Изобретение относится к области автоматики и вычислительной техники и может быть использовано в системах понимания речи, системах управления технологическим оборудованием, роботами, средствами вычислительной техники, автоматического речевого перевода, в справочных системах и др.
Известен способ лексической интерпретации слитной речи, реализованный в системе автоматического понимания речи английского языка HEARSAY II [1].
Суть способа состоит в том, что периодически произносят речевое высказывание, которое оцифровывают через фиксированные интервалы времени с заданной частотой квантования в этом интервале. Далее берут выборки этого акустического оцифрованного сигнала и по их совокупности вычисляют текущие значения параметров входного речевого сигнала, которые преобразуют класс слогов, называемый слоготипом. После этого для каждого слоготипа при построении лексической гипотезы выявляют все слова, которые содержат ударный слог, принадлежащий этому классу слоготипов. Многосложные слова отвергаются, если они плохо согласуются со смежными слоготипами. Определение слоготипов основано на группировании фонем в фонетические классы. Произношение каждого слова, принадлежащего словарю произношений, преобразуется в последовательность слоготипов путем распределения всех фонем по их классам. Последовательности значений параметров неизвестного речевого высказывания определяют гипотезы о слоготипах, используемых для построения гипотез о словах.
Особенностью известного способа является то, что вариации произношения слов учитывают путем применения широких классов фонем и включения вариантов произношения слов в словарь. Классы фонем предполагают, что каждый слоготип принадлежит только к одному классу слоготипов.
Однако этот способ имеет недостатки: невозможно разделить слоги и фонемы строго на классы, так как существуют фонемы, которые можно отнести к двум соседним классам. Это приводит к тому, что различия между классами стираются и уменьшается четкость различия слоготипов, в результате чего снижается точность лексической интерпретации слитной речи.
Известен способ лексической интерпретации слитной речи особенность, которого состоит в непосредственном переходе от распознанных звуков в высказывании к произношениям слов с учетом изменения этих звуков при коартикуляции. Этот способ реализован в системе автоматического понимания речи DRAGON [2].
Суть способа состоит в том, что периодически произносят речевое высказывание, которое оцифровывают через фиксированные интервалы времени с заданной частотой квантования в этом интервале. Далее берут выборки этого акустического оцифрованного сигнала и по их совокупности вычисляют текущие значения параметров входного речевого сигнала, которые преобразуют в фонему. После этого формируют последовательность фонем, и, используя сеть лексического декодирования, представляющую собой модель произнесения слова, строят гипотезы о возможных словах в высказывании.
Для построения сети лексического декодирования берут каноническое произношение и применяют к нему фонологические правила, чтобы представить наиболее полную вероятную модель произношения слова. При использовании словаря канонического произношения (словаря подсетей слова) каждая подсеть слова заменяется до узла. В результате чего получаем сеть, в которой каждый узел представляет собой индивидуальную фонему. Возможные фонетические реализации слова формируются путем неоднократного применения фонологических правил к основному произношению.
Каждое правило обеспечивает альтернативное произношение некоторой последовательности фонем. Для каждого фонологического правила осуществляется просмотр всей сети, чтобы найти любые узлы, которые удовлетворяют условиям контекста. Все это приводит к снижению быстродействия и точности лексической интерпретации слитной речи.
Наиболее близким к заявляемому способу, взятому в качестве прототипа, является способ лексической интерпретации слитной речи, реализованный в системе CASPERS [3] . Суть способа состоит в том, что периодически произносят речевое высказывание, которое оцифровывают через фиксированные интервалы времени с заданной частотой квантования в этом интервале. Далее берут выборки этого акустического оцифрованного сигнала, по совокупности которых вычисляют текущие значения параметров входного речевого сигнала, которые преобразуют в фонему. После этого формируют последовательность фонем, и, используя лексическую декодирующую схему, строят гипотезы о возможных словах в высказывании. При этом лексическая декодирующая схема представляет собой дерево, содержащее все ожидаемые фонетические реализации слов заданного словаря. Слова, имеющие одинаковые первые звуки, помещают в одной и той же начальной точке дерева. Далее, конец каждой ветви дерева, представляющей произношение слова, соединяют со всеми начальными формами слов, применяя при этом набор фонологических правил. В результате создается сеть фонетических решений.
Определение исходного выражения основано на поиске оптимальной последовательности фонем в сети фонетических решений. При этом для учета внутри словарных фонологических явлений, а также изменений окончаний слов из-за влияния предыдущих и последующих слов, ожидаемые фонетические реализации слова представляют путем расширения основного произношения несколькими альтернативными произношениями. Такое расширение словаря производят автоматически, с применением фонологических правил.
Однако необходимо располагать некоторой эвристической стратегией сравнения для подбора слов, соответствующих фонетической записи неизвестного выражения. Для этого необходимо вводить меру штрафа при ошибочной идентификации, возможных случаев добавления или пропуска звуков, так как автоматический фонетический анализатор допускает много ошибок такого типа. Ошибки в фонетической транскрипции могут привести в конечном счете к неустранимому рассогласованию с правильным словом.
Недостатками вышеперечисленных способов и прототипа являются низкое быстродействие, недостаточная точность лексической интерпретации слитной речи, что обусловлено следующим:
- фонетическая транскрипция, которая служит входной информацией для построения лексических гипотез, содержит ошибки замещения, лишние звуки и пропуски звуков, уменьшающие сходство интерпретируемого слова с правильной гипотезой и увеличивающее сходство интерпретируемого слова с ошибочными, особенно при большом объеме словаря;
- неоднократное применение фонологических правил к словарю произношений слов влечет за собой замедление процесса лексической интерпретации слитной речи;
- ожидаемая фонетическая реализация слова зависит от контекста предложения, в котором оно встречается. Границы слов в слитной речи полностью отсутствуют в транскрипции, так как акустические признаки их положений слабо выражены;
- положение границы между длительностями фонетических групп зависит от скорости речи, положения синтаксических границ, ударных слогов и локального фонетического окружения.
