Область техники, к которой относится изобретение
Настоящее изобретение относится к компьютерной технике и, более конкретно, к сетевому распределению множества элементов данных в виде множества ответов с контролем выбора компьютерной системы для управления контекстной информацией, используемой для передачи данных.
Уровень техники
Компьютерная техника преобразила нашу работу и игры. В настоящее время используются самые разные формы компьютерных систем, включая настольные компьютеры, портативные компьютеры, планшетные компьютеры, карманные компьютеры (КПК, PDA), бытовые устройства и т.п. В самой элементарной форме, компьютерная система включает системную память и один или несколько процессоров. Процессор может выполнять программное обеспечение, записанное в системной памяти, что обеспечивает выполнение другими аппаратными средствами компьютерной системы требуемых функций.
Сетевые технологии позволяют обеспечивать обмен информацией между компьютерными системами даже на огромных расстояниях, что расширяет функции компьютера. Например, сетевые технологии обеспечивают использование компьютеров для выполнения таких функций, как обработка электронной почты, просмотр сетевых страниц, передача файлов, мгновенная передача сообщений, электронный обмен данными через доску объявлений, совместная работа по сети и т.п.
Некоторые варианты использования сети предполагают передачу большого количества информации. Например, может потребоваться загрузить базу данных, которая имеет размер несколько терабайт. Даже с использованием сети с широкой полосой пропускания, такая загрузка может занять несколько дней. Даже в чрезвычайно надежном сетевом окружении, существует значительная вероятность, что сетевое соединение нельзя будет поддерживать в течение всего этого периода. При потере соединения часто всю передачу данных нужно будет выполнить повторно с самого начала.
Один обычный способ обеспечения надежности и эффективности передачи большого количества данных состоит в передаче данных по частям в отдельных электронных сообщениях. Иногда такая передача может быть выполнена автоматически в ответ на один запрос. Однако для обеспечения некоторой степени контроля со стороны получателя данных над процессом передачи данных, получатель данных также может передавать запрос для каждого электронного сообщения, содержащего часть передаваемых данных. Например, сетевой сайт содержит большое количество связанных с ним данных, включающих сетевые страницы, изображения, звуковые файлы, другие мультимедийные данные, сценарии или подобную информацию. Сетевой браузер часто посылает отдельные запросы для каждого из таких элементов данных. Такая технология называется ниже "технологией перечисления, управляемого запросами", в которой наборы элементов данных "перечисляют", по одной части единовременно, передаваемой в отдельных ответах на отдельные запросы.
Для того чтобы соответствовать ожиданиям компьютерной системы - получателя данных, важно обеспечить для каждого запроса правильное понимание его контекста. Например, предположим, что следует передать всего пятьдесят элементов данных, по десять элементов данных одновременно за сеанс связи в виде пяти ответов на пять различных запросов. При передаче первого запроса, важно, чтобы источник данных не только мог идентифицировать эти пятьдесят элементов данных, но также мог определить, что это первый запрос. Таким образом, источник данных определяет, что нужно передать первые десять элементов данных. При приеме второго запроса важно, чтобы источник данных установил, что предыдущие десять элементов данных уже были отправлены. В противном случае, источник данных снова передаст первые десять элементов. Для этого источник данных должен иметь соответствующий контекст для запроса в технологиях перечисления, управляемого запросами. В данном описании и в формуле изобретения "контекст" для запроса в сеансе обмена данными, в соответствии с технологией перечисления, управляемого запросами, определяется как любая информация, необходимая или используемая источником данных, по которой он определяет, какую часть элементов данных следует передать в ответ на запрос.
Обычно обеспечивается статичная ответственность за поддержание такой контекстной информации. Например, источник данных может сохранять информацию о сеансе для передачи большого объема данных в конкретный получатель данных. Такая информация о сеансе может включить контекстную информацию. В других обычных технологиях контекстную информацию содержит получатель данных. Источник данных предоставляет контекстную информацию в получатель данных. Получатель данных затем включает эту контекстную информацию в следующий запрос на передачу следующей части подборки элементов данных. Независимо от того какая система управляет контекстной информацией, ответственность за управление контекстной информацией задается в момент инициации сеанса передачи данных. Кроме того, ответственность за управление контекстом обычно не переносится в течение длительности сеанса передачи данных.
Определение предпочтительности содержания контекстной информации в источнике данных или в получателе данных зависит от окружающих обстоятельств. Многие такие окружающие обстоятельства являются чрезвычайно динамичными. В соответствии с этим, предпочтительно использовать механизмы, которые обеспечивают для компьютерной системы - источника данных большую гибкость и более динамичное управление по разделению работы между источником данных и получателем данных при управлении контекстной информацией для сеанса передачи данных.
Раскрытие изобретения
Описанные выше проблемы, связанные с известным уровнем техники, могут быть решены с использованием принципов настоящего изобретения, которые направлены на механизм передачи компьютерной системой - источником данных запрашиваемых элементов данных во время сеанса перечисления, управляемого запросами, в котором части запрашиваемых элементов данных передают в ответ на отдельные запросы, поступающие из компьютерной системы - получателя данных. Такой механизм обеспечивает для источника данных возможность управления количеством контекстной информации, сохраняемой между сообщениями в источнике информации, и количеством контекстной информации, передаваемой в получатель данных.
При приеме первого запроса на передачу элементов данных в получатель данных, источник данных идентифицирует элементы данных, предназначенные для передачи в получатель данных. Такая идентификация может быть основана, по меньшей мере, частично, на информации, содержащейся в первом запросе. Источник данных затем идентифицирует первую часть элементов данных, предназначенных для передачи в первом ответе, соответствующем первому запросу.
Кроме того, идентифицируют контекстную информацию, которая отражает, что первая часть информации была передана. Источник данных затем определяет, какое количество контекста должно быть представлено в компьютерную систему - получатель данных. Источник данных затем составляет первый ответ, который включает первую часть элементов данных. Источник данных также передает в компьютерную систему - получатель такое количество контекстной информации, которое источник информации считает соответствующим.
Получатель данных включает такую первую переданную контекстную информацию во второй запрос для получения следующей части элементов данных. При этом источнику данных не нужно сохранять эту первую представленную контекстную информацию между запросами. Вместо этого источник данных считывает первую представленную контекстную информацию из второго запроса. Это позволяет источнику данных идентифицировать вторую часть элементов данных для передачи в получатель данных. Источник данных затем генерирует вторую контекстную информацию, которая должна быть включена во второй ответ.
Такая переданная второй контекстная информация может иметь такой же или другой объем, что и предыдущая переданная первой контекстная информация, в зависимости от существующих после этого обстоятельств. Например, переданная первой контекстная информация может включать всю контекстную информацию. Если получатель данных быстро передает второй запрос, тогда следующий ответ может содержать меньше или может не включать контекстную информацию, поскольку очевидно, что получатель данных активно передает запросы в быстрой последовательности, что означает, что источнику данных не нужно будет сохранять контекстную информацию в течение длительного времени.
В соответствии с этим, принципы настоящего изобретения позволяют обеспечить значительную гибкость источника данных при динамической регулировке его роли в управлении контекстом, в зависимости от возникающих впоследствии обстоятельств. Дополнительные свойства и преимущества изобретения будут изложены в следующем описании и частично будут очевидны из описания или их можно будет понять из применения изобретения на практике. Свойства и преимущества изобретения могут быть реализованы и получены с помощью инструментов и комбинаций, в частности, указанных в приложенной формуле изобретения. Эти и другие свойства настоящего изобретения будут более понятны из следующего описания и прилагаемой формулы изобретения или их можно будет понять из применения изобретения на практике, как описано ниже.
Краткое описание чертежей
Для описания способа, с помощью которого могут быть получены указанные выше и другие преимущества и свойства изобретения, более конкретное описание изобретения, кратко изложенное выше, будет предоставлено со ссылкой на конкретные варианты его выполнения, которые изображены на прилагаемых чертежах. Следует понимать, что на этих чертежах изображены только типичные варианты выполнения изобретения и что их, поэтому, не следует рассматривать как ограничение его объема, при этом изобретение будет описано и будет поясняться с дополнительным уточнением и подробностями с использованием прилагаемых чертежей, на которых:
на фигуре 1 представлена соответствующая вычислительная система, с помощью которой можно воплотить свойства настоящего изобретения;
на фигуре 2 показано сетевое окружение, в котором вычислительная система - источник данных передает множество элементов данных в вычислительную систему - получатель данных с использованием обмена сообщениями перечисления, управляемого запросами, в соответствии с принципами настоящего изобретения;
на фигуре 3 показана схема последовательности выполнения операций способа работы вычислительной системы - источника данных при передаче множества элементов данных в вычислительную систему - получатель данных, обеспечивая возможность источнику данных контролировать баланс управления контекстом, в соответствии с принципами настоящего изобретения;
на фигуре 4 показана схема последовательности выполнения операций способа работы получателя данных при взаимодействии с вычислительной системой - получателем данных, для поддержки вычислительной системы - источника данных, обеспечивающей контроль над балансом ответственности управления контекстом между двумя вычислительными системами.
Осуществление изобретения
Принципы настоящего изобретения относятся к механизму работы вычислительной системы - источника данных, обеспечивающему передачу запрашиваемых элементов данных в сеансе перечисления, управляемого запросами, в котором части запрашиваемых элементов данных передают в ответ на отдельные запросы, поступающие из вычислительной системы - получателя данных. Этот механизм обеспечивает для источника данных возможность управления степенью, в которой контекстная информация между сообщениями сохраняется в источнике данных, и степенью, в которой контекстная информация предоставляется получателю данных.
Как показано на чертежах, на которых одинаковыми ссылочными позициями обозначены одинаковые элементы, изобретение представлено как выполненное в соответствующей вычислительной среде. Следующее описание основано на представленных вариантах выполнения изобретения, и его не следует рассматривать как ограничение изобретения в отношении альтернативных вариантов выполнения, которые явно не описаны здесь.
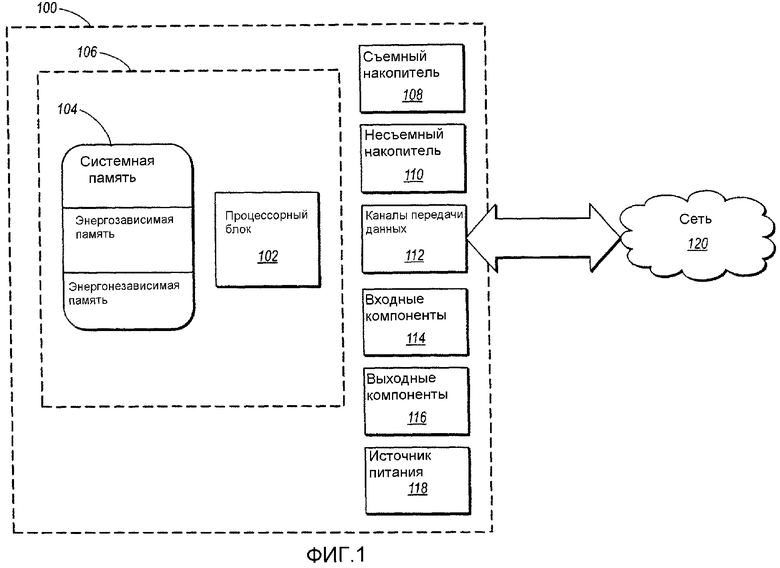
В приведенном ниже описании изобретение описано со ссылкой на действия и символические представления операций, выполняемых одним или больше компьютерами, если только не будет указано другое. При этом следует понимать, что такие действия и операции, которые иногда обозначены как выполняемые компьютером, включают манипуляцию, выполняемую процессорным блоком компьютера над электрическими сигналами, представляющими данные в структурированной форме. Такие манипуляции преобразуют или содержат данные в определенных местах в системе памяти компьютера, которые изменяют конфигурацию или по-другому изменяют работу компьютера так, как хорошо понятно для специалистов в данной области техники. Структуры данных, в которых содержатся данные, представляют собой физические места расположения в памяти, которые имеют конкретные свойства, определяемые форматом данных. Однако, хотя изобретение описано в указанном выше контексте, он не предназначен для ограничения, и для специалистов в данной области техники будет понятно, что ряд действий и операций, описанных ниже, также может быть выполнен в виде аппаратных средств. На фигуре 1 показана схема примера архитектуры компьютера, пригодного для использования с такими устройствами.
Для целей описания представленная архитектура является всего лишь одним примером возможной среды и не предназначена для какого-либо ограничения объема использования или функций изобретения. Также компьютерную систему не следует интерпретировать как зависимую от какого-либо из компонентов, представленных на фигуре 1, или их комбинации, или от требований, связанных с ними.
Изобретение может работать с различными другими средами или конфигурациями как предназначенными для вычислений или передачи данных общего назначения, так и специализированными. Примеры хорошо известных вычислительных систем, сред и конфигураций, пригодных для использования с изобретением, включают без ограничений мобильные телефоны, карманные компьютеры, персональные компьютеры, серверы, многопроцессорные системы, системы на основе микропроцессора, миникомпьютеры, главные компьютеры и распределенные вычислительные среды, которые включают любые из описанных выше систем или устройств.
В самой основной конфигурации компьютерная система 100 обычно включает, по меньшей мере, один блок 102 процессора и память 104. Память 104 может быть энергозависимой (такой, как ОЗУ), энергонезависимой (такой, как ПЗУ, память типа флэш и т.д.) или может представлять собой некоторую комбинацию этих двух видов памяти. Такая наиболее общая конфигурация представлена на фигуре 1 пунктирной линией 106.
Устройства-накопители информации могут иметь дополнительные свойства и функции. Например, они могут включать дополнительный накопитель (съемный и несъемный), включая без ограничений карты PCMCIA (МАПППК, Международная ассоциация производителей плат памяти для персональных компьютеров), магнитные и оптические диски и магнитную ленту. Такой дополнительный накопитель показан на фигуре 1 в виде съемного накопителя 108 и несъемного накопителя 110. Компьютерные носители информации включают энергозависимые и энергонезависимые, съемные и несъемные носители, выполненные с использованием любого способа или технологии накопления информации, таких как считываемые компьютером инструкции, структуры данных, программные модули или другие данные. Память 104, съемный накопитель 108 и несъемный накопитель 110 представляют собой примеры компьютерных носителей информации. Компьютерные носители информации включают без ограничений ОЗУ (RAM), ПЗУ (ROM), ЭСППЗУ (EEPROM), память типа флэш, запоминающие устройства, построенные с применением других технологий, CD-ROM, цифровые универсальные диски, другие оптические носители, магнитные кассеты, магнитную ленту, носитель на магнитном диске, другие магнитные устройства накопления информации и любые другие носители, которые можно использовать для записи требуемой информации и доступ к которым может осуществляться с помощью компьютерной системы.
Используемый здесь термин "модуль" или "компонент" может относиться к программным объектам или процедурам, которые выполняются в компьютерной системе. Разные компоненты, модули, механизмы и услуги, описанные здесь, могут быть выполнены как объекты или процессы, которые выполняются в вычислительной системе (например, в виде отдельных тредов). Хотя описанные здесь система и способы, предпочтительно, выполняются в виде программных средств, также возможно и предусматривается их выполнение в виде программных или аппаратных средств.
Вычислительная система 100 также может содержать каналы 112 передачи данных, которые позволяют главному компьютеру связываться с другими системами и устройствами, например, по сети 120. Каналы 112 связи представляют собой примеры среды передачи данных. Среда передачи данных обычно воплощает считываемые компьютером инструкции, структуры данных, программные модули или другие данные в виде сигнала, модулированного данными, такого как несущая частота, или другого транспортного механизма и включают любые среды передачи информации. В качестве примера и не для ограничений, среды передачи данных включают кабельные среды, такие как кабельные сети, и непосредственные кабельные соединения, а также беспроводные среды, такие как акустические, радио, инфракрасные и другие беспроводные среды. Используемый здесь термин считываемый компьютером носитель включает как носители информации, так и среды передачи данных.
Вычислительная система 100 также может иметь входные компоненты 114, такие как клавиатура, мышь, пишущее устройство, компоненты голосового входа, сенсорные входные устройства и т.д. Выходные компоненты 116 включают экраны дисплея, громкоговорители, принтер и т.д. и обслуживающие модули (часто называемые "адаптерами") для управления ими. Вычислительная система 100 имеет источник 118 питания. Все эти компоненты хорошо известны в данной области техники, и их не требуется подробно обсуждать здесь.
