1. Область техники
Настоящее изобретение относится к способу и устройству для последующей обработки декодированного звукового сигнала с целью повышения воспринимаемого качества этого декодированного звукового сигнала.
Эти способ и устройство последующей обработки можно применять, но не исключительно, к цифровому кодированию звуковых (в том числе речевых) сигналов. Например, эти способ и устройство последующей обработки можно также применять в более общем случае улучшения сигнала при наличии источника шума от любой среды или системы, не обязательно относящегося к шуму кодирования или квантования.
2. Краткое описание современной технологии:
2.1 Речевые кодеры
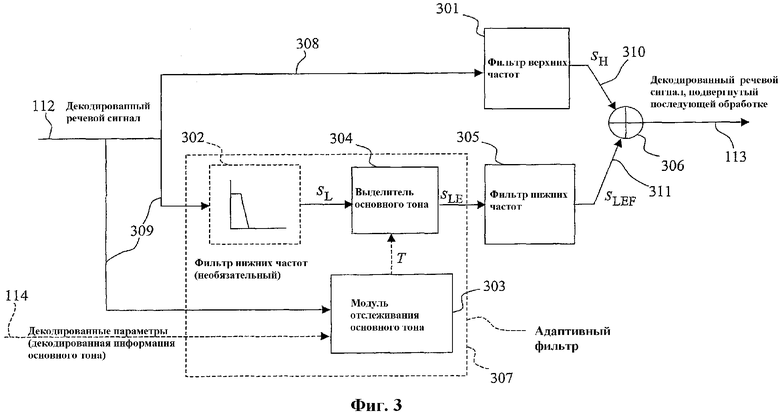
Речевые кодеры широко используются в системах цифровой связи, чтобы эффективно передавать и/или сохранять речевые сигналы. В цифровых системах аналоговый входной речевой сигнал сначала дискретизируется с определенной частотой дискретизации, и последовательные речевые выборки подвергаются дальнейшей обработке в цифровом виде. В частности, речевой кодер принимает речевые выборки в качестве входного сигнала и генерирует сжатый выходной битовый поток, подлежащий передаче по каналу или сохранению в определенной среде хранения. В приемнике, речевой декодер принимает битовый поток в качестве входного сигнала и создает выходной реконструированный речевой сигнал.
Чтобы речевой кодер был полезен, он должен создавать сжатый битовый поток с более низкой битовой скоростью, чем битовая скорость цифрового дискретизированного входного речевого сигнала. Традиционные речевые кодеры обычно достигают коэффициента сжатия, по меньшей мере, 16 к 1 и все же способны декодировать высококачественную речь. Многие из этих традиционных речевых кодеров основаны на модели CELP (линейного прогнозирования с кодовым возбуждением), с различными вариантами в зависимости от алгоритма.
При CELP-кодировании цифровой речевой сигнал обрабатывается в виде последовательных блоков речевых выборок, именуемых кадрами. Для каждого кадра, кодер извлекает из цифровых речевых выборок ряд параметров, которые подвергаются цифровому кодированию, а затем передаются и/или сохраняются. Декодер обрабатывает принятые параметры, чтобы реконструировать или синтезировать данный кадр речевого сигнала. Обычно CELP-кодер извлекает из цифровых речевых выборок следующие параметры:
- коэффициенты линейного прогнозирования (коэффициенты ЛП), передаваемые в преобразованном виде, например, как частоты линейного спектра (LSF) или частоты иммитансного спектра (ISF);
- параметры основного тона, включая задержку (или отставание) основного тона и коэффициент усиления основного тона;
- параметры инновационного возбуждения (фиксированные индекс кодовой книги и коэффициент усиления).
Параметры основного тона и параметры инновационного возбуждения совместно описывают то, что называется сигналом возбуждения. Этот сигнал возбуждения поступает в качестве входного сигнала на фильтр линейного прогнозирования (ЛП), описываемый коэффициентами ЛП. Фильтр ЛП можно рассматривать как модель речевого тракта, а сигнал возбуждения можно рассматривать как выходной сигнал голосовой щели. Коэффициенты ЛП или LSF обычно вычисляются и передаются с каждым кадром, тогда как основной тон и параметры инновационного возбуждения вычисляются и передаются несколько раз за кадр. В частности, каждый кадр делится на несколько блоков сигнала, именуемых подкадрами, и основной тон и параметры инновационного возбуждения вычисляются и передаются с каждым подкадром. Кадр обычно имеет длительность от 10 до 30 миллисекунд, а подкадр обычно имеет длительность 5 миллисекунд.
Некоторые стандарты кодирования речи основаны на модели алгебраического CELP (ACELP), точнее говоря на алгоритме ACELP. Одной из основных особенностей ACELP является использование алгебраических кодовых книг для кодирования инновационного возбуждения в каждом подкадре. Алгебраическая кодовая книга делит подкадр на группу дорожек перемежающихся позиций импульса. Допустимо лишь небольшое количество импульсов ненулевой амплитуды на дорожку, и каждый импульс ненулевой амплитуды ограничен позициями соответствующей дорожки. Кодер использует быстрые речевые алгоритмы для отыскания оптимальных позиций импульса и амплитуд этих импульсов в каждом подкадре. Описание алгоритма ACELP можно найти в статье Р. Салами (R. SALAMI) и др., "Design and description of CS-ACELP: a toll quality 8 kb/s speech coder", IEEE Trans. on Speech and Audio Proc., т.6, №2, стр. 116-130, март 1998 г., включенной в данное описание посредством ссылки, где описан алгоритм кодирования узкополосного речевого сигнала CS-ACELP по стандарту ITU-T G.729 на скорости 8 кбит/с. Заметим, что имеется несколько вариантов поиска в инновационной кодовой книге ACELP в зависимости от применяемого стандарта. Настоящее изобретение не зависит от этих вариаций, поскольку оно относится только к последующей обработке декодированного (синтезированного) речевого сигнала.
Прежний стандарт, основанный на алгоритме ACELP, представляет собой алгоритм кодирования речевого сигнала AMR-WB ETSI/3GPP, который также принят ITU-T (отделом стандартизации связи ITU (Международного союза телекоммуникаций) в виде рекомендации G.722.2 [ITU-T Recommendation G.722.2 "Wideband coding of speech at around 16 kbit/s using Adaptive Multi-Rate Wideband (AMR-WB)", Женева, 2002 г.], [3GPP TS 26.190, "A MR Wideband Speech Codec: Transcoding Functions," техническая спецификация 3GPP]. AMR-WB это многоскоростной алгоритм, предназначенный для работы на девяти разных битовых скоростях от 6,6 до 23,85 кбит/с. Специалистам в данной области известно, что качество декодированного речевого сигнала, в общем случае, повышается с увеличением битовой скорости. AMR-WB позволяет системам сотовой связи снижать битовую скорость речевого кодера в случае плохого состояния канала; биты преобразуются в биты канального кодирования для повышения защиты передаваемых битов. Таким образом, общее качество передаваемых битов можно поддерживать на более высоком уровне, чем в случае, когда речевой кодер работает на одной фиксированной битовой скорости.
