По настоящей заявке испрашивается приоритет на основании предварительной заявки США регистрационный № 60/865,827, поданной 14 ноября 2006 г., и предварительной заявки США регистрационный № 60/867,081, поданной 22 ноября 2006 г., содержание каждой из которых полностью включено в настоящую заявку посредством ссылки.
Область техники, к которой относится изобретение
Настоящее изобретение относится к сжатию данных и, более конкретно, к сжатию данных с использованием кодов переменной длины (VLC).
Уровень техники
Сжатие данных широко используется в различных областях применения для уменьшения занимаемой области для хранения данных, полосы пропускания или и того, и другого. Примеры областей применения сжатия данных включают в себя кодирование цифровых видеоданных, данных изображения, голосовых и звуковых данных. Кодирование цифровых видеоданных используется, например, в целом ряде устройств, в том числе в цифровых телевизионных устройствах, цифровых системах прямого вещания, устройствах беспроводной связи, карманных персональных компьютерах (КПК), портативных компьютерах или настольных компьютерах, цифровых камерах, цифровых записывающих устройствах, устройствах для видеоигр, сотовых или спутниковых радиотелефонах и тому подобном. Цифровые видеоустройства реализуют способы сжатия видеоданных, такие как MPEG-2, MPEG-4 или H.264/MPEG-4 улучшенного кодирования видеоданных (AVC), для более эффективной передачи и приема цифровых видеоданных.
В целом, в способах сжатия видеоданных для уменьшения или исключения избыточности, присущей видеоданным, выполняют пространственное предсказание, оценку движения и компенсацию движения. В частности, внутреннее кодирование опирается на пространственное предсказание для уменьшения или исключения пространственной избыточности в видеоданных в пределах данного видеокадра. Внешнее кодирование опирается на временное предсказание для уменьшения или исключения временной избыточности в видеоданных в пределах соседних кадров. Для внешнего кодирования устройство кодирования видеоданных выполняет оценку движения для отслеживания перемещения соответствующих видеоблоков между двумя или несколькими соседними кадрами. Оценка движения генерирует векторы движения, которые показывают смещение видеоблоков относительно соответствующих видеоблоков в одном или нескольких опорных кадрах. Компенсация движения использует вектор движения для генерации из опорного кадра видеоблока предсказания. После компенсации движения посредством вычитания видеоблока предсказания из первоначального видеоблока формируется остаточный видеоблок.
Устройство кодирования видеоданных применяет процессы кодирования с преобразованием, кодирования с квантованием и статистического кодирования для дополнительного уменьшения скорости передачи в битах остаточного блока, полученного в процессе кодирования видеоданных. Способы статистического кодирования используются на последних каскадах кодера-декодера видеосигналов (CODEC) и в различных других кодирующих приложениях перед сохранением или передачей кодированных данных. Статистическое кодирование в целом включает в себя применение арифметических кодов или кодов переменной длины (VLC) для дальнейшего сжатия остаточных коэффициентов, полученных в результате операций преобразования и квантования. Примеры способов статистического кодирования включают в себя контекстно-регулируемое двоичное арифметическое кодирование (CABAC) и контекстно-регулируемое кодирование переменной длины (CAVLC), которые можно использовать в некоторых кодерах в качестве альтернативных режимов статистического кодирования. Устройство декодирования видеоданных выполняет статистическое декодирование для распаковки остаточной информации по каждому из блоков и восстановление кодированных видеоданных с использованием информации о движении и остаточной информации.
Сущность изобретения
В целом настоящее изобретение направлено на создание способов адаптивного кодирования переменной длины (VLC) с более эффективным использованием памяти и меньшей сложностью для данных в различных областях применения, таких как кодирование цифровых видеоданных, данных изображения, звуковых или голосовых данных. В первом общем аспекте в этих способах могут использоваться определенные наборы кодовых слов для поддержки очень компактных структур данных. Во втором общем аспекте способы могут поддерживать адаптивное кодирование и декодирование с низкой степенью сложности двоичных последовательностей, созданных источниками без памяти.
Изобретение обеспечивает, в первом аспекте, способ, содержащий генерацию частичных значений базовых кодовых слов для уровней дерева кодирования, определяющего кодовые слова переменной длины, генерацию показателя пропуска, указывающего декодеру пропустить несколько битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования, и сохранению частичных значений и показателя пропуска в структуре данных в памяти.
В другом аспекте изобретение обеспечивает материальный машиночитаемый носитель, содержащий структуру данных, хранящую частичные значения базовых кодовых слов для уровней дерева кодирования, определяющего кодовые слова переменной длины, и показатель пропуска, указывающий декодеру пропустить несколько битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования.
В дополнительном аспекте изобретение обеспечивает устройство, содержащее процессор, выполненный с возможностью генерации частичных значений базовых кодовых слов для уровней дерева кодирования, определяющего кодовые слова переменной длины и генерации показателя пропуска, указывающего декодеру пропустить несколько битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования, и память, которая хранит частичные значения и показатель пропуска в структуре данных.
В еще одном аспекте изобретение обеспечивает декодирующее устройство, содержащее память, хранящую структуру данных, содержащую частичные значения базовых кодовых слов для уровней дерева кодирования, определяющего кодовые слова переменной длины, и показатель пропуска, указывающий декодеру пропустить несколько битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования, и декодер, который обращается к памяти для декодирования одного из кодовых слов из потока битов на основе частичных значений и показателя пропуска в хранящейся структуре данных.
В еще одном аспекте изобретение обеспечивает способ декодирования, содержащий обращение к структуре данных, хранящейся в памяти, причем структура данных содержит частичные значения базовых кодовых слов для уровней дерева кодирования, определяющего кодовые слова переменной длины, и показатель пропуска, указывающий декодеру пропустить несколько битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования, и декодирование одного из кодовых слов из потока битов на основе частичных значений и показателя пропуска в хранящейся структуре данных.
В еще одном аспекте изобретение обеспечивает материальный машиночитаемый носитель, содержащий команды, побуждающие процессор обращаться к структуре данных, хранящейся в памяти, причем структура данных содержит частичные значения базовых кодовых слов для уровней дерева кодирования, определяющего кодовые слова переменной длины, и показатель пропуска, указывающий декодеру пропустить множество битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования, и декодировать одно из кодовых слов из потока битов на основе частичных значений и показателя пропуска в хранящейся структуре данных.
В дополнительном аспекте изобретение обеспечивает способ, содержащий выполнение кодирования переменной длины согласно структуре кода, причем структура кода определяет группы кодовых слов в дереве кодирования, каждая из групп включает в себя кодовые слова, представляющие значения, имеющие одинаковые веса, и кодовые слова в каждой из групп упорядочены в лексикографическом порядке относительно значений, представленных кодовыми словами, и первую и вторую подгруппы кодовых слов внутри каждой из групп, причем первая подгруппа включает в себя кодовые слова, имеющие первую длину, а вторая подгруппа включает в себя кодовые слова, имеющие вторую длину, отличную от первой длины, и генерацию результата кодирования переменной длины по меньшей мере для одного из сохранения в памяти, передачи устройству или представления пользователю.
В дополнительном аспекте изобретение обеспечивает материальный машиночитаемый носитель, содержащий команды, побуждающие процессор выполнять кодирование переменной длины согласно структуре кода, причем структура кода определяет группы кодовых слов в дереве кодирования, каждая из групп включает в себя кодовые слова, представляющие значения, имеющие одинаковые веса, и кодовые слова в каждой из групп упорядочиваются в лексикографическом порядке относительно значений, представленных кодовыми словами, и первую и вторую подгруппы кодовых слов внутри каждой из групп, причем первая подгруппа включает в себя кодовые слова, имеющие первую длину, а вторая подгруппа включает в себя кодовые слова, имеющие вторую длину, отличную от первой длины, и генерировать результат кодирования переменной длины по меньшей мере для одного из сохранения в памяти, передачи устройству или представления пользователю.
В дополнительном аспекте изобретение обеспечивает устройство, содержащее процессор, выполненный с возможностью выполнения кодирования переменной длины согласно структуре кода, причем структура кода определяет группы кодовых слов в дереве кодирования, каждая из групп включает в себя кодовые слова, представляющие значения, имеющие одинаковые веса, и кодовые слова в каждой из групп упорядочиваются в лексикографическом порядке относительно значений, представленных кодовыми словами, и первую и вторую подгруппы кодовых слов внутри каждой из групп, причем первая подгруппа включает в себя кодовые слова, имеющие первую длину, а вторая подгруппа включает в себя кодовые слова, имеющие вторую длину, отличную от первой длины, и генерации результата кодирования переменной длины по меньшей мере для одного из сохранения в памяти, передачи устройству или представления пользователю.
В дополнительном аспекте изобретение обеспечивает способ, содержащий для кодовой структуры определение группы кодовых слов в дереве кодирования, определяющем кодовые слова переменной длины, причем каждая из групп включает в себя кодовые слова, представляющие значения, имеющие одинаковые веса, и кодовые слова в каждой из групп упорядочены в лексикографическом порядке относительно значений, представленных кодовыми словами, первую и вторую подгруппы кодовых слов внутри каждой из групп, причем первая подгруппа включает в себя кодовые слова, имеющие первую длину, а вторая подгруппа включает в себя кодовые слова, имеющие вторую длину, отличную от первой длины, выполнение кодирования переменной длины с использованием базовых кодовых слов для каждой из подгрупп, позиций кодовых слов внутри каждой из групп, числа кодовых слов в каждой из первых подгрупп и длин кодовых слов в каждой из подгрупп, и генерацию результата кодирования переменной длины по меньшей мере для одного из сохранения в памяти, передачи устройству или представления пользователю.
В дополнительном аспекте изобретение обеспечивает устройство, содержащее, для структуры кода, средство определения групп кодовых слов в дереве кодирования, определяющем кодовые слова переменой длины, причем каждая из групп включает в себя кодовые слова, представляющие значения, имеющие одинаковые веса, и кодовые слова в каждой из групп упорядочены в лексикографическом порядке относительно значений, представляемых кодовыми словами, и первой и второй подгрупп кодовых слов внутри каждой из групп, причем первая подгруппа включает в себя кодовые слова, имеющие первую длину, а вторая подгруппа включает в себя кодовые слова, имеющие вторую длину, отличную от первой длины, средство выполнения кодирования переменной длины с использованием базовых кодовых слов для каждой из подгрупп, позиций кодовых слов в каждой из групп, числа кодовых слов в каждой из первых подгрупп и длин кодовых слов в каждой из подгрупп, и средство генерации результата кодирования переменной длины по меньшей мере для одного из сохранения в памяти, передачи устройству или представления пользователю.
В дополнительном аспекте изобретение обеспечивает материальный машиночитаемый носитель, содержащий команды, побуждающие процессор, для структуры кода, определяющей группы кодовых слов в дереве кодирования, причем каждая из групп включает в себя кодовые слова, представляющие значения, имеющие одинаковые веса, и кодовые слова в каждой из групп упорядочиваются в лексикографическом порядке относительно значений, представленных кодовыми словами, и первую и вторую подгруппы кодовых слов внутри каждой из групп, причем первая подгруппа включает в себя кодовые слова, имеющие первую длину, а вторая подгруппа включает в себя кодовые слова, имеющие вторую длину, отличную от первой длины, выполнять кодирование переменной длины с использованием базовых кодовых слов для каждой из подгрупп, позиций кодовых слов в каждой из групп, числа кодовых слов в каждой из первых подгрупп и длин кодовых слов в каждой из подгрупп, и генерировать результат кодирования переменной длины по меньшей мере для одного из сохранения в памяти, передачи устройству или представления пользователю.
В дополнительном аспекте изобретение обеспечивает устройство, содержащее, для структуры кода, определяющей группы кодовых слов в дереве кодирования, каждая из групп включает в себя кодовые слова, представляющие значения, имеющие одинаковые веса, и кодовые слова в каждой из групп упорядочиваются в лексикографическом порядке относительно значений, представленных кодовыми словами, и первую и вторую подгруппы кодовых слов внутри каждой из групп, причем первая подгруппа включает в себя кодовые слова, имеющие первую длину, а вторая подгруппа включает в себя кодовые слова, имеющие вторую длину, отличную от первой длины, процессор, выполненный с возможностью выполнения кодирования переменной длины с использованием базовых кодовых слов для каждой из подгрупп, позиций кодовых слов в каждой из групп, числа кодовых слов в каждой из первых подгрупп и длин кодовых слов в каждой из подгрупп, и генерации результата кодирования переменной длины по меньшей мере для одного из сохранения в памяти, передачи устройству или представления пользователю.
В еще одном аспекте изобретение обеспечивает материальный машиночитаемый носитель, содержащий структуру данных для кодирования переменной длины, использующего структуру кода переменной длины, которая определяет группы кодовых слов в дереве кодирования, каждая из групп включает в себя кодовые слова, представляющие значения, имеющие одинаковые веса, и кодовые слова в каждой из групп упорядочиваются в лексикографическом порядке относительно значений, представленных кодовыми словами, и первую и вторую подгруппы кодовых слов внутри каждой из групп, причем первая подгруппа включает в себя кодовые слова, имеющие первую длину, а вторая подгруппа включает в себя кодовые слова, имеющие вторую длину, отличную от первой длины.
В еще одном аспекте изобретение обеспечивает устройство на интегральной схеме, содержащее память, хранящую структуру данных, включающую частичные значения базовых кодовых слов для уровней дерева кодирования, определяющего кодовые слова переменной длины, и показатель пропуска, указывающий декодеру пропустить несколько битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования, и декодер, который обращается к памяти для декодирования одного из кодовых слов из потока битов на основе частичных значений и показателя пропуска в хранящейся структуре данных.
В еще одном аспекте изобретение обеспечивает портативное устройство беспроводной связи, содержащее память, хранящую структуру данных, содержащую частичные значения базовых кодовых слов для уровней дерева кодирования, определяющего кодовые слова переменной длины, и показатель пропуска, указывающий декодеру пропустить несколько битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования, декодер, который обращается к памяти для декодирования одного из кодовых слов из потока битов на основе частичных значений и показателя пропуска в хранящейся структуре данных, приемник для приема кодовых слов от кодера посредством беспроводной связи, и устройство вывода, которое представляет выходной сигнал пользователю на основе, по меньшей мере частично, декодированных кодовых слов.
В еще одном аспекте изобретение обеспечивает устройство на интегральной схеме, содержащее процессор, выполненный с возможностью выполнения кодирования переменной длины согласно структуре кода, причем структура кода определяет группы кодовых слов в дереве кодирования, каждая из групп включает в себя кодовые слова, представляющие значения, имеющие одинаковые веса, и кодовые слова в каждой из групп упорядочиваются в лексикографическом порядке относительно значений, представленных кодовыми словами, и первую и вторую подгруппы кодовых слов внутри каждой из групп, причем первая подгруппа включает в себя кодовые слова, имеющие первую длину, а вторая подгруппа включает в себя кодовые слова, имеющие вторую длину, отличную от первой длины, и при этом процессор выполнен с возможностью генерации результата кодирования переменной длины по меньшей мере для одного из сохранения в памяти, передачи устройству или представления пользователю.
В еще одном аспекте изобретение обеспечивает портативное устройство беспроводной связи, содержащее процессор, выполненный с возможностью выполнения кодирования переменной длины согласно структуре кода, причем структура кода определяет группы кодовых слов в дереве кодирования, каждая из групп включает в себя кодовые слова, представляющие значения, имеющие одинаковые веса, и кодовые слова в каждой из групп упорядочиваются в лексикографическом порядке относительно значений, представленных кодовыми словами, и первую и вторую подгруппы кодовых слов внутри каждой из групп, причем первая подгруппа включает в себя кодовые слова, имеющие первую длину, а вторая подгруппа включает в себя кодовые слова, имеющие вторую длину, отличную от первой длины, и при этом процессор выполнен с возможностью генерации результата кодирования переменной длины по меньшей мере для одного из сохранения в памяти, передачи устройству или представления пользователю.
Способы, описанные в настоящей заявке, могут быть реализованы аппаратными средствами, программными средствами или их сочетанием. В случае реализации программными средствами программное обеспечение может выполняться в одном или нескольких процессорах, таких как микропроцессор, специализированная интегральная схема (ASIC), программируемая пользователем логическая матрица (FPGA) или процессор цифровых сигналов (DSP), либо другая эквивалентная интегральная или дискретная логическая схема. Программные средства, которые выполняют эти способы, могут первоначально храниться в машиночитаемом носителе и загружаться и выполняться процессором. Соответственно, настоящее изобретение предусматривает также компьютерные программные продукты, содержащие машиночитаемый носитель, который содержит команды, побуждающие процессор выполнять любой из множества способов, описанных в настоящей заявке.
Подробные сведения об одном или нескольких аспектах изобретения приведены на прилагаемых чертежах и в нижеследующем описании. Другие признаки, цели и преимущества способов, описанных в настоящей заявке, станут очевидны из описания и чертежей, а также из формулы.
Краткое описание чертежей
Фиг.1 - блок-схема, иллюстрирующая систему кодирования и декодирования видеоданных.
Фиг.2 - блок-схема, иллюстрирующая пример кодера видеоданных.
Фиг.3 - блок-схема, иллюстрирующая пример декодера видеоданных.
Фиг.4 - схема, иллюстрирующая пример дерева двоичного кодирования.
Фиг.5 - график, иллюстрирующий степень избыточности адаптивного блочного кода с асимптотическим поведением.
Фиг.6 - схема двоичного дерева, иллюстрирующая группы блоков, подгруппы и основные кодовые слова.
Фиг.7A и 7B - графики, иллюстрирующие сравнение степеней избыточности адаптивного блочного кода с различными значениями ρ.
Фиг.8 - график, иллюстрирующий чувствительность избыточности к асимметрии исходных данных.
Фиг.9 - блок-схема последовательности операций, иллюстрирующая способ построения кодирования переменной длины с эффективным использованием памяти для монотонных распределений в соответствии с одним аспектом настоящего изобретения.
Фиг.10 - блок-схема последовательности операций, иллюстрирующая способ кодирования символов с использованием кодов переменной длины, построенных согласно способу на фиг.9.
Фиг.11 - блок-схема последовательности операций, иллюстрирующая способ декодирования переменных кодов переменной длины, построенных согласно способу на фиг.9.
Фиг.12 - блок-схема последовательности операций, иллюстрирующая способ построения адаптивных блочных кодов в соответствии с другим аспектом настоящего изобретения.
Фиг.13 - блок-схема последовательности операций, иллюстрирующая способ кодирования блоков с использованием кодов переменной длины, построенных согласно способу на фиг.12.
Фиг.14 - блок-схема, иллюстрирующая способ декодирования кодов переменной длины, построенных согласно способу на фиг. 12.
Подробное описание
В целом настоящее изобретение направлено на создание способов адаптивного кодирования переменной длины (VLC) с эффективным использованием памяти и пониженной сложностью в отношении данных для множества применений, таких как кодирование цифровых видеоданных, данных изображений, звуковых или речевых данных. В некоторых аспектах эти способы могут использовать свойства определенных наборов кодовых слов для поддержки очень компактных структур данных. В других аспектах способы могут поддерживать низкую сложность, адаптивное кодирование и декодирование двоичных последовательностей, созданных источниками без памяти. Хотя способы, описанные в настоящей заявке, могут применяться к широкому кругу практических областей применения, в том числе к общему сжатию и кодированию данных, в настоящей заявке в качестве примера и иллюстрации описывается кодирование и декодирование цифровых видеоданных.
В соответствии с первым общим аспектом настоящего изобретения раскрытым способам нет необходимости опираться на какую-либо определенную схему построения кода для поддержки компактных структур данных. Например, можно использовать схемы Хаффмана, Шеннона, Шеннона-Фано, Гилберта-Мура или другие схемы построения кодов. Однако для этого первого общего аспекта предполагается, что такой код строится для источника с монотонно возрастающими вероятностями символов из входного алфавита символов. Более конкретно, предполагается, что длина кодовых слов монотонно уменьшается или, по меньшей мере, не увеличивается, и что кодовые слова одинаковой длины имеют тот же лексикографический порядок, что и символы во входном алфавите, который они представляют.
Желаемый лексикографический порядок можно обеспечивать посредством переупорядочивания входного алфавита. Для таких кодовых слов можно вычислить базовые значения кодовых слов для каждого уровня дерева кодирования. Базовые значения кодовых слов представляют собой лексикографически наименьшие канонические кодовые слова на каждом уровне дерева кодирования. Базовые значения кодовых слов и индексы их соответствующих символов могут быть сохранены в переупорядоченном массиве. Эти индексы могут быть сохранены в виде значений смещения для каждого заполненного уровня дерева. Процесс декодирования может включать в себя сравнение буфера потока битов со значениями выровненных влево базовых кодовых слов с последующим простым непосредственным вычислением индекса декодированного символа.
Вышеуказанные свойства можно использовать для уникального описания такого кода при помощи структуры данных, которую можно дополнительно сжать для получения очень компактной структуры данных, которая облегчает поэтапное декодирование кодов переменной длины. Например, значения, выровненные влево, базовых кодовых слов, обычно имеют большое число начальных нулей справа налево. Число начальных нулей монотонно уменьшается по мере перехода процесса на более глубокие слои в соответствующем дереве кодирования. Следовательно, при последовательном декодировании битов, начиная с самого первого слоя с последующим перемещением вниз, некоторые из начальных нулевых битов можно пропустить без влияния на точность процесса декодирования.
Начальные нули можно удалять с фиксированными приращениями, например, с 8-битовыми приращениями, что удобно при управлении буфером потока данных в традиционных 8-битовых/байтовых компьютерах. Для управления этим процессом может быть предусмотрена дополнительная таблица, содержащая один или несколько показателей пропуска. Например, показатель пропуска указывает декодеру прокрутить поток битов вперед в буфере на фиксированное приращение, так чтобы различные базовые кодовые слова можно было различать при опущенных начальных нулях. После удаления начальных нулей ширину результирующего массива измененных значений базовых кодовых слов можно существенно уменьшить, сэкономив тем самым свободную память.
Таким образом, в первом общем аспекте настоящее изобретение предусматривает способ, содержащий генерацию частичных значений базовых кодовых слов для уровней дерева кодирования, определяющего кодовые слова переменной длины, генерацию показателя пропуска, указывающего декодеру пропустить несколько битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования, и сохранение частичных значений и показателя пропуска в структуре данных в памяти. Структура данных может быть любой из множества структур данных, таких как таблицы, связанные списки, двоичные деревья, базисные деревья, неструктурированные файлы или тому подобное, и может быть сохранена в любом из множества различных запоминающих устройств, таких как различные виды оперативной памяти (RAM), постоянной памяти (ROM) или и то, и другое. Структура данных может храниться в такой памяти внутри кодера или декодера. Например, декодер может обращаться к структуре данных или участкам содержимого структуры данных из памяти, связанной с декодером, для выполнения декодирования переменной длины для кодовых слов с эффективным использованием памяти.
В соответствии с этим первым общим аспектом изобретение дополнительно предусматривает процессор, выполненный с возможностью генерации частичных значений базовых кодовых слов для уровней дерева кодирования, определяющего кодовые слова переменной длины, и генерации показателя пропуска, указывающего декодеру пропустить несколько битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования, а также память, которая хранит частичные значения и показатель пропуска в структуре данных. Такая информация может храниться в единственной структуре данных или во множестве структур данных. Соответственно, термин "структура данных" может относиться к одной или нескольким структурам данных, хранящим информацию, предусмотренную настоящим изобретением. Процессор, выполненный с возможностью обращения к структуре данных для выполнения кодирования переменной длины, может быть реализован в устройстве-источнике или в устройстве-приемнике либо в отдельном устройстве, которое генерирует структуры данных, определяющие структуры кодов для использования кодером и/или декодером при выполнении кодирования переменной длины.
