ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к устройству кодирования видеосигнала, используемому для кодирования видеоизображения с несколькими точками съемки, и соответствующему способу, устройству декодирования видеосигнала, используемому для декодирования данных, кодированных по соответствующей методике кодирования видеосигнала, и соответствующему способу, программе кодирования видеосигнала для реализации устройства кодирования видеосигнала и машиночитаемому носителю информации, который хранит программу, и программе декодирования видеосигнала для реализации устройства декодирования видеосигнала и машиночитаемому носителю информации, который хранит программу.
Приоритет заявляется по Заявке на патент Японии №2007-165828, зарегистрированной 25 июня 2007 г., содержимое которой включается в этот документ путем отсылки.
УРОВЕНЬ ТЕХНИКИ
Изображения с несколькими точками съемки являются множеством изображений, полученных путем фотографирования одного и того же объекта и его фона с использованием множества камер, и видеоизображения с несколькими точками съемки являются видеоизображениями для изображений с несколькими точками съемки. Ниже видеоизображение, полученное с помощью одиночной камеры, называется "двумерным видеоизображением", а набор из нескольких двумерных видеоизображений, полученный с помощью фотографирования одного и того же объекта и его фона, называется "видеоизображением с несколькими точками съемки".
Существует сильная временная корреляция в двумерном видеоизображении, и его эффективность кодирования повышается с использованием временной корреляции. К тому же для видеоизображения с несколькими точками съемки, когда камеры синхронизируются друг с другом, изображения (снятые камерами) одновременно фиксируют объект и его фон в совершенно одинаковом состоянии из разных положений, так что имеется сильная корреляция между камерами. Эффективность кодирования для кодирования видеоизображения с несколькими точками съемки может быть повышена с использованием этой корреляции.
Сначала будут показаны традиционные методики, относящиеся к кодированию двумерных видеоизображений.
Во многих известных способах кодирования двумерных видеоизображений, например H. 264, MPEG-2, MPEG-4 (которые являются международными стандартами кодирования) и т.п., высокоэффективное кодирование выполняется посредством компенсации движения, ортогонального преобразования, квантования, энтропийного кодирования или аналогичных. В методике, называемой "компенсацией движения", используется временная корреляция между кадрами.
Непатентный документ 1 раскрывает подробные методики компенсации движения, используемые в H. 264. Их общие объяснения следуют ниже.
В соответствии с компенсацией движения в H. 264 целевой кадр кодирования разделяется на блоки любого размера, и каждый блок может иметь индивидуальный вектор движения, посредством этого достигая высокого уровня эффективности кодирования даже для местного изменения в видеоизображении. К тому же, для целевого кадра кодирования в качестве кандидатов на контрольный кадр могут быть подготовлены прошлые или будущие кадры (относительно данного кадра), которые уже кодированы, чтобы каждый блок мог использовать отдельный контрольный кадр, посредством этого реализуя высокий уровень эффективности кодирования даже для видеоизображения, в котором возникает сокрытие из-за временного изменения.
Далее будут объясняться традиционные способы кодирования изображений с несколькими точками съемки или видеоизображений с несколькими точками съемки.
Так как кодирование видеоизображений с несколькими точками съемки использует корреляцию между камерами, видеоизображения с несколькими точками съемки очень эффективно кодируются в известном способе, который использует "компенсацию дисбаланса", в которой компенсация движения применяется одновременно к изображениям, полученным разными камерами, которые имеют разные точки съемки. Здесь дисбаланс является разницей между положениями, в которые проецируется одна и та же точка на изображаемом объекте, на плоскостях изображения у камер, которые расположены в разных положениях.
Фиг.12 - схематичный чертеж, показывающий принцип дисбаланса, образованного между такими камерами. То есть фиг.12 показывает состояние, в котором наблюдатель смотрит вниз на плоскости изображения камер, чьи оптические оси параллельны друг другу, с верхней стороны плоскостей изображения. Как правило, такие точки, в которые проецируется одна и та же точка на изображаемом объекте, на плоскости изображения у разных камер называются "соответствующими точками". В компенсации дисбаланса на основе вышеприведенного соответствующего отношения каждое значение пикселя у целевого кадра кодирования предсказывается с использованием контрольного кадра, и кодируются остаток предсказания и информация о дисбалансе, которая указывает соответствующее отношение.
Для каждого кадра в видеоизображении с несколькими точками съемки одновременно присутствуют временная избыточность и избыточность между камерами. Патентный документ 1 раскрывает способ для устранения обеих избыточностей одновременно.
В соответствующем способе разностное изображение между входным изображением и соответствующим изображением с компенсированным дисбалансом формируется в каждый определенный момент, и сформированные изображения рассматриваются как двумерное видеоизображение, чтобы выполнять кодирование вместе с компенсацией движения. В соответствии с таким способом временная избыточность, которая не может быть устранена с помощью компенсации дисбаланса для устранения избыточности между камерами, может быть устранена с использованием компенсации движения. Поэтому уменьшается остаток предсказания, который кодируется в финальном процессе, чтобы можно было достичь высокого уровня эффективности кодирования.
Непатентный документ 1: ITU-T Rec.H.264/ISO/IEC 11496-10, "Editor's Proposed Draft Text Modifications for Joint Video Specification (ITU-T Rec. H.264 / ISO/IEC 14496-10 AVC), Draft 7", Документ JVT-E022d7, стр.10-13 и 62-73, сентябрь 2002.
Патентный документ 1: Нерассмотренная патентная заявка Японии, первая публикация №2007-036800.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Проблема, которая должна быть решена изобретением
В соответствии с традиционным способом кодирования видеосигнала с несколькими точками съемки, выполняющим компенсацию движения наряду с рассмотрением остаточного изображения с компенсацией дисбаланса (то есть разностного изображения между входным изображением и соответствующим изображением с компенсированным дисбалансом) в качестве видеоизображения, можно уменьшить остаток предсказания в части, имеющей как временную избыточность, так и избыточность между камерами, чтобы кодирование видеосигнала с несколькими точками съемки могло выполняться эффективно.
Однако битовая глубина (то есть скорость квантования в битах) для разностного сигнала видео (изображения) на 1 разряд больше, чем порядковый видеосигнал. Поэтому кодер и декодер для реализации вышеупомянутого способа имеют более крупные размеры, чем для кодирования исходного видеоизображения. То есть, в примерном случае 8-разрядного изображения, имеющего минимальное значение 0 и максимальное значение 255, соответствующее разностное изображение имеет минимальное значение -255 и максимальное значение +255. Поэтому битовая глубина разностного видеосигнала больше порядкового видеосигнала на 1 разряд.
К тому же, существует также камера, для которой само обычное изображение кодируется и декодируется, например камера, соответствующая базовой точке съемки (то есть камера, выбранная в качестве имеющей базовую точку съемки). Поэтому совокупная система кодера и декодера видеосигнала с несколькими точками съемки обязана обладать механизмом для обработки двух разных битовых глубин, что увеличивает размер схемы или оборудования.
Более того, в области, где изображение кодирующей и декодирующей целевой камеры не может быть предсказано с использованием изображения другой камеры, вследствие сокрытия или т.п., кодирование и декодирование с использованием разностного изображения может ухудшить эффективность кодирования по сравнению с кодированием и декодированием без использования разностного изображения. Поэтому эффективность кодирования может быть повышена путем адаптивного переключения между кодированием и декодированием с использованием разностного изображения и кодированием и декодированием без использования разностного изображения.
Однако поскольку битовая глубина отличается между использованием и неиспользованием разностного изображения, система с одиночным кодером и декодером не может обработать оба случая. Поэтому при выполнении такой операции адаптивного переключения система кодера и декодера должна обработать только два типа сигналов для кодирования и декодирования видеоизображения в одной точке съемки, что увеличивает размер схемы или оборудования.
В дополнение к такой проблеме размера схемы или оборудования при применении компенсации движения к разностному видеоизображению может быть кодирован бесполезный сигнал в области, где значение пикселя у исходного видеоизображения является максимальным или минимальным значением в разрешаемом диапазоне.
В примере 8-разрядного видеоизображения предполагается, что пиксель исходного изображения имеет значение пикселя в 255, и что значение пикселя в соответствующем положении соответствующего синтетического изображения (то есть изображения с компенсированным дисбалансом) равно 250. В этом случае соответствующий пиксель в разностном изображении имеет значение пикселя, равное 5. Если значение пикселя у соответствующего пикселя предсказывается с использованием разностного изображения в разное время, и предсказанное значение равно 10, то кодируется "-5" в качестве разницы между 5 и 10.
Однако максимальное значение пикселя у исходного видеоизображения равно 255, и любое значение больше 255 преобразуется в 255 путем отсечения. Поэтому значение "260", которое получается путем прибавления предсказанного значения "10" (вследствие компенсации движения у разностного изображения) к значению пикселя "250" у синтетического изображения (то есть при кодировании "0" вместо "-5"), также может указывать значение "255" входного видеоизображения. То есть, в этом случае кодирование "-5" в качестве остатка предсказания между разностными изображениями является бесполезным, и это вызывает увеличение объема сформированного кода.
Как описано выше, при применении компенсации движения к разностному изображению может быть кодирован бесполезный сигнал в области, где значение пикселя у исходного видеоизображения является максимальным или минимальным значением в разрешаемом диапазоне.
В свете вышеприведенных обстоятельств цель настоящего изобретения - предоставить новые методики кодирования и декодирования видеосигнала, использующие предсказание разностного видеоизображения между входным видеоизображением и синтетическим видеоизображением, с помощью которых при кодировании видеоизображения с несколькими точками съемки для кодера и декодера не нужно обрабатывать разные битовые глубины путем создания предсказанного изображения для входного изображения с помощью прибавления значения пикселя синтетического изображения к соответствующему предсказанному значению, полученному с использованием разностного изображения.
Средство для решения проблемы
Чтобы решить вышеупомянутые проблемы, настоящее изобретение предоставляет устройство кодирования видеосигнала, используемое в кодировании изображения с несколькими точками съемки, полученного с помощью камер, имеющих разные точки съемки, где устройство формирует синтетическое изображение для камеры, используемой для получения целевого изображения кодирования, с использованием по меньшей мере одного уже кодированного контрольного изображения камеры, имеющего точку съемки, отличную от точки съемки камеры, используемой для получения целевого изображения кодирования, и информации о дисбалансе между контрольным изображением камеры и целевым изображением кодирования, кодирует целевое изображение кодирования с использованием синтетического изображения и содержит:
устройство предсказания разностного изображения, которое формирует предсказанное изображение для разностного изображения между входным изображением целевой области кодирования, которую нужно кодировать, и сформированным для нее синтетическим изображением;
устройство формирования предсказанного изображения, которое формирует предсказанное изображение для целевой области кодирования, где предсказанное изображение представляется суммой предсказанного разностного изображения, сформированного устройством предсказания разностного изображения, и синтетического изображения для целевой области кодирования; и
устройство кодирования остатка предсказания, которое кодирует остаток предсказания, представленный разницей между предсказанным изображением для целевой области кодирования, сформированным устройством формирования предсказанного изображения, и целевым изображением кодирования в целевой области кодирования.
В типичном примере устройство предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области кодирования, используя разностное изображение в момент, который является тем же, что и момент, когда было получено целевое изображение кодирования, где используемое разностное изображение представляется разницей между декодированным изображением уже кодированной области в целевом изображении кодирования и синтетическим изображением для уже кодированной области.
В другом типичном примере устройство предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области кодирования, используя разностное изображение в момент, отличный от момента, когда было получено целевое изображение кодирования, где используемое разностное изображение представляется разницей между декодированным изображением уже кодированного изображения, которое было получено в точке съемки, использованной для получения целевого изображения кодирования, и синтетическим изображением одновременно с декодированным изображением.
В другом типичном примере устройство кодирования видеосигнала дополнительно содержит:
устройство декодирования изображения, которое формирует декодированное изображение целевого изображения кодирования путем декодирования кодированных данных целевого изображения кодирования; и
устройство формирования и хранения декодированного разностного изображения, которое формирует декодированное разностное изображение, представленное разницей между декодированным изображением, сформированным устройством декодирования изображения, и синтетическим изображением, и сохраняет сформированное декодированное разностное изображение в запоминающем устройстве,
где устройство предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области кодирования, используя декодированное разностное изображение, сохраненное в запоминающем устройстве.
В другом типичном примере устройство кодирования видеосигнала дополнительно содержит:
устройство декодирования остатка предсказания, которое декодирует остаток предсказания, кодированный устройством кодирования остатка предсказания; и
устройство формирования и хранения декодированного разностного изображения, которое формирует декодированное разностное изображение, представленное суммой декодированного остатка предсказания, сформированного устройством декодирования остатка предсказания, и предсказанного разностного изображения, и сохраняет сформированное декодированное разностное изображение в запоминающем устройстве,
где устройство предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области кодирования, используя декодированное разностное изображение, сохраненное в запоминающем устройстве.
В предпочтительном примере для этого случая устройство формирования и хранения декодированного разностного изображения выполняет отсечение, чтобы каждый пиксель декодированного разностного изображения имел значение пикселя в пределах заранее установленного рабочего диапазона.
В другом типичном примере устройство кодирования видеосигнала дополнительно содержит:
устройство предсказания исходного изображения, которое формирует предсказанное изображение для целевого изображения кодирования, используя любое из декодированного изображения уже кодированной области в целевом изображении кодирования и декодированного изображения уже кодированного изображения, которое было получено в той же точке съемки, которая использована для получения целевого изображения кодирования, и в момент, отличный от момента целевого изображения кодирования,
где устройство формирования предсказанного изображения выборочно выполняет одно из формирования предсказанного изображения для целевого изображения кодирования на основе предсказанного разностного изображения и синтетического изображения и формирования предсказанного изображения для целевого изображения кодирования путем непосредственного использования предсказанного изображения, сформированного устройством предсказания исходного изображения.
В предпочтительном примере устройство формирования предсказанного изображения выполняет отсечение, чтобы каждый пиксель предсказанного изображения имел значение пикселя в пределах заранее установленного рабочего диапазона.
Настоящее изобретение также предоставляет устройство декодирования видеосигнала, используемое в декодировании кодированных данных изображения с несколькими точками съемки, полученного с помощью камер, имеющих разные точки съемки, где устройство формирует синтетическое изображение для камеры, используемой для получения целевого изображения декодирования, с использованием по меньшей мере одного уже декодированного контрольного изображения камеры, имеющего точку съемки, отличную от точки съемки камеры, используемой для получения целевого изображения кодирования, и информации о дисбалансе между контрольным изображением камеры и целевым изображением декодирования, декодирует кодированные данные целевого изображения декодирования с использованием синтетического изображения и содержит:
устройство декодирования остатка предсказания, которое декодирует остаток предсказания в целевом изображении декодирования, где остаток предсказания включается в кодированные данные;
устройство предсказания разностного изображения, которое формирует предсказанное изображение для разностного изображения между целевым изображением декодирования целевой области декодирования, которую нужно декодировать, и сформированным для нее синтетическим изображением; и
устройство декодирования изображения, которое декодирует целевое изображение декодирования путем сложения предсказанного разностного изображения, сформированного устройством предсказания разностного изображения, остатка предсказания, декодированного устройством декодирования остатка предсказания, и синтетического изображения.
В типичном примере устройство предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области декодирования, используя разностное изображение в момент, который является тем же, что и момент, когда было получено целевое изображение декодирования, где используемое разностное изображение представляется разницей между декодированным изображением уже декодированной области в целевом изображении декодирования и синтетическим изображением для уже декодированной области.
В другом типичном примере устройство предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области декодирования, используя разностное изображение в момент, отличный от момента, когда было получено целевое изображение декодирования, где используемое разностное изображение представляется разницей между уже декодированным контрольным изображением, которое было получено в точке съемки, использованной для получения целевого изображения декодирования, и синтетическим изображением одновременно с контрольным изображением.
В другом типичном примере устройство декодирования видеосигнала дополнительно содержит:
устройство формирования и хранения декодированного разностного изображения, которое формирует декодированное разностное изображение, представленное разницей между декодированным изображением, сформированным устройством декодирования изображения, и синтетическим изображением, и сохраняет сформированное декодированное разностное изображение в запоминающем устройстве,
где устройство предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области декодирования, используя декодированное разностное изображение, сохраненное в запоминающем устройстве.
В другом типичном примере устройство декодирования видеосигнала дополнительно содержит:
устройство формирования и хранения декодированного разностного изображения, которое формирует декодированное разностное изображение, представленное суммой декодированного остатка предсказания, сформированного устройством декодирования остатка предсказания, и предсказанного разностного изображения, и сохраняет сформированное декодированное разностное изображение в запоминающем устройстве,
где устройство предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области декодирования, используя декодированное разностное изображение, сохраненное в запоминающем устройстве.
В предпочтительном примере для этого случая устройство формирования и хранения декодированного разностного изображения выполняет отсечение, чтобы каждый пиксель декодированного разностного изображения имел значение пикселя в пределах заранее установленного рабочего диапазона.
В другом типичном примере устройство декодирования видеосигнала дополнительно содержит:
устройство предсказания исходного изображения, которое формирует предсказанное изображение для целевого изображения декодирования, используя любое из уже декодированного изображения целевого изображения декодирования и уже декодированного изображения, которое было получено в той же точке съемки, которая использовалась для получения целевого изображения декодирования, и в момент, отличный от момента целевого изображения декодирования,
где для целевой области декодирования устройство декодирования изображения выборочно выполняет одно из декодирования целевого изображения декодирования путем сложения предсказанного разностного изображения, сформированного устройством предсказания разностного изображения, остатка предсказания, декодированного устройством декодирования остатка предсказания, и синтетического изображения, и декодирования целевого изображения декодирования путем прибавления предсказанного изображения, сформированного устройством предсказания исходного изображения, к остатку предсказания, декодированному устройством декодирования остатка предсказания.
Настоящее изобретение также предоставляет способ кодирования видеосигнала, используемый в кодировании изображения с несколькими точками съемки, полученного с помощью камер, имеющих разные точки съемки, где способ формирует синтетическое изображение для камеры, используемой для получения целевого изображения кодирования, с использованием по меньшей мере одного уже кодированного контрольного изображения камеры, имеющего точку съемки, отличную от точки съемки камеры, используемой для получения целевого изображения кодирования, и информации о дисбалансе между контрольным изображением камеры и целевым изображением кодирования, кодирует целевое изображение кодирования с использованием синтетического изображения и содержит:
этап предсказания разностного изображения, который формирует предсказанное изображение для разностного изображения между входным изображением целевой области кодирования, которую нужно кодировать, и сформированным для нее синтетическим изображением;
этап формирования предсказанного изображения, который формирует предсказанное изображение для целевой области кодирования, где предсказанное изображение представляется суммой предсказанного разностного изображения, сформированного этапом предсказания разностного изображения, и синтетического изображения для целевой области кодирования; и
этап кодирования остатка предсказания, который кодирует остаток предсказания, представленный разницей между предсказанным изображением для целевой области кодирования, сформированным этапом формирования предсказанного изображения, и целевым изображением кодирования в целевой области кодирования.
В типичном примере этап предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области кодирования, используя разностное изображение в момент, который является тем же, что и момент, когда было получено целевое изображение кодирования, где используемое разностное изображение представляется разницей между декодированным изображением уже кодированной области в целевом изображении кодирования и синтетическим изображением для уже кодированной области.
В другом типичном примере этап предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области кодирования, используя разностное изображение в момент, отличный от момента, когда было получено целевое изображение кодирования, где используемое разностное изображение представляется разницей между декодированным изображением уже кодированного изображения, которое было получено в точке съемки, использованной для получения целевого изображения кодирования, и синтетическим изображением одновременно с декодированным изображением.
В другом типичном примере способ кодирования видеосигнала дополнительно содержит:
этап декодирования остатка предсказания, который декодирует остаток предсказания, кодированный этапом кодирования остатка предсказания; и
этап формирования и хранения декодированного разностного изображения, который формирует декодированное разностное изображение, представленное суммой декодированного остатка предсказания, сформированного этапом декодирования остатка предсказания, и предсказанного разностного изображения, и сохраняет сформированное декодированное разностное изображение в запоминающем устройстве,
где этап предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области кодирования, используя декодированное разностное изображение, сохраненное в запоминающем устройстве.
В другом типичном примере способ кодирования видеосигнала дополнительно содержит:
этап предсказания исходного изображения, который формирует предсказанное изображение для целевого изображения кодирования, используя любое из декодированного изображения уже кодированной области в целевом изображении кодирования и декодированного изображения уже кодированного изображения, которое было получено в той же точке съемки, которая использована для получения целевого изображения кодирования, и в момент, отличный от момента целевого изображения кодирования,
где этап формирования предсказанного изображения выборочно выполняет одно из формирования предсказанного изображения для целевого изображения кодирования на основе предсказанного разностного изображения и синтетического изображения и формирования предсказанного изображения для целевого изображения кодирования путем непосредственного использования предсказанного изображения, сформированного этапом предсказания исходного изображения.
Настоящее изобретение также предоставляет способ декодирования видеосигнала, используемый в декодировании кодированных данных изображения с несколькими точками съемки, полученного с помощью камер, имеющих разные точки съемки, где способ формирует синтетическое изображение для камеры, используемой для получения целевого изображения декодирования, с использованием по меньшей мере одного уже декодированного контрольного изображения камеры, имеющего точку съемки, отличную от точки съемки камеры, используемой для получения целевого изображения кодирования, и информации о дисбалансе между контрольным изображением камеры и целевым изображением декодирования, декодирует кодированные данные целевого изображения декодирования с использованием синтетического изображения и содержит:
этап декодирования остатка предсказания, который декодирует остаток предсказания в целевом изображении декодирования, где остаток предсказания включается в кодированные данные;
этап предсказания разностного изображения, который формирует предсказанное изображение для разностного изображения между целевым изображением декодирования целевой области декодирования, которую нужно декодировать, и сформированным для нее синтетическим изображением; и
этап декодирования изображения, который декодирует целевое изображение декодирования путем сложения предсказанного разностного изображения, сформированного этапом предсказания разностного изображения, остатка предсказания, декодированного этапом декодирования остатка предсказания, и синтетического изображения.
В типичном примере этап предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области декодирования, используя разностное изображение в момент, который является тем же, что и момент, когда было получено целевое изображение декодирования, где используемое разностное изображение представляется разницей между декодированным изображением уже декодированной области в целевом изображении декодирования и синтетическим изображением для уже декодированной области.
В другом типичном примере этап предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области декодирования, используя разностное изображение в момент, отличный от момента, когда было получено целевое изображение декодирования, где используемое разностное изображение представляется разницей между уже декодированным контрольным изображением, которое было получено в точке съемки, использованной для получения целевого изображения декодирования, и синтетическим изображением одновременно с контрольным изображением.
В другом типичном примере способ декодирования видеосигнала дополнительно содержит:
этап формирования и хранения декодированного разностного изображения, который формирует декодированное разностное изображение, представленное суммой декодированного остатка предсказания, сформированного этапом декодирования остатка предсказания, и предсказанного разностного изображения, и сохраняет сформированное декодированное разностное изображение в запоминающем устройстве,
где этап предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области декодирования, используя декодированное разностное изображение, сохраненное в запоминающем устройстве.
В этом случае предпочтительно, чтобы этап формирования и хранения декодированного разностного изображения выполнял отсечение, чтобы каждый пиксель декодированного разностного изображения имел значение пикселя в пределах заранее установленного рабочего диапазона.
В другом типичном примере способ декодирования видеосигнала дополнительно содержит:
этап предсказания исходного изображения, который формирует предсказанное изображение для целевого изображения декодирования, используя любое из уже декодированного изображения целевого изображения декодирования и уже декодированного изображения, которое было получено в той же точке съемки, которая использовалась для получения целевого изображения декодирования, и в момент, отличный от момента целевого изображения декодирования,
где для целевой области декодирования этап декодирования изображения выборочно выполняет одно из декодирования целевого изображения декодирования путем сложения предсказанного разностного изображения, сформированного этапом предсказания разностного изображения, остатка предсказания, декодированного этапом декодирования остатка предсказания, и синтетического изображения, и декодирования целевого изображения декодирования путем прибавления предсказанного изображения, сформированного этапом предсказания исходного изображения, к остатку предсказания, декодированному этапом декодирования остатка предсказания.
Устройства для формирования вышеописанного устройства кодирования видеосигнала или устройства декодирования видеосигнала из настоящего изобретения также могут быть реализованы с помощью компьютерной программы. Такая компьютерная программа может предоставляться путем сохранения ее на подходящем машиночитаемом носителе информации, или посредством сети, и может устанавливаться и работать на управляющем устройстве, например CPU, чтобы реализовать настоящее изобретение.
Как описано выше, в настоящем изобретении разностное видеоизображение между входным видеоизображением и синтетическим видеоизображением в уже кодированной области используется для предсказания разницы между входным изображением и синтетическим видеоизображением в целевой области кодирования. Синтетическое видеоизображение в целевой области кодирования добавляется к предсказанной разнице, посредством этого формируя предсказанное видеоизображение для соответствующего входного изображения.
Поэтому при кодировании остатка предсказания, аналогично обычным способам кодирования видеосигнала, кодируется остаток предсказания между входным видеоизображением и предсказанным видеоизображением. То есть не возникает никакого увеличения в битовой глубине сигнала, обработанного на этапе кодирования остатка, хотя такое увеличение происходит в традиционных способах. К тому же, поскольку само предсказание применяется к разнице между входным видеоизображением и синтетическим видеоизображением для него, то одновременно может использоваться корреляция между камерами и пространственная корреляция в кадре, посредством этого реализуя высокую степень эффективности кодирования.
В соответствующем способе синтетическое видеоизображение может формироваться (i) с использованием контрольного изображения и информации о глубине целевой сцены (как выполнялось в Патентном документе 1), (ii) с использованием множества контрольных изображений наряду с поиском соответствующих точек (как выполнялось в следующем Справочном документе), или (iii) с использованием любого другого способа. То есть можно использовать любой способ, который может синтезировать изображение, полученное в точке съемки целевой камеры кодирования.
Справочный документ: M.Kitahara, H.Kimata, M.Tanimoto, T.Fujii и K.Yamamoto, "Report of Core Experiment on View Interpolation (Multi-view Video Coding CE3)", Документ JVT-T119, стр.1-8, июль, 2006.
К тому же, аналогично многим известным способам кодирования двумерных видеоизображений, например H. 264, MPEG-2, MPEG-4 (которые являются международными стандартами кодирования) и т.п., кодирование остатка может выполняться любым способом, например DCT, квантованием или векторным кодированием, использующим шаблон.
В настоящем изобретении, когда предсказанный результат, использующий разностное видеоизображение, добавляется к синтетическому видеоизображению с тем, чтобы предсказать входное видеоизображение, вместо пространственного предсказания разностного видеоизображения между входным видеоизображением и синтетическим видеоизображением в кадре, разностное видеоизображение может быть предсказано с использованием временной корреляции разностного видеоизображения между данным кадром и другим кадром в другой момент.
Также в этом способе при кодировании остатка предсказания, аналогично обычному кодированию видеосигнала, кодируется остаток предсказания между входным видеоизображением и предсказанным видеоизображением. То есть можно решить проблему традиционных способов, в которых увеличивается битовая глубина сигнала, обработанного на этапе кодирования остатка. К тому же, корреляция между камерами и временная корреляция могут использоваться одновременно, посредством этого реализуя высокую степень эффективности кодирования.
Кроме того, кодирование может выполняться наряду с выбором пространственной корреляции в кадре или временной корреляции для остаточного изображения, что может реализовать более высокую степень эффективности кодирования.
В обычных способах кодирования видеосигнала декодированное видеоизображение уже кодированного входного видеоизображения сохраняется и используется для формирования предсказанного видеоизображения. Однако в настоящем изобретении разностное видеоизображение между входным видеоизображением и синтетическим видеоизображением используется для формирования предсказанного видеоизображения для входного видеоизображения. То есть необходимо формировать синтетическое видеоизображение и вычислять разницу от сохраненного декодированного видеоизображения каждый раз, когда формируется предсказанное видеоизображение, что требует значительной стоимости вычисления.
Поэтому после получения декодированного видеоизображения уже сформированное синтетическое видеоизображение вычитается из полученного изображения с тем, чтобы сформировать разностное видеоизображение, и разностное видеоизображение сохраняется для формирования предсказанного видеоизображения. Соответственно, можно каждый раз пропускать процесс формирования разностного видеоизображения и значительно снизить стоимость вычисления.
При выполнении предсказания с использованием разностного видеоизображения декодированные данные кодированного остатка предсказания и предсказанное значение разностного видеоизображения могут складываться, чтобы сформировать разностное видеоизображение для декодированного видеоизображения. Соответственно, по сравнению с формированием разностного видеоизображения после формирования декодированного видеоизображения можно пропустить вычисление для вычитания синтетического видеоизображения, посредством этого дополнительно снижая стоимость вычисления.
В таком случае сумма декодированных остаточных данных и предсказанного разностного видеоизображения может быть сокращена с использованием минимального значения, полученного путем применения знака "минус" к соответствующему значению пикселя синтетического видеоизображения, и максимального значения, представленного суммой минимального значения и наибольшего значения среди допустимых значений пикселей для декодированного видеоизображения. Соответственно, можно сформировать разностное видеоизображение, которое полностью идентично, полученному после формирования декодированного видеоизображения.
К тому же кодирование входного видеоизображения может выполняться наряду с выбором формирования предсказанного видеоизображения, использующего разностное видеоизображение, или формирования предсказанного видеоизображения, не использующего разностное видеоизображение.
Когда существует сокрытие, синтетическое видеоизображение не может быть точно сформировано. В таком случае значительная ошибка включается в разностное видеоизображение, сформированное входным видеоизображением и синтетическим видеоизображением, и эффективное кодирование не может быть выполнено. Поэтому в таком случае входное видеоизображение может эффективно кодироваться только с использованием временной корреляции.
При формировании разностного видеоизображения и выполнении кодирования с использованием в качестве входных данных разностного видеоизображения, как выполнялось в традиционных способах, не только входной сигнал, но также и сам кодер нужно изменить для выполнения кодирования без использования разностного изображения, потому что изменяется битовая глубина целевого видеосигнала кодирования. Это указывает, что кодер для обработки одиночного видеоизображения должен включать в себя кодеры для обработки двух разных сигналов.
В отличие от этого, в настоящем изобретении в любом случае при выполнении предсказания на основе разностного видеоизображения или входного видеоизображения входной сигнал, обработанный кодером, является входным видеоизображением, и предсказанный сигнал является предсказанным видеоизображением для входного видеоизображения. Поэтому одинаковый входной сигнал и одинаковый кодер может использоваться для любого случая. Соответственно, можно значительно уменьшить размер схемы или оборудования кодера.
Результат изобретения
Как описано выше, в соответствии с настоящим изобретением при кодировании видеоизображения с несколькими точками съемки формируется предсказанный сигнал для разностного видеоизображения между входным видеоизображением и соответствующим синтетическим видеоизображением, и сумма сформированного предсказанного разностного видеоизображения и синтетического видеоизображения рассматривается как предсказанный сигнал для входного видеоизображения. Поэтому можно выполнять высокоэффективное кодирование с использованием разностного видеоизображения с уменьшенным размером схемы или оборудования.
В традиционных методиках формируется разностное видеоизображение между входным видеоизображением и соответствующим синтетическим видеоизображением, и сформированное предсказанное разностное видеоизображение кодируется. В отличие от этого в настоящем изобретении формируется предсказанный сигнал для соответствующего разностного видеоизображения, и сумма сформированного предсказанного разностного видеоизображения и синтетического видеоизображения рассматривается как предсказанный сигнал для входного видеоизображения, чтобы входное видеоизображение кодировалось напрямую. Поэтому можно выполнять высокоэффективное кодирование с использованием предсказания разностного видеоизображения с уменьшенным размером схемы или оборудования.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1 - схема, показывающая конструкцию устройства кодирования видеосигнала из Варианта 1 осуществления в соответствии с настоящим изобретением.
Фиг.2 - технологический процесс, выполняемый устройством кодирования видеосигнала из Варианта 1 осуществления.
Фиг.3 - технологический процесс формирования предсказанного изображения.
Фиг.4А - схема, показывающая устройство кодирования видеосигнала из Варианта 1 осуществления для объяснения сравнения между устройством кодирования видеосигнала из Варианта 1 осуществления и традиционным устройством кодирования видеосигнала для кодирования видеоизображения с несколькими точками съемки.
Фиг.4В - схема, показывающая традиционное устройство кодирования видеосигнала для объяснения сравнения.
Фиг.5 - схема, показывающая конструкцию устройства кодирования видеосигнала из Варианта 2 осуществления в соответствии с настоящим изобретением.
Фиг.6 - технологический процесс, выполняемый устройством кодирования видеосигнала из Варианта 2 осуществления.
Фиг.7А - схема, показывающая устройство кодирования видеосигнала из Варианта 2 осуществления для объяснения сравнения между устройством кодирования видеосигнала из Варианта 2 осуществления и традиционным устройством кодирования видеосигнала для кодирования видеоизображения с несколькими точками съемки.
Фиг.7В - схема, показывающая традиционное устройство кодирования видеосигнала для объяснения сравнения.
Фиг.8 - схема, показывающая конструкцию устройства декодирования видеосигнала из Варианта 3 осуществления в соответствии с настоящим изобретением.
Фиг.9 - технологический процесс, выполняемый устройством декодирования видеосигнала из Варианта 3 осуществления.
Фиг.10 - схема, показывающая конструкцию устройства декодирования видеосигнала из Варианта 4 осуществления в соответствии с настоящим изобретением.
Фиг.11 - технологический процесс, выполняемый устройством декодирования видеосигнала из Варианта 4 осуществления.
Фиг.12 - принципиальная схема для объяснения дисбаланса, образованного между камерами.
Обозначения ссылок
100 устройство кодирования видеосигнала
101 модуль ввода изображения
102 модуль ввода синтетического изображения
103 формирователь предсказанного изображения
104 кодер остатка предсказания
105 декодер остатка предсказания
106 декодер разностного изображения
107 память разностных изображений
108 формирователь предсказанного разностного изображения
ЛУЧШИЙ ВАРИАНТ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Ниже настоящее изобретение будет подробно объясняться в соответствии с вариантами осуществления.
Нижеследующие варианты осуществления относятся к способу кодирования и декодирования видеоизображения, полученного в точке съемки, с использованием (i) одного или нескольких видеоизображений, которые уже кодированы и декодированы, и были получены в точках съемки, отличных от точки съемки объекта кодирования, и (ii) синтетического видеоизображения, сформированного с использованием информации о дисбалансе между другими точками съемки и точкой съемки объекта кодирования.
Информация о дисбалансе, необходимая для формирования синтетического видеоизображения, может создаваться на стороне кодера и затем передаваться на сторону декодера, либо такая же информация может вычисляться между сторонами кодера и декодера. Более того, формирование синтетического видеоизображения с использованием информации о дисбалансе может выполняться любым способом, например, путем вычисления среднего или характерного значения на основе информации о соответствующей точке среди множества точек съемки.
(1) Вариант 1 осуществления
Сначала будет объясняться первый вариант осуществления (называемый ниже "Вариант 1 осуществления").
Фиг.1 показывает конструкцию устройства 100 кодирования видеосигнала для Варианта 1 осуществления настоящего изобретения.
Как показано на фиг.1, устройство 100 кодирования видеосигнала содержит модуль 101 ввода изображения, модуль 102 ввода синтетического изображения, формирователь 103 предсказанного изображения, кодер 104 остатка предсказания, декодер 105 остатка предсказания, декодер 106 разностного изображения, память 107 разностных изображений и формирователь 108 предсказанного разностного изображения.
Модуль 101 ввода изображения вводит в устройство (видео) изображение, полученное камерой, в качестве объекта кодирования. Модуль 102 ввода синтетического изображения вводит в устройство синтетическое (видео)изображение (то есть изображение с компенсированным дисбалансом) для камеры.
Формирователь 103 предсказанного изображения формирует предсказанное изображение для входного изображения путем сложения вместе предсказанного разностного изображения, сформированного формирователем 108 предсказанного разностного изображения, и синтетического изображения, введенного модулем 102 ввода синтетического изображения, где предсказанное разностное изображение является предсказанным изображением для разностного изображения между входным изображением и синтетическим изображением и получается с помощью предсказания, использующего разностное изображение между декодированным изображением и синтетическим изображением.
Кодер 104 остатка предсказания кодирует остаток предсказания между входным изображением, введенным модулем 101 ввода, и предсказанным изображением, сформированным формирователем 103 предсказанного изображения, и выводит кодированные данные. Декодер 105 остатка предсказания декодирует остаток предсказания, кодированный кодером 104 остатка предсказания.
Декодер 106 разностного изображения определяет диапазон обработки в соответствии с синтетическим изображением, введенным модулем 102 ввода синтетического изображения, и одновременно формирует разностное изображение, представленное разницей между декодированным изображением и синтетическим изображением, путем сложения вместе предсказанного разностного изображения, сформированного формирователем 108 предсказанного разностного изображения, и остатка предсказания, декодированного декодером 105 остатка предсказания. Память 107 разностных изображений сохраняет разностное изображение, сформированное декодером 106 разностного изображения.
Формирователь 108 предсказанного разностного изображения формирует предсказанное изображение (то есть предсказанное разностное изображение) для разностного изображения, представленного разницей между входным изображением и синтетическим изображением, используя разностное изображение, сохраненное в памяти 107 разностных изображений.
Фиг.2 показывает технологический процесс, выполняемый устройством 100 кодирования видеосигнала из Варианта 1 осуществления, которое имеет вышеописанную конструкцию.
Технологический процесс показывает работу, выполняемую при кодировании изображения (то есть кадра) в заданное время с использованием устройства 100 кодирования видеосигнала из Варианта 1 осуществления. При кодировании множества кадров соответствующий технологический процесс выполняется многократно.
Ниже, в соответствии с технологическим процессом, будет подробно объясняться работа, выполняемая устройством 100 кодирования видеосигнала из Варианта 1 осуществления.
В устройстве 100 кодирования видеосигнала из Варианта 1 осуществления сначала модуль 101 ввода изображения вводит целевое изображение кодирования в устройство (см. этап A1). Ниже целевое изображение кодирования (то есть входное изображение) будет изображаться с помощью "Org[·]". К тому же применение "[]" к изображению указывает сигнал изображения для определенной области.
Далее модуль 102 ввода синтетического изображения вводит в устройство синтетическое изображение, которое соответствует входному изображению Org[·] (см. этап А2). Синтетическое изображение представляется с помощью "Syn[·]".
В варианте 1 осуществления все изображение разделяется на множество блоков, и операция многократно применяется к каждому блоку, чтобы кодировать все изображение. Здесь форма деления не ограничивается блоком, и может применяться любая форма деления. Кроме того, также возможно отсутствие деления. В нижеследующем объяснении "blk" является индексом для каждого блока, а numBlk указывает количество блоков, включенных в изображение.
Поэтому, после того, как blk инициализируется нулем (см. этап А3), следующий процесс (этапы А4-А10) многократно выполняется для того, чтобы выполнить кодирование, в то время как blk увеличивается на 1 (см. этап А11), пока blk не достигает numBlk (см. этап А12).
В процессе, повторяемом для каждого блока, сначала формирователь 108 предсказанного разностного изображения формирует предсказанное разностное изображение PredDiff[·], используя данные (сохраненные в памяти 107 разностных изображений) уже кодированного кадра в момент, отличный от заданного времени, или уже кодированный блок в целевом кадре кодирования (см. этап А4).
Как правило, предсказание с использованием кадра в другой момент называется "межкадровым предсказанием", а предсказание с использованием уже кодированной области в том же кадре в заданное время называется "внутрикадровым предсказанием". Для межкадрового предсказания и внутрикадрового предсказания, выполняемых в данной операции, могут использоваться любые способы, применяемые в известной системе кодирования видеосигнала, которые показаны в вышеописанном непатентном документе 1.
Например, как показано в следующей формуле (1), может быть обозначена область в другом кадре в другой момент, и значение области может использоваться в качестве предсказанного значения. В другом примере, как показано в следующей формуле (2), может выполняться направленное предсказание на основе уже кодированных периферийных пикселей в том же кадре в заданное время.
∀(x,y) ∈ blk, PredDiff[t, x, y] = DecDiff[t-1, x+mvx, y+mvy]… Формула (1)
∀(x,y) ∈ blk, PredDiff[t, x, y] = DecDiff[t, x, up_line]… Формула (2)
В вышеприведенных формулах DecDiff[·] представляет декодированное разностное изображение, сохраненное в памяти 107 разностных изображений, t указывает время целевого кадра кодирования, (mvx, mvy) указывает двумерный вектор, и up_line указывает положение пикселя (здесь это линия) непосредственно над "blk".
Далее формирователь 103 предсказанного изображения формирует предсказанное изображение Pred[·], представленное суммой предсказанного разностного изображения PredDiff[·] и синтетического изображения Syn[·] (см. этап А5).
В вышеприведенном процессе каждое значение пикселя отсекается, чтобы оно было в пределах рабочего диапазона. Рабочий диапазон для значения пикселя определяется в соответствии с битовой глубиной входного изображения. Для восьмиразрядного изображения минимальное значение равно 0 и максимальное значение равно 255. Процесс отсечения указывается следующей формулой (3).
∀(x,y) ∈ blk, Pred[t,x,y] = Clip(PredDiff[t,x,y]+Syn[t,x,y], min, max)… Формула (3)
В вышеприведенной формуле "min" и "max" соответственно указывают эффективные минимальные и максимальные значения для значения пикселя. К тому же функция Clip возвращает (i) значение второго аргумента, когда значение первого аргумента меньше значения второго аргумента; (ii) значение третьего аргумента, когда значение первого аргумента больше значения третьего аргумента; и (iii) значение первого аргумента в ином случае.
Затем формируется остаток предсказания Res[·], указанный разницей между входным изображением Org[·] и предсказанным изображением Pred[·] (см. этап А6). Этот процесс формирования указывается следующей формулой (4).
∀(x,y) ∈ blk, Res[t,x,y] = Org[t,x,y] - Pred[t,x,y] … Формула(4)
После того, как формируется остаток предсказания Res[·], кодер 104 остатка предсказания кодирует остаток предсказания Res[·].
Остаток предсказания Res[·] может кодироваться любым способом. В обычном способе кодирования видеосигнала преобразование частоты выполняется посредством DCT (дискретное косинусное преобразование), затем выполняется квантование, чтобы привести в двоичную форму информацию о коэффициенте DCT, и преобразованная в двоичную форму информация подвергается арифметическому кодированию.
Кодированные данные остатка предсказания Res[·], сформированного как описано выше, выводятся из устройства 100 кодирования видеосигнала, и также отправляются в декодер 105 остатка предсказания, который декодирует кодированные данные для следующего процесса предсказания (см. этап А8). Декодированный остаток предсказания изображается с помощью DecRes[·].
Остаток предсказания DecRes[·], декодированный декодером 105 остатка предсказания, отправляется в декодер 106 разностного изображениям, который использует предсказанное разностное изображение PredDiff[·], чтобы сформировать декодированное разностное изображение DecDiff[·] (см. этап А9).
В вышеприведенном процессе отсечение с использованием эффективных минимальных и максимальных значений для значения пикселя выполняется, чтобы удовлетворять следующей формуле:
min ≤ DecRes[t,x,y] + PredDiff[t,x,y] + Syn[t,x,y] ≤ max
Это процесс отсечение может указываться с использованием вышеописанной функции Clip, как следующая формула (5).
∀(x,y) ∈ blk, DecDiff[t,x,y] = Clip(DecRes[t,x,y]+PredDiff[t,x,y], min-Syn[t,x,y], max-Syn[t,x,y]) … Формула (5)
Это процесс отсечения может выполняться или пропускаться. При его исполнении такой же процесс следует выполнять на сторонах кодера и декодера.
Декодированное разностное изображение DecDiff[·], сформированное декодером 106 разностного изображения, сохраняется в память 107 разностных изображений и используется в процессе предсказания для кодирования необработанного блока (см. этап А10).
Как описано выше, устройство 100 кодирования видеосигнала из Варианта 1 осуществления формирует предсказанный сигнал для разностного изображения между входным изображением и синтетическим изображением и кодирует входное изображение с использованием суммы сформированного предсказанного разностного изображения и синтетического изображения в качестве предсказанного сигнала для входного изображения.
Ниже, в соответствии с технологическим процессом фиг.3, будет подробно описываться процесс формирования предсказанного изображения Pred[·], выполняемый на этапе А5 в технологическом процессе фиг.5.
Процесс (этап А5) формирования предсказанного изображения Pred[·] для целевого изображения кодирования выполняется формирователем 103 предсказанного изображения для каждого пикселя, включенного в соответствующий блок. Чтобы выполнить этот процесс, формирователь 103 предсказанного изображения (см. фиг.1) имеет (i) функцию сложения, состоящую в сложении значения пикселя синтетического изображения Syn[·], введенного модулем 102 ввода синтетического изображения, и соответствующего значения пикселя предсказанного разностного изображения PredDiff[·], сформированного формирователем 108 предсказанного разностного изображения, и (ii) функцию отсечения, состоящую в отсечении значения пикселя, полученного вышеупомянутой функцией сложения.
Соответствующий процесс применяется к каждому пикселю в блоке. То есть, когда "pix" является индексом для каждого пикселя, после того как pix инициализируется нулем (см. этап B1), следующий процесс (этапы B2-B6) многократно выполняется, в то время как pix увеличивается на 1 (см. этап B7), пока pix не достигает numPix, которое указывает количество пикселей в блоке (см. этап B8).
В повторяемом процессе сначала значение пикселя pix предсказанного разностного изображения PredDiff[·], сформированного формирователем 108 предсказанного разностного изображения, считывается в регистр r0 (см. этап В2), а затем значение пикселя pix синтетического изображения Syn[·], введенного модулем 102 ввода синтетического изображения, считывается в регистр r1 (см. этап B3).
Далее выполняется сложение между значениями пикселя, сохраненными в регистрах r0 и r1, используя вышеописанную функцию сложения. Результат сложения сохраняется в регистре r2 (см. этап B4).
Далее значение пикселя, сохраненное в регистре r2, подвергается отсечению с использованием вышеописанной функции отсечения, чтобы значение пикселя имело значение в рабочем диапазоне для входного изображения. Результат отсечения сохраняется в регистре r3 (см. этап B5). Рабочий диапазон определяется на основе битовой глубины входного изображения. Для 8-разрядного изображения минимальное значение равно 0 и максимальное значение равно 255.
Далее значение пикселя, сохраненное в регистре r3, выводится в качестве предсказанного изображения Pred[·] для пикселя pix в целевом изображении кодирования (см. этап В6).
Хотя в вышеприведенном объяснении используются регистры, возможна другая конструкция, не использующая регистр. К тому же на этапах B4 и B5 результат каждого процесса сохраняется в независимом регистре. Однако результат может быть перезаписан в регистр r0. Более того, если сложение может выполняться с использованием одиночного регистра, то не нужно считывать значение синтетического изображения Syn[·] в регистр r1, и может выполняться прямое сложение. Также в вышеописанном процессе выводится предсказанное изображение Pred[·] для каждого пикселя. Однако предсказанное изображение для всех пикселей может выводиться вместе посредством буферизации.
Фиг.4A и 4B - схемы для сравнения устройства 100 кодирования видеосигнала из Варианта 1 осуществления с традиционным устройством кодирования видеосигнала для кодирования видеоизображения с несколькими точками съемки.
Фиг.4A показывает конструкцию устройства 100 кодирования видеосигнала из Варианта 1 осуществления, а фиг.4B показывает конструкцию традиционного устройства кодирования видеосигнала для кодирования видеоизображения с несколькими точками съемки. На фигуре самые тонкие линии указывают части для обработки N-разрядных данных, более толстые линии указывают части для обработки (N+1)-разрядных данных, и самые толстые линии указывают части для обработки (N+2)-разрядных данных.
В устройстве 100 кодирования видеосигнала из Варианта 1 осуществления формируется предсказанный сигнал для разностного изображения между входным изображением и синтетическим изображением для него, и сумма сформированного предсказанного разностного изображения и синтетического изображения используется в качестве предсказанного сигнала для входного изображения, чтобы кодировать разницу между входным изображением и предсказанным изображением для него. В этом случае вычисление с вычитанием выполняется только один раз (см. фиг.4A), и соответственно кодирование может выполняться с битовой глубиной, равной таковой у обычного устройства кодирования видеосигнала для кодирования видеоизображения.
В отличие от этого, в традиционном устройстве кодирования видеосигнала для кодирования видеоизображения с несколькими точками съемки формируется разностное изображение между входным изображением и синтетическим изображением для него, и сформированное разностное изображение подвергается кодированию видеосигнала. В этом случае вычисление с вычитанием следует выполнить дважды (см. фиг.4B), и поэтому соответствующая битовая глубина больше, чем у обычного устройства кодирования видеосигнала для кодирования видеоизображения.
В соответствии с вышеописанным вариантом осуществления настоящего изобретения формируется предсказанный сигнал для разностного изображения между входным изображением и синтетическим изображением для него, и сумма сформированного предсказанного разностного изображения и синтетического изображения используется в качестве предсказанного сигнала для входного изображения. Поэтому эффективное кодирование с использованием разностного изображения может выполняться с небольшим размером схемы или оборудования.
Более того, в традиционной методике формируется разностное изображение между входным изображением и синтетическим изображением для него, и сформированное разностное изображение подвергается кодированию видеосигнала. Поэтому бесполезный сигнал может быть кодирован в области, где значение пикселя является максимальным или минимальным значением в разрешаемом диапазоне. В отличие от этого, в варианте осуществления настоящего изобретения соответствующее значение пикселя отсекается, чтобы иметь максимальное или минимальное значение в разрешаемом диапазоне, и поэтому такая проблема не возникает.
(2) Вариант 2 осуществления
Второй вариант осуществления (называемый ниже "Вариант 2 осуществления") будет объясняться ниже.
Фиг.5 показывает конструкцию устройства 200 кодирования видеосигнала для Варианта 2 осуществления настоящего изобретения.
Как показано на фиг.5, устройство 200 кодирования видеосигнала содержит модуль 201 ввода изображения, модуль 202 ввода синтетического изображения, первый формирователь 203 предсказанного изображения, второй формирователь 204 предсказанного изображения, кодер 205 остатка предсказания, декодер 206 остатка предсказания, декодер 207 изображения, память 208 декодированных изображений, память 209 разностных изображений, формирователь 210 предсказанного разностного изображения и переключатель 211 выбора предсказания.
Модуль 201 ввода изображения вводит в устройство (видео) изображение, полученное камерой, в качестве объекта кодирования. Модуль 202 ввода синтетического изображения вводит в устройство синтетическое (видео) изображение для камеры.
Первый формирователь 203 предсказанного изображения формирует предсказанное изображение для входного изображения на основе предсказания для разностного изображения (между входным изображением и синтетическим изображением). Первый формирователь 203 предсказанного изображения выполняет работу, аналогичную показанной на фиг.3, в которой предсказанное разностное изображение (то есть предсказанное изображение для разностного изображения), сформированное формирователем 210 предсказанного разностного изображения, и синтетическое изображение, введенное модулем 202 ввода синтетического изображения, складываются вместе с помощью операции отсечения, посредством этого формируя предсказанное изображение для входного изображения.
Второй формирователь 204 предсказанного изображения формирует предсказанное изображение для входного изображения на основе декодированного изображения, то есть формирует предсказанное изображение, не используя разностное изображение, а используя декодированное изображение, сохраненное в памяти 208 декодированных изображений.
Кодер 205 остатка предсказания кодирует остаток предсказания между входным изображением, введенным модулем 201 ввода, и предсказанным изображением, сформированным первым формирователем 203 предсказанного изображения или вторым формирователем 204 предсказанного изображения, и выводит кодированные данные. Декодер 206 остатка предсказания декодирует остаток предсказания, кодированный кодером 205 остатка предсказания.
Декодер 207 изображения формирует декодированное изображение путем сложения остатка предсказания, декодированного декодером 206 остатка предсказания, и предсказанного изображения, сформированного первым формирователем 203 предсказанного изображения или вторым формирователем 204 предсказанного изображения. Память 208 декодированных изображений сохраняет декодированное изображение, сформированное декодером 207 изображения.
Память 209 разностных изображений сохраняет разностное изображение, представленное разницей между декодированным изображением, полученным декодером 207 изображения, и синтетическим изображением, введенным модулем 202 ввода синтетического изображения.
Формирователь 210 предсказанного разностного изображения формирует предсказанное разностное изображение, то есть предсказанное изображение для разностного изображения, представленного разницей между входным изображением и синтетическим изображением, используя разностное изображение, сохраненное в памяти 209 разностных изображений.
Переключатель 211 выбора предсказания выбирает и выводит одно из предсказанного изображения, сформированного первым формирователем 203 предсказанного изображения, и предсказанного изображения, сформированного вторым формирователем 204 предсказанного изображения.
Фиг.6 показывает технологический процесс, выполняемый устройством 200 кодирования видеосигнала из Варианта 2 осуществления, которое имеет вышеописанную конструкцию.
Технологический процесс показывает работу, выполняемую при кодировании изображения в заданное время с использованием устройства 200 кодирования видеосигнала из Варианта 2 осуществления. При кодировании множества кадров соответствующий технологический процесс выполняется многократно.
Ниже, в соответствии с технологическим процессом, будет подробно объясняться работа, выполняемая устройством 200 кодирования видеосигнала из Варианта 2 осуществления. Здесь обозначения, использованные в вышеописанном Варианте 1 осуществления, также используются в нижеследующем объяснении.
В устройстве 200 кодирования видеосигнала из Варианта 2 осуществления сначала модуль 201 ввода изображения вводит целевое изображение кодирования Org[·] в устройство (см. этап С1), а модуль 102 ввода синтетического изображения вводит в устройство синтетическое изображение Syn[·], которое соответствует входному изображению Org[·] (см. этап С2).
Также в варианте 2 осуществления все изображение разделяется на множество блоков, и операция многократно применяется к каждому блоку, чтобы кодировать все изображение. Здесь форма деления не ограничивается блоком, и может применяться любая форма деления. Кроме того, также возможно отсутствие деления. В нижеследующем объяснении, аналогично Варианту 1 осуществления, "blk" является индексом для каждого блока, а numBlk указывает количество блоков, включенных в изображение.
Поэтому, после того, как blk инициализируется нулем (см. этап С3), следующий процесс (этапы С4 - С14) многократно выполняется для того, чтобы выполнить кодирование, в то время как blk увеличивается на 1 (см. этап С15), пока blk не достигает numBlk (см. этап С16).
В процессе, повторяемом для каждого блока, сначала формируется предсказанное изображение. В данном Варианте 2 осуществления первый формирователь 203 предсказанного изображения формирует предсказанное изображение с использованием разностного изображения (предсказанное изображение указывается с помощью "разностного предсказанного изображения DiffPred[·]"), а второй формирователь 204 предсказанного изображения формирует предсказанное изображение без использования разностного изображения, но с декодированным изображением (предсказанное изображение указывается с помощью "декодированного предсказанного изображения DecPred[·]". Используя предсказанные изображения, формируется одно предсказанное изображение.
В формировании разностного предсказанного изображения DiffPred[·] сначала формирователь 210 предсказанного разностного изображения формирует предсказанное разностное изображение PredDiff[·], используя данные (сохраненные в памяти 209 разностных изображений) уже кодированного кадра в момент, отличный от заданного времени, или уже кодированный блок в целевом кадре кодирования (см. этап С4). Далее первый формирователь 203 предсказанного изображения формирует разностное предсказанное изображение DiffPred[·], которое указывается суммой предсказанного разностного изображения PredDiff[·] и синтетического изображения Syn[·] (см. этап С5).
В вышеприведенной операции каждое значение пикселя отсекается, чтобы оно было в пределах рабочего диапазона. Рабочий диапазон для значения пикселя определяется в соответствии с битовой глубиной входного изображения. Для восьмиразрядного изображения минимальное значение равно 0 и максимальное значение равно 255. Процесс отсечения указывается следующей формулой (6). Процессы, выполняемые на этапах C4 и C5 соответственно, идентичны выполняемым на этапах A4 и A5 из Варианта 1 осуществления.
∀(x,y) ∈ blk, DiffPred[t,x,y] = Clip(PredDiff[t,x,y]+Syn[t,x,y], min, max)… Формула (6)
Формирование декодированного предсказанного изображения DecPred[·] выполняется вторым формирователем 204 предсказанного изображения с использованием декодированного изображения Dec[·] (сохраненного в памяти 208 декодированных изображений) уже кодированного кадра в момент, отличный от заданного времени, или уже кодированного блока в целевом кадре кодирования (см. этап С6).
Декодированное предсказанное изображение DecPred[·] может формироваться любым способом, используемым в известной системе кодирования видеосигнала, как показано в вышеописанном непатентном документе 1.
Например, как показано в следующей формуле (7), может быть обозначена область в другом кадре в другой момент, и значение области может использоваться в качестве предсказанного значения. В другом примере, как показано в следующей формуле (8), может выполняться направленное предсказание на основе уже кодированных периферийных пикселей в том же кадре в заданное время.
∀(x,y) ∈ blk, DecPred[t, x, y] = Dec[t(1, x+mvx, y+mvy ]… Формула (7)
∀(x,y) ∈ blk, DecPred[t, x, y] = Dec[t, x, up_line]… Формула (8)
В данном Варианте 2 осуществления предсказанное изображение формируется с использованием переключателя 211 выбора предсказания для выбора одного из разностного предсказанного изображения DiffPred[·], сформированного первым формирователем 203 предсказанного изображения, и декодированного предсказанного изображения DecPred[·], сформированного вторым формирователем 204 предсказанного изображения (см. этап С7). В другом способе предсказанное изображение может формироваться с использованием среднего между соответствующими пикселями.
Выбор между вышеупомянутыми двумя предсказанными изображениями может выполняться любым способом. Например, предсказанные изображения могут сначала кодироваться, и может быть выбрано одно из них, которое обладает более высокой степенью эффективности кодирования. В другом примере эффективность предсказания для целевого изображения кодирования Org[·] может измеряться посредством суммы абсолютных разниц или суммы квадратов разниц, и может быть выбрано одно из предсказанных изображений, которое обладает более высокой степенью эффективности предсказания.
Более того, в соответствии с каждым входным изображением переключение может выполняться подходящим образом для каждого кадра, каждой небольшой области или блока в кадре, или т.п.
После того, как формируется предсказанное изображение, формируется остаток предсказания Res[·], который представляется разницей между входным изображением Org[·] и предсказанным изображением, выведенным переключателем 211 выбора предсказания (см. этап С8). Процесс формирования Res[·] представляется вышеописанной формулой (4).
После того, как формируется остаток предсказания Res[·], кодер 205 остатка предсказания кодирует остаток предсказания Res[·] (см. этап С9), где кодирование может выполняться любым способом.
Сформированные кодированные данные остатка предсказания Res[·] выводятся из устройства 200 кодирования видеосигнала и одновременно передаются в декодер 206 остатка предсказания. Декодер 206 остатка предсказания декодирует кодированные данные, чтобы декодированные данные использовались в будущем предсказании (см. этап С10).
Остаток предсказания DecRes[·], декодированный в декодере 206 остатка предсказания, передается в декодер 207 изображения, где декодированное изображение Dec[·] формируется с использованием предсказанного изображения, выведенного из переключателя 211 выбора предсказания (см. этап С11).
В этом процессе выполняется операция отсечения с использованием эффективного максимального значения пикселя и эффективного минимального значения пикселя. Эта операция представляется следующей формулой (9).
∀(x,y) ∈ blk, Dec[t,x,y] = Clip(DecRes[t,x,y]+Pred[t,x,y], min, max)… Формула (9)
Декодированное изображение Dec[·], сформированное декодером 207 изображения, сохраняется в память 208 декодированных изображений и используется в процессе предсказания для кодирования необработанного блока (см. этап С12).
К тому же, декодированное разностное изображение DecDiff[·] формируется с использованием декодированного изображения Dec[(] и синтетического изображения Syn[·] в соответствии со следующей формулой (10) (см. этап С13).
∀(x,y) ∈ blk, DecDiff[t,x,y] = Dec[t,x,y]-Syn[t,x,y]… Формула (10)
Сформированное декодированное разностное изображение DecDiff[·] сохраняется в память 209 разностных изображений и используется в процессе предсказания для кодирования необработанного блока (см. этап С14).
Как описано выше, устройство 200 кодирования видеосигнала из Варианта 2 осуществления формирует предсказанный сигнал для разностного изображения между входным изображением и синтетическим изображением и кодирует входное изображение, используя предсказанный сигнал (для входного изображения), который является суммой сформированного предсказанного разностного изображения и синтетического изображения.
Фиг.7A и 7B - схемы для сравнения устройства 200 кодирования видеосигнала из Варианта 2 осуществления с соответствующим традиционным устройством кодирования видеосигнала для кодирования видеоизображения с несколькими точками съемки.
Фиг.7A показывает конструкцию устройства 200 кодирования видеосигнала из Варианта 2 осуществления, а фиг.7B показывает конструкцию соответствующего традиционного устройства кодирования видеосигнала для кодирования видеоизображения с несколькими точками съемки. На фиг. самые тонкие линии указывают части для обработки N-разрядных данных, более толстые линии указывают части для обработки (N+1)-разрядных данных, самые толстые линии указывают части для обработки (N+2)-разрядных данных, и пунктирные линии указывают части, где разряд для обработки может выбираться с переключением.
Устройство 200 кодирования видеосигнала из Варианта 2 осуществления формирует предсказанный сигнал для разностного изображения между входным видеоизображением и синтетическим видеоизображением для входного видеоизображения. Устройство 200 кодирования видеосигнала кодирует разницу между входным видеоизображением и предсказанным видеоизображением для него, используя предсказанный сигнал (для входного видеоизображения), который является суммой сформированного предсказанного разностного изображения и синтетического изображения. В этом случае вычисление с вычитанием выполняется только один раз (см. фиг.7A), и соответственно кодирование может выполняться с битовой глубиной, равной таковой у обычного устройства кодирования видеосигнала для кодирования видеоизображения.
В отличие от этого, в традиционном устройстве кодирования видеосигнала для кодирования видеоизображения с несколькими точками съемки формируется разностное изображение между входным изображением и синтетическим изображением для него, и сформированное разностное изображение подвергается кодированию видеосигнала. В этом случае вычисление с вычитанием следует выполнить дважды (см. фиг.7B), и поэтому соответствующая битовая глубина больше, чем у обычного устройства кодирования видеосигнала для кодирования видеоизображения.
К тому же, как понятно при сравнении фиг.7А с 7B, в устройстве 200 кодирования видеосигнала из Варианта 2 осуществления в обоих случаях предсказания на разностном видеоизображении и предсказания на входном видеоизображении входной сигнал, обработанный соответствующим кодером, является входным видеосигналом, а предсказанный сигнал является предсказанным видеоизображением для входного видеоизображения. Поэтому кодирование может выполняться с использованием одинакового входного сигнала и кодера в обоих случаях.
(3) Вариант 3 осуществления
Третий вариант осуществления (называемый ниже "Вариант 3 осуществления") будет объясняться ниже.
Фиг.8 показывает конструкцию устройства 300 декодирования видеосигнала для Варианта 3 осуществления настоящего изобретения.
Как показано на фиг.8, устройство 300 декодирования видеосигнала из Варианта 3 осуществления содержит модуль 301 ввода кодированных данных, модуль 302 ввода синтетического изображения, декодер 303 остатка предсказания, декодер 304 разностного изображения, память 305 разностных изображений, формирователь 306 предсказанного разностного изображения и декодер 307 изображения.
Модуль 301 ввода кодированных данных вводит в устройство кодированные данные, сформированные устройством 100 кодирования видеосигнала из Варианта 1 осуществления (то есть кодированные данные видеоизображения, полученные камерой, в качестве объекта декодирования). Модуль 302 ввода синтетического изображения вводит синтетическое (видео)изображение (то есть изображение с компенсированным дисбалансом) для камеры. Декодер 303 остатка предсказания декодирует остаток предсказания, включенный в кодированные данные.
Декодер 304 разностного изображения складывает предсказанное разностное изображение (то есть предсказанное изображение для разностного изображения между целевым изображением декодирования и синтетическим изображением), сформированное формирователем 306 предсказанного разностного изображения, и остаток предсказания, декодированный декодером 303 остатка предсказания, наряду с определением диапазона обработки на основе синтетического изображения, введенного модулем 302 ввода синтетического изображения, посредством этого формируя разностное изображение, указанное разницей между целевым изображением декодирования и синтетическим изображением. Память 305 разностных изображений сохраняет разностное изображение, сформированное декодером 304 разностного изображения.
Формирователь 306 предсказанного разностного изображения использует разностное изображение, сохраненное в памяти 305 разностных изображений, чтобы сформировать предсказанное разностное изображение, которое является предсказанным изображением для разностного изображения, указанного разницей между целевым изображением декодирования и синтетическим изображением.
Декодер 307 изображения декодирует целевое изображение декодирования путем сложения разностного изображения, сформированного декодером 304 разностного изображения, и синтетического изображения, введенного модулем 302 ввода синтетического изображения.
Фиг.9 показывает технологический процесс, выполняемый устройством 300 декодирования видеосигнала из Варианта 3 осуществления, которое имеет вышеописанную конструкцию.
Технологический процесс показывает работу, выполняемую при декодировании кодированных данных изображения в заданное время с использованием устройства 300 декодирования видеосигнала из Варианта 3 осуществления. При декодировании множества кадров соответствующий технологический процесс выполняется многократно.
Ниже, в соответствии с технологическим процессом, будет подробно объясняться работа, выполняемая устройством 300 декодирования видеосигнала из Варианта 3 осуществления. Здесь обозначения, использованные в вышеописанных Вариантах 1 и 2 осуществления, также используются в нижеследующем объяснении.
В устройстве 300 декодирования видеосигнала из Варианта 3 осуществления сначала модуль 301 ввода кодированных данных вводит кодированные данные целевого изображения декодирования в устройство (см. этап D1). Далее модуль 302 ввода синтетического изображения вводит в устройство синтетическое изображение, которое соответствует целевому изображению декодирования (см. этап D2).
В варианте 3 осуществления предполагается, что все изображение разделено на множество блоков, и каждый блок закодирован. Поэтому операция многократно применяется к каждому блоку для того, чтобы декодировать все изображение. Здесь форма деления не ограничивается блоком, и может применяться любая форма деления. Кроме того, также возможно отсутствие деления. В нижеследующем объяснении "blk" является индексом для каждого блока, а numBlk указывает количество блоков, включенных в изображение.
Поэтому, после того, как blk инициализируется нулем (см. этап D3), следующий процесс (этапы D4-D8) многократно выполняется для того, чтобы выполнить декодирование, в то время как blk увеличивается на 1 (см. этап D9), пока blk не достигает numBlk (см. этап D10).
В процессе, повторяемом для каждого блока, сначала декодер 303 остатка предсказания декодирует остаток предсказания, включенный во входные кодированные данные (см. этап D4).
Далее формирователь 306 предсказанного разностного изображения формирует предсказанное разностное изображение, используя данные (сохраненные в памяти 305 разностных изображений) уже декодированного кадра в момент, отличный от заданного времени, или уже декодированный блок в целевом кадре декодирования (см. этап D5).
Если имеется множество способов для формирования предсказанного разностного изображения, то указывается один из способов формирования с использованием информации, которая включается в кодированные данные и указывает способ предсказания, использованный в соответствующем кодировании блока "blk". Предсказанное разностное изображение формируется на основе указанного способа.
После того, как сформировано предсказанное разностное изображение с помощью формирователя 306 предсказанного разностного изображения, декодер 304 разностного изображения формирует декодированное разностное изображение, представленное суммой сформированного предсказанного разностного изображения и декодированного остатка предсказания (см. этап D6).
В этом процессе выполняется операция отсечения с использованием эффективного максимального значения пикселя и эффективного минимального значения пикселя, где эта операция идентична отсечению (представленному вышеописанной формулой (5)), выполненному на этапе A9 из Варианта 1 осуществления. Однако операция отсечения может выполняться или не выполняться. Если она выполняется, то такая же обработка должна выполняться на сторонах кодера и декодера.
Декодированное разностное изображение, сформированное декодером 304 разностного изображения, сохраняется в память 305 разностных изображений и используется в формировании предсказанного разностного изображения, выполняемом для декодирования необработанного блока (см. этап D7).
После того, как декодированное разностное изображение формируется декодером 304 разностного изображения, декодер 307 изображения формирует декодированное изображение, представленное суммой декодированного разностного изображения и синтетического изображения (см. этап D8).
В этом процессе каждое значение пикселя отсекается, чтобы иметь значение в пределах рабочего диапазона. Если отсечение выполнялось на этапе D6, то здесь не нужно никакого отсечения. Процесс отсечения указывается следующей формулой (11).
∀(x,y) ∈ blk, Dec[t,x,y] = Clip(DecDiff[t,x,y]+Syn[t,x,y],
min, max) … Формула (11)
Сформированное декодированное изображение выводится из устройства 300 декодирования видеосигнала. В данном Варианте 3 осуществления декодированное изображение выводится немедленно. Однако если никакого подходящего тайминга отображения нельзя получить на протяжении операции от кодирования до декодирования, то декодированное изображение может быть сохранено в буфере и выведено из устройства 300 декодирования видеосигнала в подходящее время отображения.
В технологическом процессе фиг.9 декодируется остаток предсказания целевого изображения декодирования, который включается в кодированные данные, и предсказанное изображение для разностного изображения целевой области декодирования формируется с использованием разностного изображения, представленного разницей между изображением уже декодированной области в целевом изображении декодирования и соответствующим синтетическим изображением. Сформированное предсказанное разностное изображение добавляется к декодированному остатку предсказания, чтобы получилось декодированное разностное изображение. Декодированное разностное изображение добавляется к синтетическому изображению, чтобы получилось декодированное изображение. Однако обработка для формирования декодированного изображения не ограничивается вышеописанной.
То есть, в другом процессе для получения декодированного изображения декодируется остаток предсказания целевого изображения декодирования, который включается в кодированные данные, и предсказанное изображение для разностного изображения целевой области декодирования формируется с использованием разностного изображения, представленного разницей между изображением уже декодированной области в целевом изображении декодирования и соответствующим синтетическим изображением. Сформированное предсказанное разностное изображение добавляется к синтетическому изображению, чтобы получилось предсказанное изображение для целевого изображения декодирования. Предсказанное изображение для целевого изображения декодирования добавляется к декодированному остатку предсказания, чтобы получилось декодированное изображение.
(4) Вариант 4 осуществления
Четвертый вариант осуществления (называемый ниже "Вариант 4 осуществления") будет объясняться ниже.
Фиг.10 показывает конструкцию устройства 400 декодирования видеосигнала для Варианта 4 осуществления настоящего изобретения.
Как показано на фиг.10, устройство 400 декодирования видеосигнала из Варианта 4 осуществления содержит модуль 401 ввода кодированных данных, модуль 402 ввода синтетического изображения, декодер 403 остатка предсказания, декодер 404 изображения, память 405 декодированных изображений, память 406 разностных изображений, формирователь 407 предсказанного разностного изображения, первый формирователь 408 предсказанного изображения, второй формирователь 409 предсказанного изображения и переключатель 410 выбора предсказания.
Модуль 401 ввода кодированных данных вводит в устройство кодированные данные, сформированные устройством 200 кодирования видеосигнала из Варианта 2 осуществления (то есть кодированные данные видеоизображения, полученные камерой, в качестве объекта декодирования). Модуль 402 ввода синтетического изображения вводит синтетическое (видео) изображение для камеры. Декодер 403 остатка предсказания декодирует остаток предсказания, включенный в кодированные данные.
Декодер 404 изображения декодирует целевое изображение декодирования путем прибавления остатка предсказания, декодированного декодером 403 остатка предсказания, к предсказанному изображению, сформированному первым формирователем 408 предсказанного изображения или вторым формирователем 409 предсказанного изображения. Память 405 декодированных изображений сохраняет декодированное изображение, сформированное декодером 404 изображения.
Память 406 разностных изображений сохраняет (декодированное) разностное изображение, представленное разницей между декодированным изображением, сформированным декодером 404 изображения, и синтетическим изображением, введенным модулем 402 ввода синтетического изображения.
Формирователь 407 предсказанного разностного изображения использует разностное изображение, сохраненное в памяти 406 разностных изображений, чтобы сформировать предсказанное разностное изображение, которое является предсказанным изображением для разностного изображения, представленного разницей между целевым изображением декодирования и синтетическим изображением.
Первый формирователь 408 предсказанного изображения формирует предсказанное изображение для целевого изображения декодирования путем сложения предсказанного разностного изображения, сформированного формирователем 407 предсказанного разностного изображения, и синтетического изображения, введенного модулем 402 ввода синтетического изображения.
Второй формирователь 409 предсказанного изображения формирует предсказанное изображение для целевого изображения декодирования на основе декодированного изображения, сохраненного в памяти 405 декодированных изображений.
Переключатель 410 выбора предсказания выбирает и выводит одно из предсказанного изображения, сформированного первым формирователем 408 предсказанного изображения, и предсказанного изображения, сформированного вторым формирователем 409 предсказанного изображения.
Фиг.6 показывает технологический процесс, выполняемый устройством 400 декодирования видеосигнала из Варианта 4 осуществления, которое имеет вышеописанную конструкцию.
Технологический процесс показывает работу, выполняемую при декодировании кодированных данных изображения в заданное время с использованием устройства 400 декодирования видеосигнала из Варианта 4 осуществления. При декодировании множества кадров соответствующий технологический процесс выполняется многократно.
Ниже, в соответствии с технологическим процессом, будет подробно объясняться работа, выполняемая устройством 400 декодирования видеосигнала из Варианта 4 осуществления. Здесь обозначения, использованные в вышеописанных Вариантах 1-3 осуществления, также используются в нижеследующем объяснении.
В устройстве 400 декодирования видеосигнала из Варианта 4 осуществления сначала модуль 401 ввода кодированных данных вводит кодированные данные целевого изображения декодирования в устройство (см. этап Е1). Далее модуль 402 ввода синтетического изображения вводит в устройство синтетическое изображение, которое соответствует целевому изображению декодирования (см. этап Е2).
В варианте 4 осуществления предполагается, что все изображение разделено на множество блоков, и каждый блок закодирован. Поэтому операция многократно применяется к каждому блоку для того, чтобы декодировать все изображение. Здесь форма деления не ограничивается блоком, и может применяться любая форма деления. Кроме того, также возможно отсутствие деления. В нижеследующем объяснении "blk" является индексом для каждого блока, а numBlk указывает количество блоков, включенных в изображение.
Поэтому, после того, как blk инициализируется нулем (см. этап Е3), следующий процесс (этапы Е4-Е9) многократно выполняется для того, чтобы выполнить декодирование, в то время как blk увеличивается на 1 (см. этап Е10), пока blk не достигает numBlk (см. этап Е11).
В процессе, повторяемом для каждого блока, сначала декодер 403 остатка предсказания декодирует остаток предсказания, включенный во входные кодированные данные (см. этап Е4).
Далее первый формирователь 408 предсказанного изображения формирует предсказанное изображение, используя декодированное разностное изображение (сохраненное в памяти 406 разностных изображений) уже декодированного кадра в момент, отличный от заданного времени, или уже декодированный блок в целевом кадре декодирования, а второй формирователь 409 предсказанного изображения формирует предсказанное изображение, используя декодированное изображение (сохраненное в памяти 405 декодированных изображений) уже декодированного кадра в момент, отличный от заданного времени (см. этап Е5).
В вышеприведенном процессе способ формирования предсказанного изображения, применяемый к каждому блоку, определяется специальным способом. То есть определение может выполняться с использованием информации об уже декодированном изображении или блоке, либо информации, которая включается в кодированные данные и обозначает способ предсказания. Дополнительно следует использовать способ определения, определенный устройством кодирования видеосигнала.
В варианте 4 осуществления способ предсказания переключается с использованием переключателя 410 выбора предсказания между предсказанием, использующим разностное изображение, которое выполняется первым формирователем 408 предсказанного изображения, и предсказанием без использования разностного изображения, которое выполняется вторым формирователем 409 предсказанного изображения.
При выполнении предсказания (выполняемого первым формирователем 408 предсказанного изображения), использующего разностное изображение, сначала формирователь 407 предсказанного разностного изображения формирует предсказанное разностное изображение с использованием разностного изображения, сохраненного в памяти 406 разностных изображений. Затем первый формирователь 408 предсказанного изображения формирует предсказанное изображение, представленное суммой предсказанного разностного изображения и синтетического изображения. Сформированное предсказанное изображение функционирует в качестве предсказанного изображения для целевого изображения декодирования.
В вышеприведенной операции выполняется операция отсечения с использованием эффективного максимального значения пикселя и эффективного минимального значения пикселя, где эта операция идентична отсечению (представленному вышеописанной формулой (6)), выполненному на этапах C4 и C5 из Варианта 2 осуществления. Однако операция отсечения может выполняться или не выполняться. Если она выполняется, то такая же обработка должна выполняться на сторонах кодера и декодера.
При выполнении предсказания (выполняемого вторым формирователем 409 предсказанного изображения) без использования разностного изображения, второй формирователь 409 предсказанного изображения формирует предсказанное изображение с использованием декодированного изображения, сохраненного в памяти 405 декодированных изображений, и сформированное предсказанное изображение функционирует в качестве предсказанного изображения для целевого изображения декодирования. Эта операция идентична выполняемой на этапе C6 из Варианта 2 осуществления.
Данный Вариант 4 осуществления содержит второй формирователь 409 предсказанного изображения и формирователь 407 предсказанного разностного изображения. Если оба формирователя используют общий способ предсказания, то они могут объединяться в виде одного формирователя предсказанного изображения, где память изображений для поставки изображения в формирователь должна выбираться с переключением. В таком случае сигнал, выведенный из формирователя предсказанного изображения, следует вводить в первый формирователь 408 предсказанного изображения только при выполнении предсказания с использованием разностного изображения. Соответственно, необходимы два переключателя, которые взаимодействуют друг с другом.
После того, как предсказанное изображение формируется с использованием первого формирователя 408 предсказанного изображения или второго формирователя 409 предсказанного изображения, декодер 404 изображения формирует декодированное изображение, представленное суммой сформированного предсказанного изображения и остатка предсказания, декодированного декодером 403 остатка предсказания (см. этап Е6).
В вышеприведенной операции каждое значение пикселя отсекается, чтобы оно было в пределах рабочего диапазона. Эта операция отсечения идентична выполняемой на этапе C11 из Варианта 2 осуществления и представляется вышеописанной формулой (9).
Сформированное декодированное изображение сохраняется в памяти 405 декодированных изображений и используется в формировании предсказанного изображения для декодирования необработанного блока (см. этап Е7).
Декодированное изображение и синтетическое изображение используются для формирования декодированного разностного изображения в соответствии с вышеописанной формулой (10) (см. этап Е8). Сформированное декодированное разностное изображение сохраняется в памяти 406 разностных изображений и используется в формировании предсказанного изображения для декодирования необработанного блока (см. этап Е9).
Декодированное изображение, сформированное на этапе E6, выводится из устройства 400 декодирования видеосигнала. В варианте 4 осуществления декодированное изображение выводится немедленно. Однако, если никакого подходящего тайминга отображения нельзя получить на протяжении операции от кодирования до декодирования, то декодированное изображение может быть сохранено в буфере и выведено из устройства 400 декодирования видеосигнала в подходящее время отображения.
ПРОМЫШЛЕННАЯ ПРИМЕНИМОСТЬ
Настоящее изобретение может применяться к кодированию видеоизображения с несколькими точками съемки, и эффективное кодирование с использованием разностного видеоизображения может выполняться с небольшим размером схемы или оборудования.
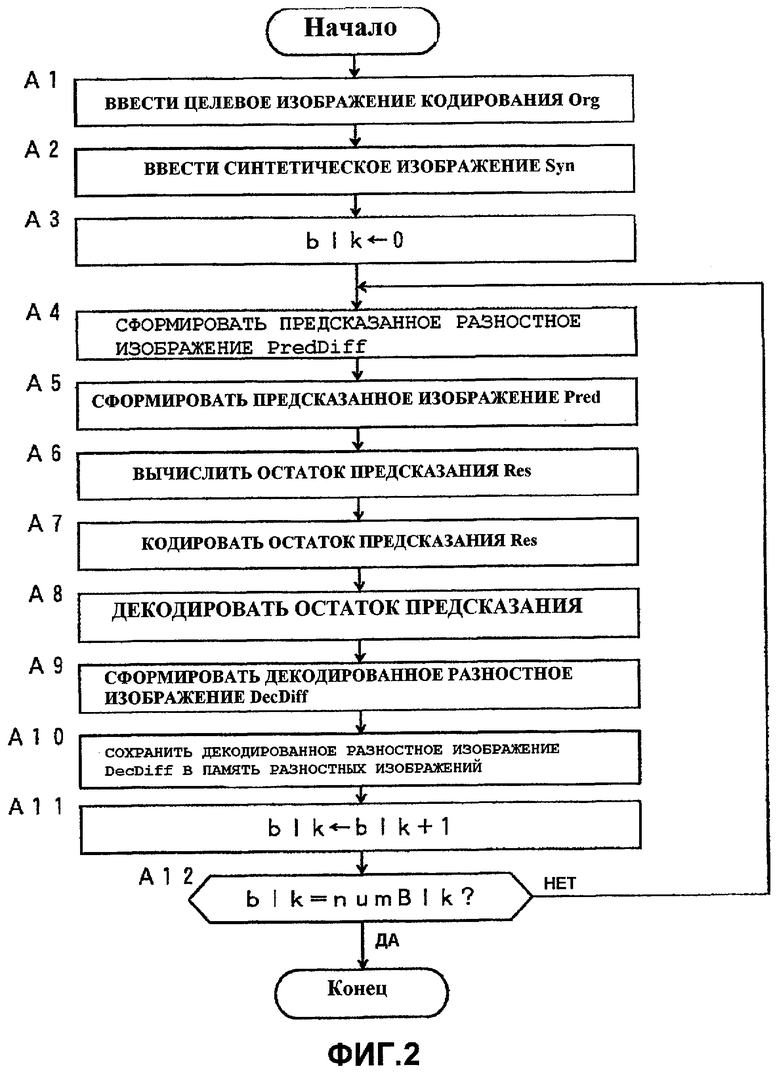
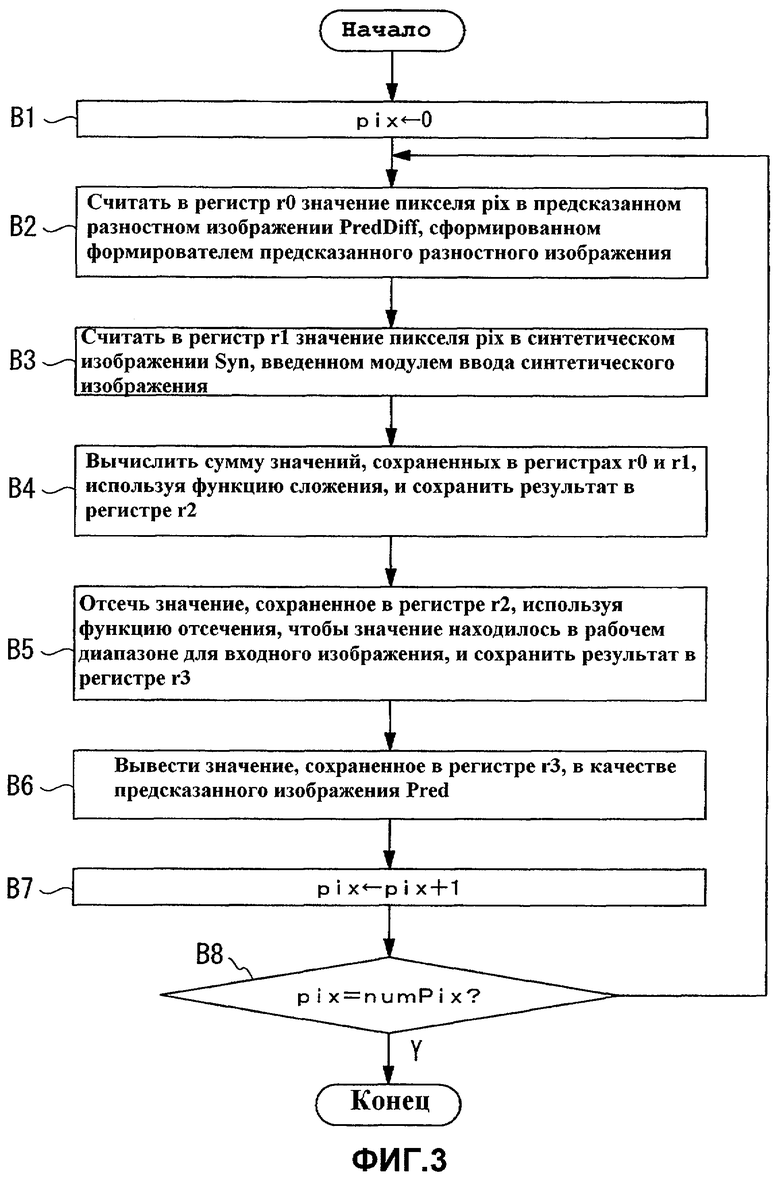
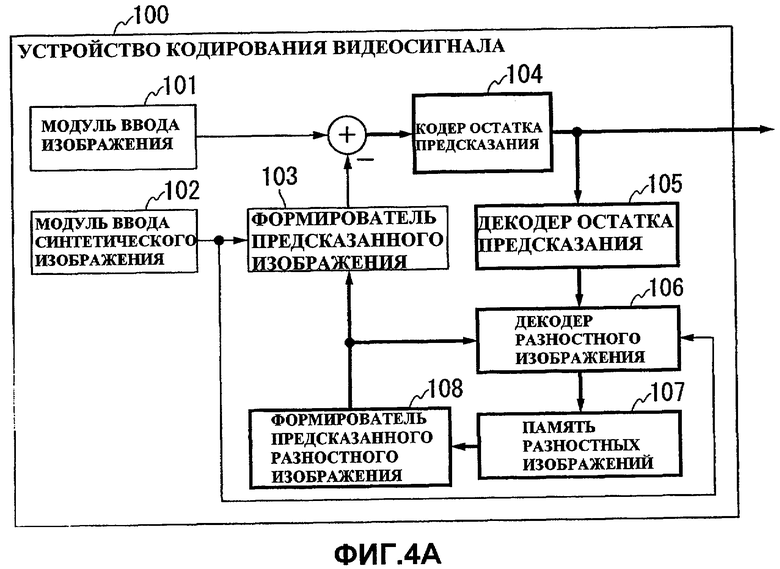
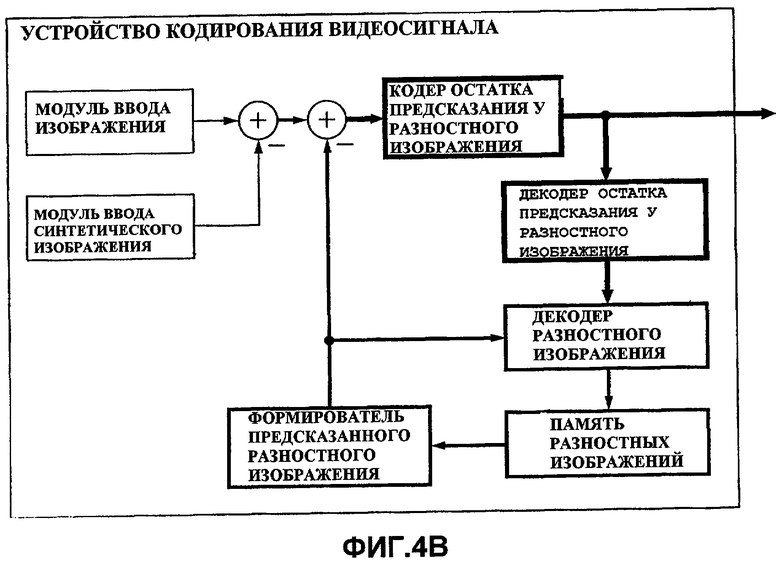
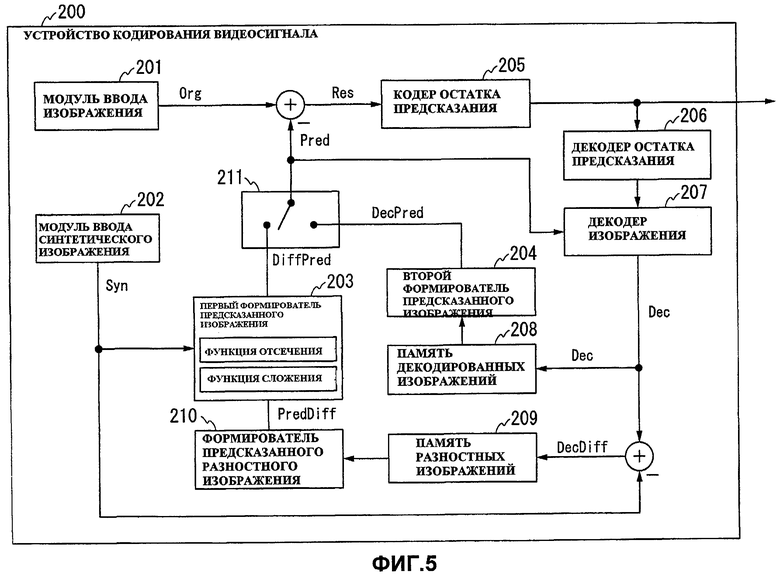
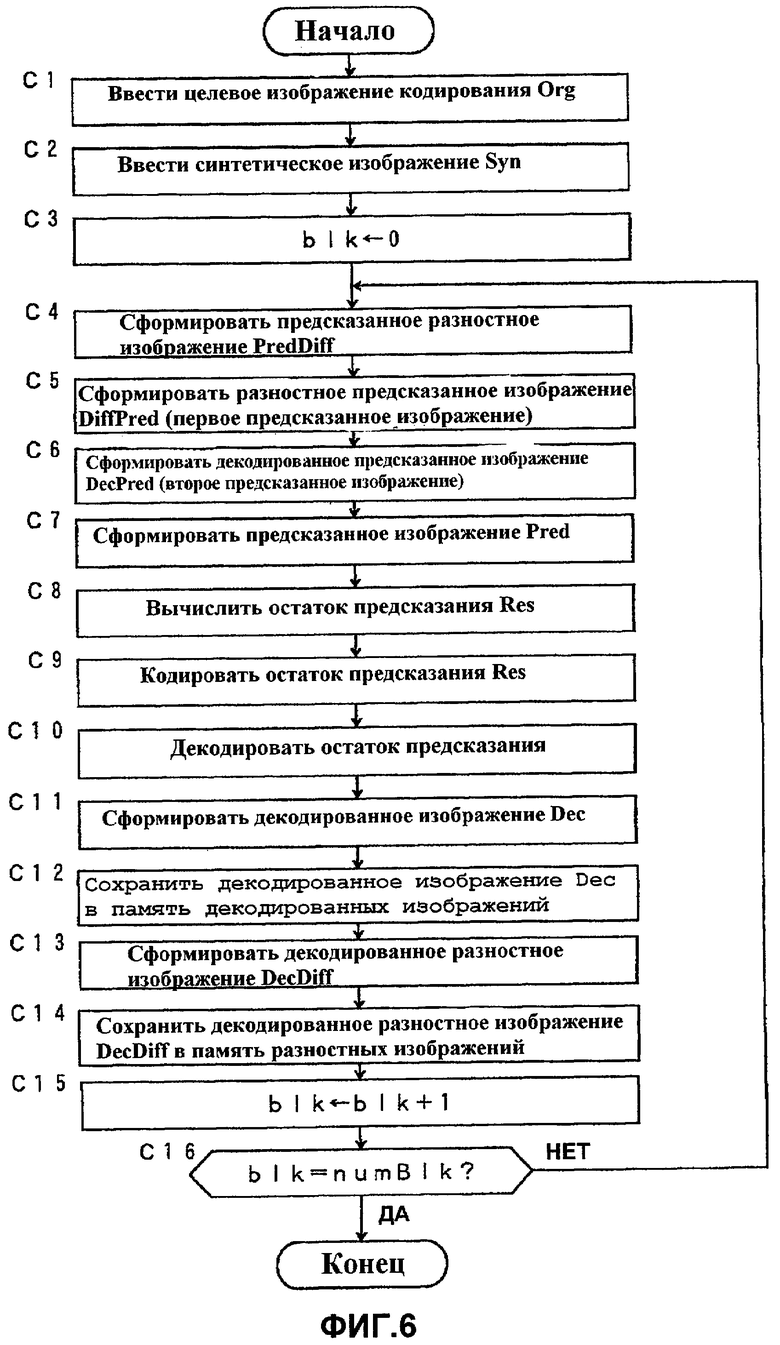
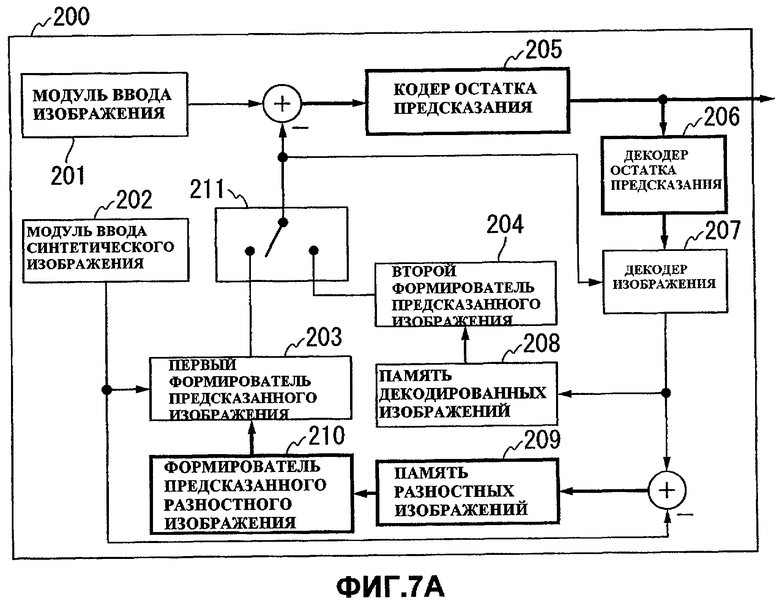
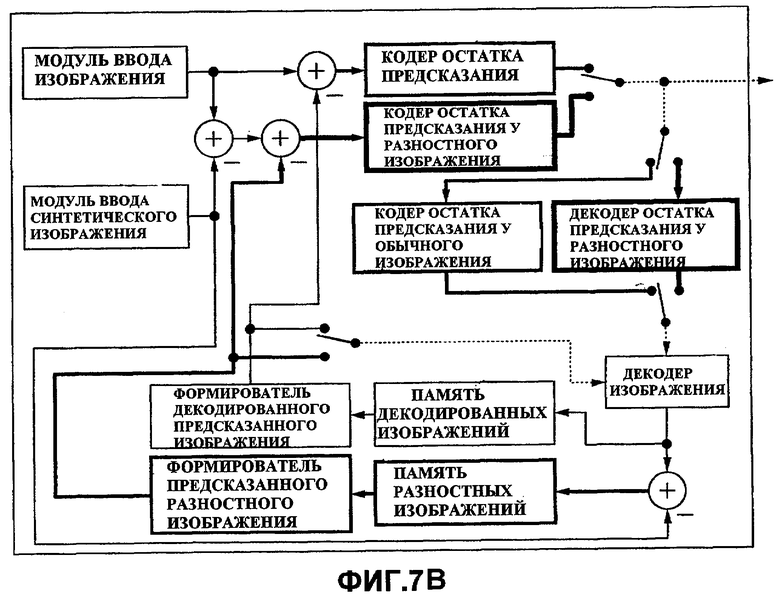
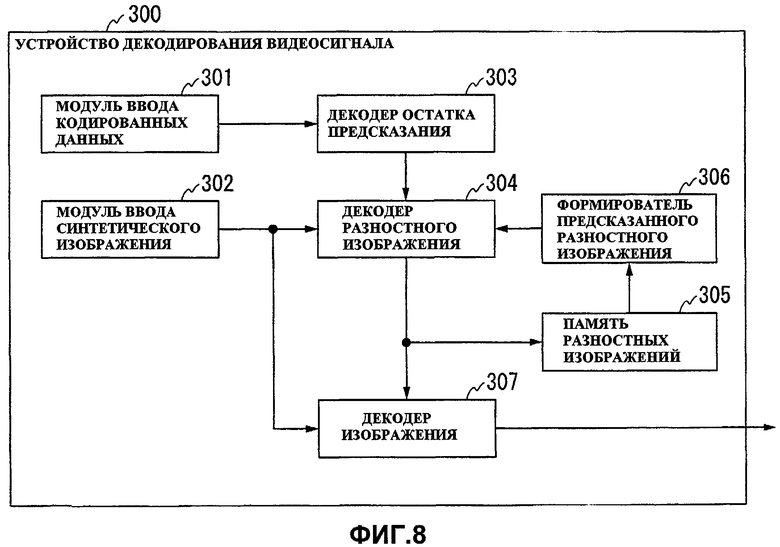
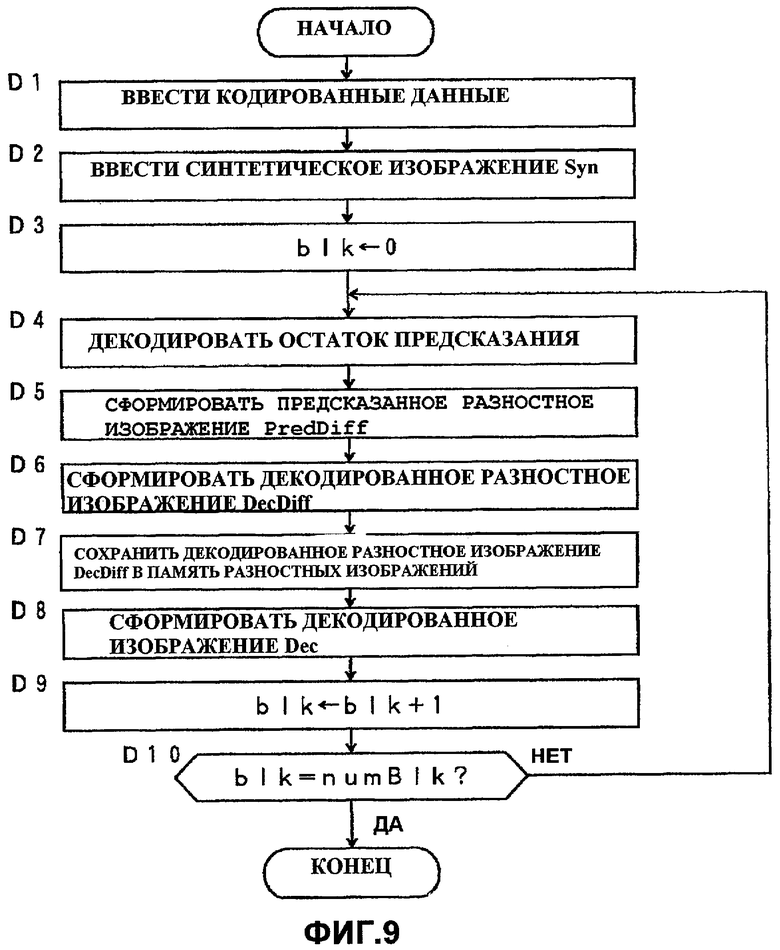
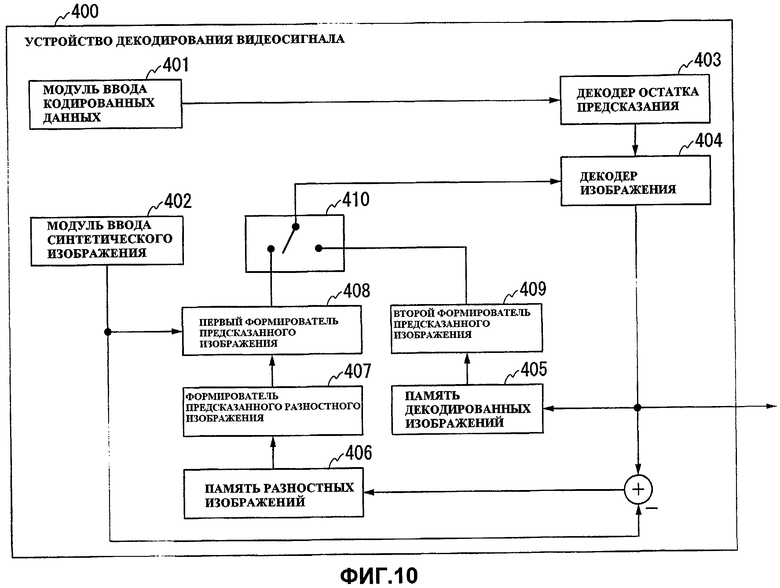
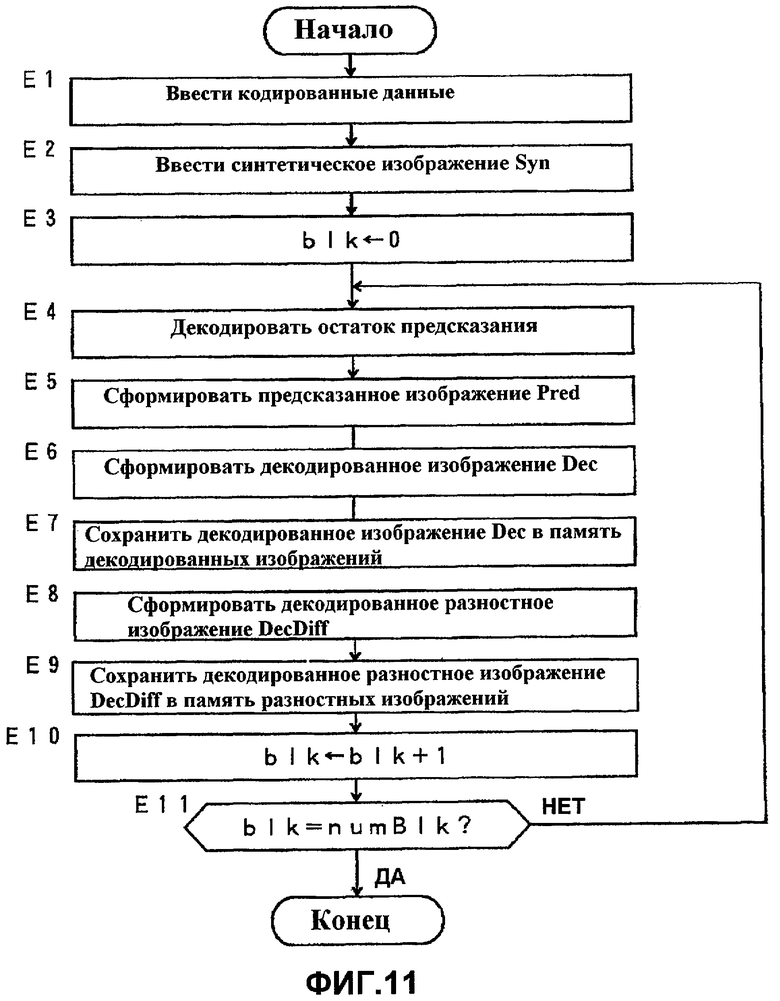
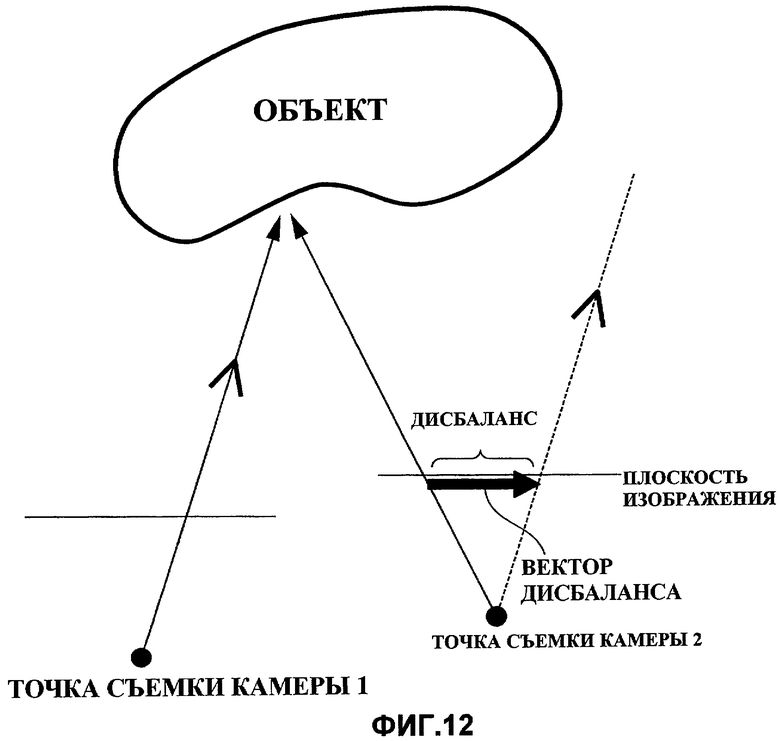
Изобретение относится к системам кодирования/декодирования видеоизображения с несколькими точками съемки (многовидового изображения). Техническим результатом является обеспечение кодера и декодера видеоизображения в котором не нужно обрабатывать разные битовые глубины путем создания предсказанного изображения для входного изображения. Указанный технический результат достигается тем, что устройство кодирования видеосигнала, формирует синтетическое изображение для камеры, используемой для получения целевого изображения кодирования, с использованием уже кодированного контрольного изображения камеры, имеющего точку съемки, отличную от точки съемки камеры, используемой для получения целевого изображения кодирования, и информации о диспаратности между контрольным изображением камеры и целевым изображением кодирования, посредством этого кодируя целевое изображение кодирования. Формируется предсказанное изображение для разностного изображения между входным изображением целевой области кодирования, которую нужно кодировать, и сформированным для него синтетическим изображением, и формируется предсказанное изображение для целевой области кодирования, которое представляется суммой предсказанного разностного изображения и синтетического изображения для целевой области кодирования. Кодируется остаток предсказания, представленный разницей между предсказанным изображением для целевой области кодирования и целевым изображением кодирования в целевой области кодирования. 6 н. и 22 з.п. ф-лы. 14 ил.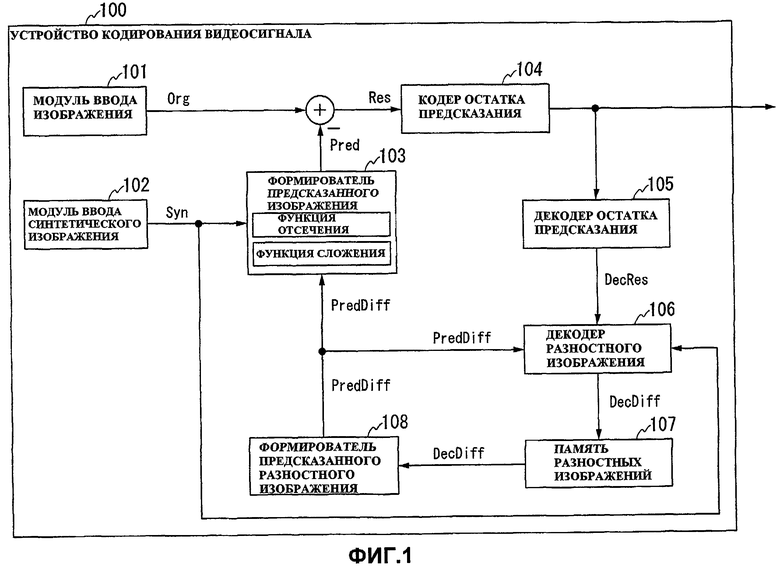
1. Устройство кодирования видеосигнала, используемое в кодировании изображения с несколькими точками съемки, полученного с помощью камер, имеющих разные точки съемки, причем устройство формирует изображение с компенсированной точкой съемки в качестве оценочного изображения для камеры, используемой для получения целевого изображения кодирования, с использованием по меньшей мере одного уже кодированного контрольного изображения камеры, имеющего точку съемки, отличную от точки съемки камеры, используемой для получения целевого изображения кодирования, и информации о диспаратности между контрольным изображением камеры и целевым изображением кодирования, кодирует целевое изображение кодирования с использованием изображения с компенсированной точкой съемки и содержит:
устройство предсказания разностного изображения, которое формирует предсказанное изображение для разностного изображения между входным изображением целевой области кодирования, которую нужно кодировать, и сформированным для нее изображением с компенсированной точкой съемки;
устройство формирования предсказанного изображения, которое формирует предсказанное изображение для целевой области кодирования, причем предсказанное изображение представляется суммой предсказанного разностного изображения, сформированного устройством предсказания разностного изображения, и изображения с компенсированной точкой съемки для целевой области кодирования; и
устройство кодирования остатка предсказания, которое кодирует остаток предсказания, представленный разницей между предсказанным изображением для целевой области кодирования, сформированным устройством формирования предсказанного изображения, и целевым изображением кодирования в целевой области кодирования.
2. Устройство кодирования видеосигнала по п.1, в котором:
устройство предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области кодирования, используя разностное изображение в момент, который является тем же, что и момент, когда было получено целевое изображение кодирования, причем используемое разностное изображение представляется разницей между декодированным изображением уже кодированной области в целевом изображении кодирования и изображением с компенсированной точкой съемки для уже кодированной области.
3. Устройство кодирования видеосигнала по п.1, в котором:
устройство предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области кодирования, используя разностное изображение в момент, отличный от момента, когда было получено целевое изображение кодирования, причем используемое разностное изображение представляется разницей между декодированным изображением уже кодированного изображения, которое было получено в точке съемки, использованной для получения целевого изображения кодирования, и изображением с компенсированной точкой съемки в тот же момент, что и в момент с декодированным изображением.
4. Устройство кодирования видеосигнала по п.1, дополнительно содержащее:
устройство декодирования изображения, которое формирует декодированное изображение целевого изображения кодирования посредством декодирования кодированных данных целевого изображения кодирования; и
устройство формирования и хранения декодированного разностного изображения, которое формирует декодированное разностное изображение, представленное разницей между декодированным изображением, сформированным устройством декодирования изображения, и изображением с компенсированной точкой съемки, и сохраняет сформированное декодированное разностное изображение в запоминающем устройстве,
в котором устройство предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области кодирования, используя декодированное разностное изображение, сохраненное в запоминающем устройстве.
5. Устройство кодирования видеосигнала по п.1, дополнительно содержащее:
устройство декодирования остатка предсказания, которое декодирует остаток предсказания, кодированный устройством кодирования остатка предсказания; и
устройство формирования и хранения декодированного разностного изображения, которое формирует декодированное разностное изображение, представленное суммой декодированного остатка предсказания, сформированного устройством декодирования остатка предсказания, и предсказанного разностного изображения, и сохраняет сформированное декодированное разностное изображение в запоминающем устройстве,
причем устройство предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области кодирования, используя декодированное разностное изображение, сохраненное в запоминающем устройстве.
6. Устройство кодирования видеосигнала по п.1, дополнительно содержащее:
устройство предсказания исходного изображения, которое формирует предсказанное изображение для целевого изображения кодирования, используя любое из декодированного изображения уже кодированной области в целевом изображении кодирования и декодированного изображения уже кодированного изображения, которое было получено в той же точке съемки, которая использована для получения целевого изображения кодирования, и в момент, отличный от момента целевого изображения кодирования,
причем устройство формирования предсказанного изображения выборочно выполняет одно из формирования предсказанного изображения для целевого изображения кодирования на основе предсказанного разностного изображения и изображения с компенсированной точкой съемки и формирования предсказанного изображения для целевого изображения кодирования посредством непосредственного использования предсказанного изображения, сформированного устройством предсказания исходного изображения.
7. Устройство кодирования видеосигнала по п.1, в котором:
устройство формирования предсказанного изображения выполняет отсечение, чтобы каждый пиксель предсказанного изображения имел значение пикселя в пределах заранее установленного рабочего диапазона.
8. Устройство кодирования видеосигнала по п.5, в котором
устройство формирования и хранения декодированного разностного изображения выполняет отсечение, чтобы каждый пиксель декодированного разностного изображения имел значение пикселя в пределах заранее установленного рабочего диапазона.
9. Устройство декодирования видеосигнала, используемое в декодировании кодированных данных изображения с несколькими точками съемки, полученного с помощью камер, имеющих разные точки съемки, причем устройство формирует изображение с компенсированной точкой съемки в качестве оценочного изображения для камеры, используемой для получения целевого изображения декодирования, с использованием по меньшей мере одного уже декодированного контрольного изображения камеры, имеющего точку съемки, отличную от точки съемки камеры, используемой для получения целевого изображения декодирования, и информации о диспаратности между контрольным изображением камеры и целевым изображением декодирования, декодирует кодированные данные целевого изображения декодирования с использованием изображения с компенсированной точкой съемки и содержит:
устройство декодирования остатка предсказания, которое декодирует остаток предсказания в целевом изображении декодирования, причем остаток предсказания включается в кодированные данные;
устройство предсказания разностного изображения, которое формирует предсказанное изображение для разностного изображения между целевым изображением декодирования целевой области декодирования, которую нужно декодировать, и сформированным для нее изображением с компенсированной точкой съемки; и
устройство декодирования изображения, которое декодирует целевое изображение декодирования посредством сложения предсказанного разностного изображения, сформированного устройством предсказания разностного изображения, остатка предсказания, декодированного устройством декодирования остатка предсказания, и изображения с компенсированной точкой съемки.
10. Устройство декодирования видеосигнала по п.9, в котором:
устройство предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области декодирования, используя разностное изображение в момент, который является тем же, что и момент, когда было получено целевое изображение декодирования, причем используемое разностное изображение представляется разницей между декодированным изображением уже декодированной области в целевом изображении декодирования и изображением с компенсированной точкой съемки для уже декодированной области.
11. Устройство декодирования видеосигнала по п.9, в котором:
устройство предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области декодирования, используя разностное изображение в момент, отличный от момента, когда было получено целевое изображение декодирования, причем используемое разностное изображение представляется разницей между уже декодированным контрольным изображением, которое было получено в точке съемки, использованной для получения целевого изображения декодирования, и изображением с компенсированной точкой съемки в тот же момент, что и в момент с контрольным изображением.
12. Устройство декодирования видеосигнала по п.9, дополнительно содержащее:
устройство формирования и хранения декодированного разностного изображения, которое формирует декодированное разностное изображение, представленное разницей между декодированным изображением, сформированным устройством декодирования изображения, и изображением с компенсированной точкой съемки, и сохраняет сформированное декодированное разностное изображение в запоминающем устройстве,
причем устройство предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области декодирования, используя декодированное разностное изображение, сохраненное в запоминающем устройстве.
13. Устройство декодирования видеосигнала по п.9, дополнительно содержащее:
устройство формирования и хранения декодированного разностного изображения, которое формирует декодированное разностное изображение, представленное суммой декодированного остатка предсказания, сформированного устройством декодирования остатка предсказания, и предсказанного разностного изображения, и сохраняет сформированное декодированное разностное изображение в запоминающем устройстве,
причем устройство предсказания разностного изображения формирует предсказанное изображение для разностного изображения относительно целевой области декодирования, используя декодированное разностное изображение, сохраненное в запоминающем устройстве.
14. Устройство декодирования видеосигнала по п.9, дополнительно содержащее:
устройство предсказания исходного изображения, которое формирует предсказанное изображение для целевого изображения декодирования, используя любое из уже декодированного изображения целевого изображения декодирования и уже декодированного изображения, которое было получено в той же точке съемки, которая использовалась для получения целевого изображения декодирования, и в момент, отличный от момента целевого изображения декодирования,
причем для целевой области декодирования устройство декодирования изображения выборочно выполняет одно из декодирования целевого изображения декодирования путем сложения предсказанного разностного изображения, сформированного устройством предсказания разностного изображения, остатка предсказания, декодированного устройством декодирования остатка предсказания, и изображения с компенсированной точкой съемки, и декодирования целевого изображения декодирования посредством прибавления предсказанного изображения, сформированного устройством предсказания исходного изображения, к остатку предсказания, декодированному устройством декодирования остатка предсказания.
15. Устройство декодирования видеосигнала по п.13, в котором
устройство формирования и хранения декодированного разностного изображения выполняет отсечение, чтобы каждый пиксель декодированного разностного изображения имел значение пикселя в пределах заранее установленного рабочего диапазона.
16. Способ кодирования видеосигнала, используемый в кодировании изображения с несколькими точками съемки, полученного с помощью камер, имеющих разные точки съемки, причем способ формирует изображение с компенсированной точкой съемки в качестве оценочного изображения для камеры, используемой для получения целевого изображения кодирования, с использованием по меньшей мере одного уже кодированного контрольного изображения камеры, имеющего точку съемки, отличную от точки съемки камеры, используемой для получения целевого изображения кодирования, и информации о диспаратности между контрольным изображением камеры и целевым изображением кодирования, кодирует целевое изображение кодирования с использованием изображения с компенсированной точкой съемки и содержит:
этап предсказания разностного изображения, на котором формируют предсказанное изображение для разностного изображения между входным изображением целевой области кодирования, которую нужно кодировать, и сформированным для нее изображением с компенсированной точкой съемки;
этап формирования предсказанного изображения, на котором формируют предсказанное изображение для целевой области кодирования, причем предсказанное изображение представляют суммой предсказанного разностного изображения, сформированного на этапе предсказания разностного изображения, и изображения с компенсированной точкой съемки для целевой области кодирования; и
этап кодирования остатка предсказания, на котором кодирует остаток предсказания, представленный разницей между предсказанным изображением для целевой области кодирования, сформированным на этапе формирования предсказанного изображения, и целевым изображением кодирования в целевой области кодирования.
17. Способ кодирования видеосигнала по п.16, в котором:
на этапе предсказания разностного изображения формируют предсказанное изображение для разностного изображения относительно целевой области кодирования, используя разностное изображение в момент, который является тем же, что и момент, когда было получено целевое изображение кодирования, причем используемое разностное изображение представляется разницей между декодированным изображением уже кодированной области в целевом изображении кодирования и изображением с компенсированной точкой съемки для уже кодированной области.
18. Способ кодирования видеосигнала по п.16, в котором:
на этапе предсказания разностного изображения формируют предсказанное изображение для разностного изображения относительно целевой области кодирования, используя разностное изображение в момент, отличный от момента, когда было получено целевое изображение кодирования, причем используемое разностное изображение представляют разницей между декодированным изображением уже кодированного изображения, которое было получено в точке съемки, использованной для получения целевого изображения кодирования, и изображением с компенсированной точкой съемки в тот же момент, что и в момент с декодированным изображением.
19. Способ кодирования видеосигнала по п.16, дополнительно содержащий:
этап декодирования остатка предсказания, на котором декодируют остаток предсказания, кодированный на этапе кодирования остатка предсказания; и
этап формирования и хранения декодированного разностного изображения, на котором формируют декодированное разностное изображение, представленное суммой декодированного остатка предсказания, сформированного на этапе декодирования остатка предсказания, и предсказанного разностного изображения, и сохраняют сформированное декодированное разностное изображение в запоминающем устройстве,
причем на этапе предсказания разностного изображения формируют предсказанное изображение для разностного изображения относительно целевой области кодирования, используя декодированное разностное изображение, сохраненное в запоминающем устройстве.
20. Способ кодирования видеосигнала по п.16, дополнительно содержащий:
этап предсказания исходного изображения, на котором формируют предсказанное изображение для целевого изображения кодирования, используя любое из декодированного изображения уже кодированной области в целевом изображении кодирования и декодированного изображения уже кодированного изображения, которое было получено в той же точке съемки, которую использовали для получения целевого изображения кодирования, и в момент, отличный от момента целевого изображения кодирования,
причем на этапе формирования предсказанного изображения выборочно выполняют одно из: формируют предсказанное изображение для целевого изображения кодирования на основе предсказанного разностного изображения и изображения с компенсированной точкой съемки и формируют предсказанное изображение для целевого изображения кодирования путем непосредственного использования предсказанного изображения, сформированного на этапе предсказания исходного изображения.
21. Способ декодирования видеосигнала, используемый в декодировании кодированных данных изображения с несколькими точками съемки, полученного с помощью камер, имеющих разные точки съемки, причем способ формирует изображение с компенсированной точкой съемки в качестве оценочного изображения для камеры, используемой для получения целевого изображения декодирования, с использованием по меньшей мере одного уже декодированного контрольного изображения камеры, имеющего точку съемки, отличную от точки съемки камеры, используемой для получения целевого изображения декодирования, и информации о диспаратности между контрольным изображением камеры и целевым изображением декодирования, декодирует кодированные данные целевого изображения декодирования с использованием изображения с компенсированной точкой съемки и содержит:
этап декодирования остатка предсказания, на котором декодируют остаток предсказания в целевом изображении декодирования, причем остаток предсказания включается в кодированные данные;
этап предсказания разностного изображения, на котором формируют предсказанное изображение для разностного изображения между целевым изображением декодирования целевой области декодирования, которую нужно декодировать, и сформированным для нее изображением с компенсированной точкой съемки; и
этап декодирования изображения, на котором декодируют целевое изображение декодирования посредством сложения предсказанного разностного изображения, сформированного на этапе предсказания разностного изображения, остатка предсказания, декодированного на этапе декодирования остатка предсказания, и изображения с компенсированной точкой съемки.
22. Способ декодирования видеосигнала по п.21, в котором:
на этапе предсказания разностного изображения формируют предсказанное изображение для разностного изображения относительно целевой области декодирования, используя разностное изображение в момент, который является тем же, что и момент, когда было получено целевое изображение декодирования, причем используемое разностное изображение представляют разницей между декодированным изображением уже декодированной области в целевом изображении декодирования и изображением с компенсированной точкой съемки для уже декодированной области.
23. Способ декодирования видеосигнала по п.21, в котором:
на этапе предсказания разностного изображения формируют предсказанное изображение для разностного изображения относительно целевой области декодирования, используя разностное изображение в момент, отличный от момента, когда получили целевое изображение декодирования, причем используемое разностное изображение представляют разницей между уже декодированным контрольным изображением, которое было получено в точке съемки, использованной для получения целевого изображения декодирования, и изображением с компенсированной точкой съемки одновременно с контрольным изображением.
24. Способ декодирования видеосигнала по п.21, дополнительно содержащий:
этап формирования и хранения декодированного разностного изображения, на котором формируют декодированное разностное изображение, представленное суммой декодированного остатка предсказания, сформированного на этапе декодирования остатка предсказания, и предсказанного разностного изображения, и сохраняют сформированное декодированное разностное изображение в запоминающем устройстве,
причем на этапе предсказания разностного изображения формируют предсказанное изображение для разностного изображения относительно целевой области декодирования, используя декодированное разностное изображение, сохраненное в запоминающем устройстве.
25. Способ декодирования видеосигнала по п.21, дополнительно содержащий:
этап предсказания исходного изображения, на котором формируют предсказанное изображение для целевого изображения декодирования, используя любое из уже декодированного изображения целевого изображения декодирования и уже декодированного изображения, которое было получено в той же точке съемки, которую использовали для получения целевого изображения декодирования, и в момент, отличный от момента целевого изображения декодирования,
причем для целевой области декодирования на этапе декодирования изображения выборочно выполняют одно из: декодируют целевое изображение декодирования посредством сложения предсказанного разностного изображения, сформированного на этапе предсказания разностного изображения, остатка предсказания, декодированного на этапе декодирования остатка предсказания, и изображения с компенсированной точкой съемки, и декодируют целевое изображение декодирования посредством сложения предсказанного изображения, сформированного на этапе предсказания исходного изображения, с остатком предсказания, декодированного на этапе декодирования остатка предсказания.
26. Способ декодирования видеосигнала по п.24, в котором:
на этапе формирования и хранения декодированного разностного изображения выполняют отсечение, чтобы каждый пиксель декодированного разностного изображения имел значение пикселя в пределах заранее установленного рабочего диапазона.
27. Машиночитаемый носитель информации, который хранит программу кодирования видеосигнала, посредством которой компьютер выполняет процесс для реализации устройства кодирования видеосигнала по п.1.
28. Машиночитаемый носитель информации, который хранит программу декодирования видеосигнала, посредством которой компьютер выполняет процесс для реализации устройства декодирования видеосигнала по п.9.
| US 2006023782 A1, 02.02.2006 | |||
| JP 2001285895 А, 12.10.2001 | |||
| ЕР 1414245 А1, 28.04.2004 | |||
| US 2005031035 А1, 10.02.2005 | |||
| WO 2006073116 А1, 13.07.2006 | |||
| JP 11341521 A, 10.12.1999 | |||
| JP 10191393 A, 21.07.1998 | |||
| УСТРОЙСТВО И СПОСОБ ПРЕДСТАВЛЕНИЯ ТРЕХМЕРНОГО ОБЪЕКТА НА ОСНОВЕ ИЗОБРАЖЕНИЙ С ГЛУБИНОЙ | 2002 |
|
RU2237283C2 |
| ВИЗУАЛЬНОЕ УСТРОЙСТВО ОТОБРАЖЕНИЯ И СПОСОБ ФОРМИРОВАНИЯ ТРЕХМЕРНОГО ИЗОБРАЖЕНИЯ | 1995 |
|
RU2168192C2 |
| PHILIPP MERKLE et al, Efficient Prediction Structures for Multi-view Video Coding, IEEE, принято | |||

