Эта заявка испрашивает приоритет под 35 U.S.C. § 119(e) U.S. Provisional Patent application Serial No. 60/626,790, которая называется «APPLICATION PROGRAMMING INTERFACE FOR TEXT MINING AND SEARCH», подана 11 ноября 2004 и полностью включена сюда по ссылке.
УРОВЕНЬ ТЕХНИКИ
В сегодняшней информационной эпохе определение местоположения и сборка данных упрощены различными инструментальными средствами, доступными потребителям. Один из способов такого сбора данных может быть облегчен с помощью интерфейса к сети компьютеров (например, интернета, интранета, LAN, WAN и т.д.), где пользователь может ввести желательную информацию в поисковый сервер и извлечь набор результатов, которые соответствуют введенным элементам поиска. Кроме того, пользователь может повторить усилия по поиску для уточнения и/или изменения данных, которые пользователь желает извлечь. Такие дополнительные поиски могут быть проведены вручную или автоматически, основываясь на желаниях пользователя.
Существует множество различных поисковых серверов, которые выполняют поиск, используя уникальные алгоритмы и/или технологии для определения местонахождения и возвращения данных пользователю. Например, один поисковый сервер может предоставить инструмент, который позволяет пользователю запрашивать данные, используя булеву строку, тогда как другой поисковый сервер может использовать естественный языковой интерфейс для пользователя. В качестве дополнительного примера, поисковый сервер может ограничить свой поиск документами, которые соответствуют предопределенным критериям, тогда как второй поисковый сервер может просматривать каждый доступный ресурс, чтобы извлечь требуемую информацию.
Как правило, поисковый сервер действует в виде службы, где служба делает запрос к желательным потенциальным источникам данных и затем получает набор информации типа, например, текста или расширяемого языка разметки (XML). Такие результаты могут быть возвращены неорганизованным способом, когда пользователь должен разбирать всю возвращенную информацию, чтобы определить, содержит ли один или более результатов информацию, которую пользователь хотел извлечь. В этом случае поиск информации может быть неэффективен и/или неполон, если пользователь будет не в состоянии определять местонахождение требуемой информации из возвращенного набора. Кроме того, если пользователь неоднократно выполняет поиск данных, может быть неэффективно для пользователя непрерывно вводить элементы поиска в поисковый сервер. Так что необходимым являются системы и/или способы, которые позволяют производить более эффективный поиск и определение местоположения данных, которые запрашивает пользователь.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Ниже представлена упрощенная сущность различных аспектов, описанных здесь, для обеспечения базового понимания таких аспектов. Это описание сущности не является обширным кратким обзором изобретения. Оно не предназначено ни для того, чтобы определить ключевые или критические элементы изобретения, ни для очерчивания возможностей изобретения. Собственно, цель состоит в том, чтобы представить некоторые понятия изобретения в упрощенной форме, в виде вводной части к более детальному описанию, которое будет представлено позднее.
Описываются системы и способы, которые позволяют осуществлять программируемый доступ к результатам поискового сервера и файлам (журналам) регистрации запросов в структурной форме. Результаты поиска могут быть извлечены, например, из поискового сервера в промежуточной XML форме, которая является подобной той, что используется для подготовки страницы языка разметки гипертекста (HTML) для web-браузеров. Эта промежуточная форма может потом быть раздроблена на машине клиента, используя локальные ресурсы, для сборки в структурные объекты. Промежуточная форма может содержать больше информации, чем та, что обычно содержится на результирующих HTML страницах, подготовленных для web-браузеров (например, но не ограничиваясь этим, отладочную статистику или классификацию данных).
Библиотека также обеспечивает кэширование результатов поиска. Это может быть обеспечено и на локальной машине, и на удаленной базе данных. Когда результаты для запроса существуют в кэше, они могут быть, например, извлечены из такого местоположения, вместо того чтобы запрашивать поисковый сервер. Документы (web-страницы) могут также кэшироваться. Библиотека может также быть предписана работать только из кэша, фактически исследуя локальный набор данных, вместо удаленного поискового сервера. Кэшируемые данные могут быть отредактированы или полностью сконструированы. Может поддерживаться множество кэш-буферов, так что если кэш-буфер изменяется через какое-то время, результаты поиска могут сравниваться для различных периодов с помощью переключения кэш-буферов.
Библиотека может быть нацелена на множество поисковых серверов, использующих тот же самый компонент API. Это позволяет приложениям, использующим компонент API, немедленно переключаться между поисковыми серверами, не изменяя их код. Библиотека обрабатывает необходимые преобразования, заставляющие все поисковые взаимодействия появляться одинаковым образом. Дополнительно библиотека может создать web-страницы, которые выглядят как страницы результата специфического поискового сервера, даже если запрос и результаты исходили из другого поискового сервера или были созданы полностью.
Для достижения вышеупомянутых и связанных целей изобретение содержит особенности, полностью описанные в дальнейшем. Данное описание и присоединенные чертежи формулируют подробно некоторые иллюстративные аспекты изобретения. Однако эти аспекты являются показательными для некоторых из различных путей, в которых принципы изобретения могут использоваться. Другие аспекты, преимущества и новые особенности изобретения станут очевидными из следующего подробного описания изобретения при рассмотрении его вместе с чертежами.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1 иллюстрирует примерную информационно-поисковую систему в соответствии с аспектом изобретения.
Фиг.2 иллюстрирует примерную информационно-поисковую систему с компонентом извлечения и компонентом результатов в соответствии с аспектом изобретения.
Фиг.3 иллюстрирует примерную информационно-поисковую систему с файлом регистрации запроса и кэшем результатов в соответствии с аспектом изобретения.
Фиг.4 иллюстрирует библиотеку и прикладной программный интерфейс в соответствии с аспектом изобретения.
Фиг.5 иллюстрирует примерную систему, которая использует библиотеку и прикладной программный интерфейс с множеством поисковых серверов в соответствии с аспектом изобретения.
Фиг.6 иллюстрирует систему сборки данных, используемую для создания страницы, в соответствии с аспектом изобретения.
Фиг.7 иллюстрирует примерную методологию, которая оптимизирует разработку через использование результатов поискового сервера в соответствии с аспектом изобретения.
Фиг.8 иллюстрирует примерную методологию, которая извлекает и собирает данные для потребления из автономных источников данных в соответствии с аспектом изобретения.
Фиг.9 иллюстрирует примерную методологию, которая использует API для определения местонахождения и реализации данных в соответствии с аспектом изобретения.
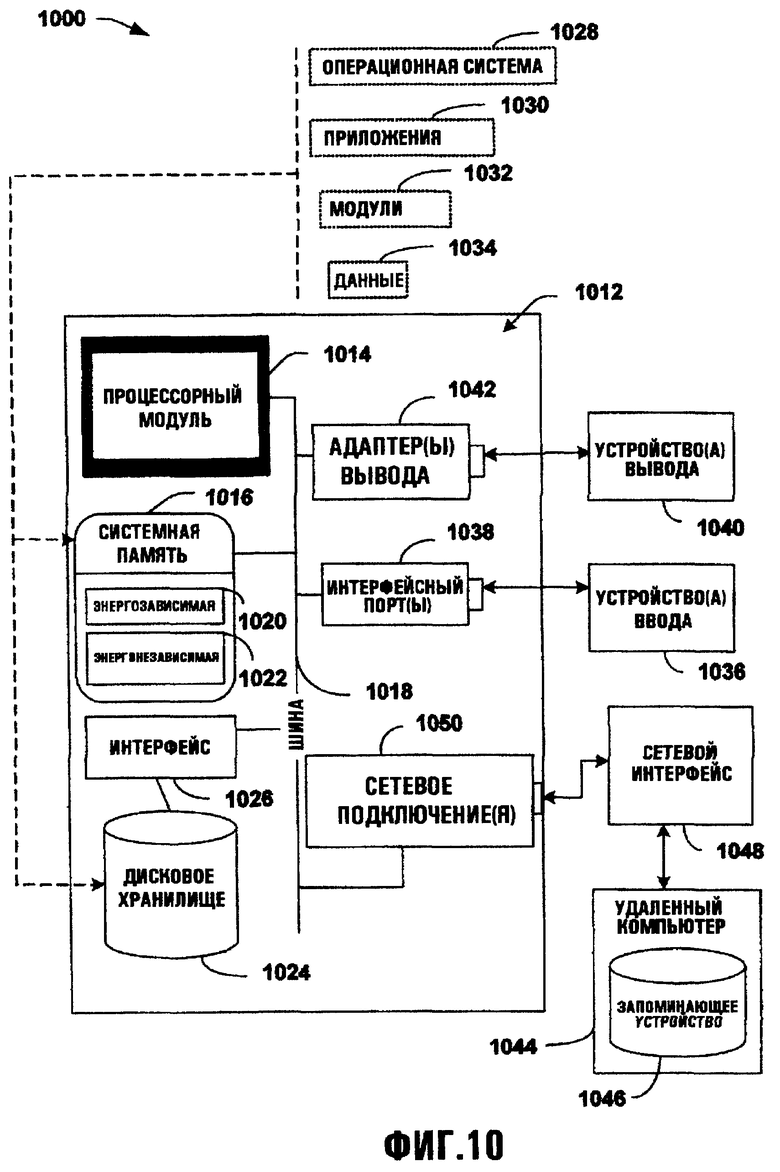
Фиг.10 иллюстрирует примерную компьютерную среду в соответствии с различными аспектами изобретения.
