УРОВЕНЬ ТЕХНИКИ
Настоящее изобретение относится к способу управления приложением с помощью преобразования вводимой пользователем информации в команды приложения. В частности, настоящее изобретение относится к преобразованию вводимой пользователем информации в команду для отображения информации из источника данных, такого как база данных.
В обычных компьютерных системах вводимая пользователем информация ограничена жестким набором ответов пользователя, имеющих фиксированный формат. Например, при использовании интерфейса командной строки вводимая пользователем информация должна иметь определенную форму, которая однозначно определяет единственную команду и выбранные параметры из ограниченного и определенного набора возможных параметров. Точно так же с помощью графического пользовательского интерфейса пользователю представляют только ограниченный набор возможностей, и является относительно традиционным для разработчика определять область ввода информации пользователем, которая состоит из ограниченного набора команд или объектов для каждой конкретной вводимой пользователем информации в ограниченном наборе вводимой пользователем информации.
Ограничивая пользователя жестким набором разрешенной для ввода информации или ответов, компьютерные системы требовали от пользователя или оператора значительного уровня навыка. Традиционно пользователь отвечал за мысленное преобразование необходимого задания, которое должно выполняться, в конкретную вводимую информацию, которую распознают приложения, выполняющиеся в компьютерной системе. Для увеличения удобства и простоты использования компьютерных систем, непрерывно продолжаются попытки обеспечить приложения интерфейсом на естественном языке (ЕЯ). Интерфейс на естественном языке расширяет функциональные возможности приложений вне ограниченного набора входной информации и открывает компьютерную систему для ввода информации в формате естественного языка. Интерфейс на естественном языке отвечает за выполнение преобразования из относительно неопределенной и чрезвычайно основанной на контексте области естественного языка в точный и жесткий набор вводимой информации, которая требуется компьютерному приложению.
Преобразование введенной на естественном языке информации для отображения информации из источника данных, такого как база данных, может быть трудным для выполнения из-за настраиваемого характера источников данных и многих способов отображения информации из источника данных. В частности, отображение таблиц для анализа информации, которая хранится в источнике данных, выполняют с помощью определенных команд от пользователя, определяющих, какая информация должна отображаться и как ее отображать. Из-за такого громоздкого интерфейса многие пользователи имеют трудности при отображении таблиц для удобного анализа данных. Обеспечение дружественного интерфейса для создания и отображения таблицы с информацией из источника данных обеспечило бы более эффективный инструмент для анализа информации.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к способу управления приложением, который включает в себя обработку данных, хранящихся в структурированном источнике данных. Данный способ включает в себя прием введенной на естественном языке информации и анализ введенной на естественном языке информации для идентификации содержащейся в ней семантической информации. Для части введенной на естественном языке информации устанавливают соответствие с объектами "команда" и объектами "объект" схемы, основываясь на семантической информации и введенной на естественном языке информации. Способ также включает в себя отображение данных из источника данных в таблице из столбцов и строк, основываясь на данной схеме и соответствующих частях введенной на естественном языке информации.
Другой аспект настоящего изобретения относится к считываемому компьютером носителю, содержащему команды для обработки данных в структурированном источнике данных, которые включают в себя измерения и значения, связанные с данными измерениями. Данные команды включают в себя модуль пользовательского интерфейса, настроенный для приема введенной на естественном языке информации и для отображения таблицы. Модуль генерации таблиц настраивают для обращения к измерениям и значениям и для определения схемы для отображения данных изображений и значений. Кроме того, модуль интерпретации настраивают для установления соответствия между терминами во введенной на естественном языке информации и объектом "объект" схемы, который соответствует измерениям в источнике данных, и для генерации кандидата на интерпретацию того, как отображать данные в источнике данных, основываясь на введенной на естественном языке информации, измерениях и схеме.
Другой аспект настоящего изобретения - способ обработки информации для управления приложением, который включает в себя прием введенной на естественном языке информации. Введенную на естественном языке информацию анализируют для идентификации содержащейся в ней семантической информации. Данный способ также включает в себя обращение к схеме для идентификации объектов "команда" и объектов "объект", основываясь на семантической информации и введенной на естественном языке информации, и выполнение действия, связанного с приложением, основываясь на объекте "команда" и объекте "объект".
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
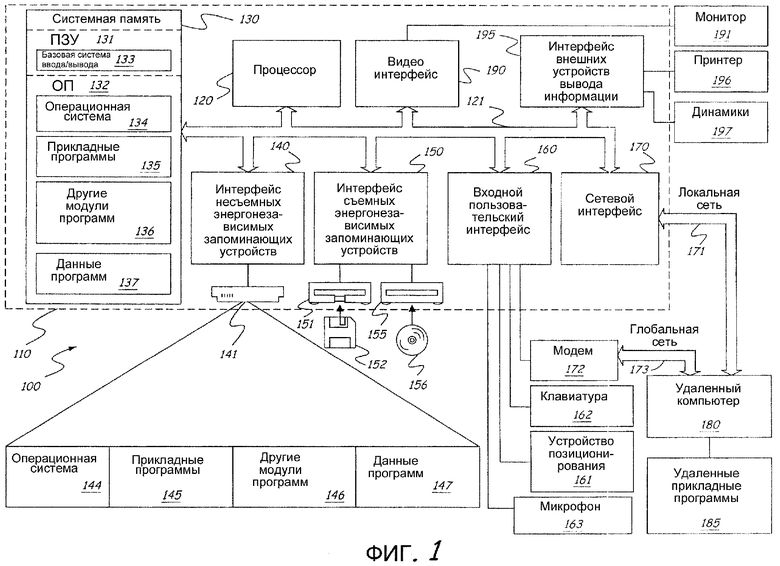
Фиг.1 - структурная схема конфигурации вычислительной системы.
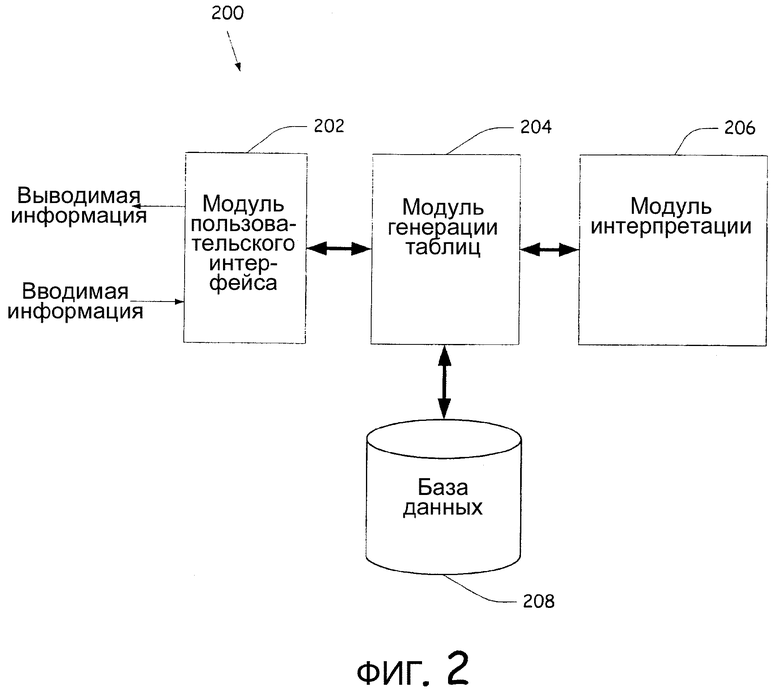
Фиг.2 - структурная схема системы для отображения таблицы на основе введенной пользователем информации.
