Область техники, к которой относится изобретение
Изобретение относится к устройству кодирования и способу кодирования, используемым в системе связи, которая кодирует и передает входные сигналы, например, речевые сигналы.
Уровень техники
В системах мобильной связи требуется сжатие речевых сигналов для их передачи с низкими скоростями передачи битов с целью эффективного использования ресурсов радиоволн и т.д. С другой стороны, также требуется повысить качество речи при телефонном вызове и обеспечить высокую точность воспроизведения, причем для удовлетворения этих требований предпочтительно не только обеспечить высококачественные речевые сигналы, но также кодировать другие высококачественные сигналы, отличные от речевых сигналов, такие как высококачественные аудиосигналы, имеющие более широкую полосу.
Для этих двух противоречивых требований предлагается технология интегрирования множества способов кодирования в уровни. Эта технология объединяет базовый уровень для кодирования входных сигналов в виде, пригодном для речевых сигналов с низкими скоростями передачи битов, и уровень улучшения для кодирования дифференциальных сигналов, представляющих разность между входными сигналами и декодированными сигналами базового уровня, в виде, пригодном для других сигналов, отличающихся от речи. Технология выполнения многоуровневого кодирования в этом случае имеет характеристики, обеспечивающие масштабируемость в битовых потоках, получаемых от кодирующего устройства, то есть получение декодированных сигналов из части информации в битовых потоках, и поэтому такой способ обычно называют «масштабируемым кодированием (многоуровневым кодированием)».
Схема масштабируемого кодирования благодаря своим характеристикам может гибко поддерживать связь между сетями с изменяющимися скоростями передачи битов, и, следовательно, эта схема пригодна для будущей сетевой среды, в которой будут интегрированы различные сети с помощью протокола IP (протокол сети Интернет). Например, в не патентном документе 1 раскрыт способ реализации масштабируемого кодирования с использованием технологии согласно стандарту MPEG-4 (стандарт Экспертной группы по вопросам движущегося изображения, Фаза 4). В этом способе на базовом уровне используется кодирование с линейным предсказанием и возбуждением кода (CELP), пригодное для речевых сигналов, а на уровне улучшения - кодирование с преобразованием, такое как в усовершенствованном аудиокодере (AAC), а также квантование вектора взвешенного чередования в области преобразования(TwinVQ) применительно к остаточным сигналам, являющимся результатом вычитания декодированного сигнала базового уровня из исходного сигнала.
Кроме того, для гибкой поддержки сетевой среды, в которой скорость передачи динамически флуктуирует из-за передачи обслуживания между сетями разных типов и возникновения перегрузки, необходимо реализовать масштабируемое кодирование со скоростями передачи битов малого масштаба, причем такое масштабируемое кодирование должно быть сконфигурировано посредством обеспечения множества уровней с низкими скоростями передачи битов.
В патентном документе 1 и патентном документе 2 раскрыт способ кодирования с преобразованием, состоящий в преобразовании сигнала, подлежащего кодированию, в частотной области и кодировании результирующего сигнала частотной области. При указанном кодировании с преобразованием сначала вычисляют энергетическую составляющую сигнала в частотной области, то есть коэффициент усиления (иными словами, масштабный коэффициент), а затем выполняют квантование по каждой субполосе, после чего вычисляют и квантуют точную компоненту вышеуказанного сигнала в частотной области, то есть вектор формы.
Не патентный документ 1: «All about MPEG-4», написанный и отредактированный Sukeichi MIKI, первая редакция, Kogyo Chosakai Publishing Inc, 30 сентября 1998 г., стр. 126-127.
Патентный документ 1: Японский перевод опубликованной патентной заявки PCT № 2006-513457.
Патентный документ 2: Опубликованная патентная заявка Японии № HEI7-261800.
Раскрытие изобретения
Проблемы, решаемые изобретением
При последовательном квантовании двух следующих один за другим параметров, тот параметр, который квантуется позже, искажается под воздействием параметра, квантуемого ранее, что приводит к повышенному искажению квантования. Таким образом, имеет место общая тенденция, состоящая в том, что при кодировании с преобразованием, раскрытом в патентном документе 1 и патентном документе 2, при квантовании по порядку вектора усиления и вектора формы наблюдается повышенное искажение квантования векторов формы, которые оказываются не способными точно представлять форму спектра. Эта проблема порождает значительное ухудшение качества в отношении сигналов насыщенной тональности, таких как гласные звуки, то есть сигналы, имеющие спектральные характеристики, на которых наблюдается множество пиков. Эта проблема отчетливо проявляется при реализации пониженной скорости передачи битов.
Таким образом, целью настоящего изобретения является создание устройства кодирования и способа кодирования для точного кодирования спектральных форм сигналов насыщенной тональности, таких как гласные звуки, то есть спектральных форм сигналов, имеющих спектральные характеристики, на которых наблюдается множество пиков, и для повышения качества декодированных сигналов, например, качества звучания декодированных сигналов.
Средство решения проблемы
В устройстве кодирования согласно настоящему изобретению используется конфигурация, включающая в себя секцию кодирования базового уровня, которая кодирует входной сигнал для получения кодированных данных базового уровня; секцию декодирования базового уровня, которая декодирует кодированные данные базового уровня для получения декодированного сигнала базового уровня; и секцию кодирования уровня улучшения, которая кодирует остаточный сигнал, представляющий разность между входным сигналом и декодированным сигналом базового уровня, для получения кодированных данных уровня улучшения, и причем секция кодирования уровня улучшения имеет секцию разделения, которая разделяет остаточный сигнал на множество субполос; первую секцию кодирования вектора формы, которая кодирует множество субполос для получения первой кодированной информации о форме и которая вычисляет целевые коэффициенты усиления для множества субполос; секцию формирования вектора усиления, которая формирует один вектор усиления с использованием множества целевых коэффициентов усиления; и секцию кодирования вектора усиления, которая кодирует вектор усиления для получения первой кодированной информации усиления.
Способ кодирования согласно настоящему изобретению включает в себя разделение коэффициентов преобразования, полученных путем преобразования входного сигнала в частотной области, на множество субполос; кодирование коэффициентов преобразования множества субполос для получения первой кодированной информации о форме и вычисление целевых коэффициентов усиления коэффициентов преобразования множества субполос; формирование одного вектора усиления с использованием множества целевых коэффициентов усиления и кодирование вектора усиления для получения первой кодированной информации усиления.
Положительные эффекты изобретения
Настоящее изобретение может более точно кодировать спектральные формы сигналов насыщенной тональности, таких как гласные звуки, то есть спектральные формы сигналов, имеющих спектральные характеристики, на которых наблюдается множество пиков, и повышает качество декодированных сигналов, например, качество звучания декодированных сигналов.
Краткое описание чертежей
Фиг. 1 - блок-схема, показывающая основную конфигурацию устройства речевого кодирования согласно варианту осуществления 1 настоящего изобретения;
фиг. 2 - блок-схема, показывающая внутреннюю конфигурацию секции кодирования второго уровня согласно варианту осуществления 1 настоящего изобретения;
фиг. 3 - блок-схема последовательности операций, показывающая этапы обработки при кодировании второго уровня в секции кодирования второго уровня согласно варианту осуществления 1 настоящего изобретения;
фиг. 4 - блок-схема, показывающая внутреннюю конфигурацию секции кодирования вектора формы согласно варианту осуществления 1 настоящего изобретения;
фиг. 5 - блок-схема, показывающая внутреннюю конфигурацию секции формирования вектора усиления согласно варианту осуществления 1 настоящего изобретения;
фиг. 6 - подробная иллюстрация работы секции размещения целевого коэффициента усиления согласно варианту осуществления 1 настоящего изобретения;
фиг. 7 - блок-схема, показывающая внутреннюю конфигурацию секции кодирования вектора усиления согласно варианту осуществления 1 настоящего изобретения;
фиг. 8 - блок-схема, показывающая основную конфигурацию устройства речевого декодирования согласно варианту осуществления 1 настоящего изобретения;
фиг. 9 - блок-схема, показывающая внутреннюю конфигурацию секции декодирования второго уровня согласно варианту осуществления 1 настоящего изобретения;
фиг. 10 - иллюстрация кодового словаря векторов формы согласно варианту осуществления 2 настоящего изобретения;
фиг. 11 - иллюстрация множества векторов-кандидатов формы, входящих в кодовый словарь векторов формы, согласно варианту осуществления 2 настоящего изобретения;
фиг. 12 - блок-схема, показывающая внутреннюю конфигурацию секции кодирования второго уровня согласно варианту осуществления 3 настоящего изобретения;
фиг. 13 - иллюстрация обработки при выборе диапазона в секции выбора диапазона согласно варианту осуществления 3 настоящего изобретения;
фиг. 14 - блок-схема, показывающая внутреннюю конфигурацию секции декодирования второго уровня согласно варианту осуществления 3 настоящего изобретения;
фиг. 15 - вариант секции выбора диапазона согласно варианту осуществления 3 настоящего изобретения;
фиг. 16 - вариант способа выбора диапазона в секции выбора диапазона согласно варианту осуществления 3 настоящего изобретения;
фиг. 17 - блок-схема, показывающая вариант конфигурации секции выбора диапазона согласно варианту осуществления 3 настоящего изобретения;
фиг. 18 - иллюстрация того, каким образом формируется информация о диапазоне в секции формирования информации о диапазоне согласно варианту осуществления 3 настоящего изобретения;
фиг. 19 - иллюстрация работы варианта секции создания коэффициентов преобразования ошибки первого уровня согласно варианту осуществления 3 настоящего изобретения;
фиг. 20 - вариант способа выбора диапазона в секции выбора диапазона согласно варианту осуществления 3 настоящего изобретения;
фиг. 21 - вариант способа выбора диапазона в секции выбора диапазона согласно варианту осуществления 3 настоящего изобретения;
фиг. 22 - блок-схема, показывающая внутреннюю конфигурацию секции кодирования второго уровня согласно варианту осуществления 4 настоящего изобретения;
фиг. 23 - блок-схема, показывающая основную конфигурацию устройства речевого кодирования согласно варианту осуществления 5 настоящего изобретения;
фиг. 24 - блок-схема, показывающая основную внутреннюю конфигурацию секции кодирования первого уровня согласно варианту осуществления 5 настоящего изобретения;
фиг. 25 - блок-схема, показывающая основную внутреннюю конфигурацию секции декодирования первого уровня согласно варианту осуществления 5 настоящего изобретения;
фиг. 26 - блок-схема, показывающая основную конфигурацию устройства речевого декодирования согласно варианту осуществления 5 настоящего изобретения;
фиг. 27 - блок-схема, показывающая основную конфигурацию устройства речевого кодирования согласно варианту осуществления 6 настоящего изобретения;
фиг. 28 - блок-схема, показывающая основную конфигурацию устройства речевого декодирования согласно варианту осуществления 6 настоящего изобретения;
фиг. 29 - блок-схема, показывающая основную конфигурацию устройства речевого кодирования согласно варианту осуществления 7 настоящего изобретения;
фиг. 30 - иллюстрация обработки при выборе диапазона, подлежащего кодированию, при обработке кодирования в устройстве речевого кодирования согласно варианту осуществления 7 настоящего изобретения;
фиг. 31 - блок-схема, показывающая основную конфигурацию устройства речевого декодирования согласно варианту осуществления 7 настоящего изобретения;
фиг. 32 - иллюстрация случая, когда цель, подлежащую кодированию, выбирают из диапазонов-кандидатов, размещенных с равными интервалами, при обработке кодирования в устройстве речевого кодирования согласно варианту осуществления 7 настоящего изобретения;
фиг. 33 - иллюстрация случая, когда цель, подлежащую кодированию, выбирают из диапазонов-кандидатов, размещенных с равными интервалами, при обработке кодирования в устройстве речевого кодирования согласно варианту осуществления 7 настоящего изобретения.
Осуществление изобретения
Далее со ссылками на сопроводительные чертежи подробно объясняются варианты осуществления настоящего изобретения. В качестве пояснительного примера устройства кодирования/устройства декодирования согласно настоящему изобретению будет использовано устройство речевого кодирования/устройство речевого декодирования.
(Вариант осуществления 1)
На фиг. 1 представлена блок-схема, иллюстрирующая основную конфигурацию устройства 100 речевого кодирования согласно варианту осуществления 1 настоящего изобретения. Здесь раскрывается пример, где в устройстве речевого кодирования и устройстве речевого декодирования согласно настоящему изобретению используется масштабируемая конфигурация с двумя уровнями. Первый уровень образует базовый уровень, а второй уровень образует уровень улучшения.
На фиг. 1 устройство 100 речевого кодирования имеет секцию 101 преобразования частотной области, секцию 102 кодирования первого уровня, секцию 103 декодирования первого уровня, вычитатель 104, секцию 105 кодирования второго уровня и секцию 106 мультиплексирования.
Секция 101 преобразования частотной области преобразует входной сигнал временной области в сигнал частотной области и выводит результирующие входные коэффициенты преобразования в секцию 102 кодирования первого уровня и вычитатель 104.
Секция 102 кодирования первого уровня выполняет обработку кодирования применительно к входным коэффициентам преобразования, полученным от секции 101 преобразования частотной области, и выводит результирующие кодированные данные первого уровня в секцию 103 декодирования первого уровня и секцию 106 мультиплексирования.
Секция 103 декодирования первого уровня выполняет обработку декодирования с использованием кодированных данных первого уровня, полученных от секции 102 кодирования первого уровня, и выводит результирующие декодированные коэффициенты преобразования первого уровня в вычитатель 104.
Вычитатель 104 вычитает декодированные коэффициенты преобразования первого уровня, полученные от секции 103 декодирования первого уровня, из входных коэффициентов преобразования, полученных от секции 101 преобразования частотной области, и выводит результирующие коэффициенты преобразования ошибки первого уровня в секцию 105 кодирования второго уровня.
Секция 105 кодирования второго уровня выполняет обработку кодирования применительно к коэффициентам преобразования ошибки первого уровня, полученным от вычитателя 104, и выводит результирующие кодированные данные второго уровня в секцию 106 мультиплексирования. Секция 105 кодирования второго уровня подробно описывается ниже.
Секция 106 мультиплексирования мультиплексирует кодированные данные первого уровня, полученные от секции 102 кодирования первого уровня, и кодированные данные второго уровня, полученные от секции 105 кодирования второго уровня, и выводит результирующий битовый поток в канал передачи.
На фиг. 2 представлена блок-схема, иллюстрирующая внутреннюю конфигурацию секции 105 кодирования второго уровня.
На фиг. 2 секция 105 кодирования второго уровня содержит секцию 151 формирования субполос, секцию 152 кодирования вектора формы, секцию 153 формирования вектора усиления, секцию 154 кодирования вектора усиления и секцию 155 мультиплексирования.
Секция 151 формирования субполос разделяет коэффициенты преобразования ошибки первого уровня, полученные от вычитателя 104, на М субполос и выводит результирующие коэффициенты преобразования М субполос в секцию 152 кодирования вектора формы. Здесь, если коэффициенты преобразования ошибки первого уровня представить как e1(k), то коэффициенты преобразования e(m,k) m-й полосы (где 0≤m≤M-1) можно представить следующим уравнением 1.
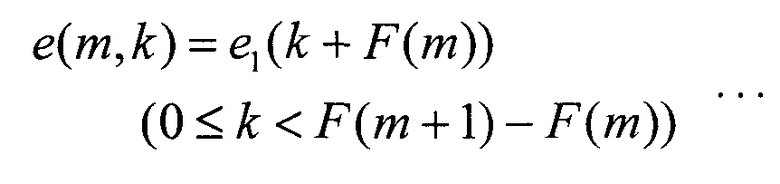
В уравнении 1 F(m) представляет частоту на границе в каждой субполосе, причем выполняется неравенство в виде 0≤F(0)<F(1)<…<F(M)≤FH. Здесь FH представляет максимальную частоту коэффициентов преобразования ошибки первого уровня, и предполагается, что m является целым числом, причем 0≤m≤M-1.
Секция 152 кодирования векторов формы выполняет квантование вектора формы применительно к коэффициентам преобразования М субполос, последовательно получаемых от секции 151 формирования субполос, для создания кодированной информации о форме для М субполос и вычисляет целевые коэффициенты усиления коэффициентов преобразования М субполос. Секция 152 кодирования вектора формы выводит созданную кодированную информацию о форме в секцию 155 мультиплексирования и выводит целевые коэффициенты в секцию 153 формирования вектора усиления. Подробное описание секции 152 кодирования векторов формы приведено ниже.
Секция 153 формирования вектора усиления формирует один вектор усиления с М целевыми коэффициентами усиления, полученными от секции 152 кодирования вектора формы, и выводит этот вектор усиления в секцию 154 кодирования вектора усиления. Подробное описание секции 153 формирования вектора усиления приведено ниже.
Секция 154 кодирования вектора усиления выполняет векторное квантование с использованием в качестве целевого значения вектора усиления, полученного от секции 153 формирования вектора усиления, и выводит результирующую кодированную информацию усиления в секцию 155 мультиплексирования. Подробное описание секции 154 кодирования вектора усиления приведено ниже.
Секция 155 мультиплексирования мультиплексирует кодированную информацию о форме, полученную от секции 152 кодирования вектора формы, и кодированную информацию усиления, полученную от секции 154 кодирования вектора усиления, и выводит результирующий битовый поток в качестве кодированных данных второго уровня в секцию 106 мультиплексирования.
На фиг. 3 показана блок-схема последовательности операций, иллюстрирующая этапы обработки кодирования второго уровня в секции 105 кодирования второго уровня.
Сначала, на этапе (далее сокращенно «ST») 1010 секция 151 формирования субполос разделяет коэффициенты преобразования ошибки первого уровня на М субполос для формирования коэффициентов преобразования М субполос.
Далее на этапе ST 1020 секция 105 кодирования второго уровня инициализирует (устанавливает в «0») счетчик m субполос, отсчитывающий субполосы.
Затем на этапе ST 1030 секция 152 кодирования вектора формы выполняет кодирование вектора формы применительно к коэффициентам преобразования m-й полосы для создания кодированной информации о форме для m-й полосы и создает целевой коэффициент усиления коэффициентов преобразования m-й полосы.
Затем на этапе ST 1040 секция 105 кодирования второго уровня увеличивает значение счетчика m субполос на единицу.
После этого на этапе ST 1050 секция 105 кодирования второго уровня определяет, выполняется ли неравенство m<M.
На этапе ST 1050, если определено, что неравенство m<M выполняется (ST 1050: «ДА»), секция 105 кодирования второго уровня возвращается к шагу ST 1030 обработки.
В противном случае, если на этапе ST 1050 определяется, что неравенство m<M не выполняется (ST 1050: «НЕТ»), то секция 153 формирования вектора усиления на этапе ST 1060 формирует один вектор усиления с использованием М целевых коэффициентов усиления.
Далее на этапе ST 1070 секция 154 кодирования вектора усиления выполняет векторное квантование с использованием в качестве целевого значения вектора усиления, сформированного в секции 153 формирования вектора усиления, для создания кодированной информации усиления.
Затем на этапе ST 1080 секция 155 мультиплексирования мультиплексирует кодированную информацию о форме, созданную в секции 152 кодирования вектора формы, и кодированную информацию усиления, созданную в секции 154 кодирования вектора усиления.
На фиг. 4 представлена блок-схема, показывающая внутреннюю конфигурацию секции 152 кодирования вектора формы.
На фиг. 4 секция 152 кодирования вектора формы имеет кодовый словарь 521 векторов формы, секцию 522 вычисления взаимной корреляции, секцию 523 вычисления автокорреляции, секцию 524 поиска и секцию 525 вычисления целевого коэффициента усиления.
В кодовом словаре 521 векторов формы хранится множество векторов-кандидатов формы, представляющих форму коэффициентов преобразования ошибки первого уровня, причем кодовый словарь 521 последовательно выдает векторы-кандидаты формы в секцию 522 вычисления взаимной корреляции и секцию 523 вычисления автокорреляции на основе сигнала управления, полученного от секции 524 поиска. Кроме того, обычно имеют место случаи, когда кодовый словарь векторов формы выбирает режим постоянной защиты места хранения и запоминания векторов-кандидатов формы, а также имеют место случаи, когда кодовый словарь векторов формы формирует векторы-кандидаты формы в соответствии с заранее определенными этапами обработки. В последних случаях нет необходимости постоянно защищать пространство хранения. Хотя в настоящем варианте осуществления изобретения можно использовать любой из кодовых словарей векторов формы, при дальнейшем объяснении предполагается, что здесь предусмотрен кодовый словарь 521 векторов формы, в котором хранятся векторы-кандидаты формы, как показано на фиг. 4. Далее i-й вектор-кандидат формы среди множества векторов-кандидатов формы, хранящихся в кодовом словаре 521 векторов формы, представлен как c(i,k). Здесь k представляет k-й элемент из множества элементов, образующих вектор-кандидат формы.
Секция 522 вычисления взаимной корреляции вычисляет взаимную корреляцию ccor(i) между коэффициентами преобразования m-й субполосы, полученными от секции 151 формирования субполос, и i-м вектором-кандидатом формы, полученным из кодового словаря 521 векторов формы, согласно следующему уравнению 2 и выводит взаимную корреляцию ccor(i) в секцию 524 поиска и секцию 525 вычисления целевого коэффициента усиления.
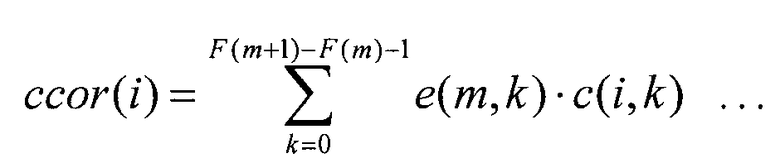
Секция 523 вычисления автокорреляции вычисляет автокорреляцию acor(i) возможного вектора формы c(i,k), полученного из кодового словаря 521 векторов формы, согласно следующему уравнению 3 и выводит автокорреляцию acor(i) в секцию 524 поиска и секцию 525 вычисления целевого коэффициента усиления.
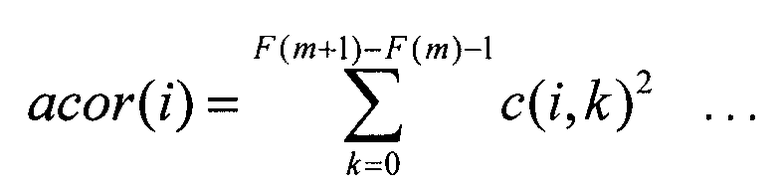
Секция 524 поиска вычисляет вклад А, представленный следующим уравнением 4, с использованием взаимной корреляции ccor(i), полученной от секции 522 вычисления взаимной корреляции, и автокорреляции acor(i), полученной от секции 523 вычисления автокорреляции, и выводит сигнал управления в кодовый словарь 521 векторов формы, пока не будет найдено максимальное значение вклада А. Секция 524 поиска выводит индекс iopt вектора-кандидата формы при максимальном вкладе А в качестве оптимального индекса в секцию 525 вычисления целевого коэффициента усиления и выводит индекс iopt в качестве кодированной информации о форме в секцию 155 мультиплексирования.
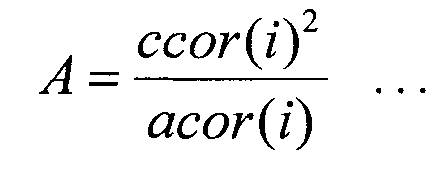
Секция 525 вычисления целевого коэффициента усиления вычисляет целевой коэффициент усиления согласно следующему уравнению 5 с использованием взаимной корреляции ccor(i), полученной от секции 522 вычисления взаимной корреляции, автокорреляции acor(i), полученной от секции 523 вычисления автокорреляции, и оптимального индекса iopt, полученного от секции 524 поиска, и выводит этот целевой коэффициент усиления в секцию 153 формирования вектора усиления.
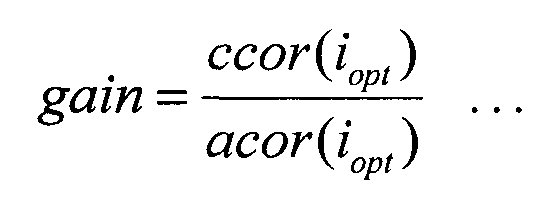
На фиг. 5 представлена блок-схема, показывающая внутреннюю конфигурацию секции 153 формирования вектора усиления.
На фиг. 5 секция 153 формирования вектора усиления имеет секцию 531 определения позиции размещения и секцию 532 размещения целевого коэффициента усиления.
Секция 531 определения позиции размещения содержит счетчик, который имеет «0» в качестве начального значения, и увеличивает свое значение на единицу каждый раз, когда от секции 152 кодирования вектора формы принимается целевой коэффициент усиления, а при достижении значения счетчика величины, равной общему количеству субполос М, вновь устанавливает значение счетчика, равное нулю. Здесь М также является длиной вектора усиления, сформированного в секции 153 формирования вектора усиления, а обработка в счетчике, предусмотренном в секции 531 определения позиции размещения, эквивалентна делению значения счетчика на длину вектора усиления и нахождению остатка. То есть предполагается, что значение счетчика является целым числом между «0» и «М-1». При каждом обновлении значения счетчика секция 531 определения позиции размещения выводит обновленное значение счетчика в качестве информации о размещении в секцию 532 размещения целевого коэффициента усиления.
Секция 532 размещения целевого коэффициента усиления имеет М буферов, начальным значением которых предполагается «0», и переключатель, который размещает целевой коэффициент усиления, полученный от секции 152 кодирования вектора усиления, в каждом буфере, причем этот переключатель размещает целевой коэффициент усиления, полученный от секции 152 кодирования вектора формы, в том буфере, которому в виде номера присвоено значение, указанное в информации о размещении, полученной от секции 531 определения позиции размещения.
На фиг. 6 показана работа секции 532 размещения целевого коэффициента усиления.
На фиг. 6, когда информация о размещении, введенная в переключатель, указывает «0», целевой коэффициент усиления размещается в 0-м буфере, а когда информация о размещении указывает «M-1», целевой коэффициент усиления размещается в (M-1)-м буфере. Когда целевые коэффициенты усиления размещены по всем буферам, секция 532 размещения целевого коэффициента усиления выводит вектор усиления, образованный целевыми коэффициентами усиления, размещенными в М буферах, в секцию 154 кодирования вектора усиления.
На фиг. 7 представлена блок-схема, показывающая внутреннюю конфигурацию секции 154 кодирования вектора усиления.
На фиг. 7 секция 154 кодирования вектора усиления содержит кодовый словарь 541 векторов усиления, секцию 542 вычисления ошибки и секцию 543 поиска.
В кодовом словаре 541 векторов усиления хранится множество векторов-кандидатов усиления, представляющих вектор усиления, причем кодовый словарь 541 последовательно выводит векторы-кандидаты усиления в секцию 542 вычисления ошибки на основании сигнала управления, полученного от секции 543 поиска. Кроме того, обычно имеют место случаи, когда кодовый словарь векторов усиления выбирает режим постоянной защиты места хранения и запоминания векторов-кандидатов усиления, и имеют место случаи, когда кодовый словарь векторов усиления формирует векторы-кандидаты усиления в соответствии с заранее определенными этапами обработки. В последних случаях нет необходимости постоянно защищать место хранения. Хотя в настоящем варианте осуществления изобретения можно использовать любой из кодовых словарей векторов усиления, пояснения к настоящему варианту осуществления приведены ниже в предположении, что предусмотрен кодовый словарь 541 векторов усиления, где хранятся векторы-кандидаты усиления, как показано на фиг. 7. Далее j-й вектор-кандидат усиления из множества векторов-кандидатов усиления, хранящихся в кодовом словаре 541 векторов усиления, представлен как g(j,m). Здесь m представляет m-й элемент из М элементов, образующих вектор-кандидат усиления.
Секция 542 вычисления ошибки вычисляет ошибку E(j) согласно следующему уравнению 6 с использованием вектора усиления, полученного от секции 153 формирования вектора усиления, и возможного вектора усиления, полученного из кодового словаря 541 векторов усиления, и выводит ошибку E(j) в секцию 543 поиска.
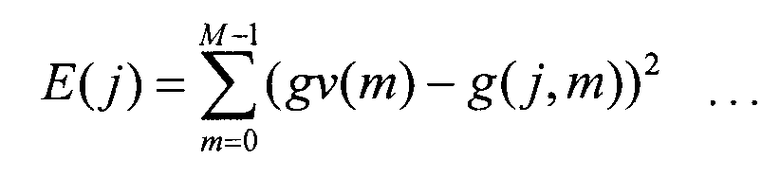
В уравнении 6 m представляет номер субполосы, а gv(m) представляет вектор усиления, полученный от секции 153 формирования вектора усиления.
Секция 543 поиска выводит сигнал управления в кодовый словарь 541 векторов усиления, пока не будет найдено минимальное значение ошибки E(j), полученной от секции 542 вычисления ошибки, ищет индекс iopt минимальной ошибки E(j) и выводит индекс iopt в качестве кодированной информации усиления в секцию 155 мультиплексирования.
На фиг. 8 представлена блок-схема, показывающая основную конфигурацию устройства 200 речевого декодирования согласно настоящему варианту осуществления.
На фиг. 8 устройство 200 речевого декодирования содержит секцию 201 демультиплексирования, секцию 202 декодирования первого уровня, секцию 203 декодирования второго уровня, сумматор 204, секцию 205 переключения, секцию 206 преобразования временной области и пост-фильтр 207.
Секция 201 демультиплексирования демультиплексирует битовый поток, переданный от устройства 100 речевого кодирования через канал передачи на кодированные данные первого уровня и кодированные данные второго уровня и выводит кодированные данные первого уровня и кодированные данные второго уровня в секцию 202 декодирования первого уровня и секцию 203 декодирования второго уровня соответственно. Однако в зависимости от состояния канала передачи (например, появление перегрузки) имеют место случаи, когда часть кодированных данных, таких как кодированные данные второго уровня или кодированные данные, включающие в себя кодированные данные первого уровня и кодированные данные второго уровня, теряются. Тогда секция 201 демультиплексирования определяет, содержатся ли в полученных кодированных данных только кодированные данные первого уровня или кодированные данные и первого, и второго уровней, причем в первом случае в качестве информации уровня выводится «1», а во втором случае в качестве информации уровня выводится «2». Кроме того, если определено, что все кодированные данные, включая кодированные данные первого уровня и кодированные данные второго уровня, потеряны, секция 201 демультиплексирования выполняет заранее определенную обработку компенсации для создания кодированных данных первого уровня и кодированных данных второго уровня, выводит кодированные данные первого уровня и кодированные данные второго уровня в секцию 202 декодирования первого уровня и секцию 203 декодирования второго уровня соответственно и выводит «2» в качестве информации уровня в секцию 205 переключения.
Секция 202 декодирования первого уровня выполняет обработку декодирования с использованием кодированных данных первого уровня, полученных от секции 201 демультиплексирования, и выводит результирующие декодированные коэффициенты преобразования первого уровня на сумматор 204 и секцию 205 переключения.
Секция 203 декодирования второго уровня выполняет обработку декодирования с использованием кодированных данных второго уровня, полученных от секции 201 демультиплексирования, и выводит результирующие коэффициенты преобразования ошибки первого уровня на сумматор 204.
Сумматор 204 суммирует декодированные коэффициенты преобразования первого уровня, полученные от секции 202 декодирования первого уровня, и коэффициенты преобразования ошибки первого уровня, полученные от секции 203 декодирования второго уровня, и выводит результирующие декодированные коэффициенты преобразования второго уровня в секцию 205 переключения.
Секция 205 переключения выводит декодированные коэффициенты преобразования первого уровня в качестве декодированных коэффициентов преобразования в секцию 206 преобразования временной области, когда информация уровня, полученная от секция 201 демультиплексирования, указывает «1», и выводит декодированные коэффициенты преобразования второго уровня в качестве декодированных коэффициентов преобразования в секцию 206 преобразования временной области, когда информация уровня указывает «2».
Секция 206 преобразования временной области преобразует декодированные коэффициенты преобразования, полученные от секции 205 переключения, в сигнал временной области и выводит результирующий декодированный сигнал на пост-фильтр 207.
Пост-фильтр 207 выполняет обработку пост-фильтрации, например, выделение формант, выделение основного тона и настройку спада спектра применительно к декодированному сигналу, полученному от секции 206 преобразования временной области, и выводит результат в виде декодированной речи.
На фиг. 9 представлена блок-схема, показывающая внутреннюю конфигурацию секции 203 декодирования второго уровня.
На фиг. 9 секция 203 декодирования второго уровня содержит секцию 231 демультиплексирования, кодовый словарь 232 векторов формы, кодовый словарь 233 векторов усиления и секцию 234 создания коэффициентов преобразования ошибки первого уровня.
Секция 231 демультиплексирования дополнительно демультиплексирует кодированные данные второго уровня, полученные от секции 201 демультиплексирования, на кодированную информацию о форме и кодированную информацию усиления и выводит кодированную информацию о форме и кодированную информацию усиления в кодовый словарь 232 векторов формы и кодовый словарь 233 векторов усиления соответственно.
Кодовый словарь 232 векторов формы содержит векторы-кандидаты формы, идентичные множеству векторов-кандидатов формы, обеспеченных в кодовом словаре 521 векторов формы на фиг. 4, и выводит вектор-кандидат формы, указанный в кодированной информации о форме, полученной от секции 231 демультиплексирования, в секцию 234 создания коэффициентов преобразования ошибки первого уровня.
Кодовый словарь 233 векторов усиления содержит векторы-кандидаты усиления, идентичные множеству векторов-кандидатов усиления, обеспеченных в кодовом словаре 541 векторов усиления на фиг. 7, и выводит вектор-кандидат усиления, указанный в кодированной информации усиления, полученной от секции 231 демультиплексирования, в секцию 234 создания коэффициентов преобразования ошибки первого уровня.
Секция 234 создания коэффициентов преобразования ошибки первого уровня умножает вектор-кандидат формы, полученный из кодового словаря 232 векторов формы, на вектор-кандидат усиления, полученный из кодового словаря 233 векторов усиления, для создания коэффициентов преобразования ошибки первого уровня и выводит коэффициенты преобразования ошибки первого уровня в сумматор 204. Если более подробно, то m-й элемент из М элементов, формирующих вектор-кандидат усиления, полученный из кодового словаря 233 векторов усиления, то есть целевой коэффициент усиления коэффициентов преобразования m-й субполосы умножается на m-й вектор-кандидат формы, полученный по порядку из кодового словаря 232 векторов формы. Здесь, как было описано выше, М представляет общее количество субполос.
Таким образом, в настоящем варианте используется конфигурация кодирования спектральной формы целевого сигнала (то есть коэффициенты преобразования ошибки первого уровня при использовании настоящего варианта осуществления) для каждой субполосы (кодирование вектора формы), с последующим вычислением целевого коэффициента усиления (то есть идеального коэффициента усиления), которое минимизирует расхождение между целевым сигналом и кодированным вектором формы, и кодированием целевого коэффициента усиления (кодирование целевого коэффициента усиления). Благодаря такому подходу, по сравнению со схемой, подобной известному уровню техники, когда кодируется энергетическая составляющая целевого сигнала для каждой субполосы (кодирование коэффициента усиления или масштабного коэффициента), целевой сигнал нормализуется с использованием кодированной энергетической составляющей с последующим кодированием спектральной формы (кодирование вектора формы), настоящее изобретение, где кодируется целевой коэффициент усиления для минимизации искажения по отношению к целевому сигналу, может существенно минимизировать искажение кодирования. Кроме того, целевой коэффициент усиления является параметром, который можно вычислить после кодирования вектора формы, как показано в уравнении 5, и поэтому, в то время как известная схема кодирования, предусматривающая выполнение кодирования вектора формы вслед за кодированием информации усиления, не может использовать целевой коэффициент усиления в качестве объекта для кодирования информации усиления, настоящее изобретение открывает возможность использования целевого коэффициента усиления в качестве объекта для кодирования информации усиления и может дополнительно минимизировать искажения при кодировании.
Кроме того, в настоящем изобретении используется конфигурация, предусматривающая формирование и кодирование одного вектора усиления с использованием целевых коэффициентов усиления для множества соседних субполос. Информация об энергии между соседними субполосами целевого сигнала сходна, и существует высокая вероятность сходства целевых коэффициентов усиления между соседними субполосами. Таким образом, в векторном пространстве создается неравномерное распределение плотности векторов усиления. Путем размещения векторов-кандидатов усиления, входящих в кодовый словарь коэффициентов усиления, таким образом, чтобы оно соответствовало указанному неравномерному распределению плотности, можно уменьшить искажение кодирования целевого коэффициента усиления.
Таким образом, согласно настоящему варианту осуществления можно уменьшить искажение кодирования целевого сигнала и, следовательно, повысить качество звучания декодированной речи. Кроме того, настоящий вариант осуществления может обеспечить точное кодирование спектральных форм для спектров сигналов с насыщенной тональностью, таких как гласные речевые звуки и музыкальные сигналы.
Кроме того, в известном уровне техники управление спектральной амплитудой осуществляется с использованием двух параметров: коэффициента усиления в субполосе и вектора формы. Это можно истолковать так, что спектральная амплитуда представляется по отдельности двумя параметрами: коэффициентом усиления субполосы и вектором формы. В отличие от этого, при использовании настоящего изобретения управление спектральной амплитудой осуществляется только одним параметром - исходным коэффициентом усиления. Кроме того, этот целевой коэффициент усиления является идеальным коэффициентом усиления, который минимизирует искажение кодирования по отношению к кодированному вектору формы. Следовательно, можно выполнять более эффективное кодирование по сравнению с известным уровнем техники и реализовать высококачественное звучание даже при низкой скорости передачи битов.
Кроме того, хотя в связи с настоящим вариантом изобретения в качестве примера объяснен случай, когда частотная область разделяется секцией 151 формирования субполос на множество субполос, и кодирование выполняется по каждой субполосе, настоящее изобретение не ограничивается этим случаем. Благодаря выполнению кодирования вектора формы до кодирования вектора усиления можно вместе кодировать множество субполос, так что можно, по аналогии с настоящим вариантом осуществления, обеспечить преимущество, состоящее в более точном кодировании спектральных форм сигналов с насыщенной тональностью, таких как гласные звуки. Например, возможна конфигурация, где сначала выполняется кодирование вектора формы, затем вектор формы разделятся на субполосы, и вычисляются целевые коэффициенты усиления для каждой субполосы, чтобы сформировать вектор усиления, с последующим кодированием этого вектора усиления.
Кроме того, хотя в связи с настоящим вариантом осуществления в качестве примера был объяснен случай, когда в секции 105 кодирования второго уровня имеется секция 155 мультиплексирования (см. фиг. 2), настоящее изобретение этим не ограничивается, и секция 152 кодирования вектора формы и секция 154 кодирования вектора усиления могут выводить кодированную информацию о форме и кодированную информацию усиления непосредственно в секцию 106 мультиплексирования в устройстве 100 речевого кодирования (см. фиг. 1). В отличие от этого, секция 203 декодирования второго уровня может не иметь секцию 231 демультиплексирования (см. фиг. 9), а секция 201 демультиплексирования в устройстве 200 речевого декодирования (см. фиг. 8) может демультиплексировать и выводить кодированную информацию о форме и кодированную информацию усиления с использованием битового потока непосредственно в кодовый словарь 232 векторов форм и кодовый словарь 233 векторов усиления соответственно.
Кроме того, хотя в связи с настоящим вариантом осуществления в качестве примера был объеснен случай, когда секция 522 вычисления взаимной корреляции вычисляет взаимную корреляцию ccor(i) согласно уравнению 2, настоящее изобретение этим не ограничивается, и секция 522 вычисления взаимной корреляции может вычислять взаимную корреляцию ccor(i) согласно следующему уравнению 7 для увеличения вклада важного для восприятия спектра путем применения большого весового коэффициента для важного для восприятия спектра.
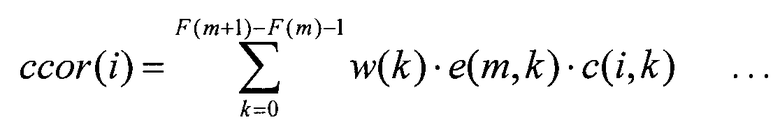
В уравнении 7 w(k) представляет весовой коэффициент, относящийся к характеристике человеческого восприятия, который увеличивается, когда частота является более важной в характеристике восприятия.
Кроме того, аналогичным образом секция 523 вычисления автокорреляции может вычислять автокорреляцию ccor(i) согласно следующему уравнению 8 для увеличения вклада важного для восприятия спектра путем применения большого весового коэффициента для важного для восприятия спектра.
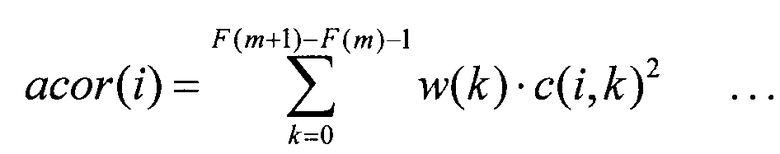
Кроме того, аналогичным образом секция 542 вычисления ошибки может вычислять ошибку E(j) согласно следующему уравнению 9 для увеличения вклада важного для восприятия спектра путем применения большого весового коэффициента для важного для восприятия спектра.
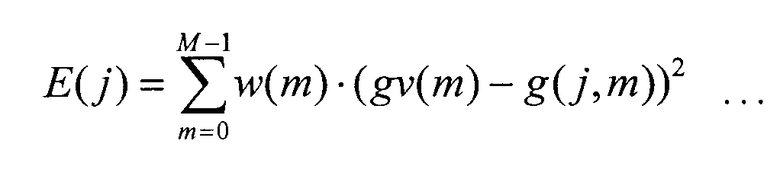
В качестве весовых коэффициентов в уравнении 7, уравнении 8 и уравнении 9 могут быть определены и использованы весовые коэффициенты на основе характеристики воспринимаемой человеком громкости или порога перцепционного маскирования, вычисляемого на основе входного сигнала или декодированного сигнала более низкого уровня (то есть декодированного сигнала первого уровня).
Кроме того, хотя в связи с настоящим вариантом осуществления в качестве примера был объяснен случай, когда секция 152 кодирования вектора формы содержит секцию 523 вычисления автокорреляции, настоящее изобретение этим не ограничивается, и, когда коэффициенты автокорреляции acor(i), вычисленные согласно уравнению 3, и коэффициенты автокорреляции acor(i), вычисленные согласно уравнению 8, становятся константами, автокорреляция acor(i) может быть вычислена заранее и использоваться без обеспечения секции 523 вычисления автокорреляции.
(Вариант осуществления 2)
В устройстве речевого кодирования и устройстве речевого декодирования согласно варианту осуществления 2 настоящего изобретения используется такая же конфигурация, и выполняются такие же операции, как в устройстве 100 речевого кодирования и устройстве 200 речевого декодирования, описанных в варианте осуществления 1, а вариант осуществления 2 отличается от варианта осуществления 1 только кодовым словарем векторов формы.
Для пояснений к кодовому словарю векторов формы согласно настоящему изобретению на фиг. 10 показан спектр японской гласной буквы «о» как примера гласного звука.
На фиг. 10 по горизонтальной оси отложена частота, а по вертикальной оси - энергия спектра в логарифмическом масштабе. Как показано на фиг. 10, в спектре гласного звука наблюдается множество пиков, указывающих на насыщенную тональность. Кроме того, Fx - это частота, на которой находится один из множества пиков.
На фиг. 11 показано множество векторов-кандидатов формы, включенных в кодовый словарь векторов формы, согласно настоящему изобретению.
На фиг. 11 среди векторов-кандидатов формы (а) иллюстрирует отсчет (то есть импульс), имеющий амплитудное значение «+1» или «-1», а (b) иллюстрирует отсчет, имеющий амплитудное значение «0». Множество векторов-кандидатов формы, показанных на фиг. 11, включает в себя множество импульсов, расположенных на произвольных частотах. Следовательно, путем поиска среди векторов-кандидатов формы, показанных на фиг. 11, можно более точно кодировать спектр с насыщенной тональностью, показанный на фиг. 10. Если более конкретно, то вектор-кандидат формы ищется и определяется в отношении сигнала насыщенной тональности, показанного на фиг. 10, так что амплитудное значение, соответствующее частоте, на которой имеется пик, например, амплитудное значение на позиции Fx, показанной на фиг. 10, предполагает «+1» или «-1» (то есть отсчет (а), показанный на фиг. 11), а амплитудное значение на частоте, отличной от частоты пика, предполагает «0» (то есть отсчет (b), показанный на фиг. 11).
В случае использования известного способа, предусматривающего выполнение кодирования коэффициента усиления до кодирования вектора формы, коэффициент усиления субполосы квантуется, нормализуется спектр с использованием коэффициента усиления субполосы, а затем кодируется точная компонента (то есть вектор формы) спектра. Если искажение квантования коэффициента усиления полосы оказывается значительным из-за снижения скорости передачи битов, эффект нормализации уменьшается, и динамический диапазон нормализованного спектра не может быть сильно уменьшен. При таком способе этап квантования в последующей секции кодирования вектора формы необходимо огрубить, что приводит к увеличению искажения квантования. Под воздействием этого искажения квантования пик спектра снижается (то есть теряется истинная форма пика), а спектр, который не образует пиковую форму, усиливается и появляется в виде пика (то есть появляется ложный пик). При этом изменяется положение пиковой частоты, что вызывает ухудшение качества звучания в части речевого сигнала, относящейся к гласному звуку с сильным пиком, а также музыкального сигнала.
В отличие от этого в настоящем изобретении используется конфигурация, предусматривающая сначала определение вектора формы, а затем вычисление целевого коэффициента усиления и квантование этого целевого коэффициента усиления. Когда некоторые элементы векторов включают в себя вектор формы, представленный импульсом +1 или -1, как в настоящем варианте, начальное определение вектора формы означает определение сначала позиции частоты, на которой нарастает этот импульс. Позиция частоты, на которой нарастает импульс, может быть определена без воздействия квантования коэффициента усиления, и поэтому не возникает явление, когда теряется истинный пик или появляется ложный пик, так что открывается возможность предотвращения вышеописанной проблемы, присущей известному уровню техники.
Таким образом, в настоящем варианте осуществления используется конфигурация, предусматривающая сначала определение вектора формы для выполнения кодирования вектора формы с использованием кодового словаря векторов формы, сформированного из векторов формы, включающих в себя импульс, так что появляется возможность задать частоту для спектра, имеющего сильный пик, и разместить импульс на этой частоте. Благодаря такому подходу можно с высоким качеством кодировать сигналы, имеющие спектры с насыщенной тональностью, такие как гласные звуки в речевых сигналах и музыкальные сигналы.
(Вариант осуществления 3)
Вариант осуществления 3 настоящего изобретения отличается от варианта осуществления 1 тем, что в нем выбирается диапазон (то есть область) с насыщенной тональностью в спектре речевого сигнала и тем, что кодируется только выбранный диапазон.
В устройстве речевого кодирования согласно варианту осуществления 3 настоящего изобретения используется та же конфигурация, что и в устройстве 100 речевого кодирования согласно варианту осуществления 1 (см. фиг. 1), и оно отличается от устройства 100 речевого кодирования только тем, что вместо секции 1065 кодирования второго уровня содержит секцию 305 кодирования второго уровня. Поэтому вся конфигурация устройства речевого кодирования согласно настоящему варианту осуществления не показана, и ее подробное описание опущено.
На фиг. 12 представлена блок-схема, показывающая внутреннюю конфигурацию секции 305 кодирования второго уровня согласно настоящему варианту осуществления. Кроме того, в секции 305 кодирования второго уровня используется та же базовая конфигурация, что и в секции 105 кодирования второго уровня, описанной в варианте осуществления 1 (см. фиг. 1), причем одинаковым компонентам присвоены одинаковые ссылочные позиции, а пояснения к ним опущены.
Секция 305 кодирования второго уровня отличается от секции 105 кодирования второго уровня согласно варианту осуществления 1 тем, что сюда дополнительно включена секция 351 выбора диапазона. Кроме того, секция 352 кодирования вектора формы в секции 305 кодирования второго уровня отличается от секции 152 кодирования вектора формы в секции 105 кодирования второго уровня в части, относящейся к обработке, и чтобы показать это отличие, им присвоены разные ссылочные позиции.
Секция 351 выбора диапазона формирует множество диапазонов с использованием произвольного количества соседних полос из коэффициентов преобразования М субполос, полученных от секции 151 формирования субполос, и вычисляет тональность в каждом диапазоне. Секция 351 выбора диапазона выбирает диапазон с самой насыщенной тональностью и выводит информацию о диапазоне, показывающую выбранный диапазон, в секцию 155 мультиплексирования и секцию 352 кодирования вектора формы. Далее подробно объясняется обработка при выборе диапазона в секции 351 выбора диапазона.
Секция 352 кодирования вектора формы отличается от секции 152 кодирования вектора формы согласно варианту осуществления 1 только выбором коэффициентов преобразования субполос, включенных в диапазон, из коэффициентов преобразования субполос, полученных от секции 151 формирования субполос, на основе информации о диапазоне, полученной от секции 351 выбора диапазона, и выполнением квантования вектора формы применительно к выбранным коэффициентам преобразования субполос, причем подробное описание этих операций здесь опущено.
На фиг. 13 показана обработка при выборе диапазона в секции 351 выбора диапазона.
На фиг. 13 по горизонтальной оси отложена частота, а по вертикальной оси - энергия в логарифмическом масштабе. Кроме того, на фиг. 13 показан случай, когда общее количество субполос М равно «8», при этом диапазон «0» формируется с использованием субполос от 0-й до третьей, диапазон 1 формируется с использованием субполос со второй по пятую, а диапазон 2 формируется с использованием субполос с четвертой по седьмую. В качестве индикатора для оценки тональности в заранее определенном диапазоне секция 351 выбора диапазона вычисляет показатель спектральной плоскостности (SFM), представляемый с использованием отношения геометрического и арифметического среднего для множества коэффициентов преобразования субполос, включенных в заранее определенный диапазон. Предполагается, что значение показателя SFM находится между «0» и «1», причем значение, близкое к «0», указывает на насыщенную тональность. Следовательно, показатель SFM вычисляется в каждом диапазоне, и выбирается диапазон, имеющий значение SFM, ближайшее к «0».
В устройстве речевого декодирования согласно настоящему варианту осуществления используется та же конфигурация, что в устройстве 200 речевого декодирования согласно варианту осуществления 1 (см. фиг. 8), причем оно отличается от устройства 200 речевого декодирования лишь тем, что вместо секции 203 декодирования второго уровня в нем содержится секция 403 декодирования второго уровня. Поэтому вся конфигурация устройства речевого декодирования согласно настоящему варианту осуществления не показана, и ее подробное описание опущено.
На фиг. 14 представлена блок-схема, показывающая внутреннюю конфигурацию секции 403 декодирования второго уровня согласно настоящему изобретению. Кроме того, в секции 403 декодирования второго уровня используется та же базовая конфигурация, что и в секции 203 декодирования второго уровня, описанной в варианте осуществления 1, причем одинаковым компонентам присвоены одинаковые ссылочные позиции и пояснения к ним опущены.
Секция 431 демультиплексирования и секция 434 создания коэффициентов преобразования ошибки первого уровня в секции 403 декодирования второго уровня отличаются от секции 231 демультиплексирования и секции 234 создания коэффициентов преобразования ошибки первого уровня в секции 203 декодирования второго уровня в части обработки, и чтобы показать это отличие, им присвоены разные ссылочные позиции.
Секция 431 демультиплексирования отличается от секции 231 демультиплексирования, описанной в варианте осуществления 1, демультиплексированием и выводом информации о диапазоне, вдобавок к кодированной информации о форме и кодированной информации усиления, в секцию 434 создания коэффициентов преобразования ошибки первого уровня, причем ее подробное объяснение опущено.
Секция 434 создания коэффициентов преобразования ошибки первого уровня умножает вектор-кандидат формы, полученный из кодового словаря 232 векторов формы, на вектор-кандидат усиления, полученный из кодового словаря 233 вектора усиления, для создания коэффициентов преобразования ошибки первого уровня, размещает эти коэффициенты преобразования ошибки первого уровня в субполосе, включенной в диапазон, указанный в информации о диапазоне, и выводит результат в сумматор 204.
При таком подходе согласно настоящему варианту осуществления устройство речевого кодирования выбирает диапазон с самой насыщенной тональностью и кодирует вектор формы до усиления каждой полосы в выбранном диапазоне. Благодаря этому спектральные формы сигналов с насыщенной тональностью, таких как гласные звуки речи или музыкальные сигналы, кодируются более точно, причем кодирование выполняется только в выбранном диапазоне, так что можно уменьшить скорость передачи бит при кодировании.
Кроме того, хотя в связи с настоящим вариантом осуществления в качестве примера был объяснен случай, когда показатель SFM вычисляется в качестве индикатора для оценки тональности в каждом заранее определенном диапазоне, настоящее изобретение этим не ограничивается. Например, благодаря преимуществу, вытекающему из сильной связи между средней энергией в заранее определенном диапазоне и насыщенностью тональности, в качестве индикатора для оценки тональности можно вычислить среднюю энергию коэффициентов преобразования, включенных в заранее определенный диапазон. Благодаря этому можно упростить вычисление по сравнению со случаем, когда вычисляется показатель SFM.
Если более подробно, то секция 351 выбора диапазона вычисляет энергию ER(j) коэффициентов e1(k) преобразования ошибки первого уровня, включенных в диапазон j, согласно следующему уравнению 10.
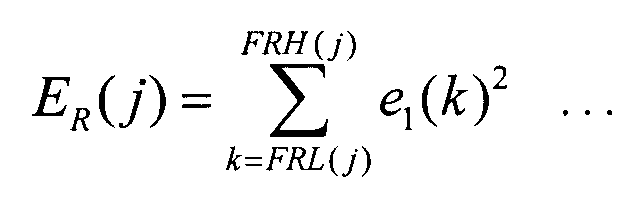
В этом уравнении j представляет идентификатор, задающий диапазон, FRL(j) представляет самую низкую частоту в диапазоне j, а FRH(j) представляет самую высокую частоту в диапазоне j. Секция 351 выбора диапазона вычисляет таким путем энергию ER(j) диапазонов, затем задает диапазон с максимальной энергией коэффициентов преобразования ошибки первого уровня и кодирует коэффициенты преобразования ошибки первого уровня, включенные в этот диапазон.
Кроме того, энергию коэффициентов преобразования ошибки первого уровня можно вычислить согласно следующему уравнению 11 посредством взвешивания, учитывающего характеристики человеческого восприятия.
