Изобретение относится к области вычислительной техники, в частности к системе идентификации готовности текстовых документов в сети распределенной обработки данных.
Особенность поставленной технической задачи заключается в том, что при распределенной обработке в сети разделов текстового документа различными исполнителями требуется зафиксировать момент готовности всех его разделов для дальнейшей обработки.
Подобные задачи приходится решать, например, редакциям газетных изданий, где различные разделы одного и того же выпуска распределяются между различными специалистами, а затем все вместе должны быть предъявлены для общей редакторской правки на автоматизированном рабочем месте главного редактора выпуска.
Известны системы, которые могли бы быть использованы для решения поставленной задачи (1, 2).
Первая из известных систем содержит блоки приема и хранения данных, соединенные с блоками управления и обработки данных, блоки поиска и селекции, подключенные к блокам хранения данных и отображения, синхронизирующие входы которых соединены с выходами блока управления (1).
Существенный недостаток данной системы состоит в невозможности решения задачи обновления данных, хранимых в памяти в виде соответствующих документов, одновременно с решением задачи выдачи содержания этих документов пользователям в реальном масштабе времени.
Известна и другая система, содержащая блоки обработки данных, информационные входы которых соединены с блоками приема данных и управления, а выходы подключены к первой группе блоков памяти, центральный процессор, входы которого соединены с выходами блоков памяти первой группы и блоков обработки данных, а выходы соединены с входами блоков памяти второй группы и блоков отображения данных (2).
Последнее из перечисленных выше технических решений наиболее близко к описываемому.
Его недостаток заключается в невысоком быстродействии системы, обусловленном тем, что выполнение процедуры определения готовности разделов текстовых документов различных исполнителей реализуется через поиск состояния данных разделов текстовых документов по всей базе данных.
Подобная организация обработки данных при больших объемах текстовых документов неизбежно приводит к необоснованно большим затратам времени.
Цель изобретения - повышение быстродействия системы путем идентификации готовности текстовых документов по моменту записи последнего готового раздела текстового документа в базу данных системы.
Поставленная цель достигается тем, что в известную систему, содержащую блок приема разделов текстовых документов, информационный и синхронизирующий входы которого являются первыми информационным и синхронизирующими входами системы, блок адресации текстовых документов, информационный и синхронизирующий входы которого являются вторыми информационным и синхронизирующими входами системы, блок приема разделов текстовых документов из базы данных сервера, информационный и синхронизирующий входы которого являются третьими информационным и синхронизирующими входами системы, блок коммутации каналов выдачи разделов текстовых документов, один информационный вход которого соединен с выходом блока приема разделов текстовых документов из базы данных сервера, другой информационный вход подключен к выходу блока адресации текстовых документов, синхронизирующий вход подключен к третьему синхронизирующему входу системы, а информационные выходы являются информационными выходами группы системы, блок формирования сигналов записи и считывания базы данных, адресный выход которого является адресным выходом системы, а первый и второй синхронизирующие выходы являются первым и вторым синхронизирующими выходами системы, введены блок селекции базовых адресов текстовых документов, информационный вход которого соединен с первым выходом блока приема разделов текстовых документов, синхронизирующий вход подключен к первому синхронизирующему входу системы, а информационный и синхронизирующий выходы соединены с одними информационным и синхронизирующим входами блока формирования сигналов записи и считывания базы данных, блок выбора структуры текстовых документов, один информационный вход которого соединен с вторым информационным выходом блока приема разделов текстовых документов, а информационный и синхронизирующий выходы подключены к другим информационным и синхронизирующим входам блока формирования сигналов записи и считывания базы данных, при этом третий информационный выход блока приема разделов текстовых документов является информационным выходом системы, блок стробирования разделов текстовых документов, синхронизирующий вход которого соединен с вторым синхронизирующим выходом блока формирования сигналов записи и считывания базы данных, а управляющие входы группы подключены к соответствующим управляющим выходам группы блока селекции базовых адресов текстовых документов, блок подсчета числа готовых разделов текстовых документов, управляющие входы группы которого соединены с соответствующими управляющими выходами группы блока стробирования разделов текстовых документов, а счетные входы группы которого подключены к соответствующим счетным выходам блока стробирования разделов текстовых документов, блок задания структуры текстовых документов, управляющие входы группы которого соединены с соответствующими управляющими выходами группы блока стробирования разделов текстовых документов, первый компаратор, один информационный вход которого соединен с выходом блока подсчета числа готовых разделов текстовых документов, другой информационный вход подключен к выходу блока задания структуры текстовых документов, а синхронизирующий вход соединен с синхронизирующим выходом блока стробирования разделов текстовых документов, при этом один выход первого компаратора подключен к первому синхронизирующему входу блока выбора структуры текстовых документов, а другой выход соединен с установочными входами блоков приема разделов текстовых документов, селекции базовых адресов текстовых документов, стробирования разделов текстовых документов, формирования сигналов записи и считывания базы данных, счетчик, счетный вход которого соединен с первым синхронизирующим выходом блока коммутации каналов выдачи разделов текстовых документов, а выход подключен к другому информационному входу блока выбора структуры текстовых документов, и второй компаратор, один информационный вход которого соединен с выходом блока задания структуры текстовых документов, другой информационный вход подключен к выходу счетчика, а синхронизирующий вход соединен с вторым выходом блока коммутации каналов выдачи разделов текстовых документов, при этом один выход второго компаратора соединен с вторым синхронизирующим входом блока выбора структуры текстовых документов, а другой выход подключен к установочным входам блоков адресации текстовых документов, приема разделов текстовых документов из базы данных сервера, выбора структуры текстового документа, формирования сигналов записи и считывания базы данных и счетчика.
Сущность изобретения поясняется чертежами, где на фиг.1 представлена структурная схема устройства, на фиг.2 - структурная схема блока селекции базовых адресов текстовых документов, на фиг.3 - структурная схема выбора структуры текстовых документов, на фиг.4 - структурная схема блока формирования сигналов записи и считывания базы данных, на фиг.5 - структурная схема блока стробирования разделов текстовых документов, на фиг.6 - структурная схема блока подсчета числа готовых разделов текстовых документов, на фиг.7 - структурная схема блока задания структуры текстовых документов, на фиг.8 - структурная схема блока коммутации каналов выдачи разделов текстовых документов.
Система (фиг.1) содержит блок 1 приема разделов текстовых документов, блок 2 селекции базовых адресов текстовых документов, блок 3 выбора структуры текстовых документов, блок 4 формирования сигналов записи и считывания базы данных, блок 5 стробирования разделов текстовых документов, блок 6 подсчета числа готовых разделов текстовых документов, блок 7 задания структуры текстовых документов, первый 8 и второй 9 компараторы, блок 10 адресации текстовых документов, блок 11 приема разделов текстовых документов из базы данных сервера, блок 12 коммутации каналов выдачи разделов текстовых документов и счетчик 13.
На фиг.1 показаны первый 20, второй 21 и третий 22 информационные входы системы, первый 23, второй 24 и третий 25 синхронизирующие входы системы, а также информационный 26 и адресный 27 выходы системы, первый 28 и второй 29 синхронизирующие выходы системы и группы 30-32 информационных выходов системы.
Блок 1 приема разделов текстовых документов выполнен в виде регистра, имеющего информационный вход 20, синхронизирующий 23 и установочный 161 входы, а также первый 162, второй 163 и третий 164 информационные выходы.
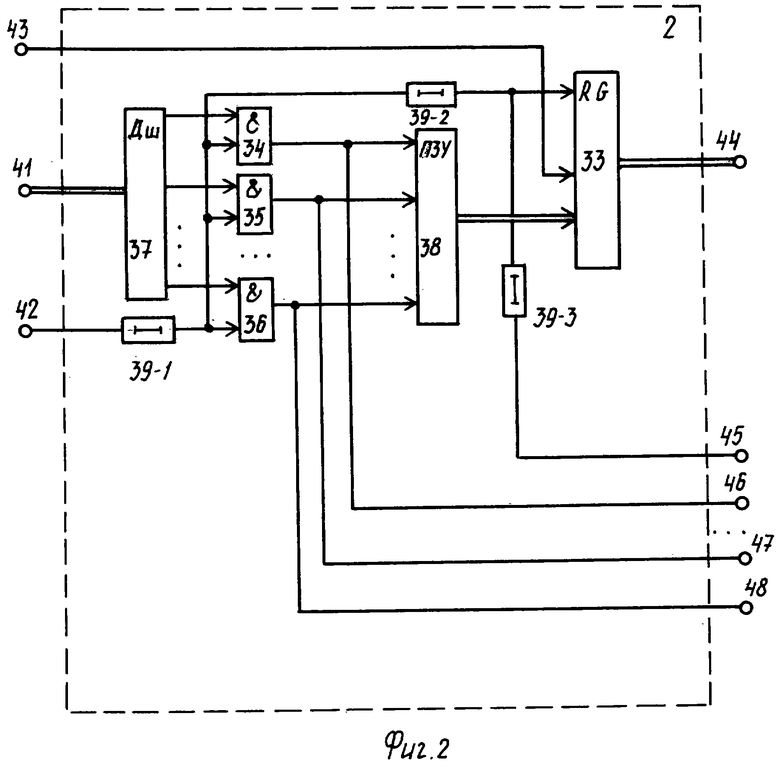
Блок 2 (фиг.2) селекции базовых адресов текстовых документов содержит регистр 33, элементы 34-36 И, дешифратор 37, блок 38 памяти, выполненный в виде постоянного запоминающего устройства, элементы 39-1, 39-2, 39-3 задержки. На фиг.2 показаны информационный 41, синхронизирующий 42 и установочный 43 входы, а также информационный 44, синхронизирующий 45 выходы и управляющие 46-48 выходы группы.
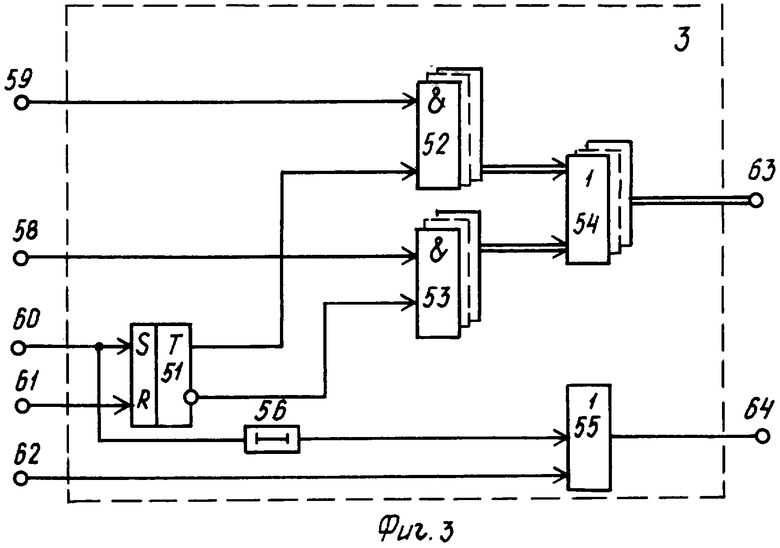
Блок 3 (фиг.3) выбора структуры текстовых документов содержит триггер 51, группы 52, 53 элементов И, группу 54 элементов ИЛИ, элемент 55 ИЛИ, элемент 56 задержки. На фиг.3 показаны информационные 58, 59, синхронизирующие 60, 62 и установочный 61 входы, а также информационный 63 и синхронизирующий 64 выходы.
