Изобретение относится к компьютерной системе создания и перевода документов и, в частности, оно относится к системе подготовки текста на языке ограничений и перевода на иностранный язык без необходимости предварительного или последующего редактирования.
Любая организация, чья деятельность требует создания больших объемов информации в разнообразных видах документов, испытывает потребность обеспечения их полной понимаемости. В идеальном случае такие документы следует подготавливать с использованием простого, декларативного языка, имеющего все необходимые выразительные атрибуты для оптимизации общения. Этот язык должен применяться последовательно, так чтобы организацию можно было распознавать по ее единому и устойчивому стилю выражения или "голосу". Этот язык должен быть лишенным неоднозначности.
Стремление выйти на подобное совершенство в написании текстов привело к внедрению ряда приемов или методик, рассчитанных на установление контроля над авторским написанием текстов. Вместе с тем, авторов с разными способностями и разным предварительным опытом и образованием нельзя удобно для них ограничить рамками унифицированного стандартного подхода. Указания, правила и нормы написания оказались мало эффективными: их трудно как определить, так и привести в исполнение. Предшествовавшие попытки одновременно стандартизовать и улучшить качество написания текстов завершались разными результатами, но какими бы они не были - положительными или удачными, эти результаты неизбежно увеличивали стоимость авторского создания документации.
Попытки последнего времени предоставить авторам текстов среду программного обеспечения, которая была бы способной повысить их производительность и улучшить качество их документов, увенчались успехом лишь в создании программы проверки правописания. Эффективность остальных программных средств для написания документов до сих пор весьма мала.
Когда потребность распространения информации делает необходимым преодоление языковых барьеров, все названные трудности многократно возрастают. Организация, нуждающаяся в четко действующем канале для своего потока информации, попадает в значительную, если не в полную зависимость от перевода.
Переводы текстов с одного языка на другой язык делаются уже много лет. До появления компьютеров такие переводы выполнялись полностью вручную специалистами - переводчиками, которые владели как языком исходного текста (оригинала), так и языком целевого текста (перевода). В общем случае предпочтение отдавалось переводчикам, исходно освоившим целевой язык как их родной язык, а впоследствии освоившим язык оригинала. Считалось, что этот подход давал в результате наиболее точные и эффективные переводы.
Даже наиболее квалифицированному переводчику требуется значительное количество времени для перевода одной страницы текста. Так, например, было подсчитано, что квалифицированный переводчик при переводе технического текста с английского языка на японский язык может перевести в час приблизительно 300 слов (порядка одной страницы). Из этого видно, что количество времени и сил, требуемых для перевода документа, в особенности технического, достаточно велико.
В течение последних ста лет потребность в переводах в рамках деловой деятельности и торговли постоянно нарастала. Причиной тому был целый ряд факторов. Одним из них явился быстрый рост объемов текстов, связанных с международным проведением деловых операций. Другим фактором является большое число языков, на которые должны переводиться также тексты для того, чтобы компания могла заниматься коммерцией в глобальном масштабе. Третий фактор - быстрый рост темпов торговли, приводящий к необходимости частых пересмотров текстовых документов, а это требует последующего перевода их новых вариантов.
Многие организации несут ответственность за создание и распространение информации на многочисленных языках. В условиях глобального рынка изготовители продукции должны обеспечивать такое положение, при котором их руководство и инструкции широко доступны на родных языках стран, являющихся их целевым рынкам сбыта. Ручной перевод документов на иностранные языки представляет собой дорогостоящий, отнимающий много времени и неэффективный процесс. Переводы бывают, как правило, противоречивыми в силу их индивидуальной интерпретации переводчиками, которые не всегда хорошо владеют специфичным языком переводимой документации, относящейся к конкретной области. В результате названных проблем фактически переводится намного меньше, чем хотелось бы, таких инструкций или руководств.
В области научных исследований и разработок тот взрыв знаний, который происходил в течение последнего столетия, также привел к росту в геометрической прогрессии потребности в переводе документов. Сегодня уже больше не существует один преобладающий язык для документов в конкретной области исследований и разработок. Как правило, такая исследовательская деятельность и разработки проводятся в нескольких ведущих промышленно-развитых странах, таких как, например, Соединенные Штаты, Великобритания, Франция, Германия и Япония. Во многих случаях есть еще и дополнительные языки, на которых появляются важные документы, имеющие отношения к какой-либо конкретной области исследований и разработки. Технический и технологический прогресс, особенно в областях электроники и вычислительной техники, еще более ускорил процесс создания текстов на всех языках.
Возможность создания текста прямо пропорциональна производительности используемой для этого техники. Так, например, если документы должны писаться от руки, их автор может написать лишь определенное ограниченное количество слов в минуту. Эта производительность, однако, значительно возросла с появлением пишущих машинок, мимеографических воспроизводящих устройств и печатных машин. Развитие электроники, компьютеров и оптических технологий еще более повысило производительность труда авторов текстов. Сегодня средний автор может создать значительно больший объем текста за единицу времени, чем с использованием приемов писания от руки в прошлом.
Этот быстрый рост объема текстов в сочетании с огромными техническими достижениями в значительной степени привлек внимание к вопросу перевода текстов с языка оригинала на целевой язык или языки. Значительный объем исследований был выполнен в университетах, в частных и в правительственных лабораториях. Эти исследования были посвящены вопросам выполнения переводов без вмешательства человека-переводчика. Были сконструированы компьютерные системы в качестве средств выполнения так называемого машинного перевода (МП). Такие компьютерные системы программируются для выполнения автоматизированного перевода исходного текста как входной информации в целевой текст как информацию на выходе. Однако исследователи обнаружили, что подобные компьютерные системы для автоматизированного машинного перевода невозможно реализовать с использованием современной технологии и теоретических знаний. Сегодня не существует ни одной системы, которая могла бы выполнять машинный перевод текста на естественном исходном языке в текст на естественном целевом языке без какого-либо вида редактирования со стороны квалифицированных редакторов или переводчиков. Один из существующих способов будет рассмотрен ниже.
В ходе операции, называемой предварительным редактированием, исходный текст сначала просматривается редактором оригинала. Задачей редактора оригинала является внесение в исходный текст изменений, которые приведут его в соответствие с так называемым оптимальным состоянием для перевода машинной системой перевода. Этому соответствию редактор оригинала обучается по методу проб и ошибок.
Описанный выше процесс предварительного редактирования может проходить несколько стадий или итераций с участием редакторов оригинала возрастающей квалификации и степени компетентности. Таким образом исходный текст готовится и передается в систему машинного перевода. Выходным продуктом является текст на целевом языке, который, в зависимости от целей перевода или требований к качеству со стороны пользователя, может подвергаться или не подвергаться конечному редактированию
Если требуемое качество перевода должно быть сопоставимым с качеством квалифицированного перевода, выполненного человеком, выходная информация машинного перевода, скорее всего, будет подвергнута конечному редактированию квалифицированным переводчиком. Причина этому заложена в сложности человеческого языка и в сравнительно скромных возможностях систем машинного перевода, которые могут быть созданы на основе современных технологий в пределах вполне понятных ограничений времени и средства и разумно оправданных ожиданий достижения требуемой экономической эффективности. И в самом деле, большинство создаваемых в настоящее время систем требует выполнения операций по конечному редактированию, предназначенных для приближения, в той или иной степени, к качественным уровням чисто человеческого перевода.
Одной из таких систем является система КВМТ-89 (см. ниже), разработанная Центром машинного перевода Университета Карнеги-Меллона, которая осуществляет переводы с английского языка на японский и с японского языка на английский. Она работает с ориентированной на достигнутые знания моделью области, помогающей в интерактивном устранении неоднозначности (т.е. в редактировании документа для придания ему однозначности). Вместе с тем, это интерактивное устранение неоднозначности, как правило, не выполняется в интерактивном или диалоговом режиме с самим автором. Как только система встречает неоднозначное предложение, которое она сама не может привести к однозначности, она вынуждена останавливать процесс и разрешать проблему неоднозначности, задавая автору или переводчику вопросы с выбором нескольких ответов. Кроме того, поскольку система КВМТ-89 не использует достаточно хорошо определенный и контролируемый язык на входе, ее так называемый процесс интерактивного устранения неоднозначности с помощью переводчика производит на выходе текст, нуждающийся в конечном редактировании.
С учетом сказанного, очевидны преимущества создания системы перевода, исключающей как предварительное, так и конечное редактирование.
Изобретение представляет собой систему интегрированных компьютеризованных процедур подготовки документов в одном языке и перевода на несколько языков. Интерактивный компьютеризованный текстовой редактор налагает лексические и грамматические ограничения на подмножество (сокращенную версию) естественного языка, используемое авторами при создании их текстов, и оказывает авторам поддержку в устранении неоднозначности в их текстах для обеспечения их переводимости. Получаемый в результате пригодный к переводу текст на исходном языке подвергается машинному переводу на любой из множества целевых языков, и при этом переведенный текст не требует никакого конечного редактирования.
Фиг. 1A и 1B представляют блок-схемы высокого уровня, иллюстрирующие архитектуру согласно настоящему изобретению.
Фиг. 2 - структурная схема высокого уровня, иллюстрирующая работу, согласно настоящему изобретению.
Фиг. 3 - блок-схема высокого уровня, иллюстрирующая информационный поток и архитектуру МП 120.
Фиг. 4 - пример информационного элемента.
Фиг. 5 - блок-схема модели области 500.
Фиг. 6 - структурная схема высокого уровня, иллюстрирующая работу языкового редактора 130.
Фиг. 7 - структурная схема, иллюстрирующая работу словарного контроллера 610.
Фиг. 8 - структурная схема высокого уровня блока 630 устранения неоднозначности.
Фиг. 9 - блок-схема, иллюстрирующая информационный поток и архитектуру МП 120.
I. Общие характеристики интегрированной системы
Компьютеризованная система в соответствии с настоящим изобретением обеспечивает функциональную интеграцию таких компонентов, как:
1) авторская окружающая среда для подготовки документов,
2) модуль для точного машинного перевода на различные языки без предварительного и конечного редактирования. При использовании этой технологии для изготовления многоязычной документации пользователю обеспечивается возможность последовательно точного, своевременного и экономически эффективного перевода в больших или малых объемах с практически одновременным выпуском информации как на исходном языке, так и на языках, намеченных для перевода оригинального текста.
Решение о связывании воедино функции авторского написания на исходном языке с функцией перевода основывается на двух принципах:
1) в условиях многонациональной и многоязычной деловой среды информация не расценивается как полностью подготовленная, если она не может быть преподнесена на различных языках ее пользователей,
2) сочетание процессов авторского написания (подготовка) и перевода в рамках единой системы дает выгоды с точки зрения эффективности, которые не могли бы быть достигнуты иным путем.
На фиг. 1А показана блок-схема высокого уровня Интегрированной системы авторской подготовки и перевода (ИСАПП) 105. ИСАПП 105 обеспечивает создание специализированной компьютерной среды, предназначенной для организации авторской подготовки документации на одном языке и для ее перевода на различные другие языки. Эти две раздельные функции поддерживаются интегрированной группой программы следующим образом.
1) Авторская подготовка - одна подгруппа программ предлагает пользователю текстовый редактор (ТР) 140, дающий авторам возможность создавать их одноязычные тексты в пределах лексических и грамматических ограничений определенного областью применения подмножества естественного языка, который здесь называется ограниченным исходным языком (ОИЯ) или языком ограничений. Кроме этого, ТР 140 также дает авторам возможность готовить их текст для перевода по процедуре устранения в тексте неоднозначностей, что делает текст переводимым без предварительного редактирования,
2) Перевод - еще одна подгруппа программ обеспечивает функцию машинного перевода (МП) 120, способную переводить ОИЯ на столько целевых языков, на сколько был запрограммирован генерирующий модуль, и при этом получаемый в результате перевод не требует конечного редактирования.
Для системы, в которой роль центрального компонента играет функция перевода, интегрирование функций авторской подготовки и перевода согласно настоящему изобретению в рамках единой системы является единственным выработанным на сегодняшний день подходом, позволяющим исключить как предварительное, так и конечное редактирование.
Текстовый редактор (ТР) 140 представляет собой набор инструментов для оказания поддержки авторам и редакторам в создании документов на ОИЯ. Эти инструменты помогают авторам использовать требуемый словарь и требуемую грамматику ОИЯ в написании ими их документов. ТР 140 напрямую общается с автором 160 и наоборот.
Как видно из фиг. 1В, ИСАПП 105 подразделена на четыре основные части для выполнения функций авторской подготовки и перевода, а именно: (1) ограниченный исходный язык (ОИЯ) 133, (2) текстовый редактор (ТР) 140, (3) МП 120, а также (4) модель области (МО) 137. Текстовый редактор 140 включает в себя языковый редактор 130 и графический редактор 150. В дополнение к названным компонентам система управления файлами (СУФ) 110 также включена в систему для управления всеми ее процессами.
ОИЯ 133 представляет собой подмножество исходного языка, в котором грамматика и словарный состав охватывают специальную область авторской документации, подлежащей переводу. Объем и состав ОИЯ определен требованиями к словарю и грамматическим конструкциям, допустимым для соответствующей области, так чтобы сделать возможным процесс перевода, не прибегая при этом к предварительному и конечному редактированию.
ТР 140 представляет собой набор инструментов для оказания поддержки авторам и редакторам в создании документов на ОИЯ. Эти инструменты помогают авторам использовать требуемый словарь и требуемую грамматику ОИЯ в написании ими их документов. ЯР 130 общается с авторами 160 (и наоборот) через текстовый редактор 140. Автор располагает двусторонней связью по линии 162 с текстовым редактором 140. ЯР 130 сообщает автору 160 о том, имеются ли используемые автором слова и выражения (фразы) в ОИЯ. ЯР также способен предложить из ОИЯ синонимы словам, которые имеют отношение к информационной области, в которую входит создаваемый документ, но которые не включены в ОИЯ. Помимо этого, ЯР 130 информирует автора 160 о том, удовлетворяет ли создаваемый им отрезок текста грамматическим ограничениям ОИЯ. Далее, он оказывает автору поддержку в устранении неоднозначности предложений, которые могут быть правильными синтаксически, но не однозначными семантически.
МП 120 разделен на две части: анализатор 127 МП и генератор 123 МП. Анализатор 127 МП служит двум целям: он анализирует документ для обеспечения того, чтобы документ однозначно соответствовал ОИЯ и представлял собой текст на промежуточном языке, называемом "интерлингва". Затем проанализированный и апробированный с точки зрения ОИЯ текст на промежуточном языке переводится на заданный иностранный (целевой) язык. МП 120 реализует подход к переводу на основе текста на промежуточном языке "интерлингва". Вместо прямого перевода документа на другой, иностранный язык генератор 123 МП сначала переводит документ в независимую от конкретного языка машиночитаемую форму, называемую межязыковой или интерлингва, а затем генерирует перевод из этого промежуточного текста интерлингва. В результате получаемые документы не требуют конечного редактирования. Для каждого из используемых языков создается свой вариант МП 120, состоящего, в первую очередь, из набора источников сведений (знаний), предназначенных для руководства переводом промежуточного текста в текст на иностранном языке. В частности, для каждого нового целевого языка должен индивидуально разрабатываться новый генератор 123 МП.
При своем функционировании в полном объеме ЯР 130 иногда вынужден просить автора 160 произвести выбор между альтернативными интерпретациями определенных предложений, которые удовлетворяют грамматическим ограничениям ОИЯ, но смысл которых не вполне ясен. Этот процесс называют устранением неоднозначности. После того, как ЯР 130 определил, что конкретная часть текста использует исключительно словарный запас ОИЯ и удовлетворяет всем грамматическим ограничениям ОИЯ, он обозначает эту часть текста как апробированную ОИЯ, но еще не прошедшую этот процесс устранения неоднозначности. Как будет объяснено ниже, устранение неоднозначности не потребует внесения никаких изменений в те аспекты текста, которые видны автору. После того, как текст прошел операцию устранения неоднозначности, он готов для перевода на целевой язык 180.
В практической реализации ЯР 130 строится как продолжение текстового редактора 140, который обеспечивает основную пословную обработку текста, требуемую авторам и редакторам для создания текстов и таблиц. Графический редактор 150 используется для создания графических изображений. Этот графический редактор 150 располагает средствами для введения и обработки текстовых надписей на графических изображениях посредством текстового редактора 140, так чтобы эти текстовые надписи также проходили апробацию ОИЯ.
ЯР 130 (через текстовый редактор 140) общается с анализатором 127 МП, а через него - с МО 137 в ходе устранения неоднозначности через двусторонние линии "от гнезда к гнезду". В предпочтительном варианте осуществления настоящего изобретения МО представляет собой одну из баз сведений, от которой получает питание анализатор 127 МП. МО является символическим выражением декларативных знаний в отношении словарного запаса ОИЯ, используемых анализатором МП 127 и ЯР 130.
На фиг. 2 показана структурная схема высокого уровня работы ИСАПП 105. МП 120, ЯР 130, текстовый редактор 140 и графический редактор 150 находятся под общим контролем и управлением СУФ 110. Управляющие линии 111-113 обеспечивают предоставление необходимой информации контроля и управления для правильной работы ИСАПП 105.
На начальной стадии автор обращается к СУФ 110 для выбора документа, подлежащего редактированию, и тогда СУФ включает в работу текстовый редактор 140, выводя на экран файл с вызванным документом. Используя текстовый редактор 140, автор вводит в ИСАПП 105 текст, который может быть не ограниченным и неоднозначным, как показано в блоках 160 и 220. Автор 160 пользуется стандартными редакторскими командами для создания и корректирования документа, пока тот не будет готов к проверке на соответствие ОИЯ. Предполагается, что авторы будут вводить, в основном, тексты, при подготовке которых они в существенной степени мысленно учитывают ограничения, накладываемые ОИЯ. Затем текст подвергается корректированию автором для соответствия ОИЯ в ответ на обратную связь со стороны системы, исходящую из допущенных нарушений заданных заранее лексических и грамматических ограничений. Разумеется, этот процесс более эффективен, если изначально не вводился текст, полностью игнорировавший заданные ограничения. Тем не менее, система будет работать правильно и в том случае, когда изначально вводимый текст полностью не учитывает этих ограничений.
Общение автора с ЯР 130 производится с помощью команд, вводимых посредством "мыши" или с клавиатуры. Вместе с тем, следует учитывать возможность других форм ввода, например использование оптического "пера", голоса и т. п., что входит в пределы объема и содержания настоящего изобретения. Примером подобного ввода может быть команда на проведение проверки по ОИЯ либо команда на поиск определения и примера использования заданного слова или выражения.
Текст в ОИЯ, который все еще может содержать остаточную неоднозначность или проблемы со стилистикой, анализируется на соответствие с ОИЯ и проверяется на согласованность с грамматическими правилами, содержащимися в базах данных, как показано в блоке 230. Автор получает обратную связь для исправления любых допущенных ошибок по линии обратной связи 215. В частности, ЯР 130 представляет автору 160 информацию в отношении использованных им, но отсутствующих в ОИЯ слов, выражений или предложений. И, наконец, текст проверяется на неоднозначные предложения, ЯР предлагает автору подсказки для выбора правильной интерпретации смысла и значения предложения. Этот процесс продолжается до тех пор, пока из текста не будет полностью устранена неоднозначность.
Когда автор внес в текст все необходимые поправки и стадия анализа 230 завершена, текст 240 с устраненной неоднозначностью и удовлетворенными ограничениями передается к анализатору и промежуточному переводчику 250 МП. Промежуточный переводчик является резидентом в анализаторе 127 МП совместно с синтаксической частью анализатора и переводит текст 240 с устраненной неоднозначностью и удовлетворенными ограничениями на промежуточный язык. Интерлингва 260. Этот промежуточный перевод 260, в свою очередь, переводится генерирующим блоком 270 в целевой текст 280. Как показано на фиг. 3, текст на промежуточном языке Интерлингва 260 имеет форму, которая может быть переведена на несколько целевых языков 306-310.
Путем требования от автора и предоставления ему возможности создания документов, соответствующих специальному словарному запасу и грамматическим ограничениям, становится возможным осуществление точных переводов текстов с ограниченным языком на иностранные языки без необходимости какого-либо последующего или конечного редактирования. Такое конечное редактирование не требуется потому, что блок 217 проверки словаря в составе ЯР и аналитический блок 230 уже заставили автора изменить и/или лишить неоднозначности все потенциально неоднозначные предложения и удалить из документа все непереводимые слова до перехода к стадии перевода.
II. Подробное описание функциональных блоков
В предпочтительном варианте осуществления изобретения каждому автору предоставляется в его личное распоряжение компьютерный абонентский пункт (автоматизированное рабочее место - АРМ) типа DEC с 32 мегабайтами ЗУПВ, 400-мегабайтным дисководом и цветным монитором размером 19 дюймов. Каждое автоматизированное рабочее место (АРМ) имеет конфигурацию, обеспечивающую возможность перекачки (свопинга) объемом не менее 100 мегабайтов с его местного дисковода. В дополнение к АРМ авторов обслуживающие процессоры DEC используются в качестве средств предоставления файлов, по одному обслуживающему процессору на каждые две авторские группы, но не более 45 пользователей на один обслуживающий процессор по представлению файлов. Помимо сказанного, авторские АРМ будут являться резидентами местной сети "Этернет" (Ethernet). ИСАПП как система использует операционную систему Unix (производная от "Стандартного распределения Беркли" - BSD - более предпочтительно, чем производная от "Системы Y" - SYSV). В распоряжении системы находятся компилятор языка программирования "C" и библиотеки OSF/Motif. ЯР будет работать в режиме организации окон Motif. Следует отметить, что настоящее изобретение не ограничено упомянутой выше аппаратной и программной поддержкой и что настоящее изобретение может быть использовано с другими конкретными видами поддержки.
A. Текстовый редактор
В предпочтительном варианте осуществления настоящего изобретения использован текстовый редактор 140, который позволяет автору вводить информацию для того, чтобы она была на последующем этапе проанализирована и в конечном итоге переведена на иностранный язык. В рамках настоящего изобретения может использоваться любое коммерчески доступное программное обеспечение текстовой обработки. В предпочтительном варианте используется текстовый редактор 140 типа SGML компании Arbor Text (Arbor Text Inc., 535 West William St. , Ann Arbor, MI 48103). Текстовый редактор 140 типа SGML (Standard Generalized Markup Language - "Стандартный обобщенный язык разметки") обеспечивает основные функции пословной текстовой обработки, требующиеся авторам и редакторам, и он предпочтительно используется в сочетании с программным пакетом Inter Cap (Аннаполисе, шт. Мериленд) для создания графических изображений.
Текстовый редактор 140 типа SGML используется предпочтительно в настоящем изобретении, так как он создает тексты с применением меток ("тегов") "Стандартного обобщенного языка разметки" (СОЯР), представляющего собой международный стандартный язык разметки для описания структуры документов в электронной форме. Он предназначен для удовлетворения требований в широком диапазоне задач обработки документов и обмена информацией. Метки СОЯР дают возможность описывать документы в аспектах их содержания (текст, изображения и т.д.) и логической структуры (главы, параграфы, рисунки, таблицы и т.д.). В случае более крупных и более сложных документов в электронной форме этот язык также предоставляет возможность описывать физическую организацию документа в виде файлов. Язык СОЯР рассчитан на то, чтобы получить возможность описания документов любого рода - простых или сложных, длинных или коротких - в таком виде, какой не зависит ни от системы, ни от ее практического применения. Эта независимость позволяет обмениваться документами между разными системами для разных применений без искажения смысла или потери информации.
Язык СОЯР - это язык разметки, т.е. язык для "маркировки" или аннотирования текста посредством кодированной информации, добавляемой к обычной текстовой информации, передаваемой конкретным отрывком текста. В большинстве случаев это выполняется в форме последовательностей символов в разных местах по всей протяженности электронного документа. Каждая такая последовательность отличима от окружающего ее текста с помощью особых знаков, которые ее начинают и заканчивают. Программные средства могут проверить правильность внесенной в текст разметки путем обследования меток СОЯР по запросу. Эта разметка обобщена в том смысле, что она не является специфичной для какой-либо конкретной системы или задачи. Более подробную информацию о метках СОЯР можно почерпнуть из Международного стандарта МОС (ISO) 8879 "Обработка информации - Текстовые и конторские системы - Стандартный обобщенный язык разметки (SMGL)" N ISO 8879 - 1986 (E).
Благодаря использованию меток СОЯР возможна реализация следующих задач:
(1) разделение документов на отрывки или доступные для перевода единицы. Программные средства текстового редактора 140 используют как знаки препинания, так и метки СОЯР для распознавания доступных для перевода единиц в исходно введенном тексте (так, например, метка СОЯР необходима для распознавания заголовков разделов),
(2) отгораживание (изоляция) текстовых единиц, не требующих перевода. Хотя вся система основана на предположении того, что все слова и предложения будут в рамках заданного ограниченного языка, этого никогда нельзя ожидать заранее в полной степени, например, в том, что касается фамилий или адресов, либо классов словаря, которые невозможно (или весьма трудно) классифицировать с исчерпывающей точностью (например, номера деталей или сигналы неисправности, поступающие от оборудования). В начале и в конце таких элементов текста можно поставить метки СОЯР, чтобы показать системе, что они исключаются из проверки,
(3) распознавание содержания документа (например, номеров деталей), как это уже обсуждалось выше в абзаце (2),
(4) обеспечение возможности перевода частей предложения (например, выделенных отрывков),
(5) оказание помощи в переводе таблиц (клетка за клеткой) путем обозначения структуры текста. Эта задача подобна задаче, описанной в абзаце (1).
(6) оказание содействия процессу грамматического и синтаксического разбора (который будет рассмотрен ниже) с помощью задач (2), (3), (4) и (5),
(7) оказание помощи в устранении неоднозначности путем предоставления средств для ввода невидимых меток в исходный текст для указания на правильную интерпретацию неоднозначного предложения,
(8) оказание помощи в переводе валют и математических позиций или единиц путем обозначения особых видов текста, требующих специальной обработки,
(9) предоставление средств отметки части текста как переводимой. Иными словами, подтверждение того, что данный текст прошел описываемый ниже процесс и представляет собой лишенный неоднозначности текст в ограниченном языке, который может быть переведен без конечного редактирования.
В прошлом авторы уже создавали (с использованием текстового редактора 140) электронные документы (только текст - без графики), представляющие собой полные "книжки". Здесь имеется в виду ситуация, когда вся работа выполняется одним пишущим автором, и полученная информация трудно поддается повторному использованию. Вместе с тем, настоящее изобретение позволяет составлять (или создавать) книги или брошюры (такие как руководства, инструкции или документы) из множества более мелких отрывков информационных элементов, а это означает, что несколько пишущих авторов могут выполнить одну совместную работу. В результате использования данного изобретения появляется большая возможность повторного использования созданных документов. Информационный элемент определяется как наименьший отдельный отрывок служебной информации в конкретной области. Следует учитывать, однако, что, хотя в предпочтительном варианте осуществления изобретения используются информационные элементы, настоящее изобретение позволяет получать точные и однозначные переведенные документы и без использования информационных элементов.
На фиг. 4 показан пример информационного элемента 410, включающего в себя "уникальный" заголовок 415, "уникальный" отрывок текста 420, "заимствованную" (совместно используемую) графику 430, "заимствованную" таблицу 435 и "заимствованный" отрывок текста 425.
"Уникальной" считается та информация, которая относится исключительно к тому информационному элементу, в котором она содержится. Это означает, что "уникальная" информация вносится в файл как составная часть информационного элемента 450.
"Заимствованной" позицией (графикой, таблицей или отрывком текста) является та информация, к которой в информационном элементе содержится "отсылка". Содержание "заимствованной" информации отображается на используемом автором инструменте, но в файле информационного элемента 450 на нее лишь "указывается".
"Заимствованные" позиции отличаются от информационных элементов тем, что они не являются "отдельно стоящими" (т.е. сами по себе они не несут достаточной информации для того, чтобы выразить существенную информацию). Каждая "заимствованная" позиция сама по себе является отдельным файлом, например информационным элементом.
Информационные элементы создаются из сочетания "уникальных" отрывков или блоков информации (текста и/или таблиц) и одной или более "заимствованных" позиций. Обратите внимание на то, как "уникальный" заголовок 415 и "уникальный" текст 420 сочетаются с "заимствованной" графикой 430, "заимствованной" таблицей 435 и "заимствованным" текстом 425. Набор из одного или более информационных элементов представляет собой полный документ ("книгу").
"Заимствованные" позиции хранятся в библиотеках "заимствования". Виды таких библиотек включают в себя библиотеки "заимствования" графики 460а, библиотеки "заимствования" таблиц 460b, библиотеки "заимствования" текстов 460c, библиотеки "заимствования" звуковой (аудио) информации 460d и библиотеки "заимствования" видеоинформации 460e. "Заимствованная" позиция вводится в память только один раз. Если такая позиция используется в отдельных информационных элементах, в информационный элемент 450 вводятся лишь "отсылки" к исходной заимствованной позиции. Это позволяет сократить требуемый объем памяти на диске. Когда исходная позиция изменяется, автоматически изменяются и все информационные элементы, содержащие "отсылки" к этой позиции. "Заимствованная" позиция может использоваться в публикациях любого рода.
Далее, "заимствованным информационным элементом" является информационный элемент, используемый более чем в одном документе. Так, например, одни и те же четыре информационных элемента в библиотеке выпуска 470 использованы для создания частей документов 480 и 485.
Всем общением между автором и ЯР 130 заведует интерфейс пользователя (ИП) языкового редактора (ЯР), выполненный либо в форме расширения стандартных средств редактора СОЯР, таких как меню с выбором вариантов, либо в форме отдельных окон. ИП предоставляет доступ к контролерам ОИЯ и к вызову словаря ОИЯ, а также управляет этим доступом и является первичным инструментом, позволяющим пользователям вести диалог с языковым редактором (ЯР) ОИЯ. Хотя выражение "интерфейс пользователя" часто применяется в более широком смысле, означая интерфейс доступа к системе программных средств в целом, в данном описании это выражение имеет более ограниченный смысл и означает интерфейс доступа к проверочным контроллерам ОИЯ, к средствам вызова на экран словаря и к средствам устранения неоднозначности.
Помимо всего прочего, здесь от ИП требуется, чтобы он представлял четкую информацию в отношении: (а) предпринимаемых ЯР действий, (б) результата этих действий и (в) любых вытекающих из них действий. Так, например, если когда-либо начинаемая посредством ИП операция приводит в реальном времени к любой паузе, кроме очень короткой, ИП обязан информировать автора о возможной задержке в виде четкого сообщения.
Автор может запустить функции ЯР выбором соответствующего варианта из спускающегося меню в текстовом редакторе 140. Предлагаемые варианты позволяют автору запустить и отслеживать ход проверки по ОИЯ (как словарной, так и грамматической проверки), а также вызывать для просмотра словарь. Автор может заказать либо запуск проверки документа, находящегося на экране, либо просмотреть словарь в отношении заданного им слова или выражения.
ИП четко показывает каждую ситуацию выявления в тексте любого несоответствия с ОИЯ. Возможными приемами указания на несоответствие с ОИЯ может быть выделение цветом либо рисунком, или размером шрифта в окошке редактора СОЯР. При этом ИП выводит на экран всю известную системе информацию в отношении не соответствующего ОИЯ слова. Например, там, где это оправдано, ИП выведет на экран сообщение, указывающее на то, что данное слово не включено в ОИЯ, но имеет в ОИЯ синонимы, а также перечень этих синонимов.
В случаях, когда сообщение словарного контроллера включает в себя список альтернатив выделенного слова, не найденного в ОИЯ (например, альтернативные написания или синонимы в ОИЯ), автор получает возможность выбрать одну из этих альтернатив и приказать произвести в документе автоматическую замену. В отдельных случаях автор будет вынужден скорректировать (например, путем придания правильного окончания) выбранную им альтернативу для обеспечения того, чтобы она была введена в документ в требуемой форме.
Когда автор запрашивает информацию из словаря, ИП показывает ему альтернативные написания, синонимы, определение и/или пример использования в текстах указанной им позиции.
Автор имеет возможность быстрого перехода от информации контроллера к информации по просмотру словаря в пределах своего ИП. Это позволяет автору проводить информационный поиск (например, просмотр синонимов) в процессе изменения документа для удаления из него не соответствующих ОИЯ слов и выражений.
В большинстве случаев ИП обеспечивает автоматическую замену отсутствующих в ОИЯ словарных единиц на словарь ОИЯ, и при этом автору не нужно изменять слово из ОИЯ для обеспечения его правильной формы в документе. Вместе с тем, в некоторых случаях словарный контроллер (описанный ниже), который не производит грамматически-синтаксического разбора документа, не может сам определить правильную форму слова для ввода в документ. Рассмотрим следующую надпись в тексте, когда слово "смотреть" отсутствует в ОИЯ, но имеет в ОИЯ синоним "видеть":
Направление вращения коленвала
(при наблюдении со стороны маховика)
Контроллер словаря может не знать, следует ли предлагать в качестве замены выражения "при наблюдении" варианты "видеть" (смотреть) или "вид". Разумеется, в подобном случае наиболее разумным выходом будет предложить оба варианта и позволить автору сделать между ними выбор правильной формы. Далее, поскольку не может быть уверенности в том, что в каждом случае автору может быть предложен такой выбор, какой позволит ему прямую замену, ЯР 130 предлагает список вариантов замены в правильной форме там, где это ему под силу. Могут быть, однако, случаи, когда автор окажется вынужден отредактировать предложенное слово или выражение из ОИЯ, прежде чем он даст команду на ввод этого слова или выражения в документ.
И, наконец, ИП ЯР оказывает поддержку в устранении неоднозначности смысла предложений. Он делает это, предлагая автору список возможных альтернативных интерпретаций, позволяя автору выбрать среди них правильную интерпретацию, а затем помечая текст, с тем чтобы указать на сделанный автором выбор.
Б. Система управления файлами
Система управления файлами (СУФ) 110 служит в качестве интерфейса авторов с библиотекой выпуска информационных элементов (ИЭ) 470 и с текстовым редактором 140 СОЯР. В общем случае авторы выбирают ИЭ для редактирования, называя в интерфейсе с СУФ тот файл, в котором этот ИЭ находится. Тогда СУФ 110 запускает сеанс работы редактора СОЯР с этим ИЭ и управляет этим сеансом. После этого законченные документы передаются человеку-редактору или программному интегратору информации через средства, управляемые СУФ.
В. Ограниченный исходный язык (ОИЯ)
С учетом сложности современной технической документации высококачественный машинный перевод текстов на неограниченном естественном языке оказывается практически невозможным. Основными препятствиями в этом отношении являются трудности языкового характера. Критическим процессом при переводе исходного текста-оригинала является передача его смысла на целевом языке. Поскольку смысл заложен под покровом текстовых сигналов, эти видимые сигналы нуждаются в анализе, и смысл, выявляемый в результате такого анализа, используется в процессе генерирования сигналов на целевом языке. Некоторые из наиболее сложных проблем перевода проистекают из тех присущих языку характеристик, которые затрудняют анализ и генерирование смысла.
Вот некоторые из таких характеристик.
1. Слова, имеющие более одного значения в неоднозначном контексте - Пример: Изготовить из материала повышенной плотности. (Какой материал имеется в виду: "менее проницаемый" или "более тяжелый"?).
2. Неоднозначные составные слова -
Пример: Природоохрана.
(Что имеется в виду: охрана природы или организация, занимающаяся этой охраной?)
3. Слова, выполняющие разные синтаксические функции -
Пример: "Течь" может быть существительным (С) или глаголом (Г).
(С) Надо ликвидировать течь в трубопроводе.
(Г) Среда должна течь без завихрений.
4. Сочетания слов, каждое из которых может иметь более одной синтаксической функции -
Пример: правые и левые здесь не пройдут.
(Кто здесь не пройдет - консерваторы и радикалы (существительные - С) или правые и левые участники шеренги (прилагательные - П)?).
5. Сочетания слов в неоднозначной конструкции -
Пример: Посещение родственников может быть утомительным.
(Что или кто здесь утомляет - факт посещения родственников или посещающие родственники?).
6. Двусмысленное использование местоимений -
Пример: Лектор скомкал доклад, потому что он был...
(Кто здесь "он" - лектор или доклад?)
На проиллюстрированные здесь трудности прочтения накладываются проблемы генерирования переводного текста, повышая тем самым общую сложность машинного перевода.
Размер проблем перевода может быть значительно уменьшен любым сокращением диапазона лингвистических проявлений, которыми изобилует естественный язык. Сокращенный язык или "под-язык" охватывает ограниченный диапазон предметов, действий и взаимоотношений в конкретно очерченной области. Вместе с тем, "под-язык" может быть ограничен по его словарному запасу, но при этом он не обязательно может быть ограничен в тонкостях своей грамматики. В контролируемой ситуации стратегия, направленная на облегчение машинного перевода, заключается в ограничении как словарного запаса, так и грамматики "под-язык".
Ограничения, накладываемые на словарный запас, сокращают его размер путем исключения синонимов и контролируют лексическую неоднозначность путем придания специализации разрешенным лексическим единицам, так чтобы они, по возможности, имели лишь одно значение на каждую единицу. Легко понять, как введение подобных ограничений позволило бы преодолеть проблемы, проиллюстрированные выше в примерах 1, 2 и 4. Грамматические ограничения могут попросту запретить такие приемы, как подмена существительных местоимениями (пример 6 выше), либо потребовать, чтобы вкладываемый в текст смысл делался яснее либо через расширение, либо через повторение информации, которая иначе могла бы показаться излишней, либо через полное перефразирование. Приводимый ниже пример указывает на параметры применимости подобного требования.
Данную фразу в неограниченном и неоднозначном английском языке можно понимать трояко (А, Б1 или Б2):
Clean the connecting rod and main bearings.
Лишенный неоднозначности вариант "А" на английском языке: Clean the connecting rod bearings and the main bearings. (Очистить подшипники шатунов и коренные подшипники).
Лишенный неоднозначности вариант "Б1" на английском языке: Clean the main bearings and the connecting rod. (Очистить коренные подшипники и шатун).
Лишенный неоднозначности вариант "Б2" на английском языке: Clean the main bearings and the connecting rods (Очистить коренные подшипники и шатуны).
С учетом сказанного выше настоящее изобретение ограничивает авторское написание документов пределами сокращенного или ограниченного языка. Ограниченный язык представляет собой "под-язык" исходного языка (например, американской разновидности английского языка), разработанный для области конкретного применения пользователем. Более подробное общее рассмотрение аспектов ограниченных языков изложено в материале Adriaens et al, From COGRAM to ALCOGRAM: Toward a controlled English Grammar Checker, Proc. of Coling-92, Nantes (Aug, 23-28, 1992) (Адриенс и др., От КОГРАМ до АЛКОГРАМ: На пути к контролируемым средствам проверки английской грамматики, Материалы конференции "Колинг-92", Нант (23-28, авг. 1992 г.), который здесь упоминается в качестве отсылки. В контексте машинного перевода в качестве задач ограниченного языка ставится следующее:
1. облегчить последовательную авторскую подготовку исходных документов и способствовать четкому и однозначному написанию,
2. создать следующие одному принципу рамки для исходных текстов, которые позволили бы быстрый, точный и высококачественный машинный перевод документов пользователя.
Тот свод правил, которому должны следовать авторы для обеспечения того, чтобы грамматика написанных ими текстов соответствовала ОИЯ, будет далее называться "Грамматическими ограничениями ОИЯ". Компьютерное воплощение грамматических ограничений ОИЯ, используемое для анализа текстов на ОИЯ в блоке МП, будет далее именоваться "Функциональной грамматикой ОИЯ", основанной на хорошо известных приемах формализации, разработанных Martin Kay и впоследствии модифицированных R. Kaplan и J. Bresnan - см. Kay M., "Parsing in Functional Unification Grammar" (Кей М., "Разбор в функциональной унифицированной грамматике") в книге под редакцией D. Dowty, L.Karttunen and A.Zwicky Natural Language Parsing: Psychological, Computational and Theoretical Perspectives (Разбор естественного языка: Психологические, компьютерные и теоретические аспекты), Cambridge, Mass.: Cambridge University Press, стр. 251-278 (1985 г.), а также Kaplan, R и J.Bresnan, "Lexical Functional Grammar: A Formal System for Grammatical Representation" (Каплан, Р. и Дж. Бреснан "Лексическая функциональная грамматика: "Формализованная система для грамматического отображения") в книге под редакцией J.Bresnan, The Mental Representation of Grammatical Relations (мысленное отображение грамматических отношений), Gambridge, Mass.: MIT Press, стр. 172-281 (1982 г.). Оба этих материала здесь упоминаются в качестве отсылок.
В последующей части данного описания мы будет часто обращаться к понятию того, что слово или фраза могут быть "в ОИЯ" или "не в ОИЯ". Ниже мы изложим наши предположения относительно тех видов словарных ограничений, которые будут накладываться ОИЯ, и объясним применение выражения "в ОИЯ".
Одно и то слово или одна и та же фраза на английском языке могут иметь много различных значений, так, например, словарь общего типа может приводить следующие определения слова "leak" (течь, протекать, утечка и т.д.):
(1) глагол: допустить убывание чего-либо через разрыв или дефект,
(2) глагол: раскрыть информацию без официальных полномочий или разрешения, а также
(3) существительное: трещина или отверстие, позволяющие чему-либо выходить из сосуда или трубопровода или входить в него.
Каждое из этих различных значений называют "смыслом" слова или выражения. Различные значения одного и того же слова или выражения способны создавать проблемы для системы МП, которая не располагает всеми теми значениями, которыми пользуются люди для понимания того из нескольких значений, какое подразумевается в конкретном предложении. Для многих слов система машинного перевода может устранить определенную часть неоднозначности путем распознавания той части речи, в качестве которой слово использовано в данном предложении (существительное, глагол, прилагательное и т.д.). Это возможно благодаря тому, что каждое из определений какого-то слова привязано к его использованию в качестве определенной части речи, как было пояснено выше на примере слова "leak".
Вместе с тем, в целях избежания тех видов неоднозначности, какие МП 120 не может устранить, условия и определения ОИЯ стремятся к тому, чтобы включать лишь одно значение слова или выражения для каждой части речи. Таким образом, если слово или выражение находится "в ОИЯ", его допустимо использовать в ОИЯ в по меньшей мере одном из его возможных значений. Так, например, автору, создающему его текст в ОИЯ, может быть разрешено использовать слова "leak" в его указанных выше значениях (1) и (3), но не в его значении (2). Если говорится, что слово или выражение находится "в ОИЯ", это отнюдь не означает, что могут быть переведены все возможные применения этого слова или выражения.
Если слово или выражение включено в ОИЯ, все формы этого слова или выражения, передающие присвоенное ему в ОИЯ значение (или значения), также включены в ОИЯ. В приведенном выше примере автору разрешено использовать не только глагол "leak" (в смысле "протекать"), но и связанные с ним глагольные формы "leaked" ("протекал"), "leaking" ("протекающий") и "leaks" ("протекает"). Если слово или выражение, имеющее смысл существительного, является частью ОИЯ, оно может быть использовано как в единственном, так и во множественном числе. Следует отметить при этом, что выражения, которые могут выступать в качестве разных частей речи, встречаются крайне редко. Поэтому изложенные здесь соображения менее существенны в случае неоднозначного выражения.
Словарем или словарным запасом называют фонд слов и выражений, используемых в конкретном языке или "под-языке". Поэтому об ограниченной области можно говорить посредством определения того ограниченного словаря, который используется для общения или передачи информации относительно ограниченного этой областью объема человеческих знаний или опыта. В качестве примера ограниченной области можно назвать сельское хозяйство, где ограниченный словарь будет включать в себя термины, относящиеся к сельскохозяйственному оборудованию и видам деятельности. Блок МП системы работает более чем с одним видом словаря. Слова и выражения для машинного перевода хранятся в словарном запасе (лексиконе) МП. Словарь как таковой можно подразделить на различные категории: (1) функциональные позиции, (2) позиции общего содержания, а также (3) техническая номенклатура.
Слова общего содержания используются по большей части для описания окружающего нас мира, их главное назначение - отражать обычное и общие для всех человеческий опыт и представления.
В типичном случае, однако, документы фокусируются на весьма специализированной части человеческих представлений и опыта (например, машины и их обслуживание). Как таковой, общий словарь будет относительно ограничен для целей МП.
Техническая номенклатура включает в себя слова и выражения технического содержания, а также специальный словарь для области применения, интересующей пользователя. Позициями технического содержания мы называем здесь слова и выражения, которые узко специфичны для конкретной области деятельности или применений. Большинство технических слов являются существительными, используемыми для обозначения таких позиций, как детали, узлы, компоненты, машины или материалы. Вместе с тем, в состав технических могут входить и другие категории слов, такие как глаголы, прилагательные или наречия. Вполне очевидно, что поскольку такие слова практически не используются в повседневных общих разговорах, они резко отличаются от слов общего содержания.
Выражения технического содержания представляют собой словосочетания, построенные из слов всех названных выше категорий. Эти выражения представляют собой наиболее характерную форму языка технической документации. Специальный прикладной словарь пользователя является частью терминологии, четко содержащей слова и сложные термины, созданные в прикладной области пользователя. Сюда может входить следующее: наименования изделий, названия документов, применяемые пользователем акронимы и аббревиатуры, а также номера бланков или стандартных форм.
Разработка полезного и полного словаря является важным компонентом любого вида деятельности в сфере документации. Когда документация впоследствии подвергается переводу, этот словарь является важным ресурсом для работы по переводу. МП рассчитан на то, чтобы оперировать большинством функциональных позиций, имеющихся в английском языке, за исключением позиций, относящихся к очень личному применению (я, меня, мой и т.д.), к применению с учетом пола (ее, она и т.д.) или к применению других местоимений (оно, их и т.д.). Сюда также входит определенное заимствование из общих слов английского языка (таких как "truck" (в значении "грузовой автомобиль") или "leangth" (в значении "отрезок")). Подавляющее большинство компонентов словаря ограниченного языка состоит из "специальных" (например, технических) терминов из одного или нескольких слов, которые обозначают предметы и процессы или операции в особой области. В той степени, в которой такой словарь может передавать полный спектр понятий в конкретной области, этот словарь можно назвать полным.
Разработка достаточно упрощенного, но полного словаря вносит большой вклад в успех функционирования системы 105 ИСАПП. Ограниченный язык, указывающий на правильное или неправильное использование словаря, обеспечивает положение, при котором документы можно создавать так, чтобы они способствовали быстрому, точному и высококачественному машинному переводу.
Словарные позиции должны отражать четкие понятия и должны быть пригодными для целевого читателя. Следует избегать таких терминов, которые несут признаки половой направленности, жаргонности, идеоматичности, излишней усложненности или техничности либо имеют иные черты, затрудняющие общение. Эти и другие общепринятые стилистические соображения, хотя они не всегда абсолютно обязательны для обработки, рассчитанной на МП, являются, тем не менее, важными отправными пунктами для создания документов вообще.
Следует учитывать, что хотя основная часть рассуждений в данном описании, относящихся к ограниченному исходному языку и/или к языку вообще, концентрируется на американской версии английского языка (т.е. на американском английском языке), аналогичные сравнения могут быть сделаны и применительно ко всем остальным языкам. В описываемой здесь системе 100 не заложено принципиально ничего такого, что делало бы ее предназначенной исключительно для использования американского английского языка в качестве исходного языка. На самом деле, система 100 не сконструирована для того, чтобы работать с американским английским языком как с единственным исходным языком. Тем не менее, базы данных (например, модель области применения), взаимодействующие с ЯР 130 и МП 120, потребуют изменений для их соответствия ограничениям конкретного исходного языка.
Необходимо следовать правилам орфографии стандартного американского английского языка. Нестандартные для американского языка написания слов, такие как "thru" вместо "through", "moulding" вместо "molding" или "hodometer" вместо "odometer", не должны употребляться. Слова с заглавной буквы (например, On - Оff ("Вкл-Выкл"), Value Planned Repair ("Плавный Ремонт")) могут применяться только в тех случаях, когда необходимо указать на особое значение этих слов. То же самое применимо к нестандартному использованию заглавных букв (Brake Saver). Аналогично, если используются аббревиатуры (ROPS, API, PIN), они должны быть перечислены и объяснены в прикладном особом словаре пользователя. Формат представления цифр, единиц измерения и календарных дат должен быть единым и последовательным.
Поисковые позиции ограниченного языка также должны использоваться в соответствии с их значениями в этом ограниченном языке. Поступая таким образом, автор обеспечивает положение, при котором МП всегда будет переводить какое-либо слово с применением его правильного значения в ограниченном языке. Как уже указывалось, некоторые слова английского языка могут принадлежать к более чем одной синтаксической категории. В ограниченном языке все синтаксически неоднозначные слова должны применяться в оборотах, лишающих их неоднозначности.
В некоторых областях частое употребление длинных составных существительных является одной из трудных проблем, вытекающих из самого характера конкретной области. Взаимоотношения подчинения, присутствующие в таких составных существительных, выражаются по-разному в разных языках. Поскольку не всегда возможно выявить эти взаимоотношения из исходного текста и выразить их в целевом языке, сложные составные существительные со следующими характеристиками могут быть заранее перечислены в словарном запасе (лексиконе) МП:
технические термины из особого прикладного словаря пользователя, а также
составные термины из более чем одного слова.
Следует по возможности избегать сложных сочетаний существительное - существительное (при котором в английском языке предшествующее слово выполняет функцию определения последующего слова). Вместо с тем, в отношении некоторых позиций, перечисленных в лексиконе, МП может справляться с этой важной характеристикой документации. Следует учитывать, что сочетания типа существительно-существительное, являющиеся весьма широко распространенными в английском языке, не обязательно могут быть привычным приемом другого языка, и в силу этого те ограничения, на основании которых создается ограниченный язык, будут различными при использовании любого конкретного исходного языка.
Далее, английский язык изобилует сочетаниями предлог-частица, в которых глагол используется совместно с предлогом, наречием или иной частью речи. Поскольку такая "частица" нередко может быть отделена от глагола дополнениями и иными выражениями, это порождает сложности при обработке исходного текста средствами МП. Таким образом, сочетания глагол-частица следует переписывать заново там, где это возможно. Как правило, этого можно достичь использованием глагола того же смысла, но из одного слова. Например, следует использовать:
"must" или "need" вместо "have to" (все три глагольные формы означают долженствование),
"consult" вместо "refer to" (отсылка к источнику),
"start the motor" вместо "turn the motor on" (и то, и другие означает "завести двигатель").
Везде, где это возможно, надо использовать полные термины и понятия. Это особенно важно в тех случаях, когда может произойти непонимание. Например, в выражении:
"Для отворачивания болта пользоваться изогнутым ключом..." (по-английски изогнутый ключ дословно звучит как "ключ-обезьяна")
недопустимо опускать слово "ключом". Хотя большинство технически сведущих людей поймут смысл сказанного и без слова "ключ" (которое в английских технических текстах иногда опускается, и ключ называют просто "обезьяной"), это выражение должно быть сделано однозначным в ходе процесса перевода. Подготовленный текст в ОИЯ должен иметь словарь, выраженный однозначно везде, где это возможно, при этом аббревиатуры или сокращенные термины следует переписывать в виде лексически полных выражений.
Рассмотрим еще один пример:
"Если плотность электролита указывает на то, что..."
В этом случае смысл будет более однозначным и полным, если идея выражена полностью:
"Если измеренная величина плотности электролита указывает на то, что..."
И, наконец, в следующих предложениях, где отдельные слова или выражения опущены, подчеркнутые слова добавлены, чтобы сделать смысл более однозначным:
"Повернуть ключ зажигания в положение ВЫКЛ и убрать этот ключ".
"Потянуть спинку (1) вверх и передвинуть спинку в требуемое положение".
"Запуск от внешнего источника стартерного тока: машины не должны касаться одна другой".
Когда такие "пробелы" заполнены, идея становится более полной, и правильное значение перевода средствами ИСАПП 105 делается более надежным. Ошибки в переводе, вызванные пропусками или пробелами, являются распространенной причиной необходимости в конечном редактировании. В силу этого пропуски или пробелы недопустимы.
Разговорный английский язык нередко прибегает к использованию слов очень широкого смысла. Это может иногда приводить к такой степени неясности, какую приходится разрешать в процессе перевода. Например, такие слова, как conditions, remove, facilities, procedure, go, do, is for, make, get (условия, убрать, убрать, объекты, предназначен для, делать, брать) и т.п. являются правильными, но зачастую неточными.
В таком, например, предложении:
"Когда температура достигает 32oF, надо прибегать к особым мерам предосторожности"
слово "достигает" не сообщает читателю, повышается ли температура или понижается, одно из этих двух слов было бы в данном случае более точным, и текст при этом был бы не менее "читаемым".
В некоторых языках различия в словах существуют там, где они не всегда имеются в английском языке, так, например, мы говорим "oil" (масло, нефть, мазут и т.д.) и про смазочное масло, и про топливное либо мы говорим "fuel" (топливо) и про дизельное топливо, и про другие виды топлива. Аналогично, когда слово "door" (дверь, дверца) применено без контекста, не всегда можно понять, о какого рода двери идет речь. Дверца автомобиля? Дверь в здании? Дверь в квартире? В некоторых языках эти двери называются разными словами. Там, где это возможно, в английском оригинале должны использоваться полные термины.
B. Модель области применения
Основанный на знаниях (сведениях) машинный перевод (ОЗМП) должен получать поддержку со стороны сведений о словах и лингвистических семантических сведений в отношении значения (смысла) лексических единиц и их сочетаний. База сведений ОЗМП должна быть способной представлять собой не только общую, таксономическую область типов объектов, таких как "автомобиль является разновидностью транспортных средств", "дверная ручка является частью двери", "изделия должны характеризоваться (помимо других качеств) свойством "сделано путем", она должна также воплощать знания о конкретных случаях видов объектов (так, "IBM" может быть включена в модель области как отмеченный случай объекта типа "корпорация"), а также о случаях видов событий (потенциально сложных) - так, например, избрание Джорджа Буша президентом Соединенных Штатов представляет собой отмеченный случай сложного действия "выбирать". Онтологическая часть базы сведений принимает форму множественной иерархии концепций, объединенных одна с другой посредством связей, строящих определенную таксономию (систематику), такие как "is a" ("является (чем-либо)"), "part-of" ("часть (чего-либо)") и некоторые другие. Мы называем получаемую в результате структуру множественной иерархией, поскольку допустимо, чтобы концепции имели множественных "родителей" в каждом виде связей.
Модель области или концептуальной лексикон включает в себя онтологическую модель, представляющую унифицированные определения базовых категорий (таких, как объекты-предметы, события-ситуации, взаимоотношения, свойства-качества, эпизоды и т.п.), используемых в качестве "кирпичиков" для построения конкретных областей. Модель "мира" является относительно статичной и организована как множественная взаимосвязанная сеть онтологических концепций. Общие принципы разработки онтологии прикладного мира или "под-мира" хорошо известны из специальной литературы - см., например, Brachman and Schmolze, An Overview of the KL-ONE Knowledge Representation System (Брахман и Шмольце, Обзор системы отображения знаний KL-ONE), Cognitive Science, vol. 9, 1985; Lenat et al, Using Common Sense Knowledge to Overcome Brittleness and Knowledge Acquisition Bottlenecks (Ленат и др., Использование здравого смысла для преодоления затруднений хрупкости и накопления знаний), Al Magazine, VI: 65-85, 1985; Hobbs, Overview of the Tacitus Project (Хоббс. "Обзор проекта Тацитус"), Computational Linguistics, 12:3, 1983; Nirenburg et al, Acquisition of Very Large Knowledge Bases: Methodology, Tools and Applications (Ниренбург и др., Накопление очень крупных баз знаний: Методология, инструменты и применения) Center for Machine Translation, Carnegie Mellon University (1988); все эти материалы упоминаются здесь в качестве отсылки.
Онтология представляет собой независимое от языка концептуальное отображение конкретного под-мира, такого, например, как обнаружение неисправностей и ремонт тяжелого оборудования либо взаимодействие между персональными компьютерами и их пользователями. Она предоставляет необходимую семантическую информацию в области под-языка для разбора исходного текста при его преобразовании в текст на промежуточном языке (интерлингва) и при генерировании целевых текстов из текстов на промежуточном языке. Модель области должна быть достаточно детализирована для того, чтобы вводить достаточные семантические ограничения, способные устранить случаи неоднозначности при разборе текста, а онтологическая модель должны представлять унифицированные определения базовых онтологических категорий, представляющих собой кирпичики для описаний в конкретных областях.
В модели мира онтологические концепции могут быть сначала подразделены на объекты (предметы), события, силы (вводимые для учитывания непреднамеренных действующих лиц - агентов) и свойства (качества). Свойства можно далее подразделить на отношения и признаки. При этом отношения получают определения как разметки связи (mappings) между концепциями (так, "принадлежит-к" является отношением, поскольку оно размечает объект в множестве (*человеческая*организация), в то время как признаки определяются как разметка концепций в особо определенные множества величин (так, "температура" является свойством, которое размечает физические объекты в величины на половинно открытой шкале (0,*), с калиброванием в виде градусов по шкале Кельвина). Концепции, как правило, отображаются как пазовые рамки, чьи пазы представляют собой свойства, получившие полные определения в системе.
Модели областей являются необходимой частью любой системы на базе знаний (сведений), причем не только системы машинного перевода на базе знаний. Модель области представляет собой семантическую иерархию концепций (понятий), имеющих место в области перевода. Так, например, мы можем дать определение объекту *О-ТРАНСПОРТНОЕ-СРЕДСТВО, включающее в себя *О-КОЛЕСНОЕ-ТРАНСПОРТНОЕ-СРЕДСТВО и *О-ГУСЕНИЧНОЕ-ТРАНСПОРТНОЕ СРЕДСТВО, и при этом первое будет включать в себя *О-ГРУЗОВОЙ-АВТОМОБИЛЬ, *О-КОЛЕСНЫЙ-ТРАКТОР, и так далее. На самом нижнем уровне иерархии находятся конкретные концепции (понятия), соответствующие терминологии в ОИЯ. Мы называем этот нижний уровень Я/МО (Ядро/Модель области). В целях получения точного перевода мы должны наложить семантические ограничения на те роли, которые играют различные концепции или понятия. Так, например, тот факт, что роль агента в действии *Е-ВЕСТИ должен выполнять человек, представляет собой семантическое ограничение, наложенное на *О-ТРАНСПОРТНОЕ-СРЕДСТВО, и это автоматически распространяется на все виды транспортных средств (тем самым экономию, повторяющуюся работу по ручному кодированию каждого образца). Часть "Авторского написания" в модели области усиливает Я/МО синонимами, не включенными в ОИЯ, а также иной полезной информацией для предоставления автору столь же полезной обратной связи, когда он или она составляет каждый из информационных элементов.
На фиг. 5 концептуально проиллюстрирована Модель области (МО), примененная в настоящем изобретении. МО 500 представляет собой отображение декларативных знаний в отношении словаря ОИЯ, используемого МП 120 и ЯР 130. МО 500 состоит из трех различных частей.
1. Ядро (Я/МО) 510 содержит всю лексическую информацию, какая нужна как анализатору 127 МП, так и ЯР 130, в частности, ядро включает в себя все лексические позиции (слова и выражения) ОИЯ вместе со связанными с ними схематическими понятиями, обозначениями частей речи, морфологической информацией и т.д.
2. Модель области для МП (МП/МО) 520, которая содержит лишь ту информацию, которая потребна анализатору 127 МП. Модель области для МП представляет собой иерархию понятий, используемых для недвузначной разметки связей и для семантических проверок при переводе. Она включает в себя выборочные ограничения в отношении понятий и иерархическую классификацию понятий.
3. Модель области для ЯР (ЯР/МО) 530 содержит информацию, которая нужна исключительно для ЯР 130, сюда входят синонимы вне пределов ОИЯ лексических позиций ОИЯ, словарные определения лексических позиций ОИЯ, а также примеры использования лексических позиций ОИЯ.
Ядро 510 рассчитано на то, чтобы содержать одну лексическую запись на каждую лексическую позицию (слово или выражение) ОИЯ. ("Лексическая запись" состоит из лексической позиции - слова или выражения - и, как минимум, связанного с ней семантического понятия и обозначения части речи). Так, например, если слов "течь" введено в ОИЯ и как существительное, и как глагол, ему будут соответствовать две лексические записи. Каждая лексическая позиция будет подвергаться обновлению дополнительной информацией, требуемой для ЯР 130 и/или для МП 120, такой как определения и "неправильные" (т.е. не соответствующие общим правилам) морфологические варианты.
Наличие заимствуемого ядра 510 ускоряет операции уточнения и расширения ОИЯ, исключает дублирование работы блоков авторского написания и перевода, а также предоставляет читаемую человеком структуру для облегчения ухода за системой и ее расширения.
Итак, ядра 510 представляют собой лексикон, содержащий и синтаксическую, и морфологическую информацию в отношении терминов (слов и выражений) в тексте, написанном на ограниченном языке. Это - центральный источник лексических знаний для аналитического аспекта процесса автоматизированного машинного перевода (МП). Далее, ядро 510 также используется в качестве основы для ЯР/МО.
Ядро 510 содержит отдельную запись для каждого термина в каждой синтаксической категории. (Так, например, слову "truck", которое является как существенным, так и глаголом ("грузовой автомобиль" или "грузовик" и "перевозить на грузовых автомобилях"), соответствуют две записи. Записи в ядре содержат следующую информацию:
корень (например, "truck");
часть речи (например, N (существительное - С));
морфологическая информация (например, неправильные изменения формы слова);
синтаксическая информация (например, является ли существительное исчисляемым или неисчисляемым);
определительная информация: короткие определения и текстовые примеры, поясняющие различные значения и применения слов, а также указание на то значение, в котором это слово должно использоваться в ограниченном языке.
МО 500 определен в трех наборах внешних, читаемых человеком файлов, которые также могут читаться в тех операциях, которые требуют обращения к этой модели. Поскольку МП 120 и ЯР 130 будут отрабатываться в раздельных процессах или операциях, информация в этой модели внутренне представлена в двух формах: одна для тех частей МО, которые требуются для работы МП 120, и другая - для той части, которая требуется для ЯР 130. Таким образом, ядро 510 определено как набор файлов, которые могут быть представлены в двух формах, при этом блок ЯР/МО 530 представлен лишь в той форме, которую использует ЯР 130, а МП/МО 530 представлен лишь в той форме, которую использует МП 120. Ниже описаны форматы внешних файлов, содержание различных частей МО и внутреннее представление информации, используемой ЯР 130.
Следует повторить, что ядро содержит информацию, требующуюся как для МП 120, так и для ЯР 130. В нее входит лексическая позиция ОИЯ - базовое слово, выражение либо цитируемое слово и семантическое понятие - и при этом семантическое понятие связано в лексической позицией, представленной в лексической записи посредством "имени понятия". Далее, там имеется часть речи - одна из фиксированного набора частей речи (например, глагол, прилагаемое и т. д. ), определение - "грубое" определение для терминов из общего словаря, уточняющее, какое значение из нескольких возможных значений может иметь данная лексическая единица ОИЯ, а также "неправильные" морфологические варианты - перечень неправильных морфологических форм и наименование требуемого морфологического преобразования для каждого из них. Примерами наименований морфологических преобразований для глаголов (английского языка) являются "форма прошедшего времени", форма "третьего лица единственного числа настоящего времени", форма "причастия настоящего времени" и форма "причастия прошедшего времени". Так, например, величинами для этого поля для глагола "drive" будут прошедшее время "drove", причастие прошедшего времени "driven", показывая, что именно эти две формы данного глагола неправильны, а все остальные формы правильны. И, наконец, ядро включает в себя типографские ограничения - так, например, если данная лексическая позиция должна иметь все заглавные буквы, указывая, что первая буква должна быть заглавной и т.д.
Блок МП/МО 520 содержит информацию, которая требуется лишь блоку МП 120. В эту информацию входят: селекционные ограничения понятий и иерархическая классификация понятий для организации и преемственности селекционных ограничений.
Блок ЯР/МО 530 содержит синонимы, не включенные в ОИЯ, в качестве оказания помощи авторам в подборе разрешенных лексических позиций из ОИЯ. Взятые вместе ядро и ЯР/МО содержат всю информацию и все ограничения, которые требуются для характеризации лексикона ОИЯ как поддержки для работы словарного контроллера ЯР (описанной ниже). ЯР/МО содержит дополнительную информацию, требуемую лишь для работы словарного контроллера ЯР. В нее входят: словарное определение - т.е. определение слова или выражения, которое будет показано автору языковым редактором (ЯР), синонимы, не включенные в ОИЯ - т. е. синонимы для лексических позиций ОИЯ, которые авторы могут применять в написании документов, а также примеры использования - т.е. пример слова или выражения в предложении, соответствующем ОИЯ, который будет показан автору ЯР.
Целью включения этой информации в ЯР/МО является оказание авторам помощи в обеспечении того, чтобы их текст был составлен из разрешенных слов и выражений ОИЯ. Определения из словаря и примеры использования помогут авторам убедиться в том, что они применяют слово и выражение в качестве разрешенной в ОИЯ части речи и в разрешенном в ОИЯ значении, вместе с тем, словарные определения и примеры пользования не требуются для всех без исключения лексических позиций ОИЯ. Скорее они потребляются лишь для малого процента неоднозначных или неясных терминов, чье значение в ОИЯ может не быть заведомо явным для авторов. Скорее всего, это составит менее половины лексических позиций в МО. Так, например, такие функциональные слова, как "for" (для) или "the" (определенный артикль) не потребуют определений или примеров использования, также могут не потребоваться определения или примеры для многих технических терминов, в особенности для терминов с весьма конкретным техническим смыслом.
Не включенные в ОИЯ синонимы, введенные в ЯР/МО, помогут автору, написавшему не включенное в ОИЯ слово или выражение, подобрать для замены синонимическое или подобное слово или выражение из ОИЯ. Желательно, чтобы словарный контроллер выдавал информацию не только о синонимах, являющихся той же частью речи, что и использованное слова не из ОИЯ, с которым они синонимичны, но также и о связанных с ними словах, которые могли бы помочь авторам перефразировать их предложения. Если последние не включены, ЯР/МО должен содержать информацию относительно этих связанных слов в дополнение к его обязательному содержанию.
Г. Языковый редактор
Как показано на фиг. 1В, редактор ограниченного языка (ЯР) 130 представляет собой набор орудий для поддержки авторов и редакторов в создании ими документов в рамках ОИЯ. Такие орудия помогут автору использовать правильный словарный запас и грамматику ОИЯ при написании служебной документации. ЯР 130 построен как "продолжение" текстового редактора 140 СОЯР. Хотя ЯР 130 использует те же каналы связи, что и текстовый редактор 140 СОЯР, функции этих двух редакторов являются взаимно исключающими. Вместе с тем, интерфейс пользователя, используемый для диалогового взаимодействия с ЯР, является "бесшовным продолжением" интерфейса текстового редактора СОЯР.
Автор 160 создает документы в текстовом редакторе 140 СОЯР и вызывает ЯР 130. ЯР 130 сообщает автору о тех отдельных словах в документе, которые не включены в ОИЯ, и имеет возможность предложить синонимы из ОИЯ для тех слов, которые имеют прямое отношение к прикладной информационной области пользователя, но отсутствуют в ОИЯ. Кроме того, ЯР 130 сообщает автору о том, соответствует ли текст в его файле синтаксическим ограничениям ОИЯ.
Программные средства ЯР 130 включают в себя следующие компоненты: словарный контроллер, грамматический контроллер, в который входит интерфейс с синтаксическим анализатором МП, обеспечивающим ключевую функцию грамматической проверки, а также интерфейс пользователя (ИП). Помимо сказанного, словарная информация ОИЯ, используемая ЯР ОИЯ, также представлена в ядре и в ЯР/МО.
Конечной задачей ЯР является подтверждение того, что все словарные структуры и предложения в документе соответствуют техническим условиям на ОИЯ. В этом случае ЯР 130 помечает документ меткой СОЯР, обозначающей это подтверждение в отношении ОИЯ. Проверка должна охватывать полный текст документа, включающий в себя следующие компоненты: предложения, заголовки, позиции в перечнях, подрисуночные и нарисуночные подписи в графической информации, а также информацию в таблицах.
Поскольку настоящее изобретение исходит из предположения того, что продуктивность авторов должна быть максимально возможной в течение проверки по ОИЯ и что авторов не следует вынуждать работать над авторским написанием нескольких документов одновременно, пакетная форма работы, при которой от пользователя требуется представлять документ для обработки, а затем ждать, пока весь документ будет закончен, прежде чем он или она получают от системы какую-либо обратную связь, не представляется здесь подходящей. ЯР 130 обеспечивает интерактивное общение с авторами при проверке словаря, при проверке грамматики и в ходе устранения неоднозначности в диалоговом режиме.
На фиг. 6 показана структурная схема высокого уровня работы ЯР 130. ЯР 130 принимает на входе документ 605, который потенциально может быть неоднозначным и неограниченным. Этот потенциально неоднозначный и неограниченный входной текст 605 сначала подвергается проверке словарным контроллером 610, выполняющим его функции (как описывалось выше) при содействии контроллера правописания 615. (Услуги контролера правописания представляются в данном варианте осуществления изобретения тем контроллером правописания, который обычно присутствует в его ТР 140 - "хозяине"). После того, как словарный контроллер 610 совершил свою проверку и внес все необходимые исправления (с помощью автора), полученный в результате лексически ограниченный текст 617 передается грамматическому контроллеру 620. Этот грамматический контроллер 620 дает на выходе синтаксически правильный текст 625 в пределах ОИЯ. Затем этот ограниченный синтаксически правильный текст 625 подвергается устранению неоднозначности, как показано в блоке 630. Результатом устранения неоднозначности является пригодный для перевода лишенный неоднозначности и ограниченный текст 635. Этот пригодный для перевода текст 635 может быть теперь переведен на иностранный язык без необходимости в предварительной редакции. Точность последующего перевода также устраняет необходимость в конечной редакции.
1. Словарный контроллер
На фиг. 7 показана структурная схема работы словарного контроллера 610. Словарный контроллер 610 выполняет встречающиеся в авторском тексте слова не из ОИЯ и помогает автору находить в ОИЯ разрешенные замены таких отсутствующих в ОИЯ слов. Он распознает границы слов в документе и выявляет каждый случай появления в тексте лексической позиции, которая не известна как находящаяся в ОИЯ.
Как показано в блоке 706, в единице текста выбирается для проверки первый термин. Затем этот термин проверяется, как показано в блоке 710, в сопоставлении с лексической базой данных ОИЯ (т.е. со словарем), содержащей все включенные в ОИЯ слова. Если использованный термин не найден в словаре ОИЯ, этот термин затем подвергается проверке правописания по стандартному словарю, как показано в блоке 722. Если данное слово было написано с нарушением правописания, автору предоставляются средства исправления ошибки правописания (т. е. словарный контроллер 610 выводит на экран альтернативы написания слова), как показано в блоке 726.
Затем данная позиция подвергается проверке на ее наличие в словаре ОИЯ, как показано в блоке 734. Если эта позиция присутствует в словаре ОИЯ, операция переходит в блок 718. Если же, однако, данная позиция отсутствует в словаре ОИЯ, система проверяет, нет ли в ЯМ/МО синонима проверяемой позиции, как это показано в блоке 736. Если в ЯР/МО найден по меньшей мере один синоним, система выводит на экран этот синоним или синонимы, являющиеся частью словаря ОИЯ, и позволяет автору сделать соответствующий выбор, как показано в блоке 738. Вместе с тем, если ЯР/МО не располагает ни одним синонимом проверяемой позиции, автор имеет возможность переработать свой входной текст, как показано в блоке 740. Результат такой переработки снова направляется в блок 710. Как только автор проделывает разрешенный выбор, эта операция 700 переходит в последующий блок 718.
Когда в тексте выявлено не включенное в ОИЯ слово, автору предлагается следующий выбор: он или она может выбрать из предложенных слов альтернативное слово и заменить им использованное в документе слово либо он или она может ввести новую позицию и заменить ею слово в документе. Как правило, для замены отсутствующей в ОИЯ позиции автор выбирает один из предложенных ему синономов. Если же автор решает вообще уйти от решения проблемы, такое бездействие приведет к тому, что текст автора не будет подтвержден как соответствующий ОИЯ.
Блок 718 проверяет, имеются ли в текстовой единице другие термины. Если других терминов нет, операция 700 останавливается. В противном случае выбирается новый термин, как показано в блоке 714, и операция 700 снова начинается из блока 710.
В частности, словарный контроллер 610 выявляет каждый случай наличия в предложенном тексте лексической единицы, не известной как часть ОИЯ. Для каждого такого слова словарный контроллер 610 определяет, какое из перечисленных ниже описаний применимо, и сообщает поддерживающую информацию интерфейсу пользователя, как это показано ниже.
Отсутствующее в ОИЯ слово, имеющее в ОИЯ известные синонимы, в этом случае словарный контроллер (СК) 610 выявит такие синонимы. Например, предположим, что слово "let" (разрешить, позволить, впустить, дать и т.д.) не включено в ОИЯ.
Вводимый автором текст, подвергаемый проверке: "Открыть кран и впустить дополнительный объем азота в пневмоаккумулятор". Сообщение СК: Этот термин "впустить" отсутствует в ОИЯ, но в ОИЯ есть связанные с ним альтернативы.
Альтернативы из ОИЯ: позволить, позволено, разрешить, разрешено, оставить, оставлено, дать войти.
Отредактированное предложение в ОИЯ: "Открыть кран и дать дополнительному объему азота войти в пневмоаккумулятор".
Слово, которому разрешено в ОИЯ появляться лишь в качестве части выражения, но которое в ОИЯ не используется в таком разрешенном выражении в том контексте, который предложен автором, в этом случае словарный контроллер 610 сообщит автору разрешенные в ОИЯ выражения, содержащие данное слово.
Вводимый автором текст, подвергаемый проверке: "При первой проверке зазора клапанов необходимо проверить синхронизацию впрыска".
Сообщение СК: Этот термин использован в контексте, отсутствующем в ОИЯ.
Альтернативы из ОИЯ: синхронизация сигнала опережения, канавка синхронизации опережения, шестерня синхронизации, механизм синхронизации.
Отредактированное предложение в ОИЯ: "При первой проверке зазора клапанов необходимо проверить механизм синхронизации впрыска".
Слово или выражение, которое в ОИЯ должно применяться в двойных кавычках, но которое в предложенном автором контексте не заключено в кавычки; в этом случае словарный контроллер 610 сообщит автору, что данный термин должен быть в кавычках.
Вводимый автором текст, подвергаемый проверке: "Более подробно об этом говорится в главе Испытания и Регулировки в следующем разделе".
Сообщение СК: Этот термин в ОИЯ в обычном случае заключается в кавычки.
Альтернативы из ОИЯ: отсутствуют.
Отредактированное предложение в ОИЯ: "Более подробно об этом говорится в главе "Испытания и Регулировки" в следующем разделе".
Слово или выражение, которое в ОИЯ должно иметь обязательные, конкретно указанные заглавные буквы, но в котором, как оно использовано автором, эти обязательные заглавные буквы отсутствуют (например, при написании строчными буквами разрешенного в ОИЯ акронима), в этом случае словарный контроллер 610 сообщит автору правильную форму или формы, разрешенные в ОИЯ.
Вводимый автором текст, подвергаемый проверке: "Поворачивать винт, пока показание манометра не будет равно 0 кПа".
Сообщение СК: Этот термин в ОИЯ имеет обязательные заглавные буквы.
Альтернативы из ОИЯ: кПа.
Отредактированное предложение в ОИЯ: "Поворачивать винт, пока показание манометра не будет равно 0 кПа".
Несуществующее слово (т.е. группа букв, представляющая собой неправильно написанное слово), у которого имеются альтернативы написания, в этом случае словарный контроллер 610 выявит альтернативы написания вне зависимости от того, будет ли выбранное в результате слово имеющимся в ОИЯ (поскольку пользователь представит выбранную им альтернативу для дальнейшей проверки).
Вводимый автором текст, подвергаемый проверке: "Когда требуется поднять стрелу, для нее должна быть обеспечена надежная опора".
Сообщение СК: Этот термин отсутствует в ОИЯ.
Альтернативы из ОИЯ: требуется.
Отредактированное предложение в ОИЯ: "Когда требуется поднять стрелу, для нее должна быть обеспечена надежная опора".
Слово, которое отсутствует в ОИЯ и в отношении которого система ничего не знает. Сообщение о полностью неизвестном слове или выражении предоставляет автору возможность либо вообще изменить его отрывок текста, либо "оградить" неразрешенное выражение от проверки, если в этом есть необходимость. В приведенном ниже примере автор использует метку СОЯР для того, чтобы приказать системе не обращать внимания на неприемлемый для нее оборот и оставить его таким, как он есть.
Вводимый автором текст, подвергаемый проверке: "Залить приблизительно 0,9 л (1 кварту) масла для гидросистемы SAE10W в азотную часть пневмоаккумулятора".
Сообщение СК: Этот термин не известен.
Альтернативы из ОИЯ: Отсутствуют.
Отредактированное предложение в ОИЯ: "Залить приблизительно 0,9 л (1 кварту) масла для гидросистем <sic>SAE10W</sic> в азотную часть пневмоаккумулятора".
Знак препинания или особый символ, который не разрешен в ОИЯ ни в каком контексте.
В случаях, когда отсутствующее в ОИЯ слово или выражение не имеет прямых синонимов в ОИЯ (т.е. таких слов, какие могли бы непосредственно заменить его в документе), система способна выявить взаимосвязанные слова или выражения в ОИЯ, которые автор мог бы применить для выражения своей мысли. Эта функциональная возможность предоставляет авторам дополнительную поддержку в перефразировании предложения таким образом, чтобы оно включало только словарь ОИЯ. Вместе с тем, изменения с использованием этих взаимосвязанных слов не могут быть завершены силами самих средств замены, предусмотренных для синонимов, поскольку такие изменения требуют определенных перемен в построении предложения. Например, если слово "может" имеется в ОИЯ, а слово "способен" или "способна" - нет, автору, написавшему такое предложение:
"Эта система способна к программированию на несколько параметров, определяемых потребителем", будет сообщено, что слово "способна" ((capable)) не является словом из ОИЯ. Хотя слово "может" ((can)) включено в ОИЯ, ни слово "способна", ни выражение "способна к" не могут быть непосредственно заменены на "может" без необходимости внесения дальнейших изменений в предложение.
2. Грамматический контроллер
Задачей грамматического контроллера является выявление мест, где текст автора не соответствует грамматическим ограничениям ОИЯ, и привлечение внимание автора к этим местам. Грамматический контроллер 620 функционально обеспечивается анализатором МП 127 системы МП 120, расширенным для того, чтобы система могла сообщать автору о случаях синтаксической или семантической неоднозначности. Интерфейс грамматического контроллера позволяет автору реагировать в диалоговом режиме на запросы о прояснении неоднозначности. Интерфейс грамматического контроллера дает автору определенные указания на два или более возможных значений предложения и просить уточнений. Примером неоднозначного предложения может быть: "Проверить цилиндры внутри". Расположены ли сами цилиндры внутри узла или предполагается, что нужно проверить внутренность этих цилиндров? Существуют два вида возможных проявлений неоднозначности.
Лексическая неоднозначность. Случаи лексической неоднозначности происходят, когда слово имеет два или более значений в ограниченном языке. Хотя желательно, чтобы в ограниченном языке каждое слово имело только одно значение на каждую часть речи, имеются некоторые слова, которые неизбежно могут иметь более одного значения.
Например, слово "gas" может иметь значения "газ", "природный газ" и "бензин".
Далее, на лексическом уровне проблемы могут вызываться словом, которое в ОИЯ может выступать в двух разных синтаксических ролях. Примером может служить слово "fuel", которое в ОИЯ может быть существительным или глаголом ("топливо" "fuel" может в английском языке также быть глаголом "топить" или выступать в роли существительного в функции прилагаемого "топливный"). Когда автор вводит в текст предложение, где эта синтаксическая роль не вполне ясна. Грамматический контроллер (ГК) 620 может дать автору следующую подсказку:
Вводимый автором текст, подвергаемый проверке: "Датчик закреплен на топливной ("fuel") рейке".
Сообщение ГК: Этот термин может использоваться как существительное (также в роли прилагательного) или как глагол.
На этом этапе автору предоставляется вариант редактирования предложения без помощи со стороны системы (для этого требуется просто переписать предложение и ввести его снова для проверки контроллером). Если же автор выбирает вариант обращения к системе за помощью, система может предложить ему конкретные указания по разрешению проблем подобного типа. В данном случае предлагаемая помощь конкретна:
Помощь!
Сообщение ГК: Если это слово - существительное, вам, возможно, целесообразно поставить перед ним определяющее слово. Если оно - глагол, может ли помочь определяющее слово после него?
Пример: "В корпусе судна течь" или "Должен ли течь корпус судна?".
После этого автор приступает к редактированию предложения и затем снова предлагает его на рассмотрение грамматическому контроллеру 620.
Структурная неоднозначность. Структурная неоднозначность имеет место, когда слова в предложении могут по-разному объединяться одно с другим. Например: Remove the valve with the lever".
(На английском языке эта фраза может означать как "снять клапан вместе с рычагом", так и "снять клапан с помощью рычага"). Объединено ли в смысловом отношении выражение "with the lever" с существительным "The valve" либо оно, напротив, объединено в смысловом отношении с глаголом "remove"? Иными словами, идет ли речь в данном предложении о снятии клапана, на котором закреплен рычаг, или речь идет о снятии клапана с помощью рычага?
Элементом ИСАПП 105, который предназначен для того, чтобы дать ответ на поставленный вопрос, является модель области (МО) 137, которая сконструирована так, чтобы свести к минимуму возможность подобной неоднозначности.
Как показано на фиг. 5, блок МО/МП 520, поддерживающий исключительно процесс машинного перевода, содержит два вида информации. С одной стороны, семантическая информация (A) обеспечивает выявление взаимоотношений между понятиями. С другой стороны, контекстуальная информация (В) определяет для конкретного глагола его так называемые "глубокие сопряжения" и те управляющие слова, с которыми он может употребляться. В рассматриваемом нами примере давайте сначала установим, каким образом семантическая информация (A) и контекстуальная информация (B) могут помочь анализатору МП 127 определить грамматическую структуру предложения "Remove the valve with the lever".
Среди многих типов семантических взаимоотношений существует взаимоотношение "является частью", применимое, например, к взаимоотношению между понятием "шляпа" и понятием "одежда", поскольку "шляпа" "является частью" "одежды". Такое же взаимоотношение применимо к понятиям "подметка" и "ботинок", "каблук" и "ботинок" и т.д. Семантическая информация (A), введенная в МО/МП 520, распознает такое и подобные отношения между понятиями в данной ограниченной области.
Когда процесс, выполняемый анализатором МП 127, обращается в МО/МП 520 за семантической информацией в части взаимоотношения понятий "клапан" и "рычаг", хранимая в МО 137 информация не подскажет анализатору МП 127, является ли "рычаг" частью "клапана" - по той простой причине, что никаких сведений о таком взаимоотношении там нет. Итак, анализатор МП 127 все еще не знает, следует ли привязывать выражение "с рычагом" к слову "клапан".
Но вот когда анализатор МП 127 обращается к контекстуальной информации (B), он обнаруживает из нее, что глагол "remove" ("снять", "убрать") может сочетаться с тремя падежами существительных: именительным (ИМЕ), винительным (ВИН), а также творительным (ТВО) (однако на более глубоком уровне анализа, чем тот, которому нас учили в школе в отношении латинской грамматики). Таким образом, глагол "remove" укладывается в следующие рамки падежей:
ГЛАГОЛ (ИМЕ, ВИН, ТВО)
Исходя из приведенной абстрактной схемы мы можем строить предложения типа приведенных в конце описания.
Поскольку в МО/МП введена информация в отношении сочетания предлога "with" (в английском языке может означать "с помощью ", "посредством", но также означает просто предлог "с") с существительными, имеющими семантический признак (+ОРУДИЕ), такое сочетание создает творительные фразы. Эта информация позволяет анализатору определить, что:
а) поскольку "lever" ("рычаг") имеет признак (+ОРУДИЕ), выражение "with the lever" является ТВО,
б) поскольку "remove" может использоваться c ТВО падежом, выражение "with the lever" связано с "remove", относится к нему и обстоятельственно его дополняет.
И вместе с тем, МО богата лишь настолько, насколько мы сами ее создадим. В тех случаях, когда семантическая информация не разработана настолько полно, насколько это возможно, лексические позиции в ограниченной области могут оказаться не способными обеспечить процесс устранения неоднозначности, выполняемый анализатором машинного перевода 127.
Давайте посмотрим на случай с "гвоздем" в предложении "Петр снял коробку гвоздем". Если МО 137 содержит информацию о том, что гвозди бывают частью деревянной рамы, но в нее не заложена информация в отношении того, что гвозди это (+ОРУДИЕ), тогда анализатор 127 никак не может определить, сочетается ли предлог "with" со словом "nail", образуя при этом творительную фразу. Так как анализатор сам не может разрешить эту структурную неоднозначность, он попросит автора ее разрешить. Итак, когда представленный автором текст проходит грамматическую проверку, имеет место следующее взаимодействие.
Вводимый автором текст, подвергаемый проверке: "Петр снял коробку гвоздем/с гвоздем".
Сообщение грамматического контроллера (ГК) 520: Предложение не однозначно.
1. Является ли гвоздь орудием?
2. Является ли "гвоздь" частью "коробки"?
Как только автор произведет выбор прочтения смысла, контроллер придаст этому предложению невидимую метку СОЯР, которая покажет системе, как именно его надо переводить.
Как уже упоминалось выше, анализатор МП 127 вызывается грамматическим контроллером для проверки того, соответствует ли введенный текст или ИЭ (или его часть) грамматическим и семантическим ограничениям ОИЯ. В этом отношении в предпочтительном варианте осуществления изобретения ответом по каждому анализируемому предложению является четкое сообщение "зеленый свет/красный свет", и в последнем случае автор обязан скорректировать построение или состав отмеченного предложения с использованием представленных ему средств. Когда либо весь введенный текст, либо рассматриваемый ИЭ полностью проверен на соответствие ОИЯ, он может быть либо переведен в память, либо направлен для немедленного перевода.
На фиг. 8 показана блок-схема высокого уровня грамматического контроллера 620 (синтаксический анализ) и контроллера на неоднозначность (семантический анализ). Далее в данном описании слово "предложение" означает единицу текста, которая либо проходит, либо не проходит проверку в аналитическом модуле 127. Такая проверяемая текстовая единица может быть частью текста без предложений, например заголовком, подзаголовком, позицией в перечне, подрисуночной подписью или нарисуночной надписью.
Грамматический контроллер 620 распознает границы предложений и границы элементов СОЯР в тексте, размеченном метками СОЯР. Он выявляет каждое предложение, не соответствующее заданным условиям ОИЯ, включая также каждое предложение, которое не может быть удовлетворительно разобрано аналитическим модулем МП 127. Разбор может не состояться по перечисленным ниже причинам, но не ограничиваясь ими.
Предложение содержит грамматические конструкции, которые анализатор МП 127 не способен разобрать. Так может быть, например, когда предложение содержит сокращенное придаточное предложение. Такое сокращение может быть результатом умышленного пропуска (в английском языке) относительного местоимения "that" ("который, -ая, -ые, т.д.) и соответствующей формы глагола "be" ("быть") в предложении типа: "Don't change the values that are programmed into the unit" ("Не менять величины, которые были запрограммированы в данный узел").
Вводимый автором текст, подвергаемый проверке: Don't change values programmed into the unit ("Не менять запрограммированные в данный узел величины").
Сообщение грамматического контроллера (ГК): Это предложение затруднительно для разбора.
Просьба проверить на наличие одной из следующих проблем:
Затем грамматический контроллер 620 перечисляет типичные и наиболее часто встречающиеся ситуации, когда разбор бывает затруднен или вообще сделан невозможным в результате использования грамматических конструкций, не включенных в "репертуар" ОИЯ.
Использование знаков препинания в предложении не соответствует ограничениям ОИЯ. Как уже указывалось выше, знаки препинания и особые знаки, которые не включены в ОИЯ, будут в любом контексте высвечены словарным контроллером 610. Вместе с тем, словарный контроллер 610 не производит разбора текстовых единиц, и потому он не может сообщать о случаях, когда подобный знак существует в ОИЯ, но использован в неправильной контексте. Такой случай вызовет со стороны грамматического контроллера 620 реакцию "не проходит".
Слово из словаря ОИЯ использовано в синтаксической форме, которая для этого слова не разрешена в ОИЯ. Словарный контроллер 610 выявит некоторые из подобных случаев: например, если слово "test" ("испытание", "испытывать") включено в словарь ОИЯ как существительное, но не как глагол. Словарный контроллер сообщит, что прошедшая форма "tested" ("испытывали") не входит в ОИЯ. Тем не менее, словарный контроллер 610 пропустит этот глагол в третьем лице настоящего времени "test" ("испытывает"), так как эта форма идентична множественному числу "tests" ("испытания") разрешенного в ОИЯ существительного. В этом случае от грамматического контроллера 620 последует реакция "не проходит".
Грамматический контроллер 620 использует анализатор МП 127 (и модель области 137) для выявления предложений, не соответствующих грамматическим ограничениям ОИЯ, - это называется синтаксическим анализом и проиллюстрировано блоком 805. В отношении каждого из названных видов предложений грамматический контроллер 620 сообщает, что предложение не соответствует ОИЯ. Также возможно, что предложение соответствует ОИЯ, но не однозначно. По этой причине настоящее изобретение включает семантический анализ, как показано в блоке 710. Если проверяемое предложение не является семантически однозначным, контроллер по устранению неоднозначности 630 даст автору определенное указание на его два или более возможных значений и потребует разъяснения, как показано в блоках 815 и 825. В предпочтительном варианте осуществления изобретения, если предложение не проходит проверку грамматическим контроллером 620 и/или контроллером на неоднозначность 630, автору представляются на выбор следующие варианты: отредактировать документ в случае его неоднозначного прочтения, устранить неоднозначность в предложении либо продолжать проверку без редактирования.
Обратите внимание на то, что настоящее изобретение обеспечивает абсолютное следование введенным ограничениям словаря и грамматики, а не просто стилистические подсказки или простое выявление очевидных ошибок (таких, как неправильное согласование подлежащего с глаголом).
Если предложение семантически однозначно, оно переводится в промежуточный язык Интерлингва, как показано в блоке 820. Как только документ прошел проверку грамматическим контроллером 620, метка СОЯР, обозначающая подтверждение соответствию ОИЯ, может быть внесена в этот документ.
В предпочтительном варианте осуществления изобретения грамматический контроллер 620 выдает автору 160 сигнал обратной связи "проходит"/"не проходит". Тем не менее, можно предусмотреть направление автору более конкретного ответного сигнала, чем просто "проходит"/"не проходит".
Более подробно вопросы грамматической проверки, включая устранение неоднозначности, рассмотрены в материалах Tomita M., "Sentence Disambiguation by Asking" (Томита М. , "Устранение неоднозначности в предложениях постановкой вопросов") в журнале Computers and Translation (Компьютеры и перевод). 1:39-51 (1986), а также Carbonell J., M. Tomita, "Knowledge-Based Machine Translation" (Карбонелл Дж. и М.Томита, "Основанный на знании машинный перевод") в сборнике Machine Translation: Theoretical and Methodological Issues (Машинные переводы: Теоретические и методологические вопросы) под ред. S. Nirenburg, Cambridge: Cambridge University Press, стр. 68-89 (1987), которые здесь упоминаются в качестве отсылки.
Д. Машинный перевод
МП 120 представляет собой систему машинного перевода на основе промежуточного языка интерлингва. В таких системах ограниченный исходный язык (ОИЯ) и целевой или конечный язык никогда не входят в непосредственное соприкосновение. Обработка текстов в подобных системах происходит, как правило, в два этапа. Во-первых, выражение смысла текста на ОИЯ в формальном промежуточном языке, не зависящем ни от какого живого языка и называемом "интерлингва", и, во-вторых, выражение этого смысла с использованием лексических единиц и синтаксических конструкций целевого языка.
Системы машинного перевода на основе промежуточного языка интерлингва, так же, как и другие виды систем машинного перевода, хорошо известны специалистам в данной области. Подробное описание этих различных подходов к машинному переводу можно найти в таких материалах, как Hutchins, Machine Translation: Past, Present, Future (Хатчинс, Машинный перевод: Прошлое, настоящее и будущее). Ellis Horwood Ltd., Chichester, UK, 1986 и Zarechnak, "The History of Machine Translation. ("Заречняк, "История машинного перевода") в сборнике Machine Translation, Trends in Linguistics: Studies and Monographs ("Машинный перевод. Тенденции в лингвистике: статьи и монографии) под ред. Henisz - Doctert, McDonald, Zarechnak, The Hague, Mouton, 1979; причем оба эти материала здесь упоминаются в качестве отсылки.
Смысл текста 350 на ОИЯ выражается в специально разработанной схеме выражения знаний, называемой "интерлингва" (промежуточный язык), которая хорошо известна специалистам в данной области. Интерлингва, в свою очередь, выражена в рамочной системе записи и в силу этого может рассматриваться как один из видов семантической сети. Подобно другим искусственным или формальным языкам интерлингва имеет свой собственный словарный запас - лексикон и свой собственный синтаксис. Словарный запас основан на той области, из которой берутся тексты для перевода (например, уход за вычислительными машинами, исследование космического пространства и т.п.). Таким образом, "существительные" в интерлингва представляют собой в онтологии "понятия предметов", глаголы интерлингва приблизительно соответствуют "событиям" в онтологии, а прилагательные и наречия в интерлингва являются различными "свойствами", определенными в онтологии. Эта онтология образует тесно взаимосвязанную сеть для понятий различного типа, называемую моделью области.
Как можно видеть на фиг. 3 и фиг. 9, система машинного перевода (МП) 120 как составная часть ИСАПП 105 состоит из двух основных секций. Первая из них - анализатор МП 127 - выполняет первые стадии обработки для выражения текста, написанного на ОИЯ, в интерлингва. Вторая главная секция - генератор МП 123 - переводит выраженные в интерлингва "проверенные по ОИЯ" тексты на целевой язык (например, французский, японский или испанский). Выполняя обе эти задачи, блок МП 120 работает в качестве одного или более независимых служебных модулей, принимающих заявки на перевод от человека, заведующего переводом (не показан). В ходе генерирования текста на целевом языке генератор МП 123 размечает текст 260 на интерлингва по соответствующим единицам целевого языка для получения высококачественного выходного текста 950, не нуждающегося в окончательном редактировании.
Как только аналитический модуль МП 127 выработал текст 260 на интерлингва для проверенного и соответствующего ОИЯ информационного элемента (ИЭ), этот текст на интерлингва может быть сохранен в памяти, доставлен по назначению либо немедленно переведен в ИЭ на целевом языке или в разные ИЭ на несколько целевых языков с помощью генератора МП 123, включающего в себя разметчик из семантики в синтаксис и генерирующий набор (см. Tomita M., E. Nyberg. The Generation Kit and Transformation Version 3,2 User's Manual, Technical Memo (1988) (Томита М. и Е. Найберг, Руководство для пользователя набором для генерирования и трансформирования. Версия 3.2, Техническая записка (1988)), который может быть получен от Center for Machine Translation, Carnegie Mellon University, Pittsburgh, Pa (Центр машинного перевода Университета Карнеги-Меллона, Питтсбург, шт. Пенсильвания). Анализатор МП 127 и генератор МП 123 взаимодействуют между собой двояким образом. Сначала выход первого является входом второго, а затем они делят между собой некоторые сведения из внешних источников, в особенности из модели области 137.
Система машинного перевода (МП) 120 подразделена как показано на фиг. 9. Аналитически она состоит из блока разбора 910 и блока перевода 920. Вторая половина МП 120 может быть подразделена на разметчик 930 и генератор 940. Овальные кружки на фиг. 9 обозначают те данные, которые производятся и являются предметом обмена между основными модулями программных средств.
МО 137 (и в особенности МП/МО 520) используется в процессе перевода по трем разным путям: (1) блок разбора 910 использует МО 137 для ограничения возможных присоединений (используя строгую суб-категоризацию синтаксических посылок и обстоятельств в ходе синтаксического разбора), (2) блок перевода 920 использует МО 137 для расстановки соответствующих понятий данной области в ходе перевода, а (3) разметчик 930 использует МО 137 для выбора соответствующего воплощения в целевом языке каждого понятия, выраженного на интерлингва.
МП 120 работает в виде одного или нескольких служебных процессов. Каждый такой процесс МП принимает заказы на переводы от СУФ 110 и возвращает в ответ результаты. Запросы включают в себя текст на ОИЯ с метками СОЯР, а результаты включают в себя перевод на целевом языке также с метками СОЯР. Поскольку перевод на несколько языков может происходить одновременно, в запросы также входит указание на требуемый целевой язык. Далее, так как процессы в служебных устройствах МП специализированы по целевым языкам, возникает потребность в функции маршрутизации. Эта функция маршрутизации автоматически выполняется СУФ 110. Точный набор процессов МП в любой заданный момент и их распределение по разным вычислительным устройствам или машинам определяются СУФ 110, который корректирует взаимодействие аппаратных средств в зависимости от набора работ по переводу, заказанных, но еще не законченных на конкретный момент.
Как видно на фиг. 9, анализатор ОИЯ 127 состоит из двух взаимосвязанных частей: блока разбора 910 и переводчика 920. Переводчик 920 также иногда называется в данной области "переводчиком правил разметки". Блок синтаксического разбора 910 получает на входе текст 305 на ОИЯ и выдает его синтаксическую структуру-схему. Блок разбора 910 использует грамматику типа ФЛГ ("функциональная лексическая грамматика"). ФЛГ представляет собой формализованную грамматику, хорошо известную специалистам по машинному переводу. В результате, полученная структура является f-структурой (функциональной структурой) ФЛГ 960. Как только создана f-структура для предложения на ОИЯ 960, переводчик 920 начинает применять к ней правила разметки в целях замены лексических единиц и синтаксических конструкций исходного языка на их переводы на интерлингва. Лексические единицы размечаются в их преломление в понятиях области применения (так, например, слово "данные" будет размечено в "информацию" на интерлингва), в то время как синтаксические структуры размечаются в концептуальные взаимосвязи (так, подлежащие предложений часто размечаются в выразителей связи типа "агент" или "исполнитель" на интерлингва) - см. материал Mitamura, The Hierarchical Organization of Predicate Frames for Interpretive Mapping in Natural Language Processing (Митамура, Иерархическая организация рамок сказуемых для разметки при переводе в ходе обработки естественного языка). Center for Machine Translation, Carnegie Mellon University (Центр машинного перевода Университета Карнеги-Меллона), май 1990, который здесь упоминается в качестве отсылки.
Анализатор машинного перевода 127, направляемый аналитическими сведениями (файлами данных), переводит входное предложение текста на ОИЯ 305 на исходном языке в рамки семантического выражения смысла этого предложения. Теми структурами сведений, которые выбраны для оказания влияния на стадии анализа, являются аналитическая грамматика, правила разметки и словарный запас понятий.
Первой частью анализа является операция разбора, направляемая синтаксическим анализом входного предложения. Блок разбора 910 использует семантические ограничения, воплощенные в словарном запасе понятий (т.е. в модели области) в качестве указаний при определении своего подхода к случаям синтаксической неоднозначности, выявленным при анализе входной информации. Правила разметки выполняют роль посредника между грамматикой синтаксического анализа и словарным запасом (лексиконом) понятий.
Выходной продукцией этого анализа являются синтаксические f-структуры, содержащие всю применимую семантическую информацию. Такая структура может быть далее обработана второй частью анализатора МП 127 для получения организованного семантически рамочного выражения в форме выделения требуемых понятий из лексикона понятий, которые были выявлены при разборе предложения. Анализатор МП 127 приходит к такой форме путем поиска и нахождения семантических признаков f-структуры, причем эти признаки содержат всю существенную семантическую информацию.
Блок разбора 910, используемый в настоящем изобретении, хорошо известен специалистам в данной области и описан подробно в материалах Tomita, Carbonell, The Universal Parser Architecture for Knowledge-Based Machine Translation, Technical Report (Томита и Карбонелл, Архитектура универсального блока разбора для основанного на знании машинного перевода. Технический отчет).
Center for Machine Translation, Carnegie Mellon University
(Центр машинного перевода Университета Карнеги-Меллона), май 1987, и The Generalized LR Parser/Compiler Version 8.1: User's Guide, Technical Memo, Tomito (ed.) et al.
(Обобщенный блок языкового разбора и составления, Версия 8.1: Инструкция для пользователя. Техническая записка, под ред. Томита и др.). Center for Machine Translation, Carnegie Mellon University
(Центр машинного перевода Университета Карнаги-Меллона), апрель 1988, которые здесь упоминаются в качестве отсылки.
Одним из преимуществ систем перевода с применением промежуточного языка интерлингва над другими системами МП является тот факт, что блок интерлингва 260 не зависит от естественных языков, т.е. ни исходный, ни целевой языки никогда напрямую не соприкасаются между собой. Это позволяет создать машинную систему, в которой потенциально можно избирать любые исходные и целевые языки с внесением лишь минимальных изменений в вычислительную структуру. Из сказанного ясно следует, что любая такая система должна быть способна производить разбор множественных исходных языков. По этой причине требуется универсальный блок разбора, способный принимать грамматику языка на своем входе, вместо того, чтобы встраивать грамматику в блок перевода как таковой. Это позволит сделать систему лучше поддающейся расширению и более обобщенной.
Другими словами, когда мы имеем дело с несколькими языками, лингвистическая структура перестает быть универсальным инвариантом, переносимым на все виды применения (как это было в случае блоков для разбора исключительно в английском языке), а, скорее, становится новой размерностью параметризации и расширяемости. Вместе с тем, семантическая информация может оставаться инвариантной от одного языка к другому (хотя, разумеется, не от одной области к другой). По этой причине принципиально важно хранить источники семантических знаний раздельно от синтаксических источников, так чтобы при добавлении новой лингвистической информации она простиралась через все семантические области, а при добавлении новой семантической информации она могла быть распределена на все соответствующие языки. Универсальный блок разбора направлен на достижение такой расстановки возможностей без сколь-нибудь существенного ухудшения показателей эффективности использования машинного времени или семантической точности.
Блок разбора 910 отличается использованием трех видов источников знаний (сведений). Один из них содержит синтаксические грамматики для разных языков, другой - базы семантических сведений для разных областей, а третий - свод правил для разметки синтаксических форм (слов и выражений) в структуры семантических сведений (знаний). Каждая из синтаксических грамматик абсолютно не зависима от какой-либо конкретной области; аналогично, каждая из баз семантических сведений не зависит ни от одной конкретной области, далее, аналогично, каждая из баз семантических сведений не зависит от какого-либо конкретного языка.
Далее, правила разметки зависят как от языка, так и от области, и поэтому для каждого сочетания язык-область создается отличный от других набор правил разметки. Синтаксические грамматики, базы сведений по областям и правила разметки записываются в весьма абстрактной форме, доступной для прочтения человеком. Такое построение облегчает возможность их расширения или видоизменения, но, вероятно, не является эффективным для блока разбора с точки зрения использования машинного времени.
Функция переводчика 920 заключается в генерировании синтаксических и семантических структур выполненного разбора и в обращении с ним, более того, она заключается в одновременном генерировании этих структур.
Блок разбора 910 производит все возможные, т.е. имеющие право на существование, f-структуры, которые можно получить из разбираемых предложений. Каждая из этих синтаксических f-структур имеет семантические признаки, и в соответствии с теорией ФЛГ эти признаки создаются в то же самое время, что и остальная часть синтаксической f-структуры. Таким образом, семантический компонент можно рассматривать как дополнительный признак f-структур.
Тем самым, семантический компонент является "видимой" частью синтаксического разбора. Этот подход одновременного создания семантических и синтаксических структур породил систему, способствующую исключить из работы "бессмысленные" частичные разборы еще до их завершения. Семантические аспекты добавляются к синтаксической структуре, когда к лексикону (словарному запасу) обращаются за определением слова. Второй частью определения каждого слова является набор правил структурной разметки. Эти правила разметки применяются, когда синтаксические уравнения в грамматических правилах усугубляют непрочность синтаксической структуры.
Генератор целевого языка 123 как часть общей системы получает на входе текст на интерлингва 260 и производит на выходе текст на целевом языке 950. Генератор целевого языка 123 состоит из двух основных модулей - одного семантического модуля и одного синтаксического модуля. Семантический модуль выполняет функцию лексического отбора на целевом языке, а синтаксический модуль производит выбор синтаксических конструкций целевого языка, в выполнении этих задач им помогают соответственно лексикон генерирования и правила разметки структуры генерирования. Выходом этого компонента является f-структура предложения на целевом языке, и это является выходом системы в целом.
Итак, целью блока генерации является получение предложений на целевом языке из рамок (кадров) текста на интерлингва 260, выданных анализатором ОИЯ 127. Генерирование целевого текста включает в себя три основные стадии.
1. Лексический отбор.
Для каждого понятия на промежуточном языке интерлингва требуется выбрать наиболее подходящую лексическую позицию.
2. Создание f-структуры.
Из рамок (кадров) текста на интерлингва необходимо получить функциональную синтаксическую структуру, определяющую грамматическую структуру целевого воплощения.
3. Синтаксическое генерирование.
Функциональная синтаксическая структура обрабатывается грамматикой генерирования для получения предложения на целевом языке.
Конструкция генерирующего модуля 940 сочетает в себе достижения последних исследований в сфере лексического выбора с парадигмой разметка-генерирование, которая уже применялась в более ранних системах перевода.
За более подробным рассмотрением вопросов машинного перевода, а также конкретных конструкций и работы описанных выше модулей можно обращаться к таким материалам, как Nirenburg и др., Machine Translation: A Knowledge - Based Appoach (Машинный перевод: Подход на основе знаний), Morgan Kaufmann Publishers, Inc. (1992); Sommers и Hutchins, Introduction to Machine Translation (Введение в машинный перевод), Academic Press, London (октябрь 1991); Mitamura и др., An Efficient Interlingua Translation System for Multi-lingual Document Production (Эффективная система перевода с использованием Интерлингва для получения документов на многих языка), Доклады на III-ей Встрече в верхах по машинному переводу. Вашингтон, окр. Колумбия (2-4 июля 1991). Nirendurg S., "Word Knowledge and Text Meaning"
("Знание слов и смыл текста") в The KBMT Project: A Case Study in Knowledge-Based Machine Translation (Проект ОЗМП: Исследование случая основанного на знаниях машинного перевода (ОЗМП). San Mateo, Calif.: Morgan Kaufmann Отчет о Проекте ОЗМР-89 может быть получен от: Center for Machine Translation, Carnegie Mellon University (Центр машинного перевода Университета Карнеги-Меллона), Питтсбург, шт. Пенсильвания (тел. (412)268-6591), 4-оe издание: март 1990, Machine Translation: Theoretical and Methodological Issues
(Машинный перевод: Теоретические и методические вопросы), Cambridge: Cambridge University Press, стр. 68 - 89, а также Carbonell и др., Steps Toward Knowledge-Based Machine Translation (продвижение к основанному на знаниях машинному переводу).
Труды IEEE по анализу схем и машинному интеллекту, т. РАМ1-3, N 4 (июль 1981), которые здесь упоминаются в качестве отсылки.
Хотя настоящее изобретение было конкретно описано и показано со ссылками на предпочтительные варианты его реализации, специалисты в данной области поймут, что в эти воплощения могут быть внесены различные изменения по форме и в деталях в пределах общего замысла и объема настоящего изобретения.

