Заявляемое изобретение относится к области обработки цифровых сигналов, а более конкретно - изобретение касается процесса цифрового сжатия многоракурсного видео (далее МРВ), сопровождаемого дополнительными данными о глубине сцены.
Отличительной чертой такого процесса является то, что каждый ракурс или вид, соответствующий определенной пространственной позиции снимающей камеры, представляет собой видеопоток, который дополнен информацией о глубине сцены, которая соответствует определенному ракурсу. При этом информация о глубине сцены представляется в виде последовательности кадров, каждый из которых хранит информацию о глубине в соответствующий момент времени для определенной пространственной позиции. Информация о глубине в кадре обычно представляется аналогично информации об яркостной составляющей пикселей, т.е. с использованием градаций серого цвета, что задает определенную точность хранения и обозначается также термином «карта глубины».
Из уровня техники известно, что в настоящее время для сжатия МРВ применяется, в основном, гибридный подход, который означает, что кадр, принадлежащий определенному виду или глубине, в заданный момент времени представляется разностным дополнением (остатком) к уже закодированному кадру, с последующим применением пространственного преобразования, этапа квантования и статистического кодирования. При этом при сжатии формируется, кодируется и передается для последующего декодирования служебная информация (поле векторов движения, правила блочного разбиения и др.). В случае если МРВ сопровождается информацией о глубине сцены, представляется возможным ее использование совместно с процедурой синтеза видов для формирования дополнительного предсказания, применяемого в гибридных схемах кодирования, для повышения степени сжатия за счет уменьшения разностного дополнения.
Однако зачастую качество синтезированных кадров оказывается недостаточным, а использование специальных методов явного выбора предсказания путем формирования списков опорных кадров требует кодирования дополнительных данных. Указанные причины не позволяют добиться существенного повышения степени сжатия.
Известно расширение распространенного стандарта кодирования видео H.264/MPEG-4 AVC (стандарт сжатия видео, предназначенный для достижения высокой степени сжатия видеопотока при сохранении высокого качества; является модификацией существующего ранее Н.263, см., например, Iain E. Richardson «The H.264 Advanced Video Compression Standard», 2nd Edition, April 2010 [1]), предназначенного для кодирования многоракурсного видео, которое устраняет межкадровую избыточность по времени и между видами путем адаптивного выбора опорных кадров с явным кодированием и передачей служебной информации для последующего декодирования. Недостатком этого метода является явная передача служебной информации, такой как вектора движения, данные об относительном смещении друг относительно друга проекций 3-мерной сцены в соседних видах, необходимость передачи информации о режиме предсказания, а также недостаточная эффективность использования корреляционных связей между видами. Это приводит к малому увеличению степени сжатия в сравнении с независимым кодированием видов. Для того чтобы преодолеть часть из указанных недостатков, были предложены различные методы эффективного предсказания кадра, а также кодирования информации о движении. В частности, в работах S.Kamp, М.Evertz и M.Wien, "Decoder side motion vector derivation for inter frame video coding", in Proc. ICIP2008, October 2008, p.1120-1123 [2] и S.Klomp, M.Munderloh, Y.Vatis и J.Ostermann, "Decoder-Side Block Motion Estimation for H.264 / MPEG-4 AVC Based Video Coding", IEEE International Symposium on Circuits and Systems, Taipei, Taiwan, May 2009, p.1641-1644 [3] описаны методы предсказания кадра, частично устраняющие указанные недостатки, характерные также и для гибридных схем кодирования обычного видеопотока.
Близкая по смыслу концепция предложена для кодирования МРВ, сопровождаемого информацией о глубине сцены, которая описана в работе S.Shimizu и H.Kimata, "Improved view synthesis prediction using decoder-side motion derivation for multi-view video coding", 3DTV Conference, June 2010 [4].
Описанный в [4] метод включает следующие основные шаги:
- Генерация синтезированных кадров, соответствующих кодируемому кадру, и соседнему с ним по времени, рассматриваемому как опорный кадр.
- Применение процедуры оценки движения для синтезированных кадров и формирование информации о движении;
- Применение процедуры компенсации движения для формирования предсказания кодируемого кадра, используя выявленную ранее информацию о движении и опорный кадр.
- Кодирование кадра путем разбиения его на блоки фиксированного размера и последующего кодирования каждого блока либо с использованием стандартных средств кодирования в соответствии со стандартом H.264/MPEG-4 AVC, либо его попиксельная аппроксимация блоком, принадлежащим ранее сформированному предсказанию кодируемого кадра, расположенному в той же пространственной позиции, что и кодируемый блок.
Несмотря на то, что предсказание кодируемого кадра осуществляется достаточно точно, достигаемое улучшение степени сжатия незначительно и составляет порядка 2,5%. Кроме того, метод формирования предсказания кадра не включает в себя дополнительных способов повышения точности предсказания в случае, если предсказание из опорного кадра, соседнего по времени, оказывается неэффективным. Помимо этого, для увеличения эффективности сжатия МРВ последовательностей известны способы, такие как: способ, основанный на формировании кадров, пространственно-совмещенных кодируемому кадру, определенному заданию порядка и способа предсказания (см. выложенную заявку на патент США №2007/0109409) [5]. Для снижения битовых затрат на кодирование информации о движении предложен ряд методов косвенного перерасчета векторов движения на основе ранее определенных векторов движения или векторов движения, общих как для карт глубин, так и для видов, например, международная заявка WO 2010/043 773 [6], а также метод явного использования вектора движения из уже закодированного ракурса (см. международную заявку WO 2009/020542) [7]. Для повышения эффективности предсказания кодируемого кадра в МРВ последовательности предложен метод коррекции опорного кадра, полученного из одного из соседних видов, при этом обеспечивается частичная компенсация различий между данными в кодируемом и опорном кадрах (см. международную заявку WO 2010/095471) [8]. В целом, однако, указанные методы не позволяют комплексно устранять информационную избыточность, присущую МРВ видеопоследовательностям, т.к. не позволяют в должной степени обеспечить эффективное кодирование служебной информации и одновременно формирование малых ошибок предсказания.
Таким образом, задачей, на решение которой направлено заявляемое изобретение, является разработка усовершенствованного способа, включающего в себя адаптивное формирование предсказания для кодируемого кадра, дополнительные средства для улучшения точности предсказания и эффективный механизм сжатия, который не должен требовать существенных битовых затрат на передачу служебной информации.
Технический результат достигается за счет применения способа кодирования многоракурсной видеопоследовательности, к которой прилагается многоракурсная последовательность карт глубин, заключающегося в том, что каждый вновь кодируемый кадр многоракурсной видеопоследовательности, определяемый в соответствии с заранее заданным порядком кодирования, представляют как совокупность неперекрывающихся блоков, определяют, по меньшей мере, один уже закодированный кадр, соответствующий данному ракурсу и обозначаемый как опорный, формируют синтезированные кадры для кодируемого и опорных кадров, при этом для каждого неперекрывающегося блока пикселей кодируемого кадра, обозначаемого как кодируемый блок, определяют пространственно-совмещенный блок внутри синтезированного кадра, соответствующего кодируемому кадру, обозначаемый как виртуальный блок, для которого определяют пространственную позицию блока пикселей в синтезируемом кадре, соответствующем опорному кадру, такую, что определенный таким образом опорный виртуальный блок является наиболее точным численным приближением виртуального блока; для определенного таким образом опорного виртуального блока определяют пространственно совмещенный блок, принадлежащий опорному кадру, обозначаемый как опорный блок, и вычисляют ошибку между виртуальным блоком и опорным виртуальным блоком, а также вычисляют ошибку между опорным виртуальным блоком и опорным блоком, затем выбирают минимальную из них и на основе этого определяют, по меньшей мере, один режим разностного кодирования, задающий, какие из найденных на предыдущих шагах блоков необходимо использовать для формирования предсказания при последующем разностном кодировании кодируемого блока, и осуществляют разностное кодирование кодируемого блока в соответствии с выбранным режимом разностного кодирования.
Как известно, избыточность МРВ существенно выше, чем избыточность обычного одноракурсного видео. Обычно системы кодирования МРВ, в частности, реализованные в соответствии с расширенной версией стандарта кодирования Н.264 и обозначаемого в литературе как MVC (Multi-View Coding), используют один или несколько дополнительных опорных кадров, которые применяются далее для разностного кодирования. Дополнительные кадры формируются на основе уже закодированных ракурсов, обеспечивая синхронность кодера и декодера, и позволяют улучшить точность предсказания для кодируемого кадра. Формирование предсказания обычно осуществляется путем синтеза вида, пространственно совмещенного с кодируемым видом, при этом точность пространственного совмещения отдельных деталей синтезированного вида определяется используемым алгоритмом синтеза, а также точностью входных данных. Также могут быть использованы и более простые методы, основанные на блочной оценке наилучшего предсказания из уже закодированного ракурса без применения процедуры синтеза. Эти методы основаны на классической процедуре временной компенсации движения (motion compensation - МС). Обычно подобные методы обозначаются в литературе как методы компенсации диспарантности (disparity compensation - DC). Также известно, что использование дополнительных опорных кадров иногда требует передачи дополнительной служебной информации, необходимой для кодирования режима предсказания, что может приводить в ряде случаев к снижению эффективности сжатия. Стоит отметить, что в ряде случаев дополнительные опорные кадры не приводят к существенному увеличению степени сжатия ввиду недостаточной схожести с кодируемым кадром в сравнении с кадрами, которые выбраны в качестве предсказания и принадлежат кодируемому виду, т.е. представляющими собой уже декодированные кадры кодируемого вида.
В отличие от известных подходов к решению вышеуказанных проблем заявляемое изобретение позволяет определить режимы предсказания и информацию о движении в кадре, а также осуществить разностное кодирование кадра, используя малый объем служебной информации за счет учета известных пространственных связей между соседними ракурсами в каждый момент времени, а также информацию, доступную как при кодировании, так и при декодировании.
Важное отличие предлагаемого подхода состоит в том, что обеспечивается компактное представление текущего кодируемого кадра за счет адаптивного выбора режима кодирования и эффективной локальной декорреляции текстуры, при этом обеспечивается существенное сокращение необходимой служебной информации за счет ее определения на основе данных, доступных одновременно при кодировании и декодировании. Повышение эффективности сжатия по сравнению со стандартными системами кодирования достигается за счет снижения количества передаваемой служебной информации и повышения точности кодирования данных за счет большего количества режимов кодирования. При этом предлагаемый подход совместим с традиционными схемами гибридного кодирования, применяемого для кодирования МРВ.
В заявляемом изобретении раскрывается усовершенствованный способ кодирования МРВ за счет формирования оценки наилучшего предсказания кодируемого кадра. Предположим, что МРВ состоит из N смежных видов и N соответствующих видеопотоков, представляющих информацию о физической глубине сцены (ВПГ) для каждого из ракурсов. Рассмотрим также гипотетическую систему кодирования МРВ и такое ее состояние, при котором в настоящий момент времени кодируется ракурс с номером К, и, по меньшей мере, один предыдущий ракурс, а также соответствующий ему ВПГ, например К-1 уже закодирован. Рассмотрим М-й кадр, который принадлежит К-му виду, предполагая, что, по меньшей мере, один из предыдущих кадров, например М-1 и возможно один или более следующих по времени кадров, например М+1, также уже закодированы. Исходя из этого, обозначим кадр, принадлежащий К-му виду в момент времени М, как F (K,М). Подразумевается, что рассматриваемый способ, включая все выражения и равенства, единообразно применим ко всем цветовым компонентам кодируемого кадра с учетом реальных геометрических размеров обрабатываемых компонент. Исходя из этого, приводимые ниже рассуждения и расчеты приведены для одного цветового канала, в частности канала яркости, и могут быть аналогично применены к другим компонентам.
Один из отличительных признаков заявляемого изобретения заключается в том, что предлагаемый способ подразумевает блочную обработку кодируемого кадра F (K,М). Обычно блок имеет фиксированные геометрические размеры, например 16 на 16 пикселей, при этом разделение кадра F (K,M) на блоки выполняется равномерно без перекрытий или неучтенных областей. В начале, для получения оценки предсказания некоторого блока В(К,М), который принадлежит кадру F (K,M), формируется синтезированный блок, который пространственно совмещен (коллоцирован) с обрабатываемым блоком В( К,М). Этот синтезированный блок, обозначаемый как VB (К,М), принадлежит синтезированному (виртуальному) виду VF(K,M), который может быть описан как:
VF(K,М)=VS[F(K-1,M), F(K+1,M), D(K-1,M), D(K+1,M)],
где VS обозначает некоторую процедуру синтеза вида,
D(K-1,M), D(K+1,M) представляют собой информацию о глубине в текущий момент времени М из вида К-1 и К+1 соответственно.
При этом специально не предъявляется никаких дополнительных требований к особенностям или специфике процедуры синтеза VS; в частности, процедура синтеза может использовать только один вид для синтеза, при этом такая процедура будет являться несимметричной, «односторонней».
Затем формируется виртуальный кадр, предшествующий по времени данному и обозначаемый здесь как VF(K, M-1). Для синтезированного блока VB(K,M) определяется опорный виртуальный блок, обозначаемый как VB(K,M-1), при этом для определения используется алгоритм оценки движения. Опорный виртуальный блок VB(K,M-1) принадлежит виртуальному кадру в предыдущий момент времени M-1 и является наилучшим приближением блока VB(K,M) в некотором заранее заданном математическом смысле, например в смысле минимума критерия SAD (Sum of Absolute Differences - сумма модулей разностей) или MSE (Mean Square Error - среднеквадратичная ошибка). Блок VB(K,M) связан с VB(K,M-1) так называемым вектором движения (dx, dy), который описывает пространственное смещение по горизонтали и вертикали опорного блока относительно кодируемого и является параметром простейшей, но не единственной, модели движения, применяемой на практике. Затем определяется блок, являющийся опорным для В(К,М), который принадлежит кадру F(K,M-1) и который пространственно совмещен с VB(K,M-1). Таким образом, определяются три блока, связанных друг с другом описанными выше связями: VB(K,M), VB(K,M-1), B(K,M-1). При этом только VB(K,M) пространственно выровнен в соответствии с ранее заданной сеткой блоков. Необходимо отметить, что каждый описанный блок помимо номера вида, к которому он принадлежит, а также временной метки М или M-1 также задается координатами верхнего левого угла, однако в целях упрощения дальнейшего изложения они не используются, если только это не приводит к некорректному толкованию описания изобретения.
Другой отличительный признак заявляемого изобретения заключается в том, что определяют, по меньшей мере, два режима предсказания для текущего кодируемого блока В(К,М), условно обозначаемых как временной (Temporal) и параллаксный (Parallax) режимы предсказания. Для того чтобы оценить режим предсказания блока В(К,М), оценивают оптимальный режим предсказания для VB(K, M-1):
- Временной режим предсказания, в котором VB(K,M-1) предсказывается из VB(K, M)
- Параллаксный режим предсказания, в котором VB(K,M-1) предсказывается из В(К,М-1).
Оптимальный режим предсказания блока VB(K,M-1) основан на вычислении и анализе ошибки предсказания из VB(K,M) или В(К,М-1). В том случае, если ошибка предсказания с использованием VB(K,M) минимальна, задается временной режим предсказания. В противном случае, задается параллаксный режим предсказания. Исходя из этого, определяется оптимальный предсказатель для блока В(К,М) в соответствии с правилом:
- в качестве оптимального предсказателя используется VB(K,M), если задан параллаксный режим;
- в качестве оптимального предсказателя используется В(К,М-1), если задан временной режим.
Данный выбор основан на предположении, что во многих случаях режим предсказания блока VB(K,M) может быть достаточно точно определен, исходя из режима предсказания блока VB(K,M-1). В этом случае не требуется передачи дополнительных бит для явного задания режима предсказания; существенное увеличение эффективности сжатия достигается за счет определения параметров движения, а также режима предсказания для кодируемого блока без явной передачи служебной информации, а также повышения точности предсказания кодируемого блока.
Следующий отличительный признак заявляемого изобретения заключается в том, что режим кодирования блока В(К,М) определяется явно, при этом вычисляется мера ошибки предсказания во временном и параллаксном режиме, и выбирается тот режим, который обеспечивает минимальную ошибку. Предсказатели при этом выбираются согласно определенному режиму и описанным выше правилам. Для того чтобы сократить объем дополнительных бит, необходимых для явного кодирования и передачи режима предсказания, используют режим предсказания блока VB(K,M-1). Один из способов заключается в том, что режим предсказания блока VB(K,M-1) используется как дополнительная контекстная информация для статистического кодирования явно определенного режима предсказания. Другой способ заключается в принудительном изменении явно определенного режима предсказания на режим, определенный для блока VB(K,M-1), если при этом мера ошибки предсказания изменится на величину, меньшую, чем заранее заданное пороговое значение.
Еще один отличительный признак заявляемого изобретения заключается в том, что предложен дополнительный режим кодирования, который основан на предсказании различий между кодируемым блоком В(К,М) и пространственно-совмещенным с ним блоком VB(K,M). При этом формирование предсказания основано на предположении, что:
VB(K,M-1)-RB(K,M-1)≅VB(K,M)-В(К,М).
Следовательно, предсказатель РВ(К,М) блока В(К,М) может быть рассчитан следующим образом:
PB(K,M)=VB(K,M)-VB(K,M-1)+В(К,М-1).
Указанный дополнительный режим предсказания обеспечивает более точное предсказание блоков в тех случаях, когда рассмотренные ранее режимы предсказания оказываются малоэффективными.
Для использования дополнительного режима предсказания необходимо явно передавать служебную информацию о выбранном режиме. Однако результаты экспериментов указывают на то, что избыточность и объем дополнительной служебной информации несущественен. В целом, способ кодирования, основанный на предложенном методе адаптивного предсказания кадра, обеспечивает эффективную декорреляцию кодируемого кадра с незначительными дополнительными битовыми затратами, что подтверждается увеличением степени сжатия МРВ. Заявляемый способ технологически совместим с традиционными системами кодирования МРВ и может быть интегрирован в стандартную цепочку кодирования.
