Область техники, к которой относится изобретение
Настоящее изобретение относится к способу, относящемуся к высокоэффективному способу кодирования изображений для эффективного кодирования и декодирования изображения (статического изображения или видео-(движущегося) изображения).
Данная заявка испрашивает приоритет японской патентной заявки номер 2007-281556, поданной 30 октября 2007 года, содержимое которой включено в данный документ по ссылке.
Уровень техники
При кодировании изображения (статического или видеоизображения) преобладающим является способ кодирования с предсказанием, в котором значения пикселов объекта кодирования предсказываются посредством пространственного или временного предсказания с использованием ранее декодированных пикселов.
Например, при горизонтальном внутреннем предсказании блоками 4×4 в H.264/AVC, блок 4×4 от пиксела A до пиксела P (описанный как "A...P", аналогичные формы должны использоваться в других описаниях) в качестве объекта кодирования предсказывается горизонтально, используя ранее декодированные смежные пикселы a...d на левой стороне, как показано ниже:
→ → → →
a | A B C D
b | E F G H
c | I J K L
d | M N O P
Таким образом, горизонтальное предсказание выполняется следующим образом:
A=B=C=D=a
E=F=G=H=b
I=J=K=L=c
M=N=O=P=d
Затем вычисляется остаток предсказания следующим образом:
A-a B-a C-a D-a
E-b F-b G-b H-b
I-c J-c K-c L-c
M-d N-d O-d P-d
После этого исполняются ортогональное преобразование, квантование и энтропийное кодирование для того, чтобы выполнить кодирование со сжатием.
Аналогичная операция выполняется при предсказании с компенсацией движения. То есть при компенсации движения блока 4×4, блок 4×4 A'...P' как результат предсказания A...P посредством использования еще одного кадра формируется следующим образом:
A′ B′ C′ D′
E′ F′ G′ H′
I′ J′ K′ L′
M′ N′ O′ P′
Затем вычисляется остаток предсказания следующим образом:
A-A′ B-B′ C-C′ D-D′
E-E′ F-F′ G-G′ H-H′
I-I′ J-J′ K-K′ L-L′
M-M′ N-N′ O-O′ P-P′
После этого исполняются ортогональное преобразование, квантование и энтропийное кодирование для того, чтобы выполнить кодирование со сжатием.
Для левой верхней позиции (в качестве примера) блока соответствующий декодер получает предсказанное значение A' и декодированное значение (A-A') остатка предсказания и обнаруживает исходное значение A пиксела как сумму вышеполученных значений. Этот случай является обратимым. Тем не менее, даже в необратимом случае декодер получает декодированное значение остатка предсказания (A-A'+Δ) (Δ - это шум кодирования) и получает информацию о (A+Δ) посредством прибавления предсказанного значения A' к вышеполученному значению.
Вышеуказанное пояснение применяется к 16 (т.е. 4×4) значениям пикселов. Ниже показывается одномерная форма на основе упрощенного принципа. Также, ниже употребляется популярное 8-битовое значение пиксела. Следовательно, значение пиксела является целым числом в пределах от 0 до 255 (т.е. включающего в себя 256 целых чисел). Аналогичные пояснения могут применяться и к другим значениям пикселов, помимо 8-битового значения пиксела.
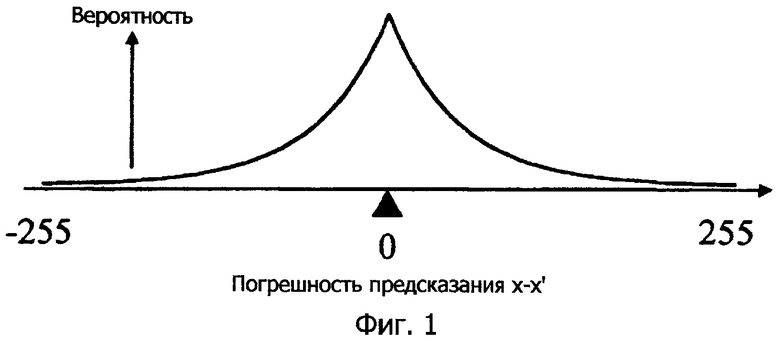
Теперь предполагается, что x обозначает значение пиксела как объект кодирования, а x' обозначает его предсказанное значение. Поскольку x' близко к x, остаток предсказания (x-x') может находиться в пределах диапазона -255...255 и концентрируется в значениях около 0, так что число больших абсолютных значений является относительно небольшим. Это отношение показано на графике фиг.1.
Поскольку объем информации смещенного распределения меньше, чем при равномерном распределении, он может быть сжат после кодирования. Традиционно, высокоэффективное сжатие достигается с использованием этого смещенного распределения.
Непатентный документ 1 относится к векторному кодированию, которое описывается в вариантах осуществления настоящего изобретения, поясненных далее, и раскрывает способ пирамидального векторного квантования, где характерные векторы упорядоченно размещаются в пространстве.
Непатентный документ 2 раскрывает способ векторного квантования на основе LBG-алгоритма для оптимизации характерных векторов векторного квантования посредством обучения, чтобы беспорядочно располагать характерные векторы в пространстве.
Непатентный документ 1. T.R.Fischer. "A pyramid vector quantizer", IEEE Trans. Inform. Theory, vol. IT-32, номер 4, стр. 568-583, июль 1986 г.
Непатентный документ 2. Y.Linde, A.Buzo and R.M.Gray. "An algorithm for vector quantizer design", IEEE Trans. on Communications, vol. com-28, номер 1, стр. 84-95, январь 1980 года.
Сущность изобретения
Проблема, разрешаемая изобретением
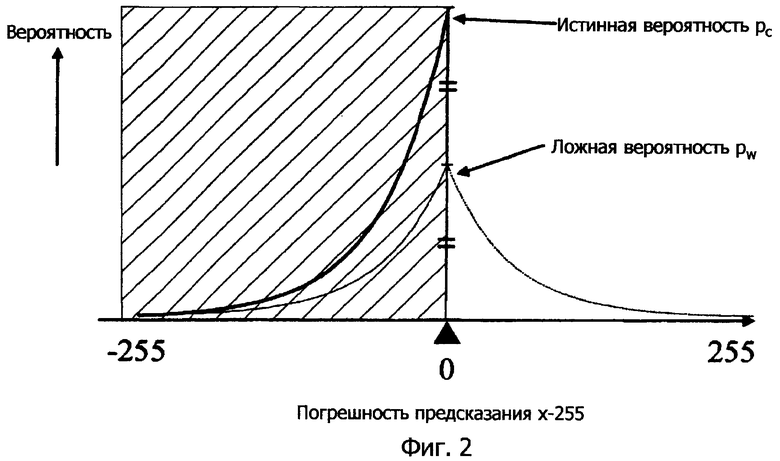
В традиционных технологиях предполагается, что предсказанное значение x'=255. Поскольку значение x пиксела принадлежит 0...255, остаток предсказания x-x'=-255...0, т.е. он должен быть 0 или меньше.
Следовательно, в релевантном распределении остатков предсказания правая половина (т.е. положительное направление) почти не используется. При качественном описании с игнорированием конечных частей (имеющих очень небольшую вероятность появления) распределения 1 бит требуется для указания информации "какие из правых и левых" (к примеру, 0 для правых и 1 для левых), поскольку распределение является симметричным в направлении слева направо. Когда правая половина распределения не используется (где расположен участок, превышающий возможный диапазон значений), вышеуказанный 1 бит первоначально является бесполезным. Также, когда предсказанное значение x'=0, левая половина релевантного распределения погрешности предсказания почти не используется, и "1 бит" первоначально является ненужным.
Вышеуказанные соотношения показаны на фиг.2. В каждой схеме, показанной ниже, возможный диапазон для значения пиксела или погрешности предсказания указывается посредством пунктирных линий.
Для качественного описания задается pw(d), которое обозначает распределение вероятностей, растущее в направлении слева направо
[формула 1]

Фактически значения в правой половине никогда не используются. Следовательно, истинное распределение "погрешности d" в два раза больше, чем pw
pc(d)=2pw(d) (когда d≤0)
pc(d)=0 (когда d>0) (2)
[формула 2]
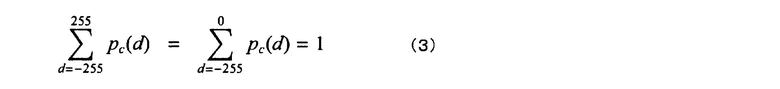
При рассмотрении pw как вероятности появления, средняя энтропия Hw оценивается следующим образом:
[формула 3]

Средняя энтропия, вычисленная с использованием истинной вероятности появления, следующая:
[формула 4]
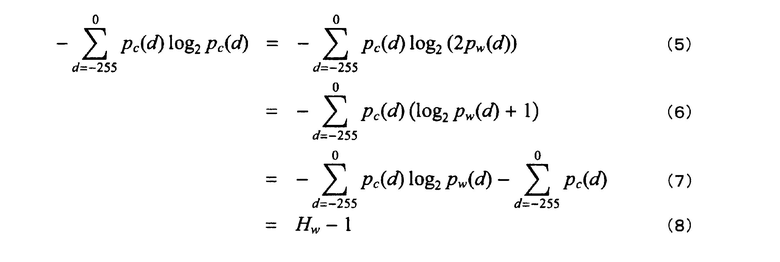
Тем не менее, при традиционном кодировании объектом является только разность (x-x'), и таким образом невозможно удалять бесполезный "1 бит".
Это обусловлено тем, что:
(i) разность (x-x') теряет информацию предсказанного значения x'; и
(ii) (для многомерных случаев) поскольку разность (x-x') подвергается ортогональному преобразованию, возможный диапазон x в пространстве после преобразования также должен быть преобразован так, что очень трудно определять избыток (сверх возможного диапазона значений) в многомерном распределении.
В свете вышеуказанных проблем, цель настоящего изобретения заключается в том, чтобы повышать эффективность кодирования с предсказанием посредством отказа от вычисления разности между исходным значением пиксела и его предсказанным значением при выполнении временного и пространственного предсказания (аналогично традиционным технологиям) и кодирования исходного значения пиксела на основе распределения, соответствующего исходному значению пиксела, с учетом вышеописанного "избытка" для распределения.
Средство решения проблемы
Настоящее изобретение применяется к кодированию с предсказанием для кодирования значения пиксела объекта кодирования (значение может быть ассоциировано с блоком пикселов) с использованием предсказанного значения, сформированного посредством пространственного или временного предсказания (компенсации движения) с использованием ранее декодированного изображения. Чтобы решить вышеописанные проблемы, основное свойство настоящего изобретения заключается в том, чтобы кодировать значение пиксела объекта кодирования (или блока пикселов) посредством использования условного распределения для предсказанного значения релевантного значения пиксела с учетом верхних и нижних пределов возможных значений пиксела.
Верхние и нижние пределы возможных значений пиксела соответствуют верхним и нижним пределам возможных значений пиксела в цифровом изображении. В 8-битовом изображении, которое используется чаще всего, верхние и нижние пределы составляют 255 и 0, тогда как они составляют 1023 и 0 для 10-битового изображения.
Не является проблемой предположить то, что пикселы, имеющие значение (к примеру, 2000), превышающее верхний предел или значение (к примеру, -1), присутствуют в исходном изображении. Это предмет рассмотрения верхних и нижних пределов, и настоящее изобретение повышает эффективность кодирования посредством использования такой ситуации.
Условное распределение для предсказанного значения пиксела - это распределение вероятностей, которое указывает то, какое значение имеет исходное значение x пиксела для предсказанного значения x', полученного для пиксела.
"Условное" равнозначно тому, что предсказанное значение составляет x'.
В математике вышеуказанное представляется посредством Pr (x|x′), который, в общем, имеет форму колокола, пик которого x'.
Распределение x при условии, что предсказанное значение составляет x', и (безусловно) распределение x без такого условия всегда включаются в пределы диапазона от нижних до верхних пределов (к примеру, соответствующих целым числам от 0 до 255 для 8-битового изображения) релевантного пиксела.
Дополнительно, при выполнении предсказания по настоящему изобретению в единицах блоков для кодирования условного распределения значения блока пикселов, полученного посредством блочного предсказания, может использоваться векторное квантование.
Полезный эффект изобретения
Согласно настоящему изобретению при обработке разности между предсказанным значением и исходным значением пиксела в традиционном способе появляется отсутствие "предсказанного значения как важной информации", но предсказанное значение полностью используется для кодирования, тем самым кодируя изображение (статическое изображение или видеоизображение) с уменьшенным объемом кода.
Краткое описание чертежей
Фиг.1 - это схема, показывающая разностное распределение для значения пиксела.
Фиг.2 - это схема, показывающая разностное распределение значения пиксела, когда предсказанное значение равно 255.
Фиг.3 - это схема, показывающая простое векторное квантование (с учетом релевантной разности).
Фиг.4 - это схема, показывающая простое векторное квантование (без учета релевантной разности).
Фиг.5 - это схема, показывающая характерные векторы, соответствующие норме L∞ в 4.
Фиг.6 - это схема, показывающая характерные векторы (для еще одного предсказанного значения), соответствующие норме L∞ в 4.
Фиг.7 - это схема, показывающая пирамидальное векторное квантование (с учетом релевантной разности).
Фиг.8 - это схема, поясняющая подсчет характерных векторов в пирамидальном векторном квантовании.
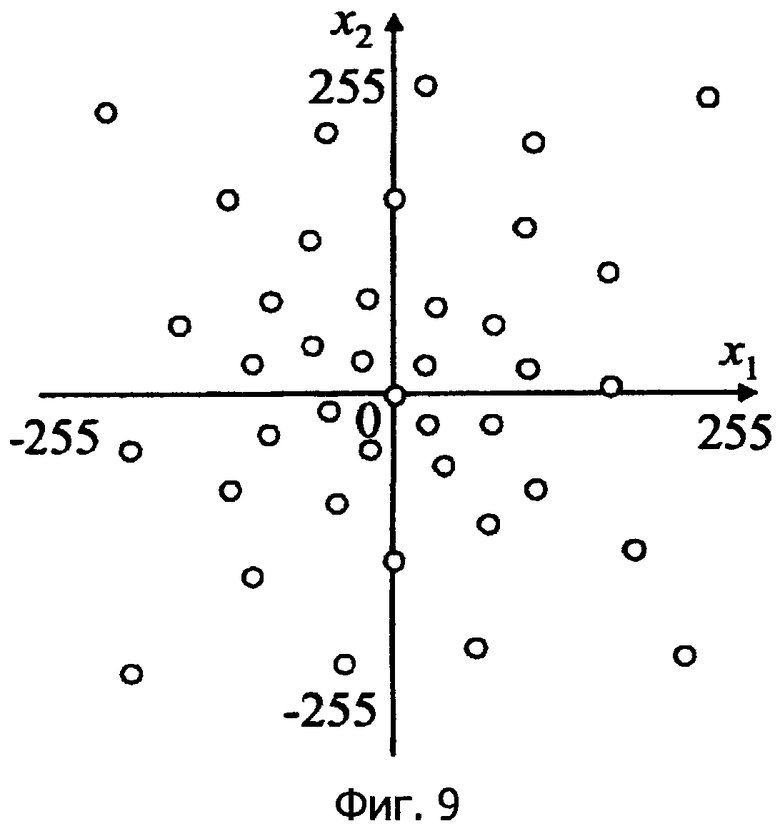
Фиг.9 - это схематичное представление, показывающее разностное векторное квантование на основе LBG-алгоритма.
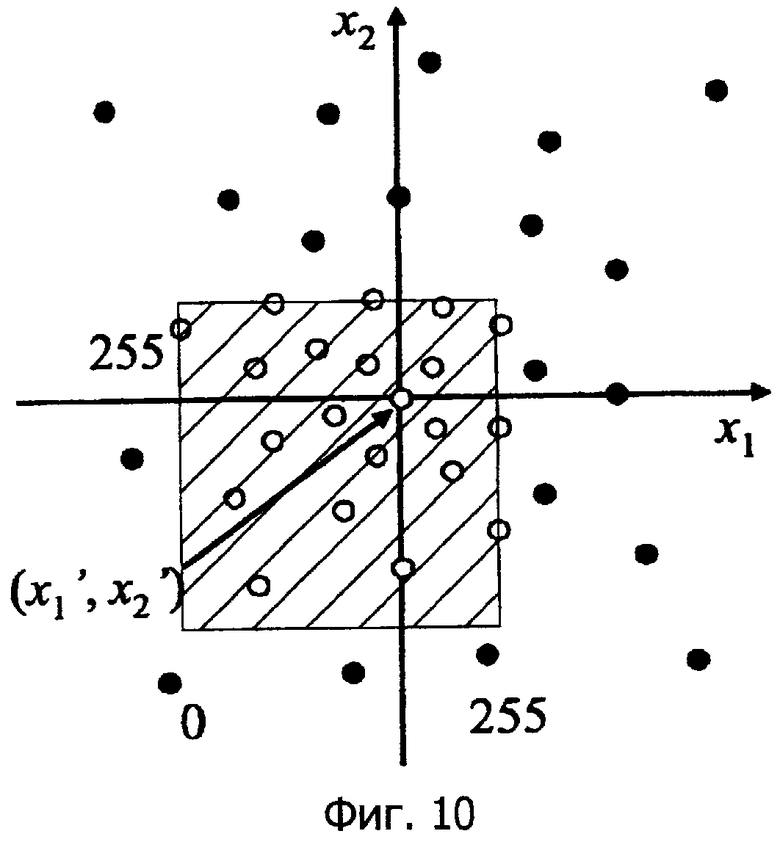
Фиг.10 - это схематичное представление, показывающее разностное векторное квантование для конкретных предсказанных значений (x1', x2').
