Настоящее изобретение относится к способу, излагаемому в ограничительной части п.1 патентов США №№ 4,559,625, выдан Берлекампу и др., и 5,299,208, выдан Блауму и др., и раскрывающему декодирование перемеженной и защищенной от ошибок информации, в которой карта ошибок, обнаруживаемая в первом слове, может обеспечивать свидетельство для определения положения ошибки в другом слове той же группы слов. Указываемые ошибки являются относительно более близкими или более прилегающими, чем другие символы данного слова, которые сформируют данное свидетельство. В этих аналогах используют стандартизированный формат и модель дефектов с многосимвольными пакетами ошибок в различных словах. Появление ошибки в отдельном слове может означать значительную вероятность того, что ошибка появится в символе, указанном в следующем слове или словах. Эта процедура будет нередко увеличивать число ошибок, которые можно исправить до отказа механизма.
Изобретатель данной заявки формулирует проблему этого способа следующим образом: свидетельство будет появляться относительно поздно в процессе, когда порождающая свидетельство информация будет уже демодулирована и также полностью скорректирована. Это усложнит применение мер более высокого уровня, таких как повторная попытка считывания данных во время последующего вращения диска. Также, по мнению изобретателя данной заявки, часть свидетельств или все свидетельства можно было бы получить значительно «дешевле» с точки зрения объема избыточности.
Краткое описание сущности изобретения.
Следовательно, помимо прочего, объект данного изобретения заключается в обеспечении формата кодирования с меньшим объемом непроизводительных издержек, который позволит обеспечение более раннего формирования, по меньшей мере, части свидетельств. Поэтому согласно одному из аспектов данного изобретения оно характеризуется согласно отличительной части пункта 1 формулы.
Данное изобретение также относится к способу декодирования упомянутой информации и носителю, снабженному упомянутой информацией. Прочие предпочтительные аспекты данного изобретения излагаются в прилагаемой формуле изобретения.
Краткое описание чертежей.
Эти и прочие аспекты и преимущества данного изобретения более подробно излагаются ниже со ссылкой на описание предпочтительных осуществлений и, в частности, на прилагаемые чертежи, на которых иллюстрируется следующее:
Фиг.1 - система, имеющая кодер, носитель и декодер;
Фиг.2А-2С - расположение приводимых в качестве примера типов синхронизации;
Фиг.3 - принцип формата кода;
Фиг.4 - пикетный код и субкод индикатора пакета.
Подробное описание предпочтительного осуществления.
Свидетельство, или сочетание свидетельств, после его обнаружения, может обусловить идентифицирование одного или нескольких ненадежных символов. Посредством такого идентифицирования, такого как путем определения символов стирания, исправления ошибок можно сделать более действенными. Многие коды будут исправлять, как максимум, t ошибок, когда местоположение ошибок неизвестно. Если имеется одно местоположение стирания, или несколько таких местоположений, то нередко можно будет исправлять большее число е>t стирания. Осуществимы и другие типы идентифицирования, не характеризующиеся символами стирания. Также можно улучшить защиту от комбинации пакетов и случайных ошибок. Либо обеспечение местоположений стирания обусловит для определенной модели дефектов использование только меньшего числа синдромных символов, тем самым упрощая вычисление. Данное изобретение можно использовать в запоминающей среде или в передающей среде.
Фиг.1 изображает систему согласно настоящему изобретению и выполненную с возможностью формирования двух типов свидетельств, из которых один выводят из групп битов синхронизации, а другой тип - из защищенных от ошибок слов свидетельства соответственно. Это осуществление применяют для кодирования, запоминания и, в конечном счете, декодирования последовательности многоразрядных символов, выводимых из аудио- и видеосигналов или из данных. Оконечное устройство 20 последовательно принимает упомянутые символы, которые, например, имеют восемь битов. Разделитель 22 возвратно и циклично пересылает символы, предназначаемые для слов свидетельства, в кодер 24, а все остальные символы - в кодер 26. В кодере 24 слова свидетельства формируют кодированием символов данных в кодовые слова первого многосимвольного кода исправления ошибок. Этот код может быть кодом Рида-Соломона, кодом произведения, перемеженным кодом или их комбинациями. В кодере 26 целевые слова формируют кодированием в кодовые слова второго многосимвольного кода исправления ошибок. В данном осуществлении все кодовые слова будут иметь единую длину, но это необязательно. Оба кода могут быть кодами Рида-Соломона, при этом первый может быть субкодом второго. Согласно фиг.4 слова свидетельства будут иметь повышенную степень защиты от ошибок.
В блоке 28 кодовые слова пересылают к одному или более выходам, число которых изображено как произвольное, и поэтому излагаемое ниже распределение на носителе станет единообразным. До самой записи на носителе все кодовые символы модулируются в канальные биты. Хорошо известное правило модулирования следует ограничению (d,k)=(1,7), которому подчиняются минимальное и максимальное расстояние между следующими друг за другом сигнальными переходами. Модулирование лучше адаптирует последовательность канальных битов для передающих и запоминающих характеристик цепочки «кодер-носитель-декодер».
В этом отношении фиг.2А изображает приводимый в качестве примера запомненный на диске тип синхронизации согласно дихотомии «есть микроуглубление/нет микроуглубления». Изображаемый тип состоит из последовательности девяти положений «нет микроуглубления», за которым непосредственно следуют девять положений «есть микроуглубление». Этот тип будет нарушать нормативные ограничения модуляции, если k соответствует длине последовательности, состоящей из менее девяти положений «есть микроуглубление/нет микроуглубления» Для краткости: сигнал обнаружения, получаемый при сканировании упомянутой последовательности, не учитывается. Все типы можно обратить по разрядам. Исходные и конечные положения разрядов данного типа можно использовать для других целей - всегда при том условии, что переходы не могут происходить в непосредственно следующих друг за другом положениях разрядов.
В фиг.1 блок 30 символизирует сам единообразный носитель, такой как лента или диск, который принимает кодированные данные. Это может означать непосредственную запись в комбинации «запись-механизм-плюс-носитель». Либо носитель можно реализовать посредством копирования главного кодированного носителя, такого как матрица. В блоке 32 канальные биты снова считывают с носителя; затем сразу следует демодулирование. Эти операции обеспечивают опознанные типы синхронизации и также кодовые символы, которые должны быть подвергнуты дальнейшему декодированию. Теперь, как правило, типы синхронизации будут находиться в тех положениях, где их будет фактически «ждать» проигрывающее устройство; и из этого будет следовать вывод о том, что данная синхронизация является верной. Но верные типы синхронизации могут обнаруживаться и на неожиданных положениях. Это может указывать на потерю синхронизма, который нужно восстанавливать с помощью трудоемкого процесса, основывающегося на принимаемых различных следующих друг за другом типах синхронизации. Как правило, синхронизацию сохраняют за счет «процедуры маховика» или исходя из решения большинства среди некоторой совокупности следующих друг за другом типов синхронизации. Либо верный тип синхронизации можно обнаруживать на основании одной или более ошибок канальных битов в данных положениях, не являющихся положениями, предназначенными для типов синхронизации. Как правило, это будет изолированной особенностью, которая не будет обуславливать необходимость производить повторную синхронизацию. С другой стороны, на ожидаемом положении демодулятор может и не обнаружить тип синхронизации. Нередко ошибкой будет являться произвольный разряд, восстанавливаемый за счет присущей избыточности в данном типе синхронизации. Тогда это обстоятельство будет приводить к верному типу синхронизации и будет обеспечивать возможность следования процесса обычным образом без последующего учета восстановленного типа синхронизации для других канальных битов. Либо ошибка может быть достаточно серьезной, чтобы сделать вывод о том, что имеет место некоторый пакет. Этот пакет тогда может предоставлять свидетельство о том, что прочие символы в данной его физической среде являются ошибочными, таким же образом, каким это будет ниже изложено в отношении слов свидетельства. В принципе выводимые из синхронизации свидетельства могли бы быть достаточными для повышения нормальной защищенности от ошибок. Поэтому они должны находиться не слишком далеко друг от друга. Если сведения выводят из типов синхронизации и также из слов свидетельства, то типы синхронизации можно использовать в качестве отдельного механизма для формирования свидетельств даже до начала декодирования слов свидетельства. При этом может обеспечиваться возможность использования двух механизмов свидетельства совместно, одним из которых будет механизм из типов синхронизации, а другой - из слов свидетельства. Либо можно комбинировать свидетельства из типов синхронизации и слов свидетельства. Выбор конкретных механизмов из числа излагаемых здесь механизмов можно производить на статистической и динамической основе. Довольно часто комбинирование со свидетельствами, обнаруживаемыми с помощью декодирования слов свидетельства, можно использовать для обеспечения улучшенного или более действенного декодирования целевых слов.