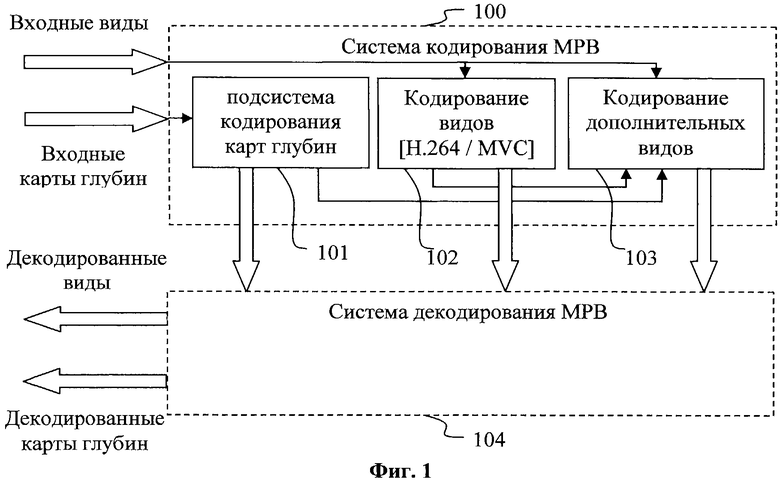
Фиг.1. - Структурная схема системы кодирования и декодирования МРВ последовательности, которая формирует MVC-совместимый битовый поток.
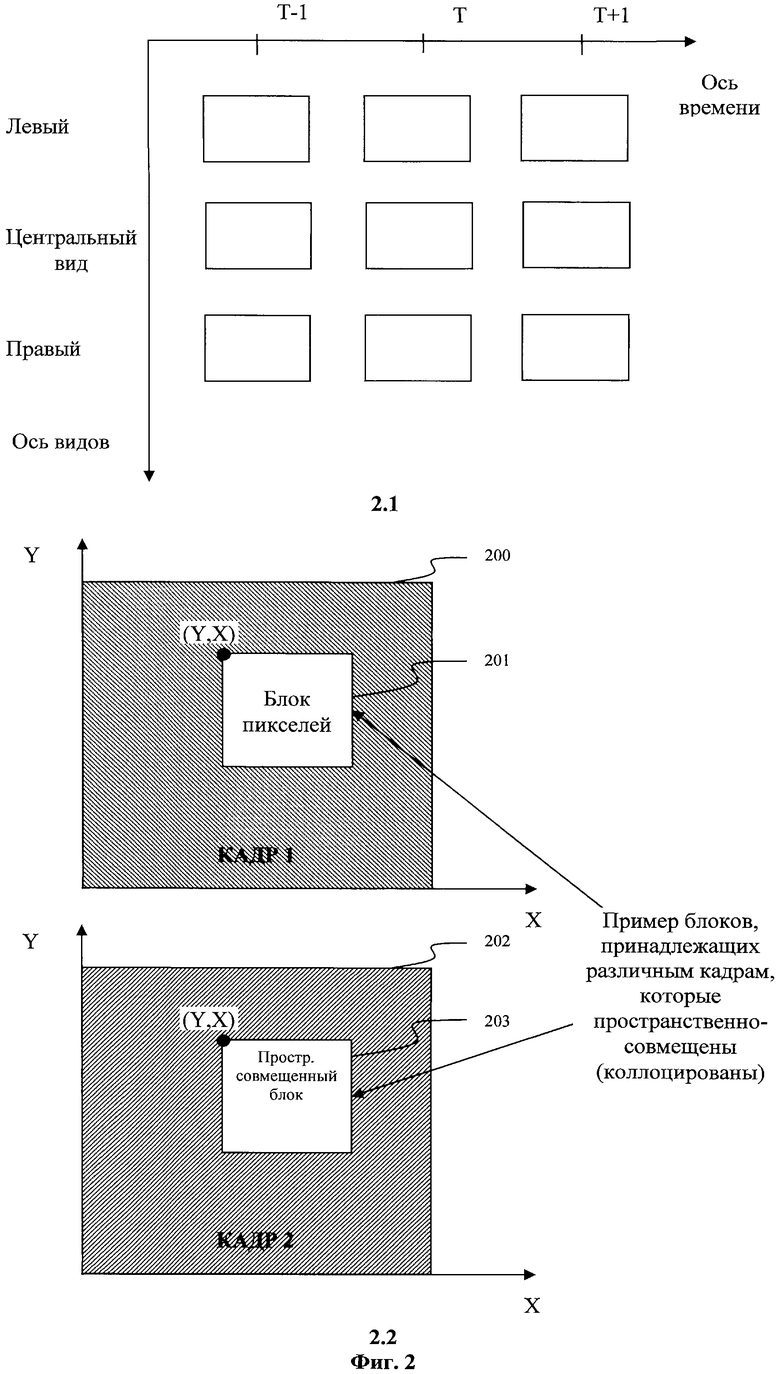
Фиг.2, вид 2.1 - Пример расположения кадров в пространстве, задаваемом временной осью и номером вида.
Фиг.2, вид 2.2 - Пример пространственно-совмещенных блоков в двух кадрах.
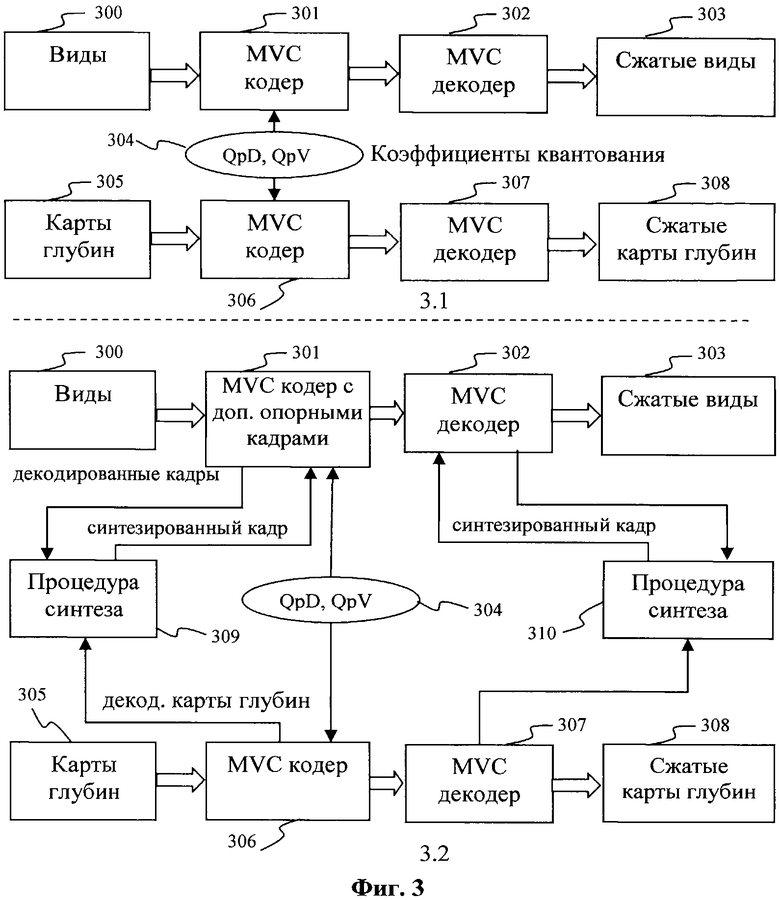
Фиг.3, вид 3.1 - Схема кодирования и декодирования МРВ последовательности с независимым кодированием видов и информации глубинах с использованием MVC кодера и декодера.
Фиг.3, вид 3.2 - Гибридная схема кодирования и декодирования МРВ последовательности, которая основана на MVC кодере и декодере и использует дополнительные кадры, частично формируемые процедурой синтеза кадра.
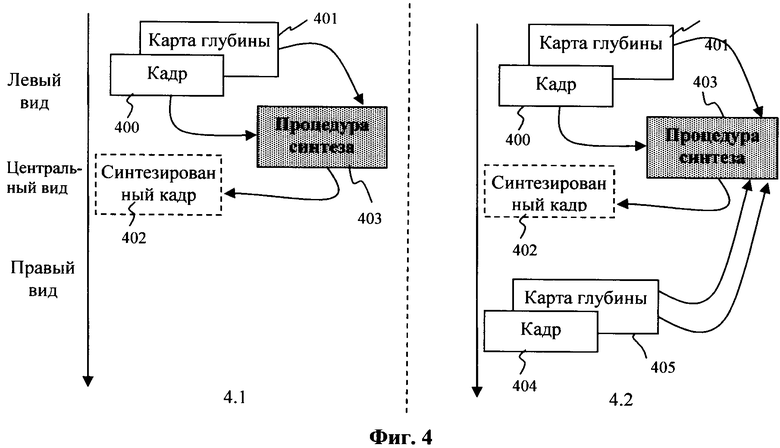
Фиг.4, вид 4.1 - Схема одностороннего синтеза кадра.
Фиг.4, вид 4.2 - Схема двухстороннего (симметричного) синтеза кадра.
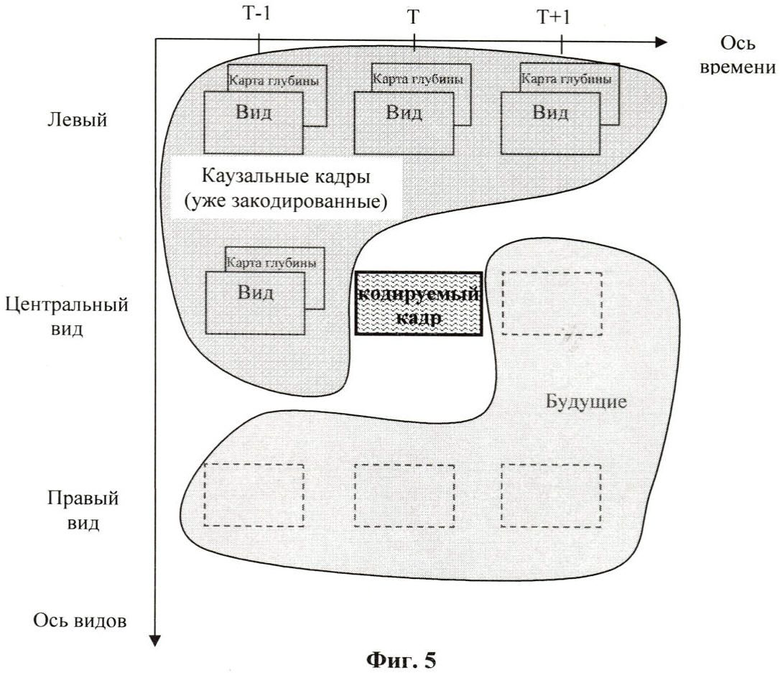
Фиг.5. Классификация кадров и карт глубин в соответствии с порядком их кодирования.