На фиг.7 показана упрощенная блок-схема, демонстрирующая принцип работы декодера AMR-WB. В частности, на фиг.7 показано высокоуровневое представление декодера и особое внимание уделено тому факту, что принимаемый битовый поток кодирует речевой сигнал только до 6,4 кГц (частота дискретизации 12,8 кГц), а частоты свыше 6,4 кГц синтезируются на декодере на основании параметров нижнего диапазона. Это подразумевает, что в кодере речевой сигнал исходного диапазона с частотой дискретизации 16 кГц сначала преобразуется с понижением частоты дискретизации до частоты дискретизации 12,8 кГц с использованием методов многоскоростного преобразования, хорошо известных специалистам в данной области. Декодер 701 параметров и речевой декодер 702, показанные на фиг.7, аналогичны декодеру 106 параметров и декодеру 107 источника, показанным на фиг.1. Принятый битовый поток 709 сначала декодируется декодером 701 параметров для извлечения параметров 710, поступающих на речевой декодер 702 для повторного синтеза речевого сигнала. В конкретном случае декодера AMR-WB эти параметры таковы:
- коэффициенты ISF для каждого кадра длительность 20 миллисекунд;
- целочисленная задержка основного тона Т0, дробное значение основного тона T0_frac вблизи Т0 и коэффициент усиления основного тона для каждого подкадра длительностью 5 миллисекунд;
- форма (позиции и знаки импульса) и коэффициент усиления алгебраической кодовой книги для каждого подкадра длительностью 5 миллисекунд.
На основании параметров 710 речевой декодер 702 синтезирует данный кадр речевого сигнала для частот, меньших или равных 6,4 кГц, и, таким образом, создает синтезированный речевой сигнал 712 нижнего диапазона с частотой дискретизации 12,8 кГц. Для восстановления сигнала полного диапазона, соответствующего частоте дискретизации 16 кГц, декодер AMR-WB содержит процессор 707 повторного синтеза верхнего диапазона, реагирующий на декодированные параметры 710 от декодера 701 параметров для повторного синтеза сигнала 711 верхнего диапазона на частоте дискретизации 16 кГц. Подробности, касающиеся процессора 707 повторного синтеза сигнала верхнего диапазона, можно найти в следующих публикациях, включенных в данное описание посредством ссылки:
- Рекомендация G.72.2.2 ITU-T "Wideband coding of speech at around 16 kbit/s using Adaptive Multi-Rate Wideband (AMR-WB)", Женева, 2002 г.;
- 3GPP TS 26.190, "A MR Wideband Speech Codec: Transcoding Functions", техническая спецификация 3GPP.
Выходной сигнал процессора 707 повторного синтеза верхнего диапазона, обозначаемый на фиг.7 как сигнал 711 верхнего диапазона, это сигнал с частотой дискретизации 16 кГц, энергия которого сконцентрирована выше 6,4 кГц. Процессор 708 суммирует сигнал 711 верхнего диапазона с речевым сигналом 713 нижнего диапазона, преобразованного до повышенной частоты дискретизации 16 кГц, для формирования полного декодированного речевого сигнала 714 декодера AMR-WB с частотой дискретизации 16 кГц.
2.2 Необходимость в последующей обработке
Всякий раз при использовании речевого декодера в системе связи синтезированный или декодированный речевой сигнал никогда не бывает идентичен исходному речевому сигналу даже в отсутствие ошибок передачи. Чем выше коэффициент сжатия, тем большее искажение вносит кодер. Это искажение можно существенно уменьшить с использованием разных подходов. Первый подход состоит в том, чтобы преобразовать сигнал в кодере так, чтобы лучше описать или закодировать субъективно значимую информацию, содержащуюся в речевом сигнале. Широко распространенным примером этого первого подхода является использование фильтра взвешивания форманты, часто обозначаемого W(z) [под ред. B. Kleijn и K. Paliwal, «Кодирование и синтез речи», Elsevier, 1995]. Этот фильтр W(z) обычно делают адаптивным и рассчитывают таким образом, чтобы он снижал энергию сигнала вблизи спектральных формант, тем самым повышая относительную энергию нижних энергетических диапазонов. Тогда кодер может лучше квантовать нижние энергетические диапазоны, которые в противном случае были бы замаскированы шумом кодирования, что повышало бы воспринимаемые искажения. Другой пример преобразования сигнала в кодере это так называемый фильтр выделения основного тона, который улучшает гармоническую структуру сигнала возбуждения в кодере. Выделение основного тона нужно для того, чтобы гарантировать, что уровень интергармонического шума остается достаточно низким в смысле восприятия.
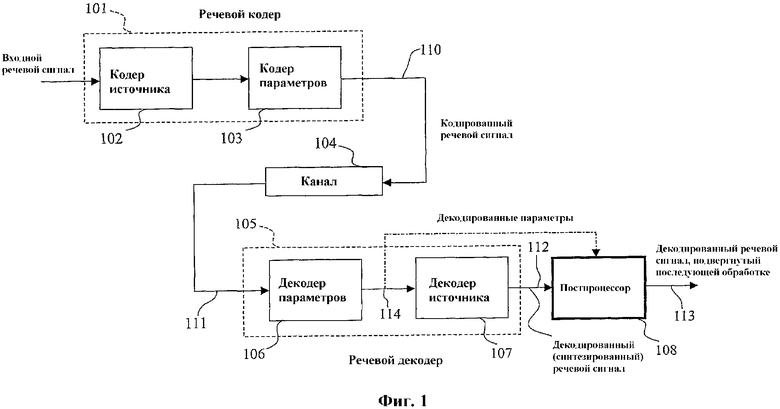
Второй подход к минимизации воспринимаемого искажения, вносимого речевым кодером, состоит в применении так называемого алгоритма последующей (постпроцессорной) обработки. Последующая обработка применяется в декодере, показанном на фиг.1. На фиг.1, речевой кодер 101 и речевой декодер 105 разбиты на два модуля. В случае речевого кодера 101 кодер 102 источника создает ряд параметров 109 кодирования речи, подлежащих передаче или сохранению. Кодер 103 параметров подвергает эти параметры 109 двоичному кодированию с использованием того или иного метода кодирования в зависимости от алгоритма кодирования речи и от параметров, подлежащих кодированию. Кодированный речевой сигнал (двоично-кодированные параметры) 110 передаются в декодер по каналу 104 связи. В декодере принятый битовый поток 111 сначала анализируется декодером 106 параметров для декодирования принятых закодированных параметров кодирования звукового сигнала, которые затем используются декодером 107 источника для генерации синтезированного речевого сигнала 112. Последующая обработка (см. постпроцессор 108 на фиг.1) нужна для того, чтобы выделить информацию, существенную для восприятия, в синтезированном речевом сигнале, или, что эквивалентно, ослабить или удалить информацию, мешающую восприятию. Две обычно используемые формы последующей обработки представляют собой последующую обработку форманты и последующую обработку основного тона. В первом случае формантная структура синтезированного речевого сигнала усиливается с использованием адаптивного фильтра, частотная характеристика которого согласуется с формантами речи. Затем спектральные пики синтезированного речевого сигнала подчеркиваются за счет спектральных провалов, относительная энергия которых снижается. В случае последующей обработки основного тона к синтезированному речевому сигналу также применяется адаптивный фильтр. Однако в этом случае частотная характеристика фильтра согласуется с тонкой спектральной структурой, а именно с гармониками. Затем постфильтр основного тона подчеркивает гармоники за счет энергии интергармонической составляющей, которая становится относительно меньше. Заметим, что частотная характеристика постфильтра основного тона обычно охватывает весь частотный диапазон. В результате гармоническая структура накладывается на речь, подвергнутую последующей обработке, даже в диапазонах частот, которые не проявляют гармоническую структуру в декодированной речи. Этот подход не является оптимальным с точки зрения восприятия для широкополосного речевого сигнала (дискретизированного с частотой 16 кГц), которая редко проявляет периодическую структуру во всем частотном диапазоне.
Сущность изобретения
Настоящее изобретение относится к способу последующей обработки декодированного звукового сигнала для повышения воспринимаемого качества этого декодированного звукового сигнала, содержащему разделение декодированного звукового сигнала на совокупность сигналов частотных поддиапазонов и применение последующей обработки к, по меньшей мере, одному из сигналов частотных поддиапазонов, но не ко всем сигналам частотных поддиапазонов.
Настоящее изобретение также относится к устройству для последующей обработки декодированного звукового сигнала для повышения воспринимаемого качества этого декодированного звукового сигнала, содержащему средство разделения декодированного звукового сигнала на совокупность сигналов частотных поддиапазонов и средство последующей обработки, по меньшей мере, одного из сигналов частотных поддиапазонов, но не всех сигналов частотных поддиапазонов.
Согласно иллюстративному варианту осуществления после последующей обработки вышеупомянутого, по меньшей мере, одного сигнала частотного поддиапазона сигналы частотных поддиапазонов суммируются для создания выходного декодированного звукового сигнала, подвергнутого последующей обработке.
Соответственно, способ и устройство последующей обработки позволяет локализовать последующую обработку в нужном(ых) поддиапазоне(ах), а другие поддиапазоны оставлять практически неизменными.
Настоящее изобретение относится также к декодеру звукового сигнала, содержащему вход для приема кодированного звукового сигнала, декодер параметров, на который подается кодированный звуковой сигнал, для декодирования параметров кодирования звукового сигнала, декодер звукового сигнала, на который подаются декодированные параметры кодирования звукового сигнала, для создания декодированного звукового сигнала, и устройство последующей обработки, описанное выше, для последующей обработки декодированного звукового сигнала для повышения воспринимаемого качества этого декодированного звукового сигнала.
Вышеизложенные и другие задачи, преимущества и признаки настоящего изобретения явствуют из нижеследующего неограничительного описания иллюстративных вариантов его осуществления, приведенных исключительно для примера, со ссылкой на прилагаемые чертежи.
Краткое описание чертежей
Фиг.1 - упрощенная блок-схема высокоуровневой структуры иллюстративной системы кодера/декодера, в которой используется последующая обработка в декодере;
Фиг.2 - упрощенная блок-схема, демонстрирующая общий принцип иллюстративного варианта осуществления настоящего изобретения с использованием банка адаптивных фильтров и фильтров поддиапазонов, в котором на адаптивные фильтры подается декодированный (синтезированный) речевой сигнал (сплошная линия) и декодированные параметры (пунктирная линия);
Фиг.3 - упрощенная блок-схема двухполосного выделителя основного тона, который представляет собой частный случай иллюстративного варианта осуществления, представленного на фиг.2;
Фиг.4 - упрощенная блок-схема иллюстративного варианта осуществления настоящего изобретения применительно к частному случаю широкополосного речевого декодера AMR-WB;
Фиг.5 - упрощенная блок-схема альтернативной реализации иллюстративного варианта осуществления, представленного на фиг.4;
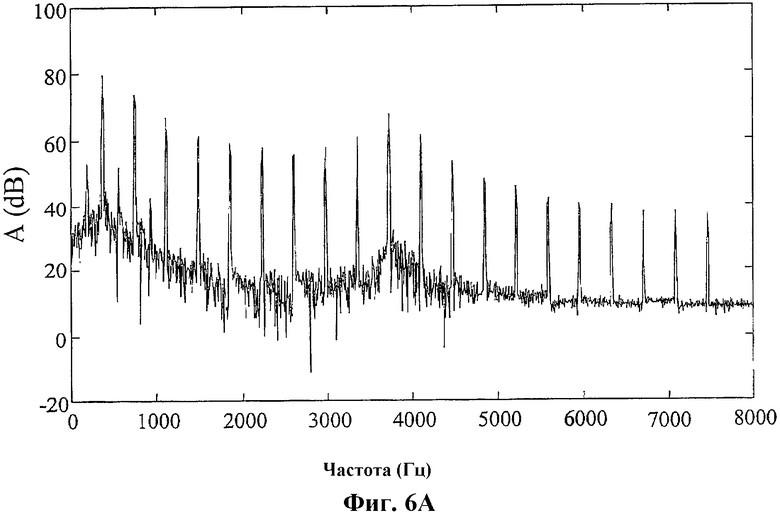
Фиг.6А - график, иллюстрирующий пример спектра предварительно обработанного сигнала;
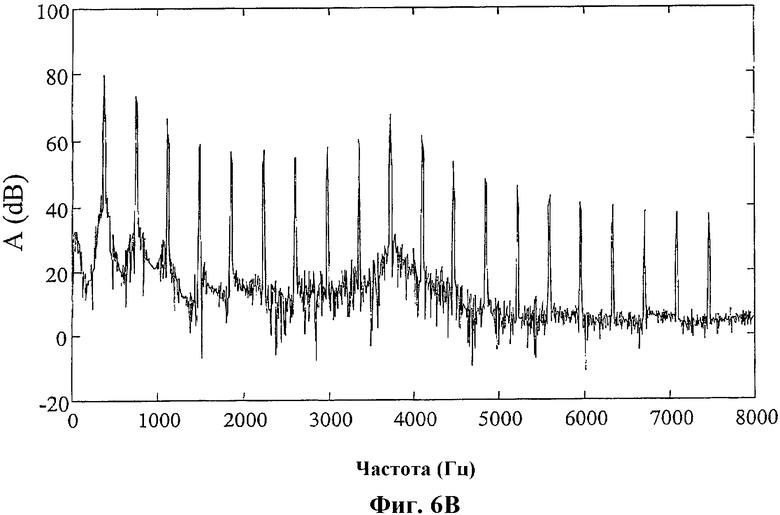
Фиг.6B - график, иллюстрирующий пример спектра сигнала, подвергнутого последующей обработке, полученного с использованием способа, описанного на фиг.3;
Фиг.7 - упрощенная блок-схема, демонстрирующая принцип работы декодера AMR-WB 3GPP;
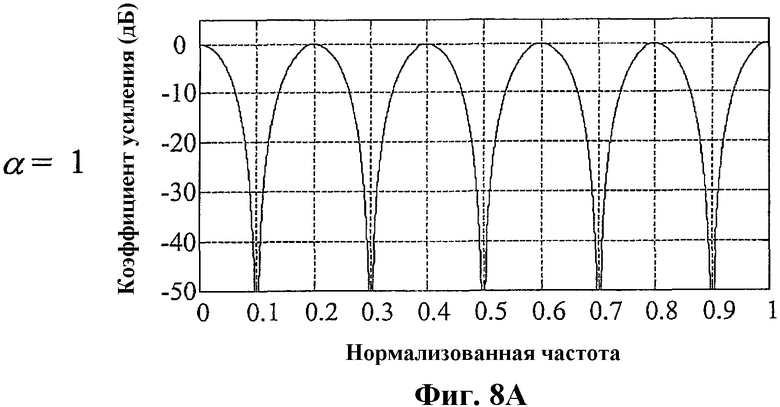
Фиг.8А и 8B - графики, показывающие пример частотной характеристики фильтра выделения основного тона, описанной уравнением (1), в особом случае периода основного тона T=10 выборок;
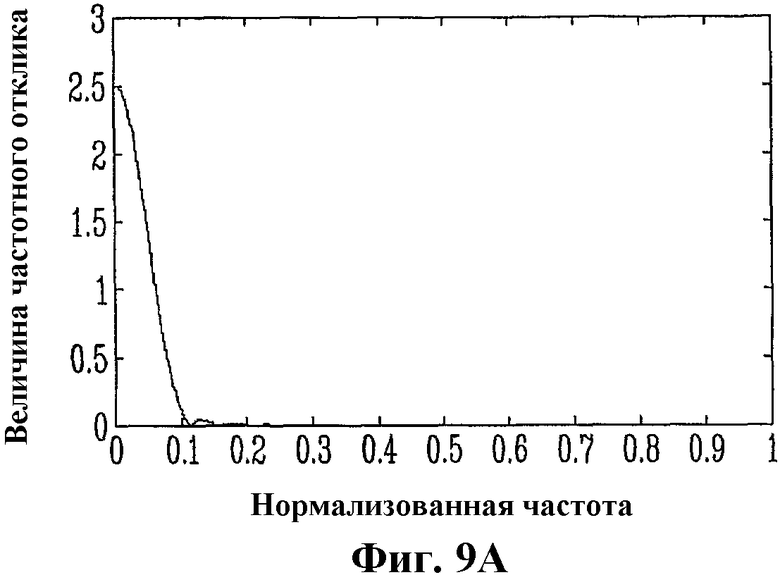
Фиг.9А - график, показывающий пример частотной характеристики фильтра 404 нижних частот, показанного на фиг.4;
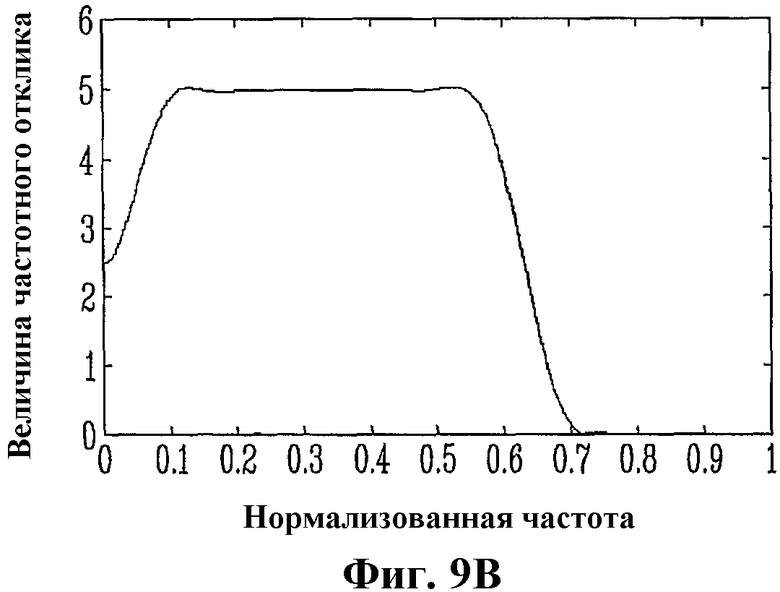
Фиг.9B - график, показывающий пример частотной характеристики полосового фильтра 407, показанного на фиг.4;
Фиг.9С - график, показывающий пример объединенной частотной характеристики фильтра 404 нижних частот и полосового фильтра 407, показанных на фиг.4; и
Фиг.10 - график, показывающий пример частотной характеристики интергармонического фильтра, описанной уравнением (2) и используемой в интергармоническом фильтре 505, показанном на фиг.5, для частного случая Т=10 выборок.
