Область техники, к которой относится изобретение
Настоящее изобретение, в целом, относится к кодированию речевого сигнала в телекоммуникационных системах, в частности к способам и устройствам для управления сглаживанием стационарного фонового шума в таких системах.
Уровень техники
Кодирование речевого сигнала является процессом получения компактного представления голосовых сигналов для эффективной передачи через проводные и беспроводные каналы ограниченной полосы частот и/или запоминания. В настоящее время кодеры речевого сигнала стали неотъемлемыми компонентами в телекоммуникационной и в мультимедийной инфраструктуре. Коммерческие системы, которые зависят от эффективного кодирования речевого сигнала, включают в себя сотовую связь, протокол передачи речи через Интернет (VOIP), проведение видеоконференций, электронные игры, архивирование и цифровой стандарт одновременной передачи речи и данных (DSVD), а также многочисленные игры и мультимедийные приложения на основе ПК.
Являясь непрерывным во времени сигналом, речевой сигнал может быть представлен в цифровом виде посредством процесса выборки и квантования. Выборки речевого сигнала обычно квантуют с использованием либо 16-битового, либо 8-битового квантования. Подобно многим другим сигналам речевой сигнал содержит большое количество информации, которая является либо избыточной (ненулевая взаимная информация между последовательными выборками в сигнале), либо перцепционно нерелевантной (информация, которая является неразличаемой слушателями). Большинству телекоммуникационных кодеров свойственны потери, заключающиеся в том, что синтезированный речевой сигнал перцепционно подобен оригиналу, но может быть физически непохожим на него.
Кодер речевого сигнала преобразует оцифрованный речевой сигнал в закодированное представление, которое обычно передают кадрами. Соответственно, декодер речевого сигнала принимает закодированные кадры и синтезирует восстановленный речевой сигнал.
Многие современные кодеры речевого сигнала принадлежат к большому классу кодеров речевого сигнала, известному как LPC (линейные предиктивные кодеры). Примерами таких кодеров являются: кодеки речи FR, EFR, AMR и AMR-WB 3GPP, кодеки речи EVRC, SMV и EVRC-WB 3GPP2 и различные кодеки ITU-T, такие как G.728, G.723, G.729 и т.д.
Все эти кодеры используют концепцию синтезирующего фильтра в процессе генерации сигнала. Фильтр используют для того, чтобы моделировать кратковременный спектр сигнала, который должен быть воспроизведен, хотя допускают, что вход в фильтр должен обрабатывать все остальные изменения сигнала.
Общим признаком этих моделей синтезирующих фильтров является то, что воспроизводимый сигнал представляют с помощью параметров, определяющих фильтр. Понятие “линейный предиктивный” относится к классу способов, часто используемых для оценки параметров фильтра. Таким образом, воспроизводимый сигнал частично представляют с помощью набора параметров фильтра и частично с помощью сигнала возбуждения, управляющего фильтром.
Преимущество такой концепции кодирования заключается в том, что как фильтр, так и его управляющий сигнал возбуждения могут быть эффективно описаны с помощью относительно малого числа бит.
Один конкретный класс кодеков, основанных на LPC, основан на принципе “анализ через синтез” (AbS). Эти кодеки включают в себя локальную копию декодера в кодере и обнаруживают управляющий сигнал возбуждения синтезирующего фильтра с помощью выбора того сигнала возбуждения среди набора возможных сигналов возбуждения, который максимизирует сходство синтезированного выходного сигнала с исходным речевым сигналом.
Концепция использования такого линейного предиктивного кодирования и, в частности, кодирования AbS, показала, что она работает относительно хорошо для речевых сигналов даже с низкими скоростями передачи данных, например 4-12 Кбит/с. Однако когда пользователь мобильного телефона, использующий такой способ кодирования, молчит, а входной сигнал содержит окружающие звуки, то из-за этого у известных в настоящее время кодеров появляются трудности, чтобы справиться с этой ситуацией, поскольку они оптимизированы для речевых сигналов. Слушатель на другой стороне может легко разозлиться, если знакомые фоновые звуки не могут быть распознаны, поскольку они “плохо обработаны” с помощью кодера.
Так называемое завихрение вызывает одно из самых серьезных ухудшений качества в воспроизведенных фоновых звуках. Это явление случается в сценариях с относительно стационарными фоновыми звуками, таким как звук автомобиля, и вызвано неестественными временными флуктуациями мощности и спектра декодированного сигнала. Эти флуктуации, в свою очередь, вызваны недостаточной оценкой и квантованием коэффициентов синтезирующего фильтра и его сигнала возбуждения. Обычно завихрение становится меньше, когда увеличивается скорость передачи данных кодека.
Завихрение ранее было определено как проблема, и многочисленные ее решения предложены в литературе. Патент США 5632004 [1] раскрывает одно из предложенных решений. В соответствии с этим патентом в течение речевой неактивности параметры фильтра модифицируют посредством фильтрации нижних частот или расширения полосы частот таким образом, что уменьшают спектральные изменения синтезированного фонового звука. Этот способ был дополнительно усовершенствован в патенте США 5579432 [2] таким образом, что описанный способ против завихрения применяют только после обнаруженной стационарности фонового шума.
Патент США 5487087 [3] раскрывает дополнительный способ обращения к проблеме завихрения. Этот способ использует модифицированную схему квантования сигнала, которая соответствует как самому сигналу, так и его временным изменениям. В частности, предусмотрено использование такого квантователя с уменьшенной флуктуацией для параметров фильтра LPC и параметров усиления сигнала в течение периодов речевой неактивности.
Ухудшения качества сигнала, вызванные нежелательными флуктуациями мощности синтезированного сигнала, имеют отношения к другому набору способов. Один из них описан в патенте США 6275798 [4] и также является частью алгоритма работы речевого кодека AMR, описанного в TS 26.090 3GPP [5]. В соответствии с этим раскрытием усиление, по меньшей мере, одной составляющей синтезированного сигнала возбуждения фильтра, фиксированного вклада кодовой книги, адаптивно сглаживают в зависимости от стационарности кратковременного спектра LPC. Этот способ дополнительно исследован в описаниях к патенту EP 1096476 [6] и заявке на патент EP 1688920 [7], в которых операция сглаживания дополнительно включает в себя ограничение усиления, используемого в синтезе сигнала. Родственный способ, используемый в вокодерах LPC, описан в US 5953697 [8]. В соответствии с этим раскрытием усилением сигнала возбуждения синтезирующего фильтра управляют таким образом, что максимальная амплитуда синтезированного речевого сигнала точно достигает огибающую входного речевого сигнала.
Другой класс способов, имеющий отношение к проблеме завихрения, работает как постпроцессор после декодера речевого сигнала. Патент ЕР 0665530 [9] описывает способ, который в течение обнаруженной речевой неактивности заменяет часть выходного декодированного речевого сигнала на отфильтрованный с помощью фильтра низких частот белый шум или подходящий сигнал шума. Подобные подходы взяты в различных публикациях, которые раскрывают родственные способы, заменяющие часть выходного сигнала речевого декодера на отфильтрованный шум.
Масштабируемое или вложенное кодирование, со ссылкой на Фиг.1, является парадигмой кодирования, в которой кодирование выполняют уровнями. Базовый или внутренний уровень кодирует сигнал с низкой скоростью передачи данных, в то время как дополнительные уровни, причем каждый один над другим, обеспечивают некоторое улучшение относительно кодирования, которое выполняют с помощью всех уровней от внутреннего до соответствующего предыдущего уровня. Каждый уровень добавляет некоторую дополнительную скорость передачи данных. Сгенерированный битовый поток является вложенным, означая, что битовый поток кодирования нижнего уровня вложен в битовые потоки верхних уровней. Это свойство делает возможным где-нибудь в передаче или в приемнике удалять биты, принадлежащие верхним уровням. Такой разделенный битовый поток все же может быть декодирован до уровня, биты которого сохранены.
Самым используемым в настоящее время алгоритмом масштабированного сжатия речевого сигнала является логарифмический кодек РСМ принципа A/U G.711 64 Кбит/с. Кодек G.711 с частотой выборки 8 kHz преобразует 12-битовые или 13-битовые линейные выборки PCM в 8-битовые логарифмические выборки. Упорядоченное битовое представление логарифмических выборок предусматривает удаление наименьших значащих битов (LSB) в битовом потоке G.711, делая кодер G.711 практически масштабируемым SNR между 48, 56 и 64 Кбит/с. Это свойство масштабируемости кодека G.711 используют в сетях связи с коммутацией каналов для целей передачи управляющих служебных сигналов в основной полосе. Последним примером использования этого свойства масштабирования G.711 является протокол TFO 3GPP, который дает возможность настройки и передачи широкополосного речевого сигнала через существующие линии связи PCM 64 Кбит/с. Восемь Кбит/с первоначального потока G.711 64 Кбит/с сначала используют для того, чтобы позволить установление вызова услуги широкополосного речевого сигнала без существенного влияния на качество узкополосной услуги. После установления вызова широкополосный речевой сигнал будет использовать 16 Кбит/с из потока G.711 64 Кбит/с. Другими, более старыми, стандартами кодирования речевого сигнала, поддерживающими масштабируемость без обратной связи, являются G.727 (вложенный ADPCM) и до некоторой степени G.722 (ADPCM поддиапазона).
Сравнительно недавним успехом в технологии масштабируемого кодирования речевого сигнала является стандарт MPEG-4, который обеспечивает расширения масштабируемости для MPEG4-CELP. Базовый уровень МРЕ может быть усовершенствован с помощью передачи дополнительной информации о параметрах фильтра или дополнительной информации о параметрах нововведения. Сектор стандартизации Международного союза электросвязи, ITU-T, недавно закончил стандартизацию нового масштабируемого кодека G.729.1, прозванного s G.729.EV. Диапазон скорости передачи данных этого масштабируемого кодека речевого сигнала лежит в интервале от 8 до 32 Кбит/с. Главное применение для этого кодека заключается в следующем: позволить эффективное совместное использование ограниченного ресурса полосы частот в домашних или офисных шлюзах, например, совместно используемой восходящей линии связи 64/128 Кбит/с xDSL между несколькими вызовами VOIP.
Одна из последних тенденций в масштабируемом кодировании речевого сигнала направлена на то, чтобы обеспечить верхние уровни поддержкой для кодирования неречевых аудиосигналов, таких как музыка. В таких кодеках нижние уровни используют простое традиционное кодирование речевого сигнала, например, в соответствии с парадигмой анализа через синтез, известным примером которой является CELP. Так как такое кодирование является очень подходящим только для речевого сигнала, и в меньшей степени для неречевых аудиосигналов, таких как музыка, верхние уровни работают в соответствии с парадигмой кодирования, которую используют в аудиокодеках. В данном случае обычно кодирование верхнего уровня работает относительно ошибки кодирования нижнего уровня.
Другим релевантным способом, касающимся кодеков речевого сигнала, является так называемая компенсация угла наклона спектральной линии, которую выполняют в контексте адаптивной пост фильтрации декодированного речевого сигнала. Проблема, решаемая с помощью этого способа, заключается в том, чтобы компенсировать угол наклона спектральной линии, внесенный кратковременными или формантными постфильтрами. Такие способы являются частью, например, кодека AMR и кодека SMV, и первичной целью являются функциональные характеристики кодека во время продолжительности речевого сигнала, а не его функциональные характеристики фонового шума. Кодек SMV применяет эту компенсацию угла наклона во взвешенной остаточной области до синтезирующей фильтрации, даже не учитывая анализ LPC остатка.
Общим для любых из вышеописанных способов, имеющих отношение к проблеме завихрения, является тот факт, что их необходимо применять таким образом, чтобы они обеспечивали наилучший возможный результат улучшения относительно завихрения без отрицательного влияния на качество воспроизведения речевого сигнала. Следовательно, все эти способы дают преимущества, только если выполнены надлежащие правила, в соответствии с которыми их активируют или деактивируют в зависимости от характеристик восстанавливаемого сигнала. В дальнейшем современные способы против завихрения обсуждены согласно конкретному аспекту того, как ими управлять.
Одна публикация [10] предшествующего уровня техники раскрывает конкретный способ сглаживания шума и специфическое управление им. Управление основано на оценке коэффициента фонового шума в декодированном сигнале, который, в свою очередь, управляет определенными коэффициентами усиления в этом специфическом способе сглаживания. Стоит подчеркнуть, что в отличие от других способов активацией этого способа сглаживания не управляют в ответ на флаг VAD или, например, другую метрику стационарности.
В отличие от описанной выше публикации другая публикация [11] предшествующего уровня техники описывает операцию сглаживания в ответ на некоторый детектор стационарного шума. Специализированный VAD не используется, вместо этого принимают строгое решение в зависимости от измерений параметров LPC (LSF) и флуктуаций энергии, а также от информации об основном тоне. Для того чтобы облегчить проблемы с неправильными классификациями речевых кадров как кадров стационарного шума, к пачкам речевых сигналов добавляют период откладывания.
Другое раскрытие публикации [9] предшествующего уровня техники описывает функцию управления способом сглаживания фонового шума, который работает в ответ на флаг VAD. Для того чтобы препятствовать объявлению речевых кадров как неактивных, период откладывания добавляют к пачкам сигналов, объявленных активными речевыми сигналами, в течение которых сглаживание шума остается неактивным. Чтобы гарантировать плавные переходы из периодов с деактивированным сглаживанием фонового шума в периоды с активированным сглаживанием, сглаживание постепенно активируют до некоторой фиксированной максимальной степени операции сглаживания. Мощность и спектральные характеристики (степень фильтрации верхних частот) сигнала шума, заменяющего части декодированного речевого сигнала, делают адаптивными к оценке уровня фонового шума в декодированном речевом сигнале. Однако степень операции сглаживания, т.е. величина, на которую декодированный речевой сигнал заменяют просто шумом, зависит от решения VAD и никоим образом от анализа характеристик (таких как стационарность или таковых) фонового шума.
Ранее упомянутое раскрытие публикации [4] описывает способ сглаживания параметров для декодера, который предусматривает постепенное сглаживание параметра (усиления) в ответ на смешанный фактор. Смешанный фактор является признаком стационарности восстанавливаемого сигнала и управляет сглаживанием параметров таким образом, что чем большее сглаживание выполняют, тем больше получается обнаруженная стационарность.
Главная проблема с алгоритмом управления сглаживанием в соответствии с вышеупомянутой публикацией [10] состоит в том, что он специально настроен на конкретное устройство сглаживания, описанное в настоящей заявке. Следовательно, не очевидно, в каком случае (и как) он мог бы быть использован в связи с любыми другими способами сглаживания шума. Тот факт, что не используют VAD, вызывает конкретную проблему, заключающуюся в том, что способ выполняет модификации сигнала точно в течение активных частей речевого сигнала, что потенциально ухудшает речевой сигнал или, по меньшей мере, влияет на натуральность его воспроизведения.
Главная проблема с алгоритмами сглаживания в соответствии с [11] и [9] состоит в том, что степень сглаживания фонового шума сильно зависит от характеристик фонового шума, который должен быть аппроксимирован. Например, в публикации [11] предшествующего уровня техники используется обнаружение кадра стационарного шума, в зависимости от чего операцию сглаживания полностью разрешают или запрещают. Подобным образом способ, раскрытый в [9], не имеет возможности управлять способом сглаживания таким образом, чтобы его использовали в меньшей степени в зависимости от характеристик фонового шума. Это означает, что способы могут страдать от неестественных воспроизведений шума для тех типов фонового шума, которые классифицируют как стационарный шум или как неактивный речевой сигнал, несмотря на то, что проявляются свойства, которые не могут быть адекватно смоделированы с помощью использованного способа сглаживания шума.
Главная проблема способа, раскрытого в [4], состоит в том, что он сильно зависит от оценки стационарности, которая принимает во внимание, по меньшей мере, текущий параметр текущего кадра и соответствующий предыдущий параметр. Однако во время исследований, связанных с настоящим изобретением, было обнаружено, стационарность, даже если она полезна, не всегда обеспечивает правильное указание, является ли сглаживание фонового шума желательным или нет. Простая зависимость от показателя стационарности может опять привести к ситуациям, в которых определенные типы шума классифицируют как стационарный шум, даже если они проявляют свойства, которые не могут быть адекватно смоделированы с помощью использованного способа сглаживания шума.
Конкретная проблема, ограничивающая все описанные способы, возникает из того факта, что они являются простыми способами декодера. Вследствие этого факта они имеют концептуальные проблемы оценки характеристик фонового шума с точностью, которая требовалась бы, если операцией сглаживания шума требовалось бы управлять с постепенным разрешением. Однако это было бы необходимо для естественного воспроизведения шума.