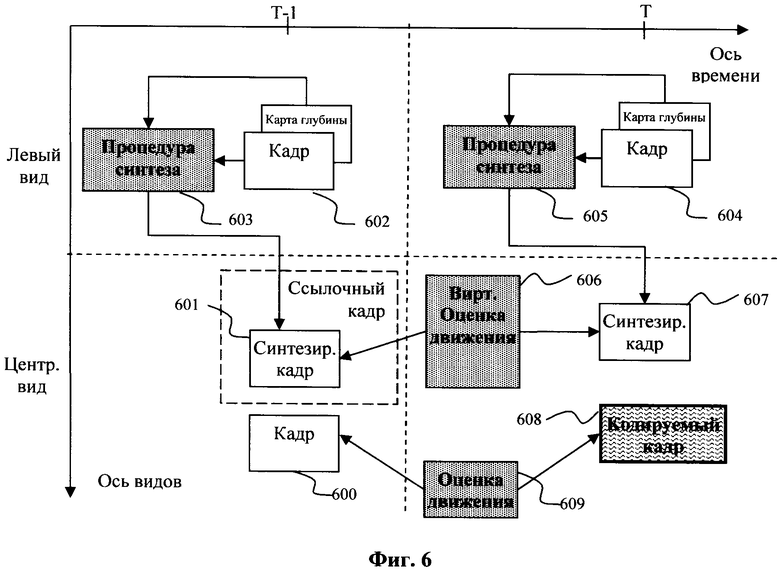
Фиг.6. Обобщенная схема формирования адаптивного предсказания кадра и определения необходимой служебной информации.
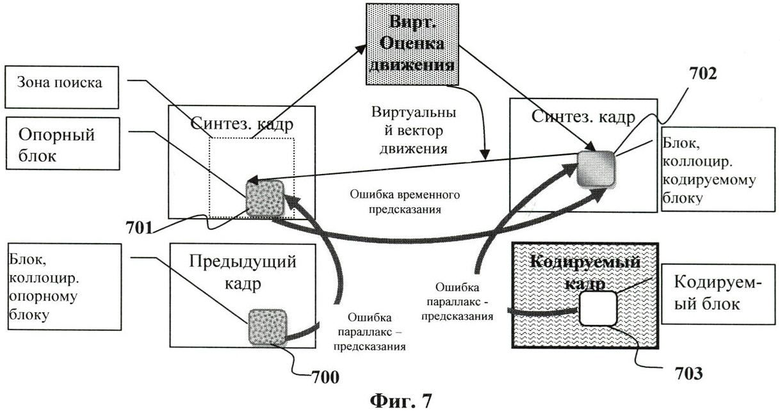
Фиг.7. Обобщенная схема формирования адаптивного предсказания и определения необходимой служебной информации для определенного кодируемого блока.
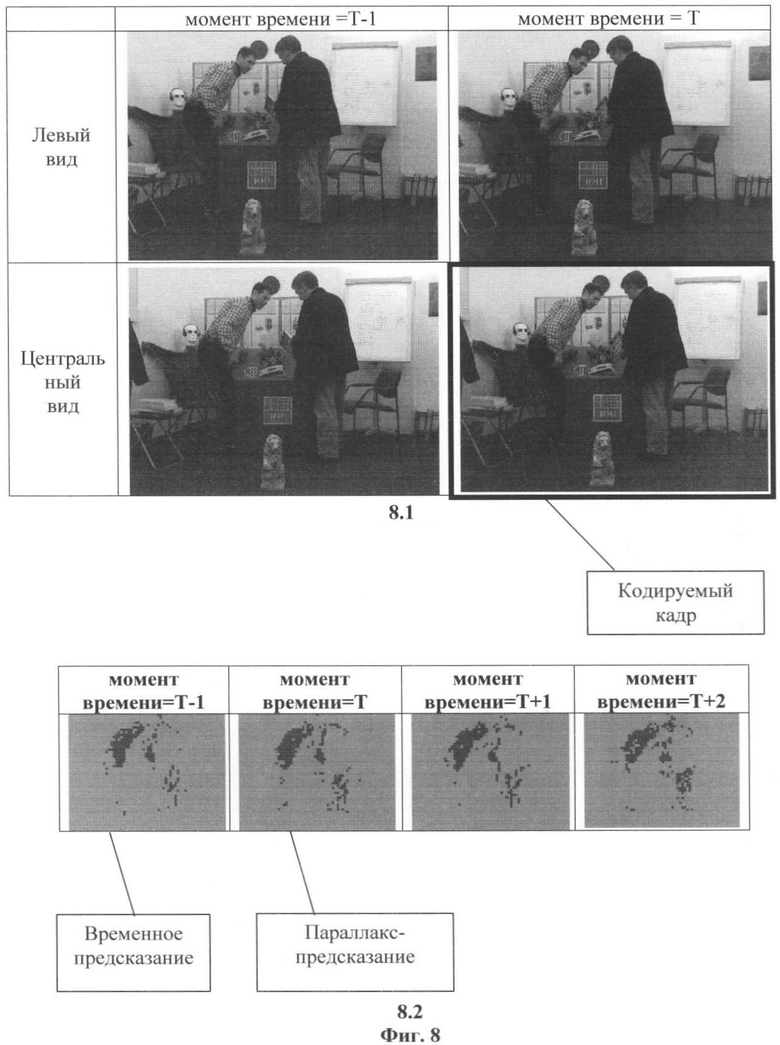
Фиг.8, вид 8.1 - Пример кадров из двух соседних видов тестовой МРВ последовательности.
Фиг.8, вид 8.2 - Визуализированная карта режимов предсказания в моменты времени Т-1, Т, Т+1 и Т+2 для кодируемого вида.
Фиг.9. Блок-схема способа определения модифицированного режима предсказания.
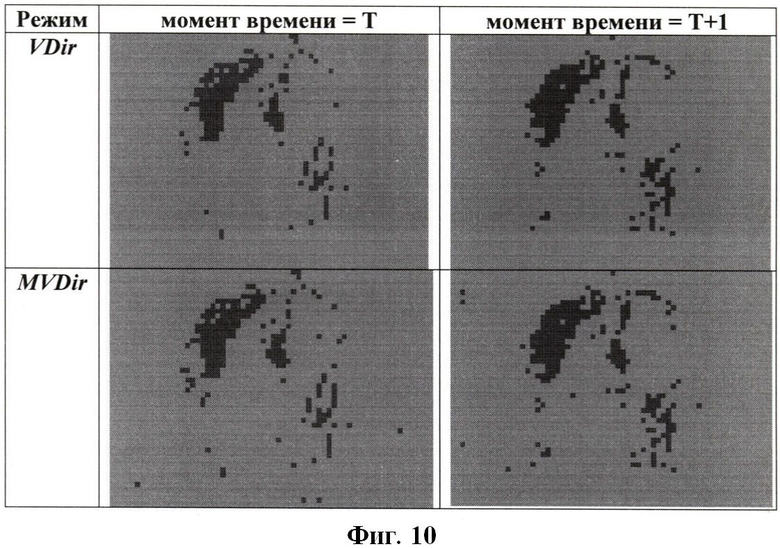
Фиг.10. Визуализированные карты режимов для режимов Dir и MDir.
