узлом следующего перехода в виртуальной сети.
С учетом того, что пункт назначения сервиса зачастую может быть достигнут через несколько IP-подсетей (предоставляемых авторитетным DNS-сервером) в нескольких местоположениях, существует несколько потенциальных выходных узлов, чтобы минимизировать задержку и обеспечить балансировку нагрузки. Таким образом, в некоторых вариантах осуществления кластер контроллеров вычисляет наилучшее местоположение и выходной узел для каждого MFN и соответственно обновляет следующий переход. Кроме того, лучший выходной узел для доступа к провайдеру SaaS (например, office365.com) может находиться через одного провайдера общедоступного облака (например, через Microsoft Azure), но лучший с точки зрения расстояния или скорости соединения входной MFN может принадлежать другому провайдеру общедоступного облака (например, AWS). В таких ситуациях прохождение в другое облако (то есть в общедоступное облако с наилучшим выходным MFN) перед выходом из виртуальной сети может быть неоптимальным с точки зрения задержки, обработки и стоимости. В таких ситуациях предоставление множества краевых узлов-кандидатов позволяет выбрать оптимальный краевой MFN и оптимальный путь к выбранному краевому MFN.
Чтобы идентифицировать оптимальный путь через виртуальную сеть к выходному MFN, который соединяется с Интернетом или соединяется с корпоративным вычислительным узлом корпоративной организации, кластер контроллеров идентифицирует оптимальные пути маршрутизации между MFN. Как указано выше, в некоторых вариантах осуществления кластер контроллеров идентифицирует лучший путь между любыми двумя MFN сначала в результате оценки стоимости каждого канала связи между парой соединенных напрямую MFN. например, на основе метрической оценки, которая отражает взвешенную сумму предполагаемой задержки и финансовых затрат. В некоторых вариантах осуществления задержка и финансовые затраты включают в себя (1) измерения задержки канала связи, (2) расчетную задержку обработки сообщений, (3) облачные расходы на исходящий трафик из конкретного дата-центра или до другого дата-центра того же провайдера общедоступного облака или для выхода из облака провайдера общедоступного облака (PC) (например, в другой дата-центр общедоступного облака другого провайдера общедоступного облака или в Интернет), и (4) расчетные затраты на обработку сообщений, связанные с исполнением MFN на хост-компьютерах в общедоступных облаках.
Использование вычисленной стоимости этих парных каналов связи позволяет кластеру контроллеров вычислить стоимость каждого пути маршрутизации, который использует один или несколько из этих парных каналов связи, за счет агрегирования затрат на отдельные парные каналы связи, которые используются по пути маршрутизации. Как указано выше, кластер контроллеров затем определяет свой граф маршрутизации на основе вычисленных затрат на пути маршрутизации и генерирует таблицы пересылки облачных маршрутизаторов MFN на основе определенных графов маршрутизации. Кроме того, как указано выше, кластер контроллеров периодически (например, каждые 12 часов. 24 часа и т.д.) или при получении обновлений измерений от агентов измерений MFN выполняет эти операции по вычислению стоимости, построению графов и обновлению и распределению таблиц пересылки.
Каждый раз, когда таблица пересылки в месте расположения CFE Ci MFN указывает на CFE Cj MFN следующего перехода, CFE Ci рассматривает Cj в качестве соседа. В некоторых вариантах осуществления CFE Ci создает безопасный, активно поддерживаемый VPN-туннель к CFE Cj. В некоторых вариантах осуществления безопасный туннель представляет собой туннель, который требует, чтобы полезные нагрузки инкапсулированных сообщений с данными были зашифрованы. Кроме того, в некоторых вариантах осуществления туннель активно поддерживается одной или обеими конечными точками туннеля, отправляющими сигналы подтверждения активности другой конечной точке.
В других вариантах осуществления CFE не создает безопасных, активно поддерживаемых VPN-туннелей. Например, в некоторых вариантах осуществления туннели между CFE являются статическими туннелями, которые не отслеживаются активно за счет передачи сигналов подтверждения активности. Кроме того, в некоторых вариантах осуществления эти туннели между CFE не шифруют свои полезные нагрузки. В некоторых вариантах осуществления туннели между парой CFE включают в себя два инкапсулирующих заголовка, причем внутренний заголовок идентифицирует ID арендатора, а также входные и выходные CFE для сообщения с данными, входящего в виртуальную сеть и выходящего из нее (т.е. входящего и выходящего из общедоступного(ых) облак(ов), а внешний инкапсулирующий заголовок определяет сетевые адреса источника и назначения (например, IP-адреса) для прохождения через ноль или более CFE от входного CFE к выходному CFE.
В дополнение к внутренним туннелям в некоторых вариантах осуществления, как указано выше, виртуальная сеть соединяет корпоративные вычислительные узлы с их краевыми MFN с помощью VPN-туннелей. Поэтому в вариантах осуществления, где для соединения CFE используются безопасные туннели, сообщения с данными проходят через виртуальную сеть с использованием полностью защищенного VPN-пути.
Так как сообщения с данными виртуальной сети пересылаются с использованием инкапсуляции внутри виртуальной сети, в некоторых вариантах осуществления виртуальная сеть использует свои собственные уникальные сетевые адреса, которые отличаются от частных адресов, используемых различными частными сетями арендатора. В других вариантах осуществления виртуальная сеть использует адресные пространства частных и общедоступных сетей общедоступных облаков, поверх которых она определена. В еще одних других вариантах осуществления виртуальная сеть использует для некоторых из своих компонентов (например, для некоторых из своих MFN, CFE и/или сервисов) некоторые из своих собственных уникальных сетевых адресов, а для других своих компонентов - адресные пространства частных и общедоступных сетей общедоступных облаков.
Кроме того, в некоторых вариантах осуществления виртуальная сеть использует коммуникационную платформу «с чистого листа» со своими собственными проприетарными протоколами. В вариантах осуществления, в которых сообщения с данными пересылаются полностью через программные маршрутизаторы MFN (например, через программные CFE), виртуальная сеть может обеспечивать оптимизированное управление скоростью для сквозных соединений на большие расстояния. В некоторых вариантах осуществления это достигается за счет работы прокси-механизма 220 оптимизации TCP на каждом MFN 150. В других вариантах осуществления, которые не нарушают сам TCP (например, с использованием HTTPS), это достигается за счет прокси-механизма 220, сегментирующего управление скоростью с помощью промежуточной буферизации каждого потока вместе с окном приемника TCP и манипуляцией с ACK.
За счет своей природы «с чистого листа» в некоторых вариантах осуществления виртуальная сеть оптимизирует многие из своих компонентов для обеспечения еще более качественных обслуживания. Например, в некоторых вариантах осуществления виртуальная сеть использует многопутевую маршрутизацию для поддержки настроек VPN с гарантированной полосой пропускания для маршрутизации через виртуальную сеть. В некоторых вариантах осуществления такие VPN включают в себя данные о состоянии в каждом MFN аналогично маршрутизации ATM/MPLS, и их создание и удаление контролируются централизованно. Некоторые варианты осуществления идентифицируют доступную полосу пропускания для каждого исходящего канала связи либо за счет ее измерения напрямую (через пару пакетов или аналогичный процесс), либо за счет наличия заданной пропускной способности для канала связи и сокращения этой пропускной способности на трафик, который уже был отправлен через этот канал связи.
Некоторые варианты осуществления в качестве ограничения используют остаточную полосу пропускания канала связи. Например, когда канал связи не имеет доступной полосы пропускания, составляющей по меньшей мере 2 Мбит/с, кластер контроллеров в некоторых вариантах осуществления удаляет канал связи из набора каналов связи, которые используются для вычисления пути с наименьшей стоимостью (например, кратчайшего пути) к любому пункту назначения (например, удаляет канал связи из графа маршрутизации, такого как граф 400). Если сквозной маршрут является все еще доступным после удаления этого канала связи, новые VPN будут маршрутизироваться по этому новому маршруту. Удаление VPN может восстановить доступную пропускную способность данного канала связи, что, в свою очередь, может позволить включить этот канал связи в расчет наименее затратного пути (например, кратчайшего пути). Некоторые варианты осуществления используют другие варианты многопутевой маршрутизации, такие как балансировка нагрузки трафика по множеству путей, например, с использованием МРТСР (многопутевого TCP).
Некоторые варианты осуществления обеспечивают лучшее обслуживание для премиальных потребителей за счет использования параллелизма путей и недорогих облачных каналов для дублирования трафика от входных MNF к выходному MFN через два непересекающихся пути (например, через максимально непересекающиеся пути) в виртуальной сети. При таком методе самое раннее поступившее сообщение принимается, а более позднее сбрасывается. Такой метод повышает надежность виртуальной сети и снижает задержку за счет увеличения сложности обработки исходящих данных. В некоторых таких вариантах осуществления методы прямого исправления ошибок (FEC) используются для повышения надежности при сокращении дублирующего трафика. За счет своей природы «с чистого листа» в некоторых вариантах осуществления виртуальная сеть выполняет другие оптимизации верхнего уровня, такие как оптимизации уровня приложения (например, операции дедублирования и кэширования) и оптимизации безопасности (например, добавление шифрование, DPI (глубокую проверку пакетов) и применение файрволов).
Виртуальная сеть в некоторых вариантах осуществления предполагает сотрудничество с провайдерами облаков, чтобы дополнительно улучшить настройку виртуальной сети за счет использования произвольной передачи сообщений. Например, в некоторых вариантах осуществления, когда все MFN получают один и тот же внешний IP-адрес, легче соединить любой новый корпоративный вычислительный узел с оптимальным краевым узлом (например, с ближайшим краевым узлом) с помощью произвольного соединения. Точно так же любой провайдер SaaS может получить этот IP-адрес и соединиться с оптимальным MFN (например, с ближайшим MFN).
Как указано выше, различные варианты осуществления используют разные типы VPN-соединений для соединения корпоративных вычислительных узлов (например, филиалов и мобильных устройств) с MFN, которые создают виртуальную сеть корпоративной организации. Некоторые варианты осуществления используют IPsec для настройки этих VPN-соединений. Фиг. 6 иллюстрирует формат сообщений с IPsec-данными в соответствии с некоторыми вариантами осуществления. В частности, эта фигура иллюстрирует исходный формат сообщения 605 с данными, сгенерированного машиной на корпоративном вычислительном узле, и сообщения 610 с инкапсулированными IPsec-данными после того, как сообщение 605 с данными было инкапсулировано (например, на корпоративном вычислительном узле или MFN) для передачи через IPsec-туннель (например, на MFN или на корпоративный вычислительный узел).
В этом примере IPsec-туннель настраивается с использованием туннельного режима ESP, порт 50. Как показано, в этом примере этот режим настраивается за счет замены идентификатора протокола TCP в заголовке IP на идентификатор протокола ESP. Заголовок ESP идентифицирует начало сообщения 615 (т.е. заголовок 620 и полезную нагрузку 625). Сообщение 615 должно быть аутентифицировано получателем сообщения с инкапсулированными IPsec-данными (например, IPsec-шлюзом MFN). Начало полезной нагрузки 625 идентифицируется значением поля 622 «следующий» в сообщении 615. Кроме того, полезная нагрузка 625 зашифрована. Эта полезная нагрузка включает в себя IP-заголовок, TCP-заголовок и полезную нагрузку исходного сообщения 605 с данными, а также поле 630 заполнителя, которое включает в себя поле 622 «следующий».
В некоторых вариантах осуществления каждый IPsec-шлюз MFN может обрабатывать множество IPsec-соединений для одного и того же или разных арендаторов виртуальных сетей (например, для одной и той же корпорации или для разных корпораций). Таким образом, в некоторых вариантах осуществления IPsec-шлюз MFN (например, шлюз 230) идентифицирует каждое IPsec-соединение с точки зрения ID туннеля, ID арендатора (TID) и подсети корпоративных вычислительных узлов. В некоторых вариантах осуществления разные корпоративные узлы (например, разные филиальные офисы) арендатора не имеют перекрывающихся IP-подсетей (согласно RFC 1579). В некоторых вариантах осуществления IPsec-шлюз имеет таблицу, сопоставляющую каждый ID IPsec-туннеля (который содержится в заголовке IPsec-туннеля) с ID арендатора. Для данного арендатора для обработки которого сконфигурирован IPsec-шлюз, IPsec-шлюз также имеет сопоставление всех подсетей этого арендатора, которые соединяются с виртуальной сетью, созданной MFN и их облачными элементами пересылки.
Когда входной первый MFN в первом дата-центре общедоступного облака получает через IPsec-туннель сообщение с данными, связанное с ID арендатора и предназначенное для пункта назначения (например, для подсети филиалов или дата-центров или для провайдера SaaS), который соединяется с выходным вторым MFN во втором дата-центре общедоступного облака, IPsec-шлюз первого MFN удаляет заголовок IPsec-туннеля. В некоторых вариантах осуществления CFE первого MFN затем инкапсулирует сообщение с двумя инкапсулирующими заголовками, которые позволяют сообщению проходить путь от входного первого MFN к выходному второму MFN напрямую или через один или более других промежуточных MFN. CFE первого MFN идентифицирует этот путь с помощью своей таблицы маршрутизации, конфигурированной контроллером.
Как указано выше, в некоторых вариантах осуществления два инкапсулирующих заголовка включают в себя (1) внешний заголовок, который определяет CFE MFN следующего перехода, чтобы позволить инкапсулированному сообщению с данными проходить через MFN виртуальной сети, чтобы достичь CFE выходного MFN, и (2) внутренний заголовок, который определяет ID арендатора и CFE входных и выходных MFN, которые идентифицируют MFN для сообщения с данными, входящего в виртуальную сеть и выходящего из нее.
В частности, в некоторых вариантах осуществления внутренний инкапсулирующий заголовок включает в себя действительный IP-заголовок с IP-адресом назначения CFE выходного второго MFN и IP-адрес источника CFE входного первого MFN. Такой метод позволяет использовать стандартное программное обеспечение IP-маршрутизатора в каждом из CFE MFN. Инкапсуляция дополнительно включает в себя ID арендатора (например, CID потребителя). Когда сообщение прибывает в CFE выходного второго MFN, оно декапсулируется и отправляется вторым MFN в его пункт назначения (например, отправляется IPsec-шлюзом второго MFN в пункт назначения через другой IPsec-туннель. который связан с ID арендатора и подсеть пункта назначения сообщения).
Некоторые облачные провайдеры запрещают машинам «подделывать» IP-адрес назначения и/или накладывают другие ограничения на TCP- и UDP-трафик. Чтобы справиться с такими возможными ограничениями, некоторые варианты осуществления используют внешний заголовок для соединения соседних пар MFN, которые используются одним или несколькими маршрутами. В некоторых вариантах осуществления этот заголовок является заголовком UDP, который определяет IP-адреса источника и назначения и параметры протокола UDP. В некоторых вариантах осуществления CFE входного MFN определяет свой IP-адрес как IP-адрес источника внешнего заголовка, a IP-адрес следующего перехода CFE MFN определяет как IP-адрес назначения внешнего заголовка.
Когда путь к CFE выходного MFN включает в себя один или более промежуточных CFE MFN, промежуточный CFE заменяет IP-адрес источника во внешнем заголовке дважды инкапсулированного сообщения, которое он получает, своим IP-адресом. Он также использует IP-адрес назначения во внутреннем заголовке для выполнения поиска маршрута в своей таблице маршрутизации, чтобы идентифицировать IP-адрес назначения CFE MFN следующего перехода, который находится на пути к IP-адресу назначения внутреннего заголовка. Затем промежуточный CFE заменяет IP-адрес назначения во внешнем заголовке на IP-адрес, который он идентифицировал при поиске в таблице маршрутов.
Когда дважды инкапсулированное сообщение с данными достигает CFE выходного MFN, CFE определяет, что это выходной узел для сообщения с данными, когда он извлекает IP-адрес назначения во внутреннем заголовке, и определяет, что этот IP-адрес назначения принадлежит ему. Затем этот CFE удаляет два заголовка инкапсуляции из сообщения с данными, а затем отправляет его в пункт назначения (например, через IPsec-шлюз своего MFN в пункт назначения через другой IPsec-туннель, который связан с ID арендатора и IP-адресом или подсетью назначения в исходном заголовке сообщения с данными).
Фиг. 7 иллюстрирует пример двух инкапсулирующих заголовков в соответствии с некоторыми вариантами осуществления, а фиг. 8 представляет пример, который иллюстрирует, как эти два заголовка используются в некоторых вариантах осуществления. В приводимом ниже обсуждении внутренний заголовок называется заголовком арендатора, так как он включает в себя ID арендатора вместе с идентификационными данными узлов входа/выхода виртуальной сети, соединенных с корпоративными конечными вычислительным узлам арендатора. Внешний заголовок ниже именуется как заголовок туннеля VN-перехода, так как он используется для идентификации следующего перехода через виртуальную сеть, когда сообщение с данными пересекает путь через виртуальную сеть между CFE входного и выходного MFN.
Фиг. 7 показывает заголовок 705 туннеля VN-перехода и заголовок 720 туннеля арендатора, инкапсулирующие исходное сообщение с данными с исходным заголовком 755 и полезной нагрузкой 760. Как показано, в некоторых вариантах осуществления заголовок 705 туннеля VN-перехода включает в себя заголовок 710 UDP и заголовок 715 IP. В некоторых вариантах осуществления заголовок UDP определяется согласно протоколу UDP. В некоторых вариантах осуществления туннель VN-перехода представляет собой стандартный UDP-туннель, а в других вариантах осуществления этот туннель является проприетарным UDP-туннелем. В еще одних других вариантах осуществления этот туннель представляет собой стандартный или проприетарный TCP-туннель. В некоторых вариантах осуществления заголовок 705 туннеля является зашифрованным заголовком, который шифрует свою полезную нагрузку, а в других вариантах осуществления это - незашифрованный туннель.
Как дополнительно описано ниже, в некоторых вариантах осуществления заголовок 705 туннеля используется для определения оверлейной сети VNP и используется каждым CFE MFN для достижения следующего перехода CFE MFN поверх нижележащих сетей общедоступных облаков. При этом IP-заголовок 715 заголовка 705 туннеля идентифицирует IP-адреса источника и назначения первого и второго CFE первого и второго соседних MFN, соединенных туннелем VNP. В некоторых случаях (например, когда MFN назначения следующего перехода и MFN источника находятся в разных общедоступных облаках разных провайдеров общедоступных облаков) IP-адреса источника и назначения являются общедоступными IP-адресами, которые используются дата-центрами общедоступных облаков, которые включают в себя MFN. В других случаях, когда CFE MFN источника и назначения принадлежат одному общедоступному облаку, IP-адреса источника и назначения могут быть частными IP-адресами, которые используются только в общедоступном облаке. В качестве альтернативы в таких случаях IP-адреса источника и назначения могут по-прежнему быть общедоступными IP-адресами провайдера общедоступного облака.
Как показано на фиг. 7, заголовок 720 туннеля арендатора включает в себя IP-заголовок 725, поле 730 ID арендатора и метку 735 виртуальной цепи (VCL). Заголовок 720 туннеля арендатора используется CFE каждого перехода после входного CFE перехода для идентификации следующего перехода для пересылки сообщения с данными в выходной CFE выходного MFN. При этом IP-заголовок 725 включает в себя IP-адрес источника, который является IP-адресом входного CFE, и IP-адрес назначения, который является IP-адресом выходного CFE. Как и в случае с IP-адресами источника и назначения заголовка 705 VN-перехода, IP-адреса источника и назначения заголовка 720 арендатора могут быть либо частными IP-адресами одного провайдера общедоступного облака (когда сообщение с данными пересекает маршрут, который проходит только через один дата-центра провайдера общедоступного облака) либо общедоступными IP-адресами одного или более провайдеров общедоступных облаков (например, когда сообщение с данными проходит по маршруту, который проходит через дата-центры двух или более провайдеров общедоступных облаков).
В некоторых вариантах осуществления IP-заголовок заголовка 720 арендатора может маршрутизироваться с помощью любого стандартного программного маршрутизатора и таблицы IP-маршрутизации. Поле 730 ID арендатора содержит ID арендатора, который является уникальным идентификатором арендатора, который может использоваться во входных и выходных MFN для уникальной идентификации арендатора. В некоторых вариантах осуществления провайдер виртуальных сетей определяет разные идентификаторы арендатора для разных корпоративных объектов, которые являются арендаторами провайдера. Поле 735 VCL является необязательным полем маршрутизации, которое некоторые варианты осуществления используют для предоставления альтернативного способа (не на основе IP) пересылки сообщений через сеть. В некоторых вариантах осуществления заголовок 720 туннеля арендатора является заголовком GUE (Generic UDP Encapsulation).
Фиг. 8 представляет пример, показывающий, как эти два заголовка 705 и 710 туннелей используются в некоторых вариантах осуществления. В этом примере сообщение 800 с данными отправляется с первой машины 802 (например, с первой VM) в первом филиальном офисе 805 компании на вторую машину 804 (например, на вторую VM) во втором филиальном офисе 810 компании. Эти две машины находятся в двух разных подсетях. 10.1.0.0 и 10.2.0.0 соответственно, где IP-адрес первой машины - 10.1.0.17, a IP-адрес второй машины - 10.2.0.22. В этом примере первый филиал 805 соединен с входным MFN 850 в первом дата-центре 830 общедоступного облака, а второй филиал 810 соединен с выходным MFN 855 во втором дата-центре 838 общедоступного облака. Кроме того, в этом примере входные и выходные MFN 850 и 855 первого и второго дата-центров общедоступных облаков косвенно связаны через промежуточный MFN 857 третьего дата-центра 836 общедоступного облака.
Как показано, сообщение 800 с данными от машины 802 отправляется на входной MFN 850 по IPsec-туннелю 870, который соединяет первый филиальный офис 805 с входным MFN 850. Этот IPsec-туннель 870 создается между IPsec-шлюзом 848 первого филиального офиса и IPsec-шлюзом 852 входного MNF 850. Этот туннель создается за счет инкапсуляции сообщения 800 с данными с заголовком 806 IPsec-туннеля.
IPsec-шлюз 852 MFN 850 декапсулирует сообщение с данными (т.е. удаляет заголовок 806 IPsec-туннеля) и передает декапсулированное сообщение в CFE 832 этого MFN напрямую или через одну или более машин мидлбокс-обслуживания (например, через машину файрвола, такую как машина 210 на фиг. 2). При передаче этого сообщения в некоторых вариантах осуществления IPsec-шлюз или некоторый другой модуль MFN 850 связывает сообщение с ID IPsec-туннеля и ID арендатора компании. Этот ID арендатора идентифицирует компанию в записях провайдера виртуальных сетей.
На основе связанного ID арендатора и/или ID IPsec-туннеля CFE 832 входного MNF 850 идентифицирует маршрут для сообщения в подсеть своих машин назначения (то есть во второй филиальный офис 810) через виртуальную сеть, которая создана MFN в разных дата-центрах общедоступных облаков. Например, CFE 832 использует ID арендатора и/или ID IPsec-туннеля, чтобы идентифицировать таблицы маршрутизации для компании. Затем в этой таблице маршрутизации CFE 832 использует IP-адрес 10.2.0.22 назначения полученного сообщения для идентификации записи, которая идентифицирует CFE 853 выходного MFN 855 дата-центра 838 общедоступного облака в качестве выходного узла пересылки в пункт назначения для сообщения 800 с данными. В некоторых вариантах осуществления идентифицированная запись сопоставляет всю подсеть 10.2.0.0/16 второго филиального офиса 810 с CFE 853 MFN 855.
После идентификации выходного CFE 853 CFE 832 входного MNF 850 инкапсулирует полученное сообщение с данными с заголовком 860 туннеля арендатора, который в своем IP-заголовке 725 включает в себя IP-адрес источника входного CFE 832 и IP-адрес назначения выходного CFE 853. В некоторых вариантах осуществления эти IP-адреса определены в пространстве общедоступных IP-адресов. Заголовок 860 туннеля также включает в себя ID арендатора, который связан с сообщением с данными на входном MFN 850. Как указано выше, в некоторых вариантах осуществления этот заголовок туннеля также включает в себя значение заголовка VCL.