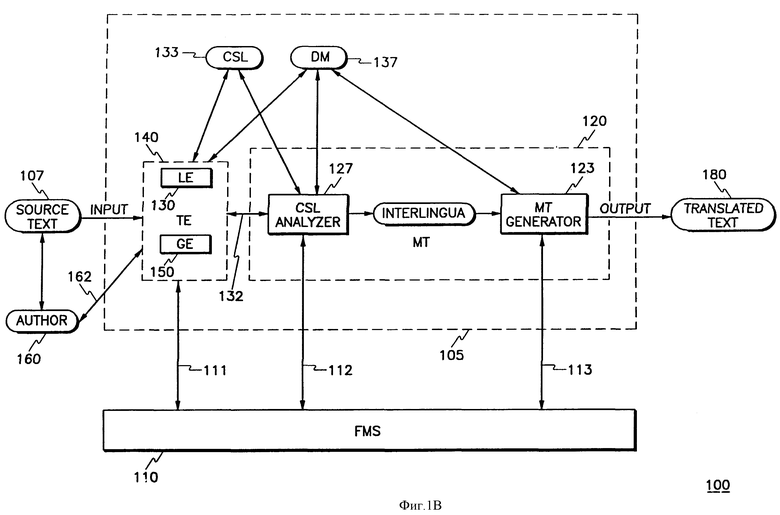
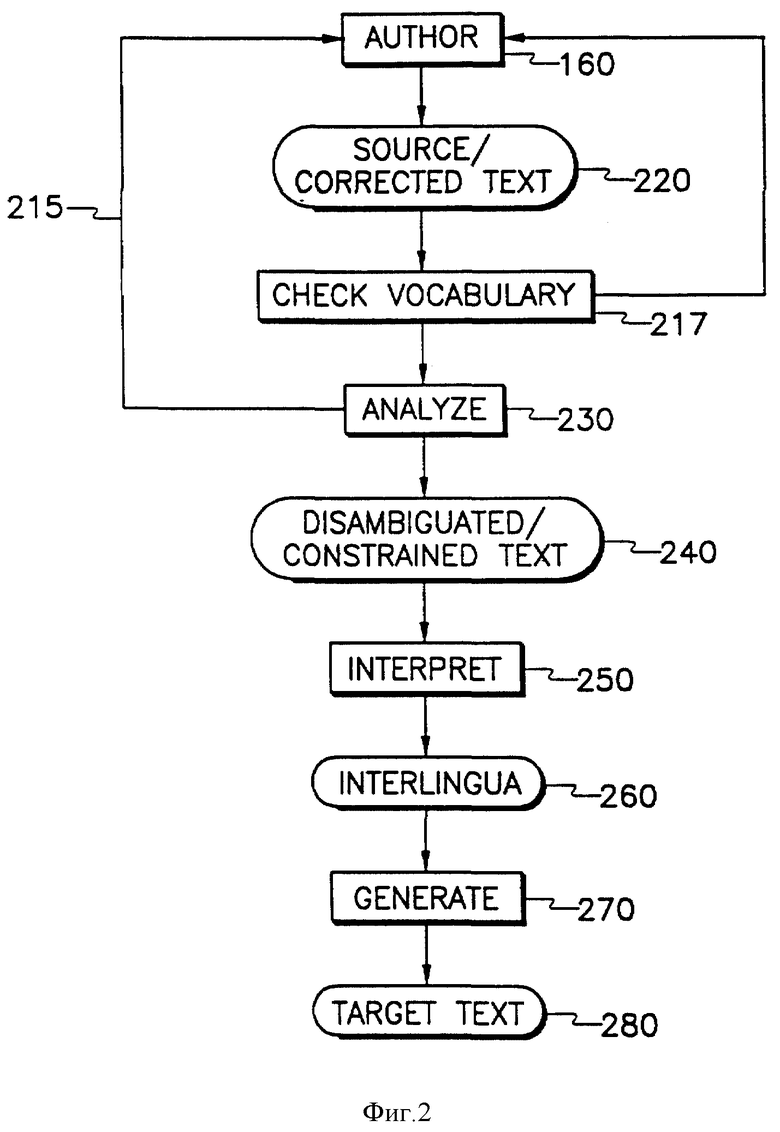
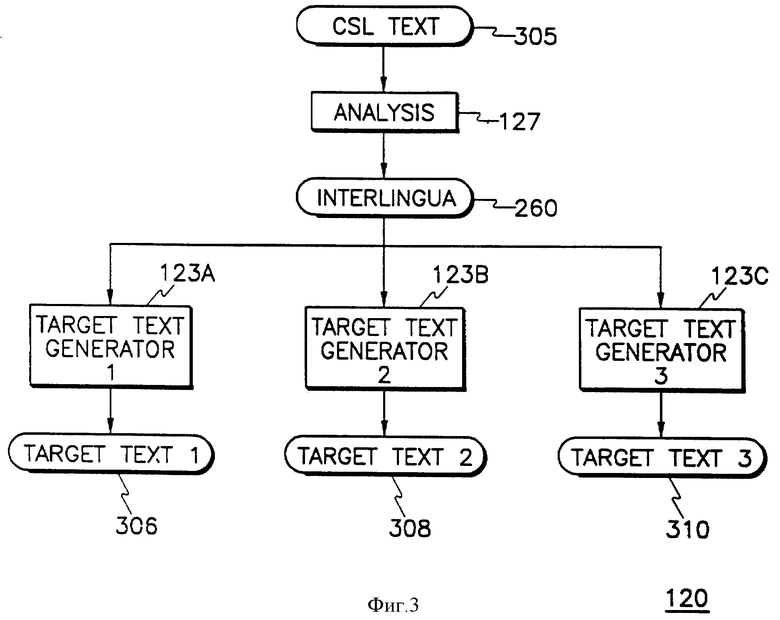
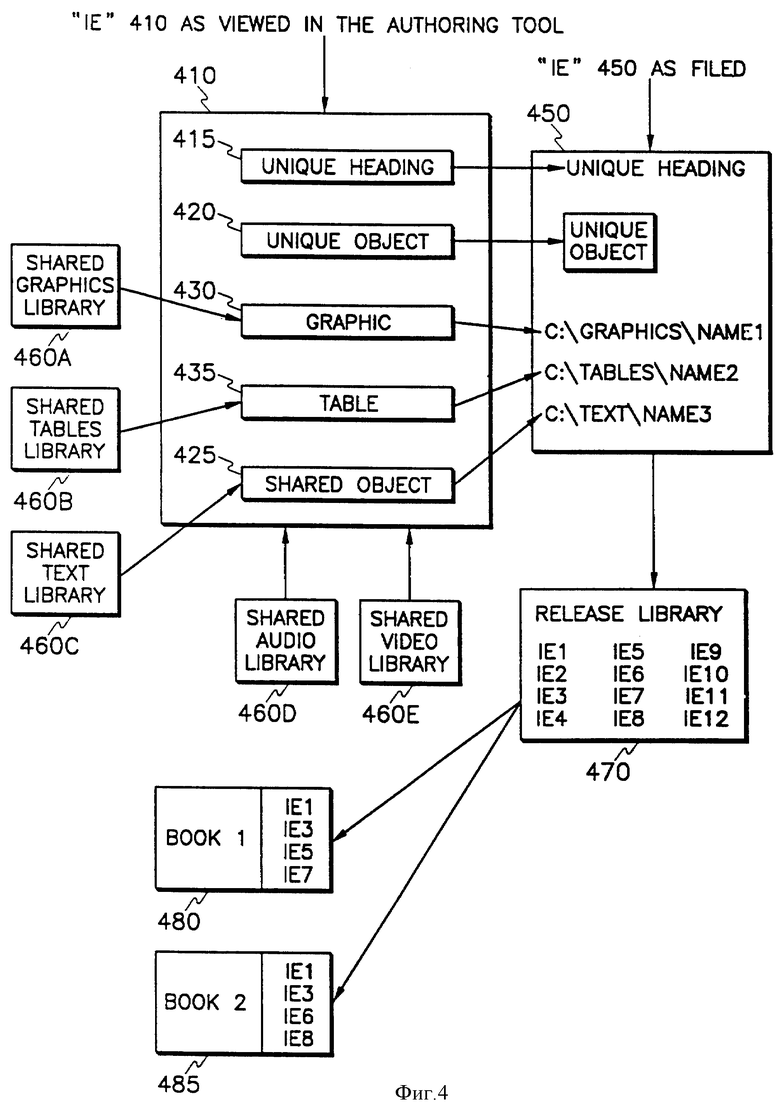
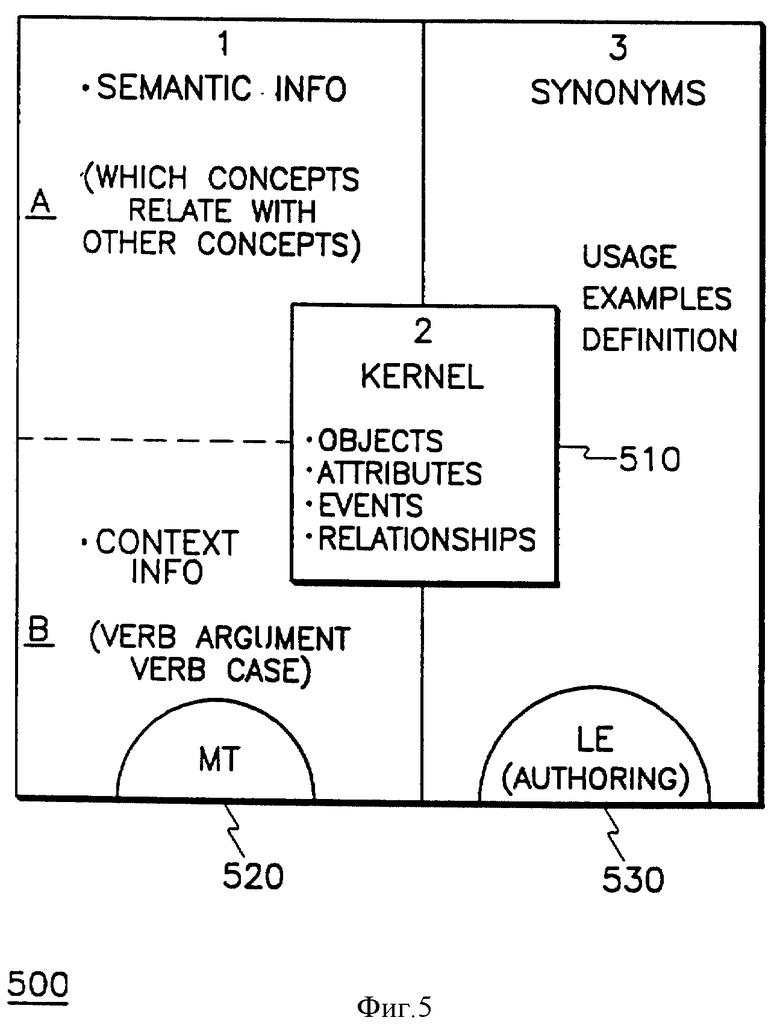
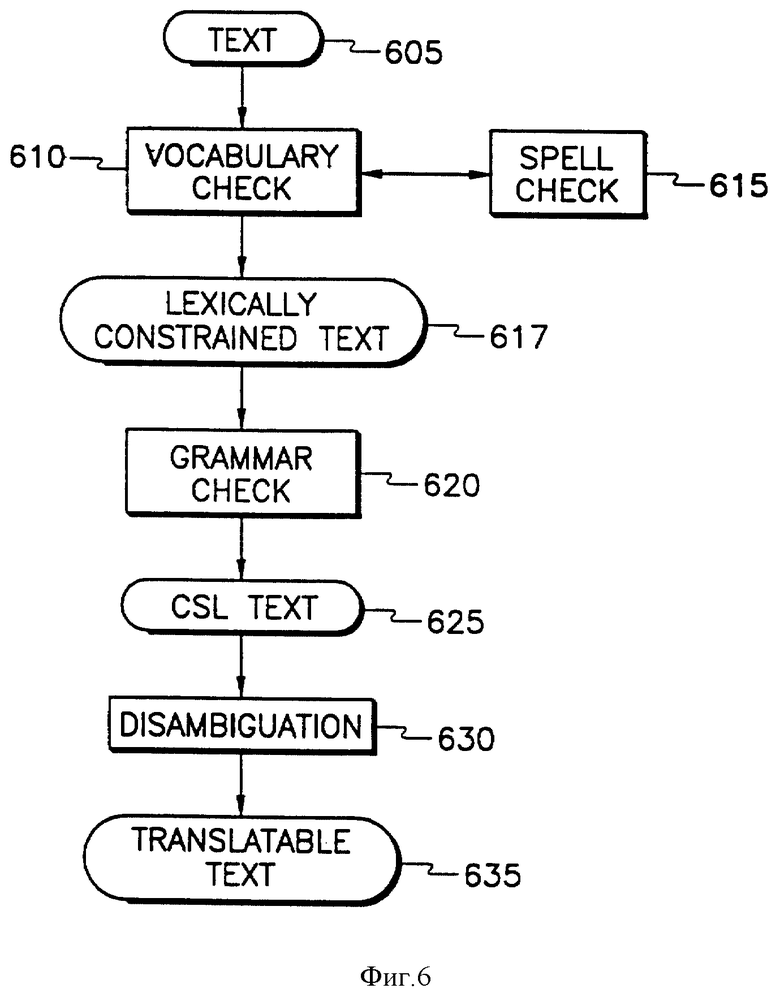
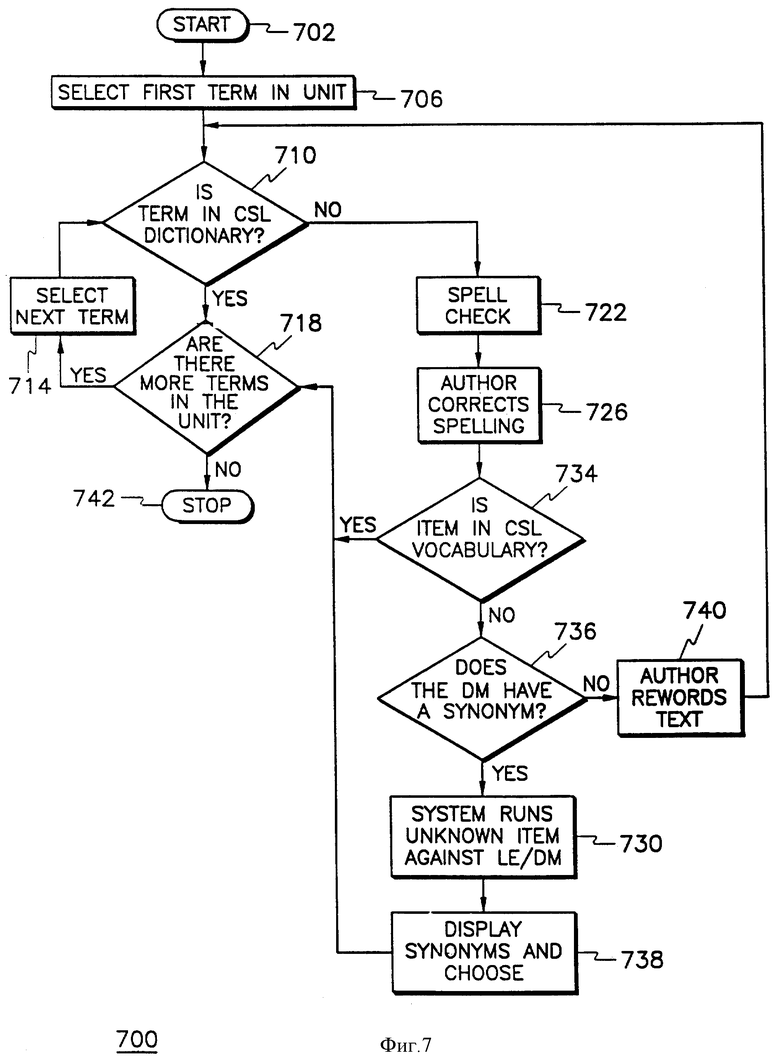
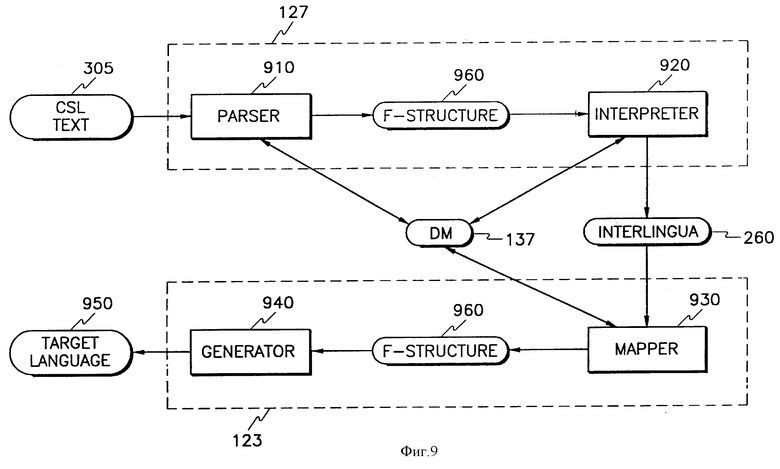
Изобретение относится к компьютерной системе создания и перевода документов, к системе подготовки текста на языке ограничений и перевода на иностранный язык. Технический результат достигается за счет возможности создания системы перевода, исключающей предварительное и конечное редактирование. В интегрированной компьютерной системе, содержащей процессор, текстовый редактор налагает лексические и грамматические ограничения на подмножество лексического языка, используемое авторами для создания текста. Получаемый в результате пригодный к переводу текст на исходном языке подвергается машинному переводу на любой из набора целевых языков. 7 с. и 44 з.п. ф-лы, 9 ил.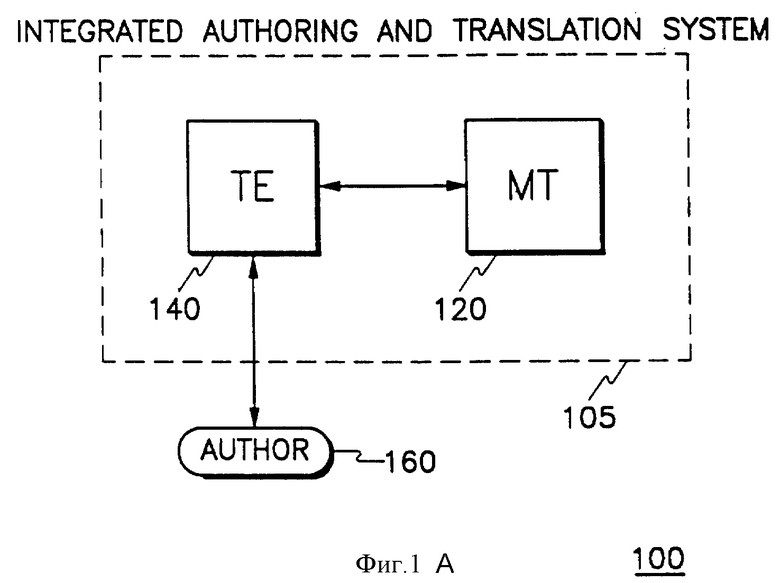
| Способ размножения копий рисунков, текста и т.п. | 1921 |
|
SU89A1 |
| Project Report | |||
| Center for Machine Translation, Carnegie Mellon University, Mar.1990, p.14-18 | |||
| Adriaens et al, From COGRAM to ALCOGRAM: Toward a controlled Englich Grammar Checker, Proc., of Coling-92, Nantes, 08.1992, p.23-28 | |||
| Machine Translation: Theoretical and Methodological Issues | |||
| Cambrige: Cambrige University Press, 1987, p.68, 89 | |||
| US 5342519 A, 07.09.93 | |||
| US 4821230 A, 11.04.89 | |||
| Электронный словарь для изучения иностранного языка | 1988 |
|
SU1702394A1 |
| Устройство синтаксически управляемого перевода | 1989 |
|
SU1651298A1 |

