УРОВЕНЬ ТЕХНИКИ
[0001] Бюджетирование является решающим аспектом для организаций, чтобы обеспечить прозрачность своих затрат и обеспечить возможность по улучшению своего баланса доходов и расходов. Бюджетирование с нуля (ZBB) является способом бюджетирования, при котором бюджеты фактически строятся с нуля, обеспечивая принудительную переоценку владельцами затрат своих расходов. Бюджеты формируются путем исследования деятельности с использованием рычагов цен и потребления для оценки требований бизнеса к тратам на предстоящий период, независимо от того, является ли каждый бюджет больше или меньше предыдущего. ZBB позволяет достигать стратегических целей высшего уровня посредством процесса бюджетирования путем привязки бюджета и соответствующих трат к конкретным функциям, местоположениям и хозяйственным единицам, и группировать затраты и, следовательно, стратегические приоритеты образом, который обеспечивает измерение по отношению к предыдущим результатам и текущим ожиданиям.
[0002] Несмотря на то, что бюджетирование с нуля может помочь снизить затраты, избегая типичных просчетов бюджетирования, таких как полное увеличение или уменьшение бюджета предыдущего периода, это как правило трудоемкий процесс, который занимает много больше времени, чем традиционное, основанное на затратах бюджетирование. В некоторых случаях, чтобы понять истинную природу факторов цены и потребления, и чтобы понять, какие части трат имеют очевидную ценность, а какие части являются расточительством, организации используют транзакционные данные. В некоторых случаях это может потребовать сортировки, классификации и установления категории тысяч или миллионов транзакций. Неточная классификация по учету, неорганизованное ведение записей, неэффективное хранение и прочие связанные проблемы с лежащими в основе финансовыми данными затрудняют экспертизу таких факторов и точное повторное установление категории расходов. Традиционные подходы требуют значительных человеческих усилий для повторной классификации данных, часто требующие работы сотен людей для просмотра и повторной классификации данных транзакционного уровня по соответствующим категориям затрат. Однако, установление категории с участием человека может стать жертвой более серьезных проблем, поскольку знания о классификации затрат у разных людей могут привести к очень непрозрачному и невоспроизводимому установлению категории. В некоторых более поздних подходах к оценке и классификации данных транзакционного уровня, методики машинного обучения используются в дополнение к этим ручным усилиям. Даже эти подходы требуют глубоких знаний в отношении конкретного набора данных для точного установления их категории. Несмотря на то, что эти подходы могут быть успешными в сокращении ручного установления категории данных о тратах, модели и системы для классификации данных о тратах часто являются очень специфичными для клиентов из их бизнеса. Модели, используемые для установления категории данных, как правило, не могут быть перенесены на других клиентов, в частности на тех, которые находятся в других отраслях промышленности. В результате точность этих моделей, как правило, является недостаточной.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0003] Различные варианты осуществления в соответствии с настоящим изобретением будут описаны со ссылкой на чертежи, на которых:
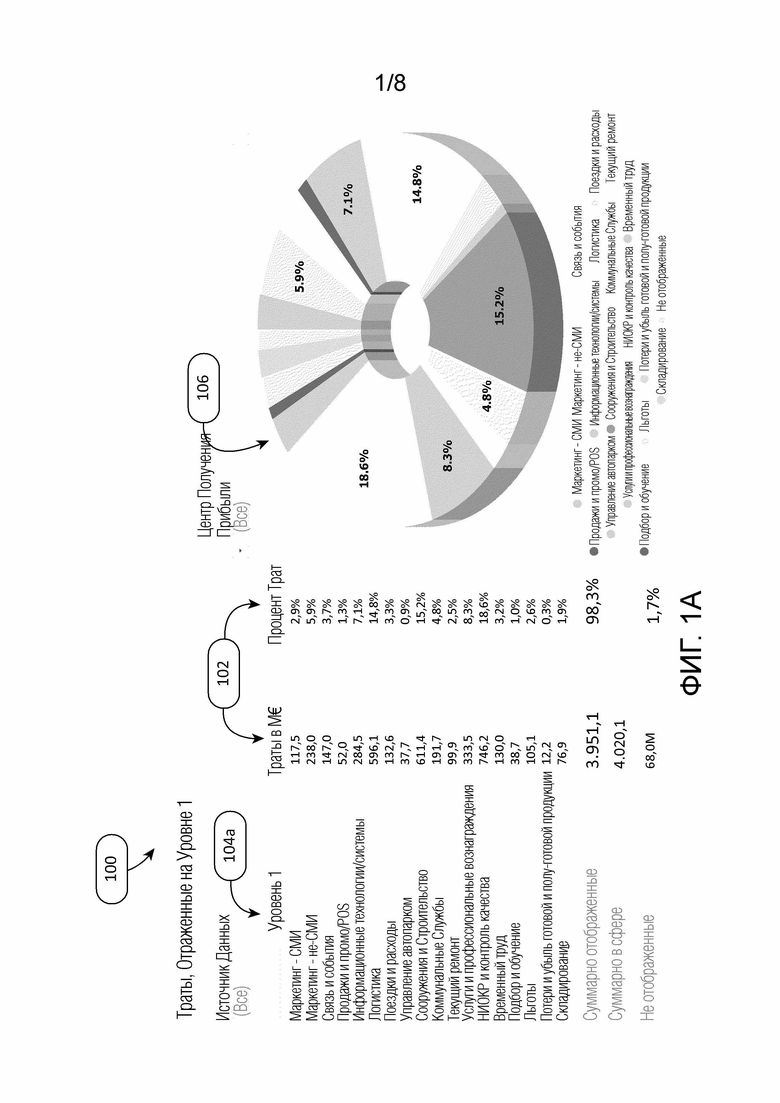
[0004] Фиг. 1A и 1B изображают интерфейс приложения для представления данных о тратах с установленной категорией и обеспечения пользователю возможности исследования данных о тратах.
[0005] Фиг. 2A и 2B изображают примеры журналов и счетов-фактур, которые могут быть включены в необработанные данные о тратах.
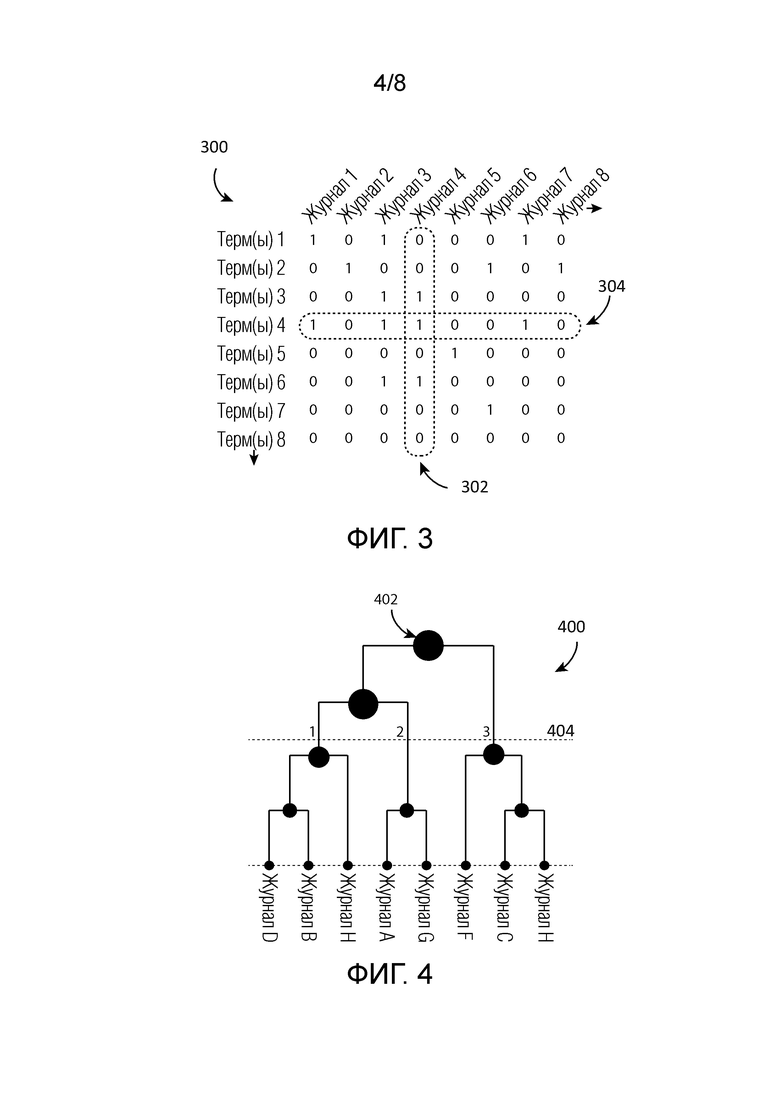
[0006] Фиг. 3 изображает матрицу встречаемости термов, которая может включать в себя векторы журнала, описывающие характеристики индивидуальных журналов.
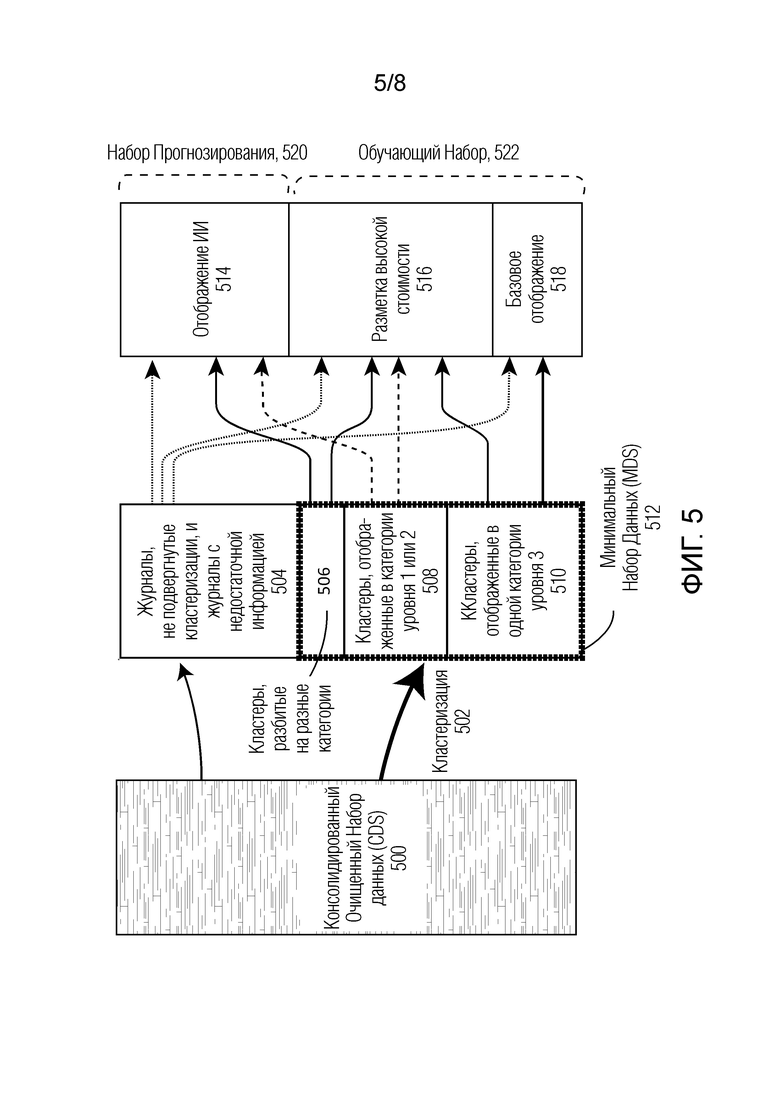
[0007] Фиг. 4 изображает дендрограмму, которая показывает один путь, посредством которого в отношении журналов может быть осуществлена иерархическая кластеризация.