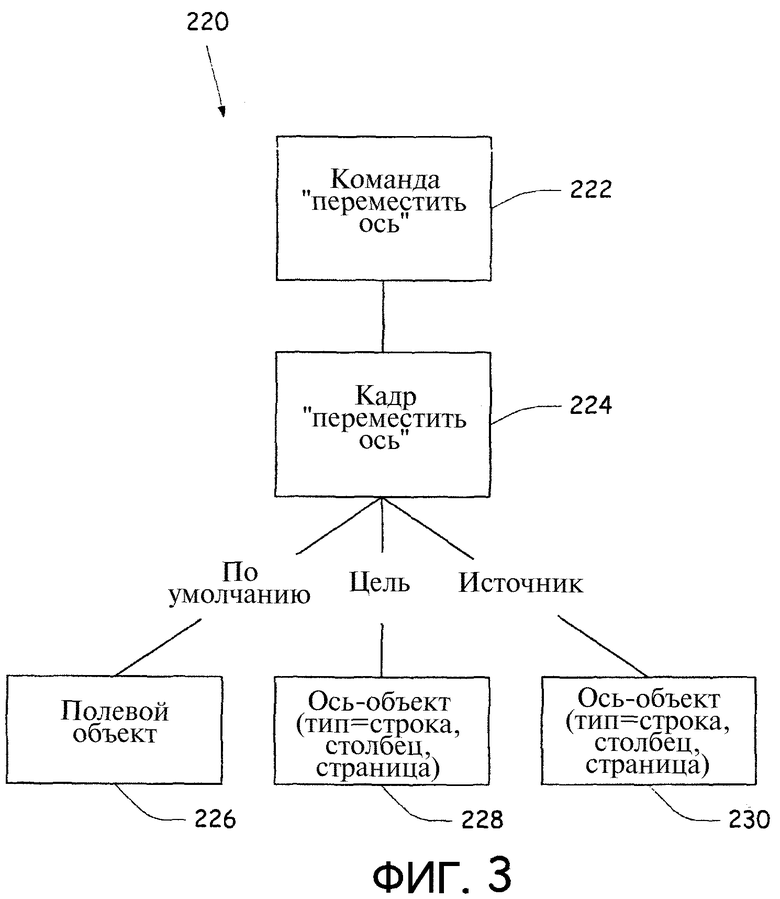
Фиг.3 - диаграмма примерной схемы.
Фиг.4 - последовательность операций примерного способа отображения таблицы.
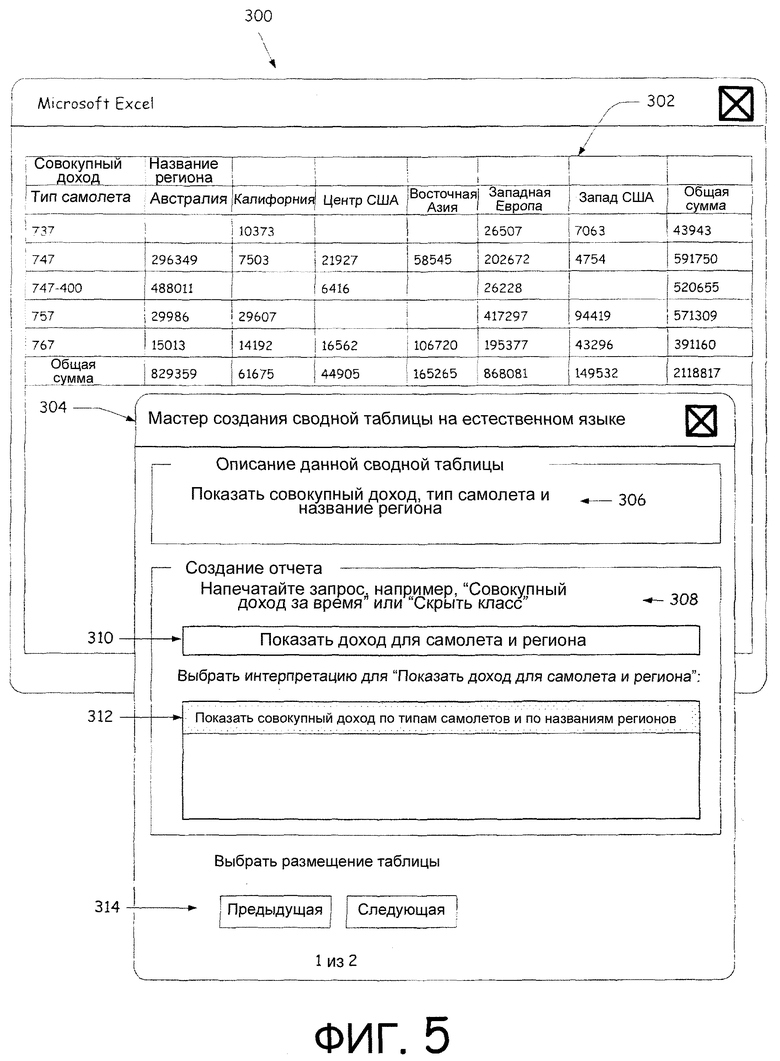
Фиг.5 - снимок экрана пользовательского интерфейса для приема от пользователя вводимой информации и для отображения информации таблицы.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Фиг.1 показывает пример соответствующей конфигурации 100 вычислительной системы, в которой может воплощаться данное изобретение. Конфигурация 100 вычислительной системы является только одним примером соответствующей вычислительной конфигурации и не вводит никаких ограничений относительно возможностей использования или функциональных возможностей данного изобретения. Вычислительная конфигурация 100 не должна интерпретироваться как имеющая какую-либо зависимость или требования, относящиеся к любому одному или комбинации компонентов, показанных в примерной конфигурации 100.
Данное изобретение может работать с множеством других конфигураций универсальных или специальных вычислительных систем. Примеры известных вычислительных систем, сред и/или конфигураций, которые могут использоваться с данным изобретением, включают в себя, но не ограничены ими, персональные компьютеры, компьютеры-серверы, карманные или портативные компьютеры, многопроцессорные системы, системы на основе микропроцессора, телеприставки, программируемую бытовую электронику, сетевые ПК, миникомпьютеры, мэйнфреймы (универсальные электронно-вычислительные машины), телефонные системы, распределенные вычислительные среды, которые включают в себя любую из указанных выше систем или устройств, и т.п.
Данное изобретение может быть описано в общем контексте выполняемых компьютером команд, таких как модули программ, выполняемые компьютером. В общем случае модули программ включают в себя подпрограммы, программы, объекты, компоненты, структуры данных и т.д., которые выполняют конкретные задачи или воплощают определенные абстрактные типы данных. Данное изобретение может также воплощаться в распределенных вычислительных средах, где задачи выполняются удаленными устройствами обработки, которые связаны через систему коммуникаций. В распределенной вычислительной среде модули программ могут располагаться и в местных, и в удаленных компьютерных носителях данных, включающих в себя запоминающие устройства. Задания, выполняемые в соответствии с программами и модулями, описаны ниже и при помощи чертежей. Специалисты могут воплощать данное описание и чертежи как выполняемые процессором команды, которые могут записываться на считываемом компьютером носителе любого вида.
Обращаясь к фиг.1, примерная система для воплощения изобретения включает в себя универсальное вычислительное устройство в форме компьютера 110. Компьютер 110 может включать в себя следующие компоненты: процессор 120, системную память 130 и системную шину 121, которая связывает различные системные компоненты, включающие в себя системную память, с процессором 120, но его состав не ограничен ими. Системная шина 121 может быть любой из нескольких видов шинных структур, которые включают в себя шину памяти или контроллер памяти, периферийную шину и локальную шину, используя любую из разнообразия шинных архитектур. Для примера, а не в качестве ограничения, такая архитектура включает в себя шину архитектуры, соответствующей промышленному стандарту (ISA), шину микроканальной архитектуры (MCA), шину расширенной стандартной архитектуры для промышленного применения (EISA), локальную шину Ассоциации по стандартам в области видеоэлектроники (VESA) и шину соединения периферийных устройств (PCI), также известную как шина расширения.
Компьютер 110 обычно включает в себя разнообразие считываемых компьютером носителей. Считываемые компьютером носители могут быть любыми доступными носителями, к которым может обращаться компьютер 110, и они включают в себя и энергозависимые, и энергонезависимые носители, съемные и несъемные носители. Для примера, но не в качестве ограничения, считываемые компьютером носители могут содержать компьютерные носители данных и средства связи. Компьютерные носители данных включают в себя и энергозависимые, и энергонезависимые, съемные и несъемные носители, воплощенные с помощью любого способа или технологии для хранения информации, такой как считываемые компьютером команды, структуры данных, модули программ или другие данные. Компьютерные носители данных включают в себя, но не ограничены ими, оперативную память (ОП), постоянное запоминающее устройство (ПЗУ), электрически стираемое постоянное запоминающее устройство (ЭСППЗУ), флэш-память или память другой технологии, компакт-диски (CD-ROM), цифровые универсальные диски (DVD) или другие оптические дисковые запоминающие устройства, магнитные кассеты, магнитную ленту, магнитные дисковые запоминающие устройства или другие магнитные запоминающие устройства или любой другой носитель, который может использоваться для хранения необходимой информации и к которому может обращаться компьютер 110. Средства связи обычно воплощают считываемые компьютером команды, структуры данных, модули программ или другие данные в модулированном сигнале данных, таком как несущая, или используют другой механизм транспортировки, и они включают в себя любые средства доставки информации. Термин "модулированный сигнал данных" означает сигнал, который имеет одну или более из своих характеристик, которые устанавливаются или изменяются таким образом, чтобы кодировать информацию в сигнале. Для примера, а не в качестве ограничения, средства связи включают в себя проводные каналы связи, такие как проводные сети или прямое проводное подключение, и беспроводные каналы связи, такие как акустический, радиочастотный (РЧ), инфракрасный и другие беспроводные каналы связи. Считываемые компьютером носители должны также включать в себя комбинации любого из указанных выше носителей.
Системная память 130 включает в себя компьютерные носители данных в форме энергозависимой и/или энергонезависимой памяти, такой как постоянное запоминающее устройство (ПЗУ) 131 и оперативная память (ОП) 132. Базовая система ввода-вывода (BIOS) 133, которая содержит основные подпрограммы, которые помогают перемещать информацию между элементами в пределах компьютера 110, например, во время запуска, обычно хранится в ПЗУ 131. Оперативная память 132 обычно содержит данные и/или модули программ, которые мгновенно доступны для обработки и/или в данный момент обрабатываются процессором 120. Для примера, но не в качестве ограничения, фиг.1 показывает операционную систему 134, прикладные программы 135, другие модули 136 программ и данные 137 программ.
Компьютер 110 может также включать в себя другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные носители данных. Для примера, фиг.1 показывает накопитель 141 на жестком диске, который считывает информацию или который записывает информацию на несъемный энергонезависимый магнитный диск, накопитель на магнитном диске, который считывает информацию или записывает информацию на съемный энергонезависимый магнитный диск 152, и привод оптического диска, который считывает информацию или записывает информацию на съемный энергонезависимый оптический диск 156, такой как компакт-диск (CD ROM) или другой оптический носитель. Другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные носители данных, которые могут использоваться в примерной конфигурации, включают в себя кассеты с магнитной лентой, платы флэш-памяти, цифровые универсальные диски, цифровую видеоленту, полупроводниковую ОП, полупроводниковое ПЗУ и т.п., но не ограничены ими. Накопитель 141 на жестком диске типично подключается к системной шине 121 через средство сопряжения (интерфейс) с несъемным запоминающим устройством, такое как средство 140 сопряжения, а накопитель 151 на магнитном диске и привод 155 оптического диска типично подключаются к системной шине 121 через средство сопряжения (интерфейс) со съемным запоминающим устройством, такое как средство 150 сопряжения.
Устройства и соответствующие компьютерные носители данных, обсуждаемые выше и показанные на фиг.1, обеспечивают хранение считываемых компьютером команд, структур данных, модулей программ и других данных для компьютера 110. На фиг.1, например, накопитель 141 на жестком диске показан в качестве устройства хранения операционной системы 144, прикладных программ 145, других модулей 146 программ и данных 147 программ. Следует отметить, что эти компоненты могут или быть тем же самыми, как операционная система 134, прикладные программы 135, другие модули 136 программ и данные 137 программ, или отличаться от них. Операционной системе 144, прикладным программам 145, другим модулям 146 программ и данным 147 программ присвоены другие обозначения для того, чтобы показать, что они как минимум являются другими копиями.
Пользователь может вводить команды и информацию в компьютер 110 через устройства ввода данных, такие как клавиатура 162, микрофон 163 и устройство 161 позиционирования, такое как "мышь", шаровой манипулятор ("трекболл") или сенсорная панель. Другие устройства ввода данных (не показаны) могут включать в себя джойстик, игровую клавиатуру, спутниковую антенну, сканер или подобные им устройства. Для приложений естественного пользовательского интерфейса пользователь может дополнительно осуществлять связь с компьютером, используя голос, рукописный ввод информации, взгляд (движение глаз) и другие знаки. Для облегчения использования естественного пользовательского интерфейса компьютер может включать в себя микрофоны, планшеты для записи, камеры, датчики движения и другие устройства для фиксации знаков пользователя. Эти и другие устройства ввода данных часто устанавливают связь с процессором 120 через входной пользовательский интерфейс 160, который связан с системной шиной, но они могут устанавливать связь с помощью другого интерфейса и шинных структур, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). Монитор 191 или другой тип устройства отображения также связан с системной шиной 121 через интерфейс, такой как видео интерфейс 190. В дополнение к монитору компьютеры могут также включать в себя другие периферийные устройства вывода информации, такие как динамики 197 и принтер 196, которые могут быть соединены через интерфейс 190 внешних устройств вывода информации.
Компьютер 110 может работать в сетевом окружении, используя логические подключения к одному или более удаленным компьютерам, таким как удаленный компьютер 180. Удаленный компьютер 180 может быть персональным компьютером, карманным устройством, сервером, маршрутизатором, сетевым ПК, равноправным устройством сети или другим обычным сетевым узлом и обычно включает в себя многие или все элементы, описанные выше по отношению к компьютеру 110. Логические подключения, изображенные на фиг.1, включают в себя локальную сеть (ЛС) 171 и глобальную сеть (ГС) 173, но могут также включать в себя другие сети. Такие конфигурации сетей обычно применяют в офисах, компьютерных сетях в масштабах предприятия, корпоративных сетях (интранет) и Интернет.
При работе в среде ЛС, компьютер 110 связан с ЛС 171 через сетевой интерфейс, или адаптер, 170. При работе в среде ГС компьютер 110 обычно включает в себя модем 172 или другое средство для установления связи по глобальной сети 173, такой как Интернет. Модем 172, который может быть внутренним или внешним, может быть связан с системной шиной 121 через входной пользовательский интерфейс 160 или другой соответствующий механизм. В сетевом окружении модули программ, изображенные относительно компьютера 110 или его частей, могут храниться в удаленном запоминающем устройстве. Для примера, а не в качестве ограничения, фиг.1 показывает удаленные прикладные программы 185 как находящиеся на удаленном компьютере 180. Очевидно, что показанные сетевые подключения приведены в качестве примера и могут использоваться другие средства установления связи между компьютерами.
Как правило, прикладные программы 135 взаимодействуют с пользователем через командную строку или графический пользовательский интерфейс (ГПИ) через входной пользовательский интерфейс 160. Однако для упрощения и расширения использования компьютерных систем были разработаны устройства ввода информации, которые могут принимать от пользователя введенную на естественном языке информацию. В отличие от естественного языка или речи графический пользовательский интерфейс является точным. Хорошо спроектированный графический пользовательский интерфейс обычно не создает неоднозначные ссылки или требует, чтобы основное приложение подтвердило конкретную интерпретацию введенной информации, принятой через данный интерфейс 160. Например, из-за того что данный интерфейс является точным, обычно не существует требований, чтобы пользователю делали дополнительный запрос относительно введенной информации, т.е.: "Вы нажали кнопку 'хорошо'?". Как правило, объектная модель, разработанная для графического пользовательского интерфейса, является механистической и очень жесткой при ее выполнении.
В отличие от ввода информации с помощью графического пользовательского интерфейса запрос или команда на естественном языке часто преобразовывается не в один, а в последовательность функциональных запросов в объектную модель ввода информации. В отличие от жестких, механистических ограничений традиционного ввода информации через командную строку или через графический пользовательский интерфейс естественный язык является средством коммуникации, в котором собеседники-люди полагаются на интеллект друг друга, часто подсознательно, для разрешения неоднозначностей. Фактически естественный язык расценивают как "естественный" как раз потому, что он не является механистическим. Люди-собеседники могут разрешать неоднозначности, основываясь на контекстной информации и подсказках, относящихся к любым действиям, окружающим произнесение. С людьми-собеседниками предложение "Отправьте протокол тем, кто принимал участие в обзорной встрече в пятницу" является совершенно понятным предложением без дополнительных объяснений. Однако с механистической точки зрения машины отдельные детали должны быть определены, такие как на какой точно документ, на какую встречу ссылаются и кому именно документ нужно отправить.
Настоящее изобретение относится к интерпретации введенной на естественном языке информации для управления приложением и связанными с ним действиями. Может определяться схема (алгоритм) и для управления интерпретацией введенной на естественном языке информации, и для инициации действий, связанных с данным приложением. В результате данная схема взаимодействует и с самим приложением, и семантическими интерпретациями введенной пользователем на естественном языке информации. Специалисты должны признать, что схема может быть отдельным кодом и/или ее может включать в себя прикладной код. Аспекты настоящего изобретения могут использоваться во множестве различных конфигураций для обеспечения улучшенного пользовательского интерфейса на естественном языке. Одна конкретная конфигурация, которая может использовать аспекты настоящего изобретения, подразумевает отображение информации из структурированного источника данных, такого как база данных. Данная схема может использоваться для отображения таблицы из столбцов и строк или, например, из одной ячейки. В случае когда отображают одну ячейку информации, информация может быть ответом на вопрос, представленным на естественном языке, вместо того чтобы обеспечивать данные в формате таблицы. Например, пользователь может ввести вопрос "Сколько исков оплатила Калифорния в 1999?". В таком случае может быть представлен ответ "3482", поэтому пользователю не нужно просматривать большое количество данных, чтобы найти ответ.
Фиг.2 показывает структурную схему системы для преобразования введенной пользователем на естественном языке информации и для отображения табличной информации, основываясь на введенной на естественном языке информации. Система 200 включает в себя модуль 202 пользовательского интерфейса, модуль 204 генерации таблиц, модуль 206 интерпретации и базу 208 данных. Следует отметить, что база 208 данных - примерный источник данных. Источник данных может иметь множество форм, например база данных SQL (языка структурированных запросов), куб OLAP (оперативного анализа данных) или рабочий лист Microsoft Excel. Пользователь обеспечивает передачу введенной на естественном языке информации к модулю 202 пользовательского интерфейса в форме команды, вопроса или другой введенной информации, относящейся к генерации таблицы. Например, пользователь может обеспечивать вопрос "Покажите валовую прибыль для самолета и направления за год", или "Каким был совокупный доход для 737 в 1999?", или просто "прибыль". Модуль 202 пользовательского интерфейса принимает введенную на естественном языке информацию и обеспечивает ее передачу к модулю 204 генерации таблиц.
Модуль 204 генерации таблиц определяет схему команд и соответствующих атрибутов для различных команд, которые могут использоваться при отображении таблицы. Например, команды могут включать в себя "создать", "показать", "добавить", "скрыть", "выделить", "фильтровать", "очистить" и т.д., и они включают в себя атрибуты, дополнительно определяющие команды. Команды могут также включать в себя печать таблицы и создание диаграммы из данных в базе 208 данных. Схема может обеспечиваться к модулю 206 интерпретации для управления интерпретацией введенной информации. Альтернативно схема может использоваться для отображения одной ячейки информации. Модуль 204 генерации таблиц использует модуль 206 интерпретации для помощи в определении, какая информация должна отображаться, основываясь на введенной на естественном языке информации, принятой от модуля 202 интерфейса, и на определенной схеме, которая управляет действиями, предварительно сформированными для создания и генерации таблицы. Модуль 204 генерации таблиц обращается к базе 208 данных для идентификации слов и/или фраз, которые соответствуют элементам, хранящимся в базе 208 данных, и обеспечивает их передачу к модулю 206 интерпретации.
Модуль 206 интерпретации анализирует вводимую пользователем информацию, схему и слова и фразы из базы данных для генерации кандидатов на семантическую интерпретацию того, какую информацию отобразить пользователю. Сначала выполняют схематический анализ вводимой пользователем информации для обеспечения семантической информации для интерпретации того, что пользователь хотел бы отобразить. Например, названный объект в вводимой информации может сообщать термин, который пользователь хочет отобразить как страницу, строку или столбец или в пределах области данных таблицы. Могут также использоваться другие семантические методики, такие как идентификация частей речи, применение частичного соответствия терминов и/или методика, которая основывается на определенных частях речи для определения соответствий, идентификация морфологических вариантов (т.е. "регион" и "региональные"), решение конкатенации названий (т.е. "владелец дома" и "домовладелец"), нормализация даты (т.е. "1/1/04" и "1 января 2004"), идентификация синонимов через тезаурус слов, разрешение изменения порядка слов (т.е. "совокупный доход" и "доход совокупный") и способы ранжирования. Другая семантическая информация может идентифицироваться модулем 206 интерпретации, например отрицание значений (т.е. "скрыть"), сравнение (т.е. значения выше порогового значения) и т.д.
Используя семантическую информацию и схему, модуль 206 интерпретации устанавливает соответствие одного или более заданий во введенной на естественном языке информации с объектом "команда" схемы и устанавливает соответствие другой информации во введенной на естественном языке информации с одним или более объектами "кадр" и/или одним или более объектами "объект" схемы. Схема может также включать в себя другие объекты, такие как объекты "обозначение" и "ограничение", которые могут обозначать другие объекты и описывать свойства объектов. Когда для введенной на естественном языке информации установлено соответствие с объектами схемы, принимают решение о кандидатах на интерпретацию и их посылают к модулю 204 генерации таблиц.
В одном примерном варианте осуществления модуль 202 пользовательского интерфейса может быть приложением электронных таблиц, таким как приложение Microsoft Excel, обеспеченное корпорацией Microsoft, Редмонд, Вашингтон. Приложение электронных таблиц может конфигурироваться для обработки и отображения всех видов информации базы данных. Например, приложение электронных таблиц может быть инструментальным средством отображения оперативной аналитической обработки (OLAP). OLAP относится к способу обработки, который предоставляет пользователю возможность легко и выборочно извлекать и просматривать данные из базы данных различными способами. В модели данных OLAP информацию рассматривают концептуально как кубы, которые состоят из описательных категорий (размерностей, измерений) и количественных значений (показателей). Многомерная модель данных упрощает пользователям формулирование сложных запросов, упорядочивание данных в отчете, переключение от обобщенных к детализованным данным и фильтрацию или разделение данных на значимые подмножества. Например, измерения в кубе, содержащем коммерческую информацию, могут включать в себя время, географическое положение, продукт, канал распределения, организацию и сценарий (бюджетный или фактический). Показатели могут включать в себя долларовые продажи, продажи в единицах, товарно-материальные запасы, численность персонала, доход и затраты.
В пределах каждого измерения модели данных OLAP данные могут быть организованы в виде иерархии, которая представляет уровни детализации данных. Например, в пределах размерности "время" можно выделить такие уровни: годы, месяцы и дни; точно так же в пределах измерения "географическое положение" можно выделить такие уровни: страна, регион, штат/провинция и город. Конкретный экземпляр модели данных OLAP имеет конкретные значения для каждого уровня иерархии. При просмотре данных OLAP пользователь перемещается вверх или вниз между уровнями для того, чтобы увидеть более подробную или менее подробную информацию.
В одном из вариантов осуществления настоящего изобретения введенная на естественном языке информация, обеспеченная пользователем, может быть преобразована для создания так называемой сводной таблицы (PivotTable) в приложении электронных таблиц, таком как Microsoft Excel, основываясь на измерениях куба OLAP. Сводная таблица - интерактивная таблица, которая может суммировать большое количество данных. Интерактивный интерфейс отображения таблицы дает возможность пользователю чередовать (менять местами) строки и столбцы информации для того, чтобы пользователь просматривал различные суммы данных в базе 208 данных, фильтровал данные с помощью отображения различных страниц и/или отображал подробную информацию из базы данных. Сводная таблица содержит поля, каждое из которых суммирует многочисленные строки информации из исходных данных. Сводная таблица может также суммировать данные с помощью использования функции суммирования, такой как суммирование, подсчет и/или вычисление среднего значения определенных ячеек в таблице. Для создания сводной таблицы пользователь может вызывать модуль 204 генерации таблиц. В одном из вариантов осуществления модуль 204 генерации таблиц - "мастер", который направляет действия пользователя при вводе информации, имеющей отношение к отображению информации таблицы.
В этом варианте осуществления модуль 204 генерации таблиц может определять схему, основываясь на действиях, доступных для создания и изменения сводной таблицы. Схема может быть представлена как иерархия объектов "команда", "кадр" и "объект". Другие объекты могут включать в себя названные объекты "обозначение", "ограничение" и "объект". Объект "команда" идентифицирует задания и действия, объект "кадр" идентифицирует действия, относящиеся к тому, как данные должны отображаться, и объект "объект" идентифицирует данные. Определенные экземпляры этих объектов могут использоваться для осуществления отображения информации. Эти экземпляры при желании могут наследовать свойства от базового класса. Схема используется модулем 204 генерации таблиц для выполнения действия с данными для генерации таблиц и модулем 206 интерпретации для управления интерпретацией введенной пользователем информации.
Фиг.3 - диаграмма примерной схемы, которая используется для перемещения поля данных между осями в таблице. Схема 220 включает в себя объект 222 "команда", который является иллюстративно командой "перемещения оси". Объект 222 "команда" включает в себя соответствующий объект 224 "кадр", который является кадром "перемещения оси". Объект 224 "кадр" включает в себя три соответствующих объекта "объект" 226, 228 и 230. Объект 224 "кадр" устанавливает соответствие каждого объекта "объект" 226, 228 и 230 с объектом 222 "команда". Объекты "объект" связаны с данными в базе 208 данных. В одном из вариантов осуществления объекты "объект" могут быть связаны со столбцом или строкой, которая будет отображаться. В показанном варианте осуществления объект 226 "объект" - объект по умолчанию, который в данном случае является полевым объектом и определяет поле данных, которое должно перемещаться. Таким образом, если интерпретация использования введенной информации не определяет конкретный объект, необходимый для выполнения команды в объекте 222 "команда", то полевой объект 226 будет определен в значение по умолчанию, которое может быть основано на различных правилах. Объект 228 "объект" - целевой объект, который определяет ось, для которой необходимо отображать данные. Объект 230 "объект" - исходный объект, который определяет текущее поле, которое должно перемещаться к другой оси.
Фиг.4 - последовательность операций примерного способа отображения пользователю таблицы. Способ 250 начинается на этапе 252, на котором вызывают модуль генерации таблиц. На этапе 254 модуль генерации таблиц может также обращаться к терминам и/или фразам базы данных, соответствующим измерениям, уровням, показателям и/или элементам базы 208 данных, которые будут использоваться для сопоставления терминам из введенной пользователем информации. Идентифицированные термины базы данных могут поддерживаться в архиве для будущего использования для улучшения производительности модуля 204 генерации таблиц. На этапе 256 от пользователя принимают введенную на естественном языке информацию. Введенная на естественном языке информация может иметь любую форму, которая включает в себя текст, введенный с клавиатуры, речевые данные и/или написанные от руки данные, и она может быть на любом языке, который включает в себя английский язык, немецкий язык, французский язык, испанский язык, японский язык и т.д.
Получив введенную на естественном языке информацию, на этапе 258 может выполняться семантический анализ введенной информации для идентификации семантической информации, связанной с введенной информацией. Затем могут получаться кандидаты на интерпретацию введенной пользователем информации, основываясь на семантической информации и соответствии частей введенной пользователем информации с частями схемы, как описано выше. Следует отметить, что команда не обязательно должна быть явно выражена во введенной на естественном языке информации, но она может подразумеваться во введенной информации. Например, при вводе информации "яблоки и бананы" может подразумеваться, что используется команда "показать". Используя кандидата на интерпретацию, на этапе 262 могут отображаться описания таблицы-кандидата. Описание таблицы-кандидата может принимать много форм для создания интерактивного, дружественного интерфейса. Например, во время печати пользователем могут показываться интерпретации и/или предварительный просмотр таблицы, могут выделяться распознанные термины в вводимой информации, могут показываться многочисленные табличные конфигурации (т.е. такие объекты, как строка или столбец), описания на естественном языке таблиц-кандидатов могут быть представлены в списке, и выбор неоднозначных терминов может быть представлен во всплывающем меню.
Дополнительно пользователь может выбирать частичные неоднозначности в описаниях кандидатов. Например, если пользователь вводит "продажи" в вводимой информации, одно из описаний кандидатов может включать в себя термин "количество продаж", который является частью базы 208 данных и может приравниваться к термину "продажи". Обеспечивая интерактивный подход к разрешению частичных неоднозначностей, пользователь может выбирать "количество продаж" как эквивалент термину "продажи". Эта информация (т.е. то, что приравнивают термины "продажи" и "количество продаж") может поддерживаться и дополнительно использоваться для управления будущими интерпретациями.
Если пользователь выбирает одно из описаний таблиц-кандидатов, то эта конкретная таблица затем отображается на этапе 266. Альтернативно при желании таблица может отображаться "на лету", когда термин распознается или изменения происходят во вводимой пользователем информации. Кроме того, часть введенной на естественном языке информации может использоваться для распознавания и визуального указания терминов при печати пользователем. Например, при печати пользователем распознанный термин может выделяться. Когда таблица отображена, пользователь может изменять таблицу, обеспечивая дополнительную команду или многочисленные команды для изменения таблицы или для отображения новой таблицы. На этапе 268 могут использоваться дополнительные команды, например, для того чтобы выделить части таблицы, скрыть и/или добавить строки и столбцы, сортировать и фильтровать информацию, а также другие команды. На этапе 266 может затем отображаться новая таблица.
Фиг.5 показывает примерный интерфейс 300, используемый в соответствии с одним из вариантов осуществления настоящего изобретения. Интерфейс 300 включает в себя экран 302 таблицы, предназначенный для отображения информации из базы 208 данных в таблице из столбцов и строк. В показанном варианте осуществления совокупный доход для различных типов самолетов показан по регионам. Окно 304 обеспечивают пользователю для просмотра описания таблицы и для обеспечения ввода информации на естественном языке, которая используется модулем 204 генерации таблиц. Окно 304 включает в себя описание 306 таблицы, которое описывает содержимое таблицы, которая в настоящее время отображается на экране 302. Дополнительно обеспечивают пример 308 вводимой информации для создания таблицы. Для отображения таблицы пользователь может вводить текст в поле 310. Дополнительно, как описано выше, пользователю могут обеспечиваться описания 312 кандидатов в списке для того, чтобы пользователь мог легко выбрать один из кандидатов из списка. Дополнительно пользователю могут обеспечиваться кнопки 314, чтобы он выбрал конкретное размещение (компоновку) таблицы. Например, кнопки 314 могут изменять измерения от столбцов к строкам. В одном из вариантов осуществления количество различных размещений (или конфигураций) может ограничиваться, основываясь на порядке терминов во введенной на естественном языке информации.
В примере, показанном на фиг.5, пользователь ввел на естественном языке информацию "показать доход для самолета и региона" в поле 310 ввода информации. Модуль 204 генерации таблиц, обратившись к терминам из базы 208 данных, идентифицировал измерения "совокупный доход", "тип самолета" и "название региона". Модуль 206 интерпретации, используя введенную в поле 310 информацию и измерения в базе 208 данных, преобразует введенную информацию и обеспечивает описание-кандидат "показать совокупный доход по типам самолета и по названиям регионов" в поле 312.
После того как пользователь выбрал эту интерпретацию, текущее описание 306 и экран 302 таблицы обновляют, чтобы показать выбранную таблицу и соответствующее описание. Пользователю затем разрешают ввести в поле 310 дополнительные команды на естественном языке, которые имеют отношение к таблице на экране 302 или которые имеют отношение к новой таблице. Например, пользователь может обеспечивать команды "скрыть Австралию", "показать только 747", "выделить доходы более 10000 $" и т.д. В этих примерах приложение скроет столбец Австралия, отобразит таблицу, в которой данные связаны только с типом самолета 747, и выделит значения совокупного дохода, которые больше 10000 $ соответственно.
В результате описанных выше вариантов осуществления обеспечивают интерфейс на естественном языке для отображения информации из источника данных, такого как база данных, в таблице из столбцов и строк. Данный интерфейс облегчает пользователям генерацию и отображение таблицы, используемой для анализа данных. Таким образом, анализ данных с помощью отображения таблиц может выполняться более эффективно по времени и более дружественным способом.
Хотя настоящее изобретение было описано в отношении конкретных вариантов осуществления, специалисты должны признать, что изменения могут быть сделаны в форме и деталях, не отступая от объема и формы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ДИНАМИЧЕСКИЙ ОПЫТ ПОЛЬЗОВАТЕЛЯ ПОСРЕДСТВОМ СЕМАНТИЧЕСКИ БОГАТЫХ ОБЪЕКТОВ | 2006 |
|
RU2417408C2 |
| СИСТЕМА И МЕТОД АВТОМАТИЧЕСКОГО СОЗДАНИЯ ШАБЛОНОВ | 2018 |
|
RU2697647C1 |
| ПОДДЕРЖКА ГРАФИЧЕСКИХ ПРЕДСТАВЛЕНИЙ, ОСНОВАННАЯ НА ПОЛЬЗОВАТЕЛЬСКИХ НАСТРОЙКАХ | 2005 |
|
RU2389069C2 |
| РАЗРЕШЕНИЕ КОРЕФЕРЕНЦИИ В ЧУВСТВИТЕЛЬНОЙ К НЕОДНОЗНАЧНОСТИ СИСТЕМЕ ОБРАБОТКИ ЕСТЕСТВЕННОГО ЯЗЫКА | 2008 |
|
RU2480822C2 |
| ПОИСК ИЗОБРАЖЕНИЙ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2688271C2 |
| СИНХРОННОЕ ПОНИМАНИЕ СЕМАНТИЧЕСКИХ ОБЪЕКТОВ ДЛЯ ВЫСОКОИНТЕРАКТИВНОГО ИНТЕРФЕЙСА | 2004 |
|
RU2352979C2 |
| СИНХРОННОЕ ПОНИМАНИЕ СЕМАНТИЧЕСКИХ ОБЪЕКТОВ, РЕАЛИЗОВАННОЕ С ПОМОЩЬЮ ТЭГОВ РЕЧЕВОГО ПРИЛОЖЕНИЯ | 2004 |
|
RU2349969C2 |
| ПОИСК ПРОИЗВОЛЬНОГО ТЕКСТА И ПОИСК ПО АТРИБУТАМ В ДАННЫХ ЭЛЕКТРОННОГО РУКОВОДСТВА ПО ПРОГРАММАМ | 2004 |
|
RU2365984C2 |
| ПОДДЕРЖКА ГРАФИЧЕСКИХ ПРЕДСТАВЛЕНИЙ, ОСНОВАННАЯ НА ПОЛЬЗОВАТЕЛЬСКИХ НАСТРОЙКАХ | 2005 |
|
RU2524473C2 |
| ИСПОЛЬЗОВАНИЕ КОНТЕКСТНОЙ ИНФОРМАЦИИ ДЛЯ ОБЛЕГЧЕНИЯ ОБРАБОТКИ КОМАНД В ВИРТУАЛЬНОМ ПОМОЩНИКЕ | 2012 |
|
RU2542937C2 |
Изобретение относится к области управления приложениями с помощью речевых команд. Техническим результатом является обеспечение более эффективного интерфейса для создания и отображения таблицы с информацией из источника данных. Способ включает в себя прием введенной на естественном языке информации и анализ введенной на естественном языке информации для идентификации содержащейся в ней семантической информации. Для части введенной на естественном языке информации устанавливают соответствие с объектами "команда" и объектами "объект" схемы, основываясь на семантической информации и введенной на естественном языке информации. Способ также включает в себя отображение данных из источника данных в таблице из столбцов и строк, основываясь на схеме и соответствующих частях введенной на естественном языке информации. 3 н. и 32 з.п. ф-лы, 5 ил.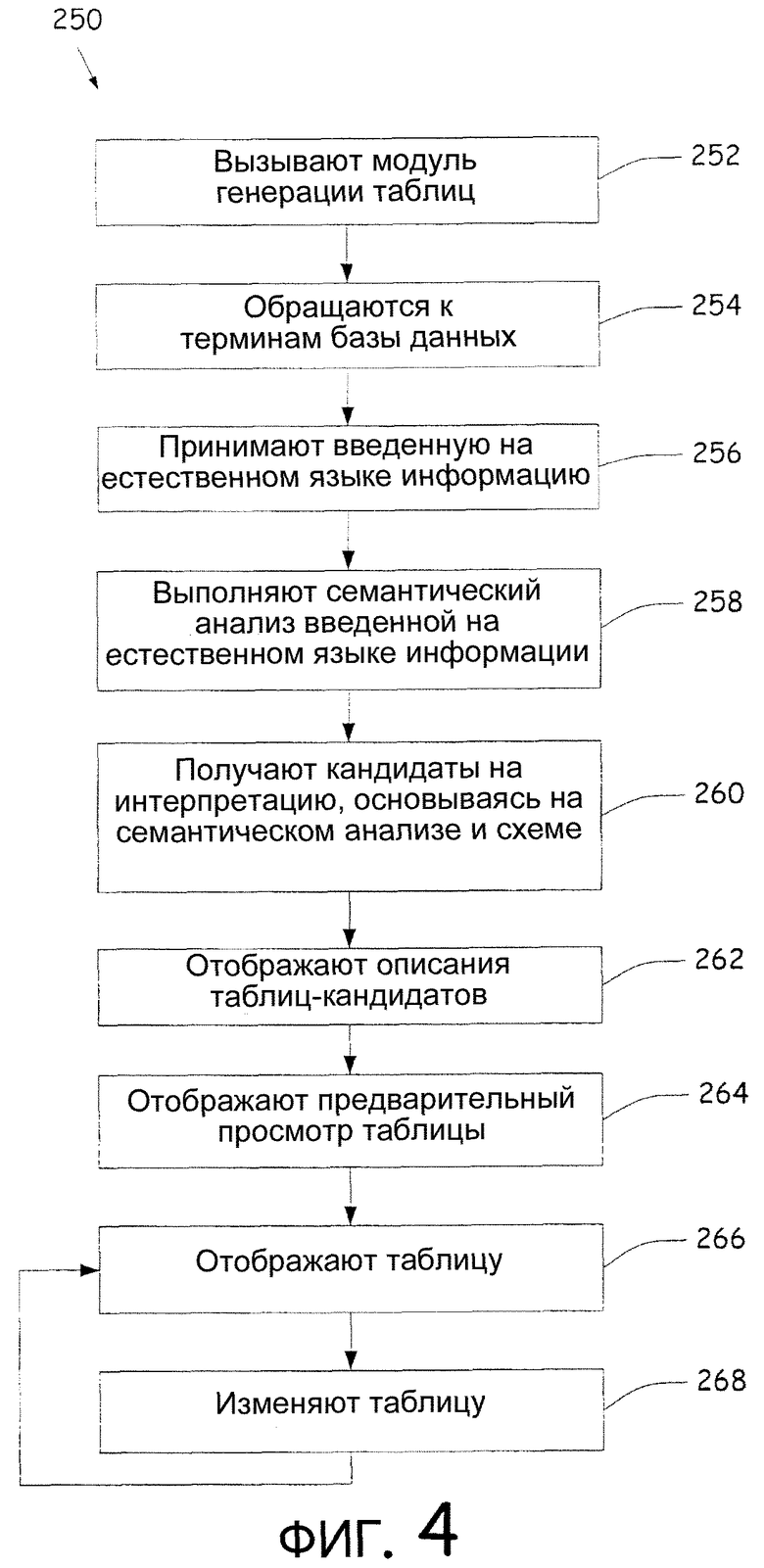
1. Способ обработки данных, хранящихся в структурированном источнике данных, данный способ содержит этапы:
принимают введенную на естественном языке информацию,
анализируют введенную на естественном языке информацию для идентификации содержащейся в ней семантической информации,
устанавливают соответствие части введенной на естественном языке информации с объектом "команда" и объектом "объект" схемы, основываясь на семантической информации и введенной на естественном языке информации, и
отображают данные из источника данных в таблице из столбцов и строк, основываясь на схеме и соответствующих частях введенной на естественном языке информации,
причем этап установления соответствия дополнительно содержит установление соответствия части введенной на естественном языке информации с объектом "кадр" схемы, причем объект "кадр" соответствует тому, как следует отображать данные.
2. Способ по п.1, дополнительно содержащий этап:
обращаются к базе данных для идентификации слов и фраз, связанных с размерностями в источнике данных.
3. Способ по п.2, в котором этап обращения дополнительно содержит идентификацию слов и фраз, связанных с уровнями и значениями в источнике данных.
4. Способ по п.1, в котором объект "команда" относится к заданию, которое будет выполняться для отображения данных.
5. Способ по п.1, в котором объект "объект" относится к данным в источнике данных или к объектам в приложении.
6. Способ по п.1, дополнительно содержащий этап:
изменяют таблицу, основываясь на дополнительной принятой команде.
7. Способ по п.6, в котором дополнительная команда выделяет часть таблицы.
8. Способ по п.6, в котором дополнительная команда сортирует часть таблицы.
9. Способ по п.6, в котором дополнительная команда фильтрует информацию в таблице.
10. Способ по п.6, в котором дополнительная команда добавляет информацию к таблице.
11. Способ по п.6, в котором дополнительная команда удаляет информацию из таблицы.
12. Способ по п.7, в котором дополнительная команда включает в себя обмен информации в столбцах и строках.
13. Способ по п.1, дополнительно содержащий этап:
представляют кандидатов на интерпретацию, основываясь на введенной на естественном языке информации.
14. Способ по п.1, дополнительно содержащий этап:
обеспечивают интерактивный пользовательский интерфейс для ввода информации на естественном языке.
15. Способ по п.14, дополнительно содержащий этап:
выполняют по меньшей мере одно из: указания распознанных терминов в введенной на естественном языке информации и обеспечения кандидатов на интерпретацию, когда пользователь вводит информацию на естественном языке.
16. Способ по п.1, дополнительно содержащий этап:
отображают описание информации в таблице на естественном языке.
17. Способ по п.1, дополнительно содержащий этап:
поддерживают архив отображаемых ранее таблиц для будущего использования.
18. Способ по п.1, дополнительно содержащий этап:
устанавливают соответствие части введенной на естественном языке информации со словами и фразами, связанными с источником данных.
19. Способ по п.1, в котором этап анализа дополнительно содержит идентификацию неоднозначных терминов во введенной на естественном языке информации и представление альтернативных кандидатов для неоднозначных терминов.
20. Считываемый компьютером носитель, содержащий команды для обработки данных в структурированном источнике данных, включающем в себя размерности и значения, связанные с этими размерностями, данные команды содержат:
модуль пользовательского интерфейса, настроенный для приема введенной на естественном языке информации и для отображения таблицы,
модуль генерации таблиц, настроенный для обращения к размерностям и значениям и для определения схемы для отображения данных размерностей и значений, и
модуль интерпретации, настроенный на выполнение семантического анализа введенной на естественном языке информации для установления соответствия между терминами во введенной на естественном языке информации и объектом "команда" который относится к заданию, которое будет выполняться объектом "объект", и объектом "кадр", который относится к тому, как следует отображать данные схемы, соответствующей размерностям в источнике данных, и для генерации кандидатов на интерпретацию того, как отображать данные в источнике данных, основываясь на введенной на естественном языке информации, размерностях и схеме.
21. Считываемый компьютером носитель по п.20, в котором модуль пользовательского интерфейса настраивают для представления кандидатов на интерпретацию таблицы.
22. Считываемый компьютером носитель по п.20, в котором источник данных включает в себя уровни, связанные с размерностями.
23. Считываемый компьютером носитель по п.20, в котором модуль пользовательского интерфейса настраивают для отображения таблицы размерностей и значений из источника данных, основываясь по меньшей мере на одном из кандидатов на интерпретацию таблицы.
24. Считываемый компьютером носитель по п.20, в котором модуль интерпретации настраивают для сравнения слов и фраз во введенной на естественном языке информации с размерностями и значениями в источнике данных.
25. Считываемый компьютером носитель по п.20, в котором модуль пользовательского интерфейса настраивают для представления пользователю кандидата на интерпретацию.
26. Считываемый компьютером носитель по п.25, в котором кандидат на интерпретацию включает в себя множество конфигураций таблицы, причем по меньшей мере одна конфигурация связана с теми же самыми данными.
27. Считываемый компьютером носитель по п.20, в котором модуль пользовательского интерфейса настраивают для предоставления возможности пользователю выбирать один из кандидатов на интерпретацию для отображения таблицы, связанной с выбранным кандидатом на интерпретацию.
28. Способ обработки информации для управления приложением, содержащий этапы:
принимают введенную на естественном языке информацию, анализируют введенную на естественном языке информацию для идентификации содержащейся в ней семантической информации,
обращаются к схеме для идентификации объекта "команда" и объекта "объект", основываясь на семантической информации и введенной на естественном языке информации, и
выполняют действие, связанное с приложением, основываясь на объекте "команда" и объекте "объект",
причем объект "команда" связан с командой, выполняемой в приложении, и объект "объект" связан с данными, используемыми приложением при выполнении данной команды.
29. Способ по п.28, в котором приложение представляет собой приложение электронных таблиц.
30. Способ по п.28, в котором действие включает в себя
отображение данных из источника данных в таблице из столбцов и строк, основываясь на схеме.
31. Способ по п.30, в котором действие включает в себя отображение одной ячейки информации из источника данных, основываясь на введенной на естественном языке информации.
32. Способ по п.28, в котором обращение к схеме дополнительно содержит идентификацию объекта "кадр", причем объект "кадр" устанавливает соответствие между объектом "объект" и объектом "команда".
33. Способ по п.28, дополнительно содержащий представление кандидата на интерпретацию введенной на естественном языке информации, основываясь на схеме и семантической информации.
34. Способ по п.28, в котором обращение к схеме включает в себя идентификацию множества объектов "объект".
35. Способ по п.28, в котором обращение к схеме включает в себя идентификацию множества объектов "команда".
| ЕР 1120720, 01.08.2001 | |||
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| СПОСОБ ЛЕКСИЧЕСКОЙ ИНТЕРПРЕТАЦИИ СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1997 |
|
RU2119196C1 |
| СПОСОБ ПОИСКА В БАЗАХ ДАННЫХ С РАЗМЕТКОЙ ДАННЫХ | 2000 |
|
RU2177174C1 |

