Изобретение относится к способу, изложенному в преамбуле к п.1 формулы патента US 4559625 (Берлекамп и др.) и патента US 5299208 (Блаум и др.), предназначенному для декодирования информационных слов, подвергнутых интерливингу и защите от ошибок, при котором ошибочная комбинация, обнаруженная в первом слове, может дать ключ к обнаружению ошибок в других словах той же группы слов. Упомянутые ссылки используют стандартизованный формат и модель возникновения помех, которая имеет мультисимвольные пакеты ошибок, которые возникают в различных словах. Возникновение ошибки в конкретном слове повышает вероятность возникновения ошибки на соответствующей позиции символа следующего слова или следующих слов. Этот способ часто повышает количество исправленных ошибок. Настоящее изобретение выявляет недостаток указанного принципа: ключ может быть получен только если ключевое слово полностью исправлено.
Сущность изобретения
Задачей настоящего изобретения является создание формата кода, при котором ключевые слова будут правильно декодированы с большей степенью надежности, чем искомое слово. Поэтому изобретение в одном из своих аспектов характеризуется отличительной частью п.1 формулы. Найденный ключ в результате может указать на стертый символ. При таком указании корректировка ошибок может происходить эффективнее. Известно, что многие коды исправляют, как максимум, t ошибок, если не известны места расположения ошибок. При указании стертых мест, вообще, может быть исправлено большее количество e>t стираний. Кроме того, улучшится защита от комбинации пакетных и случайных ошибок. С другой стороны, указание стертых мест потребует использования меньшего числа символов синдрома, что упрощает вычисления. В принципе, изобретение можно использовать как в области хранения информации, так и в области передачи информации.
Изобретение также относится к способам декодирования закодированной таким образом информации, к устройствам кодирования и/или декодирования, предназначенным для применения на основе указанных способов, и к носителю, снабженному информацией, предназначенной для такого кодирования и/или декодирования. Прочие преимущества изобретения изложены в зависимых пунктах формулы.
Краткое описание чертежей
Упомянутые и прочие аспекты и преимущества изобретения будут подробнее описаны ниже на основе предпочтительных вариантов реализации изобретения и прилагаемых чертежей, на которых:
фиг. 1 - система с кодером, носителем информации и декодером;
фиг. 2 - принцип форматирования кода;
фиг. 3 - формат композиционного кода;
фиг. 4 - "длинный" код с обнаружением пакета;
фиг. 5 - пикетирующий код и подкод для индикации пакета;
фиг. 6 - формат подкода для индикации пакета;
фиг. 7 - пикетирующий код и его композиционный подкод;
фиг. 8 - различные аспекты кода;
фиг. 9 - альтернативный формат;
фиг. 10 - подробности интерливинга.
Подробное описание предпочтительных вариантов реализации изобретения
На фиг.1 изображена полная система, соответствующая изобретению, содержащая кодер, носитель информации и декодер. Данный вариант реализации применяют для кодирования, хранения и, наконец, декодирования последовательности выборок или мультибитных символов, полученных из аудио- или видеосигнала или из данных. На вход 20 поступает поток символов, например, длиной восемь бит. Разделяющее устройство 22 работает циклически и периодически подает первые символы, предназначенные для ключевых слов, в кодер 24. Далее разделяющее устройство 22 передает остальные символы в кодер 26. В кодере 24 формируют ключевые слова путем кодирования связанных данных в кодовые слова первого мультисимвольного кода, исправляющего ошибки. Этим кодом может быть код Рида-Соломона, композиционный код на основе интерливинга или комбинация перечисленных. В кодере 26 формируют искомые слова путем кодирования в кодовые слова второго мультисимвольного кода, исправляющего ошибки. В данном варианте реализации изобретения все кодовые слова имеют одинаковую длину, хотя это и не обязательное требование. Предпочтительно, чтобы оба кода были кодами Рида-Соломона, первый из которых был бы подкодом второго кода. Как станет ясно из рассмотрения фиг.2, ключевые слова будут обладать в целом гораздо более высокой степенью защиты от ошибок и будут содержать относительно меньшее количество не избыточных символов.
В блоке 28 сформированные таким образом кодовые слова передают на один или более выходов, обозначено произвольное количество последних так, чтобы описанное ниже распределение в среде было равномерным. Блок 30 символизирует саму среду, которая принимает закодированные данные. На самом деле это распределение может относиться к прямой записи в подходящей комбинации механизм записи плюс среда. Или же среда может быть реализована как копия эталонной закодированной среды, например, как отпечаток. Предпочтительно, чтобы запоминающее устройство было оптическим и полностью последовательным, но можно использовать и другие конфигурации. В блоке 32 различные слова будут прочитаны снова из среды. Затем ключевые слова в первом коде направят в декодер 34 и декодируют с помощью их собственной избыточности. В дальнейшем, как станет ясно из обсуждения фиг.2, такое декодирование может дать ключ к местам расположения ошибок в словах, отличных от этих ключевых. Устройство 35 принимает эти ключи и содержит программу, использующую одну или несколько различных стратегий для перевода таких ключей к стертым местам. Искомые слова декодируют в декодере 36. Под управлением информации о стертых местах защиту от ошибок искомых слов поднимают до приемлемого уровня. Наконец, все декодированные слова демультиплексируют с помощью элемента 38 в соответствии с заданным форматом выхода 40. Для краткости механическая конфигурация интерфейса различных подсистем между собой здесь опущена.
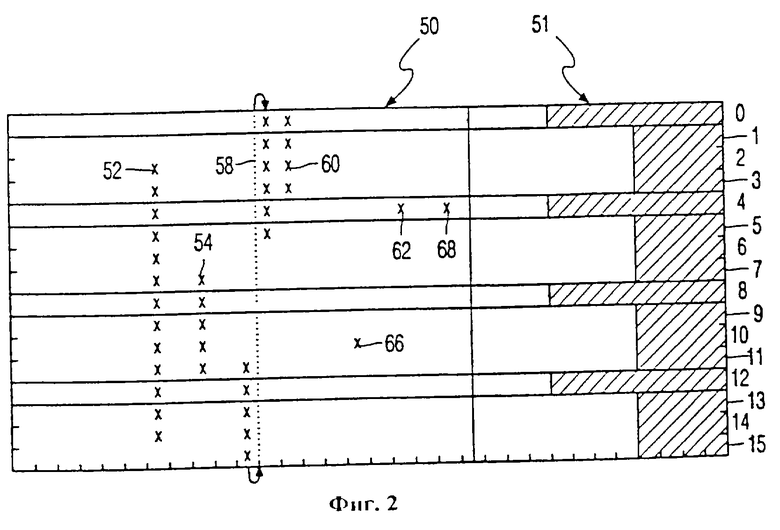
На фиг. 2 изображен относительно простой формат кода. Как показано, закодированная информация условно организована в блок символов из 16 строк • 32 столбца, что составляет 512 символов. Запоминание в среде производится последовательно от столбца к столбцу, начиная с верха левого столбца. Заштрихованная область содержит проверочные символы, и слова 0, 4, 8 и 12 имеют по 8 проверочных символов каждое, и образуют ключевые слова. Остальные слова содержат по 4 проверочных символа и образуют искомые слова. Блок в целом содержит 432 информационных символа и 80 проверочных. Последние можно располагать разреженно по отношению к соответствующим им словам. Часть информационных символов может быть ложными символами. Код Рида-Соломона позволяет исправлять в каждом ключевом слове ошибки длиной до ЧЕТЫРЕХ символов. Действительные ошибки в символах обозначены крестами. Следовательно, все ключевые слова могут быть декодированы правильно в том случае, если они содержат НЕ БОЛЕЕ четырех ошибок. Однако только слова 2 и 3 могут НЕ БЫТЬ декодированы лишь на основе собственных избыточных символов. В данном случае на фиг.2 все ошибки за исключением 62, 66, 68 представляют собой цепочки ошибок. Однако лишь цепочки 52 и 58, пересекающие, по меньшей мере, три последовательных ключевых слова, считают пакетами ошибок, так что, по меньшей мере, всем местам расположения промежуточных символов присвоят признак стирания. Кроме того, признак стирания в данном месте могут присвоить искомым словам, расположенным перед первым ключевым словом пакета с ошибкой, и непосредственно после последнего ключевого слова пакета с ошибкой, в зависимости от принятой стратегии. Цепочку 54 не считают пакетом, так как она слишком коротка.