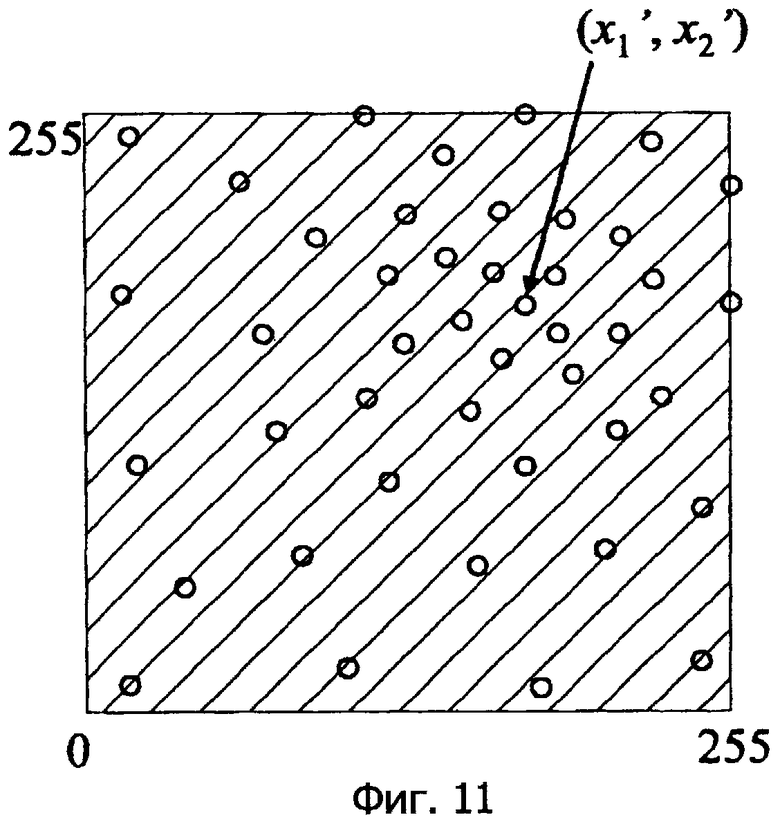
Фиг.11 - это схематичное представление, показывающее векторное квантование для конкретных предсказанных значений (x1', x2') посредством способа согласно настоящему изобретению.
Фиг.12 - это блок-схема процесса кодирования в варианте осуществления настоящего изобретения.
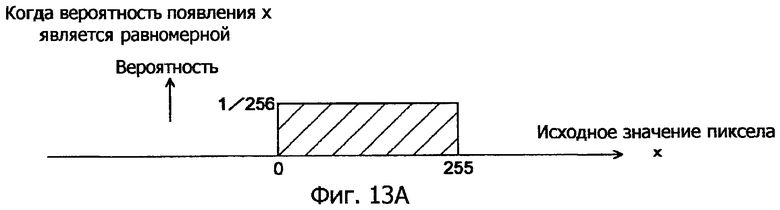
Фиг.13A - это схема, показывающая тот принцип, что исходное значение пиксела имеет равномерную вероятность появления.
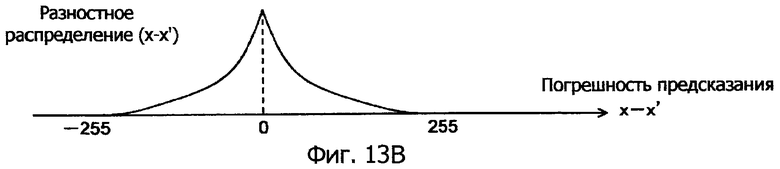
Фиг.13B - это схематичное представление, показывающее разностное распределение между исходным значением пиксела и предсказанным значением для него.
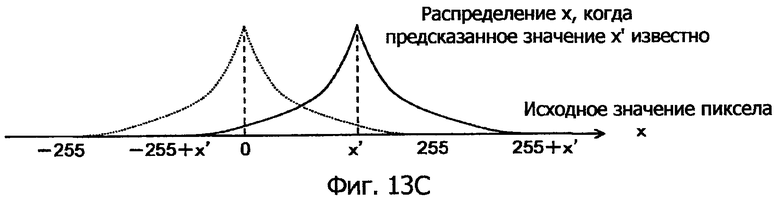
Фиг.13C - это схематичное представление, показывающее распределение, преобразованное от разностного распределения так, чтобы соответствовать исходному значению пиксела.
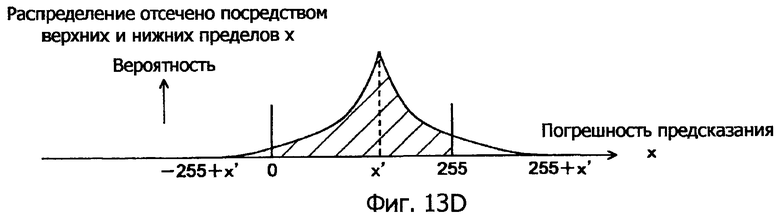
Фиг.13D - это схематичное представление, показывающее распределение, отсеченное в пределах диапазона возможных исходных значений пиксела.
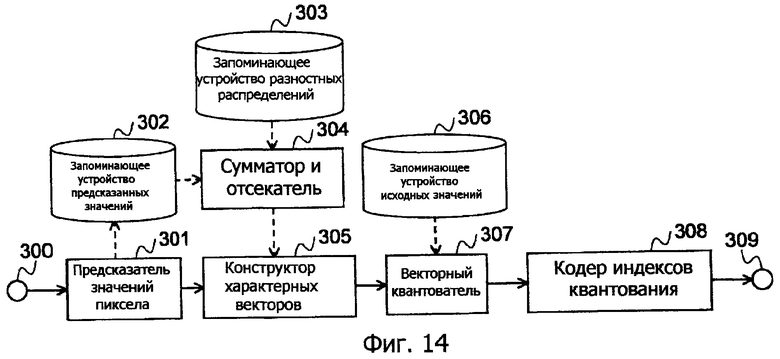
Фиг.14 - это структурная схема, показывающая аппарат кодирования по варианту осуществления.
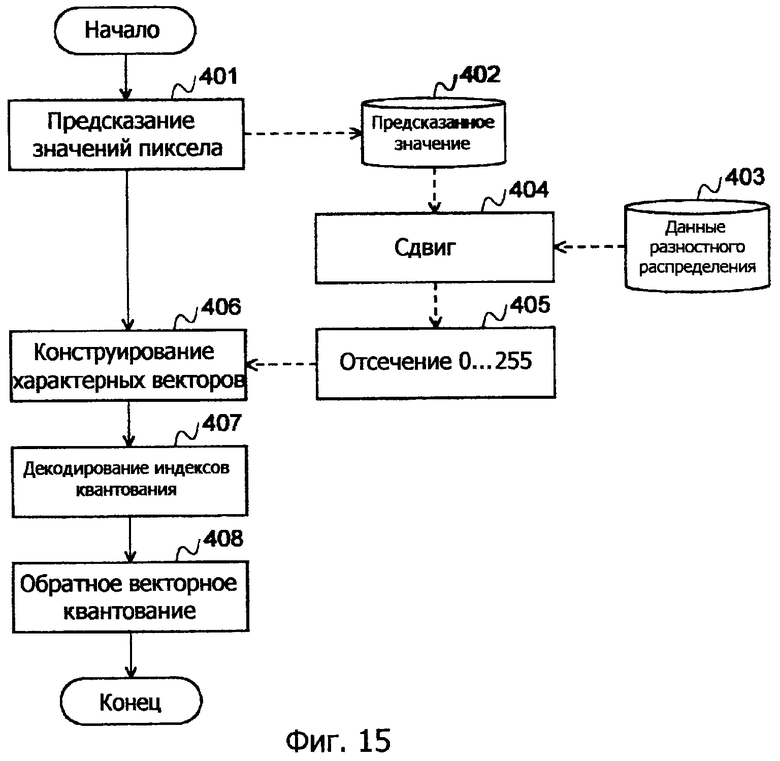
Фиг.15 - это блок-схема процесса декодирования в варианте осуществления.
Фиг.16 - это схема, показывающая пример, в котором число "избыточных" характерных векторов вычисляется неточно.
Номера ссылок
300 - сигнальный терминал
301 - предсказатель значений пиксела
302 - запоминающее устройство значений пиксела
303 - запоминающее устройство разностных распределений
304 - сумматор и отсекатель
305 - конструктор характерных векторов
306 - запоминающее устройство исходных значений пиксела
307 - векторный квантователь
308 - кодер индексов квантования
309 - выходной терминал
Наилучший режим осуществления изобретения
Общий принцип настоящего изобретения поясняется конкретно и просто.
Если неизвестно то, какое из четырех значений {-2,-1,1,2} имеет сигнал d (при этом предполагается равная вероятность 25%), для кодирования этого сигнала необходимо "2 бита". Фиг.1 показывает этот случай как распределение вероятностей (фиг.9 показывает пример соответствующего двумерного случая).
Если известно, что сигнал d является положительным, возможны только два значения {1,2}, и кодирование может выполняться с использованием "1 бита". Фиг.2 показывает этот случай как распределение вероятностей (фиг.11 показывает пример соответствующего двумерного случая).
Аналогичные пояснения могут применяться к кодированию с предсказанием для статического или видеоизображения.
Когда сигнал изображения x (0≤x) имеет предсказанное значение x', распределение погрешности предсказания d (=x-x') варьируется согласно предсказанному значению x'.
Например, если x'=0, то 0≤d0, т.е. d не имеет отрицательного значения. Если x'=255, то d0≤0, т.е. d не имеет положительного значения (см. фиг.2 снова на предмет этого принципа).
Как описано выше, перед кодированием или декодированием диапазон, где d присутствует, может быть сужен посредством обращения к предсказанному значению x', что должно повышать эффективность кодирования.
Процесс сужения диапазона присутствия d равнозначен нормализации диапазона "x'+d" (для 8-битового изображения) в 0...255.
Этот процесс также соответствует этапу 105 отсечения в способе кодирования, показанном на блок-схеме по фиг.12, и этапу 405 отсечения в способе декодирования, показанном на блок-схеме по фиг.15.
Помимо этого, оптимальные характерные векторы могут быть адаптивно сконструированы посредством конструирования характерного вектора для каждого блока как единицы предсказания (этот процесс соответствует этапу 106 конструирования характерных векторов в способе кодирования, показанном на блок-схеме по фиг.12, и этапу 406 конструирования характерных векторов в способе декодирования, показанном на блок-схеме по фиг.15).
После сужения сигнала объекта кодирования, как описано выше, обычный процесс кодирования исполняется так, что выводится код короче (т.е. имеющий более высокий уровень эффективности кодирования) традиционного кода (см. этап 109 кодирования индексов квантования на блок-схеме по фиг.12).
Предсказание значений пиксела употребляется в качестве компенсации движения либо внутреннего предсказания, которые являются существующими способами кодирования MPEG-1, MPEG-2, MPEG-4 и H.264/AVC (см. этап 101 в способе кодирования, показанном на блок-схеме по фиг.12, и этап 401 в способе декодирования, показанном на блок-схеме по фиг.15). Настоящее изобретение может широко применяться к любой сцене, где такое предсказание используется, и способствует повышению эффективности кодирования.
В существующих технологиях кодирования с предсказанием кодирование выполняется на основе предположения, что погрешность предсказания может всегда быть положительной или отрицательной (этот принцип показан на фиг.9).
Далее подробнее поясняется принципиальная функция вариантов осуществления настоящего изобретения.
Поясняется пример выполнения предсказания в единицах блоков пикселов и применения векторного квантования к кодированию условного распределения значения блока пикселов посредством блочного предсказания. Для пиксела, имеющего предсказанное значение x', основной принцип выполнения кодирования с использованием распределения вероятностей, которое указывает фактическое значение исходного значения x пиксела, также применяется к кодированию, выполняемому в единицах пикселов.
Когда показатель расстояния - это норма L∞.
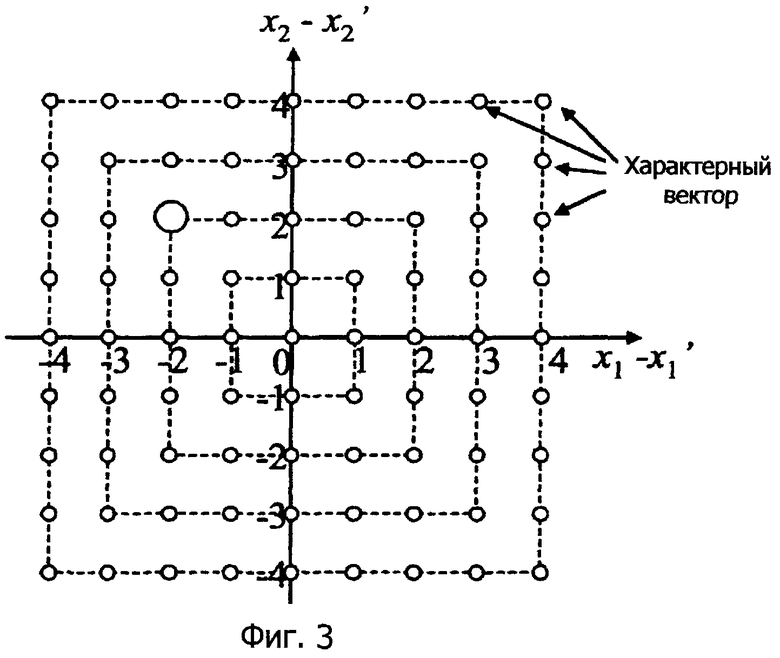
Пример квантования и кодирования в двумерном пространстве поясняется со ссылкой на фиг.3. Фиг.3 - это схематичное представление, показывающее самое простое двумерное сеточное квантование. Показатель расстояния от начала координат вычисляется на основе нормы L∞ (т.е. максимального значения из значений в абсолютных координатах).
Например, точка (0,3) и точка (-2,-3) имеют одинаковую норму L∞.
На фиг.3 предполагается, что точки (характерные векторы, которым принадлежат дискретные данные после векторного квантования), соединенные через пунктирные линии, имеют одинаковую норму L∞ и возникают с равной вероятностью.
На фиг.3 также предполагается, что исходные значения пиксела двух смежных пикселов составляют x1=253 и x2=102, и соответствующие предсказанные значения составляют x1'=255 и x2'=100. Следовательно, каждая разность составляет "x1-x1'=-2" и "x2-x2'=2".
Здесь предполагается, что вероятность появления "нормы L∞=2", которой принадлежит вектор разности (-2,2) (соответствующий исходным значениям пиксела), составляет 0,3.
Поскольку имеется 16 характерных векторов, норма L∞ которых равна 2, объем информации, требуемый для кодирования исходных значений пикселов, следующий:
-log2 0,3+log2 16=5,737 [бит] (9)
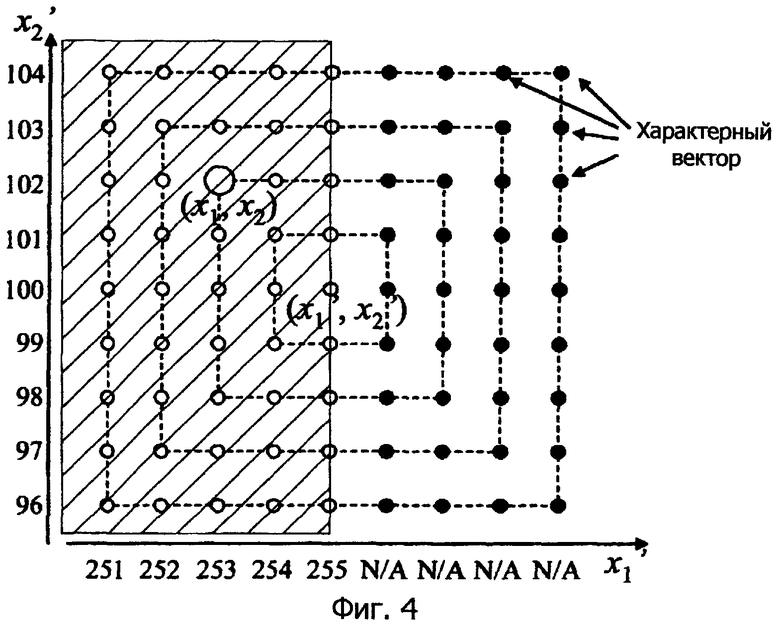
Далее оценивается объем кода, формируемого, когда погрешность предсказания не вычисляется в настоящем изобретении. Этот принцип показан на фиг.4.
На фиг.4 характерные векторы, указанные посредством белых кругов (ο), которые принадлежат затененному участку, могут иметь исходные значения пиксела, тогда как характерные векторы, указанные посредством черных кругов (•), которые принадлежат участку вне затененного участка, никогда не имеют исходных значений пиксела.
Центром является предсказанное значение (x1', x2')=(255, 100). Аналогично вышеуказанному пояснению, предполагается, что вероятность того, что норма L∞ от центра равна 2, составляет 0,3.
Поскольку 9 характерных векторов принадлежат области, удовлетворяющей вышеуказанному, объем информации, требуемый для кодирования исходных значений пиксела, следующий:
-log2 0,3+log2 9=4,907 [бит] (10)
что меньше на 0,83 бита, чем для случая вычисления релевантной разности (см. формулу (9)).
Число точек характерных векторов на плоскости, имеющей постоянную норму.
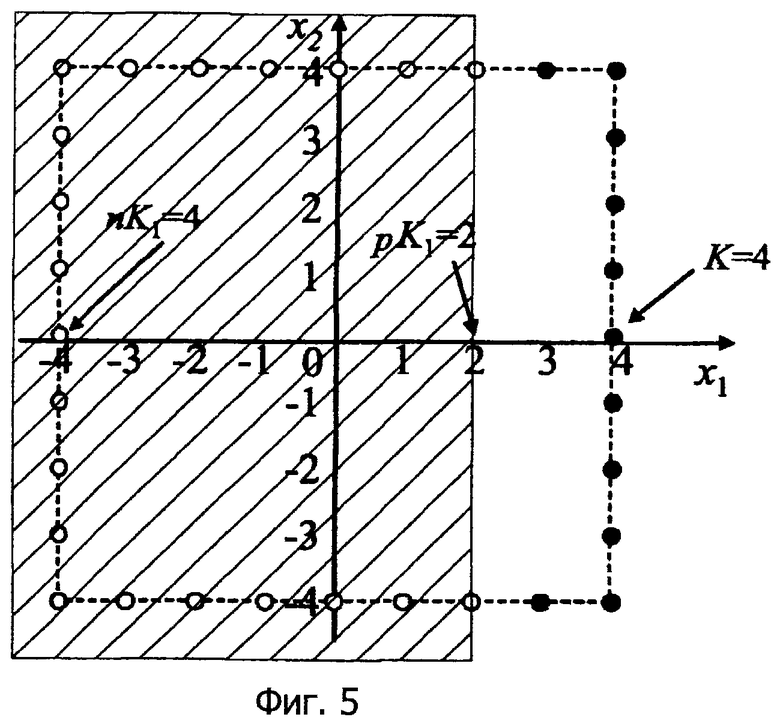
Фиг.5 показывает характерные векторы, соответствующие норме L∞, равной 4, в двумерном пространстве.
Пусть N обозначает размерность, а K обозначает норму, тогда число N(L,K) характерных векторов задается посредством следующей формулы:
N(L,K)= (2K+1)L-(2K-1)L (11)
В примере по фиг.5 получается следующий результат:
N(2,4)=92-72=81-49=32
При кодировании нижеследующий объем информации требуется для того, чтобы устанавливать характерные векторы после того, как норма установлена
log2N(L,K) [бит] (12)
Помимо этого, фиг.5 имеет "избыточный участок" (невозможный для исходных значений пиксела), указанный посредством черных кругов (•). Чтобы вычислить число белых кругов (ο) посредством исключения числа черных кругов, для соответствующих размерностей (x1, x2..., xL), имеющих верхние пределы (pK1,pK2,...,pKL) и нижние пределы (-nK1,-nK2,...,-nKL), задается следующее соотношение:
0≤nKi,pKi≤K (i=1...L)
Когда нет избыточного участка, соотношение является следующим:
Ki (верхний предел, нижний предел) ≡ K
Здесь число белых кругов (ο) указывается посредством следующего выражения:
N′(L, K, nK1,...,nKL, pK1,...,pKL)
Число вычисляется посредством следующего выражения:
[формула 5]
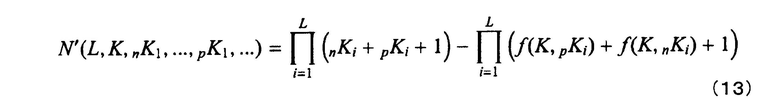
В вышеприведенной формуле:
f(K, K′)=K′-1 (когда K′=K)
f(K, K′)=K′ (когда K′<K) (14)
Поскольку L=2, K=4, nK1=4, nK2=4, pK1=2 и pK2=4 в примере по фиг.5:
N′(2,4,4,4,2,4)
=(4+2+1)(4+4+1)-(4-1+2+1)(4-1+4-1+1)
=63-42=21
Степень уменьшения энтропии согласно способу настоящего изобретения оценивается посредством следующего выражения:
log2 32-log2 21=0,608 [бит]
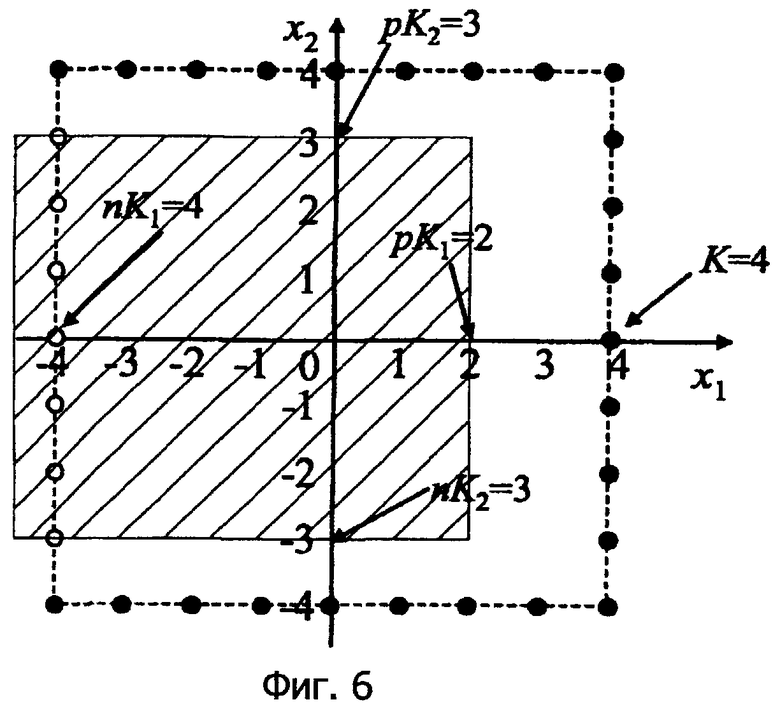
Затем, фиг.6 показывает пример, имеющий другое предсказанное значение.
Поскольку L=2, K=4, nK1=4, nK2=3, pK1=2 и pK2=3:
N′(2,4,4,3,2,3)
=(2+4+1)(3+3+1)-(2+4-1+1)(3+3+1)
=49-42=7
Следовательно, область избыточного участка значительно уменьшается.
Когда показатель расстояния - это норма L1.
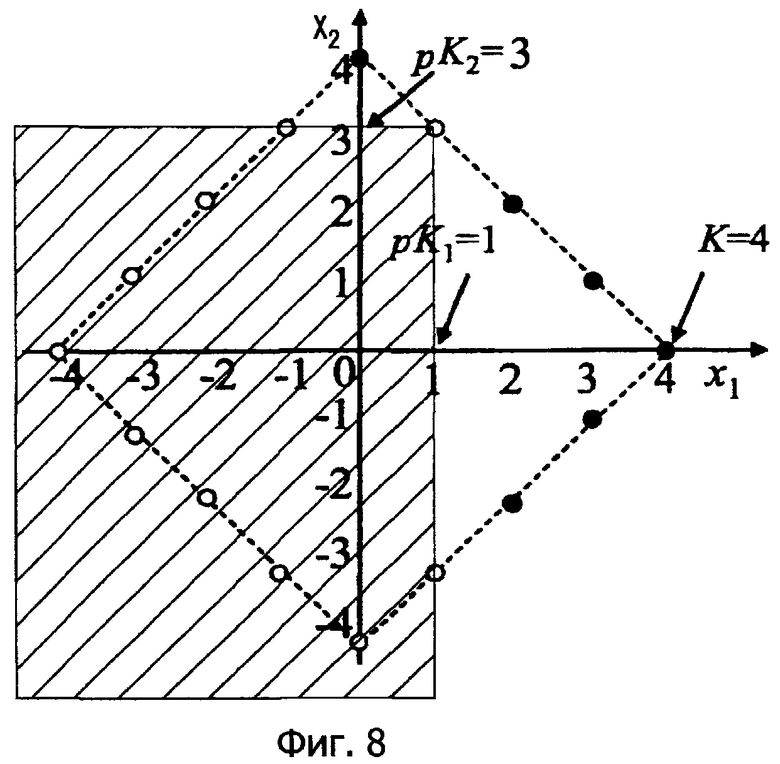
Ниже со ссылкой на фиг.7 поясняется случай так называемого пирамидального векторного квантования, в котором расстояние от начала координат соответствует норме L1. Аналогично вышеприведенному примеру, каждая пунктирная линия указывает плоскость, имеющую равномерную вероятность, и затененный участок указывает область возможных значений пиксела (0...255).
На фиг.7, (x1, x2), указанный посредством большого круга (О), - это исходный пиксел, и число характерных векторов, принадлежащих релевантной норме (т.е. "4" на фиг.7), равно 16, которые включают в себя векторы "за пределами диапазона", и имеется 10 характерных векторов в пределах релевантного диапазона.
В этом случае энтропия, полученная при невычислении разности между исходным значением пиксела и предсказанным значением (в настоящем изобретении), меньше, чем в случае вычисления разности (в традиционных способах)
log2 16-log2 10=0,678 [бит] (15)
Число точек характерных векторов на плоскости, имеющей постоянную норму.
Фиг.8 показывает участок, где норма L1 равна 4 на фиг.7.
Аналогично вышеприведенному примеру, N(L,K) указывает число характерных векторов, где норма L1 составляет K в L-мерном пирамидальном векторном квантовании и вычисляется в форме рекуррентного соотношения следующим образом (см. непатентный документ 1).
Когда K=1:
N(L,K)=2L
Когда L=1:
N(L,K)=2
В других случаях:
N(L, K)=N(L, K-1)+N(L-1, K-1)+N(L-1, K)
 ...(16)
...(16)
Поэтому:
N(2,4)=N(2,3)+N(1,3)+N(1,4)
=N(2,2)+N(1,2)+N(1,3)+2+2
=N(2,2)+2+2+4
=N(2,1)+N(1,1)+N(1,2)+8
=4+2+2+8
=16
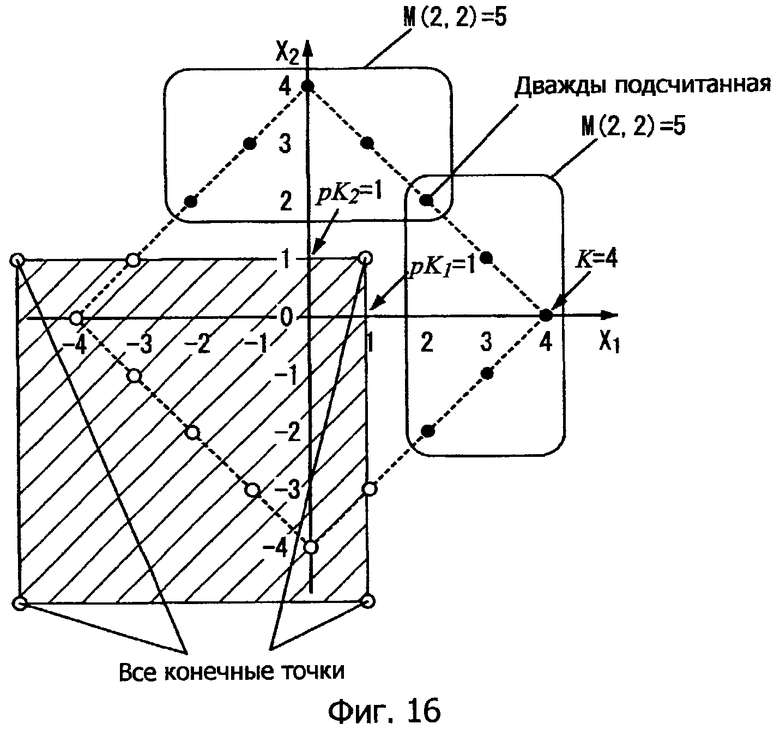
Далее рассматривается число векторов на "избыточном участке". Например, пять "избыточных" характерных векторов (•) формируются вследствие pK1=1, и один "избыточный" характерный вектор формируется вследствие pK2=3.
Сначала, для упрощения, только pK1=1 имеет соотношение pK1<K, а другие имеют следующее соотношение:
nK1, Ki=K(i=2,...,L)
В таком случае число M(L,K) "избыточных" характерных векторов (•) вычисляется с использованием N в формуле (16) следующим образом:
Когда K=0:
M(L,K)=1
Когда L=1:
M(L,K)=1
В других случаях:
M(L,K)=(N(L, K-1)+N(L-1, K))/2
...(17)
На основе этого релевантное число вычисляется посредством M(L, K-pK1-1).
Для L=2, K=4 и pK1=1 на фиг.8:
M(2, 4-1-1)=M(2,2)
=(N(2,2)+N(1,2))/2
=(8+2)/2=5
Аналогичный способ может применяться к другой размерности. Например, если pK2=3, может выполняться следующее вычисление:
M(2, 4-3-1)=M(2,0)=1
Соответственно, число белых кругов (ο) может вычисляться как "N-M", где N - это общее число характерных векторов, а M - это число избыточных характерных векторов.
Чтобы точно вычислять "избыточную" величину, как описано выше, должны удовлетворяться следующие условия.
(i) На плоскости xi=Ki, перпендикулярной i-й оси координат, норма L1 всех конечных точек всегда больше или равна K.
(ii) Таким образом, точка, в которой все значения координат за исключением оси координат j, которая предоставляет минимальное значение между |Kj| и |255-Kj| (j≠i), равны 0, имеет норму L1 (т.е. минимальную норму L1 из всех конечных точек), большую или равную K.
(iii) Следовательно, удовлетворяется следующая формула:
[формула 6]
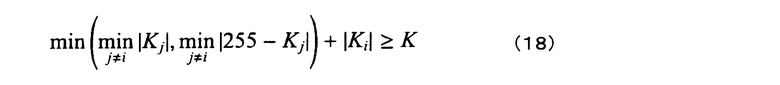
В качестве конкретного примера, на фиг.8 четыре угла затененного прямоугольника - это "все конечные точки", и все конечные точки размещаются на линии, заданной посредством "нормы L1=4" или за ее пределами, так что избыточная величина может вычисляться точно.
Если предполагается, что затененный участок задается так, как показано на фиг.16, имеется конечная точка, которая присутствует в линии "нормы L1=4" (т.е. конечная точка, размещенная в (x1, x2)=(1, 1)), так что имеется "избыточный" характерный вектор, который подсчитывается дважды (т.е. характерный вектор, размещенный в (x1, x2)=(2, 2)).
В таком случае "избыточная" величина вычисляется неточно.
При обычном векторном квантовании
При обычном векторном квантовании с использованием известного LBG-алгоритма (см. непатентный документ 2), в котором характерные векторы не являются упорядоченно расположенными, настоящее изобретение осуществляется так, как описано ниже.
Фиг.9 - это схематичное представление, показывающее векторное квантование, применяемое к обычному (двумерному) разностному сигналу. Поскольку разностный сигнал имеет значение в пределах -255...255 в каждом измерении, характерные векторы также конструируются таким образом, чтобы покрывать этот диапазон. Если вероятность того, что сигнал возникает около начала координат (0,0), является высокой относительно предсказанного разностного сигнала изображения, много характерных векторов присутствует около начала координат, тогда как меньше характерных векторов присутствует в периферийной области, как показано на фиг.9.
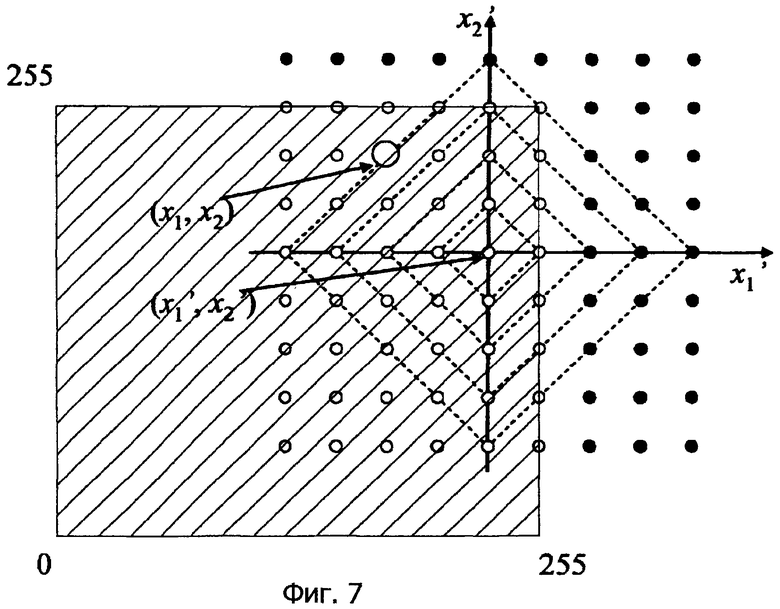
Фиг.10 - это схема, соответствующая традиционному способу кодирования, в котором исходный сигнал кодируется с использованием предсказанных значений (x1', x2'). Поскольку исходный сигнал всегда имеет значения в пределах 0...255, характерные векторы могут присутствовать вне диапазона. Следовательно, аналогично пояснению одномерного кодирования, формируется бесполезный объем кода.
Фиг.11 - это схема, соответствующая способу кодирования согласно настоящему изобретению, в котором характерные векторы конструируются на основе предсказанных значений (x1', x2').
Поскольку конструирование, безусловно, выполняется в пределах диапазона 0...255 для каждого измерения (т.е. 0≤x1, x2≤255), "избыточные" характерные векторы (которые формируются в традиционном способе на фиг.10) отсутствуют, тем самым выполняя кодирование без бесполезного объема кода.
Ниже поясняется вариант осуществления настоящего изобретения, в котором предсказание является вариантом осуществления в единицах блоков пикселов, и векторное квантование применяется к кодированию условного распределения значения блока пикселов посредством блочного предсказания.
В настоящем варианте осуществления характерные векторы для векторного квантования формируются на основе данных для обучения, которые подготавливаются заранее.
Здесь могут использоваться только данные обучения, ассоциированные с предсказанным значением x' для блока объекта кодирования. Тем не менее, число элементов данных является небольшим в этом случае. Следовательно, разность от исходного значения пиксела (т.е. x-x') может сохраняться заранее, и значение, полученное посредством прибавления предсказанного значения к разности, может использоваться в обучении.
Фиг.12 - это блок-схема настоящего варианта осуществления, где сплошные стрелки показывают последовательность операций, а пунктирные стрелки показывают поток данных.
На этапе 101 предсказания значений пикселов предсказание значений пикселов блока объекта кодирования выполняется посредством применения компенсации движения или внутреннего предсказания к каждому блоку как к единице, тем самым получая предсказанное значение 102 (векторную величину).
На этапе 104 сдвига предсказанное значение прибавляется (сдвигается) к значению разности (отдельно сохраненному) в данных 103 разностного распределения (векторная величина). На следующем этапе 105 отсечения каждый векторный элемент отсекается так, чтобы быть в пределах диапазона 0...255. Отсеченные данные функционируют в качестве исходных данных для обучения.
На этапе 106 конструирования характерных векторов, характерные векторы конструируются с использованием исходных данных для обучения, посредством LBG-алгоритма и т.п. (тем самым получая результат, как показано на фиг.11).
На следующем этапе 107 векторного квантования исходное значение 108 пиксела (векторная величина) блока объекта кодирования ассоциируется с характерным вектором, ближайшим к исходному значению пиксела.
На следующем этапе 109 кодирования индексов квантования на основе полученного индекса информация релевантного характерного вектора кодируется на основе соответствующей вероятности появления посредством энтропийного кодирования, такого как арифметическое кодирование. Полученный код выводится, и операция завершается.
Функция процесса кодирования, показанного на фиг.12, поясняется с простым примером со ссылкой на фиг.13A-13D. Для простой иллюстрации значение пиксела указывается в одномерном пространстве. Исходное значение x пиксела присутствует в пределах диапазона от 0 до 255.
Если каждое значение в этом диапазоне имеет одинаковую вероятность появления, каждое значение появляется с вероятностью 1/256 (см. фиг.13A). Такое появление значений с равной вероятностью имеет высокие затраты на кодирование.
Тем не менее, если предсказанное значение x' исходного значения x пиксела получено, распределение вероятностей для возможных значений исходного значения x пиксела может не быть равным распределению вероятностей на основе распределения известных значений погрешности предсказания. На основе этого признака настоящий способ уменьшает затраты на кодирование.
Значение погрешности предсказания (x-x') как разность между исходным значением x пиксела и предсказанным значением x' (т.е. дифференциальное значение) может быть в пределах диапазона от -255 до 255. Распределение разности может получаться посредством выполнения эксперимента кодирования с предсказанием, применяемого ко многим примерным изображениям. Данные разностного распределения накапливаются заранее с тем, чтобы сохранять данные.
Разностное распределение - это распределение частоты или вероятности каждого значения погрешности предсказания, и его пример показан на фиг.13B. Данные 103 разностного распределения на фиг.12 - это данные (здесь, векторная величина), соответствующие распределению, как показано на фиг.13B.
Чтобы кодировать исходное значение x пиксела, предсказанное значение x' вычисляется на этапе 101 предсказания значений пикселов.
На этапе S104 сдвига предсказанное значение x' прибавляется (сдвигается) к каждому значению разности в данных 103 разностного распределения, т.е. к каждому значению погрешности предсказания x-x' на горизонтальной оси в разностном распределении, показанном на фиг.13B. Это разностное распределение преобразуется в распределение, которое соответствует исходному значению x пиксела, как показано на фиг.13C.
Преобразованный результат соответствует распределению вероятностей возможных значений исходного значения x пиксела, когда предсказанное значение x' известно.
В распределении по фиг.13C диапазон распределения исходного значения x пиксела составляет от -255+x' до 255+x'. Тем не менее, предусмотрено такое предварительное условие, что исходное значение пиксела x всегда присутствует в диапазоне от 0 до 255. Следовательно, на следующем этапе 105 отсечения, как показано в распределении исходного значения x пиксела по фиг.13D, участок ниже 0 и участок выше 255 отрезаются, и полученное распределение нормализуется при необходимости так, чтобы обнаруживать распределение вероятностей.
При кодировании исходного значения x пиксела на основе распределения, показанного на фиг.13D, безусловно, получается более высокая степень эффективности кодирования, чем при кодировании на основе равномерного распределения вероятностей, как показано на фиг.13A, и дополнительно, также получается более высокая степень эффективности кодирования, чем эффективность кодирования, полученная посредством кодирования на основе распределения вероятностей, имеющего широкую нижнюю часть (в соответствии с традиционным способом), как показано на фиг.13B.
Векторное квантование является примером эффективного кодирования при таком распределении вероятностей. Кроме того, в настоящем варианте осуществления на основе распределения вероятностей, как показано на фиг.13D, расположение характерных векторов квантования определяется через этапы 106-109 на фиг.12, чтобы выполнять векторное квантование.
Фиг.14 - это структурная схема, показывающая аппарат кодирования настоящего варианта осуществления.
Исходный сигнал изображения и ранее декодированный сигнал изображения вводятся через сигнальный терминал 300.
Исходное значение пикселов блока объекта кодирования сохраняется в запоминающем устройстве 306 исходных значений пикселов.
В предсказателе 301 значений пикселов предсказание значений пикселов блока объекта кодирования выполняется посредством компенсации движения, внутреннего предсказания и т.п., выполняемого в единицах блоков, тем самым получая предсказанное значение (векторную величину), которое сохраняется в запоминающем устройстве 302 значений пикселов.
В сумматоре и отсекателе 304 вектор данных разностного распределения, который отдельно сохранен в запоминающем устройстве 303 разностных распределений, прибавляется к предсказанному значению, чтобы отсекать каждый элемент релевантного вектора, который должен быть включен в диапазон 0...255. Он выступает в качестве исходных данных для обучения.
В конструкторе 305 характерных векторов характерные векторы конструируются с использованием исходных данных для обучения, посредством LBG-алгоритма и т.п.
Затем исходное значение пиксела (векторная величина) блока объекта кодирования, которое сохранено в запоминающем устройстве 306, ассоциируется посредством векторного квантователя 307 с характерным вектором, ближайшим к исходному значению пиксела.
В кодере 308 индексов квантования индексная информация полученного характерного вектора кодируется на основе его вероятности появления посредством энтропийного кодирования, такого как арифметическое кодирование. Полученный код выводится через выходной терминал 309, и операция завершается.
Фиг.15 - это блок-схема для процесса декодирования в настоящем варианте осуществления, где сплошные стрелки показывают последовательность операций, а пунктирные стрелки показывают поток данных.
На этапе 401 предсказания значений пикселов предсказание значений пикселов блока объекта кодирования выполняется посредством применения компенсации движения или внутреннего предсказания к каждому блоку как к единице, тем самым получая предсказанное значение 402 (векторную величину).
Кроме того, на этапе 404 сложения, вектор дифференциальных значений, который отдельно сохранен, прибавляется к предсказанному значению. На следующем этапе 405 отсечения, каждый векторный элемент отсекается так, чтобы быть в пределах диапазона 0...255. Отсеченные данные функционируют в качестве исходных данных для обучения.
На этапе 406 конструирования характерных векторов, характерные векторы конструируются с использованием исходных данных для обучения, посредством LBG-алгоритма и т.п.
На основе вероятности появления индексной информации полученного характерного вектора, релевантный индекс декодируется на этапе 407 декодирования индексов квантования.
На следующем этапе 408 обратного векторного квантования получается значение характерного вектора, соответствующее индексу. Полученное значение выводится, и релевантная операция завершается.
Поскольку блочная структура аппарата декодирования настоящего варианта осуществления может быть легко выведена по аналогии на основе пояснения для структурной схемы аппарата кодирования на фиг.14 и пояснения для блок-схемы декодирования, показанного на фиг.15, пояснение блочной структуры аппарата декодирования со ссылкой на чертеж здесь опускается.
В сущности, аппарат декодирования имеет структуру, аналогичную структурной схеме аппарата кодирования, показанного на фиг.14, при этом запоминающее устройство 306 исходных значений пикселов на фиг.14 соответствует запоминающему устройству данных кодирования индексов квантования в аппарате декодирования; векторный квантователь 307 соответствует декодеру индексов квантования в аппарате декодирования, и кодер 308 индексов квантования соответствует векторному обратному квантователю в аппарате декодирования.
Вышеописанная операция кодирования и декодирования изображений или видео также может реализовываться посредством компьютера и программного обеспечения. Такая компьютерная программа может быть предоставлена посредством сохранения на машиночитаемом носителе данных или посредством сети.
Промышленная применимость
В соответствии с настоящим изобретением при обработке разности между предсказанным значением и исходным значением пиксела в традиционном способе возникает отсутствие "предсказанного значения как важной информации", но предсказанное значение полностью используется для кодирования, тем самым кодируя изображение (статическое изображение или видеоизображение) с уменьшенным объемом кода.
Изобретение относится к способу кодирования изображений (статического изображения или видеоизображения). Техническим результатом является повышение эффективности кодирования с предсказанием посредством отказа от вычисления разности между исходным значением пиксела и его предсказанным значением при выполнении временного и пространственного предсказания. Указанный технический результат достигается тем, что предложен способ кодирования изображений, при котором выполняют предсказание значения пиксела объекта кодирования и получают предсказанное значение; вычисляют данные распределения вероятностей, которое указывает то, какое значение исходное значение пиксела имеет для полученного предсказанного значения, посредством сдвига, согласно предсказанному значению, данных разностного распределения разности между исходным значением пиксела и предсказанным значением при кодировании с предсказанием, при этом данные разностного распределения заранее сохраняют; отсекают полученные данные распределения вероятностей так, чтобы вмещать данные в диапазоне от нижнего предела до верхнего предела для возможных значений исходного значения пиксела; и кодируют значение пиксела объекта кодирования с использованием отсеченных данных распределения вероятностей исходного значения пиксела от нижнего предела до верхнего предела. 6 н. и 4 з.п. ф-лы, 19 ил.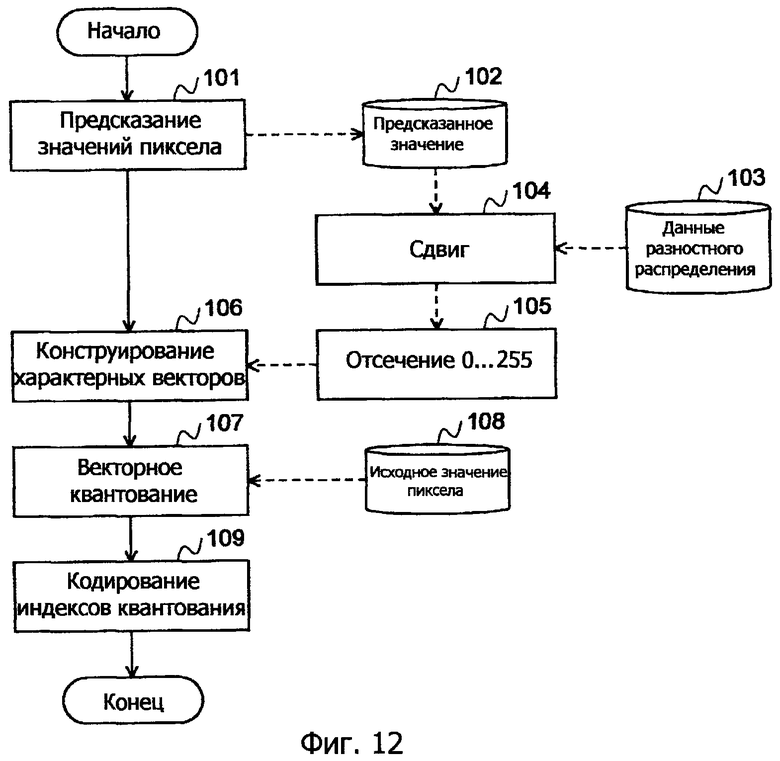
1. Способ кодирования изображений для кодирования значения пиксела объекта кодирования посредством использования предсказанного значения, сформированного посредством пространственного или временного предсказания с использованием ранее декодированного изображения, способ содержит:
- этап, на котором выполняют предсказание значения пиксела объекта кодирования и получают предсказанное значение;
- этап, на котором вычисляют данные распределения вероятностей, которые указывают то, какое значение имеет исходное значение пиксела для полученного предсказанного значения, посредством сдвига, согласно предсказанному значению, данных разностного распределения разности между исходным значением пиксела и предсказанным значением при кодировании с предсказанием, при этом данные разностного распределения сохраняют заранее;
- этап, на котором отсекают полученные данные распределения вероятностей так, чтобы вмещать данные в диапазоне от нижнего предела до верхнего предела для возможных значений исходного значения пиксела;
- этап, на котором кодируют значение пиксела объекта кодирования посредством использования отсеченных данных распределения вероятностей исходного значения пиксела от нижнего предела до верхнего предела.
2. Способ кодирования изображений по п.1, в котором:
- предсказание выполняют в единицах блоков так, что значение пиксела объекта кодирования ассоциируется с заранее определенным блоком пикселов; и
- на этапе кодирования значения пиксела характерный вектор квантования определяют на основе данных распределения вероятностей, которые вычисляют для значения блока пикселов, полученного посредством блочного предсказания, и кодирование выполняют посредством подвергания значения блока пикселов векторному квантованию.
3. Способ декодирования изображений для декодирования значения пикселов объекта декодирования посредством использования предсказанного значения, сформированного посредством пространственного или временного предсказания с использованием ранее декодированного изображения, при этом способ содержит:
- этап, на котором выполняют предсказание значения пиксела объекта декодирования и получают предсказанное значение;
- этап, на котором вычисляют данные распределения вероятностей, которые указывают то, какое значение имеет исходное значение пиксела для полученного предсказанного значения, посредством сдвига, согласно предсказанному значению, данных разностного распределения разности между исходным значением пиксела и предсказанным значением при кодировании с предсказанием, при этом данные разностного распределения сохраняют заранее;
- этап, на котором отсекают полученные данные распределения вероятностей так, чтобы вмещать данные в диапазоне от нижнего предела до верхнего предела для возможных значений исходного значения пиксела;
- этап, на котором декодируют значение пиксела объекта декодирования посредством использования отсеченных данных распределения вероятностей исходного значения пиксела от нижнего предела до верхнего предела.
4. Способ декодирования изображений по п.3, в котором:
- предсказание выполняют в единицах блоков так, что значение пиксела объекта декодирования ассоциируется с заранее определенным блоком пикселов; и
- на этапе декодирования значения пиксела характерный вектор квантования определяют на основе данных распределения вероятностей, которые вычисляют для значения блока пикселов, полученного посредством блочного предсказания, и векторно квантованное значение блока пикселов объекта декодирования декодируют на основе определенного характерного вектора квантования.
5. Устройство кодирования изображений для кодирования значения пиксела объекта кодирования посредством использования предсказанного значения, сформированного посредством пространственного или временного предсказания с использованием ранее декодированного изображения, устройство содержит:
- устройство предсказания, которое выполняет предсказание значения пиксела объекта кодирования и получает предсказанное значение;
- устройство, которое вычисляет данные распределения вероятностей, которое указывает то, какое значение имеет исходное значение пиксела для полученного предсказанного значения, посредством сдвига, согласно предсказанному значению, данных разностного распределения разности между исходным значением пиксела и предсказанным значением при кодировании с предсказанием, при этом данные разностного распределения сохраняют заранее;
- устройство, которое отсекает полученные данные распределения вероятностей так, чтобы вмещать данные в диапазоне от нижнего предела до верхнего предела для возможных значений исходного значения пиксела;
- устройство кодирования, которое кодирует значение пиксела объекта кодирования с использованием отсеченных данных распределения вероятностей исходного значения пиксела от нижнего предела до верхнего предела.
6. Устройство кодирования изображений по п.5, в котором:
- устройство предсказания выполняет предсказание в единицах блоков так, что значение пиксела объекта кодирования ассоциируется с заранее определенным блоком пикселов; и
- устройство кодирования определяет характерный вектор квантования на основе данных распределения вероятностей, которые вычисляются для значения блока пикселов, полученного посредством блочного предсказания, и выполняет кодирование посредством подвергания значения блока пикселов векторному квантованию.
7. Устройство декодирования изображений для декодирования значения пиксела объекта декодирования посредством использования предсказанного значения, сформированного посредством пространственного или временного предсказания с использованием ранее декодированного изображения, устройство содержит:
- устройство предсказания, которое выполняет предсказание значения пиксела объекта декодирования и получает предсказанное значение;
- устройство, которое вычисляет данные распределения вероятностей, которое указывает то, какое значение имеет исходное значение пиксела для полученного предсказанного значения, посредством сдвига, согласно предсказанному значению, данных разностного распределения для разности между исходным значением пиксела и предсказанным значением при кодировании с предсказанием, при этом данные разностного распределения сохраняют заранее;
- устройство, которое отсекает полученные данные распределения вероятностей так, чтобы вмещать данные в диапазоне от нижнего предела до верхнего предела для возможных значений исходного значения пиксела;
- устройство декодирования, которое декодирует значение пиксела объекта декодирования посредством использования отсеченных данных распределения вероятностей исходного значения пиксела от нижнего предела до верхнего предела.
8. Устройство декодирования изображений по п.7, в котором:
- устройство предсказания выполняет предсказание в единицах блоков так, что значение пиксела объекта кодирования ассоциируется с заранее определенным блоком пикселов; и
- устройство декодирования определяет характерный вектор квантования на основе данных распределения вероятностей, которые вычисляют для значения блока пикселов, полученного посредством блочного предсказания, и декодирует векторно квантованное значение блока пикселов объекта декодирования на основе определенного характерного вектора квантования.
9. Машиночитаемый носитель данных, который хранит программу кодирования изображений, посредством которой компьютер исполняет способ кодирования изображений по п.1.
10. Машиночитаемый носитель данных, который хранит программу декодирования изображений, посредством которой компьютер исполняет способ декодирования изображений по п.3.
| ЕР 1833256 А1, 12.09.2007 | |||
| JP 9084022 А, 28.03.1997 | |||
| WO 2007010690 А1, 25.01.2007 | |||
| JP 3145887 A, 21.06.1991 | |||
| WO 2006095501 А1, 14.09.2006 | |||
| WO 03101117 А1, 04.12.2003 | |||
| JP 2006229623 A, 31.08.2006 | |||
| ВИДЕОПЕРЕДАЮЩЕЕ УСТРОЙСТВО, ИСПОЛЬЗУЮЩЕЕ ВНУТРИКАДРОВУЮ ВИДЕОКОМПРЕССИЮ, СОВМЕСТИМУЮ СО СТАНДАРТОМ МПЕГ-2 | 1998 |
|
RU2191469C2 |
| УСТРОЙСТВО КОМПРЕССИИ С ДИФФЕРЕНЦИАЛЬНОЙ ИМПУЛЬСНО-КОДОВОЙ МОДУЛЯЦИЕЙ | 1994 |
|
RU2162280C2 |
| DETLEV MARPE et al, Context-Based Adaptive Binary Arithmetic Coding in the H.264/AVC Video | |||

