Область техники, к которой относится изобретение
Настоящее изобретение относится к способу и устройству кодирования аудиосигнала и способу и устройству декодирования аудиосигнала, в которых звуковые образы для каждого объектного аудиосигнала могут быть локализованы в любой требуемой позиции.
Уровень техники
Согласно методам кодирования и декодирования многоканального аудиосигнала некоторое количество канальных сигналов в многоканальном сигнале в общем микшируют с понижением до меньшего числа канальных сигналов, передают дополнительную информацию, относящуюся к исходным канальным сигналам, и восстанавливают многоканальный сигнал, имеющий столько же каналов, что и исходный многоканальный сигнал.
Методики кодирования и декодирования объектно-ориентированного аудиосигнала по сути аналогичны методикам кодирования и декодирования многоканального аудиосигнала в отношении понижающего микширования нескольких источников звука в меньшее число сигналов источника звука и передачи дополнительной информации, относящейся к исходным источникам звука. Тем не менее, в методах кодирования и декодирования объектно-ориентированного аудиосигнала объектные сигналы, которые являются базовыми сигналами (к примеру, музыкальный инструмент или человеческий голос) канального сигнала, интерпретируют так же, как и канальные сигналы в методах кодирования и декодирования многоканального аудиосигнала, и таким образом упомянутые сигналы могут быть кодированы.
Другими словами, в методах кодирования и декодирования объектно-ориентированного аудиосигнала каждый объектный сигнал считается объектом, который должен быть кодирован. В этом смысле методы кодирования и декодирования объектно-ориентированного аудиосигнала отличаются от методов кодирования и декодирования многоканального аудиосигнала, в которых операция кодирования многоканального аудиосигнала выполняется просто на основе межканальной информации независимо от числа элементов канального сигнала, которые должны быть кодированы.
Раскрытие изобретения
Техническая задача
Согласно настоящему изобретению предлагаются способ и устройство кодирования аудиосигнала и способ и устройство декодирования аудиосигнала, в которых аудиосигналы могут быть кодированы или декодированы таким образом, что звуковые образы могут быть локализованы в любой требуемой позиции для каждого объектного аудиосигнала.
Техническое решение
Согласно аспекту настоящего изобретения, предусмотрен способ декодирования аудиосигнала, включающий в себя этапы, на которых извлекают сигнал понижающего микширования и объектно-ориентированной дополнительной информации из аудиосигнала; формируют канально-ориентированную дополнительную информацию на основе объектно-ориентированной дополнительной информации и управляющей информации для воспроизведения сигнала понижающего микширования; обрабатывают сигнал понижающего микширования с использованием декоррелированного канального сигнала; и формируют многоканальный аудиосигнал с использованием обработанного сигнала понижающего микширования и канально-ориентированной дополнительной информации.
Согласно аспекту настоящего изобретения, предусмотрено устройство декодирования аудиосигнала, включающее в себя демультиплексор, который извлекает из аудиосигнала сигнал понижающего микширования и объектно-ориентированную дополнительную информацию; преобразователь параметров, который формирует канально-ориентированную дополнительную информацию и управляющую информацию для воспроизведения сигнала понижающего микширования; процессор понижающего микширования, который модифицирует сигнал понижающего микширования через декоррелированный сигнал понижающего микширования, если сигнал понижающего микширования является стереосигналом понижающего микширования; и многоканальный декодер, который формирует многоканальный аудиосигнал с использованием модифицированного сигнала понижающего микширования, полученного процессором понижающего микширования, и канально-ориентированной дополнительной информации.
Согласно другому аспекту настоящего изобретения, предусмотрен способ декодирования аудиосигнала, включающий в себя этапы, на которых извлекают из аудиосигнала сигнал понижающего микширования и объектно-ориентированную дополнительную информацию; формируют канально-ориентированную дополнительную информацию и один или более параметров обработки на основе объектно-ориентированной дополнительной информации и управляющей информации для воспроизведения сигнала понижающего микширования; формируют многоканальный аудиосигнал с использованием сигнала понижающего микширования и канально-ориентированной дополнительной информации; и модифицируют многоканальный сигнал с использованием параметров обработки.
Согласно другому аспекту настоящего изобретения, предусмотрено устройство декодирования аудиосигнала, включающее в себя демультиплексор, который извлекает из аудиосигнала сигнал понижающего микширования и объектно-ориентированную дополнительную информацию; преобразователь параметров, который формирует канально-ориентированную дополнительную информацию и один или более параметров обработки на основе объектно-ориентированной дополнительной информации и управляющей информации для воспроизведения сигнала понижающего микширования; многоканальный декодер, который формирует многоканальный аудиосигнал с использованием сигнала понижающего микширования и канально-ориентированной дополнительной информации; и канальный процессор, который модифицирует многоканальный сигнал с использованием параметров обработки.
Согласно другому аспекту настоящего изобретения, предусмотрен машиночитаемый носитель записи, на котором сохранен способ декодирования аудиосигнала, включающий в себя этапы, на которых извлекают из аудиосигнала сигнал понижающего микширования и объектно-ориентированную дополнительную информацию; формируют канально-ориентированную дополнительную информацию на основе объектно-ориентированной дополнительной информации и управляющей информации для воспроизведения сигнала понижающего микширования; обрабатывают сигнал понижающего микширования с использованием декоррелированного канального сигнала; и формируют многоканальный аудиосигнал с использованием обработанного сигнала понижающего микширования, полученного путем перестановки, и канально-ориентированной дополнительной информации.
Согласно другому аспекту настоящего изобретения, предусмотрен машиночитаемый носитель записи, на котором сохранен способ декодирования аудиосигнала, включающий в себя этапы, на которых извлекают из аудиосигнала сигнал понижающего микширования и объектно-ориентированную дополнительную информацию; формируют канально-ориентированную дополнительную информацию и один или более параметров обработки на основе объектно-ориентированной дополнительной информации и управляющей информации для воспроизведения сигнала понижающего микширования; формируют многоканальный аудиосигнал с использованием сигнала понижающего микширования и канально-ориентированной дополнительной информации; и модифицируют многоканальный сигнал с использованием параметров обработки.
Преимущества
Предусмотрены способ и устройство кодирования аудиосигнала и способ и устройство декодирования аудиосигнала, в которых аудиосигналы могут быть кодированы или декодированы так, что звуковые образы могут быть локализованы в любой требуемой позиции для каждого объектного аудиосигнала.
Краткое описание чертежей
Настоящее изобретение станет более понятным из нижеприведенного подробного описания и сопровождающих чертежей, которые приведены только в целях иллюстрации и поэтому не должны рассматриваться как ограничивающие настоящее изобретение, на которых:
Фиг.1 - блок-схема обычной системы кодирования/декодирования объектно-ориентированного аудиосигнала;
Фиг.2 - блок-схема устройства декодирования аудиосигнала согласно первому варианту осуществления настоящего изобретения;
Фиг.3 - блок-схема устройства декодирования аудиосигнала согласно второму варианту осуществления настоящего изобретения;
Фиг.4 - график для пояснения влияния разности амплитуд и разности времени, которые независимы друг от друга, на локализацию звуковых образов;
Фиг.5 - график функций, относящийся к соответствию между разностью амплитуд и разностью времени, которые требуются для локализации звуковых образов в заданной позиции;
Фиг.6 иллюстрирует формат управляющих данных, включающих в себя информацию гармоник;
Фиг.7 - блок-схема устройства декодирования аудиосигнала согласно третьему варианту осуществления настоящего изобретения;
Фиг.8 - блок-схема модуля художественного усиления при понижающем микшировании (ADG), который может быть использован в модуле декодирования аудиосигнала, проиллюстрированном на фиг. 7;
Фиг.9 - блок-схема устройства декодирования аудиосигнала согласно четвертому варианту осуществления настоящего изобретения;
Фиг.10 - блок-схема устройства декодирования аудиосигнала согласно пятому варианту осуществления настоящего изобретения;
Фиг.11 - блок-схема устройства декодирования аудиосигнала согласно шестому варианту осуществления настоящего изобретения;
Фиг.12 - блок-схема устройства декодирования аудиосигнала согласно седьмому варианту осуществления настоящего изобретения;
Фиг.13 - блок-схема устройства декодирования аудиосигнала согласно восьмому варианту осуществления настоящего изобретения;
Фиг.14 - схема, поясняющая применение трехмерной (3D) информации к кадру устройством декодирования аудиосигнала, проиллюстрированным на фиг. 13;
Фиг.15 - блок-схема устройства декодирования аудиосигнала согласно девятому варианту осуществления настоящего изобретения;
Фиг.16 - блок-схема устройства декодирования аудиосигнала согласно десятому варианту осуществления настоящего изобретения;
Фиг.17-19 - схемы, поясняющие способ декодирования аудиосигнала согласно варианту осуществления настоящего изобретения; и
Фиг.20 - блок-схема устройства кодирования аудиосигнала согласно варианту осуществления настоящего изобретения.
Осуществление изобретения
Далее настоящее изобретение будет описано более подробно со ссылкой на сопровождающие чертежи, на которых показаны примерные варианты осуществления изобретения.
Способ и устройство кодирования аудиосигнала и способ и устройство декодирования аудиосигнала согласно настоящему изобретению могут быть применены к операциям обработки объектно-ориентированного аудиосигнала, но настоящее изобретение не ограничено этим. Другими словами, способ и устройство кодирования аудиосигнала и способ и устройство декодирования аудиосигнала могут быть применены к различным операциям обработки сигналов, отличным от операций обработки объектно-ориентированного аудиосигнала.
Фиг.1 иллюстрирует блок-схему обычной системы кодирования/декодирования объектно-ориентированного аудиосигнала. Аудиосигналы, вводимые в устройство кодирования объектно-ориентированного аудиосигнала, в общем не соответствуют каналам многоканального сигнала, а являются независимыми объектными сигналами. В этом смысле, устройство кодирования объектно-ориентированного аудиосигнала отличается от устройства кодирования многоканального аудиосигнала, в которое вводят канальные сигналы многоканального сигнала.
Например, канальные сигналы, такие как сигнал переднего левого канала и сигнал переднего правого канала для 5.1-канального сигнала, могут быть введены в многоканальный аудиосигнал, тогда как объектные аудиосигналы, такие как человеческий голос или звук музыкального инструмента (к примеру, звук скрипки или пианино), которые являются меньшими объектами, чем канальные сигналы, могут быть введены в устройство кодирования объектно-ориентированного аудиосигнала.
Как показано на фиг. 1, система кодирования/декодирования объектно-ориентированного аудиосигнала включает в себя устройство кодирования объектно-ориентированного аудиосигнала и устройство декодирования объектно-ориентированного аудиосигнала. Устройство кодирования объектно-ориентированного аудиосигнала включает в себя объектный кодер 100, а устройство декодирования объектно-ориентированного аудиосигнала включает в себя объектный декодер 111 и блок 113 воспроизведения.
Объектный кодер 100 принимает N объектных аудиосигналов и формирует объектно-ориентированный сигнал понижающего микширования с одним или более каналами и дополнительной информацией, включающей в себя ряд извлеченных из N объектных сигналов фрагментов информации, таких как информация разности энергии, информация разности фаз и значение корреляции. Дополнительная информация и объектно-ориентированный сигнал понижающего микширования объединяются в один поток битов, и поток битов передается в объектно-ориентированное устройство декодирования.
Дополнительная информация может включать в себя флаг, указывающий, что следует выполнять кодирование канально-ориентированного аудиосигнала, либо что следует выполнять кодирование объектно-ориентированного аудиосигнала, и тем самым на основе флага дополнительной информации может быть определено, следует ли выполнять кодирование канально-ориентированного аудиосигнала или кодирование объектно-ориентированного аудиосигнала. Дополнительная информация также может включать в себя информацию огибающей, информацию группировки, информацию периода молчания и информацию задержки, относящуюся к объектным сигналам. Дополнительная информация может также включать в себя информацию разности уровней объектов, информацию корреляции между объектами, информацию усиления при понижающем микшировании, информацию разности уровней каналов понижающего микширования и информацию абсолютной энергии объекта.