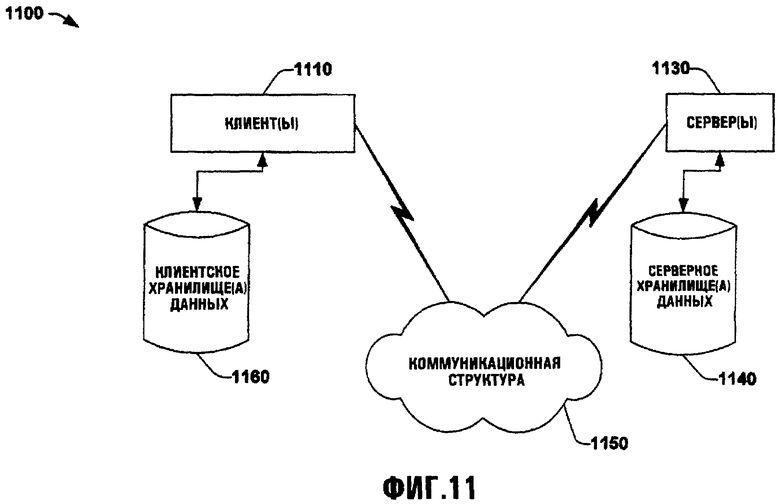
Фиг.11 иллюстрирует примерную сеть, которая может использоваться в соответствии с различными аспектами изобретения.
Приложение A описывает различные библиотеки класса и интерфейсы прикладной программы, и этот документ рассматривается как часть данного описания.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Различные аспекты данного изобретения будут теперь описаны со ссылкой на чертежи, в которых повсюду ссылки с подобными цифрами используются для обращения к подобным элементам. Изобретение относится к системам и способам, которые могут позволить разработчикам использовать компоненты прикладного программного интерфейса (API), который обеспечивает доступ к результатам поискового сервера и файлам регистрации запроса. Результаты поискового сервера могут кэшироваться, и файлы регистрации запроса могут использоваться так, чтобы разработчик мог использовать эти компоненты API для связи с помощью интерфейса с библиотекой результатов поиска и файлов регистрации запроса, для того чтобы быть способным более легко проектировать программы и/или web-сайты, которые уменьшают усилия для кэширования результатов поиска и файлов регистрации запроса. Этим способом приложение, использующее такие результаты поиска, может быть выполнено более эффективно и может ограничить загрузку обработки поисковым сервером, используя кэш-буфер результатов вместо неоднократного использования поискового сервера. Такое кэширование данных может произойти во множестве мест, таких как, например, локальный диск, память или предварительно сконфигурированный кэш-сервер.
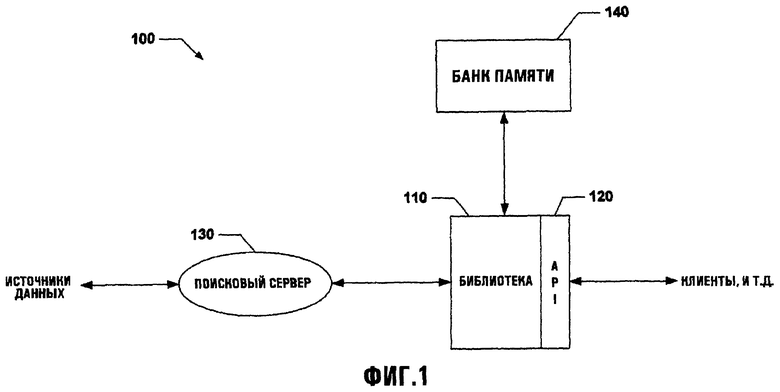
Обратимся теперь к Фиг.1, которая иллюстрирует систему 100 с библиотекой 110 и компонентом 120 API, который связывается с помощью интерфейса с поисковым сервером 130 и банком 140 памяти. Библиотека 110 может использоваться для предоставления данных одному или более пользователям в структурной форме через компонент 120 API. Такие данные могут быть собраны из различных источников типа, например, поискового сервера 130 и банка 140 памяти. Этим способом структурная форма данных может смягчить потребность в анализе желаемых данных и/или создании программируемых объектов для обращения к таким данным.
Компонент 120 API может использоваться для сборки и извлечения части информации из поискового сервера 130 и предоставлять, таким образом, эту информацию в структурном формате через библиотеку 110. Структура данных может быть сконфигурирована автоматически или вручную, основываясь на потребностях пользователя и/или приложения. Кроме того, компонент 120 API может использовать ресурсы клиента для того, чтобы, например, снизить загрузку поискового сервера 130. Структура данных может быть определена через библиотеку классов (см. Приложение A, которое рассматривается как часть данного описания). Библиотека классов может использоваться для определения структуры и содержания данных, которые возвращаются поисковым сервером и впоследствии передаются библиотеке 110. Таким образом, согласно одному подходу разработчик web-сайта может использовать компонент 120 API для интерфейса с данными от поискового сервера 130 и/или банка 140 памяти, чтобы быть способным более легко проектировать программы и/или web-сайты, которые снижают влияние данных, предоставленных любым источником данных.
Компонент 120 API может взаимодействовать с помощью интерфейса с одним или более неравноправных приложений и/или устройств (например, банк 140 памяти) для предоставления данных, фактически не обращаясь с запросами к поисковому серверу 130 каждых раз, когда желательны данные и/или результаты. Этим способом требуемые данные могут быть более быстро предоставлены запрашивающему в отличии от обычных способов, без нагрузки фактического поискового сервера. Дополнительно системные ресурсы могут распределятся и управляться таким образом, что может быть смягчен режим перегрузки. Таким образом, когда данные требуются неоднократно, результаты могут быть предоставлены более быстро, чем обычными способами.
Поисковый сервер 130 может быть любым подходящим типом приложения, способного к принятию набора критериев поиска и использования этих критериев для поиска и предоставления одного или более результатов, которые соответствуют желаемым критериям поиска. Критерии поиска могут касаться одного или более желаемых аспектов информации, таких как длина данных, формат, содержание, дата создания и так далее. Дополнительно поисковый сервер 130 может использовать один или более способов приема элементов данных для использования в поиске типа различных языков, булевских соединителей, содержания, формата и т.п. Один или более пользователей могут обратиться к поисковому серверу 130 локально и/или удаленно. Такая связь с помощью интерфейса может быть достигнута, используя, по меньшей мере, один протокол и/или стандарт, который облегчает связь между компонентом 120 API и поисковым сервером 130. Например, компонент 120 API может быть расположен на компоненте обработки, который использует Ethernet для связи с беспроводным сервером Ethernet. Беспроводный сервер в свою очередь может связаться с поисковым сервером 130 для запроса на проведение, по меньшей мере, одного поиска.
Поисковый сервер 130 может провести поиск, основываясь на событии, периодически или непрерывно, как это требуется. Например, поисковый сервер 130 может использовать набор критериев для выполнения поиска один раз в неделю сроком на шесть месяцев. Этим способом к содержанию, которое добавляется к специфической сети через какое-то время, можно обращаться на регулярной основе для уверенности, что пользователь получил текущее содержание данных. Посредством дальнейшего примера компонент искусственного интеллекта (AI) (не показан) может связаться с поисковым сервером 130 для определения наилучшего способа для выполнения поиска данных. Например, критерии данных пользователя могут изменяться для обеспечения идеального набора результатов данных. Точно так же компонент искусственного интеллекта может использоваться для определения, когда поиск выполняется, основываясь на событиях и/или дополнительной информации, доступной поисковому серверу 130.
В одном аспекте изобретения соответствующее местоположение для предоставления требуемых элементов поиска компоненту доступа может быть определено машиной, знающей, где могут использоваться для обучения системы один или более наборов данных обучения с примерами желательных результатов и/или нежелательных результатов для исследований. В другом аспекте могут использоваться начальные условия, основанные на одной или более особенностях, которые указывают на желательные результаты. Такие начальные условия могут быть откорректированы через какое-то время и в ответ на пользовательские действия связаны с возвращенными результатами для улучшения разрешающей способности. Например, результаты, используемые пользователем, могут использоваться для обучения системы изучению желательных результатов для соответствующего запроса. Кроме того, может использоваться знание того, какие результаты наиболее часто требуются для специфического элемента данных, чтобы сконфигурировать соответствующий интерфейс для выделения только той информации, в которой заинтересован и/или уполномочен для просмотра подписчик данных. Например, результат, к которому пользователь обращается больше одного раза, можно считать более полезным для пользователя. Этим способом, если определенный потребитель данных запрашивает определенные свойства и/или способы, такие аспекты данных могут использоваться в будущем.
Кроме того, как это используется здесь, термин «вывод» относится в общем случае к процессу рассуждения об или выводе о состоянии системы, среды и/или пользователя из набора наблюдений, зафиксированных через события и/или данные. Вывод может использоваться, например, для идентификации определенного контекста или действия или для генерации распределения вероятности по состояниям. Вывод может быть вероятностным, то есть вычислением распределения вероятности по состояниям, представляющим интерес, основанный на рассмотрении данных и событий. Вывод может относится к методам, используемым для составления высокоуровневых событий из набора событий и/или данных. Такой вывод может привести к конструированию новых событий или действий из набора наблюдаемых событий и/или сохраненных данных событий, являются ли или нет события коррелированными в близкой временной близости, и исходят ли события и данные из одного или нескольких событий и источников данных. Различные схемы классификации и/или системы (например, метод опорных векторов, нейронные сети (например, сети с обратным распространением ошибки, сети с прямым распространением сигнала и обратным распространением ошибки, сети на основе радиально-базисных функций, сети с нечеткой логикой), экспертные системы, байесовские сети и синтез данных) могут использоваться в связи с выполнением автоматического и/или выведенного действия в связи с данным изобретением.
В еще одном аспекте изобретения может использоваться методика для предвидения критериев поиска, используемых пользователем. Например, информация типа исторических данных, представляющих данные и атрибуты, связанные с такими данными, используемыми для предоставления требуемых элементов поиска компоненту доступа, может использоваться для предсказания предпочтительного местоположения для извлечения требуемых данных в сети. Например, интеллектуальные решения, основанные на статистике, вероятностях, выводах и классификаторах (например, явно и неявно обученные), включая байесовское изучение, байесовские классификаторы и другие статистические классификаторы типа способов с деревом решений, метода опорных векторов, линейную и нелинейную регрессию и/или нейронные сети, могут использоваться в соответствии с аспектом данного изобретения. При этом способе компонент искусственного интеллекта (не показан) может использоваться компонентом 110 доступа для обеспечения принятия решения, основываясь на изученных действиях определенного потребителя данных специфического источника данных.
Банк 140 памяти может использоваться для хранения параметров, связанных с данными, и/или хранения фактических данных. Такие данные могут быть структурированы в банке 140 памяти в требуемом виде и дополнительно могут предоставить данные, которые будут организованы и отредактированы пользователем. Например, данные, связанные с поисковым сервером 130, например запросы и результаты, могут быть сохранены в банке 140 памяти и могут быть доступны по желанию. Дополнительно данные из банка 140 памяти могут использоваться исключительно для уменьшения расхода ресурсов поискового сервера 130.
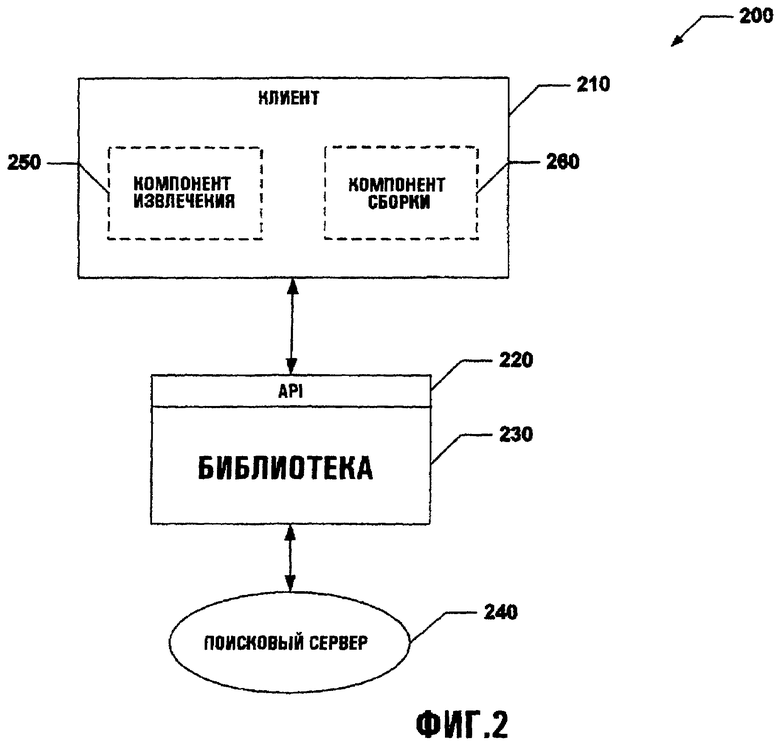
Фиг.2 иллюстрирует систему 200, где клиент присоединен к компоненту 220 API и библиотеке 230 для обращения к поисковому серверу 240. Компонент 250 сборки и компонент 260 извлечения используются с клиентом для облегчения потребления данных, полученных от компонента 220 API. Клиент 210 может быть существенно любым устройством, системой и/или компонентом, который требует данных из неравнозначного источника. Например, клиент может быть приложением, выполняющимся на процессоре, где приложение использует данные для создания и публикации web-страницы одному или более пользователям.
Компонент 250 извлечения может использоваться для принятия данных от компонента 220 API и/или библиотеки 230 в промежуточной форме, где данные могут более легко управляемы и использованы клиентом 210. Например, результаты поиска из поискового сервера 240 могут быть представлены клиенту в промежуточной XML форме, которая является существенно близкой к данным, используемым для подготовки страницы HTML для web-браузеров. Компонент извлечения может тогда анализировать требуемые данные, используя ресурсы клиента. После разделения компонент сборки может собрать извлеченные данные для создания, например, web-страницы HTML.
Фиг.3 иллюстрирует систему 300, в которой поисковый сервер 310 соединен с файлом 320 регистрации запросов и кэш-буфером 330 результатов. И файл 320 регистрации запросов, и кэш-буфер 330 результатов связаны с библиотекой 340 для того, чтобы позволить передавать данные от поискового сервера 310. Библиотека 340 может связаться с компонентом 360 сборки через компонент 350 API. Как обсуждалось выше, поисковый сервер 310 может принять объекты данных в виде терминов поиска и впоследствии выполнить поиск для извлечения данных из одного или более несопоставимых источников. Такие термины поиска могут быть сохранены в файле 320 регистрации запросов и могут быть организованы, отредактированы и извлечены в более позднее время. Точно так же данные, собранные поисковым сервером 310, могут быть сохранены в кэш-буфере результатов 330 и организованы и структурированы, как требуется.
При этом способе библиотека 340 может связаться с помощью интерфейса и с поисковым сервером 310, и с результатами поискового сервера, сохраненными в кэш-буфере 330 результатов. Библиотека может структурировать данные из любого источника для предоставления неравноправной стороне. Компонент 350 API может запросить требуемую структуру данных от библиотеки для использования компонентом 360 сборки. Надлежащий источник для требуемых данных может быть определен, основываясь на одном или более факторах, таких как частота запросов, содержание, и/или тип требуемых данных, и/или возраст требуемых данных. При этом способе можно управлять более эффективным использованием системных ресурсов при предоставлении данных, которые соответствуют ожиданиям пользователя. Кроме того, кэш-буфер 330 результатов может использоваться, например, для преобразования сохраненных данных из одного формата в другой формат. Кроме того, может быть проведен один аудит или внутренний аудит для удаления избыточных результатов поиска и для обеспечения очистки данных, если это требуется.
Кроме того, кэш-буфер 330 результатов может собирать возвращенные данные, которые пользователь может связать с помощью интерфейса и использовать для выбора требуемых данных. Например, данные, сохраненные в кэш-буфере 330 результатов, могут использоваться, например, для создания точной копии web-страницы. При этом способе компонент 360 сборки может получить данные, которые выглядят как данные в режиме реального времени. Дополнительно кэш-буфер 330 результатов может позволить компоненту 360 сборки извлекать данные в режиме реального времени, как требуется. При этом способе кэш-буфер 330 результатов может использоваться вместо или вместе с поисковым сервером 310 для извлечения требуемых данных.
Данные и/или указатели данных, которые постоянно находятся в кэш-буфере 330 результатов, могут быть организованы и отредактированы для того, чтобы облегчить эффективный доступ к данным и/или указателям данных, которые заполняют кэш-буфер 330 результатов. Например, данные могут быть сгруппированы согласно проводимым поискам, содержанию данных, формату данных и т.п. Как другой пример, содержание данных может быть отредактировано для упрощения использования неравноправным устройством типа компонента 360 сборки. Таким образом, используя кэш-буфер 330 результатов, можно предоставить предварительно отформатированные данные и уменьшить занятость ресурсов поискового сервера для обеспечения более эффективной системной архитектуры.
Библиотека 340 может запросить и получить данные как из источников в реальном масштабе времени типа поискового сервера 310, так и из сохраненных мест типа файла 320 регистрации запроса и кэш-буфера 330 результатов. Может использоваться API для запроса данных, содержания, структуры и т.п. из библиотеки для предоставления этой информации компоненту 360 сборки. Например, данными, предоставленными компоненту 360 сборки, может быть форма XML, которая может быть проанализирована и восстановлена, как требуется. Например, компонент сборки может использовать и сохраненные данные, и данные в режиме реального времени для создания точной копии интерактивной web-страницы, которая может использоваться одним или более пользователями. Таким образом, компонент 360 сборки может получить данные от API 350 и восстановить данные, как это требуется пользователем.
