Уровень техники
Технология стала неотъемлемой частью в повседневных операциях для многих, если не большинства, бизнес-моделей. Некоторые бизнес-модели полагаются на большое количество вычислительных систем в повседневных операциях; часто это называется окружением предприятия. В настоящий момент перед множеством администраторов и связанных с ними специалистов по поддержке стоит сложная и зачастую продолжительная по времени задача конфигурировать и развертывать каждую вычислительную систему. Например, администратор и персонал поддержки могут тратить множество часов и дней, устанавливая и конфигурируя ферму серверов для организации. Кроме того, при определенных обстоятельствах ранее сконфигурированная вычислительная система, возможно, должна быть переконфигурирована для конкретной цели. Переконфигурирование может длиться столько же или даже дольше по сравнению с первоначальным развертыванием. Это неэффективный и затратный процесс.
Один пример служит для иллюстрации неэффективного, затратного и во многих случаях трудоемкого процесса конфигурирования и развертывания нескольких вычислительных систем. В этом примере тестировщик должен реплицировать кластер серверов, чтобы выполнить тестирование содержимого. Тестировщик сначала должен сообщить по телефону или послать по электронной почте запрос репликации. После приема запроса системный инженер выполняет поиск доступных серверов, чтобы удовлетворить запрос. Если запрошенное число серверов доступно, системный инженер перекомпонует серверы в соответствии с конфигурационным запросом и отправляет почтовые сообщения (или делает телефонные звонки) по состоянию соответствующим участникам.
Затем системный инженер должен вручную создать новый файл machine.xml, включая добавление новых имен серверов. Системный инженер после этого извлекает пересылаемый файл для конкретного кластера. Пересылаемый файл может быть описан как файл или программа, которая включает в себя код и задания по обработке содержимого, которые развернуты для конкретного кластера и/или окружения. Системный инженер использует тогда средство развертывания (к примеру, диспетчер командной строки), чтобы использовать релевантные биты на серверах.
После того как каждый сервер успешно конфигурирован и развернут, системный инженер отправляет подтверждающее почтовое сообщение или делает телефонный звонок соответствующим сторонам, в том числе и запрос, чтобы инженер проинформировал о том, когда серверы больше не будут требоваться. Дополнительную сложность проблеме создает то, что системный инженер не имеет простого способа отслеживать всю информацию, ассоциированную с конкретной конфигурацией и развертыванием. Таким образом, текущее состояние конфигурирования и развертывания нескольких вычислительных систем типично требует множества человеко-часов и может быть затратным и подверженным ошибкам процессом.
Раскрытие изобретения
Данное раскрытие изобретения предоставлено для того, чтобы представить выбор концепций в упрощенной форме, которые дополнительно описаны ниже в осуществлении изобретения. Данное раскрытие не имеет намерения ни идентифицировать ключевые признаки или неотъемлемые признаки заявляемого предмета изобретения, ни использоваться как помощь в определении объема заявленной сущности изобретения.
Варианты осуществления предоставляются для того, чтобы динамически конфигурировать, выделять и/или развертывать одну или более вычислительных систем на основе пользовательских требований и/или ввода. Зарезервированные системы могут быть динамически сконфигурированы с помощью требуемого кода и/или содержимого согласно пользовательским требованиям. Например, ряд серверов может быть динамически сконфигурирован, выделен и развернут согласно запросу пользователя. Динамически развернутые серверы могут быть использованы для того, чтобы быстро и эффективно тестировать код и программы, выполнять отладку кода и программ и/или выполнять другие операции конфигурирования и тестирования.
Зарезервированный кластер систем может быть возвращен в доступный пул, как только резервирование истекает, давая возможность переконфигурирования, повторного выделения и/или повторного развертывания возвращенных систем для их последующего резервирования. Например, серверы могут быть переконфигурированы из одной конфигурации в другую конфигурацию. Серверы также могут быть перераспределены из одного типа службы в другой тип службы. В различных вариантах осуществления вычислительная система, такая как, к примеру, сервер, может быть зарезервирована для конкретных требований использования и/или на указанный интервал времени. На основе требований резервирования вычислительная система может быть динамически сконфигурирована, чтобы хранить конкретную конфигурацию в течение периода резервирования.
Эти и другие признаки и преимущества поясняются в последующем подробном описании и на иллюстрирующих чертежах. Следует понимать, что и вышеупомянутое общее описание, и последующее детальное описание являются только примерными и пояснительными, а не ограничивающими заявленное изобретение.
Краткое описание чертежей
Фиг.1 иллюстрирует блок-схему вычислительной сети.
Фиг.2 - схема, иллюстрирующая ряд таблиц.
Фиг.3A-3B иллюстрируют блок-схему последовательности операций способа конфигурирования, выделения и развертывания одного или более обслуживающих компьютеров.
Фиг.4A-4I иллюстрируют функциональные блок-схемы сети и конфигурирования, выделения и развертывания одного или более обслуживающих компьютеров.
Фиг.5A-5C иллюстрируют различные примеры пользовательского интерфейса.
Фиг.6 - это схема, иллюстрирующая ряд таблиц.
Фиг.7 - это блок-схема, иллюстрирующая вычислительное окружение для реализации различных вариантов осуществления, описанных в данном документе.
Детальное описание
Представлены варианты осуществления, чтобы динамически конфигурировать, выделять и/или развертывать одну или более вычислительных систем в сети. В варианте осуществления пользователь может резервировать кластер серверов, при этом кластер динамически конфигурируется, выделяется и развертывается согласно требованиям пользователя. Варианты осуществления предоставляют быстрый и эффективный способ для пользователей, чтобы тестировать код и программы, выполнять отладку кода и программ и/или выполнять другие операции конфигурирования и тестирования, используя одну или более вычислительных систем, к примеру кластер серверов. Например, ряд серверов может быть зарезервирован или для него могут быть запрошены конкретные подробности развертывания согласно требуемой реализации. Ряд серверов затем может быть выделен из общего пула. После выделения ряд серверов может быть сконфигурирован посредством установки операционных систем (OS), промежуточного программного обеспечения и/или тестовых битов в соответствии с запрошенными подробностями развертывания. Конфигурированные серверы далее могут быть развернуты так, чтобы совпадать по времени с началом резервирования. Любые необходимые уведомления и информация о состоянии могут быть автоматически предоставлены одному или более пользователям, чтобы успешно взаимодействовать (к примеру, для целей тестирования, целей отладки и т.д.) с зарезервированным кластером.
Фиг.1 - это схема вычислительной сети 100 согласно варианту осуществления. Как описано ниже, компоненты вычислительной сети 100 конфигурированы и могут действовать, чтобы динамически конфигурировать, выделять и/или развертывать одну или более вычислительных систем в сети 100 или другой сети. Например, компоненты вычислительной сети 100 конфигурированы и могут действовать, чтобы динамически конфигурировать, выделять и/или развертывать одну или более систем системного пула (к примеру, системного пула 102, системного пула 104) в сети 100. Дополнительно, компоненты могут использоваться для того, чтобы резервировать одну или более вычислительных систем для одной или более задач и на требуемый интервал времени.
Компоненты вычислительной сети 100 дополнительно конфигурированы и могут функционировать так, чтобы динамически переконфигурировать, повторно выделять и/или повторно развертывать одну или более вычислительных систем в сети 100 или другой сети. При использовании в данном документе, вычислительная система упоминается как любое вычислительное устройство или система, в том числе серверы, настольные компьютеры, карманные компьютеры, портативные компьютеры и другие вычислительные устройства и системы. При использовании в данном документе, термин "сеть" охватывает любую конфигурацию вычислительных устройств, которые передают и обрабатывают информацию и могут быть реализованы как проводная сеть, беспроводная сеть и/или комбинация проводной и беспроводной сети. Хотя фиг.1 иллюстрирует сетевую конфигурацию, доступны и другие конфигурации.
Как показано на фиг.1, сеть 100 включает в себя сеть A и сеть B. Как описано ниже, один или более веб-компонентов и других компонентов ассоциированы с сетью 100, включающей в себя сеть A и сеть B. Сеть A и сеть B включают в себя ряд компонентов, которые конфигурированы, чтобы обеспечивать динамическое конфигурирование, выделение и/или развертывание ряда вычислительных систем из одного или более системных пулов 102 и 104, к примеру, одного или более серверов из пула серверов. Хотя различные компоненты показаны как включенные в сеть 100, различные компоненты могут быть иначе размещены и/или совместно использованы между одной или более сетями. Кроме того, сеть 100 может включать в себя большее или меньшее число компонентов.
В варианте осуществления сеть A и сеть B поддерживают связь через сеть хранения данных (SAN). SAN выполнена с возможностью поддерживать синхронизацию программных библиотечных совместно используемых ресурсов. SAN выполнена так, чтобы ресурсы хранения данных и другой информации могли быть отключены от вычислительных систем (к примеру, серверов) и присоединены непосредственно к сети 100. Посредством совместного использования ресурсов хранения в сети 100 SAN обеспечивает высокомасштабируемое и гибкое распределение ресурсов хранения, высокопроизводительные решения по резервному копированию и лучшее использование ресурсов хранения.
Каждая из сетей A и B включает в себя программную библиотеку 106 и 108 соответственно. В варианте осуществления программные библиотеки 106 и 108 включают в себя файлы, пакеты, версии и/или другие данные/информацию, к которым можно осуществлять доступ и которые могут использоваться, чтобы конфигурировать вычислительную систему. Таким образом, программные библиотеки конфигурируются как центральные репозитории или хранилища справочной информации, к которым можно осуществлять доступ, чтобы конфигурировать вычислительную систему, но не ограничены таким образом. Сеть A и сеть B также включают в себя службу 110 и 112 операционной системы соответственно. Службы 110 и 112 операционной системы выполнены с возможностью выполнять различные задачи в различное время, как описано ниже. Например, службы 110 и 112 операционной системы выполнены с возможностью приводить в исполнение этапы развертывания, выполнять обслуживание системы, отслеживать состояние резервирования, возвращать серверы в пулы серверов, начинать и продолжать этапы конфигурирования, отправлять уведомления и т.д.
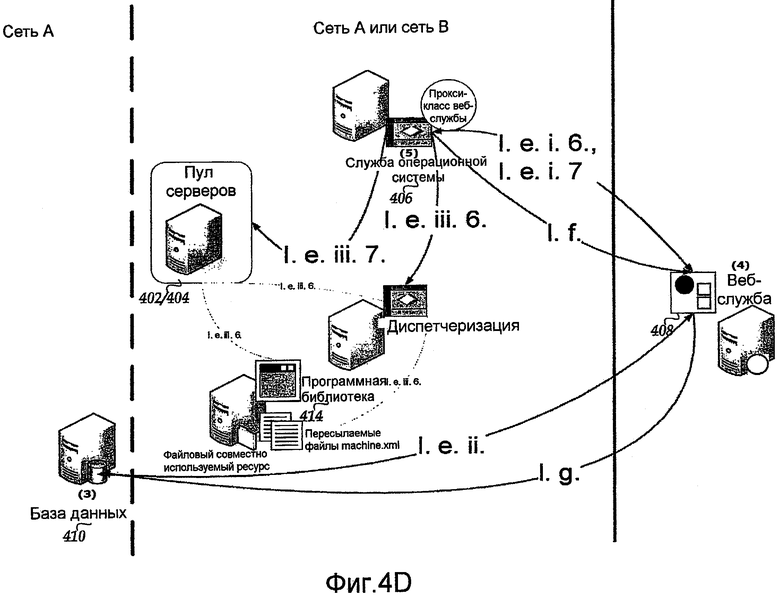
В одном варианте осуществления службы 110 и 112 операционной системы выполнены с возможностью выполнять один или более этапов развертывания (описаны ниже), как это требуется. Службы 110 и 112 операционной системы выполняют вызовы хранимых процедур в базах 122 и 126 данных для первого набора этапов развертывания. Службы 110 и 112 операционной системы включают в себя функциональность, чтобы реализовать остающиеся этапы развертывания (к примеру, Dispatch и Add Users (диспетчеризовать и добавлять пользователей)). Службы 110 и 112 операционной системы также выполняют прокси-вызовы, чтобы управлять Reservation Status (Состояние резервирования), Deployment Status (Состояние развертывания), Availability Status (Состояние доступности) и отслеживать изменения состояния (к примеру, окончание резервирования, новое выполняемое резервирование, завершение этапов развертывания и т.д.) в базе 114 данных. Службы 110 и 112 операционной системы дополнительно выполнены с возможностью отправлять уведомления, в том числе, но не ограничиваясь: начало резервирования; сутки до истечения или истечение резервирования; развертывание на резервирование начинается, завершается или сталкивается с ошибкой; помещение новых версий сборок (к примеру, версий сборок OFFICE) в программную библиотеку 108; хранение записей для сборок в базе 114 данных; и очистка накоплений machine.xml и пересылаемых файлов, ассоциированных с совместно используемыми файлами.