Согласно этому способу обеспечения компактных структур данных, соответствующему первому общему аспекту настоящего изобретения, каждая допустимая длина кодового слова может соответствовать уровню с внешним узлом в кодовом дереве. Как указывалось выше, структура данных может включать в себя частичные значения базовых кодовых слов и один или несколько показателей пропуска. Более конкретно, в некоторых вариантах осуществления структура данных может содержать следующую информацию для каждой допустимой длины кодового слова: (a) частичное значение лексикографически наименьшего (или наибольшего) кодового слова на текущем уровне кодового дерева, (b) число битов в частичном значении, (c) значение символа, соответствующего лексикографически наименьшему (или наибольшему) кодовому слову, и (d) показатель, указывающий декодеру пропускать определенное число битов перед переходом к следующему уровню кодового дерева. Соответственно, структура данных может дополнительно включать в себя значения для символов, представленных базовыми кодовыми словами, и длины частичных значений базовых основных кодовых слов, то есть число битов в каждом частичном значении базового кодового слова. Способы кодирования и декодирования могут использовать эту структуру данных для идентификации уровня, соответствующего кодовому слову, подлежащему созданию или декодированию, и затем непосредственно вычисляют значение кодового слова или декодированного символа. Соответственно, структура данных может храниться в памяти кодера или декодера видеоданных, кодера или декодера изображений, кодера или декодера аудиоданных либо кодера или декодера голосовых данных, некоторые из которых могут быть сконструированы в виде совмещенных CODEC.
Примеры существующих способов кодирования или декодирования кодов переменной длины описаны в работе A. Moffat и A. Turpin, On the Implementation of Minimum-Redundancy Prefix Codes, IEEE Trans. Communications, 45 (10) (1997) 1200-1207; J. B. Connell, A Huffman-Shannon-Fano Code, Proc. IEEE, July 1973, 1046-1047; и A. Brodnik и S. Carlsson, Sublinear Decoding of Huffman Codes Almost in Place, DIMACS Workshop on Codes and Trees: Algorithmic and Information Theoretic Approaches, October 1998, Rutgers University, DIMACS Center, NJ. По сравнению с этими существующими способами раскрытые способы обеспечения компактных структур данных могут предлагать определенные преимущества.
В качестве первого примера структура данных, созданная посредством раскрытого способа, может занимать значительно меньший объем памяти вследствие того, что лишь частичные значения лексикографически наименьших кодовых слов хранятся и используются, например, декодером видеоданных. В качестве другого примера раскрытый способ может использовать пошаговый доступ к данным потока битов, что позволяет представить буфер потока битов разумно коротким регистром и обновлять его через любые удобные интервалы, например, при помощи указания на пропуск, что еще больше уменьшает сложность реализации.
Например, в некотором варианте выполнения 32-битового регистра может быть достаточно даже для очень длинных кодов. Кроме того, могут делаться обновления с 8-битовыми интервалами. В целом, раскрытый способ позволяет значительно уменьшить сложность представления и кодирования/декодирования кодов переменной длины, что может позволить разработчикам алгоритмов сжатия применять значительно большие и, следовательно, более эффективные кодовые книги.
В соответствии со вторым общим аспектом настоящего изобретения для поддержки адаптивного кодирования и декодирования с низкой степенью сложности для двоичных последовательностей, созданных источниками без памяти, раскрытые способы позволяют реализовать универсальные блочные коды, построенные для набора контекстов, идентифицируемых по числу ненулевых битов среди предыдущих битов в последовательности. Этот второй общий аспект может обеспечиваться и применяться независимо или совместно с первым общим аспектом, описанным выше в отношении генерации очень компактных структур данных. Способы адаптивного кодирования и декодирования с низкой степенью сложности могут, в соответствии с этим вторым общим аспектом, опираться на раскрытую формулу для асимптотической избыточности таких кодов, которая уточняет оценку, описанную в работе R. E. Krichevsky и V. K. Trofimov, The Performance of Universal Encoding, IEEE Trans. Information Theory, 27 (1981) 199-207.
Способы в соответствии с этим вторым общим аспектом могут использовать массив кодов Хаффмана, предназначенный для нескольких оцениваемых плотностей и индексированный числом ненулевых битов в предыдущих блоках (контекстах) в последовательности. При использовании блоков даже умеренного размера n = 8…16 (и использовании соответствующих 1,5…5 килобайт памяти) такие способы могут обеспечивать эффективность сжатия, сравнимую или превосходящую другие существующие алгоритмы, такие как алгоритм Q-кодирования, описанный в работе W.B. Pennebaker, J.L. Mitchell, G.G. Langdon, Jr, R. B. Arps, An overview of the basic principles of the Q-coder adaptive binary arithmetic coder, IBM J. Res. Dev., 32 (6) (1988) 717, который используется в стандарте кодирования изображений JBIG, или алгоритм CABAC, описанный в работе D. Marpe, H. Schwartz и T. Wiegand, Context-Based Adaptive Binary Arithmetic Coding in the H.264/AVC video compression standard, IEEE Trans. on CSVT, 13(7):620 636, July 2003, который используется в стандартах ITU-T H.264/MPEG AVC для сжатия видеосигнала.
Адаптивное кодирование и декодирование с низкой степенью сложности, в соответствии с этим вторым общим аспектом изобретения, может быть основано на понимании того, что в модели без памяти вероятность блока битов или ее оценка зависит только от его веса (числа ненулевых битов), но не от фактической комбинации битов. Следовательно, набор всех возможных блоков некоторой фиксированной длины можно разделить на несколько групп, содержащих блоки с одинаковым весом (и, следовательно, с одинаковой вероятностью). Можно предположить, что каждая группа хранит блоки в лексикографическом порядке, либо естественным образом, либо в результате переупорядочивания.
Известно свойство кодов с минимальной избыточностью (такие как коды Хаффмана или Шеннона), что каждая группа равновероятных блоков может включать в себя максимум две подгруппы, причем блоки в каждой такой подгруппе закодированы кодовыми словами одной и той же длины. Без ограничения общности можно дополнительно предположить, что длина кодовых слов в первой подгруппе короче длины кодовых слов во второй подгруппе. Поскольку блоки (или слова) внутри группы следуют в лексикографическом порядке, ее можно просто поделить на подгруппы с более длинными кодовыми словами и подгруппы с менее длинными кодовыми словами. На положение блока внутри группы указывает значение индекса. Лексикографически наименьшему блоку (или слову) в каждой подгруппе присваивается базовое кодовое слово. При наличии базового кодового слова можно легко вычислить остальные кодовые слова в каждой подгруппе.
Таким образом, в соответствии с этим вторым общим аспектом изобретения кодирование переменной длины может быть выполнено, например, кодером или декодером с использованием структуры кодов, которая определяет группы входных блоков или слов и их соответствующие выходные кодовые слова в дереве кодирования, причем каждая из групп включает в себя кодовые слова, представляющие блоки (или слова), имеющие одинаковые веса, и первую и вторую подгруппы кодовых слов в пределах каждой из групп, причем первая подгруппа включает в себя кодовые слова, имеющие первую длину, а вторая подгруппа включает в себя кодовые слова, имеющие вторую длину, отличную от первой длины. Блоки в каждой из групп упорядочиваются в лексикографическом порядке и затем разбиваются на подгруппы, так чтобы лексикографический порядок сохранялся в каждой из подгрупп. Кроме того, кодовые слова, соответствующие каждому блоку в пределах подгруппы, присваиваются таким образом, чтобы они также следовали в том же лексикографическом порядке и облегчали кодирование и декодирование посредством прямого вычисления.
На основании этого взаимного расположения блоков и их групп и подгрупп можно непосредственным образом вычислить кодовые слова с использованием упрощенного процесса. Например, после получения значения веса и индекса для блока, если значение индекса меньше максимального числа блоков в первой подгруппе, то для определения местонахождения кодового слова выбирается первая подгруппа. В противном случае для определения местонахождения кодового слова выбирается вторая подгруппа. Затем, после извлечения базового кодового слова для выбранной подгруппы кодовое слово легко вычисляется посредством суммирования значения базового кодового слова со значением, определенным на основе значения индекса блока в пределах выбранной подгруппы. В отношении этого второго общего аспекта изобретения термины "блоки" и "слова" могут употребляться взаимозаменяемым образом для общего обозначения входных величин, подлежащих кодированию в соответствии со схемой кодирования. Блок или слово могут включать в себя последовательность символов, которые могут быть сформированы из входного алфавита, такого как двоичный алфавит {0, 1}. Кодовые слова обозначают в целом выходные величины, присвоенные блокам (или словам) в результате применения схемы кодирования.
Эти и другие аспекты способов, описанных в настоящей заявке, более подробно описываются ниже. Способы могут использоваться совместно или независимо и могут быть реализованы в любых из множества систем и устройств кодирования и декодирования, в том числе систем и устройств, выполненных с возможностью кодирования и декодирования цифровых видеоданных, данных изображений, звуковых или голосовых данных. В качестве примера и иллюстрации в заявке описывается применение таких способов к кодированию и декодированию цифровых видеоданных, что не накладывает ограничение на общее практическое применение сжатия и кодирования данных или на другие частные применения к различным типам данных.
На фиг.1 приведена блок-схема, иллюстрирующая систему 10 кодирования и декодирования видеоданных. Как показано на фиг.1, система 10 включает в себя устройство-источник 12, который передает закодированные видеоданные на устройство-приемник 14 по каналу 16 связи. Устройство-источник 12 может включать в себя источник 18 видеоданных, кодер 20 видеоданных и передатчик 22. Устройство-приемник 14 может включать в себя приемник 24, декодер 26 видеоданных и устройство 28 отображения видеоданных. Система 10 может быть выполнена с возможностью применения способов по адаптивному кодированию переменной длины (VLC) с эффективным использованием памяти и низкой степенью сложности к цифровым видеоданным. В частности, способы по адаптивному VLC с эффективным использованием памяти и низкой степенью сложности можно применять для статистического кодирования остаточных блочных коэффициентов, полученных в процессе кодирования видеоданных с предсказанием. Эти способы могут применяться к схемам кодирования видеоданных, которые кодируют положения ненулевых коэффициентов преобразования с использованием последовательностей нулей, или к другим схемам кодирования видеоданных.
В примере на фиг.1 канал 16 связи может содержать любую среду беспроводной или проводной связи, такой как радиочастотный (РЧ) спектр или одну или несколько физических передающих линий, либо любое сочетание беспроводных и проводных сред. Канал 16 может быть частью сети на основе передачи пакетов, такой как локальная сеть, территориальная сеть или глобальная сеть, такая как Интернет. Канал 16 связи в целом представляет любую подходящую среду связи или совокупность различных сред связи для передачи видеоданных от устройства-источника 12 к устройству-приемнику 14.
Устройство-источник 12 генерирует видеоданные для передачи устройству 14 назначения. В некоторых случаях, однако, устройства 12, 14 могут работать по существу симметричным образом. Например, каждое из устройств 12, 14 может включать в себя компоненты кодирования и декодирования видеоданных. Следовательно, система 10 может поддерживать одностороннюю или двухстороннюю передачу видеоданных между устройствами 12, 14 видеоданных, например, для потоковой передачи видеоданных, широковещательной передачи видеоданных или видеотелефонии. Для других областей применения сжатия и кодирования данных устройства 12, 14 могут быть выполнены с возможностью отправки и приема, или обмена других типов данных, таких как данные изображений, голосовые или звуковые данные, или сочетания двух или нескольких из видеоданных, данных изображений, голосовых и звуковых данных. Соответственно, рассмотрение применения в отношении видеоданных используется в иллюстративных целях и не должно считаться ограничивающим различные аспекты изобретения, описанного здесь наиболее широким образом.
Источник 18 видеоданных может включать в себя устройство захвата видеоизображения, такое как одна или несколько видеокамер, видеоархив, содержащий ранее захваченные видеоизображения, или видеоданные, непосредственно поступающие от поставщика видеоконтента. В качестве еще одной альтернативы источник 18 видеоданных может генерировать в качестве исходных видеоданных данные на основе компьютерной графики или сочетание непосредственных видеоданных и видеоданных, сгенерированных на компьютере. В некоторых случаях, если источником 18 видеоданных является камера, устройство-источник 12 и устройство-приемник 14 могут образовать так называемые видеотелефоны. Так, в некоторых аспектах устройство-источник 12, устройство-приемник 14 или оба устройства могут образовать портативное устройство беспроводной связи, такое как мобильный телефон. В каждом случае захваченное, предварительное захваченное или генерируемое компьютером видеоизображение может быть закодировано кодером 20 видеоданных для передачи от устройства-источника 12 видеоданных к декодеру 26 видеоданных устройства-приемника 14 видеоданных через передатчик 22, канал 16 и приемник 24. Устройство 28 отображения может включать в себя всевозможные устройства отображения, такие как жидкокристаллический дисплей (LCD), плазменный дисплей, дисплей на органических светодиодах (OLED).
Кодер 20 видеоданных и декодер 26 видеоданных могут быть выполнены с возможностью поддержки кодирования масштабируемых видеоданных для пространственной, временной масштабируемости и/или масштабируемости отношения сигнал-шум (SNR). В некоторых аспектах кодер 20 видеоданных и декодер 22 видеоданных могут быть выполнены с возможностью поддержки мелкоячеистого кодирования с SNR-масштабируемостью (FGS) для SVC. Кодер 20 и декодер 26 могут поддерживать различные степени масштабируемости посредством поддержки кодирования, передачи и декодирования базового уровня и одного или нескольких масштабируемых уровней повышения качества. Для кодирования масштабируемых видеоданных базовый уровень несет видеоданные с минимальным уровнем качества. Один или несколько слоев повышения качества несут дополнительный поток данных для поддержки более высоких пространственных, временных уровней и/или уровня отношения сигнал-шум.
Кодер 20 видеоданных и декодер 26 видеоданных могут работать в соответствии со стандартом сжатия видеоданных, таким как MPEG-2, MPEG-4, ITU-T H.263 или ITU-T H.264/MPEG-4 усовершенствованное видеокодирование (AVC). Хотя это не показано на фиг.1, в некоторых аспектах кодер 20 видеоданных и декодер 26 видеоданных могут быть объединены соответственно с кодером и декодером звука и включать в себя соответствующие блоки мультиплексирования-демультиплексирования (MUX-DEMUX), либо иные аппаратные и программные средства, для обработки кодирования одновременно звуковых и видеоданных в общем потоке данных или в раздельных потоках данных. Если возможно, блоки MUX-DEMUX могут соответствовать протоколу мультиплексора ITU H.223 или другим протоколам, таким как протокол пользовательских дейтаграмм (UDP).
Стандарт H.264/MPEG-4 (AVC) был выработан экспертной группой по кодированию видеосигналов (VCEG) ITU-T вместе с экспертной группой по движущимся изображениям (MPEG) ISO/IEC как продукт совместного партнерства, известного под названием объединенная видеогруппа (JVT). Стандарт H.264 описан в рекомендации H.264 ITU-T, "Улучшенное кодирование видеосигнала для общих аудиовизуальных служб", выпущенной исследовательской группой ITU-T и датируемой мартом 2005 г., которая может называться в настоящей заявке стандартом H.264, или техническим стандартом H.264, или стандартом или техническим стандартом H.264/AVC.
Объединенная видеогруппа (JVT) продолжает работать над расширением масштабируемого кодирования видеоданных (SVC) на H.264/MPEG-4 AVC. Технические стандарты для разрабатываемого расширения SVC имеют вид объединенного проекта (JD). Объединенная модель масштабируемых видеоданных (JSVM), созданная JVT, реализует инструменты для использования в масштабируемых видеоданных, которые можно использовать в системе 10 для различных задач кодирования, описанных в настоящей заявке. Подробная информация о мелкоячеистом кодировании с SNR-масштабируемостью (FGS) можно найти в документах по объединенному проекту, например, в объединенном проекте 6 (SVC JD6), Thomas Wiegand, Gary Sullivan, Julien Reichel, Heiko Schwartz и Mathias Wien, "Joint Draft 6: Scalable Video Coding", JVT-S 201, April 2006, Geneva, и в объединенном проекте 9 (SVC JD9), Thomas Wiegand, Gary Sullivan, Julien Reichel, Heiko Schwartz и Mathias Wien, "Joint Draft 9 of SVC Amendments," JVT-V 201, January 2007, Marrakech, Morocco.
В некоторых аспектах для случая широковещательной передачи видеоданных способы, описанные в настоящей заявке, могут быть применены к расширенному кодированию видеоданных H.264, для доставки видеоуслуг в режиме реального времени в наземных мобильных мультимедийных многоабонентских (MT3) системах, использующих технический стандарт радиоинтерфейса только с прямой линией связи (FLO) "Forward Link Only Air Interface Specification for Terrestrial Mobile Multimedia Multicast", который будет опубликован под названием технический стандарт TIA-1099 ("Технический стандарт FLO"), например, сервере беспроводной широковещательной передачи видеоданных или портативном устройстве беспроводной связи. Технический стандарт FLO включает в себя примеры, определяющие синтаксис, семантику и процессы декодирования потока битов, подходящие для радиоинтерфейса FLO. В альтернативном варианте видеоданные могут широковещательно передаваться в соответствии с другими стандартами, такими как DVB-H (широковещательная передача цифровых видеоданных - портативное устройство), ISDB-T (цифровая широковещательная передача и комплексными услугами - наземная) или DMB (широковещательная передача цифрового мультимедиа). Следовательно, устройство-источник 12 может быть мобильным беспроводным терминалом, сервером потокового видео или сервером широковещательной передачи видеоданных. Однако способы, описанные в настоящей заявке, не ограничиваются каким-либо определенным типом системы широковещательной передачи, групповой передачи или двухточечной передачи. В случае широковещательной передачи устройство-источник 12 может передавать несколько каналов видеоданных на множество устройств-приемников, каждое из которых может быть подобно устройству-приемнику 14 на фиг.1.
Кодер 20 видеоданных и декодер 26 видеоданных могут быть каждый реализованы в виде одного или нескольких микропроцессоров, процессоров цифровых сигналов (DSP), специализированных интегральных схем (ASIC), программируемых пользователем логических элементов (FPGA), дискретной логики, программных средств, аппаратных средств, программно-аппаратных средств или любых сочетаний вышеперечисленного. Так, каждый кодер 20 видеоданных и декодер 26 видеоданных может быть реализован, по меньшей мере частично, в виде чипа или устройства на интегральной схеме (ИС) и включен в состав одного или нескольких кодеров или декодеров, любой из которых может быть составной частью объединенного кодера/декодера (CODEC) в соответствующем мобильном устройстве, абонентском устройстве, широковещательном устройстве, сервере или тому подобном. Кроме того, устройство-источник 12 и устройство-приемник 14 могут каждое включать в себя соответствующие компоненты модуляции, демодуляции, преобразования частоты, фильтрования и усиления для передачи и приема кодированных видеоданных, в том числе радиочастотные (RF) компоненты и антенны, достаточные для поддержки беспроводной связи. Однако для упрощения чертежа такие компоненты на фиг.1 не показаны.
Видеопоследовательность включает в себя последовательность видеокадров. Для кодирования видеоданных кодер 20 видеоданных работает на блоках пикселов в пределах отдельных видеокадров. Видеоблоки могут иметь фиксированные или переменные размеры и могут отличаться по размеру согласно заданному стандарту кодирования. Каждый видеокадр включает в себя последовательность секций. Каждая секция может включать в себя последовательность макроблоков, которые могут быть скомпонованы в подблоки. Например, стандарт ITU-T H.264 поддерживает внутреннее предсказание в блоках различных размеров, таких как 16 на 16, 8 на 8, 4 на 4 для яркостных компонентов и 8×8 для компонентов цветности, а также внешнее предсказание в блоках различного размера, таких как 16 на 16, 16 на 8, 8 на 16, 8 на 8, 8 на 4, 4 на 8 и 4 на 4 для яркостных компонентов и соответствующих масштабированных размеров для компонентов цветности.
Блоки меньшего размера могут обеспечивать лучшее разрешение и могут использоваться в таких местах видеокадра, которые содержат более высокий уровень детализации. В целом макроблоки (MB) и различные подблоки можно считать видеоблоками. Кроме того, секция может считаться последовательностью видеоблоков, таких как MB и/или подблоки. Каждая секция может быть независимо кодируемой единицей. После предсказания может быть выполнено преобразование на остаточном блоке размером 8×8 или 4×4, и дополнительное преобразование может быть применено к DC-коэффициентам блоков размером 4×4 для компонентов цветности или компонента яркости, если используется режим внутреннего предсказания для блоков размером 16×l6.
Кодер 20 видеоданных и/или декодер 26 видеоданных системы 10 на фиг.1 могут быть выполнены с возможностью применения способов адаптивного кодирования переменной длины (VLC) с эффективным использованием памяти и низкой степенью сложности, описанного в настоящей заявке. В частности, кодер 20 видеоданных и/или декодер 26 видеоданных могут включать в себя соответственно кодер статистического кода и декодер статистического кода, которые применяют по меньшей мере некоторые из таких способов уменьшения используемого объема памяти, избыточной обработки, сложности обработки, степени занятия полосы пропускания, области хранения данных и/или энергопотребления.
На фиг.2 приведена блок-схема, иллюстрирующая пример кодера 20 видеоданных, изображенного на фиг.1. Кодер 20 видеоданных может быть выполнен, по меньшей мере частично, в виде одного или нескольких устройств на интегральной схеме, которое собирательно может называться устройством на интегральной схеме. В некоторых аспектах кодер 20 видеоданных может быть составной частью портативного устройства беспроводной связи или сервером широковещательной передачи. Кодер 20 видеоданных может выполнять внутреннее и внешнее кодирование блоков в пределах видеокадров. Внутреннее кодирование опирается на пространственное предсказание для уменьшения или исключения пространственной избыточности в видеоданных в пределах данного видеокадра. Внешнее кодирование опирается на временное предсказание для уменьшения или исключения временной избыточности в видеоданных в пределах соседних кадров видеопоследовательности. В случае внешнего кодирования кодер 20 видеоданных выполняет оценку движения для отслеживания перемещения соответствующих видеоблоков между соседними кадрами.
Как показано на фиг.2, кодер 20 видеоданных принимает текущий видеоблок 30 в пределах видеокадра, подлежащего кодированию. В примере на фиг.2 кодер 20 видеоданных содержит модуль 32 оценки движения, хранилище 34 опорных кадров, модуль 36 компенсации движения, модуль 38 преобразования блоков, модуль 40 квантования, модуль 42 обратного квантования, модуль 44 обратного преобразования и модуль 46 статистического кодирования. Модуль 46 статистического кодирования может обращаться к одной или нескольким структурам данных, хранящимся в памяти 45, для получения данных, подходящих для кодирования. Для фильтрации блоков с целью удаления артефактов блочности может применяться циклический фильтр уменьшения блочности (не показан). Кодер 20 видеоданных также включает в себя сумматор 48 и сумматор 50. На фиг.2 показаны компоненты временного предсказания кодера 20 видеоданных для внешнего кодирования видеоблоков. Кодер 20 видеоданных может также включать в себя компоненты пространственного предсказания внутреннего кодирования некоторых видеоблоков, хотя для упрощения чертежа эти компоненты не показаны.
Модуль 32 оценки движения сравнивает видеоблок 30 с блоками в одном или нескольких соседних видеокадрах для генерации одного или нескольких векторов движения. Соседний кадр или кадры могут быть извлечены из хранилища 34 опорных кадров, которое может содержать любого типа память или запоминающее устройство для хранения видеоблоков, восстановленных из ранее закодированных блоков. Оценка движения может выполняться для блоков переменных размеров, например, 16×16, 16×8, 8×16, 8×8 или блоков меньших размеров. Модуль 32 оценки движения идентифицирует один или несколько блоков в соседних кадрах, которые в наибольшей степени совпадают с текущим видеоблоком 30, например, на основе модели "затраты-искажение", и определяет смещение между блоками в соседних кадрах и текущим видеоблоком. На этой основе модуль 32 оценки движения создает один или несколько векторов движения (MV), которые указывают величину и траекторию смещения между текущим видеоблоком 30 и одним или несколькими совпадающими блоками из опорных кадров, используемых для кодирования текущего видеоблока 30.
Векторы движения могут обладать точностью в половину или четверть пиксела, и даже более высокую точность, что позволяет кодеру 20 видеоданных отслеживать движение с более высокой точностью, чем целочисленные местоположения пикселов, и получать лучший блок предсказания. Когда используются векторы движения с долевыми значениями пикселов, в модуле 36 компенсации движения выполняются операции интерполяции. Модуль 32 оценки движения идентифицирует лучшее разбиение на блоки и вектор или векторы движения для видеоблока при помощи определенных критериев, таких как модель "затраты-искажения". Например, в случае двунаправленного предсказания можно получить нечто большее, чем вектор движения. При помощи полученных в результате разбиений на блоки и векторов движения модуль 36 компенсации движения образует видеоблок предсказания.
Кодер 20 видеоданных образует остаточный видеоблок посредством вычитания видеоблока предсказания, полученного модулем 36 компенсации движения, из первоначального, текущего видеоблока 30 в сумматоре 48. Модуль 38 преобразования блоков применяет преобразование, такое как целочисленное преобразование 4×4 или 8×8, используемое в H.264/AVC, к остаточному блоку c получением коэффициентов остаточного преобразованного блока. Модуль 40 квантования квантует коэффициенты остаточного преобразованного блока для дальнейшего уменьшения скорости передачи в битах. Модуль 46 статистического кодирования статистически кодирует квантованные коэффициенты для еще большего уменьшения скорости передачи в битах.
Модуль 46 статистического кодирования действует как блок кодирования переменной длины (VLC) для применения кодирования VLC к квантованным коэффициентам блока. В частности, модуль 46 статистического кодирования может быть выполнен с возможностью выполнения кодирования VLC коэффициентов цифровых видеоблоков с использованием способов адаптивного VLC с эффективным использованием памяти и низкой степенью сложности, как описано в настоящей заявке. Таким образом, различные процессы кодирования, описанные в настоящей заявке, могут быть выполнены в модуле 46 статистического кодирования для выполнения кодирования видеоданных. В альтернативном варианте, такой модуль 46 статистического кодирования может выполнять процессы, описанные в настоящей заявке, для кодирования любых данных, в том числе, в частности, видеоданных, данных изображения, голосовых и звуковых данных. В целом декодер 26 видеоданных выполняет обратные операции, в том числе декодирование VLC для декодирования и восстановления кодированных видеоданных, как будет описано ниже со ссылкой на фиг.3.
Модуль 42 обратного квантования и модуль 44 обратного преобразования применяют соответственно обратное квантование и обратное преобразование для восстановления остаточного блока. Сумматор 50 прибавляет восстановленный остаточный блок к блоку предсказания со скомпенсированным движением, полученному модулем 36 компенсации движения для получения восстановленного видеоблока, предназначенного для сохранения в хранилище 34 опорных кадров. Восстановленный видеоблок используется модулем 32 оценки движения и модулем 36 компенсации движения для кодирования блока в следующем видеокадре.
На фиг.3 приведена блок-схема, иллюстрирующая пример декодера 26 видеоданных. Декодер 26 видеоданных может быть выполнен, по меньшей мере частично, в виде одного или нескольких устройств на интегральных схемах, которые совместно могут называться устройством на интегральной схеме. В некоторых аспектах декодер 26 видеоданных может являться составной частью переносного устройства беспроводной связи. Декодер 26 видеосигналов может выполнять внутреннее и внешнее декодирование в пределах видеокадров. Как показано на фиг.3, декодер 26 видеоданных принимает кодированный поток битов видеоданных, который был закодирован кодером 20 видеоданных. В примере на фиг.3, декодер 26 видеоданных включает в себя модуль 52 статистического декодирования, модуль 54 компенсации движения, модуль 56 обратного квантования, модуль 58 обратного преобразования и хранилище 62 опорных кадров. Модуль 52 статистического декодирования может обращаться к одной или нескольким структурам данных, хранящимся в памяти 51, для получения данных, требуемых для кодирования. Декодер 26 видеоданных может также включать в себя циклический фильтр уменьшения блочности (не показан), который фильтрует выходной сигнал с сумматора 64. Декодер 26 видеоданных включает в себя также сумматор 64. На фиг.3 приведены компоненты временного предсказания декодера 26 видеоданных для внешнего декодирования видеоблоков. Декодер 26 видеоданных может также включать в себя компоненты пространственного предсказания для внутреннего декодирования некоторых видеоблоков, хотя эти компоненты на фиг.3 не показаны.
Модуль 52 статистического декодирования принимает кодированный поток битов видеоданных и декодирует из потока битов квантованные остаточные коэффициенты, режим кодирования макроблоков и информацию о движении, которая может включать в себя векторы движения и разбиение на блоки. Таким образом, модуль 52 статистического декодирования выполняет функцию блока VLC-декодирования. Например, для декодирования квантованных остаточных коэффициентов от кодированного потока битов модуль 52 статистического декодирования на фиг.3, подобно модулю 46 статистического кодирования на фиг.2, может выполнять адаптивное VLC-декодирование коэффициентов блоков цифровых видеоданных, как описано в настоящей заявке. Однако модуль 52 статистического декодирования может выполнять VLC-декодирование обратным образом относительно модуля 46 статистического кодирования на фиг.2 для извлечения квантованных коэффициентов блоков из кодированного потока битов. Таким образом, различные процессы декодирования, описанные в настоящей заявке, могут быть реализованы в модуле 52 статистического декодирования для выполнения декодирования видеоданных. В альтернативном варианте такой модуль 52 статистического декодирования может выполнять процессы, описанные в настоящей заявке, для декодирования любых из множества типов данных, в том числе, в частности, видеоданных, данных изображения, голосовых и звуковых данных. В любом случае результат кодирования переменной длины, выполняемого модулем 52 статистического декодирования, может быть выдан пользователю, сохранен в памяти и/или передан другому устройству или блоку обработки.
Модуль 54 компенсации движения принимает векторы движения и разбиения на блоки и один или несколько восстановленных опорных кадров из хранилища 62 опорных кадров для получения блока предсказания видеоданных. Модуль 56 обратного квантования осуществляет обратное квантование, то есть деквантование квантованных коэффициентов блока. Модуль 58 обратного преобразования применяет к этим коэффициентам обратное преобразование, например, обратное DCT или обратное 4×4 или 8×8 целочисленное преобразование для получения остаточных блоков. Блоки предсказания видеоданных затем суммируются сумматором 64 с остаточными блоками для формирования декодированных блоков. Может применяться фильтр уменьшения блочности (не показан) для фильтрования декодированных блоков с целью удаления артефактов блочности. Затем фильтрованные блоки помещают в хранилище 62 опорных кадров, которое обеспечивает опорные кадры для декодирования последующих видеокадров и также создает декодированные видеоданные для управления устройством 28 отображения (фиг.1)
Кодирование с эффективным использованием памяти кодов переменной длины
В соответствии с первым общим аспектом изобретения далее подробно описывается способ, обеспечивающий эффективное использование памяти, для кодирования с переменной длиной для поддержки компактных структур данных. Этот способ не должен обязательно опираться на какую-либо определенную схему построения кода, такую как коды Хаффмана, Шеннона, Шеннона-Фано, Гильберта-Мура или другие коды. Этот способ предполагает, однако, что код строится для источника с монотонно возрастающими вероятностями символов. Более конкретно, предполагается, что кодовые слова имеют монотонно убывающие (или по крайней мере не возрастающие) длины и что кодовые слова одинаковой длины имеют тот же лексикографический порядок, что и символы во входном алфавите, который они представляют.
Этот способ при применении к кодированию видеоданных или в других областях применения использует вышеуказанные свойства для уникального описания такого кода с очень компактной структурой данных. Как описано выше, структура данных может содержать, для каждой допустимой длины кодового слова, то есть для уровня с внешними узлами на кодовом дереве, следующую информацию:
a) частное значение лексикографически наименьшего (или наибольшего) кодового слова на текущем уровне кодового дерева,
b) число битов в частичном значении,
c) значение символа, соответствующего лексикографически наименьшему (или наибольшему) кодовому слову, и
d) показатель, который указывает декодеру пропустить определенное число битов перед переходом к следующему уровню кодового дерева.
Процессы кодирования и декодирования могут использовать эту структуру для идентификации уровня кодового дерева, соответствующего кодовому слову, которое требуется получить (или декодировать), и затем непосредственно вычислить значение кодового слова (или декодированного символа).
Этот способ может позволить использование значительно меньшего объема памяти для кодирования и декодирования благодаря тому, что сохраняются только частичные значения лексикографически наименьших кодовых слов. Структура данных может относиться к любым из множества известных структур данных, таких как таблицы, связные списки, двоичные деревья, базисные деревья, бесструктурные файлы или тому подобное, и может храниться в любом из множества различных запоминающих устройств, таких как оперативная память (RAM), постоянная память (ROM), или и то, и другое одновременно. Структура данных может храниться в такой памяти внутри кодера или декодера, например, в памяти 45 или в памяти 51, приведенных соответственно на фиг.2 и 3, и в этом случае по меньшей мере некоторые из уровней дерева кодирования включают в себя кодовые слова, расположенные в лексикографическом порядке относительно порядка значений символов, представленных кодовыми словами. Соответственно, каждое из базовых кодовых слов является лексикографически наименьшим кодовым словом на соответствующем уровне дерева кодирования. Кроме того, этот способ разрешает использование поэтапного доступа к данным в потоке битов, вследствие чего буфер потока битов может быть представлен разумно коротким регистром. Например, может быть достаточно 32-битового регистра даже для очень длинных кодов. Регистр может обновляться через удобно подобранные интервалы (например, через 8 битов), что еще более снижает сложность реализации. В целом этот способ, в различных своих аспектах, может позволить значительно уменьшить сложность представления и кодирования/декодирования кодов переменной длины, что может позволить разработчикам алгоритмов сжатия использовать большие, более эффективные кодовые книги.
Теперь будет дано общее представление о кодах переменной длины с тем, чтобы способствовать иллюстрации способов, описанных в настоящей заявке. Коды переменной длины представляют собой фундаментальный инструмент в области сжатия данных. В целом коды переменной длины используются для представления последовательности символов с некоторым известным и обычно крайне несбалансированным распределением. Такие последовательности могут быть представлены двоичными последовательностями, или кодами, значительно меньшей длины. Сокращение длины обеспечивается заменой более часто встречающихся символов на более короткие коды, а менее частных символов на более длинные коды.
Примерами кодов переменной длины, используемых для сжатия данных, являются коды Хаффмана, например, описанные в работе D.A. Huffman. A method of the construction of mminimum-redundancy codes. Proc. IRE, vol.40, pp.1098-1101. Sept. 1952, коды Шеннона, например, описанные в работе C.E. Shannon, A mathematical theory of communication, Bell Syst. Tech J. Vol. 27. pp. 379-423, July 1948, коды Шеннона-Фано, например, описанные в работе М R. Fano, The transmission of information, Res. Lab. Electronics, Massachusetts Inst. of Technology, Cambridge, Mass. Tech, Rep. No. 65, 1949, и коды Гилберта-Мура, например, описанные в работе E. N. Gilbert и E. F. Moore, Variable-Length Binary Encoding, Bell. Syst. Tech. J., Vol. 7, pp. 932-967, 1959 (иногда также называемые кодами Шеннона-Фано-Элиаса).
Описанные выше коды принадлежат к классу беспрефиксных кодов, например, как описано в работе T. Cover and J. Томас, Element of Information Theory, Wiley, 1991. На фиг.4 приведена схема, иллюстрирующая пример двоичного дерева. Описанные выше коды удобно представить в виде двоичного дерева, такого как изображенное на фиг.4. Таким образом, кодер может кодировать значения символов в соответствии с деревом кодирования. Значения согласно дереву могут представлять любое из множества данных, таких как видеоданные, данные изображения, голосовые или звуковые данные. Каждый внутренний узел в таком дереве соответствует двоичному символу, значение которого, равное 0, вызывает шаг вправо, а значение, равное 1, вызывает шаг влево к дочернему узлу в дереве. Самый верхний узел называют корневым узлом, и он является узлом, с которого начинается кодирование/декодирование.
Каждый внешний узел в дереве является узлом, где процесс кодирования/декодирования возобновляется, в результате чего получается либо слово, то есть последовательность битов от корневого узла до текущего узла, либо декодированное значение символа, связанного с текущим кодовым словом. В примере дерева кодирования, приведенном на фиг.4, имеется шестнадцать кодовых слов, соответствующих символам, проиндексированным от 0 до 15. В этом примере самое короткое кодовое слово имеет длину 1 бит, а самые длинные кодовые слова имеют длины 10 бит каждое. Число уровней, содержащих внешние узлы (кодовые слова), в этом дереве равно 7, а именно, 1-й, 3-й, 4-й, 6-й, 7-й, 9-й и 10-й уровни.
Как далее показано на фиг.4, пусть n обозначает число внешних узлов в дереве кодирования (и, соответственно, число кодовых слов в коде), пусть L обозначает длину самого длинного кодового слова, и пусть K обозначает число уровней, заполненных внешними узлами в дереве кодирования. В дальнейшем рассмотрении используется обозначение "О-большое", введенное П. Бахманом. Например, выражение y(n) = O(x(n)) означает наличие некоторой постоянной M>0, так что y()≤М|x(n)| для всех достаточно больших n.
Для поддержки процесса кодирования кодер и декодер, такие как модуль 46 статистического кодирования и модуль 52 статистического декодирования, вообще говоря, должны хранить двоичное дерево в памяти компьютера, такой как память 45 или память 51. Кроме того, процессы кодирования и декодирования должны включать в себя побитовый (то есть поузельный) обход дерева кодирования, хранящегося в памяти. Следовательно, для такой реализации затраты на хранение должны составлять O(n), а число шагов может составлять до O(L). Однако, в некоторых специальных случаях, когда деревья кодирования имеют некоторую особую структуру, могут существовать более эффективные способы хранения таких структур кодов и выполнения операций кодирования или декодирования.
Например, рассматривая код, представленный в примере дерева кодирования на фиг.4, можно заметить, что длина кодовых слов не уменьшается и что все кодовые слова на одном уровне дерева кодирования имеют смежные значения. Например, кодовые слова на 4-м уровне дерева на фиг.4 имеют большую длину, чем кодовые слова на 3-м уровне дерева, а именно 0001 по сравнению с 011, 010, 001 и 000. Кроме того, кодовые слова на 3-м уровне имеют смежные значения 011, 010, 011, 000. Следовательно, вместо того чтобы хранить все коды, может быть достаточно хранить только наименьшее или наибольшее кодовое слово для каждого уровня дерева кодирования, то есть в качестве базового кодового слова, из которого можно вычислить все соседние кодовые слова.
Вышеуказанное наблюдение является ключом к пониманию способов декодирования кодов переменной длины на основе их преобразования в так называемый канонический вид, например, как описано в работе A. Moffat and A. Turpin, On the Implementation of Minimum-Redundancy Prefix Codes, IEEE Trans. Communications, 45 (10) (1997) 1200-1207. Если говорить простыми словами, канонический код имеет неубывающее распределение длин и поддерживает лексикографический заказ в отношении индексов, присвоенных его узлам. Довольно просто показать, что любой данный источник можно переупорядочить таким образом, что результирующий код будет иметь вышеуказанные свойства.
Например, код, приведенный в дереве кодирования на фиг.4, представляет собой переупорядоченный код для источника с немонотонным распределением, как показано ниже в Таблице 1. В частности, Таблица 1 служит примером канонического кода переменной длины, который был переупорядочен.
Пример канонического кода переменной длины
В приведенной выше таблице 1 символ 0 имеет самую высокую вероятность, за ним идут символы 1 и 2. Однако символ 3 имеет более низкую вероятность, чем 4, а 4 и 8 имеют такую же вероятность, что и 1 и 2. После переупорядочения все вероятности символов монотонно возрастают (не убывают) и приводят к каноническому коду, представленному деревом кодирования на фиг.4. Так называемый алгоритм Моффата-Турпина, описанный в работе A. Moffat and A. Turpin, On the Implementation of Minimum-Redundancy Prefix Codes, IEEE Trans. Communications, 45 (10) (1997) 1200-1207, дает метод декодирования канонических кодов. Способы, описанные в настоящей заявке, могут обеспечить усовершенствование алгоритма Моффата-Турпина. Другие алгоритмы, такие как описанные в работах J. B. Connell, A Huffman-Shannon-Fano Code, Proc. IEEE, July 1973, 1046-1047, и A. Brodnik and S. Carlsson, Sub linear Decoding of Huffman Codes Almost in Place, DIMACS Workshop on Codes and Trees: Algorithmic and information Theoretic Approaches, October 1998, Rutgers University, DIMACS Center, NJ, подобны алгоритму Моффата-Турпина, и их также можно улучшить посредством использования раскрытых способов аналогичным образом.
Алгоритм Моффата-Турпина для декодирования кодов переменной длины описан ниже. Предположим, что входной алфавит A содержит n букв A={α0,…αn-1}, применяется переупорядочение i:A→{0,…,n-1}, так что результирующие вероятности удовлетворяют условию: p0≤p1≤…≤pn-1. Затем может быть применен алгоритм Хаффмана или другой алгоритм построения минимальной избыточности, который присваивает длины кодовых слов li каждому индексу 1≤i≤L, где L - длина самого длинного кодового слова. В результате получаются "числа заполнения" m1, то есть число кодовых слов длины l.
При помощи этих параметров вычисляются так называемые "базовые" значения для каждого уровня в дереве по следующей формуле:
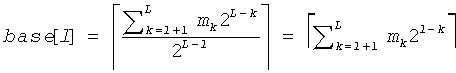 , (1≤l≤L)
, (1≤l≤L)
Эти базовые значения кодовых слов представляют лексикографически наименьшие канонические кодовые слова на каждом уровне дерева. Зная базовое значение кодового слова base[l], можно теперь вычислить j+1-го кодового слова среди ml кодовых слов длины l:
base[l]+j.
Для работы декодера удобнее хранить выровненный влево вариант базового значения кодового слова:
lj_base[l]=base[l]2W-l,
где W - длина битового буфера или регистра, используемого для хранения самых последних загруженных битов из потока битов. Предполагается, что W≥L.
Наконец, помимо базовых значений кодовых слов декодер Моффата-Турпина хранит также индексы соответствующих символов в переупорядоченном массиве. Эти индексы хранятся в виде значений смещения [l] для каждого заполненного уровня в дереве. Пример полной структуры, поддерживаемой алгоритмом Моффата-Турпина для кода, представленного деревом на фиг.4, приведен ниже в таблице 2.
Структура декодера Моффата-Турпина для кода на фиг.4
Пример псевдокода для реализации алгоритма декодирования Моффата-Турпина, использующего структуру из таблицы 2, представлен ниже в таблице 3.
Алгоритм декодирования Моффата-Турпина
((V-base[i])>>(W-l));
Из вышеприведенной таблицы 3 можно видеть, что весь процесс декодирования включает в себя до K (W-битовых) сравнений текущего буфера потока битов с выровненными влево значениями базовых кодовых слов, после чего следует простое прямое вычисление индекса декодированного символа. Можно также видеть, что массив lj_base[], используемый такой структурой, требует O(K·W) битов памяти, что могло бы быть проблемой, если бы кодовое слово было длинным, поскольку W должно использоваться таким образом, чтобы W≥1.
В примере из таблицы 3 декодер принимает W битов из потока битов и в качестве V и сравнивает V с базовыми кодовыми словами (lj_base[i]) для последующих уровней i дерева кодирования. Когда установлено, что базовое кодовое слово меньше или равно V, поиск уровня кодового слова прекращается. Затем декодер определяет длину, связанную с уровнем i, прокручивает поток битов на l бит и декодирует символ. В частности, декодированный символ определяется суммой значения смещения для уровня i и разностью между кодовым словом V из потока данных и базовым кодовым словом для уровня i, смещенного вправо на W-I битов.
В общем случае реализации декодирования Моффата-Турпина обратное отображение представляет собой: i-1: {0,…,n-1} → A. В этом случае последняя операция становится самой затратной по памяти, поскольку она требует область размером O(n). Однако во многих встречающихся на практике случаях, таких как ситуации, включающие в себя последовательное кодирование или выдачу преобразований или прогностических параметров, источники, подлежащие кодированию, уже являются упорядоченными. Следовательно, память, используемая массивом lj_base[] в структуре Моффата-Турпина, становится основным фактором в общих затратах на хранение.
В соответствии с первым общим аспектом способы, раскрытые в настоящем описании, обеспечивают усовершенствования, которые позволяют еще большее сжатие структур данных, используемых в алгоритме Моффата-Турпина или в других алгоритмах, и поддерживают поэтапное кодирование кодов переменной длины. Теперь рассмотрим эти усовершенствования более подробно. Из таблицы 2 с очевидностью следует, что значения lj_base[l] имеют большое число начальных битов, если смотреть справа налево. Следовательно, частичные значения базовых кодовых слов представляют собой удаление фиксированного числа начальных битов из базовых кодовых слов. В большинстве случаев удаляемые начальные биты являются нулями. Такое число нулей монотонно возрастает по мере расширения дерева кодирования на более глубокие уровни. Таким образом, если биты последовательно декодируются, начинаясь с самого первого уровня дерева кодирования и перемещения вниз, то можно пропустить несколько начальных нулевых битов без какого-либо влияния на правильность декодирования. Пропуск по меньшей мере нескольких начальных нулей в способах, описанных в настоящей заявке, позволяет получить сильно сжатые структуры данных и поэтапное декодирование кодов переменной длины.
Возможно, однако, что после удаления начальных битов некоторые законные коды на нижних уровнях дерева кодирования могут зайти в область удаленных начальных битов. Соответственно, чтобы не допустить потери таких кодов, предусмотрена таблица показателей пропуска. Показатель пропуска указывает декодеру пропустить несколько битов в потоке битов, который будет декодирован перед переходом к выбранному уровню дерева кодирования. В частности, показатель пропуска может указывать декодеру пропускать фиксированное число битов, например, 8 битов, в потоке битов кодовых слов перед переходом к выбранному уровню дерева кодирования. Таким образом, частичное значение базового кодового слова на выбранном уровне дерева основано на частичном смещении базового кодового слова на фиксированное число битов. Без этого сдвига базовое кодовое слово на выбранном уровне дерева распространится, по меньшей мере частично, на удаленное число начальных битов.
Нижеприведенная таблица 4 иллюстрирует пример реализации процесса кодирования, в котором удалены начальные нули, в соответствии с одним аспектом настоящего изобретения, для дальнейшего сжатия структуры данных, используемой для представления и обработки кодовых слов. В примере таблицы 4 начальные нули удаляются с шагом, равным 8, что удобно для управления буфером потока битов в обычных 8-битовых/байтовых компьютерах. Для управления удалением начальных нулей предусмотрена, как указано выше, дополнительная таблица показателей (skip_8[i]). Таким образом, таблица 4 в целом соответствует таблице 2, но в ней удалены начальные нули из каждого кодового слова и добавлен столбец с показателем пропуска.
Модифицированная структура декодирования Моффата-Турпина
В примере таблицы 4 значение r_lj_base(i) представляет значение базового кодового слова в каждом положении индекса, значение r_level[i] указывает уровень внутри дерева кодирования для положения индекса и длину кодовых слов на этом уровне, значение offset[i] указывает число начальных нулей справа налево для значения базового кодового слова, а значение skip_8[i] указывает, должен ли декодер пропустить 8 битов для получения следующего значения базового кодового слова, причем 1 обозначает пропуск, а 0 обозначает отсутствие пропуска. Эта операция пропуска периодически обновляет буфер битов через выбранные интервалы, что позволяет декодеру идентифицировать кодовые слова, которые в противном случае были бы потеряны после удаления начальных нулей. Например, если удаляются самые правые восемь начальных нолей выровненного влево кодового слова, кодовое слово, которое распространяется на самые правые восемь битов, было бы частично или полностью потеряно. Соответственно, пропуск самых левых восьми битов в ответ на показатель пропуска переместит кодовое слово в область не удаленных битов, тем самым сохраняя кодовое слово для декодирования.
Следовательно, индикатор пропуска сигнализирует, когда декодер должен сделать пропуск вперед на заданный шаг пропуска для следующего уровня кода, то есть на 8 в данном примере таблицы 4. Например, в таблице 2 значения базовых кодовых слов положениях индекса 5 и 6 (уровни дерева 9 и 10) равны соответственно 0000000010000000 и 0000000000000000, соответственно. После удаления самых правых восьми начальных нулей (выровненных влево) из этих значений базовых кодовых слов, необходимо, чтобы декодер перескочил вперед на восемь битов, так чтобы фактическое значение базового кодового слова (0000000010000000) не было потеряно при удалении восьми начальных нулей. Вместо этого фактическое значение базового кодового слова (0000000010000000) преобразуется в другое значение базового кодового слова (10000000) путем пропуска первых восьми битов (00000000) и последующего удаления самых правых восьми начальных нулей.
Из-за удаления начальных нулей ширина модифицированного массива lj_base[i] получается намного меньше. Например, в коде в таблице 4 ширина W модифицированного массива lj_base[i] W=8, вместо W=16 в случае таблицы 2. Пример реализации алгоритма, который использует такую дополнительную таблицу пропусков для периодического обновления буфера битов, приведен ниже в таблице 5. Алгоритм, построенный так, как показано в таблице 5, может быть выполнен с возможностью поддержки очень длинных кодовых слов и очень компактных таблиц значений (lj_base) базовых кодовых слов.
Модифицированный алгоритм декодера Моффата-Турпина
(W-l));
Как показано в таблице 5, декодер получает последние W битов из потока битов, представленного значением V = bitstream_buffer. Затем декодер ищет уровни i дерева кодирования для значения lj_base[i] базового кодового слова, которое меньше или равно кодовому слову V из буфера потока битов. Если текущий уровень i дерева соответствует уровню пропуска (skip_B[i]), например, как показано в таблице 5, то декодер прокручивает поток битов вправо на B битов, например, на 8 битов в некотором варианте выполнения, так чтобы кодовое слово на следующем уровне, на который ищет декодер, можно было сохранить, а не потерять при удалении B самых правых начальных битов.
После определения остаточной длины l = level[i] для кодовых слов на текущем уровне дерева, например, как указано в таблице 5, декодер прокручивает поток битов на длину l. Затем декодер непосредственно вычисляет индекс символа на основе суммы смещения для текущего уровня i и разницы между содержимым V буфера потока данных и базовым кодовым словом для текущего уровня i, смещенного вправо на W-I битов.
Декодер декодирует кодовое слово из потока битов кодового слова при помощи хранящейся структуры данных, задающей частичные значения для базовых кодовых слов, показателя пропуска, значений, представленных базовым кодовым словом, и длин (а именно, числом битов) частичных значений в базовых кодовых словах. В целом процессор, связанный с декодером, таким как модуль 52 статистического декодирования, ищет уровни дерева кодирования выбранного одного из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову из потока битов кодового слова. Процессор пропускает несколько битов в потоке битов кодового слова перед переходом к выбранному уровню дерева кодирования в ответ на показатель пропуска и вычисляет одно из множества значений, соответствующих кодовому слову, на основе разности между выбранным из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову, и кодовым словом и индексом выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову. Процессор генерирует результат декодирования для сохранения в памяти, передачи другому устройству или обрабатывающему модулю либо представления пользователю. Например, декодированные результаты можно использовать для управления устройством 28 отображения, чтобы оно представляло видео или неподвижное изображение, и/или устройством вывода звука, чтобы оно воспроизводило звук или речь.
В примере в таблице 5 декодер выполняет пошаговое обновление буфера потока битов посредством операции пропуска для сохранения кодовых слов, которые в противном случае были бы потеряны после удаления начальных нулей. Кроме того, значения базовых кодовых слов, которые декодер сравнивает на каждом уровне кода, могут быть значительно короче. Ниже рассматривается потенциальный объем сокращения длины значения базовых кодовых слов. Для анализа динамического диапазона таких величин в модифицированном алгоритме, описанном в настоящей заявке, разность между двумя соседними уровнями определяется из следующей формулы:
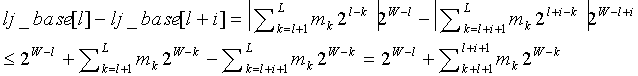
Если i - индекс следующего непустого уровня, то:
lj_base[l]- lj_base[l+i]=2W-l+ml+i2W-(l+i).
Здесь основная величина, представляющая интерес: ml+i2-i, которая влияет на эту разность. В простейшем случае, когда i=1, ясно, что эта разность просто зависит от числа внешних узлов, и, значит, W можно выбрать таким образом, что:
W ≥ max log2(ml),
и эта величина в случаях, представляющих интерес на практике, значительно меньше L. Эта разность должна быть особенно большой для крайне несбалансированных распределений.
Например, если входные символы представляют собой блоки из m битов с Бернуллиевыми вероятностями pm(1-p)m-k, то наиболее заполненный уровень должен содержать приблизительно 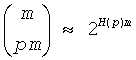 кодовых слов, а это значит, что требуется использовать приблизительно H(p)m битов, чтобы различить кодовые слова, где H(p) - функция энтропии, например, описанная в работе T. Cover and J. Thomas, Elements of Information Theory, Wiley, 1991.
кодовых слов, а это значит, что требуется использовать приблизительно H(p)m битов, чтобы различить кодовые слова, где H(p) - функция энтропии, например, описанная в работе T. Cover and J. Thomas, Elements of Information Theory, Wiley, 1991.
С другой стороны, самое длинное кодовое слово в этом случае будет иметь приблизительно 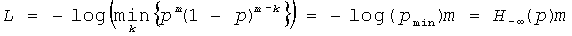 битов, причем известно, что для асимметричных распределений
битов, причем известно, что для асимметричных распределений
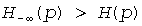 ,
,
где 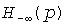 - специальный случай энтропии Реньи, например, описанный в работе W. Szpankowski, Average Case Analysis of Algorithms on Sequences. (New York, John Wiley & Sons, 2001). Эта разность может быть произвольно большой при p → 0 или p → 1.
- специальный случай энтропии Реньи, например, описанный в работе W. Szpankowski, Average Case Analysis of Algorithms on Sequences. (New York, John Wiley & Sons, 2001). Эта разность может быть произвольно большой при p → 0 или p → 1.
Из вышеприведенного рассмотрения следует, что предложенный способ должен быть эффективным при обработке больших, асимметричных структур кодов. С такими структурами традиционно трудно работать при помощи традиционных/существующих способов, и во многих случаях инженеры прибегают к упрощениям, которые влияют на эффективность сжатия кодов, чтобы сделать их более практичными.
Например, очень популярные коды Голомба, описанные, например, в работах S. Golomb, "Run-length coding," IEEE Trans. Inform. Theory, vol. IT-12, pp. 399-401, July 1966, и R. Gallager and D. van Voorhis, "Optimal source codes for geometrically distributed integer alphabets," IEEE Trans. Inform. Theory, vol. IT-21, pp. 228-230, Mar. 1975, представляют собой коды переменной длины с особенно простой структурой, но они являются оптимальными только для одного класса геометрических распределений и только для счетного числа значений параметров таких распределений. Инженеры стремятся использовать их даже для существенно отличающихся распределений, мотивируя это главным образом соображениями сложности. Такие решения могут стать одновременно не вполне оптимальными и трудными для расширения или изменения из-за присущих для таких кодов ограничений эффективности.
Другое решение, связанное с конструкцией кодов Линча-Дэвиссона, описанной в работах T. J. Lynch, Sequence time coding for data compression, Proc. IEEE (Lett.), 54 (1966) 1490-1491, и L. D. Davisson, Comments on Sequence time coding for data compression, Proc. IEEE (Lett.), 54 (1966) 2010-2011, заключается в том, чтобы расщепить коды на две части, причем только первая подвергается кодированию переменной длины, а другая передается в качестве расширения с использованием фиксированного числа битов. К сожалению, при таком расщеплении теряется эффективность, причем потеря иногда достигает 1,5-2 бита на символ.
Был разработан более изощренный вариант способа расщепления кодовой книги, получивший название алфавитного группирования, описанного, например, в работах Boris Ryabko, Jaakko Astola, Karen Egiazarian, Fast Codes for Large Alphabets, Communications in Information and Systems, v.3, n. 2, pp.139-152, и Boris Ryabko, Jorma Rissanen, Fast Adaptive Arithmetic Code for Large Alphabet Sources with Asymmetrical Distributions, IEEE Communications Letters, v. 7, no. 1, 2003, pp.33-35. Однако этот подход также реализуется за счет некоторой потери в эффективности сжатия.
В отличие от вышеуказанных способов способы, описанные в настоящей заявке, могут быть выполнены с возможностью полного сохранения структуры и оптимальности кода и потому могут быть полезны для широкого круга практических применений в области сжатия и кодирования данных, например, при кодировании и декодировании цифровых видеоданных, данных изображения, звуковых и голосовых данных.
Двоичное адаптивное блочное кодирование
Далее подробно описывается пример обладающего низкой степенью сложности способа адаптивного кодирования переменной длины для двоичных последовательностей, созданных источниками без памяти, в соответствии со вторым общим аспектом настоящего изобретения. Этот раскрытый способ может реализовывать универсальные блочные коды, построенные для набора контекстов, идентифицируемых числом ненулевых битов в предыдущих битах в последовательности. Этот второй общий аспект изобретения может быть осуществлен или предоставлен независимо или в сочетании с первым общим аспектом, описанным выше в отношении генерации очень компактных структур данных. Структуры данных могут относиться к широкому кругу структур данных, таких как таблицы, связанные списки, двоичные деревья, базисные деревья, бесструктурные файлы или тому подобное, и могут храниться в любом из множества различных запоминающих устройств, таких как многие виды оперативного запоминающего устройства (RAM), постоянного запоминающего устройства (ROM), или и того и другого. Структура данных может храниться в такой памяти в пределах кодера или декодера. В соответствии с этим вторым общим аспектом способ для обладающего пониженной степенью сложности адаптивного кодирования и декодирования может опираться, по меньшей мере частично, на формулу для асимптотической избыточности таких кодов, которая уточняет оценку, описанную в работе R. E. Krichevsky and V. K. Trofimov, The Performance of Universal Encoding, IEEE Trans. Information Theory, 27 (1981) 199-207.
Алгоритмы сжатия данных преобразуют входные последовательности битов, имеющие некоторое неизвестное распределение, в декодируемый поток битов. Сжатие данных используется, например, при разработке кодеров данных изображений и видеоданных, в масштабируемом (на основе секционирования) кодировании спектра в аудиокодерах и в других областях применения. В большинстве таких случаев биты, подлежащие кодированию, берутся из значений, созданных различными инструментами обработки сигналов, такими как преобразования, фильтры с предсказанием и т.п., а это значит, что они уже декоррелированы, и что предположение об отсутствии памяти у такого источника является оправданным.
Наиболее часто используемые варианты реализации таких двоичных адаптивных алгоритмов обычно основаны на арифметических кодах с использованием некоторых приближений и сокращений для уменьшения их сложности. Два известных примера таких алгоритмов - это алгоритм Q-кодера, описанный в работе W. B. Pennebaker, J. L. Mitchell, G. G. Langdon, Jr., R. B. Arps, An overview of the basic principles of the Q-Coder adaptive binary arithmetic coder, IBM J. Res. Dev., 32 (6) (1988) 717, который используется в стандарте кодирования изображений JBIG, или алгоритм CABAC, описанный в D. Marpe, H. Schwartz, and T. Wiegand, Context-Based Adaptive Binary Arithmetic Coding in the H.264/ AVC video compression standard, IEEE Trans, on CSVT, 13(7):620 636, July 2003, который используется в стандартах для сжатия видеоданных ITU-T H.264/MPEG AVC.
В соответствии с этим вторым общим аспектом изобретения в альтернативном варианте выполнения используется массив кодов Хаффмана, предназначенный для нескольких оцененных плотностей и индексированный числом ненулевых битов в предыдущих блоках (контекстах) в последовательности. С точки зрения как эффективности, так и реализации, такой способ может обеспечивать требуемые характеристики сжатия при использовании даже блоков битов умеренных размеров, например, n=8…16, и при использовании соответствующих объемов памяти, например, от 1,5 килобайтов до 5 килобайтов.
Этот способ можно рассматривать в контексте источника без памяти, создающего символы из двоичного алфавита {0,1} с вероятностями соответственно p и q=1-p. Если w - слово с длиной n, созданное этим источником, то его вероятность:
Pr(w)=pkqn-k, (1)
где k обозначает число единиц в этом слове. Значение k может также называться весом w.
Блочный код ϕ представляет собой инъективное отображение между словами w длины |w|=n и двоичными последовательностями (или кодовыми словами) ϕ(w):
ϕ:{0,1}n→{0,1}*,
где кодовые слова ϕ(w) представляют собой уникально декодируемый набор, как описано, например, в работе T. M. Cover and J. M. Thomas, Elements of Information Theory, (John Wiley & Sons, New York, 1991).
Как правило, когда источник (то есть его вероятность p) известен, такой код предназначен для минимизации его средней длины или, в относительных терминах, его средней избыточности:
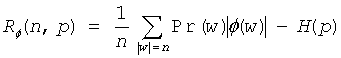 .
.
В вышеприведенной формуле H(p)=-plogp - qlogq обозначает энтропию источника.
Классические примеры кодов и алгоритмов, предлагаемых для решения этой задачи, включают в себя коды Хаффмана, Шеннона, Шеннона-Фано и Гилберта-Мура и их варианты. Характеристики таких кодов хорошо изучены, многие полезные для практического применения способы реализации таких кодов известны из литературы.
Когда источник неизвестен, наилучший доступный вариант заключается в конструировании универсального кода ϕ*, который минимизирует избыточность для худшего случая для некоторого класса источников, как, например, описано в работах B. M. Fitingof, Optimal Coding in the Case of Unknown and Changing Message Statistics, Probl. Inform. Transm., 2, (2) (1965) 3 {11 (in Russian) 1-7 (English Transl.), L. D. Davisson, Universal Noiseless Coding, IEEE Trans. Inform. Theory, 19 (6) (1973), 783-795, и R. E. Krichevsky and V. K. Trofimov, The Performance of Universal Encoding, IEEE Trans. Information Theory, 27 (1981) 199-207, и как указано ниже:
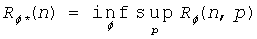 .
.
Пример такого кода может быть построен c использованием следующих оценок вероятностей слов:
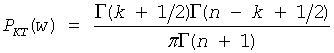 ,
,
где Γ(x) - Γ-функция, k - вес слова w и n - его длина. Вышеприведенная формула описана в работе R. E. Krichevsky and V. K. Trofimov, The Performance of Universal Encoding, IEEE Trans. Information Theory, 27 (1981) 199-207, и обеспечивает равномерную (по ρ) сходимость к истинным вероятностям по мере приближения n к бесконечности (n→∞).
В ситуации, когда точное значение параметра источника неизвестно, можно обратиться к последовательности символов u, созданной тем же источником в прошлом. Такая последовательность может называться выборкой, и ее длина может предполагаться равной |u|=t битов. Задача здесь состоит в том, чтобы сконструировать набор кодов ϕ* u, индексированных различными значениями этой выборки так, чтобы их результирующая средняя избыточность для худшего случая была минимальной, как показано ниже:
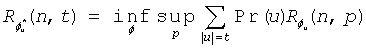 .
.
Такие коды называют основанными на выборке, или адаптивными, универсальными блочными кодами. В настоящей заявке описаны частные варианты осуществления адаптивных блочных кодов с использованием следующих оценок вероятности слов w данной выборки u:
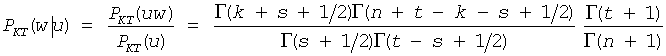 (1)
(1)
где s - вес выборки u, а t - ее длина.
Понятие и анализ основанных на выборке кодов, использующих функцию оценок (1), приведенную выше, описано в работе R. E. Krichevsky in R. E. Krichevsky, Universal Data Compression and Retrieval. (Kluwer, Norwell, MA, 1993). Асимптотически средняя степень избыточности адаптивного блочного кода равна:
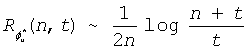 , (2)
, (2)
где n - размер блока, а t - размер выборок.
Из приведенной выше формулы (2) очевидно, что при использовании выборок длиной t=O(n) можно понизить степень избыточности таких кодов до O(1/n), что по порядку величины соответствует степени избыточности блочных кодов известных источников. Однако для понимания в полной мере потенциала таких кодов необходимо знать более точное выражение для их избыточности, в том числе члены, на которые влияет выбор фактического алгоритма построения кода, такого как код Хаффмана, Шеннона или тому подобный код.
В соответствии с этим вторым общим аспектом настоящее изобретение предлагает следующее уточнение теоремы 2 Кричевского. В частности, приведенная ниже теорема 1 уточняет теорему о средней степени избыточности для адаптивного блочного кода ϕ* u следующим образом:
Теорема 1: Средняя степень избыточности адаптивного блочного кода ϕ* u имеет следующее асимптотическое поведение (n, t → ∞):
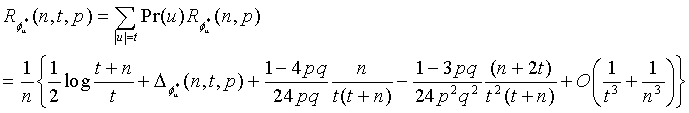
(3А)
где n - размер блока, и t - размер выборки, p, q=1-p - вероятности символов входного источника, и где:
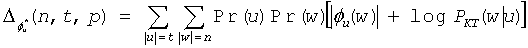
средняя избыточность кода ϕ* u относительно оцененного распределения в формуле (1).
Точное поведение величины  зависит от алгоритма. Однако для большого класса способов обеспечения минимальной избыточности, который включает в себя традиционные коды Хаффмана и Шеннона, величина этого члена ограничена следующим условием:
зависит от алгоритма. Однако для большого класса способов обеспечения минимальной избыточности, который включает в себя традиционные коды Хаффмана и Шеннона, величина этого члена ограничена следующим условием:
 ,
,
и характеризуется колебательным поведением, которое может сходиться или не сходиться к некоторой постоянной величине в зависимости от значения параметра p. Кроме того, для малых значений t и n на избыточность таких кодов может влиять следующий член:
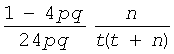
который является функцией параметра источника p. На фиг.5 приведен график, иллюстрирующий степень избыточности адаптивного блочного кода с асимптотическим поведением. Для коротких блоков/выборок характеристики таких кодов становятся чувствительны к асимметрии источника. Доказательство этой теоремы можно найти, например, в работе Asymptotic average redundancy of adaptive block codes, Y. A. Reznik, W. Szpankowski, Proceedings of IEEE International Symposium on Information Theory (ISIT), 2003.
Далее описываются примеры эффективных алгоритмов для реализации описанных выше кодов. В модели без памяти вероятность слова w (или ее оценка) зависит только от его веса k, но не от фактической комбинации его битов. Следовательно, рассматривая множество всех возможных слов из n битов, мы можем разделить это множество на n + 1 группу:
 ,
,
содержащие слова с одинаковым весом (k = 0,…,n) и одинаковой вероятностью. Размеры таких групп равны 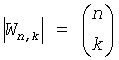 . Далее для удобства предполагается, что каждая группа Wn,k хранит слова в лексикографическом порядке. Значение In,k(w) обозначает индекс (позицию) слова w в группе Wn,k. Приведенная ниже таблица 6 служит примером кода, построенного для 4-битовых блоков с Бернуллиевыми вероятностями: pkqn-k, p=0,9.
. Далее для удобства предполагается, что каждая группа Wn,k хранит слова в лексикографическом порядке. Значение In,k(w) обозначает индекс (позицию) слова w в группе Wn,k. Приведенная ниже таблица 6 служит примером кода, построенного для 4-битовых блоков с Бернуллиевыми вероятностями: pkqn-k, p=0,9.
Пример кода, построенного для 4-битовых блоков
с Бернуллиевыми вероятностями pkqn-k, p=0,9
0001
0010
0011
0100
0101
0110
0111
1000
1001
1010
1011
1100
1101
1110
1111
1
1
2
1
2
2
3
1
2
2
3
2
3
3
4
0
1
0
2
1
2
0
3
3
4
1
5
2
3
0
0,0729
0,0729
0,0081
0,0729
0,0081
0,0081
0,0009
0,0729
0,0081
0,0081
0,0009
0,0081
0,0009
0,0009
0,0001
3
3
6
3
7
7
9
4
7
7
9
7
9
10
10
001
010
000011
011
0000001
0000010
000000001
0001
0000011
000100
000000010
0000101
000000011
0000000001
0000000000
1
1
3
1
4
4
5
2
4
4
5
4
5
6
7
Пример кода в таблице 6 будет использован для описания структуры предложенного соответствия между словами в группе Wn,k и их кодовыми словами в соответствии с некоторыми аспектами настоящего изобретения. Этот код был построен с использованием модификации алгоритма Хаффмана, в котором были выполнены дополнительные этапы, чтобы обеспечить для кодовых слов, расположенных на одном и том же уровне, тот же лексикографический порядок, что и для входных блоков, которые они представляют. Известно, что такое переупорядочение возможно без потери эффективности сжатия. Примеры известных ранее алгоритмов, которые использовали эту идею переупорядочения, включают в себя коды Хаффмана-Шеннона-Фано и канонические коды, описанные Моффатом и Турпином.
На фиг.6 приведена схема с изображением дерева кодирования, которое отображает структуру примера блочного кода, приведенного в таблице 6. Как и следовало ожидать, каждая группа Wn,k состоит максимум из двух подгрупп, содержащих кодовые слова одинаковой длины. В целом кодовая структура, представленная деревом кодирования на фиг.6 и блочными кодами из таблицы 6, определяет группы кодовых слов и первую и вторую подгруппы кодовых слов внутри каждой из групп. Каждая из групп включает в себя кодовые слова, представляющие значения с одинаковыми весами. Первая подгруппа включает в себя кодовые слова, имеющие первую длину, а вторая подгруппа включает в себя кодовые слова, имеющие вторую длину, отличную от первой длины. Кодовые слова в каждой из групп упорядочены в лексикографическом порядке относительно значений, представленных кодовыми словами, для облегчения кодирования и декодирования прямым вычислением.
Пример группы обозначен на фиг.6 номером позиции 66. Примеры первой и второй подгрупп обозначены на фиг.6 соответственно номерами позиций 68A, 68B. Аналогичные группы и подгруппы обеспечиваются для каждого веса в пределах дерева кодирования. Группа содержит блоки, имеющие одинаковый вес k. Подгруппа содержит блоки, имеющие одинаковый вес и одинаковый уровень в дереве кодирования. Это следует из того, что все слова в группе Wn,k имеют одинаковую вероятность и обладают так называемым братским свойством кодов Хаффмана. Это наблюдение сохраняет справедливость и для кодов Шеннона, обобщенных кодов Шеннона и, возможно, для других алгоритмов. Как отмечено выше, группа Wn,k включает в себя максимум две подгруппы, содержащие кодовые слова одинаковой длины, и может быть представлена в виде:
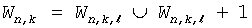 ,
,
где  - наименьшая длина кода, которая может быть присвоена блокам из группы Wn,k. Кроме того, поскольку слова в группе Wn,k следуют в лексикографическом порядке, то разделение на Wn,k,l и Wn,k,l+1 - это просто:
- наименьшая длина кода, которая может быть присвоена блокам из группы Wn,k. Кроме того, поскольку слова в группе Wn,k следуют в лексикографическом порядке, то разделение на Wn,k,l и Wn,k,l+1 - это просто:
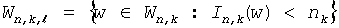 ,
,
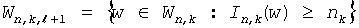 ,
,
где nk обозначает размер подгруппы с более короткими кодовыми словами. Таким образом, если в первой подгруппе три кодовых слова с длиной 3, а во второй подгруппе той же группы одно кодовое слово с длиной 4, то nk (размер подгруппы с более короткими кодовыми словами, то есть, первой подгруппа) равен 3. Этот пример соответствует подгруппам в группе, связанной с уровнями 3 и 4 дерева кодирования на фиг. 6, в котором подгруппа 68A имеет кодовые слова 001, 010 и 011, длина каждого из которых равна трем, и подгруппа 68B имеет кодовое слово 0001, длина которого равна четырем.
Лексикографически наименьшие кодовые слова в каждой подгруппе могут называться базовыми кодовыми словами, например, как описано выше в отношении первого аспекта настоящего изобретения, и могут быть представлены как:
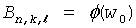 ,
,
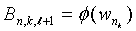 ,
,
где wi - i-й блок в группе Wn,k. Заметим, что, как указано выше, остальные кодовые слова в обеих подгруппах могут быть вычислены следующим образом:
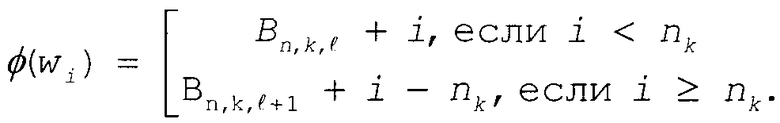
В качестве иллюстрации предположим, что имеется первая подгруппа 68A с тремя кодовыми словами длиной 3 и вторая подгруппа 68B с одним кодовым словом длиной 4, например, как в примере уровней 3 и 4 дерева кодирования на фиг.6. В этом случае, если позиция данного блока i=2, то i<nk (nk равно 3), и результирующее кодовое слово является применимым базовым словом +i. В этом примере базовое кодовое слово для подгруппы - 001, а результирующее кодовое слово - 001+2=011. Для уровней 3 и 4 дерева кодирования на фиг.6, если бы позиция применимого кодового слова была бы i≥nk, то кодовое слово было бы во второй подгруппе и было бы равно базовому кодовому слову 0000+i-nk, что равно 0000+4-3=0001.
Базовые кодовые слова определяются только непустыми подгруппами, и число таких подгрупп S в дереве, построенном для n-битовых блоков, находится в пределах:
n + 1 ≤ S ≤ 2n.
Кроме того, на одном уровне может находиться множество подгрупп, и число таких соотнесенных подгрупп не может превышать n+1. Например, на 10-м уровне дерева на фиг.6 имеются две подгруппы, соответствующие кодовым словам 1110 и 1111. Однако эти подгруппы не принадлежат к одной группе. В этом состоит существенное отличие от алгоритмов, которые присваивают уникальные базовые кодовые слова для каждого уровня, но затем для работы с такими кодами требуют большую таблицу переупорядочения размером O(n2n). В данном же случае вся структура имеет размер O (n2) битов.
В целом эта кодовая структура определяет группы W и подгруппы S. Каждая из групп включает в себя кодовые слова, представляющие значения, имеющие одинаковые веса. Кодовые слова в каждой из групп упорядочены в лексикографическом порядке относительно значений, представленных кодовыми словами. Кроме того, первая подгруппа в каждой группе включает в себя кодовые слова, имеющие первую длину, а вторая подгруппа включает в себя кодовые слова, имеющие вторую длину, отличную от первой длины. Кодовая структура может быть представлена структурой данных, к которой может обращаться кодер для выполнения кодирования переменной длины. Изобретение предусматривает применение такой кодовой структуры в кодировании или декодировании переменной длины, а также машиночитаемый носитель, содержащий структуру данных, которая определяет такую кодовую структуру.
Далее с учетом вышеприведенного рассмотрения будет описан простой алгоритм прямого вычисления блочных кодов. Предполагается, что параметры nk (0≤k≤n) доступны и что уровень l и базовое кодовое слово Bn,k,l можно получить для каждой непустой подгруппы. Тогда процесс кодирования блока w может быть выполнен по существу посредством следующих этапов:
1. При наличии блока w получить его вес k и индекс In,k(w).
2. Если In,k(w)<nk, выбрать первую подгруппу Wn,k,l; в противном случае выбрать вторую подгруппу Wn,k,l+1.
3. Затем извлечь базовое кодовое слово (Bn,k,l или Bn,k,l+1) для выбранной подгруппы (Wn,k,l или Wn,k,l+1) и вычислить соответственный код по следующей формуле:
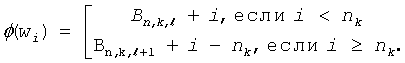 (13)
(13)
Согласно вышеприведенной формуле, если позиция i=In,k(w) блока w в выбранной подгруппе (Wn,k,l или Wn,k,l+1) меньше числа nk блоков в подгруппе, тогда кодовое слово Bn,k,l+i. Если же позиция i блока w в выбранной подгруппе (Wn,k,l или Wn,k,l+1) больше или равна числу nk блоков в подгруппе, то кодовое слово Bn,k,l+i-nk.
Как описано выше и приведено на иллюстрации для уровней 3 и 4 дерева кодирования на фиг.6, вышеуказанный процесс выдает кодовое слово 011, когда позиция данного блочного кода i=2<nk, и кодовое слово 0001, когда позиция данного блочного кода i=3≥nk. В этом примере nk равно 3, то есть числу кодовых слов в первой подгруппе 68A для веса k=1. Порядок позиции i определяется лексикографически, начиная с базового кодового слова, например, от 0 до 3 в случае веса = 1 в примере на фиг.6. В частности, позиция 0 соответствует базовому кодовому слову 001, позиция 1 соответствует кодовому слову 010, позиция 2 соответствует кодовому слову 011, все эти кодовые слова находятся в первой подгруппе 68A (i<nk), и позиция 3 соответствует кодовому слову 0001 в подгруппе 68B (i≥nk).
Этот процесс можно легко реализовать, обеспечив переупорядочение кодовых слов, расположенных на одном уровне, таким образом, чтобы они имели тот же лексикографический порядок, что входные блоки, которые они представляют. Например, вышеописанные кодовые слова следуют в лексикографическом порядке входных блоков 0001, 0010, 0100 и 1000. Затем лексикографически наименьшие кодовые слова в каждой подгруппе, например, 001 в подгруппе 68A или 0001 в подгруппе 68B можно использовать в качестве базовых кодовых слов с целью вышеописанного вычисления кодового слова. Ниже в таблице 7 приведен программный код на языке C, представляющий пример реализации описанного выше процесса прямого построения блочных кодов.
Процесс прямого построения блочных кодов
В вышеприведенном коде на языке C значение k указывает вес блока w, значение i указывает позицию In,k(w) блока внутри группы с весом k, а nk[k] указывает число кодовых слов в первой подгруппе группы с весом k. Если i больше или равно nk[k], то i уменьшается для корректировки индекса, и подгруппа устанавливается во вторую подгруппу (1) для соответствующего веса k. Эта вторая подгруппа идентифицируется посредством j=sg[k][1]. Если i меньше чем nk[k], i не уменьшается, и подгруппа устанавливается в первую подгруппу (0) для соответствующего веса k. Эта первая подгруппа идентифицирована посредством j=sg[k][0].
Затем генерируется кодовое слово в виде суммы базового кодового слова для соответствующей подгруппы j(base[j]) и значения i. В случае примера на фиг. 6, если значение i равно 2, то код представляет собой сумму базового кодового слова 001 для подгруппы 68A и значения i(2), что равно 001+010=011. Как следует из вышеприведенной формулы (13), в зависимости от подгруппы базовое кодовое слово - это либо Bn,k,l, либо Bn,k,l+1, а значение i - это либо i, либо i-nk[k]. Следовательно, вышеуказанный код в целом соответствует результату, даваемому формулой (13). После вычисления кодового слова (code), длина (len) определяется как len[j], которая является длиной кода для соответствующей подгруппы, где длина кода второй подгруппы на единицу больше длины кода первой подгруппы. Затем процесс кодирования записывает поток битов посредством операции put_bits (code, len, bs), которая записывает значение code и len в поток битов bs. Поток битов передается для декодирования другим устройством. Процесс возвращает вес k для вычисления следующего кодового слова.
Вышеизложенный процесс кодирования может включать в себя выбор одной из групп на основе веса значения, подлежащего кодированию, выбор одной из подгрупп на основе лексикографической позиции значения, подлежащего кодированию, относительно числа кодовых слов в первой подгруппе выбранной группы, выбор одного из кодовых слов в выбранной подгруппе на основе кодового слова для выбранной подгруппы и лексикографической позиции значения, подлежащего кодированию, и кодирование значения, подлежащего кодированию, при помощи выбранного кодового слова. Базовые кодовые слова для каждой из подгрупп, позиции кодовых слов внутри каждой из групп, число кодовых слов внутри каждой из первых подгрупп и длины кодовых слов внутри каждой из подгрупп могут храниться в структуре данных, к которой может обращаться кодер для поддержки кодирования переменной длины.
С точки зрения памяти процесс, приведенный в таблице 7, требует только S базовых кодовых слов (длина O(n) битов), n+1 значений nk (длина O(n) битов), S длин кода (длина O(log n) битов) и 2(n+1) индексов подгрупп (длина O(log n) битов). Возможно дополнительное сокращение памяти посредством хранения приращений базовых кодовых слов, что рассматривалось в другом месте настоящей заявки. При S=O(n) вся структура данных требует лишь O(n2) битов. В частном варианте осуществления, приведенном в таблице 7, в предположении, например, что n - 20 и S=32, размер этой структуры данных становится равным 244 байтам. Это намного меньше 220 слов, которые были бы необходимы для представления этого кода непосредственно в виде таблицы. Для разумно коротких блоков, например, для n≤12…16, вычисление весов и индексов (функции weight(.) и index(.,.) в процессе, приведенном в таблице 7), может представлять собой один-единственный поиск. В этом случае весь процесс кодирования может требовать максимум одного сравнения, двух сложений и четырех поисков.
Для блоков большего размера может использоваться следующая известная комбинаторная формула:
 ,
,
где wj представляют собой отдельные биты слова w, и предполагается, что  для всех k>n. Для реализации этой формулы можно либо заранее вычислить все биноминальные коэффициенты до уровня n в треугольнике Паскале, либо вычислять их динамически, используя следующие простые тождества:
для всех k>n. Для реализации этой формулы можно либо заранее вычислить все биноминальные коэффициенты до уровня n в треугольнике Паскале, либо вычислять их динамически, используя следующие простые тождества:
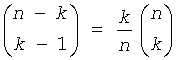 и
и 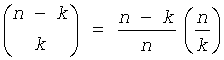 .
.
Реализация на основе заранее вычисленных коэффициентов требует 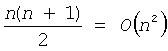 слов (O(n3) битов) памяти и O(n) сложений. Динамическое вычисление коэффициентов требует O(n) сложений, умножений и делений. Однако весь процесс может требовать лишь нескольких регистров и не требовать статистической памяти. Дополнительное обсуждение вопроса сложности вычисления индексов можно найти в работе T. Tjalkens, Implementation cost of the Huffman-Shannon-Fano code, in Proc. Data Compression Conference (DCC'05) (Snowbird, Utah, March 29-31, 2005) 123-132.
слов (O(n3) битов) памяти и O(n) сложений. Динамическое вычисление коэффициентов требует O(n) сложений, умножений и делений. Однако весь процесс может требовать лишь нескольких регистров и не требовать статистической памяти. Дополнительное обсуждение вопроса сложности вычисления индексов можно найти в работе T. Tjalkens, Implementation cost of the Huffman-Shannon-Fano code, in Proc. Data Compression Conference (DCC'05) (Snowbird, Utah, March 29-31, 2005) 123-132.
Далее описан пример конструкции декодера, реализующего вышеуказанные способы. Как и описанный выше процесс кодирования, процесс декодирования может использовать параметры nk, базовые кодовые слова и связанные с ними длины. Для удобства в нижеследующем рассмотрении используются выровненные влево варианты значений базовых кодовых слов:
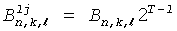 ,
,
где T - длина машинного слова (T > max l). В этом случае примерный процесс декодирования можно описать следующим образом:
1. Найти самую верхнюю подгруппу, у которой  меньше, чем T бит в потоке битов.
меньше, чем T бит в потоке битов.
2. Декодировать индекс блока In,k(w) на основе вышеприведенной формулы (13).
3. Получить восстановленный блок при помощи его веса k и индекса.
Ниже в таблице 8 приведен код на языке C, представляющий пример реализации вышеописанного процесса декодирования.
Декодирование блоков кода
Примерный процесс декодирования, приведенный в таблице 8, использует выровненные влево базовые кодовые слова lj_base[S]. В процессе работы процесс декодирования принимает содержимое val из буфера потока битов и идентифицирует подгруппу в дереве кодирования, имеющую базовое кодовое слово, соответствующее содержимому val буфера потока битов. Например, процесс продолжает пересекать, спускаясь вниз, подгруппы на различных уровнях в дереве кодирования до тех пор, пока базовые кодовые слова не станут больше принятого кодового слова. Однако когда процесс доходит до подгруппы с базовым кодовым словом, которое меньше или равно val, осуществляется выбор этой подгруппы. После нахождения соответствующей подгруппы процесс определяет длину кода для подгруппы и затем прокручивает поток битов на эту длину, чтобы перескочить декодированные биты и изолировать кодовое слово. Процесс декодирования определяет индексную позицию i кодового слова внутри подгруппы посредством вычитания значения базового кодового слова из содержимого буфера потока битов.
Если, например, кодовое слово - 011, а базовое кодовое слово - 010, то результат этой разницы равен 2, что означает, что кодовое слово находится в позиции 2 из возможных позиций 0, 1 и 2 в подгруппе. Для случая регистра шириной 32 бита эта разность может быть смещена вправо на величину 32 минус длина len кода. Затем процесс декодирования извлекает соответствующий вес k и индекс j подгруппы и восстанавливает индекс i. Процесс затем генерирует i-е слово в выбранной группе в качестве кодового слова и возвращает вес k. Выражение kj[j].j возвращает вес подгруппы, а выражение kj[j].j возвращает индекс подгруппы в виде либо 0, либо 1, что указывает либо на первую подгруппу (0), либо на вторую подгруппу (1) для данного веса. Если вторая подгруппа выбрана таким образом, что j=1, то индекс i корректируется посредством добавления значения nk[k]. Или же индекс i не корректируется, если выбрана первая подгруппа. Функция word() возвращает i-е слово в группу n,k в качестве декодированного значения слова, например, при помощи вышеприведенной формулы (13).
В целом кодер может выполнить кодирование переменной длины согласно описанной выше кодовой структуре, причем кодовая структура определяет группы и подгруппы. Повторим еще раз, что каждая из групп включает в себя кодовые слова, представляющие значения с одинаковыми весами. Кодовые слова в каждой из групп упорядочиваются в лексикографическом порядке относительно значений, представленных кодовыми словами. Кроме того, первая подгруппа в каждой группе включает в себя кодовые слова, имеющие первую длину, и вторая подгруппа включает в себя кодовые слова, имеющие вторую длину, отличную от первой длины.
Кодовая структура может быть представлена структурой данных, к которой может обращаться кодер или декодер для выполнения кодирования переменной длины. Как описано выше, структура данных может определять базовые кодовые слова для каждой из подгрупп, позиции кодовых слов внутри каждой из групп, число кодовых слов внутри каждой из первых подгрупп и длины кодовых слов внутри каждой из подгрупп. Эта структура данных может храниться в памяти, связанной с одним кодером из кодера видеоданных, кодера изображения, аудиокодера, голосового кодера, декодера видеоданнных, декодера изображения и аудиодекодера или голосового декодера, и к ней по необходимости может осуществляться обращение для поддержки операций кодирования.
Как описано выше, декодер, такой как модуль 52 статистического декодирования, может осуществлять выбор в процессе нисходящего (сверху вниз) поиска по дереву кодирования посредством выбора первой из подгрупп с базовым кодовым словом, которое меньше или равно кодовому слову, подлежащему декодированию. Затем декодер может определить позицию кодового слова, подлежащего декодированию, внутри выбранной подгруппы, то есть индекс подгруппы, на основании разности между кодовым словом, подлежащим декодированию, и базовым кодовым словом для выбранной подгруппы. Декодер определяет вес значения, представленного кодовым словом, подлежащим декодированию, на основе группы, в которой находится выбранная подгруппа, и определяет позицию, то есть индекс группы, кодового слова внутри группы, в которой находится выбранная подгруппа, основываясь на том, является ли выбранная подгруппа первой подгруппой или второй подгруппой для группы. Затем декодер выбирает одно из значений на основе веса значения, представленного кодовым словом, подлежащим декодированию, и позиции кодового слова внутри группы, в которой находится выбранная подгруппа, и декодирует кодовое слово, подлежащее декодированию, при помощи выбранного значения. Это значение может соответствовать, например, одному из блочных кодов в таблице 6.
Кодовая структура и структура данных, предусмотренные в соответствии с настоящим аспектом изобретения, могут поддерживать эффективность в смысле избыточных вычислительных затрат и продолжительности обработки. Например, пример процесса декодирования в таблице 8 требует для нахождения подгруппы от 1 до S операций сравнения и поиска, одно или два сложения, одну операцию сдвига, одну операцию дополнительного сравнения и три операции дополнительного поиска. Число этапов, необходимых для нахождения подгруппы, можно еще больше уменьшить, поместив базовые кодовые слова в дерево двоичного поиска или воспользовавшись дополнительной таблицей поиска, но в обоих случаях за счет дополнительного использования памяти.
В конце процесса декодирования, описанного выше, вес k и индекс In,k(w) для кодового слова преобразуются в фактические значения (например, при помощи функции word() в таблице 8). Если блоки являются разумно короткими, это можно обеспечить просто операцией поиска. В противном случае слово может быть синтезировано посредством использования формулы нумерации, например, как описано в работе D. A. Huffman, A method for the construction of minimum-redundancy codes. Proc. IRE, 40 (Sept. 1952) 1098-1101. С точки зрения сложности этот процесс сходен с вычислением индекса в кодере.
При помощи вышеописанных процессов кодирования и декодирования можно определить систему для адаптивного кодирования и декодирования блоков данных. В настоящем примере предполагается, что входные блоки можно кодировать при следующих условиях:
1. Отсутствует контекст, то есть реализуется универсальный код.
2. Контекст дается одним ранее наблюденным блоком, то есть, t=n.
3. Контекст дается двумя ранее наблюденными блоками, то есть t=2n.
Вместо использования в качестве контекста фактических блоков достаточно (по причине отсутствия памяти у источника) использовать их веса. Это означает, что для t-битовых выборок предоставляется массив из t+1 кодовых структур, индексированных по их весу s. Для еще большей экономии места можно использовать симметрию KT-распределений относительно s и k. В частности, процесс может осуществить замену s=t-s и перебрасывать биты (то есть, принудительно выполнять k=n-k) каждый раз, когда s>t/2. Таким образом, необходимо только определить t/2+1 таблиц. В этом примере общий объем памяти, требуемый адаптивным кодом, становится равным 1+0+1+n+1=1,5n+3 таблиц. Частные случаи оценки объема памяти для размеров блока n=8…20 приведены ниже в таблице 9.
Оценки использования памяти (в байтах) для различных размеров блока
12
16
20
24
32
40
19
25
29
140
184
216
2940
4986
7128
Вышеприведенные таблицы были сгенерированы с использованием плотностей на основе КТ-оценок и с использованием модифицированного алгоритма построения кода Хаффмана в соответствии с настоящим изобретением. Ниже приведен пример компьютерного кода для программы, реализующей адаптивный кодер блоков, описанный в настоящем изобретении.












Далее описываются экспериментальные результаты оценки характеристик процесса адаптивного кодирования, описанного в настоящей заявке, с размером блока n=16 и сравниваются с другими известными алгоритмами. В частности, процесс адаптивного кодирования сравнивается с алгоритмом Q-кодера, описанным в работе W. B. Pennebaker, J. L. Mitchell, G. G. Langdon, Jr., R. B. Arps, An overview of the basic principles of the Q-Coder adaptive binary arithmetic coder, IBM J. Res. Dev., 32 (6) (1988) 717, который используется в стандарте кодирования изображений JBIG, и с алгоритмом CABAC, описанным в работе D. Marpe, H. Schwartz, and T. Wiegand, Context-Based Adaptive Binary Arithmetic Coding in the H.264/AVC video compression standard, IEEE Trans, on CSVT, 13(7):620-636, July 2003, который используется в стандартах ITU-T H.264/MPEG AVC.
Для проведения испытаний использовались сгенерированные компьютером последовательности битов для моделирования выходных последовательностей из двоичного источника Бернулли с вероятностью p. Длина таких последовательностей находится в диапазоне от 16 до 1024, и для каждой длины генерировалось Q=1000000 выборок из таких последовательностей. Относительная степень избыточности вычислялась по формуле:
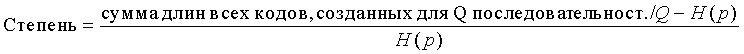
Для процесса адаптивного кодирования, описанного в настоящей заявке, использовалась следующая структура контекстов:
1) первый 16-битовый блок кодируется без контекста (универсальный код);
2) второй блок кодируется с использованием одного из его контекстов (код с t = 16); и
3) третий и все последующие блоки кодируются с использованием двух предыдущих блоков в последовательности в качестве контекстов (код на основе выборок с t = 32).
На фиг.7A и 7B приведены графики, иллюстрирующие сравнение степеней избыточности адаптивного блочного кода со способами Q-кодера и CABAC при различных значениях p. На фиг.7A приведены результаты для p=0,1, а на фиг.7B приведены результаты для p=0,5. На фиг.8 приведен график, иллюстрирующий чувствительность избыточности к асимметрии исходных данных для адаптивного блочного кода, способов Q-кодера b CABAC. Результаты экспериментального исследования приведены на фиг.7A, 7B и 8. На фиг.7A и 7B по оси X отложено число кодированных битов, а по оси Y отложено отношение (средняя длина кода - энтропия)/энтропия.
На фиг.8 по оси X отложена вероятность, а по оси Y отложено отношение (средняя длина кода - энтропия)/энтропия. Каждый граф на фиг.7A, 7B и 8 содержит графики для Q-кодера, CABAC и адаптивного кодирования с соответствующими обозначениями. Из экспериментальных результатов можно заметить, что адаптивный код, описанный в настоящей заявке, может иметь значительно более высокую скорость сходимости по сравнению с алгоритмами Q-кодера и CABAC. Процесс адаптивного кодирования превосходит алгоритмы Q-кодера и CABAC для более коротких последовательностей, и становится сравнимым с алгоритмами Q-кодера и CABAC, когда полная длина кодированных битов приближается к 1024. Кроме того, из фиг.8 следует, что после 160 кодированных битов (или, к тому времени, 16-битовых блоков) процесс адаптивного кодирования может обеспечить более низкую избыточность по сравнению с алгоритмами Q-кодера и CABAC. Такая закономерность согласуется с вышеприведенной теоремой 1.
На фиг.9 приведена блок-схема последовательности операций, иллюстрирующая метод построения кодирования переменной длины с эффективным использованием памяти для монотонных распределений в соответствии с первым общим аспектом настоящего изобретения. Способ может быть реализован процессором, связанным с кодером, декодером или другим устройством для построения кодов с целью их использования модулем 46 статистического кодирования и модулем 52 статистического декодирования, как показано на фиг.2 и 3, и может поддерживать сжатие и кодирование самых различных данных, в том числе, в частности, видеоданных, данных изображения, речевых и звуковых данных. Такой процессор может быть предусмотрен, например, в составе кодера или декодера либо в вычислительной системе общего назначения, например, для создания структуры данных, определяющей атрибуты кодовой структуры, применяющиеся при кодировании переменной длины.
Как показано на фиг.9, процессор получает алфавит входных символов, подлежащих кодированию (70). Символы имеют соответствующие веса, указывающие вероятность или частоту наличия или использования символов в данном наборе или последовательности данных. После определения соответствующих весов символов (72) процесс присваивает символам индексы на основе их весов (74) и присваивает коды символам на основе индексов и лексикографического порядка символов (76). Следовательно, символы, имеющие одинаковые веса, можно упорядочить в лексикографическом порядке для облегчения способов кодирования, описанных в настоящей заявке.
Коды могут быть организованы согласно кодовой структуре, представленной деревом двоичного кодирования. Процессор идентифицирует базовое кодовое слово для каждого уровня в дереве кодирования (78). Базовое кодовое слово является наименьшим кодовым словом на данном уровне в дереве и лексикографически соответствует самому раннему символу среди символов на этом уровне в дереве. Для обеспечения компактной структуры данных процессор удаляет фиксированное число B начальных битов из базовых кодовых слов для получения частичных базовых кодовых слов (80). Базовые кодовые слова можно определить как выровненные влево кодовые слова, а начальные биты могут быть M начальными битами при прохождении справа налево в выровненных влево кодовых словах. В некоторых вариантах осуществления число удаляемых начальных битов может быть равно 8. В других вариантах осуществления число удаляемых начальных битов может быть меньше или больше 8.
Для многих уровней дерева кодирования М начальных битов являются нулями. Однако на некоторых уровнях начальные биты могут формировать весь или часть базового кода для соответствующего уровня в дереве. На этих выбранных уровнях процессор генерирует показатели пропуска (82). Показатели пропуска обеспечивают декодер командой для прокручивания потока битов на B битов таким образом, чтобы не потерять базовый код после удаления начальных B битов. Процесс может хранить в структуре данных получающиеся в результате частичные базовые кодовые слова, длины, связанные с кодовыми словами на соответствующих уровнях дерева кодирования, и один или несколько показателей пропуска, которые указывают, когда поток битов следует прокрутить на B битов для недопущения потери базового кодового слова, которое попало, по меньшей мере частично, в начальные B битов (84). Это структуру данных можно предоставить модулю 46 статистического кодирования и модулю 52 статистического декодирования. Структура данных может принимать различные формы, в том числе представлять собой одномерные, более чем одномерные и многомерные таблицы поиска, списки ссылок, двоичные деревья, базисные деревья, бесструктурные файлы или тому подобное.
На фиг.10 приведена блок-схема последовательности операций, иллюстрирующая способ кодирования символов с использованием кодов переменной длины, построенных согласно способу на фиг.9 в соответствии с первым общим аспектом настоящего изобретения. Как показано на фиг.10, модуль 46 статистического кодирования принимает символ (86), определяет индекс для символа (87) и сравнивает индекс символа с таблицей смещений для идентификации соответствующего уровня в дереве кодирования. В частности, модуль 46 статистического кодирования определяет, является индекс символа большим или равным смещению для данного уровня дерева (88). Индекс символа представляет собой порядок символа среди других символов, ранжированных в порядке веса, причем символы с одинаковым весом упорядочиваются в лексикографическом порядке, соответствующем алфавиту символов. Смещение представляет собой разность между длиной кода или кодов для соответствующего уровня дерева и максимальной длиной кода. Если в дереве на фиг.4 максимальная длина кода равна, например, 16 и длина кода на уровне 3 дерева равна 3, то соответствующее смещение базового кодового слова равно 12.
Если индекс символа не превышает смещение для текущего уровня дерева, модуль 46 статистического кодирования переходит вниз на следующий уровень (90) дерева кодирования в процессе нисходящего поиска и повторяет сравнение индекса символа со смещением для этого следующего уровня (88). Когда модуль 46 статистического кодирования определяет, что индекс символа больше или равен смещению для определенного уровня дерева кодирования (88), блок статистического кодирования вычисляет соответствующее кодовое слово для этого символа. В частности, модуль 46 статистического кодирования устанавливает кодовое слово для символа в сумму базового кодового слова для текущего уровня дерева и разницы между индексом символа и смещением для этого уровня (92).
Если взять в качестве примера дерево на фиг.4, то если индекс символа равен 14, модуль 46 статистического кодирования определяет, что код для символа находится на уровне 3 дерева, потому что 14 больше смещения 12, присвоенного базовому кодовому слову для этого уровня. Затем модуль 46 статистического кодирования вычисляет кодовое слово в виде базового кодового слова (001) + (индекс символа (14) - смещение (12)), то есть 001 + 2 = 001 + 010 = 011. После установки кода для принятого символа (92), модуль 46 статистического кодирования выдает кодовое слово потоку битов (94) для передачи, например, приемному устройству с модулем 52 статистического декодирования. Затем модуль 46 статистического кодирования повторяет процесс для следующего символа в соответствующей последовательности данных.
На фиг.11 приведена блок-схема, иллюстрирующая способ декодирования кодов переменной длины, построенных согласно способу на фиг. 9 в соответствии с первым общим аспектом настоящего изобретения. Способ, изображенный на фиг.11, может быть реализован при помощи алгоритма, идентичного или аналогичного алгоритму, приведенному в таблице 5. В примере осуществления коды могут быть приняты модулем 52 статистического декодирования, причем коды закодированы модулем 46 статистического кодирования, как описано со ссылкой на фиг.10. Способ, изображенный на фиг.11, может использовать способы декодирования с эффективным использованием памяти, описанные в настоящей заявке, и может использовать преимущества компактной структуры данных, при помощи которой могут быть построены такие коды. Как показано на фиг.11, модуль 52 статистического декодирования принимает кодовое слово от поступающего потока битов (96). Кодовое слово может быть получено из фиксированной ширины W битов, извлеченных из буфера потока битов. Кодовое слово может быть выровнено влево или преобразовано в форматы с выравниванием влево, а ширина W может быть уменьшена посредством удаления B начальных битов из кодового слова, если идти справа налево.
Модуль 52 статистического декодирования сравнивает кодовое слово с базовым кодовым словом для различных уровней дерева кодирования, начиная с верхнего уровня и переходя к более глубоким уровням в процессе нисходящего поиска до тех пор, пока не будет найдено соответствующее базовое кодовое слово. В частности, модуль 52 статистического декодирования может определить, является ли базовое кодовое слово для текущего уровня дерева меньшим или равным кодовому слову (98). Если не является, блок статистического декодирования продолжает переход вниз на следующий уровень дерева (100) и повторяет сравнение (98) для базового кодового слова, связанного со следующим уровнем. Однако, после перехода к следующему уровню (100) модуль 52 статистического декодирования определяет, связан ли с текущим уровнем показатель пропуска (102). Если связан, то перед переходом к следующему уровню (100) модуль 52 статистического декодирования прокручивает буфер потока битов на фиксированный шаг (104). В частности, модуль 52 статистического декодирования может прокрутить буфер потока битов на М битов, так чтобы кодовое слово не потерялось при пропуске начальных М битов. Если признак пропуска отсутствует (102), модуль 52 статистического декодирования просто переходит к следующему уровню (100).
В обоих случаях модуль 52 статистического декодирования вновь сравнивает кодовое слово с базовым кодовым словом для текущего уровня (98). Когда модуль 52 статистического декодирования находит уровень, на котором базовое кодовое слово меньше или равно кодовому слову (98), модуль 52 статистического декодирования определяет остаточную длину базовых кодовых слов на соответствующем уровне (106) и прокручивает поток битов на остаточную длину (108). Затем модуль 52 статистического декодирования вычисляет символ, связанный с кодовым словом (110), на основе смещения для уровня и разности между базовым кодовым словом и декодируемым кодовым словом.
Если взять в качестве примера дерево на фиг.4, то если кодовое слово 0110000000000000, тогда частичное, урезанное кодовое слово с пропущенными 8 начальными битами - 01100000. В этом случае модуль 52 статистического декодирования определяет, что частичное базовое кодовое слово на уровне 3 (00100000) меньше или равно кодовому слову, и идентифицирует остаточную длину равной 3. Модуль 52 статистического декодирования прокручивает поток битов на 3 бита вперед для получения следующего кодового слов. Кроме того, модуль 52 статистического декодирования вычисляет символ для кодового слова, добавляя смещение для уровня 3 к разнице между кодовым словом в буфере потока данных и базовым кодовым словом для этого уровня. Например, модуль 52 статистического декодирования вычисляет код в виде смещения [3] = 12 плюс кодовое слово 01100000 минус 00100000, что эквивалентно 12 плюс 2 = 14. В этом случае 14 - это индекс символа, представленного кодом 011.
Способ, изображенный на фиг.11, может использовать преимущества очень компактной структуры данных и весьма эффективное использование памяти, как описано в другом месте настоящей заявки. В результате при реализации такого способа модуль 52 статистического декодирования может обеспечить повышенную эффективность, в том числе уменьшенные затраты на обработку, уменьшенное использование памяти и повышенную скорость обработки, причем все это желательно иметь в устройствах декодирования видеоданных и в других устройствах, выполненных с возможностью распаковки и декодирования данных.
На фиг.12 приведена блок-схема последовательности операций, иллюстрирующая способ построения адаптивных блочных кодов в соответствии со вторым общим аспектом настоящего изобретения. Способ на фиг.12 можно реализовать в процессоре, находящемся в кодере, или в процессоре общего назначения для поддержки эффективного, непосредственного построения адаптивных блочных кодов. Как показано на фиг. 12, процессор получает набор слов (112), подлежащих кодированию. Структура данных, представляющая собой результирующую кодовую структуру, может храниться в памяти внутри кодера, декодера или в том, и в другом. Слова могут быть блоками двоичных кодов. После определения весов слов (114) процессор присваивает группы кодовых слов словам на основе весов (116). Группы кодовых слов включают в себя кодовые слова для слов с одинаковым весом k и могут охватывать два соседних уровня дерева кодирования, например, как показано на фиг.6.
Как показано далее на фиг.12, процессор присваивает подгруппы словам одной группы на основе длин слов (118). В частности, группа может включать в себя первую подгруппу и вторую подгруппу. Первая подгруппа содержит одно или несколько кодовых слов, имеющих одинаковую длину и одинаковый вес. Аналогично, вторая подгруппа содержит одно или несколько кодовых слов, имеющих одинаковую длину и одинаковый вес. Однако, длина кодовых слов в первой подгруппе меньше длины кодовых слов во второй подгруппе. Таким образом, каждая подгруппа включает в себя кодовые слова, имеющие одинаковый вес и находящиеся на одном уровне в дереве кодирования.
Процессор идентифицирует базовое кодовое слово для каждой подгруппы (120). Базовое кодовое слово - это наименьшее кодовое слово в подгруппе. В примере на фиг.6 базовое кодовое слово для подгруппы 68A - 001. Однако подгруппа 68 дополнительно включает в себя кодовые слова 010 и 011 помимо базового кодового слова 001. В этом примере кодовые слова в подгруппе упорядочиваются в лексикографическом порядке слов, который они представляют, так что коды могут быть легко и непосредственно вычислены при сравнительно небольшом объеме вычислений.
Число элементов в первой подгруппе каждой группы может использоваться для вычисления кодовых слов. Для этой цели процессор хранит число элементов в первой подгруппе каждой группы (122), а также хранит отображение (124) индекса группы, отображение (126) длины кодов подгруппы и отображение (128) базового кодового слова подгруппы. Отображение индекса группы может идентифицировать позицию кодового слова для слова в группе, в которой находится это кодовое слово. Отображение длины кодов подгруппы может идентифицировать длину кодов внутри определенной подгруппы. Отображение базового кодового слова подгруппы может идентифицировать базовое кодовое слово, связанное с каждой подгруппой. В целом код может быть построен из базового кодового слова для определенной подгруппы, если известен индекс слова в группе. Сохраненная информация может храниться в структуре данных, к которой могут обращаться кодер, декодер или и то, и другое.
На фиг.13 приведена блок-схема последовательности операций, иллюстрирующей способ кодирования блоков при помощи кодов переменной длины, построенных согласно способу на фиг.12 и в соответствии со вторым общим аспектом настоящего изобретения. Способ на фиг.13 может быть реализован, например, в блоке статистического кодирования, такого как модуль 46 статистического кодирования на фиг.2. Способ, изображенный на фиг.13, может быть реализован при помощи алгоритма, идентичного или аналогичного алгоритму, приведенному в таблице 7. Как показано на фиг.13, для кодирования данного слова модуль 46 статистического кодирования получает его вес (130) и индекс группы (132). Используя вес слова, модуль 46 статистического кодирования определяет индекс группы для слова (132) в рамках соответствующего дерева кодирования. Индекс In,k(w) группы определяет индекс (позицию) слова w в группе Wn,k, которая хранит слова в лексикографическом порядке.
Модуль 46 статистического кодирования сравнивает индекс группы с числом элементов nk в первой подгруппе группы, в которой находится кодовое слово для входного слова. В частности, модуль 46 статистического кодирования определяет, является ли индекс группы большим или равным числу элементов в первой подгруппе (134). Если является, модуль 46 статистического кодирования выбирает в группе вторую подгруппу (138), то есть подгруппу 1, и уменьшает значение индекса группы (140). В частности, значение индекса группы уменьшается на число элементов в первой подгруппе nk. Если индекс группы не является большим или равным числу элементов в первой подгруппе (134), модуль 46 статистического кодирования выбирает первую подгруппу (136), то есть подгруппу 0. Каждая подгруппа имеет свое собственное базовое кодовое слово. Модуль 46 статистического кодирования получает базовое кодовое слово для выбранной подгруппы (142) и вычисляет кодовое слово на основе суммы базового кодового слова и значения индекса группы (144).
Если обратиться в качестве иллюстрации к примеру дерева кодирования на фиг.6, то если предположить, что, например, вес слова, подлежащего кодированию, равен 2, значение индекса группы равно 2 и число элементов в первой подгруппе равно 3, что соответствует группе на уровнях 3 и 4 дерева кодирования, то в этом случае модуль 46 статистического кодирования выбирает первую подгруппу (подгруппа 0), поскольку значение индекса группы (2) меньше числа элементов (3) в первой подгруппе. В результате базовое кодовое слово - 001. Для кодирования слова модуль 46 статистического кодирования добавляет значение индекса группы 2 к базовому кодовому слову 001, что дает кодовое слово 011.
Если для этой же группы значение индекса группы равнялось 3, то модуль 46 статистического кодирования выбрал бы вторую подгруппу (подгруппа 1). Однако модуль 46 статистического кодирования уменьшил бы значение индекса группы на число nk элементов в первой подгруппе (подгруппа 0). В этом случае значение индекса группы, равное 3, было бы уменьшено на 3, что равно нулю, и кодовое слово было бы вычислено как базовое кодовое слово 0001 для второй подгруппы плюс значение индекса группы 0, что дает кодовое слово 0001.
Помимо вычисления кодового слова для входного слова модуль 46 статистического кодирования может получать длину кодов в выбранной подгруппе (146). В вышеприведенном примере для подгруппы 0 на уровне 3 длина кодов была бы равна 3. Блок статистического кодирования выдает в поток битов вычисленное кодовое слово и длину кода подгруппы для сохранения и/или передачи другому устройству, такому как устройство декодирования, включающее в себя блок статистического декодирования, такой как модуль 52 статистического декодирования.
На фиг.14 приведена блок-схема, иллюстрирующая способ декодирования кодов переменной длины, построенных согласно способам на фиг.12 и фиг. 13 и в соответствии со вторым общим аспектом настоящего изобретения. Способ, изображенный на фиг.14, может быть реализован при помощи алгоритма, идентичного или аналогичного алгоритму, приведенному в таблице 8. Коды переменной длины могут быть получены от кодера, такого как кодер, включающий в себя модуль 46 статистического кодирования. Коды переменной длины могут быть получены и декодированы модулем 52 статистического декодирования. Как показано на фиг.14, модуль 52 статистического декодирования получает кодовое слово из поступающего потока битов (150) и сравнивает кодовое слово с базовым кодовым словом подгруппы. В частности, модуль 52 статистического декодирования может искать соответствующее дерево кодирования для выровненного влево базового слова подгруппы, которое меньше или равно содержимому кодового слова, полученного из буфера потока битов (152).
Если базовое кодовое слово подгруппы в подгруппе на данном уровне дерева не является меньшим или равным кодовому слову (152), то модуль 52 статистического декодирования переходит к следующей подгруппе на следующем уровне (154) дерева и повторяет сравнение. Этот процесс продолжается на поэтапной основе до тех пор, пока базовое кодовое слово не станет больше или равно кодовому слову, принятому из потока битов, то есть до тех пор, пока модуль 52 статистического декодирования не достигнет уровня, на котором базовое кодовое слово подгруппы меньше или равно кодовому слову. При сравнении кодового слова и базовых кодовых слов модуль 52 статистического декодирования может использовать частичные, прирастающие значения базовых кодовых слов для дополнительного уменьшения памяти в соответствии с первым аспектом настоящего изобретения. В частности, несколько начальных битов можно пропустить для улучшения эффективности использования памяти, как это описано выше.
Когда достигается уровень дерева кодирования, на котором базовое кодовое слово подгруппы меньше или равно кодовому слову, модуль 52 статистического декодирования определяет длину кода для подгруппы (156) и прокручивает поток битов на эту длину для пропуска декодированных битов и изоляции кодового слова. Модуль 52 статистического декодирования может определить позицию кодового слова в подгруппе при помощи базового кодового слова (158). Например, модуль 52 статистического декодирования может вычесть кодовое слово потока битов из базового кодового слова для получения разности позиций между кодовым словом и базовым кодовым словом.
Если взять в качестве примера дерево кодирования на фиг.6, то если поступающее кодовое слово - 0110000000000000, модуль 52 статистического декодирования идентифицирует базовое кодовое слово 0010000000000000 как самое верхнее базовое слово кодовое слово подгруппы, которое меньше или равно кодовому слову. Это базовое кодовое слово связано с первой подгруппой в группе на уровнях 3 и 4. После определения длины кода (3) подгруппы, связанной с базовым кодовым словом, модуль 52 статистического декодирования может прокрутить поток битов для пропуска декодированных битов. Модуль 52 статистического декодирования может определить индекс группы для кодового слова посредством вычитания базового кодового слова из кодового слова, полученного из потока битов. В данном примере 011 минус 001 дает 010, что дает значение индекса группы, равное 2.
Модуль 52 статистического декодирования может также определить вес кодового слова (160), например, на основе уровня подгруппы в дереве кодирования. Кроме того, модуль 52 статистического декодирования может определить индекс подгруппы (162), то есть индекс выбранной подгруппы в дереве кодирования. Используя вес, позицию и индекс подгруппы, модуль 52 статистического декодирования определяет индекс слова (164), тем самым декодируя кодовое слово, полученное из потока данных, для получения слова, представленного кодовым словом. Повторим еще раз, что в некоторых вариантах выполнения способ декодирования, выполняемый модулем 52 статистического декодирования, может соответствовать процессу, приведенному в таблице 8.
Специалистам в данной области техники должно быть понятно, что информация и сигналы могут быть представлены с использованием самых различных технологий и методов. Например, данные, инструкции, команды, информация, сигналы, биты, символы и элементы, которые могут упоминаться в вышеприведенном описании, могут быть представлены напряжением, током, электромагнитными волнами, магнитными полями или частицами, оптическими полями или частицами, либо любым сочетанием вышеперечисленного.
Специалистам в данной области техники должно быть также понятно, что приведенные в качестве иллюстрации различные логические блоки, модули, схемы и этапы алгоритма, описанные в связи с раскрытыми вариантами осуществления, могут быть реализованы в виде электронных аппаратных средств, компьютерных программных средств или сочетанием обоих видов средств. Для более понятной иллюстрации этой взаимозаменяемости аппаратных и программных средств, приведенных в качестве иллюстрации, различные компоненты, блоки, модули, схемы и этапы были описаны выше с точки зрения их функциональных возможностей. Будут ли такие функциональные возможности реализованы в виде аппаратных или программных средств, зависит от конкретной области применения и ограничений на конструкцию, накладываемых системой в целом. Квалифицированные специалисты могут реализовать описанные функциональные возможности различными способами для каждой конкретной области применения, но такие решения в области реализации не должны считаться вызывающими отклонение от объема настоящего изобретения.
Описанные способы могут быть реализованы аппаратными средствами, программными средствами, аппаратно-программными средствами или любым сочетанием вышеперечисленного. Такие способы могут быть реализованы в любом из множества устройств, таких как компьютеры общего назначения, телефонные устройства беспроводной связи или устройства на интегральных схемах, имеющие множество областей применения, в том числе применение в телефонных устройствах беспроводной связи и других устройствах. Любые характеристики, описанные в виде модулей или компонентов, могут быть реализованы совместно в объединенном логическом устройстве или отдельно в виде отдельных, но взаимодействующих логических устройств. В случае программной реализации эти способы могут быть реализованы, по меньшей мере, частично, посредством машиночитаемого носителя для хранения данных, содержащего программный код, включающий в себя команды, которые при исполнении выполняют один или несколько из вышеописанных способов. Машиночитаемый носитель для хранения данных может быть частью компьютерного программного продукта. Машиночитаемый носитель может содержать оперативную память (RAM), такую как синхронная динамическая оперативная память (SDRAM), постоянную память (ROM), энергонезависимую оперативную память (NVRAM), электрически стираемую программируемую постоянную память (EEPROM), флэш-память, магнитные или оптические носители для хранения данных и т. п. Дополнительно к этому или вместо этого эти способы могут быть реализованы, по меньшей мере, частично, машиночитаемой средой передачи, которая переносит или передает программный код в виде команд или структур данных и которая может быть доступна, считываема и/или исполняема для компьютера, такая как распространяющиеся сигналы или волны.
Программный код может исполняться одним или несколькими процессорами, таким как один или несколько процессоров цифровых сигналов (DPS), микропроцессоры общего назначения, специализированные интегральные схемы (ASIC), программируемые пользователем большие интегральные схемы (FPGA) или другие эквивалентные интегральные или дискретные логические схемы. Процессор общего назначения может быть микропроцессором, но в альтернативном варианте процессор может быть любым обычным процессором, контроллером, микроконтроллером или конечным автоматом. Процессор может быть также реализован в виде сочетания вычислительных устройств, например, в виде сочетания DSP и микропроцессора, множества микропроцессоров, одного или нескольких микропроцессоров в сочетании c ядром DSP и любой иной такой конфигурации. Соответственно, термин "процессор" в данной заявке может относиться к любой из вышеперечисленных структур или к любой другой структуре, подходящей для реализации описанных в заявке способов. Кроме того, в некоторых аспектах описанные функциональные возможности можно обеспечить в пределах специализированных программных модулей или аппаратных модулей, выполненных с возможностью кодирования или декодирования, или можно встроить в объединенный кодер-декодер (CODEC) видеоданных.
Были описаны различные варианты осуществления изобретения. Эти и другие варианты изобретения находятся в пределах объема нижеприведенной формулы.
