ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к способу классификации веб-страниц и организации соответствующего информационного наполнения, содержащему этап записи Интернет-адресов, содержащий выполнение процедур автоматической записи, и этап выбора, на котором указанным Интернет-адресам назначают соответствующий коэффициент релевантности.
УРОВЕНЬ ТЕХНИКИ
Как известно, подключенный к сети Интернет и снабженный браузером персональный компьютер обеспечивают возможность отображения веб-страниц.
В частности, под термином «персональный компьютер» понимают электронное устройство, снабженное интерфейсом подключения к сети Интернет, а термином «браузер» называют программное обеспечение, устанавливаемое на указанное электронное устройство для отображения веб-страниц. Примером браузера является программа Internet Explorer компании Microsoft®.
В частности, веб-страницы хранятся на серверах, которые соединены с сетью Интернет. Интернет-адрес веб-страницы записывают в браузере, например в его верхней зоне или строке, после чего браузер, как правило, в основной зоне своего окна, отображает имеющую этот адрес веб-страницу.
Также известны поисковые скрипты или поисковые программы для поиска по меньшей мере одной веб-страницы, которые функционируют на основании задаваемого пользователем критерия поиска.
Обычно работа с подобными поисковыми скриптами или поисковыми программами возможна через отображаемый с помощью браузера графический интерфейс с зоной для ввода критерия поиска и клавишей активации.
Исходя из того, что в сети Интернет имеется огромное количество веб-страниц, поисковый скрипт или поисковая программа может предоставить большое количество веб-страниц, отвечающих заданному критерию поиска.
Для того чтобы облегчить пользователю поиск нужной информации на найденных веб-страницах, поисковый скрипт снабжен или поисковая программа снабжена способом классификации, который определяет значимость каждой веб-страницы. Иными словами, после исполнения поискового скрипта или поисковой программы пользователь получает список веб-страниц, где веб-страницы упорядочены по их значимости, которая определена способом классификации.
В одном известном способе классификации, который известен под названием PageRank, каждой веб-странице присваивают показатель значимости, который обычно называют рангом. В частности, ранг веб-страницы A определяют по количеству дополнительных веб-страниц В1, …, Bx, на которых имеются ссылки на веб-страницу A.
В частности, согласно способу классификации PageRank, каждая веб-страница может голосовать за другие веб-страницы посредством ссылок на них, также известных как переходы. Иными словами, если с некоторой веб-страницы пользователь посредством ссылок может перейти на заданные веб-страницы, то ранг заданных веб-страниц повышается. Как правило, чем выше популярность веб-страницы, т.е. чем больше количество переходов на нее, тем больше голосов, отданных за эту веб-страницу.
Однако действующие по описанному выше принципу способы классификации имеют ограничения, которые понятны из нижеследующего описания.
На фиг.1 показан интерфейс 10 для активации поискового скрипта или поисковой программы для поиска веб-страниц.
Интерфейс 10 представляет собой, например, веб-страницу, которая содержит зону или строку 1 для ввода критерия поиска и клавишу 2 для активации поискового скрипта или поисковой программы.
На фиг.1 в качестве критерия поиска введено имя итальянского изобретателя и художника Леонардо да Винчи (Leonardo da Vinci). Иными словами, вводимый в строку 1 интерфейса 10 критерий поиска представлен тремя связанными ключевыми словами: «Leonardo», «da», «Vinci».
Основная зона 4 интерфейса 10 отображает результаты исполнения поискового скрипта или поисковой программы по критерию «Leonardo da Vinci». Результаты поиска представлены в виде списка 3 Интернет-адресов веб-страниц, из которых в зоне 4 отображены только несколько первых совпадений 3a-3h.
Количество идентифицируемых веб-страниц очень велико (в данном примере несколько миллионов), а поисковый скрипт или поисковая программа размещает их список внутри графического интерфейса 10 на последовательных страницах. Как правило, страницы интерфейса 10 имеют стандартную нумерацию 1…n, которая расположена в нижней зоне интерфейса 10 (на фиг.1 не показано), так что по запросу пользователя в зоне 4 может быть отображена соответствующая зона списка 3 Интернет-адресов.
Например, предположим, что поисковым скриптом или поисковой программой идентифицированы сто веб-страниц, которым соответствует список 3 из ста Интернет-адресов, а каждая страница интерфейса 10 вмещает десять таких Интернет-адресов, т.е. в нижней зоне интерфейса 10 отображены числа от единицы до десяти. При выборе числа один в зоне 4 будут отображены Интернет-адреса с первого до десятого, т.е. первая страница списка 3. В частности, при использовании поисковых скриптов или поисковых программ, описываемых в настоящем примере, Интернет-адреса в списке 3 расположены в порядке уменьшения значимости, которая определена соответствующим способом классификации, следовательно, на первой странице списка 3 расположены адреса тех веб-страниц, которые указанный способ классификации отнес к наиболее значимым.
При выборе числа два в зоне 4 интерфейса 10 будут отображены Интернет-адреса с одиннадцатого до двадцатого, которые соответствуют второй странице списка 3. При выборе числа десять будет отображена последняя страница списка 3, содержащая адреса тех веб-страниц, которые указанный способ классификации, используемый поисковым скриптом или поисковой программой, отнес к наименее соответствующим критерию поиска.
Иными словами, порядок отображения результатов поиска зависит от способа классификации.
В частности, в показанном на фиг.1 примере способ классификации, используемый программой Google®, из всех идентифицированных веб-страниц посчитал наиболее значимой веб-страницу 3a, которая относится к Интернет-сервису Wikipedia, и на которой приведена статья об изобретателе и художнике Леонардо да Винчи.
На веб-странице 3b описано наследие, оставленное человечеству изобретателем и художником Леонардо да Винчи; веб-страница 3c относится к Национальному музею науки и технологии; веб-страница 3e относится к аэропорту Рима «Леонардо да Винчи».
Из приведенного выше списка, который получен с использованием программы Google® и содержит пять первых по значимости результатов поиска, видно, что способы классификации на основе PageRank имеют следующие недостатки.
Поисковый скрипт или поисковая программа выдает лишнее: в настоящем примере целых три страницы (3d, 3f и 3h) из показанных восьми являются лишними, т.е. они находятся внутри сайтов, адреса которых (3c, 3e и 3g, соответственно) уже показаны выше. Кроме того, пользователь обычно не просматривает больше нескольких десятков результатов, выданных при использовании указанного способа, что также зачастую обусловлено чересчур широко сформулированным критерием поиска.
Хотя некоторые веб-страницы, находимые поисковым скриптом или поисковой программой, почти не релевантны или вовсе не релевантны, эти страницы все же обладают высоким рангом. Веб-страница 3e относится к аэропорту «Leonardo da Vinci», однако пользователь, который ищет информацию об аэропорте «Leonardo da Vinci», при вводе критерия поиска вряд ли опустит слово «аэропорт». Тем не менее, программа Google выдает веб-страницу 3e, относящуюся к сайту этого аэропорта, на пятой по значимости позиции. Веб-страница 3e - это типичный пример того, как информационный шум влияет на поиск, что является нежелательным, поскольку получаемые результаты не только не релевантны, но и бесполезны для выполняемого поиска. Можно убедиться, что многие из существующих сегодня поисковых скриптов или поисковых программ выдают похожий результат, т.е. в результате ввода в качестве критерия поиска «Leonardo da Vinci» присваивают адресу аэропорта «Leonardo da Vinci» высокий ранг.
Таким образом, способ классификации на основе PageRank, пусть и обеспечивает автоматическую организацию веб-страниц, но не способен выделять из найденного то, что наиболее соответствует запросу пользователя.
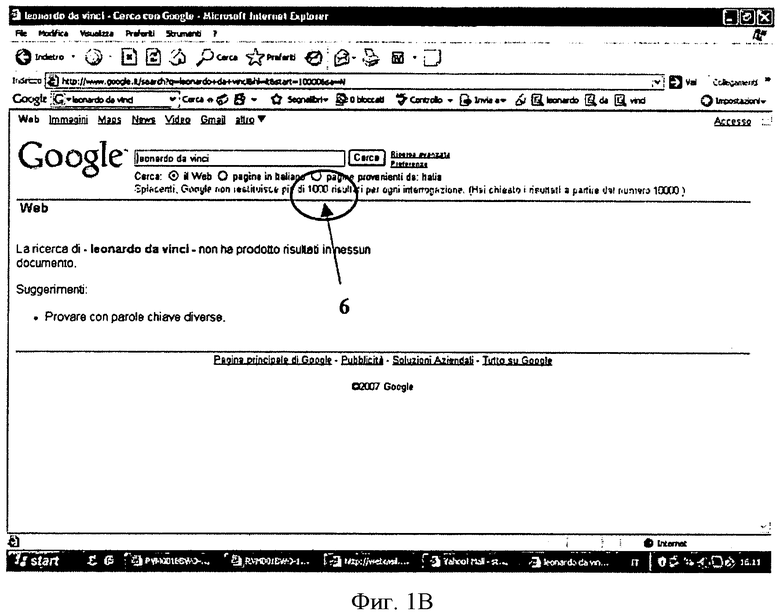
Еще одним недостатком известного способа классификации является то, что после выполнения поиска поисковый скрипт или поисковая программа сообщает пользователю количество найденных веб-страниц, но это количество не соответствует реальному количеству найденных и доступных для пользователя веб-страниц.
Например, на фиг.1A поисковый скрипт или поисковая программа сообщает, что по критерию поиска «Leonardo da Vinci» найдено 3880000 страниц, однако, как легко проверить на практике, доступными из них являются лишь первые 1000. В частности, на фиг.1B показано сгенерированное известной поисковой программой сообщение об ошибке, в котором говорится, что доступными для пользователя являются не более 1000 из найденных веб-страниц. Таким образом, сообщаемое - практически бесконечное - количество найденных по критерию поиска доступных веб-страниц не является реальным, поскольку пользователь способен открыть лишь некоторые из них, а многие веб-страницы, имеющие высокие ранги, могут даже не содержать интересующую его информацию.
Еще один недостаток описанных выше способов классификации веб-страниц связан с достоверностью источников, т.е. их известностью, признанием и авторитетом в области, которая определена критерием поиска. Иными словами, веб-страница, относящаяся к изобретателю и художнику Леонардо да Винчи, может иметь высокий ранг, но при этом содержать некорректную информацию, например ошибочные данные о дате его рождения, или недостаточную информацию, например, о некоторых наиболее известных его работах и других фундаментальных аспектах его жизни и творчества, которые могут интересовать пользователя, вводящего в качестве критерия поиска «Leonardo da Vinci».
Таким образом, веб-страница с высоким рангом может быть релевантна, но при этом не быть достоверным источником, как, например, страница 3b, которая создана индивидуальным пользователем и не является авторитетным источником.
Веб-страница, относящаяся к изобретателю Леонардо да Винчи, напротив, может содержать много избыточной информации, которая не представляет интереса для пользователя, что замедляет поиск необходимой информации, и что является примером информации с низкой релевантностью. По существу, способы классификации существующих сегодня веб-страниц не позволяют поисковым скриптам или поисковым программам выдавать отфильтрованный список, содержащий только релевантные и ожидаемые веб-страницы; вместо этого указанные скрипты и программы действуют как собиратели информации, которая зачастую очень слабо связана с задаваемым пользователем критерием поиска.
Следовательно, известные способы классификации вынуждают пользователя самостоятельно выполнять трудоемкие операции фильтрования и выбора, с тем чтобы из всех веб-страниц, найденных поисковым скриптом или поисковой программой, выбрать те, которые представляют интерес, при этом важные веб-страницы могут быть пропущены.
Задачей настоящего изобретения является разработка способа классификации веб-страниц, который лишен недостатков уровня техники, и при использовании которого результаты, выдаваемые поисковым скриптом или поисковой программой, не содержат информационного шума, соответствуют заданному пользователем критерию поиска, не содержат лишнего, а содержат только достоверное информационное наполнение, благодаря чему пользователь тратит меньше времени на фильтрацию результатов поиска.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Поставленная задача решена благодаря созданию способа классификации и организации соответствующего информационного наполнения, который способен по задаваемым на этапе конфигурации тематическим областям и леммам, используя в качестве источника различные поисковые системы и направленный глобальный сетевой поиск, отыскивать релевантные веб-страницы.
Глобальный сетевой поиск проводят в отношении сайтов, которые посчитают достоверными на этапе конфигурации сети.
Из указанной группы веб-страниц осуществляют выбор, при котором устраняют лишние веб-страницы, которые, например, представляют собой перевод одной и той же веб-страницы на разные языки или находятся на одном и том же сайте, и устраняют, при участии человека, сомнительные веб-страницы, т.е. такие, которые содержат информационный шум и/или получены из недостоверных источников.
Предлагаемый способ классификации веб-страниц и организации соответствующего информационного наполнения включает
- этап записи заданного количества Интернет-адресов, содержащий выполнение процедур автоматической записи указанных Интернет-адресов,
и
- этап выбора и назначения указанным Интернет-адресам соответствующего коэффициента релевантности.
Предлагаемый способ отличается тем, что
указанный соответствующий коэффициент релевантности на указанном этапе выбора назначают пропорционально его записи на этапе записи, и выбирают Интернет-адреса, коэффициент релевантности которых выше заданного порогового значения,
причем способ также содержит
- этап сокращения, на котором удаляют Интернет-адреса, коэффициент релевантности которых выше указанного порогового значения, но которые не удовлетворяют по меньшей мере одному критерию существенности, и
- этап проверки, на котором проверяют ряд указанных Интернет-адресов, удовлетворяющих указанным критериям существенности, при этом этап проверки содержит действия, выполняемые человеком.
При использовании предлагаемого способа классификации веб-страниц результаты, выдаваемые поисковым скриптом или поисковой программой, соответствуют заданному пользователем критерию поиска, не содержат лишних страниц и содержат веб-страницы с достоверным информационным наполнением, при этом пользователь тратит меньше времени на фильтрацию результатов поиска.
Использование предлагаемого способа позволяет повысить производительность поисков, выполняемых по веб-страницам, а наличие этапа сокращения позволяет снизить избыточность в веб-страницах (страницах с одного домена) без потери входной точки устраняемых страниц (страницы не удаляются). Кроме того, дополнительный технический результат изобретения заключается в уменьшении объема памяти, требуемого для организации информационного наполнения.
Другие характеристики и преимущества предлагаемого способа станут понятны из нижеследующего описания, которое приведено для примера, а не для ограничения со ссылками на прилагаемые чертежи.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1 показывает известный графический интерфейс поискового скрипта или поисковой программы.
Фиг.1А показывает несколько страниц, найденных поисковым скриптом или поисковой программой, представленным или представленной на фиг.1.
Фиг.1B показывает сообщение об ошибке, выдаваемое поисковым скриптом или поисковой программой, представленным или представленной на фиг.1.
Фиг.2 показывает графический интерфейс поискового скрипта или поисковой программы, в котором или в которой использован предлагаемый способ.
Фиг.3 схематично иллюстрирует организацию информационного наполнения согласно предлагаемому способу.
Фиг.4 подробно иллюстрирует организацию информационного наполнения после выполнения поиска по заданному критерию с использованием предлагаемого способа.
ПОДРОБНОЕ ОПИСАНИЕ
Ниже со ссылками на прилагаемые чертежи приведено описание способа классификации веб-страниц, содержащего несколько этапов.
В частности, первым этапом предлагаемого способа является этап конфигурации, на котором определяют тематические области для классификации веб-страниц.
Под тематической областью понимается область, относящаяся к некоторому разделу знаний, например, к технике, изобразительному искусству, литературе, спорту, текущим событиям, и определяемая группой описательных слов этого раздела знаний. Данное определение является лишь примером и не ограничивает области правовой защиты настоящего изобретения.
На этапе конфигурации для каждой тематической области задают леммы.
Термином «лемма» называют группу слов, которые связаны друг с другом морфологически, т.e. представляют собой формы одного и того же слова, или иным способом. Данное определение приведено для справки и не ограничивает объема настоящего изобретения.
Например, английские слова «run», «runs», «ran» и «running» являются формой одного и того же слова, которое принято записывать RUN. Слово RUN вносят в лемму X, которая содержит связанные с ним слова.
Кроме того, на этапе конфигурации каждую тематическую область ставят в соответствие с ключевыми словами этой области, некоторые из которых ставят в соответствие с одиночными леммами. Лемму, относящуюся более чем к одной тематической области, ставят в соответствие с несколькими ключевыми словами, относящимися к соответствующим тематическим областям.
Например, на этапе конфигурации в качестве леммы задают критерий поиска «Leonardo da Vinci». Эта лемма может относиться как к тематической области «Art» («Искусство») и быть поставлена в соответствие с ключевыми словами «Painting» («Рисование»), «Renaissance» («Ренессанс»), «Sculpture» («Скульптура»), так и к тематической области «Engineering» («Техника») и быть поставлена в соответствие с ключевыми словами «Canals» («Каналы»), «Hydraulics» («Гидравлика»).
В частности, на этапе конфигурации может быть выбран основной язык, например, итальянский, для задания тематических областей, лемм и ключевых слов.
На этапе конфигурации также задают допускаемые языки, например, те, которые имеют такой же алфавит, что и основной язык. Перечень допускаемых языков используют в качестве критерия существенности на этапе сокращения, о чем сказано ниже.
Использование основного языка и допускаемых языков позволяет осуществлять простой и комплексный поиск веб-страниц как на родном языке пользователя, так и на других языках. Иными словами, согласно предлагаемому способу классификации, по лемме «Leonardo da Vinci» могут быть идентифицированы не только веб-страницы на итальянском языке, но и веб-страницы на допускаемых языках, которые были заданы на этапе конфигурации.
Далее следует этап записи, на котором осуществляют сохранение заданного количества Интернет-адресов веб-страниц на основании тематических областей и соответствующих лемм, которые были заданы на этапе конфигурации. Указанное заданное количество Интернет-адресов веб-страниц тоже может быть определено на этапе конфигурации.
В частности, на этапе записи определяют связь веб-страницы по меньшей мере с одной леммой, например путем выявления указанной по меньшей мере одной леммы на веб-страницах. Если связь веб-страницы и леммы обнаружена, то Интернет-адрес такой веб-страницы сохраняют.
В частности, этап записи выполняют автоматическими процессами, например, глобальным сетевым поиском.
Глобальный сетевой поиск, начиная от веб-страницы х, которая связана с некоторой леммой, записывает Интернет-адреса веб-страниц z1, …, zn, которые непосредственно связаны с веб-страницей x. Также при глобальном сетевом поиске могут быть записаны Интернет-адреса веб-страниц y1, …, yn, с которыми веб-страница x связана не напрямую, а через веб-страницы z1, …, zn.
Имеется возможность настройки алгоритма глобального сетевого поиска на запись только непосредственно связанных веб-страниц, т.е. таких, на которые имеется прямой доступ с веб-страницы x, или на запись веб-страниц, связанных не напрямую, как указано выше.
Затем на этапе записи Интернет-адреса со ссылкой на соответствующую лемму сохраняют в базе данных, содержимое которой в данном способе классификации является информационным уровнем. В частности, согласно предлагаемому способу классификации указанный информационный уровень далее оптимизирован по таким показателям, как релевантность, избыточность, достоверность и информационный шум, о чем сказано ниже.
Следует отметить, что способ согласно настоящему изобретению позволяет классифицировать и организовать не только веб-страницы, но и по существу любые социальные сетевые сервисы.
Более конкретно, «социальный сетевой сервис» - это сервис в сети Интернет, позволяющий сообществам подключенных к сети людей, объединенных общими увлечениями, совместно действовать, изучая увлечения и действия других.
Большая часть социальных сетевых сервисов основана, главным образом, на сети Интернет и содержит различные средства взаимодействия между пользователями, такие как чат, передача сообщений, электронная почта, видео, голосовой чат, обмен данными, виртуальные дневники, группы для обсуждений и т.д. Наиболее распространенные социальные сетевые сервисы содержат тематические директории и средства связи с друзьями.
Согласно предлагаемому способу на этапе записи на основе тематических областей и лемм, которые были заданы на этапе конфигурации, сохраняют Интернет-адреса не только веб-страниц, но и заданного количества социальных сетевых сервисов, для чего определяют связь каждого социального сетевого сервиса по меньшей мере с одной леммой. Таким образом, задание лемм и тематических областей обеспечивают классификацию и организацию, благодаря которым по заданному критерию поиска получают те веб-страницы и социальные сетевые сервисы, которые не содержат информационного шума и не являются лишними, а являются релевантными и достоверными.
Например, если критерием поиска является слово «child» («ребенок»), то известным поисковым скриптом или поисковой программой будет идентифицировано огромное количество документов, содержащих слово «child», в то время как способ согласно настоящему изобретению классифицирует и записывает веб-страницы и социальные сетевые сервисы, связанные с леммой, которая содержит другие слова, относящиеся к слову «child».
Говоря точнее, способ согласно настоящему изобретению классифицирует и организует веб-страницы и социальные сетевые сервисы, содержащие не только слово «child», но и слова «children» («дети»), «boy» («мальчик») и т.п.
Следует указать, что информационный уровень или информационная библиотека, полученный или полученная на этапе записи, ниже называется первым информационным уровнем.
Более конкретно, этап записи содержит выполнение других автоматических процессов, например, мета-поиск. Как известно, мета-поиск предусматривает нахождение связанных с леммой веб-страниц путем опроса различных поисковых систем, каждая из которых классифицирует веб-страницы своим собственным способом.
Иными словами, при мета-поиске выполняется запрос нескольких поисковых систем для определения содержащих заданную лемму веб-страниц, которые эти системы уже сохранили, руководствуясь своими способами классификации. Примерами известных поисковых систем являются Google, Yahoo, Altavista и подобные.
Интернет-адреса веб-страниц, найденных посредством мета-поиска, вводят в первый информационный уровень или библиотеку. Кроме того, на этапе записи в первый информационный уровень записывают копию веб-страницы. Эту копию используют для ознакомительного просмотра, а также сравнивают с ее последующей версией, полученной при следующем глобальном сетевом поиске, с тем чтобы обеспечить возможность обновления веб-страницы в первом информационном уровне.
Согласно настоящему изобретению, способ классификации также содержит этап выбора, на котором выполняют сравнение Интернет-адресов, автоматически сохраненных на этапе записи.
В частности, Интернет-адреса, которые были записаны с использованием некоторой леммы алгоритмом глобального сетевого поиска, сравнивают с Интернет-адресами, которые были записаны с использованием этой же леммы посредством мета-поиска. Если Интернет-адрес был идентифицирован алгоритмом глобального сетевого поиска или на этапе конфигурации и в то же время был идентифицирован алгоритмом мета-поиска, то на этапе выбора он получает подтверждение. Фактически, идентификация адреса по одной и той же лемме сразу несколькими поисковыми алгоритмами и его идентификация на этапе конфигурации указывают на высокую вероятность того, что его информационное наполнение является релевантным.
Этап записи предпочтительно осуществляют с использованием разных автоматических алгоритмов, в основе которых необязательно лежат глобальный сетевой поиск, идентификация на этапе конфигурации, или мета-поиск. Используя записи, выполненные автоматическими алгоритмами, на этапе выбора сравнивают идентифицированные Интернет-адреса путем их статистического сопоставления. Иными словами, на этапе выбора Интернет-адресу назначают вероятный коэффициент релевантности и достоверности, который тем выше, чем чаще этот адрес встречается в записях автоматических алгоритмов.
На этапе выбора согласно настоящему изобретению первый информационный уровень путем описанной обработки преобразуют во второй информационный уровень или вторую информационную библиотеку, где содержатся Интернет-адреса, вероятный коэффициент релевантности и достоверности которых выше заранее заданного порогового значения. Второй информационный уровень может быть сохранен в той же базе данных, что и первый информационный уровень, или в другой базе данных.
Хранящиеся во второй информационной базе данных Интернет-адреса, даже если они имеют высокий вероятный коэффициент релевантности, могут представлять избыточное информационное наполнение. Фактически, благодаря тому, что на этапе выбора разным Интернет-адресам был назначен высокий вероятный коэффициент релевантности, они могут относиться к одной и той же веб-странице, например это могут быть переводы одной и той же веб-страницы на разные языки, устаревшие, но по-прежнему публикуемые версии одной и той же веб-страницы или одно и то же информационное наполнение, размещенное на веб-страницах, принадлежащих разным доменам.
Для уточнения второй информационной библиотеки способ классификации согласно настоящему изобретению содержит этап сокращения количества Интернет-адресов, подтвержденных на этапе выбора.
Интернет-адрес удаляют в том случае, если веб-страница, которой он соответствует, не отвечает критерию существенности.
Например, критерий существенности обеспечивает отсеивание веб-страниц или социальных сетевых сервисов, язык которых не входит в число допускаемых языков, заданных на этапе конфигурации. Кроме того, критерий существенности отсеивает все веб-страницы, которые соответствуют одной и той же лемме, но находятся на одном и том же домене или в одной и той же тематической области, и вместо них выдает лишь главную страницу соответствующего сайта.
На этапе сокращения из тех Интернет-адресов, которые не были отсеяны во время проверки на соответствие критерию существенности, формируют третий информационный уровень или третью информационную библиотеку, где степень фильтрации еще выше.
Таким образом, поисковый скрипт или поисковая программа, исполняемый или исполняемая на третьем информационном уровне или в третьей информационной библиотеке, идентифицирует Интернет-адреса веб-страниц или социальных сетевых сервисов, которые имеют высокую вероятность релевантности и по существу не являются лишними.
В качестве примера можно сказать, что по критерию поиска «Leonardo da Vinci» предлагаемый способ классификации на этом этапе способен выявить несколько сотен Интернет-адресов, имеющих высокую вероятность быть релевантными и по существу не лишними, в то время как поисковый скрипт или поисковая программа, где использован известный способ классификации, в окончательной выборке выдает миллионы Интернет-адресов.
Согласно настоящему изобретению, также имеется этап проверки третьего информационного уровня, на котором выявляют отдельные Интернет-адреса, относящиеся к достоверным и по существу не содержащим информационного шума веб-страницам.
Этап проверки содержит исполнение интерфейса проверки, который формирует список из Интернет-адресов или социальных сетевых сервисов третьего информационного уровня. В частности, интерфейс проверки может располагать Интернет-адреса в соответствии с вероятным коэффициентом релевантности, который был определен на этапах записи, выбора и сокращения.
С помощью интерфейса проверки специальный оператор, с учетом заданной леммы, анализирует относящиеся к указанным Интернет-адресам веб-страницы и социальные сетевые сервисы и подтверждает их релевантность. Более конкретно, оператор посредством графического интерфейса и с помощью автоматических алгоритмов сравнения и средств передачи результатов отсеивает нежелательные, не релевантные и имеющие низкую или нулевую достоверность Интернет-адреса, например, не допускает запись в четвертый информационный уровень Интернет-адреса аэропорта «Leonardo da Vinci».
Согласно настоящему изобретению, может иметься специальное средство, например кнопка-флажок, активировав которое конечный пользователь получает возможность выполнить описанный выше этап проверки самостоятельно. Конечный пользователь анализирует веб-страницы и социальные сетевые сервисы и подтверждает те из них, которые, по его мнению, являются более релевантными. Это еще более усовершенствует выполняемый оператором этап проверки, поскольку конечные пользователи наиболее осведомлены в соответствующей области своего поиска и способны наилучшим образом очистить информационный уровень или библиотеку от ненужных веб-страниц и социальных сетевых сервисов.
Согласно первому, предпочтительному, варианту реализации, если группа утвержденных конечными пользователями веб-страниц или социальных сетевых сервисов отличается от группы утвержденных операторами веб-страниц и социальных сетевых сервисов, то в интерфейсе, где отображаются результаты поиска, указанные группы вносятся в разные списки.
Согласно второму варианту реализации, веб-страницы и социальные сетевые сервисы третьего информационного уровня проверяют как конечные пользователи, так и оператор.
Для формирования четвертого информационного уровня существенной является выборка человеком Интернет-адресов третьего информационного уровня.
Таким образом, предлагаемый способ классификации веб-страниц содержит по меньшей мере следующие этапы:
A. Этап записи заданного количества Интернет-адресов, содержащий выполнение процессов автоматической записи указанных Интернет-адресов.
B. Этап выбора, на котором назначают указанным Интернет-адресам коэффициент релевантности пропорционально его записи на этапе записи, и выбирают Интернет-адреса, коэффициент релевантности которых выше заданного порогового значения'.
C. Этап сокращения, на котором удаляют Интернет-адреса, коэффициент релевантности которых выше порогового значения, но которые не удовлетворяют по меньшей мере одному критерию существенности.
D. Этап проверки, на котором проверяют Интернет-адреса, удовлетворяющие указанному по меньшей мере одному критерию существенности. Этот этап содержит выполняемые пользователем операции.
Например, по критерию поиска «Leonardo da Vinci» поисковый скрипт или поисковая программа согласно настоящему изобретению может найти несколько десятков Интернет-адресов, как показано на фиг.2.
В частности, из фиг.2 видно, как поисковый скрипт или поисковая программа для поиска веб-страниц может быть доступен или доступна через интерфейс 101. Указанный интерфейс может представлять собой веб-страницу со строкой 11 ввода критерия поиска и клавишей 21 для активации поискового скрипта или поисковой программы.
На фиг.2 в качестве критерия поиска для идентификации веб-страниц введено имя итальянского изобретателя и художника Леонардо да Винчи.
Основная зона 41 интерфейса 101 предназначена для отображения результатов исполнения поискового скрипта или поисковой программы (в данном случае по критерию поиска «Leonardo da Vinci»). В частности, результаты поиска представлены в виде списка из 31 Интернет-адреса веб-страниц, из которых отображены лишь первые 3a1-3c1.
Поисковый скрипт или поисковая программа может выдать конечному пользователю несколько десятков Интернет-адресов, относящихся к веб-страницам и социальным сетевым сервисам, которые имеют высокую релевантность и высокую достоверность, не содержат шума и не являются лишними. Интернет-адрес 3a1 относится к веб-странице Британской вещательной корпорации «ВВС», Интернет-адрес 3b1 относится к музею Метрополитен, а Интернет-адрес 3c1 относится к сюжету об изобретателе Леонардо да Винчи, который был снят известной итальянской телекомпанией «RAI».
Таким образом, поисковый скрипт или поисковая программа отсеивает веб-страницы, которые не имеют отношения к заданному пользователем критерию поиска, и предлагает лишь веб-страницы четвертого информационного уровня.
Возможно также осуществление традиционного поиска с использованием интерфейса 101, который в этом случае обеспечивает возможность поиска посредством поискового скрипта или поисковой программы на одном из информационных уровней или в одной из информационных библиотек, которые менее очищены от избыточных данных, чем четвертый информационный уровень, например, на втором информационном уровне.
Например, при нажатии показанной на фиг.2 кнопки 61 поисковый скрипт или поисковая программа выдает список Интернет-адресов второго информационного уровня, что позволяет ознакомиться с веб-страницами, которые не проходили этап проверки человеком.
В частности, также имеется возможность дополнительного выполнения предлагаемого способа классификации в случаях, когда третий информационный уровень или библиотека, полученные на этапе выбора, или четвертый информационный уровень или библиотека, полученные на этапе сокращения, пусты, т.е. по заданному критерию поиска ничего не найдено. В этом случае указанное дополнительное выполнение осуществляют по алгоритму, который обеспечивает доступ к заданной группе поисковых систем для извлечения из них наиболее релевантных результатов поиска по критерию поиска.
Интерфейс 101 предпочтительно содержит боковую зону 42, где в форме гипертекста отображается информация энциклопедического характера, относящаяся к заданному критерию поиска. Например, для критерия поиска «Leonardo da Vinci» в зоне 42 будут отображены ссылки «Биография», «Хронология жизни», «Хронология появления работ», «Рукописи» и «Библиография».
Согласно предлагаемому способу классификации веб-страниц результаты, выдаваемые поисковым скриптом или поисковой программой по заданному пользователем критерию поиска, являются релевантными, и поэтому не содержат шума; не являются лишними, т.е. адрес одной и той же страницы встречается лишь однажды; и содержат только достоверное информационное наполнение, благодаря чему пользователь тратит меньше времени на обработку результатов поиска.
Как следует из нижеследующего описания, предлагаемый способ классификации веб-страниц, и социальных сетевых сервисов не только обеспечивает получение по критерию поиска точной релевантной информации, которая не является лишней и не содержит шума, но и предоставляет удобный в использовании интерфейс.