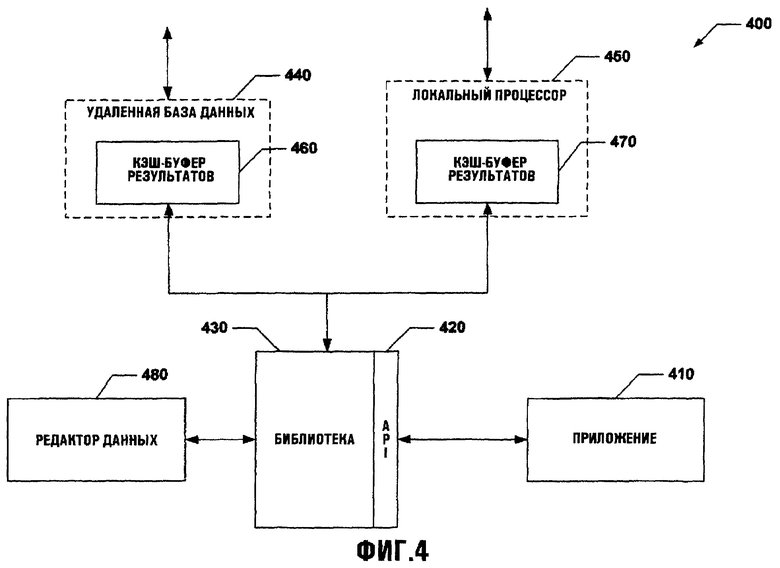
Фиг.4 иллюстрирует систему 400, в которой приложение 410 использует компонент 420 API для связи с помощью интерфейса с удаленной базой 440 данных и локальным процессором 450 через библиотеку 430. Удаленная база 440 данных и локальный процессор 450 содержат кэш-буферы 460 и 470 результатов. Эти кэш-буферы могут предоставить хранилища данных для специфических типов данных, форматов, содержания и так далее. Таким образом, результаты из запроса могут быть извлечены из одного или более кэш-буферов результатов (например, 460, 470 и т.д.), как это требуется пользователем. Библиотеке 430 может также быть предписано работать только из кэш-буфера, эффективно выдавая, например, локальный набор данных вместо удаленного поискового сервера. Кэшируемые данные могут быть отредактированы или полностью созданы через редактор 480 данных. Дополнительно может поддерживаться множество кэш-буферов, то есть если кэш-буфер изменяется через какое-то время, результаты поиска могут быть сравнены для различных временных фреймов, переключая кэш-буферы (например, из кэш-буфера 460 результатов к кэш-буферу 470 результатов).
Редактор 480 данных может использоваться библиотекой 430 для редактирования, организации и структурирования данных, как требуется. Например, приложение 410 может усилить данные от одного или более кэш-буферов результатов и может структурировать и/или сконфигурировать данные для соответствия их требованиям приложения 410. Редактор 480 данных может использовать любое число средств связи с библиотекой 430. Например, редактор данных может быть машинным интерфейсом с пользователем, который предоставляет инструментальные средства для того, чтобы делать требуемые изменения в данных в библиотеке 430.
Удаленной базой 440 данных может быть почти любая платформа, в которой сохраняются данные. Такие данные могут быть сконфигурированы, организованы, отредактированы и т.д. в пределах удаленной базы 440 данных. Удаленная база 440 данных может связываться с помощью интерфейса с компонентом 420 API через сетевое подключение (например, LAN, WAN, CAN (сеть абонентского доступа) и т.д.) и использовать различные протоколы связи и/или стандарты для связи с помощью интерфейса с компонентом 420 API. Например, удаленная база данных может быть расположена в неравноправной сети и может принять результаты после того, как каждый поиск данных выполнен.
Локальный процессор 450 может быть по существу любым типом устройства, которое может принять и обработать данные, чтобы достигнуть результата. Такая обработка может быть сделана через программное обеспечение и/или аппаратные средства, которые могут постоянно находиться в локальной среде. Поддержание локального кэш-буфера результатов поиска может уменьшить время обработки, используемое с неравноправным устройством типа, например, поискового сервера. Локальный процессор может быть компьютером, программируемым логическим контроллером, программным обеспечением, встроенным программным обеспечением и т.д. Необходимо оценить, что хотя процессор является локальным к компоненту 420 API, его можно связать с помощью интерфейса с компонентом 420 API в существенно любом местоположении, использующем любое число протоколов и/или стандартов.
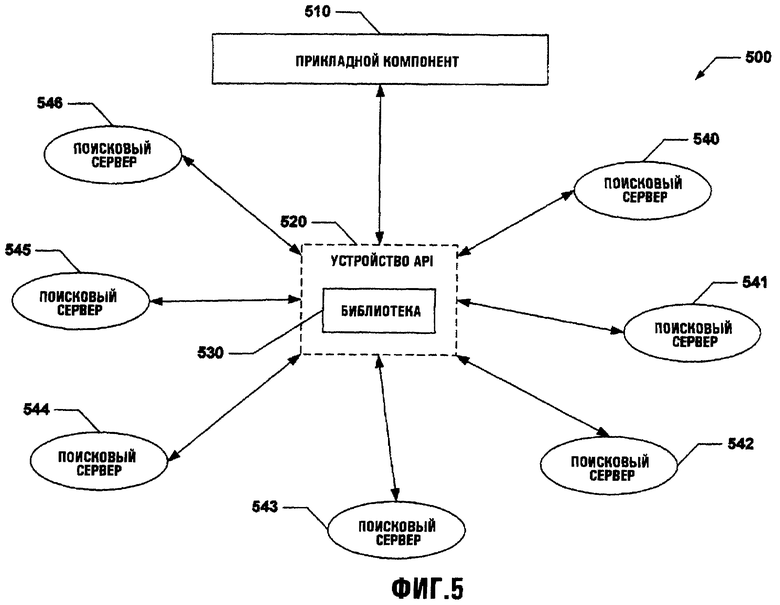
Фиг.5 показывает систему 500, в которой прикладной компонент 510 использует устройство 520 API для связи с помощью интерфейса с множеством поисковых серверов 530-536. Устройство 520 API содержит библиотеку 530, которая содержит результаты поискового сервера и/или файлы регистрации запроса одного или более поисковых серверов 530-536. Прикладной компонент 510 может быть программным обеспечением, используемым, например, для создания и сборки web-страницы. В одном подходе прикладной компонент 510 может быстро определить местонахождение и использовать специфические данные, как это необходимо, используя устройство 520 API. Устройство 520 API может использовать интерфейс для того, чтобы разрешить пользователю выбирать и конфигурировать различные элементы данных, возвращенные из одного или более поисковых серверов 530-536. Кроме того, устройство 520 API может использоваться для определения данных, которые требуется получить через поиск, так же как число и местоположение специфических поисковых серверов, связанных с ними же.
Поисковые серверы 530-536 могут быть расположены удаленно или локально на устройстве 520 API. Например, поисковый сервер 531 может быть удаленным к устройству 520 API и доступен через сеть Интернет. Напротив, поисковый сервер 534 может быть локальным приложением, используемым на том же самом компьютере, что и устройство 520 API, например. Различные протоколы могут использоваться для облегчения связи между устройством 520 API и одним или более поисковыми серверами 530-536.
Может использоваться больше чем один протокол для обеспечения связи между компонентами в системе 500, и такие протоколы могут использоваться одновременно друг с другом. Например, связь с поисковым сервером 530 может использовать беспроводный протокол (например, беспроводной Ethernet, инфракрасный и т.д.), в то время как поисковый сервер 536 одновременно использует Ethernet. При этом способе устройство 520 API не ограничено определенным интерфейсом ввода-вывода для запроса искомых данных и возврата от поисковых серверов 530-536.
Множество поисковых серверов могут быть охвачены, используя устройство 520 API. Это может позволить прикладному компоненту использовать устройство 520 API для того, чтобы прозрачно переключаться между поисковыми серверами 530-536, не изменяя их код. Кроме того, устройство API может обрабатывать преобразования, требуемые для того, чтобы сделать в основном все поисковые взаимодействия выглядящим одинаковым образом. Дополнительно устройство 520 API может создать web-страницы, которые выглядят, как страницы результата специфического поискового сервера 530-536, даже если запрос и результаты исходили из другого поискового сервера или были полностью созданы из неравноправных наборов данных.
Поисковые серверы 530-536 могут использовать любое число определенных алгоритмов и/или подпрограмм для того, чтобы принять и производить требуемые поиски данных. Кроме того, каждый поисковый сервер 530-536 может обеспечить определенную информацию, как это требуется пользователем. При этом способе устройство 520 API может действовать как библиотека, которая заполнена возвращенными результатами поисков, выполненных одним или более поисковыми серверами 530-536. Такие возвращенные данные могут быть структурированы в том виде, к которому можно обратиться прикладным компонентом 510, для устранения потребности в анализе и создании программных объектов для возвращенных данных.