Объектный декодер 111 принимает объектно-ориентированный сигнал понижающего микширования и дополнительную информацию из устройства кодирования объектно-ориентированного аудиосигнала и восстанавливает объектные сигналы, имеющие свойства, аналогичные свойствам N объектных аудиосигналов, на основе объектно-ориентированного сигнала понижающего микширования и дополнительной информации. Объектные сигналы, формируемые объектным декодером 111, еще не назначены на какую-либо позицию в многоканальном пространстве. Таким образом, блок 113 воспроизведения назначает каждый из объектных сигналов, сформированных объектным декодером 111, на заданную позицию в многоканальном пространстве и определяет уровни объектных сигналов так, что объектные сигналы могут быть воспроизведены из надлежащих соответствующих позиций, указанных блоком 113 воспроизведения, с надлежащими соответствующими уровнями, определенными блоком 113 воспроизведения. Управляющая информация, относящаяся к каждому из объектных сигналов, сформированных объектным декодером 111, может варьироваться во времени, и тем самым пространственные позиции и уровни объектных сигналов, сформированных объектным декодером 111, могут варьироваться согласно управляющей информации.
Фиг. 2 представляет собой блок-схему устройства 120 декодирования аудиосигнала согласно первому варианту осуществления настоящего изобретения. Как показано на фиг. 2, устройство 120 декодирования аудиосигнала включает в себя объектный декодер 121, блок 123 воспроизведения и преобразователь 125 параметров. Устройство 120 декодирования аудиосигнала также может включать в себя демультиплексор (не показан), который извлекает сигнал понижающего микширования и дополнительную информацию из вводимого в него потока битов, и он применяется ко всем устройствам декодирования аудиосигнала согласно другим вариантам осуществления настоящего изобретения.
Объектный декодер 121 формирует ряд объектных сигналов на основе сигнала понижающего микширования и модифицированной дополнительной информации, обеспеченной преобразователем 125 параметров. Блок 123 воспроизведения назначает каждый из объектных сигналов, сформированных объектным декодером 121, на заданную позицию в многоканальном пространстве и определяет уровни объектных сигналов, сформированных объектным декодером 121, согласно управляющей информации. Преобразователь 125 параметров формирует модифицированную дополнительную информацию путем комбинирования дополнительной информации и управляющей информации. Затем преобразователь 125 параметров передает модифицированную дополнительную информацию в объектный декодер 121.
Объектный декодер 121 может иметь возможность выполнять адаптивное декодирование путем анализа управляющей информации в модифицированной дополнительной информации.
Например, если управляющая информация указывает то, что первый объектный сигнал и второй объектный сигнал назначены на одну позицию в многоканальном пространстве и имеют одинаковый уровень, обычное устройство декодирования аудиосигнала может декодировать первый и второй объектные сигналы отдельно, а затем компоновать их в многоканальном пространстве посредством операции микширования/воспроизведения.
С другой стороны, объектный декодер 121 устройства 120 декодирования аудиосигнала узнает из управляющей информации в модифицированной дополнительной информации то, что первый и второй объектные сигналы назначены на одну позицию в многоканальном пространстве и имеют одинаковый уровень, как если бы они были одним источником звука. Соответственно, объектный декодер 121 декодирует первый и второй объектные сигналы путем интерпретации их как одного источника звука без отдельного их декодирования. Как результат, сложность декодирования снижается. Помимо этого, вследствие уменьшения числа источников звука, которые должны быть обработаны, сложность микширования/воспроизведения также снижается.
Устройство 120 декодирования аудиосигнала может быть эффективно использовано в ситуации, когда число объектных сигналов больше числа выходных каналов, поскольку множество объектных сигналов с большой вероятностью должны быть назначены на одну пространственную позицию.
В качестве альтернативы, устройство 120 декодирования аудиосигнала может быть использовано в ситуации, когда первый объектный сигнал и второй объектный сигнал назначены на одну позицию в многоканальном пространстве, но имеют различные уровни. В этом случае, устройство 120 декодирования аудиосигнала декодирует первый и второй объектные сигналы путем интерпретации первого и второго объектных сигналов как одного сигнала, вместо декодирования первого и второго объектных сигналов отдельно и передачи декодированных первого и второго объектных сигналов в блок 123 воспроизведения. Более конкретно, объектный декодер 121 может получать информацию, относящуюся к разности между уровнями первого и второго объектных сигналов, из управляющей информации в модифицированной дополнительной информации, и декодировать первый и второй объектные сигналы на основе полученной информации. Как результат, даже если первый и второй объектные сигналы имеют различные уровни, первый и второй объектные сигналы могут быть декодированы, как если бы они являлись одним источником звука.
В качестве еще одной альтернативы, объектный декодер 121 может регулировать уровни объектных сигналов, сформированных объектным декодером 121 согласно управляющей информации. Далее объектный декодер 121 может декодировать объектные сигналы, уровни которых отрегулированы. Соответственно, блок 123 воспроизведения не должен регулировать уровни декодированных объектных сигналов, обеспеченных объектным декодером 121, а просто компонует декодированные объектные сигналы, обеспеченные объектным декодером 121, в многоканальном пространстве. Вкратце, поскольку объектный декодер 121 регулирует уровни объектных сигналов, формируемых объектным декодером 121, согласно управляющей информации, блок 123 воспроизведения может легко компоновать объектные сигналы, формируемые объектным декодером 121, в многоканальном пространстве без необходимости дополнительно регулировать уровни объектных сигналов, формируемых объектным декодером 121. Следовательно, можно снижать сложность микширования/воспроизведения.
Согласно варианту осуществления по фиг. 2, объектный декодер устройства 120 декодирования аудиосигнала может адаптивно выполнять операцию декодирования путем анализа управляющей информации, тем самым снижая сложность декодирования и сложность микширования/воспроизведения. Может быть использована комбинация вышеописанных способов, выполняемых устройством 120 декодирования аудиосигнала.
Фиг. 3 представляет собой блок-схему устройства 130 декодирования аудиосигнала согласно второму варианту осуществления настоящего изобретения. Как показано на фиг. 3, устройство 130 декодирования аудиосигнала включает в себя объектный декодер 131 и блок 133 воспроизведения. Устройство 130 декодирования аудиосигнала отличается тем, что дополнительную информацию в нем передают не только в объектный декодер 131, но также в блок 133 воспроизведения.
Устройство 130 декодирования аудиосигнала может эффективно выполнять операцию декодирования, даже когда имеется объектный сигнал, соответствующий периоду молчания. Например, сигналы второго - четвертого объектов могут соответствовать периоду воспроизведения музыки, в течение которого играют музыкальные инструменты, а сигнал первого объекта может соответствовать периоду молчания, в течение которого играется аккомпанемент. В этом случае информация, указывающая то, какой из множества объектных сигналов соответствует периоду молчания, может быть включена в дополнительную информацию, и дополнительная информация может быть передана в блок 133 воспроизведения, а также в объектный декодер 131.
Объектный декодер 131 может минимизировать скорость декодирования не только путем декодирования объектного сигнала, соответствующего периоду молчания. Объектный декодер 131 задает объектный сигнал, соответствующий значению в 0, и передает уровень объектного сигнала в блок 133 воспроизведения. Объектные сигналы, имеющие значение в 0, в общем интерпретируются так же, как и объектные сигналы, имеющие значение, отличное от 0, и тем самым подвергаются операции микширования/воспроизведения.
С другой стороны, устройство 130 декодирования аудиосигнала передает дополнительную информацию, включающую в себя информацию, указывающую то, какой из множества объектных сигналов соответствует периоду молчания, в блок 133 воспроизведения, и тем самым не допускает обработки объектного сигнала, соответствующего периоду молчания, посредством операции микширования/воспроизведения, выполняемой блоком 133 воспроизведения. Следовательно, устройство 130 декодирования аудиосигнала может препятствовать излишнему возрастанию сложности микширования/воспроизведения.
Блок 133 воспроизведения может использовать информацию параметров микширования, которая включена в управляющую информацию, для того чтобы локализовать звуковой образ каждого объектного сигнала в стерео сцене. Информация параметров микширования может включать в себя только информацию амплитуды либо информацию амплитуды и информацию времени. Информация параметров микширования влияет не только на локализацию звуковых стерео образов, но также на психоакустическое восприятие пространственного качества звука пользователем.
Например, при сравнении двух звуковых образов, которые сформированы с использованием способа временного панорамирования и способа амплитудного панорамирования, соответственно, и воспроизводятся в одном месте с использованием 2-канального стерео громкоговорителя, обнаруживается, что способ амплитудного панорамирования может способствовать точной локализации звуковых образов, и что с использованием способа временного панорамирования можно формировать естественные звуки с сильным ощущением пространства. Таким образом, если блок 133 воспроизведения использует только способ амплитудного панорамирования для того, чтобы компоновать объектные сигналы в многоканальном пространстве, блок 133 воспроизведения может иметь возможность точно локализовать каждый звуковой образ, но может не иметь возможности создавать настолько сильное ощущение звука, как при использовании способа временного панорамирования. Пользователи могут иногда предпочитать локализацию звуковых образов до сильного ощущения звука или наоборот согласно типу звуковых источников.
Фиг. 4(a) и 4(b) поясняют влияние интенсивности (разности амплитуд) и разности времени на локализацию звуковых образов, выполняемую при воспроизведении сигналов с использованием 2-канального стерео громкоговорителя. Как показано на фиг. 4(a) и 4(b), звуковой образ может быть локализован под заданным углом согласно разности амплитуд и разности времени, которые независимы друг от друга. Например, разность амплитуд примерно в 8 дБ или разность времени примерно в 0,5 мс, которая эквивалентна разности амплитуд в 8 дБ, может быть использована для того, чтобы локализовать звуковой образ под углом в 20°. Следовательно, даже если в качестве информации параметров микширования обеспечена только разность амплитуд, можно получать различные звуки с различными свойствами путем преобразования разности амплитуд в разность времени, которая эквивалента разности амплитуд, в ходе локализации звуковых образов.
Фиг. 5 иллюстрирует функции, касающиеся соответствия между разностями амплитуд и разностями времени, которые требуются для того, чтобы локализовать звуковые образы под углами 10°, 20° и 30°. Функция, проиллюстрированная на фиг. 5, может быть получена на основе показанного на фиг. 4(a) и 4(b). Как показано на фиг. 5, для локализации звукового образа в заданной позиции могут быть обеспечены различные комбинации разности амплитуд - разности времени. Например, допустим, что в качестве информации параметров микширования для локализации звукового образа под углом в 20° обеспечена разность амплитуд в 8 дБ. Согласно функции, проиллюстрированной на фиг. 5, звуковой образ также может быть локализован под углом 20° с использованием комбинации разности амплитуд в 3 дБ и разности времени в 0,3 мс. В этом случае в качестве информации параметров микширования может быть обеспечена не только информация разности амплитуд, но также информация разности времени, за счет чего улучшается ощущение пространства.
Следовательно, чтобы сформировать звуки со свойствами, требуемыми пользователем, в ходе операции микширования/воспроизведения, информация параметров микширования может быть надлежащим образом преобразована так, что то, что из панорамирования амплитуды и панорамирования времени подходит пользователю, может быть выполнено. Т.е., если информация параметров микширования включает в себя только информацию разности амплитуд и пользователю нужны звуки с сильным ощущением пространства, информация разности амплитуд может быть преобразована в информацию разности времени, эквивалентную информации разности времени, со ссылкой на психоакустические данные. В качестве альтернативы, если пользователю требуются звуки как с сильным ощущением пространства, так и с точной локализацией звуковых образов, информация разности амплитуд может быть преобразована в комбинацию информации разности амплитуд и информации разности времени, эквивалентную исходной информации амплитуд. В качестве альтернативы, если информация параметров микширования включает в себя только информацию разности времени, и пользователь предпочитает точную локализацию звуковых образов, информация разности времени может быть преобразована в информацию разности амплитуд, эквивалентную информации разности времени, или может быть преобразована в комбинацию информации разности времени и информации разности амплитуд, которая может удовлетворять предпочтению пользователя путем повышения точности локализации звуковых образов и ощущения пространства.
В качестве еще одной альтернативы, если информация параметров микширования включает в себя и информацию разности амплитуд, и информацию разности времени, и пользователь предпочитает точную локализацию звуковых образов, комбинация информации разности амплитуд и информации разности времени может быть преобразована в информацию разности амплитуд, эквивалентную комбинации исходной информации разности амплитуд и информации разности времени. С другой стороны, если информация параметров микширования включает в себя и информацию разности амплитуд, и информацию разности времени, и пользователь предпочитает улучшение ощущения пространства, комбинация информации разности амплитуд и информации разности времени может быть преобразована в информацию разности времени, эквивалентную комбинации информации разности амплитуд и исходной информации разности времени. Как показано на фиг. 6, управляющая информация может включать в себя информацию микширования/воспроизведения и информацию гармоник, относящуюся к одному или более объектным сигналам. Информация гармоник может включать в себя по меньшей мере одно из информации основного тона, информации собственной частоты и информации преобладающей полосы частот, относящейся к одному или более объектным сигналам, и описаний энергии и спектра каждого поддиапазона каждого из объектных сигналов.
Информация гармоник может быть использована для того, чтобы обрабатывать объектный сигнал в ходе операции воспроизведения, поскольку разрешение блока воспроизведения, который выполняет эту операцию, в единицах поддиапазонов является недостаточным.
Если информация гармоник включает в себя информацию основного тона, относящуюся к одному или более объектным сигналам, усиление каждого из объектных сигналов может быть скорректировано путем ослабления или усиления заданной частотной области с использованием гребенчатого фильтра или обратного гребенчатого фильтра. Например, если один из множества объектных сигналов является вокальным сигналом, объектные сигналы могут быть использованы в качестве караоке путем ослабления только вокального сигнала. В качестве альтернативы, если информация гармоник включает в себя информацию преобладающей частотной области, относящуюся к одному или более объектным сигналам, может быть выполнен процесс ослабления или усиления преобладающей частотной области. В качестве еще одной альтернативы, если информация гармоник включает в себя информацию спектра, относящуюся к одному или более объектным сигналам, усиление каждого из объектных сигналов может контролироваться путем выполнения ослабления или усиления без ограничения какими-либо границами поддиапазонов.
Фиг. 7 представляет собой блок-схему устройства 140 декодирования аудиосигнала согласно другому варианту осуществления настоящего изобретения. Как показано на фиг. 7, устройство 140 декодирования аудиосигнала использует многоканальный декодер 141 вместо объектного декодера и блока воспроизведения, и декодирует ряд объектных сигналов после того, как объектные сигналы надлежащим образом скомпонованы в многоканальном пространстве.
Более конкретно, устройство 140 декодирования аудиосигнала включает в себя многоканальный декодер 141 и преобразователь 145 параметров. Многоканальный 141 декодер формирует многоканальный сигнал, объектные сигналы которого уже скомпонованы в многоканальном пространстве, на основе сигнала понижающего микширования и информации пространственных параметров, которая является канально-ориентированной дополнительной информацией, обеспечиваемой преобразователем 145 параметров. Преобразователь 145 параметров анализирует дополнительную информацию и управляющую информацию, передаваемую устройством кодирования аудиосигнала (не показано), и формирует информацию пространственных параметров на основе результата анализа. Более конкретно, преобразователь 145 параметров формирует информацию пространственных параметров путем комбинирования дополнительной информации и управляющей информации, которая включает в себя информацию настроек воспроизведения и информацию микширования. Т.е. преобразователь 145 параметров выполняет преобразование комбинации дополнительной информации и управляющей информации в пространственные данные, соответственно модулю «один к двум» (OTT) или модулю «два к трем» (TTT).
Устройство 140 декодирования аудиосигнала может выполнять операцию многоканального декодирования, в которую объединены операция объектно-ориентированного декодирования и операция микширования/воспроизведения, и тем самым может пропускать декодирование каждого объектного сигнала. Следовательно, можно снижать сложность декодирования и/или микширования/воспроизведения.
Например, когда имеется 10 объектных сигналов, и многоканальный сигнал, полученный на основе 10 объектных сигналов, должен быть воспроизведен 5.1-канальной акустической системой воспроизведения, обычное устройство декодирования объектно-ориентированного аудиосигнала формирует декодированные сигналы, надлежащим образом соответствующие 10 объектным сигналам, на основе сигнала понижающего микширования и дополнительной информации, и затем формирует 5.1-канальный сигнал путем надлежащей компоновки 10 объектных сигналов в многоканальное пространство, так что объектные сигналы могут стать подходящими для 5.1-канального акустического окружения. Тем не менее, недостаточно сформировать 10 объектных сигналов в ходе формирования 5.1-канального сигнала, и эта проблема становится более серьезной по мере того, как разность между числом объектных сигналов и числом каналов многоканального сигнала, который должен быть сформирован, возрастает.
С другой стороны, согласно варианту осуществления по фиг. 7 устройство 140 декодирования аудиосигнала формирует информацию пространственных параметров, подходящую для 5.1-канального сигнала, на основе дополнительной информации и управляющей информации и передает информацию пространственных параметров и сигнал понижающего микширования в многоканальный декодер 141. Затем многоканальный декодер 141 формирует 5.1-канальный сигнал на основе информации пространственных параметров и сигнала понижающего микширования. Другими словами, когда число каналов, которые должны быть выведены, составляет 5.1 каналов, устройство 140 декодирования аудиосигнала может просто сформировать 5.1-канальный сигнал на основе сигнала понижающего микширования без необходимости формировать 10 объектных сигналов и, таким образом, является более эффективным, чем традиционное устройство декодирования аудиосигнала, в отношении сложности.
Устройство 140 декодирования аудиосигнала считается эффективным, когда объем вычислений, требуемых для того, чтобы вычислять информацию пространственных параметров, соответствующую каждому из OTT-модуля и TTT-модуля путем анализа дополнительной информации и управляющей информации, передаваемой устройством кодирования аудиосигнала, меньше объема вычислений, требуемого для того, чтобы выполнять операцию микширования/воспроизведения после декодирования каждого объектного сигнала.
Устройство 140 декодирования аудиосигнала может быть получено путем добавления модуля для формирования информации пространственных параметров путем анализа дополнительной информации и управляющей информации в обычное устройство декодирования многоканального аудиосигнала и поэтому может сохранять совместимость с обычным устройством декодирования многоканального аудиосигнала. Также устройство 140 декодирования может повышать качество звука с использованием существующих средств обычного устройства декодирования многоканального аудиосигнала, таких как формирователь огибающей, средство временной обработки поддиапазонов (STP) и декоррелятор. С учетом всего этого следует сделать вывод о том, что все преимущества обычного способа декодирования многоканального аудиосигнала могут быть легко применены к способу декодирования объектного аудиосигнала.
Информация пространственных параметров, передаваемая в многоканальный декодер 141 преобразователем 145 параметров, может быть сжата, с тем, чтобы быть подходящей для передачи. В качестве альтернативы, информация пространственных параметров может иметь такой же формат, что и формат данных, передаваемых обычным устройством многоканального кодирования. Т.е. информация пространственных параметров может быть подвергнута операции декодирования Хаффмана или операции контрольного декодирования и тем самым может быть передана в каждый модуль как несжатые данные пространственных меток. Первое подходит для передачи информации пространственных параметров в устройство декодирования многоканального аудиосигнала в удаленном месте, а второе удобно, поскольку нет необходимости устройству декодирования многоканального аудиосигнала преобразовывать сжатые данные пространственных меток в несжатые данные пространственных меток, которые могут быть легко использованы в операции декодирования.
Конфигурация информации пространственной задержки на основе анализа дополнительной информации и управляющей информации может вызывать задержку между сигналом понижающего микширования и информацией пространственных параметров. Для того чтобы обойти это, может быть предусмотрен дополнительный буфер либо для сигнала понижающего микширования, либо для информации пространственных параметров, так, чтобы сигнал понижающего микширования и информация пространственных параметров могли быть синхронизированы друг с другом. Эти способы тем не менее являются неудобными из-за необходимости наличия дополнительного буфера. В качестве альтернативы, дополнительная информация может передаваться впереди сигнала понижающего микширования с учетом возможности возникновения задержки между сигналом понижающего микширования и информацией пространственных параметров. В этом случае информация пространственных параметров, полученная путем комбинирования дополнительной информации и управляющей информации, необязательно должна корректироваться, а может легко быть использована.
Если множество объектных сигналов из сигнала понижающего микширования имеют различные уровни, модуль художественного усиления понижающего микширования (ADG), который может непосредственно компенсировать сигнал понижающего микширования, может определять относительные уровни объектных сигналов, и каждый из объектных сигналов может быть назначен на заданную позицию в многоканальном пространстве с использованием данных пространственных меток, такие как информация разности уровней каналов, информация межканальных корреляций (ICC) и информация коэффициентов прогнозирования каналов (CPC).
Например, если управляющая информация указывает то, что заданный объектный сигнал должен быть назначен на заданную позицию в многоканальном пространстве и имеет более высокий уровень, чем другие объектные сигналы, обычный многоканальный декодер может вычислять разность между энергиями каналов в сигнале понижающего микширования и поделить сигнал понижающего микширования на число выходных каналов на основе результатов вычислений. Тем не менее, обычный многоканальный декодер не может повышать или понижать громкость определенного звука в сигнале понижающего микширования. Другими словами, обычный многоканальный декодер просто распределяет сигнал понижающего микширования по числу выходных каналов и тем самым не может повышать или понижать громкость звука в сигнале понижающего микширования.
Относительно просто назначать каждый из ряда объектных сигналов в сигнале понижающего микширования, сформированном объектным декодером, на заданную позицию в многоканальном пространстве согласно управляющей информации. Тем не менее, специальные методики требуются для того, чтобы увеличивать или уменьшать амплитуду заданного объектного сигнала. Другими словами, если сигнал понижающего микширования, сформированный объектным декодером, используется как есть, трудно уменьшать амплитуду каждого объектного сигнала в сигнале понижающего микширования.
Следовательно, согласно варианту осуществления настоящего изобретения, относительные амплитуды объектных сигналов могут варьироваться согласно управляющей информации за счет использования ADG-модуля 147, проиллюстрированного на фиг. 8. Более конкретно, амплитуда любого из объектных сигналов из сигнала понижающего микширования, передаваемого объектным кодером, может быть увеличена или уменьшена с использованием ADG-модуля 147. Сигнал понижающего микширования, полученный путем компенсации, выполненной ADG-модулем 147, может подвергаться многоканальному декодированию.
Если относительные амплитуды объектных сигналов в сигнале понижающего микширования надлежащим образом отрегулированы с использованием ADG-модуля 147, можно выполнять объектное декодирование с использованием обычного многоканального декодера. Если сигнал понижающего микширования, сформированный объектным декодером, является моно- или стереосигналом либо многоканальным сигналом с тремя или более каналами, то сигнал понижающего микширования может быть обработан ADG-модулем 147. Если сигнал понижающего микширования, сформированный объектным декодером, имеет два или более каналов, и заданный объектный сигнал, который должен быть отрегулирован ADG-модулем 147, существует только в одном из каналов сигнала понижающего микширования, ADG-модуль 147 может быть применен только к каналу, включающему в себя заданный объектный сигнал, вместо применения ко всем каналам сигнала понижающего микширования. Сигнал понижающего микширования, обработанный ADG-модулем 147 вышеописанным способом, может быть легко обработан с использованием обычного многоканального кодера без необходимости модифицировать структуру многоканального декодера.
Даже когда конечный выходной сигнал не является многоканальным сигналом, который может быть воспроизведен многоканальной акустической системой, а является стереофоническим сигналом, ADG-модуль 147 может быть использован для того, чтобы регулировать относительные амплитуды объектных сигналов конечного выходного сигнала.
В качестве альтернативы применению ADG-модуля 147, информация усиления, задающая значение усиления, которое должно быть применено к каждому объектному сигналу, может быть включена в управляющую информацию в ходе формирования ряда объектных сигналов. Для этого структура обычного многоканального декодера может быть модифицирована. Несмотря на необходимость модификации структуры существующего многоканального декодера, этот способ является удобным в отношении сложности декодирования за счет применения значения усиления к каждому объектному сигналу в ходе операции декодирования без необходимости вычислять ADG и компенсировать каждый объектный сигнал.
Фиг. 9 представляет собой блок-схему устройства 150 декодирования аудиосигнала согласно четвертому варианту осуществления настоящего изобретения. Как показано на фиг. 9, устройство 150 декодирования аудиосигнала отличается формированием стереофонического сигнала.
Более конкретно, устройство 150 декодирования аудиосигнала включает в себя многоканальный стереофонический декодер 151, первый преобразователь 157 параметров и второй преобразователь 159 параметров.
Второй преобразователь 159 параметров анализирует дополнительную информацию и управляющую информацию, которая обеспечена устройством кодирования аудиосигнала, и конфигурирует информацию пространственных параметров на основе результата анализа. Первый преобразователь 157 параметров конфигурирует информацию стереофонических параметров, которая может быть использована многоканальным стереофоническим декодером 151, за счет добавления трехмерной (3D) информации, такой как функция моделирования восприятия звука (HRTF), в информацию пространственных параметров. Многоканальный стереофонический декодер 151 формирует виртуальный трехмерный (3D) сигнал путем применения информации виртуальных трехмерных параметров к сигналу понижающего микширования.
Первый преобразователь 157 параметров и второй преобразователь 159 параметров могут быть заменены одним модулем, т.е. модулем 155 преобразования параметров, который принимает дополнительную информацию, управляющую информацию и HRTF-параметры и конфигурирует информацию стереофонических параметров на основе дополнительной информации, управляющей информации и HRTF-параметров.
Традиционно для того, чтобы сформировать стереофонический сигнал для воспроизведения сигнала понижающего микширования, включающего в себя 10 объектных сигналов, с использованием наушников, объектный сигнал должен сформировать 10 декодированных сигналов, надлежащим образом соответствующих 10 объектным сигналам на основе сигнала понижающего микширования и дополнительной информации. Затем блок воспроизведения назначает каждый из 10 объектных сигналов на заданную позицию в многоканальном пространстве со ссылкой на управляющую информацию, с тем, чтобы удовлетворять требованиям 5-канального акустического окружения. После этого блок воспроизведения формирует 5-канальный сигнал, который может быть воспроизведен 5-канальной акустической системой. Далее блок воспроизведения применяет HRTF-параметры к 5-канальному сигналу, тем самым формируя 2-канальный сигнал. Вкратце, вышеупомянутый традиционный способ декодирования аудиосигнала включает в себя воспроизведение 10 объектных сигналов, преобразование 10 объектных сигналов в 5-канальный сигнал и формирование 2-канального сигнала на основе 5-канального сигнала, и это тем самым является неэффективным.
С другой стороны, устройство 150 декодирования аудиосигнала может легко формировать стереофонический сигнал, который может быть воспроизведен с использованием наушников, на основе объектных аудиосигналов. Помимо этого, устройство 150 декодирования аудиосигнала конфигурирует информацию пространственных параметров путем анализа дополнительной информации и управляющей информации и тем самым может формировать стереофонический сигнал с использованием обычного многоканального стереофонического декодера. Более того, устройство 150 декодирования аудиосигнала может использовать обычный многоканальный стереофонический декодер, даже когда оснащено встроенным преобразователем параметров, который принимает дополнительную информацию, управляющую информацию и HRTF-параметры и конфигурирует информацию стереофонических параметров на основе дополнительной информации, управляющей информации и HRTF-параметров.
Фиг. 10 представляет собой блок-схему устройства 160 декодирования аудиосигнала согласно пятому варианту осуществления настоящего изобретения. Как показано на фиг. 10, устройство 160 декодирования аудиосигнала включает в себя процессор 161 понижающего микширования, многоканальный 163 декодер и преобразователь 165 параметров. Процессор 161 понижающего микширования и преобразователь 165 параметров могут быть заменены единым модулем 167.
Преобразователь 165 параметров формирует информацию пространственных параметров, которая может быть использована многоканальным декодером 163, и информацию параметров, которая может быть использована процессором 161 понижающего микширования. Процессор 161 понижающего микширования выполняет операцию предварительной обработки с сигналом понижающего микширования и передает сигнал понижающего микширования, получающийся в результате операции предварительной обработки, в многоканальный декодер 163. Многоканальный декодер 163 выполняет операцию декодирования сигнала понижающего микширования, передаваемого процессором 161 понижающего микширования, тем самым выводя стереосигнал, бинауральный стереосигнал или многоканальный сигнал. Примеры операции предварительной обработки, выполняемой процессором 161 понижающего микширования, включают в себя модификацию или преобразование сигнала понижающего микширования во временной области или частотной области с использованием фильтрации.
Если сигнал понижающего микширования, вводимый в устройство 160 декодирования аудиосигнала, является стереосигналом, сигнал понижающего микширования, возможно, должен быть подвергнут предварительной обработке понижающего микширования, выполняемой процессором 161 понижающего микширования, перед вводом в многоканальный декодер 163, поскольку многоканальный декодер 163 не может преобразовывать компонент сигнала понижающего микширования, соответствующий левому каналу, который является одним из множества каналов, в правый канал, который является другим из множества каналов. Следовательно, для того, чтобы сдвинуть позицию объектного сигнала, относящегося к левому каналу, в направлении правого канала, сигнал понижающего микширования, вводимый в устройство 160 декодирования аудиосигнала, может быть предварительно обработан процессором 161 понижающего микширования, и предварительно обработанный сигнал понижающего микширования может быть введен в многоканальный декодер 163.
Предварительная обработка стереосигнала понижающего микширования может выполняться на основе информации предварительной обработки, полученной из дополнительной информации и из управляющей информации.
Фиг. 11 представляет собой блок-схему устройства 170 декодирования аудиосигнала согласно шестому варианту осуществления настоящего изобретения. Как показано на фиг. 11, устройство 170 декодирования аудиосигнала включает в себя многоканальный 171 декодер, канальный процессор 173 и преобразователь 175 параметров.
Преобразователь 175 параметров формирует информацию пространственных параметров, которая может быть использована многоканальным декодером 173, и информацию параметров, которая может быть использована канальным процессором 173. Канальный процессор 173 выполняет операцию постобработки с сигналом, выводимым многоканальным декодером 171. Примеры сигнала, выводимого многоканальным декодером 171, включают в себя стереосигнал, бинауральный стереосигнал и многоканальный сигнал.
Примеры операции постобработки, выполняемой постпроцессором 173, включают в себя модификацию и преобразование каждого канала или всех каналов выходного сигнала. Например, если дополнительная информация включает в себя информацию собственной частоты, относящуюся к заданному объектному сигналу, канальный процессор 173 может удалять гармонические компоненты из заданного объектного сигнала со ссылкой на информацию собственной частоты. Способ декодирования многоканального аудиосигнала может быть недостаточно эффективным для того, чтобы использовать в системе караоке. Тем не менее, если информация собственной частоты, относящаяся к вокальным объектным сигналам, включена в дополнительную информацию, и гармонические компоненты вокальных объектных сигналов удаляются в ходе операции постобработки, можно реализовывать высокопроизводительную систему караоке путем использования варианта осуществления по фиг. 11. Вариант осуществления по фиг. 11 также может быть применен к объектным сигналам, отличным от вокальных объектных сигналов. Например, возможно удалить звук заданного музыкального инструмента с использованием варианта осуществления по фиг. 11. Также можно усиливать заданные гармонические компоненты с использованием информации собственной частоты, относящейся к объектным сигналам, с использованием варианта осуществления по фиг. 11.
Канальный процессор 173 может выполнять дополнительную обработку эффектов для сигнала понижающего микширования. Канальный процессор 173 может добавлять сигнал, полученный путем дополнительной обработки эффектов, в сигнал, выводимый многоканальным декодером 171. Канальный процессор 173 может изменять спектр объекта или модифицировать сигнал понижающего микширования при необходимости. Если не подходит непосредственно выполнять операцию обработки эффектов, такую как реверберация, для сигнала понижающего микширования и передавать сигнал, полученный посредством операции обработки эффектов, в многоканальный декодер 171, процессор 173 понижающего микширования может добавить сигнал, полученный посредством операции обработки эффектов, в вывод многоканального декодера 171 вместо выполнения обработки эффектов с сигналом понижающего микширования.
Устройство 170 декодирования аудиосигнала может быть сконструировано так, чтобы включать в себя не только канальный процессор 173, но также процессор понижающего микширования. В этом случае процессор понижающего микширования может размещаться перед многоканальным декодером 173, и канальный процессор 173 может размещаться после многоканального декодера 173.
Фиг. 12 представляет собой блок-схему устройства 210 декодирования аудиосигнала согласно седьмому варианту осуществления настоящего изобретения. Как показано на фиг. 12, устройство 210 декодирования аудиосигнала использует многоканальный декодер 213 вместо объектного декодера.
Более конкретно, устройство 210 декодирования аудиосигнала включает в себя многоканальный декодер 213, транскодер 215, блок 217 воспроизведения и базу 219 данных трехмерной информации.
Блок 217 воспроизведения определяет трехмерные позиции множества объектных сигналов на основе трехмерной информации, соответствующей индексным данным, включенным в управляющую информацию. Транскодер 215 формирует канально-ориентированную дополнительную информацию путем синтеза информации позиции, относящейся к числу объектных аудиосигналов, к которым трехмерная информация применяется блоком 217 воспроизведения. Многоканальный декодер 213 выводит трехмерный сигнал путем применения канально-ориентированной дополнительной информации к сигналу понижающего микширования.
Функция моделирования восприятия звука (HRTF) может быть использована в качестве трехмерной информации. HRTF - это передаточная функция, которая описывает передачу звуковых волн между источником звука в произвольной позиции и барабанной перепонкой и возвращает значение, которое варьируется согласно направлению и высоте источника звука. Если сигнал без направленности фильтруется с использованием HRTF, сигнал может быть услышан, как если бы он воспроизводился из определенного направления.
Когда входной поток битов принимается, устройство 210 декодирования аудиосигнала извлекает объектно-ориентированный сигнал понижающего микширования и информацию объектно-ориентированных параметров из входного потока битов с использованием демультиплексора (не показан). Далее блок 217 воспроизведения извлекает индексные данные из управляющей информации, которые используются для того, чтобы определять позиции множества объектных сигналов, и получает трехмерную информацию, соответствующую извлеченным индексным данным, из базы 219 данных трехмерной информации.
Более конкретно, информация параметров микширования, которая включена в управляющую информацию, которая используется устройством 210 декодирования аудиосигнала, может включать не только информацию уровня, но также индексные данные, требуемые для поиска трехмерной информации. Информация параметров микширования также может включать в себя информацию времени, относящуюся к разности времени между каналами, информацию позиции и один или более параметров, полученных за счет надлежащего комбинирования информации уровня и информации времени.
Позиция объектного аудиосигнала может быть определена первоначально согласно информации параметров микширования по умолчанию и может быть изменена впоследствии путем применения трехмерной информации, соответствующей позиции, требуемой пользователем, к объектному аудиосигналу. В качестве альтернативы, если пользователь хочет применять трехмерный эффект только к нескольким объектным аудиосигналам, информация уровня и информация времени, относящаяся к другим объектным аудиосигналам, к которым пользователь хочет не применять трехмерный эффект, может быть использована в качестве информации параметров микширования.
Транскодер 217 формирует канально-ориентированную дополнительную информацию, относящуюся к M каналам, за счет синтеза информации объектно-ориентированных параметров, относящейся к N объектным сигналам, переданным устройством кодирования аудиосигнала, и информации позиции определенного числа объектных сигналов, к которым блоком 217 воспроизведения применяется трехмерная информация, такая как HRTF.
Многоканальный декодер 213 формирует аудиосигнал на основе сигнала понижающего микширования и канально-ориентированной дополнительной информации, сформированной транскодером 217, и формирует трехмерный многоканальный сигнал путем выполнения операции трехмерного воспроизведения с использованием трехмерной информации, включенной в канально-ориентированную дополнительную информацию.
Фиг. 13 представляет собой блок-схему устройства 220 декодирования аудиосигнала согласно восьмому варианту осуществления настоящего изобретения. Как показано на фиг. 13, устройство 220 декодирования аудиосигнала отличается от устройства 210 декодирования аудиосигнала, проиллюстрированного на фиг. 12, тем, что транскодер 225 передает канально-ориентированную дополнительную информацию и трехмерную информацию отдельно в многоканальный декодер 223. Другими словами, транскодер 225 устройства 220 декодирования аудиосигнала получает канально-ориентированную дополнительную информацию, относящуюся к M каналам, из информации объектно-ориентированных параметров, относящейся к N объектным сигналам, и передает канально-ориентированную дополнительную информацию и трехмерную информацию, которая применяется к каждому из N объектных сигналов, в многоканальный декодер 223, тогда как транскодер 217 устройства 210 декодирования аудиосигнала передает канально-ориентированную дополнительную информацию, включающую в себя трехмерную информацию, в многоканальный декодер 213.
Как показано на фиг. 14, канально-ориентированная дополнительная информация и трехмерная информация может включать в себя множество индексов кадров. Таким образом, многоканальный декодер 223 может синхронизировать канально-ориентированную дополнительную информацию и трехмерную информацию со ссылкой на индексы кадров каждой из канально-ориентированной дополнительной информации и трехмерной информации и тем самым может применять трехмерную информацию к кадру потока битов, соответствующему трехмерной информации. Например, трехмерная информация, имеющая индекс 2, может быть применена к кадру 2, имеющему индекс 2.
Поскольку канально-ориентированная дополнительная информация и трехмерная информация включает в себя индексы кадров, можно эффективно определять временную позицию канально-ориентированной дополнительной информации, к которой должна быть применена трехмерная информация, даже если трехмерная информация обновляется во времени. Другими словами, транскодер 225 включает трехмерную информацию и число индексов кадров в канально-ориентированную дополнительную информацию, и тем самым многоканальный декодер 223 может легко синхронизировать канально-ориентированную дополнительную информацию и трехмерную информацию.
Процессор 231 понижающего микширования, транскодер 235, блок 237 воспроизведения и база данных трехмерной информации могут быть заменены одним модулем 239.
Фиг. 15 представляет собой блок-схему устройства 230 декодирования аудиосигнала согласно девятому варианту осуществления настоящего изобретения; Как показано на фиг. 15, устройство 230 декодирования аудиосигнала отличается от устройства 220 декодирования аудиосигнала, проиллюстрированного на фиг. 14, за счет дополнительного включения процессора 231 понижающего микширования.
Более конкретно, устройство 230 декодирования аудиосигнала включает в себя транскодер 235, блок 237 воспроизведения, базу 239 данных трехмерной информации, многоканальный декодер 233 и процессор 231 понижающего микширования. Транскодер 235, блок 237 воспроизведения, база 239 данных трехмерной информации и многоканальный декодер 233 являются такими же, как и их соответствующие аналоги, проиллюстрированные на фиг. 14. Процессор 231 понижающего микширования выполняет операцию предварительной обработки стереосигнала понижающего микширования для корректировки позиции. База 239 данных трехмерной информации может быть включена в блок 237 воспроизведения. Модуль для применения заданного эффекта к сигналу понижающего микширования также может быть предусмотрен в устройстве 230 декодирования аудиосигнала.
Фиг. 16 иллюстрирует блок-схему устройства 240 декодирования аудиосигнала согласно десятому варианту осуществления настоящего изобретения. Как показано на фиг. 16, устройство 240 декодирования аудиосигнала отличается от устройства 230 декодирования аудиосигнала, проиллюстрированного на фиг. 15, включением многоточечного сумматора 241 модуля управления.
Т.е. устройство 240 декодирования аудиосигнала, аналогично устройству 230 декодирования аудиосигнала, включает в себя процессор 243 понижающего микширования, многоканальный декодер 244, транскодер 245, блок 247 воспроизведения и базу 249 данных трехмерной информации. Многоточечный сумматор 241 модуля управления комбинирует множество потоков битов, полученных объектно-ориентированным кодированием, тем самым получая один поток битов. Например, когда первый поток битов для первого аудиосигнала и второй поток битов для второго аудиосигнала вводятся, многоточечный сумматор 241 модуля управления извлекает первый сигнал понижающего микширования из первого потока битов, извлекает второй сигнал понижающего микширования из второго потока битов и формирует третий сигнал понижающего микширования путем комбинирования первого и второго сигналов понижающего микширования. Помимо этого, многоточечный сумматор 241 модуля управления извлекает первую объектно-ориентированную дополнительную информацию из первого потока битов, извлекает вторую объектно-ориентированную дополнительную информацию из второго потока битов и формирует третью объектно-ориентированную дополнительную информацию путем комбинирования первой объектно-ориентированной дополнительной информации и второй объектно-ориентированной дополнительной информации. Затем многоточечный сумматор 241 модуля управления формирует поток битов путем комбинирования третьего сигнала понижающего микширования и третьей объектно-ориентированной дополнительной информации и выводит сформированный поток битов.
Следовательно, согласно десятому варианту осуществления настоящего изобретения, можно эффективно обрабатывать даже сигналы, передаваемые двумя или более партнерами связи, в сравнении со случаем кодирования и декодирования каждого объектного сигнала.
Чтобы многоточечный сумматор 241 модуля управления включал множество сигналов понижающего микширования, которые, соответственно, извлекаются из множества потоков битов и ассоциативно связаны с различными кодеками сжатия, в один сигнал понижающего микширования, сигналы понижающего микширования, возможно, должны быть преобразованы в сигналы импульсно-кодовой модуляции (PCM) или сигналы в заданной частотной области согласно типам кодеков сжатия сигналов понижающего микширования, PCM-сигналы или сигналы, полученные преобразованием, возможно, должны быть объединены, а сигнал, полученный за счет объединения, возможно, должен быть преобразован с использованием заданного кодека сжатия. В этом случае задержка может возникать согласно тому, включены сигналы понижающего микширования в PCM-сигнал или в сигнал в заданной частотной области. Тем не менее задержка, возможно, не может быть надлежащим образом оценена декодером. Следовательно, задержка, возможно, должна быть включена в поток битов и передана вместе с потоком битов. Задержка может указывать число выборок задержки в PCM-сигнале или число выборок задержки в заданной частотной области.
В ходе операции кодирования объектно-ориентированного аудиосигнала значительное число входных сигналов, возможно, должно быть обработано в сравнении с числом входных сигналов, как правило, обрабатываемых в ходе обычной операции многоканального кодирования (к примеру, операции 5.1-канального или 7.1-канального кодирования). Следовательно, способ кодирования объектно-ориентированного аудиосигнала требует гораздо больших скоростей передачи битов, чем обычный способ кодирования объектно-ориентированного многоканального аудиосигнала. Тем не менее, поскольку способ кодирования объектно-ориентированного аудиосигнала влечет за собой обработку объектных сигналов, которые меньше канальных сигналов, можно сформировать динамические выходные сигналы с использованием способа кодирования объектно-ориентированного аудиосигнала.
Далее со ссылкой на фиг. 17-20 будет подробно описан способ кодирования аудиосигнала согласно вариантам осуществления настоящего изобретения.
В способе кодирования объектно-ориентированного аудиосигнала объектные сигналы могут быть заданы так, чтобы представлять отдельные звуки, такие как человеческий голос или звук музыкального инструмента. В качестве альтернативы, звуки, имеющие аналогичные характеристики, такие как звуки струнных музыкальных инструментов (к примеру, скрипки, альта и виолончели), звуки, принадлежащие одной полосе частот, или звуки, классифицированные в одну категорию согласно направлениям и углам своих источников звука, могут быть сгруппированы и заданы одними и теми же объектными сигналами. В качестве еще одной альтернативы, объектные сигналы могут быть заданы с использованием комбинации вышеуказанных способов.
Определенное число объектных сигналов может быть передано как сигнал понижающего микширования и дополнительная информация. В ходе создания информации, которая должна быть передана, энергия или мощность сигнала понижающего микширования или каждого из объектных сигналов сигнала понижающего микширования вычисляется первоначально для цели обнаружения огибающей сигнала понижающего микширования. Результаты вычисления могут быть использованы для того, чтобы передавать объектные сигналы или сигналы понижающего микширования либо вычислять соотношения уровней объектных сигналов.
Алгоритм линейного предиктивного кодирования (LPC) может быть использован для меньших скоростей передачи битов. Более конкретно, ряд LPC-коэффициентов, которое представляют огибающую сигнала, формируется через анализ сигнала, и LPC-коэффициенты передаются вместо передачи информации огибающей, относящейся к сигналу. Этот способ является эффективным в отношении скоростей передачи битов. Тем не менее, поскольку очень вероятно, что LPC-коэффициенты отличаются от фактической огибающей сигнала, этот способ требует процесса сложения, например коррекции ошибок. Вкратце, способ, который влечет за собой передачу информации огибающей сигнала, может гарантировать высокое качество звука, но приводит к значительному увеличению объема информации, которая должна быть передана. С другой стороны, способ, который влечет за собой использование LPC-коэффициентов, позволяет уменьшать объем информации, которая должна быть передана, но требует дополнительного процесса, такого как коррекция ошибок, и приводит к снижению качества звука.
Согласно варианту осуществления настоящего изобретения, может быть использована комбинация этих способов. Другими словами, огибающая сигнала может быть представлена энергией или мощностью сигнала либо значением индекса, либо другим значением, таким как LPC-коэффициент, соответствующий энергии или мощности сигнала.
Информация огибающей, относящаяся к сигналу, может быть получена в единицах временных секций или частотных секций. Более конкретно, как показано на фиг. 17, информация огибающей, относящаяся к сигналу, может быть получена в единицах кадров. В качестве альтернативы, если сигнал представлен структурой полосы частот с использованием блока фильтров, такого как блок квадратурных зеркальных фильтров (QMF), информация огибающей, относящаяся к сигналу, может быть получена в единицах поддиапазонов частот, разделов поддиапазонов частот, которые являются меньшими объектами, чем поддиапазоны частот, групп поддиапазонов частот или групп разделов поддиапазонов частот. В качестве еще одной альтернативы, комбинация основанного на кадрах способа, основанного на поддиапазонах частот способа и основанного на секционированных поддиапазонах частот способа может быть использована в рамках объема настоящего изобретения.
В качестве еще одной альтернативы, с учетом того, что низкочастотные компоненты сигналы, в общем, имеют больше информации, чем высокочастотные компоненты сигнала, информация огибающей, относящаяся к низкочастотным компонентам сигнала, может быть передана как есть, тогда как информация огибающей, относящаяся к высокочастотным компонентам сигнала, может быть представлена LPC-коэффициентами или другими значениями, и LPC-коэффициенты или другие значения могут быть переданы вместо информации огибающей, относящейся к высокочастотным компонентам сигнала. Тем не менее, низкочастотные компоненты сигнала необязательно могут иметь больше информации, чем высокочастотные компоненты сигнала. Следовательно, вышеописанный способ должен гибко применяться согласно обстоятельствам.
Согласно варианту осуществления, информация огибающей или индексные данные, соответствующие части (далее упоминаемой как преобладающая часть) сигнала, который кажется преобладающим на частотно-временной оси, могут быть переданы, а информация огибающей или индексные данные, соответствующие непреобладающей части сигналы, могут не передаваться. В качестве альтернативы, значения (к примеру, LPC-коэффициенты), которые представляют энергию и мощность преобладающей части сигнала, могут быть переданы, а значения, соответствующие непреобладающей части сигнала, могут не передаваться. В качестве еще одной альтернативы, информация огибающей или индексные данные, соответствующие преобладающей части сигнала, могут быть переданы, и значения, которые представляют энергию и мощность непреобладающей части сигнала, могут быть переданы. В качестве еще одной альтернативы, информация, относящаяся только к преобладающей части сигнала, может быть передана с тем, чтобы непреобладающая часть сигнала могла быть оценена на основе информации, относящейся к преобладающей части сигнала. В качестве еще одной альтернативы, комбинация вышеописанных способов может быть использована.
Например, как показано на фиг. 18, если сигнал делится на преобладающий период и непреобладающий период, информация, относящаяся к сигналу, может быть передана четырьмя различными способами, как показано на позициях (a)-(d).
Для передачи определенного числа объектных сигналов в виде сигнала понижающего микширования и дополнительной информации, сигнал понижающего микширования должен быть разделен на множество элементов как часть операции декодирования, например, с учетом соотношения уровней объектных сигналов. Чтобы обеспечить независимость между элементами сигнала понижающего микширования, должна быть дополнительно выполнена операция декорреляции.
Объектные сигналы, которые являются единицами кодирования в способе объектно-ориентированного кодирования, имеют большую независимость, чем канальные сигналы, которые являются единицами кодирования в способе многоканального кодирования. Другими словами, канальный сигнал включает в себя ряд объектных сигналов и тем самым должен быть декоррелирован. С другой стороны, объектные сигналы являются независимыми друг от друга, и тем самым разделение каналов может легко выполняться с использованием характеристик объектных сигналов без необходимости операции декорреляции.
Более конкретно, как показано на фиг. 19, объектные сигналы A, B и C, как оказывается, являются преобладающими на частотной оси. В этом случае нет необходимости разделять сигнал понижающего микширования на ряд сигналов согласно соотношению уровней объектных сигналов A, B и C и выполнять декорреляцию. Вместо этого, информация, относящаяся к преобладающим периодам объектных сигналов A, B и C, может быть передана, либо значение усиления может быть применено к каждому частотному компоненту каждого из объектных сигналов A, B и C, тем самым пропуская декорреляцию. Следовательно, можно уменьшить объем вычислений и снизить скорость передачи битов на величину, которая в противном случае бы потребовалась в виде дополнительной информации, требуемой для декорреляции.
Вкратце, чтобы пропустить декорреляцию, которая выполняется для того, чтобы гарантировать независимость среди определенного числа сигналов, получаемых разделением сигнала понижающего микширования согласно соотношению соотношений числа сигналов, полученных разделением сигнала понижающего микширования согласно соотношению соотношений числа объектных сигналов, информация, относящаяся к частотной области, включающей в себя каждый объектный сигнал, может быть передана как дополнительная информация. В качестве альтернативы, различные значения усиления могут быть применены к преобладающему периоду, в течение которого каждый объектный сигнал кажется преобладающим, и непреобладающему периоду, в течение которого каждый объектный сигнал кажется менее преобладающим, и тем самым информация, относящаяся к преобладающему периоду, главным образом может быть обеспечена в качестве дополнительной информации. В качестве еще одной альтернативы, информация, относящаяся к преобладающему периоду, может быть передана в качестве дополнительной информации, а информация, относящаяся к непреобладающему периоду, может не быть передана. В качестве еще одной альтернативы, комбинация вышеописанных способов, которые являются альтернативами способу декорреляции, может быть использована.
Вышеописанные способы, которые являются альтернативами способу декорреляции, могут быть применены ко всем объектным сигналам или только к некоторым объектным сигналам, которые являются легко различаемыми преобладающими периодами. Также вышеописанные способы, которые являются альтернативами способу декорреляции, могут быть переменно применены в единицах кадров.
Кодирование объектных аудиосигналов с использованием остаточного сигнала далее описывается подробно.
В общем, в способе кодирования объектного аудиосигнала ряд объектных сигналов кодируют, и результаты кодирования передают в виде комбинации сигнала понижающего микширования и дополнительной информации. Затем ряд объектных сигналов восстанавливается из сигнала понижающего микширования через декодирование согласно дополнительной информации, и восстановленные объектные сигналы надлежащим образом микшируются, например, по запросу пользователя согласно управляющей информации, тем самым формируя первый канальный сигнал. Способ кодирования объектно-ориентированного аудиосигнала в общем направлен на то, чтобы свободно варьировать выходной канальный сигнал согласно управляющей информации с использованием микшера. Тем не менее способ кодирования объектно-ориентированного аудиосигнала также может быть использован для того, чтобы формировать канал, выводимый заранее заданным способом независимо от управляющей информации.
Для этого дополнительная информация может включать в себя не только информацию, требуемую для того, чтобы получать определенное число объектных сигналов из сигнала понижающего микширования, но также информацию параметров микширования, требуемую для того, чтобы формировать канальный сигнал. Таким образом, можно формировать конечный канальный выходной сигнал без помощи микшера. В этом случае такой алгоритм, как остаточное кодирование, может быть использован для того, чтобы повышать качество звука.
Обычный способ остаточного кодирования включает в себя кодирование сигнала и кодирование ошибки между кодированным сигналом и исходным сигналом, т.е. остаточного сигнала. В ходе операции декодирования кодированный сигнал декодируется при компенсации ошибки между кодированным сигналом и исходным сигналом, тем самым восстанавливая сигнал, который аналогичен исходному сигналу в максимально возможной степени. Поскольку ошибка между кодированным сигналом и исходным сигналом является в общем незначительной, можно уменьшить объем информации, дополнительно требуемой для того, чтобы выполнять остаточное кодирование.
Если конечный вывод сигнала декодера является фиксированным, то в качестве дополнительной информации может быть обеспечена не только информация параметров микширования, требуемая для формирования конечного канального сигнала, но также информация остаточного кодирования. В этом случае можно повысить качество звука.
Фиг. 20 представляет собой блок-схему устройства 310 кодирования аудиосигналов согласно варианту осуществления настоящего изобретения. Как показано на фиг. 20, устройство 310 кодирования аудиосигнала отличается использованием остаточного сигнала.
Более конкретно, устройство 310 кодирования аудиосигнала включает в себя кодер 311, декодер 313, первый микшер 315, второй микшер 319, сумматор 317 и формирователь 321 потоков битов.
Первый микшер 315 выполняет операцию микширования с исходным сигналом, а второй микшер 319 выполняет операцию микширования с сигналом, полученным путем выполнения операции кодирования и затем операции декодирования исходного сигнала. Сумматор 317 вычисляет остаточный сигнал между сигналом, выводимым первым микшером 315, и сигналом, выводимым вторым микшером 319. Формирователь 321 потоков битов прибавляет остаточный сигнал к дополнительной информации и передает результат сложения. Таким образом, можно повысить качество звука.
Вычисление остаточного сигнала может быть применено ко всем частям сигнала или только к низкочастотным частям сигнала. В качестве альтернативы, вычисление остаточного сигнала может быть выборочно применено к частотным областям, включающим в себя преобладающие сигналы, на покадровой основе. В качестве еще одной альтернативы, комбинация вышеописанных способов может быть использована.
Поскольку объем дополнительной информации, включающей в себя информацию остаточных сигналов, гораздо больше, чем объем дополнительной информации, не включающей в себя информацию остаточных сигналов, вычисление остаточного сигнала может быть применено только к некоторым частям сигнала, которые непосредственно влияют на качество звука, тем самым не допуская чрезмерного увеличения скорости передачи битов. Настоящее изобретение может быть реализовано в качестве машиночитаемого кода, записанного на машиночитаемом носителе записи. Машиночитаемым носителем записи может быть любой тип устройства записи, в котором данные сохраняются машиночитаемым способом. Примеры машиночитаемых носителей записи включают в себя ROM, RAM, CD-ROM, магнитные ленты, гибкие диски, устройства хранения оптических данных и волновую несущую (например, передачу данных через Интернет). Машиночитаемые носители записи могут распространяться по множеству вычислительных систем, соединенных по сети, так что машиночитаемый код записывается на них и приводится в исполнение с них децентрализованным способом. Функциональные программы, код и сегменты кода, требуемые для реализации настоящего изобретения, могут быть легко истолкованы специалистами в данной области техники.
Промышленная применимость
Как описано выше, согласно настоящему изобретению звуковые образы локализуются для каждого объектного аудиосигнала за счет преимуществ способов кодирования и декодирования объектно-ориентированного аудиосигнала. Таким образом, обеспечивается возможность создания более реалистичных звуков в ходе воспроизведения объектных аудиосигналов. Помимо этого, настоящее изобретение может быть применено к интерактивным играм и тем самым может обеспечивать пользователю более реалистичные впечатления от виртуальной реальности.
Несмотря на то что настоящее изобретение конкретно показано и описано со ссылкой на примерные варианты его осуществления, специалистам в данной области техники следует понимать, что в него могут быть внесены различные изменения по форме и содержанию, не выходящие за рамки сущности и объема настоящего изобретения, которые определены нижеследующей формулой изобретения.
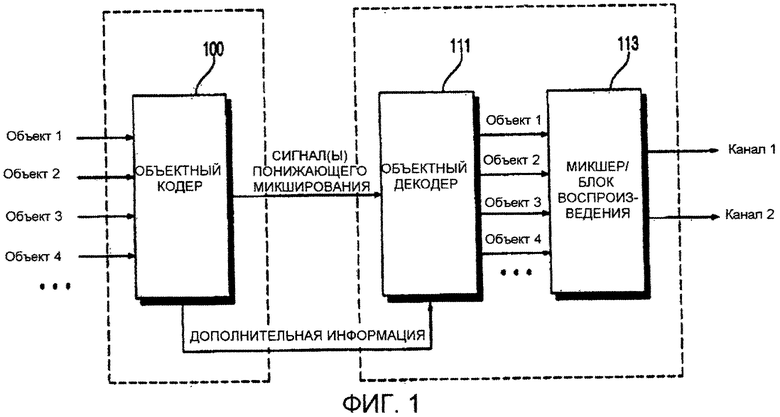
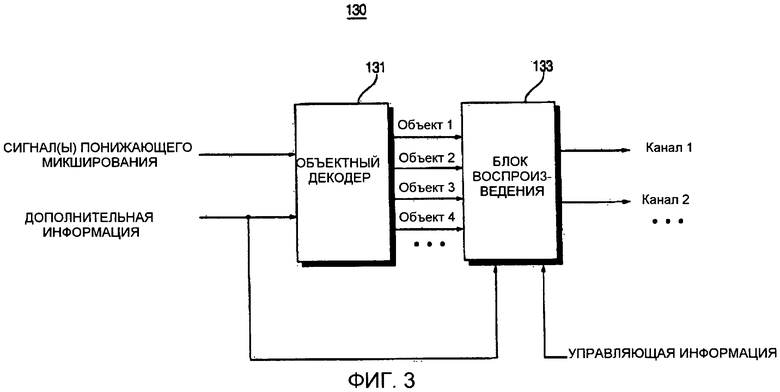
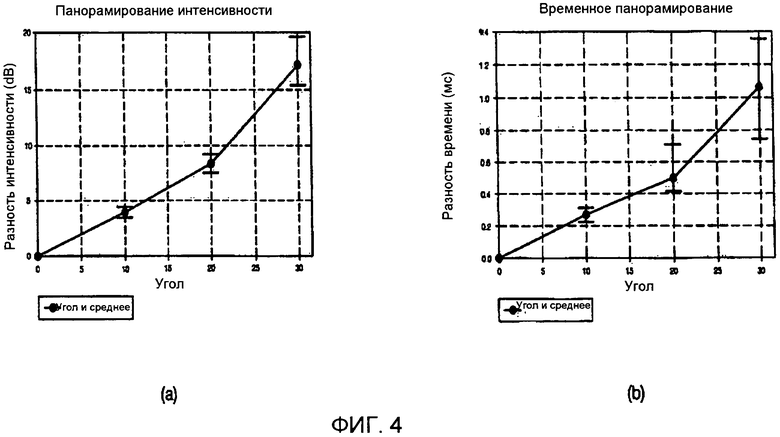
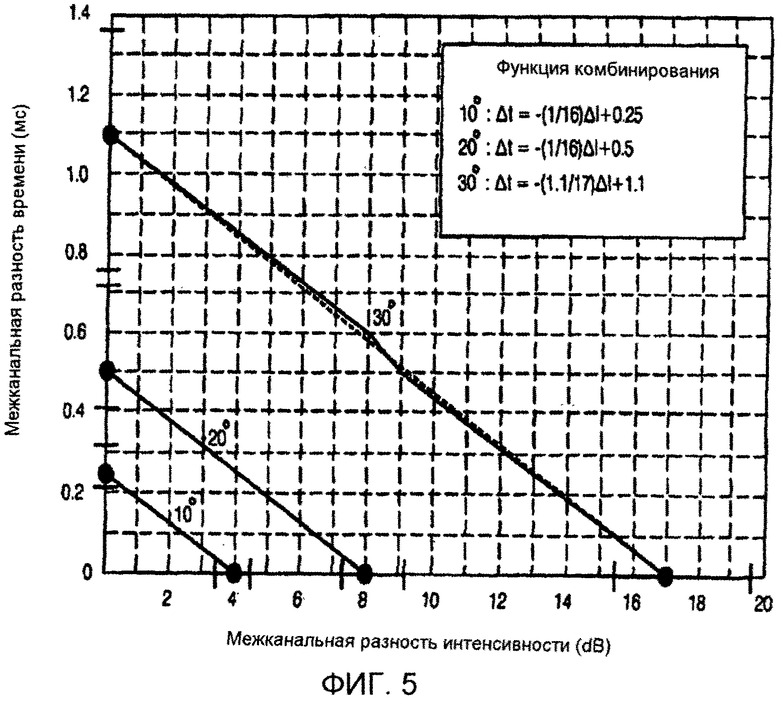
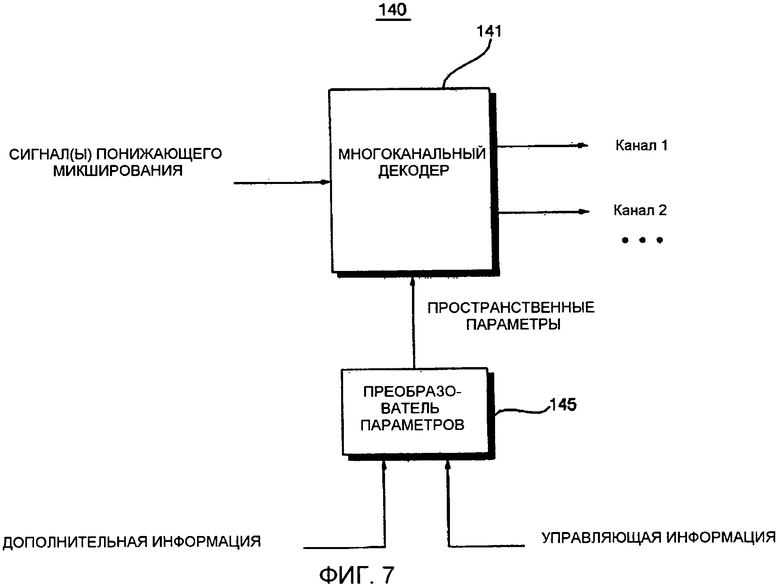
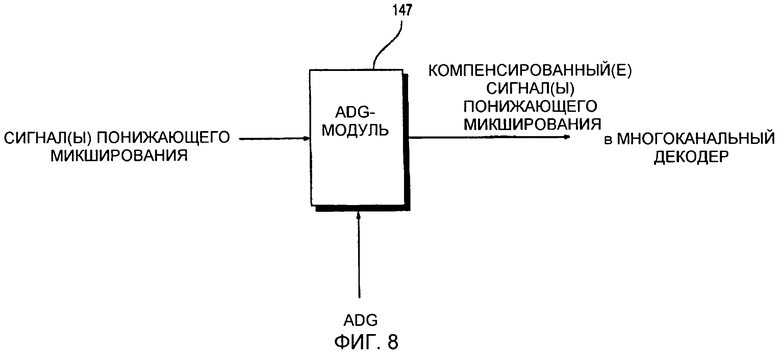
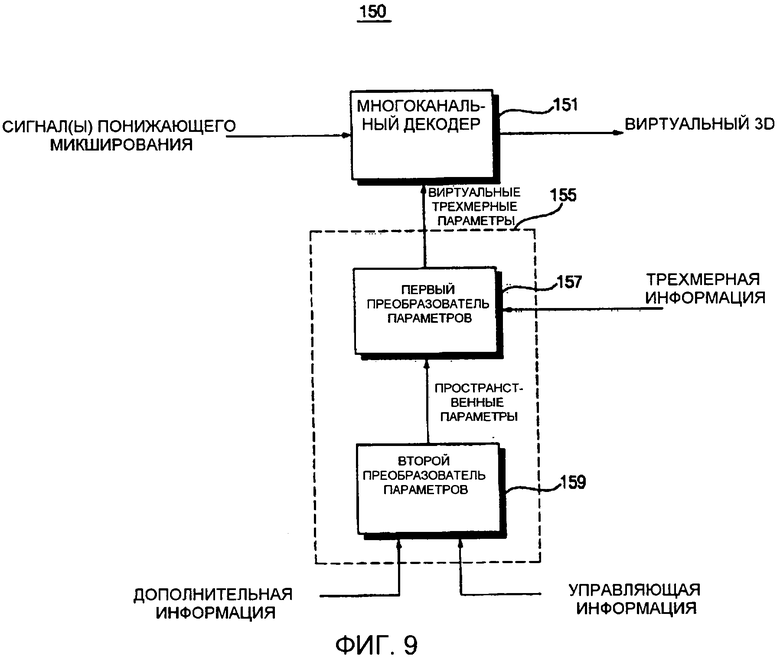
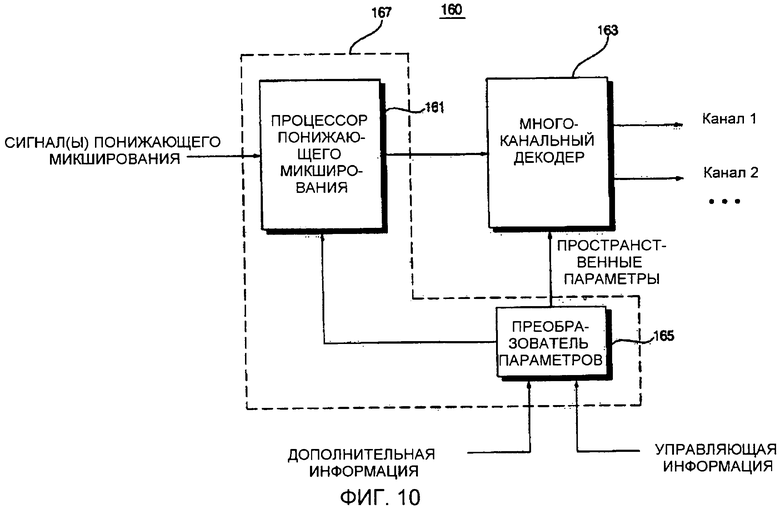
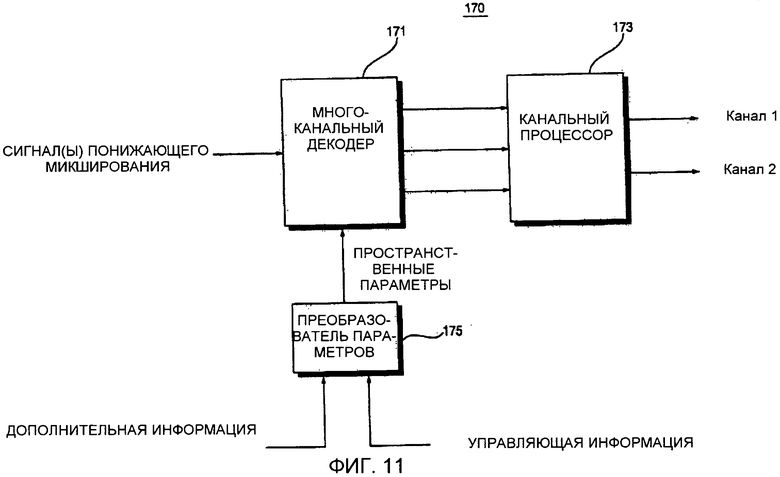
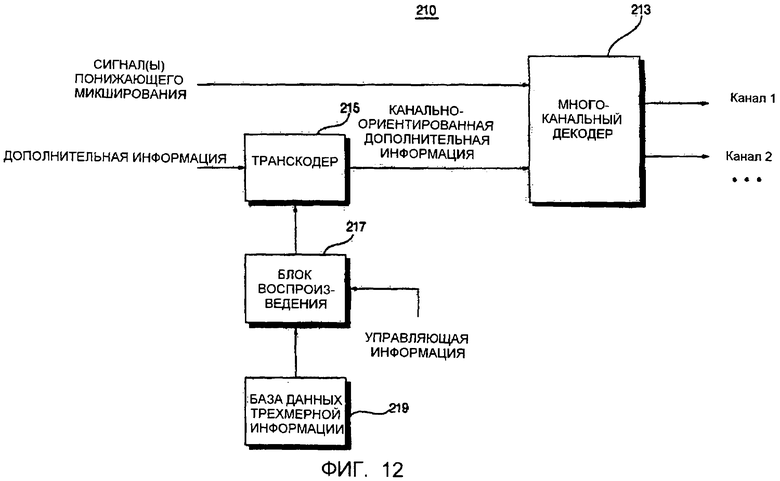
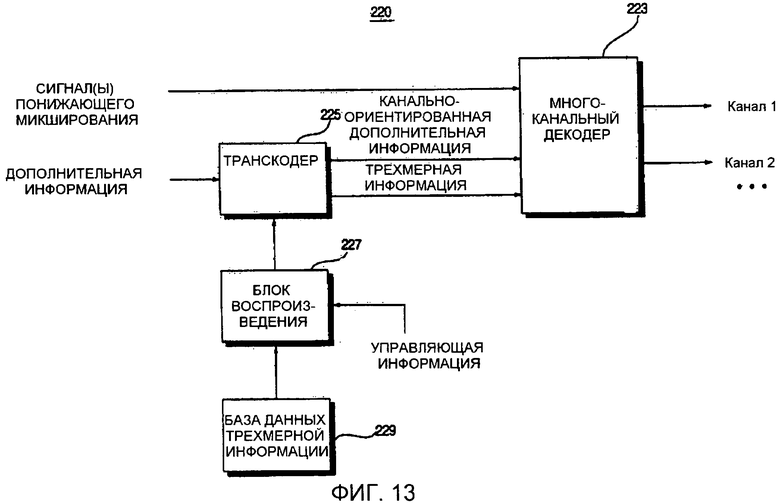
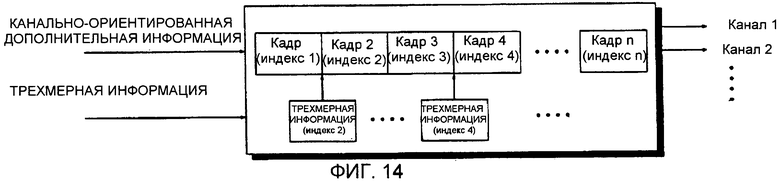
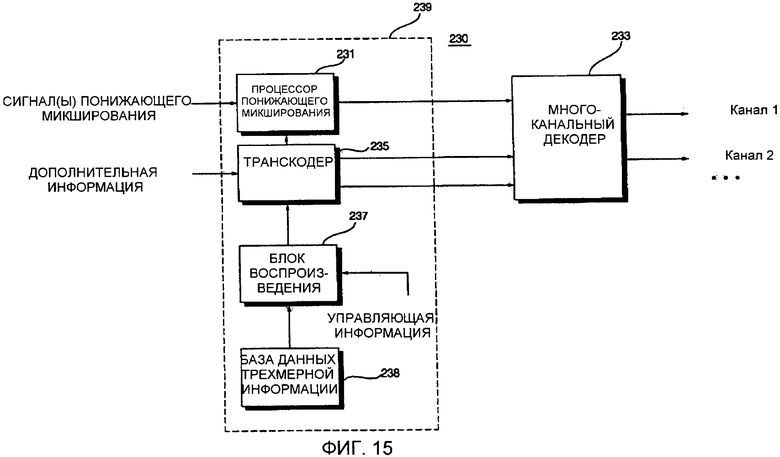
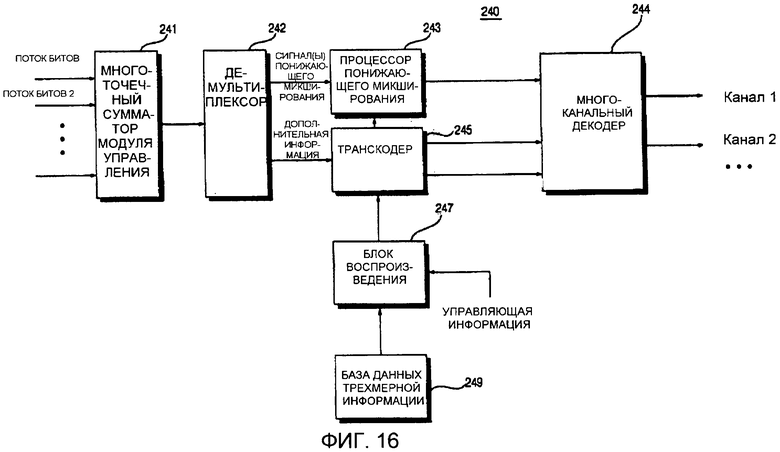
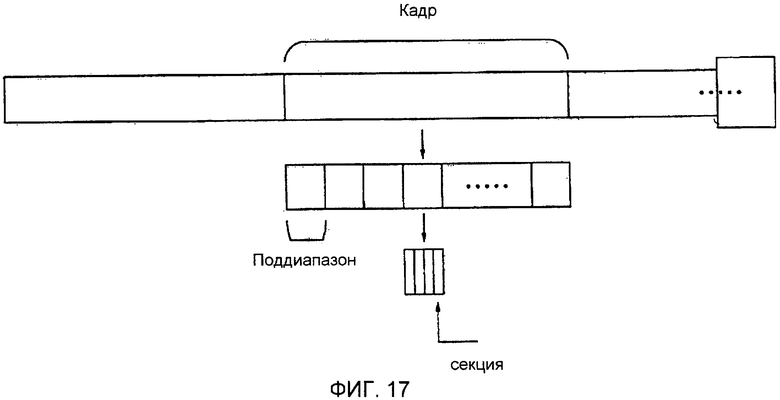
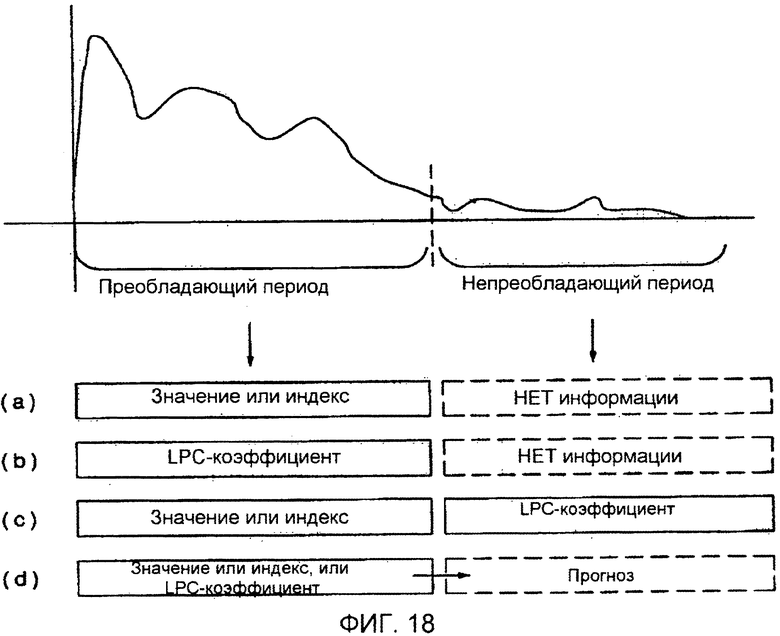
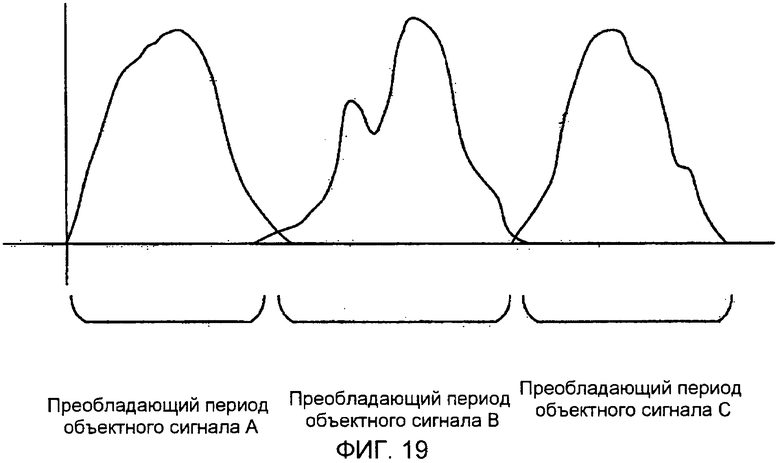
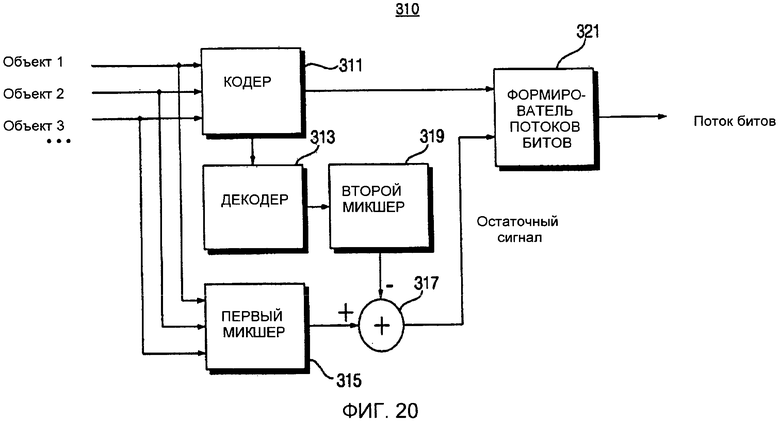
Изобретение относится к кодированию и декодированию аудиосигнала, в которых звуковые образы для каждого объектного аудиосигнала могут быть локализованы в любой требуемой позиции. Технический результат - повышение точности воспроизведения объектных аудиосигналов. Для этого в способе и устройстве кодирования аудиосигнала и в способе и устройстве декодирования аудиосигнала аудиосигналы могут быть кодированы или декодированы так, что звуковые образы могут быть локализованы в любой требуемой позиции для каждого объектного аудиосигнала. Способ декодирования аудиосигнала включает в себя извлечение из аудиосигнала сигнала понижающего микширования и объектно-ориентированной дополнительной информации; формирование канально-ориентированной дополнительной информации на основе объектно-ориентированной дополнительной информации и управляющей информации для воспроизведения сигнала понижающего микширования; обработку сигнала понижающего микширования с использованием декоррелированного канального сигнала; и формирование многоканального аудиосигнала с использованием обработанного сигнала понижающего микширования и канально-ориентированной дополнительной информации. 3 н. и 4 з.п. ф-лы, 20 ил.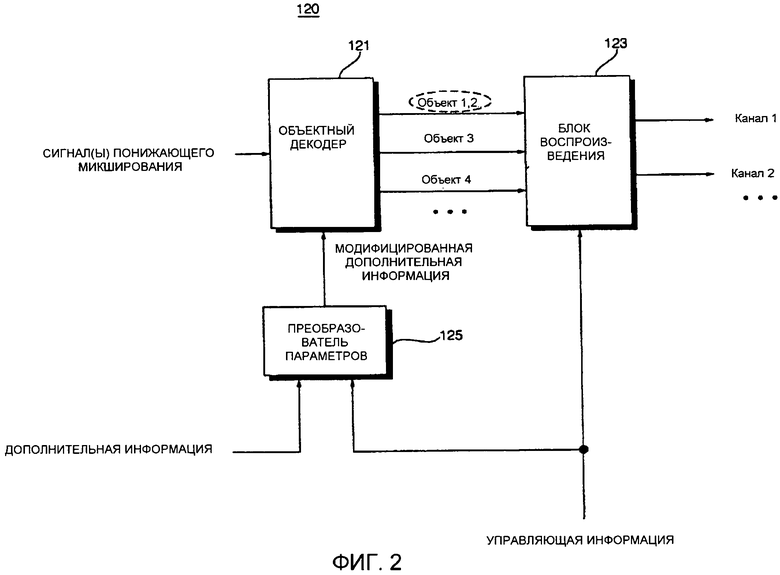
1. Способ декодирования аудиосигнала, содержащий этапы, на которых:
принимают сигнал понижающего микширования, содержащий по меньшей мере один объектный сигнал и объектно-ориентированную дополнительную информацию, формируемую, когда по меньшей мере один объектный сигнал подвергается понижающему микшированию для получения сигнала понижающего микширования, причем сигнал понижающего микширования и объектно-ориентированная дополнительная информация принимаются из аудиосигнала;
принимают управляющую информацию для управления положением или уровнем по меньшей мере одного объектного сигнала;
формируют канально-ориентированную дополнительную информацию на основе объектно-ориентированной дополнительной информации и управляющей информации;
формируют обработанный сигнал понижающего микширования на основе сигнала понижающего микширования, объектно-ориентированной дополнительной информации и управляющей информации для управления положением по меньшей мере одного объектного сигнала; и
формируют многоканальный аудиосигнал с использованием обработанного сигнала понижающего микширования и канально-ориентированной дополнительной информации,
при этом как сигнал понижающего микширования, так и обработанный сигнал понижающего микширования состоят из левого канала и правого канала.
2. Способ декодирования аудиосигнала по п. 1, в котором обработанный сигнал понижающего микширования формируют путем выполнения добавления эффектов к сигналу понижающего микширования.
3. Способ декодирования аудиосигнала по п. 1, в котором формирование сигнала понижающего микширования содержит модифицирование сигнала понижающего микширования либо во временной области, либо в частотной области.
4. Устройство декодирования аудиосигнала, содержащее:
демультиплексор, принимающий сигнал понижающего микширования, содержащий по меньшей мере один объектный сигнал и объектно-ориентированную дополнительную информацию, формируемую, когда по меньшей мере один объектный сигнал подвергается понижающему микшированию для получения сигнала понижающего микширования, причем сигнал понижающего микширования и объектно-ориентированная дополнительная информация принимаются из аудиосигнала;
преобразователь параметров, принимающий управляющую информацию для управления положением или уровнем по меньшей мере одного объектного сигнала и формирующий канально-ориентированную дополнительную информацию на основе объектно-ориентированной дополнительной информации и управляющей информации;
процессор понижающего микширования, формирующий обработанный сигнал понижающего микширования на основе сигнала понижающего микширования, объектно-ориентированной дополнительной информации и управляющей информации для управления положением по меньшей мере одного объектного сигнала; и
многоканальный декодер, формирующий многоканальный аудиосигнал с использованием обработанного сигнала понижающего микширования и канально-ориентированной дополнительной информации,
при этом как сигнал понижающего микширования, так и обработанный сигнал понижающего микширования состоят из левого канала и правого канала.
5. Устройство декодирования аудиосигнала по п. 4, в котором обработанный сигнал понижающего микширования формируется путем выполнения добавления эффектов к сигналу понижающего микширования.
6. Устройство декодирования аудиосигнала по п. 4, в котором процессор понижающего микширования модифицирует сигнал понижающего микширования либо во временной области, либо в частотной области.
7. Машиночитаемый носитель записи, на котором записан способ декодирования аудиосигнала, содержащий этапы:
приема сигнала понижающего микширования, содержащего по меньшей мере один объектный сигнал и объектно-ориентированную дополнительную информацию, формируемую, когда по меньшей мере один объектный сигнал подвергается понижающему микшированию для получения сигнала понижающего микширования, причем сигнал понижающего микширования и объектно-ориентированная дополнительная информация принимаются из аудиосигнала;
приема управляющей информации для управления положением или уровнем по меньшей мере одного объектного сигнала;
формирования канально-ориентированной дополнительной информации на основе объектно-ориентированной дополнительной информации и управляющей информации;
формирования обработанного сигнала понижающего микширования на основе сигнала понижающего микширования, объектно-ориентированной дополнительной информации и управляющей информации для управления положением по меньшей мере одного объектного сигнала; и
формирования многоканального аудиосигнала с использованием обработанного сигнала понижающего микширования и канально-ориентированной дополнительной информации,
при этом как сигнал понижающего микширования, так и обработанный сигнал понижающего микширования состоят из левого канала и правого канала.
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ получения бетонных изделий | 1989 |
|
SU1691348A1 |