При лексической интерпретации слитной речи возникает задача, суть которой состоит в том, что принятие решения на фонетическом уроне частично зависит от фактора более высокого уровня, которые не могут быть определены, пока не приняты решения на фонетическом уровне. Решение данной задачи сводится к необходимости принятия решения на фонетическом и более высоких уровнях одновременно.
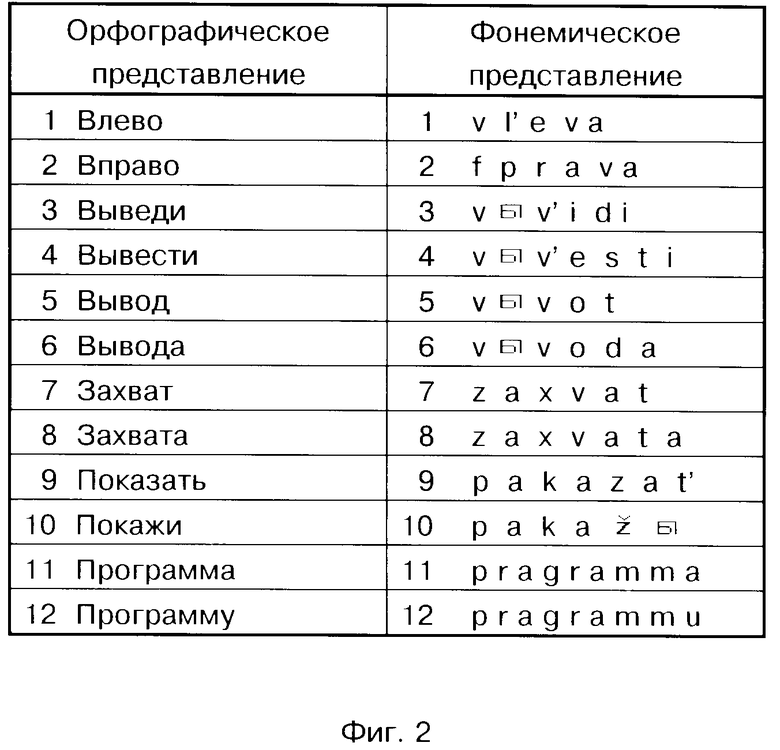
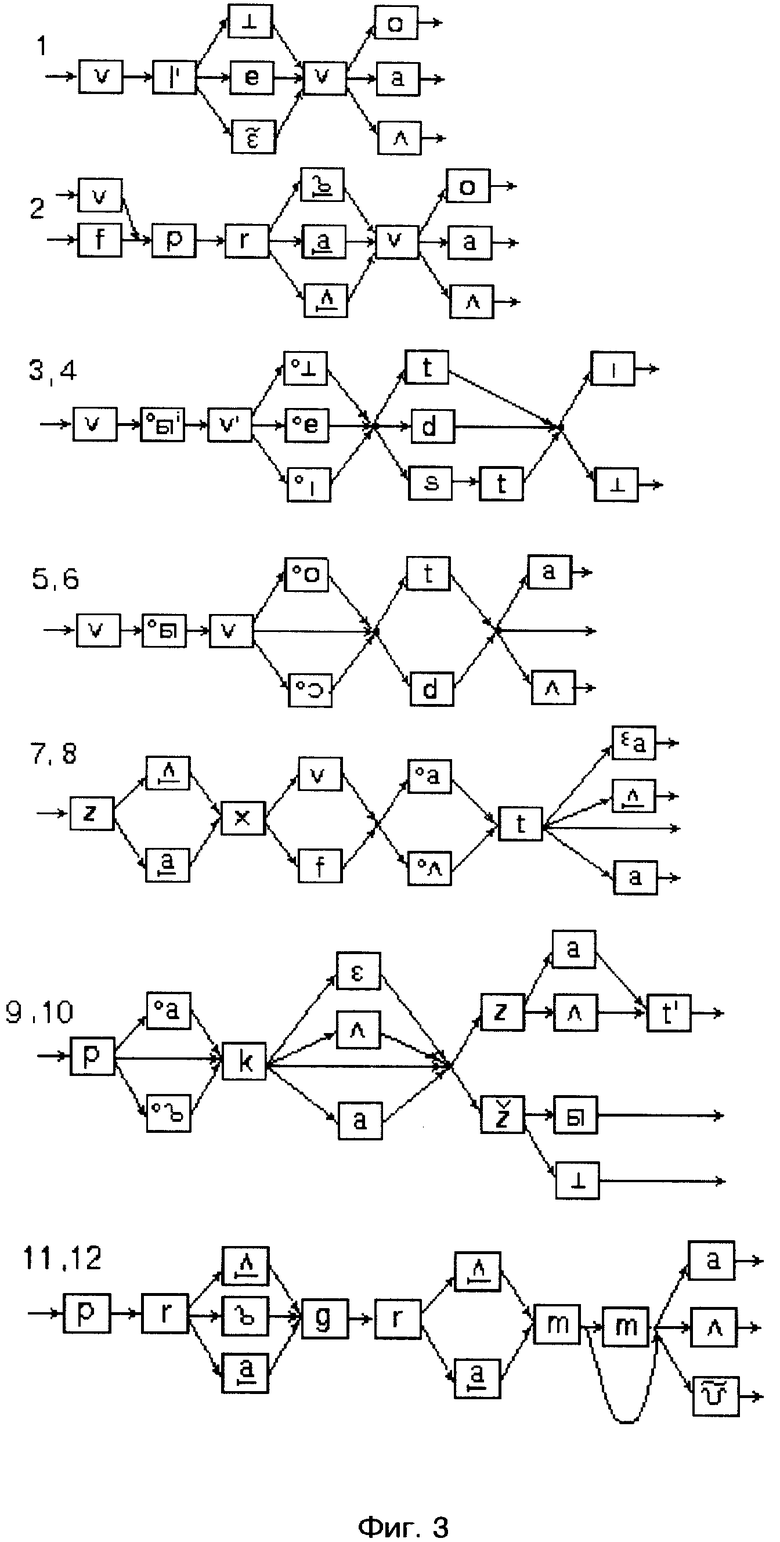
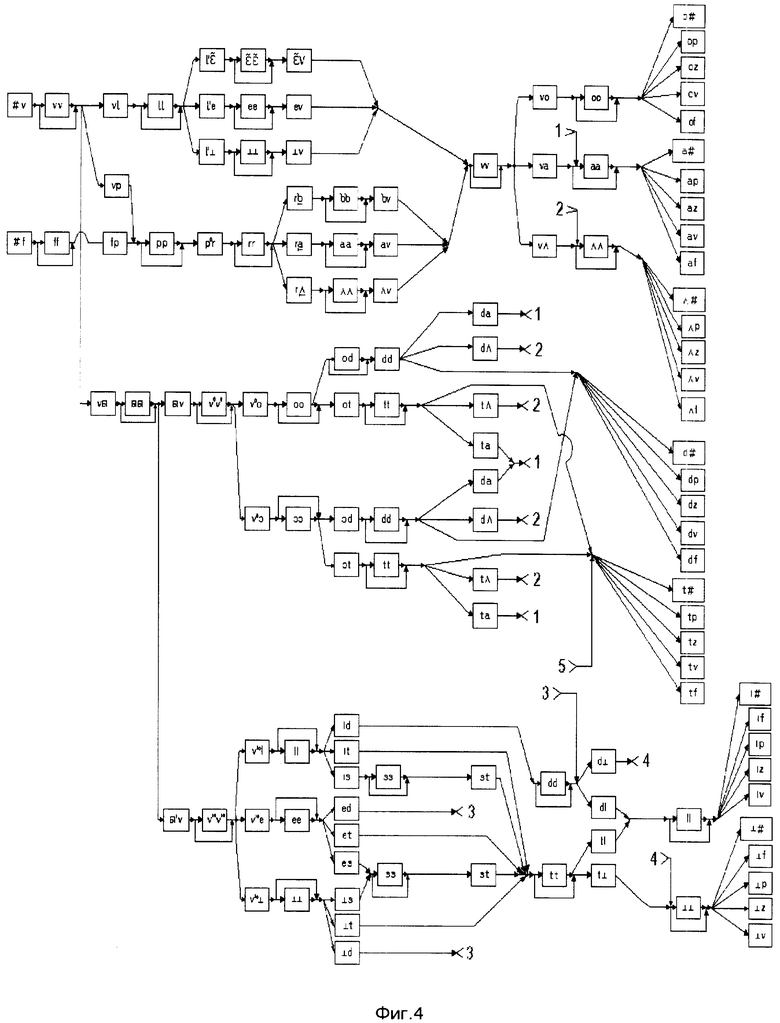
Описание предлагаемого способа лексической интерпретации слитной речи включает восемь фигур: фиг. 1 - общее представление гласной фонемы; фиг. 2 - орфографическое и фонетическое представление лексем, фиг. 3 - моделирующий граф; фиг. 4, 5 - граф альтернативных представлений; фиг. 6 - сеть альтернативных представлений; фиг. 7 - сеть лексического декодирования; фиг. 8 - пример структуры данных.
Предлагаемый способ лексической интерпретации слитной речи состоит в том, что периодически произносят речевое высказывание, которое оцифровывают через фиксированные интервалы времени с заданной частотой квантования в этом интервале. Затем берут выборки этого акустического оцифрованного сигнала, по совокупности которых вычисляют текущие значения параметров входного речевого сигнала, определяющих текущее акустическое состояние.
Способ отличается тем, что, минуя уровень фонемического преобразования, одновременно по вычисленным значениям параметров входного речевого сигнала, используя сеть лексического декодирования, строят гипотезы о возможном начале, продолжении, либо конце слов в речевом высказывании, и составляют наиболее вероятные последовательности эталонных слов, соответствующие произнесенному речевому высказыванию. При этом произносимые слова могут непрерывно следовать друг за другом в любом порядке, либо разделяться паузами, либо словами, не принадлежащими к заданному набору слов. Предлагаемая сеть лексического декодирования представляет собой интегрированную базу данных, содержащую орфографические представления заданного набора слов, ожидаемые акустические представления заданного набора слов в виде последовательностей эталонных значений параметров речевого сигнала, определяющих акустические состояния и объединяющую фонетическую транскрипцию, фонологические правила и лексику для заданного набора слов.
Результатом осуществления изобретения является повышение точности лексической интерпретации слитной речи русского языка и обеспечение быстродействия, максимально приближенного к реальному времени. Результат достигается использованием сети лексического декодирования (СЛД), лексемы которого представлены в виде последовательности акустических состояний (АС), учитывающей внутри словарные фонетические явления, а также фонетические явления, возникающие на границах слов.
Акустическим состоянием предлагается называть набор значений параметров речевого сигнала (РС), характеризующий временной интервал, соизмеримый с периодом основного тона. Суть такого подхода заключается в представлении РС конечным числом заранее выбранных типов АС. Число различных АС должно быть выбрано таким образом, чтобы отразить все значимое разнообразие импульсных реакций вокального тракта в процессе речеобразования.
В основу акустического представления сигналов слитной речи положен принцип последовательного разложения фонем на аллофоны, а аллофонов - на составляющие их АС. Аллофоны легко различимы акустически, вследствие чего исчезает потребность применения правил на более низких уровнях. Они содержат информацию о границах между слогами и словами. Такую информацию предлагается получать посредством представления аллофонов в виде трех последовательных АС: начального, серединного и конечного. При этом тип серединного АС зависит только от типа выбранного аллофона, а тип начального или конечного - переходного АС зависит, кроме того, от типа предшествующей и последующей фонемы.
Возможна различная степень детальности разложения каждой фонемы на аллофоны, а аллофонов - на АС. Для примера представим один из возможных вариантов разложения, который является достаточным для обеспечения необходимого многообразия реализаций каждой фонемы и аллофона при лексической интерпретации слитной речи русского языка.
Из русских гласных фонем выбираем множество аллофонов твердых - {А, О, У, Э, И, Ы} и мягких - 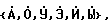 а также соответствующие им множества назализованных
а также соответствующие им множества назализованных 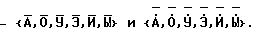
Для русских согласных необходимо различать губное, зубное, альвеолярное, велярное и латеральное место образования. Таким образом, для описания переходных (начального или конечного) интервалов РС каждого аллофона гласной необходимо иметь до 5-ти различных типов АС. Общее представление каждой гласной фонемы в виде набора АС, необходимых для акустического описания слитной речи русского языка, представлено фиг. 1 на примере гласной /А/. Аналогичным образом предлагается определять три временных интервала РС (начальный, серединный и конечный) для описания согласных звуков.
Представление русских фонем в виде АС допускает значительное изменение их количества, которое обусловлено эффектом коартикуляции с предшествующей и последующей фонемами.
Пусть V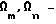 множества фонем m - го и n - го типов, где q - индекс, определяющий тип АС, q = 1, 2, 3 (q = 1 - начальное АС; q = 2 - серединное АС; q = 3 - конечное АС); ϕ - индекс, определяющий фонему ϕ = 1, 2, ..., Ф ; m - индекс, определяющий множество предшествующих фонем, m = 1, 2, ..., M; n - индекс, определяющий множество последующих фонем, n = 1, 2, ..., N. Тогда в общем случае АС можно представить в виде многозначной функции:
множества фонем m - го и n - го типов, где q - индекс, определяющий тип АС, q = 1, 2, 3 (q = 1 - начальное АС; q = 2 - серединное АС; q = 3 - конечное АС); ϕ - индекс, определяющий фонему ϕ = 1, 2, ..., Ф ; m - индекс, определяющий множество предшествующих фонем, m = 1, 2, ..., M; n - индекс, определяющий множество последующих фонем, n = 1, 2, ..., N. Тогда в общем случае АС можно представить в виде многозначной функции: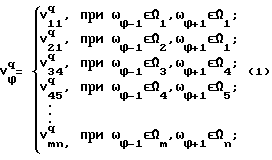
Формула (1) приобретает конкретный вид для каждой фонемы. Проиллюстрируем это на примере фонемы /А/ для трех АС. Для начального АС:
где: Ω1 = {П, Б, Ф, В, Л} - множество твердых губных и боковых согласных фонем, Ω2 = {Т, Д, С, З, Р, Ц, Ч, Ж, К, Г, Х} - множество твердых зубных, альвеолярных и небных согласных фонем, Ω3 = {П', Б', Ф', В'} - множество мягких губных согласных, Ω4 = { Т', Д', С', З', Р', Ш', Ч'} - множество мягких зубных и альвеолярных согласных фонем, Ω5 = {К', Г', Х'} - множество мягких небных согласных фонем, Ω6 = {Л'} - единичное множество мягких боковых согласных фонем, Ω7 = {М} - единичное множество твердых губных носовых согласных фонем, Ω8 = { Н} - единичное множество твердых зубных носовых согласных фонем, Ω9 = { М'} - единичное множество мягких губных носовых согласных фонем, Ω10 = { Н'} - единичное множество мягких зубных носовых согласных фонем, Ω11 = {А, О, У, Э, И, Ы, #} - множество гласных фонем и паузы.
Для серединного АС фонемы /А/ формула (1) имеет вид:
где:
Ω12 = {А, О, У, Э, И, Ы, Л, Р, В, З, Ж, Б, Д, П, Т, Г, Ф, К, С, Ш, Х, Ц} - множество твердых неносовых согласных и гласных фонем, Ω13 = {Л', Р', В', З', Ж', Б', Д', Г', П', Т', К', Ф', С', Ш', Х', Ч'} - множество мягких согласных фонем, Ω14 = {М', Н'} - множество мягких носовых согласных фонем, Ω15 = {М, Н} - множество твердых носовых согласных.
Для конечного АС фонемы /А/ формула (1) имеет вид:
где
Ω1 - Ω10 те же, что и в формуле (2), а множества Ω16 - Ω20 являются единичными и содержат соответственно гласные - {А, О, У, Э, И, Ы}.
Аналогично формулам (2), (3), (4) для каждой фонемы могут быть записаны соответствующие выражения с учетом правил их аллофонической изменчивости.
На основе вышеизложенного формируется СЛД. Формирование СЛД происходит путем выполнения последовательности операций: создание базы данных слов; представление речевого высказывания как последовательности слов, определение акустического состояния как набор значений параметров временного интервала РС; создание базы данных эталонов акустических состояний для фонетического и фонологического описания русских слов; представление слова как последовательности акустических состояний. Суть этих операций состоит в следующем.
1) Создают базу данных слов, необходимую для речевого общения, содержащую номер слова - l, для которого определяются: орфографическое представление, варианты произношений с соответствующими номерами - j.
2) Речевое высказывание представляют последовательностью слов, допускающей непрерывное следование произносимых слов друг за другом в любом порядке, либо с разделением паузами, либо с разделением словами, не принадлежащими к заданному набору (базе данных) слов:
W = C
где:
W - речевое высказывание; C - слово;
l - номер слова в базе данных слов l = 0, 1, 2, ..., L;
j - номер произношения l-го слова, j = 0, 1, 2, ..., J;
i - порядковый номер слова в высказывании, i = 1, 2, 3, ..., I;
3) Определяют акустическое состояние как набор значений параметров временного интервала РС:
V = (x1, x2, x3, ...xR) + Q, (6)
где, например: x1= F0 - частота основного тона; x2=A0 - амплитуда основного тона; x2=F1, x4=F2, где F1, F2 - частоты формант; x5=A1, x6=A2 - амплитуды первой и второй формант соответственно; x7=B1, x8=B2 - ширина пропускания первой и второй формант соответственно; x9=Z - число переходов через ноль; x10 - темп произнесения и т.д.; Q - шум.
4) Создают базу данных эталонов акустических состояний, содержащую номер АС, имя АС с набором значений параметров временного интервала речевого сигнала.
5) Представляют слова, как последовательность акустических состояний: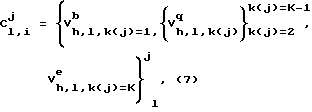
где
0≤h≤H, 0≤l≤L, 1≤k(j)≤K, 0≤j≤J, 1≤i≤I, (8)
C - слово;
V - акустическое состояние;
i - порядковый номер слова в высказывании, i = 1, 2, 3, ...,I;
h - номер АС в базе данных эталонов АС, h = 0, 1, 2, ..., H;
l - номер слова в базе данных слов, l = 0, 1, 2, ..., L;
j - номер произношения l-го слова, j = 0, 1, 2, ..., J;
b - тип начального АС, выбираемый в соответствии с формулами (1), (2) и в соответствии с произношением j для l-го слова;
e - тип конечного АС, выбираемый в соответствии с формулами (1), (4) и в соответствии с произношением j для l-го слова;
q - индекс, определяющий тип АС, выбираемый в соответствии с формулами (1) - (4) и в соответствии с произношением j для l-го слова; q = 1, 2, 3;
k - число акустических состояний в слове, изменяющееся в зависимости от j для C
Если i=1, то речевое высказывание состоит из одного слова. Тогда:
W = C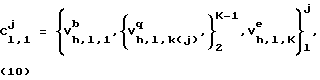
где
V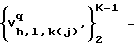 последовательность акустических состояний C
последовательность акустических состояний C
V
Если 1< i≤l, то допустимые V
Таким образом, каждое слово содержит три участка в речевом высказывании: начальный, серединный и конечный. При этом для фиксированного значения i=1 речевое высказывание состоит из одного слова и содержит начальный и конечный участки речевого высказывания, связанные с паузой, а при 1<i≤I слово C
6) Производят описания переходов из акустических состояний, используя набор фонетических и фонологических правил русского языка и п.1-п.5.
7) Создают сеть лексического декодирования с учетом п.5, п.6, с последующим формированием базы данных локальных вершин и базы данных граничных вершин.
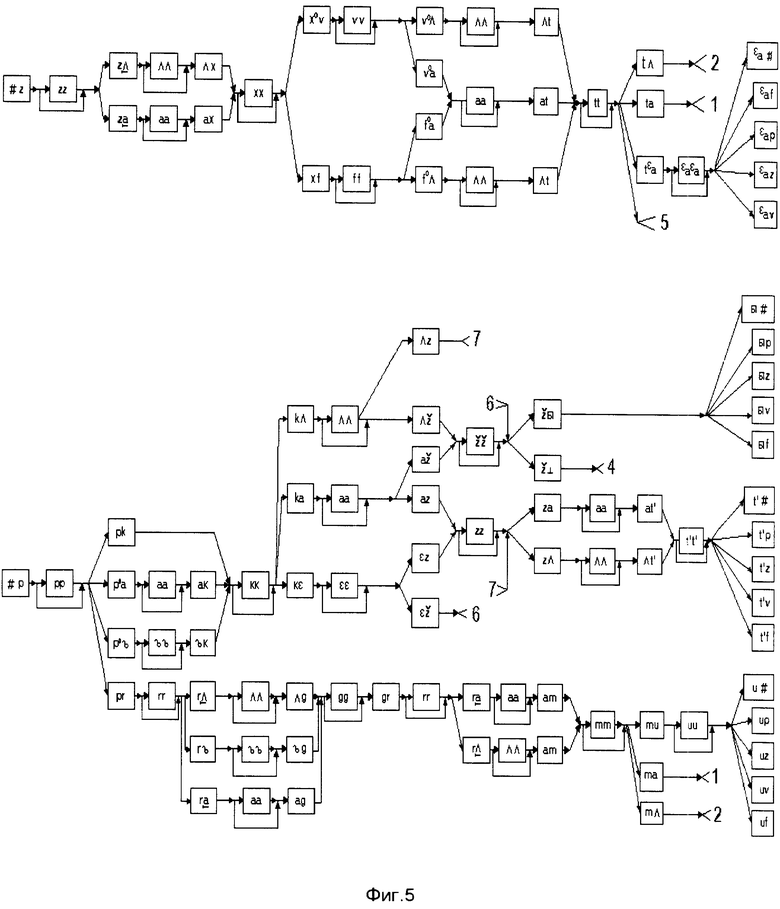
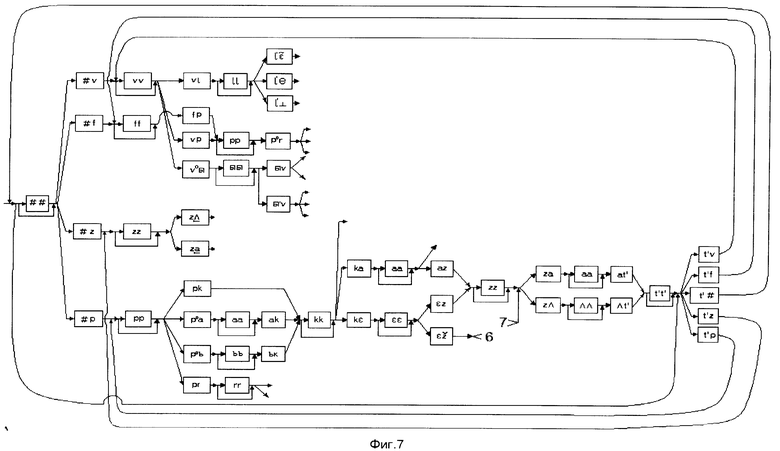
Этапы построения сети лексического декодирования представлены шестью фигурами: фиг. 2 - орфографическое и фонемическое представление лексем, фиг. 3 - моделирующий граф, вершинами которого являются аллофоны, а дугами - указатели на следующие возможные аллофоны; фиг. 4, фиг. 5 - граф альтернативных представлений, вершинами которого являются АС, а дугами - указатели на следующие возможные АС; фиг. 6 - сеть альтернативных представлений, вершинами которой являются АС, а дугами - указатели на следующие возможные АС; фиг. 7 - сеть лексического декодирования, вершинами которой являются АС, а дугами - указатели на следующие возможные акустические состояния.
Этапы построения сети лексического декодирования представлены на примере выражений, применимых для управления движением захвата манипулятора влево и вправо, а также указаний вывода программы захвата. Например, "Выведи захват влево", Вывод захвата вправо", "Показать программу захвата", "Покажи программу вывода захвата" и т.д.
На первом этапе (фиг. 2) определяют необходимый словарь для речевого общения. Определяют орфографическое и фонемическое представление каждой лексемы. На втором этапе (фиг. 3) для каждой лексемы с возможными окончаниями строят моделирующий граф ожидаемых аллофонических представлений, вершинами которого являются аллофоны, а дугами указатели на следующие возможные аллофоны. На фиг. 3 прямоугольниками обозначены вершины с именами аллофонов, а цифрами - номера лексем, соответствующие номерам лексем из фиг. 2. После этого последовательность аллофонов замещают последовательностью акустических состояний (фиг. 4, фиг. 5) для всех лексических единиц применяемого словаря с возможными окончаниями и строят их в виде дерева решений. При этом слова, имеющие одинаковые первые звуки, помещают в одной и той же начальной вершине дерева. Например, слова "покажи" и "программа" имеют первый общий звук - "п". Далее все возможные окончания каждого слова соединяются с корнем дерева и с помощью фонологических правил строится сеть альтернативных представлений для всех возможных (грамматически правильных и неправильных) последовательностей слов из словаря. Фрагмент сети альтернативных представлений изображен на фиг. 6.
В результате применения фонологических правил образуются локальные и граничные вершины.
Локальной вершиной следует считать объект, связанный с АС типа V
Граничной вершиной следует считать локальную вершину, связанную с переходными АС типа V
На завершающем этапе построения СЛД корень сети альтернативных представлений соединяется со всеми граничными вершинами.
Таким образом, получают СЛД, которая представляет собой словарь со встроенным фонетическим транскриптором, правилами фонологии и лексикой для заданного набора слов. Фрагмент сети лексического декодирования представлен на фиг. 7. На фиг. 4 - фиг. 7 прямоугольниками обозначены вершины с именами АС, а цифрами - разрывы соединений.
В соответствии с фиг. 7 начальная (корневая) вершина представляет собой паузу. Каждая вершина в столбце СЛД представляет собой объект, связанный с одним участком квантованного высказывания (фразы). Каждая вершина во втором столбце содержит АС, связанное со следующими возможными состояниями и т.д. Каждая вершина допускает переход в саму себя и минуя себя (на фиг. 7 это не показано, чтобы не загромождать схему). Это приводит к тому, что две и более вершины могут быть связаны с одним и тем же АС. Таким образом, в процессе выделения V могут возникнуть дополнительные АС, в то время как отсутствие АС приводит к существенным проблемам. Поэтому потенциально отсутствующие АС должны рассматриваться как дополнительные в процессе создания СЛД.
Такая сеть явным образом учитывает коартикуляционные эффекты, возникающие как внутри слов, так и на их границах, и позволяет, минуя уровень фонетического преобразования, формировать возможные варианты лексической интерпретации входного высказывания слитной речи.
Для определения возможных вариантов лексической интерпретации исходного выражения необходимо отыскать оптимальную последовательность вершин (путь) в СЛД. СЛД использует такое представление словаря, при котором объединены общие части различных слов. Поэтому процедура просмотра всего словаря легко реализуема с вычислительной точки зрения и не требует отдельного рассмотрения каждого слова. При этом акустико-фонетические знания проявляются в удобной и доступной форме, упрощающей процесс оптимизации выбора наилучшего пути.
На основе вышеизложенного создают базу данных локальных и базу данных граничных вершин. При этом каждой вершине присваивают весовой коэффициент η исходя из АС. Далее производят классификацию вершин по возрастанию весового коэффициента η (с соответствующей перенумерацией). В итоге, номер граничной вершины в базе данных граничных вершин (БДГВ) определяет номер вершины в базе данных локальных вершин (БДЛВ). Пример структуры данных, применяемый в БДЛВ представлен фиг. 8.
Предлагаемый способ лексической интерпретации слитной речи, основанный на применении СЛД, реализует последовательное сокращение исходного множества эталонов АС и слов по критериям акустического подобия.
Суть его состоит в следующем. Произносят речевое высказывание, которое оцифровывают через фиксированные интервалы времени с заданной частотой квантования в этом интервале. Далее берут выборки этого акустического оцифрованного сигнала, по совокупности которых вычисляют весовой коэффициент η . По этому коэффициенту определяют вероятную область поиска вершин в БДЛВ. Одновременно по полученной совокупности выборок вычисляют текущее АС - VТ. Находят вершины в БДЛВ с эталонными АС - VЭ, подобными VТ. Если VТ не подобна эталонным АС ожидаемых вершин в БДЛВ, то производится коррекция области поиска ожидаемых вершин в БДЛВ. Если не удается найти эталонные АС ожидаемых вершин в БДЛВ подобные VТ, то поиск производят в БДГВ. Если вершины с эталонными АС, подобными VТ, обнаружены, то по оценкам меры близости текущего АС и ожидаемых эталонов, формируют гипотезы о словах, акустически схожими своими начальными АС на текущее. После этого из множества сформировавшихся к этому моменту гипотез о словах отбирают эталоны, акустически схожие своими следующими эталонными АС-ми на следующее текущее АС. При этом производят формирование последовательностей слов с учетом чередования границ, составляющих их слов согласно с (7), (10). Если не удается найти эталонные АС подобные VТ, ни в БДЛВ, ни в БДГВ, то производят добавление соответствующих меток в формируемые последовательности слов, которые свидетельствуют о не найденных АС и соответствующих им слов. Этот процесс продолжается до тех пор, пока не будет обнаружена межфразовая пауза. Полученные к этому моменту последовательности слов составляют набор возможных лексических гипотез или вариантов лексической интерпретации входного высказывания. Этот набор лексических гипотез может быть подвергнут дальнейшему анализу по грамматическим, синтаксическим, семантическим и прагматическим критериям.