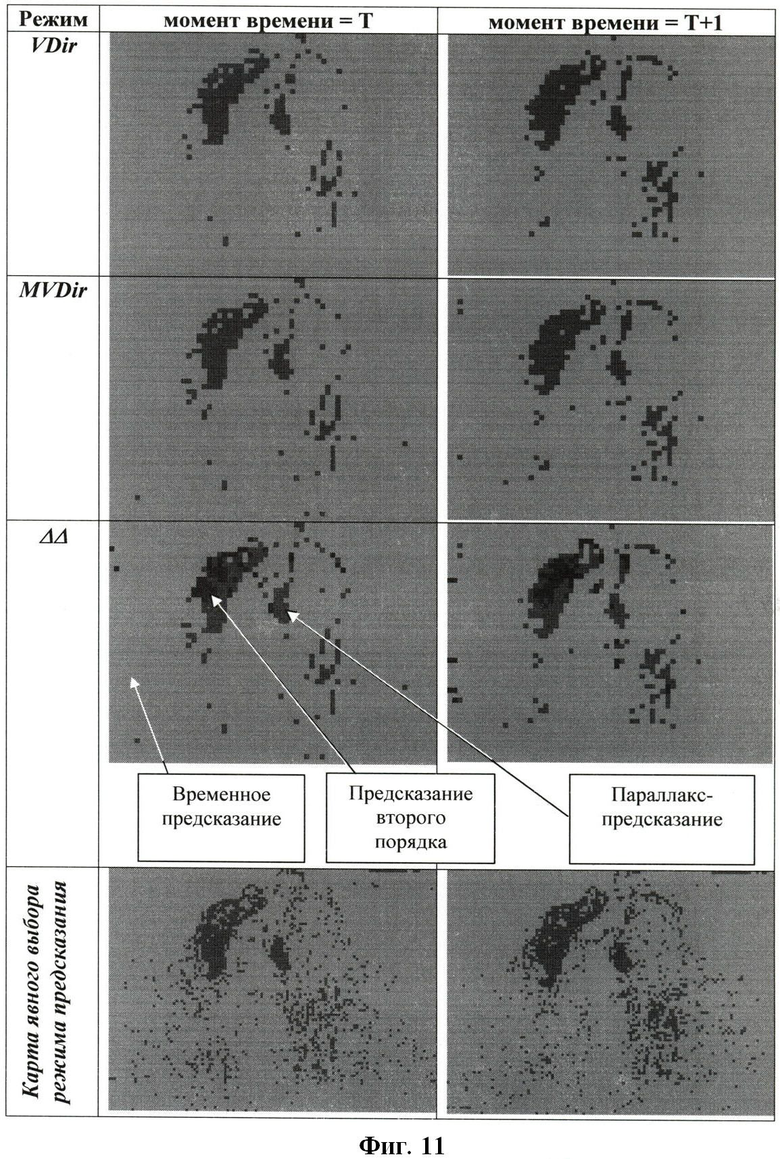
Фиг.11. Визуализированные карты режимов для режимов Dir, MDir и MDir+ΔΔ.
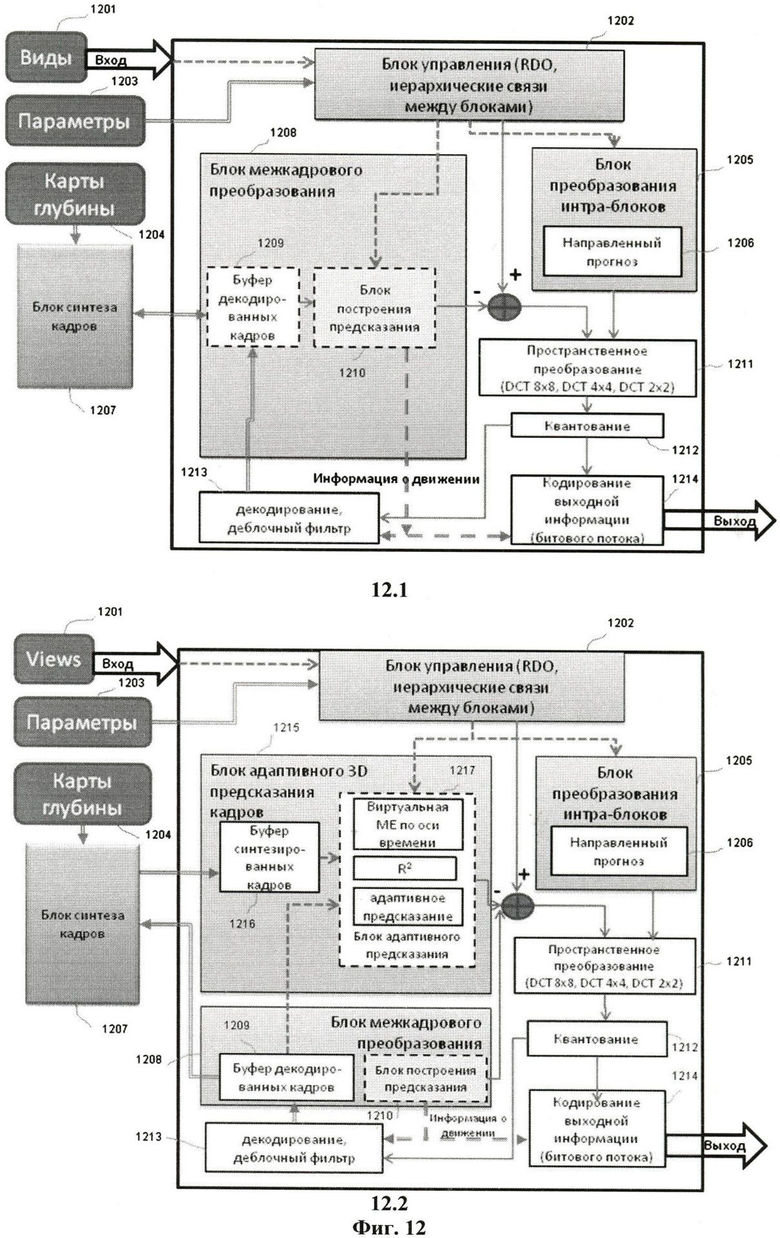
Фиг.12, вид 12.1 - Структура типового кодера МРВ последовательности, основанного на MVC кодере и учитывающего информацию о уже закодированной и декодированной информации о глубине сцены.
Фиг.12, вид 12.2 - Структура кодера МРВ последовательности, который основан на предлагаемом способе адаптивного предсказания кадра.
Из вышесказанного понятно, что заявляемое изобретение касается вопросов кодирования и декодирования МРВ, а именно устранения корреляционных связей, существующих между кадрами с помощью адаптивного предсказания. Как следует из Фиг.1, множество соседних видов (видеопоследовательностей), полученных с помощью многокамерной системы, а также соответствующие этим видам последовательности карт глубин подаются на вход кодирующей системы 100. В общем случае кодирующая система включает в себя подсистему 101 кодирования последовательностей карт глубин и подсистему кодирования видеопоследовательностей (видов), которую образуют блоки 102 и 103, при этом блок 102 обеспечивает кодирование видеопоследовательностей в соответствии со стандартом H.264/MPEG-4 AVC (совместимых видов), а блок 103 обеспечивает кодирование дополнительных видеопоследовательностей (дополнительных видов). Заявляемое изобретение может применяться при реализации подсистемы кодирования дополнительных видов.
Кадры всех кодируемых видеопоследовательностей могут быть классифицированы в соответствии с относительным временем их получения (Фиг.2, вид 2.1). Для упрощения дальнейшего описания введем несколько определений. Принцип пространственного совмещения (коллокации) (Фиг.2, вид 2.2), применяемый в настоящем изобретении, заключается в следующем. Если некоторый блок 201, принадлежащий КАДРУ 1 (200), имеет координаты (y,x) по отношению к верхнему левому углу КАДРА 1, то пространственно совмещенный блок 203 КАДРА 2 (202) будет иметь те же координаты (y,x) по отношению к верхнему левому углу КАДРА 2 (202).
На Фиг.3 изображена схема независимого кодирования видеопоследовательностей и последовательностей карт глубин. При проведении их кодирования общими параметрами являются начальные значения коэффициентов квантования QpD и QpV (304), выбор которых влияет на достигаемое качество и степень сжатия. При этом параметр QpV обозначает коэффициент квантования, используемый кодером МРВ в соответствии со стандартом ITU-T H264, annex H для кодирования видов. Параметр QpD обозначает коэффициент квантования, используемый кодером МРВ в соответствии со стандартом ITU-T H264, annex H для кодирования карт глубин.
Более сложная схема кодирования включает построение дополнительных опорных кадров путем применения процедуры синтеза кадров (309, 310). Дополнительные опорные кадры включаются в списки опорных кадров. Порядок выбора опорных кадров из списка задается при кодировании и в случае его изменения явным образом передается вместе с кодированными данными для последующего декодирования. Процедура синтеза кадров используется для повышения эффективности кодирования путем построения опорного кадра. В общем случае различают процедуру одностороннего (Фиг.4, вид 4.1) и двустороннего (симметричного) синтеза кадра (Фиг.4, вид 4.2). В случае одностороннего синтеза используется кадр 400 и соответствующая ему карта 401 глубины, которые принадлежат одной видеопоследовательности. Это соответствует использованию каузальных данных (т.е. данных, которые уже были закодированы и декодированы) при проведении синтеза. При двустороннем синтезе используют информацию из кадров 400 и 404, а также карт 401 и 405 глубины, принадлежащих двум соседним видам по отношению к кодируемому виду. Классификация кадров и карт глубин в соответствии с порядком их кодирования представлена на Фиг.5.
Необходимо отметить, что вопросы, связанные со способом выполнения процедуры синтеза, а также точностью ее результатов, выходят за рамки заявляемого изобретения. Тем не менее, структуру входных видеопоследовательностей и последовательностей карт глубин, а также качество синтезированных кадров необходимо принимать во внимание при реализации настоящего изобретения.
Для более детального анализа настоящего изобретения рассмотрим гипотетическую систему кодирования кадров (Фиг.6). Допустим, что к определенному моменту Т времени имеется уже закодированный кадр 600. Текущий кодируемый кадр 608 обозначим F(Center, Т). Закодированный кадр, относящийся к моменту Т-1 времени, обозначим как F(Center, T-1). Допустим, что кадры 602 и 604 в моменты T-1 и Т времени, которые принадлежат левой (соседней по отношению к текущей) видеопоследовательности, также уже закодированы. Тогда строятся синтезированные кадры 601 и 607 для моментов Т и Т-1 времени, принадлежащие текущей (центральной) видеопоследовательности. Обозначим синтезированные кадры 601 и 607 как VF(Center, Т-1) и VF(Center, Т) соответственно. Необходимо отметить, что синтезированные кадры и кадры F(Center, Т-1) и F(Center, Т) пространственно совмещены. В то же время, синтезированные кадры содержат окклюзии, а также ошибки, связанные с процедурой синтеза, различием в освещенности сцены с различных ракурсов и т.д. Тем не менее, из анализа эффективности процедуры синтеза кадров [4] следует, что синтезированные кадры могут содержать геометрические детали, присущие отображаемой сцене с достаточной точностью.
Представим текущий кодируемый кадр как множество блоков фиксированного размера bl_h, bl_w:
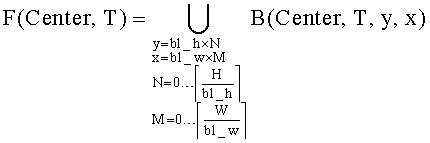 .
.
Синтезированный кадр VF(Center, Т) также можно представить 15 как множество блоков, каждый из которых пространственно совмещен с блоком из кадра F(Center, Т):
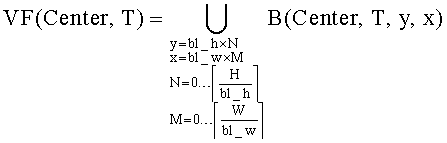 .
.
Для каждого блока, принадлежащего синтезированному кадру для момента Т времени, строится (формируется) предсказание по синтезированному кадру 601 для момента Т-1 времени с помощью того или иного метода оценки движения. Необходимо отметить, что не имеет значения, какой из методов оценки движения используется для поиска предсказания. Важным является установление связи между блоком в кадре 607 и некоторым опорным блоком в кадре 601. Кадры 601 и 607 доступны при декодировании, что позволяет избежать кодирования дополнительной информации для синхронизации процессов кодирования и декодирования. Опорный блок, который определяется в процессе оценки движения, принадлежит синтезированному кадру VF(Center, T-1) и имеет пространственно совмещенный блок в кадре F(Center, T-1). Таким образом, имеется три блока, которые могут быть построены как в процессе кодирования, так и в процессе декодирования.
На Фиг.7 изображен текущий кодируемый блок 703, который обозначим B(Center, Т, y, x). Обозначим пространственно совмещенный блок 702, принадлежащий кадру VF(Center, Т), как VB(Center, Т, у, х). Результатом применения метода оценки движения является блок 701, который принадлежит синтезированному кадру для момента T-1 времени и который обозначен как VB(Center, T-1, y+dy, x+dx). Здесь (dy, dx) определяет, так называемый, виртуальный вектор движения. В общем случае, при проведении указанных операций применима любая из моделей движения, например, аффинная модель. Для простоты изложения будем рассматривать трансляционную модель. Опорный блок 701 имеет пространственно совмещенный блок 700 в кадре F(Center, Т-1). Этот блок является обычным предсказателем и обозначается как B(Center, T-1, y+dy, x+dx).
Первый шаг заявляемого способа заключается в определении наилучшего режима предсказания для блока 703. В традиционном подходе имеется две возможности выбора предсказателя: по временной оси или по оси видов.
В случае предсказания по временной оси производится кодирование разностей (остатков):

В ходе проведенных исследований было установлено, что режим предсказания, который обеспечивает минимум метрики разностей (остатков), может быть выбран на основе анализа «дополнительных» разностей (остатков).
Произведем расчет виртуальных разностей по оси времени и оси видов в соответствии со следующими выражениями:
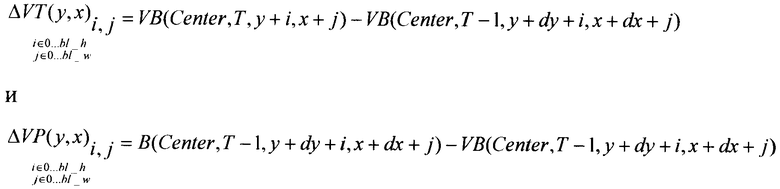
Затем проведем расчет мер полученных виртуальных разностей (остатков). В качестве численной меры может быть выбрана любая подходящая. В описываемой реализации настоящего изобретения используется сумма абсолютных разностей, которая обеспечивает необходимый баланс между эффективностью получаемой оценки и сложностью ее вычисления.
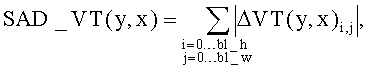
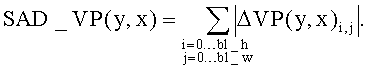
Для того чтобы определить режим предсказания для блока B(Center, Т, y, x), получим оценку для виртуального режима предсказания для блока VB(Center, T-1, y+dy, x+dx). Для этого сравним значения SAD _ VТ (y, x) и SAD _VP(y, x):
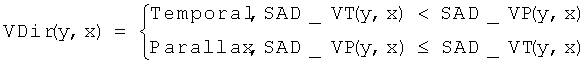 .
.
Здесь режим предсказания, обозначенный как «Temporal», означает, что блок VB(Center, T-1, y+dy, x+dx) предсказывается с помощью блока VB(Center, Т, y, х). В результате блок B(Center, Т, y, х) должен предсказываться с помощью опорного блока B(Center, T-1, у+dy, х+dx). Режим предсказания, обозначенный как «Parallax», означает, что блок VB(Center, T-1, y+dy, x+dx) предсказывается с помощью блока VB(Center, Т, y, x), а блок B(Center, Т, y, x) должен предсказываться с помощью опорного блока VB (Center, Т, y, x). «VDir» обозначает режим предсказания, определяемый по синтезированным кадрам и уже закодированным кадрам видеопоследовательности. Необходимо отметить, что (dy, dx) представляет собой вектор движения, который определяется с использованием синтезированных кадров.
Из этого факта следует, что:
- для оценки движения не требуется явной передачи дополнительной информации для последующего декодирования;
- точность получаемой оценки движения оказывается в общем случае ниже, чем в случае традиционного применения методов оценки движения;
- при декодировании необходимо проводить оценку движения, что требует применения специализированных методов, способных уменьшить вычислительную сложность процесса декодирования.
Полученная разность (остаток) определяется как:
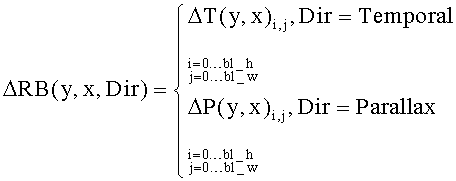
Как следует из приведенного выше описания, отсутствует необходимость явной передачи дополнительных данных для определения режима предсказания, поскольку выбор режима производиться на основе кадров, доступных как при кодировании, так и при декодировании.
В общем случае размеры блоков, используемых для оценки движения с использованием синтезированных кадров, и размеры блоков, используемых для адаптивного предсказания, могут не совпадать между собой. Например, оценка движения может быть проведена для блоков 16×16 пикселей, в то время как адаптивное предсказание может выполняться для блоков 8×8. На Фиг.8, вид 8.1, представлены кадры для двух видеопоследовательностей, которые входят в состав МРВ «BookArrival». МРВ «BookArrival» входит в состав набора тестовых МРВ, рекомендованных MPEG (см. "Description of Exploration Experiments in 3D Video Coding", MPEG2010 / N11630 Guangzhou, China October 2010) [9]. Примеры карт режимов предсказания изображены на Фиг.8, вид 8.2. Для наглядности выбранные режимы предсказания (по оси времени или оси видов) изображены как блоки соответствующего оттенка серого цвета.
С целью дальнейшего повышения эффективности предсказания в заявляемом способе предлагается использовать явный выбор наилучшего режима предсказания, который уточняется с использованием определенного выше режима предсказания VDir для более компактного дальнейшего кодирования. При этом выполняются следующие шаги: вычисление метрики для разностей (остатков), полученных путем явного предсказания по оси времени ΔT и оси видов ΔР:
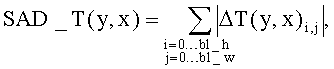
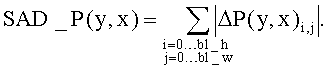
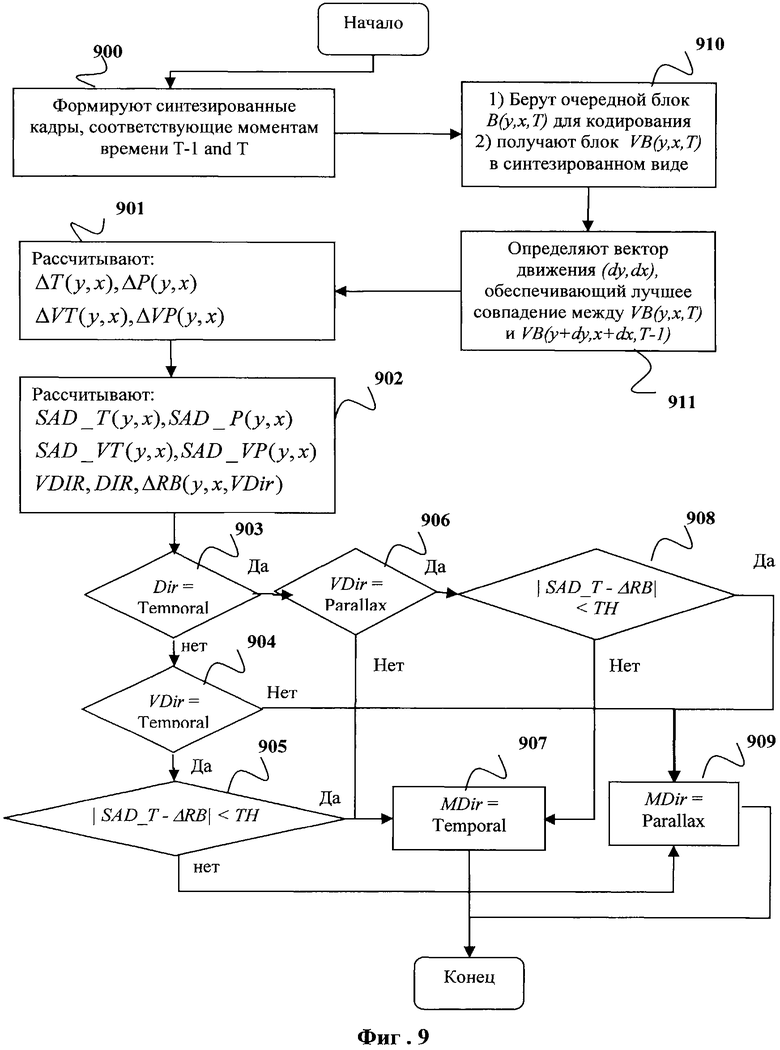
На основании полученных оценок явно определялся режим предсказания на основе значения VDir. Метод оценки эффективности выбора предсказания заключается в принудительном выборе режима VDir вместо определенного явным образом режима Dir в случае, если ошибка предсказания находится в заданном диапазоне, определяемом некоторой пороговой величиной. Режим предсказания в случае его явного определения задается выражением:
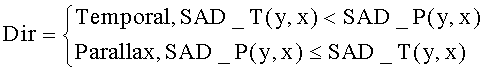
Тогда модифицированное правило выбора режима предсказания MDir можно определить как:

Здесь VDir - режим предсказания, выбранный с использованием синтезированных кадров, как описано выше; ТН - заданное значение пороговой величины, определяющее условия изменения режима кодирования Dir. Метод изменения режима предсказания, определенного явным образом, с помощью значения VDir представлен на Фиг.9. Примеры карт режимов предсказания, полученных в соответствии с приведенными выше выражениями для VDir(y, x) и MDir(y, x, VDir), изображены на Фиг.10. В описываемом случае пороговая величина ТН задавалась как (bl_h×bl_w)×2, где (bl_h×bl_w) - количество пикселей в блоке.
Описанный выше способ предоставляет механизм построения адаптивного предсказания для отдельного блока на основании зависимостей, характерных для МРВ. Предполагается, что предсказание формируется путем выбора одной из двух возможных альтернатив: предсказание по оси времени или предсказание по оси видов.
Помимо указанных выше двух альтернатив предсказания, заявляемое изобретение предлагает дополнительный способ представления значений пикселей, принадлежащих кодируемому блоку. Этот способ основан на предсказании значений разностей (остатков) ΔР, определенных для оси видов, по уже вычисленным значениям ΔVP. В простейшем случае предполагается, что
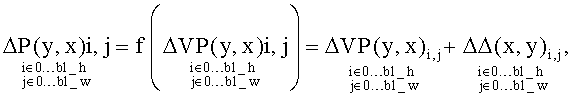
где ΔΔ обозначает так называемую разность (остаток) второго порядка. Если изменения по оси времени примерно похожи для кодируемых и синтезированных кадров и процедура синтеза кадров квазистационарна, можно предположить, что ΔΔ может достаточно компактно представлять некоторые блоки. Таким образом, такое представление кадра для некоторых блоков оказывается более эффективным с точки зрения достигаемой степени сжатия. Величина
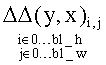
может быть представлена как:
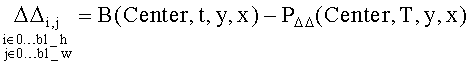 ,
,
следовательно:
PΔΔ(Center,T,y,x)=VB(Center,T,y,x)+B(Center,T-1,y+dy,x+dx)-VB(Center,T-1,y+dy,x+dx).
Заявляемый способ предсказания также может быть использован для дополнительной декорреляции кодируемого кадра. В этом случае для каждого блока должна кодироваться и передаваться дополнительная информация о выбранном режиме предсказания. Тем не менее, результаты экспериментов показывают, что в этом случае выбранные режимы предсказания оказываются коррелированными и могут быть эффективно закодированы энтропийным кодером при использовании соответствующих контекстных моделей. Примеры карт режимов предсказания в случае использования трех режимов предсказания изображены на Фиг.11.
Чтобы получить численную оценку эффективности заявляемого способа адаптивной декорреляции кадра, были получены оценки качества для декодированных кадров. Для оценки качества использовалась мера отношения сигнала к шуму ПОСШ (peak-to-peak signal-to-noise ratio - PSNR). В частности, пиксели кадра, за исключением окклюзии, были закодированы и декодированы предлагаемым способом, а затем определено их качество в дБ. Кроме того, были получены оценки качества для случаев использования предсказания по оси времени, предсказания только для синтезированных кадров и прямой комбинации предсказания по оси времени и оси видов. Необходимо подчеркнуть, что качество кадров и карт глубин, принадлежащих левой (по отношению к текущей) видеопоследовательности, напрямую влияет на качество предсказания, что также необходимо принимать во внимание при анализе. Оценка движения выполнялась с помощью традиционного метода В.Furht, J.Greenberg, R.Westwater «Motion Estimation Algorithms for Video Compression», Massachusetts: Kluwer Academic Publishers, 1997, p. 64-65 [10] полного перебора (размер зоны поиска [-16; 16] пикселей, размер блока 16×16 пикселей). Предсказание осуществлялось поблочно, размер блока составлял 8х8 пикселей. Результаты проведенного анализа приведены в таблицах T1, T2 и Т3. Здесь графа «режим предсказания» указывает на способ построения предсказания.
«Временное предсказание: Виртуальное МЕ/МС» указывает на использование способа получения виртуальных векторов движения по синтезированным кадрам. Виртуальные векторы движения затем применяются для кодирования обычных кадров.
«Временное предсказание: МЕ/МС по кодируемым кадрам» указывает на использование способа получения векторов движения по обычным кадрам. Полученные векторы движения затем применяются для кодирования обычных кадров.
Явный выбор между предсказанием по оси времени и оси видов предполагает построение предсказания, который дает наилучшую точность приближения кодируемого кадра.
Таблицы 1, 2, 3: Эффективность межкадрового предсказания для различных степеней сжатия для базовой последовательности кадров и карт глубин.
- Количество пикселей, которые являются окклюзиями: 8.5%
- Количество обработанных кадров: 19 (МРВ: «Book arrival»)
- Тип процедуры синтеза: односторонний 1-D синтез, целочисленный буфер глубины для определения окклюзии, точность расчета значения диспарантности: ¼ - пикселя.
- Количество пикселей, которые являются окклюзиями: 9%
- Количество обработанных кадров: 19 (МРВ: «Book arrival»)
- Тип процедуры синтеза: односторонний 1-D синтез, целочисленный буфер глубины для определения окклюзии,точность расчета значения диспарантности: ¼ - пикселя.
- Количество пикселей, которые являются окклюзиями: 9%
- Количество обработанных кадров: 19 (МРВ: «Book arrival»)
- Тип процедуры синтеза: односторонний 1-D синтез, целочисленный буфер глубины для определения окклюзии, точность расчета значения диспарантности: ¼ - пикселя.
В соответствии с полученными экспериментальными результатами заявляемый способ обеспечивает существенное улучшение качества по сравнению с известными способами межкадровой декорреляции, которые основаны на оценке и последующей компенсации движения.
Отличительной чертой заявляемого способа является использование 3-мерных особенностей МРВ. Синтезированные кадры, соответствующие кодируемому кадру и его непосредственным соседям, формируют уникальный каузальный контекст, который недоступен при кодировании обычной видеопоследовательности или независимого кодирования видеопоследовательностей МРВ. Этот контекст доступен как при кодировании, так и при декодировании и используется для выбора режима предсказания каждого последующего блока кодируемого кадра. Это позволяет проводить эффективную декорреляцию данных и уменьшить размер дополнительной информации, необходимой для последующего декодирования. Таким образом, заявляемый способ позволяет повысить эффективность кодирования.
Структурные схемы устройств кодирования МРВ, основанные на способе гибридного кодирования, представлены на Фиг.12, вид 12.1 и вид 12.2. Устройство кодирования, реализующее подходы, предложенные в стандарте H.264/MPEG-4 AVC для кодирования МРВ, изображено на Фиг.12, вид 12.1. Наряду со стандартными для устройств кодирования обычных видеопоследовательностей блоками (внутрикадровое преобразование 1205, так называемое, «интра», пространственное преобразование 1211, устройство 1202 управления и т.д.), присутствуют специфичные для кодирования МРВ блоки:
- блок 1210 построения предсказания (расширение стандартных средств оценки движения для кадров разных видеопоследовательностей одной МРВ),
- блок 1207 синтеза кадров, выполненный с возможностью формирования синтезированных кадров, которые затем могут выступать в качестве опорных при проведении предсказания.
Субоптимальный выбор предсказания выполняется с использованием списков кадров-предсказаний. Такой выбор назван субоптимальным, поскольку в общем случае порядок выбора предсказания является фиксированным. Изменение этого порядка при кодировании делает необходимым явное кодирование и передачу дополнительной информации, чтобы повысить эффективность кодирования.
Модифицированная схема устройства кодирования, реализующая предложенный способ адаптивного предсказания, изображена на Фиг.12, вид 12.2. Выбор предсказания с помощью списков кадров-предсказателей заменен адаптивным предсказанием, которое реализуется блоком 1215 адаптивного предсказания. Этот блок функционирует в соответствии с приведенным выше описанием и не генерирует дополнительной информации о движении в кадрах.
Заявляемый способ обеспечивает гибкий механизм уменьшения объема дополнительной информации и адаптивной декорреляции кадра в случае кодирования 3D МРВ. Благодаря использованию информации, доступной кодеру и декодеру, а также инкрементальному порядку кодирования заявляемый способ может быть органично включен в состав существующих и будущих систем кодирования, например в состав системы кодирования на основе стандарта H.264/MPEG-4 AVC. Заявляемый способ поддерживает режим совместимости со стандартом H.264/MPEG-4 AVC для различных структур построения предсказания, поскольку использует каузальный контекст кодирования кадров. Возникающая дополнительная вычислительная нагрузка при декодировании устраняется, в частности, путем использования специализированных методов оценки движения, которые обладают небольшими вычислительными затратами. Необходимо также отметить, что заявляемый способ, включая всевозможные варианты его реализации, может быть совмещен с другими способами для дальнейшего улучшения достигаемых результатов при кодировании МРВ.
Изобретение относится к области обработки цифровых сигналов, и в частности, к цифровому сжатию многоракурсного видео, сопровождаемого дополнительными данными о глубине сцены. Техническим результатом является обеспечение разностного кодирования кадра, используя малый объем служебной информации за счет учета известных пространственных связей между соседними ракурсами в каждый момент времени, а также информацию, доступную как при кодировании, так и при декодировании. Предложен способ кодирования, заключающийся в том, что каждый вновь кодируемый кадр многоракурсной видеопоследовательности, определяемый в соответствии с заранее заданным порядком кодирования, представляют как совокупность неперекрывающихся блоков, определяют, по меньшей мере, один уже закодированный кадр, соответствующий данному ракурсу и обозначаемый как опорный, формируют синтезированные кадры для кодируемого и опорных кадров, при этом для каждого неперекрывающегося блока пикселей кодируемого кадра, обозначаемого как кодируемый блок, определяют пространственно-совмещенный блок внутри синтезированного кадра, соответствующего кодируемому кадру, обозначаемый как виртуальный блок, для которого определяют пространственную позицию блока пикселей в синтезируемом кадре, соответствующем опорному кадру, такую, что определенный таким образом опорный виртуальный блок является наиболее точным численным приближением виртуального блока; для определенного таким образом опорного виртуального блока определяют пространственно совмещенный блок, принадлежащий опорному кадру, обозначаемый как опорный блок, и вычисляют ошибку между виртуальным блоком и опорным виртуальным блоком, а также вычисляют ошибку между опорным виртуальным блоком и опорным блоком, затем выбирают минимальную из них и на основе этого определяют, по меньшей мере, один режим разностного кодирования, задающий, какие из найденных на предыдущих шагах блоков необходимо использовать для формирования предсказания при последующем разностном кодировании кодируемого блока, и осуществляют разностное кодирование кодируемого блока в соответствии с выбранным режимом разностного кодирования. 4 з.п. ф-лы, 15 ил., 3 табл.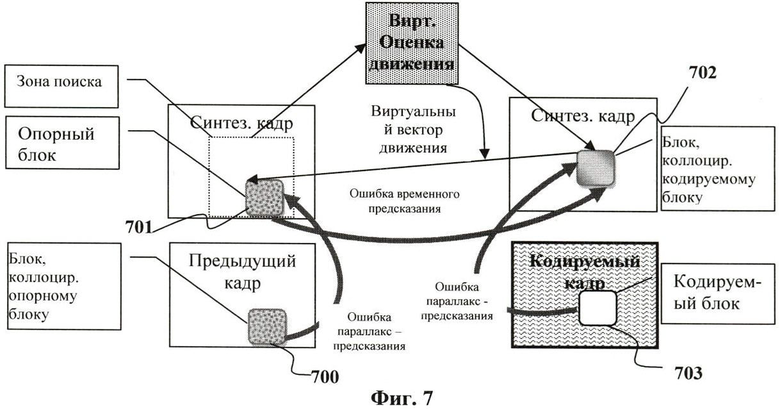
1. Способ кодирования многоракурсной видеопоследовательности, к которой прилагается многоракурсная последовательность карт глубин, заключающийся в том, что каждый вновь кодируемый кадр многоракурсной видеопоследовательности, определяемый в соответствии с заранее заданным порядком кодирования, представляют как совокупность неперекрывающихся блоков, определяют, по меньшей мере, один уже закодированный кадр, соответствующий данному ракурсу и обозначаемый как опорный, формируют синтезированные кадры для кодируемого и опорных кадров, отличающийся тем, что для каждого неперекрывающегося блока пикселей кодируемого кадра, обозначаемого как кодируемый блок, определяют пространственно-совмещенный блок внутри синтезированного кадра, соответствующего кодируемому кадру, обозначаемый как виртуальный блок, для которого определяют пространственную позицию блока пикселей в синтезируемом кадре, соответствующем опорному кадру, такую, что определенный таким образом опорный виртуальный блок является наиболее точным численным приближением виртуального блока; для определенного таким образом опорного виртуального блока определяют пространственно совмещенный блок, принадлежащий опорному кадру, обозначаемый как опорный блок, и вычисляют ошибку между виртуальным блоком и опорным виртуальным блоком, а также вычисляют ошибку между опорным виртуальным блоком и опорным блоком, затем выбирают минимальную из них и, на основе этого, определяют, по меньшей мере, один режим разностного кодирования, задающий, какие из найденных на предыдущих шагах блоков необходимо использовать для формирования предсказания при последующем разностном кодировании кодируемого блока, и осуществляют разностное кодирование кодируемого блока в соответствии с выбранным режимом разностного кодирования, который определяют при декодировании аналогичным образом без использования дополнительных битовых затрат.
2. Способ по п.1, отличающийся тем, что в случае, если ошибка между виртуальным блоком и опорным виртуальным блоком оказалась меньше, чем ошибка между опорным виртуальным блоком и опорным блоком, то выбирают режим разностного кодирования, при котором в качестве предсказания используют опорный блок; в противном случае выбирают режим разностного кодирования, при котором в качестве предсказания используют виртуальный блок.
3. Способ по п.2, отличающийся тем, что вычисляют ошибку между виртуальным блоком и кодируемым блоком, а также вычисляют ошибку между ссылочным блоком и кодируемым блоком, причем в случае, если ошибка между виртуальным блоком и кодируемым блоком оказалась меньше, чем ошибка между опорным блоком и кодируемым блоком, то в качестве предсказания выбирают виртуальный блок; в противном случае выбирают опорный блок; на основании выбранного режима разностного кодирования и выбранного блока производят кодирование информации о выбранном блоке, а также осуществляют разностное кодирование кодируемого блока.
4. Способ по п.3, отличающийся тем, что в случае, если ошибка относится к выбранному режиму разностного кодирования, при котором в качестве предсказания выбирается опорный блок, а минимальная найденная ошибка - это ошибка между виртуальным блоком и кодируемым блоком, и найденная абсолютная разность между этими ошибками не превышает предварительно заданного порогового значения, то в качестве предсказания выбирают опорный блок; в случае, если ошибка относится к выбранному режиму разностного кодирования, при котором в качестве предсказания выбирают виртуальный блок, а минимальная найденная ошибка - это ошибка между опорным блоком и кодируемым блоком, и найденная абсолютная разность между этими ошибками не превышает предварительно заданного порогового значения, то в качестве предсказания выбирают виртуальный блок; в иных случаях в качестве предсказания выбирают блок в соответствии с определенным режимом кодирования; производят кодирование информации о выбранном блоке, а также осуществляют разностное кодирование кодируемого блока.
5. Способ по п.4, отличающийся тем, что опорный виртуальный блок и опорный блок используют для вычисления разностного блока, при этом разностный блок вычисляют как попиксельную разность между виртуальным блоком и попиксельной разностью между опорным виртуальным блоком и опорным блоком; вычисляют ошибку между найденным разностным блоком и кодируемым блоком; в случае, если найденная ошибка оказывается меньше, чем ошибка между выбранным на предыдущих шагах в качестве предсказателя блоком и кодируемым блоком, то в качестве предсказателя используют найденный разностный блок; производят кодирование информации о выбранном блоке, а также осуществляют разностное кодирование кодируемого блока.
| Е.MARTINIAN et al | |||
| View Synthesis for Multiview Video Compression., Proc | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| WO 2009020542 A1, 12.02.2009 | |||
| WO 2009023091 A2, 19.02.2009 | |||
| US 2010034260 A1, 11.02.2010 | |||
| WO 2005018217 A2, 24.02.2005 | |||
| WO 2006073116 A1, 13.07.2006 | |||
| JP 10191393 A, 21.07.1998 | |||
| НОСИТЕЛЬ ДЛЯ ХРАНЕНИЯ ИНФОРМАЦИИ СО СТРУКТУРОЙ ДАННЫХ ДЛЯ МНОГОРАКУРСНОГО ПОКАЗА И УСТРОЙСТВО ДЛЯ ЭТОГО НОСИТЕЛЯ | 2003 |
|
RU2296379C2 |

