Область техники, к которой относится изобретение
Настоящее изобретение относится к устройству и способу обработки информации, и более конкретно, к устройству и способу обработки информации, которые позволяют уменьшить задержку времени при передаче/приеме пакета.
Уровень техники
До настоящего времени существовало требование передавать видео- и аудиоданные с минимальной задержкой, например, в системах передачи данных с использованием видео- и аудиосистем, таких как двунаправленные системы видеоконференции, и смешанные системы со средами, в которых не применяется сжатие в станциях широковещательной передачи, или тому подобное. В последние годы, в частности, количество данных увеличивалось по мере улучшения качества видеоизображения и звука и, соответственно, существует требование передачи данных с дополнительно уменьшенной задержкой.
Например, в системах сжатия MPEG (Экспертная группа по вопросам движущегося изображения) и Н.26х, степень сжатия увеличивают на основе прогнозирования движения. Когда выполняют прогнозирование движения, алгоритм становится сложным, и требуемое время обработки увеличивается в пропорции к квадрату размера кадра. В принципе, происходит задержка кодирования нескольких кадров. Когда требуется осуществлять двунаправленную передачу данных в режиме реального времени, время задержки становится практически допустимым временем задержки, равным 250 мс, и этой длительностью уже нельзя пренебречь.
Кроме того, в кодеках, работающих внутри кадра, представленных JPEG (Объединенная группа экспертов по машинной обработке фотографических изображений) 2000, не используется информация разности между кадрами. Таким образом, описанная выше задержка не происходит. Однако, поскольку сжатие выполняют на покадровой основе, кодек должен ожидать пока не будет получен, по меньшей мере, один кадр, перед тем, как он начнет кодирование. Поскольку в существующих общих системах во многих случаях используется частота 30 кадров в секунду, необходимо время ожидания порядка 16 мс, прежде чем начнется кодирование.
Поэтому существует потребность в дополнительном уменьшении этой задержки и в уменьшении задержки на других участках, кроме участков кодирования и декодирования, таких как обработка формирования пакетов и обработка восстановления данных из пакетов. Например, был рассмотрен способ уменьшения емкости буферного запоминающего устройства для уменьшения задержки при передаче (например, см. ссылку 1 на патент).
В настоящее время часто возникают ошибки при передаче во время передачи цифровых видеоданных, что влияет на качество воспроизведения видео- и аудиоданных.
Ссылка 1 на патент: Публикация находящейся на экспертизе заявки №2005-12753 на японский патент
Сущность изобретения
Техническая задача
Для устранения таких ошибок при передаче предпринимают определенные меры. Для дополнительного уменьшения задержки при передаче данных требуется уменьшить задержку также при выполнении обработки для устранения ошибок при передаче.
Настоящее изобретение было предложено с учетом таких обычных обстоятельств и оно позволяет уменьшить время задержки, возникающее при передаче/приеме данных,
Техническое решение
Аспект настоящего изобретения направлен на устройство обработки информации, которое кодирует данные изображения, включающее в себя: средство сравнения, предназначенное для сравнения кадров или полей, составляющих данные изображения, с последовательным приращением в размере блока строк, включающим в себя данные изображения, эквивалентные количеству строк, необходимому для генерирования данных коэффициента, эквивалентных одной строке подполос, по меньшей мере, компонентов самой низкой частоты; средство генерирования, предназначенное для генерирования информации сокрытия, обозначающей способ сокрытия ошибки в блоке строк, в соответствии с результатом сравнения, полученным средством сравнения; средство кодирования, предназначенное для генерирования кодированных данных, путем кодирования данных коэффициента, порядок которых был изменен заранее в порядке, в котором данные коэффициента используются при выполнении обработки комбинирования, состоящей в комбинировании данных коэффициента множества подполос, разложенных на полосы частот, для генерирования данных изображения; и средство управления, предназначенное для управления средством кодирования, для мультиплексирования информации сокрытия, сгенерированной средством генерирования, с кодированными данными, сгенерированными средством кодирования.
Средство управления может управлять средством кодирования для формирования пакетов из кодированных данных с информацией сокрытия, используемой как заголовок.
Средство кодирования может включать в себя средство кодирования коэффициента, предназначенное для кодирования данных коэффициента, для генерирования кодированных данных; и средство формирования пакетов, предназначенное для формирования пакетов из кодированных данных.
Информация сокрытия может включать в себя информацию флага, обозначающую, возможна или нет замена блока строк, составляющих кадр или поле, блоком строк, составляющим другой кадр или другое поле.
Средство сравнения может сравнивать в отношении данных изображения значения разности между кадрами или значения разности между полями с пороговым значением.
Средство генерирования может устанавливать информацию флага, как обозначающую возможность замены, когда значение разности между кадрами или значение разности между полями меньше чем или равно пороговому значению.
Информация сокрытия может включать в себя информацию, обозначающую, когда блок строк, составляющий кадр или поле, может быть заменен блоком строк, составляющим другой кадр или другое поле, протяженность предыдущих изображений или полей, которые можно использовать для замены.
Информация сокрытия может включать в себя информацию флага, обозначающую, когда блок строк, составляющий кадр или поле, может быть заменен блоком строк, составляющим другой кадр или другое поле, возможно или нет выполнить замену, используя изображение или поле, следующее после изображения или поля, которое можно использовать для замены.
Порядок данных коэффициента может быть изменен в порядке от компонентов низкой частоты до компонентов высокой частоты с последовательным приращением размером блок строк.
Далее, аспект настоящего изобретения направлен на способ обработки информации для устройства обработки информации, которое кодирует данные изображения, в котором: средство сравнения сравнивает кадры или поля, составляющие данные изображения, с последовательными приращениями размером блок строк, включающими в себя данные изображения, эквивалентные количеству строк, необходимому для генерирования данных коэффициента, эквивалентных одной строке подполос, по меньшей мере, компонентов самой низкой частоты; средство генерирования генерирует информацию сокрытия, обозначающую способ сокрытия ошибки в блоке строк в соответствии с результатом сравнения, полученным средством сравнения; средство кодирования генерирует кодированные данные путем кодирования данных коэффициента, порядок которых был изменен заранее, в порядке, в котором данные коэффициента используют при выполнении обработки комбинирования, состоящей в комбинировании данных коэффициента из множества подполос, разложенных по полосам частот, для генерирования данных изображения; и средство управления выполняет управление средством кодирования таким образом, чтобы мультиплексировать информацию сокрытия, генерируемую средством генерирования, с кодированными данными, генерируемыми средством кодирования.
В другом аспекте настоящее изобретение направлено на устройство обработки информации, которое выполняет обработку сокрытия ошибки по кодированным данным, полученным в результате кодирования данных изображения, включающее в себя: средство получения, предназначенное для получения для кадров или полей, составляющих данные изображения, информации сокрытия, обозначающей способ сокрытия ошибки в блоке строк, с последовательным приращением блока строк, включающего в себя данные изображения, эквивалентные количеству строк, необходимых для генерирования данных коэффициента, эквивалентных одной строке подполос, по меньшей мере, компонентов самой низкой частоты, из кодированных данных, полученных в результате кодирования данных коэффициента, порядок следования которых был заранее изменен на порядок, в котором данные коэффициента используют при выполнении обработки комбинирования состоящей в комбинировании данных коэффициента из множества подполос, полученных в результате разложения данных изображения в полосах частот, для генерирования данных изображения; и средство сокрытия, предназначенное для выполнения с последовательным приращением размером блок строк, обработки сокрытия ошибки, включенной в кодированные данные, в соответствии со способом сокрытия ошибки, обозначенным по информации сокрытия ошибки, полученной средством получения.
Из кодированных данных могут быть сформированы пакеты, при этом информация сокрытия используется как заголовок, и средство получения может получать информацию сокрытия как заголовок.
Устройство обработки информации может дополнительно включать в себя средство декодирования, предназначенное для декодирования кодированных данных, которые были обработаны для сокрытия с помощью средства сокрытия, для генерирования данных изображения.
Устройство обработки информации может дополнительно включать в себя средство записи, предназначенное для записи кодированных данных, которые были обработаны для сокрытия с помощью средства сокрытия, на носителе записи.
Кроме того, другой аспект настоящего изобретения направлен на способ обработки информации для устройства обработки информации, которое выполняет обработку сокрытия ошибки по кодированным данным, полученным в результате кодирования данных изображения, в котором:
средство получения получает, для кадров или полей, составляющих данные изображения, информацию сокрытия, обозначающую способ сокрытия ошибки в блоке строк, с последовательным приращением блока строк, включающего в себя данные изображения, эквивалентные количеству строк, требуемых для генерирования данных коэффициента, эквивалентных одной строке подполос, по меньшей мере, компонентов с самой низкой частотой, из кодированных данных, полученных в результате кодирования данных коэффициента, порядок которых был изменен заранее, в порядке, в котором данные коэффициента используют при выполнении обработки комбинирования, состоящей в комбинировании данных коэффициента из множества подполос, полученных в результате разложения данных изображения по полосам частот, для генерирования данных изображения; и средство сокрытия выполняет, с последовательным приращением размером блок строк, обработку сокрытия ошибки, включенной в кодированные данные, в соответствии с информацией сокрытия ошибки, обозначенной информацией сокрытия ошибки, полученной средством получения.
В соответствии с аспектом настоящего изобретения, кадры или поля, составляющие данные изображения, сравнивают с приращением размером блок строк, включающие в себя данные изображения, эквивалентные количеству строк, необходимых для генерирования данных коэффициента, эквивалентных одной строке подполос, по меньшей мере, компонентов с самой низкой частотой; причем информацию сокрытию, обозначающую способ сокрытия ошибки в блоке строк, генерируют в соответствии с результатом сравнения; кодированные данные генерируют путем кодирования данных коэффициента, порядок которых был заранее изменен, в порядке, в котором данные коэффициента используют при выполнении обработки комбинирования, состоящей в комбинировании данных коэффициента из множества подполос, разложенных по полосам частот, для генерирования данных изображения; и управление выполняют так, чтобы мультиплексировать сгенерированную информацию сокрытия с кодированными данными.
В соответствии с другим аспектом настоящего изобретения, для кадров или полей, составляющих данные изображения, информацию сокрытия, обозначающую способ сокрытия ошибки в блоке строк, получают с последовательным приращением размером блок строк, включающую в себя данные изображения, эквивалентные количеству строк, необходимому для генерирования данных коэффициента, эквивалентных одной строке подполос, по меньшей мере, компонентов с самой низкой частотой, из кодированных данных, полученных в результате кодирования данных коэффициента, порядок которых был изменен заранее, в порядке, в котором данные коэффициента используют при выполнении обработки комбинирования, состоящем в комбинировании данных коэффициента из множества подполос, полученных в результате разложения данных изображения на полосы частот, для генерирования данных изображения; и обработку сокрытия ошибки, включенной в кодированные данные, выполняют с приращением размером блок строк, в соответствии с информацией сокрытия ошибки, обозначенной полученной информацией сокрытия ошибки.
Предпочтительные эффекты
В соответствии с настоящим изобретением, данные можно передавать/принимать. В частности, может быть уменьшено время задержки, которое возникает при передаче/приеме данных.
Краткое описание чертежей
На фиг.1 показана блок-схема, представляющая примерную конфигурацию системы
передачи, в которой применяется настоящее изобретение.
На фиг.2 показана блок-схема, представляющая примерную структуру модуля
кодирования по фиг.1.
На фиг.3 показана схема, описывающая структуру вейвлет-преобразования.
Фиг.4 включает в себя схему, описывающую структуру вейвлет-преобразования.
На фиг.5 показана схема, представляющая пример, в котором выполняют фильтрацию на основе подъема с использованием фильтра 5×3 до уровня разложения = 2.
На фиг.6 представлена схема, изображающая структуру последовательности операций, выполняемых при вейвлет-преобразовании и обратном вейвлет-преобразовании в соответствии с данным изобретением.
На фиг.7 показана схема, представляющая примерную структуру заголовка участка.
На фиг.8 показана схема, представляющая примерную структуру заголовка изображения.
На фиг.9 показана схема, представляющая пример информации, обмен которой выполняют между модулем кодирования и модулем обработки формирования пакетов.
На фиг.10 показана блок-схема, подробно представляющая примерную структуру модуля обработки формирования пакетов по фиг.1.
На фиг.11 показана схема, предназначенная для описания примера участка.
На фиг.12 показана схема, предназначенная для описания примера генерирования пакетов.
На фиг.13 показана схема, предназначенная для описания примерной структуры заголовка RTP.
На фиг.14 показана схема для описания примерной структуры заголовка полезной нагрузки RTP.
На фиг.15 показана схема, представляющая примерную структуру общего заголовка.
На фиг.16 показана схема, представляющая примерную структуру информации параметра квантования.
На фиг.17 показана схема, представляющая примерную структуру информации размера.
На фиг.18 представлены схемы, представляющие примерную структуру информации формата.
На фиг.19 показана схема, представляющая примерную структуру информации изображения.
На фиг.20 показана схема, представляющая примерную структуру информации цвета.
На фиг.21 показана блок-схема, представляющая подробную примерную структуру модуля обработки восстановления данных из пакетов по фиг.1.
На фиг.22 показана схема, представляющая пример способа перехода режима управления.
На фиг.23 показана схема, представляющая пример информации, обмен которой выполняют между модулем обработки восстановления данных из пакетов и модулем декодирования.
На фиг.24 показана блок-схема, подробно представляющая примерную структуру модуля декодирования по фиг.1.
На фиг.25 показана блок-схема последовательности операций для описания примерной обработки кодирования.
На фиг.26 показана блок-схема последовательности операций, предназначенная для описания примерной последовательности операций при обработке формирования пакетов.
На фиг.27 показана блок-схема последовательности операций, предназначенная для описания примерной последовательности операций при обработке режима запуска.
На фиг.28 показана блок-схема последовательности операций, предназначенная для описания примерной последовательности операций при выполнении обработки общего режима.
На фиг.29 показана блок-схема последовательности операций, предназначенная для описания примерной последовательности операций при обработке в режиме ожидания.
На фиг.30 показана блок-схема последовательности операций, предназначенная для описания примерной последовательности операций при обработке в режиме обработки.
На фиг.31 показана блок-схема последовательности операций, предназначенная для описания примерной последовательности операций при обработке в режиме потери.
На фиг.32 показана блок-схема последовательности операций, предназначенная для описания примерной последовательности операций при обработке управления декодирования.
На фиг.33 показана блок-схема последовательности операций, предназначенная для описания примерной последовательности операций при обработке декодирования.
На фиг.34 показана блок-схема последовательности операций, предназначенная для описания примерной последовательности операций при обработке уведомления об ошибке.
На фиг.35 показана схема, описывающая пример способа обработки уведомления об ошибке.
На фиг.36 показана схема, представляющая другую примерную структуру заголовка полезной нагрузки RTP.
На фиг.37 показана схема, представляющая примерную структуру информации сегмента.
На фиг.38 показана блок-схема последовательности операций, для описания другой примерной последовательности обработки формирования пакетов.
На фиг.39 показана схема, представляющая структуру примера способа параллельной работы, выполняемой отдельными элементами устройства передачи и устройства приема.
На фиг.40 показана блок-схема, представляющая другую примерную структуру модуля кодирования по фиг.1.
На фиг.41 показана схема для описания потока обработки в случае, когда обработку изменения порядка вейвлет-коэффициентов выполняют на стороне модуля кодирования.
На фиг.42 показана схема для описания потока обработки в случае, когда выполняют обработку изменения порядка вейвлет-коэффициентов на стороне модуля декодирования.
На фиг.43 показана блок-схема, представляющая другую примерную структуру модуля кодирования по фиг.1.
На фиг.44 показана блок-схема, представляющая примерную структуру модуля декодирования, соответствующую модулю кодирования по фиг.43.
На фиг.45 показана блок-схема, представляющая другую примерную конфигурацию системы перехода, в которой применяют настоящее изобретение.
На фиг.46 показана блок-схема, представляющая подробные примерные структуры устройства передачи и устройства приема по фиг.45.
На фиг.47 показана схема, представляющая примерную структуру заголовка сокрытия.
На фиг.48 показана схема, представляющая примерную структуру данных изображения, предназначенных для передачи.
На фиг.49 показана блок-схема последовательности операций, описывающая примерную последовательность операций при обработке анализа.
На фиг.50 показана блок-схема, описывающая примерную последовательность операций при выполнении обработки генерирования заголовка сокрытия.
На фиг.51 показана блок-схема последовательности операций, описывающая обработку анализа потери.
На фиг.52 показана схема, представляющая примерную конфигурацию системы обработки информации, в которой применяют настоящее изобретение.
Пояснение номеров ссылочных позиций
100: система передачи, 102: устройство передачи, 103: устройство приема, 110: линия, 132: модуль обработки восстановления данных из пакетов, 133: модуль декодирования, 202: модуль генерирования заголовка RTP, 203: модуль генерирования общего заголовка, 204: модуль генерирования заголовка расширения, 205: модуль генерирования информации изображения, 206: модуль проверки флага, 207: модуль проверки размера, 208: модуль обработки фрагмента, 209: модуль формирования пакета, 252: модуль анализа информации заголовка, 253: модуль изменения режима управления, 254: модуль управления, 255: модуль подачи заголовка, 256: модуль подачи данных, 257: модуль уведомления об ошибке, 258: модуль подачи сигнала управления, 351: модуль получения информации управления, 352: модуль управления декодированием, 353: модуль выполнения обработки декодирования, 354: модуль получения заголовка, 355: модуль получения данных 356: модуль получения уведомления об ошибке, 357: модуль обработки отбрасывания, 602: устройство передачи, 603: устройство приема, 621: модуль анализа, 622: модуль сохранения, 623: модуль генерирования заголовка сокрытия, 631: модуль анализа потери, 632: модуль сохранения, 640: заголовок сокрытия, 643: ID (ИД, идентификатор) изображения заголовка замены, 644: RF, 645: SF, 646: ИД участка заголовка замены.
Подробное описание изобретения
Ниже будут описаны варианты воплощения настоящего изобретения
На фиг.1 показана блок-схема, представляющая примерную конфигурацию системы передачи, в которой применяется настоящее изобретение.
На фиг.1 показана система 100 передачи, которая представляет собой систему передачи данных, в которой устройство 102 передачи сжимает и кодирует данные изображения, генерируемые устройством 101 съемки изображения, и формирует пакеты, и передает данные изображения; устройство 103 приема принимает пакеты, передаваемые через линию 110, и восстанавливает данные из пакетов, и декодирует пакеты; и устройство 104 дисплея отображает изображение, основанное на полученных данных изображения.
Устройство 101 съемки изображения имеет устройство съемки изображения, в котором используется CCD (ПЗС, прибор с зарядовой связью), CMOS (КМОП, комплементарный металлооксидный полупроводник), или тому подобное. Устройство 101 съемки изображения снимает изображение предмета, преобразует снятое изображение в данные изображения, которые представляют собой цифровые данные, и передает снятые данные изображения в устройство 102 передачи.
Устройство 102 передачи включает в себя модуль 121 кодирования, модуль 122 обработки формирования пакетов и модуль 123 передачи. Устройство 102 передачи кодирует в модуле 121 кодирования данные изображения, переданные из устройства 101 съемки изображения, используя заданный способ; формирует пакеты в модуле 122 обработки формирования пакетов из кодированных данных, полученных в результате кодирования; и передает, в модуле 123 передачи, сгенерированные пакеты в линию 110, используя заданный способ передачи данных.
Линия 110 представляет собой произвольную среду передачи, которая соединяет устройство 102 передачи и устройство 103 приема и передает пакеты, переданные из устройства 102 передачи, в устройство 103 приема.
Устройство 103 приема включает в себя модуль 131 приема, модуль 132 обработки восстановления данных из пакетов, и модуль 133 декодирования. Устройство 103 приема принимает, в модуле 131 приема, пакеты, переданные через линию 110; выделяет, в модуле 132 обработки восстановления данных из пакетов, кодированные данные из принятых пакетов; декодирует, в модуле 133 декодирования, выделенные кодированные данные, используя способ декодирования, соответствующий модулю 121 кодирования в устройстве 102 передачи; и выводит полученные данные изображения основной полосы пропускания в устройство 104 дисплея.
Устройство 104 дисплея включает в себя дисплей и отображает на дисплее изображение, основанное на данных изображения, переданных из устройства 103 приема.
Такая система 100 передачи по фиг.1 представляет собой систему, которая может уменьшить время задержки от момента съемки изображения, выполняемой устройством 101 съемки изображения, до момента, когда изображение отображается в устройстве 104 дисплея, путем уменьшения времени задержки, связанной с обработкой формирования пакета, выполняемой модулем 122 обработки формирования пакетов, и временем задержки, связанной с обработкой восстановления данных из пакетов, выполняемой модулем 132 обработки восстановления данных из пакетов.
В системе 100 передачи по фиг.1, модуль 101 съемки изображения показан как устройство, которое предоставляет данные изображения, предназначенные для передачи устройством 102 передачи. Однако это устройство может представлять собой любое устройство, если только оно позволяет предоставлять данные изображения. Кроме того, устройство 104 дисплея показано как устройство, в котором используются данные изображения, принятые устройством 103 приема. Однако это устройство может представлять собой любое устройство, если только оно может использовать данные изображения.
Кроме того, только данные изображения описаны как данные, предназначенные для передачи. Однако другие данные, такие как аудиоданные, можно передавать вместе с данными изображения.
Способ передачи пакетов, выполняемый устройством 102 передачи, может представлять собой способ одноадресной передачи, который представляет собой передачу только в устройство 103 приема, групповой передачи, которая представляет собой передачу в множество устройств, включающих в себя устройство 103 приема, или широковещательной передачи, которая представляет собой передачу множеству неопределенных устройств.
Линия 110 может представлять собой любую линию, если только линия 110 позволяет передавать пакеты. Линия 110 может быть кабельной или беспроводной или может включать в себя оба таких способа передачи. Кроме того, хотя линия 110 на фиг.1 показана с использованием одной стрелки, линия 110 может быть выделенной линией или может представлять собой общий кабель передачи, может включать в себя одну или множество сетей передачи данных, таких как LAN (ЛВС, локальная вычислительная сеть) и Интернет, или может включать в себя, своего рода, устройство передачи данных. Кроме того, количество линий (количество каналов) в линии 110 может представлять собой любое количество.
Далее будут описаны детали отдельных модулей устройства 102 передачи и устройства 103 приема, показанных на фиг.1.
На фиг.2 показана блок-схема, представляющая примерную структуру внутреннего устройства модуля 121 кодирования в устройстве 102 передачи по фиг.1. На фиг.2 модуль 121 кодирования включает в себя модуль 150 вейвлет-преобразования, модуль 151 буфера промежуточных расчетов, модуль 152 буфера изменения порядка коэффициента, модуль 153 изменения порядка коэффициента, модуль 154 управления скоростью и модуль 155 энтропийного кодирования.
Данные изображения, подаваемые в модуль 121 кодирования, временно накапливают в модуле 151 буфера промежуточных расчетов. Модуль 150 вейвлет-преобразования применяет вейвлет-преобразование к данным изображения, накопленным в модуле 151 буфера промежуточных расчетов. То есть, модуль 150 вейвлет-преобразования считывает данные изображения из модуля 151 буфера промежуточных расчетов, применяет обработку фильтрации, используя фильтры анализа, для генерирования данных коэффициента компонентов низкой частоты и компонентов высокой частоты, и сохраняет сгенерированные данные коэффициента в модуле 151 буфера промежуточных расчетов. Модуль 150 вейвлет-преобразования включает в себя фильтр горизонтального анализа и фильтр вертикального анализа и выполняет обработку фильтрации анализа как в горизонтальном направлении экрана, так и в вертикальном направлении экрана по группе элементов данных изображения. Модуль 150 вейвлет-преобразования снова считывает данные коэффициента компонентов низкой частоты, которые сохранены в модуле 151 буфера промежуточных расчетов, и применяет обработку фильтрации, используя фильтры анализа, к считываемым данным коэффициента для дополнительного генерирования данных коэффициента компонентов высокой частоты и компонентов низкой частоты. Сгенерированные данные коэффициента сохраняют в модуле 151 буфера промежуточного расчета.
Модуль 150 вейвлет-преобразования повторяет эту обработку. Когда уровень разложения достигает заданного уровня, модуль 150 вейвлет-преобразования считывает данные коэффициента из модуля 151 буфера промежуточных расчетов и записывает считанные данные коэффициента в модуль 152 буфера изменения порядка коэффициента.
Модуль 153 изменения порядка коэффициента считывает элементы данных коэффициента, записанные в модуле 152 буфера изменения порядка коэффициента, в заданном порядке и передает считанные данные коэффициента в модуль 155 энтропийного кодирования. Модуль 155 энтропийного кодирования выполняет кодирование переданных в него данных коэффициента, используя заданную систему энтропийного кодирования, такую как кодирование Хаффмана или арифметическое кодирование.
Модуль 155 энтропийного кодирования работает совместно с модулем 154 управления скоростью. Скоростью передачи битов сжатых и кодированных данных, предназначенных для вывода, управляют так, чтобы она составляла, по существу, постоянное значение. Таким образом, модуль 154 управления скоростью передает, на основе информации кодированных данных, из модуля 155 энтропийного кодирования, сигнал управления в модуль 155 энтропийного кодирования для выполнения управления, для прекращения обработки кодирования, выполняемой модулем 155 энтропийного кодирования, в момент времени, в который скорость передачи битов данных, сжатых и кодированных модулем 155 энтропийного кодирования, достигает целевого значения, или непосредственно перед тем, как скорость передачи битов достигнет целевого значения. Модуль 155 энтропийного кодирования выводит кодированные данные в момент времени, в который прекращается обработка кодирования, в ответ на сигнал управления, переданный из модуля 154 управления скоростью.
Следует отметить, что дополнительного улучшения эффекта сжатия можно ожидать, когда модуль 155 энтропийного кодирования первоначально выполняет квантование данных коэффициента, считываемых из модуля 153 изменения порядка коэффициента, и применяет обработку кодирования источника информации, такую как кодирование Хаффмана или арифметическое кодирование, к полученным квантованным коэффициентам. В качества способа квантования можно использовать любой способ. Например, можно использовать общее средство, то есть технологию разделения данных W коэффициента на размер Δ шага квантования, как обозначено в Уравнении (1), приведенном ниже:

