Область техники
Изобретение относится к вычислительной технике и может быть использовано для автоматизированного проведения адресных кампаний в отношении покупателей, прогноза снижения и увеличения количества потребителей продукции, прогноза результатов реализации событий для различных объектов и направлений хозяйственной деятельности.
Предшествующий уровень техники
Известны прогностические методы на основе нейросетей, карт Кохонена, деревьев решений, общим для которых является получение на входе процесса моделирования «вектора признаков» фиксированной размерности после этапа «подготовки данных» (этап Data Preparation, см. CRoss Industry Standard Process for Data Mining - CRISP-DM).
Однако реальные данные, накапливаемые компаниями, содержат историю событий исследуемых объектов с переменным и часто большим количеством событий по каждому объекту, и только с большими потерями информации могут быть преобразованы в вектор. При этом каждое событие может содержать целый ряд характеристик, потенциально полезных для прогноза.
Например, информация о покупке товара по дисконтной карте одновременно содержит сумму покупки, точную дату, название и категорию товара, сумму скидки, название и адрес магазина, название отдела - всего до 100 и более полей. При этом значимыми для прогноза поведения покупателей в отношении конкретных акций могут оказаться совершенно различные характеристики, например:
- Сумма покупок со словом 'ШАМПАНСКОЕ' в 'НАЗВАНИИ ТОВАРА' УТРОМ
- Сумма покупок со словом 'МАРТИНИ' ПО ПЯТНИЦАМ,
- Количество покупок со словом 'ПАМПЕРС' ДНЕМ,
- Количество слов 'ВЫСШЕЕ' В АНКЕТЕ,
- Количество посещений web-страницы 'ШУРУПЫ И САМОРЕЗЫ' и т.д.
Таким образом, как значения текстовых полей, так и слова в них, в том числе в комбинации с числовыми полями, могут быть использованы для формирования отдельных потенциально полезных характеристик. При ассортименте торговых сетей в десятки и сотни тысяч наименований количество потенциально полезных характеристик покупателей часто превышает миллион.
Объем данных всех возможных характеристик событий миллионов покупателей превышает размер доступной оперативной памяти современных компьютеров, что вынуждает разработчиков информационных систем «уменьшать размерность» анализа до нескольких десятков тысяч переменных, то есть экспертным методом отбрасывать потенциально ценную информацию.
Известен также алгоритм ассоциативных правил, использующийся для поиска часто встречающихся комбинаций товаров в «корзинах» покупок (Association Rule and Quantitative Association Rule Mining among Infrequent Items MDM'07, Ling Zhou, Stephen Yau, 2007, San Jose, California, USA). Но этот алгоритм не позволяет использовать наряду с основным идентификатором (например, название товара) другую дополнительную информацию (дата и время покупки, адрес магазина, группа, подгруппа, категория и подкатегория товара).
Известен способ (US, 6839682) предсказания финансового поведения потребителей (например, покупателей), включающий получение ряда входных транзакций для множества потребителей относительно множества торговцев; определение, по крайней мере, одного торгового сегмента, в котором каждый торговец объединяется по крайней мере с одним из определенных торговых сегментов; и по крайней мере для одного потребителя, применяя входные транзакции потребителя компьютером к каждой по крайней мере одной торговой прогнозирующей модели сегмента, каждому торговому определению прогнозирующей модели сегмента для торгового сегмента прогноз функционирует между входными транзакциями в прошлом временном интервале и финансовым поведением в последующем временном интервале, чтобы произвести для каждого потребителя предсказанное поведение в каждом, по крайней мере, подмножестве торговых сегментов.
Этот известный способ реализует автоматизированный прогноз целевого показателя (ЦП) событий, включающий получение компьютером данных о событии с указанием по каждому событию целевого показателя и набора характеристик этого события, сегментацию, построение прогнозной модели и прогноз целевого показателя для последующих аналогичных событий.
В данном способе событием является покупка, целевым показателем - сумма продаж в торговом сегменте, характеристикой - вектор сумм продаж покупателя в других торговых сегментах, при этом все транзакционные данные о покупателе предварительно преобразуются в вектор сумм выручки по «сегментам торговли», после чего проводится компьютерный анализ только по этим упрощенным данным.
Таким образом, в этом известном способе не учитывается и не используется для прогноза информация о времени покупок, адресах магазинов, торговых сетях внутри «сегмента», анкетных данных покупателей и каких-либо других доступных данных.
Ограничением известного способа являются недостаточно высокая точность и достоверность прогноза целевых показателей (ЦП) событий, а также длительное время и сложная процедура при обработке больших объемов данных о событиях.
Раскрытие изобретения
Решаемая изобретением задача - улучшение технико-эксплуатационных характеристик и расширение функциональных возможностей прогнозирования при упрощении его процедуры.
Техническим результатом является повышение точности и достоверности прогноза целевых показателей событий, а также сокращение времени и упрощение процедуры при больших объемах данных наблюдений о различных событиях за счет оптимизации распределения данных о событиях по типам памяти компьютера и алгоритмов их обработки, что дает возможность полного анализа всех необходимых характеристик событий.
Современные процессоры компьютеров позволяют выполнять миллиарды операций в секунду, но их производительность ограничивается быстродействием устройств памяти и накопителей данных.
По этой причине в основу изобретения положен полный анализ всех возможных характеристик о событиях, что становится возможным за счет оптимизации распределения данных о событиях по типам памяти компьютера и алгоритмов их обработки.
Построение модели проводится путем последовательного построения уровней дерева решений путем разделения подмножества событий, отнесенных к узлу дерева (сегмента) на каждом уровне, на сегменты следующего уровня.
Такой подход позволяет при промышленном применении использовать только основные начальные уровни дерева решений из построенной модели, дающие максимальный экономический эффект с учетом расходов на их хранение и использование для сотен и тысяч промоакций, в том числе на точках продаж в устройствах с ограниченным объемом памяти.
Для решения поставленной задачи с достижением указанного технического результата в способе получают компьютером данные о событиях с указанием для каждого события целевого показателя и произвольного набора его числовых характеристик, посредством компьютера нумеруют события, проводят сквозную нумерацию характеристик событий, сортируют значения характеристик для событий в порядке номера характеристики события - значение характеристики события, запоминают их в этом порядке в накопителе данных компьютера с указанием номеров событий, после чего в цикле сегментации выполняют последовательное деление множества событий на подмножества - сегменты следующего уровня, соответствующие узлам дерева решений, в ходе которого выполняют последовательное чтение характеристик, их значений и номеров событий из накопителя данных, и для каждого сегмента вычисляют агрегированные данные на основе целевых показателей и количества из массива событий из оперативной памяти компьютера, и при отличии следующей характеристики события от предыдущей или ее значения от предыдущего рассчитывают экономический эффект деления на сегменты между предыдущим и следующим значениями предыдущей характеристики, запоминают наилучшую характеристику события и значение, имеющие максимальный экономический эффект деления на сегменты, после чтения последнего значения характеристики из накопителя данных проводят деление сегментов, в которых экономический эффект деления на сегменты следующего уровня положителен, на сегменты следующего уровня по наилучшей характеристике и ее значению, если обнаружены новые сегменты, то повторяют цикл сегментации, если новые сегменты не обнаружены, то для прогноза целевого показателя последующего аналогичного события последовательно сравнивают значения характеристик аналогичного события со значениями наилучших характеристик, по которым было проведено деление сегмента на сегменты следующего уровня, и по значению наилучшей характеристики определяют сегмент, к которому относится последующее аналогичное событие, среднее значение целевого показателя такого сегмента служит прогнозом для последующего аналогичного события.
Возможен дополнительный вариант способа, согласно которому при вычислении экономического эффекта деления на сегменты экономический эффект уменьшают на величину доверительного интервала экономического эффекта, для чего вычисляют дополнительные агрегированные данные, в частности сумму квадратов целевых показателей событий. В качестве критерия наилучшего деления на сегменты в этом случае используется максимальный пессимистический экономический эффект. Экономическим эффектом может быть, например, экономия в связи с отказом от проведения промоакции в нецелевом (убыточном по среднему целевому показателю) сегменте. Пессимистический экономический эффект корректируется в меньшую сторону на величину оценки статистической погрешности экономического эффекта путем расчета доверительного интервала для заданной пользователем требуемой доверительной вероятности.
Возможны также варианты способа, когда деление сегментов выполняют не более заданного количества уровней и/или не менее заданного количества событий в каждом сегменте следующего уровня. Ограничение на количество событий в сегменте может устанавливаться исходя из компромисса между требуемой достоверностью сегментов и имеющимся объемом данных, которых может оказаться недостаточно для удовлетворения этих требований.
Возможен также вариант способа, когда деление сегмента производится не более чем на два сегмента следующего уровня.
Указанные преимущества, а также особенности настоящего изобретения поясняются лучшим вариантом его выполнения со ссылками на прилагаемые фигуры.
Перечень чертежей
Фиг.1 изображает диаграмму формирования и обработки данных для построения модели и прогноза целевого показателя заявленным способом;
Фиг.2 - цикл по уровню сегментации на фиг.1;
Фиг.3 - экран формирования событий (наблюдений) на основе истории покупок покупателя для заявленного способа;
Фиг.4 - экран результата построения модели в виде дерева решений для проведения промоакции;
Фиг.5 - то же, что фиг.4, для персональных рекомендаций фильма «Pretty Woman» на данных компании NetFlix.
Лучший вариант реализации изобретения
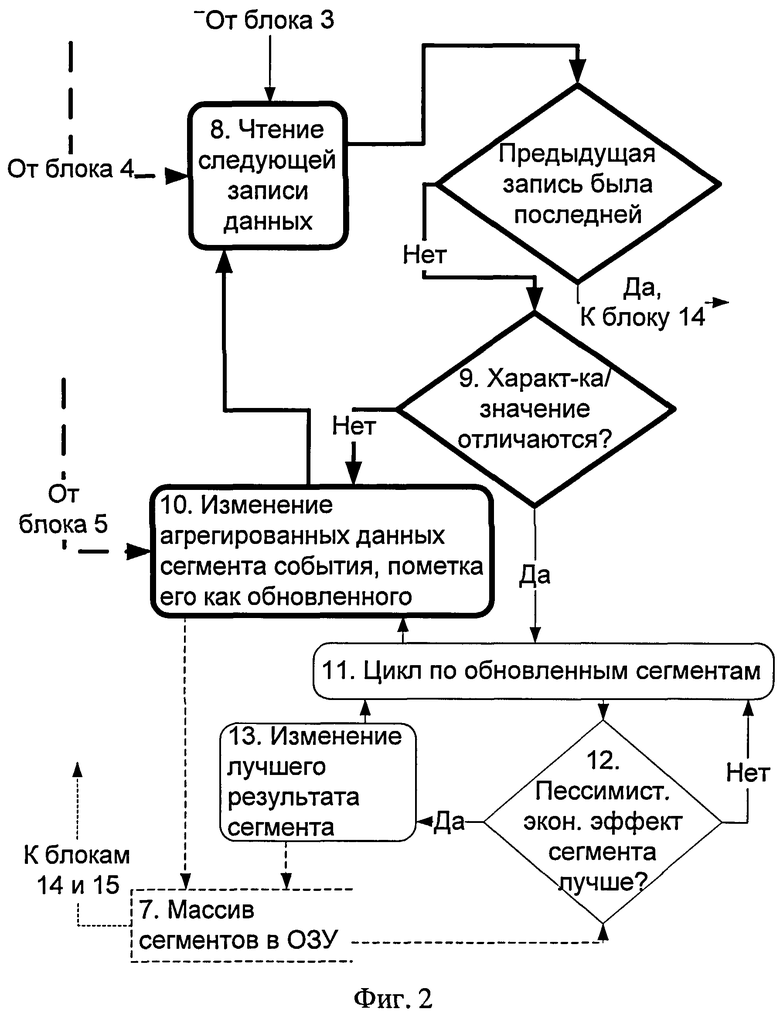
Заявленный способ может быть реализован посредством следующего алгоритма (фиг.1 и фиг.2) работы вычислительного устройства, в процессе которого строится бинарное дерево решений, то есть каждый сегмент делится не более чем на два сегмента следующего уровня. На фиг.1 и 2 штрихом выделены блоки данных и путь их передачи, сплошными линиями показаны блоки обработки данных, блоки управления и путь. Блоки, выделенные на схеме жирными линиями (фиг.2), характеризуют основной цикл, обеспечивающий максимальную производительность.
На основе журнала 1 событий, полученных компьютером (фиг.1), блок 2 формирует данные о событиях, состоящие для каждого события из числового целевого показателя (ЦП) и произвольного набора числовых характеристик с текстовыми названиями. События формируются в соответствии с необходимой для конкретной задачи бизнес-логикой, например экономикой промоакции, почтовой или CMC рассылки, раздачи купонов или персональных предложений. Здесь и далее под понятием «число» понимаются вещественные числа, которые как частный случай могли быть получены в результате присвоения сравнимым нечисловым характеристикам следующих друг за другом числовых значений, например датам, уровням образования или владения иностранным языком из анкеты покупателя и прочее.
В процессе построения модели при поступлении в обработку каждого события оно нумеруется. Каждая вновь обнаруженная характеристика (нумерация сквозная по всем событиям) также последовательно нумеруется блоком 3, в результате чего событие может выглядеть, например, так:
После этого значение каждой характеристики для каждого события сортируется и запоминается в накопителе 4 данных в порядке «Номер характеристики - значение характеристики - номер события», например:
Жирным шрифтом выделено значение характеристики из примера события для блока 3 (сортировка по значению проведена в порядке убывания).
После этого в оперативном запоминающем устройстве (ОЗУ) компьютера создают блок 5 массива событий, индексированного по номеру события с указанием целевого показателя и номера сегмента.
Далее в цикле сегментации блока 6 подсчитывают суммарные значения агрегированных данных сегментов блока 7 (фиг.2). Агрегированными данными может быть общее количество событий, сумма целевых показателей, сумма квадратов целевых показателей и другие, выбранные разработчиком.
Пример массива сегментов и агрегированных данных о них (блок 7):
Для этого в блоке 8 (фиг.2) в цикле до конца данных из накопителя блока 4 производится буферизованное чтение следующей записи значений характеристик. Каждая запись значения характеристики проверяется на совпадение номера характеристики и значения характеристики от предыдущей записи в блоке 9 принятия решения. Если они не отличаются, то целевой показатель события, полученный из массива блока 5, сразу используется в блоке 10 для накопления агрегированных данных сегмента блока 7, к которому принадлежит событие. Например, к текущему значению количества событий добавляется единица, к сумме целевых показателей (ЦП) сегмента добавляется значение целевого показателя события, к сумме квадратов ЦП добавляется квадрат текущего ЦП и т.д. При этом сегмент помечается как обновленный установлением флага Обновлен = «Да» в блоке 7.
Блоки 8, 9 и 10 в процессе построения модели используются чаще всех других при выполнении операций, поскольку данные отсортированы по номерам и значениям характеристик, и высока вероятность, что соседние записи в накопителе блока 4 имеют одинаковые значения характеристик (например, тысяча покупателей купили по одной единице товара и соответствующая характеристика у всех таких событий будет одинакова и равна единице). Для этих операций требуется только сравнение данных в ОЗУ компьютера и выполнение арифметических операций его процессором для обновления агрегированных данных, что позволяет увеличить производительность и скорость построения модели, несмотря на то, что объем данных характеристик для реальных объемов событий, как правило, не помещается в оперативной памяти.
В качестве критерия наилучшего деления на сегменты используется пессимистический экономический эффект.
Экономическим эффектом может быть, например, экономия в результате отказа от проведения промоакции в нецелевом (убыточном по среднему целевому показателю) сегменте, в этом случае экономический эффект будет равен сумме целевых показателей в убыточном сегменте со знаком минус. Другой пример экономического эффекта - сумма превышения ЦП в дочернем сегменте по сравнению со средним по родительскому сегменту.
Могут быть использованы и другие показатели оптимального деления сегмента, не являющиеся строго экономическими, но в любом случае для промышленной применимости они так или иначе должны в итоге приводить к расчету экономического эффекта, поэтому мы их рассматриваем как частный случай экономических критериев.
Для получения пессимистического экономического эффекта экономический эффект корректируется в меньшую сторону на величину оценки статистической погрешности экономического эффекта путем расчета доверительного интервала для заданной пользователем доверительной вероятности.
Таким образом, [Результат деления на сегменты]
=[Пессимистический экономический эффект]=
[Экономический эффект]-[Доверительный интервал Экономического эффекта]
[Доверительный интервал Экономического эффекта] может вычисляться исходя из стандартного отклонения целевого показателя и количества событий в сегменте с учетом коэффициентов Стьюдента или другими статистическими методами с использованием необходимых для них и накапливаемых в блоке 7 агрегированных данных в зависимости от задачи, поставленной разработчику алгоритма.
Деление на сегменты производится, если пессимистический экономический эффект от него больше нуля.
Если номер или значение характеристики отличается (а также после считывания последней записи из накопителя 4), то, прежде чем обновить данные сегмента, в цикле блока 11 для всех обновленных сегментов в блоке 12 проверяется, улучшен ли результат возможного деления данного сегмента на сегменты следующего уровня по значению между отличающимися значениями одной характеристики, сравнение которых проводилось в блоке 9, или если в блоке 9 считана запись с отличающейся характеристикой, то по значению «Присутствует-Отсутствует» предыдущей характеристики.
Например, если предыдущая и следующая запись в накопителе 4 относятся к одной характеристике:
то деление должно проводиться по значению характеристики №94512 между 8,456 и 7,232.
Поскольку между предыдущим и следующим значением характеристики при используемой сортировке значений быть не может, то более точная граница между сегментами следующего уровня не может быть определена и ее можно устанавливать в этом интервале. Например, точная граница может определяться как среднее с округлением до минимального количества значащих цифр, которые сохраняют ее в границах интервала, в данном случае 8,0.
Для варианта расчета экономического результата с отбросом сегментов с отрицательным средним значением целевого показателя экономический эффект от деления сегмента на два сегмента следующего уровня по значению характеристики 94512, равному 8,0, будет равен 12932.1 при следующих агрегированных значениях в массиве сегментов блока 7:
Если результат возможного деления сегмента (для простоты в данном примере рассчитывается без доверительного интервала) при этом улучшен, то в данных этого сегмента блока 7 могут быть установлены следующие значения:
Если же предыдущая и следующая запись в накопителе 4 относятся к разным характеристикам:
то деление должно проводиться по значению «Присутствует» - «Отсутствует» характеристики №94512, и если результат возможного деления сегмента при этом также улучшен до 12932.1, то в данных этого сегмента блока 7 должны быть установлены следующие значения:
В случае улучшения экономического результата возможного деления сегмента в блоке 13 для сегмента устанавливаются найденные новые значения результата, лучшей характеристики и ее лучшего значения.
Вычисления блока 12 требуют большего количества операций процессора компьютера, чем цикл блоков 8, 9 и 10, но выполняются реже, что позволяет не обращаться в процессе вычислений к накопителю данных и обеспечивает скорость вычислений, соизмеримую со скоростью последовательного буферизированного чтения данных с жесткого диска, то есть близкую к максимально возможной.
После каждого цикла по уровню сегментации блока 6 (фиг.1) в блоке 14 принятия решений проверяется, выявлены ли на этом уровне новые сегменты, если они обнаружены, то новые сегменты в блоке 15 добавляются к блоку 16 прогнозной модели в виде бинарного дерева решений.
После этого проводится деление сегментов, в которых выявлены сегменты следующего уровня, то есть присвоение событиям этих сегментов в блоке 5 новых сегментов, для чего считываются данные из накопителя 4 по характеристикам, по которым производится деление (вошедшим в модель блока 16), сравниваются со значением, по которому производится деление, и в зависимости от результата сравнения событие относится к соответствующему сегменту. Одновременно вычисляются средние значения целевого показателя в сегментах, которые указываются для каждого сегмента в модели блока 16, после чего она сохраняется для дальнейшего использования.
Если новых сегментов не выявлено, построение модели заканчивается.
В момент прогноза целевого показателя (возможно в реальном времени) данные о событии генерируются блоком 2 по таким же данным и правилам, что и для построения модели, что гарантирует применимость построенной модели блока 16 для прогноза. Для прогноза целевого показателя такого события в блоке 17 соответствующие значения его характеристик последовательно сравниваются со значениями этих характеристик в узлах дерева блока 16, пока событие не будет отнесено к сегменту, не имеющему сегментов. Среднее значение целевых показателей событий в этом сегменте, использованных для построения модели, является прогнозом целевого показателя такого события.
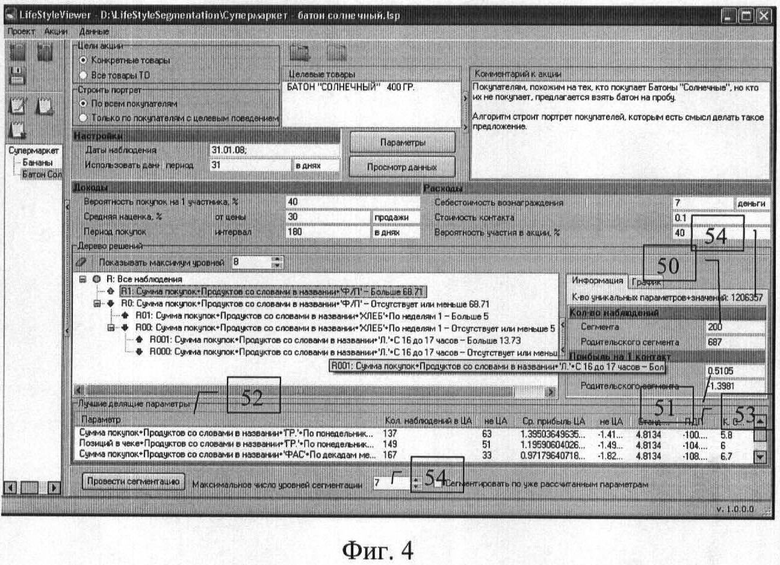
На фиг.3 отображен пример потенциального события промоакции по продвижению товара «БАТОН СОЛНЕЧНЫЙ 400 ГР» (поле 30) потенциальному клиенту, похожему на существующего клиента №5 (поле 31), и порядок вычисления целевого показателя (поле 32) и характеристик (таблица 33).
В данном случае бизнес-модель акции состоит в бесплатном предоставлении покупателям продвигаемого (целевого) товара («батон солнечный») на пробу. Целевым показателем в поле 32 является оценка прибыли от промоакции в отношении покупателя, похожего на существующего, но который еще не покупал данный товар, вычисляемого в полях 34 и 35. Все вошедшие на экран характеристики события таблицы 33 сформированы путем автоматического вычисления сумм покупок за различные временные периоды с указанием названия товара, содержащегося в первой записи 36 в журнале покупок таблицы 37: «ТОРТ «ТВОРОЖНИК» ШОКОЛАДНЫЙ 340 ГР», или слов в названии этого товара. Для остальных товаров в таблице покупок также формируются соответствующие характеристики, они не вошли на экран.
Для построения модели в соответствии с заявленным способом из каждого события указываются целевой показатель в поле 38 и характеристики события в виде таблицы 33 вещественных значений с текстовыми названиями. Пользователем должны быть введены только параметры бизнес-модели в разделах «Доходы» 39 и «Расходы» 40, а также в одном из вариантов способа может быть указана доверительная вероятность.
В результате компьютером построена прогнозная модель (фиг.4) в виде дерева решений. В поле 50 «Дерево решений - информация» отображено наличие 200 событий в сегменте из 687 в вышестоящем узле дерева (родительском сегменте), при этом средний экономический эффект в поле 51 в виде ожидаемой прибыли на 1 контакт в сегменте составляет 0.51 рубля, а в вышестоящем узле дерева - отрицателен и равен 1.39 рубля. Деление на сегменты проведено по характеристике «Сумма покупок со словом 'Ф/П' в названии», по значению 'больше 68.71'. Указание 'Ф/П' в названии товаров - сокращение от «Фин. Пакет», то есть полиэтиленовая упаковка для бюджетных молочных продуктов, таким образом, «БАТОН СОЛНЕЧНЫЙ» покупают те же клиенты, которые покупают и бюджетные молочные продукты.
В таблице 52 «Лучшие делящие параметры» показаны агрегированные данные потенциального деления на сегменты по характеристикам «Сумма покупок продуктов со словом в названии ГР' по понедельникам». Сокращение ГР' используется для указания веса в граммах фасованных товаров в упаковке. При этом количество наблюдений в возможных сегментах следующего уровня равно соответственно 137 и 63, а средняя прибыль в них равна +1,39 и -1,41. Однако с учетом стандартного отклонения и коэффициента Стьюдента пессимистический экономический эффект от возможного деления на сегменты (ПДП) 53 оказался отрицательным, в результате чего дальнейшее деление на сегменты не было произведено.
Для клиентов, ранее не покупавших целевой товар, но у которых характеристика «Сумма покупок со словом 'Ф/П' в названии» присутствует и больше 68.71, среднее значение в этом сегменте, то есть 0.51 рубля на контакт, является прогнозом целевого показателя - экономического эффекта.
Деление на сегменты также может регулироваться параметром 54 «максимальное количество уровней сегментации».
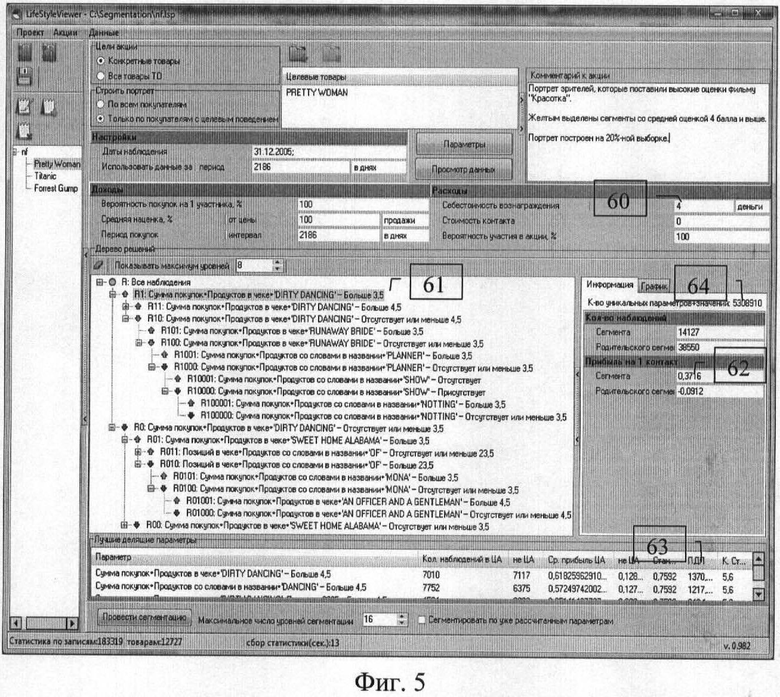
Аналогичный пример построенной модели - дерево решений для персональных рекомендаций фильма «PRETTY WOMAN» на данных компании NetFlix (фиг.5). Отличие этого примера в том, что в качестве базы для числовых характеристик вместо суммы покупки взята оценка фильма зрителем по 5-бальной шкале. В этом случае минимальный рейтинг, при котором нужно давать рекомендацию, принят равным 4 и указан в поле 60. Наилучший критерий (характеристика и значение) в узле дерева решений 61 для рекомендаций фильма «PRETTY WOMAN» на первом уровне сегментации - рейтинг фильма «DIRTY DANCING» больше 3,5. При этом средний прогнозный рейтинг в поле 62 в этом сегменте превышает требуемый, равный 4, на 0,37, при том что в вышестоящем узле дерева (родительском сегменте) он ниже требуемого на 0,09 балла.
Пессимистический эффект деления этого сегмента на сегменты следующего уровня в поле 63 также положителен, и наилучшим критерием для деления стала та же характеристика фильма «DIRTY DANCING», но уже по значению 4,5.
В обоих примерах никакого ручного ввода или подготовки данных не производилось, сегментация проводилась по всем автоматически сформированным характеристикам, общее число которых достигало сотен тысяч и более, что явствует из значений в полях 54 и 64 «Дерево решений - количество уникальных параметров + значений».
Таким образом, в заявленном способе для построения следующего уровня прогнозной модели в виде бинарного дерева решений используется пессимистический экономический эффект деления каждого сегмента на сегменты следующего уровня с учетом доверительного интервала.
Значения характеристик событий сохраняются в сортированном виде в накопителе данных, что позволяет высвободить ОЗУ компьютера для целевых показателей и сегментов, а также за счет последовательного чтения данных из накопителя максимально быстро провести полный перебор всех значений множества характеристик для всех сегментов каждого уровня бинарного дерева решений.
Построенная модель может использоваться для моментального прогнозирования целевого показателя событий, в том числе не участвовавших в ее построении. В качестве прогноза используется среднее значение целевого показателя в сегменте, к которому событие будет отнесено, путем последовательного сравнения характеристик события со значениями в узлах дерева решений.
Статистические методики вычисления доверительного интервала, в частности, на базе коэффициентов Стьюдента, как показали исследования, на большом объеме данных позволяют гарантировать выявление зависимостей в данных по миллионам показателей, автоматизируя процесс «уменьшения размерности» путем анализа всех вычисляемых характеристик и всех их значений, одновременно практически исключая при прогнозировании событий и их оценки человеческий фактор.
Промышленная применимость
Наиболее успешно изобретение применимо для формирования адресных предложений целевым сегментам покупателей на промышленных объемах данных в различных отраслях торговли.
| название | год | авторы | номер документа |
|---|---|---|---|
| СЕТЕВАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2008 |
|
RU2502122C2 |
| ОБНАРУЖЕНИЕ ОБЪЕКТОВ ИЗ ЗАПРОСОВ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2729956C2 |
| СЕТЕВАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА И СПОСОБ ВЫПОЛНЕНИЯ ВЫЧИСЛИТЕЛЬНОЙ ЗАДАЧИ (ВАРИАНТЫ) | 2013 |
|
RU2568289C2 |
| Компьютерно-реализуемый способ автоматического расчета и контроля параметров стимулирования спроса и повышения прибыли - "система Приз-Покупка" | 2017 |
|
RU2675910C2 |
| СИСТЕМЫ И СПОСОБЫ ТОРГОВЛИ СОКРАЩЕННЫМИ ВЫБРОСАМИ | 2005 |
|
RU2373576C2 |
| СИСТЕМЫ, УСТРОЙСТВА И СПОСОБЫ ИСПОЛЬЗОВАНИЯ КОНТЕКСТНОЙ ИНФОРМАЦИИ | 2009 |
|
RU2541890C2 |
| Система определения стоимости весового товара | 2021 |
|
RU2809136C2 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ ДИСТАНЦИОННОГО ЗОНДИРОВАНИЯ ЗЕМЛИ С ПОМОЩЬЮ НЕЙРОННОЙ СЕТИ СО ШТРАФОМ НА ТОЧНОСТЬ ГРАНИЦЫ СЕГМЕНТАЦИИ | 2019 |
|
RU2740736C1 |
| ТОРГОВАЯ ИНФОРМАЦИОННО-АНАЛИТИЧЕСКАЯ СИСТЕМА | 2005 |
|
RU2271571C1 |
| Способ и система поддержки принятия врачебных решений с использованием математических моделей представления пациентов | 2017 |
|
RU2703679C2 |

Изобретение относится к вычислительной технике и может использоваться для прогноза целевого показателя различных событий. Техническим результатом является повышение точности и достоверности прогноза целевых показателей событий, а также сокращение времени и упрощение процедуры при больших объемах данных. Способ включает в себя этапы: с помощью компьютера получают данные о событиях с указанием для каждого события целевого показателя и произвольного набора его числовых характеристик, производят сегментацию, создают прогнозную модель и прогноз целевого показателя последующего аналогичного события. Также нумеруют характеристики событий, сортируют их значения, выполняют последовательность циклов сегментации событий, для каждого события находят его сегмент, рассчитывают величину экономического эффекта деления на сегменты, проводят деление сегментов по наилучшей характеристике, имеющей максимальный экономический эффект, и ее значению. Для прогноза целевого показателя последующего аналогичного события последовательно сравнивают значения и характеристики аналогичного события со значениями наилучших характеристик сегментов. По значению наилучшей характеристики определяют сегмент, к которому относится событие. Среднее значение целевого показателя такого сегмента служит прогнозом последующего аналогичного события. 4 з.п. ф-лы, 5 ил.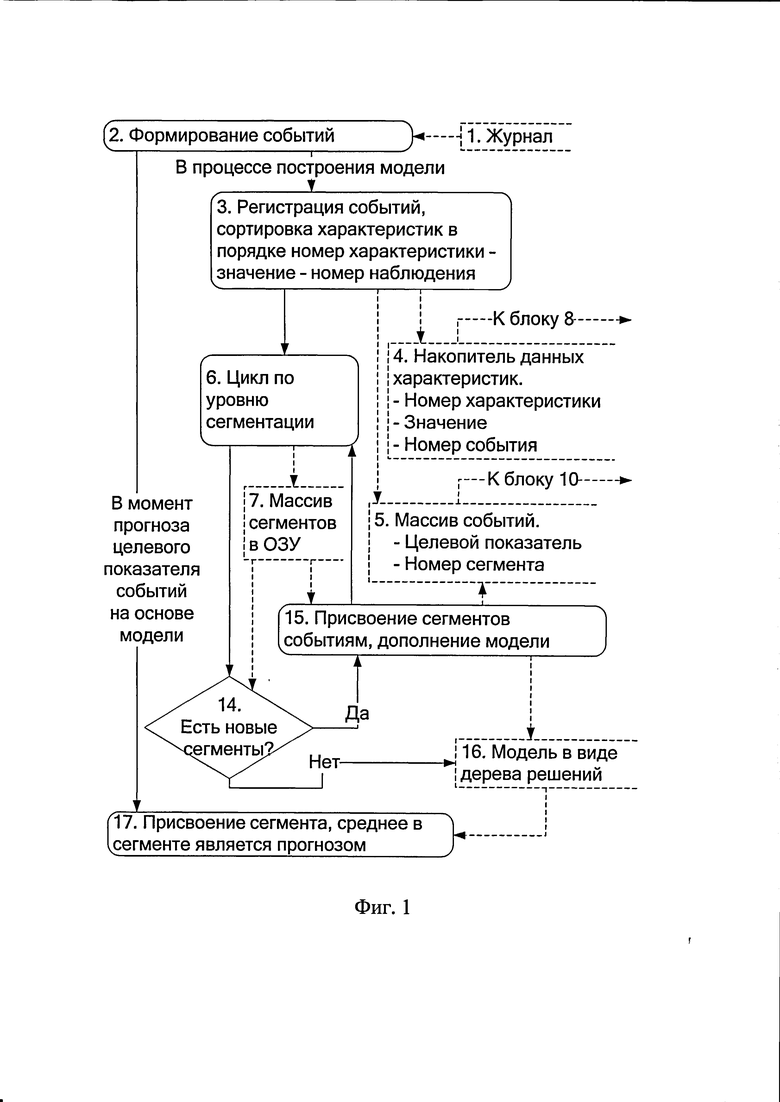
1. Способ прогноза целевого показателя событий, заключающийся в том, что получают компьютером данные о событиях с указанием для каждого события целевого показателя и произвольного набора его числовых характеристик, производят сегментацию, создают прогнозную модель и прогнозируют целевой показатель последующего аналогичного события, отличающийся тем, что посредством компьютера нумеруют события, проводят сквозную нумерацию характеристик событий, сортируют значения характеристик для событий в порядке номер характеристики события - значение характеристики события, запоминают их в этом порядке в накопителе данных компьютера с указанием номеров событий, после чего в цикле сегментации выполняют последовательное деление множества событий на подмножества - сегменты следующего уровня, соответствующие узлам дерева решений, в ходе которого выполняют последовательное чтение характеристик, их значений и номеров событий из накопителя данных, и для каждого сегмента вычисляют агрегированные данные на основе целевых показателей и количества из массива событий из оперативной памяти компьютера, и при отличии следующей характеристики события от предыдущей или ее значения от предыдущего рассчитывают экономический эффект деления на сегменты между предыдущим и следующим значениями предыдущей характеристики, запоминают наилучшую характеристику события и значение, имеющие максимальный экономический эффект деления на сегменты, после чтения последнего значения характеристики из накопителя данных проводят деление сегментов, в которых экономический эффект деления на сегменты следующего уровня положителен, на сегменты следующего уровня по наилучшей характеристике и ее значению, если обнаружены новые сегменты, то повторяют цикл сегментации, если новые сегменты не обнаружены, то для прогноза целевого показателя последующего аналогичного события последовательно сравнивают значения характеристик аналогичного события со значениями наилучших характеристик, по которым было проведено деление сегмента на сегменты следующего уровня, и по значению наилучшей характеристики определяют сегмент, к которому относится последующее аналогичное событие, среднее значение целевого показателя такого сегмента служит прогнозом для последующего аналогичного события.
2. Способ по п.1, отличающийся тем, что при расчете экономического эффекта деления на сегменты экономический эффект уменьшают на величину доверительного интервала экономического эффекта.
3. Способ по п.1, отличающийся тем, что деление сегментов выполняют не более заданного количества уровней.
4. Способ по п.1, отличающийся тем, что деление сегментов выполняют при условии, что каждый сегмент следующего уровня содержит не менее заданного количества событий.
5. Способ по п.1, отличающийся тем, что последовательное деление множества событий на подмножества - сегменты следующего уровня производят путем разделения сегмента предшествующего уровня на два сегмента следующего уровня.
| US 6839682 В2, 04.01.2005 | |||
| WO 2005109253 A2, 17.11.2005 | |||
| СПОСОБ АНАЛИЗА И ПРОГНОЗИРОВАНИЯ РАЗВИТИЯ ДИНАМИЧЕСКОЙ СИСТЕМЫ И ЕЕ ОТДЕЛЬНЫХ ЭЛЕМЕНТОВ | 2000 |
|
RU2236700C2 |
| СИСТЕМА СТРАТЕГИЧЕСКОГО ПРОГНОЗА ТЕХНИЧЕСКОГО СОСТОЯНИЯ ОБЪЕКТОВ, ПРЕИМУЩЕСТВЕННО КОМПЬЮТЕРНО-ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ | 2006 |
|
RU2326431C2 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |

