Область техники, к которой относится изобретение
Настоящее изобретение относится к устройству кодирования речи и способу кодирования речи. В частности, настоящее изобретение относится к устройству кодирования речи и способу кодирования речи для выполнения поиска фиксированной кодовой книги.
Уровень техники
В мобильной связи кодирование с сжатием для цифровой информации, касающейся речи и изображений, является существенным для эффективного использования полосы частот передачи. В особенности, высокими являются ожидания методик работы речевого кодека (кодирования и декодирования), широко используемых для мобильных телефонов, и предъявляются требования к дальнейшему улучшению качества звука для стандартного кодирования высокой эффективности сжатия.
В последнее время стандартизация масштабируемого кодека, имеющего многослойную конфигурацию, находится на пути реализации усилиями, например, ITU-T (сектор стандартизации телекоммуникаций международного объединения телекоммуникаций) и MPEG (экспертная группа по движущимся изображениям), и требуется речевой кодек c большей эффективностью и более высоким качеством.
Эффективность методики речевого кодирования, которая была значительно улучшена посредством базовой схемы "CELP (линейное предсказание с кодированием)", моделирования вокальной системы речи и принятие векторной квантизации квалифицированным образом дополнительно улучшают посредством методик фиксированного возбуждения с использованием маленького количества импульсов, как, например, алгебраическая кодовая книга, раскрытая в непатентном документе 1. ITU-T рекомендация G.729 и ETSI (европейский институт по стандартизации в области телекоммуникаций) стандарт AMR (адаптивная множественная скорость) предлагает репрезентативный кодек CELP с использованием алгебраической кодовой книги, и широко используются во всем мире.
В случае выполнения кодирования речи с использованием алгебраической кодовой книги, принимая во внимание взаимное влияние между импульсами, формирующими алгебраическую кодовую книгу, является желательным осуществлять поиск всех комбинаций импульсов (далее "полный поиск"). Однако, когда количество импульсов увеличивается, величина вычислений, требуемых для поиска, увеличивается экспоненциально. По сравнению с этим непатентный документ 2 раскрывает, например, поиск частей, сокращенный поиск и поиск Витерби как способы поиска с алгебраической кодовой книгой, чтобы значительно уменьшать величину вычислений и, по существу, поддерживать эффективность в случае полного поиска в то же время.
Среди них, особенно, поиск частей является наиболее простым способом, обеспечивающим эффект значительного уменьшения величины вычислений. Здесь, поиск частей является способом разделения замкнутого цикла в множество более маленьких замкнутых циклов и выполнения поиска открытого цикла в множестве замкнутых циклов. В этом поиске частей является возможным значительно уменьшать величину вычислений согласно количеству разделений. Также, поиск частей используется в международных стандартных схемах, и в поиске с алгебраической кодовой книгой ETSI стандарта AMR, который является стандартным кодеком мобильных телефонов третьего поколения, поиск частей выполняют после разделения четырех импульсов на два поднабора.
Например, если имеется четыре импульса, имеющих восемь предположительных положений, имеются 84 (т.е. 4096) комбинаций импульсов, которые необходимо оценить, чтобы осуществлять поиск четырех импульсов в одном замкнутом цикле. По сравнению с этим ETSI стандарт AMR разделяет четыре импульса в два поднабора двух импульсов и выполняет поиск в их замкнутых циклах индивидуально. Поэтому количество комбинаций импульсов, подлежащих оценке в ETSI стандарте AMR, - это 2·82 (т.е. 128), что является одной тридцать второй величины вычислений в случае полного поиска. Дополнительно, оценку в ETSI стандарте AMR выполняют для двух импульсов, что меньше чем четыре импульса, так что величина вычислений дополнительно уменьшается.
Непатентный документ 1: Salami, Laflamme, Adoul, "8 kbit/s ACELP Coding of Speech with 10 ms Speech-Frame: a Candidate for CCITT Standardization", IEEE Proc. ICASSP94, p.II-97n.
Непатентный документ 2: T.Nomura, K.Ozawa, M.Serizawa, "Efficient pulse excitation search methods in CELP", Proc. of the 1996 spring meeting of the Acoustic Society of Japan. 2-P-5, p.311-312, March. 1996.
Раскрытие изобретения
Проблемы, подлежащие решению посредством этого изобретения
Однако в общем эффективность кодирования речи с помощью поиска частей с алгебраической кодовой книгой являются более низкими, чем в случае полного поиска, так как положения двух импульсов, которые определены сначала, не всегда являются оптимальными.
Поэтому, в поиске частей, эффективность кодирования речи можно дополнительно улучшить в зависимости от того, какие импульсы выбрать, чтобы формировать поднабор, подлежащий поиску первым. Например, является возможным принять способ выбора двух импульсов из четырех импульсов случайным образом и выполнения поиска, и после того как этот процесс повторен несколько раз, нахождения пары импульсов, посредством чего эффективность кодирования является наивысшей. Например, посредством обеспечения четырех типов пар поднаборов и осуществления поиска этих четырех пар индивидуально является возможным делать эффективность кодирования речи близкой к эффективности кодирования в полном поиске. В этом случае требуются 128 (82×2)×4 (т.е. 512) шаблонов вычислений, что является одной восьмой величины вычислений в случае полного поиска. Здесь, в вышеописанных примерах, поднаборы формируют произвольным способом, и не имеется никакой особой причины, чтобы какие-либо пары искать первыми среди четырех типов пар. Поэтому, если поиск выполнен в множестве случаев индивидуально, результирующая эффективность кодирования показывает большие вариации, и полная эффективность кодирования является недостаточной.
Поэтому является задачей настоящего изобретения обеспечить устройство кодирования речи и способ кодирования речи для выполнения поиска частей с алгебраической кодовой книгой и улучшения эффективности кодирования.
Средство для решения проблемы
Устройство кодирования речи настоящего изобретения применяет конфигурацию, имеющую: секцию вычисления, которая вычисляет значения корреляции в предполагаемых положениях импульсов с использованием целевого сигнала и множества импульсов, формирующих фиксированную кодовую книгу, и вычисляет, на базисе на основе импульса, репрезентативные значения импульсов с использованием максимальных значений корреляции; секцию сортировки, которая сортирует репрезентативные значения, полученные на базисе на основе импульса, группирует импульсы, соответствующие отсортированным репрезентативным значениям, в множество предопределенных поднаборов и определяет первый поднабор, подлежащий поиску первым, среди множества поднаборов; и секцию поиска, которая осуществляет поиск фиксированной кодовой книгой с использованием первого поднабора и получает показывающие код положения и полярности множества импульсов для минимизации искажения кодирования.
Способ кодирования речи настоящего изобретения включает в себя этапы: вычисления значений корреляции в предполагаемых положениях импульсов с использованием целевого сигнала и множества импульсов, формирующих фиксированную кодовую книгу, и вычисления, на базисе на основе импульса, репрезентативных значений импульсов с использованием максимальных значений корреляции; сортировки репрезентативных значений, полученных на базисе на основе импульса, группировки импульсов, соответствующих отсортированным репрезентативным значениям, в множество предопределенных поднаборов и определения первого поднабора, подлежащего поиску первым, среди множества поднаборов; и поиска фиксированной кодовой книги с использованием первого поднабора и генерирования показывающих код позиций и полярностей множества импульсов для минимизации искажения кодирования.
Предпочтительный эффект этого изобретения
Согласно настоящему изобретению, при выполнении поиска частей фиксированной кодовой книгой в кодировании речи, поднабор, подлежащий поиску первым, определяют с использованием репрезентативных значений, относящихся к импульсам, как, например, максимальные значения корреляции, так что является возможным выполнять поиск частей с алгебраической кодовой книгой и улучшать эффективность кодирования.
Краткое описание чертежей
Фиг.1 - это блок-схема, показывающая конфигурацию устройства кодирования CELP согласно варианту 1 осуществления настоящего изобретения;
Фиг.2 - это блок-схема, показывающая конфигурацию внутри секции минимизации искажения согласно варианту 1 осуществления настоящего изобретения;
Фиг.3 - это блок-схема последовательности операций, показывающая этапы вычисления максимального значения корреляции каждого импульса в секции вычисления максимального значения корреляции согласно варианту 1 осуществления настоящего изобретения;
Фиг.4 - это блок-схема последовательности операций, показывающая этапы обработки сортировки над максимальным значением корреляции каждого импульса в секции сортировки согласно варианту 1 осуществления настоящего изобретения;
Фиг.5 - это блок-схема последовательности операций, показывающая этапы поиска частей фиксированной кодовой книгой в секции поиска согласно варианту 1 осуществления настоящего изобретения;
Фиг.6 - это другая блок-схема последовательности операций, показывающая этапы поиска частей фиксированной кодовой книгой в секции поиска согласно варианту 1 осуществления настоящего изобретения;
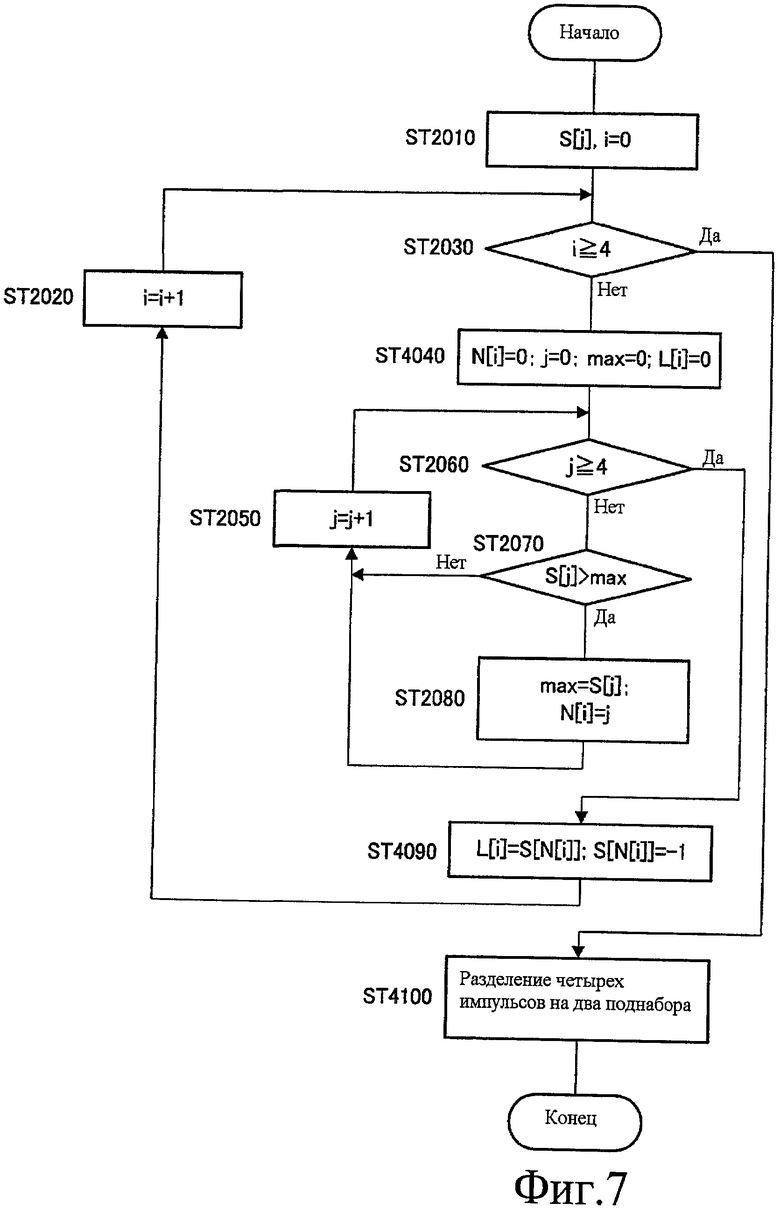
Фиг.7 - это блок-схема последовательности операций, показывающая этапы обработки сортировки над максимальным значением корреляции каждого импульса в секции сортировки согласно варианту 2 осуществления настоящего изобретения;
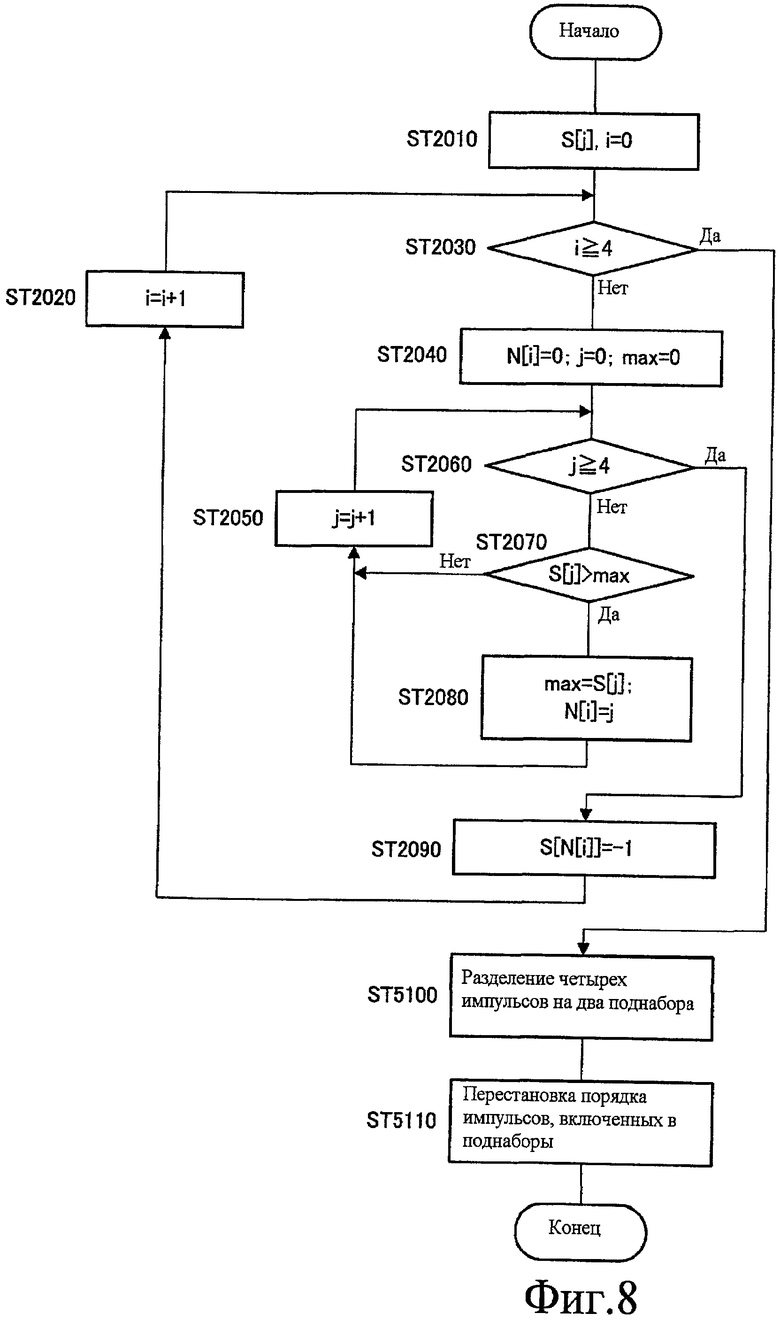
Фиг.8 - это блок-схема последовательности операций, показывающая этапы обработки сортировки над максимальным значением корреляции каждого импульса в секции сортировки согласно варианту 3 осуществления настоящего изобретения; и
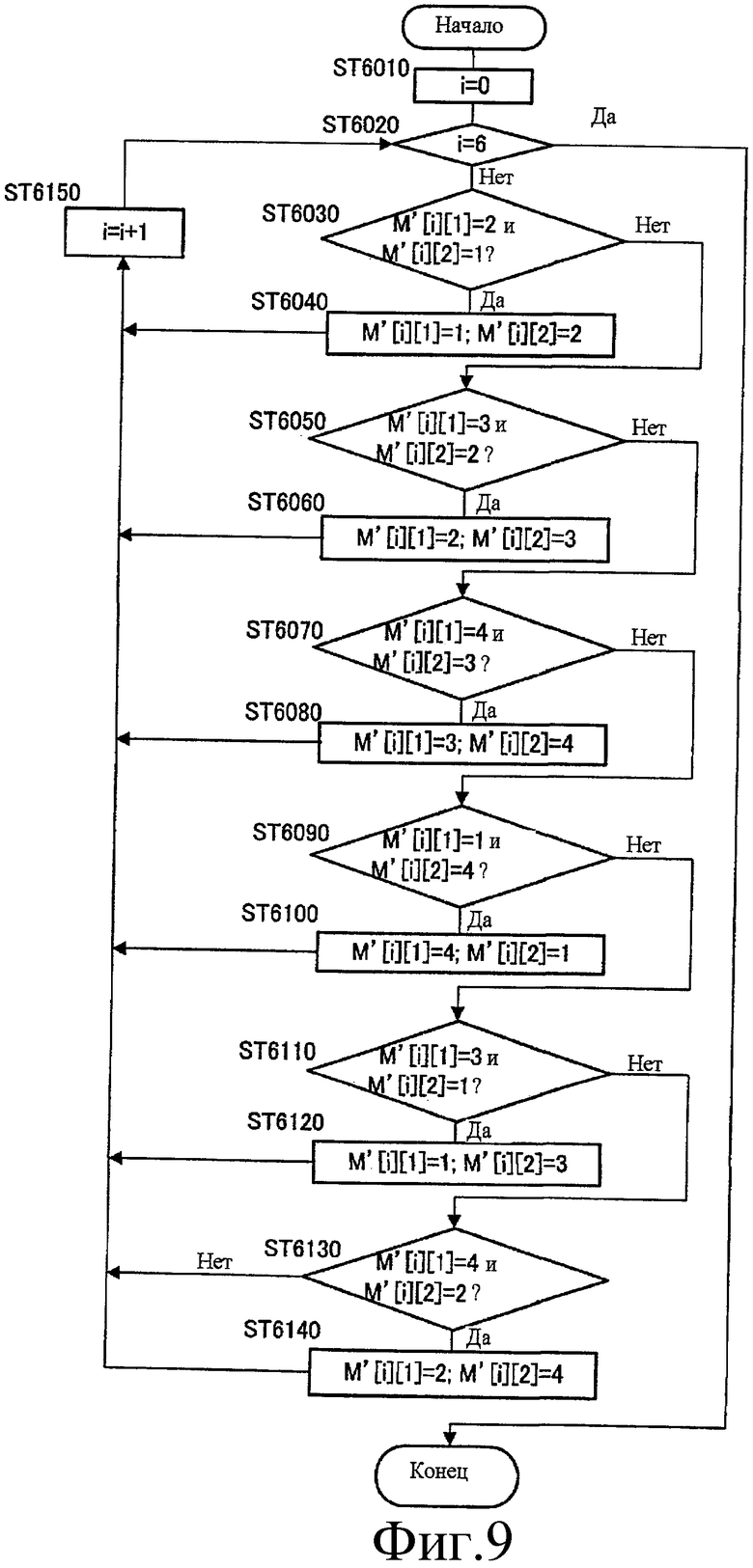
Фиг.9 - это блок-схема последовательности операций, показывающая этапы обработки перестановки над порядком импульсов в секции сортировки согласно варианту 3 осуществления настоящего изобретения.
Предпочтительный вариант осуществления изобретения
Варианты осуществления настоящего изобретения будут подробно объяснены ниже со ссылкой на сопровождающие чертежи.
Вариант 1 осуществления
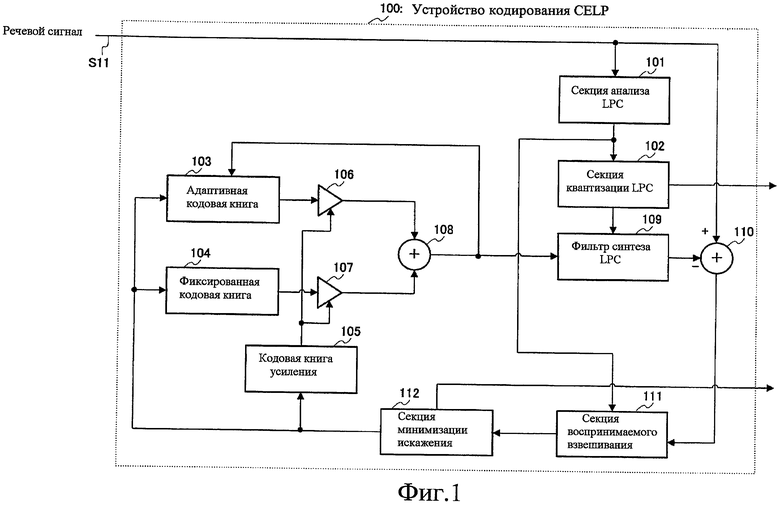
Фиг.1 - это блок-схема, показывающая конфигурацию устройства 100 кодирования CELP согласно варианту 1 осуществления настоящего изобретения. Здесь будет объяснен иллюстративный случай с использованием устройства кодирования CELP в качестве устройства кодирования речи согласно настоящему изобретению.
На фиг.1, для речевого сигнала S11, состоящего из информации вокального тракта и информации возбуждения, устройство 100 кодирования CELP кодирует информацию вокального тракта посредством вычисления параметров LPC (коэффициента линейного предсказания) и кодирует информацию возбуждения посредством определения индекса, определяющего, какую речевую модель, сохраненную заранее, использовать. То есть информация возбуждения кодирована посредством определения индекса, задающего, какой вектор возбуждения (кодовый вектор) генерировать в адаптивной кодовой книге 103 и фиксированной кодовой книге 104.
Чтобы быть более конкретными, секции устройства 100 кодирования CELP выполняют следующие операции.
Секция 101 анализа LPC выполняет анализ линейного предсказания речевого сигнала S11, вычисляет параметры LPC, которые являются информацией спектральной огибающей, и выводит параметры LPC в секцию 102 квантизации LPC и секцию 111 воспринимаемого взвешивания.
Секция 102 квантизации LPC квантует параметры LPC, выведенные из секции 101 анализа LPC, и выводит результирующие квантованные параметры LPC в фильтр 109 синтеза LPC и индекс квантованных параметров LPC во вне устройства 100 кодирования CELP.
С другой стороны, адаптивная кодовая книга 103 хранит прошлые возбуждения, использованные в фильтре 109 синтеза LPC, и генерирует вектор возбуждения одного подкадра из сохраненных возбуждений согласно запаздыванию адаптивной кодовой книги, ассоциированному с индексом, назначенным из секции 112 минимизации искажения, описанной позже. Этот вектор возбуждения выводят в множитель 106 как вектор адаптивной кодовой книги.
Фиксированная кодовая книга 104 заранее хранит множество векторов возбуждения предопределенной формы и выводит вектор возбуждения, ассоциированный с индексом, назначенным из секции 112 минимизации искажения, в множитель 107 как вектор фиксированной кодовой книги. Здесь, фиксированная кодовая книга 104 является алгебраическим возбуждением, и будет объяснен случай, где используется алгебраическая кодовая книга. Также, алгебраическое возбуждение является возбуждением, принятым во многих стандартных кодеках.
Дополнительно, вышеописанную адаптивную кодовую книгу 103 используют, чтобы представлять более периодические компоненты как голосовую речь, в то время как фиксированную кодовую книгу 104 используют, чтобы представлять менее периодические компоненты как белый шум.
Согласно назначению из секции 112 минимизации искажения кодовая книга 105 усиления генерирует усиление для вектора адаптивной кодовой книги, который выводится из адаптивной кодовой книги 103 (т.е. усиление адаптивной кодовой книги), и усиление для вектора фиксированной кодовой книги, который выводят из фиксированной кодовой книги 104 (т.е. усиление фиксированной кодовой книги), и выводит эти усиления в множители 106 и 107 соответственно.
Множитель 106 умножает вектор адаптивной кодовой книги, выведенный из адаптивной кодовой книги 103 посредством усиления адаптивной кодовой книги, выведенного из кодовой книги 105 усиления, и выводит результат в модуль 108 сложения.
Множитель 107 умножает вектор фиксированной кодовой книги, выведенный из фиксированной кодовой книги 104, посредством усиления фиксированной кодовой книги, выведенного из кодовой книги 105 усиления, и выводит результат в модуль 108 сложения.
Сумматор 108 складывает вектор адаптивной кодовой книги, выведенный из множителя 106, и вектор фиксированной кодовой книги, выведенный из множителя 107, и выводит результирующий вектор возбуждения в фильтр 109 синтеза LPC как возбуждение.
Фильтр 109 синтеза LPC генерирует сигнал синтеза с использованием фильтр-функции, включая квантованные параметры LPC, выведенные из секции 102 квантизации LPC, в качестве коэффициента фильтра и векторы возбуждения, сгенерированные в адаптивной кодовой книге 103 и фиксированной кодовой книге 104, как возбуждения, то есть с использованием фильтра синтеза LPC. Этот сигнал синтеза выводится в модуль 110 сложения.
Сумматор 110 вычисляет сигнал ошибки посредством вычитания сигнала синтеза, сгенерированного в фильтре 109 синтеза LPC, из речевого сигнала S11 и выводит этот сигнал ошибки в секцию 111 воспринимаемого взвешивания. Здесь, этот сигнал ошибки является эквивалентным искажению кодирования.
Секция 111 воспринимаемого взвешивания выполняет воспринимаемое взвешивание для искажения кодирования, выведенного из модуля 110 сложения, и выводит результат в секцию 112 минимизации искажения.
Секция 112 минимизации искажения находит индексы адаптивной кодовой книги 103, фиксированной кодовой книги 104 и кодовой книги 105 усиления на базисе основе подкадра, так чтобы минимизировать искажение кодирования, выведенное из секции 111 воспринимаемого взвешивания, и выводит эти индексы во вне устройства 100 кодирования CELP как кодированную информацию. Чтобы быть более конкретными, секция 112 минимизации искажения генерирует сигнал синтеза на основе вышеописанной адаптивной кодовой книги 103 и фиксированной кодовой книги 104. Здесь, последовательности обработки, чтобы находить искажение кодирования этого сигнала, формируют управление замкнутого цикла (управление обратной связи). Дополнительно, секция 112 минимизации искажения осуществляет поиск кодовых книг посредством различным образом изменения индексов, которые обозначают кодовые книги в одном подкадре, и выводит результирующие индексы кодовых книг, минимизирующие искажение кодирования.
Также, возбуждение, когда искажение кодирования минимизировано, подают назад в адаптивную кодовую книгу 103 на базисе на основе подкадра. Адаптивная кодовая книга 103 обновляет сохраненные возбуждения посредством этой обратной связи.
Ниже будет объясняться способ поиска фиксированной кодовой книги 104. Сначала поиск вектора возбуждения и кодовое вычисление выполняют посредством поиска вектора возбуждения, чтобы минимизировать искажение кодирования в следующем уравнении 1.
[1]
где:
E: искажение кодирования;
x: цель кодирования;
p: усиление вектора адаптивной кодовой книги;
H: фильтр синтеза воспринимаемого взвешивания;
a: вектор адаптивной кодовой книги;
q: усиление вектора фиксированной кодовой книги; и
s: вектор фиксированной кодовой книги.
В общем, вектор адаптивной кодовой книги и вектор фиксированной кодовой книги ищут в открытых циклах (то есть в отдельных циклах), и, следовательно, код адаптивной кодовой книги 104 выводят посредством поиска вектора фиксированной кодовой книги, чтобы минимизировать искажение кодирования, показанное в следующем уравнении 2.
[2]
где:
E: искажение кодирования
x: цель кодирования (воспринимаемо взвешенный речевой сигнал);
p: оптимальное усиление вектора адаптивной кодовой книги;
H: фильтр синтеза воспринимаемого взвешивания;
a: вектор адаптивной кодовой книги;
q: усиление вектора фиксированной кодовой книги;
s: вектор фиксированной кодовой книги; и
y: целевой вектор в поиске фиксированной кодовой книги.
Здесь, усиления p и q определяют после того, как код возбуждения выявлен так, что поиск выполняют с использованием оптимальных усилений. Затем вышеописанное уравнение 2 может быть выражено посредством следующего уравнения 3.
[3]
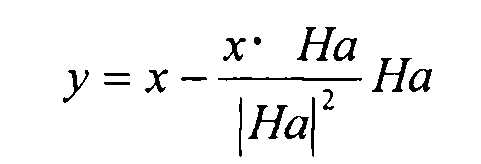
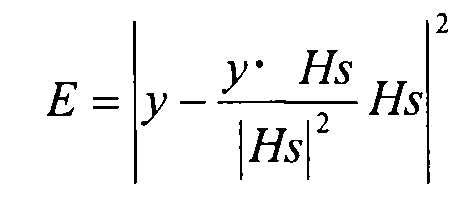
Дополнительно, минимизация этого уравнения искажения эквивалентна максимизации функции C следующего уравнения 4.
[4]
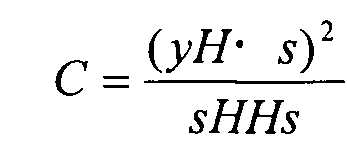 ...(Уравнение 4)
...(Уравнение 4)
Поэтому, в случае поиска возбуждения, состоящего из маленького количества импульсов, как, например, возбуждения алгебраической кодовой книги, посредством вычисления yH и HH заранее, является возможным вычислять вышеописанную функцию C с небольшим объемом вычислений. Здесь, элементы вектора yH соответствуют специфичным для импульса значениям корреляции. То есть элемент вектора yH, полученного посредством выполнения обратного по времени синтеза цели y, эквивалентен значению корреляции между сигналом синтеза импульса, который поднимается в этом положении, и целевым сигналом.
Фиг.2 - это блок-схема, показывающая конфигурацию внутри секции 112 минимизации искажения согласно настоящему варианту осуществления. Здесь будет объяснен иллюстративный случай, где, в поиске фиксированной кодовой книги в секции 112 минимизации искажения, четыре импульса, формирующих алгебраическую кодовую книгу, разделяют на два поднабора двух импульсов и ищут. Также, предполагается, что каждый импульс имеет восемь предполагаемых положений.
На фиг.2 секция 112 минимизации искажения обеспечена секцией 201 поиска адаптивной кодовой книги, секцией 202 поиска фиксированной кодовой книги и секцией 203 поиска кодовой книги усиления. Также, секция 202 поиска фиксированной кодовой книги обеспечена секцией 221 вычисления максимального значения корреляции, секцией 222 сортировки, секцией 223 предварительной обработки и секцией 224 поиска.
Секция 201 поиска адаптивной кодовой книги осуществляет поиск адаптивной кодовой книги 103 с использованием искажения кодирования в зависимости от воспринимаемого взвешивания в секции 111 воспринимаемого взвешивания. Секция 201 поиска адаптивной кодовой книги выводит код вектора адаптивной кодовой книги, полученный на этапе поиска, в адаптивную кодовую книгу 103, выводит код вектора адаптивной кодовой книги, полученный как результат поиска, в секцию 221 вычисления максимального значения корреляции в секции 202 поиска фиксированной кодовой книги и во вне устройства 100 кодирования CELP.
Секция 202 поиска фиксированной кодовой книги выполняет поиск частей адаптивной кодовой книги с использованием искажения кодирования в зависимости от воспринимаемого взвешивания в секции 111 воспринимаемого взвешивания и кода вектора адаптивной кодовой книги, принятого как ввод из секции 201 поиска адаптивной кодовой книги. Дополнительно, секция 202 поиска фиксированной кодовой книги выводит код вектора фиксированной кодовой книги, полученный на этапе поиска, в фиксированную кодовую книгу 104, и выводит код вектора фиксированной кодовой книги, полученный как результат поиска, во вне устройства 100 кодирования CELP и в секцию 203 поиска кодовой книги усиления.
Секция 203 поиска кодовой книги усиления осуществляет поиск кодовой книги усиления на основе кода вектора фиксированной кодовой книги, принятого как ввод из секции 224 поиска в секции 202 поиска фиксированной кодовой книги, искажения кодирования в зависимости от воспринимаемого взвешивания в секции 111 воспринимаемого взвешивания и кода вектора адаптивной кодовой книги, принятого как ввод из секции 201 поиска адаптивной кодовой книги. Дополнительно, секция 203 поиска кодовой книги усиления выводит усиление адаптивной кодовой книги и усиление фиксированной кодовой книги, полученные на этапе поиска, в кодовую книгу 105 усиления и выводит усиление адаптивной кодовой книги и усиление фиксированной кодовой книги, полученные как результаты поиска, во вне устройства 100 кодирования CELP.
Секция 221 вычисления максимального значения корреляции вычисляет вектор адаптивной кодовой книги с использованием кода вектора адаптивной кодовой книги, принятого как ввод из секции 201 поиска адаптивной кодовой книги, и вычисляет целевой вектор y, показанный в уравнении 2. Дополнительно, с использованием коэффициента фильтра синтеза H в секции 111 воспринимаемого взвешивания, секция 221 вычисления максимального значения корреляции вычисляет и выводит специфичное для импульса значение корреляции yH в каждом предполагаемом положении в секцию 223 предварительной обработки. Дополнительно, с использованием специфичного для импульса значения корреляции yH в каждом предполагаемом положении, секция 221 вычисления максимального значения корреляции вычисляет и выводит максимальные значения корреляции индивидуальных импульсов в секцию 222 сортировки. Здесь, вычисление максимальных значений корреляции в секции 221 вычисления максимального значения корреляции будет описано позже подробно.
Секция 222 сортировки сортирует максимальные значения корреляции индивидуальных импульсов, принятых как ввод из секции 221 вычисления максимального значения корреляции, в порядке от наибольшего максимального значения корреляции (далее "обработка сортировки"). Дополнительно, на основе результата сортировки, секция 222 сортировки разделяет четыре импульса на два поднабора двух импульсов и выводит результаты разделения в секцию 224 поиска. Обработка сортировки в секции 222 сортировки будет подробно описана позже.
Секция 223 предварительной обработки вычисляет матрицу HH с использованием коэффициента фильтра синтеза H в секции 111 воспринимаемого взвешивания. Дополнительно, из полярностей (+ и -) элементов вектора yH, принятого как ввод из секции 221 вычисления максимального значения корреляции, секция 223 предварительной обработки определяет и выводит полярности импульсов, pol, в секцию 224 поиска. Чтобы быть более конкретными, в секции 223 предварительной обработки, полярности индивидуальных импульсов, которые возникают в соответствующих положениях, координируют с полярностями значений yH в этих положениях и полярности значений yH сохраняют в другой последовательности. После того как полярности в этих положениях сохраняют в другой последовательности, секция 223 предварительной обработки делает все из значений yH абсолютными значениями, то есть секция 223 предварительной обработки преобразует значения yH в положительные значения. Дополнительно, чтобы преобразовать полярности значений HH, секция 223 предварительной обработки умножает значения HH посредством полярностей в координации с сохраненными полярностями в этих положениях. Вычисленные yH и HH выводят в секцию 224 поиска.
Секция 224 поиска выполняет поиск частей фиксированной кодовой книги с использованием результатов разделения, принятых как ввод из секции 222 сортировки, искажения кодирования в зависимости от воспринимаемого взвешивания в секции 111 воспринимаемого взвешивания, и yH и HH, принятых как ввод из секции 223 предварительной обработки. Секция 224 поиска выводит код вектора фиксированной кодовой книги, полученный на этапе поиска, в фиксированную кодовую книгу 104 и выводит код вектора фиксированной кодовой книги, полученный как результат поиска, во вне устройства 100 кодирования CELP и секцию 203 поиска кодовой книги усиления. Также, поиск частей фиксированной кодовой книги в секции 224 поиска будет подробно описан позже.
Далее обработка вычисления максимального значения корреляции каждого импульса в секции 221 вычисления максимального значения корреляции будет описана подробно.
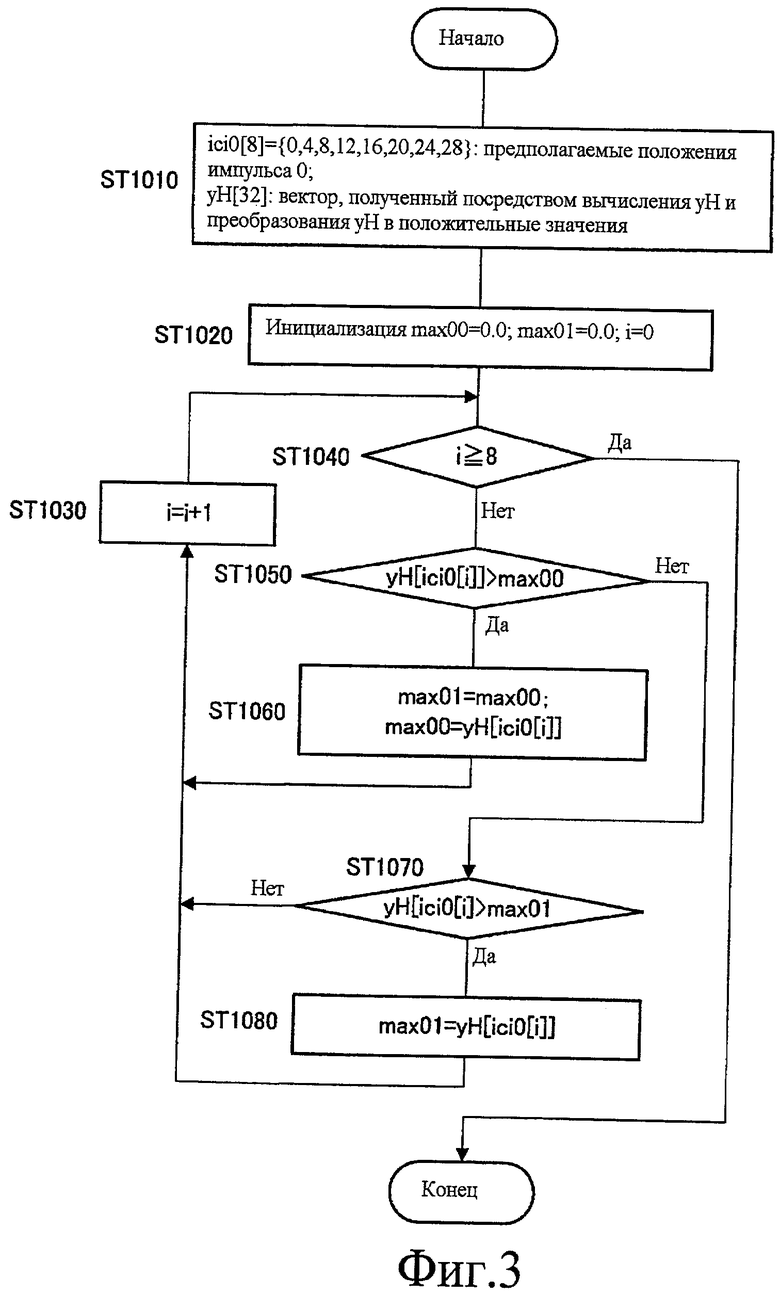
Фиг.3 - это блок-схема последовательности операций, показывающая этапы вычисления максимального значения корреляции каждого импульса в секции 221 вычисления максимального значения корреляции. Здесь будет объясняться пример обработки, где секция 221 вычисления максимального значения корреляции находит два предполагаемых положения, где значение импульса 0 (yH) является наивысшим, и, на основе этих положений, вычисляет максимальное значение корреляции импульса 0.
Сначала секция 221 вычисления максимального значения корреляции обеспечивает последовательность ici0[8] предопределенных предполагаемых положений импульса 0 и последовательность yH[32], полученную посредством преобразования значения корреляции yH, которое используется для поиска, в положительное значение (ST 1010).
Далее секция 221 вычисления максимального значения корреляции инициализирует максимальное значение max00, полумаксимальное значение (т.е. второе наивысшее значение) max01 и счетчик i (ST 1020), и этап переходит к циклу, сформированному посредством ST 1030 по ST 1080.
В этом цикле, когда значение счетчика i равно или больше чем 8 ("Да" на ST 1040), секция 221 вычисления максимального значения корреляции решает, что обработка цикла для каждого предполагаемого положения полностью завершена, и завершает обработку. В отличие от этого, когда значение счетчика i меньше чем 8 ("Нет" на ST 1040), секция 221 вычисления максимального значения корреляции решает, что обработка цикла не полностью завершена, и этап переходит на ST 1050.
Далее, если значение корреляции yH[ici0[i]] в положении, показанном посредством счетчика i, больше, чем максимальное значение max00 ("Да" на ST 1050), секция 221 вычисления максимального значения корреляции сохраняет максимальное значение max00 как полумаксимальное значение max01, присваивает значение корреляции yH[ici0[i]] в положении, показанном посредством счетчика i, максимальному значению max00 (ST 1060) и возвращает этап на ST 1030. Если значение корреляции yH[ici0[i]] в положении, показанном посредством счетчика i, равно или меньше, чем максимальное значение max00 ("Нет" на ST 1050), секция 221 вычисления максимального значения корреляции переводит этап на ST 1070.
Далее, если значение корреляции yH[ici0[i]] в положении, показанном посредством счетчика i, больше, чем полумаксимальное значение max01 ("Да" на ST 1070), секция 221 вычисления максимального значения корреляции присваивает значение корреляции yH[ici0[i]] в положении, показанном посредством счетчика i, полумаксимальному значению max01 (ST 1060) и возвращает этап на ST 1030 (ST 1080). В отличие от этого, если значение корреляции yH[ici0[i]] в положении, показанном посредством счетчика i, равно или меньше, чем полумаксимальное значение max01 ("Нет" на ST 1070), секция 221 вычисления максимального значения корреляции возвращает этап на ST 1030.
Далее, на ST 1030, секция 221 вычисления максимального значения корреляции увеличивает счетчик i на единицу и возвращает этап на ST 1040.
Таким образом, секция 221 вычисления максимального значения корреляции вычисляет максимальное значение max00 и полумаксимальное значение max01 среди значений корреляции одиночного импульса 0 в предполагаемых положениях. Дополнительно, с использованием этапов, показанных на фиг.3, секция 221 вычисления максимального значения корреляции находит два предполагаемых положения, где значения корреляции (yH) индивидуальных импульсов 1, 2 и 3 являются наивысшими. То есть секция 221 вычисления максимального значения корреляции находит max10, max11, max20, max21, max30 и max31, которые представляют максимальные значения и полумаксимальные значения индивидуальных импульсов 1, 2 и 3.
Далее, с использованием максимальных значений и полумаксимальных значений
среди значений корреляции индивидуальных импульсов 0, 1, 2 и 3, секция 221 вычисления максимального значения корреляции вычисляет максимальные значения корреляции S[0], S[1], S2[2] и S[3] индивидуальных импульсов согласно следующему уравнению 5. Как показано на фиг.5, секция 221 вычисления максимального значения корреляции находит устойчивые максимальные значения корреляции, ассоциированные с индивидуальными импульсами, посредством добавления полумаксимального значения значения корреляции при предопределенном коэффициенте к максимальному значению значения корреляции на базисе на основе импульса.
S[0] = max00 + max01×0,05
S[1] = max10 + max11×0,05
S[2] = max20 + max21×0,05
S[3] = max30 + max31×0,05...(Уравнение 5)
Далее будет подробно описана обработка сортировки над максимальным значением корреляции каждого импульса в секции 222 сортировки.
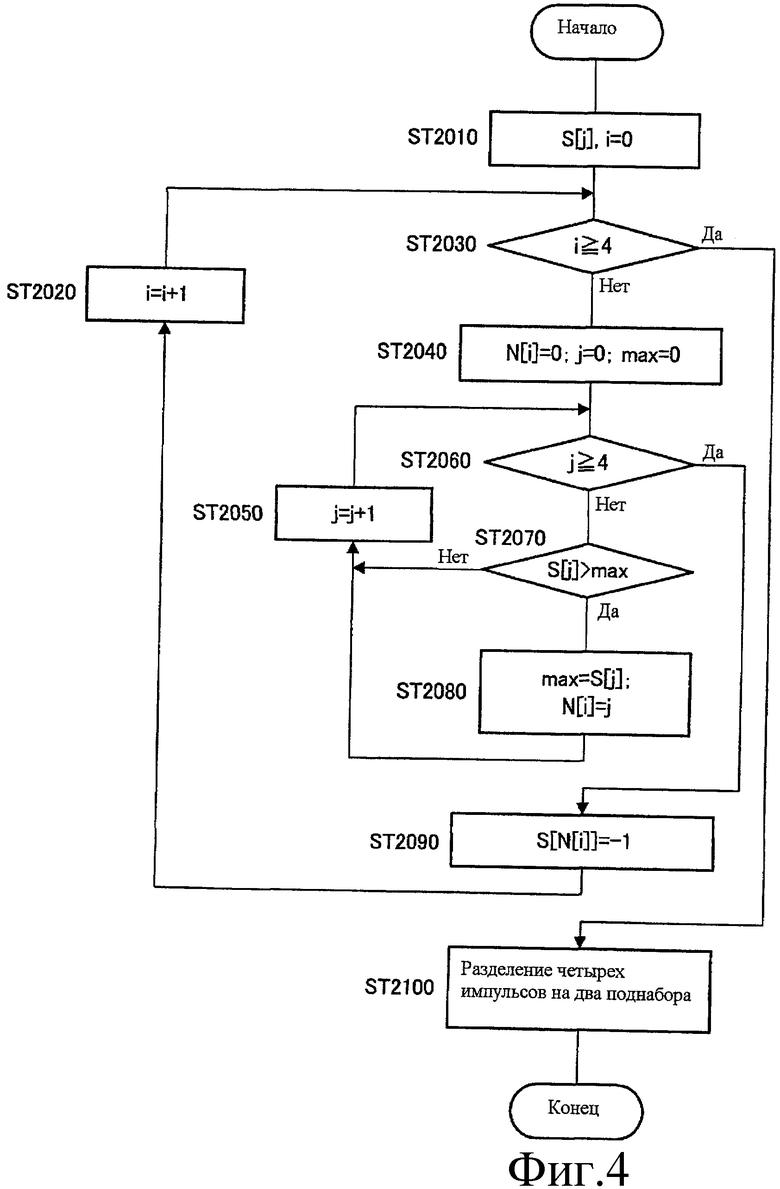
Фиг.4 - это блок-схема последовательности операций, показывающая этапы обработки сортировки максимальных значений корреляции индивидуальных импульсов в секции 222 сортировки.
Сначала секция 222 сортировки принимает как ввод максимальное значение корреляции S[j] (j=0, 1, 2, 3) каждого импульса из секции 221 вычисления максимального значения корреляции и сбрасывает в 0 счетчик i, показывающий, до какого ранга сортировка завершена (ST 2010).
Далее, когда значение счетчика i равно или больше чем 4 ("Да" на ST 2030), секция 222 сортировки решает, что сортировка полностью завершена, и переводит этап на ST 2100. В отличие от этого, когда значение счетчика i меньше чем 4 ("Нет" на ST 2030), секция 222 сортировки присваивает 0 импульсному номеру N[i], сбрасывает в 0 счетчик j для вычисления количества циклов, в которых ищут i-е максимальное значение корреляции S[N(i)], и сбрасывает переменную "max", которая хранит максимальное значение, в 0 (ST 2040).
Далее, когда значение счетчика j меньше чем 4 ("Нет" на ST 2060), секция 222 сортировки переводит этап на ST 2070.
Далее, когда максимальное значение корреляции S[j] больше, чем переменная "max" ("Да" на ST 2070), секция 222 сортировки присваивает максимальное значение корреляции S[j] переменной "max", присваивает значение счетчика j номеру импульса N[i], соответствующему i-му максимальному значению корреляции S[N[i]] (ST 2080), и переводит этап на ST 2050. В отличие от этого, когда максимальное значение корреляции S[j] равно или меньше, чем переменная "max" ("Нет" на ST 2070), секция 222 сортировки переводит этап на ST 2050. Далее, на ST 2050, секция 222 сортировки увеличивает счетчик j на единицу и возвращает этап на ST 2060.
В отличие от этого, когда значение счетчика j равно или больше чем 4 на ST 2060 ("Да" на ST 2060), секция 222 сортировки решает, что цикл, сформированный с ST 2050 по ST 2080, для поиска i-го максимального значения корреляции S[N[i]], оканчивается, и присваивает "-1" i-му максимальному значению корреляции S[N[i]] (ST 2090). Посредством этого i-е максимальное значение корреляции S[N[i]] исключают из цели обработки цикла для поиска (i+1)-го максимального значения корреляции S[N[i+1]]. Далее секция 222 сортировки увеличивает счетчик i на единицу на ST 2020 и возвращает этап на ST 2030.
Таким образом, секция 222 сортировки сортирует максимальные значения корреляции S[0], S[1], S[2] и S[3] индивидуальных импульсов в убывающем порядке и получает N[i], показывающее результат сортировки. В последующем будет объясняться иллюстративный случай, где секция 222 сортировки получает N[i]={2, 0, 3, 1}. То есть предполагается, что импульсный номер N[0], соответствующий наивысшему максимальному значению корреляции S[N[0]], - это 2, затем следуют 0, 3 и 1 в порядке.
Далее, на ST 2100, секция 222 сортировки определяет порядок поиска импульсов посредством группирования четырех импульсных чисел, N[i], соответствующих отсортированным максимальным значениям корреляции, в два шаблона разделения предопределенных поднаборов и выводит результирующий порядок поиска в секцию 224 поиска. То есть, до поиска частей фиксированной кодовой книги в секции 224 поиска, секция 222 сортировки определяет номера двух импульсов, подлежащих поиску первыми, и номера двух импульсов, подлежащих поиску далее. В секции 222 сортировки три предполагаемых шаблона порядка поиска, показанные в следующем уравнении 6, устанавливают заранее.
шаблон:
шаблон:
шаблон:
В поиске частей имеется много типов шаблонов разделения для поднабора, подлежащего поиску первым (т.е. первого поднабора), и для поднабора, подлежащего поиску следующим (т.е. второго поднабора). Для этих шаблонов разделения, как показано в уравнении 6, посредством принятия шаблона разделения, где импульс N[0] наивысшего максимального значения корреляции включен в поднабор, подлежащий поиску первым (т.е. первый поднабор), является возможным обеспечивать хорошую эффективность кодирования.
В каждом предполагаемом порядке поиска в уравнении 6 поиск выполняют в порядке от поднабора, подлежащего поиску первым (первого поднабора), к поднабору, подлежащему поиску вторым (второму поднабору).
Если N[i] в уравнении 6 выражен посредством конкретных значений, полученных посредством сортировки, получают следующее уравнение 7 и поиск выполняют в порядке от первого предполагаемого шаблона ко второму предполагаемому шаблону и к третьему предполагаемому шаблону.
шаблон:
шаблон:
шаблон:
Три порядка поиска, показанные в уравнении 7, могут быть сгруппированы в M[3][4], показанные в следующем уравнении 8. Здесь, M[3][4] представляет порядок поиска импульсов в случае выполнения поиска частей для набора четырех импульсов три раза.
M[3][4]={{2,0,3,1},{2,3,1,0},{2,1,0,3}}...(Уравнение 8)
То есть секция 222 сортировки выводит M[3][4] в секцию 224 поиска как порядок поиска.
Далее поиск частей фиксированной кодовой книги в секции 224 поиска будет описываться подробно.
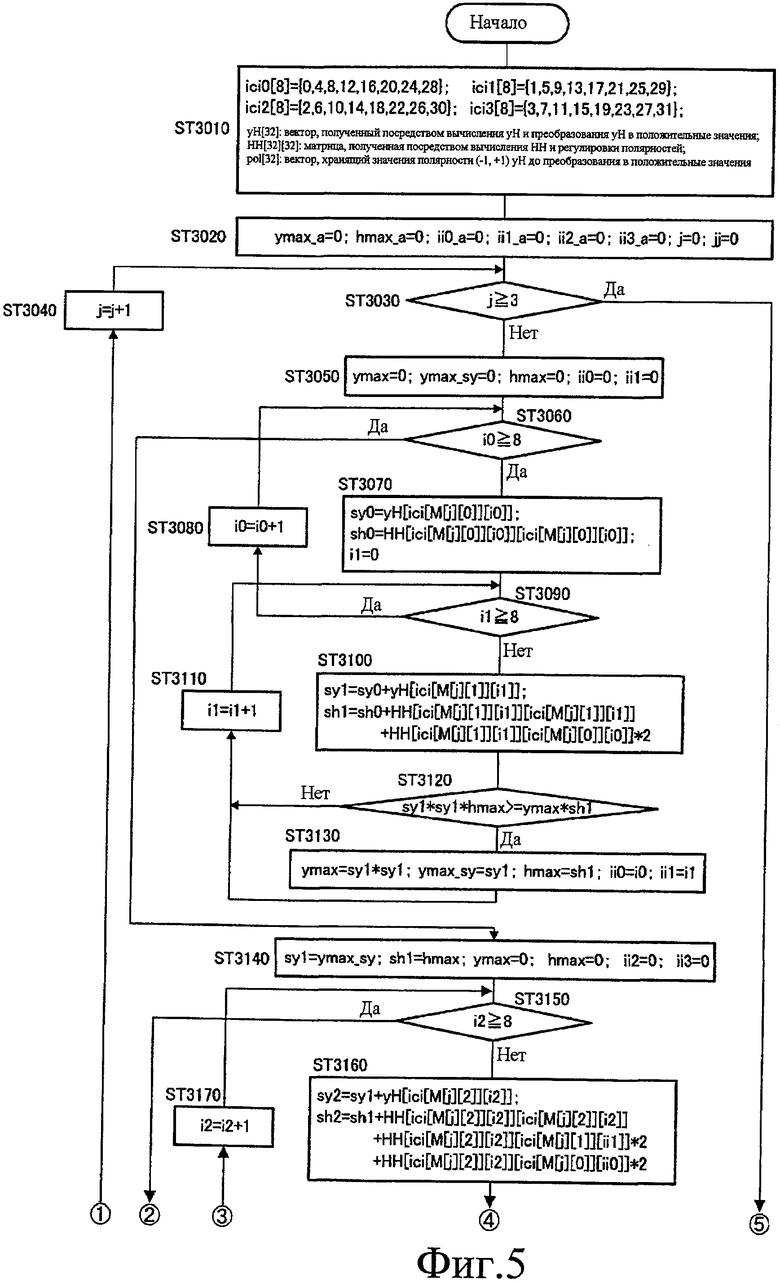
Фиг.5 и фиг.6 - это блок-схемы последовательности операций, показывающие этапы поиска частей фиксированной кодовой книги в секции 224 поиска. Здесь, параметры алгебраической кодовой книги показаны ниже.
С этими параметрами конструируют следующую алгебраическую кодовую книгу.
ici0[8]={0, 4, 8, 12, 16, 20, 24, 28}
ici1[8]={1, 5, 9, 13, 17, 21, 25, 29}
ici2[8]={2, 6, 10, 14, 18, 22, 26, 30}
ici3[8]={3, 7, 11, 15, 19, 23, 27, 31}
Сначала, на ST 3010, секция 224 поиска готовит последовательности ici0[8], ici1[8], ici2[8] и ici3[8], показывающие предполагаемые положения четырех импульсов фиксированной кодовой книги, и готовит последовательность yH[32], полученную посредством преобразования yH в положительные значения, последовательность HH[32][32], полученную посредством регулировки полярностей HH, и вектор pol[32], хранящий значения полярности (-1, +1) yH перед тем, как yH преобразуют в положительные значения. Далее, на ST 3020, инициализируют переменные, которые используют в последующем цикле поиска.
Секция 224 поиска сравнивает "j" и значение "3" на ST 3030, и если "j" равно или больше чем 3, переводит этап на ST 3250 для завершения поиска, и если "j" меньше чем 3, переводит этап на инициализацию ST 3050. На ST 3040, "j" увеличивают на единицу. Посредством этого секция 224 поиска выполняет поиск частей для набора двух поднаборов три раза согласно трем порядкам поиска, показанным в порядке поиска M[3][4], принятом как ввод из секции 222 сортировки.
ST 3050 по ST 3130 показывают обработку цикла поиска, первого поднабора. Чтобы быть более конкретными, на ST 3050, цикл поиска для первого поднабора инициализируют. Далее, на ST 3060, секция 224 поиска сравнивает i0 и значение "8" и, если i0 равно или больше чем 8, переводит этап на ST 3140 для инициализации следующего цикла поиска или, если i0 меньше чем 8, переводит этап на этап ST 3070. На ST 3070, вычисляют значение корреляции sy0 и мощность возбуждения sh0 импульса, показанного посредством M[j][0] (j=0, 1, 2). Дополнительно, счетчик i1 инициализируют на нуль. Далее на ST 3080, i0 увеличивают на единицу. Посредством этого секция 224 поиска выполняет обработку цикла восемь раз для восьми предполагаемых положений импульсов, показанных посредством M[j][0] (J=0, 1, 2). Аналогично, на ST 3090 по ST 3130, секция 224 поиска выполняет обработку цикла восемь раз для восьми предполагаемых положений импульсов, показанных посредством M[j][1] (j=0, 1, 2).
Сначала "i1" и значение "8" сравнивают на решении ST 3090, и, если "i1" равно или больше чем 8, этап переходит на этап ST 3080 увеличения, или, если "i1" меньше чем 8, этап переходит на этап ST 3100. На ST 3100, секция 224 поиска вычисляет значение корреляции sy1 и мощность возбуждения sh1 импульса, показанного посредством M[j][1] (j=0, 1, 2), с использованием значения корреляции sy0 и мощности возбуждения sh0, вычисленных на ST 3070, в дополнение к yH и HH, принятым как ввод из секции 223 предварительной обработки.
На ST 3120, секция 224 поиска вычисляет и сравнивает значения функции C согласно уравнению 4, с использованием значений корреляции и мощностей возбуждения индивидуальных импульсов, которые являются целями обработки в первом поднаборе, перезаписывает и сохраняет i0 и i1 более высоких функциональных значений в ii0 и ii1 и дополнительно перезаписывает и сохраняет член числителя и член знаменателя функции C (ST 3130). Здесь, на ST 3120, разделения, требующего некоторой большой величины вычислений, избегают и вычисление и сравнение выполняют посредством перекрестного умножения членов знаменателя и членов числителя. В вышеописанном решении, если значения корреляции ниже или если значения корреляции выше и выполняют обработку на ST 3130, этап переходит на этап ST 3110 увеличения. На этапе ST 3110 увеличения, "i1" увеличивают на единицу.
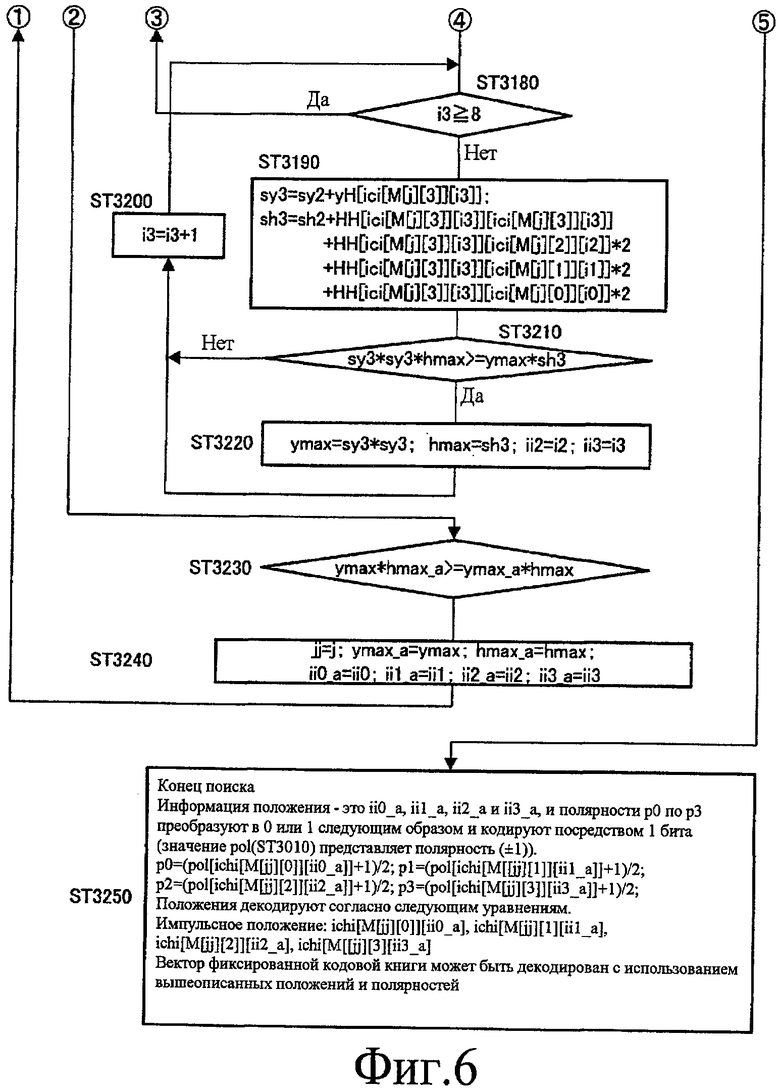
ST 3140 по ST 3220 показывает обработку цикла поиска второго поднабора. Здесь, обработка цикла поиска второго поднабора принимает в основном такие же этапы, как в обработке цикла поиска первого поднабора, показанной на ST 3050 по ST 3130. Здесь, будут описываться только отличия от обработки цикла поиска первого поднабора. Сначала, на ST 3140, инициализацию обработки цикла поиска второго поднабора выполняют с использованием результата обработки цикла поиска первого поднабора. Также, цель обработки цикла поиска второго поднабора - это импульсы, показанные посредством M[j][2] (j=0, 1, 2) и M[j][3] (j=0, 1, 2). Также, на ST 3160, значение корреляции sy2 и мощность возбуждения sh2 импульса 2 вычисляют с использованием информации счетчика ii0 и ii1, которые ищут и сохраняют в цикле поиска для первого поднабора. Также, аналогично, на ST 3190, значение корреляции sy3 и мощность возбуждения sh3 импульса 3 вычисляют с использованием информации счетчика ii0 и ii1, которые ищут и сохраняют в цикле поиска для первого поднабора.
Далее, на ST 3230 и ST 3240, секция 224 поиска находит комбинацию импульсных положений, в которых значение функции C является наивысшим во всем поиске частей.
Далее, на ST 3250, секция 224 поиска выбирает ii0, ii1, ii2 и ii3 как информацию положения импульсов. Также, значение последовательности pol представляет полярность (±1), и секция 224 поиска преобразует полярности p0, p1, p2 и p3 в 0 или 1 согласно следующему уравнению 9 и кодирует результаты посредством одного бита.
p0=(pol[ichi0[ii0]]+1)/2
p1=(pol[ichi1[ii1]]+1)/2
p2=(pol[ichi2[ii2]]+1)/2
p3=(pol[ichi3[ii3]]+1)/2...(Уравнение 9)
Здесь, в качестве способа декодирования информации положения и полярностей, импульсные положения декодируют с использованием ichi0[ii0], ichi1[ii1], ichi2[ii2] и ichi3[ii3] и вектор фиксированной кодовой книги декодируют с использованием декодированных положений и полярностей.
Как показано на фиг.5 и фиг.6, секция 224 поиска выполняет поиск частей для двух поднаборов, так что является возможным уменьшать величину вычислений значительно, по сравнению со случаем полного поиска. Чтобы быть более конкретными, в то время как обработку цикла выполняют 4096 (84) раз в полном поиске, согласно способу, показанному на фиг.5 и фиг.6, обработку цикла выполняют 64 (82) раза для поиска в каждых двух поднаборах. Дополнительно, согласно M[3][4] поиск частей для набора двух поднаборов выполняют три раза и, как результат, обработку цикла выполняют 384 (64×2 (поднаборов)×3) раза в целом. Это является одной десятой величины вычислений в случае полного поиска.
Таким образом, согласно настоящему варианту осуществления выполняют поиск частей фиксированной кодовой книги, так что является возможным уменьшать величину вычислений, по сравнению со случаем выполнения полного поиска.
Дополнительно, согласно настоящему варианту осуществления, в поиске частей, при разделении импульсов, формирующих фиксированную кодовую книгу на поднабор, подлежащий поиску первым, и поднабор, подлежащий поиску далее, поднабор, подлежащий поиску первым, формируют с использованием импульса наивысшего максимального значения корреляции, так что является возможным подавлять искажение кодирования, вызванное поиском частей. То есть, даже в случае выполнения полного поиска, импульс в положении более высокого максимального значения корреляции скорей всего должен приниматься, так что является возможным подавлять искажение кодирования посредством предварительного поиска импульса в поиске частей.
Также, хотя выше был описан случай с настоящим вариантом осуществления, где количество импульсов - это четыре и количество разделений - это два, настоящее изобретение не зависит от количества импульсов или количества разделений, и, посредством определения порядка импульсов, подлежащих поиску на основе результата сортировки максимальных значений корреляции индивидуальных импульсов, является возможным обеспечивать такой же эффект, как настоящий вариант осуществления.
Также, выше с настоящим вариантом осуществления был описан иллюстративный случай, где секция 221 вычисления максимального значения корреляции вычисляет максимальное значение корреляции посредством добавления полумаксимального значения значения корреляции при предопределенном коэффициенте к максимальному значению значения корреляции на базисе на основе импульса. Однако настоящее изобретение не ограничено этим, и также равным образом возможно вычислять максимальные значения корреляции посредством добавления третьих наивысших значений корреляции при предопределенном коэффициенте к вышеописанным значениям в индивидуальных импульсах, или также равным образом возможно использовать максимальное значение среди значений корреляции индивидуальных импульсов, как для максимальных значений корреляции.
Также, хотя выше с настоящим вариантом осуществления был описан иллюстративный случай, где предполагаемые положения каждого импульса не выбирают предварительно, настоящее изобретение не ограничено этим, и является равным образом возможным выполнять сортировку после того, как предполагаемые положения каждого импульса выбирают предварительно. Посредством этого является возможным улучшать действенность сортировки.
Также, хотя выше с настоящим вариантом осуществления был описан иллюстративный случай, где алгебраическую кодовую книгу используют в качестве фиксированной кодовой книги, настоящее изобретение не ограничено этим, и является равным образом возможным использовать многоимпульсную кодовую книгу в качестве фиксированной кодовой книги. То есть является возможным реализовывать настоящий вариант осуществления с использованием информации положения и информации полярности множественных импульсов.
Также, хотя выше с настоящим вариантом осуществления был описан иллюстративный случай, где схему кодирования CELP используют в качестве схемы кодирования речи, настоящее изобретение не ограничено этим, и существенным требованием является принимать схему кодирования с использованием кодовой книги, которая хранит векторы возбуждения, где количество векторов возбуждения известно. Это из-за того, что поиск частей согласно настоящему изобретению выполняют только для поиска фиксированной кодовой книги, и не зависит от того, присутствует ли или нет адаптивная кодовая книга и является ли или нет способ анализа спектральной огибающей одним из LPC, FFT и блока фильтров.
Вариант 2 осуществления
Вариант 2 осуществления настоящего изобретения является в основном таким же, как вариант 1 осуществления, и отличается от варианта 1 осуществления только в обработке сортировки в секции 222 сортировки (см. фиг.4). В последующем секции сортировки в этом настоящем варианте осуществления назначена ссылочная позиция "422" и помещена вместо секции 222 сортировки, и будет объяснена только обработка сортировки в секции 422 сортировки (не показана).
Фиг.7 - это блок-схема последовательности операций, показывающая этапы обработки сортировки максимального значения корреляции каждого импульса в секции 422 сортировки согласно настоящему варианту осуществления. Здесь, этапы, показанные на фиг.7, включают в себя в основном одни и те же этапы, как на фиг.4, и, следовательно, одним и тем же этапам будут назначены одни и те же ссылочные позиции и их описания будут пропущены.
На ST 4040, секция 422 сортировки присваивает "0" импульсному номеру N[i], сбрасывает счетчик j, который считает количество циклов для поиска i-го максимального значения корреляции S[N[i]], в "0", сбрасывает переменную "max", хранящую максимальное значение, в "0" и присваивает "0" переменной L[i] для хранения i-го максимального значения корреляции S[N[i]].
На ST 4090, секция 422 сортировки присваивает i-е максимальное значение корреляции S[N[i]] для L[i] и присваивает "-1" для S[N[i]]. Посредством этого i-е максимальное значение корреляции S[N[i]] хранят в L[i] и также исключено из цели обработки цикла для поиска (i+1)-го максимального значения корреляции S[N[i+1]].
Посредством обработки на ST 2010 по ST 4090, секция 422 сортировки сортирует максимальные значения корреляции S[0], S[1], S[2] и S[3] индивидуальных импульсов в убывающем порядке и получает N[i] и L[i], показывающие результат сортировки.
На ST 4100, секция 422 сортировки определяет порядок поиска импульсов посредством группирования четырех импульсных чисел, N[i], соответствующих отсортированным максимальным значениям корреляции, в два шаблона разделения предопределенных поднаборов и выводит результирующий порядок поиска в секцию 224 поиска. То есть, до поиска частей фиксированной кодовой книги в секции 224 поиска, секция 422 сортировки определяет номера двух импульсов, подлежащих поиску первыми, и номера двух импульсов, подлежащих поиску далее. В секции 422 сортировки три предполагаемых шаблона порядка поиска устанавливают заранее. Здесь, отличие от секции 222 сортировки варианта 1 осуществления состоит в том, что, для третьего предполагаемого положения, порядок поиска определяют с использованием L[i], хранящего максимальные значения корреляции.
Чтобы быть более конкретными, сначала секция 422 сортировки устанавливает два предполагаемых порядка поиска первого предполагаемого положения и второго предполагаемого положения, показанных в следующем уравнении 10, с использованием результата сортировки N[i]. То есть, как показано в уравнении 10, секция 422 сортировки включает в себя импульс наивысшего максимального значения корреляции в поднабор, подлежащий поиску первым, в первом предполагаемом положении и втором предполагаемом положении, тем самым, улучшая эффективность кодирования.
положение:
положение:
Далее секция 422 сортировки устанавливает третий предполагаемый порядок поиска с использованием результата сортировки N[i] и L[i] следующим образом. То есть секция 422 сортировки решает, равно или больше L[2]+L[3] чем (L[0]+L[1])×0,91, и если L[2]+L[3] равно или больше чем (L[0]+L[1])×0,91, принимает {N[2], N[3]} {N[0], N[1]} в качестве третьего предполагаемого положения. Если L[2]+L[3] меньше чем (L[0]+L[1])×0,91, секция 422 сортировки затем решает, равно или больше L[1]+L[3] чем (L[0]+L[2])×0,94. Если L[1]+L[3] равно или больше чем (L[0]+L[2])×0,94, секция 422 сортировки принимает {N[1], N[3]} {N[2], N[0]} в качестве третьего предполагаемого положения. Если L[1]+L[3] меньше чем (L[0]+L[2])×0,94, секция 422 сортировки затем решает, равно или больше L[0]+L[3] чем L[1]+L[2]. Если L[0]+L[3] равно или больше чем L[1]+L[2], секция 422 сортировки генерирует {N[0], N[3]} {N[1], N[2]} в качестве третьего предполагаемого положения или, если L[0]+L[3] меньше чем L[1]+L[2], принимает {N[1], N[2]} {N[3], N[0]} в качестве третьего предполагаемого положения.
При принятии третьего предполагаемого порядка поиска, когда различия между максимальными значениями корреляции импульсов являются маленькими, секция 422 сортировки формирует поднабор, подлежащий поиску первым, который не всегда включает в себя импульс наивысшего максимального значения корреляции, чтобы уменьшать избыточность поиска в последующей секции 224 поиска. То есть секция 442 сортировки формирует множество комбинаций максимальных значений корреляции индивидуальных импульсов на основе результата сортировки N[i] и группирует четыре импульса в два поднабора на основе результата сравнения множества сформированных комбинаций, умноженных на некоторый коэффициент.
Например, когда N[i]={2, 0, 3, 1} и L[i]={9,5, 9,0, 8,5, 8,0} найдены как результат сортировки, L[2]+L[3] меньше чем (L[0]+L[1])×0,91 и L[1]+L[3] больше или равно (L[0]+L[2])×0,94. Поэтому секция 422 сортировки принимает {N[1], N[3]} {N[2], N[0]} в качестве третьего предполагаемого положения.
Когда N[i] представлены посредством конкретных значений, первое, второе и третье предполагаемые положения выражают в следующем уравнении 11.
положение:
положение:
положение:
Три предполагаемых порядка поиска, показанные в уравнении 11, могут быть группированы в M[3][4], показанные в следующем уравнении 12.
M[3][4]={{2,0,3,1},{2,3,1,0},{0,1,3,2}}...(Уравнение 12)
Секция 422 сортировки выводит M[3][4] в секцию 224 поиска как предполагаемые порядки поиска.
Таким образом, согласно настоящему варианту осуществления, при разделении импульсов, формирующих фиксированную кодовую книгу, на поднабор, подлежащий поиску первым, и поднабор, подлежащий поиску далее, в поиске частей, поднабор, подлежащий поиску первым, который не всегда включает в себя импульс наивысшего максимального значения корреляции, формируют на основе не только порядка максимальных значений корреляции индивидуальных импульсов, но также значений максимальных значений корреляции этих импульсов. Посредством этого является возможным уменьшать избыточность поиска в поиске частей.
Также, хотя выше с настоящим вариантом осуществления был описан иллюстративный случай, где коэффициенты, такие как 0,91 и 0,94 используют, чтобы принимать третий предполагаемый порядок поиска, настоящее изобретение не ограничено этим и является равным образом возможным использовать другие коэффициенты, определенные статистически заранее.
Также, хотя выше с настоящим вариантом осуществления был описан иллюстративный случай, где L[i] дополнительно используют в дополнение к N[i], чтобы принимать третий предполагаемый порядок поиска, настоящее изобретение не ограничено этим, и является равным образом возможным использовать как N[i], так и L[i] даже в случае принятия первого предполагаемого порядка поиска или второго предполагаемого порядка поиска.
Вариант 3 осуществления
Вариант 3 осуществления является в основном таким же, как вариант 1 осуществления, и отличается от варианта 1 осуществления только в том, что импульсы, сгруппированные в поднаборы, дополнительно переставляют согласно предопределенному порядку. То есть настоящий вариант осуществления отличается от варианта 1 осуществления только в части обработки сортировки, показанной на фиг.4. В последующем секции сортировки в этом настоящем варианте осуществления назначена ссылочная позиция "522" и она помещена вместо секции 222 сортировки, и будет объяснена только обработка сортировки в секции 522 сортировки (не показана).
Фиг.8 - это блок-схема последовательности операций, показывающая этапы обработки сортировки максимальных значений корреляции индивидуальных импульсов в секции 522 сортировки согласно настоящему варианту осуществления. Здесь, этапы, показанные на фиг.8, включают в себя в основном такие же этапы, как на фиг.4, и, следовательно, таким же этапам будут назначены такие же ссылочные позиции и их описания будут опущены.
На ST 5100 на фиг.8, хотя секция 522 сортировки выполняет в основном такую же обработку, как обработка на ST 2100 на фиг.4, выполняемая секцией 222 сортировки согласно варианту 1 осуществления, секция 522 сортировки отличается от секции 222 сортировки в том, что нет вывода результирующего M[3][4], как такового, и в выводе его в секцию 224 поиска после последующей обработки на ST 5110 вместо этого.
На ST 5110, секция 522 сортировки формирует M'[6][2] посредством группирования элементов, включенных в M[3][4], в пары двух импульсов и выполняет регулировку перестановки порядка двух импульсов, включенных в M'[6][2], в один из {0, 1}, {1, 2}, {2, 3}, {3, 0}, {0, 2} и {1, 3}.
Фиг.9 - это блок-схема последовательности операций, показывающая этапы в секции 522 сортировки на ST 5110, показанном на фиг.8.
Сначала, на ST 6010, секция 522 сортировки инициализирует переменную "i" в "0".
Далее, на ST 6020, секция 522 сортировки решает, равно ли "i" "6".
Если решено на ST 6020, что "i" равно "6" ("Да" на ST 6020), секция 522 сортировки заканчивает обработку, показанную на фиг.9 (т.е. обработку на ST 5110).
В отличие от этого, если решено на ST 6020, что "i" не равно "6" ("Нет" на ST 6020), секция 522 сортировки переводит этап на ST 6030.
На ST 6030, секция 522 сортировки решает, истинно ли, что M'[i][1]="2" и M'[i][2]="1".
Если решено на ST 6030, что M'[i][1]="2" и M'[i][2]="1" ("Да" на ST 6030), секция 522 сортировки устанавливает M'[i][1] в "1" и M'[i][2] в "2" на ST 6040 и переводит этап на ST 6150.
В отличие от этого, если решено на ST 6030, что два условия M'[i][1]="2" и M'[i][2]="1" не встречаются в одно и то же время ("Нет" на ST 6030), секция 522 сортировки переводит этап на ST 6050.
На ST 6050, секция 522 сортировки решает, истинно ли, что M'[i][1]="3" и M'[i][2]="2".
Если решено на ST 6050, что M'[i][1]="3" и M'[i][2]="2" ("Да" на ST 6050), секция 522 сортировки устанавливает M'[i][1] в "2" и M'[i][2] в "3" на ST 6060 и переводит этап на ST 6150.
В отличие от этого, если решено на ST 6050, что два условия M'[i][1]="3" и M'[i][2]="2" не удовлетворены в одно и то же время ("Нет" на ST 6050), секция 522 сортировки переводит этап на ST 6070.
На ST 6070, секция 522 сортировки решает, истинно ли, что M'[i][1]="4" и M'[i][2]="3".
Если решено на ST 6070, что M'[i][1]="4" и M'[i][2]="3" ("Да" на ST 6070), секция 522 сортировки устанавливает M'[i][1] в "3" и M'[i][2] в "4" на ST 6080 и переводит этап на ST 6150.
В отличие от этого, если решено на ST 6070, что два условия M'[i][1]="4" и M'[i][2]="3" не удовлетворены в одно и то же время ("Нет" на ST 6070), секция 522 сортировки переводит этап на ST 6090.
На ST 6090, секция 522 сортировки решает, истинно ли, что M'[i][1]="1" и M'[i][2]="4".
Если решено на ST 6090, что M'[i][1]="1" и M'[i][2]="4" ("Да" на ST 6090), секция 522 сортировки устанавливает M'[i][1] на "4" и M'[i][2] на "1" на ST 6100 и переводит этап на ST 6150.
В отличие от этого, если решено на ST 6090, что два условия M'[i][1]="1" и M'[i][2]="4" не удовлетворены в одно и то же время ("Нет" на ST 6090), секция 522 сортировки переводит этап на ST 6110.
На ST 6110, секция 522 сортировки решает, истинно ли, что M'[i][1]="3" и M'[i][2]="1".
Если решено на ST 6110, что M'[i][1]="3" и M'[i][2]="1" ("Да" на ST 6110), секция 522 сортировки устанавливает M'[i][1] в "1" и M'[i][2] в "3" на ST 6120 и переводит этап на ST 6150.
В отличие от этого, если решено на ST 6110, что два условия M'[i][1]="3" и M'[i][2]="1" не удовлетворены в одно и то же время ("Нет" на ST 6110), секция 522 сортировки переводит этап на ST 6130.
На ST 6130, секция 522 сортировки решает, истинно ли, что M'[i][1]="4" и M'[i][2]="2".
Если решено на ST 6130, что M'[i][1]="4" и M'[i][2]="2" ("Да" на ST 6130), секция 522 сортировки устанавливает M'[i][1] на "2" и M'[i][2] на "4" на ST 6140 и переводит этап на ST 6150.
В отличие от этого, если решено на ST 6130, что два условия M'[i][1]="4" и M'[i][2]="2" не удовлетворены в одно и то же время ("Нет" на ST 6130), секция 522 сортировки переводит этап на ST 6150.
На ST 6150, секция 522 сортировки увеличивает "i" на единицу и переводит этап на ST 6020.
Например, если секция 522 сортировки формирует M'[6][2]={{2, 0}, {3, 1}, {2, 3}, {1, 0}, {2, 1}, {0, 3}} с использованием M[3][4]={{2, 0, 3, 1}, {2, 3, 1, 0}, {2, 1, 0, 3}} и дополнительно регулирует порядок пар двух импульсов, включенных в M'[6][2], согласно этапам, показанным на фиг.9, находится M'[6][2]={{0, 2}, {1, 3}, {2, 3}, {0, 1}, {1, 2}, {3, 0}}. Дополнительно, секция 522 сортировки формирует M[3][4]={{0, 2, 1, 3}, {2, 3, 0, 1}, {1, 2, 3, 0}} снова с использованием M'[6][2]={{0, 2}, {1, 3}, {2, 3}, {0, 1}, {1, 2}, {3, 0}}, полученного посредством регулировки, и выводит его в секцию 224 поиска.
Ниже будет описан эффект обработки регулировки в секции 522 сортировки, показанной на фиг.9.
Поиск импульсов, формирующих фиксированную кодовую книгу, выполнен посредством поиска импульсных положений и полярностей, посредством которых функция C в вышеописанном уравнении 4 максимизирована. Поэтому, при поиске, необходима память (RAM: оперативное запоминающее устройство) для матрицы HH члена знаменателя в уравнении 4. Например, когда длина вектора возбуждения - 32, необходима память, которая поддерживает половину 32×32 матрицы, включая в себя диагональный вектор. То есть необходима память из (32×32/2+16) байтов=528 байтов. Здесь необходима память, которая поддерживает полную матрицу (32×32 байтов=1024 байтов), чтобы уменьшать величину вычислений, требуемую, чтобы осуществлять доступ к назначенному индексу при вычислении, и, следовательно, необходима более большая память.
По сравнению с этим, как настоящее изобретение, посредством предварительного разделения импульсов, формирующих фиксированную кодовую книгу на пары поднабора, подлежащего поиску первым, и поднабора, подлежащего поиску далее, и посредством поиска импульсов в базисе на основе пары, требуется только матрица 8×8 (квадрат количества вхождений на пару), так что является возможным сохранять емкость памяти до 8×8×6=384 байтов. В этом случае эта матрица не является симметрической матрицей, и, следовательно, матрица изменяется, если порядок импульсных чисел обращают. Как результат, является необходимым дополнительно подготавливать обратную матрицу (что удваивает емкость памяти), изменять способ доступа при поиске (что увеличивает величину вычислений) или подготавливать программу на основе комбинации пары (что увеличивает емкость памяти и величины вычислений). Поэтому настоящий вариант осуществления переставляет порядок импульсов при поиске на основе пары и ограничивает полный поиск до шести пар. Посредством этого является возможным ограничивать емкость памяти, требуемую для импульсного поиска, до 384 байтов, как выше, и уменьшать объем вычислений.
Таким образом, согласно настоящему варианту осуществления, при группированиях импульсов, формирующих фиксированную кодовую книгу, в пары, импульсы, подлежащие группированию, переставляют в предопределенном порядке и ищут в базисе на основе пары, так что является возможным уменьшать емкость памяти и величины вычислений, которые требуются для поиска фиксированной кодовой книги.
Также, хотя выше с настоящим вариантом осуществления был описан иллюстративный случай, где пары импульсов, подлежащие поиску, ограничены до шести шаблонов {0, 1}, {1, 2}, {2, 3}, {3, 0}, {0, 2} и {1, 3}, настоящее изобретение не ограничено этим, и является равным образом возможным обращать порядок импульсов, включенных в вышеописанные пары, что не изменяет среднюю эффективность поиска импульса.
Варианты осуществления настоящего изобретения были описаны выше.
Также, фиксированная кодовая книга согласно вышеописанным вариантам осуществления может указываться как "шумовая кодовая книга", "стохастическая кодовая книга" или "случайная кодовая книга".
Также, адаптивная кодовая книга может указываться как "адаптивная кодовая книга возбуждения", и фиксированная кодовая книга может указываться как "фиксированная кодовая книга возбуждения".
Также, LSP может указываться как "LSF (линейная спектральная частота)", и LSF может быть заменена LSP. Также, хотя является возможным случай, где пары ISP (иммитансные спектральные пары) кодируют как спектральные параметры вместо LSP, в этом случае, посредством подстановки ISP вместо LSP, является возможным реализовывать вышеописанные варианты осуществления как устройство кодирования ISP.
Хотя выше был описан случай с вышеописанными вариантами осуществления в качестве примера, где настоящее изобретение реализовано средствами аппаратного обеспечения, настоящее изобретение может быть реализовано средствами программного обеспечения.
Дополнительно, каждый функциональный блок, примененный в описании каждого из вышеупомянутых вариантов осуществления, может обычно быть реализован как LSI, реализованный в виде интегральной схемы. Они могут быть отдельными микросхемами или частично или полностью содержаться на одиночной микросхеме. Здесь принято "LSI", но это может также быть указано как "IC", "система LSI", "супер LSI" или "ультра LSI" в зависимости от отличающихся степеней интеграции.
Дополнительно, способ схемной интеграции не ограничен LSI, и также является возможным вариант осуществления с использованием выделенных схем или процессоров общего назначения. После производства LSI, использование FPGA (программируемой пользователем вентильной матрицы) или процессора с перестраиваемой конфигурацией, где соединения и настройки схемных ячеек в LSI могут быть реконфигурированы, является также возможным.
Дополнительно, если выйдет технология интегральных схем, чтобы заменить LSI как результат развития полупроводниковой технологии или производной другой технологии, является естественно также возможным выполнять интеграцию функциональных блоков с использованием этой технологии. Применение биотехнологии также является возможным.
Раскрытия японской патентной заявки номер 2007-196782, поданной 27 июля 2007, японской патентной заявки номер 2007-260426, поданной 3 октября 2007, и японской патентной заявки номер 2008-007418, поданной 16 января 2008, включая описания, чертежи и рефераты, включены сюда по ссылке в их полноте.
Промышленная применимость
Устройство кодирования речи и способ кодирования речи согласно настоящему изобретению обеспечивают возможность кодирования речи посредством фиксированной кодовой книги с эффективным использованием битов и являются применимыми к, например, мобильным телефонам в системе мобильной связи.
Изобретение относится к устройству и способу кодирования речи, в частности к устройству и способу кодирования речи для выполнения поиска фиксированной кодовой книги. Техническим результатом является улучшение эффективности кодирования при выполнении поиска разделения над алгебраической кодовой книгой в кодировании аудио. Указанный результат достигается тем, что устройство кодирования речи содержит секцию вычисления, которая вычисляет значения корреляции в предполагаемых положениях импульсов с использованием целевого сигнала и множества импульсов, формирующих фиксированную кодовую книгу, и вычисляет на базисе на основе импульса репрезентативные значения импульсов с использованием максимальных значений корреляции; секцию сортировки, которая сортирует репрезентативные значения, полученные на базисе на основе импульса, группирует импульсы, соответствующие отсортированным репрезентативным значениям, в множество предопределенных поднаборов и определяет первый поднабор, подлежащий поиску первым, среди множества поднаборов; и секцию поиска, которая осуществляет поиск фиксированной кодовой книги с использованием первого поднабора и получает показывающие код позиции и полярности множества импульсов для минимизации искажения кодирования. 2 н. и 7 з.п. ф-лы, 9 ил.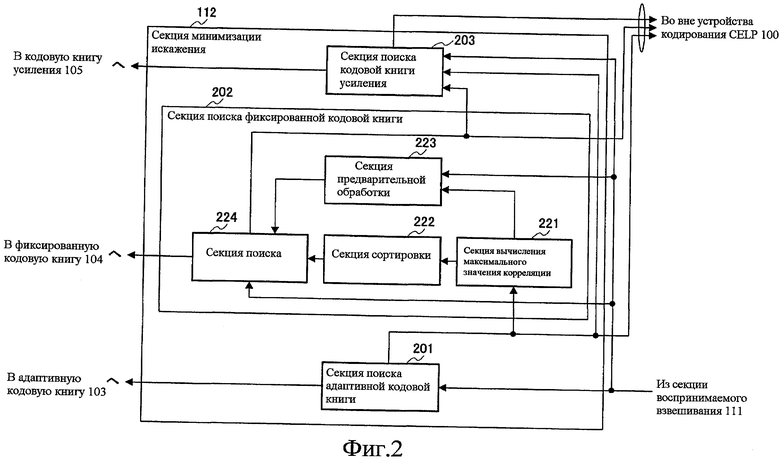
1. Устройство кодирования речи, содержащее:
секцию вычисления, которая вычисляет значения корреляции в предполагаемых положениях импульсов с использованием целевого сигнала и множества импульсов, формирующих фиксированную кодовую книгу, и вычисляет на базисе на основе импульса репрезентативные значения импульсов с использованием максимальных значений значений корреляции;
секцию сортировки, которая сортирует репрезентативные значения, полученные на базисе на основе импульса, группирует импульсы, соответствующие отсортированным репрезентативным значениям, в множество предопределенных поднаборов и определяет первый поднабор, подлежащий поиску первым, среди множества поднаборов и
секцию поиска, которая осуществляет поиск фиксированной кодовой книги с использованием первого поднабора и получает показывающие код позиции и полярности множества импульсов для минимизации искажения кодирования.
2. Устройство кодирования речи по п.1, в котором:
секция вычисления вычисляет максимальные значения корреляции импульсов, вычисленных с использованием максимальных значений значений корреляции импульсов как репрезентативные значения и
секция сортировки сортирует максимальные значения корреляции.
3. Устройство кодирования речи по п.1, в котором секция сортировки устанавливает поднабор, включающий в себя импульс, соответствующий наивысшему репрезентативному значению среди репрезентативных значений, полученных на базисе на основе импульса, в качестве первого поднабора.
4. Устройство кодирования речи по п.1, в котором:
секция сортировки группирует импульсы, соответствующие отсортированным репрезентативным значениям, в множество комбинаций из множества предопределенных поднаборов и определяет первые поднаборы в множестве комбинаций соответственно и
секция поиска осуществляет поиск фиксированной кодовой книги с использованием первых поднаборов и получает код, чтобы минимизировать искажение кодирования.
5. Устройство кодирования речи по п.2, в котором секция вычисления вычисляет максимальное значение корреляции каждого импульса посредством добавления второго наивысшего значения корреляции, умноженного на предопределенный коэффициент, к максимальному значению значения корреляции на базисе на основе импульса.
6. Устройство кодирования речи по п.1, в котором секция сортировки определяет первый поднабор с использованием репрезентативных значений, соответствующих сгруппированным импульсам.
7. Устройство кодирования речи по п.1, в котором секция сортировки генерирует множество комбинаций репрезентативных значений, соответствующих сгруппированным импульсам, и определяет первый поднабор на основе результата сравнения комбинаций, умноженных на предопределенное значение.
8. Устройство кодирования речи по п.1, в котором секция сортировки переставляет импульсы, подлежащие группировке во множество поднаборов, в предопределенном порядке.
9. Способ кодирования речи, содержащий этапы:
вычисления значений корреляции в предполагаемых положениях импульсов с использованием целевого сигнала и множества импульсов, формирующих фиксированную кодовую книгу, и вычисления на базисе на основе импульса репрезентативных значений импульсов с использованием максимальных значений значений корреляции;
сортировки репрезентативных значений, полученных на базисе на основе импульса, группировке импульсов, соответствующих отсортированным репрезентативным значениям, в множество предопределенных поднаборов и определения первого поднабора, подлежащего поиску первым, среди множества поднаборов; и
поиска фиксированной кодовой книги с использованием первого поднабора и генерирования показывающих код позиций и полярностей множества импульсов для минимизации искажения кодирования.
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Устройство для измерения дебита жидкости или газа в скважине | 1988 |
|
SU1677287A2 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| KR 20070061330 А, 13.06.2007 | |||
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| ПОИСК В ГЛУБИНУ ПО АЛГЕБРАИЧЕСКОЙ ШИФРОВАЛЬНОЙ КНИГЕ ДЛЯ БЫСТРОГО КОДИРОВАНИЯ РЕЧИ | 1996 |
|
RU2175454C2 |