Размер Δ шага квантования в данном случае рассчитывают, например, в модуле 154 управления скоростью.
Модуль 155 энтропийного кодирования передает кодированные данные, полученные в результате кодирования, в модуль 122 обработки формирования пакетов.
Далее, со ссылкой на фиг.2, будет более подробно описана обработка, выполняемая модулем 150 вейвлет-преобразования. Вначале описана структура вейвлет-преобразования. При вейвлет-преобразовании данных изображения, как схематично показано на фиг.3, рекурсивно выполняют обработку разделения данных изображения на полосу высокой пространственной частоты и полосу низкой пространственной частоты по данным в полосе низкой пространственной частоты, которые получают в результате разделения. В соответствии с этим, обеспечивается эффективное сжатие и кодирование, путем перевода данных в полосе низкой пространственной частоты в меньшую область.
Следует отметить, что фиг.3 соответствует примеру в случае, когда обработка разделения области компонента самой низкой частоты данных изображения на область L компонентов низкой частоты и область Н компонентов высокой частоты повторяется три раза, и уровень разложения, обозначающий общее количество разделенных уровней, равен 3. На фиг.3 "L" и "Н" представляют собой компоненты низкой частоты и компоненты высокой частоты соответственно. Порядок "L" и "Н" обозначает, что первый обозначает полосу, полученную в результате разделения в горизонтальном направлении, и последний обозначает полосу, полученную в результате разделения в вертикальном направлении. Кроме того, цифра перед "L" и "Н" обозначает уровень этой области. Уровень компонентов низкой частоты представлен меньшими цифрами.
Кроме того, как можно видеть из примера по фиг.3, обработку выполняют этап за этапом из нижней правой области в верхнюю левую область на экране, и, таким образом, выполняют управление низкочастотными компонентами. Таким образом, в примере по фиг.3, нижняя правая область на экране используется как область 3НН, включающая в себя наименьшее количество компонентов низкой частоты (включающая в себя наибольшее количество компонентов высокой частоты). Верхнюю левую область, полученную в результате разделения экрана на четыре области, дополнительно разделяют на четыре области, и среди этих четырех областей верхнюю левую область дополнительно разделяют на четыре области. Область в самом верхнем левом углу используется как область 0LL, включающая в себя наибольшее количество компонентов низкой частоты.
Преобразование и разделение неоднократно выполняют для компонентов низкой частоты, поскольку энергия изображения сконцентрирована в компонентах низкой частоты. Это можно понять из того факта, что по мере изменения уровня разложения из состояния, в котором уровень разложения = 1, пример чего показан в позиции А на фиг.4, в состояние, в котором уровень разложения = 3, пример чего показан в позиции В на фиг.4, формируются подполосы, как показано в позиции В на фиг.4. Например, уровень разложения вейвлет-преобразования по фиг.3 равен 3, и, в результате, формируются десять подполос.
В модуле 150 вейвлет-преобразования обычно используют набор фильтров, составленный из фильтра низкой частоты и фильтра высокой частоты, для выполнения описанной выше обработки. Следует отметить, что цифровой фильтр обычно имеет импульсный отклик с множеством длин отводов, то есть коэффициентов фильтра, и, соответственно, необходимо заранее помещать в буфер такое количество элементов данных входного изображения или данных коэффициента, которое необходимо для выполнения обработки фильтрации. Кроме того, как в случае, когда выполняют вейвлет-преобразование за множество этапов, необходимо размещать в буфер такое количество коэффициентов вейвлет-преобразования, сгенерированных на предыдущих этапах, которое требуется для выполнения обработки фильтрации.
В качестве конкретного примера такого вейвлет-преобразования будет описан способ с использованием фильтра 5×3. Такой способ использования фильтра 5×3 принят также в соответствии со стандартом JPEG 2000 для неподвижного изображения и представляет собой отличный способ, поскольку он может выполнять вейвлет-преобразование, используя малое количество отводов фильтра.
Импульсный отклик фильтра 5×3 (представление Z преобразования) состоит, как обозначено Уравнением (2) и Уравнением (3), приведенными ниже, из фильтра H0(z) низкой частоты и фильтра H1(z) высокой частоты. Из Уравнения (2) и Уравнения (3) можно видеть, что фильтр H0(z) низкой частоты имеет пять отводов, и фильтр H1 (z) высокой частоты имеет три отвода.
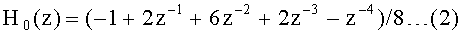
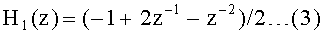
В соответствии с этими Уравнением (2) и Уравнением (3) можно непосредственно рассчитать коэффициенты компонентов низкой частоты и компонентов высокой частоты. Здесь расчеты, связанные с обработкой фильтрации, можно уменьшить, используя технологию подъема.
Далее будет более конкретно описан данный способ вейвлет-преобразования. На фиг.5 показан пример, в котором выполняют обработку фильтрации на основе подъема, используя фильтр 5×3, вплоть до уровня разложения = 2. Следует отметить, что на фиг.5 участок, обозначенный как фильтры анализа, с левой стороны чертежа, включает в себя фильтры модуля 150 вейвлет-преобразования. Кроме того, участок, обозначенный как фильтры комбинирования с правой стороны чертежа, включает в себя фильтры модуля обратного вейвлет-преобразования в модуле декодирования, описанном ниже.
Следует отметить, что в следующем описании предполагается, что, например, в устройстве отображения или тому подобное, одна строка получается в результате сканирования пикселей с левого конца в правый конец экрана, при этом пиксель в верхнем левом углу экрана используется как головной, и один экран формируют путем выполнения сканирования от верхнего конца к нижнему концу экрана на основе от строки к строке.
На фиг.5 в самой левой колонке показаны данные пикселя, расположенные в соответствующих положениях в строке оригинальных данных изображения, расположенных в вертикальном направлении. Таким образом, обработку фильтрации в модуле 150 вейвлет-преобразования выполняют путем вертикального сканирования пикселей по экрану, используя вертикальный фильтр. В первой-третьей колонках с левого конца показана обработка фильтрации на уровне разложения = 1, и в четвертой-шестой колонках показана обработка фильтрации на уровне разложения = 2. Во второй колонке с левого конца показан выход компонента высокой частоты на основе пикселей оригинальных данных изображения с левого конца, и в третьей колонке с левого конца показан выход компонента низкой частоты на основе оригинальных данных изображения и выход компонента высокой частоты. Что касается обработки фильтрации на уровне разложения = 2, как показано в четвертой колонке-шестой колонке с левого конца, обработку выполняют по выходу обработки фильтрации на уровне разложения = 1.
При обработке фильтрации на уровне разложения = 1, так же, как и при обработке фильтрации на первом этапе, данные коэффициента компонентов высокой частоты рассчитывают на основе пикселей данных оригинального изображения; и, как обработку фильтрации на втором этапе, данные коэффициента компонентов низкой частоты рассчитывают на основе данных коэффициента компонентов высокой частоты, которые были рассчитаны при обработке фильтрации на первом этапе, и пикселей данных оригинального изображения. Примерная обработка фильтрации на уровне разложения = 1 показана в первой колонке-третьей колонке с левой стороны (сторона фильтра анализа) на фиг.5. Данные рассчитанного коэффициента компонентов высокой частоты сохраняют в модуле 152 буфера изменения порядка коэффициента, фиг.2. Кроме того, рассчитанные данные коэффициента компонентов низкой частоты сохраняют в модуле 151 буфера промежуточных расчетов по фиг.2.
На фиг.5 показан модуль 152 буфера изменения порядка коэффициента в положениях, окруженных штрихпунктирными линиями, и модуль 151 буфера промежуточных расчетов показан как части, окруженные пунктирными линиями.
Обработку фильтрации на уровне разложения = 2 выполняют на основе результата обработки фильтрации на уровне разложения = 1, который содержится в модуле 151 буфера промежуточных расчетов. При обработке фильтрации на уровне разложения = 2 данные коэффициента, рассчитанные как коэффициенты компонентов низкой частоты при обработке фильтрации на уровне разложения = 1, рассматривают как данные коэффициента, включающие в себя компоненты низкой частоты и компоненты высокой частоты, и выполняют обработку фильтрации, аналогичную обработке, выполняемой на уровне разложения = 1. Данные коэффициента компонентов высокой частоты и данные коэффициента компонентов низкой частоты, рассчитанные при обработке фильтрации на уровне разложения = 2, сохраняют в модуле 152 буфера изменения порядка коэффициента.
Модуль 150 вейвлет-преобразования выполняет обработку фильтрации, как описано выше, как в горизонтальном направлении, так и в вертикальном направлении экрана. Например, вначале, модуль 150 вейвлет-преобразования выполняет обработку фильтрации на уровне разложения = 1 в горизонтальном направлении и сохраняет сгенерированные данные коэффициента компонентов высокой частоты и компонентов низкой частоты в модуле 151 буфера промежуточных расчетов. Затем модуль 150 вейвлет-преобразования выполняет обработку фильтрации на уровне разложения = 1 в вертикальном направлении по данным коэффициента, сохраненным в модуле 151 буфера промежуточных расчетов. При обработке на уровне разложения = 1 в горизонтальном и вертикальном направлениях формируют четыре области, область НН и область HL, основанные на соответствующих элементах данных коэффициента, полученных путем дальнейшего разложения компонентов высокой частоты на компоненты высокой частоты и компоненты низкой частоты, и область LH и область LL, основанные на соответствующих элементах данных коэффициента, полученных путем дальнейшего разложения компонентов низкой частоты на компоненты высокой частоты и компоненты низкой частоты.
Затем, на уровне разложения = 2 выполняют обработку фильтрации как в горизонтальном направлении, так и в вертикальном направлении данных коэффициента для компонентов низкой частоты, генерируемых на уровне разложения = 1. Таким образом, на уровне разложения = 2, область LL, разделенную и сформированную на уровне разложения = 1, дополнительно разделяют на четыре области, и область НН, область HL, область LH и область LL дополнительно формируют в области LL.
Модуль 150 вейвлет-преобразования выполнен с возможностью проведения обработки фильтрации на основе многократного последовательного вейвлет-преобразования, путем последовательного разделения обработки фильтрации на обработку в каждой из групп по несколько строк в вертикальном направлении экрана. В примере, показанном на фиг.5, в качестве первой обработки, которая представляет собой обработку, начинающуюся с первой строки на экране, выполняют обработку фильтрации по семи строкам. В качестве второй обработки, которая представляет собой обработку, начинающуюся с восьмой строки и далее, выполняют обработку фильтрации с приращением по четыре строки. Такое количество строк основано на количестве строк, требуемых для генерирования компонентов с самой низкой частотой, эквивалентных одной строке, после разложения на компоненты высокой частоты и компоненты низкой частоты.
Следует отметить, что ниже группа строк, которая включает в себя другие подполосы, необходимая для генерирования компонентов самой низкой частоты, эквивалентных одной строке (данные коэффициента, эквивалентные одной строке подполос для компонентов самой низкой частоты), будет называться участком (или блоком строк). Строка, упомянутая здесь, обозначает данные пикселя для данных коэффициента, эквивалентных одной строке, сформированной в изображении или в поле, соответствующем данным изображения перед вейвлет-преобразованием, или в каждой подполосе. Таким образом, участок (блок строк) обозначает в данных оригинального изображения перед вейвлет-преобразованием группу данных пикселей, эквивалентную множеству строк, необходимых для генерирования данных коэффициента, эквивалентных одной строке подполос компонентов самой низкой частоты после вейвлет-преобразования или группу данных коэффициента каждой из подполос, полученных путем выполнения вейвлет-преобразования этой группы данных пикселей.
В соответствии с фиг.5, коэффициент С5, полученный как результат выполнения обработки фильтрации на уровне разложения = 2, рассчитывают на основе коэффициента С4, и коэффициента Сa, который сохранен в модуле 151 буфера промежуточных расчетов, и коэффициент С4 рассчитывают на основе коэффициента Сa, коэффициента Сb и коэффициента Сc, которые сохранены в модуле 151 буфера промежуточных расчетов. Кроме того, коэффициент Сc рассчитывают на основе коэффициента С2 и коэффициента С3, которые сохранены в модуле 152 буфера изменения порядка коэффициента и данных пикселя пятой строки. Кроме того, коэффициент С3 рассчитывают на основе данных пикселя пятой строки-седьмой строки. В соответствии с этим, для получения коэффициента С5 компонентов низкой частоты на уровне разложения = 2, необходимы данные пикселя первой строки-седьмой строки.
В отличие от этого, при второй обработке фильтрации и после нее можно использовать данные коэффициента, уже рассчитанные при обработке (обработках) фильтрации до настоящего времени и сохраненные в модуле 152 буфера изменения порядка коэффициента, и, следовательно, количество требуемых строк можно поддерживать малым.
Таким образом, в соответствии с фиг.5, среди коэффициентов компонентов низкой частоты, полученных в результате обработки фильтрации, на уровне разложения = 2, коэффициент С9, который представляет собой следующий коэффициент для коэффициента С5, рассчитывают на основе коэффициента С4, коэффициента С8 и коэффициента Сc, которые сохранены в модуле 151 буфера промежуточных расчетов. Коэффициент С4 уже был рассчитан в результате выполнения описанной выше первой обработки фильтрации и сохранен в модуле 152 буфера изменения порядка коэффициента. Аналогично коэффициент Сc был уже рассчитан в описанной выше первой обработке фильтрации и сохранен в модуле 151 буфера промежуточных расчетов. В соответствии с этим, в данной второй обработке фильтрации, только обработку фильтрации для расчета коэффициента С8 выполняют в первый раз.
Такую новую обработку фильтрации выполняют путем дополнительного использования восьмой строки-одиннадцатой строки.
Поскольку во второй обработке фильтрации и далее можно использовать данные, рассчитанные при выполненной до сих пор обработке (обработках) фильтрации и сохраненные в модуле 151 буфера промежуточных расчетов и в модуле 152 буфера изменения порядка коэффициента, каждую обработку требуется выполнять только с приращением, равным четырем строкам.
Следует отметить, что когда количество строк на экране не соответствует количеству строк для кодирования, строки оригинальных данных изображения копируют с использованием заданного способа таким образом, что количество строк становится идентичным количеству строк для кодирования, и затем выполняют обработку фильтрации.
В соответствии с этим, обработку фильтрации для получения такого количества элементов данных коэффициента, эквивалентных одной строке для компонентов самой низкой частоты, выполняют множество раз последовательно для строк всего экрана (на основе от участка к участку), обеспечивая, таким образом, возможность получения декодированного изображения с уменьшенной задержкой, когда передают кодированные данные.
Для выполнения вейвлет-преобразования необходимы первый буфер, используемый для выполнения самого вейвлет-преобразования, и второй буфер, предназначенный для сохранения коэффициентов, генерируемых при выполнении обработки вплоть до заданного уровня разложения. Первый буфер соответствует модулю 151 буфера промежуточных расчетов и показан на фиг.5, окруженный пунктирными линиями. Кроме того, второй буфер соответствует модулю 152 буфера изменения порядка коэффициента, и показан на фиг.5, окруженный штрихпунктирными линиями. Поскольку коэффициенты, сохраненные во втором буфере, используют во время декодирования, эти коэффициенты подвергают обработке энтропийного кодирования на следующем этапе.
Далее со ссылкой на фиг.2 будет описана обработка, выполняемая модулем 153 изменения порядка коэффициента. Как было описано выше, элементы данных коэффициента, рассчитанные в модуле 150 вейвлет-преобразования, сохраняют в модуле 152 буфера изменения порядка коэффициента, из которого изменяют порядок считывания, выполняемого модулем 153 изменения порядка коэффициента, и передают в модуль 155 энтропийного кодирования в единицах кодирования.
Как уже было описано выше, при вейвлет-преобразовании коэффициенты генерируют со стороны компонента высокой частоты на сторону компонента низкой частоты. В примере, показанном на фиг.5, в первый момент времени, коэффициент С1, коэффициент С2 и коэффициент С3 компонентов высокой частоты последовательно генерируют при обработке фильтрации на уровне 1 разложения, на основе данных пикселей оригинального изображения. После этого выполняют обработку фильтрации на уровне разложения = 2 по данным коэффициента для компонентов низкой частоты, которые были получены при обработке фильтрации на уровне разложения = 1, и в соответствии с этим последовательно генерируют коэффициент С4 и коэффициент С5 компонентов низкой частоты. Таким образом, в первый момент времени данные коэффициента генерируют в следующем порядке: коэффициент С1, коэффициент С2, коэффициент С3, коэффициент С4 и коэффициент С5. Порядок генерирования данных коэффициента всегда становится таким порядком (порядок от высокой частоты к низкой частоте), учитывая принцип вейвлет-преобразования.
В отличие от этого, на стороне декодирования, для немедленного выполнения декодирования с уменьшенной задержкой, необходимо выполнять генерирование и вывод изображения, начиная с компонентов низкой частоты. Поэтому желательно изменять порядок данных коэффициента, генерируемых на стороне кодирования от стороны компонента самой низкой частоты в направлении стороны компонента высокой частоты, и передавать данные коэффициента с измененным порядком на сторону декодирования.
Далее приведено более конкретное описание, используя пример, показанный на фиг.5. С правой стороны фиг.5 показана сторона фильтра комбинирования, предназначенного для выполнения обратного вейвлет-преобразования. Первую обработку комбинирования, включающую в себя первую строку выходных данных изображения (обработка обратного вейвлет-преобразования) на стороне декодирования, выполняют, используя коэффициент С4 и коэффициент С5 компонентов с самой низкой частотой, которые генерируют при первой обработке фильтрации на стороне кодирования, и коэффициент С1.
Таким образом, при первой обработке комбинирования данные коэффициента поступают в порядке: коэффициент С5, коэффициент С4 и коэффициент С1 со стороны кодирования на сторону декодирования, и, на стороне декодирования, используя обработку на уровне комбинирования=2, которая представляет собой обработку комбинирования, которая соответствует уровню разложения = 2, выполняют обработку комбинирования по коэффициенту С5 и коэффициенту С4 для генерирования коэффициента Cf, и коэффициент Cf сохраняют в буфере. Затем, используя обработку на уровне комбинирования = 1, которая представляет собой обработку комбинирования, соответствующую уровню разложения = 1, выполняют обработку комбинирования по этому коэффициенту Сf и коэффициенту С1, для вывода первой строки.
Таким образом, при первой обработке комбинирования, порядок данных коэффициента, сгенерированных в порядке: коэффициент С1, коэффициент С2, коэффициент С3, коэффициент С4 и коэффициент С5 на стороне кодирования и сохраненных в модуле 152 буфера изменения порядка коэффициентов, изменяют на порядок коэффициент С5, коэффициент С4, коэффициент С1, … и передают на сторону декодирования.
Следует отметить, что на стороне фильтра комбинирования, показанной с правой стороны на фиг.5, для коэффициента, переданного со стороны кодирования, номер коэффициента на стороне кодирования представлен в круглых скобках, и порядок строк фильтров комбинирования представлен за пределами круглых скобок. Например, коэффициент С1(5) обозначает, что он представляет собой коэффициент С5 на сторонне фильтра анализа, с левой стороны на фиг.5, и представляет собой первую строку на стороне фильтра комбинирования.
Обработка комбинирования на стороне декодирования данных коэффициента, генерируемых во второй обработке фильтрации и после этого на стороне кодирования, может быть выполнена, используя данные коэффициента, скомбинированные во время предыдущей обработки комбинирования, или переданные со стороны кодирования. В примере по фиг.5 для второй обработки комбинирования на стороне декодирования, которую выполняют, используя коэффициент С8 и коэффициент С9 компонентов низкой частоты, которые сгенерированы при второй обработке фильтрации на стороне кодирования, дополнительно требуется сгенерировать коэффициент С2 и коэффициент С3, в первой обработке фильтрации на стороне кодирования, и при этом декодируют вторую-пятую строки.
Таким образом, при второй обработке комбинирования данные коэффициента передают в порядке: коэффициент С9, коэффициент С8, коэффициент С2 и коэффициент С3 со стороны кодирования на сторону декодирования. На стороне декодирования, при обработке, выполняемой на уровне комбинирования = 2, коэффициент Cq генерируют, используя коэффициент С8, и коэффициент С9, и коэффициент С4, которые передают со стороны кодирования во время первой обработки комбинирования, и коэффициент Cg сохраняют в буфере. Используя этот коэффициент Cg, описанный выше коэффициент С4 и коэффициент Cf, сгенерированный при первой обработке комбинирования, сохраняют в буфере, и коэффициент Сh генерируют и сохраняют в буфере.
Затем при обработке, выполняемой на уровне комбинирования = 1, выполняют обработку комбинирования, используя коэффициент Cg и коэффициент Сh, сгенерированные при обработке на уровне комбинирования = 2 и сохраненные в буфере, и коэффициент С2 (показан как коэффициент С6 (2) в фильтрах комбинирования), и коэффициент С3 (показан как коэффициент С7 (3) в фильтрах комбинирования), переданный со стороны кодирования, и декодируют вторую-пятую строки.
В соответствии с этим, при второй обработке комбинирования порядок данных коэффициента, сгенерированных в порядке: коэффициент С2, коэффициент С3, (коэффициент С4, коэффициент С5), коэффициент С6, коэффициент С7, коэффициент С8 и коэффициент С9 на стороне кодирования, изменяют на порядок: коэффициент С9, коэффициент С8, коэффициент С2, коэффициент С3, …, и передают на сторону декодирования.
В ходе третьей обработки комбинирования и также после нее аналогично изменяют порядок данных коэффициента, сохраненных в модуле 152 буфера изменения порядка коэффициента в заданном порядке, и передают на сторону декодирования, и строки декодируют по четыре строки одновременно.
Следует отметить, что при обработке комбинирования на стороне декодирования, соответствующей обработке фильтрации, включающей в себя строку нижней стороны на экране модуля кодирования (ниже называется, как в последний раз), все данные коэффициента, сгенерированные при обработке, выполненной до сих пор, сохраненные в буфере, выводят, и, следовательно, количество выходных строк увеличивается. В примере, показанном на фиг.5, выводят восемь строк в последний раз.
Следует отметить, что обработку изменения порядка данных коэффициента, используя модуль 153 изменения порядка коэффициента, выполняют, например, путем установки считываемых адресов в момент времени считывания в заданном порядке данных коэффициента, сохраненных в модуле 152 буфера изменения порядка коэффициента.
Описанная выше обработка будет более конкретно описана, используя фиг.6. На фиг.6 представлен пример, в котором обработку фильтрации, основанную на вейвлет-преобразовании, применяют к уровню разложения = 2, используя фильтр 5×3. В модуле 150 вейвлет-преобразования, как показано в примере А на фиг.6, выполняют первую обработку фильтрации как в горизонтальном, так и в вертикальном направлениях первой строки-седьмой строки данных входного изображения (In-1 в позиции А на фиг.6).
При обработке на уровне разложения = 1, при первой обработке фильтрации, генерируют элементы данных коэффициента, эквивалентные трем строкам, коэффициента С1, коэффициента С2 и коэффициента С3, и, как показано в примере в позиции В на фиг.6, их разлагают в области НН, области HL и области LH, которые сформированы на уровне 1 разложения соответственно (WT-1 в позиции В на фиг.6).
Кроме того, формируют область LL на уровне разложения = 1 при следующем разделении на четыре области с целью фильтрации на уровне разложения = 2 в горизонтальном и вертикальном направлениях. Что касается коэффициента С5 и коэффициента С4, сгенерированных на уровне разложения = 2, в области LL на уровне разложения = 1, одну строку, основанную на коэффициенте С5, располагают в области LL, и одну строку на основе коэффициент С4 располагают в каждой из области НН, области HL и области LH.
При обработке второй фильтрации и далее, используя модуль 150 вейвлет-преобразования, выполняют обработку фильтрации с последовательным приращением по четыре строки (In-2… в позиции А на фиг.6). Данные коэффициента каждых двух строк генерируют на уровне разложения = 1 (WT-2 в позиции В на фиг.6), и данные коэффициента каждой одной строки генерируют на уровне разложения = 2.
Во второй раз, в примере, показанном на фиг.5, элементы данных коэффициента, эквивалентные двум строкам, коэффициент С6 и коэффициент С7, генерируют при обработке фильтрации на уровне разложения = 1 и, как показано в примере В на фиг.6, располагают, начиная со следующего элемента данных коэффициента, генерируемых при первой обработке фильтрации, в области НН, области HL и области LH, сформированных на уровне 1 разложения. Аналогично, в области LL, которая основана на уровне разложения = 1, коэффициент С9, который эквивалентен одной строке и сгенерирован в ходе обработки фильтрации на уровне разложения = 2, располагают в области LL, и коэффициент С8, эквивалентный одной строке, располагают в каждой из области НН, области HL и области LH.
Как показано в позиции В на фиг.6, когда данные вейвлет-преобразования декодируют, как показано в примере в позиции С на фиг.6, выводят первую строку, основанную на первой обработке комбинирования на стороне декодирования (Out-1 в позиции С на фиг.6) для первой обработки фильтрации на основе первой строки-седьмой строки на стороне кодирования.
После этого четыре строки выводят одновременно на стороне декодирования (Out-2 … в позиции С на фиг.6) для второй через один, перед последними обработками фильтрации на стороне кодирования. После этого выводят восемь строк на стороне декодирования для последней обработки фильтрации на стороне кодирования.
Элементы данных коэффициента, сгенерированных со стороны компонента высокой частоты на сторону компонента низкой частоты в модуле 150 вейвлет-преобразования, последовательно сохраняют в модуле 152 буфера изменения порядка коэффициента. Когда накапливают такое количество данных коэффициента, которое требуется для обеспечения описанного выше изменения порядка данных коэффициента, в модуле 152 буфера изменения порядка коэффициента, модуль 153 изменения порядка коэффициента изменяет порядок элементов данных коэффициента в порядке элементов, требуемых при обработке комбинирования, и считывает элементы данных коэффициента из модуля 152 буфера изменения порядка коэффициента. Считанные элементы данных коэффициента последовательно передают в модуль 155 энтропийного кодирования.
Данные изображения, кодированные на основе от участка к участку, как было описано выше (кодированные данные), передают в модуль 122 обработки формирования пакетов. В этом случае модуль 155 энтропийного кодирования передает, на основе от участка к участку, информацию, относящуюся к данным изображения, как информацию заголовка (заголовок участка) для модуля 122 обработки формирования пакетов. На фиг.7 показана примерная структура заголовка участка.
Как показано на фиг.7, заголовок 171 участка состоит из данных, эквивалентных четырем словам (32×4 бита), и включает в себя такую информацию, как PID, AT, ATD, FT, CF, IF, штамп времени участка, коэффициент квантования и длина кода участка.
РID (ИД участка, ИДУ) представляет собой 12-битную информацию, обозначающую номер участка, подсчитанный от заголовка изображения. AT (тип модуля совмещения, ТС) представляет собой 4-битную информацию, обозначающую атрибут модуля совмещения, построенного на этом участке. Модуль совмещения представляет собой кодированные данные на участке, который разделен на последовательное приращение заданного модуля данных, такое как последовательное приращение модуля кодирования. Таким образом, участок состоит из одного или множества модулей совмещения. AID (идентификатор модуля совмещения, ИДС) представляет собой 5-битную информацию, обозначающую номер модуля совмещения, считанную с начала участка. FT (тип поля, ТП) представляет собой 2-битную информацию флага, обозначающую, который из типов полей, прогрессивный или с перемежением, представляет собой изображение. CF (флаг компонента, ФК) представляет собой 3-битную информацию, обозначающую тот факт, что среди компонентов, включающих в себя компонент Y яркости, компонент Сb цветности и компонент Cr цветности, множество компонентов сгруппированы в один модуль совмещения или участок.
IF (неполный флаг, НФ) представляет собой 1-битную информацию флага, обозначающую, что она представляет собой модуль совмещения или участок, который не удалось кодировать по какой-либо причине. Диапазон этих отказов ограничен полезной нагрузкой, обозначенной как ИДУ, ТС и ИДС.
Метка времени участка (Precinct Time Stamp) представляет собой информацию, обозначающую младшие 32 бита метки времени участка. Коэффициент квантования (QP Y или С) представляет собой 16-битную информацию, обозначающую значение коэффициента квантования, используемого во время квантования компонента Y яркости или компонентов С цветности участка. Длина кода участка (Precinct Code Length Y или С) представляет собой 26-битную информацию, обозначающую длину данных для кодированных данных компонента Y яркости или компонентов С цветности участка.
Затем модуль 155 энтропийного кодирования передает на основе от изображения к изображению информацию, относящуюся к данным изображения, в качестве информации заголовка (заголовок изображения) в модуль 122 обработки формирования пакетов. На фиг.8 показана примерная структура заголовка изображения.
Как показано на фиг.8, заголовок 172 изображения состоит из данных, эквивалентных 26 словам (32×26 битов), и включает в себя информацию, такую как PI, w, CEF, CBD, DL, WF, PDI, SF, FR, AR, DBSZ, полный штамп времени, начальное положение V0, SD, начальное положение Н, VF, общий размер V, TSD, общий размер Н, PXCS, размер V, VSD, размер Н, BRT, CTS и WTm.
PI (обозначение профиля, ОП) представляет собой 5-битную информацию, которая выполняет описание профиля. w представляет собой 1-битную информацию флага, обозначающую, следует или нет включить таблицу взвешивания, такую как информация таблицы, для установки исходного значения коэффициента взвешивания, в пакет. СЕF (флаг расширения цвета, ФРЦ) представляет собой 1-битную информацию флага, обозначающую, следует или нет использовать заголовок расширения информации цвета. CBD (глубина бита компонента, ГБК) представляет собой 5-битную информацию, обозначающую глубину битов компонента. Сохраняют значение, полученное путем вычитания "8" из заранее определенного значения. DL (уровень DWT (дискретное преобразование Уолша), УД) представляет собой 3-битную информацию, обозначающую количество разложения (уровень разложения) для вейвлет-преобразования. WF (вейвлет-фильтр, ВФ) представляет собой 2-битную информацию, обозначающую тип фильтра, используемого при вейвлет-преобразовании. PDI (обозначение разрывности изображения, ОРИ) представляет собой 1-битную информацию, обозначающую непрерывность временной метки. SF (формат выборки, ФВ) представляет собой 2-битную информацию, обозначающую способ выборки сигнала цветности.
FR (частота кадров, ЧК) представляет собой 1-битную информацию, обозначающую частоту кадров. AR (соотношение размеров, СР) представляет собой 6-битную информацию, обозначающую соотношение размеров пикселей. DBSZ (размер буфера декодера, РБДК) представляет собой 4-битную информацию, обозначающую размер буфера участка в декодере. Метка полного времени (FTS, МПВ) представляет собой 46-битную информацию, обозначающую метку времени полного размера.
Начальное положение V0 (FFVS (начало вертикального первого поля, НВПП)) представляет собой 13-битную информацию, обозначающую начальное положение действительного пикселя в вертикальном направлении в поле заголовка. SD (начальная разность, HP) представляет собой 2-битную информацию, обозначающую разность между НВПП и вторым полем. Начальное положение Н (HS (начало по горизонтали), НГ) представляет собой 13-битную информацию, обозначающую действительное начальное положение пикселя в горизонтальном направлении. VF (видеоформат, ВФ) представляет собой 4-битную информацию, обозначающую видеоформат сжатого сигнала.
Общий размер V (FFVTS (общий размер первого вертикального поля), ОРПВП) представляет собой 13-битную информацию, обозначающую общее количество пикселей, включающее в себя пробел в поле заголовка. TSD (разность общего размера, POP) представляет собой 2-битную информацию, обозначающую разность между ОРПВП и вторым полем. Общий размер Н (HTS (общий горизонтальный размер), ОГР) представляет собой 13-битную информацию, обозначающую общее количество пикселей, включающих в себя пробел в горизонтальном направлении. PXCS (масштаб тактовой частоты пикселей, МТЧП) представляет собой 3-битную информацию, обозначающую коэффициент масштабирования тактовой частоты.
Размер V (FFVVS (действительный размер первого вертикального поля), ДРПВП) представляет собой 13-битную информацию, обозначающую действительный размер пикселя в вертикальном направлении в области заголовка. VSD (разность с действительным размером, РДР) представляет собой 2-битную информацию, обозначающую разность между ДРПВП и вторым полем. Размер Н (HVS (действительный горизонтальный размер), ДГР) представляет собой 13-битную информацию, обозначающую действительный размер пикселя в горизонтальном направлении. BRT (момент времени сброса значения В, МСБ) представляет собой 2-битную информацию, обозначающую момент времени для повторной установки значения В.
CTS (размер специальной таблицы, РСП) представляет собой 16-битную информацию, обозначающую размер специальной таблицы. Как и множество последующих специальных значений, поскольку существует множество определенных значений, и их размер составляет CTS×2 байта. WTm (взвешивающая таблица (ВТ) m), ВТм представляет собой информацию размером 16×m битов, обозначающую m-ю взвешивающую таблицу.
Следует отметить, что фактически, как показано на фиг.9, информацию атрибута, информацию VALID (действительный), и т.п. передают, помимо данных, из модуля 121 кодирования в модуль 122 обработки формирования пакетов. Информация атрибута представляет собой информацию, обозначающую, являются ли передаваемые данные данными заголовка или данными изображения, или обозначает, представляют ли собой передаваемые данные компонента яркости или данные компонентов цветности. Информация VALID представляет собой информацию, представляющую уведомление о моментах времени считывания данных.
Модуль 122 обработки формирования пакетов выполняет обработку формирования пакетов для кодированных данных, переданных с последовательными приращениями с размером заданный модуль данных (участок) на основе размера этих данных и размера пакета, определенных по отдельности.
На фиг.10 показана блок-схема, представляющая примерную структуру внутреннего устройства модуля 122 обработки формирования пакетов, показанного на фиг.1.
На фиг.10 модуль 122 обработки формирования пакетов включает в себя модуль 201 получения данных, модуль 202 генерирования заголовка RTP (протокол транспортирования в режиме реального времени, ПРВ), модуль 203 генерирования общего заголовка, модуль 204 генерирования заголовка расширения, модуль 205 генерирования информации изображения, модуль 206 проверки флага, модуль 207 проверки размера, модуль 208 обработки фрагмента, модуль 209 формирования пакетов и выходной модуль 210.
Модуль 201 получения данных получает кодированные данные, пакеты и т.п., передаваемые из модуля 121 кодирования, на основе информации атрибута, информации VALID и т.п., предоставляемых вместе с данными. Например, когда получают заголовок 171 участка, модуль 201 получения данных передает его в модуль 202 генерирования заголовка ПРВ, модуль 203 генерирования общего заголовка, модуль 204 генерирования заголовка расширения, модуль 206 проверки флага и модуль 207 проверки размера. Кроме того, например, когда получают заголовок 172 изображения, модуль 201 получения данных передает его в модуль 205 генерирования информации изображения. Кроме того, например, когда получают кодированные данные, модуль 201 получения данных передает их в модуль 208 обработки фрагмента.
Когда модуль 201 получения данных получает заголовок участка, модуль 202 генерирования заголовка ПРВ генерирует, на основе полученного заголовка участка, заголовок ПРВ, который представляет собой заголовок пакета ПРВ. Подробности заголовка ПРВ будут описаны ниже. Модуль 202 генерирования заголовка ПРВ передает сгенерированный заголовок ПРВ в модуль 209 формирования пакета и передает уведомление о прекращении обработки в модуль 203 генерирования общего заголовка.
После приема уведомления из модуля 202 генерирования заголовка ПРВ, модуль 203 генерирования общего заголовка генерирует на основе заголовка 171 участка, полученного модулем 201 получения данных, общий заголовок, который представляет собой общий заголовок, добавленный к каждому пакету, сгенерированному из участка. Общий заголовок включает в себя основную информацию, относящуюся к участку. Подробности общего заголовка будут описаны ниже. Модуль 203 общего генерирования заголовка передает сгенерированный общий заголовок в модуль 209 формирования пакетов и передает уведомление о прекращении обработки в модуль 204 генерирования заголовка расширения.
После приема уведомления из модуля 203 генерирования общего заголовка, модуль 204 генерирования заголовка расширения генерирует, на основе заголовка 171 участка, полученного модулем 201 получения данных, информацию о заголовке расширения, которая добавляет, в соответствии с необходимостью, информацию, относящуюся к участку, и которая не включена в общий заголовок. При генерировании заголовка расширения отправитель может выполнять гибкое и эффективное генерирование заголовка. Хотя содержание информации в заголовке расширения является произвольным, содержание включает в себя, например, информацию, относящуюся к коэффициенту квантования, и информацию, относящуюся к размеру. Подробности заголовка расширения будут описаны ниже. Модуль 204 генерирования заголовка расширения передает сгенерированный заголовок расширения в модуль 209 формирования пакетов и предоставляет уведомление об окончании обработки в модуль 205 генерирования информации изображения.
После приема уведомления из модуля 204 генерирования заголовка расширения, когда модуль 201 получения данных получает заголовок 172 изображения, модуль 205 генерирования информации изображения генерирует на основе заголовка 172 изображения информацию изображения, включающую в себя информацию, относящуюся к изображению. Подробно информация изображения будет описана ниже. Модуль 205 генерирования информации изображения передает сгенерированную информацию изображения в модуль 209 формирования пакетов, обеспечивает вставку информации изображения в заголовок расширения и предоставляет уведомление о прекращении обработки в модуль 206 проверки флага. Следует отметить, что когда модуль 201 получения данных не получает заголовок 172 изображения, модуль 205 генерирования информации изображения не генерирует информацию изображения и предоставляет уведомление о прекращении обработки в модуль 206 проверки флага.
После приема уведомления из модуля 205 генерирования информации изображения модуль 206 проверки флага обращается к НФ, включенному в заголовок 171 участка, полученный модулем 201 получения данных, в соответствии со значением флага, определяет, следует или нет включить кодированные данные в пакет. Например, когда "НФ=1", модуль 206 проверки флага определяет, что кодирование данных в участке произошло неудачно, и инициирует модуль 201 получения данных отбросить (не получить) недекодируемые кодированные данные. Кроме того, модуль 206 проверки флага управляет модулем 209 формирования пакетов для размещения в пакете только информации заголовка (не включающей полезную нагрузку). В качестве альтернативы, например, когда "НФ=0", модуль 206 проверки флага определяет, что кодирование участка прошло успешно, инициирует модуль 209 формирования пакетов разместить в пакете данные, включающие в себя полезную нагрузку, и предоставляет уведомление о прекращении обработки в модуль 207 проверки размера.
После приема уведомления из модуля 206 проверки флага модуль 207 проверки размера проверяет, на основе длины кода участка, включенной в заголовок участка, полученный модулем 201 получения данных, превышает или нет размер данных участка размер пакета, который установлен заранее отдельно (максимальное значение размера данных полезной нагрузки, включенной в один пакет). Например, когда размер данных участка больше, чем размер пакета, модуль 207 проверки размера управляет модулем 208 обработки фрагмента для разделения кодированных данных, полученных модулем 201 получения данных, с последовательным приращением размера пакета. И наоборот, например, когда размер данных участка не превышает размер пакета, модуль 207 проверки размера управляет модулем 208 обработки фрагмента так, что не происходит разделение кодированных данных, полученных модулем 201 получения данных.
Когда размер данных участка больше, чем размер пакета, под управлением модуля 207 проверки размера, модуль 208 обработки фрагмента разделяет кодированные данные, полученные модулем 201 получения данных, с последовательным приращением размера пакета, и передает разделенные данные в модуль 209 формирования пакета. Таким образом, в этом случае, каждый раз, когда получают модуль 201 получения данных, получают кодированные данные, эквивалентные одному размеру пакета, учитывая участок заголовка, модуль 208 обработки фрагмента передает эти кодированные данные, эквивалентные размеру одного пакета, в качестве одной полезной нагрузки в модуль 209 формирования пакета.
И наоборот, когда размер данных участка не больше, чем размер пакета, под управлением модуля 207 проверки размера, модуль 208 обработки фрагмента передает кодированные данные, полученные модулем 201 получения данных, без изменения в модуль 209 упаковки. Таким образом, в этом случае, модуль 208 обработки фрагмента передает кодированные данные, полученные модулем 201 получения данных, которые эквивалентны одному участку, в качестве одной полезной нагрузки в модуль 209 формирования пакета.
Используя информацию заголовка, переданную из каждого модуля, модуль 209 формирования пакетов формирует пакет, размещая в нем полезную нагрузку (нагрузки), переданную из модуля 208 обработки фрагмента. Например, когда кодированные данные одного участка разделены модулем 208 обработки фрагмента на множество полезных нагрузок, модуль 209 формирования пакетов добавляет соответствующие элементы в виде необходимой информации заголовка к отдельным полезным нагрузкам и формирует пакеты из них по отдельности. В качестве альтернативы, например, когда модуль 208 обработки фрагмента не разделяет кодированные данные, модуль 209 формирования пакетов добавляет необходимую информацию заголовка к одной полезной нагрузке, переданной из модуля 208 обработки фрагмента, и формирует пакеты, помещая в них полезную нагрузку с информацией заголовка. Кроме того, например, когда модуль 206 проверки флага предоставляет инструкцию не включать полезную нагрузку в пакет, модуль 209 формирования пакетов выполняет, в ответ на эту инструкцию, формирование пакета, содержащего только информацию заголовка.
Кроме того, модуль 209 формирования пакетов соответствующим образом устанавливает значения элементов информации флага, такие как SFF и М, включенные в общий заголовок сгенерированных отдельных пакетов. SFF (флаг начала фрагмента, ФНФ) представляет собой информацию флага, обозначающую, является или нет данный пакет пакетом (головным пакетом), включающим в себя информацию заголовка участка. М (маркер) представляет собой информацию флага, обозначающую, является или нет пакет пакетом (конечным пакетом), включающим в себя оконечную часть участка. К этим элементам информации флага обращаются во время обработки восстановления данных из пакетов, выполняемой модулем 132 обработки восстановления данных из пакетов.
Например, когда модуль 208 обработки фрагмента разделяет кодированные данные, модуль 209 формирования пакетов устанавливает в группе полезной нагрузки, сгенерированной в результате разделения кодированных данных одного участка, ФНФ пакета полезной нагрузки заголовка, равным 1, и устанавливает М для пакета последней полезной нагрузки, равным 1.
В качестве альтернативы, например, когда модуль 208 обработки фрагмента не разделяет кодированные данные, модуль 209 формирования пакетов устанавливает каждый ФНФ и М одного из сгенерированного пакета, равным 1.
В соответствии с этим, путем установки информации флага, такой как ФНФ и М, таким образом, модуль 132 обработки извлечения данных из пакетов может легко определять, является ли данный пакет головным пакетом или конечным пакетом участка или другим пакетом среди этих пакетов, просто обращаясь к информации флага. Поэтому модуль 132 обработки извлечения данных из пакетов может уменьшить время ожидания, как будет описано ниже, и может уменьшить время задержки, связанной с обработкой извлечения данных из пакетов.
Модуль 209 формирования пакетов передает сгенерированный пакет (пакеты) в выходной модуль 210.
Выходной модуль 210 передает пакет ПРВ, переданный из модуля 209 формирования пакетов, в модуль 123 передачи (фиг.1) и обеспечивает его передачу модулем 123 передачи в устройство 103 приема (фиг.1).
Как было описано выше, модуль 121 кодирования разделяет, как показано на фиг.11, одно изображение (кадр или поле) на множество участков и выполняет кодирование отдельных участков.
Модуль 122 обработки пакетов формирует пакеты, как показано на фиг.12, размещая в них кодированные данные одного участка, в результате разделения кодированных данных с последовательным приращением заданного размера пакета. Один пакет генерируют, когда размер данных участка не превышает размер пакета. В примере, показанном на фиг.12, генерируют пять пакетов из кодированных данных одного участка.
Примерный формат передачи данных изображения представлен ниже.
На фиг.13 показана структура заголовка ПРВ, который генерирует модуль 202 генерирования заголовка ПРВ, и информация заголовка пакета. В заголовке 221 ПРВ предусмотрены отдельные поля номера (V) версии, заполнения (Р), присутствия заголовка (X) расширения, количества источников (счетчик) (СС), информации маркера (бит маркера) (М), типа (РТ) полезной нагрузки, номера последовательности, временного штампа и идентификатора источника синхронизации (SSRC).
Номер (V) версии представляет собой 2-битную информацию, обозначающую номер версии ПРВ. Заполнение (Р) представляет собой информацию 1-битного флага и, когда его значение равно "1", это обозначает, что один или больше октетов заполнения (внедренные данные) добавляют в конце полезной нагрузки. Поле присутствия заголовка (X) расширения представляет собой информацию 1-битного флага и, когда его значение равно «1», это означает что, помимо заголовка фиксированной длины, добавлен заголовок расширения (в данном случае расширение заголовка). Количество источников (СС) представляет собой информацию размером 4 бита, обозначающую количество идентификаторов CSRC, и обозначает количество идентификаторов отдельных источников данных, когда данные из множества источников данных, как многоадресной телефонной конференции, в качестве примера, собирают в один пакет ПРВ.
Информация (М) маркера представляет собой информацию флага размером 1 бит и обозначает, например, произвольное событие в полезной нагрузке. Способ использования такой информации (М) маркера установлен, например, в типе (РТ, ТПН) полезной нагрузки. Тип (ТПН) полезной нагрузки представляет собой информацию размером 7 бит, которая определяет формат полезной нагрузки, переносимой пакетом.
Номер последовательности представляет собой 16-битную информацию номера, обозначающую порядок пакета данных ПРВ. Исходное значение установлено произвольно. В последующих пакетах, следующих после него, это значение увеличивается на "1". Такой номер последовательности обозначает порядок пакета во всех кодированных данных (данных изображения), предназначенных для передачи.
Временной штамп представляет собой 32-битную информацию, обозначающую время выборки первого байта пакета ПРВ. Частоту выборки определяют по профилю данных полезной нагрузки. Например, пусть частота выборки аудиосигнала составляет 8 кГц. Поскольку значение временной метки увеличивается на "1" каждые 125 мкс и пусть пакет данных ПРВ представляет собой данные 20 мс, значение временной метки увеличивается на 160 от пакета к пакету. Следует отметить, что исходное значение установлено произвольно.
Идентификатор источника синхронизации (SSRC) представляет собой 32-битный идентификатор, обозначающий источник этого пакета. Эту информацию генерируют произвольно. Когда адрес транспортирования изменяют, этот идентификатор SSRC также обновляют.
Модуль 203 генерирования общего заголовка, модуль 204 генерирования заголовка расширения и модуль 205 генерирования информации изображения генерируют различные элементы информации, включенные в заголовок полезной нагрузки, после заголовка ПРВ. На фиг.14 показана примерная структура заголовка полезной нагрузки. Как показано на фиг.14, заголовок полезной нагрузки состоит из общего заголовка 231, информации 232 параметра квантования, информации 233 размера, информации 234 формата, информации 235 изображения и информации 236 цвета, и его добавляют перед полезной нагрузкой 237.
Общий заголовок 231 представляет собой информацию заголовка, которую генерируют с помощью модуля 203 генерирования общего заголовка, и включает в себя основную информацию, относящуюся к участку. Этот общий заголовок 231 представляет собой существенный заголовок и его добавляют ко всем пакетам.
Информация 232 параметра квантования представляет собой заголовок расширения, генерируемый модулем 204 генерирования заголовка расширения, и включает в себя информацию, относящуюся к коэффициенту квантования. Информация 233 размера представляет собой заголовок расширения, генерируемый модулем 204 генерирования заголовка расширения, и включает в себя информацию, относящуюся к размеру данных. Информация 234 формата представляет собой заголовок расширения, генерируемый модулем 204 генерирования заголовка расширения, и включает в себя информацию, относящуюся к формату данных. Информация 235 изображения представляет собой заголовок расширения, генерируемый модулем 205 генерирования информации изображения, и включает в себя информацию, относящуюся к исходному изображению (то есть данным изображения, кодируемым, размещаемым в пакеты и передаваемым). Информация 236 цвета представляет собой заголовок расширения, генерируемый модулем 204 генерирования заголовка расширения, и включает в себя информацию, относящуюся к цвету данных изображения.
Информацию 232 параметра квантования, информацию 234 формата, информацию 235 изображения и информацию 236 цвета добавляют как заголовок расширения к пакету заголовка участка (включающему в себя не фрагментированный пакет). Информацию 233 размера добавляют как заголовок расширения к произвольному пакету.
Таким образом, когда информацию размера требуется добавлять ко всем пакетам, пакет заголовка участка включает в себя все из общего заголовка 231 - полезной нагрузки 237. В отличие от этого, другие пакеты, кроме пакета заголовка участка, включают в себя только общий заголовок 231, информацию 233 размера и полезную нагрузку 237.
Подробно каждый из элементов информации будет описан ниже.
На фиг.15 показана схема, представляющая примерную структуру общего заголовка 231. Как показано на фиг.15, общий заголовок 231 включает в себя такую информацию, как ИДУ, ТС, ИДС, ФНФ, М, TSF, NF, ТП, ФК, НФ, Х и TS. Таким образом, первое слово (первый ряд сверху) и второе слово (второй ряд сверху) общего заголовка 231 генерируют, используя первое слово (Word0) и второе слово (Word1) заголовка 171 участка, передаваемого из модуля 121 кодирования в том виде, как они есть, и ФНФ, М, TSF и NF добавляют к четырем битам, которые представляли собой пустое поле (зарезервированное) первого слова.
ФНФ (флаг начала фрагмента) представляет собой 1-битную информацию, обозначающую, представляет или нет собой данный пакет заголовок полезной нагрузки, обозначенной по ИДУ, ТС и ИДС. Таким образом, когда этот пакет представляет собой пакет, находящийся в начале участка (головной пакет), значение ФНФ устанавливают равным "1"; в противном случае, его устанавливают равным "0".
М (Маркер) представляет собой 1-битную информацию флага, обозначающую, включает или нет в себя данный пакет оконечную часть полезной нагрузки, обозначенную с помощью ИДУ, ТС и ИДС. Таким образом, когда этот пакет представляет собой пакет, включающий в себя оконечную часть участка или модуль выравнивания (конечный пакет), значение М устанавливают равным "1"; в противном случае, его устанавливают равным "0".
TSF (флаг временного штампа, ФВШ) представляет собой 1-битную информацию флага, обозначающую, следует или нет включить штамп времени в общий заголовок. Таким образом, когда значение ФВШ равно "1", второе слово (Word1) заголовка 171 участка добавляют ко второму слову общего заголовка 231.
NF (следующий флаг, СФ) представляют собой 1-битную информацию флага, обозначающую присутствие последующей полезной нагрузки. Таким образом, значение СФ устанавливают равным "1", когда полезные нагрузки, состоящие из множества участков, или модули выравнивания добавлены к этому пакету и когда этот заголовок не установлен для последнего участка или модуля выравнивания в этом пакете.
TS (временной штамп, ВШ) представляет собой 32 младших значимых битов информации временной метки участка, которому принадлежит полезная нагрузка данного пакета, и соответствует второму слову (Word1) заголовка 171 участка.
Следует отметить, что третье слово, показанное на фиг.15 (третий ряд сверху), обозначает, что заголовок расширения последовательно добавлен к общему заголовку 231.
На фиг.16 показана схема, представляющая примерную структуру информации 232 параметра квантования, включенную в заголовок расширения. Как показано на фиг.16, информация 232 параметра квантования представляет собой информацию, включающую в себя такую информацию, как ЕТ, QP и X. Модуль 204 генерирования заголовка расширения использует третье слово (Word2) заголовка 171 участка, переданного из модуля 121 кодирования, для генерирования этой информации 232 параметра квантования.
ЕТ (тип расширения, ТР) представляет собой 5-битную информацию, обозначающую содержание заголовка расширения. Определенное значение, когда используют эту информацию 232 параметра квантования, является произвольным, таким как, например, "00011". QP (параметр квантования, ПК) представляет собой 16-битную информацию, обозначающую величину коэффициента квантования. Х (расширение) представляет собой флаг, обозначающий, следует ли использовать заголовок расширения.
На фиг.17 показана схема, представляющая примерную структуру информации 233 размера, включенную в заголовок расширения. Как показано на фиг.17, информация 233 размера представляет собой информацию, включающую в себя ТР, SS, Х и т.п. Модуль 204 генерирования заголовка расширения использует четвертое слово (Word3) заголовка 171 участка, переданного из модуля 121 кодирования, для генерирования этой информации 233 размера.
ТР (тип расширения) представляет собой 5-битную информацию, обозначающую содержание заголовка расширения. Определенное значение, когда используют эту информацию 233 размера, устанавливают произвольно, например, "00100". SS (размер сегмента, PC) представляет собой 26-битную информацию, обозначающую размер полезной нагрузки сегмента, выраженный в значениях длины слова. Х (расширение) представляет собой флаг, обозначающий, следует или нет использовать заголовок расширения.
Как показано на фиг.7 и фиг.15-фиг.17, модуль 121 кодирования передает заголовок 171 участка, который имеет такой же формат, что и общий заголовок 231, и заголовок расширения (информацию 232 параметра квантования и информацию 233 размера) в модуль 122 обработки формирования пакетов. В соответствии с этим, модуль 203 генерирования общего заголовка и модуль 204 генерирования заголовка расширения в модуле 122 обработки формирования пакетов могут просто и быстро генерировать общий заголовок и заголовок расширения.
На фиг.18 показана схема, представляющая примерные структуры информации 234 формата, включенной в заголовок расширения. Информация 234 формата, в принципе, включает в себя информацию, такую как ТР, ТПI и X, как показано в позиции А на фиг.18. Модуль 204 генерирования заголовка расширения использует, например, информацию, переданную из модуля 121 кодирования, для генерирования этой информации 234 формата.
ТР (тип расширения) представляет собой 5-битную информацию, обозначающую содержание заголовка расширения. Определенное значение, когда используют эту информацию 234 формата, выбирают произвольно, например, "00101". FTI (идентификатор типа формата, ИТФ) представляет собой информацию, обозначающую, о каком типе формата записана информация. Значение ТПI выбирают произвольно. Например, когда записана информация Bayer, устанавливают значение "00001". Х (расширение) представляет собой флаг, обозначающий, следует или нет использовать заголовок расширения.
В позиции В на фиг.18, показана примерная структура информации 234 формата, в случае, когда записана информация Bayer. В этом случае, информация 234 формата включает в себя, помимо ТР, ИТФ и X, такую информацию, как МТ, SMT, BLF, VLOF, SSF, EVF, DC, BL, RBL, RVLO, DSS, NSS и EV.
МТ (тип мозаики, ТМ) представляет собой 4-битную информацию, обозначающую тип мозаики полезной нагрузки. SMT (начать тип мозаики, НТМ) представляет собой 4-битную информацию, обозначающую информацию первого пикселя в верхнем левом углу кадра. BLF (флаг уровня черного, ФУЧ) представляет собой информацию 1-битного флага, обозначающую присутствие информации уровня черного. VLOF (флаг вертикального смещения строки, ФВСС) представляет 1-битную информацию флага, обозначающую присутствие информации коррекции вертикальной строки. SSF (флаг скорости затвора, ФСЗ) представляет собой 1-битную информацию флага, обозначающую присутствие информации скорости затвора. EVF (флаг EV) представляет собой 1-битную информацию флага, обозначающую присутствие информации EV. DC (коррекция дефектов, КД) представляет собой 1-битную информацию флага, обозначающую, следует или нет выполнять коррекцию дефектов.
BL (уровень черного, УЧ) представляет собой 32-битную информацию флага, обозначающую значение уровня черного. RBL (пересмотренный уровень черного, ПУЧ) представляет собой 32-битную информацию, обозначающую значение смещения коррекции уровня черного. УЧ и ПУЧ присутствуют только, когда значение ФУЧ равно "1".
RVLO (пересмотренное вертикальное смещение строки, ПВСС) представляет собой 32-битную информацию, обозначающую значение вертикального смещения коррекции строки. ПВСС присутствует только, когда значение ФВСС равно "1".
DSS представляет собой 32-битную информацию, представляющую собой числитель значения скорости затвора (единица APEX). NSS представляет собой 32-битную информацию, обозначающую знаменатель скорости затвора (единица APEX). DSS и NSS присутствуют только, когда значение ФСЗ равно "1".
EV представляет собой 32-битную информацию, обозначающую значение EV. EV присутствует только, когда значение EVF равно "1",
На фиг.19 показана схема, представляющая примерную структуру информации 235 изображения, включенную в заголовок расширения. Как показано на фиг.19, информация 235 изображения включает в себя такую информацию, как ТР, ОП, ФРЦ, ГБК, УД, ВФ, ОРИ, ФВ, ЧК, СР, РБДК, FTS, НВПП, HP, НГ, ВФ, ОРПВП, POP, ОГР, МТЧП, ДРПВП, РДР, ДГР, МСБ, WCF, X, РСП и ВТм. Модуль 205 генерирования информации изображения использует заголовок 172 изображения, переданный из модуля 121 кодирования, для генерирования этой информации 235 изображения.
Таким образом, информацию 235 изображения получают путем добавления ТР в пустое поле (зарезервированное) первого слова (Word0) и добавления WCF и Х в пустое поле (зарезервированное) шестого слова (Word5) заголовка 172 изображения, переданного из модуля 121 кодирования.
ТР (тип расширения) представляет собой 5-битную информацию, обозначающую содержание заголовка расширения. Определенное значение, когда используют эту информацию 235 изображения, выбирают произвольно, например, "00010". WCF (специальный флаг взвешивания, СФВ) представляет собой 1-битную информацию флага, обозначающую, следует ли использовать специальное значение взвешивающего коэффициента. РСП присутствует только, когда значение СФВ равно "1". X (расширение) представляет собой флаг, обозначающий, следует или нет использовать заголовок расширения, после данного заголовка.
Как показано на фиг.8 и фиг.19, модуль 121 кодирования передает заголовок 172 изображения, который имеет такой же формат, что и информация 235 изображения, в модуль 122 обработки формирования пакетов. В соответствии с этим, модуль 205 генерирования информации изображения в модуле 122 обработки формирования пакетов может легко и быстро генерировать информацию 235 изображения.
На фиг.20 показана схема, представляющая примерную структуру информации 236 цвета, включенную в заголовок расширения. Как показано на фиг.20, информация 236 цвета включает в себя такую информацию, как ТР и X. Модуль 204 генерирования заголовка расширения использует информацию или тому подобное, переданную из модуля 121 кодирования, для генерирования данной информации 236 цвета.
ТР (тип расширения) представляет собой 5-битную информацию, обозначающую содержание заголовка расширения. Х (расширение) представляет собой флаг, обозначающий, следует или нет использовать заголовок расширения.
Модуль 122 обработки формирования пакетов формирует пакеты, включая в них кодированные данные, на основе от участка к участку, как описано выше, и передает эти пакеты в модуль 123 передачи. Модуль 123 передачи последовательно передает эти пакеты в устройство 103 приема через линию 110.
Пакеты, переданные из модуля 123 передачи в описанном выше формате, подают через линию 110 в модуль 131 приема в устройство 103 приема. После приема этих пакетов модуль 131 приема передает их в модуль 132 обработки восстановления данных из пакетов.
На фиг.21 показана блок-схема, представляющая примерную структуру внутреннего устройства модуля 132 обработки восстановления данных из пакетов. Как показано на фиг.21, модуль 132 обработки восстановления данных из пакетов включает в себя, например, модуль 251 получения пакета, модуль 252 анализа информации заголовка, модуль 253 изменения режима управления, модуль 254 управления, модуль 255 подачи заголовка, модуль 256 подачи данных, модуль 257 уведомления об ошибке и модуль 258 подачи сигнала управления.
Модуль 251 получения пакета получает пакеты, переданные из модуля 131 приема. В это время, когда модуль 251 получения пакета получает информацию, вплоть до заголовка полезной нагрузки ПРВ, модуль 251 получения пакета продолжает получать и последовательно подавать уже полученные элементы информации в модуль 252 анализа информации заголовка. Таким образом, модуль 251 получения пакетов предоставляет информацию заголовка в модуль 252 анализа информации заголовка перед тем, как будет закончено получение полезной нагрузки (нагрузок). Кроме того, модуль 251 получения пакета передает информацию заголовка в модуль 255 подачи заголовка, а также передает полезную нагрузку (нагрузки) модуля 256 подачи данных.
Модуль 252 анализа информации заголовка анализирует информацию заголовка пакета ПРВ, полученного модулем 251 получения пакета, то есть информацию заголовка ПРВ и заголовка полезной нагрузки, и передает результат анализа в модуль 253 изменения режима управления и в 254 модуль управления.
На основе результата анализа информации заголовка, переданного из модуля 252 анализа информации заголовка, модуль 253 изменения режима управления управляет режимом работы модуля 254 управления и изменяет этот режим в соответствии с необходимостью.
В режиме управления, изменяемом под управлением модуля 253 изменения режима управления, модуль 254 управления управляет, на основе результата анализа, переданного из модуля 252 анализа информации заголовка, работой модуля 255 подачи заголовка, модуля 256 подачи данных, модуля 257 уведомления об ошибке и модуля 258 подачи сигнала управления.
Под управлением модуля 254 управления, модуль 255 подачи заголовка выделяет различные элементы информации, включенные в заголовок полезной нагрузки, передаваемый из модуля 251 получения пакета, восстанавливает заголовок 171 участка и заголовок 172 изображения, и подает заголовок 171 участка и заголовок 172 изображения в модуль 133 декодирования. Под управлением модулем 254 управления, модуль 256 подачи данных подает данные полезной нагрузки, переданные из модуля 251 получения пакета, в модуль 133 декодирования. Под управлением модулем 254 управления, модуль 257 уведомления об ошибке передает уведомление об ошибке, такое как возникновение потери пакета, в модуль 133 декодирования. Под управлением модулем 254 управления, модуль 258 подачи сигнала управления передает различные элементы информации управления, кроме заголовка и данных, в модуль 133 декодирования.
В качестве режимов управления модуля 254 управления, как показано на фиг.22, используются четыре режима, режим 301 запуска, режим 302 ожидания, режим 303 обработки и режим 304 потери. На основе результата анализа информации заголовка, выполняемого модулем 252 анализа информации заголовка, модуль 253 изменения режима управления определяет состояние приема пакета ПРВ и изменяет режим управления модуля 254 управления на оптимальный режим в соответствии с состоянием.
Режим 301 запуска представляет собой режим для обработки первого пакета всех кодированных данных. Во время начала обработки восстановления данных из пакетов модуль 254 управления устанавливают в этот режим 301 запуска. Режим 302 ожидания представляет собой режим для обработки пакета заголовка участка. После обработки конечного пакета участка, модуль 254 управления устанавливают в этот режим 302 ожидания. Режим 303 обработки представляет собой режим для обработки каждого пакета, кроме заголовка участка, в нормальное время, в которое не происходит потеря пакета. Когда не происходит потеря пакета, модуль 254 управления устанавливают в этот режим 303 обработки для каждого пакета кроме заголовка участка. Режим 304 потери представляет собой режим для обработки оставшихся пакетов участка, когда возникает ошибка, такая как потеря пакета. Когда возникает потеря пакета, модуль 254 управления устанавливают в этот режим 304 потери.
Подробно работа модуля 132 обработки восстановления данных из пакетов в каждом режиме будет описана ниже.
Следует отметить, что фактически, как показано на фиг.23, информацию запуска, информацию окончания, информацию VALID (действительный), информацию атрибута, уведомление об ошибке и т.п. подают, помимо данных, из модуля 132 обработки восстановления данных из пакетов в модуль 133 декодирования.
Информация запуска представляет собой информацию, обозначающую полезную нагрузку головного пакета участка или модуля выравнивания. Когда модуль 132 обработки восстановления данных из пакетов передает полезную нагрузку головного пакета участка или модуля выравнивания в модуль 133 декодирования, значение "1" устанавливают в качестве этой информации запуска. Информация окончания представляет собой информацию, обозначающую полезную нагрузку конечного пакета участка или модуля выравнивания. Когда модуль 132 обработки восстановления данных из пакетов передает полезную нагрузку конечного пакета участка или модуля выравнивания в модуль 133 декодирования, значение "1" устанавливают в качестве этой информации окончания.
Информация атрибута представляет собой информацию, обозначающую, представляют ли собой поданные данные заголовок или данные изображения, или обозначающую, представляют ли собой поданные данные данные компонента яркости или данные компонентов цветности. Информация VALID (действительный) представляет собой информацию, предоставляющую уведомление о времени считывания данных. Уведомление об ошибке представляет собой информацию, уведомляющую модуль 133 декодирования о возникновении ошибки, такой как потеря пакета.
На фиг.24 показана блок-схема, представляющая примерную структуру внутреннего содержания модуля 133 декодирования по фиг.1. Как показано на фиг.24, модуль 133 декодирования включает в себя модуль 351 получения информации управления, модуль 352 управления декодированием, модуль 353 выполнения обработки декодирования, модуль 354 получения заголовка, модуль 355 получения данных, модуль 356 получения уведомления об ошибке и модуль 357 обработки отбрасывания.
Модуль 351 получения информации управления получает из модуля 132 обработки восстановления данных из пакетов информацию управления, такую как информация запуска, информация окончания, информация VALID (действительный) и информация атрибута, и передает информацию управления в модуль 352 управления декодированием. На основе информации управления модуль 352 управления декодированием инициирует модуль 353 выполнения обработки декодирования начать обработку декодирования в заданный момент времени.
На основе информации заголовка, переданной из модуля 132 обработки восстановления данных из пакетов и полученной модулем 354 получения заголовка, модуль 353 выполнения обработки декодирования выполняет обработку декодирования кодированных данных, полученных модулем 355 получения данных. Модуль 353 выполнения обработки декодирования включает в себя, как показано на фиг.24, модуль 361 буфера, модуль 362 энтропийного декодирования и модуль 363 обратного вейвлет-преобразования. Модуль 361 буфера временно считает кодированные данные, переданные из модуля 355 получения данных, и передает эти кодированные данные в модуль 362 энтропийного декодирования в соответствии с необходимостью. Кроме того, модуль 361 буфера временно содержит данные коэффициента, которые представляют собой результат декодирования кодированных данных и которые передают из модуля 362 энтропийного декодирования, и подает данные коэффициента в модуль 363 обратного вейвлет-преобразования в соответствии с необходимостью.
Под управлением модуля 352 управления декодированием модуль 362 энтропийного декодирования считывает кодированные данные, содержащиеся в модуле 361 буфера, и декодирует эти кодированные данные, используя способ, соответствующий модулю 155 энтропийного кодирования, в модуле 121 кодирования, для генерирования данных коэффициента. Следует отметить, что когда выполняют квантование в модуле 155 энтропийного кодирования, после того, как модуль 362 энтропийного декодирования выполнит обработку энтропийного декодирования, модуль 362 энтропийного декодирования дополнительно выполняет обработку удаления квантования полученных данных коэффициента. Модуль 362 энтропийного декодирования передает полученные данные коэффициента в модуль 361 буфера и обеспечивает накопление модулем 361 буфера полученных данных коэффициента.
Модуль 363 обратного вейвлет-преобразования считывает данные коэффициента, накопленные в модуле 361 буфера, в заданный момент времени, выполняет обработку обратного вейвлет-преобразования, используя способ, соответствующий модулю 150 вейвлет-преобразования в модуле 121 кодирования, и выводит полученные данные изображения в основной полосе, в качестве выходных данных изображения в устройство 104 дисплея.
Модуль 354 получения заголовка получает информацию заголовка, такую как заголовок участка и заголовок изображения, переданную из модуля 132 обработки восстановления данных из пакетов, передает ее в модуль 361 буфера и обеспечивает содержание ее в модуле 361 буфера. Модуль 355 получения данных получает данные полезной нагрузки, передаваемой из модуля 132 обработки восстановления данных из пакетов, передает их в модуль 361 буфера и обеспечивает содержание их в модуле 361 буфера.
Модуль 356 получения уведомления об ошибке получает уведомление об ошибке, предоставляя уведомление о возникновении потери пакета при обработке приема или тому подобное, которое подают из модуля 132 обработки восстановления данных из пакетов, и передает ее в модуль 357 обработки отбрасывания. Когда модуль 357 обработки отбрасывания получает уведомление об ошибке, модуль 357 обработки отбрасывания отбрасывает кодированные данные, накопленные в модуле 361 буфера, в модуле 353 расширения обработки декодирования. Таким образом, когда возникает потеря пакета при обработке приема пакета (когда возникновение потери пакета подтверждается на основе номера последовательности), поскольку нормальную обработку энтропийного декодирования текущего участка, в котором произошла потеря пакета, выполнить невозможно, модуль 357 обработки отбрасывания отбрасывает все кодированные данные текущего участка, в котором произошла потеря пакета, который накапливали в модуле 361 буфера.
Далее будет описана последовательность обработки, выполняемой каждым модулем. Вначале, со ссылкой на блок-схему последовательности операций, показную на фиг.25, будет описана примерная последовательность обработки для обработки кодирования, выполняемой модулем 121 кодирования в устройстве 102 передачи.
Когда запускают процесс кодирования, модуль 150 вейвлет-преобразования инициирует на этапе S1 число А, предназначенное для обработки участка. В нормальном случае число А установлено равным «1». Когда установка заканчивается, модуль 150 вейвлет-преобразования получает на этапе S2 данные изображения, эквивалентные количеству строк (то есть один участок), необходимые для генерирования А-й строки, начиная сверху, для подполос самой нижней частоты. На этапе S3, для этих данных изображения модуль 150 вейвлет-преобразования выполняет обработку фильтрации вертикального анализа, состоящую в выполнении фильтрации анализа данных изображения, расположенных в вертикальном направлении на экране. На этапе S4 модуль 150 вейвлет-преобразования выполняет обработку фильтрации горизонтального анализа, состоящую в выполнении фильтрации анализа данных изображения, расположенных в горизонтальном направлении на экране.
На этапе S5 модуль 150 вейвлет-преобразования определяет, была ли выполнена обработка фильтрации анализа до конечного уровня. Когда определяют, что уровень разложения не достиг конечного уровня, обработка возвращается на этап S3, и обработку фильтрации анализа, выполняемую на этапе S3 и этапе S4, повторяют до текущего уровня разложения.
Когда на этапе S5 определяют, что обработка фильтрации анализа была выполнена до конечного уровня, модуль 150 вейвлет-преобразования переходит к обработке на этапе S6.
На этапе S6 модуль 153 изменения порядка коэффициента изменяет порядок коэффициентов участка А (А-й участок, начиная с верхней части изображения (кадра или поля)), в порядке от низкой частоты к высокой частоте. На этапе S7 модуль 155 энтропийного кодирования выполняет энтропийное кодирование коэффициентов на основании от строки к строке.
Когда энтропийное кодирование заканчивается, модуль 155 энтропийного кодирования передает заголовок 171 участка (фиг.7) на этапе S8 и определяет на этапе S9, является или нет текущий участок, предназначенный для обработки, головным участком (то есть А=1) для изображения. Когда определяют, что текущий участок представляет собой головной участок для изображения, обработка переходит к этапу S10, и модуль 155 энтропийного кодирования передает заголовок 172 изображения (фиг.8). Когда обработка на этапе S10 заканчивается, обработка переходит на этап S11. В качестве альтернативы, когда на этапе S9 определяют, что текущий участок, который предназначен для обработки, не является головным участком изображения, обработку на этапе S10 пропускают, и обработка переходит на этап S11.
На этапе S11 модуль 155 энтропийного кодирования передает после информации заголовка кодированные данные, содержащиеся в участке А, наружу.
На этапе S12, модуль 150 вейвлет-преобразования выполняет последовательное приращение значения цифры А на "1", для получения следующего участка для обработки. На этапе S13 модуль 150 вейвлет-преобразования определяет, существует или нет необработанная входная строка изображения в обрабатываемом изображении. Когда определяют присутствие, обработка возвращается на этап S2, и обработку после этого повторяют для нового участка, предназначенного для обработки.
Обработку от этапа S2 до этапа S13 многократно выполняют, как описано выше, и каждый участок кодируют. Кроме того, когда на этапе S13 определяют, что больше нет необработанной входной строки изображения, модуль 150 вейвлет-преобразования заканчивает обработку кодирования изображения. Новая обработка кодирования начинается для следующего изображения.
В случае обычного способа вейвлет-преобразования вначале выполняют обработку фильтрации горизонтального анализа по всему изображению, и затем выполняют обработку фильтрации вертикального анализа для всего изображении. Затем аналогичную обработку фильтрации горизонтального анализа и аналогичную обработку фильтрации вертикального анализа последовательно выполняют для всех компонентов низкой частоты, полученных таким образом. Обработку фильтрации анализа рекурсивно повторяют, как описано выше, до тех пор, пока уровень разложения не достигнет конечного уровня. Поэтому необходимо содержать результат каждой обработки фильтрации анализа в буфере. В этом случае буфер должен содержать результат фильтрации всего изображения или всех компонентов низкой частоты на уровне разложения в этот момент времени. Это означает, что необходима большая емкость запоминающего устройства (объем сохраняемых данных велик).
Кроме того, в этом случае, получение коэффициента и энтропийное кодирование на последующих этапах нельзя выполнять до тех пор, пока не закончится все вейвлет-преобразование по изображению, и время задержки увеличивается.
В отличие от этого, в случае, когда используют модуль 150 вейвлет-преобразования в модуле 121 кодирования, как было описано выше, обработку фильтрации вертикального анализа и обработку фильтрации горизонтального анализа постоянно выполняют до конечного уровня на основе от участка к участку. Таким образом, по сравнению с обычным способом, количество данных, которое требуется содержать (размещать в буфере) в один момент времени (одновременно), невелико, и объем памяти буфера, который должен быть подготовлен, можно существенно уменьшить. Кроме того, поскольку обработку фильтрации анализа выполняют до конечного уровня, также можно выполнять такую обработку, как изменение порядка коэффициента и энтропийное кодирование, на последующих этапах (то есть изменение порядка коэффициента и энтропийное кодирование можно выполнять на основе от участка к участку). Поэтому можно значительно уменьшить время задержки по сравнению с обычным способом.
Кроме того, поскольку модуль 155 энтропийного кодирования подает, вместе с кодированными данными, заголовок 171 участка на основе от участка к участку и заголовок 172 изображения, на основе от изображения к изображению в модуль 122 обработки формирования пакетов, модуль 122 обработки формирования пакетов может просто генерировать информацию заголовка.
Кроме того, поскольку формат заголовка 171 участка и заголовка 172 изображения аналогичен формату заголовка полезной нагрузки, добавленной к пакету модулем 122 обработки формирования пакетов, модуль 122 обработки формирования пакетов может более просто генерировать информацию заголовка.
Кроме того, когда кодирование не получается по некоторой причине, модуль 155 энтропийного кодирования устанавливает НФ заголовка 171 участка, обозначая таким образом, что участок или модуль выравнивания представляет собой участок или модуль выравнивания, который не удалось закодировать. При обращении к этому НФ, модуль 122 обработки формирования пакетов может просто воздержаться от формирования пакетов и передачи недекодируемых, ненужных данных в устройство 103 приемник.
Далее будет описан примерный поток обработки формирования пакетов, выполняемой модулем 122 обработки формирования пакетов, со ссылкой на блок-схему последовательности операций по фиг.26.
На этапе S31 модуль 201 получения данных в модуле 122 обработки формирования пакетов определяет, получен ли или нет заголовок 171 участка, и остается в режиме ожидания до тех пор, пока не будет определено, что заголовок 171 участка был получен. Когда будет определено, что заголовок 171 участка, переданный из модуля 121 кодирования, был получен, обработка переходит на этап S32.
На этапе S32 модуль 202 генерирования заголовка ПРВ генерирует заголовок 221 ПРВ. На этапе S33 модуль 203 генерирования общего заголовка генерирует общий заголовок 231 на основе заголовка 171 участка. В это время модуль 203 генерирования общего заголовка добавляет поля ФНФ, М, ФВШ и СФ к первому слову (Word0) заголовка 171 участка.
На этапе S34 модуль 204 генерирования заголовка расширения генерирует, на основе заголовка 171 участка, заголовок расширения, такой как информация 232 параметра квантования, информация 233 размера, информация 234 формата и информация 236 цвета.
На этапе S3 5 модуль 205 генерирования информации изображения определяет, был ли получен заголовок 172 изображения. Когда определяют, что заголовок 172 изображения был получен, обработка переходит на этап S36. На этапе S36 модуль 205 генерирования информации изображения обращается к заголовку 172 изображения и определяет, равно или нет "1" значение w. Когда определяют, что значение w равно "1", на этапе S37, модуль 205 генерирования информации изображения также включает взвешивающую таблицу (ВТм) в информацию изображения для формирования пакета. Когда обработка на этапе S37 заканчивается, обработка переходит на этап S39.
В качестве альтернативы, когда определяют на этапе S36, что значение w равно "0", модуль 205 генерирования информации изображения удаляет взвешивающую таблицу (ВТм) из информации изображения на этапе S38. Когда обработка на этапе S38 заканчивается, обработка переходит на этап S39.
Кроме того, когда на этапе S35 определяют, что заголовок изображения не был получен, обработка переходит на этап S39.
На этапе S39, модуль 206 проверки флага определяет, равно или нет 0 значение НФ в заголовке 171 участка. Когда определяют, что значение НФ в заголовке 171 участка равно 0, обработка переходит на этап S40.
На этапе S40 модуль 207 проверки размера определяет, превышает или нет размер данных участка максимальный размер полезной нагрузки пакета (размер пакета).
Когда определяют, что размер участка больше, чем размер пакета, обработка переходит на этап S41. На этапе S41 модуль 208 обработки фрагмента разделяет кодированные данные на одном участке с последовательным приращением на величину размера пакета для генерирования полезных нагрузок, которые отличаются друг от друга. Когда обработка на этапе S41 заканчивается, обработка переходит на этап S43.
В качестве альтернативы, когда на этапе S40 определяют, что размер данных участка не превышает размер пакета, модуль 208 обработки фрагмента не разделяет кодированные данные. Таким образом, в этом случае, обработку на этапе S41 пропускают, и обработка переходит на этап S43.
Кроме того, когда на этапе S39 не определяют, что "НФ=0", обработка переходит на этап S42. На этапе S42, модуль 201 получения данных под управлением модуля 206 проверки флага отбрасывает переданные кодированные данные. Когда обработка на этапе S42 заканчивается, обработка переходит на этап S43.
На этапе S43 модуль 209 формирования пакетов использует каждую полезную нагрузку и информацию заголовка для генерирования пакетов ПРВ и, на этапе S44, устанавливает информацию флага, такую как ФНФ и М для каждого пакета.
Когда каждый элемент информации флага установлен, как указано выше, модуль 210 вывода выводит соответствующий пакет ПРВ в модуль 123 передачи.
На этапе S45 модуль 201 получения данных определяет, обработаны или нет все участки. Когда определяют, что существует необработанный участок, обработка возвращается на этап S31, и после этого обработку повторяют. В качестве альтернативы, когда на этапе S45 определяют, что все участки были обработаны, обработка формирования пакетов заканчивается.
Как описано выше, модуль 122 обработки формирования пакетов может просто генерировать общий заголовок и заголовок расширения на основе информации заголовка, переданной из модуля 121 кодирования.
Кроме того, как описано выше, на этапе S36-этапе S38, модуль 205 генерирования информации изображения может просто и быстро управлять добавлением взвешивающей таблицы на основе значения w в заголовке 171 участка. Таким образом, модуль 205 генерирования информации изображения может соответствующим образом добавлять взвешивающую таблицу только, когда это необходимо, просто путем проверки значения w в заголовке 171 участка. В соответствии с этим, можно подавлять ненужное увеличение количества данных, передаваемых из устройства 102 передачи, в устройство 103 приема и ненужное увеличение нагрузки в каждом из их модулей.
Кроме того, как описано выше, когда значение НФ заголовка 171 участка равно "1" на этапе S39, модуль 206 проверки флага управляет модулем 201 получения данных на этапе S42 так, чтобы не получить кодированные данные и не добавить полезную нагрузку к пакету. Таким образом, в этом случае, выходной пакет ПРВ из модуля 122 обработки формирования пакетов включает в себя только информацию заголовка и не включает в себя полезную нагрузку. В соответствии с этим, модуль 122 обработки формирования пакетов может просто и быстро уменьшить передачу недекодируемых, ненужных данных, просто путем ссылки к заголовку 171 участка, переданному из модуля 121 кодирования, и может подавлять ненужное увеличение нагрузки в модуле 123 передачи в линию 110, устройстве 103 приема и т.п.
Кроме того, как было описано выше, когда модуль 207 проверки размера может определить на этапе S40, превышает или нет размер участка размер пакета, на основе заголовка 171 участка, модуль 122 обработки формирования пакетов может просто и быстро определять, следует или нет фрагментировать кодированные данные на одном участке, без их накопления.
Кроме того, на этапе S44, модуль 209 формирования пакетов устанавливает флаг ФНФ в общем заголовке 231 для головного пакета участка и устанавливает флаг М в общем заголовке 231 для замыкающего пакета участка. После того, как эти флаги будут установлены, модуль 132 обработки восстановления данных из пакетов в устройстве 103 приема может просто идентифицировать заголовок участка и окончание участка путем простой ссылки на информацию заголовка. В соответствии с этим, модуль 132 обработки восстановления данных из пакетов может быстро и просто выполнить обработку восстановления данных из пакетов, как будет описано ниже.
Кроме того, в это время, поскольку флаг НФ в общем заголовке 231 был установлен, модуль 132 обработки восстановления данных из пакетов в устройстве 103 приема может легко идентифицировать, какой из пакетов не включает в себя полезную нагрузку, просто путем ссылки на информацию заголовка. В соответствии с этим, модуль 132 обработки восстановления данных из пакетов может быстро и просто выполнить обработку восстановления данных из пакетов, как будет описано ниже.
Далее будет описана обработка, выполняемая модулем 132 обработки восстановления данных из пакетов в устройстве 103 приема, которое принимает пакет. Как было описано выше, модуль 132 обработки восстановления данных из пакетов выполняет обработку восстановления данных из пакетов в четырех режимах управления. В момент времени начала обработки восстановления данных из пакетов модуль 132 обработки восстановления данных из пакетов установлен в режим 301 запуска.
Вначале, со ссылкой на фиг.27, будет описана примерная блок-схема последовательности обработки в режиме запуска, выполняемый модулем 132 обработки восстановления данных из пакетов в режиме 301 запуска.
На этапе S61 модуль 251 получения пакета определяет, был ли или нет получен пакет и остается в режиме ожидания до тех пор, пока не будет определено, что пакет был получен через модуль 131 приема пакета. Когда определяют, что пакет был получен, обработка переходит на этап S62. На этапе S62 модуль 252 анализа информации заголовка получает информацию заголовка пакета и определяет, установлен ли "ИДУ=0", "ФК=4" и "ФНФ=1". Таким образом, модуль 252 анализа информации заголовка определяет, является или нет пакет первым пакетом участка, который представляет собой заголовок изображения, и включает в себя группу из множества компонентов. Когда определяют, что условие "ИДУ=0,", "ФК=4" и "ФНФ=1" не выполняется, обработка возвращается на этап S61, и после этого обработку повторяют. Таким образом, обработку на этапе S61 и обработку на этапе S62 повторяют до тех пор, пока не определят, что "ИДУ=0", "ФК=4" и "ФНФ=1". Когда определяют, что "ИДУ=0", "ФК=4" и "ФНФ=1", обработка переходит на этап S63.
На этапе S63 модуль 254 управления выполняет общую обработку режима, которая представляет собой обработку восстановления данных из пакетов головного пакета участка, которую выполняют в каждом режиме, как будет описано ниже. Подробная информация общей обработки для режима будет описана ниже. Когда обработка общего режима заканчивается, режим управления изменяют на другой режим, и, следовательно, обработка режима запуска заканчивается.
Как описано выше, в режиме запуска, модуль 254 управления может просто детектировать пакет заголовка участка, который находится в начале изображения, просто путем обращения к значению ФНФ в общем заголовке 231. Кроме того, путем детектирования пакета заголовка участка, который находится в начале изображения, модуль 254 управления может начать общую обработку режима в этот момент времени и начать выделять полезную нагрузку из участка. Таким образом, модуль 254 управления может определить новый участок без проверки оконченного пакета участка. Таким образом, момент времени начала выделения полезной нагрузки может быть установлен раньше, и можно уменьшить время задержки.
Ниже, со ссылкой на блок-схему последовательности операций, показанную на фиг.28, будет описан примерный поток общей обработки режима, выполняемой на этапе S63 по фиг.27. Эта обработка общего режима представляет собой, как будет описано ниже, обработку, выполняемую также в других режимах. Когда модуль 132 обработки восстановления данных из пакетов не проверил оконечный пакет предыдущего участка, но проверил головной пакет нового участка, модуль 132 обработки восстановления данных из пакетов выполняет обработку восстановления данных из пакетов этого участка.
Поэтому обработка общего режима начинается в состоянии, в котором модуль 251 получения пакета уже получил пакет.
Когда начинается обработка общего режима, на этапе S82, модуль 252 анализа информации заголовка обращается к общему заголовку 231 и определяет, выполняется или нет условие "НФ=0". Когда определяют, что "НФ=1", обработка переходит на этап S83.
Когда определяют, что "НФ=1", модуль 254 управления на этапе S83 управляет модулем 255 подачи заголовка, модуля 256 подачи данных, и обеспечивает передачу им только участка заголовка пакета в модуль 133 декодирования. В случае НФ=1, в принципе, пакет не включает в себя полезную нагрузку. Даже если пакет включает в себя полезную нагрузку, такая полезная нагрузка не может быть декодирована. Таким образом, модуль 254 управления управляет модулем 256 подачи данных и предотвращает передачу полезной нагрузки.
Когда обработка на этапе S83 заканчивается, модуль 253 изменения режима управления изменяет на этапе S84 режим управления на режим ожидания для ожидания головного пакета следующего участка. Обработка в режиме ожидания будет описана ниже. Когда режим управления изменяют, обработка общего режима заканчивается.
Когда на этапе S82 определяют, что "НФ=0", обработка переходит на этап S85. В этом случае кодированные данные полезной нагрузки представляют собой нормально кодированные данные. На этапе S85, модуль 255 подачи заголовка, под управлением модулем 254 управления, передает четыре слова заголовка участка в модуль 133 декодирования.
На этапе S86 модуль 252 анализа информации заголовка обращается к общему заголовку 231 и определяет, выполняется ли условие "ИДУ=0" и "ФК=4". Когда определяют, что "ИДУ=0" и "ФК=4", обработка переходит на этап S87. На этапе S87 модуль 252 анализа информации заголовка обращается к общему заголовку 231 и определяет, выполняется ли условие "w=1". Когда определяют, что "w=1", обработка переходит на этап S88, и модуль 255 подачи заголовка, под управлением модулем 254 управления, передает 26 слов заголовка 172 изображения в модуль 133 декодирования таким образом, что взвешивающая таблица также будет включена. Когда обработка на этапе S88 заканчивается, обработка переходит на этап S90.
В качестве альтернативы, когда на этапе S87 определяют, что условие "w=1" не выполняется, обработка переходит на этап S89, и модуль 255 подачи заголовка, под управлением модулем 254 управления, передает только шесть слов заголовка 172 изображения в модуль 133 декодирования таким образом, что взвешивающая таблица также не будет включена. Когда обработка на этапе S89 заканчивается, обработка переходит на этап S90.
В качестве альтернативы, когда на этапе S86 не определяют, что "ИДУ=0" и "CR=4", этот участок не является участком, представляющим собой начало изображения. Таким образом, модуль 255 подачи заголовка, под управлением модуля 254 управления, не передает заголовок 172 изображения в модуль 133 декодирования. Поэтому, в этом случае, обработка переходит на этап S90.
На этапе S90 модуль 256 подачи данных, под управлением модуля 254 управления, передает остающуюся полезную нагрузку пакета, то есть кодированные данные, в модуль 133 декодирования. На этапе S91 модуль 252 анализа информации заголовка обращается к общему заголовку 231 и определяет, выполняется или нет условие "М=1". Когда "М=1" и когда определяют, что пакет, предназначенный для обработки, представляет собой конечный пакет участка, обработка переходит на этап S92, и модуль 254 управления под управлением модуля 253 изменения режима управления изменяет режим управления на режим ожидания. Таким образом, поскольку обработка конечного пакета закончилась, режим управления изменяется на режим ожидания, состоящий в ожидании головного пакета следующего участка. Когда режим управления изменяется, общая обработка режим заканчивается.
В качестве альтернативы, когда на этапе S91 определяют, что условие "М=1" не выполняется и пакет, предназначенный для обработки, не представляет собой конечный пакет участка, обработка переходит на этап S93, и модуль 254 управления, под управлением модуля 253 изменения режима управления, изменяет режим управления на режим обработки. Таким образом, поскольку такая обработка передачи пакета, который не является конечным пакетом, закончилась нормально, режим управления изменяют на режим обработки, состоящий в ожидании последующего пакета того же участка. Когда режим управления изменяют, общая обработка режима заканчивается. Когда общую обработку режима выполняют на этапе S63 по фиг.27 и при этом происходит окончание общей обработки режима, обработка возвращается на этап S63 по фиг.27, и обработка режима запуска заканчивается.
Как описано выше, модуль 132 обработки восстановления данных из пакетов может просто идентифицировать, на основе значений ФНФ и М, головной пакет и конечный пакет участка. Кроме того, поскольку модуль 132 обработки восстановления данных из пакетов может идентифицировать конечный пакет на основе М, модуль 132 обработки восстановления данных из пакетов может просто и соответствующим образом изменять режим на основе от участка к участку. В соответствии с этим, модуль 132 обработки восстановления данных из пакетов может соответствующим образом выполнять обработку восстановления данных из пакетов каждого участка. Кроме того, поскольку модуль 132 обработки восстановления данных из пакетов может идентифицировать головной пакет на основе ФНФ, модуль 132 обработки восстановления данных из пакетов может определять обновление участка, без проверки конечного пакета. Таким образом, например, даже когда происходит потеря пакета, то есть даже когда номер последовательности полученного пакета не будет непрерывным с номером последовательности последнего полученного пакета, если этот пакет представляет собой головной пакет нового участка, модуль 132 обработки восстановления данных из пакетов может начать выделять полезную нагрузку из пакета нового участка, без ожидания следующего участка. Таким образом, модуль 132 обработки восстановления данных из пакетов может уменьшить ненужное время ожидания. Само собой разумеется, что поскольку модуль 132 обработки восстановления данных из пакетов может уменьшить время ожидания, выполняя общую обработку режима не только в режиме запуска, но также и в режиме обработки, и в режиме потери может быть реализовано уменьшение времени задержки.
Кроме того, так же, как и на этапе S83, модуль 132 обработки восстановления данных из пакетов может просто воздержаться от подачи неподлежащей декодированию, ненужной полезной нагрузки в модуль 133 декодирования, просто путем обращения к общему заголовку 231. В соответствии с этим, нагрузка на обработку декодирования модуля 133 декодирования может быть уменьшена. Следует отметить, что поскольку информацию заголовка можно использовать при обработке декодирования, модуль 254 управления передает только информацию заголовка.
Далее, со ссылкой на блок-схему последовательности операций, показанную на фиг.29, будет описан примерный поток обработки в режиме ожидания. Такая обработка в режиме ожидания представляет собой обработку в режиме ожидания головного пакета следующего участка. Когда режим управления изменяют с помощью модуля 253 изменения режима управления на режим ожидания, начинается обработка режима ожидания.
Когда начинается обработка режима ожидания, модуль 251 получения пакета определяет на этапе S111, был ли или нет принят пакет и остается в режиме ожидания до тех пор, пока не будет определено, что пакет был принят. Когда пакет будет подан из модуля 131 приема и будет определено, что этот пакет был принят, обработка переходит на этап S112.
На этапе S122 модуль 252 анализа информации заголовка обращается к заголовку 221 ПРВ и определяет, является или нет номер последовательности непрерывным с последним принятым пакетом. Когда номер последовательности не является непрерывным с последним принятым пакетом, это означает, что произошел неудачный прием пакета (произошла потеря пакета). Когда номер последовательности является непрерывным с последним принятым пакетом и когда определяют, что не произошла потеря пакета, обработка переходит на этап S113.
Каждую обработку на этапе S113-этапе S122 выполняют аналогично каждой обработке на этапе S82 и этапе S83, этапе S85-этапе S91 и на этапе S93 общей обработки режима, описанной со ссылкой на фиг.28.
Таким образом, обработка на этапе S113 соответствует этапу S82, и обработка на этапе S114 соответствует этапу S83. Следует отметить, что, в случае обработки в режиме ожидания, поскольку режим уже представляет собой режим ожидания, обработку, соответствующую этапу S84 по фиг.28, пропускают, и обработка переходит на этап S111 (это эквивалентно изменению режима на режим ожидания и началу обработки в режиме ожидания по фиг.28).
Кроме того, этапы S115-S121 соответствуют этапу S85-этапу S91 по фиг.28 соответственно. Следует отметить, что, в случае обработки в режиме ожидания, поскольку режим уже представляет собой режим ожидания, когда на этапе S121 определяют, что "М=1", обработку, соответствующую этапу S92 по фиг.28, пропускают, и обработка переходит на этап S111 (это эквивалентно изменению режима на режим ожидания и началу обработки режима ожидания по фиг.28).
Следует отметить, что когда на этапе S121 определяют, что условие "М=1" не выполняется, обработка переходит на этап S122. Такая обработка на этапе S122 соответствует обработке на этапе S93 по фиг.28. Когда модуль 253 изменения режима управления изменяет режим управления на режим обработки, обработка режима ожидания заканчивается.
В качестве альтернативы, когда на этапе S112 определяют, что номер последовательности не является непрерывным с последним принятым пакетом и что произошла потеря пакета, обработка переходит на этап S123.
На этапе S123 модуль 252 анализа информации заголовка обращается к общему заголовку 231 и определяет, выполняется или нет условие "ФНФ=1". Когда определяют, что "ФНФ=1", обработка возвращается на этап S113, и после этого обработку повторяют. Поскольку обработку декодирования выполняют на основе от участка к участку, если потеря пакета не произошла на участке, этот участок подлежит декодированию. Таким образом, когда "ФНФ=1", это означает, что потеря пакета произошла не на участке, к которому принадлежит текущий, предназначенный для обработки пакет, но на предыдущем участке. Кроме того, в случае режима ожидания, накопление кодированных данных на последнем участке, используя модуль 133 декодирования, заканчивается. Поэтому, даже когда происходит потеря пакета, если вновь полученный пакет представляет собой головной пакет нового участка, эту потерю пакета игнорируют, и обработка возвращается на этап S113.
Когда на этапе S123 определяют, что условие "ФНФ=1" не выполняется, обработка переходит на этап S124. В этом случае происходит потеря пакета на том же участке, которому принадлежит пакет, предназначенный для обработки. Поэтому этот участок не подлежит декодированию, и, следовательно, передачу полезной нагрузки отменяют. Таким образом, на этапе S124, модуль 256 передачи данных под управлением модуля 254 управления отбрасывает принятый пакет без передачи его в модуль 133 декодирования.
Как было описано выше, поскольку режим представляет собой режим ожидания, накопление кодированных данных для предыдущего участка, используя модуль 133 декодирования, заканчивается, и кодированные данные нового участка еще не были накоплены. Поэтому, в этом случае, поскольку модуль 133 декодирования не должен отбрасывать данные, модуль 132 обработки восстановления данных из пакетов не должен предоставлять уведомление об ошибке в модуль 133 декодирования.
На этапе S125 модуль 254 управления, под управлением модуля 253 изменения режима управления, изменяет на участке, на котором произошла ошибка, режим управления на режим потери, который представляет собой режим ожидания пакета следующего участка, который должен быть получен. Когда режим управления изменяют на режим потери, обработка режима ожидания заканчивается.
Как отмечено выше, модуль 132 обработки восстановления данных из пакетов может просто идентифицировать, на основе значений ФНФ и М, головной пакет и оконечный пакет участка в режиме ожидания. Кроме того, поскольку модуль 132 обработки восстановления данных из пакетов может идентифицировать оконечный пакет на основе М, модуль 132 обработки восстановления данных из пакетов может просто и соответствующим образом изменять режим на основе от участка к участку. В соответствии с этим, модуль 132 обработки восстановления данных из пакетов может соответствующим образом выполнять обработку восстановления данных из пакетов на каждом участке. Кроме того, поскольку модуль 132 обработки восстановления данных из пакетов может идентифицировать головной пакет на основе ФНФ, модуль 132 обработки восстановления данных из пакетов может определять обновление участка, без проверки оконечного пакета. Таким образом, например, даже когда происходит потеря пакета, то есть даже когда номер последовательности полученного пакета не является непрерывным с номером последовательности последнего полученного пакета, если этот пакет представляет собой головной пакет нового участка, модуль 132 обработки восстановления данных из пакетов может начать выделение полезной нагрузки из пакета для нового участка, без ожидания следующего участка. Таким образом, модуль 132 обработки восстановления данных из пакетов может уменьшить ненужное время ожидания.
Далее, со ссылкой на блок-схему последовательности операций, показанную на фиг.30, будет описан примерный поток обработки для режима обработки. Такая обработка в режиме обработки представляет собой обработку в режиме ожидания следующего пакета на том же участке. Когда модуль 253 изменения режима управления изменяет режим управления на режим обработки, начинается обработка в режиме обработки.
Когда начинается обработка в режиме обработки, модуль 251 получения пакета определяет на этапе S141, был или нет принят пакет, и остается в режиме ожидания до тех пор, пока не будет определено, что пакет был принят. Когда пакет подают из модуля 131 приема и определяют, что пакет был принят, обработка переходит на этап S142.
На этапе S142 модуль 252 анализа информации заголовка обращается к заголовку 221 ПРВ и определяет, является или нет номер последовательности непрерывным с последним принятым пакетом. Когда номер последовательности является непрерывным с последним принятым пакетом и когда определяют, что не произошла потеря пакета, обработка переходит на этап S143.
На этапе S143 модуль 255 подачи заголовка, под управлением модуля 254 управления, удаляет общий заголовок 231 из пакета. На этапе S144 модуль 256 подачи данных, под управлением модуля 254 управления, передает остающиеся данные полезной нагрузки в модуль 133 декодирования. На этапе S145 модуль 252 анализа информации заголовка обращается к общему заголовку 231 и определяет, выполняется ли условие "М=1". Когда определяют, что условие "М=1" не выполняется и пакет не является конечным пакетом участка, следующий пакет присутствует на том же участке. Таким образом, обработка возвращается на этап S141, и обработка после этого повторяется.
Таким образом, в то время как обработку с этапа S141 по этап S145 повторяют, полезную нагрузку выделяют из каждого пакета участка и передают в модуль 133 декодирования.
Когда на этапе S145 определяют, что "М=1" и что пакет, предназначенный для обработки, представляет собой оконечный пакет участка, обработка переходит на этап S146, и модуль 254 управления под управлением модуля 253 изменения режима управления изменяет режим управления на режим ожидания. Когда режим управления изменяют на режим ожидания, обработка в режиме обработки заканчивается.
В качестве альтернативы, когда на этапе S142 определяют, что номер последовательности не является непрерывным с последним принятым пакетом и что произошла потеря пакета, обработка переходит на этап S147.
В этом случае, поскольку данные на этой участке накапливались в модуле 133 декодирования, на этапе S147 модуль 257 уведомления об ошибке под управлением модуля 254 управления представляет уведомление об ошибке передачи в модуль 133 декодирования.
Когда уведомление об ошибке заканчивается, на этапе S148, модуль 252 анализа информации заголовка обращается к общему заголовку 231 и определяет, выполняется ли условие "ФНФ=1". Когда определяют, что "ФНФ=1", обработка переходит на этап S149. На этапе S149 модуль 254 управления выполняет общую обработку режима, описанную со ссылкой на блок-схему последовательности операций, показанную на фиг.28. В этом случае, когда общая обработка режима заканчивается, обработка возвращается на этап S149 на фиг.30, и обработка в режиме обработки заканчивается.
В качестве альтернативы, когда на этапе S148 определяют, что условие "ФНФ=1" не выполняется, обработка переходит на этап S150, и модуль 256 подачи данных, под управлением модуля 254 управления, отбрасывает принятый пакет. На этапе S151, модуль 254 управления, под управлением модуля 253 изменения режима управления, изменяет режим управления на режим потери. Когда режим управления изменяется на режим потери, обработка в режиме обработки заканчивается.
Как описано выше, модуль 132 обработки восстановления данных из пакетов может просто идентифицировать, на основе значений ФНФ и М, головной пакет и оконечный пакет участка в режиме обработки. Кроме того, поскольку модуль 132 обработки восстановления данных из пакетов может идентифицировать оконечный пакет, на основе М, модуль 132 обработки восстановления данных из пакетов может просто и соответствующим образом изменять режим на основе от участка к участку. В соответствии с этим, модуль 132 обработки восстановления данных из пакетов может соответствующим образом выполнять обработку восстановления данных из пакетов на каждом участке. Кроме того, поскольку модуль 132 обработки восстановления данных из пакетов может идентифицировать головной пакет на основе ФНФ, модуль 132 обработки восстановления данных из пакетов может определять обновление участка, без проверки оконечного пакета.
Например, когда не происходит потеря пакета, модуль 132 обработки восстановления данных из пакетов выделяет полезную нагрузку из отдельных пакетов, которые подают последовательно, проверяют оконечный пакет на основе значения М, и когда определяют, что обработка этого участка заканчивается, изменяет режим на режим ожидания.
Когда происходит потеря пакета, модуль 132 обработки восстановления данных из пакетов уведомляет модуль 133 декодирования об ошибке. Когда пакет не представляет собой головной пакет, этот пакет отбрасывают. Режим изменяют на режим потери таким образом, что обработка ожидает проверки пакета следующего участка. Следует отметить, что когда "ФНФ=1", то есть когда пакет, полученный во время проверки потери пакета, представляет собой головной пакет нового участка, модуль 132 обработки восстановления данных из пакетов выполняет общую обработку режима таким образом, что без изменения режима на режим ожидания или режим потери, то есть без ожидания пакета на новом участке, модуль 132 обработки восстановления данных из пакетов может начать выделение полезной нагрузки из этого участка. Таким образом, момент времени начала выделения полезной нагрузки может быть сделан более ранним, и при этом можно уменьшить время задержки.
Далее будет описана примерная последовательность обработки в режиме потери со ссылкой на блок-схему последовательности обработки по фиг.31. Эта обработка в режиме потери представляет собой обработку в режиме ожидания, например, когда происходит потеря пакета на том же участке, для приема пакета на следующем участке. Когда модуль 253 изменения режима управления изменяет режим управления на режим потери, начинается обработка в режиме потери.
Когда начинается обработка в режиме потери, модуль 251 получения пакета определяет на этапе S171, был ли принят пакет, и остается в режиме ожидания до тех пор, пока не будет определено, что пакет был принят. Когда пакет будет подан из модуля 131 приема и будет определено, что пакет был принят, обработка переходит на этап S172.
На этапе S172 модуль 252 анализа информации заголовка обращается к общему заголовку 231 и определяет, выполняется ли условие "ФНФ=1". Когда определяют, что условие "ФНФ=1" не выполняется и что пакет не является головным пакетом участка, обработка переходит на этап S173, и модуль 252 анализа информации заголовка определяет теперь, выполняется или нет условие "М=1". Когда определяют, что условие "М=1" не выполняется, то есть когда определяют, что пакет не представляет собой конечный пакет участка, обработка возвращается на этап S171, и после этого обработку повторяют.
Когда на этапе S173 определяют, что "М=1", обработка переходит на этап S174, и модуль 254 управления под управлением модуля 253 изменения режима управления изменяет режим управления на режим ожидания. Когда режим управления меняется на режим ожидания, обработка в режиме потери заканчивается.
В качестве альтернативы, когда на этапе S172 определяют, что "ФНФ=1", модуль
254 управления выполняет общую обработку режима, описанную со ссылкой на блок-схему последовательности операций на фиг.28. В этом случае, когда общая обработка режима заканчивается, обработка возвращается на этап S175 по фиг.31, и обработка режима потери заканчивается.
Таким образом, модуль 132 обработки восстановления данных из пакетов может просто идентифицировать, на основе значений ФНФ и М, головной пакет и оконечный пакет участка также в режиме потери. Кроме того, поскольку модуль 132 обработки восстановления данных из пакетов может идентифицировать конечный пакет на основе М, модуль 132 обработки восстановления данных из пакетов может просто и соответствующим образом изменять режим на основе от участка к участку. В соответствии с этим, модуль 132 обработки восстановления данных из пакетов может соответствующим образом выполнять обработку восстановления данных из пакетов на каждом участке. Кроме того, поскольку модуль 132 обработки восстановления данных из пакетов может идентифицировать головной пакет на основе ФНФ, модуль 132 обработки восстановления данных из пакетов может определять обновление участка без проверки оконечного пакета.
В случае режима потери модуль 132 обработки восстановления данных из пакетов, в принципе, находится в режиме ожидания при получении пакетов. Когда будет детектирован оконечный пакет на основе значения М, режим изменяется на режим ожидания, и модуль 132 обработки восстановления данных из пакетов подготовлен для получения головного пакета следующего участка. Кроме того, когда детектируют головной пакет на основе значения ФНФ, модуль 132 обработки восстановления данных из пакетов выполняет общую обработку режима, начиная, таким образом, выделение полезной нагрузки из этого участка.
В соответствии с этим, модуль 132 обработки восстановления данных из пакетов может сделать момент времени начала выделения полезной нагрузки более ранним и уменьшить время задержки.
Выполняя обработку восстановления данных из пакетов, переключая режим управления в соответствии с ситуацией, как описано выше, так, что при этом предусмотрен буфер восстановления данных из пакетов, модуль 132 обработки восстановления данных из пакетов может соответствующим образом выполнять последовательную обработку на основе информации заголовка подаваемых пакетов, без накопления пакетов на основе от участка к участку. Модуль 132 обработки восстановления данных из пакетов может просто и быстро выполнять обработку восстановления данных из пакетов. Кроме того, когда происходит потеря пакета, модуль 132 обработки восстановления данных из пакетов представляет уведомление об ошибке, в соответствии с необходимостью. Таким образом, модуль 133 декодирования может воздержаться от выполнения ненужной обработки декодирования и уменьшить нагрузку при обработке декодирования.
Кроме того, на основе значения НФ, модуль 132 обработки восстановления данных из пакетов может просто воздержаться от подачи неподлежащей декодированию, ненужной полезной нагрузки в модуль 133 декодирования. В соответствии с этим, нагрузка, связанная с обработкой декодирования, модуля 133 декодирования может быть уменьшена.
Модуль 133 декодирования выполняет, в ответ на обработку, выполняемую модулем 132 обработки восстановления данных из пакетов, как описано выше, обработку декодирования для кодированных данных, передаваемых из модуля 132 обработки восстановления данных из пакетов. Поэтому модуль 133 декодирования выполняет обработку управления декодированием, состоящую в выполнении управления обработкой декодирования. Примерная последовательность обработки управления декодирования будет описана со ссылкой на блок-схему последовательности операций, выполняемую на фиг.32. Такую обработку управления декодированием выполняют от момента начала подачи кодированных данных до окончания подачи кодированных данных.
На этапе S191 модуль 355 получения данных получает кодированные данные, поданные из модуля 132 обработки восстановления данных из пакетов. На этапе S192 модуль 361 буфера накапливает кодированные данные. На этапе S193 модуль 351 получения информации управления получает информацию управления. На этапе S194 модуль 352 управления декодированием определяет, на основе информации управления, полученной модулем 351 получения информации управления, являются или нет данные, полученные модулем 355 получения данных, полезной нагрузкой головного пакета участка. Когда определяют, что данные представляют собой полезную нагрузку головного пакета участка, обработка переходит на этап S195. На этапе S195 модуль 352 управления декодированием определяет, на основе информации управления, полученной модулем 351 получения информации управления, являются ли или нет непрерывными элементы данных, полученные модулем 351 получения информации управления и накопленные в модуле 361 буфера. Когда определяют, что потеря пакета не произошла и элементы данных, полученные модулем 355 получения данных и накопленные в модуле 361 буфера, являются непрерывными, обработка возвращается на этап S191, и обработку, начиная с этапа S191 и далее, повторяют для следующего элемента кодированных данных.
В качестве альтернативы, когда на этапе S195 определяют, что произошла потеря пакета и элементы данных не являются непрерывными, обработка переходит на этап S196. На этапе S196 модуль 352 управления декодированием управляет модулем 362 энтропийного декодирования с тем, чтобы начать обработку дополнения. Модуль 362 энтропийного декодирования выполняет обработку декодирования на основе от участка к участку. Когда данные участка отсутствуют, модуль 362 энтропийного декодирования выполняет обработку дополнения, используя данные другого участка или тому подобное.
Поэтому, когда модуль 352 управления декодированием получает головной пакет, который не является непрерывным с последним полученным пакетом, модуль 352 управления декодированием управляет модулем 362 энтропийного декодирования, для выполнения обработки дополнения последнего участка. Когда обработка дополнения заканчивается, обработка переходит на этап S197.
На этапе S197 модуль 352 управления декодированием определяет, следует или нет закончить обработку управления декодированием. Когда определяют, что обработка управления декодированием не должна закончиться, обработка возвращается на этап S191, и повторяют обработку, следующую после этого. В качестве альтернативы, когда на этапе S197 определяют, что требуется закончить обработку управления декодированием, обработку управления декодированием заканчивают.
В качестве альтернативы, когда на этапе S194 определяют, что данные, полученные модулем 355 получения данных, не представляют собой полезную нагрузку головного пакета участка, обработка переходит на этап S198, и модуль 352 управления декодированием определяет, являются или нет данные, полученные модулем 355 получения данных, полезной нагрузкой конечного пакета участка. Когда определяют, что данные представляют собой полезную нагрузку оконечного пакета участка, обработка переходит на этап S199, и модуль 352 управления декодированием управляет модулем 362 энтропийного декодирования для начала обработки декодирования кодированных данных, накопленных в модуле 361 буфера. Когда обработка на этапе S199 заканчивается, обработка возвращается на этап S197.
В качестве альтернативы, когда на этапе S198 определяют, что данные, полученные модулем 355 получения данных, не представляют собой полезную нагрузку конечного пакета участка, обработка возвращается на этап S197.
Далее, со ссылкой на блок-схему последовательности операций, показанную на фиг.33, будет описана примерная последовательность обработки декодирования, начинающаяся на этапе S199 по фиг.32. Этой обработкой декодирования управляют с помощью обработки управления декодированием по фиг.32, и выполняют ее на основе от участка к участку.
Когда начинается обработка декодирования, модуль 362 энтропийного декодирования получает на этапе S211 кодированные данные, накопленные в модуле 361 буфера, и выполняет на этапе S212 энтропийное декодирование кодированных данных на основе от строки к строке. На этапе S213 модуль 361 буфера содержит декодированные, полученные данные коэффициента. На этапе S214 модуль 363 обратного вейвлет-преобразования определяет, накоплены или нет данные коэффициента, эквивалентные одному участку, в модуле 361 буфера. Когда определяют, что данные коэффициента, эквивалентные одному участку, не накоплены в модуле 361 буфера, обработка возвращается на этап S211, и выполняют следующую после него обработку. Модуль 363 обратного вейвлет-преобразования остается в режиме ожидания до тех пор, пока данные коэффициента, эквивалентные одному участку, не будут накоплены в модуле 361 буфера.
Когда на этапе S214 определяют, что данные коэффициента, эквивалентные одному участку, накоплены в модуле 361 буфера, модуль 363 обратного вейвлет-преобразования переходит к обработке на этапе S215 и считывает данные коэффициента, эквивалентные одному участку, который содержится в модуле 361 буфера.
Затем, для считанных данных коэффициента, модуль 363 обратного вейвлет-преобразования выполняет на этапе S216 обработку фильтрации вертикального комбинирования, состоящую в выполнении обработки фильтрации комбинирования данных коэффициента, расположенных на экране в вертикальном направлении, и выполняет на этапе S217 обработку фильтрации горизонтального комбинирования, состоящую в выполнении обработки фильтрации комбинирования данных коэффициента, расположенных в горизонтальном направлении на экране. На этапе S218 определяют, закончена ли обработка фильтрации комбинирования до уровня 1 (уровень в случае, когда значение уровня разложения равно "1"), то есть выполнено ли обратное преобразование, вплоть до состояния перед вейвлет-преобразованием. Когда определяют, что уровень не достиг уровня 1, обработка возвращается на этап S216, и повторяют обработку фильтрации на этапе S216 и этапе S217.
Когда на этапе S218 определяют, что обработка обратного преобразования закончена до уровня 1, модуль 363 обратного вейвлет-преобразования переводит обработку на этап S219 и выводит наружу данные изображения, полученные в результате выполнения обработки обратного преобразования.
На этапе S220 модуль 362 энтропийного декодирования определяет, следует или нет закончить обработку декодирования. Когда определяют, что обработку декодирования не следует закончить, обработка возвращается на этап S211 и обработку, следующую после этого, повторяют. В качестве альтернативы, когда определяют на этапе S220, что следует закончить обработку декодирования, поскольку участок заканчивается или тому подобное, модуль 362 энтропийного декодирования заканчивает обработку декодирования.
В случае использования обычного способа обратного вейвлет-преобразования, вначале выполняют обработку фильтрации горизонтального комбинирования в горизонтальном направлении экрана, по всем коэффициентам на уровне разложения, предназначенным для обработки, и затем выполняют обработку фильтрации вертикального комбинирования в вертикальном направлении экрана, по всем коэффициентам на уровне разложения, предназначенным для обработки. Таким образом, каждый раз, когда выполняют каждую обработку фильтрации комбинирования, необходимо сохранять результат обработки фильтрации комбинирования в буфере. В связи с этим, буфер должен содержать результат фильтрации комбинирования на уровне разложения в этот момент времени и все коэффициенты на следующем уровне разложения. Это означает, что необходим большой объем памяти (количество данных, которое требуется сохранять, велико).
Кроме того, в этом случае не выполняют вывод входных данных изображения до тех пор, пока не закончится полное обратное вейвлет-преобразование изображения (поле для случая системы с чередованием), и, следовательно, увеличивается время задержки от входа до выхода.
В отличие от этого, в случае, когда используют модуль 363 обратного вейвлет-преобразования в модуле 133 декодирования, как было описано выше, обработку фильтрации вертикального комбинирования и обработку фильтрации горизонтального комбинирования выполняют постоянно, вплоть до уровня 1, на основе от участка к участку. Таким образом, по сравнению с обычным способом, количество данных, которые должны быть размещены в буфере в одно и то же время (одновременно), невелико, и объем памяти буфера, который должен быть подготовлен, можно значительно уменьшить. Кроме того, поскольку обработку фильтрации комбинирования (обработку обратного вейвлет-преобразования) выполняют вплоть до уровня 1, элементы данных изображения можно последовательно выводить (на основе от участка к участку) прежде, чем будут получены данные всего изображения, и время задержки можно значительно уменьшить по сравнению с обычным способом.