Вследствие изложенного, две ошибки в слове 4 устанавливают признак стирания в обоих связанных столбцах. Эти воспроизводимые слова 2 и 3 исправимы, каждое из которых содержит по одному ошибочному символу и по два стертых символа. Однако ни случайные ошибки 62, 68, ни цепочка 54 не образуют ключа к словам 5, 6, 7, так как каждая из них содержит только одно ключевое слово. В некоторых ситуациях стирание может привести к НУЛЕВОЙ ошибочной комбинации, потому что случайная ошибка в 8-битном символе может с вероятностью 1/256 породить правильный символ. Аналогично, длительный пакет, пересекая определенное ключевое слово, может породить в нем правильный символ. По стратегии перекрытия между предыдущим и последующим ключевыми символами одного и того же пакета, такой правильный символ включают в состав пакета и, так же как ошибочные ключевые символы, переводят в стертые значения для соответствующих искомых символов. Указанные решения могут быть уточнены в соответствии с тактикой декодирования, которая может быть отрегулирована с помощью других параметров.
Описание практического формата
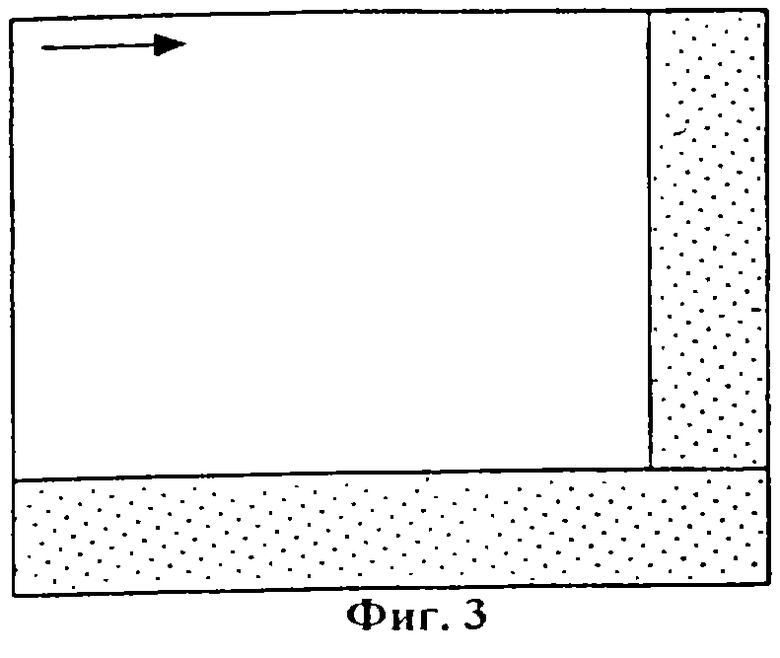
Ниже будет описан практический формат. На фиг.3 символически изображен формат композиционного кода. Слова располагаются по горизонтали и вертикали, проверочные биты заштрихованы. Фиг.4 символически изображает так называемый длинный код, обладающий особыми мерами обнаружения пакета в нескольких верхних словах, снабженных большим количеством битов. В настоящем изобретении предложен так называемый пикетирующий код, который можно сконструировать на основе комбинации принципов фиг.3 и 4. Запись производится последовательно в направлении стрелки, изображенной на фиг.3, 4.
