Ссылка на уведомление об авторском праве
Часть раскрытия настоящего патентного документа содержит материал, являющийся объектом защиты нормами авторского права. Владелец авторского права не препятствует факсимильному воспроизведению любым лицом патентного документа или патентного раскрытия в том виде, в котором оно может иметь место в патентном файле или при регистрации в Ведомстве по патентам и товарным знакам США, но в остальном сохраняет за собой все права, вытекающие из норм авторского права.
Область техники
Настоящее изобретение относится к системам передачи речи и, более конкретно, к системам для цифрового кодирования речи.
Предшествующий уровень техники
Преобладающая форма информационного обмена между людьми связана с использованием систем связи. Системы связи включают как проводные, так и беспроводные системы, основанные на использовании радиосвязи. Беспроводные системы связи электрически соединены с проводными системами и осуществляют связь с мобильными устройствами связи с использованием передач на радиочастоте. В настоящее время радиочастоты, доступные для связи, например, в сотовых системах, находятся в диапазоне частот сотовых систем связи с центральной частотой 900 МГц и в диапазоне частот услуг персональной связи с центральной частотой 1900 МГц. Передачи данных и речи в беспроводной системе имеют полосу частот, занимающую часть радиочастотного диапазона. Ввиду увеличения графика, что обусловлено ростом популярности устройств беспроводной связи, таких как сотовые телефоны, желательно уменьшить ширину полосы передач в беспроводных системах.
Цифровые передачи в беспроводных системах связи все более широко применяются для передачи как речи, так и данных ввиду устойчивости по отношению к шумам, надежности, компактности оборудования и возможности реализации сложных функций обработки сигналов с использованием цифровых методов. Цифровая передача речевых сигналов связана с этапами дискретизации аналогового речевого сигнала с помощью аналого-цифрового преобразователя, сжатия речи (кодирования), передачи, декомпрессии речи (декодирования), цифроаналогового преобразования и воспроизведения в наушниках или через громкоговоритель. Дискретизация аналогового речевого сигнала с помощью аналого-цифрового преобразователя создает цифровой сигнал. Однако количество битов, используемых в цифровом сигнале для представления аналогового речевого сигнала, создает относительно широкую полосу. Например, речевой сигнал, который дискретизируется с частотой 8000 Гц (одна выборка каждые 0,125 секунды), где каждая выборка представлена 16 битами, приводит в результате к скорости передачи в битах 128000 (16×8000) битов в секунду или 128 Кбит/с.
Сжатие речи может быть использовано для уменьшения количества битов, которые представляют речевой сигнал, тем самым уменьшая ширину полосы, требуемую для передачи. Однако сжатие речи может привести к ухудшению качества сжатого сигнала. В общем случае, более высокая скорость передачи в битах приводит к более высокому качеству, в то время как более низкая скорость передачи в битах приводит в результате к снижению качества. Однако современные методы сжатия речи, такие как методы кодирования, могут формировать речь после декомпрессии с относительно высоким качеством при относительно низких скоростях передачи в битах. В общем случае, современные методы кодирования пытаются воспроизвести важные для восприятия признаки речевого сигнала без сохранения действительной формы речевого сигнала.
Один из способов кодирования, используемый для снижения скорости передачи в битах, связан с изменением степени сжатия (компрессии) речи (т.е. изменением скорости передачи в битах) в зависимости от части речевого сигнала, подвергаемой сжатию. В типовом случае, части речевого сигнала, для которых адекватно воспринимаемое воспроизведение является более трудным (такие как звонкие части речи, взрывные звуки, звонкие начальные части речи), кодируются и передаются с использованием большего числа битов. И, наоборот, части речевого сигнала, для которых адекватно воспринимаемое воспроизведение менее трудно (такие как оглушенные части речи или паузы между словами), кодируются с использованием меньшего количества битов. Получаемая в результате средняя скорость передачи в битах для речевого сигнала будет относительно ниже, чем она была бы в случае фиксированной скорости передачи в битах, которая обеспечивает получение речи после декомпрессии с тем же качеством.
Системы сжатия речи, обычно называемые кодеками, включают в себя устройство кодирования и устройство декодирования и могут быть использованы для снижения частоты следования битов цифровых речевых сигналов. Разработано множество алгоритмов для речевых кодеков, которые снижают число битов, требуемое для цифрового кодирования исходной речи при попытках поддержания высокого качества воспроизведенной речи. Методы кодирования, такие как линейное предсказание с кодовым возбуждением (метод CELP), как описано в статье "Code-Exited Linear Prediction: High-Quality Speech at Very Low Rates", M.R.Schroeder and B.S. Atal, Proc. ICASSP-85, рр.937-940, 1985, обеспечивают эффективный алгоритм кодирования речи. Пример речевого кодера, основанного на алгоритме CELP с переменной скоростью, представлен в стандарте TIA (Ассоциации промышленности средств связи) IS-127, который разработан для применений, относящихся к множественному доступу с кодовым разделением каналов (стандарт CDMA). Метод кодирования CELP использует различные методы прогнозирования для устранения избыточности из речевого сигнала. Метод кодирования CELP является основанным на кадрах в том смысле, что он предусматривает сохранение дискретизированных входных речевых сигналов в блоке выборок, называемых кадрами. Кадры данных могут затем обрабатываться для создания сжатого речевого сигнала в цифровой форме.
Метод кодирования CELP использует два типа средств (функций) прогнозирования: краткосрочное и долгосрочное. Краткосрочное средство прогнозирования в типовом случае применимо перед долгосрочным средством прогнозирования. Ошибка прогнозирования, обусловленная краткосрочным средством прогнозирования, обычно называется краткосрочным остатком, а ошибка прогнозирования, обусловленная долгосрочным средством прогнозирования, обычно называется долгосрочным остатком. Долгосрочный остаток может кодироваться с использованием фиксированного кодового справочника (кодовой книги), который включает множество фиксированных записей или векторов. Одна из записей может быть выбрана и умножена на фиксированный коэффициент кодового справочника для представления долгосрочного остатка. Краткосрочный остаток может также определяться как LPC (кодирование путем линейного предсказания - КЛП) или спектральное представление, и в типовом случае содержит 10 параметров прогнозирования. Долгосрочное средство прогнозирования также может быть определено как средство прогнозирования основного тона или адаптивный кодовый справочник (кодовая книга) и в типовом случае содержит параметр задержки и параметр усиления долгосрочного средства прогнозирования. Каждый параметр задержки также может быть определен как задержка основного тона, а каждый параметр усиления долгосрочного средства прогнозирования также может быть определен как коэффициент адаптивного кодового справочника. Параметр задержки определяет запись или вектор в адаптивном кодовом справочнике.
CELP-кодер выполняет анализ КЛП для определения параметров краткосрочного средства кодирования. Следуя анализу КЛП, можно определить параметры долгосрочного средства кодирования. Кроме того, осуществляется определение записи фиксированной кодовой книги и выигрыша, обеспечиваемого фиксированной кодовой книгой, наилучшим образом представляющего долгосрочный остаток. При CELP-кодировании используется эффективный принцип анализа через синтез. В методе анализа через синтез наилучший вклад, обеспечиваемый фиксированной кодовой книгой, наилучший выигрыш от использования фиксированной кодовой книги и наилучшие параметры долгосрочного средства прогнозирования могут быть найдены путем их синтеза с использованием инверсного фильтра прогнозирования и применения меры перцепционного взвешивания. Коэффициенты долгосрочного прогнозирования, выигрыш от применения фиксированной кодовой книги, а также параметр задержки и параметр долгосрочного выигрыша могут затем квантоваться. Индексы квантования, а также индексы фиксированной кодовой книги могут затем быть переданы от устройства кодирования к устройству декодирования.
CELP-декодер использует индексы фиксированной кодовой книги для извлечения вектора из фиксированной кодовой книги. Вектор может умножаться на выигрыш фиксированной кодовой книги для получения долгосрочного возбуждения при прогнозировании, известного также как вклад фиксированной кодовой книги. Вклад долгосрочного средства прогнозирования может суммироваться с долгосрочным возбуждением для получения краткосрочного возбуждения, которое обычно определяют просто как возбуждение. Вклад долгосрочного средства возбуждения включает в себя краткосрочное возбуждение из прошлого, умноженное на выигрыш долгосрочного средства прогнозирования. Добавление вклада долгосрочного прогнозирования может рассматриваться как вклад адаптивной кодовой книги или как долгосрочная фильтрация (основного тона). Краткосрочное возбуждение может проходить через краткосрочный инверсный фильтр прогнозирования (КЛП), который использует краткосрочные коэффициенты прогнозирования (КЛП), квантованные устройством кодирования для генерирования синтезированной речи. Синтезированная речь может затем пропускаться через пост-фильтр, который снижает перцепционные шумы кодирования.
Данные методы сжатия речи приводили к уменьшению ширины полосы, используемой для передачи речевого сигнала. Однако дальнейшее снижение ширины полосы особенно важно в системе связи, которая должна распределять свои ресурсы большому количеству пользователей. Соответственно имеется потребность в системах и способах кодирования речи, которые обеспечивают минимизацию средней скорости передачи в битах, требуемой для представления речи, при обеспечении высокого качества речи после декомпрессии.
Раскрытие изобретения
Настоящее изобретение обеспечивает системы для кодирования и декодирования речевых сигналов. В вариантах осуществления изобретения могут использоваться методы CELP-кодирования и кодирования, основанного на прогнозировании, в качестве основы для использования функций обработки сигналов, использующих методы согласования форм сигналов, и методы, связанные с перцепционными характеристиками. Эти методы позволяют генерировать синтезированную речь, которая в максимальной степени совпадает с исходной речью, путем включения перцепционных характеристик при поддержании относительно низкой скорости передачи в битах. Одним из применений вариантов осуществления изобретения являются системы беспроводной связи. В таком применении кодирование исходной речи или декодирование для генерирования синтезированной речи могут производиться в мобильных устройствах связи. Кроме того, кодирование и декодирование могут осуществляться в системах, основанных на проводных линиях связи, или в других системах беспроводной связи для обеспечения интерфейсов с системами, основанными на проводных линиях связи.
Одним из вариантов осуществления системы сжатия речи является кодек полной скорости, кодек половинной скорости, кодек одной четвертой скорости и кодек одной восьмой скорости, каждый из которых обеспечивает кодирование и декодирование речевых сигналов. Кодеки полной скорости, половинной скорости, одной четвертой скорости и одной восьмой скорости кодируют речевые сигналы при скоростях передачи в битах, равных 8,5 Кбит/с, 4 Кбит/с, 2 Кбит/с и 0,8 Кбит/с соответственно. Система сжатия речи выполняет селекцию скорости для кадра речевого сигнала, чтобы выбрать один из кодеков. Выбор скорости выполняется на покадровой основе. Кадры создаются делением речевого сигнала на сегменты конечной длины времени. Поскольку каждый кадр может кодироваться при различной скорости передачи в битах, система сжатия речи является системой сжатия речи переменной скорости, которая кодирует речь при средней скорости передачи в битах.
Выбор скорости определяется путем определения параметров каждого кадра речевого сигнала на основе части речевого сигнала, содержащегося в конкретном кадре. Например, кадры могут характеризоваться как стационарно голосовые (звонкие), нестационарно голосовые, неозвученные, шумы фона, паузы и т.д. Кроме того, выбор скорости основывается на режиме, в котором работает система сжатия речи. Различные режимы показывают желательную среднюю скорость передачи в битах. Кодеки проектируются на оптимизированное кодирование в рамках различного определения параметров речевых сигналов. Оптимальное кодирование является компромиссом между желанием обеспечить синтезированную речь наивысшего перцепционного качества при сохранении желательной средней скорости передачи в битах, максимизируя при этом использование доступной ширины полосы. В процессе работы система сжатия речи селективно активизирует кодеки на основе режима, а также определения параметров кадра в целях оптимизации перцепционного качества синтезированной речи.
Как только выбран кодек полной или половинной скорости в результате выбора скорости, производится классификация типов речевого сигнала, чтобы далее оптимизировать кодирование. Классификация типов может включать первый тип (т.е. Тип 1) для кадров, содержащих гармоническую структуру и формантную структуру, которая быстро не изменяется, или второй тип (т.е. Тип 0) для всех других кадров. Распределение битов кодеков полной или половинной скорости может подстраиваться в ответ на классификацию типов, чтобы далее оптимизировать кодирование кадра. Подстройка распределения битов обеспечивает улучшенное перцепционное качество воспроизводимого речевого сигнала путем подчеркивания других аспектов речевого сигнала в каждом кадре.
Соответственно устройство кодирования речи имеет возможность селективной активизации кодеков для максимизации качества в целом воспроизводимого речевого сигнала при сохранении желательной средней скорости передачи в битах. Другие системы, методы, признаки и преимущества изобретения станут очевидными для специалистов в данной области техники из прилагаемых чертежей и детального описания. Предполагается, что все такие дополнительные системы, методы, признаки и преимущества включены в объем изобретения и защищаются приложенной формулой изобретения.
Краткое описание чертежей
Элементы, представленные на чертежах, не обязательно следует рассматривать как соответственно масштабированные. Вместо этого, особое внимание уделено иллюстрации принципов изобретения. Кроме того, на чертежах одинаковыми ссылочными позициями обозначены соответствующие элементы на различных видах.
Фиг.1 изображает блок-схему варианта осуществления системы сжатия речи.
Фиг.2 - расширенная блок-схема возможного варианта системы кодирования, показанной на фиг.1.
Фиг.3 - расширенная блок-схема возможного варианта системы декодирования, показанной на фиг.1.
Фиг.4 - таблица, иллюстрирующая распределение битов в возможном варианте осуществления кодека полной скорости.
Фиг.5 - таблица, иллюстрирующая распределение битов в возможном варианте осуществления кодека половинной скорости.
Фиг.6 - таблица, иллюстрирующая распределение битов в возможном варианте осуществления кодека одной четвертой скорости.
Фиг.7 - таблица, иллюстрирующая распределение битов в возможном варианте осуществления кодека одной восьмой скорости.
Фиг.8 - расширенная блок-схема возможного варианта осуществления модуля препроцессинга (предварительной обработки), показанного на фиг.2.
Фиг.9 - расширенная блок-схема возможного варианта осуществления модуля обработки исходного кадра, показанного на фиг.2, для кодеков полной и половинной скорости.
Фиг.10 - расширенная блок-схема возможного варианта осуществления первого модуля обработки субкадра, показанного на фиг.2, для кодеков полной и половинной скорости.
Фиг.11 - расширенная блок-схема возможного варианта осуществления первого модуля обработки кадра, второго модуля обработки субкадра и второго модуля обработки кадра, показанного на фиг.2, для кодеков полной и половинной скорости.
Фиг.12 - расширенная блок-схема возможного варианта системы декодирования, показанной на фиг.3, для кодеков полной и половинной скорости.
Режимы осуществления изобретения
Варианты осуществления изобретения описаны ниже со ссылками на речевые сигналы, однако возможна обработка и других сигналов. Кроме того, следует иметь в виду, что численные значения, приведенные в описании, могут быть в числовом виде представлены с плавающей запятой, с фиксированной запятой, в десятичной форме или в ином подобном числовом представлении, что может вызвать незначительные отклонения в значениях, но не повлияет на выполнение функций. Кроме того, функциональные блоки, показанные как блоки, не обязательно должны представлять фиксированные структуры, но могут комбинироваться и далее подразделяться в различных вариантах осуществления.
На фиг.1 представлена блок-схема возможного варианта осуществления системы 10 сжатия речи. Система 10 сжатия речи также содержит систему 12 кодирования, среду 14 передачи и систему 16 декодирования, которые могут быть взаимосвязаны, как показано на чертеже. Система 10 сжатия речи может представлять собой любую систему, которая способна принимать и кодировать речевой сигнал 18, и затем декодировать его для формирования прошедшей постпроцессорную обработку синтезированной речи 20. В типовой системе связи система беспроводной связи электрически соединена с коммутируемой телефонной системой общего пользования (КТСОП) в системе связи, основанной на проводных линиях связи. В системе беспроводной связи множество базовых станций в типовом случае используются для обеспечения радиосвязи с устройствами мобильной связи, такими как сотовые телефоны или портативные радиоприемопередатчики.
Система 10 сжатия речи в процессе работы принимает речевой сигнал 18. Речевой сигнал 18, излучаемый передатчиком (не показан), может представлять собой, например, сигнал, принятый микрофоном (не показан) и преобразованный в цифровую форму с помощью аналого-цифрового преобразователя (не показан). Передатчик может быть образован человеческим голосом, музыкальным инструментом или любым другим устройством, которое способно излучать аналоговые сигналы. Речевой сигнал 18 может представлять любой тип звука, например озвученную речь, неозвученную речь, шумы фона, молчание (паузы), музыку и т.п.
Система 12 кодирования в процессе работы кодирует речевой сигнал 18. Система 12 кодирования может представлять собой часть устройства мобильной связи, базовой станции, или любого другого беспроводного или проводного устройства связи, которое способно принимать и кодировать речевые сигналы 18, преобразованные в цифровую форму аналого-цифровым преобразователем. Устройство проводной связи может включать в себя устройства и системы протокола VoIP (передачи речи через Интернет). Система 12 кодирования сегментирует речевой сигнал 18 на кадры для генерирования потока битов. Один из вариантов осуществления системы 10 сжатия речи использует кадры, которые содержат 160 выборок, что при частоте дискретизации 8000 Гц соответствует 20 мс на кадр. Кадры, представленные потоком битов, могут подаваться в среду 14 передачи.
Среда 14 передачи может представлять собой любой механизм передачи, такой как коммуникационный канал, радиоволны, микроволновое излучение, проводные передачи, волоконно-оптические передачи или любую другую среду, способную переносить потоки битов, генерируемые системой 12 кодирования. Среда 14 передачи может также включать передающие устройства и приемные устройства, используемые при передаче потока битов. Примеры вариантов осуществления среды 14 передачи могут включать в себя коммуникационные каналы, антенны, связанные с ними приемопередатчики для радиосвязи в системе беспроводной связи. Среда 14 передачи может также представлять собой механизм хранения данных, такой как устройство памяти, носитель данных или иное устройство, обеспечивающее хранение и извлечение потока битов, генерируемого системой 12 кодирования. Среда 14 передачи обеспечивает передачу потока битов, генерируемого системой 12 кодирования, к системе 16 декодирования.
Система 16 декодирования принимает поток битов от среды 14 передачи. Система 16 декодирования может представлять собой часть устройства связи, базовой станции или любого другого устройства беспроводной или проводной связи, которое имеет возможность приема потока битов. Система 16 декодирования в процессе работы декодирует поток битов и генерирует в результате постпроцессорной обработки синтезированную речь 20 в форме цифрового сигнала. Подвергнутая постпроцессорной обработке синтезированная речь 20 может затем преобразовываться в аналоговый сигнал с помощью цифроаналогового преобразователя (не показан). Аналоговый выходной сигнал цифроаналогового преобразователя может приниматься приемником (не показан), который может представлять собой орган слуха человека, устройство записи на магнитной ленте или иное устройство, имеющее возможность приема аналогового сигнала. Как вариант, для приема прошедшей постпроцессорную обработку синтезированной речи 20 может использоваться устройство цифровой записи, устройство распознавания речи или любое другое устройство, способное принимать цифровой сигнал.
В одном из вариантов осуществления система 10 сжатия речи также включает линию 21 режима. По линии 21 режима передается сигнал режима, который управляет системой 10 сжатия речи путем указания желательной средней скорости передачи в битах для потока битов. Сигнал режима может генерироваться внешним образом, например системой беспроводной связи, использующей модуль генерации сигнала режима. Модуль генерации сигнала режима определяет сигнал режима на основе множества факторов, таких как желательное качество прошедшей постпроцессорную обработку синтезированной речи 20, доступная ширина полосы, услуги, на которые подписан пользователь, и любые другие релевантные факторы. Сигнал режима контролируется и селектируется системой связи, в которой работает система 10 сжатия речи. Сигнал режима может быть подан на систему 12 кодирования для поддержки определения того, какой из множества кодов может быть активизирован в системе 12 кодирования.
Кодеки содержат секцию устройства кодирования и секцию устройства декодирования, которые размещены в системе 12 кодирования и в системе 16 декодирования соответственно. В возможном варианте осуществления системы 10 сжатия речи имеется 4 кодека, а именно: кодек 22 полной скорости, кодек 24 половинной скорости, кодек 26 одной четвертой скорости и кодек 28 одной восьмой скорости. Каждый из кодеков 22, 24, 26, 28 в процессе работы генерирует поток битов. Размер потока битов, генерируемого каждым из кодеков 22, 24, 26, 28, и, следовательно, ширина полосы, необходимая для передачи потока битов в среде 24 передачи, различаются.
В одном из вариантов осуществления кодек 22 полной скорости, кодек 24 половинной скорости, кодек 26 одной четвертой скорости и кодек 28 одной восьмой скорости генерируют соответственно 170 битов, 80 битов, 40 битов и 16 битов на кадр. Размер потока битов каждого кадра соответствует скорости передачи в битах, а именно 8,5 Кбит/с для кодека 22 полной скорости, 4,0 Кбит/с для кодека 24 половинной скорости, 2,0 Кбит/с для кодека 26 одной четвертой скорости и 0,8 Кбит/с для кодека 28 одной четвертой скорости. Однако в альтернативных вариантах возможно использование меньшего или большего числа кодеков, а также других частот следования битов. Путем обработки кадров речевого сигнала 18 с использованием различных кодеков обеспечивается получение средней скорости передачи в битах. Система 12 кодирования определяет, какой из кодеков 22, 24, 26, 28 может использоваться для кодирования конкретного кадра, на основе определения параметров кадра и от желательной средней скорости передачи в битах, обеспечиваемой сигналом режима. Определение параметров кадра основывается на части речевого сигнала 18, содержащейся в конкретном кадре. Например, кадры могут характеризоваться как стационарно звонкие (голосовые, озвученные), нестационарно звонкие, глухие (неозвученные), начальные, фоновые шумы, паузы и т.д.
Сигнал режима в линии 21 сигнала режима в одном из вариантов осуществления идентифицирует режим 0, режим 1 и режим 2. Каждый из трех режимов задает отличающуюся желательную среднюю скорость передачи в битах, которая может изменять процентное соотношение использования каждого из кодеков 22, 24, 26 и 28. Режим 0 может определяться как наивысший режим, в котором большая часть кадров может кодироваться кодеком 22 полной скорости; меньше кадров могут кодироваться кодеком 24 половинной скорости, и кадры, содержащие паузы и фоновые шумы, могут кодироваться кодеком 26 одной четвертой скорости и кодеком 28 одной восьмой скорости. Режим 1 может определяться как стандартный режим, в котором кадры с высоким информационным содержанием, такие как начальные и некоторые озвученные кадры, могут кодироваться кодеком 22 полной скорости. Кроме того, другие озвученные и неозвученные кадры могут кодироваться кодеком 24 половинной скорости, некоторые неозвученные кадры могут кодироваться кодеком 25 одной четвертой скорости и кадры пауз и фоновых шумов могут кодироваться кодеком 28 одной восьмой скорости.
Режим 2 может определяться как экономный режим, в котором лишь малое количество кадров с высоким информационным содержанием могут кодироваться кодеком 22 полной скорости. Большинство кадров в режиме 2 могут кодироваться с помощью кодека 24 половинной скорости за исключением некоторых неозвученных кадров, которые могут кодироваться с помощью кодека 26 одной четвертой скорости. В режиме 2 кадры пауз и фоновых шумов могут кодироваться кодеком 28 одной восьмой скорости. Соответственно путем варьирования выбора кодеков 22, 24, 26, 28 система 10 сжатия речи может вырабатывать восстановленную речь при желательной средней скорости передачи в битах, пытаясь поддерживать наивысшее возможное качество. Дополнительные режимы, такие как режим 3, работающий в сверхэкономичном режиме, или режим максимального кодека половинной скорости, при котором максимально активизируемым кодеком является кодек 24 половинной скорости, также возможны в альтернативных вариантах осуществления.
Дополнительное управление системой 10 сжатия речи может быть обеспечено с помощью линии 30 сигнала половинной скорости. Линия 30 сигнала половинной скорости обеспечивает флаг сигнализации половинной скорости. Флаг сигнализации половинной скорости может обеспечиваться внешним источником, таким как система беспроводной связи. При активизации флаг сигнализации половинной скорости предписывает системе 10 сжатия речи использовать кодек 24 половинной скорости соответственно максимальной скорости передачи. Определение того, когда активизировать флаг сигнализации половинной скорости выполняется системой связи, в которой работает система 10 сжатия речи. Подобно определению сигнала режима модуль сигнализации половинной скорости контролирует активизацию флага сигнализации половинной скорости на основе множества факторов, которые определяются системой связи. В альтернативных вариантах осуществления флаг сигнализации половинной скорости может предписывать системе 10 сжатия речи использовать один кодек 22, 24, 26 и 28 вместо другого или указывать один или более кодеков 22, 24, 26 и 28 как соответствующего максимальной или минимальной скорости передачи.
В одном из вариантов осуществления система 10 сжатия речи кодеки 22 и 24 соответственно полной и половинной скорости могут основываться на методе eX-CELP (расширенное линейное предсказание с кодовым возбуждением), а кодеки 26, 28 одной четвертой и одной восьмой скорости соответственно могут основываться на методе перцепционного согласования. Метод eX-CELP расширяет традиционный баланс между перцепционным согласованием и согласованием форм сигнала традиционного метода CELP. В частности, метод eX-CELP определяет параметры кадров с использованием выбора скорости и классификации типа, как описано ниже. Для различных категорий кадров могут быть использованы различные методы кодирования, которые имеют различное перцепционное согласование, различное согласование форм сигналов и различные распределения битов. Метод перцепционного согласования кодека 26 одной четвертой скорости и кодека 28 одной восьмой скорости не используют согласования форм сигналов, а вместо этого концентрируются на перцепционных аспектах при кодировании кадров.
Кодирование каждого кадра либо по методу eX-CELP, либо по методу перцепционного согласования может базироваться на дальнейшем делении кадра на множество субкадров. Субкадры могут быть различными по размерам и по числу для каждого кодека 22, 24, 26 и 28. Кроме того, что касается метода eX-CELP, субкадры могут быть различными для каждой категории. В пределах субкадров параметры речи и формы сигналов могут кодироваться с использованием различных скалярных и векторных методов квантования с предсказанием и без предсказания. При скалярном квантовании параметр речи или элемент могут быть представлены местоположением индекса наиболее близкой записи в репрезентативной таблице скаляров. При векторном квантовании различные параметры речи могут быть сгруппированы для формирования вектора. Вектор может быть представлен местоположением индекса наиболее близкой записи в репрезентативной таблице векторов.
При кодировании с предсказанием элемент может прогнозироваться из прошлого. Элемент может быть скаляром или вектором. Ошибка предсказания может затем квантоваться с использованием таблицы скаляров (скалярное квантование) или таблицы векторов (векторное квантование). Метод кодирования eX-CELP подобно традиционному методу CELP использует эффективную схему анализа через синтез для выбора наилучшего представления для различных параметров. В частности, параметры могут быть адаптивной кодовой книгой, фиксированной кодовой книгой и их соответствующими выигрышами. Схема анализа через синтез использует инверсные фильтры прогнозирования и меры перцепционного взвешивания для выбора наилучших записей кодовых книг.
Возможный вариант реализации системы 10 сжатия речи может представлять собой устройство обработки сигналов, такое как интегральная схема цифрового процессора сигналов, мобильное устройство связи или радиопередающая базовая станция. Устройство обработки сигналов может программироваться исходным кодом. Исходный код может быть сначала преобразован в код с фиксированной запятой и затем переведен на язык программирования, который соответствует устройству обработки сигналов. Преобразованный исходный код может затем загружаться и исполняться в устройстве обработки сигналов. Примером исходного кода является компьютерная программа на языке С, используемая в одном из вариантов осуществления системы 10 сжатия речи, которая включена в настоящее описание в качестве приложения А и В.
На фиг.2 представлена более детальная блок-схема системы 12 кодирования, показанной на фиг.1. Один из вариантов осуществления системы 12 кодирования включает модуль 34 предпроцессорной (предварительной) обработки, устройство 36 кодирования полной скорости, устройство 38 кодирования половинной скорости, устройство 40 кодирования одной четвертой скорости и устройство 42 кодирования одной восьмой скорости, которые соединены так, как показано на чертеже. Устройства 36, 38, 40 и 42 кодирования определенной скорости включают в себя модуль 44 обработки исходного кадра и модуль 54 обработки возбуждения.
Речевой сигнал 18, принимаемый системой 12 кодирования, обрабатывается на уровне кадра с помощью модуля 34 предварительной обработки. Модуль 34 предварительной обработки обеспечивает первоначальную обработку речевого сигнала 18. Первоначальная обработка может включать в себя фильтрацию, формирование сигнала, удаление шумов, усиление и иные подобные методы, обеспечивающие оптимизацию речевого сигнала 18 для последующего кодирования.
Устройства 36, 38, 40, 42 кодирования полной, половинной, одной четвертой и одной восьмой скорости являются секциями кодирования кодеков 22, 24, 26 и 28 полной, половинной, одной четвертой и одной восьмой скорости соответственно. Модуль 44 обработки исходного кадра выполняет обработку исходного кадра, выделение параметров речи и определяет, какое из устройств 36, 38, 40, 42 кодирования полной, половинной, одной четвертой и одной восьмой скорости будет кодировать конкретный кадр. Модуль 44 обработки исходного кадра может быть подразделен на множество модулей обработки начального кадра, а именно на модуль 46 обработки исходного кадра полной скорости, модуль 48 обработки исходного кадра половинной скорости, модули 50, 52 обработки исходного кадра одной четвертой и одной восьмой скорости. Однако следует отметить, что модуль 44 обработки исходного кадра выполняет обработку, которая является общей для всех устройств 36, 38, 40, 42 кодирования соответствующих скоростей, и конкретную обработку, соответствующую каждому из устройств 36, 38, 40, 42 кодирования. Подразделение модуля 44 обработки исходного кадра на соответствующие модули 46, 48, 50 и 52 обработки исходного кадра соответствует упомянутым устройствам 36, 38, 40, 42 кодирования соответствующей скорости.
Модуль 44 обработки исходного кадра выполняет общую обработку для определения выбора скорости, который активизирует одно из устройств 36, 38, 40, 42 кодирования соответствующей скорости. В одном из вариантов осуществления выбор скорости основывается на определении параметров кадра речевого сигнала 18 и режима, в котором работает система 10 сжатия речи. Активизация одного из устройств 36, 38, 40, 42 кодирования соответствующей скорости соответственно активизирует один из модулей 46,48, 50 и 52 обработки исходного кадра.
Конкретный модуль 46, 48, 50 и 52 обработки исходного кадра активизируется для кодирования соответствующих частей речевого сигнала 18, которые являются общими для всего кадра.
Кодирование модулем 44 обработки исходного кадра квантует параметры речевого сигнала 18, содержащегося в кадре. Квантованные параметры приводят в результате к генерации части потока битов. В принципе, поток битов является сжатым представлением кадра речевого сигнала 18, который обработан системой 12 кодирования посредством одного из устройств 36, 38, 40, 42 кодирования соответствующей скорости.
В дополнение к выбору скорости модуль 44 обработки исходного кадра также выполняет обработку для определения классификации типа для каждого кадра, который обрабатывается устройствами 36 и 38 кодирования полной и половинной скорости соответственно. Классификация типа в одном из вариантов осуществления предусматривает классификацию речевого сигнала 18, представленного кадром, как первый тип (т.е. тип 1) или как второй тип (т.е. тип 0). Классификация типа в одном из вариантов осуществления зависит от свойств и характеристик речевого сигнала 18. В альтернативном варианте могут предусматриваться дополнительные классификации типов и соответствующая поддерживающая их обработка.
Классификация типа 1 включает кадры речевого сигнала 18, которые демонстрируют стационарное поведение. Кадры, демонстрирующие стационарное поведение, включают структуру гармоник и структуру формата, которые не изменяются с высокой скоростью. Все другие кадры могут классифицироваться в соответствии с классификацией типа 0. В альтернативных вариантах осуществления дополнительные классификации типов могут классифицировать кадры соответственно дополнительным классификациям на основе временной области, частотной области и т.д. Классификация типа оптимизирует кодирование модулем 46 обработки исходных кадров полной скорости и модулем 48 исходных кадров половинной скорости, как описано ниже. Кроме того, оба типа классификации и выбора скорости могут использоваться для оптимизации кодирования секциями модуля 54 обработки возбуждением, которые соответствуют устройствам 36 и 38 кодирования полной и половинной скорости.
В одном из вариантов осуществления модуль 54 обработки возбуждением может подразделяться на модуль 56 полной скорости, модуль 58 половинной скорости, модуль 60 одной четвертой скорости и модуль 62 одной восьмой скорости. Модули 56, 58, 60 и 62 соответствующих скоростей соответствуют устройствам 36, 38, 40 и 42 кодирования соответствующей скорости, как показано на фиг.2. Модули 56 и 58 полной и половинной скорости соответственно в одном из вариантов осуществления включают множество модулей обработки кадров и множество модулей обработки субкадров, которые обеспечивают существенно различающееся кодирование, как пояснено ниже.
Секция модуля 54 обработки возбуждением для устройств 36 и 38 кодирования полной и половинной скорости включает модули селектора типа первых модулей обработки субкадра, вторых модулей обработки субкадра, первых модулей обработки кадра и вторых модулей обработки кадра. Более конкретно модуль 56 полной скорости включает модуль 68 селектора F типа, первый модуль 70 обработки субкадра F0 и первый модуль 72 обработки кадра F1, второй модуль 74 обработки субкадра F1 и второй модуль 76 обработки субкадра F1. Обозначение "F" указывает на полную скорость, "0" и "1" указывают на тип 0 и тип 1 соответственно. Аналогично модуль 58 половинной скорости включает модуль 78 селектора Н типа, первый модуль 80 обработки субкадра Н0, первый модуль 82 обработки кадра H1, второй модуль 84 обработки субкадра H1 и второй модуль 86 обработки кадра H1.
Модули 68 и 78 селектора типа F и Н управляют обработкой речевых сигналов 18 так, чтобы далее оптимизировать процесс кодирования на основе классификации типа. Классификация в качестве типа 1 указывает на то, что кадр содержит структуру гармоник и структуру формата, которая не изменяется с высокой скоростью, такую как стационарная озвученная речь. Соответственно биты, использованные для представления кадра, классифицируемого как тип 1, могут быть распределены для облегчения кодирования, что использует преимущество данных свойств при восстановлении кадра. Классификация в качестве типа 0 указывает на то, что кадр может обладать нестационарным поведением, например структура гармоник и структура формата, которые изменяются с высокой скоростью, или кадр может демонстрировать стационарно неозвученные или шумоподобные характеристики. Распределение битов для кадров, классифицированных как тип 0, может быть соответственно подстроено, чтобы лучше представлять и учитывать эти характеристики.
Для модуля 56 полной скорости первый модуль 70 обработки субкадра F0 генерирует часть потока битов, когда обрабатываемый кадр классифицируется как тип 0. Классификация как тип 0 кадра активизирует первый модуль 70 обработки субкадра F0 для обработки кадра на субкадровой основе. Первый модуль 72 обработки кадра F1, второй модуль 74 обработки субкадра F1 и второй модуль 76 обработки кадра F1 объединяются для генерации части потока битов, когда обрабатываемый кадр классифицируется как тип 1. Классификация как тип 1 связана с обработкой как кадра, так и субкадра в модуле 56 полной скорости.
Аналогичным образом для модуля 58 половинной скорости первый модуль 80 обработки субкадра Н0 генерирует часть потока битов, когда обрабатываемый кадр классифицируется как тип 0. Кроме того, первый модуль 82 обработки кадра H1, второй модуль 84 обработки субкадра H1 и второй модуль 86 обработки кадра H1 объединяются для генерации части потока битов, когда обрабатываемый кадр классифицируется как тип 1. Как и в случае модуля 56 полной скорости, классификация в качестве типа 1 связана с обработкой как кадра, так и субкадра.
Модули 60 и 62 одной четвертой и одной восьмой скорости являются частями устройств 40 и 42 кодирования соответственно одной четвертой и одной восьмой скорости и не включают в себя классификации типа. Классификация типа не включена ввиду свойств обрабатываемых кадров. Модули 60 и 62 одной четвертой и одной восьмой скорости генерируют часть потока битов на субкадровой основе и на кадровой основе при их активизации.
Модули 56, 58, 60 и 62 соответствующей скорости генерируют часть потока битов, которая объединяется с соответствующей частью потока битов, генерируемого модулями 46, 48, 50 и 52 обработки исходного кадра, чтобы создать цифровое представление кадра. Например, часть потока битов, генерируемая модулем 46 обработки исходного кадра полной скорости и модулем 56 полной скорости, может объединяться для формирования потока битов, генерируемого при активизации устройства 36 кодирования полной скорости для кодирования кадра. Потоки битов с каждого из устройств 36, 38, 40 и 42 кодирования могут затем объединяться для формирования потока битов, представляющего множество кадров речевого сигнала 18. Поток битов, генерируемый устройствами 36, 38, 40 и 42 кодирования, декодируется системой 16 декодирования.
На фиг.3 представлена более подробная блок-схема системы 16 декодирования, показанной на фиг.1. В одном из вариантов осуществления система 16 декодирования содержит устройство 90 декодирования полной скорости, устройство 92 декодирования половинной скорости, устройство 94 декодирования одной четвертой скорости, устройство 96 декодирования одной восьмой скорости, модуль 98 синтезирующего фильтра и модуль 100 постпроцессорной обработки. Устройства 90, 92, 94, 96 декодирования, модуль 98 синтезирующего фильтра и модуль 100 постпроцессорной обработки являются секцией декодирования кодеков 22, 24, 26 и 28 полной, половинной, одной четвертой и одной восьмой скорости.
Устройства 90, 92, 94, 96 декодирования получают поток битов и декодируют цифровой сигнал для восстановления различных параметров речевого сигнала 18. Устройства 90, 92, 94, 96 декодирования могут активизироваться для декодирования каждого кадра на основе селекции скорости. Селекция скорости может быть обеспечена от системы 12 кодирования в систему 16 декодирования с помощью отдельного механизма передачи, такого как канал управления в системе беспроводной связи. В рассматриваемом примере осуществления выбор скорости может быть обеспечен для мобильных устройств связи в виде части широковещательных сигналов маяков, генерируемых базовыми станциями в системе беспроводной связи. В принципе, широковещательные сигналы маяков генерируются для обеспечения идентификационной информации для установления связи между базовыми станциями и мобильными устройствами связи.
Синтезирующий фильтр 98 и модуль 100 постпроцессорной обработки являются частью процесса декодирования для каждого из устройств 90, 92, 94, 96 декодирования. Объединение параметров речевого сигнала 18, который декодируется устройствами 90, 92, 94, 96 декодирования с использованием синтезирующего фильтра 98, генерирует синтезированную речь. Синтезированная речь проходит через модуль 100 постпроцессорной обработки для создания прошедшей постпроцессорную обработку синтезированной речи 20.
В одном из вариантов осуществления устройство 90 декодирования полной скорости содержит селектор 102 F типа и множество модулей воспроизведения возбуждения. Модули воспроизведения возбуждения содержат модуль 104 воспроизведения возбуждения F0 и модуль 106 воспроизведения возбуждения F1. Кроме того, устройство 90 декодирования полной скорости содержит модуль 107 воспроизведения коэффициентов линейного предсказания (КЛП). Модуль 107 воспроизведения КЛП содержит модуль 108 воспроизведения КЛП F0 и модуль 110 воспроизведения КЛП F1.
Аналогичным образом в одном из вариантов осуществления устройство 92 декодирования половинной скорости содержит селектор 102 Н типа и множество модулей воспроизведения возбуждения. Модули воспроизведения возбуждения содержат модуль 114 воспроизведения возбуждения Н0 и модуль 116 воспроизведения возбуждения H1. Кроме того, устройство 92 декодирования половинной скорости содержит модуль 118 воспроизведения коэффициентов линейного предсказания (КЛП), который является модулем 118 воспроизведения КЛП Н. Устройства 90 и 92 декодирования полной и половинной скорости, хотя и сходные в принципе, предназначены для декодирования потоков битов с соответствующих устройств 36 и 38 кодирования полной и половинной скорости соответственно.
Селекторы 102 и 112 F типа и Н типа селективно активизируют соответствующие части устройств 90 и 92 декодирования полной и половинной скорости соответственно в зависимости от классификации типа. Если классификация типа соответствует типу 0, то активизируются модули 104 или 114 воспроизведения возбуждения F0 или Н0. И, наоборот, если классификация типа соответствует типу 1, то активизируются модули 106 или 116 воспроизведения возбуждения F1 или H1. Модули 108 или 110 воспроизведения возбуждения КЛП F0 или F1 активизируются классификациями типа 0 или типа 1 соответственно. Модули 118 воспроизведения возбуждения КЛП Н активизируется только на основе выбора скорости.
Устройство 94 декодирования одной четвертой скорости содержит модуль 120 воспроизведения возбуждения Q и модуль 122 воспроизведения КЛП Q. Аналогичным образом, устройство 96 декодирования одной восьмой скорости содержит модуль 124 воспроизведения возбуждения Е и модуль 126 воспроизведения КЛП Е. Соответствующие модули 120 или 124 воспроизведения возбуждения Q или Е и соответствующие модули 122 или 126 воспроизведения КЛП Q или Е активизируются только на основе селекции скорости.
Каждый из модулей воспроизведения возбуждения при своей активизации обеспечивает краткосрочное возбуждение в линии 128 краткосрочного возбуждения. Аналогичным образом каждый из модулей воспроизведения КЛП обеспечивает генерацию коэффициентов краткосрочного прогнозирования в линии 130 коэффициентов краткосрочного прогнозирования. Краткосрочное возбуждение и коэффициенты краткосрочного прогнозирования подаются на синтезирующий фильтр 98. Кроме того, в одном из вариантов осуществления коэффициенты краткосрочного прогнозирования подаются на модуль 100 постпроцессорной обработки, как показано на фиг.3.
Модуль 100 постпроцессорной обработки может включать фильтрацию, формирование сигнала, модификацию шумов, усиление, коррекцию наклона и иные подобные методы для улучшения перцепционного качества синтезированной речи. Модуль 100 постпроцессорной обработки обеспечивает снижение прослушиваемых шумов без ухудшения синтезированной речи. Уменьшение прослушиваемых шумов может быть реализовано путем усиления формантной структуры синтезированной речи или путем подавления только шумов в частотных диапазонах, которые перцепционно не релевантны для синтезированной речи. Поскольку прослушиваемые шумы становятся более заметными на более низких скоростях передачи в битах, в одном из вариантов осуществления модуль 100 постпроцессорной обработки может активизироваться для обеспечения постпроцессорной обработки синтезированной речи различным образом в зависимости от выбора скорости. В другом варианте осуществления модуль 100 постпроцессорной обработки может обеспечивать различную постпроцессорную обработку для различных групп устройств 90, 92, 94 и 96 декодирования на основе выбора скорости.
В процессе работы модуль 44 обработки исходного кадра, показанный на фиг.2, анализирует речевой сигнал 18 для определения выбора скорости и активизации одного из кодеков 22, 24, 26 и 28. Если, например, активизирован кодек 22 полной скорости для обработки кадра на основе выбора скорости, то модуль 46 обработки исходного кадра полной скорости определяет тип классификации для кадра и генерирует часть потока битов. Модуль 56 полной скорости на основе классификации типа генерирует остальную часть потока битов для кадра.
Поток битов может быть принят и декодирован декодером 90 полной скорости на основе выбора скорости. Декодер 90 полной скорости декодирует поток битов с использованием классификации типа, которая была определена в процессе кодирования. Синтезирующий фильтр 98 и модуль 100 постпроцессорной обработки используют параметры, декодированные из потока битов, для генерирования прошедшей постпроцессорную обработку синтезированную речь 20. Поток битов, который генерируется каждым из кодеков 22, 24, 26 и 28, содержит значительно отличающиеся распределения битов для того, чтобы подчеркивать различные параметры и/или характеристики речевого сигнала 18 в кадре.
1.0 Распределение битов
На фиг.4, 5, 6 и 7 приведены таблицы, иллюстрирующие возможный вариант осуществления распределения битов для кодека 22 полной скорости, кодека 24 половинной скорости, кодека 26 одной четвертой скорости и кодека 28 одной восьмой скорости соответственно. Распределение битов обозначает часть потока битов, генерируемого модулем 44 обработки исходного кадра, и часть потока битов, генерируемого модулем 54 обработки возбуждением в соответствующем устройстве 36, 38, 40 и 42 кодирования. Кроме того, распределение битов обозначает число битов в потоке битов, которые представляют кадр. Соответственно скорости передачи в битах изменяются в зависимости от кодека 22, 24, 26 и 28, который активизирован. Поток битов может быть классифицирован на первую часть и вторую часть в зависимости от того, генерируются ли характерные биты системой 12 кодирования на базе кадра или на базе субкадра соответственно. Как пояснено ниже, первая часть и вторая часть потока битов изменяются в зависимости от кодека 22, 24, 26 и 28, выбранного для кодирования и декодирования кадра речевого сигнала 18.
1.1 Распределение битов для кодека полной скорости
Со ссылками на фиг.2, 3 и 4 ниже описан поток битов полной скорости кодека 22 полной скорости. Согласно фиг.4 распределение битов для кодека 22 полной скорости включает компонент 140 частоты линейного спектра, компонент 142 типа, компонент 144 адаптивной кодовой книги, компонент 146 фиксированной кодовой книги и компонент 147 выигрыша (усиления). Компонент 147 усиления содержит компонент 148 усиления адаптивной кодовой книги, компонент 150 усиления фиксированной кодовой книги. Распределение битов далее определяется столбцом 152 типа 0 и столбцом 154 типа 1. Столбцы 152 и 154 типа 0 и типа 1 обозначают распределение битов в потоке битов на основе классификации типа речевого сигнала 18, как описано выше. В одном из вариантов осуществления столбец 152 типа 0 и столбец 154 типа 1 оба используют 4 субкадра по 5 мс каждый для обработки речевого сигнала 18.
Модуль 46 обработки исходного кадра полной скорости, показанный на фиг.2, генерирует компонент 140 частоты линейного спектра (ЧЛС). Компонент 140 ЧЛС генерируется на основе параметров средства краткосрочного прогнозирования. Параметры средства краткосрочного прогнозирования преобразуются во множество частот линейного спектра (ЧЛС). ЧЛС представляют спектральную огибающую кадра. Кроме того, множество определяется множеством прогнозированных ЧЛС из ЧЛС предыдущих кадров. Прогнозированные ЧЛС вычитаются из ЧЛС для формирования ошибки прогнозирования ЧЛС. В одном из вариантов осуществления ошибка прогнозирования ЧЛС содержит вектор 10 параметров. Ошибка прогнозирования ЧЛС объединяется с прогнозированными ЧЛС для формирования множества квантованных ЧЛС. Квантованные ЧЛС интерполируются и преобразуются для формирования множества квантованных коэффициентов КЛП Aq(z) для каждого субкадра, как пояснено более детально ниже. Кроме того, ошибка прогнозирования ЧЛС квантуется для генерации компонента 140 ЧЛС, который передается в систему 16 декодирования.
Когда поток битов принимается в системе 16 декодирования, компонент 140 ЧЛС используется для определения квантованного вектора, представляющего квантованную ошибку прогнозирования ЧЛС. Квантованная ошибка прогнозирования ЧЛС суммируется с прогнозируемыми ЧЛС для генерации суммарных квантованных ЧЛС. Прогнозированные ЧЛС определяются из ЧЛС предыдущих кадров в системе 16 декодирования подобно системе 12 кодирования. Полученные в результате квантованные ЧЛС могут интерполироваться для каждого субкадра с использованием предварительно определенного взвешивания. Предварительно определенное взвешивание определяет путь интерполяции, который может быть фиксированным или переменным. Путь интерполяции соответствует пути между квантованными ЧЛС предыдущего кадра и квантованными ЧЛС текущего кадра. Путь интерполяции может быть использован для обеспечения представления спектральной огибающей для каждого субкадра в текущем кадре.
Для кадров, классифицированных как тип 0, в возможном варианте осуществления компонент 140 ЧЛС кодируется с использованием множества каскадов 156 и интерполяционного элемента 158, как показано на фиг.4. Каскады 156 представляют ошибку прогнозирования ЧЛС, используемую для кодирования компонента 140 ЧЛС для кадра. Интерполяционный элемент 158 может быть использован для обеспечения множества путей интерполяции между квантованными ЧЛС предыдущего кадра и квантованными ЧЛС текущего обрабатываемого кадра. В принципе, интерполяционный элемент 158 представляет выбираемую настройку в контуре частот линейного спектра (ЧЛС) в процессе декодирования. Выбираемая настройка может быть использована ввиду нестационарного спектрального характера кадров, которые классифицированы как тип 0. Для кадров, классифицированных как тип 1, компонент 140 ЧЛС может кодироваться с использованием только каскадов 156 и предварительно определенного пути интерполяции вследствие стационарного спектрального характера таких кадров.
В одном из вариантов осуществления компонент 140 ЧЛС включает 2 бита для кодирования интерполяционного элемента 158 для кадров, классифицированных как тип 0. Биты идентифицируют конкретный путь интерполяции. Каждый из путей интерполяции настраивает взвешивание предыдущих квантованных ЧЛС для каждого субкадра и взвешивание текущих квантованных ЧЛС для каждого субкадра. Выбор пути интерполяции может быть определен на основе степени изменений в спектральной огибающей между последовательными субкадрами. Например, если имеется существенное изменение в спектральной огибающей в середине кадра, то интерполяционный элемент 158 выбирает путь интерполяции, который уменьшает влияние квантованных ЧЛС из предыдущего кадра. В одном из вариантов осуществления интерполяционный элемент 158 может представлять любой один из четырех различных путей интерполяции для каждого субкадра.
Прогнозированные ЧЛС могут генерироваться с использованием множества коэффициентов средства прогнозирования со скользящим средним. Коэффициенты средства прогнозирования определяют, сколько ЧЛС из предыдущих кадров используются для прогнозирования ЧЛС текущего кадра. Коэффициенты средства прогнозирования в кодекс 22 полной скорости используют таблицу коэффициентов средства прогнозирования ЧЛС. Таблица может быть в принципе представлена в виде следующей матрицы.

В одном из вариантов осуществления m=2 и n=10. Соответственно порядок прогнозирования равен двум, и имеются два вектора коэффициентов средства прогнозирования, каждый из которых содержит 10 элементов. Возможный вариант осуществления таблицы коэффициентов средства прогнозирования ЧЛС обозначен как "Float64 B_85k" и включен в Приложение В.
После того как прогнозируемые ЧЛС определены, можно вычислить ошибку прогнозирования ЧЛС с использованием действительных ЧЛС. Ошибка прогнозирования ЧЛС может быть квантована с использованием полноразмерного многокаскадного квантователя. Таблица квантования ошибки прогнозирования ЧЛС, содержащая множество векторов квантования, представляет каждый каскад 156, который может быть использован с многокаскадным квантователем. Многокаскадный квантователь определяет часть компонента 140 ЧЛС для каждого каскада 156. Определение части компонента 140 ЧЛС основывается на методе усеченного поиска. Метод усеченного поиска определяет вероятных кандидатов вектора квантования с каждого каскада. В заключение определения кандидатов для всех каскадов одновременно принимается решение, которое выбирает наилучшие векторы квантования для каждого каскада.
На первом этапе многокаскадный квантователь определяет множество ошибок квантования кандидата для первого каскада. Ошибки квантования кандидата для первого каскада являются разностью между ошибкой прогнозирования ЧЛС и наиболее близко совпадающими векторами квантования в первом каскаде. Многокаскадный квантователь затем определяет множество ошибок квантования кандидата второго каскада путем идентификации векторов квантования, находящихся во втором каскаде, которые наилучшим образом совпадают с ошибками квантования кандидата первого каскада. Этот итеративный процесс выполняется для каждого из каскадов, и наиболее вероятные кандидаты определяются для каждого каскада. Конечный выбор наилучших характерных векторов квантования для каждого каскада осуществляется одновременно, если кандидаты определены для всех каскадов. Компонент 140 ЧЛС включает местоположения индексов наиболее близко совпадающих векторов квантования с каждого каскада. В одном из вариантов осуществления компонент 140 ЧЛМС включает 25 битов для кодирования местоположений индексов внутри каскадов. Таблица квантования ошибок прогнозирования ЧЛС для метода квантования может быть представлена в общем случае в виде следующей матрицы.
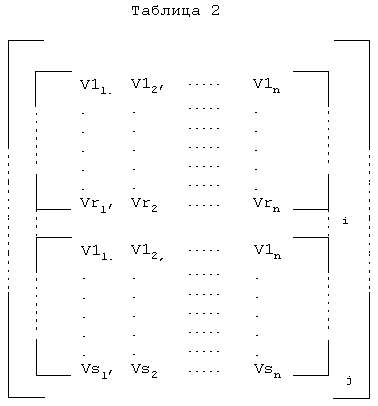
В одном из вариантов осуществления таблица квантования для классификации как типа 0, так и типа 1 использует четыре каскада (j=4), в которых каждый вектор квантования представлен 10 элементами (n=10). Каскады 156 в этом варианте осуществления включают 128 векторов квантования (r=128) для одного из каскадов 156 и 64 вектора квантования (s=64) в остальных каскадах 156. Соответственно местоположение индекса векторов квантования в каскадах 156 может кодироваться с использованием 7 битов для одного из каскадов 156, который включает 128 векторов квантования. Кроме того, местоположения индексов для каждого из каскадов 156, которое включают 64 вектора квантования, могут кодироваться с использованием 6 битов. Один из вариантов осуществления таблицы квантования ошибок прогнозирования ЧЛС, используемой для классификации как типа 0, так и типа 1, озаглавлен как "Float64CBes_85k" и включен в Приложение В.
В системе 16 декодирования модули 108 и 110 восстановления КЛП F0 или F1 в устройстве 90 декодирования полной скорости получают компонент 140 ЧЛС из потока битов, как показано на фиг.3. Компонент 140 ЧЛС может быть использован для восстановления квантованных ЧЛС, как описано выше. Квантованные ЧЛС могут интерполироваться и преобразовываться для формирования коэффициентов кодирования с линейным предсказанием для каждого субкадра текущего кадра.
Для классификации типа 0 восстановление может быть выполнено модулем 108 восстановления КПП F0. Восстановление связано с определением прогнозируемых ЧЛС, декодирования квантованных ошибок прогнозирования ЧЛС и восстановления квантованных ЧЛС. Кроме того, квантованные ЧЛС могут интерполироваться с использованием идентифицированного пути интерполяции. Как описано выше, один из четырех путей идентифицируется для модуля восстановления 108 КЛП F0 с помощью элемента 158 интерполяции, который образует часть компонента 140 ЧЛС. Восстановление классификации типа 1 связано с использованием предварительно определенного линейного пути интерполяции таблицы квантования ошибок прогнозирования ЧЛС модулем 110 восстановления КЛП F1. Компонент 140 ЧЛС образует часть первой части потока битов, поскольку он кодируется на кадровой основе для классификации как типа 0, так и типа 1.
Компонент 142 типа также образует часть первой части потока битов. Как показано на фиг.2, модуль 68 селектора типа F генерирует компонент 142 типа для представления классификации типа конкретного кадра. Согласно фиг.3 модуль 102 селектора типа F в устройстве 90 декодирования полной скорости получает компонент 142 типа из потока битов.
В одном из вариантов осуществления компонент 144 адаптивной кодовой книги может представлять собой компонент 144а адаптивной кодовой книги разомкнутого контура или компонент 144b адаптивной кодовой книги замкнутого контура. Компонент 144а, 144b адаптивной кодовой книги разомкнутого или замкнутого контура генерируется посредством модуля 46 обработки исходного кадра полной скорости или первым модулем 70 обработки субкадра F0 соответственно, как показано на фиг.2. Компонент 144а адаптивной кодовой книги разомкнутого контура может заменяться компонентом 144b адаптивной кодовой книги замкнутого контура в потоке битов, когда кадр классифицируется как тип 0. В принципе, обозначение "в разомкнутом контуре" относится к обработке на кадровой основе, которая не использует процедуру анализа через синтез. Обработка в замкнутом контуре выполняется на субкадровой основе и включает процедуру анализа через синтез.
Кодирование запаздывания основного тона, что основывается на периодичности речевого сигнала 18, генерирует компонент 144 адаптивной кодовой книги. Компонент 144а адаптивной кодовой книги разомкнутого контура генерируется для кадра, в то время как компонент 144b адаптивной кодовой книги замкнутого контура генерируется на субкадровой основе. Соответственно компонент 144а адаптивной кодовой книги разомкнутого контура является частью первой части потока битов, а компонент 144b адаптивной кодовой книги замкнутого контура является частью второй части потока битов. В одном из вариантов осуществления, как показано на фиг.4, компонент 144а адаптивной кодовой книги разомкнутого контура содержит 8 битов, а компонент 144b адаптивной кодовой книги замкнутого контура содержит 26 битов. Компонент 144а адаптивной кодовой книги разомкнутого контура и компонент 144b адаптивной кодовой книги замкнутого контура могут генерироваться с использованием вектора адаптивной кодовой книги, как описано ниже. Как показано на фиг.3, система 16 декодирования получает компонент 144а или 144b адаптивной кодовой книги разомкнутого или замкнутого контура. Компонент 144а или 144b адаптивной кодовой книги разомкнутого или замкнутого контура декодируется модулем 104 или 106 восстановления возбуждением F0 или F1 соответственно.
В одном из вариантов осуществления компонент 146 фиксированной кодовой книги может представлять собой компонент 146а фиксированной кодовой книги типа 0 или компонент 146b фиксированной кодовой книги типа 1. Компонент 146а фиксированной кодовой книги типа 0 генерируется первым модулем 70 обработки субкадра F0, как показано на фиг.2. Модуль 72 обработки субкадра F1 генерирует компонент 146b фиксированной кодовой книги типа 1. Компонент 146а или 146Ь фиксированной кодовой книги типа 0 или типа 1 генерируется с использованием вектора фиксированной кодовой книги и процедуры синтеза через анализ на субкадровой основе, как описано ниже. Компонент 146 фиксированной кодовой книги представляет долгосрочный остаток субкадра при использовании n-импульсной кодовой книги, где n - число импульсов в кодовой книге.
Согласно фиг.4 компонент 146а фиксированной кодовой книги типа 0 в одном из вариантов содержит 22 бита на субкадр. Компонент 146а фиксированной кодовой книги типа 0 включает идентификацию одной из множества n-импульсных кодовых книг, местоположение импульса в кодовой книге и знаки репрезентативных импульсов (количество "n"), которые соответствуют местоположениям импульсов. В возможном варианте осуществления до двух битов обозначают, какая одна из трех n-импульсных кодовых книг кодировалась. Более конкретно, первые два бита устанавливаются на "1" для обозначения того, что использована первая из трех n-импульсных кодовых книг. Если первый бит установлен на "0", то второй из двух битов указывает, используется ли вторая или третья из трех n-импульсных кодовых книг. Соответственно в приведенном для примера варианте осуществления первая из трех n-импульсных кодовых книг имеет 21 бита для представления местоположений и знаков импульсов, а вторая и третья из трех n-импульсных кодовых книг имеют 20 битов для такого использования.
Каждый из репрезентативных импульсов в одной из n-импульсных кодовых книг включает соответствующую дорожку. Дорожка представляет собой список местоположений выборок в субкадре, где каждое местоположение выборки в списке является одним из местоположений импульсов. Кодируемый субкадр может подразделяться на множество местоположений выборок, где каждое из местоположений выборок содержит значение выборки. Дорожки соответствующих репрезентативных импульсов перечисляют только часть местоположений выборок из субкадра. Каждый из репрезентативных импульсов в одной из n-импульсных кодовых книг может быть представлен одним из местоположений импульсов в соответствующей дорожке.
В процессе функционирования каждый из репрезентативных импульсов последовательно помещается в каждое из местоположений импульсов в соответствующей дорожке. Репрезентативные импульсы преобразуются в сигнал, который может сравниваться со значениями выборок в местоположениях выборок субкадра с использованием процедуры анализа через синтез. Репрезентативные импульсы сравниваются со значениями выборок в тех местоположениях выборок, которые по времени позже, чем местоположение выборки для местоположения импульса. Местоположение импульса, которое минимизирует разность между репрезентативным импульсом и значениями выборок, которые позже по времени, образует часть компонента 146а фиксированной кодовой книги типа 0. Каждый из репрезентативных импульсов в выбранной n-импульсной кодовой книге может быть представлен соответствующим местоположением импульса, которое образует часть компонента 146а фиксированной кодовой книги типа 0. Дорожки содержатся в таблице дорожек, которая может быть в принципе представлена следующей матрицей.

Возможный вариант осуществления таблиц дорожек представлен таблицей, озаглавленной "static short track_5_4_0", "static short track_5_3_2" и "static short track_5_3_1", в библиотеке, озаглавленной "tracks.tab", которая включена в Приложение В.
В примере, показанном на фиг.4, n-импульсные кодовые книги являются 5-импульсными кодовыми книгами 160, где первая из трех 5-импульсных кодовых книг 160 включает 5 репрезентативных импульсов, поэтому n=5. Первый репрезентативный импульс имеет дорожку, которая включает 16 (f=16) из 40 местоположений выборок в субкадре. Первый репрезентативный импульс из первой из трех 5-импульсных кодовых книг 160 сравнивается со значениями выборок в местоположениях выборок. Одно из местоположений выборок, присутствующих в дорожке, связанной с первым репрезентативным импульсом, идентифицируется как местоположение импульса с использованием 4 битов. Местоположение импульса, которое идентифицировано в дорожке, является местоположением выборки в субкадре, которое минимизирует разность между первым репрезентативным импульсом и значениями выборок, которые позже по времени, как описано выше. Идентификация местоположения импульса в дорожке формирует часть компонента 146а фиксированной кодовой книги типа 0.
В данном приведенном для примера варианте осуществления второй и четвертый репрезентативные импульсы имеют соответствующие дорожки с 16 местоположениями выборок (g и i=16), а третий и пятый репрезентативные импульсы имеют соответствующие дорожки с 8 местоположениями выборок (h и j=8) соответственно. Местоположения импульсов для второго и четвертого репрезентативных импульсов идентифицируются с использованием 4 битов, а местоположения импульсов для третьего и пятого репрезентативных импульсов идентифицируются с использованием 3 битов. В результате компонент 146а фиксированной кодовой книги типа 0 для первой из трех 5-импульсных кодовых книг 160 включает 18 битов для идентификации местоположений импульсов.
Знаки репрезентативных импульсов в идентифицированных местоположениях импульсов могут также быть идентифицированы в компоненте 146а фиксированной кодовой книги типа 0. В приведенном для примера варианте осуществления один бит представляет знак для первого репрезентативного импульса, один бит представляет объединенный знак для второго и четвертого репрезентативных импульсов, и один бит представляет объединенный знак для третьего и пятого репрезентативных импульсов. Объединенный знак использует избыточность информации в местоположениях импульсов для передачи двух различных знаков с помощью одного бита. Соответственно компонент 146а фиксированной кодовой книги типа 0 для первой из трех 5-импульсных кодовых книг 160 включает три бита для обозначения знака для полного количества 21 бит.
В рассматриваемом в качестве примера варианте осуществления вторая и третья из трех 5-импульсных кодовых книг 160 также включают 5 репрезентативных импульсов (n=5), и каждая из дорожек в таблице дорожек содержит 8 местоположений выборок (f, g, h, I, j=8). Соответственно местоположения импульсов для каждого из репрезентативных импульсов во второй и третьей из трех 5-импульсных кодовых книг 160 идентифицируются с использованием 3 битов. Кроме того, в этом варианте осуществления знаки для каждого из местоположений импульсов идентифицируются с использованием 1 бита.
Для кадров, классифицированных как тип 1, в возможном варианте осуществления n-импульсная кодовая книга представляет собой 8-импульсную кодовую книгу 162 (n=8). 8-импульсная кодовая книга 162 кодируется с использованием 30 битов на субкадр для создания компонента 146b фиксированной кодовой книги типа 1. 30 битов включают в себя 26 битов, идентифицирующих местоположения импульсов с использованием дорожек, как и для классификации как тип 0, и 4 битов, идентифицирующих знаки. В возможном варианте осуществления таблица дорожек представляет собой таблицу, озаглавленную "static INT16 track_8_4_0" в библиотеке, озаглавленной "tracks.tab", которая включена в Приложение В.
В данном приведенном для примера варианте осуществления дорожки, связанные с первым и вторым репрезентативными импульсами, содержат 16 местоположений выборок, которые кодированы с использованием 4 битов. Дорожки, связанные с остальными репрезентативными импульсами, содержат 8 местоположений выборок, которые кодированы с использованием 3 битов. Первый и пятый репрезентативные импульсы, второй и шестой репрезентативные импульсы, третий и седьмой репрезентативные импульсы и четвертый и восьмой репрезентативные импульсы используют объединенные знаки для обоих соответствующих репрезентативных импульсов. Как показано на фиг.3, когда поток битов принимается системой 16 декодирования, модули 104 или 106 восстановления возбуждением F0 и F1 декодируют местоположения импульсов дорожек. Местоположения импульсов дорожек декодируются модулями 104 или 106 восстановления возбуждением F0 и F1 для одной из трех 5-импульсных кодовых книг 160 или 8-импульсных кодовых книг 162 соответственно. Компонент 146 фиксированной кодовой книги является частью второй части потока импульсов, поскольку он генерируется на субкадровой основе.
Как показано на фиг.4, компонент 147 выигрыша (усиления) в общем случае представляет усиления адаптивной и фиксированной кодовых книг. Для классификации как тип 0 компонент 147 усиления является компонентом 148а, 150а усиления адаптивной и фиксированной кодовых книг типа 0, представляющим усиления как адаптивной, так и фиксированной кодовых книг. Компонент 148а, 150а усиления адаптивной и фиксированной кодовых книг типа 0 является частью второй части потока импульсов, поскольку он кодируется на субкадровой основе. Как показано на фиг.2, компонент 148а, 150а усиления адаптивной и фиксированной кодовых книг типа 0 генерируется первым модулем 70 обработки субкадра F0.
Для каждого субкадра, относящегося к кадру, классифицированному как тип 0, усиления адаптивной и фиксированной кодовых книг совместно кодируются с помощью двумерного (2D) векторного квантователя (ВК) 164 для генерирования компонента 148а, 150а усиления адаптивной и фиксированной кодовых книг типа. В одном варианте осуществления квантование предусматривает перевод усиления фиксированной кодовой книги в энергию фиксированной кодовой книги в дБ. Кроме того, прогнозируемая энергия фиксированной кодовой книги может генерироваться из квантованных значений энергии фиксированной кодовой книги предшествующих кадров. Прогнозируемая энергия фиксированной кодовой книги может быть получена с использованием множества коэффициентов средства прогнозирования фиксированной кодовой книги.
Подобно коэффициентам средства прогнозирования ЧЛС коэффициенты средства прогнозирования фиксированной кодовой книги определяют, какое количество энергии фиксированной кодовой книги для предыдущих кадров может быть использовано для прогнозирования энергии фиксированной кодовой книги текущего кадра. Прогнозируемая энергия фиксированной кодовой книги вычитается из энергии фиксированной кодовой книги для генерации ошибки прогнозирования энергии фиксированной кодовой книги. Путем регулирования взвешивания предыдущих кадров и текущих кадров для каждого субкадра может быть вычислена прогнозируемая энергия фиксированной кодовой книги для минимизации ошибки прогнозирования фиксированной кодовой книги.
Ошибка прогнозирования энергии фиксированной кодовой книги группируется вместе с усилением адаптивной кодовой книги для формирования двумерного вектора. Ввиду квантования ошибки прогнозирования энергии фиксированной кодовой книги и усиления адаптивной кодовой книги, как описано ниже, двумерный вектор может называться квантованным вектором усиления (gac). Двумерный вектор сравнивается с множеством предварительно определенных векторов в двумерной таблице квантования усилений. Местоположение индекса идентифицируется как местоположение в двумерной (2D) таблице квантования усилений, соответствующее предварительно определенному вектору, который наилучшим образом представляет двумерный вектор. Это местоположение индекса является компонентом 148а и 150а усиления адаптивной и фиксированной кодовой книги для субкадра. Компонент 148а и 150а усиления адаптивной и фиксированной кодовой книги для кадра представляет индексы для каждого из субкадров.
Предварительно определенные векторы содержат 2 элемента, один из которых представляет выигрыш адаптивной кодовой книги, а другой - ошибку прогнозирования энергии фиксированной кодовой книги. Двумерная таблица квантования выигрышей может быть в общем виде представлена следующим образом.

Двумерный векторный квантователь (2D ВК) 164 согласно одному из вариантов осуществления использует 7 битов на субкадр, чтобы идентифицировать местоположение индекса одного из 128 векторов квантования (n=128). В одном из вариантов осуществления двумерная таблица квантования выигрышей озаглавлена "Float64 gain VQ_2_128_8_5" и включена в Приложение В.
Для кадров, классифицированных как тип 1, компонент 148b усиления адаптивной кодовой книги типа 1 генерируется модулем 71 обработки первого кадра F1, как показано на фиг.1. Аналогичным образом модулем 72 обработки второго кадра F1 генерирует компонент 150b усиления фиксированной кодовой книги типа 1. Компонент 148b усиления адаптивной кодовой книги типа 1, компонент 150b усиления фиксированной кодовой книги типа 1 генерируются на покадровой основе для формирования части из первой части потока битов.
Согласно фиг.4 компонент 148b усиления адаптивной кодовой книги типа 1 генерируется с использованием многомерного векторного квантователя, который в одном из вариантов осуществления представляет собой четырехмерный "пре" (предварительный) векторный квантователь (4D пре-ВК) 166. Термин "пре" (предварительный) используется для отражения того факта, что в одном из вариантов усиления адаптивной кодовой книги для всех субкадров в кадре квантуются перед поиском любого из субкадров в фиксированной кодовой книге. В альтернативном варианте многомерный квантователь представляет собой n-мерный векторный квантователь, который квантует векторы для n-субкадров, где n может быть любым числом субкадров.
Вектор, квантованный четырехмерным предварительным векторным квантователем (4D пре-ВК) 166, является вектором усиления адаптивной кодовой книги с элементами, которые представляют каждый из усилений адаптивной кодовой книги из каждого из субкадров. Ввиду квантования, как описано ниже, вектор усиления адаптивной кодовой книги может называться квантованным усилением основного тона (gk a). Квантование векторы усиления адаптивной кодовой книги для генерирования компонента 148b усиления адаптивной кодовой книги выполняется путем поиска в таблице квантования предварительного усиления. Таблица квантования предварительного усиления включает множество предварительно определенных векторов, для которых может осуществляться поиск, чтобы идентифицировать предварительно определенный вектор, который наилучшим образом представляет вектор усиления адаптивной кодовой книги. Местоположение индекса идентифицированного предварительно определенного вектора в таблице квантования предварительного усиления является компонентом 148b адаптивной кодовой книги типа 1. Компонент 148b адаптивной кодовой книги типа 1 в одном из вариантов осуществления содержит 6 битов.
В одном из вариантов осуществления предварительно определенный вектор содержит 4 элемента, по одному элементу на каждый субкадр. Соответственно таблица квантования предварительного усиления в общем случае может быть представлена в следующем виде.

В одном из вариантов осуществления таблица квантования предварительного усиления включает 64 предварительно определенных вектора (n=64). Возможный вариант таблицы квантования предварительного усиления, озаглавленный "Float64 gp4_tab", включен в Приложение В.
Компонент 150b усиления фиксированной кодовой книги типа 1 может кодироваться аналогичным образом с использованием многомерного векторного квантователя для n субкадров. В одном из вариантов многомерный векторный квантователь представляет собой четырехмерный векторный квантователь с задержкой (4D ВК с задержкой) 168. Термин "с задержкой" указывает на то, что квантование усилений фиксированной кодовой книги для субкадров осуществляется только после поиска всех субкадров в фиксированной кодовой книге. Согласно фиг.2 модуль 76 обработки второго субкадра F1 определяет усиление фиксированной кодовой книги для каждого из субкадров. Усиление фиксированной кодовой книги может быть определено путем буферизации сначала параметров, генерированных на субкадровой основе, до тех пор пока не будет обработан полный кадр. Если кадр обработан, усиления фиксированной кодовой книги для всех субкадров квантуются с использованием буферизованных параметров для генерации компонента 150b усиления фиксированной кодовой книги типа 1. В одном из вариантов компонент 150b фиксированной кодовой книги типа 1 содержит 10 битов, как показано на фиг.4.
Компонент 150b фиксированной кодовой книги типа 1 генерируется путем представления усилений фиксированной кодовой книги множеством энергий фиксированной кодовой книги в дБ. Энергии фиксированной кодовой книги квантуются для формирования множества квантованных энергий фиксированной кодовой книги, которые затем преобразуются для формирования множества квантованных усилений фиксированной кодовой книги. Кроме того, энергии фиксированной кодовой книги прогнозируются из ошибок квантованных энергий фиксированной кодовой книги предыдущих кадров для генерации множества прогнозированных энергий фиксированной кодовой книги. Разность между прогнозированными энергиями фиксированной кодовой книги и энергиями фиксированной кодовой книги представляет собой множество ошибок прогнозирования фиксированной кодовой книги. В одном из вариантов осуществления могут быть использованы различные коэффициенты прогнозирования для каждых 4 субкадров, чтобы генерировать прогнозированные энергии фиксированной кодовой книги. В данном варианте прогнозированные энергии фиксированной кодовой книги первого, второго, третьего и четвертого субкадров прогнозируются из 4 квантованных ошибок энергий фиксированной кодовой книги предыдущего кадра. Коэффициенты прогнозирования для первого, второго, третьего и четвертого субкадров в данном варианте могут иметь соответственно следующие значения: {0,7; 0,6; 0,4, 0,2}, {0,4; 0,2; 0,1; 0,05}, {0,3;0,2;0,075;0,025} и {0,2;0,075; 0,025; 0,0}.
Ошибки прогнозирования энергий фиксированной кодовой книги могут быть сгруппированы для формирования вектора усилений фиксированной кодовой книги, который после квантования может быть определен как квантованное усиление фиксированной кодовой книги  . В одном из вариантов ошибка прогнозирования энергий фиксированной кодовой книги для каждого субкадра представляет элементы вектора. Ошибки прогнозирования энергий фиксированной кодовой книги квантуются с использованием множества предварительно определенных векторов в таблице квантования усилений с задержками. В процессе квантования может быть введена мера перцепционного взвешивания, чтобы минимизировать ошибку квантования. Местоположение индекса, которое идентифицирует предварительно определенный вектор в таблице квантования усилений с задержками, является компонентом 150b усиления фиксированной кодовой книги для кадра.
. В одном из вариантов ошибка прогнозирования энергий фиксированной кодовой книги для каждого субкадра представляет элементы вектора. Ошибки прогнозирования энергий фиксированной кодовой книги квантуются с использованием множества предварительно определенных векторов в таблице квантования усилений с задержками. В процессе квантования может быть введена мера перцепционного взвешивания, чтобы минимизировать ошибку квантования. Местоположение индекса, которое идентифицирует предварительно определенный вектор в таблице квантования усилений с задержками, является компонентом 150b усиления фиксированной кодовой книги для кадра.
Предварительно определенные векторы в таблице квантования усилений с задержками в одном из вариантов осуществления включают 4 элемента. Соответственно таблица квантования усилений с задержками может быть представлена вышеописанной таблицей 5. Возможный вариант таблицы квантования усилений с задержками включает 1024 предварительно определенных вектора (n=1024). Возможный вариант таблицы квантования усилений с задержками, озаглавленный "Float64 gainVQ_4_1024" включен в Приложение В.
Согласно фиг.3 компоненты 148 и 150 усилений фиксированной и адаптивной кодовых книг могут быть декодированы посредством устройства 90 декодирования полной скорости в системе 16 декодирования, основанной на классификации типа. Модуль 104 восстановления возбуждения F0 декодирует компоненты 148а и 150а усилений фиксированной и адаптивной кодовых книг типа 0. Аналогичным образом модуль 106 восстановления возбуждения F1 декодирует компоненты 148b и 150b усилений фиксированной и адаптивной кодовых книг типа 1.
Декодирование компонентов 158 и 160 усилений фиксированной и адаптивной кодовых книг связано с генерацией соответствующих прогнозированных усилений, как описано выше, с помощью устройства 90 декодирования полной скорости. Соответствующие квантованные векторы из соответствующих таблиц квантования затем определяются с использованием соответствующих местоположений индексов. Соответствующие квантованные векторы затем группируются с соответствующими прогнозированными усилениями для формирования соответствующих квантованных усилений кодовых книг. Квантованные усиления кодовых книг, сформированные компонентами 148а и 150а усилений фиксированных и адаптивных кодовых книг типа 0, представляютзначения усилений фиксированной и адаптивной кодовых книг для сукбкадра. Квантованные усиления кодовых книг, сформированные компонентами 148b и150b усилений фиксированных и адаптивных кодовых книг типа 1, представляют значения усилений фиксированной и адаптивной кодовых книг соответственно для каждого субкадра в кадре.
1.2 Распределение битов для кодека половинной скорости
Ниже со ссылками на фиг.2, 3 и 5 описан поток битов половинной скорости кодека 24 половинной скорости. Кодек 24 половинной скорости во многих отношениях подобен кодеку 22 полной скорости, но имеет отличающееся распределение битов. Для краткости, описание будет концентрироваться на различиях. На фиг.5 представлено распределение битов для возможного варианта осуществления кодека 24 половинной скорости, включающее в себя компонент 172 ЧЛС, компонент 174 типа, компонент 176 адаптивной кодовой книги, компонент 178 фиксированной кодовой книги, компонент 179 усиления. Компонент 179 усиления также содержит компонент 180 усиления адаптивной кодовой книги и компонент 182 усиления фиксированной кодовой книги. Поток битов кодека 24 половинной скорости также определяется столбцом 184 типа 0 и столбцом 186 типа 1. В возможном варианте столбец 184 типа 0 использует два субкадра по 10 мс каждый, содержащие по 80 выборок. В возможном варианте столбец 186 типа 1 использует три субкадра, причем первый и второй субкадры содержат 53 выборки, а третий субкадр содержит 54 выборки.
Компонент 172 ЧЛС, хотя и генерируется подобно кодеку 22 полной скорости, но содержит множество каскадов 188 и коммутатор 190 функции прогнозирования для классификаций типа 0 и типа 1. Кроме того, в возможном варианте осуществления компонент 172 ЧЛС содержит 21 бит, которые образуют первую часть потока битов. Модуль 48 обработки исходного кадра половинной скорости, показанный на фиг.2, формирует компонент 172 ЧЛС аналогично кодеку 22 полной скорости. Согласно фиг.5 кодеку 24 половинной скорости содержит три каскада 188, два из которых с 128 векторами, а один - с 64 векторами. Три каскада 188 кодека 24 половинной скорости работают подобно кодеку 22 полной скорости для кадров, классифицированных как тип 1, за исключением выбора из набора коэффициентов функции прогнозирования, как пояснено ниже. Местоположение индекса каждого из 128 векторов идентифицируется 7 битами, а местоположение индекса каждого из 64 векторов идентифицируется 6 битами. Возможный вариант таблицы квантования ошибок прогнозирования ЧЛС для кодека 24 половинной скорости, озаглавленный "Float64 CBes_40k", включен в Приложение В.
Кодек 24 половинной скорости отличается от кодека 22 полной скорости выбором из наборов коэффициентов функции прогнозирования. Коммутатор 190 функции прогнозирования в одном из вариантов идентифицирует один из двух возможных наборов коэффициентов функции прогнозирования с использованием 1 бита. Выбранный набор коэффициентов функции прогнозирования может быть использован для определения ЧЛС, подобно кодеку 22 полной скорости. Коммутатор 190 функции прогнозирования определяет и идентифицирует, какой из наборов коэффициентов функции прогнозирования будет наилучшим образом минимизировать ошибку квантования. Наборы коэффициентов функции прогнозирования могут содержаться в таблице коэффициентов функции прогнозирования ЧЛС, иллюстрируемой в общем виде следующей матрицей.
В одном из вариантов осуществления имеются 4 коэффициента функции прогнозирования (m=4) в каждом из двух наборов (j=2), каждый из которых содержит 10 элементов (n= 10). Таблица коэффициентов функции прогнозирования ЧЛС для кодека 24 половинной скорости в возможном варианте осуществления, озаглавленная "Float64 B_40k", включена в Приложение В. Согласно фиг.3 таблица квантования ошибок функции прогнозирования ЧЛС и таблица коэффициентов функции прогнозирования ЧЛС используются модулем 118 восстановления КЛП Н в системе 16 декодирования. Модуль 118 восстановления КЛП Н получает и декодирует компонент 172 ЧЛС из потока битов для восстановления ЧЛС квантованного кадра. Подобно кодеку 22 полной скорости для кадров, классифицированных как тип 1, кодек 24 половинной скорости использует предварительно определенный путь линейной интерполяции. Однако кодек 24 половинной скорости использует предварительно определенный путь линейной интерполяции для кадров, классифицированный как тип 0 и как тип 1.
Компонент 176 адаптивной кодовой книги в кодеке 24 половинной скорости аналогичным образом моделирует запаздывание основного тона на основе периодичности речевого сигнала 18. Компонент 176 адаптивной кодовой книги кодируется на субкадровой основе для классификации типа 0 и на кадровой основе для классификации типа 1. Как показано на фиг.2, модуль 48 обработки исходного кадра половинной скорости кодирует компонент 176а адаптивной кодовой книги разомкнутого контура для кадров с классификацией типа 1. Для кадров с классификацией типа 0 модуль 80 обработки первого субкадра Н0 кодирует компонент 176b адаптивной кодовой книги замкнутого контура.
Согласно фиг.5 компонент 176а адаптивной кодовой книги разомкнутого контура кодируется 7 битами на кадр, а компонент 176b адаптивной кодовой книги замкнутого контура кодируется 7 битами на субкадр. Соответственно компонент 176а адаптивной кодовой книги типа 0 является частью первой части потока битов, компонент 176b адаптивной кодовой книги типа 1 является частью второй части потока битов. Как показано на фиг.3, система 16 декодирования получает компонент 176b адаптивной кодовой книги замкнутого контура. Компонент 176b адаптивной кодовой книги замкнутого контура декодируется устройством 92 декодирования половинной скорости с использованием модуля 114 восстановления возбуждения Н0. Аналогичным образом компонент 176а адаптивной кодовой книги разомкнутого контура декодируется модулем 116 восстановления возбуждения H1.
В одном из вариантов компонент 178 фиксированной кодовой книги для кодека 24 половинной скорости зависит от классификации типа для кодирования долгосрочного остатка, как в случае кодека 22 полной скорости. Согласно фиг.2 компонент 178а фиксированной кодовой книги типа 0 или компонент 178b фиксированной кодовой книги типа 1 генерируется модулем 80 обработки первого субкадра Н0 или модулем 84 обработки второго субкадра H1 соответственно. Соответственно компонент 178а фиксированной кодовой книги типа 0 или компонент 178b фиксированной кодовой книги типа 1 образуют часть второй части потока битов.
Согласно фиг.5 компонент 178а фиксированной кодовой книги типа 0 кодируется с использованием 15 битов на субкадр и до двух битов для идентификации используемой кодовой книги, как в кодекс 22 полной скорости. Кодирование компонента 178а фиксированной кодовой книги типа 0 связано с использованием множества n-импульсных кодовых книг, в данном примере 2-импульсной кодовой книги 192 и 3-импульсной кодовой книги 194. Кроме того, в данном случае используется гауссовская кодовая книга 195, которая включает в себя записи, представляющие случайное возбуждение. Для n-импульсных кодовых книг кодек 24 половинной скорости использует таблицы дорожек подобно кодеку 22 полной скорости. Возможный вариант таблицы дорожек, озаглавленный "static INT16track_2_7_1", "static INT16track_1_3_0)" и "static INT16track_3_2_0", включен в библиотеку, озаглавленную "tracks.tab", в Приложении В.
В варианте 2-импульсной кодовой книги 192 каждая дорожка в таблице дорожек включает в себя 80 местоположений выборок для каждого репрезентативного импульса. Местоположения импульсов для первого и второго репрезентативных импульсов кодируются с использованием 13 битов. Кодирование 1 из 80 возможных местоположений импульсов выполняется 13 битами путем идентификации местоположения импульса для первого репрезентативного импульса, умножения местоположения импульса на 80 и добавления к результату местоположения импульса для второго репрезентативного импульса. Конечным результатом является значение, которое может кодироваться 13 битами с дополнительным битом, используемым для представления знаков обоих репрезентативных импульсов, как в кодеке 22 полной скорости.
В варианте 3-импульсной кодовой книги 194 местоположения импульсов генерируются комбинацией обобщенного местоположения, которое может является одним из 16 местоположений выборок, определенных 4 битами, и относительным смещением от него. Относительное смещение может составлять 3 значения, представляющие каждый из 3 репрезентативных импульсов в 3-импульсой кодовой книге 194. Значения представляют разность местоположений относительно обобщенного местоположения и могут быть определены 2 битами для каждого репрезентативного импульса. Знаки для трех репрезентативных импульсов могут быть определены одним битом, так что полное число битов для местоположения импульсов и знаков составляет 13 битов.
Гауссовская кодовая книга 195 представляет речевые сигналы шумового типа, которые могут кодироваться с использованием двух случайных векторов ортогонального базиса. Компонент 178а фиксированной кодовой книги типа 0 представляет два случайных вектора ортогонального базиса, генерируемые из гауссовской кодовой книги 195. Компонент 178а фиксированной кодовой книги типа 0 представляет, каким образом нарушить порядок во множестве случайных векторов ортогонального базиса в гауссовской таблице, чтобы увеличить количество случайных векторов ортогонального базиса без увеличения требований к объему памяти. В одном из вариантов осуществления количество случайных векторов ортогонального базиса увеличено с 32 до 45 векторов. Гауссовская таблица, которая включает 32 вектора, причем каждый вектор имеет 40 элементов, представляет гауссовскую кодовую книгу в данном варианте осуществления. В этом варианте два случайных вектора ортогонального базиса, используемые для кодирования, подвергнуты перемежению друг с другом, чтобы получить 80 выборок в каждом субкадре. Гауссовская кодовая книга может быть представлена следующей матрицей.

Один из вариантов гауссовской кодовой книги 195, озаглавленный "double bv" включен в Приложение В. В возможном варианте гауссовской кодовой книги 195 11 битов идентифицируют индексы (местоположение и нарушение порядка) обоих случайных векторов ортогонального базиса, используемых для кодирования, и 2 бита определяют знаки случайных векторов ортогонального базиса.
Кодирование компонента 178b фиксированной кодовой книги типа 1 связано с использованием множества n-импульсных кодовых книг, в данном примере 2-импульсной кодовой книги 196 и 3-импульсной кодовой книги 197. 2-импульсная кодовая книга 196 и 3-импульсная кодовая книга 197 функционируют аналогично 2-импульсной кодовой книге 192 и 3-импульсной кодовой книге 194 классификации типа 0, однако структура отличается. Компонент 178b фиксированной кодовой книги типа 1 кодируется с использованием 13 битов на субкадр. Из 13 битов 1 бит идентифицирует 2-импульсную кодовую книгу 196 и 3-импульсную кодовую книгу 197, и 12 битов представляют соответствующие местоположения импульсов и знаки репрезентативных импульсов. В 2-импульсной кодовой книге 196 в данном примере дорожки включают 32 местоположения выборок для каждого репрезентативного импульса, которые кодируются с использованием 5 битов, а остальные 2 бита используются для знака каждого репрезентативного импульса. В 3-импульсной кодовой книге 197 обобщенное местоположение включает 8 местоположений выборок, которые кодируются с использованием 4 битов. Относительное смещение кодируется с помощью 2 битов, а знаки репрезентативных импульсов кодируются с использованием 3 битов подобно кадрам, классифицированным как тип 0.
Согласно фиг.3 система 16 декодирования получает компоненты 178а и 178b фиксированной кодовой книги типа 0 или типа 1. Компоненты 178а и 178b фиксированной кодовой книги типа 0 или типа 1 декодируются посредством модуля 114 восстановления возбуждения Н0 или модуля 116 восстановления возбуждения HI соответственно. Декодирование компонента 178а фиксированной кодовой книги типа 0 осуществляется с использованием 2-импульсной кодовой книги 192, 3-импульсной кодовой книги 194 или гауссовской кодовой книги 195. Декодирование компонента 178b фиксированной кодовой книги типа 1 осуществляется с использованием 2-импульсной кодовой книги 196 или 3-импульсной кодовой книги 197.
Согласно фиг.5 в возможном варианте осуществления компонент 197 усиления содержит компонент 180а и 182а усиления адаптивной и фиксированной кодовой книги типа 0 соответственно. Компоненты 180а и 182а усиления адаптивной и фиксированной кодовой книги типа 0 могут квантоваться с использованием двумерного (2D) векторного квантователя (ВК) 164 и 2D таблицы квантования усилений (таблица 4), используемой для кодека 22 полной скорости. Вариант осуществления 2D таблицы квантования усилений, озаглавленной "Float54gainVQ_3_128", включен в Приложение В.
Компоненты 180b и 182b усиления адаптивной и фиксированной кодовой книги типа 1 могут генерироваться аналогично тому, как для кодека 22 полной скорости с использованием многомерных векторных квантователей. В одном варианте используются трехмерный предварительный векторный квантователь (3D пре-ВК) 198 и трехмерный векторный квантователь с задержкой (3D ВК с задержкой) 200 для компонентов 180b и 182b усилений адаптивной и фиксированной кодовой книги соответственно. Векторные квантователи 198 и 200 выполняют квантование с использованием соответствующих таблиц квантования усилений. В возможном варианте таблицы квантования усилений являются таблицей предварительного квантования и таблицей квантования с задержкой для усилений адаптивной и фиксированной кодовой книги соответственно. Многомерные таблицы усилений могут структурироваться аналогично и включают множество предварительно определенных векторов. Каждая многомерная таблица усилений в одном из вариантов включает 3 элемента для каждого субкадра для кадра, классифицированного как тип 1.
Подобно кодеку 22 полной скорости трехмерный предварительный векторный квантователь (3D пре-ВК) 198 для компонента 180b усиления адаптивной кодовой книги может непосредственно квантовать адаптивные усиления. Кроме того, трехмерный векторный квантователь с задержкой (3D ВК с задержкой) 200 для компонента 182b фиксированного усиления может квантовать ошибку прогнозирования энергии фиксированной кодовой книги. Различные коэффициенты прогнозирования могут быть использованы для прогнозирования энергии фиксированной кодовой книги для каждого субкадра. В одном предпочтительном варианте прогнозированные энергии фиксированной кодовой книги первого, второго и третьего субкадров прогнозируются из 3 квантованных ошибок энергии фиксированной кодовой книги предыдущего кадра. В этом варианте прогнозированные энергии фиксированной кодовой книги первого, второго и третьего субкадров прогнозируются с использованием набора коэффициентов {0,6; 0,3; 0,1}, {0,4; 0,25; 0,1} и {0,3; 0,15; 0,075} соответственно.
Таблицы квантования усилений для кодека 24 половинной скорости могут быть представлены в следующем виде.

Один вариант таблицы квантования предварительных усилений, используемый трехмерным предварительным векторным квантователем (3D пре-ВК) 198, включает 16 векторов (n=16). Трехмерный векторный квантователь с задержкой (3D ВК с задержкой) 200 использует один вариант таблицы квантования усилений с задержкой, которая включает 256 векторов (n=256). Таблицы квантования усилений для предварительного векторного квантователя (3D пре-ВК) 198 и векторного квантователя с задержкой (3D ВК с задержкой) 200 одного из вариантов, озаглавленные "Float64 gp3_tab" и "Float64 gainVQ_3_256" соответственно, включены в Приложение В.
Согласно фиг.2 компоненты 180а и 182а усилений адаптивной и фиксированной кодовой книги типа 0 генерируются первым модулем 80 обработки субкадра Н0. Первый модуль 82 обработки кадра H1 генерирует компонент 180b усиления адаптивной кодовой книги типа 1. Аналогичным образом второй модуль 86 обработки кадра H1 генерирует компонент 182b усиления фиксированной кодовой книги типа 1. Согласно фиг.3 система 16 декодирования получает компоненты 180а и 182а усилений адаптивной и фиксированной кодовой книги типа 0. Компоненты 180а и 182а усилений адаптивной и фиксированной кодовой книги типа 0 декодируются модулем 114 восстановления возбуждения Н0 на основе классификации типа. Аналогичным образом модуль 116 восстановления возбуждения H1 декодирует компонент 180b усиления адаптивной кодовой книги типа 1 и компонент 182b усиления фиксированной кодовой книги типа 1.
1.3 Распределение битов для кодека одной четвертой скорости
Ниже со ссылками на фиг.2, 3 и 6 описан поток битов одной четвертой скорости кодека 26 одной четвертой скорости. Показанный вариант кодека 26 одной четвертой скорости работает как на кадровой основе, так и на субкадровой основе, но не включает классификацию типа в качестве процесса кодирования, как в случае кодеков 22 и 24 полной и половинной скорости. Согласно фиг.6 поток битов, генерируемый кодеком 26 одной четвертой скорости, включает в себя компонент 202 ЧЛС и компонент 204 энергии. В одном из вариантов кодек 26 одной четвертой скорости работает с использованием двух субкадров по 10 мс каждый для обработки кадров с использованием 39 битов на кадр.
Компонент 202 ЧЛС кодируется на кадровой основе с использованием схемы квантования ЧЛС, подобной используемой в кодекс 22 полной скорости, когда кадр классифицируется как тип 0. Кодек 26 одной четвертой скорости использует элемент 206 интерполяции и множество каскадов 208 для кодирования ЧЛС для представления спектральной огибающей кадра. В одном варианте компонент 202 ЧЛС кодируется с использованием 27 битов. 27 битов представляют элемент 206 интерполяции, который кодируется в 2 битах, и четыре каскада 208, которые кодируются в 25 битах. Каскады 208 включают один каскад, кодированный с использованием 7 битов, и три каскада, кодированные с использованием 6 битов. В одном варианте кодек 26 одной четвертой скорости использует таблицу точного квантования и таблицу коэффициентов функции прогнозирования, используемые кодеком 22 полной скорости. Таблица точного квантования и таблица коэффициентов функции прогнозирования в одном варианте осуществления, озаглавленные "Float64 CBes_85k" и "Float64 B_85k" соответственно, включены в Приложение В.
Компонент 205 энергии представляет усиление энергии, которое может быть умножено на вектор подобных случайных чисел, которые могут генерироваться как системой 12 кодирования, так и системой 16 декодирования. В одном из вариантов компонент 204 энергии кодируется с использованием 6 битов на субкадр. Компонент 204 энергии генерируется путем определения сначала усиления энергии для субкадра на основе случайных чисел. Кроме того, прогнозируемое усиление энергии определяется для субкадра на основе усиления энергии для прошлых кадров.
Прогнозируемое усиление энергии вычитается из усиления энергии для определения ошибки прогнозирования усиления энергии. Ошибка прогнозирования усиления энергии квантуется с использованием квантователя усиления энергии и множества предварительно определенных скаляров в таблице квантования усилений энергии. Местоположение индексов предварительно определенных скаляров для каждого субкадра может быть представлено компонентом 204 энергии для кадра.
Таблица квантования усилений энергии может быть представлена следующей матрицей.

В одном варианте таблица квантования усилений энергии содержит 64 (п=64) предварительно определенных скаляров. Возможный вариант таблицы квантования усилений энергии, озаглавленный "Float64gainSQ_1_64", включен в Приложение В.
На фиг.2 компонент 202 ЧЛС кодируется на кадровой основе модулем 50 обработки исходного кадра одной четвертой скорости. Аналогичным образом компонент 204 энергии кодируется модулем 60 одной четвертой скорости на субкадровой основе.
Согласно фиг.3 система 16 декодирования получает компонент 202 ЧЛС. Компонент 202 ЧЛС декодируется модулем 122 восстановления КЛП Q, а компонент 204 энергии декодируется модулем 120 восстановления КЛП Q. Декодирование компонента 202 ЧЛС аналогично способам декодирования для кодека 22 полной скорости для кадров, классифицированных как тип 1. Компонент 204 энергии декодируется для определения усиления энергии. Вектор сходных случайных чисел, генерируемых в системе 16 декодирования, может умножаться на усиление энергии для генерирования долгосрочного возбуждения.
1.4 Распределение битов для кодека одной восьмой скорости
Как показано на фиг.2, 3 и 7, поток битов одной восьмой скорости кодека 28 одной восьмой скорости не может включать классификацию в качестве части процесса кодирования и может работать только на кадровой основе. Согласно фиг.7 поток битов кодека 28 одной восьмой скорости подобно случаю кодека 26 одной четвертой скорости содержит компонент 240 ЧЛС и компонент 242 энергии. Компонент 240 ЧЛС может кодироваться с использованием схемы квантования ЧЛС подобной схеме для кодека 22 полной скорости, когда кадр классифицируется как тип 1. Кодек 28 одной восьмой скорости использует множество каскадов 244 для кодирования краткосрочной функции прогнозирования или спектрального представления кадра. В возможном варианте осуществления компонент 240 ЧЛС кодируется с использованием 11 битов на кадр в трех каскадах. Два из трех каскадов 244 кодируются в 4 битах, а последний из трех каскадов 244 кодируется в 3 битах.
Метод квантования для генерации компонента 240 ЧЛС для кодека 28 одной восьмой скорости использует таблицу квантования ошибок прогнозирования ЧЛС и таблицу коэффициентов функции прогнозирования подобно случаю кодека 22 полной скорости. Таблица квантования ошибок прогнозирования ЧЛС и таблица коэффициентов функции прогнозирования могут быть представлены ранее рассмотренными таблицами 1 и 2. В возможном варианте осуществления таблица квантования ошибок прогнозирования ЧЛС для кодека 28 одной восьмой скорости включает 3 каскада (j=3) с 16 векторами квантования в двух каскадах (r=16) и с 8 векторами квантования в одном каскаде (s=8), каждый из которых имеет 10 элементов (n=10). Таблица коэффициентов функции прогнозирования в возможном варианте включает 4 вектора (m=4) по 10 элементов в каждом (n=10). Таблица квантования и таблица коэффициентов функции прогнозирования в одном из вариантов осуществления, озаглавленные как "Float64 CBes_08k" и "Float64 B_08k" соответственно включены в Приложение В.
На фиг.2 компонент 240 ЧЛС кодируется на кадровой основе посредством модуля 52 обработки исходного кадра одной восьмой скорости. Компонент 242 энергии также кодируется на кадровой основе посредством модуля 62 одной восьмой скорости. Компонент 242 энергии представляет усиление по энергии, которое может быть определено и закодировано подобно случаю для кодека 26 одной четвертой скорости. Возможный вариант компонента 242 энергии представлен 5 битами на кадр, как показано на фиг.7.
Подобно кодеку 26 одной четвертой скорости усиление по энергии и усиление по прогнозированной энергии могут быть использованы для определения ошибки прогнозирования энергии. Ошибка прогнозирования энергии квантуется с использованием квантователя усиления энергии и множества предварительно определенных скаляров в таблице квантования усилений энергии. Таблица квантования усилений энергии может быть представлена в виде таблицы 9, как описано выше. Квантователь усилений энергии в возможном варианте осуществления использует таблицу квантования усилений энергии, содержащую 32 вектора (n=32), озаглавленную "Float64 gainSQ_1_32" и включенную в Приложение В.
Согласно фиг.3 компонент 240 ЧЛС и компонент 242 энергии могут декодироваться после приема системой 16 декодирования. Компонент 240 ЧЛС и компонент 242 энергии декодируются модулем 126 восстановления КЛП Е и модулем 124 восстановления возбуждения Е соответственно. Декодирование компонента 240 ЧЛС подобно случаю для кодека 22 полной скорости для кадров, классифицированных как тип 1. Компонент 242 энергии может декодироваться путем приложения декодируемого усиления энергии к вектору сходных случайных чисел, как в случае кодека 26 одной четвертой скорости.
Возможный вариант системы 10 сжатия речи может создавать и затем декодировать поток битов с использованием четырех кодеков 22, 24, 26 и 28. Поток битов, генерируемый конкретным кодеком 22, 24, 26 и 28, может кодироваться с акцентированием различных параметров речевого сигнала 18 в кадре в зависимости от выбора скорости и классификации типа. Соответственно перцепционное качество прошедшей постпроцессорную обработку синтезированной речи 20, декодированной из потока битов, может оптимизироваться при сохранении желательной средней скорости передачи в битах.
Ниже приведено детальное описание конфигурации и работы модулей системы сжатия речи, представленных в вариантах осуществления на фиг.2 и 3. При этом можно обращаться к исходному коду, включенному в Приложение А.
Модуль предварительной обработки (препроцессинга)
На фиг.8 представлена блок-схема модуля 34 предварительной обработки, показанного на фиг.2. Возможный вариант осуществления включает модуль 302 повышения качества интервалов пауз между тональными сигналами, модуль 304 фильтра верхних частот и модуль 306 подавления шумов. Модуль 34 предварительной обработки принимает речевой сигнал 18 и выдает предварительно обработанный речевой сигнал 308. Модуль 302 повышения качества интервалов пауз между тональными сигналами получает речевой сигнал 18 и функционирует для отслеживания минимального разрешения шума. Функция повышения качества интервалов пауз между тональными сигналами адаптивно отслеживает минимальное разрешение и уровни речевого сигнала 18 относительно нуля и обнаруживает, представляет ли собой текущий кадр "шумовым сигналом пауз" ("молчания"). Если обнаружен такой шумовой сигнал пауз, то речевой сигнал 18 может быть снижен до нулевого уровня. В противном случае речевой сигнал 18 может не модифицироваться. Например, схема кодирования по А-закону может преобразовывать такой непрослушиваемый шум пауз в явно слышимый шум. Кодирование и декодирование по А-закону речевого сигнала 18 перед модулем 34 предварительной обработки может усиливать значения выборок, которые близки к 0, до значений порядка +8 или -8, тем самым преобразуя почти неслышимый шум в прослушиваемый шум. После обработки модулем 302 речевой сигнал 18 может подаваться на модуль 304 фильтра верхних частот. Модуль 304 фильтра верхних частот может представлять собой фильтр полюсов-нулей второго порядка, и может иметь следующую передаточную функцию H(z):
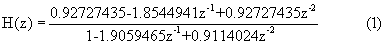
Входной сигнал может масштабироваться с понижением в 2 раза в процессе фильтрации верхних частот путем деления коэффициентов числителя на 2.
После обработки фильтром верхних частот речевой сигнал 18 может подаваться в модуль 306 шумоподавления. Модуль 306 шумоподавления использует вычитание шума в частотной области и может использовать любой из хорошо известных методов подавления шумов. Модуль 306 шумоподавления может включать программу преобразования Фурье, используемую в алгоритме шумоподавления, как описано в разделе 4.1.2 стандарта TIA/EIA IS-127, озаглавленном "Усовершенствованный кодек переменной скорости, опция 3 речевой услуги для широкополосных цифровых систем с расширенным спектром".
Модуль 306 шумоподавления в возможном варианте осуществления преобразует каждый кадр речевого сигнала 18 в частотную область, где спектральные амплитуды могут отделяться от спектральных фаз. Спектральные амплитуды могут группироваться в полосы, которые соответствуют полосам слуховых каналов органов слуха человека. Для каждой полосы может быть рассчитано ослабление усиления с меньшим акцентом на спектральных областях, которые, вероятно, имеют гармоническую структуру. В таких областях фоновый шум может маскироваться сильной озвученной речью. Соответственно ослабление речи может исказить качество исходной речи без какого-либо перцепционного улучшения в ослаблении шума.
После расчета ослабления усиления спектральные амплитуды в каждой полосе могут быть умножены на ослабление усиления. Спектральные амплитуды могут затем быть объединены с исходными спектральными фазами, и речевой сигнал 18 может быть вновь преобразован во временную область. Сигнал временной области может затем быть перекрыт и просуммирован для формирования предварительно обработанного речевого сигнала 308. Предварительно обработанный речевой сигнал 308 может быть подан на модуль 44 обработки исходного кадра.
3.0 Модуль обработки исходного кадра
На фиг.9 представлена блок-схема модуля 44 обработки исходного кадра, показанного на фиг.2. В возможном варианте осуществления модуль 44 обработки исходного кадра содержит секцию 312 генерации ЧЛС, модуль 314 фильтра перцепционного взвешивания, модуль 316 оценки основного тона разомкнутого контура, секцию 318 определения параметров, модуль 320 выбора скорости, модуль 322 предварительной обработки основного тона и модуль 324 классификации типа. Секция 318 определения параметров также содержит модуль 326 определения речевой активности (ОРА) и модуль 328 определения параметров. Секция 312 генерации ЧЛС содержит модуль 330 анализа КЛП, модуль 332 сглаживания ЧЛС и модуль 334 квантования ЧЛС. Кроме того, в устройстве 36 кодирования полной скорости секция 312 генерации ЧЛС включает в себя модуль 338 интерполяции, а в устройстве 38 кодирования половинной скорости секция генерации ЧЛС включает в себя модуль 336 коммутатора функции прогнозирования.
Согласно фиг.2 модуль 44 обработки исходного кадра обеспечивает генерацию компонентов 140, 172, 202 и 240 ЧЛС, а также определение выбора скорости и классификацию типа. Выбор скорости и классификация типа управляют обработкой посредством модуля 54 обработки возбуждения. Модуль 44 обработки исходного кадра, показанный на фиг.9, иллюстрирует возможный вариант модуля 46 обработки исходного кадра полной скорости и модуля 48 обработки исходного кадра половинной скорости. Варианты осуществления модуля 50 обработки исходного кадра одной четвертой скорости и модуля 52 обработки исходного кадра одной восьмой скорости до некоторой степени отличаются.
Как описано выше, в одном из вариантов классификация типа не производится для модуля 50 обработки исходного кадра одной четвертой скорости и модуля 52 обработки исходного кадра одной восьмой скорости. Кроме того, функция долгосрочного прогнозирования и остаток функции долгосрочного прогнозирования не обрабатываются отдельно для представления компонентов 204 энергии и 242, показанных на фиг.6 и 7. Соответственно в модуле 50 обработки исходного кадра одной четвертой скорости и модуле 52 обработки исходного кадра одной восьмой скорости действуют только секция 312 генерации ЧЛС, секция 318 определения параметров и модуль 320 выбора скорости.
Для пояснения модуля 44 обработки исходного кадра сначала описана процедура функционирования в целом, после чего дано более детальное рассмотрение. Согласно фиг.9 предварительно обработанный речевой сигнал 308 сначала подается на секцию 312 генерации ЧЛС, модуль 314 фильтра перцепционного взвешивания и секцию 318 определения параметров. Однако часть обработки в секции 318 определения параметров зависит от обработки, которая производится в модуле 316 оценки основного тона разомкнутого контура. Секция 312 генерации ЧЛС оценивает и кодирует спектральное представление предварительно обработанного речевого сигнала 308. Модуль 314 фильтра перцепционного взвешивания обеспечивает перцепционное взвешивание в процессе кодирования предварительно обработанного речевого сигнала 308 в соответствии с естественным маскированием, которое возникает при обработке системой органов слуха человека. Модуль 316 оценки основного тона разомкнутого контура определяет запаздывание основного тона в разомкнутом контуре для каждого кадра. Секция 318 определения параметров анализирует кадр предварительно обработанного речевого сигнала 308 и определяет параметры кадра для оптимизации последующей обработки.
В процессе обработки в секции 318 определения параметров и после этой обработки полученные в результате параметры кадра могут быть использованы модулем 322 предварительной обработки основного тона для генерации параметров, используемых при генерации запаздывания основного тона в замкнутом контуре. Кроме того, определение параметров кадра используется модулем 320 выбора скорости для определения выбора скорости. Основываясь на параметрах запаздывания основного тона, полученных модулем 322 предварительной обработки основного тона, и определенных параметрах, модуль 324 классификации типа определяет тип классификации.
3.1 Модуль анализа КЛП
Предварительно обработанный речевой сигнал 308 принимается модулем 330 анализа КЛП в секции 312 генерации ЧЛС. Модуль 330 анализа КЛП определяет параметры краткосрочного прогнозирования, используемые для генерации компонента 312 ЧЛС. В одном из вариантов модуля 330 анализа КЛП выполняют три анализа КЛП 10 порядка для кадра предварительно обработанного речевого сигнала 308. Этот анализ может центрироваться во второй четверти кадра, четвертой четверти кадра и предвыборке (упреждающей выборке). Предвыборка является речевьм сегментом, который переходит в следующий кадр для снижения переходных эффектов. Анализ в предвыборке включает выборки из текущего кадра и из следующего кадра предварительно обработанного речевого сигнала 308.
Различные окна могут быть использованы для каждого анализа КЛП в кадре для вычисления коэффициентов линейного прогнозирования. Анализ КЛП в одном из вариантов выполняется с использованием автокорреляционного метода для вычисления автокорреляционных коэффициентов. Автокорреляционные коэффициенты могут быть вычислены из множества выборок данных внутри каждого окна. В процессе анализа КЛП для автокорреляционных коэффициентов могут быть применены расширение полосы 60 Гц и коэффициент коррекции белого шума, равный 0,0001. Расширение полосы обеспечивает дополнительную робастность по отношению к сигналу и ошибкам округления при последующем кодировании. Коэффициент коррекции белого шума эффективно добавляет уровень собственных шумов ("шумовую подставку") величиной -40 дБ для уменьшения спектрального динамического диапазона и дополнительного снижения ошибок в процессе последующего кодирования.
Множество коэффициентов отражения могут быть вычислены с использованием алгоритма Leroux-Gueguen из автокорреляционных коэффициентов. Коэффициенты отражения затем могут быть преобразованы в коэффициенты линейного прогнозирования. Коэффициенты линейного прогнозирования могут быть затем преобразованы в ЧЛС (частоты линейного спектра), как описано выше. ЧЛС, вычисленные в четвертой четверти, могут быть квантованы и переданы в систему 16 декодирования как компоненты 140,172, 202, 240 ЧЛС. ЧЛС, вычисленные во второй четверти, могут быть использованы для определения пути интерполяции для устройства 36 кодирования полной скорости для кадров, классифицированных как тип 0. Путь интерполяции может выбираться и может быть идентифицирован интерполяционным элементом 158. Кроме того, ЧЛС, вычисленные во второй четверти и в упреждающей выборке, могут быть использованы в системе 12 кодирования для генерации краткосрочного остатка и взвешенной речи, как описано ниже.
3.2 Модуль сглаживания ЧЛС
При стационарных фоновых шумах ЧЛС, вычисленные в четвертой четверти кадра, могут быть сглажены с помощью модуля 332 сглаживания ЧЛС перед квантованием ЧЛС. ЧЛС сглаживаются для лучшего сохранения перцепционных характеристик фоновых шумов. Сглаживание управляется определением речевой активности, обеспечиваемым модулем 326 ОРА, который описан ниже, и анализом эволюции спектрального представления кадра. Коэффициент сглаживания ЧЛС обозначен как βlsf (индекс lsf означает ЧЛС). В возможном примере осуществляется следующее:
1. В начале сегментов "сглаживаемых" фоновых шумов коэффициент сглаживания может нарастать квадратично от 0 до 0,9 по 5 кадрам.
2. В течение сегментов "сглаживаемых" фоновых шумов коэффициент сглаживания может быть равным 0,9.
3. В конце сегментов "сглаживаемых" фоновых шумов коэффициент сглаживания может быть мгновенно снижен до 0.
4. В течение сегментов "несглаживаемых" фоновых шумов коэффициент сглаживания может быть равен 0.
Соответственно коэффициенту сглаживания ЧЛС ЧЛС для квантования могут быть вычислены следующим образом:

где lsfn(k) и lsfn-1(k) представляют сглаженные ЧЛС текущего и предыдущего кадров соответственно, и lsf2(k) представляет ЧЛС для анализа ЧЛС, центрированного на последней четверти текущего кадра.
3.3 Модуль квантования ЧЛС
Модель КЛП 10-го порядка, заданная сглаженными ЧЛС согласно (2), может быть квантована в области ЧЛС посредством модуля 334 квантования ЧЛС. Квантованное значение представляет собой множество квантованных коэффициентов КЛП Aq(z) 342. Схема квантования использует функцию прогнозирования со скользящим средним n-го порядка. В одном из вариантов схема квантования содержит функцию прогнозирования со скользящим средним 2-го порядка для кодека 22 полной скорости и кодека 26 одной четвертой скорости. Для кодека 24 половинной скорости может быть использована функция прогнозирования со скользящим средним 4-го порядка. Для кодека 28 одной восьмой скорости может быть использована функция прогнозирования со скользящим средним 4-го порядка. Квантование ошибки прогнозирования ЧЛС может быть выполнено посредством многокаскадных кодовых книг в соответствующих кодеках, как описано выше.
Критерий ошибки для квантования ЧЛС представляет собой меру взвешенной среднеквадратичной ошибки. Взвешивание для взвешенной среднеквадратичной ошибки является функцией спектра амплитуд ЧЛС. Соответственно цель квантования может быть представлена в следующем виде:

где взвешивание определяется как

и |P(f)| спектр мощности КЛП на частоте f (индекс n обозначает номер кадра). В приведенном для примера варианте используется 10 коэффициентов.
В одном из вариантов проверяется свойство упорядочения квантованных коэффициентов КЛП Aq(z) 342. Если одна пара ЧЛС перевернута, то их можно переупорядочить. Если две или более пар ЧЛС перевернуты, то квантованные коэффициенты КЛП Aq(z) 342 могут быть признаны стертыми и могут быть восстановлены с использованием отмены стирания кадра в системе 16 декодирования, как описано ниже. В возможном варианте может быть обеспечено минимальное расстояние 50 Гц между соседними коэффициентами квантованных коэффициентов КЛП Aq(z) 342.
3.4 Модуль коммутации функции прогнозирования
Модуль 336 коммутации функции прогнозирования работает в кодеке 24 половинной скорости. Прогнозированные ЧЛС могут генерироваться с использованием коэффициентов функции прогнозирования со скользящим средним, как описано выше. Коэффициенты функции прогнозирования определяют, сколько ЧЛС из прошлых кадров используется для прогнозирования ЧЛС текущего кадра. Модуль 336 коммутации функции прогнозирования связан с модулем 334 квантования ЧЛС для обеспечения коэффициентов функции прогнозирования, которая минимизирует ошибку квантования, как описано выше.
3.5 Модуль интерполяции ЧЛС
Квантованные и неквантованные ЧЛС могут также интерполироваться для каждого субкадра в кодексе 22 полной скорости. Квантованные и неквантованные ЧЛС интерполируются для обеспечения квантованных и неквантованных параметров линейного прогнозирования для каждого субкадра. Модуль 338 интерполяции ЧЛС выбирает путь интерполяции для кадров кодека 22 полной скорости с классификацией типа 0, как описано выше. Для всех других кадров может быть использован предварительно определенный путь линейной интерполяции.
Модуль 338 интерполяции ЧЛС анализирует ЧЛС текущего кадра по отношению к ЧЛС предыдущих кадров и ЧЛС, которые были вычислены во второй четверти кадра. Путь интерполяции может быть выбран на основе степени отклонений в спектральной огибающей между субкадрами. Различающиеся пути интерполяции регулируют взвешивание ЧЛС предыдущего кадра и взвешивание ЧЛС текущего кадра для текущего субкадра, как описано выше. После регулировки посредством модуля 338 интерполяции ЧЛС интерполированные ЧЛС могут быть преобразованы в коэффициенты функции прогнозирования для каждого субкадра.
Для классификации типа 1 в кодеке 22 полной скорости, а также для кодека 24 половинной скорости, кодека 26 одной четвертой скорости и кодека 28 одной восьмой скорости предварительно определенный путь линейной интерполяции может быть использован для регулировки взвешивания. Интерполированные ЧЛС могут аналогичным образом преобразовываться в коэффициенты функции прогнозирования вслед за интерполяцией. Кроме того, коэффициенты функции прогнозирования могут затем дополнительно взвешиваться для формирования коэффициентов, которые используются для модуля 314 фильтра перцепционного взвешивания.
3.6 Модуль фильтра перцепционного взвешивания
Модуль 314 фильтра перцепционного взвешивания осуществляет прием и фильтрацию предварительно обработанного речевого сигнала 308. Фильтрация модулем 314 фильтра перцепционного взвешивания может быть выполнена путем большего выделения областей впадин (минимумов) и сглаживания областей пиков (максимумов) предварительно обработанного речевого сигнала 308. В одном из вариантов модуль 314 фильтра перцепционного взвешивания имеет две части. Первая часть может представлять собой традиционный фильтр полюсов-нулей, заданный функцией

где A(z/γ1) и 1/А(z/γ2) соответствуют фильтру нулей и фильтру полюсов соответственно. Коэффициенты прогнозирования для фильтров нулей и фильтров полюсов могут быть получены из интерполированных ЧЛС для каждого субкадра и взвешены с помощью γ1 и γ2 соответственно. В возможном варианте модуля 314 фильтра перцепционного взвешивания взвешивание осуществляется с помощью γ1=0,9 и γ2=0,5. Вторая часть модуля 314 фильтра перцепционного взвешивания может представлять собой адаптивный фильтр нижних частот, заданный функцией

где η - функция стационарных долгосрочных спектральных характеристик, которые поясняются ниже. В одном из вариантов, если стационарные долгосрочные спектральные характеристики имеют типовой наклон соответственно характеристике коммутируемой телефонной сети общего пользования (КТСОП), то η=0,2, в противном случае η=0,0. Типовой наклон обычно определяют через модифицированную IRS-характеристику или спектральный наклон. После обработки модулем 314 фильтра перцепционного взвешивания предварительно обработанный речевой сигнал 308 может быть описан как взвешенный речевой сигнал 344. Взвешенный речевой сигнал 344 подается на модуль 316 оценки основного тона разомкнутого контура.
3.7 Модуль оценки основного тона разомкнутого контура
Модуль 316 оценки основного тона разомкнутого контура генерирует запаздывание основного тона разомкнутого контура для кадра. В возможном варианте запаздывание основного тона разомкнутого контура реально содержит три запаздывания основного тона разомкнутого контура, а именно первое запаздывание основного тона для первой половины кадра, второе запаздывание основного тона для второй половины кадра и третье запаздывание основного тона для части упреждающей выборки кадра.
Для каждого кадра второе и третье запаздывания основного тона оцениваются модулем 316 оценки основного тона разомкнутого контура на основе текущего кадра. Первое запаздывание основного тона разомкнутого контура является третьим запаздыванием основного тона разомкнутого контура (упреждающей выборки) из предыдущего кадра, которое может быть дополнительно подстроено. Три запаздывания основного тона разомкнутого контура сглаживаются для обеспечения непрерывного контура основного тона. Сглаживание запаздываний основного тона разомкнутого контура использует набор эвристических и специально подобранных правил принятия решения для сохранения оптимального контура основного тона кадра. Оценивание основного тона разомкнутого контура основывается на взвешенном речевом сигнале 344, обозначенном как sW(n). Значения оценок, полученные модулем 316 оценки основного тона разомкнутого контура в одном из вариантов, представляют собой задержки в диапазоне от 17 до 148. Первое, второе и третье запаздывания основного тона разомкнутого контура могут быть определены с использованием нормализованной корреляции R(k), которая может быть вычислена по формуле

где n=79 в одном из вариантов, что представляет число выборок в субкадре. Максимальная нормализованная корреляция R(k) определяется для каждой из множества областей. Может быть использовано четыре области, которые представляют четыре субкадра в диапазоне возможных запаздываний. Например, первая область соответствует запаздываниям 17-33, вторая область - запаздываниям 34-67, третья область - запаздываниям 68-137 и четвертая область - запаздываниям 138-148. Запаздывание основного тона разомкнутого контура, соответствующее запаздыванию, которое максимизирует нормализованные значения корреляции R(k) из каждой области, является соответствующим вероятным значением исходного запаздывания основного тона. Наилучшее вероятное значение из вероятных значений исходного запаздывания основного тона выбирается на основе нормализованной корреляции, информации определения параметров и предыстории запаздывания основного тона разомкнутого контура. Эта процедура может быть выполнена для второго запаздывания основного тона и для третьего запаздывания основного тона.
Наконец, первое, второе и третье запаздывания основного тона разомкнутого контура могут быть подстроены для оптимальной аппроксимации полного контура основного тона и формирования запаздывания основного тона разомкнутого контура для кадра. Запаздывание основного тона разомкнутого контура подается на модуль 332 предварительной обработки основного тона для последующей обработки, как описано ниже. Модуль 316 оценки основного тона разомкнутого контура также обеспечивает задержку основного тона и нормализованные значения корреляции для задержки основного тона. Нормализованные значения корреляции для задержки основного тона определяются как корреляция основного тона и обозначаются как Rp. Корреляция основного тона как Rp используется для определения параметров кадра в секции 318 определения параметров.
3.8 Секция определения параметров
Секция 318 определения параметров предназначена для анализа и определения параметров каждого кадра предварительно обработанного речевого сигнала 308. Информация определения параметров используется множеством модулей в модуле 44 обработки исходного кадра, а также модулем 54 обработки возбуждения. Более конкретно, информация определения параметров используется в модуле 320 выбора скорости и в модуле 324 классификации типа. Кроме того, информация определения параметров может использоваться в процессе квантования и кодирования, в частности, при выделении перцепционно важных признаков речи с использованием способа взвешивания, зависимого от класса, как пояснено ниже.
Определение параметров предварительно обработанного речевого сигнала 308 посредством секции 318 определения параметров осуществляется для каждого кадра. Функционирование возможного варианта секции 318 определения параметров может быть описано в общем виде как шесть категорий анализа предварительно обработанного речевого сигнала 308. Эти шесть категорий включают определение речевой активности, идентификация неозвученной шумоподобной речи, определение параметров сигналов 6 классов, отклонение отношения шум/сигнал, определение параметров 4 степеней и определение параметров стационарных долгосрочных спектральных характеристик.
3.9 Модуль обнаружения речевой активности (ОРА)
Модуль 326 обнаружения речевой активности (ОРА) выполняет обнаружение речевой активности в качестве первого этапа определения параметров. Модуль ОРА 326 определяет, является ли предварительно обработанный речевой сигнал 308 некоторой формой речи или он просто соответствует паузам или фоновым шумам. В одном из вариантов модуль ОРА 326 определяет речевую активность путем отслеживания поведения фоновых шумов. Модуль ОРА 326 контролирует различие между параметрами текущего кадра и параметрами, представляющими фоновый шум. С использованием набора предварительно определенных пороговых значений кадр может быть классифицирован как речевой кадр или как кадр фоновых шумов.
Модуль ОРА 326 определяет речевую активность на основе контроля множества параметров, таких как максимум абсолютного значения выборок в кадре, коэффициенты отражения, ошибки прогнозирования, ЧЛС и коэффициента автокорреляции 10-го порядка, обеспечиваемые модулем 330 анализа КЛП. Кроме того, в возможном варианте модуль ОРА 326 использует параметры задержки основного тона и усиление адаптивной кодовой книги из предыдущих кадров. Параметры задержки основного тона и усиление адаптивной кодовой книги, используемые модулем ОРА 326, берутся из предыдущих кадров потому, что задержки основного тона и усиления адаптивной кодовой книги для текущего кадра еще не доступны. Определение речевой активности, выполняемое модулем ОРА 326, может быть использовано для управления различными аспектами системы 12 кодирования, а также как составная часть окончательного решения по определению параметров класса, принимаемого модулем 328 определения параметров.
3.10 Модуль определения параметров
Вслед за определением речевой активности, выполняемым модулем ОРА 326, активизируется модуль 328 определения параметров. Модуль 328 определения параметров выполняет вторую, третью, четвертую и пятую категории анализа предварительно обработанного речевого сигнала 308, как описано выше. Вторая категория представляет собой обнаружение неозвученных шумоподобных кадров.
3.10.1 Обнаружение неозвученных шумоподобных кадров
В общем случае неозвученные шумоподобные кадры не имеют гармонической структуры, как это имеет место в случае озвученных кадров. Обнаружение неозвученных шумоподобных кадров в одном из вариантов основывается на предварительно обработанном речевом сигнале 308 и взвешенном остаточном сигнале Rw(z) в соответствии со следующим соотношением:

где A(z/γ1) представляет взвешенный фильтр нулей с взвешиванием γ1; S(z) - предварительно обработанный речевой сигнал 308. Для определения того, является ли текущий кадр неозвученным шумоподобным речевым сигналом, могут быть использованы различные параметры, например, такие как представленные ниже шесть следующих параметров:
1. Энергия предварительно обработанного речевого сигнала 308 на первых 3,4 кадра.
2. Число речевых выборок в кадре, которые ниже предварительно определенного порога.
3. Остаточная резкость, определенная с использованием взвешенного остаточного сигнала и размера кадра. Резкость определяется отношением среднего абсолютных значений выборок к максимуму абсолютных значений выборок.
4. Первый коэффициент отражения, представляющий наклон амплитудного спектра предварительно обработанного речевого сигнала 308.
5. Частота пересечения нулей предварительно обработанного речевого сигнала 308.
6. Измерение прогнозирования между предварительно обработанным речевым сигналом 308 и взвешенным остаточным сигналом.
В одном из вариантов набор предварительно определенных значений сравнивается с вышеуказанными параметрами для принятия решения о том, является ли текущий кадр неозвученным шумоподобным речевым сигналом. Полученный результат определения может быть использован для управления модулем 322 предварительной обработки основного тона и в фиксированной кодовой книге, как описано ниже. Кроме того, определение неозвученного шумоподобного речевого сигнала может быть использовано при определении параметров сигнала 6 классов для предварительно обработанного речевого сигнала 308.
3.10.2 Определение параметров сигнала 6 классов
Модуль 328 определения параметров сигнала может также выполнять третью категорию анализа, которая представляет собой определение параметров сигнала 6 классов. Определение параметров сигнала 6 классов выполняется путем определения параметров кадра как одного из 6 классов в соответствии с преобладающими характеристиками кадра. В возможном варианте 6 классов могут быть описаны следующим образом:
0. Паузы речи/фоновые шумы
1. Стационарный шумоподобный глухой (неозвученный) речевой сигнал
2. Нестационарный глухой речевой сигнал
3. Начало
4. Нестационарный звонкий (озвученный) речевой сигнал
5. Стационарный звонкий речевой сигнал
В альтернативных вариантах также включаются и другие классы речевых сигналов, например кадры, характеризуемые как взрывные речевые сигналы. Первоначально модуль 328 определения параметров обеспечивает различение между кадрами, представляющими паузы речи/фоновые шумы (класс 0), нестационарным глухим речевым сигналом (класс 2), начальными кадрами (класс 3) и кадрами звонкого речевого сигнала, представленными классами 4 и 5. Определение параметров озвученных кадров как нестационарных речевых сигналов (класс 4) и стационарных речевых сигналов (класс 5) может быть выполнено в процессе активизации модуля 322 предварительной обработки основного тона. Кроме того, модуль 328 определения параметров сигнала может первоначально не проводить различие между кадрами стационарного шумоподобного глухого речевого сигнала (класс 1) и кадрами нестационарного глухого речевого сигнала (класс 2). Класс определения параметров может также быть идентифицирован в процессе обработки модулем 322 предварительной обработки основного тона с использованием процедуры определения согласно ранее описанному алгоритму для шумоподобного глухого речевого сигнала.
Модуль 328 определения параметров сигнала выполняет определение параметров с использованием, например, предварительно обработанного речевого сигнала 308 и обнаружения речевой активности модулем ОРА 326. Кроме того, модуль 328 определения параметров сигнала может использовать запаздывание основного тона разомкнутого контура для кадра и нормализованную корреляцию Rp, соответствующую второму запаздыванию основного тона разомкнутого контура.
Из предварительно обработанного речевого сигнала 308 модулем 328 определения параметров сигнала может быть получено множество спектральных наклонов и множество абсолютных максимумов. В альтернативном варианте вычисляются спектральные наклоны для 4 перекрывающихся сегментов, содержащих 80 выборок каждый. 4 перекрывающихся сегмента могут быть взвешены окном Хэмминга для 80 выборок. Абсолютные максимумы в возможном варианте осуществления получены из 8 перекрывающихся сегментов предварительно обработанного речевого сигнала 308. По существу, длина каждого из 8 перекрывающихся сегментов равна примерно 1,5 периода запаздывания основного тона разомкнутого контура. Абсолютные максимумы могут быть использованы для создания сглаженного контура амплитудной огибающей.
Параметры спектрального наклона, абсолютного максимума и корреляции Rp основного тона могут обновляться или интерполироваться множество раз в течение кадра. Средние значения для этих параметров также могут быть вычислены несколько раз для кадров, характеризуемых модулем ОРА 326 как фоновые шумы. В возможном варианте осуществления получено 8 обновленных оценок каждого параметра с использованием 8 сегментов, содержащих 20 выборок каждый. Оценки параметров для фоновых шумов могут вычитаться из оценок параметров для последующих кадров, не характеризуемых как фоновый шум, чтобы сформировать набор параметров, "очищенных от шума".
Набор параметров статистически обоснованных решений может быть вычислен из параметров, "очищенных от шума", и запаздывания основного тона разомкнутого контура. Каждый из параметров статистически обоснованных решений представляет статистическое свойство исходных параметров, таких как среднее, девиация, эволюция, максимум или минимум. С использованием набора предварительно определенных пороговых параметров можно принять исходные решения по определению параметров для текущего кадра на основе параметров статистических решений. На основе исходных решений по определению параметров, последующих решений по определению параметров и решения о речевой активности модуля ОРА 326 может быть принято исходное решение о классе для кадра. Исходное решение о классе характеризует кадр как кадр классов 0, 2, 3 или как кадр озвученной речи, представленный классами 4 и 5.
3.10.3 Определение отношения шум/сигнал
В дополнение к определению параметров кадров модуль 328 определения параметров в возможном варианте осуществления также выполняет четвертую категорию анализа путем получения отношения шум/сигнал (ОШС). ОШС представляет собой традиционный критерий искажений, который может быть вычислен как отношение оценки энергии фоновых шумов к энергии кадра. В одном из вариантов вычисление ОШС за счет использования модифицированного решения о речевой активности обеспечивает, что только истинные фоновые шумы учитываются в ОШС. Модифицированное решение о речевой активности получается с использованием исходного решения о речевой активности, полученного модулем ОРА 326, энергии кадра предварительно обработанного речевого сигнала 308 и ЧЛС, вычисленных для части упреждающей выборки. Если модифицированное решение о речевой активности показывает, что кадр представляет собой фоновые шумы, то значение энергии фоновых шумов обновляется.
Значение энергии фоновых шумов обновляется исходя из энергии кадра с использованием, например, скользящего среднего. Если уровень фоновых шумов больше, чем уровень энергии кадра, то он заменяется на энергию кадра. Замена энергией кадра может быть связана со сдвигом уровня энергии вниз и с усечением полученного результата. Результат представляет оценку энергии фоновых шумов, которая может быть использована в вычислении ОШС.
После вычисления ОШС модуль 328 определения параметров выполняет коррекцию исходного решения о классе на модифицированное решение о классе. Коррекция может быть выполнена с использованием исходного решения о классе, определения речевой активности и определения неозвученного шумоподобного речевого сигнала. Кроме того, также могут быть использованы ранее вычисленные параметры, представляющие, например, спектр, выраженный коэффициентами отражения, корреляцию Rp основного тона, ОШС, энергию кадра, энергию предыдущих кадров, резкость остатка и резкость взвешенного речевого сигнала. Коррекция исходного решения о классе называется настройкой определения параметров. Настройка определения параметров может изменить исходное решение о классе, а также установить флаг начального условия и флаг зашумленного озвученного речевого сигнала, если выявлены эти условия. Кроме того, настройка может также вызвать изменение в решении о речевой активности модуля ОРА 326.
3.10.4 Определение параметров четырех степеней
Модуль 328 определения параметров может также генерировать 5-ю категорию определения параметров, а именно определение параметров 4 степеней. Определение параметров 4 степеней является параметром, который управляет модулем 322 предварительной обработки основного тона. В одном из вариантов определение параметров 4 степеней обеспечивает различение между 4 категориями. Эти категории могут быть обозначены цифрами от 1 до 4. Категория 1 используется для сброса модуля 322 предварительной обработки основного тона, чтобы предотвратить накопление задержки, которая превышает запас по задержке при предварительной обработке основного тона. В принципе, остальные категории указывают на увеличение интенсивности звучания. Увеличение интенсивности звучания является мерой периодичности речевого сигнала. В альтернативном варианте для индикации интенсивности звучания может быть использовано большее или меньшее количество категорий.
3.10.5 Стационарные долгосрочные спектральные характеристики
Модуль 328 определения параметров может также выполнять 6-ю категорию анализа путем определения стационарных долгосрочных спектральных характеристик предварительно обработанного речевого сигнала 308. Стационарные долгосрочные спектральные характеристики определяются по множеству кадров с использованием, например, спектральной информации, такой как ЧЛС, определение параметров сигналов 6 классов и усиления основного тона разомкнутого контура. Определение базируется на долгосрочных средних значениях этих параметров.
3.11 Модуль выбора скорости
После принятия модулем 328 определения параметров модифицированного решения о классе модуль 320 выбора скорости может осуществить исходный выбор скорости, определяемый как выбор скорости разомкнутого контура. Модуль 320 выбора скорости может использовать, например, модифицированное решение о классе ОШС, флаг начала, остаточную энергию, резкость, корреляцию Rp основного тона и спектральные параметры, такие как коэффициенты отражения, при определении выбора скорости разомкнутого контура. Выбор скорости разомкнутого контура может осуществляться на основе режима, в котором работает система 10 сжатия речи. Модуль 320 выбора скорости настраивается для обеспечения желательной средней скорости передачи в битах, как указано каждым из режимов. Исходный выбор скорости может быть модифицирован последующей обработкой, осуществляемой модулем 322 предварительной обработки основного тона, как описано ниже.
3.12 Модуль предварительной обработки основного тона
Модуль 322 предварительной обработки основного тона работает на покадровой основе для выполнения анализа и модифицирования взвешенного речевого сигнала 344. Модуль 322 предварительной обработки основного тона может, например, использовать методы сжатия или растяжения циклов основного тона взвешенного речевого сигнала 344, чтобы улучшить процесс кодирования. Запаздывание основного тона разомкнутого контура квантуется модулем 322 предварительной обработки основного тона для генерации компонента 144а или 176а адаптивной кодовой книги разомкнутого контура, как описано выше со ссылками на фиг.2, 4 и 5. Если конечная классификация кадра соответствует типу 1, то это квантование представляет запаздывание основного тона для кадра. Однако если классификация типа изменяется в ходе обработки модулем 322 предварительной обработки основного тона, то квантование запаздывания основного тона также изменяется для представления компонента 144b или 176b адаптивной кодовой книги замкнутого контура, как описано выше со ссылками на фиг.2, 4 и 5.
Запаздывание основного тона разомкнутого контура для кадра, которое было сформировано модулем 316 оценки основного тона разомкнутого контура, квантуется и интерполируется для формирования дорожки 348 основного тона. В принципе, модуль 322 предварительной обработки основного тона пытается модифицировать взвешенный речевой сигнал 344 для аппроксимации дорожки 348 основного тона. Если модификация успешна, то конечная классификация типа кадра соответствует типу 1. Если модификация безуспешна, то конечная классификация типа кадра соответствует типу 0.
Как пояснено более детально ниже, процедура модификации предварительной обработки основного тона может выполнять непрерывную во времени деформацию взвешенного речевого сигнала 344. Деформация вводит переменную задержку. В возможном варианте максимальная переменная задержка в системе 12 кодирования составляет 20 выборок (2,5 мс). Взвешенный речевой сигнал 344 может быть модифицирован на базе циклов основного тона при некотором перекрытии соседних циклов основного тона, чтобы избежать разрывов непрерывности между восстановленными/модифицированными сегментами. Взвешенный речевой сигнал 344 может быть модифицирован соответственно дорожке 348 для генерации модифицированного взвешенного речевого сигнала 350. Кроме того, множество неквантованных усилений 352 основного тона генерируются модулем 322 предварительной обработки основного тона. Если классификация типа кадра соответствует типу 1, то неквантованные усиления 352 основного тона используются для генерации компонента 148b усиления адаптивной кодовой книги типа 1 (для кодека 22 полной скорости) или 180b (для кодека 24 половинной скорости). Дорожка 348 основного тона, модифицированный взвешенный речевой сигнал 350 и не квантованные усиления 352 основного тона подаются на модуль 54 обработки возбуждения.
Как описано выше, определение параметров 4 степеней посредством модуля 328 определения параметров управляет предварительной обработкой основного тона. В одном из вариантов, если кадр является преимущественно фоновым шумом или неозвученным (глухим) речевым сигналом с низкой корреляцией Rp основного тона, например, категории 1, то кадр остается неизменным, и накопленная задержка основного тона сбрасывается в нуль. Если кадр является преимущественно импульсно-подобным неозвученным, например, категории 2, то накопленная задержка может сохраняться без деформации сигнала за исключением малого временного сдвига. Временной сдвиг может быть определен соответственно накопленной задержке входного речевого сигнала 18. Для кадров с остальными определениями параметров 4 степеней ядро алгоритма предварительной обработки основного тона может быть выполнено для оптимального деформирования сигнала.
В принципе ядро модуля 322 предварительной обработки основного тона в возможном варианте осуществления выполняет три основные задачи. Во-первых, взвешенный речевой сигнал модифицируется для попытки согласования с дорожкой 348 основного тона. Во-вторых, оцениваются усиление основного тона и корреляция основного тона для сигнала. И, наконец, определение параметров речевого сигнала 18 и выбор скорости уточняются на основе дополнительной сигнальной информации, получаемой в процессе анализа предварительной обработки основного тона. В другом варианте может быть включена дополнительная предварительная обработка основного тона, например интерполяция формы сигнала. В принципе, интерполяция формы сигнала может быть использована для модифицирования некоторых нерегулярных переходных сегментов с использованием методов интерполяции формы сигнала вперед/назад, чтобы улучшить регулярность и подавить нерегулярности во взвешенном речевом сигнале 344.
3.12.1 Модифицирование
Модифицирование взвешенного речевого сигнала 344 обеспечивает более точную аппроксимацию взвешенным речевым сигналом 344 модели кодирования основного тона, которая подобна методу кодирования речи в соответствии с алгоритмом линейного предсказания с релаксационным кодовым возбуждением (RCELP). Пример реализации речевого кодирования согласно алгоритму RCELP содержится в стандарте TIA IS-127. Характеристики модифицирования без каких-либо потерь перцепционного качества могут включать точный поиск основного тона, оценивание размера сегмента, деформацию целевого сигнала и деформацию сигнала. Точный поиск основного тона может быть выполнен на уровне кадра, в то время как оценивание размера сегмента, деформация целевого сигнала и деформация сигнала могут выполняться для каждого цикла основного тона.
3.12.1.1 Точный поиск основного тона
Точный поиск основного тона может быть выполнен для взвешенного речевого сигнала 344 на базе предварительно определенных второго и третьего запаздываний основного тона, выбора скорости и накопленной задержки предварительной обработки основного тона. Точный поиск основного тона направлен на поиск дробных запаздываний основного тона. Дробные запаздывания основного тона являются нецелочисленными запаздываниями основного тона, которые комбинируются с квантованием запаздываний. Комбинация выводится путем поиска в таблицах квантования запаздываний, используемых для квантования запаздываний основного тона разомкнутого контура и нахождения запаздываний, которые максимизируют корреляцию основного тона взвешенного речевого сигнала 344. В возможном варианте поиск выполняется различным образом для каждого кодека ввиду отличающихся методов квантования, связанных с различным выбором скоростей. Поиск выполняется в области поиска, которая идентифицируется запаздыванием основного тона разомкнутого контура и управляется накопленной задержкой.
3.12.1.2 Размет сегмента оценивания
Размер сегмента следует за периодом основного тона при некоторых незначительных подстройках. В принципе, комплекс основного тона (главные импульсы) цикла основного тона располагаются ближе к концу сегмента, чтобы обеспечить максимальную точность деформации для перцепционно самой важной части - комплекса основного тона. Для данного сегмента начальная точка фиксирована, а конечная точка может перемещаться для получения наилучшей аппроксимации модели. Перемещение конечной точки эффективно растягивает или сжимает временную шкалу. Следовательно, выборки в начале сегмента практически не смещены, а наибольший сдвиг возникает к концу сегмента.
3.12.1.3 Целевой сигнал для деформации
Возможный вариант целевого сигнала для временной деформации представляет собой синтез текущего сегмента, полученный из модифицированного взвешенного речевого сигнала 350, который представлен s'w(n), и дорожки 348 основного тона, представленной Lp(n). Соответственно дорожке 348 основного тона, представленной Lp(n), каждое значение выборки целевого сигнала s'w(n), n=0, ..., Ns-1, может быть получено интерполяцией модифицированного взвешенного речевого сигнала 350 с использованием Sinc-окна, взвешенного функцией Хэмминга 21-го порядка, в следующем виде:
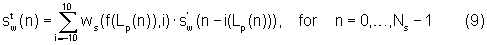
где i(Lp(n)) и f(Lp(n)) - целая и дробная части запаздывания основного тона соответственно; ws(f,i) - Sinc-окно, взвешенное функцией Хэмминга 21-го порядка, Ns - длина сегмента. Взвешенный целевой сигнал swtw(n) определяется как swtw(n)=we(n)·s'w(n). Весовая функция we(n) может представлять собой кусочно-линейную функцию, состоящую из двух частей, которая выделяет комплекс основного тона и сглаживает шум между комплексами основного тона. Взвешивание может адаптироваться соответственно классификации 4 степеней путем выделения комплекса основного тона между сегментами более высокой периодичности.
Целочисленный сдвиг, который максимизирует нормализованную взаимную корреляцию между взвешенным целевым сигналом swtw(n) и взвешенным речевым сигналом 344, соответствует sw(n+τасс), где s w(n + τасс) - взвешенный речевой сигнал 344, сдвинутый соответственно накопленной задержке τасс, которая может быть найдена путем максимизации следующего выражения:

Уточненный (дробный) сдвиг может быть определен путем поиска недискретизированной версии R(τshift) в окрестности τshift. Это может дать в результате конечный оптимальный сдвиг τopt и соответствующую нормализованную взаимную корреляцию R(τopt).
3.12.1.4 Деформация сигнала
Модифицированный взвешенный речевой сигнал 350 для сегмента может быть восстановлен в соответствии с отображением, заданным следующими выражениями:

и

где τc - параметр, определяющий функцию деформации. В принципе τc определяет начало комплекса основного тона. Отображение, заданное уравнением (11), определяет временную деформацию, а отображение, заданное уравнением (12), определяет временной сдвиг (без деформации). Оба они могут быть выполнены с использованием Sinc-окна, взвешенного функцией Хэмминга.
3.12.2 Оценивание усиления основного тона и корреляции основного тона
Усиление основного тона и корреляция основного тона могут быть оценены на базе цикла основного тона и определяются уравнениями (11) и (12) соответственно. Усиление основного тона оценивается для минимизации среднеквадратичной ошибки между целевым сигналом s'w(n), определяемым уравнением (9), и конечным модифицированным сигналом s'w(n), определяемым уравнениями (11) и (12), и может быть задано выражением

Усиление основного тона выдается в модуль 54 обработки возбуждения как неквантованные усиления 352 основного тона. Корреляция основного тона может быть задана выражением

Оба параметра доступны на основе цикла основного тона и могут быть линейно интерполированы.
3.12.3 Уточненная классификация и уточненный выбор скорости
После предварительной обработки основного тона модулем 322 предварительной обработки основного тона усредненная корреляция основного тона и усиления основного тона подаются в модуль 328 классификации и модуль 320 выбора скорости. Модуль 328 определения параметров и модуль 320 выбора скорости формируют окончательный класс определения параметров и окончательный выбор скорости соответственно, используя корреляцию основного тона и усиления основного тона. Окончательный класс определения параметров и окончательный выбор скорости могут быть определены путем уточнения определения параметров сигнала 6 классов и выбора скорости разомкнутого контура для кадра.
Более конкретно, модуль 328 определения параметров определяет, следует ли кадр, определенный как кадр озвученного речевого сигнала, определять как класс 4 - "нестационарный озвученный речевой сигнал", или класс 5 - "стационарный озвученный речевой сигнал". Кроме того, окончательное определение, что конкретный кадр является стационарным шумоподобным неозвученным речевым сигналом, может производиться на основе предыдущего определения, что конкретный кадр является модифицированным шумоподобным неозвученным речевым сигналом. Кадры, подтвержденные как шумоподобный неозвученный речевой сигнал, могут определяться как класс 1 - "стационарный шумоподобный неозвученный речевой сигнал".
На основе данных окончательного определения параметров, выбора скорости разомкнутого контура модулем 320 выбора скорости и флага сигнализации о половинной скорости в линии 30 сигнала половинной скорости (фиг.1) может быть определен окончательный выбор скорости. Окончательный выбор скорости выдается в модуль 54 обработки возбуждения как индикатор 354 выбора скорости. Кроме того, окончательный класс определения параметров для кадра выдается в модуль 54 обработки возбуждения как информация 356 управления.
3.13 Модуль классификации типа
Для кодека 22 полной скорости и кодека 24 половинной скорости окончательный класс определения параметров может также быть использован модулем 324 классификации типа. Кадр с окончательным классом определения параметров от класса 0 до 4 определяется как кадр типа 0, а кадр класса 5 определяется как кадр типа 1. Классификация типа выдается в модуль 54 обработки возбуждения как индикатор 358 типа.
4.0 Модуль обработки возбуждения
Индикатор 358 типа с модуля 324 классификации типа селективно активизирует либо модуль 54 полной скорости, либо модуль 56 половинной скорости, как показано на фиг.2, в зависимости от выбора скорости. На фиг.10 представлена блок-схема, представляющая первый модуль 70 или 80 обработки субкадра F0 или Н0, показанный на фиг.2, который активизирован для классификации типа 0. Аналогичным образом на фиг.11 представлена блок-схема, где показаны первые модули 72 или 82 обработки кадра F1 или H1, вторые модули 74 или 84 F1 или H1 обработки субкадра и вторые модули 76 или 86 обработки кадра F1 или H1, которые активизированы для классификации типа 1. Как описано выше, "F" и "Н" представляют соответственно кодек 22 полной скорости и кодек 24 половинной скорости.
Активизация модуля 60 одной четвертой скорости и модуля 62 одной восьмой скорости, показанных на фиг.2, может основываться на выборе скорости. В одном из вариантов для представления краткосрочного возбуждения генерируется и масштабируется псевдослучайная последовательность. Компонент 204 и 242 энергии (фиг.2) представляет масштабирование псевдослучайной последовательности, как пояснено выше. В одном из вариантов начальное случайное число, используемое для генерирования псевдослучайной последовательности, выделяется из потока битов, обеспечивая при этом синхронность между системой 12 кодирования и системой 16 декодирования.
Как описано выше, модуль 54 обработки возбуждения также принимает модифицированный взвешенный речевой сигнал 350, неквантованные усиления 352 основного тона, указатель 354 скорости и информацию 356 управления. Кодеки 26 и 28 одной четвертой и одной восьмой скорости соответственно не используют эти сигналы при обработке. Однако эти параметры могут использоваться для дополнительной обработки кадров речевого сигнала 18 в кодеке 22 полной скорости и в кодеке 24 половинной скорости. Использование этих параметров в кодеке 22 полной скорости и в кодексе 24 половинной скорости, как описано ниже, зависит от классификации типа кадра как тип 0 или тип 1.
4.1 Модуль обработки возбуждения для кадров типа 0 кодека полной скорости и кодека половинной скорости
Согласно фиг.10 возможный вариант первого модуля 70, 80 обработки субкадра F0 или Н0 содержит секцию 362 адаптивной кодовой книги, секцию 364 фиксированной кодовой книги и секцию 366 квантования усиления. Обработка и кодирование для кадров типа 0 в некоторой степени подобны традиционному кодированию согласно алгоритму CELP, например, как определено в стандарте TIA IS-127. Для кодека 22 полной скорости кадр может делиться на четыре субкадра, в то время как для кодека 24 половинной скорости кадр может делиться на два субкадра, как описано выше. Функции, представленные на фиг.10, выполняются на субкадровой основе.
Первые модули 70, 80 обработки субкадра F0 или Н0 (фиг.2) функционируют для определения запаздывания основного тона замкнутого контура и соответствующего усиления адаптивной кодовой книги. Кроме того, долгосрочный остаток квантуется с использованием фиксированной кодовой книги, и также определяется соответствующее усиление фиксированной кодовой книги. Также выполняются квантование запаздывания основного тона замкнутого контура и совместное квантование усиления адаптивной кодовой книги и фиксированной кодовой книги.
4.1.1 Секция адаптивной кодовой книги
Секция 362 адаптивной кодовой книги включает в себя адаптивную кодовую книгу 368, первый перемножитель 370, первый синтезирующий фильтр 372, первый фильтр 374 перцепционного взвешивания, первый вычитатель 376 и первый модуль 378 минимизации. Секция 362 адаптивной кодовой книги выполняет поиск наилучшего запаздывания основного тона замкнутого контура в адаптивной кодовой книге 368 с использованием метода анализа через синтез.
Сегмент с адаптивной кодовой книги 368, соответствующий запаздыванию основного тона замкнутого контура, может быть определен как вектор (va) 382 адаптивной кодовой книги. Дорожка 348 основного тона с модуля 322 предварительной обработки основного тона (фиг.9) может быть использована для идентификации области в адаптивной кодовой книге 368 для осуществления поиска векторов для векторов (va) 382 адаптивной кодовой книги. Первый перемножитель 370 перемножает выбранный вектор (va) 382 адаптивной кодовой книги на усиление (ga) 384. Усиление (ga) 384 является неквантованным и представляет исходное усиление адаптивной кодовой книги, которое вычисляется, как описано ниже. Результирующий сигнал подается на первый синтезирующий фильтр 372, который выполняет функцию, которая является обратной анализу КЛП, описанному выше. Первый синтезирующий фильтр 372 получает квантованные коэффициенты КЛП Aq(z) 342 с модуля 334 квантования ЧЛС и вместе с первым модулем 374 фильтра перцепционного взвешивания создает первый повторно синтезированный речевой сигнал 386. Первый вычитатель 376 вычитает первый повторно синтезированный речевой сигнал 386 из модифицированного взвешенного речевого сигнала 350 для генерации долгосрочного сигнала ошибки 388. Модифицированный взвешенный речевой сигнал 350 является целевым сигналом для поиска в адаптивной кодовой книге 368.
Первый модуль 378 минимизации получает долгосрочный сигнал ошибки 388, который является вектором, представляющим ошибку в квантовании запаздывания основного тона замкнутого контура. Первый модуль 378 минимизации выполняет вычисление энергии вектора и определение соответствующей взвешенной среднеквадратичной ошибки. Кроме того, первый модуль 378 минимизации управляет поиском и выбором векторов из адаптивной кодовой книги 368 для вектора (va) 382 адаптивной кодовой книги, чтобы снизить энергию долгосрочного сигнала ошибки 388.
Процесс поиска повторяется до тех пор, пока первый модуль 378 минимизации не выберет наилучший вектор для вектора (va) 382 адаптивной кодовой книги из адаптивной кодовой книги 368 для каждого субкадра. Местоположение индекса наилучшего вектора для вектора (va) 382 адаптивной кодовой книги в адаптивной кодовой книге 368 формирует часть компонента 144b, 176b (фиг.2) адаптивной кодовой книги замкнутого контура. Этот процесс поиска эффективно минимизирует энергию долгосрочного сигнала ошибки 388. Наилучшее запаздывание основного тона замкнутого контура выбирается путем выбора наилучшего вектора (va) 382 адаптивной кодовой книги из адаптивной кодовой книги 368. Полученный долгосрочный сигнал ошибки 388 является модифицированным взвешенным речевым сигналом 350 за вычетом отфильтрованного наилучшего вектора для вектора (va) 382 адаптивной кодовой книги.
4.1.1.1 Поиск в адаптивной кодовой книге замкнутого контура для кодека полной скорости
Запаздывание основного тона замкнутого контура для кодека 22 полной скорости представлено в потоке битов компонентом 144b адаптивной кодовой книги замкнутого контура. В одном из вариантов кодека 22 полной скорости запаздывания основного тона замкнутого контура для первого и третьего субкадров представлены 8 битами, а запаздывания основного тона замкнутого контура для второго и четвертого субкадров представлены 5 битами, как описано выше. В одном из вариантов запаздывание находится в диапазоне запаздываний от 17 до 148. 8 битов и 5 битов могут представлять одно и то же разрешение основного тона. Однако 8 битов могут также представлять полный диапазон запаздывания основного тона замкнутого контура для субкадра, а 5 битов могут представлять ограниченное значение запаздываний основного тона замкнутого контура относительно запаздывания основного тона замкнутого контура предыдущего субкадра. В возможном варианте разрешение запаздывания основного тона замкнутого контура составляет 0,2 равномерно между запаздыванием 17 и запаздыванием 33. От запаздывания 33 до запаздывания 91 в данном примере разрешение постепенно увеличивается от 0,2 до 0,5, а разрешение от запаздывания 91 до запаздывания 148 равно 1,0.
Секция 362 адаптивной кодовой книги выполняет поиск целочисленного запаздывания среди целочисленных запаздываний основного тона замкнутого контура. Для первого и третьего субкадров (т.е. тех, которые представлены 8 битами) поиск целочисленного запаздывания может выполняться в диапазоне [Lp-3, ..., Lp-3], где Lp - запаздывание основного тона субкадра. Запаздывание основного тона субкадра получают из дорожки 348 основного тона, которая используется для идентификации вектора в адаптивной кодовой книге 368.
Функция взаимной корреляции R(l) для диапазона поиска целочисленного запаздывания может быть вычислена в соответствии с выражением

где t(n) - целевой сигнал, который представляет собой модифицированный взвешенный речевой сигнал 350, e(n) - вклад адаптивной кодовой книги, представленный вектором (va) 382 адаптивной кодовой книги, h(n) - комбинированный отклик первого синтезирующего фильтра 372 и фильтра 374 перцепционного взвешивания. В возможном варианте осуществления в субкадре использовалось 40 выборок, хотя также может использоваться большее или меньшее число выборок.
Целочисленное запаздывание основного тона замкнутого контура, которое максимизирует R(l), может быть выбрано как уточненное целочисленное запаздывание. Наилучший вектор из адаптивной кодовой книги 368 для вектора (va) 382 адаптивной кодовой книги может быть определен повышенной дискретизацией функции взаимной корреляции R(l) с использованием Sinc-окна, взвешенного функцией Хэмминга 9-го порядка. За повышенной дискретизацией следует поиск векторов в адаптивной кодовой книге 368, которые соответствуют запаздываниям основного тона замкнутого контура, которые находятся в пределах 1 выборки уточненного целочисленного запаздывания. Местоположение в адаптивной кодовой книге 368 индекса наилучшего вектора для вектора (va) 382 адаптивной кодовой книги для каждого субкадра представлено компонентом 144b адаптивной кодовой книги замкнутого контура в потоке битов.
Исходное усиление адаптивной кодовой книги может быть оценено в соответствии со следующим соотношением:

где Lp opt представляет запаздывание наилучшего вектора для вектора (va) 382 адаптивной кодовой книги, е(n-Lpopt) представляет наилучший вектор для вектора (va) 382 адаптивной кодовой книги. Кроме того, в данном варианте оценка ограничена пределами 0,0≤g≤1,2 и n представляет 40 выборок в субкадре. Нормализованная корреляция адаптивной кодовой книги задана посредством R(l), если L=Lpopt. Исходное усиление адаптивной кодовой книги может быть дополнительно нормализовано соответственно нормализованной корреляции адаптивной кодовой книги, исходному решению о классе и резкости вклада адаптивной кодовой книги. Нормализация дает результат в усилении (ga) 384. Усиление (ga) 384 является неквантованным и представляет исходное усиление адаптивной кодовой книги для запаздывания основного тона замкнутого контура.
4.1.1.2 Поиск в адаптивной кодовой книге замкнутого контура для кодека половинной скорости
Запаздывание основного тона замкнутого контура для кодека 24 половинной скорости представлено компонентом 176b (фиг.2) адаптивной кодовой книги замкнутого контура. В одном из вариантов кодека 24 половинной скорости запаздывания основного тона замкнутого контура для каждого из двух субкадров кодируются в 7 битах, причем запаздывание находится в диапазоне запаздываний от 17 до 127. Поиск целочисленного запаздывания может выполняться в диапазоне [Lp-3,...,Lp+3] в противоположность поиску дробного запаздывания, выполняемому в кодеке 22 полной скорости. Функция взаимной корреляции R(l) может вычисляться как в уравнении (15), где суммирование в одном из вариантов выполняется по субкадру размером 80 выборок. Запаздывание основного тона замкнутого контура, которое максимизирует R(l), может быть выбрано как уточненное целочисленное запаздывание. Местоположение в адаптивной кодовой книге 368 индекса наилучшего вектора для вектора (va) 382 адаптивной кодовой книги для каждого субкадра представлено компонентом 176b адаптивной кодовой книги замкнутого контура в потоке битов.
Исходное значение для усиления адаптивной кодовой книги может быть вычислено соответственно уравнению (16), где суммирование выполняется в возможном варианте осуществления по субкадру размером 80 выборок. Процедуры нормализации, как описано выше, могут затем применяться, давая в результате усиление (ga)384, которое является неквантованным.
Долгосрочный сигнал ошибки 388, генерируемый кодеком 22 полной скорости или кодеком 24 половинной скорости, используется в процессе поиска посредством секции 364 фиксированной кодовой книги. Перед поиском фиксированной кодовой книги получают решение о речевой активности с модуля ОРА 326 (фиг.9), которое применяется к кадру. Решение о речевой активности для кадра может подразделяться на решение о речевой активности субкадра для каждого субкадра. Решение о речевой активности субкадра может быть использовано для улучшения перцепционного выбора вклада фиксированной кодовой книги.
4.1.2 Секция фиксированной кодовой книги
Секция 364 фиксированной кодовой книги включает фиксированную кодовую книгу 390, второй перемножитель 392, второй синтезирующий фильтр 394, второй фильтр 396 перцепционного взвешивания, второй вычитатель 398 и второй модуль 400 минимизации. Поиск вклада фиксированной кодовой книги посредством секции 364 фиксированной кодовой книги подобен поиску в секции 362 адаптивной кодовой книги.
Вектор (vc) 402 фиксированной кодовой книги, представляющий долгосрочный остаток для субкадра, получается из фиксированной кодовой книги 390. Второй перемножитель 392 перемножает вектор (vc) 402 фиксированной кодовой книги на усиление (gc) 404. Усиление (gc) 404 является неквантованным представлением исходного значения усиления фиксированной кодовой книги, которое может быть вычислено, как описано ниже. Результирующий сигнал подается на второй синтезирующий фильтр 394. Второй синтезирующий фильтр 394 получает квантованные коэффициенты КЛП Aq(z) 342 с модуля 334 квантования ЧЛС и вместе с вторым фильтром 396 перцепционного взвешивания формирует второй повторно синтезированный речевой сигнал 406. Второй вычитатель 398 вычитает повторно синтезированный речевой сигнал 406 из долгосрочного сигнала ошибки 388 для формирования вектора, который является сигналом ошибки 408 фиксированной кодовой книги.
Второй модуль 400 минимизации получает сигнал ошибки 408 фиксированной кодовой книги, который представляет ошибку в квантовании долгосрочного остатка посредством фиксированной кодовой книги 390. Второй модуль 400 минимизации использует энергию сигнала ошибки 408 фиксированной кодовой книги для управления выбором векторов для вектора (vc) 402 фиксированной кодовой книги из фиксированной кодовой книги 292, чтобы уменьшить энергию сигнала ошибки 408 фиксированной кодовой книги. Второй модуль 400 минимизации также получает информацию управления 356 из модуля 328 определения параметров (фиг.9).
Окончательный класс определения параметров, содержащийся в информации управления 356, управляет тем, каким образом второй модуль 400 минимизации выбирает вектора для векторы (vc) 402 фиксированной кодовой книги из фиксированной кодовой книги 390. Процесс повторяется до тех пор, пока поиск вторым модулем 400 минимизации не выберет наилучший вектор для вектора (vc) 402 фиксированной кодовой книги из фиксированной кодовой книги 390 для каждого субкадра. Наилучший вектор для вектора (vc) 402 фиксированной кодовой книги минимизирует ошибку во втором повторно синтезированном речевом сигнале 406 по отношению к долгосрочному сигналу ошибки 388. Индексы идентифицируют наилучший вектор для вектора (vc) 402 фиксированной кодовой книги и, как описано выше, могут быть использованы для формирования компонента 146а и 178а фиксированной кодовой книги.
4.1.2.1 Поиск в фиксированной кодовой книге для кодека полной скорости
Как описано выше со ссылками на фиг.2 и 4, компонент 146а фиксированной кодовой книги для кадров классификации типа 0 может представлять каждый из четырех субкадров кодека 22 полной скорости с использованием трех 5-импульсных кодовых книг 160. При инициировании поиска векторы для вектора (vc) 402 фиксированной кодовой книги 390 могут быть определены с использованием долгосрочного сигнала ошибки 388, который представляется в следующем виде:

Улучшение (коррекция) основного тона может применяться к трем 5-импульсным кодовым книгам 160 (фиг.4) в фиксированной кодовой книге 390 в прямом направлении в процессе поиска. Поиск представляет собой итеративный поиск управляемой сложности для нахождения наилучшего вектора для вектора (vc) 402 фиксированной кодовой книги. Исходное значение для усиления фиксированной кодовой книги, представленного усилением (gc) 404, может быть найдено одновременно с поиском наилучшего вектора для вектора (vc) 402 фиксированной кодовой книги.
В приведенном для примера варианте осуществления поиск наилучшего вектора для вектора (vc) 402 фиксированной кодовой книги выполняется в каждой из трех 5-импульсных кодовых книг 160. В завершение процесса поиска в каждой из трех 5-импульсных кодовых книг 160 идентифицируются вероятные наилучшие векторы для вектора (vc) 402 фиксированной кодовой книги. Выбор одной из трех 5-импульсных кодовых книг 160 и того, какой из вероятных наилучших векторов должен использоваться, может быть определено с использованием соответствующего сигнала ошибки 408 фиксированной кодовой книги для каждого из соответствующих вероятных наилучших векторов. Сначала во втором модуле 400 минимизации выполняется определение взвешенной среднеквадратичной ошибки (ВСКО) для каждого из соответствующих сигналов ошибки 408 фиксированной кодовой книги. В данном описании взвешенные среднеквадратичные ошибки (ВСКО) для каждого из вероятных наилучших векторов трех 5-импульсных кодовых книг 160 определены как ВСКО первой, второй и третьей фиксированных кодовых книг.
ВСКО первой, второй и третьей фиксированных кодовых книг могут сначала взвешиваться. В кодеке 22 полной скорости для кадров, классифицированных как тип 0, ВСКО первой, второй и третьей фиксированных кодовых книг могут взвешиваться решением о речевой активности субкадров. Кроме того, взвешивание может обеспечиваться мерой резкости каждой из ВСКО первой, второй и третьей фиксированных кодовых книг и ОШС с модуля 328 определения параметров (фиг.9). На основе взвешивания могут быть выбраны одна из трех 5-импульсных фиксированных кодовых книг 160 и наилучший вероятный вектор в этой кодовой книге.
Для выбранной 5-импульсной кодовой книги 160 может быть проведен точный поиск для окончательного решения о наилучшем векторе для вектора (vc) 402 фиксированной кодовой книги. Точный поиск выполняется над векторами в выбранной одной из трех 5-импульсных кодовых книг 160, которые находятся в окрестности выбранного наилучшего вероятного вектора. Индексы, которые идентифицируют наилучший вектор для вектора (vc) 402 фиксированной кодовой книги в пределах выбранной одной из трех 5-импульсных кодовых книг 160, являются частью компонента 178а фиксированной кодовой книги в потоке битов.
4.1.2.2 Поиск в фиксированной кодовой книге для кодека половинной скорости
Для классов классификации типа 0 компонент 178а фиксированной кодовой книги представляет каждый из двух субкадров кодека 24 половинной скорости. Как описано выше со ссылками на фиг.5, представление может основываться на импульсных кодовых книгах 192, 194 и гауссовской кодовой книге 195. Исходное целевое значение для усиления фиксированной кодовой книги, представленного усилением (gc) 404, может быть определено аналогично тому, как для кодека 22 полной скорости. Кроме того, поиск вектора (vc) 404 фиксированной кодовой книги в пределах фиксированной кодовой книги 390 может взвешиваться аналогично тому, как для кодека 22 полной скорости. В кодеке 24 половинной скорости взвешивание может применяться к наилучшим вероятным векторам для каждой из импульсных кодовых книг 192 и 194, а также для гауссовской кодовой книги 195. Взвешивание применяется для определения наиболее подходящего вектора (vc) 402 фиксированной кодовой книги.с перцепционной точки зрения. Кроме того, взвешивание взвешенной среднеквадратичной ошибки (ВСКО) в кодеке 24 половинной скорости может быть усилено для того, чтобы подчеркнуть перцепционный аспект. Дальнейшее улучшение может быть реализовано путем включения дополнительных параметров во взвешивание. Дополнительными факторами могут являться запаздывание основного тона замкнутого контура и нормализованная корреляция адаптивной кодовой книги.
В дополнение к улучшенному взвешиванию, перед поиском в кодовых книгах 192, 194, 195 наилучших вероятных векторов, некоторые характеристики могут быть введены в записи импульсных кодовых книг 192, 194. Эти характеристики могут обеспечить дальнейшее улучшение перцепционного качества. В одном из вариантов улучшенное перцепционное качество в процессе поисков может быть достигнуто путем модифицирования импульсной характеристики второго синтезирующего фильтра 394 с использованием трех факторов улучшения (коррекции). Первое улучшение может быть обеспечено путем ввода высокочастотного шума в фиксированную кодовую книгу, что модифицирует высокочастотную полосу. Введение высокочастотных шумов может быть осуществлено в импульсную характеристику второго синтезирующего фильтра 394 путем свертки импульсной характеристики высокочастотных шумов с импульсной характеристикой второго синтезирующего фильтра.
Второе улучшение может быть использовано для введения дополнительных импульсов в местоположения, которые могут быть определены высокими значениями корреляций в предыдущем квантованном субкадре. Амплитуда дополнительных импульсов может регулироваться в соответствии с уровнем корреляции, тем самым позволяя системе 16 декодирования выполнять ту же операцию, не требуя дополнительной информации от системы 12 кодирования. Вклад от этих дополнительных импульсов может также быть веден в импульсную характеристику второго синтезирующего фильтра 394. Третье улучшение заключается в фильтрации фиксированной кодовой книги 390 слабым краткосрочным спектральным фильтром для компенсации снижения в резкости формант, являющейся результатом расширения полосы и квантования ЧЛС.
Поиск наилучшего вектора (vc) 402 фиксированной кодовой книги основывается на минимизации энергии сигнала ошибки 408 фиксированной кодовой книги, как описано выше. Поиск сначала может быть выполнен по 2-импульсной кодовой книге 192. Затем может быть осуществлен поиск в 3-импульсной кодовой книге 194 в два этапа. На первом этапе может быть определен центр для второго этапа, который может быть определен как сфокусированный поиск. Улучшение (коррекция) взвешенного основного тона как назад, так и вперед может применяться для поиска в обеих импульсных кодовых книгах 192 и 194. Поиск в гауссовской кодовой книге 195 может быть осуществлен с использованием процедуры быстрого поиска, которая используется для определения двух векторов ортогонального базиса для кодирования, как пояснено выше.
Выбор одной из кодовых книг 192, 194 и 195 и наилучшего вектора для вектора (vc) 402 фиксированной кодовой книги может быть выполнен аналогично тому, как в кодекс 22 полной скорости. Индексы, которые идентифицируют наилучший вектор для вектора (vc) 402 фиксированной кодовой книги, являются частью компонента 178а фиксированной кодовой книги в потоке битов.
В этот момент найдены наилучшие векторы для вектора (va) 382 адаптивной кодовой книги и вектора (vc) 402 фиксированной кодовой книги соответственно в адаптивной и фиксированной кодовых книгах 368 и 390. Неквантованные значения для усиления (ga) 384 и для усиления (gc) 404 могут быть теперь заменены наилучшими значениями усиления. Наилучшие значения усиления могут быть определены на основе наилучших векторов для вектора (va) 382 адаптивной кодовой книги и вектора (vc) 402 фиксированной кодовой книги, определенных ранее. После определения наилучших усилений они совместно квантуются. Определение и квантование усилений осуществляется в секции квантования 366.
4.1.3 Секция квантования усиления
Секция 366 квантования усиления в одном из вариантов включает кодовую книгу 412 усиления двумерного векторного квантователя (2D ВК), третий перемножитель 414, четвертый перемножитель 416, сумматор 418, третий синтезирующий фильтр 420, третий фильтр 422 перцепционного взвешивания, третий вычитатель 424, третий модуль 426 минимизации и секцию 428 модифицирования энергии. Секция 428 модифицирования энергии в одном из вариантов включает модуль 430 анализа энергии и модуль 432 регулирования энергии. Определение и квантование усилений фиксированной и адаптивной кодовых книг может быть выполнено в секции 366 квантования усиления. Кроме того, дополнительное модифицирование модифицированного взвешенного речевого сигнала 350 производится в секции 428 модифицирования энергии, как будет пояснено, чтобы сформировать модифицированный целевой сигнал 434, который может быть использован для квантования.
Определение и квантование связано с поиском для определения квантованного вектора усиления  433, который представляет совместное квантование усиления адаптивной кодовой книги и фиксированной кодовой книги. Усиления адаптивной и фиксированной кодовых книг для поиска может быть получено путем минимизации взвешенной среднеквадратичной ошибки в соответствии с соотношением
433, который представляет совместное квантование усиления адаптивной кодовой книги и фиксированной кодовой книги. Усиления адаптивной и фиксированной кодовых книг для поиска может быть получено путем минимизации взвешенной среднеквадратичной ошибки в соответствии с соотношением

где νa(n) - наилучший вектор для вектора (va) 382 адаптивной кодовой книги и νc(n) - наилучший вектор для вектора (vc) 402 фиксированной кодовой книги, как пояснено выше. В приведенном для примера варианте осуществления суммирование основывается на кадре, который содержит 80 выборок, таком как в варианте кодека 24 половинной скорости. Минимизация может быть получена совместно (одновременным получением ga и gc) или последовательно (получением сначала ga, а потом gc) в зависимости от порогового значения нормализованной корреляции адаптивной кодовой книги. Усиления могут затем модифицироваться частично, чтобы сгладить флуктуации восстановленной речи в присутствии фоновых шумов. Модифицированные усиления обозначены g'a и g'c. Модифицированный целевой сигнал 434 может быть сформирован с использованием модифицированных усилений следующим образом:

Поиск наилучшего вектора для квантованного вектора усиления  433 выполняется в кодовой книге 412 усиления 2D ВК. Кодовая книга 412 усиления 2D ВК может представлять собой рассмотренную выше двумерную таблицу квантования усиления, представленную как таблица 4. Поиск в кодовой книге 412 усиления 2D ВК осуществляется для нахождения векторов для квантованного вектора усиления (gac) 433, который минимизирует среднеквадратичную ошибку, т.е. минимизируя выражение
433 выполняется в кодовой книге 412 усиления 2D ВК. Кодовая книга 412 усиления 2D ВК может представлять собой рассмотренную выше двумерную таблицу квантования усиления, представленную как таблица 4. Поиск в кодовой книге 412 усиления 2D ВК осуществляется для нахождения векторов для квантованного вектора усиления (gac) 433, который минимизирует среднеквадратичную ошибку, т.е. минимизируя выражение

где квантованное усиление (ga) 435 адаптивной кодовой книги и квантованное усиление (gc) 436 фиксированной кодовой книги могут быть получены из кодовой книги 412 усиления 2D ВК. В возможном варианте суммирование основано на кадре, который содержит 80 выборок, таком как в варианте кодека 24 половинной скорости. Квантованные векторы в кодовой книге 412 усиления 2D ВК реально представляют усиление адаптивной кодовой книги и коэффициент коррекции для усиления фиксированной кодовой книги, как объяснено выше.
После определения модифицированного целевого сигнала 434 квантованный вектор усиления 433 проходит на перемножители 414, 416. Третий перемножитель 414 умножает наилучший вектор для вектора (va) 382 адаптивной кодовой книги с адаптивной кодовой книги 368 на квантованное усиление  435 адаптивной кодовой книги. Выходной результат с третьего перемножителя 414 подается на сумматор 418. Аналогичным образом четвертый перемножитель 416 перемножает квантованное усиление
435 адаптивной кодовой книги. Выходной результат с третьего перемножителя 414 подается на сумматор 418. Аналогичным образом четвертый перемножитель 416 перемножает квантованное усиление  436 фиксированной кодовой книги на наилучший вектор для вектора (vc) 402 фиксированной кодовой книги с фиксированной кодовой книги 390. Выходной результат с четвертого перемножителя 416 подается на сумматор 418. Сумматор 418 суммирует выходные результаты перемножителей 414, 416 и выдает результирующий сигнал на третий синтезирующий фильтр 420.
436 фиксированной кодовой книги на наилучший вектор для вектора (vc) 402 фиксированной кодовой книги с фиксированной кодовой книги 390. Выходной результат с четвертого перемножителя 416 подается на сумматор 418. Сумматор 418 суммирует выходные результаты перемножителей 414, 416 и выдает результирующий сигнал на третий синтезирующий фильтр 420.
Комбинация третьего синтезирующего фильтра 420 и фильтра 422 перцепционного взвешивания генерирует третий повторно синтезированный речевой сигнал 438. Как и в случае первого и второго синтезирующих фильтров 372 и 394, третий синтезирующий фильтр 420 получает квантованные коэффициенты Aq(z) 342. Третий вычитатель 424 вычитает третий повторно синтезированный речевой сигнал 438 из модифицированного целевого сигнала 434 для генерирования третьего сигнала ошибки 442. Третий модуль 426 минимизации получает третий сигнал ошибки 442, который представляет ошибку, являющуюся результатом совместного квантования усиления фиксированной кодовой книги и усиления адаптивной кодовой книги посредством кодовой книги 412 усиления 2D ВК. Третий модуль 426 минимизации использует энергию третьего сигнала ошибки 442 для управления поиском и выбором векторов с кодовой книги 412 усиления 2D ВК, чтобы уменьшить энергию третьего сигнала ошибки 442.
Процесс повторяется до тех пор, пока третий модуль 426 минимизации не выберет наилучший вектор из кодовой книги 412 усиления 2D ВК для каждого субкадра, который минимизирует энергию третьего сигнала ошибки 442. Как только энергия третьего сигнала ошибки 442 минимизирована для каждого субкадра, местоположения индексов совместно квантованных усилений  435 и 436 используются для генерации компонента 147, 179 усиления для кадра. Для кодека 22 полной скорости компонент 147 усиления является фиксированным и адаптивным компонентом 148а, 150а усиления, а для кодека 24 половинной скорости компонент 179 усиления является фиксированным и адаптивным компонентом 180а, 182а усиления.
435 и 436 используются для генерации компонента 147, 179 усиления для кадра. Для кодека 22 полной скорости компонент 147 усиления является фиксированным и адаптивным компонентом 148а, 150а усиления, а для кодека 24 половинной скорости компонент 179 усиления является фиксированным и адаптивным компонентом 180а, 182а усиления.
Синтезирующие фильтры 372, 394 и 420, фильтры 374, 396 и 422 перцепционного взвешивания, модули 378, 400 и 426 минимизации и перемножители 370, 392, 414 и 416, сумматор 418 и вычитатели 376, 398 и 424 (а также любой другой фильтр, модуль минимизации, перемножитель, сумматор и вычитатель, описанные в данной заявке) могут быть заменены любым другим устройством или модифицированы способом, известным специалистам в данной области техники, который может быть пригоден для конкретного применения.
4.2 Модуль обработки возбуждения для кадров типа 1 кодека полной скорости и кодека половинной скорости
На фиг.11 модули 72 и 82 обработки первого кадра F1, H1 включают в себя модуль 454 3D/4D ВК разомкнутого контура. Модули 74 и 84 обработки второго субкадра F1, H1 в одном из вариантов включают в себя адаптивную кодовую книгу 368, фиксированную кодовую книгу 390, первый перемножитель 456, второй перемножитель 458, первый синтезирующий фильтр 460 и второй синтезирующий фильтр 462. Кроме того, модули 74 и 84 обработки второго субкадра F1, H1 включают первый фильтр 464 перцепционного взвешивания, второй фильтр 466 перцепционного взвешивания, первый вычитатель 468, второй вычитатель 470, первый модуль 472 минимизации и модуль 474 регулирования энергии. Модули 76 и 86 обработки второго кадра F1, H1 включают третий перемножитель 476, четвертый перемножитель 478, сумматор 480, третий синтезирующий фильтр 482, третий фильтр 484 перцепционного взвешивания, третий вычитатель 486, модуль 488 буферизации, второй модуль 490 минимизации и кодовую книгу 492 3D/4D ВК усиления.
Обработка кадров, классифицированных как тип 1, в модуле 54 обработки возбуждения обеспечивает обработку как на кадровой основе, так и на субкадровой основе, как описано выше. Для краткости последующее описание относится к модулям в кодеке 22 полной скорости. Модули в кодекс 24 половинной скорости могут рассматриваться как функционирующие аналогичным образом, если иное особо не указано. Квантование усиления кодовой книги модулем 72 обработки первого кадра F1 генерирует компонент 148b адаптивного усиления. Модуль 74 обработки второго субкадра F1 и модуль 76 обработки второго кадра F1 обеспечивают определение вектора фиксированной кодовой книги и соответствующего усиления фиксированной кодовой книги, как описано выше. Модуль 74 обработки второго субкадра F1 использует таблицы дорожек для генерирования компонента 146b фиксированной кодовой книги, как показано на фиг.2.
Модуль 76 обработки второго кадра F1 квантует усиление фиксированной кодовой книги для генерирования компонента 150b фиксированного усиления. В одном варианте кодек 22 полной скорости использует 10 битов для квантования усилений 4 фиксированных кодовых книг, а кодек 24 половинной скорости использует 8 битов для квантования усилений 3 фиксированных кодовых книг. Квантование может быть выполнено с использованием прогнозирования со скользящим средним. В общем случае перед выполнением прогнозирования и квантования состояния прогнозирования преобразуются в соответствующее измерение.
4.2.1 Первый модуль обработки кадра
Возможный вариант 3D/4D модуля 454 ВК разомкнутого контура может представлять собой ранее описанный четырехмерный предварительный векторный квантователь (4D пре-ВК) 166 и связанную с ним таблицу предварительного квантования для кодека 22 полной скорости. В другом варианте 3D/4D модуль 454 ВК разомкнутого контура может представлять собой ранее описанный трехмерный предварительный векторный квантователь (3D пре-ВК) 198 и связанную с ним таблицу предварительного квантования для кодека 24 половинной скорости. 3D/4D модуль 454 ВК разомкнутого контура получает неквантованные усиления 352 основного тона с модуля 322 предварительной обработки основного тона. Не квантованные усиления 352 основного тона представляют усиление адаптивной кодовой книги для запаздывания основного тона разомкнутого контура, как описано выше.
3D/4D модуль 454 ВК разомкнутого контура квантует не квантованные усиления 352 основного тона для генерирования квантованного усиления основного тона  496, представляющего наилучшие квантованные усиления основного тона для каждого субкадра, где k - номер субкадров. В возможном варианте имеется четыре субкадра для кодека 22 полной скорости и три субкадра для кодека 24 половинной скорости, что соответствует четырем квантованным усилениям
496, представляющего наилучшие квантованные усиления основного тона для каждого субкадра, где k - номер субкадров. В возможном варианте имеется четыре субкадра для кодека 22 полной скорости и три субкадра для кодека 24 половинной скорости, что соответствует четырем квантованным усилениям  и трем квантованным усилениям
и трем квантованным усилениям  для каждого субкадра соответственно. Местоположение индекса квантованного усиления
для каждого субкадра соответственно. Местоположение индекса квантованного усиления  основного тона 496 в таблице предварительного квантования усиления представляет компонент 148b адаптивного усиления для кодека 22 полной скорости или компонент 180b адаптивного усиления для кодека 24 половинной скорости. Квантованное усиление
основного тона 496 в таблице предварительного квантования усиления представляет компонент 148b адаптивного усиления для кодека 22 полной скорости или компонент 180b адаптивного усиления для кодека 24 половинной скорости. Квантованное усиление  основного тона 496 подается на второй модуль 74 обработки субкадра F1 или на второй модуль 84 обработки субкадра H1.
основного тона 496 подается на второй модуль 74 обработки субкадра F1 или на второй модуль 84 обработки субкадра H1.
4.2.2 Второй модуль обработки субкадра
Второй модуль 74 обработки субкадра F1 или второй модуль 84 обработки субкадра H1 использует дорожку 348 основного тона, обеспеченную модулем 322 предварительной обработки основного тона, для идентификации вектора (vk а) 498 адаптивной кодовой книги. Вектор (vk a) 498 адаптивной кодовой книги представляет вклад адаптивной кодовой книги для каждого субкадра, где k - номер субкадра. В одном из вариантов имеется 4 субкадра для кодека 22 полной скорости и три субкадра для кодека 24 половинной скорости, что соответствует четырем векторам (v1 a, v2 a, v3 a, v2 a) и трем векторам (v1 a, v2 a, v3 a) для вклада адаптивной кодовой книги для каждого субкадра соответственно.
Вектор, выбранный для вектора (vk a) 498 адаптивной кодовой книги, может быть получен из последних векторов, находящихся в адаптивной кодовой книге 368, и дорожки 348 основного тона, где дорожка 368 основного тона может быть интерполирована и представлена посредством Lp(n). Соответственно поиск не требуется. Вектор (vk a) 498 адаптивной кодовой книги может быть получен путем интерполяции последних векторов (vk a) 498 адаптивной кодовой книги в адаптивной кодовой книге с использованием Sinc-окна, взвешенного функцией Хэмминга 21-го порядка

где e(n) - последнее возбуждение, i(Lp(n)) и f(Lp(n)) - целая и дробная части запаздывания основного тона соответственно и ws(f,i) - Sinc-окно, взвешенное функцией Хэмминга.
Векторы (vk a) 498 адаптивной кодовой книги и квантованное усиление 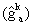 496 основного тона перемножаются в первом перемножителе 456. Первый перемножитель 456 формирует сигнал, который обрабатывается первым синтезирующим фильтром 460 и первым модулем 464 фильтра перцепционного взвешивания для обеспечения первого повторно синтезированного речевого сигнала 500. Первый синтезирующий фильтр 460 получает коэффициенты Aq(z) 342 КЛП с модуля 334 квантования ЧЛС как часть обработки. Первый вычитатель 468 вычитает первый повторно синтезированный речевой сигнал 500 из модифицированного взвешенного речевого сигнала 350, выработанного модулем 322 предварительной обработки основного тона, чтобы генерировать долгосрочный сигнал ошибки 402.
496 основного тона перемножаются в первом перемножителе 456. Первый перемножитель 456 формирует сигнал, который обрабатывается первым синтезирующим фильтром 460 и первым модулем 464 фильтра перцепционного взвешивания для обеспечения первого повторно синтезированного речевого сигнала 500. Первый синтезирующий фильтр 460 получает коэффициенты Aq(z) 342 КЛП с модуля 334 квантования ЧЛС как часть обработки. Первый вычитатель 468 вычитает первый повторно синтезированный речевой сигнал 500 из модифицированного взвешенного речевого сигнала 350, выработанного модулем 322 предварительной обработки основного тона, чтобы генерировать долгосрочный сигнал ошибки 402.
Второй модуль 74 обработки субкадра F1 или второй модуль 84 обработки субкадра H1 также выполняют поиск вклада фиксированной кодовой книги, который подобен выполняемому первым модулем 70 и 80 обработки субкадра F0 или Н0, как описано выше. Вектора для вектора (vk c) 504 фиксированной кодовой книги, который представляет долгосрочный остаток для субкадра, выбираются из фиксированной кодовой книги 390 в процессе поиска. Второй перемножитель 458 перемножает вектор (vk с) 504 фиксированной кодовой книги на усиление (gk c) 506, где k - номер субкадра. Усиление (gk c) 506 является неквантованным и представляет усиление фиксированной кодовой книги для каждого субкадра. Результирующий сигнал обрабатывается вторым синтезирующим фильтром 462 и вторым фильтром 466 перцепционного взвешивания для генерации второго повторно синтезированного речевого сигнала 508. Второй повторно синтезированный речевой сигнал 508 вычитается из долгосрочного сигнала ошибки 502 во втором вычитателе 470 для формирования сигнала ошибки 510 фиксированной кодовой книги.
Сигнал ошибки 510 фиксированной кодовой книги принимается первым модулем 472 минимизации вместе с информацией 356 управления. Первый модуль 472 минимизации работает так же, как и описанный выше второй модуль 400 минимизации, показанный на фиг.10. Процесс поиска повторяется до тех пор, пока первый модуль 472 минимизации не выберет наилучший вектор для вектора (vk c) 504 фиксированной кодовой книги из фиксированной кодовой книги 390 для каждого субкадра. Наилучший вектор для вектора (vk c) 504 фиксированной кодовой книги минимизирует энергию сигнала ошибки 510 фиксированной кодовой книги. Индексы идентифицируют наилучший вектор для вектора (vk c) 504 фиксированной кодовой книги, как описано выше, и формируют компонент 146b и 178b фиксированной кодовой книги.
4.2.2.1 Поиск в фиксированной кодовой книге для кодека полной скорости
В возможном варианте 8-импульсная кодовая книга 162, показанная на фиг.4, используется для каждого из четырех субкадров для кадров типа 1 кодеком 22 полной скорости, как описано выше. Целевым сигналом для вектора (vk c) 504 фиксированной кодовой книги является долгосрочный сигнал ошибки 502, как описано выше. Долгосрочный сигнал ошибки 502, представленный t'(n), определяется на основе модифицированного взвешенного речевого сигнала 350, представленного t(n), с удаленным вкладом адаптивной кодовой книги с модуля 44 обработки исходного кадра согласно выражению

В процессе поиска наилучшего вектора для вектора (vk c) 504 фиксированной кодовой книги в прямом направлении может быть применено усиление (коррекция) основного тона. Кроме того, процедура поиска минимизирует остаток 508 фиксированной кодовой книги с использованием итеративной процедуры поиска с контролируемой сложностью для определения наилучшего вектора для вектора (vk c) 504 фиксированной кодовой книги. Исходное усиление фиксированной кодовой книги, представленное усилением (gk c) 506, определяется в процессе поиска. Индексы идентифицируют наилучший вектор для вектора (vk c) 504 фиксированной кодовой книги и образуют компонент 146b фиксированной кодовой книги, как описано выше.
4.2.2.2 Поиск в фиксированной кодовой книге для кодека половинной скорости
В одном из вариантов долгосрочный остаток представлен 13 битами для каждого из субкадров для кадров, классифицированных как тип 1 для кодека 24 половинной скорости, как описано выше. Долгосрочный остаток может быть определен подобно тому, как в случае поиска в фиксированной кодовой книге в кодеке 22 полной скорости. Подобно поиску в фиксированной кодовой книге для кодека 24 половинной скорости для кадров типа 0 в импульсную характеристику второго синтезирующего фильтра 462 могут быть введены высокочастотный шум, дополнительные импульсы, которые определяются высокой корреляцией в предыдущем субкадре, и слабая краткосрочная фильтрация. Кроме того, в импульсную характеристику второго синтезирующего фильтра 462 может также быть введена прямая коррекция основного тона.
В одном из вариантов полный поиск выполняется для 2-импульсной кодовой книги 196 и 3-импульсной кодовой книги 197, как показано на фиг.3. Импульсная кодовая книга 196, 197 и наилучший вектор для вектора (vk c) 504 фиксированной кодовой книги, который минимизирует сигнал ошибки 510 фиксированной кодовой книги, выбираются для представления долгосрочного остатка для каждого субкадра. Кроме того, исходное усиление фиксированной кодовой книги, представленное усилением (gk c) 506, может быть определено в процессе поиска подобно случаю для кодека 22 полной скорости. Индексы идентифицируют наилучший вектор для вектора (vk c) 504 фиксированной кодовой книги и формируют компонент 178b фиксированной кодовой книги.
Как описано выше, второй модуль 74 или 84 обработки субкадра F1 или H1 работает на субкадровой основе. А второй модуль 76 или 86 обработки кадра F1 или H1 работает на кадровой основе. Соответственно параметры, определенные вторым модулем 74 или 84 обработки субкадра F1 или H1, могут быть сохранены в модуле 488 буферизации для последующего использования на кадровой основе. В одном из вариантов сохраненные параметры представляют собой наилучший вектор для вектора (vk a) 498 адаптивной кодовой книги и наилучший вектор для вектора (vk c) 504 фиксированной кодовой книги. Кроме того, могут быть сохранены модифицированный целевой сигнал 512 и усиления ,  496 и 506, представляющие исходные усиления адаптивной и фиксированной кодовых книг. Генерирование модифицированного целевого сигнала 512 описано ниже.
496 и 506, представляющие исходные усиления адаптивной и фиксированной кодовых книг. Генерирование модифицированного целевого сигнала 512 описано ниже.
На данном этапе идентифицированы наилучший вектор для вектора (vk a) 498 адаптивной кодовой книги, наилучший вектор для вектора (vk c) 504 фиксированной кодовой книги и наилучшие усиления основного тона для квантованного усиления 496 основного тона. С использованием этих наилучших векторов и наилучших усилений основного тона можно определить наилучшие усиления фиксированной кодовой книги для усиления (gk c) 506. Наилучшие усиления фиксированной кодовой книги для усиления (gk c) 506 будут заменять неквантованные исходные усиления фиксированной кодовой книги, определенные ранее для усиления (gk c) 506. Для определения наилучших усилений фиксированной кодовой книги для каждого субкадра второй модуль 76 и 86 обработки кадра выполняет совместное квантование с задержкой для усилений фиксированной кодовой книги.
4.2.3 Второй модуль обработки кадра
Второй модуль 76 и 86 обработки кадра работает на кадровой основе для генерирования усиления фиксированной кодовой книги, представленной компонентом 150b и 182b фиксированного усиления. Модифицированный целевой сигнал 512 сначала определяется аналогично определению усиления и квантованию кадров, классифицированных как тип 0. Модифицированный целевой сигнал 512 определяется для каждого субкадра и представлен посредством t"(n). Модифицированный целевой сигнал может быть получен с использование наилучших векторов для вектора (vk a) 498 адаптивной кодовой книги и для вектора (vk c) 504 фиксированной кодовой книги, а также усиления адаптивной кодовой книги и исходного значения усиления фиксированной кодовой книги, полученного из уравнения (18) согласно выражению
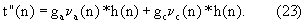
Исходное значение для усиления фиксированной кодовой книги для каждого субкадра, которое должно использоваться при поиске, может быть получено путем минимизации выражения
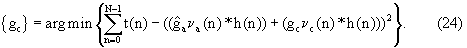
где νa(n) - вклад адаптивной кодовой книги для конкретного субкадра и νc(n) - вклад фиксированной кодовой книги для конкретного субкадра. Кроме того, 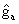 - квантованное и нормализованное усиление адаптивной кодовой книги для конкретного субкадра, т.е. один из элементов квантованного усиления 513 фиксированной кодовой книги. Вычисленное усиление gc фиксированной кодовой книги затем нормализуется и корректируется для обеспечения наилучшего согласования по энергии между третьим повторно синтезированным сигналом и модифицированным целевым сигналом 512, который был буферизован. Неквантованные усиления фиксированной кодовой книги из предыдущих субкадров могут быть использованы для генерации вектора (vk a) 498 адаптивной кодовой книги для обработки следующего субкадра согласно уравнению (21).
- квантованное и нормализованное усиление адаптивной кодовой книги для конкретного субкадра, т.е. один из элементов квантованного усиления 513 фиксированной кодовой книги. Вычисленное усиление gc фиксированной кодовой книги затем нормализуется и корректируется для обеспечения наилучшего согласования по энергии между третьим повторно синтезированным сигналом и модифицированным целевым сигналом 512, который был буферизован. Неквантованные усиления фиксированной кодовой книги из предыдущих субкадров могут быть использованы для генерации вектора (vk a) 498 адаптивной кодовой книги для обработки следующего субкадра согласно уравнению (21).
Поиск векторов для квантованного усиления  513 фиксированной кодовой книги выполняется в кодовой книге 492 усиления 3D/4D ВК. Кодовая книга 492 усиления 3D/4D ВК может представлять собой вышеописанный многомерный квантователь усиления и связанную с ним таблицу квантования усиления. В возможном варианте кодовая книга 492 усиления 3D/4D ВК может представлять собой вышеописанный квантователь 168 усиления 4D ВК с задержкой для кодека 22 полной скорости. Как описано выше, квантователь 168 усиления 4D ВК с задержкой может работать с использованием связанной таблицы квантования усиления с задержкой, представленной в виде таблицы 5. В другом варианте кодовая книга 492 усиления 3D/4D ВК может представлять собой вышеописанный квантователь 200 усиления 3D ВК с задержкой для кодека 24 половинной скорости. Квантователь 200 усиления 3D ВК с задержкой может работать с использованием связанной таблицы квантования усиления с задержкой, представленной в виде таблицы 8.
513 фиксированной кодовой книги выполняется в кодовой книге 492 усиления 3D/4D ВК. Кодовая книга 492 усиления 3D/4D ВК может представлять собой вышеописанный многомерный квантователь усиления и связанную с ним таблицу квантования усиления. В возможном варианте кодовая книга 492 усиления 3D/4D ВК может представлять собой вышеописанный квантователь 168 усиления 4D ВК с задержкой для кодека 22 полной скорости. Как описано выше, квантователь 168 усиления 4D ВК с задержкой может работать с использованием связанной таблицы квантования усиления с задержкой, представленной в виде таблицы 5. В другом варианте кодовая книга 492 усиления 3D/4D ВК может представлять собой вышеописанный квантователь 200 усиления 3D ВК с задержкой для кодека 24 половинной скорости. Квантователь 200 усиления 3D ВК с задержкой может работать с использованием связанной таблицы квантования усиления с задержкой, представленной в виде таблицы 8.
В кодовой книге 492 усиления 3D/4D ВК может производиться поиск векторов для квантованного усиления 513 фиксированной кодовой книги, которое минимизирует энергию, подобно вышеописанной кодовой книге 412 (фиг.10) усиления 2D ВК. Квантованные векторы в кодовой книге 492 усиления 3D/4D ВК в действительности представляют коэффициент коррекции для прогнозируемого усиления фиксированной кодовой книги, как описано выше. В процессе поиска третий перемножитель 476 перемножает вектор 498 адаптивной кодовой книги на квантованное усиление 496 основного тона с последующим определением модифицированного целевого сигнала 512. Кроме того, четвертый перемножитель 478 перемножает вектор (vk c) 504 фиксированной кодовой книги на квантованное усиление 513 фиксированной кодовой книги. Сумматор 480 суммирует результирующие сигналы с перемножителей 476 и 478.
Полученный в результате сигнал с сумматора 480 пропускается через третий синтезирующий фильтр 482 и модуль 484 фильтра перцепционного взвешивания для генерирования третьего повторно синтезированного речевого сигнала 514. Как и в случае первого и второго синтезирующих фильтров 460, 462, третий синтезирующий фильтр 482 получает квантованные коэффициенты Aq(z) 342 КЛП с модуля 334 квантования ЧЛС в качестве составной части обработки. Третий вычитатель 486 вычитает третий повторно синтезированный речевой сигнал 514 из модифицированного целевого сигнала 512, который был ранее сохранен в модуле 488 буферизации. Полученный в результате сигнал представляет собой взвешенную среднеквадратичную ошибку и называется третьим сигналом ошибки 516.
Третий модуль минимизации 490 получает третий сигнал ошибки 516, который представляет ошибку, являющуюся результатом квантования усиления фиксированной кодовой книги с помощью кодовой книги 492 усиления 3D/4D ВК. Третий модуль минимизации 490 использует третий сигнал ошибки 516 для управления поиском и выбором векторов из кодовой книги 492 усиления 3D/4D ВК, чтобы уменьшить энергию третьего сигнала ошибки 516. Процесс поиска повторяется до тех пор, пока третий модуль минимизации 490 не выберет наилучший вектор из кодовой книги 492 усиления 3D/4D ВК для каждого субкадра, который минимизирует ошибку в третьем сигнале ошибки 516. После того как энергия третьего сигнала ошибки 516 минимизирована, местоположение индекса квантованного усиления 513 фиксированной кодовой книги в кодовой книге 492 усиления 3D/4D ВК используется для генерирования компонента 150b усиления фиксированной кодовой книги для кодека 22 полной скорости и компонента 182b усиления фиксированной кодовой книги для кодека 24 половинной скорости.
4.2.3.1 Кодовая книга усиления 3D/4D ВК
В одном из вариантов кодовая книга 492 усиления 3D/4D ВК представляет собой 4-мерную кодовую книгу, в которой может осуществляться поиск для минимизации выражения
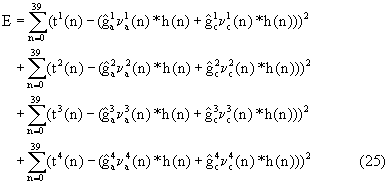
где квантованные усиления 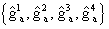 основного тона получены из модуля 44 обработки исходного кадра, {t1(n), t2(n), t3n), t4n)}, {ν1 a(n), ν2 a(n), ν3 a(n), ν4 a(n)} и {ν1 c(n), ν2 c(n), ν3 c(n), ν4 c(n)} могут быть буферизованы в процессе обработки субкадров, как описано выше. В возможном варианте усиления
основного тона получены из модуля 44 обработки исходного кадра, {t1(n), t2(n), t3n), t4n)}, {ν1 a(n), ν2 a(n), ν3 a(n), ν4 a(n)} и {ν1 c(n), ν2 c(n), ν3 c(n), ν4 c(n)} могут быть буферизованы в процессе обработки субкадров, как описано выше. В возможном варианте усиления 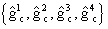 фиксированной кодовой книги получают из 10-битовой кодовой книги, где записи кодовой книги содержат 4-мерный коэффициент коррекции для прогнозируемых усилений фиксированной кодовой книги, как описано выше. Кроме того, n=40 для представления 40 выборок на кадр.
фиксированной кодовой книги получают из 10-битовой кодовой книги, где записи кодовой книги содержат 4-мерный коэффициент коррекции для прогнозируемых усилений фиксированной кодовой книги, как описано выше. Кроме того, n=40 для представления 40 выборок на кадр.
В другом варианте, где кодовая книга 492 усиления 3D/4D ВК представляет собой 3-мерную кодовую книгу, в ней может осуществляться поиск для минимизации выражения

где квантованные усиления  основного тона получены из модуля 44 обработки исходного кадра, {t1(n), t2(n), t3(n)}, {v1 a(n), ν2 a(n), ν3 a(n)} и {ν1 c(n), ν2 c(n), ν3 c(n)} могут быть буферизованы в процессе обработки субкадров, как описано выше. В возможном варианте усиления
основного тона получены из модуля 44 обработки исходного кадра, {t1(n), t2(n), t3(n)}, {v1 a(n), ν2 a(n), ν3 a(n)} и {ν1 c(n), ν2 c(n), ν3 c(n)} могут быть буферизованы в процессе обработки субкадров, как описано выше. В возможном варианте усиления  фиксированной кодовой книги получают из 8-битовой кодовой книги, где записи кодовой книги содержат 3-мерный коэффициент коррекции для прогнозируемых усилений фиксированной кодовой книги. Прогнозирование усилений фиксированной кодовой книги может основываться на прогнозировании со скользящим средним энергии фиксированной кодовой книги в логарифмической области.
фиксированной кодовой книги получают из 8-битовой кодовой книги, где записи кодовой книги содержат 3-мерный коэффициент коррекции для прогнозируемых усилений фиксированной кодовой книги. Прогнозирование усилений фиксированной кодовой книги может основываться на прогнозировании со скользящим средним энергии фиксированной кодовой книги в логарифмической области.
5.0 Система декодирования
На фиг.12 представлена блок-схема устройства 90 и 92 декодирования полной и половинной скорости по фиг.3. Устройства 90 и 92 декодирования полной и половинной скорости включают в себя модули 104, 106, 114 и 116 восстановления возбуждения и модули 107 и 118 восстановления коэффициентов линейного предсказания (КЛП). В одном из вариантов каждый из модулей 104, 106, 114 и 116 восстановления возбуждения включает в себя адаптивную кодовую книгу 368, фиксированную кодовую книгу 390, кодовую книгу 412 усиления 2D ВК, кодовую книгу 454 3D/4D ВК разомкнутого контура и кодовую книгу 492 усиления 3D/4D ВК. Модули 104, 106, 114 и 116 восстановления возбуждения также содержат первый перемножитель 530, второй перемножитель 532 и сумматор 534. В одном варианте модули 107 и 118 восстановления КЛП содержат модуль 536 декодирования ЧЛС и модуль 538 преобразования ЧЛС. Кроме того, кодек 24 половинной скорости содержит модуль 336 коммутатора функции прогнозирования, а кодек 22 полной скорости содержит модуль 338 интерполяции.
На фиг.12 также показаны модуль 98 синтезирующего фильтра и постпроцессорный модуль 100. В одном варианте постпроцессорный модуль 100 содержит модуль 540 краткосрочного постфильтра, модуль 542 долгосрочного фильтра, модуль 544 фильтра компенсации наклона и модуль 546 адаптивного управления усилением. В соответствии с выбором скорости поток битов может декодироваться для генерирования прошедшей постпроцессорную обработку синтезированной речи 20. Устройства 90 и 92 декодирования выполняют инверсное отображение компонентов потока битов на параметры алгоритма. За инверсным отображением может следовать синтез, зависящий от классификации типа, осуществляемый в кодеках 22 и 24 полной и половинной скорости.
Декодирование для кодека 26 одной четвертой скорости и для кодека 28 одной восьмой скорости аналогично тому, как это осуществляется для кодеков 22 и 24 полной и половинной скорости. Однако кодеки 26 и 28 одной четвертой скорости и одной восьмой скорости используют векторы сходных, но случайных чисел и усиление энергии, как описано выше, вместо адаптивной и фиксированной кодовых книг 368 и 390 и соответствующих усилений. Случайные числа и усиление энергии могут быть использованы для восстановления энергии возбуждения, которая представляет краткосрочное возбуждение для кадра. Модули 122 и 126 восстановления КЛП также подобны кодекам 22 и 24 полной и половинной скорости за исключением модуля 336 коммутатора функции прогнозирования и модуля 338 интерполяции.
5.1 Восстановление возбуждения
В устройствах 90 и 92 декодирования полной и половинной скорости работа модулей 104, 106, 114 и 116 восстановления возбуждения в значительной степени зависит от классификации типа, обеспечиваемой компонентом 142 и 174 типа. Адаптивная кодовая книга 368 получает дорожку 348 основного тона. Дорожка 348 основного тона восстанавливается системой 16 декодирования из компонента 144 и 176 адаптивной кодовой книги, обеспеченной в потоке битов системой 12 кодирования. В зависимости от классификации типа, обеспеченной компонентом 142 и 174 типа, адаптивная кодовая книга 368 подает квантованный вектор (vk a) 550 адаптивной кодовой книги на перемножитель 530. Перемножитель 530 перемножает квантованный вектор (vk a) 550 адаптивной кодовой книги на вектор усиления (gk a) 552 адаптивной кодовой книги. Выбор вектора усиления (gk a) 552 адаптивной кодовой книги также зависит от типа классификации, обеспечиваемого компонентами 142 и 174 типа.
В возможном варианте, если кадр классифицирован как тип 0 в кодеке 22 полной скорости, кодовая книга 412 усиления 2D ВК подает вектор усиления (gk a) 552 адаптивной кодовой книги на перемножитель 530. Вектор усиления (gk a) 552 адаптивной кодовой книги определяется из компонента 148а и 150а усиления адаптивной и фиксированной кодовой книги. Вектор усиления (gk a) 552 адаптивной кодовой книги является тем же самым, что и часть наилучшего вектора для вектора  433 квантованного усиления, определенного секцией 366 усиления и квантования модуля 70 обработки первого субкадра F0, как описано выше. Квантованный вектор (vk a) 550 адаптивной кодовой книги определяется из компонента 144b адаптивной кодовой книги замкнутого контура. Аналогичным образом квантованный вектор (vk a) 550 адаптивной кодовой книги является тем же самым, что и наилучший вектор для вектора (va) 382 адаптивной кодовой книги, определенного модулем 70 обработки первого субкадра F0.
433 квантованного усиления, определенного секцией 366 усиления и квантования модуля 70 обработки первого субкадра F0, как описано выше. Квантованный вектор (vk a) 550 адаптивной кодовой книги определяется из компонента 144b адаптивной кодовой книги замкнутого контура. Аналогичным образом квантованный вектор (vk a) 550 адаптивной кодовой книги является тем же самым, что и наилучший вектор для вектора (va) 382 адаптивной кодовой книги, определенного модулем 70 обработки первого субкадра F0.
Кодовая книга 412 усиления 2D ВК является двумерной и подает вектор усиления (gk a) 552 адаптивной кодовой книги на перемножитель 530, а вектор усиления (gk c) 554 фиксированной кодовой книги на перемножитель 532. Вектор усиления (gk c) 554 фиксированной кодовой книги определяется из компонента 148а и 150а усиления адаптивной и фиксированной кодовой книги и является частью наилучшего вектора для вектора 433 квантованного усиления. Также на основе классификации типа фиксированная кодовая книга 390 подает квантованный вектор (vk c) 556 фиксированной кодовой книги на перемножитель 532. Квантованный вектор (vk c) 556 фиксированной кодовой книги восстанавливается из идентификации кодовой книги, местоположений импульсов (или из гауссовской кодовой книги 195 для кодека 24 половинной скорости) и знаков импульсов, обеспеченных компонентом 146а фиксированной кодовой книги. Квантованный вектор (vc) 556 фиксированной кодовой книги является тем же самым, что и наилучший вектор для вектора (vc k) 402 фиксированной кодовой книги, определенного модулем 70 обработки первого субкадра F0, как описано выше. Перемножитель 532 перемножает квантованный вектор (vk c) 556 фиксированной кодовой книги на вектор усиления (gk c) 554 фиксированной кодовой книги.
Если классификация типа кадра соответствует типу 0, то многомерный векторный квантователь подает вектор усиления (gk a) 552 адаптивной кодовой книги на перемножитель 530, причем количество измерений многомерного векторного квантователя зависит от количества субкадров. В возможном варианте многомерный векторный квантователь может представлять собой 3D/4D ВК 454 разомкнутого контура. Аналогичным образом многомерный векторный квантователь подает вектор усиления (gk c) 554 фиксированной кодовой книги на перемножитель 532. Вектор усиления (gk a) 552 адаптивной кодовой книги и вектор усиления (gk c) 554 фиксированной кодовой книги обеспечиваются компонентами 147 и 179 усиления и представляют собой то же самое, что и квантованное усиление 433 основного тона и квантованное усиление 513 фиксированной кодовой книги соответственно.
Если кадры классифицированы как тип 0 или тип 1, то выходной сигнал первого перемножителя 530 принимается сумматором 534 и суммируется с выходным сигналом второго перемножителя 532. Выходной сигнал сумматора 534 представляет собой краткосрочное возбуждение. Краткосрочное возбуждение подается на модуль 98 синтезирующего фильтра по линии 128 краткосрочного возбуждения.
5.2 Восстановление КЛП
Генерирование коэффициентов краткосрочного прогнозирования (КЛП) в устройствах 90 и 92 декодирования аналогично обработке в системе 12 кодирования. Модуль 536 декодирования ЧЛС восстанавливает квантованные ЧЛС из компонентов 140 и 172 ЧЛС. Модуль 536 декодирования ЧЛС использует ту же самую таблицу квантования ошибок прогнозирования ЧЛМ и таблицы коэффициентов функции прогнозирования ЧЛС, что и используемые в системе 12 кодирования. Для кодека 24 половинной скорости модуль 36 коммутации функции прогнозирования выбирает один из наборов коэффициентов функции прогнозирования для вычисления прогнозируемых ЧЛС в соответствии с управлением от компонента 140, 172 ЧЛС. Интерполяция квантованных ЧЛС осуществляется с использованием того же самого пути линейной интерполяции, что и используемый в системе 12 кодирования. Для кодека 22 полной скорости для кадров, классифицированных как тип 0, модуль 338 интерполяции выбирает один из путей интерполяции, использованных в системе 12 кодирования, в соответствии с управлением от компонента 140, 172 ЧЛС. После взвешивания квантованных ЧЛС производится преобразование в квантованные коэффициенты Aq(z) 342 в модуле 538 ЧЛС. Квантованные коэффициенты Aq(z) 342 являются краткосрочными коэффициентами прогнозирования, которые подаются на синтезирующий фильтр 98 по линии 130 коэффициентов краткосрочного прогнозирования.
5.3 Синтезирующий фильтр
Квантованные коэффициенты Aq(z) 342 могут быть использованы синтезирующим фильтром 98 для фильтрации коэффициентов краткосрочного прогнозирования. Синтезирующий фильтр 98 может представлять собой фильтр краткосрочного инверсного прогнозирования, который генерирует синтезированную речь до постпроцессорной обработки. Синтезированная речь может затем пропускаться через постпроцессорный модуль 100.
5.4 Постпроцессорная обработка
Постпроцессорный модуль 100 обрабатывает синтезированную речь на основе выбора скорости и коэффициентов краткосрочного прогнозирования. Модуль 540 краткосрочного постфильтра может использоваться для обработки синтезированного речевого сигнала. Параметры фильтрации в модуле 540 краткосрочного постфильтра могут быть адаптированы соответственно выбору скорости и долгосрочным спектральным характеристикам, определенным модулем 328 определения параметров, как описано выше со ссылками на фиг.9. Краткосрочный постфильтр может быть описан следующим образом

где в возможном варианте осуществления γ1,n=0,75 γ1,n-1+0,25r0 и γ2=0,75, r0 определяется на основе выбора скорости и долгосрочной спектральной характеристики. Обработка продолжается в модуле 542 долгосрочной фильтрации.
Модуль 542 долгосрочной фильтрации выполняет поиск точной настройки для периода основного тона в синтезированном речевом сигнале. В возможном варианте поиск точной настройки выполняется с использованием корреляции основного тона и гармонической фильтрации, управляемой зависящим от скорости усилением. Гармоническая фильтрация отменяется для кодека 26 одной четвертой скорости и для кодека 28 одной восьмой скорости. Модуль 544 фильтра компенсации наклона в одном из вариантов осуществления представляет собой фильтр с конечной импульсной характеристикой (КИХ) 1-го порядка. Фильтр КИХ может быть настроен в соответствии с наклоном спектра модуля 314 фильтра перцепционного взвешивания, описанного выше со ссылками на фиг.9. Фильтр может также быть настроен в соответствии с долгосрочной спектральной характеристикой, определенной модулем 328 определения параметров, также описанным со ссылкой на фиг.9.
Постфильтрация может быть реализована в модуле 546 адаптивного управления усилением. Модуль 546 адаптивного управления усилением приводит уровень энергии синтезированного речевого сигнала, обработанного постпроцессорным модулем 100, на уровень синтезированного речевого сигнала до постпроцессорной обработки. В модуле 546 адаптивного управления усилением может также выполняться сглаживание уровня и адаптация. Результатом обработки в постпроцессорном модуле 100 является синтезированный речевой сигнал 20, прошедший постпроцессорную обработку.
В возможном варианте осуществления системы 16 декодирования кадры, принятые системой 16 декодирования, которые были стерты, например, вследствие потерь сигнала в процессе распространения радиосигнала, идентифицируются системой 16 декодирования. Система 16 декодирования может затем выполнять операцию маскирования стирания кадров. Эта операция связана с интерполяцией параметров речевого сигнала для стертых кадров на основе предыдущего кадра. Экстраполированные параметры речевого сигнала могут быть использованы для синтеза стертых кадров. Кроме того, может быть использовано сглаживание параметров для обеспечения непрерывного речевого сигнала для кадров, которые следуют за стертым кадром. В другом варианте осуществления система 16 декодирования также содержит средства определения плохой скорости. Индикация выбора плохой скорости для кадра, принятого системой 16 декодирования, выполняется путем идентификации некорректных последовательностей битов в потоке и установления того, что конкретный кадр стерт.
Описанные выше варианты осуществления системы 10 сжатия речи выполняют сжатие речи с переменной скоростью с использованием кодека 22 полной скорости, кодека 24 половинной скорости, кодека 26 одной четвертой скорости и кодека 28 одной восьмой скорости. Кодеки 22, 24, 26 и 28 работают с различными распределениями битов и скоростями передачи в битах, используя различные методы кодирования для кодирования кадров речевого сигнала 18. Метод кодирования кодеков 22 и 24 полной и половинной скорости использует различное перцепционное согласование, различное согласование по формам сигналов и различные распределения битов в зависимости от классификации типа кадра. Кодеки 26 и 28 одной четвертой и одной восьмой скорости используют только параметрические перцепционные представления. Сигнал режима идентифицирует желательную среднюю скорость передачи в битах для системы 10 сжатия речи. Система 10 сжатия речи селективно активизирует кодеки 22, 24, 26 и 28 для уравновешивания желательной средней скорости передачи в битах с оптимизацией перцепционного качества синтезированного речевого сигнала 20, прошедшего постпроцессорную обработку.
Хотя выше описаны различные варианты осуществления настоящего изобретения, специалистам в данной области техники должно быть очевидно, что в пределах сущности и объема настоящего изобретения возможны различные другие варианты и воплощения. Соответственно изобретение ограничивается только формулой изобретения и ее эквивалентами.




















































































































































































































































































































































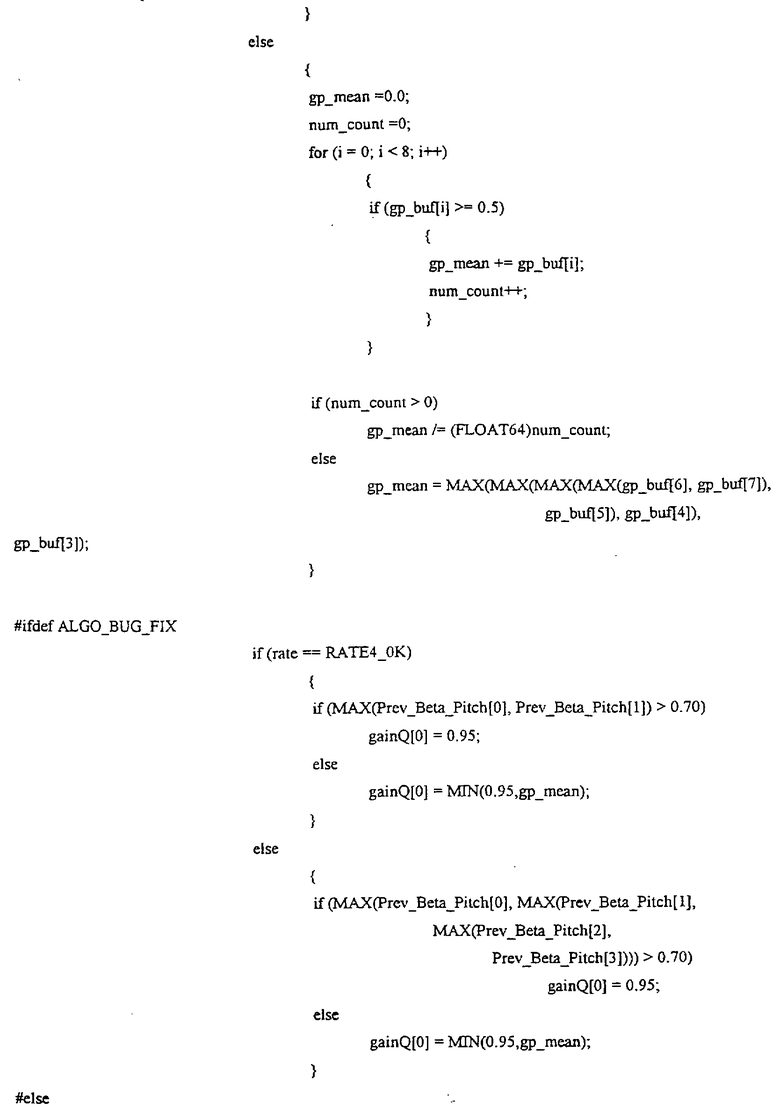
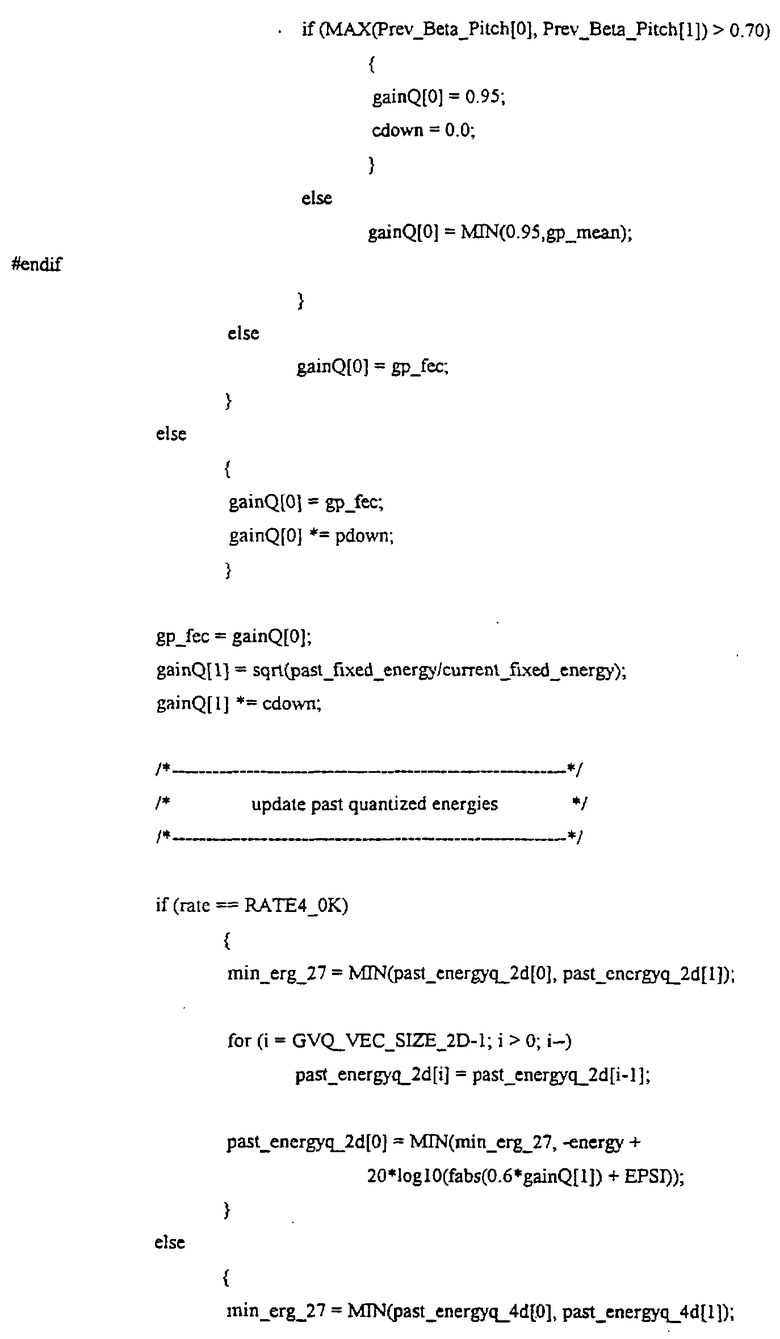





























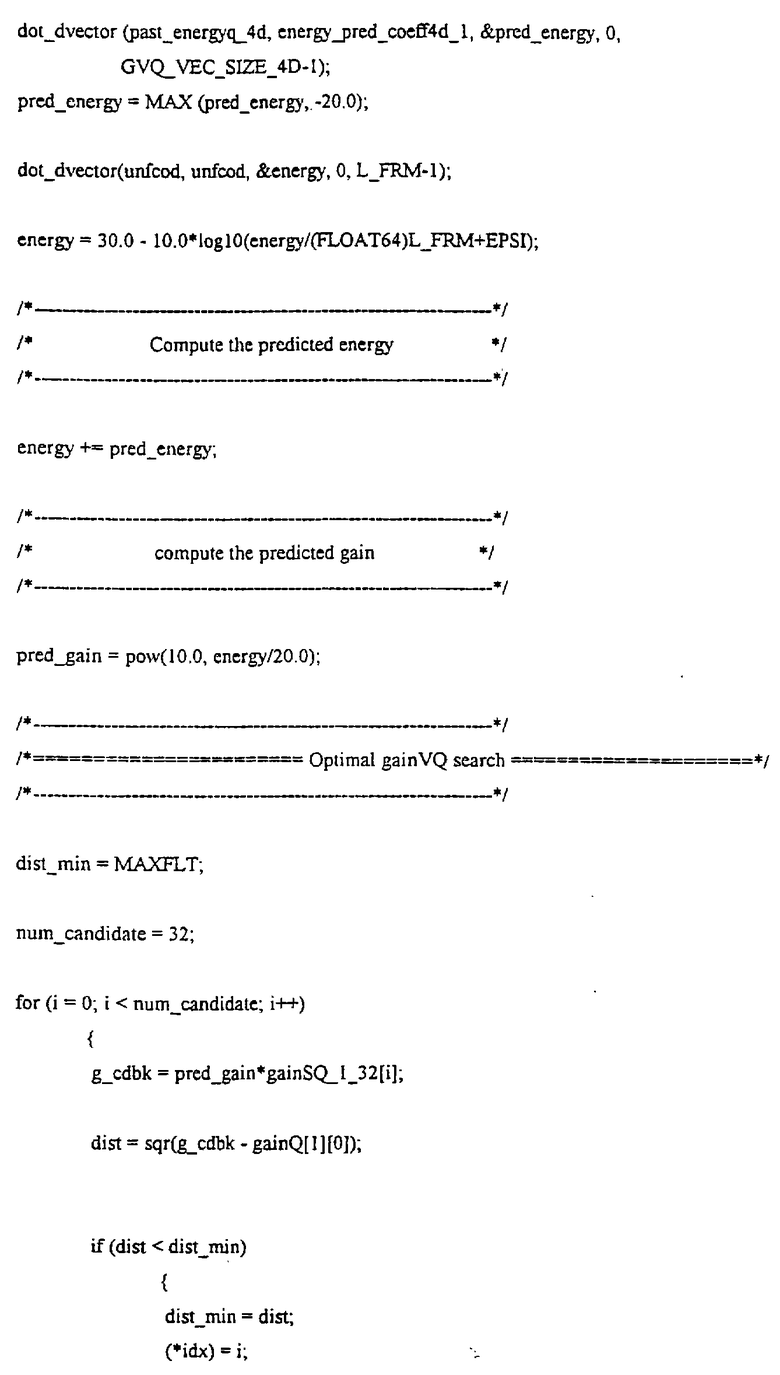


























































































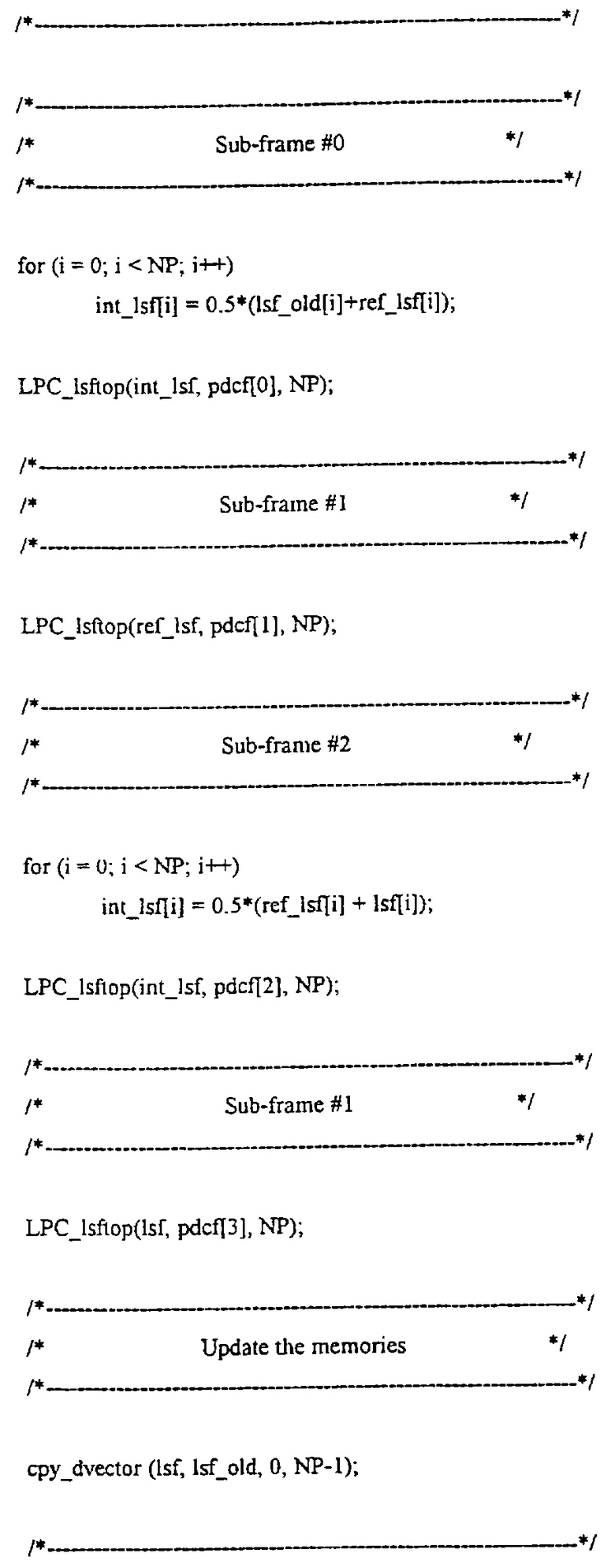






































































































































































































































































































































































































































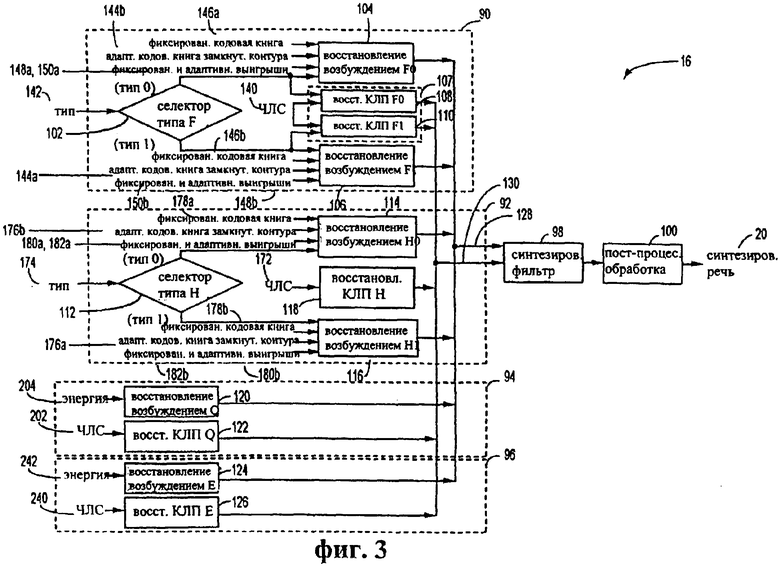


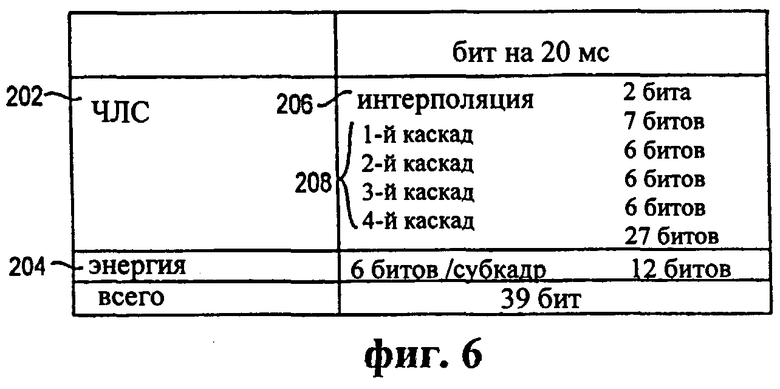
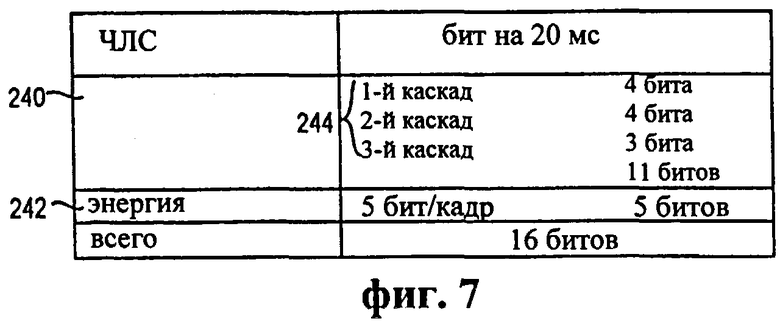





Изобретение относится к системам передачи речи и, более конкретно, к системам для цифрового кодирования речи. Система сжатия речи обеспечивает кодирование речевого сигнала в поток битов для последующего декодирования для генерирования синтезированной речи, которая содержит кодек полной скорости, кодек половинной скорости, кодек одной четверти скорости и кодек одной восьмой скорости, которые селективно активизируются на основе выбора скорости. Кроме того, кодеки полной и половинной скорости селективно активизируются на основе классификации типа. Каждый кодек селективно активизируется для кодирования и декодирования речевого сигнала при различных скоростях передачи в битах, чтобы акцентировать различные аспекты речевого сигнала для повышения общего качества синтезированного речевого сигнала. Техническим результатом, достигаемым при реализации изобретения, является оптимизация ширины полосы, требуемой для потока битов путем компромисса между желательной средней скоростью передачи в битах и перцепционным качеством восстановленной речи. 11 н. и 55 з.п. ф-лы, 12 ил., 9 табл.
65 Способ по п.64, отличающийся тем, что кодирование вклада фиксированной кодовой книги, если выбранная битовая скорость равна половинной скорости, содержит введение высокочастотного шума во множество кодовых книг, введение дополнительных импульсов в кодовые книги, фильтрацию кодовых книг и поиск в кодовых книгах для определения вклада фиксированной кодовой книги.
| US 5911128 А, 08.06.1999 | |||
| RU 97119637 А, 20.09.1999 | |||
| СПОСОБ СЖАТИЯ РЕЧЕВОГО СИГНАЛА ПУТЕМ КОДИРОВАНИЯ С ПЕРЕМЕННОЙ СКОРОСТЬЮ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ, КОДЕР И ДЕКОДЕР | 1993 |
|
RU2107951C1 |
| RU 97115902 А, 10.08.1999 | |||
| Экономайзер | 0 |
|
SU94A1 |
| US 5822370 A, 13.10.1998 | |||
| СПОСОБ СУШКИ ПИЛОМАТЕРИАЛОВ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2004 |
|
RU2280827C2 |