После демодуляции слова свидетельства направляют в декодер 34 и их декодируют на основе их собственной избыточности. В соответствии с излагаемым ниже описанием со ссылкой на фиг.3 это декодирование может представлять свидетельства о местоположениях ошибок в других местах, не являющихся этими словами свидетельства. Блок 35 принимает эти свидетельства и, в зависимости от конкретного случая, другие указания по стрелке 33 и действует на основе запомненной программы для применения одной или более различных стратегий для транслирования свидетельств в местоположения стирания или другие указания для идентифицирования ненадежных символов. Входной сигнал на линии 33 может представлять свидетельства, производимые демодуляцией групп битов синхронизации или в зависимости от конкретного случая прочие указания, такие как производимые общим качеством принимаемого сигнала, например, выводимым из его спектра частот. Целевые слова декодируют в декодере 36. С помощью местоположений стирания или других идентификаций защищенность целевых слов от ошибок поднимают на более высокий уровень. Наконец, все декодированные слова уплотняют посредством элемента 38 сообразно первоначальному формату в выходной сигнал 40. Для краткости: механическое сопряжение различных подсистем здесь не излагается.
Фиг.2В и 2С иллюстрируют прочие расположения приводимых в качестве примера типов синхронизации, распределяемых в информационном потоке. Каждый отдельный тип синхронизации может иметь вид, аналогичный изображаемому в Фиг.2А. Во-первых, эти типы синхронизации могут быть единственным источником информации свидетельства. Их предпочтительно располагают в отделяемые друг от друга периодическими интервалами местоположения в информационном потоке. Либо свидетельства можно выводить и из типов синхронизации и из слов свидетельства. Фиг.2В, 2С иллюстрируют последний случай. При этом положения символов слова свидетельства указаны крестиками. Положения групп битов синхронизации указаны точками. В фиг.2В, 2С расстояния между символами слова свидетельства находятся в местоположении группы битов синхронизации больше, чем изображаемое в другом месте, в результате чего на данном месте они расположены реже. В фиг.2А их расстояние составляет значение, меньшее, чем их двукратное значение в других местах. В фиг.2В оно составляет двукратное его значение, имеющееся в других местах. Возможны также другие распределения.
