I. ВВЕДЕНИЕ
В общей задаче кодирования мы имеем множество (моно) сигналов si(n) (1≤i≤M) источников и вектор S(n) описания сцены, где n - индекс времени. Вектор описания сцены содержит такие параметры как положения (виртуальных) источников, ширина каждого источника и акустические параметры, такие как параметры (виртуального) помещения. Описание сцены может быть инвариантным по времени или может изменяться во времени. Сигналы источников и описание сцены кодируются и передаются декодеру. Кодированные сигналы 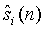 источников последовательно микшируются как функция
источников последовательно микшируются как функция 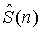 описания сцены для формирования сигналов синтеза волнового поля, многоканальных или стереофонических сигналов, как функции вектора описания сцены. Выходные сигналы декодера обозначены
описания сцены для формирования сигналов синтеза волнового поля, многоканальных или стереофонических сигналов, как функции вектора описания сцены. Выходные сигналы декодера обозначены 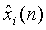 (1≤i≤N). Следует отметить, что вектор S(n) описания сцены не может быть передан, но может быть определен в декодере. В этом документе термин "стереофонический аудиосигнал" всегда относится к двухканальным стереофоническим аудиосигналам.
(1≤i≤N). Следует отметить, что вектор S(n) описания сцены не может быть передан, но может быть определен в декодере. В этом документе термин "стереофонический аудиосигнал" всегда относится к двухканальным стереофоническим аудиосигналам.
Стандарт MPEG-4 Международной организации по стандартизации (ISO)/Международной электротехнической комиссии (IEC) направлен на описанный сценарий кодирования. Он определяет описание сцены и использует для каждого ("естественного") сигнала источника отдельный монофонический аудиокодер, например аудиокодер схемы усовершенствованного кодирования звука (AAC). Однако, когда должна микшироваться сложная сцена со многими источниками, битовая скорость становится высокой, то есть битовая скорость увеличивается с увеличением количества источников. Кодирование одного сигнала источника с высоким качеством требует приблизительно 60-90 кбит/с.
Ранее рассматривался специальный случай описанной задачи кодирования ([1], [2]) с помощью схемы, названной бинауральным кодированием сигнала (BCC) для гибкого воспроизведения. Посредством передачи только суммы заданных сигналов источников и вспомогательной информации с низкой битовой скоростью достигается низкая битовая скорость. Однако сигналы источников не могут быть восстановлены в декодере, и схема была ограничена формированием сигнала стереофонического и многоканального объемного звука. Кроме того, использовалось только упрощенное микширование, основанное на амплитудном и фазовом панорамировании. Таким образом, можно было бы управлять направлением на источники, но никакими другими атрибутами звукового пространственного образа. Другим ограничением этой схемы являлось ее ограниченное качество аудио, особенно уменьшение качества аудио по мере увеличения количества сигналов источников.
Документ [1] (бинауральное кодирование сигнала, параметрическое стереофоническое аудио, объемное аудио формата MP3, объемное аудио формата MPEG) охватывает случай, в котором кодируются N аудиоканалов и затем декодируются N аудиоканалов со сходными признаками, а не первоначальные аудиоканалы. Переданная вспомогательная информация включает в себя параметры межканальных признаков, относящиеся к различиям между входными каналами.
Каналы стереофонических и многоканальных аудиосигналов содержат результаты микширования сигналов аудиоисточников и, таким образом, отличаются по характеру от чистых сигналов аудиоисточников. Стереофонические и многоканальные аудиосигналы микшируются так, что когда они воспроизводятся на соответствующей системе воспроизведения, слушатель будет воспринимать звуковой пространственный образ ("павильон звукозаписи") как зарегистрированный записывающим устройством или сконструированный инженером звукозаписи во время микширования. Ранее было предложено множество схем совместного кодирования для каналов стереофонических или многоканальных аудиосигналов.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Цель изобретения состоит в создании способа передачи множества сигналов источников при использовании минимальной ширины полосы. В большинстве известных способов формат воспроизведения (например, стерео, 5.1) является предопределенным и имеет прямое влияние на сценарий кодирования. Аудиопоток на стороне декодера должен использовать только этот предопределенный формат воспроизведения, тем самым привязывая пользователя к предопределенному сценарию воспроизведения (например, стерео).
Предложенное изобретение кодирует N сигналов аудиоисточников, обычно являющихся не каналами стереофонического аудио или многоканальными сигналами, а независимыми сигналами, такими как различные сигналы речи или инструментов. Переданная вспомогательная информация включает в себя статистические параметры, относящиеся к входным сигналам аудиоисточников.
Предложенное изобретение декодирует М аудиоканалов с разными признаками, а не первоначальные сигналы аудиоисточников. Эти разные признаки неявно синтезируются посредством применения микшера к принятому суммарному сигналу. Микшер управляется в зависимости от принятой статистической информации об источнике и принятых (или локально определенных) параметров аудиоформата и параметров микширования. Альтернативно, эти разные признаки явно вычисляются как функция принятой статистической информации об источниках и принятых (или локально определенных) параметров аудиоформата и параметров микширования. Эти вычисленные признаки используются для управления декодером предшествующего уровня техники (бинауральное кодирование сигнала, параметрическое стереофоническое аудио, объемное аудио формата MPEG) для синтеза выходных каналов на основе принятого суммарного сигнала.
Предложенная схема совместного кодирования сигналов аудиоисточников является первой в своем роде. Она разработана для совместного кодирования сигналов аудиоисточников. Сигналы аудиоисточников обычно являются монофоническими аудиосигналами, которые не подходят для воспроизведения на стереофонической или многоканальной аудиосистеме. Далее для краткости сигналы аудиоисточников часто называются сигналами источников.
Перед воспроизведением сигналы аудиоисточников сначала нужно микшировать в стереофонические, многоканальные аудиосигналы или сигналы синтеза волнового поля. Сигнал аудиоисточника может представлять отдельный инструмент или диктора или сумму множества инструментов и дикторов. Другим типом сигнала аудиоисточника является монофонический аудиосигнал, зарегистрированный с помощью точечного микрофона во время концерта. Часто сигналы аудиоисточников сохраняются на многодорожечных записывающих устройствах или в записывающих системах с жестким диском.
Заявленная схема совместного кодирования сигналов аудиоисточников основана только на передаче суммы сигналов аудиоисточников,

или взвешенной суммы сигналов источников. Факультативно, взвешенное суммирование может быть выполнено с разными весовыми коэффициентами на разных поддиапазонах, и весовые коэффициенты могут быть адаптированы во времени. Также может быть применено суммирование с компенсацией, как описано в главе 3.3.2 в [1]. Далее, когда говорится о сумме или суммарном сигнале, всегда имеется в виду сигнал, сформированный с помощью уравнения (1) или сформированный, как описано. В дополнение к суммарному сигналу передается вспомогательная информация. Сумма и вспомогательная информация представляют собой выходной аудиопоток. Факультативно, суммарный сигнал кодируется с использованием традиционного монофонического кодера. Этот поток может быть сохранен в файле (на компакт-диске, цифровом универсальном диске DVD, жестком диске) или транслирован в приемник. Вспомогательная информация представляет собой статистические свойства сигналов источников, которые являются наиболее важными факторами, определяющими пространственные признаки для восприятия выходных сигналов микшера. Будет показано, что эти свойства являются изменяющимися во времени огибающими спектра и функциями автокорреляции. На каждый сигнал источника приходится приблизительно 3 кбит/с передаваемой вспомогательной информации. В приемнике сигналы (1≤i≤M) источников восстанавливаются с помощью ранее упомянутых статистических свойств, приблизительно тождественных соответствующим свойствам первоначальных сигналов источников, и суммарного сигнала.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Изобретение поясняется со ссылками на чертежи, на которых представлено следующее:
фиг.1 - схема, в которой передача каждого сигнала источника производится независимо для дальнейшей обработки,
фиг.2 - множество источников, переданных как суммарный сигнал вместе со вспомогательной информацией,
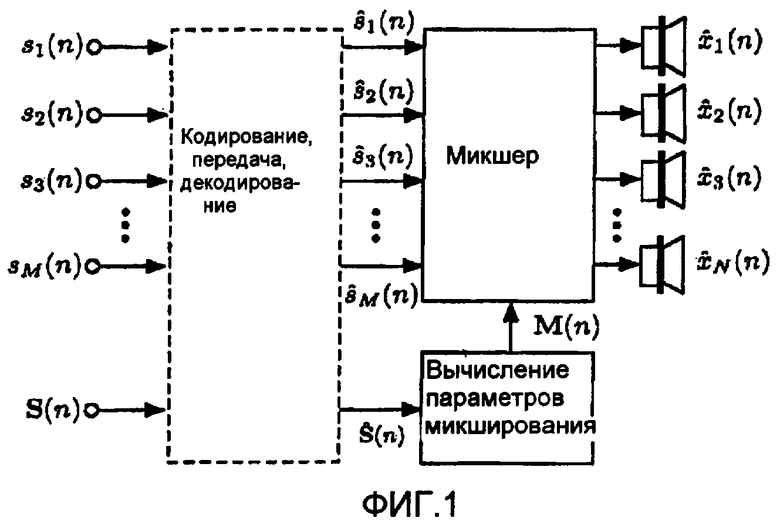
фиг.3 - блок-схема бинаурального кодирования сигнала (BCC),
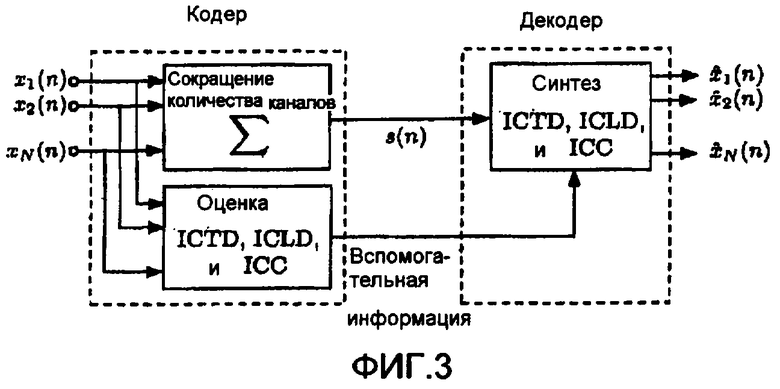
фиг.4 - микшер для формирования стереофонических сигналов на основе нескольких сигналов источников,
фиг.5 - зависимость между разностью по времени между каналами (ICTD), разностью уровней между каналами (ICLD) и когерентностью между каналами (ICC) и мощностью поддиапазона сигнала источника,
фиг.6 - процесс формирования вспомогательной информации,
фиг.7 - процесс оценки параметров кодирования с линейным предсказанием (LPC) каждого сигнала источника,
фиг.8 - процесс воссоздания сигналов источников из суммарного сигнала,
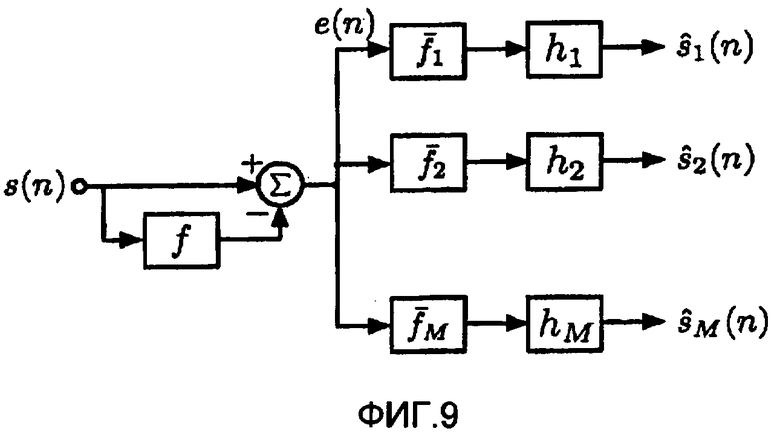
фиг.9 - альтернативная схема формирования каждого сигнала из суммарного сигнала,
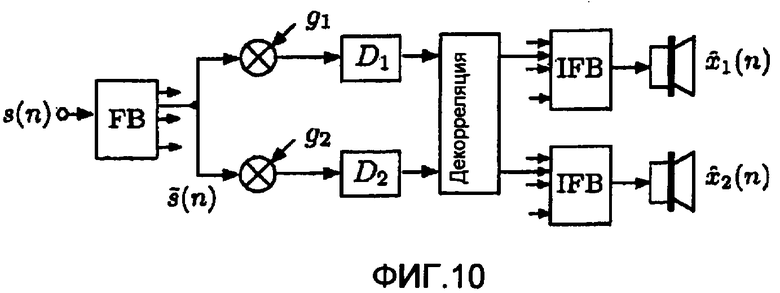
фиг.10 - микшер для формирования стереофонических сигналов на основе суммарного сигнала,
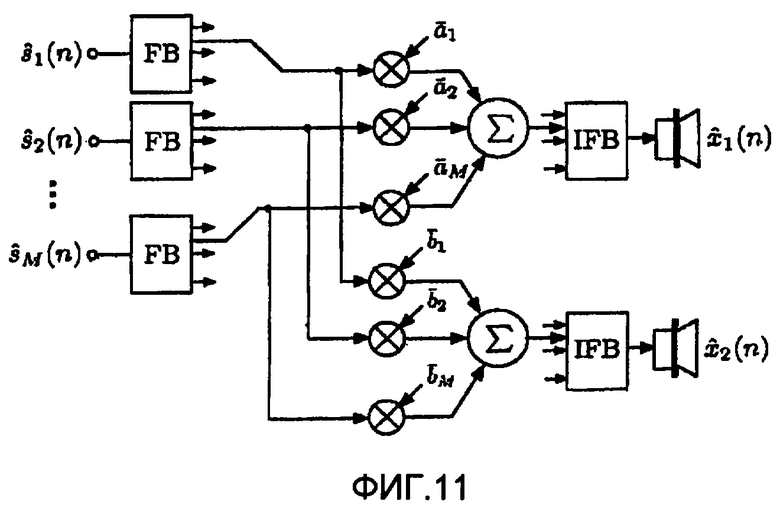
фиг.11 - алгоритм амплитудного панорамирования, предотвращающий зависимость уровней источников от параметров микширования,
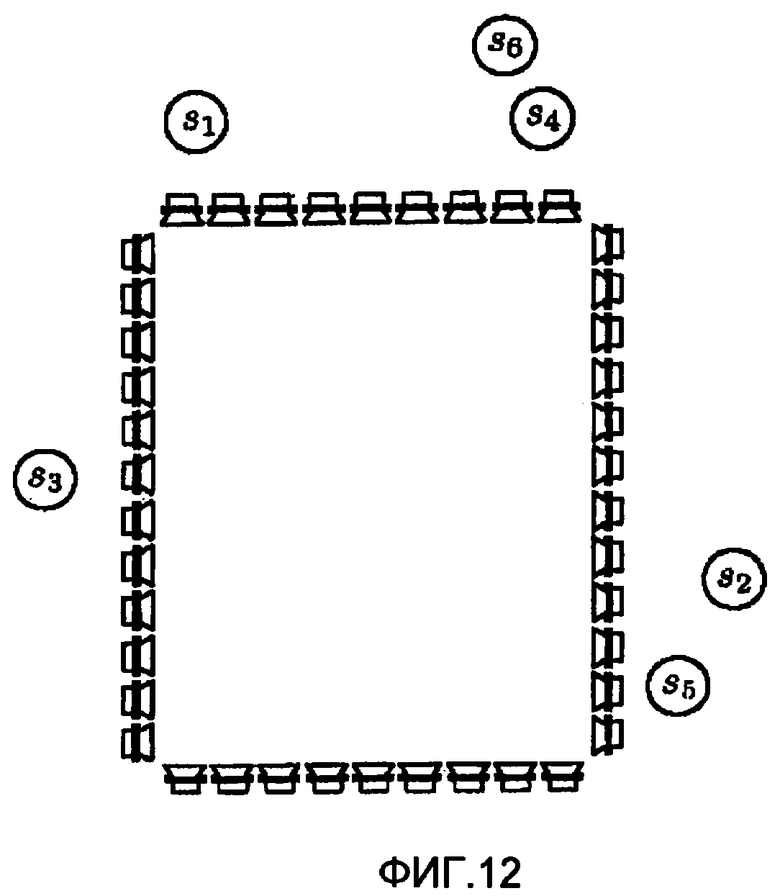
фиг.12 - массив громкоговорителей системы воспроизведения синтеза волнового поля,
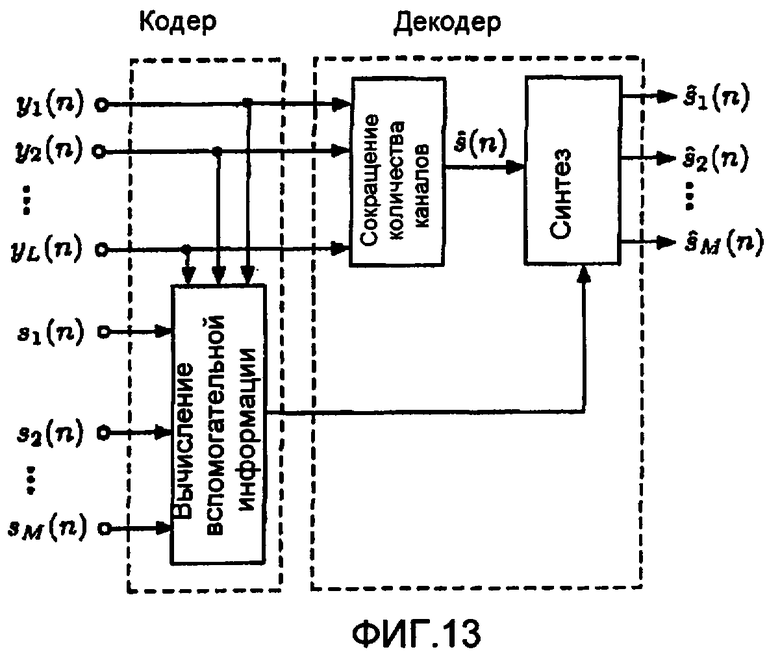
фиг.13 - схема восстановления оценки сигналов источников в приемнике посредством понижающего микширования переданных каналов,
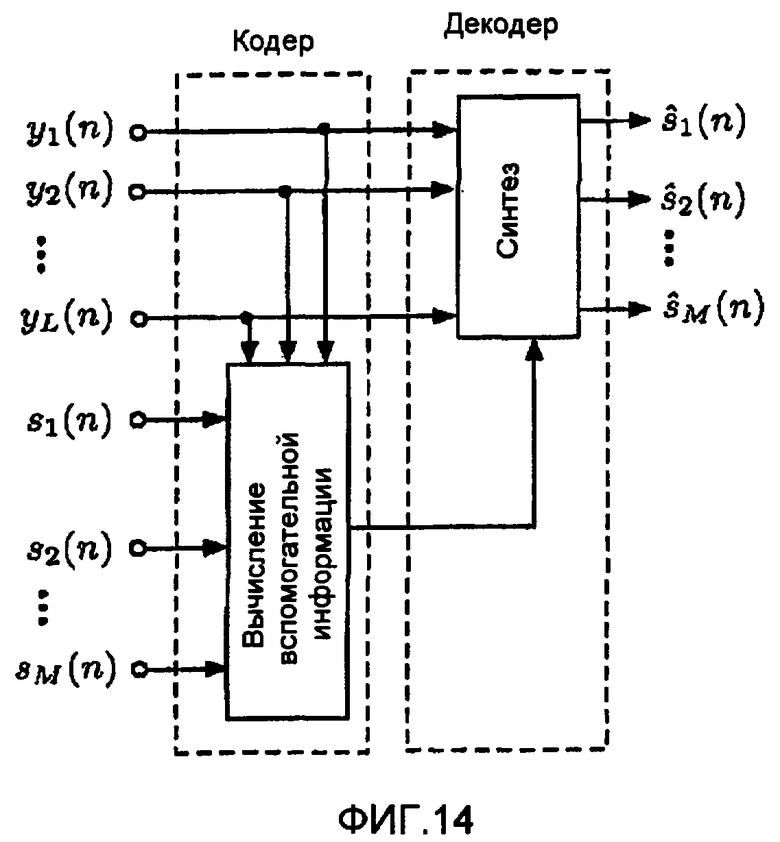
фиг.14 - схема восстановления оценки сигналов источников в приемнике посредством обработки переданных каналов.
II. ОПРЕДЕЛЕНИЯ, ОБОЗНАЧЕНИЯ И ПЕРЕМЕННЫЕ
В этом документе используются следующие обозначения и переменные:
n - индекс времени;
i - индекс аудиоканала или источника;
d - индекс задержки;
М - количество входных сигналов источников кодера;
N - количество выходных каналов декодера;
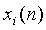 - микшированные первоначальные сигналы источников;
- микшированные первоначальные сигналы источников;
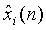 - микшированные выходные сигналы декодера;
- микшированные выходные сигналы декодера;
si(n) - входные сигналы источников кодера;
- переданные сигналы источников, также называемые сигналами псевдоисточников;
s(n) - переданный суммарный сигнал;
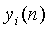 - L канальный аудиосигнал (аудиосигнал, который должен быть повторно микширован);
- L канальный аудиосигнал (аудиосигнал, который должен быть повторно микширован);
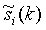 - сигнал одного поддиапазона сигнала si(n) (аналогично определяемый для других сигналов);
- сигнал одного поддиапазона сигнала si(n) (аналогично определяемый для других сигналов);
 - кратковременная оценка
- кратковременная оценка 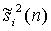 (аналогично определяемая для других сигналов);
(аналогично определяемая для других сигналов);
ICLD - разность уровней между каналами;
ICTD - разность по времени между каналами;
ICC - когерентность между каналами;
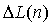 - ICLD оцениваемого поддиапазона;
- ICLD оцениваемого поддиапазона;
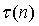 - ICTD оцениваемого поддиапазона;
- ICTD оцениваемого поддиапазона;
c(n) - ICC оцениваемого поддиапазона;
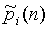 - относительная мощность поддиапазона источника;
- относительная мощность поддиапазона источника;
ai, bi - масштабные коэффициенты микшера;
ci, di - задержки микшера;
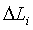 , - разность уровней и разность по времени микшера;
, - разность уровней и разность по времени микшера;
Gi - коэффициент усиления источника микшера.
III. СОВМЕСТНОЕ КОДИРОВАНИЕ СИГНАЛОВ АУДИОИСТОЧНИКОВ
Ниже описано бинауральное кодирование сигнала (BCC), представляющее собой метод параметрического кодирования многоканального аудио. Далее показано, что на основе тех же представлений, на которых основано ВСС, можно разработать алгоритм для совместного кодирования сигналов источников для сценария кодирования.
A. Бинауральное кодирование сигнала (BCC)
Схема бинаурального кодирования сигнала (BCC) ([1], [2]) для кодирования многоканального аудио показана ниже на чертеже. Количество каналов входного многоканального аудиосигнала микшируется с понижением до одного канала. В отличие от кодирования и передачи информации о формах сигналов всех каналов кодируется (при помощи традиционного монофонического аудиокодера) и передается только сигнал понижающего микширования. Дополнительно оцениваются обусловленные восприятием "различия аудиоканалов" между первоначальными аудиоканалами и также передаются декодеру. Декодер формирует свои выходные каналы таким образом, что различия аудиоканалов приблизительно тождественны соответствующим различиям аудиоканалов первоначального аудиосигнала.
Суммарная локализация подразумевает, что важные для восприятия различия аудиоканалов для пары каналов сигналов громкоговорителей являются разностью по времени между каналами (ICTD) и разностью уровней между каналами (ICLD). Разность по времени между каналами (ICTD) и разность уровней между каналами (ICLD) могут быть связаны с воспринимаемым направлением звуковых событий. Другие атрибуты звукового пространственного образа, такие как ширина кажущегося источника и охват слушателя, могут быть связаны с когерентностью между звуками, воспринимаемыми разными ушами (IC-когерентность). Для пар громкоговорителей спереди или сзади от слушателя IC-когерентность часто непосредственно связана с когерентностью между каналами (ICC-когерентностью), которая, таким образом, рассматривается схемой BCC как третья мера различия аудиоканалов. ICTD, ICLD и ICC-когерентность оцениваются в поддиапазонах как функция времени. Используемые спектральное и временное разрешение являются обусловленными восприятием.
B. Параметрическое совместное кодирование аудиоисточников
Декодер BCC может формировать многоканальный аудиосигнал с любым звуковым пространственным образом с использованием монофонического сигнала и синтезируя на равных интервалах времени отдельный заданный признак ICTD, ICLD и ICC-когерентности для каждого поддиапазона и пары каналов. Хорошие показатели работы схем BCC для широкого диапазона аудиоматериалов (см. 1) означают, что воспринятый звуковой пространственный образ в значительной степени определяется параметрами ICTD, ICLD и ICC-когерентности. Поэтому в противоположность требованию "чистых" сигналов si(n) источников на входе микшера на фиг.1 требуются лишь сигналы псевдоисточников, имеющие такое свойство, что они приводят к аналогичным параметрам ICTD, ICLD и ICC-когерентности на выходе микшера, как для случая подачи на микшер сигналов реальных источников. Для формирования сигналов имеется три цели:
- Если на микшер подаются сигналы , каналы на выходе микшера будут иметь приблизительно те же самые пространственные признаки ICLD, ICTD и ICC-когерентность, как если бы на микшер были поданы сигналы si(n).
- Сигналы должны формироваться с возможно меньшей информацией о первоначальных сигналах s(n) источников (поскольку цель состоит в использовании вспомогательной информации с низкой битовой скоростью).
- Сигналы формируются из передаваемого суммарного сигнала s(n) таким образом, что вносится минимальная величина искажения сигнала.
Для получения предложенной схемы рассматривается стереофонический микшер (М=2). Дополнительное упрощение общего случая заключается в том, что для микширования применяются только амплитудное и фазовое панорамирование. Если бы отдельные сигналы источников были доступны в декодере, то стереофонический сигнал был бы смикширован, как показано на фиг.4, то есть
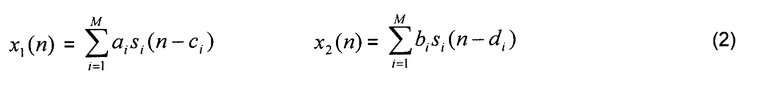
В этом случае вектор S(n) описания сцены содержит только направления на источники, которые определяют параметры микширования,
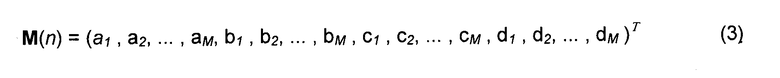
где T - транспонирование вектора. Следует отметить, что для параметров микширования опущен индекс времени для удобства обозначения.
Более удобными параметрами для управления микшером являются время Ti и разность уровней , которые связаны с ai, bi, ci и di следующим образом:
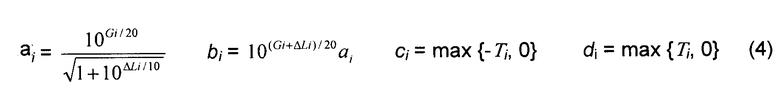
где Gi - коэффициент усиления источника в децибелах.
Далее вычисляются ICTD, ICLD и ICC-когерентность стереофонического выходного сигнала микшера как функция входных сигналов si(n) источников. Полученные выражения будут указывать, какие свойства сигнала источника определяют ICTD, ICLD и ICC-когерентность (вместе с параметрами микширования). Затем формируются сигналы таким образом, что идентифицированные свойства сигнала источника приблизительно тождественны соответствующим свойствам первоначальных сигналов источников.
B.1 Разность по времени между каналами (ICTD), разность уровней между каналами (ICLD) и когерентность между каналами (ICC) на выходе микшера
Признаки оцениваются в поддиапазонах и как функция времени. Далее предполагается, что сигналы si(n) источников являются в среднем нулевыми и взаимно независимыми. Пара сигналов поддиапазона на выходе микшера (2) обозначена как 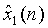 и
и 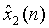 . Следует отметить, что для простоты обозначения используется один и тот же индекс времени n для сигналов в области времени и в области поддиапазона. Кроме того, индекс поддиапазона не используется, и описанные анализ/обработка применяются к каждому поддиапазону независимо. Мощность поддиапазона двух выходных сигналов микшера выражается как
. Следует отметить, что для простоты обозначения используется один и тот же индекс времени n для сигналов в области времени и в области поддиапазона. Кроме того, индекс поддиапазона не используется, и описанные анализ/обработка применяются к каждому поддиапазону независимо. Мощность поддиапазона двух выходных сигналов микшера выражается как
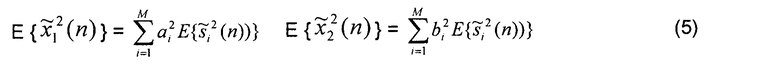
где 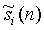 - один сигнал поддиапазона источника si(n), и E{.} обозначает кратковременную оценку, например
- один сигнал поддиапазона источника si(n), и E{.} обозначает кратковременную оценку, например

где K определяет длину скользящего среднего значения. Следует отметить, что значения 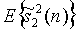 мощности поддиапазона представляют собой для каждого сигнала источника огибающую спектра как функцию времени. Разность
мощности поддиапазона представляют собой для каждого сигнала источника огибающую спектра как функцию времени. Разность 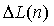 уровней между каналами (ICLD) выражается как
уровней между каналами (ICLD) выражается как

Для оценки ICTD и ICC-когерентности оценивается нормализованная функция взаимной корреляции

Когерентность c(n) между каналами (ICC) вычисляется в соответствии с

Для вычисления разности T(n) по времени между каналами (ICTD) вычисляется местоположение самого высокого пика на оси задержки

Теперь возникает вопрос, каким образом нормализованная функция взаимной корреляции может быть вычислена как функция параметров микширования. Вместе с уравнением (2) уравнение (8) может быть записано как
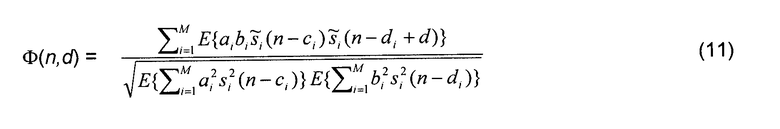
что эквивалентно
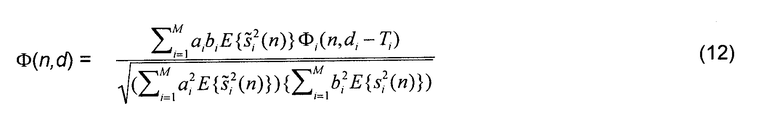
где нормализованная функция автокорреляции  выражена как
выражена как

и Ti=di-ci. Следует отметить, что для выведения уравнения (12) из уравнения (11) предполагалось, что сигналы являются в широком смысле стационарными в пределах рассматриваемого интервала задержек, то есть
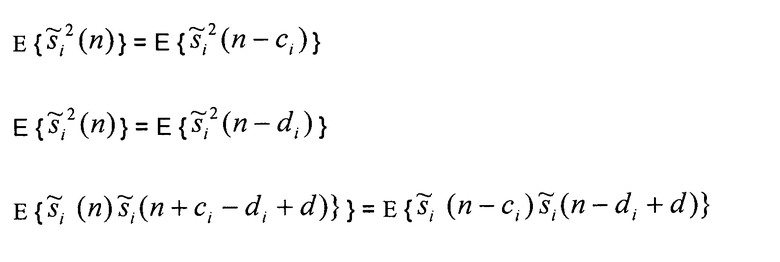
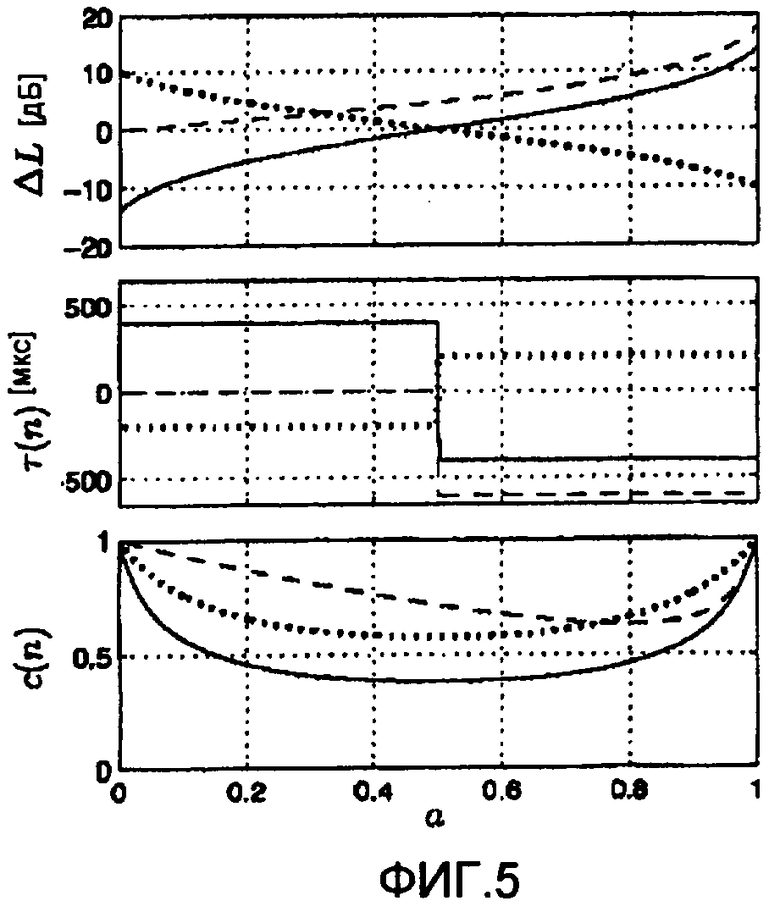
Числовой пример для двух сигналов источников, иллюстрирующий зависимость между ICTD, ICLD и ICC-когерентностью и мощностью поддиапазона источника, показан на фиг.5. Верхняя, средняя и нижняя части фиг.5 показывают соответственно , T(n) и c(n) как функцию отношения мощности поддиапазона двух сигналов источников, 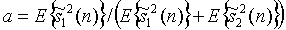 для различных параметров микширования (уравнение 4)
для различных параметров микширования (уравнение 4)  ,
,  , T1 и T2. Следует отметить, что когда в поддиапазоне мощность имеет только один источник (a=0 или a=1), тогда вычисленные значения
, T1 и T2. Следует отметить, что когда в поддиапазоне мощность имеет только один источник (a=0 или a=1), тогда вычисленные значения  и T(n) равны параметрам микширования (, , T1 и
и T(n) равны параметрам микширования (, , T1 и
T2).
B.2 Необходимая вспомогательная информация
Параметр ICLD (уравнение 7) зависит от параметров микширования (ai, bi, ci, di) и от кратковременной мощности поддиапазона источников, 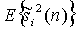 (6). Нормализованная функция
(6). Нормализованная функция 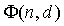 взаимной корреляции поддиапазона (уравнение 12), которая необходима для вычисления ICTD (уравнение 10) и ICC-когерентности (уравнение 9), зависит от , а также от нормализованной функции
взаимной корреляции поддиапазона (уравнение 12), которая необходима для вычисления ICTD (уравнение 10) и ICC-когерентности (уравнение 9), зависит от , а также от нормализованной функции 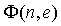 автокорреляции поддиапазона (уравнение 13) для каждого сигнала источника. Максимум функции
автокорреляции поддиапазона (уравнение 13) для каждого сигнала источника. Максимум функции 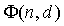 находится в пределах диапазона
находится в пределах диапазона 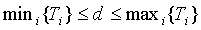 . Для источника i с параметром микширования
. Для источника i с параметром микширования 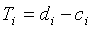 соответствующий диапазон, для которого необходимо свойство
соответствующий диапазон, для которого необходимо свойство 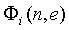 (уравнение 13) поддиапазона сигнала источника, выражен как
(уравнение 13) поддиапазона сигнала источника, выражен как

Поскольку признаки ICTD, ICLD и ICC-когерентности зависят от свойств и 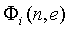 поддиапазона сигнала источника в диапазоне (14), в принципе эти свойства поддиапазона сигнала источника должны передаваться как вспомогательная информация. Предполагается, что любой другой вид микшера (например, микшер с эффектами, микшер синтеза волнового поля/конвольвер и т.д.) имеет аналогичные свойства, и, таким образом, эта вспомогательная информация также полезна, когда используются микшеры, отличающиеся от описанного. Для уменьшения количества вспомогательной информации можно хранить набор предопределенных функций автокорреляции в декодере и передавать только индексы для выбора функций, наиболее близко соответствующих свойствам сигнала источника. Первая версия рассматриваемого алгоритма предполагает, что в пределах диапазона (14)
поддиапазона сигнала источника в диапазоне (14), в принципе эти свойства поддиапазона сигнала источника должны передаваться как вспомогательная информация. Предполагается, что любой другой вид микшера (например, микшер с эффектами, микшер синтеза волнового поля/конвольвер и т.д.) имеет аналогичные свойства, и, таким образом, эта вспомогательная информация также полезна, когда используются микшеры, отличающиеся от описанного. Для уменьшения количества вспомогательной информации можно хранить набор предопределенных функций автокорреляции в декодере и передавать только индексы для выбора функций, наиболее близко соответствующих свойствам сигнала источника. Первая версия рассматриваемого алгоритма предполагает, что в пределах диапазона (14) 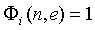 , и, таким образом, уравнение (12) вычисляется только с использованием значений (6) мощности поддиапазона в качестве вспомогательной информации. Данные, показанные на фиг.5, были вычислены в предположении, что
, и, таким образом, уравнение (12) вычисляется только с использованием значений (6) мощности поддиапазона в качестве вспомогательной информации. Данные, показанные на фиг.5, были вычислены в предположении, что 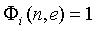 .
.
Чтобы сократить количество вспомогательной информации, относительный динамический диапазон сигналов источников ограничен. Каждый раз для каждого поддиапазона выбирается мощность самого сильного источника. Найдено достаточным ограничить снизу мощность соответствующего поддиапазона всех других источников значением на 24 дБ ниже, чем самая сильная мощность поддиапазона. Таким образом, динамический диапазон квантователя может быть ограничен значением 24 дБ.
Предполагая, что сигналы источников являются независимыми, декодер может вычислить сумму мощности поддиапазона всех источников как 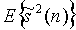 . Таким образом, в принципе достаточно передать к декодеру только значения мощности поддиапазона
. Таким образом, в принципе достаточно передать к декодеру только значения мощности поддиапазона 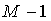 источников, в то время как мощность поддиапазона оставшегося источника может быть вычислена локально. Учитывая эту идею, скорость передачи вспомогательной информации может быть немного сокращена посредством передачи мощности поддиапазона источников с индексами
источников, в то время как мощность поддиапазона оставшегося источника может быть вычислена локально. Учитывая эту идею, скорость передачи вспомогательной информации может быть немного сокращена посредством передачи мощности поддиапазона источников с индексами  относительно мощности первого источника,
относительно мощности первого источника,

Следует отметить, что ранее описанное ограничение динамического диапазона выполняется до вычисления уравнения (15). В качестве альтернативы значения мощности поддиапазона могут быть нормализованы относительно мощности поддиапазона суммарного сигнала, в противоположность нормализации относительно мощности поддиапазона одного источника (уравнение 15). Для частоты дискретизации 44,1 кГц используются 20 поддиапазонов и передача осуществляется для каждого поддиапазона 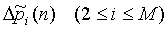 приблизительно каждые 12 мс. 20 поддиапазонов соответствуют половине спектрального разрешения слуховой системы (один поддиапазон по ширине составляет две "критические ширины полосы"). Неформальные эксперименты показывают, что только небольшое улучшение достигается при использовании более чем 20 поддиапазонов, например 40 поддиапазонов. Количество поддиапазонов и ширина полос поддиапазонов выбираются в соответствии с разрешением по времени и частоте слуховой системы. Реализация схемы с низким качеством требует, по меньшей мере, трех поддиапазонов (низкие, средние и высокие частоты).
приблизительно каждые 12 мс. 20 поддиапазонов соответствуют половине спектрального разрешения слуховой системы (один поддиапазон по ширине составляет две "критические ширины полосы"). Неформальные эксперименты показывают, что только небольшое улучшение достигается при использовании более чем 20 поддиапазонов, например 40 поддиапазонов. Количество поддиапазонов и ширина полос поддиапазонов выбираются в соответствии с разрешением по времени и частоте слуховой системы. Реализация схемы с низким качеством требует, по меньшей мере, трех поддиапазонов (низкие, средние и высокие частоты).
В соответствии с отдельным вариантом воплощения поддиапазоны имеют разную ширину полос, поддиапазоны на более низких частотах имеют меньшую ширину полосы, чем поддиапазоны на более высоких частотах.
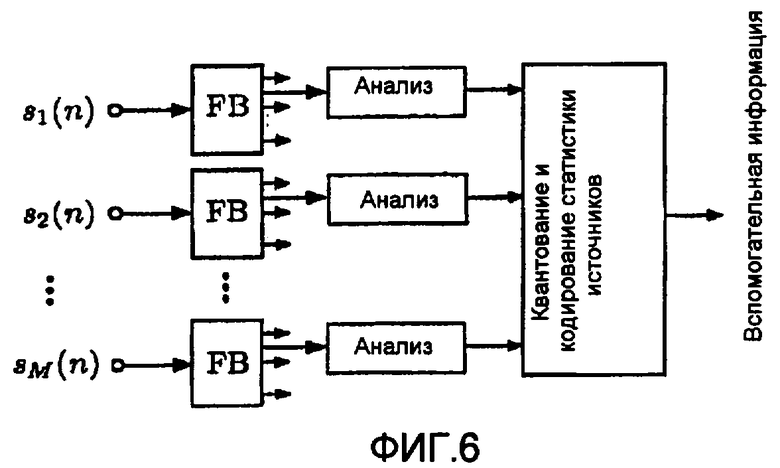
Относительные значения мощности квантуются по схеме, аналогичной квантователю ICLD, описанному в [2], что приводит к битовой скорости приблизительно 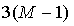 кбит/с. Фиг.6 иллюстрирует процесс формирования вспомогательной информации (соответствует блоку "Формирование вспомогательной информации" на фиг.2).
кбит/с. Фиг.6 иллюстрирует процесс формирования вспомогательной информации (соответствует блоку "Формирование вспомогательной информации" на фиг.2).
Скорость передачи вспомогательной информации может быть дополнительно сокращена посредством анализа активности для каждого сигнала источника и передачи вспомогательной информации, связанной с источником, только если он активен.
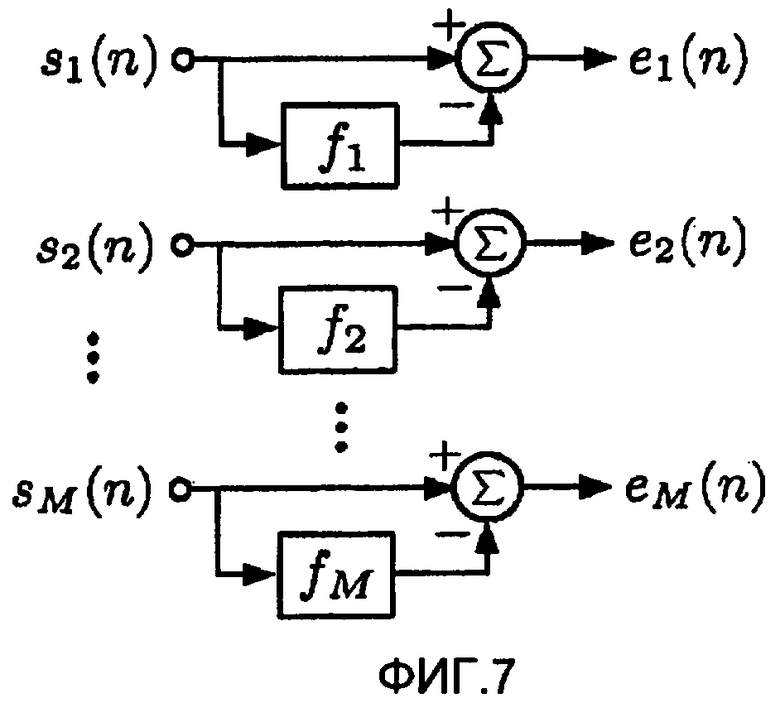
Вместо передачи значений мощности поддиапазона как статистической информации может быть передана другая информация, представляющая собой огибающие спектров сигналов источников. Например, могут быть переданы параметры кодирования с линейным предсказанием (LPC) или соответствующие другие параметры, такие как параметры решеточного фильтра или параметры пар спектральных линий (LSP). Процесс оценки параметров LPC каждого сигнала источника проиллюстрирован на фиг.7.
B.3 Вычисление сигнала
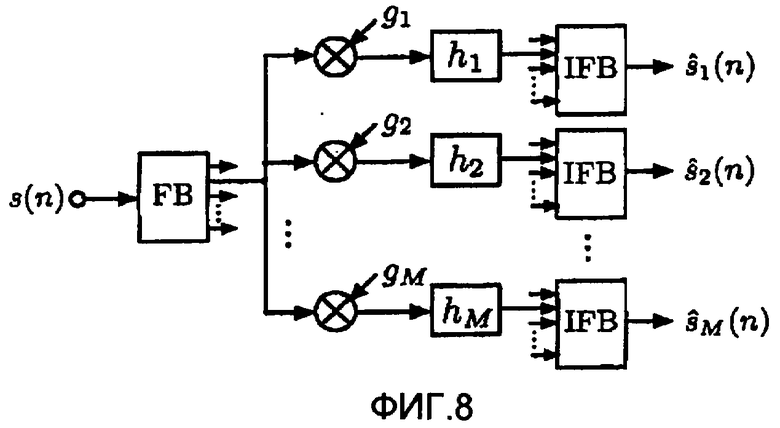
Фиг.8 иллюстрирует процесс, который используется для воссоздания сигналов источников при заданном суммарном сигнале (1). Этот процесс является частью блока "Синтез" на фиг.2. Сигналы отдельных источников восстанавливаются посредством масштабирования каждого поддиапазона суммарного сигнала с помощью gi(n) и применения фильтра декорреляции с импульсной характеристикой hi(n)},
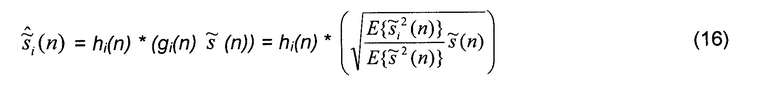
где * - оператор линейной свертки и оценка вычислена с помощью вспомогательной информации:
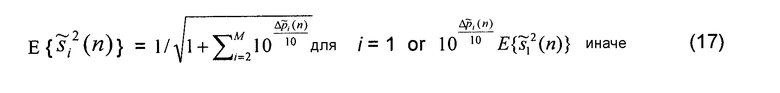
В качестве фильтров hi(n) декорреляции могут быть использованы дополнительные гребенчатые фильтры, всечастотные (фазовые) фильтры, элементы задержки или фильтры со случайными импульсными характеристиками. Цель процесса декорреляции состоит в том, чтобы уменьшить корреляцию между сигналами, не изменяя восприятие отдельных форм сигналов. Различные методы декорреляции вызывают различные артефакты. Дополнительные гребенчатые фильтры вызывают окрашивание. Все описанные методы распределяют энергию одиночных импульсов во времени, вызывая такие артефакты как "упреждающее эхо". Учитывая потенциальную возможность артефактов, метод декорреляции должен применяться в возможно меньшей степени. Следующий раздел описывает методы и стратегии, которые требуют меньшей обработки декорреляции, чем простое формирование независимых сигналов .
Альтернативная схема для формирования сигналов показана на фиг.9. Сначала спектр сигнала s(n) сглаживается посредством вычисления линейной ошибки e(n) предсказания. Затем с учетом фильтров fi кодирования с линейным предсказанием (LPC), оцененных в кодере, вычисляются соответствующие полюсные фильтры как обратное z-преобразование
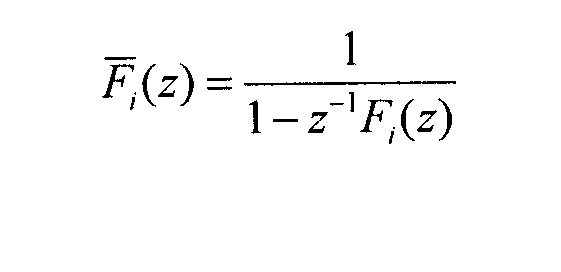
Получающиеся в результате полюсные фильтры 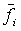 представляют собой огибающую спектра сигналов источников. Если передается вспомогательная информация, отличающаяся от параметров LPC, сначала должны быть вычислены параметры LPC как функция вспомогательной информации. Как в другой схеме, фильтры hi декорреляции используются для того, чтобы сделать сигналы источников независимыми.
представляют собой огибающую спектра сигналов источников. Если передается вспомогательная информация, отличающаяся от параметров LPC, сначала должны быть вычислены параметры LPC как функция вспомогательной информации. Как в другой схеме, фильтры hi декорреляции используются для того, чтобы сделать сигналы источников независимыми.
IV. РЕАЛИЗАЦИИ, УЧИТЫВАЮЩИЕ ПРАКТИЧЕСКИЕ ОГРАНИЧЕНИЯ
В первой части этого раздела дан пример реализации, использующей схему синтеза с BCC в качестве стереофонического или многоканального микшера. Это особенно интересно, поскольку такая схема синтеза типа BCC является частью развивающегося стандарта MPEG ISO/IEC, обозначаемого как "кодирование пространственного аудио". В этом случае сигналы источников явно не вычисляются, что дает в результате уменьшенную вычислительную сложность. Кроме того, эта схема предлагает потенциальные возможности для лучшего качества аудио, поскольку фактически требуется меньшая декорреляция, чем для случая, когда сигналы источников вычисляются явно.
Вторая часть этого раздела рассматривает случаи, в которых предложенная схема применяется с любым микшером, и обработка декорреляции вообще не выполняется. Такая схема менее сложна, чем схема с обработкой декорреляции, но, как будет описано, может иметь другие недостатки.
Предпочтительно, было бы желательно применить обработку декорреляции таким образом, чтобы сформированные сигналы можно было считать независимыми. Однако, поскольку обработка декорреляции проблематична с точки зрения внесения артефактов, желательно применять обработку декорреляции по возможности в меньшей степени. Третья часть этого раздела рассматривает, как можно сократить объем проблематичной обработки декорреляции, получая преимущества, как если бы сформированные сигналы были независимыми.
A. Реализация без явного вычисления сигналов
Микширование непосредственно применяется к переданному суммарному сигналу (1) без явного вычисления сигналов . С этой целью используется схема синтеза BCC. Далее рассматривается случай стереофонии, но все описанные принципы также могут быть применены для формирования многоканальных аудиосигналов.
Стереофоническая схема синтеза BCC (или "параметрическая стереофоническая" схема), применяемая к обработке суммарного сигнала (1), показана на фиг.10. Желательно, чтобы схема синтеза BCC формировала сигнал, который воспринимается аналогично выходному сигналу микшера, показанному на фиг.4. Это справедливо, когда параметры ICTD, ICLD и ICC-когерентность для выходных каналов схемы синтеза BCC аналогичны соответствующим признакам, появляющимся между каналами выходного сигнала микшера (уравнение 4).
Используется та же самая вспомогательная информация, как для ранее описанной более общей схемы, позволяя декодеру вычислить значения кратковременной мощности поддиапазона источников. Исходя из значений , коэффициенты g1 и g2 усиления на фиг.10 вычисляются как
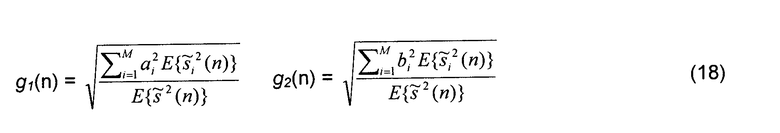
так что выходная мощность поддиапазонов и ICLD (уравнение 7) являются такими же, как для микшера на фиг.4. Разность T(n) по времени между каналами (ICTD) вычисляется согласно уравнению (10) и определяет задержки D1 и D2 на фиг.10 следующим образом:
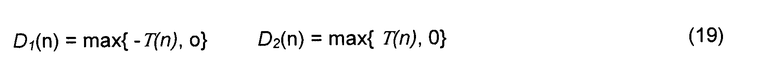
Когерентность c(n) между каналами (ICC) вычисляется согласно уравнению (9) и определяет обработку декорреляции на фиг.10. Обработка декорреляции (синтез ICC-когерентности) описана в [1]. Преимущества применения выполнения декорреляции к выходным каналам микшера по сравнению с ее применением для формирования независимых сигналов состоят в следующем:
- Обычно количество M сигналов источников больше, чем количество N выходных аудиоканалов. Таким образом, количество независимых аудиоканалов, которые должны быть сформированы, является меньшим при декорреляции N выходных каналов в отличие от декорреляции М сигналов источников.
- Часто N выходных аудиоканалов коррелированы (когерентность между каналами ICC>0), и обработка декорреляции может быть применена в меньшей степени, чем было бы необходимо для формирования M или N независимых каналов.
Из-за меньшей степени обработки декорреляции ожидается более хорошее качество звука.
Наилучшее качество звука ожидается, когда параметры микшера ограничены так, что ai 2+bi 2=1, то есть Gi=0 дБ. В этом случае мощность каждого источника в передаваемом суммарном сигнале (1) является такой же, как мощность того же самого источника в микшированном выходном сигнале декодера. В этом случае выходной сигнал декодера (фиг.10) является таким же, как если бы выходной сигнал микшера (фиг.4) был закодирован и декодирован кодером/декодером схемы BCC. Таким образом, можно ожидать аналогичного качества.
Декодер может не только определить направление, в котором должен появляться каждый источник, но также может быть изменено усиление каждого источника. Усиление увеличивается посредством выбора ai 2+bi 2>1 (Gi>0 дБ) и уменьшается посредством выбора ai 2+bi 2<1 (Gi<0 дБ).
B. Использование обработки без декорреляции
Ограничение ранее описанного метода состоит в том, что микширование выполняется с помощью схемы синтеза BCC. Можно было бы представить себе реализацию синтеза не только ICTD, ICLD и ICC-когерентности, но и обработку дополнительных эффектов в рамках синтеза BCC.
Однако может быть желательно, чтобы могли использоваться существующие микшеры и процессоры эффектов. Это также включает в себя микшеры синтеза волнового поля (часто называемые "конвольверами»). Для использования существующих микшеров и процессоров эффектов сигналы вычисляются в явном виде и используются, как если бы они были первоначальными сигналами источников.
С применением обработки без декорреляции (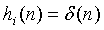 ) в уравнении (16)) также может быть достигнуто хорошее качество аудио. Это является компромиссом между артефактами, вносимыми вследствие выполнения декорреляции, и артефактами вследствие того, что сигналы источников являются коррелированными. Когда обработка декорреляции не используется, получающийся в результате звуковой пространственный образ может оказаться нестабильным [1]. Но микшер сам может вносить некоторую декорреляцию, когда используются ревербераторы или другие эффекты, и, таким образом, имеется меньше необходимости в выполнении декорреляции.
) в уравнении (16)) также может быть достигнуто хорошее качество аудио. Это является компромиссом между артефактами, вносимыми вследствие выполнения декорреляции, и артефактами вследствие того, что сигналы источников являются коррелированными. Когда обработка декорреляции не используется, получающийся в результате звуковой пространственный образ может оказаться нестабильным [1]. Но микшер сам может вносить некоторую декорреляцию, когда используются ревербераторы или другие эффекты, и, таким образом, имеется меньше необходимости в выполнении декорреляции.
Если сигналы формируются без обработки декорреляции, уровень источников зависит от направления, в котором они микшируются относительно других источников. Заменяя в существующих микшерах алгоритмы амплитудного панорамирования алгоритмом, компенсирующим эту зависимость уровня, можно избежать отрицательного эффекта зависимости громкости от параметров микширования. На фиг.11 показан амплитудный алгоритм, компенсирующий уровень, целью которого является компенсация зависимости уровня источника от параметров микширования. При заданных коэффициентах ai и bi усиления традиционного алгоритма амплитудного панорамирования (например, на фиг.4) весовые коэффициенты 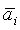 и
и 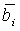 вычисляются следующим образом:
вычисляются следующим образом:
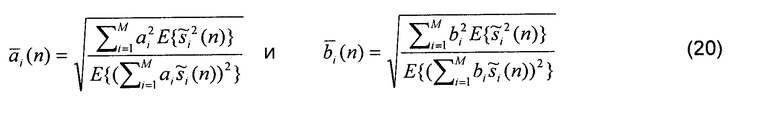
Следует отметить, что 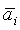 и
и 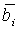 вычисляются так, что выходная мощность поддиапазона является такой же, как если бы сигналы были независимыми в каждом поддиапазоне.
вычисляются так, что выходная мощность поддиапазона является такой же, как если бы сигналы были независимыми в каждом поддиапазоне.
С. Сокращение количества обработки декорреляции
Как было упомянуто ранее, формирование независимых сигналов является проблематичным. Здесь описаны стратегии для применения меньшей обработки декорреляции с фактическим получением аналогичного эффекта, как если бы сигналы были независимыми.
Рассмотрим, например, систему синтеза волнового поля, показанную на фиг.12. Обозначены желательные позиции s1, s2,..., s6 виртуальных источников (M=6). Стратегия для вычисления сигналов (уравнение 16) без формирования M полностью независимых сигналов такова:
1. Сформировать группы индексов источников, соответствующих близким друг к другу источникам. Например, на фиг.8 это могут быть: {1}, {2, 5}, {3}, и {4, 6}.
2. Для каждого времени в каждом поддиапазоне выбрать индекс самого сильного источника,

Применить обработку без декорреляции для индексов источников, входящих в группу, содержащую imax, то есть 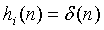 .
.
3. Для каждой другой группы выбрать одинаковый hi(n) в пределах группы.
Описанный алгоритм менее всего изменяет самые сильные компоненты сигнала. Дополнительно сокращается количество разных используемых hi(n). Это является преимуществом, поскольку декорреляция проще, когда должно быть сформировано меньше независимых каналов. Описанная техника также применима, когда микшируются стереофонические или многоканальные аудиосигналы.
V. МАСШТАБИРУЕМОСТЬ С ТОЧКИ ЗРЕНИЯ КАЧЕСТВА И БИТОВОЙ СКОРОСТИ
Предложенная схема передает только сумму всех сигналов источников, которые могут быть закодированы с помощью традиционного монофонического аудиокодера. Когда не требуется обратная совместимость с монофонией и доступна возможность для передачи/хранения более чем одной формы аудиосигнала, предложенная схема может быть масштабирована для использования с более чем одним каналом передачи. Это осуществляется посредством формирования нескольких суммарных сигналов с разными подмножествами заданных сигналов источников, то есть к каждому подмножеству сигналов источников предложенная схема кодирования применяется отдельно. Ожидается, что качество аудио улучшится с увеличением количества передаваемых аудиоканалов, поскольку из каждого передаваемого канала должно быть сформировано меньше независимых каналов посредством декорреляции (по сравнению со случаем одного переданного канала).
VI. ОБРАТНАЯ СОВМЕСТИМОСТЬ С СУЩЕСТВУЮЩИМИ ФОРМАТАМИ СТЕРЕОФОНИЧЕСКОГО И ОБЪЕМНОГО ЗВУКА
Ниже рассмотрен следующий сценарий предоставления аудио. Потребитель получает сигнал стереофонического или многоканального объемного аудио с максимальным качеством (например, посредством аудиокомпакт-диска, цифрового универсального диска DVD или интерактивного музыкального магазина и т.д.). Цель состоит в том, чтобы по желанию предоставить потребителю возможность формировать индивидуальное микширование полученного аудиосодержания без ухудшения стандартного качества воспроизведения стереофонического/объемного аудио.
Это осуществляется посредством предоставления потребителю (например, в виде варианта дополнительной покупки в интерактивном музыкальном магазине) битового потока вспомогательной информации, которая позволяет вычислять сигналы как функцию заданного стереофонического или многоканального аудиосигнала. Затем к сигналам применяется алгоритм микширования потребителя. Далее описаны две возможности вычисления сигналов при заданных стереофонических или многоканальных аудиосигналах.
A. Оценка суммы сигналов источников в приемнике
Самый прямой способ использования предложенной схемы кодирования с передачей стереофонического или многоканального аудио проиллюстрирован на фиг.13, где 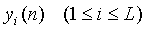 - L каналов заданного стереофонического или многоканального аудиосигнала. Суммарный сигнал источника оценивается посредством понижающего микширования в один аудиоканал. Понижающее микширование выполняется посредством вычисления суммы каналов
- L каналов заданного стереофонического или многоканального аудиосигнала. Суммарный сигнал источника оценивается посредством понижающего микширования в один аудиоканал. Понижающее микширование выполняется посредством вычисления суммы каналов 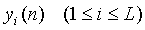 , или может быть применен более сложный метод.
, или может быть применен более сложный метод.
Для наилучших показателей работы рекомендуется, чтобы перед оценкой значений (уравнение 6) уровень сигналов источников был адаптирован таким образом, что отношение мощности между сигналами источников приблизительно тождественно отношению мощности, с которым источники содержатся в заданном стереофоническом или многоканальном сигнале. В данном случае понижающее микширование обеспечивает относительно хорошую оценку суммы источников (уравнение 1) (или ее взвешенной версии).
Для регулировки уровня сигналов si(n) источников на входе кодера перед вычислением вспомогательной информации может использоваться автоматизированный процесс. Этот процесс адаптивно во времени оценивает уровень, на котором каждый сигнал источника содержится в заданном стереофоническом или многоканальном сигнале. Затем до вычисления вспомогательной информации уровень каждого сигнала источника регулируется адаптивно во времени так, что он является равным уровню, на котором источник содержится в стереофоническом или многоканальном аудиосигнале.
B. Использование передаваемых каналов отдельно
Фиг.14 показывает другую реализацию предложенной схемы с передачей сигнала стереофонического или многоканального объемного аудио. Здесь передаваемые каналы не подвергаются понижающему микшированию, а используются отдельно для формирования сигналов . В самом общем случае сигналы поддиапазона сигналов вычисляются посредством

где wl(n) - весовые коэффициенты, определяющие специфические линейные комбинации поддиапазонов переданных каналов. Линейные комбинации выбраны так, что сигналы уже являются декоррелированными в максимально возможной степени. Таким образом, выполнение декорреляции не требуется или оно требуется лишь в малом количестве, что является благоприятным, как обсуждалось ранее.
VII. ПРИМЕНЕНИЯ
Выше было представлено множество применений для предложенных схем кодирования. Далее изложены выводы и представлено еще несколько применений.
A. Кодирование аудио для микширования
Предложенная схема может применяться всякий раз, когда сигналы аудиоисточников должны быть сохранены или переданы до их микширования в стереофонические, многоканальные аудиосигналы или сигналы синтеза волнового поля. Согласно предшествующему уровню техники, к каждому сигналу источника независимо применяется монофонический аудиокодер, что приводит к битовой скорости, которая пропорциональна количеству источников. Предложенная схема кодирования может кодировать большой объем сигналов аудиоисточников с помощью одного монофонического аудиокодера и вспомогательной информации с относительно низкой битовой скоростью. Как описано в разделе V, качество аудио может быть улучшено с использованием более чем одного переданного канала, если для этого доступны память/пропускная способность.
В. Повторное микширование с помощью метаданных
Как описано в разделе VI, существующие стереофонические и многоканальные аудиосигналы могут повторно микшироваться с помощью дополнительной вспомогательной информации (то есть "метаданных"). В отличие от продажи только оптимизированной стереофонической и многоканальной микшированной аудиоинформации могут продаваться метаданные, дающие пользователю возможность повторно микшировать свою стереофоническую и многоканальную музыку. Это может, например, также использоваться для ослабления вокалов в песне для караоке или для ослабления конкретных инструментов для игры на инструменте в сопровождении музыки.
Даже если хранение не представляет собой проблему, описанная схема будет очень привлекательной для того, чтобы дать возможность индивидуального микширования музыки. То есть, поскольку для музыкальной индустрии, вероятно, никогда не будет желательным предоставить многодорожечную запись, существует слишком большая опасность неправомочного использования. Предложенная схема дает возможность повторного микширования без выдачи многодорожечной записи.
Кроме того, когда стереофонические или многоканальные сигналы повторно микшируются, происходит некоторое ухудшение качества, что делает менее привлекательным незаконное распространение результатов повторного микширования.
C. Преобразование стереофонического/многоканального сигнала в сигнал синтеза волнового поля
Другое применение для схемы, описанной в разделе VI, заключается в следующем. Стереофоническое и многоканальное (например, объемное в формате 5.1) аудио, сопровождающее кинофильм, может быть расширено на воспроизведение синтеза волнового поля посредством добавления вспомогательной информации. Например, формат Dolby AC-3 (аудио на DVD) может быть расширен для обратно совместимого с форматом 5.1 кодирования аудио для систем синтеза волнового поля, то есть DVD воспроизводят объемный звук в формате 5.1 на традиционных унаследованных проигрывателях и звук в формате синтеза волнового поля на проигрывателях нового поколения, поддерживающих вспомогательную информацию.
VIII. СУБЪЕКТИВНЫЕ ОЦЕНКИ
Реализован декодер, работающий в реальном времени, для алгоритма, предложенного в разделе IV-A и IV-B. Использован блок фильтров кратковременного (оконного) преобразования Фурье (SFTF) на основе быстрого преобразования Фурье (FFT). Использованы 1024 - точечное БПФ и размер окна STFT, равный 768 (с дополнением нулями). Спектральные коэффициенты сгруппированы так, что каждая группа представляет собой сигнал с полосой частот, которая в два раза больше эквивалентной прямоугольной полосы частот (ERB). Неформальное прослушивание показало, что качество аудио особенно не улучшилось при выборе более высокого разрешения по частоте. Более низкое разрешение по частоте благоприятно, поскольку оно дает в результате меньшее количество параметров, которые должны быть переданы.
Для каждого источника амплитудное/фазовое панорамирование и усиление могут быть отрегулированы отдельно. Алгоритм использовался для кодирования многодорожечных аудиозаписей с 12-14 дорожками.
Декодер позволяет микшировать объемный звук в формате 5.1 с использованием микшера векторного амплитудного панорамирования (VBAP). Направление и усиление каждого сигнала источника могут быть отрегулированы. Программное обеспечение позволяет динамически переключаться между микшированием кодированного сигнала источника и микшированием первоначальных отдельных сигналов источников.
Поверхностное прослушивание обычно не выявляет различия или выявляет небольшое различие между микшированием кодированных или первоначальных сигналов источников, если для каждого источника используется коэффициент усиления Gi=0 дБ. Чем больше изменяются коэффициенты усиления источников, тем больше возникает артефактов. Небольшое усиление и ослабление источников (например, до ±6 дБ) все еще дает хороший звук. Критический сценарий представляет собой ситуацию, когда все источники микшируются на одну сторону и только один источник на другую противоположную сторону. В этом случае качество аудио может быть снижено в зависимости от конкретного микширования и сигналов источников.
IX. ЗАКЛЮЧЕНИЕ
Предложена схема совместного кодирования сигналов аудиоисточников, например каналов многодорожечной записи. Цель состоит не в кодировании формы сигнала источника с высоким качеством, когда совместное кодирование дало бы минимальную эффективность кодирования, поскольку аудиоисточники обычно независимы. Цель состоит в том, чтобы при микшировании кодированных сигналов источников получить высококачественный аудиосигнал. С учетом статистических свойств сигналов источников, свойств схем микширования и пространственного слуха показано, что посредством совместного кодирования сигналов источников достигается существенное увеличение эффективности кодирования.
Увеличение эффективности кодирования достигается вследствие того, что передается только одна форма аудиосигнала.
Дополнительно передается вспомогательная информация, представляющая собой статистические свойства сигналов источников, которые являются значимыми факторами, определяющими пространственное восприятие финального микшированного сигнала.
Битовая скорость вспомогательной информации составляет приблизительно 3 кбит/с на каждый сигнал источника. Любой микшер может быть применен к кодированным сигналам источников, например стереофонический, многоканальный микшеры или микшер для синтеза волнового поля.
Прямым способом масштабирования предложенной схемы для более высокой битовой скорости и качества является передача более чем одного аудиоканала. Кроме того, предложена разновидность схемы, которая позволяет повторно микшировать заданный стереофонический или многоканальный аудиосигнал (и даже изменять аудиоформат, например стереофонический звук на многоканальный звук или синтез волнового поля).
