Область техники, к которой относится изобретение
Данное изобретение относится к способу кодирования потока данных, конкретно потока закодированных в растровом формате данных субтитров.
Уровень техники
Широковещательное мультимедиа или мультимедиа только для чтения, содержащее видеоданные, может также содержать потоки данных со стандартными фрагментами изображения, содержащими текстовую или графическую информацию, необходимую, чтобы предоставлять субтитры, рельефные изображения или анимацию для любой конкретной цели, к примеру кнопки меню. Поскольку отображение такой информации обычно может быть включено или отключено, она накладывается на ассоциативно связанное видеоизображение как дополнительный слой и реализована как одна или более прямоугольных областей, называемых зонами. Эта зона задает набор атрибутов, таких как, например, размер области, положение области или цвет фона. Вследствие наложения зоны на видеоизображение ее фон часто определяется как прозрачный, так чтобы видеоизображение можно было видеть или несколько слоев стандартных фрагментов изображения могли быть наложены. Дополнительно, зона субтитров может быть шире, чем ассоциативно связанное изображение, так чтобы только часть зоны субтитров была видна, и видимая часть зоны перемещалась, к примеру, справа налево через всю область субтитров, что выглядит, как если бы субтитры перемещались по дисплею. Этот способ, основанный на пикселях ввода субтитров, описан в Европейской патентной заявке EP02025474.4 и называется кадрированием.
Субтитры первоначально предназначались в качестве поддержки для инвалидов или для экономии средств на переводе фильма на редко используемый язык, и поэтому для чистого текста субтитров достаточно, если поток субтитровых данных содержит, к примеру, закодированные по ASCII символы. Но субтитры сегодня также содержат другие элементы, вплоть до изображений высокого разрешения, рельефных изображений или анимированных графических объектов. Обработка этих элементов проще, если поток субтитров кодируется в растровом формате со строками области и пикселями строки, кодируемыми и декодируемыми последовательно. Этот формат является избыточным, к примеру, когда последовательные пиксели имеют один и тот же код цвета. Эта избыточность может быть уменьшена посредством различных способов кодирования, к примеру группового кодирования (RLE). RLE часто используется, когда последовательности данных имеют одно и то же значение, и его основные идеи заключаются в том, чтобы кодировать длину последовательности и значение отдельно и кодировать наиболее часто встречающиеся кодовые слова максимально коротко.
В особенности при кодировании слоя субтитров для видео высокого разрешения (HDTV) 1920x1280 пикселей алгоритм кодирования, который оптимизирован для этой цели, необходим, чтобы уменьшить требуемый объем данных.
Сущность изобретения
Цель изобретения - раскрыть способ оптимизированного кодирования слоев субтитров или стандартных фрагментов изображения для видео высокого разрешения, например HDTV, представляемого как области растрового формата, которые могут быть гораздо шире, чем видимый видеокадр.
Этот способ раскрыт в п.1. Устройство кодирования, которое использует указанный способ, раскрыто в п.7.
Устройство для декодирования, которое использует указанный способ, раскрыто в п.8.
Согласно изобретению для этой цели используется четырехэтапное групповое кодирование (RLE), при этом наиболее короткие кодовые слова используются для одиночных пикселей, имеющих отдельные коды цвета, отличные от прозрачного, вторые наиболее короткие кодовые слова используются для более коротких последовательностей прозрачных пикселей, третьи наиболее короткие кодовые слова используются для более длинных последовательностей прозрачных пикселей и более коротких последовательностей пикселей одинакового цвета, отличного от прозрачного, а четвертые наиболее короткие кодовые слова используются для более длинных последовательностей пикселей одинакового цвета, отличного от прозрачного. Обычно большинство пикселей в слое субтитров являются прозрачными. В отличие от традиционного RLE, где наиболее часто встречающиеся данные используют наиболее короткие кодовые слова, этот способ содержит использование вторых наиболее коротких кодовых слов для коротких последовательностей наиболее часто встречающегося цвета и третьих наиболее коротких кодовых слов для более длинных последовательностей наиболее часто встречающегося цвета и также коротких последовательностей других цветов. Наиболее короткие кодовые слова зарезервированы для одиночных пикселей отличного от наиболее часто встречающегося цвета. Это выгодно, когда пиксели наиболее часто встречающегося цвета почти всегда содержатся в последовательностях, что имеет место в случае прозрачных пикселей в слое субтитров, тогда как более вероятно, что одиночные пиксели отдельного цвета не являются прозрачными.
Преимущественно код согласно способу изобретения содержит только несколько избыточных резервных слов, которые заданы как более длинное кодовое слово. К примеру, одиночный пиксель любого цвета, отличного от прозрачного, идеально кодируется с помощью кодового слова наиболее короткого типа, но также может быть использовано кодовое слово третьего наиболее короткого типа, при этом длина последовательности равна одному. Хотя последняя возможность обычно не используется для этой цели, эти неиспользуемые кодовые слова или промежутки в пространстве кодовых слов могут быть использованы для переноса другой информации. Примером является информация конца строки, которая может быть использована для ресинхронизации. Согласно изобретению наиболее короткое избыточное кодовое слово используется, чтобы закодировать эту информацию.
В качестве еще одного преимущества раскрытый способ уменьшает число обязательных данных, тем самым сжимая поток данных субтитров, причем коэффициент сжатия зависит от содержимого потока данных. Конкретные высокие коэффициенты сжатия достигаются для комбинаций данных, которые очень часто встречаются в типичных потоках субтитров. Это последовательности длины меньше, чем, к примеру, 64 пикселя, которые имеют одинаковый код цвета, а также последовательности прозрачных пикселей, имеющие любую длину, и одиночные пиксели, имеющие отдельные коды цвета. Первая из этих групп часто используется в символах или рельефных изображениях, вторая из этих групп используется до, между и после отображаемых элементов потока субтитров, а третья из этих групп используется в изображениях или областях со слегка изменяющимся цветом. Поскольку прозрачные пиксели почти никогда не встречаются в очень коротких последовательностях, к примеру, меньше, чем три пикселя, достаточно закодировать их не с помощью наиболее коротких, а с помощью вторых наиболее коротких кодовых слов.
Одновременно способ изобретения может эффективно обрабатывать последовательности, имеющие длину более 1920 пикселей и, к примеру, имеющие длину до 16383 пикселей, тем самым, предоставляя возможность очень широких областей субтитров.
Дополнительно, способ кодирования генерирует уникальное значение, представляющее конец строки, и поэтому в случае потери синхронизации можно ресинхронизировать каждую строку.
Преимущественно способ изобретения оптимизирован для кодирования этого сочетания ряда функций, являющихся типичными для потоков субтитров.
Поэтому объем данных, требуемый для потока субтитров, может быть уменьшен, что приводит к более эффективному использованию ширины полосы пропускания в случае широковещательной передачи или к более низкой частоте перемещений датчика в случае носителей хранения, где один датчик считывает несколько потоков данных, как, например, в технологии Blu-Ray Disc (BD). Дополнительно, чем лучше сжаты растровые субтитры, тем более высокая пропускная способность в показателях скорости передачи в битах оставляется для потоков аудио и видео, повышая качество изображений или звука.
Предпочтительные варианты осуществления изобретения раскрыты в прилагаемой формуле изобретения, последующем описании и на чертежах.