В некоторых вариантах осуществления входной CFE 832 также идентифицирует MFN следующего перехода, который находится на требуемом пути маршрутизации CFE к выходному CFE 853. В некоторых вариантах осуществления входной CFE 832 идентифицирует этот CFE следующего перехода в своей таблице маршрутизации с помощью IP-адреса назначения выходного CFE 853. В этом примере CFE MFN следующего перехода - это CFE 856 третьего MFN 857 третьего дата-центра 836 общедоступного облака.
После идентификации CFE MFN следующего перехода CFE входного MFN инкапсулирует сообщение 800 с инкапсулированными данными с VN-переходом, вторым заголовком 862 туннеля. Этот заголовок туннеля позволяет маршрутизировать сообщение в CFE 856 следующего перехода. В IP-заголовке 715 этого внешнего заголовка 862 CFE 832 входного MFN определяет IP-адреса источника и назначения как IP-адрес источника входного CFE 832 и IP-адрес назначения промежуточного CFE 856. В некоторых вариантах осуществления он также определяет свой протокол уровня 4 как UDP.
Когда CFE 856 третьего MFN 857 получает сообщение с дважды инкапсулированными данными, он удаляет VN-переход, второй заголовок 862 туннеля и извлекает из заголовка 860 арендатора IP-адрес назначения CFE 853 выходного MFN 855. Так как этот IP-адрес не связан с CFE 856, сообщение с данными все равно должно пройти в другой MFN. чтобы достичь своего пункта назначения. Таким образом, CFE 856 использует извлеченный IP-адрес назначения для идентификации записи в своей таблице маршрутизации, которая идентифицирует CFE 853 MFN следующего перехода. Затем он повторно инкапсулирует сообщение с данными с внешним заголовком 705 и определяет IP-адреса источника и назначения в своем IP-заголовке 715 в качестве собственного IP-адреса и IP-адреса назначения CFE 853 MFN. Затем CFE 856 пересылает дважды инкапсулированное сообщение 800 с данными в выходной CFE 853 через промежуточную архитектуру маршрутизации дата-центров 836 и 838 общедоступных облаков.
После получения инкапсулированного сообщения с данными выходной CFE 853 определяет, что инкапсулированное сообщение направлено ему, когда он извлекает IP-адрес назначения во внутреннем заголовке 860, и определяет, что этот IP-адрес назначения принадлежит ему. Выходной CFE 853 удаляет оба инкапсулирующих заголовка 860 и 862 из сообщения 800 с данными и извлекает IP-адрес назначения в исходном заголовке сообщения с данными. Этот IP-адрес назначения идентифицирует IP-адрес второй машины 804 в подсети второго филиального офиса.
С помощью ID арендатора в удаленном заголовке 860 туннеля арендатора выходной CFE 853 идентифицирует корректную таблицу маршрутизации для поиска, а затем выполняет поиск в этой таблице маршрутизации на основе IP-адреса назначения, извлеченного из исходного значения заголовка полученного сообщения с данными. На основе этого поиска выходной CFE 853 идентифицирует запись, которая идентифицирует IPsec-соединение, используемое для пересылки сообщения с данными в пункт назначения. Затем он доставляет сообщение с данными вместе с идентификатором IPsec-соединения на IPsec-шлюз 858 второго MFN, который затем инкапсулирует это сообщение с заголовком 859 IPsec-туннеля и затем пересылает его на IPsec-шлюз 854 второго филиального офиса 810. Затем шлюз 854 удаляет заголовок IPsec-туннеля и пересылает сообщение с данными на свою машину 804 назначения.
Несколько более подробных примеров обработки сообщений теперь будут описаны со ссылками на фиг. 9-15. В этих примерах предполагается, что каждый IPsec-интерфейс арендатора находится на том же локальном общедоступном IP-адресе, что и туннели VNP. При этом интерфейсы в некоторых вариантах осуществления прикреплены к единому пространству имен для VRF (для виртуальной маршрутизации и пересылки). Это пространство имен для VRF упоминается ниже как пространство имен VNP.
Фиг. 9-11 иллюстрируют процессы 900-1100 обработки сообщений, которые выполняются соответственно входным, промежуточным и выходным MFN, когда они принимают сообщение, которое отправляется между двумя вычислительными устройствами в двух разных местоположениях внешних компьютеров (например, филиалы, дата-центры и др.) арендатора. В некоторых вариантах осуществления кластер 160 контроллеров конфигурирует CFE каждого MFN для работы в качестве входного, промежуточного и выходного CFE, когда каждый такой CFE является кандидатом на роль входного, промежуточного и выходного CFE для различных потоков сообщений с данными от арендатора.
Процессы 900-1100 будут объяснены ниже со ссылками на два примера с иллюстрациями на фиг. 8 и 12. Как указано выше, фиг. 8 иллюстрирует пример, когда сообщение с данными проходит через промежуточный MFN, чтобы достичь выходного MFN. Фиг. 12 иллюстрирует пример, в котором между входным и выходным MFN не используется промежуточный MFN. В частности, она иллюстрирует сообщение 1200 с данными, отправляемое с первого устройства 1202 в первом филиальном офисе 1205 на второе устройство 1210 во втором филиальном офисе 1220, когда два филиальных офиса соединяются с двумя дата-центрами 1230 и 1238 общедоступных облаков двумя MFN 1250 и 1255, которые соединены напрямую. Как показано, CFE 1232 и 1253 MFN в этих примерах выполняют операции маршрутизации, связанные с каждым MFN.
В некоторых вариантах осуществления входной CFE (например, входной CFE 832 или 1232) входных MFN 850 и 1250 выполняет процесс 900. Как показано на фиг. 9, процесс 900 входа начинается с начальной идентификации (на этапе 905) контекста маршрутизации арендатора на основе идентификатора IPsec-туннеля (например, 806 или 1206) в полученном сообщении с данными. В некоторых вариантах осуществления IPsec-шлюзы или другие модули MFN хранят ID арендаторов для IPsec-туннелей в таблицах сопоставления. При каждом приеме сообщения с данными по конкретному IPsec-туннелю IPsec-шлюз извлекает ID IPsec-туннеля, который затем этот шлюз или другой модуль MFN использует для идентификации связанного ID арендатора по ссылке на свою таблицу сопоставления. За счет идентификации ID арендатора процесс идентифицирует таблицу маршрутизации арендатора или часть пространства имен для VRF арендатора для использования.
На этапе 910 процесс выполняет приращение счетчика RX (приема) идентифицированного IPsec-туннеля, чтобы учесть получение этого сообщения с данными. Затем на этапе 915 процесс выполняет поиск маршрута (например, поиск совпадения по самому длинному префиксу (LPM) в идентифицированном контексте маршрутизации арендатора (например, в части пространства имен для VRF арендатора) для идентификации IP-адреса выходного интерфейса для выхода из виртуальной сети арендатора, построенной поверх дата-центров общедоступных облаков. Для примеров от филиала к филиалу выходной интерфейс является IP-адресом выходного CFE (например, CFE 853 или 1253) MFN, соединенного с филиалом назначения.
На этапе 920 процесс добавляет заголовок туннеля арендатора (например, заголовок 860 или 1260) к полученному сообщению с данными и встраивает исходный IP-адрес источника входного CFE (например, входного CFE 832 или 1252) и IP-адрес назначения выходного CFE (например, выходного CFE 853 или 1253) в качестве IP-адресов источника и назначения в этот заголовок туннеля. В заголовке арендатора процесс также сохраняет ID арендатора (идентифицированный на этапе 905) в заголовке арендатора. На этапе 920 процесс добавляет заголовок туннеля VN-перехода (например, заголовок 862 или 1262) в дополнение к заголовку арендатора и сохраняет его IP-адрес в качестве IP-адреса источника в этом заголовке. Процесс также определяет (на этапе 920) параметры UDP (например, UDP-порт) заголовка туннеля VNP.
Затем на этапе 925 процесс выполняет приращение счетчика VN-передачи для арендатора, чтобы учесть передачу этого сообщения с данными. На этапе 930 процесс выполняет поиск маршрута (например, поиск LPM) в идентифицированном контексте маршрутизации VNP (например, в VNP-части пространства имен для VRF), чтобы идентифицировать интерфейс следующего перехода для этого сообщения с данными. В некоторых вариантах осуществления этот поиск маршрута представляет собой поиск LPM (например, в VNP-части пространства имен для VRF), который по меньшей мере частично основан на IP-адресе назначения выходного CFE.
На этапе 935 процесс определяет, является ли выходной интерфейс следующего перехода локальным интерфейсом (например, физическим или виртуальным портом) входного CFE. Если это так, процесс определяет (на этапе 937) IP-адрес назначения в заголовке внешнего туннеля VN-перехода в качестве IP-адреса выходного интерфейса, идентифицированного на этапе 915. Затем на этапе 940 процесс доставляет сообщение с данными с двойной инкапсуляцией на свой локальный интерфейс, чтобы его можно было переслать в выходной CFE назначения. После этапа 940 процесс 900 завершается.
Фиг. 12 иллюстрирует пример операций 905-940 для сообщения 1200 с данными, которое входной CFE 1232 получает от устройства 1202 первого филиального офиса 1205. Как показано. MFN 1250 этого CFE принимает это сообщение с данными как инкапсулированное IPsec-сообщение на своем IPsec-шлюзе 1252 от IPsec-шлюза 1248 первого филиального офиса 1205. Входной CFE 1232 инкапсулирует полученное сообщение 1200 (после того, как его IPsec-заголовок был удален IPsec-шлюзом 1252) с заголовком 1262 туннеля VN-перехода и заголовком 1260 туннеля арендатора и пересылает это дважды инкапсулированное сообщение в выходной CFE 1253 MFN 1255 общедоступного облака 1238. Как показано, в этом примере IP-адреса источника и назначения обоих заголовков 1260 и 1262 туннелей идентичны. С учетом идентичности этих двух наборов IP-адресов некоторые варианты осуществления отказываются от использования внешнего IP-заголовка 1262, когда сообщение с данными не маршрутизируется через какой-либо промежуточный CFE. такой как CFE 856.
Когда процесс определяет (на этапе 935), что выходной интерфейс следующего перехода является не локальным интерфейсом входного CFE, a IP-адресом назначения другого маршрутизатора, процесс встраивает (на этапе 945) в заголовок туннеля VN-перехода IP-адрес назначения промежуточного CFE следующего перехода (например, промежуточного CFE 856) в качестве IP-адреса назначения заголовка туннеля VN-перехода.
Затем на этапе 950 процесс выполняет другой поиск маршрута (например, поиск LPM) в идентифицированном контексте маршрутизации VNP (например, в VNP-части пространства имен для VRF). На этот раз поиск основан на IP-адресе промежуточного CFE, который идентифицирован в заголовке туннеля VNP. Так как промежуточный CFE (например. CFE 856) является CFE следующего перехода в виртуальной сети для входного CFE (например, CFE 832), таблица маршрутизации идентифицирует локальный интерфейс (например, локальный порт) для сообщений с данными, отправленных на промежуточный CFE. Таким образом, этот поиск в контексте маршрутизации VNP идентифицирует локальный интерфейс, на который входной CFE доставляет (на этапе 950) дважды инкапсулированное сообщение. Затем процесс выполняет приращение (на этапе 955) счетчика промежуточной VN-передачи, чтобы учесть передачу этого сообщения с данными. После этапа 955 процесс завершается.
Фиг. 10 иллюстрирует процесс 1000, который CFE (например, CFE 853 или 1253) выходного MFN выполняет в некоторых вариантах осуществления, когда он принимает сообщение с данными, которое должно быть направлено на корпоративный вычислительный узел (например, в филиальный офис, дата-центр, местоположение удаленного пользователя), соединенный с MFN. Как показано, процесс сначала принимает (на этапе 1005) сообщение с данными на интерфейсе, связанном с виртуальной сетью. Это сообщение инкапсулируется с заголовком туннеля VN-перехода (например, с заголовком 862 или 1262) и заголовком туннеля арендатора (например, с заголовком 860 или 1260).
На этапе 1010 процесс определяет, что IP-адрес назначения в заголовке туннеля VN-перехода является его IP-адресом назначения CFE (например, IP-адресом CFE 853 или 1253). Затем на этапе 1015 процесс удаляет два заголовка туннелей. Затем процесс извлекает (на этапе 1020) ID арендатора из удаленного заголовка туннеля арендатора. Чтобы учесть полученное сообщение с данными, CFE затем выполняет приращение (на этапе 1025) счетчика RX (приема), который он поддерживает для арендатора, указанного извлеченным ID арендатора.
Затем на этапе 1030 процесс выполняет поиск маршрута (например, поиск LPM) в идентифицированном контексте маршрутизации арендатора (то есть в контексте маршрутизации арендатора, идентифицированного ID арендатора, извлеченным на этапе 1020), чтобы идентифицировать интерфейс следующего перехода для этого сообщения с данными. В некоторых вариантах осуществления процесс выполняет этот поиск на основе IP-адреса назначения в исходном заголовке (например, в заголовке 755) полученного сообщения с данными. Из записи, идентифицированной через этот поиск, процесс 1000 идентифицирует IPsec-интерфейс, через который сообщение с данными должно быть отправлено по своему назначению. Таким образом, процесс 1000 отправляет декапсулированное полученное сообщение с данными на IPsec-шлюз своего MFN (например, на шлюз 858 или 1258).
Затем этот шлюз инкапсулирует сообщение с данными с заголовком IPsec-туннеля (например, с заголовком туннеля 859 или 1259) и пересылает его на шлюз (например, шлюз 854 или 1254) в корпоративном вычислительном узле назначения (например, в филиальном офисе назначения), где он будет декапсулирован и отправлен в его пункт назначения. После этапа 1030 CFE или его MFN выполняет (на этапе 1035) приращение счетчика, который он поддерживает для передачи сообщений по IPsec-соединению на корпоративный вычислительный узел назначения (например, по IPsec-соединению между шлюзами 854 и 858 или между шлюзами 1254 и 1258).
Фиг. 11 иллюстрирует процесс 1100, который CFE (например, CFE 856) промежуточного MFN выполняет в некоторых вариантах осуществления, когда он принимает сообщение с данными, которое должно быть направлено на другой CFE другого MFN. Как показано, процесс сначала принимает (на этапе 1105) сообщение с данными на интерфейсе, связанном с виртуальной сетью. В некоторых вариантах осуществления это сообщение инкапсулируется с двумя заголовками туннелей, заголовком туннеля VN (например, с заголовком 862) и заголовком туннеля арендатора (например, с заголовком 860).
На этапе 1110 процесс закрывает туннель VN-перехода, так как он определяет, что IP-адрес назначения в этом заголовке туннеля является IP-адресом назначения его CFE (например, является IP-адресом назначения CFE 856) Затем, на этапе 1115, процесс определяет, определяет ли заголовок туннеля VN-перехода корректный UDP-порт. Если нет, то процесс завершается. В противном случае на этапе 1120 процесс удаляет заголовок туннеля VN-перехода. Чтобы учесть полученное сообщение с данными, CFE затем выполняет приращение (на этапе 1125) счетчика RX (приема), который он поддерживает для количественной оценки числа сообщений, которые он получил в качестве CFE с промежуточным переходом.
На этапе 1130 процесс выполняет поиск маршрута (например, поиск LPM) в идентифицированном контексте маршрутизации VNP (например, в VNP-части пространства имен для VRF), чтобы идентифицировать интерфейс следующего перехода для этого сообщения с данными. В некоторых вариантах осуществления этот поиск маршрута представляет собой поиск LPM (например, в VNP-части пространства имен для VRF), который, по меньшей мере, частично основан на IP-адресе назначения выходного CFE, который идентифицирован во внутреннем заголовке туннеля арендатора.
Затем процесс определяет (на этапе 1135), является ли выходной интерфейс следующего перехода локальным интерфейсом промежуточного CFE. Если это так, процесс добавляет (на этапе 1140) заголовок туннеля VN-перехода к сообщению с данными, которое уже инкапсулировано с заголовком туннеля арендатора. Процесс задает (на этапе 1142) IP-адрес назначения в заголовке туннеля VN-перехода равным IP-адресу назначения выходного CFE. который указан в заголовке туннеля арендатора. Он также задает (на этапе 1142) IP-адрес источника в заголовке туннеля VN-перехода равным IP-адресу своего CFE. В этом заголовке туннеля процесс также задает атрибуты UDP (например, UDP-порт и т.д.).
Затем на этапе 1144 процесс доставляет дважды инкапсулированное сообщение с данными на свой локальный интерфейс (идентифицированный на этапе 1130), чтобы его можно было переслать на выходной CFE назначения. Один из примеров декапсуляции и пересылки туннеля VN-перехода был описан выше со ссылкой на операции CFE 856 на фиг. 8. Чтобы учесть полученное сообщение с данными, CFE затем выполняет приращение (на этапе 1146) счетчика ТХ (передачи), который он поддерживает для количественной оценки числа сообщений, которые он передал в качестве CFE с промежуточным переходом. После этапа 1146 процесс 1100 завершается.
В то же время, когда процесс определяет (на этапе 1135), что выходной интерфейс следующего перехода является не локальным интерфейсом его CFE, а IP-адресом назначения другого маршрутизатора, процесс добавляет (на этапе 1150) заголовок туннеля VN-перехода в сообщение с данных, из которого ранее был удален заголовок туннеля VN-перехода. В новый заголовок туннеля VN-перехода процесс 1100 встраивает (на 1150) исходный IP-адрес источника его CFE и IP-адрес назначения (идентифицированный на этапе 1130) промежуточного CFE следующего перехода в качестве IP-адресов источника и назначения в заголовке туннеля VN-перехода. Этот заголовок туннеля VNP также определяет протокол уровня 4 UDP с UDP-портом назначения.
Затем на 1155 процесс выполняет другой поиск маршрута (например, поиск LPM) в идентифицированном контексте маршрутизации VNP (например, в части пространства имен VRF для VNP). На этот раз поиск основан на IP-адресе промежуточного CFE следующего перехода, который указан в заголовке нового туннеля VN-перехода. Так как этот промежуточный CFE является следующим переходом текущего промежуточного CFE в виртуальной сети, таблица маршрутизации идентифицирует локальный интерфейс для сообщений с данными, отправляемых на промежуточный CFE следующего перехода. Таким образом, этот поиск в контексте маршрутизации VNP идентифицирует локальный интерфейс, на который текущий промежуточный CFE доставляет дважды инкапсулированное сообщение. Затем процесс выполняет приращение (на этапе 1160) счетчика ТХ (передачи) промежуточной VN-передачи чтобы учесть передачу этого сообщения с данными. После этапа 1160 процесс завершается.
Фиг. 13 иллюстрирует процесс 1300 обработки сообщений, который выполняется CFE входного MNF, когда он принимает сообщение для арендатора, которое отправлено с корпоративного вычислительного устройства арендатора (например, в филиальном офисе) на другую машину арендатора (например, в другом филиальном офисе, дата-центре арендатора или дата-центре провайдера SaaS). Процесс 900 на фиг. 9 является составной частью этого процесса 1300, как дополнительно описано ниже. Как показано на фиг. 13, процесс 1300 начинается с начальной идентификации (на этапе 905) контекста маршрутизации арендатора на основе идентификатора входящего IPsec-туннеля.
На этапе 1310 процесс определяет, являются ли IP-адреса источника и назначения в заголовке полученного сообщения с данными общедоступными IP-адресами. Если это так, процесс (на этапе 1315) сбрасывает сообщение с данными и выполняет приращение счетчика сброса, который он поддерживает для IPsec-туннеля полученных сообщений с данными. На этапе 1315 процесс сбрасывает счетчик, потому что он не должен получать сообщения, адресованные на общедоступные IP-адреса и с них, когда он получает сообщения через IPsec-туннель арендатора. В некоторых вариантах осуществления процесс 1300 также отправляет обратно на корпоративную вычислительную машину источника ICMP-сообщение об ошибке.
В то же время, когда процесс определяет (на этапе 1310), что сообщение с данными поступает не с общедоступного IP-адреса и направляется не на другой общедоступный IP-адрес, процесс определяет (на этапе 1320), является ли IP-адрес назначения в заголовке полученного сообщения с данными общедоступным IP-адресом. Если это так, процесс переходит на этап 1325 для выполнения процесса 900 на фиг. 9, за исключением операции 905, которую он выполнил в начале процесса 1300. После этапа 1325 процесс 1300 завершается. В то же время, когда процесс 1300 определяет (на этапе 1320), что IP-адрес назначения в заголовке полученного сообщения с данными не является общедоступным IP-адресом, процесс выполняет приращение (на этапе 1330) счетчика RX (приема) идентифицированного IPsec-туннеля, чтобы учесть получение этого сообщения с данными.
Затем процесс 1300 выполняет (на этапе 1335) поиск маршрута (например, поиск LPM) в идентифицированном контексте маршрутизации арендатора (например, в части пространства имен арендаторов для VRF). Этот поиск идентифицирует IP-адрес выходного интерфейса для выхода из виртуальной сети арендатора, построенной поверх дата-центров общедоступных облаков. В примере с иллюстрацией на фиг. 13 процесс 1300 достигает операции 1335 поиска, когда сообщение с данными предназначено для машины в дата-центре провайдера SaaS. Поэтому этот поиск идентифицирует IP-адрес выходного маршрутизатора для выхода из виртуальной сети арендатора и достижения машины провайдера SaaS. В некоторых вариантах осуществления все маршруты провайдера SaaS размещены в одной таблице маршрутов или в одной части пространства имен VRF, а в других вариантах реализации маршруты для разных провайдеров SaaS хранятся в разных таблицах маршрутов или в разных частях пространства имен VRF.
На этапе 1340 процесс добавляет заголовок туннеля арендатора к полученному сообщению с данными и встраивает IP-адрес источника входящего CFE и IP-адрес назначения выходного маршрутизатора в качестве IP-адресов источника и назначения в этот заголовок туннеля. Затем на этапе 1345 процесс выполняет приращение счетчика VN-передачи для арендатора, чтобы учесть передачу этого сообщения с данными. На этапе 1350 процесс выполняет поиск маршрута (например, поиск LPM) в контексте маршрутизации VNP (например, в VNP-части пространства имен для VRP), чтобы идентифицировать один из его локальных интерфейсов как интерфейс следующего перехода для этого сообщения с данными. Когда следующим переходом является другой CFE (например, в другом дата-центре общедоступного облака), в некоторых вариантах осуществления процесс дополнительно инкапсулирует сообщение с данными с заголовком VN-перехода и встраивает IP-адрес своего CFE и IP-адрес другого CFE в качестве адреса источника и назначения заголовка VN-перехода. На этапе 1355 процесс доставляет инкапсулированное сообщение с данными на свой идентифицированный локальный интерфейс, чтобы сообщение с данными могло быть переадресовано его выходному маршрутизатору. После этапа 1355 процесс 1300 завершается.
В некоторых случаях входной MFN может принимать сообщение с данными для арендатора, которое его CFE может напрямую пересылать на машину назначения сообщения с данными без прохождения через CFE другого MFN. В некоторых таких случаях, когда CFE не требуется передавать какую-либо конкретную информацию об арендаторе в любой другой последующий модуль обработки VN или необходимая информация может быть доставлена в последующий модуль обработки VN через другие механизмы, инкапсулировать сообщение с данными с заголовком арендатора или заголовком VN-перехода не требуется.
Например, для прямой пересылки сообщения с данными арендатора во внешний дата-центр провайдера SaaS механизм 215 входного MNF должен будет выполнить операцию NAT на основе идентификатора арендатора, как дополнительно описано ниже. Входной CFE или другой модуль во входном MFN должен предоставить идентификатор арендатора механизму 215 NAT, связанному с входным MFN. Когда входной CFE и механизмы NAT исполняются на одном компьютере, некоторые варианты осуществления совместно используют эту информацию между этими двумя модулями и сохраняют ее в общей области памяти. В то же время, когда CFE и механизмы NAT не исполняются на одном компьютере, в некоторых вариантах осуществления используются другие механизмы (например, внеполосная связь) для совместного использования идентификатора арендатора между входным CFE и механизмами NAT. Однако в таких случаях другие варианты осуществления используют инкапсулирующий заголовок (то есть используют внутриполосную связь) для сохранения и совместного использования идентификатора арендатора между различными модулями входного MNF.
Как дополнительно описано ниже, некоторые варианты осуществления выполняют одну или две операции NAT источника над IP-адресом/адресом порта источника сообщения с данными перед отправкой сообщения за пределы виртуальной сети арендатора. Фиг. 14 иллюстрирует операцию NAT, выполняемую на выходном маршрутизаторе. Однако, как дополнительно описано ниже, некоторые варианты осуществления также выполняют другую операцию NAT в сообщении с данными на входном маршрутизаторе, даже несмотря на то, что эта дополнительная операция NAT не была описана выше со ссылками на фиг. 13.
Фиг. 14 иллюстрирует процесс 1400, который выходной маршрутизатор выполняет в некоторых вариантах осуществления, когда он принимает сообщение с данными, которое должно быть направлено в дата-центр провайдера SaaS через Интернет. Как показано, процесс сначала принимает (на этапе 1405) сообщение с данными на интерфейсе, связанном с виртуальной сетью. Это сообщение инкапсулируется с заголовком туннеля арендатора.
На этапе 1410 процесс определяет, что IP-адрес назначения в этом заголовке туннеля является IP-адресом назначения его маршрутизатора, и поэтому он удаляет заголовок туннеля арендатора. Затем процесс извлекает (на этапе 1415) идентификатор арендатора из удаленного заголовка туннеля. Чтобы учесть полученное сообщение с данными, процесс выполняет приращение (на этапе 1420) счетчика RX (приема), который он поддерживает для арендатора, указанного извлеченным ID арендатора.
Затем на этапе 1425 процесс определяет, является ли IP-адрес назначения в исходном заголовке сообщения с данными общедоступным, доступным через локальный интерфейс (например, локальный порт) выходного маршрутизатора. Этот локальный интерфейс не связан с туннелем VNP. Если нет, то процесс завершается. В противном случае процесс выполняет (на этапе 1430) операцию NAT источника для изменения IP-адреса/адреса порта источника сообщения с данными в заголовке этого сообщения. Операция NAT и причина ее выполнения будут описаны ниже со ссылками на фиг. 16 и 17.
После этапа 1430 процесс выполняет (на этапе 1435) поиск маршрута (например, поиск LPM) в контексте маршрутизации в Интернете (то есть в части маршрутизации в Интернете данных маршрутизации, например в пространстве имен для VRF в Интернете маршрутизатора), чтобы определить интерфейс следующего перехода для этого сообщения с данными. В некоторых вариантах осуществления процесс выполняет этот поиск на основе сетевого адреса назначения (например, IP-адреса назначения) исходного заголовка принятого сообщения с данными. Из записи, идентифицированной через этот поиск, процесс 1400 идентифицирует локальный интерфейс, через который сообщение с данными должно быть отправлено в его пункт назначения. Таким образом, на этапе 1435 процесс 1400 доставляет сообщение с данными с преобразованным сетевым адресом источника на его идентифицированный локальный интерфейс для пересылки в его пункт назначения. После 1435 процесс выполняет приращение (на 1440) счетчика, который он поддерживает для передачи сообщений провайдеру SaaS, а затем завершается.
Фиг. 15 иллюстрирует процесс 1500 обработки сообщений, который выполняется входным маршрутизатором, который принимает сообщение, которое отправляется с машины провайдера SaaS на машину арендатора. Как показано, процесс 1500 входа начинается с начального приема (на этапе 1505) сообщения с данными на выделенном интерфейсе ввода с общедоступным IP-адресом, который используется для коммуникаций нескольких или всех провайдеров SaaS. В некоторых вариантах осуществления этот интерфейс ввода представляет собой другой интерфейс с другим IP-адресом, отличный от того, который используется для связи с виртуальной сетью.
После получения сообщения процесс выполняет (на этапе 1510) поиск маршрута в контексте маршрутизации в общедоступном Интернете с использованием IP-адреса назначения, содержащегося в заголовке полученного сообщения с данными. На основе этого поиска процесс определяет (на этапе 1515), является ли IP-адрес назначения локальным и связан ли он с разрешенной операцией NAT. Если нет, то процесс завершается. В противном случае процесс выполняет приращение (на этапе 1520) счетчика (приема) в Интернете для учета получения сообщения с данными.
Затем на этапе 1525 процесс выполняет операцию обратного NAT, которая преобразует IP-адреса/адреса порта назначения сообщения с данными в новые IP-адреса/адреса порта назначения, которые виртуальная сеть связывает с конкретным арендатором. Эта операция NAT также создает ID арендатора (например, извлекает ID арендатора из таблицы сопоставления, которая связывает ID арендатора с преобразованными IP-адресами назначения, или извлекает ID арендатора из той же таблицы сопоставления, которая используется для получения новых IP-адресов /адресов порта назначения.). В некоторых вариантах осуществления процесс 1500 использует запись соединения, которую процесс 1400 создал, когда он выполнял (на этапе 1430) свою операцию SNAT, чтобы выполнить (на этапе 1525) свою операцию обратного NAT. Эта запись соединения содержит сопоставление между внутренним и внешним IP-адресами/адресами портов, которые используются операциями SNAT и DNAT.
На основе преобразованного сетевого адреса назначения процесс затем выполняет (на этапе 1530) поиск маршрута (например, поиск LPM) в идентифицированном контексте маршрутизации арендатора (то есть в контексте маршрутизации, определенном ID арендатора) для идентификации IP-адреса выходного интерфейса для выхода из виртуальной сети арендатора и доступа к машине арендатора в корпоративном вычислительном узле (например, в филиальном офисе). В некоторых вариантах осуществления этот выходной интерфейс является IP-адресом выходного CFE выходного MFN. На этапе 1530 процесс добавляет заголовок туннеля арендатора в полученное сообщение с данными и встраивает IP-адрес входного маршрутизатора и IP-адрес выходного CFE в качестве IP-адресов источника и назначения в этот заголовок туннеля. Затем на этапе 1535 процесс выполняет приращение счетчика VN-передачи для арендатора, чтобы учесть передачу этого сообщения с данными.
На этапе 1540 процесс выполняет поиск маршрута (например, поиск LPM) в идентифицированном контексте маршрутизации VNP (например, в части данных маршрутизации VNP, такой как пространство имен VRF маршрутизатора), чтобы идентифицировать его локальный интерфейс (например, его физический или виртуальный порт), на который входной маршрутизатор доставляет инкапсулированное сообщение. Затем процесс добавляет (на этапе 1540) заголовок VN-перехода в полученное сообщение с данными и встраивает IP-адрес входного маршрутизатора и IP-адрес CFE следующего перехода в качестве IP-адресов источника и назначения этого заголовка VN-перехода. После этапа 1555 процесс завершается.
Как указано выше, в некоторых вариантах осуществления MFN включают в себя механизмы 215 NAT, которые выполняют операции NAT на путях входа и/или выхода сообщений с данными в виртуальную сеть и из нее. В настоящее время операции NAT обычно выполняются во многих контекстах и на многих устройствах (например, на маршрутизаторах, файрволах и т.д.). Например, операция NAT обычно выполняется, когда трафик выходит из частной сети, чтобы изолировать пространство внутренних IP-адресов от регулируемого пространства общедоступных IP-адресов, используемого в Интернете. Операция NAT обычно сопоставляет один IP-адрес с другим IP-адресом.
С увеличением числа компьютеров, соединенных с Интернетом, возникает проблема, состоящая в том, что число компьютеров превышает доступное число IP-адресов. К сожалению, несмотря на то, что существует 4294967296 возможных уникальных адресов, назначать уникальный общедоступный IP-адрес для каждого компьютера уже нецелесообразно. Один из способов обойти это ограничение состоит в том, чтобы назначить общедоступные IP-адреса только маршрутизаторам на границе частных сетей, а другим устройствам внутри сетей получить адреса, которые являются уникальными только в их внутренних частных сетях. Когда устройство хочет связаться с устройством за пределами своей внутренней частной сети, его трафик обычно проходит через Интернет-шлюз, который выполняет операцию NAT для замены IP-адреса источника этого трафика на общедоступный IP-адрес назначения Интернет-шлюза.
Несмотря на то, что Интернет-шлюз частной сети получает зарегистрированный общедоступный адрес в Интернете, каждое устройство внутри частной сети, которое соединяется с этим шлюзом, получает незарегистрированный частный адрес. Частные адреса внутренних частных сетей могут быть в любом диапазоне IP-адресов. Однако Инженерный совет Интернета (IETF) предложил несколько диапазонов частных адресов для использования в частных сетях. Эти диапазоны обычно недоступны в общедоступном Интернете, поэтому маршрутизаторы могут легко различать частные и общедоступные адреса. Эти диапазоны частных адресов известны как RFC 1918 и являются следующими: (1) класс А 10.0.0.0-10.255.255.255, (2) класс В 172.16.0.0-172.31.255.255 и (3) класс С 192.168.0.0-192.168.255.255.
Важно выполнять преобразование IP источника для потоков сообщений с данными, выходящих из частных сетей, чтобы внешние устройства могли различать разные устройства в разных частных сетях, которые используют одни и те же внутренние IP-адреса. Когда внешнее устройство должно отправить ответное сообщение устройству внутри частной сети, внешнее устройство должно отправить свой ответ на уникальный и маршрутизируемый общедоступный адрес в Интернете. Оно не может использовать исходный IP-адрес внутреннего устройства, который может использоваться многочисленными устройствами в многочисленных частных сетях. Внешнее устройство отправляет свой ответ на общедоступный IP-адрес, которым исходная операция NAT заменила частный исходный IP-адрес внутреннего устройства. После получения этого ответного сообщения частная сеть (например, сетевой шлюз) выполняет другую операцию NAT, чтобы заменить общедоступный IP-адрес назначения в ответе на IP-адрес внутреннего устройства.
Многие устройства внутри частной сети и многие приложения, исполняемые на этих устройствах, должны совместно использовать один или конечное число общедоступных IP-адресов, связанных с частной сетью. Таким образом, операции NAT, как правило, также преобразуют адреса портов уровня 4 (например, UDP-адреса, ТСР-адреса, RTP-адреса и т.д.), чтобы иметь возможность однозначно связывать внешние потоки сообщений с внутренними потоками сообщений, которые начинаются или заканчиваются на различных внутренних машинах и/или различных приложениях на этих машинах. Операции NAT также зачастую являются операциями с сохранением состояния, так как во многих контекстах эти операции должны отслеживать соединения и динамически обрабатывать таблицы, повторную сборку сообщений, тайм-ауты, принудительное завершение просроченных отслеживаемых соединений и т.д.
Как указано выше, провайдер виртуальных сетей в некоторых вариантах осуществления предоставляет виртуальную сеть как сервис различным арендаторам поверх множества общедоступных облаков. Эти арендаторы могут использовать общие IP-адреса в своих частных сетях, и они совместно используют общий набор сетевых ресурсов (например, общедоступные IP-адреса) провайдера виртуальных сетей. В некоторых вариантах осуществления трафик данных различных арендаторов передается между CFE оверлейной сети через туннели, и туннель маркирует каждое сообщение уникальным ID арендатора. Эти идентификаторы арендаторов позволяют отправлять сообщения обратно на устройства источника, даже когда IP-пространства частных арендаторов перекрываются. Например, идентификаторы арендатора позволяют отличить сообщение, отправленное из филиального офиса арендатора 17 с адресом источника 10.5.12.1 на Amazon.com, от сообщения, отправленного на Amazon.com из филиального офиса арендатора 235 с тем же адресом источника (и даже с тем же номером порта источника - 55331).
Стандартные NAT, реализованные в соответствии с RFC 1631, не поддерживают понятие аренды и, следовательно, не имеют возможности различать два сообщения с одинаковыми частными IP-адресами. Однако во многих развертываниях виртуальных сетей в некоторых вариантах осуществления полезно использовать стандартные механизмы NAT, так как в настоящее время существует множество совершенных высокопроизводительных реализаций с открытым исходным кодом. Фактически многие ядра Linux в настоящее время имеют работающие механизмы NAT в качестве стандартных функций.
Чтобы использовать стандартные механизмы NAT для различных арендаторов виртуальных сетей арендаторов, провайдер виртуальной сети в некоторых вариантах осуществления использует механизмы сопоставления арендаторов (ТМ) перед использованием стандартных механизмов NAT. На фигуре 16 показаны такие механизмы 1605 ТМ, которые размещены в каждом шлюзе 1602 виртуальной сети, который находится на пути выхода виртуальной сети в Интернет. Как показано, каждый механизм 1605 ТМ располагается перед механизмом 1610 NAT на путях выхода сообщений к дата-центрам 1620 провайдеров SaaS через Интернет 1625. В некоторых вариантах осуществления каждый механизм 215 NAT MFN включает в себя механизм ТМ (например, механизм 1605 ТМ) и стандартный механизм NAT (например, механизм 1610 NAT).
В примере с иллюстрацией на фиг. 16 потоки сообщений приходят из двух филиальных офисов 1655 и 1660 и дата-центра 1665 двух арендаторов виртуальных сетей и входят в виртуальную сеть 1600 через один и тот же входной шлюз 1670, однако это не обязательно должно быть так. В некоторых вариантах осуществления виртуальная сеть 1600 определяется поверх множества дата-центров общедоступных облаков множества вендоров общедоступных облаков. В некоторых вариантах осуществления шлюзы виртуальной сети являются частью управляемых узлов пересылки, а механизмы ТМ размещаются перед механизмами 1610 NAT в выходных MFN.
Когда сообщение с данными достигает выходного шлюза 1602 для выхода из виртуальной сети на пути к дата-центру 1620 провайдера SaaS каждый механизм 1605 ТМ сопоставляет сетевой адрес источника (например, IP-адрес и/или адрес порта источника) этого сообщения с данными сообщение с новым сетевым адресом источника (например, с IP-адресом и/или адресом порта источника), а механизм 1610 NAT сопоставляет новый сетевой адрес источника с еще одним сетевым адресом источника (например, с IP-адресом и/или адресом порта другого источника). В некоторых вариантах осуществления механизм ТМ является элементом без состояния и выполняет сопоставление для каждого сообщения через статическую таблицу без использования какой-либо динамической структуры данных. В качестве элемента без состояния механизм ТМ не создает записи соединения, когда он обрабатывает первое сообщение с данными в потоке сообщений с данными, чтобы использовать эту запись соединения при выполнении сопоставления адресов для обработки последующих сообщений в потоке сообщений с данными.
В то же время в некоторых вариантах осуществления механизм 1605 NAT является элементом с отслеживанием состояния, который выполняет свое сопоставление за счет ссылки на хранилище соединений, которое хранит записи соединений, которые отражают его предыдущие сопоставления SNAT. Когда механизм NAT получает сообщение с данными, в некоторых вариантах осуществления этот механизм сначала проверяет свое хранилище соединений, чтобы определить, создавало ли оно ранее запись соединения для потока полученных сообщений. Если это так, механизм NAT использует сопоставление, содержащееся в этой записи, для выполнения своей операции SNAT. В противном случае он выполняет операцию SNAT на основе набора критериев, которые он использует для получения нового сопоставления адресов для нового потока сообщений с данными. Для этого в некоторых вариантах осуществления механизм NAT использует общие методы преобразования сетевых адресов.
В некоторых вариантах осуществления механизм NAT также может использовать хранилище соединений в некоторых вариантах осуществления, когда он получает сообщение с данными ответа от машины провайдера SaaS. чтобы выполнить операцию DNAT для пересылки сообщения с данными ответа на машину арендатора, которая отправила исходное сообщение. В некоторых вариантах осуществления запись соединения для каждого потока обработанных сообщений с данными имеет идентификатор записи, который включает в себя идентификатор потока (например, идентификатор из пяти кортежей с преобразованным сетевым адресом источника).
При выполнении своего сопоставления механизмы ТМ гарантируют, что потоки сообщений с данными от разных арендаторов, которые используют один и тот же IP-адрес и адрес порта источника, сопоставляются с пространствами уникальных неперекрывающихся адресов. Для каждого сообщения механизм ТМ идентифицирует ID арендатора и выполняет свое сопоставление адресов на основе этого идентификатора. В некоторых вариантах осуществления механизм ТМ сопоставляет IP-адреса источника разных арендаторов в разных диапазонах IP, так что любые два сообщения от разных арендаторов не будут сопоставляться с одним и тем же IP-адресом.
Следовательно, каждый тип сети с разным ID арендатора будет сопоставляться с уникальным адресом в пределах полной области 2 области IP-адреса (0.0.0.0-255.255.255.255). Сети классов А и В имеют в 256 и 16 раз больше возможных IP-адресов, чем сеть класса С. С учетом пропорции размеров сетей классов А, В и С, сеть 256 класса А может быть распределена следующим образом: (1) 240 для сопоставления 240 арендаторов с сетью класса А, (2) 15 для сопоставления 240 арендаторов с сетями класса В и (3) единая сеть класса А для сопоставления 240 арендаторов с сетями класса С. В частности, в некоторых вариантах осуществления, сети класса А с самым низким диапазоном (начиная с 0.ххх/24, 1.ххх/24… до 239.ххх/24) будут использоваться для сопоставления адресов, поступающих из 10.x сетей класса А до 240 различных целевых сетей класса А. Каждая из следующих 15 сетей класса А от 240.х.х.х/24 до 254.х.х.х/24 будет использоваться для включения каждой из 16 сетей класса В (например, всего 240 сетей (15×16)). Последняя сеть класса А 255.х.х.х/24 будет использоваться для включения до 256 частных сетей класса С. Несмотря на то, что может быть размещено 256 арендаторов, используются только 240, а 16 сетей класса С не используются. Таким образом, некоторые варианты осуществления используют следующее сопоставление:
- сети 10.х.х.х/24 → 1.х.х.х/24-239.х.х.х/24, дающие в результате 240 различных сопоставлений для каждого арендатора;
- сети 172.16-31.х.х/12 → 240х.х.х/24-254.х.х.х/24, дающие в результате 240 различных сопоставлений для каждого арендатора;
- сети 192.168.х.х/16 → 255.х.х.х/24. дающие 240 из 256 возможных сопоставлений для каждого арендатора.
Если предположить, что заранее неизвестно, какой тип класса сети будут использовать арендаторы, вышеописанные схемы могут поддерживать до 240 арендаторов. В некоторых вариантах осуществления сеть общедоступных облаков использует частный IP-адрес. В таком случае сопоставлять повторно с пространством частных адресов нежелательно. Так как некоторые варианты осуществления удаляют сеть класса А и сеть класса В, в этих вариантах осуществления может поддерживаться только 239 различных арендаторов. Для достижения уникального сопоставления в некоторых вариантах осуществления все идентификаторы арендаторов пронумерованы от 1 до 23, а затем к ID арендатора (выраженному в 8 битах) добавлены 8 младших битов немаскированной части частного домена по модулю 240. В этом случае для адресов класса А первый арендатор (номер 1) будет сопоставлен с 11.xx.xx.xx/24, а последний (239) - с 9.хх.хх.хх/24.
В реализации с иллюстрацией на фиг. 16 некоторые варианты осуществления предоставляют каждому механизму 1605 ТМ любые подсети с ID потенциальных арендаторов и способ маршрутизации сообщений обратно на любой конкретный IP-адрес в каждой такой подсети. Эта информация может динамически изменяться при добавлении или удалении арендаторов, филиалов и мобильных устройств. Поэтому эта информация должна динамически распределяться по механизмам ТМ на выходных Интернет-шлюзах виртуальной сети. Так как выходные Интернет-шлюзы провайдера виртуальных сетей могут использоваться большим числом арендаторов, объем распределяемой и регулярно обновляемой информации может быть большим. Кроме того, ограничение в 240 (или 239) ID идентификаторов арендаторов является глобальным ограничением, и может быть устранено только за счет добавления множества IP-адресов к точкам выхода.
Фиг. 17 иллюстрирует метод двойного NAT, который используется в некоторых вариантах осуществления вместо метода одиночного NAT с иллюстрацией на фиг. 16. Метод с иллюстрацией на фиг. 17 требует, чтобы меньше данных по арендаторам распределялось между большинством, если не всеми, механизмами ТМ, и позволяет сопоставлять большее число частных сетей арендаторов с внутренней сетью провайдера виртуальных сетей. Для потока сообщений с данными, который проходит от машины арендатора через виртуальную сеть 1700, а затем через Интернет 1625 на другую машину (например, на машину в дата-центре 1620 провайдера SaaS), метод с иллюстрацией на фиг. 17 помещает механизм NAT на входном шлюзе 1770 потока сообщений с данными в виртуальную сеть и на выходном шлюзе 1702 или 1704 этого потока из виртуальной сети и в Интернет 1625. Этот метод также помещает механизмы 1705 ТМ перед механизмами 1712 NAT входных шлюзов 1770.
В примере с иллюстрацией на фиг. 17 потоки сообщений поступают из двух филиальных офисов 1755 и 1760 и дата-центра 1765 двух арендаторов виртуальной сети, и входят в виртуальную сеть 1700 через один и тот же входной шлюз 1770, однако это не обязательно должно быть так. Как и виртуальная сеть 1600, в некоторых вариантах осуществления виртуальная сеть 1700 определяется поверх множества дата-центров общедоступных облаков множества вендоров общедоступных облаков. Кроме того, в некоторых вариантах осуществления шлюзы 1702. 1704 и 1770 виртуальной сети являются частью управляемых узлов пересылки, и в этих вариантах осуществления механизмы ТМ размещаются перед механизмами 215 NAT в этих MFN.
Механизмы 1605 и 1705 ТМ работают аналогично на фиг. 16 и 17. Подобно механизмам 1605 механизм 1705 ТМ сопоставляет IP-адрес и адрес порта источника сообщений с данными, поступающих в виртуальную сеть, на новые IP-адрес и адрес порта источника, когда эти сообщения с данными предназначены для (т.е. имеют IP-адреса назначения для) дата-центров 1620 провайдеров SaaS. Для каждого такого сообщения с данными механизм 1705 ТМ идентифицирует ID арендатора и выполняет сопоставление адресов на основе этого идентификатора.
Подобно механизмам 1605 ТМ в некоторых вариантах осуществления механизм 1705 ТМ является элементом без состояния и выполняет сопоставление для каждого сообщения через статическую таблицу без обращения к какой-либо динамической структуре данных. В качестве элемента без состояния механизм ТМ не создает запись соединения, когда он обрабатывает первое сообщение с данными потока сообщений с данными, чтобы использовать эту запись соединения при выполнении своего сопоставления адресов для обработки последующих сообщений потока сообщений с данными.
При выполнении своего сопоставления механизмы 1705 ТМ во входных шлюзах 1770 гарантируют, что потоки сообщений с данными от разных арендаторов, которые используют один и тот же IP-адрес и адреса порта источника, сопоставляются с пространством уникальных неперекрывающихся адресов. В некоторых вариантах осуществления механизм ТМ сопоставляет IP-адреса источника разных арендаторов в разных диапазонах IP, так что любые два сообщения от разных арендаторов не будут сопоставляться с одним и тем же IP-адресом. В других вариантах осуществления механизм 1705 ТМ может сопоставлять IP-адреса источника двух разных арендаторов с одним и тем же диапазоном IP-адресов источника, но разными диапазонами портов источника. В других вариантах осуществления механизм ТМ сопоставляет двух арендаторов с разными диапазонами IP-адресов источника, а двух других арендаторов - с тем же диапазоном IP-адресов источника, но с разными диапазонами портов источника.
В отличие от механизмов 1605 ТМ механизмам 1705 ТМ на входных шлюзах виртуальных сетей необходимо идентифицировать только арендаторов для филиальных офисов, корпоративных дата-центров и корпоративных вычислительных узлов, которые подключены к входным шлюзам. Это значительно сокращает объем данных по арендаторам, которые необходимо предоставлять изначально и периодически обновлять для каждого механизма ТМ. Кроме того, как и раньше, каждый механизм ТМ может сопоставлять с пространством уникальных адресов только 239/240 арендаторов. Однако, так как механизмы ТМ размещаются на входных шлюзах провайдера виртуальных сетей, каждый механизм ТМ может уникальным образом сопоставлять 239/240 арендаторов.
В некоторых вариантах осуществления механизм NAT 1712 входного шлюза 1770 может использовать либо внешние общедоступные IP-адреса, либо внутренние IP-адреса, которые являются специфическими для общедоступного облака (например, для AWS, GCP или Azure), в котором находится входной шлюз 1770. В любом случае механизм 1712 NAT сопоставляет сетевой адрес источника входящего сообщения (то есть сообщения, поступающего в виртуальную сеть 1700) с IP-адресом, который является уникальным в частной облачной сети своего входного шлюза. В некоторых вариантах осуществления механизм 1712 NAT преобразует IP-адрес потоков сообщений с данными каждого арендатора в другой уникальный IP-адрес. Однако в других вариантах осуществления механизм 1712 NAT преобразует IP-адреса источника потоков сообщений с данными разных арендаторов в один и тот же IP-адрес, но использует адреса порта источника, чтобы различать потоки сообщений с данными от разных арендаторов. В еще одних других вариантах осуществления механизм NAT сопоставляет исходные IP-адреса двух арендаторов с разными диапазонами IP-адресов источника при сопоставлении IP-адресов источника двух других арендаторов с тем же диапазоном IP-адресов источника, но с разными диапазонами портов источника.