Далее, со ссылкой на блок-схему последовательности операций, показанную на фиг.34, будет описана примерная последовательность обработки уведомления об ошибке, которая представляет собой обработку, выполняемую в ответ на уведомление об ошибке, из модуля 132 обработки восстановления данных из пакетов, и выполняемую в модуле 133 декодирования параллельно обработке управления декодирования, показанной на фиг.32.
На фиг.34, когда начинается обработка уведомления об ошибке, модуль 356 получения уведомления об ошибке определяет, на этапе S241, было ли получено уведомление об ошибке из модуля 132 обработки восстановления данных из пакетов. Эта обработка находится в режиме ожидания до тех пор, пока не будет определено, что было получено уведомление об ошибке. Когда на этапе S241 определяют, что было получено уведомление об ошибке, обработка переходит на этап S242. На этапе S242 модуль 357 обработки отбрасывания определяет, присутствует или нет участок, принимаемый в настоящее время (кодированные данные, принадлежащие последнему участку, в котором произошла потеря пакета), в модуле 361 буфера.
Когда определяют, что участок, принимаемый в данный момент времени, существует в модуле 361 буфера, обработка переходит на этап S243. На этапе S243, модуль 357 обработки отбрасывания отбрасывает принимаемый срез, который был накоплен в модуле 361 буфера. Когда обработка на этапе S243 заканчивается, обработка переходит на этап S244. В качестве альтернативы, когда на этапе S242 определяют, что принимаемый в данный момент времени срез не существует в модуле 361 буфера, обработку на этапе S243 пропускают, и обработка переходит на этап S244.
На этапе S244 модуль 357 обработки отбрасывания определяет, следует или нет закончить обработку уведомления об ошибке. Когда обработка восстановления данных из пакетов продолжается и также определяют, что не следует закончить обработку уведомления об ошибке, обработка возвращается на этап S241 и обработку, следующую после него, повторяют. В качестве альтернативы, когда на этапе S244 определяют, что следует закончить обработку уведомления об ошибке, обработку уведомления об ошибке заканчивают.
Как отмечено выше, поскольку модуль 133 декодирования отбрасывает кодированные данные среза, в которых произошла потеря пакета, в ответ на уведомление об ошибке из модуля 132 обработки восстановления данных из пакетов, модуль 133 декодирования может быть установлен так, что он не будет выполнять ненужную обработку декодирования. Поскольку соответствующая обработка декодирования может быть выполнена, как описано выше, модуль 133 декодирования может просто и быстро выполнить обработку декодирования. Нагрузка, связанная с обработкой декодирования, может быть уменьшена, и это позволяет уменьшить размеры схемы и ее стоимость.
Пример обработки уведомления об ошибке, выполняемой модулем 132 обработки восстановления данных из пакетов, показан на фиг.35.
На фиг.35 предполагается, что модуль 132 обработки восстановления данных из пакетов и модуль 133 декодирования соединены друг с другом через шесть линий передачи сигналов. Модуль 132 обработки восстановления данных из пакетов передает в модуль 133 декодирования кодированные данные (DTCa1), выделяемые в результате удаления заголовка ПРВ и т.п., из принятого пакета 1. В это время, когда кодированные данные (DTCa1) представляют собой заголовок нового среза, модуль 258 передачи сигнала управления в модуле 132 обработки восстановления данных из пакетов, которым управляет модуль 254 управления, получает уведомление об информации запуска (START).
Когда следующий поступающий пакет представляет собой пакет 5, определяют, что произошла потеря пакета. В это время, поскольку DTCa1, который представляет собой часть участка, уже был передан в модуль 133 декодирования, модуль 257 уведомления об ошибке в модуле 132 обработки восстановления данных из пакетов, которым управляет модуль 254 управления, выполняет уведомление об ошибке. Кроме того, поскольку пакет 5 представляет "ФНФ=1", модуль 258 подачи сигнала управления, в модуле 132 обработки восстановления данных из пакетов, которым управляет модуль 254 управления, вырабатывает уведомление об информации запуска (START).
Следует отметить, что выше было описано, что когда размер данных участка превышает размер пакета, модуль 122 обработки формирования пакетов генерирует множество пакетов путем разделения данных, и, в противном случае, модуль 122 обработки пакета генерирует один пакет, как описано выше. В качестве альтернативы, когда размер данных участка меньше, чем размер пакета, элементы данных из множества участков могут быть сгруппированы как один пакет.
В этом случае используют такую конструкцию заголовка полезной нагрузки, как показано на фиг.36, в которой, например, информация заголовка и полезные нагрузки расположены последовательно. В случае примера по фиг.36, после общего заголовка 231 до полезной нагрузки 237, которая представляет собой элементы данных на первом участке, расположена информация 431 сегмента, информация 432 параметра квантования, информация 433 размера, информация 434 формата, информация 435 изображения, информация 436 цвета и полезная нагрузка 437, которые представляют собой элементы данных на втором участке. После этого расположены элементы данных на третьем участке и т.д.
Информация 431 сегмента представляет собой общий заголовок второго участка и, как показано на фиг.37, в основном, включает в себя информацию, аналогичную общему заголовку 231. Таким образом, информацию 431 сегмента генерируют на основе заголовка 171 участка. Следует отметить, что когда после этого участка присутствуют данные другого участка, значение СФ в общем заголовке 231 (аналогично информации 431 сегмента) устанавливают равным "1".
Примерная последовательность обработки формирования пакетов в этом случае будет описана со ссылкой на блок-схему последовательности операций, показанную на фиг.38.
Как показано на фиг.38, обработку формирования пакетов в этом случае также, в принципе, выполняют аналогично случаю, описанному со ссылкой на фиг.26. Каждую обработку на этапах S301-этап S312 выполняют аналогично каждой обработке, выполняемой на этапах S31-этап S42 по фиг.26, и каждую обработку на этапе S315-этапе S317 выполняют аналогично каждой обработке, выполняемой на этапе S43-этапе S45 по фиг.26.
Следует отметить, что когда на этапе S310 определяют, что размер участка не превышает размер пакета, модуль 207 проверки размера в модуле 122 обработки формирования пакетов определяет, можно или нет добавить новую полезную нагрузку к тому же пакету. Когда определяют, что размер пакета оставляет некоторое пространство и, соответственно, может быть добавлена полезная нагрузка, обработка переходит на этап S314, и модуль 201 получения данных определяет, получен или нет заголовок участка, и остается в режиме ожидания до тех пор, пока не будет определено, что заголовок участка был получен. Когда будет определено, что заголовок участка получен, обработка возвращается на этап S303, и обработку, выполняемую после него, повторяют для участка, добавляемого к пакету. Таким образом, обработку цикла от этапа S303-этап S310, этап S313 и этап S314 повторяют, последовательно добавляя, таким образом, участки к тому же пакету до тех пор, пока общий объем кодированных данных не станет больше, чем размер пакета.
Следует отметить, что когда на этапе S315 определяют, что полезная нагрузка не может быть добавлена к пакету, обработка возвращается на этап S313, и выполняют обработку, следующую после него. Таким образом, в этом случае генерируют один пакет с кодированными данными на одном участке.
Выполняя обработку формирования пакетов, как описано выше, данные множества участков могут быть включены в один пакет.
Различную обработку, выполняемую отдельными модулями системы 100 передачи, показанной на фиг.1, как описано выше, выполняют соответствующим образом параллельно, как показано на фиг.39.
На фиг.39 показана схема, представляющая структуру примера параллельной работы отдельных элементов обработки, выполняемой отдельными модулями системы 100 передачи, показанной на фиг.1. Эта фиг.39 соответствует фиг.6, описанной выше. Первое вейвлет-преобразование WT-1 (позиция В на фиг.39) применяют ко входу In-1 (позиция А на фиг.39) данных изображения и в модуле 150 вейвлет-преобразования (фиг.2). Как было описано со ссылкой на фиг.5, такое первое вейвлет-преобразование WT-1 начинают в момент времени, в который вводят первые три строки и генерируют коэффициент С1. Таким образом возникает задержка, эквивалентная трем строкам, от момента ввода данных изображения In-1 до начала вейвлет-преобразования WT-1.
Сгенерированные данные коэффициента сохраняют в модуле 152 буфера изменения порядка коэффициента (фиг.2). После этого вейвлет-преобразование применяют ко входным данным изображения, и, когда первая обработка будет закончена, обработка непосредственно переходит к второму вейвлет-преобразованию WT-2.
Параллельно вводу данных изображения In-2 для второго вейвлет-преобразования WT-2 и обработке второго вейвлет-преобразования WT-2 выполняют изменение порядка Ord-1 трех из коэффициента С1, коэффициента С4 и коэффициента С5, с помощью модуля 153 изменения порядка коэффициента (фиг.2) (позиция С на фиг.39).
Следует отметить, что задержка от завершения вейвлет-преобразования WT-1 до начала изменения порядка Ord-1 представляет собой задержку, основанную на конфигурации устройства или системы, такую как задержка, связанная с передачей сигнала управления для инструктирования модуля 153 изменения порядка коэффициента выполнить обработку изменения порядка, задержка, требуемая для начала обработки, выполненной модулем 153 изменения порядка коэффициента, в ответ на сигнал управления, и задержка, требуемая для обработки программы, и представляет собой не существенную задержку при обработке кодирования.
Элементы данных коэффициента считывают из модуля 152 буфера изменения порядка коэффициента в порядке, в котором они были закончены, во время изменения порядка, и передают в модуль 155 энтропийного кодирования (фиг.2), и выполняют их энтропийное кодирование ЕС-1 (позиция D на фиг.39). Такое энтропийное кодирование ЕС-1 может начинаться без ожидания завершения изменения порядка всех трех коэффициентов: коэффициента С1, коэффициента С4 и коэффициента С5. Например, в момент времени, в который изменение порядка одной строки на основе коэффициента С5, который выводят первым, заканчивается, может быть начато энтропийное кодирование коэффициента С5. В этом случае задержка от начала обработки изменения порядка Ord-1 до начала обработки энтропийного кодирования ЕС-1 эквивалентна одной строке.
Заданную обработку сигналов применяют к кодированным данным, для которых было закончено энтропийное кодирование ЕС-1, выполненное модулем 155 энтропийного кодирования, и затем передают через линию 110 в устройство 103 приема (позиция Е на фиг.39). В это время из кодированных данных формируют пакеты и передают их.
После ввода данных изображения, эквивалентных семи строкам, в соответствии с первой обработкой, элементы данных изображения до строки нижнего конца экрана последовательно вводят в модуль 121 кодирования в устройстве 102 передачи. В соответствии с вводом In-n (n равняется 2 или больше) данных изображения, модуль 121 кодирования выполняет вейвлет-преобразование WT-n, изменяя порядок Ord-n и порядок энтропийного кодирования ЕС-n каждые четыре строки, как описано выше. Изменение порядка Ord и порядка энтропийного кодирования ЕС (ЭК) в модуле 121 кодирования, в ответ на последнюю обработку, выполняют по шести строкам. Эту обработку выполняют параллельно в модуле 121 кодирования, как представлено в позиции А на фиг.39 - в позиции D на фиг.39.
Пакет кодированных данных, которые были кодированы с помощью модуля 121 кодирования с энтропийным кодированием ЕС-1, передают в устройство 103 приема, выполняют обработку восстановления данных из пакетов и т.п., и последовательно подают в модуль 133 декодирования. Модуль 362 энтропийного декодирования в модуле 133 декодирования последовательно выполняет декодирование iEC-1 энтропийного кодирования кодированных данных, которые были кодированы с использованием энтропийного кодирования ЕС-1, которые были переданы в него, и восстанавливает данные коэффициента (F на фиг.39). Элементы восстановленных данных коэффициента последовательно сохраняют в модуле 361 буфера. Когда такое количество элементов данных коэффициента, которое требуется для выполнения обратного вейвлет-преобразования, сохраняют в модуле 361 буфера, модуль 363 обратного вейвлет-преобразования считывает данные коэффициента из модуля 361 буфера и выполняет обратное вейвлет-преобразование iWT-1, используя считанные данные коэффициента (G на фиг.39).
Как было описано со ссылкой на фиг.5, обратное вейвлет-преобразование iWT-1, выполняемое модулем 363 обратного вейвлет-преобразования, может начинаться в момент времени, в который коэффициент С4 и коэффициент С5 сохраняют в модуле 361 буфера. Поэтому задержка от момента начала декодирования iEC-1, выполняемого модулем 362 энтропийного декодирования, до начала обратного вейвлет-преобразования iWT-1, выполняемого модулем 363 обратного вейвлет-преобразования, эквивалентна двум строкам.
Когда обратное вейвлет-преобразование iWT-1, эквивалентное трем строкам первого вейвлет-преобразования, заканчивают в модуле 363 обратного вейвлет-преобразования, выход Out-1 данных изображения, генерируемых при обратном вейвлет-преобразовании iWT-1, выполняют (позиция Н на фиг.39). Через выход Out-1, как было описано, используя фиг.5 и фиг.6, выводят данные изображения первой строки.
Последовательно вводу данных кодированного коэффициента, эквивалентных трем строкам первой обработки, выполняемой модулем 121 кодирования, элементы данных коэффициента, кодированных при энтропийном кодировании ЕС-n (n равно 2 или больше), последовательно вводят в модуль 133 декодирования. Модуль 133 декодирования выполняет энтропийное декодирование iEC-n и обратное вейвлет-преобразование iWT-n вводимых данных коэффициента через каждые четыре строки и последовательно выполняет вывод Out-n данных изображения, восстановленных при обратном вейвлет-преобразовании iWT-n, как было описано выше. Энтропийное декодирование iEC и обратное вейвлет-преобразование iWT, в ответ на выполненное в последний раз модулем 121 кодирования, выполняют по шести строкам, и на выход Out выводят восемь строк. Эту обработку выполняют параллельно в модуле 133 декодирования, как представлено в позиции F на фиг.39 - позиции Н на фиг.39.
В результате выполнения отдельной обработки в модуле 121 кодирования и модуле 133 декодирования параллельно, в порядке от верхнего участка до нижнего участка экрана, как было описано выше, обработку сжатия изображения и обработку декодирования изображения можно выполнять с меньшей задержкой.
Как показано на фиг.39, рассчитывают время задержки от ввода изображения до вывода изображения, в случае когда выполняют вейвлет-преобразование вплоть до уровня разложения = 2, используя фильтр 5×3. Время задержки от момента ввода данных изображения первой строки в модуль 121 кодирования до момента, когда данные изображения первой строки выводят из модуля 133 декодирования, представляет собой общую сумму следующих отдельных элементов. Следует отметить, что здесь исключена задержка, которая отличается в зависимости от конфигурации системы, такая как задержка при передаче строки или задержка, связанная с фактическим временем обработки каждого модуля устройства.
(1) Задержка D_WT от первой вводимой строки до завершения вейвлет-преобразования WT-1, которое эквивалентно семи строкам.
(2) Время D_Ord, связанное с изменением порядка коэффициента Ord-1, эквивалентным трем строкам.
(3) Время D_EC, связанное с энтропийным кодированием ЕС-1, эквивалентным трем строкам.
(4) Время D_iEC, связанное с энтропийным декодированием, эквивалентным трем строкам.
(5) Время D_iWT, связанное с обратным вейвлет-преобразованием iWT-1, эквивалентным трем строкам.
Со ссылкой на фиг.39 сделана попытка расчета времени задержки каждого из отдельных элементов, описанных выше. Задержка D_WT в пункте (1) представляет собой время, эквивалентное десяти строкам. Время D_Ord в пункте (2) представляет собой время D_EC в пункте (3), время D_iEC в пункте (4) и время D_iWT в пункте (5), каждое эквивалентно трем строкам. Кроме того, энтропийное кодирование ЕС-1 может начинаться в модуле 121 кодирования, через одну строку после начала изменения порядка Ord-1. Аналогично, обратное вейвлет-преобразование iWT-1 может начинаться в модуле 133 декодирования, через две строки после начала энтропийного декодирования iEC-1. Кроме того, энтропийное декодирование iEC-1 может начинать обработку в момент времени, в который кодирование, эквивалентное одной строке, заканчивается при энтропийном кодировании ЕС-1.
Поэтому в примере, показанном на фиг.39, время задержки от ввода данных изображения первой строки в модуль 121 кодирования до вывода данных изображения первой строки из модуля 133 декодирования эквивалентно 10+1+1+2+3=17 строкам.
Рассмотрим время задержки, используя более конкретный пример. В случае, когда входные данные изображения представляют собой видеосигнал с чередованием, на основе HDTV (телевидение высокой четкости, ТВВЧ), например, один кадр конфигурируют с возможностью разрешения 1920 пикселей × 1080 строк, и одно поле состоит из 1920 пикселей × 540 строк. Поэтому, когда предполагается, что частота кадров равна 30 Гц, 540 строк, используемых как одно поле, вводят в модуль 121 кодирования в течение времени 16,67 мс (= 1 секунда/60 полей).
Поэтому время задержки, связанное с вводом данных изображения, эквивалентных семи строкам, составляет 0,216 мс (=16,67 мс × 7/540 строк), которое представляет собой очень короткое время, например, относительно времени обновления одного поля. Кроме того, что касается общей суммы описанной выше задержки D_WT в пункте (1), времени D_Ord в пункте (2), времени D_EC в пункте (3), времени D_iEC в пункте (4) и времени D_iWT в пункте (5), количество строк, которое требуется обработать, также мало, и, соответственно, время задержки будет значительно уменьшено. Если элементы для выполнения отдельной обработки будут реализованы в виде аппаратных средств, время обработки может быть дополнительно уменьшено.
ФНФ и информация флага М будут описаны ниже.
Как описано выше, в системе 100 передачи, поскольку допуск на увеличение времени задержки невелик, установлено требование как можно более эффективной передачи данных и выполнения необходимой обработки эффективным образом.
В настоящее время существуют системы, которые выполняют кодирование и декодирование с последовательным приращением заданных модулей данных. Когда выполняют формирование пакетов и передают кодированные данные, как в системе 100 передачи, показанной на фиг.1, выполняют некоторое разделение кодированных данных в модуле данных на элементы данных и формируют пакеты из отдельных элементов данных, и передают их. Следует отметить, что, в случае обычной системы, поскольку допуск на время задержки велик, пакеты, эквивалентные модулю данных, накапливают при обработке восстановления данных из пакетов, и обработку восстановления данных из пакетов выполняют с последовательным приращением размера модуля данных. В соответствии с этим, только полные кодированные данные, эквивалентные модулю данных, можно подавать в модуль декодирования и декодировать.
Однако в таком способе возникает потребность в размещении данных в буфере как в модуле обработки восстановления данных из пакетов, так и в модуле кодирования, что является нежелательным в системе 100 передачи, в которой требуется уменьшить время задержки.
Поэтому, как было описано выше, используя то факт, что обработка элементов передаваемых кодированных данных может выполняться в отдельных модулях, в порядке, в котором их подают, модуль 132 обработки восстановления данных из пакетов последовательно выделяет данные полезной нагрузки из принимаемых пакетов и передает их в модуль 133 декодирования без накопления. Модуль 133 декодирования начинает обработку декодирования каждый раз, когда накапливают последовательно подаваемые кодированные данные, эквивалентные одному участку. В соответствии с этим, количество раз, когда кодированные данные размещают в буфере, можно уменьшить, и в системе 100 передачи можно дополнительно уменьшить время задержки.
ФНФ и М представляют собой информацию флага, обозначающую заголовок участка и конец участка. На основе информации флага модуль 132 обработки восстановления данных из пакетов может детектировать заголовок и конец участка и уведомлять свой модуль 133 декодирования. На основе уведомления из модуля 132 обработки восстановления данных из пакетов, модуль 133 декодирования может определять разрыв участков и начинать обработку декодирования на основе от участка к участку.
Для достижения только этой цели достаточно использовать только М, который обозначает конец участка. Пусть имеется смесь из пакета, полученного в результате разделения участка на множество элементов, и пакета, который не был разделен. Если имеется информация флага, обозначающая, что разделение было выполнено, возможна идентификация этих пакетов.
Фактически, однако, также следует рассматривать случай, когда модуль 131 приема не в состоянии принять (теряет) пакет. Когда происходит потеря пакета, как описано выше, поскольку модуль 132 обработки восстановления данных из пакетов не размещает пакет в буфере, модуль обработки должен быть изменен по сравнению с модулем, используемым в нормальное время. Например, когда происходит потеря пакета, в случае системы 100 передачи, поскольку время, необходимое для устройства 102 передачи, для повторной передачи пакета нельзя обеспечить, кодированные данные участка будут поданы не полностью. Таким образом, в результате возникновения потери пакета модуль 133 декодирования теперь не в состоянии выполнять обработку декодирования этого участка.
Поэтому, например, когда происходит потеря пакета (пакетов) в середине участка, также предусматривается накопление кодированных данных вплоть до этой точки на участке в модуле 133 декодирования. В таком случае модуль 132 обработки восстановления данных из пакетов уведомляет модуль 133 декодирования о возникновении потери пакета и инициирует отбрасывание модулем 133 декодирования кодированных данных на том же участке, что и кодированные данные потерянного пакета (пакетов). В соответствии с этим, модуль 133 декодирования может исключить выполнение ненужной обработки декодирования (обработки декодирования, которая будет неудачной) этого участка, что позволяет уменьшить нагрузку.
Кроме того, как только происходит потеря пакета, кодированные данные, следующие после этого на участке, становятся ненужными. Поэтому, даже когда модуль 132 обработки восстановления данных из пакетов принимает пакет, такой модуль 132 обработки восстановления данных из пакетов не передает кодированные данные в модуль 133 декодирования до тех пор, пока не будет получен следующий участок и т.д. Когда пакет из нового участка будет получен, модуль 132 обработки восстановления данных из пакетов начинает подавать кодированные данные.
В соответствии с этим, модуль 132 обработки восстановления данных из пакетов изменяет режим управления в соответствии с ситуацией и выполняет соответствующую, требуемую обработку. Поэтому модуль 132 обработки восстановления данных из пакетов обращается к ФНФ и М и детектирует заголовок и окончание участка. В этом случае, когда имеется только М, который обозначает конец, модуль 132 обработки восстановления данных из пакетов не может определять, что произошло изменение участка до тех пор, пока конец участка не будет детектирован. Например, когда конечный пакет участка будет потерян, модуль 132 обработки восстановления данных из пакетов должен дополнительно ждать следующего нового участка. При этом не только увеличивается время задержки, но также не может быть выполнена обработка декодирования в модуле 133 декодирования. Это приводит к возможности ухудшения качества изображения для восстановленного изображения.
В отличие от этого, что касается значения ФНФ и детектирования головного пакета, модуль 132 обработки восстановления данных из пакетов может не только уменьшить ненужное время ожидания, например, при повторном начале подачи данных в модуль 133 декодирования, но также выполняет исключительную обработку только головного пакета, таким образом, подавая не только кодированные данные, но также информацию заголовка, в модуль 133 декодирования, пропуская уведомления об ошибке, с помощью которых уведомляют модуль 133 декодирования о возникновении потери пакета, и продолжая подавать кодированные данные в модуль 133 декодирования, даже когда происходит потеря пакета.
В соответствии с этим, модуль 132 обработки восстановления данных из пакетов может соответствующим образом выполнять обработку на основе ФНФ и информации флага М и может дополнительно уменьшить время задержки.
Кроме того, на основе этих ФНФ и М, модуль 132 обработки восстановления данных из пакетов уведомляет модуль 133 декодирования о том факте, что поданные кодированные данные находятся в заголовке или в конце участка. В соответствии с этим, модуль 133 декодирования может простоя определять начало и конец участка. Таким образом, например, когда поступает конец участка, модуль 133 декодирования может начать обработку декодирования; когда поступает заголовок нового участка, который не является непрерывным, модуль 133 декодирования может выполнять обработку дополнения предыдущего потерянного участка. Таким образом, модуль 133 декодирования может просто и быстро выполнять такое управление на основе уведомления из модуля 132 обработки восстановления данных из пакетов.
Как отмечено выше, ФНФ и М представляют собой не просто информацию флага для уведомления о начале момента времени обработки восстановления данных из пакетов и обработки декодирования, но представляет собой информацию флага, инициирующую модуль 132 обработки восстановления данных из пакетов и модуля 133 декодирования выбрать и выполнить соответствующую обработку, в соответствующие моменты времени, для того, чтобы дополнительно уменьшить время задержки до тех пор, пока кодированные данные не будут декодированы и выведены.
Теперь, со ссылкой на фиг.2, было описано, что изменение порядка коэффициентов выполняют непосредственно после вейвлет-преобразования (перед энтропийным кодированием), но необходимо только, чтобы кодированные данные были поданы в модуль 363 обратного вейвлет-преобразования в модуле 133 декодирования, в порядке от низкой частоты к высокой частоте (то есть необходимо только, чтобы кодированные данные были поданы в порядке от кодированных данных, полученных по данным коэффициента кодирования, принадлежащим подполосе низкой частоты, до кодированных данных, полученных по данным коэффициента кодирования, принадлежащим подполосе высокой частоты), и время изменения порядка может быть другими, чем непосредственно после вейвлет-преобразования.
Например, порядок кодированных данных, полученных в результате энтропийного кодирования, может быть изменен. На фиг.40 показана блок-схема, представляющая примерную структуру модуля кодирования в этом случае.
В случае по фиг.40, модуль 500 кодирования включает в себя, как и в случае модуля 121 кодирования по фиг.2, модуль 150 вейвлет-преобразования, модуль 151 буфера промежуточных расчетов, модуль 155 энтропийного кодирования и модуль 154 управления скоростью и включает в себя вместо модуля 152 буфера изменения порядка коэффициента и модуля 153 изменения порядка коэффициента по фиг.2 модуль 501 буфера изменения порядка кода и модуль 502 изменения порядка кода.
Модуль 501 буфера изменения порядка кода представляет собой буфер для изменения порядка вывода кодированных данных, которые были кодированы в модуле 155 энтропийного кодирования, и модуль 502 изменения порядка кода считывает кодированные данные, накопленные в модуле 501 буфера изменения порядка кода, в заданном порядке, изменяя, таким образом, порядок вывода кодированных данных.
Таким образом, в случае фиг.40, вейвлет-коэффициенты, выводимые из модуля 150 вейвлет-преобразования, подают в модуль 155 энтропийного кодирования и кодируют. Отдельные элементы кодированных данных, полученных в результате кодирования, последовательно подают в модуль 501 буфера изменения порядка кода и временно накапливают в нем для изменения порядка.
Модуль 502 изменения порядка кода считывает кодированные данные, записанные в модуль 501 буфера изменения порядка кода, в требуемом порядке и выводит эти кодированные данные наружу из модуля 500 кодирования.
В случае примера, показанного на фиг.40, модуль 155 энтропийного кодирования выполняет кодирование отдельных элементов данных коэффициента для вывода с помощью модуля 150 вейвлет-преобразования и записывает полученные кодированные данные в модуль 501 буфера изменения порядка кода. Таким образом, кодированные данные сохраняют в модуле 501 буфера изменения порядка кода в порядке, который соответствует порядку вывода вейвлет-коэффициентов модулем 150 вейвлет-преобразования. В нормальном случае, когда сравнивают два элемента данных коэффициента, принадлежащих одному участку, модуль 150 вейвлет-преобразования выводит элемент данных коэффициента, который принадлежит подполосе более высокой частоты в более раннее время, и выводит элемент коэффициента, который принадлежит подполосе более низкой частоты в более позднее время. Таким образом, отдельные элементы кодированных данных последовательно сохраняют в модуле 501 буфера изменения порядка кода в порядке от кодированных данных, полученных путем выполнения энтропийного кодирования данных коэффициента, принадлежащих подполосе высокой частоты, в направлении кодированных данных, полученных в результате выполнения энтропийного кодирования данных коэффициента, принадлежащих подполосе низкой частоты.
В отличие от этого, независимо от этого порядка, модуль 502 изменения порядка кода считывает отдельные элементы кодированных данных, накопленных в модуле 501 буфера изменения порядка кода, в произвольном порядке, выполняя, таким образом, изменение порядка кодированных данных.
Например, модуль 502 изменения порядка кода, предпочтительно, считывает кодированные данные, полученные в результате кодирования данных коэффициента, принадлежащих подполосе низкой частоты, и считывает, в конечном итоге, кодированные данные, полученные в результате кодирования данных коэффициента, принадлежащих подполосе самой высокой частоты. В результате считывания кодированных данных от низкой частоты в направлении высокой частоты, таким образом, модуль 502 изменения порядка кода позволяет модулю 133 декодирования декодировать отдельные элементы кодированных данных в полученном порядке, и время задержки, которое возникает при обработке декодирования, выполняемой модулем 133 декодирования, может быть уменьшено.
Модуль 502 изменения порядка кода считывает кодированные данные, накопленные в модуле 501 буфера изменения порядка кода, и выводит их за пределы модуля 500 кодирования.
Следует отметить, что данные, кодируемые и выводимые модулем 500 кодирования, показанным на фиг.40, могут быть декодированы модулем 133 декодирования, как уже было описано, используя фиг.24, как и в случае кодированных данных, выводимых из модуля 121 кодирования на фиг.2.
Кроме того, моменты времени выполнения обработки изменения порядка могут отличаться от описанных выше. Например, изменение порядка может быть выполнено в модуле кодирования, как показано в примере по фиг.41, или может быть выполнено в модуле декодирования, как показано в примере на фиг.42.
При обработке изменения порядка данных коэффициента, генерируемых при вейвлет-преобразовании, относительно большая емкость необходима в качестве емкости для сохранения в буфере изменения порядка коэффициента, и также предъявляются высокие требования к возможностям по обработке для самой обработки изменения порядка коэффициента. Даже в этом случае, вообще не возникают какие-либо проблемы, когда возможности обработки модуля кодирования выше или равны определенному уровню.
Здесь будет рассмотрен случай, в котором модуль кодирования установлен в устройстве, возможности обработки которого относительно малы, таком как, так называемый мобильный терминал, например, терминал - мобильный телефон или КПК (карманный персональный компьютер). Например, продукты в виде терминалов, таких как мобильный телефон, в которых добавлена функция съемки изображения (называются терминалы типа мобильного телефона с функцией камеры), получили широкое распространение в последние годы. При этом рассматривается возможность выполнения сжатия и кодирования данных изображения, снятых таким терминалом мобильного телефона с функцией камеры, используя вейвлет-преобразование и энтропийное кодирование, и передачи данных изображения через беспроводные или кабельные каналы передачи данных.
Что касается такого мобильного терминала, в качестве примера, возможности обработки его CPU (ЦПУ, центральное процессорное устройство) ограничены, и существует определенный верхний предел емкости памяти. В соответствии с этим, нагрузка при обработке и т.п., связанная с описанным выше изменением порядка коэффициента, вызывает проблему, которой нельзя пренебречь.
Поэтому, как показано в примере на фиг.42, нагрузка на модуле кодирования уменьшается в результате внедрения обработки изменения порядка в модуле декодирования, что позволяет устанавливать модуль кодирования в устройство, вычислительные возможности которого относительно малы, такое как мобильный терминал.
На фиг.43 показана блок-схема, представляющая примерную структуру модуля кодирования в этом случае. Следует отметить, что на фиг.43 участки, общие с описанной выше фиг.2, обозначены теми же номерами ссылочных позиций, и их подробное описание здесь не приведено.
Структура модуля 510 кодирования, показанного на этой фиг.43, представляет собой структуру, полученную в результате удаления модуля 153 изменения порядка коэффициента и модуля 152 буфера изменения порядка коэффициента из структуры модуля 121 кодирования, показанной на фиг.2, описанной выше. Таким образом, модуль 510 кодирования включает в себя, как и модуль 121 кодирования, модуль 150 вейвлет-преобразования, модуль 151 буфера промежуточных расчетов, модуль 154 управления скоростью и модуль 155 энтропийного кодирования.
Данные входного изображения временно накапливают в модуле 151 буфера промежуточных расчетов. Модуль 150 вейвлет-преобразования применяет вейвлет-преобразование к данным изображения, накопленным в модуле 151 буфера промежуточных расчетов, и последовательно передает элементы сгенерированных данных коэффициента в модуль 155 энтропийного кодирования, в порядке, в котором были сгенерированы элементы данных коэффициента. Таким образом, сгенерированные данные коэффициента подают в модуль 155 энтропийного кодирования в порядке от компонентов высокой частоты к компонентам низкой частоты, в соответствии с порядком вейвлет-преобразования. Модуль 155 энтропийного кодирования применяет энтропийное кодирование к подаваемым коэффициентам, в то время как скоростью передачи битов выходных данных управляют с помощью модуля 154 управления скоростью. Кодированные данные, полученные в результате выполнения энтропийного кодирования данных коэффициента, генерируемых в результате вейвлет-преобразования, выводят из модуля 155 энтропийного кодирования.
На фиг.44 показана блок-схема, представляющая примерную структуру устройства декодирования, соответствующего данному модулю 510 кодирования. Следует отметить, что на фиг.44 участки, общие, с описанной выше фиг.24, обозначены теми же номерами ссылочных позиций, и их подробное описание здесь не приведено.
Как показано на фиг.44, модуль 520 декодирования в данном случае включает в себя, как и модуль 133 декодирования по фиг.24, модуль 351 получения информации управления, модуль 352 управления декодированием, модуль 353 выполнения обработки декодирования, модуль 354 получения заголовка, модуль 355 получения данных, модуль 356 получения уведомления об ошибке и модуль 357 обработки отбрасывания. Модуль 353 выполнения обработки декодирования дополнительно включает в себя модуль 521 буфера изменения порядка коэффициента.
Кодированные данные, выводимые из модуля 155 энтропийного кодирования в модуль 510 кодирования, описанный со ссылкой на фиг.43, передают в модуль 362 энтропийного декодирования через модуль 361 буфера, в модуль 520 декодирования по фиг.44, и энтропийное кодирование кодированных данных декодируют для генерирования данных коэффициента. Эти данные коэффициента сохраняют в модуле 521 буфера изменения порядка коэффициента через модуль 361 буфера. Когда накапливают такое количество данных коэффициента, которое требуется для обеспечения возможности изменения порядка данных коэффициента, в модуле 521 буфера изменения порядка коэффициента, модуль 363 обратного вейвлет-преобразования изменяет порядок данных коэффициента, сохраненных в модуле 521 буфера изменения порядка коэффициента, в порядке от компонентов низкой частоты к компонентам высокой частоты, для считывания данных коэффициента, и выполняет обратное вейвлет-преобразование, используя данные коэффициента в порядке считывания. В случае, когда требуется использовать фильтр 5×3, это будет выполнено так, как показано на описанной выше фиг.42.
Таким образом, например, в случае, когда обработка начинается с заголовка одного фрейма, в момент времени, в который коэффициент С1, коэффициент С4 и коэффициент С5, энтропийное кодирование которых было декодировано, сохраняют в модуле 521 буфера изменения порядка коэффициента, модуль 363 обратного вейвлет-преобразования считывает данные коэффициента из модуля 521 буфера изменения порядка коэффициента и выполняет обратное вейвлет-преобразование. Элементы данных, которые были преобразованы с использованием обратного вейвлет-преобразования в модуле 363 обратного вейвлет-преобразования, последовательно выводят как выходные данные изображения.
Следует отметить, что в этом случае, также как уже было описано выше со ссылкой на фиг.39, обработку, выполняемую отдельными элементами в модуле 510 кодирования, передачу кодированных данных в линию передачи и процессы, выполняемые отдельными элементами в модуле 520 декодирования, выполняют параллельно.
Тот факт, что изобретение применимо к различным режимам и его можно легко применять к различным вариантам применения (то есть высокая разносторонность), как описано выше, также представляет собой большие преимущества.
Теперь, как было описано выше, часто возникает ситуация, при которой происходят ошибки при передаче в процессе передачи данных, при передаче цифровых видеоданных, в ходе которой передают видео- и аудиоданные, что влияет на качество воспроизведения.
Желательно так или иначе уменьшить влияние таких ошибок передачи. В качестве такого способа, например, существует способ, с помощью которого делают попытку восстановить сами данные, содержащие ошибки (способ восстановления данных). Однако, в случае использования такого способа, хотя полное изображение может быть воспроизведено, если восстановление было успешным, возникает вероятность увеличения времени задержки, поскольку теперь требуется время на восстановление данных, или эффективная скорость передачи данных падает в результате восстановления ошибок.
В отличие от этого, существует способ, при котором, хотя данные с ошибками оставляют в том виде, как они есть, делают так, что ошибка после декодирования становится как можно менее заметной, например, в результате отображения непосредственно предыдущего изображения без ошибки, в том виде, как оно есть, или путем оценки участка с ошибкой по предыдущему и последующему изображениям (способ сокрытия ошибки).
В случае применения такого способа сокрытия ошибки, хотя полное изображение не может быть воспроизведено, нет необходимости ожидать в течение времени восстановления данных, поскольку способ просто представляет собой замену данных, в которых возникла ошибка, другим элементом данных, таким как предыдущий или следующий кадр. Поэтому обработку можно выполнять с меньшей задержкой. Однако такая замена данных должна быть выполнена с приращением с размером величины изображения (кадр или поле) или с более грубой гранулярностью, чем эта.
Например, для ошибки, которая возникла на участке изображения (кадр или поле), когда только этот участок заменяют предыдущим или последующим изображением, структура на этом участке не соответствует структурам на других участках, и, соответственно, изображение нельзя построить из всего изображения. Таким образом, все изображение (или диапазон из множества таких изображений) должно быть заменено. Поэтому задержка одного изображения или больше требуется для замены таких данных, и, таким образом, становится трудно реализовать дополнительное уменьшение времени задержки при передаче данных.
В соответствии с этим, ниже будет описан способ уменьшения влияния ошибок при передаче, с подавлением увеличения времени задержки.
На фиг.45 показана схема, представляющая другую примерную структуру системы передачи, в которой применяется настоящее изобретение.
Система 600 передачи, показанная на фиг.45, в принципе, представляет собой систему, аналогичную системе 100 передачи, показанной на фиг.1. Система 600 передачи представляет собой систему передачи данных, в которой устройство 602 передачи сжимает и кодирует данные изображения, генерируемые устройством 101 съемки изображения, и формирует пакеты, и передает в них данные изображения; устройство 603 приема принимает пакеты, переданные через линию 110, и восстанавливает данные из пакета, и декодирует эти пакеты; и устройство 104 дисплея отображает изображение на основе полученных данных изображения.
Более детальные примерные структуры устройства 602 передачи и устройства 603 приема показаны на фиг.46.
Как показано на фиг.46, устройство 602 передачи включает в себя, помимо модуля 121 кодирования, модуль 122 обработки формирования пакетов и модуль 123 передачи, модуль 621 анализа, модуль 622 сохранения и модуль 623 генерирования заголовка сокрытия.
Модуль 621 анализа выполняет анализ сокрытия ошибки входных данных изображения. Следует отметить, что сокрытие ошибки представляет собой сокрытие ошибок передачи, которые возникают во время передачи данных. Модуль 622 сохранения включает в себя носитель сохранения, такой как жесткий диск или полупроводниковое запоминающее устройство, и содержит требуемое количество, одно изображение или больше, входных данных изображения. Модуль 621 анализа сравнивает входные данные изображения с данными изображения одного предыдущего изображения, считанного из модуля 622 сохранения. Следует отметить, что предполагается, что модуль 621 анализа выполняет обработку с последовательным приращением размера участка (блок строк), для уменьшения задержки, хотя модуль 621 анализа может выполнять анализ с приращением с размером любого модуля данных. Таким образом, модуль 621 анализа сравнивает изображения участков в одном и том же положении, в двух последовательных изображениях (кадрах или полях). Модуль 621 анализа передает результат сравнения в качестве результата анализа в модуль 623 генерирования заголовка сокрытия.
Модуль 623 генерирования заголовка сокрытия генерирует на основе результата анализа заголовок сокрытия, который представляет собой информацию сокрытия, обозначающую способ сокрытия ошибки на участке. При более конкретном описании, модуль 623 генерирования заголовка сокрытия генерирует, при обработке сокрытия ошибки, выполняемой устройством 603 приема, информацию заголовка (заголовок сокрытия), включающую в себя информацию, обозначающую участок, который может заменить участок, в котором возникла ошибка (информацию, обозначающую, какой элемент данных, на каком участке, какого изображения можно использовать для выполнения замены), и передает ее в модуль 122 обработки формирования пакетов.
Модуль 122 обработки формирования пакетов генерирует (формирует пакеты) пакеты передачи из кодированных данных, переданных из модуля 121 кодирования, и заголовка сокрытия, переданного из модуля 623 генерирования заголовка сокрытия. Таким образом, модуль 122 обработки формирования пакетов добавляет (мультиплексирует) заголовок сокрытия к кодированным данным и формирует пакеты из мультиплексированных данных. Пакеты, генерируемые таким образом, передают с помощью модуля 123 передачи в устройство 603 приема.
Кроме того, как показано на фиг.46, устройство 603 приема включает в себя, помимо модуля 131 приема, модуль 132 обработки восстановления данных из пакетов и модуль 133 декодирования, модуль 631 анализа потери и модуль 632 сохранения.
Пакеты, переданные из устройства 602 передачи, принимают с помощью модуля 131 приема и выполняют восстановление данных из пакета с помощью модуля 132 обработки восстановления данных из пакетов, для выделения кодированных данных. Выделенные кодированные данные передают в модуль 631 анализа потери. Кроме того, в это время, модуль 132 обработки восстановления данных из пакетов выделяет, вместе с кодированными данными, заголовок сокрытия и передает этот заголовок сокрытия в модуль 631 анализа потери.
На основе заголовка сокрытия модуль 631 анализа потери выполняет сокрытие ошибки для возникшей ошибки передачи, соответствующим образом используя кодированные данные, сохраненные в модуле 632 сохранения. Следует отметить, что предполагается, что модуль 631 анализа потери выполняет обработку с последовательным приращением размера участка, для уменьшения задержки, хотя модуль 631 анализа потери может выполнять анализ с последовательным приращением с размером любого модуля данных.
Модуль 632 сохранения включает в себя носитель сохранения, такой как жесткий диск или полупроводниковое запоминающее устройство, и содержит требуемое количество кодированных данных, переданных в прошлом (прошлые кодированные данные). Обращаясь к заголовку сокрытия, модуль 631 анализа потери определяет прошлые кодированные данные, которые можно использовать для замены данных (то есть, какой элемент данных, на каком участке, какого изображения используют для замены). Затем модуль 631 анализа потери считывает упомянутые кодированные данные из модуля 632 сохранения и заменяет этими данными участок, на котором возникла ошибка передачи.
Модуль 133 декодирования декодирует кодированные данные после обработки сокрытия ошибки, передаваемые из модуля 631 анализа потери, и выводит данные изображения в основной полосе.
Далее будет описан заголовок сокрытия. На фиг.47 показана схема, иллюстрирующая примерную структуру заголовка сокрытия. Как показано на фиг.47, заголовок 640 сокрытия представляет собой 32-битную информацию и включает в себя ИД 641 изображения, ИД 642 участка, ИД 643 изображения заголовка замены, RF (флаг замены, ФЗ) 644, SF (флаг слайда, ФС) 645 и ИД 646 участка заголовка замены.
ИД 641 изображения представляет собой 8-битную информацию идентификации, которая идентифицирует текущее изображение (предназначенное для обработки) во всех данных движущегося изображения. ИД 642 участка представляет собой 8-битную информацию идентификации, которая идентифицирует текущий участок (предназначенный для обработки) в изображении. ИД 643 изображения заголовка замены представляет собой 8-битную информацию идентификации, которая обозначает головное изображение в группе изображений, каждое из которых имеет участок, который может заменить текущий участок (предназначенный для обработки), и которые расположены последовательно в направлении времени до текущего изображения (предназначенного для обработки). Таким образом, ИД 643 изображения заголовка замены представляет собой информацию, обозначающую протяженность предыдущих изображений, которые можно использовать для замены текущего участка (предназначенного для обработки). Информация идентификации (ИД того же типа, что и ИД 641 изображения), которая идентифицирует изображение во всех данных движущегося изображения, установлена в этом ИД 643 головного изображения замены.
ФЗ 644 представляет собой 1-битную информацию флага и обозначает, можно или нет заменить текущий участок (предназначенный для обработки) данными изображения, следующего после ИД 643 головного изображения замены. Само собой разумеется, что хотя можно определить возможность замены, используя прошлое изображение, обращаясь к ИД 643 головного изображения замены, такому изображению способствуют, благодаря использованию ФЗ 644.
ФС 645 представляет собой 1-битную информацию флага и представляет собой бит, обозначающий, возможно ли заменить текущий участок (предназначенный для обработки) данными прошлого участка в том же изображении. ИД 646 заголовка замены представляет собой 6-битную информацию, обозначающую головной участок в группе участков, которые расположены последовательно в направлении пространства, вплоть до текущего участка (предназначенного для обработки) в текущем изображении (предназначенном для обработки), и которые могут заменить текущий участок (предназначенный для обработки). Таким образом, ИД 646 головного участка замены представляет собой информацию, обозначающую протяженность предыдущих участков, которые можно использовать для замены текущего участка (предназначенного для обработки).
Информацию идентификации (ИД того же типа, что и ИД 642 участка), которая идентифицирует текущий участок (предназначенный для обработки) в изображении, сжимают до шести битов и устанавливают в этом ИД 646 головного участка замены.
Следует отметить, что длина в битах данного заголовка 640 сокрытия может быть произвольной. Поэтому длина в битах ИД 646 головного участка замены может быть такой же длиной в битах, как и у ИД 642 участка. Кроме того, длину в битах каждого элемента описанной выше информации выбирают произвольно.
Как описано выше, информация, обозначающая диапазон данных, которые могут заменять текущий участок (предназначенный для обработки), включена в заголовок 640 сокрытия. Модуль 631 анализа потери определяет этот диапазон на основе такой информации и заменяет данные, используя кодированные данные, включенные в этот диапазон, которые содержатся в модуле 632 сохранения.
Каждый элемент информации заголовка 640 сокрытия будет более конкретно описан со ссылкой на фиг.48. На фиг.48 показана схема, представляющая примерный вид данных изображения, передаваемых из устройства 602 передачи в устройство 603 приема.
Изображение 651-изображение 653, показанные на фиг.48, схематично представляют некоторые изображения данных изображения, передаваемых из устройства 602 передачи в устройство 603 приема. Изображение 651-изображение 653 представляют собой три изображения, последовательно расположенные в данном порядке в направлении времени. Таким образом, среди трех изображений изображение 651 представляет собой по времени самое ранее (старое) изображение, и изображение 653 представляет собой самое последнее (новое) по времени изображение.
Здесь, для упрощения описания, предполагается, что каждое изображение 651-изображение 653 состоит из трех участков. То есть, изображение 651 состоит из участка 651-1 - участка 651-3; изображение 652 состоит из участка 652-1 - участка 652-3; и изображение 653 состоит из участка 653-1 - участка 653-3.
Кроме того, предполагается, что элементы данных этих участков передают в порядке от верхнего участка к нижнему участку по фиг.48. Таким образом, среди участков, показанных на фиг.48, участок 651-1 изображения 651 передают первым, и участок 653-3 изображения 653 передают последним.
Кроме того, предполагается, что участок 653-3 представляет собой текущий участок (предназначенный для обработки) и что ошибка передачи возникла на этом участке 653-3.
В этом случае, когда значение ФС 644 и ФВ 645 в заголовке 640 сокрытия, добавленном к (ко всем или к некоторым из) пакетам на участке 653-3 выключено (например, установлено равным "0"), не существует участок, который может заменить участок 653-3.
Кроме того, когда значение ФС 644 выключено, и значение ФВ 645 включено (например, установлено равным "1"), участок, который можно использовать для замены, существует в изображении 653. Например, когда ИД 646 головного участка замены представляет собой значение, обозначающее участок 653-2, участок 653-3 может быть заменен участком 653-2. В качестве альтернативы, например, когда ИД 646 головного участка замены представляет собой значение, обозначающее участок 653-1, участок 653-3 может быть заменен либо участком 653-1, или участком 653-2.
Фактически, в большинстве случаев, участок состоит из пикселей, приблизительно равных нескольким строкам. В случае общего изображения соседние участки часто имеют большое сходство и малые различия. Таким образом, ближайший участок в том же изображении имеет высокую вероятность возможности использования в качестве замены. Поэтому в заголовке 640 сокрытия, среди участков, которые можно использовать для замены, участок, который расположен дальше всего от текущего участка (предназначенного для обработки) (временно самый ранний) обозначен ИД 646 головного участка замены. Другими словами, обеспечивают, что участок, следующий после участка, обозначенного ИД 646 головного участка замены (вплоть до текущего участка), можно использовать для замены.
Кроме того, когда значение ФС 644 включено, участок, который можно использовать для замены, существует в другом изображении. Например, когда ИД 643 головного изображения замены представляет собой значение, обозначающее изображение 652, участок 653-3 можно заменить участком 652-3 в том же положении в изображении 652. В качестве альтернативы, например, когда ИД 643 головного изображения замены представляет собой значение, обозначающее изображение 651, участок 653-3 может быть заменен любым из участка 651-3 в том же положении в изображении 651 и участка 652-3 в том же положении в изображении 652.
В случае нормального движущегося изображения, в основном, структуры последующих изображений аналогичны друг другу, и разница между ними невелика, за исключением особой точки, такой как изменение сцены. Таким образом, в случае общего изображения ближайшее по времени изображение с высокой вероятностью включает в себя участок, который можно использовать для замены. Поэтому в заголовке 640 сокрытия, среди изображений, включающих в себя участки, которые можно использовать для замены, изображение, которое расположено дальше всего от текущего изображения (предназначенного для обработки) (самое ранее по времени), обозначено ИД 643 головного изображения замены. Другими словами, обеспечивается то, что изображение, следующее после изображения, обозначенного ИД 643 головного изображения замены (вплоть до текущего изображения), включает в себя участок, который можно использовать для замены.
Следует отметить, что фактически, когда модуль 632 сохранения не содержит такие данные, модуль 631 анализа потери не может заменить участок. Например, когда ИД 643 головного изображения замены представляет собой значение, обозначающее изображение 651 и, когда модуль 632 сохранения содержит данные изображения 652, модуль 631 анализа потери может заменить участок 653-3 участком 652-3.
Как отмечено выше, положение (диапазон), в котором существуют данные, которые можно использовать для замены, обозначено заголовком 640 сокрытия. Таким образом, устройство 602 передачи, которое генерирует такой заголовок 640 сокрытия, определяет данный диапазон. Более конкретно, модуль 621 анализа рассчитывает значение разности между данными на текущем входном участке и данными на одном предыдущем участке, который содержится в модуле 622 сохранения. Кроме того, модуль 621 анализа рассчитывает значение разности между данными в текущем входном участке и данными на участке в том же положении в одном из предыдущих изображений, которые содержатся в модуле 622 сохранения. На основе этих арифметических результатов модуль 621 анализа определяет сходство между данными на текущем входном участке и в одном из предыдущих участков, в одном и том же изображении, или на участке в том же положении, который следовал перед этим, и определяет, возможна ли замена.
Когда на основе такого результата определения замена невозможна, модуль 623 генерирования заголовка сокрытия соответствующим образом обновляет информацию ИД 643 головного изображения замены и ИД 646 головного участка замены.
Далее будет описана последовательность такой обработки. Вначале, со ссылкой на блок-схему последовательности операций, представленную на фиг.49, будет описана примерная последовательность обработки анализа, выполняемой модулем 621 анализа в устройстве 602 передачи.
Когда начинается обработка анализа, модуль 621 анализа выполняет расчет разности на этапе S601 между текущим участком (предназначенным для обработки) и тем же участком в предыдущем изображении (участок в том же положении в одном предыдущем изображении), который считывают из модуля 622 сохранения, и определяет на этапе S602, является или нет разность меньшей чем или равной заданному пороговому набору, установленному заранее. Когда определяют, что разность меньше чем или равна пороговому значению, модуль 621 анализа переводит обработку на этап S603, устанавливает "предыдущее изображение можно использовать для замены" в качестве результата анализа, и переводит обработку на этап S605. В качестве альтернативы, когда на этапе S602 определяют, что разность больше, чем пороговое значение, модуль 621 анализа переводит обработку на этап S604, устанавливает "предыдущее изображение невозможно использовать для замены" в качестве результата анализа, и переводит обработку на этап S605.
Модуль 621 анализа выполняет расчет разности на этапе S605 между текущим участком (предназначенным для обработки) и предыдущим участком (один предыдущий участок), считанным из модуля 622 сохранения, и определяет на этапе S606, является ли или нет разность меньшей чем или равной заданному пороговому значению, установленному заранее. Когда определяют, что разность меньше чем или равна пороговому значению, модуль 621 анализа переводит обработку на этап S607, устанавливает "предыдущий участок можно использовать для замены" в качестве результата анализа, и заканчивает обработку анализа. В качестве альтернативы, когда на этапе S606 определяют, что разность больше, чем пороговое значение, модуль 621 анализа переводит обработку на этап S608, устанавливает "предыдущий участок нельзя использовать для замены" в качестве результата анализа, и заканчивает обработку анализа.
В результате выполнения каждой описанной выше обработки, модуль 621 анализа может определять степень схожести изображений между кадрами и предоставлять информацию, необходимую для генерирования заголовка 640 сокрытия в модуль 623 генерирования заголовка сокрытия.
Далее, со ссылкой на блок-схему последовательности операций, показанную на фиг.50, будет описана примерная последовательность обработки генерирования заголовка сокрытия, выполняемая модулем 623 генерирования заголовка сокрытия.
Когда начинается обработка генерирования заголовка сокрытия, модуль 623 генерирования заголовка сокрытия определяет на этапе S621, было ли или нет установлено "предыдущее изображение можно использовать замены" в качестве результата анализа.
Когда определяют, что было установлено "предыдущее изображение возможно использовать для замены", модуль 623 генерирования заголовка сокрытия переводит обработку на этап S622 и устанавливает значение ИД 643 головного изображения замены в то же значение, что и в прошлый раз. На этапе S623 модуль 623 генерирования заголовка сокрытия включает (например, «1») значение ФЗ 644, которое представляет собой флаг замены предыдущего изображения, и переводит обработку на этап S626.
В качестве альтернативы, когда на этапе S621 определяют, что было установлено "предыдущее изображение невозможно использовать для замены", модуль 623 генерирования заголовка сокрытия переводит обработку на этап S624 и обновляет значение ИД 643 головного изображения замены по текущей информации идентификации изображения. На этапе S625 модуль 623 генерирования заголовка сокрытия выключает (например, устанавливает в "0") значение ФЗ 644, которое представляет собой флаг замены предыдущего изображения, и переводит обработку на этап S626.
На этапе S626 модуль 623 генерирования заголовка сокрытия определяет, было ли установлено "предыдущий участок можно использовать для замены" в качестве результата анализа.
Когда определяют, что было установлено "предыдущий участок возможно использовать для замены", модуль генерирования 623 заголовка сокрытия переводит обработку на этап S627 и устанавливает значение ИД 646 головного участка замены в то же значение, что и в прошлый раз. На этапе S628 модуль 623 генерирования заголовка сокрытия включает (например, устанавливает в "1") значение ФС 645, которое представляет собой флаг замены предыдущего участка, и заканчивает обработку генерирования заголовка сокрытия.
В качестве альтернативы, когда на этапе S626 определяют, что было установлено "предыдущий участок невозможно использовать для замены", модуль 623 генерирования заголовка сокрытия переводит обработку на этап S629 и обновляет значение ИД 646 головного участка замены по текущей информации идентификации участка. На этапе S630 модуль 623 генерирования заголовка сокрытия выключает (например, устанавливает в "0") значение ФС 645, которое представляет собой флаг замены предыдущего участка, и заканчивает обработку генерирования заголовка сокрытия.
В результате выполнения каждой обработки, как описано выше, модуль 623 генерирования заголовка сокрытия может генерировать заголовок 640 сокрытия, к которому обращаются для уменьшения влияния ошибок при передаче, при подавлении увеличения времени задержки. Поскольку такой заголовок 640 сокрытия предоставляют в устройство 603 приема, устройство 603 приема получает возможность правильно выполнять обработку сокрытия ошибки с последовательным приращением, равным размеру участка, который меньше, чем последовательное приращение с размером всего изображения.
Далее, со ссылкой на блок-схему последовательности операций, показанную на фиг.51, будет описана примерная последовательность обработки анализа потери, выполняемая при использовании заголовка 640 сокрытия.
Когда начинается обработка анализа потери, модуль 631 анализа потери определяет на этапе S651, произошла или нет потеря (ошибка) на текущем участке (предназначенном для обработки) и, когда он определяет, что потеря не произошла, заканчивает обработку анализа потери.
В качестве альтернативы, когда на этапе S651 определяют, что произошла потеря, модуль 631 анализа потери переводит обработку на этап S652 и определяет, был или нет получен заголовок 640 сокрытия. Когда определяют, что заголовок 640 сокрытия не был получен, поскольку трудно выполнить правильное сокрытие ошибки, модуль 631 анализа потери заканчивает обработку анализа потери.
В качестве альтернативы, когда определяют на этапе S652, что заголовок 640 сокрытия был получен, модуль 631 анализа потери переводит обработку на этап S653 и, на основе информации заголовка 640 сокрытия, определяет, возможна или нет замена, используя тот же участок в предыдущем изображении (участок в том же положении в одном предыдущем изображении). Когда значение ФЗ 644 включено (например, установлено в "1") и, таким образом, определяют, что замена возможна, модуль 631 анализа потери переводит обработку на этап S654.
На этапе S654 модуль 631 анализа потери определяет, превышает или нет или равно значение ИД изображения для предыдущего изображения, которое считывают из модуля 632 сохранения, ИД 643 головного изображения замены, то есть является ли изображение, обозначенное ИД головного изображения замены, более старым, чем предыдущее изображение, считанное из модуля 632 сохранения. Когда определяют, что предыдущее изображение, считанное из модуля 632 сохранения, следует после изображения, обозначенного ИД головного изображения замены, модуль 631 анализа потери переводит обработку на этап S655, заменяет текущий участок (предназначенный для обработки) на участок, расположенный в том же положении в предыдущем изображении, который был считан из модуля 632 сохранения, и заканчивает обработку анализа потери. В качестве альтернативы, когда на этапе S654 определяют, что значение ИД изображения предыдущего изображения, которое было считано из модуля 632 сохранения, меньше, чем ИД головного изображения замены, поскольку данные изображения, которые можно использовать для замены, не содержатся в модуле 632 сохранения, модуль 631 анализа потери заканчивает обработку анализа потери.
В качестве альтернативы, когда на этапе S653 определяют, что замена невозможна, используя участок, расположенный в том же положении в предыдущем изображении, который был считан из модуля 632 сохранения, модуль 631 анализа потери переводит обработку на этап S656 и определяет, возможна или нет замена при использовании предыдущего участка в том же изображении (один предыдущий участок в том же изображении), который был считан из модуля 632 сохранения. Когда значение ФС 645 выключено (например, установлено в "0") и, таким образом, определяют, что замена невозможна, модуль 631 анализа потери заканчивает обработку анализа потери.
В качестве альтернативы, когда на этапе S656 определяют, что значение ФС 645 включено (например, установлено в "1") и замена возможна при использовании предыдущего участка в том же изображении, который был считан из модуля 632 сохранения, модуль 631 анализа потери переводит обработку на этап S657 и определяет, превышает или нет, или равно значение ИД участка предыдущего участка, считанного из модуля 632 сохранения, ИД 646 головного участка замены.
Когда определяют, что значение ИД участка для предыдущего участка, считанного из модуля 632 сохранения, меньше, чем ИД 646 головного участка замены, то есть когда определяют, что предыдущий участок, считанный из модуля 632 сохранения, представляет собой участок, расположенный перед участком, обозначенным ИД 646 головного участка замены, поскольку участок, пригодный для использования для замены, не содержится в модуле 632 сохранения, модуль 631 анализа потери заканчивает обработку анализа потери.
В качестве альтернативы, когда определяют, что значение ИД участка у предыдущего участка, считанного из модуля 632 сохранения, больше чем или равно ИД 646 головного участка замены, то есть когда определяют, что предыдущий участок, считанный из модуля 632 сохранения, представляет собой участок, следующий после участка, обозначенного ИД 646 головного участка замены, модуль 631 анализа потери переводит обработку на этап S658, заменяет текущий участок (предназначенный для обработки) на предыдущий участок того же изображения, который был считан из модуля 632 сохранения, и заканчивает обработку анализа потери.
Как описано выше, модуль 631 анализа потери выполняет обработку анализа потери. В соответствии с этим, в результате выполнения обработки, как описано выше, модуль 631 анализа потери может соответствующим образом выполнять, на основе заголовка 640 сокрытия, обработку сокрытия ошибки с приращениями, равными размеру участка, которые меньше, чем приращения, равные размеру изображения. Таким образом, модуль 631 анализа потери может уменьшить влияние ошибок передачи, не допуская увеличение времени задержки.
Следует отметить, что устройство 603 приема может определять, возможна или нет замена, и может быть выполнено с возможностью проведения замены с приращением, равным размеру одного модуля, то есть меньшим, чем приращение изображения, без использования описанного выше заголовка 640 сокрытия. В этом случае, объем буфера устройства 603 приема увеличивается, что создает вероятность увеличения времени задержки. Кроме того, на стороне устройства 603 приема, поскольку существует вероятность дефекта данных, правильное определение может потребовать длительного времени.
Поэтому, как было описано выше, в устройстве 602 передачи, в котором содержатся полные данные, определяют, возможна или нет замена, и, используя заголовок 640 сокрытия, эту информацию передают в устройство 603 приема, что делает возможным для устройства 602 передачи инициировать уменьшение устройством 603 приема влияния ошибок передачи, не допуская увеличения времени задержки.
Описанные выше последовательности обработки могут быть выполнены с использованием аппаратных средств или могут быть выполнены на основе программных средств. Когда данные последовательности обработки требуется выполнить с помощью программных средств, программу, которая конфигурирует программное средство, устанавливают с носителя записи программы в компьютер, встроенный в специализированные аппаратные средства, общий персональный компьютер, например, компьютер, который может выполнять различные функции, используя различные программы, установленные в нем, или устройство обработки информации в системе обработки информации, состоящей из множества устройств.
На фиг.52 показана блок-схема, представляющая примерную конфигурацию системы обработки информации, которая выполняет описанную выше последовательность обработки на основе программы.
Как показано на фиг.52, система 800 обработки информации представляет собой систему, выполненную с устройством 801 обработки информации, устройством 803 сохранения, подключенным к устройству 801 обработки информации, с использованием шины 802 PCI, VTR 804-1 - VTR 804-S, которые представляют собой множество устройств записи на видеоленту (VTR, УЗЛ), мышью 805, клавиатурой 806 и контроллером 807 операций для обеспечения возможности для пользователя ввода операций в это устройство, и представляет собой систему, которая выполняет обработку кодирования изображения, обработку декодирования изображения и т.п., как описано выше на основе установленной программы.
Например, устройство 801 обработки информации в системе 800 обработки информации может сохранять кодированные данные, полученные путем кодирования содержания движущегося изображения, сохраненного в устройстве 803 сохранения большой емкости, состоящего из RAID (избыточный массив независимых дисков, ИМНД) в устройстве 803 сохранения, сохраняет в устройстве 803 сохранения декодированные данные изображения (содержание движущегося изображения), полученные в результате декодирования кодированных данных, сохраненных в устройстве 803 сохранения, и сохраняет кодированные данные и декодированные данные изображения на видеоленте через УЗЛ 804-1 - УЗЛ 804-S. Кроме того, устройство 801 обработки информации выполнено с возможностью ввода содержания движущегося изображения, записанного на видеолентах, установленных в УЗЛ 804-1 - УЗЛ 804-S в устройство 803 сохранения. В связи с этим, устройство 801 обработки информации может кодировать содержание движущегося изображения.
Устройство 801 обработки информации имеет микропроцессор 901, GPU (модуль обработки графики, МОГ) 902, XDR (повышенная скорость передачи данных, ПСП)-ОЗУ 903, южный мост 904, HDD (привод жесткого диска, ПЖД) 905, интерфейс 906 USB (универсальная последовательная шина, УПШ) ((I/F) И/Ф УПШ) и кодек 907 ввода/вывода звука.
МОГ 902 соединен с микропроцессором 901 через выделенную шину 911. ПСП-ОЗУ 903 соединено с микропроцессором 901 через выделенную шину 912. Южный мост 904 соединен с контроллером 944 I/O (ввода/вывода) микропроцессора 901 через выделенную шину. Также с южным мостом 904 соединен ПЖД 905, интерфейс 906 УПШ и кодек 907 ввода/вывода звука. Громкоговоритель 921 соединен с кодеком 907 ввода/вывода звука. Кроме того, дисплей 922 соединен с МОГ 902.
Кроме того, также к южному мосту 904 присоединена мышь 805, клавиатура 806, УЗЛ 804-1 -УЗЛ 804-S, устройство 803 сохранения и контроллер 807 операций, через шину 802 PCI (межсоединение периферийных компонентов, МПК).
Мышь 805 и клавиатура 806 принимают операции, вводимые пользователем, и передают сигналы, обозначающие содержание этих операций, введенных пользователем, в микропроцессор 901 через шину 802 МПК и южный мост 904. Устройство 803 сохранения и УЗЛ 804-1 - УЗЛ 804-S выполнены с возможностью записи или воспроизведения заданных данных.
Кроме того, к шине 802 МПК подключают, в соответствии с необходимостью, привод 808, в который соответствующим образом устанавливают съемный носитель 811, такой как магнитный диск, оптический диск, магнитооптический диск, или полупроводниковое запоминающее устройство, и компьютерную программу, считываемую с него, устанавливают на ПЖД 905, в соответствии с необходимостью.
Микропроцессор 901 выполнен с использованием многоядерной конфигурации, в которой ядро 941 основного ЦПУ общего назначения, которое выполняет основные программы, такие как OS (операционная система, ОС), ядро 942-1 вспомогательного ЦПУ - ядро 942-8 вспомогательного ЦПУ, которые представляют собой множество (восемь в данном случае) процессоров обработки сигналов типа RISC (компьютер с сокращенным набором команд, КСНК), подключенных к основному ядру 941 ЦПУ через внутреннюю шину 945, контроллер 943 запоминающего устройства, который выполняет управление запоминающим устройством ПСП-ОЗУ 903, имеющим, например, емкость 256 [Мбайт], и контроллер 944 ввода/вывода (ввода/вывода), который управляет вводом и выводом данных с южным мостом 904, интегрированы в одной микросхеме, и реализуют частоту выполнения операций, например, 4 [ГГц].
Во время активации микропроцессор 901 считывает необходимые прикладные программы, сохраненные в ПЖД 905, на основе программы управления, сохраненной в ПЖД 905, разворачивает прикладные программы в ПСП-ОЗУ 803 и последовательно выполняет необходимые обработки управления на основе прикладных программ и операций оператора.
Кроме того, в результате выполнения программных средств, микропроцессор 901 может, например, реализовать описанную выше обработку кодирования и обработку декодирования, подавать кодированные потоки, полученные в результате кодирования, через южный мост 904 в ПЖД 905 для сохранения и выполнять передачу данных видеоизображения, воспроизводимого из содержания движущегося изображения, полученного в результате декодирования, в ЦПУ 902 для отображения на дисплее 922.
В то время как способ использования каждого ядра ЦПУ в микропроцессоре 901 является произвольным, например, основное ядро 941 ЦПУ может выполнять обработку, связанную с управлением обработки кодирования изображения и обработки декодирования изображения, и может управлять восемью ядрами: ядром 942-1 вспомогательного ЦПУ - ядром 942-8 вспомогательного ЦПУ, для выполнения обработки, такой как вейвлет-преобразование, изменение порядка коэффициентов, энтропийное кодирование, энтропийное декодирование, обратное вейвлет-преобразование, квантование и устранение квантования, одновременно и параллельно, как описано, например, со ссылкой на фиг.39. В связи с этим, когда ядро 941 основного ЦПУ выполнено с возможностью назначения обработки каждому из восьми ядер: ядра 942-1 вспомогательного ЦПУ - ядра 942-8 вспомогательного ЦПУ на основе от участка к участку, обработку кодирования и обработку декодирования выполняют одновременно и параллельно на основе от участка к участку, как и в случае, описанном со ссылкой на фиг.39. Таким образом, эффективность обработки кодирования и обработки декодирования может быть улучшена, время задержки общей обработки может быть уменьшено, и, кроме того, время обработки, нагрузка и емкость памяти, необходимая для обработки, могут быть уменьшены. Само собой разумеется, что каждая обработка может быть выполнена с использованием также других способов.
Например, некоторые из восьми ядер: ядра 942-1 вспомогательного ЦПУ - ядра 942-8 вспомогательного ЦПУ микропроцессора 901 могут быть выполнены с возможностью выполнения обработки кодирования, и остальные могут быть выполнены с возможностью выполнения обработки декодирования одновременно и параллельно.
Кроме того, например, когда независимый кодер или декодер, или устройство обработки кодека подключены к шине 802 МПК, восемь ядер: ядро 942-1 вспомогательного ЦПУ - ядро 942-8 вспомогательного ЦПУ микропроцессора 901 могут быть установлены с возможностью управления обработкой, выполняемой этими устройствами через южный мост 904 и шину 802 МПК. Кроме того, когда множество таких устройств подключены или когда эти устройства включают в себя множество декодеров или кодеров, восемь ядер: ядро 942-1 вспомогательного ЦПУ - ядро 942-8 вспомогательного ЦПУ микропроцессора 901 могут быть выполнены с возможностью управления обработкой, выполняемой множеством декодеров или кодеров в режиме совместного использования.
В это время ядро 941 основного ЦПУ управляет работой восемью ядер: ядро 942-1 вспомогательного ЦПУ - ядро 942-8 вспомогательного ЦПУ, назначает обработку для отдельных ядер вспомогательного ЦПУ и получает результаты обработки. Кроме того, ядро 941 основного ЦПУ выполняет другую обработку, помимо выполняемой этими ядрами вспомогательных ЦПУ. Например, ядро 941 основного ЦПУ принимает команды, передаваемые с помощью мыши 805, клавиатуры 806 или из контроллера 807 операций через южный мост 904, и выполняет различную обработку в ответ на эти команды.
МОГ 902 управляет функциями выполнения, кроме тех, которые относятся к обработке конечного получения, например, вставляет текстуры, перемещая видеоизображение, воспроизводимое из содержания движущегося изображения, предназначенного для отображения на дисплее 922, выполняя обработку расчета преобразования координат при одновременном отображении множества видеоизображений, воспроизводимых из содержания движущегося изображения и неподвижных изображений для содержания неподвижного изображения на дисплее 922, обработку увеличения/уменьшения видеоизображения, воспроизводимого из содержания движущегося изображения, и неподвижного изображения для содержания неподвижного изображения, и т.д., устраняя, таким образом, нагрузку по обработке микропроцессора 901.
Под управлением микропроцессора 901, МОГ 902 применяет заданную обработку сигналов к данным видеоизображения, подаваемого содержания движущегося изображения, и к данным изображения содержания неподвижного изображения, передает данные видеоизображения и данные изображения, полученные в результате этой обработки, в дисплей 922 и отображает сигналы изображения на дисплее 922.
Теперь видеоизображения, воспроизводимые из множества элементов содержания движущегося изображения, декодированных одновременно и параллельно восьмью ядрами: ядром 942-1 вспомогательного ЦПУ - ядром 942-8 вспомогательного ЦПУ микропроцессора 901, передают в виде данных в МОГ 902 через шину 911. Скорость передачи в данном случае составляет, например, максимум 30 [Гбайт/сек], и, соответственно, даже сложные воспроизводимые видеоизображения со специальными эффектами можно быстро и плавно воспроизводить.
Кроме того, микропроцессор 901 применяет обработку смешивания звука для аудиоданных, видеоданных изображения и аудиоданных содержания движущегося изображения и передает отредактированные аудиоданные, полученные в результате этой обработки, в громкоговоритель 921 через южный мост 904 и кодек 907 ввода/вывода звука, выводя, таким образом, звук на основе аудиосигналов через громкоговоритель 921.
Когда описанную выше последовательность обработки выполняют с помощью программных средств, программу, конфигурирующую программное средство, устанавливают через сеть или с носителя записи.
Такой носитель записи выполнен, например, как показано на фиг.52, не только со съемным носителем 811, на котором записана программа и который распространяется отдельно от основного устройства для распространения программы пользователям, таким как магнитный диск (включая в себя гибкий диск), оптический диск (включая в себя CD-ROM и DVD), магнитооптический диск (включая в себя MD) или полупроводниковое запоминающее устройство, но также в виде ПЖД 905, устройства 803 накопителя, и т.п., на которые записана программа и которые распространяют пользователю в состоянии, в котором их заранее встраивают в основной корпус устройства. Само собой разумеется, что носитель записи также может представлять собой полупроводниковое запоминающее устройство, такое как ПЗУ или запоминающее устройство типа флэш.
Выше было описано, что в микропроцессор 901 выполнен на основе восьми ядер вспомогательного ЦПУ. Однако настоящее изобретение не ограничивается этим. Количество ядер вспомогательного ЦПУ является произвольным. Кроме того, микропроцессор 901 не обязательно должен быть выполнен на основе множества ядер, таких как ядро основного ЦПУ и ядер вспомогательного ЦПУ, и микропроцессор 901 может быть выполнен с использованием ЦПУ, который выполнен с одним ядром (одноядерный). Кроме того, вместо микропроцессора 901, можно использовать множество ЦПУ или можно использовать множество устройств обработки информации (то есть программа, которая выполняет обработку в соответствии с настоящим изобретением, выполняется во множестве устройств, работающих совместно друг с другом).
Этапы, описывающие программу, записанную на носителе записи в настоящем описании, могут, конечно, включать в себя обработку, выполняемую во временной последовательности в соответствии с описанным порядком, но также включают в себя обработку, выполняемую не обязательно во временной последовательности, но параллельно или по отдельности.
Кроме того, система в настоящем описании полностью относится к оборудованию, составленному из множества устройств (аппаратов).
Следует отметить, что структура, описанная выше, как одно устройство, может быть разделена так, что она будет выполнена как множество устройств. И, наоборот, структуры, описанные выше как представляющие собой множество устройств, могут быть объединены так, что они будут выполнены как одно устройство. Кроме того, само собой разумеется, структуры отдельных устройств могут быть добавлены к другим структурам, кроме описанных выше. Кроме того, часть структуры одного устройства может быть включена в структуру другого устройства, если только структура и работа всей системы будет, по существу, той же.
Промышленная применимость
Настоящее изобретение, описанное выше, предназначено для простого выполнения передачи данных с высокими скоростями, и его можно применять в различных устройствах или системах, если только они сжимают, кодируют, и передают изображения, и, в месте назначения передачи, декодируют сжатые и кодированные данные, и выводят изображения. Настоящее изобретение, в частности, пригодно для применения в устройствах или в системах, в которых требуется обеспечивать короткую задержку от момента времени сжатия изображения и кодирования до декодирования и вывода.
Например, настоящее изобретение пригодно для использования в вариантах применения, связанных с удаленным медицинским анализом, таких как управление манипулятором типа "главный-подчиненный", с одновременным просмотром видеоизображения, снимаемого видеокамерой, и при выполнении медицинского лечения. Кроме того, настоящее изобретение пригодно для использования в таких системах, которые кодируют и передают изображения, и декодируют, и отображают или записывают изображения в станциях широковещательной передачи и т.п.
Кроме того, настоящее изобретение можно применять в системах, которые выполняют распределение широковещательных передач с прямой трансляцией видеоизображений, системах, которые обеспечивают возможность интерактивной связи между студентами и преподавателями в образовательных учреждениях, и т.п.
Кроме того, настоящее изобретение можно применять для передачи данных изображения, снятых мобильным терминалом, имеющим функцию съемки изображения, таким как терминал типа мобильного телефона с функцией камеры, системы видеоконференции, системы, включающие в себя камеры слежения, и устройство записи, которое записывает видеоизображение, снятое камерами слежения, и т.п.