Краткое описание чертежей
Примерные варианты осуществления изобретения описаны со ссылкой на прилагаемые чертежи, из которых:
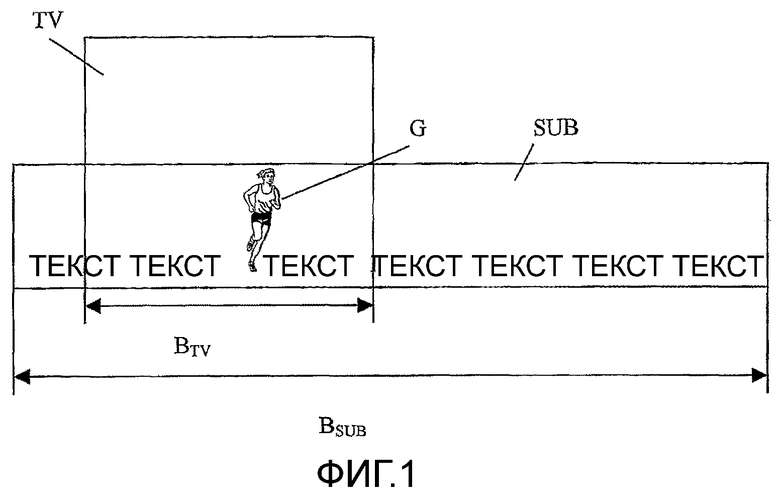
Фиг.1 - кадрирование области субтитров в видеокадре;
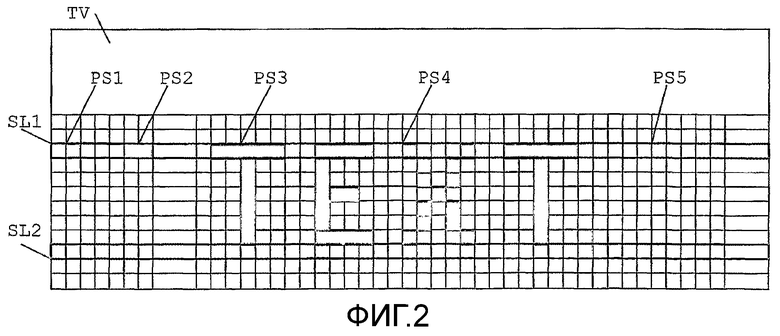
Фиг.2 - последовательность пикселей в области субтитров;
Фиг.3 - таблица кодирования для субтитров, включающая текст или графику; и
Фиг.4 - таблица с примерным синтаксисом расширенного сегмента объектных данных для стандарта Blu-Ray Prerecorded.
Осуществление изобретения
Хотя ввод субтитров в заранее генерируемый аудиовизуальный (AV) материал для широковещательной передачи или дисков с видео главным образом оптимизирован для представления статичной текстовой информации, к примеру кодированных титров между кадрами, телетекста или DVB-субтитров, развитие в разработке мультимедиа для представления и анимации текстовой и графической информации, адекватной новым форматам HDTV, требует современной адаптации растрового кодирования. Фиг.1 показывает видеокадр TV и область субтитров SUB, содержащую текстовые и графические элементы G, причем область субтитров SUB закодирована в растровом формате. Размер области субтитров SUB может превышать размеры видеокадров, как, например, для формата Blu-Ray Disc Prerecorded (BDP) растровым изображениям разрешено для одного измерения быть больше, чем видеокадр. Затем строки кадрируются перед отображением, т.е. часть, соответствующая размеру соответствующего кадра, обрезается из виртуальной строки и отображается, накладываясь на видеоизображение. На фиг.1 кадрируется область субтитров SUB ширины BSUB, так что видна только часть ширины BTV. Для стандарта HDTV, используемого, к примеру, в BDP, BTV равно 1920 пикселей, тогда как BSUB может быть гораздо больше.
Вследствие прямоугольной формы области субтитров SUB большинство пикселей в этой области являются прозрачными. Это упрощенно показано в укрупненном виде на фиг.2, поскольку обычно строка SL1, SL2 на ТВ-экране HDTV может быть на несколько пикселей шире, чтобы быть четко видной. Строка в данном документе понимается как горизонтальная структура. Каждая строка данных субтитров обычно содержит одну или более последовательностей пикселей одинакового цвета. Фиг.2 показывает часть строки субтитров SL1, содержащей прозрачные последовательности PS1, PS5, а также одиночные видимые пиксели PS4, более короткие видимые строки PS2 и более длинные видимые строки PS3. Большая часть пикселей в строке прозрачны. Это имеет место между символами, а также в начале и в конце строки субтитров. В любом случае, поскольку строки начинаются и заканчиваются прозрачными сегментами, каждая строка содержит на один прозрачный сегмент больше, чем цветных сегментов. Однако прозрачные сегменты PS1, PS5 обычно длиннее, хотя для последовательностей пикселей, отличных от прозрачных, используемых, к примеру, для символов, наиболее частым случаем является длина последовательности 64 и менее. Это может быть определено из приблизительной оценки при условии, что, по меньшей мере, 25 символов отображается одновременно и что пространство между символами имеет около одной четверти ширины символа, так чтобы один символ мог использовать не больше, чем 1920/25*(8/10)=62 пикселей в строке. Часто строка SL2 содержит небольшое количество видимых пикселей и поэтому только несколько прозрачных последовательностей очень большой длины.
Код, являющийся предпочтительным вариантом осуществления изобретения, приведен на фиг.3. Это групповой код, содержащий кодовые слова длиной от 1 байта до 4 байт (8 бит на байт). Он допускает кодирование 256 различных цветов с помощью одного предпочтительного цвета. Предпочтительный цвет в данном примере прозрачный, но при необходимости это может быть любой другой цвет. Кодовая таблица цветов (CLUT) может преобразовывать декодированные коды цветов в фактический цвет дисплея. Дополнительно, последовательности пикселей одинакового цвета могут быть закодированы в двух диапазонах, при этом более короткий диапазон имеет длину до 63 пикселей, а более длинный диапазон имеет длину до 16383 пикселей.
Наиболее короткие кодовые слова длиной 1 байт используются, чтобы кодировать одиночный пиксель, имеющий любой отдельный цвет, отличный от предпочтительного цвета, которым в данном случае является прозрачный. Код цвета CCCCCCCC может варьироваться от 1 до 255 и может представлять цвет явно или неявно. К примеру, он может представлять запись в кодовой таблице цветов (CLUT), которая содержит фактический код цвета. Одно из 8-битовых значений, содержащее только нули (00000000), выступает в качестве управляющей последовательности, указывающей, что следующие биты должны рассматриваться как часть одного и того же кодового слова. В этом случае дерево кодовых слов имеет четыре возможных ветки, помеченные двумя следующими битами.
В первой ветке, указанной следующими битами со значениями 00, допустимые кодовые слова имеют два бита, и кодируется более короткая последовательность до 63 пикселей, имеющая предпочтительный цвет, например прозрачный. Единственным недопустимым кодовым словом в данной ветке является слово, которое содержит только нули, поскольку 0 не представляет допустимую длину последовательности. Это кодовое слово "00000000 00000000" может быть использовано для других целей. Согласно изобретению оно используется, чтобы указывать конец строки, поскольку является наиболее коротким избыточным кодовым словом.
Во второй ветке, указанной следующими битами со значениями 01b, кодовое слово содержит еще один байт, и четырнадцать битов L используются, чтобы кодировать длину последовательности пикселей предпочтительного цвета, к примеру прозрачного. Таким образом, длина последовательности может быть до 214-1=16383. Кодовые слова, где биты L имеют значение меньше 64, являются избыточными и могут быть использованы для других целей.
В третьей ветке, указанной следующими битами со значениями 10b, кодовые слова содержат дополнительный байт, и шесть битов L второго байта представляют длину более короткой последовательности до 63 пикселей, которая имеет отличный от предпочтительного цвет. Фактический цвет явно или косвенно представлен значением CCCCCCCC третьего байта. Кодовые слова с длиной последовательности LLLLLL меньше трех являются избыточными, поскольку последовательность одного или двух пикселей этого цвета может быть закодирована с более низким качеством с помощью одного байта на пиксель, как описано выше, и длиной последовательности ноль является недопустимой. Эти кодовые слова могут быть использованы для других целей.
В четвертой ветке, указанной следующими битами со значениями 11b, кодовые слова содержат два дополнительных байта, при этом оставшиеся шесть бит второго байта и третьего байта дают длину более длинной последовательности в 64-16383 пикселей, и код цвета CCCCCCCC четвертого байта дает цвет, явно или неявно и не являющийся предпочтительным цветом. Кодовые слова с длиной последовательности меньше 64 являются избыточными, поскольку эти последовательности могут быть закодированы с более низким качеством с помощью третьей ветки. Эти кодовые слова могут быть использованы для других целей.
Вышеупомянутые кодовые слова могут быть использованы, чтобы расширить код, к примеру добавить внутренние контрольные суммы или другую информацию.
Таблица расширенного группового кодирования, показанная на фиг.3 и описанная выше, предоставляет главным образом два преимущества. Во-первых, она дает возможность наиболее плотного кодирования типичных потоков субтитров, в том числе прозрачных областей, небольших графических объектов и обычного текста субтитров. Одиночные пиксели любого цвета при использовании для небольшой цветной графики кодируются одним байтом. Доминантный цвет, к примеру прозрачный, для субтитров BDP всегда кодируется вместе с длиной группы. Групповые коды доступны в двух различных размерах или двух количествах пикселей. На первом этапе групповые коды до 63 пикселей доступны как 2-байтные кодовые слова для доминантного цвета и как 3-байтные кодовые слова для других цветов. На втором этапе продольные коды до 16383 пикселей доступны как 3-байтные кодовые слова для доминантного цвета и как 4-байтные кодовые слова для других цветов. Код конца строки пикселей или код конца строки - это уникальное 2-байтное кодовое слово, которое может быть использовано для ресинхронизации. Во-вторых, доступность более длинных последовательностей для области субтитров (до 16383 пикселей на кодовое слово) означает снижение избыточности и, следовательно, объема данных. Это означает, что для приложений с раздельными потоками данных, совместно использующими один канал, к примеру, несколькими потоками данных на оптическом носителе хранения данных, совместно использующими один датчик с одинаковым объемом данных, могут быть загружены более крупные части потока субтитров, тем самым уменьшая частоту доступа для потока субтитров.
Другой аспект изобретения - это дополнительная оптимизация потока данных для передачи с помощью пакетов передачи, к примеру, в пакетированном элементарном потоке (PES). Вследствие большого размера файлов растровых изображений пакетирование этих данных, к примеру, в сегменты объектных данных (ODS) является проблемой. Часто максимальный размер ODS ограничен другими факторами, к примеру размером пакета PES. Чтобы уместить крупные растровые изображения в эти пакеты, необходимо разрезать растровые изображения на небольшие растровые части перед кодированием, что снижает эффективность сжатия. Чтобы преодолеть это разделение растровых изображений, раскрыт новый дополненный сегмент объектных данных (ExODS) для BDP или совместимых приложений, как показано на фиг.4. ExODS - это структура данных, представляющая каждый из фрагментов, на которые разрезается ODS для точного умещения в последовательность сегментов ограниченного размера и пакетов PES. Полный ODS может быть восстановлен посредством конкатенации последовательности отдельных частей последовательных ExODS.
Начало и конец последовательности ExODS указывается отдельными флагами, first_in_sequence и last_in_sequence. Когда значение флага first_in_sequence flag равно 1, начинается новая последовательность. ExODS, имеющий заданным в качестве значения флага first_in_sequence flag 1, также указывает размер распакованного растрового изображения посредством включения в себя своих размеров object_width и object_height. Преимуществом указания размеров растрового изображения является поддержка целевого распределения памяти перед тем, как начинается распаковка. Другое преимущество заключается в том, что указанные размеры растрового изображения также могут быть использованы при декодировании для перекрестной проверки размеров растрового изображения. Когда значение флага last_in_sequence flag равно 1, указывается последний ExODS полного ODS. Это может быть ExODS, не имеющий заданным ни флаг first__in_sequence, ни флаг last_in_sequence. Это части ExODS в середине последовательности. Также возможен случай задания обоих признаков (first_in_sequence и last_in_sequence), если ODS может быть переносим в одном ExODS. Чтобы преодолеть это ограничение в размере, доступном для одного ODS посредством размера пакета PES в субтитрах, описанный тип ExODS может быть представлен как контейнер для частей одного ODS, к примеру, для пакетирования крупных ODS в приложении HDTV. Помимо частей ODS, ExODS также переносит флаги, указывающие, переносит ли он первую часть, последнюю часть, среднюю часть или одну, но полную часть последовательности ExODS. Более того, если передается первая часть в последовательности ExODS, размеры результирующего ODS, т.е. высота и ширина закодированного растрового изображения, содержатся в сегменте. Указанные размеры растрового изображения также могут быть использованы для декодирования перекрестной проверки.
Способ изобретения может быть использован для сжатия потоков растровых данных, содержащих, к примеру, текст, изображения или графические данные для анимации, меню, навигации, логотипов, рекламных объявлений, передачи сообщений и т.п., в таких приложениях, как, например, диски Blu-Ray Prerecorded (BDP) или в большинстве случаев записей или широковещательной передачи видео высокого разрешения (HDTV).

Изобретение относится к способу кодирования потока данных, конкретно потока закодированных в растровом формате данных субтитров. Техническим результатом является обеспечение оптимизированного кодирования слоев субтитров или стандартных фрагментов изображения для видео высокого разрешения. Указанный результат достигается тем, что субтитры используются при представлении текстовой информации и графических данных, закодированных как пиксельные растровые изображения. Размер растровых изображений субтитров может превышать размеры видеокадров, так что одновременно отображаются только части. Растровые изображения являются отдельным слоем, наложенным на видео, к примеру, для синхронизированных видеосубтитров, анимации и навигационных меню, и поэтому содержат множество прозрачных пикселей. Современная адаптация растрового кодирования для HDTV, к примеру, 1920x1280 пикселей на кадр, заданная форматом Blu-Ray Disc Prerecorded, предоставляющая оптимизированные результаты сжатия для этих растровых субтитров, достигается посредством четырехэтапного группового кодирования. Более короткие или длинные последовательности пикселей предпочтительного цвета, к примеру прозрачного, кодируются с помощью второго или третьего наиболее короткого кодового слова, тогда как одиночные пиксели отдельного цвета кодируются с помощью наиболее коротких кодовых слов, а последовательности пикселей одинакового цвета используют третье или четвертое наиболее короткое кодовое слово. 5 н. и 9 з.п. ф-лы, 4 ил.
| СИСТЕМА ДЛЯ ПЕРЕДАЧИ СУБТИТРОВ ПО ТРЕБОВАНИЮ В СЖАТОМ ЦИФРОВОМ ВИДЕОСИГНАЛЕ | 1993 |
|
RU2129758C1 |
| Сплавной лот для плотов, барж и т.п. | 1928 |
|
SU13524A1 |
| Способ получения бутиловых спиртов | 1976 |
|
SU734181A1 |
| US 5684542 А, 04.11.1997 | |||
| JEONG J et al., Adaptive Huffman coding of 2-D DCT coefficients for image sequence compression, SIGNAL PROCESSING | |||
| IMAGE COMMUNICATION, ELSEVIER SCIENCE PUBLISHERS, AMSTERDAM, vol | |||
| Способ восстановления хромовой кислоты, в частности для получения хромовых квасцов | 1921 |
|
SU7A1 |
| LLADOS-BERNAUS R et al., Codeword | |||