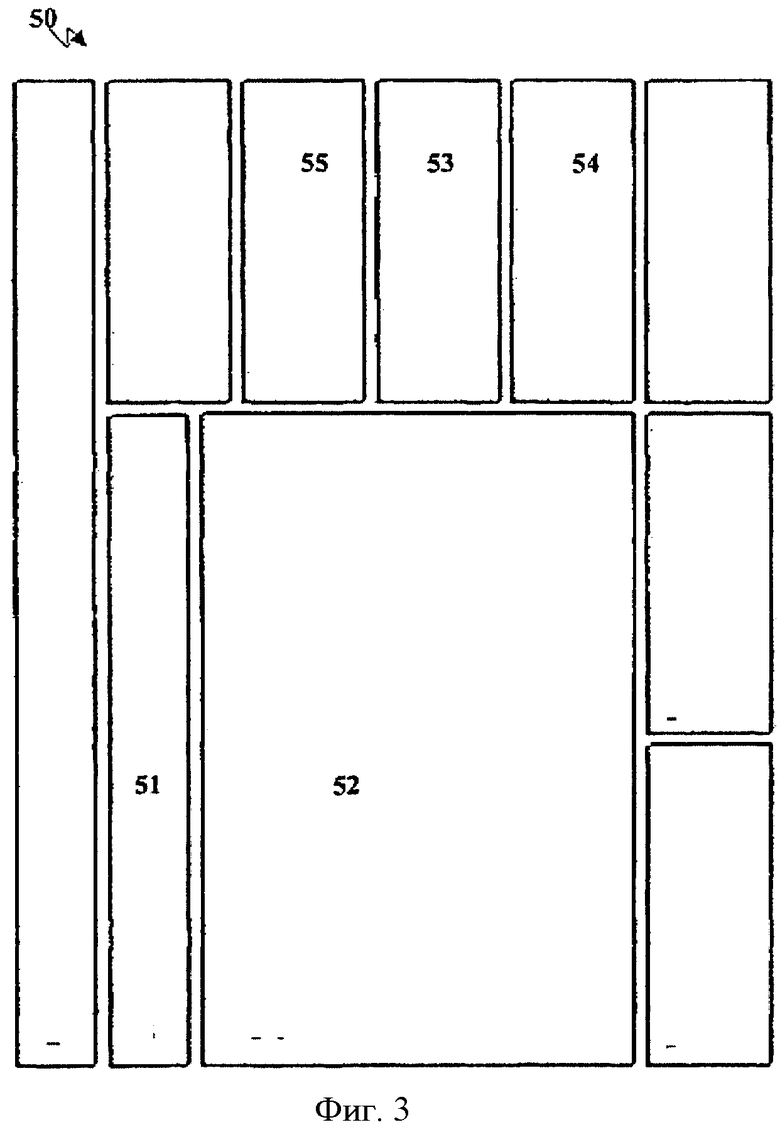
На фиг.3 схематично показан предлагаемый пользовательский интерфейс 50, выполненный с возможностью запуска классификации веб-страниц и социальных сетевых сервисов и для организации отображаемых результатов. Интерфейсом 50 может быть снабжено, например, веб-приложение, реализующее предлагаемый способ и расположенное по некоторому Интернет-адресу.
Интерфейс 50 содержит поле 51 для ввода критерия поиска, поле 52 для отображения списка найденных веб-страниц и дополнительные поля 53 для дополнительной информации, относящейся к критерию поиска.
К числу полей 53 относятся поле 54 для отображения по меньшей мере одного социального сетевого сервиса, поле 55 для отображения данных, относящихся к критерию поиска и полученных, например, из сторонних источников, и поле 56 для отображения комментариев пользователей.
В частности, данные, полученные из сторонних источников, по существу представляют собой информацию, которая взята по меньшей мере из одной сторонней базы данных, обработана и реорганизована согласно предлагаемому способу и отображена в виде списка ссылок в поле 55. Иными словами, содержимым поля 55 является результат поиска третьей стороной, основанного на критерии пользователя.
Способ согласно настоящему изобретению предпочтительно основан на технологии Web 2.0 Mashup, которая объединяет данные, полученные из разных источников, в единый интегрированный интерфейс 50.
Фактически, результаты, получаемые при выполнении этапов записи, выбора, сокращения и проверки согласно предлагаемому способу, получены из разных источников, которыми являются не только веб-страницы, но и социальные сетевые сервисы и информационное наполнение из сторонних источников.
Технология Mashup при ее применении к веб-страницам, социальным сетевым сервисам и информационному наполнению создает новый, не имеющий аналогов механизм, который изначально не предлагается тем единым источником, из которого получены ссылки на указанные веб-страницы, социальные сетевые сервисы и информационное наполнение.
Необходимо отметить, что предлагаемый способ позволяет существенно усовершенствовать известные сервисы на основе технологии Mashup, которые, фактически, просто группируют в одном окне информацию, получаемую из разных источников, и не сопоставляют эту информацию с общим критерием поиска.
Настоящее же изобретение сначала находит информационное наполнение, относящееся к общему критерию поиска, а затем распределяет его по полям 52, 53, 54, 55 интерфейса 50.
Фиг.4 подробно показывает организацию интерфейса 50 после выполнения поиска по критерию «Leonardo da Vinci».
Для обеспечения возможности изменения полей 51-54 интерфейса 50 каждое из них снабжено элементами управления, так называемыми виджетами, которые позволяют, например, перемещать поле из одной позиции в другую или увеличивать/уменьшать размеры одного поля для отображения основного количества ссылок в другом поле, а именно в модуле веб-страниц.
Также имеется возможность открывать и закрывать поля или, иными словами, убирать их из интерфейса 50 или вставлять их в интерфейс 50.
Пользователь из предоставленных результатов может выбирать те, в которых он наиболее заинтересован, например, он может максимально расширить область с перечнем социальных сетевых сервисов, область с данными, полученными из сторонних источников, или область с комментариями других пользователей.
| название | год | авторы | номер документа |
|---|---|---|---|
| Система и способ выявления мошеннических активностей при взаимодействии пользователя с банковскими сервисами | 2020 |
|
RU2762241C2 |
| СПОСОБ И СИСТЕМА ПОИСКА РЕЛЕВАНТНЫХ НОВОСТЕЙ | 2019 |
|
RU2698916C1 |
| СПОСОБ И СИСТЕМА РАНЖИРОВАНИЯ ЭЛЕМЕНТОВ СЕТЕВОГО РЕСУРСА ДЛЯ ПОЛЬЗОВАТЕЛЯ | 2013 |
|
RU2605039C2 |
| ПОСТРОЕНИЕ И ПРИМЕНЕНИЕ ВЕБ-КАТАЛОГОВ ДЛЯ ФОКУСИРОВАННОГО ПОИСКА | 2005 |
|
RU2382400C2 |
| ОБНАРУЖЕНИЕ ОБЪЕКТОВ ИЗ ЗАПРОСОВ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2729956C2 |
| ПЕРЕВОДЧЕСКИЙ СЕРВИС НА БАЗЕ ЭЛЕКТРОННОГО СООБЩЕСТВА | 2015 |
|
RU2604984C1 |
| СПОСОБ ПОИСКА ИНФОРМАЦИОННЫХ РЕСУРСОВ С ИСПОЛЬЗОВАНИЕМ ПЕРЕАДРЕСАЦИЙ | 2011 |
|
RU2453916C1 |
| СПОСОБ ОТОБРАЖЕНИЯ ВЕБ-РЕСУРСА ПОЛЬЗОВАТЕЛЮ (ВАРИАНТЫ) И ЭЛЕКТРОННОЕ УСТРОЙСТВО | 2014 |
|
RU2595497C2 |
| АССОЦИИРОВАНИЕ ИНФОРМАЦИИ С ЭЛЕКТРОННЫМ ДОКУМЕНТОМ | 2006 |
|
RU2406129C2 |
| Система и способ управления браузерным приложением, постоянный машиночитаемый носитель и электронное устройство | 2015 |
|
RU2633180C2 |



Изобретение относится к области классификации веб-страниц и организации соответствующего информационного наполнения. Техническим результатом является повышение производительности поисков, выполняемых по веб-страницам. Раскрывается способ классификации веб-страниц и организации соответствующего информационного наполнения, включающий этап записи Интернет-адресов, в свою очередь включающий выполнение процессов автоматической записи указанных Интернет-адресов, и этап выбора, на котором назначают указанным Интернет-адресам соответствующий коэффициент релевантности. На этапе выбора указанный коэффициент релевантности назначают пропорционально его записи на этапе записи и выбирают Интернет-адреса, коэффициент релевантности которых выше заданного порогового значения. Способ также содержит этап сокращения, на котором удаляют Интернет-адреса, коэффициент релевантности которых выше порогового значения, не удовлетворяющие по меньшей мере одному критерию существенности, и этап проверки, на котором проверяют ряд указанных Интернет-адресов, удовлетворяющих указанным критериям существенности, причем этап проверки содержит действия, выполняемые человеком. 2 н. и 16 з.п. ф-лы, 6 ил.
1. Способ организации информационного наполнения веб-страниц на компьютерном устройстве, содержащем память и процессор, включающий
- этап определения лемм,
- этап записи заданного количества Интернет-адресов, привязанных в памяти процессором к указанным леммам, содержащий выполнение процессов автоматической записи указанных Интернет-адресов,
- этап выбора и назначения указанным Интернет-адресам соответствующего коэффициента релевантности,
причем
на этапе выбора указанный соответствующий коэффициент релевантности назначают пропорционально его записи на этапе записи и выбирают Интернет-адреса, коэффициент релевантности которых выше заданного порогового значения,
а способ также содержит
- этап сокращения, на котором удаляют Интернет-адреса, коэффициент релевантности которых выше порогового значения, но которые не удовлетворяют по меньшей мере одному критерию существенности, включающий устранение веб-страниц, поступающих с одного домена для одной и той же леммы, и
- этап проверки, на котором проверяют те из указанных Интернет-адресов, которые удовлетворяют указанным критериям существенности, при этом этап проверки содержит действия, выполняемые человеком.
2. Способ по п.1, отличающийся тем, что он включает этап конфигурации, на котором определяют тематические области и соответствующие этим областям ключевые слова.
3. Способ по п.2, отличающийся тем, что на указанном этапе конфигурации для каждой из тематических областей задают леммы.
4. Способ по п.3, отличающийся тем, что на этапе конфигурации каждую из указанных лемм ставят в соответствие по меньшей мере с одной тематической областью из указанных тематических областей.
5. Способ по п.4, отличающийся тем, что на этапе конфигурации задают основной язык для определения указанных тематических областей, лемм и ключевых слов этих областей.
6. Способ по п.5, отличающийся тем, что на этапе конфигурации задают количество Интернет-адресов.
7. Способ по п.6, отличающийся тем, что этап записи содержит этап сопоставления указанных лемм с указанными веб-страницами.
8. Способ по п.7, отличающийся тем, что этап сопоставления содержит выявление указанных лемм на указанных веб-страницах.
9. Способ по 8, отличающийся тем, что указанный этап записи содержит сохранение указанных Интернет-адресов со ссылкой на указанные леммы в первом информационном уровне.
10. Способ по п.9, отличающийся тем, что этап записи содержит сохранение в первом информационном уровне копий указанных веб-страниц.
11. Способ по п.10, отличающийся тем, что критерий существенности обеспечивает исключение веб-страниц, которые не содержат символов алфавитов указанных допускаемых языков.
12. Способ по п.11, отличающийся тем, что критерий существенности обеспечивает исключение веб-страниц, относящихся к одному и тому же домену.
13. Способ по п.12, отличающийся тем, что этап сокращения содержит выполнение запросов на выборку.
14. Способ по п.13, отличающийся тем, что этап проверки содержит выполнение интерфейса проверки.
15. Способ по п.14, отличающийся тем, что интерфейс проверки создает список из Интернет-адресов, отсеянных на этапе сокращения.
16. Способ по п.15, отличающийся тем, что этап записи содержит выполнение по меньшей мере одного глобального сетевого поиска.
17. Способ по п.16, отличающийся тем, что этап записи содержит выполнение по меньшей мере одного мета-поиска.
18. Способ выполнения поискового скрипта или поисковой программы для выявления Интернет-адресов, отвечающих критерию поиска, отличающийся тем, что указанные Интернет-адреса выявляют способом классификации по одному из предшествующих пунктов, причем коэффициент релевантности указанных Интернет-адресов выше заданного порогового значения.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| US 6334145 B1, 25.12.2001 | |||
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| СПОСОБ ПОИСКА И ВЫБОРКИ ИНФОРМАЦИИ С ПОВЫШЕННОЙ РЕЛЕВАНТНОСТЬЮ | 2003 |
|
RU2236699C1 |