Общая проблема всех способов, зависящих от показателя стационарности, состоит в том, что сама стационарность является характеристикой, указывающей на то, сколько статистических характеристик сигнала, как энергия или спектр, остаются постоянными во времени. По этой причине показатели стационарности часто вычисляют с помощью сравнения статистических характеристик данного кадра или подкадра, с характеристиками предшествующего кадра или подкадра. Однако показатели стационарности в меньшей степени обеспечивают указание действительных перцепционных характеристик фонового сигнала. В частности, показатели стационарности не указывают на то, насколько сигнал похож на шум, что, однако, в соответствии с исследованиями, проведенными изобретателями, является существенным параметром для хорошего способа против завихрения.
Таким образом, имеется потребность в способах и устройствах, предназначенных для управления операцией сглаживания фонового шума в сеансах речевой связи в телекоммуникационных системах.
Раскрытие изобретения
Задача настоящего изобретения состоит в том, чтобы предоставить улучшенное качество сеанса речевой связи в телекоммуникационной системе.
Дополнительная задача настоящего изобретения состоит в том, чтобы предоставить возможность улучшенного управления сглаживанием стационарного фонового шума в телекоммуникационной системе.
Эти и другие задачи решают в соответствии с прилагаемой формулой изобретения.
По существу, в способе сглаживания стационарного фонового шума в телекоммуникационном сеансе речевой связи сначала принимают и декодируют S10 сигнал, представляющий сеанс речевой связи, причем упомянутый сигнал содержит как составляющую речевого сигнала, так и составляющую фонового шума. Далее, предоставляют S20 показатель шумовых свойств для сигнала и адаптивно S30 сглаживают составляющую фонового шума на основании предоставленного показателя шумовых свойств.
Преимущества настоящего изобретения заключаются в:
улучшенном качестве сеансов речевой связи в телекоммуникационной системе,
улучшенном качестве восстановления сигналов стационарного фонового шума.
Краткое описание чертежей
Изобретение совместно с его дополнительными задачами и преимуществами может быть лучше всего понято с помощью ссылки на следующее описание, взятое совместно с сопровождающими чертежами, на которых:
Фиг.1 - принципиальная блок-схема масштабируемого речевого и аудиокодека,
Фиг.2 - блок-схема последовательности этапов, иллюстрирующая вариант осуществления способа сглаживания фонового шума в соответствии с настоящим изобретением,
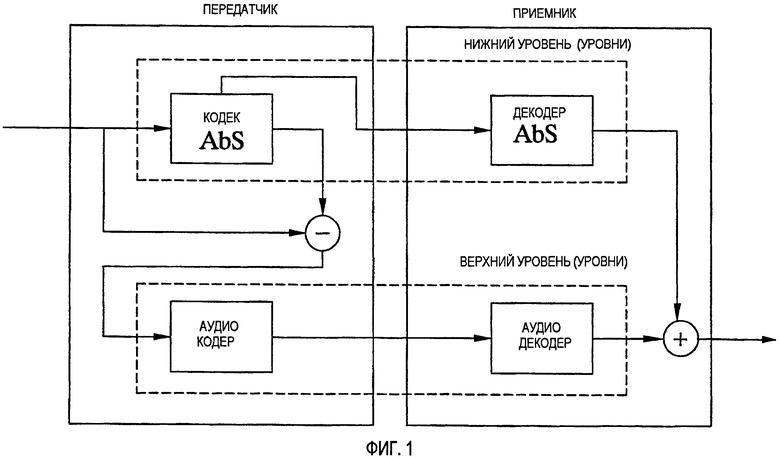
Фиг.3 - схема, иллюстрирующая временную диаграмму способа непрямого управления сглаживанием в соответствии с вариантом осуществления настоящего изобретения,
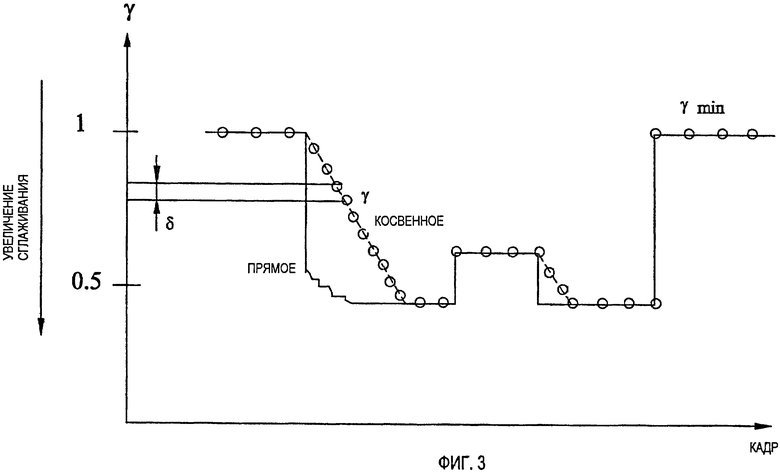
Фиг.4 - схема, иллюстрирующая временную диаграмму активации, управляемой с помощью VAD, сглаживания фонового шума в соответствии с настоящим изобретением,
Фиг.5 - блок-схема последовательности этапов, иллюстрирующая вариант осуществления устройства в соответствии с настоящим изобретением,
Фиг.6 - блок-схема, иллюстрирующая вариант осуществления устройства контроллера в соответствии с настоящим изобретением,
Фиг.7 - блок-схема, иллюстрирующая варианты осуществления устройств в соответствии с настоящим изобретением.
Сокращения
AbS - анализ через синтез
ADPCM - адаптивная дифференциальная импульсно-кодовая модуляция
AMR-WB - адаптивный многоскоростной широкополосный
EVRC-WB - усовершенствованный широкополосный кодек переменной скорости
CELP - линейное предсказание с мультикодовым управлением
DXT - дискретная передача
DSVD - цифровой стандарт одновременной передачи речи и данных
ISP - иммитансная спектральная пара
ITU-T - Международный союз электросвязи
LPC - линейные кодеры с предсказанием
LSF - линейная спектральная частота
MPEG - группа экспертов в области движущихся изображений
PCM - импульсно-кодовая модуляция
SMV - вокодер с возможностью выбора режима
VAD - детектор речевой активности
VOIP - протокол передачи речи через Интернет
Осуществление изобретения
Настоящее изобретение будет описано в контексте беспроводного мобильного сеанса речевой связи. Однако оно также применимо к проводному соединению. Во всем следующем описании термины “речь” и “голос” будут использованы как одинаковые. Таким образом, сеанс речевой связи означает передачу голосового/речевого сигнала, по меньшей мере, между двумя терминалами или узлами в телекоммуникационной сети. Допускают, что сеанс речевой связи всегда должен включать в себя две составляющие, а именно составляющую речевого сигнала и составляющую фонового шума. Составляющая речевого сигнала является действительной речевой связью сеанса, которая может быть активной (например, один человек говорит) и неактивной (например, человек молчит между словами или фразами). Составляющая фонового шума является окружающим шумом из среды, окружающей говорящего человека. Этот шум по характеру может быть более или менее стационарным.
Как было упомянуто ранее, одна проблема с сеансами речевой связи состоит в том, как улучшить качество сеанса речевой связи в среде, включающей в себя стационарный фоновый шум или любой шум в этом отношении. В соответствии с известными способами часто используют различные способы сглаживания фонового шума. Однако имеется риск того, что операция сглаживания фактически уменьшит качество или “возможность прослушивания” сеанса речевой связи за счет искажения составляющей речевого сигнала или за счет добавления помех в имеющийся фоновый шум.
В ходе исследований, лежащих в основе настоящего изобретения, было обнаружено, что сглаживание фонового шума является особенно полезным только для определенных фоновых сигналов, таких как шум автомобиля. Для других типов фоновых шумов, таких как гул, шум в офисе, поздняя реакция и т.д., сглаживание фонового шума не обеспечивает ту же степень улучшений качества в синтезированном сигнале и даже может сделать воспроизведение фонового шума неестественным. Дополнительно было обнаружено, что “шумовые свойства” являются подходящим отличительным признаком, означающим, может ли сглаживание фонового шума обеспечить улучшения качества, или нет. Также было обнаружено, что шумовые свойства являются более подходящим признаком, чем стационарность, которая использована в способах предшествующего уровня техники.
