ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
[0001] Настоящее изобретение испрашивает приоритет предварительной заявки США №62/903,647, поданной 20 сентября 2019 г., и приоритет патентной заявки США №17/019,567, поданной 14 сентября 2020 г., содержание которой целиком включено в состав настоящей заявки.
УРОВЕНЬ ТЕХНИКИ
1. Область техники
[0002] Раскрытое изобретение относится к кодированию и декодированию видео, а более конкретно - к сигнализации межуровневого предсказания в битовом потоке видео.
2. Описание существующего уровня техники
[0003] Кодирование и декодирование видео с использованием предсказания между изображениями с компенсацией движения известно уже несколько десятилетий. Цифровое видео без сжатия может состоять из последовательности изображений, каждое из которых имеет пространственный размер, например, 1920×1080 отсчетов яркости и связанных с ними отсчетов цветности. Последовательность изображений может иметь фиксированную или переменную частоту смены изображений (неформально также называемую «частотой кадров»), например, 60 изображений в секунду, или 60 Гц. К несжатым видеоданным предъявляются серьезные требования в отношении битовой скорости передаче. Например, видео 1080р60 4:2:0 с 8 битами на отсчет (разрешение отсчетов яркости 1920×1080 при частоте кадров 60 Гц) требует полосы около 1,5 Гбит/с. Час такого видео требует объема памяти более 6000 Гб.
[0004] Одной целью кодирования и декодирования видеосигнала может быть снижение избыточности во входном видеосигнале путем сжатия. Сжатие может способствовать смягчению вышеупомянутых требований к полосе или объему памяти, в ряде случаев на два порядка величины или более. Для этого может применяться сжатие как без потерь, так и с потерями. Сжатие без потерь относится к методам реконструкции точной копии исходного сигнала из сжатого исходного сигнала. При использовании сжатия с потерями реконструированный сигнал может быть не идентичен исходному сигналу, но расхождение между исходным и реконструированным сигналами достаточно мало, так чтобы реконструированный сигнал можно было использовать для намеченного применения. Сжатие с потерями широко применяется для видео. Допустимая степень искажения зависит от применения; например, пользователи некоторых заказных потоковых приложений могут мириться с более высокими искажениями, чем пользователи телевещательных приложений. Достижимая степень сжатия может отражать, что более высокое разрешенное/допустимое искажение может давать более высокую степень сжатия.
[0005] Кодер и декодер видеосигнала может использовать методы из нескольких широких категорий, включающих в себя, например, компенсацию движения, преобразование, квантование и энтропийное кодирование, некоторые из них представлены ниже.
[0006] Исторически видеокодеры и видеодекодеры были предназначены для работы с заданным размером изображения, который в большинстве случаев для кодированной видеопоследовательности (CVS, Coded Video Sequence), группы изображений (GOP, Group of Pictures) или аналогичного временного кадра с несколькими изображениями был определен и оставался постоянным. Например, что касается MPEG-2, известно, что конструкции системы изменяют горизонтальное разрешение (и, следовательно, размер изображения) в зависимости от таких факторов, как активность сцены, но только для I-изображений, что обычно является обычным для GOP. Повторная дискретизация опорных изображений для использования различных разрешений в рамках CVS известна, например, из стандарта ITU-T Rec. Н.263, приложение Р. Однако в этом случае размер изображения не изменяется, повторная дискретизация выполняется только для опорных изображений, в результате этого потенциально используются только части изображения (в случае понижающей дискретизации) или только части захватываемой сцены (в случае повышающей дискретизации). Кроме того, стандарт Н.263, приложение Q допускает повторную дискретизацию отдельного макроблока с коэффициентом два (в каждом измерении), в сторону повышения или понижения. Опять же, размер изображения не изменяется. Размер макроблока фиксирован в Н.263, и поэтому его не требуется передавать.
[0007] Изменение размера изображения в предсказанных изображениях стало господствующей тенденцией в современных способах кодирования видео. Например. VP9 предоставляет возможность повторной дискретизации опорных изображений (RPR, Reference Picture Resampling) и изменения разрешения для всего изображения. Аналогично, некоторые решения для VVC (включая, например, решение под авторством Hendry и др., «Об изменении адаптивного разрешения (ARC) для VVC», документ организации Joint Video Team JVET-M0135-vl, от 9-19 января 2019 г., целиком включенный в настоящий документ) предоставляют возможность повторной дискретизации целых опорных изображений с другим, более высоким или более низким, разрешением. В этом документе предлагается кодировать различные варианты разрешения в наборе параметров последовательности и ссылаться на них с помощью элементов синтаксиса для каждого изображения в наборе параметров изображения.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0008] Для решения одной или более различных технических проблем в этом изобретении описаны новые синтаксисы и их использование, предназначенные для сигнализации масштабирования в битовом потоке видео. Таким образом, может быть достигнута улучшенная эффективность (де)кодирования.
[0009] Согласно представленным вариантам осуществления, при повторной дискретизации опорного изображения (RPR, Reference Picture Resampling) или при изменении адаптивного разрешения (ARC, Adaptive Resolution Change) с помощью модификации синтаксиса высокого уровня (HLS, High-Level Syntax) могут быть получены дополнительные ресурсы для поддержки масштабируемости. В технических аспектах межуровневое предсказание используется в масштабируемой системе для повышения эффективности кодирования улучшенных уровней. Помимо пространственных и временных предсказаний с компенсацией движения, которые доступны в одноуровневом кодеке, для межуровневого предсказания используются передискретизированные видеоданные реконструированного опорного изображения из опорного уровня для предсказания текущего улучшенного уровня. Затем процесс передискретизации для межуровневого предсказания выполняется на уровне блоков путем модификации существующего процесса интерполяции для компенсации движения. Это означает, что для поддержки масштабируемости дополнительный процесс повторной дискретизации не требуется. В настоящем изобретении раскрыты элементы синтаксиса высокого уровня для поддержки пространственной масштабируемости/масштабируемости качества с использованием RPR.
[0010] Включены способ и устройство, содержащее память, выполненную с возможностью хранения компьютерного программного кода, и процессор или процессоры, выполненные с возможностью доступа к компьютерному программному коду и работающие под управлением компьютерного программного кода. Компьютерный программный код включает в себя код синтаксического анализа, сконфигурированный таким образом, чтобы по меньшей мере один процессор анализировал по меньшей мере один набор параметров видео (VPS, Video Parameter Set), содержащий по меньшей мере один элемент синтаксиса, указывающий, является ли по меньшей мере один уровень в масштабируемом битовом потоке одним из зависимого уровня масштабируемого битового потока и независимого уровня масштабируемого битового потока, первый код декодирования сконфигурирован таким образом, чтобы по меньшей мере один процессор декодировал изображение в зависимом уровне путем анализа и интерпретации списка межуровневых опорных изображений (ILRP, Inter-Layer Reference Picture), а второй код декодирования сконфигурирован таким образом, чтобы по меньшей мере один процессор декодировал изображение в независимом уровне без синтаксического анализа и интерпретации списка ILRP.
[0011] Согласно вариантам осуществления, второй код декодирования дополнительно конфигурируется таким образом, чтобы по меньшей мере один процессор декодировал изображение в независимом уровне путем анализа и интерпретации списка опорных изображений, в котором не содержатся декодированные изображения другого уровня.
[0012] Согласно вариантам осуществления, в списке межуровневых опорных изображений содержится декодированное изображение другого уровня.
[0013] Согласно вариантам осуществления .код синтаксического анализа дополнительно конфигурируется таким образом, чтобы по меньшей мере один процессор анализировал по меньшей мере один VPS путем определения, указывает ли другой элемент синтаксиса максимальное количество уровней.
[0014] Согласно вариантам осуществления код синтаксического анализа дополнительно конфигурируется таким образом, чтобы по меньшей мере один процессор анализировал по меньшей мере один VPS путем определения, содержит ли VPS флаг, указывающий, что другой уровень в масштабируемом битовом потоке является опорным уровнем по меньшей мере для одного уровня.
[0015] Согласно вариантам осуществления код синтаксического анализа дополнительно конфигурируется таким образом, чтобы по меньшей мере один процессор анализировал по меньшей мере один VPS путем определения, указывает ли флаг другой уровень в качестве опорного уровня по меньшей мере для одного уровня путем указания индекса другого уровня и индекса по меньшей мере одного уровня.
[0016] Согласно вариантам осуществления код синтаксического анализа дополнительно конфигурируется таким образом, чтобы по меньшей мере один процессор анализировал по меньшей мере один VPS путем определения, указывает ли флаг, что другой уровень не является опорным уровнем по меньшей мере для одного уровня путем указания индекса другого уровня и индекса по меньшей мере одного уровня.
[0017] Согласно вариантам осуществления код синтаксического анализа дополнительно конфигурируется таким образом, чтобы по меньшей мере один процессор анализировал по меньшей мере один VPS путем определения, содержит ли VPS флаг, указывающий, что должно быть декодировано множество уровней, содержащее по меньшей мере один уровень, путем интерпретации списка ILRP.
[0018] Согласно вариантам осуществления, код синтаксического анализа дополнительно конфигурируется таким образом, чтобы по меньшей мере один процессор анализировал по меньшей мере один VPS путем определения, содержит ли VPS флаг, указывающий, что должно быть декодировано множество уровней, содержащее по меньшей мере один уровень, без интерпретации списка ILRP.
[0019] Согласно вариантам осуществления, код синтаксического анализа дополнительно конфигурируется таким образом, чтобы по меньшей мере один процессор анализировал, выполняется ли по меньшей мере для одного VPS также определение, содержит ли VPS флаг, указывающий, что должно быть декодировано множество уровней, содержащее по меньшей мере один уровень, путем интерпретации списка ILRP.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0020] Дополнительные особенности, характер и различные преимущества раскрытого изобретения будут понятны из нижеследующего подробного описания и прилагаемых чертежей, на которых:
[0021] фиг.1 - схематическое представление упрощенной блок-схемы системы связи согласно варианту осуществления;
[0022] фиг.2 - схематическое представление упрощенной блок-схемы системы связи согласно вариантам осуществления;
[0023] фиг.3 - схематическое представление упрощенной блок-схемы декодера согласно вариантам осуществления;
[0024] фиг.4 - схематическое представление упрощенной блок-схемы кодера согласно вариантам осуществления;
[0025] фиг.5А - схематическое представление опций сигнализации параметров ARC/RPR согласно существующему уровню техники;
[0026] фиг.5В - схематическое представление опций сигнализации параметров ARC/RPR согласно существующему уровню техники;
[0027] фиг.5С - схематическое представление опций сигнализации параметров ARC/RPR согласно вариантам осуществления;
[0028] фиг.5D - схематическое представление опций сигнализации параметров ARC/RPR согласно вариантам осуществления;
[0029] фиг.5Е - схематическое представление опций сигнализации параметров ARC/RPR согласно вариантам осуществления;
[0030] фиг.6 - схематическое представление сигнализации разрешения изображений согласно вариантам осуществления;
[0031] фиг.7 - схематическое представление сигнализации размера изображения и окна соответствия в SPS согласно вариантам осуществления;
[0032] фиг.8 - схематическое представление сигнализации наличия межуровневого предсказания в SPS согласно вариантам осуществления;
[0033] фиг.9 - схематическое представление сигнализации индекса межуровневого предсказания в заголовке слайса согласно вариантам осуществления;
[0034] фиг.10 - схематическое представление компьютерной системы согласно вариантам осуществления.
ПОДРОБНОЕ ОПИСАНИЕ
[0035] Описываемые ниже предлагаемые функции могут использоваться отдельно или в сочетании друг с другом в любом порядке. Кроме того, каждый из вариантов осуществления может быть реализован схемой обработки (например, одним или более процессорами или одной или более интегральными схемами). В одном примере один или более процессоров выполняют программу, которая хранится на компьютерно-считываемом носителе.
