Предшествующий уровень техники
Пользователи компьютера обладают различными путями находить информацию, которая может храниться локально или удаленно. Например, для нахождения документов и других файлов с помощью ключевых слов могут использоваться поисковые машины. Поисковые машины могут также использоваться для выполнения запросов, основанных на Web. Поисковая машина пытается возвратить релевантные результаты на основании запроса.
Сущность изобретения
Это краткое изложение сущности изобретения предоставляется для того, чтобы представить в упрощенной форме подборку концепций, которые более глубоко описаны ниже в подробном описании. Это краткое описание сущности изобретения не предназначается для выявления ключевых признаков или существенных признаков заявленного изобретения, равно как и не подразумевается в качестве помощи в определении объема заявленного изобретения.
Варианты осуществления приспособлены так, чтобы предоставлять информацию, включающую использование одного или более ранжировочных признаков, при предоставлении результатов поиска. В некотором варианте осуществления система включает в себя поисковую машину, которая включает в себя ранжирующий алгоритм, который может быть сконфигурирован для использования одного или нескольких ранжировочных признаков для ранжирования и предоставления результатов поиска на основании запроса. Согласно одному варианту осуществления длина документа может быть использована в качестве ранжировочного признака или меры релевантности документа.
Эти и другие свойства и преимущества будут очевидны при прочтении последующего подробного описания и обзора соответственных чертежей. Необходимо понимать, что как предшествующее общее описание, так и последующее подробное описание являются только пояснительными и не являются ограничительными для заявленного изобретения.
Краткое описание чертежей
Фиг.1 описывает структурную схему примера системы, сконфигурированной для управления информацией.
Фиг.2 является логической блок-схемой, описывающей пример процесса ранжирования и запроса.
Фиг.3 является логической блок-схемой, описывающей пример процесса ранжирования и запроса.
Фиг.4 является структурной схемой, иллюстрирующей вычислительную среду для реализации различных вариантов осуществления, описанных здесь.
Подробное описание
Варианты осуществления приспособлены так, чтобы предоставлять информацию, включающую использование одного или более ранжировочных признаков, при предоставлении результатов поиска. В некотором варианте осуществления система включает в себя поисковую машину, которая включает в себя ранжирующий алгоритм, который может быть сконфигурирован для использования одного или нескольких ранжировочных признаков, соответствующих переходам по ссылкам, для ранжирования и предоставления результатов поиска на основании запроса. В одном варианте осуществления система включает в себя ранжирующий компонент, который может использовать параметр выбора (щелчком мыши (кликом)), параметр пропуска, один или более потоковых параметров и длину документа для ранжирования и предоставления результата поиска.
В одном варианте осуществления система включает в себя поисковый компонент, который содержит поисковое приложение, которое может быть включено как часть машиночитаемого носителя данных. Поисковое приложение может использоваться для предоставления результатов поиска на основании, частично, пользовательского запроса и другого действия и/или бездействия пользователя. Например, пользователь может ввести ключевые слова в поисковое приложение, и поисковое приложение может использовать эти ключевые слова, чтобы вернуть релевантные результаты поиска. Пользователь может кликнуть или может не кликать на результат поиска для большей информации. Как описано ниже, поисковое приложение может использовать информацию, основанную на предыдущем действии или предыдущем бездействии, при ранжировании и возвращении результатов поиска. Соответственно, поисковое приложение может использовать реакции пользователя, основанные на результате поиска, чтобы обеспечить дополнительное фокусирование при возвращении релевантных результатов поиска. Например, поисковое приложение может использовать информацию состоявшихся переходов по ссылкам при ранжировании результатов поиска и возвращении ранжированных результатов поиска на основе пользовательского запроса.
Фиг.1 является структурной схемой системы 100, которая включает индексирование, поиск и другую функциональность. Например, система 100 может включать в себя индексирование, поиск и другие приложения, которые могут быть использованы для индексирования информации в качестве части индексированной структуры данных и искать релевантные данные с использованием индексированной структуры данных. Как описано ниже, компоненты системы 100 могут использоваться для того, чтобы ранжировать и возвратить результаты поиска, основанные, по меньшей мере частично, на запросе. Например, компоненты системы 100 могут быть сконфигурированы так, чтобы обеспечивать функциональность основанной на Web поисковой машины, которая может быть использована для возвращения результатов поиска в пользовательский браузер на основании, частично, отправленного запроса, который может состоять из одного или более ключевых слов, фраз и других поисковых элементов. Пользователь может представлять запросы в поисковый компонент 102 с помощью пользовательского интерфейса 103, такого как браузер или поисковое окно, например.
Как показано на фиг.1, система 100 включает в себя поисковый компонент 102, такой как поисковая машина, например, которая может быть сконфигурирована возвращать результаты, основанные, частично, на введенном запросе. Например, поисковый компонент 102 может функционировать так, чтобы использовать слово, слова, фразы, концепции и другие данные для нахождения релевантных файлов, документов, интернет-страниц и другой информации. Поисковый компонент 102 может функционировать так, чтобы находить информацию, и может быть использован операционной системой (ОС), файловой системой, системой, основанной на Web, или другой системой. Поисковый компонент 102 может также включаться в качестве встраиваемого (add-in) компонента, при этом поисковая функциональность может использоваться главной системой или приложением.
Поисковый компонент 102 может быть сконфигурирован для предоставления результатов поиска (унифицированных указателей информационных ресурсов (URL), например), которые могут быть ассоциированы с файлами, такими как документы, например, содержимым файла, виртуальным контентом, контентом, основанным на Web, и другой информацией. Например, поисковый компонент 102 может использовать текст, информацию о свойствах и/или метаданные при возврате результатов поиска, ассоциированных с локальными файлами, файлами, переданными из удаленной сети, комбинациями локальных и удаленных файлов и т.д. В одном варианте осуществления поисковый компонент 102 может взаимодействовать с файловой системой, виртуальным Web, сетевым или другим источником информации при предоставлении результатов поиска.
Поисковый компонент 102 включает в себя ранжирующий компонент 104, который может быть сконфигурирован для ранжирования результатов поиска на основании, по меньшей мере частично, ранжирующего алгоритма 106 и одного или более ранжировочных признаков 108. В одном варианте осуществления ранжирующий алгоритм 106 может быть настроен, чтобы предоставлять число или другую переменную, которая может быть использована для целей сортировки поисковым компонентом 102. Ранжировочные признаки 108 могут быть описаны как базовые входные значения или исходные числа, которые могут использоваться при определении релевантности результата поиска. Ранжировочные признаки 108 могут быть собраны, сохранены и содержатся в компоненте 110 базы данных.
Например, ранжировочные признаки, соответствующие переходам по ссылкам, могут сохраняться и поддерживаться с использованием нескольких таблиц регистрации запросов, которые также могут содержать информацию запросов, связанную с пользовательскими запросами. В альтернативном варианте осуществления ранжировочные признаки 108 могут сохраняться и содержаться в выделенном хранилище, включая локальные, удаленные и другие средства хранения. Один или более ранжировочных признаков 108 могут быть введены в ранжирующий алгоритм 106, и ранжирующий алгоритм 106 может функционировать так, чтобы ранжировать результаты поиска, в качестве части процесса определения ранжирования. Как описано ниже, в одном варианте осуществления ранжирующий компонент 104 может оперировать одним или более ранжировочными признаками 108 в качестве части процесса определения ранжирования.
Соответственно, поисковый компонент 102 может применять ранжирующий компонент 104 и связанный с ним ранжирующий алгоритм 106 при использовании одного или более ранжировочных признаков 108 в качестве части процесса определения ранжирования для того, чтобы предоставить результаты поиска. Результаты поиска могут быть предоставлены на основании ранжирования по релевантности или какого-либо другого ранжирования. Например, поисковый компонент 102 может представить результаты поиска от наиболее релевантного до наименее релевантного, основываясь, по меньшей мере частично, на определении релевантности, обеспечиваемом ранжирующим компонентом 104 с использованием одного или более ранжировочных признаков 108.
С продолжением обращения к фиг.1, система 100 также включает в себя индексирующий компонент 112, который может использоваться для индексирования информации. Индексирующий компонент 112 может использоваться для индексирования и внесения в каталог информации, подлежащей хранению в компоненте 110 базы данных. Более того, индексирующий компонент 112 может использовать метаданные, контент и/или другую информацию при выполнении индексирования в отношении ряда принципиально различных источников информации. Например, индексирующий компонент 112 может использоваться для построения инвертированной структуры индексных данных, которая соотносит документам ключевые слова, включая указатели URL, связанные с документами.
Поисковый компонент 102 может использовать индексированную информацию при возвращении релевантных результатов поиска в соответствии с ранжированием, обеспеченным ранжирующим компонентом 104. В некотором варианте осуществления, в качестве части поиска, поисковый компонент 102 может быть настроен идентифицировать набор возможных результатов, таких как несколько возможных документов (документов-кандидатов), например, которые содержат часть или всю информацию пользовательских запросов, такую как ключевые слова или фразы, например. Например, информация о запросе может быть локализована в теле документа или метаданных, или дополнительных метаданных, связанных с документом, которые могут быть в других документах или хранилищах данных (таких как привязанный текст, например). Как описано ниже, вместо возвращения всего набора результатов поиска, если набор является большим, поисковый компонент 102 может использовать ранжирующий компонент 104 для ранжирования кандидатов по релевантности или какому-нибудь другому критерию и возвращать подмножество всего набора, основываясь на, по меньшей мере частично, определении ранжирования. Однако, если набор кандидатов не слишком большой, поисковый компонент 102 может функционировать так, чтобы возвратить полный набор.
В некотором варианте осуществления ранжирующий компонент 104 может использовать ранжирующий алгоритм 106 для предсказания степени релевантности кандидата, связанного с конкретным запросом. Например, ранжирующий алгоритм 106 может вычислять ранжировочное значение, связанное с возможным результатом поиска, при котором большее ранжировочное значение соответствует более релевантному кандидату. Множество признаков, включая один или более ранжировочных признаков 108, могут быть введены в ранжирующий алгоритм 106, который может затем вычислить некий вывод, который дает возможность поисковому компоненту 102 сортировать кандидатов по рангу или по какому-либо другому критерию. Поисковый компонент 102 может использовать ранжирующий алгоритм 106 для предотвращения ситуации, в которой пользователь вынужден проверять полный набор кандидатов, такой как большой объем интернет кандидатов и URL коллекции предприятия, например, путем ограничения набора кандидатов согласно рангу.
В одном варианте осуществления поисковый компонент 102 может отслеживать и собирать ранжировочные признаки, основанные на действии и/или основанные на бездействии. Ранжировочные признаки, основанные на действии и/или основанные на бездействии, могут сохраняться в компоненте 110 базы данных и обновляться по мере необходимости. Например, информация переходов по ссылкам может отслеживаться и сохраняться в компоненте 110 базы данных в качестве одного или более ранжировочных признаков 108, когда пользователь взаимодействует с результатом поиска, например, кликая мышью. Данная информация также может использоваться для отслеживания того, когда пользователь не взаимодействует с ним. Например, пользователь может пропустить и не кликать на один или более результатов поиска. В альтернативном варианте осуществления отдельный компонент, такой как детектор ввода или другой записывающий компонент, например, может использоваться для наблюдения за пользовательскими реакциями, связанными с результатом или результатами поиска.
Поисковый компонент 102 может использовать выбранное число собранных ранжировочных признаков, основанных на действии и основанных на бездействии, как часть процесса определения релевантности при возвращении результатов поиска. В одном варианте осуществления поисковый компонент 102 может собирать и использовать несколько параметров взаимодействия, основанных на щелчках мыши, в качестве части процесса определения релевантности при возвращении результатов поиска, основанных на запросе. Например, представьте, что пользователь кликает на результат поиска (например, документ), который не был возвращен наверху списка результатов по какой бы то ни было причине. Как описано ниже, поисковый компонент 102 может записывать и использовать признак клика для повышения ранга выбранного (кликнутого) результата, когда в следующий раз какой-либо пользователь выдает такой же или похожий запрос. Поисковый компонент 102 также может собирать и использовать другие признаки и/или параметры взаимодействия, такие как ввод прикосновением, ввод стилусом или другие утвердительные вводы пользователя.
В одном варианте осуществления поисковый компонент 102 может использовать один или более ранжировочных признаков, соответствующих переходам по ссылкам, где один или более ранжировочных признаков, соответствующих переходам по ссылкам, могут быть извлечены из косвенной пользовательской обратной связи. Ранжировочные признаки, соответствующие переходам по ссылкам, могут быть собраны и сохранены, включая обновленные признаки, в нескольких таблицах регистрации запросов компонента 110 базы данных. Например, поисковый компонент 102 может использовать функциональность интегрированной серверной платформы, такой как система MICROSOFT OFFICE SHAREPOINT SERVER®, чтобы собирать, хранить и обновлять основанные на взаимодействии признаки, которые могут использоваться в качестве части процесса определения ранжирования. Функциональность серверной платформы может включать в себя управление Web-контентом, сервисами корпоративного информационного контента, корпоративный поиск, совместные бизнес-процессы, сервисы по бизнес-аналитике и другие сервисы.
Согласно этому варианту осуществления поисковый компонент 102 может использовать один или более ранжировочных признаков, соответствующих переходам по ссылкам, в качестве части процесса определения ранжирования при возвращении результатов поиска. Поисковый компонент 102 может использовать информацию о предыдущих переходах по ссылкам при компиляции ранжировочных признаков, соответствующих переходам по ссылкам, которую он может использовать для смещения ранжирующих упорядочений в качестве части процесса определения релевантности. Как описано ниже, один или более ранжировочных признаков, соответствующих переходам по ссылкам, могут быть использованы для обеспечения самоподстраивающейся ранжировочной функциональности путем использования неявной обратной связи, которую получает результат поиска, когда пользователь реагирует или не реагирует на этот результат поиска. Например, несколько результатов поиска могут быть предоставлены поисковым компонентом 102, перечисленные в порядке релевантности на странице результата поиска, а параметры могут быть собраны на основании того, выбирает ли пользователь (щелчком мыши) результат поиска или пропускает результат поиска.
Поисковый компонент 102 может использовать информацию в компоненте 110 базы данных, включая сохраненные признаки, основанные на действии и/или бездействии, при ранжировании и предоставлении результатов поиска. Поисковый компонент 102 может использовать записи запросов и информацию, связанную с предыдущими действиями пользователя или бездействиями, связанными с результатом запроса, при предоставлении текущего списка релевантных результатов запрашивающему. Например, поисковый компонент 102 может использовать информацию, связанную с тем, как другие пользователи отреагировали на предыдущие результаты поиска (например, файлы, документы, Web-каналы и т.д.) в ответ на такие же или похожие запросы, при предоставлении текущего списка ссылок, основанного на выданных пользовательских запросах.
В одном варианте осуществления поисковый компонент 102 может использоваться в сочетании с функциональностью обслуживающей системы, такой как система MICROSOFT OFFICE SHAREPOINT SERVER®, функционирующей для записывания и использования запросов и/или последовательностей запросов, записывания и использования пользовательских действий и/или бездействий, связанных с результатами поиска, и для записывания и использования другой информации, связанной с определением соответствия. Например, поисковый компонент 102 может использоваться в сочетании с функциональностью системы MICROSOFT OFFICE SHAREPOINT SERVER® для того, чтобы записывать и использовать выданные запросы наряду с результатом поиска в виде URL, который мог быть нажат для конкретного запроса. Система MICROSOFT OFFICE SHAREPOINT SERVER® также может записывать список URL-ссылок, которые были показаны или представлены с выбранной URL-ссылкой, например, несколько URL-ссылок, которые были показаны над выбранной URL. Дополнительно система MICROSOFT OFFICE SHAREPOINT SERVER® может функционировать для записывания полученной в результате поиска URL-ссылки, которая не была выбрана, на основании конкретного запроса. Ранжировочные признаки, соответствующие переходам по ссылкам, могут быть собраны и использованы при проведении определения релевантности, описанного ниже.
В одном варианте осуществления несколько ранжировочных признаков, соответствующих переходам по ссылкам, могут быть агрегированы и определены, как следует ниже:
1) параметр выбора щелчком мышью (клика), Nc, который соответствует числу раз (по всем запросам), которое результат поиска (например, документ, файл, URL-ссылка и т.д.) был выбран щелчком мыши (кликом);
2) параметр пропуска, Ns, который соответствует числу раз (по всем запросам), которое результат поиска был пропущен. А именно, результат поиска был включен с другими результатами поиска, мог быть замечен пользователем, но не выбран. Например, наблюдаемый или пропущенный результат поиска может ссылаться на результат поиска, имеющий более высокий ранг, чем выбранный результат. В одном варианте осуществления поисковый компонент 102 может использовать допущение, что пользователь просматривает результаты поиска сверху вниз при взаимодействии с результатами поиска;
3) первый потоковый параметр, Pc, который может быть представлен как текстовый поток, соответствующий объединению всех строк запросов, связанных с выбранным щелчком мыши результатом поиска. В одном варианте осуществления объединение включает в себя все строки запросов, для которых результат был возвращен и выбран. Дубликаты строк запросов возможны (т.е. каждый индивидуальный запрос может быть использован в функционировании объединения);
4) второй потоковый параметр, Ps, который может быть представлен как текстовый поток, соответствующий объединению всех строк запросов, связанных с пропущенным результатом поиска. В одном варианте осуществления объединение включает в себя все строки запросов, для которых результат был возвращен и пропущен. Дубликаты строк запросов возможны (т.е. каждый индивидуальный запрос может быть использован в функционировании объединения).
Вышеперечисленные ранжировочные признаки, соответствующие переходам по ссылкам, могут собираться в желаемое время, таким образом, например, как одной или более системами поисковых роботов на некоторой периодической основе, и ассоциироваться с каждым результатом поиска. Например, один или более ранжировочных признаков, соответствующих переходам по ссылкам, могут быть ассоциированы с документом, который был возвращен поисковым компонентом 102 на основании запроса пользователя. Следующим шагом один или более ранжировочных признаков, соответствующих переходам по ссылкам, могут быть введены в ранжирующий компонент 104 и использованы с ранжирующим алгоритмом 106 как часть процесса определения ранжирования и релевантности. В некоторых случаях некоторые результаты поиска (например, документы, URL-ссылки и т.д.) могут не включать в себя информацию переходов по ссылкам. Для результатов поиска с отсутствующей информацией переходов по ссылкам определенные свойства текста (например, Pc и/или Ps потоки) могут быть оставлены пустыми, а определенные статические параметры (например, Nc и Ns) могут иметь нулевое значение.
В одном варианте осуществления один или более ранжировочных признаков, соответствующих переходов по ссылкам, могут использоваться с ранжирующим алгоритмом 106, который сначала требует накопления одной или более комбинаций переходов по ссылкам в процессе кроллинга (регулярного обхода страниц Интернета с целью занесения их в базу поисковой программы), включая полные и/или инкрементные кроллинги. Например, поисковый компонент 102 может задействовать поискового робота, который может совершать ряд операций для кроллинга файловой системы, коллекции, основанной на Web, или другого хранилища при накоплении информации, связанной с ранжировочными признаками, соответствующими переходам по ссылкам, и другими данными. Один или более поисковых роботов могут быть реализованы для кроллинга или кроллингов, в зависимости от целевого объекта или объектов кроллинга и конкретной реализации.
Поисковый компонент 102 может использовать собранную информацию, включая любые ранжировочные признаки, соответствующие переходам по ссылкам, для обновления не зависимых от запроса накопителей, таких как несколько таблиц регистрации запросов, например, одним или более признаками, которые могут быть использованы при ранжировании результатов поиска. Например, поисковый компонент 102 может обновлять несколько таблиц регистрации запросов параметром клика (Nc) и/или параметром пропуска (Ns) для каждого результата поиска, который включает в себя обновленную информацию переходов по ссылкам. Информация, связанная с обновленными независимыми от запроса хранилищами, может также быть использована различными компонентами, включая индексирующий компонент 112 при выполнении операций индексирования.
Соответственно, индексирующий компонент 112 может периодически получать любые изменения или обновления из одного или более независимых хранилищ. Более того, индексирующий компонент 112 может периодически обновлять один или более индексов, которые могут включать один или более динамических и других признаков. В одном варианте осуществления система 100 может включать в себя два индекса, главный индекс и второстепенный индекс, например, которые поисковый компонент 102 может использовать, чтобы обслужить запрос. Первый (главный) индекс может использоваться для индексирования ключевых слов из тела документов и/или метаданных, связанных с Web-сайтами, файловыми серверами и другими хранилищами информации. Второстепенный индекс может использоваться для индексирования дополнительных текстовых и статических признаков, которые могут не получаться прямо из документа. Например, дополнительные текстовые и статические признаки могут включать в себя закрепленный текст, дистанцию кликов, данные клика и т.д.
Второстепенный индекс также позволяет разделить расписания обновлений. Например, когда новый документ выбран, для индексирования ассоциированных данных требуется только частичное перепостроение второстепенного индекса. Таким образом, главный индекс может оставаться неизменным, а весь документ не требует повторного кроллинга. Структура главного индекса может быть структурирована как инвертированный индекс и может использоваться для соотнесения ключевых слов с идентификаторами (ID) документов, но не является столь ограниченной. Например, индексирующий компонент 112 может обновить второстепенный индекс, используя первый потоковый параметр Pc и/или второй потоковый параметр Ps для каждого результата, который включает в себя обновленную информацию переходов по ссылкам. В дальнейшем один или более ранжировочных признаков переходов по ссылкам и связанных параметров могут быть применены и использоваться поисковым компонентом 102, как, например, один или более вводов в ранжирующий алгоритм 106 как часть процесса определения релевантности, связанным с выполнением запроса.
Как описано ниже, двухслойная нейронная сеть может быть использована в качестве части процесса определения релевантности. В одном варианте осуществления реализация двухслойной нейронной сети включает в себя фазу обучения и фазу ранжирования как часть процесса прямого распространения, использующего двухслойную нейронную сеть. В качестве обучающего алгоритма во время фазы обучения может использоваться модель лямбда-ранжирования (см. C. Burges, R. Ragno, Q. V. Le, "Learning To Rank With Nonsmooth Cost Functions" in Schόlkopf, Platt and Hofmann (Ed.) Advances in Neural Information Processing Systems 19, Proceedings of the 2006 Conference, (MIT Press, 2006)), а модель нейронной сети с прямым распространением может использоваться в качестве части процесса определения ранжирования. Например, стандартная модель нейронной сети с прямым распространением может использоваться в качестве части фазы ранжирования. Один или более из ранжировочных признаков, соответствующих переходам по ссылкам, могут использоваться в сочетании с двухуровневой нейронной сетью в качестве части процесса определения релевантности при возвращении результатов запроса, основанных на запросе пользователя.
В некотором варианте осуществления ранжирующий компонент 104 использует ранжирующий алгоритм 106, который заключает в себе оценочную функцию двухуровневой нейронной сети, здесь и далее «оценочную функцию», которая включает в себя:
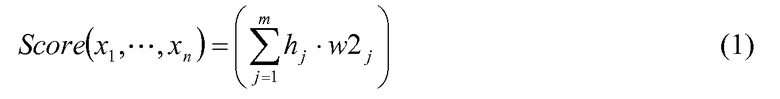
где
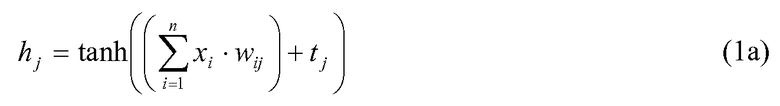
где
hj является выходом скрытого узла j,
xi является входным значением от входного узла i, такого как один или более вводов ранжировочных признаков,
w2j является весовым коэффициентом, который необходимо применить к выходу скрытого узла,
wij является весовым коэффициентом, который необходимо применить к входному значению xi скрытым узлом j,
tj является пороговым значением для скрытого узла j,
tanh является функцией гиперболического тангенса:
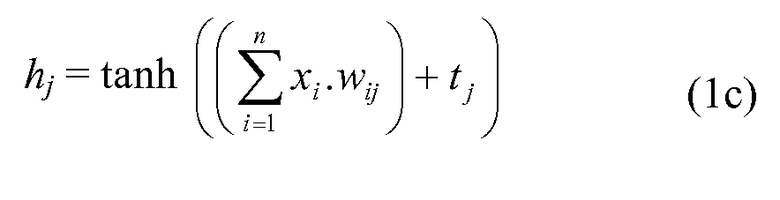
В альтернативном варианте осуществления другие функции, имеющие похожие свойства и характеристики как у функции tanh, могут быть использованы выше. В одном варианте осуществления переменная xi может представлять один или более параметров перехода по ссылкам. Тренировочный алгоритм λ-ранжирования может использоваться для обучения оценочной функции двухуровневой нейронной сети перед ранжированием в качестве части процесса определения релевантности. Более того, новые признаки и параметры могут быть добавлены в оценочную функцию без значительного влияния на точность обучения или скорость обучения.
Один или более ранжировочных признаков 108 могут быть введены и использованы ранжирующим алгоритмом 106, оценочной функцией двухуровневой нейронной сети для этого варианта осуществления, при проведении определения соответствия при возвращении результатов поиска, основанных на запросе пользователя. В одном варианте осуществления один или более ранжировочных параметров, соответствующих переходам по ссылкам (Nc, Ns, Pc, и/или Ps) могут быть введены и использованы ранжирующим алгоритмом 106 при проведении определения релевантности в качестве части возвращения результатов поиска, основанных на запросе пользователя.
Параметр Nc может использоваться для формирования дополнительного ввода в оценочную функцию двухуровневой нейронной сети. В одном варианте осуществления входное значение, связанное с параметром Nc, может быть вычислено в соответствии со следующей формулой:
входное значение=

Где в одном варианте осуществления, параметр Nc соответствует значению исходного параметра, связанного с числом раз (по всем запросам и всем пользователям), которое результат поиска был выбран;
KNc является настраиваемым параметром (например, больший чем, или равный нулю);
MNc и SNc являются параметрами среднего значения и стандартного отклонения или нормировочными константами, связанными с обучающими данными;
iNc соответствует индексу режима ввода.
Параметр Ns может использоваться для формирования дополнительного ввода в оценочную функцию двухуровневой нейронной сети. В одном варианте осуществления входное значение, связанное с параметром Ns, может быть вычислено в соответствии со следующей формулой:
входное значение=
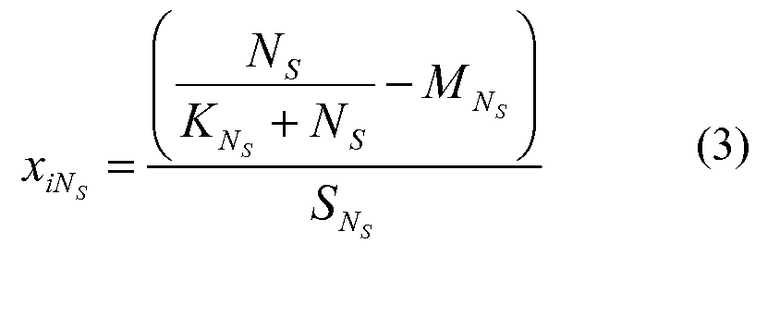
Где в одном варианте осуществления, параметр Ns соответствует значению исходного параметра, связанного с числом раз (по всем запросам и всем пользователям), которое результат поиска был сознательно пропущен;
KNs является настраиваемым параметром (например, больший чем, или равный нулю);
MNs и SNs являются параметрами среднего значения и стандартного отклонения или нормировочными постоянными, связанными с обучающими данными;
iNs соответствует индексу режима ввода.
Параметр Pc может быть включен в формулу (4) ниже, которая может использоваться для выведения зависимого от контента ввода в оценочную функцию двухуровневой нейронной сети.
входное значение=
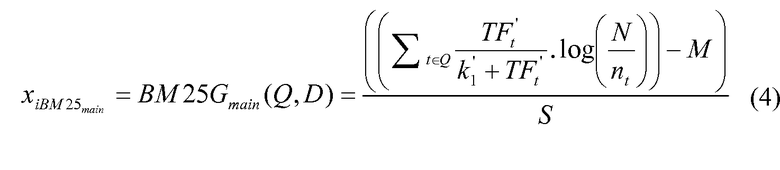
Формула для TF't может быть вычислена следующим образом:
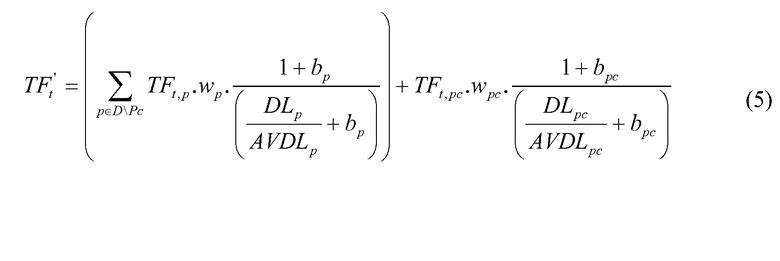
Где Q является строкой запроса,
t является отдельным элементом запроса (например, слово),
D - результат (например, документ), который оценивают,
р является индивидуальным свойством результата (например, документа) (например, заголовком, телом, текстом привязки, автором и т.д.) и любым другим текстовым свойством, которое будет использоваться для ранжирования,
N - суммарное число результатов (например, документов) в области поиска,
nt представляет собой число результатов (например, документов), содержащих термин t,
DLp является длиной свойства р,
AVDLp является усредненной длиной свойства р,
TFt,p является частотой появления термина t в свойстве р,
TFt,pc соответствует числу раз, которое заданный термин появляется в параметре Рс,
DLpc соответствует длине параметра Рс (например, количеству включенных в него терминов),
AVDLpc соответствует средней длине параметра Рс,
Wpc и bpc соответствуют настраиваемым параметрам,
D\Pc соответствует набору свойств документа D, исключая свойство Pc (элемент для Pc взят вне знака суммирования только для ясности),
iBM25main является индексом узла ввода и
M и S представляют собой нормировочные постоянные, соответствующие среднему и стандартному отклонению.
Параметр Ps может быть включен в формулу (6) ниже, которая может использоваться для выведения дополнительного ввода в оценочную функцию двухуровневой нейронной сети.
входное значение=

где
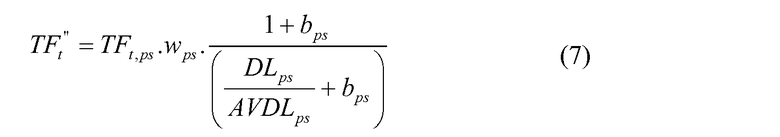
и
TFt,ps представляет собой число раз, которое заданный термин является связанным с параметром Ps,
DLps представляет собой длину параметра Ps (например, число терминов),
AVDLpc представляет собой среднюю длину параметра Ps,
N представляет собой число результатов поиска (например, документов) в собрании документов,
nt представляет собой число результатов поиска (например, документов), содержащих заданный термин запроса,
k1 ”, wps, bps представляют собой настраиваемые параметры и
M и S представляют собой нормировочные постоянные, соответствующие среднему и стандартному отклонению.
Как только одно или более входных значений вычислены, как показано выше, одно или более входных значений могут быть введены в (1), и на выход может быть выдана оценка или ранжирование, которые могут затем использоваться при ранжировании результатов поиска в качестве части процесса определения релевантности. В качестве примера, х1 может использоваться для представления вычисляемого входного значения, связанного с параметром Nc, х2 может использоваться для представления вычисляемого входного значения, связанного с параметром Ns, х3 может использоваться для представления вычисляемого входного значения, связанного с параметром Pc, а х4 может использоваться для представления вычисляемого входного значения, связанного с параметром Ps. Как описано выше, текстовые потоки могут также включать тело, заголовок, автора, URL-ссылку, текст привязки, сгенерированный заголовок и/или Pc. Соответственно, одно или более входных значений, например х1, х2, х3 и/или х4, могут быть введены в оценочную функцию (1) при ранжировании результатов поиска в качестве части процесса определения релевантности. Соответственно, поисковый компонент 102 может предоставить пользователю ранжированные результаты поиска на основании выданного запроса и одного или более ранжирующих входных значений. Например, поисковый компонент 102 может возвратить набор URL-ссылок, где URL-ссылки в рамках данного набора могут быть представлены пользователю на основании ранжирующего порядка (например, от высокого значения релевантности к низкому значению релевантности).
Другие признаки также могут быть использованы при ранжировании и предоставлении результатов поиска. В некотором варианте осуществления дистанция кликов (CD), глубина URL-ссылок (UD), тип файла или типовой приоритет (Т), язык или языковой приоритет (L) и/или другие ранжировочные признаки могут использоваться для ранжирования и предоставления результатов поиска. Один или более из дополнительных ранжировочных признаков могут использоваться в качестве части процесса определения линейного ранжирования, определения нейронной сети или другого определения ранжирования. Например, один или более статических ранжировочных признаков могут использоваться в сочетании с одним или более динамическими ранжировочными признаками в качестве части процесса определения линейного ранжирования, определения нейронной сети или другого определения ранжирования.
Соответственно, CD представляет собой дистанцию кликов, при котором CD может быть описано как независимый от запроса ранжировочный признак, который измеряет число щелчков мышью («кликов»), требуемое для достижения заданной цели, такой как страница или документ, например, из исходного положения. CD пользуется преимуществом иерархической структуры системы, которая может следовать структуре дерева, с корневым узлом (например, домашней страницей) и последующими ветвями, простирающимися к другим узлам от этого корня. Рассматривая данное дерево как граф, CD может быть представлен как кратчайший путь между корнем в качестве исходного положения и заданной страницей. UD представляет собой глубину URL-ссылок, при которой UD может использоваться для представления подсчета числа слэшей («/») в URL-ссылке. Т представляет собой приоритет типа и L представляет собой приоритет языка.
Признаки T и L могут использоваться для представления пронумерованных типов данных. Примеры таких типов данных включают тип файла и тип языка. В качестве примера, для любой заданной области поиска может присутствовать конечный набор типов файлов и/или поддерживаться ассоциированной поисковой машиной. Например, корпоративный интранет может содержать документы редактора обработки текстов, электронные таблицы, HTML Web-страницы и другие документы. Каждый из этих типов файлов может оказывать различное влияние на релевантность ассоциированного документа. Примерное преобразование может конвертировать значение типа файла в набор двоичных флагов, по одному для каждого поддерживаемого типа файла. Каждый из этих флагов может использоваться нейронной сетью индивидуально, так, что каждому может быть задан отдельный весовой коэффициент и каждый может быть обработан отдельно. Язык (на котором написан данный документ) может быть обработан аналогичным образом с использованием единственного дискретного двоичного флага для того, чтобы указать, написан ли или нет документ на конкретном языке. Сумма частот терминов может также включать тело, заголовок, автора, текст привязки, отображаемое имя URL-ссылки, извлеченный заголовок и т.д.
В конечном счете, удовлетворение пользователя является одной из несомненнейших мер функционирования поискового компонента 102. Пользователь предпочел бы, чтобы поисковый компонент 102 быстро возвращал наиболее релевантные результаты, так чтобы пользователю не требовалось тратить много времени на исследование получаемого в результате набора кандидатов. Например, метрическая оценка может использоваться для определения удовлетворения пользователя. В одном варианте осуществления метрическая оценка может быть улучшена путем изменения входных значений в ранжирующий алгоритм 106 или в разновидности ранжирующего алгоритма 106. Метрическая оценка может быть посчитана по некоторому репрезентативному или случайному набору запросов. Например, репрезентативный набор запросов может быть выбран на основании случайного отбора образцов запросов, содержащихся в журналах регистрации запросов, хранящихся в компоненте 110 базы данных. Пометки релевантности могут быть назначены или ассоциированы с каждым результатом, возвращенным поисковым компонентом 102, для каждого из запросов метрической оценки.
Например, метрическая оценка может содержать средний подсчет релевантных документов в запросе в верхних N (1, 5, 10 и т.д.) результатах (также упоминаемый как точность при 1, 5, 10 и т.д.). В качестве другого примера, более сложное измерение может применяться, чтобы оценить результаты поиска, такое как средняя точность или Нормированный Дисконтированный Накопленный Прирост (Normalized Discounted Cumulative Gain, NDCG). NDCG может быть описан как накопительная метрика, которая позволяет многоуровневые суждения и налагает пени на поисковый компонент 102 за возвращение менее релевантных документов с более высоким рангом и более релевантных документов с менее высоким рангом. Метрика может быть усреднена по набору запросов для определения количественного представления результирующей точности.
Продолжая пример с NDCG, для заданного запроса "Qi" NDCG может быть вычислена как:
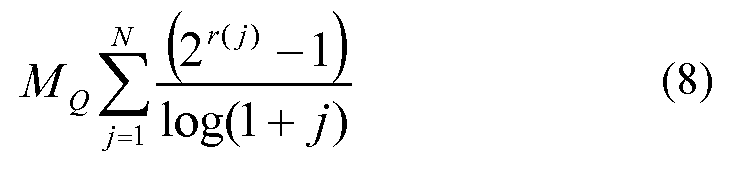
где N обычно является 3 или 10. Данная метрика может быть усреднена по набору запросов для определения числа суммарной погрешности.
Ниже находятся несколько экспериментальных результатов, полученных на основании использования параметров переходов по ссылкам Nc, Ns и Pc с оценочной функцией (1). Эксперименты проводились на наборе запросов (744 запроса, ~130 тыс. документов) с 10 разбиениями, с 5-кратным пробегом перекрестной проверки. Для каждого раза 6 разбиений использовались для обучения, 2 для подтверждения и 2 для тестирования. Использовалась стандартная версия алгоритма λ-ранжирования (см. выше).
Соответственно, собранные вместе результаты использования оценочной функции двухуровневой нейронной сети с 4 скрытыми узлами привели в результате к следующему, как показано в таблице 1 ниже:
Собранные вместе результаты использования оценочной функции двухуровневой нейронной сети с 6 скрытыми узлами привели в результате к следующему, как показано в таблице 2 ниже:
Одним дополнительным ранжировочным признаком 108, который может использоваться в качестве меры релевантности документа, является длина документа. Длина документа может быть эффективным инструментом ранжирования, поскольку короткие документы обычно не включают в себя достаточно информации, чтобы быть полезными пользователю. А именно, короткие документы, в основном, не предоставляют ответа на поисковый запрос. С другой стороны, большие документы обычно включают в себя так много информации, что иногда бывает трудно определить, какая информация в документе относится к запросу поиска.
Поскольку много различных типов документов могут быть возвращены в качестве результата поискового запроса, первым шагом при определении ранга документа является вычисление нормированного значения длины документа. Это делается для того, чтобы сделать длину документа независимой от типа документов, которые ранжируются. Нормированная длина документа определяется как являющаяся равной длине документа в словах, деленная на среднюю длину ранжируемого набора документов, например, документов, возвращенных в качестве результата поискового запроса. Это может быть представлено следующим уравнением:

где D представляет собой нормированную длину документа, LD представляет длину ранжируемого документа, а LAVG представляет среднюю длину документов в наборе документов.
Затем используется функция преобразования для предоставления ранжирующего значения, от нуля до единицы, для нормированной длины документа такого, что большее ранжирующее значение представляет более релевантный документ. В одном варианте осуществления функция преобразования может быть представлена следующим образом:
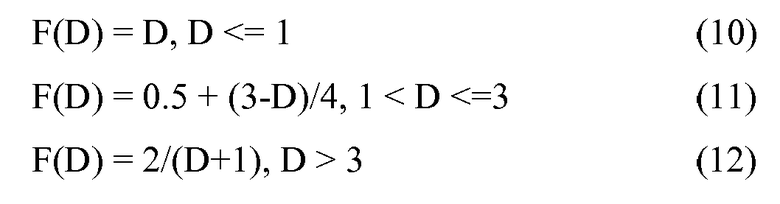
Функция преобразования в этом примере налагает пени на документы, являющиеся слишком длинными или слишком короткими. Наивысшее ранжирующее значение, равное единице, вычисляется для документа средней длины, т.е. для документа, имеющего нормированную длину, равную единице. Напротив, документ с нормированной длиной, равной 0,5 (т.е. половине от средней длины), имеет ранжирующее значение 0,5, а документ с нормированной длиной, равной семи (т.е. в семь раз больше средней длины),имеет ранжирующее значение 0,25.
Ранжирующие значения, соответствующие длине документа, могут храниться в компоненте 110 базы данных и обновляться по мере необходимости. Поисковый компонент 102 может использовать информацию длины документа в компоненте 110 базы данных при ранжировании и предоставлении результатов поиска.
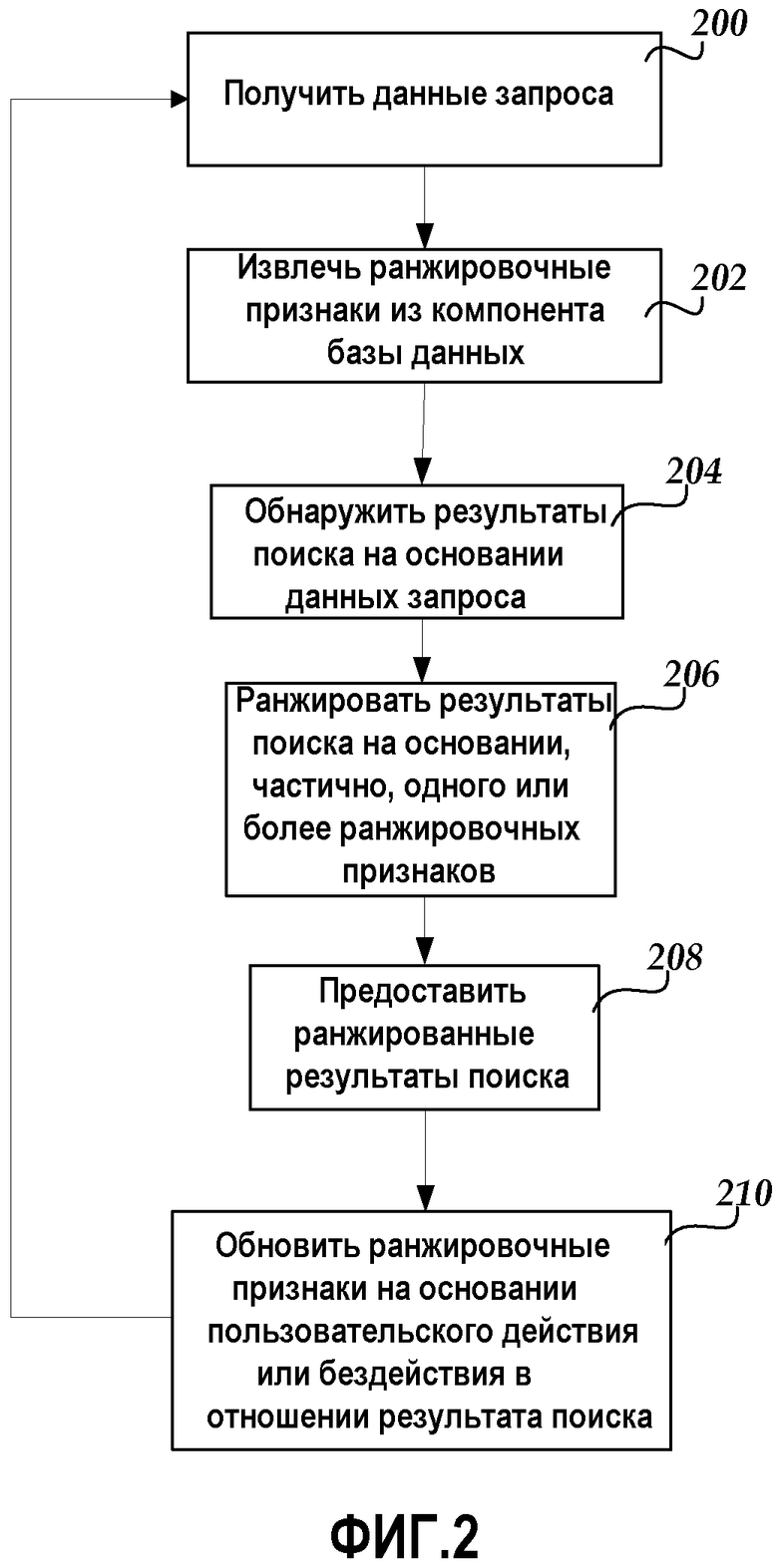
Фиг.2 является логической блок-схемой, иллюстрирующей процесс предоставления информации, основанный, частично, на запросе пользователя, в соответствии с вариантом осуществления. Компоненты по фиг.1 используются в описании по фиг.2, но данный вариант осуществления не является настолько ограниченным. На этапе 200 поисковый компонент 102 получает данные запроса, связанные с запросом пользователя. Например, пользователь, используя основанный на Web браузер, может внести текстовую строку, состоящую из нескольких ключевых слов, которые определяют пользовательский запрос. На этапе 202 поисковый компонент 102 может связаться с компонентом 110 базы данных для извлечения каких-либо ранжировочных признаков 108, связанных с пользовательским запросом. Например, поисковый компонент 102 может извлечь один или несколько ранжировочных признаков, соответствующих переходам по ссылкам, из нескольких таблиц запросов, где один или несколько ранжировочных признаков, соответствующих переходам по ссылкам, ассоциированы с ранее выданными запросами, имеющими похожие или идентичные ключевые слова.
На этапе 204 поисковый компонент 102 может использовать запрос пользователя для нахождения одного или более результатов поиска. Например, поисковый компонент 102 может использовать текстовую строку для нахождения документов, файлов и других структур данных, связанных с файловой системой, базами данных, коллекциями, основанными на Web, или каким-либо другим хранилищем информации. На этапе 206 поисковый компонент 102 использует один или несколько из ранжировочных признаков 108 для ранжирования результатов поиска. Например, поисковый компонент 102 может ввести один или несколько ранжировочных признаков, соответствующих переходам по ссылкам, в оценочную функцию (1), которая может предоставить вывод, связанный с ранжированием для каждого результата поиска.
На этапе 208 поисковый компонент 102 может использовать ранжировки для предоставления результатов поиска пользователю в ранжированном порядке. Например, поисковый компонент 102 может предоставить пользователю несколько извлеченных документов, причем извлеченные документы могут быть представлены пользователю в соответствии с численным порядком ранжирования (например, убывающим порядком, возрастающим порядком и т.д.). На этапе 210 поисковый компонент 102 может использовать действие или бездействие пользователя, связанное с результатом поиска, для обновления одного или более ранжировочных признаков 108, которые могут храниться в компоненте 110 базы данных. Например, если пользователь выбрал или пропустил результат поиска в виде URL-ссылки, поисковый компонент 102 может помещать данные переходов по ссылкам (данные выбора щелчком мыши или данные пропуска) в несколько регистрирующих запросы таблиц компонента 110 базы данных. В дальнейшем индексирующий компонент 112 может функционировать для использования обновленных ранжировочных признаков для различных индексирующих операций, включая индексирующие операции, связанные с обновлением проиндексированного каталога информации.
Фиг.3 является логической блок-схемой, иллюстрирующей процесс предоставления информации на основании, частично, запроса пользователя в соответствии с вариантом осуществления. Опять-таки, компоненты по фиг.1 используются в описании по фиг.3, но данный вариант осуществления не является настолько ограниченным. Процесс по фиг.3 является последующим к получению поисковым компонентом 102 пользовательского запроса, выданного из пользовательского интерфейса 103, при котором поисковый компонент 102 обнаружил несколько документов, которые удовлетворяют запросу пользователя. Например, поисковый компонент 102 может использовать несколько представленных ключевых слов для нахождения документов в качестве части поиска, основанного на Web.
На этапе 300 поисковый компонент 102 получает следующий документ, который удовлетворил запросу пользователя. Если все документы были обнаружены поисковым компонентом 102 на этапе 302, процесс переходит на этап 316, где поисковый компонент 102 может отсортировать найденные документы соответственно рангу. Если все документы не были обнаружены на этапе 302, процесс переходит на этап 304, и поисковый компонент 102 извлекает какие-либо признаки, соответствующие переходам по ссылкам, из компонента 110 базы данных, где извлеченные признаки, соответствующие переходам по ссылкам, связаны с текущим документом, найденным поисковым компонентом 102.
На этапе 306 поисковый компонент 102 может вычислить ввод, связанный с параметром Pc, для использования оценочной функцией (1) в качестве части процесса определения ранжирования. Например, поисковый компонент 102 может ввести параметр Pc в формулу (4) для вычисления входного значения, связанного с параметром Pc. На этапе 308 поисковый компонент 102 может вычислить второе входное значение, связанное с параметром Nc, для использования оценочной функцией (1) в качестве части процесса определения ранжирования. Например, поисковый компонент 102 может ввести параметр Nc в формулу (2) для вычисления входа, связанного с параметром Nc.
На этапе 310 поисковый компонент 102 может вычислить третье входное значение, связанное с параметром Ns, для использования оценочной функцией (1) в качестве части процесса определения ранжирования. Например, поисковый компонент 102 может ввести параметр Ns в формулу (3) для вычисления входного значения, связанного с параметром Ns. На этапе 312 поисковый компонент 102 может вычислить четвертое входное значение, связанное с параметром Ps, для использования оценочной функцией (1) в качестве части процесса определения ранжирования. Например, поисковый компонент 102 может ввести параметр Ps в формулу (6) для вычисления входного значения, связанного с параметром Ps.
На этапе 313 поисковый компонент 102 может вычислить пятое входное значение, связанное с длиной документа, для использования оценочной функцией (1) в качестве части процесса определения ранжирования. Например, поисковый компонент 102 может вычислить количество слов в каждом документе, полученном как результат запроса пользователя, причем число слов в каждом документе является показателем длины этого документа. Нормированная длина каждого документа может быть получена с использованием формулы (9) путем деления длины каждого документа на среднюю длину всех документов, полученных в качестве результата запроса. Ранжирующее значение, основанное на длине документа, может быть получено с использованием функции преобразования, определяемой формулами (10), (11) и (12), для вычисления ранжирующего значения, имеющего диапазон между нулем и единицей.
На этапе 314 поисковый компонент 102 функционирует для введения одного или более из вычисленных входных значений в оценочную функцию (1) для вычисления ранга для текущего документа. В альтернативных вариантах осуществления поисковый компонент 102 может взамен вычислить входные значения, связанные с выбранными параметрами, вместо вычисления входных значений для каждого параметра перехода по ссылке. Если больше не осталось документов для ранжирования, на этапе 316 поисковый компонент 102 сортирует документы по рангу. Например, поисковый компонент 102 может отсортировать документы согласно порядку убывания ранга, начиная с документа, имеющего наивысшее значение ранга, и заканчивая документом, имеющим наинизшее значение ранга. Поисковый компонент 102 может также использовать ранжирование в качестве порога для лимитирования числа результатов, представляемых пользователю. Например, поисковый компонент 102 может представить только документы, имеющие ранг больше чем Х, при предоставлении результатов поиска. Впоследствии, поисковый компонент 102 может предоставить отсортированные документы пользователю для дальнейшего действия или бездействия. В то время, как описан конкретный порядок по отношению к фиг.2 и 3, порядок может быть изменен согласно желаемой реализации.
Варианты осуществления и примеры, описанные здесь, как подразумевается, не являются ограничивающими, и другие варианты осуществления являются доступными. Более того, компоненты, описанные выше, могут быть реализованы как часть объединенной в сеть, распределенной или другой среды, реализованной на компьютерных технологиях. Компоненты могут обмениваться данными через проводную, беспроводную и/или комбинацию сетей связи. Ряд клиентских вычислительных устройств, включая стационарные компьютеры, ноутбуки, наладонники или другие «умные устройства» могут взаимодействовать с и/или включаться в качестве части системы 100.
В альтернативных вариантах осуществления различные компоненты могут объединяться и/или конфигурироваться соответственно желаемой реализации. Например, индексирующий компонент 112 может быть включен вместе с поисковым компонентом 102 как единый компонент для предоставления индексирующей и поисковой функциональности. В качестве дополнительного примера, нейронные сети могут быть реализованы как аппаратно, так и в программном обеспечении. В то время, как определенные варианты осуществления включают в себя программные реализации, они не являются настолько ограниченными, и они охватывают аппаратные или смешанные, аппаратно-программные решения. Другие варианты осуществления и конфигурации имеются в наличии.
Примерная рабочая среда
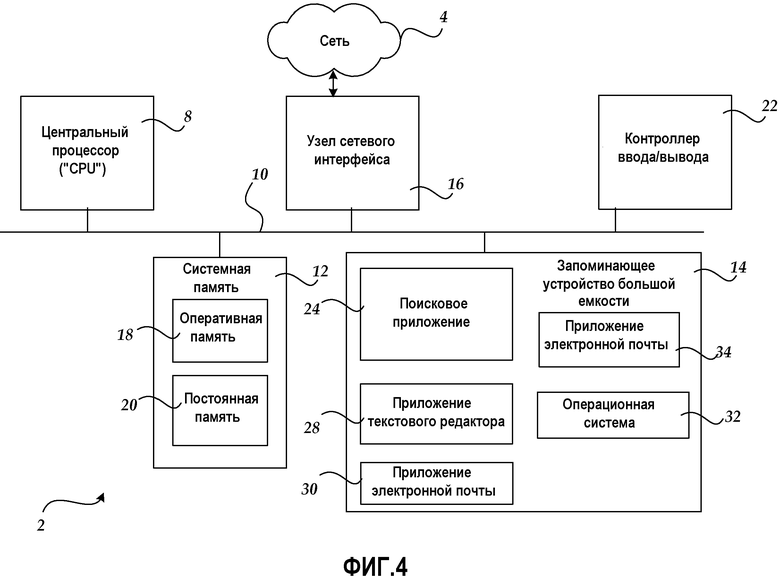
Ссылаясь теперь на фиг.4, следующее обсуждение предназначено для предоставления краткого, общего описания подходящей вычислительной среды, в которой могут быть реализованы варианты осуществления данного изобретения. В то время, как изобретение будет описываться в общем контексте программных модулей, которые исполняются в сочетании с программными модулями, которые запускаются в операционной системе на персональном компьютере, специалисты в данной области техники будут признавать, что данное изобретение может также быть реализовано в комбинации с другими типами компьютерных систем и программных модулей.
Как правило, программные модули включают в себя стандартные подпрограммы, программы, компоненты, структуры данных и другие типы структур, которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Более того, специалисты в данной области техники будут принимать во внимание, что данное изобретение может применяться с другими конфигурациями компьютерных систем, включая наладонные устройства, многопроцессорные системы, основанную на микропроцессоре или программируемую потребительскую электронику, миникомпьютеры, мэйнфрэймовые компьютеры и тому подобное. Данное изобретение может также применяться в распределенных вычислительных средах, где задачи выполняются удаленными устройствами обработки данных, которые соединены посредством сети связи. В распределенной вычислительной среде программные модули могут находиться как в локальных, так и удаленных устройствах хранения данных.
Ссылаясь теперь на фиг.4, будет описана показательная рабочая среда для вариантов осуществления данного изобретения. Как показано на фиг.4, компьютер 2 выполнен в виде стационарного компьютера общего назначения, ноутбука, наладонника или другого типа компьютера, способного исполнять одну или более прикладных программ. Компьютер 2 включает в себя по меньшей мере один центральный процессор 8 (“CPU”), системную память 12, включая оперативную память 18 (“RAM” или «ОЗУ») и постоянную память (“ROM” или «ПЗУ») 20 и системную шину 10, которая соединяет память с CPU 8. Базовая система ввода/вывода, содержащая базовые процедуры, которые помогают передавать информацию между элементами внутри компьютера, как, например, во время запуска, хранится в ПЗУ 20. Компьютер 2, далее, включает в себя запоминающее устройство 14 большой емкости для хранения операционной системы 32, программ приложений и других программных модулей.
Запоминающее устройство 14 большой емкости подсоединено к CPU 8 через контроллер хранения большой емкости (не показан), подключенный к шине 10. Запоминающее устройство 14 большой емкости и ассоциированные с ним машиночитаемые носители обеспечивают энергонезависимое хранилище для компьютера 2. Хотя описание машиночитаемых носителей, содержащееся здесь, ссылается на запоминающее устройство большой емкости, такое как жесткий диск или CD-ROM привод, специалистами в данной области техники должно приниматься во внимание, что машиночитаемые носители могут быть любыми имеющимися носителями, к которым может быть осуществлен доступ или которые могут использоваться компьютером 2.
Путем примера, а не ограничения, машиночитаемые носители могут включать в себя компьютерные носители данных и среды связи. Компьютерные носители данных включают в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым способом или технологией для хранения информации, такой как машиночитаемые инструкции, структуры данных, программные модули и другие данные. Компьютерные носители данных включают в себя, но не в ограничительном смысле, ОЗУ, ПЗУ, EPROM, EEPROM, флэш-память или другую технологию твердотельной памяти, компакт-диски (CD-ROM), универсальные цифровые диски (“DVD”) или другие оптические носители, магнитные кассеты, магнитные ленты, накопители на магнитных дисках или другие магнитные запоминающие устройства, или любым другим носителем, который может использоваться для хранения желаемой информации и к которому может быть осуществлен доступ компьютером 2.
Согласно различным вариантам осуществления данного изобретения компьютер 2 может функционировать в сетевом окружении, используя логические соединения с удаленными компьютерами через сеть 4, такую как локальная сеть, интернет и т.д., например. Компьютер 2 может подсоединяться к сети 4 через устройство 16 сетевого интерфейса, подключенное к шине 10. Должно приниматься во внимание, что устройство 16 сетевого интерфейса также может использоваться для подсоединения к другим типам сетей и удаленных вычислительных систем. Компьютер 2 также может включать в себя контроллер 22 ввода/вывода для получения и обработки ввода от многих других устройств, включая клавиатуру, мышь и т.д. (не показаны). Аналогично, контроллер 22 ввода/вывода может обеспечивать вывод на экран дисплея, принтер или другой тип устройства вывода.
Как кратко упомянуто выше, ряд программных модулей и файлов данных может быть сохранен на запоминающем устройстве 14 большой емкости и ОЗУ 18 компьютера 2, включая операционную систему 32, пригодную для управления функционированием сетевого персонального компьютера, такую как операционная система WINDOWS от корпорации Майкрософт, Редмонд, Вашингтон. Запоминающее устройство 14 большой емкости и ОЗУ 18 также могут хранить один или более программных модулей. В частности, запоминающее устройство 14 большой емкости и ОЗУ 18 могут хранить программы приложений, таких как поисковое приложение 24, приложение 28 редактора текстов, приложение 30 электронных таблиц, приложение 34 электронной почты, приложение для изображений и т.д.
Должно приниматься во внимание, что различные варианты осуществления настоящего изобретения могут быть реализованы (1) как последовательность компьютерно-реализуемых действий или программных модулей, запущенных на вычислительной системе, и/или (2) как взаимосвязанные машинные логические схемы или электронные модули в рамках вычислительной системы. Реализация является предметом выбора, зависимого от требований, налагаемых на рабочие характеристики вычислительной системы, реализующей данное изобретение. Соответственно, логические операции, включая относящиеся к ним алгоритмы, могут упоминаться различным образом как операции, структурные устройства, действия или модули. Специалистами в данной области техники будет признаваться, что эти операции, структурные устройства, действия или модули могут быть реализованы в программном обеспечении, встроенном программном обеспечении (firmware), цифровой логике специального назначения и любой комбинации таковых без отклонения от существа и объема настоящего изобретения, что определяется формулой изобретения, приведенной далее.
Хотя данное изобретение было описано в связи с различными примерными вариантами осуществления, обычным специалистам в данной области техники будет понятно, что в отношении них может быть сделано много модификаций в рамках объема формулы изобретения, которая следует ниже. Соответственно, не подразумевается, что объем данного изобретения каким-либо образом ограничивается вышеприведенным описанием, а, наоборот, всецело определяется со ссылкой на формулу изобретения, которая следует ниже.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способы и серверы для ранжирования цифровых документов в ответ на запрос | 2020 |
|
RU2775815C2 |
| СИСТЕМА И СПОСОБ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА В ПОИСКОВОЙ СИСТЕМЕ | 2024 |
|
RU2839310C1 |
| Способ и сервер для ранжирования цифровых документов в ответ на запрос | 2020 |
|
RU2818279C2 |
| ФУНКЦИИ РАНЖИРОВАНИЯ, ИСПОЛЬЗУЮЩИЕ СТАТИСТИЧЕСКИЕ ДАННЫЕ ИСПОЛЬЗУЕМОСТИ ДОКУМЕНТА | 2006 |
|
RU2419861C2 |
| СЕРВЕР ДЛЯ ОПРЕДЕЛЕНИЯ ПОИСКОВОЙ ВЫДАЧИ НА ПОИСКОВЫЙ ЗАПРОС И ЭЛЕКТРОННОЕ УСТРОЙСТВО | 2013 |
|
RU2583739C2 |
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| НАСТРОЙКА ПОИСКА В РЕАЛЬНОМ ВРЕМЕНИ | 2014 |
|
RU2663478C2 |
| СПОСОБ И СЕРВЕР ГЕНЕРИРОВАНИЯ МЕТА-ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ | 2018 |
|
RU2721159C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| СПОСОБ ОБРАБОТКИ ПОИСКОВОГО ЗАПРОСА, СЕРВЕР И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2014 |
|
RU2670494C2 |

Изобретение относится к предоставлению информации на основании запроса пользователя. Технический результат - эффективность выполнения запросов поисковыми машинами. Для этого в некотором варианте осуществления система включает в себя поисковый компонент, имеющий ранжирующий компонент, который может использоваться для ранжирования результатов поиска в качестве части ответа на запрос. В одном варианте осуществления ранжирующий компонент включает в себя ранжирующий алгоритм, который может использовать длину документа, возвращенную в ответ на поисковый запрос, для ранжирования результатов поиска. 3 н. и 12 з.п. ф-лы, 2 табл., 4 ил.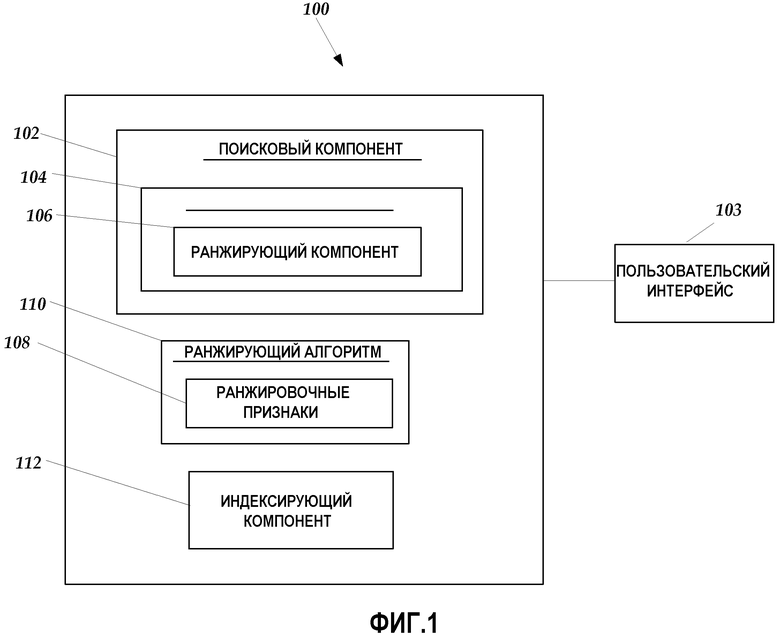
1. Система (100) для предоставления информации, содержащая
поисковый компонент (102), сконфигурированный находить результат поиска на основе введенного запроса;
компонент (110) базы данных, сконфигурированный хранить информацию, связанную с введенным запросом, включая один или более ранжировочных признаков (108), причем эти один или более ранжировочных признаков (108) могут быть связаны с действием пользователя или бездействием пользователя, связанным с результатом поиска, которые могут быть собраны по отношению к результату поиска для такого же запроса или подобного запроса, выполненного предыдущими пользователями, причем один ранжировочный признак из этих одного или более ранжировочных признаков (108) может быть связан с длиной документа; и
ранжирующий компонент (104), сконфигурированный ранжировать результат поиска на основе, по меньшей мере частично, ранжирующей функции и упомянутых одного или более ранжировочных признаков (108), включая признак, основанный на действии, признак, основанный на бездействии, и признак длины документа, причем поисковый компонент (102) может использовать ранг результата поиска при предоставлении результатов поиска в соответствии с порядком ранжирования.
2. Система по п.1, в которой длина документа нормирована делением длины документа, подлежащего ранжированию, на среднюю длину набора документов, причем документ, подлежащий ранжированию, включен в данный набор документов, причем длина документа соответствует числу слов в документе.
3. Система по п.2, в которой функция преобразования преобразует нормированную длину документа в ранжирующее значение между нулем и единицей.
4. Система по п.3, в которой функция преобразования определяется как:
где D - нормированная длина документа, а F(D) - ранжирующее значение.
5. Система по п.1, в которой ранжирующая функция дополнительно содержит оценочную функцию, определяемую как:
где
и
xi - одно или более входных значений оценочной функции,
w2j - весовые коэффициенты скрытых узлов,
wij - весовые коэффициенты входных значений,
tj - число пороговых значений и
tanh - функция гиперболического тангенса.
6. Система по п.1, в которой ранжирующий компонент (104) может использовать один или более параметров перехода по ссылке при ранжировании результата поиска, причем эти один или более параметров перехода по ссылке включают в себя одно или более из следующего:
параметр выбора щелчком мыши, ассоциированный с количеством раз, которое результат поиска был выбран щелчком мыши;
параметр пропуска, ассоциированный с количеством раз, которое результат поиска был пропущен;
первый потоковый параметр, соответствующий объединению строк запросов, связанных с выбранным щелчком мыши результатом поиска; и
второй потоковый параметр, соответствующий объединению строк запросов, связанных с пропущенным результатом поиска.
7. Система по п.1, в которой упомянутые один или более ранжировочных признаков (108) содержат один или более динамических ранжировочных признаков, выбранных из группы, состоящей из тела, заголовка, автора, сгенерированного заголовка, привязанного текста и URL-ссылки, и один или более статических ранжировочных признаков, выбранных из группы, состоящей из дистанции в щелчках мышью, глубины URL-ссылок, типа файла и языка.
8. Система по п.6, в которой ранжирующий компонент (104) дополнительно сконфигурирован для вычисления входного значения, связанного с параметром выбора щелчком мыши, где вычисленное входное значение определяется как:
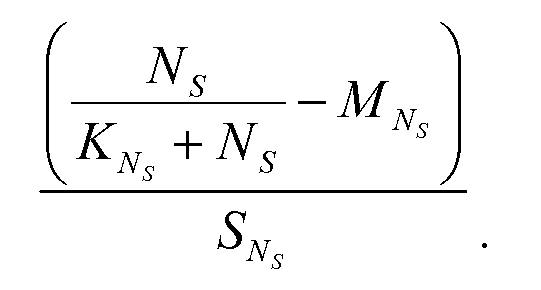
9. Система по п.6, в которой поисковый компонент (102) дополнительно сконфигурирован для вычисления входного значения, связанного с параметром пропуска, где вычисленное входное значение определяется как:
10. Система по п.6, в которой поисковый компонент (102) дополнительно сконфигурирован для вычисления входного значения, связанного с первым потоковым параметром, где вычисленное входное значение определяется как:
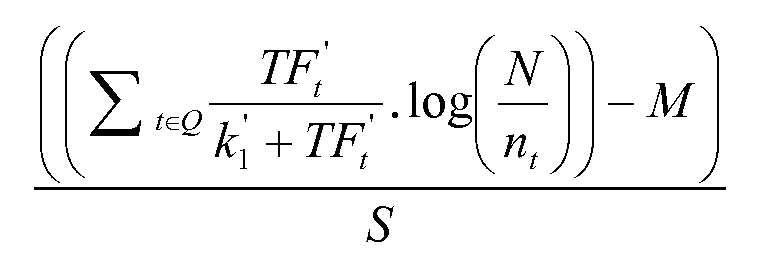
и
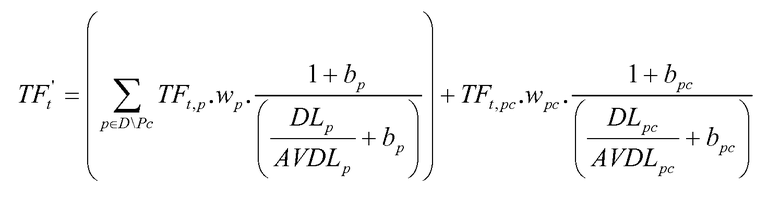
11. Система по п.6, в которой поисковый компонент (102) дополнительно сконфигурирован для вычисления входного значения, связанного со вторым потоковым параметром, где вычисленное входное значение определяется как:
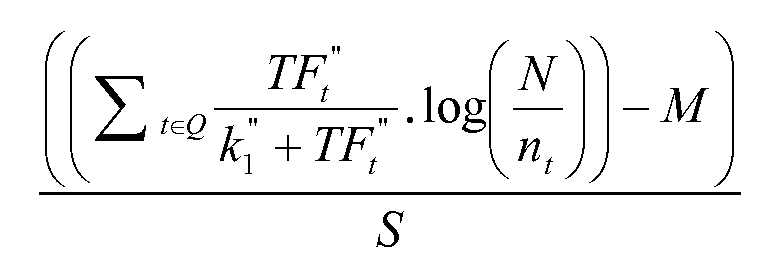
и
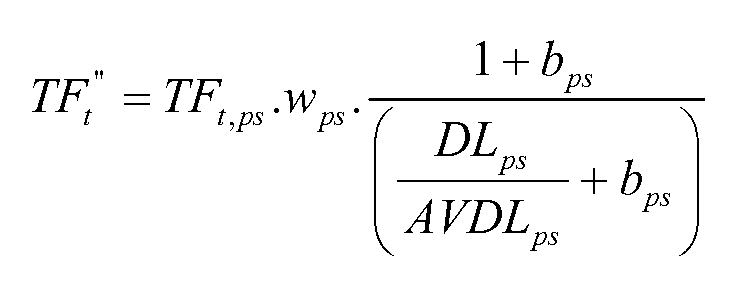
12. Поисковая машина (102), сконфигурированная:
принимать информацию, связанную с запросом;
обнаруживать результат поиска, связанный с запросом;
вычислять первое входное значение, связанное с параметром выбора щелчком мыши и результатом поиска;
вычислять второе входное значение, связанное с параметром пропуска и результатом поиска;
вычислять третье входное значение, связанное с длиной документа и результатом поиска; и
ранжировать результат поиска с использованием первого, второго и третьего входных значений.
13. Поисковая машина (102) по п.12, дополнительно сконфигурированная:
вычислять четвертое входное значение, связанное с первым потоковым параметром и результатом поиска;
вычислять пятое входное значение, связанное со вторым потоковым параметром и результатом поиска;
ранжировать результат поиска с использованием, по меньшей мере, четырех из первого, второго, третьего, четвертого и пятого входных значений.
14. Способ предоставления информации, содержащий этапы, на которых:
принимают запрос, который включает в себя одно или более ключевых слов;
осуществляют поиск возможного результата на основе, частично, этого одного или более ключевых слов;
находят возможные результаты запроса на основе, частично, этих одного или более ключевых слов;
определяют первое входное значение, связанное с действием предыдущего пользователя и по меньшей мере один из этих возможных результатов запроса;
определяют второе входное значение, связанное с бездействием предыдущего пользователя и по меньшей мере одним из этих возможных результатов запроса;
определяют третье входное значение, связанное с длиной документа упомянутых возможных результатов запроса; и
ранжируют набор упомянутых возможных результатов запроса на основе, частично, определения оценки с помощью оценочной функции и одного или более из первого, второго и третьего входных значений.
15. Способ по п.14, дополнительно содержащий этапы, на которых
определяют четвертое входное значение, связанное с текстовым потоком и выбором пользователем по меньшей мере одного из упомянутых возможных результатов запроса; и
ранжируют упомянутый набор возможных результатов запроса на основе, частично, определения оценки с помощью оценочной функции и одного или более из первого, второго, третьего и четвертого входных значений.
| СПОСОБ ПОИСКА И ВЫБОРКИ ИНФОРМАЦИИ С ПОВЫШЕННОЙ РЕЛЕВАНТНОСТЬЮ | 2003 |
|
RU2236699C1 |
| СИСТЕМА И СПОСОБ ПРЕДОСТАВЛЕНИЯ ПРЕДПОЧТИТЕЛЬНОГО ЯЗЫКА УПОРЯДОЧИВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2004 |
|
RU2319202C2 |
| US 6526440 B1, 25.02.2003 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |

