Область техники, к которой относится изобретение
Способ декодирования аудиосигнала содержит извлечение из аудиосигнала понижающего сигнала и дополнительной информации на основе объектов, формирование измененного понижающего сигнала, основанного на понижающем сигнале и извлеченной информации, которая была извлечена из дополнительной информации на основе объектов, формирование дополнительной информации на основе канала, полагаясь на дополнительную информацию на основе объектов и данные управления для воспроизведения понижающего сигнала, а также формирование многоканального аудиосигнала на основе измененного понижающего сигнала и дополнительной информации на основе объектов.
Уровень техники
Главным образом, в методиках кодирования и декодирования многоканального аудио ряд канальных сигналов многоканального сигнала понижается до сигналов с меньшим числом каналов, передается дополнительная информация, касающаяся исходных сигналов канала, и восстанавливается многоканальный сигнал, имеющий столько каналов, сколько и исходный многоканальный сигнал.
В основном, методики кодирования и декодирования аудио на основе объектов схожи с методиками кодирования и декодирования многоканального аудио, что касается, например, понижения нескольких источников звука в сигналах с меньшим количеством источников звука и передачи дополнительной информации, относящейся к исходным источникам звука. Однако в методиках кодирования и декодирования аудиосигналов на основе объектов сигналы объектов, являющиеся базовыми элементами (например, звук музыкального инструмента или человеческого голоса) канального сигнала, обрабатываются так же, как канальные сигналы в методиках кодирования и декодирования многоканального аудио, и могут таким образом быть закодированы.
Другими словами, в методиках кодирования и декодирования аудио на основе объектов каждый сигнал объекта считают сущностью, которая будет закодирована. В этом отношении технологии кодирования и декодирования аудиосигнала на основе объектов отличаются от технологий кодирования и декодирования многоканального аудио, в которых операция кодирования многоканального аудио выполняется просто, основываясь на межканальной информации независимо от ряда элементов канального сигнала, который будет закодирован.
Раскрытие изобретения
Техническая задача
Данное изобретение обеспечивает способ и устройство для кодирования аудио, а также способ и устройство декодирования аудио, в которых аудиосигналы могут быть закодированы или декодированы так, что образы звука можно располагать в любом желаемом месте для каждого объектного аудиосигнала.
Сущность изобретения
Согласно одному варианту данного изобретения, обеспечивается способ кодирования аудио, включающий в себя извлечение из входящего сигнала понижающего сигнала и основанной на объекте дополнительной информации, формирование информации воспроизведения на основе входящих данных управления, и формирование пространственной информации на основе информации воспроизведения и дополнительной информации на основе объекта.
Согласно другому аспекту данного изобретения, обеспечивается устройство кодирования аудио, включающее в себя демультиплексор, который извлекает из входящего сигнала понижающий сигнал и дополнительную информацию на основе объекта, а также рендерер, который формирует информацию воспроизведения на основе входящих данных управления, и транскодер, который формирует пространственную информацию на основе информации воспроизведения и дополнительной информации на основе объекта.
Согласно одному варианту данного изобретения, обеспечивается компьютерно-читаемый записываемый носитель, имеющий записанную компьютерную программу для выполнения способа кодирования аудио, причем способ кодирования аудио включает в себя извлечение из входящего аудиосигнала понижающего сигнала и дополнительной информации на основе объекта, формирование информации воспроизведения на основе входящих данных управления, а также формирование пространственной информации на основе информации воспроизведения и дополнительной информации на основе объекта.
Преимущества результата
Обеспечены способ и устройство кодирования аудио, а также способ и устройство декодирования аудио, в которых аудиосигналы могут быть закодированы или декодированы так, что образы звука можно располагать в любой желаемой позиции для каждого объектного аудиосигнала.
Краткое описание чертежей
Данное изобретение станет более понятным из детального описания, приведенного ниже, и сопроводительных чертежей, которые даны только с целью иллюстрации, чем не ограничивают данное изобретении, и в которых:
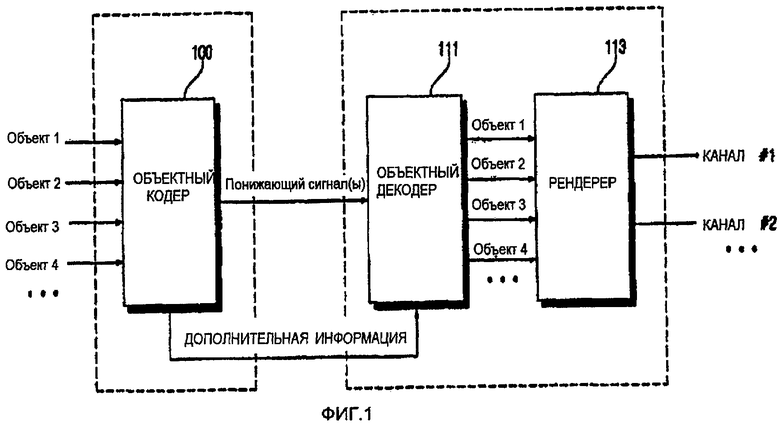
ФИГ.1 - блок-схема типовой системы кодирования/декодирования аудио на основе объекта;
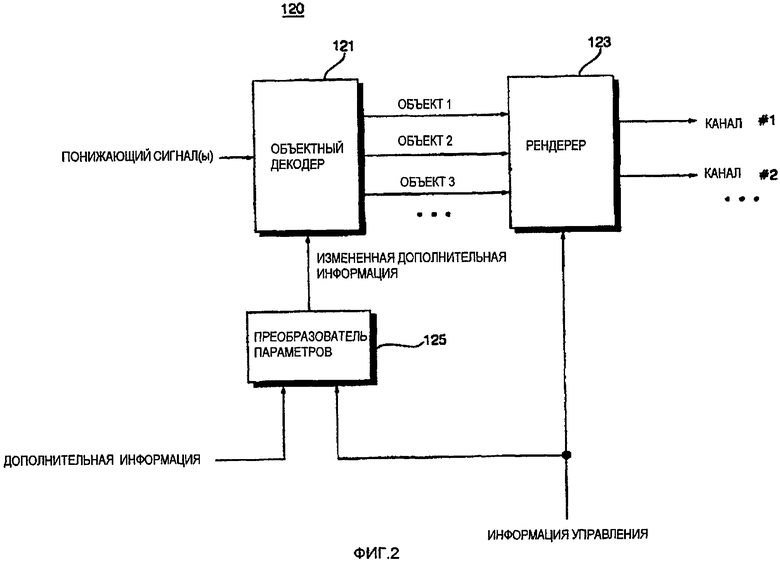
ФИГ.2 - блок-схема устройства декодирования аудио согласно первому варианту осуществления данного изобретения;
ФИГ.3 - блок-схема устройства декодирования аудио согласно второму варианту осуществления данного изобретения;
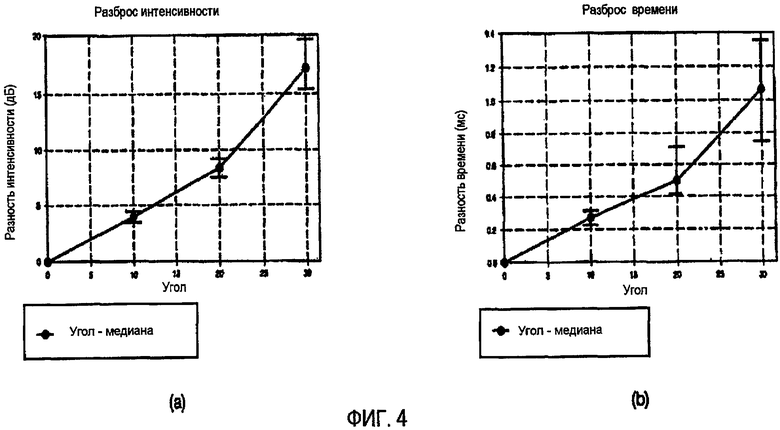
ФИГ.4 - график, объясняющий влияние разницы амплитуд и разницы времени, которые независимы друг от друга, на местоположение образов звука;
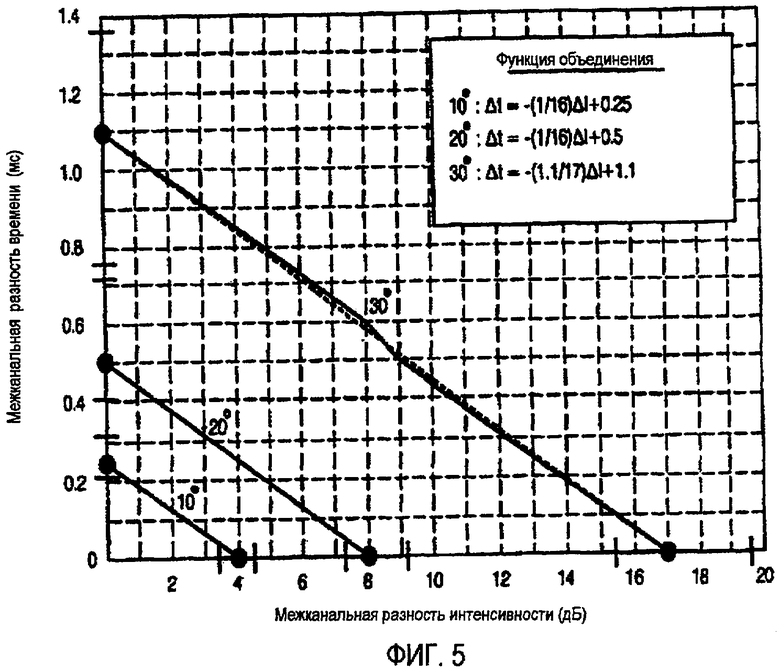
ФИГ.5 - график функций, касающихся соответствия между разницей амплитуд и разницей времени, которые требуются для расположения образов звука в предопределенной позиции;
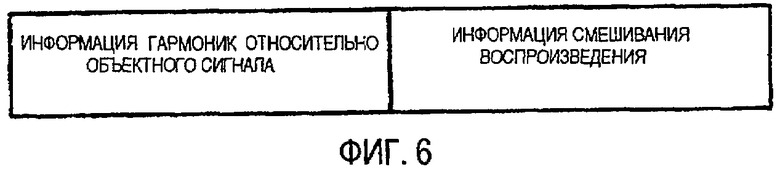
ФИГ.6 показывает формат данных управления, включающих в себя информацию гармоник;
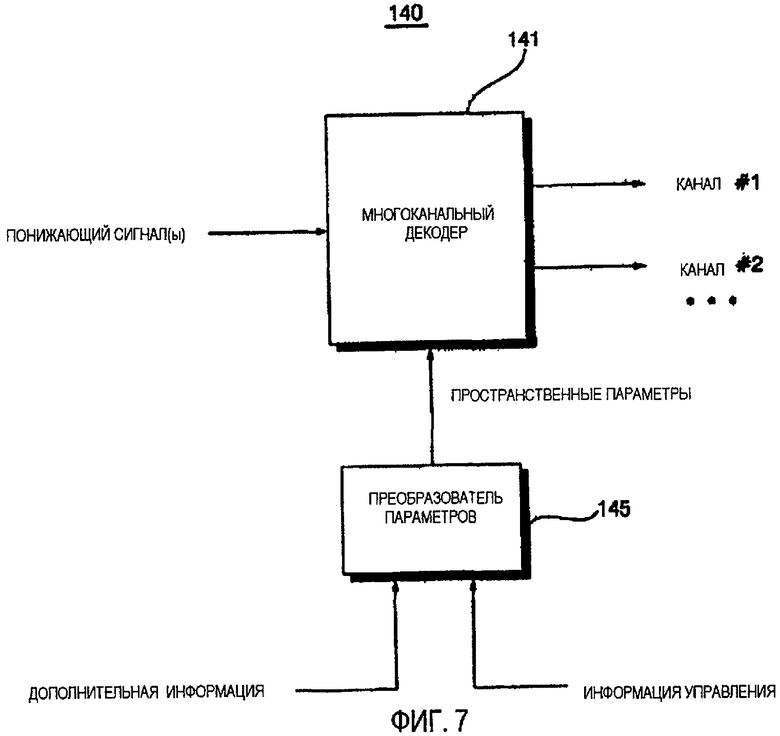
ФИГ.7 - блок-схема устройства декодирования аудио согласно третьему варианту осуществления данного изобретения;
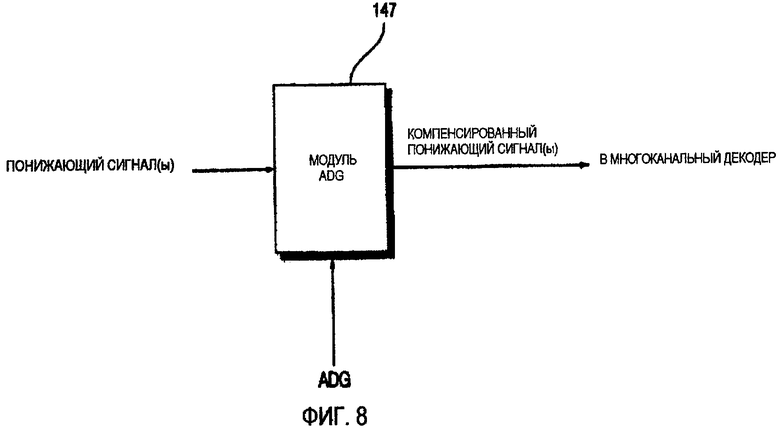
ФИГ.8 - блок-схема профессионального модуля усиления понижения(ADG), который может использоваться в устройстве декодирования аудио, показанном на ФИГ.7;
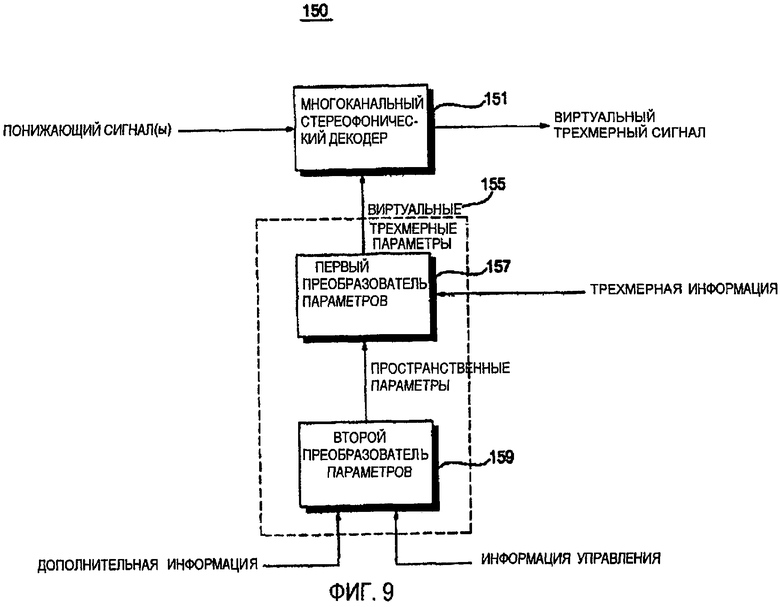
ФИГ.9 - блок-схема устройства декодирования аудио согласно четвертому варианту осуществления данного изобретения;
ФИГ.10 - блок-схема устройства декодирования аудио согласно пятому варианту осуществления данного изобретения;
ФИГ.11 - блок-схема устройства декодирования аудио согласно шестому варианту осуществления данного изобретения;
ФИГ.12 - блок-схема устройства декодирования аудио согласно седьмому варианту осуществления данного изобретения;
ФИГ.13 - блок-схема устройства декодирования аудио согласно восьмому варианту осуществления данного изобретения;
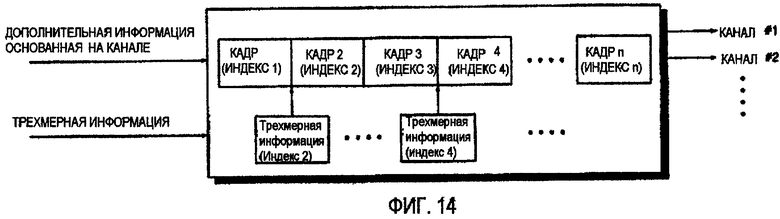
ФИГ.14 - блок-схема для объяснения применения трехмерной (3D) информации к кадру устройством декодирования аудио, показанным на ФИГ.13;
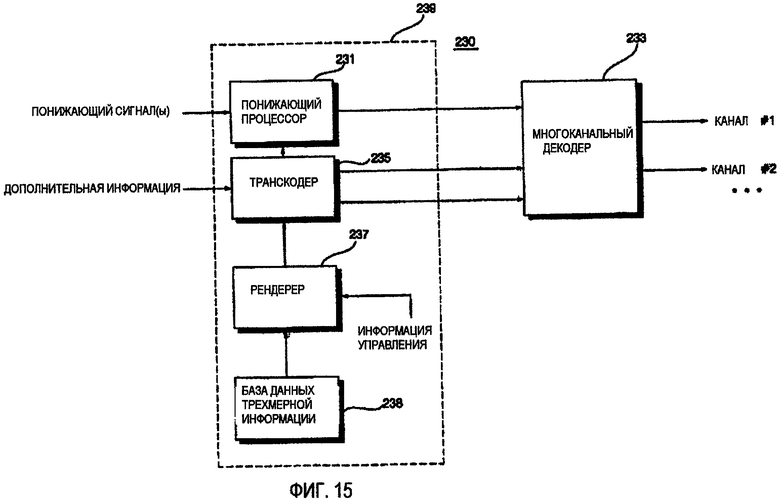
ФИГ.15 - блок-схема устройства декодирования аудио согласно девятому варианту осуществления данного изобретения;
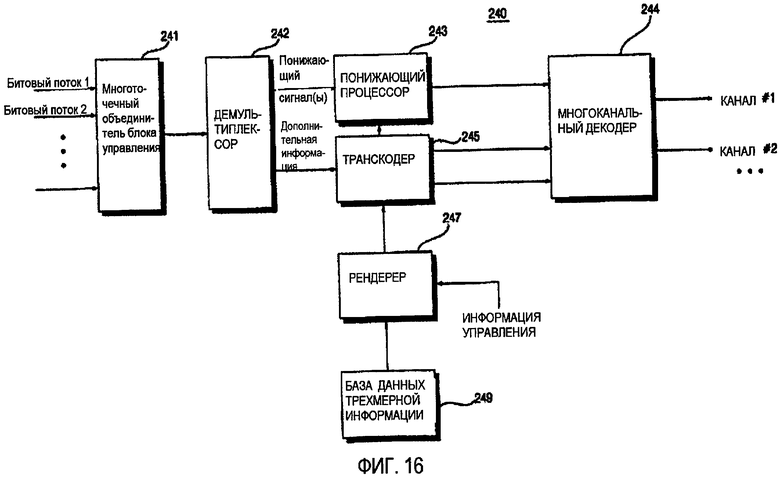
ФИГ.16 - блок-схема устройства декодирования аудио согласно десятому варианту осуществления данного изобретения;
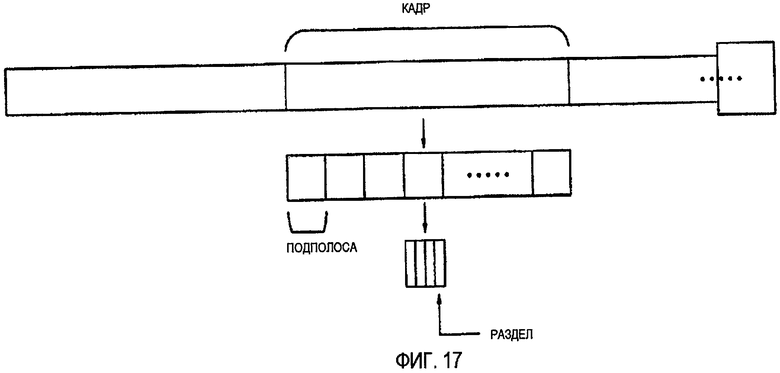
ФИГ.17-ФИГ.19 - диаграммы для объяснения способа декодирования аудио согласно одному варианту осуществления данного изобретения, и
ФИГ.20 - блок-схема устройства кодирования аудио согласно одному варианту осуществления данного изобретения.
Лучший способ выполнения изобретения
Здесь и далее данное изобретение будет описано подробно со ссылками на сопутствующие чертежи, в которых показаны характерные варианты осуществления.
Способ и устройство кодирования аудио и способ и устройство декодирования аудио согласно данному изобретению могут использоваться в операциях обработки аудио на основе объекта, но данное изобретение не ограничивается этим. Другими словами, способ и устройство кодирования аудио и способ и устройство декодирования аудио могут применяться в различных операциях обработки сигналов, а не только в операциях обработки аудио на основе объекта.
ФИГ.1 - это блок-схема типичной системы кодирования/декодирования аудио на основе объекта. В основном, аудиосигналы, вводимые в устройство кодирования аудио на основе объекта, не соответствуют каналам многоканального сигнала, а являются независимыми объектными сигналами. В этом смысле, устройство кодирования аудио на основе объекта отличается от устройства кодирования многоканального аудио, в которое вводятся канальные сигналы многоканального сигнала.
Например, канальные сигналы, такие как фронтальный сигнал левого канала и фронтальный сигнал правого канала 5.1-канального сигнала могут быть введены в многоканальный аудиосигнал, тогда как объектные аудиосигналы, как человеческий голос или звук музыкального инструмента (например, звук виолончели или пианино), которые меньше, чем канальные сигналы, могут быть введены в устройство кодирования аудио на основе объекта.
Ссылаясь на ФИГ.1, система кодирования/декодирования аудио на основе объекта, содержит устройство кодирования аудио на основе объекта и устройство декодирования аудио на основе объекта. Устройство кодирования аудио на основе объекта содержит объектный кодер 100, а устройство декодирования аудио на основе объекта содержит объектный декодер 111 и рендерер 113.
Объектный кодировщик 100 принимает N объектных аудиосигналов и формирует понижающий сигнал на основе объекта с одним или более каналов и дополнительную информацию, содержащую ряд кусочков информации, извлеченной из N объектных аудиосигналов, например разницу энергий, разницу фаз и уровень корреляции. Дополнительная информация и понижающий сигнал на основе объекта объединяются в единый битовый поток, и этот поток передается в устройство декодирования на основе объекта.