Службы 110 и 112 операционной системы дополнительно выполнены с возможностью определять, должны ли какие-нибудь задачи выполняться посредством периодического выполнения запроса к базе данных, такой как база 114 данных. Службы 110 и 112 операционной системы выполняют эти запросы через веб-службу 116, используя, например, прокси-класс. Службы 110 и 112 операционной системы могут также изменять данные и другую информацию в базе 114 данных через веб-службу 116. Веб-служба выполнена с возможностью обрабатывать обмен данными между различными компонентами сети 100, к примеру между службами 110 и 112 операционной системы и базой 114 данных. Хотя веб-служба 116 показана как поддерживающая связь с сетью A и сетью B, она не ограничена таким образом.
В варианте осуществления веб-служба 116 включает в себя следующие функции, но не ограничена таким образом:
DoDeploymentSteps(int iResvID, int iDeploymentStepFIags) - вызывает prc_do_depl_steps, чтобы задать незавершенные этапы развертывания резервирования и установить их Reservation Status на Deploying (Развертывание).
ScheduleEvent(string strTestServerName, string strEventName) - диспетчеризует событие посредством вызова sp_ins_event_schedule_IPO.
CreateResv(...) - создает новое резервирование посредством вызова prc_create_resv. Входные данные соответствуют параметрам prc_create_resv. Возвращает идентификатор недавно выполненного резервирования.
IsClusterAvailNow(int ResvID) - возвращает булеву переменную, указывающую то, может ли развертывание для рассматриваемого резервирования немедленно начаться посредством вызова prc_is_cluster_avail_now. Входными данными является идентификатор рассматриваемого резервирования.
CancelResv(int ResvID) - отменяет резервирование посредством вызова prc_cancel_resv. Входными данными является идентификатор резервирования, которое будет отменено.
GetResvInfo(int ResvID) - возвращает информацию о резервировании посредством вызова prc_get_resv_info. Поля в возвращенном наборе записей соответствуют столбцам в tblResvs. Входными данными является идентификатор рассматриваемого резервирования.
UpdateResvInfo(int ResvID,...) - обновляет информацию о резервировании в tblResvs посредством вызова prc_update_resv_info. Входными данными является идентификатор рассматриваемого резервирования, а далее они соответствуют столбцам в tblResvs.
GetServerAvailCount(int iDomainID, DateTime dtStart, DateTime dtEnd) - возвращает число серверов пула серверов, доступных в домене для диапазона дат посредством вызова prc_get_server_avail_count_info. Входными данными являются идентификатор домена для рассматриваемого домена, начало диапазона дат, конец диапазона дат.
GetShipmentFileList() - возвращает набор записей доступных пересылаемых файлов для использования посредством dispatch.exe посредством выполнения запроса к CMDB.
GetOfficeBuilds() - возвращает список доступных открытых сборок OFFICE для развертывания в зарезервированном кластере посредством вызова prc_get_office_builds.
GetExpiredResvs() - получает список идентификаторов резервирования с истекшим сроком посредством вызова prc_get_expired_resvs.
GetNewResvs() - получает список новых идентификаторов резервирования посредством вызова prc_get_ncw_rcsvs.
Согласно фиг.1 веб-служба 116 включает в себя пользовательский интерфейс 118. Пользовательский интерфейс 118 может использоваться для того, чтобы взаимодействовать с компонентами сети 100. Например, пользователь может использовать пользовательский интерфейс 118 и веб-службу 116, чтобы осуществлять доступ к различным процедурам, сохраненным в базе 114 данных, чтобы создавать и управлять резервированием и просматривать состояние доступности и резервирования. В варианте осуществления пользовательский интерфейс 118 состоит из трех страниц: Home Page (Домашняя страница), страница New Reservation/Edit Reservation (Новое резервирование/редактировать резервирование) и страница My Reservations/Administration (Мои резервирования/Администрирование) (см. фиг.5A-5C). Пользовательский интерфейс 118 выполнен с возможностью запрашивать и изменять данные через вызовы веб-службы 116. Данные, которые представляет пользователь с помощью пользовательского интерфейса 118, сохраняются в базе 114 данных.
База 114 данных включает в себя информацию, требуемую для того, чтобы завершить конфигурирование, выделение и/или развертывание одной или более вычислительных систем, такое как, к примеру, конфигурирование, выделение и развертывание ряда тестовых серверов. База 114 данных может включать в себя подробности и состояние резервирования, подробности и состояние развертывания, подробности и состояние доступности и т.д., дополнительно описанные ниже. Например, база 114 данных может включать в себя информацию, такую как число серверов в пулах серверов, имена серверов, типы серверов, роли серверов, время начала/окончания резервирования серверов, предыдущие резервирования, варианты развертывания серверов и другая ассоциативно связанная информация. Хотя база 114 данных показывается как включенная в качестве части сети A, в альтернативных вариантах осуществления, сеть B также может включать в себя подобную базу данных.
Согласно фиг.1, сеть A включает в себя ряд сценариев 120 и ассоциированную базу 122 данных. Сеть B также включает в себя ряд сценариев 124 и ассоциированную базу 126 данных. Каждый сервер в системных пулах 102 и 104 также может включать в себя ряд сценариев, описанных ниже. Сценарии включают в себя пакетные сценарии для выполнения одной или более процедур или этапов развертывания, как описано ниже. Например, каждый сценарий может быть ассоциативно связан с событием. Ассоциации и другие данные события могут быть сохранены в базах 122 и 126 данных. Когда запланированное время события наступает, может быть выполнен сценарий, который ассоциирован с событием.
В варианте осуществления сценарии включают в себя, но не ограничиваются:
Сценарий OS Installation (InstallOS.bat) - устанавливает ОС и присоединяет сервер к домену. Код может быть совместно использован из INETNUKE1.bat и INETNUKE2.bat.
Сценарий Debugging Tools Installation (InstallDebuggingTools.bat) - устанавливает средства отладки для резервирования.
Сценарии типов включают в себя:
i. IIS.bat - устанавливает программное обеспечение, задает конфигурационные настройки, чтобы создать веб-сервер,
ii. SQL.bat - устанавливает программное обеспечение, задает конфигурационные настройки, чтобы создать SQL-сервер,
iii. SEA.bat - устанавливает программное обеспечение, задает конфигурационные настройки, чтобы создать поисковый сервер,
iv. CDS.bat - устанавливает программное обеспечение, задает конфигурационные настройки, чтобы создать сервер содержимого.
Сценарии ролей включают в себя:
i. IIS-AWS1.bat - устанавливает программное обеспечение, задает конфигурационные настройки в ящике IIS для веб-службы AWS с анонимным доступом,
ii. IIS-AWS2.bat - устанавливает программное обеспечение, задает конфигурационные настройки на IIS-сервере для веб-службы AWS с аутентификацией через Passport,
iii. IIS-Rcdir.bat - устанавливает программное обеспечение, задает конфигурационные настройки на IIS-сервере для службы перенаправления OFFICE и клиент/серверной службы перенаправления,
iv. IS-R&R.bat - устанавливает программное обеспечение, задает конфигурационные настройки на IIS-сервере для службы OFFICE Research&Reference,
v. SQL-AWS.bat - устанавливает программное обеспечение, задает конфигурационные настройки на SQL-сервере для службы AWS,
vi. CDS-R&R.bat - устанавливает программное обеспечение, задает конфигурационные настройки на CDS-сервере для службы R&R,
vii. CDS-Search.bat - устанавливает программное обеспечение, задает конфигурационные настройки на CDS-сервере для службы AWS,
viii. IIS-IPOTool.bat - устанавливает программное обеспечение, задает конфигурационные настройки на IIS-сервере для внешнего интерфейса средств IPO,
ix. IIS-IPOservice.bat - устанавливает программное обеспечение, задает конфигурационные настройки на IIS-сервере для службы средств IPO,
x. SQL-IPOTools.bat - устанавливает программное обеспечение, задает конфигурационные настройки на SQL-сервере для средств IPO.
Весьма распространенно для вычислительных систем (к примеру, обслуживающих компьютеров центра обработки и хранения данных) иметь различные аппаратные конфигурации на основе типа. Например, SQL-серверы типично имеют большие жесткие диски по сравнению с веб-серверами. Различные аппаратные конфигурации могут потребовать различного конфигурирования во время установки, такого как, к примеру, настройки разделов. Частично вследствие этих аппаратных различий может быть трудным использовать систему с одним типом аппаратной конфигурации в качестве системы другого типа. Таким образом, в варианте осуществления системы, имеющие аналогичные аппаратные конфигурации, различаются и объединяются в системные пулы 102 и 104.
В варианте осуществления системы могут быть сконфигурированы согласно запрошенному типу. Например, стандартные типы серверов включают в себя SQL-серверы, серверы содержимого и веб-серверы. Во время процесса установки системы одного типа могут иметь различное программное обеспечение промежуточного уровня, установленное частично согласно службе, которая должна быть размещена. Например, один тип внешнего веб-сервера AWS имеет установленный Passport, тогда как другой веб-сервер AWS не требует Passport. Таким образом, динамическое выделение сервера и процесс установки (к примеру, процесс NNP) может применять различные компоненты промежуточного уровня к одному и тому же типу системы согласно размещаемой службе для ассоциативно связанного резервирования.
При использовании в данном документе, "тип" упоминается как вид платформенного программного обеспечения, которое может быть установлено в вычислительной системе. "Роль" упоминается как функция для ассоциированной вычислительной системы. Примерные роли включают в себя, без ограничения: FE-AWS1, которая упоминается как внешний интерфейсный сервер для веб-службы AWS с анонимным доступом; FE-AWS2, которая упоминается как внешний интерфейсный сервер для службы AWS с аутентификацией через Passport; FE-Redir, которая упоминается как внешний интерфейсный сервер для службы переназначения OFFICE и клиент-серверной службы переназначения; FE-R&R, которая упоминается как внешний интерфейсный сервер для службы OFFICE Research&Reference; SQL-AWS, которая упоминается как внутренний интерфейсный SQL-сервер для службы AWS; CDS-R&R, которая упоминается как сервер содержимого для службы R&R; CDS-Search, которая упоминается как поисковый сервер для службы AWS; FE-IPOTool, которая упоминается как веб-сервер для IPO-средств; FE-IPOservice, которая упоминается как сервер для IPO-средств; и SQL-IPOTools, которая упоминается как SQL-сервер для IPO-средств.
Первая часть (перед дефисом) роли является типом, а вторая часть (после дефиса) указывает службу, для которой он может выступить в качестве хоста. Сценарии NNP могут модулироваться для каждого типа сервера и роли. Таким образом, каждая роль может быть ассоциативно связана с типом (к примеру, IIS (веб-элемент), SQL (база данных), CDS (содержимое), SEA (поиск)). Кроме того, вычислительная система может допускать несколько ролей, но в определенных случаях каждая такая роль может иметь один и тот же тип. Например, тестовая вычислительная система может допускать роли SQL-AWS1 и роли SQL-AWS2, но не и US-AWS1, и SQL-AWS1.
Динамическое конфигурирование и выделение могут также упоминаться как ситуация, в которой аналогичный тип вычислительной системы может использоваться, чтобы установить различные службы, такие как, например, службы OFFICE. Кроме того, роль вычислительной системы может время от времени изменяться для различных резервирований и может зависеть от динамического конфигурирования и выделения. Возьмем, к примеру, внешний интерфейсный сервер, который может выступить в качестве хоста для службы AWS в одном резервировании, при этом выступая в качестве сервера R&R в другом резервировании. Файл machine.xml может быть изменен так, чтобы поддержать такое развертывание. Файл machine.xml может быть описан как файл XML-формата, задающий то, какие машины принимают какие пакеты и конкретные конфигурации служб. Как описано ниже, файл machine.xml может использоваться компонентом диспетчеризации для того, чтобы выполнять развертывание согласно требуемой реализации. Компонент диспетчеризации выполнен с возможностью управлять установкой пакетов, служб и конфигурированием параметров среды выполнения на удаленных вычислительных системах, таких как один или более удаленных серверов. Таким образом, роль может использоваться, чтобы указать требуемую конфигурацию и код (к примеру, OFFICE), чтобы применить к типу вычислительной системы согласно резервированию.
В соответствии с вариантом осуществления и с учетом понятий типа и роли предусмотрено семь этапов в развертывании для вычислительной системы, которые включают в себя, без ограничения: 1. OS Installation (Установка ОС); 2. Debugging Tools Installation (Установка средств отладки); 3. Type Application (Применение типов); 4. Role Application (Применение ролей); 5. Hotfix Application (Применение пакетов исправлений); 6. Dispatch (Диспетчеризация); и 7. Add Users (Добавление пользователей). Каждый из этапов развертывания имеет соответствующую стадию развертывания, включая дополнительные стадии развертывания, которые включают в себя, без ограничения: 0. Not Yet Started (Еще не запущено); 1. OS Installation; 2. Debugging Tools Installation; 3. Type Application; 4. Role Application; 5. Hotfix Application; 6. Dispatch; 7. Add Users; и 8. Finished (Готово).
Этапы развертывания могут отслеживаться с помощью ряда флагов развертывания. В варианте осуществления значения флагов развертывания соответствуют первым семи степеням двух. Таблица ниже иллюстрирует значения флага развертывания и соответствующий этап развертывания.
Как описано выше, каждая вычислительная система не обязательно может подвергаться всем семи этапам развертывания. Флаги развертывания могут использоваться, чтобы указать в одном значении все этапы развертывания, которые применяются к вычислительным системам в резервировании. Например, все семь этапов развертывания могут быть указаны посредством добавления флагов, соответствующих всем семи этапам развертывания: 1+2+4+8+16+32+64=127. Если этап Debugging Tools Installation не требуется, это может быть указано с помощью значения 1+4+8+16+32+64=125.
В варианте осуществления есть различные виды сценариев, которые соответствуют этапам развертывания, и они включают в себя, но не ограничиваются: 1. Сценарий OS Installation используется, чтобы приводить в исполнение код на каждой вычислительной системе в резервировании; 2. Сценарий Debugging Tools Installation используется, чтобы приводить в исполнение код на каждой вычислительной системе в резервировании; 3. Сценарий Type Application соответствует сценарию, чтобы приводить в исполнение различный код согласно каждому типу; 4. Сценарий Role Application соответствует сценарию, чтобы приводить в исполнение различный код согласно каждой роли; и 5. Сценарий Hotfix Application используется, чтобы приводить в исполнение код на каждой вычислительной системе в резервировании.
Дополнительно, как описано выше, каждый сценарий может быть ассоциативно связан с событием в базах 122 и 126 данных. События могут быть запланированы для конкретной вычислительной системы посредством службы 110 или 112 операционной системы. Служба 110 или 112 операционной системы выполнена с возможностью вызывать хранимые процедуры в соответствующих базах 122 и 126 данных, чтобы запланировать ассоциативно связанное событие. Когда время запланированного события наступает, сценарий, ассоциативно связанный с событием, помещается в целевую вычислительную систему службой 110 или 112 операционной системы и приводится в исполнение. Таким образом, каждый сценарий выполнен с возможностью выполняться локально на вычислительной системе, на которой развертывается сценарий. Пока сценарий, ассоциативно связанный с запланированным событием, выполняется, время начала, время окончания, состояние успешности/сбоя выполнения сценария, коды ошибки и т.д. могут быть записаны в ассоциативно связанную базу 122 или 126 данных. Данные выполнения сценария затем помещаются в базу 114 данных посредством службы 110 или 112 операционной системы или посредством прокси-сервера веб-службы 116.
Как описано выше, база 114 данных выступает в качестве репозитория для информации, ассоциированной с конфигурированием, выделением и/или развертыванием одной или более вычислительных систем. В варианте осуществления база 114 данных хранит информацию резервирования, которая требуется для того, чтобы предоставлять динамическое развертывание кластера тестовых серверов. Как описано ниже, база 114 данных также хранит ряд идентификаторов состояния, таких как состояние резервирования для всего резервирования, состояние развертывания для каждой вычислительной системы в резервировании и состояние доступности для каждой вычислительной системы в системном пуле, но не ограничивается ими.
Информация о резервировании включает в себя, без ограничения, следующее: даты начала и окончания резервирования; тип резервирования (к примеру, базовый тип, сборка OFFICE, закрытая версия, дубль кластера); число систем в кластерном резервировании; роль и тип каждой системы в резервировании; размещения каждого из файла machine.xml и пересылаемых файлов, ассоциированных с резервированием; и понятное имя и назначение резервирования. В варианте осуществления информация о резервировании хранится в таблице резервирования базы 114 данных. Фиг.2 иллюстрирует ряд таблиц, включая структуру таблицы резервирования по варианту осуществления. Как описано выше, этапы развертывания могут варьироваться посредством типа развертывания и могут быть сохранены в поле DeplSteps. Значение поля DeplSteps - это комбинация флагов этапа развертывания, которые представляют обязательные этапы развертывания для конкретного резервирования.
Согласно фиг.2 состояние резервирования или Reservation Status сохраняется в поле ResvStatusID. Поле ResvStatusID присоединяется к таблице ResvStatusID_ReservationStatusName. Состояния резервирования включают в себя: Not Yet Begun (Еще не начато), Deploying, Ready (Готов), Expiring (Истекает) и Archived (Архивное). Когда создается новое резервирование, Reservation Status устанавливается на Not Yet Begun. Reservation Status устанавливается на Deploying, когда наступает дата начала резервирования, пользователь повторно развертывает резервирование и/или администратор или OPM принимают меры относительно резервирования. Reservation Status устанавливается на Ready, когда конечный этап развертывания для резервирования заканчивается. Reservation Status устанавливается на Expiring, когда время резервирования истекло или когда пользователь завершает резервирование (к примеру, выходит из системы). Как только резервирование завершается, любые зарезервированные вычислительные системы разблокируются, и Reservation Status устанавливается на Archived.
Состояние развертывания или Deployment Status сохраняется в таблице Resvs_Servers. Таблица Resvs_Servers включает в себя три поля: поле Deployment Stage (Стадия развертывания) (DeplStageID); поле (DeplStatusValueID), содержащее одно из трех значений: Running (Выполняется), Error (Ошибка) или Done (Выполнено); и поле Error Code (Код ошибки) (DeplStatusError). Если DeplStatusValueID не равно Error, то его значение равно 0. Когда новое резервирование создается, значения полей Deployment Status для каждой вычислительной системы в резервировании устанавливаются на Not Yet Started, Done и 0. Когда начинается этап развертывания, значения DeplStageID, DeplStatusValueID и DeplStatusErr устанавливаются на идентификатор стадии развертывания, соответствующий этапу развертывания, Running и 0 соответственно. Если имеется ошибка на этапе развертывания, значения DeplStatusValueID и DeplStatusErr устанавливаются на Error и код ошибки соответственно. Если этап развертывания завершается без ошибки, значение DeplStatusValueID устанавливается на Done. Когда последний этап развертывания заканчивается, значения полей Deployment Status устанавливаются на Ready, Done и 0. (Кроме того, как описано выше, когда последний этап развертывания для резервирования заканчивается, Reservation Status устанавливается на Ready).
Доступность вычислительной системы (к примеру, доступность сервера) или Availability Status сохраняется в поле SrvAvailStatusID таблицы Servers по фиг.2. Поле SrvAvailStatusID присоединяется к таблице SrvAvailStatusID_SrvAvailStatusName. Эта таблица задает три состояния доступности: Unreserved (Нерезервированный), Reserved (Зарезервированный) и In Use (Используется). В ходе начальной системной установки Availability Status для всех вычислительных систем устанавливается на Unreserved. Когда новое резервирование осуществлено, Availability Status для вычислительных систем в резервировании устанавливается на Reserved. Когда резервирование начинается, Availability Status для вычислительных систем в резервировании устанавливается на In Use. Резервирование также может соответствовать Archived при определенных обстоятельствах. Если вычислительная система выделена другому резервированию, Reservation Status которого - Not Yet Started, то Availability Status устанавливается на Reserved; иначе, Availability Status устанавливается на Unreserved.
Как описано выше, предусмотрен ряд хранимых процедур, которые ассоциированы с таблицами, показанными на фиг.2. В варианте осуществления обработка информации в таблицах выполняется посредством хранимых процедур. Хранимые процедуры включают в себя, без ограничения, следующее: создание нового резервирования; получить/установить данные резервирования (Begin Date (Дата начала), End Date (Дата окончания), Reservation Type (Тип резервирования), Deployment Steps (Этапы развертывания) и т.д.); получить/установить Reservation Status; получить/установить то, какие системы ассоциированы с резервированием; получить/установить тип и роль системы резервирования; получить/установить этапы развертывания, которые должны быть выполнены в системах в рамках резервирования; получить список систем, для которых должен быть выполнен следующий этап развертывания (к примеру, резервирований, для которого Begin Date только что наступила); получить следующий этап развертывания для системы; получить список резервирований, которые истекли; получить/установить Deployment Status; и получить/установить Availability Status.
В варианте осуществления ряд хранимых процедур в базе 114 данных включает в себя, без ограничения, следующее:
prc_create_resv(...) - создает новое резервирование на основе пользовательского ввода на странице New Reservation/Edit Reservation посредством создания новой строки в tblResvs. Входные данные соответствуют столбцам в tblResvs. Возвращает идентификатор недавно выполненного резервирования.
prc_is_cluster_avail_now(ResvID) - возвращает булеву переменную, указывающую то, может ли развертывание для рассматриваемого резервирования начаться немедленно. Входными данными является идентификатор рассматриваемого резервирования.
prc_do_depl_steps(ResvID, DeplStepFlags) - устанавливает значение резервирования DeplSteps на DeplStepFlags, затем устанавливает его Reservation Status на Deploying. Когда служба операционной системы активируется, она запускает выполнение Deployment Steps.
prc_set_depl_steps(ResvID, DeplStepFlags) - устанавливает значение резервирования DeplSteps на DeplStepFlags.
prc_cancel_resv(ResvID) - отменяет резервирование посредством пометки его как Archived в таблице Reservations. Входными данными является идентификатор резервирования, которое должно быть отменено.
prc_get_resv_info(iResvID) - возвращает информацию о резервировании; поля в возвращенном наборе записей соответствуют столбцам в таблице Reservations. Входными данными является идентификатор рассматриваемого резервирования.
prc_update_rcsv_info(ResvID,...) - информация об обновлениях резервирования в таблице Reservations. Входными данными является идентификатор рассматриваемого резервирования, а далее они соответствуют столбцам в tblResvs.
prc_add_user(UserName, ResvID) - ассоциирует нового пользователя с резервированием посредством добавления поля Users в таблицу Reservations. Входными данными является идентификатор пользователя, который должен быть добавлен, и идентификатор резервирования.
prc_get_servers_by_ResvID(ResvID) - возвращает серверы, ассоциированные с резервированием, посредством выполнения запроса Resvs_Servers. Входными данными является идентификатор рассматриваемого резервирования.
prc_gct_cxpircd_rcsvs(Date) - возвращает идентификаторы резервирований, которые согласно окончанию даты, посредством выполнения запроса к таблице Reservations. Входными данными является рассматриваемая дата.
prc_get_new_resvs(Date) - возвращает идентификаторы резервирований, которые начинаются, посредством начала даты посредством выполнения запроса к таблице Reservations. Входными данными является рассматриваемая дата.
prc_release_servers(ResvID) - для использования по окончанию резервирования. Сбрасывает состояние доступности в таблице Servers для серверов, ассоциированных с идентификатором резервирования. Входными данными является идентификатор рассматриваемого резервирования.
prc_get_dispatch_info(ResvID) - возвращает информацию, требуемую для выполнения диспетчеризации, посредством выполнения запроса к таблице Reservations. Входными данными является идентификатор рассматриваемого резервирования.
prc_get_users_by_ResvID(ResvID) - возвращает имена пользователей, ассоциативно связанных с резервированием, посредством выполнения запроса к таблице Reservations. Входными данными является идентификатор рассматриваемого резервирования.
prc_get_server_avail_count_info(iDomainID, iStart, iEnd) - возвращает число серверов, доступных в домене для диапазона дат. Входными данными являются идентификатор домена для рассматриваемого домена, начало диапазона дат, конец диапазона дат.
prc_get_office_builds() - возвращает список доступных открытых сборок OFFICE для развертывания в зарезервированном кластере из таблицы OfficeBuilds.
Базы 122 и 126 данных также содержат ряд хранимых процедур, включая, без ограничения, следующее:
Процедура CREATE
sp_ins_event_schedule_IPO
@event_id int,
@name varehar(64),
@next_task_seq int = 0,
@defer_mins int = 1
as
declare @schedule_id int
declare @schedule_id2 int
declare @computer_id int
select @computer_id = computer_id
from computer
where name = @namc
exec @schedule_id = sp_get_next_system_id 'EVENT_SCHEDULE_ID'
exec @schedule_id2 = sp_del_event_schedule_comp_event @computer_id, @event_id
begin transaction
insert into evcnt_schedule
(schedule_id, computer_id, event_id, start_time, ncxt_task_scq, defer_mins)
values
(@schedule_id, @computer_id, @event_id, GetDate(), @next_task_seq, @defer_mins)
if(@@error!=0)
begin
rollback transaction
return 1
end
commit transaction
select @schedule_id as schedule_id
GO
В соответствии с вариантом осуществления, алгоритм резервирования выполнен с возможностью резервировать одну или более вычислительных систем системных пулов 102 и 104 на основе ввода пользователя с помощью пользовательского интерфейса 118. В одном варианте осуществления алгоритм резервирования сначала назначает вычислительную систему, если вычислительная система не имеет текущих резервирований. Если алгоритм резервирования должен назначать вычислительную систему, которая уже имеет резервирование, вычислительная система выбирается на основе наибольшей временным зазором между существующим резервированием и новым резервированием. Данные резервирования могут быть упорядочены или иначе структурированы (к примеру, формат таблицы или представления), предоставляя возможность упростить и рационализировать алгоритм резервирования. Алгоритм резервирования использует даты начала и окончания резервирования, чтобы составить таблицу, описанную ниже. Данные могут быть сформированы каждый раз, когда запрашивается новое резервирование.
В одном варианте осуществления таблица имеет три поля: ComputerName относится к названию вычислительной системы; LatestLastEnd относится к конечной дате резервирования, непосредственно предшествующей начальной дате запрошенного резервирования; и EarliestNextStart относится к начальной дате резервирования, следующей сразу после конечной даты запрошенного резервирования. Возможно, чтобы LatestLastEnd и EarliestNextStart были нулями. В такой ситуации они могут быть заданы равными произвольной дате. Данные для таблицы доступны посредством присоединения всех резервирований без признака Archived в таблице Reservations к таблице Resvs_Servers. При определенных обстоятельствах результирующее объединение может иметь более одной записи для каждого сервера, так как некоторые серверы могут быть зарезервированы для более чем одного резервирования.
Один вариант осуществления алгоритма резервирования следующий:
n - число серверов, необходимых для резервирования
ResvID - уникальный идентификатор резервирования для нового резервирования
StartDate и EndDate - начальная дата и конечная дата запрошенного резервирования
Возвращает, можно ли выделить достаточно серверов для резервирования
boolean AllocateServers(n, StartDate, EndDate, ResvID)
declare StackResvServers
//выделяемые серверы Unreserved сначала (тривиальная функция)
nAUocatedUnrcservedServers = AllocateUnreservedServers(n, StackResvServers)
nNeededServers = n - nAllocatedUnreservedServers;
while nNeededServers is greater than 0
if exist nNeededServers servers where ((StartDate - LatestLastEnd >0) && (EarliestNextStart - EndDate > 0))
select ComputerName with max StartDate - LatestEndDate;
push ComputerName onto StackOfAllocatedServers;
decrement nNeededServers;
//следует немного изменить алгоритм, чтобы обеспечить большую расширяемость на будущее
// новых создаваемых резервирований
else
return false;
//нельзя выделить достаточно серверов
//вместо этого можно рекурсивно вызвать AllocateServers с альтернативными датами резервирования,
//в таком случае предложить пользователю альтернативное окончание резервирования
end if
end while
while StackResvServers is not empty
pop ComputerName from StackResvServers
create entry in Resvs_Scrvcrs table with ResvID and ComputerName
end while
return true
End Function
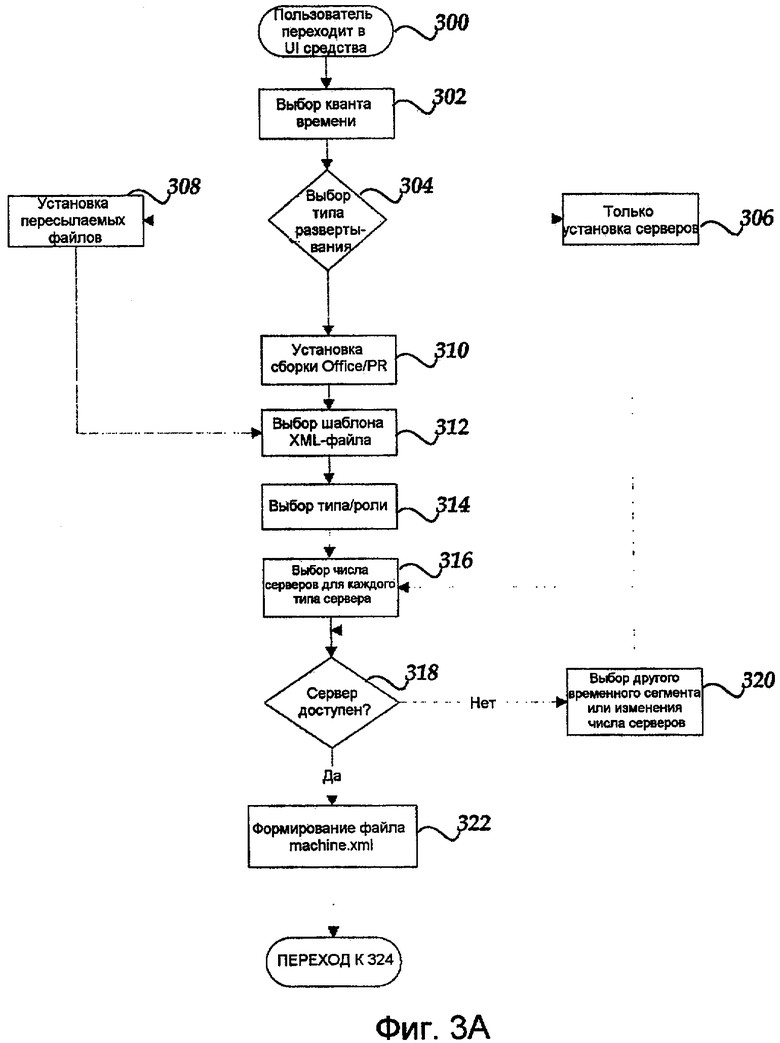
На фиг.3A-3B показана блок-схема, иллюстрирующая конфигурирование, выделение и развертывание одного или более обслуживающих компьютеров или серверов в соответствии с вариантом осуществления. На этапе 300 пользователь с помощью веб-клиента или обозревателя осуществляет доступ к пользовательскому интерфейсу 118, чтобы запросить резервирование. На этапе 302 пользователь использует пользовательский интерфейс 118, чтобы выбрать временной сегмент, ассоциированный с резервированием. На этапе 304 пользователь может выбрать тип развертывания. Если пользователь выбирает только установку сервера, последовательность операций переходит к этапу 306. Если пользователь выбирает установку пересылаемого файла, последовательность операций переходит к этапу 308. Иначе, последовательность операций переходит к этапу 310 для обеспечения инсталляции сборки OFFICE/PR. На этапе 312, если пользователь выбрал вариант установки пересылаемого файла или вариант инсталляции сборки OFFICE/PR, пользователь может выбрать шаблон файла, ассоциированный с инсталляцией, такой как, например, шаблон XML-файла.
На этапе 314 пользователь может выбрать типы сервера и роли. На этапе 316 пользователь затем может выбрать число серверов, ассоциированных с каждым типом сервера. На этапе 318 определяется, доступны ли запрошенные серверы в одном или более пулов серверов. Если серверы не доступны, на этапе 320 пользователь имеет вариант выбрать другой временной сегмент и/или запросить другое число серверов. Если запрошенные серверы доступны, на этапе 322 формируется файл machine.xml, и последовательность операций переходит к 324.
Согласно фиг.3B, на этапе 324 информация, ассоциированная с текущим резервированием, сохраняется в базе 114 данных. На этапе 326 начинается развертывание, в том числе конфигурирование серверов в соответствии с запросом пользователя (к примеру, тип/роль). На этапе 328 определяется, успешно ли запрошенное развертывание. Если развертывание безуспешно, на этапе 330 определяется, вызвал ли файл machine.xml безуспешное развертывание. Если файл machine.xml не является причиной безуспешного развертывания, на этапе 332 вспомогательному объекту и пользователям, ассоциированным с резервированием, отправляется уведомление. На этапе 334 реализуются процедуры поиска неисправностей, и как только процедуры поиска неисправностей выполнены, последовательность операций возвращается к этапу 326.
Однако если файл machine.xml является причиной безуспешного развертывания, на этапе 336 уведомление отправляется пользователю и/или OPM. На этапе 338 файл machine.xml корректируется, и последовательность операций возвращается к 326. С другой стороны, если развертывание успешно на этапе 328, последовательность операций переходит к этапу 340, и пользователю отправляется уведомление об успешном развертывании, включающее в себя любую информацию о доступе (к примеру, имя пользователя, пароль и т.д.). На этапе 342 развернутые серверы могут теперь использоваться пользователем и любыми другими уполномоченными пользователями для тестирования и других целей. На этапе 342 пользователь имеет ряд вариантов, таких как продление периода теста на этапе 344 или запрос повторного развертывания кластера в 346.
Если пользователь запрашивает продление периода теста, на этапе 348 определяется, есть ли доступные серверы, чтобы удовлетворить запрос. Если нет доступных серверов, чтобы удовлетворить запрос, последовательность операций переходит к этапу 350, где пользователь и любые другие пользователи могут закончить тестирование и выйти из системы. После этого последовательность операций переходит к этапу 354, и серверы в таком случае освобождаются для пула(ов) серверов. Если имеются доступные серверы на этапе 348, информация о резервировании обновляется на этапе 352, и последовательность операций переходит к этапу 342. Если пользователь запросил повторное развертывание запрошенных серверов, на этапе 356 файл machine.xml изменяется или обновляется, и последовательность операций возвращается к этапу 326. В противном случае, последовательность операций переходит к этапу 354, и серверы освобождаются для пула(ов) серверов.
Фиг.4A-4I иллюстрируют функциональные блок-схемы сети 400 и различных компонентов для конфигурирования, выделения и развертывания одной или более вычислительных систем, таких как один или более тестовых серверов одного или более пулов 402 и 404 серверов. Элементы фиг.2 упоминаются в последующем описании. Как показано на фиг.4B, на этапе I.a служба 406 операционной системы активируетоя и вызывает веб-службу 408 посредством прокси-сервера, чтобы получить список тестовых серверов и следующий этап развертывания, требуемый на каждом тестовом сервере. На этапе I.b веб-служба 408 выполняет запрос в базу 410 данных по резервированиям, которые имеют Reservation Status равным Deploying или Expiring.
Веб-служба 408 также находит тестовые серверы в резервированиях, DeplStatusValueID которых в таблице Resvs_Servers соответствует Done. Для этих серверов веб-служба 408 получает значение DeplSteps резервирования из таблицы Reservations и синтаксически анализирует значение на предмет флагов этапов развертывания. Флаги этапа развертывания далее сравниваются со значением DeplStatusStageID тестового сервера, чтобы определить следующий этап развертывания. На этапе I.c веб-служба 408 пары тестовых серверов/следующих этапов развертывания в службу 406 операционной системы.
Согласно фиг.4C на этапе I.d служба 406 операционной системы выполняет итерации через возвращенные пары тестовых серверов/следующих этапов развертывания. Если следующий этап развертывания - это этап развертывания 1-5, на этапе I.1-5 служба 406 операционной системы делает вызов в хранимую процедуру, чтобы запланировать событие, соответствующее этапу. На этапе I.f служба 406 операционной системы вызывает Update Deployment Status посредством прокси-сервера, чтобы обновить состояние развертывания. На этапе I.g веб-служба 408 использует хранимую процедуру для того, чтобы установить DeplStageID тестового сервера на Deployment Stage, соответствующий этапу развертывания, а DeplStatusValueID - на Running.
Согласно фиг.4D, если следующий этап развертывания - это Dispatch, на этапе I.e.i.6 служба 406 операционной системы вызывает веб-службу 408 посредством прокси-сервера, чтобы выполнить запрос на предмет местоположений пересылаемых файлов и машины. Если следующий этап развертывания - это Add Users, то на этапе I.e.i.7 служба 406 операционной системы вызывает веб-службу 408 посредством прокси-сервера, чтобы выполнить запрос на предмет пользователей резервирования. На этапе I.e.ii веб-служба 408 выполняет запрос в базу 410 данных на предмет информации. Если следующий этап развертывания - это Dispatch, то на этапе I.e.iii.6 служба 406 операционной системы создает процесс и начинает диспетчеризацию для резервирования. Если следующий этап развертывания - это Add Users, то на этапе I.e.iii.7 служба 406 операционной системы создает процесс и начинает добавлять пользователей в тестовый сервер. На этапе I.f служба 406 операционной системы вызывает веб-службу 408, чтобы обновить состояние развертывания (Update Deployment Status). На этапе I.g веб-служба 408 использует хранимые процедуры в базе 410 данных для того, чтобы задать DeplStageID тестового сервера равным Deployment Stage, соответствующему этапу развертывания, а DeplStatusValueID - равным Running.
Согласно фиг.4E, на этапе II.a.i.1-5, когда ассоциированные сценарии выполняются, состояние выполнения сценария записывается в базу 412 данных. На II.a.ii.1-5 служба 406 операционной системы активируется и получает состояние выполняющихся событий из базы 412 данных. На этапе II.a.iii.l-5 служба 406 операционной системы вызывает веб-службу 408 посредством прокси-сервера, чтобы поместить состояние в базу 410 данных. На этапе II.a.6-7, когда этапы развертывания Dispatch или Add Users выполняются, служба 406 операционной системы вызывает веб-службу 408 посредством прокси-сервера, чтобы обновить Deployment Status. Если этап развертывания заканчивается или сталкивается с ошибкой, на этапе II.b служба 406 операционной системы вызывает хранимую процедуру и сбрасывает значение DeplStatusValueID с Running на Done или Error.
Если DeplStatusValueID равен Done, но DeplStageID не представляет последний этап развертывания, указанный в DeplSteps резервирования, то служба 406 операционной системы начинает следующее развертывание, когда пробуждается в следующий раз, как описано выше. Если DeplStatusValueID равно Done, а DeplStageID представляет последний этап развертывания, указанный в DeplSteps резервирования, и если Reservation Status резервирования равен Deploying, Reservation Status сбрасывается на Ready. Если Reservation Status резервирования равен Expiring, то Reservation Status сбрасывается на Archived, и Availability Status всех серверов в резервировании сбрасывается с In Use на Reserved или на Unreserved.
Согласно фиг.4F, пользователь создает новое резервирование. На этапе III.a, если Reservation Type это Private Release (PR), пользователь сохраняет PR к программной библиотеке 414. На этапе III.b пользователь представляет новую информацию о резервировании с помощью пользовательского интерфейса 416. На этапе III.c база 410 данных использует хранимые процедуры и веб-службу 408, чтобы записать представленные данные резервирования в базу 410 данных. Эти процедуры имеют результатом: установку Reservation Status на Not Yet Begun; установку Deployment Status для каждого тестового сервера в резервировании на Not Yet Started, Done и 0; установку Server Availability Status для каждого тестового сервера в резервировании на Reserved; и установку значения DeplSteps для резервирования так, чтобы содержать Deployment Step Flag (Флаг Этапа Развертывания) для каждого этапа развертывания требуемого для Reservation Type (к примеру, если Reservation Type равен Basic, то этап Role Application не требуется).
Согласно фиг.4G, начинается новое резервирование. На этапе IV.a служба 406 операционной системы активируется и использует прокси-класс веб-службы 408 для того, чтобы выполнить запрос к базе 410 данных на предмет новых резервирований, для которых должно начаться развертывание. На этапе IV.b веб-служба 408 использует хранимые процедуры в базе 410 данных, чтобы выполнить запрос для этих резервирований, и хранимые процедуры возвращают идентификатор резервирования, который соответствует каждому резервированию. Продолжая новое резервирование, согласно фиг.4H, на этапе IV.c веб-служба 408 выполняет запрос к базе 410 данных посредством идентификатора резервирования на предмет сведений о резервировании. Если Reservation Type равен Duplicate Cluster, на этапе IV.d веб-служба 408 выполняет запрос к веб-службе 418 CMDB на предмет пересылаемого файла и копирует пересылаемый файл в файловый совместно используемый ресурс.
Если пользователь не загрузил файл machine.xml, на этапе IV.e веб-служба 408 формирует файл machine.xml на основе шаблона machine.xml и копирует файл machine.xml в файловый совместно используемый ресурс. На этапе IV.f развертывание нового резервирования готово начаться. Используя идентификатор резервирования и хранимые процедуры в базе 410 данных, веб-служба 408 сбрасывает Reservation Status резервирования с Not Yet Begun на Deploying и сбрасывает Server Availability Status для каждого тестового сервера в резервировании с Reserved на In Use. Поскольку Reservation Status теперь равен Deploying, и значения Deployment Status для каждого тестового сервера в резервировании равны Not Yet Started, Done и 0, служба 406 операционной системы начинает выполнение этапов развертывания для резервирования, когда она впоследствии активируется, как описано выше.
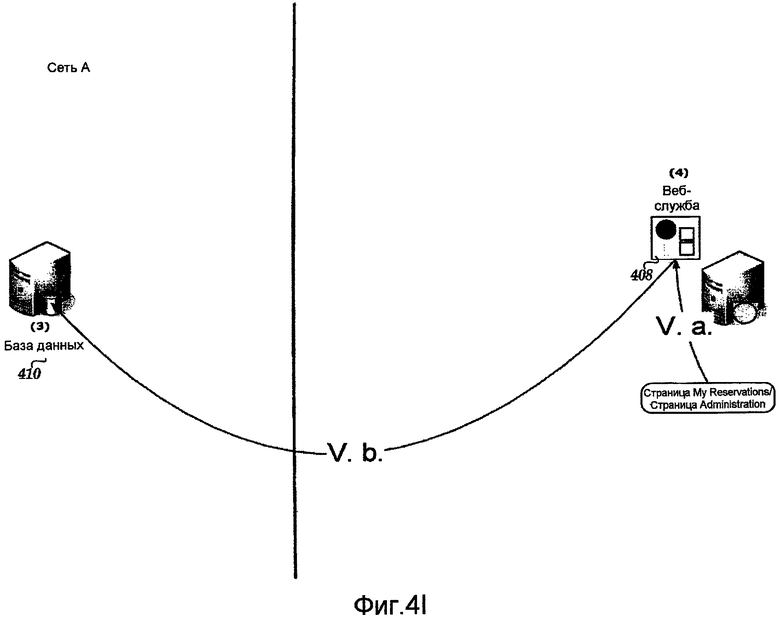
Согласно фиг.4I, на этапе V.a пользователь выходит из системы с помощью страницы My Reservation пользовательского интерфейса 410, что завершает резервирование. На этапе V.b. веб-служба 408 устанавливает значение резервирования DeplSteps так, чтобы содержать только флаг этапа развертывания OS Installation; устанавливает Deployment Status для каждого тестового сервера в резервировании на Not Yet Started, Done и 0; и устанавливает Reservation Status на Expiring. Когда служба 406 операционной системы впоследствии активируется, она начинает этап развертывания OS Installation для всех тестовых серверов в резервировании, как описано выше. Поскольку OS Installation - это единственный этап, указанный в значении DeplSteps, когда этап OS Installation закончился для всех тестовых серверов в резервировании, последний этап развертывания завершен. Как описано выше, служба 406 операционной системы теперь сбрасывает Reservation Status. Поскольку Reservation Status равен Expiring, служба 406 операционной системы сбрасывает Reservation Status на Archived и сбрасывает Availability Status всех тестовых серверов в резервировании.