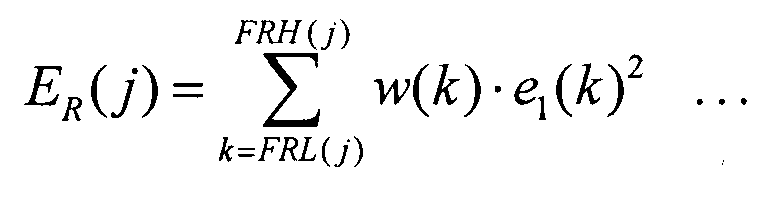
В указанном случае весовой коэффициент w(k) возрастает больше для той частоты, которая более важна для характеристики восприятия, так что скорее всего будет выбран диапазон, включающий эту частоту, причем весовой коэффициент w(k) уменьшается для менее важной частоты, так что диапазон, включающий такую частоту, скорее всего, не будет выбран. Благодаря этому при выборе отдается предпочтение полосе, важной для восприятия, так что появляется возможность повысить качество звучания декодированной речи. В качестве указанного весового коэффициента w(k) можно найти и использовать весовые коэффициенты с учетом характеристик громкости, воспринимаемой человеком, или порога перцепционного маскирования, вычисляемого, например, на основе входного сигнала или декодированного сигнала низкого уровня (то есть декодированного сигнала первого уровня).
Кроме того, секция 351 выбора диапазона может быть сконфигурирована для выбора диапазона из числа диапазонов, расположенных на более низких частотах, чем заранее определенная частота (то есть опорная частота).
На фиг. 15 показан способ выбора диапазона в секции 351 выбора диапазона из числа диапазонов, расположенных на более низких частотах, чем заранее определенная частота (то есть опорная частота).
На фиг. 15 в качестве примера показан случай, где восемь возможных выбираемых диапазонов расположены в полосах с более низкими частотами, чем заранее определенная опорная частота Fy. Каждый из этих восьми диапазонов сформирован с полосой, имеющей заранее определенную длину, начиная с одной из частот F1, F2,… и F8 в качестве базовой точки, причем секция 351 выбора диапазона выбирает один диапазон из указанных восьми возможных на основе вышеописанного способа выбора. Благодаря этому выбираются диапазоны, находящиеся на более низких частотах, чем заранее определенная частота Fy. Таким образом, преимущества выполнения кодирования, выделяющего низкочастотную полосу (или среднечастотную/низкочастотную полосу), состоят в следующем.
В структуре гармоник, являющейся одной из характеристик речевого сигнала, то есть в структуре, в которой спектр имеет пики на данных частотных интервалах, пики выглядят более острыми в полосе низких частот по сравнению с полосой высоких частот. Аналогичные пики наблюдаются в ошибке квантования (то есть в спектре ошибки или коэффициентов преобразования ошибки), возникающей при обработке кодирования, причем пики выглядят более острыми в полосе низких частот по сравнению с полосой высоких частот. Таким образом, когда энергия спектра ошибки в полосе низких частот меньше, чем в полосе высоких частот, пики спектра ошибки являются острыми, и, следовательно, спектр ошибки скорее всего превышает порог перцепционного маскирования (порог восприятия звука человеком), что вызывает ухудшение перцепционного качества звучания. То есть даже в том случае, когда энергия спектра ошибки невелика, перцепционная чувствительность в полосе низких частот выше, чем в полосе высоких частот. Поэтому, в секции 351 выбора диапазона используется конфигурация выбора диапазона из возможных вариантов, расположенных на более низких частотах, чем заранее определенная частота, так что появляется возможность задания диапазона, являющегося объектом кодирования, из полос низких частот, имеющей острые пики в спектре ошибки, и повысить качество звучания декодированной речи.
Кроме того, в качестве способа выбора диапазона, являющегося объектом кодирования, может быть выбран диапазон текущего кадра, связанный с диапазоном, выбранным в прошлом кадре. Например, имеются способы: (1) определения диапазона текущего кадра из диапазонов, находящихся в окрестностях диапазона, выбранного в предыдущем кадре; (2) перекомпоновки диапазонов-кандидатов для текущего кадра в окрестности диапазона, выбранного в предыдущем кадре, для выбора диапазона текущего кадра из числа перекомпонованных диапазонов-кандидатов; и (3) передачи информации о диапазоне через каждые несколько кадров и использования диапазона, указанного в информации о диапазоне, переданной ранее в кадре, в котором информация о диапазоне не передавалась (прерывистая передача информации о диапазоне).
Кроме того, секция 351 выбора диапазона может заранее разделить всю полосу на множество частичных полос, как показано на фиг. 16, для выбора одного диапазона из каждой частичной полосы с последующим последовательным соединением диапазонов, выбранных из каждой частичной полосы, чтобы сделать этот объединенный диапазон объектом кодирования. На фиг. 16 показан случай, когда количество частичных полос равно двум, причем частичная полоса 1 сконфигурирована так, что она покрывает полосу низких частот, а частичная полоса 2 сконфигурирована так, что она покрывает полосу высоких частот. Кроме того, частичная полоса 1 и частичная полоса 2 сформированы, каждая, из множества диапазонов. Секция 351 выбора диапазона выбирает один диапазон из каждой частичной полосы: 1 и 2. Например, как показано на фиг. 16, в частичной полосе 1 выбран диапазон 2, а в частичной полосе 2 выбран диапазон 4. Далее информация, указывающая диапазон, выбранный из частичной полосы 1, называется «информацией о диапазоне из первой частичной полосы», а информация, указывающая диапазон, выбранный из частичной полосы 2, называется «информацией о диапазоне из второй частичной полосы». Затем секция 351 выбора диапазона осуществляет последовательное соединение диапазона, выбранного из частичной полосы 1, и диапазона, выбранного из частичной полосы 2, для формирования объединенного диапазона. Этот объединенный диапазон и становится диапазоном, выбранным в секции 351 выбора диапазонов, а секция 352 кодирования вектора формы выполняет кодирование вектора формы применительно к этому объединенному диапазону.
На фиг. 17 представлена блок-схема, показывающая конфигурацию секции 351 выбора диапазона, применительно к случаю, когда количество частичных полос составляет N. На фиг. 17 коэффициенты преобразования субполосы, полученные от секции 151 формирования субполос, даны для секции 511-1 выбора из частичной полосы 1, и для секции 511-N выбора из частичной полосы N. Каждая секция 511-n выбора из частичной полосы n (где n = от 1 до N) выбирает один диапазон из каждой частичной полосы n и выводит информацию, указывающую выбранный диапазон, то есть информацию о диапазоне n-й частичной полосы, в секцию 512 формирования информации о диапазоне. Секция 512 формирования информации о диапазоне получает объединенный диапазон путем сцепления диапазонов, указанных в информации о диапазоне каждой n-й частичной полосы (где n = от 1 до N), полученной от секций выбора: с секции 511-1 выбора из частотной полосы 1 по секцию 511-N выбора из частотной полосы N. Затем секция 512 формирования информации о диапазоне выводит информацию, указывающую объединенный диапазон, в виде информации о диапазоне в секцию 352 кодирования вектора формы и секцию 155 мультиплексирования.
На фиг. 18 показывается, каким образом формируется информация о диапазоне в секции 512 формирования информации о диапазоне. Как показано на фиг. 18, секция 512 формирования информации о диапазоне формирует информацию о диапазоне путем размещения по порядку информации о диапазоне из первой частичной полосы (то есть А1 бит) вплоть до информации о диапазоне из N-й частичной полосы (то есть AN бит). Здесь длину An в битах каждой информации о диапазоне из n-й частичной полосы определяют на основе нескольких диапазонов-кандидатов, содержащихся в каждой частичной полосе n, и можно предположить, что эта длина будет разной.
На фиг. 19 показана работа секции 434 создания коэффициентов преобразования ошибки первого уровня (см. фиг. 14), поддерживающей секцию 351 выбора диапазона, показанную на фиг. 17. Здесь в качестве примера объясняется случай, когда количество частичных полос равно двум. Секция 434 создания коэффициентов преобразования ошибки первого уровня умножает вектор-кандидат формы, полученный из кодового словаря 232 векторов формы, на вектор-кандидат усиления, полученный из кодового словаря 233 векторов усиления. Затем секция 434 создания коэффициентов преобразования ошибки первого уровня размещает вышеуказанный вектор-кандидат формы после умножения на вектор усиления в каждом диапазоне, указанном в каждой информации о диапазоне для частичной полосы 1 и частичной полосы 2. Определенный таким образом сигнал выводится в виде коэффициентов преобразования ошибки первого уровня.
Способ выбора диапазона, показанный на фиг. 16, определяет один диапазон из каждой частичной полосы, причем в каждой частичной полосе может разместиться по меньшей мере один декодированный спектр. Таким образом, благодаря заблаговременной установке множества полос, для которых необходимо повысить качество звучания, можно повысить качество декодированной речи по сравнению со способом выбора диапазона, предусматривающим выбор только одного диапазона из всей полосы. Например, способ выбора диапазона, показанный на фиг. 16, эффективен тогда, когда, например, необходимо одновременно повысить качество как в полосе низких частот, так и в полосе высоких частот.
Кроме того, как вариант способа выбора диапазона, показанного на фиг. 16, можно всегда выбирать фиксированный диапазон в конкретной частотной полосе, как показано на фиг. 20. В примере, показанном на фиг. 20, в частичной полосе 2 всегда выбирается диапазон 4, который образует часть объединенного диапазона. По аналогии с результатами применения способа выбора диапазона, показанного на фиг. 16, способ выбора диапазона, показанный на фиг. 20, дает возможность заранее установить полосу, для которой необходимо повысить качество звучания, и тогда, например, не потребуется информация о диапазоне из частичной полосы 2, так что можно уменьшить количество бит для представления информации о диапазоне.
Кроме того, хотя на фиг. 20 в качестве примера показан случай, когда фиксированный диапазон всегда выбирается в полосе высоких частот (частичная полоса 2), настоящее изобретение этим не ограничивается, и фиксированный диапазон может всегда выбираться в полосе низких частот (то есть частичная полоса 1), а кроме того, фиксированный диапазон может всегда выбираться в частичной полосе средних частот, которая на фиг. 20 не показана.
Кроме того, в качестве вариантов способов выбора диапазона, показанных на фиг. 16 и фиг. 20, ширина полосы диапазонов-кандидатов, содержащихся в каждой частичной полосе, может быть различной. На фиг. 21 показан случай, когда ширина диапазона-кандидата, содержащегося в частичной полосе 2, меньше, чем у диапазонов-кандидатов, содержащихся в частичной полосе 1.
(Вариант осуществления 4)
В варианте осуществления 4 настоящего изобретения на покадровой основе принимается решение о насыщенности тональности, и определяется порядок кодирования вектора формы и кодирования коэффициентов усиления в зависимости от результата принятого решения.
В устройстве речевого кодирования согласно варианту осуществления 4 настоящего изобретения используется та же конфигурация, что и в устройстве 100 речевого кодирования согласно варианту осуществления 1 (см. фиг. 1), причем оно отличается от устройства 100 речевого кодирования только тем, что вместо секции 105 кодирования второго уровня оно содержит секцию 505 кодирования второго уровня. Поэтому вся конфигурация устройства речевого кодирования согласно настоящему варианту осуществления не показана, и ее подробное объяснение опущено.
На фиг. 22 представлена блок-схема, показывающая внутреннюю конфигурацию секции 505 кодирования второго уровня. Кроме того, в секции 505 кодирования второго уровня используется та же базовая конфигурация, что и в секции 105 кодирования второго уровня, показанная на фиг.1, причем одинаковым компонентам присвоены одинаковые ссылочные позиции, и их объяснение опущено.
Секция 505 кодирования второго уровня отличается от секции 105 кодирования второго уровня согласно варианту осуществления 1 тем, что в нее дополнительно включены секция 551 принятия решения о тональности, секция 552 переключения, секция 553 кодирования коэффициентов усиления, секция 554 нормализации, секция 555 кодирования вектора формы и секция 556 переключения. Кроме того, на фиг. 22 секция 152 кодирования вектора формы, секция 153 формирования вектора усиления и секция 154 кодирования вектора усиления образуют последовательность (а) кодирования, а секция 553 кодирования коэффициентов усиления, секция 554 нормализации и секции 555 кодирования вектора формы образуют последовательность (b) кодирования.
Секция 551 принятия решения о тональности вычисляет показатель SFM в качестве индикатора оценки тональности коэффициентов преобразования ошибки первого уровня, полученных от вычитателя 104, выводит сигнал высокого уровня в качестве информации о принятии решения о тональности в секцию 552 переключения и секцию 556 переключения, когда вычисленный показатель SFM меньше заранее определенного порога, и выводит сигнал низкого уровня в качестве информации о принятии решения о тональности в секцию 552 переключения и секцию 556 переключения, когда вычисленный показатель SFM больше или равен заранее определенному порогу.
Между тем, хотя настоящее изобретение объясняется с использованием показателя SFM в качестве индикатора для оценки тональности, изобретение этим не ограничивается, и решение может быть принято с использованием другого индикатора, такого как дисперсия коэффициентов преобразования ошибки первого уровня. Кроме того, принятие решения может осуществляться с использованием другого сигнала, например, входного сигнала для принятия решения о тональности. Например, может быть использован результат анализа основного тона входного сигнала или результат кодирования входного сигнала на более низком уровне (например, секция кодирования первого уровня при использовании настоящего варианта осуществления).
Секция 552 переключения последовательно выводит коэффициенты преобразования М субполос, полученные от секции формирования субполос, в секцию 152 кодирования вектора формы, когда информация о решении относительно тональности, полученная от секции 551 принятия решения о тональности, представляет собой сигнал высокого уровня, и последовательно выводит коэффициенты преобразования М субполос, полученные от секции 151 формирования субполос, в секцию 553 кодирования коэффициентов усиления и секцию 554 нормализации, когда информация о решении относительно тональности, полученная от секции 551 принятия решения о тональности, представляет собой сигнал низкого уровня.
Секция 553 кодирования коэффициентов усиления вычисляет среднюю энергию коэффициентов преобразования М субполос, полученных от секции 552, квантует вычисленную среднюю энергию и выводит квантованный индекс в качестве кодированной информации усиления в секцию 556 переключения. Кроме того, секция 553 кодирования коэффициентов усиления выполняет обработку декодирования с использованием кодированной информации усиления и выводит результирующий декодированный коэффициент усиления в секцию 554 нормализации.
Секция 554 нормализации нормализует коэффициенты преобразования М субполос, полученные от секции 552 переключения, с использованием декодированного коэффициента усиления, полученного от секции 553 кодирования коэффициентов усиления, и выводит результирующий нормализованный вектор формы в секцию 555 кодирования вектора формы.
Секция 555 кодирования вектора формы выполняет обработку кодирования применительно к нормализованному вектору формы, полученному от секции 554 нормализации, и выводит результирующую кодированную информацию о форме в секцию 556 переключения.
Секция 556 переключения выводит кодированную информацию о форме и кодированную информацию усиления, полученные от секции 152 кодирования вектора формы и секции 154 кодирования вектора усиления соответственно, когда информация о решении относительно тональности, полученная от секции 551 принятия решения о тональности, представляет собой сигнал высокого уровня, и выводит кодированную информацию о форме и кодированную информацию усиления, полученные от секции 553 кодирования коэффициентов усиления и секции 555 кодирования вектора формы, соответственно, когда информация о решении о тональности, полученная от секции 551 принятия решения о тональности, представляет собой сигнал низкого уровня.
Как было показано выше, устройство речевого кодирования согласно настоящему варианту осуществления выполняет кодирование вектора формы до кодирования коэффициента усиления с использованием последовательности (а) в случае, когда тональность коэффициентов преобразования ошибки первого уровня имеет высокую насыщенность, и выполняет кодирование коэффициента усиления до кодирования вектора формы с использованием последовательности (b) в случае, когда тональность коэффициентов преобразования ошибки первого уровня имеет низкую насыщенность.
Таким образом, в настоящем варианте осуществления адаптивно изменяется порядок выполнения кодирования коэффициента усиления и кодирования вектора формы в соответствии с тональностью коэффициентов преобразования ошибки первого уровня, и, следовательно, появляется возможность подавления искажения кодирования коэффициента усиления и искажения кодирования вектора формы в соответствии с входным сигналом, являющимся объектом кодирования, так что появляется возможность дополнительного повышения качества звучания декодированной речи.
(Вариант осуществления 5)
На фиг. 23 представлена блок-схема, показывающая основную конфигурацию устройства 600 речевого кодирования согласно варианту осуществления 5 настоящего изобретения.
На фиг. 23 устройство 600 речевого кодирования содержит секцию 601 кодирования первого уровня, секцию 602 декодирования первого уровня, секцию 603 задержки, вычитатель 604, секцию 605 преобразования частотной области, секцию 606 кодирования второго уровня и секцию 106 мультиплексирования. Среди их компонент секция 106 мультиплексирования идентична секции 106 мультиплексирования, показанной на фиг. 1, и поэтому ее подробное объяснение опущено. Кроме того, секция 606 кодирования второго уровня отличается от секции 305 кодирования второго уровня, показанной на фиг. 12, в части обработки, и, чтобы показать это отличие, компонентам схемы присвоены разные ссылочные позиции.
Секция 601 кодирования первого уровня кодирует входной сигнал и выводит созданные кодированные данные первого уровня в секцию 602 декодирования первого уровня и секцию 106 мультиплексирования. Подробное описание секции 601 кодирования первого уровня представлено ниже.
Секция 602 декодирования первого уровня выполняет обработку декодирования с использованием кодированных данных первого уровня, полученных от секции 601 кодирования первого уровня, и выводит созданный декодированный сигнал первого уровня на вычитатель 604. Секция 602 декодирования первого уровня подробно описывается ниже.
Секция 603 задержки осуществляет заранее определенную задержку входного сигнала и выводит его в вычитатель 604. Длительность задержки равна длительности задержки, созданной при обработке в секции 601 кодирования первого уровня и секции 602 декодирования первого уровня.
Вычитатель 604 вычисляет разность между задержанным входным сигналом, полученным от секции 603 задержки, и декодированным сигналом первого уровня, полученным от секции декодирования первого уровня, и выводит результирующий сигнал ошибки в секцию 605 преобразования частотной области.
Секция 605 преобразования частотной области преобразует сигнал ошибки, полученный от вычитателя 604, в сигнал частотной области и выводит результирующие коэффициенты преобразования ошибки в секцию 606 кодирования второго уровня.
На фиг. 24 представлена блок-схема, показывающая основную внутреннюю конфигурацию секции 601 кодирования первого уровня.
На фиг. 24 секция 601 кодирования первого уровня имеет секцию 611 понижающей дискретизации и секцию 612 основного кодирования.
Секция 611 понижающей дискретизации выполняет понижающую дискретизацию входного сигнала временной области для преобразования частоты дискретизации сигнала временной области в желаемую частоту дискретизации и выводит сигнал временной области, подвергнутый понижающей дискретизации, в секцию 612 основного кодирования.
