Область техники, к которой относится изобретение
Настоящее изобретение в общем касается области операционных систем и, более конкретно, использования команд, понимаемых виртуальной машиной (или виртуализации процессоров (создания виртуальной среды)), но определяемых предварительно определенной архитектурой процессора (например, архитектурами x86) как "недопустимое действие", так что для выполнения в пределах среды виртуальной машины изобретение использует эти команды для осуществления строго определенных допустимых действий. В некотором смысле, изобретение добавляет к существующей ранее системе команд "синтезированные" команды.
Предшествующий уровень техники
Виртуальные машины
Компьютеры включают в себя центральные процессоры (ЦП) общего назначения, которые предназначены для выполнения специального набора системных команд. Группу процессоров, которые имеют аналогичные спецификации архитектуры или конструкции, можно рассматривать как процессоры одного и того же семейства. Примеры используемых в настоящее время семейств процессоров включают в себя семейство процессоров Motorola 680X0, изготавливаемых на фирме Motorola, Inc. of Phoenix, Аризона; семейство процессоров Intel 80X86, изготавливаемых на фирме Intel Corporation of Sunnyvale, Калифорния; и семейство процессоров PowerPC, которые изготавливают на фирме Motorola, Inc. и используют в компьютерах, изготавливаемых на фирме Apple Computer, Inc. of Cupertino, Калифорния. Хотя группа процессоров может состоять в одном и том же семействе из-за схожести их архитектуры и конструкции, тактовая частота и другие параметры процессоров могут изменяться в широком диапазоне внутри семейства.
Каждое семейство микропроцессоров выполняет команды, которые являются уникальными для семейства процессоров. Совокупный набор команд, которые может выполнять процессор или семейство процессоров, известен как система команд процессора. В качестве примера, система команд, используемая семейством процессоров Intel 80X86, не совместима с системой команд, используемой семейством процессоров PowerPC. Система команд Intel 80X86 основана на формате компьютера со сложной системой команд (CISC). Система команд Motorola PowerPC основана на формате компьютера с сокращенной системой команд (RISC). Процессоры CISC используют большое количество команд, некоторые из которых могут выполнять довольно сложные функции, но для которых требуется в общем случае много тактовых циклов для исполнения. Процессоры RISC используют меньшее количество доступных команд для выполнения более простого набора функций, которые исполняются со значительно более высокой скоростью.
Уникальность семейства процессоров среди вычислительных систем также обычно приводит к несовместимости с другими элементами архитектуры аппаратных средств вычислительных систем. Вычислительная система, изготовленная с процессором из семейства процессоров Intel 80X86, будет иметь архитектуру аппаратных средств, которая отличается от архитектуры аппаратных средств вычислительной системы, изготовленной с процессором из семейства процессоров PowerPC. Из-за уникальности системы команд процессоров и архитектуры аппаратных средств вычислительных систем программы прикладного программного обеспечения обычно пишут для работы в конкретной вычислительной системе, выполняющей конкретную операционную систему.
Для фирмы-изготовителя вычислительных машин может быть желательным увеличить до максимума свою долю на рынке, имея скорее больше, чем меньше прикладных программ, выполняемых на семействе микропроцессоров, связанном с производственной линией фирмы-изготовителя вычислительных машин. Чтобы расширить количество операционных систем и прикладных программ, которые могут выполняться в вычислительной системе, развивается область технологии, в которой заданный компьютер, имеющий один тип ЦП, называемый главной вычислительной машиной, включает в себя программу эмуляции, которая позволяет главной вычислительной машине эмулировать команды несвязанного типа ЦП, называемого "гостевым". Таким образом, главная вычислительная машина выполняет прикладную программу, которая обуславливает вызов одной или более команд главной вычислительной машины в ответ на команду гостя. И, соответственно, главная вычислительная машина может выполнять как программное проектирование для своей собственной архитектуры аппаратных средств, так и программное обеспечение, написанное для компьютеров, имеющих несоответствующую архитектуру аппаратных средств. В качестве более конкретного примера вычислительная система, например, изготовленная фирмой Apple Computer, может выполнять операционные системы и программы, написанные для вычислительных систем на базе ПК (персонального компьютера). Также может оказаться возможным использовать программу эмуляции для выполнения работ одновременно во множестве несовместимых операционных систем на одном ЦП. При таком устройстве, хотя каждая операционная система является несовместимой с другой, программа эмуляции может возлагать функции ведущей на одну из этих двух операционных систем, позволяя одновременно выполнять несовместимые в других обстоятельствах операционные системы в одной и той же вычислительной системе.
Когда гостевая вычислительная система эмулирована в системе главной вычислительной машины, гостевую вычислительную систему можно называть виртуальной машиной, поскольку система главной вычислительной машины существует только как программное представление функционирования архитектуры аппаратных средств гостевой вычислительной системы. Термины "эмулятор" и "виртуальная машина" иногда используются взаимозаменяемо, чтобы обозначать способность имитировать или эмулировать архитектуру аппаратных средств всей вычислительной системы. Например, Virtual PC software (программное обеспечение виртуального ПК), созданное на фирме Connectix Corporation of San Mateo, Калифорния, эмулирует целый компьютер, который включает в себя процессор Intel 80X86 Pentium и различные компоненты и платы расширения системной платы. Действие этих компонентов эмулировано в виртуальной машине, которая работает в главной вычислительной машине. Программа эмуляции, выполняющаяся на архитектуре программного обеспечения и оборудования операционной системы главной вычислительной машины, типа вычислительной системы, имеющей процессор PowerPC, имитирует функционирование всей гостевой вычислительной системы. Программа эмуляции действует как обмен между архитектурой аппаратных средств главной вычислительной машины и командами, передаваемыми программным обеспечением, выполняющимся в пределах эмулируемой среды.
Архитектуры X86
"X86" представляет обобщенное название для серий всех семейств микропроцессоров, которые используют структуру системы команд (ISA) x86. IA32 представляет специальные архитектуры процессоров, разработанные на фирме Intel, которые используют ISA x86. X86 начинается с микропроцессора Intel 8086. Процессоры X86 включают в себя, но не в ограничительном смысле, семейства процессоров Intel 8086, 286, 386, 486, Pentium, Pentium с MMX (мультимедийным расширением), Pentium PRO, Pentium II, Pentium III и Pentium 4, так же как разработанные на фирме AMD K5, K6, K6-2, K6-3, Athlon, Enhanced Athlon (расширенный) (также известный как "thunderbird"), Athlon 4 и Athlon МР, Athlon 64, Opteron среди прочих.
Монитор (средство мониторинга) виртуальной машины (VMM) представляет собой программный уровень, который выполняется непосредственно в вышеупомянутых аппаратных средствах, и VMM осуществляет виртуализацию (виртуализирует) все ресурсы машины посредством предоставления интерфейсов, которые являются аналогичными аппаратным средствам, которые виртуализирует VMM (что дает возможность VMM продолжать действовать незаметно для уровней операционной системы, выполняющихся над ним). Однако архитектуры x86, включая архитектуру IA32 и т.п., содержат много просчетов в плане виртуализации, которые представляют ряд проблем для реализации VMM. Во-первых, архитектура x86 не делит все режимы процессоров либо на привилегированный режим, либо на пользовательский режим, где, между прочим, привилегированный режим должен включать в себя любые поля управления или состояния, которые указывают текущий уровень привилегий, а также другие ресурсы, которые должны находиться под управлением лежащей в основе операционной системы (или "уровня супервизора"), чтобы реализовать барьеры управления ресурсами и защиты между экземплярами прикладных программ пользовательского уровня. Во-вторых, архитектура x86 не вызывает исключений-ловушек во всех случаях, когда попытка доступа к привилегированному режиму (либо считывания, либо записи) предпринята на пользовательском уровне. В-третьих, архитектура x86 не имеет средства, вызывающего исключение-ловушку, когда код пользовательского уровня пытается обращаться к непривилегированному режиму, который должен быть виртуализирован (например, значения таймера, счетчики выполнения, регистры параметров процессора). В-четвертых, в то время как все структуры процессоров в оперативной памяти либо должны храниться вне текущего адресного пространства, либо быть защищаемыми от ошибочных или злонамеренных доступов в память в пределах виртуальной машины (ВМ, VM), архитектура х86 не предусматривает этого. Пятое и последнее, архитектуры х86 не могут восстанавливать все состояние процессора во время прерывания или исключения-ловушки к его состоянию до системного прерывания после того, как была проведена обработка прерывания или исключения-ловушки.
Краткое изложение сущности изобретения
Многие из этих упомянутых выше недостатков и ограничений архитектур х86 следуют из команд, которые не достигают успеха в вызове исключения-ловушки, когда оно требуется. Другими словами, если эти команды вместо этого смогут вызывать исключения-ловушки, монитор виртуальной машины (VMM) сможет правильно виртуализировать эти команды.
Настоящее изобретение компенсирует недостатки в архитектурах х86 процессоров посредством введения "синтезированных команд", которые вызывают исключение-ловушку и, таким образом, обеспечивают возможность для виртуальной машины (ВМ) надежно обрабатывать команды. Используя команды, которые являются "недопустимыми" для архитектуры х86, но которые, тем не менее, понятны для виртуальной машины, настоящий способ использует синтезированные команды для выполнения строго определенных действий в виртуальной машине, которые в других обстоятельствах являются проблематичными, когда выполняются с помощью традиционных команд, исполняемых в процессоре х86, и, таким образом, обеспечивают значительно усовершенствованную виртуализацию процессора для систем на основе процессоров x86.
Перечень фигур
Приведенное выше краткое изложение сущности изобретения, а также последующее подробное описание предпочтительных вариантов осуществления будут лучше понятны при чтении вместе с прилагаемыми чертежами. Для цели иллюстрирования изобретения здесь на чертежах показаны примерные толкования изобретения; однако изобретение не ограничено раскрытыми конкретными способами и средствами. На чертежах:
фиг.1 - иллюстрация виртуализированной вычислительной системы, содержащей программный уровень монитора виртуальной машины (VMM), выполняемый непосредственно над аппаратными средствами компьютера и взаимодействующий с двумя виртуальными машинами (ВМ);
фиг.2 - иллюстрация виртуализированной вычислительной системы по фиг.1, дополнительно содержащей главную (собственную) операционную систему, которая непосредственно взаимодействует с аппаратными средствами компьютера;
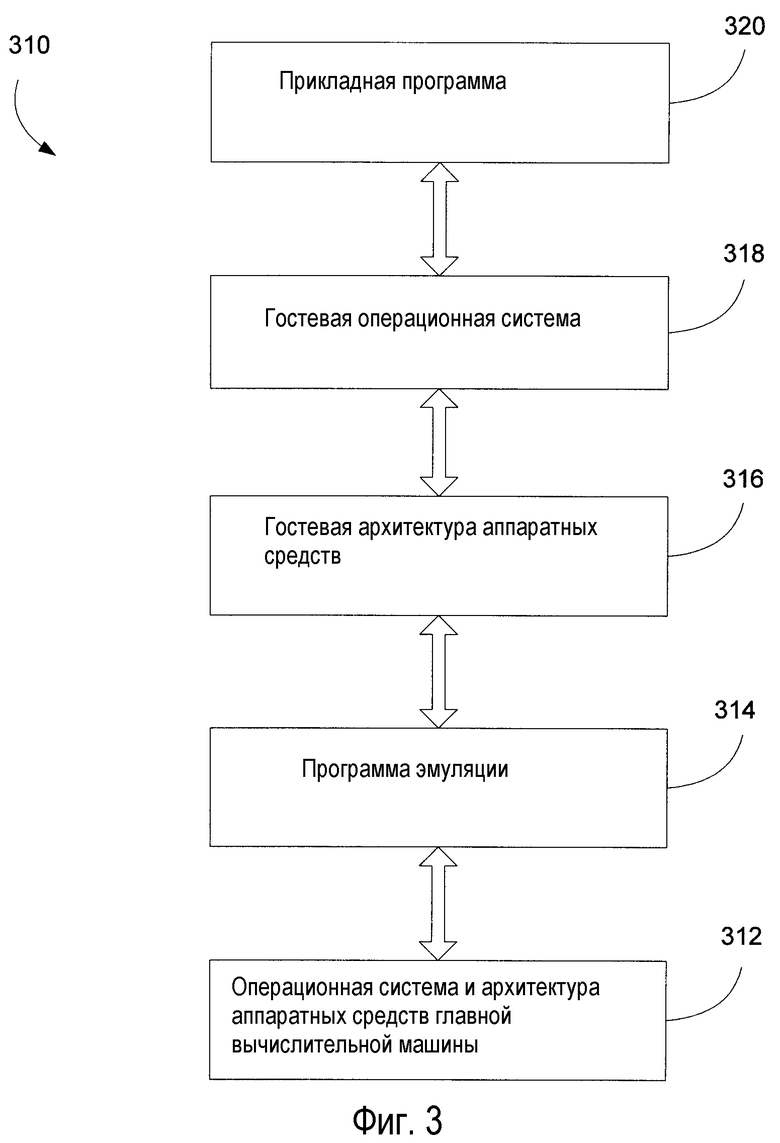
фиг.3 - схема логической зависимости элементов эмулируемой вычислительной системы, работающей в системе главной вычислительной машины;
фиг.4 - иллюстрация регистра EFLAGS процессора x86 (специально для архитектуры IA32);
фиг.5 - иллюстрация четырех отличающихся категорий режимов процессора, обычно распознаваемых монитором виртуальной машины (VMM);
фиг.6 - таблица команд x86, которые выявляют тот факт, что предполагается кодом кольца уровня 0, фактически выполняется на более высоком уровне кольца, что характеризует проблему с традиционными подходами виртуализации процессоров x86;
фиг.7 - таблица команд, которые выявляют факт того, что виртуальная машина затеняет некоторую информацию регистров х86 для гостевой операционной системы;
фиг.8 - таблица команд, которые должны выполнять исключение-ловушку для целей виртуализации, но в архитектуре х86х этого не делают;
фиг.9 - таблица проблематичных команд, имеющих отношение к полям IF и IOPL в архитектурах х86;
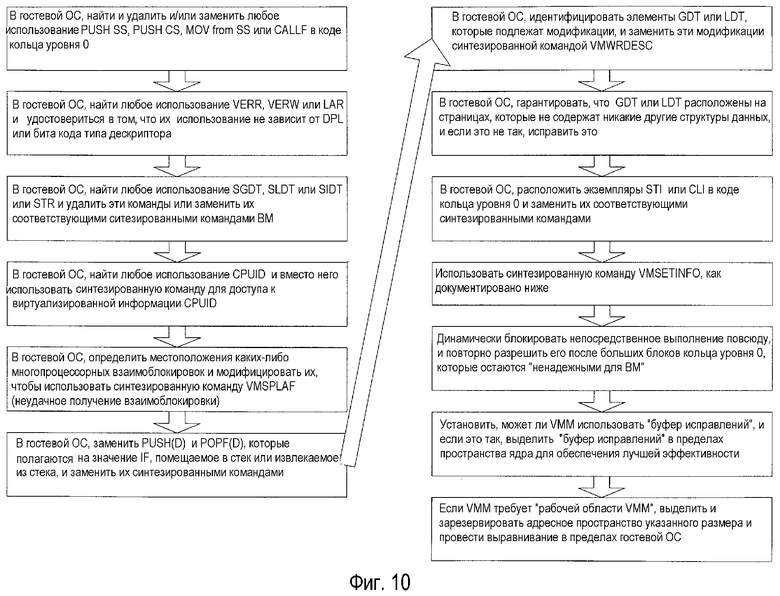
фиг.10 - схема последовательности операций, иллюстрирующая один вариант осуществления способа усовершенствования виртуализации в архитектуре IA32 посредством оптимизации кода ОС (операционной системы) и использования "синтезированных команд".
Подробное описание
Объект изобретения описан с такой спецификой, чтобы удовлетворять установленным потребностям. Однако само описание не предназначено для ограничения объема данного патента. Скорее, автор изобретения предполагает, что заявляемый объект также может быть воплощен другими способами, включая при этом различные этапы или комбинации этапов, подобные описанным в этом документе, вместе с другими существующими или будущими технологиями. Кроме того, хотя термин "этап" может использоваться здесь для обозначения различных элементов используемых способов, этот термин не следует интерпретировать как подразумевающий какой-либо конкретный порядок среди или между различными раскрытыми здесь этапами, если порядок отдельных этапов не описан явно. Наконец, хотя приведенное здесь обсуждение может время от времени сосредотачиваться на архитектуре IA32 и/или семействе процессоров x86, здесь не подразумевается, что оно предназначено для ограничения этими подгруппами, и любое такое обсуждение тем самым явно включает в себя все соответствующие архитектуры процессоров, к которым различные варианты осуществления настоящего изобретения могут применяться и/или использоваться, включая, но не в ограничительном смысле, все архитектуры процессоров х86 и их эквиваленты и явно включая архитектуры IA32 и IA64 и их эквиваленты, расширения и отклонения.
Компьютерные микропроцессоры
Микропроцессор представляет собой компьютерный процессор на микрокристалле. Он предназначен для выполнения арифметических и логических операций, которые используют малые области промежуточного хранения чисел, называемые регистрами. Типичные операции микропроцессоров включают в себя сложение, вычитание, сравнение двух чисел и извлечение чисел из одной области в другую. Эти операции представляют собой результат выполнения набора команд, которые являются частью структуры дизайна микропроцессора.
Команда представляет собой порядок, задаваемый компьютерному процессору компьютерной программой. На самом низком уровне каждая команда представляет собой последовательность 0-ей и 1-иц, которая описывает физическую операцию, подлежащую исполнению компьютером (типа "Сложения" (“Add”)), и, в зависимости от конкретного типа команды, определение специальных областей памяти, называемых регистрами, которые могут содержать данные, подлежащие использованию при выполнении команды, или местоположение данных в памяти компьютера.
Регистр представляет собой одно из небольшого набора мест хранения данных, которые являются частью компьютерного процессора. Регистр может хранить машинную команду, адрес ячейки памяти или любой вид данных (типа последовательности битов или отдельных символов). Некоторые команды определяют регистры как часть команды. Например, команда может определить, что содержимое двух заданных регистров должно быть сложено вместе и затем помещено в определенный регистр. Регистр должен быть достаточно большим, чтобы хранить команду, например, в компьютере на основе 32-битных команд регистр должен иметь длину 32 бита. В некоторых конструкциях компьютеров есть меньшие регистры, например полурегистры, для более коротких команд. В зависимости от конструкции процессора и правил языка регистры могут быть пронумерованы или иметь произвольные названия. Однако, как используются здесь, специальные регистры, специальные команды и другие технические элементы, описанные с этой спецификой, основаны на архитектуре х86 и как таковые широко известны и хорошо понятны специалистам в данной области техники.
Архитектура виртуальной машины
Фиг.1 иллюстрирует виртуализированную вычислительную систему, содержащую программный уровень 104 монитора виртуальной машины (VMM), выполняемый непосредственно над аппаратными средствами 102, и VMM 104 виртуализирует все ресурсы машины посредством представления интерфейсов, которые аналогичны аппаратным средствам, виртуализируемым VMM (что дает возможность VMM выполняться незаметно для уровней операционной системы, выполняющихся выше него). Выше VMM 104 находятся две реализации виртуальной машины (ВМ), ВМ А 108, которая представляет собой виртуализированный процессор Intel 386, и ВМ В 110, которая является виртуализированной версией одного или большего количества из семейства процессоров Motorola 680X0. Выше каждой ВМ 108 и 110 находятся гостевые операционные системы А 112 и В 114 соответственно. Выше гостевой ОС А 112 выполняются две прикладные программы, прикладная программа A1 116 и прикладная программа A2 118, а выше гостевой ОС В 114 - прикладная программа B1 120.
Фиг.2 иллюстрирует виртуализированную аналогичным образом среду вычислительной системы, но имеющую главную (собственную) операционную систему X 122, которая непосредственно взаимодействует с компьютерными аппаратными средствами 102, а выше собственной ОС X 122 выполняется прикладная программа X 124.
Фиг.3 представляет схему логических уровней архитектуры аппаратных средств и программного обеспечения для эмулируемой операционной среды в вычислительной системе 310. Программа 314 эмуляции выполняется в операционной системе и/или архитектуре аппаратных средств 312 главной вычислительной машины. Программа 314 эмуляции эмулирует архитектуру 316 гостевых аппаратных средств и гостевую операционную систему 318. Прикладная программа 320 программного обеспечения, в свою очередь, выполняется в гостевой операционной системе 319. В эмулируемой операционной среде по фиг.3A из-за действия программы 315 эмуляции прикладная программа 320 программного обеспечения может выполняться в вычислительной системе 310 даже при том, что прикладная программа 320 программного обеспечения предназначена для работы в операционной системе, которая в общем является несовместимой с операционной системой и/или архитектурой аппаратных средств 312 главной вычислительной машины.
Виртуализация процессора
Есть два способа обеспечения виртуализации процессоров в виртуальной машине (ВМ): эмуляция и непосредственное выполнение. Виртуальные машины могут использовать любой способ или оба способа ("гибрид") для выполнения виртуализации процессоров.
Эмуляция включает в себя использование либо интерпретатора, либо средства двоичной трансляции и представляет собой также единственный возможный выбор при реализации ВМ в системе, где процессоры гостевой и главной вычислительной машины значительно отличаются. Например, Microsoft Virtual PC (виртуальный ПК) для Macintosh реализует ВМ на основе x86 (эмулируя архитектуру процессора х86) в системе Macintosh на основе PowerPC. Эмуляция также необходима для ситуаций, где процессоры гостевой и главной вычислительной машины одинаковые, но где процессор выполняет неадекватную поддержку виртуализации. Некоторые рабочие режимы архитектуры х86 относятся к этой категории.
Однако, хотя эмуляция представляет собой наиболее гибкий и совместимый механизм виртуализации, обычно он является не самым быстродействующим. Эмуляция посредством либо интерпретации, либо двоичной трансляции налагает непроизводительные затраты времени выполнения. В случае интерпретации, которая является относительно простой для реализации, непроизводительные затраты часто составляют порядка 90-95% (то есть результирующая эффективность будет составлять только 5-10% от "собственной" эффективности). С другой стороны, средство двоичной трансляции является более сложным, чем интерпретатор, и поэтому более трудным для реализации, но такое средство испытывает меньшие потери эффективности и может требовать непроизводительных затрат, составляющих только 25-80% (то есть результирующая эффективность составляет 20-75% от "собственной" эффективности).
В общем, непосредственное выполнение является более быстрым и более эффективным, чем эмуляция, использующая любой подход. Хорошая реализация непосредственного выполнения может достигать, с разницей в пределах только нескольких процентов, эффективности, почти эквивалентно собственной эффективности. Однако, как должно быть известно и понятно специалистам в данной области техники, непосредственное выполнение обычно полагается на средства защиты процессоров, чтобы предотвратить "распространение" виртуализированного кода на всю систему. Более конкретно, непосредственное выполнение полагается на то, что процессор проводит различие между операциями пользовательского уровня и привилегированного уровня (то есть программное обеспечение, которое осуществляет доступ к ресурсам процессора привилегированного уровня в сравнении с ресурсами пользовательского уровня).
Программное обеспечение, выполняемое в привилегированном режиме (то есть доверенное программное обеспечение), может обращаться к привилегированным ресурсам процессора, включая регистры, режимы, установочные параметры, структуры данных в оперативной памяти и т.д. В противоположность этому пользовательский режим предназначен для недоверенного программного обеспечения, которое выполняет большую часть вычислительной работы в современной системе. Многие процессоры (но не все) проводят строгое различие между состоянием пользовательского уровня и состоянием привилегированного уровня (в соответствии с каждым режимом), и доступ к состоянию привилегированного уровня не допускается, когда процессор работает в пользовательском режиме. Это различие позволяет операционной системе главной вычислительной машины (или ее эквиваленту) защищать ключевые ресурсы и предотвращать крушение всей системы из-за содержащей ошибки или злоумышленной части программного обеспечения пользовательского уровня.
Для прямого выполнения кода пользовательского уровня любые нарушения привилегий перехватываются VMM и переадресовываются гостевым обработчикам исключений. Непосредственное выполнение кода привилегированного уровня, однако, включает в себя выполнение кода привилегированного уровня на пользовательском уровне, несмотря на то, что код привилегированного уровня записан с допущением, что он будет иметь полный доступ ко всем элементам процессора, соответствующим привилегированному состоянию. Чтобы согласовать это противоречие, ВМ полагается на то, что процессор сгенерирует исключение-ловушку для всех привилегированных команд (то есть команд, которые прямо или косвенно осуществляют доступ к привилегированному состоянию). Исключение-ловушка нарушения привилегий активирует обработчик исключений-ловушек в мониторе виртуальной машины (VMM). Тогда обработчик исключений-ловушек VMM эмулирует подразумеваемые изменения состояния привилегированной команды и возвращает управление назад к следующей команде. Эта эмуляция привилегированной команды часто включает в себя использование теневого состояния, которое является приватным для конкретного экземпляра ВМ.
Например, если архитектура процессора включает в себя регистр привилегированного режима (PMR), к которому может быть осуществлен доступ только в привилегированном режиме, любая попытка считывать или записывать в PMR из кода пользовательского уровня вызовет исключение-ловушку. Обработчик исключений-ловушек из состава VMM может определять причину исключения-ловушки и осуществить доступ к теневому значению PMR, которое является приватным для экземпляра соответствующей ВМ. (Это значение PMR может отличаться от значения, в текущий момент хранящегося в PMR процессора главной вычислительной машины.)
В зависимости от частоты перехвата команд и стоимости перехватов эта методика может вносить относительно небольшое, но заметное ухудшение эффективности. Например, некоторые VMM, разработанные IBM и Amdahl, выполняются с 80-98% собственного быстродействия, приводя, таким образом, к 2-15% потерям эффективности, обусловленным этими непроизводительными расходами на перехваты.
Ограничения x86/IA32
Идеализированный процессор, предназначенный для виртуализации, как считают, является строго виртуализируемым, то есть строго виртуализируемый процессор позволяет реализовать механизм виртуализации непосредственного выполнения, который удовлетворяет следующим требованиям:
(a) VMM должен быть способен сохранять "управление" над процессором и системными ресурсами;
(b) программное обеспечение, выполняемое в ВМ (либо на пользовательском, либо на привилегированном уровне), не должно быть в состоянии сообщать о том, что оно выполняется в виртуальной машине.
Удовлетворяя этим требованиям, строго виртуализируемый процессор демонстрирует следующие свойства:
- включает в себя блок управления памятью (MMU) или аналогичный механизм преобразования адресов;
- обеспечивает два или более уровня привилегий;
- делит все состояние процессора либо на привилегированное состояние, либо на пользовательское состояние; причем привилегированное состояние должно включать в себя любые поля управления или статуса, которые указывают текущий уровень привилегий;
- вызывает исключение-ловушку, когда какое-либо обращение к привилегированному состоянию (либо считывание, либо запись) предпринимается на пользовательском уровне;
- имеет средство, чтобы в необязательном порядке вызывать исключение-ловушку, когда код пользовательского уровня пытается осуществить доступ к непривилегированному состоянию, которое должно быть виртуализировано (например, значения таймера, счетчики выполнения, регистры параметров процессоров);
- все структуры процессора в оперативной памяти либо хранятся вне текущего адресного пространства, либо являются защищаемыми от ошибочных или злонамеренных доступов к памяти внутри ВМ;
- любое состояние процессора во время прерывания или исключения-ловушки может быть восстановлено к его состоянию перед исключением-ловушкой после того, как прерывание или исключение-ловушка обработано.
Некоторые современные процессоры, включая PowerPC и DEC Alpha, которые представляют лишь малую долю современных процессоров, удовлетворяют этим требованиям. Однако IA32 удовлетворяет только первым двум требованиям. Таким образом, архитектура IA32 содержит много просчетов в плане виртуализации, которые представляют ряд сложных проблем для реализации VMM.
Во-первых, архитектура IA32 нарушает требование разделения пользовательского/привилегированного состояния в некоторых случаях, наиболее значительный из которых включает в себя регистр EFLAGS, который содержит и пользовательское, и привилегированное состояние, как иллюстрируется на фиг.4. Следующие поля EFLAGS должны рассматриваться как привилегированные: VIP, VIF, VM, IOPL и IF. (Все другие поля представляют пользовательское состояние и не должны быть привилегированными.) Однако для IA32, команды, которые осуществляют считывание и запись в привилегированных полях регистра EFLAGS (включая PUSHF/PUSHFD, POPF/POPFD и IRET), не вызывают исключения-ловушки, когда выполняются в пользовательском режиме, и в IA32 нет средства, чтобы вынудить эти команды вызвать исключение-ловушку.
Кроме того, в IA32 команды PUSHF И POPF часто используются в гостевом коде ядра (кольца уровня 0), чтобы сохранять и восстанавливать состояние IF (флага разрешения прерывания). В пределах виртуальной машины этот код ядра выполняется в кольце более высокого уровня (например, в кольце уровня 1), а IOPL установлен так, что команды IN/OUT (ВВОД/ВЫВОД) вызывают исключение-ловушку. Поскольку операционной системе (ОС), выполняемой в пределах ВМ, нельзя позволить блокировать прерывания в процессоре главной вычислительной машины, фактическое значение IF устанавливают на 1, пока выполняется код виртуальной машины, независимо от состояния виртуального IF. Следовательно, команда PUSHF всегда размещает значение EFLAGS с IF = 1, а команда POPF всегда игнорирует поле IF в извлеченном значении EFLAGS.
В дополнение к регистру EFLAGS, в регистрах CS и SS находятся две дополнительные области, где привилегированное и пользовательское состояния смешаны. Два нижних бита этих регистров содержат текущий уровень привилегий (CPL), который является привилегированным состоянием, тогда как верхние четырнадцать битов этих регистров содержат индекс сегмента и селектор таблицы дескрипторов, который является не привилегированным. Команды, которые явно или неявно обращаются к селектору SS или CS (включая CALLF, MOV from SS и PUSH SS), не вызывают исключение-ловушку, когда выполняются из пользовательского режима. Следует отметить, что другие команды обуславливают помещение CS или SS в стек (например, INT, INTО, JMPF через шлюз вызова, CALLF через шлюз вызова), но эти команды могут вызывать исключение-ловушку, позволяя VMM виртуализировать помещенное в стек значение CPL.
Дополнительные несоответствия модели защиты x86/IA32, которые позволяют коду пользовательского уровня непосредственно осуществлять доступ к привилегированному состоянию процессора, включают в себя следующие команды: SGDT, SIDT, SLDT, SMSW и STR. По ряду причин затенение GDT (глобальной таблицы дескрипторов), LDT (локальной таблицы дескрипторов), IDT (таблицы дескрипторов прерываний) и TR необходимы для правильной виртуализации, которая означает, что TR, GDTR и IDTR (указывают на затеняемые таблицы VMM, а не на таблицу, определяемую гостевой операционной системой. Однако, поскольку непривилегированный код может считывать из этих регистров, корректно виртуализировать их содержимое невозможно. Кроме того, несколько команд, которые осуществляют доступ к дескрипторам в GDT и LDT, не перехватываются, когда выполняются из непривилегированного состояния, включая LAR (загрузку байта прав доступа), LSL (загрузку предела сегмента), VERR (проверку сегмента на чтение) и VERW (проверку сегмента на запись). Поскольку необходимо затенение GDT/LDT, эти четыре команды могут выполняться в ВМ некорректно. Кроме того, не перехватывается команда CPUID. Чтобы моделировать новые функции процессора или блокировать функции процессора в пределах виртуальной машины, важно иметь возможность отлавливать CPUID, когда она выполняется из непривилегированного режима.
Помимо этого, переключение контекста в среде ВМ полагается на способность сохранять и восстанавливать все состояние процессора, но архитектура IA32 не позволяет этого. Более конкретно, состояние дескриптора кэшированного сегмента для каждого из шести сегментов (DS, ES, SS, CS, FS и GS) хранится внутри процессора во время перезагрузки сегментов, и к этой информации не может быть осуществлен доступ через какой-либо определенный архитектурой механизм. Следовательно, это представляет существенное препятствие для правильной виртуализации. Например, если часть кода загружает сегмент, а затем модифицирует дескриптор в оперативной памяти, соответствующий этому сегменту, последующее переключение контекста не будет возможным для правильного восстановления первоначальной информации дескриптора сегмента. Аналогично этому, если процессор работает в реальном режиме и затем переключается в защищенный режим, сегменты будут содержать селекторы, которые не соответствуют дескрипторам в GDT/LDT защищенного режима, и переключение контекста на этой стадии не может обеспечить правильное восстановление кэшированных дескрипторов, которые были первоначально загружены в реальном режиме.