Дополнительная информация может содержать флаг, указывающий производить ли кодирование аудио на основе канала или кодирование аудио на основе объекта, таким образом можно определить, производить ли кодирование аудио на основе канала или кодирование аудио на основе объекта, ориентируясь по флагу дополнительной информации. Дополнительная информация также может содержать информацию огибающей, информацию группировки, информацию периода тишины и информацию о задержках относительно объектных сигналов. Дополнительная информация может также содержать информацию о разнице объектных уровней, информацию о внутриобъектной кросс-корреляции, информацию об усилении понижения, информацию о разнице в уровнях канала понижения и информацию об абсолютной энергии объекта.
Объектный декодер 111 принимает понижающий сигнал на основе объекта и дополнительную информацию из устройства кодирования аудио на основе объекта и хранит объектные сигналы, имеющие схожие свойства с N объектными сигналами, основанными на понижающем сигнале на основе объекта и дополнительной информации. Объектные сигналы, формируемые объектным декодером 111, еще не были распределены на какую-либо позицию в многоканальном пространстве. Таким образом, рендерер 113 распределяет каждый из объектных сигналов, сформированных объектным декодером 111, на предопределенные позиции в многоканальном пространстве и определяет уровни объектных сигналов так, что объектные сигналы можно воспроизводить из соответствующих позиций, обозначенных рендерером 113 с соответствующими уровнями, определенными рендерером 113. Информация управления относительно каждого из объектных сигналов, сформированных объектным декодером 111, может изменяться во времени, таким образом, пространственные позиции и уровни объектных сигналов, сформированных объектным декодером 111, могут изменяться согласно информации управления.
ФИГ.2 - это блок-схема устройства 120 декодирования аудио согласно первому варианту осуществления данного изобретения. Ссылаясь на ФИГ.2, устройство 120 декодирования аудио включает в себя объектный декодер 121, рендерер 123 и преобразователь 125 параметров. Устройство 120 декодирования аудио также может содержать демультиплексор (не показан), который извлекает понижающий сигнал и дополнительную информацию из битового потока, вводимого в него, и это применимо ко всем устройствам декодирования аудио согласно другим вариантам исполнения данного изобретения.
Объектный декодер 121 формирует ряд объектных сигналов на основе понижающего сигнала и измененной дополнительной информации, обеспеченной преобразователем 125 параметров. Рендерер 123 распределяет каждый из объектных сигналов, сформированных объектным декодером 121 по предопределенным позициям в многоканальном пространстве, и определяет уровни объектных сигналов, сформированных объектным декодером 121 согласно информации управления. Преобразователь 125 параметров формирует измененную дополнительную информацию, объединяя дополнительную и контрольную информацию. Затем преобразователь 125 параметров передает измененную дополнительную информацию в объектный декодер 121.
Объектный декодер 121 может производить адаптивное декодирование, анализируя информацию управления в измененной дополнительной информации.
Например, если информация управления показывает, что первый объектный сигнал и второй объектный сигнал распределены на одну позицию в многоканальном пространстве и имеют один уровень, обычное устройство аудиодекодирования может декодировать первый и второй объектный сигнал отдельно, а затем соединить их в многоканальном пространстве, используя операцию смешивания/воспроизведения.
С другой стороны, объектный декодер 121 устройства 120 кодирования аудио узнает из информации управления в измененной дополнительной информации, что первый и второй объектный сигналы распределены на одну позицию в многоканальном пространстве и имеют такой же уровень, как если б они были одним звуковым источником. Соответственно, объектный декодер 121 декодирует первый и второй объектный сигнал, обрабатывая их как один звуковой источник без декодирования их раздельно. В результате уменьшается сложность декодирования. В добавок, из-за уменьшения числа источников звука, требующих обработки, сложность смешивания/воспроизведения тоже снижается.
Устройство 120 декодирования аудио можно эффективно использовать в случае, когда число объектных сигналов значительно больше, чем число выходящих каналов, так как множество объектных сигналов с большей вероятностью будут распределены на одну пространственную позицию.
С другой стороны, устройство 120 декодирования аудио можно использовать в случае, когда первый объектный сигнал и второй объектный сигнал распределены на одной позиции в многоканальном пространстве, но имеют разные уровни. В этом случае, устройство 120 декодирования аудио декодирует первый и второй объектный сигнал, обрабатывая первый и второй объектный сигнал как один, вместо обработки первого и второго объектного сигнала отдельно, и направляет декодированный первый и второй объектный сигнал в рендерер 123. Более точно объектный декодер 121 может получать информацию, касающуюся разницы между уровнями первого и второго объектного сигнала из информации управления в измененной дополнительной информации и декодировать первый и второй объектный сигнал, основываясь на полученной информации. В результате, даже если первый и второй объектный сигналы имеют разные уровни, первый и второй объектные уровни могут быть декодированы, как если бы они были одним звуковым источником.
В другой ситуации, объектный декодер 121 может настраивать уровни объектных сигналов, сформированных объектным декодером 121 согласно информации управления. Кроме того, объектный декодер 121 может декодировать объектные сигналы, уровни которых настроены. Соответственно, рендереру 123 не нужно настраивать уровни декодируемых объектных сигналов, поступающих от декодера 121, а просто собрать декодируемые объектные сигналы, поступающие от декодера 121 в многоканальном пространстве. Вкратце, так как объектный декодер 121 настраивает уровни объектных сигналов, формируемых объектным декодером 121 согласно информации управления, рендерер 123 может собирать готовые объектные сигналы, сформированные объектным декодером 121 в многоканальном пространстве без необходимости дополнительно настраивать уровни объектных сигналов, сформированных объектным декодером 121. Таким образом, возможно снизить сложность смешивания/воспроизведения.
Согласно варианту исполнения на ФИГ.2, объектный декодер устройства 120 декодирования аудио может адаптивно выполнять операцию декодирования с помощью анализа информации управления, таким образом уменьшая сложность декодирования и сложность смешивания/воспроизведения. Можно использовать сочетание вышеописанных способов, выполняемых устройством 120 декодирования аудио.
ФИГ.3 - это блок-схема устройства 130 декодирования аудио согласно второму варианту выполнения данного изобретения. Ссылаясь на ФИГ.3, устройство 130 декодирования аудио содержит объектный декодер 131 и рендерер 133. Устройство 130 декодирования аудио характеризуется обеспечением дополнительной информацией не только объектного декодера 131, но также и рендерера 133.
Устройство 130 декодирования аудио может эффективно выполнять операцию декодирования, даже если существует объектный сигнал, относящийся к периоду тишины. Например, со второго по четвертый объектные сигналы могут относиться к периоду воспроизведения музыки, в течение которого музыкальный инструмент играет, а первый объектный сигнал может относиться к периоду тишины, в течение которого играет сопровождение. В таком случае, информация, указывающая какой из множества объектных сигналов относится к периоду тишины, может содержаться в дополнительной информации, причем дополнительная информация может предоставляться в рендерер 133 так же, как и в объектный декодер 131.
Объектный декодер 131 может минимизировать сложность декодирования, не кодируя объектный сигнал, относящийся к периоду молчания. Объектный декодер 131 устанавливает объектный сигнал, относящийся к значению 0, и передает уровень объектного сигнала на рендерер 133. В основном, объектные сигналы, имеющие уровень со значением 0, обрабатываются так же, как объектные сигналы, имеющие уровень, отличный от нуля, то есть операцией смешивания/воспроизведения.
С другой стороны, устройство 130 декодирования аудио передает дополнительную информацию, включая информацию, указывающую, какой из множества объектных сигналов относится к периоду тишины, рендереру 133, и таким образом предотвращать обработку объектного сигнала, относящегося к периоду тишины, операцией смешивания/воспроизведения, выполняемой рендерером 133. Таким образом, устройство 130 декодирования аудио может предотвращать ненужное усиление сложности в смешивании/воспроизведении.
Рендерер 133 может использовать информацию о параметрах смешивания, которая содержится в информации управления, для определения места образа звука каждого объектного сигнала в стереоокружении. Информация о параметрах смешивания может содержать только информацию об амплитуде или как информацию об амплитуде, так и информацию о времени. Информация о параметрах смешивания влияет не только на определение места стереозвуковых образов, но также и на психоакустическое восприятие пространственного качества звука слушателем.
Например, при сравнении двух звуковых образов, которые были получены при помощи способа временного панорамирования и способа амплитудного панорамирования и воспроизведены с использованием 2-канального стереодинамика, выяснили, что способ амплитудного панорамирования может обеспечивать точную локализацию звукового образа, в то время как способ временного панорамирования обеспечивает естественный звук с совершенным чувством пространства. Таким образом, если рендерер 133 использует только способ амплитудного панорамирования для объединения объектных сигналов в многоканальном пространстве, рендерер 133 сможет точнее локализовать каждый звуковой образ, но не сможет обеспечить совершенное чувство звука, как при использовании способа временного панорамирования. Иногда пользователи предпочитают точную локализацию звукового образа совершенному чувству звука, или, в зависимости от источников звука, наоборот.
ФИГ.4, (a) и ФИГ.4, (b) объясняют воздействие интенсивности (разницы амплитуд) и разницы во времени на локализацию звуковых образов при воспроизведении сигнала в двухканальном аудиодинамике. Ссылаясь на ФИГ.4, (a) и ФИГ.4, (b), звуковой образ может быть локализован под заданным углом согласно разницы амплитуд и разницы во времени, независимых друг от друга. Например, разницу амплитуд около 8 дБ, или разницу во времени около 0,5 мсек, что эквивалентно разнице амплитуд в 8 дБ, можно использовать для локализации звукового образа под углом 20. Следовательно, если информацией о параметрах смешивания обеспечивается только разница амплитуд, возможно получить различные звуки с различными свойствами, преобразуя разницу амплитуд в разницу во времени, которая эквивалентна разнице амплитуд в период локализации звукового образа.
ФИГ.5 показывает функции, касающиеся связи между разницей амплитуд и разницей во времени, которые требуются для локализации звуковых образов под углами 10, 20 и 30. Функция, показанная на ФИГ.5, может быть получена, основываясь на ФИГ.4, (a) и ФИГ.4, (b). Согласно ФИГ.5, различные сочетания разницы амплитуд и разницы во времени могут обеспечиваться для локализации звукового образа в предопределенной позиции. Для примера примем, что смешанной информацией о параметрах обеспечивается разница амплитуд 8 дБ для локализации звукового образа под углом 20. Согласно функции, показанной на ФИГ.5, звуковой образ может быть также локализован под углом 20 при помощи сочетания разницы амплитуд в 3 дБ и разницы во времени 0,3 мсек. В этом случае, не только информация о разнице амплитуд, но и информация о разнице во времени может предоставляться как информация о параметрах смешивания, усиливая таким образом, ощущение пространства.
Следовательно, для того чтобы сформировать звуки с желаемыми пользователем характеристиками в течение операции смешивания/воспроизведения, информация о параметрах смешивания может быть, соответственно, преобразована так, что можно произвести амплитудное панорамирование или временное панорамирование, смотря что подходит пользователю. Это значит, если информация о параметрах смешивания включает в себя только информацию о разнице амплитуд, и пользователь желает услышать звуки с совершенным ощущением пространства, информация о разнице амплитуд может быть преобразована в эквивалентную информацию о разнице во времени, со ссылкой на психоакустические данные. Или если пользователь желает как услышать звуки с совершенным ощущением пространства, так и точной локализации звукового образа, информация о разнице амплитуд может быть преобразована в сочетание информации о разнице амплитуд и информации о разнице во времени, эквивалентной первоначальной информации о разнице амплитуд. Или если смешанная информация о параметрах содержит только информацию о разнице во времени и пользователь предпочитает точную локализацию звукового образа, информация о разнице во времени может быть преобразована в информацию о разнице амплитуд, эквивалентную информации о разнице во времени, или может быть преобразована в сочетание информации о разнице амплитуд и информации о разнице во времени, что сможет удовлетворить потребности пользователя, увеличением как точности локализации звукового образа, так и ощущения пространства.
