Изобретение относится к способу предоставления первому пользователю и второму пользователю возможности получать объединенный контент и объединяющему устройству для предоставления первому пользователю и второму пользователю возможности получать объединенный контент.
Статья «Virtual Jukebox. Reviving a Classic», C.Drews, F.Pestoni, Proceedings of the 35th HICSS 2002 («Виртуальный музыкальный автомат. Возрождение классики», С.Дрюс, Ф.Престони, доклады 35-го HICSS, 2002 г.), раскрывает систему для построения и использования группового профиля для автоматического выбора контента. Система предоставляет пользователям возможность точно выражать свои предпочтения взносами на песни, которые должны воспроизводиться, и через систему голосования. Система содержит распределенное хранилище с музыкальными файлами, подключенный к сети музыкальный проигрыватель и сервер для поставки музыкальных файлов в проигрыватель. В то время как песня воспроизводится, пользователи голосуют за или против песни. Система накапливает голоса и строит групповой профиль, представляющий групповые предпочтения пользователей. На основе группового профиля адаптируется или формируется список воспроизведения из песен.
Когда голоса пользователей противоречивы в отношении воспроизводимых песен, то есть системой накапливаются положительные и отрицательные голоса, групповые предпочтения не предоставляют возможности исключить из состава или включить в состав песни в списке воспроизведения. В этой ситуации невозможно выбирать песни на основе групповых предпочтений, а выбор контента неэффективен.
Желательно предоставить способ, который дает первому пользователю и второму пользователю возможность получать объединенный контент несмотря на то, что предпочтения пользователей противоречивы.
Способ содержит этапы:
- получения множества данных о предпочтениях по контенту, содержащих первые данные о предпочтениях по контенту первого пользователя и вторые данные о предпочтениях по контенту второго пользователя,
- получения данных зависимости, указывающих зависимость первых данных о предпочтениях по контенту от вторых данных о предпочтениях по контенту, и
- использования упомянутого множества данных о предпочтениях по контенту для выбора объединенного контента под управлением упомянутых данных зависимости.
Данные о предпочтениях по контенту могут отражать предпочтения пользователей в отношении контента, например, песен и кинофильмов, которые были представлены пользователям. В одном из примеров, предпочтения пользователей по контенту выводятся, например, из характерных черт ТВ-просмотра пользователя или предыстории выбора ТВ-программ. Предпочтения по контенту также могут предопределяться в стереотипном профиле пользователя. В другом примере, пользователи снабжены средством для создания и редактирования данных о предпочтениях по контенту вручную.
Данные зависимости используются, когда объединенный контент выбирается на основе первых и вторых данных о предпочтениях по контенту. Например, данные зависимости указывают образ действий, которым первые и вторые данные о предпочтениях по контенту комбинируются в объединенные данные о предпочтениях по контенту. Последовательность операций комбинирования может включать в себя проверку того, имеет ли конкретный элемент данных положительный или отрицательный рейтинг в первых и вторых данных о предпочтениях по контенту. Кроме того, данные зависимости анализируются для определения следующего этапа. Например, если данные зависимости указывают, что положительный рейтинг конкретного элемента контента во вторых данных о предпочтениях по контенту одерживает верх над любым рейтингом конкретного контента в первых данных о предпочтениях по контенту, в объединенных данных о предпочтениях по контенту используется рейтинг конкретного элемента контента только из вторых данных о предпочтениях по контенту. Рейтинг в первых данных о предпочтениях по контенту может игнорироваться в случае, если рейтинг конкретного элемента контента в первых данных о предпочтениях по контенту является противоречивым в отношении такового из вторых данных о предпочтениях по контенту. Этим путем, противоречащие рейтинги пользователей обрабатываются так, что приоритет отдается одному из рейтингов. Бесспорно, объединенные данные о предпочтениях по контенту теперь содержат недвусмысленный рейтинг для конкретного элемента контента, а выбор контента может выполняться однозначно.
Данные зависимости могут задаваться явным образом первым пользователем в первых данных о предпочтениях по контенту, например, потому что первый пользователь предпочитает, чтобы использовался рейтинг от второго пользователя. В другом примере, данные зависимости могут выводиться автоматически, например, из объема опыта пользователей при назначении рейтинга элементам контента конкретного жанра.
Настоящее изобретение преодолевает недостаток системы, известной из статьи «Virtual Jukebox. Reviving a Classic». В известной системе, комбинация положительных и отрицательных рейтингов имеет следствием бесполезный общий рейтинг, который является нулевым. Такой общий рейтинг в объединенных данных о предпочтениях по контенту не указывает, предпочитают ли какие-нибудь пользователи конкретный элемент контента. Таким образом, конкретный элемент контента не мог бы рекомендоваться ни первому, ни второму пользователю. В противоположность, настоящее изобретение, например, предоставляет одному пользователю возможность отдавать другому пользователю приоритет на включение конкретного элемента контента в объединенный контент. Например, первые данные о предпочтениях по контенту и вторые данные о предпочтениях по контенту могут включать в себя ссылки друг на друга, чтобы оказывать влияние на выбор объединенного контента.
Объединяющее устройство по настоящему изобретению содержит процессор данных, сконфигурированный для:
- получения множества данных о предпочтениях по контенту, содержащих первые данные о предпочтениях по контенту первого пользователя и вторые данные о предпочтениях по контенту второго пользователя,
- получения данных зависимости, указывающих зависимость первых данных о предпочтениях по контенту от вторых данных о предпочтениях по контенту, и
- использования упомянутого множества данных о предпочтениях по контенту для выбора объединенного контента под управлением упомянутых данных зависимости.
Объединяющее устройство гарантирует, что первые и вторые данные о предпочтениях по контенту обрабатываются с использованием данных зависимости, например, так что первые данные о предпочтениях по контенту обладают некоторым приоритетом в отношении вторых данных о предпочтениях по контенту.
Эти и другие аспекты изобретения будут дополнительно пояснены и описаны в качестве примера со ссылкой на следующие чертежи:
фиг.1 - функциональная структурная схема варианта осуществления устройства согласно настоящему изобретению;
фиг.2 - вариант осуществления способа по настоящему изобретению.
Изобретение может быть воплощено в клиент-серверной системе 100, содержащей сервер 110 (объединяющее устройство) для осуществления связи с первым пользовательским устройством и вторым пользовательским устройством 130, как показано на фиг.1. В еще одном варианте осуществления, изобретение реализовано в распределенной системе, например, сети одноранговых узлов, содержащей первое и второе пользовательские устройства, но никакого отдельного сервера, как в клиент-серверной системе. Например, одно из пользовательских устройств в распределенной системе может быть сконфигурировано в качестве сервера.
Фиг.1 показывает вариант осуществления настоящего изобретения, содержащий сервер 110, первое пользовательское устройство 120, второе пользовательское устройство 130 и базу 140 данных контента.
База 140 данных контента может хранить аудиовизуальный контент в виде одного или более элементов контента, содержащих аудио- и/или видеоданные. Выражение «аудиоданные» или «аудиоконтент» в дальнейшем используются в качестве данных, имеющих отношение к аудио, содержащему звук в слышимом диапазоне, молчание, речь, музыку, спокойствие, внешний шум или тому подобное. Аудиоданные могут быть в форматах, подобных стандарту уровня III MPEG-1 (mp3) (Экспертной группы по киноизображению), формату AVI (перемежающихся аудио- и видеоданных), формату WMA (аудиомультимедийной среды Windows), и т.п. Выражение «видеоданные» или «видеоконтент» используется в качестве данных, которые являются видимыми, таких как движущееся изображение, «неподвижные изображения», видеотекст и т.п. Видеоданные могут быть в форматах, подобных GIF (формату графического обмена), JPEG (названному в честь Объединенной группы экспертов в области фотографии), MPEG-4 и т.п. Текстовая информация, например, может быть в формате ASCII (Американского стандартного кода для обмена информацией), формате PDF (формате Adobe Acrobat), формате HTML (языка гипертекстовой разметки). Метаданные могут быть в формате XML (расширяемого языка разметки), формате стандарта MPEG7, хранимом в базе данных SQL (языка структурированных запросов) или любом другом формате.
Аудиовизуальный контент может храниться в базе 140 данных контента на разных носителях данных, таких как аудио- или видеолента, оптические запоминающие диски, например диск CD-ROM (постоянное запоминающее устройство на компакт-диске) или диск DVD (цифровой многофункциональный диск), гибкий или жесткий диск, и т.п., в любом формате, например MPEG (Экспертной группы по киноизображению), MIDI (цифрового интерфейса музыкальных инструментов), Shockwave, QuickTime, WAV (восстановления волновой формы аудио) и т.п. Например, база 140 данных контента может содержать компьютерный накопитель на жестком диске, многофункциональную карту флэш-памяти, например устройство «Memory Stick» и т.п.
Вкратце, система 100 функционирует, как изложено ниже. Первое и второе пользовательские устройства сконфигурированы для получения объединенного контента на основе первых данных 121 о предпочтениях по контенту первого пользователя и вторых данных 131 о предпочтениях по контенту второго пользователя. Например, первые и вторые данные о предпочтениях по контенту (в дальнейшем упомянутые ссылкой как первые и вторые данные о предпочтениях) используются для фильтрации аудиовизуального контента, сохраненного в базе 140 данных контента. Последовательность операций фильтрации может выполняться сервером 110 или одним из пользовательских устройств 120 и 130. Как результат, объединенный контент отфильтровывается из базы 140 данных контента. В заключение, объединенный контент передается в первое и второе пользовательские устройства.
В конкретном варианте осуществления, показанном на фиг.1, сервер 110 сконфигурирован для приема первых и вторых данных 121 и 131 о предпочтениях по контенту с первого и второго пользовательских устройств 120 и 130, соответственно. Первые и вторые данные о предпочтениях формируются, поддерживаются и хранятся устройствами 120 и 130. Например, первое и второе пользовательские устройства 120 и 130 являются телевизорами (или персональными компьютерами с ТВ-тюнерами). Телевизоры могут быть приспособлены для отслеживания взаимодействия с пользователем посредством выбора ТВ-каналов. Излюбленные ТВ-каналы первого и второго пользователей, например часто выбираемые или просматриваемые ТВ-каналы за день или неделю, записываются в первых и вторых данных 121 и 131 о предпочтениях в первом пользовательском устройстве 120 и втором пользовательском устройстве 130, соответственно.
В качестве альтернативы, первые и вторые данные о предпочтении могут сохраняться на сервере 110. Например, первое и второе пользовательские устройства 120 и 130 могут передавать (шифрованную) информацию на сервер 110 о выборах ТВ-каналов. Сервер может анализировать информацию для формирования первых и вторых данных о предпочтениях.
Сервер 110 может содержать процессор 111 данных, сконфигурированный для выполнения функций, предусмотренных в концепции настоящего изобретения. Процессор 111 данных может быть известным (центральным) процессором (ЦП, CPU), выполненным надлежащим образом с возможностью реализации настоящего изобретения. Сервер 110 дополнительно может содержать блок 112 памяти, например известный модуль памяти ОЗУ (RAM, оперативного запоминающего устройства). Процессор 111 данных может быть выполнен с возможностью считывать из блока памяти по меньшей мере одну инструкцию (компьютерной программы), чтобы дать возможность функционирования сервера.
Из первых и вторых данных 121 и 131 о предпочтениях, процессор 111 данных может компоновать объединенные данные 113 о предпочтениях по контенту (в дальнейшем указываемые ссылкой как объединенные данные о предпочтениях). Например, первые и вторые данные о предпочтениях могут включать в себя отдельные рейтинговые значения жанра ТВ-программ, например жанра ТВ-новостей или жанра ТВ-шоу. Процессор данных может комбинировать отдельные рейтинговые значения в среднее значение и сохранять среднее значение в объединенных данных 113 о предпочтениях. В еще одном примере, процессор данных может быть сконфигурирован для идентификации перекрытий предпочтений в первых и вторых данных, чтобы создавать объединенные данные о предпочтениях. Как только объединенные данные о предпочтениях обновлены первыми и вторыми данными о предпочтениях, процессор 111 данных может сохранять объединенные данные о предпочтениях в блоке 112 памяти. С использованием объединенных данных о предпочтениях процессор 111 данных может получать объединенный контент из базы 140 данных контента. Например, процессор 111 данных может принимать из базы 140 данных контента один или более идентификаторов, например название ТВ-шоу, кинофильмов и т.п., согласующихся с объединенными данными 113 о предпочтениях.
Могут быть другие способы для получения объединенного контента, нежели использование объединенных данных 113 о предпочтениях. Например, процессор 111 данных может осуществлять доступ к базе 140 данных контента для приема контента в соответствии с первыми данными 121 о предпочтениях и для извлечения второго контента с использованием вторых данных 131 о предпочтениях. Кроме того, процессор данных может определять перекрывающийся контент в первом и втором контентах. Перекрывающийся контент мог бы интерпретироваться в качестве объединенного контента, который могли бы предпочесть оба пользователя.
Согласно настоящему изобретению, данные 114 зависимости используются для выбора объединенного контента. Данные 114 зависимости указывают зависимость первых данных 121 о предпочтениях по контенту от вторых данных 131 о предпочтениях по контенту. Например, первые данные о предпочтениях содержат список жанров и соответствующие значения предпочтений первого пользователя. Дополнительно, первые данные о предпочтениях задают условия, когда значения предпочтений отвергаются в зависимости от вторых данных о предпочтениях. Пример первых данных о предпочтениях приведен ниже, в таблице.
В примере, первые данные о предпочтениях содержат перечень жанров, например жанры видео: ТВ-новости, кинофильмы, спорт, ТВ-шоу, учебные ТВ-программы; и жанры музыки: классическая музыка, джаз. Каждому жанру установлен рейтинг со значением от 0 до 100 в зависимости от предпочтений по контенту первого пользователя в отношении соответствующего жанра. Такие первые данные о предпочтениях с оцененными рейтингом жанрами могут использоваться различными способами для выбора контента. Например, контент выбирается, если контент принадлежит к определенному жанру, оцененному рейтингом выше предопределенного порогового значения в первых данных о предпочтениях по контенту.
Первый пользователь может задавать для некоторых жанров в первых данных о предпочтениях, будут ли рейтинги жанров из вторых данных о предпочтениях второго пользователя использоваться вместо рейтингов жанров из первых данных о предпочтениях. В примере из таблицы, жанр «ТВ-шоу» имеет низкий рейтинг 10 из 100 очков. Однако данные зависимости в первых данных о предпочтениях указывают, что если вторые данные о предпочтениях второго пользователя, идентифицированного как «Питер», указывают, что жанр «ТВ-шоу» оценен рейтингом в более чем 80 очков, то «низкий» рейтинг жанра «ТВ-шоу» в первых данных о предпочтениях будет игнорироваться в поддержку «высокого» рейтинга жанра во вторых данных о предпочтениях при условии, что вторые данные о предпочтениях используются вместе с первыми данными о предпочтениях для фильтрации контента. Первые данные 121 о предпочтениях могут сохраняться в первом пользовательском устройстве 120 вместе с данными 114a зависимости (одним или более условий). Таким образом, если второму пользователю очень сильно нравится жанр «ТВ-шоу», ТВ-программы с таким жанром по-прежнему могут включаться в объединенный контент.
Первый и второй пользователи могут задавать свои собственные данные зависимости независимо друг от друга. Второе пользовательское устройство 130 также может хранить данные зависимости (не показаны), имеющие отношение ко вторым данным 131 о предпочтениях.
В качестве альтернативы условию, где жанр «ТВ-шоу» оценен рейтингом в более чем 80 очков во вторых данных о предпочтениях, другое условие в первых данных о предпочтениях может задавать, что жанр оценивается рейтингом с 80 очками, если вторые данные о предпочтениях указывают, что второй пользователь не просматривал ТВ-программу с жанром «ТВ-шоу» в течение более чем предопределенного промежутка времени.
В примере из таблицы, может указываться, что рейтинг жанра из вторых данных о предпочтениях должен быть вместо первых данных о предпочтениях, независимо от значения рейтинга. Например, идентификатор второго пользователя «Питер» или простая ссылка на вторые данные о предпочтениях может указываться в первых данных о предпочтениях в отношении определенного жанра. Этим способом первый пользователь делегирует выбор контента соответствующего жанра второму пользователю.
Должно быть отмечено, что данные зависимости, как проиллюстрировано в таблице, требуют, чтобы первые и вторые данные о предпочтениях были совместимы по классификации жанров. Совместимость первых и вторых данных о предпочтениях может гарантироваться поручением серверу 110 поддерживать первые и вторые данные о предпочтениях в одинаковом формате.
Данные 114 зависимости также могут быть реализованы другим способом. Например, процессор 111 данных сконфигурирован для анализа первых и вторых данных о предпочтениях, содержащих записи с предысторией потребления контента первым и вторым пользователями. Анализ может служить для выяснения, первый ли пользователь или второй пользователь обладает большим опытом в просмотре или прослушивании в отношении контента определенного жанра. Например, частота выбора контента и промежуток времени просмотра или прослушивания в отношении контента могут определять уровень опыта. На основе уровня опыта процессор данных может определять, будет ли использоваться в отношении жанра значение рейтинга из первых или вторых данных о предпочтениях. Процессор данных может предлагать первому или второму пользователю подтверждать определение или выполнять определение автоматически без информирования пользователей.
Данные зависимости не ограничены тем, чтобы выражаться только в отношении первого или второго пользователя. Данные зависимости также могут относиться к группам пользователей. Например, первый пользователь может задавать первые данные 121 о предпочтениях, так что «низкий» рейтинг жанра «ТВ-шоу» должен игнорироваться, если данные о предпочтениях по контенту любого другого пользователя группы (не обязательно вторые данные о предпочтениях) указывают «высокий» рейтинг жанра.
Первое пользовательское устройство и/или второе пользовательское устройство могут быть любыми из различных устройств бытовой электроники, таких как телевизор (ТВ-приемник) с кабельной, спутниковой или другой линией связи, видеокассетное или HDD-устройство записи, система домашнего кинотеатра, портативный CD-проигрыватель, устройство дистанционного управления, такое как пульт дистанционного управления iPronto, сотовый телефон и т.п.
Фиг.2 показывает вариант осуществления способа по настоящему изобретению. Способ содержит этап 210 получения множества данных о предпочтениях по контенту, содержащих первые и вторые данные о предпочтениях по контенту. Данные о предпочтениях по контенту могут указывать предпочтения соответствующего пользователя в любом виде, подходящем для выбора контента, например, с использованием спецификации данных RDF (объектной структуры описания ресурсов) семантической Web-технологии (http://www.w3.org). Например, данные о предпочтениях по контенту могут указывать степень, до которой соответствующему пользователю нравится или не нравится конкретный элемент контента, жанр или тема (природа, наука и т.п.). На этапе 220 получают данные зависимости, которые указывают зависимость первых данных о предпочтениях по контенту от вторых данных о предпочтениях по контенту. Данные зависимости могут быть частью первых или вторых данных о предпочтениях, сохраненных в устройствах 120 или 130, соответственно. В качестве альтернативы, данные зависимости могут сохраняться отдельно от данных о предпочтениях по контенту, например, в блоке 112 памяти сервера 110. Данные зависимости создаются первым или вторым пользователем либо они выводятся процессором 111 данных автоматически. Данные зависимости могут быть реализованы в виде ссылок между данными о предпочтениях по контенту с использованием URI (унифицированных идентификаторов информационных ресурсов). На этапе 230 упомянутое множество данных о предпочтениях по контенту используют для выбора объединенного контента под управлением данных зависимости. Данные зависимости могут управлять способом использования первых и вторых данных о предпочтениях для выбора. Например, первые или вторые данные о предпочтениях могут игнорироваться в пользу друг другу либо замещаться друг другом, как пояснено выше.
Варианты и модификации описанного варианта осуществления изобретения возможны в пределах объема настоящего изобретения. Например, в одном из вариантов осуществления система согласно настоящему изобретению реализована в одиночном объединяющем устройстве вместо клиент-серверной архитектуры, показанной на фиг.1. База 140 данных контента может быть отдельной от или включенной в состав сервера 110.
Процессор данных может исполнять программу программного обеспечения, чтобы предоставлять возможность выполнения этапов способа по настоящему изобретению. Программное обеспечение может управлять устройством по настоящему изобретению независимо от того, где оно исполняется. Для управления устройством процессор, например, может передавать программу программного обеспечения на другие (внешние) устройства. Независимый пункт формулы изобретения на способ и независимый пункт формулы изобретения на компьютерный программный продукт могут использоваться для защиты изобретения, когда программное обеспечение производится или эксплуатируется для работы на изделиях бытовой электроники. Внешнее устройство может присоединяться к процессору с использованием существующих технологий, таких как Blue-tooth, IEEE 802.11 [a-g] и т.п. Процессор может взаимодействовать с внешним устройством в соответствии со стандартом UPnP (универсального подключения и работы).
«Компьютерная программа» должна пониматься как означающая любой программный продукт, сохраненный на машиночитаемом носителе, таком как гибкий диск, загружаемый через сеть, такую как сеть Интернет, или годный для продажи любым другим способом. Различные программные продукты могут реализовывать функции системы и способа по настоящему изобретению и могут комбинироваться некоторыми способами с аппаратными средствами или располагаться на разных устройствах. Изобретение может быть реализовано посредством аппаратных средств, содержащих несколько отдельных элементов, и посредством подходящим образом запрограммированного компьютера.
| название | год | авторы | номер документа |
|---|---|---|---|
| РЕКОМЕНДУЮЩАЯ СИСТЕМА СО СМЕЩЕНИЕМ | 2009 |
|
RU2532703C2 |
| ЭЛЕКТРОННЫЙ ПУТЕВОДИТЕЛЬ ПО МЕДИАКОНТЕНТУ | 2013 |
|
RU2621697C2 |
| ГИБКАЯ СИСТЕМА ДЛЯ РАСПРОСТРАНЕНИЯ КОНТЕНТА НА УСТРОЙСТВО | 2006 |
|
RU2393638C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ АВТОМАТИЧЕСКОГО РЕГУЛИРОВАНИЯ ФИЛЬТРА | 2013 |
|
RU2633096C2 |
| АДАПТИВНОЕ НЕЯВНОЕ ИЗУЧЕНИЕ ДЛЯ РЕКОМЕНДАТЕЛЬНЫХ СИСТЕМ | 2009 |
|
RU2524840C2 |
| СИСТЕМА РЕКОМЕНДАТЕЛЯ С ПРИМЕНЕНИЕМ СОВМЕСТИМОГО ПРОФИЛЯ | 2011 |
|
RU2590994C2 |
| РЕЖИМЫ БЫСТРОГО ДОСТУПА К ПРОИЗВОЛЬНОЙ ТОЧКЕ ДЛЯ СЕТЕВОЙ ПОТОКОВОЙ ПЕРЕДАЧИ КОДИРОВАННЫХ ВИДЕОДАННЫХ | 2011 |
|
RU2571375C2 |
| УСТРОЙСТВО И СПОСОБ УПРАВЛЕНИЯ ПЕРСОНАЛЬНЫМ КАНАЛОМ | 2012 |
|
RU2605002C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ЭФФЕКТИВНОГО КОМПИЛИРОВАНИЯ ЭЛЕМЕНТОВ МЕДИА-КОНТЕНТА ДЛЯ ПЛАТФОРМЫ МЕДИА ПО ЗАПРОСУ | 2013 |
|
RU2649304C2 |
| СИСТЕМА И СПОСОБ ГЕНЕРАЦИИ ЗВУКОВОГО ФАЙЛА | 2014 |
|
RU2662125C2 |

Изобретение относится к способу предоставления первому пользователю и второму пользователю возможности получать объединенный контент. Техническим результатом является расширение функциональных возможностей за счет предоставления одному пользователю возможности отдавать другому пользователю приоритет на включение конкретного элемента контента в объединенный контент. Способ содержит этапы получения множества данных о предпочтениях по контенту, содержащих первые данные о предпочтениях по контенту первого пользователя и вторые данные о предпочтениях по контенту второго пользователя, получения данных зависимости, указывающих зависимость первых данных о предпочтениях по контенту от вторых данных о предпочтениях по контенту, и использования упомянутого множества данных о предпочтениях по контенту для выбора объединенного контента под управлением упомянутых данных зависимости. Изобретение также относится к объединяющему устройству для предоставления первому пользователю и второму пользователю возможности получать объединенный контент. 4 н. и 6 з.п. ф-лы, 1 табл., 2 ил.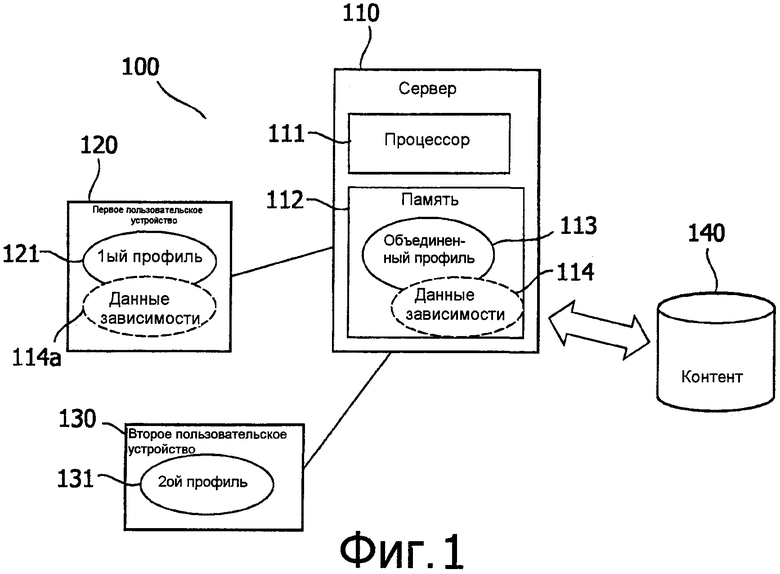
1. Способ предоставления первому пользователю и второму пользователю возможности получать объединенный контент, содержащий этапы, на которых
получают множество данных о предпочтениях по контенту, содержащих первые данные (121) о предпочтениях по контенту первого пользователя и вторые данные (131) о предпочтениях по контенту второго пользователя, причем первые и вторые данные о предпочтениях по контенту включают в себя рейтинговые значения,
получают данные (114, 114а) зависимости, указывающие зависимость рейтингового значения в первых данных о предпочтениях по контенту от соответствующего рейтингового значения во вторых данных о предпочтениях по контенту, и
используют упомянутое множество данных о предпочтениях по контенту для выбора объединенного контента под управлением упомянутых данных зависимости.
2. Способ по п.1, в котором первые данные о предпочтениях по контенту первого пользователя содержат идентификатор второго пользователя.
3. Способ по п.1 или 2, в котором данные зависимости указывают, что вторые данные о предпочтениях по контенту имеют более высокое значение приоритета для выбора, чем первые данные о предпочтениях по контенту.
4. Способ по п.1 или 2, в котором вторые данные о предпочтениях по контенту содержат данные предыстории потребления контента, относящиеся ко второму пользователю.
5. Способ по п.1 или 2, в котором первые данные о предпочтениях по контенту и вторые данные о предпочтениях по контенту комбинируются в объединенные данные (113) о предпочтениях по контенту для выбора объединенного контента.
6. Сервер (110) для предоставления первому пользователю и второму пользователю возможности получать объединенный контент, содержащий процессор (111) данных, сконфигурированный для
получения множества данных о предпочтениях по контенту, содержащих первые данные (121) о предпочтениях по контенту первого пользователя и вторые данные (131) о предпочтениях по контенту второго пользователя, причем первые и вторые данные о предпочтениях по контенту включают в себя рейтинговые значения,
получения данных (114, 114а) зависимости, указывающих зависимость рейтингового значения в первых данных о предпочтениях по контенту от соответствующего рейтингового значения во вторых данных о предпочтениях по контенту, и
использования упомянутого множества данных о предпочтениях по контенту для выбора объединенного контента под управлением упомянутых данных зависимости.
7. Сервер по п.6, сконфигурированный для получения данных зависимости из первого пользовательского устройства (120) первого пользователя, причем первое пользовательское устройство содержит сохраненные данные (114а) зависимости.
8. Сервер по п.6, сконфигурированный для передачи объединенного контента в первое пользовательское устройство (120) первого пользователя и во второе пользовательское устройство (130) второго пользователя.
9. Пользовательское устройство для предоставления первому пользователю и второму пользователю возможности получать объединенный контент, содержащее процессор данных, сконфигурированный для
получения множества данных о предпочтениях по контенту, содержащих первые данные о предпочтениях по контенту первого пользователя и вторые данные о предпочтениях по контенту второго пользователя, причем первые и вторые данные о предпочтениях по контенту включают в себя рейтинговые значения,
получения данных зависимости, указывающих зависимость рейтингового значения в первых данных о предпочтениях по контенту от соответствующего рейтингового значения во вторых данных о предпочтениях по контенту и
использования упомянутого множества данных о предпочтениях по контенту для выбора объединенного контента под управлением упомянутых данных зависимости.
10. Машиночитаемый носитель, на котором записана компьютерная программа, включающая в себя средства кода, приспособленные для реализации при их исполнении на вычислительном устройстве этапов способа по п.1.
| Фотореле | 1941 |
|
SU62223A1 |
| СПОСОБ СНАРЯЖЕНИЯ ТРАВМАТИЧЕСКИХ ПАТРОНОВ | 2007 |
|
RU2351891C2 |
| СПОСОБ ПРОВЕДЕНИЯ ТРАНСАКЦИЙ, КОМПЬЮТЕРИЗОВАННЫЙ СПОСОБ ЗАЩИТЫ СЕТЕВОГО СЕРВЕРА, ТРАНСАКЦИОННАЯ СИСТЕМА, СЕРВЕР ЭЛЕКТРОННОГО БУМАЖНИКА, КОМПЬЮТЕРИЗОВАННЫЙ СПОСОБ ВЫПОЛНЕНИЯ ОНЛАЙНОВЫХ ПОКУПОК (ВАРИАНТЫ) И КОМПЬЮТЕРИЗОВАННЫЙ СПОСОБ КОНТРОЛЯ ДОСТУПА | 2000 |
|
RU2252451C2 |
| WO 2004072761 А2, 26.08.2004 | |||
| US 20030205848 А1, 06.11.2003. | |||

