УРОВЕНЬ ТЕХНИКИ
Традиционные поисковые службы принимают запросы от пользователей, чтобы определить веб-страницы, содержащие термины, которые совпадают с терминами, включенными в принятые запросы. Традиционно поисковые службы игнорируют контекст и значение пользовательского запроса и рассматривают запрос, как набор слов. Термины, включенные в запрос, ищутся на основе частоты, и результаты, которые включают в себя термины запроса, возвращаются поисковой службой.
Соответственно традиционные поисковые службы возвращают результаты, которые могут не удовлетворять интересы пользователя. Пользователь пытается переформулировать запрос посредством выбора слов, которые вероятнее всего найдутся в интересующем его документе. Например, пользователь, ищущий информацию об акциях, может ввести запрос «Отношение цены к прибыли (РЕ), компания А акции». Традиционная поисковая служба будет рассматривать каждое слово отдельно и возвращать документы, содержащие термин «компания А», документы, содержащие термин «отношение цены к прибыли (РЕ)», документы, содержащие термины «акции», и документы, содержащие любые из этих терминов. Традиционная поисковая служба не может разумно выбирать документы в результатах, которые обсуждают поведение акций компании А, сравнение компании А с ее конкурентом, и новостях об управлении компанией А. Пользователь должен читать различные документы в результатах, чтобы определить, включает ли какой-либо из документов информацию о поведении.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Варианты осуществления изобретения относятся к системам, способам и машиночитаемым средствам для формирования контекстных запросов. Поисковая служба принимает запрос от клиентского устройства вместе с контекстной информацией, предоставляемой приложениями, используемыми во время текущего поискового сеанса. В свою очередь, компонент понимания запроса обрабатывает контекстную информацию и запрос, чтобы сформировать семантическое представление запроса. Семантическое представление запроса дополнительно обрабатывается генератором команд источника данных, чтобы выбрать несколько команд источника данных на основе лексической информации, связанной с каждым источником данных. Команды источника данных передаются из генератора команд источника данных источникам данных, чтобы вернуть ответы и результаты поисковой службе в ответ на запрос пользователя и сформированные контекстные запросы.
Это краткое изложение сущности изобретения приведено для представления подборки концепций в упрощенном виде, которые дополнительно описаны ниже в подробном описании. Данное краткое изложение сущности изобретения не предназначено ни для идентификации ключевых признаков или существенных признаков изобретения, ни для использования в качестве ограничения при определении объема изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Иллюстративные варианты осуществления изобретения подробно описаны ниже со ссылкой на прилагаемые чертежи, которые включены в материалы настоящей заявки посредством ссылки.
Фиг. 1 - структурная схема, иллюстрирующая примерное вычислительное устройство в соответствии с вариантом осуществления изобретения.
Фиг. 2 - сетевая диаграмма, иллюстрирующая примерные компоненты компьютерной системы, сконфигурированной, чтобы формировать контекстные запросы в соответствии с вариантом осуществления изобретения.
Фиг. 3 - логическая диаграмма, иллюстрирующая машинно-исполняемый способ для формирования контекстных запросов в соответствии с вариантом осуществления изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
Настоящая заявка на патент описывает изобретение для патентования со специфичностью, чтобы удовлетворить нормативным требованиям. Однако само описание не предназначено для ограничения объема настоящего патента. Скорее, изобретатели подразумевают, что изобретение также может осуществляться другими способами, чтобы включать в себя различные этапы или комбинации этапов, схожих с этапами, описанными в настоящем раскрытии, в соединении с другими настоящими или будущими технологиями. Более того, хотя термины «этап» и «блок» могут использоваться в материалах настоящей заявки, чтобы подразумевать различные элементы используемого способа, эти термины не должны интерпретироваться, как требующие какого-либо конкретного порядка среди или между различными этапами, раскрытыми в материалах настоящей заявки, за исключением ситуации, когда порядок отдельных этапов описан явно.
В качестве используемого в материалах настоящей заявки термин «контекстный запрос» указывает на команды данных, которые используются, чтобы получить доступ к источникам данных и чтобы извлечь информацию из источников данных на основе структуры информации, включенной в источник данных, и значения терминов, включенных в запрос.
В качестве используемого в материалах настоящей заявки термин «компонент» указывает на любую комбинацию аппаратного обеспечения, микропрограммного обеспечения и программного обеспечения.
Варианты осуществления изобретения предоставляют контекстные запросы, которые позволяют пользователю получать ответы на пользовательский запрос. Ответы собираются из большого набора содержимого, содержащего структурированные данные, слабоструктурированные данные и неструктурированные данные. Контекстные запросы формируются компьютерной системой на основе онтологий, связанных с терминами, включенными в запрос, и приложений, которые используются во время текущего поискового сеанса. Контекстные запросы ищут комбинацию структурированных, неструктурированных и слабоструктурированных данных для ответов на запрос.
Например, ответы на финансовые запросы пользователя возвращаются компьютерной системой, используя основанное на онтологии понимание финансовых запросов. Компьютерная система может предоставлять финансовое приложение, которое позволяет пользователю получать ответы на запросы на естественном языке, например, «Компании с отношением РЕ, близким к компании А», «Операционный доход компании А» и «Оценка компании А и В». Онтология используется компьютерной системой, чтобы понять некоторое количество ключевых отношений, которые должны рассчитываться, используя текущие данные в ответ на запросы. Ключевые отношения могут включать в себя помимо прочего «Отношение РЕ», «Отношение цены к продажам» и т.д. Запросы на естественном языке и соответствующие онтологии используются, чтобы формировать семантическое представление. Финансовое приложение может преобразовывать семантическое представление в запрос SPARQL (язык запросов к данным, представленным по модели RDF), который передается источникам данных, которые включают в себя записи, которые прослеживаются, чтобы вернуть ответы. В свою очередь, финансовое приложение возвращает сравнение этих отношений и оценочные показатели для компаний А и В.
Компьютерная система принимает запросы от пользователя. Кроме того, компьютерная система принимает контексты от одного или более приложений, прослеживаемых во время текущего поискового сеанса. Используя одну или более онтологий, компьютерная система понимает запросы и контексты и формирует семантические представления запросов и контексты приложений, в которых пользователь формулирует запрос. Концепты, экземпляры, свойства и отношения включаются в семантическое представление запросов на основе систематизации, шаблонов или определений, включенных в онтологии. В одном из вариантов осуществления семантическое представление является графом запроса, использующим извлеченные концепты, экземпляры, свойства и отношения и т.д. В свою очередь, семантическое представление может автоматически преобразовываться генератором команд источника данных в относящиеся к конкретному источнику данных языки запросов, чтобы извлечь важную информацию и ответы на запрос.
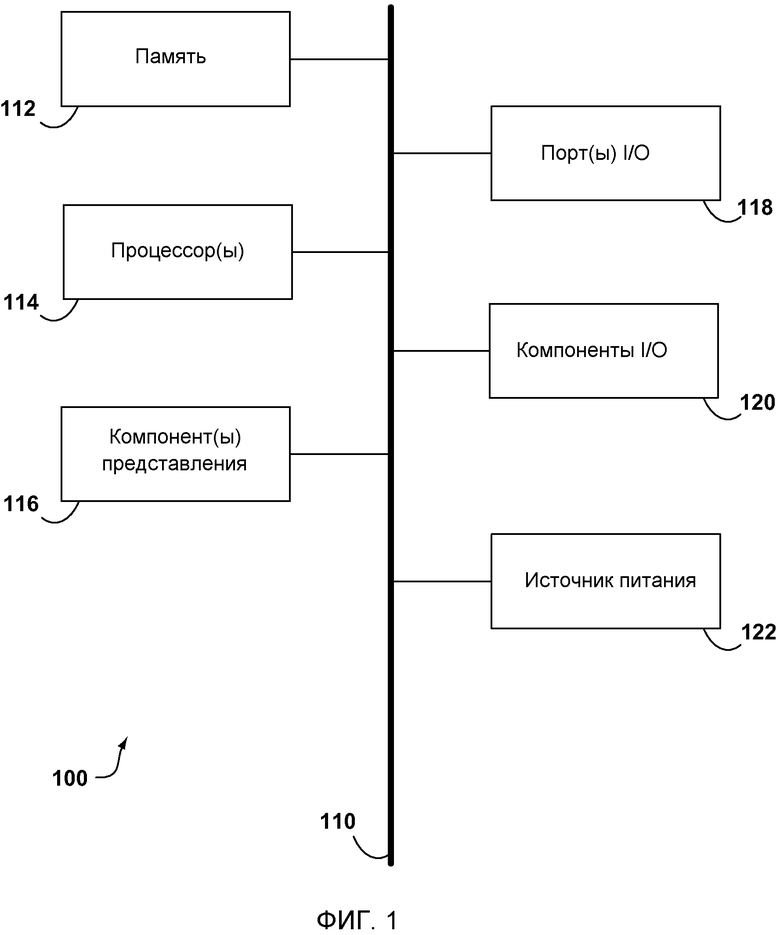
Фиг. 1 - структурная схема, иллюстрирующая примерное вычислительное устройство 100 в соответствии с вариантом осуществления изобретения. Вычислительное устройство 100 включает в себя шину 110, память 112, процессоры 114, компоненты 116 представления, порты 118 ввода/вывода (I/O), компоненты 120 ввода/вывода (I/O) и источник 122 питания. Вычислительное устройство 100 системы является всего лишь одним из примеров подходящей вычислительной среды и не имеет намерением предлагать какое-либо ограничение в отношении объема использования или функциональных возможностей изобретения. Вычислительное устройство 100 также не должно трактоваться, как имеющее какую-либо зависимость или требование, относящиеся к любому одному или сочетанию проиллюстрированных компонентов.
Вычислительное устройство 100 типично включает в себя множество машиночитаемых средств. В качестве примера, а не ограничения, машиночитаемые средства могут содержать оперативное запоминающее устройство (ОЗУ, RAM), постоянное запоминающее устройство (ПЗУ, ROM), электрически стираемое программируемое постоянное запоминающее устройство (ЭСППЗУ, EEPROM), флэш-память или другие технологии памяти, компакт-диск (CDROM), цифровые многофункциональные диски (DVD) или другие оптические или голографические средства; магнитные кассеты, магнитную ленту, магнитные дисковые запоминающие или другие магнитные запоминающие устройства, либо любое другое средство, которое может использоваться для кодирования требуемой информации и к которому может быть осуществлен доступ вычислительным устройством 100. Варианты осуществления изобретения могут реализовываться, используя компьютерный код или используемые машиной команды, включая машинно-исполняемые команды, такие как программные модули, выполняемые вычислительным устройством 100, таким как персональный информационный помощник или другое переносное устройство. Обычно программные модули, включающие в себя процедуры, программы, объекты, модули, структуры данных и тому подобное, указывают на код, который выполняет конкретные задачи или реализует конкретные абстрактные типы данных. Варианты осуществления изобретения также могут быть осуществлены на практике во множестве конфигураций систем, включая распределенные вычислительные среды, где задачи выполняются удаленными устройствами обработки, которые связаны через сеть связи.