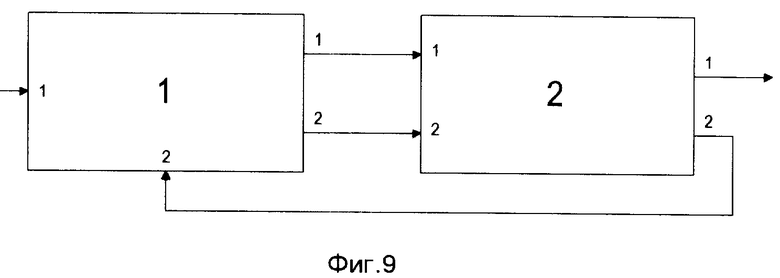
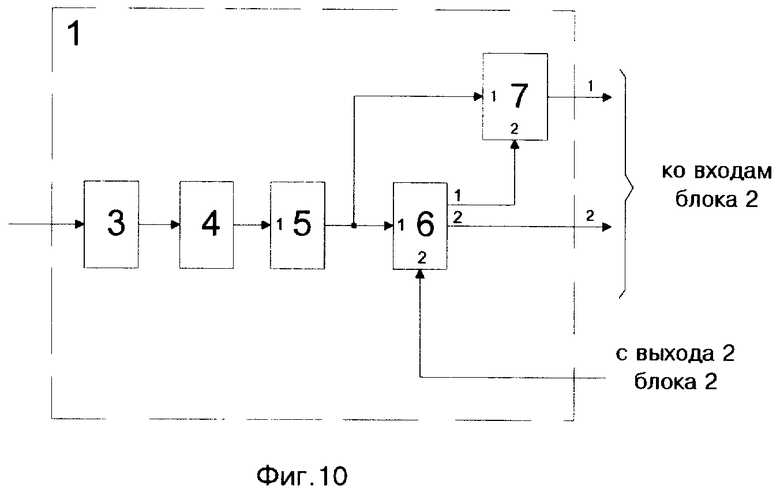
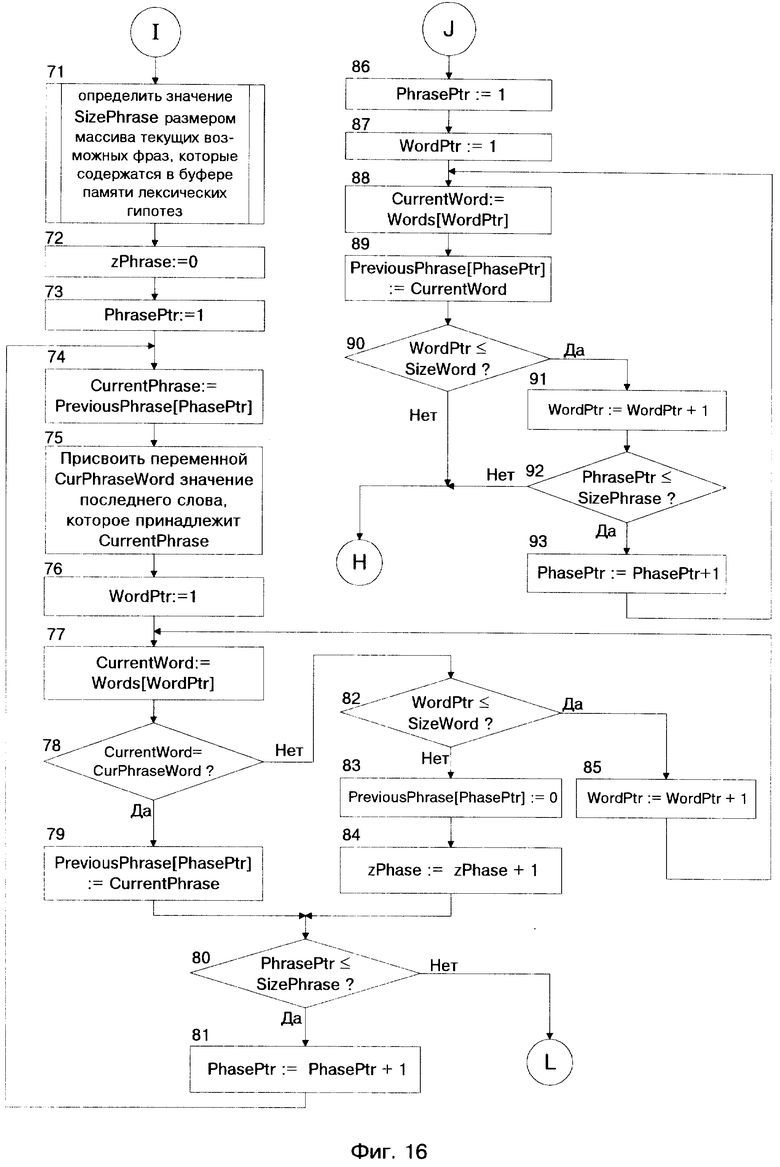
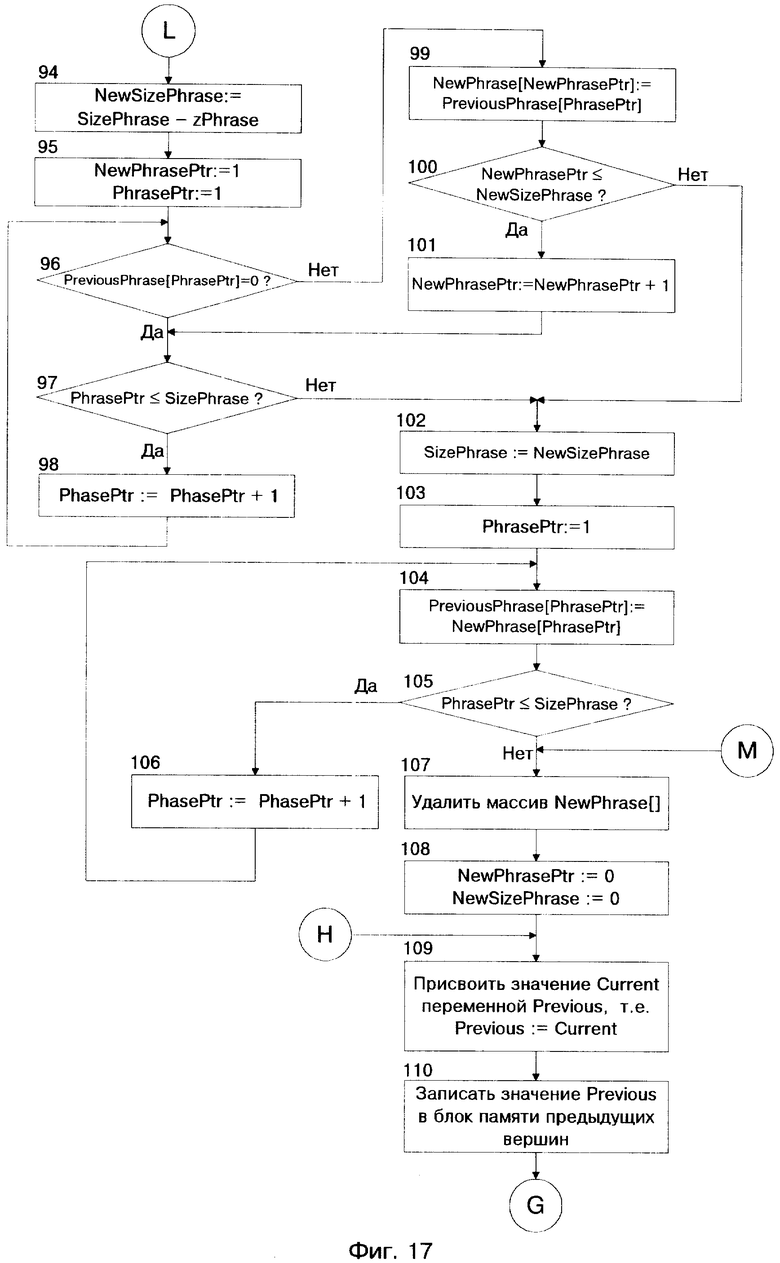
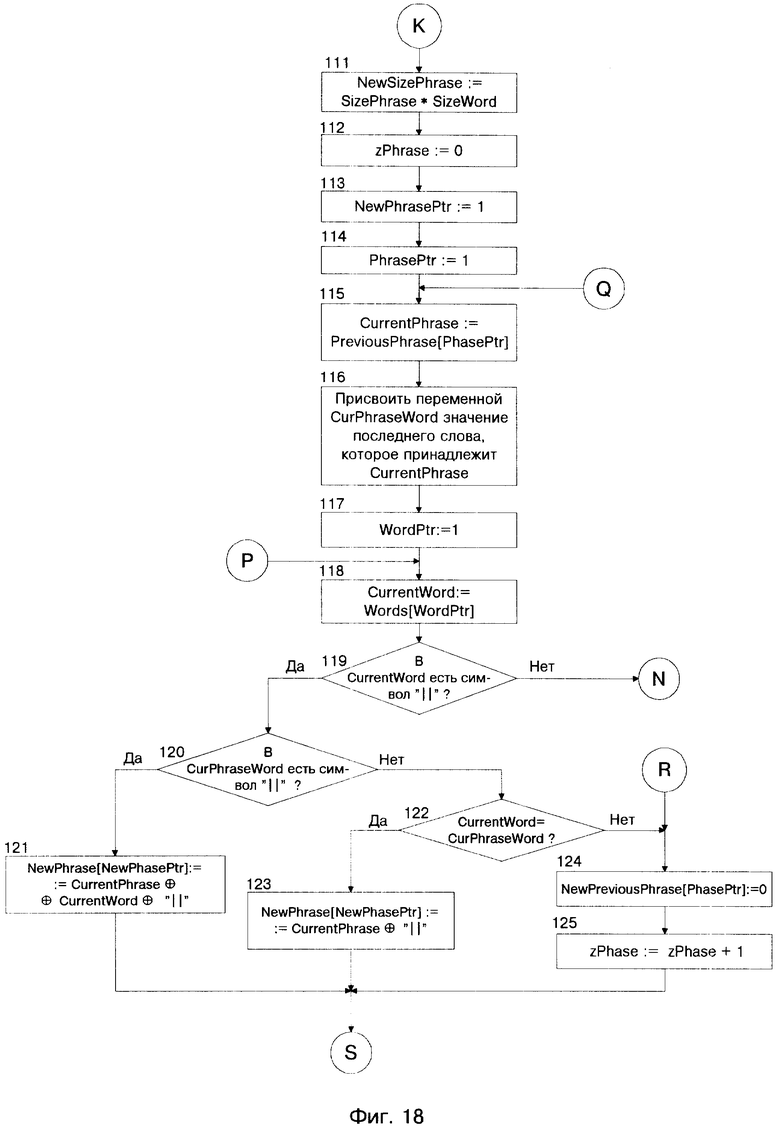
Описание системы лексической интерпретации слитной речи (СЛИСР) русского языка, реализующей предлагаемый способ включает в себя одиннадцать фигур; фиг. 9 - структурная схема системы, фиг. 10 - структурная схема блока акустического анализатора, фиг. 11 - структурная схема блока лексического анализатора, фиг. 12 - фиг. 19 - блок-схема алгоритма работы СЛИСР.
Система лексической интерпретации слитной речи, использующая СЛД и структуру данных, изображенную на фиг. 8, представлена на фиг. 9. Она состоит из акустического анализатора, представленного блоком 1, и лексического анализатора, представленного блоком 2. Система позволяет формировать варианты возможных последовательностей слов, соответствующие произнесенному высказыванию на основе информации о последовательности выявленных акустических состояний.
Блок 1 предназначен для определения акустических состояний в звуковых сигналах и содержит два входа и два выхода.
Блок 2 предназначен для определения слов из заданного словаря акустически схожих с произнесенными и содержит два входа и два выхода. Вход 1 блока 1 соединен с микрофоном, а вход 2 соединен с выходом 2 блока 2. Выходы 1 и 2 блока 1 соединены со входами 1 и 2 блока 2 соответственно. С выхода 1 блока 2 получают искомый результат.
Блок 1, структурная схема которого представлена на фиг. 10, содержит: блок 3 - предварительной обработки, блок 4 - частотный анализатор спектра, блок 5 - буфер памяти значений спектра, блок 6 - вычислитель весового коэффициента η , блок 7 - вычислитель текущего акустического состояния VТ.
Блок 2, структурная схема которого представлена на фиг. 11, содержит: блок 8 - определитель ожидаемых акустических состояний, блок 9 - сравнения с эталоном, блок 10 - блок памяти 1, блок 11 - блок управления, блок 12 - блок выбора оптимальной оценки и маркировки вершин, блок 13 - блок хранения базы данных граничных вершин, блок 14 - блок проверки, блок 15 - блок памяти 2, блок 16 - блок хранения базы данных локальных вершин, блок 17 - блок хранения базы данных акустических состояний, блок 18 - блок хранения базы данных слов, блок 19 - формирователь лексических гипотез, блок 20 - блок памяти 3, блок 21 - блок вывода.
Блок 3 предназначен для оцифровки и фильтрации акустических сигналов.
Блок 8 предназначен для приема данных с блока 6, блока 11 и блока 16, организации запросов данных в блоках 13 и 16, а также выдачи данных, связанных с определением следующих возможных вершин с их номерами и параметрами АС.
Блок 9 предназначен для вычисления оценки степени совпадения между акустическими характеристиками ожидаемых эталонов АС и текущего участка речевого сигнала.
Блок 10 предназначен для временной записи, хранения, чтения и передачи оценок степени совпадения между акустическими характеристиками ожидаемых эталонов АС и текущего участка речевого сигнала, а также вершин, к которым они принадлежат.
Блок 11 предназначен для формирования запросов данных о вершинах с помощью блоков 8, 12, 14, 15, 19, а также управления блоками 10, 15, 20.
Блок 12 предназначен для выбора наилучшей оценки степени совпадения, с соответствующими номерами вершин, имеющихся блоке 10, а также маркирования вершин.
Блок 14 предназначен для проверки вершин на содержание не нулевых значений двоичных кодов "паузы" и "границы".
Блок 15 предназначен для временной записи, хранения, чтения и передачи возможных вершин с акустическими состояниями, подобными текущему участку речевого сигнала.
Блок 19 предназначен для формирования вариантов последовательностей слов акустически подобных произнесенному высказыванию.
Блок 20 предназначен для временной записи, хранения, чтения и передачи вариантов последовательностей слов (лексических гипотез) акустически подобных произнесенному высказыванию. \
Блок 21 предназначен для вывода результатов лексической интерпретации слитной речи.
Работа системы лексической интерпретации слитной речи осуществляется следующим образом (см. фиг. 9, 10). Входное высказывание с микрофона поступает на вход блока 3 акустического анализатора 1. Блок 3 преобразует входные сигналы в цифровую форму и выполняет их фильтрацию. Далее сигналы с выхода блока 3 подаются на вход блока 4 для выделения частотного спектра. Сигналы с выхода блока 4 подаются на вход блока 5. С выхода блока 5 сигналы поступают на вход 1 блока 6 и вход 1 блока 7.