Таким образом, главной целью настоящего изобретения является постепенное управление операцией сглаживания стационарного фонового шума на основании показателя шумовых свойств или метрики фонового сигнала. Если в течение речевой неактивности обнаружено, что фоновый сигнал является очень похожим на шум, тогда используют большую степень сглаживания. Если сигнал неактивности является менее похожим на шум, тогда степень сглаживания шума уменьшают или вовсе не выполняют сглаживание. Показатель шумовых свойств предпочтительно получают в кодере и передают в декодер, в котором управление сглаживанием шума зависит от показателя шумовых свойств. Однако он может быть получен в самом декодере.
По существу, со ссылкой на Фиг.2, общий вариант осуществления в соответствии с настоящим изобретением представляет собой способ сглаживания стационарного фонового шума в телекоммуникационном сеансе речевой связи, по меньшей мере, между двумя терминалами в телекоммуникационной системе. Сначала принимают и декодируют S10 сигнал, представляющий сеанс речевой связи, т.е. обмен речевой информацией, по меньшей мере, между двумя мобильными пользователями, причем сигнал может быть описан как включающий в себя как составляющую речевого сигнала, т.е. фактическую речь, и составляющую фонового шума, т.е. окружающие звуки. Для того чтобы сгладить фоновый шум в течение периодов речевой неактивности, показатель шумовых свойств определяют для сеанса речевой связи и предоставляют S20 для сигнала. Показатель шумовых свойств - это величина, показывающая насколько шумной является составляющая стационарного фонового шума. Затем составляющую фонового шума адаптивно сглаживают S30 или модифицируют на основании предоставленного показателя шумовых свойств. В конечном счете, сигнал, представляющий переданный сигнал, синтезируют со сглаженной таким образом составляющей фонового шума, чтобы улучшить качество принятого сигнала.
В соответствии с дополнительным вариантом осуществления изобретения метрика шумовых свойств показывает, насколько сигнал похож на шум или сколько он содержит случайных составляющих. Более конкретно, показатель или метрика шумовых свойств может быть определена и описана в показателях предсказуемости сигнала, где сигналы с сильными случайными составляющими являются плохо предсказуемыми, в то время как сигналы с более слабой случайной составляющей являются более предсказуемыми. Следовательно, такой показатель шумовых свойств может быть определен посредством широко известного выигрыша предсказания LPC, Gp, сигнала, который определен следующим образом:
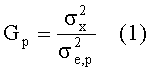
В уравнении 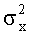 обозначает дисперсию фонового (шума) сигнала, а
обозначает дисперсию фонового (шума) сигнала, а 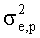 обозначает дисперсию ошибки предсказания LPC этого сигнала, полученную с помощью анализа LPC порядка p. Вместо дисперсии выигрыш предсказания также может быть определен посредством мощности или энергии. Также известно, что дисперсия ошибки предсказания
обозначает дисперсию ошибки предсказания LPC этого сигнала, полученную с помощью анализа LPC порядка p. Вместо дисперсии выигрыш предсказания также может быть определен посредством мощности или энергии. Также известно, что дисперсия ошибки предсказания 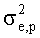 и последовательность дисперсий ошибки предсказания
и последовательность дисперсий ошибки предсказания 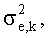 k = 1,…,p-1, без труда получают как побочные результаты алгоритма Левинсона-Дурбина, который используют для вычисления параметров LPC из последовательности параметров автокорреляции сигнала фонового шума. Обычно выигрыш предсказания выше для сигналов со слабой случайной составляющей, в то же время он ниже для сигналов, похожих на шум.
k = 1,…,p-1, без труда получают как побочные результаты алгоритма Левинсона-Дурбина, который используют для вычисления параметров LPC из последовательности параметров автокорреляции сигнала фонового шума. Обычно выигрыш предсказания выше для сигналов со слабой случайной составляющей, в то же время он ниже для сигналов, похожих на шум.
В соответствии с предпочтительным вариантом осуществления настоящего изобретения подходящую подобную метрику шумовых свойств получают с помощью взятия отношения выигрышей предсказания двух фильтров предсказания LPC с разными порядками p и q, где p>q:
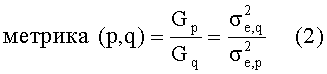
Эта метрика дает указание, насколько увеличивается выигрыш предсказания при увеличении порядка фильтра LTP от q до p. Она дает большое значение, если сигнал имеет низкие шумовые свойства, и значение, близкое к 1, если шумовые свойства являются высокими. Подходящими выборами являются q=2 p=16, хотя также возможны другие значения для порядков LPC.
Следует заметить, что предпочтительно, когда вышеописанную метрику или показатель шумовых свойств определяют или вычисляют на стороне кодера, а затем передают на сторону декодера и предоставляют на стороне декодера. Однако также можно (только с помощью незначительной адаптации) определять или вычислять метрику шумовых свойств на основании фактического принятого сигнала на стороне декодера.
Одно преимущество вычисления метрики на стороне кодера состоит в том, что вычисление может быть основано на неквантованных параметрах LPC и, следовательно, потенциально иметь наилучшее возможное разрешение. Кроме того, вычисление метрики не требует дополнительной вычислительной сложности (как объяснено выше), поскольку требуемые дисперсии ошибки предсказания без труда получают как побочный результат анализа LPC, который обычно выполняют в любом случае. Вычисление метрики в кодере требует, чтобы метрика затем была квантована и чтобы закодированное представление квантованной метрики было передано в декодер, где ее используют для управления сглаживанием фонового шума. Передача параметра шумовых свойств требует некоторой скорости передачи данных, например, 5 бит в кадр длиной 20 ms и, следовательно, 250 бит/с, что может выглядеть как недостаток. Однако учитывая то, что параметр шумовых свойств требуется только в течение периодов речевой неактивности, можно в соответствии со специальным вариантом осуществления пропустить эту передачу в течение активного речевого сигнала и передавать его только в течение неактивности, при которой обычно эта скорость передачи данных может быть доступной, поскольку кодек не требует ту же самую скорость передачи данных, что и в течение активного речевого сигнала. Подобным образом, учитывая специальный случай речевого кодека, который кодирует не звонкие звуки речи и звуки неактивности с помощью некоторого определенного низкоскоростного режима, также можно предоставить возможность этой дополнительной скорости передачи данных без дополнительных затрат.
Однако, как уже было упомянуто, можно получить показатель шумовых свойств на стороне декодера на основании принятых и декодированных параметров LPC. Эти широко известные процедуры увеличения/уменьшения предоставляют способ для вычисления последовательности дисперсий ошибки предсказания из принятых параметров LPC, которые, в свою очередь, как было объяснено выше, могут быть использованы для того, чтобы вычислить показатель шумовых свойств.
Следует подчеркнуть, что в соответствии с экспериментальными результатами показатель шумовых свойств настоящего изобретения является очень выгодным в сочетании со специальным способом сглаживания фонового шума, с которым он быть объединен в исследовании. Однако в сочетании с другими методами противодействия завихрению может быть выгодным объединить этот показатель с показателями стационарности, которые известны из уровня техники. Одним из таких показателей, с которым может быть объединен показатель шумовых свойств, является метрика подобия параметра LPC. Эта метрика оценивает параметры LPC двух последовательных кадров, например, посредством евклидового расстояния между соответствующими векторами параметра LPC, такими как, например, параметры LSF. Эта метрика приводит к большим значениям, если последовательные векторы параметра LPC являются очень разными, и, следовательно, может быть использована как указание стационарности сигнала.
Также следует заметить, что кроме вышеупомянутого концептуального различия между “шумовыми свойствами” настоящего изобретения и “стационарностью” методов уровня техники имеется, по меньшей мере, одно важное отличие между этими показателями. А именно, вычисление стационарности включает в себя получение, по меньшей мере, текущего параметра текущего кадра и получение отношения его, по меньшей мере, к предыдущему параметру некоторого предыдущего кадра. Напротив, шумовые свойства могут быть вычислены как мгновенный показатель в текущем кадре без какого-либо знания некоторого более раннего кадра. Выгодой является то, что может быть сэкономлена память для запоминания состояния из предыдущего кадра.
Следующие варианты осуществления описывают способы, в которых можно управлять способами противодействия завихрению на основании предоставленной оценки шумовых свойств. Допускается, что операцией сглаживания управляют посредством управляющих коэффициентов и, что без ограничения общности, управляющий коэффициент, равный 1, означает отсутствие операции сглаживания, в то время как коэффициент, равный 0, означает сглаживание с максимально возможной степенью.