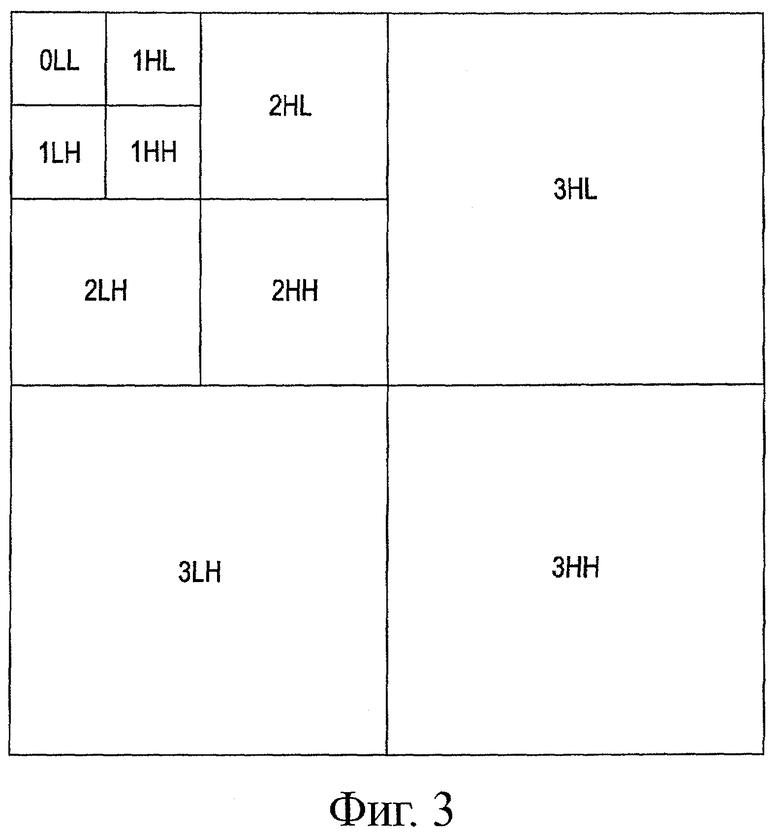



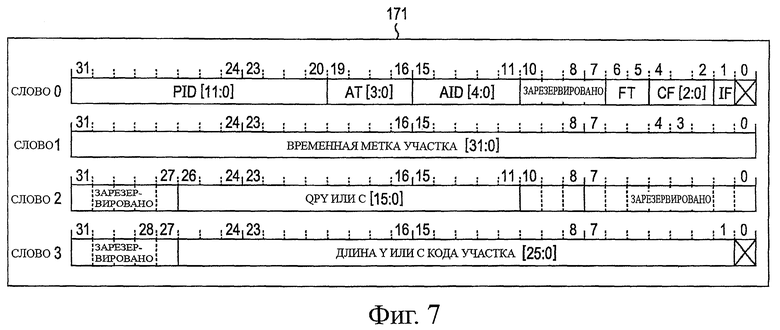

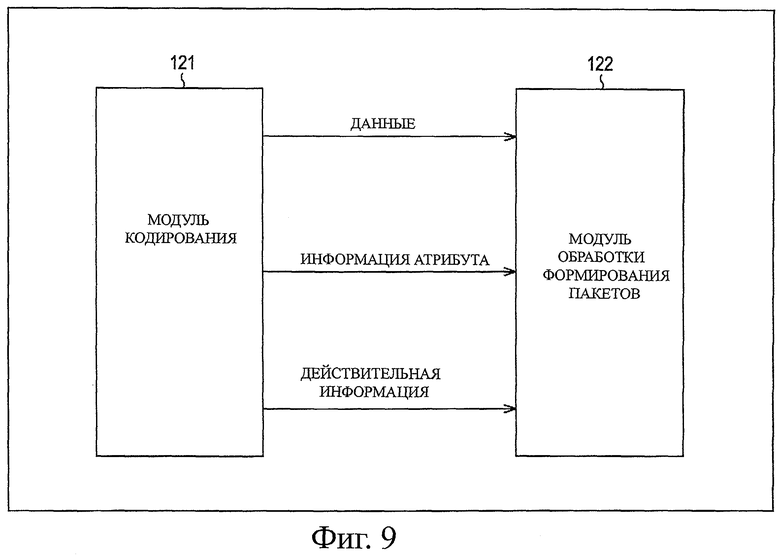


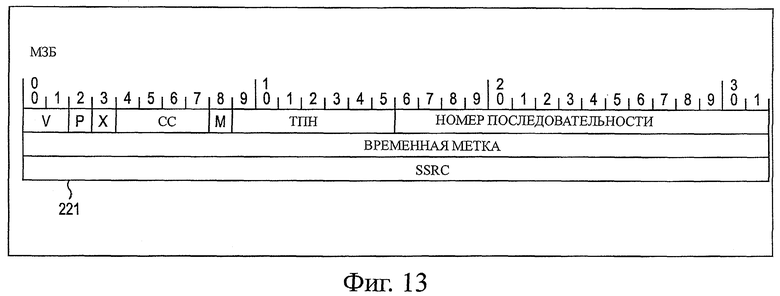

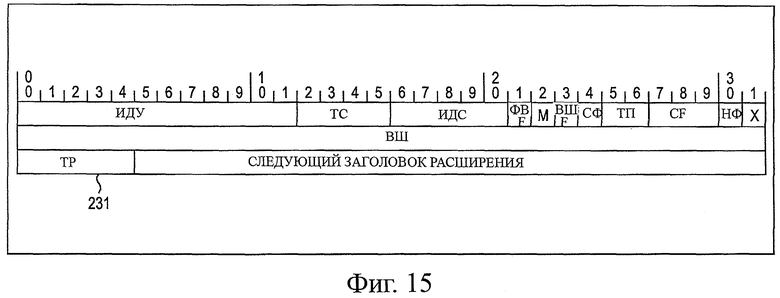

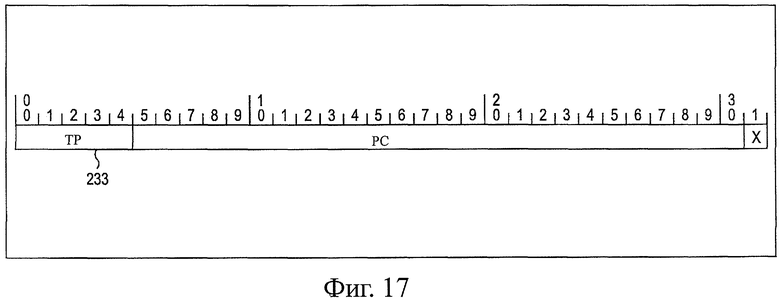

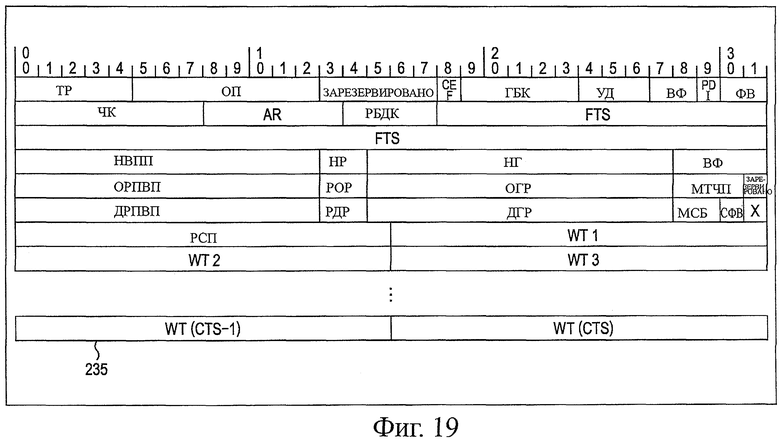


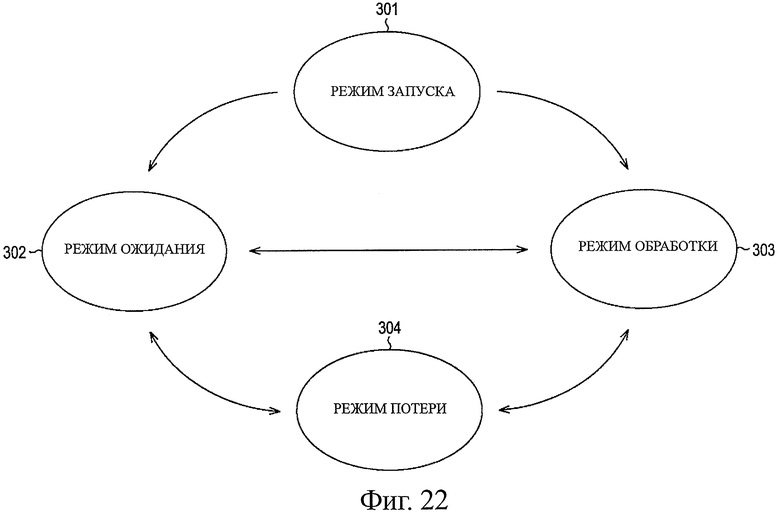

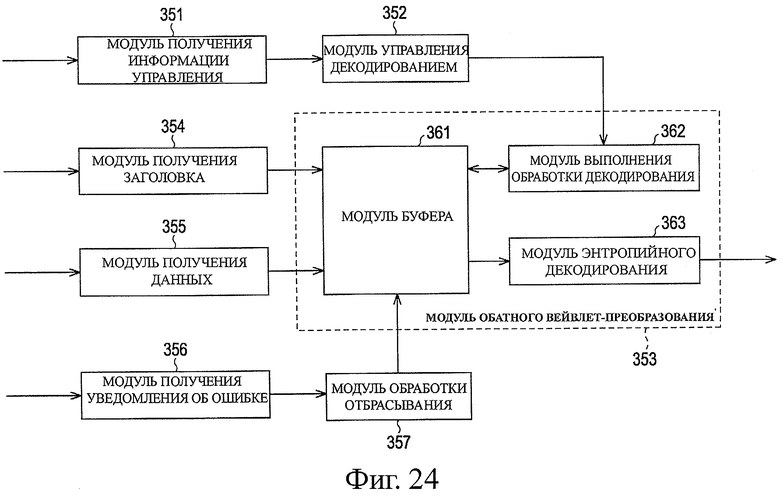

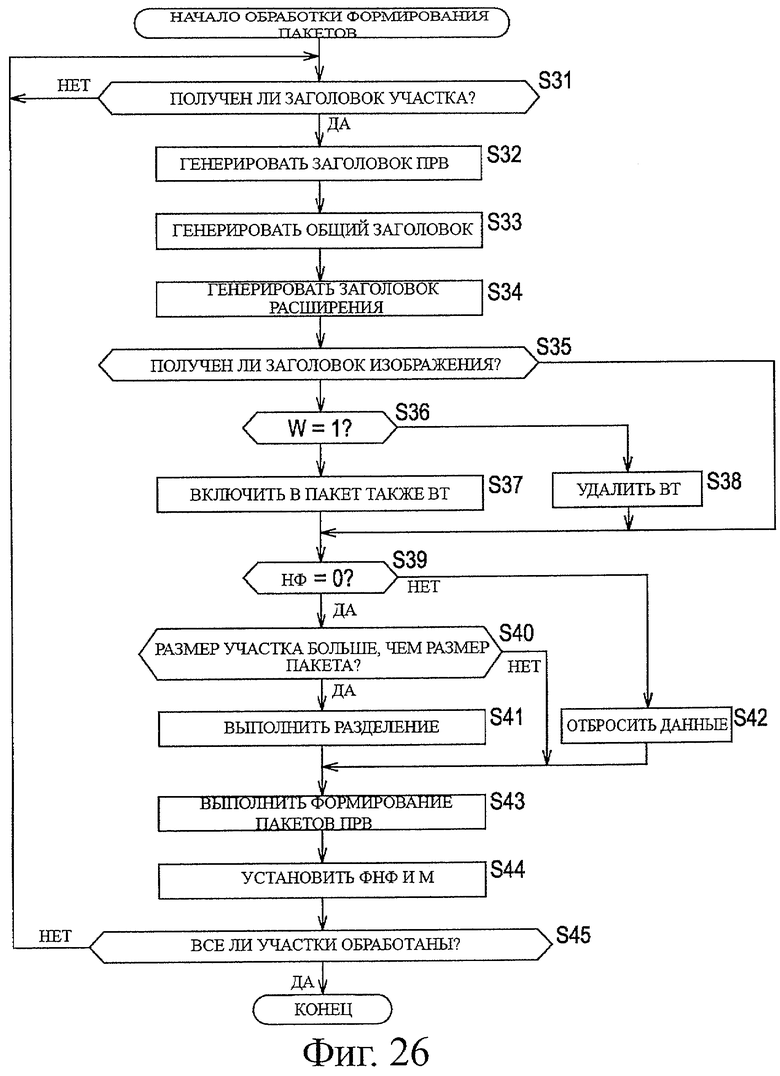

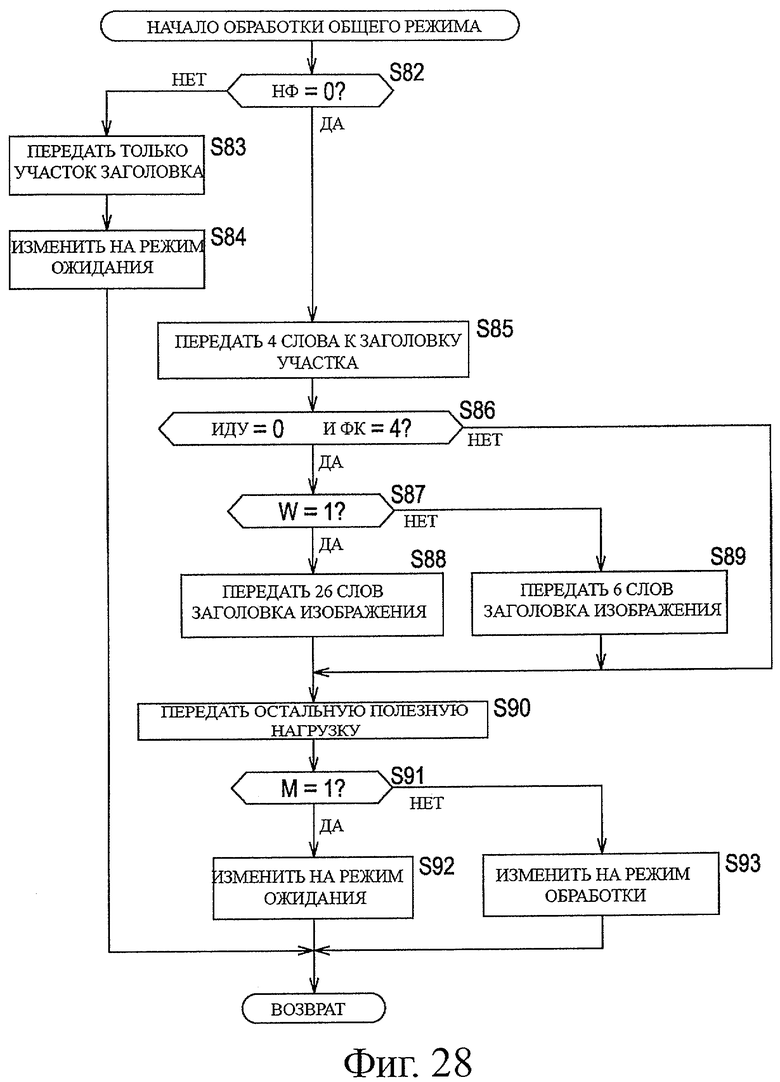

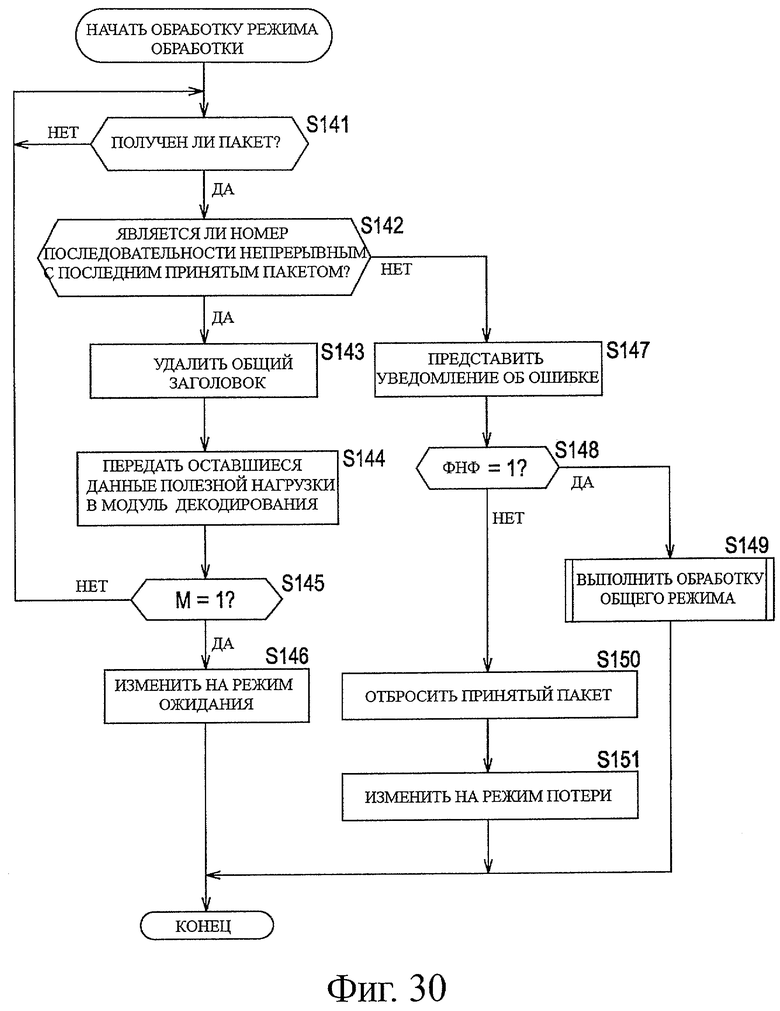
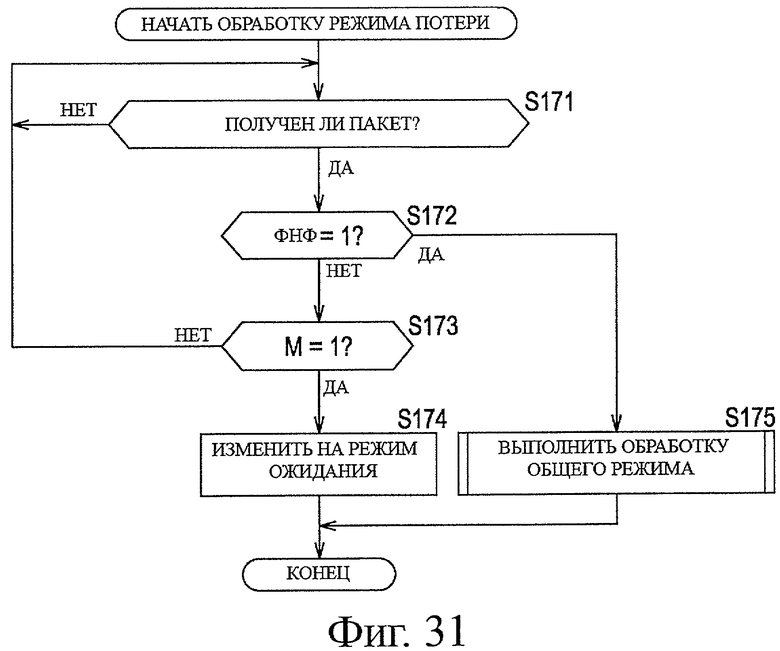