Подробное описание иллюстративных вариантов осуществления
На фиг.2 показана упрощенная блок-схема, демонстрирующая общий принцип иллюстративного варианта осуществления настоящего изобретения.
Согласно фиг.1 входной сигнал (сигнал, к которому применяется последующая обработка) является декодированным (синтезированным) речевым сигналом 112, созданным речевым декодером 105 (фиг.1) в приемнике системы связи (на выходе декодера 107 источника, показанного на фиг.1). Целью является создание декодированного речевого сигнала, подвергнутого последующей обработке, на выходе 113 постпроцессора 108, показанного на фиг.1 (который также является выходом процессора 203, показанного на фиг.2) с повышенным воспринимаемым качеством. Для этого сначала применяют, по меньшей мере, одну и, возможно, более одной, операцию адаптивной фильтрации к входному сигналу 112 (см. адаптивные фильтры 201a, 201b,..., 201N). Эти адаптивные фильтры описаны в нижеследующем описании. Здесь следует обратить внимание на то, что некоторые из адаптивных фильтров 201a-201N при необходимости могут быть тривиальными функциями, например, с выходом, равным входу. Выходной сигнал 204a, 204b,..., 204N каждого адаптивного фильтра 201a, 201b,..., 201N подвергается полосовой фильтрации с помощью фильтра 202a, 202b,..., 202N поддиапазона соответственно, и декодированный речевой сигнал 113, подвергнутый последующей обработке, получается суммированием в процессоре 203 соответствующих результирующих выходных сигналов 205a, 205b,..., 205N фильтров 202a, 202b,...,202N поддиапазона.
Согласно одному иллюстративному варианту осуществления используется двухполосное разложение, и адаптивная фильтрация применяется только к нижнему диапазону. Это обеспечивает полную последующую обработку, которая, в основном, нацелена на частоты, близкие к первой гармонике синтезированного речевого сигнала.
На фиг.3 показана упрощенная блок-схема двухполосного выделителя основного тона, который представляет собой частный случай иллюстративного варианта осуществления, представленного на фиг.2. В частности на фиг.3 показаны основные функции двухполосного постпроцессора (см. постпроцессор 108 на фиг.1). Согласно этому иллюстративному варианту осуществления в качестве последующей обработки рассматривается только выделение основного тона, хотя можно предусмотреть другие типы последующей обработки. На фиг.3 декодированный речевой сигнал (предполагается, что это выходной сигнал 112 декодера 107 источника, показанного на фиг.1) поступает через ветви 308 и 309.
В верхней ветви 308 декодированный речевой сигнал 112 фильтруется фильтром 301 верхних частот для создания сигнала 310 верхнего диапазона (SH). В этом конкретном примере в верхней ветви никакой адаптивный фильтр не используется. В нижней ветви 309 декодированный речевой сигнал 112 сначала обрабатывается адаптивным фильтром 307, содержащим необязательный фильтр 302 нижних частот, модуль 303 отслеживания основного тона и выделитель 304 основного тона, а затем фильтруется фильтром 305 нижних частот для получения сигнала 311 нижнего диапазона, подвергнутого последующей обработке (SLEF). Декодированный речевой сигнал 113, подвергнутый последующей обработке, получают суммированием на сумматоре 306 сигналов нижнего 311 и верхнего 312 диапазонов, подвергнутых последующей обработке, с выходов фильтра 305 нижних частот и фильтра 301 верхних частот соответственно. Заметим, что фильтры 305 нижних частот и 301 верхних частот могут относиться ко многим разным типам, например, с бесконечной импульсной характеристикой (БИХ) или конечной импульсной характеристикой (КИХ). В этом иллюстративном варианте осуществления используются линейные фазовые КИХ-фильтры.
Поэтому адаптивный фильтр 307, показанный на фиг.3, состоит из двух, возможно и трех, процессоров, необязательного фильтра 302 нижних частот, аналогичного фильтру 305 нижних частот, модуля 303 отслеживания основного тона и выделителя 304 основного тона.
Фильтр 302 нижних частот можно опустить, но он включен, чтобы показать, что последующая обработка, представленная на фиг.3, является двухполосным разложением с последующей особой фильтрацией в каждом поддиапазоне. После необязательной низкочастотной фильтрации (фильтр 302) декодированного речевого сигнала 112 в нижнем диапазоне, результирующий сигнал SL обрабатывается выделителем 304 основного тона. Выделитель 304 основного тона предназначен для снижения интергармонического шума в декодированном речевом сигнале. В данном иллюстративном варианте осуществления выделитель 304 основного тона реализуется посредством зависящего от времени линейного фильтра, описанного следующим уравнением:
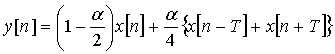 (1)
(1)
где α - коэффициент, регулирующий ослабление интергармонической составляющей, Т - период основного тона входного сигнала x[n], и y[n] - выходной сигнал выделителя основного тона. Можно также использовать более общее уравнение, где отводы фильтра на n-T и n+T могут иметь разные задержки (например, n-T1 и n+T2). Параметры T и α изменяются со временем и задаются модулем 303 отслеживания основного тона. При значении α=1, коэффициент усиления фильтра, описанного уравнением (1), в точности равен 0 на частотах 1/(27), 3/(2T), 5/(2T), и т.д., т.е. в средних точках между частотами гармоник 1/T, 3/T, 5/T, и т.д. Когда α стремится к нулю, ослабление между гармониками, создаваемое фильтром, описанным уравнением (1), снижается. При значении α=0, выходной сигнал фильтра идентичен его входному сигналу. На фиг.8 показана частотная характеристика (в дБ) фильтра, описанного уравнением (1) для значений α 0,8 и 1, когда задержка основного тона (произвольно) задана равной значению Т=10 выборок. Значение α можно вычислить с использованием нескольких подходов. Например, для регулировки коэффициента α можно использовать нормализованную корреляцию основного тона, которая хорошо известна специалистам в данной области: чем выше нормализованная корреляция основного тона (т.е. ближе к 1), тем выше значение α. Периодический сигнал x[n] с периодом Т=10 выборок будет иметь гармоники на максимумах частотных откликов, представленных на фиг.8, т.е. на нормализованных частотах 0,2; 0,4 и т.д. Из фиг.8 явствует, что выделитель основного тона, описанный уравнением (1), ослабляет энергию сигнала только между его гармониками и что фильтр не изменяет гармонические компоненты. На фиг.8 также показано, что, изменяя параметр α, можно регулировать величину ослабления интергармонической составляющей, обеспечиваемого фильтром, описанным уравнением (1). Заметим, что частотная характеристика фильтра, описанного уравнением (1), показанная на фиг.8, распространяется на все частоты спектра.
Поскольку период речевого сигнала изменяется со временем, значение Т основного тона для выделителя 304 основного тона должно изменяться соответственно. Модуль 303 отслеживания основного тона отвечает за предоставление правильного значения Т основного тона выделителю 304 основного тона для каждого кадра декодированного речевого сигнала, подлежащего обработке. С этой целью модуль 303 отслеживания основного тона принимает в качестве входного сигнала не только декодированные речевые выборки, но также декодированные параметры 114 от декодера 106 параметров, показанного на фиг.1.
Поскольку типичный речевой кодер извлекает, для каждого речевого подкадра, задержку основного тона, обозначенную как T0, и, возможно, дробное значение T0_frac, используемое для интерполяции вклада адаптивной кодовой книги в дробное разрешение выборки, модуль 303 отслеживания основного тона может использовать эту задержку декодированного основного тона, чтобы сфокусироваться на отслеживании основного тона в декодере. Одна возможность состоит в использовании T0 и T0_frac непосредственно в выделителе 304 основного тона с учетом того факта, что кодер уже выполнил отслеживание основного тона. Другая возможность, используемая в этом иллюстративном варианте осуществления, состоит в повторном вычислении отслеживания основного тона в декодере, фокусируясь на значениях вокруг и целых и дробных частях значения T0 декодированного основного тона. Модуль 303 отслеживания основного тона предоставляет задержку Т основного тона выделителю 304 основного тона, который использует это значение Т в уравнении (1) для текущего кадра декодированного речевого сигнала. Выходным сигналом является сигнал SLE.
Сигнал SLE с выделенным основным тоном подвергается низкочастотной фильтрации в фильтре 305 для изоляции низких частот сигнала SLE с выделенным основным тоном и для удаления высокочастотных составляющих, которые возникают, когда фильтр расширителя основного тона, выраженный уравнением (1), изменяется во времени, согласно задержке Т основного тона, на границах кадра декодированного речевого сигнала. В результате формируется сигнал SLEF нижнего диапазона, подвергнутый последующей обработке, который может суммироваться с сигналом SH верхнего диапазона в сумматоре 306. Результатом является декодированный речевой сигнал 113, подвергнутый последующей обработке, со сниженным интергармоническим шумом в нижнем диапазоне. Частотный диапазон, где будет применятся выделение основного тона, зависит от частоты отсечки фильтра 305 нижних частот (и необязательного фильтра 302 нижних частот).
На фиг.6А и 6B показан иллюстративный спектр сигнала, демонстрирующий воздействие последующей обработки, описанной на фиг.3. На фиг.6А показан спектр входного сигнала 112 постпроцессора 108, показанного на фиг.1 (декодированного речевого сигнала 112 на фиг.3). В этом иллюстративном примере входной сигнал состоит из 20 гармоник с основной частотой f0=373 Гц, выбранной произвольно, с «шумовыми» составляющими, добавленными на частотах f0/2, 3f0/2 и 5f0/2. Эти три шумовые составляющие можно видеть между низкочастотными гармониками на фиг.6А. В этом примере предполагается, что частота дискретизации равна 16 кГц. Сигнал, показанный на фиг.6А, поступает на двухполосный выделитель основного тона, показанный на фиг.3 и описанный выше. При частоте дискретизации 16 кГц и периодическом сигнале с основной частотой, равной 373 Гц, показанном на фиг.6А, модуль 303 отслеживания основного тона должен найти период T=16000/373 ≈ 43 выборок. Это значение, которое использовалось для фильтра выделителя основного тона, заданного уравнением (1), применяемого в выделителе 304 основного тона, показанного на фиг.3. Использовалось также значение α=0,5. Фильтр 305 нижних частот и фильтр 301 верхних частот являются симметричными линейными фазовыми КИХ-фильтрами с 31 отводами. Частота отсечки в этом примере выбрана равной 2000 Гц. Эти конкретные значения приведены только в порядке иллюстративного примера.
Декодированный речевой сигнал 113, подвергнутый последующей обработке, на выходе сумматора 306 имеет спектр, показанный на фиг.6B. Можно видеть, что три интергармонические синусоиды, показанные на фиг.6А, полностью удалены, тогда как гармоники сигнала практически не изменились. Кроме того, воздействие выделителя основного тона уменьшается по мере того, как частота приближается к частоте отсечки фильтра нижних частот (в данном примере 2000 Гц). Следовательно, последующей обработке подвергается только нижний диапазон. Это ключевая особенность этого иллюстративного варианта осуществления настоящего изобретения. Изменяя частоты отсечки необязательного фильтра 302 нижних частот, фильтра 305 нижних частот и фильтра 301 верхних частот, можно регулировать, до какой частоты применяется выделение основного тона.
Применение к речевому декодеру AMR-WB
Настоящее изобретение можно применять к любому речевому сигналу, синтезированному речевым декодером, или даже к любому речевому сигналу, искаженному интергармоническим шумом, который требуется снизить. В этом разделе показана конкретная иллюстративная реализация настоящего изобретения применительно к декодированному речевому сигналу AMR-WB. Последующая обработка применяется к синтезированному речевому сигналу 712 нижнего диапазона, показанному на фиг.7, т.е. к выходному сигналу речевого декодера 702, который создает синтезированный речевой сигнал на частоте дискретизации 12,8 кГц.
На фиг.4 показана блок-схема постпроцессора основного тона, когда входным сигналом является синтезированный речевой сигнал нижнего диапазона AMR-WB на частоте синхронизации 12,8 кГц. Точнее говоря, постпроцессор, показанный на фиг.4, заменяет блок 703 преобразования с повышением частоты дискретизации, который содержит процессоры 704, 705 и 706. Постпроцессор основного тона, показанный на фиг.4, также может применяться к синтезированному речевому сигналу, использующему повышенную частоту дискретизации 16 кГц, но применение его до преобразования с повышенной частотой дискретизации приводит к снижению количества операций фильтрации в декодере и, таким образом, способствует упрощению.
Входной сигнал (синтезированная речь нижнего диапазона AMR-WB (12,8 кГц), показанный на фиг.4, обозначен как сигнал s. В этом конкретном примере сигнал s представляет собой синтезированный речевой сигнал нижнего диапазона AMR-WB (выход процессора 702). Постпроцессор основного тона, показанный на фиг.4, содержит модуль 401 отслеживания основного тона, определяющий, для каждого 5-миллисекудного подкадра, задержку Т основного тона с использованием принятых декодированных параметров 114 (фиг.1) и синтезированного речевого сигнала s. Декодированными параметрами, используемыми модулем отслеживания основного тона, является T0 - целочисленное значение основного тона для подкадра и T0_frac - дробное значение основного тона для разрешения подкадра. Задержка Т основного тона, вычисленная в модуле 401 отслеживания основного тона, будет использоваться на следующих этапах выделения основного тона. В фильтре 402 основного тона возможно непосредственно использовать декодированные параметры T0 и T0_frac основного тона для формирования задержки Т, используемой выделителем основного тона. Однако модуль 401 отслеживания основного тона способен корректировать целые или дробные части основного тона, которые могли бы оказать неблагоприятное влияние на выделение основного тона.
Иллюстративный вариант осуществления алгоритма отслеживания основного тона для модуля 401 состоит в следующем (конкретные пороги и отслеживаемые значения основного тона приведены только для примера):
Прежде всего, декодированную информацию основного тона (задержку T0 основного тона) сравнивают с сохраненным значением декодированной задержки T_prev основного тона для предыдущего кадра. Параметр T_prev может быть изменен на некоторых последующих этапах согласно алгоритму отслеживания основного тона. Например, если T0 < 1.16*T_prev, то перейти к нижеследующему варианту 1, иначе, если T0 > 1.16*T_prev, то задать T_temp = T0 и перейти к нижеследующему варианту 2.
Вариант 1: Прежде всего, вычислить взаимную корреляцию С2 (векторное произведение) между последним синтезированным подкадром и сигналом синтеза, начиная с T0/2 выборок до начала последнего подкадра (см. корреляцию на половине декодированного значения основного тона).
Затем вычислить взаимную корреляцию С3 (векторное произведение) между последним синтезированным подкадром и сигналом синтеза, начиная с T0/3 выборок до начала последнего подкадра (см. корреляцию на половине декодированного значения основного тона).
Затем выбрать максимальное значение из С2 и С3 и вычислить нормализованную корреляцию Cn (нормализованную версию С2 или С3) при соответствующей дробной части T0 (при T0/2, если C2 > C3, и при T0/3 если C3 > C2). Определить T_new дробную часть основного тона, соответствующую наибольшей нормализованной корреляции.
Если Cn > 0,95 (сильная нормализованная корреляция), то задать новый период основного тона равным T_new (вместо T0). Вывести значение T = T_new из модуля 401 отслеживания основного тона. Сохранить T_prev = T для отслеживания основного тона в следующем подкадре и выйти из модуля 401 отслеживания основного тона.
Если 0.7 < Cn < 0,95, то сохранить T_temp = T0/2 или T0/3 (в соответствии с вышеупомянутыми С2 или С3) для сравнений в нижеследующем варианте 2. В противном случае, если Cn < 0,7, то сохранить T_temp = T0.
Вариант 2: Вычислить все возможные значения отношения Tn = [T_temp/n], где [x] означает целую часть х, и n = 1, 2, 3, и т.д. - целое число.
Вычислить все взаимные корреляции Cn при дробных частях задержки Tn основного тона. Запомнить Cn_max как максимальную взаимную корреляцию среди всех Cn. Если n > 1 и Cn > 0,8, то вывести Tn как выходное значение Т периода основного тона модуля 401 отслеживания основного тона. В противном случае вывести T1 = T_temp. В данном случае значение T_temp будет зависеть от вычислений, произведенных в вышеприведенном варианте 1.
Заметим, что вышеприведенный пример модуля 401 отслеживания основного тона приведен исключительно в иллюстративных целях. В модуле 401 (или 303 и 502) можно реализовать любой другой способ отслеживания основного тона, чтобы гарантировать лучшее отслеживание основного тона в декодере.
Поэтому выходной сигнал модуля отслеживания основного тона представляет собой период Т, подлежащий использованию в фильтре 402 основного тона, который, в данном предпочтительном варианте осуществления, описан как фильтр, заданный уравнением (1). Опять же, значение α=0 предусматривает отсутствие фильтрации (выходной сигнал фильтра 402 основного тона идентичен его входному сигналу), а значение α=1 соответствует наибольшей величине выделения основного тона.
Когда сигнал SE с выделением (фиг.4) определен, его объединяют со входным сигналом s так, что, как показано на фиг.3, выделению основного тона подвергается только нижний диапазон. На фиг.4 используется другой подход, чем на фиг.3. Поскольку постпроцессор основного тона, изображенный на фиг.4, заменяет блок 703 преобразования с повышенной частотой дискретизации, изображенный на фиг.7, то фильтры 301 и 305 поддиапазона, показанные на фиг.3, объединены с интерполяционным фильтром 705, показанным на фиг.7, с целью минимизации количества операций фильтрации и задержки фильтрации. В частности, фильтры 404 и 407, показанные на фиг.4, действуют как полосовые фильтры (для разделения частотных диапазонов) и интерполяционные фильтры (для преобразования с повышенной частотой дискретизации от 12,8 до 16 кГц). Эти фильтры 404 и 407 можно дополнительно настроить так, чтобы полосовой фильтр 407 имел менее строгие ограничения в своей низкочастотной полосе заграждения (т.е. не полностью ослаблял сигнал на низких частотах). Этого можно добиться, используя конструктивные ограничения, подобные показанным на фиг.9. На фиг.9А показан пример частотной характеристики фильтра 404 нижних частот. Заметим, что коэффициент усиления постоянного тока этого фильтра равен 5 (вместо 1), поскольку этот фильтр также действует как интерполяционный фильтр с коэффициентом интерполяции 5/4, вследствие чего коэффициент усиления фильтра при 0 Гц должен быть равен 5. На фиг.9B показана частотная характеристика полосового фильтра 407, делающая этот фильтр 407 дополнительным, в нижнем диапазоне, фильтру 404 нижних частот. В этом примере, фильтр 407 является полосовым фильтром, а не фильтром верхних частот наподобие фильтра 301, поскольку он должен действовать как фильтр верхних частот (наподобие фильтра 301) и как фильтр нижних частот (наподобие интерполяционного фильтра 705). Опять же, из фиг.9 явствует, что фильтр 404 нижних частот и полосовой фильтр 407 являются взаимодополняющими, когда рассматриваются параллельно, как показано на фиг.4. Их объединенная частотная характеристика (при параллельном использовании) показана на фиг.9С.
Для полноты ниже приведены таблицы коэффициентов фильтрации, используемых в этом иллюстративном варианте осуществления фильтров 404 и 407. Конечно, эти таблицы коэффициентов фильтрации приведены исключительно в порядке примера. Следует понимать, что эти фильтры можно заменять без изменения объема и сущности настоящего изобретения.
Коэффициенты низкочастотной фильтрации для фильтра 404
Коэффициенты полосовой фильтрации для фильтра 407
Выходной сигнал фильтра 402 основного тона, показанного на фиг.4, обозначен SE. Для повторного объединения с сигналом верхней ветви он сначала преобразуется с повышенной частотой дискретизации процессором 403, фильтром 404 нижних частот и процессором 405 и суммируется в сумматоре 409 с преобразованным к более высокой частоте дискретизации сигналом 410 верхней ветви. Операция преобразования с повышенной частотой дискретизации в верхней ветви выполняется процессором 406, полосовым фильтром 407 и процессором 408.
Альтернативный вариант осуществления предложенного
выделителя основного тона
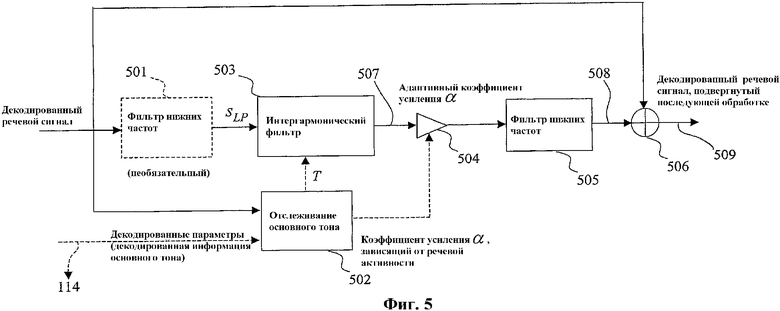
На фиг.5 показана альтернативная реализация двухполосного выделителя основного тона согласно иллюстративному варианту осуществления настоящего изобретения. Заметим, что верхняя ветвь, показанная на фиг.5, не обрабатывает входной сигнал. Это значит, что, в данном конкретном случае, фильтры в верхней ветви, показанном на фиг.2, (адаптивные фильтры 201а и 201b) имеют тривиальные передаточные характеристики (выходной сигнал идентичен входному сигналу). В нижней ветви входной сигнал (сигнал, подлежащий выделению) сначала обрабатывается необязательным фильтром 501 нижних частот, затем линейным фильтром, именуемым интергармоническим фильтром 503, который задан следующим уравнением:
 (2)
(2)
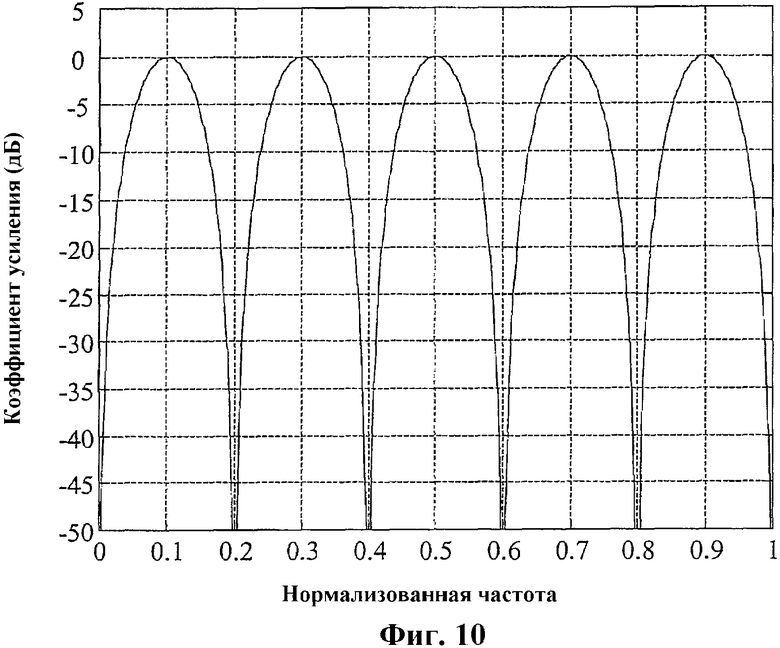
Следует обратить внимание на отрицательный знак перед вторым членом в правой части, в отличие от уравнения (1). Заметим также, что коэффициент выделения α не входит в уравнение (2), но вносится посредством активного усиления процессором 504, показанным на фиг.5. Интергармонический фильтр 503, описанный уравнением (2), имеет частотную характеристику, которая обеспечивает полное устранение гармоник периодического сигнала, имеющего период Т выборок, и прохождение синусоиды с частотой точно между гармониками через фильтр без изменения амплитуды, но с инверсией фазы точно на 180 градусов (что эквивалентно смене знака). Для примера на фиг.10 показана частотная характеристика фильтра, описанного уравнением (2), когда период (произвольно) выбран как Т=10 выборок. Периодический сигнал с периодом Т=10 выборок представляет гармоники с нормализованными частотами 0,2; 0,4; 0,6; и т.д. и на фиг.10 показано, что фильтр, заданный уравнением (2), с Т=10 выборок полностью устраняет эти гармоники. С другой стороны, частоты, находящиеся точно посередине между гармониками, появляются на выходе фильтра с той же амплитудой и сдвигом фазы на 180°. По этой причине фильтр, описанный уравнением (2) и используемый в качестве фильтра 503, называется интергармоническим фильтром.
Значение Т основного тона для использования в интергармоническом фильтре 503, получают адаптивно с помощью модуля 502 отслеживания основного тона. Модуль 502 отслеживания основного тона оперирует с декодированным речевым сигналом и декодированными параметрами аналогично ранее раскрытым способам, представленным на фиг.3 и 4.
Выходной сигнал 507 интергармонического фильтра 503 представляет собой сигнал, сформированный, по существу, из интергармонической составляющей входного декодированного сигнала 112 со сдвигом фазы на 180° посередине между гармониками сигнала. Выходной сигнал 507 интергармонического фильтра 503 умножается на коэффициент усиления α (процессором 504) и затем подвергается низкочастотной фильтрации (фильтром 505) для получения декодированного сигнала 509, подвергнутого последующей обработке (сигнала с выделением). Коэффициент α в процессоре 504 регулирует величину выделения основного тона или промежуточных гармоник. Чем ближе α к 1, тем больше выделение. Когда α равен 0, никакого выделения не происходит, т.е. выходной сигнал сумматора 506 в точности равен входному сигналу (декодированному речевому сигналу на фиг.5). Значение α можно вычислять с использованием разных подходов. Например, для регулировки коэффициента α можно использовать нормализованную корреляцию основного тона, которая хорошо известна специалистам в данной области: чем выше нормализованная корреляция основного тона (т.е. ближе к 1), тем выше значение α.
Окончательный декодированный речевой сигнал 509, подвергнутый последующей обработке, получают суммированием в сумматоре 506 выходного сигнала фильтра 505 нижних частот с входным сигналом (декодированным речевым сигналом 112, показанным на фиг.5). В зависимости от частоты отсечки фильтра 505 нижних частот влияние этой последующей обработки ограничивается нижними частотами входного сигнала 112 вплоть до заданной частоты. Верхние частоты практически не подвергаются последующей обработке.
Однополосная альтернатива с использованием
адаптивного фильтра верхних частот
Одна последняя альтернатива реализации последующей обработки в поддиапазоне состоит в использовании адаптивного фильтра верхних частот, частота отсечки которого изменяется в соответствии со значением основного тона входного сигнала. В частности, и без ссылки на какой-либо чертеж, выделение нижних частот с использованием этого иллюстративного варианта осуществления осуществляется на каждом кадре входного сигнала согласно следующим этапам:
1. Определение значения основного тона входного сигнала (периода сигнала) с использованием входного сигнала и, возможно, декодированных параметров (выходного сигнала речевого декодера 105), если декодированный речевой сигнал подвергается последующей обработке: эта операция аналогична операции отслеживания основного тона, осуществляемой модулями 303, 401 и 502.
2. Вычисление коэффициентов фильтра верхних частот, чтобы частота отсечки была ниже, но близка к основной частоте входного сигнала; альтернативно интерполяция между ранее рассчитанными, сохраненными фильтрами верхних частот с известными частотами отсечки (интерполяция может осуществляться в области отводов фильтра или в области полюсов и нулей или некоторой другой преобразованной области, например в области LSF (частот линейного спектра) или ISF (частот иммитансного спектра).
3. Фильтрация кадра входного сигнала с помощью вычисленного фильтра верхних частот для получения сигнала, подвергнутого последующей обработке, для этого кадра.
Следует обратить внимание на то, что данный иллюстративный вариант осуществления настоящего изобретения эквивалентен использованию только одной ветви обработки, показанной на фиг.2, и заданию адаптивного фильтра этой ветви как фильтра верхних частот, управляемого основным тоном. Последующая обработка, достигаемая посредством такого подхода, оказывает влияние только на частотный диапазон ниже первой гармоники, но не на энергию интергармонической составляющей выше первой гармоники.
Хотя настоящее изобретение представлено в вышеизложенном описании со ссылкой на иллюстративные варианты его осуществления, эти варианты осуществления могут быть изменены в пределах объема прилагаемой формулы изобретения без отклонения от сущности настоящего изобретения. Например, хотя иллюстративные варианты осуществления описаны в отношении декодированного речевого сигнала, специалистам в данной области очевидно, что идеи настоящего изобретения можно применить к другим типам декодированных сигналов, в частности, но не исключительно, к другим типам декодированных звуковых сигналов.




Изобретение относится к способу и устройству для последующей обработки декодированного звукового сигнала, причем декодированный звуковой сигнал делят на совокупность сигналов частотных поддиапазонов и последующую обработку применяют к, по меньшей мере, одному из совокупности сигналов частотных поддиапазонов. После последующей обработки этого, по меньшей мере, одного сигнала частотного поддиапазона, сигналы частотных поддиапазонов суммируют для создания выходного декодированного звукового сигнала, подвергнутого последующей обработке. Таким образом, последующую обработку локализуют в нужном(ых) поддиапазоне или поддиапазонах, оставляя другие поддиапазоны практически неизменными. Технический результат - повышение воспринимаемого качества декодированного звукового сигнала. 3 н. и 51 з.п ф-лы, 14 ил.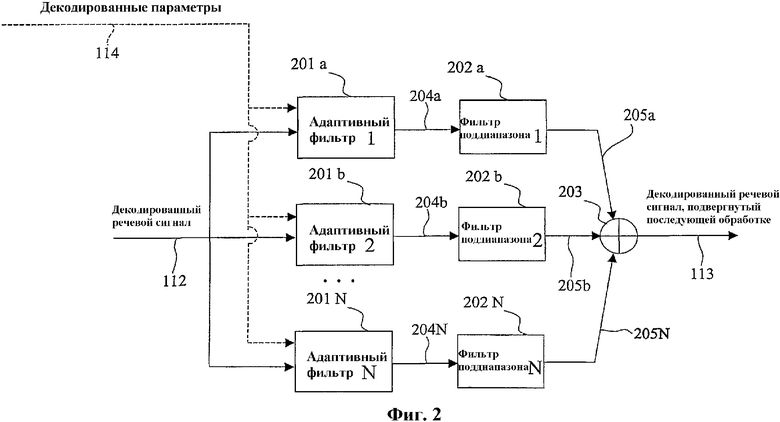
разделяют декодированный звуковой сигнал на совокупность сигналов частотных поддиапазонов, и
применяют последующую обработку только к части сигналов частотных поддиапазонов,
причем применение последующей обработки только к части сигналов частотных поддиапазонов включает в себя выделение основного тона сигналов частотных поддиапазонов только в диапазоне нижних частот декодированного звукового сигнала.
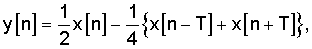
для ослабления интергармонической составляющей декодированного звукового сигнала, где x[n] - декодированный звуковой сигнал, y[n] - декодированный звуковой сигнал, подвергнутый интергармонической фильтрации в данном поддиапазоне, и Т - задержка основного тона декодированного звукового сигнала.

где x[n] - декодированный звуковой сигнал, y[n] - декодированный звуковой сигнал с выделенным основным тоном в данном поддиапазоне, Т - задержка основного тона декодированного звукового сигнала и α - коэффициент, принимающий значения между 0 и 1, для регулировки величины ослабления интергармонической составляющей декодированного звукового сигнала.
выполняют полосовую фильтрацию декодированного звукового сигнала для создания сигнала диапазона верхних частот, причем полосовую фильтрацию декодированного звукового сигнала выполняют совместно с преобразованием декодированного звукового сигнала с повышением частоты дискретизации от более низкой частоты дискретизации к более высокой частоте дискретизации, и
выполняют выделение основного тона декодированного звукового сигнала и низкочастотную фильтрацию декодированного звукового сигнала, подвергнутого выделению основного тона, для создания сигнала диапазона нижних частот, причем низкочастотную фильтрацию декодированного звукового сигнала, подвергнутого выделению основного тона, выполняют совместно с преобразованием декодированного звукового сигнала, подвергнутого последующей обработке, с повышением частоты дискретизации от более низкой частоты дискретизации к более высокой частоте дискретизации.

где x[n] - декодированный звуковой сигнал, y[n] - декодированный звуковой сигнал с выделенным основным тоном в данном поддиапазоне, Т - задержка основного тона декодированного звукового сигнала и α - коэффициент, принимающий значения между 0 и 1, для регулировки величины ослабления интергармонической составляющей декодированного звукового сигнала.
определение значения основного тона декодированного звукового сигнала,
вычисление, в отношении определенного значения основного тона, фильтра верхних частот с частотой отсечки ниже основной частоты декодированного звукового сигнала, и
обработку декодированного звукового сигнала посредством вычисленного фильтра верхних частот.
средство для разделения декодированного звукового сигнала на совокупность сигналов частотных поддиапазонов, и
средство для последующей обработки только части сигналов частотных поддиапазонов,
причем средство для последующей обработки включает в себя средство для выделения основного тона сигналов частотных поддиапазонов только в диапазоне нижних частот декодированного звукового сигнала.
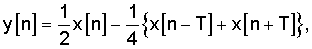
для ослабления интергармонической составляющей декодированного звукового сигнала, где x[n] - декодированный звуковой сигнал, y[n] - декодированный звуковой сигнал, подвергнутый интергармонической фильтрации в данном поддиапазоне, и Т - задержка основного тона в декодированном звуковом сигнале.
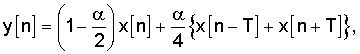
где х[n] - декодированный звуковой сигнал, y[n] - декодированный звуковой сигнал с выделенным основным тоном в данном поддиапазоне, Т - задержка основного тона декодированного звукового сигнала и α - коэффициент, принимающий значения между 0 и 1, для регулировки величины ослабления интергармонической составляющей декодированного звукового сигнала.
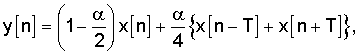
где x[n] - декодированный звуковой сигнал, y[n] - декодированный звуковой сигнал с выделенным основным тоном в данном поддиапазоне, Т - задержка основного тона декодированного звукового сигнала и α - коэффициент, принимающий значения между 0 и 1, для регулировки величины ослабления интергармонической составляющей декодированного звукового сигнала.
вход для приема кодированного звукового сигнала,
декодер параметров, на который подается кодированный звуковой сигнал, для декодирования параметров кодирования звукового сигнала,
декодер звукового сигнала, на который подаются декодированные параметры кодирования звукового сигнала, для создания декодированного звукового сигнала, и
устройство последующей обработки по любому из пп.27-53 для последующей обработки декодированного звукового сигнала для повышения воспринимаемого качества декодированного звукового сигнала.
| Устройство передачи и приема речевых сигналов | 1972 |
|
SU447853A1 |
| US 5806025 А, 08.09.1998 | |||
| Бесколесный шариковый ход для железнодорожных вагонов | 1917 |
|
SU97A1 |
| US 5864798 А, 26.01.1999 | |||
| СИНТЕЗАТОР И СПОСОБ ДЛЯ РЕЧЕВОГО СИНТЕЗА (ВАРИАНТЫ) И РАДИОУСТРОЙСТВО | 1996 |
|
RU2181481C2 |

