РОДСТВЕННЫЕ ЗАЯВКИ
Эта заявка является родственной и испрашивает приоритет по предварительной заявке на выдачу патента США под порядковым № 61/489,629, поданной 24 мая 2011 года, в отношении «Помехоустойчивой классификации режимов кодирования речи» («Noise-Robust Speech Coding Mode Classification»).
ОБЛАСТЬ ТЕХНИКИ
Настоящее раскрытие в целом относится к области обработки речи. Конкретнее, раскрытые конфигурации относятся к помехоустойчивой классификации режимов кодирования речи.
УРОВЕНЬ ТЕХНИКИ
Передача голоса посредством цифровых технологий стала широко распространенной, особенно в применениях дальней связи и цифровых радиотелефонных применениях. Это, в свою очередь, породило заинтересованность в определении минимального количества информации, которое может отправляться по каналу наряду с сохранением воспринимаемого качества реконструированной речи. Если речь передается посредством простой выборки отсчетов и преобразования в цифровую форму, скорость передачи данных порядка 64 килобит в секунду (кбит/с) требуется для достижения качества речи традиционного аналогового телефона. Однако благодаря использованию анализа речи, сопровождаемого надлежащими кодированием, передачей и повторного синтеза в приемнике, может достигаться значительное снижение скорости передачи данных. Чем точнее может выполняться анализ речи, тем уместнее могут кодироваться данные, таким образом, снижая скорость передачи данных.
Устройства, которые используют технологии для сжатия речи посредством извлечения параметров, которые относятся к модели генерации речи человеком, называются речевыми кодерами. Речевой кодер делит входящий речевой сигнал на блоки времени или кадры анализа. Речевые кодеры типично содержат кодер и декодер, или кодек. Кодер анализирует входящий речевой кадр, чтобы извлекать определенные значимые параметры, а затем квантует параметры в двоичное представление, то есть в набор битов или пакет двоичных данных. Пакеты данных передаются по каналу связи в приемник и декодер. Декодер обрабатывает пакеты данных, деквантует их, чтобы вырабатывать параметры, а затем повторно синтезирует речевые кадры с использованием деквантованных параметров.
Современные речевые кодеры могут использовать подход многорежимного кодирования, который классифицирует входные кадры на разные типы согласно различным признакам входной речи. Многорежимные кодеры используют классификацию речевого сигала, чтобы точно захватывать и кодировать высокий процент речевых сегментов с использованием минимального количества битов на кадр. Более точная классификация речи порождает более низкую скорость передачи кодированных битов и более высококачественную декодированную речь. Раньше, технологии классификации речи рассматривали минимальное количество параметров только для изолированных кадров речи, вырабатывая немного и неточные классификации режима речи. Таким образом, есть необходимость в классификаторе речи с высокой производительностью для правильной классификации многочисленных режимов речи в меняющихся условиях окружающей среды, для того чтобы обеспечить максимальную производительность технологий многорежимного кодирования с переменной скоростью передачи данных.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 - структурная схема, иллюстрирующая систему для беспроводной связи;
фиг. 2A - структурная схема, иллюстрирующая систему классификатора, которая может использовать помехоустойчивую классификацию режимов кодирования речи;
фиг. 2B - структурная схема, иллюстрирующая еще одну систему классификатора, которая может использовать помехоустойчивую классификацию режимов кодирования речи;
фиг. 3 - блок-схема последовательности операций способа, иллюстрирующая способ помехоустойчивой классификации речи;
фиг. 4A-4C иллюстрируют конфигурации процесса осуществления выбора режима для помехоустойчивой классификации речи;
фиг. 5 - схема последовательности операций, иллюстрирующая способ для настройки пороговых значений для классификации речи;
фиг. 6 - структурная схема, иллюстрирующая классификатор речи для помехоустойчивой классификации речи;
фиг. 7 - график временной последовательности, иллюстрирующий одну из конфигураций принятого речевого сигнала с ассоциированными значениями параметров и классификациями режимов речи; и
фиг. 8 иллюстрирует некоторые компоненты, которые могут быть включены в электронное устройство/беспроводное устройство.
ПОДРОБНОЕ ОПИСАНИЕ
Функция речевого кодера состоит в том, чтобы сжимать оцифрованный речевой сигнал в сигнал с низкой скоростью передачи битов посредством удаления всех естественных избыточностей, присущих речи. Цифровое сжатие достигается посредством представления входного речевого кадра набором параметров и применения квантования для представления параметров набором битов. Если входной речевой кадр имеет количество Ni битов, а пакет данных, вырабатываемый речевым кодером, имеет количество No битов, коэффициент сжатия, достигаемый речевым кодером, имеет значение Cr=Ni/No. Задача состоит в том, чтобы сохранять высокое качество голоса декодированной речи наряду с достижением целевого коэффициента сжатия. Производительность речевого кодера зависит от (1) того, насколько хороша модель речи, или насколько хорошо работает комбинация последовательности операций анализа и синтеза, описанная выше, и (2) того, насколько хорошо выполняется последовательность операций квантования на целевой скорости передачи битов No битов на кадр. Цель модели речи, таким образом, состоит в том, чтобы зафиксировать отличительные признаки речевого сигнала, или целевое качество голоса, с помощью небольшого набора параметров на каждый кадр.
Речевые кодеры могут быть реализованы в качестве кодеров временной области, которые пытаются захватывать форму речи во временной области, применяя обработку с высоким временным разрешением для кодирования небольших сегментов речи (типично, подкадров по 5 миллисекунд (мс)) во времени. Для каждого подкадра, обнаруживается образец высокой точности из пространства кодового словаря посредством различных алгоритмов поиска. В качестве альтернативы, речевые кодеры могут быть реализованы в качестве кодеров частотной области, которые пытаются захватывать краткосрочный спектр речи входного речевого кадра с набором параметров (аналитическим разложением) и применять соответствующую последовательность операций синтеза для создания формы речи из спектральных параметров. Квантователь параметров сохраняет параметры, представляя их хранимыми представлениями кодовых векторов, в соответствии с технологиями квантования, описанными в А. Гершо и Р. М. Грей, Векторное квантование и сжатие сигналов (1992 год)) (A. Gersho & R.M. Gray, Vector Quantization and Signal Compression (1992)).
Одним из возможных речевых кодеров временной области является кодер для кодирования методом линейного предсказания с кодовым возбуждением (CELP), описанный в Л. Б. Рабинер и Р. В. Шафер, Цифровая обработка речевых сигналов 396-453 (1978 год) (L.B. Rabiner & R.W. Schafer, Digital Processing of Speech Signals 396-453 (1978)), которая полностью включена в материалы настоящей заявки посредством ссылки. В кодере CELP, краткосрочные корреляции или избыточности в речевом сигнале удаляются посредством анализа линейного предсказания (LP), который находит коэффициенты краткосрочного формантного фильтра. Применение фильтра с краткосрочным предсказанием к входящему речевому кадру формирует остаточный сигнал LP, который дополнительно моделируется и квантуется с помощью параметров фильтра с краткосрочным предсказанием и являющегося результатом стохастического кодового словаря. Таким образом, кодирование CELP делит задачу кодирования формы речи во временной области на отдельные задачи кодирования коэффициентов краткосрочного фильтра LP и кодирования остатка LP. Кодирование во временной области может выполняться с постоянной скоростью (то есть с использованием одного и того же количества битов, N0, для каждого кадра) или с переменной скоростью (при которой разные скорости передачи битов используются для разных типов содержимого кадра). Кодеры переменной скорости пытаются использовать количество битов, необходимых для кодирования параметров кодека только до уровня, достаточного для получения целевого качества. Один из возможных кодеров CELP переменной скорости описан в патенте США под № 5,414,796, который переуступлен правопреемнику раскрытых некоторое время спустя конфигураций и полностью включен в материалы настоящей заявки посредством ссылки.
Кодеры временной области, такие как кодер CELP, типично полагаются на большое количество битов, N0, на каждый кадр, чтобы сохранять точность формы речи во временной области. Такие кодеры типично выдают превосходное качество голоса при условии, что количество битов, N0, на каждый кадр является относительно большим (например, 8 кбит/с или выше). Однако на низких скоростях передачи битов (4 кбит/с и ниже), кодеры временной области перестают удерживать высокое качество и устойчивую производительность вследствие ограниченного количества имеющихся в распоряжении битов. На низких скоростях передачи битов, ограниченное пространство кодового словаря ужимает возможности подгонки формы сигнала традиционных кодеров временной области, которые так успешно применяются в коммерческих применениях с более высокими скоростями.
Типично, схемы CELP применяют фильтр с краткосрочным предсказанием (STP) и фильтр с долгосрочным предсказанием (LTP). Подход анализа через синтез (AbS) применяется в кодере, чтобы находить задержки и коэффициенты усиления LTP, а также наилучшие вероятностные коэффициенты усиления и индексы кодового словаря. Современные кодеры CELP последних достижений, такие как усовершенствованный кодер переменной скорости (EVRC), могут добиваться синтезированного речевого сигала с хорошим качеством на скорости передачи данных приблизительно 8 килобит в секунду.
Более того, невокализованная речь не демонстрирует периодичность. Полоса пропускания, расходуемая при кодировании фильтра LTP в традиционных схемах CELP, используется для невокализованной речи не настолько эффективно, как для вокализованной речи, где периодичность речи сильна, и значима фильтрация LTP. Поэтому, в большей степени эффективная схема кодирования (например, с более низкой скоростью передачи битов) желательна для невокализованной речи. Точная классификация речи необходима для выбора наиболее эффективных схем кодирования и достижения низшей скорости передачи данных.
Для кодирования на более низких скоростях передачи битов, были разработаны различные способы спектрального, или в частотной области, кодирования речи, в которых речевой сигнал анализируется в качестве меняющейся во времени оценки спектров. Например, смотрите Р.Дж. Макаулэй и Т.Ф. Куатиери, Синусоидальное кодирование в кодировании и синтезе речи, гл. 4 (под редакцией В.Б. Клейна и К.К. Паливала, 1995 г.) (R.J. McAulay & T.F. Quatieri, Sinusoidal Coding, in Speech Coding and Synthesis ch. 4 (W.B. Kleijn & K.K. Paliwal eds., 1995)). В спектральных кодерах, цель состоит в том, чтобы моделировать или предсказывать краткосрочный спектр речи каждого входного кадра речи набором спектральных параметров вместо того, чтобы точно копировать меняющуюся во времени форму речи. Спектральные параметры затем кодируется и выходной речевой кадр создается с декодированными параметрами. Получающаяся в результате синтезированная речь не совпадает с исходной формой входной речи, но предлагает подобное воспринимаемое качество. Примеры кодеров частотной области включают в себя кодеры с многополосным возбуждением (MBE), кодеры с синусоидальным преобразованием (STC) и гармонические кодеры (HC). Такие кодеры частотной области предлагают высококачественную параметрическую модель, имеющую компактный набор параметров, которые могут точно квантоваться с низким количеством битов, имеющимся в распоряжении на низких скоростях передачи битов.
Тем не менее, кодирование с низкой скоростью передачи битов устанавливает критический сдерживающий фактор ограниченного разрешения кодирования или ограниченного пространства кодового словаря, которые ограничивают эффективность единого механизма кодирования, создавая кодер, не способный представлять различные типы сегментов речи в различных исходных условиях с равной точностью. Например, традиционные кодеры частотной области с низкой скоростью передачи битов не передают информацию о фазе для речевых кадров. Взамен, информация о фазе реконструируется посредством использования случайного, искусственно сформированного значения начальной фазы и технологий линейной интерполяции. Например, смотрите Х. Янг и др., Квадратичная фазовая интерполяция для синтеза вокализованной речи в модели MBE, в журнале по электронике, 29, стр. 856-57 (Май 1993 г.) (H. Yang et al., Quadratic Phase Interpolation for Voiced Speech Synthesis in the MBE Model, in 29 Electronic Letters 856-57 (May 1993)). Так как информация о фазе формируется искусственно, даже если амплитуды синусоид превосходно сохранены посредством последовательности операций квантования-деквантования, выходная речь, вырабатываемая кодером частотной области не выровнена с исходной входной речью (то есть большинство пульсаций не будут синхронными). Поэтому, оказалось трудным перенять какую-нибудь рабочую характеристику с обратной связью, например, такую как отношение сигнал/шум (SNR) или воспринимаемое SNR, в кодерах частотной области.
Одной из эффективных технологий для эффективного кодирования речи на низкой скорости передачи битов является многорежимное кодирование. Технологии многорежимного кодирования применялись для выполнения кодирования речи низкой скорости вместе с последовательностью операций выбора режима без обратной связи. Одна из таких технологий многорежимного кодирования описана в Амитава Даз и др., Многорежимное кодирование речи с переменной скоростью, в Кодирование и синтез речи, глава 7 (под редакцией В.Б. Клейна и К.К. Паливала, 1995 г.) (Amitava Das et al., Multi-mode and Variable-Rate Coding of Speech, in Speech Coding and Synthesis ch. 7 (W.B. Kleijn & K.K. Paliwal eds., 1995)). Традиционные многорежимные кодеры применяют разные режимы, или алгоритмы кодирования-декодирования, к разным типам входных речевых кадров. Каждый режим, или последовательность операций кодирования-декодирования, настраивается в соответствии с индивидуальными требованиями, чтобы представлять определенный тип сегмента речи, например, такой как вокализованная речь, невокализованная речь или фоновый шум (отсутствие речи) наиболее эффективным образом. Успех таких технологий многорежимного кодирования является сильно зависимым от правильного выбора режимов или классификаций речи. Внешний механизм выбора режима без обратной связи исследует входной речевой кадр и принимает решение касательно того, какой режим применять к кадру. Выбор режима без обратной связи типично выполняется посредством извлечения некоторого количества параметров из входного кадра, оценки параметров в отношении определенных временных и спектральных характеристик, и базирования выбора режима на оценке. Выбор режима, таким образом, осуществляется без заблаговременного знания точного состояния выходной речи, то есть насколько близким будет выходная речь к входной речи с точки зрения качества или других характеристик. Один из возможных выборов режима без обратной связи для речевого кодека описан в патенте США под № 5414796, который переуступлен правопреемнику настоящего изобретения и полностью включен в материалы настоящей заявки посредством ссылки.
Многорежимное кодирование может происходить с постоянной скоростью, используя одинаковое количество битов, N0, для каждого кадра, или с переменной скоростью, при которой разные скорости передачи битов используются для разных режимов. Цель кодирования с переменной скоростью состоит в том, чтобы использовать количество битов, необходимых для кодирования параметров кодека только до уровня, достаточного для получения целевого качества. Как результат, такое же целевое качество голоса, как у кодека постоянной скорости с более высокой скоростью, может получаться на значительно более низкой средней скорости с использованием технологий с переменной скоростью передачи битов (VBR). Один из возможных речевых кодеров переменной скорости описан в патенте США под № 5414796. В настоящее время есть всплеск изыскательского интереса и мощная коммерческая потребность в том, чтобы разработать высококачественный речевой кодер, работающий на от средних до низких скоростях передачи битов (то есть в диапазоне от 2,4 до 4 кбит/с и ниже). Области применения включают в себя беспроводную телефонию, спутниковую связь, интернет-телефонию, различные мультимедийные и применения и применения потоковой передачи голоса, голосовую почту и другие системы хранения голоса. Движущими силами являются необходимость высокой пропускной способности и потребность в надежном функционировании в ситуациях потери пакетов. Различные недавние усилия по стандартизации кодирования речи являются еще одной непосредственной движущей силой, стимулирующей опытно-конструкторские работы по алгоритмам кодирования речи низкой скорости. Речевой кодер низкой скорости создает большее количество каналов, или пользователей, для допустимой прикладной полосы пропускания. Речевой кодер низкой скорости, соединенный с дополнительным уровнем подходящего канального кодирования, может соответствовать общему битовому запасу по техническим условиям кодера и давать устойчивую производительность в условиях ошибок в канале.
Многорежимное кодирование речи VBR поэтому является эффективным механизмом для кодирования речи на низкой битовой скорости. Традиционные многорежимные схемы требуют разработки эффективных схем кодирования, или режимов, для различных сегментов речи (например, невокализованного, вокализованного, переходного), а также режима для фонового шума или молчания. Общая производительность речевого кодера зависит от устойчивости к внешним воздействиям классификации режимов и того, насколько хорошо работает каждый режим. Средняя скорость кодера зависит от скоростей передачи битов разных режимов для невокализованных, вокализованных и других сегментов речи. Для того чтобы добиваться целевого качества на низкой средней скорости, необходимо правильно определять режим речи в меняющихся условиях. Типично, вокализованные и невокализованные сегменты речи захватываются на высоких скоростях передачи битов, а сегменты фонового шума или молчания представляются режимами, работающими на значительно более низкой скорости. Многорежимные кодеры требуют правильной классификации речевого сигала, чтобы точно захватывать и кодировать высокий процент речевых сегментов с использованием минимального количества битов на кадр. Более точная классификация речи порождает более низкую скорость передачи кодированных битов и более высококачественную декодированную речь.
Другими словами, при управляемом источником кодировании с переменной скоростью, производительность этого классификатора кадров определяет среднюю скорость передачи битов на основании признаков входной речи (энергии, вокализованности, спектрального наклона, контура основного тона, и т. д.). Производительность классификатора речи может ухудшаться, когда входная речь искажена шумом. Это может вызывать нежелательные воздействия на качество и скорость передачи битов. Соответственно, способы для выявления присутствия шума и соответственной настройки логики классификации могут использоваться для обеспечения надежной работы в случаях использования в реальных условиях работы. Более того, технологии классификации речи раньше учитывали минимальное количество параметров только для изолированных кадров речи, вырабатывая немного и неточные классификации режимов речи. Таким образом, есть необходимость в классификаторе речи с высокой производительностью для правильной классификации многочисленных режимов речи в меняющихся условиях окружающей среды, для того чтобы обеспечить максимальную производительность технологий многорежимного кодирования с переменной скоростью передачи данных.
Раскрытые конфигурации предусматривают способ и устройство для улучшенной классификации речи в применениях вокодера. Параметры классификации могут анализироваться для создания классификаций речи с относительно высокой точностью. Последовательность операций осуществления выбора используется для классификации речи на основе кадр за кадром. Параметры, выведенные из исходного входной речи, могут использоваться основанным на состоянии принимающим решение, чтобы точно классифицировать различные режимы речи. Каждый кадр речи может классифицироваться посредством анализа прошлых и будущих кадров, а также текущего кадра. Режимы речи, которые могут классифицироваться раскрытыми конфигурациями, содержат по меньшей мере переход, переходы в активную речь и на конце слов, вокализованный, невокализованный и молчание.
Для того чтобы гарантировать устойчивость логики классификации, настоящие системы и способы могут использовать показатель оценки фонового шума по многочисленным кадрам (который типично выдается стандартными расположенными выше по потоку компонентами кодирования речи, такими как детектор голосовой активности) и настраивать логику классификации на основании этого. В качестве альтернативы, SNR может использоваться логикой классификации, если оно включает в себя информацию о более чем одном кадрах, например, если оно усредняется по многочисленным кадрам. Другими словами, любая оценка шума, которая относительно устойчива на протяжении многочисленных кадров, может использоваться логикой классификации. Настройка логики классификации может включать в себя изменение одного или более пороговых значений, используемых для классификации речи. Более точно, энергетический порог для классификации кадра в качестве «невокализованного» может повышаться (отражая высокий уровень кадров «молчания»), пороговое значение вокализованности для классификации кадра в качестве «невокализованного» может повышаться (отражая искажение информации о вокализованности в силу шума), пороговое значение вокализованности для классификации кадра в качестве «вокализованного» может снижаться (вновь отражая искажение информации о вокализованности), или некоторая комбинация этого. В случае, когда шум отсутствует, изменения могут не вноситься в логику классификации. В одной из конфигураций с высоким шумом (например, SNR 20 дБ, типично, низшим SNR, проверяемым при стандартизации речевых кодеков), энергетический порог невокализованного сигнала может повышаться на 10 дБ, пороговое значение вокализованности для невокализованного сигнала может повышаться на 0,06, а пороговое значение вокализованности для вокализованного сигнала может понижаться на 0,2. В этой конфигурации, случаи с промежуточным шумом могут обрабатываться посредством интерполяции между «чистыми» и «шумными» регулировками на основании показателя входного шума или с использованием жесткого порогового значения, установленного для некоторого промежуточного уровня шумов.
Фиг. 1 - структурная схема, иллюстрирующая систему 100 для беспроводной связи В системе 100, первый кодер 110 принимает оцифрованные отсчеты s(n) речи и кодирует отсчеты s(n) для передачи в среде 112 передачи, или канале 112 связи, в первый декодер 114. Декодер 114 декодирует кодированные отсчеты речи и синтезирует выходной речевой сигнал sSYNTH(n). Для передачи в противоположном направлении, второй кодер 116 кодирует оцифрованные отсчеты s(n) речи, которые передаются по каналу 118 связи. Второй декодер 120 принимает и декодирует кодированные отсчеты речи, формируя синтезированный выходной речевой сигнал sSYNTH(n).
Отсчеты речи, s(n), представляют собой речевые сигналы, которые были оцифрованы и квантованы в соответствии с любым из различных способов, в том числе, например, импульсно-кодовой модуляции (PCM), µ-закономерности с компандированием или A-закономерности. В одной из конфигураций, отсчеты речи, s(n), организованы в кадры входных данных, при этом каждый кадр содержит предварительно определенное количество оцифрованных отсчетов s(n) речи. В одной из конфигураций, применяется частота выборки отсчетов 8 кГц, причем, каждый кадр 20 мс содержит 160 отсчетов. В конфигурациях, описанных ниже, скорость передачи данных может меняться, на основе от кадра к кадру, с 8 кбит/с (полной скорости) до 4 кбит/с (половинной скорости), до 2 кбит/с (четвертичной скорости), до 1 кбит/с (восьмеричной скорости). В качестве альтернативы, могут использоваться другие скорости передачи данных. В качестве используемых в материалах настоящей заявки, термины «полная скорость» или «высокая скорость», в целом обозначают скорости передачи данных, которые являются большими чем или равными 8 кбит/с, а термины «половинная скорость» или «низкая скорость» в целом обозначают скорости передачи данных, которые являются меньшими чем или равными 4 кбит/с. Изменение скорости передачи данных является благоприятным, так как более низкие битовые скорости могут избирательно использоваться для кадров, содержащих в себе относительно меньшее количество речевой информации. Несмотря на то, что специфичные скорости описаны в материалах настоящей заявки, любые пригодные частоты выборки отсчетов, размеры кадра и скорости передачи данных могут использоваться с настоящими системами и способами.
Первый кодер 110 и второй декодер 120 вместе могут составлять первый речевой кодер или речевой кодек. Подобным образом, второй кодер 116 и первый декодер 114 вместе составляют второй речевой кодер. Речевые кодеры могут быть реализованы цифровым сигнальным процессором, (DSP), специализированной интегральной схемой (ASIC), дискретной вентильной логикой, встроенными программами или любым традиционным программируемым модулем программного обеспечения или микропроцессором. Модуль программного обеспечения мог бы находиться в памяти RAM, флэш-памяти, регистрах или любой другой форме записываемого запоминающего носителя. В качестве альтернативы, традиционные процессор, контроллер или конечный автомат могли бы быть заменены на микропроцессор. Возможные ASIC, спроектированные специально для кодирования речи, описаны в патентах США под №№ 5727123 и 5784532, переуступленных правопреемнику настоящего изобретения и полностью включены в материалы настоящей заявки посредством ссылки.
В качестве примера, без ограничения, речевой кодер может находиться в беспроводном устройстве связи. В качестве используемого в материалах настоящей заявки, термин «беспроводное устройство связи» обозначает электронное устройство, которое может использоваться для передачи голоса и/или данных через систему беспроводной связи. Примеры беспроводных устройств связи включают в себя сотовые телефоны, персональные цифровые секретари (PDA), карманные устройства, беспроводные модемы, дорожные компьютеры, персональные компьютеры, планшеты, и т.д. Беспроводное устройство связи, в качестве альтернативы, может обозначаться как терминал доступа, мобильный терминал, мобильная станция, удаленная станция, пользовательский терминал, терминал, абонентский блок, абонентская станция, мобильное устройство, беспроводное устройство, пользовательское оборудование (UE) или некоторая другая подобная терминология.
Фиг. 2A - структурная схема, иллюстрирующая систему 200a классификатора, которая может использовать помехоустойчивую классификацию режимов кодирования речи. Система 200a классификатора по фиг. 2A может находиться в кодерах, проиллюстрированных на фиг. 1. В еще одной конфигурации, система 200a классификатора может быть отдельно стоящей, выдающей выходной сигнал 246a режима классификации речи в устройства, такие как кодеры, проиллюстрированные на фиг. 1.
На фиг. 2A входная речь 212a выдается в шумоподавитель 202. Входная речь 212a может формироваться посредством аналого-цифрового преобразования голосового сигнала. Шумоподавитель 202 отфильтровывает шумовые составляющие из входной речи 212a, создавая подвергнутый шумоподавлению выходной речевой сигнал 214a. В одной из конфигураций, устройство классификации речи по фиг. 2A может использовать усовершенствованный КОДЕК переменной скорости (EVRC). Как показано, эта конфигурация может включать в себя встроенный шумоподавитель 202, который определяет оценку 216a шума и информацию 218 об SNR.
Оценка 216a шума и выходной речевой сигнал 214a могут вводиться в классификатор 210a речи. Выходной речевой сигнал 214a шумоподавителя 202 также может вводиться в детектор 204a голосовой активности, анализатор 206a LPC и блок 208a оценки основного тона без обратной связи. Оценка 216a шума также может подаваться в детектор 204a голосовой активности с информацией 218 о SNR из шумоподавителя 202. Оценка 216a шума может использоваться классификатором 210a речи, чтобы устанавливать пороговые значения периодичности и проводить различие между чистой и зашумленной речью.
Один из возможных способов для классификации речи состоит в том, чтобы использовать информацию 218 о SNR. Однако классификатор 210a речи настоящих систем и способов может использовать оценку 216a шума вместо информации 218 о SNR. В качестве альтернативы, информация 218 о SNR может использоваться, если она является относительно устойчивой на многочисленных кадрах, например, метрикой, которая включает в себя информацию 218 о SNR для многочисленных кадров. Оценка 216a шума может быть относительно долгосрочным индикатором шума, заключенного во входном речевом сигнале. Оценка 216a шума в дальнейшем обозначается как ns_est. Выходная речь 214a в дальнейшем обозначается как ns_est. Если, в одной из конфигураций, шумоподавитель 202 отсутствует, или выключен, оценка 216a шума, ns_est, может быть предварительно установлена в значение по умолчанию.
Одно из преимуществ использования оценки 216a шума вместо информации 218 о SNR состоит в том, что оценка шума может быть относительно устойчивой на основе кадр за кадром. Оценка 216a шума является оценивающей только уровень фонового шума, который имеет тенденцию быть относительно постоянным в течение длительных периодов времени. В одной из конфигураций, оценка 216a шума может использоваться для определения SNR 218 для конкретного кадра. В противоположность, SNR 218 может быть покадровым показателем, который может включать в себя относительно большие качания амплитуды в зависимости от мгновенной энергии голоса, например, SNR может раскачиваться на многие дБ между кадрами молчания и кадрами активной речи. Поэтому, если информация 218 о SNR используется для классификации, она может усредняться на более чем одном кадре входной речи 212a. Относительная устойчивость оценки 216a шума может быть полезной при проведении различия ситуаций высокого шума от просто безмолвных кадров. Даже при нулевом шуме, SNR 218 по-прежнему может быть очень низким в кадрах, где говорящий не является разговаривающим, и значит, логика выбора режима, использующая информацию 218 о SNR, может вводиться в действие в таких кадрах. Оценка 216a шума может быть относительно постоянной, если окружающие шумовые условия не изменяются, тем самым избегая проблем.
Детектор 204a голосовой активности может выводить информацию 220a о голосовой активности для текущего речевого кадра в классификатор 210a речи, например, на основании выходной речи 214a, оценки 216a шума и информации 218 о SNR. Выходной сигнал 220a информации о голосовой активности указывает, является ли текущая речь активной или неактивной. В одной из конфигураций, выходной сигнал 220a информации о голосовой активности может быть двоичным, то есть активным или неактивным. В еще одной конфигурации, выходной сигнал 220a информации о голосовой активности может быть многозначным. Параметр 220a информации о голосовой активности в материалах настоящей заявки обозначается как vad.
Анализатор 206a LPC выводит коэффициенты 222a отражения LPC для текущей выходной речи в классификатор 210a речи. Анализатор 206a LPC также может выводить другие параметры, такие как коэффициенты LPC (не показанные). Параметр 222a коэффициентов отражения LPC в материалах настоящей заявки обозначается как refl.
Блок 208a оценки основного тона без обратной связи выводит значение 224a нормированной функции коэффициентов автокорреляции (NACF) и значения 226a NACF около основного тона в классификатор 210a речи. Параметр 224a NACF в дальнейшем обозначается как nacf, а параметр 226a NACF около основного тона в дальнейшем обозначается как nacf_at_pitch. В большей степени периодический речевой сигнал дает более высокое значение nacf_at_pitch 226a. Более высокое значение nacf_at_pitch 226a более вероятно должен быть ассоциирован со стационарным типом голосовой выходной речи. Классификатор 210a речи поддерживает массив значений 226a nacf_at_pitch, которые могут вычисляться на основе подкадра. В одной из конфигураций, две оценки основного тона без обратной связи измеряются для каждого кадра выходной речи 214a посредством измерения двух подкадров за кадр. NACF около основного тона (nacf_at_pitch), 226a, может вычисляться из оценки основного тона без обратной связи для каждого подкадра. В одной из конфигураций, пятимерный массив значений 226a nacf_at_pitch (то есть nacf_at_pitch[4]) содержит в себе значения для двух с половиной кадров выходной речи 214a. Массив nacf_at_pitch обновляется для каждого кадра выходной речи 214a. Использование массива для параметра 226a nacf_at_pitch снабжает классификатор 210a речи способностью использовать информацию о текущем, прошлом и предстоящем (будущем) сигнале, чтобы осуществлять более точный и помехоустойчивый выбор режимов речи.
В дополнение к информации, введенной в классификатор 210a речи из внешних компонентов, классификатор 210a речи внутренне формирует выведенные параметры 282a из выходной речи 214a для использования в последовательности операций осуществления выбора режима речи.
В одной из конфигураций, классификатор 210a речи внутренне формирует параметр 228a скорости пересечения нуля, в дальнейшем обозначаемый как zcr. Параметр 228a zcr текущей выходной речи 214a определяется в качестве количества изменений знака в речевом сигнале за кадр речи. В вокализованной речи, значение 228a zcr является низким, тогда как невокализованная речь (или шум) имеет высокое значение 228a zcr, так как сигнал является сильно случайным. Параметр 228a zcr используется классификатором 210a речи для классификации вокализованной и невокализованной речи.
В одной из конфигураций, классификатор 210a речи внутренне формирует параметр 230a энергии текущего кадра, в дальнейшем обозначаемый как E. E 230a может использоваться классификатором 210a речи, чтобы идентифицировать переходную речь посредством сравнения энергии в текущем кадре с энергией в прошлом и будущем кадрах. Параметр vEprev является энергией предыдущего кадра, выведенным из E 230a.
В одной из конфигураций, классификатор 210a речи внутренне формирует параметр 232a энергии предстоящего кадра, в дальнейшем обозначаемый как Enext. Enext 232a может содержать значения энергии из части текущего кадра и части следующего кадра выходной речи. В одной из конфигураций, Enext 232a представляет энергию во второй половине текущего кадра и энергию в первой половине следующего кадра выходной речи. Enext 232a используется классификатором 210a речи для идентификации переходной речи. В конце речи, энергия следующего кадра 232a значительно падает по сравнению с энергией текущего кадра 230a. Классификатор 210a речи может сравнивать энергию текущего кадра 230a и энергию следующего кадра 232a, чтобы идентифицировать условия конца речи и начала речи, или переходный с повышением и переходный с понижением режимы речи.
В одной из конфигураций, классификатор 210a речи внутренне формирует параметр 234a отношения энергии полос, определенный в качестве log2(EL/EH), где EL - энергия текущего кадра в нижней полосе 0 до 2 кГц, а EH - энергия текущего кадра в верхней полосе от 2 кГц до 4 кГц. Параметр 234a отношения энергии полос в дальнейшем обозначается как bER. Параметр bER 234a предоставляет классификатору 210a речи возможность идентифицировать режимы вокализованной речи и невокализованной речи, так как вообще, вокализованная речь сосредотачивает энергию в нижней полосе, тогда как зашумленная невокализованная речь сосредотачивает энергию в верхней полосе.
В одной из конфигураций, классификатор 210a речи внутренне формирует параметр 236a усредненной по трем вокализованным кадрам энергии из выходной речи 214a, в дальнейшем обозначаемого как vEav. В других конфигурациях, vEav 236a может усредняться по количеству кадров, иному чем три. Если текущий режим речи является активным и вокализованным, vEav 236a рассчитывает скользящее среднее энергии в последних трех кадрах выходной речи. Усреднение энергии в последних трех кадрах выходной речи снабжает классификатор 210a речи более устойчивыми статистическими данными, на которых следует основывать выборы режима речи, чем только расчеты энергии одиночного кадра. vEav 236a используется классификатором 210a речи для классификации конца вокализованной речи или переходного с понижением режима, в то время как энергия 230a текущего кадра, E, будет значительно падать по сравнению со средней энергией 236a голоса, vEav, когда речь прекращается. vEav 236a обновляется, только если текущий кадр является вокализованным, или сбрасывается в постоянное значение для невокализованной или неактивной речи. В одной из конфигураций, постоянным значением сброса является 0,01.
В одной из конфигураций, классификатор 210a речи внутренне формирует параметр 238a усредненной по трем предыдущим вокализованным кадрам энергии, в дальнейшем обозначаемый как vEprev. В других конфигурациях, vEprev 238a может усредняться по количеству кадров, иному чем три. vEprev 238a используется классификатором 210a речи для идентификации переходной речи. В начале речи, энергия текущего кадра 230a значительно повышается по сравнению со средней энергией предыдущих трех вокализованных кадров 238a. Классификатор 210 речи может сравнивать энергию текущего кадра, 230a, и энергию предыдущих трех кадров, 238a, для идентификации условий начала речи или переходного с повышением режима речи. Подобным образом, в конце вокализованной речи, энергия текущего кадра 230a значительно уменьшается. Таким образом, vEprev 238a также может использоваться для классификации перехода в конце речи.
В одной из конфигураций, классификатор 210a речи внутренне формирует параметр 240a отношения энергии текущего кадра к усредненной по трем предыдущим вокализованным кадрам энергии, определяемый в качестве 10*logl0(E/vEprev). В других конфигурациях, vEprev 238a может усредняться по количеству кадров, иному чем три. Параметр 240a отношения энергии текущего кадра к усредненной по трем предыдущим вокализованным кадрам энергии в дальнейшем обозначается как vER. vER 240a используется классификатором 210a речи для классификации начала вокализованной речи и конца вокализованной речи, или переходного с повышением режима и переходного с понижением режима, так как vER 240a велик, когда речь снова останавливается, и мал в конце вокализованной речи. Параметр vER 240a может использоваться вместе с параметром vEprev 238a при классификации переходной речи.
В одной из конфигураций, классификатор 210a речи внутренне формирует параметр 242a отношения энергии текущего кадра к усредненной по трем вокализованным кадрам энергии, определенный в качестве MIN(20,10*log10(E/vEav)). Отношение 242a энергии текущего кадра к усредненной по трем вокализованным кадрам энергии в дальнейшем обозначается как vER2. vER2 242a используется классификатором 210a речи для классификации переходных голосовых режимов в конце вокализованной речи.
В одной из конфигураций, классификатор 210a речи внутренне формирует параметр 244a индекса максимальной энергии подкадра. Классификатор 210a речи поровну делит текущий кадр выходной речи 214a на подкадры и вычисляет среднеквадратическое (RMS) значение энергии каждого подкадра. В одной из конфигураций, текущий кадр делится на десять подкадров. Параметр индекса максимальной энергии подкадра является индексом подкадра, который имеет наибольшее среднеквадратическое значение энергии в текущем кадре, или во второй половине текущего кадра. Параметр 244a индекса максимальной энергии подкадра в дальнейшем обозначается как maxsfe_idx. Деление текущего кадра на подкадры снабжает классификатор 210a речи информацией о местоположениях пиковой энергии, в том числе, местоположении наибольшей пиковой энергии, внутри кадра. Большее разрешение достигается посредством деления кадра на большее количество подкадров. Параметр 244a maxsfe_idx используется вместе с другими параметрами классификатором 210a речи, чтобы классифицировать переходные режимы речи, так как энергии невокализованного режима речи или режима речи «молчание» в целом являются неизменными, тогда как энергия поднимается или угасает в переходном режиме речи.
Классификатор 210a речи может использовать параметры, введенные непосредственно из компонентов кодирования, и параметры, сформированные внутри, чтобы точнее и надежнее классифицировать режимы речи, чем было возможно раньше. Классификатор 210a речи может применять последовательность операций осуществления выбора к непосредственно введенным и сформированным внутри параметрам, чтобы давать улучшенные результаты классификации речи. Последовательность операций осуществления выбора подробно описана ниже со ссылками на фиг. 4A-4C и таблицы 4-6.
В одной из конфигураций, режимы речи, выведенные классификатором 210 речи, содержат: Переходный, Переходный с повышением, Переходный с понижением, Вокализованный, Невокализованный режимы и режим Молчания. Переходный режим является вокализованным, но с менее периодичной речью, оптимально кодируемой с помощью CELP полной скорости. Переходный с повышением режим является первым вокализованным кадром в активной речи, оптимально кодируемой CELP полной скорости. Переходный с понижением режим является вокализованной речью с низкой энергией в конце слова, оптимально кодируемой с помощью CELP половинной скорости. Вокализованный режим является высоко периодичной вокализованной речью, содержащей главным образом гласные звуки. Речь вокализованного режима может кодироваться с полной скоростью, половинной скоростью, четвертичной скоростью и восьмеричной скоростью. Скорость передачи данных для кодирования речи в вокализованном режиме выбирается, чтобы удовлетворять требованиям средней скорости передачи данных (ADR). Невокализованный режим, содержащий главным образом невокализованные звуки, оптимально кодируется с помощью метода линейного предсказания с шумовым возбуждением (NELP) четвертичной скорости. Режим молчания является неактивной речью, оптимально кодируемой с помощью CELP восьмеричной скорости.
Пригодные параметры и режимы речи не ограничены специфичными параметрами и режимами речи раскрытых конфигураций. Дополнительные параметры и режимы речи могут применяться без отступления от объема раскрытых конфигураций.
Фиг. 2B - структурная схема, иллюстрирующая еще одну систему 200b классификатора, которая может использовать помехоустойчивую классификацию режимов кодирования речи. Система 200b классификатора по фиг. 2B может находиться в кодерах, проиллюстрированных на фиг. 1. В еще одной конфигурации, система 200b классификатора может быть отдельно стоящей, выдающей выходной сигнал режима классификации речи в устройства, такие как кодеры, проиллюстрированные на фиг. 1. Система 200b классификатора, проиллюстрированная на фиг. 2B, может включать в себя элементы, которые соответствуют системе 200a классификатора, проиллюстрированной на фиг. 2A. Более точно, анализатор 206b LPC, блок 208b оценки основного тона без обратной связи и классификатор 210b речи, проиллюстрированные на фиг. 2B, могут соответствовать и включать в себя подобные функциональные возможности, как у анализатора 206a LPC, блока 208a оценки основного тона без обратной связи и классификатора 210a речи, проиллюстрированных на фиг. 2A, соответственно. Подобным образом, входные сигналы классификатора 210b речи на фиг. 2B (информация 220b о голосовой активности, коэффициенты 222b отражения, NACF 224b и NACF около основного тона, 226b) могут соответствовать входным сигналам классификатора 210a речи (информации 220a о голосовой активности, коэффициентам 222a отражения, NACF 224a и NACF около основного тона, 226a) на фиг. 2A, соответственно. Подобным образом, выведенные параметры 282b на фиг. 2B (zcr 228b, E 230b, Enext 232b, bER 234b, vEav 236b, vEprev 238b, vER 240b, vER2 242b и maxsfe_idx 244b) могут соответствовать выведенным параметрам 282a на фиг. 2A (zcr 228a, E 230a, Enext 232a, bER 234a, vEav 236a, vEprev 238a, vER 240a, vER2 242a и maxsfe_idx 244a), соответственно.
На фиг. 2B нет включенного шумоподавителя. В одной из конфигураций, устройство классификации речи по фиг. 2B может использовать КОДЕК с расширенными голосовыми возможностями (EVS). Устройство по фиг. 2B может принимать входные речевые кадры 212b из компонента шумоподавления, внешнего для речевого кодека. В качестве альтернативы, шумоподавление может не выполняться. Поскольку нет включенного шумоподавителя 202, оценка 216b шума, ns_est, может определяться детектором 204a голосовой активности. Несмотря на то, что фиг. 2A-2B описывают две конфигурации, где оценка 216b шума определяется шумоподавителем 202 и детектором 204b голосовой активности, соответственно, оценка 216a-b шума может определяться любым пригодным модулем, например, универсальным блоком оценки шума (не показанным).
Фиг. 3 - блок-схема последовательности операций способа, иллюстрирующая способ 300 помехоустойчивой классификации речи. На этапе 302, параметры классификации, введенные из внешних компонентов, обрабатываются для каждого кадра подвергнутого шумоподавлению выходной речи. В одной из конфигураций (например, системе 200a классификатора, проиллюстрированной на фиг. 2A), параметры классификации, введенные из внешних компонентов, содержат ns_est 216a и t_in 214a, введенные из компонента 202 шумоподавителя, параметры nacf 224a и nacf_at_pitch 226a, введенные из компонента 208a блока оценки основного тона без обратной связи, vad 220a, введенный из компонента 204a детектора голосовой активности, и refl 222a, введенный из компонента 206a анализа LPC. В качестве альтернативы, ns_est 216b может вводиться из другого модуля, например, детектора 204b голосовой активности, как проиллюстрировано на фиг. 2B. Входной сигнал t_in 214a-b может быть выходными речевыми кадрами 214a из шумоподавителя 202, как на фиг. 2A или входными кадрами, как 212b на фиг. 2B. Поток управления переходит на этап 304.
На этапе 304, дополнительные сформированные внутри выведенные параметры 282a-b вычисляются из параметров классификации, введенных из внешних компонентов. В одной из конфигураций, zcr 228a-b, E 230a-b, Enext 232a-b, bER 234a-b, vEav 236a-b, vEprev 238a-b, vER 240a-b, vER2 242a-b и maxsfe_idx 244a-b вычисляются из t_in 214a-b. Когда сформированные внутри параметры были вычислены для каждого выходного речевого кадра, поток управления переходит на этап 306.
На этапе 306, определяются пороговые значения NACF, и анализатор параметров выбирается согласно среде распространения речевого сигнала. В одной из конфигураций, пороговое значение NACF определяется посредством сравнения параметра 216a-b ns_est, введенного на этапе 302 с пороговым значением оценки шума. Информация 216a-b о ns_est может обеспечивать адаптивное управление пороговым значением выбора периодичности. Таким образом, другие пороговые значения периодичности применяются в последовательности операций классификации для речевых сигналов с разными уровнями шумовых составляющих. Это может давать относительно точный выбор классификации речи, когда в наибольшей степени уместное пороговое значение NACF или периодичности для уровня шума речевого сигнала выбирается для каждого кадра выходной речи. Определение в наибольшей степени уместного порогового значения периодичности для речевого сигнала предоставляет возможность выбора наилучшего анализатора параметра для речевого сигнала. В качестве альтернативы, информация 218 о SNR может использоваться, чтобы определять пороговое значение NACF, если информация 218 о SNR включает в себя информацию о многочисленных кадрах и является относительно устойчивой от кадра к кадру.
Чистые и зашумленные речевые сигналы по сути отличаются по периодичности. Когда присутствует шум, имеет место искажение речи. Когда присутствует искажение речи, мера периодичности, или nacf 224a-b, является более низкой, чем у чистой речи. Таким образом, пороговое значение NACF снижается для компенсации среды распространения зашумленного сигнала или повышается для среды распространения чистого сигнала. Технология классификации речи раскрытых систем и способов может настраивать пороговые значения периодичности (то есть NACF) для разных сред распространения, давая относительно точный и надежный выбор режима независимо от уровней шума.
В одной из конфигураций, если значение ns_est 216a-b является меньшим чем или равным пороговому значению оценки шума, применяются пороговые значения NACF для чистой речи. Возможные пороговые значения NACF для чистой речи могут определяться согласно следующей таблице:
Однако в зависимости от значения ns_est 216a-b, могут настраиваться различные пороговые значения. Например, если значение ns_est 216a-b является большим, чем пороговое значение оценки шума, могут применяться пороговые значения NACF для зашумленной речи. Пороговое значение оценки шума может быть любым пригодным значением, например 20 дБ, 25 дБ и т.д. В одной из конфигураций, пороговое значение оценки шума устанавливается, чтобы быть выше того, что наблюдается при чистой речи, и ниже того, что наблюдается при сильно зашумленной речи. Возможные пороговые значения NACF для зашумленной речи могут определяться согласно следующей таблице:
В случае когда шум не присутствует (то есть ns_est 216a-b не превышает пороговое значение оценки шума), пороговые значения вокализованности могут не настраиваться. Однако пороговое значение NACF вокализованности для классификации кадра в качестве «вокализованного» может снижаться (отражая искажение информации о вокализованности), когда есть высокий шум во входной речи. Другими словами, пороговое значение вокализованности для классификации «вокализованной» речи может снижаться на 0,2, как показано в таблице 2, по сравнению с таблицей 1.
В качестве альтернативы, или в дополнение, модификация пороговых значений NACF для классификации «вокализованных» кадров, классификатор 210a-b речи может настраивать один или более пороговых значений для классификации «невокализованных» кадров на основании значения ns_est 216a-b. Может быть два типа пороговых значений NACF для классификации «невокализованных» кадров, которые настраиваются на основании значения 216a-b: порогового значения вокализованности и энергетического порога. Более точно, пороговое значение NACF вокализованности для классификации кадра в качестве «невокализованного» может повышаться (отражая искажение информации о вокализованности при шуме). Например, пороговое значение NACF вокализованности для «невокализованного» сигнала может повышаться на 0,06 в присутствие высокого шума (то есть когда ns_est 216a-b превышает пороговое значение оценки шума), тем самым делая классификатор в большей степени разрешающим при классификации кадров в качестве «невокализованных». Если информация 218 о SNR многочисленных кадров используется вместо ns_est 216a-b, низкое SNR (указывая присутствие высокого шума), пороговое значение вокализованности для «невокализованного» сигнала может повышаться на 0,06. Примеры настроенных пороговых значений NACF вокализованности могут быть приведены согласно таблице 3:
Энергетический порог для классификации кадра в качестве «невокализованного» также может повышаться (отражая высокий уровень кадров «молчания») в присутствии высокого шума, то есть когда ns_est 216a-b превышает пороговое значение оценки шума. Например, энергетический порог невокализованного сигнала может повышаться на 10 дБ в кадрах с высоким шумом, например, энергетический порог может повышаться от -25 дБ в случае чистой речи до -15 дБ в зашумленном случае. Повышение порогового значения вокализованности и энергетического порога для классификации кадра в качестве «невокализованного» может облегчать (то есть делать в большей степени допускающей) классификацию кадра в качестве невокализованного по мере того, как оценка шума становится более высокой (или SNR становится более низким). Пороговые значения для средних шумных кадров (например, когда ns_est 216a-b не превышает порогового значения оценки шума, но находится выше минимального измерения шума) могут настраиваться посредством интерполяции между «чистыми» установками (таблица 1) и «шумными» установками (таблица 2 и/или таблица 3) на основании входной оценки шума. В качестве альтернативы, жесткие установки пороговых значений могут определяться для некоторых промежуточных оценок шума.
Пороговое значение вокализованности для «вокализованного» сигнала может настраиваться независимо от порогового значения вокализованности для «невокализованного» сигнала и энергетического порога. Например, пороговое значение вокализованности для «вокализованного» сигнала может настраиваться, но могут не настраиваться ни пороговое значение вокализованности для «невокализованного» сигнала, ни энергетический порог. В качестве альтернативы, один или оба из порогового значения вокализованности для «невокализованного» сигнала и энергетического порога могут настраиваться, но пороговое значение вокализованности для «вокализованного» сигнала может не настраиваться. В качестве альтернативы, пороговое значение вокализованности для «вокализованного» сигнала может настраиваться в зависимости только одного из от порогового значения вокализованности для «невокализованного» сигнала и энергетического порога.
Зашумленная речь является такой же, как чистая речь с вносимым шумом. С адаптивным регулированием порогового значения периодичности, может быть более вероятным, что технология надежной классификации речи будет давать идентичный выбор классификации для чистой и зашумленной речи, чем возможно ранее. Когда пороговые значения nacf были установлены для каждого кадра, поток управления переходит на этап 308.
На этапе 308, классификация 246a-b режимов речи определяется, по меньшей мере частично, на основании оценки шума. Конечный автомат или любой другой способ анализа, выбранный согласно среде распространения сигналов, применяется к параметрам. В одной из конфигураций, параметры, введенные из внешних компонентов, и сформированные внутри параметры применяются к основанной на состоянии последовательности операций осуществления выбора, подробно описанной со ссылкой на фиг. 4A-4C и таблицы 4-6. Последовательность операций осуществления выбора вырабатывает классификацию режимов речи. В одной из конфигураций, вырабатывается классификация 246a-b режимов речи Переходного, Переходного с повышением, Переходного с понижением, Вокализованного, Невокализованного или Молчания. Когда был произведен выбор 246a-b режима речи, поток управления переходит на этап 310.
На этапе 310, переменные состояния и различные параметры обновляются, чтобы учитывать текущий кадр. В одной из конфигураций, обновляются vEav 236a-b, vEprev 238a-b и вокализованное состояние текущего кадра. Энергия E 230a-b текущего кадра, nacf_at_pitch 226a-b и режим 246a-b речи текущего кадра обновляются для классификации следующего кадра. Этапы 302-310 могут повторяться для каждого кадра речи.
Фиг. 4A-4C иллюстрируют конфигурации процесса осуществления выбора режима для помехоустойчивой классификации речи. Последовательность операций осуществления выбора выбирает конечный автомат для классификации речи на основании периодичности речевого кадра. Что касается каждого кадра речи, конечный автомат, в наибольшей степени совместимый с периодичностью или шумовой составляющей речевого кадра, выбирается для последовательности операций осуществления выбора посредством сравнения показателя периодичности речевого кадра, то есть значения 226a-b nacf_at_pitch, с пороговыми значениями NACF, установленными на этапе 304 по фиг. 3. Уровень периодичности речевого кадра ограничивает и управляет переходами между состояниями последовательности операций выбора режима, обеспечивая более надежную классификацию.
Фиг. 4A иллюстрирует одну из конфигураций конечного автомата, выбранного в одной из конфигураций, когда vad 220a-b имеет значение 1 (есть активная речь), и третье значение nacf_at_pitch 226a-b (то есть nacf_at_pitch[2], пронумерованный от нуля) является очень высоким или большим, чем VOICEDTH. VOICEDTH определяется на этапе 306 по фиг. 3. Таблица 4 иллюстрирует параметры, оцененные каждым состоянием:
Таблица 4, в соответствии с одной из конфигураций, иллюстрирует параметры, оцениваемые каждым состоянием, и переходы между состояниями, когда третье значение nacf_at_pitch 226a-b (то есть nacf_at_pitch[2]) является очень высоким или большим, чем VOICEDTH. Таблица решений, проиллюстрированная в таблице 4, используется конечным автоматом, описанным на фиг. 4A. Классификация 246a-b режимов речи предыдущего кадра речи показана в самом левом столбце. Когда параметры оценены, как показано в строке, ассоциированной с каждым предыдущим режимом, классификация режима речи переходит в текущий режим, идентифицированный в верхней строке ассоциированного столбца.
Исходным состоянием является Молчание 450a. Текущий кадр всегда будет классифицироваться в качестве Молчания 450a независимо от предыдущего состояния, если vad=0 (то есть голосовой активности нет).
Когда исходным состоянием является Молчание 450a, текущий кадр может быть классифицирован в качестве Невокализованного, 452a, или Переходного с повышением, 460a. Текущий кадр классифицируется в качестве Невокализованного 452a, если nacf_at_pitch[3] является очень низким, zcr 228a-b является высоким, bER 234a-b является низким, vER 240a-b является очень низким, или если удовлетворена комбинация этих условий. Иначе, классификация устанавливается по умолчанию в Переходный с повышением, 460a.
Когда исходным состоянием является Невокализованный 452a, текущий кадр может быть классифицирован в качестве Невокализованного, 452a, или Переходного с повышением, 460a. Текущий кадр остается классифицированным в качестве Невокализованного 452a, если nacf 224a-b является очень низким, nacf_at_pitch[3] является очень низким, nacf_at_pitch[4] является очень низким, zcr 228a-b является высоким, bER 234a-b является низким, vER 240a-b является очень низким, и E 230a-b является меньшим, чем vEprev 238a-b, либо если удовлетворена комбинация этих условий. Иначе, классификация устанавливается по умолчанию в Переходный с повышением, 460a.
Когда исходным состоянием является Вокализованный 456a, текущий кадр может быть классифицирован в качестве Невокализованного, 452a, Переходного 454a, Переходного с понижением, 458a, или Вокализованного 456a. Текущий кадр классифицируется в качестве Невокализованного 452a, если vER 240a-b является очень низким, и E 230a является меньшим, чем vEprev 238a-b. Текущий кадр классифицируется в качестве Переходного 454a, если nacf_at_pitch[1] и nacf_at_pitch[3] являются низкими, E 230a-b является большим, чем половина vEprev 238a-b, или удовлетворена комбинация этих условий. Текущий кадр классифицируется в качестве Переходного с понижением, 458a, если vER 240a-b является очень низким, и nacf_at_pitch[3] имеет среднее значение. Иначе, текущая классификация устанавливается по умолчанию в Вокализованный 456a.
Когда предыдущим состоянием является Переходный 454a или Переходный с повышением, 460a, текущий кадр может классифицироваться в качестве Невокализованного 452a, Переходного 454a, Переходного с понижением, 458a, или Вокализованного 456a. Текущий кадр классифицируется в качестве Невокализованного 452a, если vER 240a-b является очень низким, и E 230a-b является меньшим, чем vEprev 238a-b. Текущий кадр классифицируется в качестве Переходного 454a, если nacf_at_pitch[1] является низким, nacf_at_pitch[3] имеет среднее значение, nacf_at_pitch[4] является низким, и предыдущее состояние не является Переходным 454a, либо если удовлетворена комбинация этих условий. Текущий кадр классифицируется в качестве Переходного с понижением, 458a, если nacf_at_pitch[3] имеет среднее значение, и E 230a-b является меньшим, чем взятый 0,05 раз vEav 236a-b. Иначе, текущая классификация устанавливается по умолчанию в Вокализованный 456a-b.
Когда предыдущий кадр является Переходным с понижением, 458a, текущий кадр может быть классифицирован как Невокализованный 452a, Переходный 454a или Переходный с понижением, 458a. Текущий кадр будет классифицироваться в качестве Невокализованного 452a, если vER 240a-b является очень низким. Текущий кадр будет классифицироваться в качестве Переходного 454a, если E 230a-b является большим, чем vEprev 238a-b. Иначе, текущая классификация остается Переходной с понижением, 458a.
Фиг. 4B иллюстрирует одну из конфигураций конечного автомата, выбранного в одной из конфигураций, когда vad 220a-b имеет значение 1 (есть активная речь), и третье значение nacf_at_pitch 226a-b является очень низким или меньшим, чем UNVOICEDTH. UNVOICEDTH определяется на этапе 306 по фиг. 3. Таблица 5 иллюстрирует параметры, оцененные каждым состоянием.
Таблица 5 иллюстрирует, в соответствии с одной из конфигураций, параметры, оцениваемые каждым состоянием, и переходы между состояниями, когда третье значение (то есть nacf_at_pitch[2]) является очень низким или меньшим, чем UNVOICEDTH. Таблица решений, проиллюстрированная в таблице 5, используется конечным автоматом, описанным на фиг. 4B. Классификация 246a-b режимов речи предыдущего кадра речи показана в самом левом столбце. Когда параметры оценены, как показано в строке, ассоциированной с каждым предыдущим режимом, классификация режима речи переходит в текущий режим 246a-b, идентифицированный в верхней строке ассоциированного столбца.
Исходным состоянием является Молчание 450b. Текущий кадр всегда будет классифицироваться в качестве Молчания 450b независимо от предыдущего состояния, если vad=0 (то есть голосовой активности нет).
Когда исходным состоянием является Молчание 450b, текущий кадр может быть классифицирован в качестве Невокализованного, 452b, или Переходного с повышением, 460b. Текущий кадр классифицируется в качестве Переходного с повышением, 460b, если nacf_at_pitch[2-4] показывает тенденцию повышения, nacf_at_pitch[3-4] имеет среднее значение, zcr 228a-b имеет значение от низкого до среднего, bER 234a-b является высоким, и vER 240a-b имеет среднее значение, или если удовлетворена комбинация этих условий. Иначе, классификация устанавливается по умолчанию в Невокализованный, 452b.
Когда исходным состоянием является Невокализованный 452b, текущий кадр может быть классифицирован в качестве Невокализованного, 452b, или Переходного с повышением, 460b. Текущий кадр классифицируется в качестве Переходного с повышением, 460b, если nacf_at_pitch[2-4] показывает тенденцию повышения, nacf_at_pitch[3-4] имеет значение от среднего до очень высокого, zcr 228a-b является очень низким или средним, vER 240a-b не является низким, bER 234a-b является высоким, refl 222a-b является низким, nacf 224a-b имеет среднее значение, и E 230a-b является большим, чем vEprev 238a-b, либо если удовлетворена комбинация этих условий. Комбинации и пороговые значения для этих условий могут меняться в зависимости от уровня шумов речевого кадра в качестве отраженного в параметрах ns_est 216a-b (или возможно информации 218 об усредненном по множеству кадров SNR. Иначе, классификация устанавливается по умолчанию в Невокализованный, 452b.
Когда предыдущее состояние является Вокализованным 456b, Переходным с повышением, 460b или Переходным 454b, текущий кадр может классифицироваться в качестве Невокализованного 452b, Переходного 454b или Переходного с понижением, 458b. Текущий кадр классифицируется в качестве Невокализованного 452b, если bER 234a-b является меньшим чем или равным нулю, vER 240a является очень низким, bER 234a-b является большим, чем ноль, и E 230a-b является меньшим, чем vEprev 238a-b, либо если удовлетворена комбинация этих условий. Текущий кадр классифицируется в качестве Переходного 454b, если bER 234a-b является большим, чем ноль, nacf_at_pitch[2-4] показывает тенденцию повышения, zcr 228a-b не является высоким, vER 240a-b не является низким, refl 222a-b является низким, nacf_at_pitch[3] и nacf 224a-b являются средними, и bER 234a-b является меньшим чем или равным нулю, либо если удовлетворена комбинация этих условий. Комбинации и пороговые значения для этих условий могут меняться в зависимости от уровня шума речевого кадра в качестве отраженного в параметре ns_est 216a-b. Текущий кадр классифицируется в качестве Переходного с понижением, 458a-b, если bER 234a-b является большим, чем ноль, nacf_at_pitch[3] является средним, E 230a-b является меньшим, чем vEprev 238a-b, zcr 228a-b не является высоким, а vER2 242a-b является меньшим, чем минус пятнадцать.
Когда предыдущий кадр является Переходным с понижением, 458b, текущий кадр может быть классифицирован как Невокализованный 452b, Переходный 454b или Переходный с понижением, 458b. Текущий кадр будет классифицироваться в качестве Переходного 454b, если nacf_at_pitch[2-4] показывал тенденцию повышения, nacf_at_pitch[3-4] является умеренно высоким, vER 240a-b не является низким, и E 230a-b является большим, чем удвоенный vEprev 238a-b, или если удовлетворена комбинация этих условий. Текущий кадр будет классифицироваться в качестве Переходного с понижением, 458b, если vER 240a-b не является низким, а zcr 228a-b является низким. Иначе, текущая классификация устанавливается по умолчанию в Невокализованный, 452b.
Фиг. 4C иллюстрирует одну из конфигураций конечного автомата, выбранного в одной из конфигураций, когда vad 220a-b имеет значение 1 (есть активная речь), и третье значение nacf_at_pitch 226a-b (то есть nacf_at_pitch[3]) является средним, то есть большим, чем UNVOICEDTH, и меньшим, чем VOICEDTH. UNVOICEDTH и VOICEDTH определяются на этапе 306 по фиг. 3. Таблица 6 иллюстрирует параметры, оцененные каждым состоянием.
Таблица 6 иллюстрирует, в соответствии с одним из вариантов осуществления, параметры, оцениваемые каждым состоянием, и переходы между состояниями, когда третье значение nacf_at_pitch 226a-b (то есть nacf_at_pitch[3]) является средним, то есть большим, чем UNVOICEDTH, но меньшим, чем VOICEDTH. Таблица решений, проиллюстрированная в таблице 6, используется конечным автоматом, описанным на фиг. 4C. Классификация режимов речи предыдущего кадра речи показана в самом левом столбце. Когда параметры оценены, как показано в строке, ассоциированной с каждым предыдущим режимом, классификация 246a-b режима речи переходит в текущий режим 246a-b, идентифицированный в верхней строке ассоциированного столбца.
Исходным состоянием является Молчание 450c. Текущий кадр всегда будет классифицироваться в качестве Молчания 450c независимо от предыдущего состояния, если vad=0 (то есть голосовой активности нет).
Когда исходным состоянием является Молчание 450c, текущий кадр может быть классифицирован в качестве Невокализованного, 452c, или Переходного с повышением, 460c. Текущий кадр классифицируется как Переходный с повышением, 460c, если nacf_at_pitch[2-4] показывал тенденцию повышения, nacf_at_pitch[3-4] является от среднего до высокого, zcr 228a-b не является высоким, bER 234a-b является высоким, vER 240a-b имеет среднее значение, zcr 228a-b является очень низким, а E 230a-b является большим, чем удвоенный vEprev 238a-b, или если удовлетворена определенная комбинация этих условий. Иначе, классификация устанавливается по умолчанию в Невокализованный, 452c.
Когда исходным состоянием является Невокализованный 452c, текущий кадр может быть классифицирован в качестве Невокализованного, 452c, или Переходного с повышением, 460c. Текущий кадр классифицируется в качестве Переходного с повышением, 460c, если nacf_at_pitch[2-4] показывал тенденцию повышения, nacf_at_pitch[3-4] имеет от среднего до очень высокого значение, zcr 228a-b не является высоким, vER 240a-b не является низким, bER 234a-b является высоким, refl 222a-b является низким, E 230a-b является большим, чем vEprev 238a-b, zcr 228a-b является очень низким, nacf 224a-b не является низким, maxsfe_idx 244a-b указывает на последний подкадр, и E 230a-b является большим, чем удвоенный vEprev 238a-b, или если удовлетворена комбинация этих условий. Комбинации и пороговые значения для этих условий могут меняться в зависимости от уровня шумов речевого кадра в качестве отраженного в параметрах ns_est 216a-b (или возможно информации 218 об усредненном по множеству кадров SNR. Иначе, классификация устанавливается по умолчанию в Невокализованный, 452c.
Когда предыдущим состоянием является Вокализованным, 456c, Переходным с повышением, 460c, или Переходным, 454c, текущий кадр может классифицироваться как Невокализованный 452c, Вокализованный 456c, Переходный 454c, Переходный с понижением, 458c. Текущий кадр классифицируется как Невокализованный, 452c, если bER 234a-b является меньшим чем или равным нулю, vER 240a-b является очень низким, Enext 232a-b является меньшим, чем E 230a-b, nacf_at_pitch[3-4] является очень низким, bER 234a-b является большим, чем ноль, и E 230a-b является меньшим, чем vEprev 238a-b, или если удовлетворена определенная комбинация этих условий. Текущий кадр классифицируется в качестве Переходного 454c, если bER 234a-b является большим, чем ноль, nacf_at_pitch[2-4] показывает тенденцию повышения, zcr 228a-b не является высоким, vER 240a-b не является низким, refl 222a-b является низким, nacf_at_pitch[3] и nacf 224a-b не являются низкими, или если удовлетворена комбинация этих условий. Комбинации и пороговые значения для этих условий могут меняться в зависимости от уровня шумов речевого кадра в качестве отраженного в параметрах ns_est 216a-b (или возможно информации 218 об усредненном по множеству кадров SNR. Текущий кадр классифицируется в качестве Переходного с понижением 458c если bER 234a-b является большим, чем ноль, nacf_at_pitch[3] не является высоким, E 230a-b является меньшим, чем vEprev 238a-b, zcr 228a-b не является высоким, vER 240-ab является меньшим, чем минус пятнадцать, и vER2 242a-b является меньшим, чем минус пятнадцать, или если удовлетворена комбинация этих условий. Текущий кадр классифицируется в качестве Вокализованного, 456c, если nacf_at_pitch[2] является большим, чем LOWVOICEDTH, bER 234a-b является большим чем или равным нулю, а vER 240a-b не является низким, или если удовлетворена комбинация этих условий.
Когда предыдущий кадр является Переходным с понижением, 458c, текущий кадр может быть классифицирован как Невокализованный 452c, Переходный 454c или Переходный с понижением, 458c. Текущий кадр будет классифицироваться в качестве Переходного 454c, если bER 234a-b является большим, чем ноль, nacf_at_pitch[2-4] показывает тенденцию повышения, nacf_at_pitch[3-4] является умеренно высоким, vER 240a-b не является низким, и E 230a-b является большим, чем удвоенный vEprev 238a-b, или если удовлетворена определенная комбинация этих условий. Текущий кадр будет классифицироваться в качестве Переходного с понижением, 458c, если vER 240a-b не является низким, а zcr 228a-b является низким. Иначе, текущая классификация устанавливается по умолчанию в Невокализованный, 452c.
Фиг. 5 - схема последовательности операций, иллюстрирующая способ 500 для настройки пороговых значений для классификации речи. Настроенные пороговые значения (например, NACF или периодичность, пороговые значения) затем могут использоваться, например, в способе 300 помехоустойчивой классификации речи, проиллюстрированном на фиг. 3. Способ 500 может выполняться классификаторами 210a-b речи 2A-2B.
Оценка шума (например, ns_est 216a-b) входной речи может приниматься 502 в классификаторе 210a-b речи. Оценка шума может быть основана на многочисленных кадрах входной речи. В качестве альтернативы, среднее значение информации 218 об SNR по многочисленным кадрам может использоваться вместо оценки шума. Любая пригодная метрика шума, которая относительно устойчива на протяжении многочисленных кадров, может использоваться в способе 500. Классификатор 210a-b речи может определять 504, превышает ли оценка шума пороговое значение оценки шума. В качестве альтернативы, классификатор 210a-b речи может определять, перестает ли информация 218 о SNR по многочисленным кадрам превышать пороговое значение SNR по многочисленным кадрам. Если нет, классификатор 210a-b речи может не настраивать 506 никаких пороговых значений NACF для классификации речи в качестве «вокализованной» или «невокализованной». Однако если оценка шума превышает пороговое значение оценки шума, классификатор 210a-b речи также может определять 508, следует ли настраивать пороговые значения NACF невокализованного сигнала. Если нет, пороговые значения NACF невокализованного сигнала могут не настраиваться, 510, то есть могут не настраиваться пороговые значения для классификации кадра в качестве «невокализованного». Если да, классификатор 210a-b речи может повышать пороговые значения NACF невокализованного сигнала, то есть повышать пороговое значение вокализованности для классификации текущего кадра в качестве Невокализованного, и повышать энергетический порог для классификатора текущего кадра в качестве Невокализованного. Повышение порогового значения вокализованности и энергетического порога для классификации кадра в качестве «невокализованного» может облегчать (то есть делать в большей степени допускающей) классификацию кадра в качестве Невокализованного по мере того, как оценка шума становится более высокой (или SNR становится более низким). Классификатор 210a-b речи также может определять 514, следует ли настраивать пороговое значение NACF невокализованного сигнала (в качестве альтернативы, могут настраиваться пороговые значения спектрального наклона или обнаружения перехода, либо скорости пересечения нуля). Если нет, классификатор 210a-b речи может не настраивать, 516, пороговое значение вокализованности для классификации кадра в качестве «вокализованного», то есть могут не настраиваться пороговые значения для классификации кадра в качестве «вокализованного». Если да, классификатор 210a-b речи может снижать 518 пороговое значение вокализованности для классификации текущего кадра в качестве «вокализованного». Поэтому, пороговые значения NACF для классификации речевого кадра в качестве «вокализованного» или «невокализованного» могут настраиваться независимо друг от друга. Например, в зависимости от того, каким образом классификатор 610 отрегулирован в чистом случае (без шумов), только одно из пороговых значений «вокализованного» или «невокализованного» может независимо настраиваться, то есть может иметь место, что классификация «невокализованного» является в большей степени чувствительной к шуму. Более того, штрафная санкция за неправильную классификацию «вокализованного» кадра может быть большей, чем за неправильную классификацию «невокализованного» кадра (оба с точки зрения качества и скорости передачи битов).
Фиг. 6 - структурная схема, иллюстрирующая классификатор 610 речи для помехоустойчивой классификации речи. Классификатор 610 речи может соответствовать классификаторам 210a-b речи, проиллюстрированным на фиг. 2A-2B, и может выполнять способ 300, проиллюстрированный на фиг. 3, или способ 500, проиллюстрированный на фиг. 5.
Классификатор 610 речи может включать в себя принятые параметры 670. Это может включать в себя принятые речевые кадры 672 (t_in), информацию 618 о SNR, оценку 616 шума (ns_est), информацию 620 о голосовой активности 620 (vad), коэффициенты 622 отражения (refl), NACF 624 и NACF около основного тона (nacf_at_pitch), 626. Эти параметры 670 могут приниматься из различных модулей, таких как проиллюстрированные на фиг. 2A-2B. Например, принятые речевые кадры 672 (t_in) могут быть выходными речевыми кадрами 214a из шумоподавителя 202, проиллюстрированного на фиг. 2A или самой входной речью 212b, как проиллюстрировано на фиг. 2b.
Модуль 674 вывода параметров также может определять набор выведенных параметров 682. Более точно, модуль 674 вывода параметров может определять скорость 628 пересечения нуля (zcr), энергию 630 текущего кадра (E), энергию 632 предстоящего кадра (Enext) 632, отношение 634 энергии полос (bER) 634, усредненную по трем вокализованным кадрам энергию 636 (vEav), энергию 638 предыдущего кадра (vEprev), отношение 640 энергии текущего кадра к усредненной по трем предыдущим вокализованным кадрам энергии (vER), отношение 642 энергии текущего кадра к усредненной по трем вокализованным кадрам энергии (vER2) и индекс 644 максимальной энергии подкадра (maxsfe_idx).
Компаратор 678 оценки шума может сравнивать принятую оценку 616 шума (ns_est) с пороговым значением 676 оценки шума. Если оценка 616 шума (ns_est) 616 не превышает пороговое значение 676 оценки шума, набор пороговых значений 684 NACF может не настраиваться. Однако если оценка 616 шума (ns_est) превышает пороговое значение 676 оценки шума (указывая присутствие высокого шума), могут настраиваться одно или более пороговых значений 684 NACF. Более точно, может снижаться пороговое значение вокализованности для классификации «вокализованных» кадров 686, может повышаться пороговое значение вокализованности для классификации «невокализованных» кадров 688, может повышаться энергетический порог для классификации «невокализованных» кадров 690 или некоторая комбинация настроек. В качестве альтернативы, вместо сравнения оценки 616 шума (ns_est) с пороговым значением 676 оценки шума, компаратор оценки шума может сравнивать информацию 618 о SNR с пороговым значением 680 SNR многочисленных кадров, чтобы определять, следует ли настраивать пороговые значения 684 NACF. В такой конфигурации, пороговые значения 684 NACF могут настраиваться, если информация 618 о SNR перестает превышать пороговое значение 680 SNR многочисленных кадров, то есть пороговые значения 684 NACF могут настраиваться, когда информация 618 о SNR падает ниже минимального уровня, таким образом, указывая присутствие высокого шума. Любая пригодная метрика шума, которая относительно устойчива на многочисленных кадрах, может использоваться компаратором 678 оценки шума.
Конечный автомат 692 классификатора затем может выбираться и использоваться для определения классификации 646 режима речи, по меньшей мере частично, на основании выведенных параметров 682, как описано выше и проиллюстрировано на фиг. 4A-4C и в таблицах 4-6.
Фиг. 7 - график временной последовательности, иллюстрирующий одну из конфигураций принятого речевого сигнала 772 с ассоциированными значениями параметров и классификациями 746 режимов речи. Более точно, фиг. 7 иллюстрирует одну из конфигураций представленных систем и способов, в которых классификация 746 режима речи выбирается на основании различных принятых параметров 670 и выведенных параметров 682. Каждый сигнал или параметр проиллюстрирован на фиг. 7 в качестве функции времени.
Например, показаны третье значение NACF около основного тона (nacf_at_pitch[2]), 794, четвертое значение NACF около основного тона (nacf_at_pitch[3]), 795, и пятое значение NACF около основного тона (nacf_at_pitch[4]), 796. Боле того, также показаны отношение энергии текущего кадра к энергии предыдущих трех вокализованных кадров (vER), 740, отношение энергии полос (bER), 734, скорость пересечения нуля (zcr), 728, и коэффициенты отражения (refl), 722. На основании проиллюстрированных сигналов, принятый речевой сигнал 772 может быть классифицирован в качестве Молчания около момента 0 времени, Невокализованного около момента 4 времени, Переходного около момента 9 времени, Вокализованного около момента 10 времени и Переходного с понижением около момента 25 времени.
Фиг. 8 иллюстрирует некоторые компоненты, которые могут быть включены в электронное устройство/беспроводное устройство 804. Электронное устройство/беспроводное устройство 804 может быть терминалом доступа, мобильной станцией, пользовательским оборудованием (UE), базовой станцией, точкой доступа, широковещательным передатчиком, Узлом Б, развитым Узлом Б и т.д. Электронное устройство/беспроводное устройство 804 включает в себя процессор 803. Процессор 803 может быть одно- или многокристальным микропроцессором общего применения (например, ARM), микропроцессором специального назначения (например, цифровым сигнальным процессором (DSP)), микроконтроллером, программируемой вентильной матрицей, и т.д. Процессор 803 может обозначаться как центральное процессорное устройство (CPU). Хотя только один процессор 803 показан в электронном устройстве/беспроводном устройстве 804 по фиг. 8, в альтернативной конфигурации, могла бы использоваться комбинация процессоров (например, ARM и DSP).
Электронное устройство/беспроводное устройство 804 также включает в себя память 805. Память 805 может быть любым электронным компонентом, способным к хранению электронной информации. Память 805 может быть воплощена в качестве оперативного запоминающего устройства (RAM), постоянного запоминающего устройства (ROM), магнитных дисковых запоминающих носителей, оптических запоминающих носителей, устройств флэш-памяти в RAM, внутрисхемной памяти, включенной в процессор, памяти EPROM, памяти EEPROM, регистров, и так далее, в том числе, их комбинаций.
Данные 807a и команды 809a могут храниться в памяти 805. Команды 809a могут быть выполняемыми процессором 803 для реализации способов, раскрытых в материалах настоящей заявки. Выполнение команд 809a может включать в себя использование данных 807a, которые хранятся в памяти 805. Когда процессор 803 выполняет команды 809a, различные части команд 809b могут загружаться в процессор 803, и различные части данных 807b могут загружаться в процессор 803.
Электронное устройство/беспроводное устройство 804 также может включать в себя передатчик 811 и приемник 813, чтобы предоставлять возможность передачи и приема сигналов на и из электронного устройства/беспроводного устройства 804. Передатчик 811 и приемник 813 могут указываться ссылкой совместно как приемопередатчик 815. Многочисленные антенны 817a-b могут быть электрически присоединены к приемопередатчику 815. Электронное устройство/беспроводное устройство 804 также может включать в себя (не показанные) многочисленные передатчики, многочисленные приемники и многочисленные приемопередатчики и/или дополнительные антенны.
Электронное устройство/беспроводное устройство 804 может включать в себя цифровой сигнальный процессор 821 (DSP). Электронное устройство/беспроводное устройство 804 также может включать в себя интерфейс 823 связи. Интерфейс 823 связи может предоставлять пользователю возможность взаимодействовать с электронным устройством/беспроводным устройством 804.
Различные компоненты электронного устройства/беспроводного устройства 804 могут быть соединены друг с другом одной или более шин, которые могут включать в себя шину питания, шину сигналов управления, шину сигналов состояния, шину данных и т.д. Ради ясности, различные шины проиллюстрированы на фиг. 8 в качестве системы 819 шин.
Технологии, описанные в материалах настоящей заявки, могут использоваться для различных систем связи, в том числе, систем связи, которые основаны на ортогональной схеме мультиплексирования. Примеры таких систем связи включают в себя системы множественного доступа с ортогональным частотным разделением каналов (OFDMA), системы множественного доступа с частотным разделением каналов на одиночной несущей (SC-FDMA), и так далее. Система OFDMA использует мультиплексирование с ортогональным частотным разделением каналов (OFDM), которое является технологией модуляции, которая разделяет общую полосу пропускания системы на многочисленные ортогональные поднесущие. Эти поднесущие также могут называться тонами, элементами дискретизации, и т.д. При OFDM, каждая поднесущая может независимо модулироваться данными. Система SC-FDMA может использовать FDMA с перемеженным разделением (IFDMA) для передачи на поднесущих, которые распределены по полосе пропускания системы, FDMA с локализованным разделением (LFDMA) для передачи в блоке смежных поднесущих или усовершенствованный FDMA (EFDMA) для передачи в многочисленных блоках смежных поднесущих. Вообще, символы модуляции отправляются в частотной области при OFDM и во временной области при SC-FDMA.
Термин «определение» охватывает широкое многообразие действий, а потому, «определение» может включать в себя расчет, вычисление, обработку, логический вывод, изучение, отыскивание (например, отыскивание в таблице, базе данных или другой структуре данных), выявление, и тому подобное. К тому же, «определение» может включать в себя прием (например, прием информации), осуществление доступа (например, осуществление доступа к данным в памяти), и тому подобное. К тому же, «определение» может включать в себя принятие решения, отбор, выбор, создание, и тому подобное.
Фраза «на основании» не означает «исключительно на основании», если явно не указано иное. Другими словами, фраза «на основании» описывает как «только на основании», так и «по меньшей мере на основании».
Термин «процессор» должен толковаться расширительно, чтобы охватывать процессор общего применения, центральное процессорное устройство (CPU), микропроцессор, цифровой сигнальный процессор (DSP), контроллер, микроконтроллер, конечный автомат, и так далее. В некоторых условиях, «процессор» может обозначать специализированную интегральную схему (ASIC), программируемое логическое устройство (PLD), программируемую пользователем вентильную матрицу (FPGA), и т.д. Термин «процессор» может обозначать комбинацию устройств обработки данных, например, комбинацию DSP и микропроцессора, множества микропроцессоров, одного или более микропроцессоров в соединении с DSP-ядром, или любой другой такой конфигурации.
Термин «память» должен толковаться расширительно, чтобы охватывать любой электронный компонент, способный к хранению электронной информации. Термин память может обозначать различные типы читаемых процессором носителей, таких как оперативное запоминающее устройство (RAM), постоянное запоминающее устройство (ROM), энергонезависимое оперативное запоминающее устройство (NVRAM), программируемое постоянное запоминающее устройство (PROM), стираемое программируемое постоянное запоминающее устройство (EPROM), электрически стираемое PROM (EEPROM), флэш-память, магнитное или оптическое хранилище данных, регистры, и т.д. Память упоминается находящейся в электронной связи с процессором, если процессор может считывать информацию с и/или записывать информацию в память. Память, которая является неотъемлемой частью процессора, находится в электронной связи с процессором.
Термин «команды» и «код» должны толковаться расширительно, чтобы включать в себя любой тип компьютерно-читаемого оператора(ов). Например, термины «команды» и «код» могут указывать на одну или более программ, стандартных программ, стандартных подпрограмм, функций, процедур, и т.д. «Команды» и «код» могут содержать одиночный компьютерно-читаемый оператор или многочисленные компьютерно-читаемые операторы.
Функции, описанные в материалах настоящей заявки, могут быть реализованы в программном обеспечении или встроенном программном обеспечении, выполняемых аппаратными средствами. Функции могут храниться в качестве одной или более команд на компьютерно-читаемом носителе. Термин «компьютерно-читаемый носитель» или «компьютерно-читаемый продукт» обозначает любой материальный запоминающий носитель, к которому может осуществляться доступ компьютером или процессором. В качестве примера, а не ограничения, компьютерно-читаемый носитель может содержать RAM, ROM, EEPROM, CD-ROM или другое оптическое дисковое запоминающее устройство, магнитное дисковое запоминающее устройство или другие магнитные устройства хранения данных, либо любой другой носитель, который может использоваться для переноса или хранения требуемой управляющей программы в виде команд или структур данных, и к которым может осуществляться доступ компьютером. Термин «диск», используемый в материалах настоящей заявки, включает в себя компакт-диск (CD), лазерный диск, оптический диск, цифровой многофункциональный диск (DVD), гибкий магнитный диск и диск Blu-ray®, причем магнитные диски обычно воспроизводят данные магнитным образом, тогда как оптические диски воспроизводят данные оптически с помощью лазеров.
Способы, раскрытые в материалах настоящей заявки, содержат один или более этапов или действий для выполнения описанного способа. Этапы и/или действия способа могут взаимно заменяться друг другом без отступления от объема формулы изобретения. Другими словами, если специфичный порядок этапов или действий не требуется для надлежащей работы способа, который описывается, порядок и/или использование специфичных этапов и/или действий могут быть модифицированы без отступления от объема формулы изобретения.
Кроме того, должно приниматься во внимание, что модули и/или другие надлежащие средства для выполнения способов и технологий, описанных в материалах настоящей заявки, таких как проиллюстрированные фиг. 3 и 5, могут загружаться и/или иным образом получаться устройством. Например, устройство может быть присоединено к серверу для содействия передаче средства для выполнения способов, описанных в материалах настоящей заявки. В качестве альтернативы, различные способы, описанные в материалах настоящей заявки, могут быть предусмотрены с помощью средства хранения (например, оперативного запоминающего устройства (RAM), постоянного запоминающего устройства (ROM), физического запоминающего носителя, такого как компакт-диск (CD) или гибкий диск, и т.д.), так чтобы устройство могло получать различные способы при присоединении или установки средства хранения в устройство.
Должно быть понятно, что формула изобретения не ограничена точной конфигурацией и компонентами, проиллюстрированными выше. Различные модификации, изменения и варианты могут быть произведены в компоновке, работе и деталях систем, способов и устройства, описанных в материалах настоящей заявки без отступления от объема формулы изобретения.
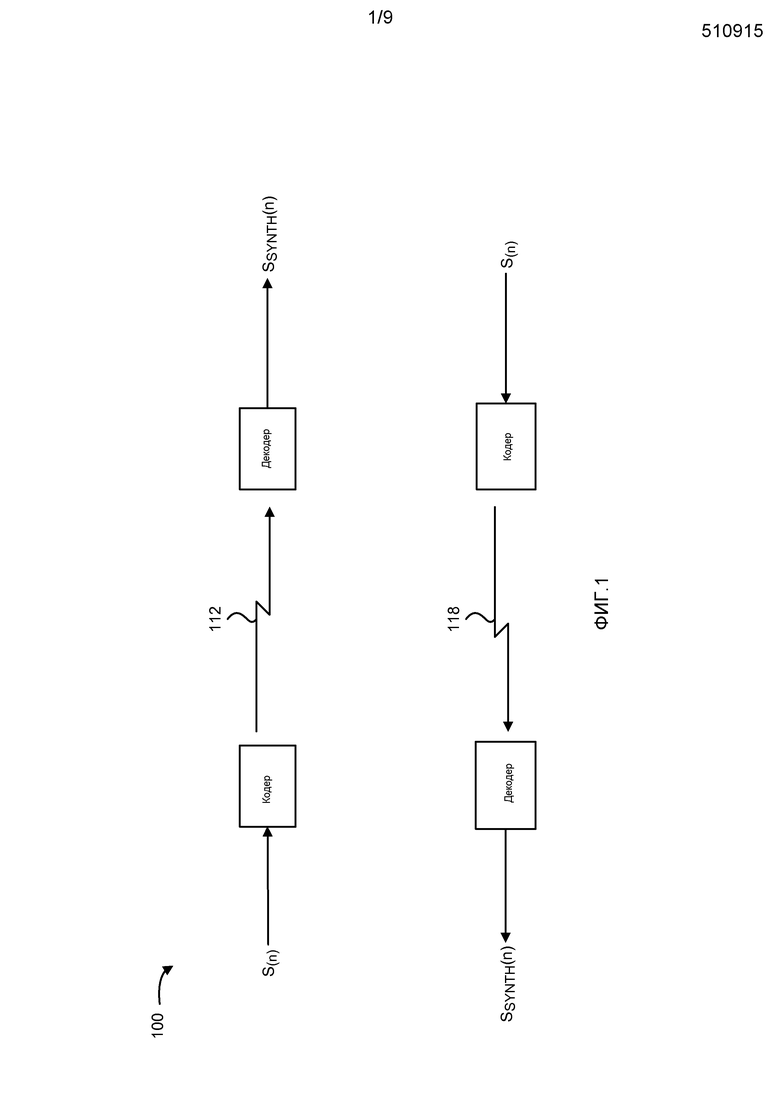
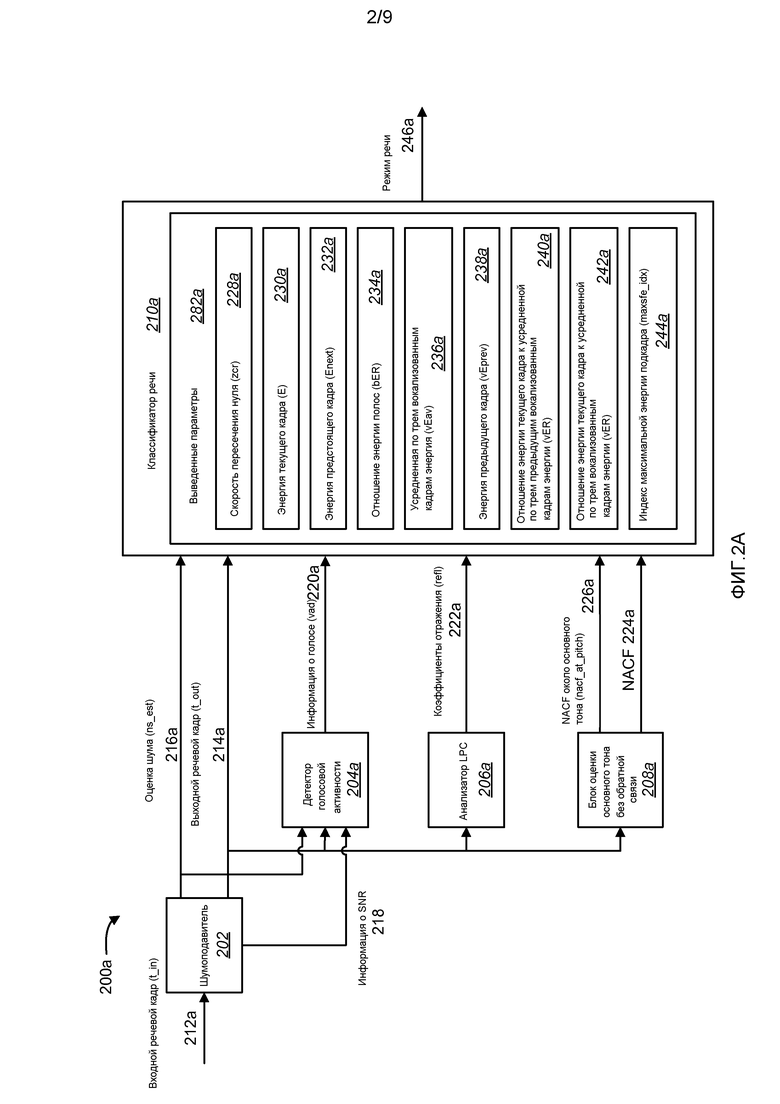
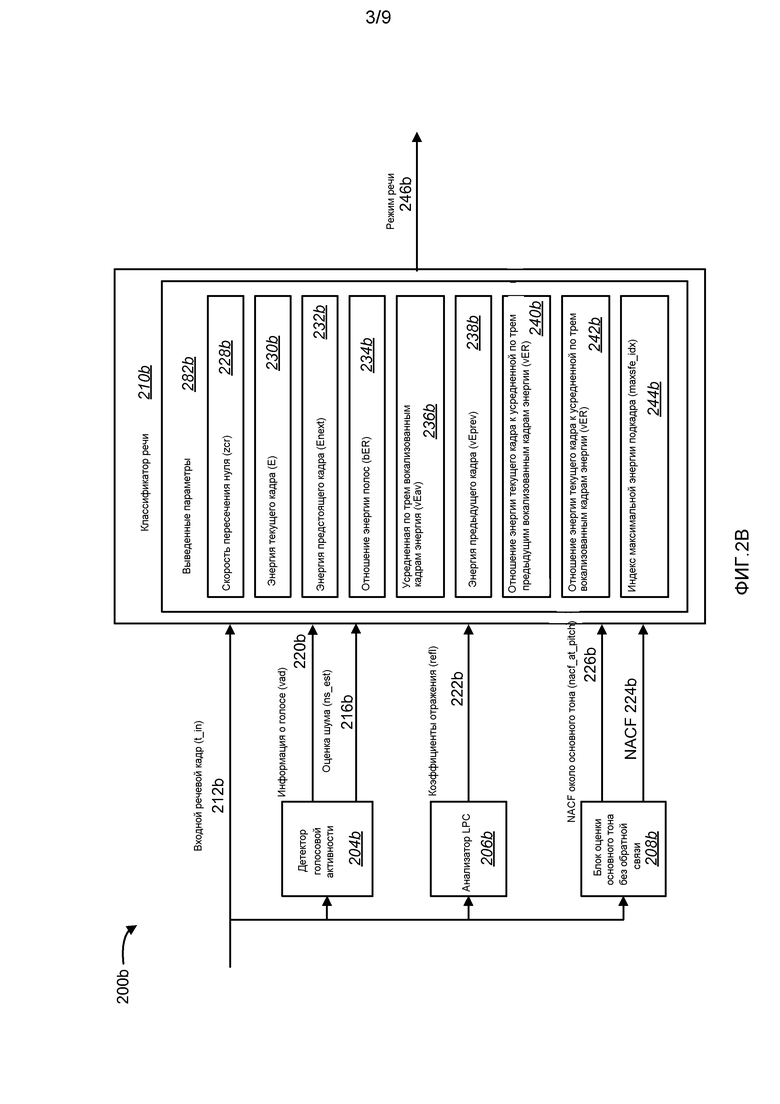
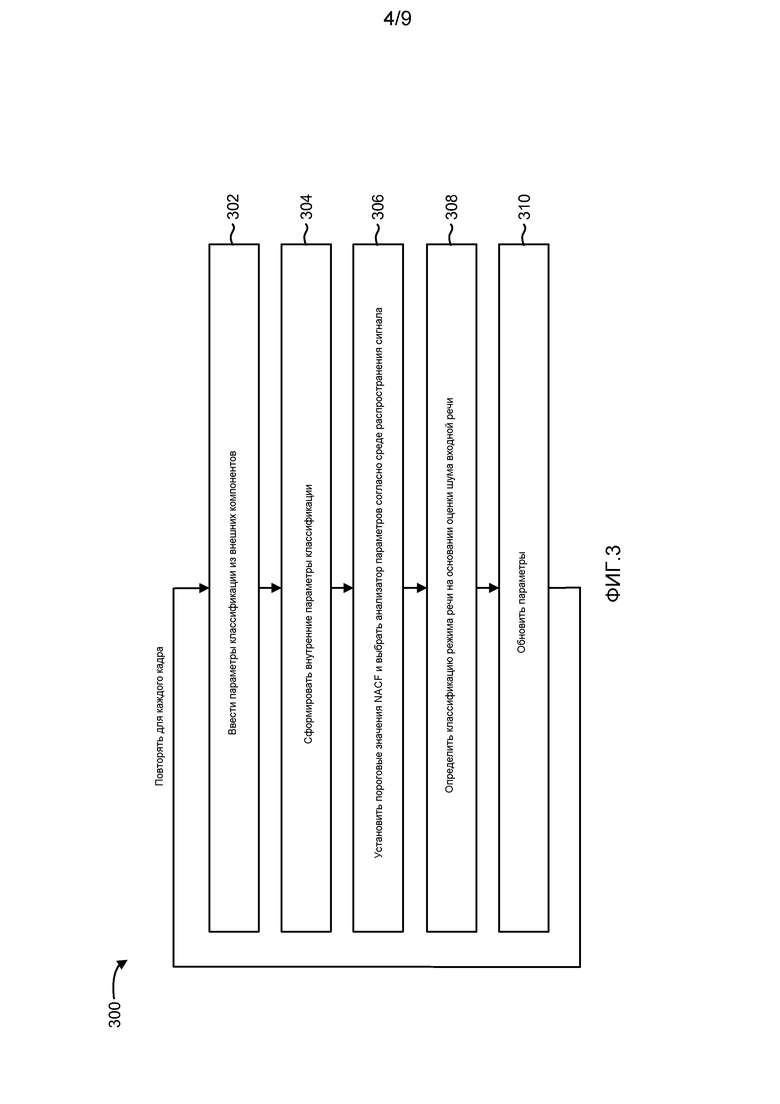
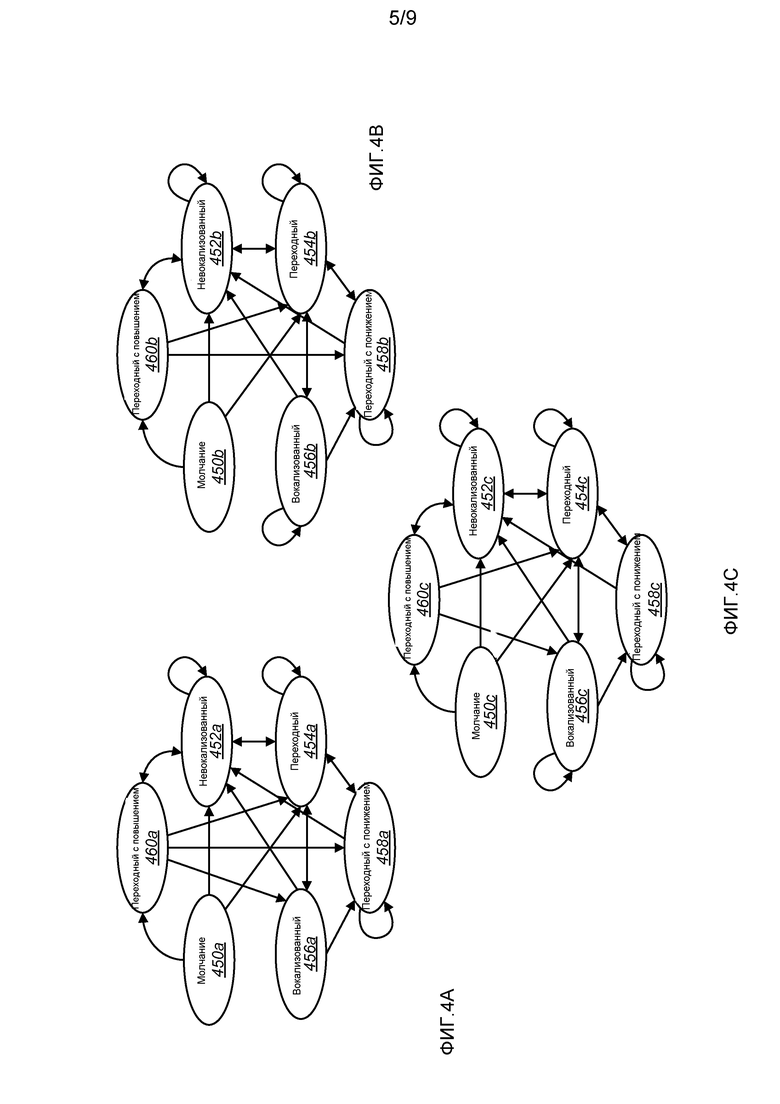
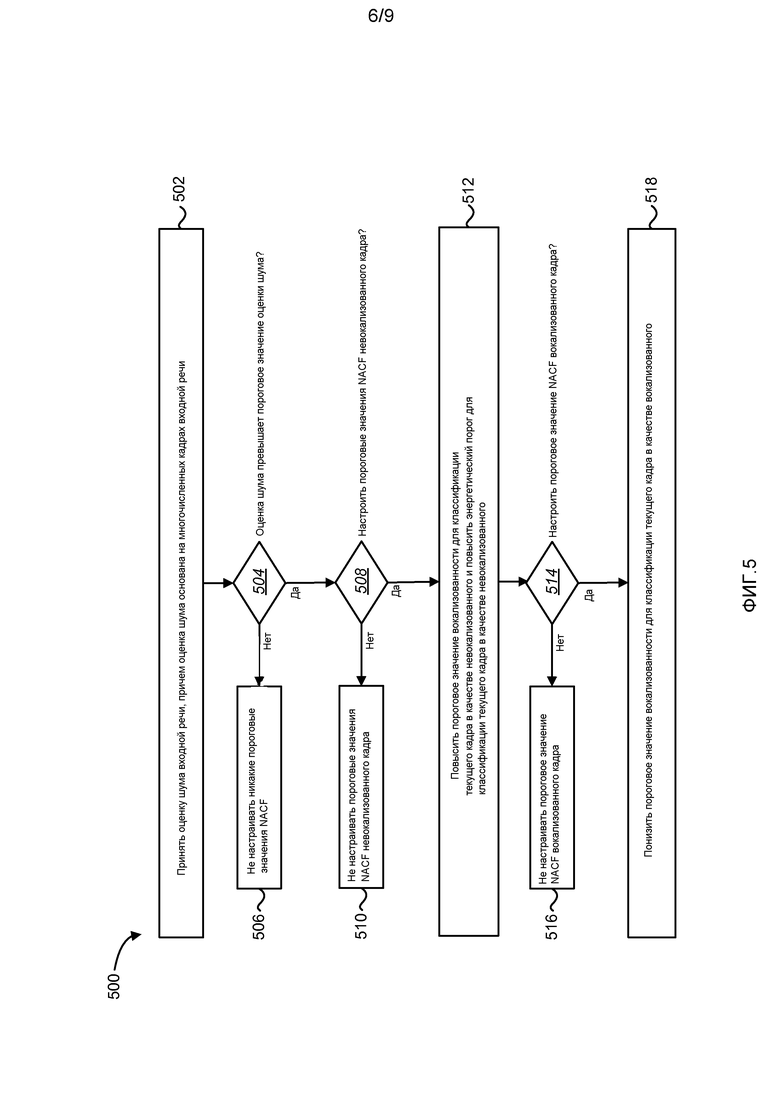
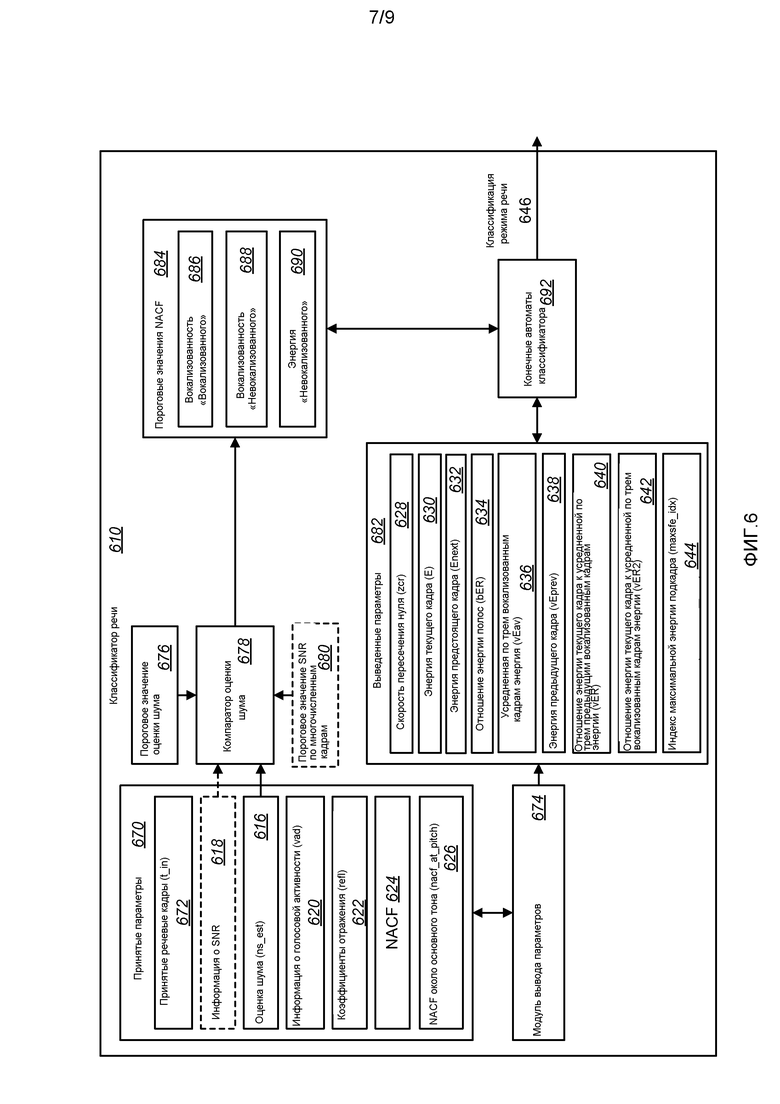
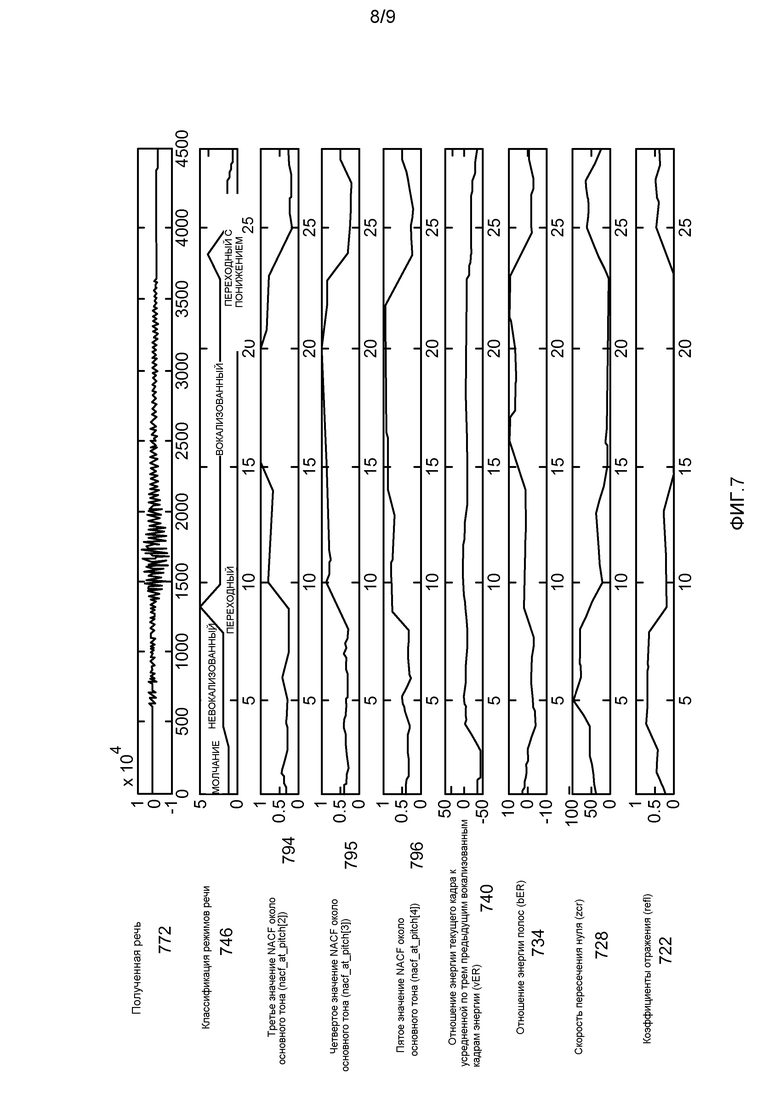
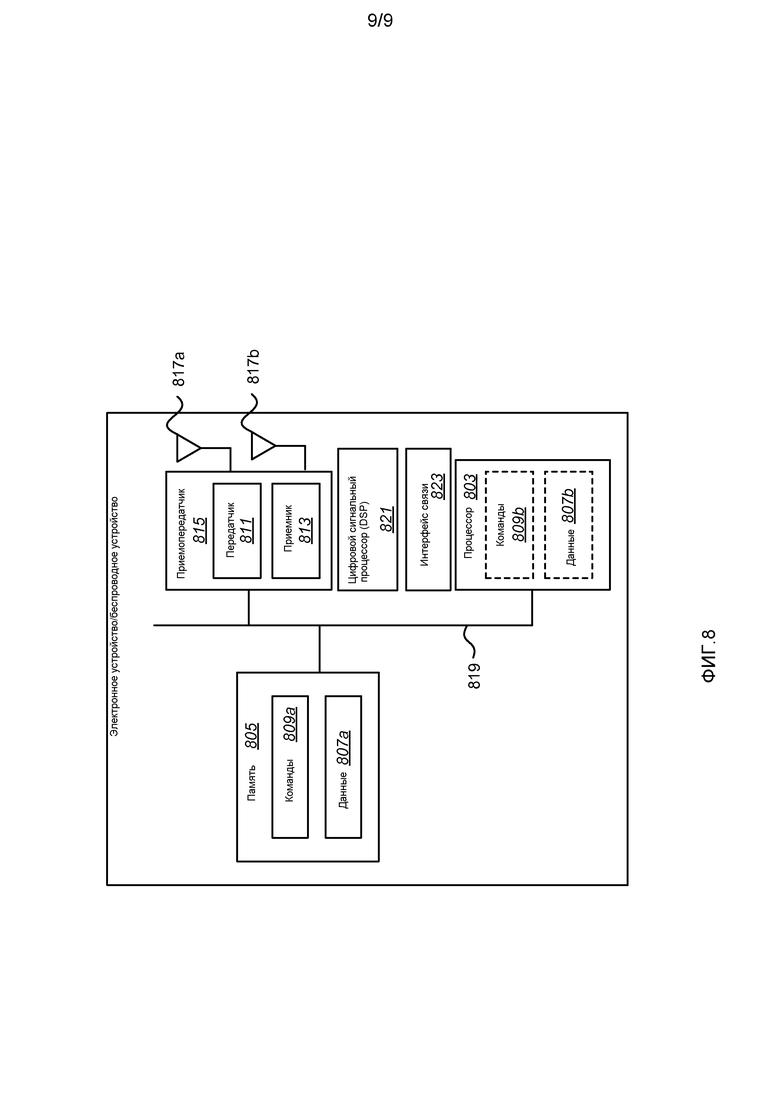
Изобретение относится к средствам помехоустойчивой классификации режимов кодирования речи. Технический результат заключается в повышении эффективности классификации режимов речи для повышения эффективности многорежимного кодирования с переменной скоростью передачи данных. Параметры классификации вводятся в классификатор речи из внешних компонентов. Внутренние параметры классификации формируются в классификаторе речи из по меньшей мере одного из входных параметров. Устанавливается пороговое значение нормированной функции коэффициентов автокорреляции. Анализатор параметров выбирается согласно среде распространения сигнала. Классификация режима речи определяется на основании оценки шума многочисленных кадров входной речи. 4 н. и 39 з.п. ф-лы, 11 ил., 6 табл.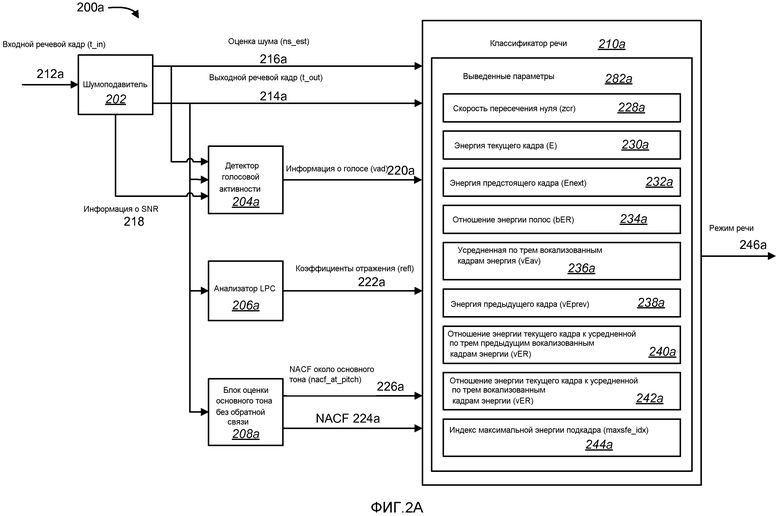
1. Способ помехоустойчивой классификации речи, содержащий этапы, на которых:
вводят параметры классификации в классификатор речи из внешних компонентов;
формируют в классификаторе речи внутренние параметры классификации из по меньшей мере одного из входных параметров классификации;
устанавливают пороговое значение нормированной функции коэффициентов автокорреляции, причем установка порогового значения нормированной функции коэффициентов автокорреляции содержит этапы, на которых:
- повышают первое пороговое значение вокализованности для классификации текущего кадра в качестве невокализованного, когда отношение сигнал/шум (SNR) не превышает первое пороговое значение SNR, при этом первое пороговое значение вокализованности не настраивают, если SNR выше первого порогового значения SNR, и
- повышают энергетический порог для классификации текущего кадра в качестве невокализованного, когда оценка шума превышает пороговое значение оценки шума, при этом энергетический порог не настраивают, если оценка шума ниже порогового значения оценки шума; и
определяют классификацию режима речи на основании первого порогового значения вокализованности и энергетического порога.
2. Способ по п. 1, в котором установка порогового значения нормированной функции коэффициентов автокорреляции дополнительно содержит этап, на котором снижают второе пороговое значение вокализованности для классификации текущего кадра в качестве вокализованного, когда SNR не превышает второе пороговое значение SNR, при этом второе пороговое значение вокализованности не настраивают, если SNR выше второго порогового значения SNR.
3. Способ по п. 1, в котором входные параметры содержат подвергнутый подавлению шумов речевой сигнал.
4. Способ по п. 1, в котором входные параметры содержат информацию о голосовой активности.
5. Способ по п. 1, в котором входные параметры содержат коэффициенты отражения линейного предсказания.
6. Способ по п. 1, в котором входные параметры содержат информацию о нормированной функции коэффициентов автокорреляции.
7. Способ по п. 1, в котором входные параметры содержат информацию о нормированной функции коэффициентов автокорреляции на основном тоне.
8. Способ по п. 7, в котором информация о нормированной функции коэффициентов автокорреляции на основном тоне является массивом значений.
9. Способ по п. 1, в котором внутренние параметры содержат параметр скорости пересечения нуля.
10. Способ по п. 1, в котором внутренние параметры содержат параметр энергии текущего кадра.
11. Способ по п. 1, в котором внутренние параметры содержат параметр энергии предстоящего кадра.
12. Способ по п. 1, в котором внутренние параметры содержат параметр отношения энергии полос, который характеризует отношение энергии текущего кадра в нижней полосе к энергии текущего кадра в верхней полосе.
13. Способ по п. 1, в котором внутренние параметры содержат параметр усредненной по трем вокализованным кадрам энергии.
14. Способ по п. 1, в котором внутренние параметры содержат параметр усредненной по трем предыдущим вокализованным кадрам энергии.
15. Способ по п. 1, в котором внутренние параметры содержат параметр отношения энергии текущего кадра к усредненной по трем предыдущим вокализованным кадрам энергии.
16. Способ по п. 1, в котором внутренние параметры содержат параметр отношения энергии текущего кадра к усредненной по трем вокализованным кадрам энергии.
17. Способ по п. 1, в котором внутренние параметры содержат параметр индекса максимальной энергии подкадра, который является индексом подкадра, имеющего максимальную энергию в текущем кадре.
18. Способ по п. 1, в котором установка порогового значения нормированной функции коэффициентов автокорреляции дополнительно содержит этап, на котором сравнивают оценку шума с предварительно определенным пороговым значением оценки сигнал/шум.
19. Способ по п. 1, в котором анализатор параметров применяет параметры к конечному автомату.
20. Способ по п. 19, в котором конечный автомат содержит состояние для каждого режима классификации речи.
21. Способ по п. 1, в котором классификация режимов речи содержит переходный режим.
22. Способ по п. 1, в котором классификация режимов речи содержит переходный режим с повышением.
23. Способ по п. 1, в котором классификация режимов речи содержит переходный режим с понижением.
24. Способ по п. 1, в котором классификация режимов речи содержит вокализованный режим.
25. Способ по п. 1, в котором классификация режимов речи содержит невокализованный режим.
26. Способ по п. 1, в котором классификация режимов речи содержит режим молчания.
27. Способ по п. 1, дополнительно содержащий этап, на котором обновляют по меньшей мере один параметр.
28. Способ по п. 27, в котором обновленный параметр содержит параметр нормированной функции коэффициентов автокорреляции на основном тоне.
29. Способ по п. 27, в котором обновленный параметр содержит параметр усредненной по трем вокализованным кадрам энергии.
30. Способ по п. 27, в котором обновленный параметр содержит параметр энергии предстоящего кадра.
31. Способ по п. 27, в котором обновленный параметр содержит параметр усредненной по предыдущим трем вокализованным кадрам энергии.
32. Способ по п. 27, в котором обновленный параметр содержит параметр обнаружения голосовой активности.
33. Устройство для помехоустойчивой классификации речи, содержащее:
процессор;
память в электронной связи с процессором;
команды, хранимые в памяти, причем команды являются выполняемыми процессором для:
ввода параметров классификации в классификатор речи из внешних компонентов;
формирования в классификаторе речи внутренних параметров классификации из по меньшей мере одного из входных параметров классификации;
установки порогового значения нормированной функции коэффициентов автокорреляции, причем команды, выполняемые для установки порогового значения нормированной функции коэффициентов автокорреляции, дополнительно содержат команды, выполняемые для:
- повышения первого порогового значения вокализованности для классификации текущего кадра в качестве невокализованного, когда отношение сигнал/шум (SNR) не превышает первое пороговое значение SNR, при этом первое пороговое значение вокализованности не настраивается, если SNR выше первого порогового значения SNR, и
- повышения энергетического порога для классификации текущего кадра в качестве невокализованного, когда оценка шума превышает пороговое значение оценки шума, при этом энергетический порог не настраивается, если оценка шума ниже порогового значения оценки шума; и
определения классификации режима речи на основании первого порогового значения вокализованности и энергетического порога.
34. Устройство по п. 33, в котором команды, выполняемые для установки порогового значения нормированной функции коэффициентов автокорреляции, дополнительно содержат команды, выполняемые для снижения второго порогового значения вокализованности для классификации текущего кадра в качестве вокализованного, когда SNR не превышает второе пороговое значение SNR, при этом второе пороговое значение вокализованности не настраивается, если SNR выше второго порогового значения SNR.
35. Устройство по п. 33, в котором входные параметры содержат одно или более из подвергнутого подавлению шумов речевого сигнала, информации о голосовой активности, коэффициентов отражения линейного предсказания, информации о нормированной функции коэффициентов автокорреляции и информации о нормированной функции коэффициентов автокорреляции на основном тоне.
36. Устройство по п. 35, в котором информация о нормированной функции коэффициентов автокорреляции на основном тоне является массивом значений.
37. Устройство по п. 35, в котором внутренние параметры содержат один или более из параметра скорости пересечения нуля, параметра энергии текущего кадра, параметра энергии предстоящего кадра, параметра отношения энергии полос, который характеризует отношение энергии текущего кадра в нижней полосе к энергии текущего кадра в верхней полосе, параметра усредненной по трем вокализованным кадрам энергии, параметра усредненной по предыдущим трем вокализованным кадрам энергии, параметра отношения энергии текущего кадра к усредненной по трем предыдущим вокализованным кадрам энергии, параметра отношения энергии текущего кадра к усредненной по трем вокализованным кадрам энергии и параметра индекса максимальной энергии подкадра, который является индексом подкадра, имеющего максимальную энергию в текущем кадре.
38. Устройство по п. 33, дополнительно содержащее команды, выполняемые для обновления по меньшей мере одного параметра.
39. Устройство по п. 38, в котором обновленный параметр содержит один или более из параметра нормированной функции коэффициентов автокорреляции на основном тоне, параметра усредненной по трем вокализованным кадрам энергии, параметра энергии предстоящего кадра, параметра усредненной по предыдущим трем вокализованным кадрам энергии и параметра обнаружения голосовой активности.
40. Устройство для помехоустойчивой классификации речи, содержащее:
средство для ввода параметров классификации в классификатор речи из внешних компонентов;
средство для формирования в классификаторе речи внутренних параметров классификации из по меньшей мере одного из входных параметров классификации;
средство для установки порогового значения нормированной функции коэффициентов автокорреляции, причем средство для установки порогового значения нормированной функции коэффициентов автокорреляции содержит:
- средство для повышения первого порогового значения вокализованности для классификации текущего кадра в качестве невокализованного, когда отношение сигнал/шум (SNR) не превышает первое пороговое значение SNR, при этом первое пороговое значение вокализованности не настраивается, если SNR выше первого порогового значения SNR, и
- средство для повышения энергетического порога для классификации текущего кадра в качестве невокализованного, когда оценка шума превышает пороговое значение оценки шума, при этом энергетический порог не настраивается, если оценка шума ниже порогового значения оценки шума; и
средство для определения классификации режима речи на основании первого порогового значения вокализованности и энергетического порога.
41. Устройство по п. 40, в котором средство для установки порогового значения нормированной функции коэффициентов автокорреляции дополнительно содержит средство для снижения второго порогового значения вокализованности для классификации текущего кадра в качестве вокализованного, когда SNR не превышает второе пороговое значение SNR, при этом второе пороговое значение вокализованности не настраивается, если SNR выше второго порогового значения SNR.
42. Компьютерно-читаемый носитель, хранящий компьютерно-исполняемый код для помехоустойчивой классификации речи, причем компьютерно-исполняемый код содержит:
код для ввода параметров классификации в классификатор речи из внешних компонентов;
код для формирования в классификаторе речи внутренних параметров классификации из по меньшей мере одного из входных параметров классификации;
код для установки порогового значения нормированной функции коэффициентов автокорреляции, причем код для установки порогового значения нормированной функции коэффициентов автокорреляции содержит:
- код для повышения первого порогового значения вокализованности для классификации текущего кадра в качестве невокализованного, когда оценка шума превышает пороговое значение оценки шума, отношение сигнал/шум (SNR) не превышает первое пороговое значение SNR, при этом первое пороговое значение вокализованности не настраивается, если SNR выше первого порогового значения SNR, и
- код для повышения энергетического порога для классификации текущего кадра в качестве невокализованного, когда оценка шума превышает пороговое значение оценки шума, при этом пороговое значение вокализованности и энергетический порог не настраивается, если оценка шума ниже порогового значения оценки шума; и
код для определения классификации режима речи на основании первого порогового значения вокализованности и энергетического порога.
43. Компьютерно-читаемый носитель по п. 42, в котором код для установки порогового значения нормированной функции коэффициентов автокорреляции содержит код для снижения второго порогового значения вокализованности для классификации текущего кадра в качестве вокализованного, когда SNR не превышает второе пороговое значение SNR, при этом второе пороговое значение вокализованности не настраивается, если SNR выше порогового значения SNR.
| US 2002111798 A1, 15.08.2002 | |||
| US 2009319261 A1, 24.12.2009 | |||
| US 2011035213 A1, 10.02.2011 | |||
| US 5742734 A, 21.04.1998 | |||
| US 2002120440 A1, 29.08.2002 | |||
| US 2001001853 A1, 24.05.2001 | |||
| US 5727123 A, 10.03.1998 | |||
| US 5784532 A, 21.07.1998 | |||
| СПОСОБ СЖАТИЯ РЕЧЕВОГО СИГНАЛА ПУТЕМ КОДИРОВАНИЯ С ПЕРЕМЕННОЙ СКОРОСТЬЮ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ, КОДЕР И ДЕКОДЕР | 1993 |
|
RU2107951C1 |

