Область техники изобретения
Настоящее изобретение относится в основном к улучшенной системе обработки данных и, в частности, к способу и устройству для анализа данных с площадки скважины. Еще более конкретно, настоящее изобретение относится к компьютерно-реализуемому способу, устройству и компьютерно-используемому программному коду для анализа данных о формации в толще пород, полученных с площадки скважины, для прогнозирования свойств формации.
Уровень техники изобретения
Во время продуктивного периода добычи природных ресурсов, таких как нефть и газ, эти типы ресурсов извлекаются из областей пласт-коллектора в геологических формациях. Разные этапы в этом продуктивном периоде включают в себя разведку, оценку, разработку пласт-коллектора, прекращение добычи и ликвидацию пласт-коллектора. В этих разных фазах принимаются решения для правильного распределения ресурсов для гарантии того, что пласт-коллектор достигнет своего потенциала добычи. На ранних стадиях этого периода распределение внутренних свойств в пределах пласт-коллектора является практически неизвестными. По мере продолжения разработки пласт-коллектора собираются различные типы данных, относящихся к пласт-коллектору. Эти данные включают в себя, например, сейсмические данные, каротажные данные и данные о добыче. Собранная информация объединяется для создания понимания распределения свойств пласт-коллектора в формации.
Это понимание распределения пласт-коллектора изменяется по мере добычи и изменения данных. При анализе этих данных было разработано несколько разных программных пакетов. Например, Petrel, является программным решением, которое предоставляет различные инструменты от интерпретации сейсмических данных до симуляции в едином приложении. Petrel является продуктом компании Schlumberger Technology Corporation. Примером другого программного пакета, используемого для анализа данных о формациях в толще пород, является GeoFrame®. Этот программный пакет поставляется компанией Schlumberger Technology Corporation и обеспечивает опрашивающую систему описания пласт-коллектора, используемую для описания и управления ежедневными работами и обеспечения детального анализа пласт-коллекторов.
Однако подходы для анализа данных с площадок скважин, которые являются на сегодняшний день доступными, имеют несколько важных недостатков для изображения формации неоднородностей. Различные варианты осуществления обнаружили, что эти доступные в настоящий момент техники не предназначены для облегчения интеграции данных из разных источников вследствие неоднородности формаций. Например, программа может позволять проводить анализ и интерпретацию сейсмических данных, в то время как другая программа позволяет проводить анализ измерений пористости. Одна и та же программа может даже включать в себя модули для анализа данных из разных источников. Различные варианты осуществления обнаружили, что эти доступные в настоящий момент техники не способны интегрировать данные из разных источников вследствие неоднородности формаций в толще пород.
Сущность изобретения
Ввиду упомянутых выше проблем предметом изобретения является обеспечение способов, устройств и систем для многомерного анализа данных для идентификации неоднородности в формациях или регионах в толще пород, с одновременным исключением или минимизацией влияния описанных проблем и ограничений.
Настоящее изобретение включает в себя компьютерно-реализуемый способ для идентификации регионов в толще пород на площадке скважины. Способ включает в себя этапы, на которых непрерывно принимают данные с площадки скважины; уменьшают избыточность непрерывных данных, принимаемых с площадки скважины для формирования обработанных данных; выполняют кластерный анализ с использованием обработанных данных для образования набора кластерных элементов, причем набор кластерных элементов включает в себя разные типы кластерных элементов, которые идентифицируют различия между регионами в толще пород на площадке скважины; идентифицируют свойства каждого типа кластерного элемента в наборе кластерных элементов для формирования модели площадки скважины. Этап выполнения может включать в себя этапы, на которых выбирают несколько кластерных групп обработанных данных; группируют обработанные данные в несколько кластерных групп для формирования сгруппированных данных; выбирают набор местоположений центроида для сгруппированных данных в нескольких кластерных группах; вычисляют расстояния между набором местоположений центроида и сгруппированными данными; избирательно изменяют набор местоположений центроида для минимизации расстояния между набором местоположений центроида и сгруппированными данными на основании расчета расстояний. Этап идентификации может включать в себя этап, на котором идентифицируют свойства для каждого кластерного элемента в наборе кластерных элементов в модели с использованием многомерных данных с площадки скважины. Многомерные данные содержат, по меньшей мере, одни из непрерывных данных с площадки скважины, непрерывных лабораторных данных, дискретных данных с площадки скважины и дискретных лабораторных данных. Способ также может включать в себя этап, на котором получают дополнительные многомерные данные из целевой скважины и выполняют разбиение на кластеры для создания второй модели для целевой скважины с использованием дополнительных многомерных данных, модели с идентифицированными свойствами и многомерных данных для площадки скважины.
Настоящее изобретение включает в себя способ анализа многомерных данных для площадки скважины. Этапы в способе включают в себя этапы, на которых получают многомерные данные с площадки скважины и выполняют кластерный анализ с использованием многомерных данных для формирования набора кластерных элементов на основании полученных многомерных данных. Различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины. Способ также может включать в себя этапы, на которых идентифицируют каждый кластерный элемент в наборе кластерных элементов с использованием многомерных данных с площадки скважины. Этапы в способе могут также включать в себя этап, на котором представляют набор кластерных элементов на дисплее с цветовым кодированием. Многомерные данные содержат непрерывные данные с площадки скважины, непрерывные лабораторные данные, дискретные данные с площадки скважины и дискретные лабораторные данные. Способ также включает в себя этап, на котором улучшают многомерные данные, полученные с площадки скважины, который выполняется до этапа выполнения. Этапы в способе могут также включать в себя этап, на котором идентифицируют минимальное количество наборов данных в многомерных данных. Минимальное количество наборов данных снижает избыточность в многомерных данных, используемых при выполнении кластерного анализа. Этап выполнения может включать в себя этапы, на которых выбирают несколько кластерных групп для многомерных данных; группируют многомерные данные в несколько кластерных групп для формирования сгруппированных данных; выбирают набор местоположений центроида для сгруппированных данных в нескольких кластерных группах; вычисляют расстояния между наборами местоположений центроида и сгруппированными данными; и избирательно изменяют набор местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными на основе рассчитанных расстояний. Этапы способа могут также включать в себя этап, на котором повторяют этапы вычисления и избирательного изменения до тех пор, пока не будет достигнут порог адекватного представления вариабельности входных переменных в сгруппированных данных. В этих вариантах осуществления кластерный анализ выполняется с использованием алгоритма К-средних. Этапы способа могут также включать в себя этап, на котором идентифицируют свойства каждого кластерного элемента в наборе кластерных элементов. При идентификации свойств для каждого кластерного элемента в наборе кластерных элементов этап может включать в себя этап, на котором идентифицируют свойства для каждого кластерного элемента в наборе кластерных элементов с использованием многомерных данных с площадки скважины. При идентификации свойств для каждого кластерного элемента в наборе кластерных элементов этап может включать в себя этапы, на которых получают дискретные данные с площадки скважины для каждого типа кластерного элемента в наборе кластерных элементов, идентифицируют свойства каждого кластерного элемента в наборе кластерных элементов с использованием дискретных данных с площадки скважины. Многомерные данные могут быть непрерывными данными и этап идентификации свойств для набора кластерных элементов может включать в себя этап, на котором идентифицируют свойства для каждого кластерного элемента в наборе кластерных элементов с использованием непрерывных данных. Этапы в способе также могут включать в себя этап, на котором сравнивают многомерные данные с различными типами кластерных элементов в наборе кластерных элементов. Площадка скважины может быть эталонной площадкой скважины, и этапы способа могут включать в себя этап, на котором коррелируют многомерные данные, сравненные с различными типами кластерных элементов в наборе кластерных элементов для эталонной площадки скважины с дополнительными многомерными данными для целевой площадки скважины. Создается вторая модель, содержащая кластерные элементы для целевой площадки скважины. Способ может также включать в себя этап, на котором соотносят все многомерные данные с эталонным масштабом глубины. Многомерные данные могут быть непрерывными, и способ может быть компьютерно-реализуемым способом. Далее, этапы способа могут включать в себя этап, на котором генерируют решения относительно работы площадки скважины с использованием свойств, идентифицированных для каждого кластерного элемента в наборе кластерных элементов. Многомерные данные включают в себя боковые пробы, и этапы включают в себя этапы, на которых получают первый керн из боковых проб с первой ориентацией относительно оси боковых проб, и получают второй керн из боковых проб со второй ориентацией относительно оси боковых проб. Этапы также могут включать в себя этап, на котором получают третий керн из боковых проб с третьей ориентацией относительно оси боковых проб.
Настоящее изобретение также включает в себя способ получения образцов из боковых проб. Этапы в способе включают в себя этапы, на которых идентифицируют различные ориентации относительно оси через боковую пробу и получают керны из боковых проб при множестве различных ориентаций. Количество различных ориентаций и количество кернов может равняться трем. Настоящее изобретение включает в себя способ для анализа площадки скважины. Этапы в этом способе включают в себя этапы, на которых получают запрос от клиента для выполнения анализа площадки скважины, при этом запрос включает в себя многомерные данные, полученные с площадки скважины; выполняют кластерный анализ с использованием многомерных данных для формирования набора кластерных элементов на основании полученного запроса, в котором набор кластерных элементов идентифицирует разницы между регионами в толще пород на площадке скважины; и отправляют клиенту результаты, полученные на основании кластерного анализа. Клиент использует результаты для выполнения действий на площадке скважины. Результаты могут принимать форму графической модели толщи пород на площадке скважины, при этом модель включает в себя набор кластеров. Результаты также могут быть инструкциями, идентифицирующими действия.
Настоящее изобретение включает в себя устройство для идентификации регионов в толще пород на площадке скважины. Устройство включает в себя принимающее средство для приема непрерывных данных с площадки скважины; сокращающее средство для уменьшения избыточности непрерывных данных, принятых с площадки скважины, для формирования обработанных данных; средство выполнения для выполнения кластерного анализа с использованием обработанных данных для формирования набора кластерных элементов, где набор кластерных элементов включает в себя различные типы кластерных элементов, которые идентифицируют разницы между регионами в толще пород на площадке скважины; и идентифицирующее средство для идентификации свойств для каждого типа кластерных элементов в наборе кластерных элементов для формирования модели для площадки скважины. Средство выполнения может включать в себя первое средство выбора для выбора нескольких кластерных групп для обработанных данных; группирующее средство для группировки обработанных данных в несколько кластерных групп для формирования сгруппированных данных; второе средство выбора для выбора набора местоположений центроида для сгруппированных данных в нескольких кластерных группах; вычисляющее средство для вычисления расстояний между набором местоположений центроида и сгруппированных данных; и изменяющее средство для избирательного изменения набора местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными на основании вычисленных расстояний. Идентифицирующее средство может включать в себя средство для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов в модели, использующей многомерные данные с площадки скважины. Многомерные данные содержат, по меньшей мере, одни из непрерывных данных с площадки скважины, непрерывных лабораторных данных, дискретных данных с площадки скважины и дискретных лабораторных данных. Устройство также может включать в себя получающее средство для получения дополнительных многомерных данных из целевой скважины и выполняющее средство для выполнения разбиения кластеров для создания второй модели для целевой скважины с использованием дополнительных многомерных данных, модели с идентифицированными свойствами и многомерных данных для площадки скважины.
Настоящее изобретение включает в себя устройство для анализа многомерных данных для площадки скважины. Устройство включает в себя принимающее средство для приема многомерных данных с площадки скважины и выполняющее средство для выполнения кластерного анализа с использованием многомерных данных для формирования набора кластерных элементов на основе принятых многомерных данных. Различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины. Устройство также может включать в себя идентифицирующее средство для идентификации каждого кластерного элемента в наборе кластерных элементов с использованием многомерных данных с площадки скважины. Устройство может включать в себя средство для представления набора кластерных элементов на дисплее с цветовым кодированием. Многомерные данные содержат непрерывные данные с площадки скважины, непрерывные лабораторные данные, дискретные данные с площадки скважины и дискретные лабораторные данные. Устройство может включать в себя улучшающее средство для улучшения многомерных данных, полученных с площадки скважины, которое выполняется до выполняющего средства. Устройство также может включать в себя идентифицирующее средство для идентификации минимального количества наборов данных в многомерных данных. Минимальное количество наборов данных снижает избыточность в многомерных данных, используемых при выполнении кластерного анализа. Средство выполнения может включать в себя средство выбора для выбора нескольких кластерных групп для многомерных данных; группирующее средство для группировки многомерных данных в несколько кластерных групп для формирования сгруппированных данных; второе средство выбора для выбора набора местоположений центроида для сгруппированных данных в нескольких кластерных группах; вычисляющее средство для вычисления расстояний между набором местоположений центроида и сгруппированных данных; и изменяющее средство для избирательного изменения набора местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными на основании вычисленных расстояний. Устройство может также включать в себя повторяющее средство для повторения исполнения вычисляющего средства и изменяющего средства, пока не будет достигнут порог адекватного представления вариабельности входных переменных в сгруппированных данных. В этих вариантах осуществления кластерный анализ выполняется с использованием алгоритма К-средних. Устройство также может включать в себя идентифицирующее средство для идентификации свойств кластерного элемента в наборе кластерных элементов. При идентификации свойств для каждого кластерного элемента в наборе кластерных элементов идентифицирующее средство может включать средство для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с использованием многомерных данных с буровой установки. При идентификации свойств для каждого кластерного элемента в наборе кластерных элементов идентифицирующее средство может включать средство для получения дискретных данных площадки скважины для каждого типа кластерного элемента в наборе кластерных элементов и идентифицирующее средство для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с использованием дискретных данных площадки скважины. Многомерные данные могут быть непрерывными данными, и идентифицирующее средство для идентификации свойств для набора кластерных элементов может включать в себя средство для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с использованием непрерывных данных. Устройство также может включать в себя сравнивающее средство для сравнения многомерных данных с разными типами кластерных элементов в наборе кластерных элементов. Площадка скважины может быть эталонной площадкой скважины и устройство может включать в себя средство коррелирования многомерных данных, сравненных с различными типами кластерных элементов в наборе кластерных элементов для эталонной площадки скважины с дополнительными многомерными данными для целевой площадки скважины. Создается вторая модель, содержащая кластерные элементы для целевой площадки скважины. Устройство также может включать в себя средство для соотнесения всех многомерных данных с эталонным масштабом глубины. Многомерные данные могут быть непрерывными, и способ может быть компьютерно-реализуемым способом. Дополнительно, устройство может включать в себя генерирующее средство для генерации решения относительно работы площадки скважины с использованием свойств, идентифицированных для каждого кластерного элемента в наборе кластерных элементов.
Настоящее изобретение включает в себя компьютерный программный продукт, имеющий компьютерно-используемый носитель, включающий в себя компьютерно-используемый программный код для идентификации регионов в толще пород на площадке скважины. Компьютерный программный продукт включает в себя компьютерно-используемый программный код для приема непрерывных данных с площадки скважины; компьютерно-используемый программный код для уменьшения избыточности в непрерывных данных, полученных с площадки скважины для формирования обработанных данных; компьютерно-используемый программный код для выполнения кластерного анализа с использованием обработанных данных для формирования набора кластерных элементов, где набор кластерных элементов включает в себя различные типы кластерных элементов, которые идентифицируют разницы между регионами в толще пород на площадке скважины; и компьютерно-используемый программный код для идентифицирования свойств для каждого типа кластерного элемента в наборе кластерных элементов для формирования модели для площадки скважины. Компьютерно-используемый программный код для выполнения кластерного анализа с использованием обработанных данных для формирования набора кластерных элементов может включать в себя компьютерно-используемый программный код для выбора нескольких кластерных групп для обработанных данных; компьютерно-используемый программный код для группировки обработанных данных в несколько кластерных групп для формирования сгруппированных данных; компьютерно-используемый программный код для выбора набора местоположений центроида для сгруппированных данных в нескольких кластерных группах; компьютерно-используемый программный код для вычисления расстояний между набором местоположений центроида и сгруппированных данных; и компьютерно-используемый программный код для избирательного изменения набора местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными на основании вычисленных расстояний. Компьютерно-используемый программный код для идентификации свойств для каждого типа кластерного элемента в наборе кластерных элементов для формирования модели для площадки скважины может включать в себя компьютерно-используемый программный код для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов в модели с использованием многомерных данных с буровой установки. Многомерные данные содержат, по меньшей мере, одни из непрерывных данных с площадки скважины, непрерывных лабораторных данных, дискретных данных с площадки скважины и дискретных лабораторных данных. Компьютерный программный продукт может также включать в себя компьютерно-используемый программный код для получения дополнительных многомерных данных из целевой скважины, и компьютерно-используемый программный код для выполнения разбиения кластеров для создания второй модели для целевой скважины с использованием дополнительных многомерных данных, модели с идентифицированными свойствами и многомерных данных для площадки скважины.
Настоящее изобретение включает в себя компьютерный программный продукт, имеющий компьютерно-используемый носитель, включающий в себя компьютерно-используемый программный код для анализа многомерных данных для буровой установки. Компьютерный программный продукт включает в себя компьютерно-используемый программный код для приема многомерных данных с буровой установки и компьютерно-используемый программный код для выполнения кластерного анализа с использованием многомерных данных для формирования набора кластерных элементов на основе принятых многомерных данных. Различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины. Компьютерный программный продукт может также включать в себя компьютерно-используемый программный код для идентификации каждого кластерного элемента в наборе кластерных элементов с использованием многомерных данных с буровой установки. Компьютерный программный продукт может включать в себя компьютерно-используемый программный код для представления набора кластерных элементов на дисплее с цветовым кодированием. Многомерные данные содержат непрерывные данные с площадки скважины, непрерывные лабораторные данные, дискретные данные с площадки скважины и дискретные лабораторные данные. Компьютерный программный продукт также включает в себя компьютерно-используемый программный код для улучшения многомерных данных, полученных с площадки скважины, которое выполняется до выполнения компьютерно-используемого программного кода для выполнения кластерного анализа с использованием многомерных данных для формирования кластерных элементов. Компьютерный программный продукт может также включать в себя компьютерно-используемый программный код для идентификации минимального количества наборов данных в многомерных данных. Минимальное количество наборов данных снижает избыточность в многомерных данных, используемых при выполнении кластерного анализа. Компьютерно-используемый программный код для выполнения кластерного анализа с использованием многомерных данных для формирования кластерных элементов может включать в себя компьютерно-используемый программный код для выбора нескольких кластерных групп для многомерных данных; компьютерно-используемый программный код для группировки многомерных данных в несколько кластерных групп для формирования сгруппированных данных; компьютерно-используемый программный код для выбора набора местоположений центроида для сгруппированных данных в нескольких кластерных группах; компьютерно-используемый программный код для вычисления расстояний между набором местоположений центроида и сгруппированных данных; и компьютерно-используемый программный код для избирательного изменения набора местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными на основании вычисленных расстояний. Компьютерный программный продукт может также включать в себя компьютерно-используемый программный код для повторения исполнения компьютерно-используемого программного кода для вычисления расстояний между набором местоположений центроида и сгруппированных данных; и компьютерно-используемый программный код для избирательного изменения набора местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными на основании вычисленных расстояний, пока не будет достигнут порог адекватного представления вариабельности входных переменных в сгруппированных данных. В этих вариантах осуществления кластерный анализ выполняется с использованием алгоритма К-средних. Компьютерный программный продукт может также включать в себя компьютерно-используемый программный код для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов. При идентификации свойств для каждого кластерного элемента в наборе кластерных элементов, компьютерно-используемый программный код для идентификации свойств может включать в себя компьютерно-используемый программный код для получения дискретных данных площадки скважины для каждого типа кластерного элемента в наборе кластерных элементов и компьютерно-используемый программный код для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с использованием дискретных данных площадки скважины. При идентификации свойств для каждого кластерного элемента в наборе кластерных элементов, компьютерно-используемый программный код для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов может включать в себя компьютерно-используемый программный код для получения дискретных данных площадки скважины для каждого типа кластерного элемента в наборе кластерных элементов и компьютерно-используемый программный код для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с использованием дискретных данных площадки скважины. Многомерные данные могут быть непрерывными данными и компьютерно-используемый программный код для идентификации свойств для набора кластерных элементов может включать в себя компьютерно-используемый программный код для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с использованием непрерывных данных. Компьютерные программные продукты могут также включать в себя компьютерно-используемый программный код для сравнения многомерных данных с разными типами кластерных элементов в наборе кластерных элементов. Площадка скважины может быть эталонной площадкой скважины и компьютерные программные продукты могут включать в себя компьютерно-используемый программный код для коррелирования многомерных данных, сравненных с различными типами кластерных элементов в наборе кластерных элементов для эталонной площадки скважины с дополнительными многомерными данными для целевой площадки скважины. Создается вторая модель, содержащая кластерные элементы для целевой площадки скважины. Компьютерный программный продукт также может включать в себя компьютерно-используемый программный код для соотнесения всех многомерных данных с эталонным масштабом глубины. Многомерные данные могут быть непрерывными данными. Дополнительно, компьютерный программный продукт может включать в себя компьютерно-используемый программный код для генерации решения относительно работы площадки скважины с использованием свойств, идентифицированных для каждого кластерного элемента в наборе кластерных элементов.
Настоящее изобретение включает в себя систему обработки данных, имеющую шину; блок связи, подсоединенный к шине; устройство хранения, подсоединенное к шине, при этом устройство хранения включает в себя компьютерно-используемый программный код; и процессор, подсоединенный к шине. Процессор исполняет компьютерно-используемый программный код для приема непрерывных данных с площадки скважины; уменьшения избыточности в непрерывных данных, принятых с площадки скважины для формирования обработанных данных; выполнения кластерного анализа с использованием обработанных данных для формирования набора кластерных элементов, где набор кластерных элементов включает в себя различные типы кластерных элементов, которые идентифицируют разницы между регионами в толще пород на площадке скважины; и идентификации свойств для каждого типа кластерных элементов в наборе кластерных элементов для формирования модели для площадки скважины. При выполнении компьютерно-используемого программного кода для выполнения кластерного анализа с использованием обработанных данных для формирования набора кластерных элементов процессор может исполнять компьютерно-используемый программный код для выбора нескольких кластерных групп для обработанных данных; группировки обработанных данных в несколько кластерных групп для формирования сгруппированных данных; выбора набора местоположений центроида для сгруппированных данных в нескольких кластерных группах; вычисления расстояний между набором местоположений центроида и сгруппированных данных; и избирательного изменения набора местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными на основании вычисленных расстояний. При выполнении компьютерно-используемого программного кода для идентификации свойств для каждого типа кластерного элемента в наборе кластерных элементов для формирования модели для площадки скважины процессор может исполнить компьютерно-используемый программный код для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов в модели с использованием многомерных данных с буровой установки. Многомерные данные содержат, по меньшей мере, одни из непрерывных данных с площадки скважины, непрерывных лабораторных данных, дискретных данных с площадки скважины и дискретных лабораторных данных. Процессор может дополнительно исполнять компьютерно-используемый программный код для получения дополнительных многомерных данных из целевой скважины и выполнения разбиения кластеров для создания второй модели для целевой скважины с использованием дополнительных многомерных данных, модели с идентифицированными свойствами и многомерных данных для площадки скважины.
Настоящее изобретение включает в себя систему обработки данных, имеющую шину; блок связи, подсоединенный к шине; устройство хранения, подсоединенное к шине, при этом устройство хранения включает в себя компьютерно-используемый программный код; и процессор, подсоединенный к шине. Процессор исполняет компьютерно-используемый программный код для приема многомерных данных с буровой установки и выполнения кластерного анализа с использованием многомерных данных для формирования набора кластерных элементов на основе принятых многомерных данных. Различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины. Процессор может также исполнять компьютерно-используемый программный код для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с использованием непрерывных данных. Процессор может также исполнять компьютерно-используемый программный код для представления набора кластерных элементов на дисплее с цветовым кодированием. Многомерные данные содержат непрерывные данные с площадки скважины, непрерывные лабораторные данные, дискретные данные с площадки скважины и дискретные лабораторные данные. Процессор может также исполнять компьютерно-используемый программный код для улучшения многомерных данных, полученных с площадки скважины, которое выполняется до выполнения компьютерно-используемого программного кода для выполнения кластерного анализа с использованием многомерных данных для формирования кластерных элементов. Процессор может также исполнять компьютерно-используемый программный код для идентификации минимального количества наборов данных в многомерных данных. Минимальное количество наборов данных снижает избыточность в многомерных данных, используемых при выполнении кластерного анализа. При выполнении компьютерно-используемого программного кода для выполнения кластерного анализа с использованием обработанных данных для формирования набора кластерных элементов процессор может исполнять компьютерно-используемый программный код для выбора нескольких кластерных групп для обработанных данных; группировки обработанных данных в несколько кластерных групп для формирования сгруппированных данных; выбора набора местоположений центроида для сгруппированных данных в нескольких кластерных группах; вычисления расстояний между набором местоположений центроида и сгруппированных данных; и избирательного изменения набора местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными на основании вычисленных расстояний. Процессор может также исполнять компьютерно-используемый программный код для повторения вычисления расстояний между набором местоположений центроида и сгруппированных данных; и избирательного изменения набора местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными на основании вычисленных расстояний, пока не будет достигнут порог адекватного представления вариабельности входных переменных в сгруппированных данных. В этих вариантах осуществления кластерный анализ выполняется с использованием алгоритма К-средних. Процессор может также исполнить компьютерно-используемый программный код для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов. При идентификации свойств для каждого кластерного элемента в наборе кластерных элементов процессор может также исполнить компьютерно-используемый программный код для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с использованием многомерных данных с площадки скважины. При идентификации свойств для каждого кластерного элемента в наборе кластерных элементов процессор может также исполнить компьютерно-используемый программный код для получения дискретных данных площадки скважины для каждого типа кластерного элемента в наборе кластерных элементов и идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с использованием дискретных данных площадки скважины. Многомерные данные могут быть непрерывными данными, и при исполнении компьютерно-используемого программного кода для идентификации свойств для набора кластерных элементов процессор может исполнить компьютерно-используемый программный код для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с использованием непрерывных данных. Процессор может также исполнить компьютерно-используемый программный код для сравнения многомерных данных с разными типами кластерных элементов в наборе кластерных элементов. Площадка скважины может быть эталонной площадкой скважины и процессор может исполнить компьютерно-используемый программный код для коррелирования многомерных данных, сравненных с различными типами кластерных элементов в наборе кластерных элементов для эталонной площадки скважины с дополнительными многомерными данными для целевой площадки скважины. Создается вторая модель, содержащая кластерные элементы для целевой площадки скважины. Процессор может также исполнить компьютерно-используемый программный код для соотнесения всех многомерных данных с эталонным масштабом глубины. Многомерные данные могут быть непрерывными данными. Дополнительно, процессор может исполнить компьютерно-используемый программный код для генерации решения относительно работы площадки скважины с использованием свойств, идентифицированных для каждого кластерного элемента в наборе кластерных элементов.
Другие цели и преимущества настоящего изобретения станут понятными специалистам в данной области техники по ссылке на чертежи, последующее описание и формулу изобретения.
Краткое описание чертежей
Фиг.1 является графическим представлением сетевой системы обработки данных, в которой может быть реализован предпочтительный вариант осуществления настоящего изобретения;
Фиг.2 является диаграммой, иллюстрирующей площадку скважины, с которой получаются данные, в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.3 является диаграммой системы обработки данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.4 является диаграммой, иллюстрирующей компоненты, используемые для анализа многомерных данных с одной или более площадок скважин, в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.5 является блок-схемой процесса для управления площадкой скважины с использованием многомерных данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.6 является диаграммой, иллюстрирующей каротажные данные, которые могут быть найдены в многомерных данных, в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.7 является диаграммой, иллюстрирующей изображения образцов керна, которые могут быть использованы для выполнения анализа многомерных данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.8 является диаграммой, иллюстрирующей непрерывные данные, наложенные на изображения образцов керна, в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.9 является диаграммой, иллюстрирующей входные данные в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.10 является изображением информации, используемой в вычислениях кластерного анализа, в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.11 является диаграммой изображения, используемого в вычислениях кластерного анализа, в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.12 является диаграммой, иллюстрирующей образование кластерных элементов из многомерных данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.13 является диаграммой изображения с результатами многомерного кластерного анализа в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.14 является диаграммой, иллюстрирующей результаты для разнородной формации в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.15 является графиком, иллюстрирующим результаты кластерного анализа в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.16 является диаграммой, иллюстрирующей интеграцию скважинных данных с результатами в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.17 является диаграммой, иллюстрирующей пробы керна в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.18 является диаграммой, иллюстрирующей отбор образцов при различных ориентациях с использованием проб боковых стенок в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.19 является диаграммой, иллюстрирующей разбиение на кластеры в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.20 является диаграммой, иллюстрирующей разбиение на кластеры и подтверждение данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.21 является диаграммой, иллюстрирующей разбиение на кластеры и подтверждение данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.22 является диаграммой, иллюстрирующей отображение моделей площадок скважины в депрессии в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.23 является блок-схемой процесса для выполнения анализа многомерных данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.24 является блок-схемой процесса для идентификации избыточностей в многомерных данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.25 является блок-схемой процесса для выполнения кластерного анализа в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.26 является блок-схемой процесса для коррелирования данных для использования в кластерном разбиении в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.27 является блок-схемой процесса для генерации модели в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.28 является блок-схемой процесса для прогнозирования кластерных элементов в областях между скважинами в соответствии с предпочтительным вариантом осуществления настоящего изобретения;
Фиг.29 является блок-схемой процесса для поддержки запросов от клиентов для услуг анализа многомерных данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения.
Подробное описание чертежей
В следующем подробном описании предпочтительного варианта осуществления и других вариантов осуществления изобретения сделаны ссылки на прилагающиеся чертежи. Следует понимать, что специалисты в данной области техники легко увидят варианты осуществления и изменения, которые могут быть сделаны без выхода за объем изобретения.
На Фиг.1 изображено графическое представление сетевой системы обработки данных, в которой может быть реализован предпочтительный вариант осуществления настоящего изобретения. В этом примере, сетевая система 100 обработки данных является сетью вычислительных устройств, в которой может быть реализован предпочтительный вариант осуществления настоящего изобретения. Сетевая система 100 обработки данных включает в себя сеть 102, которая является средой, используемой для установления соединения между различными устройствами и компьютерами, которые соединены друг с другом в сетевую систему 100 обработки данных. Сеть 102 может включать в себя соединения, такие как провода, беспроводные соединения или волоконно-оптические кабели. Данные даже могут быть доставлены вручную путем сохранения данных в устройстве хранения, таком как жесткий диск, DVD или флэш-память.
В этом изображенном примере площадки скважин 104, 106, 108 и 110 имеют компьютеры или другие вычислительные устройства, которые производят данные касательно скважин, расположенных на этих площадках скважин. В этих примерах площадки скважин 104, 106, 108 и 110 расположены в географическом регионе 112. Этот географический регион является единым пласт-коллектором для этих примеров. Конечно, эти площадки скважин могут быть распределены по различным географическим регионам и/или над множеством пласт-коллекторов, в зависимости от конкретной реализации. Площадки скважин 104 и 106 имеют проводные соединения 114 и 116 к сети 102. Площадки скважин 108 и 110 имеют беспроводные соединения 118 и 120 к сети 102.
Аналитический центр 122 является местом, в котором системы обработки данных, такие как сервера, расположены для обработки данных, собранных с площадок скважин 104, 106, 108 и 110. Конечно, в зависимости от конкретной реализации, могут быть представлены несколько аналитических центров. Эти аналитические центры могут быть, например, офисом или располагаться в географическом месте 112, в зависимости от конкретной реализации. В этих иллюстративных вариантах осуществления, аналитический центр 122 анализирует данные с площадок скважин 104, 106, 108 и 110 с использованием процессов для различных вариантов осуществления настоящего изобретения.
В изображенном примере, сетевая система 100 обработки данных является сетью Интернет с сетью 102, представляющей всемирное множество сетей и шлюзов, которые используют стек протоколов TCP/IP (Transmission Control Protocol/Internet Protocol) для соединения друг с другом. Сердцем Интернета является магистраль высокоскоростных каналов передачи данных между главными узлами или главными компьютерами, состоящими из тысяч коммерческих, правительственных, образовательных и других компьютерных систем, которые маршрутизируют данные и сообщения. Конечно, сетевая система 100 обработки данных также может быть реализована как несколько различных типов сетей, таких как, например, интранет, локальная сеть (LAN) или глобальная сеть (WAN). Фиг.1 предлагается в качестве примера и не является архитектурным ограничением для различных вариантов осуществления.
Различные варианты осуществления отмечают, что способность анализировать различные типы данных, доступных с площадок скважин, является полезным для идентификации формаций. В частности, использование различных типов данных, полученных с площадки скважины, позволяет идентифицировать неоднородность в формациях или регионах, над которыми расположены площадки скважин.
Различные варианты осуществления настоящего изобретения обеспечивают компьютерно-реализуемый способ, устройство и компьютерно-используемый программный код для идентификации неоднородности породы. Эти варианты осуществления также облегчают выбор мест взятия образцов керна на основании идентификации неоднородности и решений для различных проблем месторождения. В этих иллюстративных вариантах осуществления неоднородность формации идентифицируется с использованием непрерывных скважинных данных. Непрерывные скважинные данные включают в себя, например, каротажные данные, данные измерений во время бурения, диаграммы газового каротажа, бурового шлама и другую информацию, которая собирается вместе для формирования набора многомерных данных. После забора образцов свойства материала измеряются, и эти свойства ассоциируются с многомерными данными. Эти свойства материала включают в себя, например, свойства пласт-коллектора, геохимические, петрологические и механические свойства. Затем получаются модели распространения каждого из измеренных свойств вдоль скважины.
Также из этой информации могут быть получены модели прогнозирования свойств на других площадках скважин и сделаны решения относительно площадки скважины. Таким образом, различные иллюстративные варианты осуществления позволяют конструировать нетрадиционные трехмерные модели, которые основаны на скважинных данных для использования в управлении пласт-коллектором. Эта информация может быть использована для более лучшего определения перспективных мест добычи и для более лучшего ведения бурения и планирования добычи.
На Фиг.1 изображена диаграмма, иллюстрирующая площадку скважины, с которой получаются данные, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. Площадка скважины 200 является примером площадки скважины, такой как площадка скважины 104 на Фиг.1. Данные, полученные с площадки скважины 200, упоминаются в этих примерах как многомерные данные.
В этом примере, площадка скважины 200 расположена на формации 202. Во время создания скважины 204 в формации 202 получают различные образцы. Например, может быть получен образец 206 керна, а также боковая проба 208. Дополнительно, может быть использован каротажный инструмент 210 для получения другой информации, такой как измерения давления и информации о коэффициенте пористости. Дополнительно, при создании скважины 204 получаются буровой шлам и диаграммы газового каротажа.
Другая информация, такая как сейсмическая информация, также может быть получена с использованием сейсмического устройства 212. Эта информация может быть собрана системой 214 обработки данных и передана в аналитический центр, такой как аналитический центр 122 на Фиг.1 для анализа. Например, сейсмические измерения, сделанные сейсмическим устройством 212, могут быть собраны системой 214 обработки данных и отправлены для дальнейшего анализа.
Информация, собранная на площадке скважины 200, может быть разделена на группы непрерывных данных и группы дискретных данных. В этих примерах непрерывные данные могут быть данными с площадки скважины или лабораторными данными, и дискретные данные также могут быть данными с площадки скважины или лабораторными данными. Данные с площадки скважины являются данными, полученными посредством измерений, сделанных на площадке скважины, в то время как лабораторные данные получены из измерений образцов с площадки скважины 200. Например, непрерывные данные с площадки скважины включают в себя, например, сейсмические данные, каротажные диаграммы и измерения во время бурения. Непрерывные лабораторные данные включают в себя, например, профили напряжений и информация гамма-исследования керна. Дискретные данные с площадки скважины включают в себя, например, данные о пробах боковых стенок, буровом шламе, измерениях давления и измерениях по определению движения газа. Дискретные лабораторные данные могут включать в себя, например, лабораторные измерения, сделанные на пробах или кернах, полученных из площадки скважины 200. Конечно, различные иллюстративные варианты осуществления могут быть применены к любым непрерывным данным с площадки скважины, непрерывным лабораторным данным, дискретным данным с площадки скважины и дискретным лабораторным данным в дополнение или взамен тем, что проиллюстрированы в этих примерах.
Изображения образцов керна и другие данные, измеренные или собранные устройствами на площадке скважины 200, могут быть отправлены в систему 214 обработки данных для передачи в аналитический центр. Более конкретно, многомерные данные могут быть введены или получены системой 214 обработки данных для передачи в аналитический центр для обработки. В качестве альтернативы, в зависимости от конкретной реализации, некоторые или все обработки многомерных данных с площадки скважины 200 могут быть выполнены с использованием системы 214 обработки данных. Например, система 214 обработки данных может быть использована для предварительной обработки данных или выполнения всего анализа данных с площадки скважины 200. Если весь анализ выполняется с использованием системы 214 обработки данных, то результат может быть передан в аналитический центр для соединения с результатами с других площадок скважин для получения дополнительных результатов.
На Фиг.3 изображена диаграмма системы обработки данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения. Система обработки данных 300 является примером системы обработки данных, которая может быть использована для реализации системы 214 обработки данных на Фиг.2. Дополнительно, различные вычислительные устройства, находящиеся на других площадках скважин и в аналитическом центре 122 на Фиг.1, могут быть реализованы с использованием системы 300 обработки данных. В этом иллюстративном примере система 300 обработки данных включает в себя шину 302 связи, которая обеспечивает соединения между процессором 304, памятью 306, постоянным запоминающим устройством 308, блоком 310 связи, блоком 312 ввода/вывода и дисплеем 314.
Процессор 304 выполняет инструкции программного обеспечения, которое может быть загружено в память 306. Процессор 304 может быть набором из одного или более процессоров или может быть многопроцессорным ядром, в зависимости от конкретной реализации. Дополнительно, процессор 306 может быть реализован с использованием одного или более разнородных процессорных систем, в которых главный процессор представлен со второстепенными процессорами на одном чипе. Память 306 в этих примерах может быть, например, памятью с произвольным доступом. Постоянное запоминающее устройство 308 может принимать различные формы в зависимости от конкретной реализации. Например, постоянное запоминающее устройство 308 может быть, например, жестким диском, флэш-памятью, перезаписываемым оптическим диском, перезаписываемой магнитной лентой или их некоторой комбинацией.
Блок 310 связи в этих примерах обеспечивает связь с другими системами обработки данных или устройствами. В этих примерах блок 310 связи является сетевой интерфейсной картой. Блок 312 ввода/вывода предназначен для ввода и вывода данных с другими устройствами, которые могут быть подсоединены к системе 300 обработки данных. Например, блок 312 ввода/вывода может обеспечивать соединение для пользовательского ввода с помощью клавиатуры и мыши. Дополнительно, блок 312 ввода/вывода может отправлять вывод на принтер. Дисплей 314 обеспечивает механизм для отображения информации для пользователя.
Инструкции для операционной системы и приложения или программы расположены на постоянном запоминающем устройстве 308. Эти инструкции и программы могут быть загружены в память 306 для исполнения процессором 304. Процессы различных вариантов осуществления могут быть выполнены процессором 304 с использованием компьютерно-реализуемых инструкций, которые могут быть расположены в памяти, такой как память 306.
Различные варианты осуществления позволяют осуществлять анализ данных из разных источников, таких как данные, полученные с площадки скважины 200 на Фиг.2, для идентификации различных слоев в формации. Другими словами, разные варианты осуществления позволяют осуществлять идентификацию неоднородности формации. В иллюстративных примерах эта идентификация производится с использованием непрерывных скважинных данных, таких как непрерывные скважинные данные, полученные с площадки скважины 200 на Фиг.2. Более конкретно, разные варианты осуществления используют кластерный анализ для идентификации структур в многомерных данных о регионе в толще пород для идентификации неоднородности породы. Другими словами, эта информация с площадки скважины позволяет идентифицировать разные регионы или группировки внутри формации. В этих примерах идентификация разных регионов может быть в других зонах или структурах, отличных от формации в толще пород. В этих иллюстративных примерах зоной является некоторое выбранное поперечное сечение в толще пород или некоторая трехмерная зона в толще пород. Зона может включать в себя всю формацию, часть формации или другие структуры. Другими словами, зона может покрывать любую часть толщи пород под поверхностью толщи пород. Идентификация зон с одинаковыми или разными свойствами материала может быть проведена посредством этого типа анализа.
После получения идентификации неоднородности формации может быть сделана идентификация свойств разных регионов формации. Идентификация может быть сделана с использованием многомерных данных, уже собранных с площадки скважины. В качестве альтернативы, может быть осуществлено взятие образцов разных слоев или группировок для анализа свойств. Это взятие образцов может быть сделано посредством, например, отбора керна, боковых проб или шлама. Свойства образцов измеряются, и эти свойства могут быть связаны с многомерными данными для идентификации свойств для разных регионов внутри формации. Эти регионы в разных вариантах осуществления также известны как кластерные элементы. Далее, эта информация также используется для принятия решения об управлении площадкой скважины.
На Фиг.4 изображена диаграмма, иллюстрирующая компоненты, используемые для анализа многомерных данных с одной или более площадок скважины, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. Процесс 400 многомерного анализа может выполняться в системе обработки данных, такой как система 300 обработки данных на Фиг.3. Процесс 400 многомерного анализа принимает входные данные 402 и сохраняет входные данные 402 в базе 404 данных. В этих иллюстративных примерах входные данные 402 принимают форму многомерных данных, полученных с площадки скважины, такой как площадка скважины 200 на Фиг.2. Эти входные данные могут принимать разную форму, такую как, например, непрерывные данные или дискретные данные с площадки скважины. База 404 данных может быть реализована с использованием существующей в настоящее время системы базы данных. В этих примерах база 404 данных может принимать форму базы данных SQL (структурированный язык запросов).
Процесс 400 многомерного анализа анализирует данные в базе 404 данных для генерации результатов 406. Более конкретно, в этих вариантах осуществления процесс 400 многомерного анализа содержит различные процессы для выполнения кластерного анализа входных данных 402, хранящихся в базе 404 данных. Процесс 400 многомерного анализа идентифицирует различные регионы с одинаковыми или разными свойствами. Этот компонент программного обеспечения также может быть использован для связи измеренных свойств разных регионов и связи этих свойств с входными данными 402 таким образом, что это позволит идентифицировать разные регионы. Например, входные данные 402 могут включать в себя непрерывные скважинные данные, такие как скважинные каротажные диаграммы, измерения во время бурения, диаграммы газового каротажа, буровой шлам.
При идентификации одинаковых или разных свойств для разных регионов с использованием кластерного анализа процесс 400 многомерного анализа идентифицирует разные регионы с использованием непрерывных скважинных данных в наборе многомерных данных в этих иллюстративных вариантах осуществления. Другими словами, идентифицируются разные типы регионов или кластерных элементов под площадкой скважины вдоль скважины, но не свойства этих регионов или кластерных элементов. В этих примерах реальные свойства для идентификации региона не делаются во время этой части процесса. Например, свойства пласт-коллектора, геохимические, петрологические и механические свойства не идентифицируются посредством этого процесса. Эти типы свойств идентифицируются последовательно, с использованием образцов или других данных с площадки скважины.
После того как сделана идентификация региона, процесс 400 многомерного анализа может затем использовать многомерные данные, собранные с площадки скважины для идентификации свойств для этих разных регионов. Эти свойства могут включать в себя, например, свойства пласт-коллектора, геохимические, петрологические и механические свойства. Процесс 400 многомерного анализа затем связывает эти свойства с результатами 406. Связывание свойств с результатами 406 создает модель разных регионов под площадкой скважины вдоль скважины. Эти результаты могут быть проверены посредством отбора образцов в различных регионах в скважине. Когда эти разные регионы идентифицированы, получение данных для этих разных регионов может быть выполнено посредством таких техник, как отбор керна, боковых проб или шлама, для дополнительной проверки этих результатов. Свойства материала этих образцов могут быть измерены. Эти свойства материала являются свойствами конкретного региона, из которого взят образец.
С этой ассоциацией, модель может быть сгенерирована для распространения измеренных свойств вдоль скважины, из которой получены входные данные 402. Эта модель может быть использована для прогнозирования свойств для других скважин и для принятия решений о конкретной площадке скважины. Управление процессом 400 многомерного анализа и представление результатов 406 выполняется с использованием графического пользовательского интерфейса (GUI) 408. Графический пользовательский интерфейс 408 позволяет пользователю видеть и интерпретировать разные результаты. Дополнительно, графический пользовательский интерфейс 408 также позволяет пользователю изменять параметры, используемые для анализа входных данных 402. С результатами 406 могут быть построены трехмерные масштабные модели на основании скважинных данных, что позволит осуществлять более лучшее определение в добыче, такое как идентификация перспективных мест добычи. Дополнительно, с помощью сгенерированных из результатов 406 моделей может быть также выполнено лучшее ведение бурения и планирование добычи.
На Фиг.5 изображена блок-схема процесса для управления площадкой скважины с использованием многомерных данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения. Процесс, проиллюстрированный на Фиг.5, может быть реализован вручную и/или в системе обработки данных. При реализации с использованием системы обработки данных компоненты, проиллюстрированные на Фиг.3 и Фиг.4, являются программными и аппаратными компонентами, которые могут быть использованы для реализации процесса.
Процесс начинается со сбора входных данных (этап 500). Входные данные могут быть собраны с площадки скважины, такой как площадка скважины 200 на Фиг.2. Эти входные данные формируют входные данные, такие как входные данные 402 на Фиг.4. После этого выполняется кластерный анализ входных данных для идентификации неоднородности (этап 502). Этот кластерный анализ выполняется для идентификации кластерных элементов вдоль скважины, при этом считается, что они имеют одинаковые или различные свойства. После этого свойства внутри разных кластерных элементов являются определенными (этап 504) и результаты являются проанализированными (этап 506). Этот анализ может включать в себя результаты этапа 504, проанализированные с данными, собранными с других площадок скважины.
Затем инициируются действия для площадки скважины (этап 508), после чего процесс завершается. Эти действия могут включать в себя идентификацию перспективных мест добычи и предоставление рекомендаций по бурению и планированию добычи, а также применение рекомендованных операций. Действия, предпринятые на этапе 508, могут быть любыми действиями, относящимися к рассматриваемой площадке скважины или площадкам скважин. Разные этапы, проиллюстрированные на Фиг.5, могут быть использованы для предоставления клиенту платных услуг.
Фиг.6 изображает диаграмму, иллюстрирующую данные каротажных измерений, которые могут находиться в многомерных данных, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. В этом примере набор 600 каротажных измерений является примером каротажной диаграммы, которая может быть получена с площадки скважины, такой как площадка скважины 200 на Фиг.2. В частности, набор 600 каротажных измерений является примером непрерывных данных, которые могут быть использованы для идентификации одинаковых или разных регионов внутри формации.
Набор 600 каротажных измерений может быть использован в качестве входных данных, таких как входные данные 402 на Фиг.4. Набор 600 каротажных измерений может содержать данные любых типов, которые можно собрать с площадки скважины, таких как, например, диаграмма, число или таблица. Набор 600 каротажных измерений может включать в себя информацию, такую как пористость, удельное сопротивление, гамма-излучение, скважина, изображения, газовый каротаж, непрерывные измерения во время бурения, буровые изыскания или любой другой тип данных.
На Фиг.7 изображена диаграмма, иллюстрирующая изображения образцов керна, которые могут быть использованы для выполнения анализа многомерных данных, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. В этом иллюстративном примере образцы 700 и 702 керна являются примерами образцов керна, полученных с площадки скважины, такой как площадка скважины 200 на Фиг.2. Проба 704 керна берется из местоположения 706 в образце 702 керна. Проба 704 керна является субобразцом образца 702 керна в этих примерах. Пробы 708 и 710 керна являются субобразцами, взятыми из образца 702 керна из местоположений 712 и 714 соответственно. Проба 716 керна берется из местоположения 718 в образце 700 керна.
Эти разные образцы керна и пробы являются примерами дискретных данных, которые могут быть получены с площадки скважины для использования в качестве входных данных или в процессе анализа, таком как процесс 400 многомерного анализа на Фиг.4. Эти образцы керна и проб керна, взятые из образцов керна, могут быть использованы при выполнении анализа многомерных данных для описания неоднородности породы в формации.
На Фиг.8 изображена диаграмма, иллюстрирующая непрерывные данные, наложенные на изображения образцов керна, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. Керн 800 является изображением керна, который может содержаться в многомерных данных, используемых в качестве входных данных, таких как входные данные 402 на Фиг.4.
В этом примере керн 800 перекрыт разными типами данных. В этом иллюстративном примере линии 802, 804, 806, 808 и 810 представляют непрерывные данные профиля напряжения. Линии 812, 814, 816, 818 и 820 представляют непрерывные данные гамма-излучения керна. Эти два типа данных наложены на изображения керна 800 для иллюстрации измерений в конкретных местах из этого образца керна. Далее, зависящие от глубины измерения в керне 800 представлены в местах 822, 824, 826, 828 и 830. В этих примерах конкретные измерения могут быть сделаны посредством цилиндрических образцов, ориентированных в разных направлениях относительно оси керна. Эти зависящие от глубины измерения могут быть также выполнены на срезах керна, фрагментах керна или любом типе зависящего от глубины образца из керна 800.
Путем накладывания данных на изображение керна 800, таких как непрерывные данные профиля напряжения и непрерывные данные гамма-излучения керна, может быть сделан выбор отбираемых образцов керна. Эта информация может быть использована для выбора места, из которого берутся пробы керна или срезы. Как можно видеть, комбинирование этих трех типов данных позволяет более точно идентифицировать место, откуда должен быть взят образец относительно изображения керна 800.
На Фиг.9 изображена диаграмма, иллюстрирующая входные данные, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. Входные данные 900 собираются из разных типов данных, проиллюстрированных выше, для формирования многомерных данных для анализа. Входные данные 900 могут быть собраны из данных разных типов, получаемых с площадки скважины, такой как проиллюстрированные на Фиг.6 - Фиг.8. Эти входные данные являются примером входных данных 402 на Фиг.4, используемых при выполнения многомерного анализа. Более конкретно, входные данные 900 являются основными входными данными, используемыми для кластерного анализа. В этом конкретном примере входные данные 900 включают в себя непрерывные данные 902 скважинного каротажа, непрерывный профиль 904 керна, дискретные скважинные данные 906, дискретные данные 908 керна и сейсмические данные 910. Данные 902 скважинного каротажа могут включать в себя, например, диаграммы кабельного каротажа, газового каротажа и данных измерения во время бурения. Непрерывные профили 904 керна могут включать в себя информацию, такую как профили напряжения, гамма-измерения керна и фотографии или изображения керна. Конечно же, могут быть использованы любые непрерывные измерения. Примерами других типов непрерывных измерений, которые могут быть использованы, являются непрерывные измерения объемной плотности крена или непрерывные измерения магнитной восприимчивости керна. Дискретные данные 906 могут включать в себя, например, измерения давления, измерения потока газа и/или нефти, мини- и микроразрывы, тесты на утечку, ориентацию разрывов, расположение боковых пробок и событий прорыва скважины. Дискретные данные 908 керна могут включать в себя, например, лабораторные тесты, сделанные на образцах, а также боковые измерения.
Непрерывные скважинные данные 902 используются для идентификации регионов с одинаковыми или разными свойствами в формации или другой структуре или зоне в толще пород. После идентификации разных регионов другие части входных данных 900, такие как непрерывный профиль 904 керна, дискретные скважинные данные 906 и дискретные данные 908 керна, могут быть интегрированы для обеспечения идентификации свойств материала в различных регионах. Другими словами, непрерывные данные с площадки скважины могут быть интегрированы с дискретными данными скважины в дискретные образцы с использованием различных вариантов осуществления настоящего изобретения. Типы данных, проиллюстрированных в разных чертежах, являются только примерами данных, которые могут быть использованы различными процессами в иллюстративных вариантах осуществления настоящего изобретения. Эти примеры не предназначены для ограничения типов или количества данных, которые могут быть использованы.
В этих примерах входные данные 900 также включают в себя сейсмические данные 910. Эти сейсмические данные предназначены для секции, расположенной между площадками скважин в этих примерах. Сейсмические данные могут быть использованы для интерполяции результатов, сгенерированных при анализе с использованием разных вариантов осуществления настоящего изобретения.
На Фиг.10 показано изображение информации, используемой в вычислениях кластерного анализа, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. В этом примере дисплей 1000 является примером дисплея, представленным в графическом пользовательском интерфейсе 408 на Фиг.4. На дисплее 1000 график 1002 минимизации расстояния показан параллельно гистограмме 1004. График 1002 минимизации расстояния является линейным графиком, который иллюстрирует результаты выполнения кластерного анализа на входных данных с использованием компонента программного обеспечения, такого как процесс 400 многомерного анализа на Фиг.4. В этих примерах входные данные взяты из непрерывных данных.
На графике 1002 минимизации расстояния ось X представляет номер итерации, а ось Y представляет расстояние. В этих примерах кластерный анализ может быть запущен выбранное число раз, например пять раз на набор данных. Каждый раз наименьшее расстояние от центроида кластера показывается на графике 1002 минимизации расстояния. Гистограмма 1004 является другим видом тех же данных, представленных на графике 1002 минимизации расстояния. Гистограмма 1004 идентифицирует число раз, за которое было достигнуто конкретное расстояние. Трехмерное представление входных данных представлено на графике 1006. Точки данных, которые идентифицированы как часть кластера, представлены одинаковым цветом или знаком на графике 1006. В этом примере число групп, идентифицированных для кластера, равно шести. Данные, которые поступают для кластерного анализа, являются главными компонентами входных данных в этих примерах. Группировка основана на идентификации кластеров данных, когда главные компоненты изображаются друг против друга в трехмерном пространстве. В этих примерах число группировок равно числу кластеров. Каждый раз, когда запускается кластерный анализ, получается значение расстояния. Это значение расстояния является расстоянием каждой точки данных в центроиде кластера, членами которого являются точки данных. В изображенных вариантах осуществления желательно сохранять итерацию, которая имеет наименьшее общее расстояние. Далее, при идентификации этого наименьшего расстояния делается оценка того, как расстояние меняется от итерации к итерации, с использованием графика 1002 минимизации расстояния и гистограммы 1004. Если результат устанавливается на наименьшем расстоянии слишком быстро, то для кластерного анализа может быть необходимым задать другое число группировок. В этом примере график 1002 показывает, что наименьшее расстояние устанавливается слишком быстро. Определить, устанавливается ли расстояние слишком быстро, можно с использованием нескольких различных механизмов. Например, пользователь может посмотреть на графики и определить, установилось ли минимальное расстояние слишком быстро. В качестве альтернативы может быть использован порог, идентифицирующий слишком быстрое получение наименьшего расстояния. В этом примере график 1002 минимизации расстояния устанавливается на минимальном расстоянии за примерно три итерации кластерного анализа.
Оценки этих графиков используются в качестве управления и обратной связи в кластерном анализе. Мониторинг этих типов графиков используется для оценки сходящегося и статистического представления. Процесс может быть повторен автоматически или вручную. Анализ главного компонента является стандартной статистической техникой, которая используется для уменьшения размерности данных путем комбинирования отклонений в облаках данных. Единственным выходом являются главные компоненты собственно исходных данных. Эти главные компоненты используются в кластерном анализе в этих изображенных вариантах осуществления. Далее, несмотря на то что изображенные примеры используют анализ главных компонентов для борьбы с избыточностью данных, могут быть использованы другие механизмы или техники, в зависимости от конкретной реализации. Целью в этих примерах является уменьшение избыточности данных, представленных в многомерных данных. Например, избыточность в наборах данных может быть идентифицирована, в которых некоторые наборы данных удаляются, являясь избыточными по отношению к сохраняемым наборам данных. Ключевые главные компоненты используются в качестве входа для кластерного анализа для группировки данных в соответствии с их вариабельностью. Эта группировка данных представлена на графике 1006. График 1006 является трехмерной визуализацией группировок. Могут быть выполнены ручные или автоматические итерации для оптимизации выбора группировок.
В этих примерах ключевой главный компонент может быть, например, единственным набором данных, таких как конкретная каротажная диаграмма. Далее, ключевой главный компонент может также быть комбинацией разных наборов данных в единый набор данных. Например, внутри набора из многих наборов данных анализ главного компонента может быть использован для преобразования данных в десять наборов данных таким образом, что представлены десять новых преобразованных наборов данных. Отличительной особенностью этих трансформированных наборов данных является, например, первый набор данных, который является первым главным компонентом, может использовать или включать в себя 75 процентов вариации исходных входных данных в десяти наборах данных. Второй главный компонент может использовать до 15 процентов вариации, третий главный компонент может использовать до 5 процентов вариации и так далее, так что когда был обработан десятый главный компонент, охватывается 100 процентов вариаций.
Однако 90 процентов вариаций в исходных десяти наборах данных могут быть использованы только с двумя главными компонентами. С таким типом выбора 90 процентов исходных десяти наборов данных могут быть описаны с использованием только двух преобразованных наборов данных. В других наборах данных нет необходимости, поскольку они являются относительно менее важными, чем эти первые два главных компонента. В этих иллюстративных вариантах осуществления используемое число главных компонентов выбирается таким, чтобы учитывать, по меньшей мере, 90 процентов начальной вариации. Выбор данного процента, сделанный в этих примерах, делает анализ более простым. Другими словами, будет лучше полностью проанализировать и визуализировать три набора данных, которые могут учитывать до 90 процентов всего набора входных данных, чем обрабатывать десять наборов данных. Эти ключевые главные компоненты являются разными наборами данных для измерений, идентифицированных для использования. Каждый из набора данных может иметь несколько группировок. Например, из двух наборов данных могут быть представлены три группировки, в которых три группы данных представлены в каждом наборе данных.
На Фиг.11 показана диаграмма изображения, используемого в вычислениях кластерного анализа, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. В этом примере изображение 1100 включает в себя график 1102 минимизации расстояния, гистограмму 1104 и график 1106. В этом конкретном примере количество кластеров устанавливается равным восьми, по сравнению с шестью кластерами, показанными на Фиг.10. В этом примере наименьшее расстояние между точками данных и центроидами кластеров устанавливается не быстрее, чем некоторое пороговое значение, принятое как устанавливающее слишком быстро. В результате, этот выбор группировок может быть использован для генерации результатов для анализа.
На Фиг.12 изображена диаграмма, иллюстрирующая формирование кластерных элементов из многомерных данных, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. В этом примере пять группировок, представляющих пять кластеров, представлены для семи значений на каротажной диаграмме. В этих примерах ось X в каждом значении каротажной диаграммы представляет одну и ту же группировку для различных типов данных. Ось Y в каждом значении каротажной диаграммы представляет единицы для значений для точек данных в этих группировках.
В изображенных примерах эти значения каротажной диаграммы являются временем 1200 распространения P-волны, временем 1202 распространения S-волны, удельным сопротивлением 1204, гамма-излучением 12006, объемной плотностью 1208, нейтронной пористостью 1210, фотоэлектронным эффектом 1212. Различные графики на изображении 1214 представляют статистические распределения для каждого значения каротажной диаграммы в многомерных данных как функция кластера.
Графики этих каротажных значений также известны как диаграммы вида «ящик с усами», в которых срединное значение данных представлено линией в прямоугольнике. Например, во времени 1200 распространения P-волны линия 1216 в прямоугольнике 1218 представляет срединное значение данных. Граница прямоугольника 1218 представляет главный регион данных. Отклонения представлены другими точками данных или «усами» за пределами прямоугольника 1218. Главный регион данных может содержать от 25 до 75 процентов данных в этих примерах.
В этих примерах группировка данных на основании фотоэлектрического эффекта 1212 приводит только к двум кластерам. Группировка данных, представленных на изображении 1214 на основании фотоэлектрических эффектов 1212 и гамма-излучения 1206, дает от трех до четырех кластеров. Этот тип группировок возникает потому, что элементы с одинаковым фотоэлектрическим эффектом имеют различные эффекты гамма-излучения и, таким образом, попадают в разные группы. Использование всех данных позволяет произвести разделение на пять различных групп в этих примерах. Некоторые из этих групп могут иметь похожее количество свойств, но будут иметь, по меньшей мере, одно достаточно разное свойство, позволяющее разделять на отдельные группы.
В этих иллюстративных примерах кластерные определения выражены в виде статистических распределений. Эти определения могут быть связаны с цветами или визуализацией. Финальные группировки или кластеры образуют кластерные элементы.
На Фиг.13 показана диаграмма изображения с результатами многомерного кластерного анализа, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. Изображение 1300 показывает результаты многомерного кластерного анализа. Изображение 1300 является примером изображения, представленного с использованием пользовательского интерфейса, такого как графический пользовательский интерфейс 408 на Фиг.4. В изображении 1300 результаты многомерного кластерного анализа представлены с помощью цветового кодирования для обеспечения результатов, которые являются более простыми для понимания и интерпретации. Изображение 1300 представляет результаты, которые представляют вариабельность всех входных переменных во входных данных, в изображении с цветовым кодированием. Эти входные переменные являются, например, данными различных типов скважинного каротажа, полученными с площадки скважины, такой как площадка скважины 200 на Фиг.2.
Изображения на Фиг.10 и Фиг.11 обеспечивают пользовательский интерфейс для выбора количества кластерных элементов для представления всех вариабельностей в многомерных данных. Например, если результаты на Фиг.10 используются с количеством кластерных элементов, равным шести, то вариабельность данных равняется шести. Таким образом, представлены шесть типов кластерных элементов. Количество цветов, используемых для графика в секции 1302, равняется шести. Затем цвета назначаются по шкале глубин на основании значений данных на конкретной глубине с кластерными определениями. Если, с другой стороны, используются результаты с Фиг.11, то количество типов кластерных элементов равно восьми. В этом случае восемь разных цветов используется для идентификации разных типов кластерных элементов в секции 1302. Значения всех данных на конкретной глубине вычисляются с кластерными определениями для идентификации конкретного кластерного определения. Цвет для кластерного определения идентифицированного типа кластерного элемента связывается с глубиной для использования в секции 1302. В этих примерах каждый номер кластера связан с цветом для упрощения визуализации разных типов кластерных элементов для пользователя. Таким образом, выход в секции 1302 представляет кластерные типы на разной глубине. Эти результаты являются реальной переведенной в цвет версией кластера относительно глубины. Трехмерные графики на Фиг.10 и Фиг.11 не включают в себя информацию о глубине, позволяющую анализировать идентификацию того, как кластерные элементы расположены последовательно. Поскольку кластерные элементы были идентифицированы и каждая точка данных связана с кластерным элементом, результат выводится в виде, проиллюстрированном в секции 1302 изображения 1300.
Одинаковые цвета в секции 1302 изображения 1300 представляют регионы с одинаковыми свойствами материала и разные цвета представляют регионы с разными свойствами материала. Секция 1302, однако, еще не идентифицирует конкретные свойства материала, связанные с каждым регионом. Эти цвета только иллюстрируют, что регионы с разными или одинаковыми свойствами присутствуют в местах тех регионов скважины, из которой эти данные были собраны. Каждый дискретный регион в секции 1302 известен как кластерный элемент в иллюстративных вариантах осуществления. Кластерный элемент в секции 1302, имеющий такой же цвет, что и другой кластер в этой секции, считается кластерным элементом того же типа. Другими словами, эти два кластерных элемента имеют одинаковые свойства. Кластерный элемент, имеющий цвет, отличный от другого кластерного элемента, считается кластерным элементом другого типа по отношению к другому кластерному элементу.
Каротажные диаграммы в секции 1304 на изображении 1300 являются примерами непрерывных каротажных диаграмм, таких как данные 902 скважинных каротажных диаграмм на Фиг.9. Непрерывные данные каротажных диаграмм в секции 1304 могут быть использованы для анализа этих кластерных элементов в секции 1302 для поиска разных свойств, которые являются одинаковыми с кластерными элементами на изображении 1300, имеющими одинаковый цвет. Далее, эта информация может быть использована для идентификации того, где дискретные образцы могут быть взяты для анализа для идентификации свойств различных кластерных элементов в наборе кластерных элементов в секции 1302. Набор кластерных элементов содержит один или более кластерных элементов.
На Фиг.14 изображена диаграмма, иллюстрирующая результаты для неоднородной формации, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. В этом примере график 1400 является примером результатов, сгенерированных из кластерного анализа с использованием процесса многомерного анализа, такого как процесс 400 многомерного анализа на Фиг.4. В этом конкретном примере график 1400 представляет идентификацию кластерных элементов в формации. Для неоднородных формаций целью является забор образцов, соответствующим образом выполненный для все различных формаций, идентифицированных посредством кластерных элементов, выбранных для гарантии того, что разработана полная модель. Секция графа 1400 с помощью цветовой или штриховой индикации показывает кластерные элементы с одинаковыми свойствами. Эта информация может быть использована для выбора подходящих образцов для разных кластерных элементов, что позволяет правильно идентифицировать свойства конкретных кластерных элементов на графике 1400.
Например, если требуется стандартный выбор 90 футового (27,432 м) керна, типовым выбором может быть выбор 1402. Как можно видеть, этот выбор не обеспечивает образцы из всех различных типов кластерных элементов, идентифицированных в этой неоднородной формации на графике 1400. Далее, с используемой в настоящий момент системой выбора, может быть сделан выбор восьми боковых проб в местах 1404, 1406, 1408, 1410, 1412, 1414, 1416 и 1418. Как можно видеть из этого типа выбора, сделанного без преимущества графика 1400, образцы не обязательно взяты таким образом, чтобы позволить идентификацию свойств для различных типов кластерных элементов, представленных в скважине. В этом иллюстративном примере отбор образцов выполняется после просмотра результатов на графике 1400. С использованием графика 1400 90-футовая (27,432 м) секция керна может быть разделена на секции 1420, 1422 и 1424. Каждая из этих секций является 30-футовой (9,144 м) секцией, обеспеченной для отбора образцов из различных типов кластерных элементов, представленных в скважине. Этот выбор мест отбора образцов керна обеспечивает образцами, которые покрывают типы кластерных элементов, не покрываемых выбором в секции 1402. Далее, с использованием графика 1400 может быть сделано определение, что требуются дополнительные боковые пробы из мест 1426, 1428, 1430, 1432, 1434, 1436, 1438, 1440, 1442, 1444, 1446, 1448, 1450 и 1452. Как можно видеть, модель на графике 1400 обеспечивает целостное воспроизводимое разбиение неоднородности в формации путем разделения всей формации на дискретные кластерные элементы с уникальными свойствами материала. Отбор образцов в этих примерах выполняется путем сбора керна и боковых проб. В качестве альтернативы используется сбор шлама или другие техники для получения необходимых образцов.
На Фиг.15 изображен график, иллюстрирующий результаты кластерного анализа, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. В этом примере график 1500 является графиком в основном однородной формации. Для однородных формаций целью является подходящим образом отобрать образцы всех кластерных элементов, что обычно приводит к уменьшенному количеству образцов и значительному уменьшению издержек.
Решения по отбору образцов, принятые на основе результатов, представленных на графике 1500, также равнозначно являются применимыми для неоднородных формаций. В этом примере 120-футовый керн (36,576 м), как показано в секции 1502, является примером типичного выбора, сделанного без учета результатов на графике 1500. Без преимуществ, которые дают эти результаты, стандартный выбор боковых проб может быть сделан в местах 1504, 1506, 1508, 1510, 1512, 1514, 1516 и 1518, всего восемь боковых проб. С преимуществами, которые дают результаты на графике 1500 секция крена может быть уменьшена до 60 футов (18,288 м), как показано в секциях 1520 и 1522. Далее количество боковых проб может быть уменьшено до пяти, взятых из мест 1524, 1526, 1528, 1530 и 1532. Таким образом, с использованием результатов на графике 1500 длина керна и количество боковых проб, необходимых для анализа этой однородной формации, может быть уменьшено. На Фиг.16 изображена диаграмма, иллюстрирующая интеграцию скважинных данных с результатами, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. В частности, Фиг.16 является примером модели, сгенерированной из идентифицируемых кластерных типов на разных глубинах для площадки скважины. В этом примере график 1600 содержит непрерывные данные скважинного каротажа в секции 1602. Результаты кластерного анализа изображены в секции 1604. В дополнение к разделению между разными кластерными элементами или формациями, эта секция также включает в себя профиль непрерывных измерений напряжения. Секция 1606 обеспечивает информацию о водо-, газо- и нефтенасыщенности (SAT) в порах. Действующая пористость показана в секции 1608 графика 1600. Проницаемость породы пласт-коллектора представлена в секции 1610. Газонасыщенная пористость и общее органическое содержимое находится в секции 1612 и 1614 соответственно. Секция 1616 содержит порог качества пласт-коллектора, в то время как секция 1618 обеспечивает индикацию общего количества свободного газа по месту.
В секциях 1608, 1610, 1612 и 1614 дискретные измерения, выполняющиеся в лаборатории, проиллюстрированы точками, изображенными в этих секциях. Образцы определяются с использованием результатов, сгенерированных посредством кластерного анализа, такие как показанные в секции 1604. При выборе образцов может быть сделан непрерывный график или идентификация этих разных свойств по всей длине скважины. В этих примерах данные или образцы не обязательно должны зависеть от этой части. Например, если скважинные данные в секции 1602 показывают, что определенные секции не являются интересующими секциями. Таким образом, образцы из этих секций могут быть исключены из выбора образцов. Далее, может быть получено стандартное отклонение для каждой из секций для гарантии того, что графики являются достаточно точными в пределах некоторой погрешности.
С непрерывными профилями, сгенерированными в секциях 1608, 1610, 1612 и 1614, могут быть сделаны прогнозирования качества пласт-коллектора в секции 1616 и общего количества газа по месту в секции 1618 по всей длине скважины для площадки скважины в конкретной формации. В этих иллюстративных вариантах осуществления определение качества пласт-коллектора делается возможным с помощью кластерного анализа и отбора образцов на основании результатов кластерного анализа. Далее, может быть сделана более точная идентификация общего количества газа по месту для разных секций или глубин формации с использованием различных вариантов осуществления. Секции 1616 и 1618 представляют модели, построенные для разных проанализированных кластеров или регионов.
Секция 1604 является примером модели или результатов, таких как изображены в секции 1302 на изображении 1300 на Фиг.13. Эта модель может быть затем использована для распространения дискретных или зависящих от глубины лабораторных данных непрерывно по длине интересующего региона. Непрерывные свойства могут затем быть использованы для анализа пласт-коллектора и завершения формации. Далее, эти свойства могут также быть использованы для принятия решения относительно работ со скважиной. Например, решения могут включать в себя экономические показатели скважины и места для разрыва. В этом примере качество пласт-коллектора в секции 1616 обеспечивает визуальную индикацию зон с наилучшим качеством пласт-коллектора, что обеспечивает наилучший потенциал для коммерческой добычи для конкретной скважины. Прогнозирования общего количества газа в секции 1618 обеспечивают оценку газа по месту и позволяют рассчитать экономические показатели, необходимые для извлечения газа.
На Фиг.17 изображена диаграмма, иллюстрирующая пробы керна, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. При получении образцов из керна неоднородность керна оценивается с использованием непрерывных измерений, таких как профили напряжений, гамма-профили керна, профили цветов породы. Эти непрерывные свойства проиллюстрированы в секции 1700. Затем образцы собираются для представления секций керна с определенными измеренными значениями, такие как образцы проб керна из мест 1702, 1704, 1706, 1708, 1710, 1712, 1714, 1716, 1718 и 1720. Образцы из керна, проиллюстрированные в секции 1722, отбираются с использованием различных ориентаций относительно оси керна. Например, три образца могут быть взяты из каждого такого места для вертикальной, горизонтальной и наклонной ориентации по отношению к оси керна. Этот тип получения образцов является важным при описании анизотропных свойств керна. Получение образцов из керна, как показано в секции 1722, используется для проверки свойств для разных типов кластерных элементов, идентифицированных по длине скважины, из которой извлечен керн.
На данный момент, при взятии боковой пробы, обеспечивается только горизонтальная ориентация. В некоторых случаях керн является недоступным, и могут быть получены только боковые пробы. С существующими в настоящее время техниками оказывается невозможным точно анализировать образцы. Разные варианты осуществления настоящего изобретения отмечают, что миниатюрные образцы или субкерны могут быть взяты из боковой пробы для получения данных, которые обычно получаются из множества образцов керна, взятых из керна при различных ориентациях.
На Фиг.18 изображена диаграмма, иллюстрирующая отбор образцов при различных ориентациях с использованием боковых проб, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. Например, боковая проба 1800 может быть использована для сбора проб 1802, 1804 и 1806. Как можно видеть, эти пробы позволяют получать образцы из разных ориентаций по отношению к оси 1808 боковой пробы 1800. Этот тип отбора субкерна обеспечивает возможность проводить полный анализ анизотропных свойств боковой пробы. Эта техника особенно полезна для мелкозернистых пород. Несмотря на то что эти примеры иллюстрируют получение субкернов из трех ориентаций из боковой пробы 1800 по отношению к оси 1808, другое количество субкернов может быть взято для получения дополнительных ориентаций в зависимости от конкретной реализации. Дополнительно, некоторые реализации могут требовать только двух ориентаций. В этих примерах типичные образцы должны иметь диаметр, по меньшей мере, от 10 до 30 раз превышающий наибольший наблюдаемый признак дискретности в материале (например, размер зерна, включения, поровое пространство и так далее). Поскольку образцы боковых проб являются маленькими, приблизительно 1 дюйм (2,54 см) в диаметре и 1,5 дюйма (3,81 см) длиной, и из них получаются еще меньшие образцы, окончательные меньшие образцы (все еще представляющие весь материал породы) требуют того, чтобы содержимое породы было очень маленьким. Таким образом, существует требование к малому размеру зерна (менее чем около 10 микрон в диаметре). Более того, породы с малым размером зерна стремятся быть более локально однородными (например, сланцы) по сравнению с породами с большим размером зерна (например, конгломерат).
Для образцов с большим размером зерна мульти-компрессионное испытание и численное обращение для соответствия измеренным данным напряжения-растяжения позволяют оценить анизотропные механические данные. Использование любой из этих техник позволяет полностью описать свойства пласт-коллектора, петрологические, геохимические и механические свойства из керна или боковых проб. Таким образом, невозможность получить керн не препятствует требуемому анализу анизотропных свойств для различных глубин.
На Фиг.19 изображена диаграмма, иллюстрирующая разбиение на кластеры, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. В этом примере график 1900 является примером результатов, сгенерированных кластерным анализом. Как можно видеть, одинаковые цвета представляют одинаковые свойства для различных кластерных элементов в формации. Кластерные элементы, имеющие одинаковый цвет на графике 1900, все имеют одинаковый тип в этих примерах. Как только эти разные кластерные элементы или регионы были идентифицированы, определение этих кластеров в терминах многомерных данных может быть использовано как эталон для идентификации одинаковых типов кластеров в других последующих скважинах. Эта идентификация известна как разбиение на кластеры.
При выполнении разбиения на кластеры многомерные данные с целевой площадки скважины, имеющей одинаковые типы данных с эталонной площадкой скважины, используются для выполнения разбиения на кластеры в этих изображенных вариантах осуществления. Многомерные данные на выбранной глубине для целевой площадки скважины сравниваются с эталонным набором данных эталонной площадки скважины. Эти эталонные данные являются многомерными данными для всех разных типов кластерных элементов, которые представлены в эталонной скважине. Определяется, имеют ли данные из целевой площадки скважины на выбранной глубине наилучшее соответствие или корреляцию для данных с целевой площадки скважины для конкретного типа кластера в эталонной скважине. Если такая корреляция существует, выбранная глубина целевой площадки скважины считается имеющей одинаковый тип кластера с эталонной площадкой скважины. В некоторых случаях целевая площадка скважины имеет тип кластера, который не представлен в эталонной площадке скважины. В этом случае наилучшее соответствие или корреляция возникают, когда делается определение, но кривая соответствия показывает, что такое соответствие является плохим. Затем, многомерные данные могут быть проанализированы для идентификации характеристик для свойств, представленных в многомерных скважинных данных для каждого типа кластерного элемента, который представлен для создания модели целевой скважины. Также, подобные скважинные данные могут быть проверены для других скважин, и скважинные данные для секций, удовлетворяющих идентифицированными кластерным элементам, могут быть использованы для создания похожих идентификаций для тех скважин. Например, график 1902 и график 1904 являются примерами кластерного разбиения, выполненного для соседних скважин со ссылкой на эталонную скважину, связанную с графиком 1900. Если конкретный кластер определен как имеющий наилучшее качество пласт-коллектора на основании полного анализа для графика 1900, подобные кластерные элементы могут быть идентифицированы в других скважинах. Например, кластерный элемент 1906 определен как обеспечивающий наилучшее качество пласт-коллектора. Путем использования многомерных данных для этого конкретного кластера эта информация может быть сравнена с тем же типом данных для других скважин для идентификации кластерных элементов в тех скважинах, которые также имеют наилучшее качество пласт-коллектора. В этих примерах имеются кластерные элементы 1908, 1910, 1912, 1914 и 1916 на графике 1902. Регионы 1918, 1920 и 1922 на графике 1904 являются кластерными элементами, идентифицированными как имеющие наилучшее качество пласт-коллектора на основе сравнения многомерных скважинных данных между различными скважинами.
Таким образом, эти примеры показывают, что продуктивность скважины может наблюдаться для последовательных скважин и что вторая скважина, как представлено на графике 1902, может обеспечивать наибольшую продуктивность. Таким образом, результаты кластерного анализа, выполненного с использованием различных вариантов осуществления настоящего изобретения, могут быть использованы для прогнозирования состава или свойств в других скважинах. Этот тип кластерного разбиения может быть выполнен без необходимости такого же полного анализа, выполненного с эталонной скважиной. С помощью этой информации отбор образцов или испытания могут быть сделаны с подходящими прогнозированными кластерными элементами для проверки результатов.
На Фиг.20 изображена диаграмма, иллюстрирующая кластерное разбиение и проверку данных, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. Этот чертеж показывает применение кластерного разбиения, в котором имеется хорошее совпадение с определениями для кластерных типов в эталонной скважине. Этот чертеж также показывает хорошие прогнозирования свойств для кластерных типов, когда сравнение делается с измеренными затем лабораторными данными. В этом примере изображение 2000 включает в себя результаты из эталонной скважины на эталонной площадке скважины, чей полный анализ был выполнен с использованием различных вариантов осуществления настоящего изобретения в графике 2002. График 2004 иллюстрирует результаты выполнения кластерного разбиения в анализируемой скважине на анализируемой площадке скважины. График 2006 на изображении 2000 показывает, насколько близки каротажные данные из эталонной площадки скважины к анализируемой скважине. Порог или приемлемая граница для данных показана с использованием линии 2008. Линия 2010 является кривой совпадения или ошибки для обеспечения количественных измерений между уровнем подобия между кластерами и эталонной скважиной и новой площадкой скважины. Когда кривая ошибок расположена ниже приемлемой границы, показанной линией 2010, совпадение считается достаточно большим для обеспечения высококачественного надежного прогнозирования при применении к новой скважине. Графики 2012, 2014 и 2016 показывают прогнозирования для параметров, таких как пористость, газонасыщенность и проницаемость. Образцы из различных уровней или регионов могут быть взяты для подтверждения прогнозирований. Таким образом, прогнозирования измеренных свойств, таких как пласт-коллекторные и механические, могут быть получены быстро.
Визуализация этих результатов облегчает оценку большого количества различных типов данных для использования в генерации решений, что может повлиять на работы для конкретной площадки скважины или формации. Далее, несмотря на то что примеры представляют результаты в одномерном изображении с цветовым кодированием, результаты могут быть представлены с использованием других техник изображения. Например, результаты могут быть представлены с использованием двух- или трехмерных изображений и могут быть использованы символы в дополнение или вместо цветового кодирования на изображении 1300 на Фиг.13.
Пример на изображении 2000 иллюстрирует, что модель для эталонной скважины на графике 2002 имеет высокое совпадение. Высокое качество этой модели для эталонной скважины на графике 2000 проиллюстрировано графиком 2006, в котором большинство точек данных в линии 2010 попадают ниже порога для приемлемых данных в линии 2008. Далее, точки данных, такие как точки данных 2018, 2020, 2022, 2024, 2026 и 2028 на графиках 2012, 2014 и 2016 показывают, что конкретные свойства ближе к идентифицированным точками данных, чем реально полученные свойства. Эта возможность получать высококачественные прогнозирования для свойств различных регионов в формации в толще пород, может быть быстро получена благодаря анализу эталонной скважины. Эта информация может затем быть разослана или передана в различные места для использования в управлении операциями анализа или целевой площадки скважины, как это проиллюстрировано моделью на графике 2004.
На Фиг.21 изображена диаграмма, иллюстрирующая кластерное разбиение и подтверждение данных, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. Этот чертеж показывает применение кластерного разбиения, в котором присутствует плохое совпадение с определениями для кластерных типов в эталонной скважине. Этот чертеж также показывает плохие прогнозирования свойств для кластерных типов, когда сравнение делается с измеренными затем лабораторными данными.
В этом конкретном примере изображение 2100 включает в себя результаты с эталонной площадки скважины на график 2102. Модель, сгенерированная посредством кластерного разбиения для анализируемой площадки скважины, изображена на графике 2104. Качество модели на графике 2102 проиллюстрировано на графике 2106. Этот график изображает уровень совпадения и ошибки между прогнозированными кластерными элементами для графика 2104 и реальными свойствами для тех разных кластерных элементов. Линия 2107 на графике 2106 показывает пороговый уровень для линии 2109, которая является кривой совпадения или ошибки. Порог, идентифицированный линией 2107, показывает, что данные в линии 2109 являются неприемлемыми в этом примере. В этом иллюстративном примере совпадение является плохим, что можно видеть с помощью кривой ошибки, показанной на графике 2106. График 2108 иллюстрирует пористость, график 2110 показывает газонасыщение, и граф 2112 иллюстрирует проницаемость. Образцы, взятые на разных глубинах, показаны точками данных, такими как точки данных 2113, 2116, 2118 и 2120 на графиках 2108, 2110 и 2112. Образцы, взятые на разных глубинах, показывают, что ошибка является высокой и что совпадение модели является плохим. В результате, модель на графике 2102 для эталонной скважины является плохой моделью для прогнозирования разных свойств для разных регионов в анализируемой площадке скважины. Таким образом, кластерное разбиение позволяет прогнозировать, будут ли прогнозирования хорошего качества.
На Фиг.22 изображена диаграмма, иллюстрирующая изображение модели для площадок скважины в депрессии, в соответствии с предпочтительным вариантом осуществления настоящего изобретения. В этом примере графики 2200, 2202, 2204, 2206, 2208 и 2210 на изображении 2112 являются графиками из моделей площадок скважины в депрессии. Эти модели могут быть сгенерированы на основании анализа, как описано выше или посредством кластерного разбиения из эталонной скважины. Таким образом, эти модели обеспечивают возможность отбирать образцы и испытывать на подходящей глубине в различных площадках скважин для проверки точности моделей. Как можно видеть в этом примере, на изображении 2212 изменение в стекинге между различными типами кластерных элементов от площадки скважины к площадке скважины иллюстрирует боковую неоднородность. Далее, с этой информацией может быть осуществлен мониторинг оценки этого типа неоднородности. Сейсмические данные могут быть использованы для интерполяции типов кластеров, которые могут быть представлены в толще пород между разными скважинами. Таким образом, трехмерные модели могут быть сгенерированы представляющими вариабельность в свойствах материала поперек формации или месторождения.
На Фиг.23 изображена блок-схема процесса для выполнения анализа многомерных данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения. В этих примерах процесс, показанный на Фиг.23, может быть реализован в компоненте программного обеспечения, таком как процесс 400 многомерного анализа на Фиг.4.
Процесс начинается с приема многомерных данных (этап 2300). Затем, многомерные данные улучшаются (этап 2302). При улучшении данных к данным, таким как каротажные диаграммы, могут быть применены фильтры и коррекции. Далее, на этом этапе данные могут быть стандартизованы. Этот этап включает в себя, например, применение к каротажным диаграммам корректировок окружающей среды. Например, измерения гамма-излучения зависят от диаметров скважины. Диаграммы гамма-каротажа могут быть скорректированы с учетом диаметров скважины. В качестве другого примера, нейтронная пористость накапливается флюидом. Используемый буровой раствор принимается во внимание для удаления искусственных влияний на нейтронную пористость, как еще один пример применения к каротажным диаграммам корректировок окружающей среды.
Разные секции каротажных диаграмм могут быть отфильтрованы для исключения плохого поведения. Например, некоторые каротажные диаграммы подверглись влиянию или содержат промоины, вызванные расширением скважины. Данные в этой области считаются ненадежными. Может быть выполнено редактирование для удаления ненадежных данных. Далее, эти секции могут быть отредактированы для прогнозирования данных, которые должны быть представлены в этих секциях с плохим поведением. Коррекция данных также может включать в себя удаление пиков в данных, которые являются аномалиями или считаются шумом.
Другое улучшение данных включает в себя проведение при необходимости геометрического масштабирования взаимосвязей, такого как керн-каротажная диаграмма, каротажная диаграмма-сейсмоданные. Частотное масштабирование взаимосвязей также может быть выполнено при необходимости для керн-каротажной диаграммы и каротажной диаграммы-сейсмоданных. Это улучшение данных также может включать в себя корректировки глубины. Например, может быть скорректирована глубина керна относительно глубины каротажной диаграммы, а также измеренная глубина относительно вертикальной глубины. Другими словами, этап 2302 используется для получения данных в формате для анализа. Затем, улучшенные данные организуются и соотносятся с одной глубиной для опорной шкалы. Затем процесс выполняет анализ для идентификации и уменьшения избыточности в многомерных данных (этап 2306). Этот этап вовлекает в себя идентификацию числа наборов не избыточных данных, а также числа наборов избыточных данных, представленных в многомерных данных. Далее, этап 2306 включает в себя идентификацию главных компонентов для использования в многомерном анализе. В изображенных вариантах осуществления этап 2306 реализован с использованием анализа главного компонента для выявления избыточности в многомерных данных. Этап 2306 используется в изображенных примерах, но может быть пропущен в зависимости от реализации.
Далее, процесс группирует данные в кластеры с использованием кластерного анализа по параметрам или компонентам (этап 2308). На этапе 2308 группировка выполняется путем группировки главных компонентов в кластеры. Представляются вычисления из группировки (этап 2310). Представление группировок на этапе 2310 может вовлекать генерацию изображения, такого как изображение 1000 на Фиг.10 и изображение 1100 на Фиг.11. Затем определяется, нужна ли корректировка данных (этап 2312). Определение на этапе 2312 может быть сделано путем пользовательского ввода после просмотра результатов, представленных на этапе 2310. В качестве альтернативы, процесс может выполнить это определение на основе различных ограничений, которые были установлены для приемлемых группировок. Если данные не должны быть скорректированы, то отображается результат (этап 2314) с последующим завершением процесса. Изображение 2314 является подобным изображению 1300 на Фиг.13 в этих примерах. Возвращаясь к этапу 2312, если данные должны быть скорректированы, то параметры изменяются (этап 2316) с последующим возвратом процесса на этап 2308.
На Фиг.24 изображена блок-схема процесса для идентификации избыточности в многомерных данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения. Процесс, проиллюстрированный на Фиг.24, является более подробным описанием этапа 2306 на Фиг.23.
Процесс начинается с идентификации количества наборов не избыточных данных в многомерных данных (этап 2400). Определяется количество наборов избыточных данных в многомерных данных (этап 2402). В некоторых случаях избыточных наборов, идентифицированных на этапе 2402, может не быть. В этом случае нет необходимости в дальнейших этапах по уменьшению избыточности. С другой стороны, если избыточность имеется, то процесс затем уменьшает избыточность для уменьшения размера многомерных данных, сохраняя при этом отклонение (этап 2404). В этих примерах этап 2404 выполняется с использованием анализа главного компонента. Конечно, другие типы механизмов могут быть использованы в зависимости от конкретной реализации. Затем, отклонение, захваченное избыточными данными, идентифицируется (этап 2406). Это отклонение является вариабельностью в исходных данных. Отклонение данных из одного набора данных является отклонением данных, которое возникает между группировками для этого набора данных. Когда два набора данных, представляющих две переменных, уменьшаются до одного не избыточного главного компонента, вариабельность исходных данных сохраняется в отклонении этого главного компонента. Отклонение набора данных делится на меньшие диапазоны для каждого кластера, который формируется во время кластерного анализа.
Выполняется определение того, находится ли отклонение сжатых данных внутри порога (этап 2408). В этих примерах оптимальным решением является ситуация, когда уплотненные данные представляют, по меньшей мере, 90 процентов отклонений исходных данных. Если отклонение находится в пределах порога на этапе 2408, процесс завершается с оставшимися данными, являющимися главными компонентами исходных данных. Иначе, процесс возвращается на этап 2404 для дальнейшего уменьшения избыточности данных. Получившиеся данные являются не избыточными и будут обычно иметь маленькое количество наборов данных. Например, набор из двадцати пяти различных измерений по длине скважины может быть уменьшен до эквивалентного не избыточного набора с только десятью непрерывными измерениями.
На Фиг.25 изображена блок-схема процесса для выполнения кластерного анализа в соответствии с предпочтительным вариантом осуществления настоящего изобретения. Процесс, проиллюстрированный на Фиг.25, может быть реализован в процессе многомерного анализа, такого как процесс 400 многомерного анализа на Фиг.4. Процесс, проиллюстрированный на Фиг.25, является более детальным описанием части этапа 2308 на Фиг.23.
Процесс начинается приемом наборов данных (этап 2500). Эти наборы данных могут быть начальными наборами данных в многомерных данных или сжатый набор данных, в котором один или более главных компонентов были идентифицированы из многомерных данных. Эти данные образуют входные данные для кластерного анализа. После этого выбираются начальное количество кластерных групп (этап 2502). Это количество кластерных групп может быть выбрано на основании пользовательского ввода или некоторого значения по умолчанию, в зависимости от реализации. Затем выбирается тип минимизации (этап 2504). Типом минимизации может быть, например, квадратичный Евклидов или кластерный анализ городских кварталов, помещающий объекты в кластеры или группы. В этих примерах тип выбранной минимизации различается в зависимости от того, сколько поддерживается аномалий. Аномалия является наблюдением или точкой, которая находится далеко от остальных данных. Затем данные разделяются или помещаются в эти группы на основании расстояния до ближайшего центроида. Этап 2506 формирует сгруппированные данные, которые используются в кластерном анализе. Когда наборы данных сжимаются для уменьшения избыточности, эти наборы данных помещаются в группы способом, в котором весь набор данных представлен в группе. При группировке данных используются все данные глубины для подходящей интересующей зоны. Данные о глубине используются позже, после выполнения кластерного анализа. В этих примерах каждая точка данных в группе данных выводится в многомерном декартовом пространстве, например, с использованием оси X, оси Y и оси Z. Большее число осей может быть использовано в зависимости от реализации. Затем, идентифицируются местоположения центроидов (этап 2508). Определение положения набора центроидов выполняется для разных групп данных. Набор центроидов в этих примерах является одним или более центроидами. В разных вариантах осуществления используется более одного центроида. Это может быть выбрано или изменено на основании пользовательского ввода или автоматического выбора процессом.
Затем рассчитывается расстояние между центроидами и точками данных, связанными с центроидами (этап 2510). На этапе 2510, процесс использует алгоритм к-средних для минимизации расстояния между кластерами. Этот алгоритм связывает каждую точку данных с ближайшим к ней центроидом. Центр или центроид является среднеарифметическим всех точек в кластере. Эта функция имеет целью минимизировать общее межкластерное отклонение для функции среднеквадратичной ошибки:
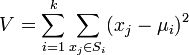
где k - число кластеров, S i - полученные кластеры, и μi - центроид, или средняя точка всех точек.
Затем оценивается расстояние между центроидами и данными (этап 2512). При выборе процессом центроиды перемещаются с каждой итерацией для минимизации расстояния между центроидами и точками данных.
Затем, выполняется определение того, требуются ли дополнительные итерации (этап 2514). Определение на этапе 2514 может быть сделано процессом на основании использования некоторого порогового значения или параметра или посредством пользовательского ввода. Если требуются больше итераций, то процесс минимизирует расстояние путем изменения положения центроида (этап 2516). Иначе процесс завершается. В этих примерах этапы 2508-2516 являются примерами этапов, реализующих алгоритм к-средних. Конечно, в зависимости от реализации, могут быть использованы другие типы алгоритмов кластеризации для выполнения кластерного анализа.
С этапа 2516 процесс затем возвращается на этап 2510 для оценки новых позиций центроидов по отношению к точкам данных. Количество итераций, выполняемых процессом на Фиг.25, различается в зависимости от реализации. Например, решение, принятое на этапе 2514, может состоять в продолжении этапа 2516 до тех пор, пока не пройдет 50 итераций. Количество итераций может быть заранее установлено или основываться на достижении некоторого порога, такого как минимальное расстояние.
На Фиг.26 изображена блок-схема процесса коррелирования данных для использования в кластерном разбиении в соответствии с предпочтительным вариантом осуществления настоящего изобретения. Процесс, проиллюстрированный на Фиг.26, может быть реализован в компоненте программного обеспечения, таком как процесс 400 многомерного анализа на Фиг.4. Этот процесс используется для сравнения данных с кластерными элементами в модели для эталонной скважины, в которой выполняется анализ. Процесс начинается с выбора типов данных из многомерных данных (этап 2600). В этих примерах некоторые или все различные типы данных в наборе многомерных данных для эталонной скважины могут быть выбраны для использования. Выбираемые типы зависят от конкретной реализации. В этих примерах используются непрерывные данные, такие как каротажные диаграммы.
Из модели выбирается необработанный кластерный элемент (этап 2602). Выбранные данные сравниваются с кластерным элементом, которые был выбран (этап 2604). Этап 2604 может быть реализован в этих примерах путем идентификации части выбранных типов данных, которые совпадают с кластерным элементом на глубинах, на которых находится кластерный элемент. Затем, определяется наличие дополнительных необработанных кластерных элементов (этап 2606). Если имеются дополнительные необработанные кластерные элементы, то процесс возвращается на этап 2602, иначе совпавшие данные сохраняются (этап 2608) с последующим завершением процесса. В кластерном анализе, выполняемом процессом на Фиг.26, процессом используется техника, называемая «дискриминантным анализом» для назначения совпавших данных целевой скважине при идентификации кластерных элементов в целевой скважине. Другие варианты осуществления, однако, могут использовать другие многочисленные техники для классификации. Классификация - это другое название для техник, которые могут быть использованы для кластерного разбиения.
На Фиг.27 изображена блок-схема процесса для генерации модели в соответствии с предпочтительным вариантом осуществления настоящего изобретения. Процесс, изображенный на Фиг.27, может быть реализован в компоненте программного обеспечения, таком как процесс 400 многомерного анализа на Фиг.4. Этот процесс используется для моделирования других скважин в формации с использованием данных из эталонной скважины, на которой был выполнен кластерный анализ. Этот процесс позволяет моделировать другие скважины без выполнения всех анализов, использованных для эталонной скважины. Например, кластерный анализ и идентификация свойств после идентификации кластерных элементов не выполняются для целевых скважин. В этом примере этапы 2600-2608 используются для выполнения кластерного разбиения с этапом 2610, используемым для генерации модели из результатов кластерного разбиения.
Процесс начинается с извлечения данных для целевой скважины (этап 2700). Данные, полученные для целевой скважины на этапе 2700, имеют тот же тип данных, использованных для сравнения кластерных типов на Фиг.26. После этого получаются совпавшие данные для необработанных типов кластерного элемента эталонной скважины. Эти совпавшие данные генерируются из процесса, проиллюстрированного на Фиг.26. Затем определяется, имеется ли корреляция между данными для целевой скважины и совпавшими данными (этап 2704). Другими словами, эти совпавшие данные являются данными, которые обеспечивают определение типа кластера в эталонной скважине. Эти данные сравниваются с подобными данными для целевой скважины для определения того, имеют ли данные на конкретной глубине для целевой скважины тот же кластерный тип, что и кластерный тип для совпавших данных. В этих примерах корреляция может присутствовать, если присутствует идентичное совпадение. Корреляция также может иметь место, даже если идентичное совпадение между данными для эталонной скважины для конкретного типа не совпадает с данными для целевой скважины. Различные доступные в настоящее время статистические техники могут быть использованы для определения наличия корреляции на этапе 2704.
Другими словами, на этапе 2704 выполняется сравнение между многомерными данными эталонной скважины и многомерными данными целевой скважины. Более конкретно, многомерные данные, связанные с идентифицированными кластерными типами в эталонной скважине, сравниваются с многомерными данными для целевой скважины для определения наличия корреляции, так что присутствие типа кластерного элемента в эталонной скважине означает его присутствие на одной или более глубине целевой скважины. Эта корреляция также известна как уровень соответствия или совпадения. Если совпадение является приемлемым, то соответствующая часть целевой скважины принимается как имеющая подобный тип кластерного элемента. Если совпадение является большим или считается неприемлемым, то секция помечается и представляет другой кластерный элемент, который имеет тип, не представленный в эталонной скважине. Другими словами, целевая скважина может содержать тип кластерного элемента, который не представлен в эталонной скважине.
Если корреляция присутствует, то процесс отмечает каждую часть целевой скважины, в которой имеется корреляция (этап 2706). Затем определяется, имеются ли дополнительные типы кластерных элементов из эталонной скважины, которые еще не были обработаны (этап 2708). Если имеются дополнительные необработанные типы кластерных элементов из эталонной скважины, то процесс возвращается на этап 2702. Иначе генерируется модель целевой скважины (этап 2710) с последующим завершением процесса. При создании модели на этапе 2710 идентифицированные кластерные элементы используются для генерации модели, содержащей цвета, которые идентифицируют кластерные типы для кластерных элементов на разных глубинах. В зависимости от сравнения данных на этапе 2704, целевая скважина может содержать кластерные типы, которые не представлены в эталонной скважине. Этот кластерный тип может быть идентифицирован цветом, но свойства кластерного типа не могут быть прогнозированы так точно, потому не представлено соответствующего кластерного типа в эталонной скважине.
В этих примерах модель, сгенерированная на этапе 2710, генерируется из идентификации кластерных определений для целевой скважины. Модель содержит непрерывные или прогнозированные свойства для целевой скважины на основе тех моделей, разработанных для эталонной скважины. Этот этап выполняется путем применения моделей, определенных на кластерном уровне, к результатам из кластерного разбиения. Модель, сгенерированная на этапе 2708, может принимать форму графика 1600 на Фиг.16. Этот тип модели создается с использованием результатов, таких как показанные на графике 1902 или 1904 на Фиг.19.
Возвращаясь опять к этапу 2704, если корреляция между данными для целевой скважины и совпавшими данными не существует, то процесс продолжается с этапа 2708, как описано выше. С использованием модели, сгенерированной на Фиг.27, соответствующий отбор образцов и лабораторное испытание может быть проведено для проверки кластерных типов. Далее, отбор образцов и лабораторное испытание может быть использовано для идентификации нового типа кластера, представленного в целевой скважине, который отсутствует в эталонной скважине. Это новое определение может быть использовано для последующего кластерного разбиения других интересующих скважин или областей. В зависимости от реализации модель может включать в себя только идентификацию различных типов кластерных элементов без фактического включения свойств каждого типа кластерного элемента. Таким образом, информация, обеспечиваемая в различных моделях в этих иллюстративных вариантах осуществления, может различаться в зависимости от конкретной реализации.
Таким образом, много скважин для площадок скважин может быть смоделировано без необходимости выполнения всех анализов, сделанных для эталонной скважины. Эти модели затем могут быть использованы для идентификации глубин, на которых образцы могут быть взяты для проверки точности моделей. С помощью этой информации результаты могут быть сделаны доступными различным площадкам скважин, соответствующим моделям для использования в облегчении принятия решения и влияния на операции площадки скважины. Эта информация может быть использована на конкретных площадках скважин для выполнения отбора керна или боковых проб или для сбора любых типов образцов из мест с определенной глубиной, определенных посредством моделей. Далее, информация, содержащая анализ пласт-коллектора, может быть использована для идентификации части формации с наилучшим качеством пласт-коллектора или наилучшим качеством завершения. Эта информация может затем быть использованной для начала скважинных операций, таких как гидроразрыв или перфорирования через конкретную зону. Далее, сейсмические данные также могут быть использованы в многомерных данных для интерполяции кластерных определений между скважинами. Таким образом, идентификация разных регионов может быть идентифицирована посредством интерполяции данных для эталонной и целевой скважин, для которых были сгенерированы модели. Трехмерное представление формации может быть сделано посредством данных, собранных из разных скважин, и прогнозирований, сделанных о регионах между скважинами.
На Фиг.28 изображена блок-схема процесса для прогнозирования кластерных элементов в областях между скважинами в соответствии с раскрытыми здесь вариантами осуществления изобретения. Процесс, проиллюстрированный на Фиг.28, может быть реализован в компоненте программного обеспечения, такого как процесс 400 многомерного анализа на Фиг.4. Процесс на этом чертеже может быть использован для прогнозирования кластерных элементов, которые могут быть представлены около смоделированной площадки скважины с использованием сейсмических данных. Таким образом, может быть построена модель пласт-коллектора или области толщи пород, в которой могут быть идентифицированы кластерные элементы.
Процесс начинается с получения сейсмических данных для области между скважинами или около скважины (этап 2800). Затем совпавшие сейсмические данные получаются для каждой смоделированной скважины для типа кластерного элемента (2802). Сейсмические данные на этапе 2802 могут быть сгенерированы с использованием процесса, изображенного на Фиг.26. Затем, определяется имеется ли корреляция между совпавшими сейсмическими данными и сейсмическими данными для интересующей области (2804). Определение того, имеется ли корреляция, может быть сделано с использованием различных доступных в настоящий момент статистических техник.
Если корреляция имеется, то глубины, на которых имеются корреляции для выбранного типа кластерного элемента, отмечаются или маркируются, как имеющие этот тип кластера. Затем определяется, имеются ли дополнительные необработанные типы кластерных элементов (этап 2808). Если имеются дополнительные необработанные типы кластерных элементов, процесс возвращается на этап 2802. Другими словами, модель генерируется с использованием результатов (этап 2810) с последующим завершением процесса. Возвращаясь опять к этапу 2804, если не существуют корреляции между совпавшими сейсмическими данными и сейсмическими данными для интересующей области, процесс продолжается с этапа 2808, как описано выше.
На Фиг.29 изображена блок-схема процесса для поддержки запросов от клиентов на услуги анализа многомерных данных в соответствии с предпочтительным вариантом осуществления настоящего изобретения. Процесс, проиллюстрированный на Фиг.29, используется для обеспечения услуг клиентам, в которых выполняется анализ многомерных данных для идентификации неоднородности породы. Эти услуги могут быть обеспечены с использованием программного обеспечения, такого как процесс 400 многомерного анализа на Фиг.4.
Процесс начинается с получения запроса от клиента на оказание услуг (этап 2900). Запрос может включать в себя многомерные данные. Запрос может быть, например, запросом на модель площадки скважины, руководством для получения кернов и боковых проб, руководством по управлению площадкой скважины или множеством скважин в некотором географическом регионе. Процесс затем продолжает обрабатывать данные, полученные от клиента (этап 2902). Эта обработка данных может включать в себя различные процессы, проиллюстрированные на блок-схемах, описанных выше для анализа многомерных данных. Определяется, есть ли необходимость в дополнительных данных (этап 2904). Например, если с площадки скважины обеспечены только непрерывные данные, то могут потребоваться другие данные, такие как дискретные данные, образцы с площадки скважины или сейсмические данные, для завершения обработки запроса клиента. Если требуется больше данных, клиенту отправляется запрос о дополнительных данных (этап 2906). Эти данные принимаются от клиента (этап 2908) с последующим возвращением процесса к этапу 2902 для обработки дополнительных данных.
Если от клиента не требуется дополнительных данных, то генерируется ответ (этап 2910). Этот ответ может принимать различные формы в зависимости от полученного от клиента запроса. Если клиент запросил модель скважины, то модель, такая как модель, проиллюстрированная в секции 1302 в изображении 1300 на Фиг.13, может быть сгенерирована в качестве ответа. Другим примером ответа является график 1400 на Фиг.14, в котором могут быть собраны рекомендации о местах отбора керна и образцов боковых проб. В зависимости от реализации, рекомендации по взятию образцов могут быть обеспечены в ответе на этапе 2910 без графической информации, идентифицирующей различия в слоях. Другим примером ответа, который может быть возвращен клиенту, является график 1600 на Фиг.16. Другие ответы, которые могут быть сгенерированы, включают в себя советы о том, как управлять конкретной площадкой скважины или набором скважин без возврата модели, также могут быть созданы в зависимости от конкретной реализации или могут включать в себя выполнение рекомендованных действий.
Затем ответ посылается (или выполняется для) клиентам (этап 2912). Клиент затем платит за услуги (этап 2914), после чего процесс завершается. Таким образом, различные варианты осуществления, используемые для выполнения анализа многомерных данных, могут быть использованы для обеспечения услуг клиентам таким образом, что дают прибыль субъекту, оказывающему услуги.
Таким образом, различные варианты осуществления настоящего изобретения обеспечивают способ, устройство и компьютерно-используемый программный код для анализа многомерных данных. Многомерные данные получаются с площадки скважины. После получения многомерных данных выполняется кластерный анализ с использованием данных для формирования набора кластерных элементов. Набор кластерных элементов идентифицирует разницы между регионами в толще пород на площадке скважины. Этот набор кластерных элементов формирует модель, которая может быть представлена пользователю для визуализации разницы или неоднородности регионов в толще пород под площадкой скважины. Затем идентифицируются свойства разных кластерных элементов для наборов кластерных элементов. Эта информация может быть использована для принятия решения относительно управления площадкой скважины.
Блок-схемы и блок-диаграммы в разных изображенных вариантах осуществления иллюстрируют архитектуру, функциональность и работу некоторых возможных реализаций устройства, способов и компьютерных программных продуктов. В связи с этим каждый блок в блок-схеме или блок-диаграмме может представлять модуль, сегмент или часть кода, который содержит одну или более исполнимых инструкций для реализации конкретной функции или функций. В некоторых альтернативных реализациях, функция или функции, упомянутые в блоке, могут появляться не в том порядке, в котором упомянуты в чертежах. Например, в некоторых случаях два блока, показанные последовательно, могут быть выполнены практически одновременно, или блоки могут иногда исполняться в обратном порядке, в зависимости от вовлеченной функциональности.
Изобретение может принимать форму целиком аппаратного варианта осуществления, целиком программного варианта осуществления или варианта осуществления содержащего и аппаратные и программные элементы. В предпочтительном варианте осуществления изобретение реализуется в программном обеспечении, которое включает в себя, но не ограничено, прошивку, постоянное программное обеспечение, микрокод и так далее. Более того, изобретение может принимать форму компьютерного программного продукта, доступного с компьютерно-используемого или компьютерно-читаемого носителя, обеспечивающего программный код для использования в соединении с компьютером или любой системой исполнения инструкций. Для целей этого описания компьютерно-используемый или компьютерно-читаемый носитель может быть любым вещественным устройством, которое может содержать, хранить, связываться, распространять или передавать программу для использования в соединении с системой исполнения инструкций или устройством.
Носитель может быть электронным, магнитным, оптическим, электромагнитным, инфракрасным или полупроводниковой системой (или устройством) или средой распространения. Примеры компьютерно-читаемого носителя включают в себя полупроводниковую или твердотельную память, магнитную ленту, съемную компьютерную дискету, память произвольного доступа (RAM), память только для чтения (ROM), жесткий магнитный диск или оптический диск. Текущие примеры оптических дисков включают в себя компакт диск только для чтения (CD-ROM), компакт диск для чтения/записи (CD-R/W) и DVD.
Несмотря на то что вышеизложенное было изложено для иллюстрирования, объяснения и описания определенных вариантов осуществления изобретения в конкретных подробностях, модификации и адаптации к описанным способам, системам и другим вариантам осуществления станут понятны специалистам в данной области техники и могут быть сделаны без выхода за пределы объема или сущности изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБЫ И ОТНОСЯЩИЕСЯ К НИМ СИСТЕМЫ ПОСТРОЕНИЯ МОДЕЛЕЙ И ПРОГНОЗИРОВАНИЯ ОПЕРАЦИОННЫХ РЕЗУЛЬТАТОВ ОПЕРАЦИИ БУРЕНИЯ | 2013 |
|
RU2600497C2 |
| ПРЕДВАРИТЕЛЬНЫЙ АНАЛИЗ БУРОВОЙ ПЛОЩАДКИ ДЛЯ ПЛАНИРОВАНИЯ РАЗРАБОТКИ МЕСТОРОЖДЕНИЯ | 2008 |
|
RU2489571C2 |
| СИСТЕМА АДМИНИСТРИРОВАНИЯ ТРАНЗАКЦИЙ С ИИ | 2020 |
|
RU2777958C2 |
| СИСТЕМЫ И СПОСОБЫ ДЕТЕКТИРОВАНИЯ ПОВЕДЕНЧЕСКИХ УГРОЗ | 2019 |
|
RU2778630C1 |
| СИСТЕМЫ И СПОСОБЫ ДЕТЕКТИРОВАНИЯ ПОВЕДЕНЧЕСКИХ УГРОЗ | 2019 |
|
RU2803399C2 |
| СИСТЕМЫ И СПОСОБЫ ДЕТЕКТИРОВАНИЯ ПОВЕДЕНЧЕСКИХ УГРОЗ | 2019 |
|
RU2772549C1 |
| СПОСОБ ВЫЯВЛЕНИЯ ИНТЕРВАЛОВ ПРИТОКА И ПОГЛОЩЕНИЯ ФЛЮИДОВ В РАБОТАЮЩИХ НЕФТЕГАЗОВЫХ СКВАЖИНАХ | 2022 |
|
RU2788999C1 |
| СИСТЕМА И СПОСОБЫ ДЛЯ ПРОГНОЗИРОВАНИЯ ПОВЕДЕНИЯ СКВАЖИНЫ | 2011 |
|
RU2573746C2 |
| СПОСОБЫ ИМИТАЦИИ РАЗРЫВА ПЛАСТА-КОЛЛЕКТОРА И ЕГО ОЦЕНКИ И СЧИТЫВАЕМЫЙ КОМПЬЮТЕРОМ НОСИТЕЛЬ | 2008 |
|
RU2486336C2 |
| СПОСОБ НАБЛЮДЕНИЯ ЗА КОЛЛЕКТОРОМ С ИСПОЛЬЗОВАНИЕМ ДАННЫХ О СКУЧЕННЫХ ИЗОТОПАХ И/ИЛИ ИНЕРТНЫХ ГАЗАХ | 2012 |
|
RU2613219C2 |
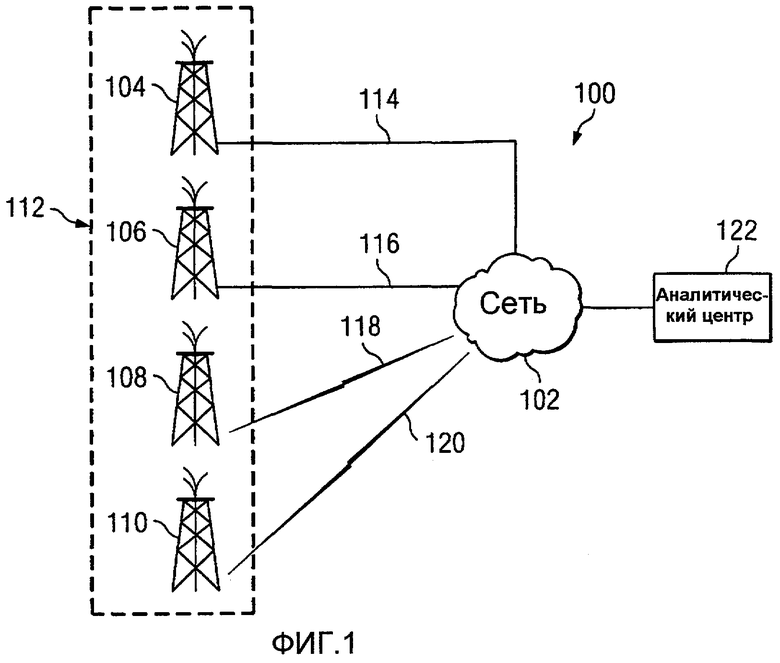
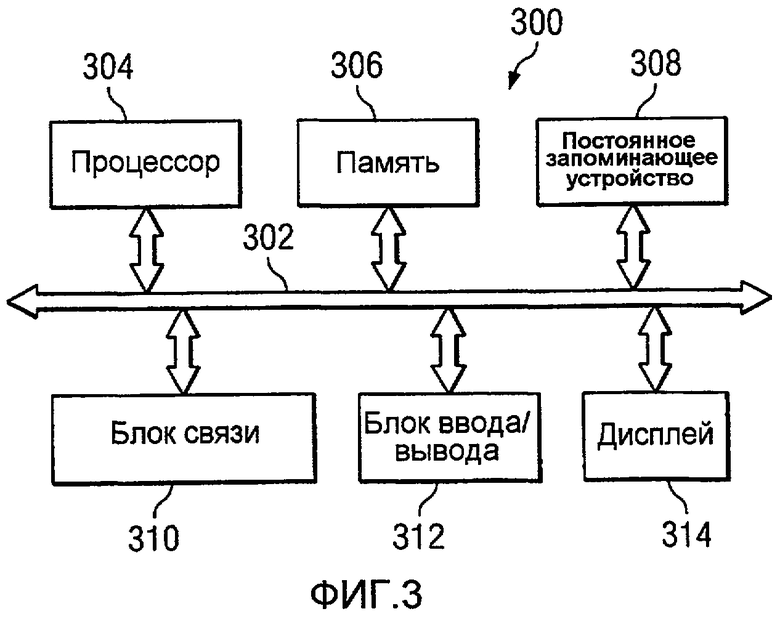
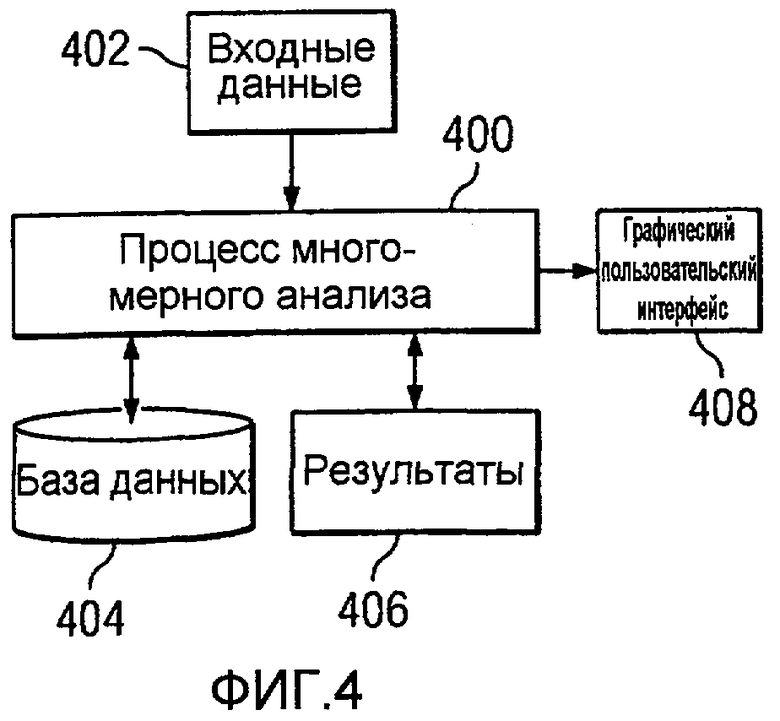
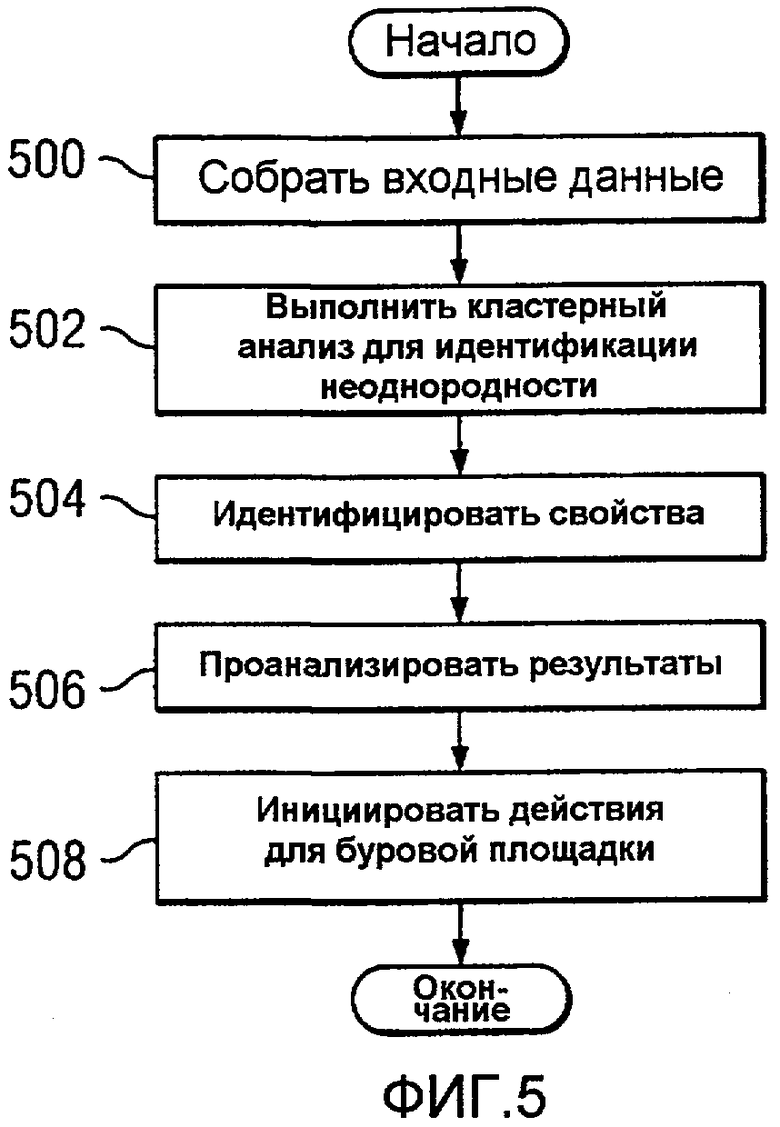

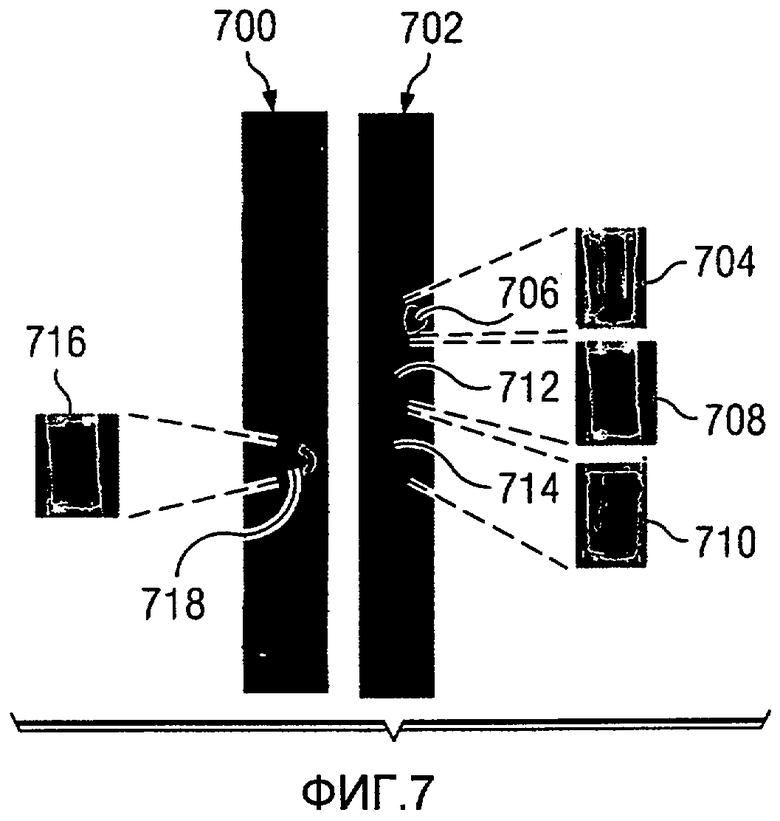
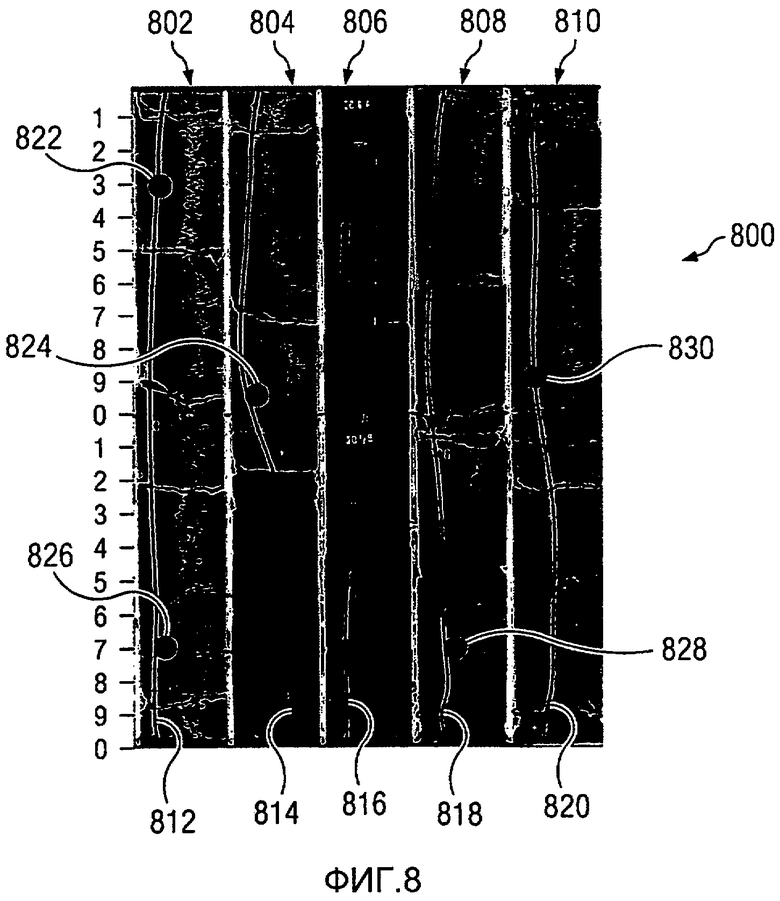
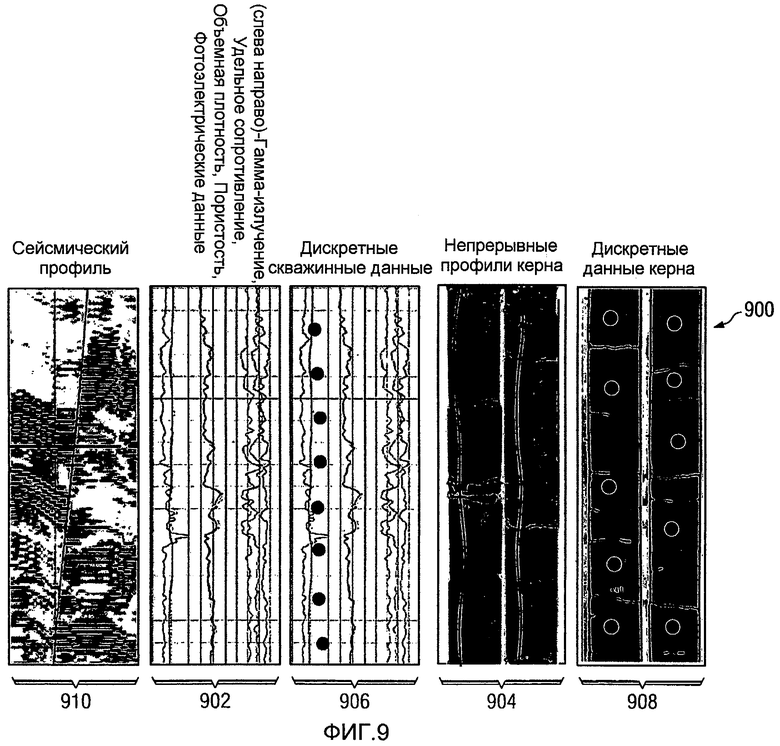
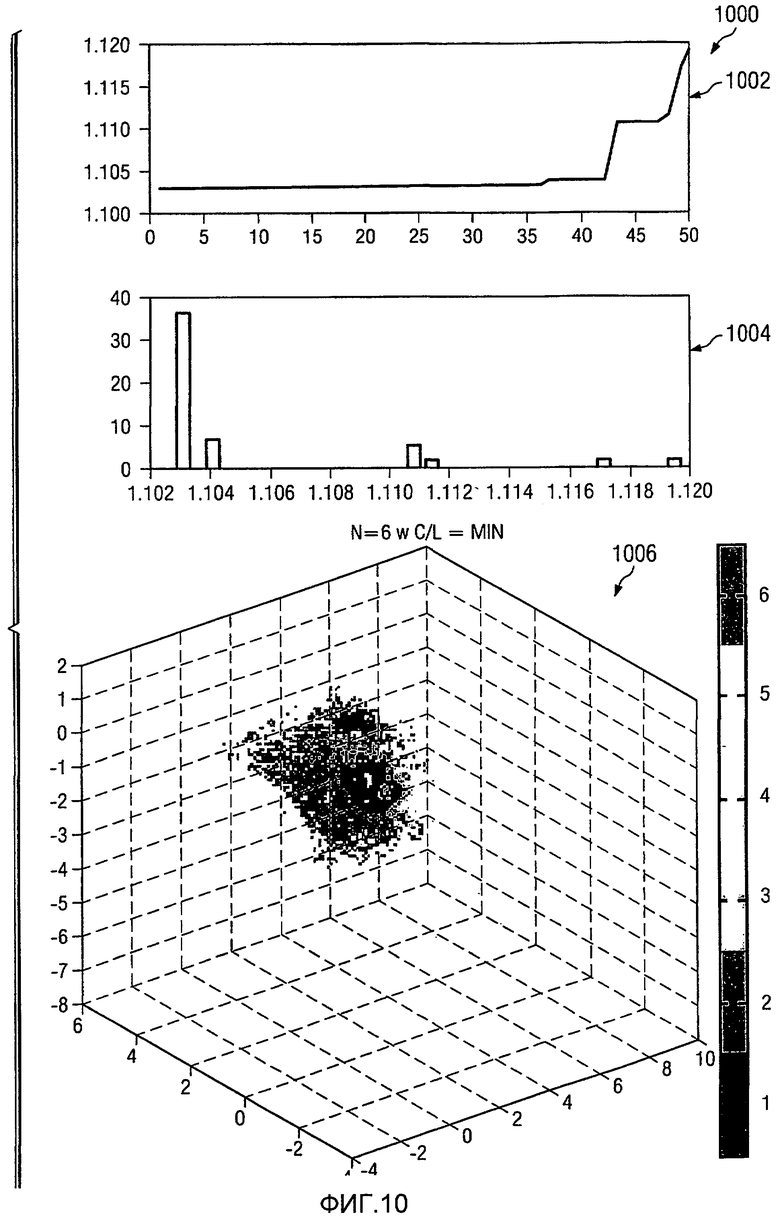
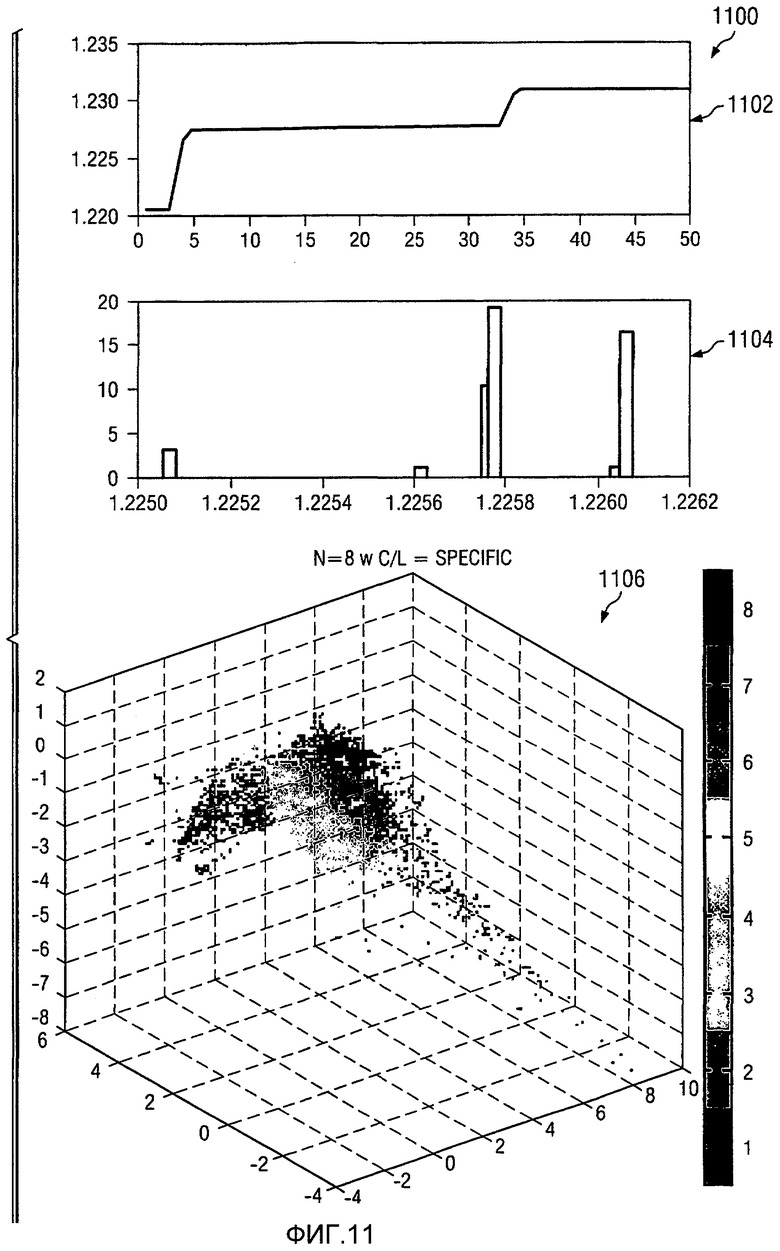
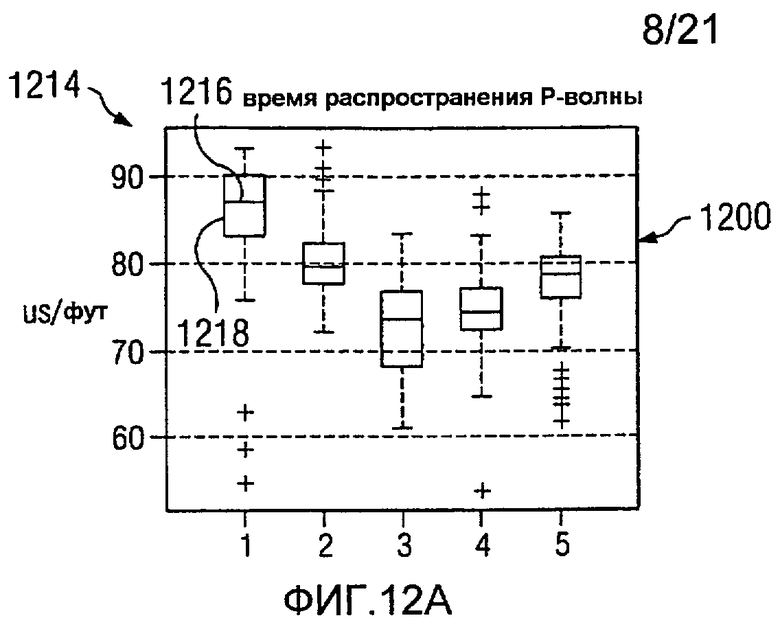
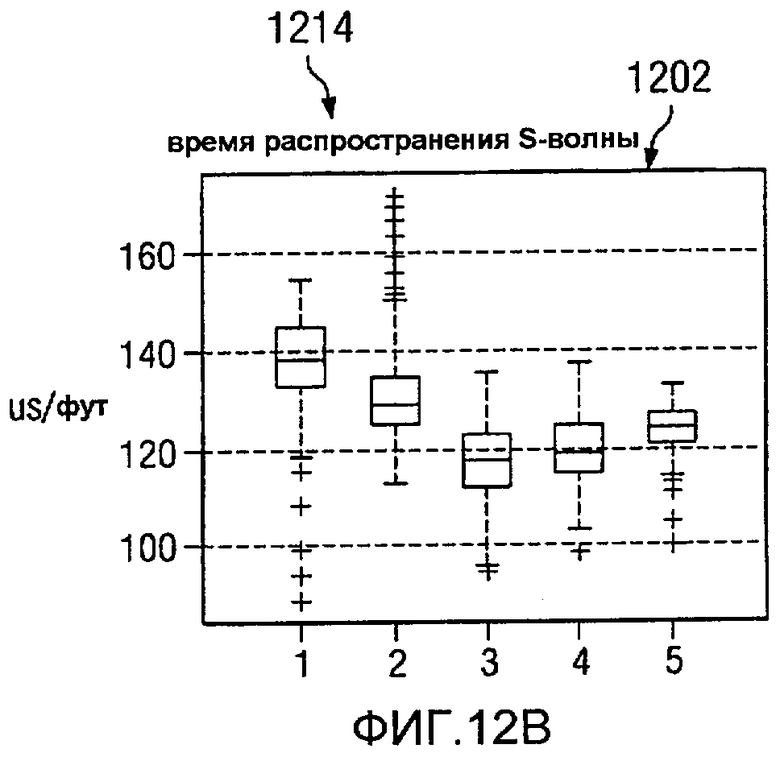
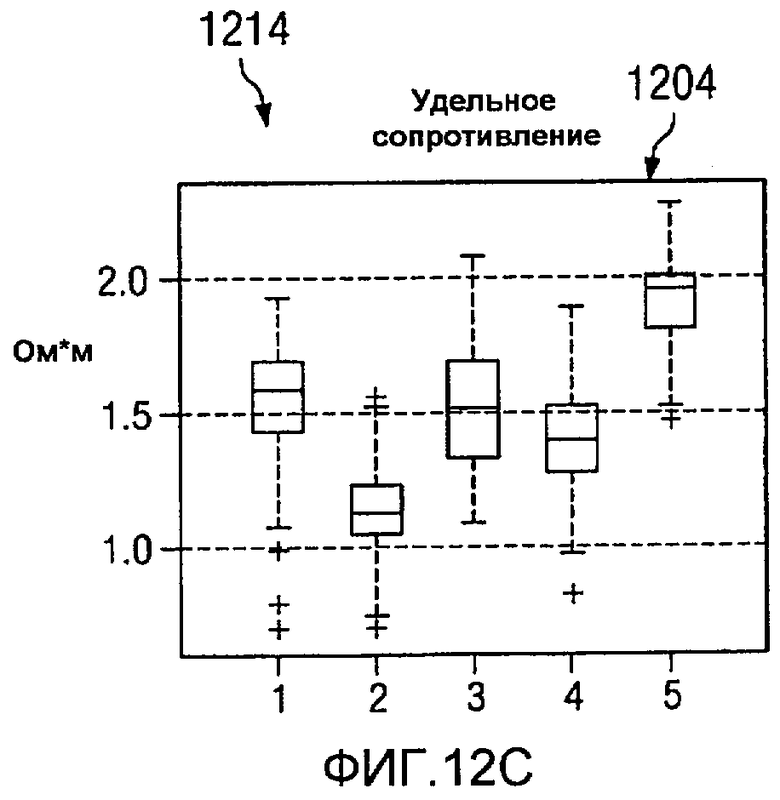
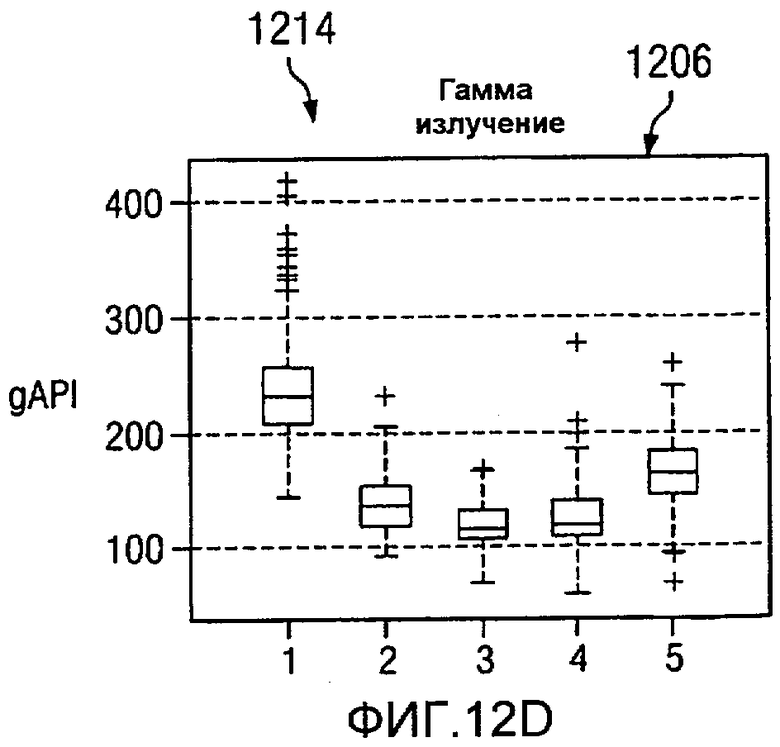
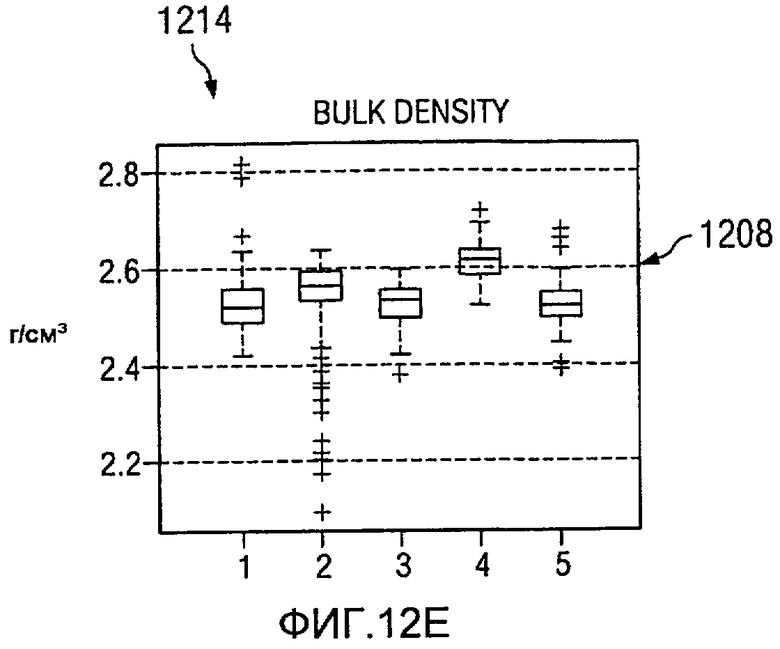
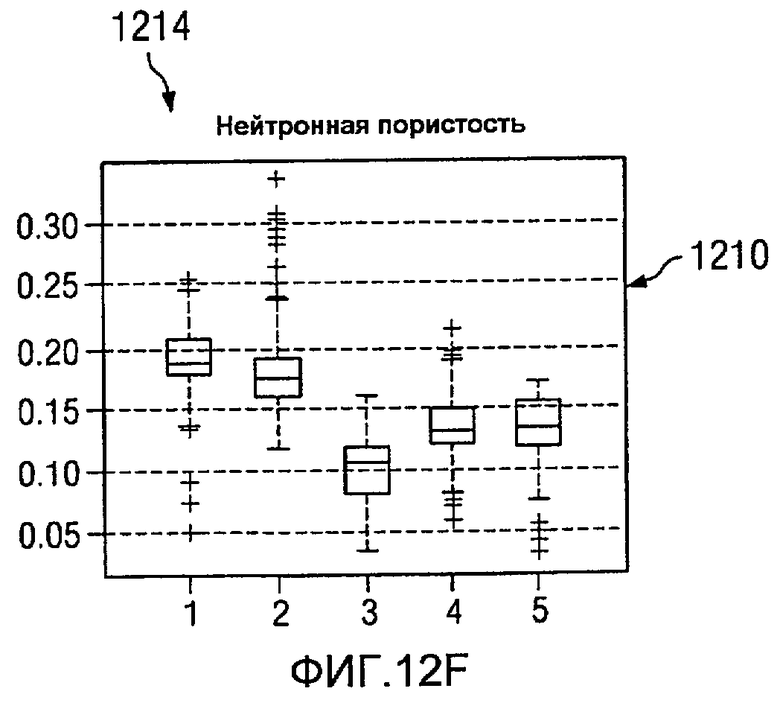
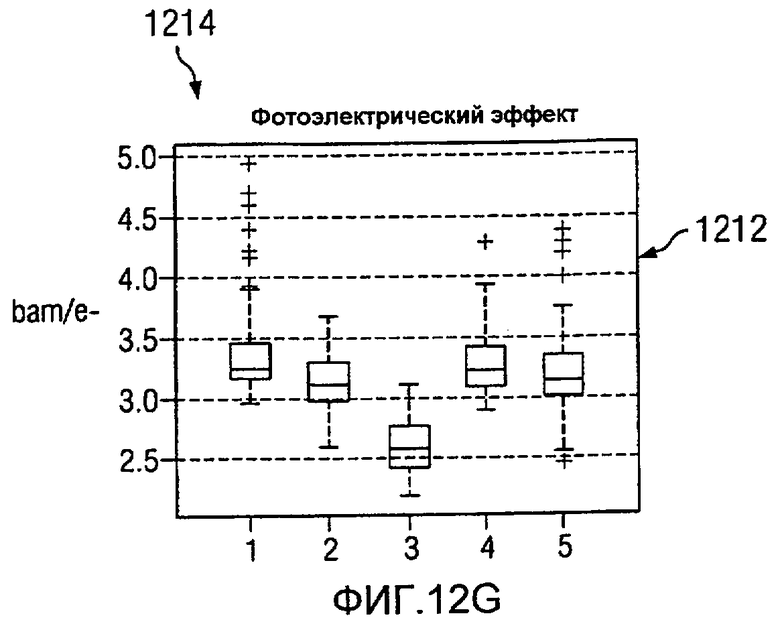
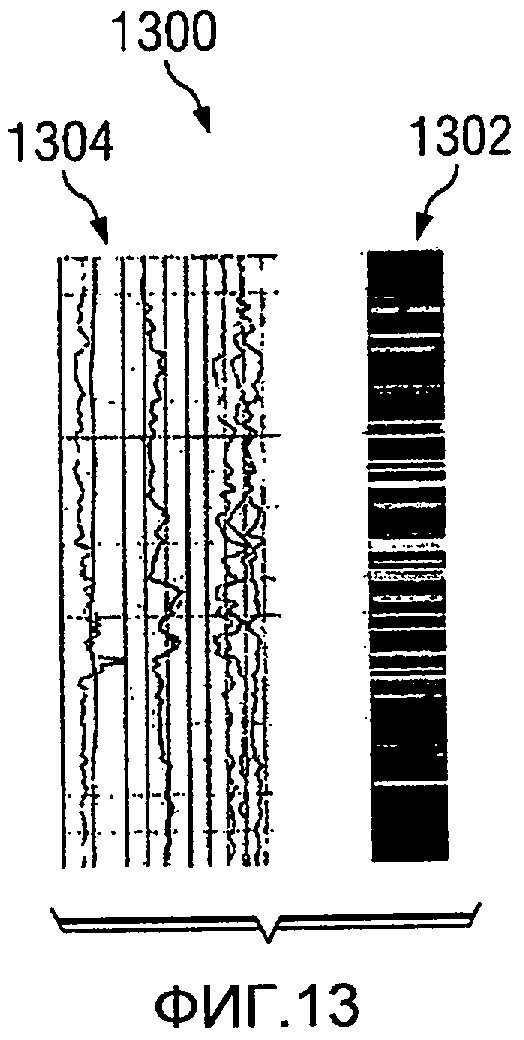
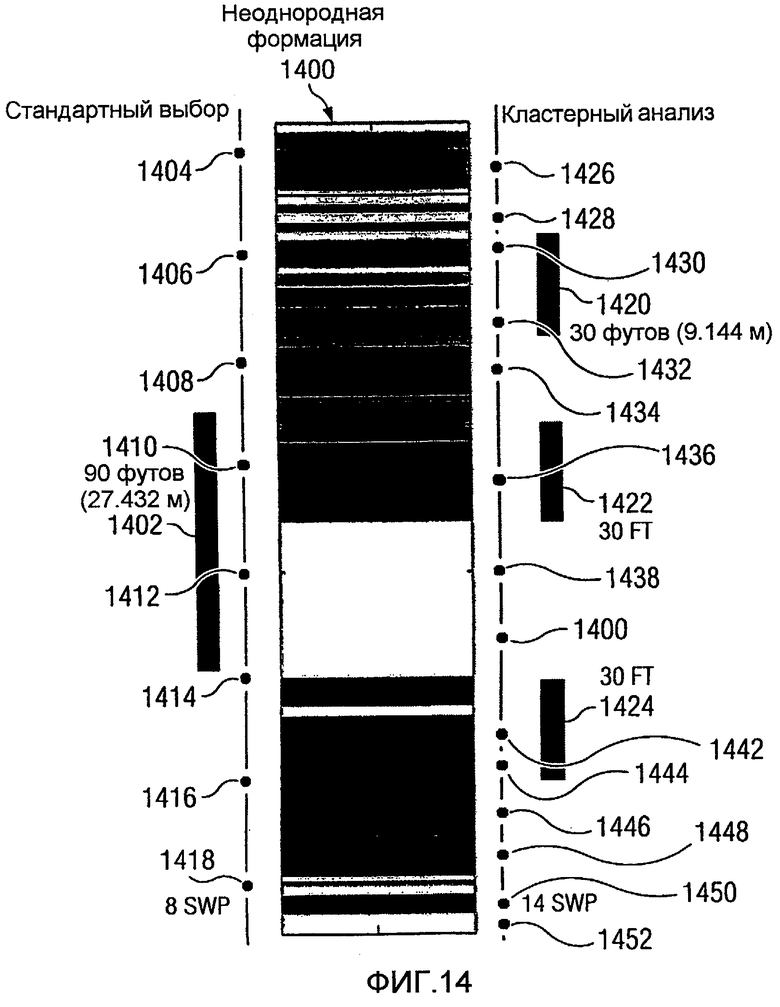