Вычислительное устройство 100 включает в себя шину 110, которая прямо или косвенно соединяет следующие компоненты: память 112, один или более процессоров 114, один или более компонентов 116 представления, порты 118 ввода/вывода (I/O), компоненты 120 I/O и иллюстративный источник 122 питания. Шина 110 представляет собой то, что может являться одной или более шинами (такими как адресная шина, информационная шина или их комбинация). Хотя различные компоненты фиг. 1 показаны линиями для ясности, в действительности разграничение различных модулей не так очевидно, и метафорически линии более точно были бы серыми и размытыми. Например, можно рассматривать компонент 116 представления, такой как устройство отображения, являющимся компонентом 120 I/O. Также процессоры 114 содержат память 112. Не делается различение между «рабочей станцией», «сервером», «портативным устройством» и т.д., так как все они попадают в объем фиг. 1.
Память 112 включает в себя машиночитаемые средства и компьютерные запоминающие носители в форме оперативной и/или постоянной памяти. Память может являться съемной, несъемной или их комбинацией. Примерные устройства аппаратного обеспечения включают в себя твердотельную память, жесткие диски, приводы оптических дисков и т.д. Вычислительное устройство 100 включает в себя один или более процессоров 114, которые считывают данные с различных объектов, таких как память 112 или компоненты 120 I/O. Компоненты 116 представления представляют индикации данных пользователю или другим устройствам. Примерные компоненты 116 представления включают в себя устройство отображения, динамик, принтер, вибрирующий модуль и подобное. Порты 118 I/O позволяют вычислительному устройству 100 физически и логически соединяться с другими устройствами, включая компоненты 120 I/O, некоторые из которых могут быть встроенными. Иллюстративные компоненты 120 I/O могут включать в себя микрофон, джойстик, игровую панель, спутниковую антенну, сканер, принтер, беспроводное устройство и подобное.
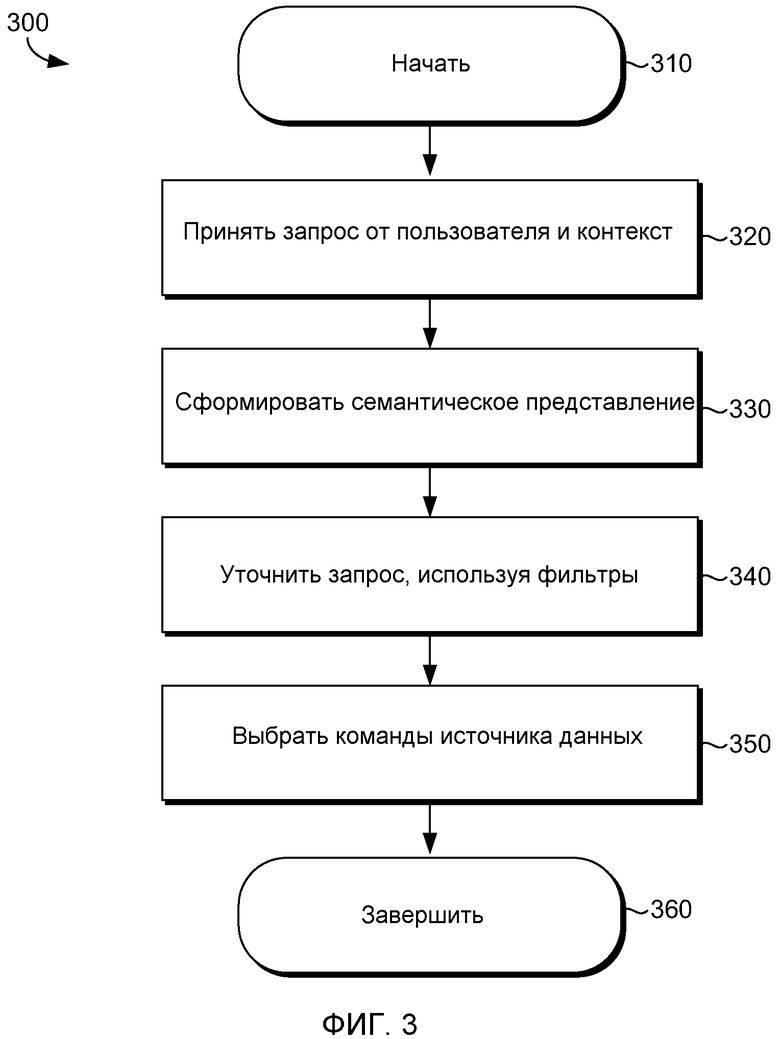
Компьютерная система, которая формирует контекстные запросы, включает в себя поисковую службу, компонент понимания запроса и генератор команд источника данных. Контекстные запросы формируются на основе онтологий, связанных с запросом, предоставленным клиентским устройством, и онтологий, соответствующих приложениям, которые сформулировали запрос. Поисковая служба принимает запрос от клиентского устройства и контекст от приложения. В свою очередь, поисковая служба передает ответы на контекстные запросы и результаты, которые включают в себя содержимое, соответствующее запросу клиентского устройства. Клиентское устройство отображает результаты вместе с ответами.
Фиг. 2 - сетевая диаграмма, иллюстрирующая примерные компоненты компьютерной системы, сконфигурированной, чтобы формировать контекстные запросы в соответствии с вариантом осуществления изобретения. Компьютерная система 200 содержит клиентское устройство 210, сеть 220, поисковую службу 230, генератор 240 команд источника данных и компонент 250 понимания запроса.
Клиентское устройство 210 соединено с поисковой службой 230 через сеть 220. В некоторых вариантах осуществления клиентское устройство 210 может являться любым вычислительным устройством, которое способно получать доступ к сети. По существу, клиентское устройство 210 может принимать множество различных форм, таких как персональный компьютер (ПК, PC), ноутбук, мобильный телефон, персональный цифровой помощник (PDA), сервер, CD-проигрыватель, МР3-проигрыватель, видеоплеер, портативные устройства связи, рабочая станция, любая комбинация этих выделенных устройств или любое другое устройство, способное получать доступ к сети.
Клиентское устройство 210 позволяет пользователю вводить запросы. Клиентское устройство 210 передает запросы поисковой службе 230. В некоторых вариантах осуществления клиентское устройство 210 также передает контекст, связанный с приложением, используемым пользователем, чтобы сформулировать запрос. В других вариантах осуществления поисковая служба 230 может предоставлять контекст. В свою очередь, клиентское устройство 210 принимает результаты, которые включают в себя ответы. Клиентское устройство 210 также может отображать ответы на контекстные запросы и результаты запросов пользователей.
Сеть 220 соединяет клиентское устройство 210 поисковую службу 230, генератор 240 команд источника данных и компонент 250 понимания запроса. Сеть 220 может быть проводной, беспроводной или обеими. Сеть 220 может включать в себя множественные сети или сети сетей. Например, сеть 220 может включать в себя одну или более глобальных вычислительных сетей (WAN), одну или более локальных вычислительных сетей (LAN), одну или более общественных сетей, таких как интернет, или одну или более частных сетей. В беспроводных сетях компоненты, такие как базовая станция, мачта связи, или даже точки доступа (а также и другие компоненты) могут предоставлять беспроводное соединение в некоторых вариантах осуществления. Хотя отдельные компоненты проиллюстрированы для ясности, специалист в данной области техники понимает, что сеть 220 может осуществлять взаимодействие между любым количеством клиентских устройств 210.
Поисковая служба 230 является серверным компьютером, который предоставляет результаты запросов, принятых от клиентских устройств 210, и ответы на контекстные запросы, динамически формируемые генератором 240 команд источника данных. Поисковая служба 230 сконфигурирована, чтобы принимать пользовательские запросы и контексты приложений. Поисковая служба 230 возвращает результаты пользовательских запросов и ответы на контекстные запросы. В некоторых вариантах осуществления поисковая служба 230 возвращает только ответы на контекстные запросы.
Генератор 240 команд источника данных коммуникативно соединен с компонентом 250 понимания запросов. В одном из вариантов осуществления генератор 240 команд источника данных включает в себя фильтры 242 и лексическую информацию 244. Генератор 240 команд источника данных сконфигурирован, чтобы преобразовывать семантическое представление, предоставляемое компонентом 250 понимания запросов, в контекстные запросы, которые применяются ко множеству источников данных, используя команды источника данных, выбранные на основе лексической информации 244, связанной с каждым источником данных. В одном из вариантов осуществления источники данных включают в себя неструктурированные, структурированные или слабоструктурированные источники данных, к которым делаются запросы, используя один из языка структурированных запросов (SQL), языка запросов к данным, представленным по модели RDF (SPARQL), или запросов текстового ключевого слова.
Фильтры 242 сконфигурированы, чтобы уточнять семантическое представление, предоставленное компонентом 250 понимания запросов. Фильтры 242 уточняют семантическое представление посредством расширения семантического представления на основе информации, связанной с текущим запросным сеансом. В одном из вариантов осуществления фильтр 242 включает в себя область знаний, сотрудничество, географию, время, задание и пользователя. Фильтр области знаний может определяться на основе контекста приложения. Например, пользователь, ищущий запасы, может интересоваться финансовой областью или областью кулинарии. Генератор 240 команд источника данных может выбирать одну из этих областей знаний на основе других фильтров 242. Например, фильтры сотрудничества или общества могут указывать, что пользователь связан с кулинарными группами или финансовыми группами. На основе группы, связанной с пользователем, генератор 240 команд источника данных выбирает значимый фильтр области знаний. Например, пользователь в финансовом сообществе вероятнее всего интересуется акциями компании. Соответственно фильтр области знаний может быть установлен на финансы. Географический фильтр может включать в себя текущее местоположение пользователя. Например, пользователь, который является британским субъектом в Англии, может отправить запрос, и географический фильтр может быть установлен на Англию компьютерной системой 200. Временной фильтр может включать в себя временные рамки запроса. Если дата или время не включены в запрос, временной фильтр может быть установлен на текущий 24-часовой период времени. Фильтр задания может выбираться на основе приложения, используемого пользователем, или может выводиться компьютерной системой 200. Фильтр задания может включать в себя проверку электронной почты, поиск содержимого, редактирование документа, т.д. Фильтр пользователя может включать в себя атрибуты профиля, которые перекрывают значения, выбранные другими фильтрами 242. Например, пользователь, являющийся британским субъектом, может указать в своем профиле, что его интересы включают в себя рынок акций США. Соответственно географическая информация для запроса об акциях может изменяться с Англии на Соединенные Штаты Америки. Эти значения для фильтров 242 включаются в семантическое представление, которое преобразуется в контекстные запросы посредством генератора 240 команд источника данных.
Компонент 244 лексической информации является частью генератора 240 команд источника данных. Компонент 244 лексической информации используется, чтобы выбирать источники данных, которые должны принимать контекстные запросы. Источники данных, содержащие лексическую информацию, схожую с терминами контекстного запроса, выбираются, чтобы принять контекстный запрос. В одном из вариантов осуществления компонент 244 лексической информации сохраняет лексическую информацию, связанную с онтологиями и источниками данных, которые хранят содержимое, которое прослежено поисковой службой. В некоторых вариантах осуществления интеллектуальный анализ текста выполняется компьютерной системой на каждом источнике данных, чтобы выбрать лексическую информацию, связанную с каждым источником данных, которая хранится в компоненте 244 лексической информации.
В свою очередь, генератор 240 команд источника данных формирует контекстные запросы, которые отправляются выбранным источникам данных. Семантическое представление запроса может дополнительно обрабатываться, чтобы выбрать подходящие команды для выбранных источников данных. Доступ к компоненту 244 лексической информации, онтологиям 252 и правилам 254 осуществляется, чтобы выделить методы для каждого источника данных, которыми осуществляется доступ к или вычисляется значимая информация из источника данных, на основе семантического описания концептов, свойств и отношений, включенных в семантическое представление.
Компонент 250 понимания запросов сконфигурирован, чтобы хранить онтологии 252, которые выделяют тип запроса и тип контекста. Компонент 250 понимания запросов также предоставляет правила 254, связанные с элементами в онтологиях 252, которые расширяют семантическое представление и выделяют методы, которыми осуществляется доступ к или вычисляется значимая информация из источников данных, на основе семантического описания концептов, свойств и отношений, выраженных в онтологиях 252. Например, тип запроса может выделять один или более типов ввода и один или более типов вывода, где типы ввода и вывода соответствуют концептам, экземплярам, свойствам или отношениям в онтологии запроса или онтологии контекста.
Компонент 250 понимания запросов сконфигурирован, чтобы формировать семантическое представление запроса и контекста. Онтология запроса и онтология контекста может использоваться компонентом 250 понимания запроса, чтобы сформировать граф семантического представления на основе универсальных идентификаторов ресурса (URI), связанных с каждым концептом, экземпляром и т.д., включенным в онтологии 252. Семантическое представление обусловлено подходящими правилами контекста пользовательского запроса и контекста приложения.
В одном из вариантов осуществления граф является семантическим представлением запроса (SQR), который форматируется на расширяемом языке разметки (XML). SQR может включать в себя следующие узлы: тип запроса (QT), контекст (СХТ) и шаблоны отображения (DSP). Например, запрос на естественном языке для компании А может иметь следующее SQR <QT : профиль экземпляра : компания; тип экземпляра : акции; URI экземпляра : компания А> <СХТ : естественный язык, финансы> <DSP : название компании, символ, новости>.
В зависимости от источника данных семантическое представление запроса переводится в относящиеся к источнику данных запросы, чтобы извлечь значимые ответы и информацию из этих источников данных. В семантическом представлении QT является формальным представлением иерархии различных типов запросов, которые приложение может ожидать от его пользователей. Каждый QT квалифицируется набором параметров ввода и вывода, которые облегчают расширения других частей онтологии. СХТ является формальным представлением иерархии различных типов контекстов, в которых пользовательский запрос может быть охвачен и интерпретирован. СХТ может явно определяться приложениями, с которыми взаимодействует пользователь, чтобы отправлять запросы, или неявно извлекаться из текста запроса. Каждый СХТ выделяет условия и критерии для интерпретации концептов, экземпляров и т.д. в заданном запросе. СХТ может либо расширять, либо устранять неоднозначность концептов, экземпляров и т.д., включенных в семантическое представление запроса. Семантический граф структурирован согласно шаблонам QT и СХТ, связанным с типом запроса в онтологии типа запроса и типом контекста в онтологии типа контекста, и лексической информации, связанной с каждым источником данных.
Онтологии 252 включают в себя слова или фразы, которые соответствуют содержимому в источниках данных. Каждая онтология 252 включает в себя систематизацию области знаний и связь между словами или фразами в области знаний. Области знаний могут включать в себя медицину, искусство, компьютеры и т.д. В одном из вариантов осуществления онтологии 252 также сохраняют тип запроса и тип контекста. Тип запроса выделяет тип и структуру текстовых пользовательских запросов. Например, тип запроса может включать в себя естественный язык, структурированную, линейную команду и т.д. Тип контекста идентифицирует и организовывает различные типы контекстов, в которых может быть выражен запрос. Например, контекст может включать в себя поисковую службу, приложение электронной почты, финансовое приложение и т.д. Онтология 252 связана с правилами 254. Правила могут указываться ссылкой в семантическом представлении запроса, используя URI, соответствующий подходящему правилу.
Правила 254 выделяют концепты, экземпляры, свойства и отношения среди множества областей. В некоторых вариантах осуществления правила 254 могут определять методы или функции, которые используются, чтобы вычислить результаты из данных, включенных в источники данных. Например, правила 254 могут включать в себя схемы сравнения, математические функции, статистические функции или другие эвристики. В других вариантах осуществления правила 254 также могут быть связаны с функциями, определенными в командах, доступных для источников данных.
В варианте осуществления ответы передаются клиентскому устройству на основе контекстных запросов, которые динамически формируются из запросов, принятых от пользователя клиентского устройства. Компьютерная система может выполнять машинно-исполняемый способ для динамического формирования контекстных запросов на основе онтологий, соответствующих запросу, и приложения, используемого пользователем при формировании запроса.
Фиг. 3 - логическая диаграмма, иллюстрирующая машинно-исполняемый способ для формирования контекстных запросов в соответствии с вариантом осуществления изобретения. Способ начинается на этапе 310, когда компьютерная система подключается к сети клиентских устройств.
На этапе 320 компьютерная система принимает пользовательский запрос и контекст приложения. Контекст предоставляется приложением, которое пользователь использует во время текущего запросного сеанса. На этапе 330 компьютерная система формирует семантическое представление запроса, используя онтологии области знаний. Компьютерная система определяет тип запроса и контекста, используя онтологии запроса и контекста. Структура для семантического представления извлекается из шаблона, связанного с типом запроса, включенным в онтологию запроса, или типом контекста, включенным в онтологию контекста.
Семантическое представление уточняется, используя фильтры, связанные с каждой областью знаний, прослеживаемой в текущем запросном сеансе, на этапе 340. Фильтры дополняют семантическое представление критериями, связанными с одним или более приложениями, используемыми пользователем во время запроса текущего запросного сеанса. На этапе 350 компьютерная система выбирает одну или более команд источника данных, чтобы отправить их источникам данных, имеющим содержимое, связанное с терминами в запросе. В конкретных вариантах осуществления источники данных включают в себя структурированные источники данных, неструктурированные источники данных и слабоструктурированные источники данных. Структурированные источники данных запрашиваются с использованием одного из языка структурированных запросов (SQL), языка запросов к данным, представленным по модели RDF (SPARQL). Неструктурированные или слабоструктурированные источники данных запрашиваются с использованием запросов текстового ключевого слова. Способ завершается на этапе 360.
Таким образом, контекстные запросы позволяют пользователю прослеживать множество источников данных, используя информацию, встроенную в онтологии, связанные с запросом, предоставленным пользователем, и онтологиями, связанными с приложениями, используемыми, чтобы сформировать запрос. Например, пользователь может отправить запрос поисковой службе, которая вернет некоторое количество результатов. Вдобавок поисковая служба может также предоставить ответы, связанные с контекстными запросами, сформулированными из пользовательского запроса.
Например, ответы на финансовые запросы пользователя возвращаются компьютерной системой, используя основанное на онтологии понимание финансовых запросов. Компьютерная система может предоставлять финансовое приложение, которое позволяет пользователю получать ответы на запросы на естественном языке, например «Компании с отношением РЕ, близким к компании А», «Операционный доход компании А» и «Оценка компании А и В». Обработка последнего запроса может использовать онтологию, чтобы понять, что оценка включает в себя определенное количество ключевых отношений, которые должны быть рассчитаны, используя текущие данные. Ключевые отношения могут включать в себя помимо прочего «Отношение РЕ», «Отношение цены к продажам» и т.д. В свою очередь, финансовое приложение возвращает сравнение этих отношений и оценочные показатели для компаний А и В. Запросы на естественном языке и соответствующие онтологии используются, чтобы сформировать семантическое представление. Финансовое приложение может преобразовывать семантическое представление в запрос SPARQL, который передается источникам данных, которые включают в себя записи, которые прослеживаются, чтобы вернуть ответы.
Компьютерная система принимает запрос: «MSFT более высокое РЕ» от пользователя и контекст приложения: «финансы» и «естественный язык» из финансового приложения. Компьютерная система выделяет онтологию финансов и онтологию естественного языка. В свою очередь, запрос преобразуется с использованием лингвистической интерпретации в «MSFT более высокое/высокое - 1 РЕ». Финансовая онтология может использоваться, чтобы дополнительно преобразовать семантическое представление, используя математические операторы и определение отношения РЕ.
Семантическое представление преобразуется в «MSFT более высокое/высокое - 1 схема сравнения РЕ». Компьютерная система может применять некоторое количество фильтров, чтобы уточнить семантическое представление. В варианте осуществления семантическое представление является графом запроса, формируемым, используя онтологии. Фильтры включают в себя область знаний, сотрудничество, географию, время, задание и интересы пользователя. После применения этих фильтров компьютерная система преобразует запрос в «Тикер MSFTUS/тикер более высокое превосходящее - 1 РЕ/отношение РЕ Дата: сегодня». В свою очередь, семантическое представление преобразуется в команды источника данных. Компьютерная система может отправить следующее: Ticker.PeRatio>MSFTQUS.PERatio&&Date=today. Эта команда источника данных отправляется множеству источников данных, чтобы найти ответы.
Множество различных систематизаций различных изображенных компонентов, а также не показанных компонентов, возможны без отклонения от сущности и объема изобретения. Варианты осуществления изобретения были описаны с намерением быть скорее иллюстративными, чем ограничительными. Понятно, что определенные признаки и субкомбинации являются полезными и могут использоваться без ссылки на другие признаки и субкомбинации, и подразумеваются включенными в объем формулы изобретения. Не все этапы, перечисленные на различных чертежах, должны выполняться в конкретном описанном порядке.
| название | год | авторы | номер документа |
|---|---|---|---|
| ИСЧЕРПЫВАЮЩАЯ АВТОМАТИЧЕСКАЯ ОБРАБОТКА ТЕКСТОВОЙ ИНФОРМАЦИИ | 2014 |
|
RU2662699C2 |
| СИСТЕМА И МЕТОД СЕМАНТИЧЕСКОГО ПОИСКА | 2013 |
|
RU2563148C2 |
| СПОСОБ КЛАСТЕРИЗАЦИИ РЕЗУЛЬТАТОВ ПОИСКА В ЗАВИСИМОСТИ ОТ СЕМАНТИКИ | 2014 |
|
RU2564629C1 |
| ПОДДЕРЖАНИЕ КОНТЕКСТНОЙ ИНФОРМАЦИИ МЕЖДУ ПОЛЬЗОВАТЕЛЬСКИМИ ВЗАИМОДЕЙСТВИЯМИ С ГОЛОСОВЫМ ПОМОЩНИКОМ | 2018 |
|
RU2785950C2 |
| ОРКЕСТРОВКА СЛУЖБ ДЛЯ ИНТЕЛЛЕКТУАЛЬНОГО АВТОМАТИЗИРОВАННОГО ПОМОЩНИКА | 2011 |
|
RU2556416C2 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ И ИСПОЛЬЗОВАНИЯ ПОЛЬЗОВАТЕЛЬСКИХ СЕМАНТИЧЕСКИХ СЛОВАРЕЙ ДЛЯ ОБРАБОТКИ ПОЛЬЗОВАТЕЛЬСКОГО ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2584457C1 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ И ИСПОЛЬЗОВАНИЯ ПОЛЬЗОВАТЕЛЬСКИХ ОНТОЛОГИЧЕСКИХ МОДЕЛЕЙ ДЛЯ ОБРАБОТКИ ПОЛЬЗОВАТЕЛЬСКОГО ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2596599C2 |
| ИСПОЛЬЗОВАНИЕ ТЕКСТА ОПОВЕЩЕНИЯ О СОБЫТИИ В КАЧЕСТВЕ ВВОДА В АВТОМАТИЗИРОВАННЫЙ ПОМОЩНИК | 2011 |
|
RU2546604C2 |
| ИЗВЛЕЧЕНИЕ СУЩНОСТЕЙ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2626555C2 |
| ОПРЕДЕЛЕНИЕ НАМЕРЕНИЯ ПОЛЬЗОВАТЕЛЯ НА ОСНОВЕ ОНТОЛОГИЙ ПРЕДМЕТНЫХ ОБЛАСТЕЙ | 2011 |
|
RU2541221C2 |
Изобретение относится к компьютерной технике, а именно к автоматизированным поисковым системам. Техническим результатом является повышение точности представления пользователям релевантной информации за счет формирования контекстных поисковых запросов, связанных с семантическим представлением данных. Предложен компьютерно-реализуемый способ формирования контекстных запросов. Способ включает в себя этап, на котором принимают пользовательский запрос и контекст, причем контекст предоставляется одним или более приложениями, которые пользователь использует во время текущего запросного сеанса. Далее согласно способу формируют семантическое представление упомянутого запроса с использованием онтологий области знаний, при этом онтологии области знаний идентифицируют фильтры, концепты и отношения в некотором количестве категорий, а также уточняют семантическое представление с использованием фильтров, связанных с каждой областью знаний, прослеживаемой в текущем запросном сеансе. 3 н. и 17 з.п. ф-лы, 3 ил.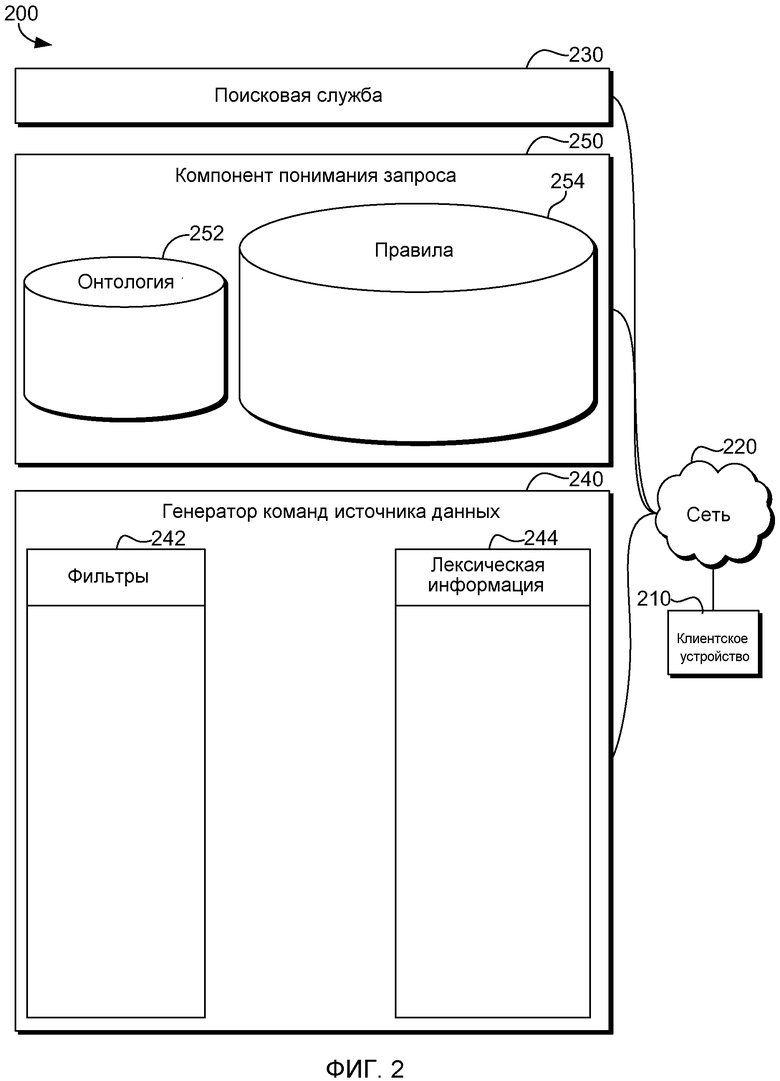
1. Компьютерно-реализуемый способ формирования контекстных запросов, содержащий этапы, на которых:
принимают пользовательский запрос и контекст, причем контекст предоставляется одним или более приложениями, которые пользователь использует во время текущего запросного сеанса;
формируют семантическое представление упомянутого запроса с использованием онтологий области знаний, при этом онтологии области знаний идентифицируют фильтры, концепты и отношения в некотором количестве категорий;
уточняют семантическое представление с использованием фильтров, связанных с каждой областью знаний, прослеживаемой в текущем запросном сеансе, при этом некоторые фильтры дополняют семантическое представление критериями упомянутых одного или более приложений, используемых пользователем во время текущего запросного сеанса; и
выбирают одну или более команд источника данных для их выдачи по отношению к источникам данных, имеющим содержимое, связанное с терминами в упомянутом запросе, на основе упомянутых контекста и семантического представления.
2. Способ по п. 1, в котором некоторые фильтры включают в себя математические операторы, которые связаны с упомянутыми одним или более приложениями, используемыми пользователем.
3. Способ по п. 1, дополнительно содержащий этап, на котором определяют тип запроса и контекста с использованием онтологий запроса и контекста.
4. Способ по п. 3, в котором структура для семантического представления получается из шаблона, связанного с типом запроса, включенным в онтологию запроса.
5. Способ по п. 1, в котором контексты приложения для одного или более приложений выбираются из онтологий области знаний при формировании семантического представления запроса.
6. Способ по п. 1, в котором источники данных включают в себя структурированные источники данных, неструктурированные источники данных и слабоструктурированные источники данных.
7. Способ по п. 6, в котором структурированные источники данных запрашиваются с использованием одного из языка структурированных запросов (SQL) и языка запросов к данным, представленным по модели RDF (SPARQL).
8. Способ по п. 6, в котором неструктурированные или слабоструктурированные источники данных запрашиваются с использованием текстовых запросов с ключевыми словами.
9. Способ по п. 6, в котором команды источника данных выбираются на основе лексической информации, связанной с каждым источником данных.
10. Машиночитаемый носитель, сконфигурированный выполнять способ обработки запросов, содержащий:
прием пользовательского запроса и контекста, причем контекст предоставляется одним или более приложениями, которые пользователь использует во время текущего запросного сеанса;
формирование семантического представления запроса с использованием онтологий области знаний;
уточнение семантического представления с использованием фильтров, связанных с каждой областью знаний, прослеживаемой в текущем запросном сеансе, при этом некоторые фильтры дополняют семантическое представление критериями упомянутых одного или более приложений, используемых пользователем во время текущего запросного сеанса; и
выбор одной или более команд источника данных для их выдачи по отношению к источнику данных, имеющему содержимое, связанное с терминами в упомянутом запросе.
11. Носитель по п. 10, причем некоторые фильтры включают в себя математические операторы, которые связаны с упомянутыми одним или более приложениями, используемыми пользователем в течение упомянутого сеанса.
12. Носитель по п. 10, причем способ дополнительно содержит определение типа запроса и контекста с использованием онтологий запроса и контекста.
13. Носитель по п. 12, причем структура для семантического представления получается из шаблона, связанного с типом запроса, включенным в онтологию запроса.
14. Носитель по п. 10, причем контексты приложения для упомянутых одного или более приложений выбираются из онтологий области знаний при формировании семантического представления запроса.
15. Носитель по п. 10, причем источник данных включает в себя структурированные источники данных, неструктурированные источники данных и слабоструктурированные источники данных.
16. Носитель по п. 15, причем структурированные источники данных запрашиваются с использованием одного из языка структурированных запросов (SQL) и языка запросов к данным, представленным по модели RDF (SPARQL).
17. Носитель по п. 15, причем неструктурированные или слабоструктурированные источники данных запрашиваются с использованием текстовых запросов с ключевыми словами.
18. Компьютерная система, содержащая процессоры и запоминающие устройства, сконфигурированные формировать контекстные запросы, причем система дополнительно содержит:
поисковую машину, сконфигурированную принимать пользовательские запросы и контексты;
компонент понимания запроса, сконфигурированный хранить онтологии, которые идентифицируют тип запроса и тип приложения, причем тип запроса идентифицирует один или более типов ввода и один или более типов вывода, при этом типы ввода и вывода соответствуют концептам, экземплярам, свойствам или отношениям в онтологии области знаний или онтологии приложения; и
генератор команд источника данных, соединенный с возможностью обмена данными с компонентом понимания запроса, при этом генератор команд источника данных сконфигурирован преобразовывать семантическое представление, предоставляемое компонентом понимания запроса, в контекстные запросы, которые применяются к множеству источников данных, используя команды источника данных, выбранные на основе лексической информации, связанной с каждым источником данных.
19. Компьютерная система по п. 18, в которой онтологии предоставляют правила, которые расширяют семантическое представление запроса и идентифицируют методы, которыми осуществляется доступ к или вычисление релевантной информации из источников данных, на основе семантического описания концептов, свойств и отношений, выраженных в онтологиях.
20. Компьютерная система по п. 18, в которой источники данных включают в себя неструктурированные, структурированные и слабоструктурированные источники данных и запрашиваются с использованием одного из языка структурированных запросов (SQL), языка запросов к данным, представленным по модели RDF (SPARQL), и текстовых запросов с ключевыми словами.
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| КОМПЬЮТЕРНЫЙ ПОИСК С ПОМОЩЬЮ АССОЦИАТИВНЫХ СВЯЗЕЙ | 2004 |
|
RU2343537C2 |
| АРХИТЕКТУРА МНОГОУРОВНЕВОГО БРАНДМАУЭРА | 2004 |
|
RU2365986C2 |