Применения предложенной схемы многообразны. Например, формат MPEG-4 может быть расширен с помощью предложенной схемы для уменьшения битовой скорости, когда требуется передать более чем один "естественный аудиообъект" (сигнал источника). Кроме того, предложенная схема предлагает компактное представление содержания для систем синтеза волнового поля. Как упомянуто, существующие стереофонические или многоканальные сигналы могут быть дополнены вспомогательной информацией, чтобы позволить пользователю повторно микшировать сигналы по его усмотрению.
ЛИТЕРАТУРА
1. C. Faller. "Параметрическое кодирование пространственного звука", докторская диссертация, Швейцарский Федеральный Институт Технологии, Лозанна (EPFL), 2004, докторская диссертация номер 3062.
2. C. Faller и F. Baumgarte. "Бинауральное кодирование сигналов. - Часть II: Схемы и применения", протоколы Института инженеров по электротехнике и радиоэлектронике (IEEE) по обработке речи и звука, том 11, номер 6, ноябрь 2003.
Изобретение касается кодирования множества сигналов аудиоисточников, которые должны быть переданы или сохранены с целью микширования сигналов для синтеза волнового поля, сигналов многоканального объемного или стереофонического аудио после декодирования сигналов источников. Предложенный способ обеспечивает эффективное кодирование при совместном кодировании сигналов источников по сравнению с их отдельным кодированием, даже когда между сигналами источников отсутствует избыточность. Это возможно с учетом статистических свойств сигналов источников, свойства метода кодирования и пространственного слуха. Сумма сигналов источников передается вместе со статистическими свойствами сигналов источников, которые главным образом определяют важные для восприятия пространственные признаки окончательно микшированных аудиоканалов. Сигналы источников восстанавливаются в приемнике так, что их статистические свойства приблизительно тождественны соответствующим свойствам первоначальных сигналов источников. Технический результат - обеспечение увеличения эффективности кодирования при микшировании кодированных сигналов источников. 6 н. и 16 з.п. ф-лы, 14 ил.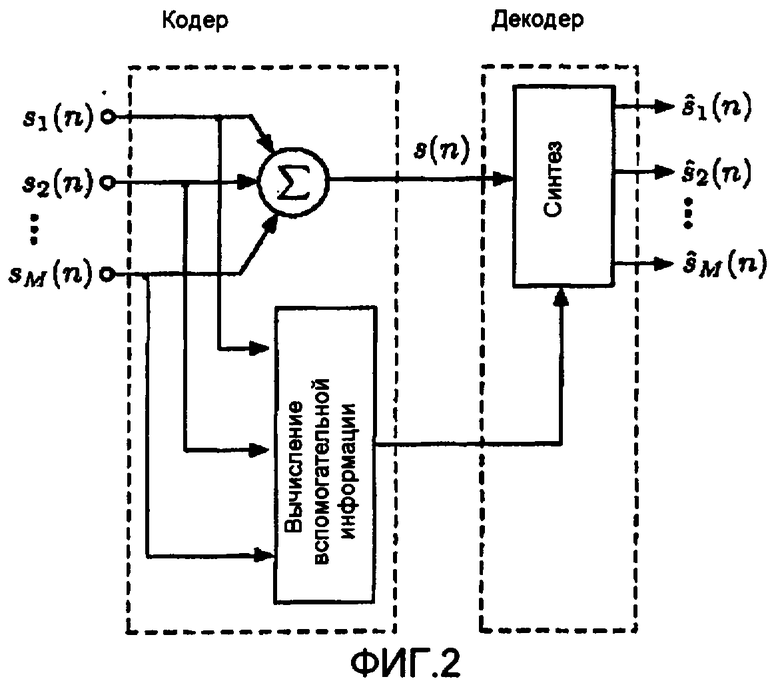
1. Способ синтезирования множества аудиоканалов, содержащий
извлечение из аудиопотока, по меньшей мере, одного суммарного сигнала, представляющего собой сумму сигналов источников,
извлечение из аудиопотока статистической информации об одном или более сигналах источников,
прием из аудиопотока или определение локально параметров, описывающих выходной аудиоформат и параметры микширования,
вычисление сигналов псевдоисточников из, по меньшей мере, одного суммарного сигналов и принятой статистической информации,
синтезирование множества аудиоканалов из сигналов псевдоисточников с использованием микшера, к которому применены принятые или локально определенные параметры аудиоформата и принятые или локально определенные параметры микширования.
2. Способ синтезирования множества аудиоканалов, содержащий
извлечение из аудиопотока, по меньшей мере, одного суммарного сигнала, представляющего собой сумму сигналов источников,
извлечение из аудиопотока статистической информации об одном или более сигналах источников,
прием из аудиопотока или определение локально параметров, описывающих выходной аудиоформат и параметры микширования источника,
вычисление выходных параметров микшера из принятой статистической информации, параметров, описывающих выходной аудиоформат, и параметров микширования источника,
синтезирование множества аудиоканалов из, по меньшей мере, одного суммарного сигнала на основе вычисленных выходных параметров микшера.
3. Способ по п.1 или 2, в котором статистическая информация представляет спектральные огибающие сигналов аудиоисточников, или спектральные огибающие одного или более сигналов аудиоисточников содержат параметры решеточного фильтра или параметры спектральных линий, или в котором статистическая информация представляет относительную мощность как функцию частоты и времени множества сигналов источников.
4. Способ по п.2, в котором этап вычисления выходных параметров микшера содержит вычисление признаков множества аудиоканалов и вычисление выходных параметров микшера с использованием вычисленных признаков множества аудиоканалов.
5. Способ по п.1, в котором сигналы псевдоисточников вычисляются в области поддиапазонов блока фильтров.
6. Способ по п.2, в котором аудиоканалы синтезируются в области поддиапазонов блока фильтров.
7. Способ по п.5 или 6, в котором количество и ширина полос поддиапазонов определяются в соответствии со спектральным и временным разрешением человеческой системы слуха.
8. Способ по п.5 или 6, в котором количество поддиапазонов составляет от 3 до 40.
9. Способ по п.5 или 6, в котором поддиапазоны в области поддиапазонов имеют разную ширину полос, при этом поддиапазоны на более низких частотах имеют меньшую ширину полос, чем поддиапазоны на более высоких частотах.
10. Способ по п.5 или 6, в котором используется блок фильтров на основе кратковременного преобразования Фурье (STFT), и спектральные коэффициенты объединены для формирования групп спектральных коэффициентов так, что каждая группа спектральных коэффициентов образует поддиапазон.
11. Способ по п.1 или 2, в котором статистическая информация также содержит функции автокорреляции.
12. Способ по п.3, в котором огибающие спектра представлены как параметры кодирования с линейным предсказанием (LPC).
13. Способ по п.1, в котором суммарный сигнал разделяют на множество поддиапазонов, и статистическую информацию используют для определения мощности каждого поддиапазона для каждого сигнала псевдоисточника.
14. Способ по п.1, в котором вычисляют ошибку линейного предсказания суммарного сигнала, после чего осуществляют полюсную фильтрацию для наложения огибающей спектра, определяемой посредством статистической информации для каждого сигнала псевдоисточника.
15. Способ по п.13 или 14, в котором используют метод декорреляции, такой как всечастотная фильтрация, чтобы сделать выходные сигналы псевдоисточников независимыми.
16. Способ по п.4, в котором вычисленными признаками являются разность уровней, разность во времени или когерентность для разных частот и моментов времени.
17. Способ по п.1, в котором микшером является алгоритм амплитудного панорамирования, компенсирующий зависимость уровней источников от параметров микширования, микшер синтеза волнового поля, бинауральный микшер, микшер трехмерного аудио.
18. Устройство для синтезирования множества аудиоканалов, при этом устройство выполнено с возможностью извлечения из аудиопотока, по меньшей мере, одного суммарного сигнала, представляющего собой сумму сигналов источников,
извлечения из аудиопотока статистической информации об одном или более сигналах источников,
приема из аудиопотока или определения локально параметров, описывающих выходной аудиоформат и параметры микширования,
вычисления сигналов псевдоисточников из, по меньшей мере, одного суммарного сигнала и принятой статистической информации,
синтезирования множества аудиоканалов из сигналов псевдоисточников с использованием микшера, к которому применены принятые или локально определенные параметры аудиоформата и принятые или локально определенные параметры микширования.
19. Устройство для синтезирования множества аудиоканалов, причем устройство выполнено с возможностью
извлечения из аудиопотока, по меньшей мере, одного суммарного сигнала, представляющего собой сумму сигналов источников,
извлечения из аудиопотока статистической информации об одном или более сигналах источников,
приема из аудиопотока, или определения локально, параметров описывающих выходной аудиоформат и параметры микширования источника,
вычисления выходных параметров микшера из принятой статистической информации параметров, описывающих выходной аудиоформат, и параметров микширования источника,
синтезирования множества аудиоканалов из, по меньшей мере, одного суммарного сигнала на основе вычисленных выходных параметров микшера.
20. Способ кодирования множества сигналов источников, содержащий
вычисление для множества сигналов источников статистической информации, представляющей спектральную огибающую одного или более сигналов источников, и
передачу вычисленной статистической информации в качестве метаданных для аудиосигнала, полученного из множества сигналов источников.
21. Способ по п.20, в котором статистическая информация содержит информацию о мощности поддиапазона множества сигналов источников, нормализованной взаимнокорреляционной функции поддиапазонов или нормализованной автокорреляционной функции поддиапазонов.
22. Устройство для кодирования множества сигналов источников, причем устройство выполнено с возможностью
вычисления для множества сигналов источников статистической информации, представляющей спектральную огибающую одного или более сигналов источников, и
передачи вычисленной статистической информации в качестве метаданных для аудиосигнала, полученного из множества сигналов источников.
| Дорожная спиртовая кухня | 1918 |
|
SU98A1 |
| СПОСОБ КОДИРОВАНИЯ РЕЧИ (ВАРИАНТЫ), КОДИРУЮЩЕЕ И ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО | 1998 |
|
RU2214048C2 |
| US 6539357 B1, 25.03.2003 | |||
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |

