Область техники
Описаны способы и инструментальные средства для кодирования/декодирования цифрового видео.
Предпосылки
С увеличением популярности цифровых видеодисков доставки музыки по сети Интернет и цифровых камер цифровые медиа стали самым обычным делом. Инженеры используют разнообразные методы, чтобы эффективно обрабатывать цифровое аудио, видео и изображения при одновременной поддержке качества. Пониманию этих методов способствует понимание того, каким образом информация аудио, видео и изображения представляется и обрабатывается в компьютере.
I. Представление информации медиа в компьютере
Компьютер обрабатывает информацию медиа как ряд чисел, представляющих эту информацию. Например, отдельное число может представлять интенсивность яркости или интенсивность цветового компонента, такого как красный, зеленый или синий для каждой элементарной малой области изображения, так что цифровое представление изображения состоит из одного или более массивов таких чисел. Каждое такое число может упоминаться как выборка. Для цветного изображения обычно используется более чем одна выборка, чтобы представлять цвет каждой элементарной области, и в типовом случае используются три выборки. Набор этих выборок для элементарной области может упоминаться как пиксел, где слово "пиксел" - сокращение, относящееся к понятию "элемент изображения" (“picture element”). Например, один пиксел может состоять из трех выборок, которые представляют интенсивность красного, зеленого и синего цвета, необходимых для представления элементарной области. Такой тип пиксела упоминается как RGB-пиксел. Несколько факторов влияют на качество информации медиа, включая глубину выборки, разрешающую способность и скорость кадров (для видео).
Глубина выборки является свойством, обычно измеряемым в битах, которое указывает диапазон чисел, которые могут использоваться, чтобы представить выборку. Когда больше значений возможно для выборки, качество может быть выше, потому что число может фиксировать более тонкие изменения в интенсивности и/или больший диапазон значений. Разрешающая способность обычно относится к числу выборок на некоторой длительности времени (для аудио) или по пространству (для изображений или индивидуальных видеоизображений). Изображения с более высокой пространственной разрешающей способностью имеют тенденцию выглядеть более четкими, чем другие изображения, и содержат более различимых полезных деталей. Скорость кадров - это обычный термин для временной разрешающей способности для видео. Видео с более высокой скоростью кадров имеет тенденцию имитировать плавное движение естественных объектов лучше, чем другое видео, и может аналогичным образом рассматриваться как содержащее больше деталей во временном измерении. Для всех этих факторов имеет место компромисс между высоким качеством и затратами на сохранение и передачу информации в терминах битовой скорости, необходимой для представления глубины выборки, разрешающей способности и скорости кадров, как показано в Таблице 1.
Битовая скорость различных уровней качества необработанного видео
Несмотря на высокую битовую скорость, необходимую для сохранения и передачи высококачественного видео (такого как HDTV), компании и потребители все больше зависят от компьютеров, чтобы создавать, распределять и воспроизводить высококачественное содержание. По этой причине инженеры используют сжатие (также называемое кодированием источника), чтобы уменьшить битовую скорость в цифровом медиа. Сжатие уменьшает затраты на хранение и передачу информации путем преобразования информации в форму более низкой битовой скорости. Сжатие может быть без потерь, в котором качество видео не ухудшается, но снижения битовой скорости ограничены сложностью видео. Или, сжатие может быть с потерями, в котором качество видео ухудшается, но снижения битовой скорости являются более значительными. Декомпрессия (также называемая декодированием) восстанавливает версию первоначальной информации из сжатой формы. "Кодек" - это система кодера/декодера.
Вообще, методы сжатия видео включают в себя сжатие с внутренним (внутрикадровым) кодированием и сжатие с межкадровым кодированием или сжатие с предсказанием. Для видеоизображений методы внутрикадрового сжатия сжимают индивидуальные изображения. Методы межкадрового сжатия сжимают изображения с опорой на предыдущее и/или последующее изображения.
II. Видео с переменной разрешающей способностью и пространственное масштабирование
Стандартные видеокодеры испытывают значительное ухудшение в характеристиках, когда целевая битовая скорость падает ниже некоторого порога. Квантование и другие стадии обработки с потерями вводят искажение. При низких битовых скоростях высокочастотная информация может быть сильно искажена или полностью потеряна. В результате, могут возникать значительные артефакты, которые могут вызвать существенное снижение качества восстановленного видео. Хотя доступные битовые скорости возрастают с усовершенствованием технологии передачи и обработки, поддержание высокого визуального качества при ограниченных битовых скоростях остается главной целью проектирования кодека. Существующие кодеки используют различные методы для улучшения визуального качества при ограниченных битовых скоростях.
Кодирование с множеством разрешающих способностей позволяет кодировать видео при различных пространственных разрешающих способностях. Видео с уменьшенной разрешающей способностью может кодироваться при существенно более низкой битовой скорости ценой потери информации. Например, предшествующий видеокодер может дискретизировать с пониженной частотой (с использованием фильтра понижающей дискретизации) видео полной разрешающей способности и кодировать его с уменьшенной разрешающей способностью в вертикальном и/или горизонтальном направлениях. Сокращение разрешающей способности в каждом направлении наполовину уменьшает измерения размера кодированного изображения наполовину. Кодер сигнализирует о кодировании с уменьшенной разрешающей способностью в декодер. Декодер получает информацию, указывающую кодирование с уменьшенной разрешающей способностью, и устанавливает из полученной информации, каким образом видео с уменьшенной разрешающей способностью должно быть дискретизировано с повышенной частотой (с использованием фильтра повышающей дискретизации), чтобы увеличить размер изображения перед отображением. Однако информация, которая была потеряна, когда кодер дискретизировал с пониженной частотой и кодировал видеоизображения, все еще отсутствует в дискретизированных с повышенной частотой изображениях.
Пространственно масштабируемое видео использует многоуровневый подход, позволяя кодеру уменьшать пространственную разрешающую способность (и, таким образом, битовую скорость) на базовом уровне при сохранении информации более высокой разрешающей способности из исходного видео на одном или более улучшенных уровнях. Например, изображение внутреннего (внутрикадрового) кодирования базового уровня может быть кодировано при уменьшенной разрешающей способности, в то время как соответствующее изображение внутрикадрового кодирования улучшенного уровня может быть кодировано при более высокой разрешающей способности. Точно так же предсказанные изображения базового уровня могут сопровождаться предсказанными изображениями улучшенного уровня. Декодер может выбирать (основываясь на ограничениях битовой скорости и/или других критериях), чтобы декодировать только изображения базового уровня при более низкой разрешающей способности, чтобы получить восстановленные изображения более низкой разрешающей способности, или декодировать изображения базового уровня и изображения улучшенного уровня, чтобы получить восстановленные изображения с более высокой разрешающей способностью. Когда базовый уровень кодируется при более низкой разрешающей способности, чем отображаемое изображение (также упоминается как понижающая дискретизация), размер кодированного изображения фактически меньше, чем отображенное изображение. Декодер выполняет вычисления, чтобы изменить размеры восстановленного изображения и использует фильтры повышающей дискретизации, чтобы сформировать интерполированные значения выборок в соответствующих позициях в восстановленном изображении. Однако предшествующие кодеки, которые используют пространственно масштабируемое видео, имели недостатки вследствие негибких фильтров повышающей дискретизации и неточных или затратных (в терминах времени вычисления или битовой скорости) методов изменения размеров изображения.
Учитывая критическую важность сжатия и декомпрессии видео для цифрового видео, неудивительно, что сжатие и декомпрессия видео являются интенсивно развивающимися областями. Однако независимо от выгод предшествующих методов сжатия и декомпрессии видео они не имеют преимуществ следующих методов и инструментальных средств.
Сущность изобретения
Настоящий раздел «Сущность изобретения» обеспечен, чтобы ввести выбор понятий в упрощенной форме, которые далее описаны ниже в разделе «Детальное описание». Настоящий раздел «Сущность изобретения» не предназначен для того, чтобы идентифицировать ключевые признаки или существенные признаки заявленного изобретения, и при этом не предназначается для использования, чтобы ограничивать объем заявленного изобретения.
В итоге, раздел «Детальное описание» направлен на различные способы и инструментальные средства для использующего переменную разрешающую способность многоуровневого пространственно масштабируемого кодирования и декодирования видео.
Например, раздел «Детальное описание» направлен на различные способы и инструментальные средства для высокоточного вычисления позиции для изменения размеров изображения в приложениях типа пространственно масштабируемого кодирования и декодирования видео. Описаны способы и инструментальные средства для высокоточного вычисления позиции для изменения размеров изображения в приложениях типа пространственно-масштабируемого кодирования и декодирования видео. В одном аспекте повторная дискретизация видеоизображения выполняется согласно коэффициенту масштаба повторной дискретизации. Повторная дискретизация включает вычисление значения выборки в позиции i, j в повторно дискретизируемом массиве. Вычисление включает вычисление выводимой горизонтальной или вертикальной позиции x или y подвыборки способом, который связан с аппроксимацией значения частично путем умножения значения 2n на инверсию (приближенную или точную) масштабного коэффициента повышающей дискретизации (или деления значения 2n на масштабный коэффициент повышающей дискретизации, или аппроксимацию масштабного коэффициента повышающей дискретизации). Экспонента n может быть суммой двух целых чисел, включая целое число F, которое представляет множество битов в дробном компоненте. Аппроксимация может быть округлением или некоторым другим видом аппроксимации, такой как функция ограничения сверху или снизу, которая аппроксимирует ближайшее целое число. Значение выборки интерполируется с использованием фильтра.
Некоторые альтернативы для описанных способов обеспечивают измененное вычисление позиции выборки, которое в одном выполнении обеспечивает приблизительно один дополнительный бит точности в вычислениях, без значительного изменения процесса вычисления позиции выборки или его сложность. Некоторые дальнейшие альтернативы для описанных способов относятся к тому, как вычисление позиции выборки работает со структурами дискретизации 4:2:2 и 4:4:4. Эти альтернативные способы для таких структур дискретизации связывают вычисления позиции выборки сигнала яркости и сигнала цветности вместе, когда разрешающая способность сетки дискретизации сигнала цветности и сигнала яркости является той же самой в конкретном измерении.
Дополнительные признаки и преимущества будут очевидными из следующего детального описания различных воплощений, которое изложено со ссылками на иллюстрирующие чертежи.
Краткое описание чертежей
Фиг.1 - блок-схема подходящей вычислительной среды, во взаимосвязи с которой могут быть осуществлены некоторые описанные воплощения.
Фиг.2 - блок-схема обобщенной системы кодера видео, во взаимосвязи с которой могут быть осуществлены некоторые описанные воплощения.
Фиг.3 - блок-схема обобщенной системы декодера видео, во взаимосвязи с которой могут быть осуществлены некоторые описанные воплощения.
Фиг.4 - диаграмма формата макроблока, используемого в некоторых описанных воплощениях.
Фиг.5A - диаграмма части чересстрочного видеокадра, показывающая чередующиеся строки верхнего поля и нижнего поля.
Фиг.5B - диаграмма чересстрочного видеокадра, организованного для кодирования/декодирования как кадра, и
Фиг.5C - диаграмма чересстрочного видеокадра, организованного для кодирования/ декодирования как полей.
Фиг.5D показывает шесть примерных пространственных выравниваний местоположений 4:2:0 выборки сигнала цветности относительно местоположений выборки сигнала яркости для каждого поля видеокадра.
Фиг.6 - блок-схема, показывающая обобщенный способ для кодирования видео с переменной разрешающей способностью.
Фиг.7 - блок-схема, показывающая обобщенный способ для декодирования видео с переменной разрешающей способностью.
Фиг.8 - блок-схема, показывающая способ для кодирования с переменной разрешающей способностью изображений с внутрикадровым кодированием и предсказанных изображений с межкадровым кодированием.
Фиг.9 - блок-схема, показывающая способ для декодирования с переменной разрешающей способностью изображений с внутрикадровым кодированием и предсказанных изображений с межкадровым кодированием.
Фиг.10 - блок-схема, показывающая способ для кодирования пространственно масштабируемых уровней битового потока для обеспечения возможности кодирования видео с различными разрешающими способностями.
Фиг.11 - блок-схема, показывающая способ для декодирования пространственно масштабируемых уровней битового потока для обеспечения возможности декодирования видео с различными разрешающими способностями.
Фиг.12 и 13 - диаграммы кода, показывающие псевдокод для примерного многоэтапного способа вычисления позиции.
Фиг.14 - диаграмма кода, показывающая псевдокод для примерного инкрементного способа вычисления позиции.
Детальное описание
Описанные воплощения направлены на способы и инструментальные средства для многоуровневого, с переменной разрешающей способностью пространственно масштабируемого видеокодирования и декодирования.
Различные способы и инструментальные средства, описанные здесь, могут использоваться независимо. Некоторые из способов и инструментальных средств могут использоваться в комбинации (например, на различных стадиях объединенного процесса кодирования и/или декодирования).
Различные способы описаны ниже со ссылкой на блок-схемы действий обработки. Различные действия обработки, показанные на блок-схемах, могут быть объединены в меньшее количество действий или разделены на большее количество действий. Ради простоты, отношение действий, показанных в конкретной блок-схеме, к действиям, описанным в другом месте, часто не показано. Во многих случаях действия в блок-схеме могут быть переупорядочены.
Большая часть детального описания относится к представлению, кодированию и декодированию видеоинформации. Способы и инструментальные средства, описанные здесь для представления, кодирования и декодирования видеоинформации, могут быть применены к аудиоинформации, информации неподвижного изображения или другой информации медиа.
I. Вычислительная среда
Фиг.1 иллюстрирует обобщенный пример подходящей вычислительной среды 100, в которой могут быть осуществлены несколько из описанных воплощений. Вычислительная среда 100 не предназначена для какого-либо ограничения объема использования или функциональных возможностей, поскольку способы и инструментальные средства могут быть осуществлены в разнообразных универсальных или специализированных вычислительных средах.
Согласно фиг.1, вычислительная среда 100 включает в себя, по меньшей мере, один процессор 110 и память 120. На фиг.1 эта наиболее базовая конфигурация 130 показана внутри пунктирного контура. Процессор 110 исполняет компьютерные команды и может представлять собой реальный или виртуальный процессор. В многопроцессорной системе множество модулей обработки исполняют компьютерные команды для увеличения производительности обработки. Память 120 может быть энергозависимой памятью (например, регистры, кэш, ОЗУ (RAM)), энергонезависимой памятью (например, ПЗУ (ROM), стираемое программируемое ПЗУ (СППЗУ, EEPROM), флэш-память и т.д.), или некоторой комбинацией указанного. Память 120 хранит программное обеспечение 180, реализующее кодер или декодер видео с одним или более описанных способов и инструментальных средств.
Вычислительная среда может иметь дополнительные признаки. Например, вычислительная среда 100 содержит ЗУ 140, одно или более устройств 150 ввода, одно или более устройств 160 вывода и одно или более коммуникационных соединений 170. Механизм межсоединений (не показан), такой как шина, контроллер или сеть, связывает компоненты вычислительной среды 100. Как правило, программное обеспечение операционной системы (не показано) обеспечивает операционную среду для другого программного обеспечения, выполняющегося в вычислительной среде 100, и координирует действия компонентов вычислительной среды 100.
ЗУ 140 может быть сменным или несменным и включает в себя магнитные диски, магнитные ленты или кассеты, CD-ROM, цифровые видеодиски (DVD), флэш-память или любой другой носитель, который может использоваться, чтобы хранить информацию, и к которому можно обращаться в пределах вычислительной среды 100. ЗУ 140 хранит команды для программного обеспечения 180, реализующего кодер или декодер видео.
Устройство 150 ввода может быть сенсорным устройством ввода данных типа клавиатуры, мыши, пера, сенсорного экрана или шарового манипулятора (трекбола), устройства голосового ввода, сканирующего устройства или другого устройства, которое обеспечивает ввод в вычислительную среду 100. Для кодирования аудио или видеоустройство 150 ввода может быть звуковой платой, видеоплатой, платой ТВ блока настройки или подобным устройством, которое принимает аудио или видеоввод в аналоговой или цифровой форме, или CD-ROM, CD-RW или DVD, который считывает выборки аудио или видео в вычислительную среду 100. Устройство 160 вывода может быть дисплеем, принтером, динамиком, устройством записи на CD или DVD или другим устройством, которое обеспечивает вывод из вычислительной среды 100.
Коммуникационные соединения 170 обеспечивают связь по среде связи с другим вычислительным объектом. Среда связи передает информацию типа исполняемых компьютером команд, ввода или вывода аудио или видео или других данных в модулированном сигнале данных. Модулированный сигнал данных - это сигнал, в котором одна или более из его характеристик установлена или изменяется таким способом, чтобы кодировать информацию в сигнале. Для примера, но не в качестве ограничения, среда связи включают проводные или беспроводные методы, реализованные с электрической, оптической, радиочастотной, инфракрасной, акустической или другой несущей.
Способы и инструментальные средства могут быть описаны в общем контексте машиночитаемых носителей. Машиночитаемые носители - это любые доступные носители, к которым можно обращаться в пределах вычислительной среды. Для примера, но не в качестве ограничения, для вычислительной среды 100 машиночитаемые носители включают в себя память 120, ЗУ 140, коммуникационную среду и комбинации любых из вышеупомянутых средств.
Способы и инструментальные средства могут быть описаны в общем контексте исполняемых компьютером команд, таких как включенные в модули программы, исполняемые в вычислительной среде на одном или более целевых реальных процессорах или виртуальных процессорах. Вообще, модули программы включают подпрограммы, программы, библиотеки, объекты, классы, компоненты, структуры данных и т.д., которые исполняют конкретные задачи или осуществляют некоторые абстрактные типы данных. Функциональные возможности программных модулей могут быть объединены или разбиты между программными модулями, как желательно в различных воплощениях. Исполняемые компьютером команды для программных модулей могут исполняться в пределах локальной или распределенной вычислительной среде.
Для целей представления детальное описание использует термины, подобные "кодируют", "декодируют" и "выбирают" для описания компьютерных операций в вычислительной среде. Эти термины являются абстракциями высокого уровня для операций, выполняемых компьютером, и не должны смешиваться с действиями, выполняемыми человеком. Действительные компьютерные операции, соответствующие этим терминам, изменяются в зависимости от реализации.
II. Иллюстративные видеокодер и декодер
На фиг.2 показана блок-схема приведенного для примера видеокодера 200, во взаимосвязи с которым могут быть осуществлены некоторые описанные воплощения. На фиг.3 показана блок-схема обобщенного видеодекодера 300, во взаимосвязи с которым могут быть осуществлены некоторые описанные воплощения.
Взаимосвязи, показанные между модулями в пределах кодера 200 и декодера 300, указывают общие потоки информации в кодере и декодере; другие взаимосвязи не показаны ради наглядности представления. В частности, фиг.2 и 3 не показывают побочную информацию, указывающую настройки кодера, режимы, таблицы и т.д., используемые для видеопоследовательности, изображения, сектора, макроблока, блока и т.д. Такая побочная информация посылается в выходном битовом потоке обычно после энтропийного кодирования побочной информации. Формат выходного битового потока может изменяться в зависимости от реализации.
Кодер 200 и декодер 300 обрабатывают изображения, которые могут быть видеокадрами, видеополями или комбинациями кадров и полей. Синтаксис и семантика битового потока на уровне изображения и макроблока могут зависеть от того, каким образом используются кадры или поля. Могут иметь место изменения в организации макроблока и общей синхронизации. Кодер 200 и декодер 300 являются основанными на блоках и используют макроблочный формат 4:2:0 для кадров, причем каждый макроблок включает четыре 8х8 блока сигнала яркости (иногда обрабатываемые как один 16х16 макроблок) и два 8х8 блока сигнала цветности. Для полей могут использоваться те же или отличающиеся организация макроблока и формат. 8х8 блоки могут быть далее подразделены на различных этапах, например, на этапе частотного преобразования или энтропийного кодирования. Примерные организации видеокадра описаны более подробно ниже. Альтернативно, кодер 200 и декодер 300 являются основанными на объекте, используют отличающийся формат макроблока или блока или выполняют операции над наборами выборок с размером или конфигурацией иными, чем 8х8 блоки и 16х16 макроблоки.
В зависимости от выполнения и типа желательного сжатия, модули кодера или декодера могут добавляться, опускаться, разбиваться на множество модулей, объединяться с другими модулями и/или заменяться подобными модулями. В альтернативных воплощениях кодеры или декодеры с отличающимися модулями и/или другими конфигурациями модулей исполняют один или более из описанных способов.
A. Организации видеокадра
В некоторых реализациях кодер 200 и декодер 300 обрабатывают видеокадры, организованные следующим образом. Кадр содержит строки пространственной информации видеосигнала. Для прогрессивного (построчного) сканирования видео эти строки содержат выборки, представляющие снимок содержания сцены, дискретизированный в один и тот же момент времени и охватывающий полную сцену от верха до низа кадра. Прогрессивный видеокадр разделен на макроблоки типа макроблока 400, показанного на фиг.4. Макроблок 400 включает четыре 8×8 блока яркости (от Y1 до Y4) и два 8×8 блока цветности, которые расположены совместно с четырьмя блоками яркости, но с половинной разрешающей способностью по горизонтали и вертикали, следуя обычному 4:2:0 макроблочному формату. 8×8 блоки могут быть далее подразделены на различных этапах, например, на этапах частотного преобразования (например, 8×4, 4×8 или 4×4 DCT) и энтропийного кодирования. Прогрессивный I-кадр является интра- (внутри) кодированным строчным видеокадром, где термин "интра" относится к методам кодирования, которые не используют предсказание из содержания других ранее декодированных изображений (кадров). Прогрессивный P-кадр является прогрессивным видеокадром, кодированным с использованием предсказания из одного или более других изображений (кадров) в моменты времени, которые отличаются по времени от момента времени текущего изображения (иногда называется прямым предсказанием в некоторых контекстах), и прогрессивный B-кадр представляет собой прогрессивный видеокадр, кодированный с использованием межкадрового предсказания с использованием (возможно, взвешенного) усреднения множества значений предсказания в некоторых областях (иногда называется двойным предсказанием или двунаправленным предсказанием). Прогрессивные P- и B-кадры могут включать «внутрикодированные» (с внутрикадровым кодированием) макроблоки, а также различные типы макроблоков межкадрового предсказания.
Чересстрочная развертка видеокадра состоит из чередующейся последовательности двух типов разверток сцены - один, называемый верхним полем, включает в себя четные строки (строки, пронумерованные 0, 2, 4 и т.д.) кадра, и другой, называемый нижним полем, включает в себя нечетные строки (строки, пронумерованные 1, 3, 5 и т.д.) кадра. Эти два поля обычно представляют два различных момента времени снимка. Фиг.5A показывает часть чересстрочного видеокадра 500, включающую в себя чередующиеся строки верхнего поля и нижнего поля в верхней левой части чересстрочного видеокадра 500.
Фиг.5B показывает чересстрочный видеокадр 500 по фиг.5A, организованный для кодирования/декодирования как кадр 530. Чересстрочный видеокадр 500 был разделен на макроблоки или другие такие области типа макроблоков 531 и 532, которые используют формат 4:2:0, как показано на фиг.4. В плоскости яркости каждый макроблок 531, 532 включает в себя 8 строк из верхнего поля, чередующихся с 8 строками нижнего поля для общего количества 16 строк, и каждая строка имеет длину 16 выборок. (Действительная организация изображения в макроблоки или другие такие области и размещение блоков яркости и блоков цветности в пределах макроблоков 531, 532 не показана, и фактически может измениться для различных решений кодирования и для различных схем видеокодирования). В пределах данного макроблока информация верхнего поля и информация нижнего поля может быть кодирована совместно или отдельно на любой из различных стадий.
Чересстрочный I-кадр является внутрикодированным чересстрочным видеокадром, содержащим два поля, где каждый макроблок включает в себя информацию для одного или обоих полей. Чересстрочный P-кадр является чересстрочным видеокадром, содержащим два поля, который кодирован с использованием межкадрового предсказания, где каждый макроблок включает в себя информацию для одного или обоих полей, как чересстрочный B-кадр. Чересстрочные P- и B-кадры могут включать в себя внутрикодированные макроблоки, а также различные типы макроблоков межкадрового предсказания.
Фиг.5C показывает чересстрочный видеокадр 500 по фиг.5A, организованный для кодирования/декодирования как поля 560. Каждое из двух полей чересстрочного видеокадра 500 разделено на макроблоки. Верхнее поле разделено на макроблоки, такие как макроблок 561, и нижнее поле разделено на макроблоки, такие как макроблок 562. (Вновь макроблоки используют формат 4:2:0, как показано на фиг.4, и организация изображения в макроблоки или другие такие области и размещение блоков яркости и блоков цветности в пределах макроблоков не показаны и могут варьироваться). В плоскости яркости макроблок 561 включает в себя 16 строк из верхнего поля, и макроблок 562 включает в себя 16 строк из нижнего поля, и каждая строка имеет длину 16 выборок.
Чересстрочное I-поле является единым, отдельно представляемым полем чересстрочного видеокадра. Чересстрочное P-поле является единым, отдельно представляемым полем чересстрочного видеокадра, использующим межкадровое предсказание, как чересстрочное B-поле. Чересстрочные P-и B-поля могут включать в себя внутрикодированные макроблоки, а также различные типы макроблоков межкадрового предсказания.
Чересстрочные видеокадры, организованные для кодирования/декодирования как поля, могут включать в себя различные комбинации различных типов полей. Например, такой кадр может иметь тот же самый тип поля (I-поле, P-поле или B-поле) как в верхних, так и в нижних полях или различные типы полей в каждом поле.
Термин «изображение» в общем случае относится к кадру или полю источника, кодированных или восстановленных данных изображения. Для видеопрогрессивной развертки изображение в типовом случае является прогрессивным видеокадром. Для чересстрочного видео изображение может относиться к чересстрочному видеокадру, верхнему полю кадра или нижнему полю кадра, в зависимости от контекста.
Фиг.5D показывает шесть примерных пространственных выравниваний местоположений выборок сигнала цветности формата 4:2:0 относительно местоположений выборок сигнала яркости для каждого поля видеокадра.
Альтернативно, кодер 200 и декодер 300 являются основанными на объектах, использует различный формат макроблока (например, 4:2:2 или 4:4:4) или формат блока, или выполняют операции на наборах выборок с размером или конфигурацией иными, чем для 8×8 блоков и 16×16 макроблоков.
В. Видеокодер
На фиг.2 показана блок-схема иллюстративной системы 200 видеокодера. Система 200 кодера 200 получает последовательность видеоизображений, включая текущее изображение 205 (например, прогрессивный видеокадр, чересстрочный видеокадр или поле чересстрочного видеокадра), и формирует сжатую видеоинформацию 295 как вывод. Конкретные воплощения видеокодеров в типовом случае используют разновидность или дополненную версию приведенного для прима кодера 200.
Система 200 кодера использует процессы кодирования для внутри- (интра-) кодированных изображений (I-изображений) и предсказанных на меж- (интер-) кадровой основе изображений (P-или В-изображений). В целях представления фиг.2 показывает путь для I-изображений через систему 200 кодера и путь для предсказанных на межкадровой основе изображений. Многие из компонентов системы 200 кодера используются для сжатия как I-изображений так и предсказанных на межкадровой основе изображений. Точные операции, выполняемые этими компонентами, могут измениться в зависимости от типа сжимаемой информации.
Предсказанное на межкадровой основе изображение представлено в терминах предсказания (или различия) из одного или более других изображений (кадров) (которые обычно упоминаются как опорные изображения). Остаток предсказания - это разность между тем, что было предсказано, и первоначальным изображением. Напротив, I-изображение сжимается без ссылки на другие изображения. I-изображения могут использовать пространственное предсказание или предсказание частотной области (то есть внутрикадровое предсказание), чтобы предсказать некоторые части I-изображения, используя данные из других частей самого I-изображения. Однако, ради краткости, такие I-изображения не упоминаются в этом описании как "предсказанные" изображения, так, чтобы фраза "предсказанное изображение" могла пониматься как предсказанное на межкадровой основе изображение (например, P-или В-изображение).
Если текущее изображение 205 является предсказанным изображением, то блок 210 оценки движения оценивает движение макроблоков или других наборов выборок текущего изображения 205 относительно одного или более опорных изображений, например, восстановленного предыдущего изображения 225, буферизированного в ЗУ 220 изображений. Блок 210 оценки может оценивать движение относительно одного или более предыдущих по времени опорных изображений и одного или более будущих по времени опорных изображений (например, в случае изображения двойного предсказания). Соответственно, система 200 кодера может использовать отдельные ЗУ 220 и 222 для множества опорных изображений.
Блок 210 оценки движения 210 может оценивать движение посредством приращений на полную выборку, ½ выборки, ¼ выборки или других приращений и может переключать разрешающую способность оценки движения на основе от изображения к изображению или на другой основе. Блок 210 оценки движения (и компенсатор 230) также может переключаться между типами интерполяции выборок опорного изображения (например, между интерполяцией кубической свертки и скручивания и билинейной интерполяцией) на покадровой или иной основе. Разрешающая способность оценки движения может быть той же самой или может различаться по горизонтали и вертикали. Блок 210 оценки движения выводит, в качестве побочной информации, информацию 215 движения, такую как дифференциальная информация вектора движения. Кодер 200 кодирует информацию 215 движения, например, вычисляя один или более прогнозирующих параметров для векторов движения, вычисляя различия между векторами движения и прогнозирующими параметрами, и энтропийного кодирования различий. Для восстановления вектора движения компенсатор 230 движения объединяет прогнозирующий параметр с информацией различия вектора движения.
Компенсатор 230 движения применяет восстановленный вектор движения к восстановленному(ым) изображению(ям) 225, чтобы сформировать скомпенсированное по движению предсказание 235. Однако предсказание редко бывает совершенным, и различие между скомпенсированным по движению предсказанием 235 и первоначальным текущим изображением 205 является остатком 245 предсказания. В течение последующего восстановления изображения аппроксимация остатка 245 предсказания будет добавляться к скомпенсированному по движению предсказанию 235, чтобы получить восстановленное изображение, которое ближе к первоначальному текущему изображению 205, чем скомпенсированное по движению предсказание 235. При сжатии с потерями, однако, некоторая информация все еще теряется из первоначального текущего изображения 205. Альтернативно, блок оценки движения и компенсатор движения применяют другой тип оценки/компенсации движения.
Частотный преобразователь 260 преобразует видеоинформацию пространственной области в данные частотной области (то есть спектральные данные). Для кодирования видео на блочной основе частотный преобразователь 260 в типовом случае применяет дискретное косинусное преобразование (DCT), вариант DCT или некоторое другое блочное преобразование к блокам данных выборок или остаточным данным предсказания, формируя блоки коэффициентов преобразования частотной области. Альтернативно, частотный преобразователь 260 применяет другой тип частотного преобразования типа Фурье-преобразования или использует вейвлет-анализ, или анализ поддиапазонов. Частотный преобразователь 260 может применять частотное преобразование размера 8×8, 8×4, 4×8, 4×4 или другого размера.
Квантователь 270 затем квантует блоки коэффициентов преобразования частотной области. Квантователь применяет скалярное квантование к коэффициентам преобразования согласно размеру шага квантования, который изменяется на основе от изображения к изображению (покадровой основе), на основе макроблоков или на некоторой другой основе, где размер шага квантования является параметром управления, который управляет интервалом равномерного разнесения между дискретными представимыми точками реконструкции в процессе обработки обратного квантователя декодера, что может дублироваться в процессе обработки обратного квантователя 276 кодера. Альтернативно, квантователь применяет другой тип квантования к коэффициентам преобразования частотной области, например, скалярный квантователь с неравномерными точками реконструкции, векторный квантователь или неадаптивное квантование, или непосредственно квантует данные пространственной области в системе кодера, которая не использует частотные преобразования. В дополнение к адаптивному квантованию кодер 200 может использовать пропуск кадра, адаптивную фильтрацию или другие методы для управления скоростью.
Когда восстановленное текущее изображение необходимо для последующей оценки/компенсации движения, обратный квантователь 276 выполняет обратное квантование на квантованных коэффициентах преобразования частотной области. Обратный частотный преобразователь 266 выполняет тогда инверсию операций частотного преобразователя 260, формируя восстановленную аппроксимацию остатка предсказания (для предсказанного изображения) или восстановленную аппроксимацию I-изображения. Если текущим изображением 205 было I-изображение, то восстановленная аппроксимация I-изображения принимается в качестве восстановленной аппроксимации текущего изображения (не показано). Если текущее изображение 205 было предсказанным изображением, то восстановленная аппроксимация остатка предсказания добавляется к скомпенсированному по движению предсказанию 235 для формирования восстановленной аппроксимации текущего изображения. Одно или более ЗУ 220, 222 изображений буферизуют восстановленную аппроксимацию текущего изображения для использования в качестве опорного изображения в скомпенсированном по движению предсказании последующих изображений. Кодер может применять фильтр разблокирования или другой процесс уточнения изображения к восстановленному кадру, чтобы адаптивно сглаживать нарушения непрерывности и удалять другие артефакты из изображения перед сохранением аппроксимации изображения в одном или более ЗУ 220, 222 изображений.
Энтропийный (статистический) кодер 280 сжимает выходной сигнал квантователя 270, а также некоторую побочную информацию (например, информацию 215 движения, размер шага квантования). Типовые методы энтропийного кодирования включают в себя арифметическое кодирование, дифференциальное кодирование, кодирование Хаффмана, кодирование длины серий, Lempel-Ziv кодирование, кодирование словаря и комбинации вышеупомянутых методов. Энтропийный кодер 280 в типовом случае использует различные методы кодирования для различных видов информации (например, низкочастотных коэффициентов, высокочастотных коэффициентов, коэффициентов нулевой частоты, различных видов побочной информации) и может выбирать из множества кодовых таблиц в рамках конкретного метода кодирования.
Энтропийный кодер 280 обеспечивает сжатую видеоинформацию 295 на мультиплексор ["MUX"] 290. MUX 290 может включать в себя буфер, и индикатор уровня заполнения буфера может подаваться назад на адаптивные модули битовой скорости для управления скоростью. Перед или после MUX 290 сжатая видеоинформация 295 может быть канально кодированной для передачи по сети. Канальное кодирование может применять данные обнаружения и исправления ошибок к сжатой видеоинформации 295.
C. Видеодекодер
На фиг.3 показана блок-схема иллюстративной системы 300 видеодекодера. Система 300 декодера получает информацию 395 для сжатой последовательности видеоизображений и формирует выходной сигнал, включающий в себя восстановленное изображение 305 (например, прогрессивный видеокадр, чересстрочный видеокадр или поле чересстрочного видеокадра). Конкретные воплощения видеодекодеров в типовом случае используют разновидность или дополненную версию обобщенного декодера 300.
Система 300 декодера выполняет декомпрессию предсказанных изображений и I-изображений. В целях представления фиг.3 показывает путь для I-изображений через систему 300 декодера и путь для предсказанных изображений. Многие из компонентов системы 300 декодера используются для декомпрессии как I-изображений, так и предсказанных изображений. Точные операции, выполняемые этими компонентами, могут изменяться в зависимости от типа информации, подвергаемой декомпрессии.
Демультиплексор (DEMUX) 390 получает информацию 395 для сжатой видеопоследовательности и предоставляет полученную информацию энтропийному декодеру 380. DEMUX 390 может включать в себя буфер флуктуаций, а также другие буферы. Перед или внутри DEMUX 390 сжатая видеоинформация может быть канально декодированной и обработанной для обнаружения и исправления ошибок.
Энтропийный декодер 380 энтропийно декодирует энтропийно кодированные квантованные данные, а также энтропийно кодированную побочную информацию (например, информацию движения 315, размер шага квантования), обычно применяя инверсию энтропийного кодирования, выполненного в кодере. Методы энтропийного декодирования включают в себя арифметическое декодирование, дифференциальное декодирование, декодирование Хаффмана, декодирование длины серий, Lempel-Ziv декодирование, декодирование словаря и комбинации вышеупомянутых методов. Энтропийный декодер 380 в типовом случае использует различные методы декодирования для различных видов информации (например, низкочастотных коэффициентов, высокочастотных коэффициентов, коэффициентов нулевой частоты, различных видов побочной информации) и может выбирать из множества кодовых таблиц в рамках конкретного метода декодирования.
Декодер 300 декодирует информацию 315 движения, например, вычисляя один или более параметров предсказания для векторов движения, энтропийно декодируя разности вектора движения (в энтропийном декодере 380) и объединяя декодированные разности вектора движения с параметрами предсказания, чтобы восстановить векторы движения.
Компенсатор 330 движения применяет информацию 315 движения к одному или более опорным изображениям 325 для формирования предсказания 335 восстанавливаемого изображения 305. Например, компенсатор 330 движения использует один или более макроблочных векторов движения, чтобы найти блоки выборок или интерполировать дробные позиции между выборками в опорном(ых) изображении(ях) 325. Одно или более ЗУ изображений (например, ЗУ 320, 322 изображений) сохраняют предыдущие восстановленные изображения для использования в качестве опорных изображений. Как правило, В-изображения имеют более одного опорного изображения (например, по меньшей мере, одно предыдущее по времени опорное изображение и, по меньшей мере, одно будущее по времени опорное изображение). Соответственно, система 300 декодера 300 может использовать отдельные ЗУ 320 и 322 изображений для множества опорных изображений. Компенсатор 330 движения может компенсировать движение с приращениями полной выборки, 1/2 выборки, 1/4 выборки или другими приращениями и может переключать разрешающую способность компенсации движения на основе от изображения к изображению (на покадровой основе) или на другой основе. Компенсатор 330 движения также может переключаться между типами интерполяции выборки опорного изображения (например, между интерполяцией кубической свертки и билинейной интерполяцией) на покадровой основе или на другой основе. Разрешающая способность компенсации движения может быть одной и той же или различной по горизонтали и вертикали. Альтернативно, компенсатор движения применяет другой тип компенсации движения. Предсказание компенсатором движения редко является совершенным, так что декодер 300 также восстанавливает остатки предсказания.
Обратный квантователь 370 выполняет обратное квантование энтропийно декодированных данных. Как правило, обратный квантователь применяет равномерное скалярное обратное квантование к энтропийно декодированным данным с размером шага восстановления, который изменяется на основе от изображения к изображению (на покадровой основе), на макроблочной основе или на некоторой другой основе. Альтернативно, обратный квантователь применяет другой тип обратного квантования к данным, например, неравномерное, векторное, или неадаптивное обратное квантование, или непосредственно обратно квантует данных пространственной области в системе декодера, которая не использует обратные частотные преобразования.
Обратный частотный преобразователь 360 преобразует обратно квантованные коэффициенты преобразования частотной области в видеоинформацию пространственной области. Для видеоизображений на блочной основе обратный частотный преобразователь 360 применяет обратное дискретное косинусное преобразование ["IDCT"], вариант IDCT или некоторое другое обратное блочное преобразование к блокам коэффициентов частотного преобразования, формируя данные выборок или данные остатка межкадрового предсказания для I-изображений или предсказанных изображений, соответственно. Альтернативно, обратный частотный преобразователь 360 применяет другой тип обратного частотного преобразования типа обратного преобразования Фурье или использует вейвлет-синтез или синтез поддиапазонов. Обратный частотный преобразователь 360 может применять обратное частотное преобразование размера 8×8, 8×4, 4×8, 4×4 или другого размера.
Для предсказанного изображения декодер 300 объединяет восстановленный остаток 345 предсказания со скомпенсированным по движению предсказанием 335 для формирования восстановленного изображения 305. Когда декодеру требуется восстановленное изображение 305 для последующей компенсации движения, одно или более ЗУ (например, ЗУ 320 изображений) буферизуют восстановленное изображение 305 для использования в предсказании следующего изображения. В некоторых воплощениях декодер 300 применяет фильтр разблокирования (распаковки) или другой процесс уточнения изображения к восстановленному изображению, чтобы адаптивно сглаживать нарушения непрерывности и удалять другие артефакты из изображения перед сохранением восстановленного изображения 305 в одном или более ЗУ изображений (например, ЗУ 320 изображений) или перед отображением декодированного изображения в течение воспроизведения декодированного видео.
III. Общий обзор кодирования и декодирования с переменной разрешающей способностью
Видео может кодироваться (и декодироваться) при различных разрешающих способностях. Для целей этого описания кодирование и декодирование с переменной разрешающей способностью могут быть описаны как кодирование и декодирование на кадровой основе (например, повторная дискретизация опорного изображения) или многоуровневое (иногда упоминаемое как пространственно масштабируемое) кодирование и декодирование. Кодирование и декодирование с переменной разрешающей способностью могут также использовать кодирование и декодирование чересстрочного видео и основанное на поле кодирование и декодирование и переключение между основанным на кадре кодированием и декодированием и основанным на поле кодированием и декодированием на основе конкретной разрешающей способности или на некоторой другой основе. Однако, в целях упрощения описания принципа, в этом кратком обзоре описано кадровое кодирование прогрессивного видео.
A. Основанное на кадре кодирование и декодирование с переменной разрешающей способностью
При основанном на кадре кодировании с переменной разрешающей способностью кодер кодирует входные изображения при различных разрешающих способностях. Кодер выбирает пространственную разрешающую способность для изображений на основе от изображения к изображению (на кадровой основе) или на некоторой другой основе. Например, при повторной дискретизации опорного изображения опорное изображение может быть повторно дискретизировано, если оно закодировано с отличающейся разрешающей способностью по сравнению с разрешающей способностью кодируемого изображения. Термин «повторная дискретизация» используется для описания увеличения (повышающая дискретизация) или уменьшения (понижающая дискретизация) числа выборок, используемых для представления области изображения или некоторого другого сегмента дискретизированного сигнала. Число выборок на единичную область или на сегмент сигнала упоминается как разрешающая способность дискретизации.
Пространственная разрешающая способность может быть выбрана на основе, например, уменьшения/увеличения доступной скорости передачи, уменьшения/увеличения размера шага квантования, уменьшения/увеличения в степени движения во входном видеоконтенте, других свойств видеоконтента (например, присутствие резких границ, текста или другого контента, который может быть значительно искажен при более низких разрешающих способностях), или на некоторой другой основе. Пространственная разрешающая способность может изменяться по вертикальному, горизонтальному или по вертикальному и горизонтальному измерениям. Горизонтальная разрешающая способность может быть той же, что и вертикальная разрешающая способность, или может отличаться от нее. Декодер декодирует кодированные кадры, используя комплементарные методы.
Как только кодер выбрал пространственную разрешающую способность для текущего изображения или области в пределах текущего изображения, кодер повторно дискретизирует первоначальное изображение при желательной разрешающей способности перед его кодированием. Кодер может затем сигнализировать о выборе пространственной разрешающей способности декодеру.
Фиг.6 показывает способ (600) для кодирования на кадровой основе изображений с переменной разрешающей способностью. Кодер, такой как кодер 200 на фиг.2, устанавливает разрешающую способность (610) для изображения. Например, кодер учитывает критерии, приведенные выше, или другие критерии. Кодер затем кодирует изображение (620) при этой разрешающей способности. Если кодирование всех изображений, которые должны быть закодированы, выполнено (630), то кодер выполняет выход. В противном случае кодер устанавливает разрешающую способность (610) для следующего изображения и продолжает кодирование. Альтернативно, кодер устанавливает разрешающие способности на некотором уровне ином, чем уровень изображения, например, устанавливает разрешающую способность различной для различных частей изображения или осуществляет выбор разрешающей способности для группы или последовательности изображений.
Кодер может кодировать предсказанные изображения так же, как внутрикадровые изображения. Фиг.8 показывает способ (800) для кодирования на кадровой основе с переменной разрешающей способностью внутрикадровых изображений и изображений межкадрового предсказания. Сначала кодер проверяет на этапе 810, является ли текущее изображение, которое должно кодироваться, внутрикадровым изображением или предсказанным изображением. Если текущее изображение является внутрикадровым изображением, то кодер устанавливает разрешающую способность для текущего изображения на этапе 820. Если изображение является предсказанным изображением, то кодер устанавливает разрешающую способность для опорного изображения на этапе 830 перед установкой разрешающей способности для текущего изображения. После установки разрешающей способности для текущего изображения кодер кодирует текущее изображение (840) с этой разрешающей способностью. Установка разрешающей способности для изображения (независимо от того, является ли оно текущим изображением источника или сохраненным опорным изображением) может использовать повторную дискретизацию изображения, чтобы согласовать выбранную разрешающую способность, и может использовать кодирование сигнала для указания выбранной разрешающей способности декодеру. Если кодирование всех изображений, которые должны быть закодированы, выполнено (850), то кодер осуществляет выход. В противном случае кодер продолжает кодировать дополнительные изображения. Альтернативно, кодер обрабатывает предсказанные изображения отличающимся способом.
Декодер декодирует кодированное изображение и, в случае необходимости, повторно дискретизирует изображение перед отображением. Подобно разрешающей способности кодированного изображения, разрешающая способность декодированного изображения может настраиваться различными способами. Например, разрешающая способность декодированного изображения может быть настроена, чтобы соответствовать разрешающей способности выходного устройства отображения или области выходного устройства отображения (например, при многооконной визуализации ("картинка в картинке") или отображении окна рабочего стола PC).
Фиг.7 показывает способ (700) для декодирования на кадровой основе изображений с переменной разрешающей способностью. Декодер, такой как декодер 300 на фиг.3, устанавливает разрешающую способность (на этапе 710) для изображения. Например, декодер получает информацию разрешающей способности от кодера. Декодер затем декодирует изображение (720) с той разрешающей способностью. Если декодирование всех изображений, которые должны быть декодированы, выполнено (730), то декодер осуществляет выход. В противном случае декодер устанавливает разрешающую способность (710) для следующего изображения и продолжает декодировать. Альтернативно, декодер устанавливает разрешающие способности на некотором уровне ином, чем уровень изображения.
Декодер может декодировать предсказанные изображения так же, как внутрикадровые изображения. Фиг.9 показывает способ (900) декодирования на кадровой основе с переменной разрешающей способностью внутрикадровых изображений и предсказанных изображений.
Сначала декодер проверяет, является ли текущий кадр, который должен декодироваться, внутрикадровым изображением или предсказанным изображением (910). Если текущее изображение является внутрикадровым изображением, то декодер устанавливает разрешающую способность для текущего изображения (920). Если изображение является предсказанным изображением, то декодер устанавливает разрешающую способность для опорного изображения (930) перед установкой разрешающей способности для текущего изображения (920). Установка разрешающей способности опорного изображения может быть связана с повторной дискретизацией сохраненного опорного изображения для согласования с выбранной разрешающей способностью. После установки разрешающей способности для текущего изображения (920) декодер декодирует текущее изображение (940) при этой разрешающей способности. Если декодирование всех изображений, которые должны быть декодированы, выполнено (950), то декодер осуществляет выход. В противном случае декодер продолжает декодирование.
Декодер в типовом случае декодирует изображения при тех же самых разрешающих способностях, что и используемые в кодере. Альтернативно, декодер декодирует изображения при отличающихся разрешающих способностях, например, как в случае, когда разрешающие способности, доступные декодеру, не точно такие же, как используемые в кодере.
B. Многоуровневое кодирование и декодирование с переменной разрешающей способностью
В многоуровневом кодировании с переменной разрешающей способностью кодер кодирует видео на уровнях, причем каждый уровень имеет информацию для декодирования видео при различной разрешающей способности. Этим способом кодер кодирует, по меньшей мере, некоторые индивидуальные изображения в видео при более чем одной разрешающей способности. Декодер может тогда декодировать видео при одной или более разрешающих способностях, обрабатывая различные комбинации уровней. Например, первый уровень (иногда называемый базовым уровнем) содержит информацию для декодирования видео при более низкой разрешающей способности, в то время как один или более других уровней (иногда называемых улучшенными уровнями) содержат информацию для декодирования видео при более высоких разрешающих способностях.
Базовый уровень может быть создан таким образом, чтобы он сам был независимо декодируемым битовым потоком. Таким образом, при такой схеме, декодер, который декодирует только базовый уровень, будет формировать действительный декодированный битовый поток при более низкой разрешающей способности базового уровня. Надлежащее декодирование изображений более высокой разрешающей способности с использованием улучшенного уровня может потребовать также декодирования некоторых или всех кодированных данных базового уровня и, возможно, одного или более уровней расширения. Декодер, который декодирует базовый уровень и один или более других уровней более высокой разрешающей способности, сможет сформировать контент более высокой разрешающей способности, чем декодер, который декодирует только базовый уровень. Два, три или более уровней могут использоваться, чтобы обеспечить возможность реализации двух, трех или более различных разрешающих способностей. Альтернативно, уровень с более высокой разрешающей способностью сам также может быть независимо декодируемым битовым потоком. (Такая схема часто упоминается как метод кодирования с одновременной множественной разрешающей способностью).
Фиг.10 показывает способ (1000) для кодирования уровней битового потока для обеспечения возможности декодирования при различных разрешающих способностях. Кодер типа кодера 200 на фиг.2 получает информацию видео полной разрешающей способности в качестве входного сигнала (1010). Кодер выполняет понижающую дискретизацию информации видео полной разрешающей способности (1020) и кодирует базовый уровень, используя информацию понижающей дискретизации (1030). Кодер кодирует один или более уровней более высокой разрешающей способности, используя базовый уровень и информацию видео более высокой разрешающей способности (1040). Уровнем более высокой разрешающей способности может быть уровень, который позволяет декодировать при полной разрешающей способности, или уровень, который позволяет декодировать при некоторой промежуточной разрешающей способности. Кодер затем выводит многоуровневый битовый поток, содержащий два или более кодированных уровня. Альтернативно, кодирование уровня более высокой разрешающей способности (1040) может не использовать информацию базового уровня и может, таким образом, разрешить выполнение независимого декодирования данных уровня более высокой разрешающей способности в случае способа с одновременной множественной разрешающей способностью.
Кодер может выполнить многоуровневое кодирование с переменной разрешающей способностью несколькими способами, следуя базовой схеме, показанной на фиг.10. Для получения дополнительной информации см., например, патент США 6510177 или MPEG-2 стандарт или другие видеостандарты.
Фиг.11 показывает способ (1100) для декодирования уровней битового потока, чтобы обеспечить возможность декодирования видео при различных разрешающих способностях. Декодер типа декодера 300 на фиг.3 получает многоуровневый битовый поток в качестве входного сигнала (1110). Уровни включают в себя уровень более низкой разрешающей способности (базовый уровень) и один или более уровней, включающих в себя информацию более высокой разрешающей способности. Уровни более высокой разрешающей способности необязательно должны содержать независимо закодированные изображения; в типовом случае уровни более высокой разрешающей способности включают в себя остаточную информацию, которая описывает различия между версиями изображения более высокой и более низкой разрешающей способности. Декодер декодирует базовый уровень (1120), и, если декодирование более высокой разрешающей способности желательно, декодер выполняет повышающую дискретизацию декодированных изображений базового уровня (1130) до желательной разрешающей способности. Декодер декодирует один или более уровней более высокой разрешающей способности (1140) и объединяет декодированную информацию более высокой разрешающей способности с подвергнутыми повышающей дискретизации декодированными изображениями базового уровня, чтобы сформировать изображения более высокой разрешающей способности (1150). В зависимости от желательного уровня разрешающей способности, изображения более высокой разрешающей способности могут быть изображениями полной разрешающей способности или изображениями промежуточной разрешающей способности. Для получения дополнительной информации см., например, патент США 6510177 или MPEG-2 стандарт или другие видеостандарты.
Декодер в типовом случае декодирует изображения при одной из разрешающих способностей, используемых в кодере. Альтернативно, разрешающие способности, доступные декодеру, не точно те же самые, что и используемые в кодере.
IV. Фильтры повторной дискретизации для масштабируемого видеокодирования и декодирования
Этот раздел описывает способы и инструментальные средства для масштабируемого видеокодирования и декодирования. Хотя некоторые из описанных способов и инструментальных средств описаны в многоуровневом (или пространственно-масштабируемом) контексте, некоторые из описанных способов и инструментальных средств могут также использоваться в контексте способов на кадровой основе (или дискретизации опорного изображения) или в некотором другом контексте, который использует фильтры повторной дискретизации. Кроме того, хотя некоторые из описанных способов и инструментальных средств описаны в контексте изображений повторной дискретизации, некоторые из описанных способов и инструментальных средств могут также использоваться для повторной дискретизации остатка или разностных сигналов, которые являются результатом предсказания сигналов более высокой разрешающей способности.
Масштабируемое видеокодирование (SVC) - это тип цифрового видеокодирования, который позволяет декодировать поднабор большего битового потока для формирования декодированных изображений с качеством, которое является приемлемым для некоторых приложений (хотя такое качество изображения было бы ниже, чем качество, получаемое при декодировании всего битового потока более высокой битовой скорости). Один известный тип SVC упоминается как пространственное масштабирование или масштабирование разрешающей способности. В схеме пространственного SVC процесс кодирования (или функция предварительной обработки, которая должна выполняться перед процессом кодирования, в зависимости от точного определения области процесса кодирования) в типовом случае включает понижающую дискретизацию видео до более низкой разрешающей способности и кодирование данного видео более низкой разрешающей способности, чтобы обеспечить возможность процесса декодирования более низкой разрешающей способности, и повышающую дискретизацию декодированных изображений более низкой разрешающей способности, чтобы использовать в качестве предсказания значений выборок в изображениях видео более высокой разрешающей способности. Процесс декодирования для видео более высокой разрешающей способности тогда включает в себя декодирование видео более низкой разрешающей способности (или некоторой его части) и использование этого видео повышенной дискретизации в качестве предсказания значения выборок в изображениях видео более высокой разрешающей способности. Такие схемы требуют использования фильтров повторной дискретизации. В частности, схемы кодека включают использование фильтров повышающей дискретизации как в декодерах, так и в кодерах, и использование фильтров понижающей дискретизации в кодерах и препроцессорах кодирования. В частности, настоящее описание фокусируется на фильтрах повышающей дискретизации, используемых в таких схемах. Как правило, процесс повышающей дискретизации проектируется идентичным в кодерах и декодерах, чтобы предотвратить явление, известное как дрейф, который является накоплением ошибки, обусловленной использованием различающихся предсказаний того же самого сигнала в процессе кодирования и декодирования.
Один недостаток некоторых схем пространственного SVC обусловлен использованием фильтров низкого качества (например, двухотводных билинейных фильтров) в процессе декодирования. Использование фильтров более высокого качества было бы выгодно для обеспечиваемого качества видео.
Пространственное SVC может включать фильтры повторной дискретизации, которые обеспечивают высокую степень гибкости для коэффициента повторной дискретизации фильтра. Однако это может потребовать большого количества конкретных схем фильтра для каждой различной "фазы" такого фильтра, подлежащего разработке, и значений "отводов" этих фильтров, подлежащих сохранению, в реализациях кодеров и декодеров.