[0036] На фиг.1 показана упрощенная блок-схема системы (100) связи согласно варианту осуществления настоящего изобретения. Система (100) может включать в себя по меньшей мере два оконечных устройства (110 и 120), соединенных друг с другом через сеть (150). В случае однонаправленной передачи данных первое оконечное устройство (110) может кодировать видеоданные в локальном местоположении для передачи на другое оконечное устройство (120) через сеть (150). Второе оконечное устройство (120) может принимать кодированные видеоданные другого оконечного устройства из сети (150), декодировать кодированные данные и отображать реконструированные видеоданные. Однонаправленная передача данных может быть свойственна приложениям служб массовой информации и т.п.
[0037] На фиг.1 показана вторая пара оконечных устройств (130, 140), предназначенных для поддержки двунаправленной передачи кодированных видеоданных, которая может осуществляться, например, в процессе видеоконференцсвязи. В случае двунаправленной передачи данных каждое оконечное устройство (130, 140) может кодировать видеоданные, захваченные в локальном местоположении, для передачи на другое оконечное устройство через сеть (150). Каждое оконечное устройство (130, 140) также может принимать кодированные видеоданные, переданные другим оконечным устройством, может декодировать кодированные данные и может отображать реконструированные видеоданные на локальном устройстве отображения.
[0038] На фиг.1, оконечные устройства (110, 120, 130 и 140) могут быть проиллюстрированы как серверы, персональные компьютеры и смартфоны, но это не ограничивает принципы настоящего изобретения. Варианты осуществления настоящего изобретения находят применение для портативных компьютеров, планшетных компьютеров, медиаплееров и/или специального оборудования для видеоконференцсвязи. Сеть (150) представляет любое количество сетей, которые переносят кодированные видеоданные между оконечными устройствами (110, 120, 130 и 140), включая, например, проводные и/или беспроводные сети связи. Сеть (150) связи позволяет обмениваться данными в режиме канальной коммутации и/или пакетной коммутации. Иллюстративные сети включают в себя телекоммуникационные сети, локальные сети, глобальные сети и/или Интернет. В целях настоящего рассмотрения, архитектура и топология сети (150) могут не иметь отношения к настоящему изобретению, если конкретно не указаны ниже.
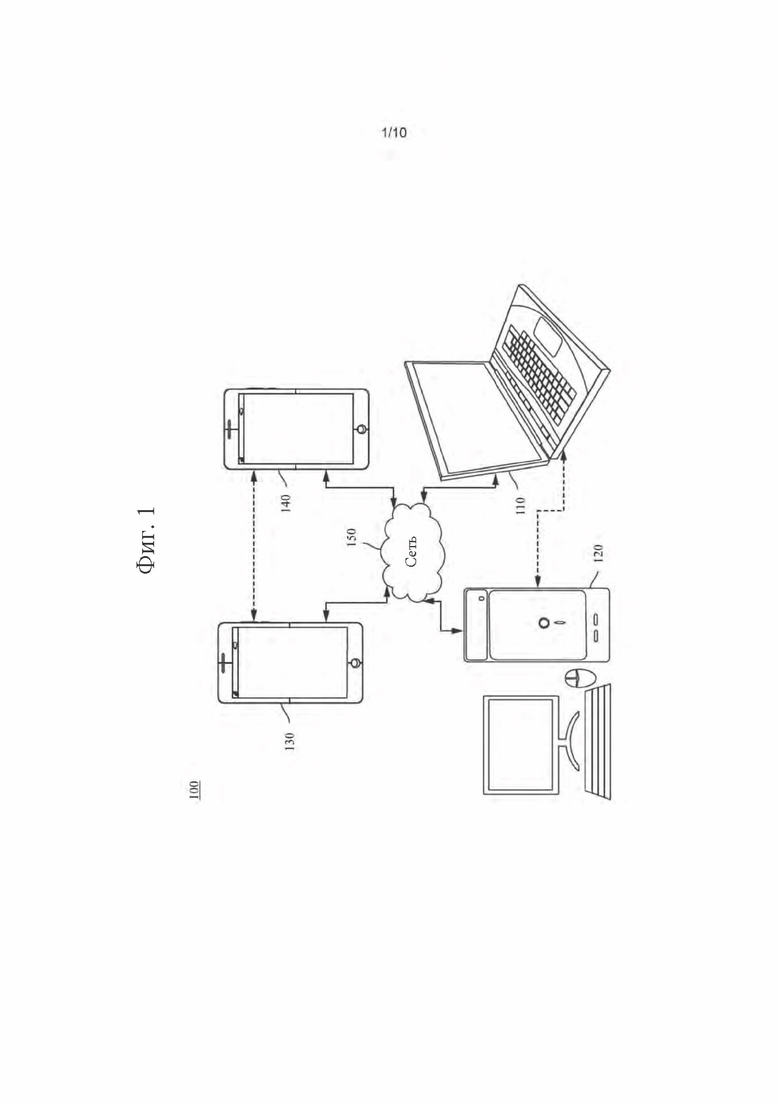
[0039] На фиг.2 показано, в порядке примера применения раскрытого изобретения, размещение видеокодера и видеодекодера в окружении потоковой передачи. Раскрытое изобретение может быть в равной степени применимо к другим применениям обработки видео, включая, например, видеоконференцсвязь, цифровое телевидение, хранение сжатого видео на цифровых носителях, в том числе на CD-диске, DVD-диске, карте памяти и т.п., и т.д.
[0040] Система потоковой передачи может включать в себя подсистему (213) захвата, которая может включать в себя источник (201) видеосигнала, например, цифровую камеру, создающую, например, поток (202) отсчетов видео, не подвергнутых сжатию. Этот поток (202) отсчетов, показанный жирной линией, чтобы подчеркнуть большой объем данных по сравнению с битовыми потоками кодированного видео, может быть обработан кодером (203), подключенным к камере (201). Кодер (203) может включать в себя оборудование, программное обеспечение или их комбинацию для обеспечения или реализации аспектов раскрытого изобретения, как более подробно описано ниже. Битовый поток (204) кодированного видео, показанный тонкой линией, чтобы подчеркнуть меньший объем данных по сравнению с потоком отсчетов, может храниться на потоковом сервере (205) для использования в будущем. Один или более клиентов (206, 208) потоковой передачи могут осуществлять доступ к потоковому серверу (205) для извлечения копий (207, 209) битового потока (204) кодированного видео. Клиент (206) может включать в себя видеодекодер (210), который декодирует входящую копию битового потока (207) кодированного видео и создает исходящий поток (211) отсчетов видео, который может отображаться на дисплее (212) или на другом устройстве визуализации (не показано). В некоторых системах потоковой передачи битовые потоки видео (204, 207, 209) могут кодироваться согласно тем или иным стандартам кодирования/сжатия видео. Примеры этих стандартов включают в себя ITU-T Recommendation Н.265. Разрабатывается стандарт видеокодирования под официальным названием «Универсальное видеокодирование» (Versatile Video Coding) или VVC. Раскрытое изобретение может использоваться в контексте VVC.
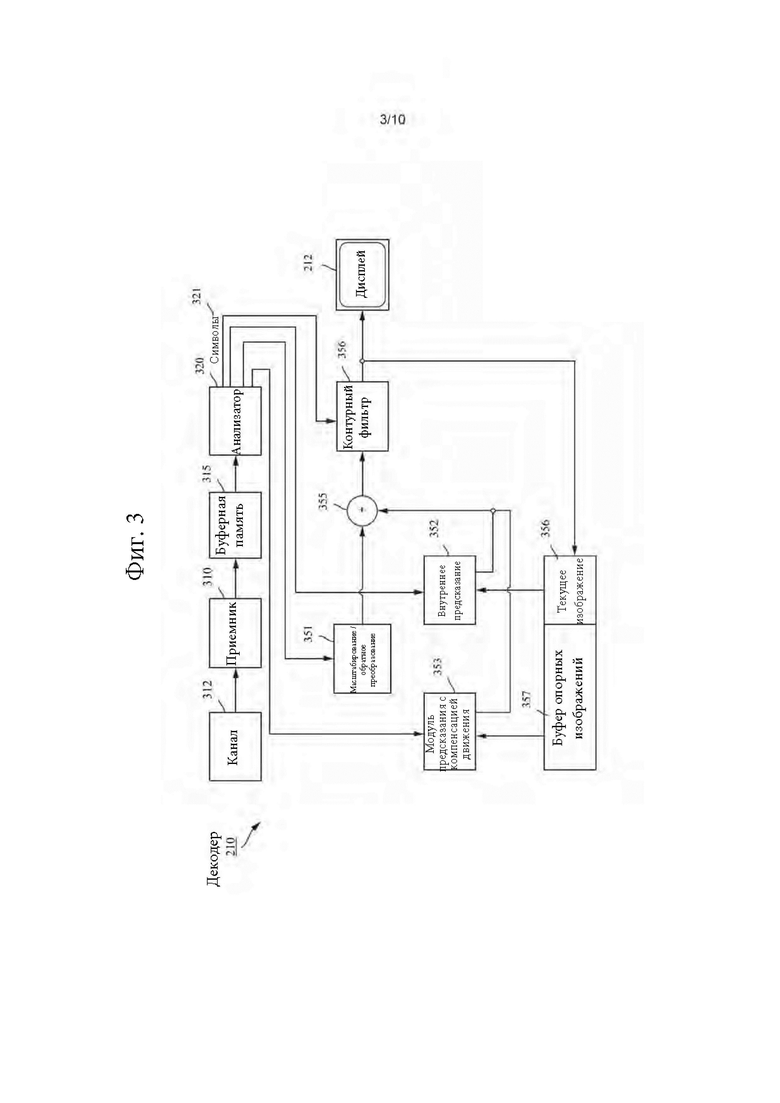
[0041] Фиг. 3 может быть функциональной блок-схемой видеодекодера (210) согласно варианту осуществления настоящего изобретения.
[0042] Приемник (310) может принимать одну или более видеопоследовательностей кодека для декодирования декодером (210); в том же или другом варианте осуществления, по одной кодированной видеопоследовательности за раз, где декодирование каждой кодированной видеопоследовательности не зависит от других кодированных видеопоследовательностей. Кодированная видеопоследовательность может приниматься из канала (312), который может быть аппаратной/программной линией связи с запоминающим устройством, где хранятся кодированные видеоданные. Приемник (310) может принимать кодированные видеоданные с другими данными, например, кодированными аудиоданными и/или вспомогательными потоками данных, которые могут ретранслироваться на соответствующие им используемые объекты (не показаны). Приемник (310) может отделять кодированную видеопоследовательность от других данных. Для борьбы с джиттером сети буферная память (315) может быть подключена между приемником (310) и энтропийным декодером / анализатором (320) (далее «анализатором»). Если приемник (310) принимает данные из запоминающего устройства/устройства пересылки с достаточной полосой пропускания и управляемостью или из изосинхронной сети, буфер (315) может не использоваться или иметь небольшой размер. Для использования в пакетных сетях наилучшей попытки, например, в Интернете, может потребоваться буферная память (315), которая может быть сравнительно большой и может иметь преимущественно адаптивный размер. [0043] Видеодекодер (210) может включать в себя анализатор (320) для реконструкции символов (321) из энтропийно кодированной видеопоследовательности. Категории этих символов включают в себя информацию, используемую для управления работой видеодекодера (210), и возможно информацию для управления устройством визуализации, например, дисплеем (212), который не является неотъемлемой частью декодера, но может быть подключен к нему, как показано на фиг.2. Информация управления для устройств(а) визуализации может представлять собой сообщения информации дополнительного улучшения (SEI, Supplementary Enhancement Information) или фрагменты набора параметров информации пригодности видео (VUI, Video Usability Information) (не показаны). Анализатор (320) может анализировать / энтропийно декодировать принятую кодированную видеопоследовательность. Кодирование кодированной видеопоследовательности может выполняться согласно методу или стандарту видеокодирования и может следовать принципам, хорошо известным специалисту в этой области техники, включая кодирование с переменной длиной, кодирование по методу Хаффмана, арифметическое кодирование с учетом или без учета контекстной зависимости и т.д. Анализатор (320) может извлекать из кодированной видеопоследовательности набор параметров подгруппы по меньшей мере для одной из подгрупп пикселей в видеодекодере на основании по меньшей мере одного параметра, соответствующего группе. Подгруппы могут включать в себя группы изображений (GOP, Groups of Pictures), изображения, тайлы, слайсы, макроблоки, единицы кодирования (CU, Coding Units), блоки, единицы преобразования (TU, Transform Units), единицы предсказания (PU, Prediction Units) и т.д. Энтропийный декодер / анализатор также может извлекать из кодированной видеопоследовательности информацию, например, коэффициенты преобразования, значения параметров квантователя, векторы движения и т.д.
[0044] Анализатор (320) может осуществлять операцию энтропийного декодирования / анализа видеопоследовательности, принятой из буфера (315), для создания символов (321).
[0045] Для реконструкции символов (321) могут использоваться несколько разных модулей в зависимости от типа кодированного видеоизображения или его частей (например, интер- и интра-изображения, интер- и интра-блока) и других факторов. Какие модули используются, и как, может определяться информацией управления подгруппами, выделенной из кодированной видеопоследовательности анализатором (320). Поток такой информации управления подгруппами между анализатором (320) и множественными модулями для простоты в дальнейшем не показан.
[0046] Помимо ранее упомянутых функциональных блоков, декодер (210) может принципиально подразделяться на несколько функциональных модулей, как описано ниже. В практической реализации, работающей в условиях коммерческих ограничений, многие из этих модулей тесно взаимодействуют друг с другом и могут, по меньшей мере частично, встраиваться один в другой. Однако в целях описания раскрытого изобретения уместно принципиальное подразделение на нижеперечисленные функциональные модули.
[0047] Первым модулем является модуль (351) масштабирования / обратного преобразования. Модуль (351) масштабирования / обратного преобразования принимает квантованный коэффициент преобразования, а также информацию управления, включающую в себя используемое преобразование, размер блока, коэффициент квантования, матрицы масштабирования квантования и т.д. в качестве символа(ов) (321) от анализатора (320). Этот модуль может выводить блоки, содержащие значения отсчетов, которые можно вводить в агрегатор (355).
[0048] В ряде случаев, выходные отсчеты блока (351) масштабирования / обратного преобразования могут относиться к внутренне-кодированному блоку; то есть блоку, который не использует предсказанную информацию из ранее реконструированных изображений, но может использовать предсказанную информацию из ранее реконструированных частей текущего изображения. Такая предсказанная информация может обеспечиваться модулем (352) предсказания внутри изображения. В ряде случаев модуль (352) предсказания внутри изображения генерирует блок такого же размера и формы, как блок, подлежащий реконструкции, с использованием информации ранее реконструированного окружения, извлеченной из текущего (частично реконструированного) изображения (356). Агрегатор (355) в ряде случаев добавляет для каждого отсчета информацию предсказания, сгенерированную модулем (352) внутреннего предсказания, в информацию выходных отсчетов, обеспеченную модулем (351) масштабирования / обратного преобразования.
[0049] В других случаях выходные отсчеты модуля (351) масштабирования / обратного преобразования могут относиться к внутренне кодированному блоку, возможно, с компенсацией движения. В таком случае модуль (353) предсказания с компенсацией движения может осуществлять доступ к памяти (357) опорных изображений для извлечения отсчетов, используемых для предсказания. После применения компенсации движения к извлеченным отсчетам в соответствии с символами (321), относящимися к блоку, эти отсчеты могут добавляться агрегатором (355) к выходному сигналу модуля масштабирования / обратного преобразования (в этом случае именуемому «остаточными отсчетами» или «остаточным сигналом») для генерации информации выходных отсчетов. Адреса в памяти опорных изображений, откуда модуль предсказания с компенсацией движения извлекает предсказанные отсчеты, могут регулироваться векторами движения, доступными модулю предсказания с компенсацией движения, в форме символов (321), которые могут иметь, например, компоненты X, Y и опорного изображения. Компенсация движения также может включать в себя интерполяцию значений отсчетов, извлеченных из памяти опорных изображений, когда используются точные векторы движения подотсчетов, механизмы предсказания векторов движения и т.д.
[0050] К выходным отсчетам агрегатора (355) можно применять различные методы контурной фильтрации в модуле (356) контурного фильтра. Технологии сжатия видео могут включать в себя методы деблокирующего фильтра под управлением параметров, включенных в битовый поток кодированного видео, и становиться доступными модулю (356) контурного фильтра в качестве символов (321) от анализатора (320), но также могут реагировать на метаинформацию, полученную в ходе декодирования предыдущих (в порядке декодирования) частей кодированного изображения или кодированной видеопоследовательности, а также реагировать на ранее реконструированные и подвергнутые контурной фильтрации значения отсчетов.
[0051] Модуль (356) контурного фильтра может выдавать поток отсчетов, который может поступать на устройство (212) визуализации, а также сохраняться в памяти (356) опорных изображений для использования в будущем предсказании между изображениями.
[0052] Некоторые кодированные изображения, будучи полностью реконструированными, могут использоваться в качестве опорных изображений для будущего предсказания. Когда кодированное изображение полностью реконструировано, и кодированное изображение идентифицировано как опорное изображение (например, анализатором (320)), буфер (356) текущего изображения может становиться частью буфера (357) опорных изображений, и свежий буфер текущего изображения может повторно выделяться до начала реконструкции следующего кодированного изображения.
[0053] Видеодекодер 320 может выполнять операции декодирования в соответствии с предварительно определенным методом сжатия видеоданных, которая может документироваться в стандарте, таком как рекомендация ITU-T Н.265. Кодированная видеопоследовательность может соответствовать синтаксису, указанному используемым методом или стандартом сжатия видеоданных, в том смысле, что она придерживается синтаксиса метода или стандарта сжатия видеоданных, заданным в документе или стандарте по технологии сжатия видеоданных и, в особенности, в профильных документах этих стандартов. Также для согласованности может быть необходимо, чтобы сложность кодированной видеопоследовательности оставалась в границах, заданных уровнем технологии или стандарта сжатия видео. В ряде случаев, уровни ограничивают максимальный размер изображения, максимальную частоту кадров, максимальную частоту отсчетов для реконструкции (измеряемую, например, в мегаотсчетах в секунду), максимальный размер опорного изображения и т.д. Пределы, установленные уровнями, в ряде случаев могут дополнительно ограничиваться спецификациями гипотетического эталонного декодера (HRD, Hypothetical Reference Decoder) и метаданными для управления буфером HRD, сигнализируемого в кодированной видеопоследовательности.
[0054] Согласно вариантам осуществления приемник (310) может принимать дополнительные (избыточные) данные с кодированным видео. Дополнительные данные могут быть включены как часть кодированной(ых) видеопоследовательности(ей). Дополнительные данные могут использоваться видеодекодером (320) для правильного декодирования данных и/или более точной реконструкции исходных видеоданных. Дополнительные данные могут предоставляться в виде, например, временных, пространственных или усовершенствованных уровней SNR, избыточных уровней, избыточных изображений, кодов с прямым исправлением ошибок и т.д.
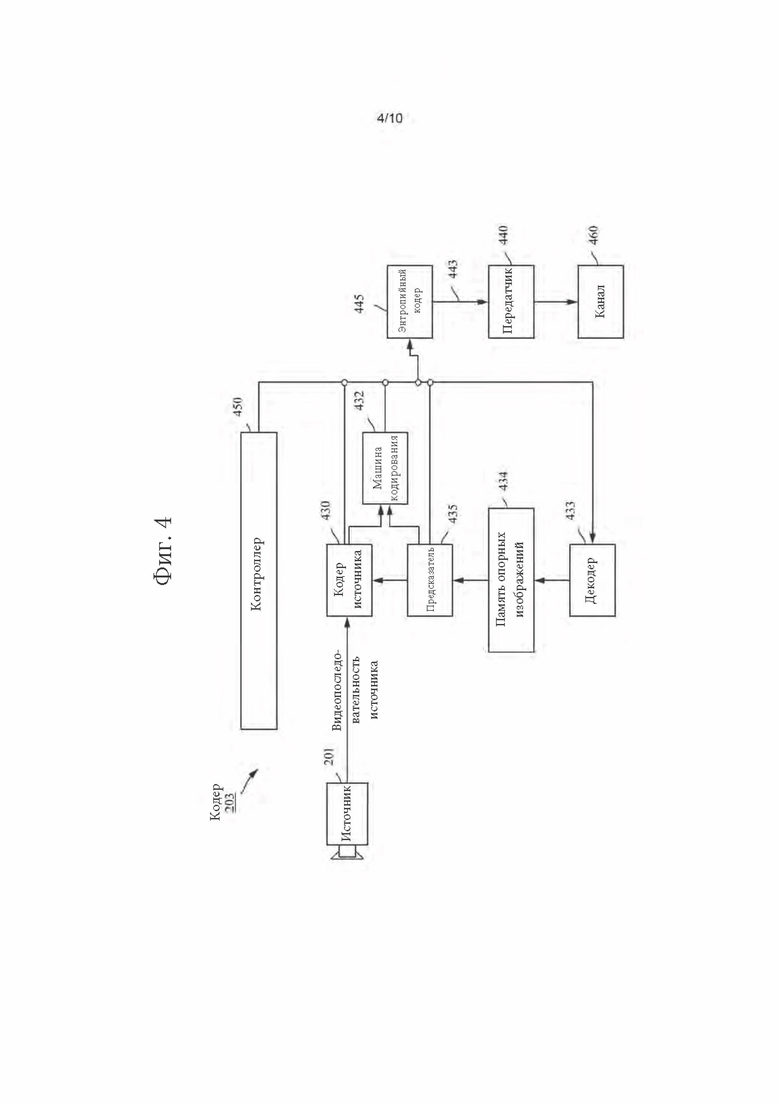
[0055] Фиг. 4 может быть функциональной блок-схемой видеокодера (203) согласно варианту осуществления настоящего изобретения.
[0056] Кодер (203) может принимать отсчеты видео из источника (201) видео (который не входит в состав кодера), который может захватывать видеоизображение(я), подлежащее(ие) кодированию кодером (203).
[0057] Источник (201) видео может обеспечивать исходную видеопоследовательность, подлежащую кодированию кодером (203), в форме потока отсчетов цифрового видео любой подходящей битовой глубины (например, 8 битов, 10 битов, 12 битов и т.д.), любого цветового пространства (например, ВТ.601 Y CrCB, RGB и т.д.), и любой подходящей структуры дискретизации (например, Y CrCb 4:2:0, Y CrCb 4:4:4). В системе службы массовой информации источником (201) видеосигнала может быть запоминающее устройство, где хранится ранее подготовленное видео. В системе видеоконференцсвязи источником (203) видеосигнала может быть камера, которая захватывает информацию локального изображения как видеопоследовательность. Видеоданные могут обеспечиваться как множество отдельных изображений, которые создают ощущение движения при наблюдении в последовательности. Непосредственно изображения могут быть организованы как пространственный массив пикселей, каждый из которых может содержать одну или более выборок, в зависимости от используемых структуры дискретизации, цветового пространства и т.д. Специалисту в данной области техники нетрудно понять соотношение между пикселями и отсчетами. Нижеследующее описание посвящено отсчетам.
[0058] Согласно варианту осуществления кодер (203) может кодировать и сжимать изображения исходной видеопоследовательности в кодированную видеопоследовательность (443) в реальном времени или с учетом любых других временных ограничений, налагаемых применением. Установление надлежащей скорости кодирования является одной из функций контроллера (450). Контроллер управляет другими функциональными модулями, как описано ниже, и функционально подключен к этим функциональным модулям. Подключение для простоты не показано. Параметры, установленные контроллером, могут включать в себя параметры, связанные с регулировкой частоты (пропуск изображения, квантователь, значение лямбда, применяемое при оптимизация скорости-искажения т.д.), размер изображения, схему групп изображений (GOP, Group Of Pictures), максимальную зону поиска вектора движения и т.д. Специалист в этой области техники может легко идентифицировать другие функции контроллера (450) в той мере, в какой они могут относиться к видеокодеру (203), оптимизированному для конструкции определенной системы.