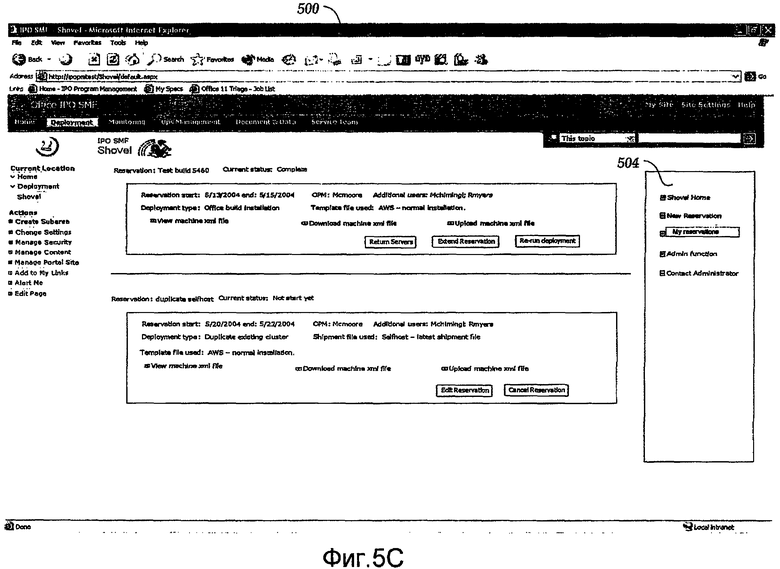
Фиг.5A-5C иллюстрируют различные реализации пользовательского интерфейса 500, который дает возможность пользователю выполнить новое резервирование и/или управлять существующим резервированием, но не ограничивается этим. В качестве примера, пользователь может использовать пользовательский интерфейс 500 для того, чтобы зарезервировать ряд серверов для конкретной цели тестирования. Далее пользовательский интерфейс 500 визуализирует информацию о доступности сервера для пула серверов в данном домене. Как только запрос представлен, компоненты, описанные выше, действуют, чтобы динамически конфигурировать, выделять и/или развертывать ряд серверов согласно запросу пользователя. Как описано выше, пользователь принимает уведомление (к примеру, почтовое сообщение), как только запрос выполнен и серверы сконфигурированы, выделены и развернуты. Как показано на фиг.5A, пользовательский интерфейс 500 включает в себя область 502 оповещений для отображения различной информации, которая служит для того, чтобы оповещать и информировать пользователя. Пользовательский интерфейс 500 включает в себя область 504 навигации, где для взаимодействия с пользователем представляется ряд вариантов.
Пользовательский интерфейс 500 также включает в себя область 506 календаря, где пользователь может просмотреть доступность сервера для определенного периода времени (к примеру, ежедневно, еженедельно и т.д.). Например, предположим, что пользователь хочет выполнить новое резервирование, которое требует два сервера для определенной цели тестирования. Пользователь может использовать пользовательский интерфейс 500, чтобы видеть то, что пункт Редмонд имеет 54 сервера в пуле серверов, тогда как пункт вне Редмонда имеет 26 серверов в пуле серверов. Пользователь может также видеть резервирования других пользователей с помощью пользовательского интерфейса 500. Например, пользователь может видеть, что 9 серверов зарезервировано 1/27/2004-1/28/2004, 5 серверов зарезервировано 1/28/2004-1/29/2004 и что 3 сервера зарезервировано 1/28/2004-1/31/2004.
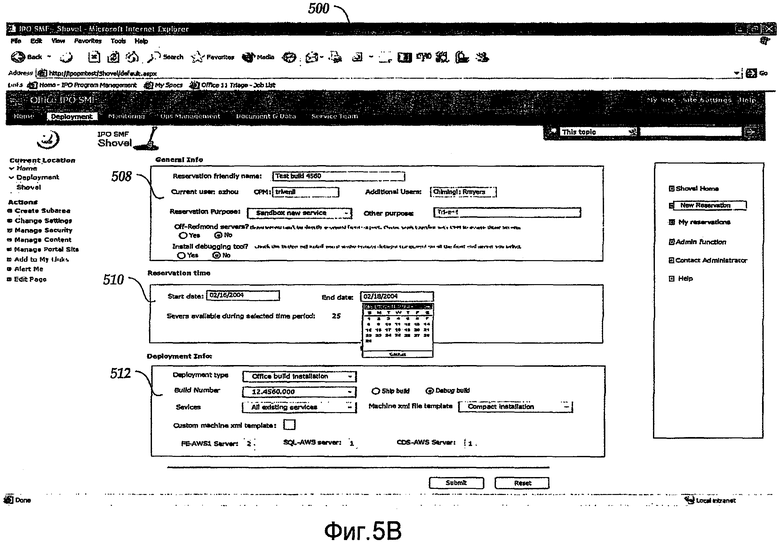
Согласно фиг.5B пользователь выбрал New Reservation (Новое Резервирование) в области 504 навигации. Информация New Reservation включает в себя область 508 общей информации. Область 508 общей информации включает в себя текущего пользователя, дополнительных пользователей, цель резервирования, OPM, обозначение сервера и запрос средства отладки. Информация New Reservation включает в себя область 510 времени резервирования. Пользователь может выбрать даты начала и завершения с помощью раскрывающегося календаря или посредством ввода дат с клавиатуры. Область 510 времени резервирования включает в себя уведомление о числе серверов, доступных для периода времени, после того, как только пользователь ввел предпочтительные даты начала и окончания. Информация New Reservation также включает в себя область 512 Deployment Info (Информация развертывания). Область 512 Deployment Info включает в себя тип развертывания, номер сборки, службы, варианты сборки Ship или Debug, вариант шаблона machine.xml, специализированный вариант machine.xml и варианты типов/ролей. Как показано на фиг.5B, пользователь запросил 2 сервера FE-AWS1, 1 сервер SQL-AWS и 1 сервер CDS-AWS. Как описано выше, ввод пользователя используется различными компонентами для того, чтобы конфигурировать, выделять и развертывать запрошенные элементы.
Фиг.5C иллюстрирует пользовательский интерфейс 500 после того, как пользователь выбрал My Reservations в области 504 навигации. Как показано на фиг.5C, пользователь может просматривать все надлежащие сведения, ассоциированные с различными резервированиями. Пользователь имеет ряд доступных вариантов, к примеру: редактирование резервирований, отмена резервирований, возврат серверов в пул серверов, продление резервирований и повторный запуск конкретного развертывания. Пользовательский интерфейс 500, описанный в данном документе, может быть сконфигурирован согласно требуемому предпочтению, и изобретение не имеет намерение быть ограниченным какими-либо конкретными примерами и/или вариантами осуществления, описанными в данном документе.
Как показано на фиг.5C, пользовательский интерфейс 500 включает в себя поле Current Status (Текущее состояние). В одном варианте осуществления поле Current Status может включать в себя ряд значений, таких как Not started yet (Еще не начато) (развертывание не началось на зарезервированных машинах); Deploying (в процессе развертывания); Complete (Закончено) (развертывание завершено успешно, и пользователь теперь может использовать машины); XML file error (Ошибка XML-файла) (ошибка в используемом машинном XML-файле; требуется пользователь или OPM, чтобы скорректировать машинный XML-файл); и System error (Системная ошибка) (проблема в процессе развертывания).
Пример использования тестировщиком пользовательского интерфейса заключается в следующем. Тестировщик должен верифицировать один признак на веб-узле OFFICE AWS прежде, чем разработчик может проверить код и добавлять пакет MSI в кластер SH/ST. Тестировщик использует веб-обозреватель, чтобы загрузить пользовательский интерфейс 500. Используя пользовательский интерфейс 500, тестировщик регистрирует тип кластера AWS в течение следующего дня. Тестировщик также редактирует файл machine.xml с помощью пользовательского интерфейса 500, чтобы добавить новый пакет и указать путь для перехода к PR. Тестировщик следующим утром принимает уведомление по электронной почте, которое перечисляет серверы в зарегистрированном кластере и указывает, что развертывание закончено согласно введенной информации. После этого тестировщик может выполнить любые тесты для того кластера, при этом также локально входя в систему на серверах, чтобы проверить различные функции. После верификации того, что все в порядке, тестировщик отправляет почтовое сообщение разработчику, чтобы проверить код. Тестировщик может выйти из My Reservations, что завершает резервирование.
Далее приводится пример отладки. Разработчик - это часть группы AWS. Одна функция непонятным образом сбоит на кластере интеграции. Разработчик не может выполнить отладку непосредственно в среде интеграции, поскольку это может повлиять на весь кластер и другие службы. Разработчик использует пользовательский интерфейс 500, чтобы зарегистрировать кластер типа AWS, и выбирает последний пересылаемый файл из интеграции. На основе входных данных точное содержимое и код устанавливается, как описано в данном документе, в зарегистрированный кластер согласно выбранному пересылаемому файлу. Разработчик теперь имеет подобную среду для отладки без влияния на первоначальный кластер интеграции.
Фиг.6 иллюстрирует ряд событий и таблиц сценария, которые ассоциированы с различными сценариями и соответствующими событиями, в соответствии с вариантом осуществления. Каждый сценарий может иметь соответствующую запись события в таблицах событий, и каждое событие может быть связано с соответствующим сценарием посредством записи в таблице script_task, как показано на фиг.6. Когда событие запланировано для вычислительной системы, такой как, например, тестовый сервер, новая запись создается в таблице event_schedule, которая включает в себя ссылку на вычислительные системы и событие. Когда запланированное время запланированного события наступает, состояние выполнения сценария записывается на вычислительной системе в другие поля таблицы eventschedule: start_time, end_time, status, status_code (к примеру, для кодов ошибки) и т.д.
Ряд конфигураций развертывания является доступным с помощью различных компонентов, описанных выше. Ряд возможностей развертывания представляется ниже.
Инсталляция выпущенной сборки OFFICE заключается в том, чтобы установить кластер серверов посредством использования официальной сборки OFFICE. Пользователь может сначала определить сборку и затем выбрать шаблон файла machine.xml для использования. Как описано выше, пользователь может также использовать специализированный шаблон файла machine.xml, который должен быть загружен и проверен. Список типов машин перечисляется для инсталляции согласно роли сервера, заданной в шаблоне.
Пользователь также может определить число серверов, требуемых для каждой серверной роли. Запрошенное число серверов автоматически выбирается из пула(ов) серверов, и файл machine.xml формируется с помощью имен серверов из выбранных серверов пула(ов) серверов. Пользователь может просматривать файл machine.xml, включая ручные обновления, в случае необходимости. Обновленная версия может быть представлена и сохранена так, чтобы она могла использоваться для развертывания. Синтаксис и тэги автоматически верифицируются в обновленном файле machine.xml перед сохранением.
Установка может поддерживать ряд служб, включая, без ограничения, следующее: компонент совместно используемых ресурсов; ULS; AWS; служба переназначения; R&R; Watson; средства IPO; Visio. В пользовательский интерфейс включен ряд заранее заданных XML-шаблонов, сгруппированных по службам. Для каждой службы предусмотрено несколько шаблонов, которые задают общий сценарий установки для каждой службы (к примеру, компактная установка с установкой всех возможных компонентов на совместно используемом сервере, сборка со встроенным содержимым или без содержимого и т.д.). Также предусмотрены шаблоны, которые имеют все службы, установленные в настоящий момент для определенных окружений (к примеру, TC5, интеграция и т.д.).
Установка пересылаемого файла состоит в том, чтобы включить все задания (к примеру, код и содержимое), в настоящий момент развернутые в кластере или окружении. Существующий кластер может быть быстро дублирован с помощью установки пересылаемого файла. Эта установка полезна для выполнения отладки или тестов, которые должны моделировать определенные окружения. Развертывание на основе пересылаемого файла также является эффективным способом установить код с соответствующим содержимым. Некоторые пересылаемые файлы включают в себя selfhost, selftest, integration и т.д. Каждый раз, когда задание развертывается на этих кластерах, пересылаемые файлы для конкретных кластеров обновляются и сохраняются в службе CMDB. Предыдущий пересылаемый файл после этого отмечается как Archived. Самая последняя сборка кода также включается в пересылаемый файл.
После того как пользователь выбирает пересылаемый файл, пользователь также может выбрать шаблон файла machine.xml для использования. Используя различные файлы machine.xml, пользователь может настроить под себя развернутое содержимое. Например, пользователь может выбрать и установить английский язык вместо всех языков. Необходимые роли сервера автоматически определяются на основе информации, включенной в файл machine.xml. Затем пользователь может определить число серверов для каждой серверной роли, и зарезервированные имена сервера автоматически добавляются, чтобы сформировать корректный файл machine.xml.
Установка PR аналогична установке выпущенной сборки OFFICE. Тем не менее, вместо использования официальной сборки OFFICE пользователь запрашивает сборку PR существующей службы или новой службы. Пользователь может установить биты PR посредством предоставления обозначения местоположения PR. Другие изменения также могут потребоваться, к примеру, для новой службы (например, добавление нового свойства автоматического воспроизведения и т.д.).
Основная установка с развертыванием сервера не должна применять код OFFICE во время установки. Пользователь может выбрать тип сервера и затем определить число серверов. Основная установка с развертыванием сервера должна установить ОС плюс общие элементы конфигурации на зарезервированные серверы. Основная установка с развертыванием сервера может использоваться для установки сервера OFFICE посредством быстрой установки ряда чистых серверов. Другие этапы могут быть добавлены, чтобы установить другие серверные компоненты.
Например, кластеры серверов могут быть динамически сконфигурированы, выделены и/или развернуты, чтобы тестировать службу прежде, чем служба назначается посредством хоста, интегрируется и в конце концов освобождается. В качестве дополнительного примера, пользователи могут непосредственно резервировать кластер серверов в требуемое время (к примеру, ежедневно). Зарезервированный кластер серверов может быть динамически сконфигурирован с помощью необходимого кода и/или содержимого согласно запросу пользователя. Дополнительно пользователям может назначаться разрешение доступа на основе содержимого резервирования. После этого один или более пользователей могут выполнять тесты и другие сценарии производительности и конфигурирования на выделенном кластере серверов. Кластер серверов может быть возвращен в доступный пул серверов после того, как резервирование завершается, и освобожденные серверы могут использоваться для последующего резервирования. Варианты осуществления также выполнены с возможностью конфигурировать специальный кластер для нечастых целей. Например, большой кластер в типичном варианте требуется для теста производительности. Большой кластер может быть сконфигурирован, выделен и/или развернут посредством группировки всех доступных серверов в один большой кластер.
Примерное операционное окружение
Ссылаясь теперь на фиг.7, нижеследующее обсуждение имеет намерение предоставить краткое общее описание подходящей вычислительной среды, в которой могут быть реализованы варианты осуществления изобретения. Хотя изобретение описано в общем контексте программных модулей, которые приводятся в исполнение вместе с программными модулями, которые запущены в операционной системе на персональном компьютере, специалисты в данной области техники должны принимать во внимание, что изобретение также может быть реализовано в сочетании с другими типами вычислительных систем и программных модулей.
В общем, программные модули включают в себя алгоритмы, программы, компоненты, структуры данных и другие типы структур, которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Более того, специалистам в данной области техники следует принимать во внимание, что изобретение может быть реализовано на практике с другими конфигурациями вычислительных систем, включающими в себя карманные устройства, многопроцессорные системы, основанную на микропроцессорах или программируемую бытовую электронную аппаратуру, мини-компьютеры, мейнфреймы и т.п. Изобретение также может быть реализовано на практике в распределенных вычислительных средах, в которых задачи выполняются удаленными обрабатывающими устройствами, которые связаны через сеть связи. В распределенной вычислительной среде программные модули могут размещаться и на локальных, и на удаленных устройствах хранения данных.
На фиг.7 представлена иллюстративная операционная среда для вариантов осуществления изобретения. Как показано на фиг.7, компьютер 2 содержит универсальный настольный компьютер, портативный компьютер, карманный компьютер или другой тип компьютера, способный выполнять одну или более прикладных программ. Компьютер 2 включает в себя, по меньшей мере, один центральный процессор 8 (CPU), системное запоминающее устройство 12, включающее в себя оперативное запоминающее устройство 18 (RAM) и постоянное запоминающее устройство (ROM) 20, и системную шину 10, которая соединяет запоминающее устройство с CPU 8. Базовая система ввода/вывода, содержащая основные подпрограммы, которые помогают передавать информацию между элементами в компьютере, к примеру, во время запуска, сохраняется в ROM 20. Компьютер 2 дополнительно включает в себя устройство 14 хранения большой емкости для хранения операционной системы 32, прикладных программ и других программных модулей.
Устройство 14 хранения большой емкости подключено к CPU 8 посредством контроллера устройства хранения большой емкости (не показан), подключенного к шине 10. Устройство 14 хранения большой емкости и ассоциированные с ним машиночитаемые носители предоставляют энергонезависимое хранение для компьютера 2. Хотя описание машиночитаемых носителей, содержащееся в данном документе, ссылается на устройство хранения большой емкости, такое как жесткий диск или накопитель CD-ROM, специалисты в данной области техники должны принимать во внимание, что могут быть доступны другие типы машиночитаемых носителей, к которым можно осуществлять доступ или использовать посредством компьютера 2.
В качестве примера, но не в ограничительном смысле, машиночитаемые носители могут содержать компьютерные носители хранения и среду связи. Компьютерные носители хранения включают в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым способом или технологией для хранения информации, такой как машиночитаемые инструкции, структуры данных, программные модули или другие данные. Компьютерные носители хранения включают в себя, но не в ограничительном смысле, память по технологии RAM, ROM, EPROM, EEPROM, флэш-памяти или другой твердотельной технологии, CD-ROM, универсальный цифровой диск (DVD) или другое оптическое запоминающее устройство, магнитные кассеты, магнитную ленту, магнитный диск или другие магнитные устройства хранения, либо любой другой носитель, который может быть использован для хранения требуемой информации и к которому можно осуществлять доступ с помощью компьютера 2.
Согласно различным вариантам осуществления изобретения компьютер 2 может работать в сетевой среде, использующей логические соединения с удаленными компьютерами по сети 4, такой как, например, Интернет и т.п. Компьютер 2 может подключаться к сети 4 через сетевой интерфейсный блок 16, подключенный к шине 10. Следует принимать во внимание, что сетевой интерфейсный блок 16 может также использоваться для подключения к другим типам сетей и удаленных компьютерных систем. Компьютер 2 также может включать в себя контроллер 22 ввода/вывода для приема и обработки входных данных из ряда других устройств, в том числе клавиатуры, мыши и т.д. (не показаны). Также контроллер 22 ввода/вывода может предоставлять вывод на экран дисплея, принтер или другой тип устройства вывода.
Как вкратце упоминалось выше, ряд программных модулей и файлов данных могут быть сохранены в устройстве 14 хранения большой емкости и RAM 18 компьютера 2, в том числе операционная система 32, подходящая для управления работой сетевого персонального компьютера, такая как операционная система WINDOWS XP от MICROSOFT CORPORATION, Редмонд, штат Вашингтон. Устройство 14 хранения большой емкости и RAM 18 также могут хранить один или более программных модулей. В частности, устройство 14 хранения большой емкости и RAM 18 могут хранить прикладные программы, такие как приложение 28 обработки текста, приложение 30 электронной таблицы, почтовое приложение 34, графическое приложение и т.д.
Следует принимать во внимание, что различные варианты осуществления могут быть реализованы (1) как последовательность реализуемых машиной действий или программных модулей, выполняющихся в вычислительной системе, и/или (2) как взаимосвязанные машинные логические схемы или модули схем в рамках вычислительной системы. Реализация выбирается и зависит от требований к производительности вычислительной системы, реализующей изобретение. Соответственно, логические операции, включая связанные алгоритмы, могут упоминаться в разных случаях как операции, структурные устройства, действия или модули. Специалистам в данной области техники следует принимать во внимание, что эти операции, структурные устройства, действия и модули могут быть реализованы в программном обеспечении, микропрограммном обеспечении, цифровой логике специального назначения и любой комбинации означенного без отступления от сущности и объема настоящего изобретения, изложенных в прилагаемой формуле изобретения.
Хотя изобретение описано в связи с различными примерными вариантами осуществления, специалисты в данной области техники должны понимать, что множество модификаций может быть выполнено в них в рамках объема нижеследующей формулы изобретения. Соответственно, нет намерения, чтобы объем изобретения был каким-либо образом ограничен вышеупомянутым описанием, а вместо этого он должен полностью определяться согласно нижеследующей формуле изобретения.
Приложения A и B, которые приведены далее, иллюстрируют типичные файлы схемы для использования в динамическом конфигурировании, выделении и развертывании ряда вычислительных систем в соответствии с вариантом осуществления.














































| название | год | авторы | номер документа |
|---|---|---|---|
| БРОКЕР И ПРОКСИ ОБЕСПЕЧЕНИЯ БЕЗОПАСТНОСТИ ОБЛАЧНЫХ УСЛУГ | 2014 |
|
RU2679549C2 |
| СИСТЕМА И СПОСОБ РАЗВЕРТЫВАНИЯ ПРЕДВАРИТЕЛЬНО СКОНФИГУРИРОВАННОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ | 2012 |
|
RU2541935C2 |
| ПРИОРИТЕТ МНОГОМОДАЛЬНОЙ СВЯЗИ ПО БЕСПРОВОДНЫМ СЕТЯМ | 2013 |
|
RU2630588C2 |
| ОСНОВАННОЕ НА МОДЕЛИ УПРАВЛЕНИЕ КОМПЬЮТЕРНЫМИ СИСТЕМАМИ И РАСПРЕДЕЛЕННЫМИ ПРИЛОЖЕНИЯМИ | 2004 |
|
RU2375744C2 |
| ИНФРАСТРУКТУРА РАСШИРЯЕМОГО И АВТОМАТИЧЕСКИ РЕПЛИЦИРУЮЩЕГО УПРАВЛЕНИЯ КОНФИГУРАЦИЕЙ ПУЛА СЕРВЕРОВ | 2006 |
|
RU2404451C2 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ ПОИСКА ПРИКЛАДНЫХ ПРОГРАММ | 2014 |
|
RU2598988C2 |
| РАСПРЕДЕЛЯЕМАЯ, МАСШТАБИРУЕМАЯ, ПОДКЛЮЧАЕМАЯ АРХИТЕКТУРА КОНФЕРЕНЦСВЯЗИ | 2007 |
|
RU2459371C2 |
| РАЗВЕРТЫВАНИЕ РЕШЕНИЙ В ФЕРМЕ СЕРВЕРОВ | 2006 |
|
RU2417416C2 |
| ПРЕДСТАВЛЕНИЕ СЛИТНОГО ВИДА ЯРЛЫКОВ НА УДАЛЕННЫЕ ПРИЛОЖЕНИЯ ОТ МНОЖЕСТВА ПОСТАВЩИКОВ | 2004 |
|
RU2367009C2 |
| СИСТЕМА УПРАВЛЕНИЯ И ДИСПЕТЧЕРИЗАЦИИ КОНТЕЙНЕРОВ | 2019 |
|
RU2751576C2 |












Изобретение относится к области конфигурирования и развертывания вычислительных систем. Техническим результатом является возможность динамического конфигурирования для хранения конкретной конфигурации в течение периода резервирования. Система для динамического развертывания одной или более вычислительных систем в сети, причем упомянутая система содержит процессор и память, кодирующую инструкции, которые, при исполнении процессором, побуждают процессор создавать компонент базы данных, включающий в себя множество хранимых информации и процедур для манипулирования упомянутой информацией, содержащий состояние резервирования, определяющее состояние резервирования для одной вычислительной системы в пуле вычислительных систем, состояние конфигурации, определяющее конфигурацию вычислительной системы в пуле, причем конфигурации включают в себя веб-сервер, SQL-сервер, сервер поиска и сервер контента, состояние доступности, определяющее доступность вычислительной системы в пуле, и состояние развертывания, указывающее состояние развертывания для каждой из вычислительных систем в пуле; и компонент веб-службы, для предоставления интерфейса связи между компонентом базы данных и компонентом службы операционной системы. 3 н. и 15 з.п. ф-лы, 18 ил., 1 табл.
1. Система для динамического развертывания одной или более вычислительных систем в сети, причем упомянутая система содержит процессор и память, кодирующую инструкции, которые, при исполнении процессором, побуждают процессор создавать компонент базы данных, включающий в себя множество хранимых информации и процедур для манипулирования упомянутой информацией, содержащий
состояние резервирования, определяющее состояние резервирования для одной вычислительной системы в пуле вычислительных систем, причем состояние резервирования включает в себя состояние «еще не начато», указывающее, что резервирование выполнено; состояние «развертывание», указывающее, когда наступил период времени для резервирования; состояние «готов», указывающее, когда все этапы развертывания, требуемые для резервирования, завершены, причем одно значение оценивается как сумма уникальных числовых значений, определяющих все этапы развертывания, требуемые для выполнения резервирования, причем каждое уникальное числовое значение соответствует этапу развертывания, выбранному из множества этапов развертывания, для отслеживания, выполнен ли конкретный этап развертывания или нет; состояние «истекает», указывающее, когда истекает период времени для резервирования; и состояние «архивирование», указывающее, когда все ресурсы, ассоциированные с резервированием, освобождены,
состояние конфигурации, определяющее конфигурацию вычислительной системы в пуле, причем конфигурации включают в себя веб-сервер, SQL-сервер, сервер поиска и сервер контента,
состояние доступности, определяющее доступность вычислительной системы в пуле, причем состояние доступности включает в себя состояние «не резервировано» для каждой вычислительной системы, которая не зарезервирована в резервировании; состояние «резервировано» для каждой вычислительной системы, которая зарезервирована в резервировании; и состояние «в использовании» для каждой вычислительной системы, которая в текущий момент развернута в резервировании, и
состояние развертывания, указывающее состояние развертывания для каждой из вычислительных систем в пуле, причем состояние развертывания включает в себя состояние «еще не запущено», когда резервирование выполнено, но развертывание еще не запущено; состояние «этап развертывания», указывающее каждый этап развертывания, когда развертывание запущено; и состояние «готов», когда развертывание завершено, указывающее, что сервер готов для другого развертывания; компонент службы операционной системы для периодической связи с компонентом базы данных для одной или более задач, которые требуется выполнить; и
компонент веб-службы для предоставления интерфейса связи между компонентом базы данных и компонентом службы операционной системы, причем компоненты работают совместно для развертывания одной или более вычислительных систем, включая конфигурирование и выделение одной или более вычислительных систем; причем вычислительная система пула резервируется, основываясь, частично, на алгоритме резервирования, который конфигурирован для выделения, по меньшей мере, одной вычислительной системы, основываясь на, по меньшей мере, состоянии резервирования, состоянии конфигурации, состоянии доступности и состоянии развертывания вычислительной системы.
2. Система по п.1, в которой база данных включает в себя информацию, ассоциированную с конфигурацией развертывания, причем информация дополнительно включает в себя, по меньшей мере, одно из роли системы и типа системы.
3. Система по п.2, в которой база данных включает в себя информацию, ассоциированную с, по меньшей мере, одним из тестовой конфигурации и конфигурации отладки.
4. Система по п.2, в которой тип системы выбирается из, по меньшей мере, одного из базового типа, офисного типа, типа закрытой версии и типа дубля кластера.
5. Система по п.1, дополнительно содержащая компонент сценария для выполнения одной или более процедур конфигурирования, выделения и развертывания, причем компонент сценария включает в себя, по меньшей мере, один сценарий, ассоциированный с, по меньшей мере, одним событием, и, по меньшей мере, один сценарий выполняется в ассоциации с возникновением, по меньшей мере, одного события.
6. Система по п.5, в которой, по меньшей мере, один сценарий выбирается из, по меньшей мере, одного из сценария установки операционной системы (ОС), сценария установки средства отладки, сценария типа и сценария роли.
7. Система по п.1, в которой служба операционной системы дополнительно конфигурирована для предоставления электронного уведомления, по меньшей мере, одному пользователю о том, что развертывание закончено и готово к использованию.
8. Машиночитаемый носитель, включающий в себя исполняемые инструкции, которые при исполнении выделяют, по меньшей мере, один сервер из пула серверов посредством
использования алгоритма резервирования, который конфигурирован для выделения, по меньшей мере, одного сервера из пула серверов, основываясь на, по меньшей мере, состоянии резервирования, причем состояние резервирования определяет состояние резервирования для, по меньшей мере, одного сервера, причем состояние резервирования включает в себя состояние «еще не начато», указывающее, что резервирование выполнено; состояние «развертывание», указывающее, когда наступил период времени для резервирования; состояние «готов», указывающее, когда все этапы развертывания, требуемые для резервирования, завершены, причем одно значение оценивается как сумма уникальных числовых значений, определяющих все этапы развертывания, требуемые для выполнения резервирования, причем каждое уникальное числовое значение соответствует этапу развертывания, выбранному из множества этапов развертывания для отслеживания, выполнен ли конкретный этап развертывания или нет; состояние «истекает», указывающее, когда истекает период времени для резервирования; и состояние «архивирование», указывающее, когда все ресурсы, ассоциированные с резервированием, освобождены;
использования входных данных развертывания, чтобы конфигурировать, по меньшей мере, один сервер из пула серверов, причем входные данные развертывания включают в себя тип развертывания, время начала развертывания и время окончания развертывания;
определения доступности, по меньшей мере, одного сервера, основываясь, частично, на входных данных развертывания;
сохранения входных данных развертывания, если, по меньшей мере, один сервер из пула серверов доступен; и
развертывания, по меньшей мере, одного сервера из пула серверов, основываясь, частично, на доступности, по меньшей мере, одного сервера, причем развертывание, по меньшей мере, одного сервера включает в себя динамическое конфигурирование, по меньшей мере, одного сервера в соответствии с входными данными развертывания.
9. Машиночитаемый носитель по п.8, в котором инструкции при исполнении выделяют, по меньшей мере, один сервер из пула серверов посредством использования входных данных типа развертывания, причем входные данные типа развертывания выбираются из, по меньшей мере, одного из базового типа, офисного типа, типа закрытой версии и типа дубля кластера.
10. Машиночитаемый носитель по п.9, в котором инструкции при исполнении выделяют, по меньшей мере, один сервер из пула серверов посредством использования числовых входных данных, ассоциированных с числом серверов типа развертывания.
11. Машиночитаемый носитель по п.8, в котором инструкции при исполнении выделяют, по меньшей мере, один сервер из пула серверов посредством определения того, выполнено ли развертывание, по меньшей мере, одного сервера успешно.
12. Машиночитаемый носитель по п.11, в котором инструкции при исполнении выделяют, по меньшей мере, один сервер из пула серверов посредством оценки ассоциированного машинного файла, если развертывание, по меньшей мере, одного сервера выполнено безуспешно.
13. Машиночитаемый носитель по п.8, в котором инструкции при исполнении выделяют, по меньшей мере, один сервер из пула серверов посредством отправки уведомления после успешного развертывания, по меньшей мере, одного сервера.
14. Машиночитаемый носитель по п.8, в котором инструкции при исполнении выделяют, по меньшей мере, один сервер из пула серверов посредством освобождения, по меньшей мере, одного сервера из выделения по истечении времени окончания развертывания.
15. Машиночитаемый носитель по п.8, в котором инструкции при исполнении выделяют, по меньшей мере, один сервер из пула серверов посредством продления развертывания.
16. Способ динамического конфигурирования ряда вычислительных систем в пуле вычислительных систем, причем упомянутый способ содержит
прием входных данных, ассоциированных с конфигурацией развертывания ряда вычислительных систем, причем входные данные включают в себя тип развертывания для ряда вычислительных систем и период времени для резервирования ряда вычислительных систем для развертывания; использование алгоритма резервирования, который конфигурирован для выделения, по меньшей мере, одного сервера из пула серверов, основываясь на, по меньшей мере, состоянии резервирования, причем состояние резервирования определяет состояние резервирования для, по меньшей мере, одного сервера, причем состояние резервирования включает в себя состояние «еще не начато», указывающее, что резервирование выполнено; состояние «развертывание», указывающее, когда наступил период времени для резервирования; состояние «готов», указывающее, когда все этапы развертывания для резервирования завершены; состояние «истекает», указывающее, когда истекает период времени для резервирования; и состояние «архивирование», указывающее, когда все ресурсы, ассоциированные с резервированием, освобождены;
назначение уникального числового значения каждому этапу развертывания из этапов развертывания; вычисление одного значения как суммы уникальных числовых значений, назначенных каждому из этапов развертывания и определяющих все этапы развертывания, требуемые для выполнения резервирования, причем каждое уникальное числовое значение соответствует этапу развертывания, выбранному из множества этапов развертывания для отслеживания, выполнен ли конкретный этап развертывания или нет;
использование упомянутого одного значения для отслеживания состояния этапов развертывания;
выделение ряда вычислительных систем, основываясь, частично, на доступности ряда вычислительных систем в течение периода времени; и,
развертывание ряда вычислительных систем в течение периода времени, если ряд вычислительных систем доступен в течение периода времени, причем развертывание включает в себя автоматическое конфигурирование ряда вычислительных систем согласно типу развертывания.
17. Способ по п.16, дополнительно содержащий автоматическое уведомление пользователя о развертывании ряда вычислительных систем.
18. Способ по п.16, в котором развертывание дополнительно содержит автоматическую инсталляцию, по меньшей мере, одного из ОС, промежуточного программного обеспечения и одного или более тестовых битов для ряда вычислительных систем.
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| US 6360366 B1, 19.03.2002 | |||
| US 6202206 B1, 13.03.2001 | |||
| СПОСОБ УСТАНОВКИ И КОНФИГУРИРОВАНИЯ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ | 2003 |
|
RU2260839C2 |

