Область техники, к которой относится изобретение
Настоящее изобретение относится в целом к сжатию видеосигнала и, в частности, касается кодирования видеосигнала с временной масштабируемостью посредством временной фильтрации с компенсацией движения в соответствии с последовательностью временных уровней с ограничениями.
Предшествующий уровень техники
Разработка технологий передачи информации, включая Интернет, привела к росту объема обмена видеосигналами. Однако потребители не удовлетворены существующими схемами связи на основе текстов. Для удовлетворения потребностей пользователей обеспечивается увеличение объема мультимедийных данных, содержащих различную информацию, в том числе текст, изображения, музыку и т.п. Мультимедийные данные обычно весьма объемны, так что для них требуется запоминающий носитель большой емкости. Также для передачи мультимедийных данных требуется широкая полоса пропускания. Например, для изображения 24-разрядного правильного цвета с разрешением 640×480 необходимо иметь 640×480×24 бита на кадр, то есть примерно 7,37 Мбит данных. В этом отношении необходимо иметь пропускную способность порядка 1200 Гбит, с тем чтобы передавать эти данные с частотой 30 кадров/с, а для запоминания кинофильма продолжительностью 90 минут потребуется объем памяти порядка 1200 Гбит. С учетом вышесказанного при передаче мультимедийных данных, включая текст, изображение или звук, необходимо использовать схему кодирования со сжатием.
Базовым принципом сжатия данных является устранение избыточности данных. Избыточность данных предполагает три типа избыточности: пространственную избыточность, временную избыточность и избыточность визуального восприятия. Пространственная избыточность относится к дублированию идентичных цветов или объектов в изображении, временная избыточность относится к отсутствию или небольшому изменению между соседними кадрами в кадре движущегося изображения или последовательному повторению одинаковых звуков в аудиосигнале, а избыточность визуального восприятия относится к притуплению человеческого зрения и чувствительности к высоким частотам. Устранив избыточность этих типов, данные можно сжать. Типы сжатия данных можно подразделить на: сжатие с потерями/без потерь в зависимости от того, потеряны ли исходные данные; внутрикадровое/межкадровое сжатие в зависимости от того, сжимаются ли данные независимо от кадра к кадру; и симметричное/асимметричное сжатие в зависимости от того, требуется ли для сжатия и восстановления данных одинаковый период времени. Вдобавок, когда общая длительность сквозной задержки при сжатии и распаковывании не превышает 50 мс, это называется сжатием в реальном времени. Когда кадры имеют различные значения разрешающей способности, это называется масштабируемым сжатием. Сжатие без потерь обычно используют при сжатии текстовых данных или медицинских данных, а сжатие с потерями обычно используют при сжатии мультимедийных данных.
С другой стороны, внутрикадровое сжатие обычно используют при устранении пространственной избыточности, а межкадровое сжатие используют при устранении временной избыточности.
Соответствующие передающие среды для передачи мультимедийных данных имеют разную пропускную способность. Используемые в настоящее время передающие среды имеют различные скорости передачи, включая сверхвысокоскоростную сеть связи, способную передавать данные со скоростями порядка десятков Мбит в секунду, сеть мобильной связи со скоростью передачи 384 Кбит в секунду и т.д. В стандартных алгоритмах кодирования видеосигнала, например MPEG-1, MPEG-2, H.263 или H.264, временная избыточность устраняется путем компенсации движения на основе схемы кодирования с предсказанием и компенсацией движения, а пространственная избыточность устраняется схемой кодирования с преобразованием. Эти схемы имеют хорошие рабочие характеристики при сжатии, но не отличаются большой гибкостью для реального масштабируемого битового потока, поскольку в основных алгоритмах этих схем используются рекурсивные подходы. По этой причине исследования в последнее время сфокусированы на масштабируемом кодировании видеосигнала на основе вейвлет-преобразования. Масштабируемое кодирование видеосигнала относится к кодированию видеосигнала с масштабируемостью, которая позволяет декодировать части сжатого битового потока. Благодаря этому свойству из битового потока можно получить различные видеосигналы. Здесь термин «масштабируемость» используется для совокупного указания на: специальную масштабируемость, предусмотренную для управления разрешающей способностью видеосигнала; масштабируемость по отношению сигнал/шум (SNR), предусмотренную для управления качеством видеосигнала; и временную масштабируемость, предусмотренную для управления значениями частоты кадров видеосигнала, а также из комбинации.
Среди многочисленных способов, используемых в схеме масштабированного кодирования видеосигнала на основе вейвлет-преобразования, базовым способом устранения временной избыточности и выполнения масштабируемого кодирования видеосигнала с временной гибкостью является временная фильтрация с компенсацией движения (MCTF), предложенная Ohm (J.R. Ohm, "Three-dimensional subband coding with motion compensation", IEEE Trans. Image Proc., Vol.3, No. 5, Sept. 1994) и усовершенствованная Choi и Wood (S.J. Choi и J.W. Woods, "Motion compensated 3-D subband coding of video", IEEE Trans. Image Proc., Vol.8, No.2, Feb. 1999). При фильтрации MCTF операция кодирования выполняется на основе группы изображений (GOP), а пары, состоящие из текущего кадра и опорного кадра, подвергаются временной фильтрации в направлении движения. Этот способ подробно описывается ниже со ссылкой на фиг. 1.
На фиг. 1 показаны временные декомпозиции в процессах масштабируемого кодирования и декодирования видеосигнала, где используется схема MCTF.
На фиг. 1 L кадр указывает на низкочастотный или обыкновенный кадр, а H кадр указывает на высокочастотный или разностный кадр. Как здесь показано, для выполнения процесса кодирования временная фильтрация сначала выполняется для пар кадров на самом низком временном уровне, чтобы преобразовать эти кадры на низком временном уровне в L кадры и H кадры на более высоком временном уровне, а затем пары преобразованных L кадров вновь подвергаются временной фильтрации и преобразуются в кадры на более высоких временных уровнях. Кодер создает битовый поток, используя L кадр на самом высоком уровне, и H кадры, которые прошли вейвлет-преобразование. Кадры, помеченные более темным цветом на фиг. 1, указывают, что они подвергаются вейвлет-преобразованию. Последовательность временных уровней распространяется от кадров на более низком уровне к кадрам на более высоком уровне. Декодер восстанавливает кадры, оперируя кадрами с более темной окраской, полученными посредством обратного вейвлет-преобразования, в порядке следования кадров от более высокого уровня к кадрам на более низком уровне. Два L кадра на втором временном уровне восстанавливают, используя L кадр и H кадр на третьем временном уровне, а четыре L кадра на первом временном уровне восстанавливают, используя два L кадра и два H кадра на втором временном уровне. Наконец, восемь кадров восстанавливают, используя четыре L кадра и четыре H кадра на первом временном уровне. Кодирование видеосигнала, использующее оригинальную схему MCTF, обладает временной гибкой масштабируемостью, но может иметь ряд недостатков, таких как неудовлетворительные рабочие характеристики при оценке однонаправленного движения, а также низкое качество при низких временных скоростях и т.д. В процессе исследования был предпринят ряд попыток с целью устранения этих недостатков. Одной из таких попыток является фильтрация MCTF без ограничений (UMCTF), предложенная Turaga и Mihaela (D.S. Turaga and Mihaela van der Schaar, "Unconstrained motion compensated temporal filtering", ISO/IEC JTC1/SC29/WG11, MPEG03/M8388, 2002). Фильтрация типа UMCTF описывается со ссылками на фиг. 2.
На фиг. 2 показаны временные декомпозиции в процессах масштабируемого кодирования и декодирования видеосигнала, где используется схема UMCTF.
В схеме UMCTF имеется возможность использовать множество опорных кадров и двунаправленную фильтрацию, что обеспечивает несколько общих структур. Вдобавок, в схеме UMCTF возможна недиадическая временная фильтрация на основе использования соответствующей вставки неотфильтрованного кадра (А кадра). Использование А кадров вместо отфильтрованных L кадров повышает визуальное качество на более низких временных уровнях, поскольку визуальное качество L кадров иногда серьезно ухудшается из-за отсутствия точной оценки движения. Множество экспериментальных результатов, полученных в прошлых исследованиях, показали, что фильтрация UMCTF без шага обновления имеет лучшие рабочие характеристики, чем исходная фильтрация MCTF. По этой причине обычно используют специальный вид фильтрации UMCTF, не содержащей шага обновления, хотя в наиболее общем варианте UMCTF есть возможность адаптивного выбора фильтров нижних частот.
Сущность изобретения
Техническая проблема
Во многих приложениях, где необходима малая сквозная задержка, таких как видеоконференции, требуется малая задержка как на стороне кодера, так и на стороне декодера. Поскольку как при фильтрации MCTF, так и при фильтрации UMCTF анализ выполняется, начиная с кадров на самом низком временном уровне, задержка на стороне кодера должна соответствовать по величине размеру группы GOP. Однако кодирование видеосигнала, дающее задержку, эквивалентную размеру GOP, реально неприемлемо для многих приложений, работающих в реальном времени. Хотя известно, что фильтрация UMCTF может снизить требование к задержке, ограничив количество будущих опорных кадров, это не является точным решением для управления сквозной задержкой. Вдобавок, не обеспечивается временная масштабируемость на стороне кодера, где кодирование видеосигнала не может прекратиться на каком-либо временном уровне и битовый поток не сможет передаваться. Однако временная масштабируемость на стороне кодера очень полезна для двунаправленных видеопотоковых приложений, работающих в реальном времени. Другими словами, работа на текущем временном уровне должна быть приостановлена, и должен быть немедленно передан битовый поток, когда операция кодирования невозможна. В этом отношении традиционные схемы имеют недостатки.
Техническое решение
В свете вышеописанных проблем имеется потребность в алгоритме кодирования видеосигнала, имеющем сравнительно небольшое влияние на визуальное качество и способном управлять сквозной задержкой так, чтобы она оставалась малой. Вдобавок, необходим алгоритм кодирования видеосигнала, обеспечивающий временные структуры с самого высокого временного уровня до самого низкого временного уровня, с тем чтобы иметь временную масштабируемость как на стороне кодера, так и на стороне декодера.
Соответственно, настоящее изобретение было задумано для удовлетворения вышеописанных потребностей. Одним аспектом настоящего изобретения является обеспечение способа и устройства для кодирования и декодирования видеосигнала, где можно управлять временем сквозной задержки и где временная масштабируемость имеется также на стороне кодера.
Согласно примерному варианту настоящего изобретения способ для кодирования видеосигнала содержит устранение временной избыточности в последовательности временных уровней с ограничениями из множества кадров, образующих входную видеопоследовательность, и формирование битового потока путем квантования коэффициентов преобразования, полученных из кадров, в которых была устранена временная избыточность.
Кадры, введенные на этапе устранения, могут являться кадрами, чья пространственная избыточность была устранена после прохождения через вейвлет-преобразование.
Коэффициенты преобразования на этапе формирования могут быть получены путем выполнения пространственного преобразования кадров, в которых была устранена временная избыточность. Пространственное преобразование выполняется на основе вейвлет-преобразования.
Временные уровни кадров могут иметь диадические иерархические структуры.
Последовательность временных уровней с ограничениями может являться последовательностью кадров на временных уровнях от самого высокого до самого низкого и последовательностью кадров, имеющих индексы с самого нижнего до самого верхнего на одном и том же временном уровне. Последовательность временных уровней с ограничениями периодически повторяется на основе размера GOP. В то же время кадр на самом высоком временном уровне имеет самый низкий кадровый индекс группы GOP среди кадров, образующих GOP.
Устранение временной избыточности выполняется на основе GOP, где первый кадр на самом высоком временном уровне в GOP кодируется как I кадр, после чего из соответствующих оставшихся кадров устраняется временная избыточность в соответствии с последовательностью временных уровней с ограничениями, причем для указанного устранения каждый из оставшихся кадров ссылается на один или несколько опорных кадров на более высоких временных уровнях, чем сам этот кадр, или имеет ссылку на один или несколько опорных кадров, чьи кадровые индексы ниже, чем у него самого, среди кадров на временном уровне, эквивалентном ему самому. Опорные кадры, на которые делается ссылка для устранения временной избыточности из соответствующих кадров, могут содержать один или два кадра с минимальным различием в индексах между одним или несколькими кадрами, имеющими более высокие временные уровни, чем сами указанные кадры.
Опорные кадры, на которые ссылается каждый кадр в процессе устранения временной избыточности, дополнительно содержат сами эти кадры (кадры, находящиеся в настоящее время в процессе фильтрации). Кадры, находящиеся в данный момент в процессе фильтрации, кодируются как I кадры, где относительная доля ссылок на самих себя в процессе устранения временной избыточности, больше заранее определенного значения.
Опорные кадры, на которые делается ссылка в процессе устранения временной избыточности, могут дополнительно содержать один или несколько кадров в следующей группе GOP, чьи временные уровни выше, чем у каждого из кадров, находящихся в данный момент в процессе фильтрации.
Последовательность временных уровней с ограничениями определяется в зависимости от режима кодирования. Последовательность временных уровней с ограничениями, определенная в зависимости от режима кодирования, периодически повторяется на основе GOP в одном и том же режиме кодирования. Кадр на самом высоком временном уровне из числа кадров, образующих GOP, может иметь самый низкий кадровый индекс.
На этапе формирования в битовый поток добавляется информация о режиме кодирования.
На этапе формирования в битовый поток добавляется информация о последовательностях пространственного устранения и временного устранения.
Режим кодирования определяется в зависимости от параметра D сквозной задержки, когда последовательность временных уровней с ограничениями продвигается от кадров на временных уровнях с самого высокого до самого низкого из числа кадров, имеющих индексы, не превышающие D, в сравнении с кадром на самом низком временном уровне, который еще не прошел временную фильтрацию, и от кадров с индексами от самого низкого к самому высокому на одном и том же временном уровне. Устранение временной избыточности выполняется на основе GOP, где первый кадр на самом высоком временном уровне в GOP кодируется как I кадр, после чего из соответствующих оставшихся кадров устраняется временная избыточность в соответствии с последовательностью временных уровней с ограничениями, причем для указанного устранения каждый из оставшихся кадров ссылается на один или несколько опорных кадров на более высоких временных уровнях, чем сам этот кадр, или ссылается на один или несколько опорных кадров, чьи индексы ниже, чем у него самого, среди кадров на временном уровне, эквивалентном самому указанному кадру. Предпочтительно, чтобы опорные кадры, на которые делается ссылка для устранения временной избыточности из соответствующих кадров, содержали бы один или два кадра с минимальным различием в индексах между одним или несколькими кадрами, имеющими более высокие временные уровни, чем сами указанные кадры.
Кадр на самом высоком временном уровне в GOP имеет самый низкий кадровый индекс.
В процессе устранения временной избыточности один или несколько опорных кадров, на которые ссылается каждый кадр, включают самих себя. Кадры, находящиеся в данный момент в процессе фильтрации, кодируются как I кадры, где относительная доля ссылок на самих себя в процессе устранения временной избыточности превосходит заранее определенное значение для коэффициента.
Опорные кадры, на которые делается ссылка в процессе устранения временной избыточности, дополнительно содержат один или несколько кадров в следующей группе GOP, чьи временные уровни выше, чем для каждого из кадров, находящихся в данный момент в процессе фильтрации, и чьи временные расстояния от каждого из кадров, находящихся в данный момент в процессе фильтрации, находятся в пределах D.
Согласно примерному варианту осуществления настоящего изобретения видеокодер содержит: блок временного преобразования, устраняющий временную избыточность в последовательности временных уровней с ограничениями из множества введенных кадров; блок пространственного преобразования, устраняющий пространственную избыточность из кадров; блок квантования, квантующий коэффициенты преобразования, полученные в процессах устранения временной и пространственной избыточностей; и блок формирования битового потока, создающий битовые потоки с использованием квантованных коэффициентов преобразования.
Блок временного преобразования видеосигнала устраняет временную избыточность кадров и передает кадры, чья временная избыточность была устранена, в блок пространственного преобразования, после чего блок пространственного преобразования устраняет пространственную избыточность кадров, чья временная избыточность была устранена, в результате чего получают коэффициенты преобразования. В то же время блок пространственного преобразования устраняет пространственную избыточность кадров посредством вейвлет-преобразования.
Кодер пространственного преобразования устраняет избыточность кадров посредством вейвлет-преобразования и передает кадры, чья пространственная избыточность была устранена, в блок временного преобразования, а затем блок временного преобразования устраняет временную избыточность кадров, чья пространственная избыточность была устранена, в результате чего получают коэффициенты преобразования.
Блок временного преобразования содержит: блок оценки движения, получающий векторы движения из множества введенных кадров; блок временной фильтрации, осуществляющий временную фильтрацию в последовательности временных уровней с ограничениями из множества введенных кадров, путем использования векторов движения; и блок выбора режима, определяющий последовательность временных уровней с ограничениями. Последовательность временных уровней с ограничениями, которую выбирает блок выбора режима, основана на периодической функции от размера GOP.
Блок выбора режима определяет последовательность временных уровней с ограничениями, состоящую из кадров на уровнях с самого высокого до самого низкого, и из кадров с индексами с самого маленького до самого большого на одном и том же временном уровне. Последовательность временных уровней с ограничениями, определенная блоком выбора режима, может периодически повторяться на основе размера GOP.
Блок выбора режима определяет последовательность временных уровней с ограничениями путем обращения к параметру D управления задержкой, причем определенная таким образом последовательность временных уровней является последовательностью кадров на уровнях с самого высокого до самого низкого из числа кадров с индексами, не превышающими D, в сравнении с кадром на самом нижнем уровне, чья временная избыточность не устранена, и последовательностью кадров с индексами от самого малого до самого большого на одном и том же временном уровне.
Блок временной фильтрации устраняет временную избыточность на основе GOP в соответствии с последовательностью временных уровней с ограничениями, выбранной блоком выбора режима, причем кадр, находящийся на самом высоком временном уровне в GOP, кодируется как I кадр, а затем устраняется временная избыточность из соответствующих оставшихся кадров, и при этом устранении каждый из оставшихся кадров ссылается на один или несколько опорных кадров на временных уровнях, более высоких, чем он сам, или ссылается на один или несколько опорных кадров, чьи индексы ниже, чем у него самого, из числа кадров на временном уровне, эквивалентном ему самому. Опорный кадр, относящийся к устранению временной избыточности из кадров, может содержать один или два кадра, имеющих минимальное отличие по индексу от кадра, находящегося в данный момент в процессе фильтрации, среди одного или нескольких кадров, находящихся на более высоких временных уровнях, чем кадры, проходящие в данный момент фильтрацию.
Кадр на самом высоком временном уровне в группе GOP имеет самый низкий временной кадровый индекс.
Блок временной фильтрации дополнительно включает кадр, находящийся в данный момент в процессе фильтрации, в опорные кадры, на которые делается ссылка при устранении временной избыточности из фильтруемого в данный момент кадра. В то же время блок временной фильтрации кодирует фильтруемый в данный момент кадр как I кадр, где относительная доля ссылок на самого себя для фильтруемого в данный момент кадра превышает заранее определенное значение.
Блок формирования битового потока создает битовый поток, включающий в себя информацию о последовательности временных уровней с ограничениями. Блок формирования битового потока может создать битовый поток, включающий в себя информацию о последовательностях устранения временной и пространственной избыточностях (последовательности устранения избыточностей) для получения коэффициентов преобразования.
Согласно примерному варианту настоящего изобретения способ декодирования видеосигнала содержит: выделение информации в кодированных кадрах путем приема входных битовых потоков и их интерпретации; получение коэффициентов преобразования путем обратного квантования информации в кодированных кадрах; и восстановление кадров посредством обратного временного преобразования коэффициентов преобразования в последовательности временных уровней с ограничениями.
На этапе восстановления кадры получают посредством обратного временного преобразования коэффициентов преобразования с последующим обратным вейвлет-преобразованием результатов.
На этапе восстановления кадры получают посредством обратного пространственного преобразования коэффициентов перед обратным временным преобразованием с последующим обратным временным преобразованием результатов. При обратном пространственном преобразовании предпочтительно используется обратное вейвлет-преобразование.
Последовательность временных уровней с ограничениями относится к последовательности кадров на временных уровнях от самого высокого до самого низкого, а также к кадрам с индексами от самого большого до самого малого на одном и том же временном уровне. Последовательность временных уровней с ограничениями периодически повторяется на основе размера группы GOP. Обратное временное преобразование относится к обратной временной фильтрации кадров, начиная с кодированных кадров на самом высоком временном уровне, и обработке последовательности временных уровней с ограничениями в группе GOP.
Последовательность временных уровней с ограничениями определяется в соответствии с информацией о режиме кодирования, выделенной из входного битового потока. Последовательность временных уровней с ограничениями периодически повторяется на основе размера GOP в одном и том же режиме кодирования.
Информация о режиме кодирования, определяющая последовательность временных уровней с ограничениями, может содержать параметр D управления сквозной задержкой, причем последовательность временных уровней с ограничениями, определенная информацией о режиме кодирования, продвигается от кодированных кадров на временных уровнях с самого высокого до самого низкого из числа кадров, имеющих индексы, не превышающие D, в сравнении с кадром на самом низком временном уровне, который еще не был декодирован, и от кадров с индексами от самого низкого до самого высокого на одном и том же временном уровне.
Последовательность устранения избыточности выделяется из входного битового потока.
Согласно примерному варианту настоящего изобретения видеодекодер, восстанавливающий кадры из входного битового потока, содержит: блок интерпретации битового потока, интерпретирующий битовый поток для выделения из него информации о кодированных кадрах; блок обратного квантования, осуществляющий обратное квантование информации о кодированных кадрах для получения из нее коэффициентов преобразования; блок обратного пространственного преобразования, выполняющий процесс обратного пространственного преобразования; и блок обратного временного преобразования, выполняющий процесс обратного временного преобразования в последовательности временных уровней с ограничениями, где кадры восстанавливаются посредством процессов обратного временного преобразования коэффициентов преобразования.
Видеодекодер дополнительно содержит блок обратного вейвлет-преобразования, выполняющий обратное вейвлет-преобразование результатов, полученных путем оперирования с коэффициентами преобразования с помощью блока обратного временного преобразования.
Видеодекодер дополнительно содержит блок обратного пространственного преобразования, выполняющий обратное пространственное преобразование коэффициентов преобразования, где результаты, полученные посредством обратного пространственного преобразования коэффициентов преобразования, подвергаются обратному временному преобразованию блоком обратного временного преобразования.
Блок обратного пространственного преобразования выполняет обратное пространственное преобразование на основе обратного вейвлет-преобразования, а последовательность временных уровней с ограничениями начинается с кодированных кадров на временных уровнях с самого высокого до самого низкого. Последовательность временных уровней с ограничениями периодически повторяется на основе размера группы GOP.
Блок обратного временного преобразования выполняет обратное временное преобразование на основе GOP, а кодированные кадры подвергаются обратной временной фильтрации, начиная с кадров на самом высоком временном уровне до кадров на самом низком временном уровне в GOP.
Блок интерпретации битового потока выделяет информацию о режиме кодирования из входного битового потока и определяет последовательность временных уровней с ограничениями в соответствии с информацией о режиме кодирования. Последовательность временных уровней с ограничениями периодически повторяется на основе GOP.
Информация о режиме кодирования, определяющая последовательность временных уровней с ограничениями, содержит параметр D управления сквозной задержкой, причем последовательность временных уровней с ограничениями, определенная информацией о режиме кодирования, продвигается от кодированных кадров на временных уровнях с самого высокого до самого низкого из числа кадров, имеющих индексы, не превышающие D, в сравнении с кадром на самом низком временном уровне, который еще не был декодирован, и от кадров с индексами с самого низкого до самого высокого на одном и том же временном уровне.
Последовательность устранения избыточности выделяется из входного потока.
Перечень чертежей
Вышеуказанные и другие цели, признаки и преимущества настоящего изобретения станут более очевидными из последующего подробного описания, взятого вместе с сопроводительными чертежами, на которых:
фиг. 1 - временные декомпозиции в процессах масштабируемого кодирования и декодирования видеосигнала при использовании схемы MCTF;
фиг. 2 - временные декомпозиции в процессах масштабируемого кодирования и декодирования видеосигнала при использовании схемы UMCTF;
фиг. 3 - функциональная блок-схема, иллюстрирующая масштабируемый видеокодер согласно примерному варианту настоящего изобретения;
фиг. 4 - функциональная блок-схема, иллюстрирующая масштабируемый видеокодер согласно примерному варианту настоящего изобретения;
фиг. 5 - функциональная блок-схема, иллюстрирующая масштабируемый видеодекодер согласно примерному варианту настоящего изобретения;
фиг. 6 - иллюстрация базовой концепции алгоритма последовательной временной аппроксимации и формирования ссылок (STAR) согласно примерному варианту настоящего изобретения;
фиг. 7 - иллюстрация множества возможных связей между кадрами в алгоритме STAR;
фиг. 8 - формирование ссылок между группами GOP согласно примерному варианту настоящего изобретения;
фиг. 9 - иллюстрация возможных связей между кадрами при не диадической временной фильтрации согласно примерному варианту настоящего изобретения;
фиг. 10 - иллюстрация возможных связей между кадрами при временной фильтрации, когда параметр управления сквозной задержкой равен нулю, согласно примерному варианту настоящего изобретения;
фиг. 11 - иллюстрация возможных связей между кадрами при временной фильтрации, когда параметр управления сквозной задержкой равен единице, согласно примерному варианту настоящего изобретения;
фиг. 12 - иллюстрация возможных связей между кадрами при временной фильтрации, когда параметр управления сквозной задержкой равен трем, согласно примерному варианту настоящего изобретения;
фиг. 13 - иллюстрация возможных связей между кадрами при временной фильтрации, когда параметр управления сквозной задержкой равен трем, а размер GOP равен 16, согласно примерному варианту настоящего изобретения;
фиг. 14 - иллюстрация прямого режима, обратного режима, двунаправленного режима и режима с внутрикадровым предсказанием;
фиг. 15 - иллюстрация возможных связей между кадрами с использованием четырех режимов предсказания при временной фильтрации согласно примерному варианту настоящего изобретения;
фиг. 16 - пример видеокодирования в быстро изменяющейся видеопоследовательности согласно примерному варианту по фиг. 15;
фиг. 17 - пример видеокодирования в медленно изменяющейся видеопоследовательности согласно примерному варианту по фиг. 15;
фиг. 18 - график, показывающий результаты отношения пиковый сигнал/шум (PSNR) для последовательности с общим промежуточным форматом (CIF) Foreman в схеме кодирования видеосигнала;
фиг. 19 - график, показывающий результаты PSNR для последовательности Mobile CIF в схеме кодирования видеосигнала;
фиг. 20 - график, показывающий результаты PSNR для последовательности CIF Foreman с различными уставками сквозной задержки в схеме кодирования видеосигнала;
фиг. 21 - график, показывающий результаты PSNR для последовательности Mobile CIF с различными уставками сквозной задержки в схеме кодирования видеосигнала; и
фиг. 22 - график, показывающий результаты PSNR, когда часть быстро изменяемой сцены из кинофильма «Матрица-2», кодируется с использованием четырех режимов предсказания, а также кодируется без использования четырех режимов предсказания.
Варианты осуществления изобретения
Далее со ссылками на сопроводительные чертежи подробно описываются примерные варианты осуществления настоящего изобретения.
На фиг. 3 представлена функциональная блок-схема, иллюстрирующая масштабируемый видеокодер согласно примерному варианту настоящего изобретения.
Масштабируемый видеокодер принимает множество введенных кадров для образования видеопоследовательности и сжимает их для формирования битового потока. Для выполнения этих операций масштабируемый видеокодер содержит: блок 10 временного преобразования, устраняющий временную избыточность между множеством кадров; блок 20 пространственного преобразования, устраняющий пространственную избыточность между кадрами; блок 30 квантования, квантующий коэффициенты преобразования, сформированные путем устранения временной и пространственной избыточностей; и блок 40 формирования битового потока, который формирует битовый поток, объединяющий квантованные коэффициенты преобразования и другую информацию.
Блок 10 временного преобразования содержит блок 12 оценки движения, блок 14 временной фильтрации и блок 16 выбора режима для компенсации движения между кадрами и выполнения временной фильтрации.
Блок 12 оценки движения получает векторы движения для компенсации движения между каждым макроблоком кадров, подвергающихся в данный момент временной фильтрации, и каждым макроблоком соответствующих им опорных кадров. Информация о векторах движения подается в блок 14 временной фильтрации, а блок 14 временной фильтрации выполняет временную фильтрацию для множества кадров, используя информацию о векторах движения. В данном примерном варианте временная фильтрация выполняется на основе группы GOP.
Блок 16 выбора режима определяет последовательность для временной фильтрации. Временная фильтрация в этом примерном варианте в основном обрабатывается в последовательности, начиная с кадра на самом высоком временном уровне до кадра на самом низком временном уровне в группе GOP. Когда кадры находятся на одном и том же временном уровне, обработка для временной фильтрации выполняется в последовательности, начиная с кадра с самым низким индексом до кадра с самым высоким индексом. Кадровый индекс является индексом, указывающим временную последовательность между кадрами, образующими группу GOP. Таким образом, когда количество кадров, образующих одну группу GOP, равно n, то последний кадр во временной последовательности имеет индекс n-1, если первый кадр GOP, который является кадром GOP, пришедшим раньше всех, определен с индексом 0.
В данном примерном варианте в качестве кадра, имеющего самый высокий временной уровень среди кадров, образующих данную группу GOP, используется, к примеру, кадр с самым низким индексом. Это обстоятельство следует интерпретировать в том смысле, что выбор другого кадра на самом высоком временном уровне в GOP также не противоречит технической концепции настоящего изобретения.
Блок 16 выбора режима может выполнять процесс кодирования видеосигнала в режиме с ограниченной задержкой для уменьшения сквозной задержки, создаваемой в процессе кодирования видеосигнала. В этом случае блок 16 выбора режима может ограничивать временную фильтрацию, с тем чтобы обеспечить последовательность кадров на временных уровнях с самого высокого до самого низкого, как было описано выше, в соответствии со значением параметра D управления сквозной задержкой. Вдобавок, блок 16 выбора режима может изменять последовательность временной фильтрации или выполнять временную фильтрацию с удалением некоторых кадров, учитывая ограничения на производительность обработки в процессе кодирования. Здесь будет использоваться термин «последовательность временных уровней с ограничениями», который обозначает последовательность временной фильтрации с учетом всех значимых факторов. Последовательность временных уровней с ограничениями определяет, что временная фильтрация начинается с кадра на самом верхнем временном уровне.
Кадры, из которых устраняется временная избыточность, то есть кадры, подвергающиеся временной фильтрации, проходят через блок 20 пространственного преобразования для устранения в них пространственной избыточности. Блок 20 пространственного преобразования устраняет специальную избыточность из кадров, которые прошли временную фильтрацию, путем использования пространственного преобразования. В данном примерном варианте используется вейвлет-преобразование. При вейвлет-преобразовании, известном специалистам в данной области техники, один кадр делится на четыре части, одна четверть кадра заменяется уменьшенным изображением (L изображение) с четвертной площадью, но почти идентичным целому изображению в кадре, а другие три четверти кадра заменяются информацией (H изображение), доступной для использования при восстановлении целого изображения. Аналогичным образом, L кадр можно вновь разделить на четыре части и заменить L изображением, имеющим четвертную площадь, и информацией для восстановления L изображения. Схема сжатия такого рода, использующая вейвлет-преобразование, была применена в схеме сжатия JPEG2000. Пространственную избыточность кадров можно устранить посредством вейвлет-преобразования. В отличие от дискретного косинусного преобразования (DCT) при вейвлет-преобразовании информация исходного изображения хранится в преобразованном изображении, уменьшенном в размере, что позволяет обеспечить кодирование видеосигнала с пространственной масштабируемостью путем использования уменьшенного изображения. Однако схема вейвлет-преобразования используется здесь в качестве примера. Когда нет необходимости в пространственной масштабируемости, в качестве стандартной схемы сжатия движущихся изображений, например MPEG-2, можно использовать схему DCT.
Кадры, прошедшие временную фильтрацию, преобразуются в коэффициенты преобразования посредством пространственного преобразования. Коэффициенты преобразования передаются в блок 30 квантования, а затем квантуются. Блок 30 квантования квантует коэффициенты преобразования, которые являются коэффициентами, представленными в виде чисел с плавающей точкой, и преобразует их в коэффициенты преобразования целочисленного типа. То есть посредством квантования можно уменьшить количество бит для представления данных изображения. В данном примерном варианте процесс квантования коэффициентов преобразования выполняется посредством схемы встроенного квантования. Поскольку квантование коэффициентов преобразования выполняется посредством схемы встроенного квантования, объем информации, необходимой для видеопоследовательности, можно уменьшить посредством квантования, а масштабируемость по SNR может быть достигнута посредством встроенного квантования. Термин «встроенное» используется для указания на то, что кодированный битовый поток несет в себе квантование. Другими словами, сжатые данные создаются в визуально значимом порядке и снабжаются метками визуальной значимости. Уровень квантования (или визуальной значимости) в действительности может быть полезным в декодере или канале передачи. Если пропускная способность передачи, емкость памяти и ресурсы дисплея это позволяют, изображение может быть восстановлено с высоким качеством. В противном случае, изображение квантуется настолько, насколько это допустимо по наиболее ограниченным ресурсам. Стандартные алгоритмы встроенного квантования включают в себя вейвлет-преобразование на основе вложенных пуль-деревьев (EZW), разбиение множеств в иерархических деревьях (SPIHT), встроенное блочное кодирование относительно нуля (EZBC), встроенное блочное кодирование с оптимальным усечением (EBCOT) и т.п. В данном примерном варианте можно использовать любой из известных алгоритмов.
Блок 40 формирования битового потока создает битовый поток, объединяющий информацию, которая касается кодированных изображений, и информацию, касающуюся векторов движения, полученных от блока 12 оценки движения путем присоединения к ним заголовка. В данном примерном варианте информация, относящаяся к последовательности временных уровней с ограничениями, битовый поток, параметр задержки и т.п. включены в информацию, касающуюся битового потока.
Когда для устранения пространственной избыточности используется вейвлет-преобразование, форма исходного изображения преобразованного кадра сохраняется. По этой причине, в отличие от схемы кодирования движущихся изображений на основе DCT-преобразования, изображение может последовательно пройти через пространственное преобразование, временное преобразование и квантование для формирования битового потока. Другой примерный вариант этого процесса описан ниже со ссылками на фиг. 4.
На фиг. 4 представлена функциональная схема, иллюстрирующая масштабируемый видеокодер согласно примерному варианту настоящего изобретения.
Обратимся к фиг. 4, где масштабируемый видеокодер содержит: блок 60 пространственного преобразования, устраняющий пространственную избыточность из множества кадров; блок 70 временного преобразования, устраняющий временную избыточность из кадров; блок 80 квантования, квантующий коэффициенты преобразования, полученные путем устранения как пространственной, так и временной избыточностей; и блок 90 формирования битового потока, создающий битовый поток, который объединяет информацию изображений и другую информацию.
Термин «коэффициент преобразования» в общем случае относится к значению, сформированному в результате пространственного преобразования, поскольку пространственное преобразование было использовано после временной фильтрации при стандартном сжатии движущихся изображений. Этот термин в альтернативном варианте относится к коэффициенту DCT, где значение формируется посредством DCT-преобразования. Соответственно термин «коэффициент вейвлет-преобразования» используется, когда значение коэффициента создается посредством вейвлет-преобразования. В настоящем изобретении термин «коэффициент преобразования» указывает на значение, сформированное в результате устранения из множества кадров как пространственной, так и временной избыточности перед их квантованием (встраиванием). По этому поводу следует заметить, что термин «коэффициент преобразования» означает коэффициент, сформированный посредством пространственного преобразования по фиг. 3, а также коэффициент, сформированный посредством временного преобразования по фиг. 4.
Блок 60 пространственного преобразования устраняет пространственную избыточность между множеством кадров, образующих видеопоследовательность. В этом случае блок 60 пространственного преобразования устраняет пространственную избыточность, существующую в кадрах, используя вейвлет-преобразование. Кадры, из которых устранена пространственная избыточность, то есть пространственно преобразованные кадры передаются в блок 70 временного преобразования.
Блок 70 временного преобразования устраняет временную избыточность пространственно преобразованных кадров. Для выполнения этой работы блок 70 временного преобразования содержит блок 72 оценки движения, блок 74 временной фильтрации и блок 76 выбора режима. В этом примерном варианте блок 70 временного преобразования действует таким же образом, как на фиг. 3, за исключением того, что введенные кадры являются пространственно преобразованными кадрами, в отличие от фиг. 3. Кроме того, различие между примерным вариантом по фиг. 4 и примерным вариантом по фиг. 3 состоит в том, что блок 70 временного преобразования создает коэффициенты преобразования для квантования кадров, чья временная избыточность устранена после того, как была устранена их пространственная избыточность.
Блок 80 квантования квантует коэффициенты преобразования для формирования квантованной информации изображения (кодированная информация изображения) и передает сформированную информацию изображения в блок 40 формирования битового потока. Подобно фиг. 3 выполняется встроенное квантование, и достигается масштабируемость SNR применительно к окончательно создаваемому битовому потоку.
Блок 90 формирования битового потока формирует битовый поток, объединяющий кодированную информацию изображения и информацию, касающуюся векторов движения, путем присоединения к ней заголовка. В то же время подобно фиг. 3 может быть введен параметр управления сквозной задержкой и последовательность временных уровней.
Блок 40 формирования битового потока по фиг. 3 и блок 90 формирования битового потока по фиг. 4 могут включать информацию, относящуюся к последовательностям устранения временной избыточности и пространственной избыточности (здесь это называется «последовательность устранения избыточности») в битовый поток с тем, чтобы на стороне декодера была возможность определить, закодирована ли видеопоследовательность согласно фиг. 3 или видеопоследовательность закодирована согласно фиг. 4. Последовательность устранения избыточности может быть включена в битовый поток с использованием различных схем. Можно выбрать одну схему в качестве базовой схемы и отдельно указать другие схемы в битовом потоке. Например, если в качестве базовой схемы выбрана схема, использованная на фиг. 3, то битовый поток, сформированный масштабируемым видеокодером по фиг. 3, может быть указан без информации о последовательности устранения избыточности, а только с последовательностью устранения избыточности, созданной масштабируемым видеокодером по фиг.4. Наоборот, информация, касающаяся обеих последовательностей устранения избыточности, может быть указана в обеих схемах, использованных на фиг. 3 и фиг. 4.
Также можно сформировать битовый поток с очень высокой эффективностью кодирования путем создания масштабируемого видеокодера, реализующего обе функции на стороне масштабируемого видеокодера согласно фигурам 3 и 4, соответственно, путем кодирования и сравнения видеопоследовательностей в схемах по фигурам 3 и 4. В этом случае последовательность устранения избыточности может быть включена в битовый поток. Последовательность устранения избыточности может быть определена на основе очередности или на основе GOP. В первом случае последовательность устранения избыточности должна быть включена в заголовок видеопоследовательности; в последнем случае, последовательность устранения избыточности должна быть включена в заголовок группы GOP.
Примерные варианты осуществления, показанные на фигурах 3 и 4, могут быть оба реализованы аппаратными средствами, но также могут быть реализованы с помощью любого устройства, имеющего программные модули и вычислительные возможности для их исполнения.
На фиг. 5 показана функциональная блок-схема, иллюстрирующая масштабируемый видеодекодер согласно примерному варианту настоящего изобретения.
Масштабируемый видеодекодер содержит: блок 100 интерпретации битового потока, интерпретирующий входной битовый поток и выделяющий каждую компоненту, образующую битовый поток; первый блок 200 декодирования, восстанавливающий изображение, закодированное согласно фиг. 3; и второй блок 300 декодирования, восстанавливающий изображение, закодированное согласно фиг. 4.
Первый и второй блоки 200 и 300 декодирования могут быть реализованы аппаратными или программными модулями. При их реализации аппаратными или программными модулями они могут быть выполнены по отдельности или в интегрированном виде. Если они реализованы в интегрированном виде, то первый и второй блоки 200 и 300 декодирования восстанавливают устраненные данные из битового потока, полученного в блоке 100 интерпретации битового потока, путем использования последовательности устранения избыточности обратным образом.
Масштабируемый видеодекодер может быть реализован так, чтобы восстанавливались все изображения, закодированные в разных последовательностях устранения избыточности, но также может быть реализован таким образом, чтобы восстанавливаться могло только то изображение, которое закодировано в одной из двух последовательностей устранения избыточности.
Блок 100 интерпретации битового потока интерпретирует входной битовый поток, выделяет закодированную информацию изображения (кодированные кадры) и определяет последовательность для устранения избыточности. Если последовательность устранения избыточности подвергается декодированию первым блоком 200 декодирования, то видеопоследовательность восстанавливается через первый блок 200 декодирования. Если последовательность устранения избыточности подвергается декодированию вторым блоком 300 декодирования, то видеопоследовательность восстанавливается вторым блоком 300 декодирования. Вдобавок, блок 100 интерпретации битового потока интерпретирует битовый поток, с тем чтобы определить последовательность временных уровней с ограничениями, то есть последовательность для временной фильтрации кадров при устранении временной избыточности. В этом примерном варианте последовательность временных уровней с ограничениями может быть определена на основе значения параметра управления задержкой, определяющего режим кодирования. В процессе восстановления видеопоследовательности из закодированной информации изображения сначала будет описано декодирование первым блоком 200 декодирования, после чего описывается декодирование вторым блоком 300 декодирования.
Информация о кодированных кадрах, введенных в первый блок 200 декодирования, подвергается обратному квантованию блоком 210 обратного квантования и преобразуется в коэффициенты преобразования. Коэффициенты преобразования подвергаются обратному пространственному преобразованию блоком 220 обратного пространственного преобразования. Тип обратного пространственного преобразования зависит от типа пространственного преобразования кодированных кадров. Если для пространственного преобразования использовано вейвлет-преобразование, то для обратного пространственного преобразования выполняется обратное вейвлет-преобразование. Если для пространственного преобразования использовано DCT преобразование, то для обратного пространственного преобразования выполняется обратное DCT преобразование. Коэффициенты преобразования преобразуются в I кадры и H кадры, каждый из которых подвергается обратной временной фильтрации посредством обратного пространственного преобразования. В этой связи блок 230 обратного временного преобразования восстанавливает кадры, образующие видеопоследовательность, посредством обратного временного преобразования в последовательности временных уровней с ограничениями. Последовательность временных уровней с ограничениями может быть получена путем интерпретации входного битового потока блоком 100 интерпретации битового потока. Для обратного временного преобразования блок 230 обратной временной фильтрации использует векторы движения, полученные в результате интерпретации битового потока.
Информация о кодированных кадрах, введенных во второй блок 300 декодирования, подвергается обратному квантованию блоком 310 обратного квантования и преобразуется в коэффициенты преобразования. Коэффициенты преобразования подвергаются обратному временному преобразованию блоком 320 обратного временного преобразования. Векторы движения для обратного временного преобразования и последовательность временных уровней с ограничениями могут быть взяты из информации, полученной посредством интерпретации битового потока блоком 100 интерпретации битового потока. Информация о кодированных изображениях, проходящая через обратное временное преобразование, преобразуется в кадры в состоянии, которое имеет место после проведения пространственного преобразования. Кадры, находящиеся в состоянии после проведения пространственного преобразования, подвергаются обратному пространственному преобразованию в блоке 330 обратного пространственного преобразования и восстанавливаются в кадры, образующие видеопоследовательность. При обратном пространственном преобразовании, применяемом в блоке 330 обратного пространственного преобразования, используется схема обратного вейвлет-преобразования.
Далее подробно описывается процесс временного преобразования кадров в последовательности временных уровней с ограничениями с поддержкой временной масштабируемости и управлением сквозной задержкой.
Согласно настоящему изобретению можно обеспечить, чтобы кадры имели временную масштабируемость как на стороне кодера, так и на стороне декодера, а также имеется возможность управления сквозной задержкой с помощью алгоритма последовательной временной аппроксимации и формирования ссылок, а именно алгоритма STAR.
На фиг. 6 показана базовая концепция алгоритма STAR.
Для описания базовой концепции алгоритма STAR каждый кадр на каждом временном уровне представлен в виде узла, а отношение ссылки между кадрами представлено в виде дуги. На каждом временном уровне расположены только необходимые кадры, например, на самом высоком временном уровне необходим только первый кадр GOP. В этом примерном варианте кадр F(0) находится на самом высоком временном уровне. На следующем временном уровне последовательно повышается временное разрешение, и с помощью исходных кадров с уже обработанным кадровым индексом предсказываются недостающие кадры с высокой частотой. Если размер группы GOP равен восьми, то кадр с индексом 0 кодируется как I кадр на самом высоком временном уровне, а кадр с индексом 4 кодируется как «межкадр» (H кадр) на следующем временном уровне путем использования исходного кадра с индексом 0. Затем в качестве «межкадров» кодируются кадры с индексами 2 и 6 с использованием исходных кадров с индексами 0 и 4. Наконец, в качестве «межкадров» кодируются кадры с индексами 1, 3, 5 и 7 с использованием исходных кадров с индексами 0, 2, 4 и 6. Здесь термин «исходные кадры» относится в основном к кадрам, образующим видеопоследовательность, но также может быть использован применительно к кадрам, полученным путем декодирования ранее закодированных кадров. В процессе декодирования сначала декодируется кадр с индексом 0. Затем декодируется кадр с индексом 4 по ссылке на декодированный кадр с индексом 0. Таким же образом декодируются кадры с индексами 2 и 6 по ссылке на декодированные кадры с индексами 0 и 4. Наконец, по ссылке на декодированные кадры с индексами 1, 3, 5 и 7 в качестве «межкадров» декодируются кадры с индексами 0, 2, 4 и 6.
Как показано на фиг. 6, как на стороне кодера, так и на стороне декодера можно использовать один и тот же временной процесс, что может обеспечить временную масштабируемость на стороне кодера. Работа на стороне кодера может прекратиться на любом временном уровне, но на стороне декодера декодирование кадров должно осуществляться вплоть до намеченного временного уровня. То есть, поскольку кадр на самом высоком временном уровне кодируется первым, сторона кодера может получить временную масштабируемость. Например, если процесс кодирования останавливается, когда закодированы кадры с индексами 0, 4, 2 и 6, на стороне декодера декодируются кадры с индексами 0 и 4 по ссылке на декодированные кадры с индексами 0, 2 и 6 по ссылке на декодированные кадры с индексами 0 и 4. В этом случае сторона декодера может выдать кадры 0, 2, 4 и 6. Предпочтительно, чтобы кадр на самом высоком временном уровне (F(0) в данном примерном варианте осуществления) был закодирован как I кадр, а не как L кадр, что необходимо при работе с другими кадрами, с тем чтобы поддерживать временную масштабируемость на стороне кодера.
Для сравнения стандартные алгоритмы масштабируемого кодирования видеосигнала на основе MCTF или UMCTF могут иметь временную масштабируемость на стороне декодера, но на стороне кодера с поддержкой временной масштабируемости возникают трудности. Обратимся к фигурам 1 и 2, где для выполнения процесса декодирования требуется L кадр или A кадр на временном уровне 3. Однако в случае использования алгоритмов MCTF и UMCTF L кадр или А кадр на самом высоком временном уровне можно получить только после завершения процесса кодирования, но процесс декодирования может прекратиться на любом временном уровне.
Далее описываются требования к поддержанию временной масштабируемости как на стороне кодера, так и на стороне декодера.
Положим, что F(k) - это k-й кадр, а T(k) - это временной уровень F(k). Временная масштабируемость устанавливается, если кадр на некотором временном уровне кодируется по ссылке на кадр на том же или более низком временном уровне. Например, кадр с индексом 4 не может иметь ссылку на кадр с индексом 2. Причина этого состоит в том, что процесс кодирования не может прекратиться на кадрах с индексами 0 и 4, если указанная ссылка разрешена. Другими словами, кадр с индексом 2 можно кодировать, когда кадр с индексом 4 уже закодирован. Набор Rk опорных кадров, на которые может ссылаться кадр F(k), определяется уравнением (1)
Rk={F(I)|(T(I)>T(k)) или (T(I)=T(k) и (I<=k))} (1)
(1)
где T указывает кадровый индекс.
В уравнении (1) ((T(l)=T(k)) и (l=k)) означает, что кадр (k) выполняет временную фильтрацию со ссылкой на самого себя в процессе временной фильтрации (внутренний режим), как описывается ниже.
Процессы кодирования и декодирования с использованием алгоритма STAR описываются ниже.
Операции процесса кодирования:
(1) Кодирование первого кадра группы GOP как I кадра.
(2) Для кадров на следующем временном уровне - выполнение предсказания движения и кодирование остатков межкадрового предсказания с использованием возможных опорных кадров, удовлетворяющих уравнению (1). На том же самом временном уровне кадры кодируются в порядке слева направо (порядок кадровых индексов с самого низкого до самого высокого).
(3) Повторение операции (2), пока не будут закодированы все кадры, а затем кодирование следующей группы GOP, пока не будет завершено кодирование для всех кадров.
Операции процесса декодирования:
(1) Декодирование первого кадра из группы GOP.
(2) Декодирование кадров на следующем временном уровне с использованием подходящих опорных кадров из числа уже декодированных кадров. Кадры на одном и том же временном уровне декодируются в порядке слева направо (в порядке кадровых индексов с самого низкого до самого высокого).
(3) Повторение операции (2), пока не будут декодированы все кадры, а затем декодирование следующей группы GOP, пока не будет завершено декодирование для всех кадров.
Как показано на фиг. 6, кадр, помеченный символом I, является кадром с внутрикадровым кодированием (не имеет ссылок на другие кадры), а кадры, помеченные символом H, являются кадрами высокочастотной субполосы. Высокочастотная субполоса указывает на то, что кадры закодированы со ссылкой на один или несколько кадров.
На фиг. 6, где размер группы GOP составляет восемь, временной уровень кадра в иллюстративных целях представлен в виде последовательности 0, 4, (2, 6), (1, 3, 5, 7). Вдобавок, имеется небольшая проблема с временной масштабируемостью на стороне кодера и временной масштабируемостью на стороне декодера, когда эта последовательность представляет собой 1, 5, (3, 7), (0, 2, 4, 6). Аналогичным образом допустима последовательность временных уровней 2, 6, (0, 4), (1, 3, 5, 7). Другими словами, допустимы любые кадры на временном уровне, если может быть обеспечена временная масштабируемость на стороне кодера и временная масштабируемость на стороне декодера.
Однако, когда кадры находятся в последовательности временных уровней 0, 5, (2, 6), (1, 3, 4, 7), это может обеспечить временную масштабируемость на стороне кодера и временную масштабируемость на стороне декодера, но этот вариант нецелесообразен, поскольку интервалы между кадрами не равны.
На фиг. 7 показано множество возможных связей между кадрами в алгоритме STAR.
Обратимся к фиг. 7, на основании которой будут описаны примеры возможных связей между кадрами для временной фильтрации.
Согласно уравнению (1) кадр F(k) может иметь ссылки на множество кадров. Это свойство делает алгоритм STAR подходящим для использования множества опорных кадров. В этом примерном варианте показаны возможные связи между кадрами, размер группы GOP которых составляет восемь. Дуга, берущая начало от одного кадра и возвращающаяся назад к этому же кадру (так называемый «кадр с петлей»), указывает, что этот кадр предсказывается во внутрикадровом режиме. В качестве опорных кадров можно использовать все исходные кадры, имеющие закодированные ранее индексы, включая индексы на позиции H кадра, на одном и том же временном уровне, в то время как в большинстве традиционных способов ссылаться можно только на L или A кадры из числа исходных кадров на позиции H кадра среди кадров на одном и том же уровне. Этот признак отличает настоящее изобретение от известных способов. Например, в традиционных способах F(5) может ссылаться на F(3) и F(1), но F(5) не может ссылаться на F(0), F(2) и F(4).
Хотя множество опорных кадров сильно увеличивают объем памяти, необходимой для временной фильтрации и обработки задержки, возможность поддержки этого признака является весьма ценной.
Как было описано выше, предположим, что кадр на самом высоком временном уровне в одной группе GOP имеет, например, самый низкий кадровый индекс. Вдобавок, следует отметить, что кадр на самом высоком временном уровне может иметь иной кадровый индекс.
Для удобства количество опорных кадров, используемых для кодирования одного кадра, в экспериментальных результатах ограничено двумя кадрами для двунаправленного предсказания и одним кадром для однонаправленного предсказания.
На фиг. 8 показано формирование ссылок между группами GOP согласно одному примерному варианту осуществления настоящего изобретения. На фиг. 8 показан алгоритм кодирования STAR, использующий двунаправленное предсказание и перекрестную оптимизацию по группам GOP.
Алгоритм STAR может кодировать кадры, ссылаясь на кадры других групп GOP, что носит название «перекрестная оптимизация по группам GOP». Фильтрация UMCTF также поддерживает перекрестную оптимизацию по группам GOP, поскольку как алгоритм кодирования UMCTF, так и алгоритм кодирования STAR используют А или I кадры, которые не подвергаются временной фильтрации. Обратимся к фигурам 6 и 7, где ошибка предсказания в кадре с индексом 7 равна сумме ошибок предсказания кадров с индексами 0, 4 и 6. Однако, если кадр с индексом 7 ссылается на кадр с индексом 0 следующей группы GOP (кадр с индексом 8, если вычисления производятся с текущей группой GOP), то этот дрейф ошибок предсказания можно значительно уменьшить. Кроме того, поскольку кадр с индексом 0 следующей группы GOP является кадром с внутрикадровым кодированием, качество кадра с индексом 7 может быть значительно повышено.
На фиг. 9 показаны возможные связи между кадрами при недиадической временной фильтрации согласно еще одному примерному варианту осуществления настоящего изобретения.
Если алгоритм кодирования UMCTF естественным образом поддерживает не диадическую временную декомпозицию путем произвольной вставки А-кадров, алгоритм STAR также может поддерживать не диадическую временную декомпозицию путем изменения структуры графа достаточно простым образом. В этом примерном варианте показан пример декомпозиции STAR, поддерживающей временные декомпозиции 1/3 и 1/6. В алгоритме STAR можно легко получить любые произвольные дробные значения полной частоты кадров, изменив структуру графа.
Алгоритм STAR задает одинаковую последовательность обработки на стороне кодера и стороне декодера на временном уровне и поддерживает множество опорных кадров, а также перекрестную оптимизацию по группам GOP, как было описано выше. Некоторые из этих признаков могут быть реализованы в ограниченной степени традиционными способами, но при этом с помощью традиционных способов трудно управлять сквозной задержкой. Как правило, способ уменьшения размера GOP использовался для уменьшения задержки, но это приводило к заметному ухудшению рабочих характеристик. При использовании алгоритма STAR можно легко управлять сквозной задержкой, пока кадр не будет восстановлен в видеопоследовательность после выполнения процессов кодирования и декодирования снова в видеопоследовательность, если реализовать концепцию управления на основе параметра (D) управления сквозной задержкой.
Обратимся к фигурам с 10 по 13, где алгоритм STAR рассматривается для случая, когда задержка ограничена.
Для управления задержкой условия временной масштабируемости согласно уравнению (1) должны быть слегка модифицированы, как это определено в уравнении (2)
Rk D={F(I)|((T(I)>T(k) и (l-k)<=D)) или (T(I)=T(k) и (l<=k))} (2)
где Rk D представляет набор опорных кадров, на которые в данный момент могут ссылаться закодированные кадры, когда разрешенная задержка определена в виде параметра D. Согласно уравнению (2) любой кадр на более высоком временном уровне никогда не может быть опорным кадром. В частности, различие между индексом опорного кадра и индексом текущего кодированного кадра не превышает D. В этой связи следует заметить, что параметр D указывает максимальную сквозную задержку, разрешаемую для кодирования F(k). Обратимся к фиг. 8, где кадр с индексом 4 необходим для кодирования кадра с индексом 2, поэтому достаточно, если D будет равен двум. Однако следует заметить, что кадр с индексом 2 необходим для кодирования кадра с индексом 1, а кадр с индексом 4 необходим для кодирования кадра с индексом 2, и поэтому D равен трем. Если кадр с индексом 1 не имеет ссылку на кадр с индексом 2, а кадр с индексом 5 не имеет ссылку на кадр с индексом 6, то достаточно, чтобы D был равен двум. Суммируя вышесказанное, для кодирования структуры, показанной на фиг. 8, параметр D следует установить равным трем. Также следует отметить, что в случае использования уравнения (2) можно применять множество опорных кадров или вышеописанную перекрестную оптимизацию по группам GOP. Этот признак дает преимущество, состоящее в том, что управление задержкой можно осуществлять непосредственным и простым образом.
Преимущество подхода на основе алгоритма STAR заключается в том, что при этом не придется отказываться от временной масштабируемости. Традиционные способы уменьшения размера GOP приводят к уменьшению размеров максимального временного уровня, так что временная масштабируемость на стороне декодера существенно ограничивается. Например, когда размер GOP равен восьми, частоты кадров, доступные для выбора на стороне декодера, ограничены значениями 1, 1/2, 1/4 и 1/8. При размере GOP, равном четырем, для задания параметра D равным трем выбираемые частоты кадров составят 1, 1/2 и 1/4. Когда размер GOP равен двум, то выбираемые частоты кадров составят только 1 и 1/2. Как было описано выше, уменьшение размера GOP имеет недостаток, состоящий в том, что серьезно снижается эффективность кодирования видеосигнала. Наоборот, временная масштабируемость на стороне декодера не страдает, даже когда D сведен к нулю в результате использования алгоритма STAR, то есть масштабируемость ухудшается только на стороне кодера. То есть, когда размер GOP составляет восемь и D равен нулю, если возможности обработки на стороне кодера на основе GOP ограничены двумя кадрами, то должны кодироваться кадры с индексами 0 и 1, а затем передаваться на сторону декодера. В этом случае на стороне декодера можно восстановить видеопоследовательность с частотой кадров, составляющей 1/4, но временные интервалы восстановленных видеокадров окажутся неравными.
Далее со ссылками на фигуры с 10 по 13 описываются примеры различных сквозных задержек.
На фиг. 10 показаны возможные связи между кадрами при временной фильтрации, когда параметр управления задержкой установлен в 0, согласно другому примерному варианту настоящего изобретения.
На фиг. 10 показана временная структура алгоритма STAR, поддерживающего двунаправленное предсказание и перекрестную оптимизацию по группам GOP с ограничением задержки, когда значение D установлено в нуль. Поскольку параметр управления задержкой равен нулю, перекрестная оптимизация по группам GOP автоматически блокируется, и все кадры ссылаются только на более поздние по времени кадры (а именно кадры с более низкими индексами). Таким образом, кадры передаются в последовательности 0, 1, 2, 3, 4, 5, 6 и 7. То есть один кадр обрабатывается и немедленно передается на сторону декодера. В этом случае задержка существует только во время буферизации I кадра. Этот признак также сохраняется и на стороне декодера, где декодер может начать декодирование, как только поступает кадр. Конечная задержка составляет только два кадра (67 мс при 30 Гц), включая рабочую задержку на стороне декодера, но в этом случае несколько ухудшаются рабочие характеристики по сравнению со случаем, когда значение D установлено большим нуля.
На фиг. 11 показаны возможные связи между кадрами при временной фильтрации, когда параметр управления задержкой равен единице, согласно примерному варианту настоящего изобретения.
В этом примерном варианте автоматически активизируется перекрестная оптимизация по группам GOP. Все кадры на самом низком временном уровне могут быть предсказаны путем использования двунаправленного предсказания, а последний кадр одной группы GOP может ссылаться на первый кадр следующей группы GOP. В этом случае последовательность кодирования кадров составит 0, 2, 1, 4, 3, 6, 5, 7 и 8 (0 из следующего кадра). Потребуется лишь задержка для буферизации двух кадров на стороне кодера и задержка на обработку на стороне декодера. Общее время задержки составит три кадра (100 мс при 30 Гц), причем для большинства кадров используется двунаправленное предсказание, а также перекрестная оптимизация по группам GOP для последнего кадра.
На фиг. 12 показаны возможные связи между кадрами при временной фильтрации, когда параметр управления временем задержки равен трем, согласно примерному варианту настоящего изобретения.
Если D равно трем, то кадр с индексом 2 может ссылаться на кадр с индексом 4, а кадр с индексом 6 может ссылаться на первый кадр следующей группы GOP, как показано на фиг. 12.
Причиной того, почему D равен трем, а не двум, является то, что задержка в два кадра достаточна, поскольку кадр с индексом 4 необходим для кодирования кадра с индексом 2, кадр с индексом 2 необходим для кодирования кадра с индексом 1, а кадру с индексом 2 необходима задержка в два кадра, что потребует общего времени задержки в три кадра. Когда время задержки равно трем, возможна ссылка на все кадры за исключением ссылки на кадр с индексом 8 (кадр 0 следующей группы GOP) со стороны кадра с индексом 4. В этом случае последовательность кодирования составит 0, 4, 2, 1, 3, 8 (кадр 0 следующей группы GOP), 6, 5 и 7. Если параметр D равен четырем, то возможна структура, показанная на фиг. 8. Увеличение размера GOP до 16 показано на фиг. 13.
На фиг. 13 показаны возможные связи между кадрами при временной фильтрации, когда параметр управления временем задержки равен трем при размере GOP, равном 16, согласно еще одному примерному варианту настоящего изобретения. В этом случае последовательность кодирования кадров (такая же, как последовательность передачи) составит 0, 4, 2, 1, 3, 8, 6, 5, 7, 12, 10, 9, 11, 16 (кадр 0 следующей группы GOP), 14, 13 и 15. Следует заметить, что алгоритм STAR задает возможность управления суммарной сквозной задержкой с помощью одного параметра D. Этот признак упрощает управление задержкой, приводя к постепенному снижению эффективности кодирования с точки зрения суммарной сквозной задержки. Такая гибкая задержка в одной структуре очень полезна, поскольку суммарной сквозной задержкой можно легко управлять в соответствии с возможностями какого-либо приложения к системе кодирования без ее значительной модификации. При однонаправленном видеопотоке суммарная сквозная задержка незначительна. Таким образом, значение параметра D можно установить максимальным (например, 1/2 от размера группы GOP). Суммарная сквозная задержка скорее представляет весьма важную проблему при двунаправленной видеоконференции. В этом случае, если суммарная сквозная задержка установлена равной меньше двух, то суммарная сквозная задержка может оказаться очень короткой, даже если эффективность кодирования несколько снизится. Взаимосвязь между суммарной сквозной задержкой и значением параметра D задержки показана в Таблице 1.
Суммарная сквозная задержка Т может быть просто представлена в виде уравнения (3)
Т=min(2, 2D+1), (3)
(3)
где Т представляет значение суммарной сквозной задержки, единицей измерения которой является время одного кадра.
Экспериментальные результаты, относящиеся к ухудшению параметра PSNR из-за суммарной сквозной задержки, будут описаны ниже.
На фиг. 14 показаны прямой, обратный и двунаправленный режимы, а также режим внутримакроблочного предсказания.
Алгоритм STAR в основном поддерживает мультирежимные временные предсказания. Как показано на фиг. 4, поддерживаются режим прямого предсказания (1), режим обратного предсказания (2), режим двунаправленного предсказания (3) и режим внутримакроблочного предсказания (4). Первые три режима уже поддерживаются в связи с масштабируемым кодированием видеосигнала при традиционных способах, но алгоритм STAR повышает эффективность кодирования быстро изменяющихся видеопоследовательностей путем добавления режима внутрикадрового предсказания.
Ниже в первую очередь описывается определение режима межмакроблочного предсказания.
Поскольку алгоритм STAR позволяет обеспечить двунаправленное предсказание и множество опорных кадров, прямое, обратное и двунаправленное предсказание можно легко реализовать. Хотя для такой настройки можно использовать хорошо известный алгоритм HVBSM, настоящий примерный вариант изобретения будет ограничен схемой оценки движения с фиксированным размером блока. Пусть E (k, -1) является k-й суммой абсолютных разностей (SAD) при прямом предсказании, а B(k, -1) - это общие биты движения для квантования векторов движения для прямого предсказания. Аналогичным образом предположим, что E (k, +1) является k-й SAD в режиме обратного предсказания; B(k, +1) - общие биты движения, присваиваемые для квантования векторов движения в режиме обратного предсказания; E(k, *) - k-я SAD в режиме двунаправленного предсказания, а B(k, *) - общие биты движения, присваиваемые для квантования векторов движения в режиме двунаправленного предсказания. Затраты для режимов прямого, обратного и двунаправленного предсказания могут быть описаны в виде уравнения (4)
Cf=E(k, -1)+λB(k, -1),
Cb=E(k, 1)+λB(k, 1), и
Cbi=E(k, *)+λ{B(k, -1)+B(k, 1)} (4)
(4)
где Cf, Cb и Cbi относятся к затратам для режимов прямого, обратного и двунаправленного предсказания соответственно;
λ - множитель Лагранжа для регулирования соотношения между битами движения и текстуры (изображения).
Поскольку масштабируемому видеокодеру не могут быть известны конечные скорости передачи в битах, λ необходимо оптимизировать в соответствии с характером видеопоследовательности и битовыми скоростями передачи данных, в основном используемыми в выходном приложении. В результате вычисления минимальных затрат, заданных в уравнении (4), можно определить оптимальный режим межмакроблочного предсказания.
Далее определяется, что означает режим внутримакроблочного предсказания.
В некоторых видеопоследовательностях сцены изменяются очень быстро. В экстремальном случае можно наблюдать один кадр, вообще не имеющий временной избыточности по отношению к соседним кадрам. Для разрешения этой ситуации способ кодирования, реализованный кодеком MC-EZBC, поддерживает функцию «адаптивности к размеру группы GOP». Такая адаптивность к размеру группы GOP прекращает временную декомпозицию и кодирует кадр как L кадр, когда количество несвязанных пикселей превышает заранее определенное пороговое значение (как правило 30% от общего количества пикселей). Этот способ может быть применен для алгоритма STAR, но в данном примерном варианте изобретения используются более гибкие подходы, заимствованные из концепции внутримакроблочных режимов, используемых в стандартных гибридных кодерах. Обычно кодеки без обратной связи, включая кодек на основе алгоритма STAR, не могут использовать какую-либо информацию о соседних макроблоках из-за дрейфа предсказания, в то время как гибридный кодек может использовать режим многократного внутримакроблочного предсказания. Таким образом, в данном примерном варианте для режима внутрикадрового предсказания используется DC предсказание. В этом режиме выполняется внутрикадровое предсказание макроблока с помощью значений DC для Y, U и V компонент. Если затраты на режим внутрикадрового кодирования меньше, чем наилучший вариант затрат в режиме межкадрового кодирования, описанном выше, можно выбрать режим внутрикадрового предсказания. В этом случае кодируется разность между исходным пикселем и значением DC и разность между тремя значениями DC вместо векторов движения. Затраты на режим внутрикадрового кодирования могут быть определены по уравнению (5).
Ci=E(k, 0)+λB(k, 0) (5)
(5)
где Е(k, 0) - SAD (разность между значениями исходной яркости и значениями DC при k-м внутрикадровом предсказании), а B (k, 0) - суммарные биты для кодирования трех значений DC.
Если Сi меньше значений, вычисленных по уравнению (4), то кодирование реализуется в режиме внутримакроблочного предсказания. В заключение, если все макроблоки в кадре закодированы в режиме внутримакроблочного предсказания с использованием только одного набора значений DC, кадр может быть закодирован как I кадр. Между тем, желательно иметь множество I кадров в видеопоследовательностях, если пользователь хочет иметь возможность просмотра произвольного места по ходу видеопоследовательностей или автоматически редактировать видео. В этом случае хорошим решением является замена H кадра на I кадр.
Когда не все макроблоки в кадре закодированы в режиме внутрикадрового предсказания, если в режиме внутрикадрового предсказания закодировано в процентном отношении больше заранее определенного значения (например, 90%), то кадр может быть закодирован как I кадр. При таком кодировании возрастает количество I кадров в видеосигнале, и в результате пользователю легче просматривать произвольное место в видеопоследовательности или ее редактировать.
Хотя алгоритм STAR обеспечивает простые способы для реализации многорежимного временного предсказания, следует отметить, что можно также использовать и другие способы, которые применяются кодеком MC-EZBC и другими кодеками. Все макроблоки во всех остальных кадрах кроме первого кадра могут кодироваться с предсказанием любого типа из числа четырех вышеописанных: прямое предсказание, обратное предсказание, двунаправленное предсказание и внутримакроблочное предсказание. Специалистам в области техники, имеющей отношение к настоящему изобретению, очевидно, что «H» кадр на описанной выше фигуре в алгоритме STAR относится к смешанной форме макроблоков с внутренним и межкадровым предсказанием. Кроме того, известно, что кадр, расположенный в H кадре, превращают в I кадр, а затем кодируют. Такая гибкость очень полезна в случае быстро изменяющихся видеопоследовательностей и медленно наплывающих/исчезающих кадров.
На фиг. 15 показаны возможные связи между кадрами в четырех режимах предсказания при временной фильтрации согласно еще одному примерному варианту настоящего изобретения. На фиг. 15 «I+H» означает, что кадр содержит как макроблоки, полученные с внутренним предсказанием, так и макроблоки, полученные с внутрикадровым предсказанием, а Т означает, что весь кадр кодируется сам без межкадрового предсказания. Хотя внутрикадровое предсказание можно использовать в начальном кадре GOP (на самом высоком временном уровне), на фиг. 15 это не используется, поскольку это не так эффективно, как вейвлет-преобразование исходных кадров.
На фигурах 16 и 17 показаны примеры кодирования видеосигнала в быстро изменяющейся видеопоследовательности и медленной или мало изменяющейся видеопоследовательности с множеством режимов, где «процент» указывает частоту режима предсказания. А именно I указывает частоту блоков с внутренним предсказанием в кадре (причем в первом кадре GOP не используется внутрикадровое предсказание), BI указывает частоту двунаправленного предсказания, F указывает частоту прямого предсказания, а B указывает частоту обратного предсказания.
Обратимся к фиг. 16, где, поскольку кадр с индексом 1 очень похож на кадр с индексом 0, процент F составляет подавляющую часть в 75%, а BI составляет подавляющую часть в 87% в кадре с индексом 2, потому что он тяготеет к промежуточному положению между кадрами с индексами 0 и 4 (то есть изображение для кадра с индексом 0). Поскольку кадр с индексом 4 отличается от других кадров, закодированные I блоки имеют 100%. Но в кадре с индексом 6 закодированные B блоки имеют 94%, поскольку кадр с индексом 4 сильно отличается от кадра с индексом 6, но похож на кадр с индексом 6.
Обратимся к фиг. 17, где все кадры на вид похожи, причем среди них BI фактически демонстрирует наилучшее качество в весьма похожих кадрах. Соответственно, на фиг. 17 соотношение BI является вообще наибольшим.
Реализовано несколько имитаций для выяснения эффективности алгоритма STAR, когда алгоритм STAR применялся для процесса временной фильтрации. Для оценки движения был использован вариант хорошо известного быстрого ромбоидального поиска с многоступенчатыми расчленениями размеров субблоков от 4 на 4 до 16 на 16. Для сравнения рабочих характеристик использовался кодек MC-EZBC, а также применялся алгоритм EZBC при реализации встроенного квантования по настоящему изобретению.
В качестве материалов для проверки использовались первые 64 кадра Foreman и последовательности Mobile CIF. Одной из целей настоящего изобретения является улучшение временной передачи. По этой причине проверка пространственной масштабируемости не проводилась. Указанные материалы кодировались с достаточными битовыми скоростями, а их битовые потоки усекались, с тем чтобы обеспечить битовые скорости 2048 кбит/с, 1024 кбит/с, 512 кбит/с, 256 кбит/с и 128 кбит/с для передачи, после чего они декодировались.
Для оценки рабочих характеристик использовался параметр PSNR, имеющий взвешенное значение. Взвешенное значение PSNR определялось по уравнению (6).
PSNR=(4PSNRY+PSNRU+PSNRV)/6 (6)
(6)
При тестировании алгоритма STAR были задействованы все вышеописанные признаки за исключением множества опорных кадров с целью упрощения исследования. В итоге, для алгоритма STAR было использовано постоянное распределение битовой скорости на основе уровня GOP, в то время как для алгоритма MC-EZBC использовалось переменное распределение битовой скорости. Переменное распределение битовой скорости может улучшить рабочие характеристики, если применить его для алгоритма STAR.
На фигурах 18 и 19 представлены графики, показывающие результаты тестирования для PSNR (отношение пиковый сигнал/шум) для последовательности Foreman CIF и последовательности Mobile CIF в схеме кодирования видеосигнала.
Для скоростей 2048 кбит/с и 1024 кбит/с использовалась частота кадров 30 Гц. Для скоростей 512 кбит/с и 256 кбит/с использовалась частота кадров 15 Гц. Для 128 кбит/с использовалась частота кадров 7,5 Гц. Для алгоритма STAR использовалось как двунаправленное предсказание, так и перекрестная оптимизация по группам GOP, причем для обоих кодеров использовался размер GOP, равный 16, и точность движения в четверть пикселя. Вдобавок, в кодеке, реализованном для алгоритма STAR, применялся алгоритм MCTF, использующий двунаправленное предсказание, в то время как все другие части не изменялись для сравнения только эффективности временной декомпозиции без учета рабочих характеристики других частей. На указанных фигурах это отмечено аббревиатурой MCTF. Из указанных фигур следует, что эффективность алгоритма STAR возрастает на 1 дБ в последовательности Foreman CIF по сравнению со схемами MC-EZBC и MCTF. Эффективность MCTF практически аналогична эффективности MC-EZBC. Однако алгоритм STAR практически идентичен по эффективности схеме MC-EZBC в Mobile последовательности, но демонстрирует более высокую эффективность, чем MCTF. Можно предположить, что другие важные способы кодирования, использованные в схеме MC-EZBC, такие как способ согласования с переменным распределением бит и переменным размером блоков, будут отличаться, и если тот и другой способ применить в алгоритме STAR, можно ожидать лучшие результаты, чем в схеме MC-EZBC. Алгоритм STAR превосходит MCTF до 3,5 дБ, из чего очевидно, что алгоритм STAR лучше, чем MCTF. Можно сделать вывод, что алгоритм STAR очевидно превосходит MCTF и совместим с кодером MC-EZBC в отношении эффективности временной декомпозиции.
Для сравнения рабочих характеристик режима кодирования с малой задержкой было проведено несколько экспериментов для различных уставок сквозной задержки. Для алгоритма STAR параметр D управления задержкой изменялся от 0 до 8, что соответствует значениям сквозной задержки от 67 мс до 567 мс в соответствии с размерами GOP от 2 до 16. Однако для измерения различных параметров сквозной задержки использовались битовые скорости от 2048 до 256 кбит/с, но без пространственной масштабируемости. Также не использовался режим внутримакроблочного предсказания, с тем чтобы сравнивать только различие между структурами временной декомпозиции.
На фиг. 20 показано снижение PSNR по сравнению с максимальной уставкой задержки, равной 567 мс, для последовательности Foreman CIF при изменении параметров сквозной задержки. Как показано на фиг. 20, значения PSNR в MC-EZBC значительно уменьшаются с уменьшением размера GOP. Наибольшее ухудшение наблюдается в случае, когда размер GOP равен 2, по сравнению с другими размерами GOP. Даже при размере GOP, равном 4, сквозная задержка превышает 150 мс. Наоборот, в алгоритме STAR уменьшение PSNR не столь велико. Даже при самой непродолжительной сквозной задержке (67 мс) снижение PSNR составляет всего порядка 1,3 дБ, а снижение PSNR при варианте с приемлемой низкой задержкой (100 мс) составляет только 0,8 дБ. Максимальное различие в уменьшении максимальных значений PSNR между этими двумя алгоритмами доходит до 3,6 дБ.
На фиг. 21 показано, как снижается PSNR по сравнению с максимальной уставкой задержки для последовательности Mobile CIF. На фиг. 21 снижение PSNR для MC-EZBC более значительно, чем в уже описанном случае для последовательности Foreman CIF. Для алгоритма STAR перепад между максимальной и минимальной сквозными задержками составляет до 2,3 дБ и до 6,9 дБ в кодере MC-EZBC. Снижение PSNR при сквозной задержке, равной 100 мс, составляет только 1,7 дБ, а для MC-EZBC до 6,9 дБ. Максимальное различие для перепадов PSNR между двумя алгоритмами при сквозной задержке 100 мс составляет до 5,1 дБ. Кроме того, алгоритм STAR поддерживает полную временную масштабируемость даже при минимальной уставке задержки, в то время как известный способ поддерживает только одноуровневую временную масштабируемость при размере GOP, равном 2. Различия между значениями PSNR представлены в Таблице 2.
Далее со ссылками на фиг. 22 описываются результаты сравнения быстро изменяющихся видеопоследовательностей.
На фиг. 22 представлен график, показывающий результаты для PSNR при кодировании части быстро меняющейся сцены из кинофильма «Матрица 2» путем использования четырех режимов предсказания и при кодировании без использования этих четырех режимов предсказания.
Во время эксперимента использовалась только одна группа GOP из 16 кадров. Выбранный кадр включал очень быстрое движение, смену сцены, пустые кадры и наплыв/плавное исчезновение. Алгоритм STAR применялся для случаев с внутримакроблочным предсказанием и без внутримакроблочного предсказания, причем для сравнения сюда включены результаты для алгоритма MC-EZBC. При тестировании функции адаптивности к размеру группы GOP были получены результаты как для случая включенного, так и для случая выключенного флага 'adapt_flag' в поле конфигурации MC-EZBC.
Как показано на фиг. 22 эффективность внутрикадрового предсказания блестяще подтвердилась. Разница для PSNR между алгоритмами STAR с внутрикадровым предсказанием и без него превышает 5 дБ, а также превышает 10 дБ между алгоритмами MC-EZBC с функцией адаптации к размеру GOP и без нее. Вдобавок, рабочие характеристики алгоритма STAR с внутримакроблочным предсказанием превосходят алгоритм MC-EZBC с функцией адаптации к размеру GOP на величину, доходящую до 1, 5 дБ, главным образом за счет более гибкого способа внутрикадрового предсказания на основе макроблоков.
Промышленная применимость
Согласно настоящему изобретению можно управлять сквозной задержкой и выполнять кодирование видеосигнала, что вызывает незначительное ухудшение рабочих характеристик при небольшой сквозной задержке. Вдобавок, можно эффективно сжимать быстро изменяющиеся видеопоследовательности. Кроме того, управление задержкой не влияет на временную масштабируемость видеопоследовательностей.
Хотя предпочтительные варианты настоящего изобретения были раскрыты в иллюстративных целях, специалистам в данной области техники должно быть ясно, что возможны различные модификации, добавления и замены в рамках объема и существа изобретения, раскрытого в прилагаемой формуле изобретения.

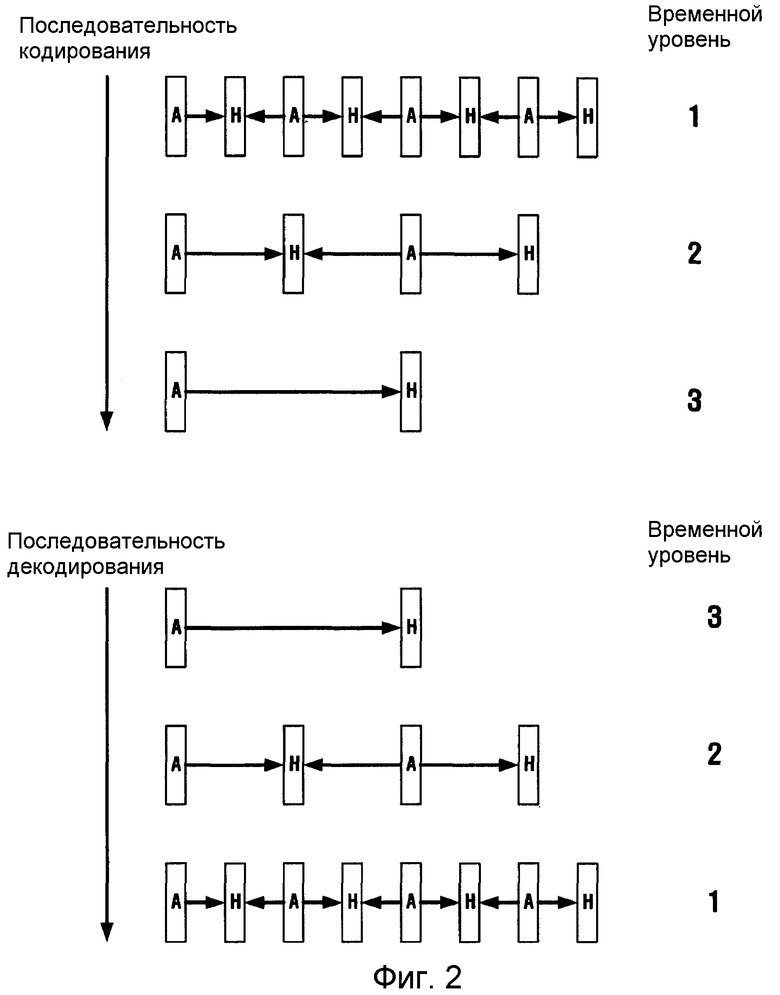
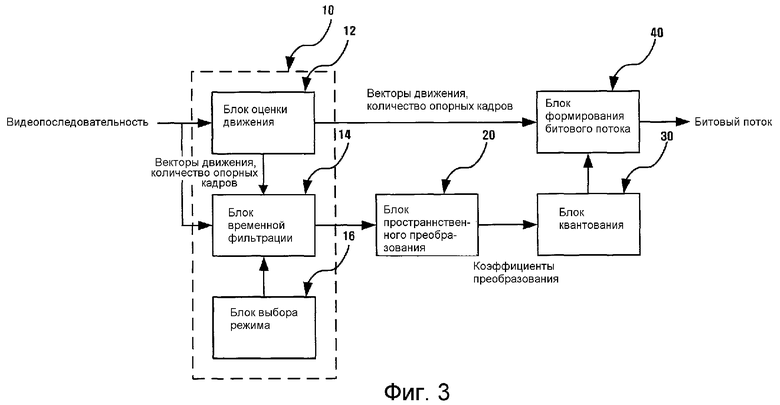
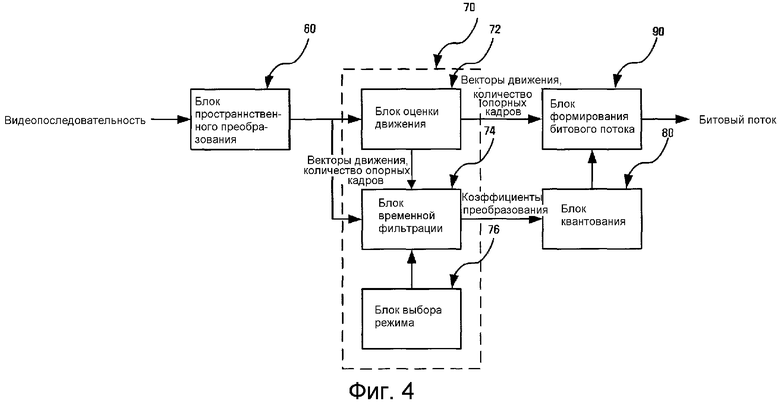
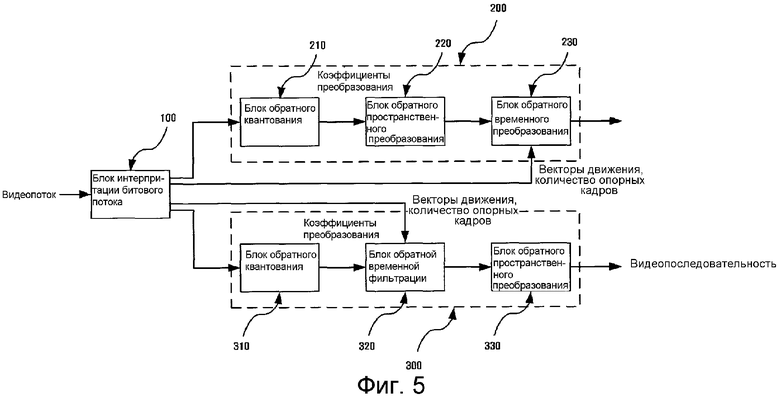
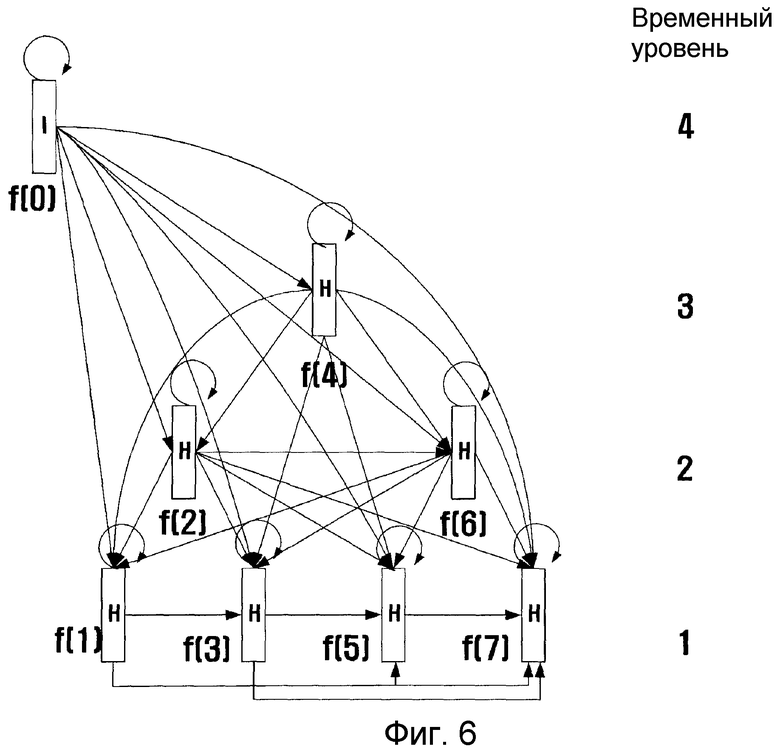
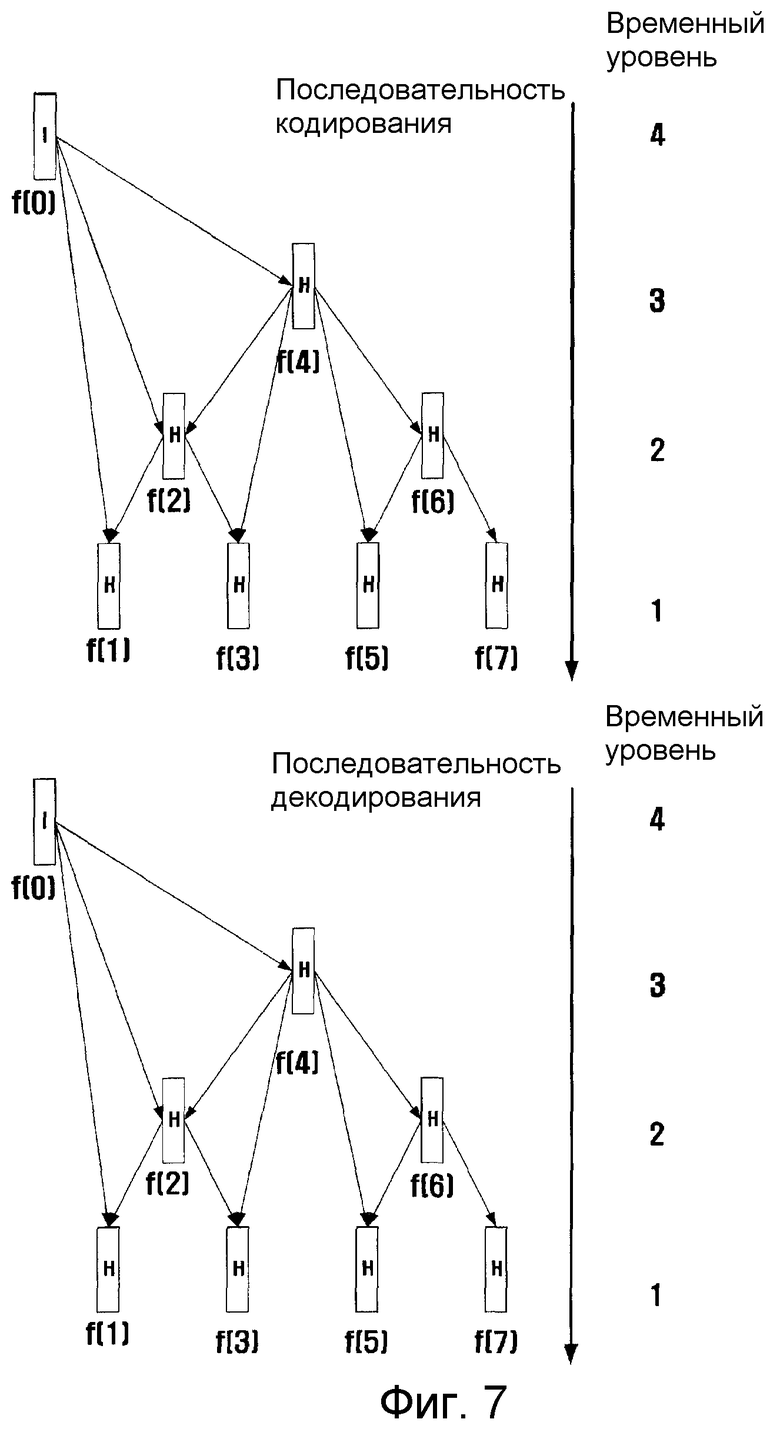



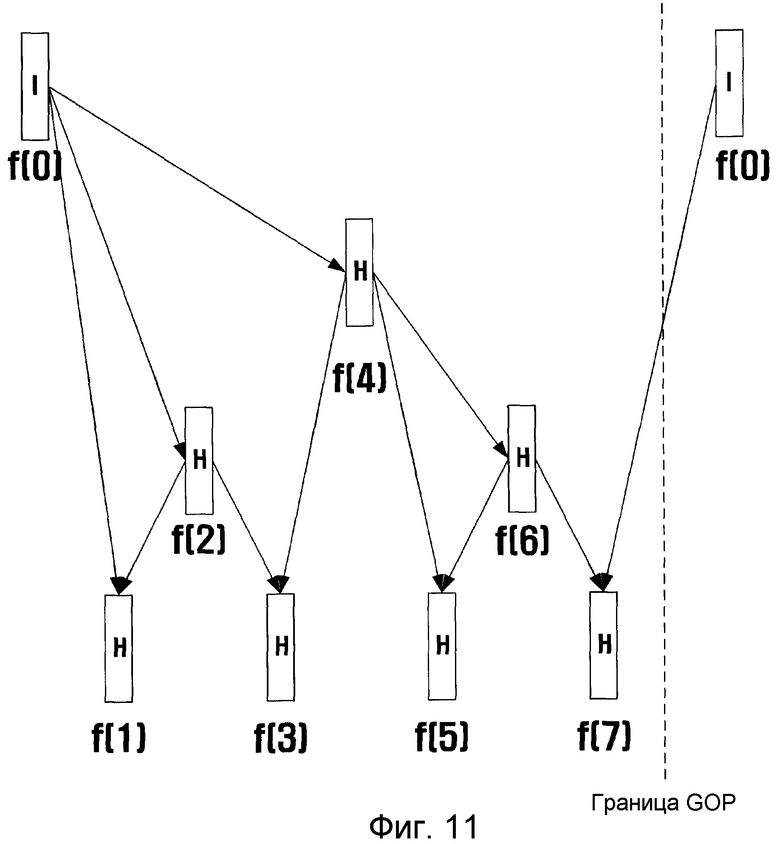
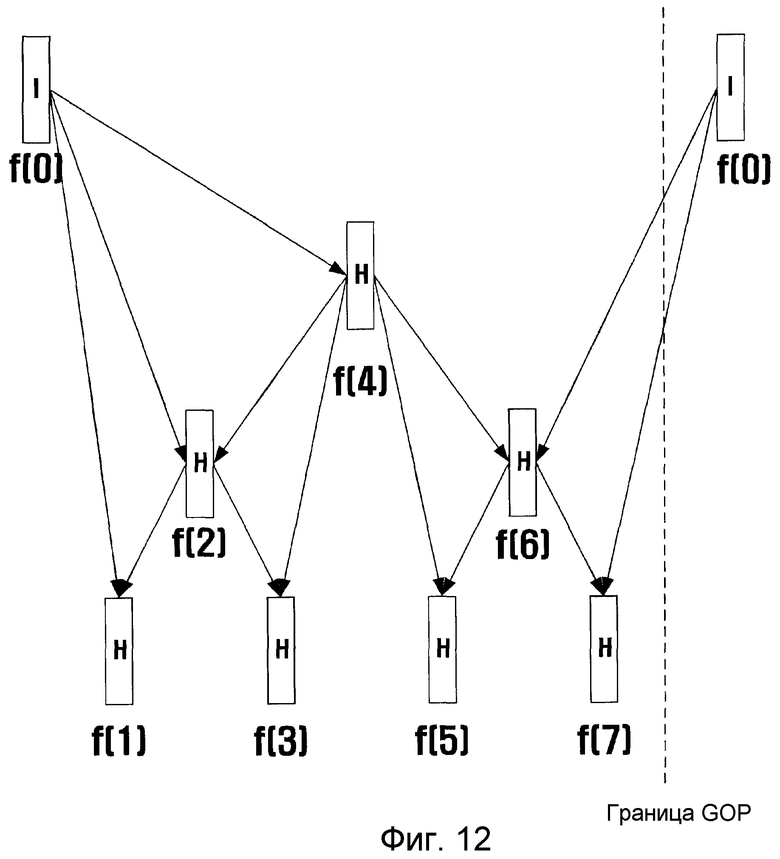
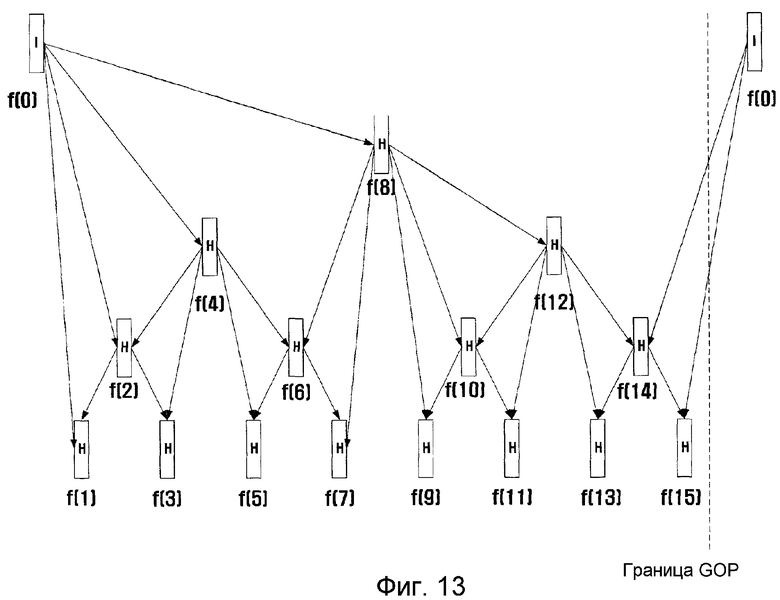
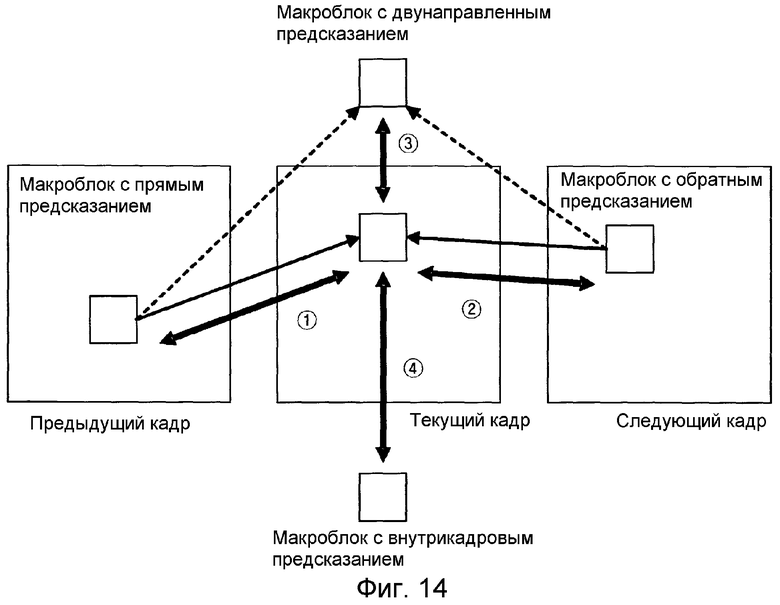
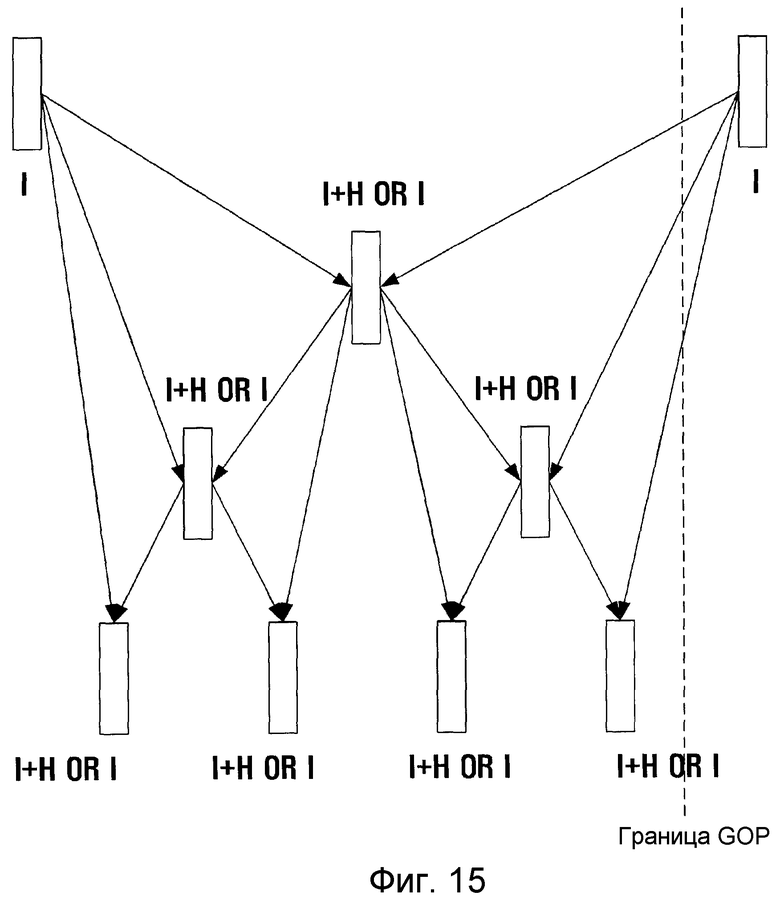
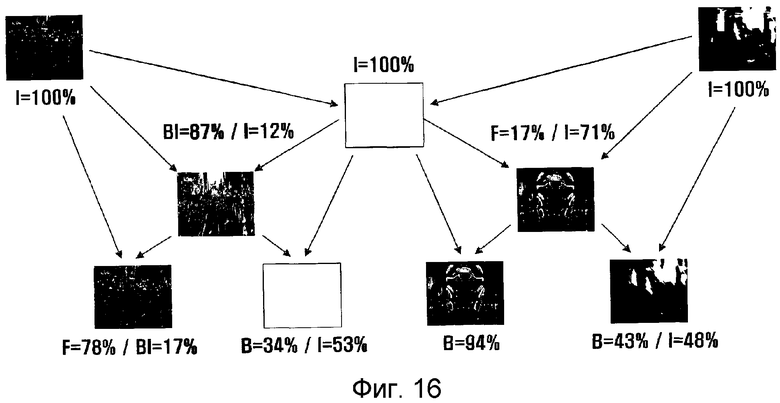

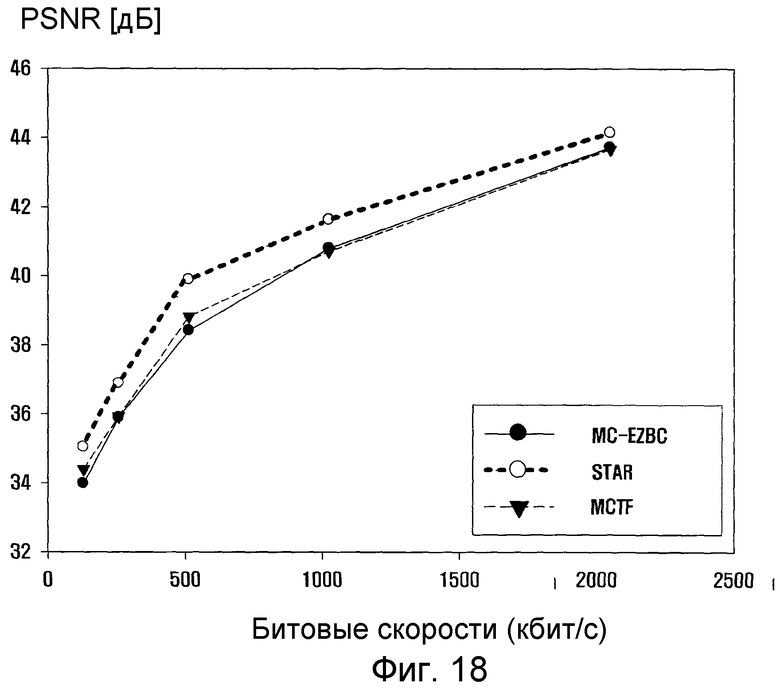
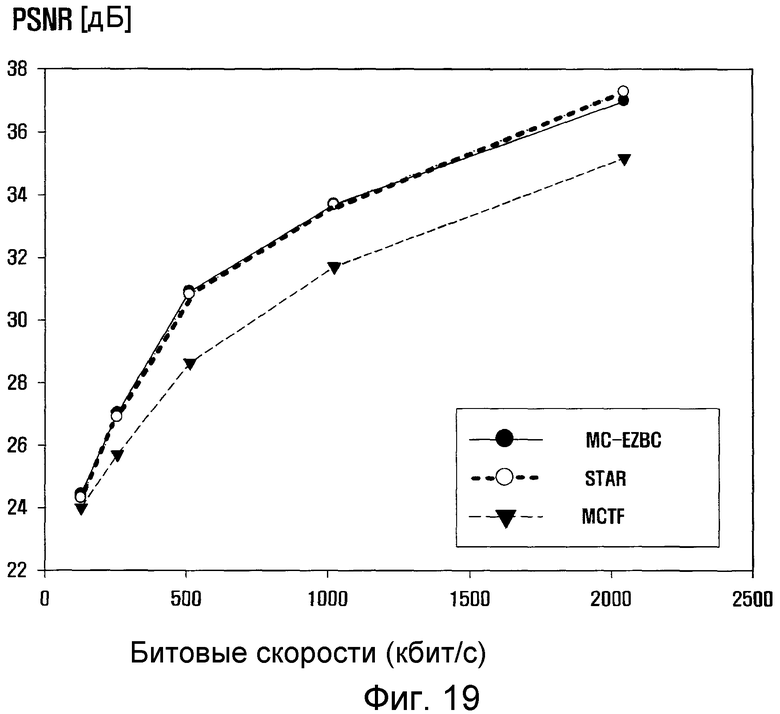

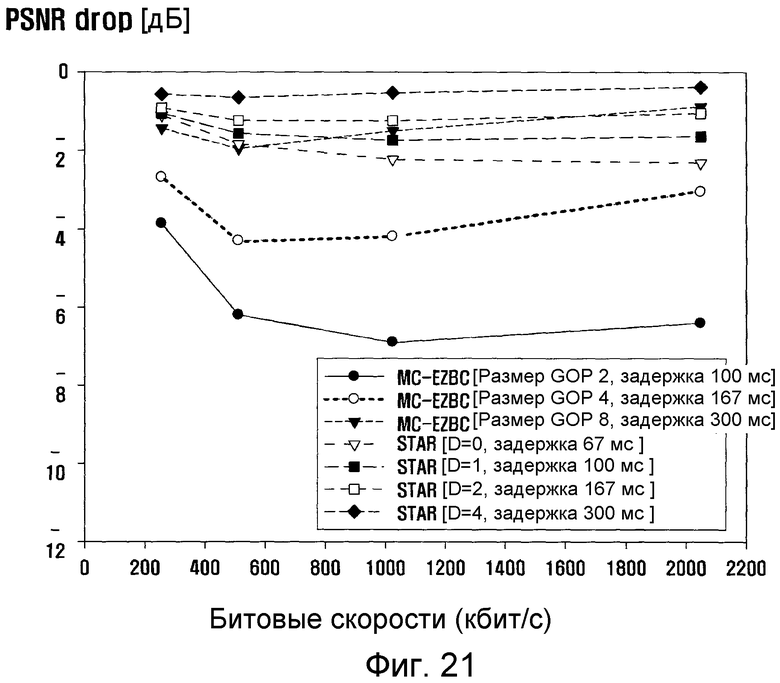
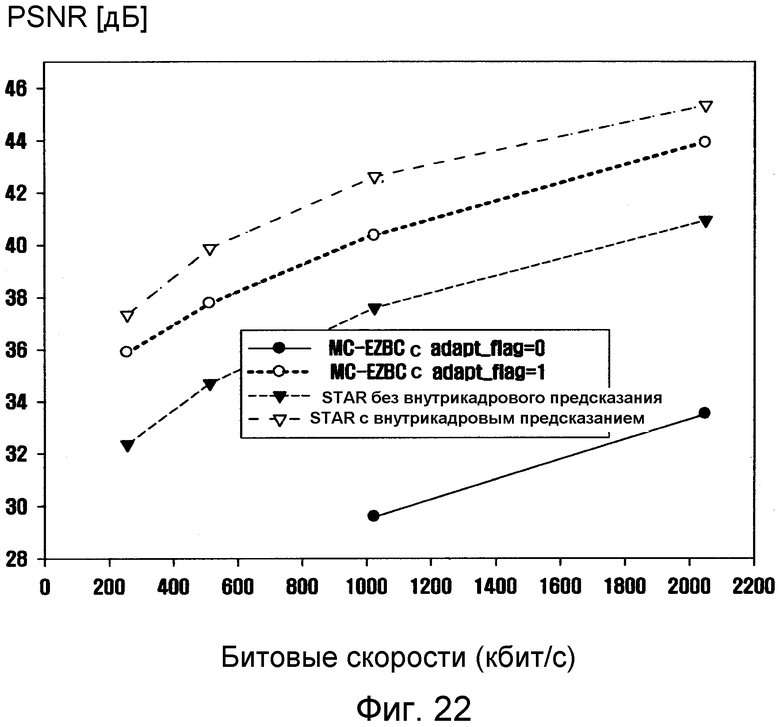
Изобретение относится в целом к сжатию видеосигнала и, в частности, касается кодирования видеосигнала с временной масштабируемостью посредством временной фильтрации с компенсацией движения в соответствии с последовательностью временных уровней с ограничениями. Технический результат заключается в уменьшении сквозной задержки как на стороне кодера, так и на стороне декодера. Предлагается способ и устройство для масштабируемого кодирования и декодирования видеосигнала. Способ кодирования видеосигнала включает в себя устранение временной избыточности в последовательности временных уровней с ограничениями из множества кадров, образующих входную видеопоследовательность, и формирование битового потока путем квантования коэффициентов преобразования, полученных из кадров, временная избыточность которых была устранена. Видеокодер для выполнения способа кодирования включает в себя блок временного преобразования, блок пространственного преобразования, блок квантования и блок создания битового потока. Способ декодирования видеосигнала в принципе выполняется в последовательности, обратной последовательности кодирования видеосигнала, причем декодирование выполняется путем выделения информации в кодированных кадрах посредством приема введенных битовых потоков и их интерпретации. 11 н. и 62 з.п. ф-лы, 22 ил., 2 табл.
(a) устранение временной избыточности в последовательности временных уровней с ограничениями из множества кадров видеопоследовательности; и
(b) формирование битового потока путем квантования коэффициентов преобразования, полученных из кадров, в которых была устранена временная избыточность.
блок временного преобразования, устраняющий временную избыточность в последовательности временных уровней с ограничениями из множества кадров входной видео последовательности;
блок пространственного преобразования, устраняющий пространственную избыточность из кадров;
блок квантования, квантующий коэффициенты преобразования, полученные от устранения временных избыточностей в блоке временного преобразования и пространственных избыточностей в блоке пространственного преобразования; и
блок формирования битового потока, формирующий битовый поток на основе квантованных коэффициентов преобразования, сформированных блоком квантования.
блок оценки движения, получающий векторы движения из кадров;
блок временной фильтрации, осуществляющий временную фильтрацию кадров в последовательности временных уровней с ограничениями на основе векторов движения, полученных блоком оценки движения; и
блок выбора режима, определяющий последовательность временных уровней с ограничениями.
(a) выделение информации, касающейся кодированных кадров, путем приема и интерпретации битового потока;
(b) получение коэффициентов преобразования путем обратного квантования информации, касающейся кодированных кадров; и
(c) восстановление кодированных кадров посредством обратного временного преобразования коэффициентов преобразования в последовательности временных уровней с ограничениями.
блок интерпретации битового потока, интерпретирующий битовый поток для выделения из него информации, касающейся кодированных кадров;
блок обратного квантования, осуществляющий обратное квантование информации, касающейся кодированных кадров, для получения из нее коэффициентов преобразования;
блок обратного пространственного преобразования, выполняющий процесс обратного пространственного преобразования; и
блок обратного временного преобразования, выполняющий процесс обратного временного преобразования в последовательности временных уровней с ограничениями,
при этом кодированные кадры битового потока восстанавливаются путем выполнения процесса обратного пространственного преобразования и процесса обратного временного преобразования коэффициентов преобразования.
устранение временной избыточности в последовательности временных уровней с ограничениями из множества кадров видеопоследовательности; и
формирование битового потока путем квантования коэффициентов преобразования, полученных из кадров, в которых была устранена временная избыточность.
выделение информации, касающейся кодированных кадров, путем приема и интерпретации битового потока;
получение коэффициентов преобразования путем обратного квантования информации, касающейся кодированных кадров; и
восстановление кодированных кадров посредством обратного временного преобразования коэффициентов преобразования в последовательности временных уровней с ограничениями.
установку временных уровней кадров;
выбор в качестве опорных кадров по меньшей мере одного кадра среди кадров на временном уровне, находящемся выше временного уровня текущего кадра, подлежащего кодированию, или среди кадров, находящихся на том же временном уровне, что и текущий кадр; и
устранение избыточности текущего кадра с использованием выбранных опорных кадров.
выбор в качестве опорных кадров по меньшей мере одного кадра среди кадров на временном уровне, находящемся выше временного уровня текущего кадра, или среди кадров, находящихся на том же временном уровне, что и текущий кадр; и
восстановление текущего кадра из выбранных опорных кадров.
анализ входного битового потока и выделение данных для исходного изображения;
формирование множества кадров путем обратного квантования, обратного пространственного преобразования и обратной временной фильтрации данных; и
выбор в качестве опорных кадров по меньшей мере одного кадра среди кадров, находящихся на более высоком временном уровне, чем временной уровень текущего кадра, подлежащего восстановлению, или среди кадров, находящихся на том же временном уровне, что и текущий кадр; и
восстановление текущего кадра из выбранных опорных кадров.
блок интерпретации битового потока, который в качестве опорных кадров выбирает по меньшей мере один кадр среди кадров, находящихся на более высоком временном уровне, чем временной уровень текущего кадра, или среди кадров, находящихся на том же временном уровне, что и текущий кадр; и
блок обратного временного преобразования, который восстанавливает текущий кадр из выбранных опорных кадров.
определение уровня времени задержки;
выбор в качестве опорных кадров по меньшей мере одного кадра, имеющего расстояние от текущего кадра, подлежащего кодированию, меньшее, чем время задержки; и
устранение избыточности текущего кадра с использованием выбранных опорных кадров.
| КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ ИЗОБРАЖЕНИЙ | 1997 |
|
RU2189120C2 |
| УСТРОЙСТВО ДЛЯ СЖАТИЯ ВИДЕОСИГНАЛА (ВАРИАНТЫ), УСТРОЙСТВО ДЛЯ ПРИЕМА СЖАТОГО ВИДЕОСИГНАЛА И УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ВИДЕОСИГНАЛА | 1994 |
|
RU2115258C1 |
| US 2003202599 A1, 30.10.2003 | |||
| US 2001014125 A1, 16.08.2001 | |||
| US 6381276 B1, 30.04.2002. | |||