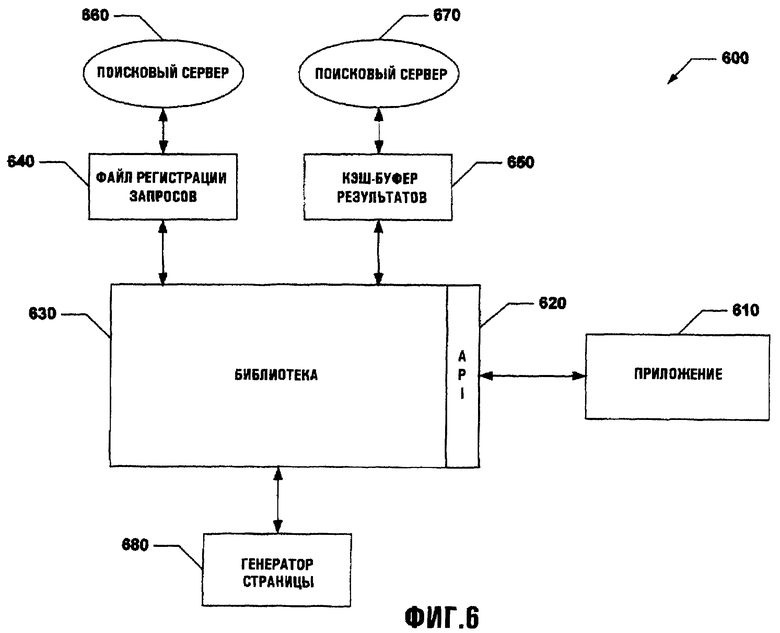
Фиг.6 иллюстрирует систему 600, в которой приложение 610 связывается с компонентом 620 API и библиотекой 630. Библиотека 630 связывается с файлом 640 регистрации запросов, соединенным с поисковым сервером 660, и кэш-буфером 650 результатов, соединенным с поисковым сервером 670. Поисковые серверы 660 и 670 могут провести требуемые поиски специфических данных. Кэш-буфер 650 результатов может быть заполнен документами и/или формами XML, возвращенными, например, одним из поисковых серверов 660 и 670. Результаты поиска могут быть извлечены из поискового сервера в промежуточном XML формате, подобном форме данных, используемой для подготовки страницы HTML для web-браузеров.
Файл 640 регистрации запроса может быть соединен с библиотекой 630 для обеспечения хранения различных данных, связанных с одним или более поисков данных. Файл 640 регистрации запроса может содержать одну или более инструкций, элементы поиска, описатели и т.п., которые использовались для проведения поиска специфических данных. Файл 640 регистрации запроса может использовать компонент редактирования (не показан), который может организовать и делить данные, как это требуется пользователем. Например, данные могут быть сортированы по сеансу, поиску, ключевому слову и так далее.
Генератор 680 страницы может быть соединен с библиотекой 630 для создания точной копии web-страницы, используя неравноправные источники данных. Например, генератор 680 страницы может использовать данные для создания web-страницы, которая выглядит, как страница результатов специфического поискового сервера, даже если запрос и результаты исходили из неравноправных поисковых серверов (например, поисковые серверы 660 и 670) или были созданы полностью. Посредством дальнейшего примера, web-страница или страницы могут быть созданы, используя данные от того же самого поискового сервера и файла регистрации запроса и кэш-буфера результатов, связанного с ними же.
Фиг.7, 8 и 9 иллюстрируют методологии 700, 800 и 900 в соответствии с предметом изобретения. Для простоты объяснения методологии изображены и описаны как ряд действий. Должно быть понято и оценено, что предмет изобретения не ограничен проиллюстрированными действиями и/или порядком действий, например, действия могут произойти в различном порядке и/или одновременно с другими действиями, не представленными и не описанными здесь. Кроме того, не все иллюстрированные действия могут быть обязаны осуществлять методологии в соответствии с предметом изобретения. Кроме того, специалисты в данной области техники поймут и оценят, что методологии могут быть альтернативно представлены как ряд взаимодействующих состояний через диаграмму состояний или события.
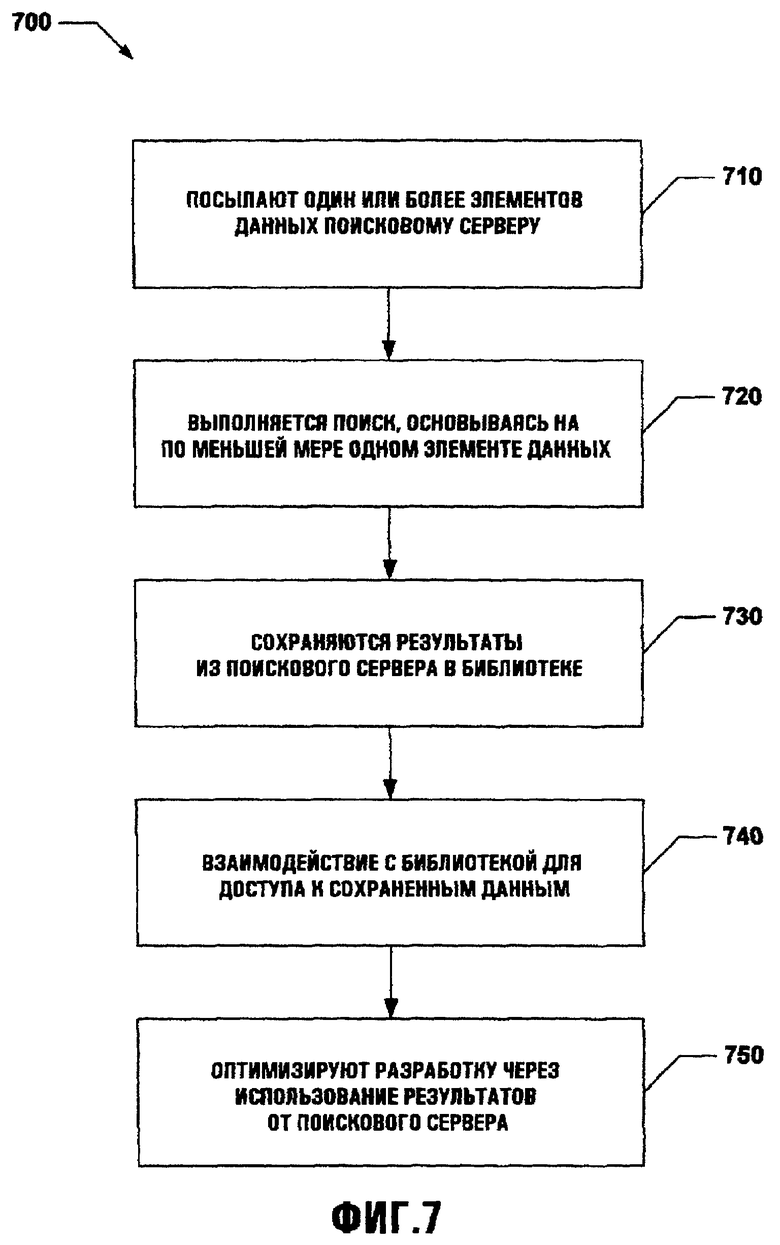
Фиг.7 иллюстрирует методологию 700, которая использует, по меньшей мере, один поисковый сервер для определения местонахождения и извлечения специфических данных для использования с одним или более компонентами. На этапе 710 один или более элементов данных посылают поисковому серверу. Такие элементы данных могут быть по существу любой требуемой длины данных, формата, содержания, упаковки и так далее. Один или более элементов данных могут быть переданы поисковому серверу, использующему различные протоколы и/или стандарты. Кроме того, поисковый сервер может использовать один или более алгоритмов для связи с помощью интерфейса с различными источниками данных для того, чтобы определить местонахождение требуемых данных. Такие поисковые серверы могут быть расположены локально к стороне, посылающей элементы данных (например, на том же самом компьютере), или удаленно, например на неравноправной сети.
На этапе 720 поиск выполняется, основываясь на, по меньшей мере, одном элементе данных, посланном просителем. Проводимый поиск может быть приспособлен к потребностям или требованиям пользователя. Например, поиск может быть ограничен только подмножеством доступных ресурсов или ограничен данными, которые соответствуют одному из нескольких предопределенных форматов. Поиск может проводиться вручную (например, инициализацией пользователя) или автоматически (например, основываясь на событии, периодически или один раз). На этапе 730 результаты из поискового сервера сохраняются. Такие результаты могут быть проанализированы и организованы так, чтобы данные были доступными пользователю в более потребляемой форме. Сохранение данных может быть ограничено, основываясь на времени и/или других факторах, для поддержки только набора данных, который соответствует, например, специфическому ограничению по времени. В качестве дополнительного примера данные могут быть сгруппированы так, что подобные данные сохраняются вместе, и/или данные, которые соответствуют некоторым критериям, сохраняются как подмножество, как это требуется.
На этапе 740 сохраненные данные связываются с помощью интерфейса с одним или более приложениями. Такие приложения могут использовать результаты поискового сервера для создания точной интерактивной копии данных. Связь с сохраненными данными может вовлечь множество неравноправных протоколов, структур данных, и т.п. для того, чтобы должным образом обращаться к требуемым данным. На этапе 750 результаты поискового сервера используются для оптимизации разработки. При одном подходе различные результаты сохраняются в специфической структуре (например, XML, HTML и т.д.) для использования при создании и/или моделировании активности поискового сервера. При этом способе разработчик может использовать такую оптимизацию, например, для обращения и использования данных для специфического приложения.