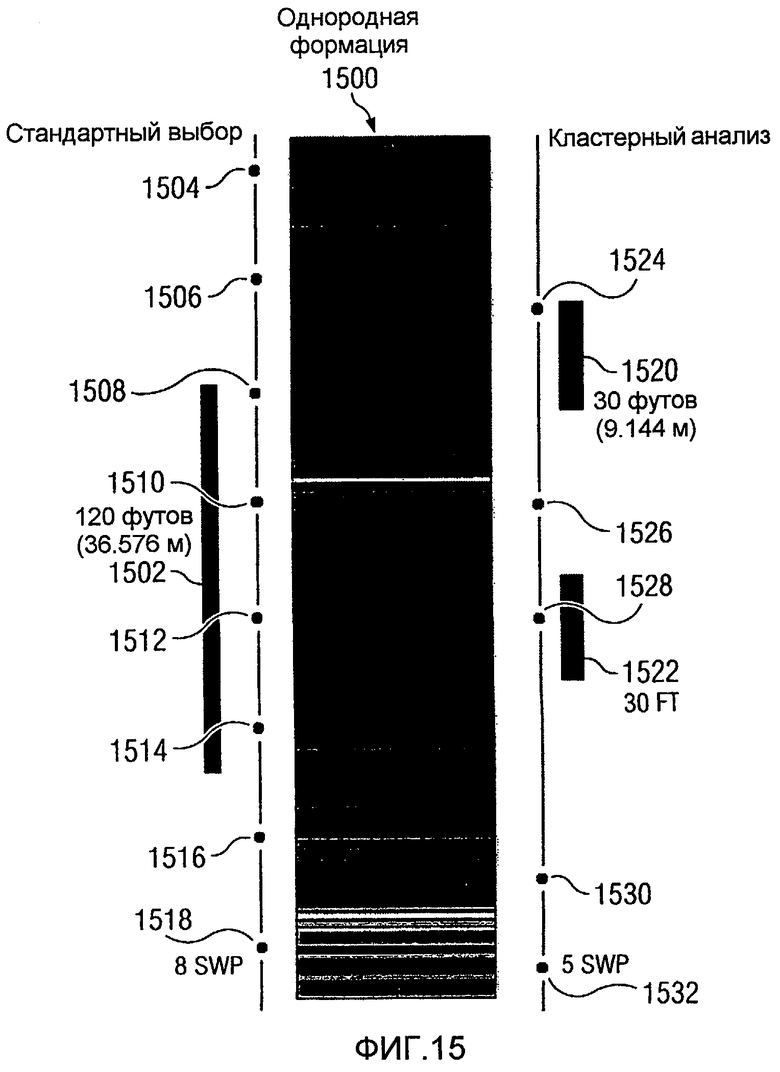

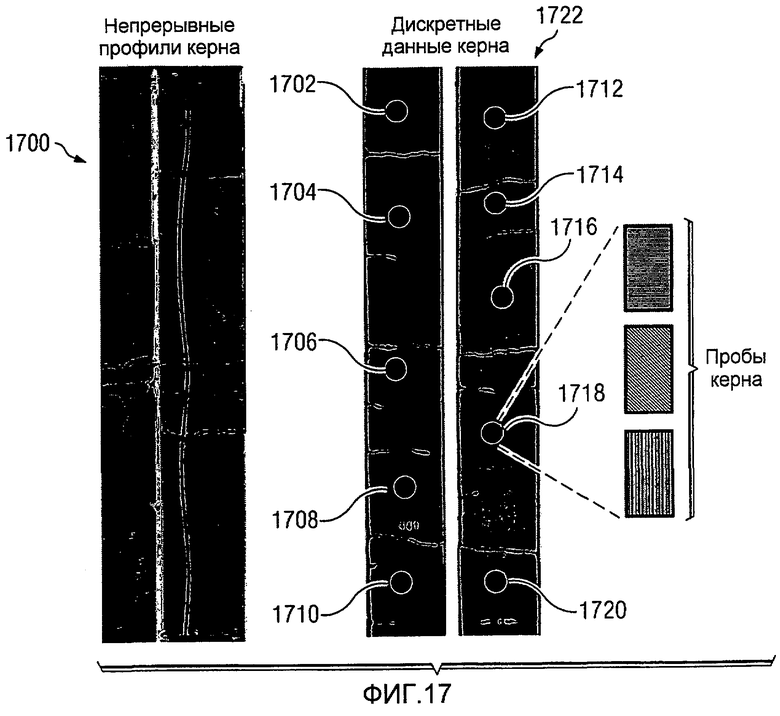
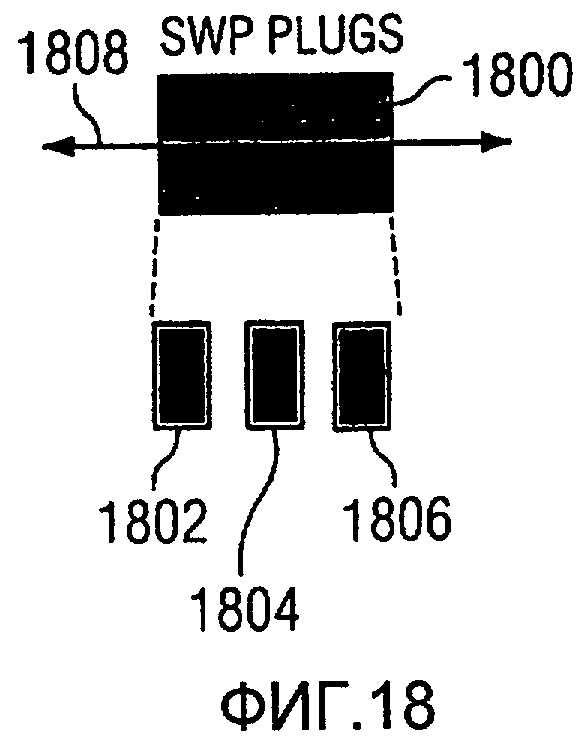
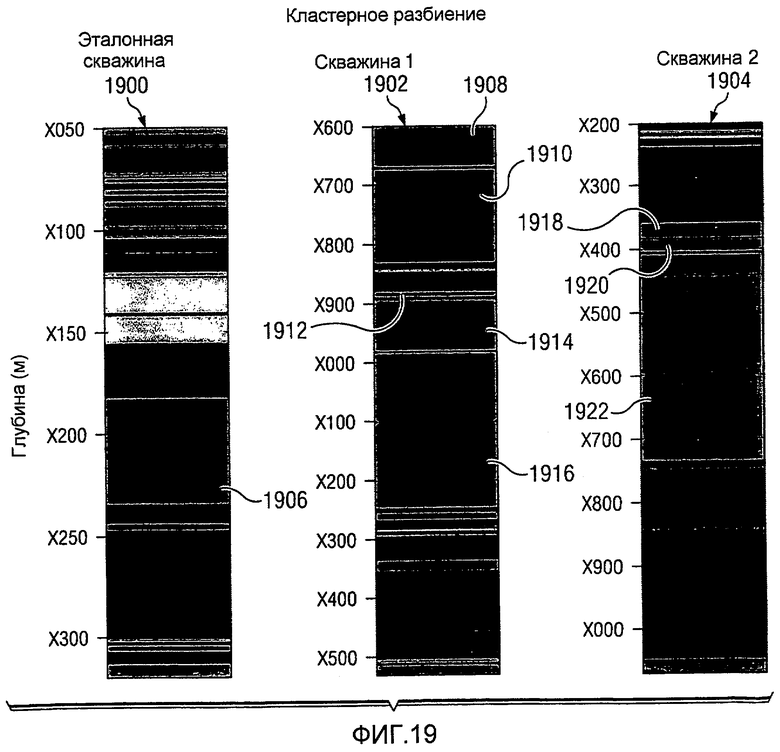
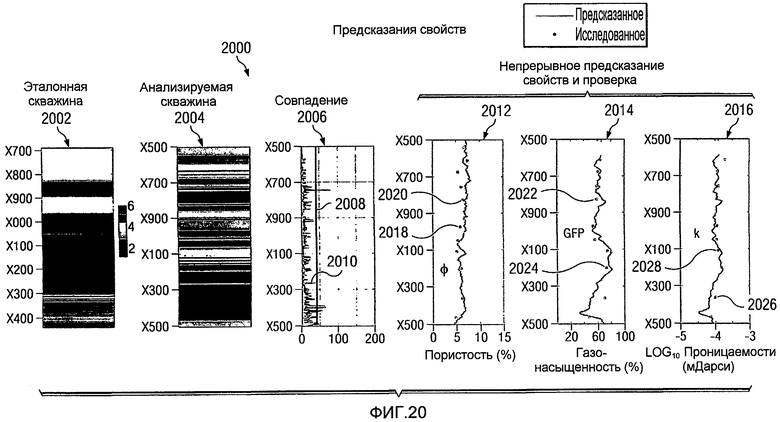
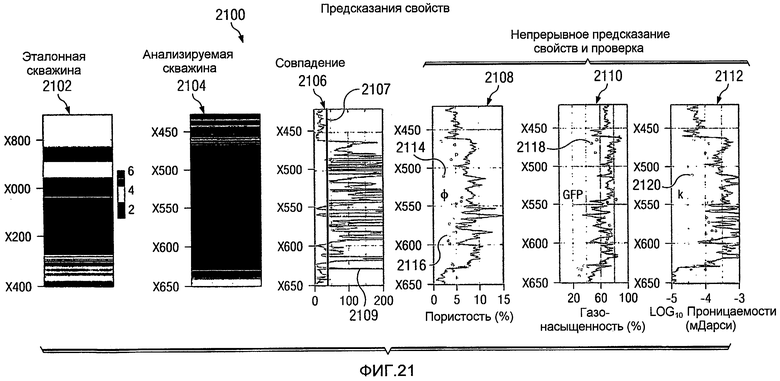
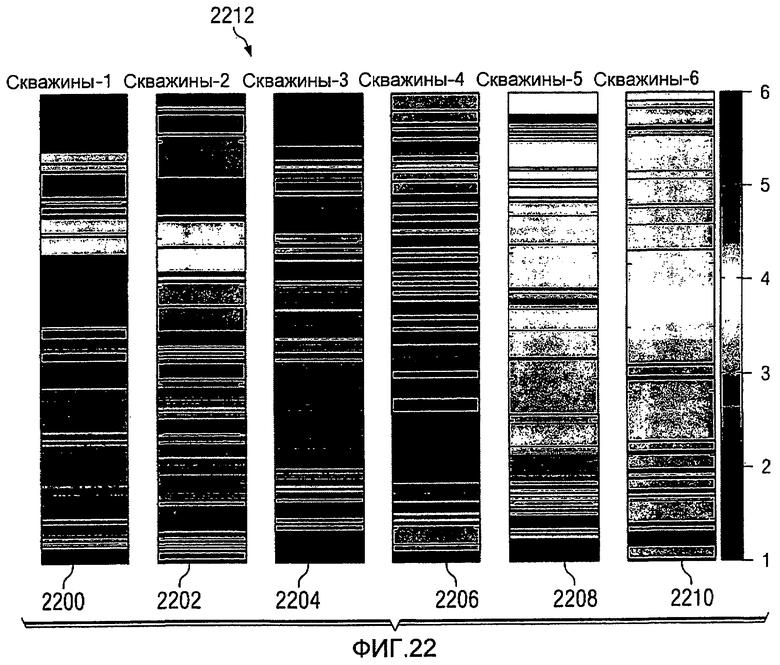
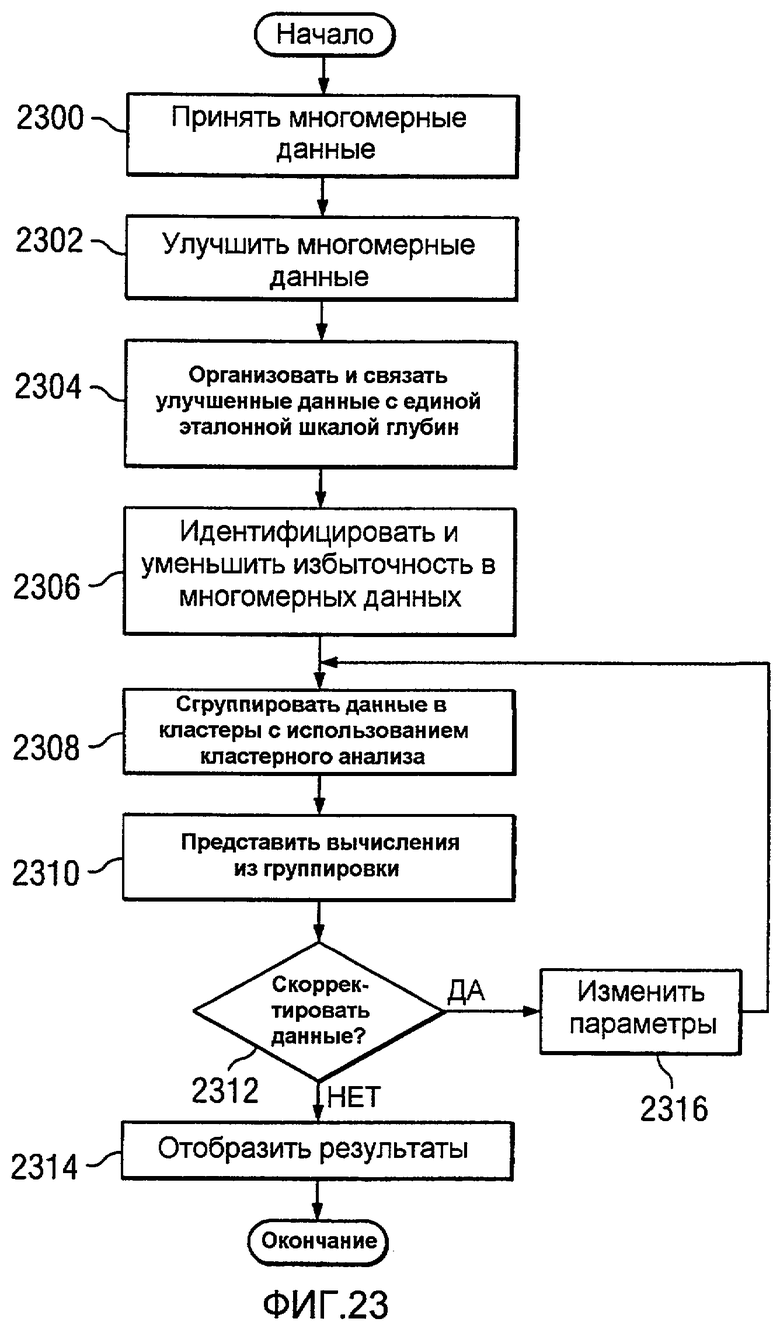
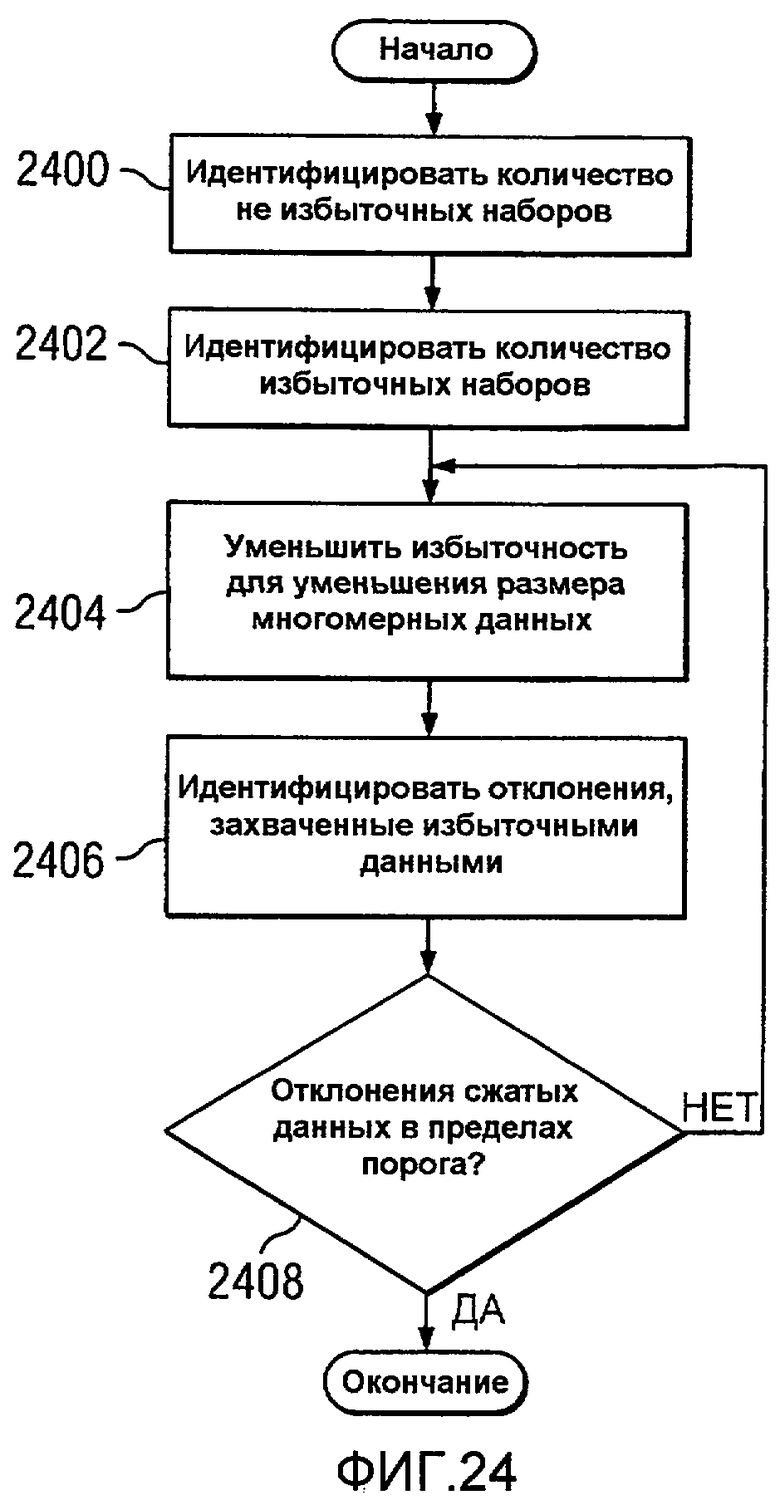
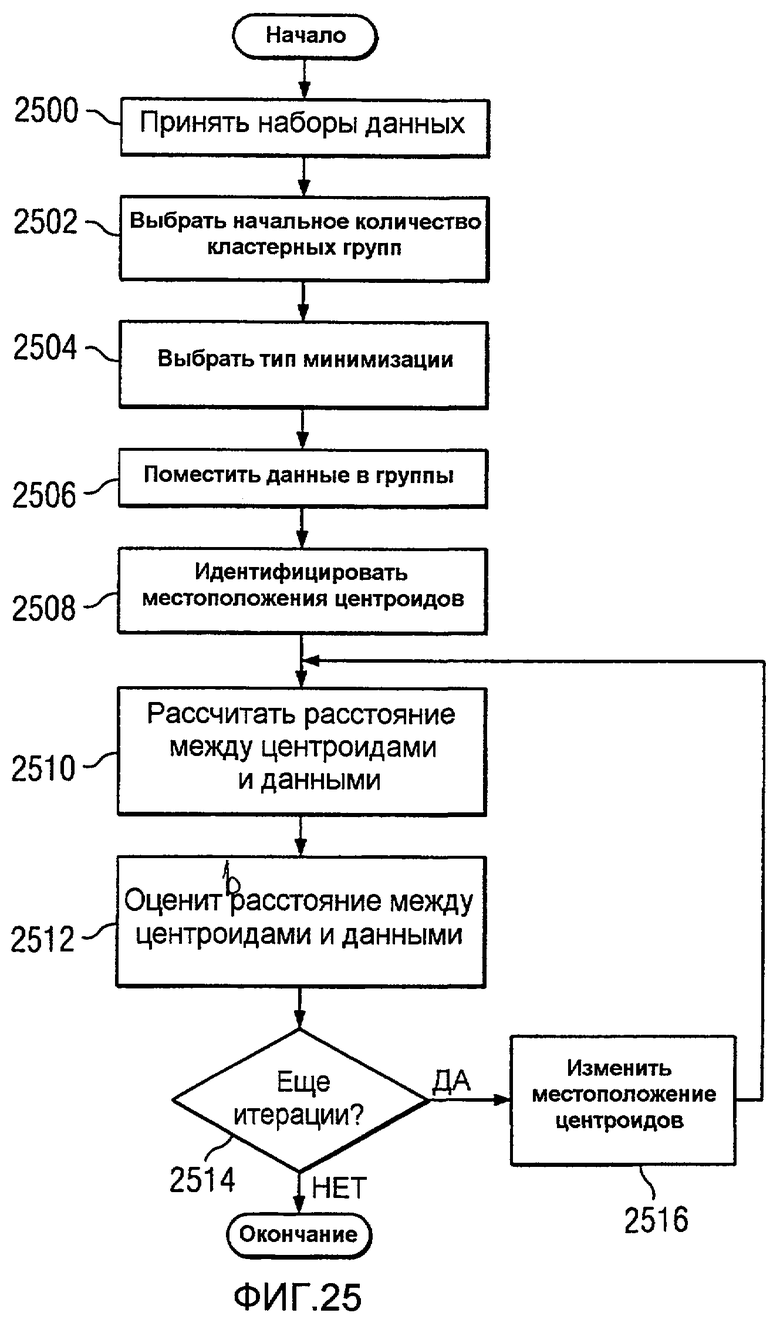
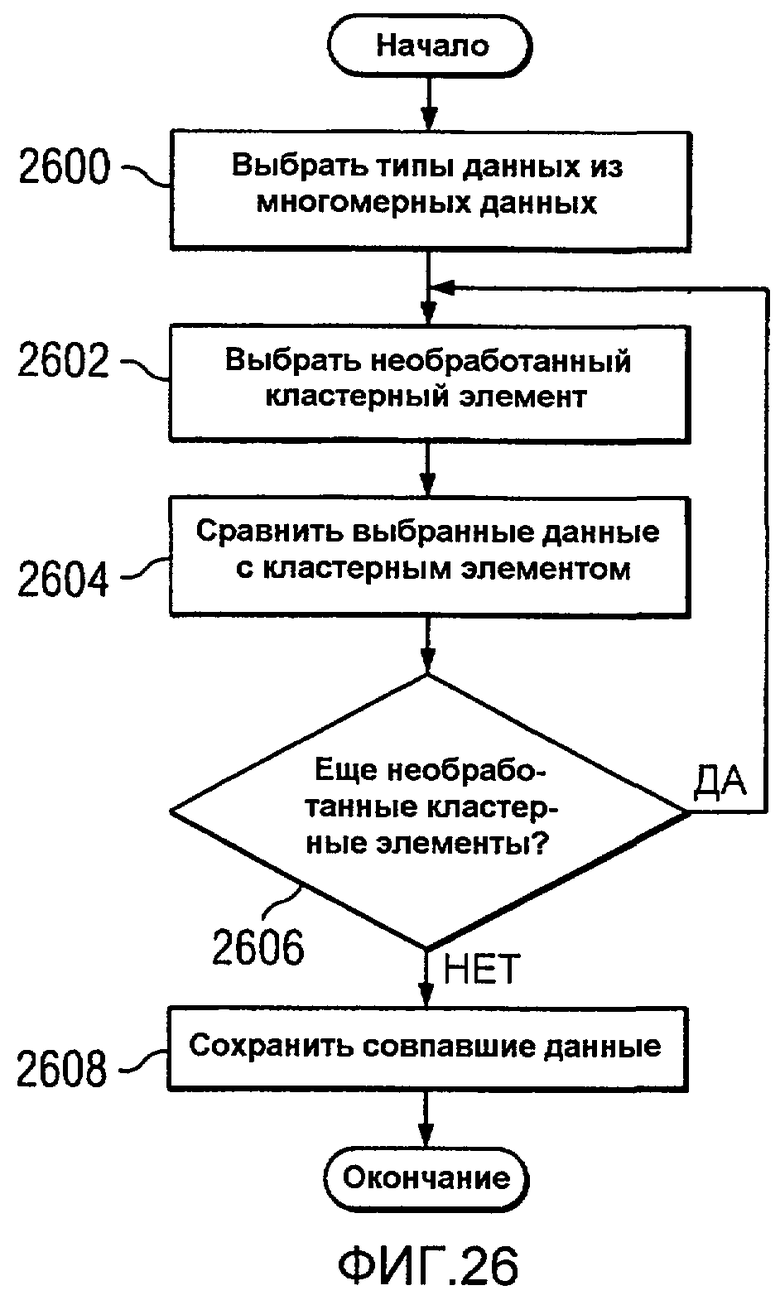
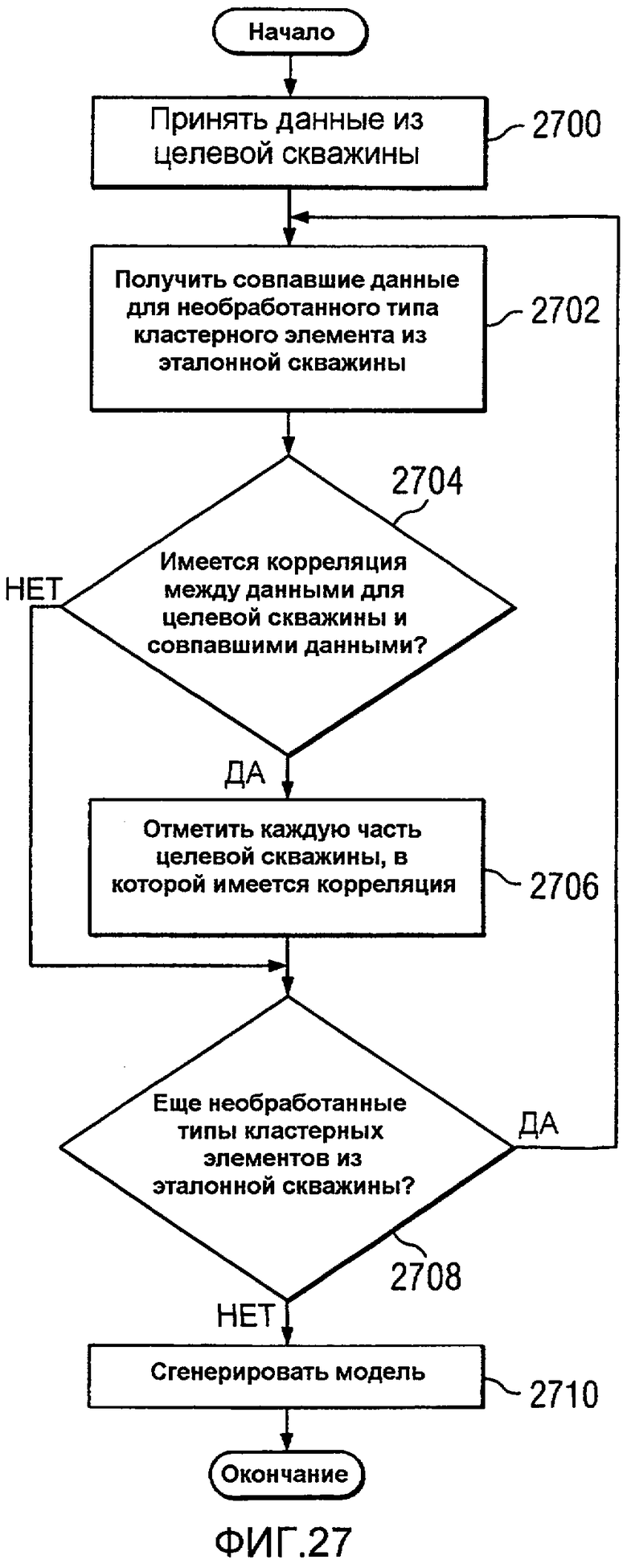
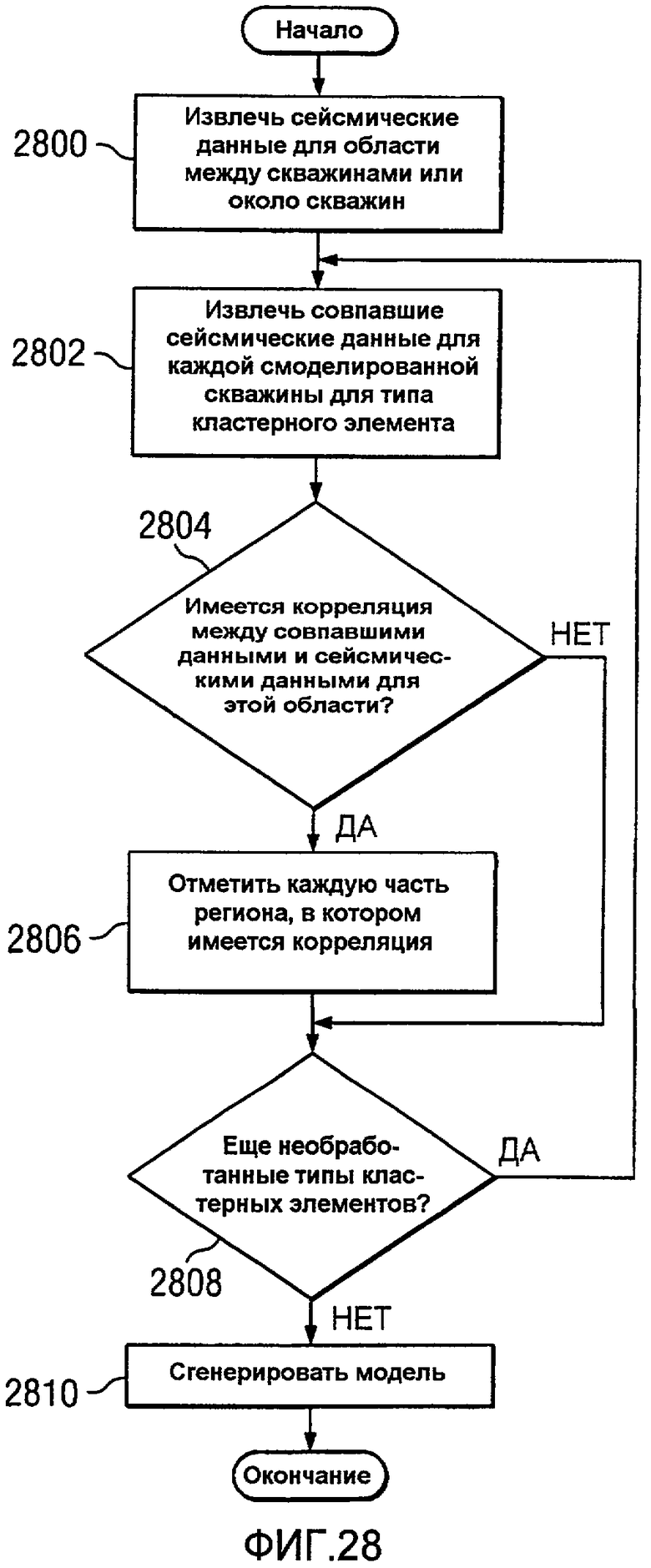
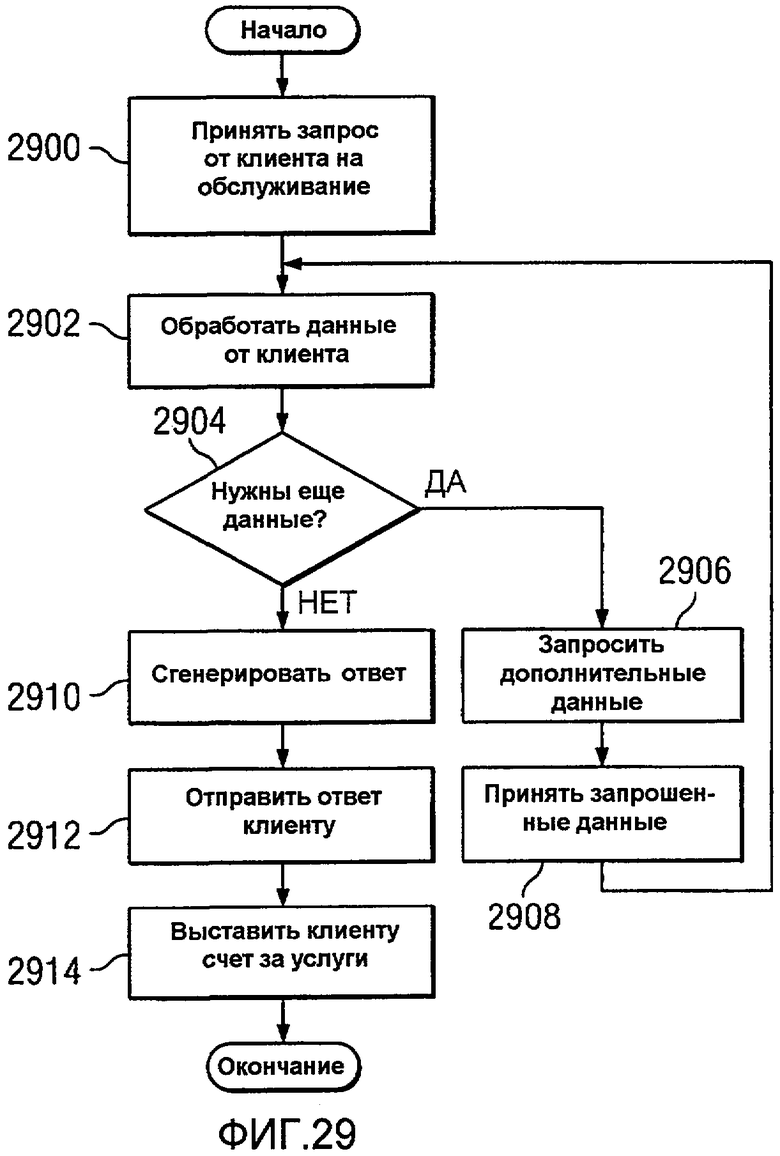
Заявленная группа изобретений относится к улучшенной системе обработки данных и, в частности, к способу и устройству для анализа данных с площадки скважины. Заявленные способы, устройства и считываемый компьютером носитель, имеющий компьютерно-используемый программный код для идентификации регионов в толще пород на площадке скважины (200), основаны на том, что непрерывные данные (902) принимают с площадки скважины (200), уменьшают избыточность в непрерывных данных (902), принятых с площадки скважины (200), для формирования обработанных данных. Выполняют кластерный анализ (2308) с использованием обработанных данных для формирования набора кластерных элементов, где набор кластерных элементов (1402) включает в себя различные типы кластерных элементов, которые идентифицируют различия между регионами в толще пород на площадке скважины (200). Идентифицируют свойства для каждого типа кластерного элемента в наборе кластерных элементов (1400) для формирования модели для площадки скважины (200). Технический результат, достигаемый от реализации заявленной группы изобретений, заключается в обеспечении способов, устройств и систем для многомерного анализа данных для идентификации неоднородности в формациях или регионах в толще пород с одновременным исключением или минимизацией влияния существующих проблем и ограничений, также в обеспечении различной ориентации при взятии боковой пробы, также в обеспечении визуальной индикации зон с наилучшим качеством пласт-коллектора, что обеспечивает наилучший потенциал для коммерческой добычи для конкретной скважины. 19 н. и 72 з.п. ф-лы, 29 ил.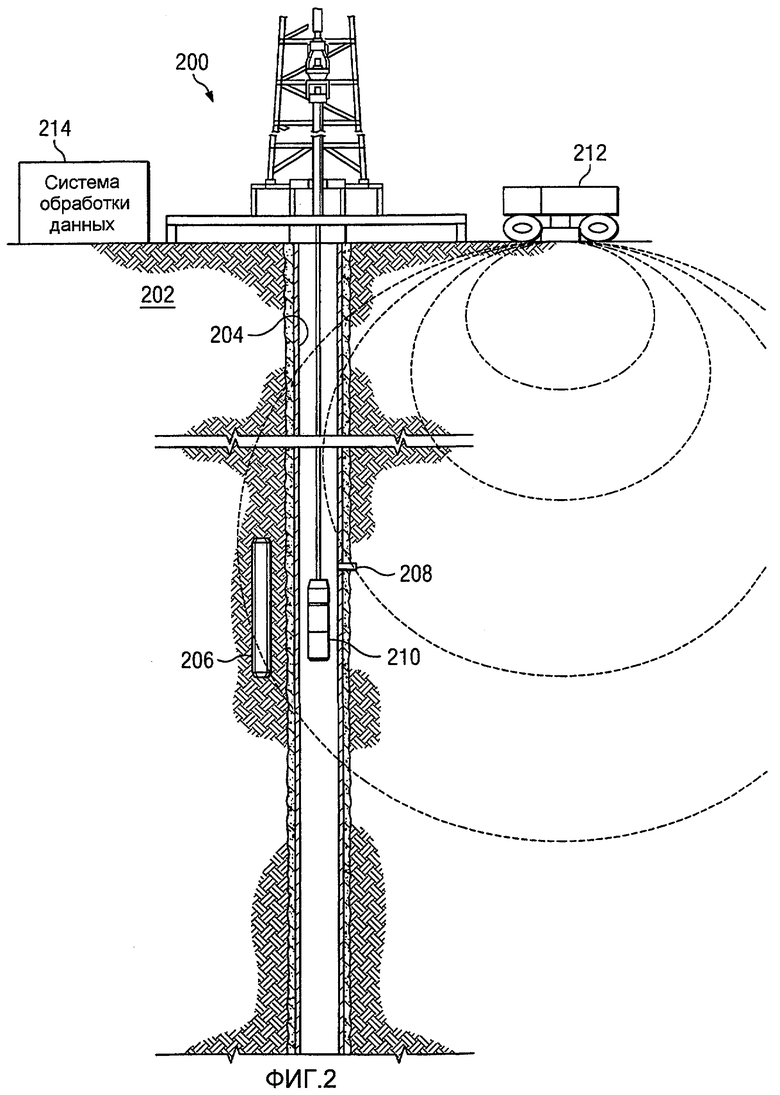
1. Компьютерно-реализуемый способ для идентификации регионов в толще пород на площадке скважины, содержащий этапы, на которых:
принимают непрерывно данные с площадки скважины;
уменьшают избыточность непрерывных данных, принимаемых с площадки скважины для формирования обработанных данных;
выполняют кластерный анализ с использованием обработанных данных для образования набора кластерных элементов, причем набор кластерных элементов включает в себя разные типы кластерных элементов, которые идентифицируют различия между регионами в толще пород на площадке скважины; и
идентифицируют свойства для каждого типа кластерного элемента в наборе кластерных элементов для формирования модели для площадки скважины.
2. Компьютерно-реализуемый способ по п.1, в котором этап выполнения содержит этапы, на которых: выбирают несколько кластерных групп обработанных данных; группируют обработанные данные в несколько кластерных групп для формирования сгруппированных данных; выбирают набор местоположений центроида для сгруппированных данных в нескольких кластерных группах; вычисляют расстояния между набором местоположений центроида и сгруппированными данными и в ответ на вычисление расстояния избирательно изменяют набор местоположений центроида для минимизации расстояния между набором местоположений центроида и сгруппированными данными.
3. Компьютерно-реализуемый способ по п.2, в котором этап выполнения содержит этапы, на которых идентифицируют свойства для каждого кластерного элемента в наборе кластерных элементов в модели с использованием многомерных данных с площадки скважины.
4. Компьютерно-реализуемый способ по п.3, в котором многомерные данные содержат, по меньшей мере, одни из непрерывных данных с площадки скважины, непрерывных лабораторных данных, дискретных данных с площадки скважины и дискретных лабораторных данных.
5. Компьютерно-реализуемый способ по п.3, дополнительно содержащий этапы, на которых: получают дополнительные многомерные данные из целевой скважины и выполняют разбиение на кластеры для создания второй модели для целевой скважины с использованием дополнительных многомерных данных, модели с идентифицированными свойствами и многомерных данных для площадки скважины.
6. Компьютерно-реализуемый способ по п.3, дополнительно содержащий этап, на котором генерируют одну или более рекомендаций касательно работы площадки скважины с использованием свойств, идентифицированных для каждого кластерного элемента в наборе кластерных элементов.
7. Компьютерно-реализуемый способ по п.б, дополнительно содержащий этап, на котором реализуют, по меньшей мере, одну из сгенерированных рекомендаций.
8. Способ анализа многомерных данных для площадки скважины, содержащий этапы, на которых: получают многомерные данные с площадки скважины, причем многомерные данные содержат непрерывные данные с площадки скважины, непрерывные лабораторные данные, дискретные данные с площадки скважины и дискретные лабораторные данные; и
в ответ на получение многомерных данных выполняют кластерный анализ с использованием многомерных данных для формирования набора кластерных элементов, в которых различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины, и
идентифицируют каждый кластерный элемент в наборе кластерных элементов с использованием многомерных данных с площадки скважины.
9. Способ анализа многомерных данных для площадки скважины, содержащий этапы, на которых:
получают многомерные данные с площадки скважины,
в ответ на получение многомерных данных выполняют кластерный анализ с использованием многомерных данных для формирования набора кластерных элементов, в которых различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины, и представляют набор кластерных элементов на дисплее с цветовым кодированием.
10. Способ по п.8, дополнительно содержащий этап, на котором улучшают многомерные данные, полученные с площадки скважины, до выполнения этапа выполнения.
11. Способ анализа многомерных данных для площадки скважины, содержащий этапы, на которых:
получают многомерные данные с площадки скважины,
в ответ на получение многомерных данных выполняют кластерный анализ с использованием многомерных данных для формирования набора кластерных элементов, в которых различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины, и идентифицируют минимальное количество наборов данных в многомерных данных, при этом минимальное количество наборов данных снижает избыточность в многомерных данных, используемых при выполнении кластерного анализа.
12. Способ анализа многомерных данных для площадки скважины, содержащий этапы, на которых:
получают многомерные данные с площадки скважины,
в ответ на получение многомерных данных выполняют кластерный анализ с использованием многомерных данных для формирования набора кластерных элементов, в которых различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины, и
причем этап выполнения содержит этапы, на которых: выбирают несколько кластерных групп для многомерных данных; группируют многомерные данные в несколько кластерных групп для формирования сгруппированных данных; выбирают набор местоположений центроида для сгруппированных данных в нескольких кластерных группах; вычисляют расстояния между наборами местоположений центроида и сгруппированными данными; и после вычисления расстояния избирательно изменяют набор местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными.
13. Способ по п.12, дополнительно содержащий этап, на котором: повторяют этапы вычисления и избирательного изменения до тех пор, пока не будет достигнут порог адекватного представления вариабельности входных переменных в сгруппированных данных.
14. Способ по п.12, в котором кластерный анализ выполняется с использованием алгоритма К-средних.
15. Способ по п.8, в котором этап выполнения содержит этап, на котором: идентифицируют свойства для каждого кластерного элемента в наборе кластерных элементов.
16. Способ по п.15, в котором этап идентификации свойств для каждого кластерного элемента в наборе кластерных элементов дополнительно содержит этап, на котором: идентифицируют свойства для каждого кластерного элемента в наборе кластерных элементов с использованием многомерных данных с площадки скважины.
17. Способ анализа многомерных данных для площадки скважины, содержащий этапы, на которых:
получают многомерные данные с площадки скважины,
в ответ на получение многомерных данных выполняют кластерный анализ с использованием многомерных данных для формирования набора кластерных элементов, в которых различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины,
идентифицируют свойства для каждого кластерного элемента в наборе кластерных элементов, причем этап идентификации свойств для каждого кластерного элемента в наборе кластерных элементов дополнительно содержит этап, на котором: получают дискретные данные с площадки скважины для каждого типа кластерного элемента в наборе кластерных элементов; и идентифицируют свойства каждого кластерного элемента в наборе кластерных элементов с использованием дискретных данных с площадки скважины.
18. Способ анализа многомерных данных для площадки скважины, содержащий этапы, на которых:
получают многомерные данные с площадки скважины,
в ответ на получение многомерных данных выполняют кластерный анализ с использованием многомерных данных для формирования набора кластерных элементов, в которых различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины,
сравнивают многомерные данные с различными типами кластерных элементов в наборе кластерных элементов.
19. Способ по п.18, в котором площадка скважины является эталонной площадкой скважины, и дополнительно содержит этап, на котором: коррелируют многомерные данные, сравненные с различными типами кластерных элементов в наборе кластерных элементов для эталонной площадки скважины с дополнительными многомерными данными для целевой площадки скважины, и где создается вторая модель, содержащая кластерные элементы для целевой площадки скважины.
20. Способ анализа многомерных данных для площадки скважины, содержащий этапы, на которых:
получают многомерные данные с площадки скважины,
в ответ на получение многомерных данных выполняют кластерный анализ с использованием многомерных данных для формирования набора кластерных элементов, в которых различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины,
соотносят все многомерные данные с эталонным масштабом глубины.
21. Способ анализа многомерных данных для площадки скважины, содержащий этапы, на которых:
получают многомерные данные с площадки скважины,
в ответ на получение многомерных данных выполняют кластерный анализ с использованием многомерных данных для формирования набора кластерных элементов, в которых различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины,
причем многомерные данные являются непрерывными данными.
22. Способ по п.8, в котором способ является компьютерно-реализуемым способом.
23. Способ анализа многомерных данных для площадки скважины, содержащий этапы, на которых:
получают многомерные данные с площадки скважины,
в ответ на получение многомерных данных выполняют кластерный анализ с использованием многомерных данных для формирования набора кластерных элементов, в которых различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины,
идентифицируют свойства каждого кластерного элемента в наборе кластерных элементов,
генерируют решения относительно работы площадки скважины с использованием свойств, идентифицированных для каждого кластерного элемента в наборе кластерных элементов.
24. Способ анализа многомерных данных для площадки скважины, содержащий этапы, на которых:
получают многомерные данные с площадки скважины,
в ответ на получение многомерных данных выполняют кластерный анализ с использованием многомерных данных для формирования набора кластерных элементов, в которых различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины, и
причем многомерные данные включают в себя боковые пробы, и этапы включают в себя этапы, на которых получают первый керн из боковые пробы с первой ориентацией относительно оси боковые пробы, и получают второй керн из боковые пробы со второй ориентации относительно оси боковые пробы.
25. Способ по п.24, дополнительно содержащий этап, на котором: получают третий керн боковые пробы с третьей ориентацией относительно оси боковые пробы.
26. Способ для анализа площадки скважины, содержащий этапы, на которых: получают запрос от клиента для выполнения анализа площадки скважины, при этом запрос включает и себя многомерные данные, полученные с площадки скважины; в ответ на получение запроса выполняют кластерный анализ с использованием многомерных данных для формирования набора кластерных элементов, в котором набор кластерных элементов идентифицирует разницы между регионами в толще пород на площадке скважины; и отправляют клиенту результаты, полученные на основании кластерного анализа, при этом клиент использует результаты для выполнения действии на площадке скважины.
27. Способ по п.26, в котором результаты являются графической моделью толщи пород на площадке скважины, и в котором модель включает в себя набор кластеров.
28. Способ по п.26, в котором результаты являются инструкциями, идентифицирующими действия.
29. Считываемый компьютером носитель, имеющий сохраненный на нем компьютерно-используемый программный код, который при выполнении на компьютере побуждает компьютер выполнять способ для идентификации регионов в толще пород на площадке скважины, при этом способ содержит: прием непрерывных данных с площадки скважины; уменьшение избыточности в непрерывных данных, полученных с площадки скважины для формирования обработанных данных; выполнение кластерного анализа с использованием обработанных данных для формирования набора кластерных элементов, где набор кластерных элементов включает в себя различные типы кластерных элементов, которые идентифицируют разницы между регионами в толще пород на площадке скважины; и
идентификацию свойств для каждого типа кластерного элемента в наборе кластерных элементов для формирования модели для площадки скважины.
30. Считываемый компьютером носитель по п.29, в котором выполнение кластерного анализа с использованием обработанных данных для формирования набора кластерных элементов, в котором набор кластерных элементов включает в себя различные типы кластерных элементов, которые идентифицируют разницы между регионами в толще пород на площадке скважины, содержит: выбор нескольких кластерных групп для обработанных данных; группировку обработанных данных в несколько кластерных групп для формирования сгруппированных данных; выбор набора местоположений центроида для сгруппированных данных в нескольких кластерных группах; вычисление расстояний между набором местоположений центроида и сгруппированных данных; и избирательное изменение набора местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными после вычисления расстояний.
31. Считываемый компьютером носитель по п.30, в котором идентификация свойств для каждого типа кластерного элемента в наборе кластерных элементов для формирования модели для площадки скважины содержит идентификацию свойств для каждого кластерного элемента в наборе кластерных элементов в модели с использованием многомерных данных с буровой установки.
32. Считываемый компьютером носитель по п.31, в котором многомерные данные содержат, по меньшей мере, одни из непрерывных данных с площадки скважины, непрерывных лабораторных данных, дискретных данных с площадки скважины и дискретных лабораторных данных.
33. Считываемый компьютером носитель по п.31, в котором способ дополнительно содержит получение дополнительных многомерных данных из целевой скважины; выполнение разбиения кластеров для создания второй модели для целевой скважины с использованием дополнительных многомерных данных, модели с идентифицированными свойствами и многомерных данных для площадки скважины.
34. Система обработки данных для идентификации регионов в толще пород на площадке скважины, содержащая: принимающее средство для приема непрерывных данных с площадки скважины; сокращающее средство для уменьшения избыточности непрерывных данных, принятых с площадки скважины, для формирования обработанных данных; средство выполнения для выполнения кластерного анализа с использованием обработанных данных для формирования набора кластерных элементов, где набор кластерных элементов включает в себя различные типы кластерных элементов, которые идентифицируют разницы между регионами в толще пород на площадке скважины; и идентифицирующее средство для идентификации свойств для каждого типа кластерных элементов в наборе кластерных элементов для формирования модели для площадки скважины, причем средство выполнения содержит:
первое средство выбора для выбора нескольких кластерных групп для обработанных данных;
группирующее средство для группировки обработанных данных в несколько кластерных групп для формирования сгруппированных данных;
второе средство выбора для выбора набора местоположений центроида для сгруппированных данных в нескольких кластерных группах;
оценивающее средство для оценивания расстояний между набором местоположений центроида и сгруппированных данных; и изменяющее средство для избирательного изменения набора местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными после вычисления расстояний.
35. Система обработки данных по п.34, в которой идентифицирующее средство содержит идентифицирующее средство для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов в модели с использованием многомерных данных с буровой установки.
36. Система обработки данных по п.35, в которой многомерные данные содержат, по меньшей мере, одни из непрерывных данных с площадки скважины, непрерывных лабораторных данных, дискретных данных с площадки скважины, и дискретных лабораторных данных.
37. Система обработки данных по п.35, дополнительно содержащая получающее средство для получения дополнительных многомерных данных из целевой скважины и выполняющее средство для выполнения разбиения кластеров для создания второй модели для целевой скважины с использованием дополнительных многомерных данных, модели с идентифицированными свойствами и многомерных данных для площадки скважины.
38. Система обработки данных для идентификации регионов в толще пород на площадке скважины, содержащая шину; блок связи, подсоединенный к шине; устройство хранения, подсоединенное к шине, при этом устройство хранения включает в себя компьютерно-используемый программный код; и процессор, подсоединенный к шине, где процессор исполняет компьютерно-используемый программный код для приема непрерывных данных с площадки скважины; уменьшения избыточности в непрерывных данных, принятых с площадки скважины для формирования обработанных данных; выполнения кластерного анализа с использованием обработанных данных для формирования набора кластерных элементов, где набор кластерных элементов включает в себя различные типы кластерных элементов, которые идентифицируют разницы между регионами в толще пород на площадке скважины; и идентификации свойств для каждого типа кластерных элементов в наборе кластерных элементов для формирования модели для площадки скважины, и причем при выполнении компьютерно-используемого программного кода для выполнения кластерного анализа с использованием обработанных данных для формирования набора кластерных элементов, процессор исполняет компьютерно-используемый программный код для выбора нескольких кластерных групп для обработанных данных; группировки обработанных данных в несколько кластерных групп для формирования сгруппированных данных; выбора набора местоположений центроида для сгруппированных данных в нескольких кластерных группах; вычисления расстояний между набором местоположений центроида и сгруппированных данных; и избирательного изменения набора местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными после вычисления.
39. Система обработки данных для идентификации регионов в толще пород на площадке скважины по п.38, в которой при выполнении компьютерно-используемого программного кода для идентификации свойств для каждого типа кластерного элемента в наборе кластерных элементов для формирования модели для площадки скважины, процессор исполняет компьютерно-используемый программный код для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов в модели с использованием многомерных данных с буровой установки.
40. Система обработки данных для идентификации регионов в толще пород на площадке скважины по п.39, в которой многомерные данные содержат, по меньшей мере, одни из непрерывных данных с площадки скважины, непрерывных лабораторных данных, дискретных данных с площадки скважины и дискретных лабораторных данных.
41. Система обработки данных для идентификации регионов в толще пород на площадке скважины по п.39, в которой процессор может дополнительно исполнять компьютерно-используемый программный код для получения дополнительных многомерных данных из целевой скважины; и выполнения разбиения кластеров для создания второй модели для целевой скважины с использованием дополнительных многомерных данных, модели с идентифицированными свойствами и многомерных данных для площадки скважины.
42. Считываемый компьютером носитель, имеющий компьютерно-используемый программный код, сохраненный на нем, который при выполнении на компьютере побуждает компьютер выполнять способ для анализа многомерных данных для буровой установки, при этом способ содержит: прием многомерных данных с буровой установки и выполнение кластерного анализа с использованием многомерных данных для формирования набора кластерных элементов, в которых различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины.
43. Считываемый компьютером носитель по п.42, в котором способ дополнительно содержит идентификацию каждого кластерного элемента в наборе кластерных элементов с использованием многомерных данных с площадки скважины.
44. Считываемый компьютером носитель по п.42, в котором способ дополнительно содержит представление набора кластерных элементов на дисплее с цветовым кодированием.
45. Считываемый компьютером носитель по п.43, в котором многомерные данные содержат непрерывные данные с площадки скважины, непрерывные лабораторные данные, дискретные данные с площадки скважины и дискретные лабораторные данные.
46. Считываемый компьютером носитель по п.42, в котором способ дополнительно содержит улучшение многомерных данных, полученных с площадки скважины, до выполнения кластерного анализа с использованием многомерных данных для формирования наборов кластерных элементов, в которых различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины.
47. Считываемый компьютером носитель по п.42, в котором способ дополнительно содержит идентификацию минимального количества наборов данных в многомерных данных, где минимальное количество наборов данных снижает избыточность и многомерных данных, используемых при выполнении кластерного анализа.
48. Считываемый компьютером носитель по п.42, в котором в ответ на прием многомерных данных для выполнения кластерного анализа с использованием многомерных данных для формирования набора кластерных элементов на основе принятых многомерных данных, и в котором различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины, содержит: выбор нескольких кластерных групп для многомерных данных; группировку многомерных данных в несколько кластерных групп для формирования сгруппированных данных; выбор набора местоположений центроида для сгруппированных данных в нескольких кластерных группах; вычисление расстояний между набором местоположений центроида и сгруппированных данных; и избирательное изменение набора местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными на основании вычисленных расстояний.
49. Считываемый компьютером носитель по п.48, дополнительно содержащий: повторение вычисление расстояний между набором местоположений центроида и сгруппированных данных; и избирательное изменение набора местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными на основании вычисленных расстояний, пока не будет достигнут порог адекватного представления вариабельности входных переменных в сгруппированных данных.
50. Считываемый компьютером носитель по п.48, в котором кластерный анализ выполняется с использованием алгоритма К-средних.
51. Считываемый компьютером носитель по п.42, в котором способ дополнительно содержит идентификацию свойств для каждого кластерного элемента в наборе кластерных элементов.
52. Считываемый компьютером носитель по п.51, в котором идентификация свойств для каждого кластерного элемента в наборе кластерных элементов содержит идентификацию свойств для каждого кластерного элемента в наборе кластерных элементов с использованием многомерных данных площадки скважины.
53. Считываемый компьютером носитель по п.51, в котором идентификация свойств для каждого кластерного элемента в наборе кластерных элементов содержит получение дискретных данных площадки скважины для каждого типа кластерного элемента в наборе кластерных элементов и идентификацию свойств для каждого кластерного элемента в наборе кластерных элементов с использованием дискретных данных площадки скважины.
54. Считываемый компьютером носитель по п.51, в котором многомерные данные являются непрерывными данными, и в котором идентификация свойств для каждого кластера в наборе кластерных элементов содержит идентификацию свойств для каждого кластерного элемента в наборе кластерных элементов с использованием непрерывных данных.
55. Считываемый компьютером носитель по п.42, в котором способ дополнительно содержит сравнение многомерных данных с разными типами кластерных элементов в наборе кластерных элементов.
56. Считываемый компьютером носитель по п.55, в котором площадка скважины является эталонной площадкой скважины, и способ дополнительно содержит коррелирование многомерных данных, сравненных с различными типами кластерных элементов в наборе кластерных элементов для эталонной площадки скважины с дополнительными многомерными данными для целевой площадки скважины.
57. Считываемый компьютером носитель по п.42, в котором способ дополнительно содержит соотнесение всех многомерных данных с эталонным масштабом глубины.
58. Считываемый компьютером носитель по п.42, в котором многомерные данные являются непрерывными данными.
59. Считываемый компьютером носитель по п.51, в котором способ дополнительно содержит генерацию решения относительно работы площадки скважины с использованием свойств, идентифицированных для каждого кластерного элемента в наборе кластерных элементов.
60. Система обработки данных для анализа многомерных данных для площадки скважины, система обработки данных, содержащая принимающее средство для приема многомерных данных с площадки скважины, причем многомерные данные содержат непрерывные данные с площадки скважины, непрерывные лабораторные данные, дискретные данные с площадки скважины и дискретные лабораторные данные,
и выполняющее средство для выполнения кластерного анализа с использованием многомерных данных для формирования набора кластерных элементов на основе принятых многомерных данных, где различные типы кластерных элементов внутри набора кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины, и
идентифицирующее средство для идентификации каждого кластерного элемента в наборе кластерных элементов с использованием многомерных данных с площадки скважины.
61. Система обработки данных по п.60, дополнительно содержащая средство для представления набора кластерных элементов на дисплее с цветовым кодированием.
62. Система обработки данных для анализа многомерных данных для площадки скважины по п.60, дополнительно содержащая улучшающее средство для улучшения многомерных данных, полученных с площадки скважины, до выполнения выполняющего средства.
63. Система обработки данных для анализа многомерных данных для площадки скважины, по п.60, дополнительно содержащая идентифицирующее средство для идентификации минимального количества наборов данных в многомерных данных, где минимальное количество наборов данных снижает избыточность в многомерных данных, используемых при выполнении кластерного анализа.
64. Система обработки данных для анализа многомерных данных для площадки скважины по п.60, в которой выполняющее средство содержит первое средство выбора для выбора нескольких кластерных групп для многомерных данных; группирующее средство для группировки многомерных данных в несколько кластерных групп для формирования сгруппированных данных; второе средство выбора для выбора набора местоположений центроида для сгруппированных данных в нескольких кластерных группах; вычисляющее средство для вычисления расстояний между набором местоположений центроида и сгруппированных данных; и избирательно изменяющее средство для избирательного изменения набора местоположений центроида для минимизации расстояний между набором местоположений центроида сгруппированными данными на основании вычисленных расстояний.
65. Система обработки данных для анализа многомерных данных для площадки скважины по п.64, дополнительно содержащая повторяющее средство для повторения исполнения вычисляющего средства и избирательно изменяющего средства, пока не будет достигнут порог адекватного представления вариабельности входных переменных в сгруппированных данных.
66. Система обработки данных для анализа многомерных данных для площадки скважины по п.64, в которой кластерный анализ выполняется с использованием алгоритма К-средних.
67. Система обработки данных для анализа многомерных данных для площадки скважины по п.64, дополнительно содержащая идентифицирующее средство для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов.
68. Система обработки данных для анализа многомерных данных для площадки скважины по п.67, в которой идентифицирующее средство содержит средство для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с использованием многомерных данных с площадки скважины.
69. Система обработки данных для анализа многомерных данных для площадки скважины по п.67, в которой идентифицирующее средство содержит средство для получения дискретных данных площадки скважины для каждого типа кластерного элемента в наборе кластерных элементов; и идентифицирующее средство для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с использованием дискретных данных площадки скважины.
70. Система обработки данных для анализа многомерных данных для площадки скважины по п.67, в которой многомерные данные могут быть непрерывными данными, и идентифицирующее средство содержит средство для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с использованием непрерывных данных.
71. Система обработки данных для анализа многомерных данных для площадки скважины по п.60, дополнительно содержащая средство для сравнения многомерных данных с разными типами кластерных элементов в наборе кластерных элементов.
72. Система обработки данных для анализа многомерных данных для площадки скважины по п.71, в которой площадка скважины является эталонной площадкой скважины, и дополнительно содержащая средство коррелирования многомерных данных, сравненных с различными типами кластерных элементов в наборе кластерных элементов для эталонной площадки скважины с дополнительными многомерными данными для целевой площадки скважины, и где создается вторая модель, содержащая кластерные элементы для целевой площадки скважины.
73. Система обработки данных для анализа многомерных данных для площадки скважины по п.60, дополнительно содержащая средство для соотнесения всех многомерных данных с эталонным масштабом глубины.
74. Система обработки данных для анализа многомерных данных для площадки скважины по п.60, в которой многомерные данные являются непрерывными данными.
75. Система обработки данных для анализа многомерных данных для площадки скважины по п.60, дополнительно содержащая средство для генерации решения относительно работы площадки скважины с использованием свойств, идентифицированных для каждого кластерного элемента в наборе кластерных элементов.
76. Система обработки данных для анализа многомерных данных для площадки скважины, содержащая шину; блок связи, подсоединенный к шине; устройство хранения, подсоединенное к шине, при этом устройство хранения включает в себя компьютерно-используемый программный код; и процессор, подсоединенный к шине, где процессор исполняет компьютерно-используемый программный код для приема многомерных данных с площадки скважины; причем многомерные данные содержат непрерывные данные с площадки скважины, непрерывные лабораторные данные, дискретные данные с площадки скважины, и дискретные лабораторные данные,
и выполняет кластерный анализ с использованием многомерных данных для формирования набора кластерных элементов после получения многомерных данных, где различные типы кластерных элементов в наборе кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины, причем процессор дополнительно исполняет компьютерно-используемый программный код для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с использованием многомерных данных для площадки скважины.
77. Система обработки данных для анализа многомерных данных для площадки скважины, содержащая,
шину;
блок связи, подсоединенный к шине;
устройство хранения, подсоединенное к шине, при этом устройство хранения включает в себя компьютерно-используемый программный код; и процессор, подсоединенный к шине, где процессор исполняет компьютерно-используемый программный код для приема многомерных данных с площадки скважины; и выполняет кластерный анализ с использованием многомерных данных для формирования набора кластерных элементов после получения многомерных данных, причем различные типы кластерных элементов в наборе кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины, и причем процессор дополнительно исполняет компьютерно-используемый программный код для представления набора кластерных элементов на дисплее с цветовым кодированием.
78. Система обработки данных для анализа многомерных данных для площадки скважины по п.76, в которой процессор дополнительно исполняет компьютерно-используемый программный код для улучшения многомерных данных, полученных с площадки скважины, до этапа выполнения.
79. Система обработки данных для анализа многомерных данных для площадки скважины по п.76, в которой процессор дополнительно исполняет компьютерно-используемый программный код для идентификации минимальное количество наборов данных в многомерных данных, где минимальное количество наборов данных снижает избыточность в многомерных данных, используемых при выполнении кластерного анализа.
80. Система обработки данных для анализа многомерных данных для площадки скважины по п.76, в которой при исполнении компьютерно-используемого программного кода для указания целевому процессору выполнять кластерный анализ с использованием многомерных данных для формирования набора кластерных элементов после получения многомерных данных, где различные типы кластерных элементов в наборе кластерных элементов идентифицируют разницы между регионами в толще пород на площадке скважины, процессор исполняет компьютерно-используемый программный код для выбора нескольких кластерных групп для многомерных данных; группировки многомерных данных в несколько кластерных групп для формирования сгруппированных данных; выбора набора местоположений центроида для сгруппированных данных в нескольких кластерных группах; вычисления расстояний между набором местоположений центроида и сгруппированных данных; и избирательного изменения набора местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными на основании вычисленных расстояний.
81. Система обработки данных для анализа многомерных данных для площадки скважины по п.80, в которой процессор дополнительно исполняет компьютерно-используемый программный код для повторения вычисления расстояний между набором местоположений центроида и сгруппированных данных; и избирательного изменения набора местоположений центроида для минимизации расстояний между набором местоположений центроида и сгруппированными данными на основании вычисленных расстояний, пока не будет достигнут порог адекватного представления вариабельности входных переменных в сгруппированных данных.
82. Система обработки данных для анализа многомерных данных для площадки скважины по п.80, в которой кластерный анализ выполняется с использованием алгоритма К-средних.
83. Система обработки данных для анализа многомерных данных для площадки скважины по п.80, в которой процессор дополнительно исполняет компьютерно-используемый программный код для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов.
84. Система обработки данных для анализа многомерных данных для площадки скважины по п.83, в которой при исполнении компьютерно-используемого программного кода для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов, процессор исполняет компьютерно-используемый программный код для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с использованием многомерных данных с площадки скважины.
85. Система обработки данных для анализа многомерных данных для площадки скважины по п.83, в которой при исполнении программного кода для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов, процессор исполняет компьютерно-используемый программный код для получения дискретных данных площадки скважины для каждого типа кластерного элемента в наборе кластерных элементов; и идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с пользованием дискретных данных площадки скважины.
86. Система обработки данных для анализа многомерных данных для площадки скважины по п.83, в которой многомерные данные являются непрерывными данными, и в которой при исполнении компьютерно-используемого программного кода для идентификации свойств для набора кластерных элементов процессор исполняет компьютерно-используемый программный код для идентификации свойств для каждого кластерного элемента в наборе кластерных элементов с использованием непрерывных данных.
87. Система обработки данных для анализа многомерных данных для площадки скважины по п.71, в которой процессор дополнительно исполняет компьютерно-используемый программный код для сравнения многомерных данных с разными типами кластерных элементов в наборе кластерных элементов.
88. Система обработки данных для анализа многомерных данных для площадки скважины по п.87, в которой площадка скважины является эталонной площадкой скважины, и где процессор дополнительно исполняет компьютерно-используемый программный код для коррелирования многомерных данных, сравненных с различными типами кластерных элементов в наборе кластерных элементов для эталонной площадки скважины с дополнительными многомерными данными для целевой площадки скважины, и где создается вторая модель, содержащая кластерные элементы для целевой площадки скважины.
89. Система обработки данных для анализа многомерных данных для площадки скважины по п.76, в которой процессор дополнительно исполняет компьютерно-используемый программный код для соотнесения всех многомерных данных с эталонным масштабом глубины.
90. Система обработки данных для анализа многомерных данных для площадки скважины по п.76, в которой многомерные данные являются непрерывными данными.
91. Система обработки данных для анализа многомерных данных для площадки скважины по п.83, в которой процессор дополнительно исполняет компьютерно-используемый программный код для генерации решения относительно работы площадки скважины с использованием свойств, идентифицированных для каждого кластерного элемента в наборе кластерных элементов.
| WO 9534037 А1, 14.12.1995 | |||
| УСТРОЙСТВО ДЛЯ ВЗЯТИЯ ОБРАЗЦОВ ПОЧВЫ | 1990 |
|
RU2087707C1 |
| US 2005171697 А1, 04.08.2005 | |||
| US 6067340 А, 23.05.2000. | |||