В соответствии с основным вариантом осуществления предоставленный показатель шумовых свойств непосредственно управляет степенью сглаживания, которую применяют в течение декодирования сигнала фонового шума. Допускается, что степенью сглаживания управляют посредством параметра 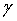 . Затем, например, можно преобразовать показатель шумовых свойств из вышеупомянутого в
. Затем, например, можно преобразовать показатель шумовых свойств из вышеупомянутого в 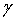 в соответствии со следующим иллюстративным выражением
в соответствии со следующим иллюстративным выражением
γ=Q{(метрика-1)·µ}+ν (3)
Подходящий выбор для ν равен 0,5, а для значения µ - между 0,5 и 2. Также следует заметить, что Q{.} обозначает оператор квантования, который также выполняет ограничение диапазона чисел, такого, что управляющие коэффициенты не могут превышать 1. Дополнительно следует заметить, что предпочтительно коэффициент µ выбирают в зависимости от спектрального содержания входного сигнала. В частности, если кодек является широкополосным кодеком, работающим со скоростью выборки 16 кГц, а входной сигнал имеет широкополосный спектр (0-7 кГц), тогда метрика приведет к относительно меньшим значениям, чем в случае, когда входной сигнал имеет узкополосный спектр (0-3400 Гц). Для того чтобы компенсировать этот эффект, µ должно быть больше для широкополосного содержания, чем для узкополосного содержания. Подходящим выбором является µ=2 для широкополосного содержания и µ=0,5 для узкополосного содержания. Однако возможны другие значения в зависимости от конкретной ситуации. Таким образом, степень операции сглаживания может быть конкретно откалибрована посредством параметра µ в зависимости от того, содержит ли сигнал широкополосное содержание или узкополосное содержание.
Один важный аспект, влияющий на качество восстановленного сигнала фонового шума, состоит в том, что метрика шумовых свойств в течение периодов неактивности может изменяться очень быстро. Если вышеупомянутую меру шумовых свойств используют для того, чтобы непосредственно управлять сглаживанием фонового шума, это может внести нежелательные флуктуации сигнала. В соответствии с дополнительным предпочтительным вариантом осуществления изобретения, со ссылкой на Фиг.3, показатель шумовых свойств используют не для прямого управления сглаживанием фонового шума, а для косвенного управления. Одной возможностью могло бы быть сглаживание показателя шумовых свойств, например, посредством фильтрации нижних частот. Однако это могло бы привести к ситуации, когда могла бы быть применена более сильная степень сглаживания, чем указано с помощью метрики, что, в свою очередь, могло бы повлиять на естественность синтезированного сигнала. Следовательно, предпочтительным принципом является избегать быстрых увеличений степени сглаживания фонового шума и, с другой стороны, допускать быстрые изменения, когда метрика шумовых свойств внезапно указывает меньшую степень подходящего сглаживания. Следующее описание определяет один предпочтительный способ управления степенью сглаживания фонового шума, для того чтобы достичь этого характера изменения. Допускается, что степенью сглаживания управляют посредством параметра γ. В отличие от вышеописанного прямого управления, теперь показатель шумовых свойств управляет параметром косвенного управления γmin в соответствии с
γmin=Q{(метрика-1)·µ}+ν (4)
Затем параметр управления сглаживанием γ устанавливают в максимум между γmin и параметром управления сглаживанием γ', использованным ранее (т.е. в предыдущем кадре), уменьшенный на некоторую величину δ:
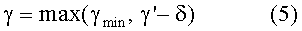
Результат этой операции состоит в том, что γ управляется пошагово до γmin, пока γ еще больше γmin. Иначе он равен γmin. Подходящий выбор для размера шага δ равен 0,05. Описанная операция представлена на Фиг.3.
Исследования, проведенные изобретателями, показали, что сглаживание фонового шума в прямой или косвенной зависимости от предоставленного показателя шумовых свойств может обеспечить улучшения качества восстановленного сигнала фонового шума. Также обнаружено, что важно для качества убедиться, что операцию сглаживания избегают в течение активной речи и что степень сглаживания фонового шума не изменяется слишком часто и слишком быстро.
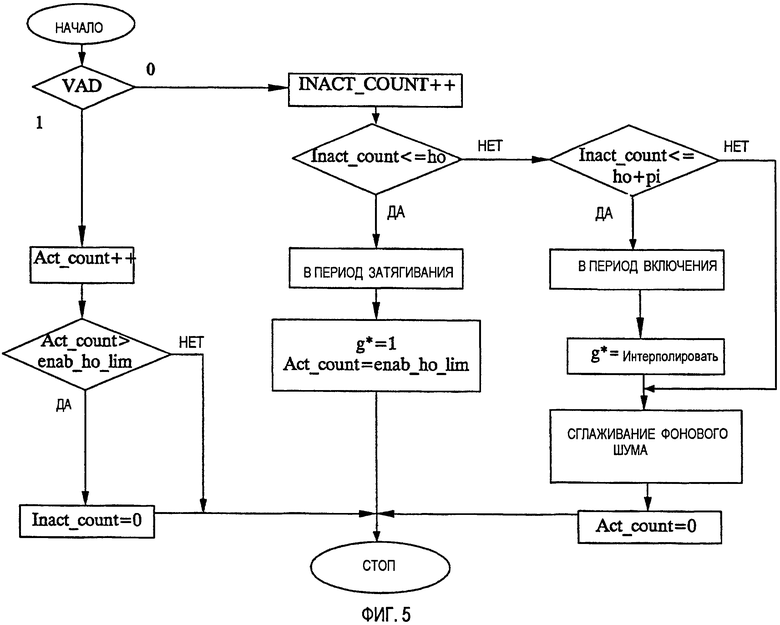
Связанным аспектом является операция обнаружения речевой активности (VAD), которая управляет тем, разрешено ли или нет сглаживание фонового шума. В идеальном случае, VAD должен бы обнаруживать периоды неактивности между активными частями речевого сигнала, в которые разрешено сглаживание фонового шума. Однако в реальности не имеется такого идеального VAD и случается, что части активной речи объявляют неактивными или что неактивные части объявляют активной речью. Для того чтобы обеспечить решение для проблемы, когда активная речь может быть объявлена неактивной, обычной практикой, например при передаче речевого сигнала с помощью дискретной передачи (DTX), является добавлять так называемый период затягивания к сегментам, объявленным активными. Это является средством, которое искусственно увеличивает периоды, объявленные активными, и уменьшает вероятность того, что кадр будет ошибочно объявлен неактивным. Обнаружено, что соответствующий принцип также может быть применен с выгодой в контексте управления операцией сглаживания фонового шума.
В соответствии с предпочтительным вариантом осуществления изобретения, со ссылкой на Фиг.2 и Фиг.6, раскрыт дополнительный этап S25 обнаружения статуса активности составляющей речевого сигнала. Далее операция сглаживания фонового шума является управляемой и инициированной только в ответ на обнаруженную неактивность составляющей речевого сигнала. Кроме того, используют задержку или затягивание, которая означает, что сглаживание фонового шума применимо только к предварительно определенному числу кадров, после которых VAD начинает объявлять кадры неактивными. Подходящим, но не ограничивающим выбором является, например, ждать 5 кадров (=100 ms), после того как VAD начал объявлять кадры неактивными, до разрешения сглаживания шума. Что касается проблемы, когда VAD может объявлять неречевые кадры активными, обнаружено, что лучше выключать операцию сглаживания фонового шума всякий раз, когда VAD объявляет, что кадр является активным, независимо от того, является ли это решение VAD правильным или нет. Кроме того, выгодно немедленно возобновить сглаживание фонового шума, т.е. без откладывания, после ложной активации VAD. Это имеет место, если обнаруженный период активности является только коротким, например, меньшим или равным 3 кадрам (60 ms).