В некоторых вариантах осуществления механизм 1712 NAT является элементом с отслеживанием состояния, который выполняет свое сопоставление за счет ссылки на хранилище соединений, которое хранит записи соединений, которые отражают его предыдущие сопоставления SNAT. В некоторых вариантах осуществления, когда механизм NAT получает сообщение с данными ответа от машины провайдера SaaS, в некоторых вариантах осуществления механизм NAT также может использовать хранилище соединений, чтобы выполнить операцию DNAT для пересылки сообщения с данными ответа на машину арендатора, которая отправила исходный сообщение. В некоторых вариантах осуществления механизмы 1705, 1710 и 1712 ТМ и NAT конфигурируются кластером 160 контроллеров (например, снабжаются таблицами, описывающими сопоставление, которое должно использоваться для разных арендаторов и разных диапазонов пространства сетевых адресов).
Фиг. 18 представляет пример, который иллюстрирует преобразование порта источника входным механизмом 1712 NAT. В частности, она показывает сопоставление адресов источника, которое механизм 1705 сопоставления арендаторов и входной механизм 1712 NAT выполняют над сообщением 1800 с данными, когда оно входит в виртуальную сеть 1700 через входной шлюз 1770 и при выходе из виртуальной сети через выходной шлюз 1702. Как показано, шлюз 1810 арендатора отправляет сообщение 1800 с данными, которое поступает на IPsec-шлюз 1805 с IP-адресом источника 10.1.1.13, и адресом порта источника 4432. В некоторых вариантах осуществления эти адреса источника являются адресами, используемыми машиной арендатора (непоказанной), а в других вариантах осуществления один или оба этих адреса источника являются адресами источника, которые создаются с помощью операции NAT источника, выполняемой шлюзом арендатора или другим сетевым элементом в дата-центре арендатора.
После того, как это сообщение было обработано шлюзом IPsec-1805, этот шлюз или другой модуль входного MNF связывает это сообщение с ID арендатора 15, который идентифицирует арендатора виртуальной сети, которому принадлежит сообщение 1800. Как показано, на основе этого идентификатора арендатора механизм 1705 сопоставления арендаторов затем сопоставляет IP-адрес и адреса порта источника с IP-адресом и парой IP-адреса и адреса порта источника 15.1.1.13 и 253. Этот IP-адрес и адреса порта источника уникальным образом идентифицируют поток сообщений сообщения 1800 с данными. В некоторых вариантах осуществления механизм 1705 ТМ выполняет это сопоставление без сохранения состояния (то есть без ссылки на записи отслеживания соединения). В других вариантах осуществления механизм ТМ выполняет это сопоставление с отслеживанием состояния.
Затем входной механизм 1712 NAT преобразует (1) IP-адрес источника сообщения 1800 с данными в уникальный частный или общедоступный (внутренний или внешний) IP-адрес 198.15.4.33, и (2) адрес порта источника этого сообщения в адрес 714 порта. В некоторых вариантах осуществления виртуальная сеть использует этот IP-адрес для других потоков сообщений с данными того же или разных арендаторов. Поэтому в этих вариантах осуществления операция преобразования сетевого адреса источника (SNAT) механизма 1712 NAT использует адреса порта источника, чтобы различать разные потоки сообщений разных арендаторов, которые используют один и тот же IP-адрес в виртуальной сети.
В некоторых вариантах осуществления адрес порта источника, назначенный операцией SNAT входного механизма NAT, также является адресом порта источника, который используется для различения различных потоков сообщений за пределами виртуальной сети 1700. Это имеет место в примере с иллюстрацией на фиг. 18. Как показано, выходной механизм 1710 NAT в этом примере не изменяет адрес порта источника сообщения с данными, когда он выполняет свою операцию SNAT. Вместо этого он просто меняет IP-адрес источника на внешний IP-адрес 198.15.7.125. который в некоторых вариантах осуществления является общедоступным IP-адресом выходного(ых) шлюза(ов) виртуальной сети. В некоторых вариантах осуществления этот общедоступный IP-адрес также является IP-адресом дата-центра общедоступного облака, в котором работают входной и выходной шлюзы 1770 и 1702.
С IP-адресами и адресами портов источника 198.15.7.125 и 714 сообщение с данными маршрутизируется через Интернет, чтобы достичь шлюза 1815 дата-центра провайдера SaaS. В этом дата-центре машина провайдера SaaS выполняет операцию на основе этого сообщения и отправляет обратно ответное сообщение 1900, обработка которого будет описана ниже со ссылками на фиг. 19. В некоторых вариантах осуществления машина провайдера SaaS выполняет одну или более операций обслуживания (например, операцию мидлбокс-обслуживания, такую как операция файрвола. операция IDS, операция IPS и т.д.) в сообщении с данными на основе одного или нескольких правил обслуживания, которые определены ссылкой на IP-адрес и адрес порта источника 198.15.7.125 и 714. В некоторых из этих вариантов осуществления разные правила обслуживания для разных арендаторов могут определять один и тот же IP-адрес источника (например, 198.15.7.125) в идентификаторах правил при определении разных адресов портов источника в этих идентификаторах правил. Идентификатор правил определяет набор атрибутов для сравнения с атрибутами потока сообщений с данными при выполнении операции поиска, которая идентифицирует правило, которое совпадает с сообщением с данными.
Фиг. 19 иллюстрирует обработку ответного сообщения 1900, которое SaaS-машина (непоказанная) отправляет в ответ на свою обработку сообщения 1800 данных. В некоторых вариантах осуществления ответное сообщение 1900 может быть идентично исходному сообщению 1800 с данными, это может быть измененная версия исходного сообщения 1800 с данными или это может быть полностью новое сообщение с данными. Как показано, шлюз 1815 SaaS отправляет сообщение 1900 на основе IP-адреса и адреса порта назначения 198.15.7.125 и 714, которые являются IP-адресом и адресом порта источника сообщения 1800 с данными, когда это сообщение поступает на шлюз 1815 SaaS.
Сообщение 1900 принимается на шлюзе (непоказанном) виртуальной сети, и этот шлюз доставляет сообщение с данными в механизм 1710 NAT, который выполнил последнюю операцию SNAT в сообщении 1800 перед тем, как это сообщение было отправлено провайдеру SaaS. Несмотря на то, что в примере с иллюстрацией на фиг. 19, сообщение 1900 с данными принимается на том же механизме 1710 NAT, который выполнил последнюю операцию SNAT, это не обязательно должно быть так в каждом развертывании.
Механизм 1710 NAT (теперь действующий как входной механизм NAT) выполняет операцию DNAT (NAT назначения) над сообщением 1900 с данными. Эта операция изменяет внешний IP-адрес назначения 198.15.7.125 на IP-адрес назначения 198.15.4.33, который используется виртуальной сетью для пересылки сообщения 1900 с данными через архитектуру общедоступной облачной маршрутизации и между компонентами виртуальной сети. Кроме того, в некоторых вариантах осуществления IP-адрес 198.15.4.33 может быть общедоступным или частным IP-адресом.
Как показано, механизм 1712 NAT (теперь действующий как выходной механизм NAT) принимает сообщение 1900 после того, как механизм 1710 NAT преобразовал его IP-адрес назначения. Затем механизм 1712 NAT выполняет вторую операцию DNAT над этим сообщением 1900, которая заменяет его IP-адрес и адрес порта назначения на 15.1.1.13 и 253. Эти адреса являются адресами, распознаваемыми механизмом 1705 ТМ. Механизм 1705 ТМ заменяет эти адреса на IP-адрес и адрес порта назначения 10.1.1.13 и 4432, связывает сообщение1900 с данными с ID арендатора 15 и доставляет сообщение 1900 с этим ID арендатора на IPsec-шлюз 1805 для пересылки на шлюз 1810 арендатора.
В некоторых вариантах осуществления провайдер виртуальных сетей использует описанные выше процессы, системы и компоненты для предоставления множества виртуальных WAN множеству разных арендаторов (например, множества разных корпоративных WAN множеству корпораций) поверх множества общедоступных облаков одного и того же или различные провайдеров общедоступных облаков. На фиг. 20 представлен пример, который показывает М виртуальных корпоративных WAN 2015 для М арендаторов провайдера виртуальных сетей, который имеет сетевую инфраструктуру и кластер(ы) 2010 контроллеров в N общедоступных облаках 2005 одного или более провайдеров общедоступных облаков.
Виртуальная WAN 2015 каждого арендатора может охватывать все N общедоступных облаков 2005 или часть этих общедоступных облаков. Виртуальная WAN 2015 каждого арендатора соединяет один или несколько филиальных офисов 2020, дата-центров 2025, дата-центров 2030 провайдера SaaS и удаленные устройства арендатора. В некоторых вариантах осуществления виртуальная WAN каждого арендатора охватывает любое общедоступное облако 2005, которое кластер контроллера VNP считает необходимым для эффективной пересылки сообщений с данными между различными вычислительными узлами 2020-2035 арендатора. В некоторых вариантах осуществления при выборе общедоступных облаков кластер контроллеров также учитывает общедоступные облака, которые арендатор выбирает, и/или общедоступные облака, в которых арендатор или по меньшей мере один провайдер SaaS арендатора имеет одну или более машин.
Виртуальная WAN 2015 каждого арендатора позволяет удаленным устройствам 2035 (например, мобильным устройствам или удаленным компьютерам) арендатора избегать взаимодействия со шлюзом WAN арендатора в любом филиальном офисе или дата-центре арендатора, чтобы получить доступ к сервису провайдера SaaS (например, доступ к машине провайдера SaaS или кластеру машин). В некоторых вариантах осуществления WAN арендатора позволяет удаленным устройствам избегать использования шлюзов WAN в филиальных офисах и дата-центрах арендатора за счет перемещения функциональных возможностей этих шлюзов WAN (например, шлюзов безопасности WAN) на одну или несколько машин в общедоступных облаках, охватываемых виртуальной WAN.
Например, чтобы позволить удаленному устройству получить доступ к вычислительным ресурсам арендатора или сервисам его провайдера SaaS, в некоторых вариантах осуществления шлюз WAN должен обеспечить принудительное применение правил файрвола, которые управляют тем, как удаленное устройство может получить доступ к ресурсам компьютера арендатора или сервисам его провайдера SaaS. Чтобы избежать использования шлюзов WAN филиала или дата-центра арендатора, механизмы 210 файрвола арендатора размещаются в MFN виртуальной сети в одном или более нескольких общедоступных облаках, охватываемых виртуальной WAN арендатора.
Механизмы 210 файрвола в этих MFN выполняют операции обслуживания файрвола над потоками сообщений с данными от и к удаленным устройствам. При выполнении этих операций в виртуальной сети, развернутой поверх одного или нескольких общедоступных облаков, трафик сообщений с данными, связанный с удаленными устройствами арендатора, не нужно без необходимости маршрутизировать через дата-центр(ы) арендатора или филиальные офисы, чтобы получить обработку правил файрвола. Это уменьшает перегрузку трафика в дата-центрах арендатора и филиальных офисах и позволяет избежать использования дорогостоящей полосы пропускания входной/выходной сети в этих местоположениях для обработки трафика, который не предназначен для вычислительных ресурсов в этих местоположениях. Это также помогает ускорить пересылку трафика сообщений с данными от и к удаленным устройствам, так как этот метод позволяет выполнять промежуточную обработку правил файрвола в виртуальной сети по мере того, как потоки сообщений с данными проходят к своим пунктам назначения (например, на их входных MFN, выходных MFN или MFN промежуточных переходов).
В некоторых вариантах осуществления механизм 210 принудительного применения файрвола (например, VM обслуживания файрвола) MFN принимает правила файрвола от центральных контроллеров 160 VNP. В некоторых вариантах осуществления правило файрвола включает в себя идентификатор правила и действие. В некоторых вариантах осуществления идентификатор правила включает в себя одно или более значений соответствия, которые должны сравниваться с атрибутами сообщений с данными, такими как атрибуты уровня 2 (например, MAC-адреса), атрибуты уровня 3 (например, пять идентификаторов кортежей и т.д.), ID арендатора, ID местоположения (например, ID местоположения офиса, ID дата-центра, ID удаленного пользователя и т.д.), чтобы определить, соответствует ли правило файрвола сообщению с данными.
В некоторых вариантах осуществления действие правил файрвола определяет действие (например, разрешить, сбросить, перенаправить и т.д.), которое механизм 210 принудительного выполнения файрвола должен предпринять в отношении сообщения с данными, когда правило файрвола совпадает с атрибутами сообщения с данными. Чтобы исключить возможность того, что множество правил файрвола совпадают с сообщением с данными, механизм 210 принудительного выполнения файрвола сохраняет правила файрвола (которые он получает от кластера 160 контроллеров) в хранилище данных о правилах файрвола в иерархическом порядке, так что одно правило файрвола может иметь более высокий приоритет, чем другое правило файрвола. Когда сообщение с данными совпадает с двумя правилами файрвола, в некоторых вариантах осуществления механизм принудительного применения файерфола применяет правило с более высоким приоритетом. В других вариантах осуществления механизм принудительного применения файрвола проверяет правила файрвола в соответствии с их иерархией (т.е. проверяет правила с более высоким приоритетом перед правилами с более низким приоритетом), чтобы убедиться, что оно сначала совпадает с правилом с более высоким приоритетом в случае, если другое правило с более низким приоритетом также может совпадать с сообщением с данными.
Некоторые варианты осуществления позволяют кластеру контроллеров конфигурировать компоненты MFN, чтобы механизмы обслуживания файрвола проверяли сообщения с данными на входном узле (например, на узле 850), когда оно входит в виртуальную сеть, на промежуточном узле (например, на узле 857) в виртуальной сети или на выходном узле (например, на узле 855), когда оно выходит из виртуальной сети. В некоторых вариантах осуществления на каждом из этих узлов CFE (например. 832, 856 или 858) вызывает связанный с ним механизм 210 обслуживания файрвола, чтобы выполнить операцию обслуживания файрвола над сообщением с данными, которое получает CFE. В некоторых вариантах осуществления механизм обслуживания файрвола возвращает свое решение в модуль, который его вызвал (например, в CFE), чтобы этот модуль мог выполнить действие файрвола над сообщением с данными, а в других вариантах осуществления механизм обслуживания файрвола выполняет свое действие файрвола над сообщением с данными.
В некоторых вариантах осуществления другие компоненты MFN поручают механизму обслуживания файрвола выполнять свои операции. Например, в некоторых вариантах осуществления на входном узле шлюз VPN (например, 225 или 230) поручает связанному с ним механизму обслуживания файрвола выполнение своих операций, чтобы определить, следует ли передавать сообщение с данными на CFE входного узла. Кроме того, в некоторых вариантах осуществления на выходном узле CFE передает сообщение с данными в связанный с ним механизм обслуживания файрвола, который, если он решает разрешить пропустить сообщение с данными, затем передает сообщение с данными через внешнюю сеть (например, через Интернет) в его пункт назначения, или передает сообщение с данными в связанный с ним механизм 215 NAT для выполнения своей операции NAT перед передачей сообщения с данными в его пункт назначения через внешнюю сеть.
В некоторых вариантах осуществления провайдеры виртуальных сетей позволяют шлюзу безопасности WAN арендатора, который определен в общедоступных облаках, реализовывать другие сервисы безопасности в дополнение к сервисам файрвола или вместо них. Например, распределенный шлюз безопасности WAN арендатора (который в некоторых вариантах осуществления распределен поверх каждого дата-центра общедоступного облака, охватываемого виртуальной сетью арендатора) включает в себя не только механизмы обслуживания файрвола, но также включает в себя механизмы обнаружения вторжений и механизмы предотвращения вторжений. В некоторых вариантах осуществления механизмы обнаружения вторжений и механизмы предотвращения вторжений архитектурно встроены в MFN 150, чтобы занимать положение, аналогичное механизму 210 обслуживания файрвола.
В некоторых вариантах осуществления каждый из этих механизмов включает в себя одно или несколько хранилищ, которые хранят политики обнаружения/предотвращения вторжений, распределенные кластером 160 центрального контроллера. В некоторых вариантах осуществления эти политики конфигурируют механизмы для обнаружения/предотвращения несанкционированных вторжений в виртуальную сеть арендатора (которая развернута поверх нескольких дата-центров общедоступных облаков), а также для принятия мер в ответ на обнаруженные события вторжения (например, для генерирования журналов, отправки уведомлений, завершения работы сервисов или машин и т.д.). Как и правила файрвола, политики обнаружения/предотвращения вторжений могут принудительно применяться на различных управляемых узлах пересылки (например, на входных MFN, промежуточных MFN и/или выходных MFN потоков сообщений с данными), поверх которых определена виртуальная сеть.
Как указано выше, провайдер виртуальных сетей развертывает виртуальную WAN каждого арендатора за счет развертывания по меньшей мере одного MFN в каждом общедоступном облаке, охватываемом виртуальной WAN, и конфигурирует развернутые MFN для определения маршрутов между MFN, которые позволяют потокам сообщений арендатора входить в и выходить из виртуальной WAN. Кроме того, как указано выше, в некоторых вариантах осуществления каждый MFN может совместно использоваться разными арендаторами, а в других вариантах осуществления каждый MFN развертывается только для одного конкретного арендатора.
В некоторых вариантах осуществления виртуальная WAN каждого арендатора представляет собой защищенную виртуальную WAN, которая создана за счет соединения MFN, используемых этой WAN, через оверлейные туннели. В некоторых вариантах осуществления этот метод с оверлейными туннелями инкапсулирует потоки сообщений с данными каждого арендатора с заголовком туннеля, который является уникальным для каждого арендатора, например, содержит идентификатор арендатора, который однозначно идентифицирует арендатора. Для арендатора в некоторых вариантах осуществления CFE провайдеров виртуальных сетей используют один заголовок туннеля для идентификации входных/выходных элементов пересылки для входа/выхода из виртуальной WAN арендатора и другой заголовок туннеля для прохождения промежуточных элементов пересылки виртуальной сети. В других вариантах осуществления CFE виртуальной WAN используют другие механизмы для оверлейной инкапсуляции.
Чтобы развернуть виртуальную WAN для арендатора поверх одного или более общедоступных облаков, кластер контроллеров VNP (1) идентифицирует возможные краевые MFN (которые могут служить входными или выходными MFN для различных потоков сообщений с данными) для арендатора на основе местоположений корпоративных вычислительных узлов арендатора (например, филиальных офисов, дата-центров, мобильных пользователей и провайдеров SaaS) и (2) идентифицирует маршруты между всеми возможными краевыми MFN. Как только эти маршруты идентифицированы, они передаются в таблицы пересылки CFE (например, распространяются с помощью OpenFlow на различные виртуальные сетевые маршрутизаторы на основе OVS). В частности, чтобы идентифицировать оптимальные маршруты через виртуальную WAN арендатора, MFN, связанные с этой WAN, генерируют значения измерений, которые количественно определяют качество сетевого соединения между ними и их соседними MEN, и регулярно доставляют свои измерения в кластер контроллеров VNP.
Как указано выше, кластер контроллеров затем агрегирует измерения из разных MFN, генерирует графы маршрутизации на основе этих измерений, определяет маршруты через виртуальную WAN арендатора, а затем распределяет эти маршруты по элементам пересылки CFE MFN. Чтобы динамически обновлять определенные маршруты для виртуальной WAN арендатора, MFN, связанные с этой WAN, периодически генерируют свои измерения и доставляют эти измерения в кластер контроллеров, который затем периодически повторяет свои агрегирование измерений, генерирование графов маршрутов, идентификацию маршрутов и распределение маршрутов на основе полученных обновленных измерений.
При определении маршрутов через виртуальную WAN арендатора кластер контроллеров VNP оптимизирует маршруты для достижения требуемых сквозной производительности, надежности и безопасности при стремлении минимизировать маршрутизацию потоков сообщений арендатора через Интернет. Кластер контроллеров также конфигурирует компоненты MFN для оптимизации обработки уровня 4 потоков сообщений с данными, проходящих через сеть (например, для оптимизации сквозной скорости TCP-соединений за счет разделения механизмов управления скоростью по пути соединения).
С распространением общедоступных облаков зачастую очень легко найти крупный дата-центр общедоступного облака рядом с каждым филиальным офисом корпорации. Точно так же провайдеры SaaS все чаще размещают свои приложения в общедоступных облаках или аналогичным образом располагают поблизости от какого-либо дата-центра общедоступного облака. Следовательно, виртуальные корпоративные WAN 2015 безопасно используют общедоступные облака 2005 в качестве корпоративной сетевой инфраструктуры, которая находится поблизости от корпоративных вычислительных узлов (например, от филиальных офисов, дата-центров, удаленных устройств и провайдеров SaaS).
Корпоративные WAN требуют гарантий полосы пропускания, чтобы предоставлять критически важное для бизнеса приложение с приемлемой производительностью в любое время. Такие приложения могут быть интерактивными информационными приложениями, например ERP, финансы или снабжение, приложение, ориентированное на сроки (например, промышленное или IoT-управление), приложение в реальном времени (например, VoIP или видеоконференцсвязь). Следовательно, традиционная инфраструктура WAN (например, Frame Relay или MPLS) предоставляет такие гарантии.
Основным препятствием для предоставления гарантии полосы пропускания в сети со многими арендаторами является необходимость резервировать полосу пропускания по одному или нескольким путям для определенного потребителя. В некоторых вариантах осуществления VNP предлагает сервисы QoS и обеспечивает гарантию фиксированной скорости входящего трафика (ICR) и гарантию фиксированной скорости исходящего трафика (ECR). ICR относится к скорости трафика, входящего в виртуальную сеть, a ECR относится к скорости трафика, исходящего из виртуальной сети на сайт арендатора.
До тех пор, пока трафик не превышает пределы ICR и ECR, в некоторых вариантах осуществления виртуальная сеть предоставляет гарантии полосы пропускания и задержки. Например, до тех пор, пока входящий или исходящий HTTP-трафик не превышает 1 Мбит/с, полоса пропускания и низкая задержка гарантированы. Это модель «точка-облако», так как для целей QoS VNP не нужно отслеживать пункты назначения трафика до тех пор, пока его пункты назначения находятся в пределах границ ICR/ECR. Эту модель иногда называют моделью шланга.
Для более строгих приложений, где потребитель желает гарантировать двухточечную связь, необходимо создать виртуальный канал передачи данных для доставки критически важного трафика. Например, предприятию может потребоваться два узловых сайта или дата-центра, которые гарантируют соединение с соглашением о высоком уровне обслуживания. С этой целью маршрутизация VNP автоматически выбирает путь маршрутизации, который соответствует ограничениям полосы пропускания для каждого арендатора. Это называется двухточечной моделью или моделью трубы.
Основное преимущество VNP в предоставлении конечным пользователям гарантированной полосы пропускания является возможность настраивать инфраструктуру VNP в соответствии с меняющимися требованиями к полосе пропускания. Большинство общедоступных облаков предоставляют гарантии минимальной полосы пропускания между каждыми двумя устройствами, расположенными в разных регионах одного облака. Если текущая сеть не имеет достаточно неиспользованной пропускной способности для обеспечения гарантированной полосы пропускания для нового запроса, то VNP добавляет новые ресурсы к своим средствам. Например, VNP может добавлять новые CFE в регионах с высоким спросом.
Одна из задач состоит в том, чтобы оптимизировать производительность и стоимость этого нового измерения при планировании маршрутов и масштабировании инфраструктуры вверх и вниз. Для упрощения алгоритмов и учета полосы пропускания в некоторых вариантах осуществления предполагается, что сквозное резервирование полосы пропускания не разделяется. То есть, если определенная полоса пропускания (например, 10 Мбит/с) зарезервирована между филиалом А и филиалом В определенного арендатора, то полоса пропускания распределяется по единственному пути, который начинается от входного CFE, с которым соединяется филиал А, а затем проходит через нуль или более промежуточных CFE для достижения выходного CFE, который соединен с филиалом В. Некоторые варианты осуществления также предполагают, что путь с гарантированной полосой пропускания проходит только через одно общедоступное облако.