Или если смешанная информация о параметрах содержит как информацию о разнице амплитуд, так и информацию о разнице во времени, а пользователь предпочитает точную локализацию звукового образа, сочетание информации о разнице амплитуд и информации о разнице во времени может быть преобразовано в информацию о разнице амплитуд, эквивалентную сочетанию информации о разнице амплитуд и информации о разнице во времени. С другой стороны, если смешанная информацию о параметрах содержит как информацию о разнице амплитуд, так и информацию о разнице во времени, и пользователь предпочитает усиление ощущения пространства, сочетание информации о разнице амплитуд и информации о разнице во времени может быть преобразовано в информацию о разнице во времени, эквивалентную сочетанию информации о разнице амплитуд и информации о разнице во времени. Согласно ФИГ.6, информация управления может содержать информацию смешивания/воспроизведения и информацию гармоник относительно одного или более объектных сигналов. Информация гармоник может содержать по меньшей мере одно из информации о тоне, информацию об основной частоте или информацию о преобладающей полосе частот относительно одного или более объектных сигналов и описания энергии и спектра каждой подполосы каждого объектного сигнала.
Информация гармоник может использоваться для обработки объектных сигналов во время операции воспроизведения, так как разрешение рендерера, который производит эту операцию, в единицах подполос недостаточно.
Если информация гармоник содержит информацию тона, касающуюся одного или более объектных сигналов, усиление каждого объектного сигнала можно настроить ослаблением или усилением предопределенной области частот, используя гребенчатый фильтр или обратный гребенчатый фильтр. Например, если один из множества объектных сигналов - звук голоса, объектные сигналы могут использоваться как караоке, путем ослабления только звука голоса. Или если информация гармоник содержит информацию о преобладающей области частот, касающуюся одного или более объектных сигналов, можно производить процесс ослабления или усиления преобладающей области частот. Или если информация гармоник содержит информацию о спектре, касающуюся одного или более объектных сигналов, усиление каждого объектного сигнала можно контролировать выполнением ослабления или усиления без ограничения какой-либо подполосой.
ФИГ.7 - это блок-схема устройства 140 декодирования аудио, согласно другому варианту осуществления данного изобретения. Согласно ФИГ.7, устройство 140 декодирования аудио использует многоканальный декодер 141 взамен объектного декодера и рендерера и декодирует ряд объектных сигналов после того, как они надлежащим образом собраны в многоканальном пространстве.
Более точно, устройство 140 декодирования аудио содержит многоканальный декодер 141 и преобразователь 145 параметров. Многоканальный декодер 141 формирует многоканальный сигнал, чьи объектные сигналы уже собраны в многоканальном пространстве на основе понижающего сигнала и пространственной информации о параметрах, которая является дополнительной информацией на основе канала, обеспечиваемой преобразователем 145 параметров. Преобразователь 145 параметров анализирует дополнительную информацию и информацию управления, передающуюся устройством кодирования аудио (не показан), и формирует пространственную информацию о параметрах на основе результатов анализа. Более точно, преобразователь 145 параметров формирует пространственную информацию о параметрах с помощью сочетания дополнительной информации и информации управления, которая содержит информацию о запуске воспроизведения и информацию о смешивании. Значит, преобразователь 145 параметров выполняет преобразование сочетания дополнительной информации и информации управления в пространственных данных, относящихся к приставкам OTT (One-To-Two) или TTT (Two-To-Three).
Устройство 140 декодирования аудио может производить операцию многоканального декодирования, в которой объединены операция декодирования на основе объекта и операция смешивания/воспроизведения и может таким образом пропускать декодирование каждого объектного сигнала. Следовательно, возможно уменьшить сложность декодирования и смешивания/воспроизведения.
Например, когда 10 объектных сигналов и многоканальный сигнал, полученный на основе 10 объектных сигналов, необходимо воспроизвести 5.1-канальной акустической системой, обычное устройство декодирования аудио на основе объекта декодирует сигналы в указанном порядке соответственно 10 объектным сигналам на основе понижающего сигнала и дополнительной информации, а затем формирует 5.1-канальный сигнал, соответствующим образом собирая 10 объектных сигналов в многоканальном пространстве так, что объектные сигналы смогут стать подходящими для 5.1-канального окружения. Однако неэффективно формировать 10 объектных сигналов во время формирования 5.1-канального сигнала, и эта проблема становится более серьезной по мере того, как разница между количеством объектных сигналов и количеством каналов многоканального сигнала для формирования возрастает.
С другой стороны, согласно варианту исполнения на ФИГ.7, устройство 140 декодирования аудио формирует информацию о пространственных параметрах, подходящую для 5.1-канального сигнала, основываясь на дополнительной информации и понижающий сигнал в многоканальный декодер 141. Затем, многоканальный декодер 141 формирует 5.1-канальный сигнал на основе пространственной информации о параметрах и понижающего сигнала. Другими словами, когда число каналов на выходе равно 5.1, устройство 140 декодирования аудио может без труда сформировать 5.1-канальный сигнал на основе понижающего сигнала без необходимости формировать 10 объектных сигналов и, таким образом, работать в смысле сложности более эффективно, чем традиционное устройство декодирования аудио.
Устройство 140 декодирования аудио считается эффективным, когда число вычислений, требуемых для вычисления пространственной информации о параметрах, относящейся как к OTT, так и TTT, через анализ дополнительной информации и информации управления, переданной устройством кодирования аудио, меньше, чем число вычислений, необходимых для выполнения операции смешивания/воспроизведения после декодирования каждого объектного сигнала.
Устройство 140 декодирования аудио может быть получено простым добавлением модуля для формирования пространственной информации о параметрах через анализ дополнительной информации и информации управления к типичному устройству декодирования многоканального аудио и может таким образом поддержать совместимость с типичным устройством декодирования многоканального аудио. Кроме того, устройство 140 декодирования аудио может улучшить качество звука, используя существующие инструменты типичного устройства декодирования многоканального аудио, такие как формирователь огибающей, инструмент временной обработки подполосы (STP) и декоррелятор. Учитывая все это, можно сделать заключение, что все преимущества типичного способа декодирования многоканального аудио могут быть с готовностью применены к способу декодирования объектного аудио.
Пространственная информация о параметрах, переданная многоканальному декодеру 141 преобразователем 145 параметров, возможно, была сжата, чтобы быть подходящей для того, чтобы быть переданной. Альтернативно, у пространственной информации о параметрах может быть тот же самый формат, как у данных, переданных типичным многоканальным устройством кодирования. Таким образом, пространственная информация о параметрах, возможно, была подвергнута операции декодирования Хаффмана или операции декодирования пилот-сигнала и может таким образом быть передана каждому модулю как ключевые несжатые пространственные данные. Первый вариант является подходящим для передачи пространственной информации о параметрах устройству декодирования многоканального аудио в удаленном месте, а последнее подходит, потому что не существует никакой потребности в устройстве декодирования многоканального аудио, чтобы преобразовывать ключевые сжатые пространственные данные в ключевые несжатые пространственные данные, которые могут с готовностью использоваться в операции декодирования.
Конфигурирование пространственной информации о параметрах на основе анализа дополнительной информации и информации управления может вызвать задержку между понижающим сигналом и пространственной информацией о параметрах. Чтобы избежать этого, дополнительный буфер может быть предоставлен или для понижающего сигнала, или для пространственной информации о параметрах так, чтобы понижающий сигнал и пространственная информация о параметрах могли быть синхронизированы друг с другом. Эти способы, однако, неудобны из-за требования обеспечить дополнительный буфер. Альтернативно, дополнительная информация может быть передана перед понижающим сигналом с учетом возможности возникновения задержки между понижающим сигналом и пространственной информацией о параметрах. В этом случае, пространственная информация о параметрах, полученная сочетанием дополнительной информации и информации управления, не требует настройки и может сразу использоваться.
Если у множества объектных сигналов понижающего сигнала различные уровни, профессиональный модуль усиления понижения (ADG), который может непосредственно влиять на понижающий сигнал, может определить относительные уровни объектных сигналов, и каждый из объектных сигналов может быть расположен в предопределенном положении в многоканальном пространстве, используя ключевые пространственные данные, такие как информация различия уровня канала, информация о межканальной корреляции (ICC) и информация о коэффициенте предсказания канала (CPC).
Например, если информация управления указывает, что предопределенный объектный сигнал должен быть размещен в предопределенном положении в многоканальном пространстве и имеет более высокий уровень, чем другие объектные сигналы, типичный многоканальный декодер может вычислить различие между энергиями каналов понижающего сигнала и разделить понижающий сигнал на несколько исходящих каналов на основе результатов вычисления. Однако типичный многоканальный декодер не может увеличить или уменьшить громкость определенного звука в понижающем сигнале. Другими словами, типичный многоканальный декодер просто распределяет понижающий сигнал по нескольким исходящим каналам и таким образом не может увеличить или уменьшить громкость звука в понижающем сигнале.
Относительно легко разместить каждый из нескольких объектных сигналов понижающего сигнала, сформированного объектным кодером, в предопределенном положении в многоканальном пространстве согласно информации управления. Однако специальные методики требуются для увеличения или уменьшения амплитуды предопределенного объектного сигнала. Другими словами, если понижающий сигнал, сформированный объектным кодером, используется в этом качестве, трудно уменьшить амплитуду каждого объектного сигнала понижающего сигнала.
Поэтому, согласно этому варианту осуществления данного изобретения, относительные амплитуды объектных сигналов могут быть изменены согласно информации управления, используя модуль 147 ADG, показанный на ФИГ.8. Более определенно, амплитуда любого из множества объектных сигналов понижающего сигнала, переданного объектным кодером, может быть увеличена или уменьшена, используя модуль 147 ADG. Понижающий сигнал, полученный компенсацией, выполненной модулем 147 ADG, может быть подвергнут многоканальному декодированию.
Если относительные амплитуды объектных сигналов понижающего сигнала соответственно настроены, используя модуль 147 ADG, возможно выполнить объектное декодирование, используя типичный многоканальный декодер. Если понижающий сигнал, сформированный объектным кодировщиком, является сигналом моно или стерео или многоканальным сигналом с тремя или больше каналами, понижающий сигнал может быть обработан модулем 147 ADG. Если у понижающего сигнала, сформированного объектным кодировщиком, есть два или больше канала, а предопределенный объектный сигнал, который должен быть настроен модулем 147 ADG, только существует в одном из каналов понижающего сигнала, модуль 147 ADG может быть применен только к каналу, включающему предопределенный объектный сигнал, вместо того, чтобы быть примененным ко всем каналам понижающего сигнала. Понижающий сигнал, обработанный модулем 147 ADG вышеописанным образом, может быть без труда обработан, используя типичный многоканальный декодер без потребности изменять структуру многоканального декодера.
Даже когда заключительный выходящий сигнал не является многоканальным, который может быть воспроизведен многоканальным громкоговорителем, но является стереофоническим сигналом, модуль 147 ADG может использоваться, чтобы приспособить относительные амплитуды объектных сигналов итогового выходящего сигнала.
Альтернативно к использованию модуля 147 ADG, информация усиления, определяющая коэффициент усиления, который будет применен к каждому объектному сигналу, может быть включена в информацию управления во время выработки ряда объектных сигналов. Для этого может быть изменена структура типичного многоканального декодера. Даже при том, что требуя модификации к структуре существующего многоканального декодера, этот способ удобен в условиях сокращения сложности декодирования, применяя коэффициент усиления к каждому объектному сигналу во время операции декодирования без потребности вычислять ADG и влиять на каждый объектный сигнал.
ФИГ.9 - это блок-схема устройства 150 декодирования аудио согласно четвертому варианту осуществления данного изобретения. Согласно ФИГ.9, устройство 150 декодирования аудио характеризуется формированием стереофонического сигнала.
Более точно, устройство 150 декодирования аудио включает в себя многоканальный стереофонический декодер 151, первый преобразователь 157 параметров и второй преобразователь 159 параметров.
Второй преобразователь 159 параметров анализирует дополнительную информацию и информацию управления, которые предоставлены устройством для кодирования аудио, и конфигурирует пространственную информацию о параметрах на основе результатов анализа. Первый преобразователь 157 параметров формирует стереофоническую информацию параметров, которая может использоваться многоканальным стереофоническим декодером 151, добавляя трехмерную (3D) информацию, как, например, параметры функции моделирования восприятия звука (HRTF), к пространственной информации о параметрах. Многоканальный стереофонический декодер 151 формирует виртуальный трехмерный (3D) сигнал, применяя виртуальную трехмерную информацию о параметрах к понижающему сигналу.
Первый преобразователь 157 параметров и второй преобразователь 159 параметров могут быть заменены единственным модулем, то есть, модуль 155 преобразований параметров, который получает дополнительную информацию, информацию управления и параметры HRTF и формирует стереофоническую информацию о параметрах на основе дополнительной информации, информации управления, и параметров HRTF.
Традиционно, чтобы произвести стереофонический сигнал для воспроизведения понижающего сигнала, включающего 10 объектных сигналов, с помощью наушников, объектный сигнал должен сформировать 10 декодированных сигналов, соответствующих этим 10 объектным сигналам, на основе понижающего сигнала и дополнительной информации. После этого рендерер размещает каждый из этих 10 объектных сигналов в предопределенном положении в многоканальном пространстве в отношении информации управления, чтобы соответствовать 5-канальному окружению. После этого рендерер формирует 5-канальный сигнал, который может быть воспроизведен, используя 5-канальный громкоговоритель. После этого рендерер применяет параметры HRTF к 5-канальному сигналу, таким образом производя 2-канальный сигнал. Вкратце, вышеупомянутый традиционный способ декодирования аудио включает в себя воспроизведение 10 объектных сигналов, преобразование этих 10 объектных сигналов в 5-канальный сигнал, и формирование 2-канального сигнала на основе 5-канального сигнала, и таким образом неэффективен.
С другой стороны, устройство 150 декодирования аудио может сразу сформировать стереофонический сигнал, который может быть воспроизведен, используя наушники, на основе объектных аудиосигналов. Кроме того, устройство 150 декодирования аудио конфигурирует пространственную информацию о параметрах через анализ дополнительной информации и информации управления и может таким образом сформировать стереофонический сигнал, используя типичный многоканальный стереофонический декодер. Кроме того, устройство 150 декодирования аудио все еще может использовать типичный многоканальный стереофонический декодер, даже будучи оборудованным объединенным преобразователем параметров, который получает дополнительную информацию, информацию управления и параметры HRTF, и формирует стереофоническую информацию о параметрах на основе дополнительной информации, информации управления и параметров HRTF.
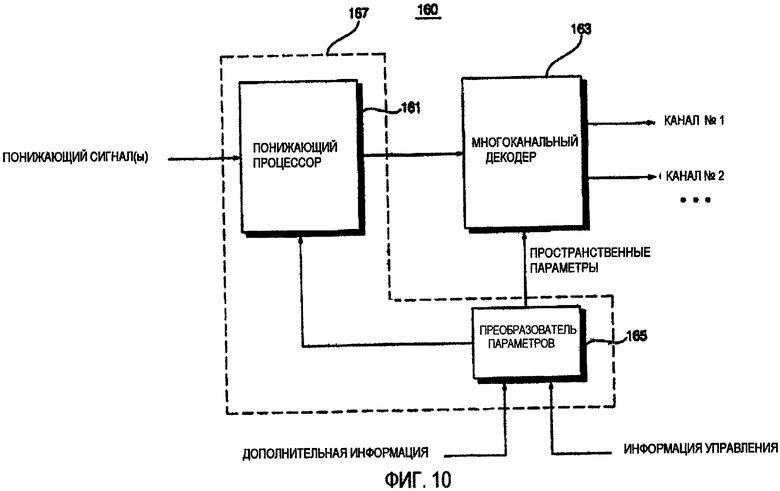
ФИГ.10 - это блок-схема устройства 160 декодирования аудио согласно пятому варианту осуществления данного изобретения. Согласно ФИГ.10, устройство 160 декодирования аудио включает в себя понижающий процессор 161, многоканальный декодер 163 и преобразователь 165 параметров. Понижающий процессор 161 и преобразователь 165 параметров может быть заменен единственным модулем 167.
Преобразователь 165 параметров формирует пространственную информацию о параметрах, которая может использоваться многоканальным декодером 163, и информацию о параметрах, которая может использоваться понижающим процессором 161. Понижающий процессор 161 выполняет операцию предварительной обработки понижающего сигнала и передает понижающий сигнал, полученный из операции предварительной обработки, многоканальному декодеру 163. Многоканальный декодер 163 выполняет операцию декодирования понижающего сигнала, переданного понижающим процессором 161, таким образом выводя стереосигнал, стереофонический стереосигнал или многоканальный сигнал. Примеры операции предварительной обработки, выполненной понижающим процессором 161, включают модификацию или преобразование понижающего сигнала во временной области или частотной области, используя фильтрование.
Если понижающий сигнал, входящий в устройство 160 декодирования аудио, является стереосигналом, понижающий сигнал может быть подвергнут понижающей предварительной обработке, выполняемой понижающим процессором 161, перед тем, как быть введенным в многоканальный декодер 163, потому что многоканальный декодер 163 не может отобразить компонент понижающего сигнала, соответствующего левому каналу, который является одним из нескольких каналов, на правый канал, который является другим из нескольких каналов. Поэтому, чтобы сместить положение объектного сигнала, классифицированного как левый канал, в направлении правого канала, понижающий сигнал, входящий в устройство 160 декодирования аудио, может быть предварительно обработан понижающим процессором 161, и предварительно обработанный понижающий сигнал может быть введен в многоканальный декодер 163.
Предварительная обработка понижающего стереосигнала может быть выполнена на основе информации предварительной обработки, полученной из дополнительной информации и из информации управления.
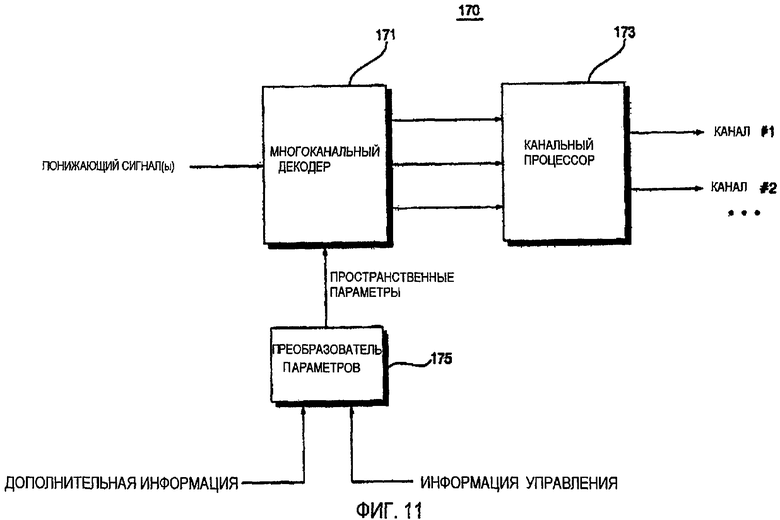
ФИГ.11 - блок-схема устройства 170 декодирования аудио согласно шестому варианту осуществления данного изобретения. Согласно ФИГ.11, устройство 170 декодирования аудио включает в себя многоканальный декодер 171, канальный процессор 173 и преобразователь 175 параметров.
Преобразователь 175 параметров формирует пространственную информацию о параметрах, которая может использоваться многоканальным декодером 173, и информацию о параметрах, которая может использоваться канальным процессором 173. Канальный процессор 173 выполняет операцию постобработки сигнала, выводимого многоканальным декодером 173. Примеры сигнала, выводимого многоканальным декодером 173, включают в себя стереосигнал, стереофонический стереосигнал и многоканальный сигнал.
Примеры операции постобработки, выполняемой постпроцессором 173, включают в себя модификацию и преобразование каждого канала или всех каналов выводимого сигнала. Например, если дополнительная информация включает в себя информацию об основной частоте относительно предопределенного объектного сигнала, канальный процессор 173 может удалить гармонические компоненты из предопределенного объектного сигнала со ссылкой на информацию об основной частоте. Способ декодирования многоканального аудио, возможно, не достаточно эффективен для использования в системе караоке. Однако, если информация об основной частоте относительно вокальных объектных сигналов включена в дополнительную информацию и гармонические компоненты вокальных объектных сигналов удаляются во время операции постобработки, возможно реализовать высокоэффективную систему караоке, используя вариант осуществления ФИГ.11. Вариант осуществления ФИГ.11 может также быть применен к объектным сигналам, кроме вокальных объектных сигналов. Например, возможно удалить звук предопределенного музыкального инструмента, используя вариант осуществления ФИГ.11. Кроме того, возможно усилить предопределенные гармонические компоненты, используя информацию об основной частоте относительно объектных сигналов, используя вариант осуществления ФИГ.11.
Канальный процессор 173 может выполнить дополнительную обработку эффектов понижающего сигнала. Альтернативно, канальный процессор 173 может добавить сигнал, полученный дополнительной обработкой эффектов сигнала, выводимого многоканальным декодером 171. Канальный процессор 173 может изменить спектр объекта или изменить понижающий сигнал всякий раз, когда необходимо. Если не уместно непосредственно выполнить операцию обработки эффектов, такую как реверберация, на понижающем сигнале и передать сигнал, полученный операцией обработки эффектов, многоканальному декодеру 171, понижающий процессор 173 может добавить сигнал, полученный операцией обработки эффектов к выходу многоканального декодера 171, вместо выполнения обработки эффектов на понижающем сигнале.
Устройство 170 декодирования аудио может быть выполнено так, чтобы включать в себя не только канальный процессор 173, но также и понижающий процессор. В этом случае понижающий процессор может быть расположен перед многоканальным декодером 171, а канальный процессор 173 может быть расположен после многоканального декодера 171.
