Область техники, к которой относится изобретение
Данное изобретение относится к идентификации перефразирования в тексте. Более определенно, данное изобретение относится к методикам машинного перевода, используемым для идентификации и генерации перефразирования.
Предшествующий уровень техники
Распознавание и генерация перефразирования - ключевой аспект многих приложений систем обработки естественного языка. Способность идентификации того, что две различные части текста являются эквивалентными по значению, обеспечивает возможность системе вести себя намного более разумно. Фундаментальная цель работы в этой области состоит в том, чтобы сделать программу, которая будет способна переформулировать часть текста при сохранении ее семантического содержания при манипулировании такими признаками, как словарь, порядок слов, уровень понимания и степень осмысленности.
Одно иллюстративное применение, которое может извлечь выгоду из идентификации и генерации перефразирования, включает в себя систему ответа на вопросы. Например, рассмотрим вопрос "Когда Джон До уволился с работы?", где объект "Джон До" - известный человек. Вероятно, что большая совокупность данных, такая как глобальная компьютерная сеть (или система передачи новостей, которая публикует статьи в глобальной компьютерной сети), может уже содержать текст, который отвечает на этот вопрос. Фактически, такая совокупность может уже содержать текст, который отвечает на вопрос и выражен точно в тех же самых терминах, что и вопрос. Поэтому обычное средство поиска может не иметь трудностей при нахождении текста, который соответствует вопросу, и при выдаче, таким образом, адекватного результата.
Однако эта проблема становится намного более трудноразрешимой при поиске в меньшей совокупности данных, например соответствующей интрасети (внутренней компьютерной сети). В этом случае, даже при том, что эта малая совокупность данных может содержать текст, который отвечает на вопрос, ответ может быть выражен в отличных от вопроса терминах. В качестве примера, все следующие предложения отвечают на вопрос, изложенный выше, но выражены в отличных от вопроса терминах:
Джон До ушел в отставку вчера.
Джон До оставил свою должность вчера.
Джон До оставил свой правительственный пост вчера.
Джон До уступил свою должность вчера.
Вчера, Джон До решил исследовать новые карьерные возможности.
Так как эти ответы выражены по-другому по сравнению с вопросом, обычный поисковый сервер, вероятно, столкнется с трудностями в выдаче хорошего результата, учитывая только эти текстовые ответы в совокупности, в которой он осуществляет поиск.
Предшествующие системы, ориентированные на решение проблемы распознавания и генерации перефразирования, включают большие усилия по ручному кодированию в попытке направить силы на решение проблемы в ограниченных контекстах. Например, большие системы, закодированные вручную, пытаются связать широкое разнообразие различных способов высказывания одной и той же вещи и форму, приемлемую для системы управления и команд. Конечно, это чрезвычайно трудно, потому что автор кода, вероятно, не может продумать все различные способы, которыми пользователь мог бы выразить что-то. Поэтому фокус в исследовательском сообществе сдвинулся от ручных усилий к автоматическим способам идентификации и генерации перефразирования.
Недавняя работа над системами, нацеленными на автоматическую идентификацию отношений перефразированных текстов, включает в себя статью D. Lin и P. Pantel “DIRT-DISCOVERY OF INFERENCE RULES FROM TEXT”, материалы ACMSIGKDD Conference on Knowledge Discovery and Data Mining, страницы 323-328 (2001) (в дальнейшем обозначаемую ссылкой DIRT). В статье DIRT исследуются свойства распространения путей зависимости, связывающих идентичные "местоположения анкеров" (то есть идентичные или подобные слова) в анализируемой совокупности новостных данных. Ни одно из специальных свойств новостных данных не эксплуатируется, так как анализируемая совокупность просто рассматривается как большой источник одноязычных данных. Основной идеей является то, что часто встречающиеся в пути в графе зависимости, которые связывают идентичные или подобные слова, вероятно, сами должны быть подобны по значению. Когда выполнялась обработка газетных данных объемом гигабайт, система идентифицировала образцы типа:
X разрешается посредством Y.
X разрешает Y.
X находит решение для Y.
X пробует решить Y.
Система DIRT ограничена очень узкой разновидностью "тройных" отношений, типа "X глагол Y".
Другая статья, которая относится к идентификации перефразирования, это работа Y. Shinyama, S. Sekine, K. Sudo и R. Grisham, “AUTOMATIC PARAPHRASE ACQUISITION FROM NEWS ARTICLES”, материалы Human Language Technology Conference, San Diego, CA (HLT 2002). В статье Shinyama и др. сделано наблюдение, что для статей из различных газет, которые описывают одно и то же событие, часто характерны отношения перефразирования. Статья описывает методику, которая основывается на условии, что именованные объекты (такие, как люди, места, даты и адреса) остаются неизменными в различных газетных статьях относительно одной и той же темы или в один и тот же день. Статьи кластеризуют, используя существующую информационно-поисковую систему, по группам или кластерам, например "убийство" или "персонал". Именованные объекты аннотируют, используя статистический маркировщик, и данные затем подвергают морфологическому и синтаксическому анализу для получения деревьев синтаксической зависимости. В пределах каждого кластера предложения кластеризованы, основываясь на именованных объектах, которые они содержат. Например, следующие предложения кластеризованы, потому что они вместе используют одни и те же четыре именованных объекта:
Вице-президент “Nihon Yamamuri Glass Corp” Осаму Курода был выдвинут в Президенты.
“Nihon Yamamuri Glass Corp.” решила продвинуть по службе вице-президента Осаму Курода в Президенты в понедельник.
Учитывая совпадение в именованных объектах, эти предложения предполагаются связанными отношениями перефразирования. Shinyama и др. после этого пытаются идентифицировать образцы, которые связывают эти предложения, используя существующие средства из области извлечения информации.
Shinyama и др. также пытаются изучать очень простые образцы уровня фразы, но эта методика ограничена тем, что она основывается на местоположениях анкеров именованных объектов. Без этих легко идентифицируемых анкеров Shinyama и др. не могут изучить что-либо из пары предложений. Образцы, которые изучали Shinyama и др., все фокусировались на отношениях между специфическим типом объекта и некоторым типом события в пределах специфической области. Результаты довольно бедны, особенно когда обучающие предложения содержат очень мало именованных объектов.
