МАШИННОЕ ОБУЧЕНИЕ
Предшествующий уровень техники
Это описание относится к машинному обучению в системе автоматизированного ответа.
Один вариант применения, в котором осуществляется управление сеансами общения, находится в центрах контактов с клиентами. Центры контактов с клиентами, например центры обработки звонков или call-центры, появились как одна из самых важных и динамических областей предприятий в новой экономике. В сегодняшнем жестком экономическом климате рентабельное обслуживание и сохранение клиентов имеет стратегическое значение. Большинство компаний понимает, что сохранение удовлетворенных клиентов менее затратно, чем приобретение новых. Как точка соприкосновения с предприятием для больше половины всех взаимодействий с клиентами центр контактов является краеугольным камнем в успешной деловой стратегии.
Растущая важность центра контактов является феноменом последнего времени. Исторически служба обслуживания клиентов рассматривается большинством организаций как дорогостоящая, но необходимая для ведения дел, чреватая проблемами и неэффективностью. Большой объем звонков регулярно заваливает недостаточно обученный персонал, приводя к долгим очередям, обусловленным занятостью линии связи, для клиентов. Неадекватные информационные системы требуют, чтобы большинство звонящих повторило основную информацию несколько раз. Из-за этого приблизительно двадцать процентов покупателей отказываются от Web-сайтов при столкновении с необходимостью звонить в call-центр организации, и много больше отказываются от звонка, когда сталкиваются с нахождением в очередях или раздражающим выбором в меню. Кроме того, центры контактов с клиентами связаны с ненормальными эксплуатационными расходами, потребляя почти десять процентов доходов среднего бизнеса. Стоимость рабочей силы доминирует в этих расходах, и необычно высокая норма товарооборота для промышленности приводит к безостановочному найму и обучению новых агентов.
К сожалению, для бизнеса обеспечение рентабельного обслуживания клиентов становится все более трудным. Интернет вызвал взрыв в обмене информацией между организациями и их клиентами. Клиенты придают все более высокое значение обслуживанию в Интернет-экономике, потому что продукты и услуги, приобретенные в режиме онлайн, приводят к большей интенсивности наведения справок, чем те, что были приобретены через традиционные коммерческие каналы. Роль центра контактов расширилась так, чтобы включать обслуживание новых пользователей, типа деловых партнеров, инвесторов и даже служащих компании. Новые, очень эффективные инициативы в области рекламы и маркетинга приводят прямых клиентов к взаимодействию с уже перегруженными центрами контактов для получения информации. В дополнение к телефонным звонкам наведение справок теперь делается по новым текстовым каналам на основе Web, включая электронную почту, Web-почту и чат, которые вызывают огромное напряжение в операциях по обслуживанию клиентов.
Комбинация растущей важности хорошей службы обслуживания клиента и препятствий по ее обеспечению составляет проблему в области обслуживания клиентов.
КРАТКОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
В одном аспекте изобретение характеризуется использованием сообщений агентов (например, высказываний, текстовых посланий и т.д.), зафиксированных в наборе предварительно записанных сеансов общения между агентом и звонящими (например, сеансов разговоров между агентами-людьми и звонящими) для обучения набора классификаторов агентов. Из классификаторов агентов высказывания звонящих могут быть обнаружены и кластеризованы. Кластеризованные высказывания звонящих могут использоваться для обучения набора кластеров звонящих.
В другом аспекте изобретение характеризуется пополнением кластеров звонящих с помощью использования классификаторов (например, классификаторов агентов или звонящих) для классификации сообщений в предварительно записанных сеансах общения между звонящими и агентами, добавлением классифицированных сообщений к обучающему набору для ассоциированного классификатора и перестроением классификатора.
В другом аспекте изобретение характеризуется использованием классификаторов агентов для идентификации общих шаблонов запросов агентов в наборе предварительно записанных сеансов общения между агентами и звонящими. Эти общие шаблоны запросов агентов могут быть связаны с определенными типами звонков (например, звонки, касающиеся одного и того же начального запроса звонящего). Эти шаблоны запросов агентов могут использоваться, например, разработчиком приложения для проектирования хода общения автоматизированной системы ответа.
В другом аспекте изобретение характеризуется использованием распределений ответов звонящих на по-разному выраженные вопросы агентов в отношении одной и той же информации для определения формулировки вопроса для автоматизированной системы ответа, на который с наибольшей вероятностью будет получен желательный ответ от звонящего.
В другом аспекте изобретение относится к способу, который включает в себя прием набора сеансов общения между членами стороны первого типа (например, агентами-людьми или программными агентами) и членами стороны второго типа (например, звонящими людьми), причем каждый из сеансов общения включает в себя сообщение члена стороны первого типа и сообщение (например, произнесенный запрос) члена стороны второго типа, которое является ответом на сообщение члена стороны первого типа (например, произнесенный ответ на запрос). Способ также включает в себя группирование сообщений членов стороны первого типа в первый набор кластеров, и затем группирование ответных сообщений членов стороны второго типа во второй набор кластеров, основываясь на группировании сообщений членов стороны первого типа. Способ также включает в себя генерацию с помощью машины, набора классификаторов стороны второго типа (например, на основе метода опорных векторов или дерева решений) для одного или более кластеров во втором наборе кластеров.
Реализации этого аспекта изобретения включают в себя один или более из следующих признаков. Способ может использоваться для разработки первоначального приложения для автоматизированной системы ответа, такой как голосовая автоматизированная система ответа или автоматизированная система ответа на основе текстовых посланий. Сообщения членов стороны первого типа могут быть сгруппированы, используя компьютер, в первый набор кластеров. Например, компьютерный процесс может сначала определить семантические особенности сообщений и затем сгруппировать сообщения в кластеры, основываясь на этих семантических особенностях.
Группы сообщений членов первой группы могут быть сгруппированы, основываясь на смысловом значении их сообщений. Другими словами, сообщения могут быть сгруппированы так, чтобы все сообщения в группе имели одно и то же смысловое значение, но могли иметь разные формулировки. Группы сообщений членов стороны второго типа образуют группы, соответствующие ответам на запросы информации от членов стороны первого типа.
Способ может дополнительно включать в себя прием второго набора из набора сеансов общения между членами стороны первого типа и членами стороны второго типа, применение классификаторов стороны второго типа для группирования сообщений членов стороны второго типа и с помощью машины повторное генерирование классификаторов стороны второго типа для кластера во втором наборе кластеров, используя данные, касающиеся сообщений, сгруппированных в этом кластере.
В другом аспекте изобретение характеризуется применением набора классификаторов для категоризации инициирующих сообщений (например, запросов информации от агента), которые являются частью сеансов общения, которые также включают в себя ответные сообщения, и использованием категоризированных сообщений для идентификации общих шаблонов сообщений.
Реализации изобретения могут включать в себя один или более из следующих признаков. Способ может дополнительно включать в себя группирование сеансов общения в набор сеансов общения по предмету (например, предмету цели звонящего для звонка в центр контактов) и ассоциирование идентифицированных общих шаблонов сообщений с группами.
В другом аспекте изобретение характеризуется применением набора классификаторов (например, метода опорных векторов) для категоризации сообщений членов стороны первого типа в сеансах общения между членами стороны первого типа и членами стороны второго типа и определением предмета сеанса общения, основываясь на комбинации или последовательности категоризированных сообщений члена стороны первого типа.
Реализации изобретения могут включать в себя один или более из следующих признаков. Способ может также включать в себя сопоставление последовательности категоризированных сообщений с последовательностью категоризированных сообщений, ассоциированной с сеансом общения, имеющим известный предмет.
В другом аспекте изобретение характеризуется использованием примеров сообщений, которые имели место между звонящими и автоматизированной системой ответа (например, автоматизированной системой ответа текстовыми посланиями или голосовой автоматизированной системой ответа) для повышения эффективности системы.
В другом аспекте изобретение характеризуется выбором примеров в качестве возможностей обучения для автоматизированной системы ответа на основе некоторых критериев выбора. Критерии выбора могут быть выбраны (например, пользователем через графический интерфейс пользователя) так, чтобы помочь убедиться в том, что примеры, на которых учится система, надежны. Критерии выбора могут также быть выбраны так, чтобы гарантировать, что система выбирает только примеры, которые приводят к значимому усовершенствованию в системе. Отказываясь от примеров, которые не приводят к значимому усовершенствованию в системе, система помогает минимизировать затраты в ресурсах (например, ресурсах обработки, задачей которых является осуществление усовершенствования, или человеческих административных ресурсах, задачей которых является рассмотрение или одобрение обучающих примеров).
В другом аспекте изобретение соответствует способу выбора возможностей обучения для автоматизированной системы ответа, ассоциированной связанной с центром контактов, который включает в себя прием цифровых представлений сеансов общения, по меньшей мере некоторые из которых включают в себя ряд сообщений (например, высказываний, текстовых посланий, и т.д.) между человеком и агентом (например, агентом-человеком или программным агентом), связанным с центром контактов, и выбор сообщения в качестве возможности обучения, если один или более критериев выбора удовлетворены.
Реализации могут включать в себя один или более из следующих признаков. Критерии выбора могут быть требованием, чтобы сообщение сопровождалось обменом сообщениями между человеком и агентом, требование, чтобы сообщение сопровождалось множеством успешных последующих обменов сообщениями между человеком и агентом, требование, чтобы сообщение было включено в сеанс общения, в котором человек ответил положительно на вопрос об удовлетворении, поставленный агентом, требование, чтобы сообщение в первом сеансе общения было подтверждено сходными сообщениями, имеющими место в некотором количестве других сеансов общения, или требование, чтобы сообщение не обуславливало то, что набор классификаторов, построенный с использованием этого сообщения, приводит к некорректной классификации сообщений, которые были классифицированы корректно предыдущим набором классификаторов.
В некоторых реализациях сообщения между людьми и агентами могут включать в себя взаимодействия с содействием, в которых человек-агент выбрал ответ на сообщение от человека из ранжированного списка предложенных ответов, сгенерированных автоматизированной системой ответа. Для этих взаимодействий с содействием критерии выбора могут включать в себя требование, чтобы выбранный ответ во взаимодействии с содействием был рангом выше порога, или требование, чтобы выбранный ответ во взаимодействии с содействием был выбран от доверенного агента-человека.
Выбранные сообщения могут использоваться для того, чтобы повысить эффективность системы с помощью перестроения классификаторов, используя выбранное сообщение, генерирования языковой модели для автоматического средства распознавания речи, используя выбранное сообщение, или изменения сети с конечным числом состояний, используя выбранное сообщение.
В реализации, связанной с голосовым ответом, способ может также включать в себя выполнение распознавания речи в автономном средстве распознавания речи в отношении высказывания, выбранного как возможность обучения. Способ может также включать в себя перед выполнением распознавания речи определение того, выполнять ли распознавание речи в отношении выбранного высказывания, основываясь на уровне уверенности в смысловом значении высказывания, ассоциированного с цифровым представлением сообщения.
В другом аспекте изобретение соответствует способу выбора возможностей обучения для голосовой автоматизированной системы ответа, ассоциированной с центром контактов, который включает в себя прием цифрового представления сеанса общения, который имел место между звонящим и одним или более агентами, связанными с центром контактов, и выбор высказывания, зафиксированного в цифровом представлении сеанса общения, для транскрипции, основываясь на одном или более критериях выбора.
Реализации могут включать в себя один или более из следующих признаков. Критерии выбора могут включать в себя требование, чтобы уровень уверенности в ответе автоматизированной голосовой системой ответа был в некотором диапазоне значений, либо требование, чтобы уровень уверенности в процессе распознавания речи, выполняемом в отношении высказывания во время сеанса общения, был в некотором диапазоне значений. Способ может также включать в себя выполнение распознавания речи в отношении высказывания и добавление распознанных слов в этом высказывании к словарю слов, используемому процессом распознавания речи, используемым системой для распознавания высказываний во время сеанса общения.
В другом аспекте изобретение соответствует способу, согласно которому, основываясь на взаимодействии между человеком и агентом-человеком, связанным с автоматизированной системой ответа, в которой агент выбрал ответ на сообщение этого человека из числа ответов, предложенных автоматизированной системой ответа, выбирают сообщение в качестве примера для обучения автоматизированной системы ответа.
Реализации изобретения могут включать в себя один или более из следующих признаков. Выбор сообщения может быть основан на уровне уверенности в ответе, выбираемом агентом, или на уровне доверия агенту-человеку, который выбрал ответ.
В другом аспекте изобретение соответствует способу, предусматривающему идентификацию сообщения от человека, осуществляющего контакт с автоматизированной системой ответа,Распознавание ввода что приводит к тому, что ответ обрабатывается агентом-человеком, и модификацию автоматизированной системы ответа для того, чтобы отвечать в будущем на подобные сообщения от людей, осуществляющих контакт с данной системой.
В одном специфическом варианте осуществления модификация автоматизированной системы ответа может включать в себя модификацию сети переходов с конечным числом состояний, ассоциированной с данной системой.
В другом аспекте изобретение соответствует способу выбора возможностей обучения для автоматизированной системы ответа, который включает в себя добавление сообщения в набор обучающих примеров для классификатора в средстве распознавания понятий, генерацию нового классификатора, используя упомянутый набор примеров обучения, который включает в себя добавленное сообщение, и игнорирование этого нового классификатора, основываясь на требовании эффективности для нового классификатора.
Реализации могут включать в себя один или более из следующих признаков. Требование эффективности может быть требованием, чтобы новый классификатор правильно классифицировал по меньшей мере предопределенное число других примеров, или требование, чтобы новый классификатор имел новый характеристический набор примеров, который отличается от характеристического набора примеров, соответствующего предыдущему классификатору, на предопределенную величину.
В другом аспекте изобретение характеризуется генерированием набора классификаторов для по меньшей мере одного кластера ответных сообщений, причем данный кластер основывается на одном или более кластерах инициирующих сообщений, с которыми ответные сообщения ассоциированы в сеансах общения.
Реализации могут включать в себя один или более из следующих признаков. Инициирующие сеансы общения могут исходить от члена стороны первого типа (например, агента в центре обслуживания клиентов), а ответные сеансы общения могут исходить от члена стороны второго типа (например, клиента, осуществляющего контакт с центром обслуживания клиентов). Способ может также включать в себя прием набора сеансов общения, по меньшей мере, некоторые из которых включают в себя инициирующее сообщение и ассоциированные ответные сообщения. Кластер ответных сообщений может включать в себя ответные сообщения, ассоциированные с инициирующим сообщением.
Другие преимущества, признаки и варианты осуществления будут очевидны из следующего описания, а также из формулы изобретения.
ПЕРЕЧЕНЬ ФИГУР ЧЕРТЕЖЕЙ
Фиг.1 - линейная диаграмма перехода между состояниями и Фиг.1A - граф перехода состояний.
Фиг.2 - взаимодействия между клиентом, системой и агентом-человеком.
Фиг.3 - блок-схема последовательности операций.
Фиг.4 - обзор системы программной архитектуры.
Фиг.5 - более детализированное представление программной архитектуры по Фиг.4.
Фиг.6 - блок-схема системы компонентов организации последовательности действий.
Фиг.7 - блок-схема компонентов канала взаимодействия.
Фиг.8 - блок-схема средства распознавания речи.
Фиг.9 - блок-схема средства распознавания понятий.
Фиг.10 - представление организации документов языка разметки.
Фиг.11 - представление подмножества графа перехода между состояниями для примерного графа.
Фиг.12 - представление итерационного процесса разработки приложения.
Фиг.13 - снимок экрана.
Фиг.14 - еще один снимок экрана.
Фиг.15 - представление процесса разработки первоначального приложения.
Фиг.16A-16F - представления процесса разработки первоначального приложения.
Фиг.17 - блок-схема сервера обучения.
ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Технология обработки естественного языка, основанная на понятиях или смысловом значении типа технологии, описанной в патенте США 6401061, полностью включенного сюда по ссылке, может быть усилена для того, чтобы интеллектуальным образом взаимодействовать с информацией, основываясь скорее на смысловом значении информации или семантическом контексте, чем на ее буквальной формулировке. Система может тогда быть построена для управления сообщениями, например сообщениями, в которых пользователь излагает вопрос, а система предоставляет ответ. Такая система является очень эффективной, дружественной и отказоустойчивой, потому что она автоматически извлекает ключевые понятия из пользовательского запроса, независимо от буквальной формулировки. Средство (машина) распознавания понятий (вида, описанного в патенте США 6401061) допускает формирование соответствующих ответов на основе того, что клиенты спрашивают, когда они задействуют лежащую в основе систему при общении по голосовым или основанным на тексте каналам связи. Общение может соответствовать синхронному обмену информацией с клиентом (типа диалога в реальном времени, используя голос или мгновенный обмен посланиями, или другую связь через web-страницу) или асинхронный обмен информацией (типа электронной почты или посланий речевой почты). В сеансах общения с использованием режима асинхронной передачи ответы обеспечиваются в более позднее время относительно запросов клиента.
В примере, соответствующем центру контактов с клиентами, до времени выполнения система управления сообщениями создает базу знаний, используя зарегистрированные фактические сеансы общения между клиентами и агентами-людьми в центре контактов с клиентами. Использование зарегистрированных сеансов общения этим способом вместо того, чтобы пытаться запрограммировать систему для каждого возможного взаимодействия с клиентом, делает конфигурирование простым, быстрым и в пределах способностей широкого диапазона системных администраторов.
В отличие от традиционных систем самообслуживания, которые являются неспособными к быстрому приспособлению к постоянно изменяющимся условиям бизнеса, система, описанная здесь, может быстро моделировать типичные пары вопросов и ответов и автоматизировать будущие сеансы общения.
Каждый сеанс общения, который обрабатывается системой (или построением базы знаний до времени выполнения, или обработкой сообщений реального времени во время выполнения), моделируется как упорядоченный набор состояний и переходов к другим состояниям, при этом переход от каждого состояния включает в себя вопрос или утверждение клиентом и ответ агента-человека (или в некоторых случаях действие, которое должно быть предпринято в ответ на этот вопрос, такое как постановка вопроса обратно пользователю). Символическая последовательность состояние - переход - состояние для сеанса общения, который обрабатывается из записанного взаимодействия, проиллюстрирована на Фиг.1. В некоторых вариантах осуществления разделитель для каждого утверждения или сообщения от клиента или ответа агента-человека является периодом тишины или произнесенным прерыванием.
Текст для каждого из этих утверждений или ответов извлекают из любой среды сообщения, использованной в сеансе общения, например текста или речи. Например, онлайновое средство автоматического распознавания речи (ASR) может использоваться для того, чтобы преобразовать разговорное общение в текст. Затем система извлекает ключевые понятия из вопроса клиента или утверждения, или ответа агента-человека. Это извлечение делается так, как описано в патенте США 6401061, с помощью создания библиотеки текстовых элементов (S-морфем) и их смысловых значений в терминах набора понятий (семантических факторов) в качестве базы знаний для использования средством распознавания понятий. Средство распознавания понятий выполняет разбор текста от клиента или агента на эти S-морфемы, и затем собираются понятия, соответствующие этим S-морфемам. Эти ключевые понятия для сообщения (вопрос или ответ в обсуждаемом примере) могут быть сохранены как неупорядоченный набор и могут упоминаться как «совокупность понятий». Также возможны высокоуровневые организации понятий в различные структуры, отражающие синтаксис или близость. После того, как весь набор зарегистрированных сеансов общения (то есть диалогов) обработан, каждый сеанс общения выражается как последовательность состояние - переход - состояние. Система накапливает все из последовательностей перехода между состояниями сеанса связи в единый граф так, чтобы начальное состояние могло перейти к любому из сеансов связи. Этот совокупный граф переходов затем сжимают, используя методики теории графов, которые заменяют дублированные состояния и переходы. Система рекурсивно определяет, какие переходы от данного состояния дублированы, посредством сравнения переходов с их «понятиями». Последующие состояния, соответствующие дублированным переходам от одного и того же состояния, затем сливаются в одно состояние со всеми из переходов от этих последующих состояний. Текст одного из ответов, соответствующих дублированным переходам, сохраняется в базе знаний как стандартный ответ. Этот текст может быть возвращен клиенту как часть диалогового обмена в форме текста или преобразованным в речь. Результирующий сжатый граф переходов между состояниями формирует базу знаний для системы. Пример сжатого графа переходов между состояниями проиллюстрирован на Фиг.1A. В некоторых реализациях вся информация в этой базе знаний сохраняется с использованием четкой определенной грамматики XML. Примеры языков разметки включают в себя язык гипертекстовой разметки (HTML) и для речи язык разметки с расширениями (VoiceXML). В этом случае язык разметки сеанса общения (CML) используется для того, чтобы хранить информацию для базы знаний.
После того, как база знаний сформирована, система может перейти к рабочему режиму (режиму времени выполнения), в котором она используется для того, чтобы управлять сообщениями в, например, центре контактов с клиентами. Файлы-журналы регистрации, которые использовались для построения базы знаний для заданного центра контактов с клиентами, в некоторых реализациях будут записаны из сеансов общения, имеющих место в одном и том же центре контактов с клиентами, или будут характеризоваться подобными видами сеансов общения. Используя базу знаний, система может следить за текущим состоянием сеансов общения во время выполнения, основываясь на графе переходов между состояниями для центра контактов с клиентами. Например, после того, как клиент выполняет свое первое сообщение (преобразованное в текст) с центром контактов с клиентами (например, пользователь мог бы сделать произнесенный запрос на произвольном естественном языке), система использует средство распознавания понятий для того, чтобы извлечь понятия из текста. Затем система пытается сопоставить понятия из текста с переходами от начального состояния в графе перехода между состояниями центра контактов. Это сопоставление делается посредством сравнения набора понятий, ассоциированных с текущим сообщением, с наборами понятий, сохраненных в базе знаний. Чем ближе два набора, тем больше степень уверенности в точности их согласованности. Если наилучшим образом согласующийся переход в базе знаний согласуется с текстом клиента со степенью уверенности выше некоторого порога, то система предполагает, что она идентифицировала правильный переход, определяет местонахождение соответствующего ответа в базе знаний и сообщает этот соответствующий ответ клиенту. Система переходит к следующему состоянию в графе переходов между состояниями и ждет следующего сообщения клиента. Этот обход последовательности состояний и переходов может продолжаться до того, как либо клиент закончит сеанс связи, либо граф переходов между состояниями достигнет состояния конца. Однако ошибки в тексте, принимаемом средством распознавания понятий, и нестандартные (или неожиданные) вопросы или утверждения клиента могут потребовать вмешательства агента-человека. Когда сообщение клиента имеет форму речи, преобразование из речи в текст может иметь такие ошибки. Из-за возможности таких ошибок в некоторых реализациях система не полагается на полную автоматизацию ответов клиенту, но имеет гладкий переход к ручному вмешательству агента-человека, когда автоматизация неудачна. Вообще, этот тип постепенной автоматизации предлагается на Фиг.2, которая показывает взаимодействия между клиентом 1, системой 3 и агентом-человеком 5. (В других реализациях системы автоматизированные ответы могут даваться в случаях с высокой степенью уверенности, в то время как никакой ответ (кроме указывающего на то, что система является неспособной ответить) не дается пользователю).
В некоторых примерах система использует технологию распознавания речи для того, чтобы привлечь клиентов к сеансам общения по телефону. Технология распознавания речи преобразовывает речь клиента в текст, который становится вводимыми данными для средства распознавания понятий. Объединяя средство распознавания понятий с распознаванием речи, лежащая в основе система распознает то, о чем говорит клиент, на уровне понятий понимая, что подразумевает клиент. Эта комбинация обеспечивает новые уровни автоматизации в центре обслуживания клиентов посредством привлечения пользователей к интуитивному, интеллектуальному и конструктивному взаимодействию по множеству каналов. И это дает возможность организациям разгрузить существенные объемы стандартных клиентских транзакций по всем предназначенным для контактов каналам, сохраняя значительные средства и улучшая уровень обслуживания.
В других реализациях эти сеансы общения с клиентом могут происходить через звуковой интерфейс с использованием, например, браузера VoiceXML, Web с использованием браузера HTML, службу мгновенного обмена посланиями с использованием приложения IM, электронную почту с использованием приложения электронной почты, а также через другие, еще не используемые каналы.
Необходимо отметить, что эта система дает возможность ответу центра контактов использовать режимы сообщения, отличные от сообщения клиента. Например, клиент может выполнять сообщение, используя голос, а центр контактов может ответить текстом, либо клиент может выполнять сообщение, используя текст, а центр контактов может ответить машинно-генерируемым голосом. Это достигается или непосредственным использованием сохраненного текста ответа или преобразованием сохраненного текста ответа в машинно-генерируемую речь.
В некоторых реализациях система обеспечивает три типа или уровня управления сеансами общения и система может переключаться между ними во время заданного сеанса общения:
1. Автоматизированный - система в состоянии произвести соответствующие ответы на запросы клиента и автоматизировать транзакцию полностью независимо от агента-человека. Например, клиент А позвонил в центр контактов с клиентами компании, чтобы спросить их о гарантиях на новые продукты. Клиента А приветствует автоматизированная система, которая представляется и дает краткое объяснение того, как автоматизированная система работает, включая типовые запросы. После этого ему предлагается выразить свой запрос собственными словами. Клиент А излагает свой запрос диалоговым способом. Автоматизированная система сообщает клиенту всестороннюю гарантийную политику компании. Система спрашивает клиента, было ли решение его проблемы полезно и имеет ли он какие-нибудь дополнительные вопросы. Ответ на его вопрос получен, клиент завершает звонок.
2. Смешанный с содействием агента - в этом режиме система вовлекает агента-человека, представляя ему запрос клиента и множество предложенных ответов, ранжированных на основе степени уверенности/подобием ("балл согласованности"). Агент-человек выбирает один из предложенных ответов, давая возможность системе закончить звонок. Агент-человек может также выполнить поиск по системной базе знаний в отношении альтернативного ответа, вводя вопрос в систему. В смешанном режиме с содействием агента звонок не переадресуется агенту и агент непосредственно не взаимодействует с клиентом. Смешанная модель, как ожидается, сократит время агента при звонке, позволяя ему быстро «направить» систему для корректного решения проблемы. Агент-человек может тогда перейти к новой транзакции. Например, клиент B звонит в организацию обслуживания клиентов компании для того, чтобы спросить адрес, где он может ночью заплатить за обслуживание. Клиента B приветствует автоматизированная система, которая представляется и подтверждает имя клиента. После подтверждения его имени клиенту B дают краткое объяснение того, как автоматизированная система работает, включая типовые запросы. Он после этого озвучивает свой запрос своими словами. Клиент B высказывает свой запрос диалоговым способом. Автоматизированная система просит клиента подождать мгновение, в то время как она находит ответ на его вопрос. Система передает звонок следующему доступному агенту. В то время как клиент ждет, система соединяется с доступным агентом-человеком и проигрывает шепотом вопрос клиента B. Агент-человек получает всплывающую подсказку на экране с несколькими предложенными ответами на вопрос клиента. Агент-человек выбирает соответствующий предложенный ответ и нажимает «ответить», давая возможность системе закончить взаимодействие. Система возобновляет свое взаимодействие с клиентом B, обеспечивая ночной адрес. Система спрашивает клиента B, было ли полезно решение его проблемы и имеет ли он какие-нибудь дополнительные вопросы. На его вопрос получен ответ, клиент B заканчивает звонок, не зная, что агент-человек выбрал какой-либо из ответов.
3. Содействие с взятием под контроль агента - в модели взятия под контроль система обращается к агенту-человеку, и агент-человек берет звонок под контроль полностью, вовлекая звонящего в прямое общение. Модель взятия под контроль, как ожидается, улучшит производительность агента с помощью предварительного сбора диалоговой информации из звонка для агента службы обслуживания клиентов и обеспечения возможности агенту искать информацию в базе знаний системы во время звонка, сокращая время, которое требуется потратить на звонок. Например, клиент С звонит в организацию обслуживания клиентов компании, чтобы закрыть свою учетную запись. Клиента С приветствует автоматизированная система, которая представляется и подтверждает имя клиента. После подтверждения его имени клиенту С дают краткое объяснение того, как автоматизированная система работает, включая типовые запросы. После этого его просят озвучить свой запрос своими словами. Клиент С заявляет, что он хотел бы закрыть свою учетную запись в компании. Автоматизированная система просит, чтобы клиент подтвердил свой номер счета. Клиент С набирает номер счета на телефонной клавиатуре. Система говорит клиенту С, чтобы он подождал некоторое время, в то время как звонок передается агенту. Система передает звонок в соответствующий пул агентов для этой транзакции. Следующий доступный агент получает запись запроса клиента C и получает всплывающее на экране окно с информацией его учетной записи. Агент берет контроль над звонком, спрашивая, когда клиент С хотел бы закрыть свою учетную запись.
Система переключается среди трех режимов управления сеансами общения, основываясь на способности системы обрабатывать ситуацию. Например, в автоматизированном режиме общения, если система неспособна сопоставить запрос клиента со стандартной парой вопрос/ответ с достаточной степенью уверенности, то система может переключиться на смешанный режим с содействием агента. Кроме того, в смешанном режиме с содействием агента, если агент-человек решает, что ни один из машинно-генерируемых ответов не соответствует заданному запросу клиента, тогда система может переключиться на режим содействия агента с взятием под контроль, и агент-человек заканчивает сеанс общения. В предпочтительном варианте воплощения этого изобретения клиент также имеет возможность переключать режимы сеанса общения. Например, клиент может захотеть переключиться из автоматизированного режима общения. В другом варианте воплощения система может корректировать порог степени уверенности при интерпретации сообщения клиента, основываясь на том, насколько заняты агенты-люди. Это может дать клиентам возможность пробовать автоматизированные ответы вместо того, чтобы ждать занятых агентов-людей.
Дополнительный режим управления сеансами общения возникает, когда агент-человек имеет достаточные навыки работы с шаблонами сообщений системы. В этом случае, если сообщение клиента сопоставляется с переходами с низким уровнем уверенности, агент-человек может решить перефразировать вопрос клиента с помощью замещающего текста, что может привести к более успешному сопоставлению. Если это так, то диалог может продолжаться в автоматизированном режиме.
Сеансы общения между клиентом и центром контактов, которые управляются системой с использованием этих трех режимов общения, смоделированы блок-схемой последовательности операций, проиллюстрированной на Фиг.3. В этой последовательности операций сначала пользователь инициирует сеанс общения, сообщая вопрос или утверждение центру (2) контактов. Затем сообщение преобразовывается в текст (4). Идентифицированный переход может содержать переменные данные, которые являются подходящими для последующего ответа системы. Эти переменные данные могут быть именем клиента или идентификационным номером и имеют конкретный тип данных {строка, число, дата, и т.д.}. Переменные данные (когда они представлены) извлекаются из текста сообщения клиента (6). Могут использоваться специальные правила для того, чтобы идентифицировать переменные данные. Затем средство распознавания понятий разбирает остающийся текст на S-морфемы и собирает «совокупность понятий», согласующихся с этими S-морфемами (8). Затем система идентифицирует переход от текущего состояния, понятия которого согласуются с извлеченными из сообщения клиента понятиями с самым высоким уровнем уверенности (10). Если переменные данные ожидаются в переходе, то согласованность типа данных ожидаемых переменных с типом данных извлеченных переменных включается в сравнение. Если степень уверенности в согласованности выше, чем установленный порог (12), то система предполагает, что клиент находится на идентифицированном переходе. В этом случае, системе, вероятно, придется искать данные для ответа, согласующегося с идентифицированным переходом (14). Например, если сообщение клиента является вопросом, в котором спрашивается о часах работы бизнес-компании, то система может найти часы работы в базе данных. Затем система посылает согласующийся ответ пользователю с дополнительными данными, если это является частью ответа (16). Этот ответ может быть одной из многих форм сообщения. Если сеанс общения является телефонным, то ответ системы может быть машинно-генерируемой речью. Если сеанс общения основан на тексте, то ответ может быть текстом. Ответ может быть в тексте даже притом, что вопрос является голосовым, или наоборот. Если система идентифицирует переход с недостаточной степенью уверенности (12), то агент-человек в центре контактов запрашивается для содействия. Агент-человек рассматривает графический интерфейс пользователя с представлением сеанса общения до настоящего времени (18). Система также показывает агенту-человеку список ожидаемых переходов от текущего состояния, ранжированный в порядке от перехода с наилучшей согласованностью соответствием с сообщением клиента до самой худшей согласованности. Агент-человек определяет, является ли один из ожидаемых переходов подходящим для контекста сеанса общения (20). Если один переход является подходящим, то агент-человек указывает этот переход системе и система продолжает диалог в автоматизированном режиме (14). Иначе, если агент-человек решает, что никакой переход не является подходящим для контекста сеанса общения, тогда агент-человек берет контроль над сеансом общения до его завершения (28).
Система может продолжить расширять свою базу знаний в рабочем режиме (во время выполнения). Система записывает сеансы общения между агентом-человеком и клиентом, когда система находится в режиме содействия агента с взятием под контроль. С равномерными интервалами эти сеансы общения обрабатываются как при первоначальном создании базы знаний, так и при добавлении новых последовательностей переходов между состояниями к базе знаний. Одним различием является то, что режим содействия агента с взятием под контроль типично начинается с состояния после начального состояния. Таким образом, одна из новых последовательностей переходов между состояниями типично добавляется к совокупному графу переходов между состояниями как переход от неначального состояния. Каждый раз новая последовательность переходов между состояниями добавляется к совокупному графу переходов между состояниями в базе знаний, совокупный граф переходов между состояниями сжимают, как описано ранее.
Вариант осуществления примера системы проиллюстрирован на Фиг.4. Сервер 30 сеансов общения является средством режима времени выполнения из состава системы. Сервер 30 сеансов общения является приложением Java 2 Enterprise Edition (J2EE), развернутым на сервере приложений J2EE. Это приложение разработано и развернуто на сервер сеансов общения, используя студию 32 сеансов общения. Фиг.4 показывает отношения между сервером 30 сеансов общения и студией 32 сеансов общения.
Система является многоканальным диалоговым приложением. В сервере 30 сеансов общения, наборы автоматизированных программных агентов выполняют системное приложение. Под многоканальным подразумевается, например, то, что программные агенты выполнены с возможностью взаимодействия с звонящими по множеству каналов взаимодействия, таким как телефоны, Web, мгновенный обмен посланиями и электронная почта. Под диалоговым подразумевается то, что программные агенты имеют интерактивные сеансы общения с звонящими, подобные сеансам общения, которые агенты-люди имеют с звонящими. Система использует итерационную парадигму разработки и исполнения приложения. Как объяснялось ранее, диалоги между звонящими и агентами, которые поддерживают системное приложение, основываются на фактических диалогах между звонящими и являющимися людьми-агентами поддержки клиентов в центре контактов.
Фиг.4 также показывает отношение между сервером сеансов общения и другими элементами системы. Сервер 30 сеансов общения взаимодействует с информационным сервером (34) предприятия, который принимает данные, приходящие от клиентов, и обеспечивает данные для ответов на вопросы клиентов. Рабочая станция 36 агента исполняет программное обеспечение с графическим интерфейсом пользователя, который позволяет агенту-человеку выбирать переходы для системы, когда сеанс общения находится в смешанном режиме с содействием агента. Телефон 38 агента дает возможность агенту-человеку вступить в оперативный устный сеанс общения с клиентом, когда диалог находится в режиме содействия агента с взятием под контроль.
Система также включает в себя сервер 31 обучения, который осуществляет процессы для помощи системе в обучении на основе запросов после того, как система развернута. Сервер 31 обучения описан более подробно ниже относительно Фиг.17.
Внутренняя архитектура сервера 30 сеансов общения изображена на Фиг.5. Сервер 30 сеансов общения имеет базовый набор из четырех слоев, которые поддерживают логику системного приложения. Эти слои являются четырьмя слоями, которые традиционно имеются в серверах Web-приложений. Этими слоями являются слои представления 40, организации последовательности действий 42, бизнеса 44 и интеграции 46.
Слой представления 40 ответственен за представление информации конечным пользователям. Сервлеты (небольшие программы на языке Java или Perl, исполняющиеся на Web-сервере или сервере приложений) типа Java Server Pages (JSP) соответствуют технологиям J2EE, традиционно используемым в этом слое. Слой представления составлен из двух подсистем: подсистемы каналов взаимодействия 48 и подсистемы взаимодействия с агентами 50. Подсистема каналов взаимодействия 48 обрабатывает взаимодействие сервера 30 сеансов общения с клиентами по каждому из каналов взаимодействия: сеть 52, VoiceXML 54, чат обмена мгновенными посланиями 56 и электронная почта 58. Подсистема взаимодействия с агентами обрабатывает взаимодействие сервера 30 сеансов общения с агентами-людьми в центре контактов.
Слой 42 организации последовательности действий отвечает за организацию последовательности действий. Эти действия включают в себя транзакции в отношении объектов бизнеса в слое бизнеса и взаимодействия с конечными пользователями. На сервере 30 сеансов общения слой технологического процесса 42 заполняется программными агентами 60, которые понимают сеансы общения, проводимые с клиентами. Кроме того, эти агенты взаимодействуют с объектами бизнеса на слое 44 бизнеса. Программные агенты 60 являются интерпретаторами языка разметки, произведенного студией 32 сеансов общения (система разработки приложений).
Слой 44 бизнеса содержит объекты бизнеса для домена приложений. Enterprise Java Beans (EJB) является технологией, традиционно используемой на слое бизнеса. Сервер сеансов общения не вводит специфическую для конкретной системы технологию в этот слой. Скорее это использует тот же самый набор компонентов, доступных для других приложений, развернутых на сервере приложений J2EE.
Слой 46 интеграции ответственен за интерфейс сервера приложений к базам данных и внешним системам. Коннекторы J2EE и Web-службы являются традиционными технологиями, используемыми в этом слое. Как и для слоя 44 бизнеса, сервер 30 сеансов общения не вводит специфическую для конкретной системы технологию в этот слой. Скорее он использует традиционные компоненты J2EE. Значимость общего слоя интеграции состоит в том, что любая работа по объединению внешних систем является доступной для других приложений, развернутых на сервере J2EE.
Окружением базового набора из четырех слоев является набор подсистем, которые обеспечивают операции сервера 30 сеансов общения. Этими подсистемами являются подсистемы развертывания 62, регистрации 64, интерфейса 66 сервера контактов, статистики 68 и управления 70.
Подсистема развертывания поддерживает итерационное, оперативное развертывание системных приложений. Это подпадает под итерационную разработку приложений, где сеансы общения регистрируются и передаются обратно к студии 32 сеансов общения, где персонал в центре контактов может дополнить приложение фразами, которые системное приложение не понимало.
Подсистема 64 регистрации поддерживает файл регистрации сеансов общения, которые программные агенты 60 имеют с клиентами и агентами по поддержке клиентов. Этот файл регистрации является входными данными для итерационного процесса разработки приложений, поддерживаемого студией 32 сеансов общения. Сервер 31 обучения использует эти зарегистрированные звонки для генерации набора возможностей обучения для средства 74 распознавания понятий (CRE).
Интерфейс (CTI) 66 сервера контактов обеспечивает унифицированный интерфейс к множеству CTI и серверам 72 контактов.
Подсистема статистики 68 поддерживает статистику обработки звонков запросов для агентов-людей. Эти статистические данные эквивалентны статистике, предоставляемой посредством ACD и/или серверами 72 контактов. Отвечающий за операции центра контактов персонал может использовать эти статистические данные для того, чтобы гарантировать, что центр имеет достаточную рабочую силу агентов-людей для обслуживания трафика, который ожидает центр.
Подсистема 70 управления позволяет серверу 30 сеансов общения управляться персоналом управления сетью предприятия. Подсистема 70 поддерживает стандартный протокол управления сетью, типа SNMP, так чтобы сервер 30 сеансов общения мог управляться системами управления сетью, типа Hewlett-Packard OpenView.
Фиг.6 показывает компоненты слоя 40 организации последовательности действий из состава системы. Программные агенты 60 являются основными объектными сущностями в слое 40 организации последовательности действий. Программные агенты 60 являются автоматизированными объектными сущностями, которые поддерживают сеансы общения с клиентами, агентами-людьми в центре контактов и серверными системами управления базами данных. Все эти сеансы общения поддерживаются в соответствии с приложениями, разработанными и развернутыми студией 32 сеансов общения. Функциональные требования к слою 40 организации последовательности действий следующие:
выделение, создание пула и обеспечение доступности программных агентов, выполненных с возможностью обработки любого из приложений, развернутых на сервере сеансов общения 30. Эта возможность создания пулов агентов подобна возможности создания пулов экземпляров, соответствующей EJB. Это также подпадает под модель управления рабочей силой центров контактов.
Канал взаимодействия выделяет программного агента 60 и запрашивает, чтобы программный агент 60 обработал конкретное приложение. Слой 40 организации последовательности действий взаимодействует с менеджером (средством управления) приложений, который управляет приложениями. Менеджер приложений выберет версию приложения для использования (как назначено разработчиком приложения).
Программный агент 60 сверяется с менеджером лицензий, чтобы гарантировать, что взаимодействия разрешаются по запрашивающему каналу. В противном случае программный агент 60 возвращает соответствующий ответ.
Программные агенты выполнены с возможностью удерживания сразу множества сеансов общения. Программные агенты могут удерживать сеанс общения по меньшей мере с одним клиентом, общаясь при этом с агентом-человеком во время получения ответа на вопрос. Эта возможность может быть расширена так, чтобы агенты могли говорить с клиентами по множеству каналов сразу.
Программные агенты 60 удерживают сеанс общения в соответствии с приложением, разработанным в студии 32 сеансов общения.
Программные агенты 60 вызывают средство распознавания понятий (CRE) 74 так, чтобы интерпретировать ввод клиента в контексте, в котором он был принят, и действовать в отношении возвращаемых результатов.
Каждый программный агент 60 поддерживает стенограмму сеанса общения, который он имеет. Эта стенограмма в конечном счете регистрируется через подсистему регистрации сеансов связи. Стенограмма содержит следующую информацию, каждая из которых помечена меткой времени:
• Исполняемое приложение
• Путь через сеанс общения с клиентом, включающий в себя:
- входные данные клиента в виде как распознанного текста, так и произнесенной фразы.
- состояние диалога (контекст, переходы и т.д.)
- результаты распознавания смыслового значения
- действия, которые программный агент предпринимает на основе результатов распознавания смыслового значения.
- вывод, посланный клиенту.
Одним из действий, которые программный агент 60 может предпринять, является запрос содействия агента-человека. Это приведет к субстенограмме для диалога с агентом-человеком. Эта стенограмма содержит:
• Статистику очереди для группы агентов в начале звонка
• Когда звонок был помещен и взят на обработку
• Субстенограмма действий агента в отношении звонка, включающая в себя
- содействует ли агент или берет под полный контроль.
- действия, которые агент предпринимает при содействии, например, выбор из списка ответов, представленных программным агентом 60, корректирование запроса и поиск в базе знаний, создание индивидуальным образом сконфигурированного ответа.
- помечает ли агент конкретный ответ для обзора и примечания агента к ответу.
- команды агента программному агенту 60.
• Слой 42 организации последовательности действий сформирует статистику для пула(ов) программных агентов 60. Эти статистика будет опубликована через подсистему статистики 68.
• Рабочие параметры, управляющие слоем организации последовательности действий 42 (например, минимум и максимум агентов/приложений, приращения роста) будут извлечены из базы данных конфигурации, управляемой через подсистему управления 70.
Фиг.6 показывает компоненты, которые составляют слой 42 организации последовательности действий - менеджер агентов 76 и экземпляр агента. Менеджер агентов 76 обрабатывает создание пула экземпляров агентов и выделение этих экземпляров для конкретного приложения. Менеджер агентов 76 ответственен за взаимодействие с другими менеджерами/подсистемами, которые составляют сервер 32 сеансов общения (не показанным является взаимодействие менеджера агентов 76 с подсистемой статистики 68). Каждый экземпляр агента 60 регистрирует стенограмму сеанса общения с менеджером регистрации 78.
Слой представления состоит из двух подсистем: подсистемы каналов 48 взаимодействия и подсистемы 50 взаимодействия с агентами.
Имеется канал взаимодействия, ассоциированный с каждым из режимов взаимодействий, поддерживаемых сервером сеансов общения: HTML 80, VoiceXML 82, мгновенный обмен посланиями 84 и электронная почта 86. Подсистема каналов взаимодействия 48 построена на инфраструктуре обработки Cocoon XSP. Обработка каналов взаимодействия 48 изображена на Фиг.7. Функциональные требования к каналам взаимодействия:
• Инициирование, поддержка и завершение сеанса взаимодействия для каждого сеанса общения с клиентом (конечным пользователем). Как часть этого сеанса взаимодействия канал взаимодействия будет удерживать экземпляр агента, который управляет состоянием диалога с клиентом.
• Определение типа канала и приложения на основе входящего унифицированного указателя информационного ресурса (URL). URL может принять форму http://host address/application name.mime type?parameters, где host address = адрес IP и порт; application name = развернутое имя приложения; MIME type = указывает тип канала (например, html, vxml и т.д.); parameters = запрошенные параметры.
• Для HTML и каналов VoiceXML, пересылка HTTP-запроса агенту на обработку. Для канала IM и канала электронной почты - выполнение эквивалентного этапа обработки запроса.
• Преобразование независимого от канала ответа в специфичный для конкретного канала ответ, используя соответствующий язык описания документа (HTML, VoiceXML, SIMPL, SMTP и т.д.). Управление этим преобразованием осуществляется посредством таблицы стилей XSL. Определение ответов и обработка таблиц стилей является частью определения приложения, которая возвращается агентом в ответ на каждую активацию для обработки запроса.
Определение ответов и таблиц стилей XSL относится к трем случаям использования. Канал взаимодействия обычно не знает об этих случаях использования.
Документ ответа и таблица стилей XSL определены на основании канала для приложения. Документ ответа запрашивает содержимое тэга <вывод> CML, а так же другие артефакты, сгенерированные из CML (например, файл грамматики).
В случае использования «файла» пользователь определяет документ ответа в приложении. Документ ответа обрабатывается, используя таблицу стилей XSL, заданную в канале. Документ ответа должен придерживаться DTD, который управляет документами ответа. Этот DTD учитывает формы с множеством полей, которые должны быть определены.
В случае «открытого» использования пользователь определяет документ ответа, а также таблицу стилей XSL. Никакие ограничения не помещены ни в один документ, и сервер 30 сеансов общения не ответственен за какие-либо результаты обработки ответа.
Это преобразование обрабатывает как трансформацию к специфическому для конкретного канала языка документа, так и помечание ответа для конкретного клиента.
Для канала VoiceXML 54 канал взаимодействия 82 ответственен за регистрацию записанного запроса клиента и информирование агента о местоположении записи для включения в файл регистрации сеанса общения и/или передачи шепотом агенту-человеку.
Как утверждалось ранее, подсистема каналов взаимодействия 48 реализована с использованием инфраструктуры Cocoon. Инфраструктура Cocoon обеспечивает парадигму «модель - представление - контроллер» в слое представления 40 из инфраструктуры серверов Web-приложений.
Сервлет 90 (контроллер) обрабатывает HTTP-запросы и взаимодействует с экземпляром агента 60 так, чтобы обработать запрос. Экземпляр агента 60 возвращает являющийся ответом документ XSP и таблицу стилей XSL, чтобы применить их к выводу документа.
Документ XSP (модель) компилируется и исполняется как сервлет 92. Документ запрашивает параметры экземпляра агента для формирования его вывода - потока XML. Документ XSP является эквивалентом документа JSP. Как и обработка JSP, компиляция XSP происходит только в том случае, если документ XSP изменился с тех пор, когда он был скомпилирован в последний раз.
Поток XML преобразовывается согласно таблице стилей XSL (Представление) на язык, специфичный для канала взаимодействия (например, HTML, VXML).
Подсистема взаимодействия с агентом-человеком (AIS) ответственна за установление диалога с агентом-человеком в центре контактов и управление сотрудничеством между программным агентом и агентом-человеком, чтобы выполнить разрешение в отношении ответа, который является неопределенным. Эта подсистема также используется, когда перенос приложения запрашивается в приложении. Подсистема взаимодействия с агентом взаимодействует с интерфейсом сервера CTI для того, чтобы выполнить соединение с центром контактов. Интерфейс сервера CTI также предоставляет подсистеме взаимодействия с агентом статистику очередей, которая может изменить ее поведение относительно соединения с группой агентов.
Подсистема взаимодействия с агентом (AIS) делает следующие действия:
• Инициирует, поддерживает и заканчивает диалог с агентом-человеком в центре контактов, чтобы выполнить разрешение в отношении ответа, который рассматривается. Агент-человек является членом заданной группы агентов, назначенной для обработки вариантов разрешения этого конкретного приложения.
• Как часть инициирования диалога с агентом AIS выделяет и пересылает описатель сеансу агента, что позволяет приложению рабочего стола агента-человека участвовать в совместной работе для выполнения разрешения в отношении ответа.
• AIS обеспечивает интерфейс прикладного программирования (API), через который приложение рабочего стола агента-человека может извлечь следующее: запрос клиента и предложенные ответы, в настоящее время требующие разрешения; пороговые параметры настройки, которые приводили к соответствующему разрешению запросу, и касающиеся того, обусловлен ли этот соответствующий разрешению запрос слишком большим количеством хороших ответов или слишком малым количеством хороших ответов; тип канала взаимодействия с клиентом; стенограмма сеанса общения на конкретную дату; текущее состояние последовательности действий, ассоциированной с этим сеансом общения с клиентом, например число раз, когда агенты-люди оказывали содействие в этом сеансе общения, отрезок времени, в течение которого клиент говорил с программным агентом, состояние (контекст), в котором клиент находится относительно сеанса общения и потенциально, некоторая мера близости к завершению на основе состояния и времени общения; и текущие свойства приложения (и сети).
• API AIS также позволяет агенту-человеку выбрать ответ для возврата клиенту, изменить запрос и осуществить поиск в базе данных MRE, и потенциально выбирать ответ для возврата клиенту, взять контроль над звонком у программного агента; и пометить запросно/ответное взаимодействие для обзора в файле регистрации сеанса общения и ассоциировать примечание с взаимодействием.
• API AIS также предоставляет интерфейс JTAPI, чтобы позволить агенту-человеку осуществлять логический вход/выход по отношению к серверу 72 контактов и управлять их рабочим состоянием относительно очередей в центре контактов.
• API AIS использует независимый от языка формат, что позволяет осуществлять доступ к нему из множества технологий реализации.
• AIS поддерживает маршрутизацию голосовых звонков сервера VoiceXML 54 к центру контактов и последующее ассоциирование этих голосовых звонков с сеансом конкретного агента.
• AIS позволяет проектировщику приложения определять представление данных приложения агенту-человеку. Это представление должно использовать ту же самую XSL-обработку, что используется в канале взаимодействия (82, 84, 86 или 88).
Частью подсистемы взаимодействия с агентом-человеком является приложение рабочего стола агента, которое позволяет агенту центра контактов обрабатывать требующий разрешения звонок. Это приложение принимает две формы:
• Обычный рабочий стол агента-человека. Этот рабочий стол функционирует в неинтегрированной среде управления отношениями с клиентами (CRM) и исполняется как отдельный процесс на настольном компьютере агента, соединенном с сервером CS и CTI.
• CRM-компонент. Этот рабочий стол упаковывается в качестве компонента (компонента ActiveX или апплета), который исполняется в пределах контекста пакета CRM.
Распознавание речи является областью техники, соответствующей автоматическому преобразованию человеческого разговорного языка в текст. Есть много примеров систем распознавания речи. В варианте осуществления системы, в которой клиент разговаривает по телефону, распознавание речи (выполняемое онлайновым ASR) является этапом сопоставления сообщения клиента с надлежащими ответами. Типичное распознавание речи влечет за собой применение способов обработки сигналов к речи для того, чтобы извлечь значимые фонемы. Затем используется программное поисковое средство для поиска слов в словаре, который мог бы быть создан из этих фонем. Секция распознавания речи из состава системы ведет этот поиск, зная вероятный контекст сообщения. Блок-схема этой секции распознавания речи из состава системы проиллюстрирована на Фиг.8. Как описано предварительно, система имеет доступ к базе знаний, состоящей из языка разметки, CML, который определяет граф перехода между состояниями для стандартных сеансов общения между клиентом и центром контактов с звонящими. Поскольку программный агент отслеживает текущее состояние сеанса общения, он может искать все из вероятных переходов из этого состояния. Каждый из этих переходов имеет «совокупность понятий» или «совокупность S-морфем» 104. Эти S-морфемы 104 могут быть преобразованы в соответствующий текст 112. Сочленение согласующегося текста из всех вероятных переходов является поднабором всех слов в словаре. Вообще, более эффективно искать согласование с поднабором группы, а не со всей группой. Таким образом, средство 102 поиска для этого средства распознавания речи сначала пробует сопоставить фонемы сообщения клиента с текстом 112 из всех вероятных переходов. Средство 102 поиска ищет в словаре любую оставшуюся комбинации фонем, которые не были сопоставлены с этим текстом.
Средство 74 распознавания понятий (показанное на Фиг.5), используемое в некоторых реализациях системы, является усовершенствованной технологией обработки естественного языка, которая обеспечивает устойчивый, независимый от языка путь понимания вопросов пользователей на естественном языке из текстовых и из звуковых источников. Эта технология автоматически индексирует информацию и взаимодействует с информацией на основе смыслового значения или семантического контекста этой информации, а не буквальной формулировки. Средство распознавания понятий понимает путь, которым люди действительно говорят и печатают, давая возможность системе интеллектуальным образом задействовать пользователей в сложных сеансах общения, независимо от построения фраз или языка, облегчая доступ к желательной информации.
Средство распознавания понятий основано на анализе фраз на уровне морфем, давая возможность получения «понимания» главных компонентов скрытого смыслового значения. Эта технология в вычислительном отношении эффективна, быстрее чем традиционные технологии естественного языка, и является независимой от языка, в дополнение к чрезвычайной точности и устойчивости.
Большинство других систем, которые применяют обработку естественного языка, используют синтаксический анализ для того, чтобы найти синонимичные фразы для входа пользователя. Этот анализ сначала идентифицирует каждое слово или компонент слова, в фразе, используя чрезвычайно большие лингвистические словари. Затем системы пытаются сопоставить эти элементы с конкретными входами в фиксированном списке (то есть слов или индексов ключевого слова). В результате эти системы используют сопоставления, основанные на уровне символьных строк; если по меньшей мере один символ отличается от целевого входа индекса, сопоставление терпит неудачу. С помощью средства понятий, используемого в некоторых реализациях системы, сопоставление не основано на фиксированном наборе слов, фраз или элементов слова, но на фиксированном наборе понятий.
В результате его акцентирования на семантическую обработку процесс распознавания понятий является, по существу, устойчивым - он работает чрезвычайно хорошо с «зашумленными» входными данными. Это полезно для способности системы распознавать произнесенное слово, используя программное обеспечение распознавания речи. Система использует процесс для того, чтобы точно распознать смысловое значение в реальном диалоговом взаимодействии, несмотря на обычные типографские ошибки, ошибки, сгенерированные программным обеспечением распознавания речи, или слова вне контекста. Пользователи могут сказать любую комбинацию слов, и система является достаточно гибкой, чтобы понять намерение пользователей.
Средство распознавания понятий основано на алгоритмах, которые создают и сравнивают семантические метки. Семантическая метка для порции текста любой длины является коротким кодированием, которое фиксирует самые важные компоненты его смыслового значения. Когда элементы в хранилище(ах) исходных данных маркированы семантическими тэгами, они могут быть извлечены или могут управляться другими способами, посредством выборочного задания их соответствия голосовым или текстовым запросам в свободной форме или другим источникам входного текста, независимо от фактических слов и пунктуации, используемой в этих источниках входного текста. Например, пользователь, спрашивающий систему, «Как я могу вернуть брюки, которые не подошли по размеру?», будет получать релевантную информацию из базы данных политик возврата из состава организации, даже если правильная информация не будет содержать слова «брюки» или «вернуть» где-нибудь в его пределах. Для альтернативно сформулированных пользовательских запросов в отношении той же самой информации на уровне понятий задается соответствие тем же самым политикам возврата, независимо от фактических слов, используемых во входной строке.
Этот подход устраняет пробел между преимуществами программного обеспечения автоматического распознавания речи на основе статистической языковой модели (SLM ASR) и ASR-грамматики с конечным числом состояний. Эту технологию называют средством распознавания понятий (CRE), алгоритмом обработки естественного языка.
Средство распознавания понятий (CRE) обеспечивает устойчивый, независимый от языка способ понимания вопросов пользователей на естественном языке из текстовых и из звуковых источников. Эта технология является усовершенствованной технологией обработки естественного языка для индексации, задания соответствия и взаимодействия с информацией на основе скорее смыслового значения или семантического контекста, этой информации, а не буквальной формулировки. В противоположность большинству других усилий в области естественного языка данная технология не полагается на полный формальный лингвистический анализ фраз в попытке получения полного «понимания» текста. Вместо этого данная технология основана на анализе фраз на уровне морфем, что дает возможность получить «понимание» главных компонентов скрытого смыслового значения.
Морфемы определены как наименьший модуль языка, который содержит смысловое значение, или семантический контекст. Слово может содержать одну или несколько морфем, каждая из которых может иметь единственное или множественное смысловые значения. Относительно простой пример этого проиллюстрирован, используя географию слова, которая состоит из морфем geo, означая земной шар, и graph, которая означает иллюстрацию. Эти две отличающиеся морфемы при объединении формируют понятие, означающее исследование земного шара. Таким образом, отдельные модули смыслового значения могут быть объединены, чтобы сформировать новые понятия, которые являются легко понятными всем при нормальном сообщении.
Рассматриваемая технология основана на алгоритмах для создания и сравнения семантических меток. Семантическая метка для заданной порции текста любой длины является коротким кодированием, которое фиксирует самые важные компоненты его смыслового значения. Когда элементы в «базе данных» маркированы семантическими тэгами, они могут быть выборочно извлечены или поставлены в соответствие посредством разбора сгенерированных пользователем текстовых запросов в свободной форме или других типов входных текстовых строк, независимо от фактических слов и пунктуации, используемых во входных строках.
CRE определяет контекст в тандеме с ASR SLM, анализируя получающийся машинный вывод и назначая семантические метки, которые могут после этого сравниваться с индексированной базой данных информации компании. Кроме того, CRE помогает подавлять эффекты ошибок распознавания речи, игнорируя те обычно нераспознаваемые слова (маленькие слова) и используя более контекстно наполненные слова в своем анализе. Поэтому эффект CRE состоит в обеспечении самообслуживающихся систем, которые точно распознают значение при реальном диалоговом взаимодействии, несмотря на обычные типографские ошибки или ошибки, сгенерированные программным обеспечением распознавания речи. Говоря проще, комбинация этих двух технологий дает возможность системам распознать то, что вы говорите, посредством понимания того, что вы подразумеваете.
Во время проектирования CRE автоматически индексирует данные, которые будут искаться и извлекаться пользователями. В диалоговых приложениях эти данные являются транскрибированными записями диалогов клиентов с агентами центра обработки звонков (call-центра), но любой набор текстовой информации (документы, листинги часто задаваемых вопросов (FAQ), бесплатная текстовая информация в базе данных, тематические чаты, электронная почта и т.д.) может быть индексирован, используя CRE. Индексация является процессом, которым CRE группирует или «кластеризует» данные согласно их понятийному подобию. В отличие от традиционных алфавитных индексов кластеры, созданные CRE, являются специальными понятийными ссылками, которые хранятся в многомерном пространстве, названном пространством понятий. Они «маркируются», используя набор первичных атомарных понятий (базовых стандартных блоков смыслового значения), которые могут быть объединены для того, чтобы генерировать описание любого понятия, без необходимости вручную создавать и поддерживать специализированную и очень большую базу данных понятий. Поскольку индексация понятий дает возможность поиска или управления информацией на основе ее смыслового значения вместо слов, может быть разработано намного более эффективное, отказоустойчивое и интеллектуальное приложение управления диалогами. С помощью этого процесса кластеризации CRE также извлекает переходы между кластерами (то есть последовательность действий по звонку) и генерирует индекс, который позже задаст соответствие запросов клиентов в свободной форме ответам агентов, найденным в файле регистрации звонка.
Во время выполнения, в некоторых примерах CRE выполняет тот же самый процесс в отношении запросов клиента в реальном времени. Ими берутся выходные данные от средства распознавания речи и разбивает его на его ассоциированный набор морфем, используя морфологические методики анализа. Система хорошо справляется с беспорядочными входными данными, включая орфографические ошибки, ошибки пунктуации, и слова вне контекста или вне порядка, и нет никаких предварительно установленных ограничений на длину входной фразы.
CRE затем использует анализ понятий для того, чтобы преобразовать морфемы в первичные атомарные понятия, описанные выше, компонует этот набор атомарных понятий в единый код понятия для всех входных данных и затем задает соответствие этого кода его эквивалентному коду в индексированных данных. В диалоговом приложении этот процесс, по существу, «указывает» пользовательские входные данные системному состоянию диалога, которое может быть системным ответом, существующим деревом меню интерактивных голосовых ответов (IVR) или командой на опрос транзакционных систем на предмет информации учетной записи клиента.
Этот процесс приводит к устойчивому средству автоматического распознавания и «понимания» в высокой степени неоднозначных диалоговых пользовательских запросов в пределах контекста самообслуживающегося приложения центра контактов.
Эффект этой комбинации CRE и распознавания речи SLM заключается в усилении способности делать информацию доступной клиентам через автоматизацию. Корпоративная информация, которая не вписывается аккуратно в меню IVR с пятью опциями или предопределенную речевую грамматику, может быть сделана доступно через диалоговый интерфейс. Поскольку получающиеся входные данные клиента имеют контекст, ассоциированный с ними, больше опций становится доступным в отношении того, как системы интеллектуальным образом обрабатывают сложные взаимодействия.
Приложение, соответствующее основывающемуся на векторной модели подходу к пространству семантических факторов вместо пространства слов обеспечивает следующие выгоды:
1. Сам по себе переход от слов к понятиям двигается от того, чтобы быть более статистическим, к тому, чтобы быть более семантическим.
2. Традиционную векторную модель часто называют «моделью совокупности слов», чтобы подчеркнуть комбинаторный характер модели, игнорирующей любые синтаксические или семантические взаимоотношения между словами. По аналогии мы можем называть векторную модель «моделью множества понятий». В традиционной векторной модели мы вычисляем некоторые внешние параметры (слова), статистически связанные с внутренними параметрами нашего интереса - понятиями. В векторной модели мы вычисляем понятия непосредственно.
3. Пока число семантических факторов является намного меньшим, чем число слов, даже на основном языке вычислительная интенсивность векторной модели значительно ниже. Другие технологии машинного обучения могут использоваться для того, чтобы сформировать основанное на доверии ранжирование согласованностей. Например, можно было использовать индукцию дерева решений или построение машин, реализующих метод опорных векторов. Комбинации методик обучения с использованием стимулирования также были бы возможными.
Мы описали выше отдельные части целого двухэтапного цикла модельной работы: входной языковой текстовый объект > семантическая метка > выходной языковой текстовый объект. Важно видеть, что эти два этапа в цикле явно независимы. Они связаны только через семантическую метку, которая является внутренним «языком», не связанным с каким-либо из человеческих языков. Эта особенность делает возможным относительно просто в любом приложении изменять язык и на стороне ввода и на стороне вывода.
Первый этап является чрезвычайно зависимым от языка. Это означает, что переключение на другой язык требует автоматической генерации семантической метки для фразы на данном языке. Ниже мы описываем два возможных способа решить эту проблему. Второй этап основан на семантическом индексе. Сам по себе индекс не заботится о языке объектов, он только указывает на них, и семантические метки, ассоциированные с указателями, независимы от языка. В семантическом индексе нет никакой специфической для конкретного языка информации.
Первый подход компилирует новые словари S-морфем для нового языка. Для каждого человеческого письменного языка может быть скомпилирован набор S-морфем. Процесс компиляции может быть основанным на анализе словаря либо из большой совокупности текстов либо из большого словаря на этом языке.
Наличие такого полного набора S-морфем на одном языке (английском языке) полезно для создания подобного набора S-морфем на другом языке. В качестве отправной точки мы можем пробовать искать только морфемные эквиваленты на втором языке. Это уменьшает усилие трудоемкого, в другом случае, анализа совокупности на втором языке. Это особенно истинно, когда мы переходим с языка на язык в одной и той же группе языков, потому что такие языки совместно используют много лексического «материала». Набор испанских S-морфем примерно имеет тот же самый размер, что и английский. Примеры испанских S-морфем: LENGU, FRAS, MULTI, ESPAN, SIGUI.
После того, как это сделано, мы, возможно, нуждаемся в некоторой настройке алгоритма идентификации S-морфем. Хорошими новостями об этом алгоритме является то, что большая часть его работы является общей для языков одной и той же группы. Даже переключение английского языка на испанский язык без каких-либо изменений в алгоритме дает удовлетворительные результаты. Почти никакие изменения не являются необходимыми для большинства индоевропейских языков. Испанский эксперимент демонстрировал мощь межъязыковых возможностей системы: после того, как мы скомпилировали испанские морфемы, стало возможным сделать испанский язык входным языком для всех приложений, предварительно разработанных для английского языка.
Языковая база знаний используется для того, чтобы хранить информацию, необходимую для средства распознавания понятий. Эта база знаний имеет три главных компонента: словарь семантических факторов, словари S-морфем и словарь синонимов. Каждый вход в словаре семантических факторов включает в себя:
a) Имя семантического фактора;
b) Определение/описание семантического фактора;
c) Пример кода понятия слова, который использует этот семантический фактор.
Каждая запись в словарях S-морфем включает в себя:
a) текст S-морфемы;
b) Код понятия семантического фактора с отдельными частями - семемами для альтернативных смысловых значений полисемных морфем;
c) В мультифакторных кодах метки для головных факторов, к которым может быть применена модификация.
Функциональная блок-схема средства распознавания понятий проиллюстрирована на Фиг.9. Блоки этой схемы описаны следующим образом. Словарь 122 S-морфем и словарь 124 семантических факторов используют анализатор (средство анализа) 128 для того, чтобы получить набор кодов понятий.
Затем файл CML генерируют на основе примеров 142. Это приводит к файлу CML, который является данными, управляемыми на основе тезауруса. Следующий этап должен сделать поиск и редактирование файла CML. Этот поиск и редактирование состоят из следующих этапов:
a) Отображение возникновения строк с различными критериями поиска;
b) Добавление новой парафразы;
c) Добавление новой пары вопроса/ответа;
d) Удаление парафразы или нескольких парафраз;
e) Удаление пары вопроса/ответа (со всеми парафразами) или нескольких пар;
f) Слияние двух пар вопроса/ответа (с выбором входных и выходных фраз);
g) Разделение одой пары на две пары с назначением входных и выходных фраз;
h) Редактирование фраз (включая редактирование групп).
Затем файл CML берется как входная информация в любой точке редактирования и индекс построен. Впоследствии две записи сопоставляют и делается вычисление подобия с заданным CML/индексом. Это может быть сделано для двух фраз; для двух кодов понятий; для фразы и кода понятия; для двух фраз, для двух кодов понятия, или для фразы и когда понятия в циклическом режиме с одним из вводов, поступающих каждый раз из файла-источника; и для автоматического сопоставления и вычисления подобия с одним из вводов, приходящих каждый раз из файла-источника и результатов, сохраненных в выходном файле. Затем соответствующий предварительному анализу разбор выполняется созданием псевдофакторов для имен; обработкой личных имен из одного слова и нескольких слов; обработкой наименований фирм и продуктов из одного слова и нескольких слов; и генерацией тэгов, соответствующих частям речи.
В этой точке выполняются управление приложением и тестирование. Оно состоит из следующих этапов:
a) Анализ файла входных сеансов общения как посредством циклов, так и автоматически с отображением или посылкой в выходной файл отличий от предыдущей обработки того же самого файла.
b) Управление порогом подобия;
c) Разностный интервал (промежуток в подобии между первым и вторым согласованиями);
d) Управление количеством возвращаемых согласований.
Главной целью языка разметки сеанса общения (CML) является задание набора команд для сервера сеансов общения для обработки «сеансов общения» с клиентами автоматизированным или полуавтоматизированным способом. Автоматизированные сеансы общения - это те, которые полностью обрабатываются сервером сеансов общения с начала до конца. Полуавтоматизированные сеансы общения обрабатываются сначала сервером сеансов общения, затем пересылаются агенту-человеку наряду с любой информацией, которая была собрана.
CML является языком разметки, который определяет следующее:
• Клиентские входные данные, включая парафразы, которые сервер сеансов общения может обработать.
• Выходные данные сервера (например, TTS и/или аудио файлы) для ответа
• Последовательность действий сеанса общения. Эта последовательность действий описывается с использованием набора сетей с переходами между состояниями, которые включают в себя:
- Контексты, в которых может иметь место каждый ввод и вывод.
- Переходы к другим контекстам на основе клиентского ввода и результатах из объектов Java.
- Вызовы к объектам слоя бизнеса серверного средства управления базами данных
- Встроенные логические средства приложений
В дополнение к языку CML для описания сеансов общения между сервером сеансов общения и пользователем язык CMLApp позволяет приложениям быть созданными из компонентов, допускающих многократное использование.
В некоторых примерах CML описывает запросно/ответное взаимодействия, в типичном случае обнаруживаемые в конкретных центрах контактов и поддержки клиентов, которые включают в себя следующее:
• Общие информационные запросы типа биржевых цен, запросов перспектив фонда и т.д.
• Специфический для конкретного клиента запрос типа остатков на счете, хронология операций и т.д.
• Инициированные клиентом транзакции типа биржевых/фондовых сделок и т.д.
• Инициированные центром взаимодействия типа телемаркетинга и т.д.
CML спроектирован так, чтобы интерпретироваться и исполниться сервером сеансов общения (CS). Как объяснено ранее, CS имеет набор программных агентов, которые интерпретируют основанные на CML приложения. Этим агентам предшествует набор каналов взаимодействия, которые осуществляют преобразование между специфическими для конкретных каналов языками документа типа HTML, VoiceXML, SIMPL, SMTP, и независимым от канала представлением CML, и наоборот.
Документ CML (или ряд документов, называемых приложением) формирует диалоговую сеть с переходами между состояниями, которая описывает диалог программного агента с пользователем. Пользователь находится всегда в одном диалоговом состоянии или контексте в каждый момент времени. Набор переходов определяет условия, при которых диалог двигается к новому контексту. Эти условия включают в себя новый запрос от пользователя, конкретное состояние в пределах диалога или комбинацию вышеперечисленного. Исполнение заканчивается, когда достигнут заключительный контекст.
Четыре элемента используются для того, чтобы определить сети с переходами между состояниями, которые являются диалогами между программным агентом и пользователем: сети, контекст, подконтекст и переходы.
Схема является коллекцией контекстов (состояний) и переходов, определяющих диалог, который программный агент имеет с пользователем. Могут быть одна или более сетей на каждый документ CML, каждая с уникальным именем, по которому на нее ссылаются. В добавление к определению синтаксиса диалога с пользователем сеть определяет набор свойств, которые являются активными, в то время как сеть активно исполняется. Эти свойства содержат данные, которые представляются в выходных данных пользователю вместе, а также данные, которые управляют исполнением сети. Например, предусловия переходов и пост-условия контекста определены в терминах свойств.
Контексты представляют собой состояния в диалоге между программными агентами и пользователями. Каждый контекст имеет набор переходов, определенных так, что они приводят приложение к другому контексту (или циклически приводят назад к тому же самому контексту). Контекст представляет собой состояние, где запрос пользователя ожидается и интерпретируется. Некоторые контексты помечены как конечные. Конечный контекст представляет собой конец диалога, представленного сетью.
Подконтекст является специальным контекстом, в котором вызывается другая сеть в контексте содержащей сети. Подконтексты являются связанными вызовами библиотечных подпрограмм, и имеется привязка свойств вызывающей и вызываемой сетей. Подконтексты могут быть или модальные или немодальные. В модальном подконтексте переходы содержащей его сети (или предки) не активны. В немодальном подконтексте переходы содержащей его сети (и предки) активны.
Переход определяет изменение от одного контекста к другому. Переход предпринимается, если его предусловие выполнено и/или пользовательский запрос согласуется с кластером произнесений, ассоциированных с переходом. Если переход не определяет предусловие, то только согласованность между пользовательским запросом и произнесениями перехода требуется для инициирования перехода. Если переход не будет определять кластер произнесений, то переход будет инициироваться всякий раз, когда его предусловие истинно. Если ни предусловие, ни кластер произнесений не определены, переход инициируется автоматически. Инициирование перехода приводит к исполнению сценария перехода и перехода к контексту, на который указывает переход.
В некоторых примерах приложение CML требует единственного документа CMLApp, единственного документа CML и документа кластера. Многодокументное приложение влечет за собой единственный документ CMLApp, единственный документ кластера и множественные документы CML. Фиг.10 показывает отношения документа 150 CMLApp, документа CML 154, документа 152 кластера, выходных документов 156, ссылочных файлов данных 158 и бизнес-объектов 160.
Приложение 1 формулирует текст примера документа CMLApp, названного «abcl2app.ucmla», документа кластера CML, названного «abcl2clusters.ucmlc», и документа CML, названного «abcl2ucml.ucml». Документ CMLApp определяет файл кластера, используя элемент разметки «clusterFile», и файл CML, используя элемент разметки «document» («документ»). Документ CMLApp также определяет канал сообщения с клиентом, используя элемент разметки «channel type» («тип канала»). В этом случае типом канала является «VXML». Сначала документ кластера хранит текст всех записанных сообщений от клиентов, которые были сгруппированы в кластер для заданного перехода из заданного состояния или контекста. В примерном документе кластера кластеры именуются как c1-c41. Переменные данные, ассоциированные с кластерами, определены, используя элемент разметку «variable», («переменная») и имеют такие типы как «properName» и «digitString». На эти кластеры ссылаются в документе примерном CML. Документ CML определяет граф перехода состояний (или сеть). Примерный документ CML определяет набор состояний (обозначенный элементом разметки «context name» («имя контекста»)) и переходы (обозначенные элементом разметки «transition name» («имя перехода»)). Например, строки 11-16 из документа CML следующие:
“<context name=”s0” final”false”toToAgent=”false”>.
<transitions>
<transition name=”t0”to=”s1”>
<input cluster=”c7”>да, я хотел бы проверить баланс своего счета, пожайлуста </input>
<output> вы знаете Ваш номер счета, сэр?</output>
<transition>
Строки 11-16 определяют, что есть состояние (или контекст) s0, которое имеет переход t0 к состоянию (или контексту) S1. Переход t0 имеет сообщение клиента «да, я хотел бы проверить баланс моего счета, пожалуйста», и ответ центра контактов «Вы знаете Ваш номер счета, сэр?». Фиг.11 иллюстрирует подмножество полного графа переходов между состояниями, определенного в соответствии с примерным документом CML. Это подмножество включает в себя переходы от начального состояния к s0 (162) к S1 (164) к s2 (166) к s3 (168) к s4 (170) к s5 (172) к s6 (174) и наконец к s7 (176).
Обратимся к Фиг.12, где процесс 180 для разработки приложения CML для голосовой автоматизированной системы ответа включает в себя два первичных процесса машинного обучения, процесс разработки 182 первоначального приложения и процесс обучения во время выполнения 190. Процесс разработки 182 первоначального приложения генерирует первоначальное приложение CML, используя образцы записанных сеансов общения между звонящим агентом-человеком. Процесс обучения во время выполнения 190 использует образцы записанных сеансов общения между системой и звонящим так, чтобы непрерывно улучшать приложение CML.
Набор транскрибированных сеансов общения между звонящим агентом-человеком 181 является входными данными для процесса разработки 182 первоначального приложения. Транскрибированный сеанс общения между звонящим и агентом 181 представляет собой записанные сеансы общения между являющимися людьми агентами по поддержке клиентов и звонящими, которые были транскрибированы в текст, используя ручную транскрипцию или автоматизированный процесс транскрипции (например, обычный процесс распознавания речи). В центрах контактов, в которых агенты-люди и звонящие общались по телефону, образцы сеансов общения между звонящими и агентами могут быть получены от средств аудиозаписи с проверкой качества, имеющихся в центре контактов. В одном варианте осуществления являющиеся образцами стенограммы общения между звонящими и агентами-людьми находятся в форме файла языка разметки импорта (IML), когда они поставляются в процесс разработки 182 первоначального приложения.
Процесс разработки 182 первоначального приложения использует являющиеся образцами стенограммы для построения первоначального приложения CML. Процесс разработки первоначального приложения (пример которого описан более подробно на Фиг.15-16), вовлекает следующие три фазы:
1. Построение классификаторов. В этой фазе наборы классификаторов для произнесений агентов и произнесений звонящих строятся, используя образцы записанных сеансов общения между звонящими и агентами-людьми. Когда приложение развертывается и выходит на режим онлайн, эти классификаторы используются для того, чтобы классифицировать произнесения звонящих. После того, как произнесение звонящего классифицировано, программный агент может определить подходящий ответ, используя сеть с конечным числом состояний. До развертывания приложения два набора классификаторов могут также использоваться для того, чтобы генерировать сети с конечным числом состояний и идентифицировать и разрабатывать эффективные запросы агента об информации.
2. Генерация сетей с конечным числом состояний. В этой фазе диалоги фиксируются как сети с конечным числом состояний или свободные от контекста сети, используя подконтексты. Элемент CML, контекст (или состояние) является основной конструкцией определения состояния.
3. Фаза вставки кода. В этой фазе сети состояний включаются в приложение, чтобы произвести автоматизацию, ассоциированную с диалогом. Относительно фазы, в которой строятся классификаторы, может быть выгодным, особенно в приложении центра обработки звонков, сначала кластеризовать произнесения агентов в набор классификаторов и затем использовать эти классификаторы агентов для нахождения и классификации произнесений звонящих.
В приложении центра обработки звонков диалогами между звонящим и агентом-человеком типично управляет агент. Действительно, агенты часто инструктируются следовать стандартизированным сценариям во время сеансов общения с звонящими. Эти сценарии предназначены для направления и ограничения сеансов общения между звонящими и агентами так, чтобы ответы на запросы звонящих предоставлялись надежным и эффективным образом. Общее правило для агентов-людей состоит в том, что они никогда не должны терять контроль над ходом сеанса общения.
Если произнесения звонящих и агентов кластеризованы на основе смыслового значения произнесения, используя, например, алгоритм частота термина - обратная частота документа (TF-IDF), распределения кластеров агентов и звонящих окажется весьма различными.
Распределение кластеров произнесений звонящих имеет тенденцию иметь лишь несколько очень общих кластеров ответа (например, кластер произнесений, в котором звонящий сказал число или идентифицировал себя), сопровождаемых быстрым уменьшением в частотах кластеров для относительно небольшого числа менее общих ответов, и затем очень длинный хвост одноэлементных кластеров. Одноэлементные кластеры в типичном случае учитывают половину всех произнесений звонящего и составляют приблизительно 90-95% всех кластеров. Произнесения, которые представляют начальный запрос звонящего на предмет информации (например, «Какой у меня остаток на счете?»), которые представляют один из самых важных типов произнесений звонящих для проектирования голосовой автоматизированной системы ответа, типично образуют очень малую процентную долю от всех произнесений (приблизительно 1 из каждых 20-30 произнесений в зависимости от длительности звонка). Поскольку есть много путей, которыми может быть выражен конкретный запрос, эти типы произнесений начальных запросов звонящих обычно образуют массив по всему распределению, так что многие произнесения подпадают под их собственные одноэлементные категории.
Распределение кластеров произнесений агентов типично очень отличается от распределения кластеров произнесений звонящих в значительной степени из-за сценарной природы произнесений агентов. В частности, распределение кластеров произнесений агентов (с использованием алгоритма TF-IDF для того, чтобы кластеризовать произнесения агентов) является намного более плоским, чем распределение, наблюдаемое для звонящих, с более низкими совокупными частотами для наиболее общих кластеров произнесений и намного более постепенным уменьшением в частотах кластеров. Поскольку агенты часто участвуют в сеансах общения со звонящими, распределение кластеров произнесений агентов также имеет длинный хвост одноэлементных множеств. Другое различие между распределениями кластеров агента и звонящего в среде центра обработки звонков заключается в том, что для высокочастотных кластеров агентов характерно содержать запросы по сбору информации (например, "Могу я узнать номер карточки Вашего социального обеспечения, пожалуйста?"), которые являются самыми важными произнесениями для проектирования голосовой автоматизированной системы ответа. Действительно, часто возможно характеризовать почти все важное поведение агента (например, запросы агента на предмет информации) посредством анализа самых частых 20% из кластеров.
Обратимся к Фиг.15, где процесс разработки 182 первоначального приложения использует технологию центрированной на агенте интеллектуального анализа данных, которая сначала генерирует набор классификаторов агентов и затем использует этот набор классификаторов агентов для того, чтобы идентифицировать и генерировать набор классификаторов звонящих.
Процесс разработки 182 первоначального приложения принимают как входные данные статистически существенное количество записанных заранее сеансов общения между агентами и звонящими 181, которые были транскрибированы в текст. Все произнесения агентов в этих записанных заранее сеансах общения между агентами и звонящими кластеризуются 302 в набор кластеров агентов, и существенные кластеры агентов (например, те кластеры с произнесениями, в которых агент выспрашивает информацию у звонящего) затем идентифицируются. Эти существенные кластеры агентов используются затем для обучения (то есть являются входными данными для) процесса 304 машинного обучения, например метода опорных векторов (SVM), из которых генерируется набор классификаторов агентов.
Как только классификаторы агентов сгенерированы, эти классификаторы используются для нахождения 306 ответов звонящих в сеансах общения. Эти произнесения звонящих затем кластеризуются 307 в набор кластеров звонящих. Эти кластеризованные произнесения звонящих затем используются для обучения 308 (то есть являются входными данными для) процесса машинного обучения, например метода опорных векторов, из которых генерируется набор классификаторов звонящих. После того, как наборы классификаторов агентов и звонящих определены, они могут использоваться для того, чтобы классифицировать произнесения агентов и звонящих в новых стенограммах сеансов общения. Подходящие ответы звонящих на важные запросы агентов затем автоматически извлекаются из этих новых стенограмм и добавляются к кластерам звонящих. Эти пополненные кластеры звонящих используются для построения нового, улучшенного набора классификаторов звонящих 310.
При наличии набора транскрибированных сеансов общения, произнесения из которых были классифицированы с использованием набора классификаторов агентов и звонящих, канонические шаблоны сеансов общения агентов могут быть идентифицированы 312. Канонические шаблоны сеансов общения являются общими шаблонами информационных запросов и ответов, используемых агентами при ответе на конкретные типы запросов звонящих. Например, если звонящий входит в контакт с агентом и запрашивает его или ее об остатке на счете, общий шаблон ответа среди агентов состоит в том, чтобы задать вопрос X (например, «как Вас зовут?»), сопровождаемый вопросом Y (например, «Ваш номер социального обеспечения?»), сопровождаемый вопросом Z (например, «Девичья фамилия вашей матери?»). С другой стороны, если звонящий просит литературу, вопрос X агента может сопровождаться вопросом (например, «Ваш почтовый индекс?») и вопрос B (например, «Ваш почтовый адрес?»). Эти канонические шаблоны сеансов общения могут использоваться при генерации 314 сети с конечным числом состояний для приложения.
Кроме того, пары классифицированных произнесений агентов и звонящих в транскрибированных сеансах общения могут использоваться для идентификации 316 успешных запросов агентов на предмет информации. Исследование распределений типов ответов звонящих на по-другому сформулированные вопросы агентов, которые были предназначены для выспрашивания той же самой информации, может показать, что один способ спрашивать информацию более эффективен, чем другие пути. Например, первый запрос агента, выраженный как «Я могу узнать Ваш номер социального обеспечения?», может иметь существенное число ответов звонящих «да» без предоставления звонящим номера социального обеспечения. Однако другой классификатор агента, который классифицирует запрос агента, выраженный как "Какой ваш номер социального обеспечения?», может привести к распределению, в котором очень высокая процентная доля ответов звонящих на этот вопрос предоставляет требуемую информацию (то есть номер социального обеспечения звонящего).
Один пример процесса разработки первоначального приложения показан более подробно на Фиг.16A-16E.
Как показано на Фиг.16A, программное инструментальное средство разработки первоначального приложения собирает 322 два равных по размеру, случайно отобранных образца записанных сеансов общения между звонящими и агентами-людьми 318, обучающий набор и испытательный набор. Разработчик приложения затем категоризирует звонки 324a, 324b из каждого образца на набор вместилищ согласно начальному запросу звонящего. Например, звонки, в которых звонящий запрашивал остаток на своем счете, могут быть помещены в одно вместилище, тогда как звонки, в которых звонящий просил изменить адрес, могут быть помещены в другое вместилище.
После того, как разработчик приложения категоризирует звонки по вместилищам, разработчик приложения использует программное инструментальное средство для того, чтобы исследовать распределения 326 начальных запросов звонящего для каждого набора звонков. Если распределения обучающих и испытательных наборов звонков не подобны, разработчик приложения получает больший образец случайно отобранных звонков 330 и повторяет процесс помещения во вместилища до тех пор, пока обучающие и испытательные наборы не приведут к подобным распределениям типов звонков.
Как только определено, что обучающие и испытательные наборы имеют подобные распределения типов звонков, разработчик приложения использует программное инструментальное средство, чтобы кластеризовать 332 произнесения агентов, соответствующие звонкам в обучающем наборе. Чтобы кластеризовать произнесения агентов, программное инструментальное средство прогоняет произнесения через средство распознавания понятий (описанное более подробно выше), чтобы определить список семантических особенностей для каждого произнесения, и затем использует алгоритм TF-IDF, чтобы кластеризовать произнесения, основываясь на их списке семантических особенностей.
Обратимся к Фиг.16B, где разработчик приложения исследует кластеры агентов, объединяет 334 любые перекрывающиеся кластеры и утверждает 336 кластеры агентов, имеющие больше, чем определенное число произнесений (например, больше чем 4 произнесения) для использования в классификации. Разработчик приложения типично не классифицировал бы каждый кластер агента, так как кластеры, имеющие низкую частоту возникновения, вряд ли будут произнесениями агентов, в которых агент выспрашивает существенную информацию у звонящего (например, «Могу я узнать ваше имя, пожалуйста?»). Скорее кластеры с низкой частотой (например, одноэлементные кластеры), вероятно, будут содержать произнесения агентов, в которых агент привлек звонящего к сеансу общения (например, «Как там погода сегодня?»).
После того, как разработчик приложения утверждает кластеры (например, используя графический интерфейс пользователя для программного инструментального средства), разработчик приложения дает команду программному инструментальному средству на генерацию набора классификаторов на основе понятийных особенностей произнесений в утвержденных кластерах (то есть обучающие данные). Набор классификаторов является выходными данными процесса машинного обучения (например, дерева решений, метода опорных векторов). Классификаторы используются для того, чтобы определить, каким кластерам из обучающего набора каждое новое произнесение является наиболее подобным. В предпочтительном варианте осуществления программное инструментальное средство строит набор классификаторов, используя метод опорных векторов (SVM) для процесса машинного обучения. Этот процесс приводит к набору попарных дискриминаторов, один для каждого кластера по сравнению со всеми другими, которые затем применяются к новым произнесениям. Кластер, который «выигрывает» большинство сравнений, определен как являющийся кластером, к которому должно быть отнесено новое произнесение. Например, если классификатор будет построен с использованием SVM для трех кластеров, то этот классификатор будет иметь набор из трех попарных дискриминаторов для того, чтобы сравнивать кластер 1 с кластером 2, кластер 1 с кластером 3 и кластер 2 с кластером 3. Когда новое произнесение представлено классификаторам, каждое из этих трех сравнений применяется к семантическим факторам (определенным средством распознавания сеанса общения) произнесения. Кластер, который «победил» в большинстве сравнений, является кластером, к которому должно быть отнесено произнесение.
Как только набор классификаторов агентов построен, обучающий набор звонков подается в эти классификаторы для того, чтобы убедиться в 340 целостности классификаторов. Целостность классификаторов проверяется путем сравнения кластеров, в которых классификаторы, отнесенные к произнесениям агентов из обучающего набора, с кластерами, на которые произнесения агентов были классифицированы до генерации классификаторов агентов. Если классификаторы не классифицируют обучающий набор так, что при этом они не удовлетворяют некоторым критериям проверки правильности (например, классификаторы должны классифицировать по меньшей мере 98% произнесений агентов в обучающем наборе по их надлежащим кластерам), то разработчик приложения корректирует 344 исходные кластеры и перестраивает классификаторы агентов 338.
Как только классификаторы удовлетворяют критериям проверки правильности, произнесения агентов в испытательном наборе звонков аннотируются 346, используя классификаторы. Это означает, что произнесения агентов классифицированы и тэг, идентифицирующий кластер, для которого произнесение сочтено наиболее подобным, ассоциирован с каждым произнесением агента. Например, произнесение агента «Какой вашим номер социального обеспечения?» может аннотироваться с помощью тэга "REQ_SSN", указывающего, что произнесение агента было классифицировано в кластер, соответствующий запросу агента на предмет номера социального обеспечения звонящих.
После аннотирования произнесения агента в испытательном наборе разработчик приложения делает обзор 348 аннотаций и оценивает аннотированный испытательный набор на предмет того, было ли произнесение агента классифицировано правильно. Например, если произнесение агента «Какой у вас номером социального обеспечения?» является классифицированным как "REQ_ADDRESS", то разработчик приложения оценил бы эту классификацию как неправильную. Если разработчик приложения не удовлетворен тем, что оценка (например, процентная доля правильных классификаций) приемлема 350, разработчик приложения корректирует 344 исходные кластеры и перестраивает классификаторы агента 338.
Как только разработчик приложения удовлетворен тем, что испытательный набор получил приемлемую оценку, текущие классификаторы агентов устанавливаются как «золотые» классификаторы агентов.
Обратимся к Фиг.16C, где проиллюстрирован процесс разработки набора классификаторов начальных запросов звонящих. Начальные запросы звонящих относятся к произнесению, которое идентифицирует основную причину(ы) звонящего для осуществления звонка (например, запрос на предмет остатка на текущем счете звонящего, запрос о смене адреса и т.д.).
Как показано на Фиг.16C, произнесения агентов из обучающего набора звонков аннотируются 354 с помощью «золотых» классификаторов агентов, используя программное инструментальное средство. Программное инструментальное средство затем кластеризует 356 ответы звонящих на классификаторы агентов, соответствующие запросу агента касаемо начального запроса звонящего (например, классификатора, соответствующего "Как я могу помочь Вам?").
Кластеризованные начальные запросы звонящих затем используются для построения 358 набора классификаторов для начальных запросов звонящих (например, используя метод опорных векторов).
Поскольку число произнесений звонящего, соответствующих начальному запросу звонящего, является малым (обычно только один начальный запрос на каждый звонок), разработчик приложения может выбрать вручную идентифицировать 360 произнесения запросов звонящих, например, читая текст запросов и помещая начальный запрос(ы) для каждого звонка в кластер.
После того, как начальный набор классификаторов начальных запросов звонящих построен, правильность этих классификаторов подтверждается 362 посредством подачи обучающего набора звонков через классификаторы и сравнения кластеров, в которых классификаторы отнесены к произнесениям начальных запросов звонящих из обучающего набора, с кластерами, в которых произнесения начальных запросов звонящих были классифицированы до генерирования классификаторов начальных запросов звонящих. Если классификаторы не классифицируют обучающий набор так, что при этом они не удовлетворяют некоторым критериям проверки правильности (например, классификаторы должны классифицировать по меньшей мере 95% произнесений начальных запросов звонящих в обучающем наборе по их надлежащим кластерам), то разработчик приложения корректирует 366 исходные кластеры и восстанавливает классификаторы 358 начальных запросов звонящих.
Когда критерии проверки правильности удовлетворены, испытательный набор звонков аннотируется 368 с помощью классификаторов начальных запросов звонящих и затем просматривается и оценивается 370 разработчиком приложения. Если классификаторы начальных запросов не приводят к приемлемой оценке, разработчик приложения корректирует кластеры и перестраивает классификаторы. (Отметим, что если кластеры скорректированы, основываясь на информации, подбираемой из испытательного набора, то оценивание на основе SVM, построенных из скорректированных кластеров, должно быть проверено на новом наборе испытательных данных.) Как только классификаторы начальных запросов приводят к приемлемой оценке, предварительный набор 374 классификаторов начальных запросов звонящих сформирован.
Обратимся к Фиг.16D, где проиллюстрирован процесс для построения набора неначальных ответов звонящих на запросы агентов на предмет информации. Процесс, проиллюстрированный на Фиг.16D, подобен процессу, проиллюстрированному на Фиг.16C. Как и процесс, который показан на Фиг.16C, процесс, который показан на Фиг.16D, использует «золотые» классификаторы агента для нахождения произнесений звонящих. Однако в процессе, который показан на Фиг.16D, произнесения звонящих, которые классифицированы, представляют собой те произнесения, которые соответствуют запросам агента на предмет информации, не относящейся к начальному запросу (то есть произнесения звонящего, в которых звонящий отвечал на запросы агента на предмет информации, отличающиеся от запроса агента на предмет цели звонка звонящего). Ответы звонящих на запросы агентов на предмет о имени звонящего, адресе, номере социального обеспечения и данных о рождении являются примерами произнесений звонящих, которые соответствуют запросам агентов на предмет информации, не относящейся к начальному запросу.
Как показано на Фиг.16D, произнесение агентов из обучающего набора звонков аннотируются 376 с помощью "золотых" классификаторов агентов, используя программное инструментальное средство. Программное инструментальное средство тогда кластеризует 378 ответы звонящего на классификаторы агента, соответствующие запросу агента на предмет информации, отличающемуся от начального запроса звонящего (например, классификатора соответствующего, «Какой у вас номер социального обеспечения?»).
Кластеризованные ответы звонящего на неначальные информационные запросы агента используются для построения 380 набора классификаторов для неначальных ответов звонящего (например, используя метод опорных векторов).
Как только начальный набор классификаторов неначальных ответов звонящих построены, проверяется правильность классификаторов 384 посредством подачи обучающего набора звонков через классификаторы и сравнения кластеров, в которых классификаторы отнесены к произнесениям неначальных ответов звонящих из обучающего набора, с кластерами, в которых произнесения неначальных ответов звонящих были классифицированы до генерации классификаторов неначальных ответов звонящих. Если классификаторы не классифицируют обучающий набор так, что при этом они не удовлетворяют некоторым критериям проверки правильности (например, классификаторы должны классифицировать по меньшей мере 98% произнесений звонящих в обучающем наборе по их надлежащим кластерам), тогда разработчик приложения корректирует 386 исходные кластеры и перестраивает классификаторы неначальных ответов звонящих.
Как только критерии проверки правильности удовлетворены, испытательный набор звонков 388 аннотируется с помощью классификаторов неначальных ответов звонящих и затем просматривается и оценивается разработчиком приложения 390. Если классификаторы неначальных ответов не приводят к приемлемой оценке, разработчик приложения корректирует 386 кластеры и перестраивает классификаторы. Как только классификаторы неначальных ответов приводят к приемлемой оценке, предварительный набор 394 классификаторов неначальных ответов звонящих сформирован.
Предварительный набор классификаторов неначальных ответов звонящих и классификаторы начальных запросов звонящих объединяются 396 для того, чтобы сформировать объединенный набор предварительных классификаторов звонящих.
Обратимся к Фиг.16E, где проиллюстрирован процесс для пополнения предварительных классификаторов звонящих. В этом процессе некоторое количество (N) случайных образцов обучающих и испытательных наборов транскрибированных звонков между звонящими и агентами-людьми используется для повышения эффективности классификаторов.
Первый обучающий набор случайных образцов (например, 1000 случайно отобранных образцов) аннотируется 400 с помощью «золотых» классификаторов агентов и предварительных классификаторов звонящих, используя программное инструментальное средство. Программное инструментальное средство затем добавляет данные (то есть семантические особенности) произнесений звонящих, соответствующих запросам агента на предмет информации (или запросы на предмет причины звонка звонящего, или запросы агента на предмет другой информации), к кластерам звонящих соответствующего классификатора. Например, если произнесение звонящего «да, это 123-45-6789» дается в ответ на запрос агента на предмет номера социального обеспечения звонящего, семантические особенности произнесения звонящего добавляются к кластеру звонящего, соответствующему ответу о номере социального обеспечения.
Как только все данные из произнесений звонящих в наборе образцов добавлены к соответствующим кластерам, классификаторы звонящих (и классификаторы начальных запросов звонящих, и классификаторы неначальных ответов) перестраиваются 404, используя, например, метод опорных векторов.
После этого проверяется правильность перестроенных кластеров 408 посредством подачи обучающего набора звонков через вновь построенные классификаторы и сравнения кластеров, в которых классификаторы отнесены к произнесениям звонящих из обучающего набора с кластерами, в которых произнесения звонящих были классифицированы до генерации классификаторов звонящих. Если вновь построенные классификаторы не классифицируют обучающий набор так, что при этом они не удовлетворяют некоторым критериям проверки правильности (например, новые классификаторы должны правильно классифицировать более высокую процентную долю произнесений звонящих, чем предыдущие классификаторы), то разработчик приложения корректирует 410 кластеры и перестраивает классификаторы звонящих.
Как только критерии проверки правильности удовлетворены, испытательный набор запросов повторно аннотируется 410 с помощью классификаторов звонящего и затем просматривается и оценивается 412 разработчиком приложения для того, чтобы улучшить классификаторы. (Никакая корректировка кластеров не происходит, поскольку предполагается, что новые данные будут улучшать классификаторы). Процесс, проиллюстрированный на Фиг.16E, может продолжиться до тех пор, пока оценки новых классификаторов не приблизятся к асимптоте, и в этот момент устанавливается окончательный набор классификаторов агентов и звонящих.
Окончательный набор классификаторов агентов и звонящих может использоваться для идентификации канонических шаблонов сеансов общения агентов, которые разработчик приложения может использовать для разработки сети с конечным числом состояний для системы. Например, как показано на Фиг.16F, набор случайно отобранных образцов общения между звонящими и агентами 420 аннотируется 422 с помощью тэгов классификаторов, используя окончательные классификаторы агентов и звонящих. Звонки тогда характеризуются 424 по типу звонка. Этот этап может быть выполнен вручную разработчиком приложения, просматривающим аннотированные образцы общения между звонящими агентами, или может выполняться автоматически программным процессом, который оптимизирует сетевой путь(и), ассоциированный с начальным запросом каждого звонящего.
Программный процесс затем может идентифицировать 426 общие шаблоны запросов агентов для каждого типа звонка посредством сравнения последовательности запросов агентов для каждого типа звонка. Например, если один тип запроса является запросом на предмет остатка на счете, программный процесс может исследовать каждую последовательность запросов агента для ответа на запрос на предмет остатка на счете, чтобы идентифицировать один или более общих шаблонов запросов (например, большое количество агентов сделали запрос А, сопровождаемый запросом B, сопровождаемым запросом C). Программный процесс затем использует идентифицированные общие шаблоны запросов (например, наиболее общий шаблон запроса для каждого типа звонка), чтобы автоматически сгенерировать 428 предварительную сеть с конечным числом состояний. Разработчик приложения обычно должен добавлять узлы к предварительной сети с конечным числом состояний, например, чтобы допускать повторные приглашения для ответов, не понятых системой, или попросить, чтобы звонящий ждал, в то время как система ищет информацию, и т.д.
В дополнение к использованию общих шаблонов запросов агентов для генерации предварительной сети с конечным числом состояний разработчик приложения может также использовать общие шаблоны запросов агентов для того, чтобы идентифицировать типы звонков. Например, как только набор общих шаблонов запросов агентов для различных типов звонков идентифицирован, классификаторы агентов могут быть применены к непроанализированному набору сеансов общения между агентами и звонящими для того, чтобы идентифицировать шаблоны запросов агентов в этом непроанализированном наборе. Если шаблон запроса агента в сеансе общения между агентом и звонящим в непроанализированном наборе согласуется с одним из общих шаблонов запросов для известного типа запроса, разработчик приложения (или программное инструментальное средство, используемое разработчиком приложения) может предположить, что этот сеанс общения между агентом и звонящим имеет тип звонка, соответствующий общему шаблону запроса между агентом и звонящим. Тип звонка, соответствующий сеансу общения между агентом и звонящим, может быть определен, основываясь на наборе имеющихся в сеансе общения классификаторов агента, независимо от какого-либо конкретного упорядочения классификаторов. Альтернативно тип звонка может быть определен, основываясь на последовательности имеющихся в сеансе общения классификаторов агента.
Пары классифицированных произнесений агента и звонящего в транскрибированных сеансах общения могут использоваться, чтобы идентифицировать успешные запросы агентов на предмет информации. Распределение ответов звонящих на по-разному сформулированные вопросы агентов, которые были предназначены, чтобы выявить одну и ту же информацию (и следовательно, были в одном и том же кластере), может показать, что один путь спрашивать информацию более эффективен, чем другие пути. Например, первый запрос агента, выраженный фразой «Я могу узнать номер вашего социального обеспечения?», может иметь значительное количество ответов звонящего «да» без предоставления номера социального обеспечения звонящего. Однако другой классификатор агента, который классифицирует запрос агента, выраженный фразой «Какой у вас номер социального обеспечения?», может привести к распределению, в котором очень высокая процентная доля ответов звонящего на данный вопрос предоставляет требуемую информацию (то есть номер социального обеспечения звонящего). Идентифицируя, какие типы ответов звонящего являются надлежащими ответами и какие являются ненадлежащими ответами, можно посмотреть на ассоциированные произнесения звонящего и определить, были ли формулировки таких произнесений агента ответственны за надлежащий ответ звонящего.
Обратимся вновь к Фиг.12, где как только описание первоначального 184 приложения CML было разработано (например, используя процесс развития разработки первоначального приложения, проиллюстрированный на Фиг.16A-16F), оно разворачивается 186 на сервер сеансов общения (например, сервер 30 сеансов общения, показанный на Фиг.5-6). Сервер сеансов общения предпочтительно поддерживает «оперативное развертывание» приложений CML, что означает, что новые версии описания приложения CML могут быть повторно развернуты, когда оно уже исполняется на сервере сеансов общения. Оперативное развертывание предпочтительно гарантирует, что: (i) уже активным сеансам приложения будет разрешено исполниться до завершения; (ii) все ресурсы, используемые версией приложения (например, файлы приглашений и т.д.), не будут удалены или замещены до тех пор, пока они больше не будут требоваться; (iii) все новые сеансы приложения используют самую новую версию приложения; и (iv) все устаревшие версии приложения и поддерживаемые ресурсы будут удалены из сервера сеансов общения, когда в них больше нет необходимости со стороны активных сеансов приложения.
После того, как описание приложения CML было развернуто на сервере сеансов общения и начинает обрабатывать запросы, сервер сеансов общения записывает все из сеансов общения между системой и звонящими в хранилище (репозитории) 187 данных и выполняет регистрацию этих сеансов общения в файле регистрации сеансов общения 188.
Хранилище 187 данных включает в себя исходные данные из сеансов общения между системой и звонящими (например, звуковые файлы записанного телефонного сеанса общения между системой и звонящим, текстовые файлы сеанса общения посредством мгновенного обмена посланиями между системой и звонящим). Подсистема аудиозаписи (не показана) записывает все звонки клиентов со времени начала (когда система начинает обрабатывать звонок) до завершения звонка. Для звонков с взятием агентом под контроль подсистема аудиозаписи продолжает записывать взаимодействие между агентом и клиентом до его завершения. В предпочтительном варианте осуществления подсистема аудиозаписи записывает все, что звонящий сказал в сеансе общения, в одном звуковом файле, и все, что агент(ы) (программный агент и/или агент-человек) сказал в другом файле. Кроме того, подсистема аудиозаписи предпочтительно устраняет периоды тишины в записанном сеансе общения.
Файл регистрации сеансов общения 188 генерируется подсистемой 64 регистрации (показанной на Фиг.5). Подсистема регистрации генерирует файл регистрации сеансов общения 188 посредством создания объекта сеанса для каждого звонка, который обрабатывается сервером сеансов общения. Объект сеанса включает в себя следующие данные:
• исполняющееся приложение (могут быть многодиалоговые приложения, используемые на сервере сеансов общения),
• метка, указывающая, как взаимодействие было обработано системой (например, автоматизированный сеанс общения, смешанный сеанс общения, или сеанс общения с взятием агентом под контроль),
• индикатор канала (телефон, сеть, чат/IM, электронная почта),
• ссылки на ассоциированный звуковой файл, хранящийся в хранилище звуковых данных,
• представление всего сеанса общения в хронологическом порядке, который включает в себя:
(i) ввод клиента, распознанный речевым механизмом (распознанный ввод);
(ii) для полностью автоматизированных взаимодействий (то есть взаимодействий, которые были полностью обработаны программными агентами), представление также включает в себя:
- ответы, данные по каждому вопросу, и оценки их согласованности при наличии взаимодействия;
(iii) для смешанных взаимодействий (то есть взаимодействий, в которых агент-человек выбрал ответ из списка ответов, представленных системой), представление также включает в себя:
- находящийся вверху списка предложенный ответ(ы) и их оценки согласованности;
- ответ, отобранный агентом, и его оценка согласованности и ранг среди списка предложенных ответов;
(iv) для взаимодействия с взятием под контроль, представление также включает в себя:
- звуковой диалог между агентом-человеком и клиентом.
• Временные метки, указывающие время начала звонка, время, когда звонок передавался агенту-человеку (если применимо), и время завершения звонка.
• Последовательность состояний сеансов общения, которые проходят агент и звонящий, и события, которые вызвали переходы между состояниями; например, выбор агентом-человеком конкретного ответа или выбор ответа программным агентом.
• Идентификационные данные агента-человека, который содействовал при звонке или взял звонок под свой контроль (если применимо).
• Запись всех запросов к серверным системам управления базами данных (например, системам, содержащим информацию, являющуюся ответом на запросы звонящих) и результаты этих запросов. Например, если приложение должно извлечь информацию об остатке на счете клиента, это требует вызова к серверной системе управления базами данных.
Хранилище 187 данных и файл регистрации сеансов общения 188 доступны для процесса 190 обучения времени выполнения для того, чтобы облегчить корректировки приложения CML.
Процесс обучения 190 времени выполнения использует адаптивный цикл обучения, в котором хронология исполнения системы (зафиксированная в регистрации 188 соответствия и хранилище 187 данных) используется для развития приложения CML с целью улучшить способность системы к автоматизации сеансов общения. Более подробно процесс обучения времени выполнения выбирает определенные взаимодействия между звонящими и агентами из хронологии сеансов общения между звонящими и агентами, которые определены как являющиеся "хорошими" возможностями обучения для системы. Отобранные взаимодействия между звонящими и агентами не обязательно должны соответствовать всему сеансу общения между звонящим и агентом, а могут быть только частью сеанса общения между звонящим и агентом. Следующее является примерами взаимодействий агента и звонящего, которые могут быть отобраны процессом обучения времени выполнения для улучшения системы:
1. В сеансе общения, в котором агент-человек выбрал ответ из ранжированного списка ответов на произнесение звонящего, сгенерированного системой, смысловое значение произнесения звонящего может быть отличено системой от ответа, отобранного агентом-человеком. Соответственно произнесение звонящего может быть отобрано как возможность обучения для улучшения классификаторов, используемых системой. Таким образом, если звонящий сделает подобное произнесение в будущем, то система с большой вероятностью будет в состоянии ответить без содействия со стороны агента-человека. Кроме того, распознанная произнесенная речь, соответствующая произнесению звонящего (которая может быть распознана онлайновым ASR, автономным ASR или ручной транскрипцией) может использоваться для того, чтобы улучшить языковые модели, используемые онлайновым ASR. Таким образом, если звонящий делает произнесение, используя сходную речь, в будущем онлайновое ASR с большой вероятностью точно распознает речь.
2. В сеансе общения, в котором система дала автоматизированный ответ на произнесение звонящего, это произнесение звонящего, предшествующее автоматизированному ответу, может быть отобрано как возможность обучения для системы для того, чтобы усовершенствовать поведение системы. В этом случае распознанная речь, соответствующая произнесению звонящего (которая может быть распознана онлайновым ASR, автономным ASR или ручной транскрипцией), может использоваться для того, чтобы улучшить языковые модели, используемые онлайновым ASR и/или улучшить классификаторы, используемые для различения смыслового значения произнесений звонящего.
3. В сеансе общения, в котором агент-человек взял этот сеанс общения под свой контроль, взаимодействия между звонящим и агентом-человеком могут быть отобраны как возможности обучения. В этом случае системный администратор может проанализировать обмен между звонящими и агентами-людьми на предмет сеансов общения, которые не ожидались системой (и, таким образом, не являются частью сети с конечным числом состояний этой системы). Системный администратор может использовать обмен между звонящими и агентами-людьми, чтобы добавить узлы к сети с конечным числом состояний системы и построить классификаторы так, чтобы, если звонящий осуществит контакт с центром обработки звонков в будущем, система будет готова обработать этот звонок. Например, если ошибка печати привела к отправке по почте пустых счетов клиентам в определенном месяце, система может принять некоторое количество запросов звонящих касаемо этих пустых счетов. Это, по всей вероятности, является сеансом общения, который не ожидался системой. После приема некоторых из этих запросов системный администратор может построить набор классификаторов и обновить сеть с конечным числом состояний (например, используя процесс, описанный на Фиг.15 выше) так, чтобы система смогла обработать подобные звонки в будущем.
Процесс обучения времени выполнения подает отобранные взаимодействия между звонящими и агентами в студию 32 сеансов общения (показанную на Фиг.4-5), где они используются для перестроения классификаторов, улучшения языковых моделей, используемых для распознавания речи во время выполнения, и/или модификации сети переходов между состояниями.
В одном варианте осуществления процесс обучения времени выполнения просматривает сеансы общения между системой и звонящими на предмет следующих возможностей обучения:
1. Содействие - в сеансах общения, где агент-человек сообщает программному агенту надлежащие интерпретации утверждения звонящего, когда программный агент был неуверен, интерпретация агентом утверждения звонящего используется для того, чтобы улучшить классификаторы, используемые средством распознавания понятий для понимания речи звонящего. Другие варианты осуществления используют интерпретацию агентом утверждения звонящего для того, чтобы улучшить языковые модели, используемые онлайновым ASR.
2. Взятие под контроль - в диалогах, в которых агент-человек берет под контроль сеансы общения от программного агента, обмен между звонящими и агентами-людьми анализируется системным администратором для того, чтобы идентифицировать новые сеансы общения. Если идентифицирован новый сеанс общения, новый набор классификаторов звонящих и обновленная сеть с конечным числом состояний могут быть разработаны (например, используя процесс, описанный на Фиг.15 выше) для добавления этого нового сеанса общения к приложению.
3. Усиление - в сеансах общения, где программный агент успешно распознает одно или более произнесений звонящего, произнесение(я) звонящего используется для того, чтобы улучшить языковые модели, используемые онлайновым ASR (который является компонентом средства распознавания речи) для распознавания речи звонящего. Другие варианты осуществления используют эти сеансы общения для того, чтобы улучшить классификаторы, используемые средством распознавания понятий для понимания смыслового значения речи звонящего.
Когда процесс 190 обучения времени выполнения использует взаимодействие между звонящим и агентом как возможность обучения, есть риск, что это взаимодействие в качестве возможности обучения не является корректным. Обработка «плохих» взаимодействий (например, взаимодействий, в которых система неправильно интерпретировала вопрос звонящего и дала неправильный ответ) представляет опасность уменьшения точности и степени автоматизации системы. Соответственно процесс обучения времени выполнения предпочтительно включает в себя одну или более мер предосторожности, которые помогают гарантировать то, что им выбираются только «хорошие» взаимодействия из предназначенных для обучения.
В предпочтительном варианте воплощения процесс обучения в времени выполнения является конфигурируемым системным администратором или другим пользователем через графический интерфейс пользователя в студии 32 сеансов общения (показанной на Фиг.4-5) для того, чтобы требовать, чтобы выбранные взаимодействия удовлетворяли определенным критериям выбора. В одном варианте осуществления системный администратор может выбрать один или более следующих критериев выбора для того, чтобы выбрать возможности обучения:
1. Выбрать взаимодействия между звонящими и агентами в качестве соответствующей усилению возможности обучения, если n (например, n = 2, 3, 4, и т.д.) последующих взаимодействий между звонящими и агентами были успешны (например, взаимодействия, которые не приводили к тому, что звонящий повесил трубку или попросил помощи или поговорить с агентом-человеком).
2. Выбрать взаимодействия между звонящими и агентами в качестве соответствующих усилению и/или содействию возможностей обучения, только если звонящий отвечал положительно на вопрос об удовлетворении, поставленный программным агентом или агентом-человеком (например, «Было ли это ответом на Ваш вопрос?», «Вы удовлетворены обслуживанием, которое Вы получили?»).
3. Выбрать взаимодействия между звонящими и агентами в качестве соответствующих усилению и/или содействию возможностей обучения, которые подтверждены m (например, m = 2, 3, 4, и т.д.) других примеров. Это позволяет системе избежать экстраполирования ограниченное число примеров.
4. Выбрать взаимодействия с содействием агента в качестве возможностей обучения, если они подтверждены некоторым числом других агентов.
5. Выбрать взаимодействия с содействием агента, если содействие оказано «доверенным» агентом. Доверенный агент может быть определен согласно некоторой мере «доверия», типа времени работы человека в качестве агента или совокупная оценка в отношении предыдущих примеров обучения с содействием, отнесенных к агенту.
6. Выбрать взаимодействия с содействием агента в качестве возможностей обучения, только если они находятся среди верхних n вариантов выбора (например, n = 1, 2, 3 и т.д.), предложенных системой.
7. Избегать выбора взаимодействий в качестве возможностей обучения, если добавление новых примеров к кластеру сместило бы предопределенное число предыдущих примеров из этого кластера. Например, предположим, что существующий кластер содержит 100 произнесений-примеров, все из которых означают, «Я хочу узнать остаток на моем счете», и новое произнесение звонящего из отобранного взаимодействия добавляется к кластеру, и новый набор классификаторов повторно генерируется, используя новый обучающий набор из 101 произнесения (первоначальные 100 плюс новое). Это 101 произнесение может быть применено к новому набору классификаторов для того, чтобы видеть, как этот новый набор классификаторов классифицирует их. В идеале новые классификаторы должны классифицировать их всех как принадлежащие кластеру «Я хочу узнать остаток на моем счете», так как это то, на чем классификаторы обучались. Однако если было обнаружено, что некоторое число (например, 1, 2, 3, и т.д.) первоначальных произнесений теперь не классифицированы неверно как принадлежащие некоторому другому кластеру или являются теперь неоднозначно классифицированными, тогда это указывает на то, что новое произнесение для обучения ухудшило точность классификаторов и, в первую очередь, не должно было быть добавлено к этому кластеру. Эти критерии выбора могли бы быть объединены с критериями выбора 3 выше, чтобы требовать более сильную степень очевидности в отношении добавления нового примера к кластеру, что приводит к устранению предопределенного числа предыдущих примеров.
В дополнение к риску ухудшения системы вследствие обучения на «плохих» примерах может также быть выгодно ограничить возможности обучения для того, чтобы сохранить ресурсы обработки и/или людские административные ресурсы. Например, средний североамериканский центр контактов обрабатывает приблизительно 3 миллиона звонков в год, и, предполагая 10 обменов между агентом и звонящим за звонок, это означает, что средний центр обработки звонков генерирует 120000 потенциальных событий обучения в день. Многие организации не будут (или юридически не смогут) разрешить системе изменять ее поведение без одобрения некоторого ответственного человека. Даже в тех случаях, где автоматическое развитие системы является желательным, смещающий объем примеров может в конечном счете стать бременем на ресурсы обработки. Таким образом, может быть выгодным для процесса обучения времени выполнения гарантировать, чтобы только релевантные или полезные примеры обрабатывались и/или представлялись для обзора человеком. В предпочтительном варианте воплощения процесс обучения времени выполнения является конфигурируемым системным администратором или другим пользователем через графический интерфейс пользователя в студии 32 сеансов общения (показанной на Фиг.4-5) в контексте требования, чтобы выбранные взаимодействия удовлетворяли одному или более критериям выбора для того, чтобы помочь избежать перегрузки системы и/или пользователей:
1. Не выбирать взаимодействие, которое не классифицирует по меньшей мере n (например, n = 1, 2, 3 и т.д.) других взаимодействий, потому что взаимодействие, которое несет свое собственное понимание, обычно не очень полезно.
2. Ранжировать взаимодействия по числу других взаимодействий, которые они классифицируют. Добавить только верхние n=1, 2, 3... из этих самых продуктивных примеров в качестве возможностей обучения.
3. Не добавлять взаимодействие, которое не изменяет характеризующийся набор с, по меньшей мере, некоторым порогом. Как объяснено выше, классификаторы создаются из обучающего набора примеров. Некоторые примеры в обучающем наборе являются значащими, а некоторые нет. Иными словами, при намерении устранить примеры, которые не являются значащими, и воссоздать классификатор, получается тот же самый классификатор, что и прежде. Примеры, которые действительно являются значащими, называют характеристическим набором (известны программные процессы, используемые для определения характеристического набора классификатора SVM). Эти критерии выбора означают то, что если взаимодействие добавляется к обучающему набору для классификатора через процесс обучения и новый классификатор строится с использованием этого нового обучающего набора, но характеристический набор классификатора не изменяется с некоторым порогом (например, большинство его членов те же самые, что и прежде), то классификатор не обучился в значительной степени из этого дополнительного взаимодействия, и это может игнорироваться (в каковом случае исходные классификаторы остаются без изменений). Полезными взаимодействиями для обучения являются те взаимодействия, которые имеют значимое воздействие на характеристический набор.
4. Ограничьте число или разнообразие примеров, которые система сохраняет, помещая количественный или временной порог в отношении примеров в кластере. Одним временным порогом является то, когда в последний раз пример использовался для того, чтобы классифицировать некоторое число других примеров. Это может быть особенно важным в начале, когда система, обучаемая на данных общения между человеком и человеком, обучается различным стилям, которые люди могут использовать, говоря с машиной.
Хотя вышеупомянутые критерии выбора применяются к любой форме сообщения между системой и звонящими (например, речь, мгновенный обмен посланиями и т.д.), специфические проблемы возникают, когда среда взаимодействия является речью или рукописным вводом, или любой другой модальностью, где существенный шанс неправильного распознавания может иметь место в онлайновом ASR (или онлайновой системе оптического распознавания символов (OCR) в случае распознавания рукописного текста).
В некоторых случаях распознавание речи звонящего (или рукописного ввода), которая зафиксирована в файле регистрации сеансов общения, может не оказаться достаточно точным, чтобы служить в качестве полезного примера. Это особенно является проблемой при обучении с содействием или взятием под контроль, где агент-человек дает правильную интерпретацию в случае, когда система не может понять то, что звонящий сказал или написал. Обучение на неточно распознанной речи или рукописном вводе может понизить эффективность системы или как минимум потратить впустую системные ресурсы. Система обучения времени выполнения предпочтительно принимает меры против обучения на неточно распознанных данных, требуя, чтобы агент выбрал ответ, который должен быть среди набора верхних n (например, n=1, 2, 3...) гипотез, представленных системой. Система может также требовать, чтобы некоторая внутренняя мера уверенности в распознанных данных (сгенерированных онлайновым или автономным ASR) превышала порог для того, чтобы избежать обучения на неправильно распознанных примерах.
Угроза неточно распознанных данных в файле регистрации сеансов общения существенна, потому что когда система работает, она обычно сталкивается с ограничением по времени, заключающееся в том, что звонящие не желают ждать ответ больше, чем несколько секунд. Это ограничивает объем обработки, который онлайновое ASR может использовать, чтобы распознать и классифицировать пользовательский запрос. Однако процесс обучения времени выполнения может повторно распознать ввод звонящего ради обучения без такого строгого ограничения по времени. Это автономное распознавание может использовать другие алгоритмы или модели или параметры, чтобы достигнуть лучших результатов, посредством использования большего количества ресурсов и даже сделать многократные проходы в отношении того же самого и/или связанного пользовательского ввода. Например, все общение звонящего (все 10 обращений) мог использоваться как обучающее при повторном распознавании каждого обращения. Процесс обучения времени выполнения может быть спроектирован так, чтобы использовать лишнюю сверхнормативную пропускную способность периода пиковой нагрузки в период вне пиковой нагрузки, чтобы выполнить эту задачу. Процесс обучения времени выполнения может также использовать вычислительные ресурсы в сети (например, Интернет), чтобы повторно распознать ввод звонящего.
Распознавание ввода звонящего (например, речи) является в вычислительном отношении интенсивным процессом, и также процесс обучения времени выполнения может не иметь ресурсов обработки, доступных для выполнения обработки с целью повторного распознания каждого пользовательского произнесения. Одним путем, которым процесс обучения времени выполнения может ограничить ресурсы обработки, является выбор только тех взаимодействий между системой и звонящими, которые были отобраны как возможности обучения с использованием одного или более критериев выбора, изложенных выше. В дополнение к вышеупомянутым методикам процесс может использовать уровень уверенности во взаимодействии в качестве фильтра. Взаимодействия с высоким уровнем уверенности могут предполагаться как правильные, взаимодействия с низким уровнем уверенности могут предполагаться настолько проблематичными, что их можно считать незаслуживающими доверия (слишком много внешнего шума, например). Соответствующие «высокие» и «низкие» пороги могут быть вычислены системой из обучающих примеров.
Кроме того, методики распознавания часто предполагают, что они знают объем словаря системы. Конкретная проблема состоит в том, когда и как расширить основную опись примитивных модулей системы. Процесс обучения времени выполнения может использовать автономное распознавание, может использовать другой (обычно большего размера) словарь для определения того, когда следует расширить словарь системы распознавания понятий. Если больший словарь дает лучшие внутренние и внешние оценки, процесс обучения времени выполнения может предположить, что этот словарь «лучше» для средства распознавания понятий. Процесс обучения времени выполнения может динамически создать новый словарь из, например, лент новостей так, чтобы он содержал новые статьи и комбинации. Мера уверенности низкого уровня может идентифицировать области возможно новых статей. При превышении некоторого порога сгруппированными по подобию новыми статьями может быть запрошено содействие человека при идентификации этих новых статей.
Наконец, много систем распознавания имеют отдельные модели для различных уровней заданий. Например, система ответа голосом могла бы иметь Гауссовы акустические модели для классификации единичных блоков фонетического уровня, словари для задания соответствия фонетических последовательностей словам, статистические языковые модели для оценивания последовательностей слов и SVM для классификации целых произнесений на эквивалентные семантические группы. Процесс обучения времени выполнения может использовать отобранные примеры обучения, чтобы обучать модели на различных уровнях или независимо, или совместно в различных комбинациях.
Обратимся к Фиг.17, где представлен сервер 450 обучения, реализующий процесс обучения времени выполнения. В этом конкретном варианте осуществления сервер обучения включает в себя средство 456 хранения регистрации, модули 458 обучения, базу 460 данных обучения, средство извлечения 462 звуков, автономное приложение 464 автоматического распознавания речи и хранилище 466 приложений.
При функционировании файлы регистрации сеансов общения между системой и звонящими помещаются в средство 456 хранения регистрации из файла 452 регистрации сеансов общения по мере того, как файлы регистрации генерируются сервером сеансов общения. Сервер сеансов общения (например, сервер 30 сеансов общения, показанный на Фиг.4-5) или другое средство (например, другой сервер) могут быть сконфигурированы так, чтобы помещать файлы регистрации записи в средство хранения регистрации.
По мере того, как средство хранения регистрации получает файлы регистрации записи сеансов общения, он направляет эти файлы регистрации к одному из модулей 458a, 458b обучения для анализа. Модули обучения соответствуют модульному подходу введения возможностей обучения в сервер обучения. Например, в одном варианте осуществления один модуль обучения выделяется для идентификации возможностей обучения из содействия агента, второй модуль обучения выделяется для идентификации соответствующих усилению возможностей обучения, и третий модуль обучения выделяется для идентификации возможностей обучения, соответствующих взятию под контроль. Если есть новые возможности обучения, которые подлежат добавлению к серверу, новый модуль обучения разрабатывается и вводится в сервер обучения. Так, например, словарный модуль обучения может быть добавлен к серверу обучения для того, чтобы исследовать слова, используемые в произнесениях звонящих, для расширения словаря системы.
Модули обучения также функционируют для того, чтобы выбирать события, зафиксированные в файлах регистрации сеансов общения и звуковых файлах, в качестве возможностей обучения. Модули обучения системы выбирают события, зафиксированные в файле регистрации сеансов общения/звуковых файлах согласно критериям выбора (обсужденным выше), которые задаются системным администратором. Некоторые критерии выбора, типа выбора взаимодействия между системой и пользователем для обучения, если определенное число последующих взаимодействий между системой и звонящим было успешным, можно определить из файла регистрации сеанса общения, соответствующего являющемуся кандидатом взаимодействию системы с звонящим. Однако другие критерии выбора требуют, чтобы модули обучения исследовали множество файлов регистрации сеансов общения для того, чтобы определить, должно ли взаимодействие между системой и звонящим быть отобрано. Например, если критерии выбора определяют, что взаимодействие между звонящим и агентом не должно быть отобрано, если оно не подтверждено определенным числом других примеров, модуль обучения не будет делать множество проходов в отношении взаимодействий между звонящими и агентами. В первом проходе модуль обучения идентифицирует и сохраняет взаимодействия между звонящими и агентами в качестве возможностей обучения. После того, как определенное количество взаимодействий-кандидатов сохранены или по истечении определенного времени модуль обучения анализирует сохраненные взаимодействия-кандидаты для того, чтобы выбрать взаимодействия, чтобы в конечном счете отобрать их в качестве возможностей обучения.
По мере того, как модули обучения отбирают взаимодействия между системой и звонящими в качестве возможностей обучения, отобранные взаимодействия между системой и звонящими сохраняются в базе данных обучения 460.
В дополнение к критериям выбора для фильтрации взаимодействий между системой и звонящими модули обучения также сконфигурированы для исследования уровня оценок согласованности, о котором сообщает средство распознавания понятий (который включен в файлы регистрации сеансов общения) для определения того, послать ли отобранное взаимодействие между системой и звонящим на автономное ASR 464 или ручную транскрипцию 468. Пороговый диапазон оценок согласованности может быть конфигурируемым пользователем (например, системным администратором) или он может быть предварительно запрограммированным. Пороговый диапазон оценок согласованности предпочтительно исключает оценки с очень низкой степенью уверенности (что указывает на то, что произнесение является слишком проблематичным, чтобы заслуживать доверия) и оценки с очень высокой степенью уверенности (что указывает, что первоначальное распознавание является правильным). Если транскрипция направлена к автономному ASR 464, автономный процесс ASR 464 осуществляет доступ к определению приложения в хранилище 466 приложений для того, чтобы извлечь языковую модель ASR, используемую для конкретного состояния распознавания (каждое состояние распознавания использует отдельную языковую модель). Модули обучения сконфигурированы для того, чтобы направить все взаимодействия, взятые под контроль агентами, к автономному ASR или ручной транскрипции, так как средство распознавания понятий не распознает произнесений звонящих или агентов во время взятия агентом под контроль. В некоторых конфигурациях модули обучения сконфигурированы так, чтобы направлять случаи взятия агентами под контроль для ручной транскрипции, в противоположность автоматизированной транскрипции автономным ASR, чтобы получить высококачественную транскрипцию взаимодействия между звонящим и агентом-человеком.
Наконец, разработчик приложения использует графический интерфейс пользователя на студии 32 сеансов общения для того, чтобы извлечь возможности обучения, которые готовы к рассмотрению. Разработчик приложения в необязательном порядке одобряет возможности обучения (например, через графический интерфейс пользователя) и обновляет приложение одобренными возможностями обучения. Как только приложение было обновлено, новая версия помещается в хранилище 466 приложений и развертывается на сервере сеансов общения.
Соответствующие содействию возможности обучения приводят к новым произнесениям звонящих, которые добавляются к подходящим понятийным кластерам, которые затем используются для повторной генерации классификатора, используемого для распознавания понятий. Обновленное приложение тогда будет в состоянии классифицировать подобные произнесения должным образом в следующий раз, когда они будут проговариваться звонящими. Соответствующие усилению возможности обучения приводят к новым произнесениям, которые добавляются к языковым моделям, используемым для распознавания речи, чтобы улучшить точность онлайнового ASR. Соответствующие взятию под контроль возможности обучения расширяют сеть с конечным числом состояний для того, чтобы обработать новые темы и новые взаимодействия вокруг существующих тем.
Фиг.13 изображает графический интерфейс 208 пользователя, который является компонентом обычного рабочего стола агента, который позволяет агенту-человеку осуществлять логический вход в рабочие группы, управлять состоянием его работы и принимать и заказывать звонки; причем все из перечисленного осуществляется через взаимодействия с сервером CTI. Пользовательский интерфейс 208 является панелью управления, через которую агент запускает приложения, которые используют сервер CTI, включая приложение рабочего стола.
Интерфейс 208 смоделирован на рабочем столе агента IP Avaya. Самые обычные функции рабочего стола предоставляются через инструментальные панели. Инструментальные панели, которые показаны на Фиг.13, таковы: Телефон 200 (обеспечивает управление выбранным звонком), Набор номера 202 (обеспечивает средство заказа звонка), Агент 204 (обеспечивает средства установки состояния работы агента относительно ACD), и Приложение 206 (обеспечивает средство запуска приложений, которые были загружены в интерфейс 208).
После логического входа агента-человека конфигурация для рабочего стола загружается с сервера. Частью этой конфигурации является определение приложений, которые могут быть запущены с рабочего стола. Конфигурация приложений включает в себя классы, которые реализуют приложение, и местоположение в сети, из которого приложение должно быть загружено. В добавление конфигурация будет включать приложения, которые указывают, что звонок предназначен приложению.
Фиг.14 изображает приложение разрешения проблем или графический интерфейс 210 пользователя. Это приложение вызывается каждый раз, когда звонок приходит с данными приложения, указывающими, что звонок является звонком разрешения проблем. Пользовательский интерфейс приложения разбит на три главных раздела. Представленная информация следующая: Application (Приложение) 212 (исполняемое приложение CML), Context (Контекст) 214 (текущее состояние в приложении), Channel (Канал) 216 (канал, через который клиент осуществлял контакт с центром), Threshold (Порог) 218 (установка порога для контекста), Under/Over (Мало/Много) 220 (причина, по которой разрешение проблемы было представлено агенту; то есть или есть слишком много ответов по отношению к порогу или недостаточное количество ответов по отношению к порогу), Assist (Содействие) 222 (число раз, когда клиенту оказывалось содействие в этом сеансе), и Time (Время) 224 (отрезок времени, когда клиент был в этом сеансе).
В панели 226 разрешения вопросов (Question) агент-человек в состоянии выбрать надлежащий ответ на вопрос клиента. Действия, которые агент может выполнить в этой панели: Search KB (Поиск в базе знаний) 228 (чтобы изменить запрос и осуществить поиск ответов в базе знаний), Respond (Ответить) 230 (чтобы проинструктировать программного агента ответить клиенту выбранным ответом). Ответы 232, согласующиеся с запросом, отображаются в таблице внизу панели. Для каждого ответа 232 показывается, находится ли он ниже или выше соответствующего контексту порога степени уверенности, его ранг по согласованности и резюме его вопроса, Take Over (Взять под контроль) 234 (Чтобы принять от программного агента контроль над звонком), Whisper (Шептать) 236 (Чтобы прослушать запись запроса клиента) и Submit Original Question (Представить Первоначальный Вопрос) 238 (Чтобы представить первоначальный вопрос клиента в качестве запроса базе знаний. Это является начальным действием, выполняемым приложением).
Графический интерфейс 210 пользователя также дает возможность агенту-человеку ввести заменяющий текст для сообщения клиента в поле, называемое «Замещающий Вопрос». Если уровни степени уверенности в машинно-генерируемых ответах низки, агент-человек может решить перефразировать сообщение клиента таким образом, что агент-человек знает, что система выполнит его сопоставление лучше.
Есть два набора управляющих элементов внизу пользовательского интерфейса: «Стенограмма» и «Данные». Кнопка 240 «Transcript» («Стенограмма») запускает web-страницу, которая показывает стенограмму диалога программного агента с клиентом в виде стенограммы стиля чата. Эта web-страница генерируется посредством выполняемого стенографирования программным агентом сеанса общения через ту же самую инфраструктуру Cocoon, что используется в каналах взаимодействия. Кнопка 242 «Data» («Данные») запускает web-страницу, которая показывает данные приложения, которые были собраны программным агентом до настоящего времени. Эта web-страница генерируется из прикладных и сетевых свойств программного агента через ту же самую инфраструктуру Cocoon, что используется в каналах взаимодействия. Как в случае с каналами взаимодействия, можно определить представление этих данных на прикладном уровне, сетевом уровне и/или контекстном уровне с определением на более специализированном уровне, отменяющем определение на более общем уровне; например, определение на контекстном уровне отменит определение на сетевом или прикладном уровне.
Элементы управления «Заключить» позволяют агенту-человеку предоставлять наставление, которое помещается в файл регистрации сеанса общения. Кнопка 244 «Attach Note» («Присоединить Примечание») позволяет агенту-человеку прикреплять примечание к этому взаимодействию в файле регистрации сеанса общения. Флаговая кнопка 246 «Mark For Review» «Пометить для просмотра» используется для того, чтобы указать, что это взаимодействие необходимо отметить для просмотра в файле записи диалога. Кнопка 248 «Done» («Завершено») указывает, что агент закончил с разрешением проблемы. Система проактивно индексирует, категоризирует и отслеживает архивированные основанные на голосе и тексте сеансы общения для проверки качества, урегулирования споров и целей изучения рыночной конъюнктуры. Поскольку это полностью автоматизировано, система может проактивно осуществлять мониторинг архивов звонков для отклонений в шаблонах звонков клиентов, предупреждая кураторов посредством механизма регулярной отчетности.
Например, в категории детального анализа сеансов общения система транскрибирует звук клиента для последующего детального анализа данных (например, проверки качества для финансового обслуживания). Это вовлекает взятие транскрибированных сеансов общения из группового процесса распознавания с использованием CRE для кластеризации файлов регистрации и обеспечивает возможность искать в пределах кластеров определенные темы (то есть реклама, проблемные области и т.д.) Система может также кластеризовать запрос по определенной теме (подкластер), определять местонахождение и помечать отклонения в шаблонах звонков в пределах подкластеров и обеспечивать возможность администратору осуществлять доступ к конкретной точке в пределах звукового потока, где происходит отклонение. Эти функциональные возможности обеспечивают возможность ревизии того, что сказал агент. Например, кластер о возвратах продуктов мог бы указать, что различные агенты направляют клиентов возвращать продукты в другие места. Чтобы сделать это, кластеры сохраняют данные, ассоциированные с файлом регистрации перед многопроходным ASR. Для другого примера кластеры могли бы показать, что некоторые агенты ассоциируют существующий ответ в базе знаний с вопросом клиента (смешанная последовательность действий), в то время как другие агенты берут звонки (последовательность действий с взятием под контроль) и дают свой собственный ответ.
Хотя были описаны определенные варианты осуществления изобретения, включая специфический вариант применения, связанный с управлением центром контактов, широкий выбор других вариантов осуществления находится в рамках объема, определяемого приложенной формулой изобретения.
ПРИЛОЖЕНИЕ 1
Abc12app.ucmla file
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE ucmlApp SYSTEM "http://dtd.unveil.com/dtd/ucmlApp.dtd">
<ucmlApp name="abc12App" version="1.1" initialNetwork="text/main">
<version> 1.0</version>
<clusterFile src="abc 12clusters.ucmlc"/>
<documents>
<document src="abc12ucml.ucml"/>
</documents>
<properties/>
<bObjects/>
<channels>
<channel type="VXML">
<default-output src="default.xsp"/>
<default-template src="default.xsl"/>
</channel>
</channels>
<resolutionService dnis="http://agent.unveil.com/resolutionservice"/>
</ucmlApp>
abc12clusters.ucmla file
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE clusters SYSTEM "http://dtd.unveil.com/dtd/cluster.dtd">
<clusters radius="0.85">
<cluster name="c0">
<utterance> о, хорошо, большое спасибо </utterance>
<utterance> хорошо, большое спасибо </utterance>
<utterance> хорошо, спасибо </utterance>
<utterance> хорошо, э-э-э, что гм, благодарю Вас </utterance>
<utterance> хорошо, очень благодарю Вас </utterance>
<utterance> хорошо, все в порядке, спасибо </utterance>
<similar cluster="c4" similarity="0.7685892367350193" />
</cluster>
<cluster name="c1">
<utterance> пока </utterance>
<utterance> до свидания </utterance>
<utterance> хорошо, пока </utterance>
<utterance> хорошо, до свидания </utterance>
<utterance> хорошо, пока </utterance>
<utterance> гм, хм, пока </utterance>
</cluster>
<cluster name="c2">
<variables>
<variable name="proper" туре="properName" required="true"/>
<variable name="number" type="digitString" required="false''/>
</variables>
<utterance> <instance variable="proper"> Рик Блайн</instance></utterance>
<utterance> <instance variable="proper"> Блайн</instance></utterance>
<utterance>да<instance variable="proper">Виктор Лазло</instance>
<instance variable="number"> ноль семь четыре два восемь пять пять два шесть
</instance>
</utterance>
<utterance> да, это - Луи Рено, пять один пять четыре ноль два шесть шесть </utterance>
<utterance> уверен, Лиза Лунд, один шесть три девять улица Касабланки, Беркли, Калифорния девять четыре семь один три</utterance>
<utterance> два четыре пять четыре один Блайн, это Блайн </utterance>
</cluster>
<cluster name="c3">
<utterance> восемнадцать пятьдесят </utterance>
<utterance> восемь два восемь четыре семь восемь один о восемь о </utterance>
<utterance> три один шесть два восемь шесть два один четыре </utterance>
<utterance> четыре один три восемь три восемь один шесть три </utterance>
<utterance> два пять ноль шесть шесть восемь семь три четыре </utterance>
</cluster>
<cluster name="c4">
<utterance> хорошо </utterance>
<utterance> гм хм </utterance>
<utterance> да </utterance>
<similar cluster="c0" similarity="0.7685892367350193" />
</cluster>
<cluster name="c5">
<utterance> хорошо, восемь ноль ноль два один семь ноль пять два девять </utterance>
<utterance> да, это восемь ноль ноль ноль восемь два четыре девять пять восемь </utterance>
</cluster>
<cluster name="c6">
<utterance> вот </utterance>
<utterance> хм </utterance>
</cluster>
<cluster name="c7">
<utterance> да, я хотел бы проверить остаток на моем на счете, пожалуйста </utterance>
</cluster>
<cluster name="c8">
<utterance> которое должно сделать это </utterance>
</cluster>
<cluster name="c9">
<utterance> спасибо </utterance>
</cluster>
<cluster name="c10">
<utterance> привет, я хотел бы проверить остаток на счете при выборе, мой социальный номер три семь семь пять шесть один четыре один три </utterance>
</cluster>
<cluster name="c11">
<utterance>и величина …номер</utterance>
</cluster>
<cluster name="c12">
<utterance> пока </utterance>
</cluster>
<cluster name="c13">
<utterance> привет, я хотел бы проверить мой остаток на счете, моя учетная запись восемьсот семь девятнадцать восемьдесят два пятьдесят пять </utterance>
</cluster>
<cluster name="c14">
<utterance> и сколько это </utterance>
</cluster>
<cluster name="c15">
<utterance> и как сделать это </utterance>
</cluster>
<cluster name="cl6">
<variables>
<variable name="fund" type="Fund"/>
<variable name="navDate" type="date" default="yesterday()"/>
</variables>
<utterance> я хотел бы знать цену на момент закрытия биржи
<instance variable="fund"> акции Касабланки с фиксированным доходом </instance>
on
<instance variable="navDate">тридцать первого января </instance>
</utterance>
</cluster>
<cluster name="c17">
<utterance> уверен</utterance>
</cluster>
<cluster name="c18">
<utterance> спасибо, очень любезно, это является информацией, в которой я нуждался </utterance>
</cluster>
<cluster name="c19">
<utterance>не сегодня</utterance>
</cluster>
<cluster name="c20">
<utterance> я сделаю это, большое спасибо, пока </utterance>
</cluster>
<cluster name="c21">
<utterance> да, у нас пока нет наших 1099 в Касабланкском Фонде </utterance>
</cluster>
<cluster name="c22">
<utterance> это находится под Луи Рено </utterance>
</cluster>
<cluster name="c23">
<utterance> хорошо, ждем еще несколько дней до того, как я позвоню снова </utterance>
</cluster>
<cluster name="c24">
<utterance>привет, можете, Вы, пожалуйста, дать мне для вашего Касабланкского фонда один один нуль </utterance>
</cluster>
<cluster name="c25">
<utterance> очень большое спасибо </utterance>
</cluster>
<cluster name="c26">
<utterance> привет, я хотел только проверить, что выбор все еще закрыт </utterance>
</cluster>
<cluster name="c27">
<utterance> привет, Джон, мое имя Рик Блайн, я делал передачу персонального пенсионного счета от другого фонда и я хотел видеть, пришло ли оно </utterance>
</cluster>
<cluster name="c28">
<utterance> ах да, у вас есть раздел пять двадцать девять планов </utterance>
</cluster>
<cluster name="c29">
<utterance> Вы не делаете </utterance>
</cluster>
<cluster name="c30">
<utterance>да, у меня вопрос: маленький фонд, который платит любые распределения в две тысячи, и один это за мои налоги </utterance>
</cluster>
<cluster name="c31">
<utterance> привет, я интересуюсь Касабланкским Фондом один, я хотел бы проспект и приложение по возможности </utterance>
</cluster>
<cluster name="c32">
<utterance>Блайн и почтовый индекс четыре восемь шесть три семь</utterance>
</cluster>
<cluster name="c33">
<utterance> не только плоскость Блайн, это и Касабланкский Мичиган </utterance>
</cluster>
<cluster name="c34">
<utterance> правильная учетная запись </utterance>
</cluster>
<cluster name="c35">
<utterance> киплингер </utterance>
</cluster>
<cluster name="c36">
<utterance> пока это все, благодарю Вас </utterance>
</cluster>
<cluster name="c37">
<utterance> я только хочу узнать полную сумму моей учетной записи </utterance>
</cluster>
<cluster name="c38">
<utterance> восемь три ноль восемь два девять два шесть четыре </utterance>
</cluster>
<cluster name="c39">
<utterance> Виктор Лазло </utterance>
</cluster>
<cluster name="c40">
<utterance> один нуль восемь три восемь три два девять два </utterance>
</cluster>
<cluster name="c41">
<utterance> очень большое спасибо </utterance>
</cluster>
</clusters>
abc12ucml.ucml file
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE ucml SYSTEM "http://dtd.unveil.com/dtd/ucml.dtd">
<ucml name="text" version="1.1">
<network name="main" initial="true"mre_field="input" threshold="0.75">
<initialTransition name="initial" to="s0">
<output>
спасибо за то, что позвонили в Касабланкский Фонд. Это Натали, Ваш автоматизированный представитель обслуживания клиентов. Как я могу помочь Вам сегодня? </output>
</initialTransition>
<contexts>
<context name"s0"final="false" goToAgent="false">
<transitions>
<transition name="t0"to="s1">
<input cluster="c7" > да, я хотел бы проверить остаток на моем счете пожалуйста</input>
<output> Вы имеете ваш номер счета, сэр </output>
</transition>
<transition name="t1" to="s8">
<input cluster="c10"> привет, я хотел бы проверить остаток на счете на выбор, мой социальный номер три семь семь пять два один четыре один три </input>
<output> спасибо, и можете Вы, пожалуйста, подтвердить Ваше имя и адрес электронной почты</output>
</transition>
<transition name="t2" to="sl5">
<input cluster="с3" > привет, я хотел бы проверить мой остаток на счете, моя учетная запись восемьсот семь семнадцать восемьдесят девять пятьдесят пять </input>
<output> пожалуйста, проверьте Ваше имя и номер социального обеспечения для меня </output>
</transition>
<transition name="t3"to="s23">
<input cluster="c16" > я хотел бы знать цену на момент закрытия биржи Касабланкского Фонда тридцать первого января </input>
<output> хорошо, один момент, сэр </output>
</transition>
<transition name="t4" to="s29">
<input cluster="c21"> да, у нас все же нет наших 1099 на Касабланкском Фонде</input>
<output> хорошо, могу я узнать Ваш номер счета, мэм </output>
</transition>
<transition name="t5" to="s36">
<input cluster="c24" > привет, можете Вы, пожалуйста, дайте мне номер для Вашего Касабланкского Фонда один один нуль </input>
<output> уверен, номер четыре один три восемь три восемь один ноль три</output>
</transition>
<transition name="t6" to="s33">
<input cluster="c26" > привет, я только хотел проверить, что выбор все еще закрыт </input>
<output> да сэр, это есть </output>
</transition>
<transition name="t7" to="s42">
<input cluster="c27"> привет, Джон, мое имя Рик Блайн, я делал передачу пенсионного счета от другого фонда и я хотел видеть, пришло ли все </input>
<output> хорошо, один момент, пожалуйста, и какой ваш номер социального обеспечения, сэр</output>
</transition>
<transition name="t8" to="s48">
<input cluster="c28" > ах да, делаете, Вы имеете раздел пять двадцать девять планов</input>
<output>нет, мы не делаем </output>
</transition>
<transition name="t9" to="s33">
<input cluster="c30"> да, у меня есть вопрос, когда маленький фонд платит любые распределения в две тысячи и за мои налоги</input>
<output> никакого сэра, это не сделало </output>
</transition>
<transition name="t10" to="s56">
<input cluster="c31" > привет, я интересуюсь Касабланкским Фондом один, я хотел бы проспект и приложение по возможности </input>
<output> могу я узнать вашу фамилию </output>
</transition>
<transition name="t11" to="s64">
<input cluster="c37"> я только хочу узнать полное значение моей учетной записи</input>
<output> ваш номер счета пожалуйста </output>
</transition>
</transitions>
</context>
<context name="s1" final="false" goToAgent="false">
<transitions>
<transition name="t12" to="s2">
<input cluster="c5" size="2"> да, это восемь ноль ноль ноль восемь два четыре девять пять восемь </input>
<output> и можете Вы, пожалуйста, проверить имя и номер социального обеспечения, сэр
</output>
</transition>
</transitions>
</context>
<context name="s2" final="false" goToAgent="false">
<transitions>
<transition name="t13" to="s3">
<input cluster="c2" size="6"> да, Рик Блайн, ноль семь четыре два восемь пять восемь три шесть </input>
<output> спасибо, сэр, один момент </output>
</transition>
</transitions>
</context>
<context name="s3" final="false" goToAgent="false">
<transitions>
<transition name="tl4" to="s4">
<input cluster="c4" size="3"> ой </input>
<output> хорошо, на прошлую ночь закрытие баланса в вашу пользу, и традиционный пенсионный счет сорок две тысячи шестьсот сорок один доллар и тридцать два цента</output>
</transition>
</transitions>
</context>
<context name="s4" final="false" goToAgent="false">
<transitions>
<transition name="t15" to="s5">
<input cluster="c0" size="6"> хорошо, благодарю Вас </input>
<output> пожалуйста, что-нибудь еще, в чем Вы нуждаетесь </output>
</transition>
</transitions>
</context>
<context name="s5" final="false" goToAgent="false">
<transitions>
<transition name="t16" to="s6">
<input cluster="c8" > который должен сделать это </input>
<output> не стесняются звонить снова </output>
</transition>
</transitions>
</context>
<context name="s6" final="false" goToAgent="false">
<transitions>
<transition name="t17"to="s7">
<input cluster="c9" >спасибо</input>
<output> пожалуйста пока </output>
</transition>
</transitions>
</context>
<context name="s7" final=''true" goToAgent="false">
<transitions />
</context>
<context name="s8" final="false" goToAgent="false">
<transitions>
<transition name="t18" to="s9">
<input cluster="c2" size="6"> Лиза Лунд один шесть четыре девять улица Касабланки Беркли Калифорния девять четыре семь ноль три </input>
<output> спасибо </output>
</transition>
</transitions>
</context>
<context name="s9" final="false" goToAgent="false">
<transitions>
<transition name="t19" to="s10">
<input cluster="c4" size="3"> хм </input>
<output> хорошо, на закрытие прошлой ночью значение вашей учетной записи было пятнадцать тысяч двести шестьдесят семь долларов и тридцать восемь центов </output>
</transition>
</transitions>
</context>
<context name="s10" final="false" goToAgent="false">
<transitions>
<transition name="t20" to="s11">
<input cluster="c11" > и общее значение акций </input>
<output> значения акций было пятьсот пятьдесят один точка три шесть восемь</output>
</transition>
</transitions>
</context>
<context name="s11" final="false" goToAgent="false">
<transitions>
<transition name="t21" to="s12">
<input cluster="c0" size="6"> хорошо мм, благодарю Вас </input>
<output> хорошо, пожалуйста </output>
</transition>
</transitions>
</context>
<context name="s12" final="false" goToAgent="false">
<transitions>
<transition name="t22"to="s13">
<input cluster="cl2" > пока, теперь </input>
<output> не стесняется звонить снова </output>
</transition>
</transitions>
</context>
<context name="s13" final="false" goToAgent="false">
<transitions>
<transition name="t23" to="s7">
<input cluster="c6" size="2"> хм </input>
<output> пока </output>
</transition>
</transitions>
</context>
<context name="s15" final="false" goToAgent="false">
<transitions>
<transition name="t24"to="sl6">
<input cluster="c2" size="6"> да, это Луи Рено пять ноль один пять, пять ноль ноль шесть шесть </input>
<output>спасибо</output>
</transition>
</transitions>
</context>
<context name="s16" final="false" goToAgent="false">
<transitions>
<transition name="t25" to="s17">
<input cluster="c4" size="3"> хмм </input>
<output> я вижу, что этот счет имеет нулевой баланс </output>
</transition>
</transitions>
</context>
<context name="s17" final="false" goToAgent="false">
<transitions>
<transition name="t26" to="s18">
<input cluster="c4" size="3"> хорошо </input>
<output> там была передача, которая произошла вчера </output>
</transition>
</transitions>
</context>
<context name="s18" final="false" goToAgent="false">
<transitions>
<transition name="t27" to="s19">
<input cluster="c14" > и сколько было </input>
<output> фактическую сумму в долларах по проверке пятнадцать тысяч пятьсот двадцать четыре доллара </output>
</transition>
</transitions>
</context>
<context name="s19"final="false" goToAgent="false">
<transitions>
<transition name="t28" to="s20">
<input cluster="c0" size="6"> хорошо, все в порядке, спасибо </input>
<output> что-нибудь еще </output>
</transition>
</transitions>
</context>
<context name="s20" final="false" goToAgent="false">
<transitions>
<transition name="t29"to="s6">
<input cluster="c15" > это все </input>
<output> если Вы будете нуждаться в чем-нибудь в будущем, пожалуйста не стесняйтесь звонить вновь, сэр</output>
</transition>
</transitions>
</context>
<context name="s23" final="false" goToAgent="false">
<transitions>
<transition name="t30" to="s24">
<input cluster="c17" > конечно </input>
<output> хорошо, тридцать первого января две тысячи два цена на момент закрытия биржи и доход был восемнадцать пятьдесят </output>
</transition>
</transitions>
</context>
<context name="s24"final="false" goToAgent="false">
<transitions>
<transition name="t31" to="s25">
<input cluster="c3" size="5"> восемнадцать пятьдесят </input>
<output> да сэр </output>
</transition>
</transitions>
</context>
<context name="s25" final="false" goToAgent="false">
<transitions>
<transition name="t32" to="s26">
<input cluster="c18"> спасибо большое, это является информацией, в которой я нуждался </input>
<output> хорошо сэр, что-нибудь еще, в чем Вы нуждаетесь сегодня </output>
</transition>
</transitions>
</context>
<context name="s26" final="false" goToAgent="false">
<transitions>
<transition name="t33"to="s27">
<input cluster="c19" > не сегодня </input>
<output> хорошо сэр, пожалуйста звоните снова, если мы можем помочь Вам с чем-нибудь в будущем </output>
</transition>
</transitions>
</context>
<context name ="s27"final="false" goToAgent="false">
<transitions>
<transition name="t34" to="s7">
<input cluster="c20" > я сделаю это, спасибо, пока </input>
<output> до свидания </output>
</transition>
</transitions>
</context>
<context name="s29" final="false" goToAgent="false">
<transitions>
<transition name="t35" to="s30">
<input cluster="c5" size="2"> хорошо, восемь ноль ноль два один семь ноль шесть три девять </input>
<output> и Ваше имя, пожалуйста </output>
</transition>
</transitions>
</context>
<context name="s30" final="false" goToAgent="false''>
<transitions>
<transition name="t36" to="s31">
<input cluster="c22" > это находится под Виктором Лазло </input>
<output> и можете, Вы, проверить номер социального обеспечения на учетной записи </output>
</transition>
</transitions>
</context>
<context name="s31" final="false" goToAgent="false">
<transitions>
<transition name="t37" to="s32">
<input cluster="c3" size="5"> два пять ноль шесть шесть восемь шесть ноль четыре </input>
<output> хорошо, Вы будете получать 1099 на этой учетной записи, последние из них вышли на начало прошлой недели, и Вы должны получить их в течение следующего дня или двух и если мы не сможем перевыпустить их </output>
</transition>
</transitions>
</context>
<context name="s32" final="false" goToAgent="false">
<transitions>
<transition name="t38"to="s33">
<input cluster="c23" > хорошо, ждет еще несколько дней до того, как я позвоню снова </input>
<output> мы можем перевыпустить вам еще одну </output>
</transition>
</transitions>
</context>
<context name="s33" final="false" goToAgent="false">
<transitions>
<transition name="t39" to="s34">
<input cluster-="c0" size="6">хорошо, благодарю Вас </input>
<output> приветствую Вас, мэм </output>
</transition>
</transitions>
</context>
<context name="s34" final="false" goToAgent="false">
<transitions>
<transition name="t40" to="s7">
<input cluster="c1"size="6"> до свидания </input>
<output> хорошего дня </output>
</transition>
</transitions>
</context>
<context name="s36" final="false" goToAgent="false">
<transitions>
<transition name="t41" to="s37">
<input cluster="c3" size="5"> четыре один три восемь три восемь четыре нуль три </input>
<output> это правильно </output>
</transition>
</transitions>
</context>
<context name="s37" final="false" goToAgent="false">
<transitions>
<transition name="t42" to="s7">
<input cluster="c25" > очень большое спасибо </input>
<output> рады приветствовать вас, пока </output>
</transition>
</transitions>
</context>
<context name="s42" final="false" goToAgent="false">
<transitions>
<transition name="t43" to="s43">
<input cluster="c3" size="5"> три один шесть два восемь шесть пять один четыре </input>
<output> и Ваше имя, пожалуйста </output>
</transition>
</transitions>
</context>
<context name="s43" final="false" goToAgent="false">
<transitions>
<transition name=:"t44" to="s44">
<input cluster="c2" size="6"> Рик Блайн </input>
<output> номер телефона, пожалуйста, сначала код города </output>
</transition>
</transitions>
</context>
<context name="s44" final="false" goToAgent="false">
<transitions>
<transition name="t45" to="s33">
<input cluster="c3" size="5" восемь два восемь четыре семь восемь два о восемь о </input>
<output> давайте посмотрим на количество, никакие деньги не были получены </output>
</transition>
</transitions>
</context>
<context name="s48" final="false" goToAgent="false">
<transitions>
<transition name="t46" to="s49">
<input cluster="c29" > Вы не делаете </input>
<output> к сожалению, нет </output>
</transition>
</transitions>
</context>
<context name="s49" final="false" goToAgent="false'">
<transitions>
<transition name="t47" to="s50">
<input cluster="c0" size="6" хорошо, большое спасибо </input>
<output> пожалуйста </output>
</transition>
</transitions>
</context>
<context name="s50" final="false" goToAgent="false">
<transitions>
<transition name="t48" to="s34">
<input cluster="c1" size="6"> хм пока </input>
<output> если у вас есть еще вопросы, мэм, пожалуйста, звоните нам </output>
</transition>
</transitions>
</context>
<context name="s56" final="false" goToAgent="false">
<transitions>
<transition name="t49" to="s57">
<input cluster="c2" size="6"> Блайн </input>
<output> назовите, пожалуйста, Ваше имя и почтовый индекс </output>
</transition>
</transitions>
</context>
<context name="s57" final="false" goToAgent="false">
<transitions>
<transition name="t50" to="s58">
<input cluster="c32" > Блайн и почтовый индекс четыре восемь два два семь </input>
<output>могу я узнать ваш адрес, пожалуйста </output>
</transition>
</transitions>
</context>
<context name="s58" final="false" goToAgent="false">
<transitions>
<transition name="t51" to="s59">
<input cluster="c2" size="6"> два четыре четыре четыре один Касабланка, это Касабланка </input>
<output> проезд </output>
</transition>
</transitions>
</context>
<context name="s59" final="false" goToAgent="false">
<transitions>
<transition name="t52" to="s60">
<input cluster="c33" > не только просто Блайн, и это - Виши, Мичиган </input>
<output> это специальный пенсионный счет или оба </output>
</transition>
</transitions>
</context>
<context name="s60" final="false" goToAgent="false">
<transitions>
<transition name="t53" to="s61">
<input cluster="c34" > регулярный счет </input>
<output> как Вы узнали о Касабланке, сэр </output>
</transition>
</transitions>
</context>
<context name="s61" final="false" goToAgent="false">
<transitions>
<transition name="t54" to="s62">
<input cluster="c35" > киплингер </input>
<output> хорошо, Вы должны получить информацию по почте в пределах следующих пяти-семи рабочих дней и есть что-нибудь еще, чем я могу помочь Вам </output>
</transition>
</transitions>
</context>
<context name="s62" final="false" goToAgent="false">
<transitions>
<transition name="t55" to="s7">
<input cluster="c36" > пока это все, благодарю Вас </input>
<output> пожалуйста, сэр, хорошего дня </output>
</transition>
</transitions>
</context>
<context name="s64" final="false" goToAgent="false">
<transitions>
<transition name ="t56"to="s65">
<input cluster="c38" > восемь три ноль восемь два девять шесть восемь четыре </input>
<output> Ваше имя </output>
</transition>
</transitions>
</context>
<context name="s65" final="false" goToAgent="false">
<transitions>
<transition name="t57" to="s66">
<input cluster="c39" > Рик Блайн </input>
<output> ваш номер социального обеспечения </output>
</transition>
</transitions>
</context>
<context name="s66" final="false" goToAgent="false">
<transitions>
<transition name="t58" to="s67">
<input cluster="c40" > один нуль восемь три восемь три три пять два </input>
<output>баланс на вашей учетной записи на закрытие прошлым вечером был две тысячи восемьсот семьдесят шесть долларов и восемьдесят один цент </output>
</transition>
</transitions>
</context>
<context name="s67" final="false" goToAgent"="false">
<transitions>
<transition name="t59" to="s68">
<input cluster="c41l" > очень хорошо, спасибо </input>
<output> что-нибудь еще </output>
</transition>
</transitions>
</context>
<context name="s68" final="false" goToAgent="false">
<transitions>
<transition name="t60" to="s34">
<input cluster="c6" size="2"> это все </input>
<output> звоните нам снова с любыми другими вопросами </output>
</transition>
</transitions>
</context>
</contexts>
</network>
</ucml>



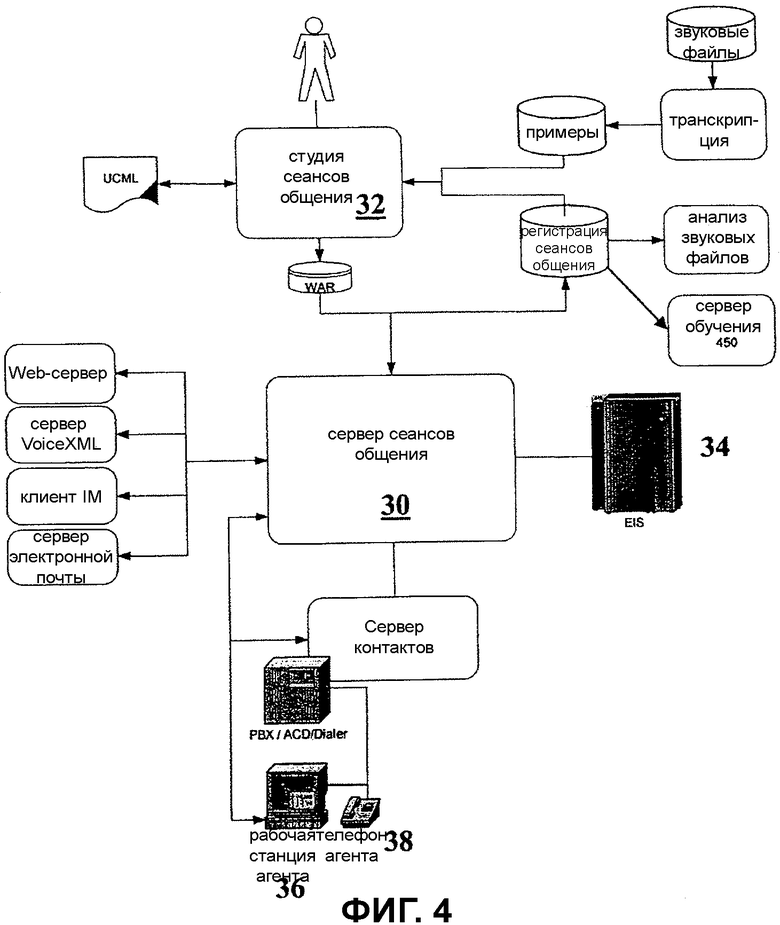
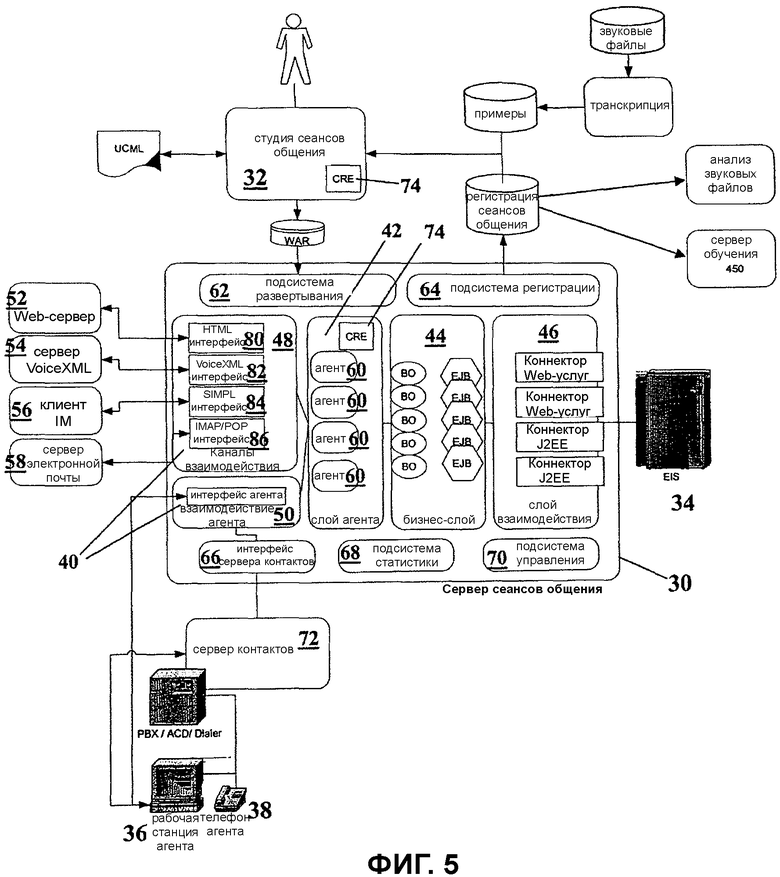
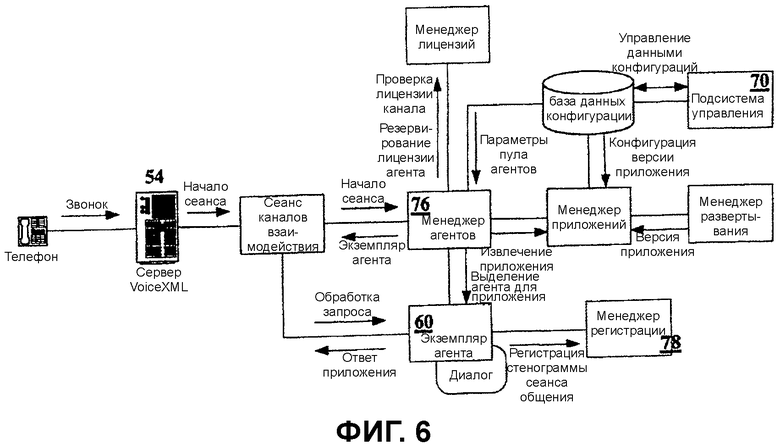
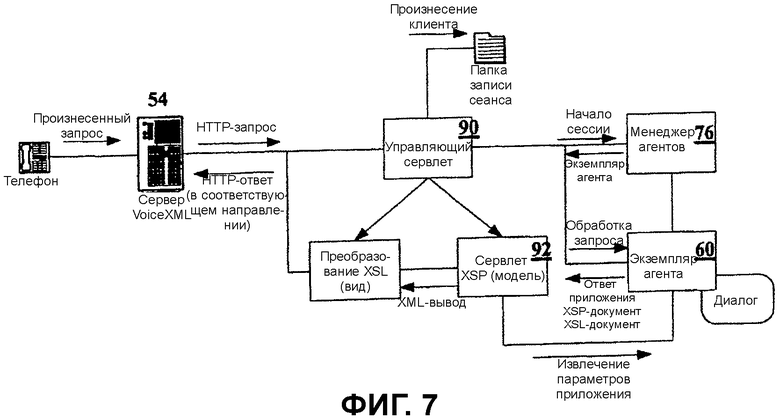
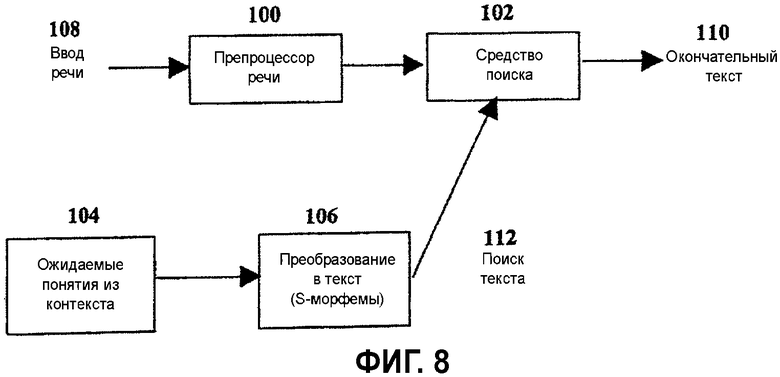

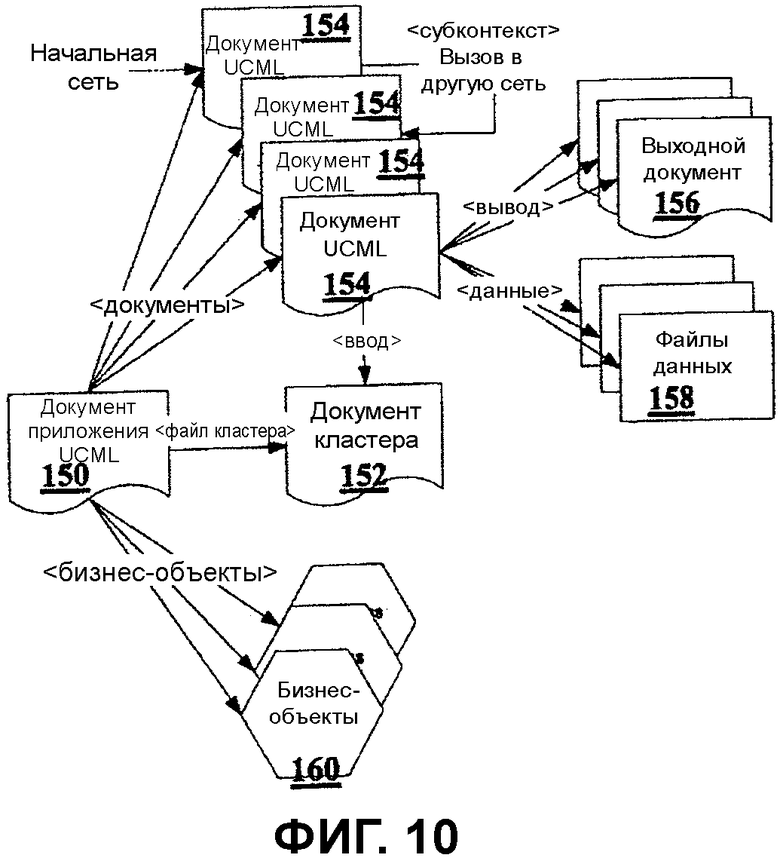
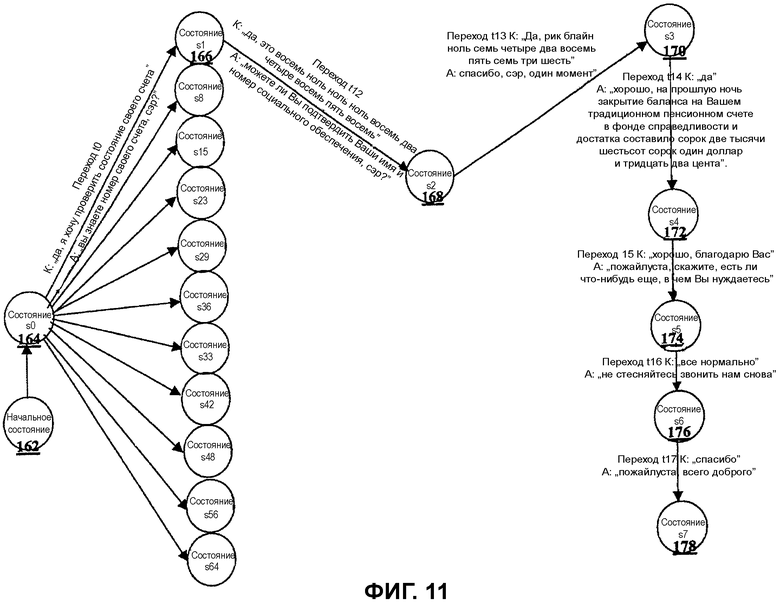


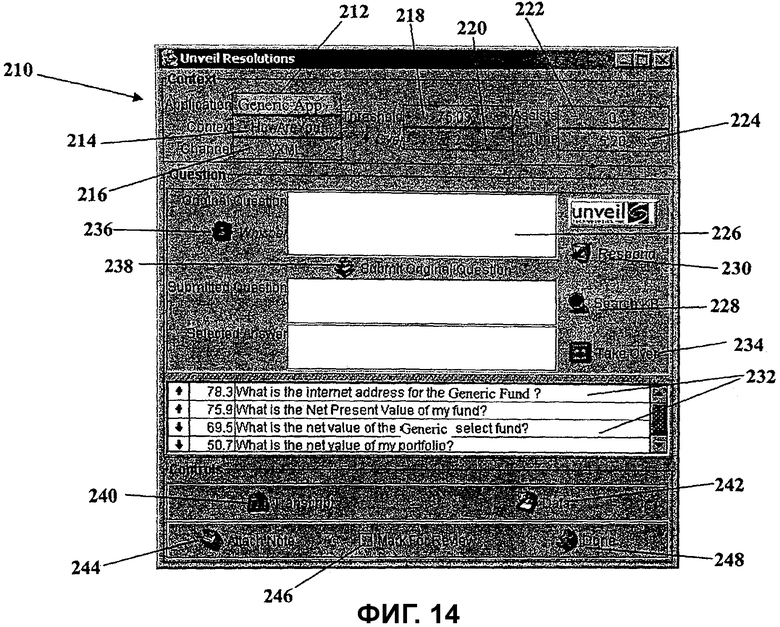
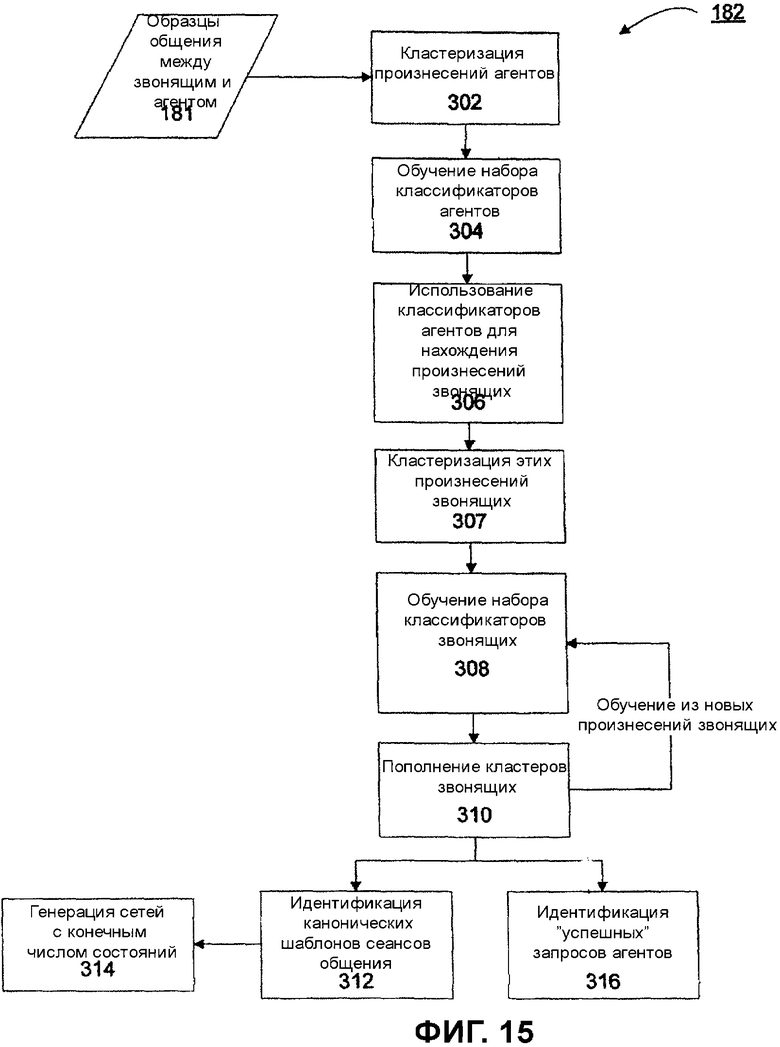
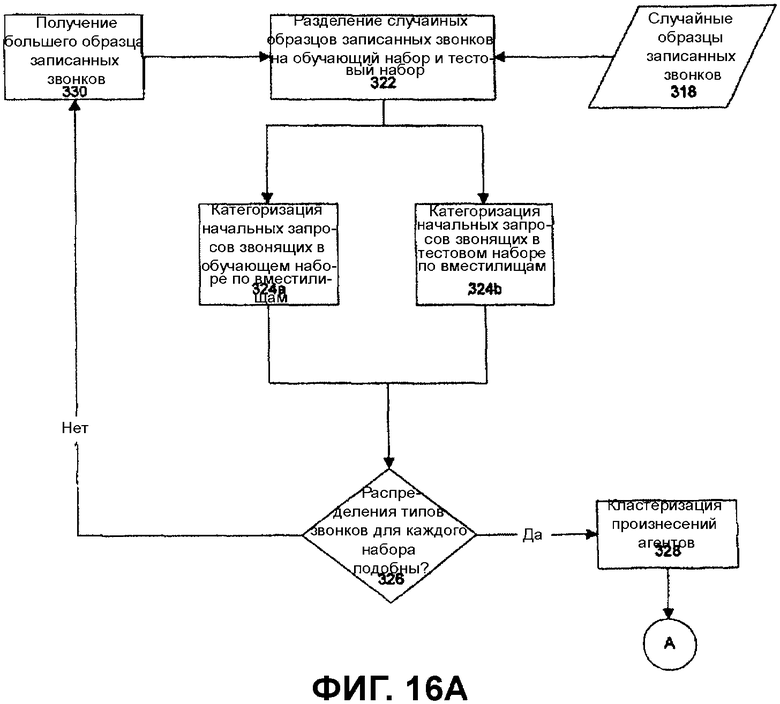
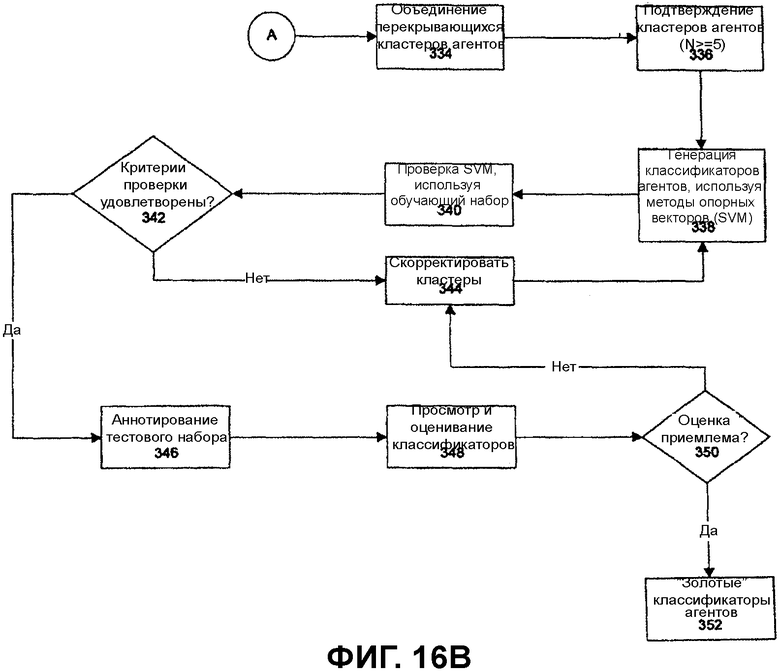
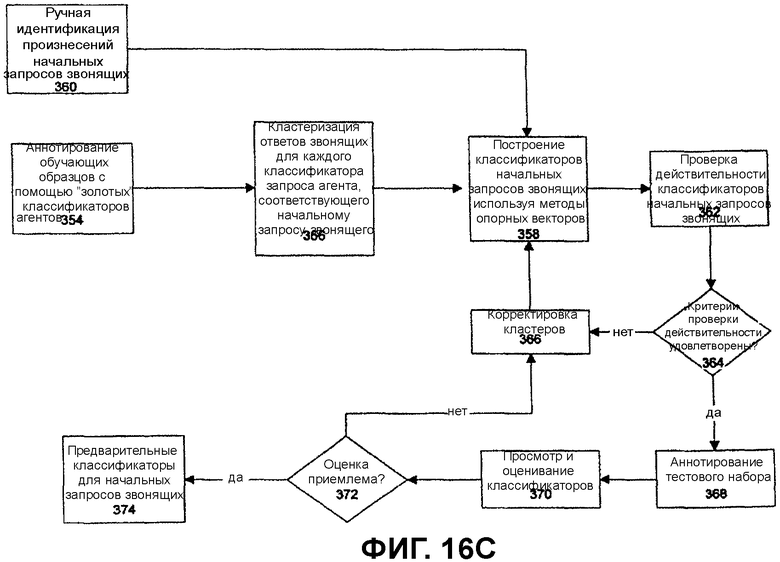

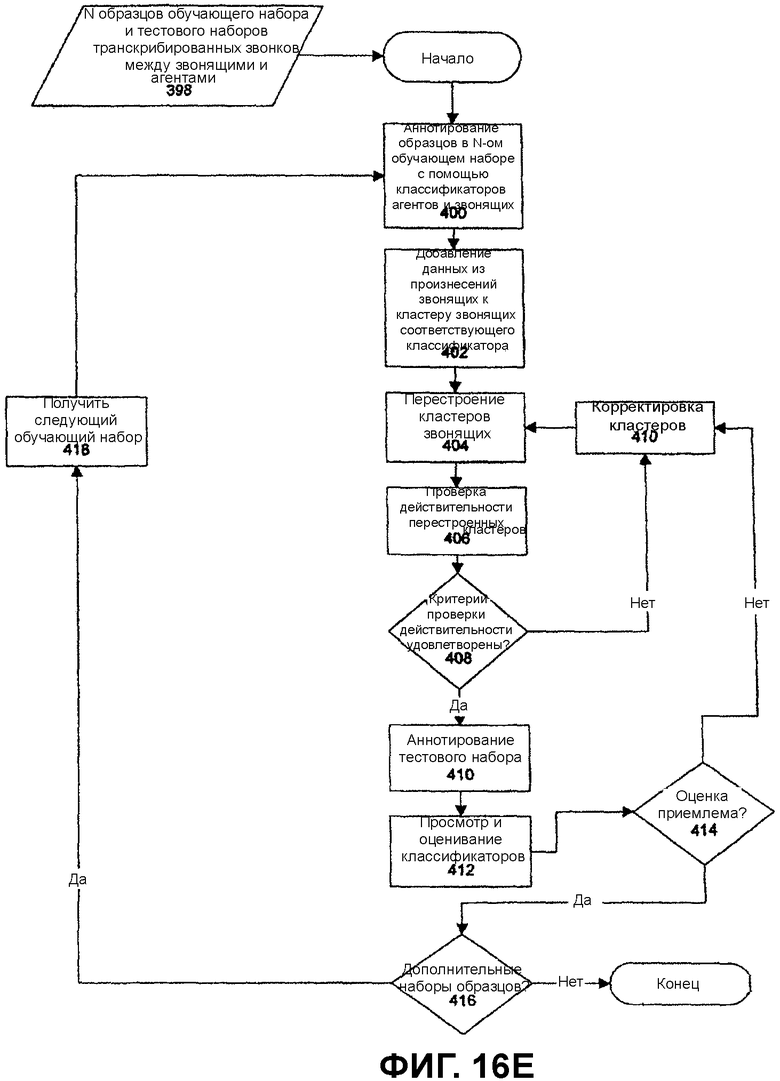


Изобретение относится к машинному обучению в автоматизированной системе ответа. Техническим результатом является расширение функциональных возможностей. Способ обучения включает в себя использование сообщений (например, произнесений, текстовых посланий и т.д.) одной стороны в сеансе общения (например, агента службы обслуживания клиентов) для идентификации и классификации сообщений другой стороны в этом сеансе общения (например, звонящего). Классификаторы могут быть построены из категоризированных сообщений. Классификаторы могут использоваться для того, чтобы идентифицировать общие шаблоны сообщений стороны в диалоге (например, агента). Стратегии обучения могут также включать в себя выбор сообщений в качестве возможностей обучения для совершенствования возможностей автоматизированного ответа на основе критериев выбора. 15 з.п. ф-лы, 17 ил.
1. Способ обеспечения классификации сообщений в системе автоматизированного управления сообщениями, содержащий этапы, на которых:
принимают набор сеансов общения между членами стороны первого типа и членами стороны второго типа, причем каждый из этих сеансов общения включает в себя сообщение члена стороны первого типа и сообщение члена стороны второго типа, которое является ответом на упомянутое сообщение члена стороны первого типа;
группируют сообщения членов стороны первого типа в первый набор кластеров;
генерируют набор классификаторов стороны первого типа для первого набора кластеров;
группируют ответные сообщения членов стороны второго типа во второй набор кластеров на основе упомянутого набора классификаторов стороны первого типа и
генерируют набор классификаторов стороны второго типа для одного или более кластеров во втором наборе кластеров.
2. Способ по п.1, в котором сообщения содержат произнесения.
3. Способ по п.1, в котором сообщения содержат текстовые послания.
4. Способ по п.1, в котором сообщения членов стороны первого типа содержат сообщения являющихся людьми агентов по обслуживанию клиентов в центре обработки звонков.
5. Способ по п.1, в котором сообщения членов стороны первого типа содержат сообщения программных агентов, сконфигурированных для того, чтобы общаться с людьми, которые обращаются в центр обработки звонков.
6. Способ по п.1, в котором сообщения членов стороны второго типа содержат сообщения людей, которые обратились в центр обработки звонков.
7. Способ по п.1, в котором классификаторы содержат средства, реализующие метод опорных векторов.
8. Способ по п.1, в котором классификаторы содержат деревья решений.
9. Способ по п.1, в котором сообщения членов стороны первого типа группируют в первый набор кластеров, используя компьютер.
10. Способ по п.9, в котором при группировании сообщений членов стороны первого типа в первый набор кластеров определяют семантические особенности этих сообщений.
11. Способ по п.1, в котором группирование сообщений членов стороны первого типа в первый набор кластеров основывается на смысловом значении этих сообщений членов стороны первого типа.
12. Способ по п.1, в котором при группировании сообщений членов стороны первого типа в первый набор кластеров группируют сообщения, соответствующие запросам на предмет информации от членов стороны первого типа, в первый набор кластеров.
13. Способ по п.12, в котором при группировании ответных сообщений членов стороны второго типа во второй набор кластеров на основе упомянутого набора классификаторов стороны первого типа группируют сообщения членов стороны второго типа в группы, соответствующие ответам на запросы на предмет информации от членов стороны первого типа.
14. Способ по п.12, в котором при группировании ответных сообщений членов стороны второго типа во второй набор кластеров, основываясь на группировании сообщений членов стороны первого типа, используют классификаторы стороны первого типа для классификации сообщения члена стороны первого типа в кластер стороны первого типа;
группируют сообщение члена стороны второго типа, которое следует за классифицированным сообщением члена стороны первого типа, в кластер стороны второго типа, который соответствует упомянутому кластеру стороны первого типа.
15. Способ по п.14, в котором кластер стороны первого типа имеет отношение к запросу на предмет информации, сделанному членом стороны первого типа, а кластер стороны второго типа имеет отношение к ответу на упомянутый запрос на предмет информации, выданному членом стороны второго типа.
16. Способ по п.1, дополнительно содержащий этапы, на которых:
принимают второй набор сеансов общения между членами стороны первого типа и членами стороны второго типа, причем каждый из этих сеансов общения включает в себя сообщение члена стороны первого типа и сообщение члена стороны второго типа, которое является ответом на сообщение члена стороны первого типа;
применяют классификаторы для группирования сообщений членов стороны второго типа;
повторно генерируют классификаторы стороны второго типа для кластера во втором наборе кластеров, используя данные, касающиеся сообщений, сгруппированных в этом кластере.
| СПОСОБ ПЕРЕДАЧИ СООБЩЕНИЯ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 1994 |
|
RU2097924C1 |
| СПОСОБ ОПТИМАЛЬНОЙ ПЕРЕДАЧИ СООБЩЕНИЙ ЛЮБОЙ ФИЗИЧЕСКОЙ ПРИРОДЫ, НАПРИМЕР, СПОСОБ ОПТИМАЛЬНОГО ЗВУКОВОСПРОИЗВЕДЕНИЯ И СИСТЕМА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ, СПОСОБ ОПТИМАЛЬНОГО, ПРОСТРАНСТВЕННОГО, АКТИВНОГО ПОНИЖЕНИЯ УРОВНЯ СИГНАЛОВ ЛЮБОЙ ФИЗИЧЕСКОЙ ПРИРОДЫ | 1997 |
|
RU2145446C1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| US 2002129015 A1, 12.09.2002. | |||