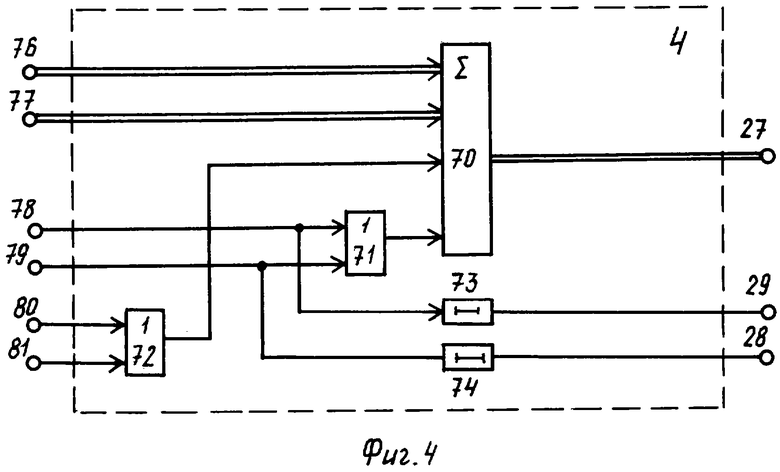
Блок 4 (фиг.4) формирования сигналов записи и считывания базы данных содержит сумматор 70, элементы 71, 72 ИЛИ, элементы 73, 74 задержки. На фиг.4 показаны информационные 76, 77 входы, синхронизирующие 78, 79 и установочные 80, 81 входы, а также адресный 27 выход, первый 28 и второй 29 синхронизирующие выходы.
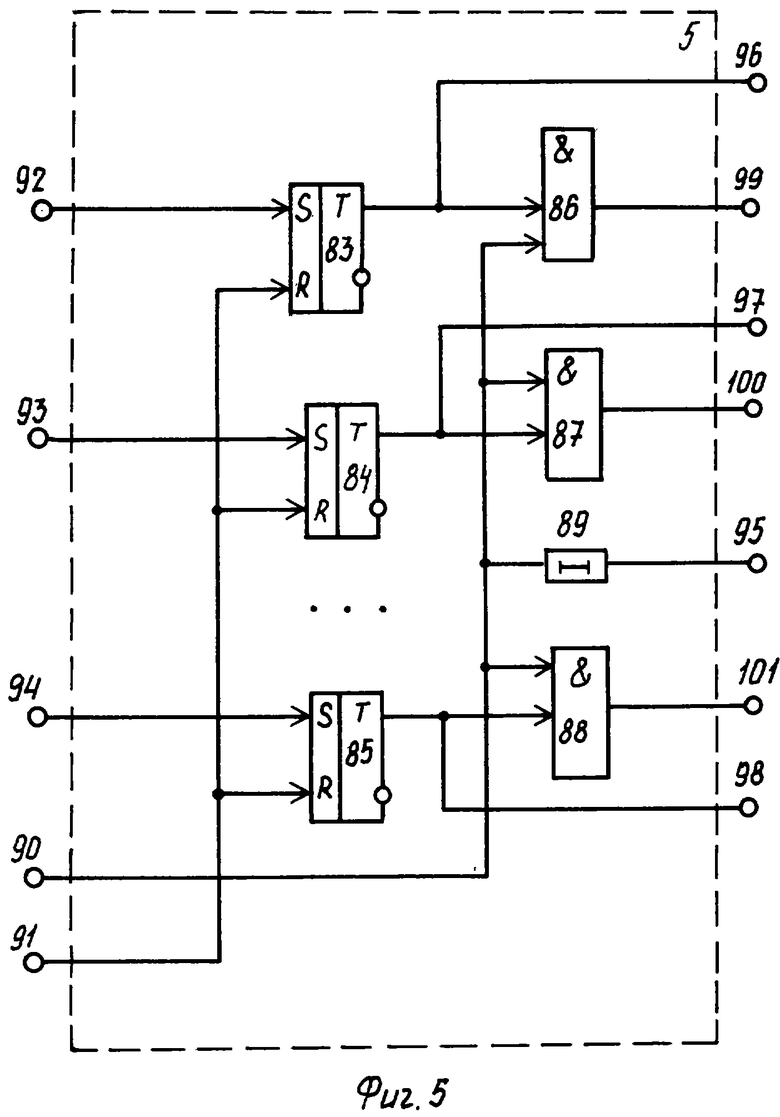
Блок 5 (фиг.5) стробирования разделов текстовых документов содержит триггеры 83-85, элементы 86-88 И, элемент 89 задержки. На фиг.5 показаны счетный 90, установочный 91 и управляющие 92-94 входы, а также синхронизирующий 95 выход, управляющие 96-98 выходы группы и счетные 99-101 выходы группы.
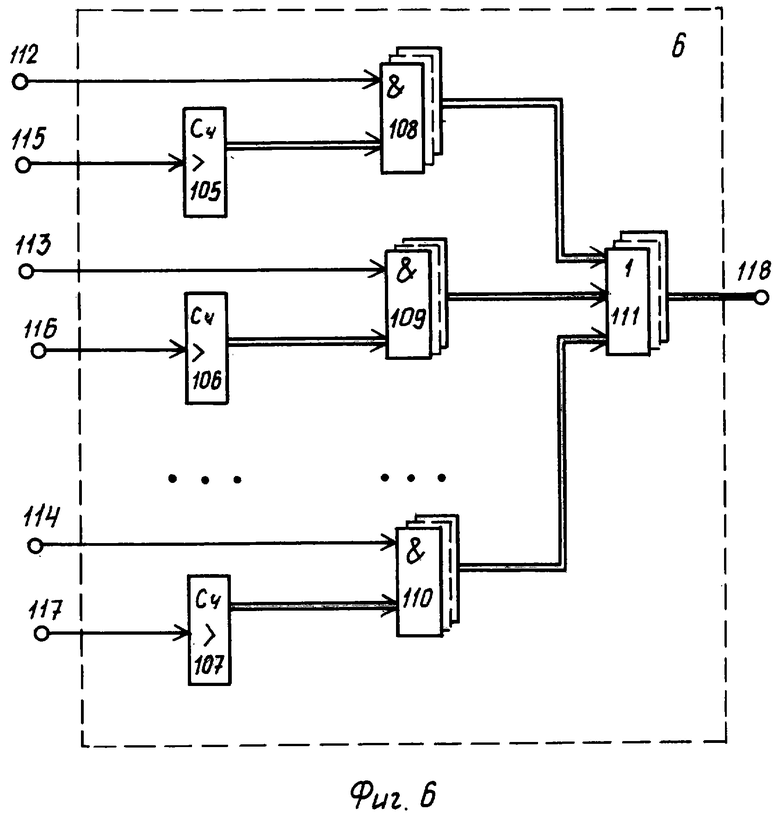
Блок 6 (фиг.6) подсчета числа готовых разделов текстовых документов содержит счетчики 105-107, группы 108-110 элементов И и группу 111 элементов ИЛИ. На фиг.6 показаны управляющие 112-114 входы группы, счетные 115-117 входы группы, а также информационный 118 выход.