Практические аспекты настоящего изобретения вызваны появлением новейших способов для цифровых оптических запоминающих устройств. В частности, особенность в случае считывания подслоя падающим лучом заключается в том, что верхний проводящий слой имеет толщину всего 100 микрон. Канальные биты имеют размер около 0,14 мкм, так что байт данных при коэффициенте канала 2/3 будет иметь длину всего 1,7 мкм. Диаметр луча на наружной поверхности составляет около 125 мкм. Коробка или конверт для диска уменьшают вероятность больших пакетов. Однако дефектные частицы размером 50 мкм могут вызывать короткие сбои. Авторы изобретения использовали, между прочим, модель возникновения сбоев, при которой такие сбои за счет размножения ошибок могли приводить к пакетам длиной 200 мкм, что соответствует примерно 120 байтам. В частности, авторы изобретения использовали модель ошибок с фиксированной длиной пакета 120 байт, начало которой случайно приходится с вероятностью 2,5•10-5 на байт или в среднем один пакет на блок в 32 кбайт. Изобретение было вызвано разработкой запоминающего устройства на оптическом диске, но от применения улучшенного подхода, описанного здесь, могут выиграть и другие конфигурации, например, многодорожечная пленка и прочие способы, например, магнитные и магнитооптические способы.
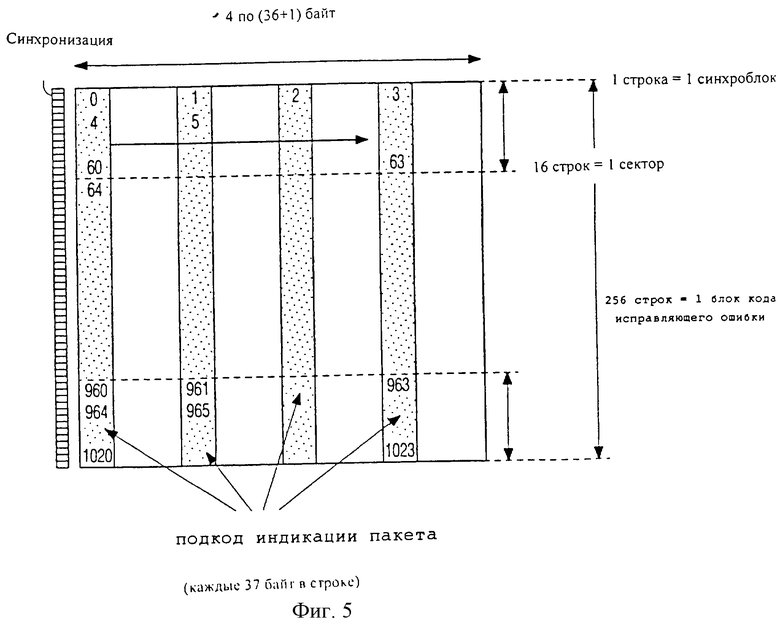
Фиг. 5 изображает пикетирующий код и подкод для индикации пакета. Пикетирующий код состоит из двух подкодов А и В. Подкод индикации пакета (ПИП) содержит ключевые слова. В соответствии с форматом это длинный код, подвергнутый глубокому интерливингу, позволяющий локализовать места расположения ошибок многочисленных пакетов. Обнаруженные таким образом ошибочные конфигурации обрабатывают с целью получения информации о стирании для искомых слов, которые в данном варианте реализации изобретения образуют композиционный подкод (КПК). Композиционный подкод скорректирует комбинации многочисленных пакетов и случайных ошибок за счет использования признаков стирания, полученных от подкода индикации пакетов.
Предлагается следующий формат:
- 32-килобайтный блок содержит 16 DVD-совместимых секторов - каждый такой сектор содержит 2064=2048+16 байт данных
- каждый сектор после кодирования кодом, исправляющим ошибки, содержит 2368 байт
- следовательно, коэффициент кодирования равен 0,872
- в блоке имеется 256 синхронизирующих блоков, форматированных как описано ниже:
- каждый сектор имеет 16 синхронизирующих блоков
- каждый синхронизирующий блок состоит из 4 групп по 37 байт
- каждая группа из 37 байт содержит 1 байт подкода индикации пакета, подвергнутый глубокому интерливингу, и следующие за ним 36 байт композиционного подкода.