Чтобы учесть различное резервирование полосы пропускания, которое пересекается в топологии сети, в некоторых вариантах осуществления VNP определяет маршрутизацию по пути зарезервированной полосы пропускания статически, так что потоки сообщений с данными всегда проходят через те же маршруты, которые были зарезервированы в соответствии с требованиями к полосе пропускания. В некоторых вариантах осуществления каждый маршрут идентифицируется с помощью одного тега, который каждый CFE, пройденный маршрутом, соответствует одному исходящему интерфейсу, связанному с этим маршрутом. В частности, каждый CFE сопоставляет один исходящий интерфейс с каждым сообщением с данными, которое имеет этот тег в своем заголовке и поступает из определенного входящего интерфейса.
В некоторых вариантах осуществления кластер контроллеров поддерживает сетевой граф, который образован несколькими взаимосвязанными узлами. Каждый узел n в графе имеет выделенную общую гарантированную полосу пропускания (TBWn), связанную с этим узлом, и объем полосы пропускания, уже зарезервированной (выделенной для определенного зарезервированного пути) этим узлом, (RBWn). Кроме того, для каждого узла граф включает в себя стоимость в центах за гигабайт (Су) и задержку в миллисекундах (Dy), связанную с отправкой трафика между этим узлом и всеми другими узлами в графе. Вес, связанный с отправкой трафика между узлом i и узлом j, равен Wij=a*Cij+Dij, где а - системный параметр, который обычно составляет от 1 до 10.
Когда принимается запрос на резервирование полосы пропускания со значением BW между филиалами А и В, кластер контроллеров сначала сопоставляет запрос с конкретными входными и выходными маршрутизаторами n и m, которые привязаны к филиалам А и В соответственно. Затем кластер контроллеров выполняет процесс маршрутизации, который проводит два вычисления с наименьшей стоимостью (например, кратчайшего пути) между n и m. Первый является самым дешевым (например, кратчайшим путем) маршрутом между n и m, независимо от доступной полосы пропускания вдоль вычисленного маршрута. Общий вес этого маршрута вычисляется как Wi.
Второе вычисление с наименьшей стоимостью (например, кратчайшего пути) сначала модифицирует граф за счет удаления всех узлов i, где BW>TBWi-RBWi. Модифицированный граф называется усеченным графом. Затем кластер контроллеров выполняет вычисление второго маршрута с наименьшей стоимостью (например, кратчайшего пути) по усеченному графу. Если вес второго маршрута не более, чем на K процентов (K обычно составляет 10-30%) выше, чем у первого маршрута, второй маршрут выбирается как предпочтительный. В то же время, когда это требование не выполняется, кластер контроллеров добавляет к первому пути узел i с наименьшим значением TBWi-RBWi, а затем повторяет два вычисления с наименьшей стоимостью (например, кратчайшего пути). Кластер контроллеров будет продолжать добавлять маршрутизаторы до тех пор, пока условие не будет выполнено. В этот момент BW зарезервированной полосы пропускания добавляется ко всей RBWi, где i - маршрутизатор на выбранном маршруте.
Для особого случая запроса дополнительной полосы пропускания для маршрута, который уже имеет зарезервированную полосу пропускания, кластер контроллеров сначала удалит текущее резервирование полосы пропускания между узлами А и В и вычислит путь для общего запроса полосы пропускания между этими узлами.. Для этого в некоторых вариантах осуществления информация, хранящаяся для каждого узла, также включает в себя полосу пропускания, зарезервированную для каждого тега или каждого филиала источника и назначения, а не только общую зарезервированную полосу пропускания. После того, как резервирование полосы пропускания добавлено в сеть, некоторые варианты осуществления не пересматривают маршруты до тех пор, пока нет значительных изменений в измеренных сетевых задержках или затратах через виртуальную сеть. Однако, когда измерения и/или затраты изменяются, эти варианты осуществления повторяют процессы резервирования полосы пропускания и вычисления маршрута.
Фиг. 21 концептуально иллюстрирует процесс 2100, выполняемый кластером 160 контроллеров провайдера виртуальной сети для развертывания и управления виртуальной WAN для конкретного арендатора. В некоторых вариантах осуществления процесс 2100 выполняется несколькими различными программами контроллера, исполняющимися в кластере 160 контроллеров. Операции этого процесса не обязательно должны следовать последовательности с иллюстрацией на фиг. 21, так как эти операции могут выполняться разными программами параллельно или в другой последовательности. Таким образом, эти операции с иллюстрациями на этой фигуре показаны только для описания одной примерной последовательности операций, выполняемых кластером контроллеров.
Как показано, кластер контроллеров сначала развертывает (на этапе 2105) несколько MFN в нескольких дата-центрах общедоступных облаков нескольких различных провайдеров общедоступных облаков (например, Amazon AWS, Google GCP и т.д.). В некоторых вариантах осуществления кластер контроллеров конфигурирует (на этапе 2105) эти развернутые узлы MFN для одного или нескольких других арендаторов, которые отличаются от конкретного арендатора, для которого иллюстрирован процесс 2100.
На этапе 2110 кластер контроллеров получает от конкретного арендатора данные об атрибутах внешних машин и местоположениях конкретного арендатора. В некоторых вариантах осуществления эти данные включают в себя частные подсети, используемые конкретным арендатором, а также идентификаторы для одного или нескольких офисов арендатора и дата-центров, в которых этот конкретный арендатор имеет внешние машины. В некоторых вариантах осуществления кластер контроллеров может получать данные арендаторов через интерфейсы API или через пользовательский интерфейс, который предоставляет кластер контроллеров.
Затем на этапе 2115 кластер контроллеров генерирует граф маршрутизации для конкретного арендатора из измерений, собранных агентами 205 измерений узлов MFN 150, которые являются MFN-кандидатами на использование для создания виртуальной сети для конкретного арендатора. Как упоминалось выше, граф маршрутизации имеет узлы, которые представляют узлы MFN, и каналы связи между узлами, которые представляют сетевые соединения между узлами MFN. Каналы связи имеют связанные веса, которые представляют собой значения стоимости, которые количественно оценивают качество и/или стоимость использования сетевых соединений, представленных каналами связи. Как упоминалось выше, кластер контроллеров сначала генерирует граф измерений из собранных измерений, а затем генерирует граф маршрутизации путем удаления из графа измерений каналов связи, которые не являются оптимальными (например, имеют большие задержки или частоту сброса).
После построения графа маршрутизации кластер контроллеров выполняет (на этапе 2120) поиск путей для идентификации возможных маршрутов между различными парами входных и выходных узлов-кандидатов (т.е. узлов MFN), которые внешние машины арендаторов могут использовать для отправки сообщений с данными в виртуальную сеть (развернутую узлами MFN) и получать сообщения с данными из виртуальной сети. В некоторых вариантах осуществления кластер контроллеров использует известные алгоритмы поиска путей для идентификации различных путей между каждой парой входных/выходных узлов-кандидатов. Каждый путь для такой пары использует один или несколько каналов связи, которые при объединении проходят от входного узла к выходному узлу через ноль или более промежуточных узлов.
В некоторых вариантах осуществления стоимость между любыми двумя MFN содержит взвешенную сумму расчетной задержки и финансовых затрат на канал соединения между двумя MFN. В некоторых вариантах осуществления задержка и финансовые затраты включают в себя одно или более из следующего: (1) измерения задержки канала связи, (2) расчетную задержку обработки сообщений, (3) облачные расходы на исходящий трафик из конкретного дата-центра или до другого дата-центра того же самого провайдера общедоступного облака или для выхода из облака провайдера общедоступного облака (PC) (например, в другой дата-центр общедоступного облака другого провайдера общедоступного облака или в Интернет), и (4) расчетные затраты на обработку сообщений, связанные с исполнением MFN на хост-компьютерах в общедоступных облаках.
Некоторые варианты осуществления оценивают штраф для каналов соединения между двумя MFN, которые проходят через общедоступный Интернет, чтобы минимизировать такое прохождение, когда это возможно. Некоторые варианты осуществления также стимулируют использование частных сетевых соединений между двумя дата-центрами (например, за счет снижения стоимости канала соединения), чтобы смещать генерирование маршрута в сторону использования таких соединений. Использование вычисленной стоимости этих парных каналов связи позволяет кластеру контроллеров вычислить стоимость каждого пути маршрутизации, который использует один или несколько из этих парных каналов связи, за счет агрегирования затрат на отдельные парные каналы связи, используемые на пути маршрутизации.
Затем кластер контроллеров выбирает (на этапе 2120) один или до N идентифицированных путей (где N - целое число больше, чем 1) на основе вычисленных затрат (например, на основе наименьшей совокупной стоимости) идентифицированных путей-кандидатов между каждой парой входных/выходных узлов-кандидатов. В некоторых вариантах осуществления вычисленные затраты для каждого пути основаны на стоимости веса каждого канала связи, используемого на этом пути (например, это сумма связанных значений веса каждого канала связи), как указано выше. Кластер контроллеров может выбирать более одного пути между парой входных/выходных узлов, когда требуется более одного маршрута между двумя MFN, чтобы позволить входному MFN или промежуточному MFN выполнять операцию с несколькими путями.
После выбора (на этапе 2120) одного или N путей для каждой пары входных/выходных узлов-кандидатов кластер контроллеров определяет один или N маршрутов на основе выбранных путей, а затем генерирует таблицы маршрутов или части таблицы маршрутов для MFN, которые реализуют виртуальную сеть конкретного арендатора. Сгенерированные записи маршрутов идентифицируют краевые MFN для достижения различных подсетей конкретного арендатора и идентифицируют MFN следующих переходов для прохождения маршрутов от входных MFN к выходным MFN.
На этапе 2125 кластер контроллеров распределяет записи маршрутов по MFN, чтобы конфигурировать элементы 235 пересылки этих MFN для реализации виртуальной сети для конкретного арендатора. В некоторых вариантах осуществления кластер контроллеров взаимодействует с элементами пересылки для передачи записей маршрутов с помощью протоколов связи, которые в настоящее время используются в программно-определяемом дата-центре со многими арендаторами для конфигурирования программных маршрутизаторов, исполняющихся на хост-компьютерах, для реализации логической сети, охватывающей хост-компьютеры.
После того, как MFN сконфигурированы и виртуальная сеть работает для конкретного арендатора, краевые MFN получают сообщения с данными от внешних машин арендатора (т.е. машин вне виртуальной сети) и пересылают эти сообщения с данными в краевые MFN в виртуальной сети, которая, в свою очередь, пересылает эти сообщения с данными в другие внешние машины арендатора. При выполнении таких операций пересылки входные, промежуточные и выходные MFN собирают статистику, касающуюся своих операций пересылки. Кроме того, в некоторых вариантах осуществления один или несколько модулей на каждом MFN в некоторых вариантах осуществления собирают другую статистику, касающуюся потребления сети или вычислений в дата-центрах общедоступного облака. В некоторых вариантах осуществления провайдеры общедоступных облаков собирают такие данные о потреблении и передают собранные данные провайдеру виртуальной сети.
При приближении к циклу выставления счетов кластер контроллеров собирает (например, на этапе 2130) статистику, собранную узлами MFN. и/или данные о потреблении сети/вычислений, собранные узлами MFN или предоставленные провайдерами общедоступных облаков. На основе собранной статистики и/или предоставленных данных о потреблении сети/вычислений кластер контроллеров генерирует (на этапе 2130) отчеты о выставлении счетов и отправляет отчеты о выставлении счетов конкретному арендатору.
Как указано выше, сумма, выставленная на счет в отчете о выставлении счетов, учитывает статистику и данные о сети/потреблении, которые получает кластер контроллеров (например, на этапе 2130). Кроме того, в некоторых вариантах осуществления счет учитывает стоимость эксплуатации MFN (которые реализуют виртуальную сеть для конкретного клиента) провайдером виртуальной сети плюс норма прибыли (например, увеличение на 10%). Эта схема выставления счетов удобна для конкретного арендатора, так как ему не нужно иметь дело со счетами от множества разных провайдеров общедоступных облаков, через которые развернута виртуальная сеть арендатора. В некоторых вариантах осуществления затраты VNP включают в себя стоимость, взимаемую с VNP провайдерами общедоступных облаков. На этапе 2130 кластер контроллеров также взимает плату с кредитной карты или в электронном виде снимает средства с банковского счета по расходам, отраженным в отчете о выставлении счетов.
На этапе 2135 кластер контроллеров определяет, получил ли он новые измерения от агентов 205 измерений. Если нет, то процесс переходит на этап 2145, который будет описан ниже. В то же время, когда кластер контроллеров определяет, что он получил новые измерения от агентов измерений, он определяет (на этапе 2140), нужно ли перепроверять свой граф маршрутизации для конкретного арендатора на основе новых измерений. При отсутствии сбоя MFN кластер контроллеров в некоторых вариантах осуществления обновляет свой граф маршрутизации для каждого арендатора не более одного раза в течение определенного периода времени (например, один раз каждые 24 часа или каждую неделю) на основе полученных обновленных измерений.
Когда кластер контроллеров определяет (на этапе 2140), что ему необходимо перепроверить граф маршрутизации на основе новых измерений, которые он получил, процесс генерирует (на этапе 2145) новый граф измерений на основе вновь полученных измерений. В некоторых вариантах осуществления кластер контроллеров использует взвешенную сумму для смешивания каждого нового измерения с предыдущими измерениями, чтобы гарантировать, что значения измерений, связанные с каналами связи графа измерений, не будут сильно колебаться при каждом получении нового набора измерений.
На этапе 2145 кластер контроллеров также определяет, нужно ли ему корректировать граф маршрутизации на основе скорректированного графа измерений (например, нужно ли ему корректировать значения весов для каналов связи графа маршрутизации или добавлять или удалять каналы связи в графе маршрутизации из-за скорректированных значений измерений, связанных с каналами связи). Если это так, то кластер контроллеров (на этапе 2145) корректирует граф маршрутизации, выполняет операции поиска пути (например, операции 2120) для идентификации маршрутов между парами входных/выходных узлов, генерирует записи маршрутов на основе идентифицированных маршрутов и распределяет записи 1705 маршрутов по узлам MFN. С этапа 2145 процесс переходит на этап 2150.
Процесс также переходит на этап 2150. когда кластер контроллеров определяет (на этапе 2140), что ему не нужно перепроверять граф маршрутизации. На этапе 2150 кластер контроллеров определяет, приближается ли он к другому циклу выставления счетов, для которого он должен собирать статистику, касающуюся обработанных сообщений с данными и потребленных сетевых/вычислительных ресурсов. Если нет, то процесс возвращается на этап 2135, чтобы определить, получил ли он новые измерения от агентов измерений MFN. В противном случае процесс возвращается на этап 2130, чтобы собрать статистику, данные о потреблении в сети/вычислениях, а также генерировать и отправить отчёты о выставлении счетов. В некоторых вариантах осуществления кластер контроллеров повторяет выполнение операций процесса 2100 до тех пор, пока конкретному арендатору больше не понадобится виртуальная сеть, развёрнутая в дата- центрах общедоступных облаков.
В некоторых вариантах осуществления кластер контроллеров не только развёртывает виртуальные сети для арендаторов в дата-центрах общедоступных облаков, но также помогает арендаторам в развёртывании и конфигурировании машин вычислительных узлов и машин обслуживания в дата-центрах общедоступных облаков. Развёрнутые машины обслуживания могут быть машинами, отдельными от машин обслуживания MFN. В некоторых вариантах осуществления отчёт о выставлении счетов кластера контроллеров конкретному арендатору также учитывает вычислительные ресурсы, потребляемые развёрнутыми вычислительными машинами и машинами обслуживания. Кроме того, наличие одного счёта от одного провайдера виртуальных сетей за использование сетевых и вычислительных ресурсов множеством дата-центров общедоступных облаков множества провайдеров общедоступных облаков более предпочтительно для арендатора, чем получение множества счетов от множества провайдеров общедоступных облаков.
Многие из описанных выше функций и приложений реализованы как программные процессы, которые определены как набор инструкций, записанных на компьютерно- считываемом информационном носителе (также называемым компьютерно-считываемым носителем данных). Когда эти инструкции исполняются одним или несколькими блоками обработки данных (например, одним или несколькими процессорами, ядрами процессоров или другими блоками обработки данных), они заставляют блок (блоки) обработки данных выполнять действия, указанные в инструкциях. Примеры машиночитаемых носителей включают, но не ограничиваются ими, CD-ROM, флэш-накопители, микросхемы RAM, жёсткие диски, EPROM и т.д. Машиночитаемые носители не включают в себя несущие волны и электронные сигналы, проходящие по беспроводной сети или через проводные соединения.
В данном описании термин «программное обеспечение» включает в себя встроенное программное обеспечение, находящееся в постоянной памяти, или приложения, хранящиеся в магнитном хранилище, которые могут быть считаны в память для обработки процессором. Кроме того, в некоторых вариантах осуществления множество программных изобретений могут быть реализованы как части более крупной программы и оставаться при этом отдельными программными изобретениями. В некоторых вариантах осуществления изобретения множество программных изобретений также могут быть реализованы как отдельные программы. Наконец, любая комбинация отдельных программ, которые вместе реализуют описываемое здесь программное изобретение обеспечение, находится в пределах объёма настоящего изобретения. В некоторых вариантах осуществления программно-реализованные программы, когда они инсталлированы для работы в одной или более электронных системах, определяют одну или более конкретных машинных реализаций, которые исполняют и выполняют операции программно-реализованных программ.
Фиг. 22 концептуально иллюстрирует компьютерную систему 2200, с помощью которой реализуются некоторые варианты осуществления изобретения. Компьютерная система 2200 может быть использована для реализации любого из описанных выше хостов, контроллеров и менеджеров. При этом её можно использовать для исполнения любого из описанных выше процессов. Эта компьютерная система включает в себя различные типы энергонезависимых машиночитаемых носителей данных и интерфейсов для различных других типов машиночитаемых носителей данных. Компьютерная система 2200 включает в себя шину 2205, блок(и) 2210 обработки данных, системную память 2225, постоянную память (ROM) 2230, постоянное запоминающее устройство 2235, устройства 2240 ввода и устройства 2245 вывода.
Шина 2205 в совокупности представляет все системные шины, шины периферийных устройств и шины наборов микросхем, которые коммуникативно соединяют многочисленные внутренние устройства компьютерной системы 2200. Например, шина 2205 коммуникативно соединяет блок(и) 2210 обработки данных с постоянной памятью 2230, системной памятью 2225 и постоянным запоминающим устройством 2235.
Из этих различных блоков памяти блок(и) 2210 обработки данных извлекает(ют) инструкции для исполнения и данные для обработки, чтобы исполнить процессы согласно настоящему изобретению. В различных вариантах осуществления блок(и) обработки данных может(гут) быть одиночным процессором или многоядерным процессором. Постоянная память (ROM) 2230 хранит статические данные и инструкции, которые необходимы блоку(ам) 2210 обработки данных и другим модулям компьютерной системы. В то же время постоянное запоминающее устройство 2235 представляет собой запоминающее устройство для чтения и записи. Это у стройство представляет собой энергонезависимую память, в которой хранятся инструкции и данные, даже когда компьютерная система 2200 выключена. Некоторые варианты осуществления изобретения в качестве постоянного запоминающего устройства 2235 используют запоминающее устройство большой ёмкости (такое как магнитный или оптический диск и соответствующий ему дисковод).
Другие варианты осуществления используют в качестве постоянного запоминающего устройства съёмное запоминающее устройство (такое как гибкий диск, флэш-накопитель и т.д.). Подобно постоянному запоминающему устройству 2235 системная память 2225 является запоминающим устройством для чтения и записи. Однако, в отличие от запоминающего устройства 2235, системная память является энергозависимой памятью для чтения и записи, такой как оперативная память. Системная память хранит некоторые инструкции и данные, которые необходимы процессору во время выполнения. В некоторых вариантах осуществления процессы согласно изобретению хранятся в системной памяти 2225, постоянном запоминающем устройстве 2235 и/или постоянной памяти 2230. Из этих различных блоков памяти блок(и) 2210 обработки данных извлекает(ют) инструкции для исполнения и данные для обработки, чтобы исполнить процессы некоторых вариантов осуществления.
Шина 2205 также соединяется с устройствами ввода и вывода 2240 и 2245. Устройства ввода позволяют пользователю передавать информацию в компьютерную систему и выбирать команды. Устройства 2240 ввода включают в себя буквенно¬цифровые клавиатуры и указательные устройства (также называемые «устройствами управления курсором»). Устройства 2245 вывода отображают изображения, генерируемые компьютерной системой. Устройства вывода включают в себя принтеры и устройства отображения, такие как электронно-лучевые трубки (ЭЛТ) или жидкокристаллические дисплеи (ЖКД). Некоторые варианты осуществления включают в себя такие устройства, как сенсорный экран, который работает как устройства ввода и вывода.
Наконец, как показано на фиг. 22, шина 2205 также соединяет компьютерную систему 2200 с сетью 2265 через сетевой адаптер (непоказанный). Таким образом, компьютер может быть частью компьютерной сети (такой как локальная сеть («LAN»), глобальной сети («WAN») или Интранета, или сети сетей, такой как Интернет. Любые или все компоненты компьютерной системы 2200 могут быть использованы в сочетании с настоящим изобретением.
Некоторые варианты осуществления включают в себя электронные компоненты, такие как микропроцессоры, хранилище и память, которые хранят инструкции компьютерных программ на машиночитаемом или компьютерно-считываемом носителе данных (альтернативно называемых компьютерно-считываемыми информационными носителями, машиночитаемыми носителями данных или компьютерно-считываемыми носителями данных). Некоторые примеры таких компьютерно-считываемых носителей данных включают в себя RAM. ROM, компакт-диски только для чтения (CD-ROM), записываемые компакт-диски (CD-R). перезаписываемые компакт-диски (CD-RW), цифровые универсальные диски только для чтения (например, DVD-ROM, двухслойный DVD-ROM), различные записываемые/перезаписываемые DVD (например, DVD-RAM, DVD-RW, DVD + RW и т.д.), флэш-память (например, SD-карты. карты mini-SD, карты micro-SD и т.д.), магнитные и/или твердотельные жёсткие диски, диски Blu-Ray® только для чтения и записываемые, оптические диски сверхвысокой плотности, любые другие оптические или магнитные носители данных и гибкие диски. Компьютерно-считываемые носители данных могут хранить компьютерную программу', которая исполняется по меньшей мере одним блоком обработки данных и включает в себя наборы инструкций для выполнения различных операций. Примеры компьютерных программ или компьютерного кода включают в себя машинный код, такой как созданный компилятором, и файлы, включающие в себя код более высокого уровня, который исполняется компьютером, электронным компонентом или микропроцессором с использованием интерпретатора.
Приведённое выше обсуждение в основном относится к микропроцессорам или многоядерным процессорам, которые исполняют программное обеспечение, однако некоторые варианты осуществления выполняются одной или более интегральными схемами, такими как специализированные интегральные схемы (ASIC) или программируемые пользователем вентильные матрицы (FPGA). В некоторых вариантах осуществления такие интегральные схемы исполняют инструкции, которые хранятся в самой схеме.
Используемые в данном описании термины «компьютер», «сервер», «процессор» и «память» относятся к электронным или другим технологическим устройствам. Эти термины не включают в себя людей или группы людей. Для целей данного описания термины «отображение» или «отображающий» означают отображение на электронном устройстве. Используемые в данном описании термины «компьютерно-считываемый носитель данных», «компьютерно-считываемые носители данных» и «машиночитаемый носитель данных» полностью ограничиваются материальными физическими объектами, которые хранят информацию в форме, считываемой компьютером. Эти условия не включают в себя никакие беспроводные сигналы, проводные сигналы загрузки и никакие кратковременные или быстро меняющиеся сигналы.
Настоящее изобретение было описано со ссылками на многочисленные конкретные детали, однако специалист в данной области техники поймёт, что это изобретение может быть реализовано в других конкретных формах без отступления от сущности изобретения. Например, некоторые из описанных выше примеров иллюстрируют виртуальные корпоративные WAN корпоративных арендаторов провайдера виртуальных сетей. Специалист в данной области техники поймет, что в некоторых вариантах осуществления провайдер виртуальных сетей развертывает виртуальные сети в нескольких дата-центрах общедоступного облака одного или более провайдеров общедоступных облаков для некорпоративных арендаторов (например, для школ, колледжей, университетов, некоммерческих организаций и т.д.). Эти виртуальные сети представляют собой виртуальные WAN, которые соединяют множество конечных точек вычислений (например, офисы, дата-центры, компьютеры и устройства удаленных пользователей и т.д.) некорпоративных организаций.
Несколько вариантов осуществления, описанных выше, включают в себя различные фрагменты данных в оверлейных заголовках инкапсуляции. Специалист в данной области техники поймет, что другие варианты осуществления могут не использовать заголовки инкапсуляции для ретрансляции всех этих данных. Например, вместо включения идентификатора арендатора в оверлейный заголовок инкапсуляции другие варианты осуществления выводят идентификатор арендатора из адресов CFE, которые пересылают сообщения с данными, например, в некоторых вариантах осуществления, в которых разные арендаторы имеют свои собственные MFN, развернутые в общедоступных облаках, идентификационные данные арендатора связаны с MFN, которые обрабатывают сообщения арендатора.
Кроме того, несколько фигур концептуально иллюстрируют процессы некоторых вариантов осуществления изобретения. В других вариантах осуществления конкретные операции этих процессов могут выполняться не в точном порядке, показанном и описанном на этих фигурах. Конкретные операции могут выполняться не в одной непрерывной серии операций, и в разных вариантах осуществления могут выполняться различные конкретные операции. Кроме того, процесс может быть реализован с использованием нескольких подпроцессов или как часть более крупного макропроцесса. Таким образом, специалист в данной области техники поймет, что изобретение должно не ограничиваться приведенными выше иллюстративными деталями, а определяться прилагаемой формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ДИНАМИЧЕСКОГО СОЕДИНЕНИЯ ДЛЯ ВИРТУАЛЬНЫХ СЕТЕЙ ЧАСТНОГО ПОЛЬЗОВАНИЯ | 2007 |
|
RU2438254C2 |
| БРОКЕР И ПРОКСИ ОБЕСПЕЧЕНИЯ БЕЗОПАСТНОСТИ ОБЛАЧНЫХ УСЛУГ | 2014 |
|
RU2679549C2 |
| СПОСОБ СОЕДИНЕНИЯ ПЕРВОЙ КОМПЬЮТЕРНОЙ СЕТИ ПО МЕНЬШЕЙ МЕРЕ СО ВТОРОЙ РАСШИРЕННОЙ КОМПЬЮТЕРНОЙ СЕТЬЮ | 2009 |
|
RU2507696C2 |
| ДИНАМИЧЕСКАЯ ЗАЩИЩЕННАЯ КОММУНИКАЦИОННАЯ СЕТЬ И ПРОТОКОЛ | 2016 |
|
RU2769216C2 |
| ДИНАМИЧЕСКАЯ ЗАЩИЩЕННАЯ КОММУНИКАЦИОННАЯ СЕТЬ И ПРОТОКОЛ | 2016 |
|
RU2707715C2 |
| ЧАСТНЫЕ ПСЕВДОНИМЫ КОНЕЧНЫХ ТОЧЕК ДЛЯ ИЗОЛИРОВАННЫХ ВИРТУАЛЬНЫХ СЕТЕЙ | 2015 |
|
RU2669525C1 |
| ТЕХНОЛОГИИ ДЛЯ ПРЕДОСТАВЛЕНИЯ МАКСИМАЛЬНОЙ ГЛУБИНЫ ИДЕНТИФИКАТОРА СЕГМЕНТА УЗЛА И/ИЛИ ЛИНИИ СВЯЗИ, ИСПОЛЬЗУЮЩИЕ OSPF | 2016 |
|
RU2704714C1 |
| СПОСОБЫ И УСТРОЙСТВО ГИПЕРЗАЩИЩЕННОЙ СВЯЗИ "ПОСЛЕДНЕЙ МИЛИ" | 2018 |
|
RU2754871C2 |
| ДОМАШНЯЯ БАЗОВАЯ СТАНЦИЯ | 2008 |
|
RU2448428C2 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ОБЕСПЕЧЕНИЯ СРЕДЫ СВЯЗИ ReNAT | 2014 |
|
RU2685036C2 |
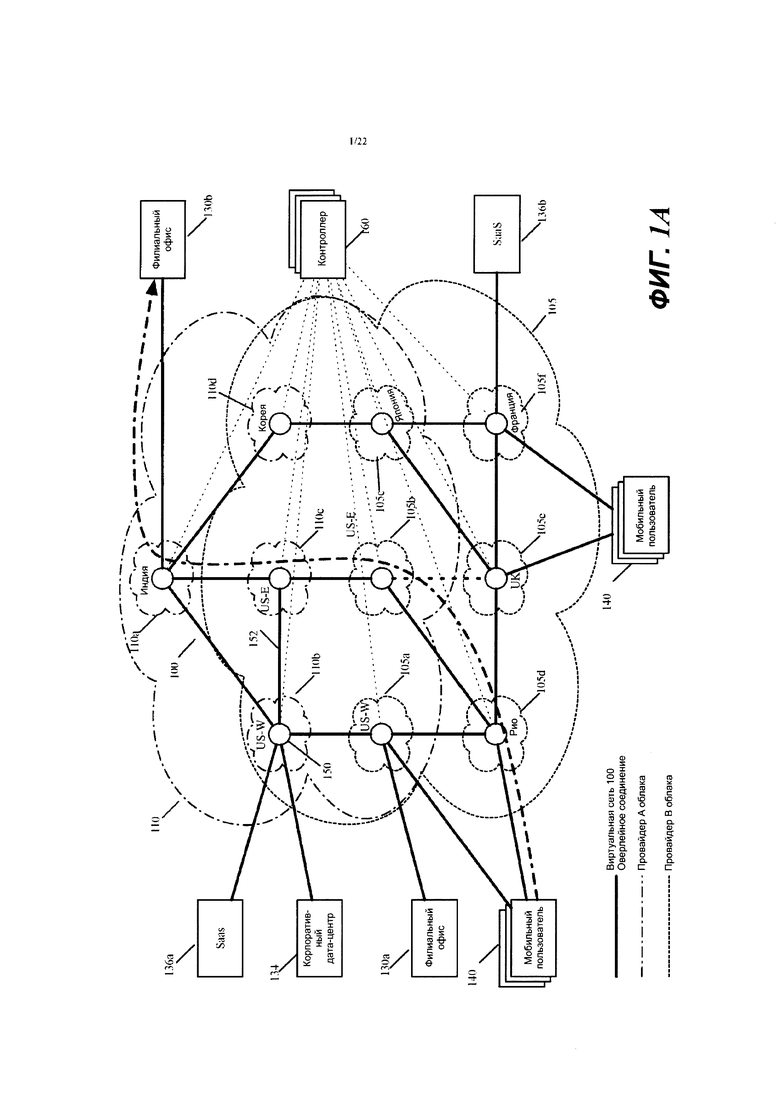
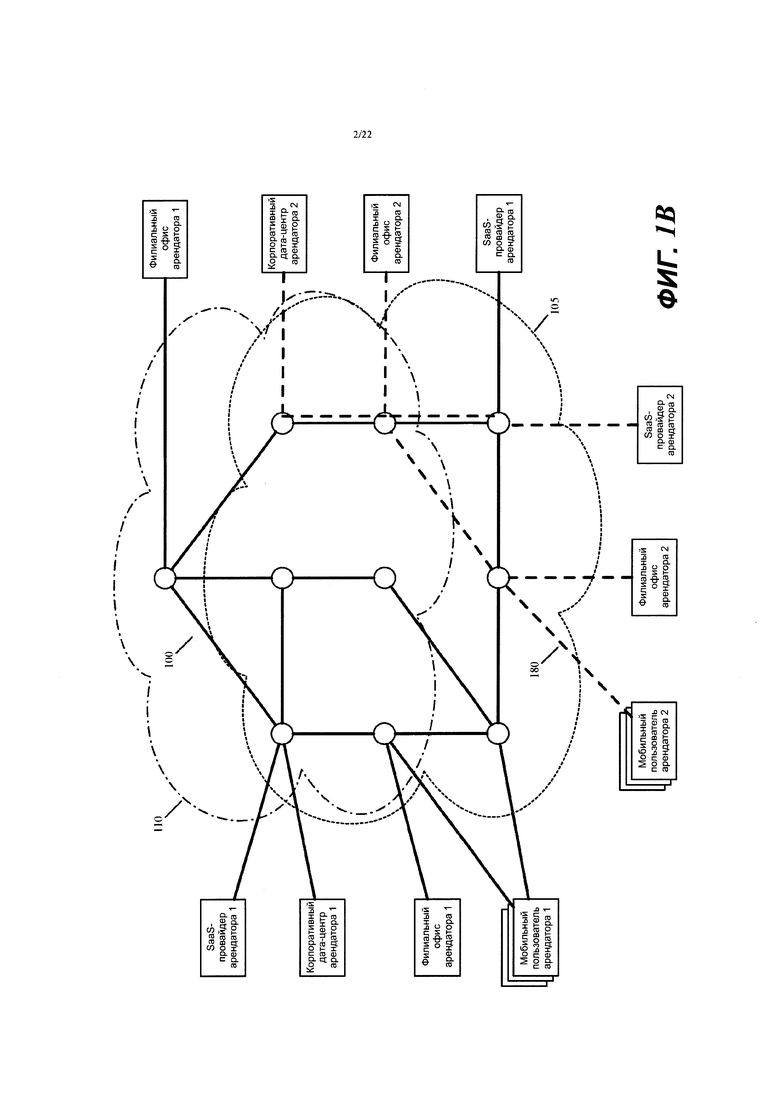
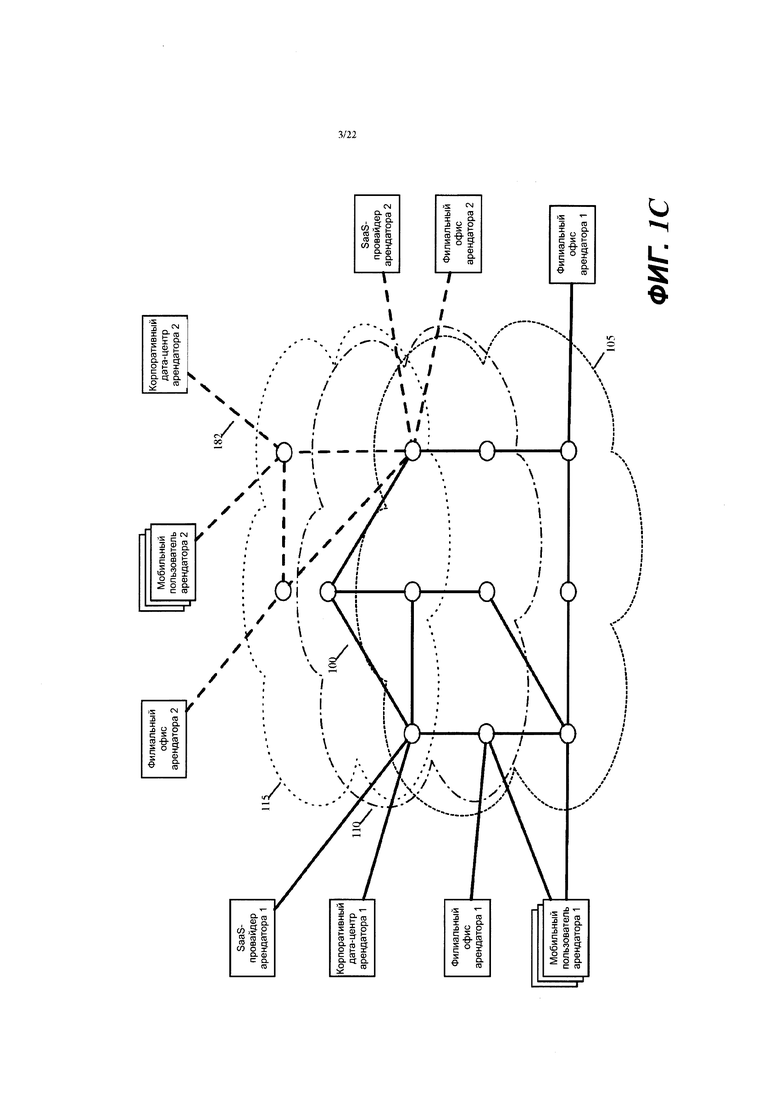
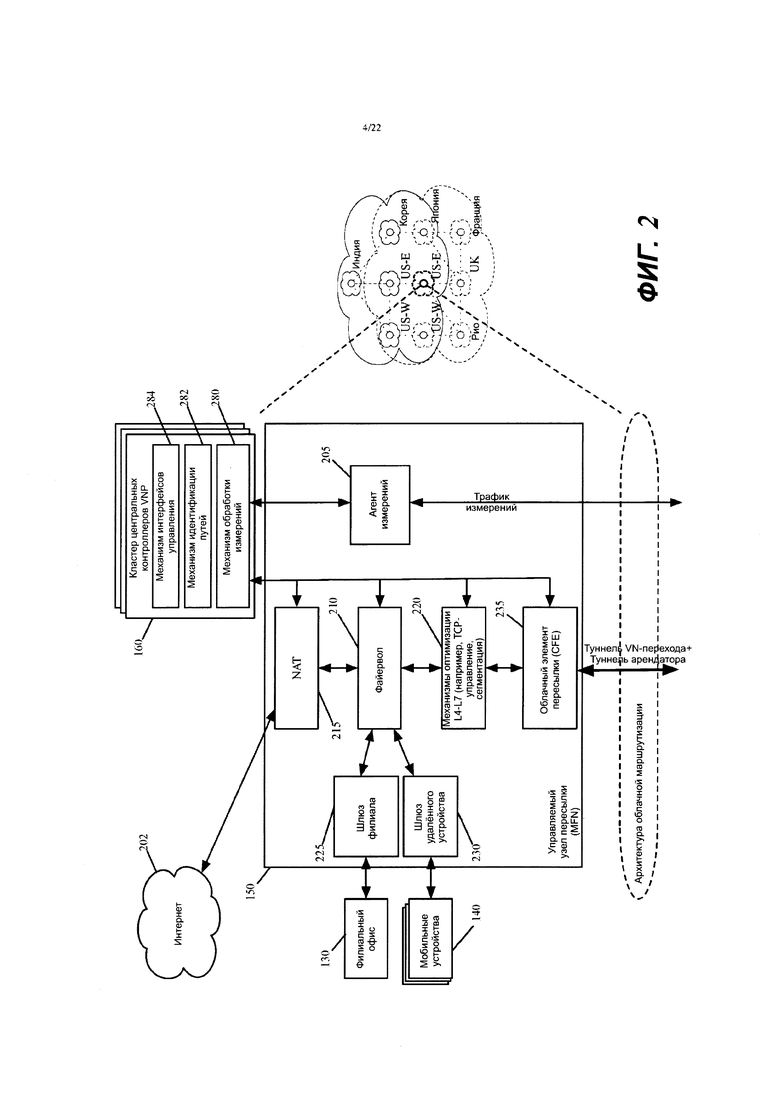
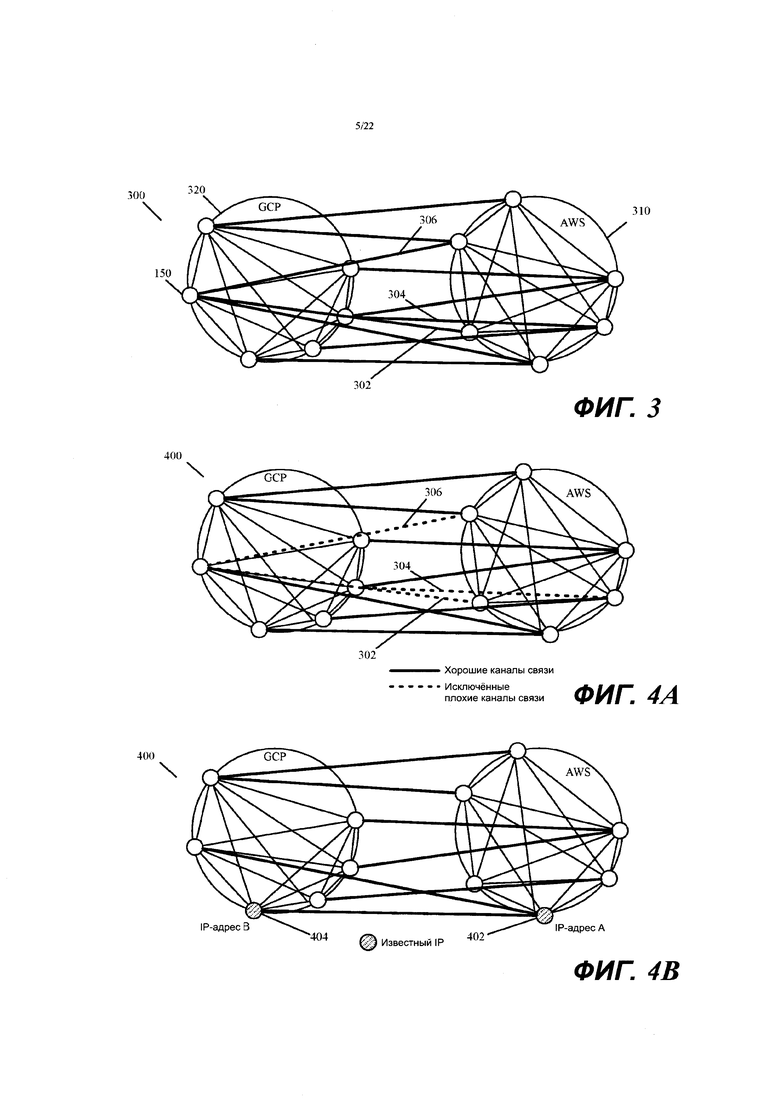
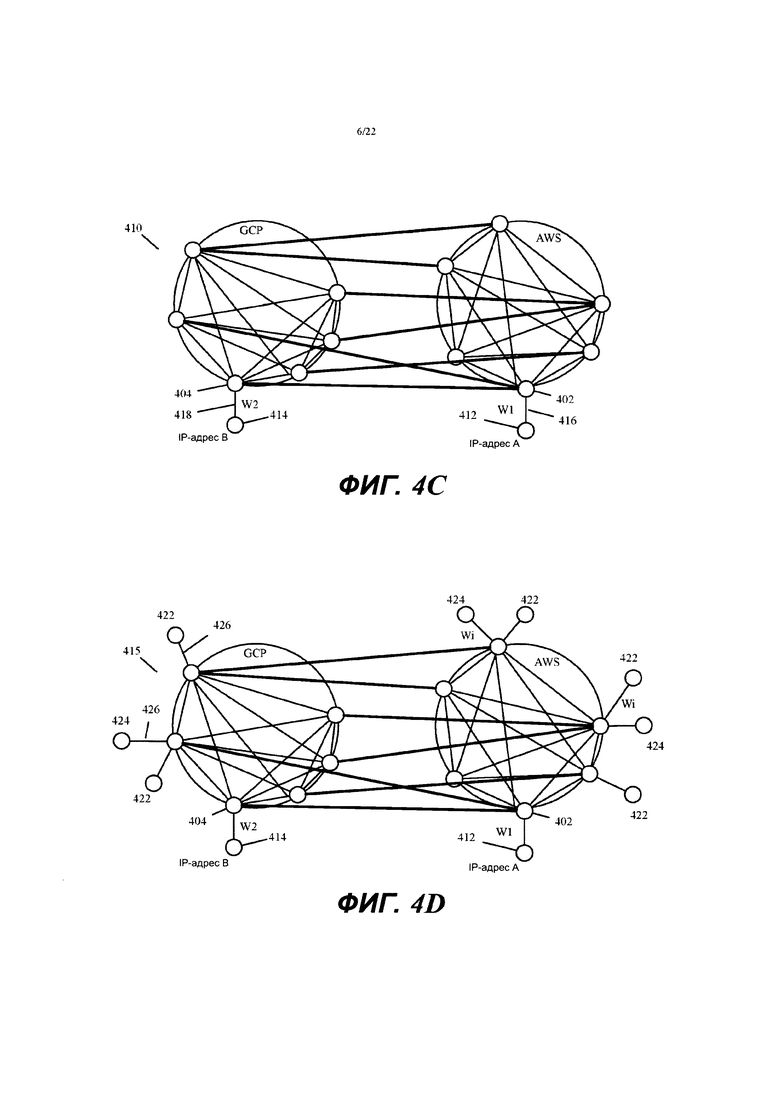
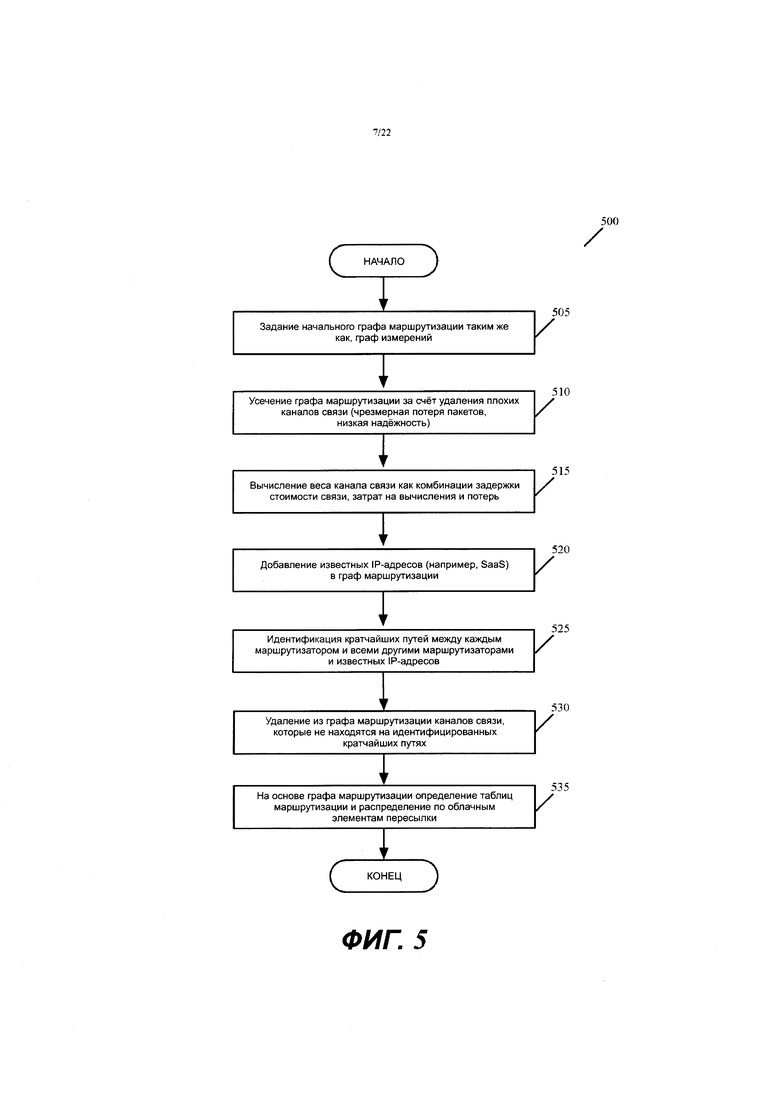
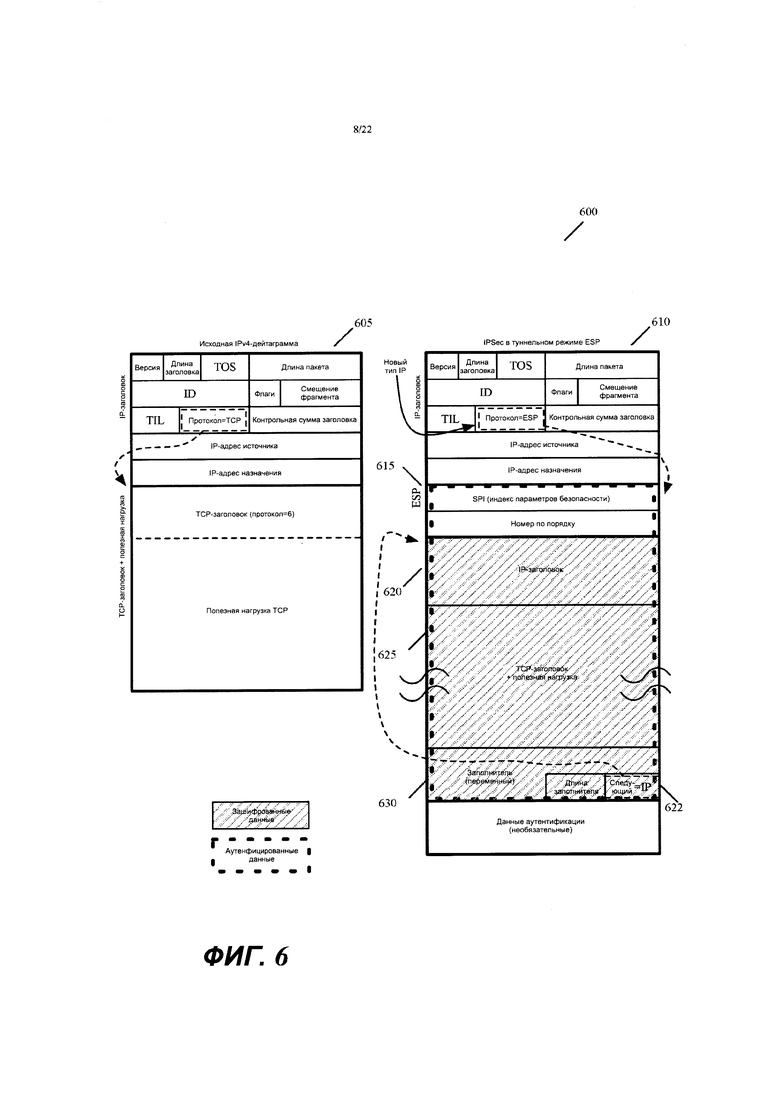
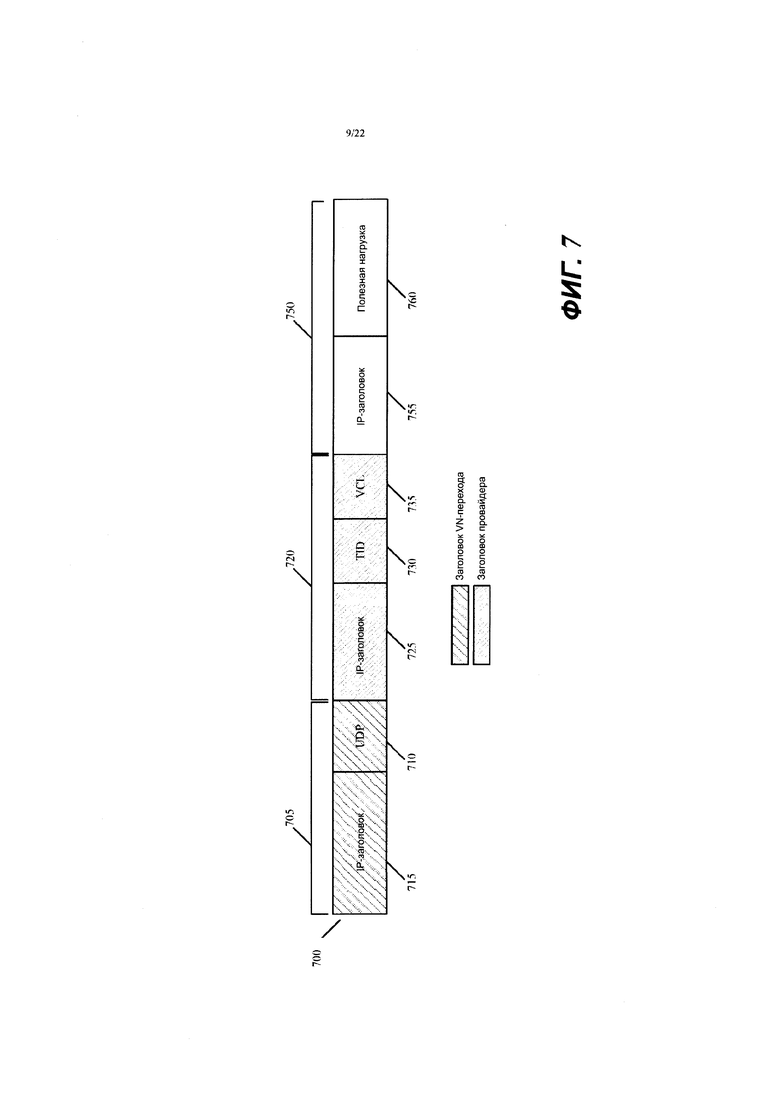
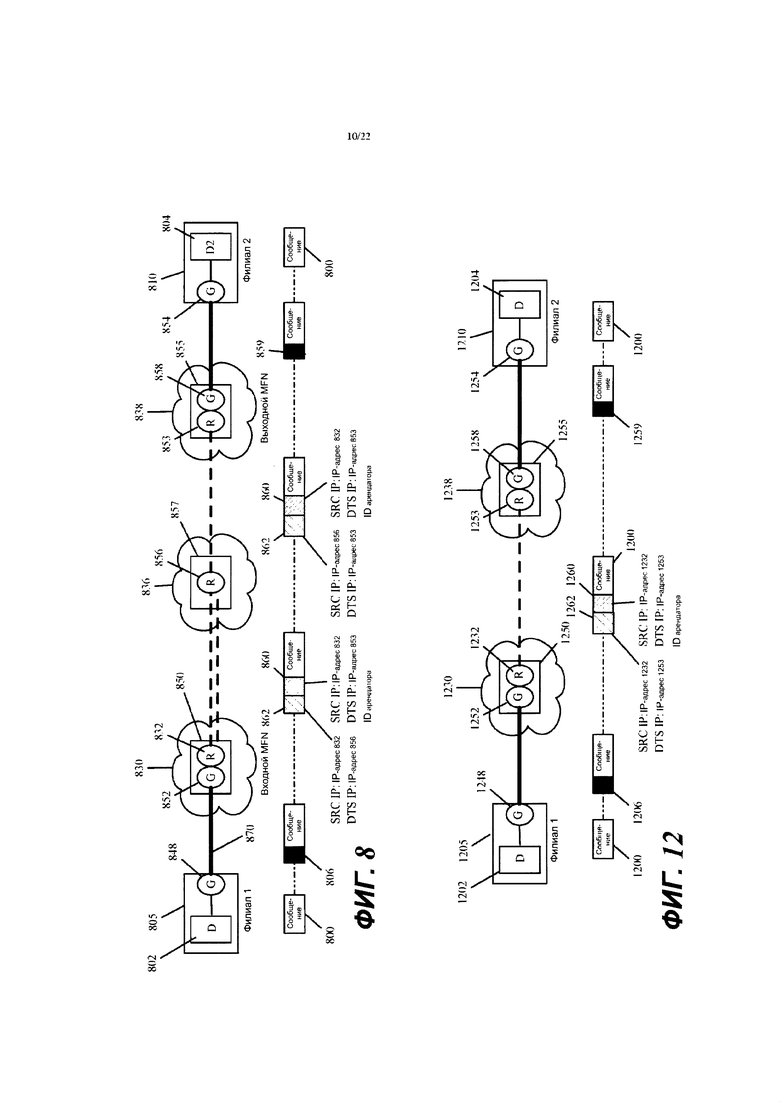
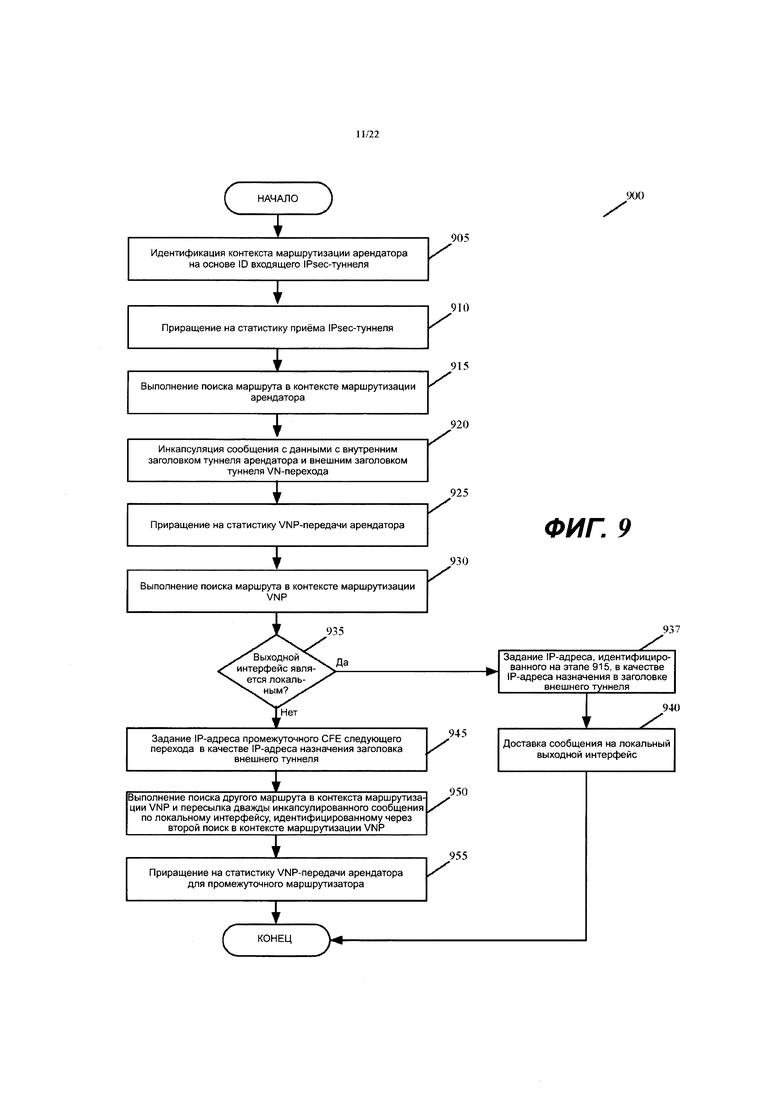
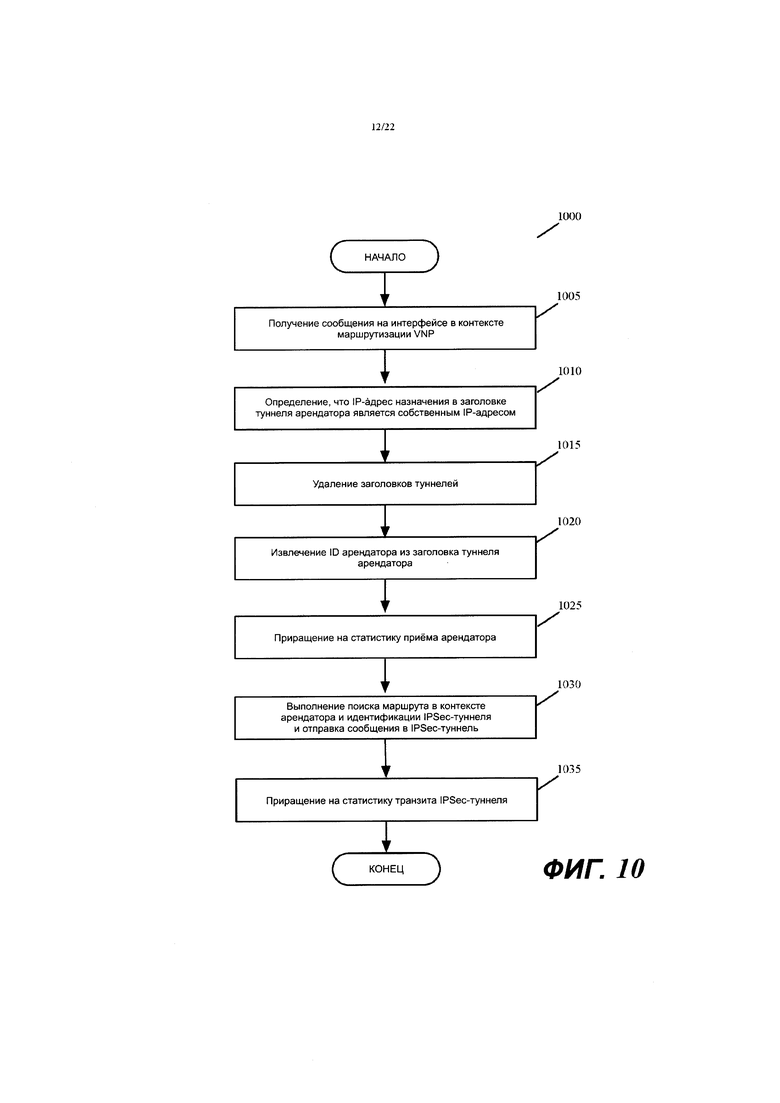
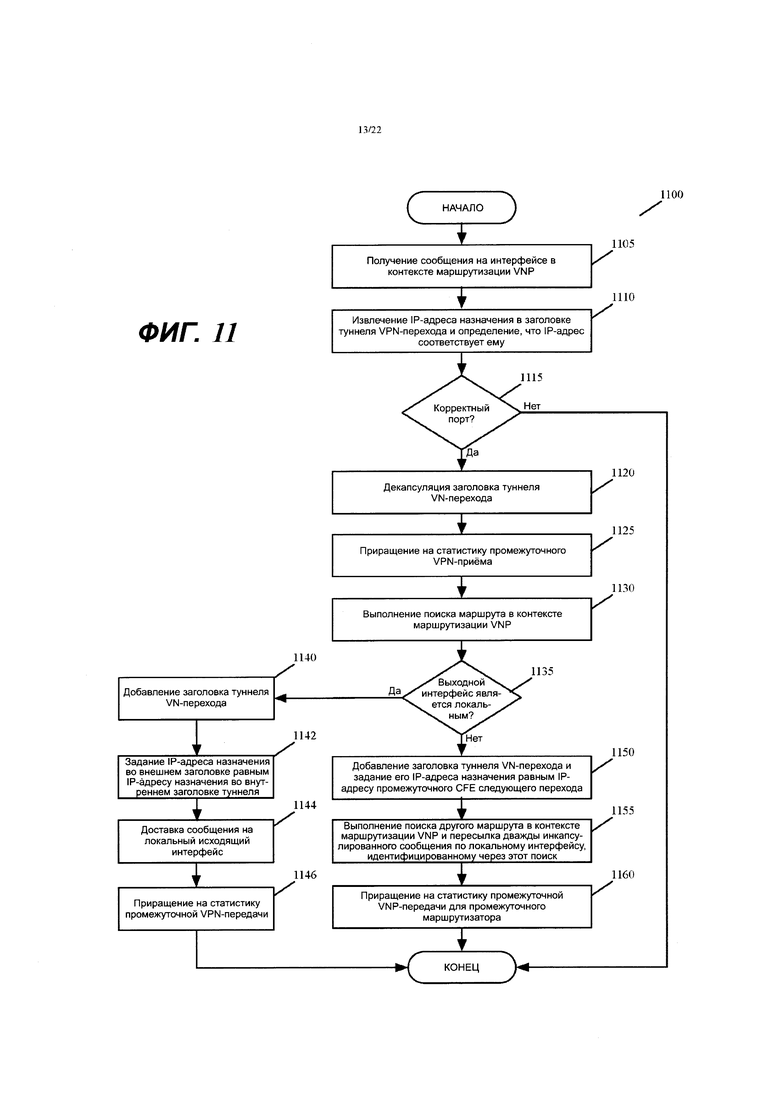
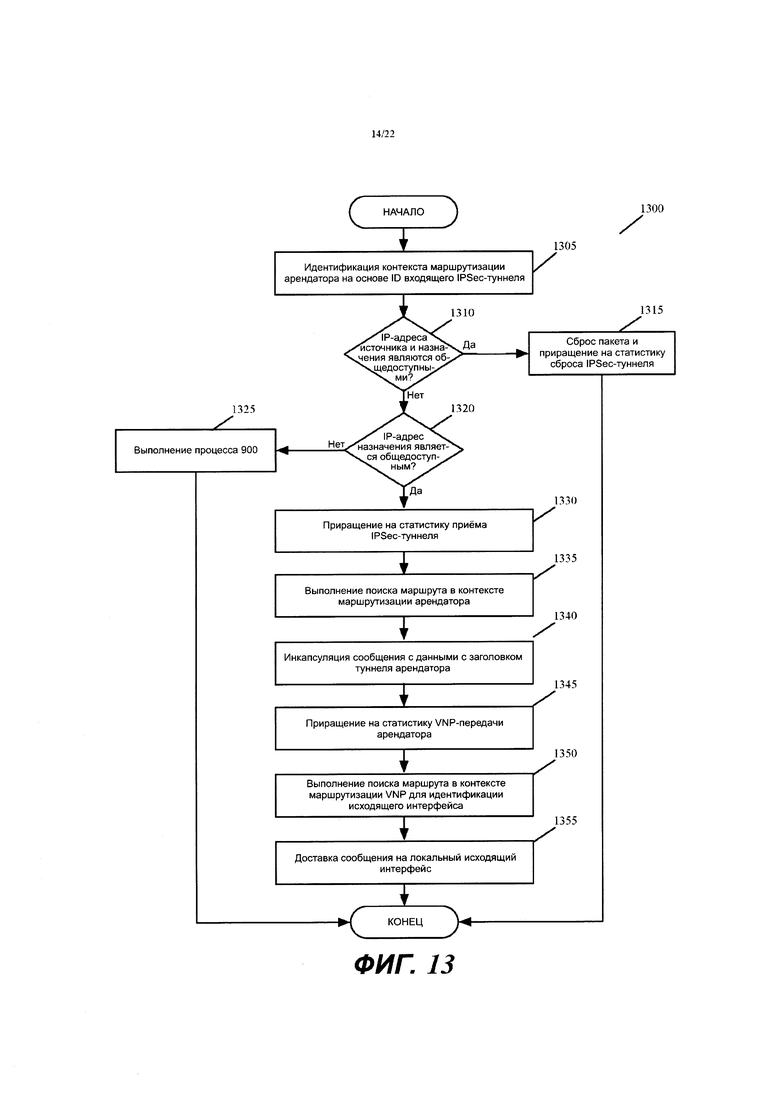
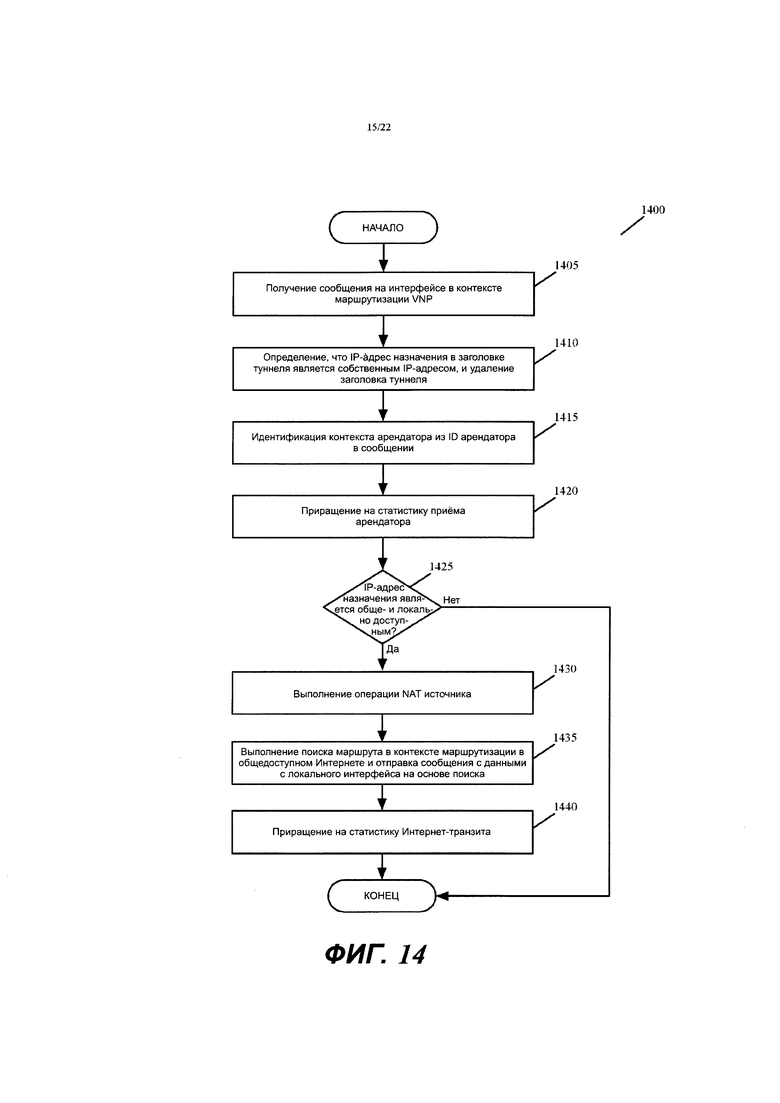
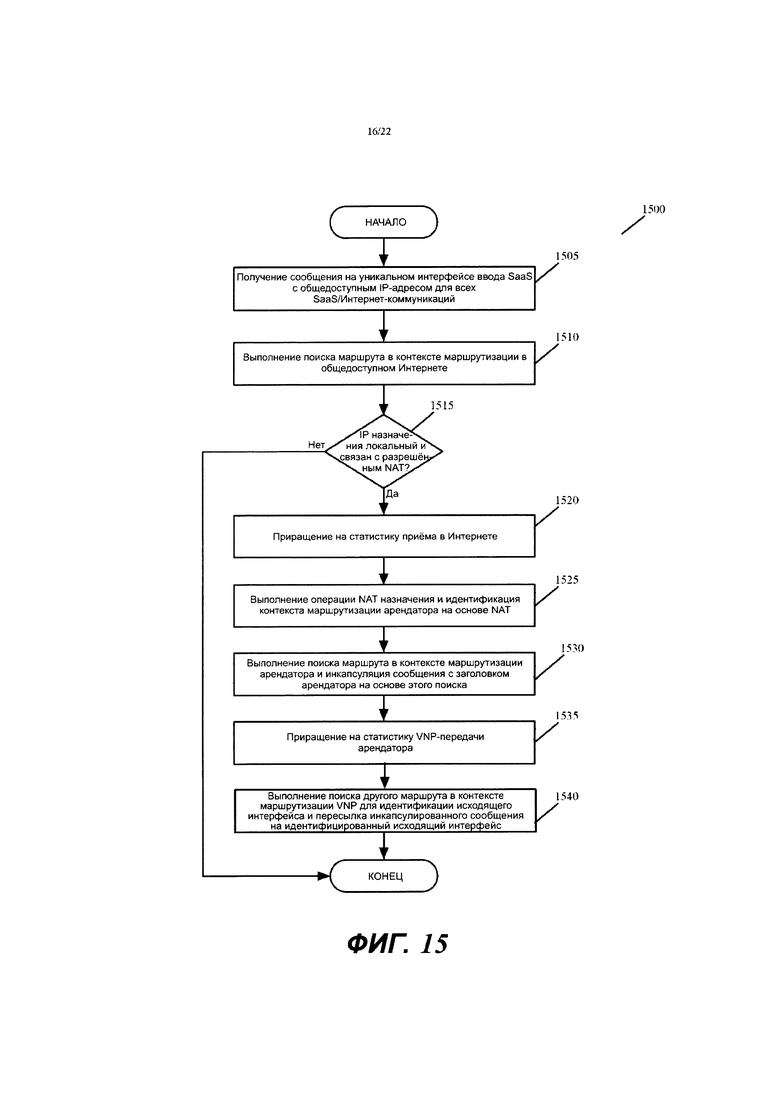
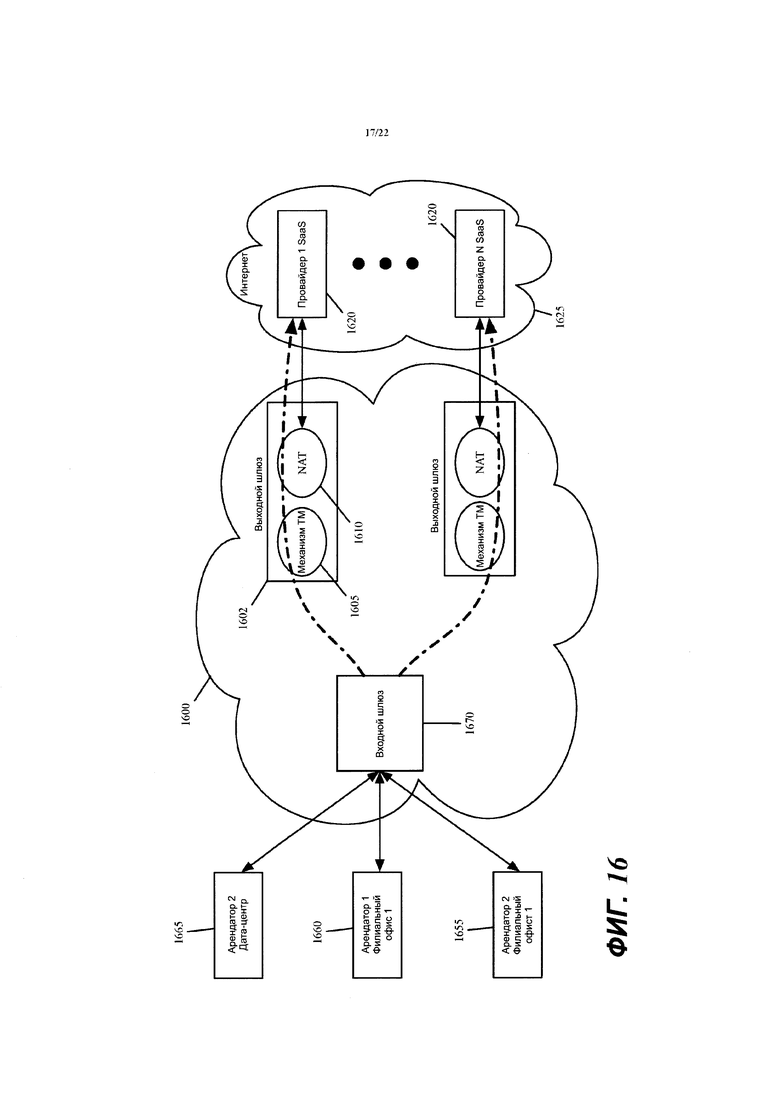
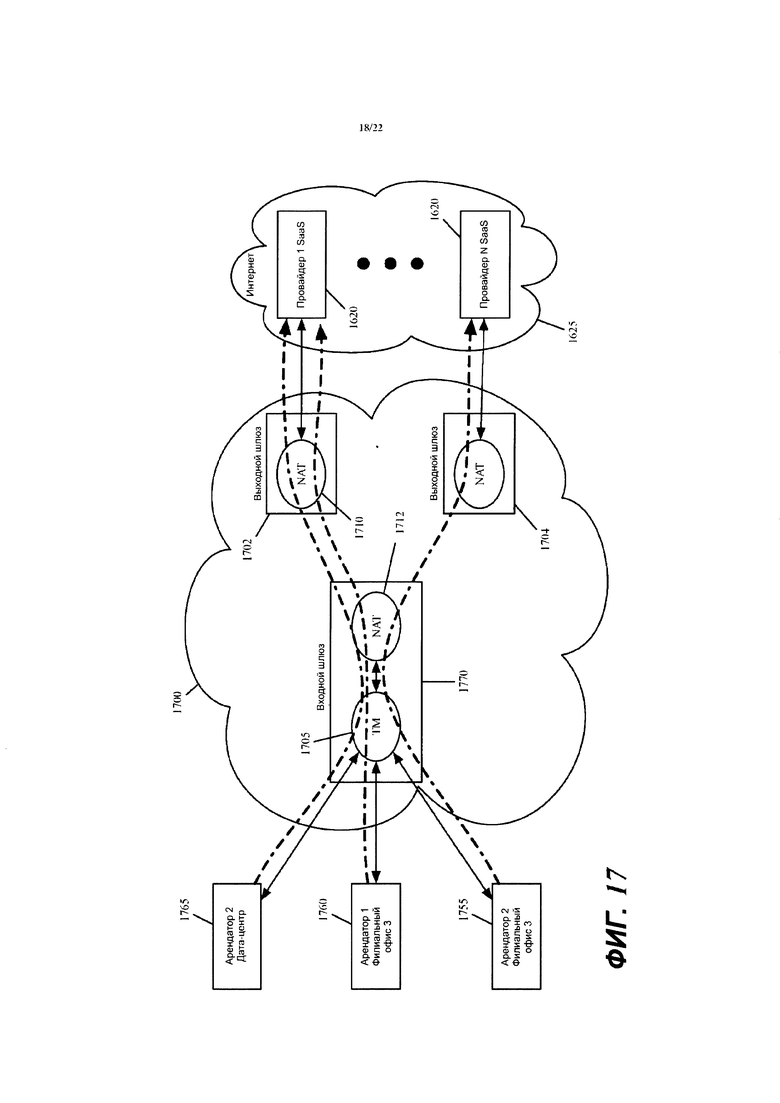
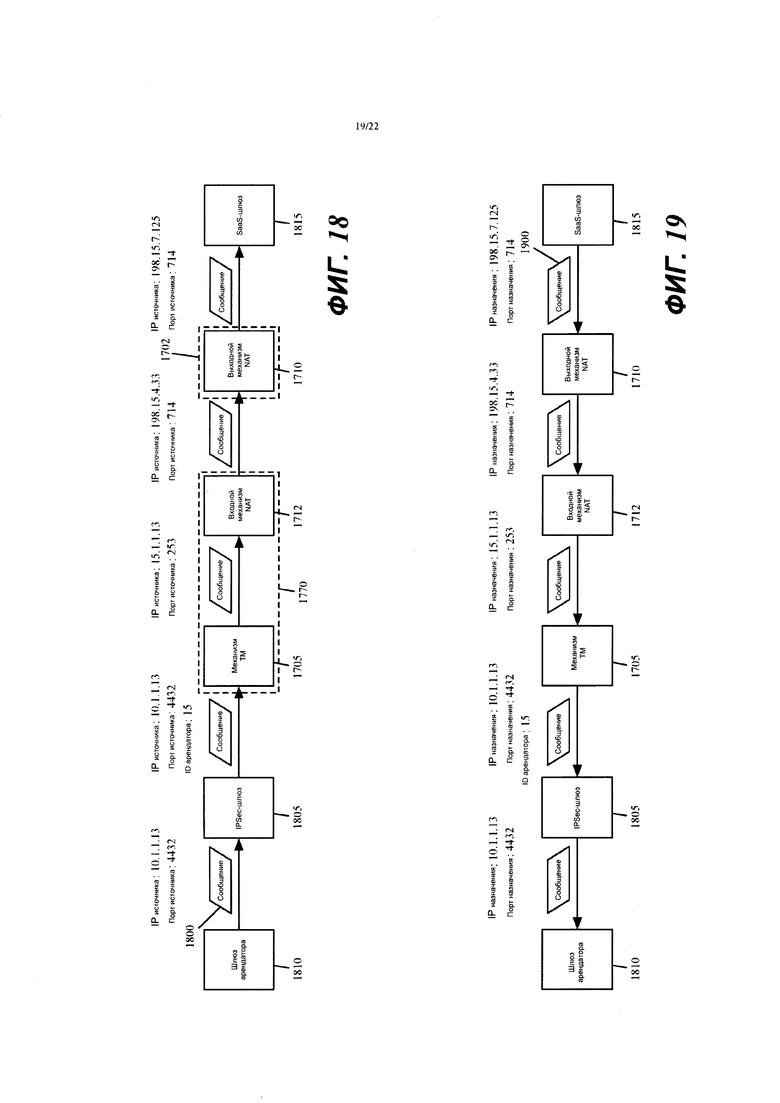
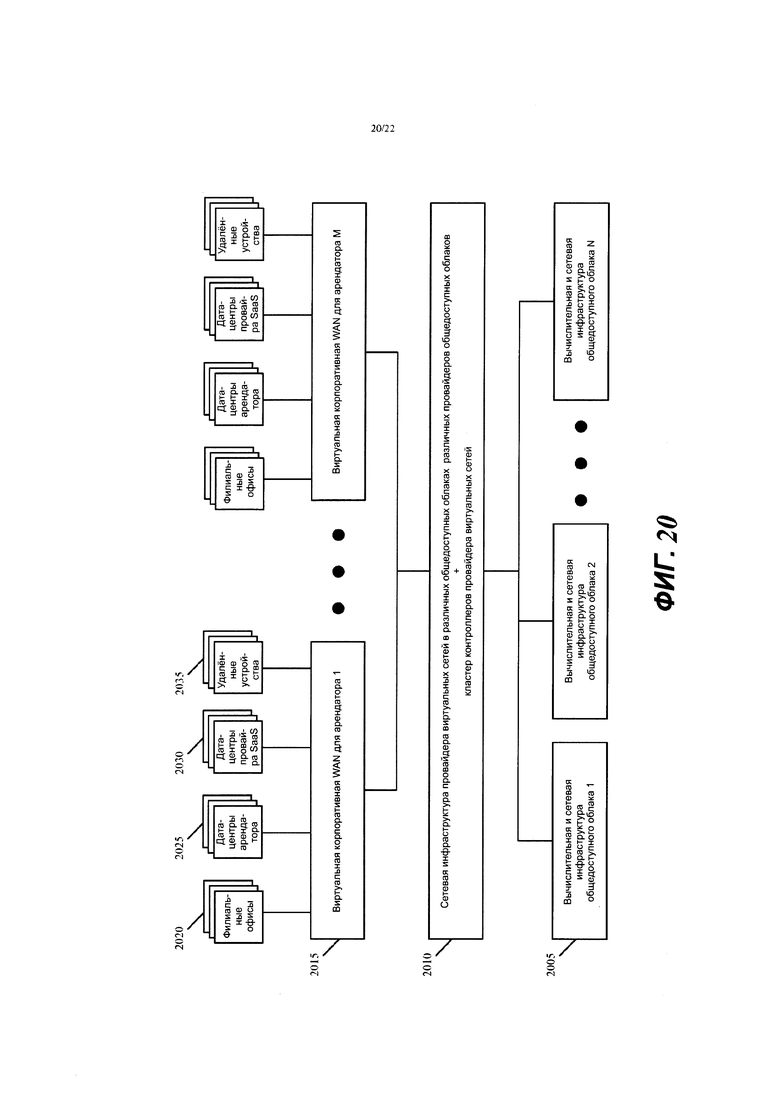
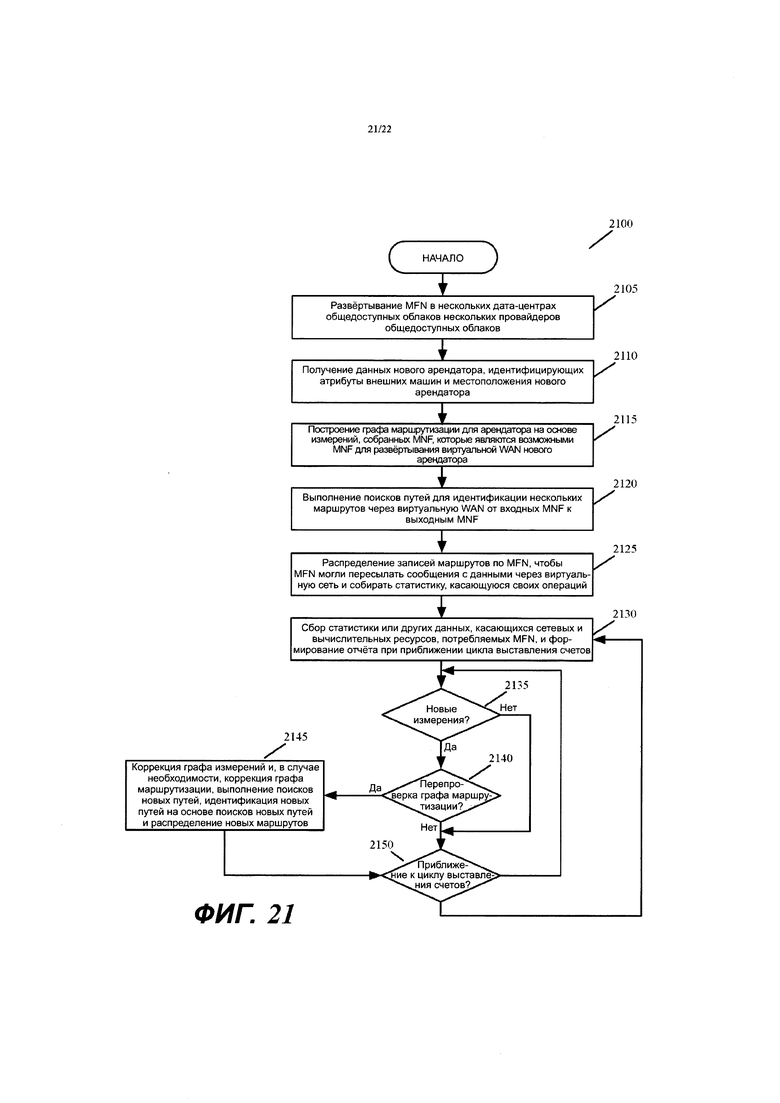
Изобретение относится к области связи. Технический результат заключается в обеспечении возможности организации виртуальной сети поверх нескольких дата-центров общедоступных облаков одного или более провайдеров общедоступных облаков в одном или более регионах, оптимизируя маршрутизацию сообщений для достижения наилучшей сквозной производительности, надежности и безопасности при стремлении минимизировать маршрутизацию трафика через Интернет. Такой результат достигается тем, что конфигурируют первый набор элементов пересылки в первом и втором дата-центрах общедоступных облаков со многими арендаторами для реализации первой виртуальной глобальной сети (WAN) для первой организации, где упомянутая первая виртуальная WAN соединяет множество машин, работающих в наборе из двух или более местоположений машин первой организации и конфигурируют второй набор элементов пересылки в первом и втором дата-центрах общедоступных облаков со многими арендаторами для реализации второй виртуальной глобальной сети для второй организации, где упомянутая вторая виртуальная WAN соединяет множество машин, работающих в наборе из двух или более местоположений машин второй организации. 5 н. и 29 з.п. ф-лы, 27 ил.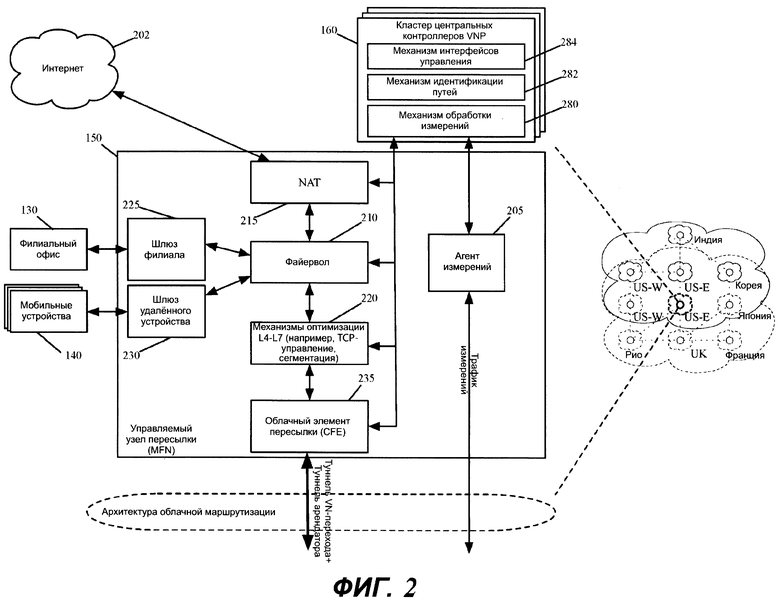
1. Способ создания виртуальных сетей поверх множества дата-центров общедоступных облаков, где этот способ включает в себя:
конфигурирование первого набора элементов пересылки в первом и втором дата-центрах общедоступных облаков со многими арендаторами для реализации первой виртуальной глобальной сети (WAN) для первой организации, где упомянутая первая виртуальная WAN соединяет множество машин, работающих в наборе из двух или более местоположений машин первой организации; и
конфигурирование второго набора элементов пересылки в первом и втором дата-центрах общедоступных облаков со многими арендаторами для реализации второй виртуальной глобальной сети для второй организации, где упомянутая вторая виртуальная WAN соединяет множество машин, работающих в наборе из двух или более местоположений машин второй организации.
2. Способ по п. 1, в котором набор местоположений машин первой организации включает в себя два или более местоположений офисов.
3. Способ по п. 2, в котором набор местоположений машин первой организации дополнительно включает в себя по меньшей мере одно местоположение дата-центра.
4. Способ по п. 3, в котором набор местоположений машин первой организации дополнительно включает в себя местоположения удалённых устройств.
5. Способ по п. 1, в котором набор местоположений машин первой организации включает в себя местоположение офиса и местоположение дата-центра.
6. Способ по п. 5, в котором набор местоположений машин первой организации дополнительно включает в себя местоположение, содержащее множество машин провайдера SaaS (программного обеспечения как услуги).
7. Способ по п. 1, в котором машины включают в себя по меньшей мере одну из виртуальных машин, контейнеров или автономных компьютеров.
8. Способ по п. 1, в котором по меньшей мере поднабор элементов пересылки в первом наборе элементов пересылки также находится во втором наборе элементов пересылки.
9. Способ по п. 8, в котором по меньшей мере другой поднабор элементов пересылки в первом наборе элементов пересылки отсутствует во втором наборе элементов пересылки.
10. Способ по п. 1, в котором
конфигурирование первого набора элементов пересылки содержит конфигурирование первого набора элементов пересылки для использования первого набора заголовков оверлейных виртуальных WAN для инкапсуляции сообщений с данными, которыми обмениваются машины первой организации в разных местоположениях машин;
а конфигурирование второго набора элементов пересылки содержит конфигурирование второго набора элементов пересылки для использования второго набора заголовков оверлейных виртуальных WAN для инкапсуляции сообщений с данными, которыми обмениваются машины второй организации в разных местоположениях машин;
причём первый набор заголовков оверлейных WAN хранит первый идентификатор организации, идентифицирующий первую организацию, а второй набор заголовков оверлейных виртуальных WAN хранит второй идентификатор организации, идентифицирующий вторую организацию.
11. Способ по п. 10, в котором первый и второй наборы элементов пересылки перекрываются, так что по меньшей мере один элемент пересылки находится в обоих наборах элементов пересылки.
12. Способ по п. 1, в котором конфигурирование первого и второго наборов элементов пересылки выполняется набором из одного или более контроллеров провайдера виртуальных сетей, который развёртывает разные виртуальные WAN для разных организаций поверх дата-центров общедоступных облаков разных провайдеров общедоступных облаков и в разных регионах.
13. Способ по п. 1, в котором первый и второй наборы элементов пересылки содержат множество программных элементов пересылки, исполняемых на компьютерах.
14. Способ по п. 1. в котором первый и второй наборы элементов пересылки содержат множество программных элементов пересылки, исполняемых на хост-компьютерах в дата-центрах.
15. Способ по п. 14, в котором множество программных элементов пересылки являются машинами, исполняемыми на хост-компьютерах.
16. Способ по п. 15, в котором по меньшей мере поднабор машин, реализующих множество программных элементов пересылки, исполняется на хост-компьютерах вместе с другими машинами.
17. Способ по п. 15, в котором по меньшей мере поднабор машин, реализующих множество программных элементов пересылки, являются виртуальными машинами.
18. Способ пересылки потоков сообщений с данными по меньшей мере через два дата-центра общедоступных облаков по меньшей мере двух разных провайдеров общедоступных облаков, где этот способ содержит:
на входном элементе пересылки в первом дата-центре общедоступного облака:
получение от первой внешней машины за пределами дата-центров общедоступных облаков сообщения с данными, адресованного второй внешней машине за пределами дата-центров общедоступных облаков, где упомянутая вторая внешняя машина доступна через входной элемент пересылки, который находится во втором дата-центре общедоступного облака;
инкапсуляцию сообщения с данными с первым заголовком, который включает в себя сетевые адреса для входных и выходных элементов пересылки в качестве адресов источника и назначения; и
инкапсуляцию сообщения с данными со вторым заголовком, который определяет сетевые адреса источника и назначения в качестве сетевого адреса входного элемента пересылки и сетевого адреса элемента пересылки следующего перехода, который находится в дата-центре общедоступного облака и который является следующим переходом на пути к выходному элементу пересылки.
19. Способ по п. 18, в котором элемент пересылки следующего перехода находится в третьем дата-центре общедоступного облака.
20. Способ по п. 19, в котором первый, второй и третий дата-центры общедоступных облаков принадлежат трём разным провайдерам общедоступных облаков.
21. Способ по п. 19, в котором первый и второй дата-центры общедоступных облаков принадлежат первому провайдеру общедоступного облака, а третий дата-центр общедоступного облака принадлежит другому - второму провайдеру общедоступного облака.
22. Способ по п. 19, в котором первый и второй дата-центры общедоступных облаков принадлежат двум разным провайдерам общедоступных облаков, а третий дата-центр общедоступного облака принадлежит провайдеру общедоступного облака первого дата-центра общедоступного облака или второго дата-центра общедоступного облака.
23. Способ по п. 19, в котором
элемент пересылки следующего перехода является первым элементом пересылки следующего перехода, и
этот первый элемент пересылки следующего перехода идентифицирует второй элемент пересылки следующего перехода вдоль пути как следующий переход для сообщения с данными и определяет сетевые адреса источника и назначения во втором заголовке как сетевые адреса первого элемента пересылки следующего перехода и второго элемента пересылки следующего перехода.
24. Способ по п. 23, в котором второй элемент пересылки следующего перехода является выходным элементом пересылки.
25. Способ по п. 24, в котором после получения инкапсулированного сообщения с данными выходной элемент пересылки определяет из сетевого адреса назначения в первом заголовке, что инкапсулированное сообщение с данными адресовано выходному элементу пересылки, удаляет первый и второй заголовки из сообщения с данными и пересылает сообщение с данными на вторую внешнюю машину.
26. Способ по п. 23, в котором второй элемент пересылки следующего перехода является четвёртым элементом пересылки, который отличается от второго элемента пересылки.
27. Способ по п. 18, в котором элемент пересылки следующего перехода является вторым элементом пересылки.
28. Способ по п. 18, дополнительно содержит:
обработку на входных и выходных элементах пересылки сообщений с данными, принадлежащих разным арендаторам провайдера виртуальных сетей, который определяет разные виртуальные сети поверх дата-центров общедоступных облаков для разных арендаторов; и
сохранение идентификатора арендатора, который идентифицирует арендатора, связанного с первой и второй внешними машинами, при инкапсуляции первого заголовка полученного сообщения.
29. Способ по п. 28, в котором инкапсуляция сообщения с данными с первым и вторым заголовками определяет для первого арендатора оверлейную виртуальную сеть, которая охватывает группу сетей групповых дата-центров общедоступных облаков, включающих в себя первый и второй дата-центры общедоступных облаков.
30. Способ по п. 29. в котором арендаторы являются корпорациями, а виртуальные сети - корпоративными глобальными сетями (WAN).
31. Способ по п. 18, в котором
первая внешняя машина является машиной в первом филиальном офисе, машиной в первом частном дата-центре или удалённой машиной, а
вторая внешняя машина является машиной во втором филиальном офисе или машиной во втором частном дата-центре.
32. Машиночитаемый носитель данных, хранящий программу, которая при исполнении по меньшей мере одним блоком обработки данных реализует способ по любому из пп. 1-31.
33. Электронное устройство для организации виртуальных сетей поверх множества дата-центров общедоступных облаков, где электронное устройство содержит:
набор блоков обработки данных; а также
машиночитаемый носитель данных, хранящий программу, которая при исполнении по меньшей мере одним блоком обработки данных реализует способ по любому из пп. 1-31.
34. Система для организации виртуальных сетей поверх множества дата-центров общедоступных облаков, где система содержит по меньшей мере один блок обработки данных, системную память, постоянную память (ROM), постоянное запоминающее устройство, шину коммуникативно соединяющую по меньшей мере один процессор с постоянной памятью, системной памятью и постоянным запоминающим устройством, устройства ввода и устройства вывода для реализации способа по любому из пп. 1-31.
| Токарный резец | 1924 |
|
SU2016A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| КОМПЬЮТЕРНАЯ СИСТЕМА И СПОСОБ ОСУЩЕСТВЛЕНИЯ СВЯЗИ В КОМПЬЮТЕРНОЙ СИСТЕМЕ | 2011 |
|
RU2574350C2 |

