Ссылки на связанные заявки
Настоящая заявка содержит предмет, связанный с заявкой на патент США 10/687602, поданной 29 октября 2003 г., и с заявкой на патент США 10/918713, поданной 25 августа 2004 г., полное содержание которых включено сюда посредством ссылки. Настоящая заявка также заявляет приоритет по предварительной заявке 60/610221, поданной 16 сентября 2004 г., полное содержание которой включено сюда посредством ссылки.
Область техники, к которой относится изобретение
Способ, устройство и компьютерный программный продукт для помощи в поиске и навигации среди файлов. Способ обеспечивает построение сети ссылок, соединяющих документы, и пригоден по меньшей мере в случае, когда такая сеть не существует предварительно, например для отдельного пользователя или маленькой группы, совместно использующей документы.
Уровень техники
Текущее состояние удручает любого пользователя персонального компьютера. Пользователь приучен находить в Сети по существу немедленно почти все, что его интересует, по любой теме, выбирая из сетевых документов, число которых сейчас превышает 8 миллиардов, причем результаты ранжированы так хорошо, что обычно несколько совпадений при поиске с наивысшим рангом дают пользователю то, что он просил. Кроме того, для пользователя несложно, найдя хорошее совпадение, следовать по связям от этого совпадения и таким образом обнаруживать связанные документы.
В то же время у того же пользователя есть, возможно, тысячи или миллионы файлов на его персональном компьютере. Этому пользователю нужно также осуществлять поиск и навигацию по этим файлам. Причина этого, конечно, в том, что число файлов делает невозможным запомнить, что это за файлы, где они находятся в иерархической файловой системе и что они содержат. Таким образом, пользователю нужна помощь: а) в поиске конкретных файлов и б) в поиске файлов, относящихся к теме. Это, конечно, в точности тот тип помощи, который можно получить - в случае Сети - от существующих поисковых машин Сети. Удрученный пользователь может спросить, почему настолько труднее найти что-то в его собственном компьютере?
Настоящее изобретение предназначено для удовлетворения как раз этой потребности. То есть это изобретение предлагает способы для поиска и навигации среди персональных файлов. Оно также подходит для поддержки тех же функций для файлов, совместно используемых группами (пользователей).
Текущее состояние технологии поддержки поиска и навигации по персональным файлам достаточно ограниченно. Как отмечено выше, в настоящее время имеется отчетливый разрыв между потребностями пользователя в поиске по растущим объемам персонального содержимого и способностью современной технологии удовлетворить эту потребность. В последнее время многие различные компании осознали этот разрыв и усиленно работают над его заполнением, так как большая неудовлетворенная потребность представляет большую возможность для предпринимательства. Следовательно, при обсуждении текущего состояния техники мы будем включать в него как ограниченные технологические решения, которые можно купить и использовать сегодня, так и такие, относительно которых были сделаны объявления или намеки в средствах массовой информации. Особенность состоит в том, что эта область находится в состоянии быстрого роста и изменения.
Идея «поиска на рабочем столе» - означающая поисковое приспособление для локального запуска на собственном компьютере пользователя - уже существует некоторое время. Одна из первых поисковых машин Интернета, AltaVista, в 1998 году начала «дарить» свободное программное обеспечение для персональных компьютеров под названием AltaVista Discovery. Здесь мы видим раннее осознание факта, который сейчас понимают многие: абсолютное число цифровых документов, к которым должен иметь отношение даже один пользователь, возросло настолько, что старый иерархический метод организации и навигации по файлам стал безнадежно неадекватным.
Microsoft осознала проблему, перед которой стоят пользователи ПК, ищущие информацию в компьютерных файлах, более десяти лет назад. Microsoft'овское видение унифицированного хранилища данных в ее операционной системе Windows (Cairo, включающей в себя OFS - объектную файловую систему (Object File System); идеи, восходящие по меньшей мере к 1990 г.) явилось источником многих публичных сообщений. Эти сообщения продолжаются до настоящего времени и часто пересматриваются. (После нескольких отсрочек текущая объявленная дата запуска для следующей версии Windows под кодовым именем Longhorn - это 2006 г.) Решение, предлагаемое Microsoft, состоит в замене базового доступа в ее операционной системе Windows технологией, заимствованной из ее программного обеспечения баз данных SQL Server. В настоящее время документы, сетевые страницы, файлы электронной почты, электронные таблицы и другая информация запоминаются в раздельных, большей частью несовместимых программах. Новая технология под кодовым именем WinFS обещает унифицировать хранение в единой базе данных, встроенной в Windows, которая будет допускать более легкий поиск, будет более надежна и доступна из корпоративных сетей и Интернета.
В октябре 2004 г. Google выпустила бета-версию своей машины Google Desktop Search. В противоположность «все капитально ремонтирующему» подходу Microsoft Google Desktop Search состоит из относительно малого и легко загружаемого набора программных модулей, которые сканируют и индексируют содержимое пользовательского компьютера. Индекс затем используется для поддержки быстрого поиска. Индексируемые документы включают в себя текстовые файлы, файлы Word, Powerpoint, Excel, почтовые файлы Outlook и просмотренные сетевые документы.
Впоследствии (в декабре 2004 г.) Microsoft выпустила бета-версию ее Microsoft Toolbar Suite, охватывающую как поиск на рабочем столе, так и поиск в Сети. Перед этим Microsoft приобрела технологию поиска на рабочем столе Lookout; Lookout, как очевидно из ее названия, ориентирована на поиск в файлах Outlook.
Также в декабре 2004 г. Ask Jeeves представила бета-версию загружаемой машины поиска на рабочем столе. Эта машина, вероятно, включает в себя технологию, полученную от компании Tukaroo, которую купила Ask Jeeves. В том же месяце Yahoo объявила, что она выпустит тест-версию в начале 2005 г. Yahoo закупила большое количество ранее разработанных технологий, из которых наиболее заметна Overture, которая сама закупила некоторые (поисковые) машины, в том числе AllTheWeb. Yahoo разрабатывает свою машину поиска на рабочем столе совместно с X1.
Есть много других компаний, предлагающих продукты для поиска на рабочем столе. Краткое резюме выше, без сомнения, быстро устаревает; поэтому мы не стремимся к полноте. Обзор компаний и продуктов для поиска на рабочем столе может быть найден в http://www.goebelgroup.com/desktopmatrix.htm.
Важный вопрос состоит в том, какую технологию используют эти новые игроки. Некоторая информация может быть обнаружена в общедоступных объявлениях этих компаний; но очень трудно найти какие-либо детали о действительной технологии поиска, которая используется. Кажется ясным, что громадное большинство этих фирм предлагает поиск, основанный на ключевых словах, с использованием индексации по различным типам файлов; многие также предлагают поиск как по рабочему столу, так и по предприятию. Однако мы не нашли ни одной компании, которая явным образом основывает ранжирование результатов поиска на анализе связей. На самом деле неясно, использует ли какая-либо из этих компаний связи вообще - либо для ранжирования, либо для навигации.
Технология, очевидно использующая связи, - это технология Autonomy Corporation. Autonomy недавно запустила IDOL Enterprise Desktop Search. Технология Autonomy включает симметричные «связи подобия» между документами. Мера подобия сложна и использует вероятностные измерения подобия понятий. В процессе поиска также используется анализ понятий вместо опоры исключительно на ключевые слова. Однако нет признаков использования односторонних гиперсвязей, таких как использованные в настоящем изобретении, и нет свидетельств использования анализа связей. Фактически Autonomy явным образом отказалась от использования любого вида техники ранжирования страниц. То есть, как отмечено в пресс-релизе, доступном на http://www.autonomy.com/content/Press/Archives/2004/1206.html: «Вместо ранжирования страниц, подхода, доказавшего свою неэффективность в области, свободной от связей, Руководство Автоматического Запроса использует кластеризацию понятий».
Таким образом, как обнаружено авторами настоящего изобретения, для построения хороших средств поиска, ранжирования и навигации для широкого множества видов документов предпочтительно иметь соответствующую структуру связей в локальной файловой системе, которая может быть использована в анализе связей. Вид структуры связей, присутствующий во Всемирной Паутине, представляет людям много лучший способ связываться с информацией, чем традиционная иерархическая файловая система, в которой каждый документ втиснут в единственное место иерархического дерева. Если такая структура связей уже присутствует на сегодняшних компьютерах, то, возможно, уже существует и основанное на анализе связей устройство поиска и ранжирования для локальных жестких дисков.
Ни одно из решений, предложенных к настоящему времени, не строит необходимую инфраструктуру связей для обеспечения основанного на анализе связей ранжирования для поиска и навигации по файлам для отдельного пользователя или небольшой группы. Настоящее изобретение исправляет это положение, предлагая способ генерации локальной структуры связей.
Как детально объясняется ниже, гиперсвязи (гиперссылки) могут обеспечивать два типа информации: они могут показывать подобие между двумя файлами (симметрично) и (или) предполагать рекомендацию, что пользователь, начинающий с файла A, может посчитать файл B интересным (односторонне или асимметрично). Кроме того, связи могут быть использованы для двух целей: они могут помочь в поиске (через ранжирование) и в навигации.
Существующие технологии для систем документов не из Всемирной паутины либо совсем не имеют гиперсвязей - таким образом упуская преимущества как ранжирования, так и навигации - или используют только подобие (как Autonomy). В последнем случае теряется возможность использования человеческих суждений для обеспечения рекомендаций о файлах и об отношениях между файлами. Без таких рекомендаций и поиск (ранжирование), и навигация теряют в качестве.
Анализ связей (ссылок) сыграл решающую роль в огромном успехе машины поиска в Сети Google. До Google основные подходы к ранжированию совпадений при поиске использовали одно или несколько из: релевантности текста, «популярности связи» и человеческого суждения (Yahoo). Релевантность текста важна всегда, но сама по себе недостаточна для получения хороших результатов ранжирования. Популярность связи характеризуется подсчетом связей, указывающих на страницу. Популярность связи - это самая грубая форма анализа связей, и ее слишком легко исказить фальшивыми связями. Наконец, человеческое суждение, хотя и всегда полезно, слишком медленно и дорого для распределенных систем документов с большим количеством документов и высокой скоростью оборота.
Google была первой, известной авторам изобретения, поисковой машиной в Сети, использующей нетривиальный анализ связей при помощи хорошо известного алгоритма PageRank (ранжирования страниц). Преимущество PageRank - вместе с другими формами нетривиального анализа связей, такими как указано в заявке на патент США 10/687602 и заявке на патент США 10/918613, - состоит в том, что PageRank использует коллективную форму человеческого суждения. Это значит, что большая часть громадного числа связей, соединяющих миллиарды сетевых страниц, проложена миллионами людей (разработчиками сетевых страниц). Следовательно, нетривиальный анализ связей является разумным способом использовать бесплатную работу этих миллионов людей, извлекая их коллективное суждение, чтобы найти лучшие сетевые страницы.
Большей частью, когда разработчик сетевой страницы устанавливает связь со своей собственной страницы A на другую страницу B, это значит (по мнению разработчика сетевой страницы), что читатель, заинтересовавшийся страницей A, возможно, также заинтересуется страницей B. То есть такая связь может интерпретироваться как влекущая некоторую смесь двух факторов: (i) что страница B подобна странице A и (или) (ii) что страница B, возможно, интересна кому-либо, заинтересовавшемуся страницей A.
Коротко: анализ связей ценен потому, что связи выражают две вещи: подобие и рекомендацию.
Хотя эти подходы и применялись в сетевых окружениях, потребители оказались перед дилеммой, как работать с тысячами или миллионами файлов, расположенных на их персональных компьютерах.
Авторы настоящего изобретения осознали желательность инструментов разработки Персональной Сети связей, позволяющей пользователю ранжировать совпадение при поиске по ключевому слову и обеспечивающей навигацию по этим файлам. Термин «Персональная Сеть» относится к сети связей между документами, построенных при помощи настоящего изобретения. Персональная Сеть включает в себя комбинацию из: (i) ненаправленных взвешенных связей, основанных на подобии; (ii) направленных взвешенных связей, которые могут или не могут быть привязанными к тексту в указывающем или указанном документе и которые представляют рекомендацию, и (iii) весов (оценок важности), приписанных документам самим по себе - опять-таки представляющим рекомендацию.
Ранжирование и навигация всегда будут важными функциями в мире больших информационных массивов. Персональная сеть поддерживает обе эти функции единственным и эффективным способом - включением в себя двух решающих аспектов подобия и рекомендаций - как детально обсуждается далее.
Сначала мы рассмотрим подобие. Настоящее изобретение использует машинные алгоритмы для вычисления подобия между документами или файлами. Как отмечено выше, по меньшей мере один из других подходов (подход Autonomy) использует анализ подобия между документами для поддержки пользователя при поиске и навигации по этим документам. Данная мера подобия отличается от меры, принятой Autonomy. Другое отличие состоит в использовании взвешенных связей подобия, которые генерируются ранее описанным анализом подобия как компонентом общего подхода к анализу связей, который, в свою очередь, поддерживает ранжирование совпадений при поиске. Кроме того, связи подобия играют важную роль в поддержке навигации.
Затем мы переходим к рекомендации. Рекомендации часто лучше всего выполняются людьми. Однако в случае единственного пользователя оценка его собственных файлов несколько отличается от случая оценки файлов в Сети. В Сети миллионы пользователей сотрудничают в рекомендациях относительно миллиардов сетевых страниц. В этой ситуации каждый пользователь дает рекомендации для относительно малого числа других документов. В случае одного пользователя для него часто оказывается невозможным или непрактичным проходить через множество ранее существовавших файлов и пытаться установить связи, указывающие на другие связанные или интересные файлы. Иными словами, невозможно просто создать «Сеть на рабочем столе», пытаясь создать персональную Сеть так же, как Всемирную паутину, так как бремя работы для одного пользователя слишком велико.
Другое отличие от Всемирной паутины также существенно. Это отличие состоит в том, что единственный пользователь часто оказывается единственным человеком, который может оценить степень интереса к его собственным файлам - никто другой не может сделать этого, и машина также не может. Пользователь должен прочитать или, по меньшей мере, хотя бы немного знать все эти файлы. В противоположность этому во Всемирной паутине не существует способа, которым один человек мог бы оценить все страницы Сети.
Подводя итог этим двум различиям: в Сети многие люди выполняют работу чтения и многие люди выполняют работу рекомендации/оценивания через гиперсвязи. В случае единственного пользователя можно ожидать, что один человек (хотя и не безупречно) выполняет работу чтения файлов; и, кроме того, нельзя ожидать, что этот же человек захочет выполнять работу установления связей от каждого файла к другим. Это несоответствие между ресурсами лиц, дающих рекомендации, и числом документов, которые должны быть просмотрены/рекомендованы, препятствует какому-либо систематическому применению гиперсвязей к системам документов, отличных от Всемирной паутины.
Для учета этого несоответствия настоящее изобретение включает в себя гибридную форму рекомендации. Эта гибридная форма обеспечивает пользователю возможность установки гиперсвязи от одного файла к другому. Эта гибридная форма обеспечивает также другой механизм рекомендации: каждому файлу дается «оценка качества файла» (ОКФ) (FQS). У каждого файла есть значение по умолчанию, которое находится достаточно низко на шкале возможных FQS. Это значение может быть изменено автоматически на основании таких измерений, как новизна и/или частота использования документа. Кроме того, пользователь может увеличить (или уменьшить) эту FQS по желанию, когда это удобно - например, после открытия/чтения файла. FQS является наименее трудоемким способом включения рекомендаций в систему документов. Настоящее изобретение добавляет даже еще бóльшую гибкость за счет обеспечения дополнительной возможности выбранных пользователем гиперсвязей. Именно в этом смысле один вариант осуществления системы рекомендаций является гибридным: он включает в себя как веса вершин в графе (документы с их FQS), так и направленные связи между вершинами (тем самым рекомендуя указанный документ из указывающего документа).
Сущность изобретения
Способ, устройство и компьютерный программный продукт для персональной поисковой машины, включающей в себя Персональную Сеть, состоящую из: сети подобия, гиперсвязей (генерируемых вручную и автоматически) и оценок качества файлов, обновляемых как вручную, так и автоматически. Компоненты включают в себя синтаксический анализатор (выделяющий слова из документов); анализатор релевантности текстов; способ анализа связей; сеть подобия; анализатор подобия и гиперсвязи, применяемые к персональным файлам на компьютере. Другие компоненты включают в себя навигационное окно и FQS. Комбинация всего вышеперечисленного может быть включена в работающую машину персонального поиска.
Краткое описание чертежей
Фиг.1 иллюстрирует два типа гиперсвязей между документами, используемых в настоящем изобретении.
Фиг.2 представляет собой блок-схему алгоритма поисковой машины согласно одному варианту осуществления настоящего изобретения.
Фиг.3 является представлением гибридной Сети согласно одному варианту осуществления изобретения.
Фиг.4 представляет собой блок-схему алгоритма навигации согласно одному варианту осуществления изобретения.
Фиг.5 является иллюстрацией структуры единственной группы с точки зрения единственного пользователя согласно одному варианту осуществления изобретения.
Фиг.6 является иллюстрацией согласно одному варианту осуществления изобретения двух возможных путей определения поднабора файлов, используемых для построения подграфа и выполнения анализа связей, для случая нескольких групп.
Фиг.7 является иллюстрацией согласно одному варианту осуществления изобретения двух возможных подграфов, используемых для анализа связей, для случая нескольких групп.
Фиг.8 представляет собой блок-схему компьютера, используемого в одном варианте осуществления изобретения.
Подробное описание изобретения
Настоящее изобретение включает в себя построение «Персональной Сети» среди документов, которые иначе имели бы ограниченную структуру связей или не имели бы никакой. Персональная Сеть включает в себя комбинацию из: (i) ненаправленных взвешенных связей на основе подобия; (ii) направленных взвешенных связей, которые могут или не могут быть привязанными к тексту в указывающем или указанном документе и которые представляют рекомендацию, и (iii) весов (оценок важности), приписанных документам самим по себе - опять-таки представляющих рекомендацию.
Для описания этой структуры мы используем также термин «гибридная Сеть». Персональная Сеть является гибридной в двух смыслах. Во-первых, она использует гибридную смесь взвешенных симметричных связей подобия и взвешенных направленных связей рекомендации. Во-вторых, важная функция рекомендации достигается с помощью гибридной смеси направленных связей и оценок качества файлов (FQS).
Далее мы тщательно разрабатываем гибридную форму рекомендации, используемую в настоящем изобретении. Этот гибридный подход обеспечивает пользователю возможность прокладки гиперсвязи от любого файла к любому иному файлу. (Как видно ниже, эта гиперсвязь может или не может быть привязана к конкретному тексту с любого конца.) В этом контексте мы предлагаем точное определение термина «гиперсвязь», чтобы избежать неопределенности. Логически гиперсвязь представляет собой указатель, который указывает из файла (скажем, файла А) на другой файл (скажем, файл В). Помимо того, можно связать с этим указателем вес гиперсвязи (HLW). Это логическое определение (указатель плюс вес) подразумевается, когда бы мы ни использовали термин гиперсвязь в описании настоящего изобретения. Физически такие гиперсвязи воплощаются, как правило, в виде метаданных, которые обычно включаются в метаданные файла А (хранятся с ними) - указывающий файл. Кроме того, любой вес, связанный с гиперсвязями, также хранится как метаданные - обычно (опять-таки) для файла А.
В дополнение к гиперсвязям подход гибридных рекомендаций обеспечивает другой механизм рекомендации: каждому файлу будет придана оценка качества файла, или FQS. Первоначально каждому файлу для его FQS дается значение по умолчанию, которое достаточно низко по шкале возможных FQS. Пользователь может затем увеличить (или даже уменьшить) эту FQS по желанию.
Кроме того, в одном варианте осуществления изобретения могут использоваться автоматические способы изменения FQS. Например, компьютер может сам зарегистрировать число раз, когда файл открывается и (или) редактируется за период времени, и дать более высокие оценки FQS файлам, которые открываются часто. Кроме того, недавность обращения может быть использована как мера важности.
Обоснование для этой гибридной системы состоит в следующем. Во-первых, не требуется никакого истощающего труда. Рекомендации получают только файлы, для которых пользователь побуждается сделать это. Во-вторых, выбор FQS легче, чем установка связей, - это, по всей видимости, наименее требовательная форма возможной рекомендации. И еще здесь необходимы минимальные усилия пользователя. Файлы начинаются с FQS по умолчанию; ее, в свою очередь, можно видоизменить определенными измеряемыми машиной указателями (индикаторами) важности. Только те файлы, которые пользователь сочтет «раздражающими», получат видоизмененное пользователем (как правило, увеличенное) значение FQS.
Отсюда проявляется следующая картина. Пользователь без сомнения начнет свое первое использование «поисковой машины персональной Сети» с большого задела файлов. Машина сама затем примется бороздить систему пользовательских файлов, сканировать тексты файлов, строить инвертированный индекс и строить «сеть подобия», которая помещает взвешенные симметричные связи между каждой парой файлов. Вес связи является мерой подобия. Кроме того, машина назначает низкую FQS по умолчанию каждому файлу, возможно, видоизменяя это значение по умолчанию на основе информации из файловых журналов.
Следовательно, пользователь вообще без каких-либо усилий получает сеть подобия, соединяющую все файлы, оценку важности для каждого файла и инвертированный индекс. Эти признаки уже позволяют проводить поиск и навигацию. Пользователь может затем дополнить эту начальную картину установкой рекомендаций. Мотивацией для этого является то, что они представляют собой «напоминания самому себе». Если пользователь прокладывает гиперсвязь от файла А к файлу В, то это напоминание, которое говорит: «Когда я открыл А, я, вероятно, захочу перейти к В». Далее, используемые здесь гиперсвязи, как и гиперсвязи в Сети, можно встраивать в текст так, чтобы они указывали на конкретные места в тексте в файле А и (или) на конкретные места в файле В.
Читатель/владелец файла может также проложить рекомендации (самому или самой себе) с помощью FQS. Например, если читатель взамен выбирает увеличение FQS файла С от его заданного значения, то это напоминание вида «Я хочу, чтобы файл С имел шанс подняться выше среднего, когда я провожу поиск файлов». Аналогично читатель может пожелать понизить FQS файла, который он счел малоинтересным, даже хотя его и не надо удалять.
Получающаяся гибридная сеть будет иметь как симметричные (ненаправленные) связи, так и односторонние или направленные связи. Математически такой граф является все же направленным графом, а потому его можно обрабатывать подходящими для направленных графов способами (такими как описанные в ранее присоединенной заявке на патент США №10/687602, поданной 29 октября 2003 г., и в заявке на патент США №10/918713, поданной 25 августа 2004 г.).
Сюда вовлекается настроечный параметр при определении того, сколько веса должна иметь направленная записанная пользователем гиперсвязь по сравнению с весами подобия на симметричных связях подобия. То есть один вариант осуществления настоящего изобретения использует анализ связей для ранжирования документов; и входом в анализ связей является гибридная Сеть, составленная как из ненаправленных связей подобия, так и из направленных гиперсвязей. Относительные веса этих двух типов связей будут, таким образом, влиять на результаты анализа связей. В предпочтительном варианте осуществления изобретения веса подобия будут попадать в диапазон от 0 до 1. Далее, в одном варианте осуществления изобретения гиперсвязям придается вес по умолчанию, равный 1. Альтернативно (поддерживая веса подобия в том же самом диапазоне от 0 до 1) гиперсвязям может быть придан вес по умолчанию, но настраиваемый (т.е. регулируемый пользователем) HLW.
FQS дают для каждого документа еще и третью оценку, которую можно использовать в дополнение к оценкам из анализа связей и анализа релевантности текстов. То есть ранжирование совпадений поиска основывается на комбинации: (i) оценки релевантности текста, (ii) веса анализа связей и (iii) FQS. Опять-таки здесь имеется два настроечных параметра для использования при определении относительной значимости, которую надо придать этим трем весам.
Наконец, мы переходим к навигации. Настоящий вариант осуществления включает в себя три механизма помощи в навигации.
Во-первых, имеются те гиперсвязи, которые присоединены к тексту. Присоединенные гиперсвязи работают для пользователя аналогично использованию гиперсвязей для навигации по Всемирной паутине: текст в документе выделяется, тем самым сообщая пользователю, что этот текст соединен с гиперсвязью на другой документ (или на другое место в этом же документе). Во-вторых, вариант осуществления позволяет пользователю устанавливать неприсоединенные гиперсвязи, которые указывают из файла А на файл В. В-третьих, сеть подобия обеспечивает связи к каждому иному файлу из файла А.
Отметим здесь, что термин «гиперсвязь» обычно используется для ссылки на тот выделенный текст, который используется для представления пользователю (на интерфейсе) присоединенной гиперсвязи. В данном документе термин «гиперсвязь» относится к логическому указателю (с весом), как обсуждалось выше. Следовательно, мы будем использовать термин «активная иконка» для любого выделенного текста (или иного символа), который представляется пользователю на интерфейсе, чтобы пользователь мог активировать эту иконку и тем самым открыть указываемый файл. То есть иконка на интерфейсе не является гиперсвязью по нашему определению; скорее, гиперсвязью является логический (взвешенный) указатель «позади» иконки.
Как показано на фиг.1, гиперсвязь присоединяется к тексту в указывающем документе 3 и указывает на указываемый документ 4. Неприсоединенная гиперсвязь 2 указывает из указывающего документа 3 на указываемый документ 4. Возможно также иметь гиперсвязь, присоединенную к конкретному тексту в указываемом документе. К примеру, на фиг.1 присоединенная гиперсвязь 5 указывает из текста «текст 1» в указывающем документе 3 на текст «важный» в указываемом документе 4.
Для поддержки навигации настоящее изобретение позволяет пользователю, который открыл файл О, остановить навигационное окно, показывающее файлы, с которыми связан О. Это окно будет иметь три ранжированных списка. Один список будет заполняться связями подобия высшего ранга. Эти связи будут ранжироваться весом подобия, оценкой анализа связей и FQS связанного файла. Второй список будет иметь файлы высшего ранга, на которые указывают гиперссылки из О, - ранжированные согласно их значениям FQS, их оценкам АС (LA) анализа связей и их весам гиперсвязи. Третий список будет затем иметь файлы высшего ранга, которые указывают на О, - опять-таки ранжированные своими FQS, своими оценками АС и весами гиперсвязи.
Теперь перейдем более детально к компонентам описанного выше изобретения со ссылкой на фиг.2, которая описывает как процесс поиска, так и настоящее изобретение в виде поисковой машины и ее компонентов.
Пользователь инициирует поиск 225 ведением ключевых слов 223 в поисковый интерфейс. Ключевые слова подаются в генератор 235 списка совпадений. Генератор списка совпадений использует ключевые слова для получения списка 237 совпадений из инвертированного индекса 233.
Инвертированный индекс представляет собой файл, который берет одно ключевое слово в качестве входных данных, а затем выдает список файлов, содержащих это ключевое слово, в качестве выходных данных. Это стандартная технология, она использует методы, которые общеизвестны специалистам. Для многоключевых поисков нужна также способность извлекать из инвертированного индекса все файлы, удовлетворяющие некоторой булевой комбинации ключевых слов. Здесь снова можно использовать известные методы. Этот вид сортирующей по булевым выражениям функции включается в компонент, называемый «инвертированный индекс».
Чтобы построить инвертированный индекс, нужен синтаксический анализатор (221 на фиг.2). Этот компонент сканирует файлы 201 и распознает слова в этих файлах. Многие типы файлов в настоящее время позволяют использовать синтаксические анализаторы, например файлы программы Word, файлы с расширением pdf, текстовые файлы, файлы в формате html, файлы почты Outlook. Действие синтаксического анализатора и построение и обновление инвертированного индекса имеют место в фоновом процессе, который не инициируется поиском.
Отметим здесь, что персональные файлы обычно имеют большое число нетекстовых файлов, в частности музыкальных файлов и файлов цифровых изображений. Один вариант осуществления изобретения будет способен обрабатывать нетекстовые файлы в предположении, что метаданные можно подвергать синтаксическому анализу для выделения слов. Это предположение остается в силе для многих типов текстовых файлов, но не для всех.
Анализ релевантности текстов также будет использоваться в настоящем изобретении, в компьютере 239 релевантности текстов. Этот модуль принимает на своем входе ключевые слова 223 вместе со списком 237 неранжированных совпадений и выдает список тех же самых совпадений, сопровождаемых их оценками TR текстовой релевантности, в базу 241 данных (БД) (DB) оценок релевантности. Оценка текстовой релевантности TR вычисляется для каждого документа в списке совпадений и относительно заданных ключевых слов с помощью известной технологии.
Стоит здесь отметить, что простые формы анализа релевантности текстов нежелательны для поиска в Сети, потому что они подвержены введению в заблуждение посредством «спаммирования», т.е. нечестный разработчик Сетевой страницы вводит в эту страницу много копий некоторых ключевых слов, которые обнаруживаются Сетевым поисковиком, но тем не менее невидимы для читателя-человека. Однако спаммирование, вероятно, не является проблемой для персональной поисковой машины по персональному контенту. Пользователь же не будет спаммировать самого себя. Кроме того, с любыми файлами, содержащими спам, которые находят свой путь в собрание пользователя, пользователь разбирается самостоятельно. Следовательно, простые формы анализа релевантности текстов могут быть вполне адекватны для персональной поисковой машины. Однако и более сложные формы тоже можно использовать.
Далее мы обращаемся к компьютеру 205 подобия. Этот процесс происходит в фоновом режиме. Проблема измерения подобия очень близка к проблеме релевантности текстов. В первой задают набор ключевых слов и документ и стараются определить, насколько релевантным является документ к понятию, представленному ключевыми словами. Для вычисления меры подобия задают два документа и нужно определить, какое перекрытие существует между понятиями, рассматриваемыми в одном документе, с понятиями, рассматриваемыми в другом документе. Один вариант осуществления настоящего изобретения использует синтаксический анализатор 203 для проверки документов 201 попарно в фоновом процессе. Синтаксический анализатор распознает слова в паре документов и подает свои результаты в компьютер 205 подобия.
Понятия измерений являются гораздо большей проблемой, нежели синтаксический анализ и подсчет ключевых слов. Однако (опять-таки) существуют простые способы, которые подходят для персональной поисковой машины. Ниже следует простой способ измерения подобия, который будет использоваться в одном варианте осуществления изобретения.
Начинаем со «словаря», а именно с набора слов, который используется в инвертированном индексе. Имеются полезные слова, которые находятся в файлах. (Примерами бесполезных слов являются «стоп»-слова, такие как: артикль, и, он, если и т.п.) Затем для каждого слова w и для каждого файла f синтаксический анализатор подсчитывает число раз Nf(w), когда слово w появлялось в файле f. Далее делим Nf(w) на Nf - общее число слов в файле, обозначая результат nf(w). Термин nf(w) называется «профиль слов» файла f.
Подобие S(1,2) между файлом 1 и файлом 2 определяется следующим образом:
S(1,2)=K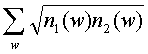 .
.
Здесь постоянная К является другим настроечным параметром, который устанавливает шкалу мер подобия. В предпочтительном варианте осуществления изобретения постоянная К равна 1. В этом случае подобие является положительным числом между нулем и единицей. Далее подобие двух идентичных файлов при К=1 точно равно 1.
Как отмечено выше, простота не является обязательно недостатком при поиске и навигации по персональной файловой системе. В любом случае не ожидается, что спаммирование частот слов станет проблемой.
Каждый файл в системе 201 будет иметь вес подобия по отношению к каждому другому файлу. Таким образом, можно ожидать, что граф, сформированный из связей подобия, будет завершенным. (Для завершенного графа каждая вершина (документ) связана с каждой другой.) Однако может случиться, что вес подобия для двух файлов может быть в точности равен нулю (когда эти два файла не имеют общих словарных слов). Можно ожидать, что такие случаи будут редкими. Однако, если имеются какие-либо связи подобия с нулевым весом, граф подобия перестает быть завершенным. (Он остается неотрицательным, т.е. все связи подобия имеют положительные или нулевые веса.) Завершенность графа, однако, не является необходимым условием для получения положительного веса из анализа связей для всех вершин. Вместо этого необходимым условием является то, чтобы граф был «сильно связанным». В сильно связанном графе для любых двух вершин А и В имеется по меньшей один путь из А в В и по меньшей мере один путь (необязательно тот же самый путь) из В в А. Симметричный граф, такой как граф подобия, будет сильно связанным, пока он связан, т.е. пока граф нельзя разбить на несвязанные куски без связей между этими кусками.
Ожидается, что появление нулевой меры подобия будет настолько редким, что граф подобия будет всегда связанным, а следовательно, сильно связанным. Однако в качестве резервной меры в одном варианте осуществления изобретения можно наложить минимальную меру подобия δ>0. Т.е., когда K<δ, можно установить S(1,2)=δ. Это гарантирует, что граф подобия завершен, а следовательно, связан.
Меры подобия хранятся в базе 207 данных подобия. Теперь можно обратиться к добавлению направленных гиперсвязей, которые в комбинации со связями подобия образуют основу для анализа 213 связей. (Ненаправленные) связи подобия вместе с направленными гиперсвязями образуют гибридную Сеть, соединяющую документы 201.
Один вариант осуществления изобретения позволяет пользователю 217 в любое время проложить гиперсвязи с помощью ручного интерфейса генератора 209 гиперсвязей. Как показано на фиг.1, эти гиперсвязи могут присоединяться в тексте в указывающем документе и (или) в указываемом документе. Они также могут быть неприсоединенными гиперсвязями, которые указывают из файла А на файл В. Все такие вручную созданные гиперсвязи хранятся в Базе 211 данных гиперсвязей. Как отмечено выше, этим гиперсвязям придается вес HLW, который в одном варианте осуществления изобретения равен единице. В другом варианте осуществления изобретения пользователь может выбирать значение HLW.
Гиперсвязи также генерируются автоматически генератором 209 гиперсвязей с помощью автоматического интерфейса для файлов 201, которые выполняются в фоновом режиме. То есть генератор гиперсвязей может в некоторых случаях распознавать, что файл А ссылается исключительно на файл В. Например, в одном варианте осуществления изобретения почтовый файл MF2, который является ответом на другой файл MF1 или его отправкой, запустит генератор гиперсвязей проложить гиперсвязь, указывающую из MF2 на MF1. Автоматически генерируемые гиперсвязи также посылаются в базу 211 данных гиперсвязей.
Что касается природы графа, формируемого гибридной Сетью в настоящем изобретении, то, как отмечено выше, связи подобия (для δ>0) образуют завершенный граф, поскольку каждая вершина (файл) соединяется с каждой другой. (Для δ=0 можно все же ожидать, что граф будет сильно связанным.) Далее, этот граф является взвешенным (с неотрицательными весами) и симметричным. Когда в этот граф добавляются односторонние гиперсвязи, получающийся гибридный граф теряет свойство симметрии, но все же остается взвешенным, неотрицательным и сильно связанным. Поскольку он является сильно связанным, он не имеет стоков. (Сток в направленном графе представляет собой набор вершин, для которых имеется прямой путь, но нет обратного.) Стоки нежелательны для алгоритмов анализа связей, т.к. они делают невозможным вычисление полезного веса в анализе связей для всех вершин. Алгоритм PageRank, к примеру, вводит много избыточных искусственных связей, чтобы сделать граф завершенным. Кроме того, заявка на патент США 10/918713, поданная 25 августа 2004 г., описывает другие виды «средств от стока» для графов со стоками.
Здесь важно отметить, что гибридный граф имеет два свойства, которые достаточны, чтобы придать значимый вес в анализе связей каждой вершине: этот гибридный граф является сильно связанным и его веса неотрицательны. Следовательно, ожидается, что никакого «средства от стока» не потребуется для этого графа. Тем не менее, в тех случаях, где такое средство необходимо, можно использовать применение таких средств от стока, как описанные в заявке на патент США 10/918713.
Что касается гиперсвязей, то имеется два их типа.
Неприсоединенные гиперсвязи. Это те гиперсвязи из файла А в файл В, которые не присоединены к какому-то конкретному тексту в указывающем файле А. (См., например, п.2 на фиг.1.) В персональной файловой системе для прокладки таких связей нет проблем, подлежащих решению. Гиперсвязь становится типом метаданных для файла А. Назначением для гиперсвязи (соответствующей URL указываемой страницы Сети) является имя пути для указываемого файла. Имя пути представляет собой стандартный объект в файловой системе; он используется для точного указания уникального логического адреса для файла (который другие вспомогательные программы переводят затем в физические блоки, где этот файл хранится).
Гиперсвязи, присоединенные в указывающем файле. Эти гиперсвязи (п.1 на фиг.1) могут также выражаться в виде метаданных для указывающего файла А. Однако, чтобы быть полезными, гиперсвязи, которые присоединяются к тексту в указывающем файле А, должны отображаться пользователю в графическом представлении файла А, которое пользователь может увидеть. Кроме того, это отображение должно быть интерактивным, т.е. связанным с пользовательским устройством ввода (обычно это мышь), чтобы пользователь мог активировать переход к указываемому файлу. То есть присоединенный текст становится «активной иконкой» по нашему приведенному выше определению. Многие типы файлов (к примеру, файлы pdf, Word и PowerPoint) поддерживают выражение гиперсвязей в этой форме.
Гиперсвязи, присоединенные к указываемому файлу. Некоторые типы файлов, такие как html, позволяют присоединять гиперсвязи к месту в тексте указываемого файла. Для таких типов файлов несложно позволить гиперсвязи из файла А в файл В указать на конкретное местоположение в файле В. (См. п.5 на фиг.1.)
Все эти типы гиперсвязей хранятся в базе 211 данных гиперсвязей. Эта база данных имеет входы в виде 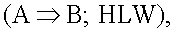 т.е. списки всех гиперсвязей и их веса независимо от того, присоединены они или нет. В альтернативном варианте осуществления изобретения присоединенный текст (если он имеется) в указывающем файле и (или) указываемом файле также хранится в базе данных гиперсвязей; эта информация может использоваться в сочетании с ключевыми словами при поиске.
т.е. списки всех гиперсвязей и их веса независимо от того, присоединены они или нет. В альтернативном варианте осуществления изобретения присоединенный текст (если он имеется) в указывающем файле и (или) указываемом файле также хранится в базе данных гиперсвязей; эта информация может использоваться в сочетании с ключевыми словами при поиске.
Гиперсвязи плюс сеть подобия образуют гибридную сеть. Фиг.3 показывает два документа из гибридной сети. Документ 1 (п.3) имеет направленную гиперсвязь 5, указывающую на Документ 2 (п.4). Кроме того, как и со всеми парами документов в гибридной сети, эти два документа связаны ненаправленной связью 6 подобия. (Некоторые связи подобия могут иметь нулевой вес.) Эта гибридная сеть (граф с вершинами = документам) представляет собой начальную точку для анализа связей (213 на фиг.2). Как отмечено выше, гибридная сеть присутствует в форме направленного графа (поскольку она не полностью симметрична). Следовательно, здесь можно использовать способы анализа связей, которые пригодны для направленных графов.
Популярность связи не является подходящим вариантом. Причина этого состоит в том, что сеть подобия, которая многое берет от гибридной сети, дает каждой вершине (документу) много связей; следовательно, она нечувствительна к связи важности (центральности) вершины с числом связей.
Предпочтительный вариант осуществления изобретения использует алгоритмы, описанные в заявке на патент США 10/687602, поданной 29 октября 2003 г., для анализа связей. Реально в этой заявке на патент имеется два отличных алгоритма. В тестах каждый показал хорошие результаты; и все же эти результаты существенно различны.
Эти два алгоритма можно вкратце обозначить «Вперед» и «Назад». Эти два способа различаются, когда граф является направленным. Следовательно, в предельном случае, в котором пользователь устанавливает мало или не устанавливает никаких гиперсвязей, граф является почти симметричным, и эти два способа будут давать почти одинаковые результаты.
Таким образом, один вариант осуществления изобретения, который все же дает хорошие характеристики, состоит в использовании оператора Вперед. Другой вариант осуществления изобретения вычисляет два веса в анализе связей (с помощью обоих способов) для каждого документа, а затем предоставляет пользователю выбор того, который результат (или оба) он/она желает видеть в финале из ранжированных результатов. Этот альтернативный вариант осуществления, вероятно, наиболее подходит для пользователя с сильным и активным интересом в эффективном поиске. Такой пользователь, вероятно, будет устанавливать много гиперсвязей (дающих значимое различие между двумя способами), а также будет заинтересован попробовать различные алгоритмы для нахождения наилучших возможных результатов поиска.
Наконец, что происходит для пользователя, который занимает противоположное крайнее положение. То есть предположим, что пользователь не заинтересован в гиперсвязях, он/она хочет хороших результатов в поиске и навигации. Без гиперсвязей гибридный граф становится (симметричным) графом подобия плюс автоматически генерируемыми гиперсвязями. Эти последние гиперсвязи будут, вероятно, небольшим меньшинством всего графа. Следовательно, в этом случае способы Вперед и Назад дают почти одинаковые результаты, что, в свою очередь, грубо эквивалентно способу, известному в социальных науках как «центральность собственного вектора». Центральность собственного вектора все же дает значимую меру важности; следовательно, результаты будут все же полезны для этого вида пользователя.
Модуль 213 анализа связей также исполняется в фоновом режиме, т.е. он не зависит от инициации поиска. Он берет в качестве входов базу 207 данных подобия и базу 211 данных гиперсвязей. Его выходами является набор оценок LA в анализе связей по одному на каждый документ. Эти оценки LA хранятся в базе 215 данных оценок анализа связей.
Оценка качества файла или FQS хранится для каждого файла в базе 219 данных FQS. Шкала FQS не фиксируется в данном изобретении; но пригодна любая шкала, которая удобна для пользователя (например, от 1 до 10), поскольку относительные веса FQS, подобие и центральность анализа связей будут определяться настроечными параметрами (см. ниже). FQS определяется как пользовательским устройством 217 ввода, так и информацией из компонента 240 Журнала. В одном варианте осуществления изобретения пользователю подсказывают каждый раз, когда он/она закрывает открытый файл, выбрать FQS для этого файла. В другом варианте осуществления машиночитаемые измерения, такие как даты и частота обращения, могут использоваться для изменения значений FQS от значения по умолчанию. В любом случае пользователь всегда будет иметь возможность переписать FQS для любого выбранного файла.
Возвращаясь к описанию процесса поиска, напомним, что пользователь начинает поиск 225 с одного или нескольких ключевых слов 223. Генератор 235 совпадений использует затем эти ключевые слова 223 и инвертированный индекс 233 для генерирования неранжированного списка 237 совпадений. Этот неранжированный список совпадений подается в компьютер 239 релевантности текстов вместе с ключевыми словами 223. Выходные данные компьютера релевантности текстов представляют собой далее оценки TR релевантности текстов для каждого файла в списке совпадений. Эти оценки хранятся в базе 241 данных оценок релевантности текстов.
Теперь можно ранжировать совпадения на основе трех различных оценок. Объединяющий модуль 229 привлекает оценки релевантности текстов из базы 241 данных релевантности текстов, оценки LA в анализе связей из базы 215 данных анализа связей и FQS из базы 219 данных FQS. Чистый составной вес W для каждого совпадения равен тогда:
W=a(TR)+b(LA)+c(FQS)
Здесь появляются три настроечных параметра; но поскольку для ранжирования имеют значение только относительные веса, один из этих трех настроечных параметров можно выбирать совершенно свободно; тогда только два других влияют на результаты ранжирования. В одном варианте осуществления изобретения пользователь может выбрать вес с, т.е. пользователь может решать, какой вес он/она может захотеть придать своим оценкам файлов.
Объединяющий модуль вычисляет чистый вес W согласно вышеприведенной формуле. Затем он переупорядочивает список 237 совпадений в ранжированный список, чтобы уменьшить чистый вес W. Результирующий ранжированный список усекается до размера 227, заданного при поиске, а затем сохраняется в базе 231 данных объединенного ранжирования. Эти результаты поиска могут далее быть представлены в подходящем формате с результатами, представленными как активные иконки, которые связаны с соответствующими файлами (как и в Сетевой поисковой машине).
Настоящая поисковая процедура обеспечивает простую форму обновления поиска. То есть можно брать список совпадений предыдущего поиска и строить подграф, составленный из всех этих совпадений и связей между ними (как связей подобия, так и гиперсвязей). Новый поиск по этому подграфу даст затем новые результаты, даже если вводятся те же самые слова, потому что анализ связей оценит документы в подграфе по отношению друг к другу. Можно представить это изменение символически следующим образом: для каждого файла оценка LA в анализе связей (на основании всего графа) будет заменена новой оценкой LA(sub) анализа связей (которая появляется из выполнения анализа связей на подграфе, определенном совпадениями). В любом последующем поиске, который ограничен подграфом совпадений, новые совпадения ранжируются, таким образом, согласно выражению:
W=a(TR)+b(LA(sub))+c(FQS).
Для пользователя может быть очень полезно иметь возможность обновлять поиск таким способом. После начального поиска пользователь может сузить дополнительные поиски ограниченной областью документов. Эта ограниченная область определяется предыдущим списком совпадений и фокусируется таким образом на интересующей пользователя теме. Отметим, наконец, что этот подход может быть вполне практичным, т.к. подграф либо не слишком велик, чтобы начать с него, либо может быть сделан удобного размера путем усечения (оставляя, к примеру, только документы наивысшего ранга из начального списка совпадений). Следовательно, в настоящем изобретении могут быть практически воплощены итерированные обновленные поиски, поддерживаемые анализом связей в реальном времени.
Этим завершается описание процесса поиска и вовлеченных в него компонентов (фиг.2). Фиг.4 показывает, как настоящее изобретение помогает в навигации. Предположим, что пользователь имеет открытый файл О (41 на фиг.4) и желает найти связанные файлы. Один уже описанный выше способ состоит в том, чтобы щелкнуть на любой активной иконке (представляющей присоединенную гиперссылку), которая появляется в отображении файла. Однако можно представить три других набора файлов, к которым можно перескочить из открытого файла О: (i) все файлы, которые лежат в конце выходящих из О гиперссылок; (ii) все файлы, которые указывают на О с помощью входящих гиперссылок, и (iii) все файлы, соединенные с О связями подобия. Каждая из этих трех навигационных опций может быть представлена в соответствующем окне, которое вызывается задействованием «навигационной» кнопки.
Все файлы, которые соединяются с О гиперсвязями (входящими или выходящими), могут быть вызваны из базы 47 данных гиперсвязей. (Это та же самая база данных, что и пронумерованная позицией 211 на фиг.2.) Можно ранжировать эти файлы (для целей навигации): согласно весу HLW гиперссылки, соединяющей их с О; согласно значениям FQS; а также согласно их оценкам LA в анализе связей. Оценки FQS извлекаются из базы 45 данных FQS (219 на фиг.2), а оценки LA извлекаются из базы 48 данных оценок LA (215 на фиг.2). Затем можно определить подходящий параметр ранжирования для навигации с помощью уравнения:
HNW=d(HNW)+e(LA)+f(FQS),
где «HNW» означает «вес соседней гиперсвязи», а d, e и f являются настроечными параметрами. Ранжирующий модуль 495 выполняет затем операцию ранжирования (на основе весов HNW) и посылает результат в базу 497 данных ранжированного списка связанных файлов. Результирующий ранжированный список файлов может быть представлен пользователю как активные иконки вместе с их значениями FQS через интерфейс. Тем самым пользователь может найти и перескочить к наиболее важным файлам, которые указывают на открытый файл О или на которые указывают открытым файлом О.
Всегда будет много связей подобия. Однако они будут ранжированы, поскольку можно ожидать, что оценки S(1,2) подобия изменяются в широком диапазоне. Далее, можно ожидать, что пользователь будет заинтересован вновь - т.е. в контексте навигации, как и поиска - в мерах качества файла, как и подобия, таких как его/ее собственные оценки FQS для этих файлов и оценки LA из анализа связей. Следовательно, можно ранжировать связанные подобием файлы согласно всем этим оценкам. Простой способ сделать это состоит в определении веса SNW навигации подобия из О в файл В, который должен быть таким:
SNW(O,B)=g·S(O,B)+h·LA(B)+m·FQS(В)
Параметры g, h и m вновь являются настроечными параметрами.
Компьютер 491 подобия навигации, таким образом, берет входные данные из базы 43 данных подобия (позиция 207 на фиг.2), базы 45 данных FQS (позиция 219 на фиг.2) и базы 48 данных оценок LA (позиция 215 на фиг.2) и генерирует вес SNW навигации подобия для каждого файла В. В одном варианте осуществления изобретения число файлов, извлеченных из базы данных подобия, ограничивается взятием только тех файлов, у которых подобие с О больше, чем некоторое пороговое значение Sмин.
Наконец, принимая во внимание веса SNW навигации подобия, компьютер 491 подобия навигации ранжирует результирующий список подобных файлов В и посылает результат в базу 493 данных ранжированных списков подобных файлов. Этот список опять-таки может быть представлен активными иконками вместе с их соответствующими значениями FQS через интерфейс пользователю.
Отметим, что в одном варианте осуществления изобретения навигация может быть сведена к ограниченной области файлов, как раз такой, которую может проверить поиск. То есть пользователь может ввести в навигационном интерфейсе одно или несколько ключевых слов. Эти ключевые слова используются в реальном времени для генерирования списка совпадений как для поиска. Этот список совпадений определяет вершины сфокусированного на теме подграфа.
В одном варианте осуществления обновленной навигации оценки SNW не изменяется от их значений в полном графе, но документы, отображенные в ранжированном навигационном списке, берутся только из вершин сфокусированного на теме подграфа или, иными словами, из списка совпадений, генерируемого ключевыми словами.
В другом варианте осуществления обновленной навигации подходящие соседи файла О вновь ограничиваются этими документами в подграфе; но получаются и оценки LA(sub) анализа связей относительно сфокусированного на теме подграфа для каждого такого подходящего соседа. Эти оценки анализа связей могут быть затем использованы при ранжировании связанных файлов для представления пользователю путем генерирования новых весов соседей следующим образом:
HNW(sub)=d(HLW)+e(LA(sub))+f(FQS)
для соседей по гиперсвязи и
SNW(sub)(O,B)=g·S(O,B)+h·LA(sub)(B)+m·FQS(В)
для соседей, связанных подобием.
Сценарии иные, нежели для единичного пользователя
Во всем вышеприведенном тексте изобретение описывается для использования в сценарии, где имеется единственный пользователь, который добивается помощи при поиске и навигации по персональным файлам. Этот сценарий является общим, и в нем имеется большая неудовлетворенная потребность. Однако настоящее изобретение может также применяться и в других сценариях. Далее здесь обсуждаются четыре сценария, а именно: (i) небольшие совместно работающие группы, (ii) сетевое хранение информации, (iii) корпоративный поиск и (iv) физические объекты.
(i) Небольшие группы
Общую ситуацию с компьютерными файлами представляет случай, когда эти файлы являются «почти» персональными, т.е. только малая группа людей имеет доступ к данному набору файлов. Люди в этой небольшой группы почти постоянно имеют некоторый сорт отношений друг с другом, например рабочие отношения или семейные отношения, и совместно используемый набор файлов является тогда релевантным для этих отношений.
Совместный доступ проявляется в двух формах: разрешение на чтение и разрешение на запись. Последнее является более сильным разрешением, чем первое (поскольку разрешение записывать заключает в себе разрешение читать, но не наоборот). Следовательно, разумный путь для определения набора файлов для данной небольшой группы состоит в выборе того набора, для которого группа имеет общее разрешение на чтение. Поскольку как поиск, так и навигация требуют только разрешения на чтение, это определение файлов гарантирует, что каждый член группы может проводить поиск и навигацию по общему набору файлов. Мы называем этот набор файлов «групповыми файлами».
Конечно, может быть более одной группы, и все группы используют общую файловую систему (структуру физического хранения и логического наименования пути). Тогда может быть несколько, возможно, перекрывающихся наборов групповых файлов. Следовательно, можно рассматривать как случай одной группы, так и случай нескольких групп, совместно использующих общую файловую систему. Каждая группа должна иметь некоторую форму уникального группового идентификатора (ИД) (ID) (имя), которую мы назовем ее ГИДом.
Одна группа
Сначала можно рассмотреть случай файловой системы, состоящей из единственной группы. Поскольку групповой набор определяется общим разрешением на чтение, любой процесс, вовлекающий только чтение файлов, может быть воплощен по существу как для единичного пользователя. Например, те процессы, которые не требуют ввода - в частности, сканирование и синтаксический анализ файлов, построение инвертированного индекса, генерирование оценок подобия, автоматическое обновление FQS и автоматическое генерирование гиперсвязей - могут выполняться на всем наборе файлов, как и с единственным пользователем. Любой поиск по ключевым словам может затем использовать весь инвертированный индекс, и все файлы будут ранжированы в общей ранжирующей схеме. Поиск и навигация могут затем свободно проводиться по всей файловой системе.
Отличия от картины с единственным пользователем возникают для операций, требующих разрешения на запись. Один вариант осуществления вышеописанной персональной поисковой машины имеет две такие операции (сверх очевидного редактирования файлов): запись гиперсвязей и назначение FQS.
Гиперсвязи не являются проблемой, т.к. они не исключительны по своей природе. То есть записанные пользователем гиперсвязи являются рекомендациями. Следовательно, разумно снабдить всех пользователей разрешением на запись для файла F устанавливать гиперсвязи, указывающие из F на любой файл в групповом наборе. Это та же самая ситуация, что и в Сети: разрешается рекомендовать файлы, в которые нельзя записывать, и устанавливать указатели в файлах, в которых можно записывать.
Ранжирующий алгоритм требует единственной FQS; но можно предположить, что каждый пользователь с разрешением на запись может иметь ввод к FQS. Возможны многие решения для генерирования составной FQS из нескольких вводов. Одно решение состоит в хранении для каждого файла одной FQS для каждого пользователя с разрешением на запись - хранение определенного машиной значения для тех пользователей, которые не дают ввода, - и затем в их усреднении.
Картина единственной небольшой группы показана на фиг.5. Вся группа 51 определяется как имеющая общее разрешение на чтение. В одном варианте осуществления изобретения разрешение на чтение затем влечет за собой разрешение находить файл в запросе поиска или навигации и разрешение указывать на этот файл гиперсвязью. Каждый пользователь будет также иметь разрешение на запись для некоторого поднабора 53 групповых файлов 51. Для тех файлов, для которых пользователь имеет разрешение на запись, он/она может установить гиперсвязи, указывающие из этих файлов, и может также изменить значение FQS для этих файлов.
Наконец, в альтернативном варианте осуществления изобретения все пользователи с разрешением на чтение могут предлагать значения FQS для данного файла.
В итоге не существует значительных проблем с расширением вышеописанного варианта осуществления персональной Сетевой поисковой машины на случай одной группы с небольшим числом пользователей.
Несколько групп
Теперь можно предположить, что имеется несколько групп, совместно использующих единственную файловую систему. Можно предположить, что списки членов групп могут перекрываться, как могут перекрываться и наборы групповых файлов. Однако в духе данного раздела можно предположить, что имеется не очень много групп и не очень много пользователей всего.
Как инвертированный индекс, так и база данных подобия могут воплощаться для всего набора файлов, как и ранее, но с дополнительным требованием хранения для каждого файла ГИДов для групп, которые имеют разрешение на чтение для этого файла. Инвертированный индекс может, к примеру, иметь вхождения в виде:
тогда как база данных подобия может иметь вхождения в виде:
файл1 ГИД1, ГИД2, …, файл2 ГИД5, ГИД7 оценка подобия(1,2)
(Можно описать эту же базу данных для единственной группы путем удаления всех вхождений ГИДов.)
При такой структуре базы данных поиск по ключевым словам может всегда включать в себя неявное требование, что в дополнение к ключевому слову (ключевым словам) по меньшей мере один из ГИДов поисковика должен присутствовать для файла, подлежащего включению. Таким образом, пользователь может проводить поиск только по тем файлам (т.е. только видеть совпадения из тех файлов), для которых он/она имеет разрешение на чтение.
Аналогичное утверждение действует и для навигации. Пользователь, обращающийся за помощью в навигации, будет лишь видеть связи (гиперсвязи и связи подобия, представленные как активные иконки) к тем файлам, для которых он/она имеет разрешение на чтение.
Операции, вовлекающие разрешение на запись, по существу такие же, как для случая одной группы. То есть в отношении прокладки гиперсвязей разрешается рекомендовать файлы, которые можно читать, но в которые нельзя записывать и прокладывать указатель на файлы, в которые можно записывать. А FQS можно обрабатывать тем же самым путем, что и в случае одной группы.
Наконец, подходим к вопросу ранжирования файлов. В случае одного пользователя ранжирование основано на сравнении всех файлов друг с другом с помощью релевантности текстов, анализа связей и FQS. Релевантность текстов та же самая, будь то один пользователь или много пользователей и групп; и предыдущие абзацы обсуждают, как обращаться с FQS. Для анализа связей, однако, ситуация усложняется. Из-за того что группы могут перекрываться и пользователи могут принадлежать к более чем одной группе, для некоторых пользователей может случиться, что гиперсвязь указывает из файла, который пользователь U может читать, на файл, который U читать не может. Аналогично сеть подобия охватывает все группы. Вкратце, различные подграфы для различных групп будут соединяться связями. Далее, анализ связей дает результаты, которые зависят от свойств всего графа. Тогда проблема в том, чтобы выбрать, какой «весь граф» (т.е. какой подграф, взятый из целого графа) должен быть начальным пунктом для анализа связей, относящегося к поиску пользователем U.
Перефразируем вопрос: каждый пользователь U хочет ранжировать файлы. Если ранжирование было основано на единственной оценке наподобие FQS, которая прикрепляется к каждому документу, то относительное ранжирование файла А и файла В было бы независимым от того, какие другие файлы включены в ранжированный список. Однако в силу природы анализа связей изменение топологии графа - к примеру, путем изменения того, какие файлы и связи присутствуют, - может изменить относительное ранжирование любых двух заданных файлов А и В. Поэтому должен быть задан вопрос: для каждого пользователя U, что является «эталонным набором» файлов, который должен быть использован для получения весов LA в анализе связей?
Ниже обсуждаются три возможных ответа.
1. Использовать целый граф, т.е. тот, который основан на каждом файле в общей файловой системе.
2. Выбрать усеченный граф, построенный из всех файлов, для которых единственная группа имеет разрешение на чтение.
3. Выбрать усеченный граф, построенный из всех файлов, взятых из всех групп, для которых пользователь U является членом с разрешением чтения.
Фиг.6 показывает варианты 2 и 3. На этом чертеже имеются три группы (G1, G2 и G3), совместно использующие файлы; и пользователь U является членом G1 и G3. Левая сторона 61 фиг.6 показывает вариант 2: подграф строится из всех файлов (заштрихованных), для которых группа G1 имеет разрешение чтения. С правой стороны 63 фиг.6 все файлы, для которых U имеет разрешение чтения (т.е. файлы в группах G1 и G3), заштрихованы; эти файлы используются для получения подграфа для пользователя U.
На фиг.7 показан процесс усечения графа. Предположим, что кто-то желает построить подграф только из заштрихованных вершин на левой стороне 71 фиг.7; следовательно, белая вершина и все связи, соединяющие с белыми вершинами, должны быть удалены. Результат показан на правой стороне 73 фиг.7: только заштрихованные вершины и соединяющие их связи оставлены в усеченном графе. Для иллюстрации можно вообразить, что используется вариант 3, так что белые файлы представляют собой файлы, для которых U не имеет разрешения на чтение, хотя U имеет разрешение на чтение для заштрихованных файлов.
Кажется, что вариант 3 предлагает построение подграфа для каждого пользователя. На деле он равносилен построению подграфа для каждой комбинации групп, для которых некоторый пользователь является членом. Зачастую более чем один пользователь будет иметь одну и ту же комбинацию групп; кроме того, зачастую будет много комбинаций групп, которые не представляют ни одного пользователя. Таким образом, число подграфов, вовлеченных в вариант 3, будет в общем случае меньше, чем либо полное число пользователей, либо полное число возможных комбинаций групп.
Ниже обсуждаются явные преимущества и недостатки каждого варианта.
Вариант 1 имеет то преимущество, что имеется единственный уникальный вес LA в анализе связей для каждой вершины, полученный из анализа связей всего графа. Это снижает как вычислительную нагрузку, так и требования к хранению данных в анализе связей. Далее, можно воплотить «фильтры совпадений», как описано выше, так что списки совпадений, получающиеся в результате запросов поиска и навигации, отображают только файлы, которые пользователь U может читать.
С другой стороны, если пользователь U имеет доступ к чтению только к малому числу файлов по отношению к общему их числу, то может статься, что этот пользователь получит неудовлетворительные результаты ранжирования - все файлы, которые он/она сможет видеть, получат веса LA в анализе связей, которые вычисляются относительно большого невидимого (для U) набора файлов. Следовательно, вариант 1 кажется нежелательным для этого случая, который может возникнуть, если имеется очень много групп примерно равного размера (в терминах числа файлов) или если имеется большое рассогласование в размерах этих групп. Первый случай исключается предположением: в данном разделе можно предположить малое число групп. Однако даже с малым числом групп и пользователей может случиться, что некоторые пользователи имеют доступ к чтению только к малой части полного набора файлов; и в таком случае вариант 1, вероятно, будет неудовлетворительным для таких пользователей.
Вариант 3 требует нескольких вычислений в анализе связей, по одному для каждой комбинации групп, которые представляют какого-то пользователя. Следовательно, как вычислительная нагрузка, так и нагрузка хранения варианта 3 больше, чем для варианта 1. Однако и этот вариант, и вариант 1 избегают нагрузки вычисления ранжирования в анализе связей для каждого поиска. Вместо этого можно обновлять оценки LA, когда бы ни произошло изменение (или достаточное число изменений) в наборе файлов и (или) связей для релевантного подграфа. Кроме того, если имеется много пользователей, то будет немного комбинаций групп, для которых нужно делать вычисление в анализе связей.
Преимущество варианта 3 состоит в том, что каждый пользователь получает ранжирование, которое рассматривает только те файлы, которые этот пользователь может видеть. Это, вероятно, желательное свойство для большинства поисков. Следовательно, вариант 3 можно, вероятно, считать хорошим вариантом, когда вычислительная способность и способность запоминания достаточны для поддержания этого варианта.
Можно вообразить случаи, для которых преимущественным является вариант 2. Предположим для примера, что пользователь U имеет файлы и группы, связанные как с семьей, так и с работой, находящиеся в той же самой файловой системе; что ключевые слова, которые U может придумать, дают файлы, которые находятся как в семейной группе, так и в одной или нескольких из рабочих групп, и что U хочет искать только в семейных файлах. В этом случае можно легко и эффективно сузить поиск, указав только семейную группу, т.е. с помощью варианта 2. Таким образом, видно (см. также фиг.6), что вариант 2 предлагает новый путь концентрации внимания на поиске.
(ii) Сетевое хранение
Теперь можно рассмотреть случай, когда персональные файлы, представляющие интерес, не хранятся на единственном частном ПК. Вместо этого они хранятся коммерческим поставщиком таких услуг. Примерами, существующими ныне, являются портал, такой как Yahoo, или поисковый провайдер, такой как Google. Эти компании в настоящее время предлагают только хранить почтовые файлы; но от этого короткий шаг до предложения хранения всех видов персональных файлов. Этот вид хранения называется «сетевым хранением».
Одним преимуществом сетевого хранения является надежное резервное хранение. Другим является тот факт, что к таким файлам можно обращаться откуда угодно в мире, который имеет доступ к Интернету. Кроме того, с помощью сетевого хранения облегчается установка видов совместного использования в малой группе, описанного в предыдущем разделе. К примеру, семьи могут хранить фотоальбомы, которые затем доступны любому члену определенной семейной группы из любого из нескольких домов, а также путешествующими членами семьи.
Таким образом, сетевое хранение персональных файлов обеспечивает более высокую мобильность для пользователя, где бы и когда бы этот пользователь ни захотел иметь сетевой доступ. В этом смысле сетевое хранение файлов является аналогом (для содержимого) мобильного телефона: соединение остается с пользователем, а не с устройством. И на деле это рассуждение предлагает многообещающее использование настоящего изобретения, когда оно прилагается к персональным файлам, хранящимся в сети: обращение к этим файлам, в том числе поиск и навигацию, можно сделать доступными с помощью подходящего интерфейса по мобильному телефону или устройству для беспроводной местной сети.
Еще одно преимущество сетевого хранения состоит в том, что провайдер хранения может предложить пользователю вспомогательные услуги, такие как услуги поиска и навигации по настоящему изобретению. Это освобождает пользователя от существующей ныне почти монопольной ситуации, при которой ему/ей нужно ждать, пока Microsoft введет желательное свойство. Далее, пользователь может приобрести преимущество от таких новых услуг безболезненно, без необходимости покупать и изучать полностью новую операционную систему и без риска столкнуться с новой монополией.
Следующие технические соображения, привлеченные для проведения поиска и навигации, направлены с использованием идей в настоящем изобретении на персональные файлы с сетевым хранением. Основным пунктом здесь является то, что все предыдущие технические соображения по сути дела не зависят от того, где файлы хранятся физически. Следовательно, можно рассматривать описанную таким образом технологию поиска и навигации дальше в этом разделе - как в случае единственного пользователя, так и в случае малой группы - как применимую к сетевому хранению, а также к хранению на единственном ПК.
Можно увидеть по меньшей мере одно техническое преимущество сетевого хранения над хранением на личном ПК для поиска и навигации. То есть можно ожидать экономии масштаба, реализуемого в первом случае. Например, программному обеспечению для анализа релевантности текстов, вычисления подобия и анализа связей нет необходимости присутствовать на каждом ПК. Кроме того, вовлеченные базы данных могут быть непомерно большими для единственного ПК, и (или) может быть больше эффективных путей хранения многих таких персональных баз данных в единой централизованной системе.
Одним из наиболее вероятных применений сетевого хранения являются файлы изображений. Файлы изображений велики; пользователи имеют аппетит на их большое число, и имеется ясная необходимость в хороших инструментах управления для помощи таким пользователям в организации, нахождении и навигации по этим файлам. Вследствие этого здесь вкратце обсуждаются файлы изображений. Следует отметить, что бóльшая часть последующего обсуждения также применима к другим видам нетекстовых файлов, таких как видео- и музыкальные файлы; но для краткости ниже обсуждаются изображения.
В предшествующем обсуждении все имело своей целью текстовые или основанные на текстах файлы. В частности, поиск в настоящем изобретении направляется ключевыми словами и обратным каталогом. Настоящее изобретение далее применимо и к файлам изображений, только если эти файлы имеют метаданные в виде текста (или которые могут быть по меньшей мере распознаны как текст синтаксическим анализатором). Представляется, что это ограничение разделяется всеми существующими системами для поиска по файлам изображений.
Можно ожидать, что будущая технология предложит одну или обе из следующих разработок: (i) программное обеспечение для улучшения для пользователя простоты записи метаданных для файлов изображения; или (ii) программное обеспечение для автоматизации записи метаданных путем машинного анализа изображений. Первое усовершенствование должно произойти обязательно. Разработка, которая аналогична второму, является недавним продвижением StreamSage в использовании машинного анализа речи для генерирования текста из видеофайлов. Машинный анализ изображений представляет собой более трудную задачу, которая предположительно будет решаться медленнее.
Вкратце: пока ввод пользователем осуществляется в виде слов, поиск по файлам изображений (и другим видам нетекстовых файлов, таких как видео- и музыкальные файлы) будет зависеть от метаданных. Настоящее изобретение, таким образом, зависит от некоторого компонента - интерактивного интерфейса или более изощренного подхода - для обеспечения этих метаданных для изображений. При наличии метаданных несложно затем построить инвертированный индекс и сеть подобия.
Два других аспекта настоящего изобретения не зависят от природы вовлеченных файлов. Во-первых, использование FQS не зависит от природы файла; следовательно, их можно использовать с файлами изображений, как и с любыми иными. Во-вторых, пользователи могут устанавливать гиперсвязи, указывающие на файлы изображений и из них. Однако принцип присоединения гиперсвязей к релевантному тексту может быть бесполезным, когда текстом являются только метаданные.
В итоге: предполагая механизм обеспечения метаданных, файлы изображений (и прочие нетекстовые файлы) могут все же встраиваться в описанную здесь гибридную сеть со связями подобия, введенными вручную и (или) автоматически гиперсвязями и оценками качества файлов, чтобы помогать как при поиске, так и при навигации. Отметим также, что нет нужды строить отдельную сеть для нетекстовых файлов: пока имеются значимые метаданные для нетекстовых файлов - даже если всего в несколько слов - полезные оценки подобия можно все же вычислить на том уровне, что и все остальные оценки подобия.
(iii) Корпоративный поиск
Настоящее изобретение до сих пор обсуждалось в терминах частных пользователей или малых групп. Корпоративный поиск имеет, однако, много общего с этими ранее обсужденными случаями. Следовательно, для полноты нужно здесь рассмотреть возможность использования настоящего изобретения в контексте корпоративного поиска. Таким образом, можно сосредоточиться на наборе (предположительно большом) документов, которые могут читаться всеми членами компании, как в случае более мелких и более ограниченных групп, который обсужден выше.
Среда корпоративного поиска аналогична Сети в том (для многих, если не для всех файлов), что имеется много пользователей с разрешением на чтение, но относительно мало с разрешением на запись. В техническом отношении, далее, представляется, что условия подходят для применения написанных пользователем (рекомендательных) гиперсвязей: каждый из многих пользователей способен комментировать (рекомендовать) много файлов. Кроме того, как и в Сети, не все файлы могут прочитываться всеми пользователями, но многие могут.
Представляется, что принципиальное различие между Сетевым поиском и корпоративным поиском состоит в мотивации этих многих пользователей. То есть пишущие Сетевые страницы мотивированы устанавливать гиперсвязи и не только к их собственным страницам, тогда как неясно, имеют ли пишущие документы для корпоративного поиска такую же мотивацию. На этот вопрос трудно, однако, ответить, не дав этим пользователям возможности самим устанавливать гиперсвязи.
Если эта картина верна, то такая гибридная сеть, как описанная в настоящем изобретении, может предложить великолепный способ построить мостик от корпоративного поиска, где участники не поддерживают друг друга, к тому, где поддерживают. Система поиска и навигации, которая направляется сетью подобия, автоматически генерируемыми гиперсвязями и записанными пользователями гиперсвязями, обеспечивает безболезненный запуск, поскольку связи подобия и автоматические гиперсвязи дают намного больше помощи как в поиске (ранжировании), так и навигации. Пользователи, которые используют эту систему, могут также постичь, что они сами получают выгоду от установки гиперсвязей к файлам, которые они воспринимают как значимые. Таким образом, возможно, высокий уровень участия в установке гиперсвязей можно построить постепенно, когда связи подобия обеспечивают фундамент для запуска процесса.
Представляется также, что в этой картине использование ОКФ не является необходимым. Кроме того, ОКФ имеют недостаток в этой среде множества пользователей, из которых пишет малое число пользователей, а читают многие: например, кто получает оценку заданного файла? И как обходить «спамовые» оценки, поддерживающие чьи-то собственные файлы? ОКФ полезны и необходимы, когда технически невозможно использовать гиперсвязи для завершенного выполнения рекомендательной функции. В случае корпоративного поиска техника прямо пригодна для гиперсвязей; но имеется вопрос построения культуры их использования. Сами по себе гиперсвязи предлагают децентрализованный демократический путь участия для пользователей выражать свои рекомендации, и гиперсвязи имеют далее преимущество подталкивать пользователя помещать рекомендацию в контексте указывающего файла.
(iv) Физические объекты
Другим применением настоящего изобретения является поддержка поиска и навигации по набору физических объектов.
Основа этой идеи в следующем. Такие технологии, как маркеры RFID (радиочастотная идентификация), позволяют маркировать большое число физических объектов электронно считываемыми метаданными. Считывание таких метаданных дает цифровое представление фонда физических объектов. Следовательно, можно применить настоящее изобретение к поиску по такому фонду во многом таким же образом, как обсуждалось выше для нетекстовых файлов (таких как изображения). Все свойства этой гибридной сети можно применить: сеть подобия, выражающие рекомендации гиперсвязи и оценки качества для каждого объекта. Получающуюся гибридную сеть можно использовать как для поиска, так и для навигации, как описано выше.
В качестве иллюстративного примера представим себе случай хранения вин, продаваемых в розницу. Когда имеется запрос потребителя, где потребителю доступно более чем одно возможное вино, владелец хранилища может использовать описанную здесь поисковую машину, чтобы выдать ранжированный список вин, отвечающих критериям потребителя. Ранжирование может быть основано на «релевантности текстов» (степени соответствия с запросом потребителя), анализе связей и оценках качества. Анализ связей может включать в себя оба типа связей: связи подобия (генерируемые с помощью метаданных) и гиперсвязи. Последние опять-таки выражают рекомендации и могут быть проложены знающими людьми, которые могут, если дано вино (или сопровождающее блюдо), рекомендовать другие вина, которые также могут быть, вероятно, интересны.
Наконец, в этом контексте возможна также навигация. Если задан объект (тип вина), можно интересоваться информацией о других винах, которые связаны с данным вином подобием или рекомендацией.
Фиг.8 иллюстрирует компьютерную систему 1201, на которой может быть воплощен вариант осуществления настоящего изобретения. Конструкция компьютера подробно обсуждается в книге STALLINGS, W., Computer Organization and Architecture, 4th ed., Upper Saddle River, NJ, Prentice Hall, 1996, все содержание которой включено сюда посредством ссылки. Компьютерная система 1201 включает в себя шину 1202 или иной механизм связи для передачи информации и процессор 1203, соединенный с шиной 1202, для обработки информации. Компьютерная система 1201 включает в себя также основную память 1204, такую как оперативно запоминающее устройство (ОЗУ) (RAM) или иное динамическое запоминающее устройство (к примеру, динамическое ОЗУ (ДОЗУ) (DRAM), статическое ОЗУ (СОЗУ) (SRAM) и синхронное ДОЗУ (СДОЗУ) (SDRAM)), соединенное с шиной 1202, для хранения информации и команд, подлежащих исполнению процессором 1203. Помимо этого основная память 1204 может использоваться для хранения временных переменных и иной промежуточной информации во время исполнения команд процессором 1203. Компьютерная система 1201 далее включает в себя постоянно запоминающее устройство ПЗУ (ROM) 1205 или иное статическое запоминающее устройство (например, программируемое ПЗУ (ППЗУ) (PROM), стираемое ППЗУ (СППЗУ) (EPROM) и электрически стираемое ППЗУ (ЭСППЗУ) (EEPROM)), соединенное с шиной 1202, для хранения статической информации и команд для процессора 1203.
Компьютерная система 1201 включает в себя также дисковый контроллер 1206, соединенный с шиной 1202, для управления одним или несколькими запоминающими устройствами для хранения информации и команд, такими как магнитный жесткий диск 1207, и съемными медиадисками 1208 (например, запоминающее устройство на гибком диске, постоянно запоминающий компакт-диск, компакт-диск для считывания-записи, магазинное запоминающее устройство на компакт-дисках, запоминающее устройство на магнитной ленте и запоминающее устройство на съемном магнитооптическом диске). Запоминающие устройства могут добавляться к компьютерной системе 1201 с помощью подходящих интерфейсов устройств (например, интерфейс малых вычислительных систем (SCSI), встроенная электроника (IDE), расширенная встроенная электроника (E-IDE), процессор прямого доступа (DMA) или сверх-DMA).
Компьютерная система 1201 может также включать в себя логические устройства специального назначения (например, специализированные интегральные схемы (СИС) (ASIC)) или конфигурируемые логические устройства (например, простые программируемые логические устройства (SPLD), сложные программируемые логические устройства (CPLD) и программируемые пользователем логические микросхемы (FPGA)).
Компьютерная система 1201 может также включать в себя контроллер 1209 дисплея, соединенный с шиной 1202, для управления дисплеем 1210, таким как электронно-лучевая трубка (ЭЛТ) (CRT), для отображения информации пользователю компьютера. Компьютерная система включает в себя устройства ввода, такие как клавиатура 1211 и координатное устройство 1212, для взаимодействия с пользователем компьютера и подачи информации в процессор 1203. Координатное устройство 1212, например, может быть мышью, трэкболом или джойстиком для передачи информации направления и выбора команд в процессор 1203 и для управления перемещением курсора на дисплее 1210. Помимо этого может быть предусмотрен принтер для распечатки листингов данных, хранящихся и (или) генерируемых компьютерной системой 1201.
Компьютерная система 1201 выполняет часть или все из шагов обработки по изобретению в ответ на исполнение процессором 1203 одной или нескольких последовательностей из одной или нескольких команд, содержащихся в памяти, такой как основная память 1204. Такие команды могут считываться в основную память из другого машиночитаемого носителя, такого как жесткий диск 1207 или сменное запоминающее устройство 1208. Для исполнения последовательностей команд, хранящихся в основной памяти 1204, могут применяться один или несколько процессоров в многопроцессорной компоновке. В альтернативных вариантах осуществления аппаратная схема может использоваться вместо программных команд или в комбинации с ними. Таким образом, варианты осуществления не ограничиваются какой-либо конкретной комбинацией аппаратной схемы и программного обеспечения.
Как изложено выше, компьютерная система 1201 включает в себя по меньшей мере один машиночитаемый носитель или память для хранения команд, запрограммированных согласно указаниям изобретения и для хранения структур данных, таблиц, записей или иных данных, описанных здесь. Примерами машиночитаемых носителей являются компакт-диски, жесткие диски, гибкие диски, ленты, магнитооптические диски, ППЗУ (СПРПЗУ, ЭСППЗУ, флэш-СППЗУ), ДОЗУ, СОЗУ, СДОЗУ или любой иной магнитный носитель, компакт-диски (например, CD-ROM) или любой иной оптический носитель, перфокарты, бумажная лента или любой иной физический носитель с узором отверстий, несущее колебание (описанное ниже) или любой иной носитель, с которого компьютер может считывать информацию.
Настоящее изобретение включает в себя хранящееся на одном или на комбинации машиночитаемых носителей программное обеспечение для управления компьютерной системой 1201, для приведения в действие устройства или устройств, воплощающих изобретение, и для обеспечения компьютерной системе 1201 возможности взаимодействовать с пользователем-человеком (например, персоналом печатного производства). Такое программное обеспечение может включать в себя - но не ограничиваться этим - драйверы устройств, операционные системы, средства разработки и прикладное программное обеспечение. Такие машиночитаемые носители включают в себя далее компьютерный программный продукт по настоящему изобретению для выполнения всей или обработки части (если обработка распределенная), выполняемой при воплощении изобретения.
Устройства компьютерных кодов по настоящему изобретению могут быть любыми интерпретируемыми или исполняемыми кодовыми механизмами, в том числе - но без ограничения ими - наборами символов, интерпретируемыми программами, динамически компонуемыми библиотеками (DLL), классами Java и полными исполняемыми программами. Кроме того, части обработки по настоящему изобретению могут распределяться для лучшей производительности, надежности и (или) стоимости.
Термин «машиночитаемый носитель», как он используется здесь, относится к любому носителю, который участвует в предоставлении команд процессору 1203 для исполнения. Машиночитаемый носитель может принимать множество форм, в том числе - но не ограничиваясь ими - энергонезависимые носители, энергозависимые носители и средства связи. Энергонезависимые носители включают в себя, например, оптические, магнитные диски и магнитооптические диски, такие как жесткий диск 1207, или сменные запоминающие устройства 1208. Энергозависимые носители включают в себя динамическую память, такую как основная память 1204. Средства связи включают в себя коаксиальные кабели, медные провода и волоконную оптику, в том числе провода, которые образуют шину 1202. Средства связи могут также принимать вид звуковых или световых волн, таких как генерируемые во время передачи данных с помощью радиоволн или инфракрасных волн.
Разнообразные формы машиночитаемого носителя могут вовлекаться в перенос одной или нескольких последовательностей одной или нескольких команд к процессору 1203 для исполнения. Например, команды могут первоначально переноситься на магнитном диске удаленного компьютера. Удаленный компьютер может загружать эти команды в динамическую память для воплощения всего или части настоящего изобретения и посылать команды по телефонной линии с помощью модема. Локальный для компьютерной системы 1201 модем может принимать данные по телефонной линии и использовать инфракрасный передатчик для преобразования этих данных в инфракрасный сигнал. Инфракрасный детектор, соединенный с шиной 1202, может принимать данные, переносимые инфракрасным сигналом, и помещать эти данные на шину 1202. Шина 1202 переносит эти данные в основную память 1204, из которой процессор 1203 извлекает команды и исполняет их. Команды, принятые основной памятью 1204, могут опционально храниться в запоминающем устройстве 1207 или 1208 как до, так и после их исполнения процессором 1203.
Компьютерная система 1201 включает в себя также интерфейс 1213 связи, соединенный с шиной 1202. Интерфейс 1213 связи предоставляет двунаправленную передачу данных, связанную с сетевой линией 1214, которая соединяется, например, с местной сетью (LAN) 1215 или с другой сетью 1216 связи, такой как Интернет. Например, интерфейс 1213 связи может быть сетевой интерфейсной картой для присоединения к LAN с пакетной коммутацией. В качестве другого примера интерфейс 1213 связи может быть картой асимметричной цифровой абонентской линии (ADSL), картой цифровой сети с интегрированными услугами (ISDN) или модемом для обеспечения соединения передачи данных с соответствующим типом линии связи. Могут быть также воплощены беспроводные линии. В любом таком воплощении интерфейс 1213 связи посылает и принимает электрические, электромагнитные или оптические сигналы, которые переносят потоки цифровых данных, представляющих различные типы информации.
Сетевая линия 1214 обычно обеспечивает связь по одной или нескольким сетям с другими устройствами данных. Например, сетевая линия 1214 может обеспечивать соединение с другим компьютером через местную сеть 1215 (например, LAN) или через оборудование, управляемое поставщиком услуг (сервисным провайдером), который предоставляет услуги связи по сети 1216 связи. Местная сеть 1214 и сеть 1216 связи используют, к примеру, электрические, электромагнитные или оптические сигналы, которые переносят потоки цифровых данных, и связанный с ними физический уровень (например, кабель САТ 5, коаксиальный кабель, оптическое волокно и т.п.). Сигналы по различным сетям и сигналы на сетевой линии 1214 и через интерфейс 1213 связи, которые переносят цифровые данные к компьютерной системе 1201 и из нее, могут воплощаться в сигналы основной полосы частот или сигналы, основанные на несущем колебании. Сигналы основной полосы частот переносят цифровые данные как немодулированные электрические импульсы, которые описывают битовый поток цифровых данных, где термин «биты» должен пониматься в широком значении для обозначения символа, когда каждый символ переносит по меньшей мере один или несколько информационных битов. Цифровые данные могут использоваться для модуляции несущего колебания, например, с помощью амплитудно-манипулированных, фазоманипулированных и (или) частотно-манипулированных сигналов, которые распространяются по проводящей среде или передаются как электромагнитные волны через среду распространения. Таким образом, цифровые данные могут посылаться как немодулированные данные основной полосы частот по «проводному» каналу связи и (или) посылаться в заранее заданном частотном диапазоне, отличном от основной полосы частот, путем модуляции несущего колебания. Компьютерная система 1201 может передавать и принимать данные, в том числе программный код, по сети(-ям) 1215 и 1216, сетевой линии 1214 и интерфейсу 1213 связи. Кроме того, сетевая линия 1214 может быть соединена через LAN 1215 с мобильным устройством 1217, таким как портативный компьютер персонального цифрового ассистента (PDA) или сотовый телефон.
Успешное воплощение изобретения на персональных ПК, на хранящемся в сети персональном контенте или в системах корпоративных документов позволит пользователям более эффективно осуществлять поиск релевантных документов способом, сравнимым с поиском и навигацией во Всемирной паутине. Настоящее изобретение предоставляет блок построения перехода к полному использованию основанного на анализе связей ранжирования вместе с основанной на связях навигацией в любой среде, которая в настоящее время не имеет структуры связей.
Настоящее изобретение может также применяться для распределенного (сетевого) хранения персонального контента. Вообразим сетевое хранение, к которому пользователь может обратиться с терминала любого типа и которым управляет и которое выдает сетевой оператор. Пользователь может загрузить весь свой контент (изображения, документы, презентации, видео, МР3 и т.п.) в это сетевое хранение. Настоящее изобретение представляет ключевую составляющую при воплощении приложения поиска и навигации с помощью основанного на анализе связей ранжирования для поиска пользовательского контента в сетевом хранении. Настоящее изобретение может также обеспечить новый и гораздо лучший путь для корпоративного поиска.
В свете вышеприведенных разъяснений возможны многочисленные модификации и варианты настоящего изобретения. Поэтому понятно, что в объеме приложенной формулы изобретения данное изобретение может осуществляться на практике иначе, чем конкретно описано здесь.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ДЛЯ ВЫЯВЛЕНИЯ АНОМАЛЬНОГО РЕЙТИНГОВАНИЯ | 2019 |
|
RU2776034C2 |
| РАСШИРЕНИЕ ВОЗМОЖНОСТЕЙ ИНФОРМАЦИОННОГО ПОИСКА | 2015 |
|
RU2618375C2 |
| ДИАГРАММА РАНЖИРОВАНИЯ | 2007 |
|
RU2449357C2 |
| КОМПЬЮТЕРНЫЙ ПОИСК С ПОМОЩЬЮ АССОЦИАТИВНЫХ СВЯЗЕЙ | 2004 |
|
RU2343537C2 |
| СПОСОБ СУММАРИЗАЦИИ ТЕКСТА И ИСПОЛЬЗУЕМЫЕ ДЛЯ ЕГО РЕАЛИЗАЦИИ УСТРОЙСТВО И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ИНФОРМАЦИИ | 2016 |
|
RU2635213C1 |
| Способ и сервер для ранжирования цифровых документов в ответ на запрос | 2020 |
|
RU2818279C2 |
| Способ и система для формирования карточки объекта | 2018 |
|
RU2739554C1 |
| ДЛИНА ДОКУМЕНТА В КАЧЕСТВЕ СТАТИЧЕСКОГО ПРИЗНАКА РЕЛЕВАНТНОСТИ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2009 |
|
RU2517271C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ РАНЖИРОВАННЫХ ПОЗИЦИЙ ЭЛЕМЕНТОВ СИСТЕМОЙ РАНЖИРОВАНИЯ | 2020 |
|
RU2781621C2 |
| СПОСОБ И СЕРВЕР ГЕНЕРИРОВАНИЯ МЕТА-ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ | 2018 |
|
RU2721159C1 |
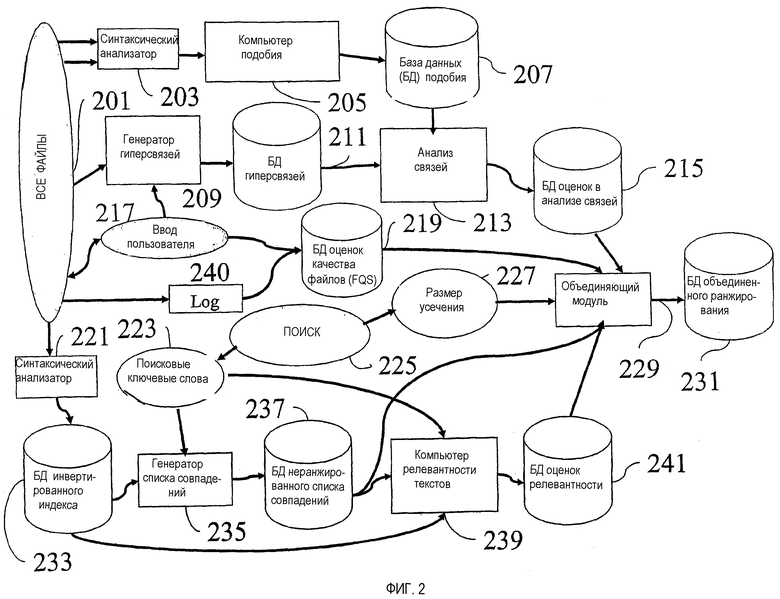
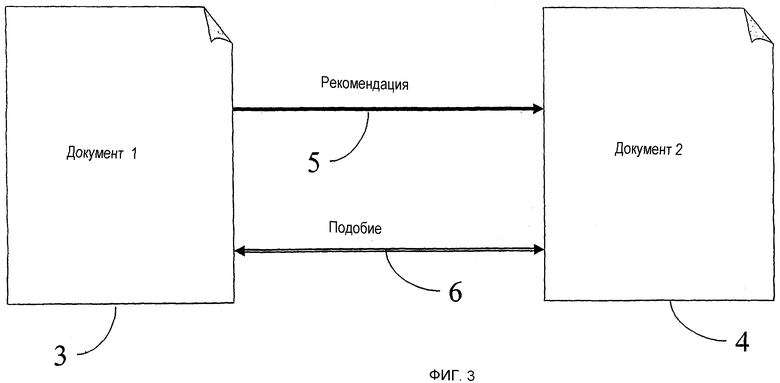
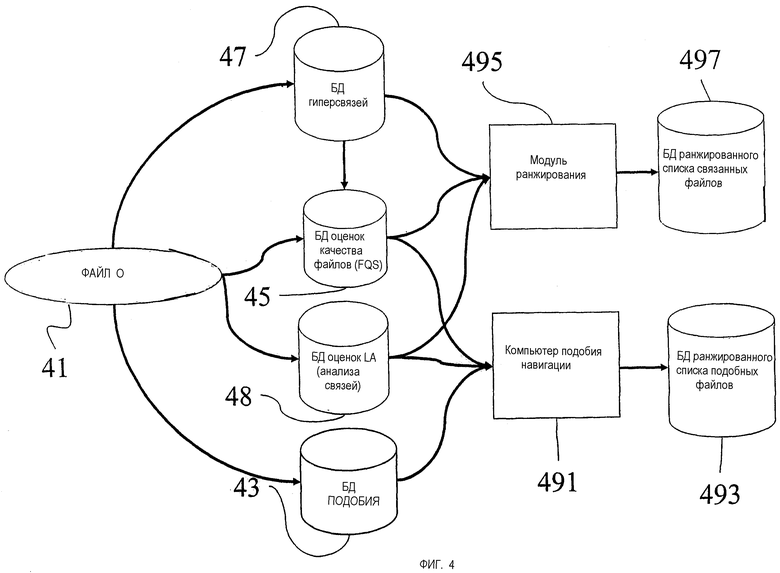
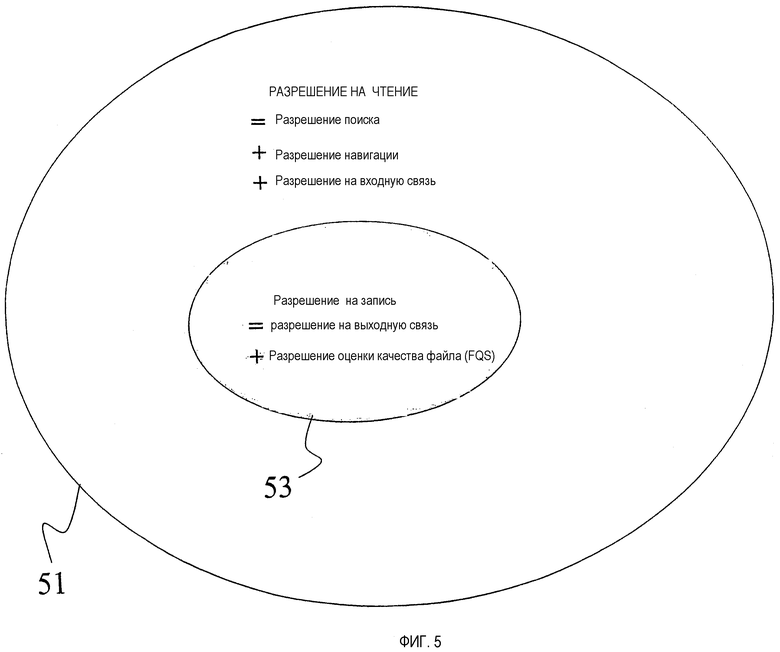
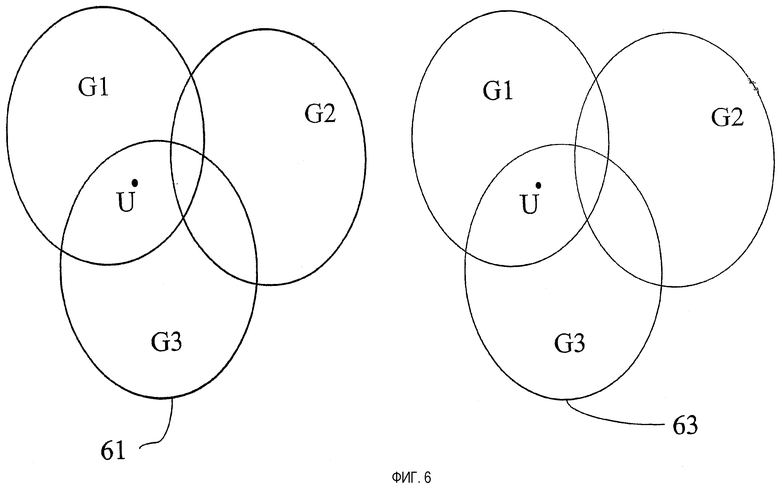
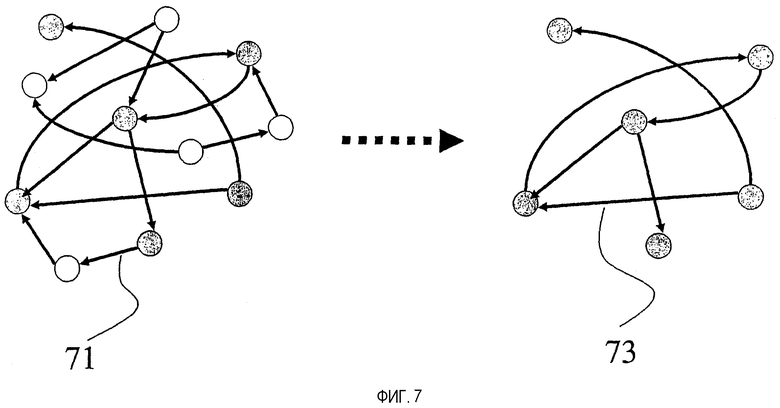
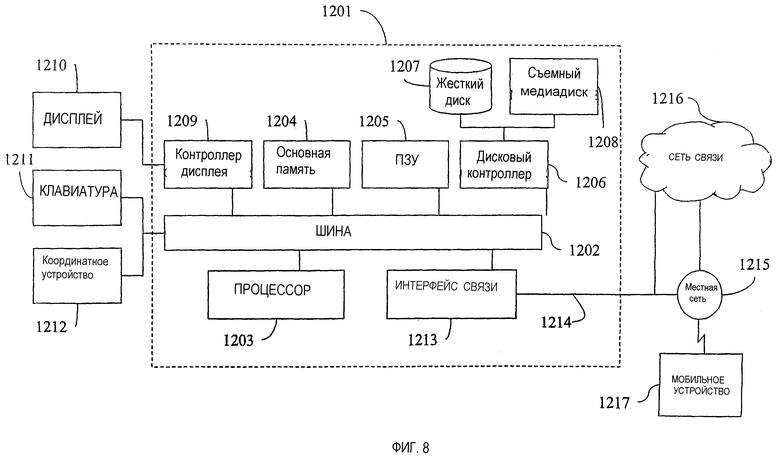
Изобретение относится к средствам поиска электронного материала, хранящегося в компьютерной среде. Техническим результатом является повышение быстродействия поиска и достоверности предъявляемого материала. В способе определяют ненаправленную взвешенную связь между по меньшей мере двумя из упомянутого множества документов на основе подобия; определяют направленную взвешенную связь между по меньшей мере двумя из упомянутого множества документов; добавляют упомянутые определенные ненаправленные взвешенные связи к упомянутым определенным направленным взвешенным связям для создания гибридной сети, имеющей связи, и выполняют алгоритм анализа связей, получающий связи упомянутой гибридной сети в качестве своих входных данных, причем упомянутый алгоритм включает в себя по меньшей мере анализ связей вперед и анализ связей назад. Выходными данными упомянутого алгоритма является набор оценок в анализе связей. 3 н. и 94 з.п. ф-лы, 8 ил.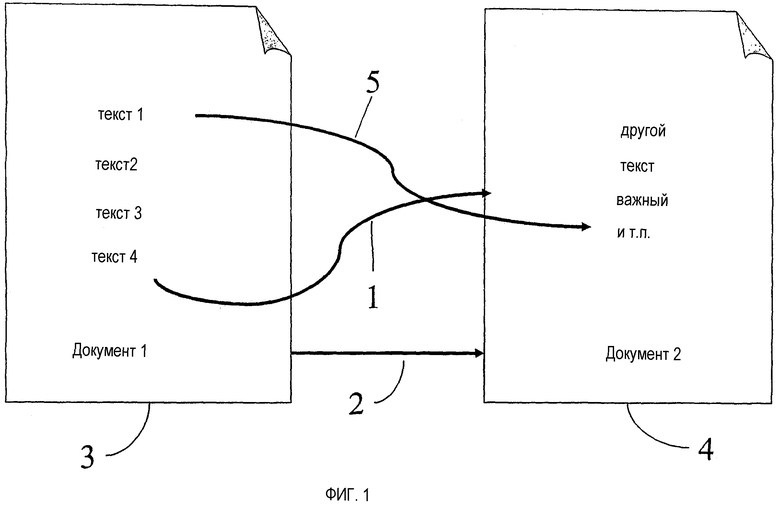
1. Способ проведения поиска электронного материала, хранящегося в компьютерной среде, содержащий этапы, на которых:
обеспечивают множество документов;
определяют ненаправленную взвешенную связь между, по меньшей мере, двумя из упомянутого множества документов на основе подобия;
определяют направленную взвешенную связь между, по меньшей мере, двумя из упомянутого множества документов;
добавляют упомянутые определенные ненаправленные взвешенные связи к упомянутым определенным направленным взвешенным связям для создания гибридной сети, имеющей связи; и
выполняют алгоритм анализа связей, получающий связи упомянутой гибридной сети в качестве своих входных данных, причем упомянутый алгоритм включает в себя, по меньшей мере, анализ связей вперед и анализ связей назад,
при этом выходными данными упомянутого алгоритма является набор оценок в анализе связей.
2. Способ по п.1, в котором упомянутый алгоритм основан на собственном векторе.
3. Способ по п.1, в котором упомянутый, по меньшей мере, один из анализа связей вперед и анализа связей назад содержит использование, по меньшей мере, одного из несоставного оператора Вперед и несоставного оператора Назад.
4. Способ по п.1, в котором упомянутый, по меньшей мере, один из анализа связей вперед и анализа связей назад содержит использование, по меньшей мере, одного из ненормированного оператора Вперед и ненормированного оператора Назад.
5. Способ по п.1, дополнительно содержащий этап, на котором
оценивают каждый из упомянутых, по меньшей мере, двух документов посредством, по меньшей мере, одного из анализа релевантности текстов и анализа качества файлов.
6. Способ по п.1, в котором этап определения направленной взвешенной связи между, по меньшей мере, двумя из упомянутого множества документов включает в себя этап, на котором устанавливают гиперсвязь между первым документом и вторым документом, при этом упомянутый этап установления гиперсвязи содержит один из этапов, на которых:
присоединяют упомянутую гиперсвязь в тексте одного из упомянутых первого и второго документов,
связывают упомянутые первый и второй документы неприсоединенной гиперсвязью, при этом
упомянутый этап установления гиперсвязи дополнительно содержит один из этапов, на которых
вводят упомянутую гиперсвязь через терминал ввода и устанавливают упомянутую гиперсвязь автоматически.
7. Способ по п.6, в котором упомянутая направленная взвешенная связь может быть или может не быть присоединенной к тексту в указывающем или указываемом документе.
8. Способ по п.6, дополнительно содержащий этап, на котором
сохраняют информацию гиперсвязи (указывающий файл, указываемый файл, вес гиперсвязи и присоединенный текст) в базе данных структуры связей.
9. Способ по п.1, в котором упомянутый, по меньшей мере, один из анализа связей вперед и анализа связей назад содержит этапы, на которых:
определяют подобную полномочию оценку для документа, используя несоставной ненормированный оператор Вперед и не используя оператор Назад; и определяют подобную ядру оценку для документа, используя несоставной ненормированный оператор Назад и не используя оператор Вперед, так что упомянутые этапы определения подобной полномочию оценки и определения подобной ядру оценки математически разделены.
10. Способ по п.5, дополнительно содержащий этапы, на которых:
проходят по файловой системе;
сканируют текст файлов в упомянутой файловой системе и создают инвертированный индекс.
11. Способ по п.10, дополнительно содержащий этапы, на которых:
сравнивают документы попарно и вырабатывают оценку подобия.
12. Способ по п.11, дополнительно содержащий этап, на котором сохраняют упомянутую оценку подобия в базе данных оценок подобия.
13. Способ по п.11, в котором упомянутый этап сравнения документов попарно содержит этапы, на которых:
подсчитывают число раз Nf(w), когда слово w появляется в документе f; и делят Nf(w) на общее число Nf слов в документе для выработки профиля fnf(w) документа.
14. Способ по п.13, в котором упомянутый этап выработки оценки подобия содержит этап, на котором
вычисляют подобие S(1, 2) между первым документом и вторым документом следующим образом:
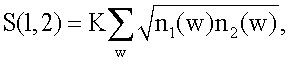
где K является настроечным параметром.
15. Способ по п.14, дополнительно содержащий этап, на котором устанавливают минимальную меру подобия δ>0 так, что, когда 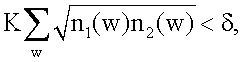 S(1,2)=δ.
S(1,2)=δ.
16. Способ по п.5, в котором упомянутый анализ релевантности текстов содержит этап, на котором
оценивают документ на основе релевантности с набором ключевых слов.
17. Способ по п.5, в котором упомянутый анализ качества файлов содержит этап, на котором
назначают для оценки качества файла значение по умолчанию.
18. Способ по п.17, дополнительно содержащий этап, на котором
регулируют упомянутую оценку качества файла автоматически или вручную.
19. Способ по п.18, в котором упомянутый этап регулировки содержит этапы, на которых определяют, когда открывался или редактировался файл; и назначают файлу, который недавно открывали или редактировали, более высокую оценку качества файла.
20. Способ по п.18, в котором упомянутый этап регулировки содержит этапы, на которых регистрируют за период времени число раз, когда файл открывали или редактировали; и назначают файлу, который открывали или редактировали чаще, более высокую оценку качества файла.
21. Способ по п.5, дополнительно содержащий этапы, на которых:
вводят ключевое слово в поисковый интерфейс;
подают это ключевое слово в генератор списков совпадений и выводят список совпадений из тех же совпадений, сопровождаемый соответствующим списком оценок релевантности текстов.
22. Способ по п.21, дополнительно содержащий этапы, на которых:
проходят по файловой системе;
сканируют текст файлов в упомянутой файловой системе и создают инвертированный индекс.
23. Способ по п.22, в котором упомянутый этап выведения списка совпадений из тех же самых совпадений содержит этап, на котором
используют ключевое слово для извлечения упомянутого списка совпадений из упомянутого инвертированного индекса.
24. Способ по п.22, в котором упомянутый инвертированный индекс включает в себя текст, выделенный из метаданных нетекстовых файлов.
25. Способ по п.21, в котором упомянутый этап вычисления оценки важности содержит этап, на котором
вычисляют оценку W важности для каждого документа, причем
W=a(TR)+b(LA)+c(FQS),
где TR - оценка релевантности текстов из анализа текстов,
LA - оценка в анализе связей,
FQS - оценка качества файла и
а, b, с являются настроечными параметрами.
26. Способ по п.25, дополнительно содержащий этап, на котором регулируют любой из весов a, b или с.
27. Способ по п.26, дополнительно содержащий этап, на котором перегруппировывают упомянутый список совпадений в ранжированный список.
28. Способ по п.27, дополнительно содержащий этап, на котором усекают упомянутый ранжированный список.
29. Способ по п.28, дополнительно содержащий этап, на котором отображают упомянутый ранжированный список.
30. Способ по п.23, дополнительно содержащий этапы, на которых:
вводят второе ключевое слово в поисковый интерфейс;
подают второе ключевое слово в упомянутый генератор списков совпадений и выводят второй список совпадений из тех же самых совпадений, сопровождаемый соответствующим вторым списком оценок релевантности текстов.
31. Способ по п.30, в котором упомянутый этап выведения списка совпадений из тех же самых совпадений содержит этап, на котором используют второе ключевое слово для выделения упомянутого второго списка совпадений из упомянутого инвертированного индекса.
32. Способ по п.31, дополнительно содержащий этапы, на которых:
формируют подграф из упомянутого второго списка совпадений и всех связей среди документов упомянутого второго списка совпадений;
получают ограниченные оценки LA(sub) анализа связей для каждого из упомянутых документов в упомянутом втором списке совпадений путем выполнения анализа связей на этом подграфе и
упомянутый этап вычисления оценки важности включает в себя этап, на котором вычисляют вторую оценку W важности для каждого документа, причем
W=a(TR)+b(LA(sub))+c(FQS),
где TR - оценка релевантности текстов из анализа текстов,
LA(sub) - оценка в анализе связей подграфа,
FQS - оценка качества файла и
а, b, с являются настроечными параметрами.
33. Способ по п.32, дополнительно содержащий этап, на котором регулируют любой из весов a, b или с.
34. Способ по п.33, дополнительно содержащий этап, на котором перегруппировывают упомянутый второй список совпадений во второй ранжированный список.
35. Способ по п.34, дополнительно содержащий этап, на котором усекают упомянутый второй список совпадений.
36. Способ по п.35, дополнительно содержащий этап, на котором отображают упомянутый второй ранжированный список.
37. Способ по п.5, дополнительно содержащий этап, на котором осуществляют навигацию между документами, оцененными на упомянутом шаге оценивания.
38. Способ по п.37, в котором упомянутый этап осуществления навигации содержит этап, на котором
начинают с начального файла О, который является одним из исходного файла или открытого в текущее время файла.
39. Способ по п.38, в котором упомянутый этап осуществления навигации дополнительно содержит этап, на котором
идентифицируют соседей В начального файла О, имеющих оценку S(O, B)
подобия по отношению к файлу О, которая больше, чем пороговое значение с Sмин.
40. Способ по п.39, в котором упомянутая оценка S(O, B) подобия является ненулевой.
41. Способ по п.38, в котором упомянутый этап идентифицирования соседей В содержит этап, на котором идентифицируют соседей начального файла О, имеющих, по меньшей мере, одно из следующего:
направленную связь, указывающую из В на О, и направленную связь, указывающую из О на В.
42. Способ по п.39, в котором упомянутый этап осуществления навигации содержит этапы, на которых сравнивают документы попарно и вырабатывают оценку подобия.
43. Способ по п.42, в котором упомянутый этап сравнения документов попарно содержит этапы, на которых:
подсчитывают число раз Nf(w), когда слово w появляется в документе f; и делят Nf(w) на общее число Nf слов в документе для выработки профиля fnf(w) документа.
44. Способ по п.43, в котором упомянутый этап выработки оценки подобия содержит этап, на котором
вычисляют подобие S(1, 2) между первым документом и вторым документом следующим образом:
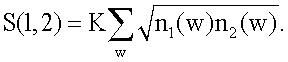
45. Способ по п.44, дополнительно содержащий этап, на котором устанавливают минимальную меру подобия δ>0 так, что, когда 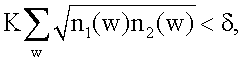 S(1,2)=δ.
S(1,2)=δ.
46. Способ по п.42, дополнительно содержащий этап, на котором
сохраняют упомянутую оценку подобия в базе данных оценок подобия.
47. Способ по п.46, дополнительно содержащий этап, на котором вычисляют оценку SNW(O,B) навигации подобия, где
SNW(O,B)=g·S(O,B)+h·LA(B)+m·FQS(B),
LA(B) есть оценка В в анализе связей, FQS(B) есть оценка качества файла В, а g, h и m являются настроечными параметрами.
48. Способ по п.47, дополнительно содержащий этап, на котором ранжируют связанные подобием файлы для обеспечения ранжированных связанных подобием файлов.
49. Способ по п.48, дополнительно содержащий этап, на котором усекают упомянутые ранжированные связанные подобием файлы.
50. Способ по п.49, дополнительно содержащий этап, на котором отображают упомянутые ранжированные связанные подобием файлы.
51. Способ по п.50, дополнительно содержащий этап, на котором переходят к связанному подобием файлу.
52. Способ по п.39, дополнительно содержащий этапы, на которых:
вводят ключевые слова;
получают список совпадений для упомянутых ключевых слов и ограничивают отображение соседей теми соседями, которые найдены в списке совпадений.
53. Способ по п.52, дополнительно содержащий этапы, на которых:
формируют подграф из упомянутого списка совпадений и всех связей среди документов в упомянутом списке совпадений;
получают ограниченные оценки LA(sub) анализа связей для каждого из упомянутых документов путем выполнения анализа связей на упомянутом подграфе и ранжируют соседей согласно оценке соседей по подобию подграфа SNW(sub)(O,B)=g·S(O,B)+h·LA(sub)(B)+m·FQS(B).
54. Способ по п.53, дополнительно содержащий этап, на котором ранжируют связанные подобием файлы для обеспечения ранжированных связанных подобием файлов.
55. Способ по п.54, дополнительно содержащий этап, на котором усекают упомянутые ранжированные связанные подобием файлы.
56. Способ по п.55, дополнительно содержащий этап, на котором отображают упомянутые ранжированные связанные подобием файлы.
57. Способ по п.56, дополнительно содержащий этап, на котором переходят к связанному подобием файлу.
58. Способ по п.41, дополнительно содержащий этап, на котором устанавливают гиперсвязь между первым документом и вторым документом, при этом этап установления гиперсвязи содержит этапы, на которых:
присоединяют упомянутую гиперсвязь в тексте одного из упомянутых первого и второго документов,
связывают упомянутые первый и второй документы неприсоединенной гиперсвязью, при этом упомянутый этап установления гиперсвязи дополнительно содержит один из следующих этапов: вводят упомянутую гиперсвязь через терминал ввода и устанавливают упомянутую гиперсвязь автоматически.
59. Способ по п.58, в котором упомянутая направленная взвешенная связь может быть или может не быть присоединенной к тексту в указывающем или указываемом документе.
60. Способ по п.58, дополнительно содержащий этап, на котором сохраняют информацию гиперсвязи (указывающий файл, указываемый файл, вес гиперсвязи и присоединенный текст) в базе данных структуры связей.
61. Способ по п.60, дополнительно содержащий этап, на котором идентифицируют соседство по гиперсвязи начального файла О, при этом упомянутое соседство по гиперсвязи составлено, по меньшей мере, из одного из следующего:
все файлы В, имеющие направленную связь, указывающую на О, и все файлы, на которые указывает О.
62. Способ по п.61, в котором оценку (HNW) соседа по гиперсвязи вычисляют для каждого файла в упомянутом соседстве по гиперсвязи согласно следующей формуле:
HNW=d(HLW)+e(LA)+f(FQS),
где HLW - вес гиперсвязи, LA есть оценка в анализе связей для соседа, FQS равна оценке качества файла для соседа, a d, e и f представляют собой настроечные параметры.
63. Способ по п.62, дополнительно содержащий этап, на котором ранжируют упомянутое соседство по гиперсвязи согласно соответствующей оценке соседей по гиперсвязи.
64. Способ по п.63, дополнительно содержащий этап, на котором усекают упомянутое соседство по гиперсвязи.
65. Способ по п.64, дополнительно содержащий этап, на котором отображают упомянутое соседство по гиперсвязи.
66. Способ по п.65, дополнительно содержащий этап, на котором переходят к файлу в упомянутом соседстве по гиперсвязи.
67. Способ по п.61, дополнительно содержащий этапы, на которых:
вводят ключевое слово;
получают список совпадений для упомянутого ключевого слова и ограничивают соседей, подлежащих отображению, теми соседями, которые найдены в списке совпадений.
68. Способ по п.67, дополнительно содержащий этапы, на которых:
проходят по файловой системе; сканируют текст файлов в упомянутой файловой системе и создают инвертированный индекс.
69. Способ по п.68, в котором упомянутый этап получения списка совпадений содержит этап, на котором
используют ключевое слово для выделения упомянутого списка совпадений из упомянутого инвертированного индекса.
70. Способ по п.68, в котором упомянутый инвертированный индекс включает в себя текст, выделенный из метаданных нетекстовых файлов.
71. Способ по п.69, дополнительно содержащий этапы, на которых:
формируют подграф из упомянутого второго списка совпадений и всех связей среди документов в упомянутом втором списке совпадений;
получают ограниченные оценки LA(sub) анализа связей для каждого из упомянутых документов в упомянутом втором списке совпадений путем выполнения анализа связей на этом подграфе и ранжируют соседей согласно оценке соседей по гиперсвязи подграфа HNW((sub)=d(HLW)+e(LA(sub))+f(FQS).
72. Способ по п.71, дополнительно содержащий этап, на котором ранжируют упомянутое соседство по гиперсвязи согласно соответствующей оценке соседей по гиперсвязи подграфа.
73. Способ по п.72, дополнительно содержащий этап, на котором усекают упомянутое соседство по гиперсвязи.
74. Способ по п.73, дополнительно содержащий этап, на котором отображают упомянутое соседство по гиперсвязи.
75. Способ по п.74, дополнительно содержащий этап, на котором переходят к файлу в пределах упомянутого соседства по гиперсвязи.
76. Способ по п.21, дополнительно содержащий этапы, на которых:
осуществляют поиск файлов совместного доступа одной или нескольких определенных групп, совместно находящихся в общей среде;
осуществляют поиск файлов, которые хранятся в сети;
осуществляют поиск файлов корпорации и осуществляют поиск физических объектов.
77. Способ по п.37, в котором упомянутый этап осуществления навигации содержит этапы, на которых:
осуществляют навигацию среди файлов совместного доступа одной или нескольких определенных групп, совместно находящихся в общей среде;
осуществляют навигацию среди файлов, которые хранятся в сети;
осуществляют навигацию среди файлов корпорации и осуществляют навигацию среди физических объектов.
78. Способ по п.76 или 77, в котором упомянутый этап осуществления поиска или навигации по файлам совместного доступа одной или нескольких определенных групп содержит этап, на котором
соединяют первый подграф упомянутой одной или нескольких определенных групп со вторым подграфом упомянутой одной или нескольких определенных групп.
79. Способ по п.78, дополнительно содержащий этапы, на которых:
устанавливают гиперсвязи, которые указывают из выбранного файла; и модифицируют оценку качества файла для выбранного файла;
при этом упомянутые этапы установления и модифицирования ограничиваются для пользователя разрешением на запись для выбранного файла.
80. Способ по п.79, в котором упомянутый этап модифицирования оценки качества файла содержит этап, на котором усредняют множество оценок качества файла.
81. Способ по п.79, дополнительно содержащий этап, на котором модифицируют упомянутую оценку качества файла любым пользователем, имеющим разрешение на чтение.
82. Способ по п.79, в котором упомянутый пользователь является членом, по меньшей мере, двух групп, каждая из которых имеет отличные привилегии на запись и чтение.
83. Способ по п.82, дополнительно содержащий этап, на котором выполняют анализ связей графа, который охватывает все документы, доступные для упомянутых, по меньшей мере, двух групп.
84. Способ по п.82, дополнительно содержащий этапы, на которых:
выполняют анализ связей подграфа, который охватывает все документы, доступные для первой из упомянутых, по меньшей мере, двух групп, по соответствующему первому разрешению на чтение;
выполняют анализ связей подграфа, который охватывает все документы, доступные для второй из упомянутых, по меньшей мере, двух групп, по соответствующему второму разрешению на чтение.
85. Способ по п.82, дополнительно содержащий этап, на котором выполняют анализ связей подграфа, который охватывает все документы, доступные для пользователя.
86. Машиночитаемый носитель, на котором сохранены команды для осуществления поиска электронного материала, хранящегося в компьютерной среде, причем упомянутые команды содержат команды для выполнения этапов, на которых:
обеспечивают множество документов;
определяют ненаправленную взвешенную связь между, по меньшей мере, двумя из упомянутого множества документов на основе подобия;
определяют направленную взвешенную связь между, по меньшей мере, двумя из упомянутого множества документов;
добавляют упомянутую определенную ненаправленную взвешенную связь к упомянутым определенным направленным взвешенным связям для создания гибридной сети, имеющей связи; и
выполняют алгоритм анализа связей, получающий связи упомянутой гибридной сети в качестве своих входных данных, причем упомянутый алгоритм включает в себя, по меньшей мере, анализ связей вперед и анализ связей назад,
при этом выходными данными упомянутого алгоритма является набор оценок в анализе связей.
87. Машиночитаемый носитель по п.86, в котором упомянутый алгоритм основан на собственном векторе.
88. Машиночитаемый носитель по п.86, в котором упомянутый, по меньшей мере, один из анализа связей вперед и анализа связей назад содержит использование, по меньшей мере, одного из несоставного оператора Вперед и несоставного оператора Назад.
89. Машиночитаемый носитель по п.86, в котором упомянутый, по меньшей мере, один из анализа связей вперед и анализа связей назад содержит
использование, по меньшей мере, одного из ненормированного оператора Вперед и ненормированного оператора Назад.
90. Машиночитаемый носитель по п.86, дополнительно содержащий команды для этапа, на котором
оценивают каждый из упомянутых, по меньшей мере, двух документов посредством, по меньшей мере, одного из анализа релевантности текстов и анализа качества файлов.
91. Машиночитаемый носитель по п.86, в котором команды для этапа определения направленной взвешенной связи между, по меньшей мере, двумя из упомянутого множества документов включают в себя команды для этапа, на котором устанавливают гиперсвязь между первым документом и вторым документом, при этом упомянутые команды для этапа установления гиперсвязи содержат команды для одного из этапов, на которых:
присоединяют упомянутую гиперсвязь в тексте одного из упомянутых первого и второго документов,
связывают упомянутые первый и второй документы неприсоединенной гиперсвязью, при этом
упомянутые команды для установления гиперсвязи дополнительно содержат для выполнения одного из этапов, на которых:
вводят упомянутую гиперсвязь через терминал ввода и устанавливают упомянутую гиперсвязь автоматически.
92. Поисковое устройство, выполненное с возможностью осуществления поиска электронного материала, хранящегося в компьютерной среде, содержащее:
средство для обеспечения множества документов;
средство для определения ненаправленной взвешенной связи между, по меньшей мере, двумя документами из упомянутого множества на основе подобия;
средство для определения направленной взвешенной связи между, по меньшей мере, двумя документами из упомянутого множества;
средство для добавления упомянутых определенных ненаправленных взвешенных связей к упомянутым определенным направленным взвешенным связям для создания гибридной сети, имеющей связи; и
средство для выполнения алгоритма анализа связей, получающего связи упомянутой гибридной сети в качестве своих входных данных, причем упомянутый алгоритм включает в себя, по меньшей мере, одно из анализа связей вперед и анализа связей назад,
при этом выходными данными упомянутого алгоритма является набор оценок в анализе связей.
93. Поисковое устройство по п.92, в котором упомянутый алгоритм основан на собственном векторе.
94. Поисковое устройство по п.92, в котором упомянутый, по меньшей мере, один из анализа связей вперед и анализа связей назад содержит использование, по меньшей мере, одного из несоставного оператора Вперед и несоставного оператора Назад.
95. Поисковое устройство по п.92, в котором упомянутый, по меньшей мере, один из анализа связей вперед и анализа связей назад содержит использование, по меньшей мере, одного из ненормированного оператора Вперед и ненормированного оператора Назад.
96. Поисковое устройство по п.92, дополнительно содержащее средство для оценивания каждого из упомянутых, по меньшей мере, двух документов посредством, по меньшей мере, одного из анализа релевантности текстов и анализа качества файлов.
97. Поисковое устройство по п.92, в котором средство для определения направленной взвешенной связи между, по меньшей мере, двумя из упомянутого множества документов включает в себя средство для установления гиперсвязи между первым документом и вторым документом, при этом упомянутое средство для установления гиперсвязи содержит одно из следующего:
средство для присоединения упомянутой гиперсвязи в тексте одного из упомянутых первого и второго документов,
средство для связывания упомянутых первого и второго документов неприсоединенной гиперсвязью, при этом
упомянутое средство для установления гиперсвязи дополнительно содержит одно из следующего:
средство для введения упомянутой гиперсвязи через терминал ввода и средство для установления упомянутой гиперсвязи автоматически.
| US 6622139 B1, 16.09.2003 | |||
| АППАРАТ ДЛЯ ИЗВЛЕЧЕНИЯ ЭФИРНЫХ МАСЕЛ ИЗ ДЕСТИЛЛЯЦИОННЫХ ВОД | 1933 |
|
SU36541A1 |
| US 6738678 B1, 18.05.2004 | |||
| СИСТЕМА И СПОСОБ, ПРЕДНАЗНАЧЕННЫЕ ДЛЯ ПЕРЕДАЧИ И ПРИЕМА ДАННЫХ | 2003 |
|
RU2338324C2 |
| WOLBER D et al | |||
| "Exposing document context in personal WEB', IUI 02.2002 INTERNATIONAL CONFERENCE ON INTELLIGENT USER INTERFACE ACM NEW YORK, NY, USA, 2002, p.151-158. | |||