Аналогично этому, команда PAUSE (пауза) (предварительно зафиксированная форма NOP (нет операции), которая была недавно добавлена для обеспечения подсказок гипермногопоточных процессоров относительно выполнения взаимоблокировки) вносит проблемы, касающиеся эффективности, когда используется с взаимоблокировками во многопроцессорной (МП) ВМ. Например, один виртуальный процессор может переходить к блокировке, которая удерживается вторым виртуальным процессором, и, если второй виртуальный процессор работает в потоке, который в настоящее время не выполняется, первый виртуальный процессор может находиться в блокировке в течение длительного времени и, таким образом, в результате тратить впустую циклы процессора. Хотя может быть полезным, чтобы монитор виртуальной машины мог быть уведомлен при переходе ВМ к блокировке - чтобы позволить VMM запланировать другую ВМ для запуска потока второго виртуального процессора или для сигнализации ему, который подлежит планированию - в настоящее время такого доступного способа уведомления нет.
Некоторые среды ВМ используют несколько различных способов, чтобы предусмотреть эти недостатки и в общем использовать гибридный способ и эмуляцию, и непосредственное выполнение. Конкретные способы выбирают на основании режимов процессоров и другой информации, полученной непосредственно от ОС. Для таких систем имеется в общем четыре отличающиеся категории режимов процессоров, распознаваемые VMM, как показано на фиг.5. Это является возможным и желательным, чтобы обойти заданное по умолчанию поведение в случае режима кольца уровня 0 (который используется для кода на уровне ядра большинства современных ОС). Большая часть приведенного ниже описания посвящена обсуждению требований для надежного выполнения всего кода кольца уровня 0 для механизма непосредственного выполнения.
Многие среды ВМ используют методику, называемую "кольцевое сжатие" (которую первыми использовали специалисты фирмы DEC для виртуализирования архитектуры VAX). Кольцевое сжатие включает в себя выполнение кода кольца уровня 0 в пределах менее привилегированного кольца (например, в кольце уровня 1), чтобы позволять VMM перехватывать некоторые команды привилегированного уровня, которые осуществляют доступ к виртуализированным ресурсам. Например, указатель базы таблицы страниц IA32 хранится в регистре CR3. Команда, которая считывает CR3, может выполняться только в пределах кольца уровня 0. При выполнении в кольце уровня 1 эта команда приводит к генерации процессором исключения-ловушки (в частности, исключения типа 6 "недопустимая операция"). Во время исключения-ловушки VMM получает управление и эмулирует команду, возвращаясь к виртуализированному CR3 (гостевого процессора), а не к CR3 VMM (процессора главной вычислительной машины).
Большей частью VMM может скрывать тот факт, что код, предназначенный для выполнения в кольце уровня 0, фактически выполняется в пределах кольца отличающегося уровня. В предшествующем примере код, который осуществлял доступ к CR3, не был осведомлен о том, что произошло исключение-ловушка, потому что все важные изменения состояния, связанные с командой, были эмулированы. Однако эти недостатки виртуализации IA32 предотвращают ситуацию, когда кольцевое сжатие является полностью непрозрачным. Команды, иллюстрируемые на фиг.6, выявляют факт, что код кольца уровня 0 выполняется на более высоком уровне кольца и код, который использует эти команды, является проблематичным и в общем ненадежным для работы в условиях прямого выполнения программы.
Кроме того, архитектура IA32 включает в себя как глобальную, так и локальную таблицы дескрипторов (GDT и LDT соответственно). Эти таблицы содержат сегменты кода и данных, а также средства, которые управляют переходами между кольцами. Гостевая ОС может конфигурировать свою GDT или LDT, чтобы позволить переходы между кольцом уровня 3 и кольцом уровня 0. Однако VMM не может позволять какой-либо переход непосредственно в кольцо уровня 0, потому что это дает гостевой ОС прямой контроль над процессором главной вычислительной машины. Вместо этого, VMM должен быть вовлечен в какой-либо переход в кольцо уровня 0, чтобы он мог должным образом перенаправить выполнение на уровень кольца ниже привилегированного. Это означает, что VMM не может непосредственно использовать гостевые GDT и LDT. Скорее, он должен скрыть содержимое гостевых GDT и LDT в приватных таблицах, внося изменения по мере необходимости, чтобы предотвратить любые переходы непосредственно к кольцу уровня 0. Эти регулирования ограничены полем DPL (уровня привилегий дескриптора) и битом кода поля типа дескриптора. Из-за этих незначительных модификаций теневые таблицы дескрипторов могут слегка отличаться от гостевых таблиц дескрипторов.
В большинстве случаев эти различия не видимы для программного обеспечения; однако в архитектуре IA32 есть несколько команд, иллюстрируемых на фиг.7, которые выявляют это различие. Например, VMM защищает страницы от записи, которые перекрывают гостевые GDT и LDT, так что любая попытка модифицировать эти таблицы приводит к нарушению защиты при записи в VMM. В ответ на это VMM гарантирует, что изменение гостевых GDT или LDT отражается в ее внутренних теневых таблицах. Однако, когда элементы GDT или LDT, соответствующие загруженному в данный момент селектору, модифицируются, модификация соответствующих дескрипторов в оперативной памяти является необратимой, поскольку архитектура IA32 не обеспечивает какого-либо способа считывания загруженных в данный момент дескрипторов сегментов. В этой ситуации VMM должен полагаться на эмуляцию до того, как разрешить произвести модификацию дескриптора в оперативной памяти.
Один особенно проблематичный аспект виртуализации IA32 включает в себя IF (флаг разрешения прерывания) в регистре EFLAGS, заключающийся в том, что хотя это состояние должно быть безусловно привилегированным, оно без труда считывается непривилегированным кодом. Кроме того, попытки модифицировать IF изнутри непривилегированного кода просто игнорируются вместо генерирования исключения-ловушки, другими словами, хотя можно перехватить некоторые команды, которые манипулируют IF (включая STI и CLI), другие команды, которые осуществляют доступ к IF, не приводят к исключению-ловушке. Другие команды, которые также не приводят к исключению-ловушке (но должны приводить, с точки зрения виртуализации), иллюстрируются на фиг.8.
К сожалению, хотя код выполняется в пределах виртуальной машины, невозможно отразить реальный IF в виртуализированном IF, потому что это позволило бы гостевой ОС без ограничений отключать прерывания, то есть может возникнуть ситуация, когда ошибочная гостевая ОС приведет к зависанию всей системы главной вычислительной машины. По этой причине IF главной вычислительной машины остается всегда разблокированным (то есть прерывания не замаскированы), когда выполняется гостевой код, даже когда виртуализированный (гостевой) IF сброшен.
Точно так же перехват команд STI/CLI требует корректировки поля IOPL EFLAGS, при этом IOPL является еще одним примером привилегированного поля, которое без труда открывается для непривилегированного кода, с недостатками, подобными недостаткам, связанным с IF. Проблематичные команды, имеющие отношение к полям IF и IOPL, иллюстрируются на фиг.9.
Архитектура IA32 также определяет некоторые структуры данных, которые используются процессором, включая TSS, GDT, LDT и IDT, и эти структуры данных расположены в пределах логического адресного пространства, определенного таблицами страниц. Когда гостевая ОС выполняется в пределах виртуальной машины, ее таблицы страниц определяют, какие области адресного пространства используются для отображения памяти, кадровых буферов, отображенных в памяти регистров и т.д. Почти неизменно некоторая часть адресного пространства остается неиспользованной. В то время как гостевая ОС поддерживает свои собственные TSS, GDT, LDT и IDT, VMM выполняет свои собственные приватные версии этих структур данных. Однако эти структуры должны быть отображены где-нибудь в пределах адресного пространства, которое управляется гостевой ОС. Код VMM и внутренние структуры данных также должны быть отображены в том же самом адресном пространстве. Следовательно, VMM должен найти некоторый (относительно небольшой) участок адресного пространства, который в настоящее время не используется гостевой ОС. Эта область называется "рабочей областью VMM". VMM активно отслеживает таблицы страниц гостевой ОС, чтобы определить, пытается ли гостевая ОС отображать страницы в области, в настоящее время занятой рабочей областью VMM. Если так, VMM находит другой неиспользованный участок адресного пространства и перемещает себя туда.
Эта методика обеспечивает возможность совместимости гостевой ОС в широком диапазоне, но она проблематична, когда используется все гостевое адресное пространство, что может происходить, когда для виртуальной машины назначены большие объемы физической памяти. По этой причине VMM обеспечивает механизм, с помощью которого гостевая ОС может резервировать часть ее адресного пространства, в частности, для рабочей области VMM. Как только это пространство определено, VMM перемещает себя в это пространство и останавливает активные отслеживания изменений в таблицах страниц (согласно допущению, что гостевая ОС будет выполнять свое обязательство больше не использовать зарезервированную область).
Команды, вызывающие исключения-ловушки, являются неоднозначными. С одной стороны, если команда вызывает исключение-ловушку, она может быть должным образом виртуализирована. С другой стороны, исключения-ловушки вносят очень большие непроизводительные потери эффективности. Например, команде STI обычно требуется для выполнения один цикл, но когда STI выполняется в среде ВМ, она вызывает исключение-ловушку, обрабатываемое VMM, который на процессоре Pentiumе 4 часто требует для выполнения больше 500 циклов. Некоторые ВМ попытаются уменьшить эти непроизводительные затраты, прослеживая команды, наиболее часто вызывающие исключения-ловушки, и, где возможно, внося в них исправления ("заплатки") с помощью эквивалентного кода, не вызывающего исключений-ловушек, который сохраняет семантику первоначальной команды в пределах виртуализированной среды. Это выполняют посредством использования "буфера исправлений" с бесстраничной организацией, выделенного в пределах пространства ядра гостевой ОС.
Однако при работе допускающие исправления вызывающие исключения-ловушки команды требуют участок размером по меньшей мере пять байтов, принимая во внимание длинную команду JMP - без этих необходимых пяти байтов, VMM должен записать поверх другого текста команду или команды, которые следуют за вызывающей исключения-ловушки, потому что команда, подлежащая исправлению, может иметь размер меньше пяти байтов.
Улучшенная виртуализация (например, IA32)
Многие из вышеизложенных недостатков и ограничений архитектуры IA32 следуют из команд, которые не в состоянии вызывать исключение-ловушку, когда оно требуется. Другими словами, если эти команды будут вместо этого вызвать исключение-ловушку, VMM сможет правильно эмулировать эти команды. Настоящее изобретение обеспечивает различные варианты осуществления, чтобы эффективно создавать исключения-ловушки для этих проблематичных команд. Различные варианты осуществления настоящего изобретения направлены на улучшение виртуализации в архитектуре IA32 посредством оптимизации кода ОС и использования "синтезированных команд" (подробно обсуждаемых ниже). Несколько вариантов осуществления настоящего изобретения содержат ряд этапов, иллюстрируемых на фиг.10, чтобы оптимизировать гостевую ОС следующим образом:
- В гостевой ОС найти и удалить и/или заменить любое использование PUSH SS, PUSH SS, MOV from SS или CALLF в коде кольца уровня 0. Как обсуждалось выше, эти команды выявляют факт, что код кольца уровня 0, выполняющийся в виртуальной машине, фактически выполняется на уровне кольца более низкой привилегии. Однако эти команды очень редки в большинстве операционных систем, и их можно в общем либо совсем удалять, либо заменять другими существующими командами или группами существующих команд.
- В гостевой ОС найти любое использование VERR, VERW или LAR и подтвердить, что их использование не зависит от DPL или бита кода типа дескриптора. Опять же, эти команды в большинстве ОС не используются.
- В гостевой ОС найти любое использование SGDT, SLDT, SIDT или STR и удалить эти команды или заменить их соответствующими синтезированными командами ВМ. Для реализации этого этапа элемент таблицы дескрипторов в гостевой операционной системе заменяется синтезированной командой (например, VMWRDESC), которая обновляет элемент таблицы дескрипторов, избегая непроизводительных потерь, связанных с сохранением теневых таблиц дескрипторов.
- В гостевой ОС найти любое использование CPUID, то есть место, где к нему осуществляют доступ в ОС с помощью общей подпрограммы, которую все части системы используют для доступа к информации CPUID, и модифицировать общую подпрограмму, которая считывает CPUID, чтобы использовать синтезированную команду для обращения к виртуализированной информации CPUID вместо прямого считывания CPUID. Хотя виртуализация CPUID не является необходимой, пока конкретная информация CPUID, возвращенная процессором главной вычислительной машины, не окажется в конфликте с функциями гостевой системы, если новый процессор должен реализовать функцию, которой VMM не обеспечивает поддержку, тогда виртуализированное значение CPUID может указать, что функция не была представлена, в то время как невиртуализированное значение CPUID укажет, что она была.
- В гостевой ОС определить местоположение каких-либо взаимоблокировок МП и модифицировать их, чтобы использовать синтезированную команду VMSPLAF (неудачное получение взаимоблокировки).
- В гостевой ОС найти какие-либо экземпляры PUSHF(D) и POPF(D) и, если использование этих команд полагается на значение IF, помещаемое в стек или извлекаемое из стека, заменить их соответствующей синтезированной командой. Этот этап будет обычно представлять большую часть работы, включенной в создание "очистки ВМ" ОС.
- В гостевой ОС идентифицировать местоположения, где элементы GDT или LDT модифицированы, и уменьшить до минимума количество модификаций, а затем заменить остающиеся модификации синтезированной командой VMWRDESC. (Следует быть особенно осторожным, чтобы избежать ситуации, когда модифицируется загруженный в настоящее время селектор.)
- В гостевой ОС гарантировать, что GDT и LDT расположены на страницах, которые не содержат никакие другие структуры данных, и, если это не так, исправить это.
- В гостевой ОС определить местоположение экземпляров STI и CLI в коде кольца уровня 0 и заменить их соответствующими синтезированными командами, которые имеют размер пять байтов. Используя синтезированные формы, VMM будет иметь возможность лучше исправлять код, чтобы снизить необходимость в исключениях-ловушках, поскольку прямое исправление команд STI И CLI, каждая из которых имеет размер меньше, чем пять байтов, требует, чтобы VMM перезаписывал команду или команды, которые следуют за командой, вызывающей исключение-ловушку, вследствие того, что типичные допускающие исправление вызывающие исключения-ловушки команды требуют по меньшей мере пяти байтов для обеспечения длинной команды JMP.
- Использовать синтезированную команду VMSETINFO, как документировано ниже. Вышеизложенные девять команд завершаются "очисткой ВМ" так, чтобы эта синтезированная команда могла допускать непосредственное выполнение в пределах кольца уровня 0.
- Динамически блокировать непосредственное выполнение повсюду и повторно разрешить после больших блоков кода кольца уровня 0, которые остаются "не надежными для ВМ". Посредством обеспечения синтезированной команды для гостевой операционной системы, чтобы динамически блокировать (например, VMDXDSBL) и повторно разрешить (VMDXENBL) непосредственное выполнение, гостевая операционная система может избегать больших блоков "не безопасного для ВМ" кода кольца уровня 0.
- Установить, может ли VMM использовать "буфер исправлений" и, если это так, выделить "буфер исправлений" в пределах пространства ядра для обеспечения лучшей эффективности. Этот "буфер исправлений" должен быть бесстраничной организации, отображаемым во все контексты адресного пространства, где выполняется код кольца уровня 0, и иметь размер, указанный синтезированной командой VMGETINFO. Расположение и размер "буфера исправлений" можно устанавливать, используя команду VMSETINFO, как документировано ниже. "Буфер исправлений" должен быть выделен один раз для всей системы, а не для каждого виртуального процессора.
- Определить, требует ли VMM "рабочей области VMM", и, если это так, выделить и зарезервировать адресное пространство указанного размера и провести выравнивание в пределах гостевой ОС. Установить базовый адрес этой зарезервированной области с помощью команды VMSETINFO, как обсуждается ниже.
"Синтезированные команды" ВМ являются недопустимыми в других обстоятельствах командами процессора, которые имеют специальные значения для ВМ. По существу, когда синтезированные команды выполняются в ВМ, которая не поддерживает синтезированные команды, или в среде без ВМ, они генерируют исключение типа 6 (недопустимая операция), и поэтому для ОС важно проверить поддержку синтезированных команд перед их использованием. Чтобы проверить поддержку синтезированных команд ВМ, ОС выполняет команду VMCPUID, и, если эта команда генерирует ошибку, соответствующую недопустимой команде, ОС определяет, что синтезированные команды не поддерживаются. (Следует отметить, что VMCPUID может быть выполнена на всех уровнях привилегий, так что она является надежной при использовании в коде пользовательского уровня.) Такую же проверку можно использовать для определения того, проводится ли выполнение в пределах среды ВМ, и, если это так, последующего позволения виртуальной машине осуществлять доступ или модифицировать признаки или режимы лежащего в основе VMM. Ниже представлен примерный код, который использует механизм “попытка/исключение” (try/except) и структурированную обработку исключений для выполнения такой проверки:

Используя синтезированные команды, команда ISA x86, которая неблагоприятным образом воздействует на виртуализацию в процессоре x86, может быть, таким образом, заменена или дополнена синтезированной командой, которая в процессоре x86 вызывает исключение, которое затем перехватывается виртуальной машиной, работающей на упомянутом процессоре x86, для обработки упомянутой виртуальной машиной. Аналогично этому для рекурсивной виртуализации, в которой первая виртуальная машина работает на второй виртуальной машине, команда, которая либо заменяется, либо дополняется синтезированной командой, чтобы вызвать исключение в процессоре x86, может пропускаться через вторую виртуальную машину для перехвата упомянутой первой виртуальной машиной с целью обработки.
Для некоторых вариантов осуществления настоящего изобретения все синтезированные команды имеют величину, составляющую пять байтов, с обеспечением возможности исправления с помощью команды JMP, чтобы сократить непроизводительные затраты на перехваты. (В других вариантах осуществления синтезированные команды могут иметь большую или меньшую длину.) При шестнадцатеричном кодировании для синтезированных команд используется следующий формат: 0F C7 C8 XX XX (где "XX" представляет собой двухзначные шестнадцатеричные переменные для идентификации специальных синтезированных команд). Эта команда декодируется как команда CMPXCHG8B, но она рассматривается как "недопустимое действие", потому что заданный операнд назначения представляет собой регистр (и, таким образом, приводит к исключению-ловушке). Однако в некоторых вариантах осуществления настоящего изобретения синтезированные команды не поддерживают никакую форму префиксов команд (например, LOCK, REP, переопределения сегмента, переопределения размера операнда, переопределения длины адреса), и попытки использовать префиксы в таких вариантах осуществления приведут к исключению, соответствующему недопустимой команде (UD#).
Синтезированные команды
Здесь подробно описано подмножество синтезированных команд для различных вариантов осуществления настоящего изобретения. Дополнительные синтезированные команды, не перечисленные здесь, также были описаны выше. Кроме того, дополнительные синтезированные команды, описанные здесь неявно, тем не менее подразумеваются различными вариантами осуществления настоящего изобретения, и ничто в этом описании не следует рассматривать в качестве ограничения изобретения специальными синтезированными командами, которые явно идентифицированы.
VMGETINFO - получение информации ВМ
VMGETINFO извлекает специальную часть информации ВМ и размещает ее в EDX:EAX. Возвращенная информация зависит от индекса в ECX. Если определенный индекс относится к части информации, которая не поддерживается виртуальным процессором, генерируется GP(0). Если индекс относится к поддерживаемой части информации, EDX:EAX устанавливается на информационное значение. (Следует отметить, что условное обозначение регистра, использованное для этой команды, подобно команде RDMSR.) Эта команда отличается от большинства команд процессора тем, что она воздействует на состояние всей системы. В системах с множеством процессоров состояние, полученное с VMGETINFO, рассматривается как "глобальное". Например, установление Базового адреса рабочей области VMM при использовании VMSETINFO на одном процессоре обеспечивает возможность это значение затем считывать обратно, используя VMGETINFO на втором процессоре.
VMSETINFO - установка информации ВМ
VMSETINFO устанавливает специальную часть информации ВМ, как определено в EDX:EAX. Информация, подлежащая установлению, зависит от индекса в ECX. Если заданный индекс ссылается на часть информации, которая не поддерживается виртуальным процессором или является неперезаписываемой, генерируется GP(0). (Следует отметить, что условное обозначение регистра, использованное для этой команды, подобно команде WRMSR.) Эта команда отличается от большинства команд процессора, в том что она воздействует на состояние всей системы. В системах с множеством процессоров состояние, установленное с помощью VMSETINFO, рассматривается как "глобальное". Например, установление Базового адреса рабочей области VMM при использовании VMSETINFO на одном процессоре обеспечивает возможность затем считывать эти данные обратно, используя VMGETINFO на втором процессоре.
VMDXDSBL - блокировка прямого выполнения
VMDXDSBL блокирует непосредственное выполнение до тех пор, пока в следующий раз непосредственное выполнение не будет разрешено посредством использования VMDXENBL. Эта команда может быть выполнена только из кода кольца уровня 0 и должна выполняться, только когда прерывания (или любая форма вытеснения) заблокированы, чтобы предотвратить блокирование непосредственного выполнения в течение длительных периодов времени. Ее можно использовать для предохранения небольших блоков кода, которые не являются "надежными для ВМ" (то есть содержат ряд невиртуализируемых команд или допущений, которые нарушаются при работе с непосредственным выполнением в среде ВМ). Эта команда воздействует только на процессор, на котором она выполняется. Она не воздействует на другие виртуальные процессоры в виртуальной машине. Если непосредственное выполнение уже заблокировано, эта команда ничего не делает.
VMDXENBL - разрешение непосредственного выполнения
VMDXENBL допускает непосредственное выполнение, где это возможно. Эта команда может выполняться только из кода кольца уровня 0 и должна выполняться, только когда прерывания (или любая форма вытеснения) заблокированы. Она может использоваться вместе с командой VMDXDSBL для защиты небольших блоков кода, которые не являются "надежными для ВМ" (то есть содержат ряд невиртуализируемых команд или допущений, которые нарушаются при работе с непосредственным выполнением в среде ВМ). Эта команда воздействует только на процессор, на котором она выполняется. Она не воздействует на другой виртуальный процессор в виртуальной машине. Если непосредственное выполнение уже допускается, эта команда ничего не делает.
VMCPUID - виртуализированная информация ЦП
VMCPUID подобна реальной команде CPUID за исключением того, что она возвращает теневую информацию ЦП.
VMHLT - останов
VMHLT подобна нормальной команде HLT (останов) за исключением того, что она может быть выполнена из любого режима процессора, включая кольцо уровня 3 и режим v86. Она может быть вставлена в любой "неактивный цикл", чтобы сократить использование процессора в виртуальной машине. В некоторых вариантах осуществления эта синтезированная команда для остановки процессора (например, VMHALT) может быть выполнена как гостевой код пользовательского уровня.
VMSPLAF - неудачное получение взаимоблокировки
Взаимоблокировки часто используются в операционных системах, которые поддерживают симметричную мультипроцессорную обработку. Эти блокировки обычно предохраняют критический ресурс, который совместно используется процессорами. Они полагаются на факт, что блокировка будет удерживаться в течение относительно небольшого числа циклов еще одним другим процессором. В многопроцессорной системе ВМ обычное поведение взаимоблокировки может приводить к низкой эффективности и высокому использованию ЦП, если виртуальный процессор, который удерживает взаимоблокировку, временно вытесняется и не работает, в то время как другие виртуальные процессоры ожидают ресурс, удерживаемый приостановленным процессором. Чтобы избегать такой ситуации, можно использовать команду VMSPLAF для уведомления VMM о том, что ОС ожидает взаимоблокировки, которую она не смогла получить. В ответ на это VMM может либо запланировать другой виртуальный процессор для работы, либо перевести в состояние ожидания текущий виртуальный процессор и запланировать его для более позднего выполнения в тот момент времени, когда ресурс будет освобожден.
VMPUSHFD - помещение в стек виртуализированного регистра флагов
VMPUSHFD подобна нормальной команде PUSHFD за исключением того, что она является "надежной для ВМ". Она допускает и 32-битный размер операнда, и 32-битный указатель вершины стека. Если CS и SS в настоящее время не являются 32-битными, их поведение не определено. Также не гарантировано осуществление проверок в отношении границ сегментов или операций записи таким же путем, как это выполнила бы реальная команда PUSHFD. Значение регистра EFLAGS, помещенного в стек, будет содержать теневое значение IF. Однако значение поля IOPL может не быть корректным. Код, который требует считывания IOPL, должен использовать значение EFLAGS, помещенного в стек, в ответ на команду INT, внешнее прерывание или исключение. Эта команда может использоваться только в коде кольца уровня 0.
VMPOPFD - извлечение из стека виртуализированного регистра флагов
VMPOPFD подобна нормальной команде POPFD за исключением того, что она является "надежной для ВМ". Она допускает и 32-битный размер операнда, и 32-битный указатель вершины стека. Если CS и SS в настоящее время не являются 32-битными, их поведение не определено. Также не гарантировано осуществление проверок в отношении границ сегментов или операций записи таким же путем, как это выполнила бы реальная команда PUSHFD. Значение поля IF в извлеченном EFLAGS будет приниматься на обработку. Однако значение поля IOPL может игнорироваться. Код, который требует корректировки IOPL, должен использовать команду IRETD или VMIRETD. Эта команда может использоваться только в коде кольца уровня 0.
VMCLI - сброс флага прерывания
VMCLI подобна нормальной команде CLI за исключением того, что она имеет размер пять байтов и может быть исправлена, чтобы избежать исключений-ловушек в VMM. Эта команда может использоваться только в коде кольца уровня 0.
VMSTI - установка флага прерывания
VMSTI подобна нормальной команде STI за исключением того, что она имеет размер пять байтов и может быть исправлена, чтобы избежать прерывания в VMM. Она также отличается от нормальной STI тем, что не предотвращает возникновение прерывания до завершения следующей команды. Единственным исключением для этого правила является ситуация, если VMSTI сопровождается командой SYSEXIT, которая атомарно выполняется наряду с VMSTI. Эта команда может использоваться только в коде кольца уровня 0.
VMIRETD - возврат из прерывания
VMIRETD подобна нормальной команде IRETD за исключением того, что она является "надежной для ВМ". В отличие от нормальной команды IRETD эта команда всегда допускает 32-битный размер операнда и 32-битный указатель вершины стека. Ее поведение не определено, если текущий размер CS и SS не является 32-битным. Эта команда может использоваться только в коде кольца уровня 0. Она должна использоваться везде, где потенциально используется IRETD, чтобы возвратиться к режиму v86. Использование VMIRETD избегает неподходящего поведения процессора IA32 при возвращении к режиму v86 от ТУП > 0. (Следует отметить, что кольцевое сжатие приводит к выполнению кода кольца уровня 0 в среде ВМ на менее привилегированном уровне кольца.)
VMSGDT - сохранение глобальной таблицы дескрипторов
VMSGDT подобна реальной команде SGDT за исключением того, что она сохраняет базовый адрес и длину теневой GDT. Это предполагает, что режим адресации для операнда памяти представляет собой DS:[ЕАХ] и что DS представляет незащищенный перезаписываемый сегмент. Если DS не является незащищенным перезаписываемым сегментом, его поведение не определено.
VMSIDT - сохранение таблицы дескрипторов прерываний
VMSIDT подобна реальной команде SIDT за исключением того, что она сохраняет базовый адрес и длину теневой IDT. Это предполагает, что режим адресации для операнда памяти представляет собой DS:[ЕАХ] и что DS является незащищенным перезаписываемым сегментом. Если DS не является незащищенным перезаписываемым сегментом, его поведение не определено.
VMSLDT - сохранение локальной таблицы дескрипторов
VMSLDT подобна реальной команде SLDT за исключением того, что она сохраняет селектор теневой LDT. Это предполагает, что операнд назначения представляет собой регистр ЕАХ.
VMSTR - сохранение регистра задачи
VMSTR подобна реальной команде STR за исключением того, что она сохраняет селектор теневой LDT. Это предполагает, что операнд назначения представляет собой регистр ЕАХ.
VMSDTE - сохранение в элементе таблицы дескрипторов
VMSDTE используется для обновления элемента дескриптора в GDT или LDT. Для ее использования в ECX загружают селектор. Верхние 16 битов и нижние два бита (бит 0 и 1) ECX игнорируются. Бит 2 из ECX указывает, относится ли селектор к глобальной или локальной таблице дескрипторов. Остающаяся часть (биты 3-15) кодирует селектор, то есть смещение в таблице дескрипторов. EDX:EAX должен быть загружен значением для записи в заданном элементе таблицы дескрипторов. Эта команда должна использоваться вместо прямого модифицирования таблиц дескрипторов, так что теневые таблицы дескрипторов VMM могут обновляться в одно и то же время. Нельзя модифицировать элемент дескриптора, соответствующий загруженному в настоящее время селектору сегмента. Это приведет к неопределенному поведению. Нельзя использовать эту команду, если это не рекомендует VMM (как обозначено битом 4 информации VMM, возвращаемым командой VMGETINFO). Использование данной команды, когда это не рекомендуется, может привести к низкой эффективности при выполнении на будущих реализациях VMM. Эта команда может использоваться только в коде кольца уровня 0.
Заключение
Описанные здесь различные системы, способы и методики могут быть воплощены с помощью аппаратных средств или программного обеспечения или, где это подходит, с помощью их комбинации. Таким образом, способы и устройства по настоящему изобретению или некоторые их аспекты или части могут принимать форму кода программы (то есть команд), воплощенного в материальных носителях типа гибких дискет, неперезаписываемых компакт-дисков, накопителей на жестких дисках или любого другого машиночитаемого носителя данных, в котором, когда код программы загружен и выполняется машиной, такой как компьютер, машина становится устройством для практической реализации изобретения. В случае выполнения кода программы на программируемых компьютерах компьютер будет в общем включать в себя процессор, среду для хранения информации, считываемую процессором (включая энергозависимую и энергонезависимую память и/или запоминающие элементы), по меньшей мере одно устройство ввода данных и по меньшей мере одно устройство вывода данных. Одна или более программ предпочтительно реализованы на процедурном или объектно-ориентированном языке программирования высокого уровня для связи с вычислительной системой. Однако программа (программы) может быть, при желании, реализована на языке ассемблера или на машинном языке. В любом случае язык может быть транслируемым или интерпретируемым языком и объединенным с аппаратными реализациями.
Способы и устройства по настоящему изобретению также могут быть воплощены в форме кода программы, который передается по некоторой передающей среде типа электрической проводной или кабельной сети, по волоконно-оптическим кабелям или с помощью какой-либо другой формы передачи, в которой, когда код программы принят и загружен в машину и выполняется этой машиной, такой как программируемое постоянное запоминающее устройство, вентильной матрицы, программируемого логического устройства (ПЛУ), клиентского компьютера, видеомагнитофона или аналогичного устройства, машина становится устройством для практического осуществления изобретения. При воплощении на процессоре общего назначения код программы объединяется с процессором с целью обеспечения уникального устройства, которое функционирует для осуществления функциональных возможностей индексации согласно настоящему изобретению.
Хотя настоящее изобретение было описано в связи с предпочтительными вариантами осуществления по различным иллюстрациям, должно быть понято, что также можно использовать другие аналогичные варианты осуществления или можно делать модификации и добавления к описанному варианту осуществления, чтобы осуществлять такую же функцию настоящего изобретения, при этом не отходя от него. Например, хотя примерные варианты осуществления изобретения описаны в контексте цифровых устройств, эмулирующих функциональные возможности персональных компьютеров, специалистам в данной области техники должно быть понятно, что настоящее изобретение не ограничено такими цифровыми устройствами, как описано в настоящей заявке, а может применяться к любому количеству существующих или появляющихся вычислительных машин или сред типа игровых консолей, "карманных" компьютеров, портативных компьютеров и т.д., как проводных, так и беспроводных, и может применяться к любому количеству таких вычислительных устройств, связанных через сеть связи и взаимодействующих через сеть. Кроме того, следует подчеркнуть, что рассмотренный здесь ряд компьютерных платформ, включая операционные системы "карманных" устройств и другие специализированные системы аппаратного/программного сопряжения, особенно таких как ряд беспроводных сетевых устройств, продолжает быстро увеличиваться. Поэтому настоящее изобретение не должно быть ограничено никаким единственным вариантом осуществления, а скорее его нужно рассматривать во всей широте и объеме в соответствии с прилагаемой формулой изобретения.
Наконец, описанные здесь раскрытые варианты осуществления могут быть адаптированы для использования в других архитектурах процессоров, автоматизированных системах или виртуализациях систем, и такие варианты осуществления специально подразумеваются сделанными здесь раскрытиями, и, таким образом, настоящее изобретение не должно быть ограничено описанными здесь специфически вариантами осуществления, а вместо этого истолковано наиболее широко. Аналогично этому, использование синтезированных команд для целей, отличающихся от виртуализации процессоров, также подразумевается сделанными здесь раскрытиями, и любое такое использование синтезированных команд в контекстах, отличающихся от виртуализации процессоров, следует поинтерпретировать наиболее широко в контексте приведенных здесь раскрытий.







Изобретение относится к области создания виртуальной среды. Техническим результатом является повышение надежности работы виртуальной машины за счет компенсирования недостатков в архитектурах процессоров х86 посредством обеспечения набора "синтезированных команд", которые вызывают исключение-ловушку. Благодаря использованию команд, которые являются "недопустимыми" для архитектуры х86, но которые, тем не менее, понимаются виртуальной машиной, способ использования этих синтезированных команд выполняет строго определенные действия в виртуальной машине, которые при других обстоятельствах проблематичны, когда выполняются традиционными командами на процессоре х86, но обеспечивают значительно усовершенствованную виртуализацию процессора для систем процессоров х86. 5 н. и 46 з.п. ф-лы, 10 ил.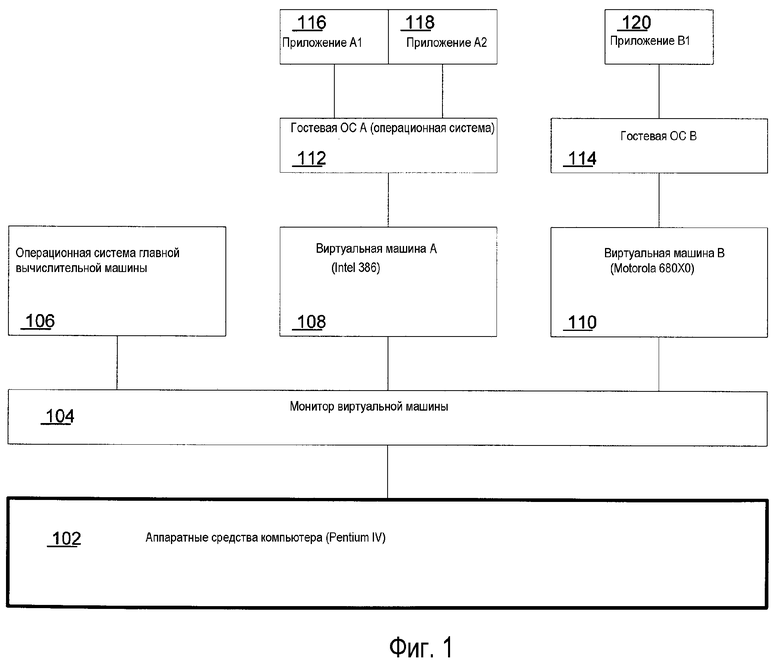
1. Способ обеспечения среды виртуальных машин в компьютерной системе, имеющей первую архитектуру процессора, причем компьютерная система дополнительно имеет: уровень монитора виртуальных машин, который функционирует поверх аппаратного обеспечения, ассоциированного с первой архитектурой процессора, и предоставляет интерфейсы для виртуализации этого аппаратного обеспечения для виртуальных машин; по меньшей мере одну виртуальную машину, которая функционирует поверх уровня монитора виртуальных машин и имитирует по меньшей мере одну вторую архитектуру процессора в упомянутой компьютерной системе, при этом упомянутая виртуальная машина выполнена с возможностью функционировать как в режиме эмуляции, так и в режиме непосредственного выполнения; и по меньшей мере одну гостевую операционную систему, выполняющуюся в упомянутой по меньшей мере одной виртуальной машине, при этом упомянутый способ содержит этапы, на которых:
идентифицируют в наборе команд гостевой операционной системы одну или более предопределенных команд, выполнение которых не приводит к тому, что процессор генерирует исключение-ловушку;
удаляют, заменяют или дополняют идентифицированные одну или более предварительно определенных команд по меньшей мере одной синтезированной командой, которая вызывает по меньшей мере одно исключение, перехватываемое уровнем монитора виртуальных машин, причем эти синтезированные команды являются недопустимыми для первой архитектуры процессора, и
используют по меньшей мере одну из упомянутых синтезированных команд для обеспечения непосредственного выполнения на первой архитектуре процессора команд, выдаваемых упомянутой гостевой операционной системой, при этом упомянутая по меньшей мере одна из упомянутых синтезированных команд выполняется в пределах кода уровня ядра упомянутой гостевой операционной системы.
2. Способ по п.1, в котором упомянутые одна или более предопределенных команд содержат команды х86, включающие в себя одну или более из PUSH CS, PUSH SS, MOV from SS, CALLF, VERR, VERW и LAR.
3. Способ по п.2, в котором команду, неблагоприятно воздействующую на виртуализацию в процессоре х86, либо заменяют, либо дополняют синтезированной командой, вызывающей исключение в процессоре х86, которое затем перехватывается виртуальной машиной, работающей на упомянутом процессоре х86, для обработки упомянутой виртуальной машиной.
4. Способ по п.3, в котором для первой виртуальной машины, работающей на второй виртуальной машине, команда, которую либо заменяют, либо дополняют синтезированной командой, чтобы вызвать исключение в процессоре х86, которое затем перехватывается упомянутой первой виртуальной машиной, работающей на упомянутом процессоре х86, предназначена для обработки упомянутой виртуальной машиной, эффективно обходя упомянутую вторую виртуальную машину.
5. Способ по п.3, в котором по меньшей мере одна синтезированная команда из упомянутых синтезированных команд пригодна для использования и в пользовательском режиме, и в привилегированном режиме.
6. Способ по п.3, в котором по меньшей мере одна синтезированная команда из упомянутых синтезированных команд не имеет никаких последствий для существующей команды х86.
7. Способ по п.3, в котором по меньшей мере одна синтезированная команда из упомянутых синтезированных команд представляет собой команду для блокирования непосредственного выполнения.
8. Способ по п.3, в котором для команды, которая заменяется синтезированной командой, синтезированная команда семантически подобна команде, которая подлежит замене.
9. Способ по п.8, в котором команду с длиной меньше, чем пять байтов, заменяют синтезированной командой, имеющей длину по меньшей мере пять байтов (например, для облегчения внесения исправлений).
10. Способ по п.9, в котором команду STI заменяют синтезированной командой, имеющей длину по меньшей мере пять байтов.
11. Способ по п.9, в котором команду CLI заменяют синтезированной командой, имеющей длину по меньшей мере пять байтов.
12. Способ по п.3, в котором команду CPUID в гостевой операционной системе заменяют синтезированной командой, которая считывает виртуализированную информацию CPUID.
13. Способ по п.3, в котором по меньшей мере одну команду многопроцессорной взаимоблокировки в гостевой операционной системе дополняют синтезированной командой для определения того, когда получение взаимоблокировки было неудачным.
14. Способ по п.3, в котором команду PUSHF(D) в гостевой операционной системе заменяют синтезированной командой, которая помещает IF (флаг разрешения прерывания) в стек.
15. Способ по п.3, в котором команду POPF(D) в гостевой операционной системе заменяют синтезированной командой, которая извлекает IF из стека.
16. Способ по п.3, в котором команду, которая модифицирует элементы таблицы дескрипторов в гостевой операционной системе, заменяют синтезированной командой, которая обновляет элементы таблицы дескрипторов, избегая непроизводительных потерь, связанных с поддержанием теневых таблиц дескрипторов.
17. Способ по п.3, в котором команду SGDT в гостевой операционной системе заменяют синтезированной командой, которая сохраняет текущий базовый адрес и длину GDT (глобальной таблицы дескрипторов) в ЕАХ.
18. Способ по п.3, в котором команду SLDT в гостевой операционной системе заменяют синтезированной командой, которая сохраняет текущий селектор LDT (локальной таблицы дескрипторов) в ЕАХ.
19. Способ по п.3, в котором команду SIDT в гостевой операционной системе заменяют синтезированной командой, которая сохраняет текущий базовый адрес и длину IDT (таблицы дескрипторов прерываний) в ЕАХ.
20. Способ по п.3, в котором команду STR в гостевой операционной системе заменяют синтезированной командой, которая сохраняет селектор текущего TR (регистра задачи) в ЕАХ.
21. Способ по п.3, в котором команду CLI в гостевой операционной системе заменяют синтезированной командой, которая сбрасывает виртуализированный IF.
22. Способ по п.3, в котором команду STI в гостевой операционной системе заменяют синтезированной командой, которая устанавливает виртуализированный IF.
23. Способ по п.3, в котором синтезированная команда для остановки процессора может быть выполнена как гостевой код пользовательского уровня.
24. Способ, реализуемый в компьютерной системе, имеющей первую архитектуру процессора, причем компьютерная система дополнительно имеет:
уровень монитора виртуальных машин, который функционирует поверх аппаратного обеспечения, ассоциированного с первой архитектурой процессора, и предоставляет интерфейсы для виртуализации этого аппаратного обеспечения для виртуальных машин; по меньшей мере одну виртуальную машину, которая функционирует поверх уровня монитора виртуальных машин и имитирует по меньшей мере одну вторую архитектуру процессора в упомянутой компьютерной системе, при этом упомянутая виртуальная машина выполнена с возможностью функционировать как в режиме эмуляции, так и в режиме непосредственного выполнения; и по меньшей мере одну гостевую операционную систему, выполняющуюся в упомянутой по меньшей мере одной виртуальной машине, причем данная гостевая операционная система имеет синтезированные команды, сконфигурированные таким образом, чтобы вызывать по меньшей мере одно исключение, перехватываемое уровнем монитора виртуальных машин, причем эти синтезированные команды являются недопустимыми для первой архитектуры процессора, и предназначенный для определения для гостевой операционной системы того, работает ли она на виртуализированном процессоре или работает непосредственно на аппаратном процессоре, при этом упомянутый способ содержит этапы, на которых выполняют синтезированную команду, которая сконфигурирована выполняться с любого уровня привилегий, для возвращения значения, представляющего идентификационные данные для центрального процессора,
когда значение возвращено, делают вывод о том, что операционная система выполняется на виртуализированном процессоре, и используют синтезированные команды, а
когда происходит исключение, делают вывод о том, что операционная система выполняется непосредственно на аппаратном процессоре, и не используют синтезированные команды.
25. Способ по п.24, дополнительно содержащий этап, на котором, если значение возвращено, то осуществляют доступ к признакам или режимам лежащего в основе монитора виртуальных машин или модифицируют их.
26. Способ по п.24, в котором шестнадцатеричный код операции для упомянутой синтезированной команды представляет собой 0F С7 С8 01 00.
27. Способ, реализуемый в компьютерной системе, имеющей первую архитектуру процессора, причем компьютерная система дополнительно имеет:
уровень монитора виртуальных машин, который функционирует поверх аппаратного обеспечения, ассоциированного с первой архитектурой процессора, и предоставляет интерфейсы для виртуализации этого аппаратного обеспечения для виртуальных машин; по меньшей мере одну виртуальную машину, которая функционирует поверх уровня монитора виртуальных машин и имитирует по меньшей мере одну вторую архитектуру процессора в упомянутой компьютерной системе, при этом упомянутая виртуальная машина выполнена с возможностью функционировать как в режиме эмуляции, так и в режиме непосредственного выполнения; и по меньшей мере одну гостевую операционную систему, выполняющуюся в упомянутой по меньшей мере одной виртуальной машине, и предназначенный для усовершенствования кода гостевой операционной системы для эффективных исправлений перехватываемых команд, с использованием длинной команды JMP, причем упомянутый способ содержит этапы, на которых:
в гостевой операционной системе определяют местоположение экземпляров перехватываемых команд, которые имеют размер меньше, чем пять байтов, включая команды которые выполняются в коде кольца уровня 0, и заменяют эти перехватываемые команды соответствующими синтезированными командами, которые имеют размер, составляющий по меньшей мере пять байтов,
при этом упомянутые синтезированные команды сконфигурированы таким образом, чтобы вызывать по меньшей мере одно исключение, перехватываемое уровнем монитора виртуальных машин, и
при этом упомянутые синтезированные команды являются недопустимыми для первой архитектуры процессора.
28. Система, реализованная в компьютерном устройстве, имеющем первую архитектуру процессора, относящуюся к архитектурам процессоров х86 и их эквивалентам, причем компьютерное устройство дополнительно имеет:
уровень монитора виртуальных машин, который функционирует поверх аппаратного обеспечения, ассоциированного с первой архитектурой процессора, и предоставляет интерфейсы для виртуализации этого аппаратного обеспечения для виртуальных машин; по меньшей мере одну виртуальную машину, которая функционирует поверх уровня монитора виртуальных машин и имитирует по меньшей мере одну вторую архитектуру процессора в упомянутом компьютерном устройстве, при этом упомянутая виртуальная машина выполнена с возможностью функционировать как в режиме эмуляции, так и в режиме непосредственного выполнения; и по меньшей мере одну гостевую операционную систему, выполняющуюся в упомянутой по меньшей мере одной виртуальной машине, причем данная гостевая операционная система имеет синтезированные команды, сконфигурированные таким образом, чтобы вызывать по меньшей мере одно исключение, перехватываемое уровнем монитора виртуальных машин, причем эти синтезированные команды являются недопустимыми для первой архитектуры процессора, и предназначенная для обработки синтезированных команд, при этом упомянутая система содержит подсистему для перехвата упомянутых синтезированных команд, выданных гостевой операционной системой, после того, как упомянутые синтезированные команды вызвали исключение в процессоре х86, и подсистему для обработки упомянутых синтезированных команд для гостевой операционной системы,
при этом по меньшей мере одна синтезированная команда из упомянутых синтезированных команд сконфигурирована таким образом, чтобы обеспечивать непосредственное выполнение в пределах уровня привилегий, соответствующего кольцу уровня 0.
29. Система по п.28, в которой упомянутые подсистемы дополнительно сконфигурированы перехватывать и обрабатывать синтезированную команду для определения того, когда получение взаимоблокировки было неудачным.
30. Система по п.28, в которой подсистема для обработки синтезированных команд дополнительно сконфигурирована обрабатывать синтезированную команду для помещения IF в стек.
31. Система по п.28, в которой подсистема для обработки синтезированных команд дополнительно сконфигурирована обрабатывать синтезированную команду для извлечения IF из стека.
32. Система по п.28, в которой подсистема для обработки синтезированных команд дополнительно сконфигурирована обрабатывать синтезированную команду, которая обновляет элементы таблицы дескрипторов, избегая непроизводительных потерь, связанных с поддержанием теневых таблиц дескрипторов.
33. Система по п.28, в которой подсистема для обработки синтезированных команд дополнительно сконфигурирована обрабатывать синтезированную команду для сохранения базового адреса и длины текущей GDT в EAX.
34. Система по п.28, в которой подсистема для обработки синтезированных команд дополнительно сконфигурирована обрабатывать синтезированную команду для сохранения селектора текущей LDT в ЕАХ.
35. Система по п.28, в которой подсистема для обработки синтезированных команд дополнительно сконфигурирована обрабатывать синтезированную команду для сохранения базового адреса и длины текущей IDT в ЕАХ.
36. Система по п.28, в которой подсистема для обработки синтезированных команд дополнительно сконфигурирована обрабатывать синтезированную команду для сохранения селектора текущего TR в ЕАХ.
37. Система по п.28, в которой подсистема для обработки синтезированных команд дополнительно сконфигурирована обрабатывать синтезированную команду для сброса виртуализированного IF.
38. Система по п.28, в которой подсистема для обработки синтезированных команд дополнительно сконфигурирована обрабатывать синтезированную команду для установки виртуализированного IF.
39. Система по п.28, в которой подсистема для обработки синтезированных команд дополнительно сконфигурирована обрабатывать синтезированную команду для остановки процессора, которая может быть выполнена как гостевой код пользовательского уровня.
40. Система по п.28, дополнительно выполненная с возможностью определения того, выполняется ли упомянутая система на виртуализированном процессоре или выполняется непосредственно на процессоре х86, при этом упомянутые подсистемы дополнительно сконфигурированы выполнять синтезированную команду для возвращения значения, представляющего идентификационные данные для признаков, поддерживаемых центральным процессором, и
определять, возвращено ли значение и (а), если это так, заключать, что система выполняется на виртуализированном процессоре, и после этого использовать синтезированных команд, и (b), если нет, заключать, что операционная система выполняется непосредственно на процессоре х86, и после этого не использовать синтезированные команды.
41. Система по п.40, в которой подсистема для обработки синтезированных команд дополнительно сконфигурирована осуществлять доступ к признакам или режимам лежащего в основе монитора виртуальных машин или модифицировать их, если значение возвращено.
42. Система по п.40, в которой шестнадцатеричный код операции для упомянутой синтезированной команды представляет собой 0F С7 С8 01 00.
43. Система по п.28, в которой упомянутые синтезированные команды содержат синтезированную команду для блокирования непосредственного выполнения.
44. Система по п.28, в которой упомянутые синтезированные команды содержат синтезированную команду для разрешения (или повторного разрешения) непосредственного выполнения.
45. Система по п.28, в которой упомянутые синтезированные команды содержат
синтезированную команду для помещения IF в стек и
синтезированную команду для извлечения IF из стека.
46. Система по п.45, в которой упомянутые синтезированные команды дополнительно содержат
синтезированную команду для сохранения базового адреса и длины текущей GDT в EAX,
синтезированную команду для сохранения селектора текущей LDT в ЕАХ,
синтезированную команду для сохранения базового адреса и длины текущей IDT в ЕАХ и
синтезированную команду для сохранения селектора текущего TR в ЕАХ.
47. Система по п.45, в которой упомянутые синтезированные команды дополнительно содержат
синтезированную команду для сброса виртуализированного IF и
синтезированную команду для установки виртуализированного IF.
48. Система по п.45, в которой упомянутые синтезированные команды дополнительно содержат синтезированную команду для определения того, когда получение взаимоблокировки было неудачным, которая перехватывается и обрабатывается.
49. Система по п.45, в которой упомянутые синтезированные команды дополнительно содержат синтезированную команду для возвращения значения, представляющего идентификационные данные для центрального процессора.
50. Система по п.49, в которой шестнадцатеричный код операции для упомянутой синтезированной команды представляет собой 0F С7 С8 01 00.
51. Способ, реализуемый в компьютерной системе, имеющей первую архитектуру процессора, относящуюся к архитектурам процессоров х86 и их эквивалентам, причем компьютерная система дополнительно имеет: уровень монитора виртуальных машин, который функционирует поверх аппаратного обеспечения, ассоциированного с первой архитектурой процессора, и предоставляет интерфейсы для виртуализации этого аппаратного обеспечения для виртуальных машин; по меньшей мере одну виртуальную машину, которая функционирует поверх уровня монитора виртуальных машин и имитирует по меньшей мере одну вторую архитектуру процессора в упомянутой компьютерной системе, при этом упомянутая виртуальная машина выполнена с возможностью функционировать как в режиме эмуляции, так и в режиме непосредственного выполнения; и по меньшей мере одну гостевую операционную систему, выполняющуюся в упомянутой по меньшей мере одной виртуальной машине, и предназначенный для оптимизации упомянутой гостевой операционной системы, причем упомянутый способ содержит этапы, на которых удаляют экземпляры одной или большего количества из следующих предварительно определенных команд в упомянутой гостевой операционной системе: PUSH CS, PUSH SS, MOV from SS, CALLF, VERR, VERW и LAR,
либо заменяют эти экземпляры другими существующими командами, заменяют команды CPUID в гостевой операционной системе синтезированными командами, которые считывают виртуализированную информацию CPUID,
дополняют команды взаимоблокировки в гостевой операционной системе синтезированными командами для определения того, когда получение взаимоблокировки было неудачным,
заменяют команды PUSHF(D) в гостевой операционной системе синтезированными командами для помещения IF в стек,
заменяют команды POPF(D) в гостевой операционной системе синтезированными командами для извлечения IF из стека,
заменяют команды SGDT в гостевой операционной системе синтезированными командами для сохранения базового адреса и длины текущей GDT в ЕАХ,
заменяют команды SLDT в гостевой операционной системе синтезированными командами для сохранения селектора текущей LDT в ЕАХ,
заменяют команды SIDT в гостевой операционной системе синтезированными командами для сохранения базового адреса и длины текущей IDT в ЕАХ,
заменяют команды STR в гостевой операционной системе синтезированными командами для сохранения селектора текущего TR в ЕАХ,
заменяют команды CLI в гостевой операционной системе синтезированными командами для сброса виртуализированного IF,
заменяют команды STI в гостевой операционной системе синтезированными командами для установки виртуализированного IF.
| СПЕЦИАЛИЗИРОВАННЫЙ ПРОЦЕССОР | 1995 |
|
RU2147378C1 |
| ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 1991 |
|
RU2042193C1 |
| DE 4217444 A, 03.12.1992 | |||
| US 5317705 A, 31.05.1994. | |||