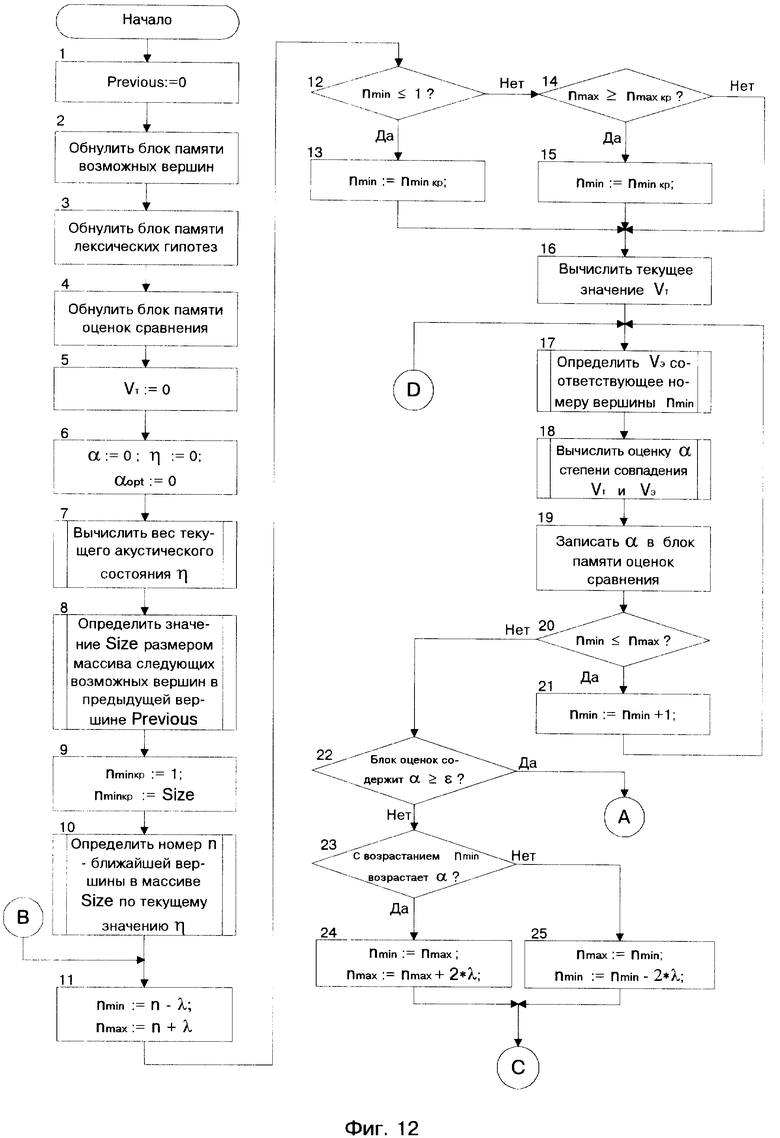
Блок 6 вычисляет весовой коэффициент η , применяемый для поиска входной вершины первого столбца СЛД (см. фиг. 11, фиг. 7). Вычисленное значение весового коэффициента с выхода 2 блока 6 поступает на вход 2 блока 8. С выхода 2 блока 8 значение весового коэффициента η поступает на вход 3 блока 16. С выхода 3 блока 16 значение номера ближайшей вершины поступает на вход 3 блока 8. Далее блок 8 определяет номера вершин nmin и nmax, обозначающие соответственно верхнюю и нижнюю границы области, в которой необходимо проводить поиск начального акустического состояния. После этого блок 8 формирует запросы данных о вершинах, номера которых принадлежат области поиска начального акустического состояния и посылает их со своего выхода 2 на вход 3 блока 16. По принятым номерам вершин блок 16 определяет соответствующие номера эталонных акустических состояний VЭ, их имена и значения параметров АС. Блок 16 со своего выхода 3 подает эти данные на вход 3 блока 8. На выходе 4 блока 8 формируется сигнал разрешения, поступающий на вход 2 блока 6. В свою очередь блок 6 на выходе 1 формирует сигнал разрешения, поступающий на вход 2 блока 7.
Блок 7 вычисляет текущие значения параметров АС состояния VТ и со своего выхода подает их на вход 1 блока 9. Одновременно с этим блок 8, определив значения параметров ожидаемых эталонов АС - VЭ, вместе с соответствующими номерами вершин, со своего выхода 1 последовательно, начиная с VЭ с номером вершины nmin подает их на вход 2 блока 9.
Блок 9 вычисляет оценку α-степени совпадения текущего и эталонного акустического состояния. Значение этой оценки, вместе с соответствующим номером вершины, с выхода блока 9 поступает на вход 1 блока 10.
Блок 11 проверяет содержание блока 10 на достижение верхней границы области поиска nmax. Если nmax не достигнута, то происходит дальнейшее сравнение ожидаемых АС с текущим. Если nmax достигнута, то с выхода 6 блока 11 передаются данные, содержащиеся в блоке 10, которые поступают на вход блока 12.
Блок 12 проверяет данные, поступающие с блока 10 через блок 11 на наличие оценки α, превышающей пороговое значение ε. Если таковой оценки не найдено, то блок 12 анализирует возрастание (убывание) α с возрастанием nmin. После этого на выходе 2 блока 12 формируются сигналы, изменяющие границы области поиска, которые поступают на вход 5 блока 11. Блок 11, изменив границы поиска на своем выходе 1, формирует сигнал управления, который поступает на вход 2 блока 10 и производит обнуление содержимого блока 10. Одновременно на выходе 1 блока 11 формируется сигнал, поступающий на вход 1 блока 8, который разрешает определение следующей возможной вершины. В случае, когда VЭ акустически подобных VТ блок 8 в блоке 16 не обнаружил, то блок 8 производит их поиск в блоке 13.
Если оценка α, превышающая пороговое значение ε не найдена и превышены ограничения на допустимую область поиска в блоке 13 и блоке 16, то блок 12 на выходе 1 формирует данные, определяющие VТ как предыдущее АС вершины с именем previous. В этом случае вершине с именем previous присваивается метка неизвестного АС. На выходе 2 блока 12 формируется сигнал, информирующий о неизвестном АС, который поступает на вход 5 блока 11. Блок 11 на выходе 5 формирует управляющий сигнал, который поступает на вход 2 блока 15. По этому сигналу блок 15 на входе 1 принимает информацию, поступающую с выхода 1 блока 12 через блок 14.
Блок 11 с выхода 5 посылает сигнал на вход 2 блока 15. Блок 11 на входе 3 принимает данные с выхода 2 блока 15. Далее блок 11 производит проверку этих данных на содержание вершины с именем previous.
Если вершина с именем previous не содержит информацию о VЭ акустически подобном VТ, то блок 11 на выходе 2, подготовив сигнал, по которому будет производиться обработка следующего (нового) участка РС, подает его на вход 1 блока 8. В этом случае на выходе 4 блока 8 формируется сигнал разрешения, поступающий на вход 2 блока 6. Блок 6 с выхода 2, вычислив весовой коэффициент η , подает его на вход 2 блока 8. С выхода 2 блока 8 значение весового коэффициента η поступает на вход 3 блока 16. С выхода 3 блока 16 на вход 3 блока 8 поступает значение номера ближайшей вершины. Далее блок 8 определяет номера вершин nmin и nmax, обозначающие соответственно верхнюю и нижнюю границы области, в которой необходимо проводить поиск начального акустического состояния. После этого блок 8 формирует запросы данных о вершинах, номера которых принадлежат области поиска начального акустического состояния и посылает их со своего выхода 2 на вход 3 блока 16. По принятым номерам вершин блок 16 определяет соответствующие номера эталонных акустических состояний - VЭ, их имена и значения параметров АС. Блок 16 со своего выхода 3 подает эти данные на вход 3 блока 8. На выходе 4 блока 8 формируется сигнал разрешения, поступающий на вход 2 блока 6. В свою очередь блок 6 на выходе 1 формирует сигнал разрешения, поступающий на вход 2 блока 7.
Блок 7 вычисляет текущие значения параметров АС состояния VТ и со своего выхода подает их на вход 1 блока 9. Одновременно с этим блок 8, определив значения параметров ожидаемых эталонов АС - VЭ, вместе с соответствующими номерами вершин, со своего выхода 1 последовательно, начиная с VЭ с номером вершины nmin подает их на вход 2 блока 9.
Если вершина с именем previous содержит информацию о VЭ акустически подобном VТ, то блок 11 на выходе 2, подготовив сигнал, по которому будет производиться обработка следующего (нового) участка РС, подает его на вход 1 блока 8. В этом случае на выходе 4 блока 8 формируется сигнал разрешения, поступающий на вход 2 блока 6. В свою очередь блок 6 на выходе 1 формирует сигнал разрешения, поступающий на вход 2 блока 7.
Одновременно блок 7 вычисляет текущее значение акустического состояния VТ, а блок 8 определяет вершины с ожидаемыми VЭ, следующими за вершиной previous в блоке 16. Значения параметров VЭ вместе с соответствующими номерами вершин с выхода 1 блока 8 последовательно поступают на вход 2 блока 9, а значение VТ с выхода блока 6 поступает на вход 1 блока 9.