Секция 612 основного кодирования выполняет обработку кодирования применительно к входному сигналу, преобразованному до желаемой частоты дискретизации, и выводит созданные кодированные данные первого уровня в секцию 602 декодирования первого уровня и секцию 106 мультиплексирования.
На фиг. 25 представлена блок-схема, показывающая основную внутреннюю конфигурацию секции 602 декодирования первого уровня.
На фиг. 25 секция 602 декодирования первого уровня имеет секцию 621 основного декодирования, секцию 622 повышающей дискретизации и секцию 623 добавления высокочастотной компоненты, причем секция 602 заменяет высокочастотную полосу аппроксимированным сигналом. В основе этого лежит способ общего повышения качества звучания декодированной речи путем представления высокочастотной полосы, не очень важной для восприятия, с помощью аппроксимирующего сигнала и увеличения взамен количества бит, распределяемых в важной для восприятия низкочастотной полосе (или среднечастотной/низкочастотной полосе) для повышения точности воспроизведения этой полосы в отношении исходного сигнала.
Секция 621 основного декодирования выполняет обработку декодирования с использованием кодированных данных первого уровня, полученных от секции 601 кодирования первого уровня, и выводит результирующий сигнал, подвергшийся основному декодированию, в секцию 622 повышающей дискретизации. Кроме того, секция 621 основного декодирования выводит декодированные коэффициенты LPC, найденные при обработке декодирования, в секцию 623 добавления компоненты высокочастотной полосы.
Секция 622 повышающей дискретизации осуществляет повышающую дискретизацию декодированного сигнала, полученного от секции 621 основного декодирования, для преобразования частоты дискретизации декодированного сигнала в ту же частоту дискретизации, что и у входного сигнала, и выводит сигнал, подвергшийся основному декодированию и повышающей дискретизации, в секцию 623 добавления компоненты высокочастотной полосы.
Используя аппроксимирующий сигнал, секция 623 добавления компоненты высокочастотной полосы компенсирует компоненту высокочастотной полосы, которая пропала в результате обработки, связанной с понижающей дискретизацией, в секции 611 понижающей дискретизации. В качестве способа создания аппроксимирующего сигнала известен способ, состоящий в формировании синтезирующего фильтра с декодированными LPC коэффициентами, определяемыми при обработке декодирования в секции 621 основного декодирования, и последовательной фильтрации шумового сигнала, энергия которого регулируется, посредством синтезирующего фильтра и полосового фильтра. Полученная в этом способе компонента высокочастотной полосы вносит свой вклад в улучшение восприятия полосы, но она имеет совершенно другую форму сигнала, отличную от компоненты высокочастотной полосы исходного сигнала, и поэтому энергия в высокочастотной полосе сигнала ошибки, получаемого в вычитателе, увеличивается.
Когда обработка кодирования первого уровня включает в себя указанные особенности, энергия в высокочастотной полосе сигнала ошибки возрастает, так что низкочастотная полоса, которая по существу имеет высокую перцепционную чувствительность, скорее всего, не будет выбрана. Следовательно, секция 606 кодирования второго уровня согласно настоящему варианту осуществления выбирает диапазон из диапазонов-кандидатов, расположенных на более низких частотах, чем заранее определенная частота (то есть опорная частота), так что появляется возможность предотвращения вышеописанной проблемы, вызванной увеличением энергии сигнала ошибки в высокочастотной области. То есть секция 606 кодирования второго уровня выполняет обработку выбора, показанную на фиг. 15.
На фиг. 26 представлена блок-схема, показывающая основную конфигурацию устройства 700 речевого кодирования согласно варианту осуществления 5 настоящего изобретения. Между прочим, устройство речевого декодирования 700 имеет ту же базовую конфигурацию, что и устройство 200 речевого декодирования, показанное на фиг. 8, причем одинаковым компонентам присвоены одинаковые ссылочные позиции, и их объяснение опущено.
Секция 702 декодирования первого уровня в устройстве 700 речевого декодирования отличается от секции 202 декодирования первого уровня в устройстве 200 речевого декодирования в части обработки, и поэтому ее компонентам присвоены другие ссылочные позиции. Кроме того, конфигурация и работа секции 702 декодирования первого уровня такие же, как в секции 602 декодирования первого уровня в устройстве 600 речевого кодирования, и поэтому их объяснение опущено.
Секция 706 преобразования временной области в устройстве 700 речевого декодирования отличается от секции 206 преобразования временной области в устройстве 200 речевого декодирования только позициями размещения, но она выполняет ту же обработку, и поэтому ее компонентам присвоены другие ссылочные позиции, но их подробное объяснение опущено.
Таким образом, в настоящем варианте осуществления выполняется замена высокочастотной полосы аппроксимирующим сигналом, таким как шум, при обработке кодирования на первом уровне вместо увеличения количества бит, распределяемых в важной для восприятия низкочастотной полосе (или среднечастотной/низкочастотной полосе) для повышения точности воспроизведения по отношению к исходному сигналу этой полосы, что, кроме того, предотвращает проблему, связанную с увеличением энергии сигнала ошибки в высокочастотной полосе, с использованием диапазона более низких частот, чем заранее определенная частота, в качестве объекта кодирования при обработке кодирования второго уровня, и выполнения кодирования вектора формы до кодирования коэффициента усиления, так что появляется возможность более точно кодировать спектральные формы сигналов насыщенной тональности, таких как гласные звуки, дополнительно уменьшить искажение кодирования вектора усиления без увеличения скорости передачи бит и, следовательно, дополнительно повысить качество звучания декодированной речи.
Кроме того, хотя здесь в качестве примера был объяснен случай, когда вычитатель 604 находит разность между сигналами во временной области, настоящее изобретение этим не ограничивается, и вычитатель 604 может находить разность между коэффициентами преобразования в частотной области. В указанном случае входные коэффициенты преобразования находят путем размещения секции 605 преобразования частотной области между секцией 603 задержки и вычитателем 604, а декодированные коэффициенты преобразования первого уровня находят благодаря размещению другой секции преобразования частотной области между секцией 602 декодирования первого уровня и вычитателем 604. Затем вычитатель 604 определяет разность между входными коэффициентами преобразования и декодированными коэффициентами преобразования первого уровня и подает эти коэффициенты преобразования ошибки непосредственно в секцию 606 кодирования второго уровня. Эта конфигурация позволяет осуществлять адаптивную обработку при вычитании, состоящую в определении разности в данной полосе, а не в других полосах, так что появляется возможность дополнительного повышения качества звучания декодированной речи.
Кроме того, хотя в связи с настоящим вариантом осуществления в качестве примера была проанализирована конфигурация, где информация, относящаяся к высокочастотной полосе, не передается в устройстве речевого декодирования, настоящее изобретение этим не ограничивается, причем возможна конфигурация, где сигнал высокочастотной полосы кодируется с низкой скоростью передачи бит по сравнению с низкочастотной полосой и передается в устройство речевого декодирования.
(Вариант осуществления 6)
На фиг. 27 представлена блок-схема, показывающая основную конфигурацию устройства 800 речевого кодирования согласно варианту осуществления 6 настоящего изобретения. Кроме того, в устройстве 800 речевого кодирования используется та же базовая конфигурация, что и в устройстве 600 речевого кодирования, показанном на фиг. 23, и одинаковым компонентам присвоены одинаковые ссылочные позиции, и пояснения к ним опущены.
Устройство 800 речевого кодирования отличается от устройства 600 речевого кодирования тем, что оно дополнительно содержит взвешивающий фильтр 801.
Взвешивающий фильтр 801 выполняет перцепционное взвешивание путем фильтрации сигнала ошибки и выводит сигнал ошибки после взвешивания в секцию 605 преобразования частотной области. Взвешивающий фильтр 801 сглаживает (делает «белым») спектр входного сигнала или изменяет его, приближая к спектральным характеристикам сглаженного спектра. Например, передаточная функция w(z) взвешивающего фильтра может быть представлена следующим уравнением 12 с использованием декодированных коэффициентов LPC, полученных в секции 602 декодирования первого уровня.
В уравнении 12 α(i) - коэффициенты LPC, NP - порядок коэффициентов LPC, а γ - параметр для управления степенью сглаживания (получение белого) спектра, причем предполагается, что значения γ находятся в диапазоне 0 ≤ γ ≤ 1. Чем больше γ, тем больше степень сглаживания, причем для γ в качестве примера здесь используется значение 0,92.
На фиг. 28 представлена блок-схема, показывающая основную конфигурацию устройства 900 декодирования речи согласно варианту осуществления 6 настоящего изобретения. Кроме того, устройство 900 речевого декодирования имеет ту же базовую конфигурацию, что и устройство 700 речевого декодирования, показанное на фиг. 26, причем одинаковым компонентам присвоены одинаковые ссылочные позиции, и пояснения к ним опущены.
Устройство 900 речевого декодирования отличается от устройства 700 речевого декодирования тем, что оно содержит синтезирующий фильтр 901.
Синтезирующий фильтр 901 формируется из фильтра, имеющего обратные спектральные характеристики по отношению к взвешивающему фильтру 801 в устройстве 800 речевого кодирования, причем фильтр 901 выполняет обработку фильтрации в отношении сигнала, полученного от секции 706 преобразования временной области, с последующим выводом результата. Передаточная функция B(z) синтезирующего фильтра 901 представлена с использованием следующего уравнения 13.
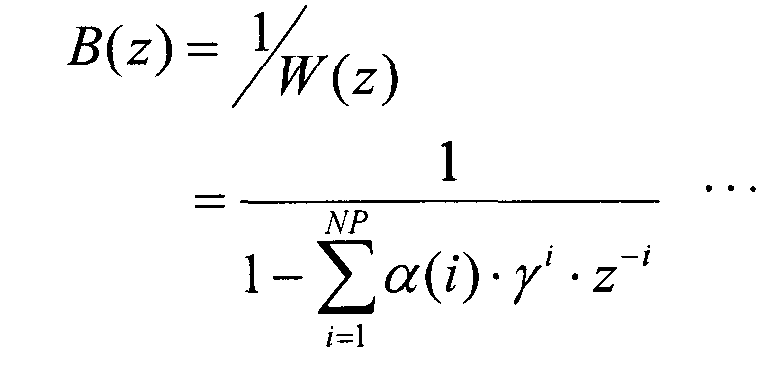
В уравнении 13 α(i) - коэффициенты LPC, NP - порядок коэффициентов LPC, а γ - параметр для управления степенью сглаживания (получения белого) спектра, причем предполагается, что значения γ находятся в диапазоне 0 ≤ γ ≤ 1. Чем больше γ, тем больше степень сглаживания, причем для γ здесь в качестве примера используется значение 0,92.
Как было описано выше, взвешивающий фильтр 801 устройства 800 речевого кодирования формируется из фильтра, имеющего обратные спектральные характеристики по отношению к спектральной огибающей входного сигнала, и синтезирующий фильтр 901 в устройстве 900 речевого декодирования формируется из фильтра, имеющего обратные характеристики по отношению к взвешивающему фильтру. Таким образом, синтезирующий фильтр имеет характеристики, аналогичные спектральной огибающей входного сигнала. Обычно, в низкочастотной полосе энергия выше, чем в высокочастотной полосе в спектральной огибающей речевого сигнала, так что даже в том случае, когда в низкочастотной полосе и высокочастотной полосе имеется одинаковое искажение кодирования сигнала до его прохождения через синтезирующий фильтр, в низкочастотной полосе искажение кодирования увеличивается, после того как сигнал прошел синтезирующий фильтр. Хотя в идеале взвешивающий фильтр 801 устройства 800 речевого кодирования и синтезирующий фильтр 901 устройства 900 речевого кодирования вводятся так, чтобы искажение кодирования не было слышно благодаря эффекту перцепционного маскирования, однако когда искажение кодирования нельзя уменьшить из-за низкой скорости передачи бит, эффект перцепционного маскирования недостаточно проявляется, и искажение кодирования скорее всего будет восприниматься. В указанном случае синтезирующий фильтр 901 в устройстве 900 речевого декодирования повышает энергию в низкочастотной полосе, включая искажение кодирования, и поэтому ухудшение качества скорее всего четко проявится. При использовании настоящего варианта осуществления, как описано в варианте осуществления 5, секция кодирования второго уровня выбирает диапазон, являющийся объектом кодирования, из диапазонов-кандидатов, расположенных на более низких частотах, чем заранее определенная частота (то есть опорная частота), так что появляется возможность снять вышеописанную проблему искажения кодирования в низкочастотной полосе и повысить качество звучания декодированной речи.
Таким образом, настоящий вариант осуществления обеспечивает взвешивающий фильтр в устройстве речевого кодирования, повышает качество путем обеспечения синтезирующего фильтра в устройстве речевого декодирования и использования эффекта перцепционного маскирования, а также использует диапазон с более низкими частотами, чем заранее определенная частота, в качестве объекта кодирования при обработке кодирования второго уровня для устранения проблемы, связанной с увеличением энергии в низкочастотной области, включая искажение кодирования, и для выполнения кодирования вектора формы до кодирования коэффициента усиления, так что появляется возможность более точно кодировать спектральные формы сигналов насыщенной тональности, таких как гласные звуки, уменьшить искажение при кодировании вектора усиления без увеличения скорости передачи битов и, следовательно, дополнительно повысить качество звучания декодированной речи.
(Вариант осуществления 7)
Выбор диапазона, являющегося объектом, подлежащим кодированию на каждом уровне улучшения, объясняется в варианте осуществления 7 настоящего изобретения для случая, где устройство речевого кодирования и устройство речевого декодирования сконфигурированы так, что они включают три или более уровней, сформированных с одним базовым уровнем и множеством уровней улучшения.
На фиг. 29 представлена блок-схема, показывающая основную конфигурацию устройства 1000 речевого кодирования согласно варианту осуществления 7 настоящего изобретения.
Устройство 1000 речевого кодирования содержит секцию 101 преобразования частотной области, секцию 102 кодирования первого уровня, секцию 602 декодирования первого уровня, вычитатель 604, секцию 606 кодирования второго уровня, секцию 1001 декодирования второго уровня, сумматор 1002, вычитатель 1003, секцию 1004 кодирования третьего уровня, секцию 1005 декодирования третьего уровня, сумматор 1006, вычитатель 1007, секцию 1008 кодирования четвертого уровня и секцию 1009 мультиплексирования, причем устройство 1000 сформировано с четырьмя уровнями. Среди указанных компонент конфигурации и работа секции 101 преобразования частотной области и секции 102 кодирования первого уровня такие же, как показаны на фиг. 1, конфигурации и работа секции 602 декодирования первого уровня, вычитателя 604 и секции 606 кодирования второго уровня такие же, как показано на фиг. 23, а конфигурации и работа модулей под номерами с 1001 по 1009 аналогичны конфигурациям и работе модулей 101, 102, 602, 604 и 606, и поэтому их подробное объяснение здесь опущено.
На фиг. 30 показана обработка при выборе диапазона, являющегося объектом кодирования, при обработке кодирования в устройстве 1000 речевого кодирования. На фигурах с 30А по 30С показана обработка при выборе диапазонов при кодировании второго уровня в секции 606 кодирования второго уровня, кодировании третьего уровня в секции 1004 кодирования третьего уровня и кодировании четвертого уровня в секции 1008 кодирования четвертого уровня.
Как показано на фиг. 30А, возможные для выбора диапазоны размещены в полосах с более низкими частотами, чем опорная частота второго уровня Fy(L2), при кодировании второго уровня, диапазоны-кандидаты для выбора размещены в полосах с более низкими частотами, чем опорная частота третьего уровня Fy(L3), при кодировании третьего уровня и диапазоны-кандидаты для выбора размещены в полосах с более низкими частотами, чем опорная частота четвертого уровня Fy(L4), при кодировании четвертого уровня. Кроме того, между опорными частотами уровней улучшения поддерживается следующее соотношение: Fy(L2) < Fy(L3) < Fy(L4). Количество диапазонов-кандидатов для выбора в каждом уровне улучшения одинаково, и в качестве примера здесь описывается случай, когда количество диапазонов-кандидатов равно четырем. То есть на более низком уровне с низкой скоростью передачи битов (например, второй уровень) диапазон, являющийся целью кодирования, выбирают из низкочастотных полос с высокой чувствительностью восприятия, а на более высоком уровне с более высокой скоростью передачи битов (например, четвертый уровень) диапазон, являющийся объектом кодирования, выбирают из более широких полос, включая высокочастотную полосу. Благодаря использованию указанной конфигурации более низкий уровень выделяет низкочастотную полосу, а более высокий уровень покрывает более широкую полосу, так что появляется возможность реализовать качественное звучание речевых сигналов.
На фиг. 31 представлена блок-схема, показывающая основную конфигурацию устройства 1100 речевого декодирования согласно настоящему варианту осуществления.
На фиг. 31 устройство 1100 речевого декодирования содержит секцию 1101 демультиплексирования, секцию 1102 декодирования первого уровня, секцию 1103 декодирования второго уровня, секцию 1104 суммирования, секцию 1105 декодирования третьего уровня, секцию 1106 суммирования, секцию 1107 декодирования четвертого уровня, секцию 1108 суммирования, секцию 1109 переключения, секцию 1110 преобразования временной области и пост-фильтр 1111, то есть устройство 1100 сформировано с четырьмя уровнями. Между тем, конфигурации и работа этих модулей аналогичны конфигурациям и работе модулей в устройстве 200 речевого декодирования, показанного на фиг. 8, и поэтому их подробное объяснение опущено.
Таким образом, согласно настоящему варианту осуществления устройство масштабируемого речевого кодирования выбирает диапазон, являющийся целью кодирования, из низкочастотных полос с более высокой чувствительностью восприятия на более низком уровне с более низкой скоростью передачи битов и выбирает диапазон, являющийся объектом кодирования, из более широких полос, включая высокочастотную полосу, на более высоком уровне с более высокой скоростью передачи битов, чтобы выделить низкочастотную полосу на более низком уровне и покрыть более широкие полосы на более высоком уровне, а также выполнить кодирование вектора формы до кодирования коэффициента усиления, так что появляется возможность более точно кодировать спектральные формы сигналов насыщенной тональности, таких как гласные звуки, а кроме того, уменьшить искажения при кодировании вектора усиления без увеличения скорости передачи битов и дополнительно повысить качество звучания декодированной речи.
Кроме того, хотя здесь в связи с настоящим вариантом осуществления в качестве примера был объяснен случай, где цель кодирования выбирают из возможных для выбора диапазонов, показанных на фиг. 30, при обработке кодирования на каждому уровне улучшения, настоящее изобретение этим не ограничивается, и цель кодирования можно выбрать из диапазонов-кандидатов, расположенных с одинаковыми интервалами, как показано на фиг. 32 и фиг. 33.
На фиг. 32А, 32В и 33 показана обработка при выборе диапазона при кодировании второго уровня, кодировании третьего уровня и кодировании четвертого уровня. Как показано на фиг. 32 и фиг. 33, количество диапазонов-кандидатов для выбора варьируется от одного уровня улучшения к другому, причем здесь показан случай, где количество диапазонов-кандидатов для выбора составляет четыре, шесть и восемь. При указанной конфигурации диапазон, являющийся объектом кодирования, определяют из низкочастотных полос на более низком уровне, причем количество диапазонов-кандидатов для выбора меньше по сравнению с более высоким уровнем, так что появляется возможность упростить вычисления и уменьшить скорость передачи битов.
Кроме того, в качестве способа выбора диапазона, являющегося целью кодирования для каждого уровня улучшения, можно предложить способ, в котором диапазон текущего уровня можно выбрать вместе с диапазоном, выбранным на более низком уровне. Например, имеются способы: (1) определения диапазона текущего уровня из диапазонов, расположенных в окрестности диапазона, выбранного на более низком уровне; (2) переупорядочивания диапазонов-кандидатов для текущего уровня в окрестности диапазона, выбранного на более низком уровне, чтобы определить диапазон текущего уровня из переупорядоченных диапазонов-кандидатов; и (3) передачи информации о диапазоне через каждые несколько кадров и использовании диапазона, указанного в информации о диапазоне, переданной ранее в том кадре, в котором не передается информация о диапазоне (прерывистая передача информации о диапазоне).
Выше были объяснены варианты осуществления настоящего изобретения.
Кроме того, хотя в качестве примера конфигурации устройства речевого кодирования и устройства речевого декодирования была раскрыта масштабируемая конфигурация с двумя уровнями, настоящее изобретение этим не ограничивается, то есть возможна масштабируемая конфигурация с тремя или более уровнями. Кроме того, настоящее изобретение также применимо к устройству речевого кодирования, в котором не используется масштабируемая конфигурация.
Вдобавок, в вышеописанных вариантах осуществления в качестве способа кодирования первого уровня можно использовать способ CELP.
В вышеописанных вариантах секция преобразования частотной области реализуется с использованием быстрого преобразования Фурье (FFT), дискретного преобразования Фурье (DFT), дискретного косинусного преобразования (DCT), модифицированного дискретного косинусного преобразования (MDCT), фильтра субполос и т.д.
Хотя в вышеописанных вариантах осуществления в качестве декодированных сигналов подразумеваются речевые сигналы, настоящее изобретение этим не ограничивается, то есть декодированными сигналами могут быть, например, аудио-сигналы.
Также, хотя в связи с вышеописанным вариантом осуществления в качестве примеров были описаны случаи, где настоящее изобретение сконфигурировано в виде аппаратных средств, его также можно реализовать программными средствами.
Каждый функциональный модуль, использованный в описании каждого из вышеупомянутых вариантов изобретения, как правило, может быть реализован в виде большой интегральной схемы (LSI), сформированной как интегральная схема. Это могут быть отдельные микросхемы, либо они частично или полностью могут содержаться в единой микросхеме. Здесь принято сокращение «LSI», но она также может называться «IC» (интегральная схема), «system LSI» (системная LSI), «super LSI» (схема сверхвысокой степени интеграции), «ultra LSI» (схема ультравысокой степени интеграции), в зависимости от той или иной степени интеграции.
Кроме того, способ схемной интеграции не ограничивается схемами LSI, то есть также возможна реализация с использованием специализированных схем или процессоров общего назначения. Также после изготовления схемы LSI возможно использование программируемой вентильной матрицы (FPGA), или реконфигурируемого процессора, где имеется возможность реконфигурации соединений и настроек схемных ячеек в LSI.
Кроме того, если в результате развития полупроводниковой технологии или другой родственной технологии, новая технология интегральных схем приведет к замене LSI, то также возможно реализовать функциональные модули в интегральном исполнении, используя эту новую технологию. Также возможно применение биотехнологии.
Описания патентной заявки Японии №2007-053502, поданной 2 марта 2007 года, патентной заявки Японии №2007-133545, поданной 18 мая 2007 года, патентной заявки Японии №2007-185077, поданной 13 июля 2007 года, и патентной заявки Японии №2008-045259, поданной 26 февраля 2008 года, включая спецификации, чертежи и рефераты, целиком включены в настоящую заявку посредством ссылки.
Промышленная применимость
Устройство речевого кодирования и способ речевого кодирования согласно настоящему изобретению применимы к терминальному устройству беспроводной связи, устройству базовой станции беспроводной связи и т.п. в системе мобильной связи.
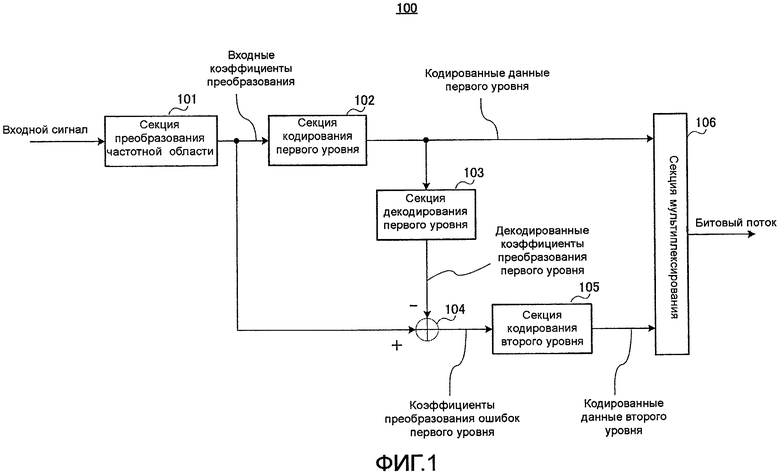
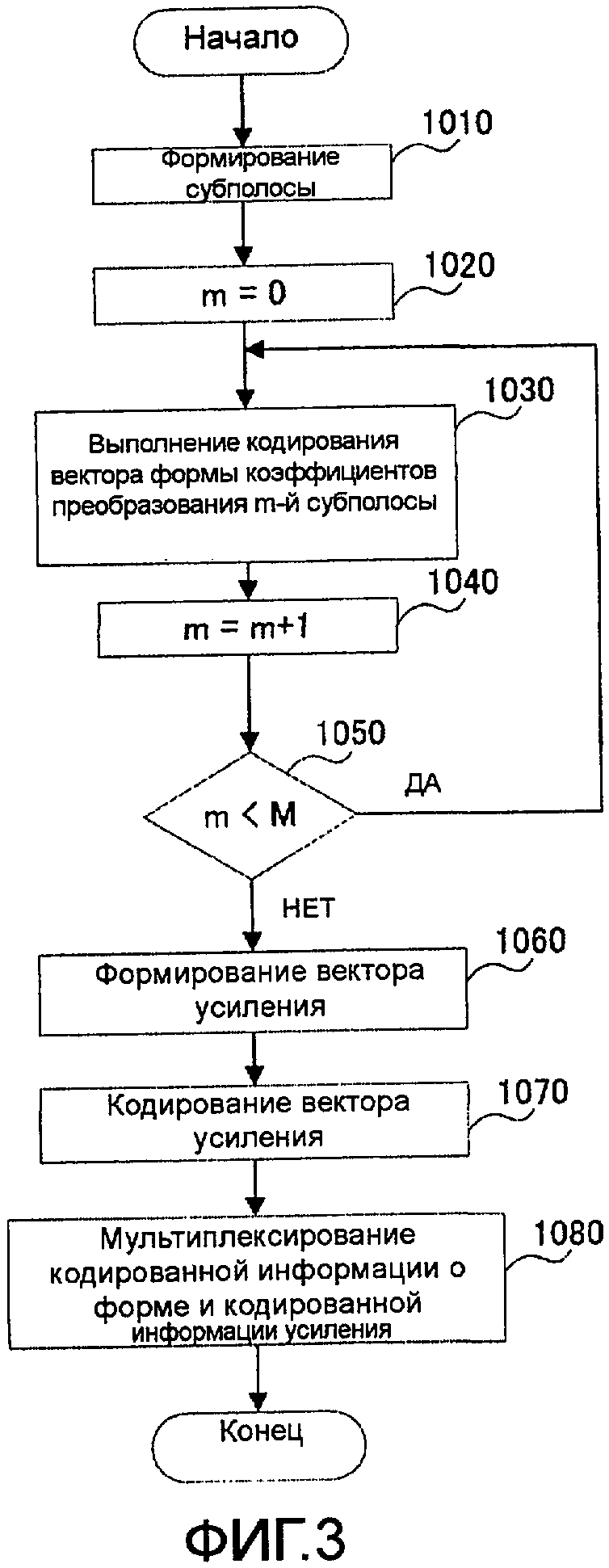
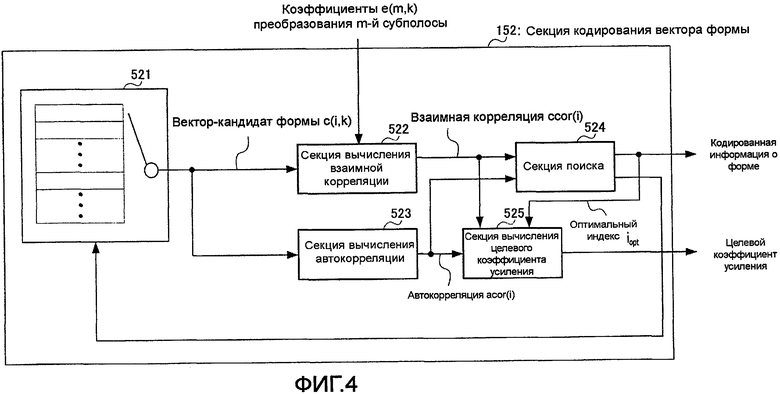
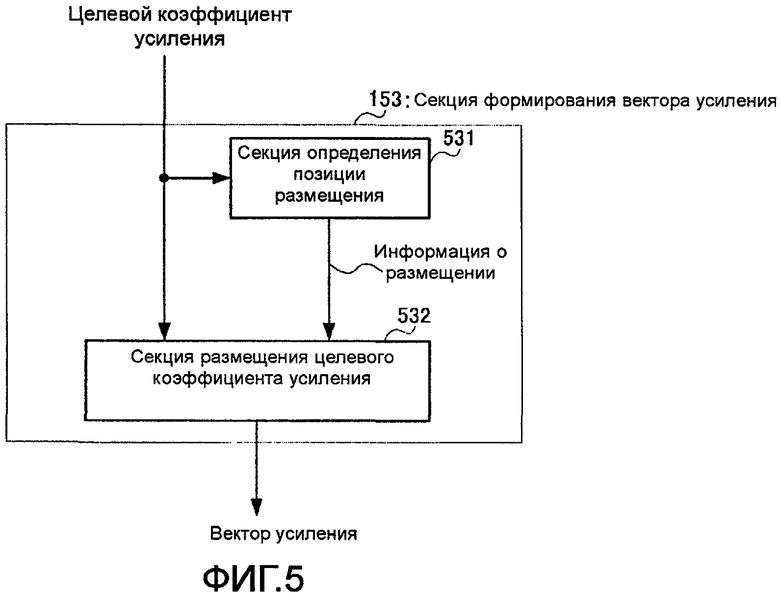
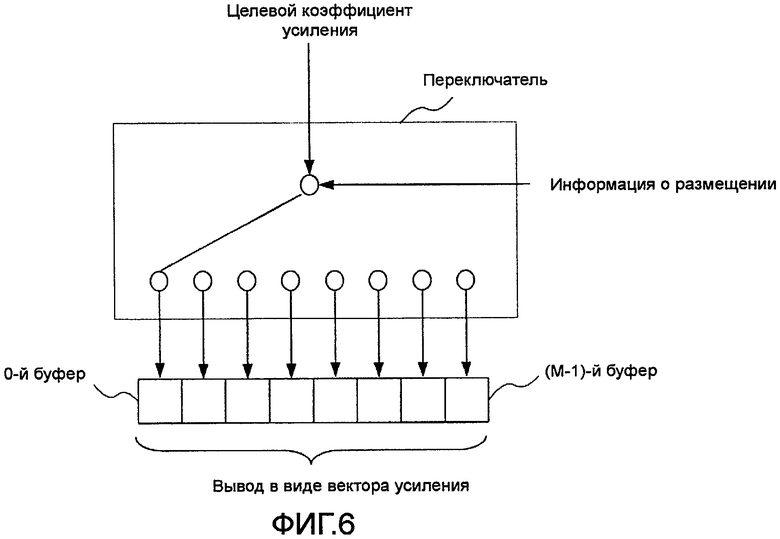
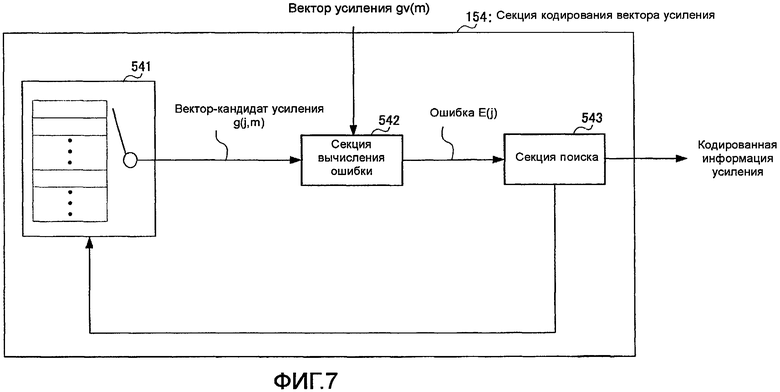
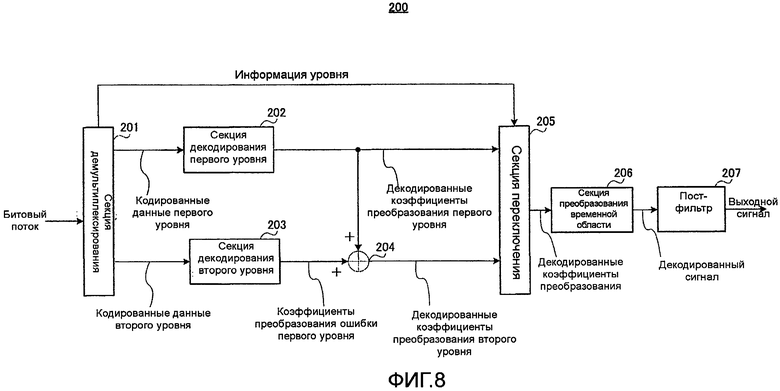
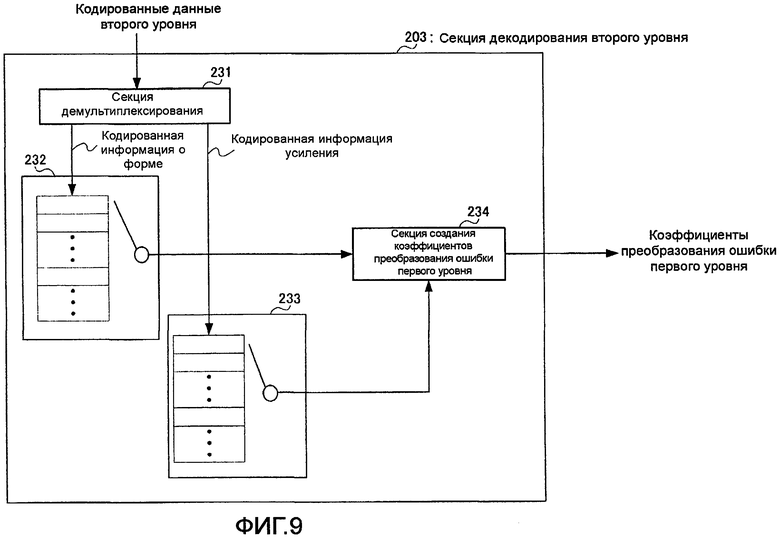
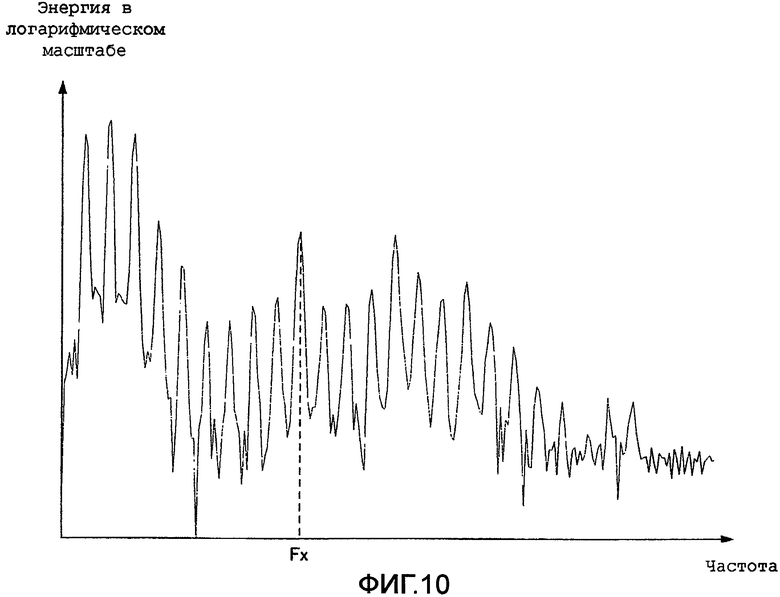
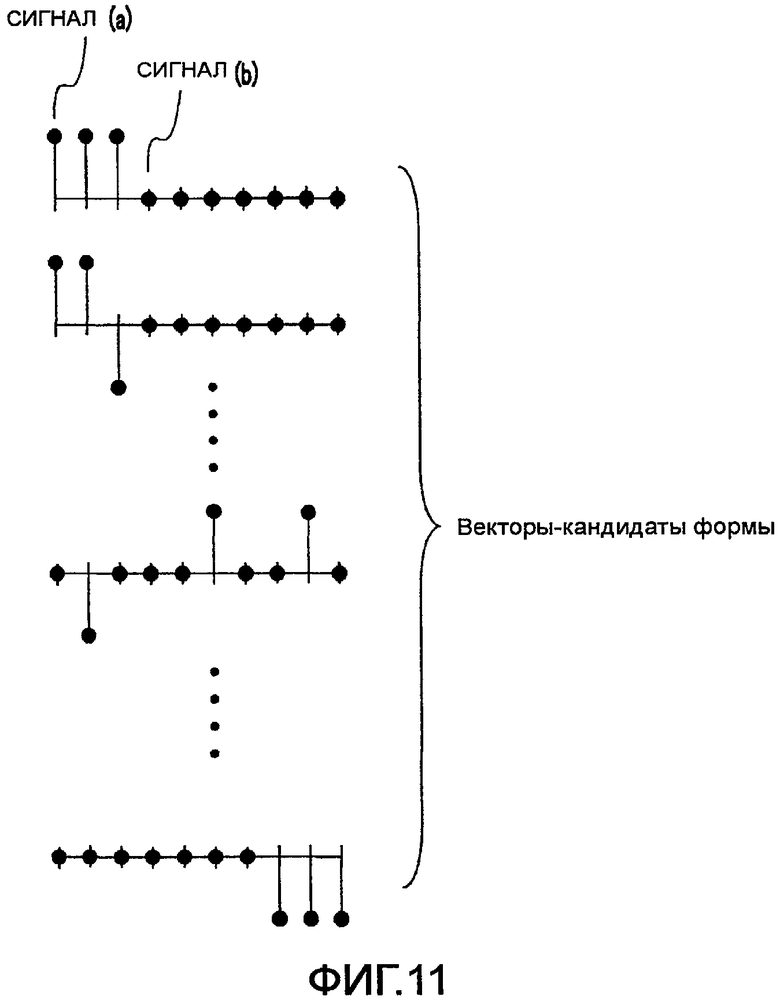
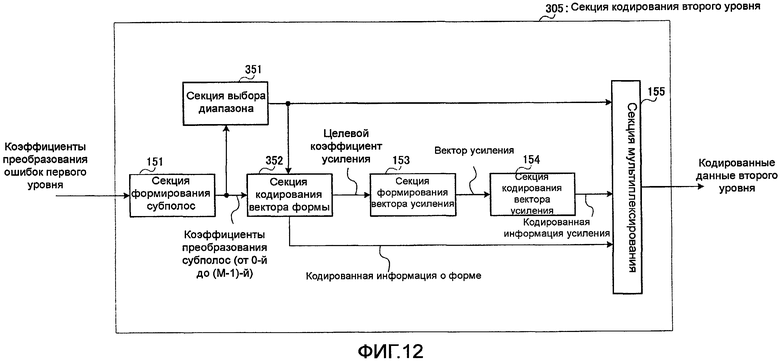
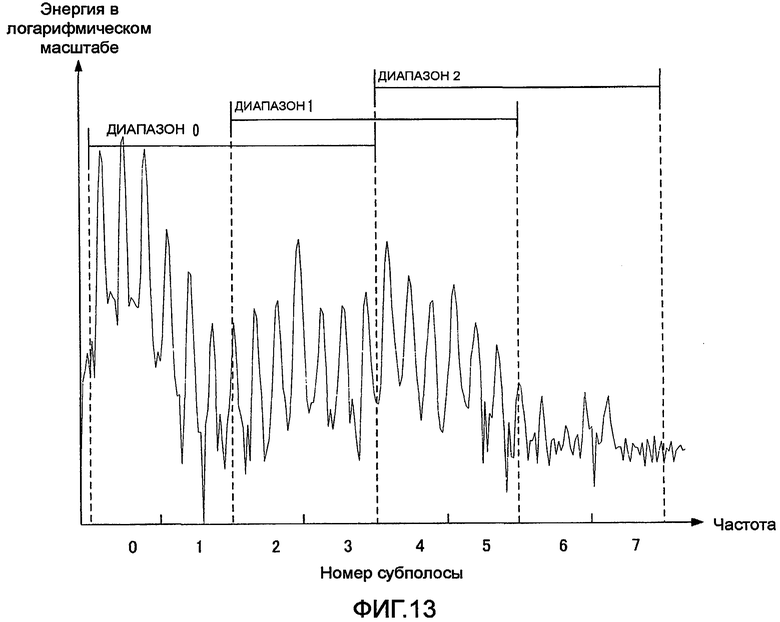
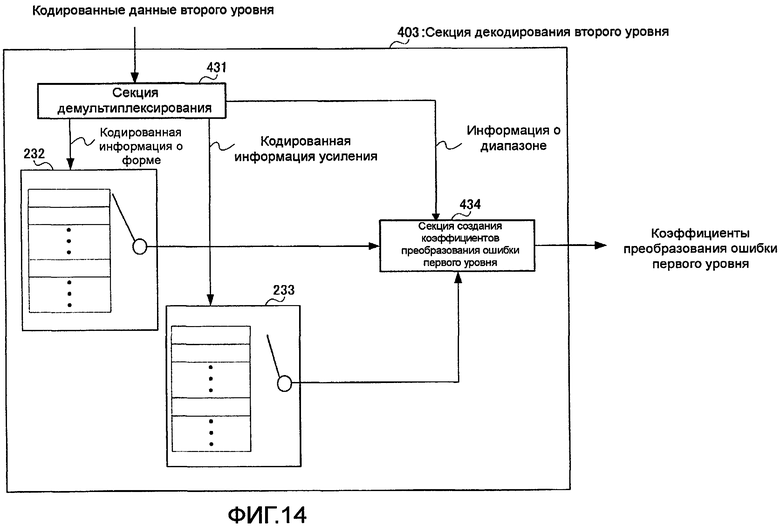
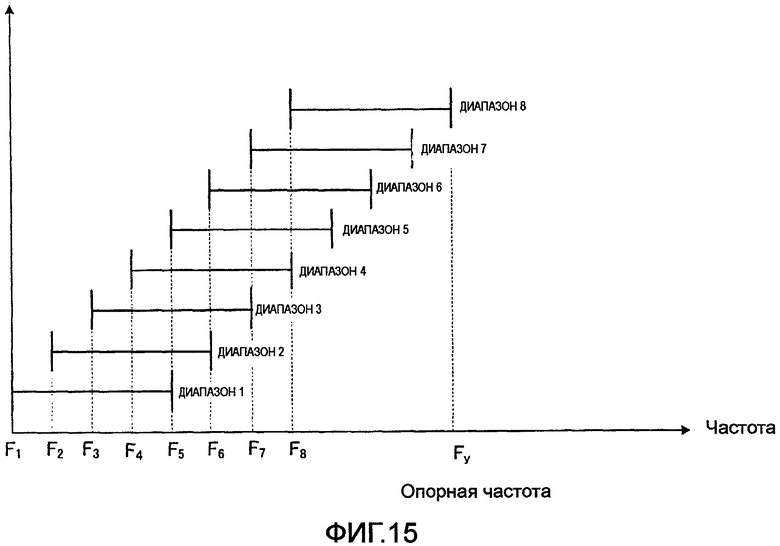
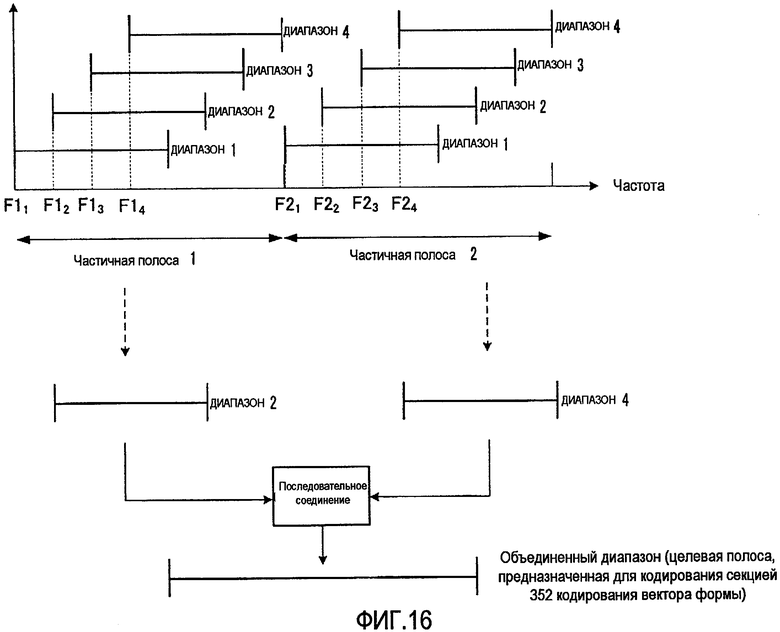