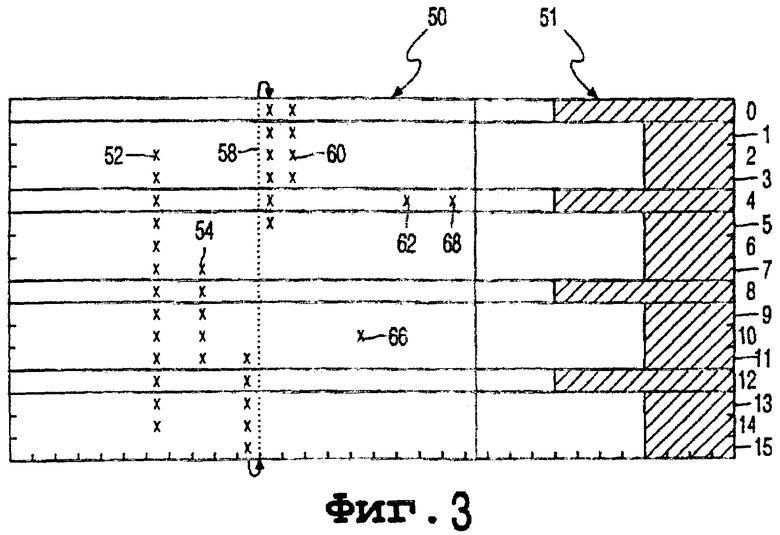
Фиг.3 иллюстрирует простой формат кода без участия групп битов синхронизации. Кодированная информация 512 символов предположительно размещена в блоке из 16 рядов 32 колонок. На носителе информация хранится последовательно по колонкам, начиная сверху слева. Заштрихованный участок содержит контрольные символы; каждое из слов свидетельств 0, 4, 8 и 12 имеет по 8 контрольных символов. Каждое из целевых слов содержит 4 контрольных символа. Весь блок содержит 432 информационных символа и 80 контрольных символов. Последние могут находиться в более распределенном порядке по своим соответствующим словам. Некоторая часть информационных символов может быть пустыми символами. Код Рида-Соломона позволяет корректировать в каждом слове свидетельства до четырех ошибок символов. Действительно имеющиеся ошибки символов указаны крестиками. Поэтому все слова свидетельства можно декодировать верно, поскольку в них никогда не содержится более четырех ошибок. Нужно отметить, что слова 2 и 3 могут, тем не менее, не декодироваться только на основе их собственных избыточных символов. Теперь в фиг.3 все ошибки, за исключением 62, 66, 68, представляют цепочки ошибок, но только цепочки 52 и 58 пересекают, по меньшей мере, три следующие друг за другом слова свидетельства. Они рассматриваются как пакеты ошибок и обуславливают появление флагов стирания во всех промежуточных местоположениях символов. Одно целевое слово, или несколько целевых слов, перед первой ошибкой слова свидетельства данного пакета, и одно целевое слово, или несколько целевых слов, идущих сразу за последним символом свидетельства данного пакета, могут также получить флаг стирания, в зависимости от применяемого метода. Цепочка 54 является слишком короткой, чтобы ее считать пакетом.
Поэтому две ошибки из числа ошибок в слове 4 дают флаг стирания в соответствующих колонках. Это делает слова 2 и 3 подлежащими исправлению; каждое из них содержит один символ ошибки и два символа стирания. Но ни произвольные ошибки 62, 68, ни цепочка 54 не составляют свидетельств для слов 5, 6, 7, поскольку каждое из них содержит только одно слово свидетельства. Иногда результатом стирания может быть нулевое распределение ошибок, поскольку произвольная ошибка в 8-битовом символе имеет вероятность обусловить верный символ, равный 1/256. Аналогично, пакет, пересекающий определенное слово свидетельства, может произвести в нем верный символ. Стратегия перехода между предшествующими и последующими символами свидетельства в одном пакете может ввести этот верный символ в данный пакет и таким же образом, каким ошибочные символы свидетельства могут преобразовать его в стирания для соответствующих целевых символов.
Описание практического осуществления
Применение данного изобретения относится к новым способам для цифрового оптического запоминающего устройства. В настоящее время считывание подложки падающим лучом может иметь пропускающий слой толщиной 100 микрон. Канальные биты могут иметь размер порядка 0,4 микрона и поэтому байт данных при коэффициенте канала 2/3 будет иметь длину, составляющую только 1,7 микрона. Верхняя поверхность луча имеет диаметр 125 микрон. Заключение диска в т.н. чехол может снизить вероятность крупных пакетов. Но нестандартные частицы размером менее 50 микрон могут вызывать краткие дефекты. Заявители использовали модель дефектов, в которой эти дефекты, возникающие из-за распространения ошибок, могут иметь результатом пакеты размером 200 микрон, что соответствует 120 байтам. Эта модель предлагает пакеты фиксированного размера 120 Б, которые начинаются произвольно с вероятностью из расчета на один байт, равной 2,6*10-5, или в среднем один пакет на один блок 32 кБ. Изобретатель предполагает последовательное хранение на оптическом диске, но такие конфигурации, как многодорожечная лента, и другие технологии, такие как магнитная или магнитно-оптическая, также могут воспользоваться предлагаемым здесь решением.