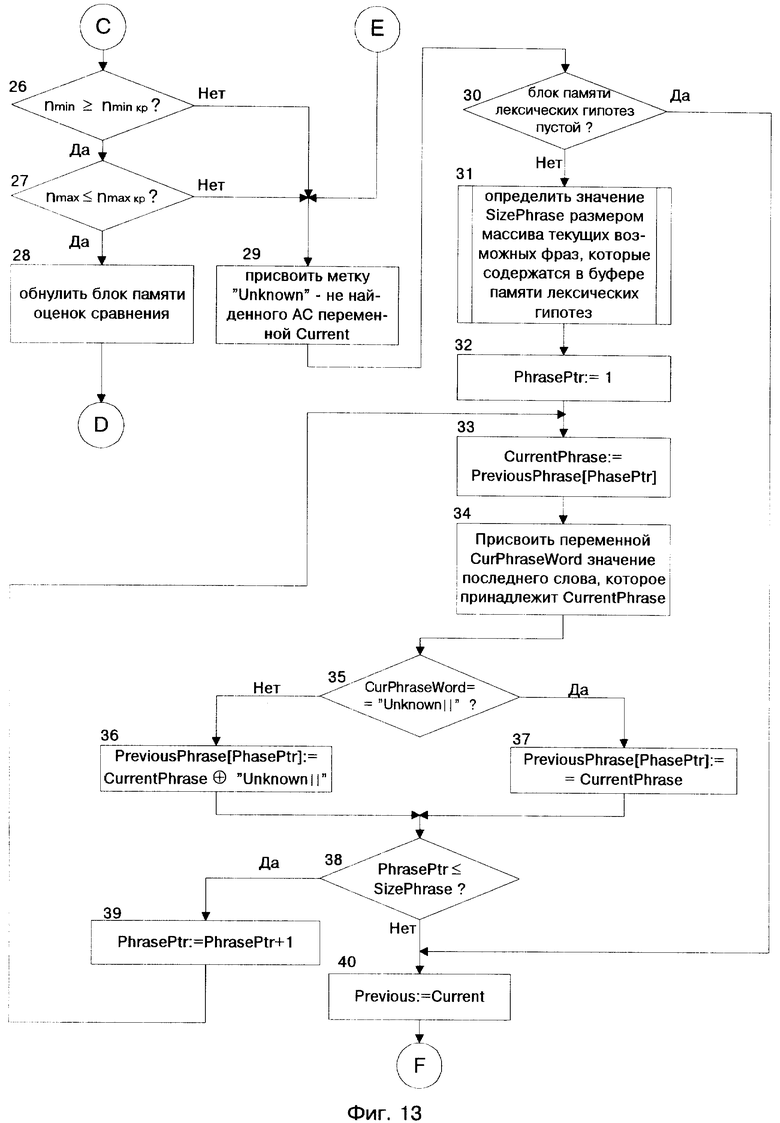
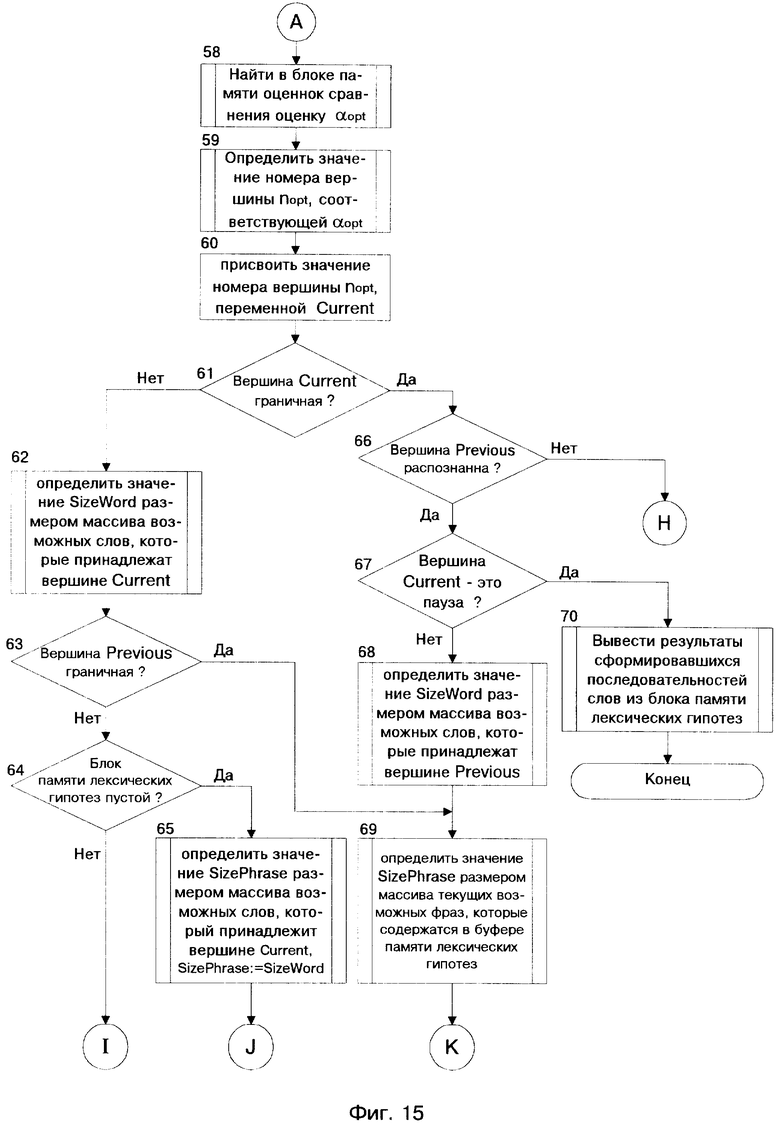
Если блок 12, проверив содержание блока 10, обнаружил оценку α, превышающую пороговое значение ε, то блок 12 принимает значение α в качестве оптимальной - αopt. В этом случае блок 12 переопределяет номер вершины, соответствующий αopt как оптимальный - nopt, маркирует значение nopt именем current и передает его с выхода 1 на вход 1 блока 14. Блок 14 на выходе 2 формирует запрос двоичных кодов вершины и подает его на вход 2 блока 16. С выхода 1 блока 16 на вход 2 блока 14 поступают значение номера вершины, по которому проводился запрос, а также значения двоичных кодов "паузы" и "границы". Блок 14 проверяет значения двоичных кодов у поступившей вершины. После этого на выходе 3 блока 14 формируется сигнал, поступающий на вход 4 блока 11, по которому блок 11 с выхода 5 подает на вход 2 блока 15 сигнал, разрешающий блоку 15 на входе 1 принять данные с выхода 1 блока 14. Блок 19 на своем входе 2 производит чтение данных с выхода 1 блока 15.
Если вершина current - не пауза, то блок 19 с выхода 2 подает значение номера вершины на вход 1 блока 16, по которому блок 16 с выхода 2 посылает на вход 3 блока 19 номер вершины, а также список слов с соответствующими признаками их окончания, связанный с этим номером. Блок 19 на основе принятых слов формирует массив (список) соответствующих последовательностей, каждой из которой присваивает имя PreviousPhrase и соответствующий этому имени номер. Далее блок 19 с выхода 1 записывает сформированный массив последовательностей слов, с соответствующими именами и номерами на вход 1 блока 20. На выходе 3 блока 19 формируется сигнал, поступающий на вход 2 блока 11, по которому блок 11 присваивает значение вершины с именем current переменной previous и с выхода 5 производит его запись в блок 15. После этого блок 11 на выходе 2, подготовив сигнал, по которому будет производиться обработка следующего (нового) участка РС, подает его на вход 1 блока 8.
Если вершина current - пауза, то блок 19 с выхода 3 подает на вход 2 блока 11 сигнал, по которому блок 11 на выходе 3 формирует разрешающий сигнал и подает его на вход 1 блока 21. По этому сигналу блок 21 производит чтение данных с выхода блока 20 и выводит результаты вариантов возможных последовательностей слов, акустически схожих с произнесенным высказыванием.
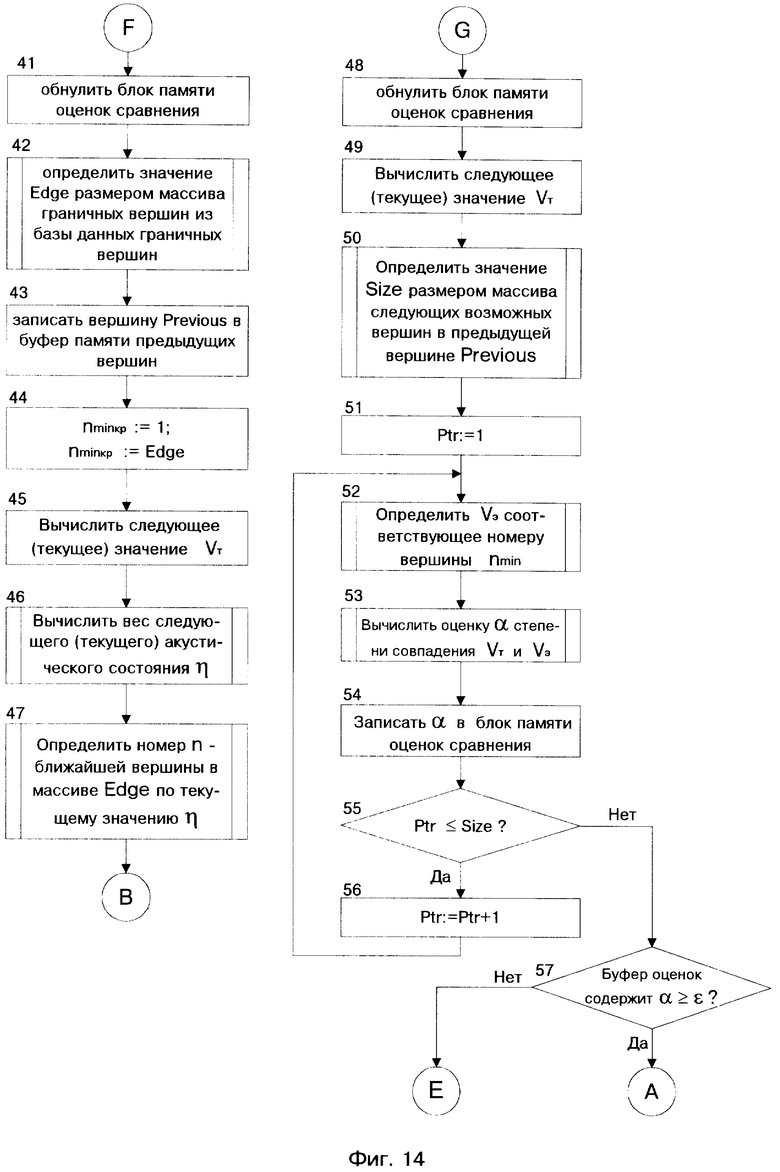
Более подробный алгоритм работы СЛИСР представлен блок-схемой на фиг. 12 - фиг. 19. Условные обозначения в представленном алгоритме приведены на страницах 29 - 31.
Предлагаемая СЛИСР, использующая СЛД, по своей сути позволяет отслеживать несколько акустически схожих траекторий (последовательностей вершин), из которых можно выбирать наиболее оптимальную. Для этого необходимо модернизировать лексический анализатор путем введения в него блока выбора траектории.
Система ведет поиск, перебирая все допустимые вершины (либо только в выделенной области), содержащие АС, которые могут следовать за начальной. Поиск оптимальной последовательности АС осуществляется в пределах некоторой части СЛД. В связи с тем, что на каждом шаге обработки входных данных перебирается несколько возможных вариантов АС, отпадает необходимость возврата назад.
Преимущества предлагаемой системы состоят в том, что она позволяет с более высоким быстродействием и более высокой вероятностью проводить лексическую интерпретацию слитной речи.
Блок 3 представляет собой стандартный аналого-цифровой преобразователь для ввода акустических сигналов в ЭВМ и набор фильтров, который может быть реализован как аппаратно, так и программно. Блоки 5, 10, 13, 15, 16, 17, 18, 20 - являются блоками памяти и могут быть выполнены, как, например, в виде запоминающих: устройств, плат, узлов и т.д. и в зависимости от объема используемых слов могут быть реализованы на основе больших, средних и малых интегральных схем, с соответствующей им периферией или на основе накопителей на магнето-оптических, электронных дисках, и т.д. с соответствующей им периферией. Блоки 4, 6 - 9, 11, 12, 14, 19 могут быть реализованы как аппаратно, так и программно. Программная реализация этих блоков представлена в виде блок-схемы алгоритма работы на фиг. 12 - 19. Блок 21 может быть реализован в виде устройства с визуальным отображением информации (например, дисплей), с соответствующей ему периферией или в виде интерфейса, обеспечивающего логическое или физическое взаимодействие СЛИСР и системы: распознавания или понимания речи, управления технологическим оборудованием или роботом, средствами вычислительной техники, автоматического речевого перевода и др.
Условные обозначения
Previous - предыдущая вершина;
Current - текущая вершина;
Size - размер массива (списка) следующих возможных вершин;
Edge - размер массива (списка) граничных вершин;
SizeWord - размер массива (списка) ожидаемых слов;
SizePhrase - размер массива (списка) ожидаемых последовательностей слов;
NewSizePhrase - размер нового массива (списка)ожидаемых последовательностей слов;
Words[] - массив (список) ожидаемых слов;
PreviousPhrase[] - массив (список) предыдущих последовательностей слов;
NewPhrase[] - новый массив (список) ожидаемых последовательностей слов;
zPhrase - счетчик нулевых последовательностей слов;
CurrentPhrase - текущая последовательностей слов;
CurPhraseWord - последнее слово из последовательности CurrentPhrase;
Ptr - индикатор текущей вершины массива следующих возможных вершин, исходящих из предыдущей вершины Previous;
WordPtr - указатель текущего (ожидаемого) слова;
PhrasePtr - указатель текущей (ожидаемой) последовательности слов;
NewPhrasePrt - указатель новой (ожидаемой) последовательности слов;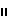 - символ окончания слова;
- символ окончания слова;
⊕ - символ конкатенации (склейки);
Unknown - метка не найденного АС;
η - весовой коэффициент;
n - номер ближайшей вершины;
Vт - текущее АС;
Vэ - эталонное АС;
λ - коэффициент, определяющий смещение границ области поиска;
nmin - номер вершины, обозначающий нижнюю границу области поиска; - номер вершины, обозначающий критическое значение нижней границы области поиска;
- номер вершины, обозначающий критическое значение нижней границы области поиска;
nmax - номер вершины, обозначающий верхнюю границу области поиска; - номер вершины, обозначающий критическое значение верхней границы области поиска;
- номер вершины, обозначающий критическое значение верхней границы области поиска;
α - оценка степени совпадения текущего и эталонного акустического состояния;
ε - пороговое значение оценки степени совпадения текущего и эталонного акустического состояния;
αopt - оптимальное значение оценки степени совпадения текущего и эталонного акустического состояния;
nopt - номер вершины, соответствующий αopt
Библиографические данные
1. Lesser V.R., Fennel R.D., Erman L.D., Reddy D.R., Organization of the HEARSAY II Speech Understanding System, IEEE Trans. ASSP, 23, 1, pp. 11-24, 1975.
2. Baker J. K., The DRAGON System - An overview, IEEE Trans. ASSP, 23, No. 1. February, 1975, pp. 24 - 29.
3. Klowstad J. W. , Mondshein L. F., The CASPERS Linguistic Analysys System, IEEE Trans. ASSP, 23, No. 1. February, 1975, pp. 118 - 123.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ РАСПОЗНАВАНИЯ СЛОВ В СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1996 |
|
RU2101782C1 |
| СПОСОБ РАСПОЗНАВАНИЯ СЛОВ В СЛИТНОЙ РЕЧИ | 2005 |
|
RU2297676C2 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ НА ОСНОВЕ ДВУХУРОВНЕВОГО МОРФОФОНЕМНОГО ПРЕФИКСНОГО ГРАФА | 2015 |
|
RU2597498C1 |
| СПОСОБ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКИ ТЕКСТА | 2007 |
|
RU2386178C2 |
| СИСТЕМА И СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ | 2011 |
|
RU2466468C1 |
| СИСТЕМА И СПОСОБ ПЕРЕВОДА РЕЧЕВОГО СИГНАЛА В ТРАНСКРИПЦИОННОЕ ПРЕДСТАВЛЕНИЕ С МЕТАДАННЫМИ | 2014 |
|
RU2589851C2 |
| КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ ЧТЕНИЯ ПЛОСКОПЕЧАТНОГО ТЕКСТА | 1996 |
|
RU2113726C1 |
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ТЕКСТА И КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ РЕАЛИЗАЦИИ ЭТОГО СПОСОБА | 2011 |
|
RU2460154C1 |
| СПОСОБ СИНТЕЗА РЕЧИ | 2009 |
|
RU2421827C2 |
| Способ дикторонезависимого распознавания фонемы в речевом сигнале | 2021 |
|
RU2763124C1 |




Изобретение относится к автоматике и вычислительной технике и может быть использовано в системах понимания речи, системах управления технологическим оборудованием, роботами, средствами вычислительной техники, автоматического речевого перевода, в справочных системах и др. Суть способа состоит в том, что, минуя уровень фонемического преобразования, при помощи сети лексического декодирования, строят гипотезы о возможном начале, продолжении, либо конце слов в речевом высказывании и составляют наиболее вероятные последовательности эталонных слов, соответствующие произнесенному речевому высказыванию. При этом произносимые слова могут непрерывно следовать друг за другом в любом порядке, либо разделяться паузами, либо словами, не принадлежащими к заданному набору слов. Предлагаемая сеть лексического декодирования представляет собой интегрированную базу данных, содержащую орфографические представления заданного набора слов, ожидаемые акустические представления заданного набора слов в виде последовательностей эталонных значений параметров речевого сигнала, определяющих акустические состояния и объединяющую фонетическую транскрипцию, фонологические правила и лексику для заданного набора слов. Система, реализующая предлагаемый способ, содержит последовательно соединенные акустический и лексический анализаторы. Акустический анализатор включает в себя блок предварительной обработки, частотный анализатор спектра, буфер хранения значений спектра, вычислители весового коэффициента и текущего акустического состояния. А лексический анализатор - определитель ожидаемых акустических состояний, блок сравнения с эталоном, блок памяти оценок сравнения, блок управления, блок выбора оптимальной оценки и маркировки вершин, блок хранения базы данных граничных вершин, блок проверки, блок памяти возможных вершин, блок хранения базы данных локальных вершин, блок хранения базы данных акустических состояний, блок хранения базы данных слов, формирователь лексических гипотез, блок памяти лексических гипотез, блок вывода. Технический результат - повышение точности и быстродействия лексической интерпретации слитной речи русского языка. 2 с.п. ф-лы, 19 ил.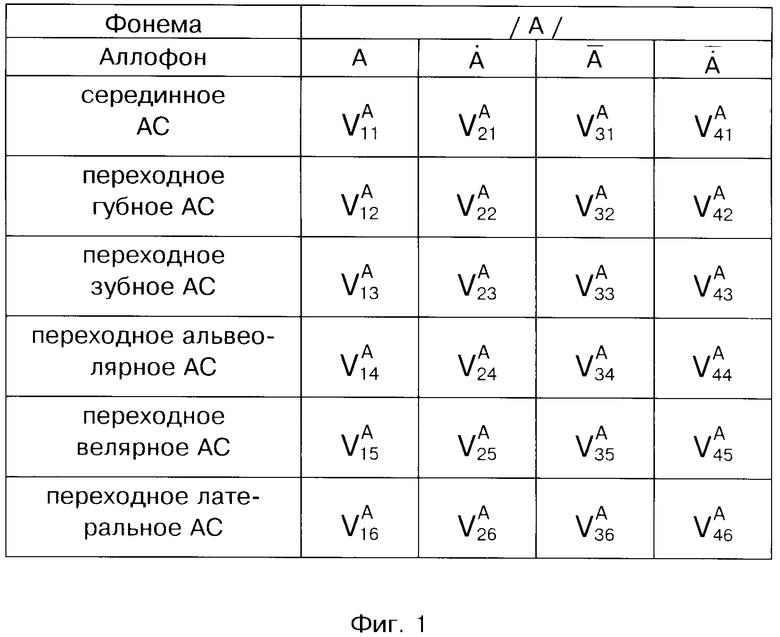
| Leser V.R., Fennel R.D., Erman L.D., Reddy D.R | |||
| Organization of the HEARSAY II, Speech Understanding System, IEEE Trans, ASSP, 23, 1, p.p.11 - 24, 1975 | |||
| Baker I.K., The DRAGON System - An Overtien, IEEE Trans, ASSP, 23, N 1, February, 1975, pp | |||
| Пишущая машина для тюркско-арабского шрифта | 1922 |
|
SU24A1 |
| Klowstad J.W., Mondshein L.F., The CASPERS Linguistic Analysys System, IEEE Trans, ASSP, 23, N 1, February, 1975, pp.118 - 123 | |||
| US 4712243 A, 08.12.87 | |||
| US 4625327 A, 25.11.86 | |||
| US 4624011 A, 18.11.86 | |||
| US 4624010 A, 18.11.86 | |||
| US 4620316 A, 28.10.86 | |||
| US 4618983 A, 21.10.96 | |||
| Торфодобывающая машина с вращающимся измельчающим орудием | 1922 |
|
SU87A1 |
| Способ смысловой интерпретации слитно произносимых слов | 1985 |
|
SU1408449A1 |
| Способ распознавания слитно произнесенных слов и устройство для его осуществления | 1983 |
|
SU1159059A1 |