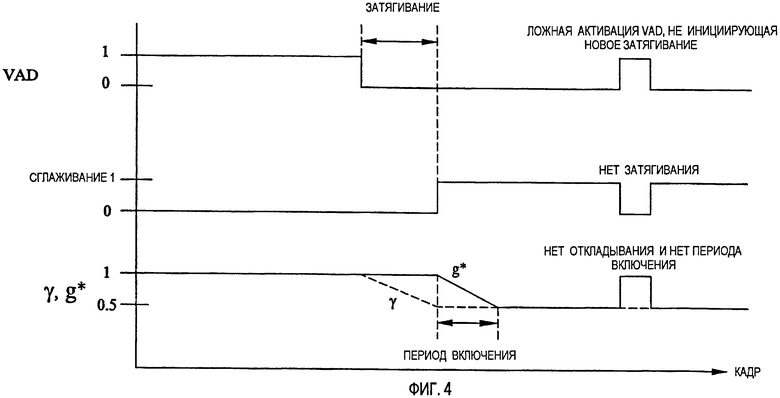
Как было обнаружено, для того чтобы дополнительно улучшить эффективность сглаживания фонового шума, выгодно постепенно давать возможность сглаживания фонового шума после периода затягивания, а не включать ее слишком резко. Для того чтобы выполнить такое постепенное включение, надо определить период включения, в течение которого операцией сглаживания постепенно управляют, начиная с деактивации и до полного включения. Допуская, что период включения равен по длительности К кадрам, и затем допуская, что текущий кадр является n-ым кадром в этом периоде включения, то параметр управления сглаживанием g* для этого кадра получают с помощью интерполяции между его первоначальным значением 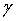 и его величиной, соответствующей деактивации операции сглаживания (
и его величиной, соответствующей деактивации операции сглаживания (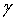
 =1):
=1):
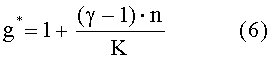
Следует заметить, что выгодно активировать периоды включения только после периодов затягивания, т.е. не после резкой активации VAD.
Фиг.4 иллюстрирует иллюстративную временную диаграмму, указывающую, как параметр управления сглаживанием g* зависит от флага VAD, добавленного откладывания и периодов включения. Кроме того, проиллюстрировано, что сглаживание разрешено только, если VAD равен 0, и после периода откладывания.
Дополнительный вариант осуществления процедуры, осуществляющей описанный способ с активацией, управляемой речевой активностью (VAD), сглаживания фонового шума, проиллюстрирован на блок-схеме последовательности этапов Фиг.5 и объяснен в дальнейшем. Процедуру выполняют для каждого кадра (или подкадра), начиная с начальной точки. Сначала выбирают флаг VAD и, если он имеет значение, равное 1, выполняют маршрут активной речи. В данном маршруте увеличивают счетчик для кадров активной речи (Act_count). Затем проверяют, находится ли счетчик выше предела ложной активации VAD (Act_count>enab_ho_lim) и, если это имеет место, счетчик для неактивных кадров сбрасывают (Inact_count=0), что, в свою очередь, является сигналом, что период откладывания будет добавлен в течение следующего периода неактивности. После этого процедура останавливается.
Однако если флаг VAD имеет значение, равное 0, указывающее неактивность, тогда выполняют маршрут неактивного речевого сигнала. В данном маршруте сначала увеличивают счетчик неактивных кадров (Inact_count). Затем проверяют, меньше или равен этот счетчик пределу затягивания (Inact_count<=ho), в этом случае выполняется маршрут для периода затягивания. В этом случае параметр управления сглаживанием g* устанавливают в 1, что запрещает сглаживание. Кроме того, инициируют счетчик активных кадров с пределом ложной активации VAD (Act_count=enab_ho_lim), что означает, что периоды откладывания все еще не запрещены в случае следующей ложной активации VAD. После этого процедура останавливается. Если счетчик неактивных кадров меньше или равен пределу откладывания, тогда проверяют, меньше или равен счетчик неактивных кадров пределу затягивания плюс предел включения (Inact_count<=ho+pi). Если это имеет место, тогда выполняют обработку периода включения, что означает, что получают параметр управления сглаживанием посредством интерполяции (g*=interpolate), как было описано выше. Иначе, параметр управления сглаживанием шума оставляют немодифицированным. После этого выполняют процедуру сглаживания фонового шума со степенью в соответствии с параметром сглаживания шума. Затем сбрасывают счетчик активных кадров (Act_count=0), что означает, что следующие периоды затягивания запрещены после ложной активации VAD. После этого процедура останавливается.
В зависимости от качества, достигнутого с помощью процедуры сглаживания шума, можно получить улучшения качества не только в течение неактивного речевого сигнала, но также в течение непроизнесенного речевого сигнала, который имеет характер, похожий на шум. Следовательно, в этом случае активация сглаживания фонового шума, управляемая речевой активностью, может извлечь выгоду из расширения, которое активируется в течение не только кадров неактивного речевого сигнала, но также непроизнесенных кадров.
Предпочтительный вариант осуществления изобретения получен с помощью объединения способов с косвенным управлением сглаживания фонового шума и с активацией сглаживания фонового шума, управляемой речевой активностью.
В соответствии с дополнительным вариантом осуществления изобретения в связи с масштабируемым кодеком степень сглаживания обычно уменьшают, если декодирование выполняют с помощью уровня с более высокой скоростью. Это объясняется тем, что кодирование речевого сигнала более высокой скорости обычно имеет меньше проблем завихрения в течение периодов фонового шума.
Особенно выгодный вариант осуществления настоящего изобретения может быть объединен с операцией сглаживания, в которой есть сочетание сглаживания параметра LPC (например, фильтрация нижних частот) и модификации сигнала возбуждения. Вкратце, операция сглаживания содержит этап, на котором принимают и декодируют сигнал, представляющий сеанс речевой связи, причем сигнал содержит как составляющую речевого сигнала, так и составляющую фонового шума. Затем следует этап, на котором определяют параметры LPC и сигнал возбуждения для сигнала. Затем выполняется этап, на котором модифицируют определенный сигнал возбуждения с помощью уменьшения мощности и спектральных флуктуаций сигнала возбуждения, чтобы предоставить сглаженный выходной сигнал. Наконец, следует этап, на котором синтезируют и выводят выходной сигнал на основании определенных параметров LPC и сигнала возбуждения. В сочетании с операцией управления настоящего изобретения предоставляется синтезированный речевой сигнал с улучшенным качеством.
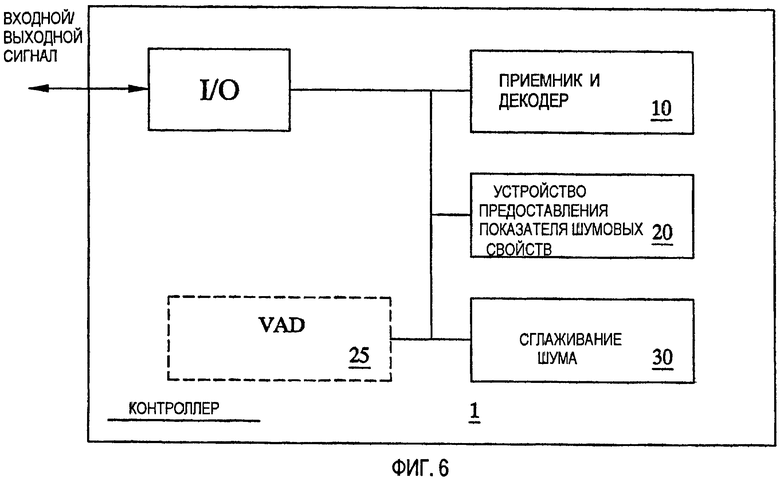
Устройство в соответствии с настоящим изобретением описано ниже со ссылкой на Фиг.6 и Фиг.7. Любые широко известные обычные функциональные возможности передачи/приема и/или кодирования/декодирования, не связанные с конкретными режимами работы настоящего изобретения, неявно раскрыты в обычных устройствах ввода/вывода, I/O, на Фиг.6 и Фиг.7.
На Фиг.6 изображено устройство 1 контроллера, предназначенное для управления сглаживанием составляющих стационарного фонового шума в телекоммуникационных сеансах речевой связи. Контроллер 1 адаптирован для приема и передачи входных/выходных сигналов, связанных с сеансами речевой связи. Таким образом, контроллер 1 содержит общее устройство ввода/вывода, I/O, предназначенное для обработки входящих и выходящих сигналов. Кроме того, контроллер включает в себя устройство 10 приемника и декодера, адаптированное для приема и декодирования сигналов, представляющих сеансы речевой связи, содержащие как составляющие речевого сигнала, так и составляющие фонового шума. Кроме того, устройство 1 включает в себя устройство 20 для предоставления метрики шумовых свойств, относящейся к входному сигналу. Устройство 20 предоставления шумовых свойств, в соответствии с одним вариантом осуществления, может быть адаптировано для фактического определения показателя шумовых свойств на основании принятого сигнала или, в соответствии с дополнительным вариантом осуществления, для приема показателя шумовых свойств из некоторого другого узла в телекоммуникационной системе, предпочтительно из узла или терминала пользователя, откуда пришел принятый сигнал. Кроме того, контроллер 1 включает в себя устройство 30 сглаживания фона, которое дает возможность сглаживать восстановленный речевой сигнал на основании показателя шумовых свойств из устройства 20 показателя шумовых свойств.
В соответствии с дополнительным вариантом осуществления, также со ссылкой на Фиг.6, устройство 1 контроллера включает в себя детектор речевой активности или VAD 25, как указано с помощью пунктирного прямоугольника на чертеже. VAD 25 работает для обнаружения статуса активности речевой составляющей сигнала и предоставления его в качестве дополнительного входного сигнала, чтобы способствовать улучшенному сглаживанию в устройстве 30 сглаживания.
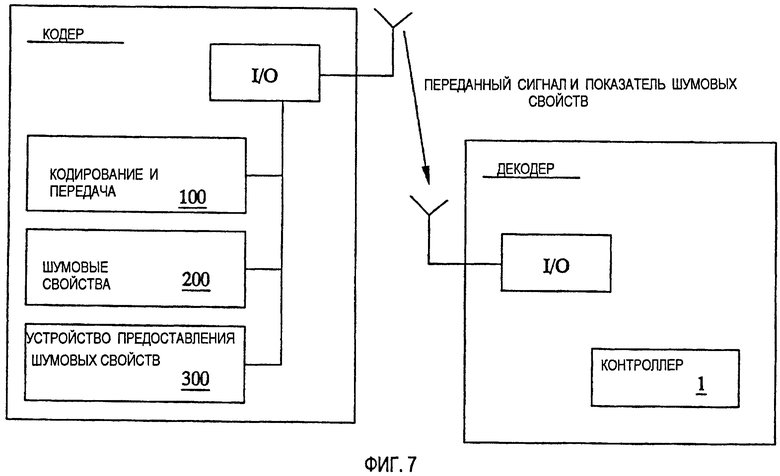
Согласно Фиг.7, устройство 1 контроллера предпочтительно интегрировано в устройство декодера в телекоммуникационной системе. Однако, как описано со ссылкой на Фиг.6, устройство, предназначенное для предоставления показателя шумовых свойств в контроллере 1, может быть адаптировано только принимать показатель шумовых свойств, переданный из другого узла в телекоммуникационной системе. Таким образом, устройство кодера также раскрыто на Фиг.7. Кодер включает в себя общее устройство ввода/вывода, I/O, предназначенное для передачи и приема сигналов. Это устройство неявно раскрывает все необходимые известные функциональные возможности для предоставления возможности кодеру работать. Одна такая функциональная возможность конкретно раскрыта как устройство 100 кодирования и передачи, предназначенное для кодирования и передачи сигналов, представляющих сеанс речевой связи. Кроме того, кодер включает в себя устройство 200, предназначенное для определения показателя шумовых свойств для переданных сигналов, и устройство 300, предназначенное для передачи определенного показателя шумовых свойств в устройство 20 предоставления шумовых свойств контроллера 1.
Преимущества настоящего изобретения включают в себя:
улучшенную операцию сглаживания фонового шума,
улучшенное управление сглаживанием фонового шума.
Специалисты в данной области техники поймут, что различные модификации и изменения могут быть сделаны в настоящем изобретении, не выходя за рамки его объема, которые определены с помощью прилагаемой формулы изобретения.
Литература
[1] Патент США 5632004,
[2] Патент США 5579432,
[3] Патент США 5487087,
[4] Патент США 6275798 В1,
[5] 3GPP TS 26.090, AMR Speech Codec; Transcoding functions
[6] EP 1096476
[7] EP 1688920
[8] Патент США 5953697
[9] EP 665530 B1
[10] Tasaki et al., Post noise smoother to improve low bit rate speech-coding performance, IEEE Workshop on speech coding, 1999,
[11] Ehara et al., Noise Post-Processing Based on Stationary Noise Generator, IEEE Workshop on speech coding, 2002.
Изобретение относится к кодированию речевого сигнала в телекоммуникационных системах, в частности, к способам и устройствам для управления сглаживанием стационарного фонового шума в таких системах. Техническим результатом является улучшение управления операцией сглаживания фонового шума в сеансах речевой связи в телекоммуникационных системах. Указанный результат достигается тем, что в способе сглаживания стационарного фонового шума принимают и декодируют сигнал, представляющий сеанс речевой связи, причем упомянутый сигнал содержит как составляющую речевого сигнала, так и составляющую фонового шума; предоставляют показатель шумовых свойств для упомянутого сигнала, причем упомянутый показатель шумовых свойств указывает предсказуемость сигнала, причем упомянутая предсказуемость определена в показателях выигрыша предсказания линейного предиктивного кодера (LPC) упомянутого сигнала, и адаптивно сглаживают упомянутую составляющую фонового шума в зависимости от предоставленного показателя шумовых свойств. Упомянутой операцией сглаживания управляют с помощью упомянутого показателя шумовых свойств посредством параметра управления сглаживанием, изменяемого постепенно, соответственно обнаруженному увеличению упомянутого показателя шумовых свойств, и изменяемого немедленно, соответственно обнаруженному уменьшению упомянутого показателя шумовых свойств. 4 н. и 18 з.п. ф-лы, 7 ил.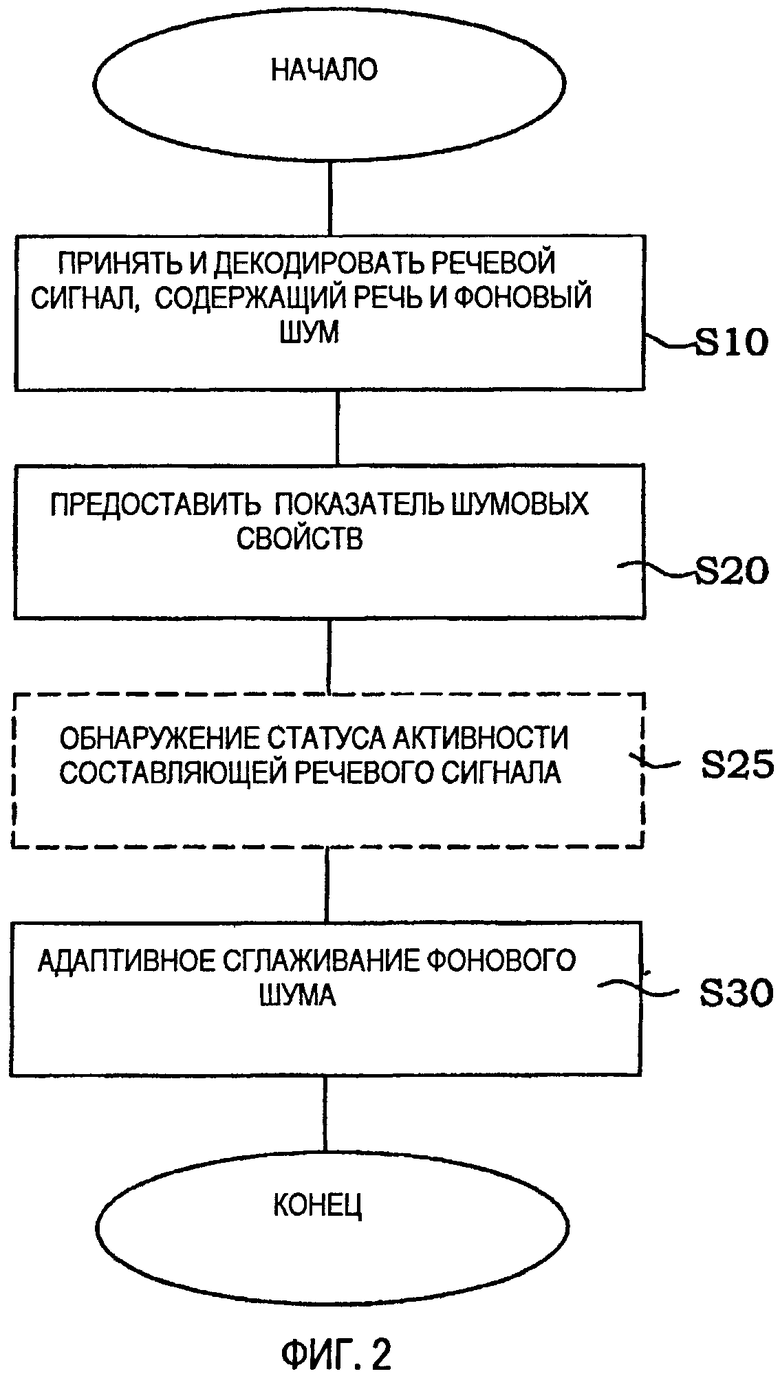
1. Способ сглаживания стационарного фонового шума в телекоммуникационном сеансе речевой связи, содержащий этапы, на которых:
принимают и декодируют сигнал, представляющий сеанс речевой связи, причем упомянутый сигнал содержит как составляющую речевого сигнала, так и составляющую фонового шума;
предоставляют показатель шумовых свойств для упомянутого сигнала, причем упомянутый показатель шумовых свойств указывает предсказуемость сигнала, причем упомянутая предсказуемость определена в показателях выигрыша предсказания линейного предиктивного кодера (LPC) упомянутого сигнала, и
адаптивно сглаживают упомянутую составляющую фонового шума в зависимости от предоставленного показателя шумовых свойств, при этом упомянутой операцией сглаживания управляют с помощью упомянутого показателя шумовых свойств посредством параметра управления сглаживанием, изменяемого постепенно, соответственно обнаруженному увеличению упомянутого показателя шумовых свойств, и изменяемого немедленно, соответственно обнаруженному уменьшению упомянутого показателя шумовых свойств.
2. Способ по п.1, в котором упомянутый показатель шумовых свойств является обратно зависимым от предсказуемости.
3. Способ по п.2, в котором упомянутый показатель шумовых свойств основан на отношении дисперсий ошибки предсказания, связанных с фильтрацией анализа LPC с разными порядками.
4. Способ по п.1, в котором упомянутый показатель шумовых свойств адаптируется в ответ на обнаруженное узкополосное или широкополосное содержание упомянутого входного сигнала.
5. Способ по п.1, в котором упомянутый этап предоставления показателя шумовых свойств выполняется по меньшей мере один раз для каждого кадра упомянутого сигнала.
6. Способ по п.5, в котором упомянутый этап предоставления показателя шумовых свойств выполняется для каждого подкадра каждого упомянутого кадра упомянутого сигнала.
7. Способ по любому из предыдущих пунктов, дополнительно содержащий этап обнаружения статуса активности упомянутой составляющей речевого сигнала и инициирования упомянутого адаптивного сглаживания в ответ на упомянутую составляющую речевого сигнала, имеющую неактивный статус.
8. Способ по п.7, содержащий инициирование упомянутого адаптивного сглаживания с предварительно определенной задержкой в ответ на обнаруженную неактивную составляющую речевого сигнала.
9. Способ по п.8, содержащий возобновление упомянутого сглаживания фонового шума немедленно после ложной активации VAD меньшего, чем предварительно определенное, числа кадров.
10. Способ по п.8, содержащий постепенное инициирование упомянутой операции сглаживания в конце упомянутой задержки.
11. Способ по п.7, содержащий завершение упомянутого адаптивного сглаживания немедленно в ответ на обнаружение активной составляющей речевого сигнала.
12. Контроллер для сглаживания стационарного фонового шума в телекоммуникационном сеансе речевой связи, содержащий:
средство для приема и декодирования сигнала, представляющего сеанс речевой связи, причем упомянутый сигнал содержит как составляющую речевого сигнала, так и составляющую фонового шума;
средство для предоставления показателя шумовых свойств для упомянутого сигнала, причем упомянутый показатель шумовых свойств указывает предсказуемость сигнала, причем упомянутая предсказуемость определена в показателях выигрыша предсказания LPC упомянутого сигнала; и
средство для адаптивного сглаживания упомянутой составляющей фонового шума на основании упомянутого предоставленного показателя шумовых свойств, причем упомянутое средство для сглаживания управляется с помощью упомянутого показателя шумовых свойств посредством параметра управления сглаживанием, изменяемого постепенно, соответственно обнаруженному увеличению упомянутого показателя шумовых свойств, и изменяемого немедленно, соответственно обнаруженному уменьшению упомянутого показателя шумовых свойств.
13. Контроллер по п.12, в котором упомянутое средство для предоставления показателя шумовых свойств выполнено с возможностью приема упомянутого показателя шумовых свойств из узла сети.
14. Контроллер по п.12, в котором упомянутое средство для предоставления выполнено с возможностью получения показателя шумовых свойств на основании принятых и декодированных параметров LPC для упомянутого сигнала.
15. Контроллер по п.12, дополнительно содержащий средство для обнаружения статуса активности упомянутой составляющей речевого сигнала, причем упомянутое средство для сглаживания выполнено с возможностью инициирования упомянутого адаптивного сглаживания в ответ на упомянутую составляющую речевого сигнала, имеющую неактивный статус.
16. Контроллер по п.15, в котором упомянутое средство для сглаживания дополнительно выполнено с возможностью инициирования упомянутого адаптивного сглаживания с предварительно определенной задержкой в ответ на обнаруженную неактивную составляющую речевого сигнала.
17. Контроллер по п.15, в котором упомянутое средство для сглаживания выполнено с возможностью постепенного инициирования упомянутой операции сглаживания в конце упомянутой задержки.
18. Контроллер по п.15, в котором упомянутое средство для сглаживания выполнено с возможностью немедленного завершения упомянутого адаптивного сглаживания в ответ на обнаружение активной составляющей речевого сигнала.
19. Устройство декодера в телекоммуникационной системе, содержащее
средство для приема и декодирования сигнала, представляющего сеанс речевой связи, причем упомянутый сигнал содержит как составляющую речевого сигнала, так и составляющую фонового шума;
средство для предоставления показателя шумовых свойств для упомянутого сигнала, причем упомянутый показатель шумовых свойств указывает предсказуемость сигнала, причем упомянутая предсказуемость определена в показателях выигрыша предсказания LPC упомянутого сигнала; и
средство для адаптивного сглаживания упомянутой составляющей фонового шума на основании упомянутого предоставленного показателя шумовых свойств, причем упомянутое средство для сглаживания управляется с помощью упомянутого показателя шумовых свойств посредством параметра управления сглаживанием, изменяемого постепенно, соответственно обнаруженному увеличению упомянутого показателя шумовых свойств, и изменяемого немедленно, соответственно обнаруженному уменьшению упомянутого показателя шумовых свойств.
20. Устройство декодера по п.19, в котором упомянутое средство для предоставления показателя шумовых свойств выполнено с возможностью приема упомянутого показателя шумовых свойств из узла сети.
21. Устройство декодера по п.19, в котором упомянутое средство для предоставления выполнено с возможностью получения показателя шумовых свойств на основании принятых и декодированных параметров LPC для упомянутого сигнала.
22. Устройство кодера в телекоммуникационной системе, содержащее
средство для кодирования и передачи сигнала, представляющего сеанс речевой связи, в терминал пользователя, причем упомянутый сигнал содержит как составляющую речевого сигнала, так и составляющую фонового шума;
средство для определения показателя шумовых свойств для упомянутого переданного сигнала, причем упомянутый показатель шумовых свойств указывает предсказуемость сигнала, причем упомянутая предсказуемость определена в показателях выигрыша предсказания LPC упомянутого сигнала;
средство для предоставления упомянутого определенного показателя шумовых свойств в упомянутом терминале пользователя.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| WO 00/11659 A1, 02.03.2000 | |||
| US 7124079 B1, 17.10.2006 | |||
| EP 0665530 A1, 02.08.1995 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Перекатываемый затвор для водоемов | 1922 |
|
SU2001A1 |
| US 7020605 B2, 28.03.2006 | |||
| Перекатываемый затвор для водоемов | 1922 |
|
SU2001A1 |
| WO 00/11649 A1, 02.03.2000 | |||
| КОДИРОВАНИЕ РЕЧИ С ФУНКЦИЕЙ ИЗМЕНЕНИЯ КОМФОРТНОГО ШУМА ДЛЯ ПОВЫШЕНИЯ ТОЧНОСТИ ВОСПРОИЗВЕДЕНИЯ | 1999 |
|
RU2237296C2 |
| RU 99114452 A, 10.06.2001. | |||