[0059] Некоторые видеокодеры работают в режиме, который специалисту в этой области техники известен как «петля кодирования». В качестве очень упрощенного описания петля кодирования может включать в себя компонент кодирования кодера (430) (далее «исходного кодера») (отвечающего за создание символов на основе входного изображения, подлежащего кодированию, и опорного(ых) изображения(ий)), и (локального) декодера (433), встроенного в кодер (203), который реконструирует символы для создания данных отсчетов, которые (удаленный) декодер также должен создавать (поскольку любое сжатие между символами и битовым потоком кодированного видео происходит без потерь в технологиях сжатия видео, рассматриваемых в раскрытом изобретении). Этот реконструированный поток отсчетов поступает в память (434) опорных изображений. Поскольку декодирование потока символов приводит к результатам, с точностью до бита, не зависящим от положения декодера (локального или удаленного), содержимое буфера опорных изображений также будет одинаковым с точностью до бита для локального кодера и удаленного кодера. Другими словами, предсказанная часть кодера «видит» в качестве отсчетов опорного изображения точно такие же значения отсчетов, как «видел» бы декодер при использовании предсказания в ходе декодирования. Этот фундаментальный принцип синхронизма опорного изображения (и, в итоге, дрейф, если синхронизм не удается поддерживать, например, вследствие канальных ошибок) хорошо известен специалисту в этой области техники.
[0060] «Локальный» декодер (433) может действовать таким же образом, как «удаленный» декодер (210), подробно описанный выше со ссылкой на фиг.3. Однако, опять же, согласно фиг.3, поскольку символы доступны, и кодирование/декодирование символов в кодированной видеопоследовательности энтропийным кодером (445) и анализатором (320) может осуществляться без потерь, части энтропийного декодирования декодера (210), включающие в себя канал (312), приемник (310), буфер (315) и анализатор (320), могут быть не полностью реализованы в локальном декодере (433).
[0061] При этом можно сделать вывод, что любая технология декодирования, присутствующая в декодере, за исключением анализа/энтропийного декодирования, также обязательно должна присутствовать, по существу в идентичной функциональной форме в соответствующем кодере. По этой причине раскрытое изобретение сконцентрировано на работе декодера. Описание технологий кодирования может быть сокращено, поскольку они являются обратными подробно описанным технологиям декодирования. Только в некоторых областях требуется более детальное описание, которое приведено ниже.
[0062] В ходе работы исходный кодер (430) может осуществлять кодирование с предсказанием и компенсацией движения, при котором входной кадр кодируется с предсказанием на основании одного или более ранее кодированных кадров из видеопоследовательности, указанных как «опорные кадры». Таким образом, машина (432) кодирования кодирует различия между пиксельными блоками входного кадра и пиксельными блоками опорного кадра(ов), которое(ые) может(ут) выбираться в качестве предсказанной(ых) ссылки(ок) на входной кадр.
[0063] Локальный видеодекодер (433) может декодировать кодированные видеоданные кадров, которые могут быть указаны как опорные кадры основе символов, созданных исходным кодером (430). Операции машины (432) кодирования могут быть преимущественно процессами с потерями. Если кодированные видеоданные декодируются в видеодекодере (не показан на фиг.4), то реконструированная видеопоследовательность обычно может представлять собой копию исходной видеопоследовательности с некоторыми ошибками. Локальный видеодекодер (433) дублирует процессы декодирования, которые могут осуществляться видеодекодером на опорных кадрах, и может предписывать сохранение реконструированных опорных кадров в кэш-памяти (434) опорных изображений. Таким образом, кодер (203) может локально сохранять копии реконструированных опорных кадров, имеющих такое же содержимое, как реконструированные опорные кадры, которые будут получены видеодекодером на стороне приемника (в отсутствие ошибок передачи).
[0064] Предсказатель (435) может осуществлять поиски предсказания для машины (432) кодирования. Таким образом, для нового кадра, подлежащего кодированию, предсказатель (435) может искать в памяти (434) опорных изображений данные отсчетов (в качестве кандидатов на роль опорных пиксельных блоков) или те или иные метаданные, например, векторы движения опорного изображения, формы блоков и т.д., которые могут служить надлежащей ссылкой для предсказания новых изображений. Предсказатель (435) может работать на основе «блоки отсчетов пиксельные блоки» для нахождения надлежащих ссылок для предсказания. В ряде случаев, согласно результатам поиска, полученным предсказателем (435), входное изображение может иметь ссылки для предсказания, извлеченные из множества опорных изображений, хранящихся в памяти (434) опорных изображений.
[0065] Контроллер (450) может управлять операциями кодирования видеокодера (430), включая, например, установление параметров и параметров подгруппы, используемых для кодирования видеоданных.
[0066] Выходной сигнал всех вышеупомянутых функциональных модулей может подвергаться энтропийному кодированию в энтропийном кодере (445). Энтропийный кодер переводит символы, сгенерированные различными функциональными модулями, в кодированную видеопоследовательность путем сжатия символов без потерь согласно технологиям, известным специалисту в этой области техники, например кодирования по Хаффману, кодирования с переменной длиной серии, арифметического кодирования и т.д.
[0067] Передатчик (440) может буферизовать кодированную(ые) видеопоследовательность(и), созданную энтропийным кодером (445), для подготовки к передаче через канал (460) связи, который может быть аппаратной/программной линией связи с запоминающим устройством, где хранятся кодированные видеоданные. Передатчик (440) может объединять кодированные видеоданные от видеокодера (430) с другими данными, подлежащими передаче, например, кодированными аудиоданными и/или вспомогательными потоками данных (источники не показаны).
[0068] Контроллер (450) может управлять работой кодера (203). В ходе кодирования контроллер (450) может назначать каждому кодированному изображению тот или иной тип кодированного изображения, который может определять методы кодирования, применимые к соответствующему изображению. Например, изображениям часто могут назначаться следующие типы кадров:
[0069] Внутреннее изображение (I-изображение) может представлять собой изображение, которое может кодироваться и декодироваться без использования любого другого кадра в последовательности в качестве источника предсказания. Некоторые видеокодеки допускают разные типы интра-изображений, включая, например, изображения в формате независимого обновления декодера (IDR, Independent Decoder Refresh). Специалисту в данной области техники известны разновидности 1-изображений и их соответствующие варианты применения и особенности.
[0070] Предсказанное изображение (Р-изображение), которое можно кодировать и декодировать с использованием внутреннего предсказания или внешнего предсказания с использованием не более одного вектора движения и опорного индекса для предсказания значений отсчетов каждого блока.
[0071] Двунаправленно-предсказанное изображение (В-изображение), которое можно кодировать и декодировать с использованием внутреннего предсказания или внешнего предсказания с использованием не более двух векторов движения и опорных индексов для предсказания значений отсчетов каждого блока. Аналогично, мультипредсказанные изображения могут использовать более двух опорных изображений и связанные метаданные для реконструкции единого блока.
[0072] Исходные изображения обычно допускают пространственное разделение на множество блоков отсчетов (например, блоки 4×4, 8×8, 4×8 или 16×16 отсчетов каждый) и кодирование на поблочной основе (блок за блоком). Блоки могут кодироваться предиктивно со ссылкой на другие (ранее кодированные) блоки, определенные назначением кодирования, применяемым к соответствующим изображениям этих блоков. Например, блоки 1-изображений могут кодироваться без предсказания или с предсказанием со ссылкой на ранее кодированные блоки того же изображения (пространственным предсказанием или внутренним предсказанием). Блоки пикселей Р-изображений могут кодироваться без предсказания, с использованием пространственного предсказания или временного предсказания со ссылкой на одно предварительно кодированное ссылочное изображение. Блоки В-изображений могут кодироваться без предсказания путем пространственного предсказания или временного предсказания со ссылкой на одно или два ранее кодированных опорных изображения.
[0073] Видеокодер (203) может осуществлять операции кодирования согласно заранее заданной технологии или стандарту видеокодирования, например, ITU-T Rec. Н.265. В своей работе видеокодер (203) может осуществлять различные операции сжатия, в том числе операции предиктивного кодирования, которые используют временные и пространственные избыточности во входной видеопоследовательности. Поэтому кодированные видеоданные могут согласовываться с синтаксисом, заданным используемой технологией или стандартом видеокодирования.
[0074] Согласно варианту осуществления передатчик (440) может передавать дополнительные данные с кодированным видео. Видеокодер (430) может включать такие данные как часть кодированной видеопоследовательности. Дополнительные данные могут включать в свой состав временные/пространственные/SNR усовершенствованные уровни, другие виды избыточных данных, такие как избыточные изображения и слайсы, сообщения дополнительной усовершенствованной информации (SEI, Supplementary Enhancement Information), фрагменты набора параметров применимости визуальной информации (VUI, Visual Usability Information) и т.д.
[0075] Перед более подробным описанием определенных аспектов раскрытого изобретения необходимо ввести несколько терминов, на которые будут выполняться ссылки в оставшейся части этого описания.
[0076] Далее субизображение относится, в некоторых случаях, к прямоугольной компоновке отсчетов, блоков, макроблоков, единиц кодирования или подобных объектов, которые семантически сгруппированы и которые могут независимо кодироваться с измененным разрешением. Одно или более субизображений могут формировать изображение. Одно или более кодированных субизображений могут формировать кодированное изображение. Одно или более субизображений может быть ассемблировано в изображение, и одно или более субизображений может быть извлечено из изображения. В определенных средах одно или более кодированных субизображений может быть ассемблировано в сжатой области без перекодирования до уровня отсчетов в кодированное изображение, и в тех же или в других определенных случаях одно или более кодированных субизображений может быть извлечено из кодированного изображения в сжатой области.
[0077] Далее повторная дискретизация опорного изображения (RPR, Reference Picture Resampling) или изменение адаптивного разрешения (ARC, Adaptive Resolution Change) относится к механизмам, которые позволяют изменять разрешение изображения или субизображения в кодированной видеопоследовательности, например, путем повторной дискретизации опорного изображения. Далее параметры RPR/ARC относятся к управляющей информации, требующейся для выполнения изменения адаптивного разрешения, которая может включать в себя, например, параметры фильтров, коэффициенты масштабирования, разрешения выходных и/или опорных изображений, различные флаги управления и т.д.
[0078] Описание выше ориентировано на кодировании и декодировании одиночного семантически независимого кодированного видеоизображения. Перед описанием реализации кодирования/декодирования множества субизображений с независимыми параметрами RPR/ARC и подразумеваемого дополнительного усложнения рабочего процесса должны быть описаны варианты сигнализации параметров RPR/ARC.
[0079] На фиг.5 показано несколько новых опций сигнализации параметров RPR/ARC. Необходимо отметить, что каждая из опций имеет определенные преимущества и недостатки с точки зрения эффективности кодирования, сложности и архитектуры. В стандарте или в технологии видеокодирования для сигнализации параметров RPR/ARC может быть выбрана одна или более этих опций или опций, известных из предшествующего уровня техники. Параметры могут не быть взаимоисключающими и предположительно могут меняться местами в зависимости от требований применения, используемых стандартов или выбора кодера.
[0080] Классы параметров RPR/ARC могут включать:
- коэффициенты повышающей/понижающей дискретизации, отдельные или объединенные в измерениях X и Y;
- коэффициенты повышающей/понижающей дискретизации с добавлением временного измерения, указывающего увеличение/уменьшение масштаба с постоянной скоростью для заданного количества изображений;
- любой из указанных выше двух пунктов может инициировать кодирование одного или более предположительно коротких элементов синтаксиса, которые могут указывать на таблицу, содержащую коэффициенты);
- разрешение, по измерению X или Y, в единицах отсчетов, блоков, макроблоков, CU или в любой другой подходящей степени детализации входного изображения, выходного изображения, опорного изображения, кодированного изображения, объединенного или отдельного. (Если имеется более одного разрешения (например, одно для входного изображения, и одно для опорного изображения); в некоторых случаях один набор значений может быть выведен из другого набора значений. Управление этим может выполняться, например, с помощью флагов. Более подробный пример см. ниже.);
- координаты «деформации», подобные используемым в приложении Р стандарта Н.263, опять же с подходящей степенью детализации, как описано выше (в приложении Р стандарта Н.263 определяется один эффективный способ кодирования таких координат деформации, но, возможно, также разрабатываются другие, потенциально более эффективные способы. Например, согласно вариантам осуществления, реверсивное кодирование с переменной длиной по Хаффману координат деформации согласно приложению Р заменяется двоичным кодированием с подходящей длиной, где длина двоичного кодового слова может быть, например, определена на основе максимального размера изображения, возможно умноженного на определенный коэффициент и смещенного на определенное значение, чтобы допустить «деформацию» за пределами границ максимального размера изображения), и/или
- параметры фильтра повышающей или понижающей дискретизации (В самом простом случае может использоваться только один фильтр для повышающей и/или понижающей дискретизации. Однако в некоторых случаях предпочтительнее может быть обеспечение большей гибкости в конструкции фильтра, для этого может потребоваться сигнализация параметров фильтра. Такие параметры могут быть выбраны с помощью индекса в списке возможных конструкций фильтров, фильтр может быть полностью определен (например, с помощью списка коэффициентов фильтра с использованием подходящих методов энтропийного кодирования), фильтр может быть неявно выбран с помощью соотношений повышающей/понижающей дискретизации в соответствии с которыми, в свою очередь, выполняется сигнализация в соответствии с любым из упомянутых выше механизмов и т.д.).
[0081] В дальнейшем описании предполагается кодирование конечного набора коэффициентов повышающей/понижающей дискретизации (тот же коэффициент, который должен использоваться как в измерении X, так и в измерении Y), указанных с помощью кодового слова. Для этого кодового слова преимущественно используется кодирование с переменной длиной, например, с использованием экспоненциального кода Голомба, общего для определенных элементов синтаксиса в спецификациях кодирования видео, таких как Н.264 и Н.265. Одно подходящее отображение значений на коэффициенты повышающей/понижающей дискретизации может, например, соответствовать следующей Табл. 1:
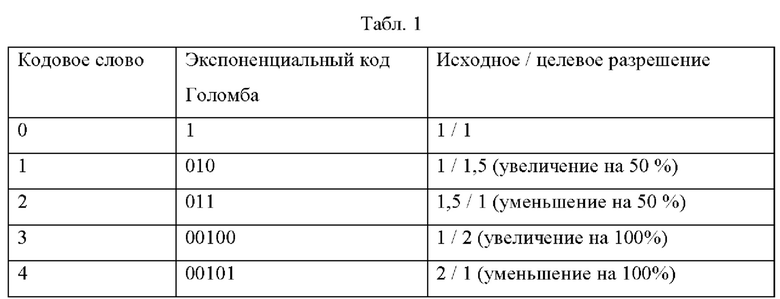
[0082] Многие аналогичные отображения могут быть разработаны в соответствии с требованиями применения и возможностями механизмов увеличения и уменьшения дискретизации, доступных в технологии или стандарте сжатия видео. Эта таблица может содержать большее количество значений. Значения также могут быть представлены механизмами энтропийного кодирования, отличными от экспоненциальных кодов Голомба, например, с использованием двоичного кодирования. Это может иметь определенные преимущества, когда коэффициенты повторной дискретизации представляют интерес за пределами самих механизмов обработки видео (прежде всего кодера и декодера), например, с помощью MANE. Необходимо отметить, что для (предположительно) наиболее распространенного случая, когда изменение разрешения не требуется, можно выбрать короткий экспоненциальный код Голомба; в таблице выше это только один бит.Это может иметь преимущество по эффективности кодирования по сравнению с использованием двоичных кодов для наиболее распространенного случая.
[0083] Количество записей в таблице, а также их семантика могут быть полностью или частично конфигурируемыми. Например, основная структура таблицы может быть передана в наборе параметров «высокого» уровня, таком как последовательность или набор параметров декодера. В альтернативном варианте или дополнительно одна или несколько таких таблиц могут быть определены в методе технологии или стандарте видеокодирования и могут быть выбраны, например, с помощью декодера или набора параметров последовательности.
[0084] Ниже описывается, как коэффициент повышающей/понижающей дискретизации (информация ARC), кодированный согласно описанию выше, может быть включен в синтаксис метода или стандарта кодирования видео. Подобные соображения могут применяться к одному или более кодовым словам, управляющим фильтрами повышающей/понижающей дискретизации. См. ниже обсуждение случая, когда для фильтра или других структур данных требуются сравнительно большие объемы данных.
[0085] Как показано в примере на фиг.5А, иллюстрация (500А) показывает, что приложение Р стандарта Н.263 включает в себя информацию (502) ARC в форме четырех координат деформации в заголовке (501) изображения, в частности, в расширении заголовка Н.263 PLUSPTYPE (503). Это может быть разумным выбором конструкции, когда а) имеется доступный заголовок изображения и б) ожидаются частые изменения информации ARC. Однако объем данных при использовании сигнализации в стиле Н.263 может быть довольно большим, и коэффициенты масштабирования могут не относиться к границам изображения, поскольку заголовок изображения может иметь временный характер. Кроме того, как показано в примере на фиг.5В, иллюстрация (500 В) показывает, что JVET-M0135 включает в себя информацию (504) PPS, опорную информацию (505) ARC, информацию (507) SPS и информацию (506) таблицы целевого разрешения.
[0086] Согласно примеру осуществления, на фиг.5С показан пример (500С), в котором показана информация (508) заголовка группы тайлов и информация (509) ARC; на фиг.5D показан пример (500D), в котором показана информация (514) заголовка группы тайлов, опорная информация (513) ARC, информация (516) SPS и информация (515) ARC, а на фиг.5Е показан пример (500Е), в котором показана информация (511) набора(ов) параметров адаптации (APS) и информация (512) ARC.
[0087] На фиг.6 показан пример (600) таблицы, в которой используется адаптивное разрешение, в этом примере выходное разрешение кодируется в единицах отсчетов (613). Числовое значение (613) относится как элементу синтаксиса output_pic_width_in_luma_samples, и к элементу синтаксиса output_pic_height_in_luma_samples, которые вместе могут определять разрешение выходного изображения. В другом месте в методе или стандарте кодирования видео могут быть определены определенные ограничения для любого значения. Например, определение уровня может ограничивать количество общих выходных отсчетов, которые могут быть произведением значений этих двух элементов синтаксиса. Кроме того, определенные методы или стандарты кодирования видео, или внешние методы или стандарты, такие как, например, системные стандарты, могут ограничивать диапазон нумерации (например, одно или оба измерения должны делиться на степень числа 2) или формат изображения (например, ширина и высота должны иметь отношение 4:3 или 16:9). Такие ограничения могут быть введены для облегчения аппаратных реализаций, либо по другим причинам, которые будут понятны специалисту в этой области техники с точки зрения раскрытия настоящего изобретения.
[0088] В некоторых вариантах применения может быть целесообразно, чтобы кодер выдавал декодеру указание на использование определенного размера опорного изображения, а не предполагать, что этот размер является размером выходного изображения. В этом примере элемент синтаксиса reference_pic_size_present_flag (614) блокирует условное присутствие размеров (615) опорного изображения (опять же, числовое значение относится и к ширине, и к высоте).
[0089] Определенные методы или стандарты видеокодирования, например VP9, поддерживают пространственную масштабируемость путем реализации определенных форм повторной дискретизации опорных изображений (реализуется совершенно иначе, чем раскрытое изобретение) в сочетании с временной масштабируемостью для обеспечения пространственной масштабируемости. В частности, для некоторых опорных изображений может выполняться повышающая дискретизация с использованием методов в стиле ARC с более высоким разрешением для формирования основы уровня пространственного улучшения. Эти изображения, для которых выполнена повышающая дискретизация, можно улучшить, используя обычные механизмы прогнозирования с высоким разрешением для добавления деталей.
[0090] Раскрытое изобретение может использоваться и используется в такой среде согласно вариантам осуществления. В некоторых случаях, в том же или в другом варианте осуществления, значение в заголовке блока NAL, например, поле временного идентификатора, может использоваться для указания не только временного, но и пространственного уровня. Это дает определенные преимущества для определенных систем; например, существующие выбранные блоки пересылки (SFU, Selected Forwarding Unit), созданные и оптимизированные для пересылки, выбранной на временном уровне на основе значения временного идентификатора заголовка блока NAL, могут использоваться без модификации для масштабируемых сред. Чтобы сделать это возможным, может существовать требование для соответствия между размером кодированного изображения и временным уровнем, указываемым полем временного идентификатора в заголовке блока NAL.
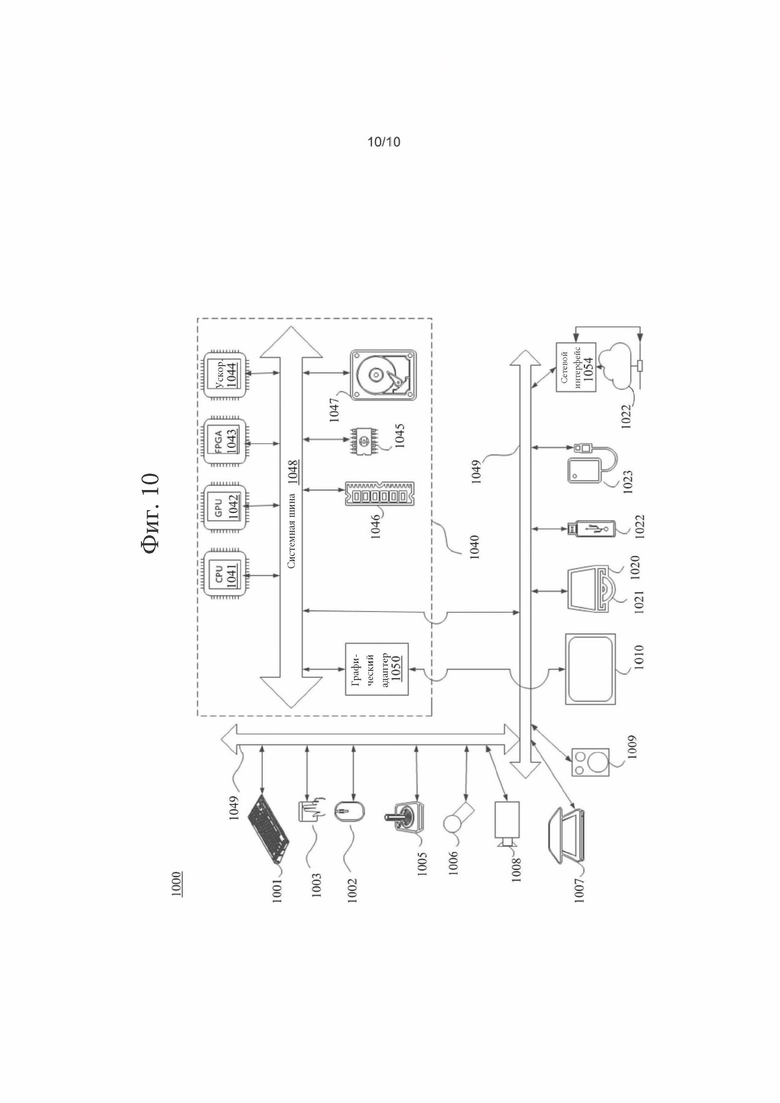
[0091] Согласно вариантам осуществления, информация о зависимости между уровнями может передаваться в VPS (или в сообщениях DPS, SPS или SEI). Информация о зависимости между уровнями может использоваться для идентификации того, какой уровень используется в качестве опорного для декодирования текущего уровня. Декодированное изображение picA в прямо зависимом уровне с nuh_layer_id, равным т, может использоваться в качестве опорного изображения для изображения picB с nuh_layer_id, равным n, когда n больше, чем m, и два изображения picA и picB относятся к одному и тому же блоку доступа.