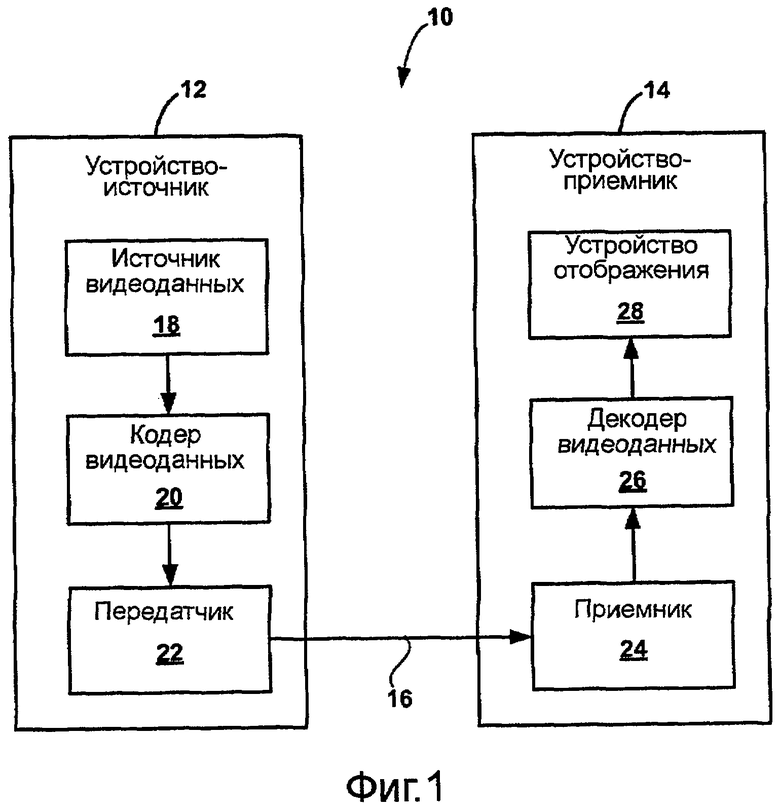
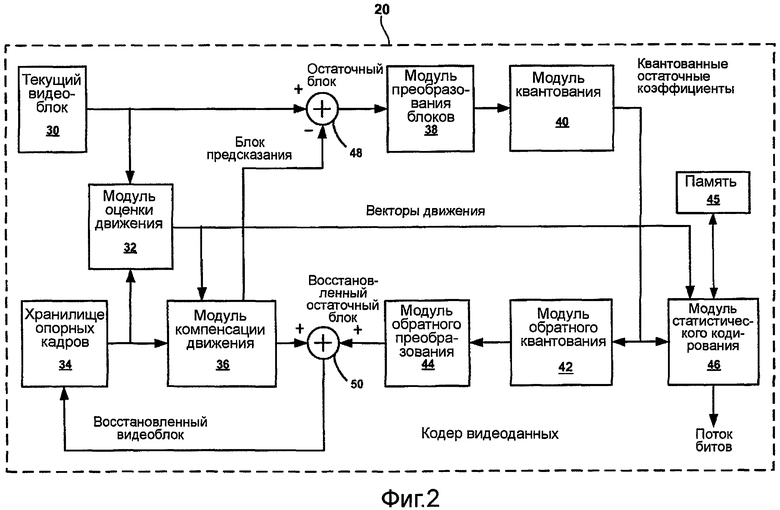
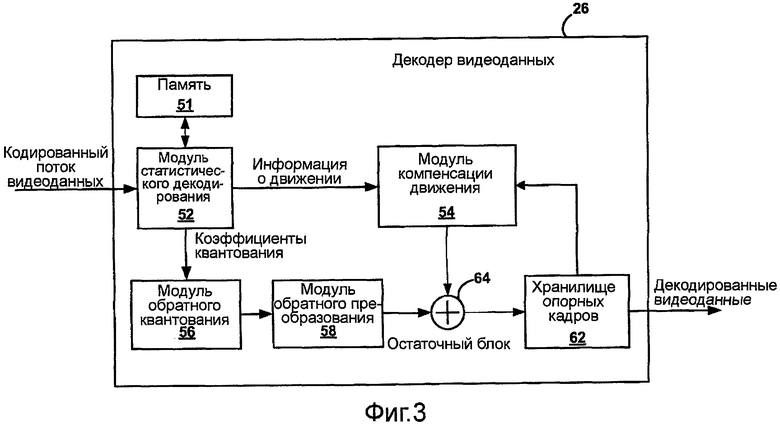
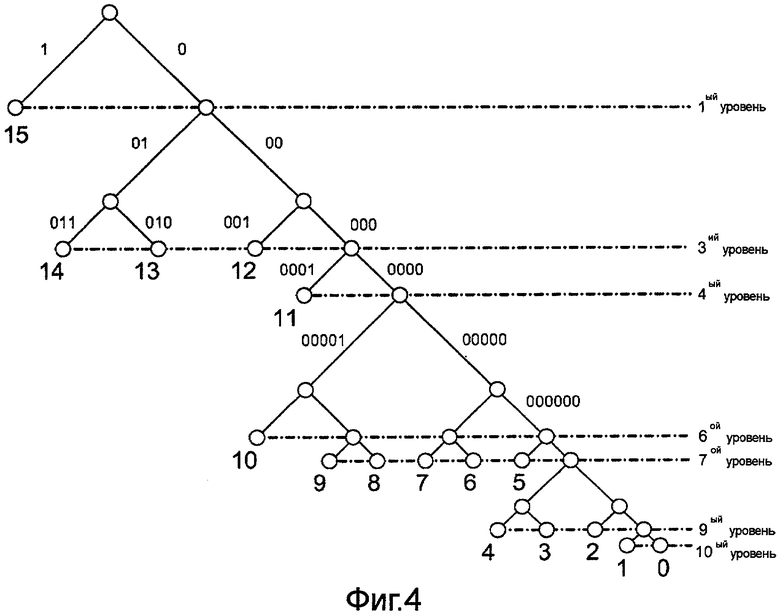
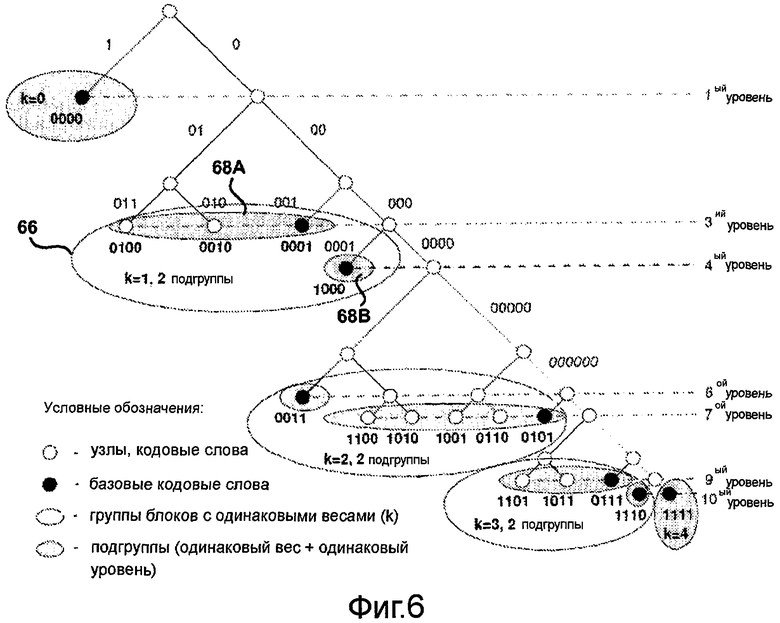
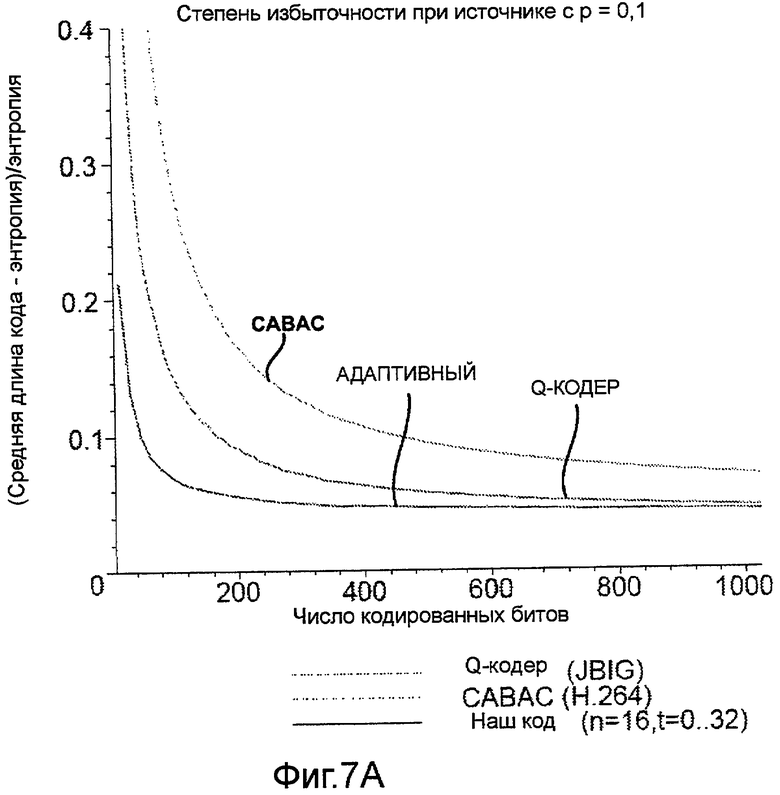
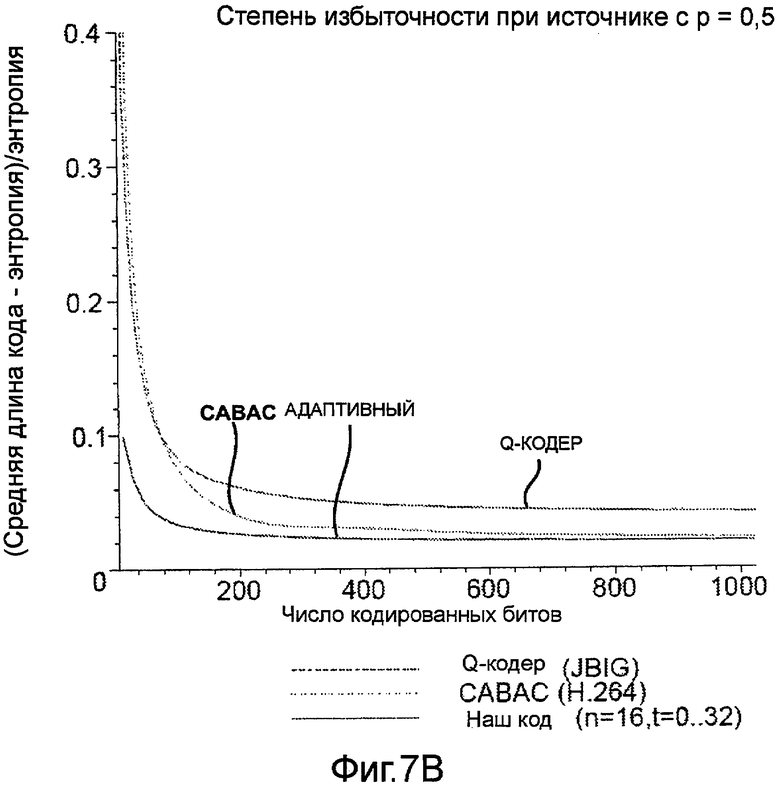
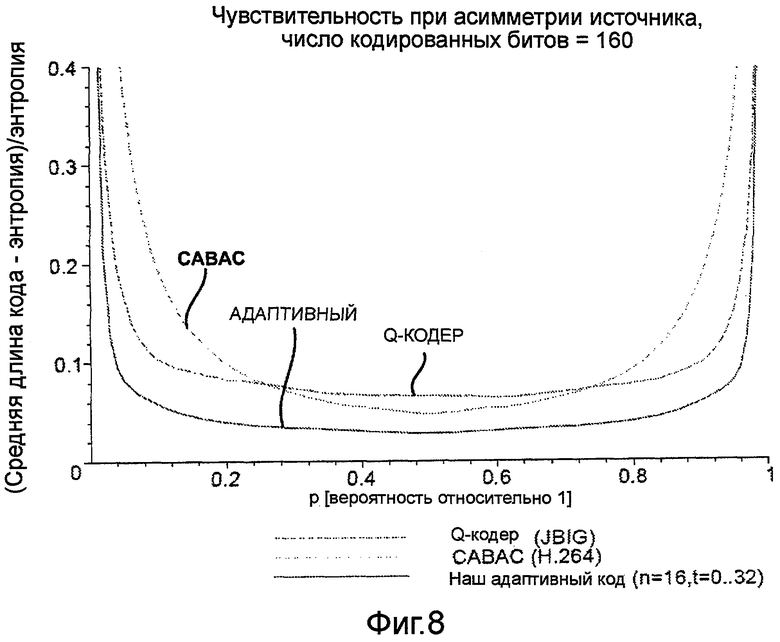
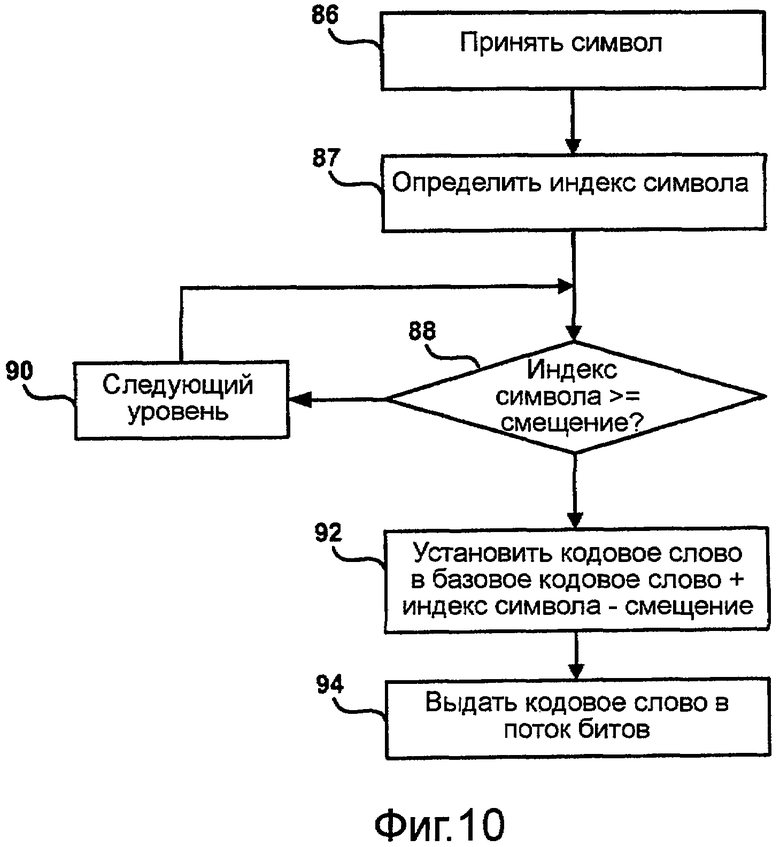
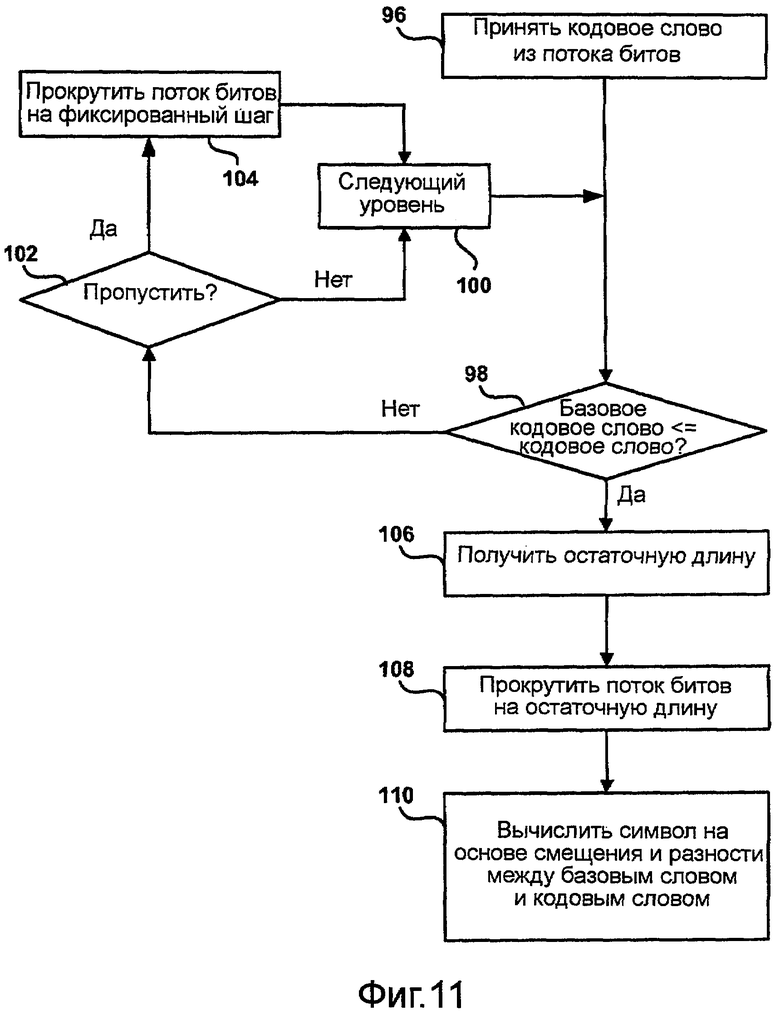
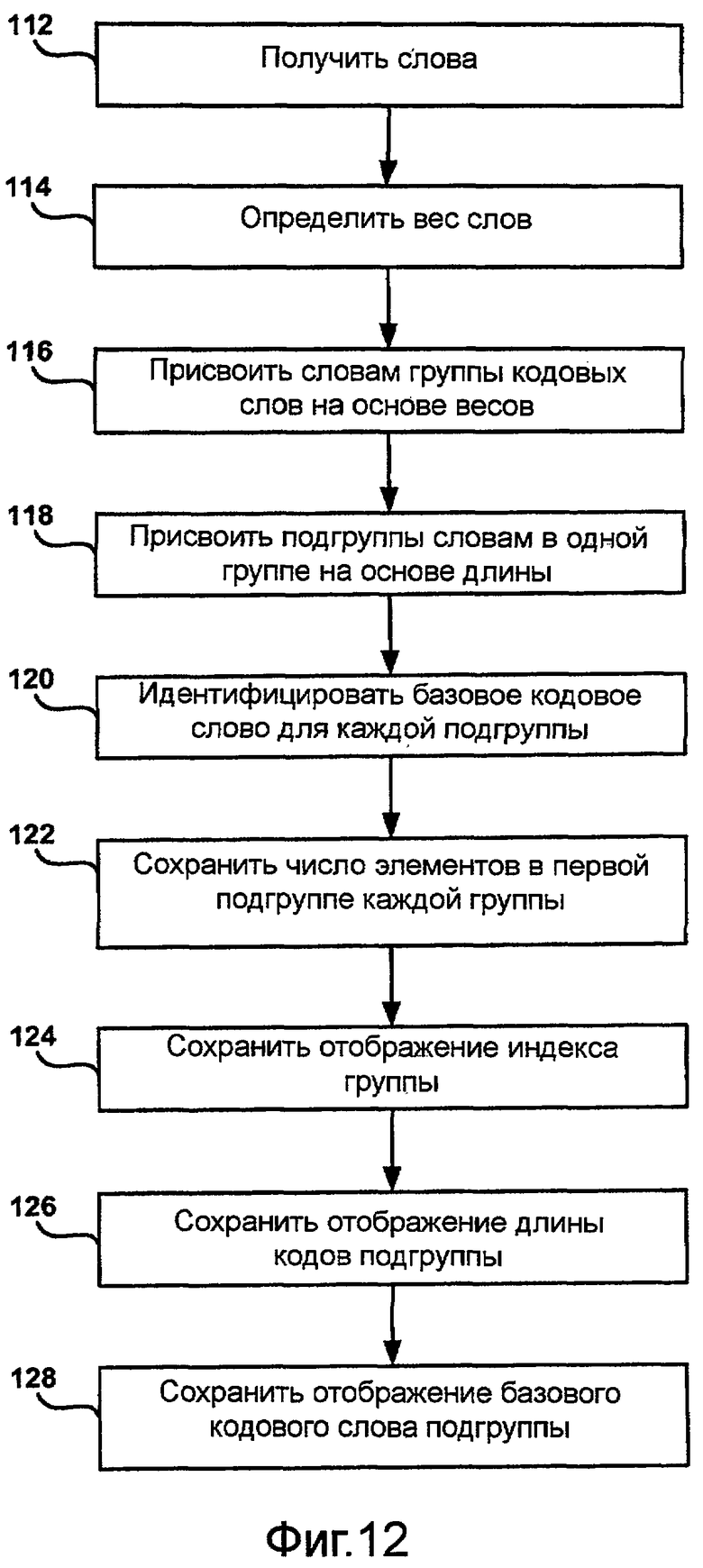
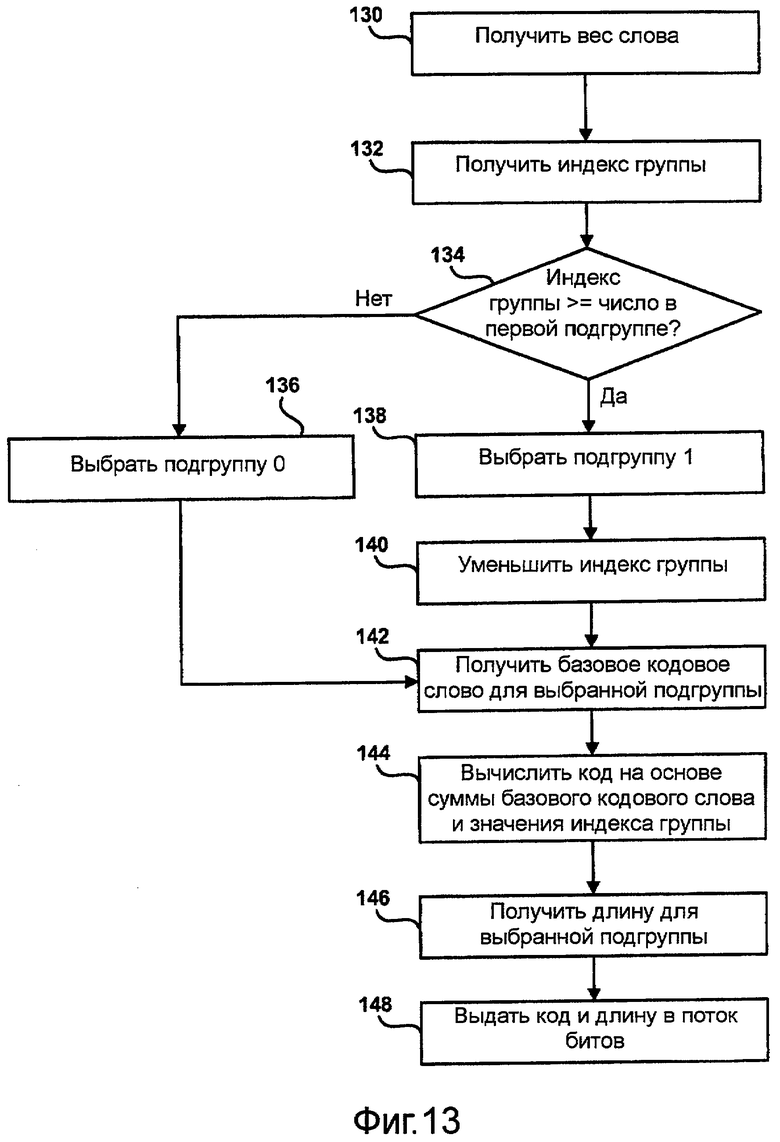
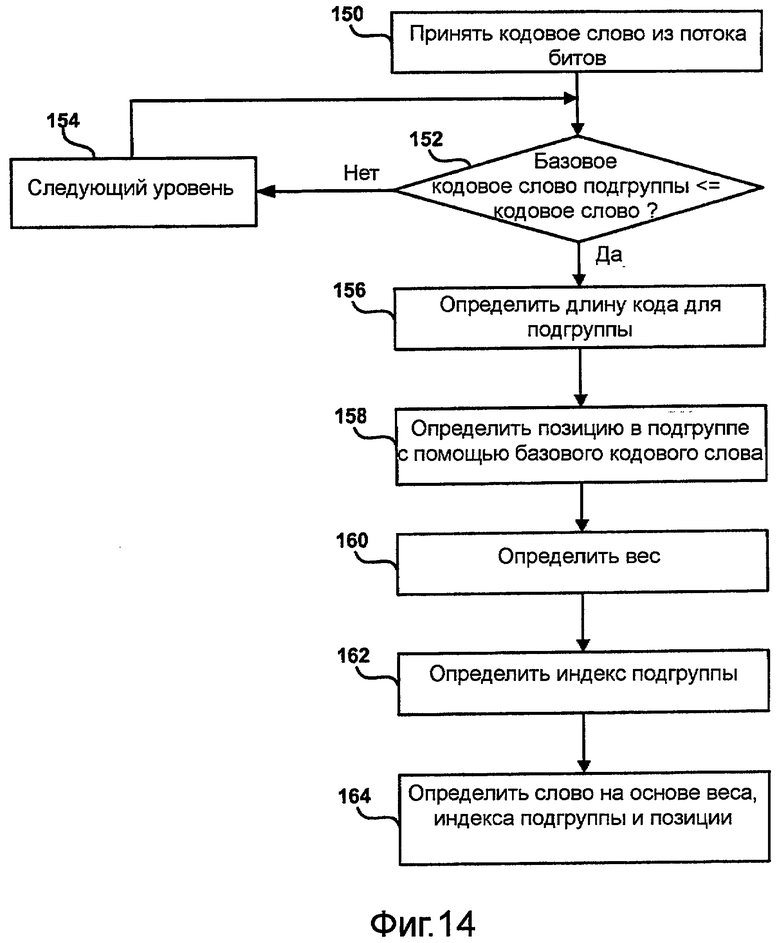
Изобретение направлено на способы адаптивного кодирования переменной длины (VLC) с эффективным использованием памяти и низкой степенью сложности в отношении данных для различных областей применения, таких как цифровые видеоданные, данные изображения, звуковые или голосовые данные. В некоторых аспектах эти способы могут использовать свойства определенных наборов кодовых слов для поддержки очень компактных структур данных. В других аспектах способы могут поддерживать адаптивное кодирование и декодирование с низкой степенью сложности в отношении двоичных последовательностей, созданных источниками без памяти. Технический результат - обеспечение адаптивного кодирования переменной длины (VLC) с более эффективным использованием памяти и меньшей сложностью для данных в различных областях применения, таких как кодирование цифровых видеоданных, данных изображения, звуковых или голосовых данных. 10 н. и 73 з.п. ф-лы, 15 ил., 9 табл.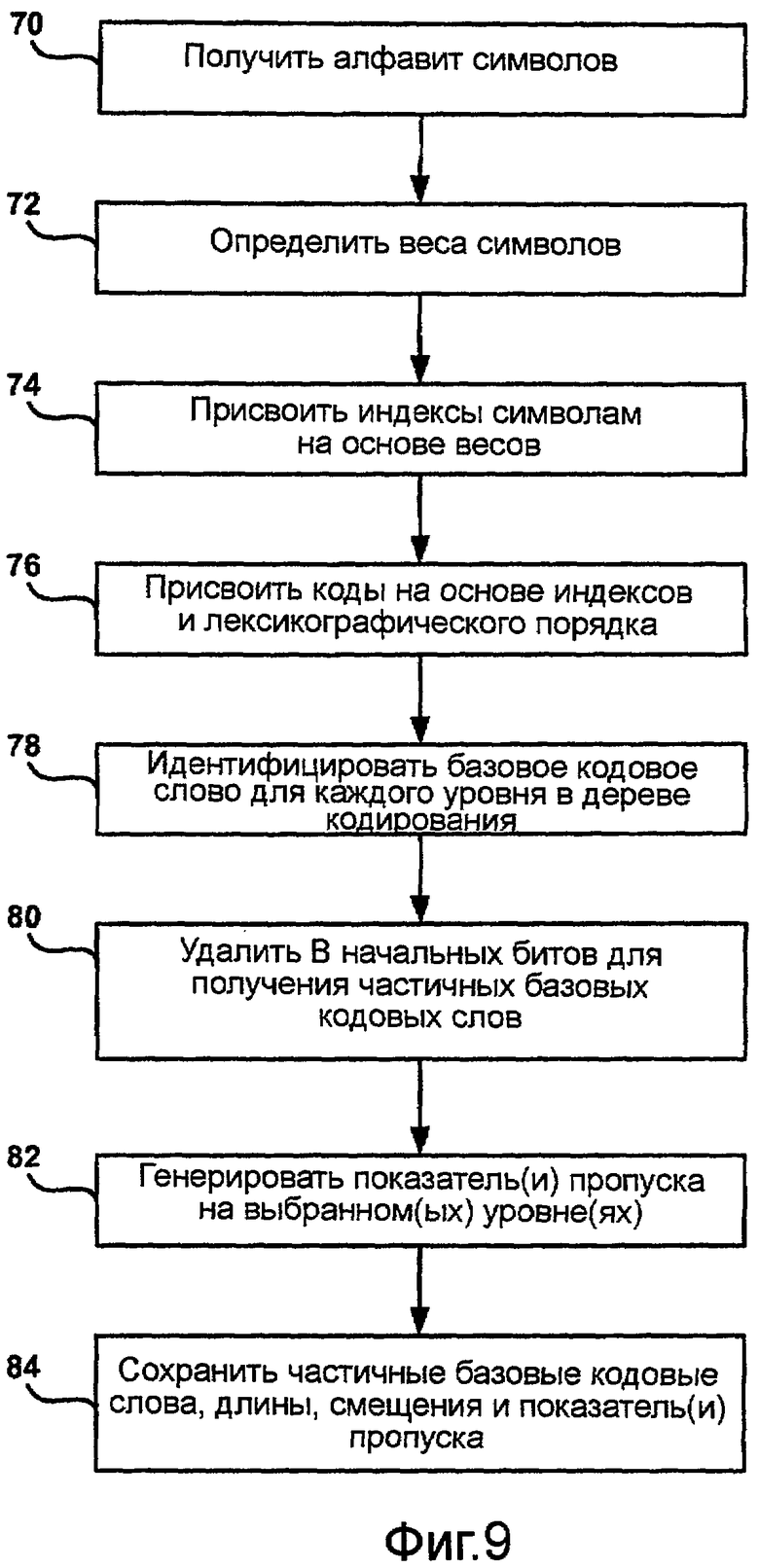
1. Способ создания данных для кодирования кодовых слов переменной длины, содержащий этапы, на которых:
генерируют частичные значения базовых кодовых слов, причем базовые кодовые слова соответствуют уровням дерева кодирования, определяющего канонические кодовые слова переменной длины, и причем частичные значения основаны на смещении базовых кодовых слов на фиксированное число битов;
генерируют показатель пропуска, указывающий декодеру пропустить фиксированное число битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования; и
сохраняют частичные значения и показатель пропуска в структуре данных в памяти.
2. Способ по п.1, дополнительно содержащий этапы, на которых:
генерируют значения, представленные базовыми кодовыми словами;
генерируют длины частичных значений базовых кодовых слов и сохраняют значения и длины в структуре данных в памяти.
3. Способ по п.1, дополнительно содержащий этап, на котором сохраняют структуру данных в памяти одного из декодера видеоданных, декодера изображений и звукового декодера или голосового декодера.
4. Способ по п.1, в котором некоторые из уровней дерева кодирования включают в себя кодовые слова, расположенные в лексикографическом порядке относительно значений, представленных кодовыми словами, и каждое из базовых кодовых слов является лексикографически наименьшим кодовым словом на соответствующем уровне в дереве кодирования.
5. Способ по п.1, в котором частичные значения базовых кодовых слов представляют собой удаление фиксированного числа начальных битов из базовых кодовых слов.
6. Способ по п.5, в котором при отсутствии упомянутого смещения базовое кодовое слово на выбранном уровне дерева распространяется, по меньшей мере, частично, на удаленное число начальных битов.
7. Способ по п.1, дополнительно содержащий этап, на котором декодируют одно из кодовых слов из потока битов с кодовыми словами при помощи хранящейся структуры данных, причем декодирование содержит этапы, на которых:
осуществляют поиск уровней дерева кодирования для выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову из потока битов с кодовыми словами;
пропускают фиксированное число битов в потоке битов с кодовыми словами перед переходом к выбранному уровню дерева кодирования в ответ на показатель пропуска;
вычисляют одно из множества значений, соответствующих кодовому слову, на основе разности между выбранным значением из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову, и кодовым словом и индекс выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову.
8. Способ по п.7, дополнительно содержащий этап, на котором представляют выходные данные пользователю на основе, по меньшей мере, частично, вычисленного значения.
9. Способ по п.1, дополнительно содержащий этап, на котором кодируют значения кодовыми словами, согласующимися с деревом кодирования, причем значения, представленные кодовыми словами, представляют, по меньшей мере, одно из видеоданных, данных изображения, голосовых данных или звуковых данных.
10. Устройство для создания данных для кодирования кодовых слов переменной длины, содержащее:
средство генерации частичных значений базовых кодовых слов, причем базовые кодовые слова соответствуют уровням дерева кодирования, определяющего канонические кодовые слова переменной длины, и причем частичные значения основаны на смещении базовых кодовых слов на фиксированное число битов;
средство генерации показателя пропуска, указывающего декодеру пропустить фиксированное число битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования; и
средство сохранения частичных значений и показателя пропуска в структуре данных в памяти.
11. Устройство по п.10, дополнительно содержащее:
средство генерации значений, представленных базовыми кодовыми словами;
средство генерации длин частичных значений базовых кодовых слов, и
средство сохранения значений и длин в структуре данных в памяти.
12. Устройство по п.10, дополнительно содержащее средство сохранения структуры данных в памяти одного из декодера видеоданных, декодера изображений, звукового декодера или голосового декодера.
13. Устройство по п.10, в котором некоторые из уровней дерева кодирования включают в себя кодовые слова, расположенные в лексикографическом порядке относительно значений, представленных кодовыми словами, и каждое из базовых кодовых слов является лексикографически наименьшим кодовым словом на соответствующем уровне в дереве кодирования.
14. Устройство по п.10, в котором частичные значения базовых кодовых слов представляют собой удаление фиксированного числа начальных битов из базовых кодовых слов.
15. Устройство по п.14, в котором при отсутствии упомянутого смещения базовое кодовое слово на выбранном уровне дерева распространяется, по меньшей мере, частично, на удаленное число начальных битов.
16. Устройство по п.10, дополнительно содержащее средство декодирования одного из кодовых слов из потока битов с кодовыми словами при помощи сохраненной структуры данных, причем средство декодирования содержит:
средство поиска уровней дерева кодирования для выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову из потока битов с кодовыми словами;
средство пропуска фиксированного числа битов в потоке битов с кодовыми словами перед переходом к выбранному уровню дерева кодирования в ответ на показатель пропуска;
средство вычисления одного из множества значений, соответствующих кодовому слову, на основе разности между выбранным значением из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову, и кодовым словом и индекса выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову.
17. Устройство по п.16, дополнительно содержащее средство представления выходных данных пользователю на основе, по меньшей мере, частично, вычисленного значения.
18. Устройство по п.10, дополнительно содержащее средство кодирования значений кодовыми словами, согласующимися с деревом кодирования, причем значения, представленные кодовыми словами, представляют, по меньшей мере, одно из видеоданных, данных изображения, голосовых данных или звуковых данных.
19. Материальный машиночитаемый носитель, содержащий структуру данных, хранящую частичные значения базовых кодовых слов, причем базовые кодовые слова соответствуют уровням дерева кодирования, определяющего канонические кодовые слова переменной длины, и причем частичные значения основаны на смещении базовых кодовых слов на фиксированное число битов, и показатель пропуска, указывающий декодеру пропустить фиксированное число битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования.
20. Машиночитаемый носитель по п.19, в котором структура данных дополнительно хранит значения, представленные базовыми кодовыми словами, и длины частичных значений базовых кодовых слов.
21. Машиночитаемый носитель по п.19, в котором некоторые из уровней дерева кодирования включают в себя кодовые слова, расположенные в лексикографическом порядке относительно значений, представленных кодовыми словами, и каждое из базовых кодовых слов является лексикографически наименьшим кодовым словом на соответствующем уровне в дереве кодирования.
22. Машиночитаемый носитель по п.19, в котором частичные значения базовых кодовых слов представляют собой удаление фиксированного числа начальных битов из базовых кодовых слов.
23. Машиночитаемый носитель по п.22, в котором при отсутствии упомянутого смещения базовое кодовое слово на выбранном уровне дерева распространяется, по меньшей мере, частично, на удаленное число начальных битов.
24. Машиночитаемый носитель по п.22, в котором значения, представленные кодовыми словами, представляют, по меньшей мере, одно из видеоданных, данных изображения, голосовых данных или звуковых данных.
25. Устройство для создания данных для кодирования кодовых слов переменной длины, содержащее:
процессор, выполненный с возможностью генерации частичных значений базовых кодовых слов, причем базовые кодовые слова соответствуют уровням дерева кодирования, определяющего кодовые слова переменной длины, и причем частичные значения основаны на смещении базовых кодовых слов на фиксированное число битов, и генерации показателя пропуска, указывающего декодеру пропустить фиксированное число битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования; и
память, которая хранит частичные значения и показатель пропуска в структуре данных.
26. Устройство по п.25, в котором процессор генерирует значения, представленные базовыми кодовыми словами, и генерирует длины частичных значений базовых кодовых слов, а память хранит значения и длины в структуре данных.
27. Устройство по п.25, в котором устройство содержит одно из декодера видеоданных, декодера изображения и звукового декодера или голосового декодера.
28. Устройство по п.25, в котором некоторые из уровней дерева кодирования включают в себя кодовые слова, расположенные в лексикографическом порядке относительно значений, представленных кодовыми словами, и каждое из базовых кодовых слов является лексикографически наименьшим кодовым словом на соответствующем уровне в дереве кодирования.
29. Устройство по п.25, в котором частичные значения базовых кодовых слов представляют собой удаление фиксированного числа начальных битов из базовых кодовых слов.
30. Устройство по п.29, в котором при отсутствии упомянутого смещения базовое кодовое слово на выбранном уровне дерева распространяется, по меньшей мере, частично, на удаленное число начальных битов.
31. Устройство по п.25, дополнительно содержащее декодер, который декодирует одно из кодовых слов из потока битов с кодовыми словами при помощи хранящейся структуры данных, причем декодер:
ищет уровни дерева кодирования для выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову из потока битов с кодовыми словами;
пропускает фиксированное число битов в потоке битов с кодовыми словами перед переходом к выбранному уровню дерева кодирования в ответ на показатель пропуска;
вычисляет одно значение из множества значений, соответствующих кодовому слову, на основе разности между выбранным значением из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову, и кодовым словом и индекс выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову.
32. Устройство по п.31, дополнительно содержащее устройство вывода, которое представляет выходные данные пользователю на основе, по меньшей мере, частично, вычисленного значения.
33. Устройство по п.25, в котором значения, представленные кодовыми словами, представляют, по меньшей мере, одно из видеоданных, данных изображения, голосовых данных или звуковых данных.
34. Устройство по п.25, дополнительно содержащее беспроводной приемник, который принимает кодовые слова от кодера по беспроводной связи.
35. Декодирующее устройство, содержащее:
память, хранящую структуру данных, содержащую частичные значения базовых кодовых слов, причем базовые кодовые слова соответствуют уровням дерева кодирования, определяющего канонические кодовые слова переменной длины, причем частичные значения основаны на смещении базовых кодовых слов на фиксированное число битов, и показатель пропуска, указывающий декодеру пропустить фиксированное число битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования; и
декодер, который обращается к памяти для декодирования одного из кодовых слов из потока битов на основе частичных значений и показателя пропуска в хранящейся структуре данных.
36. Устройство по п.35, в котором декодер:
осуществляет поиск уровней дерева кодирования для выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову из потока битов с кодовыми словами,
пропускает фиксированное число битов в потоке битов с кодовыми словами перед переходом к выбранному уровню дерева кодирования в ответ на показатель пропуска; и
вычисляет одно значение из множества значений, соответствующих кодовому слову, на основе разности между выбранным значением из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову, и кодовым словом и индекс выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову.
37. Устройство по п.36, дополнительно содержащее устройство вывода, которое представляет выходные данные пользователю на основе, по меньшей мере, частично, вычисленного значения.
38. Устройство по п.37, в котором структура данных содержит значения, представленные базовыми кодовыми словами, и длины частичных значений базовых кодовых слов.
39. Устройство по п.35, в котором декодер содержит мультимедийное декодирующее устройство, и декодер включает в себя одно из декодера видеоданных, декодера изображения и звукового декодера или голосового декодера.
40. Устройство по п.35, в котором некоторые из уровней дерева кодирования включают в себя кодовые слова, расположенные в лексикографическом порядке относительно значений, представленных кодовыми словами, и каждое из базовых кодовых слов является лексикографически наименьшим кодовым словом на соответствующем уровне в дереве кодирования.
41. Устройство по п.35, в котором частичные значения базовых кодовых слов представляют собой удаление фиксированного числа начальных битов из базовых кодовых слов.
42. Устройство по п.41, в котором при отсутствии упомянутого смещения базовое кодовое слово на выбранном уровне дерева распространяется, по меньшей мере, частично, на удаленное число начальных битов.
43. Устройство по п.35, дополнительно содержащее приемник для приема кодовых слов от кодера по беспроводной связи.
44. Способ декодирования, содержащий этапы, на которых:
обращаются к структуре данных, хранящейся в памяти, причем структура данных содержит частичные значения базовых кодовых слов, причем базовые кодовые слова соответствуют уровням дерева кодирования, определяющего кодовые слова переменной длины, причем частичные значения основаны на смещении базовых кодовых слов на фиксированное число битов, и показатель пропуска, указывающий декодеру пропустить фиксированное число битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования; и
декодируют одно из кодовых слов из потока битов на основе частичных значений и показателя пропуска в хранящейся структуре данных.
45. Способ по п.44, в котором декодирование содержит этапы, на которых:
осуществляют поиск уровней дерева кодирования для выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову из потока битов с кодовыми словами;
пропускают фиксированное число битов в потоке битов с кодовыми словами перед переходом к выбранному уровню дерева кодирования в ответ на показатель пропуска; и
вычисляют одно из множества значений, соответствующих кодовому слову, на основе разности между выбранным значением из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову, и кодовым словом и индекс выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову.
46. Способ по п.44, дополнительно содержащий этап, на котором представляют выходные данные пользователю на основе, по меньшей мере, частично, вычисленного значения.
47. Способ по п.44, в котором структура данных содержит значения, представленные базовыми кодовыми словами, и длины частичных значений базовых кодовых слов.
48. Способ по п.44, в котором декодирование содержит этап, на котором декодируют кодовые слова для получения значений, представляющих, по меньшей мере, одно из видеоданных, данных изображения, звуковых данных и голосовых данных.
49. Способ по п.44, в котором некоторые из уровней дерева кодирования включают в себя кодовые слова, расположенные в лексикографическом порядке относительно значений, представленных кодовыми словами, и каждое из базовых кодовых слов является лексикографически наименьшим кодовым словом на соответствующем уровне в дереве кодирования.
50. Способ по п.44, в котором частичные значения базовых кодовых слов представляют собой удаление фиксированного числа начальных битов из базовых кодовых слов.
51. Способ по п.50, в котором при отсутствии упомянутого смещения базовое кодовое слово на выбранном уровне дерева распространяется, по меньшей мере, частично, на удаленное число начальных битов.
52. Способ по п.44, дополнительно содержащий этап, на котором принимают кодовые слова от кодера по беспроводной связи.
53. Декодирующее устройство, содержащее:
средство хранения структуры данных, содержащей частичные значения базовых кодовых слов, причем базовые кодовые слова соответствуют уровням дерева кодирования, определяющего кодовые слова переменной длины, причем частичные значения основаны на смещении базовых кодовых слов на фиксированное число битов, и показатель пропуска, указывающий декодеру пропустить фиксированное число битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования; и
средство декодирования одного из кодовых слов из потока битов на основе частичных значений и показателя пропуска в хранящейся структуре данных.
54. Устройство по п.53, в котором средство декодирования содержит:
средство поиска уровней дерева кодирования для выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову из потока битов с кодовыми словами;
средство пропуска фиксированного числа битов в потоке битов с кодовыми словами перед переходом к выбранному уровню дерева кодирования в ответ на показатель пропуска; и
средство вычисления одного из множества значений, соответствующих кодовому слову, на основе разности между выбранным значением из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову, и кодовым словом и индекса выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову.
55. Устройство по п.53, далее дополнительно содержащее средство представления выходных данных пользователю на основе, по меньшей мере частично, вычисленного значения.
56. Устройство по п.53, в котором структура данных содержит значения, представленные базовыми кодовыми словами, и длины частичных значений базовых кодовых слов.
57. Устройство по п.53, в котором средство декодирования содержит средство декодирования кодовых слов для получения значений, представляющих, по меньшей мере, одно из видеоданных, данных изображения, звуковых данных и голосовых данных.
58. Устройство по п.53, в котором некоторые из уровней дерева кодирования включают в себя кодовые слова, расположенные в лексикографическом порядке относительно значений, представленных кодовыми словами, и каждое из базовых кодовых слов является лексикографически наименьшим кодовым словом на соответствующем уровне в дереве кодирования.
59. Устройство по п.53, в котором частичные значения базовых кодовых слов представляют собой удаление фиксированного числа начальных битов из базовых кодовых слов.
60. Устройство по п.59, в котором при отсутствии упомянутого смещения базовое кодовое слово на выбранном уровне дерева распространяется, по меньшей мере, частично, на удаленное число начальных битов.
61. Устройство по п.53, дополнительно содержащее средство приема кодовых слов от кодера по беспроводной связи.
62. Материальный машиночитаемый носитель, содержащий команды для побуждения процессора:
обращаться к структуре данных, хранящейся в памяти, причем структура данных содержит частичные значения базовых кодовых слов, причем базовые кодовые слова соответствуют уровням дерева кодирования, определяющего канонические кодовые слова переменной длины, причем частичные значения основаны на смещении базовых кодовых слов на фиксированное число битов, и показатель пропуска, указывающий декодеру пропустить фиксированное число битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования; и
декодировать одно из кодовых слов из потока битов на основе частичных значений и показателя пропуска в хранящейся структуре данных.
63. Машиночитаемый носитель по п.62, в котором команды побуждают процессор:
осуществлять поиск уровней дерева кодирования для выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову из потока битов с кодовыми словами;
пропускать фиксированное число битов в потоке битов с кодовыми словами перед переходом к выбранному уровню дерева кодирования в ответ на показатель пропуска; и
вычислять одно из множества значений, соответствующих кодовому слову, на основе разности между выбранным значением из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову, и кодовым словом и индекс выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову.
64. Машиночитаемый носитель по п.62, дополнительно содержащий команды, побуждающие процессор управлять устройством вывода для представления выходных данных пользователю на основе, по меньшей мере, частично, вычисленного значения.
65. Машиночитаемый носитель по п.62, в котором структура данных содержит значения, представленные базовыми кодовыми словами, и длины частичных значений базовых кодовых слов.
66. Машиночитаемый носитель по п.62, в котором команды побуждают процессор декодировать кодовые слова для получения значений, представляющих, по меньшей мере, одно из видеоданных, данных изображения, звуковых данных и голосовых данных.
67. Машиночитаемый носитель по п.62, в котором некоторые из уровней дерева кодирования включают в себя кодовые слова, расположенные в лексикографическом порядке относительно значений, представленных кодовыми словами, и каждое из базовых кодовых слов является лексикографически наименьшим кодовым словом на соответствующем уровне в дереве кодирования.
68. Машиночитаемый носитель по п.62 в котором частичные значения базовых кодовых слов представляют собой удаление фиксированного числа начальных битов из базовых кодовых слов.
69. Машиночитаемый носитель по п.68, в котором при отсутствии упомянутого смещения базовое кодовое слово на выбранном уровне дерева распространяется, по меньшей мере, частично, на удаленное число начальных битов.
70. Переносное устройство беспроводной связи, содержащее:
память, хранящую структуру данных, содержащую частичные значения базовых кодовых слов, причем базовые кодовые слова соответствуют уровням дерева кодирования, определяющего кодовые слова переменной длины, причем частичные значения основаны на смещении базовых кодовых слов на фиксированное число битов, и показатель пропуска, указывающий декодеру пропустить фиксированное число битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования; и
декодер, который обращается к памяти для декодирования одного из кодовых слов из потока битов на основе частичных значений и показателя пропуска в хранящейся структуре данных;
приемник для приема кодовых слов от кодера по беспроводной связи; и
устройство вывода, которое представляет выходные данные пользователю на основе, по меньшей мере, частично, декодированных кодовых слов.
71. Переносное устройство беспроводной связи по п.70, в котором декодер:
осуществляет поиск уровней дерева кодирования для выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову из потока битов с кодовыми словами,
пропускает фиксированное число битов в потоке битов с кодовыми словами перед переходом к выбранному уровню дерева кодирования в ответ на показатель пропуска; и
вычисляет одно значение из множества значений, соответствующих кодовому слову, на основе разности между выбранным значением из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову, и кодовым словом и индекс выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову.
72. Переносное устройство беспроводной связи по п.70, в котором структура данных содержит значения, представленные базовыми кодовыми словами, и длины частичных значений базовых кодовых слов.
73. Переносное устройство беспроводной связи по п.70, в котором декодер включает в себя одно из декодера видеоданных, декодера изображения и звукового декодера или голосового декодера.
74. Переносное устройство беспроводной связи по п.70, в котором некоторые из уровней дерева кодирования включают в себя кодовые слова, расположенные в лексикографическом порядке относительно значений, представленных кодовыми словами, и каждое из базовых кодовых слов является лексикографически наименьшим кодовым словом на соответствующем уровне в дереве кодирования.
75. Переносное устройство беспроводной связи по п.70, в котором частичные значения базовых кодовых слов представляют собой удаление фиксированного числа начальных битов из базовых кодовых слов.
76. Переносное устройство беспроводной связи по п.75, в котором при отсутствии упомянутого смещения базовое кодовое слово на выбранном уровне дерева распространяется, по меньшей мере, частично, на удаленное число начальных битов.
77. Интегральная схема устройства беспроводной связи, содержащая:
память, хранящую структуру данных, содержащую частичные значения базовых кодовых слов, причем базовые кодовые слова соответствуют уровням дерева кодирования, определяющего канонические кодовые слова переменной длины, причем частичные значения основаны на смещении базовых кодовых слов на фиксированное число битов, и показатель пропуска, указывающий декодеру пропустить фиксированное число битов в потоке битов, подлежащем декодированию, перед переходом к выбранному уровню дерева кодирования; и
декодер, который обращается к памяти для декодирования одного из кодовых слов из потока битов на основе частичных значений и показателя пропуска в хранящейся структуре данных.
78. Интегральная схема по п.77, в которой декодер:
осуществляет поиск уровней дерева кодирования для выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову из потока битов с кодовыми словами,
пропускает фиксированное число битов в потоке битов с кодовыми словами перед переходом к выбранному уровню дерева кодирования в ответ на показатель пропуска; и
вычисляет одно значение из множества значений, соответствующих кодовому слову, на основе разности между выбранным значением из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову, и кодовым словом и индекс выбранного значения из частичных значений базовых кодовых слов, которое меньше или равно кодовому слову.
79. Интегральная схема по п.77, в которой структура данных содержит значения, представленные базовыми кодовыми словами, и длины частичных значений базовых кодовых слов.
80. Интегральной схема по п.77, в которой декодер включает в себя одно из декодера видеоданных, декодера изображения и звукового декодера или голосового декодера.
81. Интегральная схема по п.77, в которой некоторые из уровней дерева кодирования включают в себя кодовые слова, расположенные в лексикографическом порядке относительно значений, представленных кодовыми словами, и каждое из базовых кодовых слов является лексикографически наименьшим кодовым словом на соответствующем уровне в дереве кодирования.
82. Интегральная схема по п.77, в котором частичные значения базовых кодовых слов представляют собой удаление фиксированного числа начальных битов из базовых кодовых слов.
83. Интегральная схема по п.82, в которой при отсутствии упомянутого смещения базовое кодовое слово на выбранном уровне дерева распространяется, по меньшей мере, частично, на удаленное число начальных битов.
| US 6144322 A, 2000.11.07 | |||
| EP 1248468 A2, 2002.10.09 | |||
| RU 2005113308 A, 2006.01.20 | |||
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| RU 2004125588 A, 2006.01.27 | |||
| US 2003151529 A1, 2003.08.14. | |||