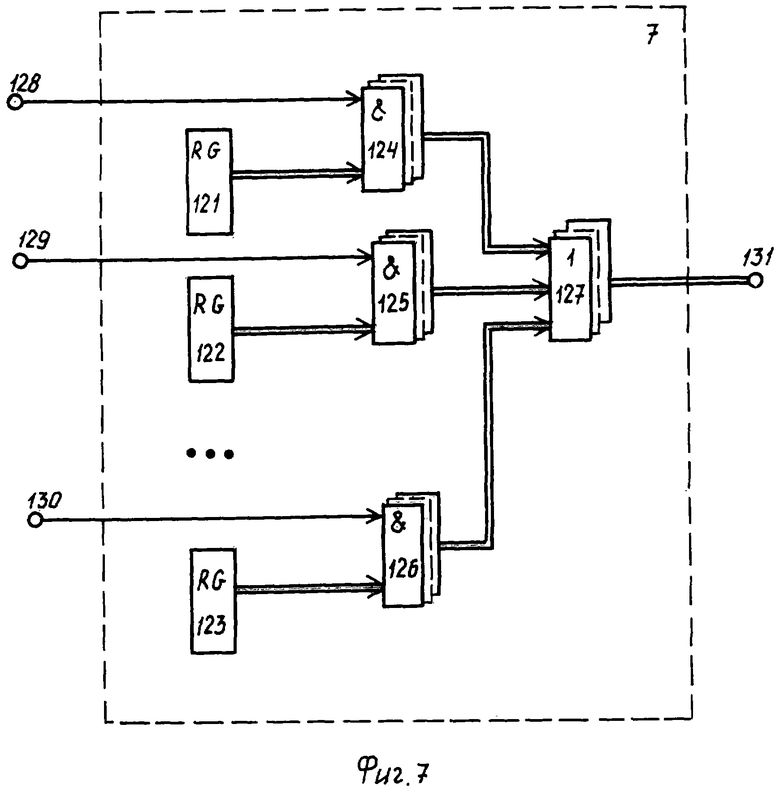
Блок 7 (фиг.7) задания структуры текстовых документов содержит регистры 121-123, группы 124-126 элементов И, группу 127 элементов ИЛИ. На фиг.7 показаны управляющие 128-129 входы группы, а также информационный 131 выход.
Блок 10 адресации текстовых документов выполнен в виде регистра, имеющего информационный 21, синхронизирующий 24 и установочный входы, а также информационный выход.
Блок 11 приема разделов текстовых документов из базы данных сервера выполнен в виде регистра, имеющего информационный 22 и синхронизирующий 25 входы, а также информационный выход.
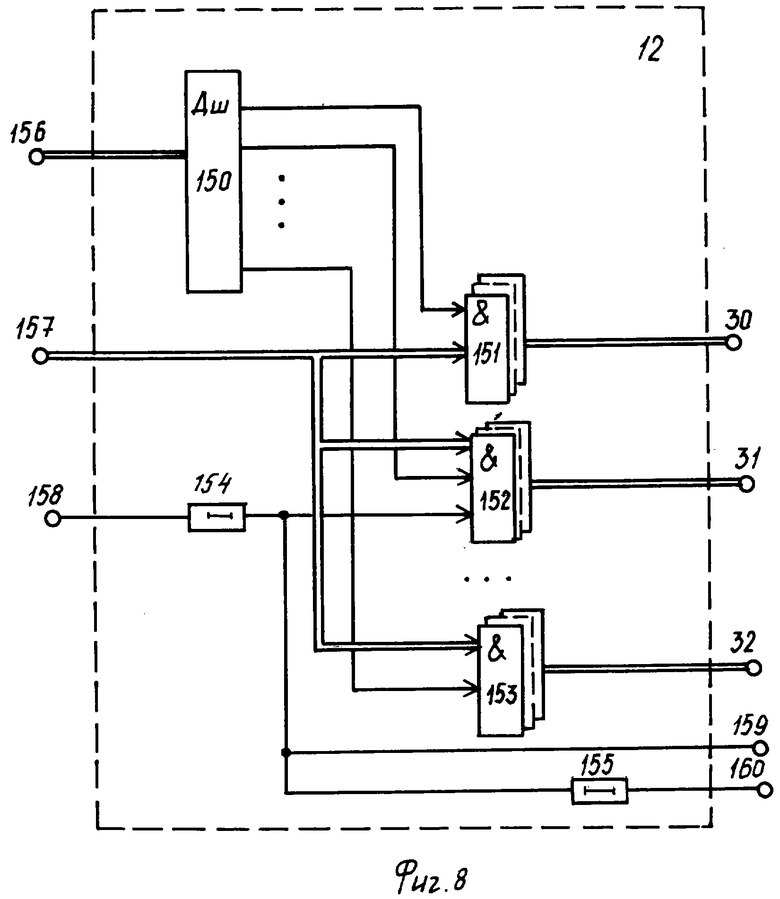
Блок 12 (фиг.8) коммутации каналов выдачи разделов текстовых документов содержит дешифратор 150, группы 151-153 элементов И, элементы 154-155 задержки. На фиг.8 показаны информационные 156-157 входы, синхронизирующий 158 вход, а также первый 159 и второй 160 синхронизирующие выходы и группа 30-32 информационных выходов.
Все узлы и элементы системы выполнены на стандартных потенциально-импульсных элементах.
Система работает следующим образом.
В процессе выполнения заданий по обработке разделов текстовых документов в распределенной сети каждый из исполнителей, работая за удаленным автоматизированным рабочим местом, закончив выполнение задания, формирует кодограмму, в которой указывает идентификатор текстового документа, над соответствующим разделом которого была выполнена заданная работа, номер самого раздела и его содержание.