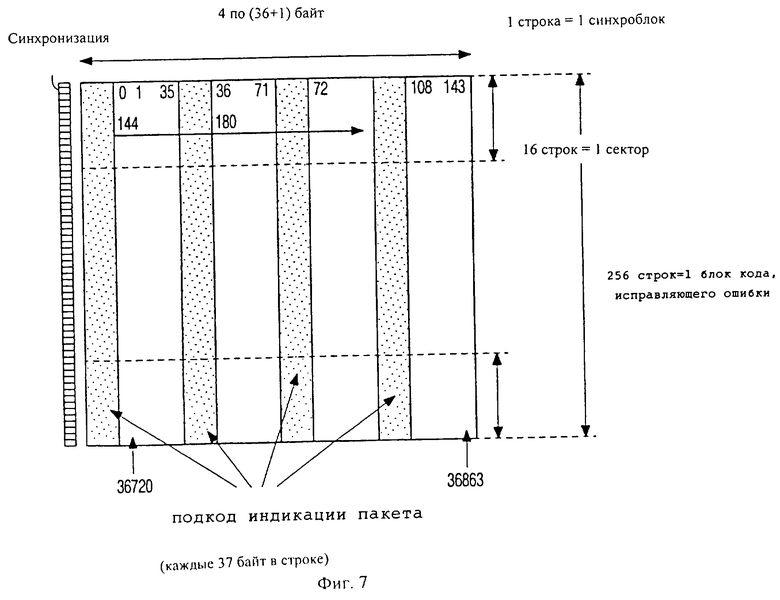
Как показано на фиг.5, строки считывают с диска последовательно, начиная с предшествующей синхронизирующей комбинации. Каждая строка содержит 4 байта ПИП, отмеченных штриховкой и пронумерованных последовательно и разделенных 36-ю другими байтами. Шестнадцать строк образуют один сектор, и 256 строк образуют один синхронизирующий блок.
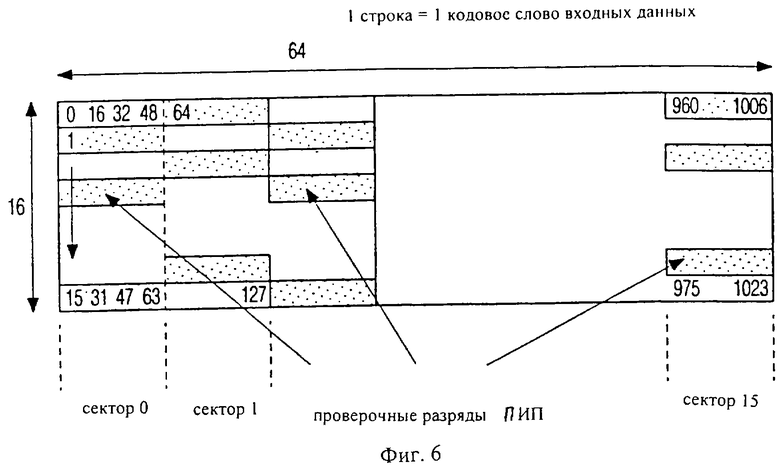
Фиг.6 изображает исключительно формат подкода индикации пакета, т.е. тех же 64 пронумерованных байт на сектор, изображенный на фиг.5; формат сконструирован следующим образом:
- имеется 16 строк, каждая из которых представляет собой код Рида-Соломона [64,32,33] с t=16;
- столбцы получают с диска последовательно в направлении стрелки, так что группы из четырех столбцов получают с одного сектора для ускорения адресации;
- ПИП может указывать, по меньшей мере, 16 пакетов по 592 байта (ок. 1 мм) каждый;
- ПИП содержит 32 байта данных на сектор, 4 столбца ПИП и, в частности, 16 байт DVD-заголовка, 5 байт контроля по четности заголовка для обеспечения быстрой адресации считывания и 11 байт данных пользователя.
Фиг. 7 изображает пикетирующий код и его композиционный подкод, построенный из искомых слов. Байты композиционного подкода пронумерованы в том порядке, в котором они считываются с диска, игнорируя байты ПИП.
