ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к устройству, способу и компьютерной программе для кодирования и декодирования видеосигналов.
УРОВЕНЬ ТЕХНИКИ
В настоящее время исследуются и разрабатываются различные технологии реализации трехмерного (3D) видеоконтента. Главным образом, серьезные исследования были сфокусированы на различных многоракурсных применениях, в которых наблюдатель с одной точки обзора способен видеть только одну пару стереоскопических видеоизображений, а другую пару - с другой точки обзора. Один из наиболее осуществимых подходов для таких многоракурсных применений заключается в том, что на сторону декодера подается только ограниченное количество входных ракурсов, например моноизображений или стереоскопических изображений, совместно с некоторыми дополнительными данными, и затем все требуемые ракурсы для отображения на дисплее локально визуализируются (то есть, синтезируются) декодером.
Существуют несколько технологий для визуализации ракурсов, и, например, свою конкурентоспособность показал способ визуализации на основе глубины изображения (DIBR, depth image-based rendering). Согласно типовому применению DIBR, в качестве входных данных выбирается стереоскопическое видеоизображение и соответствующая информация о глубине со стереоскопическим базисом, и выполняется синтез ряда виртуальных ракурсов между двумя входными ракурсами. Таким образом, алгоритмы DIBR также позволяют экстраполировать ракурсы, расположенные вне двух входных ракурсов, а не только между ними. Подобным образом, алгоритмы DIBR позволяют выполнять синтез на основе одного ракурса текстуры и соответствующего ракурса глубины.
При кодировании трехмерного видеоконтента могут использоваться системы сжатия видеоинформации, такие как стандарт H.264/AVC (Advanced Video Coding, усовершенствованное кодирование видеосигнала) или кодирование MVC (Multiview Video Coding, многоракурсное кодирование видеосигнала), определенные в качестве дополнения к стандарту H.264/AVC. Однако способ предсказания вектора движения, приведенный в H.264/AVC/MVC, может быть не оптимальным для систем кодирования видеосигнала, использующих межракурсное (inter-view) предсказание и/или предсказание синтеза ракурса (VSP, view synthesis prediction) совместно со взаимным предсказанием (inter prediction).
Таким образом, существует необходимость в улучшении способа предсказания вектора движения (MVP, motion vector prediction) с целью многоракурсного кодирования (MVC), кодирования видеосигнала с улучшенной глубиной, многоракурсного кодирования+кодирования по глубине (MVD, multiview+depth) и/или многоракурсного кодирования с цикличным синтезом ракурсов (MVC-VSP, multi-view with in-loop view synthesis).
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Это изобретение основано на том, что информация о глубине или диспаратности (Di, disparity information) для текущего блока (cb, current block) данных текстуры становится доступной посредством декодирования кодированной информации о глубине или диспаратности либо может оцениваться на стороне декодера перед декодированием текущего блока cb текстуры, благодаря чему возможно использовать информацию о глубине или диспаратности в процессе MVP. Использование информации о глубине или диспаратности (Di) в MVP повышает степень сжатия в системах многоракурсного кодирования, многоракурсного кодирования + кодирования по глубине и в системах кодирования MVC-VSP.
Ниже в этом описании применяется следующее соглашение о наименованиях. Термин cb используется для обозначения текущего блока данных текстуры, а связанная с cb информация о глубине или диспаратности обозначается как d(cb). Текущий блок данных текстуры определяется как блок текстуры, кодируемый кодером или посредством способа кодирования, либо декодируемый декодером или посредством способа декодирования.
В процессе предсказания вектора движения (MVP) для cb кодер/декодер может использовать двумерные блоки данных текстуры (А, В, С и т.д.). Эти блоки называются смежными блоками, и они пространственно прилегают к области изображения cb (двумерные фрагменты изображения, прилегающего к блоку cb или окружающего этот блок), и, как предполагается, доступны перед выполнением кодирования/декодирования cb. См. фиг. 15, на котором серым цветом показан фрагмент двумерного изображения, смежного с cb и используемого в процессе MVP.
В некоторых случаях в процессе MVP для cb могут использоваться смежные двумерные блоки данных текстуры (А, В, С и т.д.), которые расположены в двумерных фрагментах других изображений в пределах той же видеоинформации (фрагмента видеосигнала), прилегающей к блоку cb, см. фиг. 16. Предполагается, что этот фрагмент видеоинформации должен быть доступен (в кодированном/декодированном виде) до выполнения процесса кодирования/декодирования cb.
В некоторых случаях в процессе MVP для cb могут использоваться смежные двумерные блоки данных текстуры (А, В, С и т.д.), которые расположены в двумерных фрагментах других изображений, размещенных в других ракурсах в пределах той же многоракурсной видеоинформации (во фрагменте многоракурсного видеосигнала), прилегающей к блоку cb, см. фиг. 16. Предполагается, что этот многоракурсный фрагмент видеосигнала должен быть доступен (в кодированном/декодированном виде) до выполнения процесса кодирования/декодирования cb.
Другими словами, смежные блоки А, В, С и т.д. могут быть расположены в пространственной/временной/межракурсной близости от блока cb в нескольких двумерных изображениях, которые доступны (в кодированном/декодированном виде) перед выполнением процесса кодирования текущего изображения.
Кодер/декодер может использовать информацию о движении (такую как компонент mv_x вектора горизонтального движения, компонент mv_y вектора вертикального движения и опорные кадры, которые могут идентифицироваться, например, с использованием индексов refldx, указывающих на один ли более списков опорных изображений), связанную с блоками MV(A), MV(B), MV(C), а также с информацией о глубине/диспаратности, связанной с этими блоками - d(A), d(B), d(C) - в предположении, что они доступны перед кодированием/декодированием cb. Для простоты описания следующие термины эквивалентны и их использование относится к одним и тем же объектам: cb и cb_t, Di(cb_t) и d(cb), Di(cb_t) и cb_d, mvX и MV(X), "соседний блок" и "смежный блок".
Пространственное разрешение изображения определяется как количество пикселей (дискретных элементов изображения), представляющих изображение в горизонтальном и вертикальном направлении. Ниже в этом документе выражение "изображения с разным разрешением" может интерпретироваться как описание двух изображений, для воспроизведения которых используется различное количество пикселей либо в горизонтальном, либо в вертикальном направлении, либо в обоих направлениях.
Информация о движении может предоставляться с определенной точностью или достоверностью MV(A), соответствующей определенному разрешению. Например, в стандарте кодирования H.264/AVC используется точность вектора движения, соответствующая ¼ пикселя, которая во многих применениях требует, чтобы к опорному изображению применялась повышающая дискретизация с коэффициентом 4х по отношению к разрешению исходного изображения по обеим координатным осям.
Ниже в рамках раскрытия изобретения под разрешением вектора движения понимается разрешение опорного изображения, в котором находится этот вектор движения в процессе выполнения процедуры оценки движения. Например, разрешение вектора движения составляет 4х относительно разрешения исходного изображения по обеим координатным осям, если используется точность вектора движения, соответствующая ЛА пикселя. Согласно множеству схем кодирования точность вектора движения определяется предварительно, хотя также описаны схемы кодирования с адаптивной точностью вектора движения, в которых вектор движения выбирается кодером. Кодер может выбрать точность вектора движения, то есть определить, каким образом фактически следует оценивать движение, уменьшить или оставить на прежнем уровне точности, в процессе многократного использования кодерами заданной точности вектора движения. Например, векторы движения в схеме кодирования представлены с точностью до ¼ пикселя в битовом потоке, однако кодер может выбрать способ оценки движения с точностью до ½ пикселя, то есть выполнять поиск только целого или половинного пикселя. Далее в этом описании термины точность и погрешность вектора движения могут использоваться взаимозаменяемо как синонимы.
В соответствии с первым аспектом настоящего изобретения предлагается способ, включающий декодирование из битового потока первого кодированного блока текстуры первого кодированного изображения текстуры в первый блок cb текстуры, при этом процедура декодирования первого кодированного блока текстуры включает: выбор первого смежного блока А текстуры и второго смежного блока В текстуры; получение первого смежного блока d(A) глубины/диспаратности и второго смежного блока d(B) глубины/диспаратности; получение первого блока d(cb) глубины/диспаратности, пространственно совмещенного с первым блоком cb текстуры; сравнение первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/диспаратности и вторым смежным блоком d(B) глубины/диспаратности; выбор одного или обоих из первого смежного блока А текстуры и второго смежного блока В текстуры на основе значения подобия, вычисленного посредством указанного сравнения; получение одного или более параметров предсказания для декодирования первого кодированного блока cb текстуры на основе значений, связанных с выбранными первым смежным блоком А текстуры и/или вторым смежным блоком В текстуры; и декодирование первого кодированного блока cb текстуры с использованием полученных одного или более параметров предсказания.
В соответствии со способом, реализуемым согласно первому варианту осуществления настоящего изобретения, к указанным параметрам предсказания могут относиться одна или более следующих величин: количество блоков предсказания, например однонаправленного и двунаправленного предсказания; тип одного или более используемых базовых способов предсказания, таких как межкадровое, межракурсное и синтез ракурсов; одно или более используемых опорных изображений; применяемые предсказатели вектора движения или векторы движения; применяемый способ предсказания вектора движения; результирующий сигнал ошибки предсказания с нулевым значением.
Способ в соответствии с первым вариантом осуществления настоящего изобретения может также включать создание условий для выбора первого смежного блока А текстуры и/или второго смежного блока В текстуры на основе значения подобия, полученного в результате указанного сравнения с одним или более пороговыми значениями, полученными из битового потока.
Способ в соответствии с первым вариантом осуществления настоящего изобретения может также включать получение первого блока d(cb) глубины/диспаратности посредством декодирования из битового потока или путем оценки.
В соответствии с первым вариантом осуществления настоящего изобретения, если предсказатель вектора движения недоступен для кодированного блока cb текстуры, и указанным типом предсказания для кодированного блока текстуры является межракурсное предсказание, то способ может также включать установку для предсказателя вектора движения величины, полученной на основе информации о глубине/диспаратности для текущего блока данных d(cb) текстуры.
В соответствии с первым вариантом осуществления настоящего изобретения при выполнении способа процедура декодирования первого кодированного блока cb текстуры может включать обработку более двух смежных блоков.
В соответствии с первым вариантом осуществления настоящего изобретения при выполнении способа указанная процедура выбора первого смежного блока А текстуры и второго смежного блока В текстуры для первого блока cb текстуры может включать выполнение следующих операций: выбор первого смежного блока А текстуры и второго смежного блока В текстуры, расположенных в двумерном фрагменте изображения (набор пикселей, принадлежащий одному изображению), смежном или окружающем cb; выбор первого смежного блока А текстуры и второго смежного блока В текстуры, расположенных в видеофрагменте (набор пикселей, принадлежащий различным изображениям тех же видеоданных) или в многоракурсном видеофрагменте (набор пикселей, принадлежащий различным изображениям тех же многоракурсных видеоданных), смежном с блоком cb.
В соответствии с первым вариантом осуществления настоящего изобретения, при выполнении способа указанная процедура получения блока глубины/диспаратности, связанного со смежным блоком текстуры, может включать выполнение следующих операций: выбор первого смежного блока Ζ текстуры и второго смежного блока Υ текстуры; получение информации MV(Z) о движении, используемой для декодирования блока Ζ текстуры, и информации MV(Y) о движении, используемой для декодирования второго смежного блока Υ текстуры; получение одного или более подходящих элементов информации MV(X), извлеченных из информации MV(Z) о движении и/или из информации MV(Y) о движении; получение одного или более подходящих элементов информации MV(d(cb)) о движении, извлеченных из информации d(cb) о глубине/диспаратности, связанной с первым блоком cb текстуры; получение блока А текстуры путем применения информации MV(Z) о движении и отсчитанного от местоположения первого блока cb текстуры; получение блока В текстуры путем применения информации MV(Y) о движении и отсчитанного от местоположения второго блока cb текстуры; получение одного или более блоков текстуры путем применения информации MV(X) о движении и отсчитанных от местоположения первого блока cb текстуры; получение одного или более блоков текстуры путем применения информации MV(d(cb)) о движении и отсчитанных от местоположения первого блока cb текстуры; получение блоков d(A), d(B) глубины/диспаратности и остальных блоков, связанных с полученными блоками А, В текстуры и остальными блоками.
В соответствии с первым вариантом осуществления настоящего изобретения, при выполнении способа указанная процедура выбора первого смежного блока А текстуры и второго смежного блока В текстуры для первого блока cb текстуры может включать выполнение следующих операций: выбор совмещенного блока в первом опорном изображении в качестве первого смежного блока А текстуры и выбор второго смежного блока В текстуры на основе информации MV(A) и/или d(A) о движении или информации о глубине, связанной с первым смежным блоком текстуры; использование первого блока d(cb) глубины/диспаратности для выбора блока во втором опорном изображении в качестве первого смежного блока А текстуры и выбор второго смежного блока В текстуры на основе значений, связанных с первым смежным блоком А текстуры; использование первого блока d(cb) глубины/диспаратности для выбора блока в третьем опорном изображении в качестве первого смежного блока А текстуры и выбор второго смежного блока В текстуры, который расположен в двумерном фрагменте изображения или в видеофрагменте, или в многоракурсном видеофрагменте, смежном с первым совмещенным блоком А текстуры.
В соответствии с первым вариантом осуществления настоящего изобретения, если изображение текстуры и изображение глубины, связанное с указанным изображением текстуры, представлены с различным пространственным разрешением, способ может также включать выполнение следующих операций: нормализация пространственных разрешений изображений текстуры и глубины путем повторной дискретизации любого из двух компонентов (текстуры или глубины) до уровня разрешения другого компонента (глубины или текстуры), либо повторная дискретизация обоих компонентов до одного уровня пространственного разрешения.
В соответствии с первым вариантом осуществления настоящего изобретения, если изображение текстуры и изображение глубины, связанное с указанным изображением текстуры, представлены с различным пространственным разрешением, и разрешение изображения глубины отличается от разрешения изображения текстуры, способ может также включать выполнение следующих операций: изменение масштаба соответственно информации MV(A) и MV(B) о движении смежных блоков А и В текстуры с целью достижения требуемого уровня пространственного разрешения изображения глубины вместо повторной дискретизации изображения глубины. В состав указанной информации о движении могут входить компоненты вектора движения, размеры разделов движения и т.д.
В соответствии с первым вариантом осуществления настоящего изобретения, если изображение текстуры и изображение глубины, связанное с указанным изображением текстуры, представлены с различным пространственным разрешением и разрешение изображения глубины отличается от разрешения изображения текстуры, способ может также включать выполнение следующих операций: корректировка указанной операции сравнения, посредством которой формируются показатели подобия, путем применения информации о движении смежных блоков MV(A), MV(B) текстуры к изображению глубины, для отражения различия уровней разрешения изображений текстуры и глубины. Указанная процедура корректировки может включать прореживание, субдискретизацию, интерполяцию или повышающую дискретизацию информации d(MV(A), d(cb)) и d(MV(B), d(cb)) о глубине для согласования с разрешением информации о движении, полученной на основе смежных блоков А, В текстуры и т.д.
В соответствии с первым вариантом осуществления настоящего изобретения, если изображение текстуры и изображение глубины, связанное с указанным изображением текстуры, представлены с различным разрешением, и/или данные о глубине представлены в формате неравномерной дискретизации или с использованием способа дискретизации, отличающегося от способа дискретизации, применяемого для представления данных текстуры, то способ может также включать выполнение следующих операций: корректировка указанной операции сравнения, посредством которой формируются показатели подобия, путем применения информации о движении смежных блоков MV(A), MV(B) текстуры к нерегулярно дискретизированной информации о глубине, для отражения различия в представлении или способе дискретизации, используемом для данных текстуры и глубины. Указанная процедура корректировки может включать повторную дискретизацию (понижающую дискретизацию, повышающую дискретизацию, изменение масштабирования) информации о глубине, текстуре или движении, а также линейные и нелинейные операции объединения или агрегирования информации о глубине, представленной в результате выполнения способа неоднородной дискретизации.
В соответствии с первым вариантом осуществления настоящего изобретения, если изображение текстуры и изображение глубины, связанное с указанным изображением текстуры, представлены с различным пространственным разрешением и/или данные о глубине представлены в формате неоднородной дискретизации или с использованием способа дискретизации, отличающегося от способа дискретизации, применяемого для представления данных текстуры, то способ может также включать выполнение следующих операций: передача декодеру через битовый поток информации, требуемой для операции декодирования. В состав указанной информации могут входить данные сигнализации о способе, используемом для нормализации пространственного разрешения изображений текстуры и/или глубины, или данные сигнализации о способах, применяемых для изменения масштаба информации о движении (например, об округлении, коэффициенте понижающей/повышающей дискретизации и т.д.), или данные сигнализации о способе, используемом для корректировки сравнения (изменение масштабирования, повторная дискретизация либо нелинейные операции объединения или агрегирования).
В соответствии со вторым аспектом настоящего изобретения, предлагается устройство, содержащее видеодекодер, сконфигурированный для декодирования из битового потока первого кодированного блока текстуры первого кодированного изображения текстуры в первый блок cb текстуры, при этом процедура декодирования первого кодированного блока текстуры включает: выбор первого смежного блока А текстуры и второго смежного блока В текстуры; получение первого смежного блока d(A) глубины/диспаратности и второго смежного блока d(B) глубины/диспаратности; получение первого блока d(cb) глубины/диспаратности, пространственно совмещенного с первым блоком cb текстуры; сравнение первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/диспаратности и вторым смежным блоком d(B) глубины/диспаратности; выбор первого смежного блока текстуры и/или второго смежного блока текстуры (А и/или В) на основе значения подобия, вычисленного посредством указанного сравнения первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/диспаратности и вторым смежным блоком d(B) глубины/диспаратности; получение одного или более параметров предсказания для декодирования первого кодированного блока cb текстуры на основе значений, связанных с выбранными первым смежным блоком А текстуры и/или вторым смежным блоком В текстуры; и декодирование первого кодированного блока cb текстуры с использованием полученных одного или более параметров предсказания.
В соответствии со вторым вариантом осуществления настоящего изобретения, если изображение текстуры и изображение глубины, связанное с указанным изображением текстуры, представлены с различным пространственным разрешением, устройство может также выполнять следующие операции: нормализация пространственных разрешений изображений текстуры и глубины путем цикличной повторной дискретизации любого из двух компонентов (текстуры или глубины) до уровня разрешения другого компонента (глубины или текстуры), либо повторная дискретизация обоих компонентов до одного уровня пространственного разрешения.
В соответствии со вторым вариантом осуществления настоящего изобретения, устройство сконфигурировано таким образом, что если изображение текстуры и изображение глубины, связанное с указанным изображением текстуры, представлены с различным пространственным разрешением, и разрешение изображения глубины отличается от разрешения изображения текстуры, способ может также включать выполнение следующих операций: изменение масштаба соответственно информации MV(A) и MV(B) о движении смежных блоков А и В текстуры с целью достижения требуемого уровня пространственного разрешения изображения глубины вместо повторной дискретизации изображения глубины. В состав указанной информации о движении могут входить компоненты вектора движения, размеры разделов движения и т.д.
В соответствии со вторым вариантом осуществления настоящего изобретения, устройство сконфигурировано таким образом, что если изображение текстуры и изображение глубины, связанное с указанным изображением текстуры, представлены с различным пространственным разрешением, и разрешение изображения глубины отличается от разрешения изображения текстуры, способ может также включать выполнение следующих операций: корректировка указанной операции сравнения, посредством которой формируются показатели подобия путем применения информации MV(A), MV(B) о движении смежных блоков текстуры к изображению глубины, для отражения различия уровней разрешения изображений текстуры и глубины. Указанная процедура корректировки может включать прореживание, субдискретиизацию, интерполяцию или повышающую дискретизацию информации d(MV(A), d(cb)) and d(MV(B), d(cb)) о глубине для согласования с разрешением информации о движении, полученной на основе смежных блоков А, В текстуры и т.д.
В соответствии со вторым вариантом осуществления настоящего изобретения, устройство сконфигурировано таким образом, что если изображение текстуры и изображение глубины, связанное с указанным изображением текстуры, представлены с различным разрешением, и/или данные о глубине представлены в формате неоднородной дискретизации или с использованием способа дискретизации, отличающегося от способа дискретизации, применяемого для представления данных текстуры, то способ может также включать выполнение следующих операций: корректировка указанной операции сравнения, посредством которой формируются показатели подобия, путем применения информации о движении смежных блоков MV(A), MV(B) текстуры к нерегулярно дискретизированной информации о глубине, для отражения различия в представлении или способе дискретизации, используемом для данных текстуры и глубине. Указанная процедура корректировки может включать повторную дискретизацию (понижающую дискретизацию, повышающую дискретизацию, изменение масштабирования) информации о глубине, текстуре или движении, а также линейные и нелинейные операции объединения или агрегирования информации о глубине, представленной в результате выполнения способа неоднородной дискретизации.
В соответствии со вторым вариантом осуществления настоящего изобретения, если изображение текстуры и изображение глубины, связанное с указанным изображением текстуры, представлены с различным пространственным разрешением, и/или данные о глубине представлены в формате неоднородной дискретизации или с использованием способа дискретизации, отличающегося от способа дискретизации, применяемого для представления данных текстуры, то способ может также включать выполнение следующих операций: декодирование из битового потока информации, требуемой для операции декодирования. В состав указанной информации могут входить индексы декодирования для способа, используемого для нормализации пространственного разрешения изображений текстуры и/или глубиной, или индексы декодирования для способов, применяемых для изменения масштаба информации о движении (например, для округления, коэффициент понижающей/повышающей дискретизации и т.д.), или индексы декодирования для способа, используемого для корректировки сравнения (для изменения масштабирования, повторной дискретизации или нелинейных операций объединения или агрегирования).
Согласно третьему аспекту настоящего изобретения, предлагается компьютерный машиночитаемый носитель информации, на котором хранится используемый устройством код, при исполнении которого процессором устройство выполняет следующие операции: декодирование из битового потока первого кодированного блока текстуры первого кодированного изображения текстуры в первый блок cb текстуры, при этом процедура декодирования первого кодированного блока текстуры включает: выбор первого смежного блока А текстуры и второго смежного блока В текстуры; получение первого смежного блока d(A) глубины/диспаратности и второго смежного блока d(B) глубины/диспаратности; получение первого блока d(cb) глубины/диспаратности, пространственно совмещенного с первым блоком cb текстуры; сравнение первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/диспаратности и вторым смежным блоком d(B) глубины/диспаратности; выбор первого смежного блока текстуры и/или второго смежного блока текстуры (А и/или В) на основе значения подобия, вычисленного посредством указанного сравнения первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/ диспаратности и вторым смежным блоком d(B) глубины/диспаратности; получение одного или более параметров предсказания для декодирования первого кодированного блока cb текстуры на основе значений, связанных с выбранным первым смежным блоком А текстуры и/или вторым смежным блоком В текстуры; и декодирование первого кодированного блока cb текстуры с использованием полученных одного или более параметров предсказания.
В соответствии с четвертым аспектом настоящего изобретения предлагается устройство, содержащее по меньшей мере один процессор и по меньшей мере один модуль памяти, в котором хранится код, при исполнении которого по меньшей мере одним указанным процессором устройство выполняет следующие операции: декодирование из битового потока первого кодированного блока текстуры первого кодированного изображения текстуры в первый блок cb текстуры, при этом процедура декодирования первого кодированного блока текстуры включает: выбор первого смежного блока А текстуры и второго смежного блока В текстуры; получение первого смежного блока d(A) глубины/диспаратности и второго смежного блока d(B) глубины/диспаратности; получение первого блока d(cb) глубины/диспаратности, пространственно совмещенного с первым блоком cb текстуры; сравнение первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/диспаратности и вторым смежным блоком d(B) глубины/диспаратности; выбор первого смежного блока текстуры и/или второго смежного блока текстуры (А и/или В) на основе значения подобия, вычисленного посредством указанного сравнения первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/ диспаратности и вторым смежным блоком d(B) глубины/диспаратности; получение одного или более параметров предсказания для декодирования первого кодированного блока cb текстуры на основе значений, связанных с выбранным первым смежным блоком А текстуры и/или вторым смежным блоком В текстуры; и декодирование первого кодированного блока cb текстуры с использованием полученных одного или более параметров предсказания.
В соответствии с пятым аспектом настоящего изобретения предлагается видеодекодер, сконфигурированный для декодирования на основе битового потока первого кодированного блока текстуры первого кодированного изображения текстуры в первый блок cb текстуры, при этом процедура декодирования первого кодированного блока текстуры включает: выбор первого смежного блока А текстуры и второго смежного блока В текстуры; получение первого смежного блока d(A) глубины/диспаратности и второго смежного блока d(B) глубины/диспаратности; получение первого блока d(cb) глубины/диспаратности, пространственно совмещенного с первым блоком cb текстуры; сравнение первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/ диспаратности и вторым смежным блоком d(B) глубины/диспаратности; выбор первого смежного блока А текстуры и/или второго смежного блока В текстуры на основе значения подобия, вычисленного посредством указанного сравнения первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/диспаратности и вторым смежным блоком d(B) глубины/диспаратности; получение одного или более параметров предсказания для декодирования первого кодированного блока cb текстуры на основе значений, связанных с выбранным первым смежным блоком А текстуры и/или вторым смежным блоком В текстуры; и кодирование/декодирование первого кодированного блока cb текстуры с использованием полученных одного или более параметров предсказания.
В соответствии с шестым аспектом настоящего изобретения, предлагается способ, включающий кодирование первого несжатого блока cb текстуры первого несжатого изображения текстуры в первый кодированный блок текстуры первого кодированного изображения текстуры в битовом потоке, при этом процедура кодирования первого несжатого блока cb текстуры включает: выбор первого смежного блока А текстуры и второго смежного блока В текстуры; получение первого смежного блока d(A) глубины/диспаратности и второго смежного блока d(B) глубины/ диспаратности; получение первого блока d(cb) глубины/диспаратности, пространственно совмещенного с первым блоком cb текстуры; сравнение первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/диспаратности и вторым смежным блоком d(B) глубины/диспаратности; выбор первого смежного блока А текстуры и/или второго смежного блока В текстуры на основе значения подобия, вычисленного посредством указанного сравнения первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/ диспаратности и вторым смежным блоком d(B) глубины/диспаратности; получение одного или более параметров предсказания для кодирования первого кодируемого блока cb текстуры на основе значений, связанных с выбранным первым смежным блоком А текстуры и/или вторым смежным блоком В текстуры; и кодирование первого несжатого блока cb текстуры в первый кодированный блок текстуры с использованием полученных одного или более параметров предсказания.
В соответствии с седьмым аспектом настоящего изобретения предлагается устройство, содержащее видеокодер, сконфигурированный для кодирования первого несжатого блока cb текстуры первого несжатого изображения текстуры в первый кодированный блок текстуры первого кодированного изображения текстуры в битовом потоке, при этом процедура кодирования первого несжатого блока cb текстуры включает: выбор первого смежного блока А текстуры и второго смежного блока В текстуры; получение первого смежного блока d(A) глубины/диспаратности и второго смежного блока d(B) глубины/диспаратности; получение первого блока d(cb) глубины/диспаратности, пространственно совмещенного с первым блоком cb текстуры; сравнение первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/диспаратности и вторым смежным блоком d(B) глубины/диспаратности; выбор первого смежного блока А текстуры и/или второго смежного блока В текстуры на основе значения подобия, вычисленного посредством указанного сравнения первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/ диспаратности и вторым смежным блоком d(B) глубины/диспаратности; получение одного или более параметров предсказания для кодирования первого кодируемого блока cb текстуры на основе значений, связанных с выбранным первым смежным блоком А текстуры и/или вторым смежным блоком В текстуры; и кодирование первого несжатого блока cb текстуры в первый кодированный блок текстуры с использованием полученных одного или более параметров предсказания.
Согласно восьмому аспекту настоящего изобретения предлагается компьютерный машиночитаемый носитель информации, на котором хранится используемый устройством код, при исполнении которого процессором устройство выполняет следующие операции: кодирование первого несжатого блока cb текстуры первого несжатого изображения текстуры в первый кодированный блок текстуры первого кодированного изображения текстуры в битовом потоке, при этом процедура кодирования первого несжатого блока cb текстуры включает: выбор первого смежного блока А текстуры и второго смежного блока В текстуры; получение первого смежного блока d(A) глубины/диспаратности и второго смежного блока d(B) глубины/диспаратности; получение первого блока d(cb) глубины/диспаратности, пространственно совмещенного с первым блоком cb текстуры; сравнение первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/диспаратности и вторым смежным блоком d(B) глубины/диспаратности; выбор первого смежного блока А текстуры и/или второго смежного блока В текстуры на основе значения подобия, вычисленного посредством указанного сравнения первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/ диспаратности и вторым смежным блоком d(B) глубины/диспаратности; получение одного или более параметров предсказания для кодирования первого кодируемого блока cb текстуры на основе значений, связанных с выбранным первым смежным блоком А текстуры и/или вторым смежным блоком В текстуры; и кодирование первого несжатого блока cb текстуры в первый кодированный блок текстуры с использованием полученных одного или более параметров предсказания.
В соответствии с девятым аспектом настоящего изобретения, предлагается по меньшей мере один процессор и по меньшей мере один модуль памяти, в котором хранится код, при исполнении которого по меньшей мере одним указанным процессором устройство выполняет следующие операции: кодирование первого несжатого блока cb текстуры первого несжатого изображения текстуры в первый кодированный блок текстуры первого кодированного изображения текстуры в битовом потоке, при этом процедура кодирования первого несжатого блока cb текстуры включает: выбор первого смежного блока А текстуры и второго смежного блока В текстуры; получение первого смежного блока d(A) глубины/диспаратности и второго смежного блока d(B) глубины/ диспаратности; получение первого блока d(cb) глубины/диспаратности, пространственно совмещенного с первым блоком cb текстуры; сравнение первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/диспаратности и вторым смежным блоком d(B) глубины/диспаратности; выбор первого смежного блока А текстуры и/или второго смежного блока В текстуры на основе значения подобия, вычисленного посредством указанного сравнения первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/ диспаратности и вторым смежным блоком d(B) глубины/диспаратности; получение одного или более параметров предсказания для кодирования первого кодируемого блока cb текстуры на основе значений, связанных с выбранным первым смежным блоком А текстуры и/или вторым смежным блоком В текстуры; и кодирование первого несжатого блока cb текстуры в первый кодированный блок текстуры с использованием полученных одного или более параметров предсказания.
В соответствии с десятым аспектом настоящего изобретения, предлагается устройство, содержащее видеодекодер, сконфигурированный для кодирования первого несжатого блока cb текстуры первого несжатого изображения текстуры в первый кодированный блок текстуры первого кодированного изображения текстуры в битовом потоке, при этом процедура кодирования первого несжатого блока cb текстуры включает: выбор первого смежного блока А текстуры и второго смежного блока В текстуры; получение первого смежного блока d(A) глубины/диспаратности и второго смежного блока d(B) глубины/диспаратности; получение первого блока d(cb) глубины/диспаратности, пространственно совмещенного с первым блоком cb текстуры; сравнение первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/диспаратности и вторым смежным блоком d(B) глубины/диспаратности; выбор первого смежного блока А текстуры и/или второго смежного блока В текстуры на основе значения подобия, вычисленного посредством указанного сравнения первого блока d(cb) глубины/диспаратности с первым смежным блоком d(A) глубины/ диспаратности и вторым смежным блоком d(B) глубины/диспаратности; получение одного или более параметров предсказания для кодирования первого кодируемого блока cb текстуры на основе значений, связанных с выбранным первым смежным блоком А текстуры и/или вторым смежным блоком В текстуры; и кодирование первого несжатого блока cb текстуры в первый кодированный блок текстуры с использованием полученных одного или более параметров предсказания.
Согласно одиннадцатому аспекту настоящего изобретения, способ включает кодирование первого элемента данных с использованием первого способа, соответствующего первому варианту осуществления настоящего изобретения; вычисление первой метрики Costl оценки для кодированного первого элемента данных; кодирование второго элемента данных с использованием второго способа, являющегося способом предсказания вектора движения, альтернативным первому способу; вычисление второй метрики Cost2 оценки для кодированного второго элемента данных; выбор из первого и второго способа такого способа, который определяется в качестве оптимального с учетом первой и второй метрик, Cost1 и Cost2, оценки; кодирование первого и второго элементов данных с использованием выбранного способа; передача в битовом потоке индекса, указывающего выбранный способ.
Согласно способу, соответствующему одиннадцатому варианту осуществления настоящего изобретения, первый элемент данных может включать в свой состав либо отдельный блок Cb текстуры, либо набор кодированных блоков (секция, изображение, группа изображений).
Согласно способу, соответствующему одиннадцатому варианту осуществления настоящего изобретения, второй элемент данных может включать в свой состав набор блоков (А, В) текстуры.
Согласно способу, соответствующему одиннадцатому варианту осуществления настоящего изобретения, указанная метрика оценки может формироваться на основе метрики зависимости искажений от скорости передачи или других метрик оценки, например метрики сложности алгоритма вычисления и зависимости искажений от скорости передачи.
Согласно способу, соответствующему одиннадцатому варианту осуществления настоящего изобретения, указанная процедура передачи индекса выполняется на различных уровнях представления кодированных данных.
Согласно способу, соответствующему одиннадцатому варианту осуществления настоящего изобретения, индекс передается по меньшей мере в одном из следующих компонентов: в наборе параметров последовательности, в наборе параметров изображения, в заголовке секции (слайса) или совместно с информацией о движении для конкретного раздела блока.
В соответствии с двенадцатым аспектом настоящего изобретения, способ включает декодирование из битового потока индекса, указывающего способ, используемый для декодирования набора данных; декодирование из битового потока характеристик декодируемого набора данных, к которому применим указанный способ, обозначенный индексом; применение первого способа по п.1 формулы изобретения, если указано, что декодирование битового потока должно выполняться таким способом; применение второго способа, являющегося способом предсказания вектора движения, альтернативным первому способу, если указано, что декодирование битового потока должно выполняться таким способом.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Для лучшего понимания сути настоящего изобретения далее в примерах приводятся ссылки на прилагаемые чертежи, на которых:
на фиг. 1 показана упрощенная двумерная модель устройства стереоскопических камер;
на фиг. 2 показана упрощенная модель устройства многоракурсной камеры;
на фиг. 3 показана упрощенная модель многоракурсного автостереоскопического дисплея (ASD);
на фиг. 4 показана упрощенная модель системы 3DV, основанной на технологии DIBR;
на фиг. 5 и 6 показан пример системы оценки глубины на основе TOF;
на фиг. 7а и 7b показано пространственное и временное окружение текущего кодируемого блока, служащего в качестве подходящего образца для MVP согласно H.264/AVC;
на фиг. 8 показан алгоритм MVP, выполняемый на основе информации о глубине/диспаратности, в соответствии с вариантом осуществления настоящего изобретения;
на фиг. 9 показан алгоритм MVP, выполняемый на основе информации о глубине/диспаратности, в соответствии с другим вариантом осуществления настоящего изобретения;
на фиг. 10 схематично показан электронный прибор, подходящий для использования в некоторых вариантах осуществления настоящего изобретения;
на фиг. 11 схематично показано пользовательское оборудование, подходящее для использования в некоторых вариантах осуществления настоящего изобретения;
на фиг. 12 схематично показаны другие электронные приборы, использующие варианты осуществления настоящего изобретения и подключенные с помощью соединений беспроводной и проводной сетей;
на фиг. 13 показан пример структуры блоков cb, А, В, С, D;
на фиг. 14 показаны блоки данных текстуры (cb, S, Τ, U) и блоки d(cb), d(S), d(T) и d(U) данных о глубине/диспаратности, связанные соответственно с этими блоками;
на фиг. 15 показана концепция пространственно смежных блоков данных текстуры;
на фиг. 16 показана концепция смежных блоков в данных двумерной или многоракурсной текстуры;
на фиг. 17 показан алгоритм примера реализации процесса отбора вектора движения на основе глубины в режиме Skip для Р-секций;
на фиг. 18 показан алгоритм примера реализации процесса отбора вектора движения на основе глубины в режиме Direct для В-секций;
на фиг. 19 показан алгоритм выполнения процесса предсказания возможного вектора движения (MVP);
на фиг. 20 показаны опорное неоднородно дискретизированное изображение глубины и опорное однородно дискретизированное изображение текстуры;
на фиг. 21 показан пример отображения карты глубины на другой ракурс;
на фиг. 22 показан пример генерации начальной оценки карты глубины после кодирования первого зависимого ракурса блока произвольного доступа;
на фиг. 23 показан пример получения оценки карты глубины для текущего изображения с использованием параметров движения уже кодированного ракурса того же блока доступа; и
на фиг. 24 показан пример обновления оценки карты глубины для зависимого ракурса на основе кодированных векторов движения и диспаратности.
ПОДРОБНОЕ ОПИСАНИЕ НЕКОТОРЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Для понимания различных аспектов настоящего изобретения и вариантов его осуществления ниже кратко описываются некоторые тесно связанные с ним аспекты процесса кодирования видеосигнала.
В этом разделе приводятся некоторые ключевые определения, описываются структуры битового потока и кодирования, а также концепции стандарта H.264/AVC в виде примеров видеокодера, декодера, способа кодирования, способа декодирования и структуры битового потока, согласно которым может быть реализовано настоящее изобретение. Аспекты изобретения не ограничены стандартом H.264/AVC, однако описание приводится для одного из возможных вариантов, на основе которого частично или полностью может быть реализовано настоящее изобретение.
Стандарт H.264/AVC разработан объединенным коллективом видеоэкспертов (JVT, Joint Video Team) в составе группы экспертов по кодированию видеосигналов (VCEG, Video Coding Experts Group) сектора стандартизации электросвязи международного телекоммуникационного союза (ITU-T, International Telecommunication Union) и группы по движущемуся изображению (MPEG, Moving Picture Experts Group) международной организации по стандартизации (ISO, International Standardisation Organisation) / международной электротехнической комиссии (IEC, International Electrotechnical Commission). Стандарт H.264/AVC опубликован обеими организациями, занимавшимися его разработкой, и известен как рекомендация ITU-T Н.264 и международный стандарт ISO/IEC 14496-10, а также известен под названием "усовершенствованное кодирование видеосигналов MPEG-4, часть 10" (AVC, MPEG-4 Part 10 Advanced Video Coding). Было разработано несколько версий стандарта H.264/AVC, в спецификации каждой из которых включены новые дополнения и возможности. К этим дополнениям относятся алгоритмы масштабируемого кодирования видеосигнала (SVC, Scalable Video Coding) и многоракурсного кодирования видеосигнала (MVC, Multiview Video Coding).
Высокоэффективное кодирование видеосигнала (HEVC, High Efficiency Video Coding) является примером другой недавней разработки, направленной на развитие технологии кодирования видеосигнала и выполненной объединенным коллективом по кодированию видеосигналов (JCT-VC, Joint Collaborative Team - Video Coding), входящим в состав групп VCEG и MPEG.
В этом разделе приводятся некоторые ключевые определения, описываются структуры битового потока и кодирования, а также концепции стандартов H.264/AVC и HEVC в виде примеров видеокодера, декодера, способа кодирования, способа декодирования и структуры битового потока, согласно которым может быть реализовано настоящее изобретение. Некоторые ключевые определения, структуры битового потока и кодирования, а также концепции стандарта H.264/AVC и рабочей версии стандарта HEVC совпадают и поэтому ниже описываются совместно. Аспекты настоящего изобретения не ограничены стандартом H.264/AVC или HEVC, однако описание приводится для одного из возможных вариантов, на основе которого частично или полностью может быть реализовано настоящее изобретение.
Подобно многим ранее разработанным стандартам кодирования видеосигналов, в стандартах H.264/AVC и HEVC определен синтаксис и семантика битового потока, а также процесс декодирования для безошибочной передачи битовых потоков. Процесс кодирования не определен в стандарте, однако кодеры должны генерировать согласованные битовые потоки. Соответствие характеристик битового потока и декодера может быть проверены с помощью гипотетического эталонного декодера (HRD, Hypothetical Reference Decoder), определенного в приложении С стандарта H.264/AVC. В стандарте описаны средства кодирования, позволяющие избежать ошибок и потери данных при передаче, однако использование таких средств при кодировании является необязательным, и процесс декодирования не определен для битовых потоков с ошибками.
Элементарным блоком на входе кодера H.264/AVC или HEVC и на выходе декодера H.264/AVC или HEVC является изображение (picture). Изображение может представлять собой кадр или поле. Кадр содержит матрицу отсчетов яркости и соответствующих отсчетов цветности. Поле представляет собой набор чередующихся строк выборки кадра и может использоваться в качестве входных данных кодера в случае чересстрочного исходного сигнала. Цветовые изображения могут подвергаться субдискретизации по сравнению с яркостными изображениями. Например, при использовании шаблона выборки вида 4:2:0 пространственное разрешение цветовых изображений в два раза меньше разрешения яркостных изображений по обеим осям координат, и соответственно макроблок содержит один блок размером 8x8 выборок цветности на каждый компонент цветности. Изображение разделяется на одну или более групп секций (слайсов), и каждая группа секций содержит одну или более секций. Секция содержит целое число макроблоков, последовательно упорядоченных в процессе растрового сканирования в пределах определенной группы секций.
Согласно H.264/AVC, макроблок представляет собой блок размером 16×16, содержащий яркостные выборки и соответствующие блоки цветовых выборок. Например, при использовании шаблона выборки вида 4:2:0 макроблок содержит один блок размером 8×8 цветовых выборок для каждого компонента цветности. Согласно H.264/AVC, изображение разделяется на одну или более групп секций, и каждая группа секций содержит одну или более секций. В соответствии с H.264/AVC секция содержит целое число макроблоков, последовательно упорядоченных в процессе растрового сканирования в пределах определенной группы секций.
Согласно рабочей версии стандарта HEVC, видеоизображения разделены на блоки кодирования (CU, coding unit), перекрывающие область изображения. CU содержит один или более блоков предсказания (PU, prediction unit), определяющих процесс предсказания для выборок в пределах CU, и один или более блоков преобразования (TU, transform unit), определяющих процесс кодирования ошибки предсказания для выборок в указанном CU. Обычно CU содержит квадратный блок выборок, размер которого выбирается из предварительно определенного множества возможных размеров CU. Блок CU с максимально допустимым размером обычно называется LCU (largest coding unit, наибольший блок кодирования), и видеоизображение разделяется на неперекрывающиеся LCU. LCU также можно разбить на комбинацию меньших по размеру CU, например, путем рекурсивного разбиения LCU и результирующих CU. Каждый результирующий CU обычно содержит по меньшей мере один PU и по меньшей мере один связанный с ним TU. Каждый PU и TU далее можно разбить на меньшие PU и TU для увеличения, соответственно, степени детализации процессов предсказания и кодирования ошибки предсказания. Разбиение PU можно выполнить путем разбиения CU на четыре одинаковых по размеру квадратных PU или путем разбиения CU на два прямоугольных PU по вертикали или горизонтали симметричным или асимметричным образом. Способ разделения изображения на CU и разделения CU на PU и TU обычно сообщается в битовом потоке, что позволяет декодеру воспроизвести требуемую структуру этих блоков.
Согласно рабочей версии стандарта HEVC изображение может разделяться на мозаичные прямоугольные элементы, содержащие целое число LCU. В соответствии с текущей рабочей версией HEVC при разделении на мозаичные элементы формируется регулярная сетка, при этом значения высоты и ширины мозаичных элементов отличаются друг от друга максимум на один LCU. Согласно рабочей версии HEVC секция состоит из целого числа CU. CU сканируются в порядке растрового сканирования блоков LCU в мозаичных элементах или в пределах изображения, если мозаичные элементы не используются. В пределах LCU используется специфический порядок сканирования CU.
Далее описываются некоторые ключевые определения и концепции разделения изображения согласно рабочей версии (WD, Working Draft) 5 HEVC. Разделение определяется как деление множества на подмножества таким образом, чтобы каждый элемент множества находился в точности в одном подмножестве.
Базовый блок кодирования в WD5 HEVC представляет собой древовидный блок. Древовидный блок представляет собой блок размерностью Ν×N выборок яркости и два соответствующих блока выборок цветности изображения, который содержит три массива выборок, или блок размерностью Ν×N выборок монохромного изображения или изображения, который кодирован с использованием трех отдельных цветовых плоскостей. Древовидный блок может разделяться для различных процессов кодирования и декодирования. Раздел древовидного блока представляет собой совокупность блока выборок яркости и двух соответствующих блоков выборок цветности, полученных в результате разделения древовидного блока для изображения, которое содержит три массива выборок, или блок выборок яркости, полученный в результате разделения древовидного блока для монохромного изображения или изображения, кодированного с использованием трех отдельных цветовых плоскостей. Каждому древовидному блоку назначаются данные сигнализации о разделении для идентификации размеров блока с целью внутреннего или взаимного предсказания, а также для кодирования с преобразованием. Разделение выполняется рекурсивно путем разбиения на дерево квадрантов. Корень дерева квадрантов связан с древовидным блоком. Дерево квадрантов разбивается до тех пор, пока не достигается лист дерева, который называется узлом кодирования. Узел кодирования является корневым узлом двух деревьев - дерева предсказания и дерева преобразования. Дерево предсказания указывает позицию и размер блоков предсказания. Дерево предсказания и связанные с ним данные предсказания называются блоком предсказания. Дерево преобразования указывает позицию и размер блоков преобразования. Дерево преобразования и связанные с ним данные преобразования называются блоком преобразования. Разбиение информации о яркости и цветности выполняется идентично для дерева предсказания и может выполняться идентично или по-разному для дерева преобразования. Узел кодирования и связанные с ним блоки предсказания и преобразования совместно формируют блок кодирования.
Согласно WD5 HEVC изображения разделяются на секции и мозаичные элементы. Секция может представлять собой последовательность древовидных блоков, а также (если имеется в виду так называемая мелкозернистая секция) может быть ограничена древовидным блоком в местоположении, в котором блоки преобразования и предсказания совпадают. Древовидные блоки в пределах секции кодируются и декодируются в порядке растрового сканирования. Для первично кодированного изображения процесс разделения представляет собой деление каждого изображения на секции.
Согласно WD5 HEVC мозаичный элемент определяется как целое число древовидных блоков, совместно входящих в один столбец и одну строку, последовательно упорядоченных в процессе растрового сканирования в пределах мозаичного элемента. Для первично кодированного изображения процесс деления каждого изображения на мозаичные элементы представляет собой разделение. Мозаичные элементы упорядочиваются последовательно в процессе растрового сканирования в пределах изображения. Хотя секция содержит древовидные блоки, последовательные при растровом сканировании в пределах секции, эти древовидные блоки не обязательно должны быть последовательны при растровом сканировании в пределах изображения. Секции и мозаичные элементы не должны содержать одинаковую последовательность древовидных блоков. Мозаичный элемент может содержать древовидные блоки, входящие в несколько секций. Таким же образом, секция может содержать древовидные блоки, входящие в несколько мозаичных элементов.
Согласно H.264/AVC и HEVC предсказание в изображении может быть запрещено при переходе границ секции. Таким образом, секции можно рассматривать в качестве средства для разбиения кодированного изображения на независимо декодируемые фрагменты, и, следовательно, секции часто рассматриваются как элементарные блоки для передачи. Во многих случаях кодеры могут указывать в битовом потоке, какие типы предсказания в изображении отключаются на границах секции, и при функционировании декодера эта информация принимается во внимание, например, в случае принятия решения о том, какие источники предсказания доступны. Например, выборки из соседних макроблоков или CU можно рассматривать в качестве недоступных для внутреннего предсказания, если соседний макроблок или CU располагается в другой секции.
Элементарным блоком на выходе кодера H.264/AVC или HEVC и на входе декодера H.264/AVC или HEVC является блок уровня абстракции сети (NAL, Network Abstraction Layer). Декодирование частично потерянных или искаженных блоков NAL обычно является достаточно трудным процессом. Для транспортировки по пакетно-ориентированным сетям или для сохранения в структурированных файлах блоки NAL обычно инкапсулируются в пакетах или в подобных структурах данных. Формат байтового потока определен стандартом H.264/AVC или HEVC для сред передачи или хранения данных, которые не поддерживают кадровые структуры. В формате байтового потока блоки NAL отделяются друг от друга с помощью начального кода, который присоединяется в начале каждого блока NAL. Во избежание ложного обнаружения границ блока NAL кодеры выполняют побайтовый алгоритм предотвращения эмуляции начального кода, с помощью которого в полезную нагрузку блока NAL добавляется байт предотвращения эмуляции на тот случай, если начальный код все же появится. Для того чтобы инициировать непосредственную шлюзовую передачу данных между пакетными и потоковыми системами, всегда выполняется процедура предотвращения эмуляции начального кода, вне зависимости от того, используется ли формат байтового потока.
Некоторые профили H.264/AVC позволяют использовать до восьми групп секций для кодированного изображения. Если используются несколько групп секций, изображение разделяется на блоки карты групп секций, которые равны двум вертикальным последовательным макроблокам в случае адаптивного к макроблокам кодирования кадров-полей (MBAFF, macroblock-adaptive frame-field), и равны макроблоку в противном случае. Набор параметров изображения содержит данные, основанные на том, какой из блоков карты группы секций изображения связан с конкретной группой секций. Группа секций может содержать любые блоки карты группы секций, включая несмежные блоки карты. Если для изображения указано несколько групп секций, используется функция гибкого упорядочивания макроблоков (FMO, flexible macroblock ordering), определенная в стандарте.
В соответствии с H.264/AVC секция содержит один или более последовательных макроблоков (или пар макроблоков, если используется MBAFF) в пределах определенной группы секций, упорядоченных в порядке растрового сканирования. Если используется только одна группа секций, то согласно H.264/AVC секции содержат последовательные макроблоки в порядке растрового сканирования, и, таким образом, они схожи с секциями, определенными в множестве предшествующих стандартов кодирования. В некоторых профилях стандарта H.264/AVC секции кодированного изображения могут появляться в любом порядке по отношению друг к другу в битовом потоке, и такая структура называется произвольным упорядочиванием секций (ASO, arbitrary slice ordering). В противном случае секции в битовом потоке должны быть упорядочены в соответствии с растровым кодированием.
Блоки NAL содержат заголовок и полезную нагрузку. Заголовок блока NAL указывает тип этого блока, а также указывает на то, является ли кодированная секция, содержащаяся в блоке NAL, частью опорного изображения или изображения, отличного от опорного. Согласно H.264/AVC и HEVC заголовок блока NAL указывает тип этого блока, а также указывает на то, является ли кодированная секция, содержащаяся в блоке NAL, частью опорного изображения или изображения, отличного от опорного. В стандарт H.264/AVC включен 2-битовый синтаксический элемент nal_ref_idc, значение 0 которого указывает на то, что кодированная секция, содержащаяся в блоке NAL, является частью изображения, отличного от опорного, в то время как значение, большее 0, указывает на то, что кодированная секция, содержащаяся в блоке NAL, является частью опорного изображения. В рабочую версию стандарта HEVC включен 1-битовый синтаксический элемент nal_ref_idc, также обозначаемый nal_ref_flag, значение 0 которого указывает на то, что кодированная секция, содержащаяся в блоке NAL, является частью изображения, отличного от опорного, в то время как значение, равное 1, указывает на то, что кодированная секция, содержащаяся в блоке NAL, является частью опорного изображения. Заголовок блоков NAL для SVC и MVC дополнительно содержит различные индикаторы, связанные со стабильностью и многоракурсной иерархией.
Согласно стандартам H.264/AVC и HEVC блоки NAL могут быть классифицированы как NAL уровня кодирования видеосигнала (VCL, Video Coding Layer) и блоки NAL, отличные от VCL.
Блоки NAL VCL в H.264/AVC представляют собой либо блоки NAL кодированной секции, либо блоки NAL раздела данных кодированной секции, либо блоки NAL префикса VCL. Блоки NAL кодированной секции содержат синтаксические элементы, представляющие один или более кодированных макроблоков, каждый из которых соответствует блоку выборок в несжатом изображении. Существует четыре типа блоков NAL кодированной секции: кодированная секция в изображении с мгновенным обновлением декодирования (IDR, Instantaneous Decoding Refresh), кодированная секция в изображении, отличном от IDR, кодированная секция во вспомогательном кодированном изображении (таком, как альфа-плоскость) и расширение кодированной секции (для секций SVC, находящихся на уровне, отличном от базового, или для секций MVC, расположенных в ракурсе, отличном от базового). Набор из трех блоков NAL раздела данных кодированной секции содержит те же синтаксические элементы, что и кодированная секция. Раздел А данных кодированной секции содержит заголовки макроблоков и векторы движения секции, в то время как разделы В и С данных кодированной секции содержат кодированные остаточные данные соответственно для интра- и интер- макроблоков. Следует отметить, что поддержка разделов данных секции предусмотрена только в некоторых профилях H.264/AVC. Блок NAL префикса VCL предшествует кодированной секции базового уровня в битовых потоках SVC и MVC и содержит индикаторы иерархии масштабирования связанной кодированной секции.
Согласно HEVC блоки NAL кодированной секции содержат синтаксические элементы, представляющие один или более CU. Согласно HEVC блоки NAL кодированной секции могут идентифицироваться как кодированная секция в изображении с мгновенным обновлением декодирования (IDR) или кодированная секция в изображении, отличном от IDR. В соответствии с HEVC, блок NAL кодированной секции может идентифицироваться как кодированная секция в изображении с полным обновлением декодирования (CDR, Clean Decoding Refresh) (который может также называться изображением с полным произвольным доступом (Clean Random Access picture)).
Блок NAL, отличный от VCL, может представлять собой пример блока одного из следующих типов: набор параметров последовательности, набор параметров изображения, блок NAL дополнительной информации уровня расширения (SEI, supplemental enhancement information), разделитель блока доступа, блок NAL завершения последовательности, блок NAL завершения потока или блок NAL данных заполнения. Наборы параметров играют существенную роль в процессе реконструкции декодируемых изображений, в то время как другие блоки NAL, отличные от VCL, не обязательно предназначены для реконструкции значений декодируемых выборок и служат для иных целей, описываемых ниже. Параметры, остающиеся неизменными в кодированной последовательности видеоинформации, включаются в набор параметров последовательности. Помимо параметров, существенных для процесса декодирования, набор параметров последовательности может дополнительно содержать информацию о применимости видеосигнала (VUI, video usability information), в состав которой входят параметры, имеющие важное значение для буферизации, синхронизации вывода изображения, визуализации и резервирования ресурсов. Набор параметров изображения содержит такие параметры, которые, скорее всего, не будут изменяться в нескольких кодированных изображениях. В битовых потоках H.264/AVC отсутствует заголовок изображения, однако часто изменяющиеся данные уровня изображения повторяются в каждом заголовке секции, а наборы параметров изображения переносят оставшиеся параметры уровня изображения. Синтаксис H.264/AVC допускает наличие множества экземпляров наборов параметров последовательности и изображения, при этом каждый экземпляр идентифицируется уникальным идентификатором. Каждый заголовок секции содержит идентификатор набора параметров изображения, который является активным для декодирования изображения, содержащего секцию, и каждый набор параметров изображения содержит идентификатор активного набора параметров последовательности. Следовательно, передача наборов параметров изображения и последовательности не должна быть точно синхронизирована с передачей секций. Вместо этого достаточно, чтобы активные наборы параметров последовательности и изображения принимались в любой момент перед тем, как к ним будет осуществляться обращение, благодаря чему передача наборов параметров может выполняться с помощью более надежного механизма передачи по сравнению с протоколами, используемыми для данных секции. Например, для сеансов транспортного протокола реального времени (RTP, Real-time Transport Protocol) H.264/AVC наборы параметров могут включаться в качестве параметра в описание сеанса. Если для передачи наборов параметров используется внутриполосный механизм, эти наборы могут повторяться для повышения уровня устойчивости к ошибкам.
Согласно рабочей версии HEVC существует также третий тип наборов параметров, называемый в этом описании набором параметров адаптации (APS, Adaptation Parameter Set), в состав которого входят параметры, которые, скорей всего, не должны изменяться в нескольких кодированных секциях. Согласно рабочей версии HEVC структура синтаксиса APS предполагает включение параметров или синтаксических элементов, связанных с адаптивным бинарным арифметическим кодированием, основанным на контексте (САВАС, context-based adaptive binary arithmetic coding), сдвигом адаптивной выборки, адаптивной кольцевой фильтрацией и фильтрацией разблокирования. В соответствии с рабочей версией HEVC набор APS представляет собой блок NAL, кодированный без использования ссылки или предсказания, полученного из какого-либо иного блока NAL. Идентификатор, обозначаемый как синтаксический элемент aps_id, включается в блок APS NAL, а также включается и используется в заголовке секции для ссылки на конкретный набор APS.
Блок NAL SEI содержит одно или более сообщений SEI, которые не требуются для декодирования выходных изображений, но помогают выполнять соответствующие процессы, такие как синхронизация вывода изображений, визуализация, обнаружение ошибок, маскирование ошибок и резервирование ресурсов. В H.264/AVC и HEVC определены несколько сообщений SEI, и сообщения SEI с пользовательскими данными позволяют организациям и компаниям указывать сообщения SEI для собственного использования. В H.264/AVC и HEVC определяется синтаксис и семантика указанных сообщений SEI, однако не определен процесс для обработки сообщений на стороне приема. Следовательно, требуется, чтобы кодеры удовлетворяли стандарту H.264/AVC или HEVC при создании сообщений SEI, а для обработки сообщений SEI для согласования порядка вывода декодеры, соответствующие стандарту H.264/AVC или HEVC, не требуются. Одной из причин включения синтаксиса и семантики сообщений SEI в H.264/AVC и HEVC является предоставление возможности формирования спецификаций различных систем для идентичной интерпретации дополнительной информации и, таким образом, для поддержки взаимодействия систем. Предполагается, что для спецификаций системы может потребоваться использование конкретных сообщений SEI как в конце процесса кодирования, так и в конце процесса декодирования, а также может быть определен процесс обработки конкретных сообщений SEI на приемной стороне.
Согласно H.264/AVC кодированное изображение содержит блоки NAL VCL, которые требуются для декодирования изображения. Кодированное изображение может представлять собой первично кодированное изображение либо изображение, кодированное с избыточностью. Первично кодированное изображение используется в процессе декодирования действительных битовых потоков. Согласно H.264/AVC изображение, кодированное с избыточностью, представляет собой избыточное представление, которое должно декодироваться только в том случае, если не удается успешно декодировать первично кодированное изображение.
Блок доступа в H.264/AVC содержит первичное кодированное изображение и связанные с ним блоки NAL. Порядок появления блоков NAL в блоке доступа устанавливается следующим образом. Дополнительный блок NAL разделителя блока доступа может указывать на начало блока доступа. За ним может следовать несколько блоков NAL SEI либо ни одного из таких блоков. Далее располагаются кодированные секции или разделы данных секций первичного кодированного изображения, за которыми следуют кодированные секции для нуля или более изображений, кодированных с избыточностью.
Блок доступа в MVC определен как набор блоков NAL, которые последовательно расположены в порядке декодирования и содержат в точности одно первичное кодированное изображение, состоящее из одного или более компонентов ракурса. Помимо первичного кодированного изображения, блок доступа также может содержать одно или более изображений, кодированных с избыточностью, одно дополнительно кодированное изображение или другие блоки NAL, не содержащие секции или разделы данных секций кодированного изображения. В результате декодирования блока доступа всегда формируется одно декодированное изображение, содержащее один или более декодированных компонентов ракурса. Другими словами, блок доступа в MVC содержит компоненты ракурсов одного выходного временного экземпляра.
Компонент ракурса в MVC называется кодированным представлением ракурса в отдельном блоке доступа. Изображение привязки (якорное изображение) представляет собой кодированное изображение, в котором все секции могут ссылаться только на секции в том же блоке доступа, то есть может использоваться межракурсное, но не межкадровое предсказание, и все последующие изображения в порядке вывода не используют межкадровое предсказание на основе любого изображения, предшествующего кодированному изображению в порядке декодирования. Межракурсное предсказание может использоваться для компонентов ракурса IDR, являющихся частью ракурса, отличного от базового. Базовый ракурс согласно MVC представляет собой ракурс с минимальным значением порядкового индекса ракурса в кодированной последовательности видеосигнала. Базовый ракурс может декодироваться независимо от других ракурсов без использования межракурсного предсказания. Базовый ракурс может декодироваться декодерами H.264/AVC, поддерживающими только профили одного ракурса, такие как базисный профиль (Baseline Profile) или профиль высокой четкости (High Profile), определенные стандартом H.264/AVC.
Согласно стандарту MVC множество подпроцессов процесса декодирования MVC используют соответствующие подпроцессы стандарта H.264/AVC путем замены в спецификациях этого стандарта терминов "изображение", "кадр" и "поле" на термины "компонент ракурса", "компонент ракурса кадра" и "компонент ракурса поля", соответственно. Таким же образом, далее термины "изображение", "кадр" и "поле" часто используются для замены терминов "компонент ракурса", "компонент ракурса кадра" и "компонент ракурса поля", соответственно.
Кодированная видеопоследовательность определяется как последовательность следующих друг за другом блоков доступа в порядке декодирования, начиная с блока доступа IDR (включительно) и заканчивая следующим блоком доступа IDR (не включаемым в текущую последовательность) либо блоком завершения битового потока, в зависимости от того, какой из последних двух блоков появляется раньше.
Группа изображений (GOP, group of pictures), а также характеристики этой группы могут быть определены следующим образом. GOP может декодироваться вне зависимости от того, были ли декодированы предшествующие изображения. Открытая группа GOP представляет собой такую группу изображений, в которой изображения, предшествующие в порядке вывода начальному внутреннему изображению, могут быть декодированы некорректно, если процесс декодирования начинается от начального внутреннего изображения открытой группы GOP. Другими словами, изображения открытой группы GOP могут ссылаться (в процессе взаимного предсказания) на изображения, входящие в предшествующую группу GOP. Декодер H.264/AVC может распознавать внутреннее изображение, с которого начинается открытая GOP, с помощью сообщения SEI о точке восстановления, передаваемого в битовом потоке H.264/AVC. Закрытая GOP представляет собой группу изображений, в которой все изображения могут быть корректно декодированы, если процесс декодирования начинается с начального внутреннего изображения закрытой GOP. Другими словами, в закрытой GOP отсутствуют изображения, ссылающиеся на изображения в предшествующих GOP. В стандарте H.264/AVC определено, что закрытая группа GOP начинается блоком доступа IDR. В результате структура закрытой GOP потенциально в большей степени устойчива к ошибкам по сравнению со структурой открытой GOP, однако при этом эффективность сжатия уменьшается. Структура кодирования открытой GOP потенциально более эффективна с точки зрения сжатия, поскольку в этом случае выбор опорных изображений осуществляется более гибко.
В синтаксисе битового потока, определенном в стандарте H.264/AVC, указывается, является ли конкретное изображение опорным для взаимного предсказания любого другого изображения. Изображения любого типа кодирования (I, Р, В) в рамках стандарта H.264/AVC могут являться опорными или отличными от опорных. Заголовок блока NAL указывает тип этого блока, а также указывает на то, является ли кодированная секция, содержащаяся в блоке NAL, частью опорного изображения или изображения, отличного от опорного. Множество гибридных видеокодеков, включая те, что соответствуют стандартам H.264/AVC и HEVC, кодируют видеоинформацию с использованием двух фаз. На первой фазе выполняется предсказание значений пикселей или выборок в определенной области изображения или в "блоке". Эти значения пикселей или выборок могут быть предсказаны, например, с помощью механизмов компенсации движения, в которых задействованы процессы обнаружения и индикации области в одном из ранее кодированных видеокадров, которая наиболее точно соответствует кодируемому блоку. Кроме того, значения пикселей или выборок могут быть предсказаны путем пространственных механизмов, в которых задействованы процессы обнаружения и индикации взаимосвязи пространственных областей.
Принципы предсказания с использованием информации об изображении на основе предварительно кодированного изображения также могут называться способами взаимного предсказания, временного предсказания и компенсации движения. Принципы предсказания с использованием информации об изображении на основе одного изображения также могут называться способами внутреннего предсказания.
На второй фазе выполняется кодирование ошибки между предсказанным блоком пикселей или выборок и исходным блоком пикселей или выборок. Эта процедура может выполняться путем преобразования разности в значениях пикселей или выборок посредством указанного вида преобразования. Для этого может использоваться дискретное косинусное преобразование (DCT, Discrete Cosine Transform) или различные его варианты. После преобразования разности выполняется квантование и энтропийное кодирование этой преобразованной разности.
Путем изменения точности процесса квантования кодер может управлять балансом между точностью представления пикселей или выборок (другими словами, визуальным качеством изображения) и размером результирующего кодированного видеопредставления (то есть, размером файла или величиной битовой скорости передачи).
Декодер реконструирует выходной видеосигнал путем применения механизма предсказания, сходного с тем, что использовался кодером, для того чтобы сформировать предсказанное представление блоков пикселей или выборок (с помощью информации о движении или пространственной области, созданной кодером и хранимой в сжатом представлении изображения), и декодирования ошибки предсказания (операция, обратная кодированию ошибки предсказания, выполняемая для восстановления квантованного сигнала ошибки предсказания в пространственной области).
После применения процессов предсказания пикселей или выборок и декодирования ошибки декодер объединяет сигналы предсказания и ошибки предсказания (значения пикселей или выборок) для формирования выходного видеокадра.
Декодер (и кодер) может также выполнять дополнительный процесс фильтрации, для того чтобы повысить качество выходного видеосигнала перед выводом его для отображения и/или сохранения в качестве опорного сигнала предсказания для последующих изображений в видеопоследовательности.
В большинстве видеокодеков, включая кодеки, соответствующие стандартам H.264/AVC и HEVC, информация о движении указывается векторами движения, связанными с каждым блоком изображения с компенсацией движения. Каждый из этих векторов движения представляет смещение блока изображения в изображении, подлежащем кодированию (в кодере) или декодированию (в декодере), и исходного блока предсказания в одном из ранее кодированных или декодированных изображений (или кадров).
Согласно H.264/AVC и HEVC и множеству других стандартов сжатия видеосигналов, выполняется разделение изображения на сетку прямоугольников, для каждого из которых с целью внутреннего предсказания указывается подобный блок в одном из опорных изображений. Местоположение блока предсказания кодируется в виде вектора движения, который указывает позицию блока предсказания по отношению к блоку, подлежащему кодированию.
Процесс внутреннего предсказания можно охарактеризовать с использованием одного или более следующих факторов.
Точность представления вектора движения. Точность вектора движения, например, может определяться четвертью пикселя, и значения выборок в позициях частей пикселей определяются с использованием фильтра с конечной импульсной характеристикой (FIR, finite impulse response).
Разделение на блоки для взаимного предсказания. Множество стандартов кодирования, включая H.264/AVC и HEVC, позволяют выбирать размер и форму блока, для которого применяется вектор движения, с целью компенсации движения в кодере, при этом выбранные размер и форма указываются в битовом потоке таким образом, чтобы декодеры могли воспроизвести способ предсказания с компенсацией движения, выполненный в кодере.
Базовый блок для взаимного предсказания во многих стандартах кодирования, включая H.264/AVC, представляет собой макроблок, соответствующий блоку размером 16×16 выборок яркости и соответствующих выборок цветности. В соответствии с H.264/AVC макроблок также может разбиваться на разделы макроблока размером 16×8, 8×16 или 8×8, а раздел 8×8 может также разбиваться на разделы частей макроблока размером 4×4, 4×8 или 8×4, и при этом вектор движения кодируется для каждого раздела. Далее понятие "блок" используется для ссылки на элемент для взаимного предсказания, который может характеризоваться разными уровнями в структуре разделения. Например, в случае применения H.264/AVC далее блок может обозначать макроблок, раздел макроблока или раздел части макроблока, в зависимости от того, какой из этих компонентов используется в качестве элемента для взаимного предсказания.
Количество опорных изображений для взаимного предсказания. Источниками взаимного предсказания являются ранее декодированные изображения. Многие стандарты кодирования, включая H.264/AVC и HEVC, позволяют сохранять множество опорных изображений для взаимного предсказания и выбора опорного изображения на основе макроблока или раздела макроблока.
Предсказание вектора движения. Для эффективного представления векторов движения в битовом потоке эти векторы могут кодироваться по-разному с учетом предсказанных векторов движения, специфичных для блока. В множестве видеокодеков предсказанные векторы движения создаются заранее заданным образом, например, путем вычисления-медианы кодируемых или декодируемых векторов движения смежных блоков. Дифференциальное кодирование векторов движения обычно запрещается при пересечении границ секций.
Многогипотезное предсказание с компенсацией движения. Стандарты H.264/AVC и HEVC позволяют использовать один блок предсказания в секциях Ρ и SP (которые в данном случае называются секциями с одиночным предсказанием) или линейную комбинацию двух блоков предсказания с компенсацией движения для секций с двойным предсказанием, которые также называются В-секциями. В отдельных блоках в В-секциях может использоваться двойное предсказание, одиночное предсказание или внутреннее предсказание, а в отдельных блоках секций Ρ или SP может использоваться одиночное предсказание или внутреннее предсказание. Согласно H.264/AVC и HEVC опорные изображения для изображения с двойным предсказанием не ограничены последующим изображением и предшествующим изображением в порядке вывода, вместо них могут использоваться любые опорные изображения.
Во многих стандартах кодирования, таких как H.264/AVC и HEVC, один список опорных изображений, обозначаемый как список 0 опорных изображений, создается для Р-секций, и два списка опорных изображений, список 0 и список 1, создаются для В-секций. Для В-секций предсказание в прямом направлении может относиться к предсказанию от опорного изображения в списке 0 опорных изображений, а предсказание в обратном направлении может относиться к предсказанию от опорного изображения в списке 1 опорных изображений, хотя опорные изображения для предсказания могут находиться в любом порядке декодирования или вывода по отношению друг к другу или к текущему изображению.
Взвешенное предсказание. Во многих стандартах используется вес предсказания, равный 1, для блоков предсказания между (Р) изображениями и вес 0,5 для блоков предсказания В-изображений (что выражается в усреднении). Во многих стандартах кодирования, таких как H.264/AVC и HEVC, допускается взвешенное предсказание как для Р-секций, так и для В-секций. В случае неявного взвешенного предсказания веса пропорциональны порядковому количеству изображений, в то время как в случае явного взвешенного предсказания веса указываются явным образом.
Во многих видеокодеках остаточные данные предсказания после компенсации движения вначале трансформируются с использованием ядра преобразования (например, DCT), а затем кодируются. Причина этого состоит в том, что часто все еще существует некоторая корреляция между остаточными данными, и преобразование может во многих случаях способствовать уменьшению этой корреляции и обеспечению более эффективного кодирования.
Согласно рабочей версии HEVC каждый PU содержит связанную с ним информацию о предсказании, определяющую вид предсказания, применяемый для пикселей в этом PU (например, информацию о векторе движения для взаимно предсказанных PU и информацию о направленности внутреннего предсказания для внутренне предсказанных PU). Таким же образом, каждый TU связан с информацией, описывающей процесс декодирования ошибки предсказания для выборок в пределах указанного TU (включая, например, информацию о коэффициенте DCT). Обычно на уровне CU сообщается, применяется или нет кодирование ошибки предсказания для каждого CU. В отсутствие остаточных данных ошибки предсказания, связанных с CU, можно предположить, что отсутствуют TU для указанного CU.
В некоторых форматах кодирования и кодеках вводится различие между так называемыми краткосрочными и долгосрочными опорными изображениями. Это различие может оказывать воздействие на некоторые процессоры декодирования, такие как масштабирование вектора движения в режиме временного направления или неявное взвешенное предсказание. Если оба изображения, используемые в режиме временного направления, являются краткосрочными опорными изображениями, то вектор движения, применяемый в процессе предсказания, может масштабироваться в соответствии с разностью РОС между текущим изображением и каждым из опорных изображений. Однако, если по меньшей мере одно опорное изображение в режиме временного направления является долгосрочным опорным изображением, используется масштабирование вектора движения по умолчанию, например, может использоваться масштабирование движения до половинного уровня. Таким же образом, если краткосрочное опорное изображение используется для неявного взвешенного предсказания, то вес предсказания может масштабироваться в соответствии с разностью РОС между РОС текущего изображения и РОС опорного изображения. Однако, если для неявного взвешенного предсказания используется долгосрочное опорное изображение, то может использоваться применяемый по умолчанию вес предсказания, например 0,5, в случае неявного взвешенного предсказания для блоков с двойным предсказанием.
Стандарт H.264/AVC определяет процесс маркировки декодированного опорного изображения для управления потреблением памяти в декодере. Максимальное количество опорных изображений, используемых для взаимного предсказания, обозначаемое М, определяется в наборе параметров последовательности. Если опорное изображение декодировано, оно отмечается как "используемое в качестве опорного". Если в процессе декодирования опорного изображения количество изображений, отмеченных как "используемые в качестве опорных", превышает значение М, то по меньшей мере одно изображение помечается как "неиспользуемое в качестве опорного". Существуют операции двух типов для отметки декодированного опорного изображения: адаптивное управление памятью и подвижное окно. Режим отметки декодированного опорного изображения выбирается в зависимости от изображения. Процедура адаптивного управления памятью позволяет осуществлять явную сигнализацию изображений, помеченных как "неиспользуемые в качестве опорных", а также назначать долговременные индексы кратковременным опорным изображениям. Для адаптивного управления памятью требуется наличие в битовом потоке параметров операций административного управления памятью (ММСО, memory management control operation). Если используется режим функционирования с подвижным окном и имеется Μ изображений, помеченных как "используемые в качестве опорных", то краткосрочное опорное изображение, которое было декодировано первым из набора краткосрочных опорных изображений, помеченных как "используемые в качестве опорных", помечается как "неиспользуемое в качестве опорного". Другими словами, в режиме функционирования с подвижным окном к краткосрочным опорным изображениям применяется операция буферизации по принципу "первым прибыл, первым обслужен" (first-in-first-out). В соответствии с одним из механизмов административного управления памятью, определенных в стандарте H.264/AVC, все опорные изображения, за исключением текущего, должны помечаться как "неиспользуемые в качестве опорных". Изображение мгновенного обновления декодирования (IDR) содержит только секции внутреннего кодирования и вызывает похожую "перезагрузку" опорных изображений.
В рабочей версии 5 стандарта HEVC синтаксические структуры отметки опорного изображения и связанные с ними процессы декодирования были изъяты, а вместо них с той же целью были включены синтаксическая структура набора опорных изображений (RPS, reference picture set) и соответствующий процесс декодирования. Набор опорных изображений, действительный или активный для изображения, содержит все опорные изображения, используемые в качестве опорных для этого изображения, и все опорные изображения, которые сохранили отметку "используемый в качестве опорного" для любых последующих изображений в порядке декодирования. Существует шесть подмножеств, входящих в набор опорных изображений, которые обозначаются следующим образом: RefPicSetStCurr0, RefPicSetStCurr1, RefPicSetStFoll0, RefPicSetStFoll1, RefPicSetLtCurr и RefPicSetLtFoll. Ниже приводится нотация этих шести подмножеств. "Curr" обозначает опорные изображения, которые включены в списки опорных изображений для текущего изображения и, следовательно, могут использоваться в качестве опорных при взаимном предсказании для текущего изображения. "Foll" обозначает опорные изображения, которые не включены в списки опорных изображений для текущего изображения, но могут использоваться в качестве опорных изображений в последующих изображениях в порядке декодирования. "St" обозначает краткосрочные опорные изображения, которые, в целом, могут идентифицироваться с помощью определенного количества младших битов их значения РОС. "Lt" обозначает долгосрочные опорные изображения, которые идентифицируются специальным образом и для которых, в целом, значения РОС относительно текущего изображения различаются в большей степени, чем те, что представлены упомянутым определенным количеством младших битов. "0" обозначает те опорные изображения, значение РОС которых меньше, чем у текущего изображения. "1" обозначает те опорные изображения, значение РОС которых больше, чем у текущего изображения. Совместно подмножества RefPicSetStCurr0, RefPicSetStCurr1, RefPicSetStFoll0 и RefPicSetStFoll1 называются краткосрочным подмножеством набора опорных изображений. Совместно подмножества RefPicSetLtCurr и RefPicSetLtFoll называются долгосрочным подмножеством набора опорных изображений. Набор опорных изображений может указываться в наборе параметров изображения и использоваться в заголовке секции посредством индекса, указывающего на набор опорных изображений. Набор опорных изображений также может указываться в заголовке секции. Долгосрочное подмножество набора опорных изображений обычно указывается только в заголовке секции, в то время как краткосрочное подмножество набора опорных изображений может быть указано в наборе параметров изображения и в заголовке секции. Изображения, включенные в набор опорных изображений, используемый текущей секцией, помечаются как "используемые в качестве опорных", а изображения, не включенные в набор опорных изображений, используемый текущей секцией, помечаются как "неиспользуемые в качестве опорных". Если текущее изображение представляет собой изображение IDR, подмножества RefPicSetStCurr0, RefPicSetStCurr1, RefPicSetStFoll0, RefPicSetStFoll1, RefPicSetLtCurr и RefPicSetLtFoll являются пустыми.
В кодере и/или в декодере может использоваться буфер декодированных изображений (DPB, Decoded Picture Buffer). Имеются две причины, по которым следует выполнять буферизацию декодированных изображений: буферизация выполняется для опорных изображений в процессе взаимного предсказания и для переупорядочения декодированных изображений в порядке вывода. Поскольку стандарт H.264/AVC обеспечивает высокую степень гибкости как для маркировки опорных изображений, так и для переупорядочения вывода, использование отдельных буферов для буферизации опорных изображений и буферизации выходных изображений может привести к растрачиванию ресурсов памяти. Вследствие этого с DPB может быть связан унифицированный процесс буферизации декодированных изображений для опорных изображений и для переупорядочения вывода. Декодированное изображение удаляется из DPB, если оно более не используется в качестве опорного и не требуется для вывода.
Во многих режимах кодирования, определенных стандартами H.264/AVC и HEVC, опорное изображение для взаимного предсказания обозначается индексом, который указывает на список опорных изображений. Индекс кодируется путем кодирования переменной длины, то есть, чем меньше индекс, тем короче становится соответствующий синтаксический элемент.
Обычно высокоэффективные видеокодеки, такие как кодек, определенный в рабочей версии HEVC, применяют дополнительный механизм кодирования/декодирования информации о движении, часто называемый режим/процесс/механизм объединения/слияния, согласно которому вся информация о движении для блока/PU предсказывается и используется без каких-либо изменений/коррекций. Вышеупомянутая информация о движении для PU включает в свой состав следующие компоненты: 1) информацию о том, является ли PU 'блоком PU с одиночным предсказанием, использующим только список list0 опорных изображений1 или 'блоком PU с двойным предсказанием, использующим оба списка, list0 и list1, опорных изображений'; 2) значение вектора движения, соответствующее списку list0 опорных изображений; 3) индекс опорного изображения в списке list0 опорных изображений; 4) значение вектора движения, соответствующее списку list1 опорных изображений; 5) индекс опорного изображения в списке list1 опорных изображений. Таким же образом, предсказание информации о движении выполняется с использованием информации о движении смежных блоков и/или совмещенных блоков во временных опорных изображениях. Обычно список, часто называемый списком объединения, создается путем включения в него подходящих элементов с предсказанием движения, связанных со смежными/совмещенными блоками, при этом сообщается индекс выбранного подходящего элемента с предсказанием движения в списке. Затем информация о движении для выбранного подходящего элемента копируется в информацию о движении текущего PU. Если механизм объединения применяется для всего CU, и сигнал предсказания для CU используется в качестве сигнала реконструкции, то есть остаточные данные предсказания не обрабатываются, то этот тип кодирования/декодирования CU обычно называется режимом пропуска (Skip) или объединением, основанным на режиме Skip. Помимо реализации режима пропуска, механизм объединения применяется также для отдельных PU (не обязательно для всего CU, как в режиме пропуска), и в этом случае остаточные данные предсказания могут использоваться для повышения качества предсказания. Этот тип режима предсказания обычно называется режимом взаимного объединения (inter-merge mode).
Список опорных изображений формируется с помощью двух шагов: вначале генерируется исходный список опорных изображений. Исходный список опорных изображений может быть сгенерирован, например, на основе значений frame_num, РОС, temporal_id и/или набора опорных изображений. На втором шаге может быть переупорядочен начальный список опорных изображений с использованием команд переупорядочения списка опорных изображений (RPLR, reference picture list reordering), содержащихся в заголовках секций. Команды RPLR указывают изображения, которые располагаются в начале соответствующего списка опорных изображений. Если используется набор опорных изображений, список 0 опорных изображений, может быть инициализирован таким образом, чтобы в начале включался набор RefPicSetStCurr0, затем RefPicSetStCurr1, а затем набор RefPicSetLtCurr. Список 1 опорных изображений, может быть инициализирован таким образом, чтобы в начале включался набор RefPicSetStCurr1, а затем набор RefPicSetStCurr0. Исходные списки опорных изображений могут модифицироваться с помощью синтаксической структуры модификации списка опорных изображений, при этом изображения в исходных списках опорных изображений могут идентифицироваться посредством входного индекса, указывающего на список.
Список объединения может генерироваться на основе списка 0 опорных изображений и/или списка 1 опорных изображений, например, с использованием синтаксической структуры комбинации списков опорных изображений, включенной в синтаксис заголовка секции. Это может быть синтаксическая структура комбинации списков опорных изображений, создаваемая в битовом потоке кодером, декодируемая из битового потока декодером и указывающая содержимое списка объединения. Синтаксическая структура может указывать на то, что список 0 опорных изображений и список 1 опорных изображений объединяются в виде дополнительной комбинации списков опорных изображений, используемой для блоков предсказания в процессе однонаправленного предсказания. В синтаксическую структуру может входить флаг, определенное значение которого указывает на то, что список 0 опорных изображений и список 1 опорных изображений идентичны, и, таким образом, список 0 опорных изображений используется в качестве комбинации списков опорных изображений. В состав синтаксической структуры может входить список записей, каждая из которых указывает список опорных изображений (список 0 или список 1), и опорный индекс на указанный список, при этом запись определяет опорное изображение, подлежащее включению в список объединения.
Согласно стандарту H.264/AVC синтаксический элемент frame_num используется для различных процессов декодирования, связанных с множеством опорных изображений. В соответствии со стандартом H.264/AVC для изображений IDR значение frame_num должно равняться 0. Значение frame_num для изображений, отличных от IDR, должно быть равно значению frame_num предыдущего опорного изображения в порядке декодирования, увеличенному на 1 (по арифметическому модулю, то есть значение frame_num обнуляется после достижения максимальной величины).
В соответствии с H.264/AVC и HEVC значение порядкового номера изображения (РОС, picture order count) вычисляется для каждого изображения и не уменьшается с наращиванием позиции изображения в порядке вывода по отношению к предшествующему изображению IDR или изображению, содержащему команду административного управления памятью, помечающую все изображения как "неиспользуемые в качестве опорных". Таким образом, значение РОС определяет порядок вывода изображений. Оно также используется в процессе декодирования с целью неявного масштабирования векторов движения в режиме временного направления секторов двойного предсказания, для неявно полученных весов при взвешенном предсказании и для инициализации списка опорных изображений для В-секций. Кроме того, значение РОС используется в процессе верификации соответствия порядка вывода.
Согласно MVC, зависимости ракурсов указываются в дополнении MVC, относящемся к набору параметров последовательности (SPS, sequence parameter set). Зависимости для изображений привязки и изображений, не являющихся изображениями привязки, указываются независимо. Таким образом, изображения привязки и изображения, не являющиеся изображениями привязки, могут характеризоваться различными зависимостями ракурсов. Однако для набора изображений, который ссылается на тот же SPS, все изображения привязки и все изображения, не являющиеся изображениями привязки, характеризуются одинаковой зависимостью ракурсов. Кроме того, согласно дополнению к MVC, относящемуся к SPS, сигнализация о зависимых ракурсах осуществляется отдельно для ракурсов, используемых в качестве опорных изображений в списке 0 опорных изображений, и для ракурсов, используемых в качестве опорных изображений в списке 1 опорных изображений.
В MVC вводится значение "inter_view_flag" в заголовке блока уровня абстракции сети (NAL), которое указывает, можно или нет использовать текущее изображение с целью межракурсного предсказания для изображений в других ракурсах. Изображения, отличные от опорных (для которых значение "nal_ref_idc" равно 0), но используемые в качестве опорных при межракурсном предсказании (то есть, те, для которых значение "inter_view_flag" равно 1), называются "только межракурсными" опорными изображениями. Изображения, для которых значение "nal_ref_idc" больше 0 и которые используются в качестве опорных при межракурсном предсказании (то есть, те, для которых значение "inter_view_flag" равно 1), называются межракурсными опорными изображениями.
Согласно MVC, межракурсное предсказание поддерживается предсказанием текстуры (то есть, значения реконструированных выборок могут использоваться для межракурсного предсказания), и только компоненты декодированного ракурса того же временного выходного отсчета (то есть, того же блока доступа), что и компонент текущего ракурса, используются для межракурсного предсказания. Факт использования реконструированных выборок в процессе межракурсного предсказания также означает, что для MVC применяется многоцикловое декодирование. Другими словами, процессы компенсации движения и реконструкции компонентов декодированных ракурсов выполняются для каждого ракурса.
Процесс формирования списков опорных изображений в MVC в целом описывается следующим образом. Вначале с помощью описываемых ниже двух операций генерируется исходный список опорных изображений: i) формируется исходный список опорных изображений, включающий все краткосрочные и долгосрочные опорные изображения, помеченные как "используемые в качестве опорных" и принадлежащие к тому же ракурсу, что и текущая секция в соответствии с H.264/AVC. Для простоты эти краткосрочные и долгосрочные опорные изображения называются внутриракурсными опорными изображениями; ii) затем для формирования исходного списка опорных изображений добавляются межракурсные опорные изображения и "только межракурсные" опорные изображения после внутриракурсных опорных изображений в соответствии с порядком ракурсовой зависимости, указанным в активном SPS и с помощью значения "inter_view_flag".
После генерации начального списка опорных изображений в процессе MVC этот список может быть переупорядочен посредством команд переупорядочения списка опорных изображений (RPLR), которые могут быть включены в заголовок секции. С помощью процесса RPLR можно переупорядочить внутриракурсные опорные изображения, межракурсные опорные изображения и "только межракурсные" опорные изображения таким образом, чтобы их порядок отличался от порядка изображений в начальном списке. Как начальный, так и окончательный список после переупорядочения должен содержать только определенное количество записей, указанных синтаксическим элементом в заголовке секции или наборе параметров изображения, на который ссылается секция.
Под "ракурсом текстуры" понимается изображение, которое представляет обычный видеоконтент, например, зафиксированный с использованием обыкновенной камеры и подходящий для визуализации на дисплее.
Под видеосигналом с усовершенствованным кодированием по глубине понимается видеосигнал текстуры с одним или более ракурсами, связанными с видеосигналом кодирования по глубине, имеющим один или более ракурсов глубины. Для представления видеосигнала с усовершенствованным кодированием по глубине может использоваться ряд подходов, включая применение видеосигнала плюс информации о глубине (V+D, video plus depth), многоракурсного видеосигнала плюс информации о глубине (MVD, multiview video plus depth) и многоуровневого видеосигнала глубины (LDV, layered depth video). В случае представления в формате видеосигнала с информацией о глубине (V+D) один ракурс текстуры и соответствующий ракурс глубины представляются в виде последовательности изображения текстуры и изображения глубины, соответственно. В представлении MVD содержится ряд ракурсов текстуры и соответствующих ракурсов глубины. В представлении LDV текстура и глубина центрального ракурса представлены обычным образом, в то время как текстура и глубина других ракурсов представлены частично и охватывают только незакрытые области, требуемые для корректного синтеза промежуточных ракурсов.
Видеосигнал с усовершенствованным кодированием по глубине может кодироваться таким образом, чтобы текстура и глубина кодировались независимо друг от друга. Например, ракурсы текстуры могут кодироваться в виде одного битового потока MVC, а ракурсы глубины - в виде другого битового потока MVC. В альтернативном варианте видеосигнал с усовершенствованным кодированием по глубине может кодироваться таким образом, чтобы текстура и глубина кодировались совместно. Если для представления видеосигнала с усовершенствованным кодированием по глубине применяются совместно кодируемые ракурсы текстуры и глубины, некоторые декодируемые выборки изображения текстуры или элементы данных для декодирования изображения текстуры предсказываются или выводятся на основе некоторых декодированных выборок изображения глубины или элементов данных, получаемых в процессе декодирования изображения глубины. Альтернативно или дополнительно, некоторые декодированные выборки изображения глубины или элементы данных для декодирования изображения глубины предсказываются или выводятся на основе некоторых декодированных выборок изображения текстуры или элементов данных, получаемых в процессе декодирования изображения текстуры.
В случае совместного кодирования текстуры и глубины для видеосигнала с усовершенствованным кодированием по глубине может применяться синтез ракурсов в цикле кодека, благодаря чему осуществляется предсказание синтеза ракурса (VSP). В VSP сигнал предсказания, такой как опорное изображение VSP, формируется с помощью DIBR или алгоритма синтеза ракурса, использующего информацию текстуры и глубины. Например, синтезированное изображение (то есть, опорное изображение VSP) может включаться в список опорных изображений таким же образом, как это делается для межракурсных опорных изображений и "только межракурсных" опорных изображений. В альтернативном варианте или дополнительно, для определенных блоков предсказания кодером может определяться специфический режим предсказания VSP, указываемый кодером в битовом потоке и используемый декодером на основе информации, полученной в битовом потоке.
В случае MVC, как при взаимном предсказании, так и при межракурсном предсказании используется по существу одинаковый процесс предсказания с компенсацией движения. Межракурсные опорные изображения и "только межракурсные" опорные изображения в сущности обрабатываются как долгосрочные опорные изображения в различных процессах предсказания. Таким же образом, предсказание синтеза ракурса может быть реализовано так, чтобы использовался по существу тот же процесс предсказания с компенсацией движения, что и для взаимного предсказания и межракурсного предсказания. Для отличия от предсказания с компенсацией движения, выполняемого только в пределах одного ракурса без какого-либо использования VSP, процесс предсказания с компенсацией движения, который включает и способен гибко выбирать смешанное взаимное предсказание, взаимное предсказание и/или предсказание синтеза ракурса, в этом описании называется предсказанием с компенсацией движения в смешанном направлении. Поскольку списки опорных изображений в режимах MVC и MVD могут содержать опорные изображения нескольких типов, то есть взаимные опорные изображения (также называемые внутриракурсными опорными изображениями), межракурсные опорные изображения, "только межракурсные" опорные изображения и опорные изображения VSP, термин "направление предсказания" определяется для указания на использование внутриракурсных опорных изображений (временное предсказание), межракурсного предсказания или VSP. Например, кодер может выбрать для конкретного блока опорный индекс, который указывает на межракурсное опорное изображение, при этом направление предсказания блока является межракурсным.
В процессе предсказания вектора движения (MV), определенного в H.264/AVC/MVC, используется корреляция, имеющаяся в соседних блоках одного изображения (пространственная корреляция) или в ранее кодированном изображении (временная корреляция). Векторы движения (MV) текущего кодируемого блока (cb) оцениваются с помощью процесса оценки и компенсации движения, кодируются посредством дифференциальной импульсно-кодовой модуляции (DPCM, differential pulse code modulation) и передаются в виде остаточных данных или разности векторов движения (MVd) между предсказанием/предсказателем (MVp) вектора движения и фактическим MV, то есть в следующем виде: MVd(x, у)=MV(x, у) - MVp(x, у). Горизонтальный остаточный компонент, MVd(x)=MV(x) - MVp(x), может кодироваться и передаваться в кодовом слове, отдельном от вертикального остаточного компонента: MVd(y)=MV(y) - MVp(y). Согласно H.264/AVC компоненты MVd(x) и MVd(y) вектора движения для Р-макроблоков или разделов макроблока (блок cb, см. фиг. 13) кодируются дифференциально с использованием либо медианного, либо направленного предсказания, начиная от соседних в пространственном измерении блоков, при этом соседний блок может представлять собой макроблок, раздел макроблока или раздел части макроблока. На фиг. 13 показана маркировка соседних в пространстве блоков для текущего блока cb. Согласно H.264/AVC блоки от А до D могут использоваться как источники предсказания вектора движения для различных режимов предсказания. В других способах кодирования в качестве источников предсказания вектора движения могут использоваться другие соседние блоки, например блок Е.
Направленное предсказание вектора движения используется для определенных форм разделов макроблока, а именно: 8×16 и 16×8, если опорный индекс блока cb такой же, что и в конкретном соседнем в пространстве блоке, определенном формой раздела текущего макроблока и его местоположением в текущем макроблоке. Если используется направленное предсказание вектора движения, то вектор движения определенного блока выбирается в качестве предсказателя вектора движения для текущего раздела макроблока.
На фиг. 13 показано местоположение соседних блоков А-С по отношению к текущему блоку cb. В случае медианного предсказания вектора движения, определенного в H.264/AVC и унаследованного также в MVC, опорные индексы соседних блоков, расположенные непосредственно выше (блок В), выше по диагонали и правее (блок С) и непосредственно слева (блок А) от текущего блока cb, первыми сравниваются с опорным индексом блока cb. Если один и только один из опорных индексов блоков А, В и С равен опорному индексу блока cb, то предсказатель вектора движения для cb равен вектору движения того блока А, В или С, опорный индекс которого равен опорному индексу блока cb. В противном случае предсказатель вектора движения для cb вычисляется как медиана векторов движения блоков А, В и С, вне зависимости от их значений опорных индексов. На фиг. 7а показано, каким образом блоки А, В и С размещены в пространстве относительно текущего кодируемого блока (cb).
Другими словами, процесс медианного предсказания вектора движения для получения MVp определен в H.264/AVC следующим образом:
1. Если опорный индекс только одного из соседних в пространстве блоков (А, В, С) совпадает с опорным индексом текущего блока (cb):
MVp=mvN, где N представляет собой один из блоков (А, В, С);
2. Если опорный индекс нескольких из соседних блоков (А, В, С) совпадает с опорным индексом текущего блока (cb), или ни один из этих опорных индексов не равен опорному индексу текущего блока:
MVp=median {mvA, mvB, mvC},
где mvA, mvB, mvC представляют собой векторы движения (без опорных индексов) соседних в пространстве блоков.
Согласно H.264/AVC, векторы движения и опорные индексы для блоков А, В, С, соседних по отношению к текущему блоку cb, определяются следующим образом на основе их доступности. Если правый верхний блок (С) недоступен, например, находится в секции, отличной от той, в которой находится cb, или за пределами границ изображения, местоположение в правой верхней части (С) заменяется верхним левым блоком (D). Если недоступен один из блоков А, В или С, например, он находится в секции, отличной от той, в которой находится cb, или за пределами границ изображения, или кодирован в режиме внутреннего кодирования, то вектор движения mvA, mvB или mvC, соответственно, равен 0, и опорный индекс для блока А, В или С, соответственно, равен -1 для предсказания вектора движения и предсказания с компенсацией движения в смешанном направлении. Помимо режимов макроблоков с компенсацией движения, для которых кодирован дифференциальный вектор движения, Р-макроблок может также кодироваться с использованием так называемого режима типа P_Skip в соответствии со стандартом H.264/AVC. Для этого типа кодирования в битовом потоке не кодируется дифференциальный вектор движения, опорный индекс или квантованный сигнал ошибки предсказания. Опорному изображению макроблока, кодированному с использованием типа P_Skip, назначается индекс 0 в списке 0 опорных изображений. Вектор движения, используемый для реконструкции макроблока P_Skip, рассчитывается с использованием медианного предсказания вектора движения для макроблока, без необходимости добавления какого-либо дифференциального вектора движения. Режим P_Skip может быть удобен для эффективного сжатия, в частности, в зонах, в которых области движения характеризуются плавными переходами. В В-секциях, определенных в H.264/AVC, поддерживаются четыре различных вида взаимного предсказания: одиночное предсказание на основе списка 0 опорных изображений, однонаправленное предсказание на основе списка 1 опорных изображений, двойное предсказание, направленное предсказание и предсказание типа B_skip. Тип взаимного предсказания может выбираться отдельно для каждого раздела макроблока. В В-секциях способ разделения на макроблоки подобен способу, применяемому в Р-секциях. Для разделения макроблока с двойным предсказанием сигнал предсказания формируется посредством взвешенного усреднения сигналов предсказания списка 0 и списка 1 с компенсацией движения. Опорные индексы, разностные значения векторов движения, а также квантованный сигнал ошибки предсказания могут быть кодированы для разделов В-макроблока, в которых используется одиночное и двойное предсказание.
Два режима направления, временное и пространственное, включены в стандарт H.264/AVC, причем один из них может выбираться в заголовке секции для использования в этой секции. В режиме временного направления опорный индекс для списка 1 опорных изображений обнуляется, а опорный индекс для списка 0 опорных изображений указывает на опорное изображение, которое используется в совмещенном блоке (по сравнению с cb) опорного изображения с индексом 0 в списке 1 опорных изображений, если это опорное изображение доступно, или обнуляется, если это опорное изображение недоступно. Предсказатель вектора движения для cb, в сущности, вычисляется с учетом информации о движении в пределах совмещенного блока опорного изображения с индексом 0 в списке 1 опорных изображений. Предсказатели векторов движения для блока временного направления выводятся путем масштабирования вектора движения на основе совмещенного блока, при этом вес масштабирования пропорционален разностям порядковых значений текущего изображения и опорных изображений, связанных с выведенными опорными индексами в списках 0 и 1, и путем выбора знака для предсказателя вектора движения в зависимости от того, какой список опорных изображений используется. На фиг. 7b показан пример блоков, совмещенных с текущим кодируемым блоком (cb), для MVP в режиме временного направления согласно стандарту H.264/AVC. Использование режима временного направления не поддерживается в каком-либо из существующих профилей кодирования для MVC, хотя синтаксис стандарта поддерживает также и режим временного направления.
В режиме пространственного направления согласно стандарту H.264/AVC информация о движении пространственно смежных блоков используется таким же образом, как и для Р-блоков. Процесс предсказания вектора движения в режиме пространственного направления можно разделить на три этапа: определение опорного индекса, определение одинарного или двойного способа предсказания и предсказание вектора движения. На первом шаге из каждого списка (0 и 1) опорных изображений смежных блоков А, В и С выбирается опорное изображение с минимальным неотрицательным значением опорного индекса (то есть, не внутренний блок). Если неотрицательное значение опорного индекса существует в списке 0 опорных изображений смежных блоков А, В и С, а также неотрицательное значение опорного индекса отсутствует в списке 1 опорных изображений смежных блоков А, В и С, то выбирается опорный индекс 0 для обоих списков опорных изображений.
Использование одинарного или двойного предсказания для режима пространственного направления H.264/AVC определяется следующим образом. Если на шаге определения опорного индекса найден минимальный неотрицательный опорный индекс для обоих списков опорных изображений, то используется двойное предсказание. Если на шаге определения опорного индекса минимальный неотрицательный опорный индекс найден только для одного из списков опорных изображений, то соответственно используется одиночное предсказание на основе либо списка 0 опорных изображений, либо списка 1 опорных изображений. В процессе предсказания вектора движения в режиме пространственного направления H.264/AVC проверяются определенные условия, такие как наличие отрицательного опорного индекса, найденного на первом шаге, и при выполнении этого условия определяется нулевой вектор движения. В противном случае предсказатель вектора движения выводится подобно предсказателю вектора движения Р-блоков, использующих векторы движения пространственно смежных блоков А, В и С.
Для блока направленного режима (direct) разности векторов движения или опорные индексы отсутствуют в битовом потоке, в то время как квантованный сигнал ошибки предсказания может быть кодирован и, таким образом, присутствовать в битовом потоке. Режим макроблока B_skip похож на направленный режим, однако сигнал ошибки предсказания не кодируется и не включается в битовый поток.
Во многих видеокодерах для нахождения оптимальных режимов кодирования с учетом искажения в зависимости от скорости передачи (например, требуемого режима макроблока и связанных векторов движения) используется функция оценки Лагранжа. Функция оценки этого типа использует весовой коэффициент или λ для связывания точного или ожидаемого искажения изображения, вносимого в результате применения способов кодирования с потерей данных, и точного или ожидаемого объема информации, требуемого для представления значений пикселей/выборок в области изображения. Функция оценки Лагранжа может быть представлена с помощью следующей формулы:
С=D+AR,
где С представляет собой величину оценки Лагранжа, которая должна быть минимизирована, D - искажение изображения (другими словами, среднеквадратическая ошибка между значениями пикселей/выборок в исходном и кодированном блоках изображения) при использовании режима и векторов движения, рассматриваемых в настоящий момент, λ - коэффициент Лагранжа, и R - количество битов, необходимых для представления требуемых данных с целью реконструкции блока изображения в декодере (включая объем данных, требуемых для представления подходящих векторов движения).
В упомянутом выше дополнении к стандарту Н.264, касающемуся многоракурсного кодирования видеосигнала (MVC), описываются средства реализации многоракурсной функциональности в декодере, благодаря чему появляется возможность разработки трехмерных (3D) многоракурсных применений. Далее для лучшего понимания вариантов осуществления настоящего изобретения кратко описываются некоторые аспекты трехмерных многоракурсных применений и тесно связанные с ними концепции формирования информации о глубине и диспаратности.
Стереоскопический видеоконтент включает в свой состав пары смещенных изображений, которые отображаются отдельно для левого и правого глаза. Эти смещенные изображения фиксируются специальным устройством стереоскопических камер, при этом предполагается, что камеры находятся на конкретном стереоскопическом базисном расстоянии друг от друга.
На фиг. 1 показана упрощенная двумерная модель такого устройства стереоскопических камер. На фиг. 1 С1 и С2 обозначают отдельные камеры устройства стереоскопических камер, а более конкретно - центральное местоположение камер, b обозначает расстояние между центрами двух камер (то есть, стереоскопический базис), f обозначает фокусное расстояние камер, а X - снимаемый объект реальной трехмерной сцены. Объект X реального окружения проецируется на различные местоположения, соответственно х1 и х2, в изображениях, снимаемых камерами С1 и С2. Расстояние по горизонтали между х1 и х2 в абсолютных координатах изображения называется диспаратностью. Изображения, снимаемые устройством стереоскопических камер, называются стереоскопическими изображениями, а диспаратность, имеющаяся между этими изображениями, создает или увеличивает иллюзию глубины. Для того чтобы изображения были видны для левого и правого глаза отдельно, зритель обычно должен надевать специальные 3D-очки. Адаптация диспаратности является ключевой функцией для настройки стереоскопического видеоконтента с целью удобного просмотра на различных дисплеях.
Однако адаптация диспаратности не является простым процессом. Она требует либо наличия дополнительных ракурсов камеры с различным базисным расстоянием (то есть, величина b должна быть переменной), либо визуализации виртуальных ракурсов камеры, отсутствующих в реальном окружении. На фиг. 2 показана упрощенная модель такого устройства многоракурсных камер, подходящего для этого решения. Это устройство способно предоставлять стереоскопический видеоконтент, зафиксированный с помощью нескольких дискретных значений для стереоскопической базы, и, таким образом, позволяет стереоскопическому дисплею выбирать пару камер, подходящих для условий обзора.
Более усовершенствованный подход для получения 3D-изображений состоит в реализации многоракурсного автостереоскопического дисплея (ASD, autostereoscopic display), не требующего специальных очков. ASD излучает изображения нескольких ракурсов одновременно, однако излучение локализовано в пространстве таким образом, чтобы наблюдатель с определенной позиции обзора видел только стереопару, как показано на фиг. 3, при этом лодка видна посередине вида при просмотре из крайней правой точки обзора. Кроме того, наблюдатель может видеть другую стереопару с другой точки обзора, например, как показано на фиг. 3, лодка видна на правой границе вида при просмотре с крайней левой точки обзора. Таким образом, при просмотре поддерживается параллакс движения, если последовательные ракурсы представляют собой стереопары, которые размещены должным образом. Технологии ASD позволяют одновременно показывать, например, 52 или более различных изображений, причем из конкретной точки обзора видна только стереопара. Это позволяет поддерживать многопользовательское трехмерное видеопредставление без использования очков, например, в среде жилого помещения.
Для описанных выше стереоскопических и ASD-применений требуется, чтобы на дисплее было доступно многоракурсное видеоизображение. Дополнение MVC к стандарту H.264/AVC кодирования видеосигналов позволяет реализовать многоракурсную функциональность на стороне декодера. Базовый ракурс битовых потоков MVC может декодироваться с помощью декодера H.264/AVC, который облегчает включение стереоскопического и многоракурсного контента в существующие услуги. MVC позволяет выполнять межракурсное предсказание, в результате чего можно добиться существенной экономии битового потока по сравнению с независимым кодированием всех ракурсов, в зависимости от способа корреляции смежных ракурсов. Однако скорость передачи кодированного сигнала в формате MVC пропорциональна количеству ракурсов. В предположении, например, что для ASD может потребоваться 52 входных ракурса, общий объем битового потока для такого количества ракурсов может создать проблемы с точки зрения доступной полосы пропускания.
В результате для таких многоракурсных применений было найдено более удобное решение, заключающееся в использовании ограниченного количества входных ракурсов, например монохромное изображение или стереоскопическое изображение совместно с некоторыми дополнительными данными, и визуализации (то есть синтеза) всех требуемых ракурсов локально на стороне декодера. В сравнении с различными технологиями для визуализации ракурсов, способ визуализации на основе глубины изображения (DIBR, depth image-based rendering) показал свою конкурентоспособность. На фиг. 4 показана упрощенная модель системы 3DV, основанной на DIBR. На вход кодека трехмерного видеосигнала поступают стереоскопический видеосигнал и соответствующая информация о глубине со стереоскопическим базисом b0. Затем кодек трехмерного видеосигнала синтезирует ряд виртуальных ракурсов между двумя входными ракурсами с базисной линией (b1<b0). Алгоритмы DIBR также позволяют экстраполировать ракурсы, расположенные вне двух входных ракурсов, а не только между ними. Подобным образом, алгоритмы DIBR позволяют выполнять синтез на основе одного ракурса текстуры и соответствующего ракурса глубины. Однако, для того чтобы можно было выполнить многоракурсную визуализацию на основе DIBR, данные текстуры должны быть доступны на стороне декодера совместно с соответствующими данными о глубине.
В такой системе 3DV информация о глубине генерируется на стороне кодера в формате изображений глубины (также называемых картами глубины) для каждого видеокадра. Карта глубины представляет собой изображение с информацией о глубине для пикселя. Каждая выборка в карте глубины представляет расстояние соответствующей выборки текстуры от плоскости, в которой расположена камера. Другими словами, если ось z является осью съемки камер (и следовательно, она ортогональна к плоскости, в которой расположены камеры), отсчет в карте глубины представляет значение по оси z.
Информация о глубине может быть получена различными способами. Например, глубина трехмерной сцены может вычисляться на основе диспаратности, зарегистрированной камерами, выполняющими съемку. При выполнение алгоритма оценки глубины используется стереоскопический ракурс в качестве входного ракурса и вычисляется локальная диспаратность между двумя сдвинутыми изображениями ракурса. Каждое изображение обрабатывается по пикселям в перекрывающихся блоках, и для каждого блока пикселей выполняется поиск, локализованный в горизонтальном направлении, совпадающего блока в смещенном изображении. После вычисления диспаратности по пикселям соответствующее значение ζ глубины рассчитывается по формуле (1):

где f представляет собой фокусное расстояние камеры, a b - базисное расстояние между камерами, показанное на фиг. 1. Кроме того, D относится к диспаратности, наблюдаемой между двумя камерами, и смещение Δα камеры отражает возможное горизонтальное отклонение оптических центров двух камер. Однако, поскольку алгоритм основан на совпадении блоков, качество оценки глубины по диспаратности зависит от содержимого и очень часто надлежащий уровень точности не обеспечивается. Например, отсутствует простое решение по оценке глубины для фрагментов изображения очень ровных областей с отсутствием текстуры или с высоким уровнем шума. В альтернативном варианте или в дополнение к вышеописанному способу оценки глубины стереоскопического ракурса, значение глубины может выводиться с использованием принципа времени пролета (TOF, time-of-flight). На фиг. 5 и фиг. 6 показан пример системы оценки глубины на основе принципа TOF. Для освещения сцены камера оснащена источником света, например инфракрасным излучателем. Такой осветитель выполнен для генерации электромагнитного излучения, модулированного по яркости, с частотным диапазоном 10-100 МГц, для которого обычно требуется использование светодиодов или лазерных диодов. Инфракрасное излучение обычно требуется, для того чтобы освещение было незаметным. Свет, отраженный от объектов, расположенных в сцене, обнаруживается датчиком изображения, который модулируется синхронно на той же частоте, что и излучатель. Датчик изображения оснащен оптическими элементами, такими как линза, поглощающая отраженный свет, и оптический полосовой фильтр, служащий для пропускания только светового потока с той же длиной волны, на которую настроен излучатель, что упрощает подавление фонового освещения. Датчик изображения измеряет для каждого пикселя время, в течение которого световой поток перемещается от излучателя к объекту и обратно. Расстояние до объекта представляется в виде фазового сдвига в процессе модуляции освещения, который может быть определен на основе данных, выбранных одновременно для каждого пикселя в сцене.
В отличие от оценки глубины стереоскопического ракурса точность оценки глубины на основе TOF по большей части зависит от контента. Например, на нее не слишком влияет отсутствие текстурного представления в контенте. Однако доступные в настоящее время камеры TOF оснащены датчиками с низким разрешением по пикселям, и на оценку глубины в значительной степени влияет случайный и систематический шум.
Карты диспаратности или параллакса, такие как карты параллакса, определенные в международном стандарте 23002-3 ISO/IEC, могут обрабатываться таким же образом, как и карты глубины. Глубина и диспаратность строго соответствуют друг другу, и значения каждой этих величин может вычисляться по формуле, в которую входит значение другой величины.
В описанных выше системах 3DV, таких как системы 3DV на основе DIBR, обычно используется предсказание с компенсацией движения в смешанном направлении, включая межракурсное предсказание и/или предсказание синтеза ракурса. Однако способ предсказания вектора движения, приведенный в H.264/AVC/MVC, может быть условно оптимальным для систем кодирования видеосигнала, использующих межракурсное предсказание и/или предсказание синтеза ракурса (VSP).
Далее приводится набор новых механизмов MVP, основанных на использовании информации о глубине и диспаратности (Di), связанной с кодированными данными текстуры, и предназначенных для улучшения способа предсказания вектора движения (MVP, motion vector prediction) с целью многоракурсного кодирования (MVC), кодирования видеосигнала по глубине, многоракурсного кодирования+кодирования по глубине (MVD, multiview+depth) и/или многоракурсного кодирования с цикличным синтезом ракурсов (MVC-VSP, multi-view with in-loop view synthesis).
На фиг. 14 показана связь блоков d(cb), d(S), d(T) и d(U) диспаратности/глубины с блоками cb, S, Τ и U текстуры, соответственно. В различных вариантах осуществления настоящего изобретения блок глубины/диспаратности для блока или связанный с блоком текстуры размещен совместно с таким блоком. Другими словами, пространственное расположение блока глубины/диспаратности по отношению к кадру глубины/диспаратности, в котором он размещен, совпадает с пространственным расположением соответствующего блока текстуры по отношению к кадру глубины/диспаратности, в котором он размещен. В различных вариантах осуществления настоящего изобретения пространственная протяженность, то есть количество выборок, может различаться в кадре глубины/диспаратности по сравнению с кадром яркостной текстуры. Для получения информации о связи между блоком глубины/диспаратности и блоком текстуры местоположение блоков может быть нормализовано, так как если бы оба кадра имели одинаковую пространственную протяженность, например, с помощью масштабирования координат блока и/или повторной дискретизации одного или обоих кадров. В целом, связь блока глубины/диспаратности и соответствующего блока текстуры может также определяться на основе критерия, отличного от критерия пространственного совмещения.
Предполагается, что информация о глубине или диспаратности (Di) для текущего блока (cb) или для предшествующих кодированных/декодированных данных текстуры становится доступной посредством декодированная кодированной информации о глубине или диспаратности либо может оцениваться на стороне декодера перед декодированием текущего блока текстуры, благодаря чему возможно использовать эту информацию в процессе MVP.
Фрагмент изображения или двухмерный фрагмент, или двухмерный фрагмент изображения определяется как подмножество изображения. Фрагмент изображения обычно, но не обязательно, имеет форму прямоугольника. Фрагмент видеосигнала определяется как подмножество видеосигнала. Фрагмент видеосигнала может представлять собой временной фрагмент видеосигнала, состоящий из подмножества кадров изображений одноракурсной видеопоследовательности. Фрагмент видеосигнала может представлять собой пространственно-временной фрагмент видеосигнала, состоящий из фрагментов изображения в подмножестве кадров или изображений одноракурсной видеопоследовательности. Фрагмент видеосигнала может представлять собой многоракурсный фрагмент видеосигнала, состоящий из кадров/изображений или фрагментов изображений из различных ракурсов одного блока доступа (то есть, момента выборки) многоракурсной видеопоследовательности. Возможны также другие комбинации для формирования фрагмента видеосигнала, такого как пространственно-временной многоракурсный фрагмент видеосигнала.
На фиг. 15 показано текущее кодируемое/декодируемое изображение данных текстуры, текущий кодируемый блок cb данных текстуры и фрагмент изображения (показанный серым цветом) данных текстуры, который в пространстве смежен или размещен в непосредственной близости от блока cb и который, как предполагается, должен быть доступен (декодирован) перед кодирование/декодированием блока cb. Двухмерные блоки данных текстуры, называемые "смежными блоками" (белые блоки А, В, С, D и F), в отношении которых предполагается, что они должны быть доступны (декодированы) перед кодированием/декодированием cb, могут использоваться процессом MVP для кодирования/декодирования блока cb текстуры. Следует отметить, что блоки А, В, С, D и F показаны на фиг. 15 только в качестве примеров выбора смежных блоков, вместо которых, дополнительно и/или альтернативно, могут быть выбраны другие блоки.
В математике евклидов вектор может быть представлен линейным отрезком определенного направления, соединяющим начальную и оконечную точки. Информация о движении (например, горизонтальные и вертикальные компоненты mv_x и mv_y вектора движения и опорный индекс) обычно применяется к позиции блока, для которой информация о движении включается в битовый поток. Например, информация о векторе движения для блока cb, MV(cb) в битовом потоке обычно применяется для получения блока предсказания путем установки начальной точки вектора движения в пространственном местоположении cb. Этот блок предсказания обозначается (cb, MV(cb)). Если информация о движении для блока Μ применяется для предсказания с компенсацией движения в местоположении блока Ν, блок предсказания обозначается как (Ν, MV(M)).
На фиг. 16 показана концепция смежных блоков данных текстуры, которая распространяется на применения, связанные с видеосигналом и многоракурсным видеосигналом. Текущее кодируемое изображение данных текстуры блока cb показано в виде блока, окрашенного в серый цвет, при этом предполагается, что фрагменты смежного изображения (показанные в виде светло-серых фрагментов нескольких изображений данных текстуры) должны быть доступны (в кодированном/декодированном ракурсе) перед кодированием блока cb. Следует отметить, что фрагменты смежного изображения могут принадлежать ранее кодированным/декодированным изображениям того же ракурса (двухмерное кодирование видеосигнала) или ранее кодированным изображениям других ракурсов (многоракурсное кодирование видеосигнала). Соответствие между cb и смежными блоками может устанавливаться различными способами, несколько примеров которых описываются ниже. Блоки А и В текстуры пространственно прилегают к cb в текущем кодируемом изображении, блок D текстуры расположен в ранее кодированном/декодированном изображении в тех же пространственных координатах (х, у), что и cb, в то время как блоки Е, F и G, расположенные в других изображениях, связаны с блоками А, В, С посредством их информации MV(A), MV(B) и MV(C) о движении, соответственно. Другими словами блок Ε может быть равен (cb, MV(C)), блок F может быть равен (cb, MV(B)), и блок G может быть равен (cb, MV(A)). В других вариантах осуществления настоящего изобретения блок E может быть равен (С, MV(С)), блок F может быть равен (В, MV(B)), и блок G может быть равен (A, MV(A)).
Во многих вариантах осуществления настоящего изобретения порядок кодирования компонентов ракурса текстуры и глубины с использованием блока доступа выбирается таким образом, чтобы при любом порядке компоненты базового ракурса текстуры и глубины кодировались вначале. Затем кодируется компонент ракурса глубины, отличного от базового, перед компонентом ракурса текстуры того же отличного от базового ракурса. Компоненты ракурса глубины кодируются в соответствующем порядке межракурсной зависимости, так же как и компоненты ракурса текстуры. Например, могут использоваться три ракурса текстуры и глубины (Т0, Т1, Т2, D0, D1, D2), при этом межракурсный порядок зависимости определен как 0, 1, 2 (0 - базовый ракурс, 1 - ракурс, отличный от базового, который может быть предсказан на основе ракурса 0, и 2 - ракурс, отличный от базового, который может быть предсказан на основе ракурсов 0 и 1). Эти три ракурса текстуры и глубины могут быть кодированы, например, в следующем порядке: Т0 D0 D1 Т1 D2 Т2 или D0 D1 D2 Т0 Т1 Т2, или D0 Т0 D1 Т1 D2 Т2. Порядок битового потока компонентов кодированного ракурса может совпадать с их порядком кодирования, так же как порядок декодирования компонентов кодированного ракурса может совпадать с порядком битового потока. Порядок межракурсной зависимости для глубины обычно, но не обязательно, совпадает с порядком межракурсной зависимости для текстуры. Количество ракурсов глубины может отличаться от количества ракурсов текстуры. Например, ракурс глубины может не кодироваться для ракурса текстуры, начиная с которого не предсказывается никакой другой ракурс текстуры. Секции компонентов ракурса глубины могут отличаться от секций компонентов ракурса текстуры, например, различными значениями типа блока NAL.
В некоторых вариантах осуществления настоящего изобретения порядок кодирования/декодирования текстуры и глубины может перемежаться с использованием элементов, меньших чем компоненты ракурса, например, на основе блока или секции. Соответствующий порядок кодирования/декодирования кодированных элементов текстуры и глубины, таких как блоки, может соответствовать правилам упорядочения, описанным в предыдущем разделе Например, могут существовать два смежных в пространстве блока (ta и tb) текстуры, при том что блок tb следует за блоком ta в порядке кодирования/декодирования, и два блока (da и db) глубины/диспаратности, пространственно совмещенных, соответственно, с блоками ta и tb. При вычислении параметров для ta и tb с помощью da и db, соответственно, порядок кодирования/декодирования может выглядеть следующим образом: (da, ta, db, tb) или (da, db, ta, tb). Порядок битового потока блоков может совпадать с порядком кодирования.
В некоторых вариантах осуществления настоящего изобретения порядок кодирования/декодирования текстуры и глубины может перемежаться с использованием блоков, больших чем компоненты ракурса, таких, например, как группа изображений или кодированные видеопоследовательности. Далее описываются некоторые параметры, связанные со многими вариантами осуществления настоящего изобретения.
Оценка диспаратности
В этом описании предполагается, что в решениях MVP используется информация, основанная на глубине и диспаратности и связанная с кодируемым в настоящий момент блоком данных текстуры, и, таким образом, допускается, что информация о глубине и диспаратности заранее доступна на стороне декодера. В некоторых системах MVD данные текстуры (двумерный видеосигнал) кодируются и передаются совместно с картой глубины, сформированной по пикселям, или с информацией о диспаратности. Таким образом, кодированный блок (cbt) данных текстуры может по пикселям быть связан с блоком (cbd) данных о глубине/диспаратности. Последний блок может использоваться в предлагаемых цепочках MVP без модификаций.
В некоторых вариантах осуществления настоящего изобретения вместо данных карты глубины может потребоваться фактическая информация о диспаратности или по меньшей мере ее оценка. Таким образом может потребоваться преобразование данных карты глубины в информацию о диспаратности. Преобразование выполняется согласно следующей формуле:
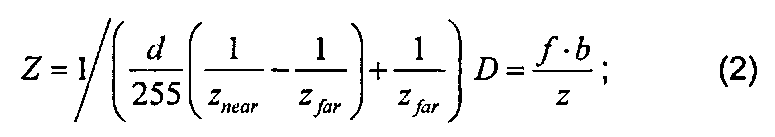
где d представляет собой значение карты глубины, z - фактическое значение глубины, и D - результирующая диспаратность. Параметры f, b, Znear и Zfar определяются в соответствии с установками камеры, то есть представляют собой используемое фокусное расстояние (f), расстояние между камерами (b) и диапазон глубины (Znear, Ζfar), соответственно.
В соответствии с вариантом осуществления настоящего изобретения оценку информации о диспаратности можно получить на основе доступных текстур на сторонах кодера/декодера посредством процедуры сопоставления блоков или с помощью других средств.
Параметры глубины и/или диспаратности блока
Пиксели кодируемого блока (cbt) текстуры могут быть связаны с блоком (cbd) информации о глубине для каждого из указанных пикселей. Информация о глубине/диспаратности может быть совокупно представлена с помощью средних значений глубины/диспаратности для cb_d и сдвига (например, дисперсии) cb_d. Среднее значение Av(cb_d) глубины/диспаратности для блока cb_d информации о глубине вычисляется следующим образом:
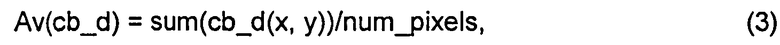
где x и у представляют собой координаты пикселей в cb_d, num_pixels является количеством пикселей в cb_d, и функция sum складывает все значения выборок/пикселей в заданном блоке, то есть функция sum(block(x, у)) вычисляет сумму значений выборок в пределах данного блока для всех значений x и у, соответствующих горизонтальному и вертикальному размеру блока.
Отклонение Dev(cb_d) значений глубины/диспаратности в пределах блока cb_d информации о глубине может вычисляться следующим образом:
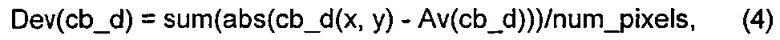
где функция abs возвращает абсолютное значение величины, заданной на входе. Для определения тех кодированных блоков текстуры, которые связаны с гомогенной информацией о глубине может быть указано специфическое для применения, заранее заданное пороговое значение Т1 следующим образом:

Другими словами, если отклонение значений глубины/диспаратности в блоке cb_d информации о глубине не превышает значения Т1, то такой блок cb_d может рассматриваться как гомогенный.
Кодируемый блок cb данных текстуры может сравниваться со своими соседними блоками nb с использованием соответствующей им информации о глубине/диспаратности. Выбор соседнего блока может определяться, например, на основе режима кодирования cb. Среднее отклонение (разность) между текущим кодируемым блоком (cb_d) глубины/диспаратности и каждым из соседних блоков (nb_d) глубины/диспаратности может вычисляться следующим образом:
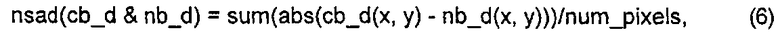
где x и у представляют собой координаты пикселей в cb_d и в соседних к нему блоках глубины/диспаратности (nb_d), num_pixels - количество пикселей в cb_d, и функции sum и abs определены выше. Формулу (6) можно также рассматривать как выражение, определяющее сумму абсолютных разностей (SAD, sum of absolute differences) между заданными блоками, нормализованными посредством количества пикселей в блоке.
В различных вариантах осуществления настоящего изобретения сравнивается подобие двух блоков глубины/диспаратности. Подобие может определяться, например, с использованием формулы (6), однако также могут использоваться любые другие метрические соотношения подобия или искажения. Например, может использоваться сумма квадратов разностей (SSD, squared differences), нормализованных посредством количества пикселей, в соответствии с формулой (7):
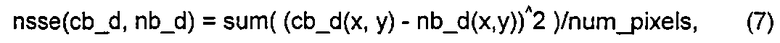
где x и у представляют собой координаты пикселей в cb_d и соседних с ним блоках (nb_d) глубины/диспаратности,
num_pixels - количество пикселей в пределах cb_d, нотация "Л2" обозначает возведение в квадрат, а функция sum определена выше.
В другом примере в качестве оценки подобия или искажения может использоваться сумма преобразованных разностей (SATD, sum of transformed differences). Как текущий блок cb_d глубины/диспаратности, так и соседний блок nb_d глубины/диспаратности преобразуются с использованиемг например, способа DCT или его вариантов, обозначенных в этом описании как функция Т(). Предположим tcb_d равен T(cb_d), и tnb_d равен T(nb_d). Далее вычисляется либо сумма абсолютных разностей, либо сумма квадратичных разностей, которая может быть нормализована с использованием количества пикселей/отсчетов (num_pixels) в блоке cb_d или nb_d и которая также равна количеству коэффициентов преобразования в cb_d или nb_d. Версия получения суммы преобразованных разностей с использованием суммы абсолютных разностей представлена формулой (8):

Также могут использоваться другие показатели искажения, такие как индекс структурного подобия (SSIM, structural similarity index).
Функция diff(cb_d, nb_d), представленная ниже, может определяться для разрешения доступа к любому метрическому соотношению подобия или искажения:
diff(cb_d, nb_d)=
nsad(cb_d, nb_d), если используется сумма абсолютных разностей
nsse(cb_d, nb_d), если используется сумма квадратичных разностей
nsatd (cb_d, nb_d), если используется сумма преобразованных абсолютных разностей. (9)
Любой показатель подобия/искажения может добавляться в определение функции diff, представленной в формуле (9). В некоторых вариантах осуществления настоящего изобретения используемый показатель подобия/искажения определен заранее и, таким образом, не изменяется в кодере и декодере. В некоторых вариантах осуществления настоящего изобретения используемый показатель подобия/искажения определяется кодером, например, с использованием оптимизации уровня зависимости искажений от скорости передачи, и кодируется в битовом потоке в качестве индикатора. Индикатор используемого показателя подобия/искажения может быть включен, например, в набор параметров последовательности, набор параметров изображения, набор параметров секции, в заголовок изображения, в заголовок секции, в синтаксическую структуру макроблока или в любую другую подобную структуру. В некоторых вариантах осуществления настоящего изобретения указанный показатель подобия/искажения может использоваться в операциях предварительного- определения как в цикле кодирования, так и в цикле декодирования, таком как предсказание вектора движения на основе глубины/диспаратности. В некоторых вариантах осуществления настоящего изобретения процессы декодирования, для которых идентифицируется указанный показатель подобия/искажения, также указываются в битовом потоке, например, в наборе параметров последовательности, наборе параметров изображения, наборе параметров секции, в заголовке изображения, в заголовке секции, в синтаксической структуре макроблока или в любой другой подобной структуре. В некоторых вариантах осуществления настоящего изобретения возможно использование в битовом потоке нескольких пар индикаторов для показателя глубины/диспаратности и процессов декодирования, к которым применяется показатель, с теми же характеристиками для процесса декодирования, то есть применимых к декодированию тех же блоков доступа. Кодер может выбрать показатель подобия/искажения, используемый для каждого конкретного процесса декодирования, в котором применяется выбор на основе подобия/искажения или другой способ обработки, такой как предсказание вектора движения на основе глубины/диспаратности, и кодировать соответствующие индикаторы выбранных показателей подобия/ искажения, а также указать в битовом потоке, к какому процессу они применимы.
Если сравнивается подобие блоков диспаратности, точки обзора блоков обычно нормализуются, например, таким образом, чтобы значения диспаратности масштабировались в соответствии с расстоянием от одной камеры в обоих сравниваемых блоках.
Предлагаются следующие элементы, которые могут быть объединены в одном решении, как описано ниже, или использоваться отдельно. Как объяснялось выше, видеокодер и видеодекодер обычно применяют механизм предсказания, следовательно, следующие элементы в равной степени могут применяться как к видеокодеру, так и к видеодекодеру.
1. Выбор опорного индекса и подходящих векторов движения для MVP в режиме пропуска (Skip) и/или в направленном (Direct) режиме
Для режима P_Skip, определенного в стандарте H.264/AVC, опорному изображению макроблока, кодированного в режиме P_Skip, назначается индекс 0 в списке 0 опорных изображений. Такой способ выбора нулевого опорного индекса в этом описании называется предсказанием с "нулевым значением" опорного индекса.
Опорный индекс(ы) для блока в направленном режиме и для блока B_skip согласно H.264/AVC выбирается на основе минимального доступного неотрицательного опорного индекса в соседних блоках.
В соответствии с вариантом осуществления настоящего изобретения вместо выбора опорного индекса согласно H.264/AVC опорный индекс(ы) для режима пропуска и/или направленного режима, а также для других подобных режимов может выбираться на основе подобия глубины/диспаратности текущего блока и глубины/диспаратности соседних блоков. Например, опорный индекс соседнего блока с наименьшим отклонением глубины/диспаратности по сравнению с текущим блоком может быть выбран в качестве опорного индекса текущего блока.
В соответствии с вариантом осуществления настоящего изобретения, в режиме пропуска и/или в направленном режиме и в подобных им режимах направленное и/или медианное предсказание вектора движения и т.п. применяется только к векторам движения тех соседних блоков, опорный индекс которых совпадает с опорным индексом текущего блока, или которые дополнительно характеризуются достаточным подобием глубины/ диспаратности по сравнению с глубиной/диспаратностью текущего блока.
2. Предсказатель используемого по умолчанию вектора движения с компенсацией диспаратности
Для каждого блока cb, использующего межракурсное предсказание, то есть использующего опорный индекс, который указывает на (только) межракурсное опорное изображение, и для которого не доступен вектор движения для блока А, В, и С в процессе MVP, предсказатель вектора движения устанавливается в соответствии с информацией о диспаратности текущего блока Di(cb) данных текстуры.
Всякий раз когда предсказатель вектора движения недоступен и опорный индекс указывает на межракурсное опорное изображение или на только межракурсное опорное изображение, предсказателю вектора движения присваивается значение, полученное на основе Di(cb), такое как средняя диспаратность, полученное на основе всех выборок Di(cb). Согласно H.264/AVC ситуация, в которой отсутствует вектор движения для блоков А, В и С, приводит к использованию вектора движения, равного 0 (и опорного изображения с опорным индексом 0 в режиме пространственного направления); в дальнейшем этот режим называется использованием "нулевого значения по умолчанию". Замена предсказания вектора движения с "нулевым значением по умолчанию" на вектор движения с компенсацией диспаратности, используемый по умолчанию, как описано выше, может быть также обусловлено только тем фактом, что уровень отклонения или диспаратности значений выборок в Di(cb) ниже определенного порогового значения.
3. Определение совмещенного блока с компенсацией диспаратности для режима временного направления и/или подобных режимов
Согласно H.264/AVC совмещенный блок с опорным индексом 0 в списке 1 опорных изображений выбирается в качестве источника для предсказателя вектора движения для текущего блока cb при использовании режима временного направления. В соответствии с вариантом осуществления настоящего изобретения, в том случае если выбирается режим временного направления предсказания или любой другой режим предсказания, в котором используется предсказание вектора движения на основе ранее кодированных/декодированных изображений, а не на основе пространственно совмещенного блока, в качестве источника для предсказания вектора движения выбирается совмещенный блок с компенсацией диспаратности. Например, информация о диспаратности текущего блока Di(cb) данных текстуры может усредняться и квантоваться по отношению к сетке блока для предсказания с компенсацией движения с целью формирования вектора движения, определяющего диспаратность. Вектор движения диспаратности затем используется для нахождения совмещенного блока с компенсацией диспаратности, чей вектор движения применяется в качестве источника для предсказания вектора движения.
В некоторых вариантах осуществления настоящего изобретения информация о глубине/диспаратности совмещенного блока с компенсацией диспаратности сравнивается с информацией о глубине/диспаратности текущего блока. Если информация о глубине/диспаратности этих двух блоков в достаточной мере совпадает, например, если их отклонение ниже определенного порогового значения, вектор движения совмещенного блока с компенсацией диспаратности используется в процессе предсказания вектора движения текущего блока. В противном случае вектор движения совмещенного блока с компенсацией диспаратности не используется в процессе предсказания вектора движения текущего блока. Информация о глубине/диспаратности этих двух блоков может различаться, если объект, охватываемый текущим блоком, закрыт другим объектом в совмещенном блоке с компенсацией диспаратности.
В некоторых вариантах осуществления настоящего изобретения поиск подобия информации о глубине/диспаратности выполняется между данными о глубине/диспаратности текущего блока Di(cb) и выбранной областью в опорном изображении. Вектор движения диспаратности может использоваться в качестве начальной позиции для поиска подобия, и только блоки, смежные с блоком, в котором присутствует вектор движения диспаратности, могут находиться в области поиска. Блок с наименьшим значением показателя искажения или расстояния, например отклонения, по сравнению с Di(cb) выбирается в качестве совмещенного блока с компенсацией диспаратности, чей вектор движения используется в качестве источника для предсказания вектора движения текущего блока cb.
В некоторых вариантах осуществления настоящего изобретения предсказание вектора движения во временном направлении может использоваться в режиме одиночного предсказания, и совмещенный блок с компенсацией диспаратности выбирается в качестве источника для предсказания вектора движения.
4. Применение направленного и/или медианного MVP, и/или других подобных способов только для смежных блоков, совместно использующих одинаковое направление предсказания друг с другом и/или с текущим блоком (cb).
В некоторых вариантах осуществления настоящего изобретения в процессе MVP классифицируются соседние блоки текущего блока (cb) с учетом их направлений предсказания (внутриракурсное, межракурсное, VSP), и каждое направление предсказания (группа соседних блоков) обрабатывается независимо. Таким образом, в MVP не задействуется объединение временного, межракурсного направлений или направления VSP в рамках одного решения. Следовательно, если опорный индекс текущего блока (cb) доступен, вычисляется направленное и/или медианное предсказание вектора движения, соответственно, начиная с соседних блоков с идентичным направлением предсказания (также без использования объединения временного, межракурсного направлений или направления VSP). Другими словами, соседние блоки А, В и С могут быть доступны для предсказания вектора движения и/или предсказания с компенсацией движения в смешанном направлении только в том случае, если они характеризуются тем же направлением предсказания, что и текущий блок (cb).
5. Выбор подходящих способов предсказания на основе подобия глубины/диспаратности
Помимо прочего, предсказатель вектора движения на основе соседних блоков может выбираться с учетом подобия глубины/диспаратности, например, в виде минимальной (по абсолютному значению) разности усредненного (на пиксель) значения глубины/диспаратности между кодируемым в настоящий момент блоком и соседними блоками данных текстуры. Например, вектор движения соседнего блока с минимальной (по абсолютному значению) разностью усредненного (на пиксель) значения глубины/диспаратности по сравнению глубины/диспаратностью блока cb может быть выбран в качестве предсказателя вектора движения для текущего кодируемого или декодируемого блока текстуры (cb). Согласно другому примеру все те соседние блоки nb, для которых степень подобия блока глубины/диспаратности для nb по сравнению с блоком глубины/диспаратности для cb ниже порогового значения, могут быть выбраны для направленного и/или медианного MVP или других подобных способов.
6. Выбор одиночного/двойного предсказания и списка (списков) опорных изображений, используемых для предсказания
Ряд параметров предсказания для декодирования кодируемого или декодируемого в настоящий момент блока (cb) может определяться на основе значений, связанных с соседними блоками. Например, количество используемых списков опорных изображений, то есть количество блоков предсказания, применяемых для текущего кодируемого блока cb, может определяться на основе количества блоков предсказания, используемых в соседнем блоке с наибольшим уровнем подобия глубины/диспаратности, например с наименьшей средней (по абсолютному значению) разностью (на пиксель) глубины/диспаратности по сравнению с текущим блоком глубины.
Альтернативно или дополнительно в направленном режиме и/или в режиме пропуска, а также в подобных режимах подобие глубины/диспаратности текущего блока cb и блока предсказания может использоваться для определения способа предсказания (одиночного или двойного) и списка опорных изображений, используемого для одиночного предсказания. При двойном предсказании используются два блока предсказания, которые далее обозначаются pb0 и pb1, и оба этих блока создаются на основе изображения из списка 0 опорных изображений и списка 1 опорных изображений, соответственно. Далее предполагается, что информация о глубине/диспаратности pb0 и pb1 обозначается как Di(pb0) и Di(pb1), соответственно. Di(pb0) сравнивается с информацией о глубине/диспаратности Di(cb) текущего блока. Если информация Di(pb0) подобна Di(cb), то pb0 используется в качестве блока предсказания; в противном случае pb0 не используется в качестве блока предсказания для текущего блока. Таким же образом, если информация Di(pb1) подобна Di(cb), то pb1 используется в качестве блока предсказания; в противном случае pb1 не используется в качестве блока предсказания для текущего блока. Если pb0 и pb1 остаются блоками предсказания, то используется двойное предсказание. Если блоком предсказания является pb0, а не pb1, используется одиночное предсказание начиная с pb0 (то есть, на основе списка 0 опорных изображений). Таким же образом, если блоком предсказания является pb1, а не pb0, используется одиночное предсказание начиная с pb1 (то есть, на основе списка 1 опорных изображений). Если ни pb0, ни pb1 не являются блоками предсказания, то может быть выбран другой режим кодирования, такой как режим двойного предсказания с кодированием разницы векторов движения, или, например, может быть выбрана другая пара опорных изображений.
Согласно H.264/AVC может использоваться одиночное предсказание (с использованием одного списка опорных изображений) или двойное предсказание (с использованием двух списков опорных изображений), однако обычно может использоваться любое количество блоков предсказания (так называемое многогипотезное предсказание). Следовательно, вышеупомянутые варианты осуществления настоящего изобретения могут обобщаться в рамках более двух гипотез предсказания.
7. Режим кодирования и предсказание направления
Помимо прочего, в качестве дополнительного примера определения параметра предсказания для декодирования кодируемого или декодируемого текущего блока (cb) на основе значений, связанных с соседними блоками, может определяться режим кодирования (например, в пространственном, временном направлении или в режиме пропуска), совпадающий с режимом кодирования соседнего блока с наибольшим уровнем подобия глубины/диспаратности, например, с наименьшей средней (по абсолютному значению) разностью (на пиксель) глубины/диспаратности по сравнению с текущим блоком глубины.
Помимо прочего, направление предсказания (внутриракурсное, межракурсное, VSP) может выбираться на основе максимального уровня подобия глубины/диспаратности, например, в виде минимальной разности усредненного (на пиксель) значения глубины/диспаратности между текущим кодируемым блоком (cb) текстуры и соседними блоками текстуры. Таким же образом, опорный индекс может выбираться на основе максимального уровня подобия глубины/диспаратности, например, в виде минимальной разности усредненного (на пиксель) значения глубины/диспаратности, между текущими кодируемыми блоками (cb) и соседними блоками текстуры. В алгоритмах реализации множества вариантов осуществления настоящего изобретения следует выделить последовательность указанных ниже операций:
1. Кодер/декодер выбирает несколько смежных блоков (S, Т, U) по отношению к текущему блоку cb
2. Кодер/декодер получает блоки глубины/диспаратности, связанные с одним или более смежными блоками, обозначенными как d(S), d(T), d(U), …
3. Кодер/декодер сравнивает текущий блок d(cb) глубины/диспаратности с блоками глубины/диспаратности, связанными с несколькими смежными блоками d(S), d(T), d(U), …, с использованием показателя подобия/искажения, определяемого, например, по формуле (9).
4. Кодер/декодер выбирает несколько блоков глубины/диспаратности, связанных с одним или более смежными блоками, обозначенными как d(S), d(T), d(U), на основе сравнения (например, минимизации искажения или максимизации подобия по сравнению с d(cb)).
5. Кодер/декодер получает информацию о движении в процессе MVP для cb на основе выбранных блоков d(S), d(T), d(U) глубины/диспаратности, связанных с одним или более смежными блоками S, Т, U, …, или на основе выбранных смежных блоков S, Т, U.....или на основе информации, кодированной для выбранных блоков d(S), d(T), d(U), … или выбранных блоков S, Т, U, …
6. Кодер/декодер кодирует/декодирует блок cb с использованием информации о движении в процессе MVP. Кодер/декодер может, например, использовать MVP в качестве опорного индекса и предсказателя вектора движения и кодировать/декодировать разницу векторов движения относительно MVP; или кодер/декодер может, например, использовать MVP в качестве вектора движения для cb.
В различных вариантах осуществления настоящего изобретения могут применяться различные способы выбора смежных блоков, используемых в процессе MVP для cb. Способы принятия решения о смежных блоках, используемых в процессе MVP, могут, помимо прочего, выбираться на основе приведенных ниже пунктов или их комбинации:
1. Выбор смежных блоков, которые совместно используют границу с cb и кодированы/декодированы перед cb.
Для идентичного выбора смежных блоков кодером и декодером могут использоваться предварительно определенные алгоритмы или правила. Например, в качестве смежных блоков могут выбираться блоки А, В, С, D и Е, показанные на фиг. 13, при условии что они кодированы/декодированы ранее cb.
2. Выбор смежных блоков, начиная с фрагмента изображения, также содержащего cb и кодированного/декодированного перед cb.
В некоторых вариантах осуществления настоящего изобретения кодер может выбирать смежные блоки и кодировать информацию в битовом потоке для идентификации смежных блоков, например в виде относительных координат смежных блоков по отношению к позиции cb. Кодер может, например, использовать оптимизацию уровня зависимости искажений от скорости передачи для выбора смежных блоков. В некоторых вариантах осуществления настоящего изобретения кодер и декодер могут выполнять оценку движения или процедуру сопоставления блоков для d(cb) в пределах изображения глубины/диспаратности, содержащего d(cb), и каждая позиция, тестируемая в процессе сопоставления блоков, может рассматриваться как совмещенная со смежным блоком. В некоторых вариантах осуществления настоящего изобретения кодер и декодер могут выполнять оценку движения или процедуру сопоставления блоков для d(cb) в пределах изображения глубины/диспаратности, содержащего d(cb), и смежные блоки могут быть выбраны для совмещения с несколькими позициями, характеризующимися наименьшей оценкой в процедуре сопоставления блоков.
3. Выбор смежных блоков из изображений, отличных от изображения, содержащего cb, например, следующим образом.
Вначале, например, с использованием операций 1 или 2, описанных выше, могут выбираться соседние в пространстве блоки, такие как А, В, С, D и Ε, показанные на фиг. 13, при условии что они кодированы/декодированы ранее cb. Затем векторы движения этих блоков могут применяться в местоположении cb с целью получения смежных блоков; например, смежным блоком, полученным на основе соседнего в пространстве блока А, может быть (cb, MV(A)). В альтернативном варианте или дополнительно, вектор движения, используемый для получения смежных блоков, может быть получен на основе нескольких векторов движения выбранных соседних в пространстве блоков. Например, вектор MVcvm движения может быть получен путем вычисления медианного значения горизонтальных компонентов векторов движения выбранных соседних в пространстве блоков и вычисления медианного значения вертикальных компонентов векторов движения выбранных соседних в пространстве блоков. Затем смежный блок может быть получен путем применения MVcvm в позиции cb, то есть смежным блоком будет (cb, MVcvm).
4. Выбор смежных блоков из изображений, отличных от изображения, содержащего cb, например, следующим образом.
Во первых, могут быть выбраны опорные изображения для вектора-движения, например, на основе опорных индексов векторов движения соседних в пространстве блоков, выбранных, например, с использованием одной или более операций 1-3, описанных выше. Во-вторых, может быть выбрано местоположение окна поиска на основе, например, местоположения смежного блока, полученного с использованием одной или более операций 1-3, описанных выше. В-третьих, кодер и декодер могут выполнять процедуры оценки движения или сопоставления блоков для d(cb) в пределах выбранных опорных изображений глубины/диспаратности и окна поиска. Смежные блоки могут выбираться таким образом, чтобы они располагались в изображении текстуры, связанном с выбранным опорным изображением глубины/диспаратности, и совмещались с одной или более позициями, характеризующимися наименьшей оценкой, полученной в процессе сопоставления блоков.
5. Выбор смежных блоков путем получения информации о движении через связанный блок d(cb) глубины/диспаратности.
При необходимости значения глубины/диспаратности блока d(cb) могут преобразовываться в блок dref(cb) диспаратности относительно другого ракурса vref. Среднее значение avg(dref(cb)) диспаратности для блока dref(cb) может использоваться в качестве вектора движения, указывающего на компонент ракурса vref. В процессе усреднения также может выполняться квантование или округление, например, точности векторов движения, например, до позиции в пределах четверти пикселя. Смежный блок может быть получен путем применения вычисленного межракурсного вектора движения, avg(dref(cb)), в позиции cb, то есть смежным блоком в этом случае будет avg(dref(cb)).
6. Выбор указанным ниже способом смежных блоков с использованием векторов движения в изображении глубины/диспаратности, содержащем d(cb).
Вначале, например, с использованием операций 1 или 2, описанных выше, могут выбираться соседние в пространстве блоки глубины/диспаратности, такие как А, В, С, D и Е, показанные на фиг. 13. В альтернативном варианте или дополнительно, может выбираться совмещенный или связанный блок d(cb). Соответствующие векторы движения могут обозначаться как MV(d(A)), MV(d(B)), MV(d(C)), MV(d(D)), MV(d(E)) и MV(d(cb)). Затем смежные блоки могут находиться путем применения векторов движения выбранных совмещенных или находящихся в пространственной близости блоков глубины/диспаратности к позиции cb, например, в этом случае смежным блоком, соответствующим соседнему блоку А, является (cb, MV(d(A))).
В некоторых вариантах осуществления настоящего изобретения процесс оценки движения, например процедура сопоставления блоков, может выполняться для текущего блока d(cb) глубины/диспаратности следующим образом. Диапазон поиска может выбираться в пределах текущего изображения глубины/диспаратности, то есть в пределах изображения, в котором также расположен блок d(cb). В некоторых вариантах осуществления настоящего изобретения диапазон поиска может дополнительно или альтернативно выбираться в пределах другого изображения глубины/диспаратности, то есть в пределах изображения, отличного от того, в котором расположен блок d(cb). Например, диапазон поиска может выбираться в пределах изображения глубины/диспаратности, которое связано с изображением текстуры, указанным опорным индексом блока cb. В другом примере диапазон поиска может выбираться в пределах изображения глубины/диспаратности, которое получено в качестве опорного изображения для направленного режима предсказания или подобного режима предсказания для cb или d(cb).
В некоторых вариантах осуществления настоящего изобретения диапазон поиска может ограничиваться в пространстве с целью исключения фрагментов, связанных с недоступными блоками (то есть, еще не кодированными/декодированными) в изображении текстуры, содержащем текущий блок cb. Диапазон поиска может также пространственно ограничиваться для того, чтобы не выйти за пределы определенного фрагмента изображения конкретного размера и формы, который окружает блок d(cb) или смежен с ним.
Процедура поиска соответствия блоков может выполняться в пределах диапазона поиска с использованием определенного алгоритма. В некоторых вариантах осуществления настоящего изобретения кодер указывает алгоритм и/или значения параметров для используемого алгоритма путем кодирования в битовом потоке одного или более индикаторов, а декодер декодирует один или более индикаторов и выполняет процедуру поиска соответствия блоков согласно декодированной информации об используемом алгоритме и/или значениям параметров для используемого алгоритма. Процедура поиска соответствия блоков может, например, выполняться с использованием процесса полного поиска, согласно которому проверяется позиция каждого блока в пределах диапазона поиска. В процессе поиска соответствия блоков вычисляется оценка в ходе сравнения исходного блока, d(cb), и каждого блока в пределах диапазона поиска, который выбирается алгоритмом поиска соответствия блоков. Например, в качестве оценки при поиске соответствия блоков могут использоваться значения SAD, SSD или SATD. В некоторых вариантах осуществления настоящего изобретения алгоритм поиска соответствия блоков может ограничиваться только поиском определенных позиций блоков, которые могут располагаться на прямоугольной сетке, используемой для разделения изображения. Позиция/позиции блоков, которые минимизируют указанную оценку при поиске соответствия блоков, обозначаемые (xbb, ybb), могут затем обрабатываться следующим образом. Информация MV(xbb) о движении может быть получена для позиции (xbb, ybb) блока, например, через блок d(xbb), имеющий размер и форму d(cb) и расположенный в координатах (xbb, ybb) в пределах изображения глубины/диспаратности, содержащего диапазон поиска, и/или через блок xbb, имеющий размер и форму d(cb) и расположенный в координатах (xbb, ybb) в пределах изображения текстуры, связанного или соответствующего изображению глубины/диспаратности, содержащему диапазон поиска, например, посредством одного из приведенных ниже способов или их комбинации:
- Если блок d(xbb) охватывает один блок d(bb), для которого информация MV(d(bb)) о движении была получена и кодирована/декодирована ранее, то информация MV(xbb) может выбираться таким образом, чтобы она была идентична информации MV(d(bb)).
- Если блок d(xbb) охватывает несколько блоков d(bbn) (где значение n может находиться в диапазоне от единицы до количества таких блоков), для которых информация MV(d(bbn)) о движении- получена и кодирована/декодирована ранее, то MV(xbb) может выбираться на основе MV(d(bbn)), например, путем выбора вначале опорного индекса, используемого для информации о движении для большинства выборок в пределах d(xbb), а затем вычисления медианного вектора движения, компонентов медианного вектора движения, среднего вектора движения, компонентов среднего вектора движения или MV(d(bbn)), охватывающих область, в которой нормализованная оценка является наименьшей среди всех значений n, указываемых выбранным опорным индексом.
- Если блок xbb охватывает один блок bb, для которого информация MV(bb) о движении была получена и кодирована/декодирована ранее, то информация MV(xbb) может выбираться таким образом, чтобы она была идентична информации MV(bb).
- Если блок xbb охватывает несколько блоков bbn (где значение η может находиться в диапазоне от единицы до количества таких блоков), для которых информация MV(bbn) о движении получена и кодирована/декодирована ранее, то MV(xbb) может выбираться на основе MV(bbn), например, путем выбора вначале опорного индекса, используемого для информации о движении для большинства выборок в пределах xbb, а затем вычисления медианного вектора движения, компонентов медианного вектора движения, среднего вектора движения, компонентов среднего вектора движения или MV(bbn), охватывающих область, в которой нормализованная оценка является наименьшей среди всех значений n, указываемых выбранным опорным индексом. В некоторых вариантах осуществления настоящего изобретения информация MV(xbb) о движении может использоваться для получения смежных блоков для MVP блока cb. Другими словами, смежный блок может быть получен путем применения MV(xbb) в позиции cb, то есть смежным блоком может быть (cb, MV(xbb)).
В некоторых вариантах осуществления настоящего изобретения информация MV(xbb) о движении может использоваться для предсказания cb.
Например, блок предсказания для cb может быть получен путем применения MV(xbb) в местоположении cb, то есть блоком предсказания может быть (cb, MV(xbb)).
В некоторых вариантах осуществления информация о движении для декодирования кодированного или декодируемого текущего блока (cb) может определяться следующим образом. Алгоритмы выполнения процесса для отбора вектора движения на основе глубины (DMC, Depth-based Motion Competition) в режимах Skip и Direct показаны на фиг. 17 и фиг. 18, соответственно. В режиме Skip векторы движения {MVi} блоков {А, В, С} данных текстуры сгруппированы в соответствии с их направлением предсказания и формируют группу 1 и группу 2 для временного и межракурсного предсказания, соответственно. Процесс DMC, который детализируется в сером блоке, изображенном на фиг. 17, выполняется независимо для каждой группы.
Для каждого вектора MVi в заданной группе определяется блок d(cb, MVi) с компенсацией движения, в котором вектор MVi движения применяется по отношению к позиции cb для получения блока глубины на основе опорного изображения, на которое указывает MVi. Затем оценивается подобие d(cb) и d(cb, MVi) в соответствии с формулой (10).
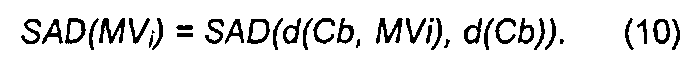
Вектор MVi, обеспечивающий минимальное значение SAD в пределах текущей группы, выбирается в качестве оптимального предсказателя для конкретного направления mvpdir:
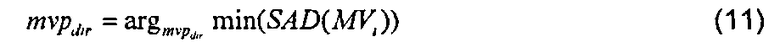
После этого предсказатель (mvptemp) во временном направлении сравнивается с предсказателем (mvpinter) в межракурсном направлении. Для использования в режиме Skip выбирается предсказатель, обеспечивающий минимальное значение SAD:

Процесс MVP в режиме Direct для В-секций, показанный на фиг. 18, подобен процессу, выполняемому в режиме Skip, однако процедура DMC (блоки, показанные серым цветом) выполняется для обоих списков опорных изображений (0 и 1) независимо. Таким образом, для каждого направления предсказания (временного или межракурсного) в процессе выполнения процедуры DMC формируются два предсказателя (mvp0dir и mvp1dir) соответственно для списков 0 и 1. Значения SAD предсказателей mvp0dir and mvp1dir вычисляются в соответствии с формулой (10) и усредняются для формирования SAD двойного предсказания независимо от каждого направления:

И наконец, MVP в режиме Direct выбирается на основе доступных векторов mvpinter и mvptemp, в соответствии с формулой (12).
Согласно еще одному варианту осуществления настоящего изобретения, схема предсказания вектора движения может быть реализована следующим образом. Все доступные, смежные по отношению к cb блоки (А,…Е) классифицируются в соответствии с направлением их предсказания (временным или межракурсным). Если cb использует межракурсное опорное изображение, то все соседние блоки, которые не применяют межракурсное предсказание, помечаются как недоступные для MVP и не рассматриваются при расчете медианного или направленного MVP и т.п. Наоборот, если cb использует временное предсказание, соседние блоки, использующие межракурсные опорные кадры, помечаются как недоступные для MVP. Алгоритм этого процесса показан на фиг. 18. Кроме того, процесс MVP "с нулевым MV", в котором используется внутриракурсное предсказание, пересмотрен следующим образом: если подходящие векторы движения недоступны на основе соседних блоков, MVx устанавливается равным значению 

где D(cb(i)) - диспаратность, вычисленная по формуле (2) для пикселя cb(i), i - индекс пикселя в блоке со, а N - количество пикселей в блоке cb.
В некоторых вариантах осуществления настоящего изобретения вывод всех или некоторых упомянутых выше параметров предсказания для cb на основе соседнего блока, характеризующегося наибольшим уровнем подобия глубины/диспаратности, например, наименьшей средней (абсолютной) разностью (на пиксель) глубины/диспаратности по сравнению с текущим блоком глубины, может выполняться только в том случае, если значение подобия глубины/диспаратности удовлетворяет условию, связанному с пороговым значением, например, превосходит это пороговое значение. Для параметров предсказания могут также использоваться различные пороговые значения.
Ниже раскрываются некоторые варианты осуществления настоящего изобретения, согласно которым основные аспекты, описанные выше, объединяются в рамках одного решения, но, тем не менее, необходимо отметить, что каждый из указанных аспектов также может использоваться отдельно.
Приведенные выше параметры и формулы могут использоваться в различных вариантах осуществления описываемого ниже процесса предсказания вектора движения (MVP) на основе информации о глубине/диспаратности.
В соответствии с вариантом осуществления настоящего изобретения вместо процедуры установки в качестве опорного индекса кадра текущего блока значения, всегда равного нулю или получаемого на основе опорных индексов соседних блоков текстуры, в режиме пропуска и/или в направленном режиме и т.п., например в режиме PSKIP, определенном в стандарте H.264/AVC, в этом описании раскрывается модифицированная процедура для определения опорного индекса и подходящих векторов движения для предсказания вектора движения в режиме пропуска и/или в направленном режиме и т.п., которая называется далее режимом предсказания с нулевым значением и компенсацией диспаратности.
Для того чтобы проанализировать, содержит ли текущий кодированный блок cb гомогенную информацию о глубине, согласно формулам (3) и (4) могут вычисляться среднее значение Av(cb_d) глубины/диспаратности для блока информации о глубине и значения Dev(cb_d) отклонения глубины/диспаратности в пределах блока информации о глубине. Затем, если отклонение значений глубины/диспаратности в блоке cb_d информации о глубине не превышает порогового значения Т1 согласно формуле (5), текущий кодированный блок cb_d может рассматриваться как гомогенный.
- Далее на основе среднего-значения-Av(cb_d) глубины/диспаратности для блока информации о глубине в соответствии с формулой (2) может быть вычислено значение d(cb) диспаратности, общее для всего кодируемого блока cb. Результирующее значение d(cb) диспаратности затем может использоваться в качестве предсказателя вектора движения, и опорный индекс может быть выбран равным опорному индексу межракурсного опорного изображения или только межракурсного опорного изображения, для которого применима диспаратность. Однако, если на основе формулы (5) замечено, что информация о глубине текущего кодируемого блока cb не является гомогенной, то может использоваться предсказание с нулевым значением, раскрытое в текущем стандарте H.264/AVC MVP; например, в режиме PSkip согласно H.264/AVC применяется медианное предсказание вектора движения, и опорный индекс обнуляется.
В соответствии с вариантом осуществления настоящего изобретения подобие информации о глубине/диспаратности текущего кодируемого блока (cb) и каждого из соседних с ним блоков (nb) используется в качестве основы с целью определения одного или более параметров для предсказания вектора движения текущего кодируемого блока (cb). Вначале с помощью формулы (9) вычисляется среднее отклонение между текущим кодируемым блоком cb и каждым из соседних с ним блоков nb (А, В, С,…). С использованием результирующих значений отклонения осуществляется поиск минимального значения min(diff(cb, nb)). Если минимальное значение min(diff(cb, nb)) не превосходит порогового значения Т2 (то есть, если min(diff(cb, nb))=<Т2), то это указывает на то, что соседний блок с минимальным различием по отношению к текущему кодируемому блоку характеризуется достаточной степенью подобия с текущим кодируемым блоком. Следовательно, соседний блок с минимальным различием по отношению к текущему кодируемому блоку выбирается в качестве источника параметров MVP, и один или более параметров для предсказания вектора движения копируются из указанного соседнего блока для использования в процессе предсказания вектора движения текущего блока.
В соответствии с вариантом осуществления настоящего изобретения, если в достаточной степени схожий соседний блок не найден (то есть, если min(diff(cb, nb))>Т2), то для предсказания вектора движения может использоваться процесс предварительного выбора соседнего блока на основе глубины/диспаратности. На первом шаге соседние блоки группируются согласно их направлению предсказания. Соответственно могут быть образованы три группы блоков (Gx): G1: предсказываемые во временном направлении блоки (внутриракурсное предсказание), G2: блок межракурсного предсказания и G3: блоки предсказания VSP. Для всех доступных в текущий момент групп с помощью формулы (9) вычисляется среднее отклонение (разность) между текущим кодируемым блоком (cb) и каждой группой блоков (Gx).
С использованием результирующих значений отклонения осуществляется поиск группы (Gmin), обеспечивающей минимальное значение min(diff(cb, Gx)). Если минимальное значение min(diff(cb, Gx)) указанной группы Gmin не превосходит порогового значения Т3 (то есть, если (diff(cb, Gx))=<Т3), то блоки в указанной группе помечаются как доступные для предсказания вектора движения и/или для предсказания с компенсацией движения в смешанном направлении, а оставшиеся блоки помечаются в качестве недоступных для предсказания вектора движения и/или для предсказания с компенсацией движения в смешанном направлении. Затем для текущего кодируемого блока выполняется процесс предсказания вектора движения, такой как направленное и/или медианное предсказание вектора движения на основе соседних блоков, принадлежащих группе Gmin. Однако если минимальное значение min(diff(cb, Gx)) указанной группы Gmin превышает пороговое значение Т3 (то есть, если min(diff(cb, Gx))>Т3), то может использоваться описанная выше реализация режима предсказания с нулевым значением и компенсацией диспаратности.
Последний вариант осуществления может быть проиллюстрирован с помощью алгоритма, показанного на фиг. 8, на котором изображены соседние в пространстве блоки А, В и С, доступные для предсказания вектора движения текущего блока cb. Если не удается найти идентичного направления предсказания для блоков А, В и С (800), то блоки А, В и С группируются (802) в соответствии с их направлением предсказания и образуют три возможные группы, при этом для всех доступных в настоящий момент групп вычисляется среднее отклонение между текущим кодируемым блоком и каждой группой блоков (804, 806, 808). Группа направления предсказания, обеспечивающая минимальное значение min(diff(cb7 Gx)), выбирается (810) в качестве направления предсказания. Затем блоки в указанной группе помечаются (812) в качестве доступных для предсказания вектора движения и/или для предсказания с компенсацией движения в смешанном направлении, а оставшиеся блоки помечаются как недоступные для предсказания вектора движения и/или для предсказания с компенсацией движения в смешанном направлении. Затем для текущего кодируемого блока выполняется (814) процесс предсказания вектора движения (MVP0), такой как направленное и/или медианное предсказание вектора движения согласно H.264/AVC на основе соседних блоков, принадлежащих указанной группе. Если для текущего блока используется режим Skip или Direct и т.п. и делается вывод (816) о том, что для стандартного процесса предсказания вектора движения, такого как MVP H.264/AVC, следует использовать "нулевой" опорный индекс и/или предсказатель вектора движения с "нулевым значением по умолчанию", то в блоке 818 выбирается предсказатель вектора движения следующим образом. Если для стандартного процесса предсказания вектора движения следует использовать "нулевой" опорный индекс, то опорный индекс вместо этого выбирается для ссылки на опорное изображение, характеризующееся наименьшим опорным индексом и тем же направлением предсказания, что и выбранная группа направления предсказания. Если выбранное направление предсказания является межракурсным предсказанием и принимается решение об использовании предсказателя вектора движения с "нулевым значением по умолчанию", то в процессе кодирования или декодирования (820) применяется значение d(cb) диспаратности, вычисленное по формуле (2), а не "нулевой" предсказатель вектора движения. В противном случае должен использоваться предсказателя вектора движения с "нулевым значением по умолчанию", например, таким образом, как это определено в текущем стандарте MVP H.264/AVC.
На фиг. 9 показан алгоритм реализации для режима временного направления или подобного ему режима. Вначале на шаге 900 следующим образом определяются подходящие пары опорных индексов, подлежащих использованию для текущего cb. Сначала обнуляется переменная cri опорного индекса для списка 1. Совмещенный блок А находится в опорном изображении, опорный индекс cri которого содержится в списке 1 опорных изображений. Если направление предсказания блока А является межракурсным, выбор блока А может выполняться с компенсацией диспаратности, как описано ранее. Для совмещенного блока А используется предсказание с компенсацией движения в смешанном направлении на основе блока В из опорного изображения, представленного в списке 0 опорных изображений. Если направление предсказания для блока А является межракурсным, и опорные изображения, содержащие блоки А и В, находятся в том же ракурсе, что и изображение, содержащее cb, то блоки А и В рассматриваются как доступные, и соответствующие опорные индексы считаются подходящей парой опорных индексов. Если направление предсказания для блока А является межракурсным, и опорные изображения, содержащие блоки А и В, находятся в различных ракурсах (но в том же блоке доступа) относительно изображения, содержащего cb, то блоки А и В рассматриваются как доступные, и соответствующие опорные индексы считаются подходящей парой опорных индексов. В противном случае блоки А и В рассматриваются как недоступные. Затем значение cri увеличивается на 1 и повторяются описанные выше шаги, до тех пор пока cri не укажет на опорный индекс, отсутствующий в списке 1 опорных изображений. Если пара подходящих опорных индексов по окончании процесса 900 не найдена, то может, например, применяться процесс выбора опорного индекса для режима временного направления согласно H.264/AVC.
В блоке 902 с помощью формулы (9) может вычисляться среднее отклонение глубины/диспаратности между текущим блоком cb и блоками А и В каждой подходящей пары опорных индексов.
С использованием результирующих значений отклонения может быть выбрана (906) подходящая пара опорных индексов с минимальным значением min(diff(cb, nb)). Если минимальное значение min(diff(cb, nb)) выбранной подходящей пары опорных индексов не превосходит порогового значения Τ (908), то для cb применяется предсказание во временном направлении или в подобном режиме (910). В некоторых вариантах осуществления настоящего изобретения шаги 902, 906 и 908 могут опускаться, и предсказание в режиме временного направления и т.п. может выполняться с использованием первой подходящей пары опорных индексов, найденной на шаге 900. Если направление предсказания является межракурсным, различия индексов камер, векторы преобразования камер, разделение камер и т.п. могут использоваться в режиме временного направления или в подобном ему режиме для масштабирования вектора движения на основе совмещенного блока в случае применения его для получения предсказателя вектора движения для текущего блока cb.
Если минимальное значение min(diff(cb, nb)) выбранной пары опорных индексов превосходит пороговое значение Т4 (908), то может приниматься решение об использовании другого режима предсказания, например стандартного двойного предсказания (912).
В различных вариантах осуществления настоящего изобретения, представленных выше, выбираются соседние блоки по отношению к кодируемому/декодируемому блоку cb. К примерам выбираемых соседних блоков относятся соседние в пространстве (например, показанные на фиг. 7а) или совмещенные по времени соседние блоки, например, определяемые в процессе выбора опорного индекса в режиме временного направления и т.п. (например, показанные на фиг. 7b). Другими примерами являются соседние блоки с компенсацией диспаратности в смежных ракурсах, посредством которых может применяться компенсация диспаратности для определения соответствия соседнего блока блоку cb. Аспекты настоящего изобретения не ограничены упомянутыми способами выбора соседних блоков, однако описание приводится для одного из возможных вариантов, на основе которого частично или полностью могут быть реализованы другие варианты настоящего изобретения.
В некоторых вариантах осуществления настоящего изобретения кодер может определять величину любого из вышеупомянутых пороговых значений, например, на основе кодирования блоков с различными пороговыми значениями и выбора оптимального порогового значения в соответствии с оптимизацией уровня зависимости искажений от скорости передачи по формуле Лагранжа. Кодер может указывать определенное пороговое значение в битовом потоке путем кодирования его в виде синтаксического элемента, например, в наборе параметров последовательности, наборе параметров изображения, наборе параметров секции, заголовке изображения, заголовке секции, в пределах синтаксической структуры макроблока и т.п., и в некоторых вариантах осуществления настоящего изобретения декодер определяет пороговое значение на основе информации, кодированной в битовом потоке, например, в виде кодового слова, указывающего пороговое значение.
В некоторых вариантах осуществления настоящего изобретения кодер выполняет оптимизацию, такую как оптимизация уровня зависимости искажений от скорости передачи, совместно при выборе значений синтаксических элементов для текущего блока cb текстуры и совмещенного текущего блока Di(cb) глубины/диспаратности. В процессе совместной оптимизации уровня зависимости искажений от скорости передачи кодер может, например, кодировать cb и Di(cb) в нескольких режимах и выбирать пару режимов, благодаря чему выбирается наилучший протестированный режим с точки зрения такой характеристики, как уровень зависимости искажений от скорости передачи. Например, возможна ситуация, в которой для Di(cb) режим Skip был бы оптимальным с точки зрения характеристик зависимости искажений от скорости передачи, но если характеристики зависимости искажений от скорости передачи для cb и Di(cb) оптимизируются совместно, дополнительных преимуществ можно добиться, например, в случае выбора режима Direct для Di(cb), вследствие чего сигнал ошибки предсказания для Di(cb) кодируется, и выбор параметра предсказания, такого как предсказание вектора движения, основанное на декодированном Di(cb), может выполняться таким образом, что указанные характеристики при кодировании cb улучшаются. При совместной оптимизации уровня зависимости искажений от скорости передачи для текстуры и глубины, для расчета искажения, например, могут использоваться один или более синтезированных ракурсов, поскольку искажение изображения текстуры, возможно, не удастся непосредственно сравнить с искажением изображения глубины. Кодер также может выбирать значения для синтаксических элементов таким образом, чтобы получить эффективный параметр предсказания, основанного на глубине/диспаратности. Например, кодер может выбрать режим Skip или Direct, или другой подобный режим для текущего блока cb текстуры, если некоторые из соседних блоков характеризуются схожим уровнем глубины/диспаратности по сравнению с уровнем глубины/диспаратности cb, и, следовательно, выбор предсказателя(-ей) вектора движения на основе глубины/диспаратности, скорей всего, должен также привести к успешному результату. Таким же образом, кодер может избегать выбора режима Skip или Direct, или подобного режима для cb, если отсутствуют соседние блоки, которые характеризуются схожим уровнем глубины/диспаратности по сравнению с уровнем глубины/диспаратности cb.
В некоторых вариантах осуществления настоящего изобретения кодер может кодировать некоторые ракурсы текстуры без расчета параметра предсказания, основанного на глубине/диспаратности, в то время как другие ракурсы текстуры могут кодироваться с использованием расчета параметра предсказания, основанного на глубине/диспаратности. Например, кодер может кодировать базовый ракурс текстуры без расчета параметра предсказания, основанного на глубине/диспаратности, а вместо этого использовать стандартные механизмы предсказания. Например, кодер может кодировать битовый поток, совместимый со стандартом H.264/AVC, путем кодирования базового ракурса без расчета параметра предсказания, основанного на глубине/диспаратности, и, следовательно, этот битовый поток может декодироваться декодерами H.264/AVC. Таким же образом, кодер может кодировать битовый поток, в котором ряд ракурсов совместим с MVC, путем кодирования базового ракурса и других ракурсов в наборе ракурсов без расчета параметра предсказания, основанного на глубине/диспаратности. В результате набор ракурсов может декодироваться декодерами MVC.
В то время как варианты осуществления настоящего изобретения описаны для предсказания с компенсацией движения в смешанном направлении и предсказания вектора движения для яркости, следует принимать во внимание, что во многих схемах кодирования цветовая информация о движении может быть получена на основе яркостной информации о движении с использованием предварительно определенных связей. Например, можно предположить, что одинаковые опорные индексы используются для цветовых и яркостных компонентов и что векторы движения цветовых компонентов масштабируются на основе векторов движения яркостных компонентов в том же соотношении, что и пространственное разрешение цветных изображений по сравнению с пространственным разрешением яркостных изображений. В некоторых вариантах осуществления настоящего изобретения пространственное разрешение изображений глубины/диспаратности может различаться, или в кодере может выполняться операция повторной дискретизации на стадии предварительной обработки для установки разрешения, отличного от того, что используется в яркостных изображениях текстуры. В некоторых вариантах осуществления настоящего изобретения для изображений глубины/диспаратности может выполняться повторная дискретизация в циклах кодирования и/или декодирования для достижения разрешения, идентичного разрешению соответствующих яркостных изображений текстуры. В других вариантах осуществления настоящего изобретения соответствующие друг другу в пространстве блоки изображений глубины/диспаратности находятся путем масштабирования местоположений и размеров пропорционально отношению размеров изображений глубины и яркостных изображений текстуры.
Для некоторых вариантов осуществления настоящего изобретения изображение текстуры и изображение глубины, связанное с изображением текстуры, представлены с различным пространственным разрешением, и, таким образом, размеры кодируемого блока Cb и связанного с ним блока d(Cb) в пространственной области отличаются (различное количество пикселей в горизонтальном и вертикальном направлениях или по любому из этих направлений).
Кодер может использовать несколько способов для индикации различных разрешений изображений текстуры по отношению к разрешению изображений глубины. Например, разрешение изображения текстуры и разрешение изображения глубины могут отдельно указываться кодером в наборе параметров последовательности, кодированном в битовом потоке. В другом примере кодер может кодировать два набора параметров последовательности - один используемый для декодирования компонентов ракурса текстуры, а другой используемый для декодирования компонентов ракурса глубины - при этом каждый набор параметров последовательности содержит синтаксические элементы, указывающие пространственное разрешение. Согласно этому примеру, кодер кодирует секции для текстуры со ссылкой на набор параметров последовательности для компонентов ракурса текстуры и соответствующие секции для глубины со ссылкой на набор параметров последовательности для компонентов ракурса глубины. Ссылка для набора параметров последовательности может быть косвенной, например, через ссылку, содержащуюся в наборе параметров изображения, который может указываться в заголовке кодированной секции. Декодер разрешает или декодирует ссылку между синтаксическими структурами и использует сообщенные значения пространственного разрешения для декодирования компонентов ракурса текстуры и ракурса глубины. В некоторых схемах кодирования соотношение между разрешением текстуры и глубины может определяться предварительно, например, как 1:1 или 2:1 (по обеим осям координат), при этом информацию, относящуюся к разрешению текстуры или глубины, не требуется кодировать в битовом потоке или декодировать из битового потока.
Для выполнения предлагаемого предсказания вектора движения может выполняться нормализация (установка единого разрешения) пространственных разрешений изображений текстуры и глубины путем повторной дискретизации (интерполяции) любого из двух компонентов (текстуры или глубины) до уровня разрешения другого компонента (глубины или текстуры, соответственно). Повторная дискретизация для получения более высокого разрешения может выполняться различными средствами, например, с помощью интерполяции линейными фильтрами (такими как билинейный, кубический фильтр, фильтр Ланцоша или интерполяционный фильтр, используемыми согласно H.264/AVC или HEVC) или повышающей дискретизации посредством нелинейных фильтров, или простого дублирования выборок изображения. Повторная дискретизация для получения более низкого разрешения может выполняться различными средствами, например, путем прореживания или прореживания с использованием низкочастотной фильтрации.
Кодер может определять процесс повторной дискретизации, его компоненты, пороговые значения или другие используемые значения на основе одной или более функций оценки и посредством (приблизительной) минимизации/максимизации этих нескольких функций оценки. Например, пиковое отношение сигнал/шум (PSNR, peak signal-to-noise ratio) повторно дискретизированного изображения глубины по отношению к исходному изображению глубины может использоваться в качестве основы функции оценки. Кодер может выполнять оптимизированный (с точки зрения уровня зависимости искажений от скорости передачи) выбор одного или более процессов повторной дискретизации, их компонентов, пороговых значений или других значений параметров, при этом искажения определяются в соответствии с выбранной функцией оценки. Функция оценки, используемая кодером, может быть также основана на процессе синтезирования изображения, при выполнении которого используется повторно дискретизированное изображение глубины, и на применении критерия подобия, такого как PSNR, к синтезированному изображению.
Кодер может кодировать индикаторы, указывающие по меньшей меры части используемого способа повторной дискретизации. К таким индикаторам могут относиться один или более следующих элементов:
- Идентификация используемого при кодировании процесса повторной дискретизации и/или подлежащего использованию при декодировании процесса повторной дискретизации.
- Пороговые значения и/или значения других параметров для процесса повторной дискретизации.
Кодер может кодировать такие индикаторы в различных частях кодируемого битового потока, например в наборе параметров последовательности, наборе параметров изображения, наборе параметров адаптации, в заголовке изображения или секции.
Декодер в соответствии с настоящим изобретением может декодировать из битового потока индикаторы, указывающие по меньшей мере компоненты способа повторной дискретизации, используемые при кодировании и/или подлежащие использованию при декодировании. Затем декодер может выполнить процесс повторной дискретизации в соответствии с декодированными индикаторами.
Как в кодере, так и в декодере повторная дискретизация может выполняться в цикле (де)кодирования, то есть глубина с повышенной дискретизацией может использоваться в других процессах (де)кодирования. Повышающая дискретизация может выполняться для всего изображения или для части изображения, такой как множество смежных строк выборок, например, охватывающее строку блоков кодирования.
В некоторых вариантах осуществления настоящего изобретения информация MV(A) и MV(B) о движении первого смежного блока А текстуры и второго смежного блока В текстуры, соответственно, представляется с конкретной точностью (например, с точностью местоположения до % пикселя для векторов движения согласно стандарту H.264/AVC или с точностью местоположения до 1/8 пикселя согласно другим стандартам). В этих вариантах осуществления настоящего изобретения цикловая повышающая дискретизация опорного изображения с коэффициентом 4х по горизонтальной и вертикальной осям может осуществляться как на стороне кодера, так и на стороне декодера для выполнения предсказания с компенсацией движения или диспаратности. Соответственно, компоненты вектора движения MV(A) и MV(B), полученные в результате такой оценки движения, представлены и обработаны в масштабе 4х от разрешения исходного изображения. Для реализации предлагаемого MVP в таких вариантах осуществления может выполняться повышающая дискретизация данных текстуры и глубины до этого конкретного разрешения, которое может называться общим разрешением, полученного в процессе цикловой повышающей дискретизации. Повышающая дискретизация может быть реализована для всего кадра (обычно этот процесс выполняется в кодере), либо интерполяция может выполняться локально, например, на уровне блока (обычно этот процесс выполняется в декодере).
В некоторых вариантах осуществления настоящего изобретения с целью достижения требуемого уровня пространственного разрешения изображения глубины вместо повторной дискретизации изображения глубины может изменяться масштаб компонентов MV(A) и MV(B) смежных блоков А и В текстуры, соответственно. Например, если MV(A) и MV(B) данных текстуры представлены на уровне исходного разрешения текстуры и разрешение по глубине меньше разрешения текстуры, то масштаб компонентов (mv_x и mv_y) векторов MV(A) и MV(B) уменьшается пропорционально различию значений разрешения данных текстуры и глубины. После уменьшения масштаба компонентов векторов движения может выполняться квантование компонентов векторов движения уменьшенного масштаба с определенной точностью, при этом операция квантования может включать округление, например, до ближайшего уровня квантования. Уровень квантования может выбираться таким образом, чтобы не требовалась повторная дискретизация изображения глубины, или чтобы повторная дискретизация выполнялась до разрешения, меньшего того, что потребовалось бы в отсутствие квантования. Разрешение, до уровня которого выполняется повторная дискретизация изображений глубины в цикле кодирования или декодирования с целью реализации предлагаемого MVP, может называться цикловым разрешением по глубине. Например, разрешение изображения глубины может быть в два раза меньше разрешения яркостного изображения текстуры по обеим осям координат (например, разрешение яркостного изображения текстуры составляет 1024×768, а изображения глубины - 512×384), при этом точность компонентов вектора движения яркостного изображения текстуры составляет 1/4-пикселя (например, значение mv_x равно 5,25, а значение mv_y равно 4,25). В этом случае компоненты вектора движения, подлежащие использованию для глубины в соответствии с предлагаемым MVP, масштабируются с использованием коэффициента 2 (например, mv_x равно 2,625, a mv_y равно 2,125, с учетом представленного выше примера), и, таким образом, точность в пределах изображения глубины составляет 1/8 пикселя. Для того чтобы избежать повторной дискретизации по глубине, масштабированные компоненты вектора движения могут квантоваться с точностью до целого пикселя в пределах изображения глубины (например, mv_x равно 3, a mv_y равно 2, с учетом представленного выше примера). Согласно другому примеру, масштабированные компоненты вектора движения могут квантоваться с точностью до половины пикселя в пределах изображения глубины (например, mv_x равно 2,5; a mv_y равно 2, с учетом представленного выше примера), и, таким образом, для изображения глубины следует выполнить повышающую дискретизацию с коэффициентом 2 по обеим координатным осям (например, 1024×768, с учетом представленного выше примера), при этом может использоваться билинейная повышающая дискретизация. Такие способы реализации предлагаемого MVP позволяют избежать повторной дискретизации данных о глубине до требуемого разрешения, при этом степень сложности вычислений может быть уменьшена.
Кодер может кодировать индикаторы или синтаксические элементы, указывающие способ масштабирования вектора движения, подлежащий использованию в рамках предлагаемого MVP. К таким индикаторам могут относиться один или более следующих элементов:
- Цикловое разрешение по глубине.
- Точность, до уровня которой масштабируются компоненты вектора движения, например ¼ пикселя, ½ пикселя или пиксель.
- Способ квантования, например, следует ли масштабировать компоненты отрицательного вектора движения, находящиеся в точности посередине двух уровней квантования, в направлении нуля или в обратном направлении. Например, если используется точность на уровне целого пикселя, такая индикация может указывать, округлять до 0 или до -1 значение -0,5 компонента вектора движения.
Кодер может кодировать такие индикаторы в различных частях кодируемого битового потока, например в наборе параметров последовательности, наборе параметров изображения, наборе параметров адаптации, в заголовке изображения или секции.
Декодер в соответствии с настоящим изобретением может декодировать из битового потока индикаторы, указывающие способ масштабирования вектора движения по глубине, используемый в предлагаемом MVP. Затем декодер может соответствующим образом выполнять масштабирование вектора движения и впоследствии использовать масштабированные векторы движения в предлагаемом MVP для текстуры. В некоторых вариантах осуществления настоящего изобретения показатели подобия, которые применяются в предлагаемом MVP, могут настраиваться для использования размера и/или формы блока, отличных от размера и/или формы cb, в процессе сравнения подобия. Например, если цикловое разрешение по глубине отличается от циклового разрешения яркостной текстуры, размер блока при выполнении сравнения подобия может быть изменен в соответствии с отношением циклового разрешения по глубине к цикловому разрешению яркостной текстуры. Например, если цикловое разрешения яркостной текстуры в два раза превосходит цикловое разрешения по глубине по обеим координатным осям, для сравнения подобия может использовать блок, размер которого в два раза меньше размера cb по обеим координатным осям.
В некоторых вариантах осуществления настоящего изобретения показатель подобия, применяемый в MVP, может настраиваться для отражения различия в пространственном разрешении между данными текстуры или глубине. Например, если в рамках предлагаемого MVP выполнена повторная дискретизация изображения глубины для получения общего циклового разрешения повышающей дискретизации, то показатель подобия, который применяется при MVP, может настраиваться в соответствии с отношением, с использованием которого выполнена повышающая дискретизация глубины.
Указанная настройка может выполняться с использованием прореживания или субдискретизации, если разрешение данных о глубине выше разрешения векторов движения, или с использованием интерполяции или повышающей дискретизации информации d(MV(A), d(cb)) о глубине, если разрешение по глубине меньше разрешения данных текстуры или векторов (MV(A), MV(B)) движения. Например, если пространственное разрешение данных о яркостной текстуре в два раза выше пространственного разрешение данных о глубине по обеим координатным осям, и выполняется повторная дискретизация по глубине для получения общего циклового разрешения повышающей дискретизации, то каждый второй пиксель глубины по обеим координатным осям в изображении глубины на уровне общего циклового разрешения повышающей дискретизации может включаться в расчеты в рамках способа проверки подобия. Кодер может кодировать индикаторы или синтаксические элементы, указывающие показатель подобия, используемый в предлагаемом MVP. К таким индикаторам могут относиться один или более следующих элементов:
- Общее цикловое разрешение повышающей дискретизации.
- Схема прореживания и соотношение, подлежащее использованию при выборе пикселей по глубине для расчета показателей подобия. Например, может быть указано, что каждый второй пиксель по глубине (по обеим координатным осям) из изображения глубины на уровне общего циклового разрешения повышающей дискретизации используется при расчете показателей подобия.
- Размер блока или соотношение, указывающее взаимосвязь между изображениями текстуры и глубины, подлежащие использованию при расчете показателей подобия. Например, может быть указано, что для показателя подобия используется размер блока, в два раза меньший размера текущего блока cb текстуры по обеим координатным осям.
Кодер может кодировать такие индикаторы в различных частях кодируемого битового потока, например в наборе параметров последовательности, наборе параметров изображения, наборе параметров адаптации, в заголовке изображения или секции.
Декодер в соответствии с настоящим изобретением может декодировать из битового потока индикаторы, указывающие способ расчета показателей подобия, используемый в предлагаемом MVP. Затем декодер может выполнять расчет указанного показателя подобия для текстуры согласно предлагаемому MVP.
В соответствии с некоторыми другими вариантами осуществления настоящего изобретения, изображения текстуры и связанные изображения глубины могут представляться с использованием другого способа дискретизации. Например, каждый раздел кодированных данных текстуры (блоки PU, 4×4, 8×8, 16×8, 8×16 и другие блоки) может быть связан с одним значением глубины, которое может представлять среднее значение глубины для текущего раздела текстуры. Этот формат для изображения глубины можно рассматривать как неравномерное представление данных о глубине, и он может отличаться от типовой схемы дискретизации, используемой для изображений данных текстуры (однородная дискретизация).
На фиг. 20 показан пример такого представления, в котором серый прямоугольник справа обозначает границы изображения текстуры с регулярной дискретизацией, а серый прямоугольник слева обозначает границы изображения глубины, связанного с этими данными текстуры. Блоки {Cb1-Cb3} изображения текстуры состоят из группы пикселей изображения текстуры, представленного с помощью однородной схемы дискретизации. Однако информация о глубине {d(Cb1)-d(Cb3)} представлена одним значением глубины для блоков текстуры {Cb1-Cb3}, и эти значения показаны в красных кругах в левой части нижнего изображения. С использованием такого представления непосредственный доступ к блокам d(MV(A), d(Cb)) и d(MV(B), d(Cb)) глубины, на которые осуществляется ссылка, может отсутствовать, и для извлечения значения глубины, возможно, понадобится выполнение некоторых операций.
Предположим, что в примере на фиг. 20 блок X текстуры, на который осуществляется ссылка, адресуется посредством MV(A) из местоположения Cb, и пространственный размер блока X равен пространственному размеру блока Cb. В опорном изображении текстуры блок X может перекрывать несколько разделов данных текстуры (которые помечены как Cb1, Cb2, Cb3) и представлены с помощью однородной дискретизации. Поскольку данные о глубине представлены посредством неоднородной дискретизации, блок d(X), на который осуществляется ссылка, равный d(MV(A), d(Cb)), охватывает область глубины, которая представлена с помощью нескольких значений (d(Cb1), d(Cb2), d(Cb3)} карты глубины, показанных в красных кругах в пределах областей белых блоков.
Для выполнения MVP в случае, представленном на фиг. 20, значение d(X) глубины опорного блока X текстуры, на который осуществляется ссылка, требуется извлекать из доступных неоднородно дискретизированных данных {d(Cb1), d(Cb2) или d(Cb3)} о глубине или из соседних блоков путем повторной дискретизации. К примерам такой повторной дискретизации могут относиться линейные или нелинейные операции слияния (объединения) или усреднения доступных выборок глубины, которые инициируются для представления блоков d(X), на которые осуществляется ссылка, в таком неоднородном представлении. В некоторых случаях для совершенствования процесса оценки глубины могут использоваться данные о глубине из дополнительных выборок глубины в окружении {d(Cb1), d(Cb2), d(Cb3)}.
Для некоторых вариантов осуществления данные о глубине в неоднородном представлении могут передаваться в синтаксических элементах кодированных изображений текстуры, например, в заголовке секции или в синтаксических структурах кодированного блока текстуры. В таких вариантах осуществления настоящего изобретения для выполнения операции расчета d(X) потребуется извлечение информации о глубине из синтаксических элементов Cb1-Cb3 и последующее слияние/объединение или агрегирование информации о глубине d(Cb1)-d(Cb3), или выполнение других действий для формирования данных d(X).
В некоторых других вариантах осуществления настоящего изобретения данные о глубине при неоднородном представлении для соответствующих блоков Cb1-Cb3 могут извлекаться/оцениваться/ формироваться на стороне декодера на основе доступного многоракурсного представления данных текстуры. В таких вариантах осуществления настоящего изобретения для выполнения операции расчета d(X) потребуется оценка информации о глубине для блоков Cb1-Cb3 текстуры на основе доступного многоракурсного представления данных текстуры с целью последующего слияния/объединения или агрегирования информации о глубине d(Cb1)-d(Cb3), или выполнение других действий для формирования данных d(X). Далее описываются два примера способа, посредством которого может быть получена подходящая оценка для карты глубины текущего компонента ракурса текстуры на основе уже переданной информации.
Согласно первому способу, данные о глубине передаются как часть битового потока, и декодер с помощью этого способа декодирует карты глубины ранее кодированных ракурсов для декодирования зависимых ракурсов. Другими словами, оценка карты глубины может основываться на уже (де)кодированной карте глубины другого ракурса того же блока доступа или экземпляра дискретизации изображения. Если карта глубины для опорного ракурса кодирована перед текущим изображением, реконструированная карта глубины может отображаться или накладываться, или синтезироваться по ракурсам на координатную систему текущего изображения для получения подходящей оценки карты глубины для текущего изображения. На фиг. 21 показан такой способ отображения для простой карты глубины, состоящей из квадратного объекта переднего плана и фона с постоянной глубиной. Для каждой выборки заданной карты глубины значение выборки глубины преобразуется в пространственный вектор с точностью выборки. Затем каждая выборка карты глубины заменяется пространственным вектором диспаратности. Если две или более выборки перемещаются в одно и то же местоположение выборки, то выбирается значение выборки, представляющее минимальное расстояние от камеры (то есть, выборка с большим значением в некоторых вариантах осуществления настоящего изобретения). В целом, описанный способ отображения приводит к обнаружению в целевом ракурсе местоположений выборок, которым не назначено значение выборки глубины. Эти местоположения выборок обозначены в виде черной области в середине изображения, показанного на фиг. 21. Эти области представляют незаполненные части фона вследствие передвижения камеры, и они могут заполняться с использованием значений выборок окружающего фона. Для этого может использоваться простой алгоритм заполнения пустот, который позволяет по строкам обрабатывать преобразованную карту глубины. Каждый линейный сегмент, состоящий из последовательного местоположения выборки, которому не назначено значение, заполняется значением глубины двух соседних выборок, представляющих большее расстояние до камеры (то есть, меньшее значение глубины в некоторых вариантах осуществления настоящего изобретения).
На фиг. 21 в левой части показана исходная карта глубины; в центре показана преобразованная карта глубины после перемещения исходных выборок; и справа показана окончательная преобразованная карта глубины после заполнения пустот.
Согласно второму примеру реализации способа, оценка карты глубины основывается на кодированных диспаратности и векторах движения. В элементах произвольного доступа все блоки базового изображения ракурса кодируются внутренним образом. В изображениях зависимых ракурсов большинство блоков обычно кодированы с использованием предсказания с компенсацией движения (DCP (disparity-compensated prediction), также называемого межракурсным предсказанием), а оставшиеся блоки кодируются внутренним образом. При кодировании первого зависимого ракурса в блоке произвольного доступа информация о глубине или диспаратности отсутствует. Следовательно, подходящие векторы диспаратности могут быть получены только с использованием локального окружения, то есть посредством стандартного предсказания вектора движения. Однако после кодирования первого зависимого ракурса в блоке произвольного доступа переданные векторы диспаратности могут использоваться для получения оценки карты глубины, как это показано на фиг. 22. Таким образом, векторы диспаратности, используемые для предсказания с компенсацией диспаратности, преобразуются в значения глубины, и все выборки глубины блока с компенсацией диспаратности устанавливаются равными полученному значению глубины. Выборки глубины внутренне кодированных блоков получаются на основе выборок глубины соседних блоков, и используемый алгоритм подобен пространственному внутреннему предсказанию. Если кодируются более двух ракурсов, полученная карта глубины может отображаться на другие ракурсы с использованием описанного выше способа и применяться в качестве оценки карты глубины для получения подходящих векторов диспаратности.
Оценка карты глубины для изображения первого зависимого ракурса в блоке произвольного доступа используется для получения карты глубины следующего изображения первого зависимого ракурса. Базовый принцип алгоритма показан на фиг. 23. После кодирования изображения первого зависимого ракурса в блоке произвольного доступа полученная карта глубины отображается на базовый ракурс и сохраняется совместно с реконструированным изображением. Для следующего изображения базового ракурса обычно может применяться взаимное кодирование. Для каждого блока, кодированного с использованием предсказания с компенсацией движения (МСР, motion compensated prediction), связанные параметры движения применяются к оценке карты глубины. Соответствующий блок выборок карты глубины получается путем предсказания с компенсацией движения с использованием тех же параметров движения, что и связанный блок текстуры, при этом вместо реконструированного видеоизображения в качестве опорного изображения применяется связанная оценка карты глубины. С целью упрощения процесса компенсации движения и устранения генерации новых значений карты глубины в ходе предсказания с компенсацией движения для блока глубины может не задействоваться какой-либо вид интерполяции. Векторы движения перед использованием могут округляться с точностью до выборки. Выборки карты глубины внутренне кодированных блоков снова определяются на основе выборок карты глубины соседних блоков. Наконец, оценка карты глубины для первого зависимого ракурса, который используется для межракурсного предсказания параметров движения, выводится путем отображения полученной карты глубины базового ракурса на первый зависимый ракурс.
После кодирования второго изображения первого зависимого ракурса оценка карты глубины обновляется на основе фактически кодированных параметров движения и диспаратности, как это показано на фиг. 24. Для блоков кодируемых с использованием предсказания с компенсацией диспаратности, выборки карты глубины получаются посредством преобразования вектора диспаратности в значение глубины. Выборки карты глубины для блоков, кодируемых с использованием предсказания с компенсацией движения, могут быть получены путем предсказания с компенсацией движения ранее оцененных карт глубины, подобно тому, как это происходит для базового ракурса. Для учета потенциальных изменений глубины может использоваться механизм, с помощью которого определяются новые значения глубины путем внесения коррекции глубины. Уровень коррекции глубины определяется путем преобразования разности между векторами движения для текущего блока и соответствующего опорного блока базового ракурса в разность значений глубины. Значения глубины для внутренне кодированных блоков снова определяются путем пространственного предсказания. Обновленная карта глубины отображается на базовый ракурс и сохраняется совместно с реконструированным изображением. Она также может использоваться для получения оценки карты глубины для других ракурсов в том же блоке доступа.
Описанный процесс повторяется для последующих изображений. После кодирования изображения базового ракурса определяется оценка карты глубины для изображения базового ракурса путем предсказания с компенсацией движения с использованием переданных параметров движения. Эта оценка отображается на второй ракурс и используется для межракурсного предсказания параметров движения. После кодирования изображения второго ракурса оценка карты глубины обновляется с использованием фактически применяемых параметров кодирования. В следующем блоке произвольного доступа межракурсное предсказание параметров движения не используется, и после декодирования первого зависимого ракурса блока произвольного доступа карта глубины может повторно инициализироваться, как это описано выше.
В некоторых других вариантах осуществления настоящего изобретения предлагаемая схема MVP может комбинироваться с другими схемами предсказания вектора движения, такими как MVP в H.264/AVC или MVP в проекте высокоэффективного кодирования видеосигнала (HEVC). Например, для контента MVD. B котором доступная информация о глубине является неточной или зашумленной, предлагаемая схема MVP может адаптивно дополняться альтернативными схемами MVP. Решение о применении альтернативных схем MVP может приниматься на стороне кодера и сообщаться декодеру в битовом потоке. Выбор MVP, например, может основываться на оптимизации уровня искажений в зависимости от скорости передачи на уровне кадра. В этом варианте осуществления настоящего изобретения кадр кодируется с использованием различных схем MVP, и выбирается MVP, обеспечивающий минимальную оценку уровня искажений в зависимости от скорости передачи, о чем сообщается в наборе параметров изображения (PPS, picture parameter set), наборе параметров адаптации (APS), заголовке изображения, заголовке секции и т.п. В альтернативном варианте выбор MVP может осуществляться на уровне секции, блока или раздела блока, и индекс MVP или подобный ему индикатор, указывающий используемую схему MVP, сообщается в заголовке секции или в синтаксической структуре блока перед кодированным разделом блока. В таких вариантах осуществления декодер извлекает индекс MVP или подобный ему индикатор из битового потока и соответствующим образом конфигурирует процесс декодирования.
Ниже более подробно описывается подходящее устройство и возможные механизмы для реализации вариантов осуществления настоящего изобретения. Вначале со ссылкой на фиг. 10 рассматривается блок-схема типового устройства или электронного прибора 50, который может включать в свой состав кодек, соответствующий варианту осуществления настоящего изобретения.
Электронный прибор 50 может, например, представлять собой мобильный терминал или пользовательское оборудование системы беспроводной связи. Однако следует отметить, что варианты настоящего изобретения могут быть реализованы в рамках любого электронного прибора или устройства, для которого может потребоваться выполнение операций кодирования и декодирования либо кодирования или декодирования видеоизображений.
Устройство 50 может содержать корпус 30, предназначенный для размещения и защиты компонентов прибора. Устройство 50 может также содержать дисплей 32, выполненный в виде жидкокристаллического дисплея. В других вариантах осуществления настоящего изобретения дисплей может быть выполнен в соответствии с любой подходящей технологией, позволяющей отображать изображение или видеокадры. Устройство 50 может также содержать клавиатуру 34. В других вариантах осуществления настоящего изобретения могут использоваться любые подходящие механизмы поддержки интерфейса ввода данных или пользовательского интерфейса. Например, пользовательский интерфейс может быть реализован в виде виртуальной клавиатуры или системы ввода данных, являющейся частью сенсорного дисплея. Устройство может содержать микрофон 36 или любое подходящее средство приема аудиосигнала, которое может представлять собой цифровое или аналоговое средство приема сигнала. Устройство 50 может также содержать средства вывода аудиосигнала, которое в вариантах осуществления настоящего изобретения может представлять собой одно из следующих средств: наушники 38, динамик либо аналоговое или цифровое подключение к аудиовыходу. Устройство 50 может также содержать батарею 40 (или в других вариантах осуществления настоящего изобретения устройство может получать питание от любого подходящего мобильного источника энергии, такого как солнечный фотоэлемент, топливный элемент или аккумулятор часового механизма). Устройство может также содержать инфракрасный порт 42 для ближней связи (в пределах видимости) с другими устройствами. В других вариант осуществления настоящего изобретения устройство 50 может также содержать любое подходящее средство для ближней связи, такое, например, как беспроводное соединение Bluetooth или беспроводное соединение USB/firewire.
В состав устройства 50 может входить контроллер 56 или процессор для управления устройством 50. Контроллер 56 может быть соединен с памятью 58, в которой, согласно вариантам осуществления настоящего изобретения, могут храниться данные, представляющие как изображение, так и аудиосигнал, и/или инструкции, предназначенные для выполнения контроллером 56. Контроллер 56 может быть также соединен со схемой 54 кодека, подходящей для выполнения кодирования и декодирования аудио и/или видеоинформации или участия в процессах кодирования и декодирования, выполняемых контроллером 56.
Устройство 50 может также содержать блок 48 считывания карт и смарт-карту 46, например UICC и блок считывания UICC, позволяющие предоставлять пользовательскую информацию и подходящие для предоставления аутентификационной информации с целью аутентификации и авторизации пользователя.
Устройство 50 может содержать схему 52 радиоинтерфейса, соединенную с контроллером и позволяющую генерировать сигналы для беспроводной связи, например для связи с сетью сотовой связи, сетью беспроводной связи или локальной сетью беспроводной связи. Устройство 50 также может включать в свой состав антенну 44, соединенную со схемой 52 радиоинтерфейса и предназначенную для передачи радиочастотных сигналов, сгенерированных в схеме 52 радиоинтерфейса, в другие устройства, и для приема радиочастотных сигналов из других устройств.
В некоторых вариантах осуществления настоящего изобретения устройство 50 содержит камеру, позволяющую записывать или обнаруживать отдельные кадры, которые затем передаются для обработки в кодек 54 или в контроллер. В других вариантах осуществления настоящего изобретения устройство может принимать для обработки данные, представляющие видеоизображение, из другого устройства, чтобы затем передать и/или сохранить эти данные. В других вариантах осуществления настоящего изобретения устройство 50 может принимать изображение для кодирования/декодирования по беспроводной или проводной линии. На фиг. 12 показан пример системы, в рамках которой могут использоваться варианты осуществления настоящего изобретения. Система 10 содержит множество устройств связи, которые могут взаимодействовать друг с другом через одну или более сетей. Система 10 может включать в свой состав любое сочетание проводных или беспроводных сетей, включая, но не ограничиваясь этими примерами, беспроводную телефонную сотовую сеть (например, сеть GSM, UMTS, CDMA и т.д.), локальную беспроводную сеть (WLAN, wireless local area network), например, определенную любым из стандартов IEEE 802.x, персональную сеть Bluetooth, локальную сеть Ethernet, кольцевую локальную сеть с маркерным доступом (token ring), глобальную сеть и Интернет.
Система 10 может содержать как проводные, так и беспроводные средства связи или устройства 50, подходящие для реализации вариантов настоящего изобретения.
Например, на фиг. 12 показана мобильная телефонная сеть 11 и графическое представление Интернета 28. Соединение с Интернетом 28 может осуществляться (без ограничения приведенными ниже примерами) с помощью беспроводных соединений для дальней связи, ближней связи и различных проводных соединений, включая (но не ограничиваясь этими примерами) телефонные линии, кабельные линии, линии электропитания и подобные тракты связи. К примерам устройств связи, показанным в рамках системы 10, можно отнести (без ограничения этими примерами) электронный прибор или устройство 50, комбинированное устройство 14, состоящее из персонального информационного устройства (PDA, personal digital assistant) и мобильного телефона, PDA 16, интегрированное устройство 18 обработки сообщений (IMD, integrated messaging device), настольный компьютер 20, ноутбук 22. Устройство 50 может быть стационарным или мобильным устройством, перемещаемым отдельным пользователем. Устройство 50 может также располагаться в транспортном средстве, включая (но не ограничиваясь приведенными примерами) легковой автомобиль, грузовик, такси, автобус, поезд, судно, самолет, велосипед, мотоцикл или любое подобное подходящее транспортное средство. Некоторые другие устройства могут посылать и принимать вызовы и сообщения и осуществлять связь с провайдерами услуг через беспроводное соединение 25 с базовой станцией 24. Базовая станция 24 может соединяться с сетевым сервером 26, который позволяет выполнять связь между мобильной телефонной сетью 11 и Интернетом 28. Система может содержать дополнительные устройства связи различных типов.
Устройства связи могут осуществлять связь с использованием различных технологий связи, включая (но не ограничиваясь приведенными примерами) множественный доступ с кодовым разделением (CDMA, code division multiple access), глобальные системы для мобильной связи (GSM, global system for mobile communications), универсальную систему мобильной связи (UMTS, universal mobile telecommunications system), множественный доступ с разделением по времени (TDMA time divisional multiple access), множественный доступ с разделением по частоте (FDMA, frequency division multiple access), протокол управления передачей/Интернет-протокол (TCP-IP, transmission control protocol-internet protocol), службу передачи коротких сообщений (SMS, short messaging service), службу передачи мультимедийных сообщений (MMS, multimedia messaging service), электронную почту, службу мгновенного обмена сообщениями (IMS, instant messaging service), Bluetooth, IEEE 802.11 и любые другие подобные технологии беспроводной связи. Устройства связи, задействованные в реализации различных вариантов осуществления настоящего изобретения, могут осуществлять связь с использованием различных сред передачи, включая (но не ограничиваясь приведенными примерами) радиоинтерфейс, инфракрасные, лазерные, кабельные соединения и любые другие подходящие соединения.
Хотя в приведенных выше примерах описываются варианты осуществления настоящего изобретения в рамках кодека, расположенного в электронном приборе, следует принимать во внимание, что изобретение, как описано ниже, может быть реализовано как часть любого видеокодека. Таким образом, например, варианты осуществления настоящего изобретения могут быть реализованы в видеокодеке, который может выполнять кодирование видеосигнала, передаваемого по фиксированным или проводным линиям связи.
Следовательно, пользовательское оборудование может содержать видеокодек, подобный тем, что описаны в представленных выше вариантах осуществления настоящего изобретения. Следует отметить, что термин пользовательское оборудование охватывает пользовательское оборудование беспроводной связи любого подходящего типа, например мобильные телефоны, портативные устройства обработки данных или портативные веб-браузеры.
Кроме того, элементы наземной сети мобильной связи общего пользования (PLMN, public land mobile network) также могут содержать описанные выше видеокодеки.
В целом, различные варианты осуществления настоящего изобретения могут быть реализованы в виде аппаратуры или специализированных схем, программного обеспечения, логических схем или любой комбинации указанных средств. Например, некоторые аспекты могут быть реализованы в виде аппаратных средств, в то время как другие аспекты могут быть реализованы в виде микропрограммного или программного обеспечения, которое может выполняться контроллером, микропроцессором или другим вычислительным устройством, хотя изобретение не ограничено только перечисленными средствами. Хотя различные аспекты настоящего изобретения могут быть проиллюстрированы и описаны в виде блок-схем, алгоритмов или с использование некоторых других графических представлений, достаточно очевидно, что описанные здесь блоки, устройства, системы, методы или способы могут быть реализованы (не ограничиваясь приведенными примерами) в виде аппаратного, программного, микропрограммного обеспечения, специализированных схем или логических схем, универсальных аппаратных средств или контроллера, или других вычислительных устройств, или некоторой комбинации указанных средств.
Варианты осуществления этого изобретения могут быть реализованы с помощью компьютерного программного обеспечения, выполняемого процессором данных мобильного устройства, например блоком процессора, или с помощью аппаратного обеспечения, или посредством комбинации программного и аппаратного обеспечения. Кроме того, в этом отношении следует отметить, что различные показанные на чертежах блоки логических алгоритмов могут представлять собой шаги программы или взаимосвязанные логические схемы, блоки и функции, или комбинацию шагов программы и логических схем, блоков и функций. Программное обеспечение может храниться на физических носителях, таких как микросхемы памяти или блоки памяти, реализованные в процессоре, на магнитных носителях, таких как жесткий диск или дискеты, и на оптических носителях, таких, например, как диски DVD и их разновидности и диски CD.
Блоки памяти могут быть любого типа, подходящего к локальной технической среде, и могут быть реализованы с использованием любых подходящих технологий хранения данных и представлять собой, например, устройства полупроводниковой памяти, устройства и системы магнитной памяти, устройства и системы оптической памяти, постоянное запоминающее устройство и съемные блоки памяти. Процессоры данных могут быть любого типа, подходящего для локальной технической среды, и могут, например, содержать один или более универсальных компьютеров, специализированных компьютеров, микропроцессоров, цифровых сигнальных процессоров (DSP, digital signal processor) и процессоров, основанных на многоядерной архитектуре, а также другие подобные устройства.
Варианты осуществления настоящего изобретения могут быть выполнены в виде различных компонентов, таких как модули интегральных схем. В целом, конструирование интегральных схем является в высшей степени автоматизированным процессом. Имеются комплексные и эффективные программные средства для преобразования конструкции логического уровня в полупроводниковую схему, подготовленную для травления и формирования полупроводниковой основы.
Программы, производимые, например, компанией Synopsys, Inc., расположенной в Маунтин Вью, Калифорния, и компанией Cadence Design, расположенной в Сан Хосе, Калифорния, автоматически разводят проводники и размещают компоненты на полупроводниковом кристалле с использованием четко установленных правил конструирования, а также библиотек, в которых хранятся заранее записанные конструктивные модули. По окончании разработки полупроводниковой схемы полученная в результате конструкция в стандартизованном электронном формате (например, Opus, GDSII и т.п.) может быть передана в средство производства полупроводникового устройства или производственный модуль для изготовления.
Приведенное описание с помощью типовых примеров, не ограничивающих возможности реализации изобретения, предоставляет полное и информативное описание примеров осуществления настоящего изобретения. Однако специалисту в соответствующей области техники в свете изложенного описания, изученного в совокупности с прилагаемыми чертежами и формулой изобретения, могут быть очевидны различные модификации и адаптации. Тем не менее, любые виды таких и подобных модификаций изложенных идей остаются в пределах объема настоящего изобретения.


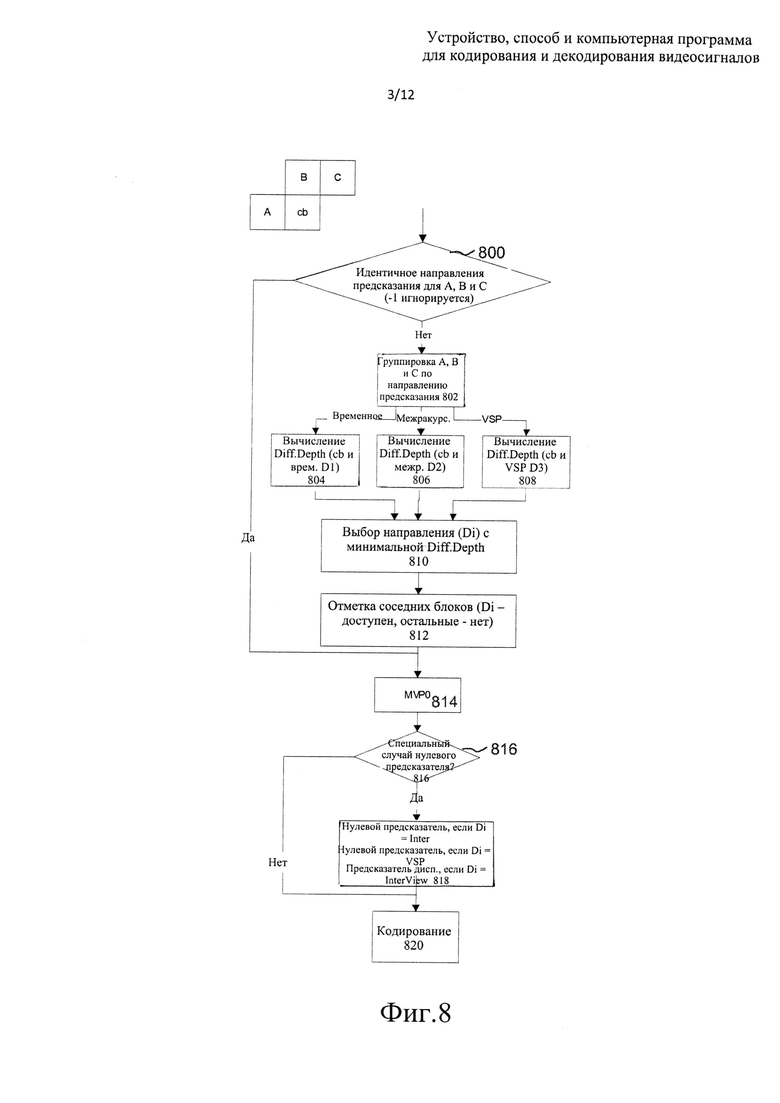




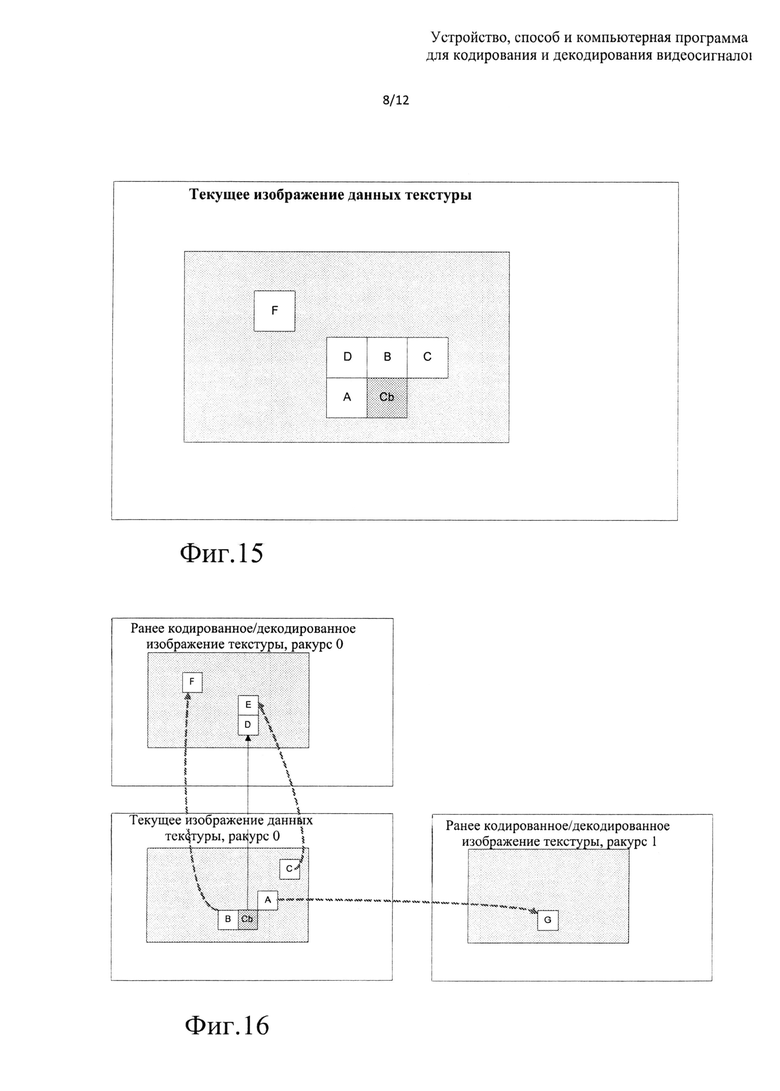
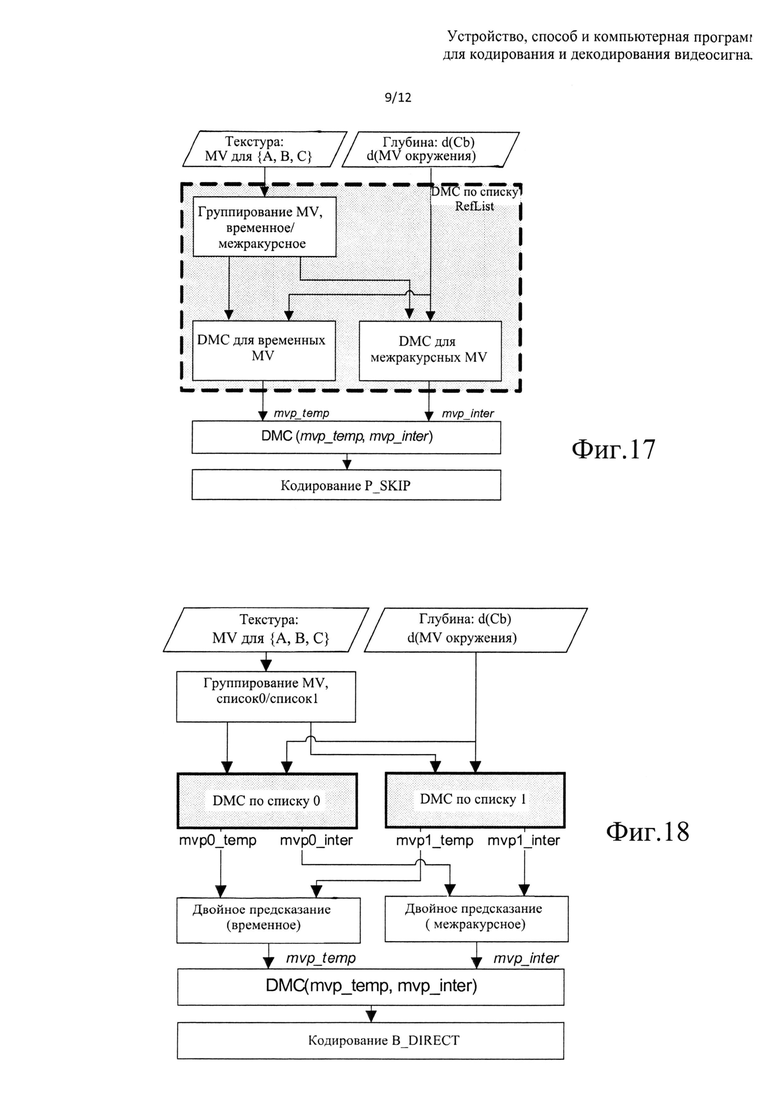


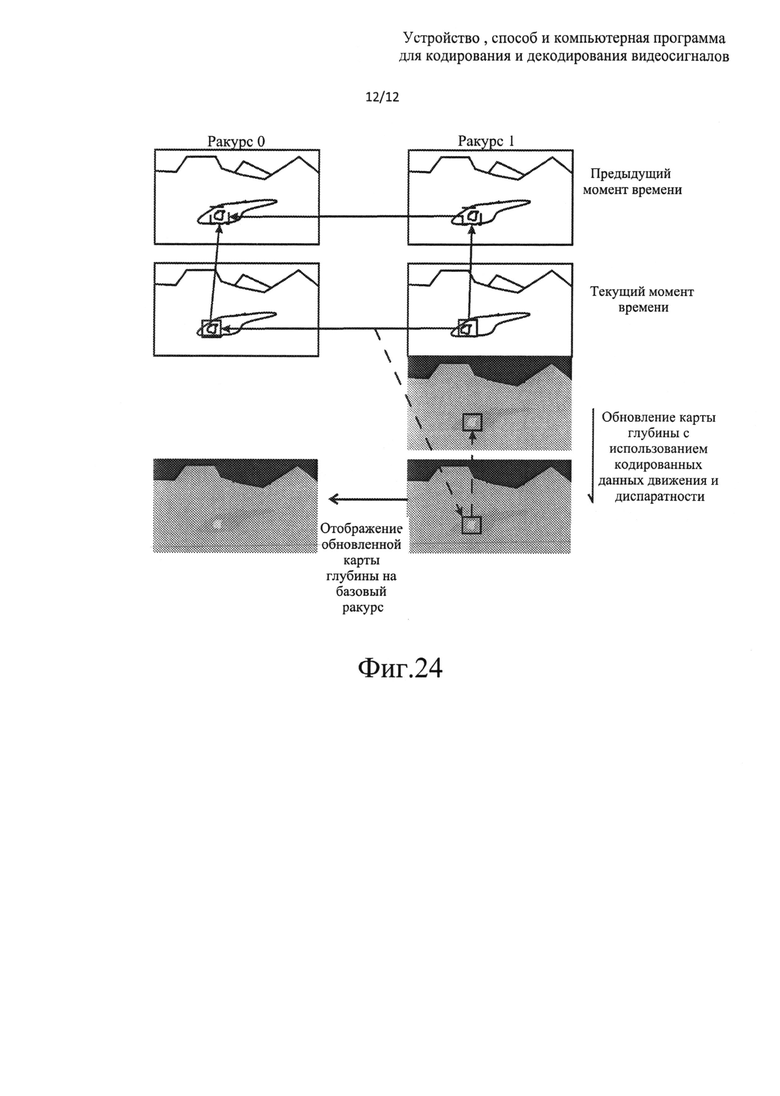
Изобретение относится к кодированию и декодированию трехмерного видеоконтента на основе стандарта H.264/AVC (усовершенствованное кодирование видеосигнала) или MVC (многоракурсное кодирование видеосигнала). Техническим результатом является улучшение эффективности предсказания вектора движения (MVP) для многоракурсного кодирования. Указанный технический результат достигается тем, что информация о движении блока текстуры используется для получения информации о движении, характеризующейся глубиной/диспаратностью. В альтернативном варианте информация о движении, характеризующаяся глубиной/диспаратностью, используется для получения информации о движении блока текстуры. 8 н. и 4 з.п. ф-лы, 24 ил. 
1. Способ декодирования видеосигналов, включающий:
декодирование, из битового потока, первого кодированного блока текстуры первого кодированного изображения текстуры с получением первого блока текстуры, при этом декодирование первого кодированного блока текстуры включает:
получение первого блока глубины/диспаратности, пространственно совмещенного с первым блоком текстуры;
извлечение вектора движения диспаратности из первого блока глубины/диспаратности;
использование вектора движения диспаратности для нахождения во втором изображении текстуры совмещенного блока с компенсацией диспаратности, вектор движения которого используется при предсказании вектора движения для первого блока текстуры, и
декодирование первого кодированного блока текстуры с использованием предсказания вектора движения.
2. Способ по п. 1, также включающий:
извлечение списка подходящих векторов движения и
декодирование, из битового потока, индекса выбранного подходящего предсказания движения из списка подходящих векторов движения.
3. Устройство для декодирования видеосигналов, содержащее видеодекодер, сконфигурированный для
декодирования, из битового потока, первого кодированного блока текстуры первого кодированного изображения текстуры с получением первого блока текстуры, при этом декодирование первого кодированного блока текстуры включает:
получение первого блока глубины/диспаратности, пространственно совмещенного с первым блоком текстуры;
извлечение вектора движения диспаратности из первого блока глубины/диспаратности;
использование вектора движения диспаратности для нахождения во втором изображении текстуры совмещенного блока с компенсацией диспаратности, вектор движения которого используется при предсказании вектора движения для первого блока текстуры, и
декодирование первого кодированного блока текстуры с использованием предсказания вектора движения.
4. Устройство по п. 3, отличающееся тем, что видеодекодер также сконфигурирован для
извлечения списка подходящих векторов движения и
декодирования, из битового потока, индекса выбранного подходящего предсказания движения из списка подходящих векторов движения.
5. Машиночитаемый носитель информации, на котором хранится используемый устройством код, при исполнении которого процессором устройство выполняет следующие операции:
декодирование, из битового потока, первого кодированного блока текстуры первого кодированного изображения текстуры с получением первого блока текстуры, при этом декодирование первого кодированного блока текстуры включает:
получение первого блока глубины/диспаратности, пространственно совмещенного с первым блоком текстуры;
извлечение вектора движения диспаратности из первого блока глубины/диспаратности;
использование вектора движения диспаратности для нахождения во втором изображении текстуры совмещенного блока с компенсацией диспаратности, вектор движения которого используется при предсказании вектора движения для первого блока текстуры, и
декодирование первого кодированного блока текстуры с использованием предсказания вектора движения.
6. Устройство для декодирования видеосигналов, содержащее по меньшей мере один процессор и по меньшей мере один модуль памяти, в котором хранится код, при исполнении которого по меньшей мере одним указанным процессором устройство выполняет следующие операции:
декодирование на основе битового потока первого кодированного блока текстуры первого кодированного изображения текстуры в первый блок текстуры, при этом процедура декодирования первого кодированного блока текстуры включает:
декодирование, из битового потока, первого кодированного блока текстуры первого кодированного изображения текстуры с получением первого блока текстуры, при этом декодирование первого кодированного блока текстуры включает:
получение первого блока глубины/диспаратности, пространственно совмещенного с первым блоком текстуры;
извлечение вектора движения диспаратности из первого блока глубины/диспаратности;
использование вектора движения диспаратности для нахождения во втором изображении текстуры совмещенного блока с компенсацией диспаратности, вектор движения которого используется при предсказании вектора движения для первого блока текстуры, и
декодирование первого кодированного блока текстуры с использованием предсказания вектора движения.
7. Способ кодирования видеосигналов, включающий:
кодирование первого кодированного блока текстуры первого кодированного изображения текстуры с получением первого блока текстуры, при этом кодирование первого кодированного блока текстуры включает:
получение первого блока глубины/диспаратности, пространственно совмещенного с первым блоком текстуры;
извлечение вектора движения диспаратности из первого блока глубины/диспаратности;
использование вектора движения диспаратности для нахождения во втором изображении текстуры совмещенного блока с компенсацией диспаратности, вектор движения которого используется при предсказании вектора движения для первого блока текстуры, и
кодирование первого кодированного блока текстуры с использованием предсказания вектора движения.
8. Способ по п. 7, также включающий:
извлечение списка подходящих векторов движения и
кодирование индекса, указывающего вектор движения диспаратности в списке подходящих векторов движения.
9. Устройство для кодирования видеосигналов, содержащее видеокодер, сконфигурированный для
кодирования первого кодированного блока текстуры первого кодированного изображения текстуры с получением первого блока текстуры, при этом кодирование первого кодированного блока текстуры включает:
получение первого блока глубины/диспаратности, пространственно совмещенного с первым блоком текстуры;
извлечение вектора движения диспаратности из первого блока глубины/диспаратности;
использование вектора движения диспаратности для нахождения во втором изображении текстуры совмещенного блока с компенсацией диспаратности, вектор движения которого используется при предсказании вектора движения для первого блока текстуры, и
кодирование первого кодированного блока текстуры с использованием предсказания вектора движения.
10. Устройство по п. 9, отличающееся тем, что видеодекодер также сконфигурирован для
извлечения списка подходящих векторов движения и
кодирования индекса, указывающего вектор движения диспаратности в списке подходящих векторов движения.
11. Машиночитаемый носитель информации, на котором хранится используемый устройством код, при исполнении которого процессором устройство выполняет следующие операции:
кодирование первого кодированного блока текстуры первого кодированного изображения текстуры с получением первого блока текстуры, при этом кодирование первого кодированного блока текстуры включает:
получение первого блока глубины/диспаратности, пространственно совмещенного с первым блоком текстуры;
извлечение вектора движения диспаратности из первого блока глубины/диспаратности;
использование вектора движения диспаратности для нахождения во втором изображении текстуры совмещенного блока с компенсацией диспаратности, вектор движения которого используется при предсказании вектора движения для первого блока текстуры, и
кодирование первого кодированного блока текстуры с использованием предсказания вектора движения.
12. Устройство для кодирования видеосигналов, содержащее по меньшей мере один процессор и по меньшей мере один модуль памяти, в котором хранится код, при исполнении которого по меньшей мере одним указанным процессором устройство выполняет следующие операции:
кодирование первого кодированного блока текстуры первого кодированного изображения текстуры с получением первого блока текстуры, при этом кодирование первого кодированного блока текстуры включает:
получение первого блока глубины/диспаратности, пространственно совмещенного с первым блоком текстуры;
извлечение вектора движения диспаратности из первого блока глубины/диспаратности;
использование вектора движения диспаратности для нахождения во втором изображении текстуры совмещенного блока с компенсацией диспаратности, вектор движения которого используется при предсказании вектора движения для первого блока текстуры, и
кодирование первого кодированного блока текстуры с использованием предсказания вектора движения.
| SEUNGCHUL RYU ET AL, Adaptive competition for motion vector prediction in multi-view video coding, 3DTV CONFERENCE: THE TRUE VISION - CAPTURE, TRANSMISSION AND DISPLAY OF 3D VIDEO (3DTV-CON), 2011, IEEE, 16 May 2011 | |||
| RU 2008132834 A, 2010-02-20 | |||
| WO 2010087955 A1, 2010-08-05 | |||
| US 2010284466 A1, 2010-11-11 | |||
| WO 2010043773 A1, 2010-04-22. |