Структура подобной кодограммы имеет следующий вид:
Данная кодограмма с входа 20 системы поступает на информационный вход регистра блока 1, куда и заносится синхронизирующим импульсом с входа 23 системы.
С выхода 161 блока 1 идентификатор текстового документа поступает на информационный вход 41 блока 2, откуда он выдается на вход дешифратора 37.
Дешифратор 37 расшифровывает идентификатор текстового документа и подготавливает цепь прохождения сигнала с входа 42, открывая один из элементов 34-36 И. Для определенности положим, что высокий потенциал поступил на один вход элемента 36 И.
Параллельно с этим, синхронизирующий импульс с входа 23 системы поступает на вход 42 блока 2, задерживается элементом 39-1 на время занесения кодограммы в блок 1 и срабатывания дешифратора 37 и далее он поступает на входы элементов 34-36 И.
Учитывая то обстоятельство, что открытым по одному входу будет только элемент 36 И, то, пройдя этот элемент И, синхроимпульс поступает на вход считывания фиксированной ячейки памяти постоянного запоминающего устройства 38, где хранится код базового адреса базы данных сервера, соответствующий идентификатору текстового документа.
Код базового адреса базы данных сервера считывается на информационный вход регистра 33, куда и заносится тем же синхронизирующим импульсом, задержанным элементом 39-2 на время считывания кода из блока памяти 38.
Базовый адрес с выхода 44 блока 2 поступает на вход 77 блока 4, а синхронизирующий импульс с выхода элемента 39-2 задержки вновь задерживается элементом 39-3 на время занесения кода базового адреса в регистр 33 и через выход 45 блока 2 поступает на синхронизирующий вход 78 блока 4.
Параллельно с этим, код готового раздела текстового документа с выхода 162 блока 1 поступает на вход 58 блока 3. Учитывая, что в исходном состоянии триггер 51 выдает на инверсный выход высокий потенциал, то открыты будут элементы 53 И группы. В результате код номера раздела текстового документа проходит через элементы 53 И группы, затем через элементы 54 ИЛИ группы и затем с выхода 63 блока 3 выдается на вход 76 блока 4, а оттуда поступает на вход сумматора 70, на другой вход которого через вход 77 блока 4 подается код базового адреса текстового документа с выхода 44 блока 2.
Синхронизирующий сигнал с входа 78 блока 4 через элемент 71 поступает на синхронизирующий вход сумматора 70, который суммирует базовый адрес текстового документа с номером раздела, выполненным исполнителем, и формирует на выходе 27 системы адрес базы данных сервера, по которому должен быть записан готовый раздел текстового документа.
Кроме того, тот же синхронизирующий импульс задерживается элементом задержки 73 на время срабатывания сумматора и выдается на выход 29 системы в качестве синхронизирующего импульса управления записью поступившего раздела текстового документа. С выхода 29 системы данный импульс поступает на вход первого канала прерывания сервера базы данных.
По этому сигналу сервер переходит на подпрограмму записи содержимого раздела текстового документа, которое с выхода 163 блока 1 выдается на выход 26 системы, по адресу, сформированному на выходе 27 системы.
Кроме того, параллельно с процессом записи раздела текстового документа в базу данных сервера синхронизирующий импульс с выхода 29 блока 4 поступает на вход 90 блока 5. К этому моменту времени синхронизирующий импульс с выхода элемента 36 И блока 2 поступает также через выход 48 блока 2 на вход 94 блока 5 и далее на единичный вход триггера 85, устанавливая его в единичное состояние, при котором на прямом выходе триггера 85 устанавливается высокий потенциал, открывающий элемент 88 И.
Синхронизирующий импульс с входа 90 блока 5 через элемент 88 И проходит на выход 101 блока 5 и далее поступает на счетный вход 117 блока 6, откуда он поступает на счетный вход счетчика 107, который фиксирует факт записи одного готового раздела текстового документа в базу данных сервера.
Кроме того, учитывая, что высокий потенциал триггера 85 с выхода 98 также поступает через вход 114 блока 6 на одни входы элементов 110 И группы и открывает их, код счетчика 107 через элементы 110 ИЛИ группы и элементы 111 ИЛИ группы выдается на выход 118 блока 6, откуда данный код выдается на вход 133 компаратора 8.
Высокий потенциал с триггера 85 через выход 98 блока 5 также выдается на вход 130 блока 7 и открывает по одному входу элементы 126 И группы, подключая тем самым выход регистра 123 через элементы 126 И группы и элементы 127 ИЛИ группы на выход 131 блока 7 и далее на вход 134 компаратора 8.
В регистры 121-123 заранее занесено количество разделов, которые содержат обрабатываемые в распределенной системе текстовые документы. Выбор соответствующего регистра осуществляется по идентификатору текстового документа блоком 2, который обеспечивает управление соответствующим триггером в блоке 5.
С поступлением синхронизирующего импульса на вход 135 компаратор 8 сравнивает входные коды и, учитывая, что показания счетчика 107 меньше числа разделов с входа 134, на выходе 137 компаратора 8 формируется импульс, который поступает на установочные входы блоков 1, 2, 4, 5, возвращая их в исходное состояние ожидания готовности следующего раздела текстового документа.
Кроме того, параллельно с процессом записи содержимого первого раздела текстового документа в базу данных сервера синхронизирующий импульс с выхода элемента 93 задержки блока 4 поступает также на счетный вход счетчика 92 и увеличивает его показания еще на одну единицу, а с выхода 98 блока 4 он вновь поступает на вход 66 блока 2, где проходит элемент 61 ИЛИ и задерживается элементом 63 на время записи содержимого первого раздела текстового документа в память базы данных, после чего с выхода 69 блока 2 он вновь выдается на вход 95 блока 4.
Описанный процесс записи разделов текстового документа в базу данных сервера будет продолжаться до тех пор, пока все разделы текстового документа не будут записаны в память базы данных сервера. Этот момент времени будет зафиксирован компаратором 91 блока 4 выдачей сигнала на выход 99 и на установочный вход счетчика 92, возвращая его в исходное состояние.
Кроме того, с выхода 99 блока 4 сигнал окончания записи разделов текстового документа в базу данных сервера поступает на установочный вход 67 блока 2, где возвращает регистр 57 в исходное состояние, и на установочный вход 45 блока 1, где, во-первых, устанавливает в исходное состояние регистр 41 а во-вторых, возвращает в исходное состояние триггер 42, снимая, тем самым, сигнал блокировки с выхода 52 блока 1.
Таким образом, каждый текстовый документ будет занесен в базу данных сервера, где будет размещен следующим образом:
Руководитель распределенной обработки текстовых документов, например главный редактор, на своем автоматизированном рабочем месте (АРМе) просматривает разделы текстовых документов и назначает исполнителей по обработке каждого из них. С этой целью он последовательно формирует кодограммы следующего содержания:
Каждая из подобных кодограмм с выхода АРМа главного редактора поступает на вход 24 системы, а синхронизирующий сигнал с выхода АРМа поступает на вход 29 системы.
Синхронизирующий сигнал с входа 29 через вход 83 блока 3 поступает на вход элемента 74 И, который будет открыт только после того, как закончится запись входных текстовых документов в базу данных сервера, высоким потенциалом с инверсного выхода 52 триггера 42. Пройдя элемент 74 И, синхронизирующий импульс с выхода 85 блока 3 поступает на синхронизирующий вход 87 блока 7 и заносит в него входную кодограмму.
Код идентификатора текстового документа с выхода 88 блока 7 поступает через вход 81 блока 3 на вход дешифратора 72. Дешифратор 72 расшифровывает идентификатор текстового документа и подготавливает цепь прохождения сигнала с выхода элемента задержки 78, открывая один из элементов 75-77 И. Для определенности положим, что высокий потенциал поступил на один вход элемента 75 И.
Параллельно с этим, синхронизирующий импульс с выхода элемента 74 И задерживается элементом 78 на время занесения кодограммы в блок 7 и срабатывания дешифратора 72 и далее опрашивает состояния элементов 75-77 И.
Учитывая то обстоятельство, что открытым по одному входу будет только элемент 75 И, то, пройдя этот элемент И, синхроимпульс поступает на вход считывания фиксированной ячейки памяти постоянного запоминающего устройства 71, где хранится код базового адреса базы данных сервера, соответствующий идентификатору текстового документа.
Код базового адреса базы данных сервера считывается на информационный вход регистра 73, куда и заносится тем же синхронизирующим импульсом, задержанным элементом 79 на время считывания кода из блока памяти 71.
Базовый адрес с выхода 84 блока 3 поступает на вход 117 блока 8, а синхронизирующий импульс с выхода элемента 79 задержки вновь задерживается элементом 80 на время занесения кода базового адреса в регистр 73 и через выход 86 блока 3 поступает на синхронизирующий вход 119 блока 8, на другой информационный вход 118 которого подается код номера раздела текстового документа с выхода 89 блока 7.
Блок 8 суммирует базовый адрес с номером раздела текстового документа и выдает суммарный адрес с выхода 120 на вход 186 блока 15, откуда итоговый код адреса считывания проходит через элементы 180 ИЛИ группы на адресный 31 выход системы.
Кроме того, синхронизирующий импульс с выхода 86 блока 3 поступает на вход 192 блока 15, где задерживается на время формирования адреса считывания в блоке 8, и через выход 34 системы поступает на вход второго канала прерывания сервера базы данных.
По этому сигналу сервер переходит на подпрограмму считывания содержимого того раздела текстового документа, адрес которого сформирован на выходе 31 системы.
Параллельно с этим процессом код идентификатора исполнителя с выхода 90 блока 7 поступает на вход 176 блока 14 и далее на вход дешифратора 171, который расшифровывает код идентификатора исполнителя и открывает соответствующую группу 172-174 элементов И, например группу элементов 172 И, подключая тем самым вход 177 блока 14 к выходу 35.
В результате считывания указанного раздела данного текстового документа его содержимое поступает на вход 22 блока 9, куда и заносится синхронизирующим импульсом сервера, поступающим на вход 27 системы.
Одновременно с этим, импульс с входа 27 системы сразу же поступает на синхронизирующий вход блока 14, где задерживается элементом 175 на время занесения кода в блок 9, и далее поступает на третий вход элементов 172 И группы, переписывая содержимое раздела текстового документа через выход 35 системы на автоматизированное рабочее место соответствующего исполнителя, который, получив соответствующий раздел, приступает к его обработке, например к переводу или редактированию.
Аналогичным образом, главный редактор распределяет содержание разделов соответствующих документов между всеми исполнителями, работающими в данной системе.
В процессе выполнения порученных заданий каждый из исполнителей на своем автоматизированном рабочем месте формирует кодограмму, имеющую следующую структуру:
Эта кодограмма поступает на вход 23 системы и далее на вход блока 10, куда она и записывается по синхронизирующему сигналу, поступающему на вход 28 системы с АРМа исполнителя.
Код идентификатора исполнителя с выхода 196 блока 10 поступает на вход 136 блока 11 и далее на вход дешифратора 126. Дешифратор 126 расшифровывает кодовую комбинацию и подготавливает цепь прохождения сигнала с входа 137, открывая один из элементов 128-130 И. Для определенности положим, что высокий потенциал поступил на один вход элемента 130 И.
Параллельно с этим, синхронизирующий импульс с входа 28 системы поступает на вход 137 блока 11, где задерживается элементом 131 на время занесения кодограммы в блок 10 и срабатывания дешифратора 126, и далее опрашивает состояния элементов 128-130 И.
Учитывая то обстоятельство, что открытым по одному входу будет только элемент 130 И, то, пройдя этот элемент И, синхроимпульс поступает на вход считывания фиксированной ячейки памяти постоянного запоминающего устройства 125, где хранится код опорного адреса области базы данных, отведенной для записи результатов выполненной работы соответствующим исполнителем.
Код опорного адреса области базы данных из блока памяти 125 считывается на информационный вход регистра 127. Параллельно с описанным процессом, тот же импульс считывания с выхода элемента 131 задержки, задерживающего импульс на время считывания содержимого фиксированной ячейки ПЗУ 125, поступает на синхронизирующий вход регистра 127, фиксируя считанный код. Код адреса с выхода регистра 127 выдается на вход 166 блока 13, на другой вход которого подключен выход 164 блока 12.
Одновременно с этим, импульс с выхода элемента 130 И через выход 141 блока 12 поступает на вход 161 блока 12 и далее поступает на прямой вход триггера 148, устанавливая его в единичное состояние, при котором высоким потенциалом с прямого выхода триггер 148 открывает по одному входу элемент 151 И, а также группу элементов 154 И, подключая тем самым выход счетчика 145 через элементы 154 И, а также элементы 157 ИЛИ группы к выходу 164 блока 12 и далее к входу 167 блока 13.
Параллельно с этим, импульс с выхода элемента 132 задержки вновь задерживается элементом 133 на время срабатывания триггера 148 и поступает на синхронизирующий вход 168 блока 13, который суммирует код адреса с выхода 138 блока 11 с показаниями счетчика 145 блока 12 и формирует адрес базы данных для записи результатов выполненной работы.
Этот адрес с выхода 169 блока 13 через вход 187 блока 15 проходит элементы 180 И группы на выход 31 системы, а синхронизирующий импульс с выхода элемента задержки 133 вновь задерживается на время формирования адреса записи блоком 13 и с выхода 140 блока 11, во-первых, поступает на вход 191 блока 15, где проходит элемент 182 ИЛИ, и через выход 33 системы он поступает на вход первого канала прерывания сервера.
По синхронизирующему сигналу первый канал прерывания переходит на подпрограмму записи содержимого выполненной работы исполнителем с выхода 32 системы в базу данных сервера по адресу, сформированному на выходе 31 системы.
С этой целью содержимое выполненной работы с выхода 197 блока 10 выдано на вход 189 блока 15 и далее через элементы 181 ИЛИ группы на информационный выход 32 системы.
Кроме того, параллельно с процессом записи содержимого выполненной работы в базу данных сервера, синхронизирующий импульс с выхода 140 блока 11 поступает на вход 160 блока 12, где задерживается элементом 158 на время записи содержимого выполненной работы в базу данных сервера и затем через открытый элемент 151 И поступает на счетный вход счетчика 145, увеличивая его показания на единицу.
Следующая выполненная этим же исполнителем работа будет записана по следующему за предыдущим адресом, так как показания счетчика 145 будут добавлены к базовому адресу исполнителя.
Показания счетчиков 145-147 также выведены на автоматизированное рабочее место главного редактора (не показано), поэтому по их показаниям главный редактор определяет степень готовности разделов текстовых документов, обрабатываемых на автоматизированных рабочих местах исполнителей.
По полной готовности соответствующих разделов главный редактор запускает программу форматирования нового содержания всего текстового документа в целом.
Таким образом, введение новых узлов и блоков позволило существенно повысить быстродействие системы путем идентификации готовности текстовых документов по моменту записи последнего готового раздела текстового документа в базу данных системы.
Источники информации
1. Патент США №5136708, М.кл. G 06 F 15/16, 1992.
2. Патент США №5129083, М.кл. G 06 F 12/00, 15/40, 1992 (прототип).
| название | год | авторы | номер документа |
|---|---|---|---|
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА РАСПРЕДЕЛЕННОЙ ОБРАБОТКИ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2005 |
|
RU2280276C1 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА ПОДДЕРЖКИ ЗАКОНОТВОРЧЕСКОЙ ДЕЯТЕЛЬНОСТИ | 2012 |
|
RU2486582C1 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА УПРАВЛЕНИЯ МАРШРУТИЗАЦИЕЙ ТЕКСТОВЫХ ДОКУМЕНТОВ В СЕТИ ОБРАБОТКИ ДАННЫХ | 2005 |
|
RU2282237C1 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА СБОРА И ОБРАБОТКИ ДАННЫХ СУДЕБНОГО И ИСПОЛНИТЕЛЬНОГО ДЕЛОПРОИЗВОДСТВА | 2006 |
|
RU2305316C1 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА | 2006 |
|
RU2334273C2 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА ПРИ ПРОВЕДЕНИИ ДИСТАНЦИОННОГО ЭЛЕКТРОННОГО ГОЛОСОВАНИЯ | 2010 |
|
RU2421788C1 |
| СИСТЕМА ПЕРСОНАЛИЗАЦИИ ПАСПОРТНО-ВИЗОВЫХ ДОКУМЕНТОВ НОВОГО ПОКОЛЕНИЯ | 2010 |
|
RU2432609C1 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА ВЕДЕНИЯ СУДЕБНОГО И ИСПОЛНИТЕЛЬНОГО ДЕЛОПРОИЗВОДСТВА | 2006 |
|
RU2305318C1 |
| СИСТЕМА ИНФОРМАЦИОННОГО ОБЕСПЕЧЕНИЯ ЗАКОНОДАТЕЛЬНОГО ПРОЦЕССА ПРЕДСТАВИТЕЛЬНЫХ ОРГАНОВ ВЛАСТИ | 2014 |
|
RU2565525C1 |
| АВТОМАТИЗИРОВАННАЯ ИНФОРМАЦИОННАЯ СИСТЕМА СУДЕБНОГО ДЕЛОПРОИЗВОДСТВА | 2005 |
|
RU2291480C1 |
Изобретение относится к вычислительной технике, в частности к системе идентификации готовности текстовых документов в сети распределенной обработки данных. Техническим результатом является повышение быстродействия системы. Система содержит блок приема разделов текстовых документов, блок селекции базовых адресов текстовых документов, блок выбора структуры текстовых документов, блок формирования сигналов записи и считывания базы данных, блок стробирования разделов текстовых документов, блок адресации текстовых документов, блок приема разделов текстовых документов из базы данных сервера, блок коммутации каналов выдачи разделов текстовых документов, блок подсчета числа готовых разделов текстовых документов, компаратор, счетчик. 8 ил.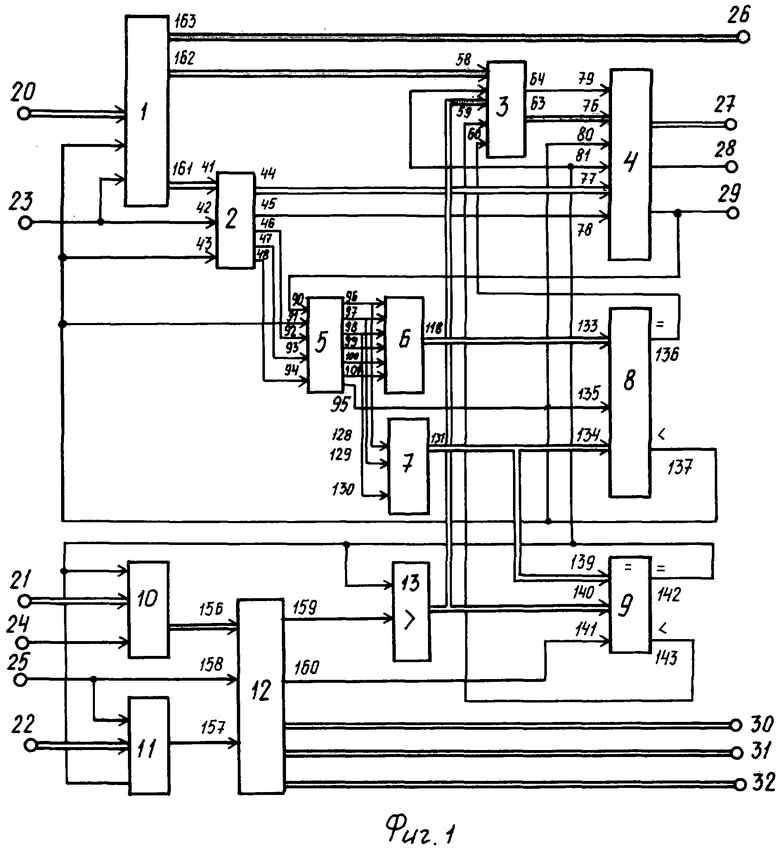
Система идентификации готовности текстовых документов в сети распределенной обработки данных, содержащая блок приема разделов текстовых документов из базы данных сервера, информационный и синхронизирующий входы которого являются первыми информационным и синхронизирующими входами системы, блок адресации текстовых документов, информационный и синхронизирующий входы которого являются вторыми информационным и синхронизирующим входами системы, блок приема разделов текстовых документов из базы данных сервера, информационный и синхронизирующий входы которого являются третьими информационным и синхронизирующим входами системы, блок коммутации каналов выдачи текстовых документов, один информационный вход которого соединен с выходом блока приема текстовых документов из базы данных сервера, другой информационный вход подключен к выходу блока адресации текстовых документов, синхронизирующий вход подключен к третьему синхронизирующему входу системы, а информационные выходы являются информационными выходами группы системы, блок формирования сигналов записи и считывания базы данных, адресный выход которого является адресным выходом системы, а первый и второй синхронизирующие выходы являются первым и вторым синхронизирующими выходами системы, отличающаяся тем, что система содержит блок селекции базовых адресов текстовых документов, информационный вход которого соединен с первым выходом блока приема разделов текстовых документов, синхронизирующий вход подключен к первому синхронизирующему входу системы, а информационный и синхронизирующий выходы соединены с одними информационным и синхронизирующим входами блока формирования сигналов записи и считывания базы данных, блок выбора структуры текстовых документов, один информационный вход которого соединен со вторым информационным выходом блока приема разделов текстовых документов, а информационный и синхронизирующий выходы подключены к другим информационным и синхронизирующим входам блока формирования сигналов записи и считывания базы данных, при этом третий информационный выход блока приема разделов текстовых документов является информационным выходом системы, блок стробирования разделов текстовых документов, синхронизирующий вход которого соединен со вторым синхронизирующим выходом блока формирования сигналов записи и считывания базы данных, а управляющие входы группы подключены к соответствующим управляющим выходам группы блока селекции базовых адресов текстовых документов, блок подсчета числа готовых разделов текстовых документов, управляющие входы группы которого соединены с соответствующими управляющими выходами группы блока стробирования разделов текстовых документов, а счетные входы группы подключены к соответствующим счетным выходам блока стробирования разделов текстовых документов, блок задания структуры текстовых документов, управляющие входы группы которого соединены с соответствующими управляющими выходами группы блока стробирования разделов текстовых документов, первый компаратор, один информационный вход которого соединен с выходом блока подсчета числа готовых разделов текстовых документов, другой информационный вход подключен к выходу блока задания структуры текстовых документов, а синхронизирующий вход соединен с синхронизирующим выходом блока стробирования разделов текстовых документов, при этом один выход первого компаратора подключен к первому синхронизирующему входу блока выбора структуры текстовых документов, а другой выход соединен с установочными входами блоков приема разделов текстовых документов, селекции базовых адресов текстовых документов, стробирования разделов текстовых документов, формирования сигналов записи и считывания базы данных, счетчик, счетный вход которого соединен с первым синхронизирующим выходом блока коммутации каналов выдачи текстовых документов, а выход подключен к другому информационному входу блока выбора структуры текстовых документов, и второй компаратор, один информационный вход которого соединен с выходом блока задания структуры текстовых документов, другой информационный вход подключен к выходу счетчика, а синхронизирующий вход соединен со вторым выходом блока коммутации каналов выдачи текстовых документов, при этом один выход второго компаратора соединен со вторым синхронизирующим входом блока выбора структуры текстовых документов, а другой выход подключен к установочным входам блоков адресации текстовых документов, приема разделов текстовых документов из базы данных сервера, выбора структуры текстовых документов, формирования сигналов записи и считывания базы данных и счетчика.
| УСТРОЙСТВО СОРТИРОВКИ ИНФОРМАЦИИ | 1995 |
|
RU2128855C1 |
| US 2004088157 A, 06.05.2004 | |||
| УСТРОЙСТВО СОРТИРОВКИ СЛОВ | 2002 |
|
RU2223538C2 |
| JP 90006974 A, 10.01.1997 | |||
| JP 2000352988 A, 19.12.2000. | |||