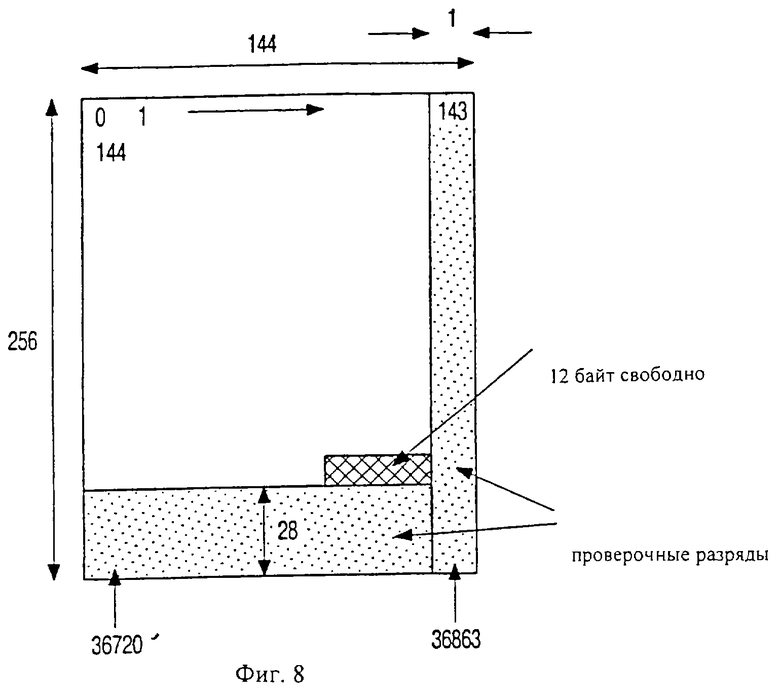
Фиг.8 изображает различные дополнительные аспекты данного варианта реализации подкомпозиционного подкода. В частности, композиционный подкод является композиционным кодом [256, 228, 29]•[144, 143, 2] кодов Рида-Соломона. Количество байтов данных равно 228•143=32604, что составляет шестнадцатикратно (2048+11) байт данных пользователя плюс 12 свободных байт.
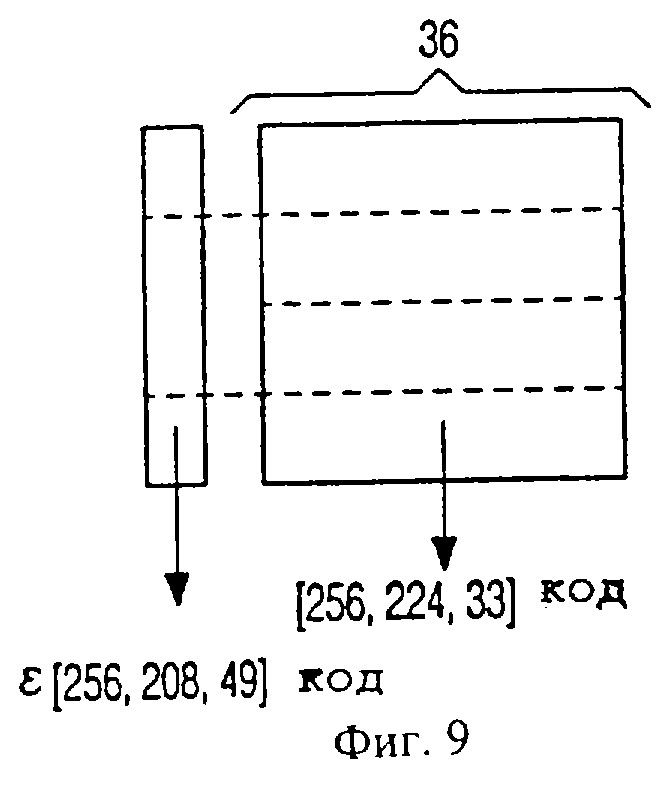
На фиг.9 изображен альтернативный формат по отношению к фиг.8, при котором горизонтальный код Рида-Соломона целиком вынесен. Размер горизонтального блока составляет 36 байт (одна четверть от изображенного на фиг.7) и использует код Рида-Соломона [256, 224, 33]. Каждый сектор содержит 2368 байт, и не требуются фиктивные (ложные) байты.
Код в первом столбце формируют в два этапа. Из каждого сектора сперва кодируют 16 байт заголовка кодом [20, 16, 5], чтобы обеспечить быстрое считывание адреса. Полученные 20 байт плюс дополнительные 32 байта данных пользователя на сектор образуют байты данных и коллективно кодируются позднее. Символы данных 2-килобайтного сектора могут располагаться только в одном физическом секторе, и располагают их следующим образом. Каждый столбец кода [256, 224, 33] содержит 8 символов контроля по четности на 2-килобайтный сектор. Далее, каждый код [256, 208, 49] имеет 12 символов контроля по четности на 2-килобайтный сектор и 4 символа контроля по четности кода [20, 16, 5], чтобы образовать код [256, 208, 49] с 48 избыточными байтами.
Фиг. 10 изображает подробности интерливинга. Здесь символ "X" обозначает байты заголовка, квадратики ≪□≫ - проверочные символы контроля по четности кода [20, 16], кружки ≪•≫ - 32 дополнительных байта данных и 12 байт проверочных символов контроля по четности для кода [256, 208].

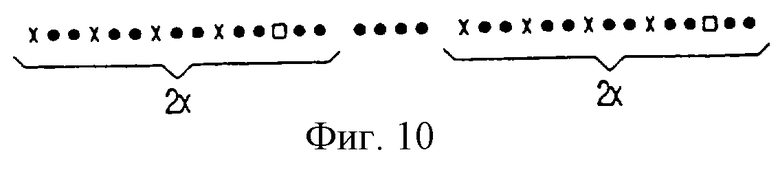
Изобретение относится к средствам кодирования с защитой данных. Технический результат заключается в обеспечении правильного декодирования с большой степенью надежности. Многословную информацию кодируют на основе многобитных символов, при словообразовании осуществляют интерливинг, кодирование обеспечивается ключами определения местоположения ошибки по многословным группам, ключи создают в ключевых высокозащищенных словах, при этом они указывают на искомые слабозащищенные слова. Ключевые слова могут иметь первый одинаковый размер и распределены первым равномерным способом. Искомые слова могут иметь второй одинаковый размер и распределяться вторым равномерным способом. Способ используется в оптических запоминающих устройствах. 5 с. и 16 з.п. ф-лы, 10 ил.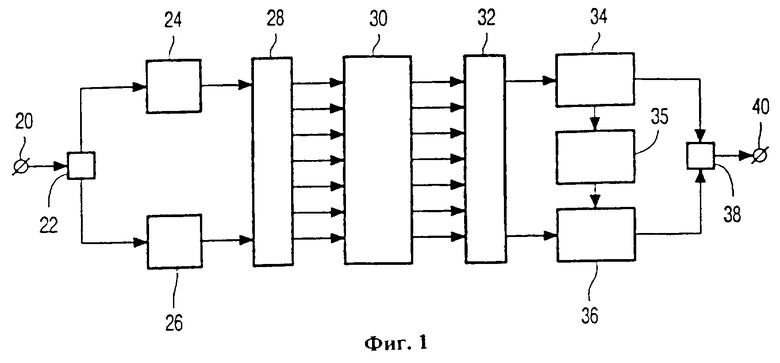
| СПОСОБ ЗАПИСИ ВИДЕОИНФОРМАЦИИ НА НОСИТЕЛЕ ЗАПИСИ, НОСИТЕЛЬ ЗАПИСИ И УСТРОЙСТВА ДЛЯ ПОИСКА И ВОСПРОИЗВЕДЕНИЯ ИЗОБРАЖЕНИЯ | 1991 |
|
RU2073914C1 |
| Устройство для снятия излишков припоя с облуженных печатных плат | 1975 |
|
SU571019A1 |
| УСТРОЙСТВО ДЕКОДИРОВАНИЯ КАСКАДНОГО КОДА РИДА-СОЛОМОНА | 1993 |
|
RU2036512C1 |
| US 4559625 A, 17.12.1985 | |||
| US 5623504 A, 22.04.1997. | |||