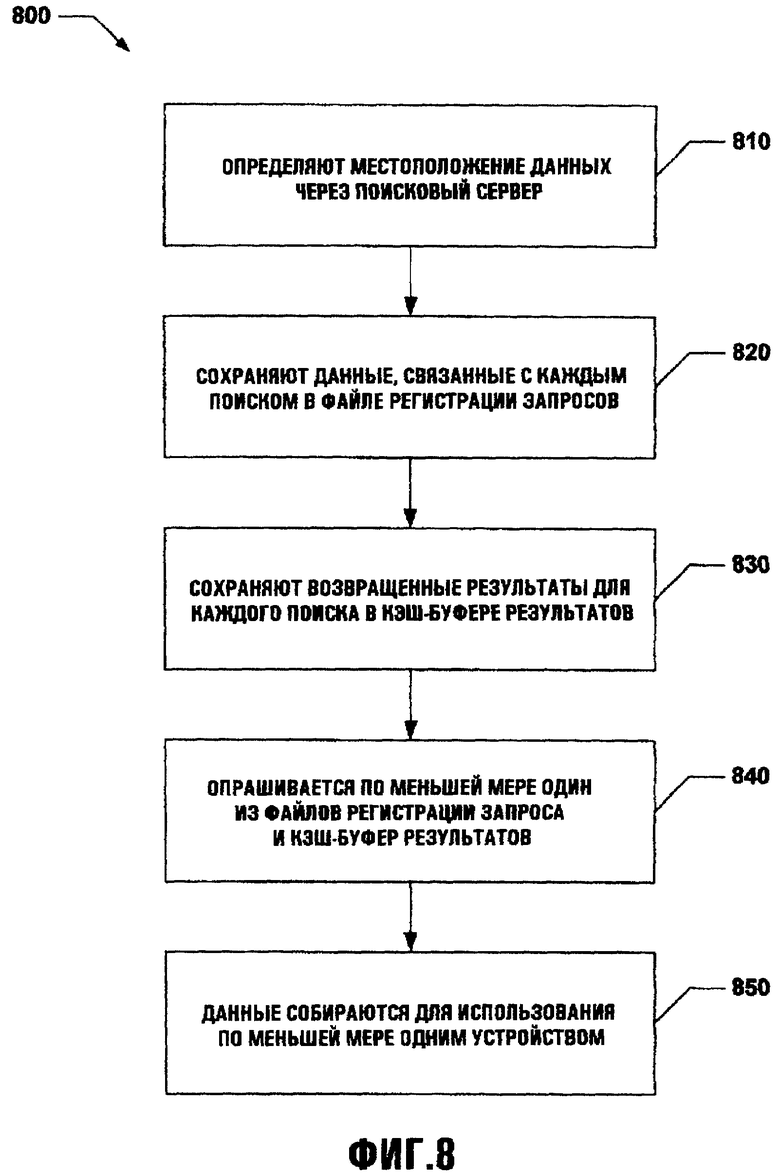
Фиг.8 иллюстрирует методологию 800, при которой сохраненные данные собираются и используются, по меньшей мере, одним устройством. На этапе 810 данные локализуются через поисковый сервер в соответствии с различными параметрами, как определено, по меньшей мере, одним пользователем. На этапе 820 данные (например, термины поиска, команды поиска, элементы данных и т.д.), связанные с каждым поиском, сохраняются в файле регистрации запроса. После того как такой поиск выполнен, возвращенные результаты каждого поиска сохраняются в кэш-буфере результатов. Кэш-буфер результатов может хранить данные, возвращенные из одного или более поисков, как это требуется. Такие возвращенные результаты могут включить не только сами данные, но также и метаданные, которые могут описывать различные свойства данных. Такие свойства могут включать местоположение данных, формат данных, соответствие стандартам данных и т.п.
На этапе 840 опрашивается, по меньшей мере, один из файлов регистрации запроса и кэш-буфер результатов. При этом способе, например, требуемые данные могут быть получены без использования поискового сервера (или другого механизма в режиме реального времени). Получение таких данных без увеличения системных ресурсов (например, поискового сервера) обеспечивает отличное преимущество перед обычными способами. Такие преимущества включают, но не ограничены, эффективность системы, доступ к большему количеству потребляемых данных, предварительное форматирование данных и т.д. На этапе 850 данные, извлеченные из, по меньшей мере, одного из файлов регистрации запроса и/или кэш-буфера результатов, собраны для использования, по меньшей мере, одним устройством.
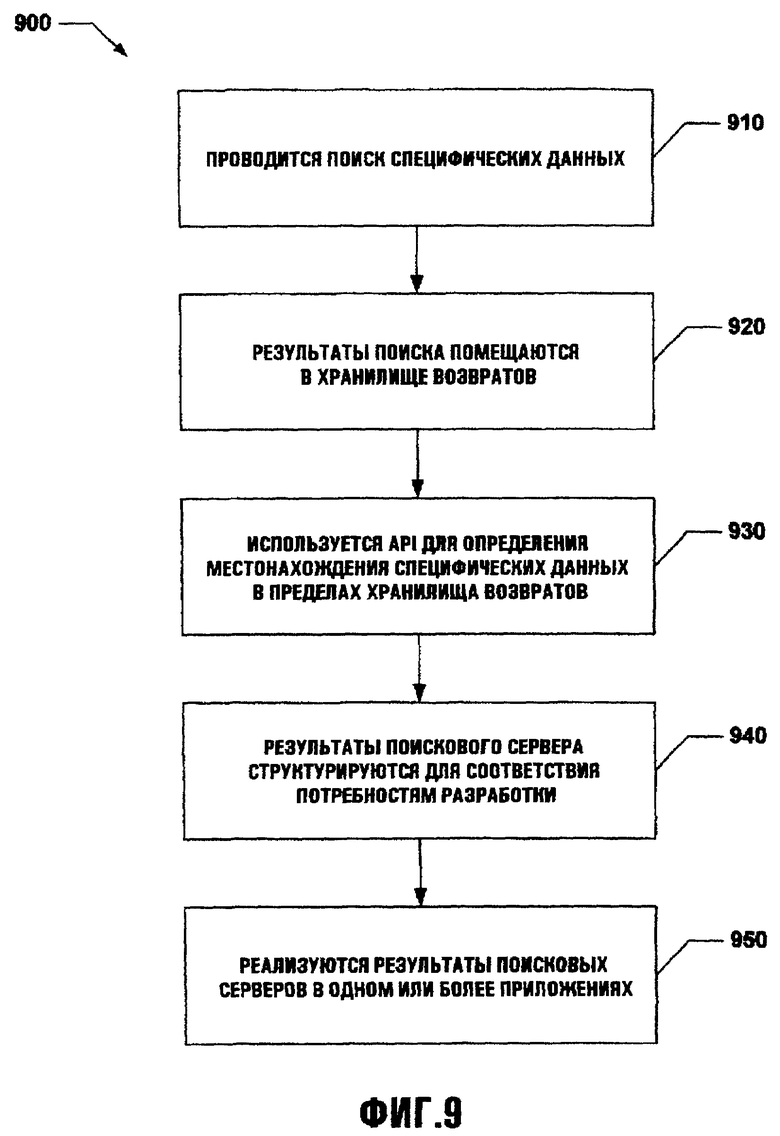
Фиг.9 иллюстрирует методологию, в которой используется API для определения местонахождения и осуществления данных. На этапе 910 проводится поиск специфических данных. Как отмечено выше, различные аспекты данных могут быть определены и использованы для определения местонахождения и извлечения требуемых данных. На этапе 920 результаты поиска помещаются в хранилище возвратов. Такие данные могут быть доступны по существу любому неравноправному устройству, которое может связаться с помощью интерфейса с хранилищем возвратов. Дополнительно данные могут включать указатели на источники данных так, что к данным, которые фактически не находятся в хранилище, можно немедленно обратится через один или более указателей данных. На этапе 930 API используется для определения местонахождения специфических данных в пределах хранилища возвратов. Такие данные могут быть локализованы, основываясь на различных факторах, как упомянуто ранее.
На этапе 940 результаты поискового сервера структурируются для соответствия потребностям разработки. Такая структура данных может включать тип, формат, класс, содержание и т.д. информации, которая будет реализована при разработке. При этом способе в данных можно вскрыть противоречия и повторно собирать впоследствии более эффективно. Кроме того, такие структурированные данные могут исходить, например, из поискового сервера, хранилища возвратов и/или файла регистрации запроса. На этапе 950 эти данные реализованы в одном или более приложениях. Такая реализация данных может использовать в своих интересах результаты поискового сервера, оптимизируя использование таких данных при содействии требований разработчика и/или приложения, с которым такие данные реализуются.
На Фиг.10 изображена примерная среда 1000 для осуществления различных аспектов изобретения, включающая компьютер 1012. Компьютер 1012 включает процессорный модуль 1014, системную память 1016 и системную шину 1018. Системная шина 1018 соединяет компоненты системы, включая, но не ограничиваясь этим, системную память 1016 с процессорным модулем 1014. Процессорный модуль 1014 может быть любым из различных доступных процессоров. Двойные микропроцессоры и другая многопроцессорная архитектура также могут использоваться как процессорный модуль 1014.
Системная шина 1018 может быть любой из нескольких типов шинных структур(ы), включая шину памяти или контроллер памяти, периферийную шинную или внешнюю шину и/или локальную шину, использующие любое из разнообразия доступных шинных архитектур, включая, но не ограничиваясь этим, восьмибитные шины, архитектуру промышленного стандарта (ISA), микроканальную архитектуру (MSA), расширенную ISA (EISA), встроенный интерфейс накопителей (IDE), локальную шину VESA (VLB), шину соединения периферийных устройств (PCI), универсальную последовательную шину (USB), расширенный графический порт (AGP), шину международной ассоциации производителей плат памяти для персональных компьютеров (PCMCIA) и интерфейс малых компьютерных систем (SCSI).
Системная память 1016 включает энергозависимую память 1020 и энергонезависимую память 1022. Базовая система ввода-вывода (BIOS), содержащая основные подпрограммы для передачи информации между элементами в компьютере 1012, например, во время запуска, сохраняется в энергонезависимой памяти 1022. В качестве иллюстрации, но не ограничения, энергонезависимая память 1022 может включать постоянное запоминающее устройство (ROM), программируемое ROM (PROM), электрически программируемое ROM (EPROM), электрически стираемый ROM (EEPROM) или флэш-память. Энергозависимая память 1020 включает оперативную память (RAM), которая действует как внешняя кэш-память. В качестве иллюстрации, а не ограничения, оперативная память доступна во многих формах типа синхронной оперативной памяти (SRAM), динамической оперативной памяти (DRAM), синхронной динамической оперативной памяти (SDRAM), SDRAM с двойной скоростью передачи данных (DDR SDRAM), расширенной SDRAM (ESDRAM), Synchlink DRAM (SLDRAM) и direct Rambus RAM (DRRAM).
Компьютер 1012 также включает съемные/несъемные, энергозависимые/энергонезависимые компьютерные носители данных. Фиг.10 иллюстрирует, например, память 1024 на диске. Память на 1024 диске включает, но не ограничена этим, устройства, подобные дисководу магнитных дисков, накопителю на гибких магнитных дисках, накопителю на магнитной ленте, Jaz-диску, Zip-диску, LS-100 диску, плате флэш-памяти или memory stick. Кроме того, память 1024 на диске может включать носители данных отдельно или в комбинации с другими носителями данных, включая, но не ограничиваясь этим, оптический дисковод типа устройства ROM компакт-диска (CD-ROM), дисковод записываемого компакт-диск (CD-R Drive), дисковод перезаписываемого компакт-диска (CD-RW Drive) или дисковод цифрового универсального диска (DVD-ROM). Чтобы облегчить подключение устройств памяти 1024 на диске к системной шине 1018, обычно используется сменный или несменный интерфейс типа интерфейса 1026.
Необходимо отметить, что Фиг.10 описывает программное обеспечение, которое действует как посредник между пользователями и основными компьютерными ресурсами, описанными в подходящей среде 1000. Такое программное обеспечение включает операционную систему 1028. Операционная система 1028, которая может быть сохранена в памяти 1024 на диске, действует для управления и распределения ресурсов компьютерной системы 1012. Системные приложения 1030 используют в своих интересах управление ресурсами операционной системы 1028 через программные модули 1032 и программные данные 1034, сохраненные или в системной памяти 1016, или в памяти 1024 на диске. Необходимо оценить, что данное изобретение может быть осуществлено с различными операционными системами или комбинациями операционных систем.
Пользователь вводит команды или информацию в компьютер 1012 через устройство(а) 1036 ввода данных. Устройства 1036 ввода данных включают, но не ограничены этим, устройство управления позицией типа мыши, координатного шара, пера, сенсорной клавиатуры, клавиатуры, микрофона, джойстика, игровой клавиатуры, спутниковой антенны, сканера, платы телевизионного приемника, цифровой камеры, цифровой видеокамеры, web-камеры и т.п. Эти и другие устройства ввода данных соединяются с процессорным модулем 1014 через системную шину 1018 через порт(ы) 1038 интерфейса. Порт(ы) 1038 интерфейса включает, например, последовательный порт, параллельный порт, игровой порт и универсальную последовательную шину (USB). Устройство(а) 1040 вывода использует часть того же самого типа портов, что и устройство(а) 1036 ввода данных. Таким образом, например, USB порт может использоваться для обеспечения ввода в компьютер 1012 и вывода информации из компьютера 1012 на устройство 1040 вывода. Адаптер 1042 вывода присутствует для иллюстрации того, что есть некоторые устройства 1040 вывода, подобно мониторам, динамикам и принтерам, среди других устройств 1040 вывода, которые требуют специальных адаптеров. Адаптеры 1042 вывода включают, в качестве иллюстрации, а не ограничения, видео и звуковые платы, которые предоставляют средство подключения между устройством 1040 вывода и системной шиной 1018. Должно быть отмечено, что другие устройства и/или системы устройств предоставляют обе возможности ввода и вывода типа удаленного компьютера(ов) 1044.
Компьютер 1012 может работать в сетевой среде, используя логические подключения к одному или более удаленным компьютерам типа удаленного компьютера(ов) 1044. Удаленный компьютер(ы) 1044 может быть персональным компьютером, сервером, маршрутизатором, сетевым PC, рабочей станцией, прибором на основе микропроцессора, одноранговым устройством или другим общим сетевым узлом и т.п. и обычно включает многие или все элементы, описанные для компьютера 1012. Для целей краткости с удаленным компьютером(ами) 1044 проиллюстрировано только запоминающее устройство 1046. Удаленный компьютер(ы) 1044 логически связан с компьютером 1012 через сетевой интерфейс 1048 и затем физически связан через сетевое подключение 1050. Сетевой интерфейс 1048 охватывает коммуникационные сети типа локальных сетей (LAN) и глобальных сетей (WAN). Технологии LAN включают интерфейс передачи данных по оптоволокну (FDDI), распределенный интерфейс передачи данных (CDDI), Ethernet/IEEE 802.3, Token Ring/IEEE 802.5 и т.п. Технологии WAN включают, но не ограничены этим, подключения точка-точка, сети с коммутацией каналов, подобные цифровым сетям комплексного обслуживания (ISDN), и их разновидности, сети пакетной коммутации и цифровые абонентские линии (DSL).
Сетевое подключение(я) 1050 относится к аппаратному/программному использованию для соединения сетевого интерфейса 1048 с шиной 1018. В то время как сетевое подключение 1050 показано для иллюстративной ясности в компьютере 1012, оно может также быть внешним к компьютеру 1012. Аппаратные/программные требования для подключения к сетевому интерфейсу 1048 включают, только для целей примера, внутренние и внешние технологии типа модемов, включая класс регулярных телефонных модемов, кабельные модемы и модемы DSL, адаптеры ISDN и платы Ethernet.
Фиг.11 иллюстрирует примерную компьютерную среду 1100, в которой данное изобретение может использоваться. Система 1100 включает один или более клиентов(ов) 1110. Клиент(ы) 1110 может быть аппаратным и/или программным (например, потоки, процессы, компьютерные устройства). Система 1100 дополнительно включает один или более серверов 1130. Аналогично сервер(ы) 1130 может быть аппаратным и/или программным (например, потоками, процессами, компьютерными устройствами).
Одна возможная связь между клиентом 1110 и сервером 1130 может быть в форме пакета данных, передаваемого между двумя или более компьютерными процессами. Система 1100 дополнительно включает коммуникационную структуру 1150, которая может использоваться для облегчения связи между клиентом(ами) 1110 и сервером(ами) 1130. Клиент(ы) 1110 может связаться с помощью интерфейса с одним или более хранилищами данных клиента 1160, которые могут использоваться для хранения информация, локальной для клиента(ов) 1110. Точно так же сервер(ы) 1130 может связаться с помощью интерфейса с одним или более хранилищами данных сервера 1140, которые могут использоваться для хранения информации, локальной для серверов 1130.
Приложение A описывает различные библиотеки классов и прикладной программный интерфейс (API) и рассматривается как часть данного описания. Необходимо оценить, что в то время как библиотеки классов, API и т.д., описанные в Приложении А, используются вместе с различными аспектами, сформулированными здесь, такие библиотеки классов и/или API не должны интерпретироваться в смысле ограничения или как очерчивающие возможности данного изобретения. Скорее, библиотеки и API, описанные в Приложении A, являются примерными по своей природе, и данное изобретение может использоваться вместе с ними и/или любыми другими подходящими библиотеками классов, API и т.д.
Как было описано, упомянутое выше включает примеры данного изобретения. Конечно, невозможно описать каждую мыслимую комбинацию компонентов или методологий для описания данного изобретения, но специалист в данной области техники может распознать, что возможны многие дополнительные комбинации и перестановки данного изобретения. Соответственно данное изобретение предназначено для того, чтобы охватить все такие изменения, модификации и разновидности, которые попадают в пределы сущности и объема, определенного приложенной формулой изобретения. В этом отношении следует также отметить, что изобретение включает систему, а также читаемый компьютером носитель информации, имеющий компьютерные выполнимые команды для выполнения этапов для различных способов изобретения. Кроме того, в то время как определенное отличие изобретения, возможно, было раскрыто относительно только одного из нескольких аспектов или реализации изобретения, такое отличие может быть объединено с одним или более другими отличиями другой реализации, что может быть желательно и выгодно для любого данного или специфического приложения. Кроме того, в той степени, в которой термины «включают», «включающий», «имеют», «имеющий» и их варианты используются или в описании, или в формуле изобретения, эти термины предназначены для понимания, подобно термину «содержать» и его вариантам.






































































Изобретение относится к информационному поиску. Техническим результатом является эффективный поиск и определение местоположения данных, которые запрашивает пользователь. Система, которая предоставляет данные пользователю, содержит: компонент-библиотеку, который хранит информацию, касающуюся результата поискового сервера, при этом компонент-библиотека может автоматически изменить структуру результата поискового сервера на основании требований приложения или требований пользователя, компонент прикладного программного интерфейса (API), который определяет, как приложения связываются с помощью интерфейса с компонентом-библиотекой для оптимизации использования результата поискового сервера, компонент искусственного интеллекта (AI), который определяет соответствующее местоположение результата поискового сервера и уведомляет компонент доступа о соответствующем местоположении для обеспечения запрошенных элементов поиска вместе с принятием решения, основанным на изученном действии заданного потребителя данных по отношению к заданному источнику данных, и кэш-буфер результатов, который хранит объект данных, возвращенный из запроса, при этом в кэш-буфере результатов могут быть организованы, отредактированы и сконструированы объекты данных. 2 н. и 11 з.п. ф-лы, 11 ил., 1 прилож.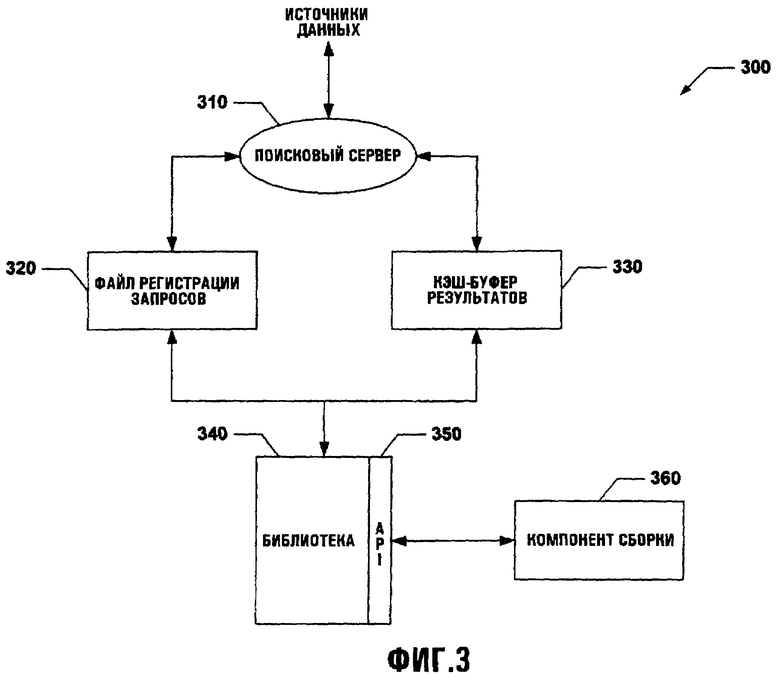
1. Система, которая предоставляет данные пользователю, содержащая следующие компоненты, сохраненные в компьютерной памяти и исполняемые процессором:
компонент-библиотека, который хранит информацию, касающуюся, по меньшей мере, одного результата поискового сервера, при этом результат сохранен в форме расширяемого языка разметки (XML), при этом компонент-библиотека может автоматически изменить структуру, по меньшей мере, одного результата поискового сервера на основании, по меньшей мере, одного требования приложения или одного требования пользователя; и
компонент прикладного программного интерфейса (API), который определяет, как одно или более приложений связываются с помощью интерфейса с компонентом-библиотекой для оптимизации использования, по меньшей мере, одного результата поискового сервера, включая, по меньшей мере, одну созданную web-страницу, которая является страницей результатов заданного поискового сервера, содержащая сохраненные результаты возвращенных наборов результатов поиска множества поисковых серверов, отличных от заданного поискового сервера, при этом web-страница собрана из данных, извлеченных из сохраненных результатов;
компонент искусственного интеллекта (AI), который определяет соответствующее местоположение, по меньшей мере, одного результата поискового сервера и уведомляет компонент доступа о соответствующем местоположении для обеспечения запрошенных элементов поиска вместе с принятием решения, основанным на изученном действии заданного потребителя данных по отношению к заданному источнику данных, при этом компонент AI делает определение, основываясь, по меньшей мере, частично, на одном из следующего: методе опорных векторов, нейронной сети, сети с обратным распространением ошибки, сети с прямым распространением сигнала и обратным распространением ошибки, сети на основе радиально-базисных функций, сети с нечеткой логикой, экспертной системы, Байесовой сети, сети синтеза данных или их комбинации; и
кэш-буфер результатов, который хранит, по меньшей мере, один объект данных, возвращенный из запроса, при этом в кэш-буфере результатов могут быть организованы, отредактированы и сконструированы один или более объектов данных, причем в кэш-буфере результатов могут быть созданы web-страницы, которые копируют результаты одного или более поисков данных с или без модификаций, добавлений и удалений.
2. Система по п.1, которая также содержит поисковый сервер, который может принять набор элементов поиска и возвратить набор объектов данных, удовлетворяющих принятым элементам поиска.
3. Система по п.2, в которой компонент API может связаться с помощью интерфейса с больше, чем одним поисковым сервером, и может переключаться между поисковыми серверами, не изменяя код приложения.
4. Система по п.1, которая также содержит журнал регистрации запросов, который хранит информацию, связанную с, по меньшей мере, одним запросом поиска, используемым с поисковым сервером.
5. Система по п.1, в которой компонент-библиотека соединяет, по меньшей мере, два набора результатов поискового сервера для реализации в, по меньшей мере, одном приложении.
6. Осуществляемый на компьютере способ для оптимизации использования данных, полученных от, по меньшей мере, одного поискового сервера, содержащий этапы, на которых:
сохраняют, по меньшей мере, два результата поискового сервера из набора результатов поиска, возвращенных двумя или более поисковыми серверами;
извлекают, по меньшей мере, один элемент данных из, по меньшей мере, двух результатов поискового сервера;
определяют с помощью, по меньшей мере, одной методики искусственного интеллекта соответствующее местоположение, по меньшей мере, двух результатов поискового сервера и уведомляют компонент доступа о соответствующем местоположении для обеспечения запрошенных элементов поиска вместе с принятием решения, основанным на изученном действии заданного потребителя данных по отношению к заданному источнику данных, при этом методики искусственного интеллекта включают в себя: метод опорных векторов, нейронную сеть, сеть с обратным распространением ошибки, сеть с прямым распространением сигнала и обратным распространением ошибки, сеть на основе радиально-базисных функций, сеть с нечеткой логикой, экспертную систему, Байесову сеть, сеть синтеза данных или их комбинацию;
собирают извлеченные данные для оптимизации разработки приложения на основании, по меньшей мере, одного требования приложения или одного требования пользователя;
осуществляют реализацию собранных результатов поискового сервера в, по меньшей мере, одном приложении; и
сохраняют, по меньшей мере, один объект данных, возвращенный из запроса, при этом в кэш-буфере результатов могут быть организованы, отредактированы и сконструированы один или более объектов данных, причем в кэш-буфере результатов могут быть созданы web-страницы, которые копируют результаты одного или более поисков данных с или без модификаций, добавлений и удалений.
7. Способ по п.6, который также содержит этап сохранения данных, используемых для выполнения поиска в журнале регистрации запросов.
8. Способ по п.6, который также содержит этап опроса одного или более сохраненных результатов поиска, где один или более результат поиска содержит, по меньшей мере, один из ресурсов и указатель на ресурс.
9. Способ по п.8, в котором указатель является унифицированным указателем ресурса.
10. Способ по п.6, который также содержит этап использования прикладного программного интерфейса (API) для определения местонахождения одного или более результатов и извлечения одного или более сохраненных результатов.
11. Способ по п.6, который также содержит этап структурирования, по меньшей мере, двух результатов поисковых серверов для того, чтобы соответствовать требованиям разработки программ.
12. Способ по п.6, который также содержит этап кэширования, по меньшей мере, одного из запросов и результатов в, по меньшей мере, одном из следующего: локальной памяти, локальном запоминающем устройстве и удаленном сервере.
13. Способ по п.6, который также содержит этап переключения между двумя или более поисковыми серверами.
| СПОСОБ ПОИСКА И ВЫБОРКИ ИНФОРМАЦИИ С ПОВЫШЕННОЙ РЕЛЕВАНТНОСТЬЮ | 2003 |
|
RU2236699C1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| US 6263332 B1, 17.07.2001 | |||
| US 6526440 B1, 25.02.2003 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |