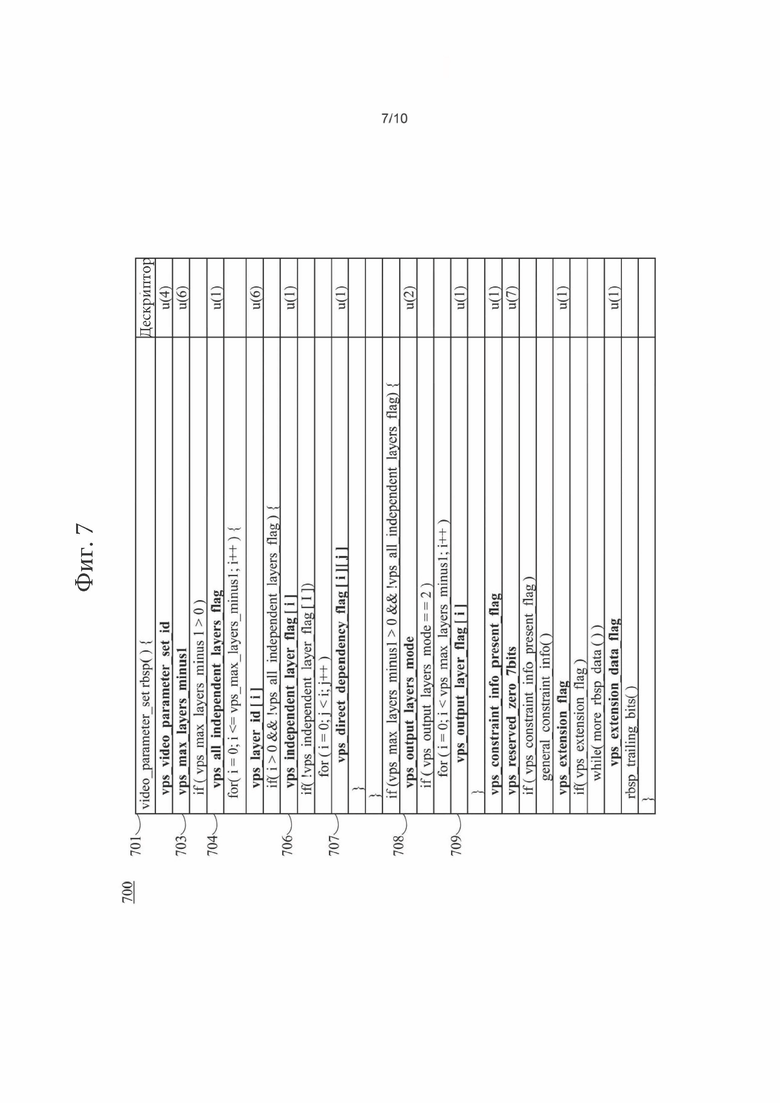
[0092] Согласно тому же или другим вариантам осуществления, список межуровневых опорных изображений (ILRP, Inter-Layer Reference Picture) может явно передаваться со списком опорных изображений внутреннего предсказания (IPRP, biter-Prediction Reference Picture) в заголовке слайса (или в наборе параметров). И списки ILRP, и списки IPRP могут использоваться для формирования списков опорных изображений предсказания в прямом и в обратном направлениях.
[0093] Согласно тому же или другим вариантам осуществления, элементы синтаксиса в VPS (или в другом наборе параметров) могут указывать, является ли каждый уровень зависимым или независимым. В примере (700), показанном на фиг.7, элемент синтаксиса vps _ax_layers_minus1 (703) плюс 1 может указывать максимальное количество уровней, разрешенных в одном или более, потенциально всех, CVS, относящихся к VPS (701). Элемент синтаксиса vps_all_independent_layers_flag (704), равный 1, может указывать, что все уровни в CVS кодируются независимо, то есть без использования межуровневого предсказания. Элемент синтаксиса vps_all_independent_layers_flag (704), равный 0, может указывать, что один или более уровней в CVS могут использовать межуровневое предсказание. Когда этот элемент синтаксиса отсутствует, можно полагать, что значение элемента синтаксиса vps_all_independent_layers_flag равно 1. Когда значение элемента синтаксиса vps_all_independent_layers_flag равно 1, можно полагать, что значение элемента синтаксиса vps_independent_layer_flag[i] (706) равно 1. Когда значение элемента синтаксиса vps_all_independent_layers_flag равно 0, можно полагать, что значение элемента синтаксиса vps_independent_layer_flag[0] равно 1. На фиг.7 показано, что элемент синтаксиса vps_independent_layer_flag[i] (706), равный 1, может указывать, что на уровне с индексом i межуровневое предсказание не используется. Элемент синтаксиса vps_independent_layer_flag[i], равный 0, может указывать, что на уровне с индексом i может использоваться межуровневое предсказание, а vps_layer_dependency_flag [i] имеется в VPS. Элемент синтаксиса vps_direct_dependency_flagf[i][j] (707), равный 0, может указывать, что уровень с индексом j не является прямым опорным уровнем для уровня с индексом i. Элемент синтаксиса vps_direct_dependency_flag[i][j], равный 1, может указывать, что уровень с индексом j не является прямым опорным уровнем для уровня с индексом i. Когда vps_direct_dependency_flagf[i][j] отсутствует для i и j в диапазоне от 0 до vps_max_layers_minusl включительно, можно полагать, что он равен 0. Переменная DirectDependentLayerIdx[i][j], указывающая j-ый прямой зависимый уровень i-го уровня, определяется следующим образом:

[0094] Переменная GeneralLayerldx [i], указывающая индекс уровня с nuh_layer_id, равным vps_layer_id [i], определяется следующим образом:

[0095] Согласно тому же или другим вариантам осуществления? на фиг.7 показано, что, когда значение элемента синтаксиса vps_max_layers_minusl больше нуля и значение элемента синтаксиса vps_all_independent_layers_flag равно нулю, могут передаваться элементы синтаксиса vps_output_layers_mode и vps_output_layer_flags [i]. Элемент синтаксиса vps_output_layers_mode (708), равный 0, может указывать, что выводится только самый высокий уровень. Элемент синтаксиса vps_output_layer_mode, равный 1, может указывать, что могут выводиться все уровни. Элемент синтаксиса vps_output_layer_mode, равный 2, может указывать, что выводятся уровни с элементом синтаксиса vps_output_layer_flag [i] (709), равным 1. Значение элемента синтаксиса vps_output_layers_mode должно находиться в диапазоне от 0 до 2 включительно. Значение 3 элемента синтаксиса vps_output_layer_mode может быть зарезервировано для использования в будущем. Когда этот элемент синтаксиса отсутствует, можно полагать, что значение элемента синтаксиса vps_output_layers_mode равно 1. Элемент синтаксиса vps_output_layer_flag[i], равный 1, может указывать, что выводится i-ый уровень. Элемент синтаксиса vps_output_layer_flag[i], равный 0, может указывать, что i-ый уровень не выводится. Список OutputLayerFlagf[i], для которого значение 1 может указывать, что выводится i-ый уровень, а значение 0 указывает, что i-ый уровень не выводится, определяется следующим образом:

[0096] Согласно тому же или другим вариантам осуществления, вывод текущего изображения может быть определен следующим образом:
- Если значение элемента синтаксиса PictureOutputFlag равно 1, и значение элемента синтаксиса DpbOutputTimef [n] равно значению элемента синтаксиса CpbRemovalTime[n], то выводится текущее изображение.
- В противном случае, если значение элемента синтаксиса PictureOutputFlag равно 0, то текущее изображение не выводится, но будет сохранено в DPB, как указано в ниже.
В противном случае (значение элемента синтаксиса PictureOutputFlag равно 1, а значение элемента синтаксиса DpbOutputTimef [n] больше значения элемента синтаксиса CpbRemovalTime [n]) текущее изображение выводится позже и сохраняется в DPB (как указано ниже) и выводится в момент времени DpbOutputTimef [n], если не указано, что оно выводится путем декодирования или вывода элемента синтаксиса no_output_of_prior_pics_flag, равного 1, в момент времени, предшествующий времени DpbOutputTimef [n].
При выводе изображение обрезается с использованием соответствующего окна
обрезки, указанного в PPS для изображения.
[0097] Согласно тому же или другим вариантам осуществления, элемент синтаксиса PictureOutputFlag может быть определен следующим образом:
- Если выполняется одно из следующих условий, то для PictureOutputFlag устанавливается значение 0:
- текущее изображение является изображением RASL, а значение NoIncorrectPicOutputFlag связанного изображения IRAP равно 1.
- значение gdr_enabled_flag равно 1, а текущее изображение является изображением GDR с NohicorrecfPicOutputFlag, равным 1.
- значение gdr_enabled_flag равно 1, текущее изображение связано с изображением GDR с NomcorrectPicOutputFlag, равным 1, и
значение PicOrderCntVal текущего изображения меньше значения RpPicOrderCntVal связанного изображения GDR.
- значение vps_output_layer_mode равно 0 или 2, а значение OutputLayerFlag[GeneralLayerldx[nuh layer id]] равно 0.
- В противном случае для PictureOutputFlag устанавливается значение pic_output_flag.
[0098] Согласно тому же или другим вариантам осуществления элемент синтаксиса PictureOutputFlag также может быть определен следующим образом:
Если выполняется одно из следующих условий, то для PictureOutputFlag
устанавливается значение 0:
- текущее изображение является изображением RASL, а значение NoIncorrectPicOutputFlag связанного изображения IRAP равно 1.
- значение gdr_enab_led_flag равно 1, а текущее изображение является изображением GDR с NoIncorrectPicOutputFlag, равным 1.
- значение gdr_enabled_flag равно 1, текущее изображение связано с изображением GDR с NoIncorrectPicOutputFlag, равным 1, и
значение PicOrderCntVal текущего изображения меньше значения RpPicOrderCntVal связанного изображения GDR.
Значение vps_output_layer_mode равно 0, а текущий блок доступа содержит изображение, у которого значение PictureOutputFlag равно 1, а значение nuh_layer_id nuhLid больше, чем у текущего изображения, и относится к выходному уровню (то есть, значение OutputLayerFlag[GeneralLayerIdx[nuhLid]] равно 1).
- значение vps_output_layer_mode равно 2, а значение OutputLayerFlag[GeneralLayerldx[nuh layer id]] равно 0.
- В противном случае для PictureOutputFlag устанавливается значение pic_output_flag.
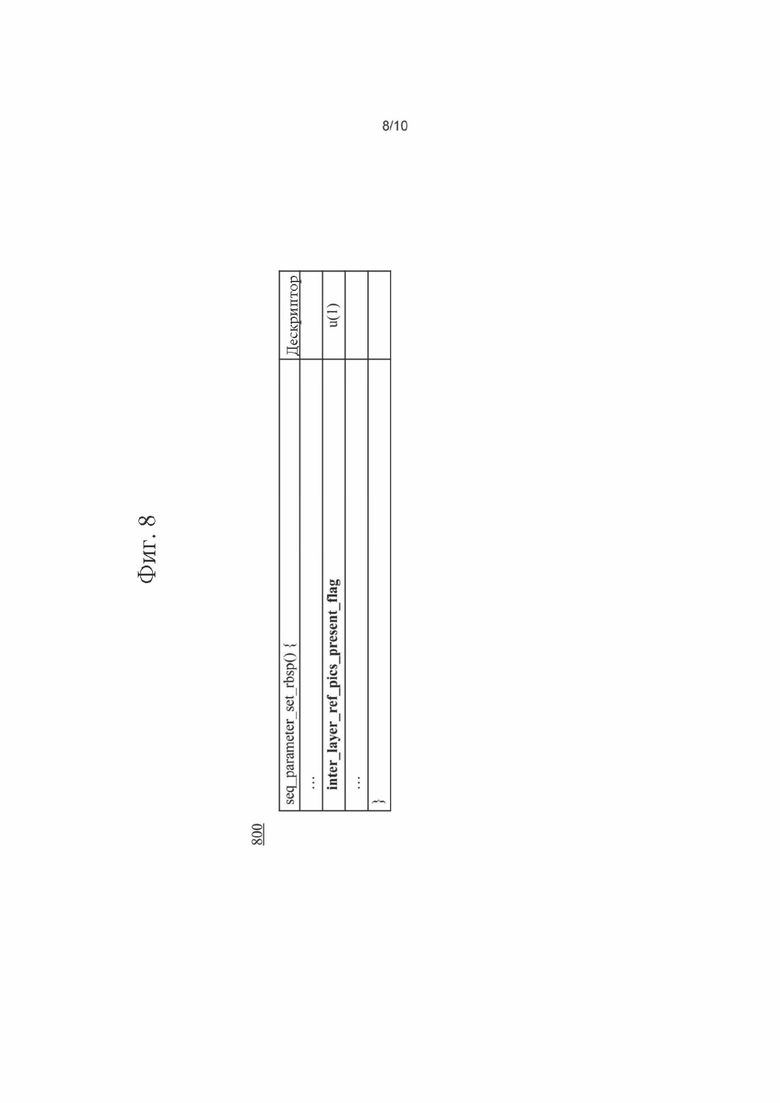
[0099] Согласно тому же или другим вариантам осуществления, флаг в VPS (или в другом наборе параметров) может указывать, передаются ли списки ILRP для текущего слайса (или изображения). Например, в примере (800), показанном на фиг.8, элемент синтаксиса inter_layer_refjtics_jtresent flag, равный 0, может указывать, что никакие ILRP не используются для внутреннего предсказания кодированных изображений в CVS. Элемент синтаксиса inter_layer_ref_pics flag, равный 1, может указывать, что ILRP могут использоваться для внутреннего предсказания одного или более кодированных изображений в CVS.
[0100] Согласно тому же или другим вариантам осуществления, список межуровневых опорных изображений (ILRP, Inter-Layer Reference Picture) для изображения на k-ом уровне может передаваться или может не передаваться, когда k-ый уровень является зависимым уровнем. Однако список ILRP для изображения на k-ом уровне не должен передаваться, и никакой ILRP не должен вводиться в список опорных изображений, когда k-ый уровень является независимым уровнем.
Для inter_layer_ref_pics_present_flag может быть установлено значение 0, когда значение sps_video_parameter_set_id равно 0, когда значение nuhlayerid равно 0 или когда значение vpsindependentlayer_flag[GeneralLayerIdx[nuh layer id]] равно 1.
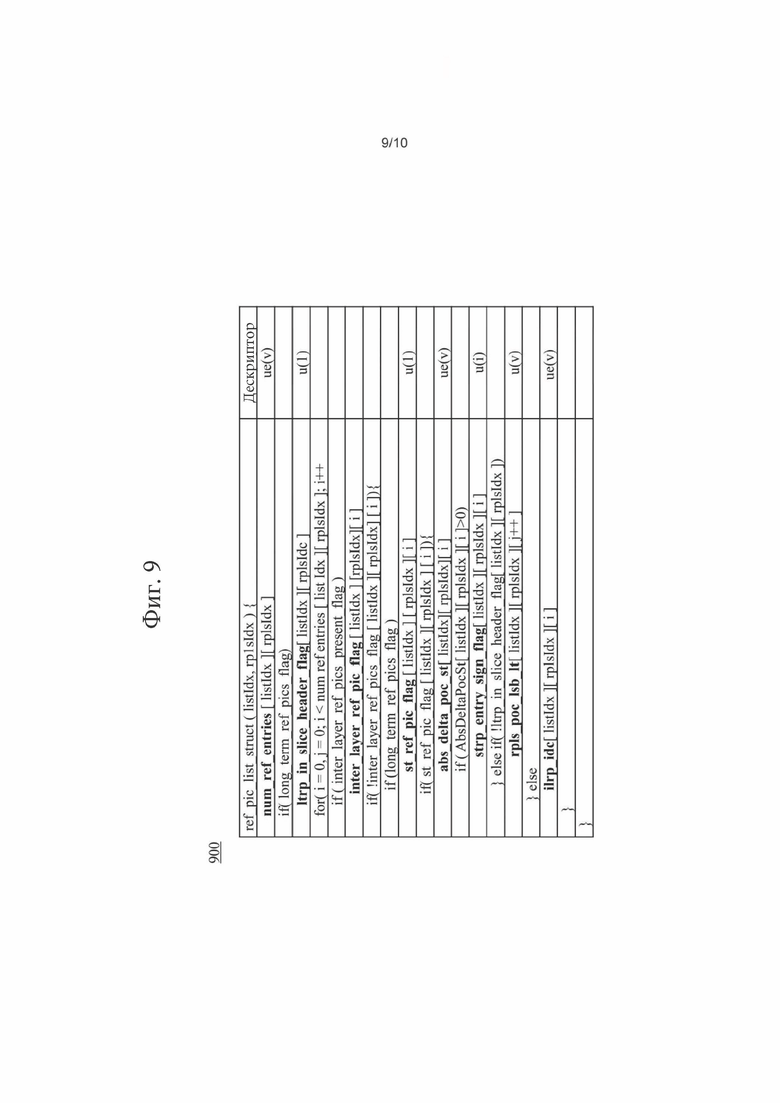
[0101] Согласно тому же или другим вариантам осуществления, в примере (900) на фиг.9 показано, что списки опорных изображений RefPicList[0] и RefPicListf[1] могут формироваться следующим образом:



[0102] Описанные выше методы передачи параметров адаптивного разрешения могут быть реализованы в виде компьютерного программного обеспечения, использующего компьютерно-считываемые инструкции и физически хранящегося на одном или более компьютерно-считываемых носителях. Например, на фиг.10 показана компьютерная система (1000), пригодная для реализации некоторых вариантов осуществления раскрытого изобретения.
[0103] Компьютерное программное обеспечение может быть кодировано с использованием любого подходящего машинного кода или языка программирования, который может ассемблироваться, компилироваться, компоноваться или с помощью подобных механизмов формировать код, содержащий команды, которые могут выполняться непосредственно или интерпретироваться, выполняться в виде микрокоманд и т.п. центральными процессорами компьютера (CPU, Central Processing Unit), графическими процессорами (GPU, Graphics Processing Unit) ит.п.
[0104] Инструкции могут выполняться на компьютерах различных типов или их компонентах, включая, например, персональные компьютеры, планшетные компьютеры, серверы, смартфоны, игровые устройства, устройства интернета вещей и т.п.
[0105] Компоненты, показанные на фиг.10 для компьютерной системы (1000), носят иллюстративный характер и не призваны налагать какое-либо ограничение на объем применения или функциональные возможности компьютерного программного обеспечения, реализующего варианты осуществления настоящего изобретения. Конфигурацию компонентов также не следует интерпретировать как имеющую какую-либо зависимость или требование в связи с любым одним или комбинацией компонентов, показанных в иллюстративном варианте осуществления компьютерной системы (1000).
[0106] Компьютерная система (1000) может включать в себя некоторые устройства ввода интерфейса с человеком. Такое устройство ввода может отвечать за ввод одним или более пользователями посредством, например, тактильного ввода (например, нажатий на клавиши, махов, движений информационной перчатки), аудио-ввода (например, голосового, хлопков), визуального ввода (например, жестов), обонятельного ввода (не показан). Устройства интерфейса с человеком также могут использоваться для захвата некоторых информационных носителей, не обязательно напрямую связанных с осознанным вводом человеком, например звука (например, речи, музыки, внешнего звука), изображений (например, отсканированных изображений, фотографических изображений, полученных от камеры неподвижных изображений), видео (например, двухмерного видео, трехмерного видео, включающего в себя стереоскопическое видео).
[0107] Входной человеческий интерфейс устройства может включать в себя один или более следующих компонентов (по одному из изображенных): клавиатуры (1001), мыши (1002), сенсорной панели (1003), сенсорного экрана (1010), джойстика (1005), микрофона (1006), сканера (1007), камеры (1008).
[0108] Компьютерная система (1000) также может включать в себя некоторые устройства вывода интерфейса с человеком. Такие устройства вывода могут стимулировать органы чувств одного или более пользователей посредством, например, тактильного вывода, звука, света и запаха/вкуса. Такие устройства вывода могут включать в себя устройства тактильного вывода (например, тактильной обратной связи посредством сенсорного экрана (1010) или джойстика (1005), но также могут быть устройствами тактильной обратной связи, которые не служат устройствами ввода), устройства вывода аудио (например, громкоговорители (1009), наушники (не показаны)), устройства визуального вывода (например, экраны (1010), в том числе CRT-экраны, LCD-экраны, плазменные экраны, OLED-экраны, каждый с возможностями сенсорного экранного ввода или без них, каждый с возможностями тактильной обратной связи или без них, некоторые из которых способны к двухмерному визуальному выводу или более чем трехмерному выводу посредством, например, стереографического вывода; очков виртуальной реальности (не показаны), голографических дисплеев и дымовых баков (не показаны)) и принтеров (не показаны).
[0109] Компьютерная система (1000) также может включать в себя доступные человеку запоминающие устройства и связанные с ними носители, например, оптические носители, включающие в себя CD/DVD ROM/RW (1020) с носителями (1021) CD/DVD и т.п., карты (1022) флэш-памяти, сменный жесткий диск или твердотельный диск (1023), традиционные магнитные носители, например, ленту и флоппи-диск (не показан), специализированные устройства на основе ROM/ASIC/PLD, например, защитные аппаратные ключи (не показаны) и т.п.
[0110] Специалисты в данной области техники также должны понимать, что термин «компьютерно-считываемые носители», используемый в связи с раскрытым здесь изобретением, не охватывает среды передачи, несущие волны или другие кратковременные сигналы.
[0111] Компьютерная система (1000) также может включать в себя интерфейс с одной или более сетями связи. Сети могут быть, например, беспроводными, проводными, оптическими. Сети могут быть, дополнительно, локальными, глобальными, городскими, транспортными и промышленными, реального времени, допускающими задержку и т.д. Примеры сетей включают в себя локальные сети, например, Ethernet, беспроводные LAN, сотовые сети, в том числе GSM, 3G, 4G, 5G, LTE и т.п., глобальные цифровые сети проводного или беспроводного телевидения, в том числе кабельное телевидение, спутниковое телевидение и наземное телевещание, транспортные и промышленные включают в себя CANBus и т.д. Некоторые сети обычно требуют внешних адаптеров сетевого интерфейса, которые подключены к некоторым портам данных общего назначения или периферийным шинам (1049) (например, USB-порты компьютерной системы (1000)); другие обычно встраиваются в ядро компьютерной системы (1000) путем подключения к системной шине, как описано ниже (например, интерфейс Ethernet в компьютерную систему PC или интерфейс сотовой сети в компьютерную систему смартфона). Используя любую из этих сетей, компьютерная система (1000) может осуществлять связь с другими объектами. Такая связь может быть однонаправленной с возможностью только приема (например, телевещания), однонаправленной с возможностью только передачи (например, CANBus к некоторым устройствам CANBus) или двунаправленной, например, к другим компьютерным системам с использованием локальной или глобальной цифровой сети. Некоторые протоколы и стеки протоколов могут использоваться в каждой из этих сетей и вышеописанных сетевых интерфейсов.
[0112] Вышеупомянутые устройства человеческого интерфейса, доступные человеку запоминающие устройства и сетевые интерфейсы могут подключаться к ядру (1040) компьютерной системы (1000).
[0113] Ядро (1040) может включать в себя один или более центральных процессоров (CPU) (1041), графические процессоры (GPU) (1042), специализированные программируемые модули обработки в форме вентильных матриц, программируемых пользователем (FPGA, Field Programmable Gate Arrays) (1043), аппаратные ускорители для некоторых задач (1044) и т.д. Эти устройства, совместно с постоянной памятью (ROM) (1045), оперативной памятью (1046), внутренним хранилищем данных большой емкости, например, внутренними жесткими дисками, недоступными пользователю, SSD и т.п. (1047), могут соединяться посредством системной шины (1048). В некоторых компьютерных системах системная шина (1048) может быть доступна в форме одного или более физических разъемов для обеспечения расширений за счет дополнительных CPU, GPU и т.п. Периферийные устройства могут подключаться либо напрямую к системной шине (1048) ядра, либо через периферийную шину (1049). Архитектуры периферийной шины включают в себя PCI, USB и т.п.
[0114] CPU (1041), GPU (1042), FPGA (1043) и ускорители (1044) могут выполнять некоторые инструкции, которые совместно могут составлять вышеупомянутый компьютерный код. Этот компьютерный код может храниться в ROM (1045) или RAM (1046). Переходные данные также могут храниться в RAM (1046), тогда как постоянные данные могут храниться, например, во внутреннем хранилище (1047) данных большой емкости. Быстрое сохранение и извлечение из любого запоминающего устройства может обеспечиваться за счет использования кэш-памяти, которая может быть тесно связана с один или более CPU (1041), GPU (1042), хранилищем (1047) данных большой емкости, ROM (1045), RAM (1046) и т.п.
[0115] На компьютерно-считываемых носителях может храниться компьютерный код для осуществления различных компьютерно-реализуемых операций. Носители и компьютерный код могут быть специально созданы в целях настоящего изобретения или могут относиться к хорошо известным и доступным специалистам в области компьютерного программного обеспечения.
[0116] В порядке примера, но не ограничения, компьютерная система, имеющая архитектуру (1000), и, в частности, ядро (1040) может обеспечивать функциональные возможности благодаря выполнению процессором(ами) (включающим(и) в себя CPU, GPU, FPGA, ускорители и т.п.) программного обеспечения, воплощенного в одном или более материальных компьютерно-считываемых носителей. Такие компьютерно-считываемые носители могут быть носителями, связанными с доступным пользователю хранилищем данных большой емкости, представленным выше, а также некоторым хранилищем ядра (1040), носящим долговременный характер, например, внутренним хранилищем (1047) данных большой емкости или ROM (1045). Программное обеспечение, реализующее различные варианты осуществления настоящего изобретения, может храниться в таких устройствах и выполняться ядром (1040). Компьютерно-считываемый носитель может включать в себя одно или более запоминающих устройств или микросхем, в соответствии с конкретными требованиями. Программное обеспечение может предписывать ядру (1040) и, в частности, его процессорам (включая CPU, GPU, FPGA и т.п.) выполнять конкретные процессы или конкретные части описанных здесь конкретных процессов, включая задание структур данных, хранящихся в RAM (1046), и модификацию таких структур данных согласно процессам, заданным программным обеспечением. Дополнительно или альтернативно, компьютерная система может обеспечивать функциональные возможности благодаря логике, зашитой или иным образом воплощенной в схеме (например, ускоритель (1044)), который может действовать вместо или совместно с программным обеспечением для выполнения конкретных процессов или конкретных частей описанных здесь конкретных процессов. Ссылка на программное обеспечение может охватывать логику, и наоборот, когда это уместно. Ссылка на компьютерно-считываемые носители может охватывать схему (например, интегральную схему (IC, Integrated Circuit)), где хранится программное обеспечение для выполнения, схему, воплощающую логику для выполнения, или обе из них, когда это уместно. Настоящее изобретение охватывает любую подходящую комбинацию оборудования и программного обеспечения.
[0117] Хотя здесь описано несколько иллюстративных вариантов осуществления, возможны изменения, перестановки и различные эквиваленты для замены, которые находятся в объеме изобретения. Таким образом, специалисты в данной области техники могут предложить многочисленные системы и способы, которые, хотя в явном виде здесь не показаны и не описаны, воплощают принципы изобретения и, таким образом, соответствуют его сущности и объему.


Изобретение относится к средствам для кодирования видео. Технический результат заключается в повышении эффективности кодирования видео. Выполняют синтаксический анализ по меньшей мере одного набора параметров видео (VPS), содержащего по меньшей мере один элемент синтаксиса, указывающий, является ли по меньшей мере один уровень в масштабируемом битовом потоке одним из зависимого уровня масштабируемого битового потока и независимого уровня масштабируемого битового потока. Выполняют декодирование изображения в зависимом уровне путем анализа и интерпретации списка межуровневых опорных изображений (ILRP). Выполняют декодирование каждого из изображения в независимом уровне и другого изображения в зависимом уровне без синтаксического анализа и интерпретации списка ILRP. 3 н. и 17 з.п. ф-лы, 14 ил.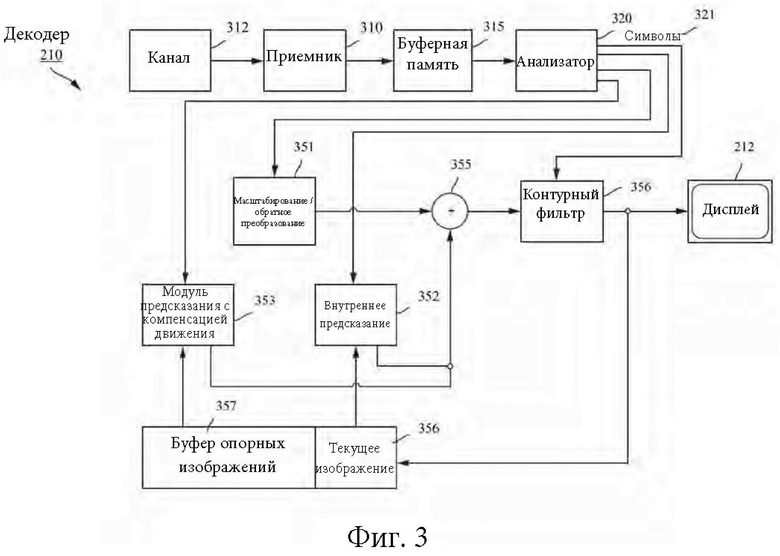
1. Способ видеодекодирования масштабируемого битового потока, содержащий:
синтаксический анализ по меньшей мере одного набора параметров видео (VPS), содержащего по меньшей мере один элемент синтаксиса, указывающий, является ли по меньшей мере один уровень в масштабируемом битовом потоке одним из зависимого уровня масштабируемого битового потока и независимого уровня масштабируемого битового потока;
декодирование изображения в зависимом уровне путем анализа и интерпретации списка межуровневых опорных изображений (ILRP); и
декодирование каждого из изображения в независимом уровне и другого изображения в зависимом уровне без синтаксического анализа и интерпретации списка ILRP.
2. Способ по п. 1, в котором декодирование изображения в независимом уровне включает в себя анализ и интерпретацию списка опорных изображений, в котором не содержатся декодированные изображения другого уровня.
3. Способ по п. 1, в котором в списке межуровневых опорных изображений содержится декодированное изображение другого уровня.
4. Способ по п. 1, в котором анализ по меньшей мере одного VPS также включает в себя определение, указывает ли другой элемент синтаксиса максимальное количество уровней.
5. Способ по п. 1, в котором анализ по меньшей мере одного VPS также включает в себя определение, содержит ли VPS флаг, указывающий, является ли другой уровень в масштабируемом битовом потоке опорным уровнем для упомянутого по меньшей мере одного уровня.
6. Способ по п. 5, в котором анализ по меньшей мере одного VPS также включает в себя определение, указывает ли упомянутый флаг другой уровень в качестве опорного уровня для упомянутого по меньшей мере одного уровня путем указания индекса другого уровня и индекса упомянутого по меньшей мере одного уровня.
7. Способ по п. 5, в котором анализ по меньшей мере одного VPS также включает в себя определение, указывает ли упомянутый флаг, что другой уровень не является опорным уровнем для упомянутого по меньшей мере одного уровня путем указания индекса другого уровня и индекса упомянутого по меньшей мере одного уровня.
8. Способ по п. 1, в котором анализ по меньшей мере одного VPS также включает в себя определение, содержит ли VPS флаг, указывающий, должно ли быть декодировано множество уровней, содержащее упомянутый по меньшей мере один уровень, путем интерпретации списка ILRP.
9. Способ по п. 1, в котором анализ по меньшей мере одного VPS также включает в себя определение, содержит ли VPS флаг, указывающий, должно ли быть декодировано множество уровней, содержащее упомянутый по меньшей мере один уровень, без интерпретации списка ILRP.
10. Способ по п. 1, в котором список ILRP передают со списком опорных изображений внутреннего предсказания (IPRP) в VPS.
11. Устройство для видеодекодирования масштабируемого битового потока, содержащее:
по меньшей мере одну память, сконфигурированную для хранения компьютерного программного кода; и
по меньшей мере один процессор, сконфигурированный для доступа к компьютерному программному коду и для работы под управлением компьютерного программного кода, при этом компьютерный программный код содержит:
код синтаксического анализа, сконфигурированный таким образом, чтобы по меньшей мере один процессор анализировал по меньшей мере один набор параметров видео (VPS), содержащий по меньшей мере один элемент синтаксиса, указывающий, является ли по меньшей мере один уровень в масштабируемом битовом потоке одним из зависимого уровня масштабируемого битового потока и независимого уровня масштабируемого битового потока;
первый код декодирования, сконфигурированный таким образом, чтобы по меньшей мере один процессор декодировал изображение в зависимом уровне путем анализа и интерпретации списка межуровневых опорных изображений (ILRP); и
второй код декодирования, сконфигурированный таким образом, чтобы по меньшей мере один процессор декодировал каждое из изображения в независимом уровне и другого изображения в зависимом уровне без синтаксического анализа и интерпретации списка ILRP.
12. Устройство по п. 11, в котором второй код декодирования дополнительно конфигурирован таким образом, чтобы по меньшей мере один процессор декодировал изображение в независимом уровне путем анализа и интерпретации списка опорных изображений, в котором не содержатся декодированные изображения другого уровня.
13. Устройство по п. 11, в котором в списке межуровневых опорных изображений содержится декодированное изображение другого уровня.
14. Устройство по п. 11, в котором код синтаксического анализа дополнительно конфигурирован таким образом, чтобы по меньшей мере один процессор анализировал по меньшей мере один VPS путем определения, указывает ли другой элемент синтаксиса максимальное количество уровней.
15. Устройство по п. 11, в котором код синтаксического анализа дополнительно конфигурирован таким образом, чтобы по меньшей мере один процессор анализировал по меньшей мере один VPS путем определения, содержит ли VPS флаг, указывающий, является ли другой уровень в масштабируемом битовом потоке опорным уровнем для упомянутого по меньшей мере одного уровня.
16. Устройство по п. 15, в котором код синтаксического анализа дополнительно конфигурирован таким образом, чтобы по меньшей мере один процессор анализировал по меньшей мере один VPS путем определения, указывает ли упомянутый флаг другой уровень в качестве опорного уровня для упомянутого по меньшей мере одного уровня путем указания индекса другого уровня и индекса упомянутого по меньшей мере одного уровня.
17. Устройство по п. 15, в котором код синтаксического анализа дополнительно конфигурирован таким образом, чтобы по меньшей мере один процессор анализировал по меньшей мере один VPS путем определения, указывает ли упомянутый флаг, что другой уровень не является опорным уровнем для упомянутого по меньшей мере одного уровня путем указания индекса другого уровня и индекса упомянутого по меньшей мере одного уровня.
18. Устройство по п. 11, в котором код синтаксического анализа дополнительно конфигурирован таким образом, чтобы по меньшей мере один процессор анализировал по меньшей мере один VPS путем определения, содержит ли VPS флаг, указывающий, должно ли быть декодировано множество уровней, содержащее упомянутый по меньшей мере один уровень, путем интерпретации списка ILRP.
19. Устройство по п. 11, в котором код синтаксического анализа дополнительно конфигурирован таким образом, чтобы по меньшей мере один процессор анализировал по меньшей мере один VPS путем определения, содержит ли VPS флаг, указывающий, должно ли быть декодировано множество уровней, содержащее упомянутый по меньшей мере один уровень, без интерпретации списка ILRP.
20. Компьютерно-считываемый носитель, на котором хранится программа, сконфигурированная так, чтобы заставлять компьютер выполнять:
синтаксический анализ по меньшей мере одного набора параметров видео (VPS), содержащего по меньшей мере один элемент синтаксиса, указывающий, является ли по меньшей мере один уровень в масштабируемом битовом потоке одним из зависимого уровня масштабируемого битового потока и независимого уровня масштабируемого битового потока;
декодирование изображения в зависимом уровне путем анализа и интерпретации списка межуровневых опорных изображений (ILRP); и
декодирование каждого из изображения в независимом уровне и другого изображения в зависимом уровне без синтаксического анализа и интерпретации списка ILRP.
| Токарный резец | 1924 |
|
SU2016A1 |
| US 10368089 B2, 30.07.2019 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 9813722 B2, 07.11.2017 | |||
| US 9648326 B2, 09.05.2017. | |||