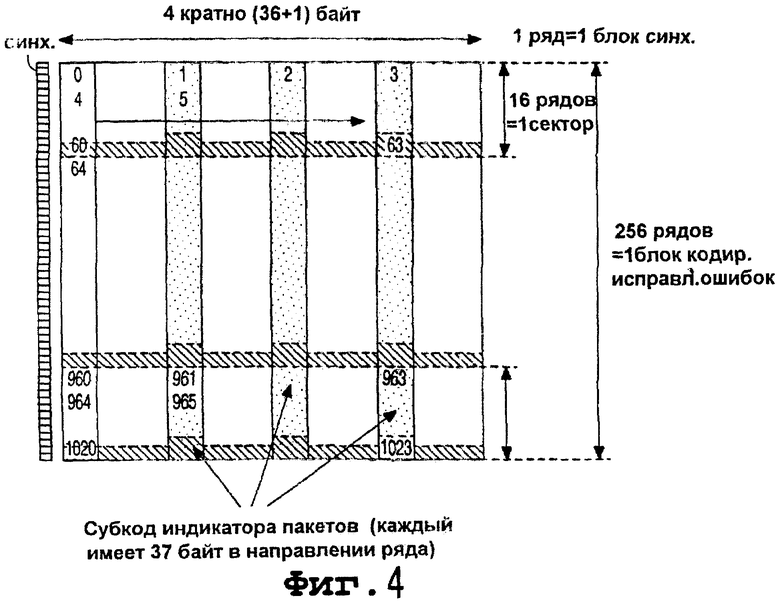
Фиг.4 изображает пикетный код и субкод индикатора пакета. Пикетный код состоит из двух субкодов А и В. Субкод индикатора пакета содержит слова свидетельства. Его форматируют как глубокоперемеженный код большого расстояния, который позволяет определять местоположения многократных пакетных ошибок. Обнаруживаемые таким образом распределения ошибок обрабатывают для получения информации стирания для целевых слов, которые конфигурируют в данном осуществлении как субкод произведения. Этот субкод затем корректирует комбинации многократных пакетов и случайных ошибок с помощью флагов стирания, полученных из субкода индикатора пакета. Индикаторы, предоставляемые группами битов синхронизации, можно использовать изолированно или в сочетании с указаниями от слов свидетельства. Как правило, если слова свидетельства не предоставлены совсем, то число групп битов синхронизации увеличится. Разработка свидетельств будет аналогична процедуре, излагаемой со ссылкой на фиг.3 для слов свидетельства.
Предлагается следующий формат:
- блок из 32 кБ содержит 16 секторов, совместимых с ЦВД;
- каждый сектор содержит данные, составляющие 2064=2048+16 байтов;
- каждый сектор после кодирования с исправлением ошибок содержит 2368 байтов;
- поэтому коэффициент кодирования составляет 0,872;
- в блоке 256 блоков синхронизации форматируют следующим образом;
- каждый сектор содержит 16 блоков синхронизации;
- каждый блок синхронизации состоит из 4 групп по 37 Б.
Каждая группа из 37 Б содержит 1 Б глубокоперемеженного субкода индикатора пакетов и 36 Б субкода произведения.
В Фиг.4 ряды считывают последовательно, причем каждый ряд начинается со своим вводящим типом синхронизации. Каждый ряд содержит 3 байта субкода индикатора пакетов, который изображен в сером цвете, последовательно пронумерован и отделен интервалом, составляющим другие 36 байтов. Шестнадцать рядов составляют один сектор, и 256 рядов формируют один блок синхронизации. Общая избыточность заштрихована. Байты синхронизации можно использовать для получения свидетельств посредством имеющейся в них избыточности вне основных кодовых средств. Аппаратура фиг.1 может выполнять обработку групп битов синхронизации, которые составляют слова другого формата, не являющиеся байтами данных на предварительном этапе операции. Помимо этого, информация может указывать, что определенные слова или символы являются ненадежными, например, исходя из качества сигнала, выводимого с диска, или согласно ошибкам демодуляции. Необходимо отметить, что в фиг.4 одна колонка слева сейчас уже не является необходимой для слов свидетельства субкода индикатора пакетов. Согласно этому изображению эта колонка заполнена целевыми словами. Либо эту колонку исключают совсем. В обоих случаях последующая плотность хранения для данных пользователя повышается.
Группа битов синхронизации является хорошим средством для обнаружения пакетов за счет присущего ей значительного хэммингового расстояния от типов, пораженных пакетами в наибольшей степени. Обычный интервал между группами битов синхронизации может составлять около 1000 канальных битов. Другой формат заключается в расщеплении 24-битовой структуры битов синхронизации на две половины по двенадцать битов в каждой, каждая из которых будет нарушать принцип модуляции только раз. Интервал между группами битов синхронизации затем разделяют на две части, составляющие около 500 бит каждая, в результате чего непроизводительные издержки остаются теми же. Для обнаружения пакетов можно исключительно использовать заранее определенные разрядные фракции из данной группы битов синхронизации. Необходимо отметить, что в Фиг.3 группа битов синхронизации будет занимать горизонтальный ряд над первым положением слова свидетельства.


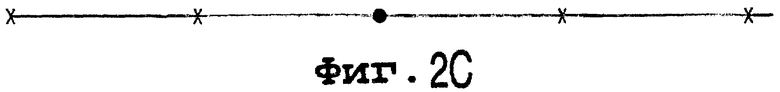
Изобретение относится к способам кодирования информации и декодирования перемеженной и защищенной от ошибок информации, а также к устройству и носителю для кодирования этой информации. Техническим результатом является обеспечение формата кодирования с меньшим объемом непроизводительных издержек. Устройство кодирования информации содержит средство пословного перемежения, средства пословного кодирования защиты от ошибок, формирующее средство для формирования ключей. Способ кодирования описывает работу указанного устройства. На носитель записан указанный способ. Способ декодирования заключается в обеспечении пословного обращенного перемежения и выведения ключей, определяющих местонахождение ошибок в словах группы, состоящей из многих слов. 5 н. и 15 з.п. ф-лы, 6 ил.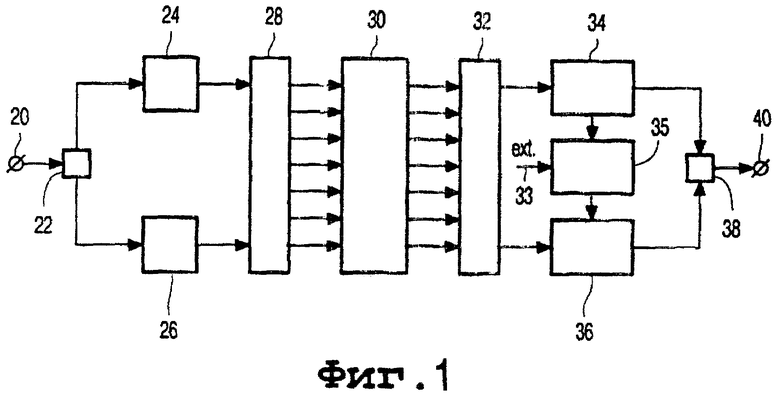
| US 5696774 A, 09.12.1997.RU 2110148 C1, 27.04.1998.US 5651015 A, 22.07.1997.US 4559625 A, 17.12.1985.US 5299208 A, 29.03.1994. |

