Область техники, к которой относится изобретение
Настоящее изобретение относится к устройству и способу для обработки многоканального звукового сигнала и, в частности, к устройству и способу для обработки многоканального звукового сигнала способом, совместимым со стереофоническим.
Уровень техники
В последнее время методика многоканального звуковоспроизведения становится более и более важной. Это может быть обусловлено фактом, что методики звукового сжатия/кодирования, например хорошо известная методика mp3, сделали возможным распространять звуковые записи через Интернет или другие каналы передачи, имеющие ограниченную пропускную способность. Методика кодирования mp3 стала такой известной из-за факта, что она позволяет распространение всех записей в стереофоническом формате, т.е. цифровом представлении звуковой записи, включающем в себя первый, или левый, стереофонический канал и второй, или правый, стереофонический канал.
Тем не менее, существуют основные недостатки традиционных двухканальных звуковых систем. Поэтому разработана методика объемного звучания. Рекомендуемое многоканально-объемное представление включает в себя, в дополнение к двум стереофоническим каналам L и R, дополнительный центральный канал С и два канала Ls, Rs окружающего (объемного звука). Этот эталонный звуковой формат также называется стереофонией три/два, которая означает три передних канала и два канала окружающего звука. Обычно требуются пять каналов передачи. В среде звуковоспроизведения необходимо по меньшей мере пять динамиков на соответствующих пяти различных местах, чтобы добиться оптимальной зоны наилучшего восприятия на определенном расстоянии от пяти хорошо размещенных громкоговорителей.
Несколько методик известны в данной области техники, уменьшающие количество данных, необходимых для передачи многоканального звукового сигнала. Такие методики называются методиками квазистереофонии. С этой целью сделана ссылка на Фиг.10, которая показывает устройство 60 квазистереофонии. Это устройство может являться устройством, реализующим, например, мощную стереофонию (IS) или бинауральное кодирование сигнала (BCC). Такое устройство обычно принимает - в качестве входа - по меньшей мере два канала (CH1, CH2, ... CHn) и выводит единый высокочастотный канал и параметрические данные. Параметрические данные определяются из условия, чтобы в декодере могло быть рассчитано приближенное значение исходного канала (CH1, CH2, ... CHn).
Обычно высокочастотный канал будет включать в себя выборки поддиапазона, спектральные коэффициенты, выборки временного интервала и т.д., которые обеспечивают относительно точное представление основного сигнала, в то время как параметрические данные не включают в себя такие выборки спектральных коэффициентов, но включают в себя параметры управления для управления определенным алгоритмом восстановления, например, взвешиванием с помощью умножения, временной манипуляцией, смещением частоты,... Параметрические данные, следовательно, включают в себя только относительно грубое представление сигнала или ассоциативно связанного канала. Выраженный в цифрах объем данных, требуемый высокочастотным каналом, будет находиться в диапазоне 60-70 Кбит/с, тогда как объем данных, требуемый параметрической дополнительной информацией для одного канала, будет находиться в диапазоне 1,5-2,5 Кбит/с. Примером для параметрических данных являются хорошо известные масштабные коэффициенты, информация о мощной стереофонии или параметры бинаурального сигнала, которые будут описаны далее.
Мощная стереофония описывается в препринте AES 3799, «Intensity Stereo Coding» (Мощное стереофоническое кодирование), J. Herre (Дж. Херр), K. H. Brandenburg (К.Х. Бранденбург), D. Lederer (Д. Ледерер), февраль 1994 г., Амстердам. В целом концепция мощной стереофонии основывается на преобразовании основной оси, которое нужно применить к данным обоих стереофонических звуковых каналов. Если большинство точек данных концентрируется вокруг оси первоисточника, цель кодирования может быть достигнута с помощью поворота обоих сигналов на определенный угол до кодирования. Это, однако, не всегда верно для настоящих методик создания стереофонии. Следовательно, эта методика модифицируется посредством исключения второй ортогональной компоненты из передачи в потоке двоичных сигналов. Таким образом, восстановленные сигналы для левых и правых каналов состоят из вариантов того же переданного сигнала, по-разному взвешенных или масштабированных. Тем не менее, восстановленные сигналы отличаются в своей амплитуде, но идентичны относительно своей информации о фазе. Кривые энергии-времени обоих исходных звуковых каналов, однако, сохраняются посредством операции выборочного масштабирования, которая обычно действует способом выборочной частоты. Это соответствует человеческому восприятию звука на высоких частотах, где преобладающие пространственные сигналы определяются с помощью кривых энергии.
Кроме того, в практических реализациях переданный сигнал, т.е. высокочастотный канал, формируется из суммарного сигнала левого канала и правого канала вместо смены обоих компонентов. Более того, эта обработка, т.е. формирование параметров мощной стереофонии для выполнения операции масштабирования, выполняется выборочно по частоте, т.е. независимо для каждого диапазона масштабного коэффициента, т.е. распределения частоты кодера. Предпочтительно, чтобы оба канала объединялись для образования комбинированного или «высокочастотного» канала, и в дополнение к комбинированному каналу определяется информация мощной стереофонии, которая зависит от энергии первого канала, энергии второго канала или энергии комбинированного канала.
Методика BCC описана в конвенционном документе AES 5574 «Binaural cue coding applied to stereo and multi-channel audio compression» (Бинауральное кодирование сигнала, применяемое к стереофонии и сжатию многоканального звука), C. Faller (К.Фоллер), F. Baumgarte (Ф. Баумгарт), май 2002 г., Мюнхен. При кодировании BCC некоторое количество входящих звуковых каналов преобразуется в спектральное представление, используя преобразование на основе DFT (дискретное преобразование Фурье) с перекрывающимися окнами. Результирующий однородный спектр разделяется на неперекрывающиеся части, каждая из которых имеет индекс. Каждая часть имеет пропускную способность, пропорциональную эквивалентной прямоугольной полосе частот (ERB). Межканальная разность уровней (ICLD) и межканальная разность времени (ICTD) оцениваются для каждой части для каждого кадра k. ICLD и ICTD квантуются и кодируются, что приводит к потоку двоичных сигналов BCC. Межканальные разности уровней и межканальные разности времени задаются для каждого канала относительно опорного канала. Затем рассчитываются параметры в соответствии с принятой формулой, которая зависит от определенных частей сигнала, которые необходимо обработать.
На стороне декодера декодер принимает монофонический сигнал и поток двоичных сигналов ВСС. Монофонический сигнал преобразуется в частотную область и вводится в блок пространственного синтеза, который также принимает декодированные значения ICLD и ICTD. В блоке пространственного синтеза значения параметров BCC (ICLD и ICTD) используются для выполнения операции взвешивания монофонического сигнала, для того чтобы синтезировать многоканальные сигналы, которые после частотного/временного преобразования представляют восстановление исходного многоканального звукового сигнала.
В случае BCC, модуль 60 квазистереофонии выполнен с возможностью вывода дополнительной информации канала из условия, чтобы параметрические данные канала являлись квантованными и кодированным параметрами ICLD или ICTD, где один из исходных каналов используется как опорный канал для кодирования дополнительной информации канала.
Обычно высокочастотный канал образуется из суммы составляющих исходных каналов.
Естественно, вышеизложенные методики только обеспечивают монофоническое представление для декодера, который может лишь обрабатывать высокочастотный канал, но не способен обрабатывать параметрические данные для формирования одного или нескольких приближенных значений более чем одного входного канала.
Методика звукового кодирования, известная как бинауральное кодирование сигнала (BCC), также хорошо описывается в публикациях патентных заявок США US 2003/0219130 A1, 2003/0026441 A1 и 2003/0035553 A1. Дополнительная ссылка сделана также на «Binaural Cue Coding. Part II: Schemes and Applications» (Бинауральное кодирование сигнала. Часть II: схемы и применения), C. Faller (K.Фоллер) и F. Baumgarte (Ф. Баумгарт), IEEE Trans. On Audio and Speech Proc., том 11, номер 6, ноябрь 1993. Приведенные публикации патентных заявок США и две приведенные технические публикации по методике BCC под авторством Фоллера и Баумгарте включаются в данный документ полностью с помощью ссылки.
Далее детально разрабатывается типовая общая схема ВСС для многоканального звукового кодирования со ссылкой на Фиг.11-13. Фиг.11 показывает такую общую схему бинаурального кодирования сигнала для кодирования/передачи многоканальных звуковых сигналов. Многоканальный звуковой входной сигнал на входе 110 кодера 112 BCC низводится в блоке 114 низведения (downmix - уменьшение числа каналов, используемое для преобразования цифрового 5.1-канального звукового формата «Dolby Digital» в двухканальный сигнал «Dolby Surround». В настоящем примере исходный многоканальный сигнал на входе 110 является 5-канальным сигналом окружающего звука, имеющим передний левый канал, передний правый канал, левый канал окружающего звука, правый канал окружающего звука и центральный канал. В предпочтительном варианте осуществления настоящего изобретения блок 114 низведения создает суммарный сигнал с помощью простого дополнения этих пяти каналов в монофонический сигнал. В данной области техники известны другие схемы низведения, так что, используя многоканальный входной сигнал, может быть получен низведенный сигнал, имеющий единственный канал. Этот единственный канал выводится на линии 115 суммарного сигнала. Дополнительная информация, полученная с помощью блока 116 анализа ВСС, выводится на линии 117 дополнительной информации. В блоке анализа ВСС межканальные разности уровней (ICLD) и межканальные разности времени (ICTD) рассчитываются, как описано выше. В последнее время блок 116 анализа ВСС улучшен, чтобы рассчитывать также межканальные корреляционные значения (значения ICC). Суммарный сигнал и дополнительная информация передается предпочтительно в квантованной и кодированной форме на декодер 120 ВСС. Декодер ВСС разлагает на составные части переданный суммарный сигнал на некоторое количество поддиапазонов и применяет масштабирование, задержки и другую обработку, чтобы формировать поддиапазоны выходных многоканальных звуковых сигналов. Эта обработка выполняется из условия, чтобы параметры (сигналы) ICLD, ICTD и ICC восстановленного многоканального сигнала на выходе 121 являлись похожими на соответствующие сигналы для исходного многоканального сигнала на входе 110 в кодер 112 ВСС. С этой целью декодер 120 ВСС включает в себя блок 122 синтеза ВСС и блок 123 обработки дополнительной информации.
Далее внутреннее устройство блока 122 синтеза ВСС объясняется со ссылкой на Фиг.12. Суммарный сигнал на линии 115 вводится в блок частотного/временного преобразования или гребенку 115 фильтров FB. На выходе блока 125 существует некоторое количество N сигналов поддиапазона или, в крайнем случае, группа спектральных коэффициентов, когда гребенка 125 звуковых фильтров выполняет преобразование 1:1, т.е. преобразование, которое создает N спектральных коэффициентов из N выборок временной области.
Блок 122 синтеза ВСС дополнительно содержит этап 126 задержки, этап 127 модификации уровня, этап 128 обработки корреляции и этап 129 обратной гребенки фильтров IFB. На выходе этапа 129 восстановленный многоканальный звуковой сигнал, имеющий, например, пять каналов в случае 5-канальной системы окружающего (объемного) звука, может быть выведен на комплект громкоговорителей 124, как проиллюстрировано на Фиг.11.
Как показано на Фиг.12, входной сигнал s(n) преобразуется в частотную область или область гребенки (блока) фильтров посредством элемента 125. Выход сигнала с помощью элемента 125 умножается, так что получаются несколько вариантов одного и того же сигнала, как проиллюстрировано с помощью узла 130 умножения. Количество вариантов исходного сигнала равно количеству выходных каналов в выходном сигнале, который необходимо восстановить. Затем, в общем, каждый вариант выходного сигнала на узле 130 подвергается определенной задержке d1, d2, ..., di, ..., dN. Параметры задержки вычисляются блоком 123 обработки дополнительной информации на Фиг.11 и выводятся из межканальных разностей времени, как определено блоком 116 анализа ВСС.
То же самое является верным для коэффициентов умножения a1, a2, ..., ai, ..., aN, которые также рассчитываются блоком 123 обработки дополнительной информации на основе межканальных разностей уровней, которые рассчитываются блоком 116 анализа ВСС.
Параметры ICC, рассчитанные блоком 116 анализа BCC, используются для управления функциональными возможностями блока 128 из условия, чтобы определенные взаимосвязи между задержанными и регулируемыми по уровню сигналами получались на выходах блока 128. Здесь следует заметить, что порядок этапов 126, 127, 128 может отличаться от случая, показанного на Фиг.12.
Здесь следует заметить, что в покадровой обработке звукового сигнала анализ ВСС выполняется покадрово, т.е. в зависимости от времени, а также частотно. Это означает, что для каждой спектральной полосы получаются параметры ВСС. Это означает, что, если гребенка 125 звуковых фильтров разлагает на составные части входной сигнал, например на 32 сигнала полосы пропускания, блок анализа ВСС получает совокупность параметров ВСС для каждой из 32 полос. Естественно, блок 122 синтеза ВСС из Фиг.11, который показан подробно на Фиг.12, выполняет восстановление, которое также основано на 32 полосах в примере.
В дальнейшем сделана ссылка на Фиг.13, показывающую установку для определения некоторых параметров ВСС. Обычно параметры ICLD, ICTD и ICC могут быть определены между парами каналов. Однако предпочтительно определять параметры ICLD и ICTD между опорным каналом и каждым другим каналом. Это проиллюстрировано на Фиг.13A.
Параметры ICC могут быть определены различными способами. В более общем смысле можно оценить параметры ICC в кодере между всеми возможными парами каналов, как показано на Фиг.13В. В этом случае декодер синтезировал бы ICC так, что он был бы приблизительно тот же, что и исходный многоканальный сигнал между всеми возможными парами каналов. Однако было предложено оценивать только параметры ICC между сильнейшими каналами в каждый момент времени. Эта схема проиллюстрирована на Фиг.13С, где показан пример, в котором в один временной момент параметр ICC оценивается между каналами 1 и 2, и в другой временной момент параметр ICC рассчитывается между каналами 1 и 5. Затем декодер синтезирует межканальное соотношение между сильнейшими каналами в декодере и применяет некоторое эвристическое правило для вычисления и синтезирования межканальной когерентности для оставшихся пар каналов.
Относительно расчета, например, коэффициентов умножения a1, aN, основанных на переданных параметрах ICLD, сделана ссылка на конвенционный документ AES 5574, упомянутый выше. Параметры ICLD представляют собой распределение энергии в исходном многоканальном сигнале. Без потери универсальности на Фиг.13А показано, что существуют четыре параметра ICLD, показывающих разность энергии между всеми другими каналами и передним левым каналом. В блоке 123 обработки дополнительной информации коэффициенты умножения a1, ..., aN выводятся из параметров ICLD из условия, чтобы общая энергия всех восстановленных выходных каналов являлась бы той же (или пропорциональной), что и энергия переданного суммарного сигнала. Простым способом для определения этих параметров является 2-этапный процесс, в котором на первом этапе коэффициент умножения для левого переднего канала устанавливается за единицу, тогда как коэффициенты умножения для других каналов на Фиг.13А устанавливаются по переданным значениям ICLD. Затем на втором этапе энергия всех пяти каналов рассчитывается и сравнивается с энергией переданного суммарного сигнала. Затем все каналы масштабно понижаются, используя коэффициент понижения, который является одинаковым для всех каналов, в которых коэффициент понижения выбирается из условия, чтобы общая энергия всех восстановленных выходных каналов являлась после масштабирования с понижением равной общей энергии переданного суммарного сигнала.
Естественно, существуют другие способы для расчета коэффициентов умножения, которые не полагаются на 2-этапный процесс, но которым необходим лишь 1-этапный процесс.
Относительно параметров задержки следует отметить, что параметры задержки ICTD, которые передаются из кодера ВСС, могут быть использованы сразу, когда параметр задержки d1 для левого переднего канала установлен в ноль. Здесь не нужно делать изменение масштаба, поскольку задержка не изменяет энергию сигнала.
Относительно измерения межканальной когерентности ICC, переданной от кодера ВСС к декодеру ВСС, здесь следует отметить, что управление когерентностью может быть сделано посредством изменения коэффициентов умножения a1, ..., an, например посредством перемножения весовых коэффициентов всех поддиапазонов со случайными числами со значениями между 20log10(-6) и 20log10(6). Псевдослучайная последовательность предпочтительно выбирается так, что дисперсия является приблизительно постоянной для всех критических полос, а среднее является нулем внутри каждой критической полосы. Та же последовательность применяется к спектральным коэффициентам для каждого другого кадра. Таким образом, ширина слухового образа управляется посредством изменения дисперсии псевдослучайной последовательности. Большая дисперсия создает большую ширину образа.
Изменение дисперсии может быть выполнено в индивидуальных полосах, которые являются широкими критическими полосами. Это делает возможным одновременное существование множества объектов в акустической обстановке и каждый объект, имеющий различную ширину образа. Подходящее амплитудное распределение для псевдослучайной последовательности является равномерным распределением на логарифмической шкале, как это обрисовано в публикации патентной заявки США 2003/0219130 A1. Тем не менее, вся обработка синтеза ВСС относится к единственному входному каналу, переданному как суммарный сигнал от кодера ВСС к декодеру ВСС, как показано на Фиг.11.
Для передачи пяти каналов совместимым способом, т.е. в формате битового потока, который также является понятным для обычного стереофонического декодера, так называемая методика матрицирования, использована, как описано в «MUSICAM surround: a universal multi-channel coding system compatible with ISO 11172-3» (Окружение MUSICAM: универсальная многоканальная система кодирования, совместимая с ISO 11172-3), G. Theile (Дж. Тейл) и G. Stoll (Дж. Столл), препринт AES 3403, октябрь 1992 г., Сан-Франциско. Эти пять входных каналов L, R, C, Ls и Rs вводятся в матрицирующее устройство, выполняющее операцию матрицирования, чтобы рассчитать основные или совместимые стереофонические каналы Lo, Ro из пяти входных каналов. В частности, эти основные стереофонические каналы Lo/Ro рассчитываются, как изложено ниже:
Lo = L + xC + yLs
Ro = R + xC + yRs
x и y являются константами. Остальные три канала C, Ls, Rs передаются, будучи в уровне расширения, в дополнение к основному стереофоническому уровню, который включает в себя кодированный вариант основных стереофонических сигналов Lo/Ro. Что касается битового потока, этот основной стереофонический уровень Lo/Ro включает в себя заголовок, информацию, такую как шкала факторов и выборки поддиапазонов. Многоканальный уровень расширения, т.е. центральный канал и два канала окружающего звука включаются в многоканальное поле расширения, которое также называется полем служебных данных.
На стороне декодера выполняется операция обратного матрицирования для того, чтобы создать восстановления левого и правого каналов в пятиканальном представлении, используя основные стереофонические каналы Lo, Ro и три дополнительных канала. Кроме того, три дополнительных канала декодируются из служебных данных для того, чтобы получить декодированное пятиканальное или представление окружающего звука исходного многоканального звукового сигнала.
Другой подход к многоканальному кодированию описывается в публикации «Improved MPEG-2 audio multi-channel encoding» (Улучшенное звуковое многоканальное кодирование MPEG-2) B. Grill (Б. Грилл), J. Herre (Дж. Херр), K. H. Brandenburg (К.Г. Бранденбург), E. Eberlein (Е. Эберлейн), J. Roller (Дж. Роллер), J. Muellera (Дж. Мюллер), препринт AES 3865, февраль 1994 г., Амстердам, в которой для того, чтобы достичь полной совместимости с предыдущими версиями, рассматриваются обратно совместимые режимы. С этой целью используется матрица совместимости, чтобы получить так называемые низведенные каналы Lc, Rc из исходных пяти входных каналов. Более того, возможно динамически выбирать три вспомогательных канала, переданных как служебные данные.
Для того чтобы использовать стереофоническую нерелевантность, методика квазистереофонии применяется к группам каналов, например трем передним каналам, т.е. для левого канала, правого канала и центрального канала. С этой целью эти три канала объединяются, чтобы получить комбинированный канал. Этот комбинированный канал квантуется и упаковывается в битовый поток.
Затем этот комбинированный канал вместе с соответствующей квазистереофонической информацией вводится в модуль декодирования квазистереофонии, чтобы получить декодированные каналы квазистереофонии, т.е. декодированный левый канал квазистереофонии, декодированный правый канал квазистереофонии и декодированный центральный канал квазистереофонии. Эти декодированные каналы квазистереофонии вместе с левым каналом окружающего звука и правым каналом окружающего звука вводятся в блок совместимости матриц для образования первого и второго низведенных каналов Lc, Rc. Затем квантованные варианты обоих низведенных каналов и квантованный вариант комбинированного канала пакуются в битовый поток вместе с параметрами кодирования квазистереофонии.
Используя мощное стереофоническое кодирование, следовательно, группа независимых исходных сигналов канала передается внутри одной части «высокочастотных» данных. Затем декодер восстанавливает включенные сигналы как идентичные данные, которые заново масштабируются согласно их исходных кривых энергии-времени. Следовательно, линейная комбинация переданных каналов приведет к результатам, которые совершенно отличны от исходного низведения. Это применяется к любому виду квазистереофонического кодирования, основанного на концепции мощной стереофонии. Для кодирующей системы, обеспечивающей совместимые низведенные каналы, существует прямое следствие: восстановление с помощью обратного матрицирования, как описано в предыдущей публикации, страдает от искажений, вызванных несовершенным восстановлением. Использование так называемой схемы предыскаженной квазистереофонии, в которой квазистереофоническое кодирование левого, правого и центрального каналов выполняется до матрицирования в кодере, смягчает эту проблему. Таким образом, схема обратного матрицирования для восстановления представляет меньше искажений, поскольку на стороне кодера декодированные квазистереофонические сигналы использованы для формирования низведенных каналов. Таким образом, несовершенный процесс восстановления смещается к совместимым низведенным каналам Lc и Rc, где более вероятно замаскироваться с помощью самого звукового сигнала.
Хотя такая система привела к меньшим искажениям из-за обратного матрицирования на стороне декодера, тем не менее она имеет некоторые недостатки. Недостаток в том, что стереофонически-совместимые низведенные каналы Lc и Rc выводятся не из исходных каналов, а из кодированных/декодированных с мощной стереофонией вариантов исходных каналов. Следовательно, потери данных из-за кодирующей системы с мощной стереофонией включаются в совместимые низведенные каналы. Только стереофонический декодер, который только декодирует совместимые каналы вместо улучшения кодированных каналов с мощной стереофонией, поэтому обеспечивает выходной сигнал, на который подвергается вынужденным потерям данных мощной стереофонии.
Кроме того, полный дополнительный канал должен быть передан помимо двух низведенных каналов. Этот канал является комбинированным каналом, который образуется посредством квазистереофонического кодирования левого канала, правого канала и центрального канала. Кроме того, информация о мощной стереофонии для восстановления исходных каналов L, R, C из комбинированного канала также должна быть передана декодеру. На декодере обратное матрицирование, т.е. операция дематрицирования выполняется для выведения каналов окружающего звука из двух низведенных каналов. Дополнительно, исходный левый, правый и центральный каналы оцениваются с помощью квазистереофонического декодирования, используя переданный комбинированный канал и переданные квазистереофонические параметры. Следует отметить, что исходный левый, правый и центральный каналы выводятся с помощью квазистереофонического декодирования комбинированного канала.
Обнаружено, что в случае методик мощной стереофонии, когда используемые в сочетании с многоканальными сигналами, могут быть созданы только полностью когерентные выходные сигналы, которые основаны на том же самом основном канале.
В методиках ВСС довольно дорого уменьшать межканальную когерентность в восстановленном многоканальном выходном сигнале, поскольку необходим генератор псевдослучайного числа для влияния на взвешивающие участки. Кроме того, показано, что этот вид обработки является проблематичным в тех искажениях, из-за того что могут быть привнесены случайно влияющие коэффициенты умножения или коэффициенты задержки времени, которые могут стать слышимыми при определенных обстоятельствах и, следовательно, ухудшать качество восстановленного многоканального исходного сигнала.
Сущность изобретения
Следовательно, задачей настоящего изобретения является предоставление концепции для обработки, эффективной по битам и с уменьшенными искажениями, или обратной обработки многоканального звукового сигнала.
В соответствии с первым аспектом настоящего изобретения эта задача решается с помощью устройства для создания многоканального выходного сигнала с использованием входного сигнала и параметрической дополнительной информации, при этом входной сигнал включает в себя первый входной канал и второй входной канал, выведенные из исходного многоканального сигнала, причем исходный многоканальный сигнал имеет множество каналов, при этом множество каналов включает в себя по меньшей мере два исходных канала, которые определяются как расположенные по одну сторону от предполагаемого расположения слушателя, причем первый исходный канал является первым из по меньшей мере двух исходных каналов, а второй канал является вторым из по меньшей мере двух исходных каналов, и параметрическая дополнительная информация описывает взаимосвязи между исходными каналами многоканального исходного сигнала, содержащего: исходный многоканальный сигнал; средство для определения первого основного канала путем выбора одного из первого и второго входных каналов или комбинации первого и второго входных каналов и для определения второго основного канала путем выбора оставшегося из первого и второго входных каналов или другой комбинации первого и второго входных каналов, так что второй основной канал отличается от первого основного канала; и средство для синтезирования первого выходного канала с использованием параметрической дополнительной информации и первого основного канала для получения первого синтезированного выходного канала, который является воспроизведенным вариантом первого исходного канала, который располагается по одну сторону от предполагаемого расположения слушателя, и для синтезирования второго выходного канала с использованием параметрической дополнительной информации и второго основного канала, при этом второй исходный канал является воспроизведенным вариантом второго исходного канала, который располагается на той же стороне от предполагаемого расположения слушателя.
В соответствии со вторым аспектом настоящего изобретения эта задача решается с помощью способа создания многоканального выходного сигнала с использованием входного сигнала и параметрической дополнительной информации, при этом входной сигнал включает в себя первый входной канал и второй входной канал, выведенные из исходного многоканального сигнала, причем исходный многоканальный сигнал имеет множество каналов, включающее в себя по меньшей мере два исходных канала, которые определяют как расположенные по одну сторону от предполагаемого расположения слушателя, причем первый исходный канал является первым из по меньшей мере двух исходных каналов, а второй исходный канал является вторым из по меньшей мере двух исходных каналов, и параметрическая дополнительная информация описывает взаимосвязи между исходными каналами многоканального исходного сигнала, заключающегося в том, что определяют первый основной канал путем выбора одного из первого и второго входных каналов или комбинации первого и второго входных каналов, и определяют второй основной канал путем выбора оставшегося из первого и второго входных каналов или другой комбинации первого и второго входных каналов, так что второй основной канал отличается от первого основного канала; и синтезируют первый выходной канал с использованием параметрической дополнительной информации и первого основного канала для получения первого синтезированного выходного канала, который является воспроизведенным вариантом первого исходного канала, который располагается по одну сторону от предполагаемого расположения слушателя, и синтезируют второй выходной канал с использованием параметрической дополнительной информации и второго основного канала, при этом второй выходной канал является воспроизведенным вариантом второго исходного канала, который располагается на той же стороне от предполагаемого расположения слушателя.
В соответствии с третьим аспектом настоящего изобретения эта задача решается с помощью устройства формирования низведенного сигнала из многоканального исходного сигнала, причем низведенный сигнал имеет количество каналов, меньшее чем количество исходных каналов, содержащего средство для расчета первого низведенного канала и второго низведенного канала с использованием правила низведения; средство для расчета параметрической информации уровня, представляющей распределение энергии между каналами в многоканальном исходном сигнале; средство для определения критерия когерентности между двумя исходными каналами, причем два исходных канала располагаются по одну сторону от предполагаемого расположения слушателя; и средство для образования выходного сигнала с использованием первого и второго низведенных каналов, параметрической информации уровня и только по меньшей мере одного критерия когерентности между двумя исходными каналами, расположенными на упомянутой одной стороне, или значения, выведенного из, по меньшей мере, одного критерия когерентности, но без использования какого-либо критерия когерентности между каналами, расположенными на различных сторонах от предполагаемого расположения слушателя.
В соответствии с четвертым аспектом настоящего изобретения эта задача решается с помощью способа формирования низведенного сигнала из многоканального исходного сигнала, причем низведенный сигнал имеет количество каналов, меньшее чем количество исходных каналов, заключающегося в том, что рассчитывают первый низведенный канал и второй низведенный канал, используя правило низведения; рассчитывают параметрическую информацию уровня, представляющей распределение энергии между каналами в многоканальном исходном сигнале; определяют критерий когерентности между двумя исходными каналами, причем два исходных канала располагают по одну сторону от предполагаемого расположения слушателя; и формируют выходной сигнал, используя первый и второй низведенные каналы, параметрическую информацию уровня и только по меньшей мере один критерий когерентности между двумя исходными каналами, расположенными на упомянутой одной стороне, или значение, выведенное, по меньшей мере, из одного критерия когерентности, но не используя какой-либо критерий когерентности между каналами, расположенными на различных сторонах от предполагаемого расположения слушателя.
В соответствии с пятым аспектом и шестым аспектом настоящего изобретения эта задача решается с помощью компьютерной программы, включающей в себя способ создания многоканального выходного сигнала либо способ формирования низведенного сигнала.
Настоящее изобретение основано на открытии, что эффективное и с уменьшенными искажениями восстановление многоканального выходного сигнала достигается, когда существуют два или более каналов, которые могут быть переданы от кодера к декодеру, причем каналы, которые предпочтительно являются левым и правым стереофоническим каналом, показывают определенную степень некогерентности. Это будет обычным случаем, поскольку левый и правый стереофонические каналы или левый и правый стереосовместимые каналы, которые получены путем низведения многоканального сигнала, будут в большинстве случаев показывать определенную степень некогерентности, т.е. не будут полностью когерентными или полностью коррелированными.
В соответствии с настоящим изобретением восстановленные выходные каналы многоканального выходного сигнала декоррелируются друг от друга с помощью определения различных основных каналов для различных выходных каналов, причем различные основные каналы получаются с помощью использования переменных степеней некоррелированных переданных каналов.
Другими словами, восстановленный выходной канал, имеющий, например, левый передаваемый входной канал в качестве основного канала, будет - в области поддиапазона ВСС - полностью коррелированным с другим восстановленным выходным каналом, который имеет тот же, например левый канал, в качестве основного канала, не предполагающего никакого дополнительного «синтеза корреляции». В этом контексте следует отметить, что детерминированная задержка и установки уровня не уменьшают когерентность между этими каналами. В соответствии с настоящим изобретением когерентность между этими каналами, которая составляет 100% в вышеприведенном примере, уменьшается на определенную степень когерентности, или критерий (меру) когерентности, путем использования первого основного канала для создания первого выходного канала и использования второго основного канала для создания второго выходного канала, причем первый и второй основные каналы имеют различные «доли» двух переданных (декоррелированных) каналов. Это означает, что первый основной канал сильнее находится под влиянием первого переданного канала или даже идентичен первому переданному каналу, по сравнению со вторым основным каналом, который меньше находится под влиянием первого канала, т.е. который находится под большим влиянием второго переданного канала.
В соответствии с настоящим изобретением внутренняя декорреляция между переданными каналами используется для предоставления декоррелированных каналов в многоканальном выходном сигнале.
В предпочтительном варианте осуществления критерий когерентности между соответствующими парами каналов, такими как передний левый и левый окружающего звука или передний правый или правый окружающего звука, определяется в кодере зависящим от времени и частотно-зависимым способом и передается как дополнительная информация в декодер согласно изобретению, так что могут быть достигнуты динамическое определение основных каналов и, следовательно, динамическое управление когерентностью между восстановленными выходными каналами.
В сравнении с вышеупомянутым случаем предшествующего уровня техники, в котором передается только сигнал ICC для двух наиболее сильных каналов, системе согласно изобретению легче управлять, и она обеспечивает восстановление лучшего качества, поскольку нет необходимости в определении самых сильных каналов в кодере или декодере, поскольку критерий когерентности согласно изобретению всегда относится к той же самой паре каналов независимо от факта, включает ли в себя эта пара каналов самые сильные каналы. Более высокое качество, сравнимое с системами предшествующего уровня техники, достигается в том, что два низведенных канала передаются от кодера в декодер так, что отношение левой/правой когерентности автоматически передается из условия, чтобы не требовалось никакой дополнительной информации о левой/правой когерентности.
Дополнительное преимущество настоящего изобретения следует видеть в том факте, что вычислительный объем работы на стороны декодера может быть уменьшен, поскольку нагрузка по обычной декоррелирующей обработке может быть уменьшена или даже полностью исключена.
Предпочтительно параметрическая дополнительная информация канала для одного или нескольких исходных каналов выводится из условия, что они относятся к одному из низведенных каналов, а не к дополнительному «комбинированному» квазистереофоническому каналу, как в предыдущем уровне техники. Это означает, что параметрическая дополнительная информация канала рассчитывается из условия, что на стороне декодера устройство восстановления канала использует дополнительную информацию канала и один из низведенных каналов или комбинацию низведенных каналов, чтобы восстановить приближенное значение исходного звукового канала, которому назначена дополнительная информация канала.
Эта концепция обладает преимуществом в том, что она обеспечивает многоканальное расширение, эффективное по битам, из условия, что многоканальный звуковой сигнал может быть воспроизведен на декодере.
Кроме того, концепция является обратно совместимой, поскольку декодер меньшего масштаба, который приспособлен только для двухканальной обработки, может просто пренебрегать информацией о расширении, т.е. дополнительной информацией канала. Декодер меньшего масштаба может только воспроизводить два низведенных канала, чтобы достичь стереофонического представления исходного многоканального звукового сигнала.
Однако декодер более высокого масштаба, который предназначен для многоканальной работы, может использовать переданную дополнительную информацию канала, чтобы восстановить приближенные значения исходных каналов.
Настоящий вариант осуществления обладает преимуществом в том, что он эффективнее по битам, поскольку в отличие от предыдущего уровня техники, не требуется дополнительного высокочастотного канала за первым и вторым низведенными каналами Lc, Rc. Вместо этого, дополнительная информация канала относится к одному или обоим низведенным каналам. Это означает, что низведенные каналы сами по себе служат как высокочастотные каналы, с которыми объединяется дополнительная информация канала, чтобы восстановить исходный звуковой канал. Это означает, что дополнительная информация канала является предпочтительно параметрической дополнительной информацией, т.е. информацией, которая не включает в себя какие-либо выборки поддиапазона или спектральные коэффициенты. Вместо этого параметрическая дополнительная информация является информацией, используемой для взвешивания (по времени и/или частоте) соответствующего низведенного сигнала или комбинации соответствующих низведенных каналов, чтобы получить восстановленный вариант выбранного исходного канала.
В предпочтительном варианте осуществления настоящего изобретения достигается обратно-совместимое кодирование многоканального сигнала на основе совместимого стереофонического сигнала. Предпочтительно, чтобы совместимый стереофонический сигнал (низведенный сигнал) формировался с использованием матрицирования исходных каналов многоканального звукового сигнала.
Предпочтительно, чтобы дополнительная информация канала для выбранного исходного канала получалась на основе квазистереофонических методик, таких как мощное стереофоническое кодирование или бинауральное кодирование сигнала. Таким образом, на стороне декодера не нужно выполнять никакой операции дематрицирования. Аннулируются проблемы, связанные с дематрицированием, т.е. определенные искажения, относящиеся к нежелательному распределению шума квантования в операциях дематрицирования. Это происходит вследствие того факта, что декодер использует устройство восстановления канала, который восстанавливает исходный сигнал посредством использования одного из низведенных каналов или комбинации низведенных каналов и переданной дополнительной информации канала.
Предпочтительно, чтобы изобретательская концепция применялась к многоканальному звуковому сигналу, имеющему пять каналов. Этими пятью каналами являются левый канал L, правый канал R, центральный канал C, левый канал Ls окружающего звука и правый канал Rs окружающего звука. Предпочтительно, чтобы низведенные каналы являлись стереофонически совместимыми низведенными каналами Ls и Rs, которые обеспечивают стереофоническое представление исходного многоканального звукового сигнала.
В соответствии с предпочтительным вариантом осуществления настоящего изобретения для каждого исходного канала дополнительная информация канала рассчитывается на стороне кодера, упакованная в выходные данные. Дополнительная информация канала для исходного левого канала выводится с использованием левого низведенного канала. Дополнительная информация канала для исходного левого канала окружающего звука выводится с использованием левого низведенного канала. Дополнительная информация канала для исходного правого канала выводится из правого низведенного канала. Дополнительная информация канала для исходного правого канала окружающего звука выводится из правого низведенного канала.
В соответствии с предпочтительным вариантом осуществления настоящего изобретения информация канала для исходного центрального канала выводится с использованием первого низведенного канала, а также второго низведенного канала, т.е. с использованием комбинации двух низведенных каналов. Предпочтительно, когда эта комбинация является суммированием.
Таким образом, группировки, т.е. связь между дополнительной информацией канала и сигналом несущей, т.е. используемый низведенный канал для предоставления дополнительной информацией канала для выбранного исходного канала, являются таковыми, что для оптимального качества выбирается определенный низведенный канал, который содержит максимальное относительное количество соответствующего исходного многоканального сигнала, который представляется посредством дополнительной информации канала. По существу, используются высокочастотный квазистереофонический сигнал, первый и второй низведенные каналы. Предпочтительно, когда также может использоваться сумма первого и второго низведенных каналов. Естественно, сумма первого и второго низведенных каналов может использоваться для расчета дополнительной информации канала для каждого из исходных каналов. Тем не менее предпочтительно, чтобы сумма низведенных каналов использовалась для расчета дополнительной информации канала о исходном центральном канале в объемном окружении, например пятиканальном окружении, семиканальном окружении, окружении 5.1 или окружении 7.1. Использование суммы первого и второго низведенных каналов является особенно выгодным, поскольку не нужно выполнять никакой дополнительной служебной передачи. Это благодаря тому обстоятельству, что оба низведенных канала присутствуют на декодере, так что суммирование этих низведенных каналов может быть легко выполнено в декодере без необходимости каких-либо дополнительных битов передачи.
Предпочтительно, чтобы дополнительная информация канала, образующая многоканальное расширение, вводилась в выходной поток битов данных совместимым образом из условия, что декодер меньшего масштаба просто игнорирует многоканальные данные о расширении и только предоставляет стереофоническое представление многоканального звукового сигнала.
Тем не менее, кодер более высокого масштаба не только использует два низведенных канала, но, кроме того, применяет дополнительную информацию канала для восстановления полного многоканального представления исходного звукового сигнала.
Краткое описание чертежей
Предпочтительные варианты осуществления настоящего изобретения последовательно описаны с помощью ссылок на прилагаемые чертежи, в которых:
Фиг.1А является блок-схемой предпочтительного варианта осуществления кодера согласно изобретению;
Фиг.1В является блок-схемой кодера согласно изобретению для предоставления критерия когерентности для соответствующих пар входных каналов;
Фиг.2А является блок-схемой предпочтительного варианта осуществления кодера согласно изобретению;
Фиг.2В является блок-схемой кодера согласно изобретению, имеющего разные основные каналы для разных выходных каналов;
Фиг.2С является блок-схемой предпочтительного варианта осуществления средства для синтезирования Фиг.2В;
Фиг.2D является блок-схемой предпочтительного варианта осуществления устройства, показанного на Фиг.2С для 5-канальной системы с объемным звучанием;
Фиг.2Е является схематическим представлением средства для определения критерия когерентности в кодере согласно изобретению;
Фиг.2F является схематическим представлением предпочтительного примера для определения весового коэффициента для расчета основного канала, имеющего определенный критерий когерентности по отношению к другому основному каналу;
Фиг.2G является схематической диаграммой предпочтительного способа получения восстановленного выходного канала на основе определенного весового коэффициента, рассчитанного посредством схемы, показанной на Фиг.2F;
Фиг.3А является блок-схемой для предпочтительной реализации средства для расчета, чтобы получить дополнительную информацию частотно-избирательного канала;
Фиг.3В является предпочтительным вариантом осуществления средства для расчета (калькулятора), реализующего квазистереофоническую обработку, например мощное кодирование или бинауральное кодирование сигнала;
Фиг.4 иллюстрирует другой предпочтительный вариант осуществления средства для расчета дополнительной информации канала, в которой дополнительной информацией канала являются коэффициенты усиления;
Фиг.5 иллюстрирует предпочтительный вариант осуществления реализации декодера, когда кодер реализуется как на Фиг.4;
Фиг.6 иллюстрирует предпочтительную реализацию средства для предоставления низведенных каналов;
Фиг.7 иллюстрирует группировки исходного и низведенного каналов для расчета дополнительной информации канала для соответствующих исходных каналов;
Фиг.8 иллюстрирует другой предпочтительный вариант осуществления кодера согласно изобретению;
Фиг.9 иллюстрирует другую реализацию кодера согласно изобретению; и
Фиг.10 иллюстрирует квазистереофонический кодер предшествующего уровня техники;
Фиг.11 является блок-схемой представления системы кодера/декодера ВСС предшествующего уровня техники;
Фиг.12 является блок-схемой реализации блока синтеза ВСС на Фиг.11 предшествующего уровня техники;
Фиг.13 является представлением хорошо известной схемы определения параметров ICLD, ICTD и ICC;
Фиг.14А является схематическим представлением схемы для присвоения атрибутов различным основным каналам для воспроизведения различных выходных каналов;
Фиг.14В является представлением пар каналов, необходимых для определения параметров ICC и ICTD;
Фиг.15А является схематичным представлением первого выбора основных каналов для создания 5-канального выходного сигнала; и
Фиг.15В является схематичным представлением второго выбора основных каналов для создания 5-канального выходного сигнала.
Подробное описание предпочтительных вариантов осуществления
Фиг.1А показывает устройство для обработки многоканального звукового сигнала 10, имеющего по меньшей мере три исходных канала, например R, L и C. Предпочтительно, чтобы исходный звуковой сигнал имел более трех каналов, например пять каналов в объемном окружении, которое проиллюстрировано на Фиг.1А. Пятью каналами являются левый канал L, правый канал R, центральный канал C, левый канал Ls окружающего звука и правый канал Rs окружающего звука. Устройство согласно изобретению включает в себя средство 12 для предоставления первого низведенного канала Lc и второго низведенного канала Rc, причем первый и второй низведенные каналы выводятся из исходных каналов. Для выведения низведенных каналов из исходных каналов существуют несколько возможностей. Одной возможностью является получение низведенных каналов Lc и Rc посредством матрицирования исходных каналов с использованием операции матрицирования, как проиллюстрировано на Фиг.6. Операция матрицирования выполняется во временной области.
Параметры a, b и t матрицирования выбираются из условия, чтобы они были меньше либо равны 1. Предпочтительно a и b равнялись 0,7 или 0,5. Суммарный весовой параметр t предпочтительно выбирается из условия, чтобы избежать урезания канала.
В качестве альтернативы, как это указывается на Фиг.1А, низведенные каналы Lc и Rc могут быть также подведены внешне. Это может быть сделано, когда низведенные каналы Lc и Rc являются результатом операции «смешивания вручную». В этом сценарии звукооператор смешивает низведенные каналы скорее самостоятельно, чем с помощью использования автоматической операции матрицирования. Звукооператор выполняет творческое смешивание для получения оптимизированных низведенных каналов Lc и Rc, которые дают наилучшее возможное стереофоническое представление исходного многоканального звукового сигнала.
В случае внешнего подведения низведенных каналов средство для предоставления не выполняет операцию матрицирования, но просто перенаправляет подведенные наружно низведенные каналы к следующему рассчитывающему средству 14.
Средство 14 расчета выполнено с возможностью расчета дополнительной информации канала, например li, lsi, ri или rsi для выбранных исходных каналов, например L, Ls, R или Rs соответственно. В частности, средство 14 для расчета выполнено с возможностью расчета дополнительной информации канала из условия, что низведенный канал, будучи взвешенным с использованием дополнительной информации канала, дает в результате приближенное значение выбранного исходного канала.
В качестве альтернативы или дополнительно средство для расчета дополнительной информации канала дополнительно выполнено с возможностью расчета дополнительной информации канала для выбранного исходного канала из условия, чтобы комбинированный низведенный канал, включающий в себя сочетание первого и второго низведенных каналов, будучи взвешенным с использованием рассчитанной дополнительной информации канала, дает в результате приближенное значение выбранного исходного канала.
Чтобы показать это свойство, на фигуре показаны сумматор 14а и калькулятор 14b дополнительной информации комбинированного канала.
Специалистам в данной области техники понятно, что эти элементы не нужно реализовывать как отдельные элементы. Вместо этого общие функциональные возможности блоков 14, 14а и 14b могут быть реализованы посредством определенного процессора, который может быть процессором общего назначения или любым другим средством для выполнения необходимых функциональных возможностей.
Кроме того, здесь следует отметить, что сигналы канала, будучи выборками поддиапазона или значениями частотной области, указываются заглавными буквами. Дополнительная информация канала указывается маленькими буквами, в отличие от самих каналов. Дополнительная информация ci канала, следовательно, является дополнительной информацией канала для исходного центрального канала С.
Дополнительная информация канала, а также низведенные каналы Lc и Rc или кодированный вариант Lc' и Rc', которые созданы звуковым кодером 16, вводятся в средство 18 форматирования выходных данных. Обычно средство 18 форматирования выходных данных действует как средство для формирования выходных данных, при этом выходные данные включают в себя дополнительную информацию канала, по меньшей мере, для одного исходного канала, первого низведенного канала или сигнала, выведенного из первого низведенного канала (например, его кодированный вариант) и второго низведенного канала или сигнала, выведенного из второго низведенного канала (например, его кодированный вариант).
Выходные данные или выходной битовый поток 20 могут затем быть переданы декодеру битового потока или могут быть сохранены или распространены. Предпочтительно, чтобы выходной битовый поток 20 являлся совместимым битовым потоком, который также может быть считан с помощью декодера меньшего масштаба, не имеющего возможности многоканального расширения. Такие кодеры меньшего масштаба, например большинство существующих mp3 декодеров обычного уровня техники, будут просто игнорировать многоканальные данные расширения, т.е. дополнительную информацию канала. Они будут только декодировать первый и второй низведенные каналы, чтобы создать стереофонический выход. Декодеры более высокого масштаба, например декодеры с многоканальной возможностью, будут считывать дополнительную информацию канала, и затем сформируют приближенное значение исходных звуковых каналов из условия, чтобы получался многоканальный звуковой эффект.
Фиг.8 показывает предпочтительный вариант осуществления настоящего изобретения в окружении пяти каналов объемного звука/mp3. Здесь предпочтительно записывать данные улучшения окружения в поле служебных данных в стандартизированном синтаксе потока двоичных сигналов mp3 из условия, что получается поток двоичных сигналов «окружения mp3».
Фиг.1В иллюстрирует более подробное представление элемента 14 в Фиг.1А. В предпочтительном варианте осуществления настоящего изобретения калькулятор 14 включает в себя средство 141 для расчета параметрической информации уровня, представляющей собой распределение энергии между каналами в многоканальном исходном сигнале, показанном на 10 в Фиг.1А. Элемент 141, следовательно, способен формировать выходную информацию уровня для всех исходных каналов. В предпочтительном варианте осуществления эта информация уровня включает в себя параметры ICLD, полученные посредством обычного синтеза ВСС, как описано применительно к Фиг.10 по Фиг.13.
Элемент 14 дополнительно содержит средство 142 для определения критерия когерентности между двумя исходными каналами, расположенными по одну сторону от предполагаемого расположения слушателя. В случае примера 5-канального окружения, показанного на Фиг.1А, такая пара каналов включает в себя правый канал R и правый канал Rs окружающего звука или, в альтернативном варианте или дополнительно, левый канал L и левый канал Ls окружающего звука. В альтернативном варианте элемент 14 дополнительно содержит средство 143 для расчета разности времени для такой пары каналов, т.е. пары каналов, имеющей каналы, которые располагаются по одну сторону от предполагаемого расположения слушателя.
Средство 18 форматирования выходных данных из Фиг.1А выполнено с возможностью ввода в поток данных на 20 информации уровня, представляющей распределение энергии между каналами в многоканальном исходном сигнале, и критерия когерентности только для пары левого канала и левого канала окружающего звука и/или пары правого канала и правого канала окружающего звука. Однако средство форматирования выходных данных предназначено не для включения в себя каких-либо других критериев когерентности, или необязательно разниц времени в выходной сигнал из условия, чтобы объем дополнительной информации уменьшался по сравнению со схемой предшествующего уровня техники, в которой сигналы ICC передавались для всех возможных пар каналов.
Чтобы проиллюстрировать кодер согласно изобретению, который показан на Фиг.1В, подробнее, сделана ссылка на Фиг.14А и Фиг.14В. На Фиг.14А размещение динамиков каналов для примера 5-канальной системы дается в отношении расположения предполагаемого местоположения слушателя, которое находится в центральной точке окружности, на которую помещены соответствующие динамики. Как очерчено выше, 5-канальная система включает в себя левый канал окружающего звука, левый канал, центральный канал, правый канал и правый канал окружающего звука. Конечно, такая система может также включать в себя низкочастотный канал, который не показан на Фиг.14.
Здесь следует отметить, что левый канал окружающего звука может также быть обозначен как «тыловой левый канал». То же самое справедливо для правого канала окружающего звука. Этот канал также известен как тыловой правый канал.
В отличие от уровня техники ВСС с одним каналом передачи, в котором тот же основной канал, т.е. переданный монофонический сигнал, который показан на Фиг.11, используется для формирования каждого из N выходных каналов, система согласно изобретению использует в качестве основного канала один из N переданных каналов либо линейную комбинацию из них как основной канал для каждого из N выходных каналов.
Следовательно, Фиг.14 показывает схему N-к-M, т.е. схему, в которой N исходных каналов низводятся в два низведенных канала. В примере Фиг.14 N равен 5, в то время как M равен 2. В частности, для восстановления переднего левого канала используется переданный левый канал Lc. Аналогично, для восстановления переднего правого канала второй переданный канал Rc используется в качестве основного канала. Кроме того, одинаковое сочетание Lc и Rc используется в качестве основного канала для восстановления центрального канала. В соответствии с вариантом осуществления настоящего изобретения, критерии когерентности дополнительно передаются из кодера к декодеру. Следовательно, для левого канала окружающего звука используется не только переданный левый канал Lc, но и переданный канал Lc + α1Rc из условия, что основной канал для восстановления левого канала окружающего звука не является полностью когерентным с основным каналом для восстановления переднего левого канала. Аналогично, та же самая процедура выполняется для правой стороны (относительно предполагаемого расположения слушателя), в которой основной канал для восстановления правого канала окружающего звука отличается от основного канала для восстановления переднего правого канала, где разница зависит от критерия α2 когерентности, который предпочтительно передается от кодера к декодеру в качестве дополнительной информации.
Следовательно, процесс согласно изобретению является уникальным в том, что для воспроизведения предпочтительно каждого выходного канала используется различный основной канал, причем основные каналы идентичны переданным каналам или их линейной комбинации. Эта линейная комбинация может зависеть от переданных основных каналов с переменными степенями, где эти степени зависят от критериев когерентности, которые зависят от исходного многоканального сигнала.
Процесс получения N основных каналов, заданных M передаваемыми каналами, называется «возведением» (upmix-процесс, обратный downmix). Это возведение может быть реализовано с помощью умножения вектора с переданными каналами посредством матрицы N×M, чтобы сформировать N основных каналов.
Поступая так, линейные комбинации переданных сигнальных каналов образуются для выпуска основных сигналов для выходных сигналов канала.
Отдельный пример для возведения показывается на Фиг.14А, который является схемой 5-к-2, примененной для формирования 5-канального выходного сигнала окружающего звука с 2-канальной стереофонической передачей. Предпочтительно, чтобы основной канал для дополнительного низкочастотного выходного канала являлся тем же, что и центральный канал L+R. В предпочтительном варианте осуществления настоящего изобретения зависящий от времени и - необязательно - переменный по частоте критерий когерентности предоставлялся из условия, чтобы получалась приспосабливающаяся ко времени матрица возведения, которая - необязательно - также является частотно-избирательной.
Далее сделана ссылка на Фиг.14В, показывающую предшествующий уровень для реализации кодера согласно изобретению, проиллюстрированной на Фиг.1В. В этом контексте, следует отметить, что сигналы ICC и ICTD между левым и правым и левым окружающего звука и правым окружающего звука являются теми же самыми, что и в переданном стереофоническом сигнале. Таким образом, в соответствии с настоящим изобретением, нет необходимости в использовании сигналов ICC и ICTD между левым и правым и левым окружающего звука и правым окружающего звука для синтезирования или восстановления выходного сигнала. Другой причиной для отсутствия синтезирования сигналов ICC и ICTD между левым и правым и левым окружающего звука и правым окружающего звука является общее объективное утверждение, что основные каналы должны быть модифицированы как можно меньше, чтобы сохранять максимальное качество сигнала. Любая модификация сигнала потенциально вносит искажения или неестественность.
Следовательно, предусмотрено только представление уровня исходного многоканального сигнала, которое достигается с помощью предоставления сигналов ICLD, тогда как в соответствии с настоящим изобретением параметры ICC и ICTD только рассчитываются и передаются для пар каналов на одной стороне от предполагаемого расположения слушателя. Это проиллюстрировано с помощью пунктирной линии 144 для левой стороны и пунктирной линии 145 для правой стороны на Фиг.14В. В отличие от ICC и ICTD, синтез ICLD гораздо менее проблематичен в отношении искажений и неестественности, так как он только содержит масштабирование сигналов поддиапазона. Таким образом, ICLD синтезируются также обычно, как и в традиционном ВСС, т.е. между опорным каналом и всеми остальными каналами. Говоря в более общем смысле, в схеме N-к-M ICLD синтезируются между парами каналов аналогично обычному ВСС. Однако сигналы ICC и ICTD, в соответствии с настоящим изобретением, синтезируются только между парами каналов, которые находятся на той же стороне относительно предполагаемого расположения слушателя, т.е. для пары каналов, включающей в себя передний левый и левый канал окружающего звука, или пары каналов, включающей в себя передний правый и правый канал окружающего звука.
В случае 7-канального или более высоких систем с объемным звучанием, в которых имеется три канала на левой стороне и три канала на правой стороне, может применяться та же схема, где только для возможных пар каналов на левой стороне или на правой стороне, параметры когерентности передаются для предоставления различных основных каналов для восстановления различных выходных каналов на одной стороне от предполагаемого расположения слушателя. Кодер N-к-M согласно изобретению, который показан на Фиг.1А и Фиг.1В, следовательно, уникален в том, что входные сигналы низводятся не в один единый канал, а в M каналов, и эти сигналы ICTD и ICC оцениваются и передаются только между парами каналов, для которых это необходимо.
В 5-канальной системе с объемным звучанием ситуация показывается на Фиг.14В, из которой становится понятно, что по меньшей мере один критерий когерентности должен быть передан между левым и левым окружающего звука. Этот критерий когерентности может быть также использован для предоставления декорреляции между правым и правым окружающего звука. Это реализация младшей дополнительной информации. Если имеется большая доступная пропускная способность канала, то можно также формировать и передавать отдельный критерий когерентности между правым и правым каналом окружающего звука из условия, чтобы в декодере согласно изобретению также могли получаться различные степени декорреляции на левой стороне и на правой стороне.
Фиг.2А показывает иллюстрацию декодера согласно изобретению, функционирующего как устройство для обратной обработки входных данных, принятых во входном порте 22 данных. Данные, принятые в входном порте 22 данных, являются теми же данными, что и выход на выходном порте 20 данных на Фиг.1А. В качестве альтернативы, когда данные не передаются через проводной канал, а через беспроводной канал, данные, принятые в выходном порте 22 данных, являются данными, выведенными из исходных данных, выпущенных кодером.
Входные данные декодера вводятся в считывающее устройство 24 потока данных для считывания входных данных, чтобы окончательно получить дополнительную информацию 26 канала и левый низведенный канал 28 и правый низведенный канал 30. В случае, если входные данные включают в себя кодированные варианты низведенных каналов, которые соответствуют случаю, в котором звуковой кодер 16 присутствует на Фиг.1А, то считывающее устройство 24 потока данных также включает в себя звуковой декодер, который приспособлен к звуковому кодеру, используемому для кодирования низведенных каналов. В этом случае звуковой декодер, который является частью считывающего устройства 24 потока данных, выполнен с возможностью формирования первого низведенного канала Lc и второго низведенного канала Rc, или как установлено более точно, декодированного варианта этих каналов. Для облегчения описания разграничение между сигналами и их декодированными вариантами сделано лишь, где это ясно сформулировано.
Дополнительная информация 26 канала и левый и правый низведенные каналы 28 и 30, выведенные считывающим устройством 24 потока данных, направляются в устройство 32 многоканального восстановления для предоставления восстановленного варианта 34 исходных звуковых сигналов, которые могут быть воспроизведены посредством многоканального проигрывателя 36. Если устройство многоканального восстановления функционирует в частотной области, многоканальный проигрыватель 36 примет входные данные частотной области, которые должны быть определенным образом декодированы, например, преобразованы во временную область перед их воспроизведением. С этой целью многоканальный проигрыватель 36 может также включать в себя декодирующее оборудование.
Здесь следует заметить, что декодер меньшего масштаба будет лишь иметь считывающее устройство 24 потока данных, которое только выводит левый и правый низведенные каналы 28 и 30 на стереофонический выход 38. Однако улучшенный декодер согласно изобретению будет извлекать дополнительную информацию 26 канала и использовать эту дополнительную информацию и низведенные каналы 28 и 30 для восстановления восстановленных вариантов 34 исходных каналов, используя устройство 32 многоканального восстановления.
Фиг.2В показывает реализацию согласно изобретению устройства 32 многоканального восстановления на Фиг.2А. Следовательно, Фиг.2В показывает устройство для создания многоканального выходного сигнала, используя входной сигнал и параметрическую дополнительную информацию, причем входной сигнал включает в себя первый входной канал и второй входной канал, выведенные из исходного многоканального сигнала, и параметрическая дополнительная информация описывает взаимосвязи между каналами многоканального исходного сигнала. Устройство согласно изобретению, показанное на Фиг.2В, включает в себя средство 320 для предоставления критерия когерентности, зависящего от первого исходного канала и второго исходного канала, причем первый исходный канал и второй исходный канал включаются в исходный многоканальный сигнал. Если критерий когерентности включается в параметрическую дополнительную информацию, то параметрическая дополнительная информация вводится в средство 320, которое проиллюстрировано на Фиг.2В. Критерий когерентности, предоставляемый средством 320, вводится в средство 322 для определения основных каналов. В частности, средство 322 выполнено с возможностью определения первого основного канала посредством выбора одного из первого и второго входных каналов или заранее определенного сочетания первого и второго входных каналов. Средство 322 дополнительно выполнено с возможностью определения второго основного канала, используя критерий когерентности из условия, чтобы второй основной канал отличался от первого основного канала вследствие критерия когерентности. В примере, показанном на Фиг.2В, который относится к 5-канальной системе с объемным звучанием, первый входной канал является левым совместимым стереофоническим каналом Lc; и второй входной канал является правым совместимым стереофоническим каналом Rc. Средство 322 выполнено с возможностью определения основных каналов, которые уже описаны применительно к Фиг.14А. Таким образом, на выходе средства 322 получается отдельный основной канал для каждого из подлежащих восстановлению выходных каналов, где предпочтительно, чтобы основные каналы, выведенные средством 322, все отличались друг от друга, т.е. имели критерий когерентности между ими самими, который отличается для каждой пары.
Основные каналы, выводимые средством 322, и параметрическая дополнительная информация, например ICLD, ICTD или информация о мощной стереофонии вводятся в средство 324 для синтезирования первого выходного канала, например L, используя параметрическую дополнительную информацию и первый основной канал для получения первого синтезированного выходного канала L, который является воспроизведенным вариантом соответствующего первого исходного канала, и для синтезирования второго выходного канала, например Ls, используя параметрическую дополнительную информацию и второй основной канал, причем второй выходной канал является воспроизведенным вариантом второго исходного канала. Кроме того, средство 324 для синтезирования выполнено с возможностью воспроизведения правого канала R и правого канала Rs окружающего звука, используя другую пару основных каналов, причем основные каналы в этой другой паре отличаются друг от друга вследствие критерия когерентности или вследствие дополнительного критерия когерентности, который выведен для пары каналов правого/правого окружающего звука.
Более подробная реализация декодера согласно изобретению показывается на Фиг.2С. Можно увидеть, что в предпочтительном варианте осуществления, который показывается на Фиг.2С, общая структура сходна со структурой, которая уже описана применительно к Фиг.12 для уровня техники, предшествующего уровню техники декодера ВСС. Несмотря на Фиг.12, схема согласно изобретению, показанная на Фиг.2С, включает в себя две звуковые гребенки фильтров, т.е. одна гребенка фильтров для каждого входного сигнала. Конечно, единственная гребенка фильтров также является достаточной. В этом случае необходимо управление, которое вводит в единственную гребенку фильтров входные сигналы в последовательном порядке. Гребенка фильтров иллюстрируется блоками 319а и 319b. Функциональность элементов 320 и 322, которые проиллюстрированы на Фиг.2В, включается в блок 323 возведения на Фиг.2С.
На выходе блока 323 возведения получаются основные каналы, которые отличаются друг от друга. Это в отличие от Фиг.12, на которой основные каналы на узле 130 являются идентичными друг другу. Средство 324 синтезирования, показанное на Фиг.2В, включает в себя предпочтительно этап 324а задержки, этап 324b модификации уровня и, в некоторых случаях, этап 324с обработки для выполнения дополнительных задач обработки, а также соответствующее количество обратных звуковых гребенок 324d фильтров. В одном варианте осуществления функциональность элементов 324а, 324b, 324c и 324d может быть той же, что и в устройстве предшествующего уровня техники, описанного применительно к Фиг.12.
Фиг.2D показывает более подробный пример Фиг.2С для настройки 5-канального окружения, в котором два входных канала y1 и y2 являются входом, и получаются пять созданных выходных каналов, как показано на Фиг.2D. В отличие от Фиг.2С дается более подробная модель блока 323 возведения. В частности, показывается устройство 330 суммирования для предоставления основных каналов для восстановления центрального выходного канала. Кроме того, два блока 331, 332, озаглавленные «W», показываются на Фиг.2D. Эти блоки выполняют взвешенную комбинацию двух входных каналов на основе критерия К когерентности, который вводится во вход 334 критерия когерентности. Предпочтительно, чтобы блок 331 или 332 взвешивания также выполнял соответствующие операции постобработки для основных каналов, например, сглаживание во времени и частоте, как будет очерчено ниже. Таким образом, Фиг.2С является общим случаем Фиг.2D, где Фиг.2С иллюстрирует, как формируются N выходных каналов, заданные M входными каналами декодера. Переданные сигналы преобразуются в область поддиапазона.
Процесс вычисления основных каналов для каждого выходного канала обозначается возведением, так как каждый основной канал является предпочтительно линейной комбинацией переданных каналов. Возведение может быть выполнено во временной области или в поддиапазоне или в частотной области.
Для вычисления каждого основного канала может применяться определенная обработка для уменьшения влияний прекращения/усиления, когда переданные каналы являются несовпадающими по фазе или синфазными. ICTD синтезируются с помощью налагаемых задержек на сигналы поддиапазона, а ICLD синтезируются посредством масштабирования сигналов поддиапазона. Различные методики могут использоваться для синтезирования ICC, например управление весовыми коэффициентами или временными задержками посредством последовательности случайных чисел. Однако здесь следует отметить, что предпочтительно не выполняется когерентной/коррелируемой обработки между выходными каналами, за исключением определения согласно изобретению различных основных каналов для каждого выходного канала. Следовательно, предпочтительное устройство согласно изобретению обрабатывает сигналы ICC, принятые от кодера для создания основных каналов, и сигналы ICTD и ICLD, принятые от кодера для управления уже созданным основным каналом. Таким образом, сигналы ICC или - говоря более общо - критерии когерентности не используются для управления основным каналом, но используются для создания основного канала, который управляется позднее.
В отдельном примере, показанном на Фиг.2D, 5-канальный сигнал окружающего звука декодируется из 2-канальной стереофонической передачи. Переданный 2-канальный стереофонический сигнал преобразуется в область поддиапазона. Затем применяется возведение для формирования пяти предпочтительных основных каналов. Сигналы ICTD синтезируются только между левым и левым окружающего звука и правым и правым окружающего звука посредством применения задержек di (k), как обсуждалось применительно к Фиг.14В. Также критерии когерентности скорее используются для создания основных каналов (блоки 331 и 332) на Фиг.2D, чем для выполнения какой-либо постобработки в блоке 324с.
Согласно изобретению сигналы ICC и ICTD между левым и правым и левым окружающего звука и правым окружающего звука поддерживаются как в переданном стереофоническом сигнале. Следовательно, параметр единственного сигнала ICC и единственного сигнала ICTD будет достаточным и, следовательно, будет передан от кодера к декодеру.
В другом варианте осуществления сигналы ICC и сигналы ICTD для обеих сторон могут быть рассчитаны в кодере. Эти два значения могут быть переданы от кодера к декодеру. В качестве альтернативы кодер может вычислить результирующий сигнал ICC или ICTD посредством ввода сигналов для обеих сторон в математическую функцию, например, усредняющую функцию и т.д., для выведения результирующей величины из двух критериев когерентности.
Далее сделана ссылка на Фиг.15А и 15В для показа реализации, изобретательской концепции с низкой сложностью. Хотя реализация с высокой сложностью требует определения на стороне кодера критерия когерентности, по меньшей мере, между парой каналов на одной стороне от предполагаемого расположения слушателя и передачи этого критерия когерентности предпочтительно в квантованном и кодированном с энтропией виде, вариант с низкой сложностью не требует определения какого-либо критерия когерентности на стороне кодера и какой-либо передачи от кодера к декодеру такой информации. Тем не менее, для того чтобы достичь хорошего субъективного качества восстановленного многоканального выходного сигнала, заранее определенный критерий когерентности или, формулируя другими словами, заранее определенные весовые коэффициенты для определения весовой комбинации переданных входных каналов, используя такой заранее определенный весовой коэффициент, предусматривается средством 324 на Фиг.2D. Существует несколько возможностей для уменьшения когерентности в основных каналах для восстановления выходных каналов. Без критерия согласно изобретению соответствующие выходные каналы были бы полностью когерентными в базовой реализации, в которой никакие ICC и ICTD не закодированы и не передаются. Следовательно, любое использование заранее определенного критерия когерентности уменьшит когерентность в восстановленных выходных сигналах из условия, что воспроизведенные выходные сигналы являются лучшими приближенными значениями соответствующих исходных каналов.
Следовательно, чтобы избежать того, что основные каналы являются полностью когерентными, осуществляется возведение, как показано для примера на Фиг.15А в качестве одной альтернативы или Фиг.15В в качестве другой альтернативы. Пять основных каналов вычисляются из условия, чтобы никакой из них не являлся полностью когерентным, если переданный стереофонический сигнал также не является полностью когерентным. Это приводит к тому, что межканальная когерентность между левым каналом и левым каналом окружающего звука или между правым каналом и правым каналом окружающего звука автоматически уменьшается, когда межканальная когерентность между левым каналом и правым каналом уменьшается. Например, для звукового сигнала, который независим между всеми каналами, например подтверждающий сигнал, такое возведение имеет преимущество в том, что определенная независимость между левым и левым окружающего звука и правым и правым окружающего звука формируется без необходимости синтезирования (и кодирования) явной межканальной когерентности. Конечно, этот второй вариант возведения может быть объединен со схемой, которая еще синтезирует ICC и ICTD.
Фиг.15А показывает возведение, оптимизированное для переднего левого и переднего правого, в котором поддерживается наибольшая независимость между передним левым и передним правым.
Фиг.15В показывает другой пример, в котором передний левый и передний правый с одной стороны, и левый окружающего звука и правый окружающего звука с другой стороны обрабатываются тем же способом, в котором степень независимости переднего и тылового каналов является одинаковой. Это можно увидеть на Фиг.15В с помощью факта, что угол между передним левым/правым является тем же, что и угол между левым окружающего звука/правым.
В соответствии с предпочтительным вариантом осуществления настоящего изобретения используется динамическое возведение вместо статического выбора. С этой целью изобретение также относится к улучшенному алгоритму, который может динамически приспосабливать матрицу возведения для того, чтобы оптимизировать динамическую характеристику. В примере, проиллюстрированном далее, матрица возведения может выбираться для обратных каналов из условия, чтобы становилось возможным оптимальное воспроизведение передней/тыловой когерентности. Алгоритм согласно изобретению содержит следующие этапы:
Для передних каналов используется простое назначение основных каналов, как описанное на Фиг.14А или 15А. С помощью этого простого выбора сохраняется когерентность каналов вдоль левой/правой оси.
В кодере значения передней/тыловой когерентности, например сигналы ICC, измеряются между парами левый/левый окружающего звука и предпочтительно между правый/правый окружающего звука.
В декодере основные каналы для левого тылового и правого тылового каналов определяются с помощью создания линейных комбинаций переданных сигналов каналов, т.е. переданного левого канала и переданного правого канала. В особенности коэффициенты возведения определяются из условия, чтобы фактическая когерентность между левым и левым окружающего звука и правым и правым окружающего звука достигала значений, измеренных в кодере. Для практических целей это может быть достигнуто, когда переданные сигналы каналов показывают достаточные декорреляции, что обычно является фактом в обычных 5-канальных сценариях.
В предпочтительном варианте осуществления динамического возведения будет приведен пример реализации, который рассматривается в качестве лучшего варианта осуществления настоящего изобретения, по отношению к Фиг.2Е как к реализации кодера и Фиг.2F и Фиг.2G по отношению к реализации декодера. Фиг.2E показывает один пример для измерения передних/тыловых значений когерентности (значений ICC) между левым и левым каналом окружающего звука или между правым и правым каналом окружающего звука, т.е. между парой каналов, расположенной на одной стороне относительно предполагаемого расположения слушателя.
Равенство, показанное в прямоугольнике на Фиг.2Е, дает критерий cc когерентности между первым каналом x и вторым каналом y. В одном случае первый канал x является левым каналом, в то время как второй канал y является левым каналом окружающего звука. В другом случае первый канал x является правым каналом, в то время как второй канал y является правым каналом окружающего звука. xi обозначает пример соответствующего канала x в случае i времени, в то время как yi обозначает пример в случае времени другого исходного канала y. Здесь следует отметить, что критерий когерентности может быть рассчитан полностью во временной области. В этом случае индекс i суммирования продолжается от нижней границы до верхней границы, где другая граница обычно является той же, что и количество выборок в одном кадре в случае покадровой обработки.
В качестве альтернативы критерии когерентности также могут быть рассчитаны между сигналами полосы пропускания, т.е. сигналами, имеющими уменьшенную ширину полосы по отношению к исходному звуковому сигналу. В последнем случае критерий когерентности является не только зависящим от времени, но также и частотно-зависимым. Результирующие передние/тыловые сигналы ICC, т.е. CC1 для левой передней/тыловой когерентности и CCr для правой передней/тыловой когерентности передаются декодеру как параметрическая дополнительная информация, предпочтительно в квантованном и кодированном виде.
Далее будет сделана ссылка на Фиг.2F для показа предпочтительной схемы возведения декодера. В проиллюстрированном случае переданный левый канал сохраняется как основной канал для левого выходного канала. Для того чтобы вывести основной канал для левого тылового выходного канала, определяется линейная комбинация между левым (l) и правым (r) переданным каналом, т.е. l + αr. Весовой коэффициент α определяется из условия, чтобы взаимная корреляция между l и l + αr была равна переданному желаемому значению CCl для левой стороны и CCr для правой стороны, или вообще критерию k когерентности.
Расчет соответствующего значения описывается на Фиг.2F. В частности, нормированная взаимная корреляция двух сигналов l и r определяется, как показано в равенстве в блоке Фиг.2Е.
При заданных двух переданных сигналах l и r весовой коэффициент α нужно определить из условия, чтобы нормированная взаимная корреляция сигнала l и l + αr равнялась желаемому значению k, т.е. критерию когерентности. Этот критерий определяется между -1 и +1.
Используя определение взаимной корреляции для двух каналов, получается равенство, данное на Фиг.2F для значения k. Используя некоторые сокращения, которые приводятся внизу Фиг.2F, условие для k может быть переписано как квадратичное уравнение, решение которого дает весовой коэффициент α.
Может быть показано, что уравнение всегда имеет решение с действительными значениями, т.е. что дискриминант гарантированно неотрицательный.
В зависимости от основной взаимной корреляции сигнала l и r и от желаемой взаимной корреляции k, одно из двух высказанных решений может в действительности привести к отрицательному желаемому значению взаимной корреляции и, следовательно, отбрасывается для всего дальнейшего расчета.
После расчета сигнала основного канала, как линейной комбинации сигнала l и сигнала r, результирующий сигнал нормируется (изменяется масштаб) по энергии исходного сигнала переданного сигнала l или r канала.
Аналогично, сигнал основного канала для правого выходного канала может быть выведен путем переставления роли левого и правого каналов, т.е. принимая во внимание взаимную корреляцию между r и r + αl.
На практике предпочтительно сглаживать результаты процесса расчета для значения α по времени и частоте для того, чтобы достичь максимального качества сигнала. Также измерения передней/тыловой корреляции по-другому, чем левой/левой тыловой и правой/правой тыловой могут использоваться для дополнительной максимизации качества сигнала.
Впоследствии будет дано пошаговое описание функциональности, выполняемой устройством 32 многоканального восстановления из Фиг.2А, со ссылкой на Фиг.2G.
Предпочтительно весовой коэффициент α вычисляется (200) на основе динамического критерия когерентности, предоставленного от кодера к декодеру, или на основе статичного обеспечения критерия когерентности, как описано применительно к Фиг.15А и Фиг.15В. Затем весовой коэффициент сглаживается по времени и/или частоте (этап 202), чтобы получить сглаженный весовой коэффициент αs. Затем основной канал b вычисляется, как, например, l + αsr (этап 204). Основной канал b затем используется вместе с другими основными каналами для расчета необработанных выходных сигналов.
Как становится ясно из блока 206, представление уровня ICLD, так же как и представление задержки ICTD, требуется для расчета необработанных выходных сигналов. Затем необработанные выходные сигналы масштабируются, чтобы обладать той же энергией, что и сумма отдельных энергий левого и правого входных каналов. Изложенные другими словами, необработанные выходные сигналы масштабируются посредством коэффициента масштабирования из условия, чтобы сумма отдельных энергий масштабированных необработанных сигналов была той же, что и сумма отдельных энергий переданного левого и правого входных каналов.
В качестве альтернативы можно также вычислять сумму левого и правого переданных каналов и использовать энергию результирующего сигнала. Кроме того, можно также вычислять суммарный сигнал посредством примерного метода, суммирующего выходные сигналы, и использовать энергию результирующего сигнала для целей масштабирования.
Затем на выходе блока 208 получаются восстановленные выходные каналы, которые являются уникальными в том, что ни один из восстановленных выходных каналов не является полностью когерентным к другим восстановленным выходным каналам из условия, что получается максимальное качество воспроизводимого выходного сигнала.
Чтобы подвести итог, изобретательская концепция является выгодной в том, что может быть использовано произвольное число (M) переданных каналов и производное число (N) выходных каналов.
Кроме того, преобразование между переданными каналами и основными каналами для выходных каналов осуществляется предпочтительно через динамическое возведение.
В существенном варианте осуществления возведение состоит из умножения с помощью матрицы возведения, т.е. образования линейных комбинаций переданных каналов, где передние каналы предпочтительно синтезируются с использованием соответствующих переданных основных каналов в качестве основных каналов, тогда как тыловые каналы состоят из линейной комбинации переданных каналов, причем степень линейной комбинации зависит от критерия когерентности.
Кроме того, этот процесс возведения предпочтительно выполняется адаптировано к сигналу зависящим от времени способом. В особенности процесс возведения предпочтительно зависит от дополнительной информации, переданной от кодера ВСС, например сигналы межканальной когерентности для передней/тыловой когерентности.
Если задан основной канал для каждого выходного канала, то применяется обработка, аналогичная обычному бинауральному кодированию сигнала для синтезирования пространственных сигналов, т.е. применение масштабирований и задержек в поддиапазонах и применение методик для снижения когерентности между каналами, где каналы ICC используются дополнительно или в качестве альтернативы для создания соответствующих основных каналов, чтобы получить оптимальное воспроизведение передней/тыловой когерентности.
Фиг.3А показывает вариант осуществления калькулятора 14 согласно изобретению для расчета дополнительной информации канала, с которой звуковой кодер с одной стороны и калькулятор дополнительной информации канала с другой стороны функционируют на том же спектральном представлении многоканального сигнала. Фиг.1, однако, показывает другую альтернативу, в которой звуковой кодер с одной стороны и калькулятор дополнительной информации канала с другой стороны функционируют на разных спектральных представлениях многоканального сигнала. Когда вычислительные ресурсы не так важны, как качество звука, предпочтительна альтернатива Фиг.1А, поскольку могут быть использованы гребенки фильтров, индивидуально оптимизированные для звукового кодирования и расчета дополнительной информации. Когда, однако, вычислительные ресурсы являются результатом, предпочтительна альтернатива Фиг.3А, поскольку эта альтернатива требует меньше вычислительной мощности вследствие совместного использования элементов.
Устройство, показанное на Фиг.3А, выполнено с возможностью приема двух каналов А, В. Устройство, показанное на Фиг.3А, выполнено с возможностью расчета дополнительной информации для канала В из условия, чтобы с использованием этой дополнительной информации канала для выбранного исходного канала В мог быть рассчитан восстановленный вариант канала В из сигнала канала А. Кроме того, показанное на Фиг.3А устройство выполнено с возможностью формирования дополнительной информации канала частотной области, например параметров для взвешивания (посредством умножения или временной обработки, как, например, в кодировании ВСС) спектральных значений или выборок поддиапазона. С этой целью калькулятор согласно изобретению включает в себя средство 140а кодирования и преобразования времени/частоты, чтобы получить частотное представление канала А на выходе 140b или представления частотной области канала В на выходе 140c.
В предпочтительном варианте осуществления определение дополнительной информации (посредством средства 140f определения дополнительной информации) выполняется, используя квантованные спектральные значения. Тогда квантователь 140d также присутствует, который предпочтительно управляется с использованием психоакустической модели, имеющей вход 140е управления психоакустической моделью. Тем не менее, квантователь не требуется, когда средство 140с определения дополнительной информации использует неквантованное представление канала А для определения дополнительной информации канала для канала В.
Если дополнительная информация канала для канала В рассчитывается посредством представления частотной области канала А и представления частотной области канала В, средство 140а кодирования и преобразования времени/частоты может быть тем же, что и используемое в звуковом кодере на основе гребенки фильтров. В этом случае, когда рассматривается AAC (ISO/IEC 13818-3), средство 140а реализуется как гребенка фильтров MDCT (MDCT = модифицированное дискретное косинусное преобразование) с 50% перекрывающей и добавляющей функциональностью.
В таком случае квантователь 140d является итеративным квантователем, например, используемым, когда формируются кодируемые в формате mp3 или AAC звуковые сигналы. Представление частотной области канала А, которое предпочтительно уже квантовано, может затем непосредственно использоваться для энтропийного кодирования, используя энтропийный кодер 140g, который может быть основанным на кодере Хаффмана или энтропийным кодером, реализующим арифметическое кодирование.
При сравнении с Фиг.1 выходом устройства на Фиг.3А является дополнительная информация, например li, для одного исходного канала (соответствующая дополнительной информации для В на выходе устройства 140f). Энтропийно кодированный битовый поток для канала А соответствует, например, кодированному левому низведенному каналу Lc' на выходе блока 16 на Фиг.1. Из Фиг.3А становится понятно, что элемент 14 (Фиг.1), т.е. калькулятор для расчета дополнительной информации канала и звуковой кодер 16 (Фиг.1) могут быть реализованы как отдельное средство или могут быть реализованы как совместно используемый вариант из условия, чтобы оба устройства совместно использовали некоторые элементы, например гребенку 140а фильтров MDCT, квантователь 140е и энтропийный кодер 140g. Конечно, если нужно различное преобразование и т.д. для определения дополнительной информации канала, тогда кодер 16 и калькулятор 14 (Фиг.1) будут реализовываться в разных устройствах из условия, чтобы оба элемента не использовали совместно гребенку фильтров и т.д.
Обычно фактический определитель для расчета дополнительной информации (или как сформулировано в общем, калькулятор 14) может реализовываться как квазистереофонический модуль, который показан на Фиг.3В, который функционирует в соответствии с любой из методик квазистереофонии, например мощным стереофоническим кодированием или бинауральным кодированием сигнала.
В отличие от таких мощных стереофонических кодеров предшествующего уровня техники, средство 140f определения согласно изобретению не должно рассчитывать комбинированный канал. «Комбинированный канал» или высокочастотный канал, как говорят, уже существует и является левым совместимым низведенным каналом Lc или правым совместимым низведенным каналом Rc или комбинированным вариантом этих низведенных каналов, например Lc + Rc. Следовательно, устройству 140f согласно изобретению нужно только рассчитывать информацию масштабирования для масштабирования соответствующего низведенного канала из условия, чтобы получалась кривая энергии/времени соответствующего выбранного исходного канала, когда низведенный канал взвешивается с использованием информации масштабирования или, как говорят, информации о направленной мощности.
Следовательно, квазистереофонический модуль 140f на Фиг.3В проиллюстрирован из условия, что он принимает в качестве входа «комбинированный» канал А, который является первым или вторым низведенным каналом или комбинацией низведенных каналов, и исходный выбранный канал. Этот модуль, конечно, выводит «объединенный» канал А и квазистереофонические параметры в качестве дополнительной информации канала из условия, чтобы при использовании объединенного канала А и квазистереофонических параметров могло быть рассчитано приближенное значение исходного выбранного канала В.
В качестве альтернативы квазистереофонический модуль 140f может быть реализован для выполнения бинаурального кодирования сигнала.
В случае ВСС квазистереофонический модуль 140f выполнен с возможностью вывода дополнительной информации канала из условия, чтобы дополнительная информация канала квантовалась, и кодированные параметры ICLD или ICTD, где выбранный исходный канал служит в качестве канала, который фактически необходимо обработать, тогда как соответствующий низведенный канал, используемый для расчета дополнительной информации, например первый, второй или комбинация первого и второго низведенных каналов, используется в качестве опорного канала в значении методики кодирования/декодирования ВСС.
Ссылаясь на Фиг.4, дается простая, ориентированная на энергию реализация элемента 140f. Это устройство включает в себя переключатель 44 полосы частот, выбирающий полосу частот из канала А и соответствующую полосу частот канала В. Затем в обеих полосах частот рассчитывается энергия посредством калькулятора 42 энергии для каждого ответвления. Подробная реализация калькулятора 42 энергии будет зависеть от того, является ли выходной сигнал из блока 40 сигналом поддиапазона или частотными коэффициентами. В других реализациях, где рассчитываются масштабные коэффициенты для диапазонов коэффициентов масштаба, можно уже использовать масштабные коэффициенты первого и второго канала А, В как величины энергии EA и EB или по меньшей мере как оценки энергии. В устройстве 44 расчета коэффициента усиления коэффициент gB усиления для выбранной полосы частот определяется на основе определенного правила, например правила определения усиления, проиллюстрированного в блоке 44 на Фиг.4. Здесь коэффициент gB усиления может быть непосредственно использован для взвешивания выборок временной области или частотных коэффициентов, например, которые будут описаны позже на Фиг.5. С этой целью коэффициент gB усиления, который действителен для выбранной полосы частот, используется в качестве дополнительной информации канала для канала В, как выбранного исходного канала. Этот выбранный исходный канал В не будет передаваться декодеру, но будет представлен параметрической дополнительной информации канала, которая рассчитана калькулятором 14 на Фиг.1.
Здесь следует отметить, что нет необходимости передавать значения усиления как дополнительную информацию канала. Также достаточно передавать зависимые от частоты значения, относящиеся к абсолютной энергии выбранного исходного канала. Затем декодер должен рассчитать фактическую энергию низведенного канала и коэффициент усиления на основе энергии низведенного канала и переданной энергии для канала В.
Фиг.5 показывает возможную реализацию настройки декодера применительно к перцептивному звуковому кодеру на основе преобразования. По сравнению с Фиг.2 функциональные возможности энтропийного декодера и обратного квантователя 50 (Фиг.5) будут включены в состав блока 24 Фиг.2. Функциональные возможности элементов 52a, 52b преобразования частоты/времени (Фиг.5) будут, тем не менее, реализованы в элементе 36 Фиг.2. Элемент 50 на Фиг.5 принимает кодированный вариант первого или второго низведенного сигнала L'c или R'c. На выходе элемента 50 присутствует по меньшей мере частично декодированный вариант первого и второго низведенного канала, который впоследствии называется каналом А. Канал А вводится в переключатель 54 полосы частот для выбора определенной полосы частот из канала А. Эта выбранная полоса частот взвешивается, используя устройство 56 умножения. Устройство 56 умножения принимает для умножения определенный коэффициент gB усиления, который назначается выбранной полосе частот, выбранной посредством переключателя 54 полосы частот, который соответствует переключателю 40 полосы частот на Фиг.4 на стороне кодера. На входе преобразователя 52а частоты-времени вместе с другими полосами существует представление частотной области канала А. На выходе устройства 56 умножения и, в частности, на входе средства 52b преобразования частоты/времени будет находиться восстановленное представление частотной области канала В. Следовательно, на выходе элемента 52а будет представление временной области для канала А, тогда как на выходе элемента 52b будет представление временной области восстановленного канала В.
Здесь следует отметить, что в зависимости от определенной реализации, декодированный низведенный канал Lc или Rc не воспроизводится в многоканальном улучшенном декодере. В таком многоканальном улучшенном декодере декодированные низведенные каналы используются только для восстановления исходных каналов. Декодированные низведенные каналы воспроизводятся только в стереофонических декодерах меньшего масштаба.
С этой целью сделана ссылка на Фиг.9, которая показывает предпочтительную реализацию настоящего изобретения в многоканальном/mp3 окружении. Улучшенный объемный битовый поток mp3 вводится в стандартный mp3-декодер 24, который выводит декодированные варианты исходных низведенных каналов. Эти низведенные каналы могут затем непосредственно воспроизводиться посредством декодера низкого уровня. В качестве альтернативы эти два канала вводятся в усовершенствованное квазистереофоническое декодирующее устройство 32, которое также принимает многоканальные данные расширения, которые предпочтительно вводятся в поле служебных данных в приспособленном к mp3 битовом потоке.
Позже сделана ссылка на Фиг.7, оказывающую группировку выбранного исходного канала и соответствующего низведенного канала или комбинированного низведенного канала. В этом смысле правый столбец таблицы на Фиг.7 соответствует каналу A на Фиг.3А, 3В, 4 и 5, тогда как столбец в центре соответствует каналу В на этих фигурах. В левом столбце Фиг.7 подробно изложена соответствующая дополнительная информация канала. В соответствии с таблицей Фиг.7 дополнительная информация li канала для исходного левого канала L рассчитывается с использованием левого низведенного канала Lc. Дополнительная информация lsi левого канала окружающего звука определяется посредством исходного выбранного левого канала Ls окружающего звука, и левый низведенный канал Lc является несущим. Дополнительная информация ri правого канала для исходного правого канала R определяется с использованием правого низведенного канала Rc. Кроме того, дополнительная информация канала для правого канала Rs окружающего звука определяется с использованием правого низведенного канала Rc в качестве несущего. В заключение дополнительная информация ci канала для центрального канала C определяется с использованием комбинированного низведенного канала, который получается посредством объединения первого и второго низведенных каналов, который может быть легко рассчитан как в кодере, так и в декодере и который не требует каких-либо дополнительных разрядов для передачи.
Конечно, можно также рассчитать дополнительную информацию канала для левого канала, например, на основе комбинированного низведенного канала или даже низведенного канала, который получается посредством взвешенного сложения первого и второго низведенных каналов, например 0,7 Lc и 0,3 Rc, пока параметры взвешивания известны декодеру или передаются соответственно. Однако для большинства применений будет предпочтительно только выводить дополнительную информацию канала для центрального канала из комбинированного низведенного канала, т.е. из объединения первого и второго низведенных каналов.
Чтобы показать потенциал экономии битов настоящего изобретения, приводится следующий типичный пример. В случае пятиканального звукового сигнала обычному кодеру необходима скорость передачи битов в 64 кбит/c для каждого канала, доходящая до общей скорости передачи битов в 320 кбит/c для пятиканального сигнала. Левый и правый стереофонические сигналы требуют скорости передачи битов в 128 кбит/с. Дополнительная информация каналов для одного канала находится между 1,5 и 2 кбит/с. Таким образом, даже в случае, в котором передается дополнительная информация канала для каждого из пяти каналов, эти дополнительные данные прибавляют всего лишь от 7,5 до 10 кбит/с. Таким образом, изобретательская концепция дает возможность передачи пятиканального звукового сигнала, используя скорость передачи битов в 138 кбит/с (по сравнению с 320 (!) кбит/с) с хорошим качеством, поскольку декодер не использует проблематичную операцию дематрицирования. Вероятно, даже более важным является тот факт, что изобретательская концепция является полностью обратно совместимой, поскольку каждый из существующих mp3-проигрывателей может воспроизводить первый низведенный канал и второй низведенный канал для создания традиционного стереофонического вывода.
В зависимости от условий применения, способы создания или формирования согласно изобретению могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализацией может являться цифровой запоминающий носитель, например диск или компакт-диск, имеющий электронно-считываемые сигналы управления, который может взаимодействовать с программируемой вычислительной системой из условия, чтобы выполнялись способы согласно изобретению. Формулируя в целом, изобретение, следовательно, также относится к компьютерному программному продукту, который имеет программный код, сохраненный на машиночитаемом носителе, причем программный код предназначен для выполнения способов согласно изобретению, когда компьютерный программный продукт выполняется на компьютере. Другими словами, изобретение, следовательно, также относится к компьютерной программе, имеющей программный код для выполнения способов, когда компьютерная программа выполняется на компьютере.
| название | год | авторы | номер документа |
|---|---|---|---|
| МНОГОКАНАЛЬНЫЙ СИНТЕЗАТОР И СПОСОБ ДЛЯ ФОРМИРОВАНИЯ МНОГОКАНАЛЬНОГО ВЫХОДНОГО СИГНАЛА | 2005 |
|
RU2345506C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ФОРМИРОВАНИЯ МНОГОКАНАЛЬНОГО ВЫХОДНОГО СИГНАЛА | 2005 |
|
RU2361185C2 |
| КОМПАКТНАЯ ДОПОЛНИТЕЛЬНАЯ ИНФОРМАЦИЯ ДЛЯ ПАРАМЕТРИЧЕСКОГО КОДИРОВАНИЯ ПРОСТРАНСТВЕННОГО ЗВУКА | 2005 |
|
RU2383939C2 |
| МНОГОКАНАЛЬНОЕ ИЕРАРХИЧЕСКОЕ АУДИОКОДИРОВАНИЕ С КОМПАКТНОЙ ДОПОЛНИТЕЛЬНОЙ ИНФОРМАЦИЕЙ | 2006 |
|
RU2367033C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ФОРМИРОВАНИЯ МНОГОКАНАЛЬНОГО СИГНАЛА ИЛИ НАБОРА ПАРАМЕТРИЧЕСКИХ ДАННЫХ | 2005 |
|
RU2355046C2 |
| ДЕКОДИРОВАНИЕ БИНАУРАЛЬНЫХ АУДИОСИГНАЛОВ | 2007 |
|
RU2409912C9 |
| ПАРАМЕТРИЧЕСКОЕ СОВМЕСТНОЕ КОДИРОВАНИЕ АУДИОИСТОЧНИКОВ | 2006 |
|
RU2376654C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ФОРМИРОВАНИЯ ЗАКОДИРОВАННОГО СТЕРЕОСИГНАЛА АУДИОЧАСТИ ИЛИ ПОТОКА ДАННЫХ АУДИО | 2006 |
|
RU2376726C2 |
| ИНДИВИДУАЛЬНОЕ ФОРМИРОВАНИЕ КАНАЛОВ ДЛЯ СХЕМ ВСС И Т.П. | 2005 |
|
RU2339088C1 |
| ДЕКОДИРОВАНИЕ БИНАУРАЛЬНЫХ АУДИОСИГНАЛОВ | 2007 |
|
RU2409911C2 |
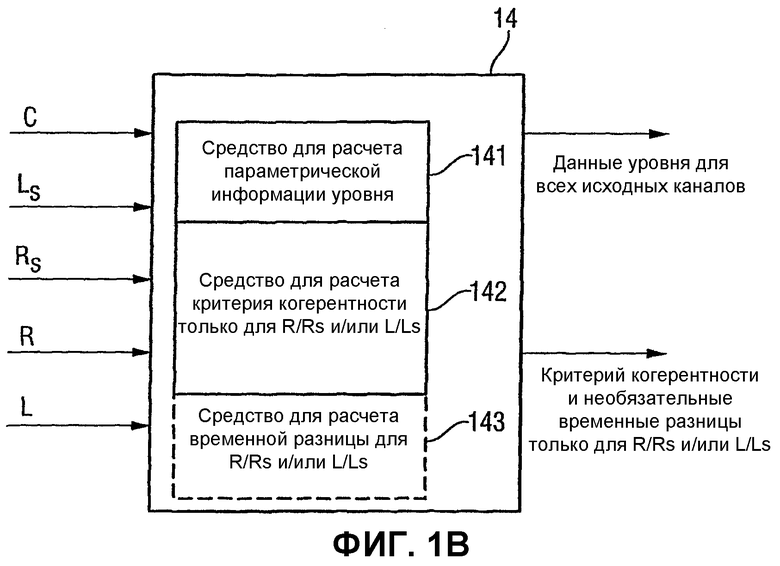
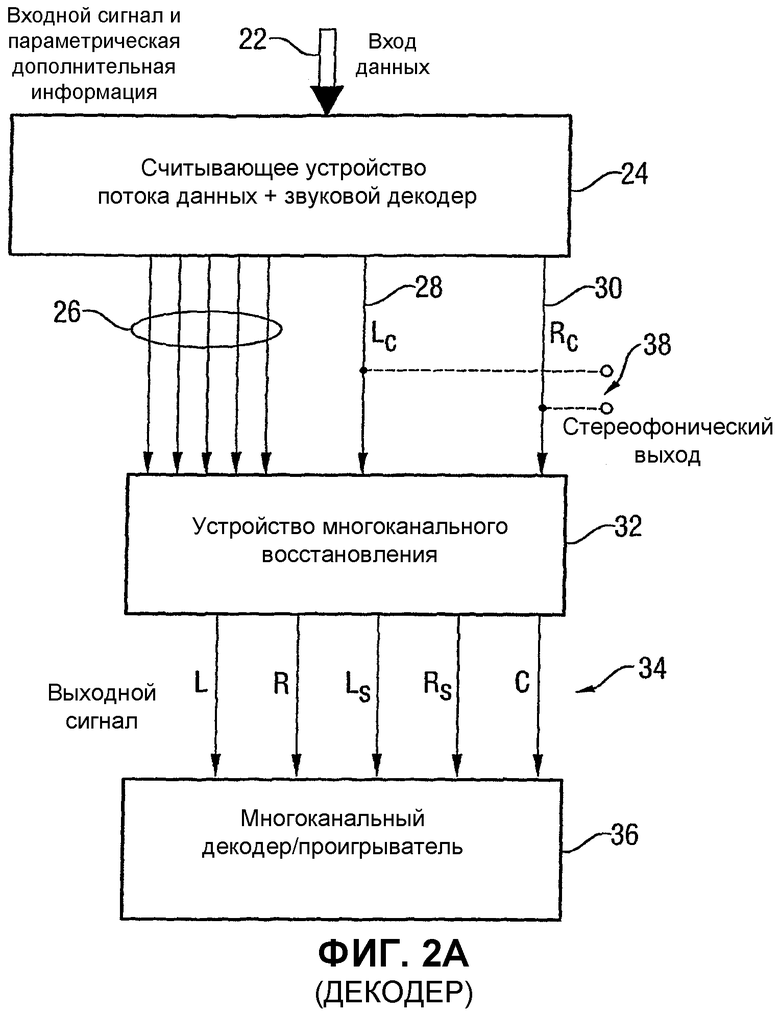
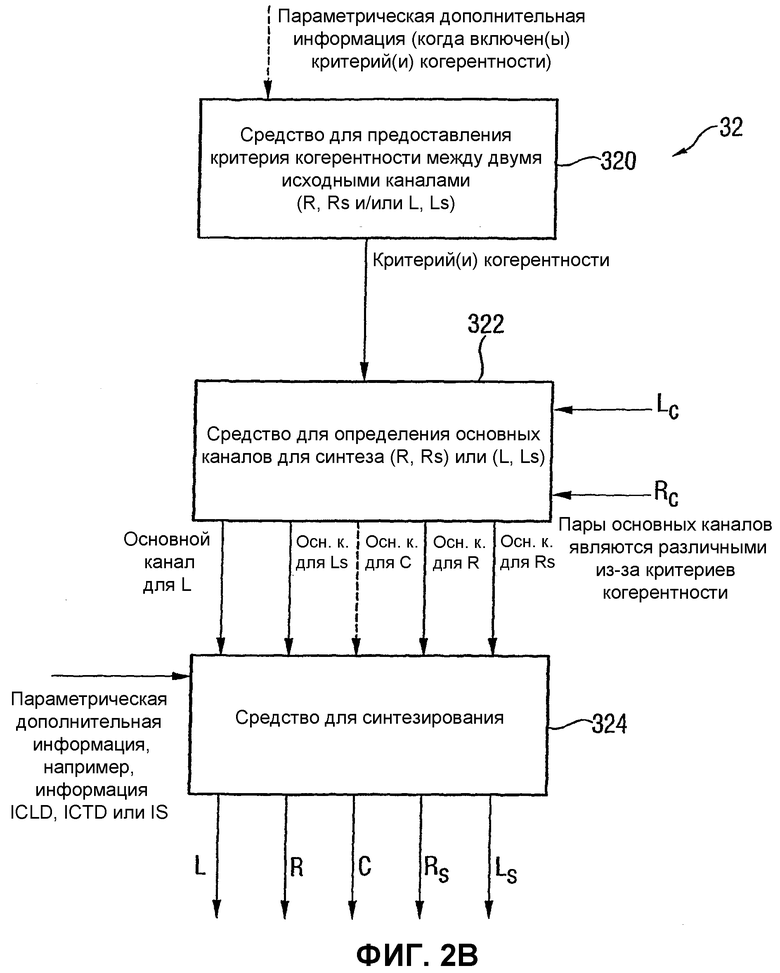
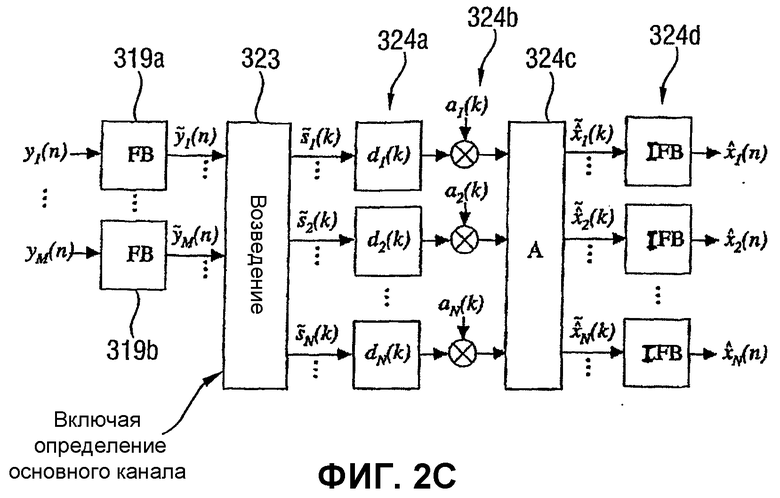
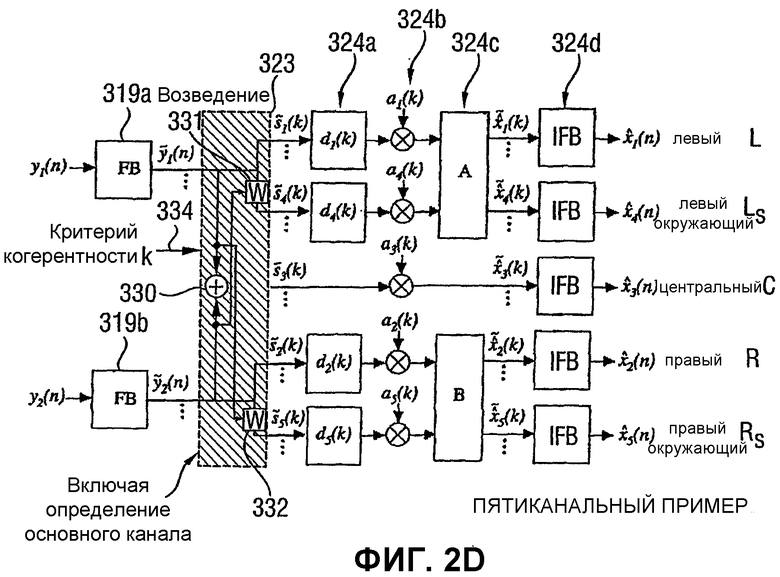
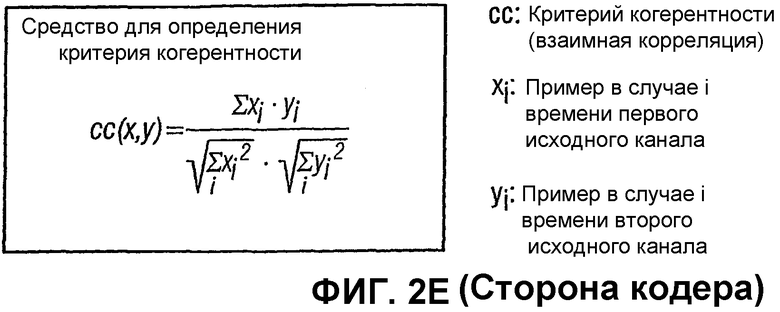

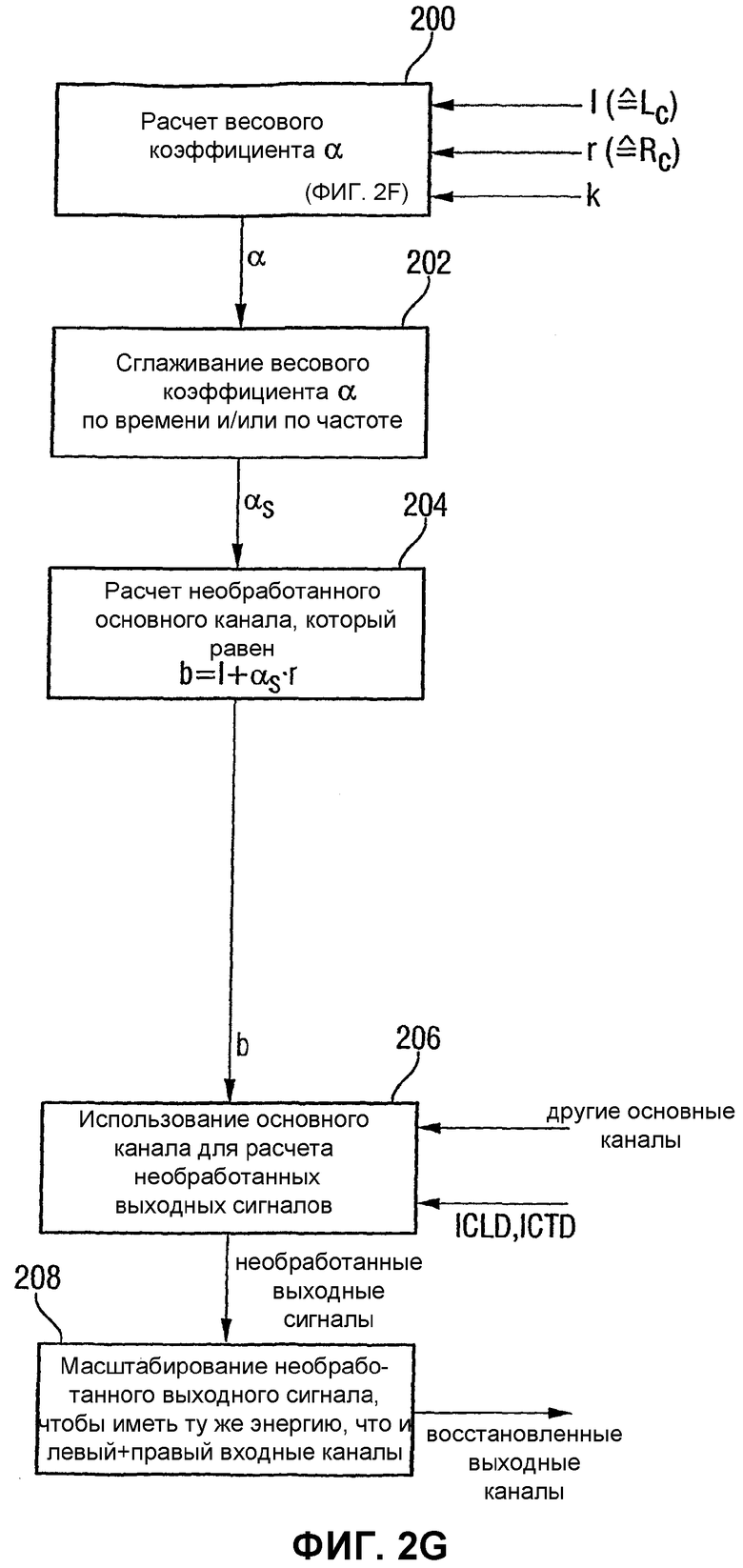
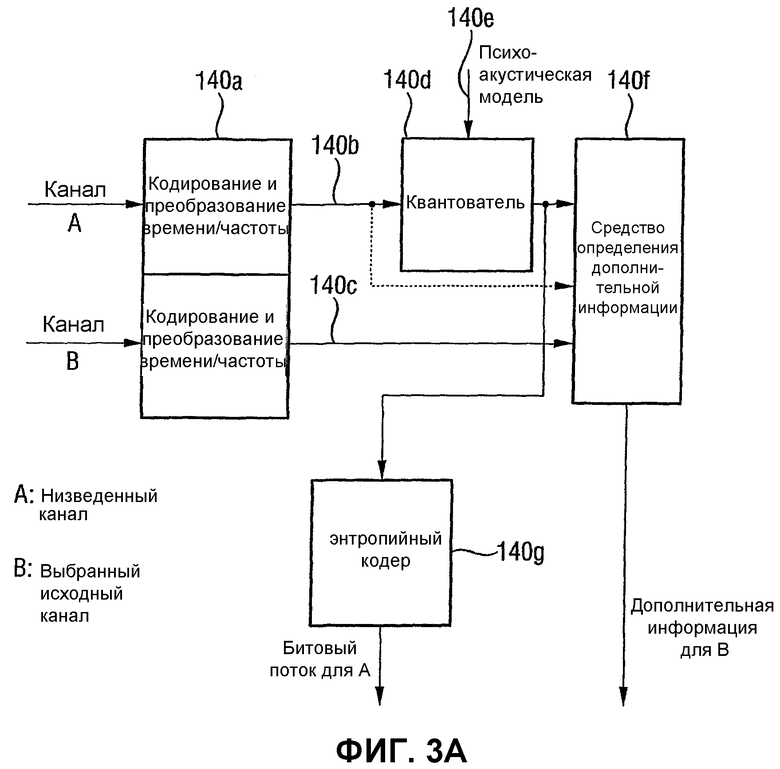
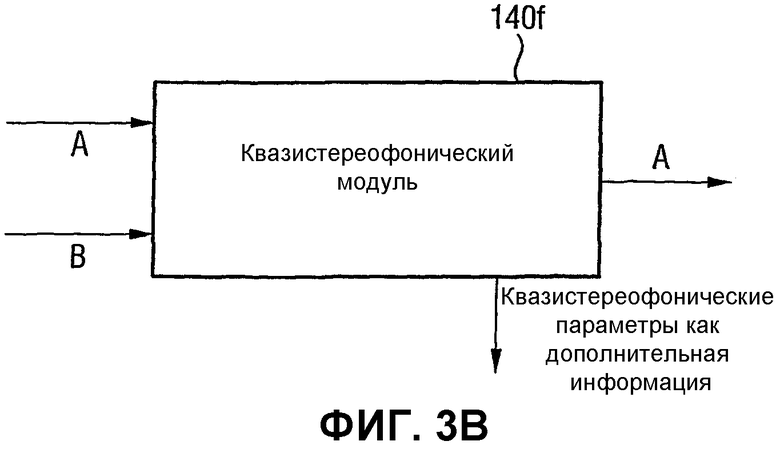
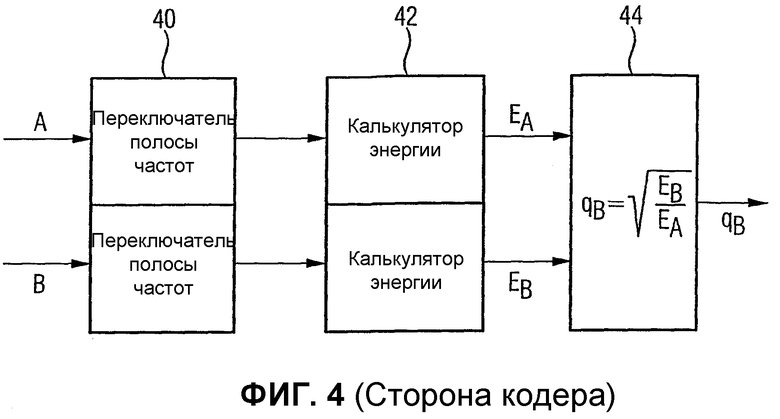
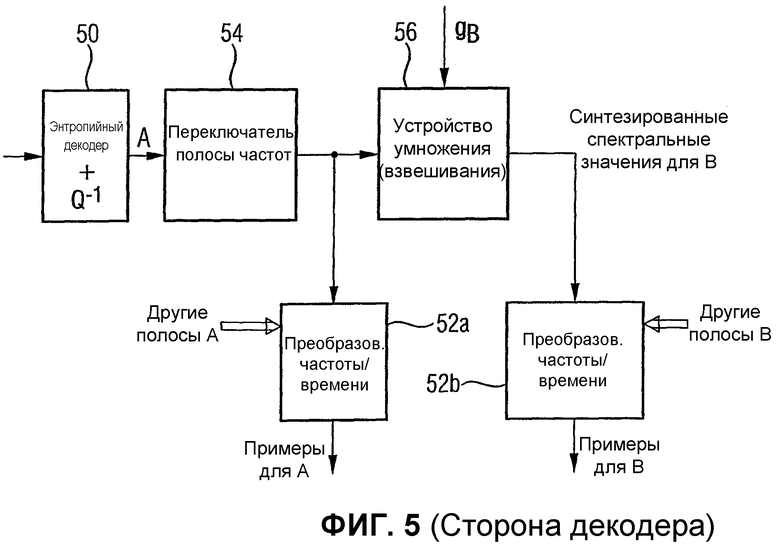
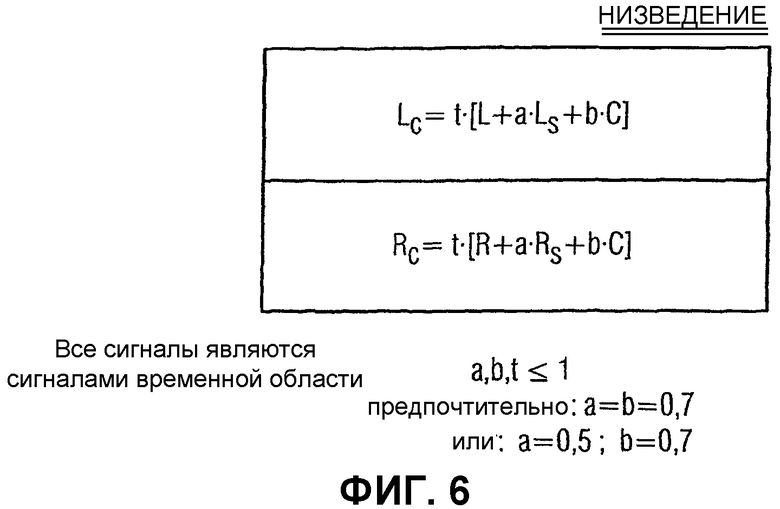
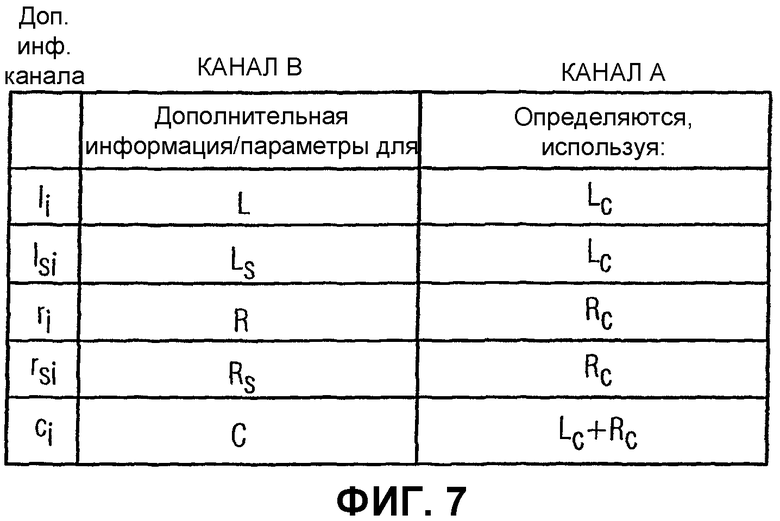
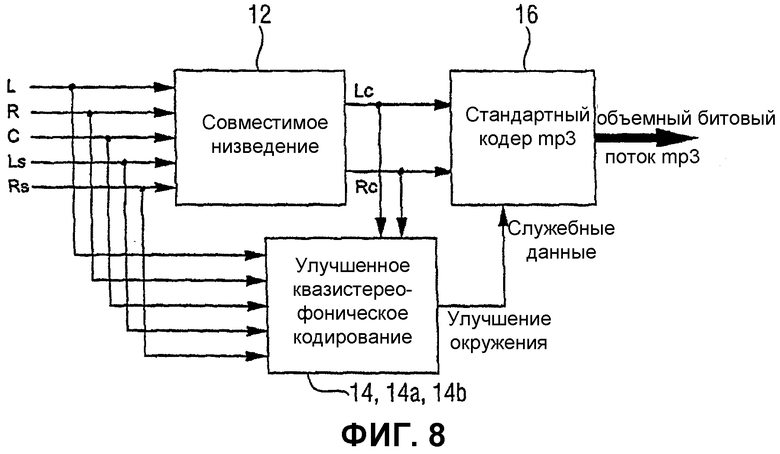
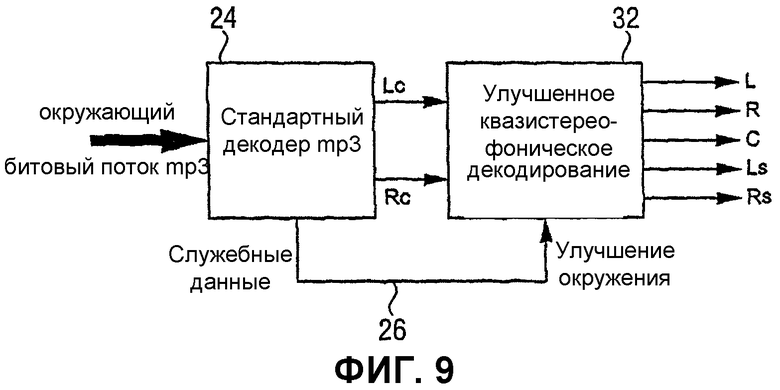
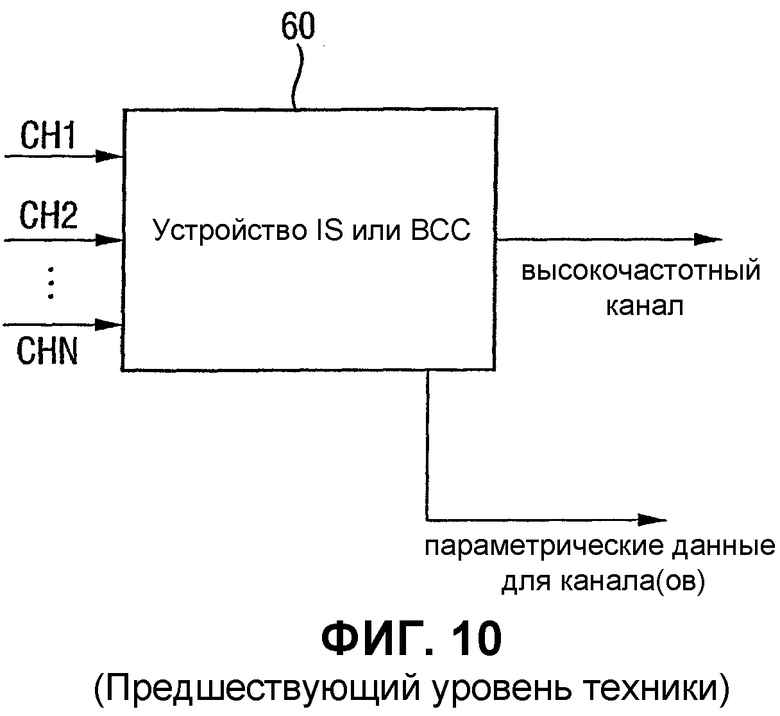
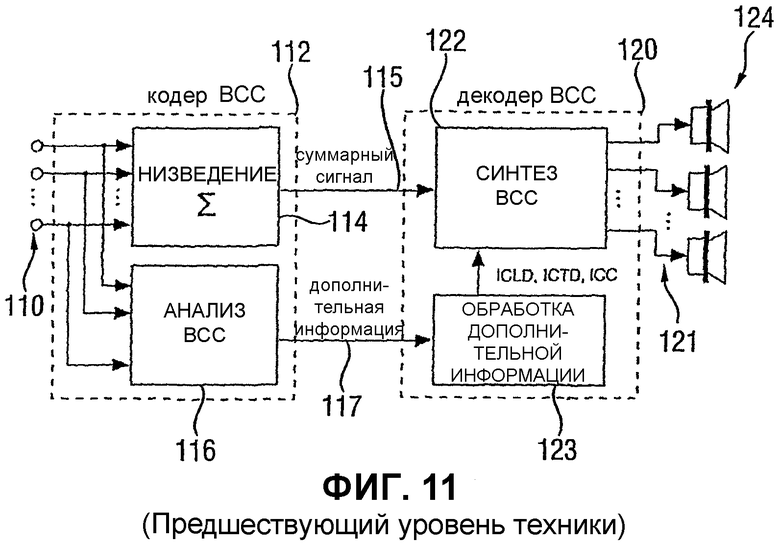
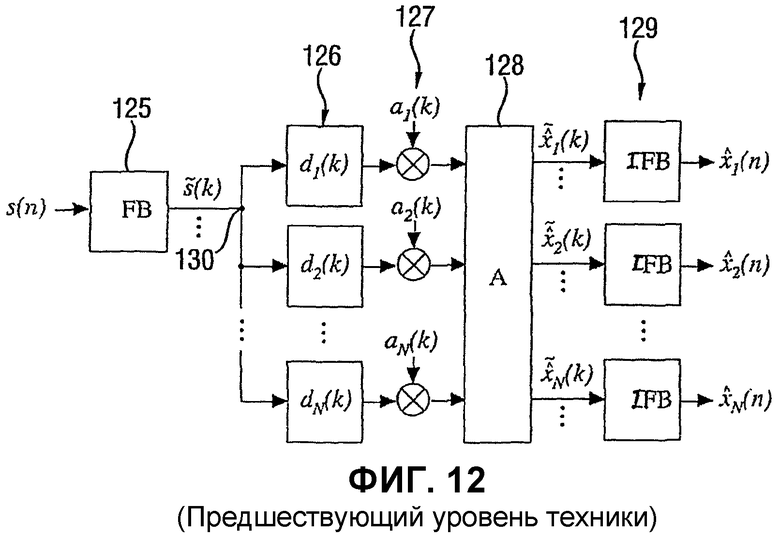
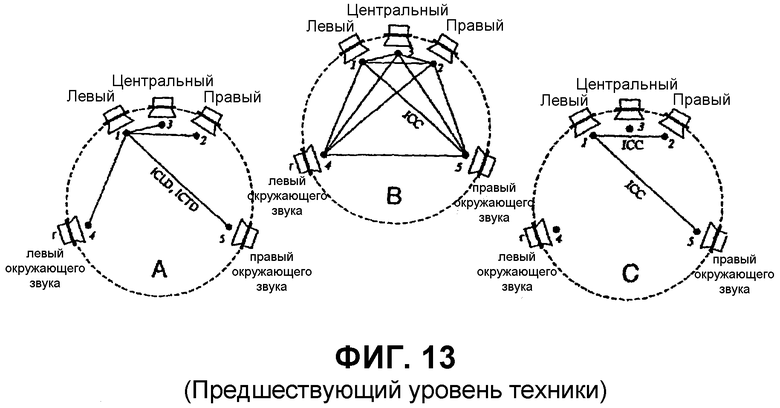
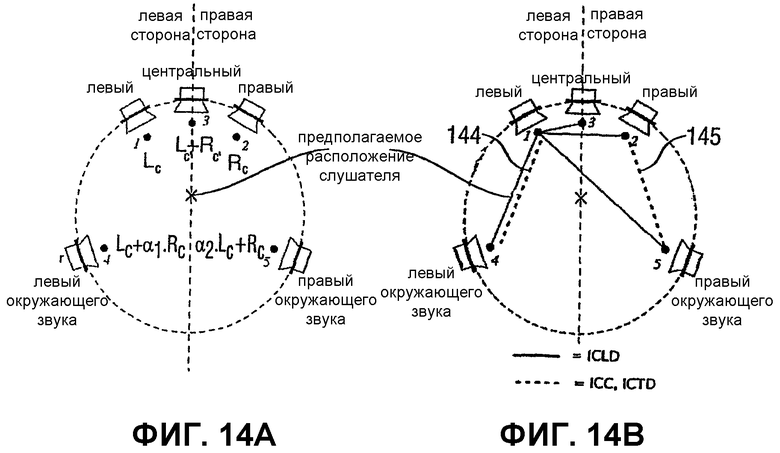
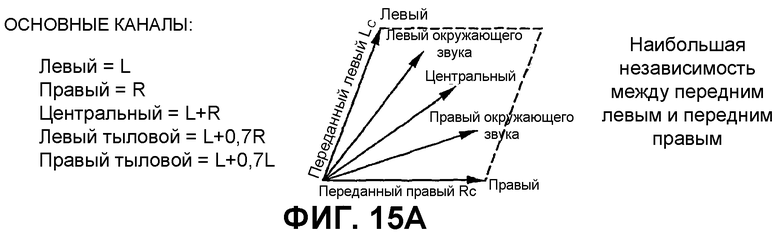
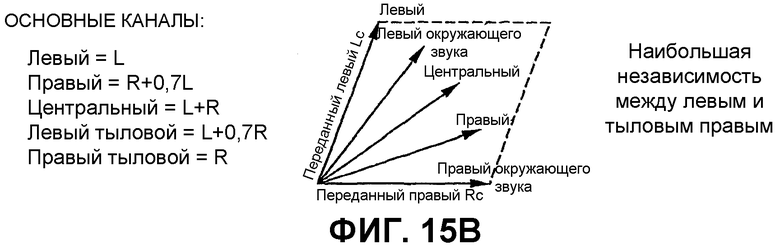
Изобретение относится к устройству и способу для обработки многоканального звукового сигнала, в частности к способу, совместимому со стереофоническим. Предложено устройство с использованием входного сигнала и параметрической дополнительной информации, при этом входной сигнал включает в себя первый входной канал и второй входной канал, выведенные из исходного многоканального сигнала; параметрическая дополнительная информация, описывающая взаимосвязи между каналами многоканального исходного сигнала, использует основные каналы для синтезирования (324) первого и второго выходных каналов по одну сторону от предполагаемого расположения слушателя, которые отличаются друг от друга вследствие критерия когерентности. Когерентность между основными каналами (например, левым и левым восстановленным каналом окружающего звука) снижается посредством расчета (322) основного канала для одного из этих каналов посредством комбинации входных каналов, при этом комбинация определяется посредством критерия когерентности. Технический результат - обеспечение эффективного восстановления многоканального сигнала за счет уменьшения искажений. 5 н. и 20 з.п. ф-лы, 25 ил.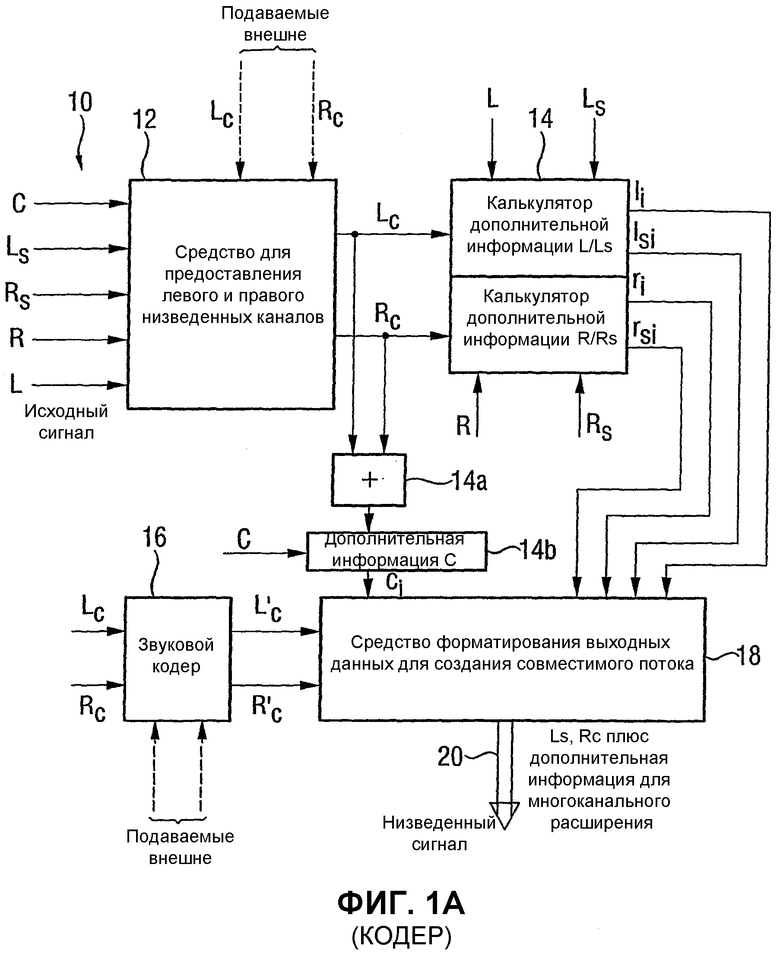
средство (322) для определения основных каналов, причем средство (322) для определения основных каналов выполнено с возможностью определения первого основного канала посредством выбора одного из первого и второго входных каналов или комбинации первого и второго входных каналов и с возможностью определения второго основного канала посредством выбора другого из первого и второго входных каналов или другой комбинации первого и второго входных каналов из условия, чтобы второй основной канал отличался от первого основного канала; и
средство (324) для синтезирования первого выходного канала с использованием параметрической дополнительной информации и первого основного канала для получения первого синтезированного выходного канала, который является воспроизведенным вариантом первого исходного канала, который располагается по одну сторону от предполагаемого расположения слушателя, и для синтезирования второго выходного канала с использованием параметрической дополнительной информации и второго основного канала, причем второй выходной канал является воспроизведенным вариантом второго исходного канала, который располагается на той же стороне от предполагаемого расположения слушателя.
где α является весовым коэффициентом и где А, В, С определяются следующим образом
A=C2-k2LR; B=2LC(1-k2); C=L2(1-k2),
где L, R, С определяются следующим образом
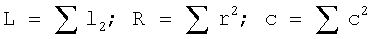
и где k является критерием когерентности, и где 1 является первым входным каналом и г является вторым входным каналом.
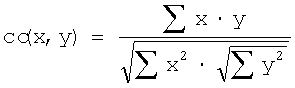
где сс(х, у) является критерием когерентности между двумя исходными каналами х, у, где хi является выборкой в момент i времени первого исходного канала, и где yi является выборкой в момент i времени второго исходного канала.
левого канала как основного канала для синтеза переднего левого канала (L),
правого канала как основного канала для синтеза переднего правого канала (R),
комбинации левого канала и правого канала как основного канала для левого канала (Ls) окружающего звука или правого канала (Rs) окружающего звука.
в котором входной сигнал включает в себя левый канал и правый канал, и исходный сигнал включает в себя передний левый канал, левый канал окружающего звука, передний правый канал и правый канал окружающего звука, и в котором упомянутое средство для определения выполнено с возможностью определения
левого канала как основного канала для синтеза переднего левого канала,
правого канала как основного канала для синтеза правого канала окружающего звука, и
комбинации первого и второго входных каналов как основного канала для синтеза переднего правого канала или левого канала окружающего звука.
определяют (322) первый основной канал посредством выбора одного из первого и второго входных каналов или комбинации первого и второго входных каналов, и определяют второй основной канал посредством выбора другого из первого и второго входных каналов или другой комбинации первого и второго входных каналов из условия, чтобы второй основной канал отличался от первого основного канала; и
синтезируют (324) первый выходной канал, используя параметрическую дополнительную информацию и первый основной канал для получения первого синтезированного выходного канала, который является воспроизведенным вариантом первого исходного канала, который располагают по одну сторону от предполагаемого расположения слушателя, и синтезируют второй выходной канал, используя параметрическую дополнительную информацию и второй основной канал, при этом второй выходной канал является воспроизведенным вариантом второго исходного канала, который располагают на той же стороне от предполагаемого расположения слушателя.
средство (12) для расчета первого низведенного канала и второго низведенного канала с использованием правила низведения;
средство (14) для расчета параметрической информации уровня, представляющей распределение энергии между каналами в многоканальном исходном сигнале;
средство (142) для определения критерия когерентности между двумя исходными каналами, причем два исходных канала располагаются по одну сторону от предполагаемого расположения слушателя; и
средство (18) для форматирования выходного сигнала с использованием первого и второго низведенных каналов, параметрической информации уровня и только по меньшей мере одного критерия когерентности между двумя исходными каналами, расположенными на упомянутой одной стороне, или значения, выведенного из по меньшей мере одного критерия когерентности, но без использования какого-либо критерия когерентности между каналами, расположенными на разных сторонах от предполагаемого расположения слушателя.
рассчитывают (12) первый низведенный канал и второй низведенный канал, используя правило низведения;
рассчитывают (124) параметрическую информацию уровня, представляющую распределение энергии между каналами в многоканальном исходном сигнале;
определяют (142) критерий когерентности между двумя исходными каналами, причем два исходных канала располагают по одну сторону от предполагаемого расположения слушателя; и
формируют (18) выходной сигнал, используя первый и второй низведенные каналы, параметрическую информацию уровня и только по меньшей мере один критерий когерентности между двумя исходными каналами, расположенными на упомянутой одной стороне, или значение, выведенное из, по меньшей мере, одного критерия когерентности, но не используя какой-либо критерий когерентности между каналами, расположенными на разных сторонах от предполагаемого расположения слушателя.
| Приспособление для сборки изделий под сварку | 1976 |
|
SU591297A1 |
| СПОСОБ ПЕРЕДАЧИ И/ИЛИ ЗАПОМИНАНИЯ ЦИФРОВЫХ СИГНАЛОВ НЕСКОЛЬКИХ КАНАЛОВ | 1993 |
|
RU2129336C1 |
| US 2003219130 А1, 27.11.2003 | |||
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| ЕР 1376538 A1, 02.01.2004. | |||