Другая статья также относится к перефразированию. В работе Barzilay R. и L. Lee, “LEARNING TO PARAPHRASE: AN UNSUPERVISED APPROACH USING MULTIPLE-SEQUENCE ALIGNMENT”, материалы HLT/NAACL: (2003), Edmonton, Canada, используется программное обеспечение обнаружения темы для кластеризации тематически подобных газетных статей из единого источника и из данных за несколько лет. Более определенно, Barzilay и др. пытаются идентифицировать статьи, описывающие террористические инциденты. Они затем кластеризуют предложения из этих статей для того, чтобы найти предложения, которые совместно используют основную общую форму или которые совместно используют множество ключевых слов. Эти кластеры используются как основание для построения шаблонных моделей предложений, которые учитывают некоторые заменяющие элементы. Короче говоря, Barzilay и др. сосредотачиваются на обнаружении подобных описаний различных событий, даже событий, которые, возможно, произошли в разные годы. Это фокусирование на группировании предложений по форме означает, что такая методика не найдет часть из более интересных перефразирований.
Также Barzilay и Lee требуют сильного подобия порядка слов для того, чтобы классифицировать два предложения как подобные. Например, они не могут классифицировать даже активные/пассивные варианты описания событий как родственные. Шаблонные отношения перефразирования, изученные Barzilay и др., получены из набора предложений, которые совместно используют полный фиксированный порядок слов. Перефразирование, изученное такой системой, эквивалентно областям гибкости в пределах этой большей фиксированной структуры. Необходимо отметить, что Barzilay и Lee оказались единственными в литературных источниках, кто предложил схему генерирования. Другая работа, обсуждаемая в этом разделе, нацелена только на распознавание перефразирования.
Другая статья, Barzilay и McKeown “Extracting Paraphrases From a Parallel Corpus”, материалы ACL/EACL (2001), основывается на множественных переводах одного исходного документа. Однако Barzilay и McKeown определенно отличают их работу от методик машинного перевода. Они утверждают, что без полного соответствия между словами в родственных предложениях невозможно использовать “способы, разработанные в сообществе MT (машинного перевода), основанные чисто на параллельных массивах”. Таким образом, Barzilay и McKeown отклоняют идею, что стандартные методики машинного перевода могут быть применены к задаче изучения одноязычного перефразирования.
Другая соответствующая предшествующему уровню техники система в данной области техники также относится к перефразированию. Эта система основывается на множественных переводах единого источника для построения конечных состояний представлений отношений перефразирования. B. Pang, K. Knight и D. Marcu, “SYNTAX BASED ALIGNMENT OF MULTIPLE TRANSLATION: EXTRACTING PARAPHRASES AND GENERATING NEW SENTENCES”, материалы NAACL-HLT, 2003.
Кроме того, другая соответствующая предшествующему уровню техники ссылка также относится к распознаванию перефразирования. Магистерская диссертация Ibrahim, Ali, “EXTRACTING PARAPHRASES FROM ALIGNED CORPORA”, MIT (2002), расположена по адресу HTTP://www.ai.mit.edu/people/jimmylin/papers/ibrahim02.pdf. В своей диссертации Ibrahim указывает, что предложения “совмещают” или подвергают “совмещению” и идентифицируют перефразирование. Однако термин “совмещение”, как он используется в упомянутой диссертации, означает совмещение предложений вместо совмещения слов или фраз и не относится к обычному совмещению слов и фраз, выполняемому в системах машинного перевода. Вместо этого совмещение, обсужденное в данной диссертации, основано на следующей статье, в которой сделана попытка совмещения предложений на одном языке с их соответствующими переводами на другой язык: Gale, William, A. и Church, Kenneth W., “A PROGRAM FOR ALIGNING SENTENCES IN BILINGUAL CORPORA”, материалы the Associations for Computational Linguistics, страницы 177-184 (1991). Ibrahim использует этот алгоритм для совмещения предложений в пределах множества английских переводов, например, романов Жюля Верна. Однако структура предложения может разительно изменяться от перевода к переводу. То, что один переводчик представляет как отдельное длинное предложение, другой может отобразить на два более коротких. Это означает, что полное число предложений в различных переводах отдельного романа не совпадает, и некоторый вид автоматизированной процедуры совмещения предложений необходим для идентификации эквивалентных предложений. В совокупности методика, которую Ibrahim использует для выделения перефразирования из этих совмещенных одноязычных предложений, является производной от концепций множественных переводов, сформулированных в ссылке на Barzilay, McKeown, и разновидности структуры DIRT, описанной Lin и др.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Согласно настоящему изобретению получают набор текстовых сегментов из множества различных статей (кластера статей), написанных об общем событии. Текстовые сегменты в этом наборе затем подвергают методикам совмещения слов/фраз для идентификации перефразирования. Может использоваться декодер для генерации перефразирования на основе пар текстовых сегментов.
В одном воплощении источниками набора текстовых сегментов являются различные статьи, написанные об одном и том же событии в периоды времени, близкие друг к другу. Текстовые сегменты могут, например, быть конкретными предложениями, извлеченными из этих статей. Например, было обнаружено, что первые два предложения новостных статей, написанных об одном и том же событии приблизительно в одно и то же время, часто содержат очень похожую информацию. Поэтому в одном воплощении первые два предложения множества различных статей, написанных об одном и том же событии приблизительно в одно и то же время, кластеризуют вместе и используют как источник наборов предложений. Конечно, может быть сформировано множество кластеров статей, где относительно большое количество статей написано о вариантах различных событий и где каждый кластер включает в себя группу статей, написанных об одном и том же событии.
В одном воплощении текстовые сегменты в заданном наборе текстовых сегментов, полученном из кластера статей, затем организуют в пары по отношению к другим текстовым сегментам в этом наборе и используют методики совмещения слов/фраз (или машинного перевода) для идентификации перефразирования, получая на входе парные текстовые сегменты. В то время как системы совмещения слов/фраз обычно обрабатывают текстовые сегменты на разных языках, в соответствии с одним воплощением данного изобретения, система совмещения обрабатывает текстовые сегменты на общем языке. Текстовые сегменты рассматриваются просто как различные пути высказывания одной и той же вещи.
В одном воплощении наборы текстовых сегментов могут быть отфильтрованы, используя эвристические или иные методики фильтрации. В еще одном воплощении модели, сгенерированные для идентификации перефразирования в системе совмещения слов/фраз, также используются для идентификации перефразирования в последующих обучающих данных.
В соответствии с другим воплощением данного изобретения алгоритм декодирования используется для генерации перефразирования при наличии перефразирования и моделей, выдаваемых системой совмещения.
ПЕРЕЧЕНЬ ФИГУР
Фиг.1 - блок-схема одного воплощения среды, в которой может использоваться данное изобретение.
Фиг.2 - блок-схема системы распознавания и генерации перефразирования в соответствии с одним воплощением данного изобретения.
Фиг.2a - иллюстрация использования компоненты распознавания перефразирования для выбора перефразированных наборов текстовых сегментов для использования при обучении.
Фиг.3 - блок-схема последовательности операций, иллюстрирующая функционирование системы, показанной на фиг.2.
Фиг.4 - иллюстрация одного иллюстративного совмещения между двумя парными предложениями в соответствии с одним воплощением данного изобретения.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЛЛЮСТРАТИВНЫХ ВОПЛОЩЕНИЙ
Данное изобретение относится к идентификации и, потенциально, генерации отношений перефразирования с использованием методик совмещения слов/фраз. Однако до обсуждения данного изобретения в деталях будет обсуждена одна иллюстративная среда, в которой может использоваться данное изобретение.
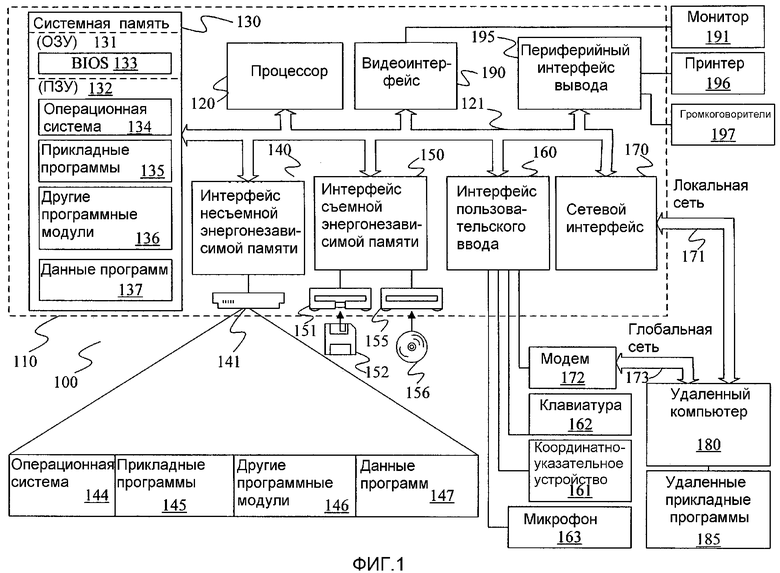
Фиг.1 иллюстрирует пример подходящей среды 100 вычислительной системы, в которой настоящее изобретение может быть реализовано. Среда 100 вычислительной системы представляет собой только один пример подходящей вычислительной среды, при этом не подразумевается, что она накладывает какие-либо ограничения относительно диапазона использования или функциональных возможностей изобретения. Также не следует интерпретировать вычислительную среду 100 как имеющую какие-либо зависимости или требования, касающиеся какого-либо компонента или комбинации компонентов, проиллюстрированных в примерной рабочей среде 100.
Изобретение может функционировать в других многочисленных средах или конфигурациях вычислительных систем общего или специального назначения. Примеры широко известных вычислительных систем, сред и/или конфигураций, которые могут быть подходящими для использования с изобретением, включают в себя, но не в ограничительном смысле, персональные компьютеры, серверные компьютеры, карманные или портативные устройства, многопроцессорные системы, системы на основе микропроцессоров, телевизионные компьютерные приставки, программируемую бытовую электронику, сетевые персональные компьютеры (ПК), мини-компьютеры, универсальные компьютеры (мейнфреймы), распределенные вычислительные среды, которые включают в себя любые из вышеупомянутых систем или устройств, и т.п.
Изобретение может быть описано в общем контексте машиноисполняемых команд, таких как программные модули, исполняемые компьютером. Вообще, программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и т.д., которые выполняют специфические задачи или реализуют специфические абстрактные типы данных. Изобретение может также применяться в распределенных вычислительных средах, где задачи выполняются удаленными устройствами обработки данных, которые связаны между собой сетью связи. В распределенной вычислительной среде программные модули могут быть расположены как на локальных, так и на удаленных компьютерных носителях информации, включая запоминающие устройства.
Со ссылкой на фиг.1, примерная система для осуществления изобретения включает в себя вычислительное устройство общего назначения в форме компьютера 110. Компоненты компьютера 110 могут включать в себя, но не в ограничительном смысле, процессор 120, системную память 130 и системную шину 121, которая подсоединяет различные системные компоненты, включая системную память, к процессору 120. Системная шина 121 может относиться к любому из нескольких типов шинных структур, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, использующие любой тип из многообразия шинных архитектур. В качестве примера, но не ограничения, такие архитектуры включают в себя шину Архитектуры Промышленного Стандарта (ISA), шину Микроканальной Архитектуры (MCA), расширенную шину ISA (EISA), локальную шину Видео Электронной Ассоциации Стандартов (VESA) и шину Межсоединения Периферийных Устройств (PCI), известную также как мезонинная шина.
Компьютер 110 обычно включает в себя разнообразные машиночитаемые носители информации. Машиночитаемые носители информации могут быть любыми возможными носителями, к которым компьютер 110 может осуществить доступ, и включают в себя как энергонезависимые, так и энергозависимые, как съемные, так и несъемные носители. В качестве примера, но не ограничения, машиночитаемые носители информации могут включать в себя компьютерные носители информации и среды передачи. Компьютерные носители информации включают в себя как энергонезависимые, так и энергозависимые, как съемные, так и несъемные носители, созданные любым методом или с помощью любой технологии для хранения информации, такой как машиночитаемые команды, структуры данных, программные модули или другие данные. Компьютерные носители информации включают в себя, но не в ограничительном смысле, оперативное запоминающее устройство (RAM, ОЗУ), постоянное запоминающее устройство (ROM, ПЗУ), электрически стираемое программируемое ПЗУ (EEPROM), флеш-память или память другой технологии, ПЗУ на компакт-диске (CDROM), универсальные цифровые диски (DVD) или другие оптические диски для хранения информации, магнитные кассеты, магнитные ленты, магнитные диски или другие магнитные устройства для хранения информации или любые другие носители, которые могут использоваться для хранения желаемой информации и к которым компьютер 110 может осуществить доступ. Среды передачи обычно воплощают машиночитаемые команды, структуры данных, программные модули или другие данные в модулированном информационном сигнале, таком как несущее колебание или другой механизм транспортировки, и включают в себя любые среды доставки информации. Термин “модулированный информационный сигнал” обозначает сигнал, одна или более характеристик которого установлены или изменены так, чтобы обеспечить кодирование информации в этом сигнале. В качестве примера, но не ограничения, среды передачи включают в себя проводные среды, такие как проводные сети или прямые проводные соединения, и беспроводные среды, такие как акустические, радиочастотные, инфракрасные и другие беспроводные среды. Комбинации любых из вышеперечисленных носителей и сред также охватываются понятием “машиночитаемый носитель информации”.
Системная память 130 включает в себя компьютерные носители информации в форме энергонезависимых и/или энергозависимых запоминающих устройств, таких как постоянное запоминающее устройство (ПЗУ) 131 и оперативное запоминающее устройство (ОЗУ) 132. Базовая система ввода/вывода 133 (BIOS), включающая основные процедуры, помогающие передаче информации между устройствами внутри компьютера 110, используемые, например, во время запуска системы, обычно хранится в ПЗУ 131. ОЗУ 132 обычно включает в себя данные и/или программные модули, которые оперативно доступны процессору 120 и/или обрабатываются процессором 120 в текущий момент. В качестве примера, но не ограничения, фиг.1 показывает операционную систему 134, прикладные программы 135, другие программные модули 136 и данные 137 программ.
Компьютер 110 может также включать в себя другие съемные/несъемные, энергонезависимые/энергозависимые компьютерные носители информации. Только для примера, фиг.1 показывает накопитель 140 на жестких магнитных дисках, который читает или записывает данные на несъемный, энергонезависимый магнитный носитель, магнитный дисковод 151, который читает или записывает данные на съемный энергонезависимый магнитный диск 152, и оптический дисковод, который читает или записывает данные на съемный энергонезависимый оптический диск 156, такой как компакт-диск CD-ROM или другой оптический носитель. Другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные носители информации, которые можно использовать в иллюстративной операционной среде, включают в себя, но не в ограничительном смысле, кассеты с магнитной лентой, карты флеш-памяти, универсальные цифровые диски, ленты для цифрового видео, твердотельные ОЗУ, твердотельные ПЗУ и тому подобное. Накопитель 141 на жестких магнитных дисках обычно подсоединен к системной шине 121 с помощью интерфейса несъемной памяти, такого как интерфейс 140, а магнитный дисковод 151 и оптический дисковод 155 обычно подсоединены к системной шине 121 с помощью интерфейса съемной памяти, такого как интерфейс 150.
Накопители и дисководы и используемые ими компьютерные носители информации, рассмотренные выше и показанные на фиг.1, обеспечивают хранение машиночитаемых команд, структур данных, программных модулей или других данных для компьютера 110. На фиг.1 для примера накопитель 141 на жестких магнитных дисках показан как хранящий операционную систему 144, прикладные программы 145, другие программные модули 146 и данные 147 программ. Следует отметить, что эти компоненты могут либо быть одинаковыми, либо отличаться от операционной системы 134, прикладных программ 135, других программных модулей 136 и данных 137 программ. Операционная система 144, прикладные программы 145, другие программные модули 146 и данные 147 программ показаны под другими ссылочными номерами, чтобы проиллюстрировать, что они, как минимум, являются другими копиями.
Пользователь может вводить команды и информацию в компьютер 110 с помощью устройств ввода, таких как клавиатура 162 и координатно-указательное устройство 161, такое как мышь, шаровой манипулятор или сенсорная панель. Другие устройства ввода (не показанные здесь) могут включать в себя микрофон, джойстик, игровую панель, спутниковую тарелку, сканер или подобные им устройства. Эти и другие устройства ввода зачастую подсоединены к процессору 120 с помощью интерфейса 160 пользовательского ввода, связанного с системной шиной, но могут также быть подсоединены посредством других структур интерфейсов и шин, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). Монитор 191 или другой тип устройства отображения также подсоединяется к системной шине 121 через интерфейс, такой как видеоинтерфейс 190. В добавлении к монитору компьютеры могут также включать в себя другие периферийные устройства вывода, такие как громкоговорители 197 и принтер 196, которые могут быть подсоединены через периферийный интерфейс 195 вывода.
Компьютер 110 может работать в сетевой среде, используя логические соединения с одним или более удаленными компьютерами, такими как удаленный компьютер 180. Удаленный компьютер 180 может быть персональным компьютером, сервером, маршрутизатором, сетевым ПК, одноранговым устройством или другим обычным сетевым узлом и обычно включает в себя некоторые или все элементы, описанные выше по отношению к компьютеру 110, хотя только запоминающее устройство 181 показано на фиг.1. Логические соединения, изображенные на фиг.1, включают в себя локальную сеть (LAN) 171 и глобальную сеть (WAN) 173, но также могут включать в себя и другие сети. Такая сетевая среда обычно характерна для офисов, компьютерных сетей масштаба предприятия, интрасетей и сети Интернет.
При использовании в сетевой среде LAN компьютер 110 подсоединяется к LAN через сетевой интерфейс или адаптер 170. При использовании в сетевой среде WAN компьютер 110 обычно включает в себя модем 172 или другие средства, предназначенные для осуществления связи через WAN, такую как Интернет. Модем 172, который может быть внутренним или внешним, может быть подсоединен к системной шине 121 через интерфейс 160 пользовательского ввода или другое подходящее устройство. В сетевой среде программные модули, показанные в отношении к компьютеру 110, или их части, могут храниться в удаленном запоминающем устройстве. В качестве примера, но не ограничения, фиг.1 показывает удаленную прикладную программу 185 как постоянно хранящуюся на удаленном компьютере 180. Важно отметить, что показанные сетевые соединения являются иллюстративными и могут быть также использованы другие средства установления линии связи между компьютерами.
Необходимо отметить, что данное изобретение может быть осуществлено на компьютерной системе, такой как описанная при рассмотрении фиг.1 система. Однако данное изобретение может быть осуществлено на сервере, компьютере, предназначенном для обработки сообщений, или на распределенной системе, в которой различные части данного изобретения осуществляются на различных частях распределенной компьютерной системы.
Фиг.2 является блок-схемой одного воплощения системы 200 обработки перефразирования. Система 200 имеет доступ к базе 202 данных документов и включает в себя систему 204 кластеризации документов, систему 206 выбора текстовых сегментов, систему 210 совмещения слов/фраз, систему 211 идентификации на основе входного текста и систему 212 генерации на основе входного текста. Фиг.3 является блок-схемой последовательности операций, иллюстрирующей работу системы 200, показанной на фиг.2.
База 202 данных документов в качестве иллюстрации включает в себя множество различных новостных статей, написанных множеством различных агентств новостей. Каждая из статей в качестве иллюстрации включает в себя временную метку, указывающую, когда приблизительно эта статья создавалась. Также упомянутое множество статей от различных агентств новостей в качестве иллюстрации описывает широкое множество различных событий.
Конечно, хотя данное изобретение и описано относительно новостных статей, также могли бы быть использованы другие исходные документы, такие как технические статьи, описывающие общий процесс, различные медицинские статьи, описывающие общую медицинскую процедуру, и т.д.
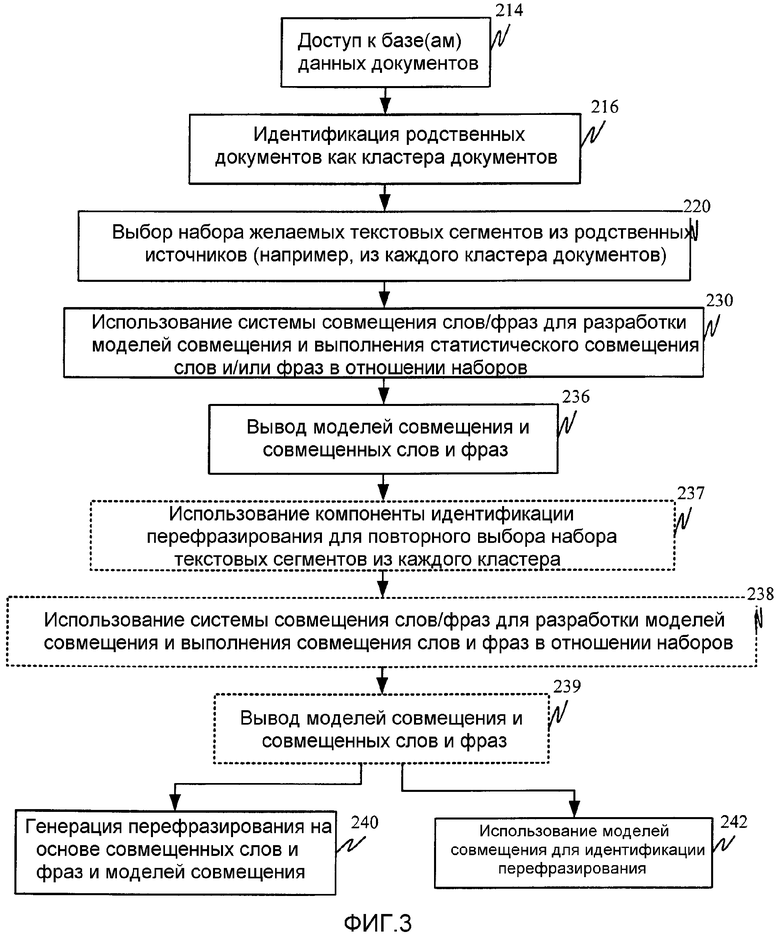
Система 204 кластеризации документов осуществляет доступ к базе 202 данных документов, как проиллюстрировано этапом 214 на фиг.3. Необходимо отметить, что хотя на фиг.2 проиллюстрирована отдельная база 202 данных, вместо этого можно было бы осуществить доступ к множеству баз данных.
Система 204 кластеризации идентифицирует статьи в базе 202 данных документов, которые написаны об одном и том же событии. В одном воплощении статьи также идентифицируются как написанные в приблизительно одно и то же время (например, в пределах заранее определенного порога времени между ними, такого как один месяц, одна неделя, один день, в течение нескольких часов и т.д., как это желательно). Статьи, идентифицированные как написанные об одном и том же событии (и, возможно, в приблизительно одно и то же время), образуют кластер 218 документов. Это обозначено этапом 216 на фиг.3.
После того как родственные исходные статьи идентифицированы как кластер 218, желательно, чтобы были извлечены текстовые сегменты (такие как предложения, фразы, заголовки, абзацы и т.д.) в этих статьях. Например, журналистское соглашение о новостных статьях советует, чтобы первые 1-2 предложения статьи представляли собой резюме остальной части статьи. Поэтому в соответствии с одним воплощением данного изобретения статьи (которые в качестве иллюстрации были написаны разными агентствами новостей) кластеризуются в кластеры 218 и передаются системе 206 выбора текстовых сегментов, где извлекаются первые два предложения каждой статьи в каждом кластере 218. Хотя данное описание представлено по отношению к предложениям, необходимо отметить, что это является только примером, и другие текстовые сегменты могут также легко использоваться. Предложения из каждого кластера 218 статей выводятся как набор 222 предложений, соответствующих кластеризованным статьям. Наборы 222 предложений выдаются системой 206 выбора текстовых сегментов системе 210 совмещения слов/фраз. Это обозначено этапом 220 на фиг.3.
В данном конкретном примере, в котором используются предложения, многие из предложений, собранных этим способом, являются версиями некоторого единственного первоначального исходного предложения, в незначительной степени переписанного редакторами различных агентств новостей по стилистическим причинам. Отмечено, что часто эти наборы предложений имеют минимальные отличия, например в порядке слов, появляющихся в предложении.
Система 206 выбора текстовых сегментов генерирует наборы 222 предложений для каждого кластера. Необходимо отметить, что система 210 совмещения слов/фраз может обрабатывать большие наборы предложений, извлекая связи между словами или фразами на основе целостного анализа предложений в наборе. Однако далее в настоящем описании рассматривается формирование пар предложений и выполнение совмещения в отношении этих пар как одно из иллюстративных воплощений. Таким образом, в одном воплощении идентифицированные наборы предложений формируют в пары предложений. Поэтому система 206 выбора текстовых сегментов ставит в пару каждому предложению в наборе каждое другое предложение в этом наборе для формирования пар предложений для каждого набора. Пары предложений в одном воплощении подвергаются дополнительному этапу фильтрации, а в другом воплощении выдаются непосредственно системе 210 совмещения слов/фраз. Хотя фильтрация и будет описана относительно данного воплощения, необходимо отметить, что этапы, связанные с фильтрацией, являются необязательными.
В одном иллюстративном воплощении система 206 выбора текстовых сегментов реализует эвристическое правило, согласно которому фильтруют пары предложений на основе общих ключевых слов содержимого. Например, в одном иллюстративном воплощении система 206 фильтрует пары предложений, удаляя те пары предложений, которые не используют совместно, по меньшей мере, три слова не менее четырех символов каждое. Конечно, фильтрация является необязательной, и если она используется, то реализация алгоритма фильтрации может широко варьироваться. Может использоваться любая из множества различных методик фильтрации, например фильтрация на основе прошлых результатов (для чего требуется контур обратной связи для организации вывода из системы 210 совмещения слов/фраз в обратном направлении к системе 206 выбора текстовых сегментов), фильтрация на основе другого числа слов содержимого, фильтрация на основе другой семантической или синтаксической информации и т.д. В любом случае в наборах предложений может быть выполнено формирование пар и эти наборы могут быть отфильтрованы и переданы системе 210 совмещения слов/фраз.
В одном иллюстративном воплощении система 210 совмещения слов/фраз реализует общепринятый алгоритм совмещения слов/фраз, известный из литературы по статистическому машинному переводу, в попытке изучения лексических соответствий между предложениями в наборах 222. Например, предположим, что два следующих предложения вводятся в систему 210 машинного перевода как пара предложений:
Штормы и торнадо уничтожили не менее 14 человек, когда они пронеслись сквозь центральные американские штаты Канзас и Миссури.
Множество разрушительных торнадо прокатилось через Средний Запад, уничтожив не менее 19 человек в Канзасе и Миссури.
Эти предложения могут иметь общий редакционный источник, несмотря на некоторые различия. В любом случае они в качестве иллюстрации были написаны двумя различными агентствами новостей об одном и том же событии в приблизительно одно и то же время. Различия в предложениях включают “пронеслись сквозь”, соответствующее “прокатилось через”, различия в порядке слов “центральные американские штаты”, соответствующие “Среднему Западу”, морфологическое различие между словами “уничтожили” и “уничтожив” и различие в числе жертв, о которых сообщается.
Фиг.4 иллюстрирует соответствия между словами и множеством, составленных из слов фраз в предложениях, после того как слова и фразы были совмещены согласно известной системе 210 совмещения. Для большинства из этих соответствий статистический алгоритм совмещения установил связи между различными, но параллельными частями информации, как показано линиями, соединяющими слова. Например, фразы из существительных “штормы и торнадо” и “множество торнадо” непосредственно не сопоставимы. Поэтому по мере получения большего количества данных связь между “штормы” и “множество” исчезает. Различие в порядке слов можно заметить по пересекающейся комбинации связей между двумя предложениями.
В одном иллюстративном воплощении система 210 совмещения слов/фраз реализована с использованием методик, изложенных в статье P.F. Brown et al., “The Mathematics of Statistical Machine Translation: Parameter Estimation”, Computational Linguistics, 19:263-312, (июнь 1993). Конечно, могут использоваться другие методики машинного перевода или совмещения слов/фраз для идентификации ассоциаций между словами и входным текстом. Использование системы 210 совмещения для разработки моделей совмещения и выполнения статистического совмещения слов и/или фраз в отношении наборов предложений обозначено этапом 230 на фиг.3.
Система 210 совмещения слов/фраз после этого выдает совмещенные слова и фразы 232, наряду с моделями 234 совмещения, которые она сгенерировала на основе входных данных. В основном в вышеназванной системе совмещения модели обучены идентифицировать соответствия между словами. Согласно этой методике совмещения вначале находят совмещения слов между словами в текстовых сегментах, как проиллюстрировано на фиг.4. Затем система назначает вероятность каждому из этих совмещений и оптимизирует вероятности на основе последующих обучающих данных для генерации более точных моделей. Вывод моделей 234 совмещения и совмещенных слов и фраз 232 проиллюстрирован этапом 236 на фиг.3.
Модели 234 совмещения в качестве иллюстрации включают в себя обычные параметры модели перевода, такие как вероятности перевода, назначенные совмещениям слов, вероятности перемещения, показывающие вероятность того, что слово или фраза перемещаются в пределах предложения, и вероятности многозначности, показывающие вероятность того, что отдельное слово может соответствовать двум различным словам в другом текстовом сегменте.
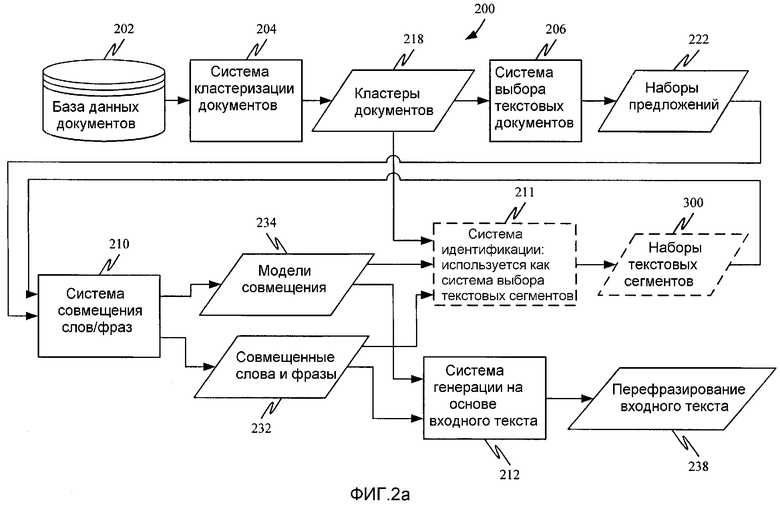
Этапы 237, 238 и 239 являются необязательными этапами обработки, используемыми при начальной загрузке системы для самообучения. Они описаны в больших деталях ниже при рассмотрении фиг.2a.
В воплощении, в котором начальная загрузка не используется, система 211 получает выходные данные системы 210 и идентифицирует слова, фразы или предложения, которые являются перефразированием друг друга. Идентифицированные перефразирования 213 выводятся системой 211. Это обозначено этапом 242 на фиг.3.
Совмещенные фразы и модели могут также быть преданы системе 212 генерации на основе входного текста. Система 212 является в качестве иллюстрации обычным декодером, который принимает в качестве входных данных слова и/или фразы и генерирует перефразирование 238 для этих входных данных. Таким образом, система 212 может использоваться для генерации перефразирования входного текста, используя совмещенные слова и фразы 232 и модели 234 совмещения, сгенерированные системой 210 совмещения. Генерация перефразирования для входного текста на основе совмещенных слов и фраз и моделей совмещения обозначена этапом 240 на фиг.3. Одна иллюстративная система генерации изложена в статье Y. Wang и A. Waibel “Decoding Algorithm in Statistical Machine Translation”, материалы 35th Annual Meeting of the Association of Computational Linguistics (1997).
Фиг.2a подобна фиг.2 за исключением того, что система 211 идентификации также используется при начальном обучении. Это дополнительно проиллюстрировано этапами 237-239 на фиг.3. Например, предположим, что система 210 совмещения слов/фраз выдала модели 234 совмещения и совмещенные слова и фразы 232, как описано выше относительно фиг.2 и 3. Теперь, однако, полный текст каждого кластера 218 документов подан системе 211 идентификации для идентификации дополнительного набора 300 предложений (опять же, предложения используются только в качестве примера, другие текстовые сегменты также могут быть использованы) для использования при дальнейшем обучении системы. Система 211 идентификации с помощью моделей 234 совмещения и совмещенных слов и фраз 232 может обработать текст в кластерах документов 218, чтобы осуществить повторный выбор наборов 300 предложений для каждого из кластеров. Это обозначено этапом 237. Повторно выбранные наборы 300 предложений после этого передаются системе 210 совмещения слов/фраз, которая генерирует или повторно вычисляет модели 234 совмещения и совмещенные слова и фразы 232 и связанные с ними метрики вероятности на основе повторно выбранных наборов 300 предложений. Выполнение совмещения слов и фраз и генерация моделей совмещения и совмещенных слов и фраз на основе повторно выбранных наборов предложений обозначены этапами 238 и 239 на фиг.3.
Теперь повторно вычисленные модели 234 совмещения и новые совмещенные слова и фразы 232 могут снова быть введены в систему 211 идентификации и использованы системой 211, чтобы снова обработать текст в кластерах документов 218 для идентификации новых наборов предложений. Эти новые наборы предложений могут снова быть выданы в систему 210 совмещения слов/фраз, и процесс может быть продолжен для повышения качества обучения системы.
Существует широкое разнообразие применений для перефразирований, обработанных с использованием данной системы. Например, потенциальные применения для систем обработки перефразирования включают в себя систему ответа на вопросы, типа изложенной при описании предшествующего уровня техники, и более общую информационно-поисковую систему. Такая система может генерировать оценку перефразирования для определения подобия двух текстовых сегментов при выдаче набора документов на основе запроса. Подобным образом, такая система может использовать возможность генерации перефразирования для выполнения расширения запроса (получения множества форм единственного исходного запроса) для нахождения лучшего соответствия результатов или улучшения повторного запроса.
Кроме того, другие применения распознавания и генерации перефразирования включают в себя рефератирование множества документов. Используя распознание перефразирования, автоматическая система рефератирования документов может найти сходные отрывки в различных документах для выбора самой существенной информации в наборе документов для того, чтобы сгенерировать реферат.
Другим применением распознавания и генерации перефразирования является диалоговая система. Такая система может сгенерировать ответ, который повторяет ввод, но выражен по-другому во избежание бессмысленного повторения одного и того же ввода. Это придает системе диалога более естественное или разговорное звучание.
Распознавание и генерация перефразирования может также использоваться в системах обработки текстов. Система обработки текстов может использоваться для автоматической генерации стилистических вариантов написанного и предложения этих вариантов пользователю. Это может быть полезно, например, когда пользователь, будучи автором документа, повторил фразу большое количество раз, возможно, даже в одном абзаце. Точно так же система обработки текстов может включать в себя возможность помечания повторной (но по-другому перефразированной) информации, которая разбросана по документу. Точно так же, такая система может включать в себя возможность переписывать часть прозы в качестве парафразы.
Данное изобретение может также использоваться в системах управления и команд. Люди обычно спрашивают о вещах, используя весьма разную терминологию. Идентификация перефразирования позволяет такой системе выполнить надлежащую команду и управляющие действия, даже если входные данные сформулированы различными путями.
Таким образом, в соответствии с одним воплощением данного изобретения текстовые источники, описывающие общее событие, являются кластеризоваными. Заранее определенные текстовые сегменты в этих текстовых источниках извлекаются в наборы текстовых сегментов. Текстовый сегмент в каждом наборе передается системе совмещения для идентификации перефразирования. Таким образом, данное изобретение идентифицирует перефразирование по многим кластерам. Идентифицированные отношения перефразирования могут быть найдены, используя пары текстовых сегментов во множестве различных кластеров. Кроме того, в одном воплощении найденные перефразирования используются для нахождения большего числа отношений перефразирования при дальнейших процессах обучения. Это более выгодно по сравнению с предшествующими системами распознавания перефразирования.
Хотя данное изобретение было описано со ссылками на специфические воплощения, специалисты в данной области техники могут увидеть, что изменения могут быть сделаны в форме и деталях, но не отступая от сущности и объема данного изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ПЕРЕФРАЗИРОВАНИЯ ТЕКСТА | 2023 |
|
RU2814808C1 |
| ОПРЕДЕЛЕНИЕ НАМЕРЕНИЯ ПОЛЬЗОВАТЕЛЯ НА ОСНОВЕ ОНТОЛОГИЙ ПРЕДМЕТНЫХ ОБЛАСТЕЙ | 2011 |
|
RU2541221C2 |
| ВЫВЕДЕНИЕ НАМЕРЕНИЯ ПОЛЬЗОВАТЕЛЯ НА ОСНОВЕ ПРЕДЫДУЩИХ ВЗАИМОДЕЙСТВИЙ С ГОЛОСОВЫМ ПОМОЩНИКОМ | 2011 |
|
RU2544787C2 |
| ОРКЕСТРОВКА СЛУЖБ ДЛЯ ИНТЕЛЛЕКТУАЛЬНОГО АВТОМАТИЗИРОВАННОГО ПОМОЩНИКА | 2011 |
|
RU2556416C2 |
| ПОДДЕРЖАНИЕ КОНТЕКСТНОЙ ИНФОРМАЦИИ МЕЖДУ ПОЛЬЗОВАТЕЛЬСКИМИ ВЗАИМОДЕЙСТВИЯМИ С ГОЛОСОВЫМ ПОМОЩНИКОМ | 2015 |
|
RU2653250C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА | 2023 |
|
RU2817524C1 |
| РАЗРЕШЕНИЕ НЕОДНОЗНАЧНОСТИ НА ОСНОВЕ АКТИВНОГО ЗАПРАШИВАНИЯ ВВОДА ИНТЕЛЛЕКТУАЛЬНЫМ АВТОМАТИЗИРОВАННЫМ ПОМОЩНИКОМ | 2011 |
|
RU2546605C2 |
| ПРИОРИТИЗАЦИЯ КРИТЕРИЕВ ВЫБОРА ПОСРЕДСТВОМ ИНТЕЛЛЕКТУАЛЬНОГО АВТОМАТИЗИРОВАННОГО ПОМОЩНИКА | 2011 |
|
RU2546606C2 |
| ПЕРЕФРАЗИРОВАНИЕ ПОЛЬЗОВАТЕЛЬСКИХ ЗАПРОСОВ И РЕЗУЛЬТАТОВ ПОСРЕДСТВОМ ИНТЕЛЛЕКТУАЛЬНОГО АВТОМАТИЗИРОВАННОГО ПОМОЩНИКА | 2011 |
|
RU2541202C2 |
| АКТИВНОЕ ЗАПРАШИВАНИЕ ВВОДА ИНТЕЛЛЕКТУАЛЬНЫМ АВТОМАТИЗИРОВАННЫМ ПОМОЩНИКОМ | 2011 |
|
RU2541208C2 |

Изобретение относится к идентификации перефразирования в тексте. Изобретение позволяет идентифицировать отношения перефразирования в различных текстах, относящихся к одному событию. Получают набор текстовых сегментов из кластера различных статей, написанных об общем событии. Затем набор текстовых сегментов обрабатывают согласно методикам текстового совмещения для идентификации перефразирования на основе текстовых сегментов в тексте. Идентифицированные перефразирования можно использовать в системах машинного перевода. 6 з.п. ф-лы, 5 ил.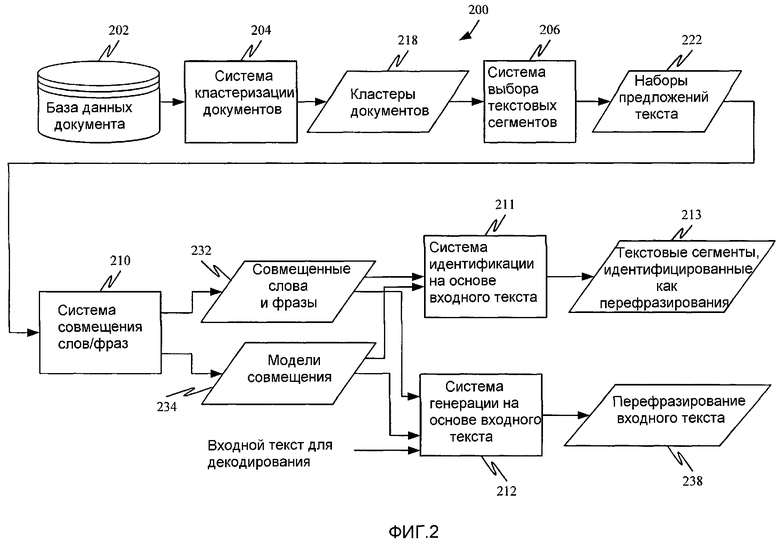
1. Способ обучения системы обработки перефразирования, содержащий этапы, на которых
осуществляют доступ к множеству документов;
идентифицируют из упомянутого множества документов кластер родственных текстов, написанных различными авторами по общей теме, причем упомянутые родственные тексты дополнительно идентифицируются как исходящие от различных агентств новостей и относящиеся к общему событию;
принимают кластер родственных текстов;
выбирают набор текстовых сегментов из этого кластера, причем при упомянутом выборе группируют желаемые текстовые сегменты родственных документов в набор родственных текстовых сегментов; и
используют текстовое совмещение для идентификации отношений перефразирования между текстами в текстовых сегментах, включенных в упомянутый набор родственных текстовых сегментов;
при этом при использовании текстового совмещения:
используют статистическое текстовое совмещение для совмещения слов в текстовых сегментах в упомянутом наборе и
идентифицируют отношения перефразирования на основе совмещенных слов.
2. Способ по п.1, дополнительно содержащий этап, на котором вычисляют модели совмещения на основе идентифицированных отношений перефразирования.
3. Способ по п.2, дополнительно содержащий этапы, на которых
принимают входной текст и
генерируют перефразирование входного текста на основе модели совмещения.
4. Способ по п.1, в котором при выборе набора текстовых сегментов выбирают текстовые сегменты для упомянутого набора на основе ряда общих слов в текстовых сегментах.
5. Способ по п.1, в котором при идентификации кластера родственных текстов идентифицируют тексты, написанные в пределах заранее определенного времени друг по отношению к другу.
6. Способ по п.1, в котором при группировании желаемых текстовых сегментов группируют первое заранее определенное число предложений каждой новостной статьи в каждом кластере в набор родственных текстовых сегментов.
7. Способ по п.6, в котором при выборе набора текстовых сегментов формируют пару каждого предложения в заданном наборе родственных текстовых сегментов с каждым другим предложением в этом заданном наборе.
| Brazilay R | |||
| et al | |||
| Extracting Paraphrases from a Parallel Corpus, Proceeding of the ACL/EACL, Toulouse, France, 05.07.2001 | |||
| КОМПЬЮТЕРНАЯ СИСТЕМА И СПОСОБ ПОДГОТОВКИ ТЕКСТА НА ИСХОДНОМ ЯЗЫКЕ И ПЕРЕВОДА НА ИНОСТРАННЫЕ ЯЗЫКИ | 1993 |
|
RU2136038C1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| US 5237502 A, 17.08.1993 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |