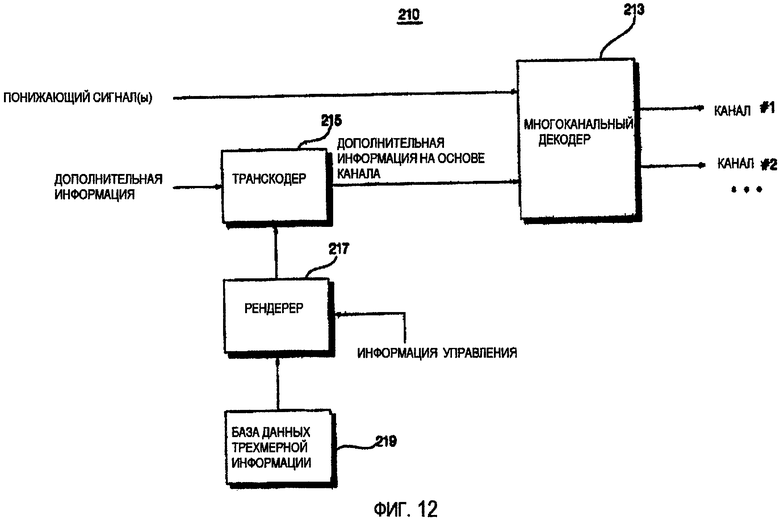
ФИГ.12 - это блок-схема устройства 210 декодирования аудио согласно седьмому варианту осуществления изобретения. Согласно ФИГ.12, вместо объектного декодера устройство 210 декодирования аудио использует многоканальный декодер 213.
Более точно, устройство 210 декодирования аудио содержит многоканальный декодер 213, транскодер 215, рендерер 217 и базу 219 данных трехмерной информации.
Рендерер 217 определяет трехмерные положения множества объектных сигналов на основе трехмерной информации, соответствующей индексным данным, включенным в информацию управления. Транскодер 215 формирует дополнительную информацию на основе канала, синтезируя информацию положения относительно нескольких объектных сигналов аудио, к которым трехмерная информация применена рендерером 217. Многоканальный декодер 213 выводит трехмерный сигнал, применяя дополнительную информацию на основе канала к понижающему сигналу.
Функция моделирования восприятия звука (HRTF) может использоваться как трехмерная информация. HRTF - функция передачи, которая описывает передачу звуковых волн между звуковым источником в произвольном положении и барабанной перепонкой и возвращает значение, которое изменяется согласно направлению и высоте звукового источника. Если ненаправленный сигнал фильтруется, используя HRTF, сигнал можно услышать, как будто он был воспроизведен с определенного направления.
Когда принимается входящий битовый поток, устройство 210 декодирования аудио извлекает понижающий сигнал на основе объекта и информацию о параметрах на основе объекта из входящего потока, используя демультиплексор (не показан). Затем, рендерер 217 извлекает индексные данные из информации управления, которая используется, чтобы определить положения множества объектных сигналов аудио, и вынимает трехмерную информацию, соответствующую извлеченным данным индекса из базы 219 данных трехмерной информации.
Более точно, информация о параметрах смешивания, которая включена в информацию управления, которая используется устройством 210 декодирования аудио, может включать в себя не только информацию уровня, но также и индексные данные, необходимые для того, чтобы искать трехмерную информацию. Информация о параметрах смешивания может также включать в себя информацию о времени относительно разницы во времени между каналами, информацию положения и один или более параметров, полученных, соответственно, сочетая информацию уровня и информацию времени.
Положение объектного сигнала аудио может быть определено первоначально согласно первоначальной информации о параметрах смешивания и может быть изменено позже, применяя трехмерную информацию, соответствующую положению, желаемому пользователем, к объектному сигналу аудио. Или если пользователь желает применить трехмерное воздействие только к нескольким объектным сигналам аудио, информация уровня и информация времени относительно других объектных сигналов аудио, к которым пользователь желает не применять трехмерный эффект, могут использоваться как информация о параметрах смешивания.
Транскодер 215 формирует дополнительную информацию на основе канала относительно М каналов, синтезируя информацию о параметрах на основе объекта относительно N объектных сигналов, переданных устройством кодирования аудио, и информацию положения нескольких объектных сигналов, к которым трехмерная информация, такая как HRTF применена рендерером 217.
Многоканальный декодер 213 формирует сигнал аудио на основе понижающего сигнала и дополнительной информации на основе канала, предоставленной транскодером 215, и формирует трехмерный многоканальный сигнал, выполняя операцию трехмерного воспроизведения, используя трехмерную информацию, включенную в дополнительную информацию на основе канала.
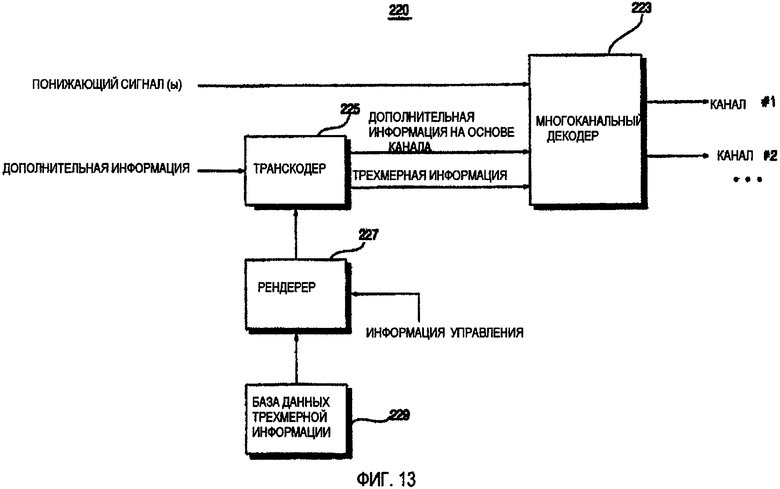
ФИГ.13 - это блок-схема устройства 220 декодирования аудио согласно восьмому варианту осуществления данного изобретения. Согласно ФИГ.13, устройство 220 декодирования аудио отличается от устройства 210 декодирования аудио, показанного на ФИГ.12, в том, что транскодер 225 передает дополнительную информацию на основе канала и трехмерную информацию отдельно в многоканальный декодер 223. Другими словами, транскодер 225 из устройства 220 декодирования аудио получает дополнительную информацию на основе канала относительно М каналов из информации о параметрах на основе объекта относительно N объектных сигналов и передает дополнительную информацию на основе канала и трехмерную информацию, которая применяется к каждому из N объектных сигналов, в многоканальный декодер 223, тогда как транскодер 215 из устройства 210 декодирования аудио передает дополнительную информацию на основе канала, включающую трехмерную информацию, в многоканальный декодер 213.
Согласно ФИГ.14, дополнительная информация на основе канала и трехмерная информация могут включать множество индексов кадров. Таким образом, многоканальный декодер 223 может синхронизировать дополнительную информацию на основе канала и трехмерную информацию в отношении индексов кадра каждой из дополнительной информации на основе канала и трехмерной информации и может таким образом применять трехмерную информацию к кадру битового потока, соответствующего трехмерной информации. Например, трехмерная информация, имеющая индекс 2, может быть применена в начале кадра 2 индекса 2.
Так как на основе канала дополнительная информация и трехмерная информация включают индексы кадров, возможно эффективно определить временное положение дополнительной информации на основе канала, к которой должна быть применена трехмерная информация, даже если трехмерная информация обновляется со временем. Другими словами, транскодер 225 включает в себя трехмерную информацию и многие индексы кадров в дополнительной информации на основе канала и, таким образом, многоканальный декодер 223 может легко синхронизировать дополнительную информацию на основе канала и трехмерную информацию.
Понижающий процессор 231, транскодер 235, рендерер 237 и база данных о трехмерной информации могут быть заменены единственным модулем 239.
ФИГ.15 - это блок-схема устройства 230 декодирования аудио согласно девятому варианту осуществления данного изобретения. Согласно ФИГ.15, устройство 230 декодирования аудио отличается от устройства 220 декодирования аудио, показанного на ФИГ.14, дополнительным включением в него понижающего процессора 231.
Более точно, устройство 230 декодирования аудио содержит транскодер 235, рендерер 237, базу 238 данных трехмерной информации, многоканальный декодер 233 и понижающий процессор 231. Транскодер 235, рендерер 237, база 238 данных трехмерной информации и многоканальный декодер 233 являются их соответствующими копиями, показанными на ФИГ.14. Понижающий процессор 231 выполняет операцию предварительной обработки понижающего стереосигнала для настройки положения. База 238 данных трехмерной информации может быть объединена с рендерером 237. Модуль для применения предопределенного эффекта к понижающему сигналу может также быть обеспечен в устройстве 230 декодирования аудио.
ФИГ.16 показывает блок-схему устройства 240 декодирования аудио согласно десятому варианту осуществления данного изобретения. Согласно ФИГ.16, устройство 240 декодирования аудио отличается от устройства 230 декодирования аудио, показанного на ФИГ.15, включением в него многоточечного объединителя 241 блока управления.
Таким образом, устройство 240 декодирования аудио, как и устройство 230 декодирования аудио, включает в себя понижающий процессор 243, многоканальный декодер 244, транскодер 245, рендерер 247 и базу 249 данных трехмерной информации. Многоточечный объединитель 241 блока управления соединяет множество битовых потоков, полученных кодированием на основе объекта, таким образом получая единственный битовый поток. Например, когда первый битовый поток для первого сигнала аудио и второй битовый поток для второго сигнала аудио введены, многоточечный объединитель 241 блока управления извлекает первый понижающий сигнал из первого битового потока, извлекает второй понижающий сигнал из второго битового потока и формирует третий понижающий сигнал, сочетая первый и второй понижающие сигналы. Кроме того, многоточечный объединитель 241 блока управления извлекает первую дополнительную информацию на основе объекта из первого потока, извлекает вторую дополнительную информацию на основе объекта из второго потока и формирует третью дополнительную информацию на основе объекта, сочетая первую дополнительную информацию на основе объекта и вторую дополнительную информацию на основе объекта. После этого многоточечный объединитель 241 блока управления формирует поток, сочетая третий понижающий сигнал и третью дополнительную информацию на основе объекта и выводит сформированный битовый поток.
Поэтому, согласно десятому варианту осуществления данного изобретения, возможно эффективно обработать даже сигналы, переданные двумя или больше партнерами по связи по сравнению со случаем кодирования или декодирования каждого объектного сигнала.
Для многоточечного объединителя блока управления 241, чтобы объединить множество понижающих сигналов, которые соответственно извлечены из множества битовых потоков и связаны с различными кодеками сжатия, в единственный понижающий сигнал, понижающие сигналы, возможно, должны быть преобразованы в сигналы импульсно-кодовой модуляции (PCM) или сигналы в предопределенной частотной области согласно типам кодеков сжатия понижающих сигналов, сигналы PCM или сигналы, полученные преобразованием, возможно, должны быть объединены вместе, и сигнал, полученный сочетанием, возможно, должен быть преобразован, используя заданный кодек сжатия. В этом случае, задержка может произойти согласно тому, включены ли понижающие сигналы в сигнал PCM или в сигнал в предопределенной частотной области. Задержка, однако, возможно, не будет должным образом оценена декодером. Поэтому, задержка, возможно, должна быть включена в битовый поток и передана вместе с битовым потоком. Задержка может указывать число образцов задержки в сигнале PCM или число образцов задержки в заданной области частоты.
Во время операции кодирования аудио на основе объекта значительное число входящих сигналов может, а иногда и должно быть обработано по сравнению с числом входящих сигналов, обычно обрабатываемых во время типичной многоканальной кодирующей операции (например, 7.1-канальной или 5.1-канальной кодирующих операций). Поэтому способ кодирования аудио на основе объекта требует намного большей скорости передачи битов, чем типичный способ кодирования многоканального аудио на основе канала. Однако, так как способ кодирования аудио на основе объекта вовлекает обработку объектных сигналов, которые меньше, чем канальные сигналы, возможно сформировать динамические исходящие сигналы, используя способ кодирования аудио на основе объекта.
Способ кодирования аудио согласно одному из вариантов исполнения данного изобретения будет в дальнейшем описан подробно согласно ФИГ.17-20.
В способе кодирования аудио на основе объекта объектные сигналы могут быть определены, чтобы представить индивидуальные звуки, такие как голос человека или звук музыкального инструмента. Или звуки, имеющие подобные особенности, такие как звуки струнных музыкальных инструментов (например, скрипка, альт и виолончель), звуки, принадлежащие тому же самому диапазону частот, или звукам, классифицированным в ту же самую категорию согласно указаниям и углам их звуковых источников, могут группироваться и определяться теми же самыми объектными сигналами. Или объектные сигналы могут быть определены, используя сочетание вышеописанных способов.
Несколько объектных сигналов могут быть переданы как понижающий сигнал и дополнительная информация. Во время создания информации, которая будет передана, энергия, или мощность понижающего сигнала, или каждое множество объектных сигналов понижающего сигнала вычисляется первоначально с целью обнаружения огибающей понижающего сигнала. Результаты вычисления могут использоваться, чтобы передать объектные сигналы или понижающий сигнал или вычислить отношение уровней объектных сигналов.
Алгоритм линейного прогнозирующего кодирования (LPC) может использоваться, чтобы понизить скорость передачи битов. Более точно, ряд коэффициентов LPC, которые представляют огибающую сигнала, формируются через анализ сигнала, и коэффициенты LPC передаются вместо передачи информации об огибающей относительно сигнала. Этот способ эффективен в смысле скорости передачи битов. Однако, так как коэффициенты LPC, очень вероятно, будут отличаться от фактического сигнала огибающей, этот способ требует процесса дополнения, такого как коррекция ошибок. Короче говоря, способ, который использует передачу информации об огибающей сигнала, может гарантировать высокое качество звука, но привести к значительному увеличению количества информации, которую необходимо передать. С другой стороны, метод, который вовлекает использование коэффициентов LPC, может уменьшить количество информации, которая должна быть передана, но требует дополнительного процесса, такого как коррекция ошибок и приводит к уменьшению качества звука.
Согласно этому варианту осуществления данного изобретения может использоваться сочетание этих способов. Другими словами, огибающая сигнала может быть представлена энергией или мощностью сигнала или значением индекса, или другим значением, например коэффициентом LPC, соответствующим энергии или мощности сигнала.
Информация об огибающей относительно сигнала может быть получена в единицах временных секций или частотных секций. Более точно, согласно ФИГ.17, информация об огибающей относительно сигнала может быть получена в единицах кадров. Или если сигнал представлен структурой полосы частот, используя модуль фильтра, такой как модуль квадратурно-зеркального фильтра (QMF), информация об огибающей относительно сигнала может быть получена в единицах подполос частот, разделы подполос частот, которые являются меньшими, чем подполосы частот, группы подполос частот или группы разделов подполос частот. Или сочетание способа на основе кадров, способа на основе подполос частот и способа на основе разделов подполос частот может использоваться в рамках данного изобретения.
Или при условии, что низкочастотные компоненты сигнала обычно имеют больше информации, чем высокочастотные компоненты сигнала, информацию об огибающей относительно низкочастотных компонентов сигнала можно передать как есть, а информация об огибающей относительно высокочастотных компонентов сигнала может быть представлена коэффициентами LPC или другими значениями и коэффициентами LPC, или другие значения могут быть переданы вместо информации об огибающей относительно высокочастотных компонентов сигнала. Однако у низкочастотных компонентов сигнала может не обязательно быть больше информации, чем у высокочастотных компонентов сигнала. Поэтому вышеописанный способ должен быть гибко применен согласно обстоятельствам.
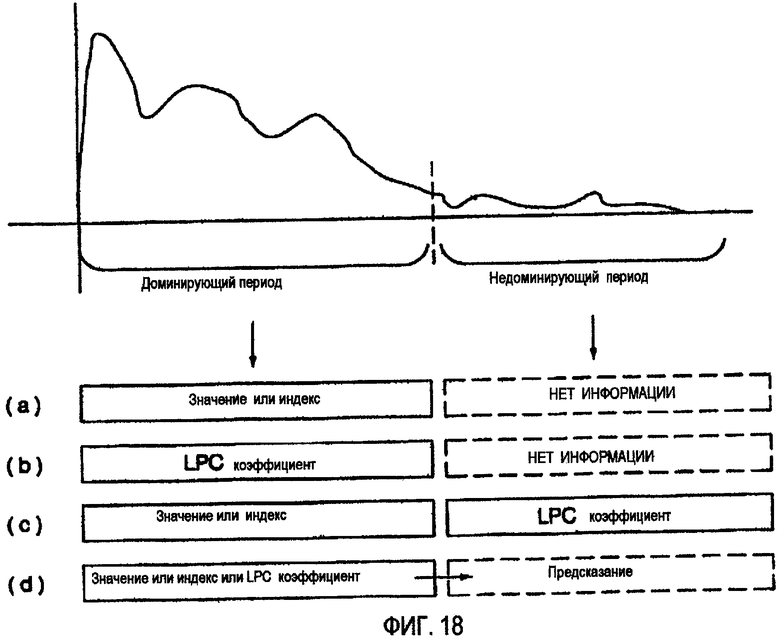
Согласно варианту осуществления данного изобретения, могут быть переданы информация об огибающей или индексные данные, соответствующие частям (в дальнейшем называемым доминирующими частями) сигнала, который оказывается доминирующим на оси времени/частот, и ни одно из информации об огибающей и индексных данных, соответствующих недоминирующей части сигнала, не может быть передано. Или значения (например, коэффициенты LPC), которые представляют энергию и мощность доминирующей части сигнала, могут быть переданы, и никакие другие значения, соответствующие недоминирующей части сигнала, не могут быть переданы. Или информация об огибающей или индексные данные, соответствующие доминирующей части сигнала, могут быть переданы, и значения, которые представляют энергию или мощность недоминирующей части сигнала, могут быть переданы. Или информация только относительно доминирующей части сигнала может быть передана так, чтобы недоминирующая часть сигнала могла быть оценена как основанная на информации относительно доминирующей части сигнала. Или может использоваться сочетание вышеописанных способов.
Например, согласно ФИГ.18, если сигнал разделен на доминирующий период и недоминирующий период, информация относительно сигнала может быть передана четырьмя различными способами, как показано на (a)-(d).
Чтобы передать несколько объектных сигналов как сочетание понижающего сигнала и дополнительной информации, понижающий сигнал должен быть разделен на множество элементов как часть операции декодирования, например, с учетом отношения уровней объектных сигналов. Чтобы гарантировать независимость между элементами понижающего сигнала, дополнительно должна быть выполнена операция декорреляции.
Объектные сигналы, являющиеся единицами кодирования в способе кодирования на основе объекта, имеют больше независимости, чем канальные сигналы, являющиеся единицами кодирования в многоканальном способе кодирования. Другими словами, канальный сигнал включает в себя несколько объектных сигналов и, таким образом, должен быть декоррелирован. С другой стороны, объектные сигналы независимы от друг друга и, таким образом, разделение канала может быть легко выполнено, просто используя особенности объектных сигналов без требования операции декорреляции.
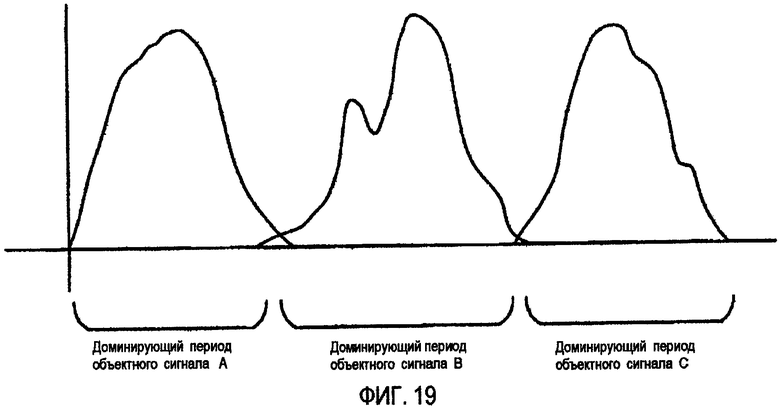
Более точно, согласно ФИГ.19, объектные сигналы A, B, и С сменяются, чтобы казаться доминирующими на оси частоты. В этом случае, нет никакой потребности разделять понижающий сигнал на несколько сигналов согласно отношению уровней объектных сигналов A, B, и С и выполнять декорреляцию. Вместо этого информация относительно доминирующих периодов объектных сигналов A, B, и С может быть передана, или можно применить коэффициент усиления к каждому компоненту частоты каждого из объектных сигналов A, B, и C, таким образом пропуская декорреляцию. Поэтому возможно уменьшить количество вычислений и уменьшить скорость передачи битов количеством, которое иначе требовалось бы для дополнительной информации, необходимой для декорреляции.
Вкратце, чтобы пропустить декорреляцию, которую выполняют, чтобы гарантировать независимость среди нескольких сигналов, полученных разделением понижающего сигнала согласно отношению отношений объектных сигналов понижающего сигнала, информация относительно области частот, включающей каждый объектный сигнал, может быть передана как дополнительная информация. Или к доминирующему периоду могут быть применены различные коэффициенты усиления, во время которого каждый объектный сигнал кажется доминирующим, и к недоминирующему периоду, во время которого каждый объектный сигнал кажется менее доминирующим, и, таким образом, информация относительно доминирующего периода может быть главным образом предоставлена как дополнительная информация. Или информация относительно доминирующего периода может быть передана как дополнительная информация, и никакая информация относительно недоминирующего периода не может быть передана. Или сочетание вышеописанных способов, которые являются альтернативами способу декорреляции, может использоваться.
Вышеописанные способы, которые являются альтернативами способу декорреляции, могут быть применены ко всем объектным сигналам или только к некоторым объектным сигналам с легко различимыми доминирующими периодами. Кроме того, вышеописанные способы, которые являются альтернативами способу декорреляции, могут быть временно применены в единицах кадров.
Кодирование объектных аудиосигналов, используя остаточный сигнал, будет в дальнейшем описано подробно.
В основном, в способе кодирования аудио на основе объекта несколько объектных сигналов кодируются, и результаты кодирования передаются как комбинация понижающего сигнала и дополнительной информации. Затем, несколько объектных сигналов восстанавливаются из понижающего сигнала до декодирования согласно дополнительной информации, и восстановленные объектные сигналы, соответственно, смешиваются, например, по требованию пользователя согласно информации управления, таким образом формируя заключительный канальный сигнал. Способ кодирования аудио на основе объекта, в общем, нацелен свободно изменять исходящий канальный сигнал согласно информации управления при помощи микшера. Однако способ кодирования аудио на основе объекта может также использоваться, чтобы формировать исходящий канал предопределенным образом, независимо от информации управления.
Для этого дополнительная информация может включать в себя не только информацию, необходимую, чтобы сформировать несколько объектных сигналов из понижающего сигнала, но также и информацию о параметрах смешивания, необходимую, чтобы сформировать канальный сигнал. Таким образом, возможно сформировать заключительный исходящий канальный сигнал без помощи микшера. В этом случае, такой алгоритм, как остаточное кодирование, может использоваться, чтобы улучшить качество звука.
Типичный способ кодирования остатка включает в себя кодирование сигнала и кодирование ошибки между закодированным сигналом и оригинальным сигналом, то есть остаточный сигнал. Во время операции декодирования закодированный сигнал декодируется, компенсируя ошибку между закодированным сигналом и оригинальным сигналом, таким образом восстанавливая сигнал, который настолько подобен оригинальному сигналу, насколько возможно. Поскольку ошибка между закодированным сигналом и оригинальным сигналом обычно незначительна, возможно уменьшить количество информации, дополнительно необходимой, чтобы выполнить кодирование остатка.
Если выход заключительного канала декодера фиксирован, не только информация о параметрах смешивания, необходимая для формирования заключительного канального сигнала, но также и информация кодирования остатка может быть предоставлена как дополнительная информация. В этом случае возможно улучшить качество звука.
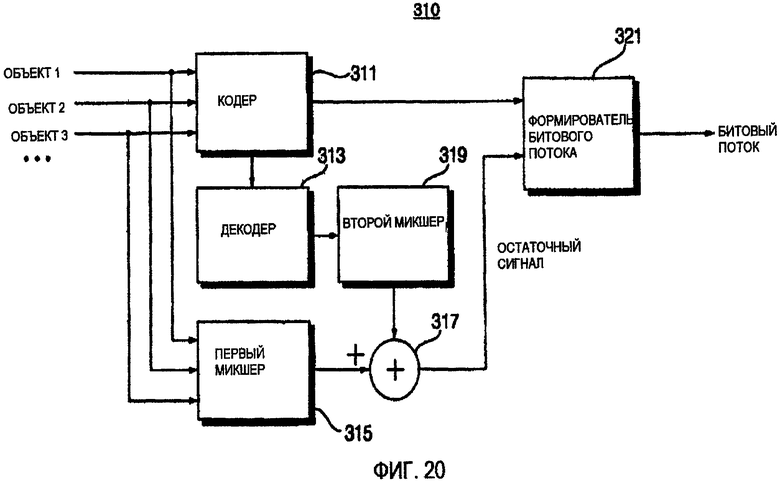
ФИГ.20 является блок-схемой устройства 310 кодирования аудио согласно одному варианту осуществления данного изобретения. Согласно ФИГ.20, устройство 310 кодирования аудио характеризуется использованием остаточного сигнала.
Более точно, устройство 310 кодирования аудио содержит кодер 311, декодер 313, первый микшер 315, второй микшер 319, сумматор 317 и генератор 321 битового потока.
Первый микшер 315 выполняет операцию смешивания на оригинальном сигнале, и второй микшер 319 выполняет операцию смешивания на сигнале, полученном выполнением операции кодирования, и затем операцией декодирования на оригинальном сигнале. Сумматор 317 вычисляет остаточный сигнал между сигналом, произведенным первым микшером 315, и сигналом, произведенным вторым микшером 319. Генератор 321 потока добавляет остаточный сигнал к дополнительной информации и передает результат сложения. Таким способом возможно улучшить качество звука.
Вычисление остаточного сигнала может быть применено ко всем частям сигнала или только для низкочастотных частей сигнала. Или вычисление остаточного сигнала может быть непостоянно применено только к областям частоты, включая доминирующие сигналы на покадровой основе. Или используется сочетание вышеописанных способов.
Так как количество дополнительной информации, включающей остаточную информацию сигнала, намного больше, чем количество дополнительной информации, не включающей остаточной информации сигнала, вычисление остаточного сигнала может быть применено только к некоторым частям сигнала, которые непосредственно затрагивают качество звука, таким образом предотвращая чрезмерное увеличение скорости передачи битов. Существующее изобретение может быть понято как компьютерно-читаемый код, написанный на компьютерно-читаемом носителе записи. Компьютерно-читаемый носитель записи может быть любым типом записывающего устройства, в котором данные хранятся в компьютерно-читаемом виде. Примеры компьютерно-читаемых носителей записи включают в себя ROM, RAM, CD-ROM, магнитную ленту, гибкий диск, оптическое хранилище данных и несущую волну (например, передача данных через Интернет). Компьютерно-читаемый носитель записи может быть распределен по множеству компьютерных систем, соединенных с сетью так, чтобы компьютерно-читаемый код записывался на него и выполнялся с него децентрализованным способом. Функциональные программы, код, и сегменты кода, необходимые для реализации настоящего изобретения, могут быть легко истолкованы специалистами в данной области.
Промышленная применимость
Как описано выше, согласно данному изобретению, звуковые образы располагаются для каждого объектного сигнала аудио, используя преимущества способа кодирования и декодирования аудио на основе объекта. Таким образом, возможно предложить более реалистические звуки через воспроизведение объектных сигналов аудио. Кроме того, существующее изобретение может быть применено к интерактивным играм и может таким образом предоставить пользователю более реалистический опыт виртуального мира.
В то время как существующее изобретение было показано и описано согласно отдельным вариантам его осуществления, специалистами в данной области будет понято, что различные изменения в форме и деталях могут быть сделаны, не отступая от объема и области существующего изобретения, как определено в соответствии со следующей формулой изобретения.
Изобретение относится к декодированию аудиосигналов. Представлены способ и устройство кодирования аудиосигналов и способ и устройство декодирования аудиосигналов. Способ декодирования аудио включает в себя извлечение понижающего сигнала и дополнительной информации на основе объекта из входящего сигнала аудио, формирование информации воспроизведения на основе входящих данных управления и формирование пространственной информации на основе информации воспроизведения и дополнительной информации на основе объекта. Технический результат - обеспечение декодирования аудиосигналов, при котором образы звука можно располагать в любом желаемом положении для каждого объектного аудиосигнала. 3 н. и 8 з.п. ф-лы, 20 ил.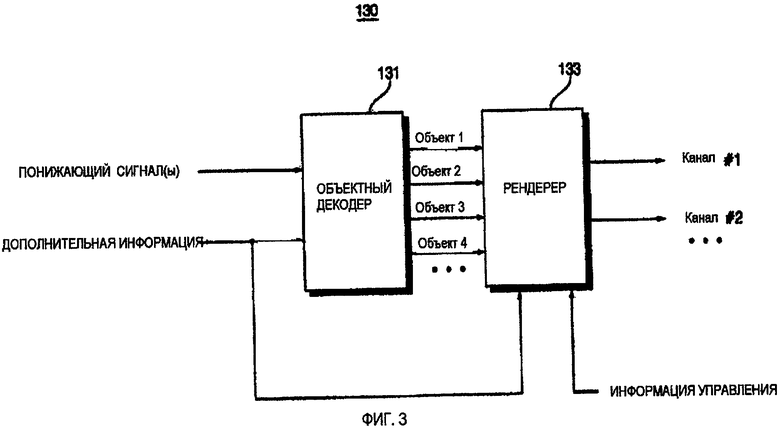
1. Способ декодирования аудио, содержащий:
прием понижающего сигнала, содержащего, по меньшей мере, один объектный сигнал, и дополнительной информации на основе объекта, сформированные при понижении, по меньшей мере, одного объектного сигнала до понижающего сигнала;
прием информации управления для управления положением или уровнем, по меньшей мере, одного объектного сигнала;
формирование информации о параметрах для того, чтобы изменить понижающий сигнал на основании дополнительной информации на основе объекта и информации управления;
формирование пространственного параметра на основе канала на основании информации управления и дополнительной информации на основе объекта;
формирование обработанного понижающего сигнала путем применения информации о параметрах к понижающему сигналу;
формирование многоканального сигнала путем применения пространственного параметра на основе канала к обработанному понижающему сигналу;
причем пространственный параметр на основе канала содержит данные, соответствующие приставке ОТТ (One-TO-TWO) или приставке ТТТ (TWO-TO-Three).
2. Способ декодирования аудио по п.1, в котором информация управления содержит, по меньшей мере, одну из трехмерной (3D) информации, информации смешивания или информации гармоник для обработки предопределенного объектного сигнала.
3. Способ декодирования аудио по п.2, в котором информация гармоник содержит, по меньшей мере, одно из: информации тона, информации основной частоты и информации доминирующей частоты предопределенного объектного сигнала.
4. Способ декодирования аудио по п.3, дополнительно содержащий настройку усиления предопределенного объектного сигнала на основе информации гармоник.
5. Способ декодирования аудио по п.3, дополнительно содержащий компенсирование объектного сигнала в предопределенной полосе частот на основе информации гармоник.
6. Способ декодирования аудио по п.1, дополнительно содержащий компенсирование задержки между дополнительной информацией на основе канала и понижающим сигналом.
7. Устройство декодирования аудио, содержащее:
демультиплексор, который принимает понижающий сигнал, содержащий, по меньшей мере, один объектный сигнал, и дополнительную информацию на основе объекта, сформированные при понижении, по меньшей мере, одного объектного сигнала до понижающего сигнала и информацию управления для управления положением или уровнем, по меньшей мере, одного объектного сигнала;
преобразователь параметров, который формирует пространственный параметр на основе канала и информацию о параметрах для того, чтобы изменить понижающий сигнала на основании дополнительной информации на основе объекта и информации управления;
понижающий процессор, который формирует обработанный понижающий сигнал путем применения информации о параметрах к понижающему сигналу; и
многоканальный декодер, который формирует многоканальный сигнал путем применения пространственного параметра на основе канала к обработанному понижающему сигналу;
причем пространственный параметр на основе канала содержит данные, соответствующие приставке ОТТ (One-TO-TWO) или приставке ТТТ (TWO-TO-Three).
8. Устройство декодирования аудио по п.7, в котором информация управления содержит, по меньшей мере, одно из: трехмерной информации, информации смешивания и информации гармоник для обработки предопределенного объектного сигнала.
9. Устройство декодирования аудио по п.8, в котором информация гармоник содержит, по меньшей мере, одно из: информации тона, информации основной частоты и информации доминирующей частоты предопределенного объектного сигнала.
10. Устройство декодирования аудио по п.7, дополнительно содержащее буфер, который компенсирует задержку между дополнительной информацией на основе канала и обработанным понижающим сигналом.
11. Компьютерно-читаемый носитель записи, имеющий записанную на нем компьютерную программу для выполнения способа декодирования аудио, причем способ декодирования аудио содержит:
прием понижающего сигнала, содержащего, по меньшей мере, один объектный сигнал, и дополнительной информации на основе объекта, сформированные при понижении, по меньшей мере, одного объектного сигнала до понижающего сигнала;
прием информации управления для управления положением или уровнем, по меньшей мере, одного объектного сигнала;
формирование информации о параметрах для того, чтобы изменить понижающий сигнала на основании дополнительной информации на основе объекта и информации управления;
формирование дополнительной информации на основе канала на основании информации управления и дополнительной информации на основе объекта;
формирование обработанного понижающего сигнала путем применения информации о параметрах к понижающему сигналу;
формирование многоканального сигнала путем применения пространственного параметра на основе канала к обработанному понижающему сигналу;
причем дополнительная информация на основе канала содержит данные, соответствующие приставке ОТТ (One-TO-TWO) или приставке ТТТ (TWO-TO-Three).
| WO 2006016735 A1, 16.02.2006 | |||
| RU 2005104123 A, 10.07.2005 | |||
| US 2003167173 A1, 04.09.2003 | |||
| Раковина | 1979 |
|
SU857375A1 |
| JP 2001028800 A, 30.01.2001 | |||
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |