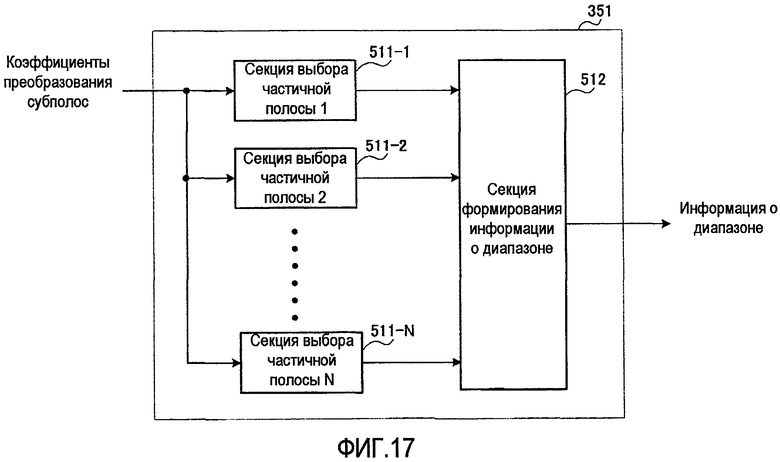

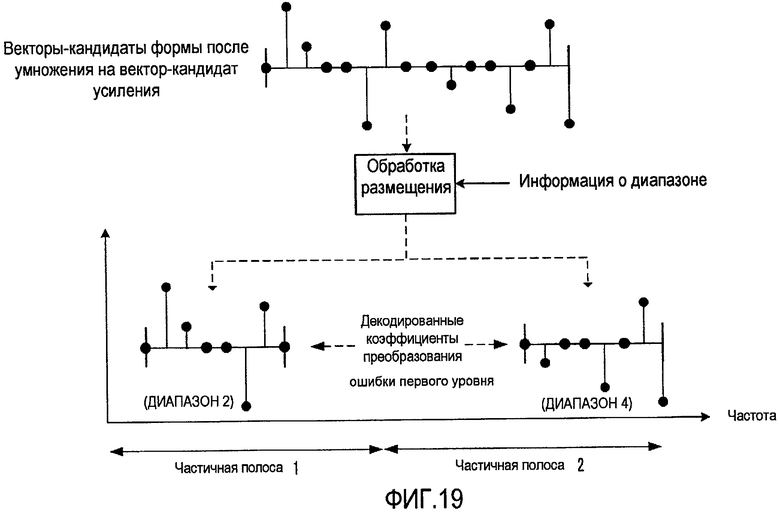
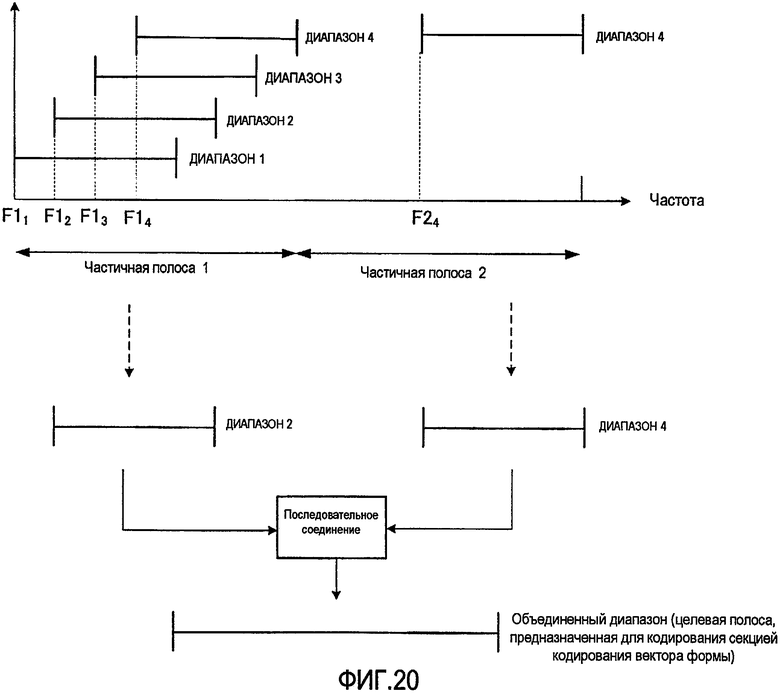
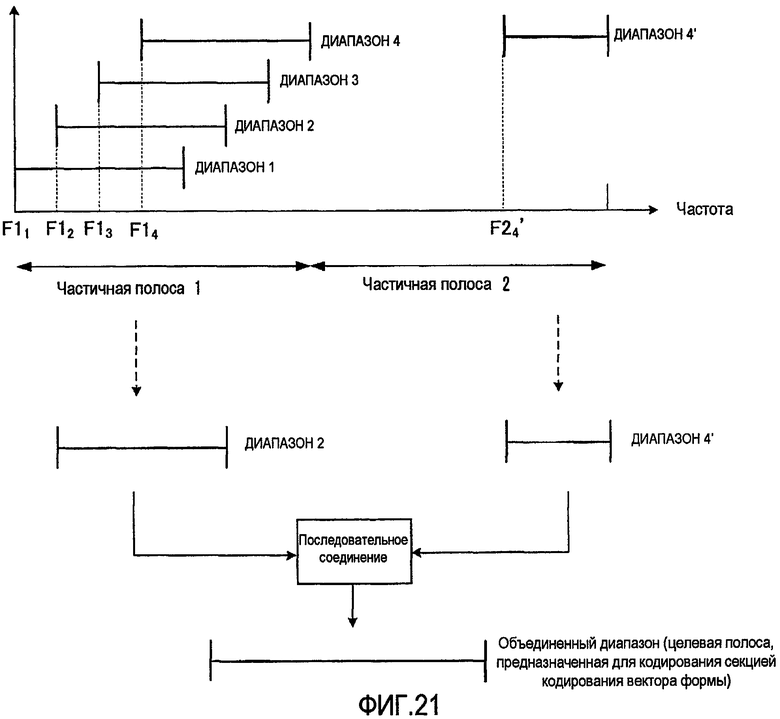
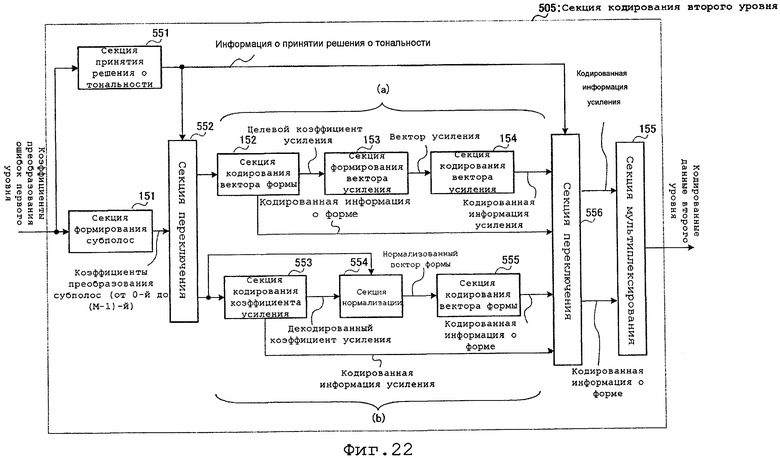
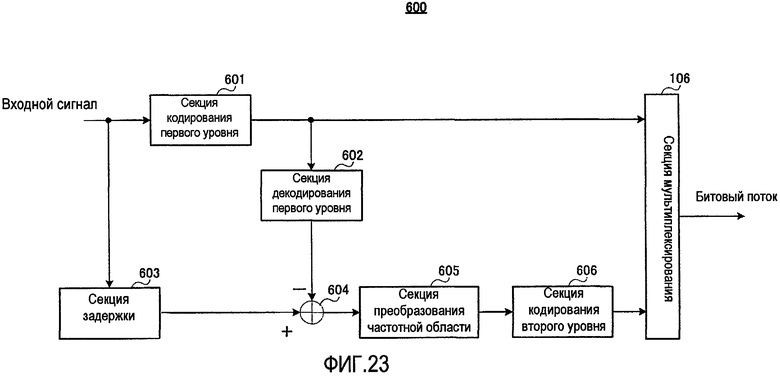
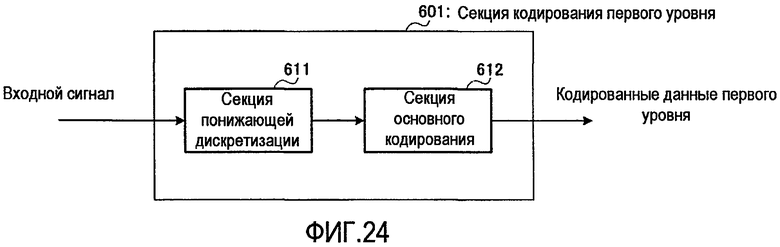
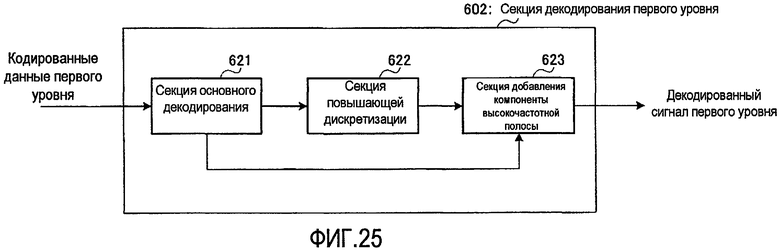
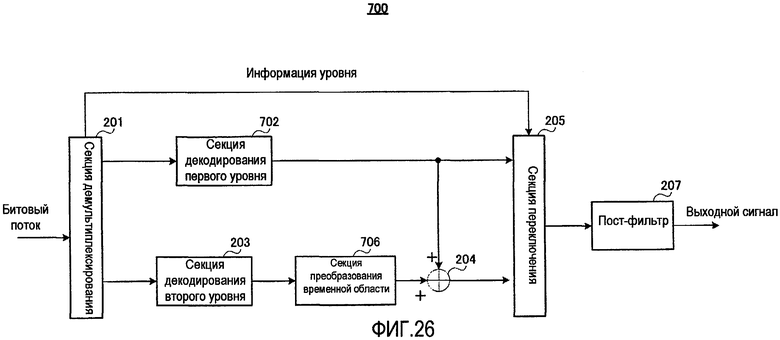
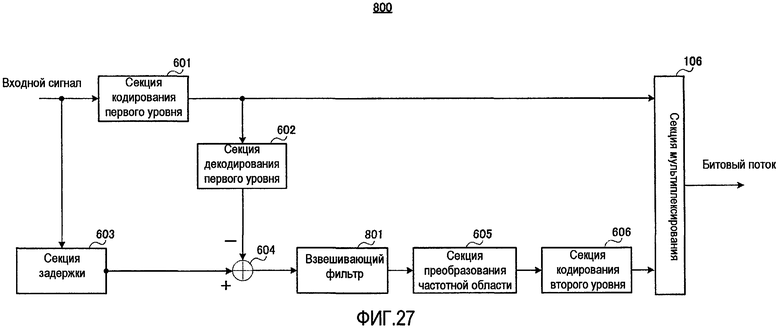
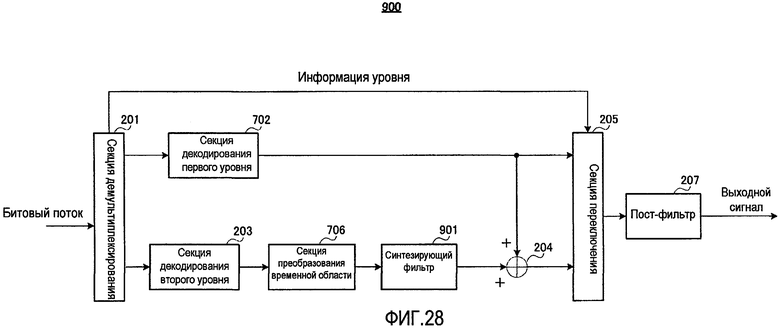
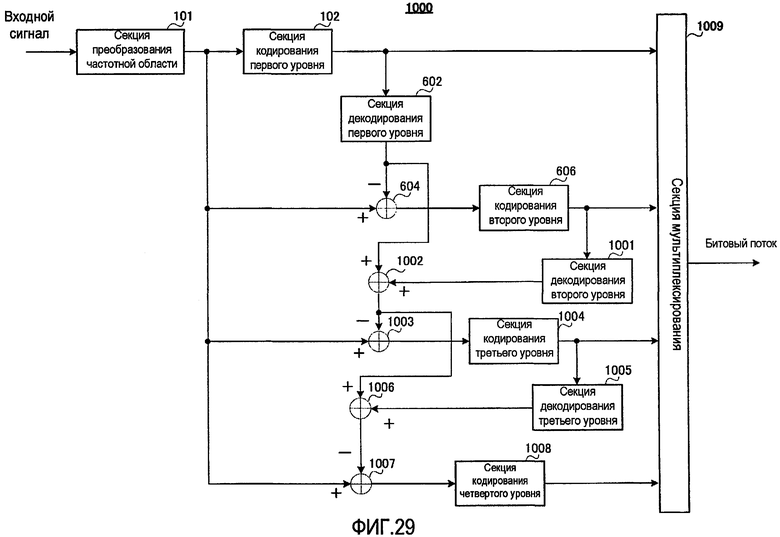
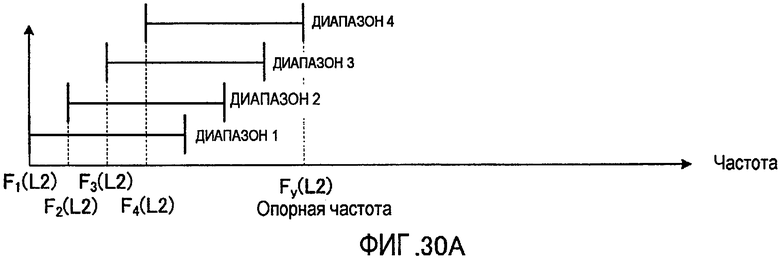
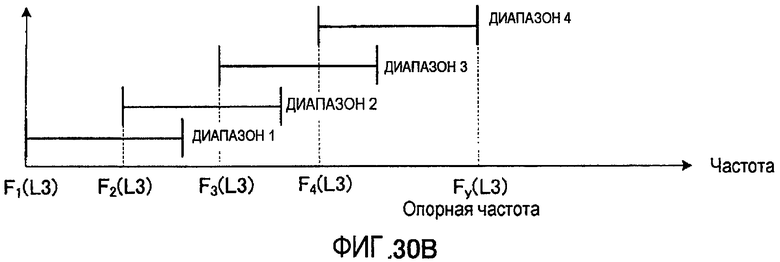
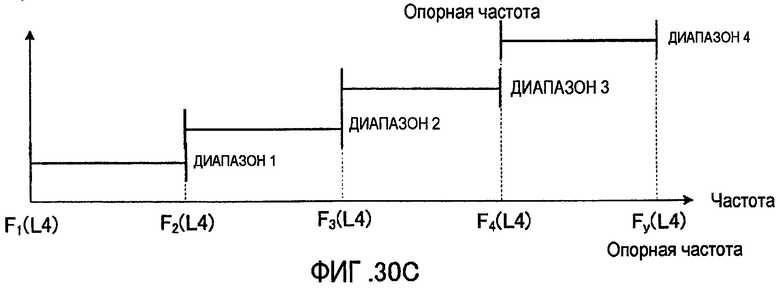
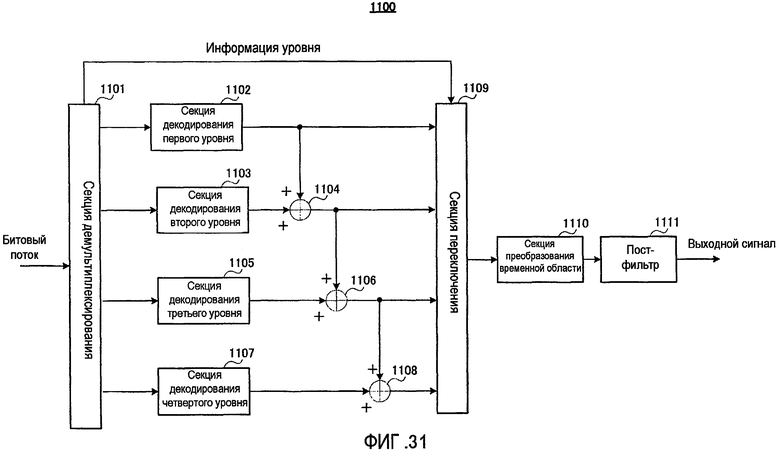
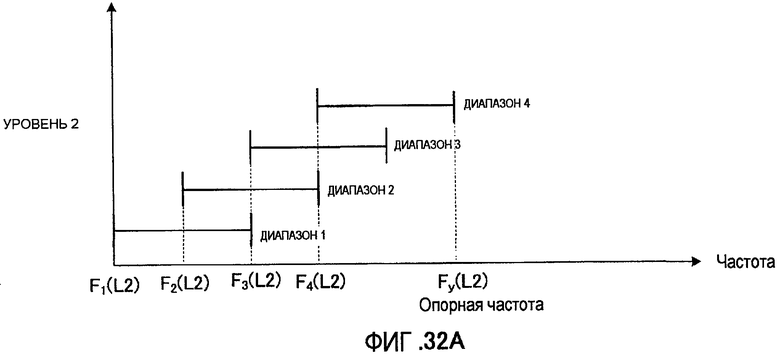
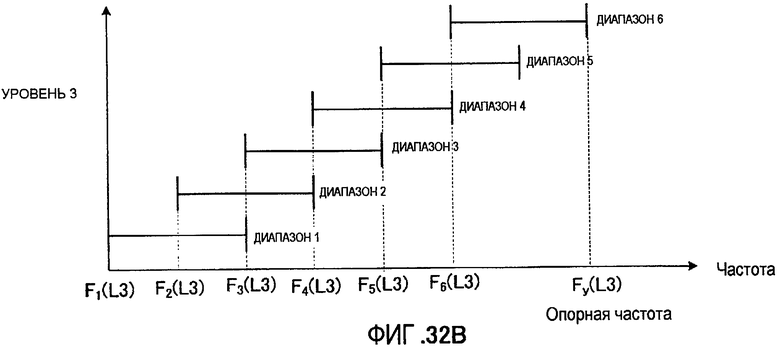
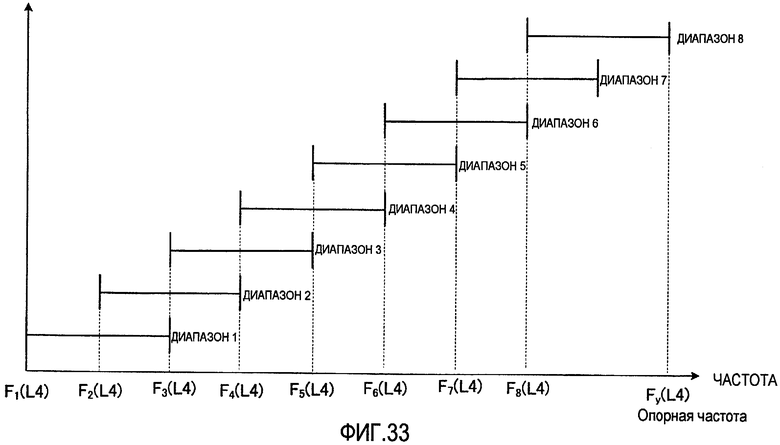
Изобретение относится к устройству и способу кодирования, используемым в системе связи, которая кодирует и передает входные сигналы, например, речевые сигналы. Техническим результатом является повышение качества звучания декодированных сигналов. Указанный результат достигается тем, что устройство кодирования содержит секцию кодирования входного сигнала для получения кодированных данных базового уровня; секцию декодирования кодированных данных базового уровня для получения декодированных данных базового уровня и секцию кодирования остаточного сигнала, представляющего разность между входным сигналом и декодированным сигналом базового уровня, для получения кодированных данных уровня улучшения. Секция кодирования уровня улучшения содержит секцию разделения остаточного сигнала на множество субполос; первую секцию кодирования вектора формы, которая кодирует спектральную форму каждой из множества субполос для получения, сначала, первой кодированной информации о форме и которая вычисляет целевые коэффициенты усиления, которые минимизируют расхождение между каждой из множества субполос и формой, основанной на первой кодированной информации о форме, после кодирования спектральной формы на по-субполосной основе; секцию формирования вектора усиления, которая формирует один вектор усиления с использованием множества целевых коэффициентов усиления; и секцию кодирования вектора усиления для получения первой кодированной информации усиления. 2 н. и 12 з.п. ф-лы, 33 ил.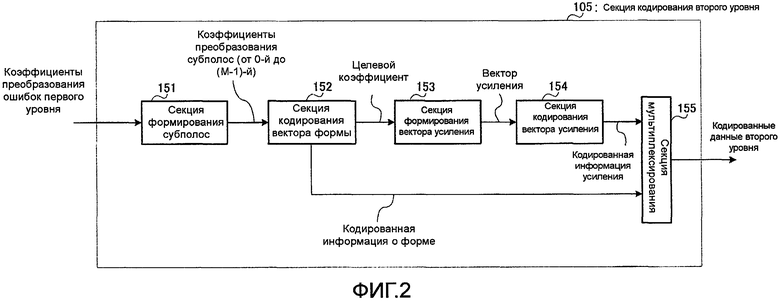
1. Устройство кодирования, содержащее секцию кодирования базового уровня, которая кодирует входной сигнал для получения кодированных данных базового уровня; секцию декодирования базового уровня, которая декодирует кодированные данные базового уровня для получения декодированного сигнала базового уровня; и секцию кодирования уровня улучшения, которая кодирует остаточный сигнал, представляющий разность между входным сигналом и декодированным сигналом базового уровня, для получения кодированных данных уровня улучшения, причем секция кодирования уровня улучшения содержит секцию разделения, которая разделяет остаточный сигнал на множество субполос; первую секцию кодирования вектора формы, которая кодирует спектральную форму каждой из множества субполос, полученных разделением секцией разделения, для получения сначала первой кодированной информации о форме и которая вычисляет целевые коэффициенты усиления, которые минимизируют расхождение между каждой из множества субполос и формой, основанной на первой кодированной информации о форме, после кодирования спектральной формы на по-субполосной основе; секцию формирования вектора усиления, которая формирует один вектор усиления с использованием множества целевых коэффициентов усиления; и секцию кодирования вектора усиления, которая кодирует вектор усиления для получения первой кодированной информации усиления.
2. Устройство кодирования по п.1, в котором первая секция кодирования вектора формы кодирует множество субполос с использованием кодового словаря векторов формы, сформированного из множества векторов-кандидатов формы, которые включают в себя по меньшей мере один импульс, расположенный на произвольной частоте.
3. Устройство кодирования по п.2, в котором первая секция кодирования вектора формы кодирует множество субполос с использованием информации о корреляции, относящейся к вектору-кандидату формы, выбранному из кодового словаря векторов формы.
4. Устройство кодирования по п.1, в котором секция кодирования уровня улучшения дополнительно содержит секцию выбора диапазона, которая вычисляет тональности множества диапазонов, сформированных с использованием произвольного количества соседних субполос, и которая выбирает один диапазон с самой насыщенной тональностью из множества диапазонов; и первая секция кодирования вектора формы, секция формирования вектора усиления и секция кодирования вектора усиления работают с множеством субполос, формирующих выбранный диапазон.
5. Устройство кодирования по п.1, в котором секция кодирования уровня улучшения дополнительно содержит секцию выбора диапазона, которая вычисляет средние значения энергии множества диапазонов, сформированных с использованием произвольного количества соседних субполос, и которая выбирает один диапазон с самым большим значением средней энергии из множества диапазонов; и первая секция кодирования вектора формы, секция формирования вектора усиления и секция кодирования вектора усиления работают с множеством субполос, формирующих выбранный диапазон.
6. Устройство кодирования по п.1, в котором секция кодирования уровня улучшения дополнительно содержит секцию выбора диапазона, которая вычисляет перцепционные взвешенные значения энергии множества диапазонов, сформированных с использованием произвольного количества соседних субполос, и которая выбирает один диапазон с самым большим перцепционным взвешенным значением энергии из множества диапазонов; и первая секция кодирования вектора формы, секция формирования вектора усиления и секция кодирования вектора усиления работают с множеством субполос, формирующих выбранный диапазон.
7. Устройство кодирования по любому из пп.4-6, в котором секция выбора диапазона выбирает один из множества диапазонов в более низких полосах, чем заранее определенная частота.
8. Устройство кодирования по любому из пп.4-6, дополнительно содержащее множество уровней улучшения, причем заранее определенная частота выше в более высоких уровнях.
9. Устройство кодирования по п.1, в котором секция кодирования уровня улучшения дополнительно содержит секцию выбора диапазона, которая формирует множество диапазонов с использованием произвольного количества соседних субполос, которая формирует множество частичных полос с использованием произвольного количества диапазонов, которая выбирает один диапазон с самым большим значением средней энергии из каждой из множества частичных полос и которая конкатенирует множество выбранных диапазонов для создания объединенного диапазона; и первая секция кодирования вектора формы, секция формирования вектора усиления и секция кодирования вектора усиления работают с множеством субполос, формирующих выбранный объединенный диапазон.
10. Устройство кодирования по п.9, в котором секция выбора диапазона всегда выбирает фиксированный диапазон, который задан заранее, в по меньшей мере одной из множества частичных полос.
11. Устройство кодирования по п.1, в котором секция кодирования уровня улучшения дополнительно содержит секцию принятия решения о тональности, которая принимает решение о насыщенности тональности входного сигнала; и когда принято решение о том, что насыщенность тональности входного сигнала больше или равна заранее определенному уровню, уровень улучшения разделяет остаточный сигнал на множество субполос; кодирует множество субполос для получения первой кодированной информации о форме и вычисляет целевые коэффициенты усиления множества субполос; формирует один вектор усиления с использованием множества целевых коэффициентов усиления; и кодирует вектор усиления для получения первой кодированной информации усиления.
12. Устройство кодирования по п.1, в котором секция кодирования базового уровня содержит секцию понижающей дискретизации, которая выполняет понижающую дискретизацию входного сигнала для получения сигнала, подвергнутого понижающей дискретизации; и секцию основного кодирования, которая кодирует сигнал, подвергнутый понижающей дискретизации для получения данных, подвергнутых основному кодированию, в качестве кодированных данных; и секция декодирования базового уровня содержит секцию основного декодирования, которая декодирует данные, подвергнутые основному кодированию, для получения сигнала, подвергнутого основному декодированию; секцию повышающей дискретизации, которая выполняет повышающую дискретизацию сигнала, подвергнутого основному декодированию, для получения сигнала, подвергнутого повышающей дискретизации, и секцию замены, которая заменяет компоненту высокочастотной полосы сигнала, подвергнутого повышающей дискретизации, шумом.
13. Устройство кодирования по п.1, дополнительно содержащее секцию кодирования коэффициентов усиления, которая кодирует коэффициенты усиления коэффициентов преобразования множества субполос для получения второй кодированной информации усиления; секцию нормализации, которая нормализует коэффициенты преобразования множества субполос с использованием вторых декодированных коэффициентов усиления, полученных путем декодирования кодированной информации усиления, для получения множества нормализованных векторов формы; вторую секцию кодирования вектора формы, которая кодирует множество нормализованных векторов формы, для получения второй кодированной информации о форме; и секцию принятия решения, которая вычисляет тональность входного сигнала на покадровой основе, которая выводит коэффициенты преобразования множества субполос в первую секцию кодирования вектора формы, когда принято решение о том, что тональность больше или равна пороговому значению, и которая выводит коэффициенты преобразования множества субполос в секцию кодирования коэффициентов усиления, когда принято решение о том, что тональность ниже порогового значения.
14. Способ кодирования, содержащий разделение коэффициентов преобразования, полученных путем преобразования входного сигнала в частотной области, на множество субполос; кодирование коэффициентов преобразования каждой из множества субполос, полученных разделением секцией разделения, для получения первой кодированной информации о форме, и вычисление целевых коэффициентов усиления, которые минимизируют расхождение между каждым из коэффициентов преобразования множества субполос и формой, основанной на первой кодированной информации о форме, после кодирования коэффициентов преобразования на по-субполосной основе; формирование одного вектора усиления с использованием целевых коэффициентов усиления; и кодирование вектора усиления для получения первой кодированной информации усиления.
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| JP 11030997 A, 02.02.1999 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| KR 20060022236 A, 09.03.2006 | |||
| US 6931373 B1, 16.08.2005 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| EP 0673014 A2, 20.09.1995 | |||
| RU 2002111665 A, 10.11.2003. | |||