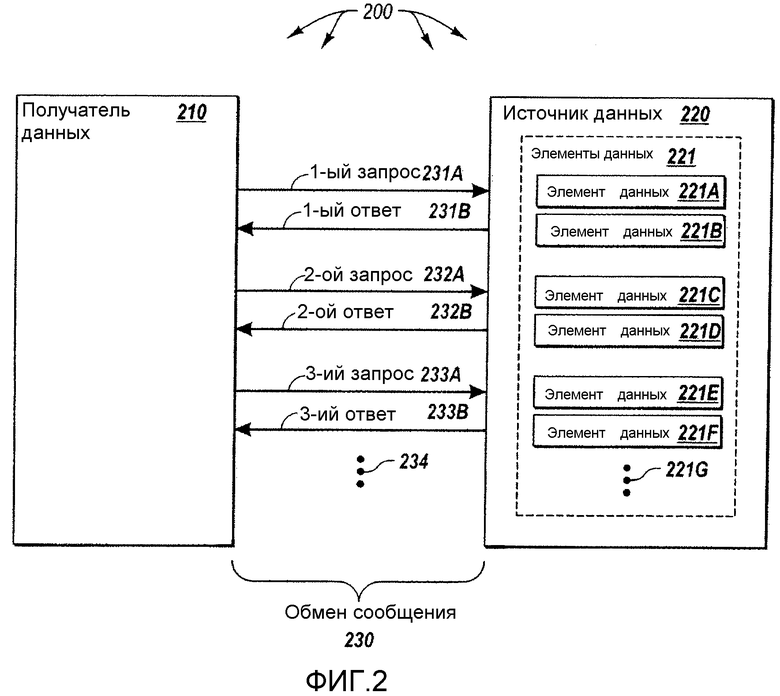
На фигуре 2 представлена сетевая среда 200, которая включает вычислительную систему 220 - источник данных, которая может быть подключена через сеть к вычислительной системе 210 - получателю данных. В данном описании и в формуле изобретения "вычислительная система" определена как любое устройство или система, которая имеет системную память и, по меньшей мере, один процессор, позволяющий выполнять инструкции из системной памяти. В качестве альтернативы или в дополнение, вычислительная система может обладать определенной способностью логической обработки, даже если она выполнена полностью в виде аппаратного средства. В соответствии с этим, вычислительная система 210 - получатель данных и вычислительная система 220 - источник данных, дополнительно могут иметь структуру, описанную выше в отношении вычислительной системы 100.
Кроме того, использование терминов "источник данных" и "получатель данных" в отношении вычислительных систем 210 и 220 не подразумевает, что получение данных является единственной функцией, поддерживаемой вычислительной системой 210, что передача данных является единственной функцией, поддерживаемой вычислительной системой 220. Действительно, такие вычислительные системы могут быть очень сложными вычислительными системами общего назначения, хотя это и не обязательно. Вычислительная система 210 - получатель данных может также называться здесь "получателем данных". Аналогично вычислительная система 220 - источник данных может также называться здесь "источником данных".
Источник 220 данных управляет множеством элементов 221 данных, которые должны быть переданы в получатель 210 данных. Источник 220 данных также может управлять другими элементами данных, которые не предназначены для передачи в получатель 210 данных. В представленном случае, источник 220 данных должен передавать элементы 221A-221F данных в вычислительную систему - получатель данных, а также, возможно, другие элементы данных, которые представлены вертикальным рядом точек 221G.
Источник 220 данных передает элементы 221 данных в получатель 210 данных с использованием обмена 230 сообщениями, в соответствии с технологией сеанса перечисления, управляемого запросами. В частности, элементы 221 данных не передают в источник данных в форме одного ответа на один запрос. Вместо этого, элементы 221 данных предоставляются в получатель 210 данных по частям, причем каждую часть передают отдельно в ответ на запрос. В одном варианте выполнения сеанс передачи в соответствии с технологией перечисления, управляемого запросами, может быть инициирован получателем 210 данных, который передает предварительный запрос на перечисление в источник 220 данных. Источник 220 данных может подтверждать сеанс путем передачи ответа о перечислении обратно в получатель 210 данных. В одном конкретном примере, более подробно описанном ниже, запрос на перечисление и ответ на него могут быть организованы в форме конвертов простого протокола доступа к объекту (ППДО, SOAP), содержащих документ на расширяемом языке разметки гипертекста (РЯР, XML). Однако запрос на перечисление и ответ на него также могут быть представлены в виде сообщений, соответствующих технологии построения распределенных приложений (ПРП, RMI) в спецификации языка Java.
Как показано на фигуре 2, получатель 210 данных передает первый запрос 231А. В ответ источник 220 данных передает элементы 221А и 221В данных в первом ответе 231В на первый запрос 231А. Этот процесс может повторяться до тех пор, пока получатель 210 данных не получит все элементы 221 данных. В частности, получатель 210 данных передает второй запрос 232А. В ответ источник 220 данных передает элементы 221C и 221D данных во втором ответе 232В на второй запрос 232А. Получатель 210 данных затем передает третий запрос 233А. В ответ источник 220 данных передает элементы 221Е и 221F данных в третьем ответе 233В на третий запрос 233А. Этот процесс может продолжаться, как представлено вертикальными точками 234, для любых других элементов данных, представленных вертикальными точками 221G.
В представленном случае показано, что, по меньшей мере, шесть элементов данных переданы в получатель 210 данных, по два элемента данных одновременно на каждый запрос. Однако принципы настоящего изобретения не ограничиваются этим вариантом выполнения. Любой один сеанс передачи в соответствии с технологией перечисления, управляемого запросами, можно использовать для передачи любого количества элементов данных. Кроме того, источник 220 данных может передавать любое количество элементов данных (или даже частей элементов данных) в любом данном ответе на любой данный запрос. Кроме того, поскольку перечисление элементов данных в получатель 210 данных выполняется под управлением запросами, получатель 210 данных может остановить передачу данных, просто прекратив передачу любого следующего запроса.
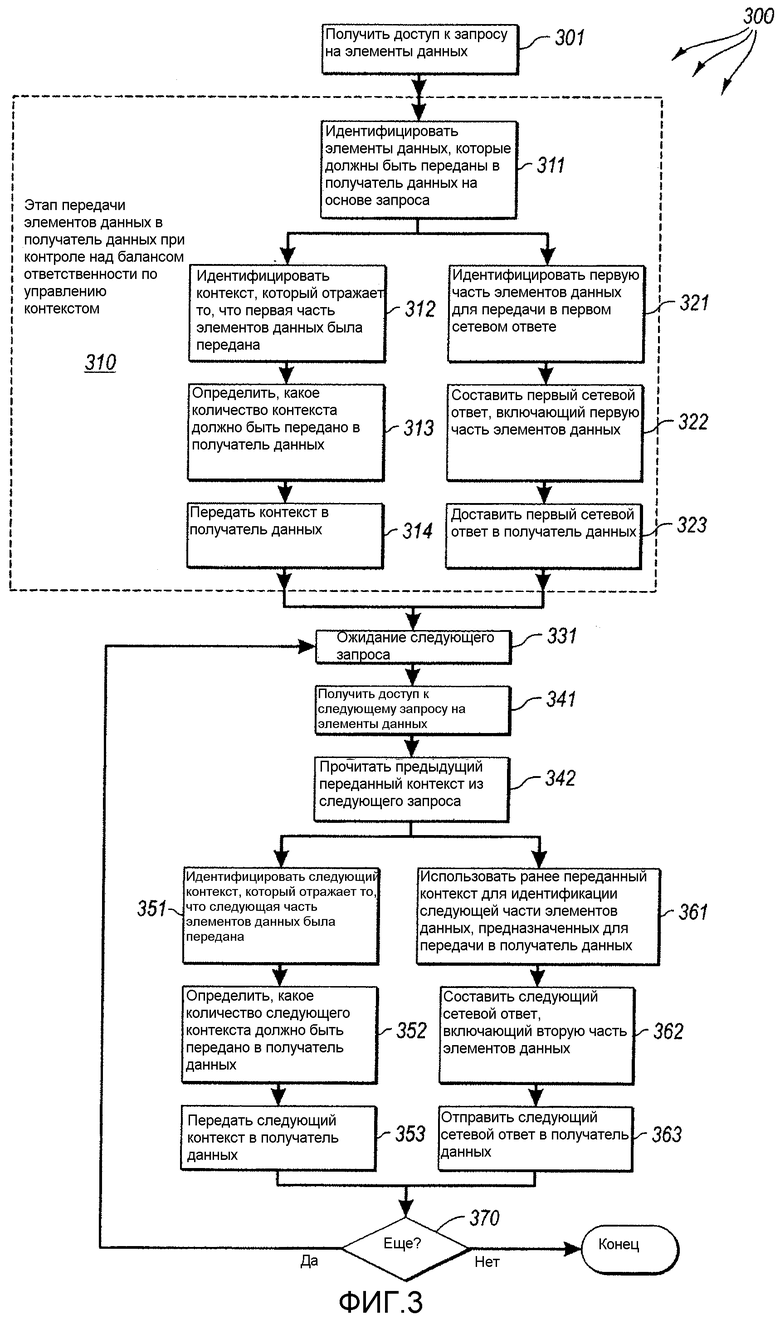
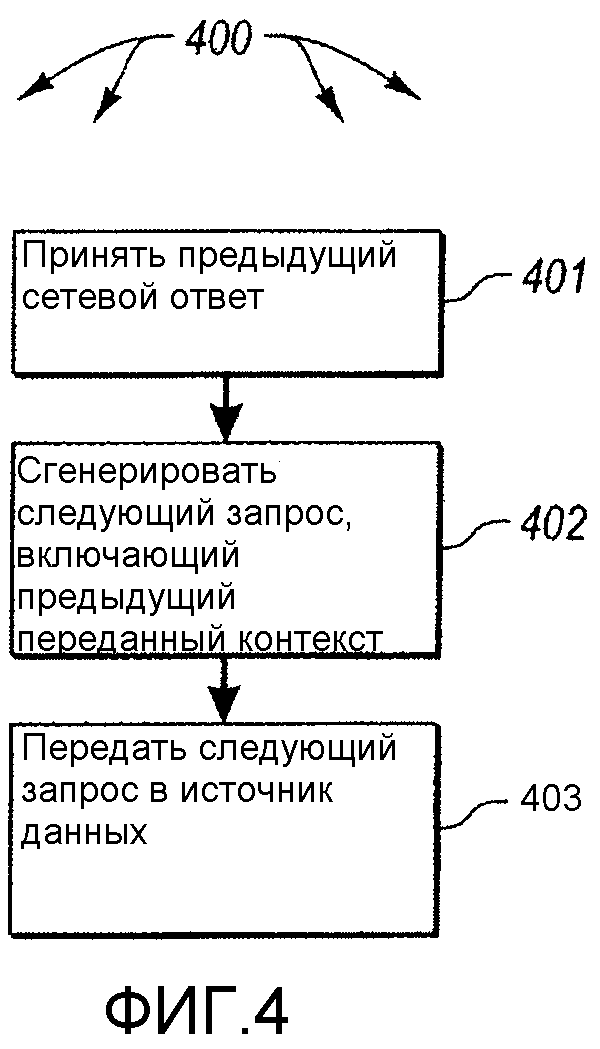
На фигуре 3 показана схема последовательности операций способа 300 передачи источником данных элементов данных в получатель данных, которые обеспечивают для источника данных возможность поддерживать контроль над балансом управления контекстом между двумя вычислительными системами. Аналогично, на фигуре 4 показана схема последовательности выполнения операций способа 400 поддержки получателем данных источника данных в этой роли. Поскольку способы 300 и 400 могут выполняться в сетевой среде 200, фигуры 3 и 4 будут описаны ниже с частой ссылкой на фигуру 2.
Как показано на фигуре 3, источник 220 данных получает доступ к запросу на передачу элементов данных в вычислительную систему - получатель данных (действие 301). Этот запрос может представлять собой внутренний запрос, помещенный в источник 220 данных, например, через запрос функции. В качестве альтернативы, доступ к запросу может быть получен в результате приема запроса из других вычислительных систем. В варианте выполнения, показанном на фигуре 2, источник 220 данных получает доступ к запросу путем приема первого запроса 231А от получателя 210 данных. В одном варианте выполнения этот запрос, а также все последующие запросы от получателя данных, представляет собой "запрос на извлечение информации", вырабатываемый получателем 210 данных. В описанном варианте выполнения запрос на извлечение информации может быть включен в конверт SOAP и может быть представлен в форме документа XML. Пример запроса на извлечение информации более подробно представлен ниже. Запрос на извлечение информации также может быть представлен с использованием технологии построения распределенных приложений (RMI).
Источник 220 данных затем выполняет функциональный, ориентированный на результат, этап передачи элементов данных в получатель 210 данных, управляя при этом балансом контекста управления между источником данных и получателем данных (этап 310). В представленном варианте выполнения это включает, по меньшей мере, действия 311-314 и 321-323, хотя любые действия, позволяющие достичь этого результата, будут достаточными.
В частности, источник 220 данных идентифицирует набор элементов данных, предназначенных для передачи в вычислительную систему - получатель данных, на основе, по меньшей мере, частично, информации, содержащейся в запросе (действие 311). Элементы данных могут быть непосредственно указаны в запросе. Кроме того, элементы данных могут быть опосредованно указаны с использованием описывающего набора элементов данных (также называется здесь исходным набором или множеством элементов данных). Запрос может включать фильтр, который должен быть приложен к исходному набору элементов данных, для генерирования конечного набора элементов данных. В одном варианте выполнения подборка идентифицируемого набора элементов выполняется путем считывания идентификатора сеанса в запросе. Идентификатор сеанса может быть скоррелирован с предшествующим запросом на перечисление, в котором элементы данных были явно идентифицированы. Такой предшествующий запрос на перечисление также может содержать фильтр для идентификации элементов данных.
Источник 220 данных затем идентифицирует первый контекст, который отражает, что первая часть набора элементов данных передана в вычислительную систему - получатель данных (действие 312). Если набор элементов данных представлял собой, например, элементы XML, контекст может включать идентификацию последнего элемента XML, который был передан ранее, или следующего элемента XML, который должен быть передан, или любую другую информацию, которую можно было бы использовать для индикации части набора элементов данных, уже переданной в получатель 210 данных, и части элементов данных, которую следует передать.
Источник 220 данных затем определяет количество первого контекста, которое должно быть передано в получатель 210 данных (действие 313). Такое количество может включать никакой, некоторый или весь полностью первый контекст, идентифицированный в действии 312. Следует отметить, что даже при том что контекстная информация может быть передана в получатель 210 данных, источник данных может избыточно сохранять некоторый или весь переданный контекст для последующей проверки контекста. Решение в отношении того, какую часть контекста следует передать в получатель 210 данных, может быть принято в соответствии с любыми критериями принятия решения. Соответствующие критерии принятия решения могут включать, например, текущую рабочую нагрузку и доступные возможности по обработке источника 220 данных или его доступную память, текущую рабочую нагрузку и доступные способности по обработке получателя 210 данных или его доступную память, доступную ширину полосы пропускания сети между получателем 210 данных и источником 220 данных, важность сетевого получателя или ассоциированного с ним пользователя или тому подобное. Источник 220 данных затем передает соответствующим образом первый контекст в получатель 210 данных (действие 314).
Кроме того, источник 220 данных идентифицирует первую часть (которая меньше, чем все данные) набора элементов данных для передачи в первом сетевом ответе в получатель данных (действие 321). Термины "первый" не обязательно подразумевают, что до этого не было каких-либо запросов или ответов между двумя вычислительными системами. Фактически, в одном варианте выполнения, описанном ниже, выполняется полный обмен запросом/ответом в форме запроса на перечисление и ответа на перечисление для получения точки в сеансе, в которой можно использовать операции по извлечению информации для выделения элементов данных по принципу одна часть единовременно.
Источник данных затем строит первый сетевой ответ, который включает эту первую часть (действие 322). Пример такого ответа описан ниже в форме ответа на извлечение информации, которому придают форму конверта SOAP, имеющего конкретную структуру XML. Первый сетевой ответ затем отправляют в получатель 210 данных (действие 323). В одном варианте выполнения источник 220 данных включает первый контекст, передаваемый в получатель 210 данных, в сам первый сетевой ответ. На фигуре 2 такой первый сетевой ответ представлен как сетевой ответ 231В.
Поскольку сеанс перечисления выполняется под управлением запросами, источник 220 данных ожидает следующий запрос (действие 331) перед переходом к дальнейшему выполнению сеанса. Как показано на фигуре 4, получатель 210 данных на данном этапе должен предпринять дальнейшее действие прежде, чем сеанс будет продолжен. Способ 400 по фигуре 4 описывает действие, предпринимаемое получателем 210 данных при приеме любого сетевого ответа во время сеанса перечисления, как первого сетевого ответа, так и других. В частности, получатель 210 данных принимает сетевой ответ (действие 401), генерирует следующий запрос, включающий контекст, представленный в сетевом ответе (действие 402), и затем передает следующий запрос в источник 220 данных (действие 403). Хотя этот контекст может быть непосредственно перенесен из предыдущего сетевого ответа в следующий сетевой запрос, это не обязательно. Возможно, только часть контекста, переданного в предыдущем сетевом ответе, будет передана в следующем запросе. Кроме того, контекстная информация, передаваемая в следующем запросе, может иметь другое кодирование по сравнению с ее кодированием в предыдущем сетевом ответе. Помимо этого контекст, передаваемый в следующем запросе, может быть дополнительно обработан (например, зашифрован и/или сжат) получателем данных.
После приема второго или любого следующего запроса на любую часть оставшегося набора элементов данных (действие 341), источник 220 данных считывает ранее переданный контекст из второго запроса (действие 342), идентифицирует второй контекст, который отражает ту, вторую часть из множества элементов данных, которая должна быть передана в вычислительную систему - получатель данных (действие 351), и определяет, какое количество следующего контекста должно быть передано в вычислительную систему - получатель данных (действие 352).
Часть контекста, переданного в получатель 210 данных, может иметь тот же объем, что и контекст, переданный ранее в получатель 210 данных, хотя это не обязательно. Источник 220 данных может передавать существенно другой контекст, чем переданный ранее, если это обосновано обстоятельствами. Например, предположим, что источник 220 данных обнаруживает, что получатель 210 данных активно участвует в сеансе перечисления, управляемого запросами, быстро передавая запросы после получения предыдущего ответа. В этом случае для источника 220 данных может быть более обоснованно сохранять весь контекст, без какой-либо его передачи в получатель 210 данных, поскольку сеанс, вероятно, будет быстро завершен и не будет занимать ресурсы памяти в течение существенного периода времени. Источник 220 данных затем передает ту часть следующего контекста, которую источник 220 данных предполагает передать в получатель 210 данных (действие 353).
Источник 220 данных также использует предыдущий контекст, считанный из запроса, для идентификации следующей части набора элементов данных для передачи в получатель данных (действие 361). Источник 220 данных затем составляет следующий сетевой ответ, включающий следующую часть набора элементов данных (действие 362). Этот следующий сетевой ответ затем отправляют в получатель 210 данных (действие 363). На данном этапе, если больше нет элементов данных в наборе элементов данных для передачи ("Нет" в блоке 370 принятия решения), сеанс может быть закончен. Однако, если существуют дополнительные элементы данных ("Да" в блоке 370 принятия решения), сеанс продолжается, и ожидается следующий запрос в действии 331.
После описания общих принципов настоящего изобретения, ниже подробно будет описан конкретный вариант выполнения настоящего изобретения. В этом конкретном варианте выполнения каждый из запросов и ответов в сеансе структурирован как конверты SOAP, содержащие документ XML.
Ниже представлена форма запроса на перечисление, кратко описанного выше. Как указано выше, получатель 210 данных передает запрос на перечисление в источник 220 данных для начала сеанса перечисления, управляемого запросами. Нумерация строк добавлена для ясности.
1) <s:Envelope…>
2) <s:Header…>
3) <wsa:Action>
4) http://schemas.xmlsoap.org/ws/2004/04/enumeration/Enumerate
5) </wsa:Action>
6) <wsa:MessageID>xs:anyURI</wsa:MessageID>
7) <wsa:To>xs:anyURJ</wsa:To>
8) …
9) </s:Header>
10) <s:Body…>
11) <wsen:Enumerate…>
12) <wsen:FilterDialect="xs:anyURI"?>xs:any</wsen:Filter>?
13) …
14) </wsen:Enumerate>
15) </s:Body>
16) </s:Envelope>
Строки 1-16 представляют элемент XML, который определяет весь конверт SOAP.
Строки 2-9 представляют элемент заголовка для конверта SOAP. Строки 3-5 представляют элемент действия XML, который определяет, что действие представляет собой запрос на перечисление (см. "Enumerate" в строке 4). Строка 6 идентифицирует идентификатор сеанса. Строка 7 представляет адрес источника данных. Строка 8 представляет, что могут существовать дополнительные элементы XML в заголовке элемента XML. Строки 10-15 представляют элемент тела XML SOAP. Строки 11-14 представляют элемент перечисления XML, который определяет информацию, необходимую для сеанса перечисления. Например, строка 12 идентифицирует элемент фильтра. Элемент фильтра включает атрибут диалекта фильтра, который определяет язык критерия поиска объектов для выражения фильтра (например, SQL, ХРАТН или другие URI). Кроме того, элемент фильтра включает атрибут "any", который выражает фильтр с использованием указанного языка критерия поиска объектов. В данном описании и в формуле изобретения, "язык критерия поиска объектов" представляет собой любой набор семантических правил, которые можно использовать для выражения фильтра на исходном множестве элементов данных, для генерирования отфильтрованных элементов данных, которые содержат никакие, некоторые или все элементы данных из исходного множества.
Ниже приведен пример запроса на перечисление, который соответствует форме, описанной выше, причем нумерация строк добавлена для ясности описания.
(01) <s:Envelope xmlns:S='http://www.w3.org/2003/05/soap-envelope'
(02) xmlns:wsa='http://schemas.xmlsoap.org/ws/2004/03/addressing'
(03) xmlns:wxf="http://schemas.xmlsoap.org/ws/2004/04/enumeration'>
(04) <s:Header>
(05) <wsa:Action>
(06) http://schemas.xmlsoap.org/ws/2004/04/enumeration/Enumerate
(07) </wsa:Action>
(08) <wsa:MessageID>
(09) uuid:e7c5726b-de29-4313-b4d4-b3425b200839
(10) </wsa:MessageID>
(11) <wsa:To>http://www.example.com/relayAgent/enum19</wsa:To>
(12) </s:Header>
(13) <s:Body>
(14) <wsen:Enumerate/>
(15) <S/:Body>
(16) </s:Envelope>
Строки (05-07) указывают, что данное сообщение представляет собой запрос на перечисление и что ожидается ответ от источника данных с сообщением - ответом на перечисление. При этом отсутствует элемент wse:Filter так, что полученный в результате контекст перечисления, как ожидается, будет возвращать все доступные элементы.
Источник 220 данных может ответить на запрос на перечисление ответом на перечисление для полной инициализации сеанса перечисления, управляемого запросами, и может соблюдать следующую форму, в которой нумерация строк добавлена для ясности описания.
1) <s:Envelope…>
2) <s:Header…>
3) <wsa:Action>
4) http://schemes.xmlsoap.org/ws/2004/04/enumeration/EnumerateResponse
5) </wsa:Action>
6) …
7) </s:Header>
8) <s:Body…>
9) <wsen:EnumerateResponse…>
10) <wsen:EnumerationContext>…</wsen:EnumerationContext>
11) …
12) </wsen:EnumerateResponse>
13) </s:Body>
14) </s:Envelope>
Строки 1-14 представляют элемент XML, который определяет весь конверт SOAP. Строки 2-7 представляют элемент заголовка для конверта SOAP. Строки 3-5 представляют элемент действия XML, который определяет, что действие представляет собой ответ на перечисление (см. "EnumerateResponse" в строке 4). Строка 6 представляет, что могут существовать дополнительные элементы XML в элементе заголовка XML, которые расположены в строках 2-7. Строки 8-13 представляют элемент XML тела SOAP. Строки 9-12 представляют элемент XML ответа на перечисление, который определяет информацию, используемую для завершения инициализации сеанса по перечислению. Например, строка 10 представляет элемент XML контекста перечисления, который включает исходный контекст, который может включать достаточно информации для идентификации контекста, для любых будущих запросов на извлечение информации во время сеанса. Элемент EnumerationContext содержит представление XML нового контекста на перечисление. Получатель 210 данных помещает эти данные XML в запрос на получение информации для этого контекста перечисления, до тех пор и пока сообщение - ответ на извлечение информации (дополнительно описано ниже) не обновит контекст перечисления. Строка 11 представляет, что могут присутствовать дополнительные элементы XML, включенные в элемент XML контекста перечисления.
Ниже представлен гипотетический ответ на перечисление, который имеет описанную выше форму.
(01) <s:Envelope xmlns:S='http://www.w3.org/2003/05/soap-envelope'
(02) xmlns:wxf='http://schemas.xmlsoap.org/ws/2004/0 4/enumeration'
(03) xmlns:wsa=thttp://schemas.xmlsoap.org/ws/2004/03/addressing'
(04) >
(05) <s:Header>
(06) <wsa:Action>
(07) http://schemas.xmlsoap.org/ws/2004/04/enumeration/EnunierateResponse
(08) </wsa:Action>
(09) <wsa:RelatesTo>
(10) uuid:e7c5726b-de29-4313-b4d4-b3425b200839
(11) </wsa:RelatesTo>
(12) </s:Header>
(13) <s:Body>
(14) <wsen:EnumerateResponse>
(15) <wsen:EnumerationContext>
(16) 123
(17) </wsen:EnumerationContext>
(18) </wsen:EnumerateResponse>
(19) </s:Body>
(20) </s:Envelope>
Строки 06-08 указывают, что данное сообщение представляет собой сообщение - ответ на перечисление. Строки 15-17 представляют собой представление XML контекста на перечисление, который поддерживает описанную ниже операцию на получение информации.
Операция по извлечению информации может быть инициирована получателем 210 данных путем передачи сообщения запроса на извлечение информации в источник 220 данных. Ниже приведена форма примера запроса на извлечение информации, в котором нумерация строк добавлена для ясности описания.
1) <s:Envelope…>
2) <s:Header…>
3) <wsa:Action>
4) http://schemas.xmlsoap.org/ws/2004/04/enumeration/Pull
5) </wsa:Action>
6) <wsa:MessageID>xs:anyURI</wsa:MessageID>
7) <wsa:ReplyTo>wsa:EndpointReference</wsa:ReplyTo>
8) <wsa:To>xs:anyURI</wsa:To>
9) …
10) </s:Header>
11) <s:Body…>
12) <wsen:Pull…>
13) <wsen:EnumerationContext>…</wsen:EnumerationContext>
14) <wsen:MaxTime>xsd:duration</wsen:MaxTime>?
15) <wsen:MaxElements>xsd:long</wsen:MaxElements>?
16) <wsen:MaxCharacters>xsd:long</wsen:MaxCharacters>?
17) …
18) </wsen:Pull>
19) </s:Body>
20) </s:Envelope>
Строки 1-20 определяют весь элемент XML, который представляет собой запрос на извлечение информации, имеющий структуру SOAP. Строки 2-10 определяют элемент XML заголовка. Строки 3-5 представляют собой элемент действия, в котором определено действие, такое как запрос на получение информации (см. "Pull" в строке 4). Строка 6 представляет собой элемент XML идентификатора сообщения. Этот элемент включает идентификатор, который скоррелирован с запросом на извлечение информации в сеансе. Строка 7 представляет собой элемент XML "reply to", который предоставляет адрес для ответа на запрос на извлечение информации. Строка 8 представляет собой элемент XML адреса, который определяет адрес источника 220 данных. Строка 9 обозначает, что могут быть другие элементы XML, содержащиеся в элементе XML заголовка.
Строки 11-19 представляют элемент тела XML. В частности, строки 12-18 представляют элемент XML на извлечение информации, который содержит информацию, используемую в запросе на извлечение информации. Например, строка 13 представляет собой элемент контекста на перечисление, в который вставлен контекст перечисления, переданный ранее. Такой контекст перечисления используется источником 220 данных для идентификации того, что собой представляет контекст сеанса.
Строка 14 представляет собой элемент XML максимального времени, который отражает максимальную продолжительность, предоставляемую источником 220 данных после приема запроса на извлечение информации до передачи источником 220 данных соответствующего ответа на извлечение информации. Перед передачей соответствующего ответа на извлечение информации, источник 220 данных проверяет, не превышено ли это максимальное время.
Строка 15 представляет собой элемент XML максимального количества элементов, который отражает максимальное количество элементов XML, разрешенное для передачи источником 220 в соответствующем ответе на извлечение информации. Перед отправкой соответствующего ответа на извлечение информации, источник 220 данных проверяет, что ответ на извлечение информации не содержит более чем это максимальное количество элементов XML.
Строка 16 содержит элемент XML максимального количества знаков, который представляет максимальное количество знаков, разрешенных для передачи источником 220 в соответствующем ответе на извлечение информации. Перед отправкой соответствующего ответа на извлечение информации источник данных 220 проверяет, не содержит ли ответ на извлечение информации более чем это максимальное количество знаков.
Ниже приведен пример запроса на извлечение информации, в котором нумерация строк добавлена для ясности описания:
(01) <s:Envelope xmlns:S=Ihttp://www.w3.org/2003/05/soap-envelope'
(02) xmlns:wsa='http://schemas.xmlsoap.org/ws/2004/03/addressing'
(03) xmms:wsen="http://schemas.xmlsoap.org/ws/2004/04/enumeration'>
(04) <s:Header>
(05) <wsa:Action>
(06) http://schemas.xmlsoap.org/ws/2004/04/enumeration/Pull
(07) </wsa:Action>
(08) <wsa:MessageID>
(09) uuid:e7c5726b-de29-4313-b4d4-b3425b200839
(10) </wsa:MessageID>
(11) <wsa:To>http://www.example.com/relayAgent</wsa:To>
(12) </s:Header>
(13) <s:Body>
(14) <wsen:Pull>
(15) <wsen:EnumerationContext>123</wsen:EnumerationContext>
(16) <wsen:MaxTime>P30S</wsen:MaxTime>
(17) <wsen:MaxElements>10</wsen:MaxElements>
(18) </wsen:Pull>
(19) <S/:Body>
(20) </s:Envelope>
Строки (05-07) в Таблице 2 указывают, что это сообщение представляет собой запрос на извлечение информации и что ожидается ответ от источника данных в виде сообщения - ответа на извлечение информации. Строка (16) указывает, что сообщение - ответ должно быть сгенерировано не более чем через 30 секунд после приема сообщения запроса на извлечение информации. Строка (17) указывает, что должно быть возвращено не более чем 10 элементов в теле сообщения - ответа на извлечение информации.
После приема и обработки запроса на извлечение информации получатель 210 данных может генерировать ответ на извлечение информации. Ниже приведена форма примера такого ответа на извлечение информации, в котором нумерация строк добавлена для ясности описания.
1) <s:Envelope…>
2) <s:Header…>
3) <wsa:Action>
4) http://schemas.xmlsoap.org/ws/2004/04/enumeration/PullResponse
5) </wsa:Action>
6) …
7) </s:Header>
8) <s:Body…>
9) <wsen:PullResponse…>
10) <wsen:EnumerationContext>…</wsen:EnumerationContext>?
11) <wsen:Items>?
12) <xs:any>enumeration-specific element</xs:any>+
13) </wsen:Items>
14) <wsen:EndOfSequence/>?
15) …
16) </wsen:PullResponse>
17) </s:Body>
18) </s:Envelope>
Строки 1-18 представляют весь элемент XML конверта SOAP. Строки 2-7 представляют элемент заголовка конверта SOAP. Строки 3-5 представляют элемент XML действия, который определяет, что действие представляет собой ответ на извлечение информации (см. "PullResponse" в строке 4). Строка 6 представляет, что имеются дополнительные элементы XML в элементе XML заголовка, который расположен в строках 2-7.
Строки 8-17 представляют элемент XML тела. Строки 9-16 представляют элемент XML ответа на извлечение информации, который содержит элементы, представляющие собой часть ответа. Строка 10 представляет собой элемент XML контекста перечисления, который содержит контекст перечисления для следующего запроса. Строки 11-13 представляют элементы XML элементов информации, которые содержат всю часть элементов данных, передаваемых в этом ответе. Строка 12 представляет потомок элемента XML, который в действительности содержит элементы данных. Строка 14 содержит конец последовательности элемента XML, который может быть передан, когда все элементы данных были переданы в получатель 210 данных. Таким образом, получатель 210 данных может быть проинформирован об окончании сеанса перечисления. Элемент XML тела также может иметь другой дополнительный элемент XML, который указывает, что переданные элементы данных не являются непрерывными, поскольку один или больше элементов данных были пропущены. Элемент XML также может указывать, почему эти элементы данных были пропущены. Например, предположим, что элемент данных в данный момент используется и, таким образом, доступ к нему ограничен. Кроме того, предположим, что не все элементы данных могут быть включены в ответ из-за ограничения максимального времени, количества элементов или знаков, наложенного в запросе на извлечение информации.
Ниже показан пример ответа на извлечение информации, в котором нумерация строк добавлена для ясности описания:
(01) <s:Envelope xmlns:S=rhttp://www.w3.org/2003/05/soap-envelope'
(02) xmlns:wsen='http://schemas.xmlsoap.org/ws/2004/04/enumeration'
(03) xmlns:wsa=Tittp://schemas.xmlsoap.org/ws/2004/03/addressing'
(04) >
(05) <s:Header>
(06) <wsa:Action>
(07) http://schemas.xmlsoap.org/ws/2004/04/enumeration/PullResponse
(08) </wsa:Action>
(09) <wsa:RelatesTo>
(10) uuid:e7c5726b-de29-4313-b4d4-b3425b200839
(11) </wsa:RelatesTo>
(12) </s:Header>
(13) <s:Body>
(14) <wsen:PullResponse>
(15) <wsen: Items xmlns:xx="http://fabrikaml23.com/schema/log">
(16) <xx:LogEntry id="1">System booted</xx:LogEntry>
(17) <xx:LogEntry id="2">AppX started</xx:LogEntry>
(18) <xx:LogEntry id="3">John Smith logged on</xx:LogEntry>
(19) <xx:LogEntry id="4">AppY started</xx:LogEntry>
(20) <xx:LogEntry id="5">AppX crashed</xx:LogEntry>
(21) </wsen:Items>
(22) <wsen:EndOfSequence/>
(23) </wsen:PullResponse>
(24) </s:Body>
(25) </s:Envelope>
Строки (06-08) в Таблице 3 указывают, что данное сообщение представляет собой сообщение - ответ на извлечение информации. Строки 15-19 представляют собой пять элементов, возвращаемых этим запросом на извлечение информации. Наличие элемента wsen:EndOfSequence (строка (20) указывает, что другие элементы больше не доступны и что контекст перечисления теперь является недействительным.
В качестве одной из оптимизаций, может выполняться операция снятия, которая позволяет получателю 210 данных заканчивать сеанс до того, как будут переданы все элементы данных. Операция снятия инициируется получателем 210 данных, который передает запрос на разъединение в источник 220 данных. Пример сообщения - разъединения имеет следующую форму, в которой нумерация строк добавлена для ясности описания.
1) <s:Envelope…>
2) <s:Heacier…>
3) <wsa:Action>
4) http://schemas.xmlsoap.org/ws/2004/04/enumeration/Release
5) </wsa:Action>
6) <wsa:MessageID>xs:anyURl</wsa:MessageID>
7) <wsa:ReplyTo>wsa:EndpointReference</wsa:ReplyTo>
8) <wsa:To>xs:anyURI</wsa:To>
9) …
10) </s:Header>
11) <s:Body…>
12) <wsen:Release…>
13) <wsen:EnumerationContext>…</wsen:EnumerationContext>
14) …
15) </wsen:Release>
16) </s:Body>
17) </s:Envelope>
Строка 4 идентифицирует сообщение как запрос на разъединение, в котором строки 12-15 идентифицируют контекст перечисления для разъединяемого сеанса перечисления.
После успешной обработки запроса на разъединение, источник 220 данных может передать ответ на разъединение, который может иметь следующую форму, в которой нумерация строк добавлена для ясности описания.
1) <s:Envelope…>
2) <s:Header…>
3) <wsa:Action>
4) http://schemas.xmlsoap.org/ws/2004/04/enumeration/ReleaseResponse
5) </wsa:Action>
6) …
7) </s:Header>
8) <s:Body/>
9) </s:Envelope>
Строка 4 идентифицирует сообщение как ответ на разъединение.
В соответствии с этим, принципы настоящего изобретения позволяют источнику данных обеспечить значительную гибкость путем динамической регулировки своей роли при управлении контекстом, в зависимости от возникающих в последующем обстоятельств.
Настоящее изобретение может быть выполнено в других конкретных формах без отхода от его сущности или существенных характеристик. Описанные варианты выполнения следует рассматривать во всех аспектах только как иллюстрацию, а не как ограничение. Объем изобретения, поэтому, определен прилагаемой формулой изобретения, а не приведенным выше описанием. Все изменения, которые входят в значение и диапазон эквивалентности формулы изобретения, должны входить в его объем.
Гибкое управление включает способ и компьютерный продукт. Способ относится к передаче вычислительной системой - источником данных множества запрашиваемых элементов данных в множестве отдельных электронных сообщений в вычислительную систему - получатель данных, с управлением количеством информации о состоянии, сохраняемым между сообщениями в вычислительной системе - источнике данных, используется в среде, которая включает вычислительную систему - источник данных, которая может быть подключена через сеть к вычислительной системе - получателю данных, и включает действие по доступу к запросу на передачу элементов данных, действие по идентификации первой части из множества элементов данных, предназначенных для передачи в первом сетевом ответе, в вычислительную систему - получатель данных, причем первая часть меньше, чем все множество элементов данных, действие по составлению первого сетевого ответа, включающего первую часть из множества элементов данных, действие по отправке первого сетевого ответа в вычислительную систему - получатель данных, действие по идентификации контекста, который отражает, что первая часть из множества элементов данных была передана в вычислительную систему - получатель данных, действие по определению, какое количество контекста должно быть передано в вычислительную систему - получатель данных, и действие по передаче контекста в вычислительную систему - получатель данных, определенного в соответствии с действием по определению количества контекста, которое следует передать в вычислительную систему - получатель данных. Компьютерный продукт предназначен для осуществления способа. Технический результат: обеспечение гибкости источника данных при динамической регулировке его роли в управлении контекстом. 2 н. и 46 з.п. ф-лы, 4 ил.
1. Способ передачи вычислительной системой - источником данных множества запрашиваемых элементов данных в множестве отдельных электронных сообщений в вычислительную систему - получатель данных, с управлением количеством информации о состоянии, сохраняемым между сообщениями в вычислительной системе - источнике данных, используемый в среде, которая включает вычислительную систему - источник данных, которая может быть подключена через сеть к вычислительной системе - получателю данных, и включающий действие по доступу к запросу на передачу элементов данных в вычислительную систему - получатель данных, действие по идентификации множества элементов данных для передачи в вычислительную систему - получатель данных на основе, по меньшей мере, частично, информации, содержащейся в запросе, действие по идентификации первой части из множества элементов данных, предназначенных для передачи в первом сетевом ответе, в вычислительную систему - получатель данных, причем первая часть меньше чем все множество элементов данных, действие по составлению первого сетевого ответа, включающего первую часть из множества элементов данных, действие по отправке первого сетевого ответа в вычислительную систему - получатель данных, действие по идентификации контекста, который отражает, что первая часть из множества элементов данных была передана в вычислительную систему - получатель данных, действие по определению, какое количество контекста должно быть передано в вычислительную систему - получатель данных, и действие по передаче контекста в вычислительную систему - получатель данных, определенного в соответствии с действием по определению количества контекста, которое следует передать в вычислительную систему - получатель данных.
2. Способ по п.1, в котором переданный контекст содержится в первом сетевом ответе.
3. Способ по п.1, в котором переданный контекст указывает, что последний из множества элементов данных был передан.
4. Способ по п.1, в котором действие по доступу к запросу на элементы данных, которые должны быть переданы в вычислительную систему - получатель данных, содержит действие по доступу к внутреннему запросу на элементы данных, которые должны быть переданы в вычислительную систему - получатель данных.
5. Способ по п.1, в котором действие по доступу к запросу на передачу элементов данных в вычислительную систему - получатель данных содержит действие по приему сетевого запроса из вычислительной системы - получателя данных для элементов данных, которые должны быть переданы в вычислительную систему - получатель данных.
6. Способ по п.1, в котором множество элементов данных представляет собой конечное множество элементов данных, в котором действие по идентификации множества элементов данных, предназначенных для передачи в вычислительную систему - получатель данных, основывается, по меньшей мере, частично, на информации, содержащейся в запросе, включающий действие по идентификации исходного множества элементов данных на основе, по меньшей мере, частично, информации, содержащейся в запросе, и действие по выбору конечного множества элементов данных, на основе дополнительных критериев, указанных в запросе.
7. Способ по п.6, в котором действие по выбору конечного множества элементов данных, основанном на дополнительном критерии, указанном в запросе, содержит действие по идентификации языка критерия поиска объектов на основе, по меньшей мере, частично, информации, содержащейся в запросе, действие по интерпретации критерия поиска объектов, содержащегося в запросе, включающем идентифицированный язык критерия поиска объектов, и действие по фильтрации конечного множества элементов данных путем применения интерпретированного критерия поиска объектов.
8. Способ по п.1, в котором действие по идентификации первой части множества элементов данных, которые должны быть переданы в первом сетевом ответе в вычислительную систему - получатель данных, содержит действие по считыванию из запроса максимального количества элементов данных, которые должны быть переданы в первом сетевом ответе, и действие по определению, что первая часть из множества элементов данных равна максимальному количеству элементов данных.
9. Способ по п.1, в котором действие по идентификации первой части множества элементов данных, которые должны быть переданы в первом сетевом ответе в вычислительную систему - получатель данных, содержит действие по считыванию из запроса максимального количества знаков, которые должны быть переданы в первом сетевом ответе, и действие по определению того, что первая часть множества элементов данных равна или меньше чем максимальное количество знаков.
10. Способ по п.1, в котором действие по идентификации первой части множества элементов данных, которые должны быть переданы в первом сетевом ответе в вычислительную систему - получатель данных, содержит действие по считыванию из запроса максимального времени на ответ для передачи первого сетевого ответа, и действие по определению того, что первый сетевой ответ может быть возвращен в течение максимального времени на ответ, заданного для первой части множества элементов данных.
11. Способ по п.1, в котором действие по определению, какое количество контекста должно быть передано в вычислительную систему - получатель данных, содержит действие по определению, что контекст не должен быть передан в вычислительную систему - получатель данных.
12. Способ по п.1, в котором действие по определению, какое количество контекста должно быть передано в вычислительную систему - получатель данных, содержит действие по определению, что некоторая часть контекста должна быть передана в вычислительную систему - получатель данных.
13. Способ по п.12, дополнительно содержащий действие по избыточному сохранению некоторой части контекста, переданного в вычислительную систему - получатель данных.
14. Способ по п.1, в котором действие по определению, какое количество контекста должно быть передано в вычислительную систему - получатель данных, содержит действие по определению, что весь контекст должен быть передан в вычислительную систему - получатель данных.
15. Способ по п.14, дополнительно содержащий действие по избыточному сохранению некоторой части контекста, переданного в вычислительную систему - получатель данных.
16. Способ по п.1, в котором запрос представляет собой конверт простого протокола доступа к объекту (SOAP).
17. Способ по п.1, в котором запрос соответствует технологии построения распределенных приложений (RMI).
18. Способ по п.1, в котором элементы данных представляют собой элементы расширяемого языка разметки гипертекста (XML).
19. Способ по п.1, в котором передаваемый контекст представляет собой первый контекст, причем способ дополнительно содержит действие по доступу ко второму запросу в форме сетевого запроса на элементы данных из вычислительной системы - получателя данных, действие по считыванию первого переданного контекста из второго запроса, и действие по использованию первого переданного контекста, считанного из второго запроса, для идентификации второй части множества элементов данных, предназначенных для передачи в вычислительную систему - получатель данных.
20. Способ по п.19, дополнительно содержащий действие по составлению второго сетевого ответа, включающего вторую часть множества элементов данных, действие по отправке второго сетевого ответа в вычислительную систему - получатель данных, действие по идентификации второго контекста, который отражает, что вторая часть из множества элементов данных была передана в вычислительную систему - получатель данных, действие по определению, какое количество второго контекста должно быть передано в вычислительную систему - получатель данных, и действие по передаче второго контекста в вычислительную систему - получатель данных, как определено в соответствии с действием по определению, какое количество второго контекста должно быть передано в вычислительную систему - получатель данных.
21. Способ по п.20, в котором второй контекст имеет тот же объем, что и первый контекст.
22. Способ по п.20, в котором второй контекст имеет объем, отличающийся от первого контекста.
23. Способ по п.22, в котором действие по определению, какое количество второго контекста должно быть передано в вычислительную систему - получатель данных, содержит действие по оценке поведения вычислительной системы - получателя данных.
24. Способ по п.22, в котором определение, какое количество второго контекста должно быть передано в вычислительную систему - получатель данных, содержит действие по оценке текущего состояния вычислительной системы - источника данных.
25. Компьютерный программный продукт, предназначенный для использования в среде, которая включает вычислительную систему - источник данных, которая может быть подключена через сеть к вычислительной системе - получателю данных, причем компьютерный программный продукт предназначен для выполнения для вычислительной системой - источником данных при передаче множества запрашиваемых элементов данных в множестве отдельных электронных сообщений в вычислительную систему - получатель данных с одновременным контролем, какое количество информации о состоянии между сообщениями сохраняется в вычислительной системе - источнике данных, причем компьютерный программный продукт содержит исполняемые компьютером инструкции, которые при выполнении одним или больше процессорами вычислительной системы - источника данных обеспечивает выполнение вычислительной системой - источником данных действия по доступу к запросу на элементы данных, которые должны быть переданы в вычислительную систему - получатель данных, действия по идентификации множества элементов данных, которые должны быть переданы на вычислительную систему - получатель данных, на основе, по меньшей мере, частично, информации, содержащейся в запросе, действия по идентификации первой части из множества элементов данных, которые должны быть переданы в первом сетевом ответе в вычислительную систему - получатель данных, причем первая часть меньше чем все множество элементов данных, действия по построению первого сетевого ответа, включающего первую часть из множества элементов данных, действия по отправке первого сетевого ответа в вычислительную систему - получатель данных, действия по идентификации контекста, который отражает то, что первая часть из множества элементов данных была передана в вычислительную систему - получатель данных, действия по определению, какое количество контекста должно быть передано в вычислительную систему - получатель данных, и действия по передаче контекста в вычислительную систему - получатель данных, как определено в соответствии с действием по определению, какое количество контекста должно быть передано в вычислительную систему - получатель данных.
26. Компьютерный программный продукт по п.25, в котором переданный контекст указывает, что был передан последний из множества элементов данных.
27. Компьютерный программный продукт по п.25, в котором переданный контекст содержится в первом сетевом ответе.
28. Компьютерный программный продукт по п.25, в котором действие по доступу к запросу на элементы данных, которые должны быть переданы в вычислительную систему - получатель данных, содержит действие по доступу к внутреннему запросу на элементы данных, которые должны быть переданы в вычислительную систему - получатель данных.
29. Компьютерный программный продукт по п.25, в котором действие по доступу к запросу на элементы данных, которые должны быть переданы в вычислительную систему - получатель данных, содержит действие по приему сетевого запроса из вычислительной системы - получателя данных для элементов данных, которые должны быть переданы в вычислительную систему - получатель данных.
30. Компьютерный программный продукт по п.25, в котором множество элементов данных представляет собой конечное множество элементов данных, в котором действие по идентификации множества элементов данных, которые должны быть переданы в вычислительную систему - получатель данных, основано, по меньшей мере, частично на информации, содержащейся в запросе, содержащий действие по идентификации исходного множества элементов данных на основе, по меньшей мере, частично, информации, содержащейся в запросе, и действие по выбору конечного множества элементов данных на основе дополнительного критерия, указанного в запросе.
31. Компьютерный программный продукт по п.30, в котором действие по выбору конечного множества элементов данных на основе дополнительного критерия, указанного в запросе, содержит действие по идентификации языка критерия поиска объектов на основе, по меньшей мере, частично, информации, содержащейся в запросе, действие по интерпретации языка критерия поиска объектов, содержащегося в запросе, с использованием идентифицированного языка критерия поиска объектов, и действие по фильтрации конечного множества элементов данных путем применения интерпретированного критерия поиска объектов.
32. Компьютерный программный продукт по п.25, в котором действие по идентификации первой части множества элементов данных, которые должны быть переданы в первом сетевом ответе в вычислительную систему - получатель данных, содержит действие по считыванию из запроса максимального количества элементов данных, которые должны быть переданы в первом сетевом ответе, и действие по определению того, что первая часть из множества элементов данных равна максимальному количеству элементов данных.
33. Компьютерный программный продукт по п.25, в котором действие по идентификации первой части из множества элементов данных, которые должны быть переданы в первом сетевом ответе в вычислительную систему - получатель данных, содержит действие по считыванию из запроса максимального количества знаков, которое должно быть передано в первом сетевом ответе, и действие по определению того, что первая часть множества элементов данных равна или меньше, чем максимальное количество знаков.
34. Компьютерный программный продукт по п.25, в котором действие по идентификации первой части из множества элементов данных, которые должны быть переданы в первом сетевом ответе в вычислительную систему - получатель данных, содержит действие по считыванию из запроса максимального времени на ответ, которое должно потребоваться для первого сетевого ответа, и действие по определению того, что первый сетевой ответ может быть возвращен в течение максимального времени на ответ, заданного для первой части множества элементов данных.
35. Компьютерный программный продукт по п.25, в котором действие по определению, какое количество контекста должно быть передано в вычислительную систему - получатель данных, содержит действие по определению, что контекст не должен быть передан в вычислительную систему - получатель данных.
36. Компьютерный программный продукт по п.25, в котором действие по определению, какое количество контекста должно быть передано в вычислительную систему - получатель данных, содержит действие по определению, что некоторая часть контекста должна быть передана в вычислительную систему - получатель данных.
37. Компьютерный программный продукт по п.36, дополнительно обеспечивающий действие по избыточному сохранению некоторой части контекста, переданного в вычислительную систему - получатель данных.
38. Компьютерный программный продукт по п.25, в котором действие по определению, какое количество контекста должно быть передано в вычислительную систему - получатель данных, содержит действие по определению, что весь контекст должен быть передан в вычислительную систему - получатель данных.
39. Компьютерный программный продукт по п.38, дополнительно обеспечивающий действие по избыточному сохранению некоторой части контекста, переданного в вычислительную систему - получатель данных.
40. Компьютерный программный продукт по п.25, в котором запрос представляет собой конверт простого протокола доступа к объекту (SOAP).
41. Компьютерный программный продукт по п.25, в котором запрос соответствует технологии построения распределенных приложений (RMI).
42. Компьютерный программный продукт по п.25, в котором элементы данных представляют собой элементы расширяемого языка разметки гипертекста (XML).
43. Компьютерный программный продукт по п.25, в котором переданный контекст представляет собой первый контекст, и который дополнительно обеспечивает действие по доступу ко второму запросу в форме сетевого запроса на элементы данных из вычислительной системы - получателя данных, действие по считыванию первого полученного контекста из второго запроса, и действие по использованию первого переданного контекста, считанного из второго запроса, для идентификации второй части множества элементов данных, которые должны быть переданы в вычислительную систему - получатель данных.
44. Компьютерный программный продукт по п.43, в котором контекст представляет собой первый контекст, и который дополнительно обеспечивает действие по построению второго сетевого ответа, включающего вторую часть множества элементов данных, действие по отправке второго сетевого ответа в вычислительную систему - получатель данных, действие по идентификации второго контекста, который отражает то, что вторая часть из множества элементов данных была передана в вычислительную систему - получатель данных, действие по определению, какое количество второго контекста должно быть передано в вычислительную систему - получатель данных, и действие по передаче второго контекста в вычислительную систему - получатель данных, как определено в соответствии с действием по определению, какое количество второго контекста должно быть передано в вычислительную систему - получатель данных.
45. Компьютерный программный продукт по п.44, в котором второй контекст имеет тот же объем, что и первый контекст.
46. Компьютерный программный продукт по п.44, в котором второй контекст имеет объем, отличающийся от объема первого контекста.
47. Компьютерный программный продукт по п.46, в котором действие по определению, какое количество второго контекста должно быть передано в вычислительную систему - получатель данных, содержит действие по оценке поведения вычислительной системы - получателя данных.
48. Компьютерный программный продукт по п.46, в котором определение, какое количество второго контекста должно быть передано в вычислительную систему - получатель данных, содержит действие по оценке текущего состояния вычислительной системы - источника данных.
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| СИСТЕМА ПОИСКА ИНФОРМАЦИИ В КОМПЬЮТЕРНОЙ СЕТИ | 1998 |
|
RU2138076C1 |
| ИНФОРМАЦИОННО-ПОИСКОВАЯ СИСТЕМА | 2001 |
|
RU2199778C1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |