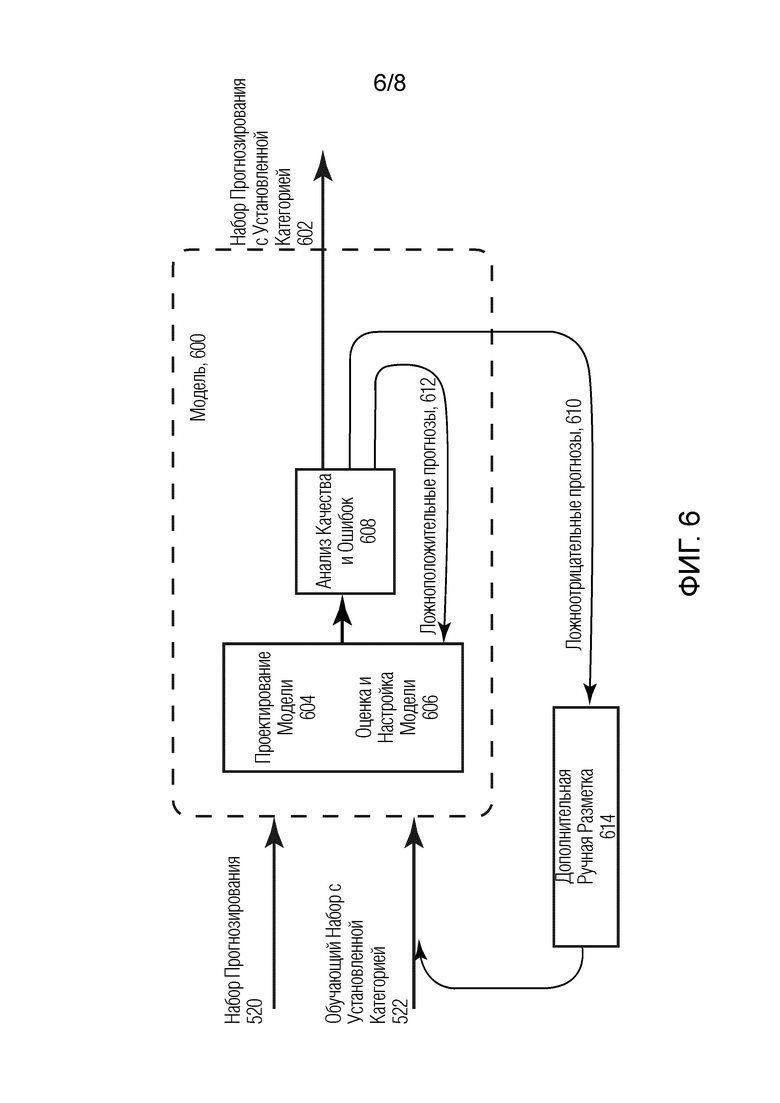
[0008] Фиг. 5 иллюстрирует аспекты кластеризации и установления категории журналов расходов.
[0009] Фиг. 6 иллюстрирует аспекты модели, которая использует одну или более методик машинного обучения, чтобы прогнозировать категории для журналов расходов.
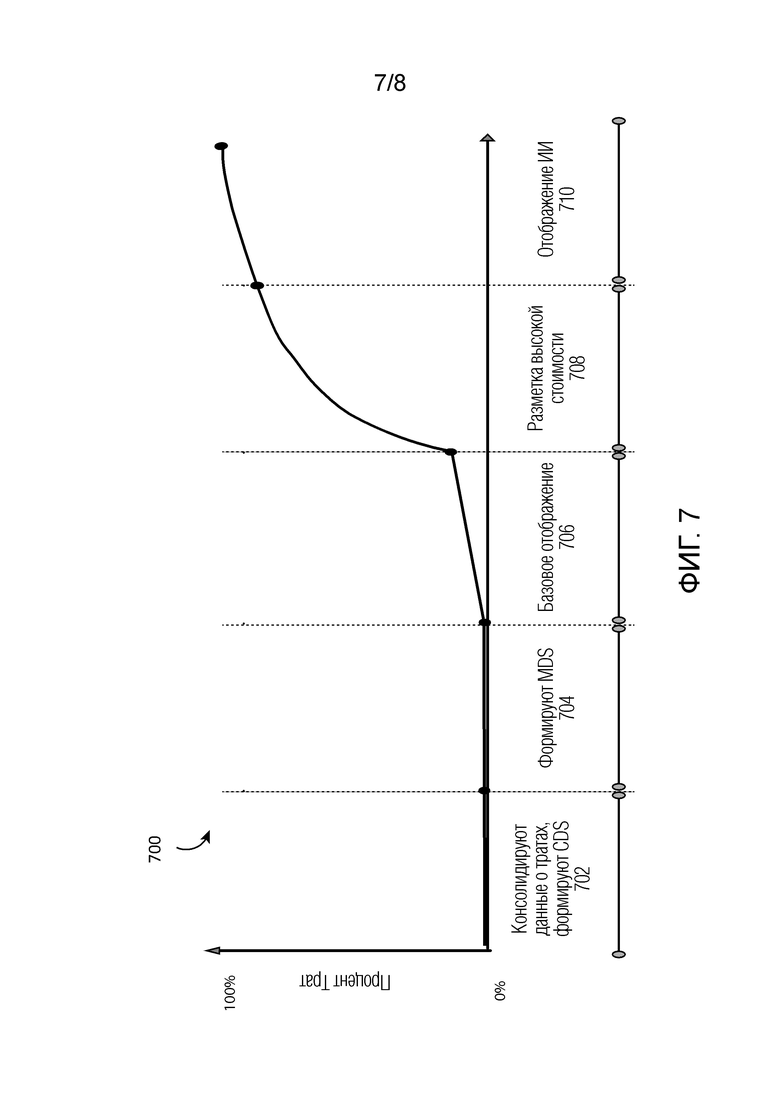
[0010] Фиг. 7 является графиком, представляющим один пример того, как может быть установлена категория данных о тратах во время фаз базового отображения, разметки высокой стоимости и отображения ИИ согласно способам, описанным в данном документе.
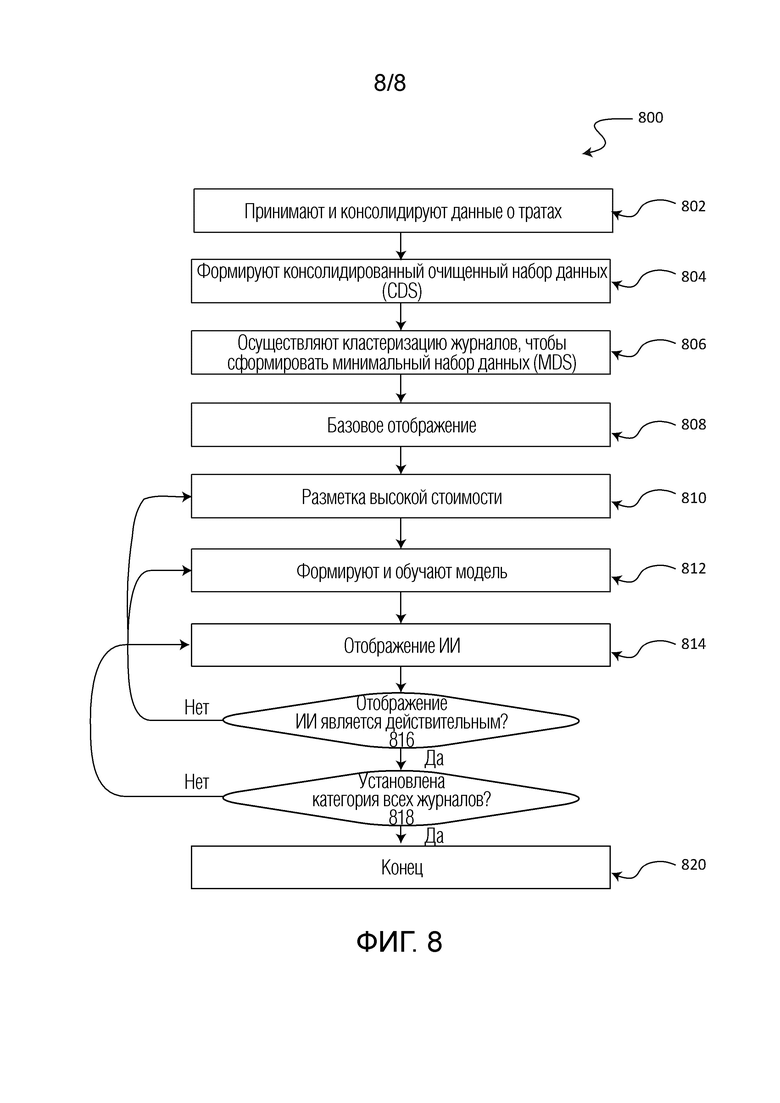
[0011] Фиг. 8 представляет способ для установления категории данных о тратах, который может быть использован в некоторых вариантах осуществления.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0012] Системы и способы в соответствии с различными вариантами осуществления настоящего изобретения могут преодолевать один или более из вышеупомянутых или прочих недостатков, которые встречаются в традиционных подходах к установлению категории и анализу данных.
[0013] В частности, различные варианты осуществления, описанные в данном документе, предлагают способы для установления категории данных о тратах, которые могут включать в себя информацию главной книги (GL), кредиторской задолженности (AP), заказа на поставку (PO), включая, но не ограничиваясь, транзакции, счета-фактуры, расходные квитанции, основанные на поставщике наборы данных и прочие документированные расходы, которые в данном документе совокупно упоминаются как журналы трат (или просто журналы). После сбора данных о тратах из всех соответствующих систем и/или источников данных, данные обрабатываются и консолидируются, чтобы сформировать очищенный набор данных (CDS). CDS включает в себя данные о тратах, которые были отфильтрованы, чтобы удалить менее важную информацию, и/или обработаны для стандартизации информации, используемой для установления категории журнала. В некоторых случаях CDS включает в себя организованную структуру, которая разбивает информацию о тратах по типам полей (например, суммарные затраты, продавец, дата транзакции и т.д.). В некоторых случаях стандартизация данных о тратах вызывает применение операций обработки на естественном языке к текстовой информации, ассоциированной с журналами. Затем в отношении журналов из CDS осуществляется кластеризация на группы на основе сходства слов, затрат, дат или других шаблонов и признаков, которая формирует новый набор данных меньшего размера: минимальный набор данных (MDS). MDS составляет группы журналов, представляющих собой один и тот же тип транзакции (например, «Плата за такси» или «Поставщик A»). На основе операции кластеризации каждый журнал в рамках одного и того же кластера может быть отображен в одной и той же категории затрат.
[0014] В некоторых случаях иерархическая структура категорий определяется по меньшей мере частично в кластерной структуре и в некоторых случаях структура категорий основана на конкретных потребностях клиента. Затем журналы размечаются или устанавливается их категория по фазам, где один или более характерные журналы из каждого кластера используются, чтобы определять информацию о категории для каждого из журналов, ассоциированных с кластером. На фазе один установление категории некоторых из журналов или кластеров может быть осуществлено посредством интеллектуального алгоритма предварительно определенных правил - например, может быть автоматически установлена категория журналов или кластеров, отвечающих особым критериям и включающих в себя информацию о контексте клиента (например, включающих структуру счетов). На второй фазе выбираются кластеры высокой стоимости, и их категория устанавливается вручную. На третьей фазе модель машинного обучения обучается с использованием данных о тратах с установленной категорией, и она используется, чтобы автоматически устанавливать категорию оставшихся данные о тратах с не установленной категорией. В некоторых случаях способ Человек-в-Цикле (HITL) может быть использован для повышения точности установления категории. Таким образом алгоритм определяет качество выполнения прогнозирования моделью. Если он определяет качество для фрагмента трат как находящееся ниже особой пороговой величины, то алгоритм либо регулирует параметры модели, либо идентифицирует дополнительные журналы, категория которых должна быть установлена вручную. Затем фазы два и три повторяются до тех пор, пока не будет установлена категория 95-100% трат.
[0015] В отличие от традиционных способов, способы, описанные в данном документе подходят даже когда отсутствуют предварительные глубокие знания в отношении практической деятельности клиента. Например, пространственные базы данных предварительного установления категории (например, путем согласования поставщиков) не нужны при использовании раскрытых способов. Посредством операций в виде формирования MDS данных о тратах, кластеризации журналов, соответствующих сходным транзакциям, и запроса у пользователя установления категории кластеров высокой стоимости, может быть быстро получен приемлемый обучающий набор данных, который подходит для обучения моделей, которые, в свою очередь, могут быть использованы для автоматического установления категории оставшихся журналов с высокой степенью точности. Путем кластеризации журналов значительно сокращается количество определений категории, что в свою очередь делает процесс быстрее и менее ресурсоемким. Раскрытые способы дополнительно обеспечивают методики машинного обучения, которые позволяют процессу стать менее трудоемким и более точным со временем. Эти и прочие преимущества станут очевидными в нижеследующем описании.
[0016] Фиг. 1A изображает приложение для представления пользователю данных о тратах с установленной категорией, которые часто упоминаются как куб трат. В изображенном интерфейсе 100 изображены суммы 102 расходов для различных категорий 104a уровня 1, как, впрочем, и визуальные данные 106 (графы, таблицы, диаграммы и аналогичное), чтобы выразить деление распределенных на категории данных о тратах пользователю. Интерфейс может предусматривать многообразие выбираемых пользователем признаков, чтобы позволять пользователю исследовать данные о тратах - позволяя пользователю быстро понимать состояние трат организации за выбранный период (например, 1 месяц, 6 месяцев, 1 год или другая выбранная величина, для которой были предоставлены данные о тратах). Куб трат позволяет пользователю увидеть, каким образом траты распределены по и между организационными единицами компании, обеспечивая прозрачность на наиболее детальном уровне по всем пакетам затрат.
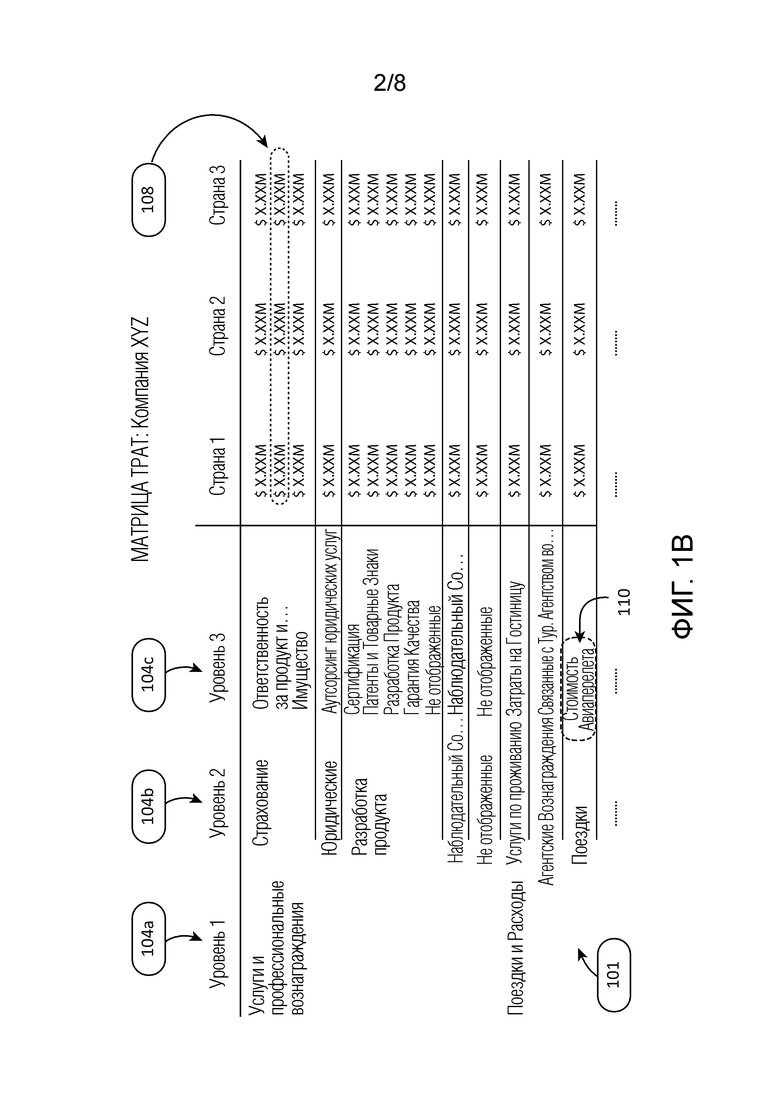
[0017] Фиг. 1B изображает снимок 101 с экрана, представленный приложением, показывающий вид с более высоким разрешением данных о тратах с установленной категорией и, таким образом, обеспечивающий более глубокий анализ, чем тот, что показан снимком с экрана на Фиг. 1A. Дополнительные подробности представлены с использованием иерархической структуры категорий, в которой установлена категория различных журналов расходов. В изображенном интерфейсе каждая категория 104a уровня 1 состоит из одной или более категорий 104b уровня 2, и каждая категория уровня 2 в свою очередь состоит из одной или более категорий 104c уровня 3. Несмотря на то, что изображена трехъярусная иерархическая структура, может присутствовать больше или меньшей ярусов. В некоторых случаях поиск или демонстрация данных о тратах могут осуществляться на основе одной или более категорий журнала или счета-фактуры, которые не попадают в иерархическую структуру категорий. Это может быть выполнено в контексте категорий 104a-c трат. Например, расходы 108 на имущество для международной организации могут быть разбиты по странам, в которых работает организация. В некоторых случаях пользователь может фильтровать данные о тратах на основе журналов расходов, которые удовлетворяют критериям даты, критериям местоположения, критериям отдела или любым другим выбранным критериям, которые могут быть полезными для классификации данных о расходах. В других случаях пользователь может осуществлять поиск по данным о тратах на основе альтернативной иерархической структуры категорий. Например, пользователь может иметь возможность выбора альтернативной иерархической структуры категорий, чтобы увидеть, каким образом затраты распределяются по различным организационным единицам компании, таким как хозяйственные единицы, суб-хозяйственные единицы или регионы, страны и аналогичное.
[0018] В некоторых случаях приложение может быть использовано для вычисления метрик затрат на основе данных о тратах с установленной категорией. В некоторых случаях приложение может предлагать пользователю рекомендации или предупреждения на основе данных о тратах. Например, приложение может извещать пользователя о том, что конкретная категория расходов была очень непостоянной в течение прошедших периодов бюджетирования и что пользователь или организации должны осуществлять планирование соответствующим образом или расследовать источник непостоянства. Следует иметь в виду, что много инструментов программного обеспечения для представления и дальнейшего анализа данных о тратах, известных в настоящее время или разработанных позже, может быть использовано с наборами данных с установленной категорией, созданными посредством способов, описанных в данном документе. Для краткости такие известные инструменты для анализа и представления данных о тратах не обсуждаются очень подробно в данном документе.
[0019] Используемый в данном документе клиент может быть любой организацией, торгово-промышленным предприятием, человеком, группой или субъектом, который ведет журналы хозяйственных расходов (также упоминаемых как траты клиента). В целом способы, описанные в данном документе, будут исполняться стороной отличной от клиента. Однако это не обязательно так. Как правило требования к данным клиента определяются до установления категории данных о тратах. Определение требований к данным может включать в себя, например, определение того, сколько уровней иерархической структуры данных будет использовано, или с какими дополнительными категориями будут ассоциированы журналы. Например, некоторые клиенты могут пожелать, чтобы расходы были классифицированы по географическому местоположению, дате, ассоциированному персоналу и аналогичному. В некоторых случаях клиенты уже используют иерархическую структуру категорий по отношению к которой они хотели бы установить категорию журналов расходов.
[0020] В некоторых случаях более базовое установление категорий данных о тратах (например, меньше ярусов у структуры категорий) может быть предложено клиенту по сниженной цене. Фаза подготовки в виде определения требований клиента также может быть использована, чтобы определять или оценивать уровень детализации, на котором может быть установлена категория данных о тратах. Например, если большинство записей о расходах клиента неполные или отсутствуют достаточные подробности, то клиент может быть проинформирован о том, как это может отразиться на достоверности результатов и с какой детализацией (например, сколько ярусов) может быть установлена категория журналов расходов. В некоторых случаях данная фаза включает в себя автоматическую или вручную экспертизу данных клиента, включающих в себя отчеты о прибылях и убытках, главные книги, Акты Сверки Начислений AP и PO. Как правило это выполняется, чтобы продемонстрировать клиенту потенциал ценности полного установления категории трат. Как показывает опыт значительный потенциал экономии теряется из-за отсутствия прозрачности трат в частности на уровне детализации.
[0021] После того, как определены требования к данным, консолидируются необработанные данные о тратах. Необработанные данные о тратах могут включать в себя, например, бумажные и электронные копии счетов-фактур и квитанций и прочей документации о хозяйственных расходах. В некоторых случаях требуется, чтобы необработанные данные о тратах были отсканированы и переведены в цифровую форму из бумажных записей. В некоторых случаях необработанные данные о тратах могут включать в себя счета-фактуры, которые были отсканированы (например, изображения JPEG, PDF, PNG), но не имеют текста с возможностью поиска. В некоторых случаях журналы расходов могут быть на разных языках. В таких случаях текст из данных изображения может быть распознан с использованием усовершенствованных методик оптического распознавания символов (OCR). В зависимости от качества записей клиента сбор данных может включать в себя различные операции миграции, транскрипции, декодирования и кодирования.
[0022] При консолидировании необработанных данных о тратах журналы сохраняются в общей базе данных, которая упоминается в данном документе как база данных затрат. База данных затрат может быть, например, базой данных на Языке Структурированных Запросов (SQL) или любой другой реляционной или не реляционной базой данных. База данных может быть консолидирована на одном устройстве памяти, распределена по нескольким запоминающим устройствам или может быть сохранена в, например, облаке. В некоторых случаях база данных затрат используется только для хранения журналов для одного периода бюджетирования, а в некоторых случаях база данных затрат может включать в себя журналы за прошедшие платежные периоды, которые могут быть сохранены с целью сравнения.
[0023] Фиг. 2A и 2B иллюстрируют примеры журналов, которые могут быть включены в оборот необработанных данных о тратах клиента. Фиг. 2A изображает пример счета-фактуры, который аккуратно отформатирован для обеспечения удобочитаемости перечисленных полей. В традиционных автоматических или ручных операциях четкое форматирование счета-фактуры может увеличить вероятность того, что существенные поля данных идентифицируются корректно. В противоположность Фиг. 2B изображает счет-фактуру, который не включает в себя форматирование, которое способствует распознаванию данных о тратах. Отсутствие форматирования может быть результатом машинного перевода или предыдущего преобразования типа файлов. В некоторых случаях журналы могут даже быть исходно созданы без четкого форматирования. Журналы расходов, такие как изображенные на Фиг. 2B, затрудняют людям идентификацию соответствующей информации. Эти счета-фактуры также могут привести к ошибкам, когда для анализа данных журнала используются компьютеры. Иногда компьютеры могут объединять текстовые поля, которые должны быть разделены, что может привести к неверному или некогерентному анализу данных о тратах. Например, ненадлежащее форматирование может привести к тому, что поле даты объединяется с полем затрат. Путем применения методик обработки на естественном языке (NLP) к данным журнала можно избежать многих затруднений форматирования. В некоторых случаях операции NLP могут быть применены только к журналам с форматированием, которое мешает автоматическому анализу, а в некоторых случаях операции NLP применяются к всем журналам, чтобы нормализовать форматирование данных о тратах.
[0024] Для увеличения скорости, с которой журналы классифицируются и устанавливается их категория, данные затрат сначала очищаются и предварительно обрабатываются, чтобы сформировать консолидированный очищенный набор данных (CDS). CDS содержит данные о тратах с четкими и понятными описаниями, где искаженные, дублирующие или неинформативные данные удалены. Использование CDS в качестве базы для классификации журналов значительно повышает эффективность и скорость установления категории, поскольку неважная информация и затеняющее форматирование могут быть удалены, что может препятствовать способности человека или компьютера быстро и точно обрабатывать данные журнала.
[0025] Формирование CDS может вызывать операции фильтрации для удаления дублирующих транзакционных данных. Дублирующие данные транзакции часто возникают, когда данные счета-фактуры сохраняются в больше чем одном местоположении или сохраняются несколько раз в записях клиента. Пренебрежение идентификацией этих дублирующих транзакций может вводить ошибку и требовать значительно больше усилий для коррекции позже. Что еще хуже, неспособность идентифицировать дубликаты может привести к плохому бюджетированию, если бюджет создан на предпосылке ложных данных. В некоторых случаях идентичные или совпадающие записи могут быть определены и удалены автоматически на основе сравнения текстовых данных для каждого журнала. В некоторых случаях дублирующие или совпадающие журналы идентифицируются, и у пользователя может быть запрошена проверка того, что журналы являются дубликатами.
[0026] При формировании очищенного набора данных различные не относящиеся к делу транзакции, такие как обесценение, амортизация и налоги, также могут быть удалены. В некоторых случаях удаляются внутренние финансовые перемещения (например, начисления и сторнирования), как, впрочем, и ‘не имеющие ценности’ транзакции и журналы, которые включают в себя искаженные данные. Чтобы верифицировать то, что CDS является правильным и не включает в себя не относящиеся к делу или дублирующие транзакции, суммарные затраты, представленные данными журнала в CDS, сравниваются с базисными значениями клиента, как записано в, например, отчете о Прибылях и Убытках для соответствующего периода или оборотно-сальдовой ведомости. Если идентифицируется солидное расхождение или несоответствие, то разница может быть согласована путем коррекции идентифицированных ошибок в журнале или путем добавления дополнительных журналов в базу данных затрат, чтобы учитывать транзакции, отсутствующие в необработанных данных. Когда данные о тратах в CDS могут быть прослежены до значений, указанных в отчете о Прибылях и Убытках (или ином эквивалентном финансовом документе), то впоследствии данным о тратах с установленной категорией можно доверять, как точно представляющим суммарные траты.
[0027] При формировании CDS различные этапы обработки на естественном языке (NLP) применяются к данным расходов, чтобы обеспечить последующий анализ каждой транзакции. Эти операции могут помочь в определении релевантных ключевых слов и в определении зависимости между транзакциями для кластеризации. Некоторые из этих операций NLP включают в себя (1) преобразование в строчный текст, (2) удаление дублирующих слов, (3) удаление пунктуации, (4) удаление не буквенно-цифровых символов, (5) удаление чисел (в некоторых случаях только из определенных полей), (6) удаление (в некоторых случаях) слов, которые меньше порогового количества символов (например, 2 символов), (7) удаление кодов, идентифицированных как сочетания букв и чисел, (8) перевод текста на один язык (например, английский язык), (9) определение ведущих слов и сортировка словосочетаний путем преобразования слов в их базовую словарную форму (например, «расходы» становятся «расход»), (10) удаление названий месяцев и сокращений, (11) удаление стоп-слов, таких как «для», артикли, (12) удаление названий городов, (13) удаление собственных имен и названий, (14) замена фамилии поставщика, если отсутствует поле поставщика, (15) удаление имени поставщика, когда присутствует в полном описании, (16) выбор ключевых слов по предварительно определенным спискам или узкоспециализированный анализ, аналогичный их вхождению в одну/несколько категорий, (17) использование информативной оценки, аналогичной мере частота терма - обратная частота документа (TF-IDF) и (18) использование моделей Машинного Обучения для Распознавания Именованных Сущностей. Следует понимать, что могут присутствовать дополнительные или меньшее число операций NLP, которые применяются к каждому журналу. Дополнительно некоторые операции NLP могут быть применены к определенным полям или фрагментам транзакции. Например, в некоторых случаях операции NLP применяются только к полям описания счета-фактуры, а не к полям, перечисляющим, например, имя поставщика или контактную информацию поставщика.
[0028] После формирования и проверки достоверности CDS, один или более алгоритмы кластеризации используются, чтобы выполнять кластеризацию журналов на группы на основе сходства, чтобы построить минимальный набор данных (MDS). Когда они достаточно похожи, то можно предположить, что журналы попадают в одну и ту же категорию и могут быть размечены в массе. Это позволяет избежать необходимости индивидуальной оценки и установления категории множества сходных журналов, которые в конечном итоге получат точно такое же обозначение категории. Например, если кластер имеет 500 журналов, тогда может быть установлена категория всех 500 журналов расходов вместе, а не индивидуально. Это значительно сокращает усилия, требуемые для установления категории журналов в базе данных затрат.
[0029] При кластеризации рассматриваются очищенные данные журнала из CDS. В некоторых вариантах осуществления векторы журнала для каждого журнала определяются на основе ассоциированного текста, включенного в CDS. Эти векторы журнала используются для характеристики журналов по словам, найденным в журналах. Как упомянуто CDS включает в себя текст для каждого журнала расходов, который был обработан с помощью одной или более операций обработки на естественном языке. Операции NLP, исполненные над текстовыми данными, могут включать в себя, например, удаление стоп-слов, таких как артикли или «в», которые не переносят существенного смысла, удаление собственных имен и преобразование слов в их базовую форму. Операции NLP помогают стандартизировать текст по журналам так, что они могут быть легко сравнены в целях кластеризации.
[0030] В некоторых случаях база данных затрат может включать в себя дополнительную информацию, которой нет в MDS. К такой дополнительной информации можно обратиться, если не может быть установлена категория журнала посредством информации только в MDS, или чтобы сохранить подробные записи клиента. Дополнительная информация может включать в себя, например, весь текст, ассоциированный со счетом-фактурой, или размещение и форматирование текста в счете-фактуре. В некоторых случаях могут быть даже охарактеризованы такие аспекты, как размер шрифта текста и относительный интервал. В некоторых случаях дополнительные данные могут включать в себя метаданные из электронного файла, такого как PDF, ассоциированного со счетом-фактурой. Информация метаданных может включать в себя данные, такие как отметка времени, когда был создан счет-фактура, счет пользователя, ассоциированный с созданием счета-фактуры, данные местоположения, ассоциированные со счетом-фактурой, или системные данные машины, которая создала электронный файл. В некоторых случаях может быть записано изображение счета-фактуры. Эта дополнительная информация может быть полезной при, например, связывании журнала расходов с другими журналами расходов в базе данных затрат. В некоторых случаях доступ к дополнительной информации, хранящейся в базе данных затрат, может быть осуществлен пользователем через приложение, такое как изображенное на Фиг. 1A и 1B. Например, пользователь может запросить постатейный перечень транзакций в категории и предоставить выбор, запрашивающий демонстрацию дополнительной информации для одного или более журналов. Несмотря на то, что представлены в качестве примеров «дополнительной информации», в некоторых случаях данные, которые относятся к этим полям, могут быть сохранены в MDS, как например, когда поле было идентифицировано в качестве релевантного для кластеризации или разметки данных журнала.
[0031] В некоторых вариантах осуществления словарь термов может быть сформирован на основе слов и общих фраз, найденных в MDS. В некоторых случаях, как изображено на Фиг. 3, может быть создана матрица 300 встречаемости термов, которая имеет векторы 302 журнала и векторы 304 терма. Векторы журнала могут записывать различные признаки журнала наряду с множеством измерений журнала. Например, индексы векторов журнала могут представлять значения, указывающие количество вхождений терма в журнал или значение, указывающее некоторую другую характеристику (например, затраты, время транзакции, местоположение транзакции и т.д.). Векторы 304 терма указывают для конкретного терма количество вхождений терма в каждый журнал расходов. В некоторых случаях вектор терма может соответствовать другой характеристике, такой как сумма в долларах, и в этом случае индексы вектора будут указывать сумму в долларах для каждого журнала.
[0032] В некоторых случаях матрица встречаемости термов может быть упрощена, например, путем удаления векторов терма из матрицы встречаемости термов, которые встречаются в максимальном пороговом количестве журналов расходов (например, термы, которые встречаются в более чем 50%, 75% или в некоторых случаях в 80% журналов расходов). Если терм появляется в большинстве журналов, то терм вероятно несет меньше смысла для целей установления категории. В некоторых случаях термы из словаря могут быть определены как нерелевантные для разметки и соответствующие векторы терма могут быть удалены из матрицы встречаемости термов. В некоторых случаях имена собственные и коды замещаются подходящей классификацией во время операций NLP. В качестве примеров, «Нью-Йорк» и «Берлин» каждый могут быть замещены с помощью «город». Сходным образом «06-24-2017» может быть замещено с помощью «дата». В некоторых вариантах осуществления вектор терма может относиться к измерению отличному от количества вхождений слова. Например, значения в векторе могут представлять собой размерную информацию текста, демонстрируемого в счете-фактуре, текстовые данные информации шаблона, время, когда счет-фактура был создан, и аналогичное. В некоторых случаях вектор терма может быть удален из матрицы встречаемости термов, когда соответствующий терм не обнаруживается в минимальном пороговом количестве журналов расходов.
[0033] Кластеризация может учитывать сходства и шаблоны слов между журналами расходов. Например, повторяющиеся покупки вероятно используют уникальный набор слов и данных, которые могут идентифицировать купленный товар или услугу, продавца, регулярный интервал покупки и аналогичное. Эти шаблоны и сходства отражаются в векторах журнала для журналов расходов и используются, чтобы группировать журналы на основе меры сходства.
[0034] В дополнение прочие признаки журнала могут быть извлечены с использованием моделей машинного обучения, использующих методики вложения слов, такие как Word2Vec или GLOVE. Затем кластеризация может использовать эти векторы признака, используя различные метрики расстояния, аналогичные косинусному сходству, евклидовому расстоянию или специально спроектированному расстоянию Word Mover («From Word Embeddings To Document Distances», M. J. Kusner, Y. Sun, N. I. Kolkin, K. Q. Weinberger, Материалы 32-й Международной Конференции по Машинному Обучению, 2015 г.).
[0035] В некоторых вариантах осуществления если описания счета-фактуры обладают достаточной длиной, то Скрытое Распределение Дирихле (LDA) также может быть использовано в качестве неконтролируемого алгоритма для обнаружения тем в описаниях счетов-фактур. Для каждого журнала выходные данные могут представлять собой относительный весовой коэффициент каждой темы, ассоциированной с текстовым описанием журнала. Эти выходные данные затем вкладываются в вектор журнала и задаются в качестве входных признаков в алгоритм кластеризации.
[0036] Фиг. 4 представляет иллюстративное представление иерархической кластерной структуры 400, которая может быть использована в соответствии с различными вариантами осуществления. Данный иллюстративный пример изображает один способ, в соответствии с которым может быть выполнена кластеризация над восемью журналами (Журнал A - Журнал I). Кластеры могут существовать на нескольких уровнях, начиная с каждого кластера, представляющего один журнал, до одного кластера 402 на корневом уровне, который включает в себя все журналы. Требуемая пороговая величина 404 сходства (в данном примере возвращающая 3 кластера) может быть выбранным параметром для операции кластеризации. В некоторых случаях кластер может быть разбит на два или более суб-кластера с использованием соответствующих векторов журнала у журналов в кластере, если определяется, что кластер включает в себя журналы, представленные непохожими категориями. Несмотря на то, что Фиг. 4 показывает кластеры, организованные иерархическим образом, также могут быть использованы не иерархические кластеры. Дополнительно больше или меньше кластеров может быть создано в зависимости от типов и многообразия анализируемых журналов трат.
[0037] Итоговые категории трат структурируются в иерархическом дереве. В некоторых вариантах осуществления дендограмма (дерево кластеров), такая, как показанная на Фиг. 4, может отражать по меньшей мере частично структуру категорий трат. В некоторых случаях одна или более категории могут быть предложены на основе термов или других переменных, ассоциированных с кластером. В некоторых случаях предложенная структура категорий может быть предоставлена через интерфейс приложения с опциями для пользователя, чтобы редактировать имена категорий или структуру категорий. Например, пользователю может быть предоставлена опция назначения количества ярусов для структуры категорий, или опции объединения или разделения категорий.
[0038] Процесс иерархической кластеризации может включать в себя, например, рекурсивное разбиение множества журналов расходов на кластеры. В некоторых вариантах осуществления в отношении векторов журнала может быть выполнена кластеризация с использованием основанных на соединяемости методик кластеризации и, в некоторых случаях кластеризация в отношении векторов журнала выполняется с использованием основанной на плотности кластеризации. В некоторых вариантах осуществления кластеризация в отношении векторов журнала может быть выполнена с использованием традиционной методики иерархической кластеризации k-средних, как та, что описана в документе автора Nistér и др. «Scalable Recognition with a Vocabulary Tree», Материалы Конференции Института Инженеров по Электротехнике и Радиоэлектроники по Компьютерному Зрению и Распознаванию образов (CVPR), 2006 г., способа Варда, представленного в документе автора Ward, J. H. «Hierarchical Grouping to Optimize an Objective Function», Журнал Американской Статистической Ассоциации, 1963 г., или алгоритма DBSCAN, представленного в документе автора Ester M. и др. «A density-based algorithm for discovering clusters in large spatial databases with noise», Материалы Второй Международной Конференции по Обнаружению Знаний и Нахождению Скрытых Структур (KDD-96), 1996 г. Следует иметь в виду, что в некоторых вариантах осуществления глубокие знания отрасли могут быть использованы, чтобы регулировать меру сходства, например путем добавления весовых коэффициентов в процесс кластеризации так, что определенное измерение вектора журнала несет больший вес, чем другие. В некоторых случаях весовые коэффициенты и взвешенные значения могут быть выбраны вручную, а в некоторых вариантах осуществления весовые коэффициенты могут быть определены со времени, используя различные методики машинного обучения. Следует иметь в виду, что различные методики кластеризации известные в области техники могут быть использованы для выполнения кластеризации в отношении векторов журнала.
[0039] Когда выполняется кластеризация журналов на аналогичные группы журналов с одним и тем же категориальным обозначением, значительно сокращаются усилия для установления категории данных о тратах. Например, если база данных затрат имеет 8000000 журналов, то эти транзакции могут быть сгруппированы в менее чем примерно 500000 кластеров. В данном примере количество решений, которые требуются для установления категории всех журналов, будет сокращено до примерно 1/16. В некоторых случаях операции кластеризации используются, чтобы группировать журналы в кластеры, насчитывающие меньше примерно 1/10 от количества журналов, а в некоторых случаях, чтобы группировать журналы в кластеры, насчитывающие меньше примерно 1/50 от количества журналов. В некоторых случаях используемое количество кластеров может зависеть от, например, разрешения установления категории расходов, которое требуется клиенту (например, сколько требуется ярусов установления категории). Количество кластеров будет зависеть от разнообразия деятельности по тратам клиента (например, разнообразия поставщиков или типов расходов) и уровня детализации, который требуется для установления категории.
[0040] Фиг. 5 изображает аспекты кластеризации и установления категории журналов расходов, когда используется трехъярусная иерархия категорий, как изображенная на Фиг. 1B. Несмотря на то, что объясняются в контексте трехъярусной иерархии категорий, следует иметь в виду, что описанный процесс также применим к другим структурам категорий. Блок 500 представляет собой консолидированный очищенный набор данных (CDS) для журналов расходов в базе данных затрат. В зависимости от клиента и периода, которые представляют журналы, это может представлять собой миллионы журналов расходов. Кластеризация (502) журналов из CDS приводит к минимальному набору 512 данных (MDS), который состоит из кластерных групп 506, 508 и 510. После кластеризации группы журналов анализируются с их соответствующей структурой счета клиента из отчета о прибылях и убытках, главной книги, Акта Сверки Начислений AP и PO. В зависимости от результата того анализа кластеры затем разбиваются на кластерные группы 506, 508 и 510 чтобы облегчить усилия по установлению категории. Журналы в блоке 504 представляют собой журналы, в отношении которых не может быть выполнена кластеризация в целом из-за отсутствующих данных.
[0041] Кластерная группа 510 включает в себя кластеры с журналами, которые все будут отображены в одной категории уровня 3 (т.е. будет полностью установлена их категория) в структуре категорий. Каждый кластер в данной группе содержит журналы, которые совместно используют ассоциированную структуру счетов из отчета о прибылях и убытках, главной книги и Акта Сверки Начислений AP и PO. Другими словами, ассоциированные данные о тратах в MDS являются достаточными, чтобы обеспечить по меньшей мере установление категории уровня 3 для каждого кластера с высокой достоверностью. В целом журналы в группе 510 представляют собой наиболее полные журналы в данных о тратах клиента.
[0042] Кластерная группа 508 представляет собой кластеры, категория которых может быть совокупно установлена как категория уровня 1 или уровня 2. В данной группе по меньшей мере в некоторых журналах или их ассоциированной структуре счета отсутствуют достаточные подробности, чтобы подходить под определенную категорию второго или третьего уровня иерархической структуры категорий. В некоторых случаях эти категории могут быть помещены в категорию «не отображенные» на втором или третьем уровне иерархической структуры категорий.
[0043] Кластерная группа 506 представляет собой кластеры, содержащие журналы, которые подходят под разные категории на первом, втором или третьем уровне иерархической структуры категорий. Эти кластеры содержат журналы, которые ассоциированы с более чем одной структурой счета. Это как правило происходит, когда данные, релевантные для кластеризации, могут не содержать достаточных подробностей, чтобы иметь возможность различать категории на детализации уровня 3. Например, обращаясь к иерархической структуре категорий на Фиг. 1B кластер в данной группе может иметь некоторые журналы, категория которых должна быть установлена как «Патент и Товарные Знаки», и некоторые журналы, категория которых должна быть установлена как «Разработка Продукта». Такие кластеры могут не представлять собой фактические группы журналов одного и того же типа трат и возможно они должны быть разбиты на суб-кластеры с использованием дополнительного контекста журнала (такого как структура счета) так, что соответствующие журналы расходов этих суб-кластеров все попадают в одну категорию уровня 3 соответственно.
[0044] Наконец итоговая группа 504 включает в себя журналы, в отношении которых не может быть выполнена кластеризации из-за недостаточных или отсутствующих данных, которые требуются для обработки алгоритму кластеризации. Как подробно обсуждалось в другом месте данного документа, категория некоторых из этих журналов может быть установлена посредством базовых правил отображения. В определенных случаях дополнительный контекст журнала позволяет объединить некоторые из этих журналов вместе с журналами из другого кластера. Это выполняется с использованием алгоритма машинного обучения, используя признаки контекста клиента. В некоторых случаях эти журналы могут быть отображены пользователем, если, например, журнал представляет собой достаточный фрагмент трат клиента. В целом, однако, установление категории большей части журналов в группе 504 осуществляется с использованием обученной модели. Следует отметить, что изображенные размеры групп 504, 506, 508 и 510 представлены лишь в качестве примерных процентов трат клиента. Отдельные кластерные группы могут занимать больший или меньший процент трат клиента на основе факторов, таких как качество данных о тратах, используемая методика кластеризации и количество сформированных кластеров.
[0045] После кластеризации может быть автоматически установлена категория некоторых кластеров посредством базового процесса 518 отображения. Базовое отображение может быть основано на правилах, которые соответствуют доверенным категориям клиента. В некоторых случаях эти правила отображения могут быть сформированы путем установления категории трат клиента в течение предыдущего периода бюджетирования с использованием раскрытых способов. В некоторых случаях эти базовые правила могут относиться к сектору промышленности или могут быть обобщенными правилами, которые используются множеством клиентов. В некоторых случаях эти базовые правила могут быть основаны на особой структуре счета, которая обладает непосредственным качеством установления категории уровня 3. В некоторых случаях базовые правила отображения могут быть предоставлены клиентом или определены на основе аспекта практики клиента.
[0046] В качестве иллюстративного примера одним правилом отображения будет помещение кластеров в категорию 110 «стоимость авиаперелета» (категория уровня 3 иерархической структуры категорий, изображенной на Фиг. 1B), которые включают в себя журналы с известным ключевым словом, связанным с данной категорией, таким как «рейс» или «авиа», 1 или 2 полями города, 1 или 2 полями времени, кодом рейса и известным поставщиком авиабилета. Эти ограничения будут представлять город прибытия (и возможно город вылета), время прибытия (и возможно время вылета) и код рейса (например, две буквы, за которыми следуют 1-4 цифры), которые могут быть перечислены в счете-фактуре для билета на самолет. В некоторых случаях правило также может рассматривать затраты, ассоциированные с журналом, чтобы увидеть, находятся ли они в ценовом диапазоне, который можно ожидать для расходов на перелет. Данный шаблон может быть определен из соответствующей кластерной матрицы, которая включает в себя векторы журнала у журналов в матрице. Например, может быть определено, что каждый вектор журнала имеет значение выше или равное 1 для измерения, соответствующего количеству городов, значение выше или равное 1 для измерения, соответствующего количеству полей времени, перечисленных в счете-фактуре, значение 1 для измерения, соответствующего количеству кодов рейса, и по меньшей мере значение 1 для измерения, соответствующих известным кодовым словам и поставщикам, которые связаны с категорией стоимость авиаперелета. Следует иметь в виду, что в некоторых случаях базовые правила отображения могут быть значительно более комплексными - часто, правила для базового отображения могут быть очень особенными, чтобы сокращать вероятность того, что будет неправильно установлена категория журналов посредством базового правила. В некоторых случаях, однако, эти базовые правила отображения также могут быть относительно простыми. Например, правила в некоторых случаях могут зависеть только от одного ключевого слова или поставщика, ассоциированных с кластером.
[0047] После базовых основанных на правиле операций отображения поднабор оставшихся кластеров, представляющих собой кластерные группы высокой стоимости, автоматически определяется посредством алгоритма. Выбор может быть основан на суммарных затратах, которые переносятся на кластер, количестве транзакций в кластере и/или соответствующей ассоциации кластера с недостаточно представленными или чрезмерно представленными категориями, чтобы улучшить модель машинного обучения. Поднабор кластерных групп высокой стоимости может в некоторых случаях представлять между 30% и 60% суммарных трат и может представлять кластер из каждой из кластерных групп 504, 506, 508 и 510. Затем установление категории этих кластеров осуществляется вручную. Например, характерный журнал для кластера может быть представлен пользователю, который определяет выбор того, как будет установлена категория всех журналов в кластере. В некоторых случаях характерный журнал может быть определен автоматически, например, путем определения журнала, который представляет собой среднее или центроид кластерной группы. В некоторых случаях у пользователя будет запрошено установление категории нескольких журналов из кластера. Например, если кластер представляет собой достаточный процент суммарных трат, или если присутствует по меньшей мере одно четкое измерение для разделения кластера на два или более суб-кластера, тогда у пользователя может быть запрошена верификация того, что журналы, представляющие собой суб-кластеры, принадлежат к одной и той же категории.
[0048] В некоторых случаях процесс разметки высокой стоимости продолжается до тех пор, пока не будет установлена категория определенного процента суммарных трат и/или пока не будет установлена категория порогового количества журналов в каждой категории иерархической структуры категорий. В некоторых случаях кластеры могут быть выбраны из рассредоточенных фрагментов кластерного дерева, чтобы сокращать количество выборов, предоставление которых запрашивается у пользователя для порогового количества журналов, категория которых должна быть установлена в каждой категории. Данный способ придерживается принципа Человек-в-Цикле (HITL), где прогнозы, сделанные моделью, которые считаются недостаточными, отправляются человеку для установления категории вручную.
[0049] Кластеры и журналы, размеченные вручную, или отображенные через базовые правила отображения, затем используются в качестве обучающего набора 522 для обучения модели машинного обучения. Данная модель используется для установления категории оставшихся журналов и кластеров 514, также упоминаемых как набор 520 прогнозирования. Набор прогнозирования кластеров представляет собой поднабор кластерных групп 504, 506 и 508.
[0050] Фиг. 6 изображает то, каким образом модель 600 может быть использована для выбора подходящих категорий для набора прогнозирования кластеров. Модель принимает обучающие данные 522, установление категории которых было осуществлено посредством базовых операций 518 отображения и разметки 516 высокой стоимости. Обучающие данные используются чтобы определять параметры модели, используемые для определения категории журнала или кластера на основе ассоциированных данных в MDS. Как только модель обучена и применяется к набору 520 прогнозирования, она обеспечивает прогнозы 602 категории. Наборы 520 и 522 обеспечивают модели вектор журнала для каждого журнала. В некоторых вариантах осуществления только поднабор данных журнала обеспечивается модели, а в некоторых случаях дополнительные данные о тратах в базе данных затрат могут быть представлены модели. В некоторых случаях журналы также могут быть изъяты из обучающего набора во время калибровки модели, чтобы сбалансировать вероятность категорий, по которым она будет учиться (например, чтобы избежать того, что конкретная категория чрезмерно представлена).
[0051] В некоторых случаях модель может развиваться и становиться более точной со временем посредством итерационного процесса, изображенного на Фиг. 6. Данный итерационный процесс обусловлен автоматизированным анализом качества и ошибок, чтобы улучшать модель. В дополнение дальнейшая разметка вручную может быть выполнена для журналов с прогнозом категории низкого качества. На операции 604 проектируется модель. Проектирование модели может включать в себя, например, выбор того, какие признаки в векторах журнала использовать в качестве входных переменных, и какой тип или структура модели будут использоваться. В некоторых случаях модель может включать в себя один или более алгоритмы машинного обучения, такие как модели логистической регрессии, алгоритмы линейного дискриминантного анализа, деревья классификации и регрессии, наивные байесовские алгоритмы, как в документе «Tackling the Poor Assumptions of Naïve Bayes Text Classifiers», J. D. M. Rennie, L. Shih, J. Teevan, D. R. Karger, Материалы 20-й Международной Конференции по Машинному Обучению, 2003 г., алгоритмы K-ближайших соседей, алгоритмы квантования обучающего вектора, машины опорных векторов, алгоритмы Бэггинга, Бустинга, Случайного Леса, XGBoost, LightGBM, искусственные нейронные сети и аналогичное. Несмотря на то, что некоторые примеры в данном документе приведены в контексте модели глубокого обучения или модели нейронной сети, следует понимать, что также могут быть использованы прочие модели или сочетания моделей привычных специалистам в соответствующей области техники.
[0052] Пример модели нейронной сети, которая может быть использована в некоторых вариантах осуществления для прогнозирования категорий для индивидуальных журналов или кластеров журналов может принимать форму любого количества нейронных сетей, включая сети Персептроны (P), сети Прямого Распространения (FF), Сети Радиально-Базисных Функций (RBF), сети Глубинного Прямого Распространения (DFF), Рекуррентные Нейронные Сети (RNN), Сети с Долгосрочной/Краткосрочной Памятью (LSTM), сети с Управляемым Рекуррентным Нейроном (GRU), Сети с Автокодировщиком (AE) Сети, Сети с Вариационным Автокодировщиком (VAE), Сети с Шумоподавляющим Автокодировщиком (DAE), Сети с Разряженным Автокодировщиком (SAE), Сети с Марковской Цепью (MC), Сети Хопфилда (HN), Сети с Машиной Больцмана (BM), Сети с Ограниченной Машиной Больцмана (BRM), Глубокие Сети Доверия (DBN), Глубокие Сверточные Сети (DCN), Развертывающиеся Сети (DN), Глубокие Сверточные Обратные Графические Сети (DCIGN), Генеративные Состязательные Сети (GAN), Сети Машины Жидкого Состояния (LSM), Сети Машины Экстремального Обучения (ELM), Сети с Эхо-Состоянием (ESN), Сети с Глубокими Разностями (DRN), Сети Кохонена (KN), Сети Машины Опорных Векторов (SVM), сети с Нейронной Машиной Тьюринга (NTM) и аналогичное. В некоторых случаях модель основана на более чем одной модели или алгоритме машинного обучения.
[0053] На операции 606 модель обучается с использованием обучающего набора данных. Обучение может включать в себя любое количество методик машинного обучения, известных специалистам в соответствующей области техники. Например, модели могут быть сформированы и обучены на Python с использованием инструментальных средств scikit-learn или могут быть обучены с использованием библиотек, таких как TensorFlow, Keras, MLib, gensim и аналогичного. Во время обучения параметры модели изучаются алгоритмами Машинного Обучения из обучающего набора с установленной категорией, и различные гиперпараметры модели могут быть определены и/или оптимизированы путем использования разных методик, аналогичных поиску по сетке, перекрестной проверке и байесовской оптимизации для увеличения выбранных метрик модели.
[0054] На операции 608 автоматически выполняется анализ качества и ошибок модели. В некоторых случаях анализ качества и ошибок может происходить после того, как устанавливается категория набора 520 прогнозирования, чтобы верифицировать то, что журналы отображены корректно. В некоторых случаях анализ качества и ошибок может выполняться периодически или непрерывно при установлении категории набора 520 прогнозирования. Если определяется, что модель неправильно прогнозирует категории, то модель может быть обновлена путем пересмотра проекта модели 604. Также может присутствовать автоматизированная регулировка гиперпараметров, которые относятся к заданным категориям 606 (например, если обнаруживаются ложноположительные прогнозы). Или также может присутствовать дополнительная разметка вручную для этих особых категорий 614.
[0055] Существует некоторое количество ручных и автоматических путей проверки того, что модель 600 может быть верифицирована на качество прогнозирования. Например, спрогнозированные категории могут быть проверены с помощью ожидаемого распределения трат для каждой категории на основе структуры счета клиента. Существует несколько других расчетов распределения, которые могут быть использованы в сочетании, такие как распределение частоты ключевого слова, распределение затрат статьи и т.д. Дополнительно тестовые поднаборы обучающего набора могут быть использованы, чтобы получать хорошие показатели выбранной метрики (например, точность, взвешенная точность, погрешность или отзыв). В дополнение обучающие тестовые поднаборы могут быть использованы, чтобы сравнивать автоматизированные прогнозы с фактической разметкой, и чтобы характеризовать ошибки в каждой категории, исходя из вектора журнала. В некоторых случаях журнал может обеспечивать метрику достоверности с каждым прогнозом категории. В некоторых случаях матрица неточностей может характеризовать ошибки путем сравнения прогнозов с фактическими категориями (как например ложноположительные результаты или ложноотрицательные результаты).
[0056] В некоторых случаях у пользователя может быть запрошена верификация категории, которая определена для журнала, когда ассоциированная метрика достоверности находится ниже пороговой величины. В некоторых случаях значения суммарных трат в категориях могут быть проверены в качестве контроля корректности. В некоторых вариантах осуществления, если значение трат для конкретной категории превышает некоторый предварительно определенный диапазон (например, определенный как процент суммарных трат), тогда пользователь может быть извещен и у него может быть запрошена выборочная проверка журналов и кластеров, которые были назначены той категории.
[0057] Если метрика достоверности прогнозирования считается недостаточной на операции 608, например, ниже определенной пороговой величины, то алгоритм машинного обучения может либо регулировать гиперпараметры модели, либо идентифицировать дополнительные журналы, категория которых должна быть установлена вручную. В случаях ложноположительных прогнозов, когда определяется, что модель ошибочно спрогнозировала журналы в одной категории (например, если определяется, что траты применительно к одной категории значительно превышают ожидаемое значение), проект модели и параметры настройки могут быть отрегулированы 612, чтобы скорректировать ошибку. В некоторых случаях модель может приблизиться к ожидаемому распределению путем регулирования весовых коэффициентов машинного обучения. В некоторых случаях тонкая настройка других параметров модели может привести к сокращению ложноположительных результатов.
[0058] Ложноотрицательные прогнозы относятся к ситуациям, когда модели не удается поместить журнал в подходящую категорию. В некоторых случаях матрицы неточностей могут быть использованы, чтобы идентифицировать журналы, которые неправильно спрогнозированы или вероятно неправильно спрогнозированы моделью машинного обучения. Эти идентифицированные журналы затем могут быть представлены пользователю для корректной разметки категории журнала. Размеченные вручную журналы затем могут быть добавлены в обучающий набор 522 с установленной категорией и использоваться для дальнейшего обучения модели, или в некоторых случаях модифицировать проект модели.
[0059] Прогнозы установления категории, которые прошли определенную пороговую величину метрики достоверности, считаются с установленной категорией на операции 602. Для всех других кластеров журналов цикл проектирования модели, настройки и анализа качества и ошибок итерационно повторяется до тех пор, пока, например, категория не будет установлена для 95-100% трат.
[0060] Фиг. 7 изображает график 700, иллюстрирующий то, каким образом может быть установлена категория данных о тратах во время фаз отображения, описанных в данном документе. Следует отметить, что данный график является иллюстративным и что определенные варианты осуществления могут включать в себя дополнительные фазы или могут иметь меньше фаз. В определенных вариантах осуществления изображенное может перекрываться как например, когда базовое отображение и разметка высокой стоимости происходят в одно и то же время.
[0061] На фазе 702 необработанные данные о тратах принимаются от клиента и консолидируются в базе данных затрат. Как обсуждалось, это может включать в себя операции, такие как преобразование в цифровую форму и/или распознавание текста в документах, объединение полей данных, преобразование в стандартизованную целевую схему и сверку отрицательных и не относящихся к делу трат. Затем данные консолидируются, очищаются (например, удаляются поврежденные и дублирующие журналы), и различные операции обработки на естественном языке применяются, чтобы распознать текст, что приводит к консолидированному очищенному набору данных (CDS). На фазе 704 минимальный набор данных (MDS) формируется с использованием различных методик кластеризации над многомерными журналами CDS. На операции 706 применяются базовые правила отображения, чтобы автоматически отобразить журналы в категориях затрат уровня 3. В некоторых случаях данная фаза может учитывать установление категории примерно 10%-20% суммарных трат. В случаях, когда известны глубокие знания практики клиента или, когда раскрытые процессы установления категории были выполнены для предшествующего периода бюджетирования, во время данной фазы может быть размечен более высокий процент суммарных трат.
[0062] После фазы базового отображения кластеры высокой стоимости размечаются вручную на операции 708. Как описано это может включать в себя запрос у пользователя, такого как бухгалтер, разметки вручную одного или более журналов из каждого кластера высокой стоимости. В конце фазы разметки высокой стоимости может быть учтена большая часть суммарных трат, несмотря на то, что это может быть не так при всех обстоятельствах. В заключение на последней фазе 710 осуществляется установлении категории журналов, соответствующих оставшимся тратам, с использованием модели машинного обучения. Модель может быть обучена с помощью журналов, категория которых установлена на предыдущих фазах, журналов, категория которых установлена во время предыдущих периодов бюджетирования, или в некоторых случаях с использованием предварительно обученных моделей на основе установления категории для других клиентов в той же самой отрасли промышленности. В некоторых случаях в конце фазы 710 может быть охарактеризовано более 95% данных о тратах для категории уровня три иерархической структуры категорий. Для достижения высокого уровня журналов с установленной категорией при высоком качестве и достоверности используется процесс, называемый Человек-в-цикле. Данный процесс построен на концепции «активного обучения», особый случай полу-контролируемого машинного обучения. В некоторых случаях автоматизированный алгоритм может определять, что эффективность модели в отношении определенных категорий находится ниже определенной пороговой величины. В таких случаях в зависимости от анализа, модель может либо автоматически настраивать гиперпараметры модели, либо выбирать особые журналы или кластеры, которые должны быть размечены вручную экспертом-человеком. После такого действия изменения подаются обратно системе и модель запускается вновь, как, впрочем, и анализ эффективности, до тех пор, пока для 95%-100% трат не будет установлена категория на уровне три.
[0063] Фиг. 8 иллюстрирует способ 800, который может быть использован, чтобы классифицировать и устанавливать категорию данных о тратах. Следует понимать, что для данного и прочих процессов, которые обсуждались в данном документе, могут присутствовать дополнительные, меньше или альтернативные этапы, выполняемые в рамках объема различных вариантов осуществления, если не указано иное. На операции 802 необработанные данные о тратах принимаются от клиента. Это может включать в себя прием квитанций, счетов-фактур и прочей документации о понесенных затрат. Когда данные принимаются, они также консолидируются в единый набор данных или базу данных, такую как база данных SQL. Данная операция может включать в себя, например, преобразование в цифровой вид и распознавание текста, ассоциированного с журналами расходов, объединение полей данных, преобразование в стандартизованную целевую схему и сверку отрицательных и не относящиеся к делу трат. На операции 804 создается консолидированный очищенный набор данных (CDS). Как описано в другом месте, создание CDS вызывает различные операции обработки на естественном языке, используемые чтобы удалять данные, которые считаются ненужными или неполезными для кластеризации и установления категории. Данные, которые не удалены, очищаются, чтобы улучшить анализ, используемый для кластеризации и установления категории. Например, каждое слово, ассоциированное с журналом, может быть замещено его базовой словарной формой. На операции 806 выполняется кластеризация журналов CDS, чтобы сформировать MDS. MDS содержит группы журналов, которые происходят от транзакций одного и того же характера, которые должны попасть в одну и ту же категорию трат. Способ кластеризации регулируется для каждого случая приложения, рассматривая доступные данные и требуемый уровень детализации кластеров. Формирование MDS сокращает вычислительные потребности, необходимые для кластеризации журналов и прогнозирования категорий для данных о тратах.
[0064] Вслед за операцией кластеризации может быть выполнено установление категории (или разметка) журналов расходов в кластерах. Например, может быть установлена категория характерного журнала для кластера MDS, в результате чего каждому из других журналов в том же самом кластере должно быть обеспечено точно такое же обозначение категории. Установление категории журналов на уровне кластера в отличии от установления категории каждого журнала индивидуально эффективно сокращает требуемое количество решений по категории и ускоряет время установления категории данных о тратах клиента. Первая операция 808 отображения соответствует установлению категории журналов и кластеров на основе того, удовлетворяют ли они набору предварительно определенных правил. В целом эти правила умеют тенденцию быть слишком особыми так, что установление категории журналов лишь редко, если вообще когда-либо, является неправильным.
[0065] Операция 810 разметки высокой стоимости затем выполняется над кластерными группами, представляющими собой пропорционально высокий процент суммарных трат, или большое количество журналов в кластере, или ассоциацию с чрезмерно представленными категориями. Классификация на операции 810 выполняется вручную обученным персоналом. Поскольку человеческий выбор является золотым стандартом точности установления категории, то счета сосредоточены на классификации кластеров высокой стоимости, поскольку эти решения представляют собой более существенный фрагмент суммарных трат. В некоторых случаях разметка высокой стоимости может включать в себя запрос у пользователя правильного установления категории характерного счета-фактуры из каждого из наборов кластеров высокой стоимости. По приему выбора категории пользователя для характерного журнала, каждому из прочих журналов в кластере может быть задано точно такое же обозначение категории. В некоторых случаях, как когда определяется, что кластер может быть легко дополнительно разделен по одному или более измерениям, у пользователя может быть запрошено установление категории для более чем одного из характерных журналов из каждого кластера. Если пользователь устанавливает категорию характерных журналов из одного и того же кластера в соответствии с дискретными категориями, тогда кластер может быть разбит на суб-кластеры, установление категории которых осуществляется с использованием дискретных выборов категории, представленных пользователем.
[0066] Вслед за операциями базового отображения и разметки высокой стоимости модель формируется и обучается 812 с использованием журналов, классифицированных на предшествующих операциях разметки. Обученная модель затем используется для установления категории оставшихся журналов на операции 814. В некоторых вариантах осуществления модель может быть использована для установления категории оставшихся кластеров, а в некоторых случаях модель может быть использована для установления категории оставшихся журналов индивидуально. В некоторых случаях модель может быть использована для установления категории оставшихся журналов автоматически на основе ассоциированных векторов журнала.
[0067] На операции 816 проверяется достоверность категорий, спрогнозированных с использованием модели. Проверка достоверности может быть автоматизированным процессом, который может привести к неожиданным тенденциям в установлении категории трат или нарушениям базовых правил отображения. В некоторых случаях, если значение категории трат превышает ожидаемое значение из-за прогнозов категории посредством модели, то у пользователя может быть запрошена верификация прогнозов категории, представленных моделью. Например, если категория превысила ожидаемый бюджет на величину, соответствующую кластеру, назначенному категории моделью, тогда у пользователя может быть запрошено определение того, была ли правильно установлена категория конкретного кластера. Дополнительным вводом пользователя может быть, например, итерационный процесс HITL, и может иметь сходство с тем, что запрашивалось у пользователя на операции 810. Если установления категории корректируются пользователем, то данная информация может быть использована для дальнейшего обучения модели на операции 812. В некоторых случаях для каждого журнала, для которого категория была установлена с использованием обученной модели, может быть повторно осуществлено установление категории, если модель была обновлена или повторно обучена, как уже упоминалось в другом месте. На операции 818 определяется, установлена ли категория всех журналов. В некоторых случаях все или солидный фрагмент журналов должен отвечать предварительно определенной пороговой величине достоверности для того, чтобы процесс был завершен. Если для некоторых журналов еще не была установлена категория, то процесс возвращается к операции 814. Если установлена категория для всех журналов, или если только оставшиеся журналы обладают недостаточной информацией, чтобы им было обеспечено какое-либо обозначение категории, тогда процесс завершается 820. В случаях, когда присутствуют оставшиеся журналы с недостаточной информацией, эти журналы могут быть представлены пользователю для определения подходящего обозначения категории.
[0068] После того как все журналы были отнесены к категории, данные о тратах с установленной категорией предоставляются клиенту. В некоторых случаях данные установления категории добавляются в базу данных затрат, которые затем могут быть предоставлены клиенту. Если клиент использует приложение, такое как изображенное на Фиг. 1B, для изучения данных с установленной категорией, то клиент может в некоторых случаях иметь возможность доступа к особой информации о журнале, такой как текст, включенный в счет-фактуру, или изображение счета-фактуры. В некоторых случаях приложение клиента, такое как изображенное на Фиг. 1A и 1B, может предоставлять пользователю опции для коррекции данных с неправильной установленной категорией или внесения правок в иерархическую структуру категорий. В некоторых случаях может быть обеспечена анонимность, подчистка данной информации, и она может использоваться для формирования весовых коэффициентов модели для других клиентов в будущем (например, других клиентов в том же самом секторе производства). В некоторых случаях базовые правила отображения могут быть обновлены с тем, чтобы установление категории для статей осуществлялось с даже большей точностью в будущих периодах бюджетирования или для других клиентов. В отношении любой информации, которая сохраняется или иным образом используется для улучшения установления категории отображением для других клиентов, обеспечивается анонимность и подчистка таким образом, что отсутствует возможность отслеживания важной информации обратно до клиента. С использованием искусственных нейронных сетей это может быть выполнено путем удаления определенных слоев модели.
[0069] Несмотря на то, что вышеупомянутые примеры были представлены в контексте установления категории данных о тратах, следует иметь в виду, что раскрытые способы могут быть применены для организации различных наборов данных в иерархической структуре категорий. Раскрытые способы могут обеспечивать преимущества над другими способами установления категории в ситуациях, когда требуется сортировка значительных объемов данных, когда есть несколько предварительно созданных правил сортировки данных и, например, когда цель установления категории состоит в определении шаблонов в данных. В контексте ZBB описанные способы главным образом используются для косвенных трат, маркетинга и продаж. Они также могут быть использованы для других типов затрат, подобных сырью и цепочке поставки. В дополнение не только текущие расходы (OPEX), но также и капитальные расходы (CAPEX) могут рассматриваться в качестве данных о тратах.
[0070] Операции способа 800 реализуются с использованием программного обеспечения и соответственно одной из предпочтительных реализаций изобретения является набор инструкций (программный код) в модуле кода, размещенном в памяти с произвольным доступом компьютера. До тех пор, пока не запрошен компьютером, набор инструкций может быть сохранен в другой компьютерной памяти, например, на накопителе на жестком диске, или в съемной памяти, такой как оптический диск (для возможного использования в CD ROM) или гибкий диск (для возможного использования в накопителе на гибком диске), или загружен через Интернет или некоторую другую компьютерную сеть. В дополнение, несмотря на то, что различные описанные способы традиционно реализуются в компьютере общего назначения, который выборочно активируется или реконфигурируется посредством программного обеспечения, специалисту в соответствующей области техники будет понятно, что способы могут быть выполнены в аппаратном обеспечении, во встроенном программном обеспечении или в более специализированном устройстве, сконструированном для выполнения указанных этапов способа.
[0071] Несмотря на то, что выше были описаны различные варианты осуществления, следует понимать, что они были представлены в качестве примера, а не ограничения. Специалистам в соответствующей области техники будет очевидно, что различные изменения по форме и в деталях могут быть здесь выполнены, не отступая от сущности и объема. В действительности после прочтения вышеупомянутого описания специалисту в соответствующей области техники будет очевидно, каким образом реализовать альтернативные варианты осуществления.
[0072] В дополнение следует понимать, что любые фигуры, которые подчеркивают функциональные возможности или преимущества, представлены только для примера. Раскрытая методология и система каждое является достаточно гибким и конфигурируемым так, что они могут быть использованы путем отличным от показанного.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМЫ И СПОСОБЫ ДЕТЕКТИРОВАНИЯ ПОВЕДЕНЧЕСКИХ УГРОЗ | 2019 |
|
RU2803399C2 |
| СИСТЕМЫ И СПОСОБЫ ДЕТЕКТИРОВАНИЯ ПОВЕДЕНЧЕСКИХ УГРОЗ | 2019 |
|
RU2772549C1 |
| СИСТЕМЫ И СПОСОБЫ ДЕТЕКТИРОВАНИЯ ПОВЕДЕНЧЕСКИХ УГРОЗ | 2019 |
|
RU2778630C1 |
| СПОСОБ И СИСТЕМА СОЗДАНИЯ ВЕКТОРОВ АННОТАЦИИ ДЛЯ ДОКУМЕНТА | 2017 |
|
RU2720074C2 |
| Система и способ классификации писем электронной почты | 2024 |
|
RU2828611C1 |
| Способ классификации писем электронной почты и система, его реализующая | 2024 |
|
RU2828610C1 |
| МАШИННОЕ ОБУЧЕНИЕ | 2005 |
|
RU2391791C2 |
| КОНТЕЙНЕРНОЕ РАЗВЕРТЫВАНИЕ МИКРОСЕРВИСОВ НА ОСНОВЕ МОНОЛИТНЫХ УНАСЛЕДОВАННЫХ ПРИЛОЖЕНИЙ | 2017 |
|
RU2733507C1 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ ДАННЫХ, ПОДВЕРЖЕННЫХ ДЕАНОНИМИЗАЦИИ, В ОБЕЗЛИЧЕННОМ НАБОРЕ ДАННЫХ | 2024 |
|
RU2837785C1 |
| КЛАСТЕРИЗАЦИЯ ДОКУМЕНТОВ | 2020 |
|
RU2768209C1 |

Изобретение относится к области вычислительной техники. Технический результат заключается в реализации автоматического формирования отчетов о совершенных транзакциях. Технический результат достигается за счет выполнения следующих этапов: прием данных транзакций; формирование на их основе очищенного набора данных; осуществление кластеризации; идентификация конкретного поднабора из набора кластеров и прием пользовательского определения типа для каждого кластера этого конкретного поднабора; обучение модели прогнозирования с использованием журналов; определение типов транзакций для журналов в очищенном наборе данных, которые еще не ассоциированы с типом транзакции; формирование отчета о транзакциях. 3 н. и 17 з.п. ф-лы, 10 ил.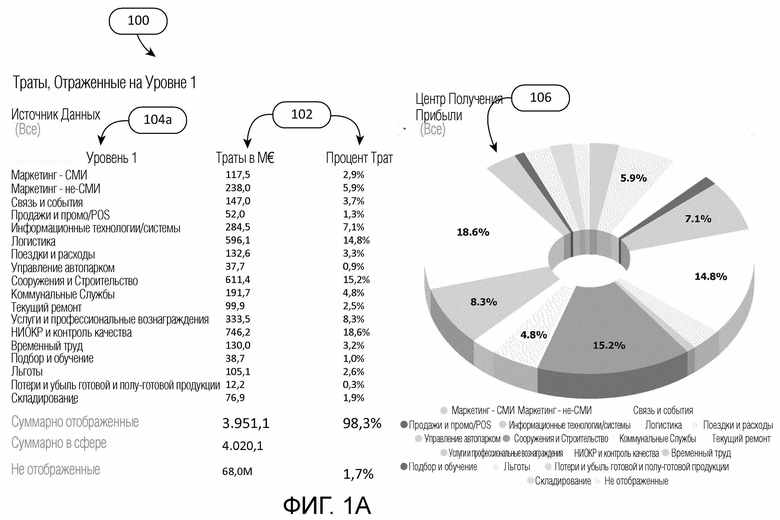
1. Компьютерно-реализуемый способ обработки записей транзакций, содержащий этапы, на которых:
принимают данные транзакций;
формируют на основе данных транзакций очищенный набор данных (CDS), содержащий журналы для множества транзакций, при этом каждый журнал ассоциирован с текстом, по меньшей мере фрагмент которого был обработан с использованием обработки на естественном языке (NPL);
осуществляют кластеризацию, по меньшей мере, подмножества журналов из CDS на основе, по меньшей мере отчасти, ассоциированного текста и пороговой величины сходства, при этом результатом кластеризации является набор кластеров;
идентифицируют конкретный поднабор из набора кластеров и принимают пользовательское определение типа транзакции для характерного журнала для каждого кластера этого конкретного поднабора, при этом принятые типы транзакций ассоциируются с каждым журналом соответствующего кластера;
обучают модель прогнозирования с использованием журналов из упомянутого конкретного поднабора кластеров и ассоциированных типов транзакций;
определяют с использованием прогнозирующей модели типы транзакций для журналов в CDS, которые еще не ассоциированы с типом транзакции; и
формируют отчет о транзакциях, причем отчет о транзакциях содержит множество вычисленных параметров, определенных на основе, по меньшей мере отчасти, журналов и их ассоциированных типов транзакций.
2. Компьютерно-реализуемый способ по п.1, дополнительно содержащий этапы, на которых: идентифицируют дополнительный поднабор из набора кластеров и определяют с использованием набора базовых правил отображения типы транзакций, которые должны быть ассоциированы с журналами из дополнительного поднабора кластеров, при этом при упомянутом обучении модели прогнозирования данную модель обучают с использованием журналов из дополнительного поднабора и ассоциированных типов транзакций.
3. Компьютерно-реализуемый способ по п.1, в котором упомянутая идентификация конкретного поднабора кластеров содержит этап, на котором выбирают кластеры для этого поднабора на основе, по меньшей мере отчасти, значения транзакции, ассоциированного с каждым кластером.
4. Компьютерно-реализуемый способ по п.1, в котором упомянутая идентификация конкретного поднабора из набора кластеров содержит этап, на котором выбирают кластеры на основе, по меньшей мере отчасти, метрики расстояния между соответствующими кластерами в данном поднаборе.
5. Компьютерно-реализуемый способ по п.1, в котором упомянутое формирование CDS содержит этап, на котором удаляют не относящиеся к делу или дублирующие журналы.
6. Компьютерно-реализуемый способ обработки записей транзакций, содержащий этапы, на которых:
принимают данные транзакций, содержащие множество журналов, причем с журналами ассоциирован текст;
формируют на основе данных транзакций очищенный набор данных (CDS), содержащий журналы для множества транзакций;
осуществляют кластеризацию, по меньшей мере, подмножества журналов из CDS на основе ассоциированного текста и пороговой величины сходства, при этом результатом кластеризации является набор кластеров;
принимают пользовательское определение типа транзакции для каждого конкретного поднабора из набора кластеров, при этом принятые типы транзакций ассоциируются с каждым журналом соответствующего кластера;
обучают модель прогнозирования с использованием журналов из этого конкретного поднабора кластеров и ассоциированных типов транзакций; и
прогнозируют типы транзакций для дополнительных журналов с использованием модели прогнозирования.
7. Компьютерно-реализуемый способ по п.6, дополнительно содержащий этапы, на которых идентифицируют дополнительный поднабор из набора кластеров и определяют с использованием набора базовых правил отображения типы транзакций, которые должны быть ассоциированы с журналами из дополнительного поднабора кластеров, при этом при упомянутом обучении модели прогнозирования данную модель обучают с использованием журналов из дополнительного поднабора и ассоциированных типов транзакций.
8. Компьютерно-реализуемый способ по п.6, в котором упомянутое формирование CDS журналов из данных транзакций содержит этап, на котором обрабатывают, по меньшей мере, фрагмент текста, ассоциированного с журналами, с использованием обработки на естественном языке (NLP).
9. Компьютерно-реализуемый способ по п.8, в котором упомянутое формирование CDS дополнительно содержит этап, на котором удаляют не относящиеся к делу или дублирующие журналы из множества журналов.
10. Компьютерно-реализуемый способ по п.6, дополнительно содержащий этап, на котором предоставляют для демонстрации характерный журнал для кластера из упомянутого конкретного поднабора перед приемом соответствующего пользовательского определения типа транзакции для этого кластера.
11. Компьютерно-реализуемый способ по п.6, дополнительно содержащий этапы, на которых:
предоставляют для демонстрации два характерных журнала для кластера из упомянутого конкретного поднабора;
принимают разные пользовательские определения типов транзакций для этих двух характерных журналов; и
разбивают данный кластер на основе, по меньшей мере отчасти, этих разных пользовательских определений типов транзакций для двух характерных журналов.
12. Компьютерно-реализуемый способ по п.6, дополнительно содержащий этап, на котором проверяют достоверность типов прогнозирования, обеспечиваемых обученной моделью прогнозирования, с использованием способа Человек-в-Цикле.
13. Компьютерно-реализуемый способ по п.6, в котором упомянутая идентификация конкретного поднабора кластеров содержит этап, на котором выбирают кластеры для этого поднабора на основе, по меньшей мере отчасти, значения транзакции, ассоциированного с каждым кластером.
14. Компьютерно-реализуемый способ по п.6, дополнительно содержащий этапы, на которых:
выполняют автоматизированный анализ качества и ошибок касаемо типов транзакций, спрогнозированных моделью прогнозирования; и
модифицируют по меньшей мере один параметр модели на основе анализа качества и ошибок.
15. Компьютерно-реализуемый способ по п.6, дополнительно содержащий этапы, на которых:
выполняют автоматизированный анализ качества и ошибок касаемо типов транзакций, спрогнозированных моделью прогнозирования;
идентифицируют один или более журналов для ручной разметки на основе анализа качества и ошибок; и
принимают пользовательское определение типа транзакции для каждого из этих одного или более журналов.
16. Компьютерно-реализуемый способ по п.6, дополнительно содержащий этап, на котором обучают модель прогнозирования с использованием одного или более журналов и ассоциированных типов транзакций.
17. Компьютерно-реализуемый способ по п.6, в котором упомянутое прогнозирование типов транзакций для дополнительных журналов приводит к тому, что ассоциировано более 95% из множества журналов.
18. Компьютерно-реализуемый способ по п.6, дополнительно содержащий этап, на котором используют обученную модель для прогнозирования типов транзакций для журналов из другого набора данных транзакций.
19. Долговременный машиночитаемый носитель информации, хранящий инструкции для обработки записей транзакций, причем инструкции при их исполнении процессором предписывают процессору:
принимать данные транзакций, содержащие множество журналов, причем с журналами ассоциирован текст;
формировать на основе данных транзакций очищенный набор данных (CDS), содержащий журналы для множества транзакций;
осуществлять кластеризацию, по меньшей мере, подмножества журналов из CDS на основе ассоциированного текста и пороговой величины сходства, при этом результатом кластеризации является набор кластеров;
принимать пользовательское определение типа транзакции для каждого конкретного поднабора из набора кластеров, при этом принятые типы транзакций ассоциируются с каждым журналом соответствующего кластера;
обучать модель прогнозирования с использованием журналов из этого конкретного поднабора кластеров и ассоциированных типов транзакций; и
прогнозировать типы транзакций для дополнительных журналов с использованием модели прогнозирования.
20. Долговременный машиночитаемый носитель информации по п.19, дополнительно содержащий инструкции, которые при их исполнении процессором предписывают процессору:
идентифицировать дополнительный поднабор из набора кластеров и определять с использованием набора базовых правил отображения типы транзакций, которые должны быть ассоциированы с журналами из дополнительного поднабора кластеров; и
обучать модель прогнозирования с использованием журналов из дополнительного поднабора и ассоциированных типов транзакций.
| Колосоуборка | 1923 |
|
SU2009A1 |
| US 7249717 B2, 31.07.2007 | |||
| US 8620919 B2, 31.12.2013 | |||
| СПОСОБ ПРОВЕРКИ ТРАНЗАКЦИЙ, АВТОМАТИЧЕСКАЯ СИСТЕМА ДЛЯ ПРОВЕРКИ ТРАНЗАКЦИЙ И УЗЕЛ ДЛЯ ПРОВЕРКИ ТРАНЗАКЦИЙ (ВАРИАНТЫ) | 2008 |
|
RU2388053C1 |
| Система и способ признания транзакций доверенными | 2016 |
|
RU2625050C1 |