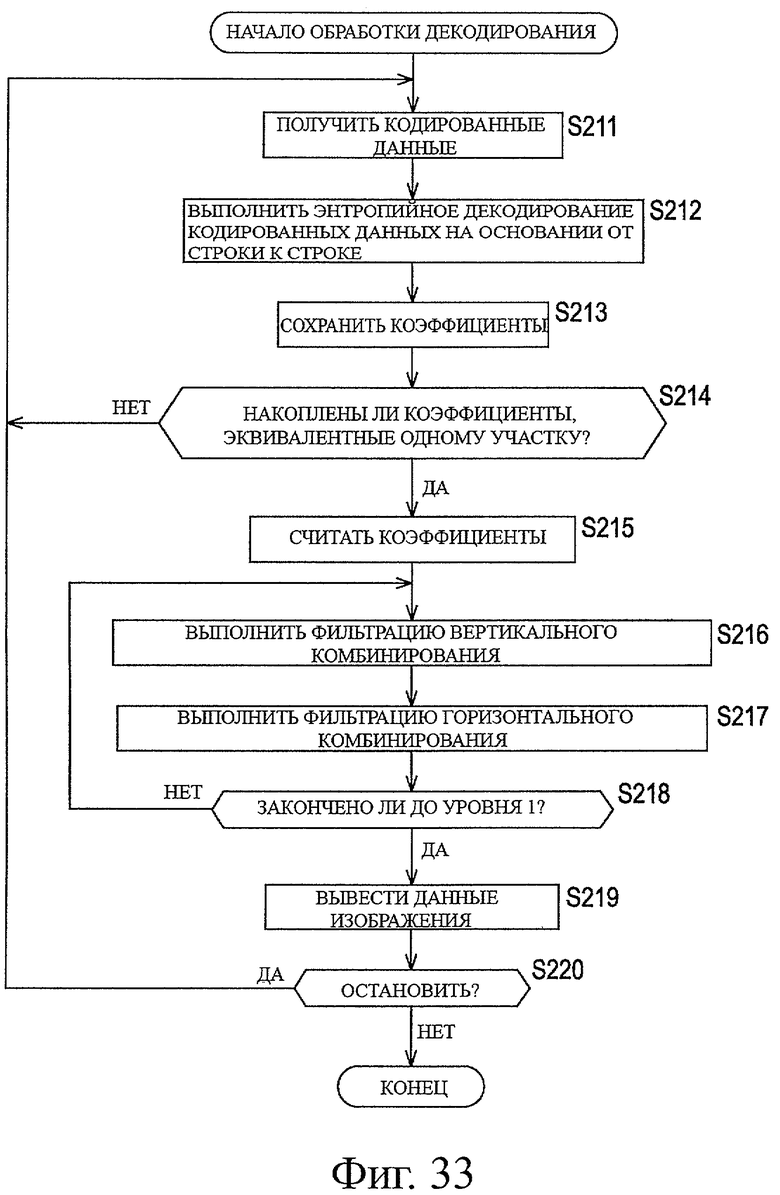
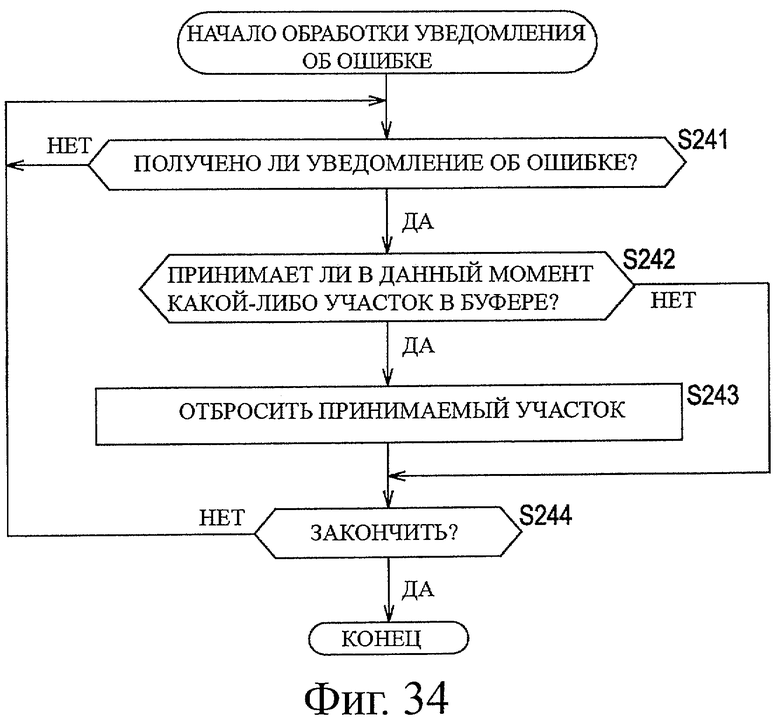

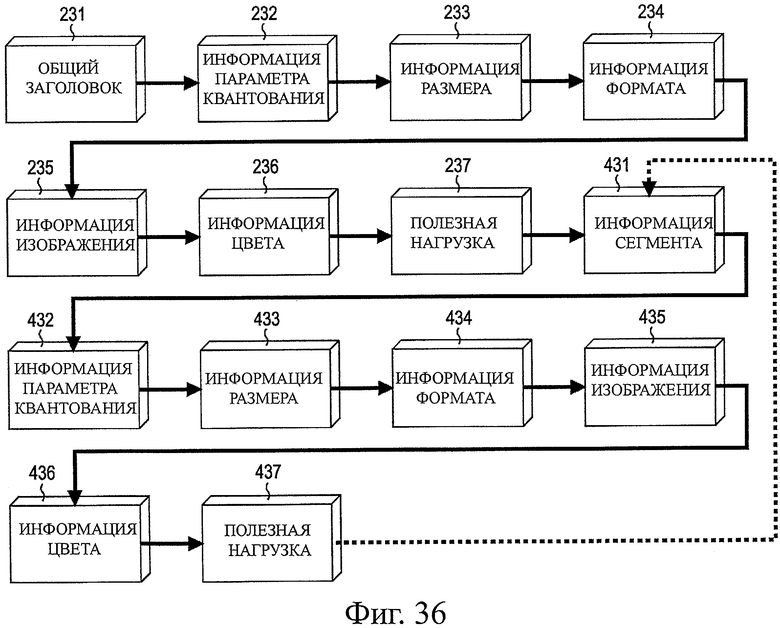

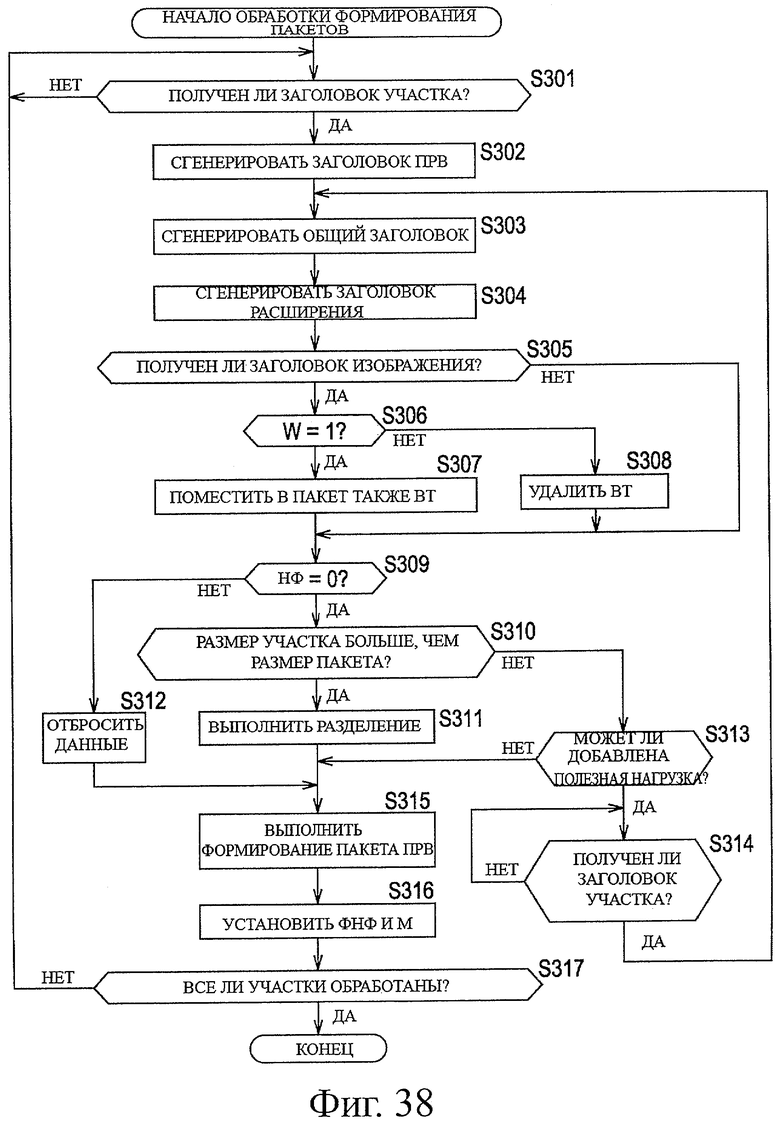

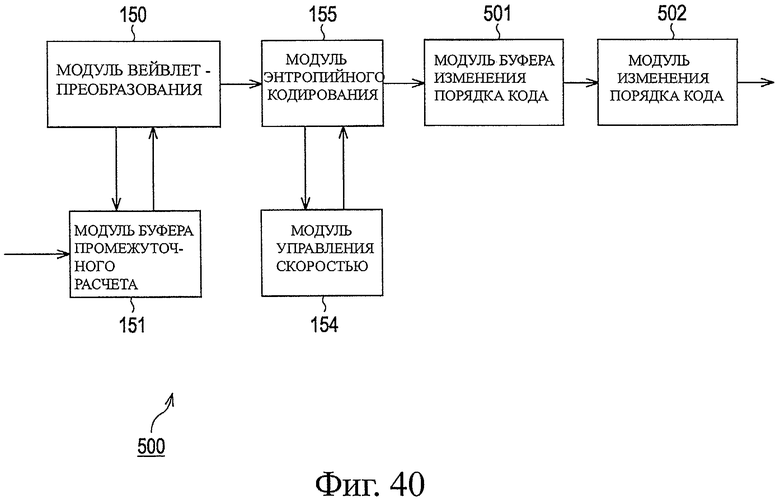
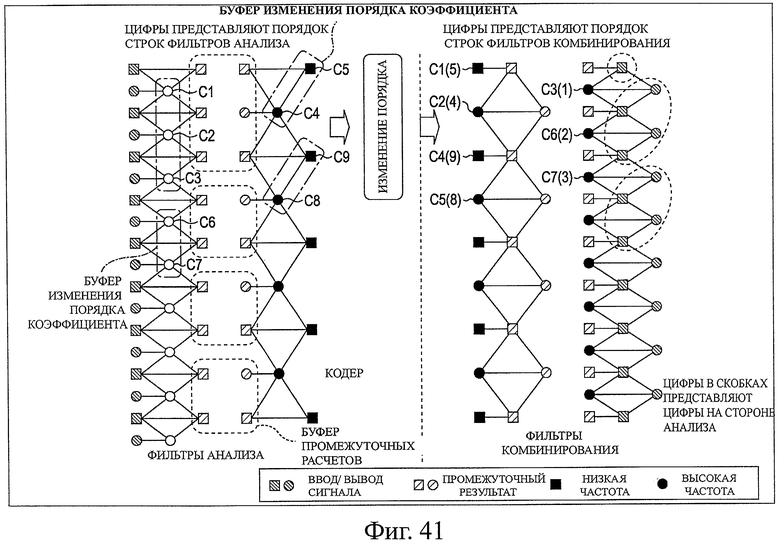
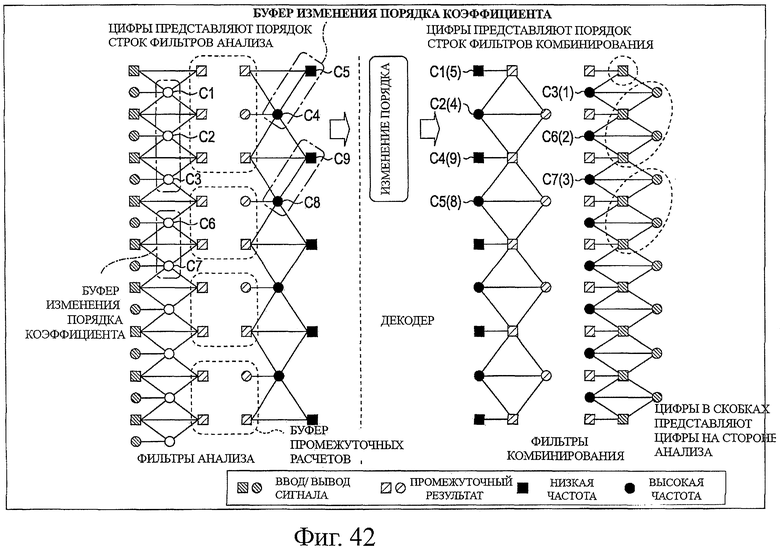
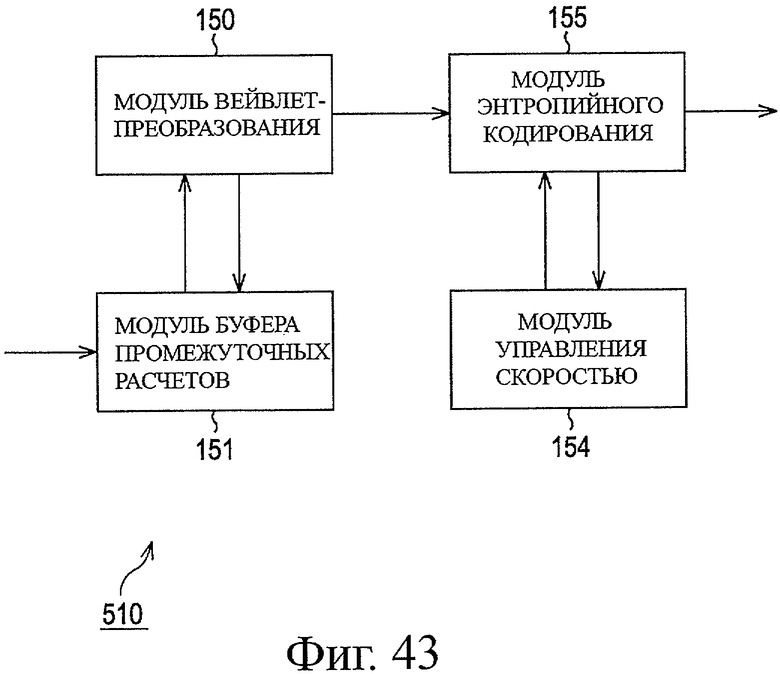
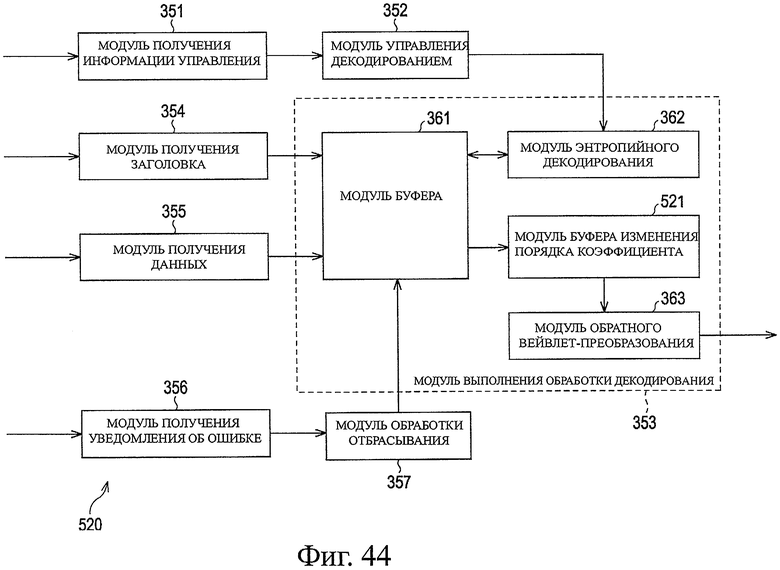
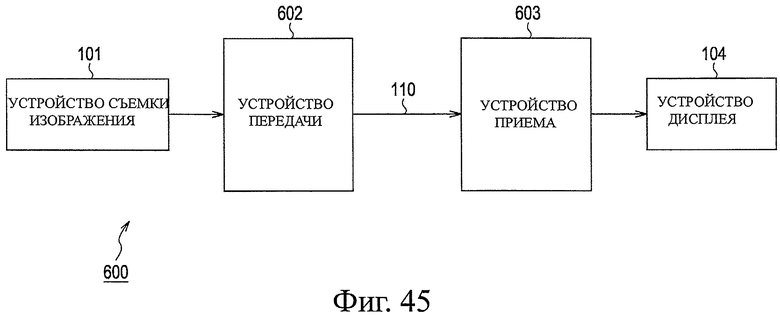
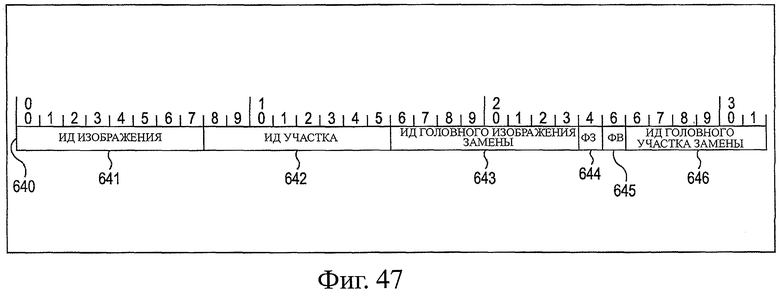

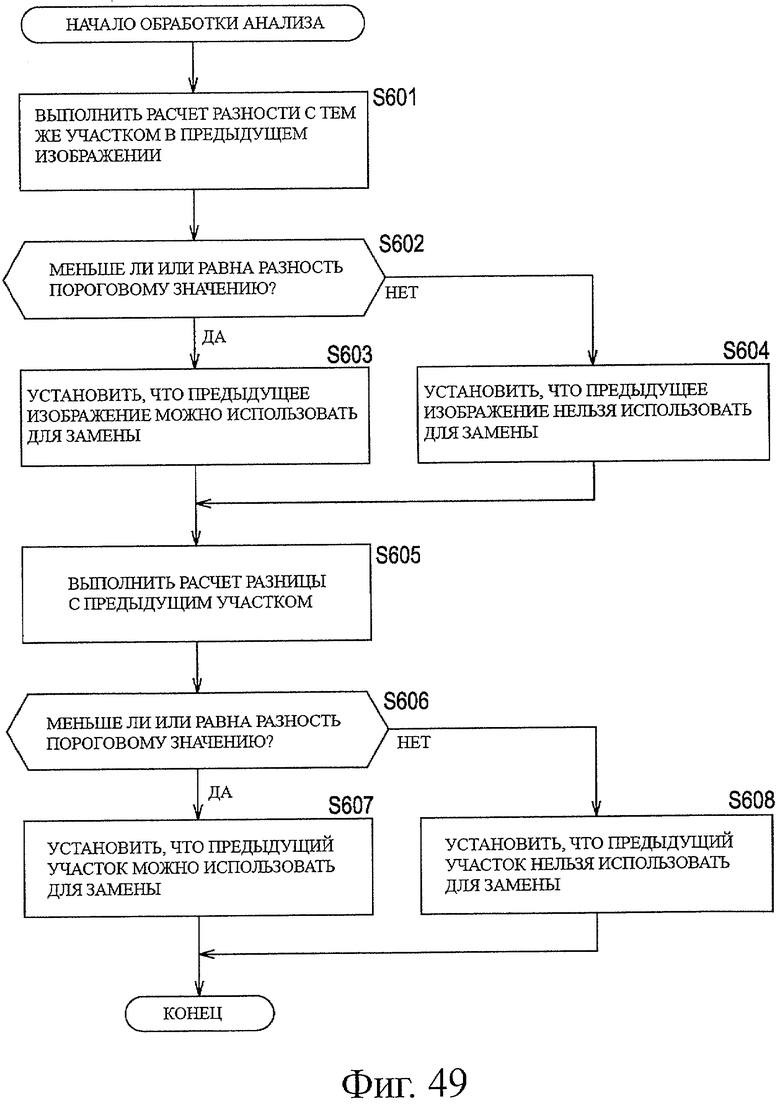
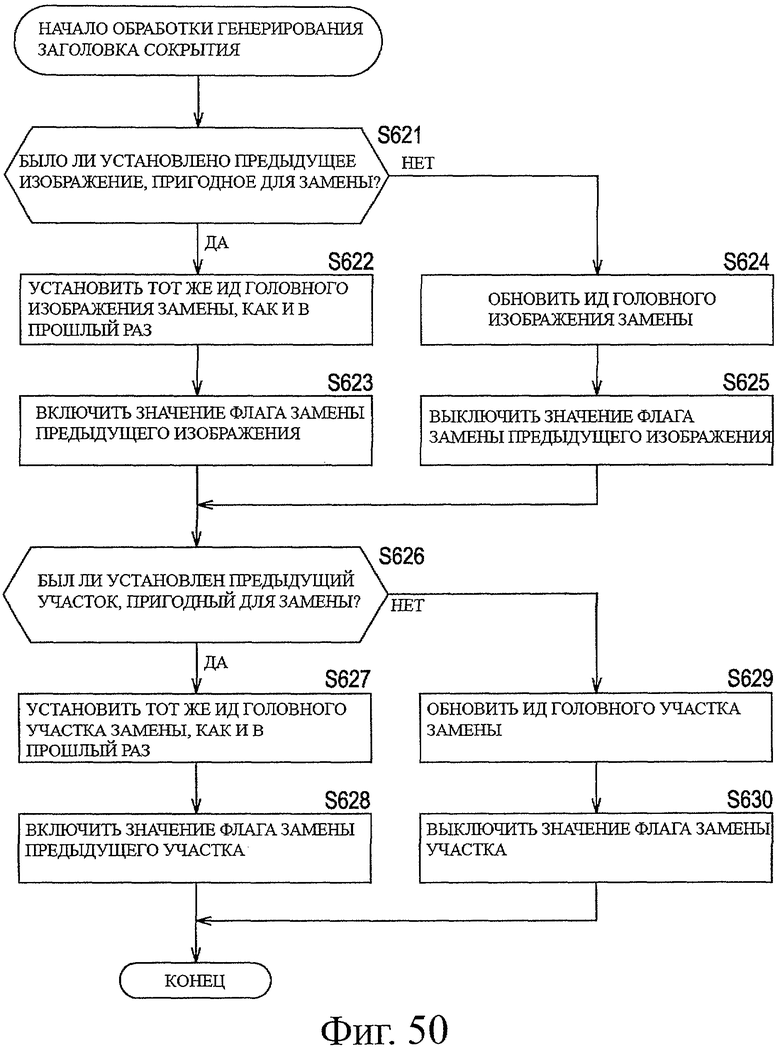


Изобретение относится к устройству и способу обработки информации, и более конкретно, к устройству и способу обработки информации, которые позволяют уменьшить задержку времени при передаче/приеме пакета. Техническим результатом является уменьшение времени ожидания при обработке восстановления данных из пакетов и обеспечение выполнения обработки просто и с высокой скоростью, что может быть использовано в устройстве кодирования. Указанный технический результат достигается тем, что модуль 621 анализа сравнивает входные данные изображения с данными изображения одного предыдущего изображения, считанного из модуля 622 сохранения. На основе результата анализа модуль 623 генерирования заголовка сокрытия генерирует заголовок сокрытия, к которому обращается устройство 603 приема во время обработки сокрытия ошибки. На основе заголовка сокрытия модуль 631 анализа потери выполняет сокрытие ошибки в случае возникновения ошибки при передаче путем соответствующего использования кодированных данных, сохраненных в модуле 632 сохранения. 4 н. и 10 з.п. ф-лы, 52 ил.
1. Устройство обработки информации, предназначенное для кодирования данных изображения, содержащее:
средство сравнения, предназначенное для сравнения кадров или полей, составляющих данные изображения, с последовательным приращением в размере блока строк, включающим в себя данные изображения, эквивалентные количеству строк, необходимому для генерирования данных коэффициента, эквивалентных одной строке подполос, по меньшей мере, компонентов самой низкой частоты;
средство генерирования, предназначенное для генерирования информации сокрытия, обозначающей способ сокрытия ошибки в блоке строк, в соответствии с результатом сравнения, полученным средством сравнения;
средство кодирования, предназначенное для генерирования кодированных данных, путем кодирования данных коэффициента, порядок которых был изменен заранее в порядке, в котором данные коэффициента используются при выполнении обработки комбинирования, состоящей в комбинировании данных коэффициента множества подполос, разложенных на полосы частот, для генерирования данных изображения; и
средство управления, предназначенное для управления средством кодирования, для мультиплексирования информации сокрытия, сгенерированной средством генерирования, с кодированными данными, сгенерированными средством кодирования, в котором информация сокрытия включает в себя информацию, обозначающую, когда блок строк, составляющий кадр или поле, может быть заменен блоком строк, составляющим другой кадр или другое поле, протяженность предыдущих изображений или полей, которые можно использовать для замены.
2. Устройство обработки информации по п.1, в котором средство управления управляет средством кодирования для формирования пакетов из кодированных данных с информацией сокрытия, используемой как заголовок.
3. Устройство обработки информации по п.2, в котором средство кодирования включает в себя: средство кодирования коэффициента, предназначенное для кодирования данных коэффициента для генерирования кодированных данных; и средство формирования пакетов для формирования пакетов из кодированных данных.
4. Устройство обработки информации по п.1, в котором информация сокрытия включает в себя информацию флага, обозначающую, возможна или нет замена блока строк, составляющих кадр или поле, блоком строк, составляющим другой кадр или другое поле.
5. Устройство обработки информации по п.4, в котором средство сравнения сравнивает в отношении данных изображения значения разности между кадрами или значения разности между полями с пороговым значением.
6. Устройство обработки информации по п.5, в котором средство генерирования устанавливает информацию флага как обозначающую возможность замены, когда значение разности между кадрами или значение разности между полями меньше, чем или равно пороговому значению.
7. Устройство обработки информации по п.1, в котором информация сокрытия включает в себя информацию флага, обозначающую, когда блок строк, составляющий кадр или поле, может быть заменен блоком строк, составляющим другой кадр или другое поле, возможно или нет выполнить замену, используя изображение или поле, следующее после изображения или поля, которое можно использовать для замены.
8. Устройство обработки информации по п.1, в котором порядок данных коэффициента изменяют в порядке от компонентов низкой частоты до компонентов высокой частоты с последовательным приращением размером блок строк.
9. Способ обработки информации для устройства обработки информации, предназначенного для кодирования данных изображения, в котором:
средство сравнения сравнивает кадры или поля, составляющие данные изображения, с последовательными приращениями размером блок строк, включающими в себя данные изображения, эквивалентные количеству строк, необходимому для генерирования данных коэффициента, эквивалентных одной строке подполос, по меньшей мере, компонентов самой низкой частоты;
средство генерирования генерирует информацию сокрытия, обозначающую способ сокрытия ошибки в блоке строк в соответствии с результатом сравнения, полученным средством сравнения;
средство кодирования генерирует кодированные данные путем кодирования данных коэффициента, порядок которых был изменен заранее, в порядке, в котором данные коэффициента используют при выполнении обработки комбинирования, состоящей в комбинировании данных коэффициента из множества подполос, разложенных на полосы частот, для генерирования данных изображения; и
средство управления выполняет управление средством кодирования таким образом, чтобы мультиплексировать информацию сокрытия, генерируемую средством генерирования, с кодированными данными, генерируемыми средством кодирования, при этом информация сокрытия включает в себя информацию, обозначающую, когда блок строк, составляющий кадр или поле, может быть заменен блоком строк, составляющим другой кадр или другое поле, протяженность предыдущих изображений или полей, которые можно использовать для замены.
10. Устройство обработки информации, предназначенное для выполнения обработки сокрытия ошибки по кодированным данным, полученным в результате кодирования данных изображения, содержащее:
средство получения, предназначенное для получения для кадров или полей, составляющих данные изображения, информации сокрытия, обозначающей способ сокрытия ошибки в блоке строк, с последовательным приращением блока строк, включающего в себя данные изображения, эквивалентные количеству строк, необходимых для генерирования данных коэффициента, эквивалентных одной строке подполос, по меньшей мере, компонентов самой низкой частоты, из кодированных данных, полученных в результате кодирования данных коэффициента, порядок следования которых был заранее изменен на порядок, в котором данные коэффициента используют при выполнении обработки комбинирования, состоящей в комбинировании данных коэффициента из множества подполос, полученных в результате разложения данных изображения в полосах частот, для генерирования данных изображения; и
средство сокрытия, предназначенное для выполнения с последовательным приращением размером блок строк, обработки сокрытия ошибки, включенной в кодированные данные, в соответствии со способом сокрытия ошибки, обозначенным по информации сокрытия ошибки, полученной средством получения, при этом информация сокрытия включает в себя информацию, обозначающую, когда блок строк, составляющий кадр или поле, может быть заменен блоком строк, составляющим другой кадр или другое поле, протяженность предыдущих изображений или полей, которые можно использовать для замены.
11. Устройство обработки информации по п.10, в котором из кодированных данных формируют пакеты, причем информацию сокрытия используют как заголовок, и в котором средство получения получает информацию сокрытия как заголовок.
12. Устройство обработки информации по п.10, дополнительно содержащее: средство декодирования, предназначенное для декодирования кодированных данных, которые были обработаны для сокрытия с помощью средства сокрытия, для генерирования данных изображения.
13. Устройство обработки информации по п.10, дополнительно содержащее: средство записи, предназначенное для записи кодированных данных, которые были обработаны для сокрытия с помощью средства сокрытия на носителе записи.
14. Способ обработки информации для устройства обработки информации, предназначенного для выполнения обработки сокрытия ошибки по кодированным данным, полученным путем кодирования данных изображения, в котором:
средство получения получает, для кадров или полей, составляющих данные изображения, информацию сокрытия, обозначающую способ сокрытия ошибки в блоке строк, с последовательным приращением блока строк, включающего в себя данные изображения, эквивалентные множеству строк, требуемых для генерирования данных коэффициента, эквивалентных одной строке подполос, по меньшей мере, компонентов с самой низкой частотой, из кодированных данных, полученных в результате кодирования данных коэффициента, порядок которых был изменен заранее, в порядке, в котором данные коэффициента используют при выполнении обработки комбинирования, состоящей в комбинировании данных коэффициента из множества подполос, полученных в результате разложения данных изображения по полосам частот, для генерирования данных изображения; и
средство сокрытия выполняет, с последовательным приращением размером блок строк, обработку сокрытия ошибки, включенной в кодированные данные, в соответствии с информацией сокрытия ошибки, обозначенной информацией сокрытия ошибки, полученной средством получения, при этом информация сокрытия включает в себя информацию, обозначающую, когда блок строк, составляющий кадр или поле, может быть заменен блоком строк, составляющим другой кадр или другое поле, протяженность предыдущих изображений или полей, которые можно использовать для замены.
| JP 4252689 А, 1992.09.08 | |||
| US 2002064232 A1, 2002.05.30 | |||
| US 6295624 B1, 2001.09.25 | |||
| JP 6311052 A, 1994.11.04 | |||
| US 6510251 B1, 2003.01.21 | |||
| US 2003044089 A1, 2003.03.06 | |||
| JP 2002281507 A, 2002.09.27 | |||
| US 6707948 В1, 2004.03.16 | |||
| СПОСОБЫ И УСТРОЙСТВА ОБРАБОТКИ НАБОРА КОЭФФИЦИЕНТОВ ПРЕОБРАЗОВАНИЯ, СПОСОБЫ И УСТРОЙСТВА ОБРАТНОГО ОРТОГОНАЛЬНОГО ПРЕОБРАЗОВАНИЯ НАБОРА КОЭФФИЦИЕНТОВ ПРЕОБРАЗОВАНИЯ, СПОСОБЫ И УСТРОЙСТВА ДЛЯ УПЛОТНЕНИЯ И РАСШИРЕНИЯ СИГНАЛА ДВИЖУЩЕГОСЯ ИЗОБРАЖЕНИЯ, НОСИТЕЛЬ ЗАПИСИ УПЛОТНЕННОГО СИГНАЛА, ПРЕДСТАВЛЯЮЩЕГО ДВИЖУЩЕЕСЯ ИЗОБРАЖЕНИЕ | 1994 |
|
RU2119727C1 |
| IVAN V | |||
| BAJJC, ROBUST SUBBAND/WAVELET CODING AND TRANSMISSION OF IMAGES AND VIDEO, Rensselaer Polytechnic Institute Troy, New York, August 2003. | |||