Кроме того, может быть выгодно, для обеспечения качества видео, позволить кодеру управлять степенью смазанности (нерезкости) для фильтров повторной дискретизации, используемых для пространственного SVC. Таким образом, для каждой "фазы" повторной дискретизации, подлежащей проектированию для повышающей дискретизации или понижающей дискретизации, может быть выгодно иметь несколько различных фильтров, чтобы выбирать из них, в зависимости от желательной степени смазанности, вводимой в процесс. Выбор степени смазанности, подлежащий выполнению при повышающей дискретизации, может посылаться с кодера на декодер в качестве информации, передаваемой для использования в процессе декодирования. Эта дополнительная гибкость дополнительно усложняет схему, поскольку это значительно увеличивает число необходимых значений отводов, которые могут потребоваться для сохранения в кодере или декодере.
Унифицированная схема могла бы использоваться, чтобы определять множество фильтров повторной дискретизации с различными фазами и различными степенями смазанности изображения. Одно возможное решение состоит в использовании метода проектирования фильтра Mitchell-Netravali. Прямое применение метода проектирования фильтра Mitchell-Netravali к этим проблемам может потребовать дополнительных вычислительных ресурсов в форме чрезмерного динамического диапазона возможных значений для величин, которые должны вычисляться в кодере или декодере. Например, одна такая схема могла бы потребовать использования 45-битовой арифметической обработки вместо 16-битовых или 32-битовых элементов обработки, обычно используемых в универсальных CPU и DSP. Для рассмотрения этой проблемы ниже приведены некоторые уточнения проектирования.
Типичная схема SVC требует нормативного фильтра повышающей дискретизации для пространственного масштабирования. Чтобы поддерживать произвольные коэффициенты повторной дискретизации (характеристика, известная как расширенное пространственное масштабирование), описана схема фильтра повышающей дискретизации, которая реализует большую гибкость относительно коэффициентов повторной дискретизации. Другой ключевой аспект - относительное выравнивание сигнала яркости и сигнала цветности. Поскольку разнообразие структур выравнивания (см., например, H.261/MPEG-1 по сравнению с MPEG-2 выравниванием для 4:2:0 сигнала цветности, и H.264/MPEG-4 AVC) найдено в одноуровневых подходах, описанные способы и инструментальные средства поддерживают гибкое разнообразие выравниваний, при простом способе для кодера, чтобы указывать декодеру, как соответствующим образом применять фильтрацию.
Описанные способы и инструментальные средства включают фильтры повышающей дискретизации, обеспечивающие возможность повышающей дискретизации высокого качества и подавление помех дискретизации. В частности, описанные способы и инструментальные средства имеют качество выше того, которое обеспечивается предшествующими схемами билинейных фильтров для пространственного масштабирования. Описанные способы и инструментальные средства имеют фильтры повышающей дискретизации высокого качества, которые обеспечивают визуально привлекательное представление и хорошее поведение частоты обработки сигналов. Описанные способы и инструментальные средства включают схему фильтра, которая является простой для определения и не требует больших таблиц, сохраняемых в ЗУ, для хранения значений отводов, и операции самой фильтрации в вычислительном отношении являются простыми для реализации. Например, описанные способы и инструментальные средства используют фильтр не чрезмерной длины, который не требует чрезмерной математической точности или чрезмерно сложных математических функций.
Настоящий раздел описывает схемы, имеющие одно или более следующих свойств:
- гибкость выравнивания фазы сигнала яркости/сигнала цветности;
- гибкость коэффициента повторной дискретизации;
- гибкость частотных характеристик;
- высокое визуальное качество;
- не слишком мало и не слишком много отводов фильтра (например, от 4 до 6);
- простота определения;
- простота работы (например, с использованием арифметики практичной длины слова).
A. Фильтры повышающей дискретизации Mitchell-Netravali
Описанные способы и инструментальные средства используют подход разделимой фильтрации, поэтому следующее обсуждение будет фокусироваться прежде всего на обработке одномерного сигнала, поскольку двумерный случай является простым разделимым применением одномерного случая. Сначала предлагается двухпараметрический набор фильтров, основанных на концептуально-непрерывной импульсной характеристике h (x), определяемой следующим образом:
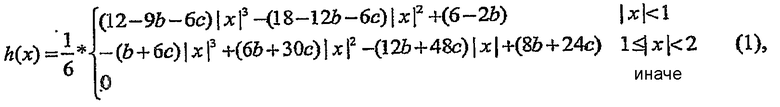
где b и c - два параметра. Для относительного положения фазового сдвига 0 ≤ x <1 это ядро формирует 4-отводный фильтр с конечным импульсным откликом (FIR) со значениями отводов, определяемыми следующим матричным уравнением:
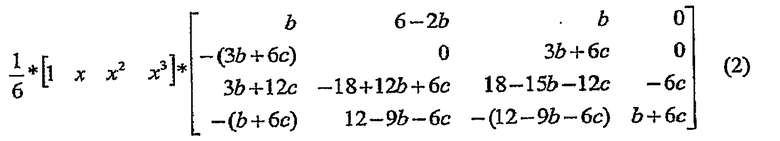
Фактически, достаточно рассмотреть только диапазон x от 0 до 1/2, так как ядро фильтра FIR для х является просто ядром фильтра FIR для 1-x в обратном порядке.
Эта схема имеет ряд интересных и полезных свойств. Ниже приведены некоторые из них:
- Никакие тригонометрические функции, трансцендентные функции или обработка иррациональных чисел не требуются для вычисления значений отводов фильтра. Фактически, значения отводов для такого фильтра могут быть непосредственно вычислены только с несколькими простыми операциями. Они не должны обязательно сохраняться для различных возможных значений параметров и фаз, которые должны использоваться; они могут просто быть вычислены, когда необходимо. (Так, чтобы стандартизировать использование таких фильтров, необходимо только несколько формул - никакие огромные таблицы чисел или стандартизированные попытки аппроксимировать функции, подобные косинусам или функциям Бесселя, не требуются).
- Результирующий фильтр имеет 4 отвода. Это является весьма практичным количеством.
- Фильтр имеет только единственный боковой лепесток на каждой стороне от основного лепестка. Поэтому не создается избыточных артефактов переходных процессов.
- Фильтр имеет гладкую импульсную характеристику. Его значение и его первая производная непрерывны.
- Он имеет DC отклик единичного усиления, что означает, что нет никакого усиления или ослабления яркости в информации повышающей дискретизации.
- Члены этого семейства фильтра включают относительно хорошие аппроксимации известных хороших фильтров типа схемы "Lanczos-2" и схемы "Catmull-Rom". Кроме того, описанные способы и инструментальные средства включают конкретные отношения между двумя параметрами для выбора приятных для визуального восприятия фильтров. Такие отношения могут быть выражены следующим образом:

Это уменьшает степени свободы до единственного параметра b управления шириной полосы. Этот параметр управляет степенью дополнительной нечеткости, вводимой фильтром. Отметим, что членом этого семейства, ассоциированным со значением b=0, является превосходный известный фильтр повышающей дискретизации Catmull-Rom (также известный как фильтр интерполяции Keys «кубической свертки»).
Фильтр повышающей дискретизации Catmull-Rom имеет ряд хороших собственных свойств, в дополнение к основным преимуществам, найденным для всех членов семейства фильтра Mitchell-Netravali:
- Он является фильтром "интерполяции" - то есть для значений фаз x=0 и x=1 фильтр имеет единственный ненулевой отвод, равный 1. Другими словами, сигнал повышающей дискретизации будет проходить точно через значения входных выборок на границах каждого сегмента кривой повышающей дискретизации.
- Если набор входных выборок формирует параболу (или прямую линию, или статическое значение), выходные точки будут лежать точно на параболической кривой (или прямой линии, или статическом значении).
В действительности, до некоторой степени, повышающий дискретизатор Catmull-Rom может рассматриваться как лучший фильтр повышающей дискретизации этой длины по этим причинам, хотя введение некоторой дополнительной размытости (увеличения b) может иногда быть более визуально приятным. Также, введение некоторой размытости дополнительного пространства может помочь сгладить артефакты сжатия низкой битовой скорости и, таким образом, действовать более сходно с алгоритмом оценки на фильтре Wiener (известный фильтр, используемый для фильтрации шума) для истинного изображения повышающей дискретизации.
Простая подстановка уравнения (3) в уравнение (2) приводит к следующим значениям сигнала:
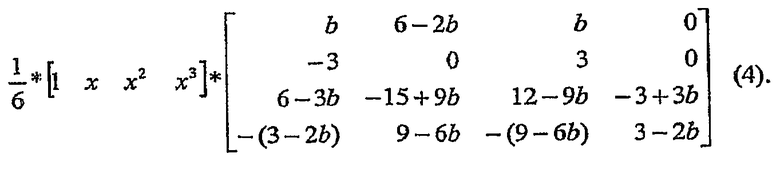
Сообщалось, что, основываясь на субъективных испытаниях с 9 экспертными средствами просмотра и более чем 500 выборками:
- пригодный для использования диапазон составил 0 ≤ b ≤ 5/3;
- диапазон 0 ≤ b ≤ 1/2 категоризирован как визуально "удовлетворительно", причем b = 1/3 оценивалось как визуально приятное;
- значения b > 1/2 категоризированы как "размытость", причем b=3/2 оценивалось как чрезмерная размытость.
В. Преобразование в целочисленное представление параметра управления шириной полосы
Деление на 6 в уравнении (4) может быть нежелательным. Вместо этого может быть желательным преобразовать в целочисленное представление параметр управления шириной полосы и значения отводов фильтра, поскольку бесконечная точность непрактична при проектировании декодера. Рассмотрим подстановку с использованием новой целочисленной переменной а, определенной следующим образом:

где S - целочисленный коэффициент сдвига, и а - целое число без знака, действующее как преобразованный в целочисленное представление параметр управления шириной полосы. Параметр а может быть закодирован в явном виде как элемент синтаксиса кодером на уровне видеопоследовательности в битовом потоке. Например, параметр а может кодироваться в явном виде кодом переменной длины или фиксированной длины, совместно кодироваться с другой информацией или сигнализироваться в явном виде. Альтернативно, параметр а сигнализируется на некотором другом уровне в битовом потоке.
Преобразование в целочисленное представление приводит к целочисленным значениям отводов:

Результат затем потребовалось бы масштабировать на S позиций вниз в бинарной арифметической обработке.
Если a имеет диапазон от 0 до М, то b имеет диапазон от 0 до 6*M/2S. Некоторые возможные полезные варианты выбора для М включают следующее:
- M=2(S-2)-1, приводя к диапазону b от 0 до 3/2-6/2S.
- M=Ceil(2S/6), что возвращает наименьшее целое число больше или равное 2S/6, приводя к диапазону b от 0 до несколько больше, чем 1.
- M=2(S-3)-1, приводя к приблизительному диапазону b от 0 до 3/4-6/2S.
Эти варианты выбора для М достаточно велики, чтобы охватывать большинство полезных случаев, причем первый вариант выбора (M=2S-2)-1) является большим из этих трех вариантов выбора. Полезный диапазон для S составляет от 6 до 8. Например, при S=7 и M=2(S-2)-1, M=31. Альтернативно, могут использоваться другие значения М и S.
C. Преобразование в целочисленное представление позиционирования дробных выборок
Рассмотрим гранулярность значения x. Для практичности также следует аппроксимировать x. Например, можно определить целое число i так, что:

где F представляет поддерживаемую точность позиции дробной выборки. Для примера достаточно точной операции повторной дискретизации примем F ≥ 4 (точность позиционирования выборки одна шестнадцатая или больше). Это приводит к следующим преобразованным в целочисленное представление значениям отводов фильтра:
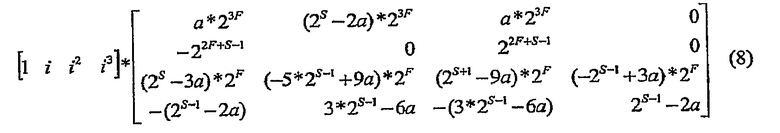
Например, пусть F=4. Тогда результат следовало бы уменьшить на 3F+S позиций.
Заметим, что каждая запись в матрице, приведенной выше, содержит общий коэффициент 2 (предполагая, что S больше, чем 1). Таким образом, вместо этого можно сформулировать значения отводов следующим образом:
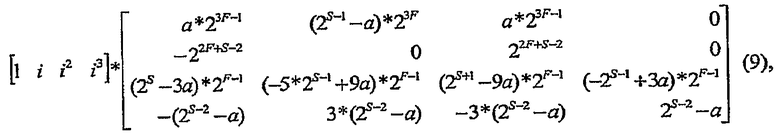
где каждое из значений отводов разделено на 2. Результат тогда нужно было бы уменьшить только на 3F+S-1 позиций.
Для понижающего масштабирования определяем функцию RoundingRightShift (p, R) как вывод сдвига вправо на R битов (с округлением), вычисленный для входного значения p, вычисленную следующим образом:
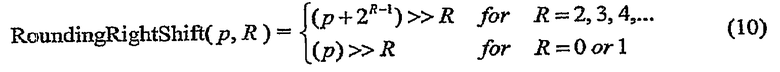
где запись ">>" относится к оператору сдвига вправо двоичной арифметики, использующему двоичную арифметику дополнения до двух. Альтернативно, сдвиг вправо с округлением выполняется по-другому.
Некоторые примерные применения для сдвига вправо с округлением представлены ниже.
D. Рассмотрение динамического диапазона
Если мы фильтруем изображения с N битами битовой глубины выборки и выполняем это двумерным способом перед выполнением любого округления, то нам потребуется динамический диапазон в 2*(3F+S-1) +N+1 битов в сумматоре перед понижающим сдвигом результата на 2*(3F+S-1) позиций и ограничение вывода до N-битового диапазона. Например, если F=4, S=7 и N=8, то может потребоваться использование сумматора на 45 битов, чтобы вычислить отфильтрованный результат.
В следующих подразделах описываются некоторые подходы к уменьшению этой проблемы. Эти подходы могут использоваться отдельно или в комбинации друг с другом. Понятно, что на основе представленного описания возможны изменения описанных подходов к уменьшению динамического диапазона.
1. Первый примерный подход к уменьшению динамического диапазона
Рассмотрим пример, где сначала выполняется горизонтальная фильтрация, за которой следует вертикальная фильтрация. Рассмотрим максимальную длину слова W битов для любой точки в двумерном конвейере обработки. В первом подходе уменьшения динамического диапазона, чтобы реализовать фильтрацию, мы используем сдвиг вправо с округлением на RH битов на выходе первой (горизонтальной) стадии процесса и сдвиг вправо с округлением на RV битов на выходе второй (вертикальной) стадии процесса.
Таким образом, вычисляем следующее:
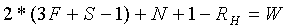
 (11)
(11)
и поэтому
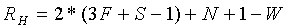 (12)
(12)
Тогда сдвиг вправо для второй (вертикальной) стадии может быть вычислен из
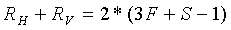

 (13)
(13)
и поэтому
 (14)
(14)
Например, для F=4 и S=7 и N=8 и W=32 мы получаем RH=13 и RV=23. Таким образом, вместо динамического диапазона 45 битов при сдвигах вправо с округлением динамический диапазон уменьшен до 32 битов. Сдвиги вправо на различные числа битов могут использоваться для различных значений W.
2. Второй примерный подход к уменьшению динамического диапазона
Второй подход к уменьшению динамического диапазона предусматривает снижение точности значений отводов вместо снижения точности позиционирования фазы (то есть сокращение F), сокращение гранулярности параметра настройки ширины полосы фильтра (то есть сокращение S) или снижение точности вывода первой стадии (то есть увеличение RH).
Обозначим четыре целочисленных значения отвода, сформированные согласно уравнению (9), как [t-1, t0, t1, t2]. Отметим, что сумма четырех значений отводов фильтра будет равна 23F+S-1, то есть
t-1 + t0 + t1 + t2 = 23F+S-1
 (15)
(15)
Это важное свойство этого примерного подхода к уменьшению динамического диапазона, потому что всякий раз, когда все четыре входных выборки имеют одинаковое значение, вывод будет иметь то же самое значение.
Используя примерное определение сдвига вправо с округлением согласно уравнению (10) и заданную величину сдвига вправо Rt для значений отводов, определим следующее:
u-1=RoundingRightShift(t-1, Rt);
u1=RoundingRightShift(t1, Rt);
u2=RoundingRightShift(t2, Rt);
u0=23F+S-1 - u-1 - u1 - u2.
Затем выполняем фильтрацию со значениями отводов [u-1, u0, u1, u2], вместо [t-1, t0, t1, t2]. Каждое увеличение на 1 в значении R1 представляет уменьшение на один бит динамического диапазона, необходимого в арифметическом сумматоре, и уменьшение на один бит сдвига вправо, который должен выполняться в последующих стадиях обработки.
3. Третий примерный подход к уменьшению динамического диапазона
Один предшествующий подход использует прием, который подобен по концепции, но отличается от первого примерного подхода к уменьшению динамического диапазона тем, что он делает величину сдвига вправо после первой стадии процесса функцией значения переменной i позиционирования фазы.
Понятно, что значения отводов фильтра, показанные в уравнении (9), будут содержать K нулевых младших битов, когда значение i является целым кратным 2K. Таким образом, если вторая стадия процесса фильтрации использует переменную i позиционирования фазы, которая является целым кратным 2K, то можно сдвинуть вправо значения отводов второй стадии на K битов и уменьшить величину сдвига вправо для первой стадии на K битов.
Отслеживать это было бы довольно трудным при действии обобщенного коэффициента повторной дискретизации. Однако при выполнении простых коэффициентов повторной дискретизации 2:1 или других простых коэффициентов, легко видеть, что все фазы, используемые для второй стадии процесса фильтрации, содержат то же самое кратное 2K, позволяя применять этот подход в этих специальных случаях.
V. Способы и инструментальные средства вычисления позиции
Ниже описаны способы и инструментальные средства для вычисления информации позиционирования для пространственного SVC.
Некоторые способы и инструментальные средства направлены на то, как задать длину слова B и оптимизировать точность вычисления при ограничении этой длиной слова. Вместо того, чтобы только выбрать точность и потребовать некоторую необходимую длину слова, применение нового способа обеспечит более высокую точность в реальном выполнении и расширит диапазон эффективного применения способа, потому что он использует всю доступную длину слова для максимизации точности в пределах этого ограничения.
Некоторые из способов и инструментальных средств направлены на a) смещение начала координат системы координат и b) использование целых чисел без знака вместо целых чисел со знаком, чтобы достигнуть лучшего компромисса между точностью и длиной слова/динамическим диапазоном. Небольшое увеличение в вычислениях необходимо для добавления параметра смещения начала координат к каждой вычисляемой позиции.
Некоторые из способов и инструментальных средств направлены на разбиение производимого вычисления различных сегментов строки выборок на различные стадии обработки, причем начало координат системы координат изменяется в начале каждой стадии. Вновь это обеспечивает лучший компромисс между точностью и длиной слова/динамическим диапазоном при еще одном незначительном увеличении в требованиях к вычислениям (так как некоторые дополнительные вычисления выполняются в начале каждой стадии). Если данный способ довести до его логической крайности, потребность в операциях умножения может быть устранена, и компромисс между точностью и длиной слова/динамическим диапазоном может быть дополнительно улучшен. Однако некоторые дополнительные операции потребовалось бы выполнять для каждой выборки (так как дополнительное вычисление, необходимое для "каждой стадии", становится необходимым для каждой выборки, когда каждая стадия содержит только одну выборку).
В качестве общей идеи описаны алгоритмы для части обработки, относящейся к вычислению позиции, чтобы достигнуть желательных компромиссов между точностью вычисленных результатов и длиной слова/динамическим диапазоном элементов обработки и числом и типом математических операций, вовлеченных в обработку (например, операций сдвига, сложения и умножения).
Например, описанные способы и инструментальные средства обеспечивают возможность вычислений гибкой точности, используя B-битовую (например, 32-битовую) арифметику. Это позволяет пространственному кодеру/декодеру SVC гибко адаптироваться к различным размерам изображения, не требуя преобразования в другую арифметику (например, 16-битовую или 64-битовую арифметику) для вычислений. С использованием B-битовой (например, 32-битовой) арифметикой гибкой точности кодер/декодер может отводить переменное число битов для дробного компонента. Это позволяет достичь увеличенной точности для вычислений, когда количество требуемых битов для представления целочисленного компонента уменьшается (например, для меньшего размера кадра). Когда количество требуемых битов для представления целочисленного компонента увеличивается (например, для большего размера кадра), кодер/декодер может использовать больше битов для целочисленного компонента и меньшего количества битов для дробного компонента, снижая точность, но поддерживая В-битовую арифметику. Таким способом существенно упрощается переход между различными точностями и различными размерами кадра.
Настоящий раздел включает конкретные детали приведенной для примера реализации. Однако следует отметить, что описанные здесь детали могут изменяться в других реализациях согласно описанным здесь принципам.
A. Введение и принципы вычисления позиции
Описаны способы для вычисления информации позиции и фазы, приводящие к намного более низким требованиям к вычислениям без какой-либо существенной потери точности. Например, описанные способы могут значительно уменьшить вычислительные требования, например, существенно сокращая требования к номинальному динамическому диапазону (на десятки битов). Учитывая разнообразие возможных позиций сигнала цветности, которые могут использоваться в базовом и улучшенном уровнях, желательно найти решение, обеспечивающее надлежащее позиционирование повторно дискретизированных выборок сигнала цветности относительно выборок сигнала яркости. Соответственно, описанные способы позволяют выполнять настройки для вычисления позиций для видеоформатов с различными соотношениями между позициями сигнала цветности и сигнала яркости.
Один предшествующий способ повышающей дискретизации, разработанный для расширенного пространственного масштабирования, использует довольно громоздкий метод вычисления информации позиции и фазы при повышающей дискретизации уровня низкого разрешения; он масштабирует сдвинутую вверх приближенную инверсию знаменателя, что вызывает увеличение ошибки округления в приближении инверсии, когда числитель увеличивается (то есть, когда процесс повышающей дискретизации перемещается слева направо или сверху вниз). По сравнению с этим, способы, описанные здесь, отличаются высокой точностью и простотой вычисления. В частности, описаны способы, которые уменьшают динамический диапазон и величину сдвига вправо в вычислениях позиции на десятки битов.
Например, описан способ для вычисления информации позиционирования, чтобы получить целочисленную позицию и переменную i позиционирования фазы, где i=0,2F-1, для использования в пространственной повышающей дискретизации SVC.
Описанные способы применяют процесс повторной дискретизации к приложению пространственного масштабируемого кодирования видео, а не к прямой повторной дискретизации опорного изображения. В этом приложении пространственного масштабируемого кодирования видео могут применяться некоторые упрощения. Вместо общего процесса деформирования изображения необходима только операция изменения размеров изображения. Это может быть отдельным алгоритмом для каждого измерения.
B. Проектирование вычисления позиции
Рассмотрим постановку задачи по каждому измерению (x или y), как формирование последовательности выборок, лежащих концептуально в диапазоне действительных значений от L до R> L в новом массиве (повышающей дискретизации). Этот диапазон действительных значений должен соответствовать диапазону от L' к R'> L' в опорном массиве более низкой разрешающей способности.
Для позиции Т в новом массиве, где L ≤ T ≤ R, потребуется вычислить позицию в опорном массиве, которая соответствует позиции в новом массиве. Это было бы позицией T' = L' + (T-L) * (R'-L') ÷ (R-L).
Теперь вместо того, чтобы рассматривать изменение размеров диапазона от L до R, определим целое число M > 0 и рассмотрим изменение размеров диапазона от L до L + 2М с тем же самым отношением изменения размеров (R'-L') ÷ (R-L). Соответствующий диапазон в координатах опорных выборок будет тогда от L' до R", где R" = L' +2М * (R '-L') ÷ (R-L). Если М является достаточно большим, то есть, если M ≥ Ceil(Log2(R-L)), то R''≥ R'. (Предположим теперь, что это ограничение выполняется, чтобы объяснить концепции, изложенные ниже, хотя это ограничение не является действительно необходимым для надлежащего действия уравнений).
Теперь мы можем использовать линейную интерполяцию между позициями L' и R" для вычислений позиционирования. Позиция L отображается на позицию L', и позиция T ≥ L отображается на позицию ((2М - (T-L))*L' + (T-L) *R")÷2М. Это преобразует знаменатель операции в степень 2, таким образом, снижая вычислительную сложность операции деления, позволяя заменить ее двоичным сдвигом вправо.
Соответствующие модификации могут быть сделаны для преобразования вычислений в целочисленное представление. Округляем значения L' и R" до целых кратных 1÷2G, где G - целое число, такое, что L' аппроксимируется посредством k÷2G, и R" аппроксимируется посредством r÷2G, где k и r - целые числа. Используя эту настройку, получаем позицию T, отображенную на позицию
((2М - (T-L))*k + (T-L)*r) ÷2(M+G).
Теперь предположим, что релевантными значениями T и L являются целые кратные 1÷2J, где J - целое число, такое как T-L=j÷2J. Используя эту настройку, получаем позицию T, отображенную на позицию
((2(M+J)-j)*k + j*r) ÷ 2(M+G+J).
Напомним, что, согласно разделу IV выше, дробная фаза фильтра повторной дискретизации должна быть целым числом в единицах 1÷2F. Тогда вычисленная позиция, в этих единицах, равна
Round(((2(M+J)-j)*k + j*r) ÷2(M+G+J-F), или
где
Единственная ошибка, формируемая в способе, описанном здесь (в предположении отсутствия ошибки в представлении L и R и L' и R') перед округлением вычисленной позиции до ближайшего кратного 1÷2F (которая является ошибкой, присутствующей в обеих схемах) представляет собой ошибку округления из-за округления позиции R" до ближайшего кратного 1÷2G. Эта величина очень мала, если G+M относительно велико. Фактически, этот источник ошибки тесно связан с величиной приблизительно (T-L) ÷2(G/M+1), требования длины слова для вычисления результатов умеренны, и арифметика по модулю позволяет отделить целочисленную часть результата, чтобы минимизировать длину слова, или также позволяет разбить вычисление другими подобными способами.
F может, например, быть равным 4 или более. (Для некоторых приложений F=3 или F=2 может быть достаточным). Примерные значения J включают J=1 для вычислений позиции сигнала яркости и J=2 - для позиций выборок сигнала цветности. Объяснение для этих примерных значений J приведено ниже.
1. Первый примерный упрощенный способ вычисления позиции с использованием В-битовой арифметики со знаком
Если R'> 0 и L'>-R', то все позиции t', которые должны вычисляться в изображении, подвергаемом повышающей дискретизации, как целое число в единицах 1 ÷ 2F, будет лежать между -2Z и 2Z-1, где Z=Ceil(Log2(R')) + F. Если длина слова (j*C+D) вычисления равна B битов и предполагается использование двоичной арифметики дополнения до двух со знаком, то можно потребовать, чтобы B-1 ≥ Z+S. Высокая точность достигается, если это ограничение является строгим, то есть, если B-1=Z+M+G+J-F.
Для приемлемо малых размеров изображения (например, для уровней вплоть до уровня 4.2 в современном стандарте H.264/MPEG-4 AVC) B=32 может использоваться в качестве длины слова. Другие значения B также могут использоваться. Для очень больших изображений может использоваться большее В. Вычисления могут также быть легко расчленены на подвычисления с меньшей длиной слова для использования на 16-разрядных или других процессорах.
Оставшиеся две степени свободы - это М и G. Их соотношение является гибким, пока G является достаточно большим, чтобы избежать любой потребности в ошибке округления при представлении L' как k ÷ 2G. Таким образом, основываясь на вопросах, осужденных в следующем разделе для SVC, можно выбрать G=2, что дает:
M=B+F-(G+J+Z+1),
то есть
M=32+4-(2+1+Z+1),
то есть
M=32-Z.
Например, если желательна повышающая дискретизация массива сигнала яркости изображения, которое имеет ширину 1000 выборок сигнала яркости при B=32 и L' =0, то можно использовать F=4, G=2, J=1, M=18, S=17, и Z=14, используя этот первый примерный способ вычисления позиции.
Когда T очень близко (или равно) R, и R' очень близко (или равно) целой степени 2, особенно когда (T-L) * (R '-L') ÷ 2F велико (например, более чем 1/2), то гипотетически возможно, что верхняя граница будет нарушена на 1. Далее здесь не рассматриваются такие случаи, хотя настройки для разрешения таких случаев являются тривиальными.
2. Второй примерный способ вычисления позиции с использованием В-битовой арифметики без знака
Если все позиции, которые должны вычисляться в изображении низкого разрешения, больше или равны 0, что является случаем, который может быть сделан истинным путем добавления соответствующего смещения к началу координат системы координат, то лучшим выбором может быть вычисление t' = (j*C + D) с использованием целочисленной арифметики без знака, вместо двоичной арифметики дополнения до двух. Это обеспечивает возможность динамического диапазона на один бит больше без переполнения в вычислениях (то есть мы можем использовать B битов величины динамического диапазона, а не B-1 битов), таким образом, увеличивая М (или G) и S на 1 каждый и далее увеличивая точность вычисленных результатов. Таким образом, после включения смещения E для настройки начала координат системы координат, форма вычисления имела бы вид: t' = ((j*C+D')>> S') + E вместо t' = (j*C+D)>> S.
Далее приведено подробное описание этого более точного способа, использующего арифметику без знака, путем идентификации, когда смещение Е начала координат не будет необходимым, следующим образом.
- Выбираются значения для B, F, Г, J, и Z, как описано выше.
- Устанавливается M=B+F-(G+J+Z).
- Вычисляется S, C и D, как определено выше в уравнениях (18), (19) и (20) соответственно, где D вычисляется как число со знаком.
- Если D больше или равно нулю, никакое смещение начала координат (то есть E не используется) не требуется, и вычисление может выполняться просто как t' = (j*C + D)>> S с использованием арифметики без знака, и результат будет иметь большую точность, чем в первом примерном способе вычисления позиции, описанном выше в разделе V.B.1.
В дополнение к улучшению точности путем обеспечения возможности вычисления с использованием целых чисел без знака, смещение начала координат также может иногда использоваться, чтобы обеспечить улучшенную точность, допуская уменьшение в значении Z. Без смещения начала координат Z является функцией R'. Но со смещением начала координат Z может становиться функцией R'-L', что делает вычисление более точным, если это приводит к меньшему значению Z.
Далее приведено подробное описание этого более точного способа, использующего арифметику без знака, показывающего возможный способ смещения начала координат, для получения D' и E следующим образом.
- Выбираются значения для B, F, Г и J, как описано выше.
- Устанавливается Z = Ceil(Log2(R'-L')) + F.
- Устанавливается M = B + F -(G+J+Z).
- Вычисляются S, C и D, как определено выше в уравнениях (18), (19) и (20) соответственно, где D вычисляется как число со знаком.
- Устанавливается E = D>> S.
- Устанавливается D' = D -(E <<S).
- Затем вычисление позиции может быть выполнено как t' = ((j*C + D')>> S) + E.
Если D' и E (и М, S и Z) вычислены этим способом, математический результат уравнения t'=((j*C + D')>> S) + E в действительности всегда будет теоретически тем же самым, что и результат уравнения t' = (j*C + D)>> S, за исключением того, что значение (j*C+D) может иногда выходить за пределы из диапазона значений от 0 до 2B-1, в то время как значение (j*C+D') не будет.
Например, если желательно выполнить повышающую дискретизацию массива сигнала яркости изображения, которое имеет ширину 1000 выборок сигнала яркости при B=32 и L'=0, то можно использовать F=4, G=2, J=1, M=19, S=18 и Z=14, используя этот второй примерный способ вычисления позиции. Другая возможность, которая работала бы одинаково хорошо, вместо смещения начала координат, чтобы все значения j*C+D' были неотрицательны и, таким образом, позволяли использовать В-битовый диапазон вычислений от 0 до 2B-1, используя арифметику без знака, состояла бы в смещении начала координат далее вправо еще на 2(B-1), чтобы позволить использовать B-битовый диапазон вычислений от -2(B-1) до 2(B-1)-1 с использованием арифметики со знаком.
Как в первом примерном способе вычисления позиции в предыдущем разделе, могли бы иметь место настройки «краевого случая», необходимые, когда T очень близко (или равно) R, и R'-L' очень близко (или равно) целочисленной степени 2.
3. Примерные многоэтапные способы для вычисления позиции
Выше описаны способы, разработанные с той целью, чтобы иметь возможность выполнять вычисление, используя то же самое уравнение, например, t' = ((j*C + D')>> S)+E, с теми же самыми значениями переменных C, D', S и E для всех значений j, охватывающих диапазон выборок, которые должны генерироваться (то есть для всех значений T между L и R). Теперь будет описано, каким образом это допущение может быть ослаблено, обеспечивая выполнение требований большей точности и/или уменьшенного вычислительного динамического диапазона.
Обычно, процесс повторной дискретизации проходит слева направо (или сверху вниз), чтобы генерировать строку последовательных выборок в равномерно разнесенных позициях. Во втором примерном способе вычисления позиции, описанном выше в разделе V.B.2, было показано, каким образом изменение начала координат с использованием параметра E смещения может применяться, чтобы эффективно использовать B-битовый динамический диапазон регистра, используемого для вычисления части (j*C + D') позиционного вычисления.
Напомним, что в предыдущем разделе только S младших битов D были сохранены в D', и остаток был перемещен в E. Таким образом, главная остающаяся проблема для вычисления (j*C+D') состоит в величине j*C.
Напомним, что T и L - целые кратные 1÷2J. Обычно мы выполняем процесс повышающей дискретизации, чтобы генерировать строку выборок с целочисленными приращениями в изображении высокой разрешающей способности, например, с интервалом 2J между последовательно сгенерированными выборками. Таким образом, желательно вычислить позиции t'i, которые соответствуют позициям Ti = (p+i*2J)÷2J для i от 0 до N-1 для некоторых значений p и N.
Этот процесс может быть получен в итоге в псевдокоде, как показано в псевдокоде 1200 на фиг.12, для некоторых значений p и N. С увеличением i до N значение q увеличивается, и максимальное значение q должно сохраняться в пределах доступного динамического диапазона B битов. Максимальное значение, вычисленное для q, есть (p + (N-1)*2J)*C + D'.
Теперь, вместо того, чтобы генерировать все выборки в одном цикле этим способом, рассмотрим разбиение процесса на множество этапов, например, на два этапа. Например, в двухэтапном процессе, на первом этапе генерируются первые N0 < N выборок, и на втором этапе генерируются остальные N-N0 выборок. Также, поскольку p является константой относительно цикла, мы можем переместить ее воздействие в D' и E перед первым этапом. Это приводит к двухэтапному процессу, проиллюстрированному в псевдокоде 1300 на фиг.13.
В начале каждого этапа в псевдокоде 1300 начало координат устанавливается в исходное состояние, так что все, кроме S младших битов первого значения q для данного этапа, перемещаются в E (то есть в E0 для первого этапа и E1 для второго этапа). Таким образом, во время действия каждого из двух этапов q требует меньшего динамического диапазона. После разбиения процесса на этапы этим способом максимальное значение q будет N0*C' + D0 или ((N-N0-1)*C' + D1, в зависимости от того, какое из них больше. Но поскольку D0 и D1 каждый имеет не более чем S битов динамического диапазона без знака, это обычно будет меньшим максимальным значением, чем в ранее описанной одноэтапной схеме. Число выборок, сгенерированных на этапе (то есть N0 для первого этапа и N-N0 для второго этапа), может повлиять на динамический диапазон для ассоциированных вычислений. Например, использование меньшего количества выборок на каждом этапе приведет к меньшему динамическому диапазону для ассоциированных вычислений.
Каждый этап может быть разбит далее на большее количество этапов, и, таким образом, генерация всех N выборок может быть далее разбита на любое количество таких меньших этапов. Например, процесс мог бы быть разбит на этапы равного размера так, чтобы блоки, например, из 8 или 16 последовательных выборок были сгенерированы на каждом этапе. Этот способ может использоваться либо для уменьшения необходимого количества битов динамического диапазона B для вычисления q, либо для повышения точности вычисления (увеличивая S и G+M) при сохранении динамического диапазона тем же самым, или для получения комбинации этих двух выгод.
Этот способ разбиения процесса вычисления позиции на этапы может также использоваться для выполнения непрерывного процесса повторной дискретизации по очень длинной строке входных выборок (концептуально, строка могла бы быть бесконечно длинной), как при выполнении преобразования частоты дискретизации, когда выборки поступают от аналого-цифрового преобразователя для аудиосигнала. Ясно, что без разбиения процесса на этапы конечного размера и установления в исходное состояние начала координат с приращением от каждого этапа до следующего бесконечно-длинная строка выборок не могла бы быть обработана способами, описанными в предыдущих разделах, так как это потребовало бы бесконечного динамического диапазона в длине слова обработки. Однако трудность в применении способов к эффективно бесконечным длинам строк не является существенным ограничением таких способов, так как применение к эффективно бесконечной длине было бы полезно только тогда, когда никакая ошибка округления не вызывается представлением гипотетических эталонных позиций L' и R" в целочисленных блоках, представляющих ратные 1÷2G.
При этих обстоятельствах, когда могут быть применены многоэтапные способы вычисления позиции, они обеспечивают способ вычислений, выполняемых над строкой бесконечной длины выборок без "дрейфующего" накопления ошибки округления где угодно в операции вычислений позиции во всем процессе преобразования скорости.
4. Примерная инкрементная операция вычисления позиции
Интересным специальным случаем для концепции многоэтапной декомпозиции, описанной выше, является то, когда число выборок для генерации на каждом этапе снижается полностью до только одной выборки на этап. Псевдокод 1400 на фиг.14 представляет процесс для генерации N позиций t'i для i от 0 до N-1.
Так как процесс описан как процесс повышающей дискретизации (хотя те же самые принципы могли бы также применяться к процессу понижающей дискретизации), мы знаем, что для каждого приращения i есть интервал 1 в изображении более высокой разрешающей способности и поэтому есть приращение меньше или равное 1 в изображении более низкой разрешающей способности. Приращение 1 в пространственной позиции в изображении более низкой разрешающей способности соответствует значению 2(S+F) для C'. Также, мы знаем что D' <2S. Поэтому q = C '+ D' имеет диапазон от 0 до менее чем 2(S+F) + 2S, и поэтому q может быть вычислено с требованием динамического диапазона не более чем B=S+F+1 битов, используя целочисленную арифметику без знака. В одной реализации это требование динамического диапазона является инвариантным к размеру изображения (то есть оно не зависит от значения R' или R'-L').
Для масштабируемого видеокодирования и многих других таких приложений может не иметься реальной потребности поддерживать коэффициенты повышающей дискретизации, которые очень близки к 1. В таких приложениях мы можем предположить, что C' фактически требует не более чем S+F битов.
Например, если желательно выполнить повышающую дискретизацию массива сигнала яркости изображения, которое имеет ширину 1000 выборок сигнала яркости при B=32 и L' =0, то можно использовать F=4, G=2, J=1, M=29, S=28 и Z=14, используя этот способ. Результат был бы настолько чрезвычайно точным, что принятие меньшего значения B представляется более целесообразным вариантом выбора.
Альтернативно, если желательно выполнить повышающую дискретизацию массива сигнала яркости изображения, которое имеет ширину 1000 выборок сигнала яркости при B=16 и L'=0, то можно использовать F=4, G=2, J=1, M=13, S=12, Z=14, используя этот способ.
Дополнительное знание обстоятельств операции повышающей дискретизации, которая должна выполняться, может обеспечить дальнейшие возможности оптимизации. Например, если коэффициент повышающей дискретизации значительно больше двух, требование динамического диапазона будет снижено еще на один бит, и так далее для коэффициентов повышающей дискретизации больше четырех, шестнадцати и т.д.
Ни одно из изменений (относительно примерного многоэтапного способа вычисления позиции, обсужденного выше), описанных со ссылкой на примерный инкрементный способ вычисления позиции в этом разделе, не влияет на действительно вычисленные значения позиций t'i для данных значений C, D и S. Изменяется только динамический диапазон, необходимый для поддержки вычисления.
Внутренний цикл в псевдокоде 1400 для этой формы декомпозиции не требует никаких операций умножения. Этот факт может быть выгоден для обеспечения уменьшенного времени вычисления на некоторых вычислительных процессорах.
5. Дополнительные замечания
Для обычных отношений повторной дискретизации, таких как 2:1, 3:2 и т.д. - любой случай, в котором округление не было бы необходимым для аппроксимации позиций L' и R" как целого числа в единицах 1÷2G, - ошибки округления нет вообще при использовании этих способов (ошибка иная, чем ошибка округления, может быть вызвана при округлении конечного результата до целого числа в единицах 1÷2F, которая является ошибкой, которая присутствовала бы независимо от способа вычисления позиции).
C. Позиции и соотношения сигнала яркости и сигнала цветности
В предположении точного выравнивания полных массивов нового (повышенной дискретизации) изображения и опорного изображения, относительно координат индекса сетки дискретизации сигнала яркости, позиции L и R в текущих координатах изображения являются следующими: L = -1/2 и R = W - 1/2, где W - число выборок в изображении по вертикали или горизонтали, в зависимости от соответствующего измерения повторной дискретизации. Эквивалентно, можно было бы установить начало координат системы пространственных координат изображения на половину выборки влево от (или выше) позиции индекса 0 сетки и добавить 1/2 при преобразовании из пространственных координат изображения в значения индекса сетки, таким образом, избегая необходимости обращения с отрицательными числами при выполнении вычислений в системе пространственных координат.
Позиции L' и R' в опорном (с более низкой разрешающей способностью) изображении соотносятся с координатами сетки дискретизации тем же способом, где в этом случае W - число выборок в опорном изображении, а не в новом изображении.
Для сетки дискретизации сигнала цветности (как в новом изображении, так и в опорном изображении) ситуация является несколько менее простой. Чтобы создавать определяемое выравнивание выборок сигнала цветности относительно сигнала яркости, рассмотрим прямоугольник изображения, который представлен выборками сигнала цветности, который должен быть тем же самым, что и прямоугольник, который представлен выборками сигнала яркости. Это создает следующие случаи:
- По горизонтали, для типов 0, 2 и 4 дискретизации 4:2:0 сигнала цветности (см. фиг.5D) текущие координаты изображения определены как L = -1/4 и R = W - 1/4.
- По горизонтали, для типов 3, 1 и 5 дискретизации 4:2:0 сигнала цветности (см. фиг.5D) текущие координаты изображения определены как L = -1/2 и R = W - 1/2.
- По вертикали, для типов 2 и 3 дискретизации 4:2:0 сигнала цветности (см. фиг.5D) текущие координаты изображения определены как L = -1/4 и R = W - 1/4.
- По вертикали, для типов 0 и 1 дискретизации 4:2:0 сигнала цветности (см. фиг.5D) текущие координаты изображения определены как L = -1/2 и R = W - 1/2.
- По вертикали, для типов 4 и 5 дискретизации 4:2:0 сигнала цветности (см. фиг.5D) текущие координаты изображения определены как L = -3/4 и R = W - 3/4.
- По горизонтали, для дискретизации 4:2:2 сигнала цветности, текущие координаты изображения для 4:2:2 дискретизации, используемой в типовом случае в промышленной практике, определены как L = -1/4 и R = W - 1/4.
- По вертикали, для дискретизации 4:2:2 сигнала цветности, текущие координаты изображения для 4:2:2 дискретизации, используемой в типовом случае в промышленной практике, определены как L = -1/2 и R = W - 1/2.
- Как по горизонтали, так и по вертикали, для дискретизации 4:4:4 сигнала цветности, текущие координаты изображения определены как L = -1/2 и R = W - 1/2.
Вновь может использоваться смещение, чтобы поместить начало координат системы координат в достаточной степени влево от позиции L и избежать необходимости обращаться с отрицательными числами.
Целочисленные координаты и дробный остаток сдвига фазы вычисляются настройкой позиций целочисленных координат выборок, которые должны генерироваться в массиве повышающей дискретизации, чтобы скомпенсировать дробное смещение L, и затем применяя преобразование, показанное в конце раздела V.B. Концептуально, сдвиг результата вправо на F битов приводит к целочисленному координатному указателю в опорное изображение, и вычитание сдвинутой влево целочисленной координаты (сдвинутой на F битов) дает остаток сдвига фазы.
D. Дополнительная точность для вычисления позиции для повышающей дискретизации
Этот раздел описывает, как отобразить способ вычисления позиции, изложенный выше в разделе V.C.4, на конкретный процесс повышающей дискретизации, такой как процесс повышающей дискретизации, который может использоваться для расширения H.264 SVC. Вычисление позиции применяется весьма гибким способом, чтобы максимизировать точность для каналов как сигнала яркости, так и сигнала цветности в различных форматах сигнала цветности, а также для прогрессивного и чересстрочного форматов кадра. Способы, описанные в этом разделе, могут варьироваться в зависимости от реализации и для различных процессов повышающей дискретизации.
В вышеописанных вычислениях позиции (в приведенных выше разделах V.A-C) параметр изменения масштаба (который является переменной C и далее обозначается как deltaX (или deltaY) в последующих уравнениях) увеличен на коэффициент масштабирования, равный 2J (где J=1 - для сигнала яркости и 2 - для сигнала цветности), чтобы формировать приращение, добавляемое для генерации каждой позиции выборки слева направо или сверху вниз. Масштабирование выбиралось так, чтобы увеличенное приращение вмещалось в 16 битов.
1. Максимальная точность для масштабирования вычисления позиции
Прямой способ применения способа вычисления позиции состоит в увеличении параметра изменения масштаба на коэффициент масштабирования, равный 2J, где J=1 - для сигнала яркости и 2 - для сигнала цветности, чтобы сформировать приращение, добавляемое для генерации каждой позиции выборки слева направо или сверху вниз. Параметры масштабирования затем выбираются, чтобы гарантировать, что увеличенное приращение будет вмещаться в определенную длину слова, такую как 16 битов. Более гибкая схема описана в следующих разделах, чтобы максимизировать точности позиции.
a. Канал сигнала яркости
"Прямой" способ вычисления позиции сигнала яркости может быть получен в итоге со следующими уравнениями, приведенными для примера при F=4 и S=12 (по горизонтальному направлению):
deltaX = Floor(((BasePicWidth<<15)+(ScaledBaseWidth>>1)÷
ScaledBaseWidth)
xf=((2*(xP-ScaledBaseLeftOffset)+1)*deltaX-30720)>>12.
Здесь, BasePicWidth - горизонтальная разрешающая способность базового уровня или изображения низкого разрешения; ScaledBaseWidth - горизонтальная разрешающая способность области или окна изображения с высоким разрешением; deltaX - промежуточный параметр изменения масштаба, который в этом случае является округленным приближением 32768, умноженным на инверсию коэффициента повышающей дискретизации; xP представляет позицию выборки в изображении с высоким разрешением; ScaledBaseLeftOffset представляет относительную позицию окна изображения в изображении с высоким разрешением, и Floor() обозначает наибольшее целое число, которое меньше или равно его аргументу. Постоянное значение 30720 получается из добавления 2S-1 в качестве смещения округления перед сдвигом вправо и вычитания 2S*2F/2 для смещения на половину выборки опорного местоположения сетки дискретизации сигнала яркости, как обсуждено в начале раздела V.C выше.
Примечательно, что каждое приращение xP приводит к приращению 2*deltaX в уравнениях. И младший бит величины 2*deltaX является всегда нулевым, так что один бит вычислительной точности по существу теряется. Приблизительно один дополнительный бит точности может быть получен, без какого-либо существенного увеличения в сложности, путем изменения этих уравнений к виду:
deltaX = Floor(((BasePicWidth<<16)+(ScaledBaseWidth>>1))÷
ScaledBaseWidth)
xf =((xP-ScaledBaseLeftOffset)*deltaX+(deltaX>> 1)-30720)>> 12.
или (несколько) более точная форма в следующем виде:
deltaXa = Floor(((BasePicWidth<<16)+(ScaledBaseWidth>>1)÷
ScaledBaseWidth)
deltaXb = Floor(((BasePicWidth<<15)+(ScaledBaseWidth>>1)÷
ScaledBaseWidth)
xf =((xP-ScaledBaseLeftOffset)*deltaXa+deltaXb-30720)>>12
Последняя из этих двух форм предложена вследствие ее более высокой точности и незначительного влияния на сложность (хотя различие по точности также представляется весьма малым).
Отметим, что для архитектур обработки, на которых трудно выполнить вычисления деления, получение результата одного из этих уравнений может упростить вычисление другого. Значение deltaXa всегда будет в диапазоне 2*deltaXa плюс или минус 1. Поэтому может быть выведено следующее упрощенное правило, чтобы избежать необходимости выполнения операции деления для вычисления deltaXa:
deltaXa = (deltaXb <<1)
remainderDiff = (BasePicWidth <<16) + (ScaledBaseWidth>>1)
- deltaXa,
if (remainderDiff <0)
deltaXa-
else if (remainderDiff ≥ ScaledBaseWidth)
deltaXa ++
b. Каналы сигнала цветности
Множитель "коэффициент четыре" может использоваться для каналов сигнала цветности вместо множителя "коэффициент два" в этой части схемы, чтобы обеспечить возможность представления позиций сигнала цветности для 4:2:0 дискретизации (используя J=2 для сигнала цветности, а не J=1, как описано для сигнала яркости). Поэтому "прямые" уравнения имеют вид:
deltaXC = Floor(((BasePicWidthC<<14)+(ScaledBaseWidthC>>1))÷
ScaledBaseWidthC)
xfC=((((4*(xC-ScaledBaseLeftOffsetC)+
(2+scaledBaseChromaPhaseX))*deltaXC)
+ 2048)>> 12)-4 * (2+baseChromaPhaseX).
Здесь, baseChromaPhaseX и scaledBaseChromaPhaseX представляют смещения позиции сетки дискретизации сигнала цветности для изображений с низким и высоким разрешением, соответственно. Значения этих параметров могут быть явно переданы как информация, посланная с кодера на декодер, или могут иметь конкретные значения, определенные приложением. Все другие переменные подобны тем, которые определены для канала сигнала яркости с дополнительным суффиксом "C", чтобы представить применение для канала сигнала цветности.
Каждое приращение xC приводит к приращению 4*deltaXC в уравнении. Поэтому могут быть получены приблизительно два дополнительных бита точности без какого-либо существенного увеличения в сложности, путем изменения этих уравнений в следующую форму:
deltaXC = Floor(((BasePicWidthC<<16)+(ScaledBaseWidthC>>1)÷
ScaledBaseWidthC
xfC = (((xC-ScaledBaseLeftOffsetC)*deltaXC
+(2+scaledBaseChromaPhaseX)*((deltaXC+K)>>2)
+2048)>>12)-4*(2+baseChromaPhaseX),
где K=0, 1 или 2. Использование K=0 позволило бы избежать дополнительной операции. Использование K=1 или K=2 позволило бы получить несколько более высокую точность.
Соответствующая несколько более точная форма была бы следующей:
DeltaXCa= Floor(((BasePicWidthC<<16)+(ScaledBaseWidthC>>1))÷
ScaledBaseWidthC)
deltaXCb = Floor((BasePicWidthC<<14)+(ScaledBaseWidthC>>1)÷
ScaledBaseWidthC)
xfC =(((xC-ScaledBaseLeftOffsetC)*deltaXCa+
(2+scaledBaseChromaPhaseX)*delta-XCb
+2048)>> 12)-4*(2+baseChromaPhaseX).
Как в случае сигнала яркости, последний вариант является предпочтительным, так как различие в сложности представляется незначительным (хотя различие точности также представляется весьма малым).
C. Координаты чересстрочного поля
Опора для системы координат изображения обычно основана на позициях половины выборки в координатах кадра сигнала яркости, таким образом, приводя к масштабному коэффициенту два для позиций опорных координат сигнала яркости, как описано выше. Сдвиг на половину выборки в координатах кадра сигнала яркости соответствует сдвигу на четверть выборки в координатах 4:2:0 кадра сигнала цветности, вследствие чего мы теперь используем коэффициент четыре, а не коэффициент два в масштабировании для координат сигнала цветности, как описано выше.
По горизонтали нет никакого существенного различия в операциях для кодированных изображений, которые представляют кадр, и тех, которые представляют отдельное поле чересстрочного видео. Однако, когда кодированное изображение представляет отдельное поле, сдвиг позиции на половину выборки вертикальных координатах кадра сигнала яркости соответствует сдвигу позиции на четверть выборки в вертикальных координатах поля сигнала яркости. Таким образом, коэффициент масштаба четыре, а не два должен быть применен в вычислении позиций вертикальных координат сигнала яркости.
Точно также, когда кодированное изображение представляет отдельное поле, сдвиг позиции на половину выборки в вертикальных координатах сигнала яркости соответствует сдвигу позиции на одну восьмую выборки в вертикальных координатах поля сигнала цветности. Таким образом, коэффициент масштаба восемь, а не четыре должен быть применен в вычислении позиций вертикальных координат сигнала цветности.
Эти коэффициенты масштабирования для вычисления позиций вертикальных координат в кодированных изображениях поля могут быть включены в вычисление вертикального приращения deltaY тем же самым способом, как описано выше для вычисления приращения в кодированных изображениях кадра. В этом случае из-за увеличенного коэффициента масштабирования, который применен, улучшение точности приблизительно соответствует двум битам добавленной точности для позиций сигнала яркости и трем битам добавленной точности для сигнала цветности (по вертикали).
2. Ограничение и уточнение 4:2:2 и 4:4:4 сигнала цветности
Способ вычисления позиции, представленный в разделе V.D.1.b, требует использования различного коэффициента умножения для сигнала цветности и для сигнала яркости. Это имеет смысл для 4:2:0 видео, и это также целесообразно для 4:2:2 видео по горизонтали, но это необязательно для 4:2:2 видео по вертикали или для 4:4:4 видео как по горизонтали, так и по вертикали, поскольку в этих случаях разрешающая способность сигнала яркости и сигнала цветности является одинаковой, и поэтому выборки сигнала яркости и сигнала цветности предположительно являются совместно расположенными.
В результате, способ, представленный в разделе V.D.1.b, мог бы потребовать отдельных вычислений для определения позиций сигнала яркости и сигнала цветности, даже когда разрешающая способность сигнала яркости и сигнала цветности одинакова по некоторому измерению, и не предусматривается никакой сдвиг фазы только потому, что округление будет выполняться несколько иначе в этих двух случаях. Это является нежелательным, так что несколько иная обработка сигнала цветности предложена в этом разделе для использования со структурами дискретизации 4:2:2 и 4:4:4.
a. Позиции 4:2:2 по вертикали и 4:4:4 по горизонтали и вертикали
Для вертикального измерения 4:2:2 видео и для как вертикального, так и горизонтального измерений 4:4:4 видео, нет никакой очевидной необходимости в специальном управлении фазой сигнала цветности. Поэтому, если разрешающая способность сигнала цветности та же самая, что и разрешающая способность сигнала яркости по некоторому измерению, то уравнения для вычисления позиций сигнала цветности должны быть модифицированы, чтобы привести к вычислению точно тех же самых позиций выборок как сигнала яркости, так и сигнала цветности, если формат дискретизации сигнала цветности имеет ту же самую разрешающую способность для сигнала яркости и сигнала цветности по конкретному измерению. Один вариант выбора состоит в установке переменных позиции сигнала цветности равными переменным позиции сигнала яркости, а другой вариант выбора состоит в определении уравнений позиции сигнала цветности так, чтобы они имели тот же самый результат.
b. 4:2:2 позиции по горизонтали
В то время как нет никакой функциональной проблемы в обеспечении возможности настройки фазы сигнала цветности по горизонтали для 4:2:2 видео, если есть только один тип структуры горизонтальной субдискретизации, которая используется для 4:2:2, типа той, которая соответствует значению -1 для scaledBaseChromaPhaseX или BaseChromaPhaseX в уравнениях раздела V.D.1.b, может быть желательным рассмотреть вынужденное использование этих значений, когда формат дискретизации цвета есть 4:2:2.
VI. Расширения и альтернативы
Способы и инструментальные средства, описанные здесь, также могут быть применены к видеокодированию с переменной разрешающей способностью с использованием повторной дискретизации опорного изображения, как изложено, например, в Приложении P Рекомендации H.263 Международного стандарта ITU-T.
Способы и инструментальные средства, описанные здесь, также могут быть применены не только к повышающей дискретизации массивов выборок изображения, но также и к повышающей дискретизации остаточных сигналов данных или других сигналов. Например, способы и инструментальные средства, описанные здесь, также могут быть применены к повышающей дискретизации остаточных сигналов данных для кодирования обновления пониженной разрешающей способности, как изложено, например, в Приложении Q Рекомендации H.263 Международного стандарта ITU-T. В качестве другого примера, способы и инструментальные средства, описанные здесь, могут также быть применены к повышающей дискретизации остаточных сигналов данных для предсказания остаточных сигналов с высоким разрешением из остаточных сигналов более низкой разрешающей способности в схеме для видеокодирования с пространственным масштабированием. В качестве еще одного примера, способы и инструментальные средства, описанные здесь, могут также быть применены к повышающей дискретизации полей вектора движения в схеме для видеокодирования с пространственным масштабированием. В качестве еще одного примера, способы и инструментальные средства, описанные здесь, могут также быть применены к повышающей дискретизации графических изображений, фотографических неподвижных изображений, сигналов аудиовыборок и т.д.
На основе описания и иллюстрации принципов заявленного изобретения со ссылкой на различные описанные воплощения будет понятно, что описанные воплощения могут изменяться по форме и в деталях без отступления от этих принципов. Должно быть понятно, что программы, процессы или способы, описанные здесь, не относятся или не ограничены конкретным типом вычислительной среды, если иное не указано. Различные типы универсальных или специализированных вычислительных сред могут использоваться или исполнять операции в соответствии с раскрытием, описанным здесь. Элементы описанных воплощений, показанных в программном обеспечении, могут быть осуществлены в аппаратных средствах, и наоборот.
Ввиду многих возможных воплощений, к которым могут быть применены принципы заявленного изобретения, в качестве изобретения заявляются все такие воплощения, которые могут находиться в пределах объема и сущности следующих пунктов формулы изобретения и их эквивалентов.
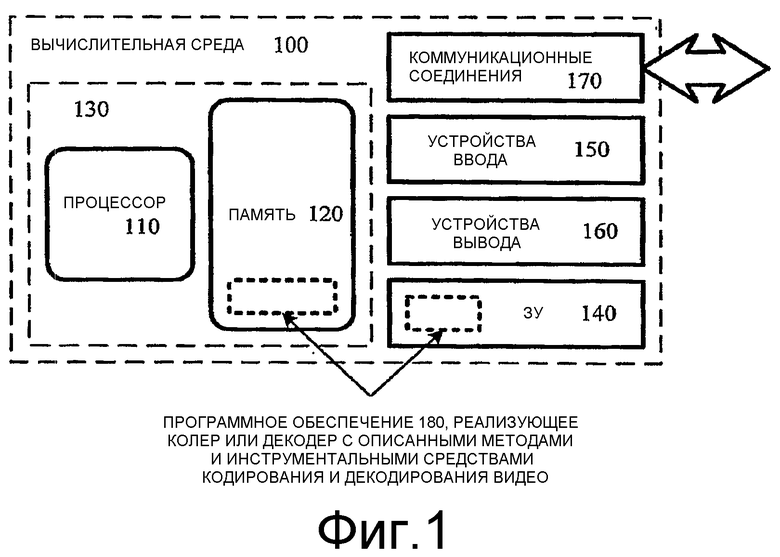
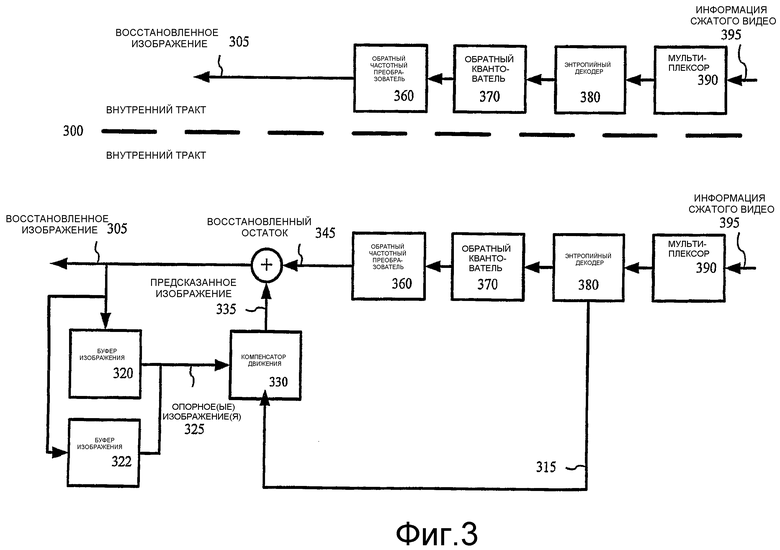
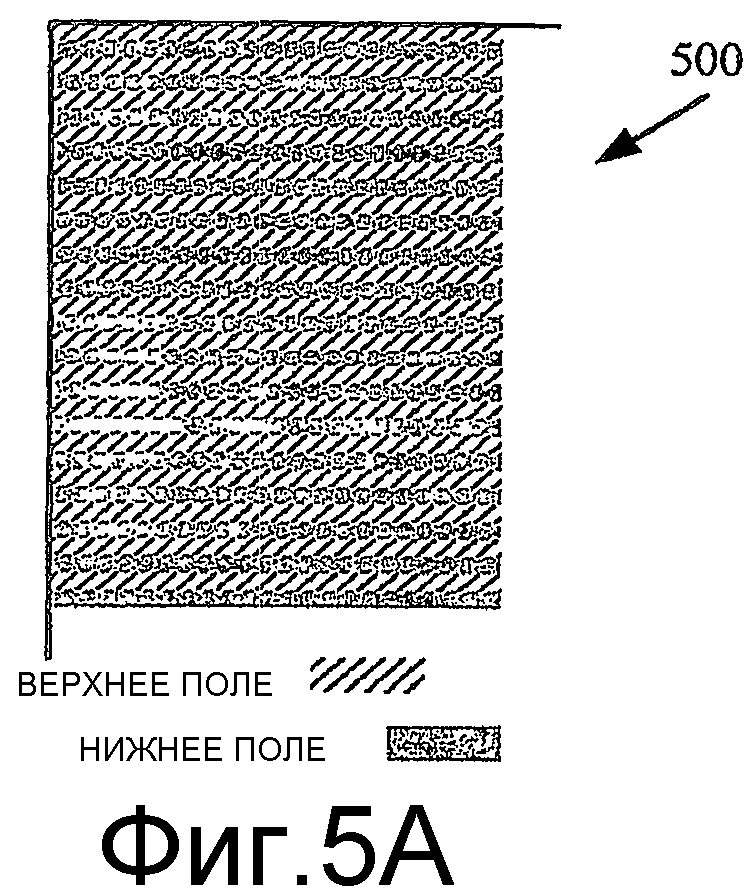
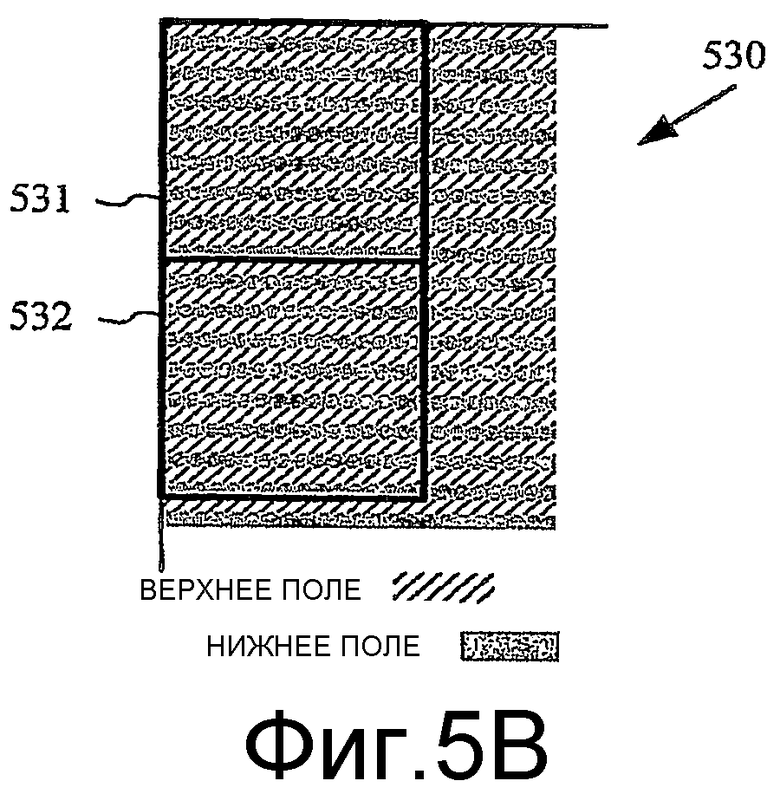
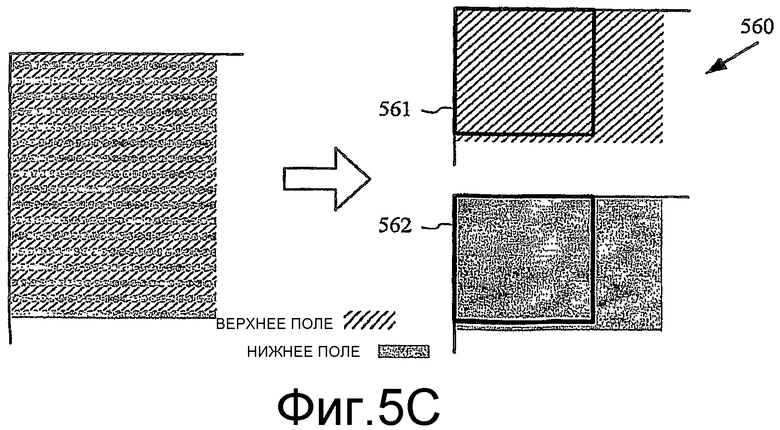
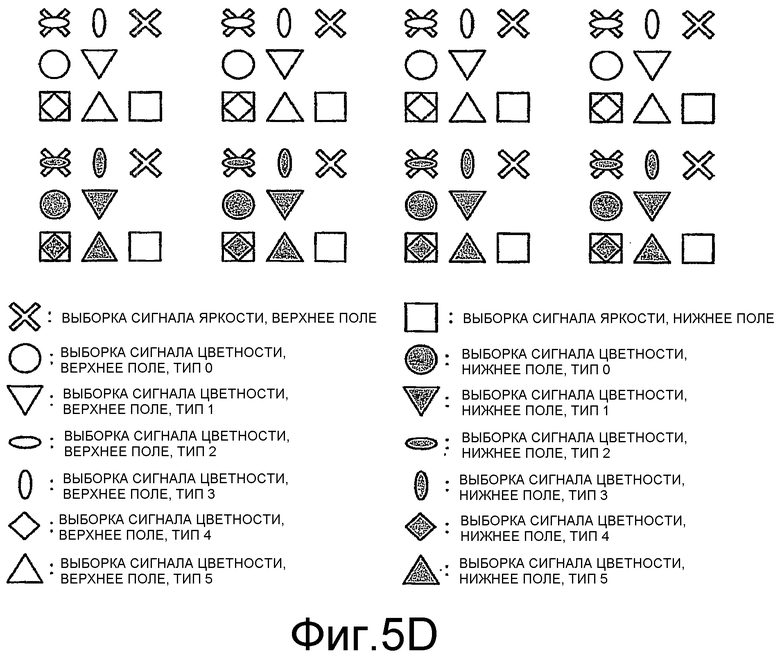
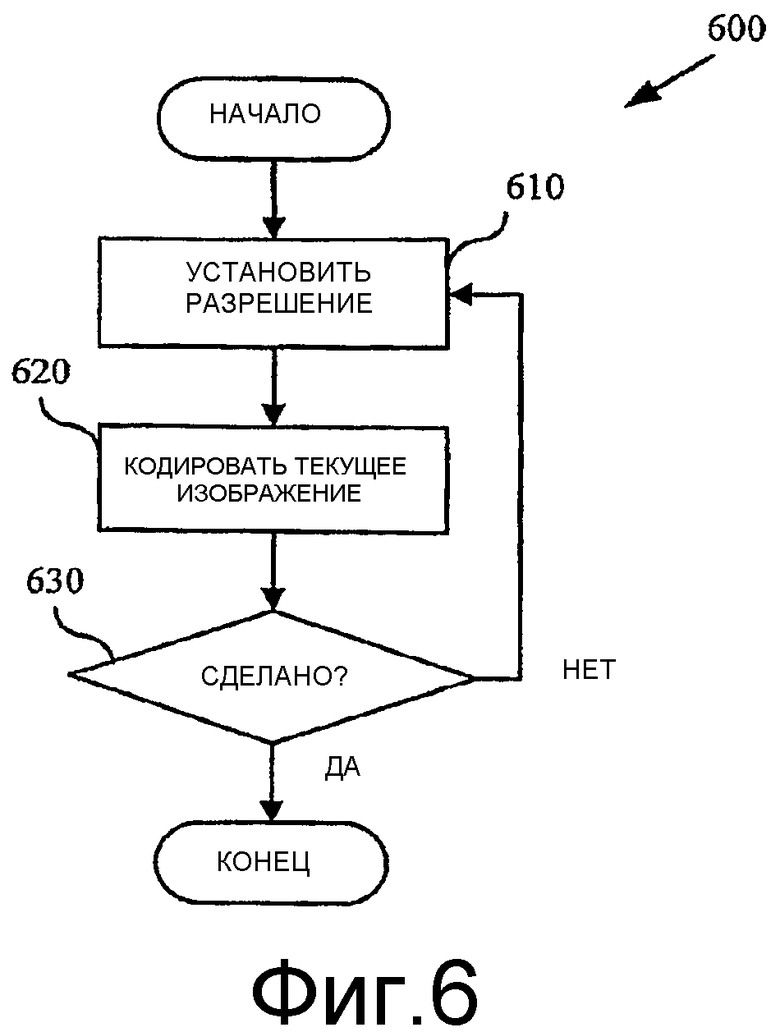

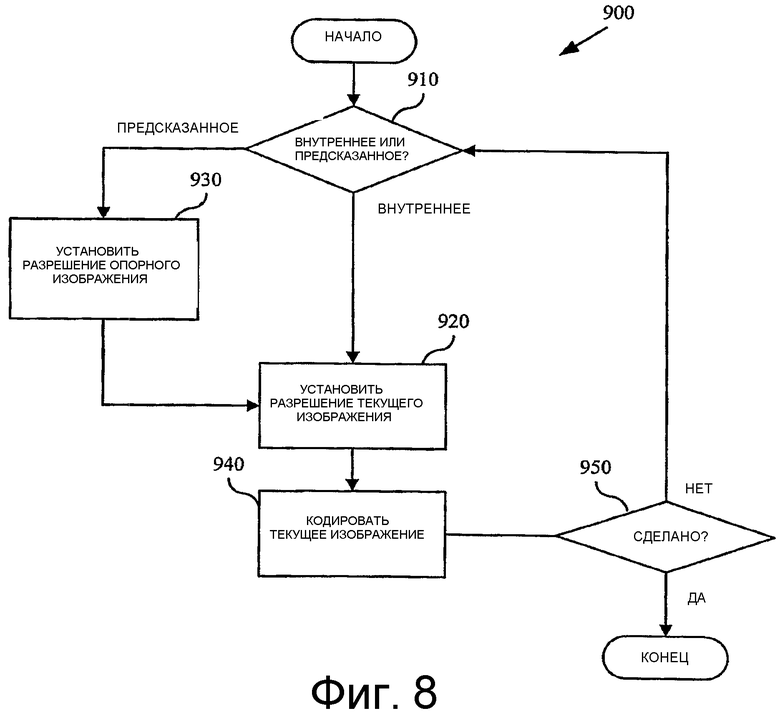
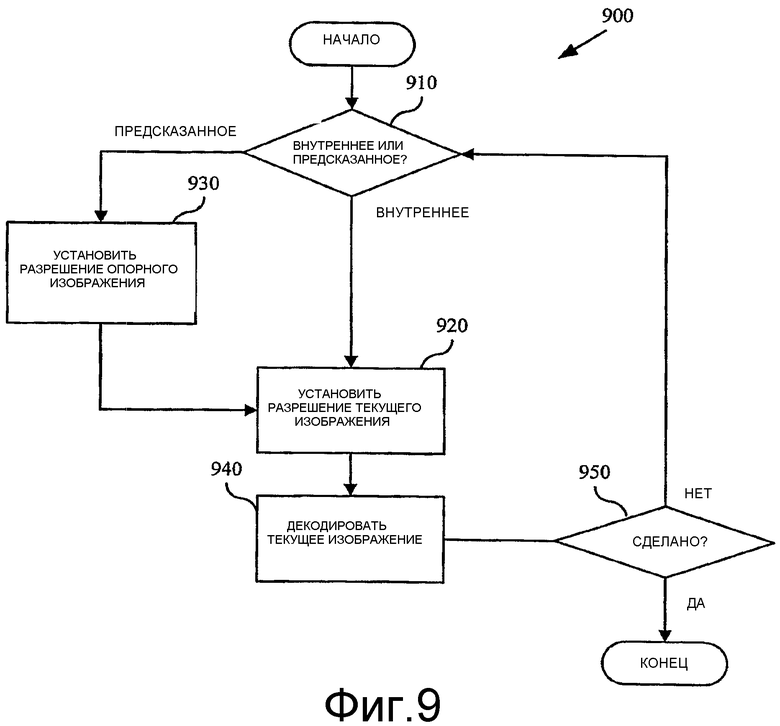
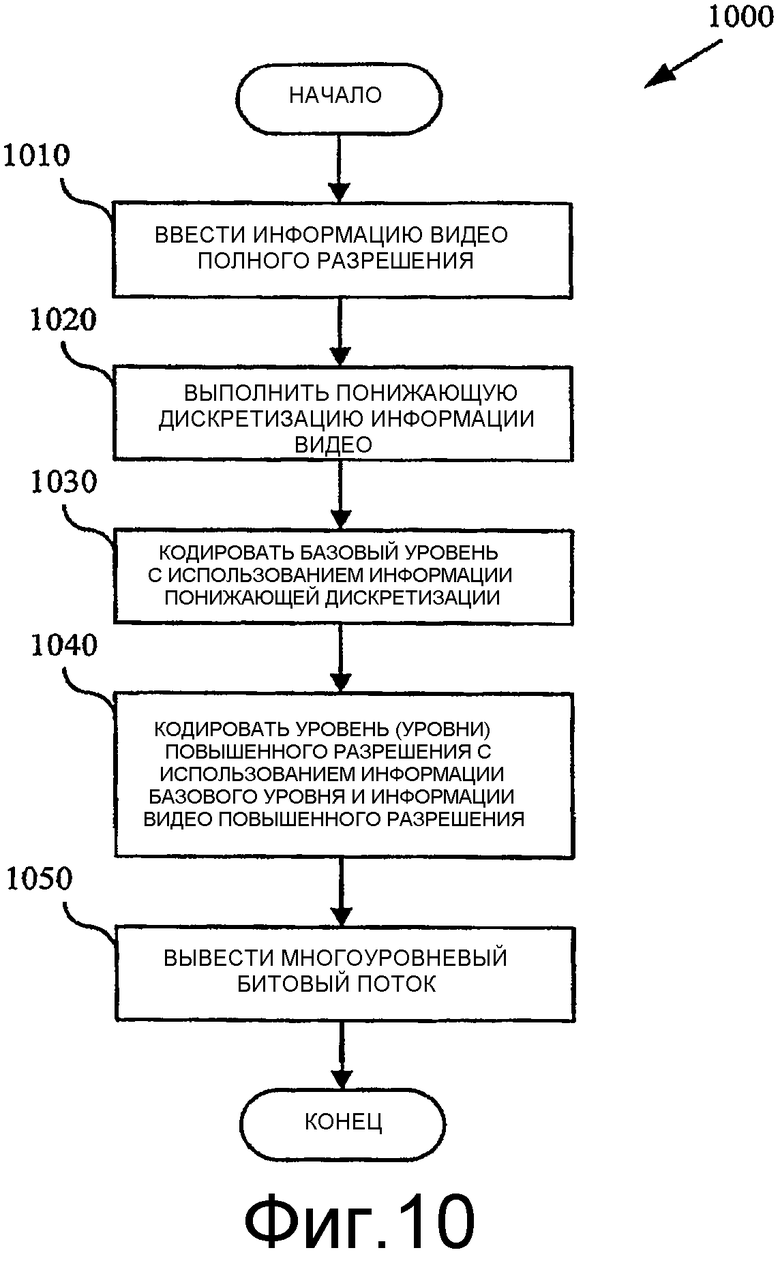
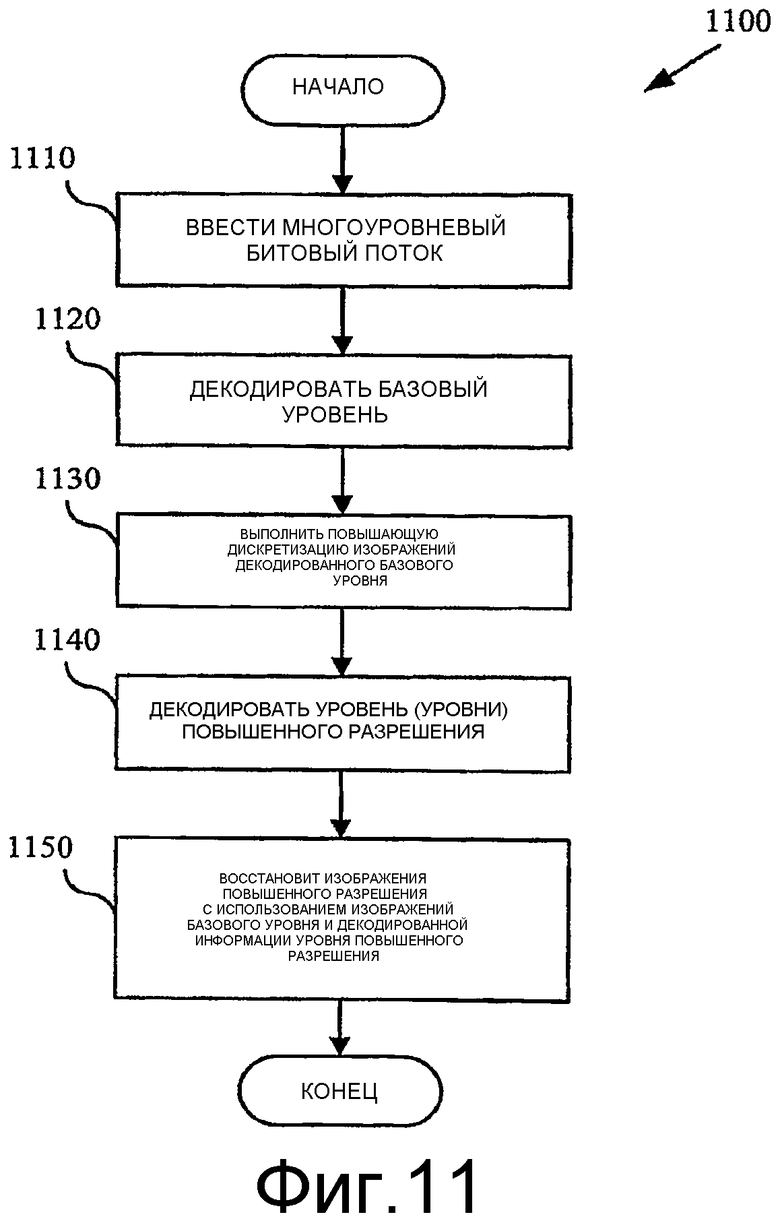
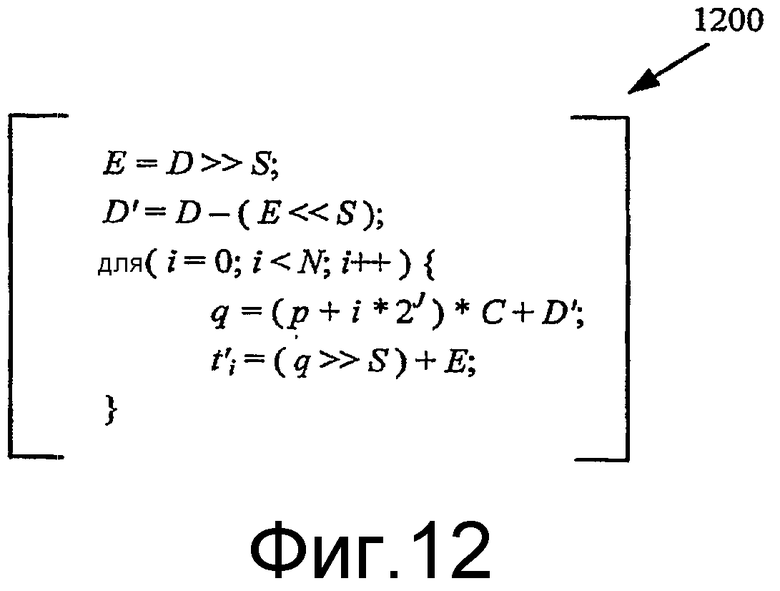


Изобретение относится к области кодирования/декодирования цифрового видео. Техническим результатом является высокоточное вычисление позиции для изменения размеров изображения в приложениях пространственно масштабируемого видеокодирования и декодирования, что обеспечивает повышение эффективности кодирования/декодирования цифрового видео. Указанный технический результат достигается тем, что повторная дискретизация видеоизображения выполняется согласно масштабному коэффициенту повторной дискретизации. Повторная дискретизация включает в себя вычисление значения выборки в позиции i, j в массиве повторной дискретизации. Вычисление включает вычисление выводимой горизонтальной или вертикальной позиции x или y подвыборки способом, который связан с аппроксимацией значения частично путем умножения значения 2n на инверсию (приближенную или точную) масштабного коэффициента повышающей дискретизации. Аппроксимация может быть округлением или некоторым другим видом аппроксимации, такой как функция ограничения сверху или снизу, которая аппроксимирует ближайшее целое число. Значение выборки интерполируется с использованием фильтра. 2 н. и 18 з.п. ф-лы, 17 ил.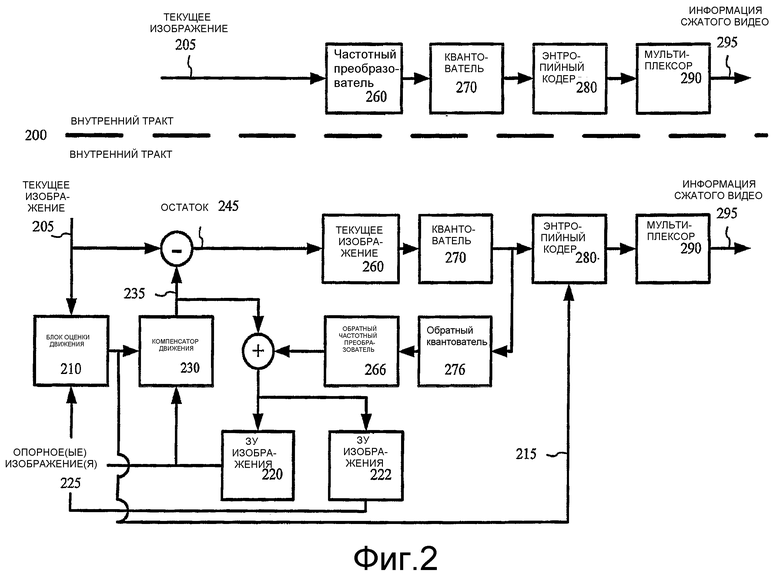
1. Способ выполнения повышающей дискретизации данных изображения базового уровня во время кодирования или декодирования масштабируемого видео, содержащий этапы, на которых, для позиции в массиве повышающей дискретизации:
вычисляют позицию в данных изображения базового уровня, причем y указывает вертикальное значение позиции в данных изображения базового уровня, и получение y включает в себя вычисление, которое является математически эквивалентным по результату (j·C+D)>>S,
где j указывает вертикальное значение позиции в массиве повышающей дискретизации;
С - аппроксимация 2S+F, умноженного на инверсию коэффициента масштабирования по вертикали;
D является смещением;
S является значением сдвига и
F основано на числе битов в дробной компоненте y.
2. Способ по п.1, в котором j, С и D частично зависят от того, предназначены ли данные изображения базового уровня для кадра или поля, а j и D частично зависят от того, предназначены ли данные изображения базового уровня для сигнала яркости или сигнала цветности.
3. Способ по п.1, в котором:
S задает динамический диапазон и точность; и
D зависит от вертикальной разрешающей способности данных изображения базового уровня, коэффициента масштабирования по вертикали и S.
4. Способ по п.1, в котором F равно 4 и S равно 12.
5. Способ по п.1, в котором x указывает горизонтальное значение позиции в данных изображения базового уровня, и получение x включает в себя вычисление, которое является математически эквивалентным по результату (i·C'+D')>>S',
где i указывает горизонтальное значение позиции в массиве повышающей дискретизации;
С' - аппроксимация 2S'+F', умноженного на инверсию коэффициента масштабирования по горизонтали;
D' является смещением, которое может быть равным или отличающимся от D;
S' является значением сдвига, которое может быть равным или отличающимся от S; и
F' основано на числе битов в дробной компоненте x.
6. Способ по п.5, в котором i основано на T-L, где Т указывает горизонтальное смещение, a L указывает смещение влево.
7. Способ по п.5, в котором F' равно 4 и S' равно 12.
8. Способ по п.7, в котором С' получается в соответствии с:
((BasePicWidth<<16)+(ScaleBaseWidth>>1))÷ScaledBaseWidth, где BasePicWidth указывает горизонтальную разрешающую способность данных изображения базового уровня, и ScaledBaseWidth указывает горизонтальную разрешающую способность после повышающей дискретизации.
9. Способ по п.5, в котором x дополнительно зависит от смещения Е, и получение x включает в себя вычисление, которое является математически эквивалентным по результату ((i·C'+D')>>S')+Е.
10. Способ по п.5, дополнительно содержащий этапы, на которых:
выбирают вертикальный фильтр на основе F младших битов y, и выбирают вертикальные целочисленные позиции, подлежащие фильтрации, на основе оставшихся битов y, причем вертикальный фильтр используется в этих вертикальных целочисленных позициях при вертикальной интерполяции данных изображения базового уровня; и
выбирают горизонтальный фильтр на основе F' младших битов x, и выбирают горизонтальные целочисленные позиции, подлежащие фильтрации, на основе оставшихся битов x, причем горизонтальный фильтр используется в этих горизонтальных целочисленных позициях при горизонтальной интерполяции результатов вертикальной интерполяции.
11. Способ по п.1, дополнительно содержащий этапы, на которых:
интерполируют значение в упомянутой позиции в данных изображения базового уровня; и
назначают интерполированное значение для позиции в массиве повышающей дискретизации.
12. Способ по п.1, в котором данные изображения базового уровня являются значениями выборки.
13. Способ по п.1, в котором данные изображения базового уровня являются значениями остаточных данных.
14. Система, содержащая процессор, память и машиночитаемый носитель, который хранит исполняемые компьютером команды для выполнения способа повышающей дискретизации данных изображения базового уровня во время кодирования или декодирования масштабируемого видео, причем способ содержит этапы, на которых, для позиции в массиве повышающей дискретизации:
вычисляют позицию в данных изображения базового уровня, причем y указывает вертикальное значение позиции в данных изображения базового уровня, и получение y включает в себя вычисление, которое является математически эквивалентным по результату (j·C+D)>>S,
где j указывает вертикальное значение позиции в массиве повышающей дискретизации;
С - аппроксимация 2S+F, умноженного на инверсию коэффициента масштабирования по вертикали;
D является смещением;
S является значением сдвига и
F основано на числе битов в дробной компоненте y.
15. Система по п.14, в которой:
j, С и D частично зависят от того, предназначены ли данные изображения базового уровня для кадра или поля;
j и D частично зависят от того, предназначены ли данные изображения базового уровня для сигнала яркости или сигнала цветности;
D зависит от вертикальной разрешающей способности данных изображения базового уровня, коэффициента масштабирования по вертикали и S;
F равно 4; и
S равно 12.
16. Система по п.14, в которой x указывает горизонтальное значение позиции в данных изображения базового уровня, и получение x включает в себя вычисление, которое является математически эквивалентным по результату (i·С'+D')>>S', где:
i указывает горизонтальное значение позиции в массиве повышающей дискретизации;
С' - аппроксимация 2S'+F', умноженного на инверсию коэффициента масштабирования по горизонтали;
D' является смещением, которое может равняться или отличаться от D;
S' является значением сдвига, которое может равняться или отличаться от S; и
F' основано на числе битов в дробной компоненте x.
17. Система по п.16,
в которой i основано на T-L, где Т указывает горизонтальное смещение, a L указывает смещение влево;
F' равно 4;
S' равно 12; и
С' получается в соответствии с:
((BasePicWidth<<16)+(ScaleBaseWidth>>1))÷ScaledBaseWidth, где BasePicWidth указывает горизонтальную разрешающую способность данных изображения базового уровня, и ScaledBaseWidth указывает горизонтальную разрешающую способность после повышающей дискретизации.
18. Система по п.16, в которой способ дополнительно содержит этапы, на которых:
выбирают вертикальный фильтр на основе F младших битов y, и выбирают вертикальные целочисленные позиции, подлежащие фильтрации, на основе оставшихся битов y, причем вертикальный фильтр используется в этих вертикальных целочисленных позициях при вертикальной интерполяции данных изображения базового уровня; и
выбирают горизонтальный фильтр на основе F' младших битов x, и выбирают горизонтальные целочисленные позиции, подлежащие фильтрации, на основе оставшихся битов x, причем горизонтальный фильтр используется в этих горизонтальных целочисленных позициях при горизонтальной интерполяции результатов вертикальной интерполяции.
19. Система по п.18, причем система дополнительно содержит буфер для хранения кодированных данных и один или более модулей для адаптивного управления скоростью, при этом машиночитаемый носитель дополнительно хранит исполняемые компьютером команды для выполнения кодирования улучшенного уровня для данных изображения базового уровня с использованием интерполированных значений выборки из позиций в массиве повышающей дискретизации.
20. Система по п.18, причем система дополнительно содержит сенсорное устройство ввода, соединение беспроводной связи и дисплей, при этом машиночитаемый носитель дополнительно хранит выполняемые компьютером команды для декодирования улучшенного уровня для данных изображения базового уровня, с использованием интерполированных значений выборки из позиций в массиве повышающей дискретизации.
| US 6501484 B1, 31.12.2002 | |||
| RU 2004103743 A, 10.06.2005 | |||
| US 6259741 B1, 10.07.2001 | |||
| Узел уплотнения штока гидроцилиндра | 1986 |
|
SU1401211A1 |
| US 2004101058 A1, 27.05.2004 | |||
| ВИДЕОПЕРЕДАЮЩЕЕ УСТРОЙСТВО, ИСПОЛЬЗУЮЩЕЕ ВНУТРИКАДРОВУЮ ВИДЕОКОМПРЕССИЮ, СОВМЕСТИМУЮ СО СТАНДАРТОМ МПЕГ-2 | 1998 |
|
RU2191469C2 |
| SUN S et al, Resampling Process for Interlaced Materials in SVC, JOINT VIDEO TEAM (JVT) OF ISO/IEC MPEG & ITU-T VCEG, JVT-Rxxx, 18th Meeting: Bangkok, Thailand, 14-20 January 2006. | |||

